
Abstract
A new numerical approximation method for a class of Gaussian random fields on compact connected oriented Riemannian manifolds is introduced. This class of random fields is characterized by the Laplace–Beltrami operator on the manifold. A Galerkin approximation is combined with a polynomial approximation using Chebyshev series. This so-called Galerkin–Chebyshev approximation scheme yields efficient and generic sampling algorithms for Gaussian random fields on manifolds. Strong and weak orders of convergence for the Galerkin approximation and strong convergence orders for the Galerkin–Chebyshev approximation are shown and confirmed through numerical experiments.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Models for random fields defined on manifolds are of key importance in many application areas such as environmental sciences, geosciences and cosmological data analysis [40]. While one area of interest is dealing with actual data that lies on surfaces and doing inference based on these data, we focus in this work on the primarily needed modeling and sampling of these random fields. More specifically, we propose a generic approach to define and numerically approximate a particular class of Gaussian random fields on (compact) Riemannian manifolds in a computationally efficient manner.
The main contributions of this work are the following. First, we propose a general approach to model and discretize a class of Gaussian random fields \(\mathscr {Z}\) defined on compact connected oriented Riemannian manifolds \(\mathscr {M}\) via functions of the Laplace–Beltrami operator \(-\varDelta _{\mathscr {M}}\) of the manifold. We define the random field \(\mathscr {Z}\) through a series expansion, and derive a finite-dimensional approximation \(\mathscr {Z}_n\) on any finite-dimensional function space \(V_n\), e.g. a finite element space and not necessarily the spectral representation of the series expansion. To do so, we use (functions of) the Galerkin approximation of \(-\varDelta _{\mathscr {M}}\) on \(V_n\). This approximation of the field allows us to give a closed form for the covariance matrix of the coefficients in basis representation of \(\mathscr {Z}_n\), and hence an explicit way to sample these correlated random coefficients. Secondly, we propose an approximation of the discretized field \(\mathscr {Z}_n\) based on Chebyshev polynomials which allows to sample these coefficients in a computationally efficient manner. Finally, we show convergence in mean-square and in the covariance of \({\mathscr {Z}}_n\) to \({\mathscr {Z}}\) and give the associated convergence rates. We also derive a convergence result for the root-mean-squared error induced by the Chebyshev approximation.
This approach, which we call Galerkin–Chebyshev approximation, provides efficient and scalable algorithms for computing samples of the discretized field. For instance, when defining the discretized field using a linear finite element space of dimension n, we obtain sampling costs that scale linearly with n and with the order of the considered Chebyshev polynomial approximation, and storage costs that scale linearly with n. In particular, computational costs of essentially \(\mathscr {O}(\epsilon ^{-2/\rho })\) are then required to sample, with accuracy \(\epsilon >0\), Gaussian random fields with a Matérn covariance function on a two-dimensional manifold (where \(\rho \) denotes the rate at which the root-mean-squared error between the random field and its discretization converges to zero).
So far the focus of the literature for random fields on manifolds has been on the sphere. Extensive literature on the definition, properties, and efficient use of random fields on the sphere is available (see [40] for a review). A first simulation approach aims at characterizing valid covariance functions on the sphere that model the correlation between two points using the arc length distance separating them [25, 29]. A second approach relies on the fact that stationary Gaussian random fields on the sphere have a basis expansion with respect to the spherical harmonic functions [31]. The resulting Karhunen–Loève expansion is used to derive simulation methods and to characterize the covariance structure of the resulting fields [15, 21, 35, 36, 40]. Finally, models have also been proposed to deal with both space-time data [45] and anisotropy [22] on the sphere. Discretization methods that do not rely on Karhunen–Loève expansions are, for instance, using the existence of Parseval frames on the sphere [3] or relying on a regular discretization of the sphere, Markov properties, and fast Fourier transforms [17].
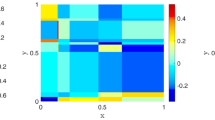
However, the work done for random fields on a sphere hardly generalizes to other spatial domains, as they heavily rely on the intrinsic properties of the sphere as a surface, and on the spherical harmonics. If now random fields on more general manifolds are of interest, Adler and Taylor [1] provide a review of the theory used to define them, primarily focused on their geometry and excursion sets. The goal of this work is to propose and analyze a second approach, which generalizes the expansion approach on the sphere, and results in efficient algorithms for sampling Gaussian random fields on a manifold. Examples of samples of the resulting fields on different manifolds are shown in Fig. 1 and show the flexibility of the approach, since it can be applied to widely different domains.

Simulations of Gaussian random fields on various (compact Riemannian) manifolds
Our approach extends previous methods proposed for the numerical approximation of Gaussian random fields defined on manifolds. Several authors worked on the approximation of Gaussian random fields seen as solutions to stochastic partial differential equations (SPDEs), and in particular Whittle–Matérn fields which were popularized by Lindgren et al. [38]. A quadrature approximation allowed them to derive numerical approximations of such fields defined on bounded Euclidean domains [6, 7] and even compact metric spaces [28]. This approach requires to solve multiple (large but sparse) linear systems in order to generate samples of the random fields, and work has been done to find suitable and efficient preconditioners to tackle them [26]. In contrast, our approach does not rely on the fact that the random field is the solution of some SPDE (since we do not require the function of \(-\varDelta _{\mathscr {M}}\) to be invertible), but still includes Whittle–Matérn fields as a particular case. Also, the use of a Chebyshev polynomial approximation allows in some cases to avoid solving any linear system while generating samples.
The idea of using functions of the Laplacian to model Gaussian random fields on manifolds was recently investigated by Borovitskiy et al. [10] and Borovitskiy et al. [11]. Contrary to Borovitskiy et al. [10], our approach does not require an explicit approximation of the eigenvalues and eigenfunctions of the Laplace–Beltrami operator. Besides, we propose a convergence analysis, both in mean-square and covariance, of the approximations we propose. This analysis extends to the approximations in [10], as they can be seen as a particular instance of our more general framework. Finally, our work provides a theoretical justification for the use of functions of Laplacian matrices to model Gaussian fields on graphs, as proposed in Borovitskiy et al. [11]. Indeed, such matrices arise naturally when examining the discretization of random fields [43].
The outline of this paper is as follows. In Sect. 2, we present some background material on functional analysis on Riemannian manifolds and the class of Gaussian random fields considered in this work. Section 3 is devoted to the Galerkin approximation of these random fields. Then, in Sect. 4, we introduce the Chebyshev polynomial approximation used to numerically compute the weights of the Galerkin-discretized random fields. In Sect. 5 we expose the convergence analysis of the Galerkin and Chebyshev approximations and give the corresponding error estimates, and in Sect. 6 we present an analysis of the computational complexity and storage required to generate samples of a random field using its Galerkin–Chebyshev approximation. Finally, in Sect. 7, we confirm error estimates through numerical experiments on the sphere and a hyperboloid.
Throughout the paper, we denote by \(\varvec{I}\) the identity matrix and for any \(a, b \in \mathbb {N}_0\) we write \([\![a, b]\!]= \lbrace a, \dots , b\rbrace \) if \(a\le b\), and adopt the convention \([\![a, b]\!]= \emptyset \) if \(a>b\). The entries of a vector \(\varvec{u}\in \mathbb {R}^n\) are denoted by \(u_1,\dots ,u_n\), and the entries of a matrix \(\varvec{A}\in \mathbb {R}^{n\times n}\) are denoted by \(A_{ij}\), \(1\le i,j\le n\). If \(\varvec{X}\) is a Gaussian vector with mean \(\mu \) and covariance matrix \(\varvec{\varSigma }\), we write \(\varvec{X} \sim \mathscr {N}(\varvec{\mu }, \varvec{\varSigma })\). Finally, for any two functions f and g depending on some argument \(x\in \mathbb {R}\), and for \(a\in \lbrace 0, +\infty \rbrace \), we write \(f(x)=\mathscr {O}(g(x))\) if f is asymptotically bounded by g as \(x\rightarrow a\), i.e. if there exists some constant \(M_a\) independent of x such that \(\vert f(x)\vert \le M_a \vert g(x) \vert \) when \(x\rightarrow a\).
2 Functional analysis background and random fields on manifolds
2.1 Laplace–Beltrami operator on a compact Riemannian manifold
We first introduce a few notions of Riemannian geometry, and refer the interested reader to [4, 32, 34] and the references therein for a more in-depth introduction on the subject.
Let \((\mathscr {M},g)\) be a compact connected oriented Riemannian manifold of dimension \(d\ge 1\), such that \(\mathscr {M}\) has either a smooth boundary \(\partial \mathscr {M}\) or no boundary at all (\(\partial \mathscr {M}=\emptyset \)). A function \(f: \mathscr {M} \rightarrow \mathbb {R}\) is called smooth if for any coordinate patch \((U, \phi )\) (where \(U\subset \mathscr {M}\) and \(\phi : U \rightarrow \mathbb {R}^d\) defines local coordinates on U), the function \(f\circ \phi ^{-1}\) is a smooth function from \(\mathbb {R}^d\) to \(\mathbb {R}\). Let then \(C^{\infty }(\mathscr {M})\) be the set of smooth functions from \(\mathscr {M}\) to \(\mathbb {R}\). The gradient operator \(\nabla _{\mathscr {M}}\) acting on functions of \(C^{\infty }(\mathscr {M})\) associates to each \(f\in C^{\infty }(\mathscr {M})\) the vector field \(\nabla _{\mathscr {M}}f\) described in local coordinates \((x^1, \dots , x^d)\) by
where \(\phi \) denotes the local chart associated with the coordinates and \((g^{ij})_{1\le i,j\le d}\) is the inverse of the metric tensor \(g=(g_{ij})_{1\le i,j\le d}\). Similarly, the Laplace–Beltrami operator \(-\varDelta _{\mathscr {M}}\) acting on functions of \(C^{\infty }(\mathscr {M})\) associates to each \(f\in C^{\infty }(\mathscr {M})\) the function \(-\varDelta _{\mathscr {M}}f\) described by
where \(\vert g\vert \) is the determinant of the metric tensor g. Note in particular that both definitions are independent of the choice of local charts and associated local coordinates.
Let \(\textrm{d}v_g\) denote the canonical measure of \((\mathscr {M}, g)\), which is given by
where \(\textrm{d}x^1\cdots \textrm{d}x^d\) denotes the standard Lebesgue measure on \(\mathbb {R}^d\). We denote by \(H=L^2(\mathscr {M}, g)\) the space of square-integrable functions on \((\mathscr {M},g)\), which is defined as
In particular, H is a Hilbert space when equipped with the inner product \((\cdot , \cdot )_0\) defined by
and we denote by \(\Vert \cdot \Vert _0\) the norm associated with this inner product.
Consider the eigenvalue problem
with Dirichlet or (homogeneous) Neumann boundary conditions whenever \(\partial \mathscr {M}\ne \emptyset \). A standard result of spectral theory [34, Theorem 4.3.1] states that this problem admits solutions in the form of a set of eigenpairs \((\lambda _k, e_k)_{k\in \mathbb {N}}\), where \(\lambda _k\ge 0\) and such that each eigenvalue has a finite multiplicity, the eigenspaces corresponding to distinct eigenvalues are H-orthogonal, and the direct sum of the eigenspaces is dense in H. Hence this theorem provides a decomposition of any function \(f\in H\) into an orthonormal basis \(\lbrace e_k \rbrace _{k\in \mathbb {N}}\) of eigenfunctions of \(-\varDelta _{\mathscr {M}}\), as
where the equality is understood in the \(L^2\)-sense.
Without loss of generality, we assume in the remainder of this paper that the eigenpairs of \(-\varDelta _{\mathscr {M}}\) are ordered so that \(0\le \lambda _{1} \le \lambda _{2}\le \cdots \). In particular we have \(\lambda _{1}=0\) whenever \(\partial \mathscr {M}=\emptyset \) or Neumann boundary conditions are considered, and \(\lambda _{1}>0\) when Dirichlet boundary conditions are considered [34, Proposition 4.5.6]. Hence, in this work, the multiplicity \(M_0\) of the eigenvalue 0 satisfies \(M_0 \in \lbrace 0, 1\rbrace \). The following can be stated about the growth rate of the eigenvalues.
Proposition 2.1
(Weyl’s asymptotic law) For \(\alpha =2/d\), there exist constants \(c_\lambda >0\) and \(C_\lambda >0\) such that all non-negative eigenvalues \(\lbrace \lambda _j\rbrace _{j\in \mathbb {N}}\) satisfy
This property is a direct consequence of Weyl’s asymptotic formula which holds for connected compact Riemannian manifolds of dimension d and states that the constants \(c_\lambda \) and \(C_\lambda \) depend on d and on the volume of the manifold [34, Theorem 7.6.4].
2.2 Function spaces on a compact Riemannian manifold
The Sobolev space \(H^1\) is defined as the completion of \(C^{\infty }(\mathscr {M})\) with respect to the norm \(\Vert \cdot \Vert _{H^1}\) defined by
This space is a Hilbert space when equipped with the inner product \((\cdot , \cdot )_{H^1}\) defined by
In particular, the definition of the gradient operator is here extended to functions of \(H^1\) using a density argument. More generally, Sobolev spaces of fractional order \(H^\sigma \), \(\sigma > 0\), can be defined on compact Riemannian manifolds by stating that \(f\in H^\sigma \) when, for any coordinate patch \((U, \phi )\), and any function \(\psi \) with compact support in U, the function \((f\psi )\circ \phi ^{-1}\) belongs to the Sobolev space \(H^\sigma (\mathbb {R}^d)\) as usually defined on \(\mathbb {R}^d\) [51, Chapter 4, Section 3]. For \(\sigma =1\), this last characterization coincides with our used definition of \(H^1\). Finally, let \(\sigma \ge 0\) and let \(\mathscr {F} \subset H\) be the space of finite linear combinations of the eigenfunctions \(\lbrace e_k\rbrace _{k \in \mathbb {N}}\) of \(-\varDelta _{\mathscr {M}}\). Following the definition of spaces of generalized functions on manifolds introduced by Taylor [51, Chapter 5, Section A], let \(\dot{H}^\sigma \) be the completion of \(\mathscr {F}\) under the norm \(\Vert \cdot \Vert _{\sigma }\) defined by
where by convention the first sum vanishes if \(M_0=0\). In particular, we have \(\dot{H}^0=H\) and more generally, \(\dot{H}^\sigma \) is a Hilbert space when equipped with the inner product \((\cdot , \cdot )_\sigma \) defined by
Remark 2.2
When manifolds without boundary are considered, the definition of \(\dot{H}^\sigma \) given above is equivalent to the definition of the fractional Sobolev space of order \(\sigma \) through Bessel potentials (used for instance by Strichartz [50] or Herrmann et al. [27]). Indeed, recall that the latter is defined as the subspace of H composed of functions \(f\in H\) satisfying \( \Vert f \Vert _\sigma ' < +\infty \), where \( \Vert \cdot \Vert _\sigma '\) is the norm defined by
Equivalence follows from the equivalence of the norms \(\Vert \cdot \Vert _\sigma \) and \(\Vert \cdot \Vert _\sigma '\): we have
When manifolds with boundary are considered, and \(\sigma >0\), \(\dot{H}^\sigma \) can be seen as a subspace of a fractional Sobolev space composed of functions satisfying the same boundary conditions as the ones considered for the eigenvalue problem of the Laplace–Beltrami operator [51, Chapter 5, Section A].
For \(\sigma <0\), we define \(\dot{H}^\sigma \) to be the dual space of \(\dot{H}^{-\sigma }\): these spaces are Hilbert spaces when endowed with the inner product (2.1), and their elements are seen as distributions [50].
2.3 Functions of the Laplacian
We now introduce a class of operators acting on H, called functions of the Laplacian. These operators are classically used to express solutions of some differential equations and to prove Weyl’s asymptotic formula [12]. To define functions of the Laplacian, we first introduce the notion of power spectral density.
Definition 2.3
A power spectral density is a function \(\gamma : [0,+\infty ) \rightarrow \mathbb {R}\) with the following properties. First, there exists some \(\nu \in \mathbb {N}\) for which \(\gamma \) is \(\nu \) times differentiable, with continuous derivatives up to order \((\nu -1)\) and a derivative of order \(\nu \) of bounded variation. Second, \(\gamma (\lambda ) \rightarrow 0\) as \(\lambda \rightarrow \infty \). And finally, there exist constants \(L_\gamma , C_{\gamma }', \beta >0\) such that for all \(\lambda \ge L_\gamma \), the first derivative \(\gamma '\) of \(\gamma \) satisfies
Note in particular that these last two conditions imply that there exists \(C_{\gamma }>0\) such that
In particular, the power spectral density considered in this work should satisfy the relation given in the next assumption.
Assumption 2.4
The power spectral density considered in this work satisfy the relation
where \(\beta >0\) is defined in Definition 2.3 and \(\alpha >0\) is defined in Proposition 2.1.
This assumption allows us to define the notion of functions of Laplacian as a endomorphism of H. Indeed, given a power spectral density \(\gamma \) satisfying Assumption 2.4, we define the function of the Laplacian \(\gamma (-\varDelta _{\mathscr {M}})\) associated with \(\gamma \) as the operator \(\gamma (-\varDelta _{\mathscr {M}}): H \rightarrow H\) given by:
The next proposition extends the domain of this operator.
Proposition 2.5
Let Assumption 2.4 be satisfied. For any \(\sigma \in \mathbb {R}\), the function of the Laplacian \(\gamma (-\varDelta _{\mathscr {M}})\) can be extended to an operator (also denoted \(\gamma (-\varDelta _{\mathscr {M}})\) with a slight abuse of notation)
where \(\alpha >0\) and \(\beta >0\) are defined respectively in Proposition 2.1 and Definition 2.3.
Proof
Let \(\sigma \in \mathbb {R}\) and \(f\in \dot{H}^{\sigma }\).
Following Definition 2.3, and since \(\lambda _{k} \rightarrow +\infty \) as \(k\rightarrow +\infty \), we set
where \(K_\gamma = \sup \lbrace k \in \mathbb {N}: \lambda _{k} < L_{\gamma }\rbrace \). We then obtain that \(\gamma (-\varDelta _{\mathscr {M}})f\in \dot{H}^{\sigma +2\beta }\) since
\(\square \)
Note in particular that Proposition 2.5 implies that, for all \(\sigma \ge -2\beta \), \(\gamma (-\varDelta _{\mathscr {M}})\) maps \(\dot{H}^\sigma \) into (a subspace of) H.
2.4 Random fields on a Riemannian manifold
Let us start by introducing some notation. Let \((\varOmega , \mathscr {A}, \mathbb {P})\) be a complete probability space. Let Q denote some arbitrary Hilbert space (with inner product \((\cdot , \cdot )_Q\) and associated norm \(\Vert \cdot \Vert _{Q}\)). We denote by \(L^2(\varOmega ; Q)\) the set of all Q-valued random variables defined on \((\varOmega , \mathscr {A},\mathbb {P})\) satisfying, for any \(\mathscr {Z} \in L^2(\varOmega ; Q)\), \(\mathbb {E}[\mathscr {Z}]=0\) and \(\mathbb {E}[\Vert \mathscr {Z}\Vert _{Q}^2]<+\infty \). In particular, this implies that any \(\mathscr {Z}\in L^2(\varOmega ; Q)\) is almost surely in Q. Finally, note that \(L^2(\varOmega ; Q)\) is a Hilbert space when equipped with the inner product \(( \cdot , \cdot )_{L^2(\varOmega ; Q)}\) (and associated norm \(\Vert \cdot \Vert _{L^2(\varOmega ; Q)}\)) defined by
We now define the notion of Gaussian white noise on the manifold \(\mathscr {M}\). Let \(\lbrace W_j \rbrace _{j\in \mathbb {N}}\) be a sequence of independent, standard Gaussian random variables. The linear functional \(\mathscr {W}\) defined over H by
is called Gaussian white noise on \(\mathscr {M}\). Note that for any \(\varphi \in H\), the series \(\langle \mathscr {W}, \varphi \rangle \) converges in quadratic mean since \(\mathbb {E}\left[ \langle \mathscr {W}, \varphi \rangle \right] =0\) and by independence of the variables \(\lbrace W_k\rbrace _{k\in \mathbb {N}}\),
In particular, \(\mathscr {W}\) satisfies, for any \(\varphi \in H\), \(\mathbb {E}\left[ \langle \mathscr {W},\varphi \rangle \right] =0\), and for any \(\varphi _1, \varphi _2 \in H\),
The next proposition details the domain of definition and regularity of \(\mathscr {W}\).
Proposition 2.6
For any \(\epsilon >0\), \(\mathscr {W}\in L^2(\varOmega ; \dot{H}^{-(\alpha ^{-1} + \epsilon )})\), where \(\alpha >0\) is given in Proposition 2.1.
Proof
Let \(\epsilon >0\) and \(N\in \mathbb {N}\). Consider the truncated white noise \(\mathscr {W}_N\) defined by
By definition of \(M_0\),
which gives, using Proposition 2.1,
where \(\zeta \) denotes the Riemann zeta function satisfying \(\zeta (1+\epsilon \alpha )<\infty \) since \(\epsilon \alpha >0\). Taking the limit \(N\rightarrow \infty \) implies that \(\mathbb {E}[\Vert \mathscr {W}\Vert _{-(\alpha ^{-1}+\epsilon )}^2]<\infty \), which proves the claim.\(\square \)
We now introduce a class of random fields defined using the white noise \(\mathscr {W}\) and functions of the Laplacian. Let \(\gamma \) be a power spectral density satisfying Assumption 2.4 be satisfied and let \(\mathscr {Z}\) be the random field defined by
By Propositions 2.5 and 2.6, for any \(\epsilon >0\), \(\mathscr {Z}\) is (a.s.) an element of \(\dot{H}^{2\beta -(\alpha ^{-1}+\epsilon )}\). The next proposition links \(\mathscr {Z}\) to H-valued random variables.
Proposition 2.7
Let \(\gamma \) be a power spectral density satisfying Assumption 2.4 and let \(\mathscr {Z}\) be defined by (2.4). Then, \(\mathscr {Z}\in L^2(\varOmega ; H)\) and \(\mathscr {Z}\) can be decomposed as
where the weights \(\lbrace W_j \rbrace _{j\in \mathbb {N}}\) define a white noise as in (2.3).
Proof
Since Assumption 2.4 is satisfied, Propositions 2.5 and 2.6 give that \(\mathscr {Z}\) is in H (almost surely). Recall that, by definition of functions of the Laplacian,
By linearity, we then have
and following Definition 2.3 and Proposition 2.1,
where \(\zeta (2\beta \alpha ) <\infty \) since \(2\alpha \beta >1\), and \(R_\gamma \) is defined in (2.2). Hence \(\mathbb {E}[\Vert \mathscr {Z}\Vert _0^2]<\infty \) and therefore \(\mathscr {Z}\in L^2(\varOmega ; H)\).\(\square \)
The class of Gaussian random fields described in this section can be seen as an extension to arbitrary compact connected oriented Riemannian manifolds of the class of isotropic random fields on the sphere described in [35]. In this last case, the eigenfunctions \(\lbrace e_k\rbrace _{k\in \mathbb {N}}\) of the Laplace–Beltrami operator are the spherical harmonics, and the power spectral density \(\gamma \) defines the angular power spectrum of the field. In this sense, the decomposition introduced in Proposition 2.7 can be seen as the Karhunen–Loève expansion of a Gaussian random field on a compact connected oriented Riemannian manifold.
In the particular case where the power spectral density \(\gamma \) takes the form
for some parameters \(\kappa >0\) and \(\beta >1/(2\alpha )=d/4\), the resulting field \(\mathscr {Z}\) is a solution to the fractional elliptic SPDE
As such, \(\mathscr {Z}\) is an instance of a Whittle–Matérn random field on a manifold, as introduced in [38] for compact Riemannian manifolds. This class of random fields was studied in [30] for the particular case where the manifold is a sphere, and in [26, 28] for compact Riemannian manifolds.
More generally, the random fields defined by (2.4) are particular instances of regular zero-mean generalized Gaussian fields (GeGF) as defined in [39, Section 3.2.1]. To a field \(\mathscr {Z}\) defined by (2.4), we can associate the continuous linear functional \(f\in H \mapsto (\mathscr {Z}, f)_0\), which corresponds to a GeGF with a covariance operator \(K: H \rightarrow H\) given by \(K=\gamma ^2(-\varDelta _{\mathscr {M}})\) (where by definition the covariance operator is defined as \(\mathbb {E}[(\mathscr {Z}, f)_0(\mathscr {Z}, f')_0]=(K(f),f')_0\)). The fact that this GeGF is regular stems directly from the fact that, under the assumptions used in Proposition 2.7, the operator \(\gamma ^2(-\varDelta _{\mathscr {M}})\) is nuclear. Conversely, since \(-\varDelta _{\mathscr {M}}\) and \(\gamma ^2(-\varDelta _{\mathscr {M}})\) have the same eigenfunctions, and since the function \(\gamma ^2\) maps the eigenvalues of \(-\varDelta _{\mathscr {M}}\) to those of \(\gamma ^2(-\varDelta _{\mathscr {M}})\), any regular GeGF with covariance operator \(\gamma ^2(-\varDelta _{\mathscr {M}})\) can be decomposed as in Proposition 2.7 (cf. [39, Theorem 3.2.15] and its proof).
3 Discretization of Gaussian random fields
We now aim at computing numerical approximations of the random fields \(\mathscr {Z}\) defined in (2.4) using a discretization of the Laplace–Beltrami operator. The discretization we propose is based on a Galerkin approximation, and can be seen as an extension of the approach in [7]. It leads to an approximation by a weighted sum of basis functions defined on the manifold.
For \(n\ge 1\), let \(\lbrace \psi _k \rbrace _{1\le k \le n}\) be a family of linearly independent functions of \(\dot{H}^1\) and denote by \(V_n \subset \dot{H}^1\) its linear span. In particular, \(V_n\) is a n-dimensional subspace of \(\dot{H}^1\), and we assume that the constant functions are in \(V_n\). Examples that are included in our framework are spectral methods, where \(V_n\) is spanned by finitely many eigenfunctions of \(-\varDelta _{\mathscr {M}}\), boundary element methods [48], and with an extra approximation step surface finite elements [20].
3.1 Galerkin discretization of the Laplace–Beltrami operator
We first introduce a discretization \(-\varDelta _n\) of the Laplace–Beltrami operator over \(V_n\) by a Galerkin approximation [2, Chapter 4]. For any \(\varphi \in V_n\), we set \(-\varDelta _n\varphi \) to be the element of \(V_n\) satisfying for all \(v\in V_n\)
which uniquely defines \(-\varDelta _n: V_n \rightarrow V_n\). In particular, if \(\lbrace f_{k} \rbrace _{1\le k \le n}\) denotes any orthonormal basis of \((V_n, \Vert \cdot \Vert _0)\), this operator satisfies
Let \(\varvec{C}\) and \(\varvec{R}\) be the matrices called (in the context of finite element methods) mass matrix and stiffness matrix respectively, and defined by
As defined, \(\varvec{C}\) is a symmetric positive definite matrix and \(\varvec{R}\) is a symmetric positive semi-definite matrix (cf. Lemma SM2.1 of the Supplementary Materials). Consequently, the generalized eigenvalue problem (GEP) defined by the matrix pencil \((\varvec{R}, \varvec{C})\), which consists in finding all so-called eigenvalues \(\lambda \in \mathbb {R}\) and eigenvectors \(\varvec{w}\in \mathbb {R}^n \backslash \lbrace \varvec{0}\rbrace \) such that
admits a solution consisting of n nonnegative eigenvalues and n eigenvectors mutually orthogonal with respect to the inner product \((\cdot , \cdot )_{\varvec{C}}\) (and norm \(\Vert \cdot \Vert _{\varvec{C}}\)) defined by (see [42, Theorem 15.3.3]).
We observe further that since \(\varvec{C}\) is symmetric and positive definite, \(\sqrt{\varvec{C}}\in \mathbb {R}^{n\times n}\) satisfying \(\sqrt{\varvec{C}}(\sqrt{\varvec{C}})^T=\varvec{C}\) exists and is invertible. Therefore denoting by \(\Vert \cdot \Vert _2\) the Euclidean norm, we obtain \(\Vert \cdot \Vert _{\varvec{C}} = \Vert (\sqrt{\varvec{C}})^T\cdot \Vert _2\) and an isometry between \((\mathbb {R}^n,\Vert \cdot \Vert _{\varvec{C}})\) and \((\mathbb {R}^n,\Vert \cdot \Vert _2)\) via the linear bijection \(F: \mathbb {R}^n \rightarrow \mathbb {R}^n\) defined by \(F(\varvec{x}) = (\sqrt{\varvec{C}})^{T}\varvec{x}\).
The next result links the GEP to the operator \(-\varDelta _n\), and is proven in “Appendix B”.
Theorem 3.1
The operator \(-\varDelta _n\) is diagonalizable and its eigenvalues are those of the GEP defined by the matrix pencil \((\varvec{R}, \varvec{C})\). In particular, \(E_0: \mathbb {R}^n \rightarrow V_n\), defined by
is an isomorphism that maps the eigenvectors of \((\varvec{R}, \varvec{C})\) to eigenfunctions of \(-\varDelta _n\), and an isometry between \((\mathbb {R}^n,\Vert \cdot \Vert _C)\) and \((V_n, \Vert \cdot \Vert _0)\).
We continue with a corollary that will be useful later on.
Corollary 3.2
The eigenvalues of \(-\varDelta _n\) are those of the matrix
and the mapping \(E: \mathbb {R}^n \rightarrow V_n\), defined by
is an isomorphism that maps the eigenvectors of \(\varvec{S}\) to the eigenfunctions of \(-\varDelta _n\) and an isometry between \((\mathbb {R}^n,\Vert \cdot \Vert _{2})\) and \((V_n,\Vert \cdot \Vert _0)\).
Proof
Note first that \(\varvec{S}\) is well-defined and symmetric positive semi-definite by the properties of \(\varvec{C}\) and recall the bijection F given by \(F(\varvec{x}) = (\sqrt{\varvec{C}})^{T}\varvec{x}\). Let \((\lambda , \varvec{w})\) be an eigenpair of \((\varvec{R}, \varvec{C})\) and set \(\varvec{v}=F^{-1}(\varvec{w})\), then
and therefore \((\lambda , \varvec{v})\) is an eigenpair of \(\varvec{S}\). Hence F maps the eigenvectors of \((\varvec{R}, \varvec{C})\) to those of \(\varvec{S}\), and conversely \(F^{-1}\) maps the eigenvectors of \(\varvec{S}\) to those of \((\varvec{R}, \varvec{C})\). Noting that \(E=E_0\circ F^{-1}\) and applying Theorem 3.1 concludes the proof.\(\square \)
We denote by \(\lbrace \lambda _{k}^{(n)}\rbrace _{1\le k\le n} \subset \mathbb {R}_+\) the eigenvalues of the matrix \(\varvec{S}\) (cf. Corollary 3.2), ordered in non-decreasing order. Let \(\lbrace \varvec{v}_{k}\rbrace _{1\le k\le n}\subset \mathbb {R}^n\) be a set of eigenvectors associated with these eigenvalues, and chosen to form an orthonormal basis of \(\mathbb {R}^n\). Hence, if \(\varvec{V}\) is the matrix whose columns are \(( \varvec{v}_1, \dots , \varvec{v}_n)\), we have \(\varvec{V}^T\varvec{V}=\varvec{V}\varvec{V}^T=\varvec{I}\) and
where \(\mathop {\textrm{Diag}}(\lambda _{1}^{(n)}, \dots ,\lambda _{n}^{(n)})\) denotes the diagonal matrix whose entries are \(\lambda _{1}^{(n)}, \dots ,\lambda _{n}^{(n)}\). Given that E defined in Corollary 3.2 is a linear isometry, it maps orthonormal sequences in \((\mathbb {R}^n,\Vert \cdot \Vert _{2})\) to orthonormal sequences in \((V_n,\Vert \cdot \Vert _0)\). Hence, the set \(\lbrace e_{k}^{(n)}\rbrace _{1\le k\le n}\subset V_n\), where
is an orthonormal family of functions of \(V_n\). Moreover, given that E is linear and bijective, \(\lbrace E(\varvec{v}_k)\rbrace _{1\le k\le n}\) is a basis of \(V_n\). Consequently, \(\lbrace e_{k}^{(n)}\rbrace _{1\le k\le n}\) defines an orthonormal basis of \(V_n\) composed of eigenfunctions of \(-\varDelta _n\).
Consider a power spectral density \(\gamma \) satisfying Assumption 2.4. Following the definition of the discretized operator \(-\varDelta _n\) and analogously to the definition of the operator \(\gamma (-\varDelta _{\mathscr {M}})\), the discretization of the operator \(\gamma (-\varDelta _\mathscr {M})\) on \(V_n\) is defined as the endomorphism \(\gamma (-\varDelta _n)\) of \(V_n\) given by
Note that this definition does not depend on the choice of orthonormal basis (cf. Theorem SM2.1 of the Supplementary Materials).
3.2 Galerkin discretization of Gaussian random fields
Let \(\mathscr {W}_n\) be the \(V_n\)-valued random variable defined by
where \(W_1, \dots , W_n\) are independent standard Gaussian random variables. Then, \(\mathscr {W}_n\) is called white noise on \(V_n\) and satisfies, for any \(\varphi , \varphi _1, \varphi _2 \in V_n\), \(\mathbb {E}[( \mathscr {W}_n, \varphi )_0]=0\) and
It can be expressed in the basis functions \(\lbrace \psi _k\rbrace _{1\le k \le n}\) of \(V_n\), as stated in the next proposition which leads to an expression of the white noise using a basis that does not have to be orthonormal or an eigenbasis of \(-\varDelta _{n}\).
Proposition 3.3
Let \(\mathscr {W}_n\) be a white noise on \(V_n\). Then, \(\mathscr {W}_n\) can be written as
where \(\tilde{\varvec{W}}=(\tilde{W}_1, \dots , \tilde{W}_n)^T\) is a centered Gaussian vector with covariance matrix \(\varvec{C}^{-1}\).
Proof
Let \(\varvec{W}=(W_1, \cdots , W_n)^T\) be the vector containing the random weights defining \(\mathscr {W}_n\) in (3.4). Using the linearity of E in Corollary 3.2, \(\mathscr {W}_n\in V_n\) can be written as
where \(\varvec{W} \sim \mathscr {N}(\varvec{0},\varvec{I})\). But also, denoting by \(\tilde{\varvec{W}}=(\tilde{W}_1, \dots , \tilde{W}_n)^T\) the vector containing the coordinates of \(\mathscr {W}_n\) in the basis \(\lbrace \psi _k\rbrace _{1\le k\le n}\) of \(V_n\), we get from Corollary 3.2,
Hence, since E is bijective, we get \(\tilde{\varvec{W}} =(\sqrt{\varvec{C}})^{-T}\varvec{V}{\varvec{W}} \) which proves the result.\(\square \)
Inspired by the definition of the H-valued random field \(\mathscr {Z}\) in (2.4), we introduce its Galerkin discretization \(\mathscr {Z}_n\) as the \(V_n\)-valued random field defined by
where \(W_1, \dots , W_n\) are independent standard Gaussian random variables. Expressing \(\mathscr {Z}_n\) in the basis functions \(\lbrace \psi _k\rbrace _{1\le k \le n}\) can then be done straightforwardly using the next theorem, leading to a first method to generate approximations of \(\mathscr {Z}\).
Theorem 3.4
The discretized field \(\mathscr {Z}_n\) can be decomposed in the basis \(\lbrace \psi _k\rbrace _{1\le k\le n}\) as
where \(\varvec{Z}=(Z_1, \dots , Z_n)^T\) is a centered Gaussian vector with covariance matrix given by
with
Proof
Notice that \(\mathscr {Z}_n\) is \(V_n\)-valued, hence there exists some random vector \(\varvec{Z}\in \mathbb {R}^n\) such that \(\mathscr {Z}_n=\sum _{k=1}^n Z_k \psi _k\). Following Corollary 3.2, we obtain \(\mathscr {Z}_n=E((\sqrt{\varvec{C}})^{T}\varvec{Z})\). But following instead the definition of \(\mathscr {W}_n\) in (3.4) and the linearity of E, we get
where \(\varvec{W}=(W_1, \dots , W_n)^T \sim \mathscr {N}(\varvec{0}, \varvec{I})\). Therefore, given that E is bijective,
which proves the result.\(\square \)
Theorem 3.4 provides an explicit expression for the covariance matrix of the weights of \(V_n\)-valued random variables. Consequently, generating realizations of such random functions can be done by simulating a centered Gaussian random vector of weights with covariance matrix (3.7) and then building the weighted sum (3.6).
A particular case, investigated in [10], is when \(V_n\) is spanned by the set of eigenfunctions associated with the first n eigenvalues (sorted in non-decreasing order and counted with their multiplicities) of the Laplace–Beltrami operator. Then, the discretized random field \(\mathscr {Z}_n\) corresponds to a truncation of order n of the series in Proposition 2.7 that defines the random field \(\mathscr {Z}\). Hence, we have a direct extension to Riemannian manifolds of the spectral methods used to sample isotropic random fields with spectral density \(\gamma ^2\) on a bounded domain of \(\mathbb {R}^d\) [14] or a sphere [35]. In practice though, for arbitrary compact, connected and oriented Riemannian manifolds, the eigenfunctions of the Laplace–Beltrami operator are not readily available and must be computed numerically, rendering such spectral methods potentially cumbersome. But since the only requirement on \(V_n\) was for this space to be a finite-dimensional subspace of \(\dot{H}^1\), Theorem 3.4 is applicable to more general choices of approximation spaces \(V_n\).
4 Chebyshev approximation of the discretized random field
Since the weights of the discretized random field characterized in Theorem 3.4 form a centered Gaussian random vector, they are entirely characterized by their covariance matrix. We show how the particular form of this covariance matrix can be used to propose efficient sampling methods.
Let \(\varvec{Z}\) be the centered Gaussian random vector generating \(\mathscr {Z}_n\) in Theorem 3.4. Then, \(\varvec{Z}\) can be expressed as the solution to the linear system
where \(\varvec{X}\) is a centered Gaussian random vector with covariance matrix \(\gamma ^2(\varvec{S})\). In this section, we review ways of generating the right-hand side of this linear system.
A rather straightforward way to generate samples of \(\varvec{X}\) would be to compute the product
where \(\varvec{W} \sim \mathscr {N}(\varvec{0}, \varvec{I})\) and \(\sqrt{\gamma ^2(\varvec{S})}\) is a square-root of \(\gamma ^2(\varvec{S})\), i.e., a matrix satisfying \(\gamma ^2(\varvec{S})=\sqrt{\gamma ^2(\varvec{S})}\big (\sqrt{\gamma ^2(\varvec{S})}\big )^T\). Suitable choices are the Cholesky factorization of \(\gamma ^2(\varvec{S})\) and the matrix \(\gamma (\varvec{S})\). However these choices would entail to fully diagonalize the matrix \(\varvec{S}\) since they rely on matrix functions. This requires a workload of \(\mathscr {O}(n^3)\) operations and a storage space of \(\mathscr {O}(n^2)\). To reduce these high costs, we propose to use a polynomial approximation of the square-root based on Chebyshev series instead.
Let \(\varvec{X}\) be a sample of the weights obtained through the relation
where \(\varvec{W} \sim \mathscr {N}(\varvec{0}, \varvec{I})\). Note that in the particular case where \(\gamma = P\) is a polynomial of degree K with coefficients \(a_0, \dots ,a_{K}\in \mathbb {R}\), we have
This means in particular that the product \(P(\varvec{S})\varvec{W}\) can be computed iteratively, while requiring at each iteration only a single product between \(\varvec{S}\) and a vector. Hence, no diagonalization of the matrix is needed in this case. Building on this idea, we propose to approximate, for a general function \(\gamma \), the vector \(\varvec{X}\) in (4.2) by the vector \(\widehat{\varvec{X}}\) defined by
where \(P_{\gamma ,K}\) is a polynomial approximation of degree \(K\in \mathbb {N}\) of \(\gamma \), over an interval containing all the eigenvalues of \(\varvec{S}\). In particular, since \(\varvec{S}\) is positive semi-definite, we consider this interval to be \([0, \lambda _{\max }]\) where \(\lambda _{\max }\) is some upper bound of the greatest eigenvalue of \(\varvec{S}\).
We choose the basis of Chebyshev polynomials (of the first kind) to compute the expression of the approximating polynomial \(P_{\gamma ,K}\). These polynomials are the family \(\lbrace T_k\rbrace _{k\in \mathbb {N}_0}\) of polynomials defined over \([-1,1]\) by:
or equivalently via the recurrence relation:
Note in particular that for any \(k\in \mathbb {N}_0\), \(T_k\) is a polynomial of degree k and that for any \(t\in [-1, 1]\), \(\vert T_k(t) \vert \le 1\). A remarkable property of Chebyshev polynomials is that they form a set of orthogonal functions of the space \(L^2_c([-1,1])\) defined by
and equipped with the inner product \(\langle \cdot , \cdot \rangle _c\) defined by
As such, the truncated Chebyshev series of order \(K\ge 0\) of any function \(f\in L^2_c([-1, 1])\) is the polynomial of degree (at most) K given by
where the coefficients \(c_k\) are defined by
Truncated Chebyshev series of continuous functions are pointwise convergent in the \(L^2_c\)-sense [41, Theorem 5.6], and for power spectral densities they are uniformly convergent (cf. “Appendix A” for more details). This motivates their use to approximate a power spectral density \(\gamma \). Besides, using truncated Chebyshev series also guarantees:
-
the fact that at any order of approximation K, the polynomial \(P_{\gamma ,K}\) is near optimal in the sense that
$$\begin{aligned} \Vert B_{\gamma }^* - \gamma \Vert _{\infty } \le \Vert P_{\gamma ,K} - \gamma \Vert _{\infty } \le (1+\varLambda _K)\Vert B_{\gamma }^* - \gamma \Vert _{\infty }, \end{aligned}$$where \(B_{\gamma }^*\) is the best polynomial approximation of \(\gamma \) of order K and
$$\begin{aligned} \varLambda _K= (4/\pi ^2)\log (K)+C+\mathscr {O}(K^{-1}), \end{aligned}$$where \(C\approx 1.27\) is the so-called Lebesgue constant of the approximation [41, Chapter 5, Section 5];
-
the fact that the coefficients of the polynomial in the Chebyshev basis of polynomials can be computed very efficiently using the Fast Fourier Transform (FFT) algorithm [16], with a complexity that can be bounded by \(\mathscr {O}(K\log K)\) to compute K coefficients (see [43, Section B.4.4] for an algorithm).
Since Chebyshev polynomials are defined on \([-1, 1]\), the interval of approximation \([0, \lambda _{\max }]\) must be mapped onto \([-1, 1]\) and vice versa, which is done with the linear of variable \(\theta : [-1,1] \rightarrow [0, \lambda _{\max }]\), given by \(\theta (t)=0.5\lambda _{\max }(1+t)\), \(t\in [-1, 1]\). The function \(\tilde{\gamma }: [-1, 1] \rightarrow \mathbb {R}\) given by
can then be approximated by a truncated Chebyshev series of order K, and the polynomial \(P_{\gamma ,K}\) approximating \(\gamma \) on \([0,\lambda _{\max }]\) takes the form
where \(\mathscr {S}_K[\tilde{\gamma }]\) is the truncation of order K of the Chebyshev series of \(\tilde{\gamma }\).
Ultimately, the approximation \(\widehat{\mathscr {Z}}_{n,K}\) of the discretized field \(\mathscr {Z}_n\) that results from the polynomial approximation introduced in this subsection takes the form
where the random weights \(\widehat{\varvec{Z}} = (\widehat{Z}_1, \dots , \widehat{Z}_n)^T\) are given by
with \(\varvec{W} \sim \mathscr {N}(\varvec{0}, \varvec{I})\) and \(c_0, \dots , c_K\) denote the first K coefficients of the Chebyshev series of \(\tilde{\gamma }\). We call \(\widehat{\mathscr {Z}}_{n,K}\) a Galerkin–Chebyshev approximation of discretization order \(n\in \mathbb {N}\) and polynomial order \(K\in \mathbb {N}\) of the Gaussian random field \(\mathscr {Z}\).
5 Convergence analysis
The goal of this section is to derive the overall error between the random field \(\mathscr {Z}\), as defined in (2.4), and its Galerkin–Chebyshev approximation \(\widehat{\mathscr {Z}}_{n,K}\) associated with a functional discretization space \(V_n\) of dimension n and a Chebyshev polynomial approximation of order K of the power spectral density. To derive this error, we assume for simplicity that the upper bound \(\lambda _{\max }\) of the eigenvalues of the stiffness matrix \(\varvec{S}\) (on which the Chebyshev polynomial approximation is defined) is equal to the maximal eigenvalues of \(\varvec{S}\), i.e., \(\lambda _{\max } = \lambda _n^{(n)}\).
To prove convergence result between \(\mathscr {Z}\) and \(\widehat{\mathscr {Z}}_{n,K}\), we need an additional assumption on the space \(V_n\), or more precisely on the approximating properties of the discretized operator \(-\varDelta _n\) that this space yields. We assume the following link between the eigenpairs of \(-\varDelta _n\) and those of \(-\varDelta _{\mathscr {M}}\) (arranged in non-decreasing order).
Assumption 5.1
Let \(\alpha >0\) be defined in Proposition 2.1. There exist constants \(N_0, C_1, C_2>0\), \(l_\lambda \in (0,1]\), and exponents \(r, s > 0\) and \(q\ge 1\), satisfying the inequality
such that for all \(n \ge N_0\) and \(k\in [\![M_0+1, n]\!]\),
and
Remark 5.2
In the assumption above, we do not need to treat the case \(\lambda _k=0\) (i.e., \(M_0\ne 0\) and \(k\le M_0\)). Indeed, recall that the manifold is connected, and that therefore \(M_0\in \lbrace 0, 1\rbrace \). Hence, if \(\lambda _k=0\) arises, there is exactly one such eigenvalue to approximate, namely \(\lambda _{1}=0\). And in this case, since the discretized operator \(-\varDelta _n\) is positive semi-definite, we have \(\lambda _1^{(n)}=0=\lambda _{1}\) for any \(n\in \mathbb {N}\). The same conclusion can be derived for the eigenfunctions since in both cases, they can be taken equal to a constant function with value 1.
In Assumption 5.1, the requirement (5.2) states that eigenvalues and eigenfunctions of \(-\varDelta _n\) should asymptotically lie within a ball around the eigenvalues and eigenfunctions of \(-\varDelta _{\mathscr {M}}\), where the radius of the ball may grow with the magnitude of the eigenvalue but, for a fixed index k, decreases as \(n\rightarrow +\infty \). The requirement (5.3) expresses that, asymptotically, the eigenvalues of \(-\varDelta _n\) should grow at the same rate as the eigenvalues of \(-\varDelta _{\mathscr {M}}\). This last requirement may seem redundant with the first one but ensures that, even for large indices \(k\approx n\), the eigenvalues \(\lambda _{k}^{(n)}\) do not stay too far away from \(\lambda _k\) (which is not always ensured by the first requirement).
A straightforward example of a discretization space \(V_n\) for which Assumption 5.1 is satisfied is when \(V_n\) is defined as the set containing the first n eigenfunctions of the Laplace–Beltrami operator, since then \(\lambda _{k}^{(n)}=\lambda _{k}\) and \(e_k^{(n)}=e_k\) for any \(k\in [\![1, n]\!]\). The resulting Galerkin–Chebyshev approximation of the field then amounts to a classical spectral method. In this case, one can use directly the Galerkin approximation of the random field for sampling purposes without requiring a Chebyshev polynomial approximation of the power spectral density (cf. Sect. 6.2.1 for more details). However, considering this particular discretization space \(V_n\) implies that the eigenfunctions of the Laplace–Beltrami operator are known, which is seldom in practice.
An alternative to the spectral method consists in building the discretization space \(V_n\) from basis functions of a finite element space. If the Riemannian manifold \((\mathscr {M}, g)\) is a bounded convex polygonal domain equipped with the Euclidean metric, and \(V_n\) is the linear finite element space associated with a quasi-uniform triangulation of \(\mathscr {M}\) with mesh size \(h \lesssim n^{-1/d}\), then Assumption 5.1 is satisfied for the exponents \(r=s=\alpha =2/d\) and \(q=2\) [49, Theorems 6.1 & 6.2].
If now \(\mathscr {M}\) is a smooth compact 2-dimensional surface in \(\mathbb {R}^3\) without boundary, equipped with the metric g induced by the Euclidean metric on \(\mathbb {R}^3\) (and called pullback metric, see [37, Chapter 13] for more details), the surface finite element method (SFEM) provides a way to construct a finite element space on the surface \(\mathscr {M}\) by “lifting” on \(\mathscr {M}\) a linear finite element space defined on a polyhedral approximation of \(\mathscr {M}\) that lies “close” to the surface (see [19] and [18, Section 2.6] for more details). The discretization space \(V_n\) can then be taken as the linear span of the lifted finite element basis functions defined on the polyhedral surface. One can show that, \(\vert \lambda _{k}^{(n)}-\lambda _{k}\vert \lesssim \lambda _k^2 n^{-1}\) and that \(\lambda _{k}^{(n)}\le \lambda _{k}\) (cf. “Appendix C” for more details). Proving the eigenfunction inequality is open and ongoing work, but our numerical experiments in Sect. 7 indicate that our error estimates hold.
Remark 5.3
In practice, when using SFEM, it is usual to consider the eigenfunctions and eigenvalues of the discrete operator defined on the polyhedral approximation \(\widehat{\mathscr {M}}\) of the surface \(\mathscr {M}\) (as opposed to the original surface \(\mathscr {M}\)). In that case, \(V_n\) is not a subset of functions of \(\mathscr {M}\) but rather a subset of functions of \(\widehat{\mathscr {M}}\), which is considered in the numerical experiments in Sect. 7. Then, the error on the approximation in \(V_n\) of the eigenvalues and eigenvectors of the Laplace–Beltrami operator of \(\mathscr {M}\) can be written as (see [8]):
where the explicit dependence of the constants \(\widehat{C}_1\) and \(\widehat{C}_2\) on \(\lambda _k\) is given in [8]. Hence, if one can write \(C_1(\lambda _k)\lesssim \lambda _{k}^q\) and \(C_2(\lambda _k)\lesssim \lambda _{k}^q\) for some \(q\in [1,2]\), then Assumption 5.1 is satisfied, which is ongoing work.
We now state the main results of this section.
Theorem 5.4
Let Assumptions 2.4 and 5.1 be satisfied. Then, the approximation error of the random field \(\mathscr {Z}\) by its Galerkin–Chebyshev approximation \(\widehat{\mathscr {Z}}_{n,K}\) of discretization order \(n\in \mathbb {N}\) big enough and polynomial order \(K\in \mathbb {N}\), satisfies
where \(C_{\text {Galer}}\) and \(C_{\text {pol}}\) are constants independent of n and K, \(\rho =\min \left\{ s;\; r;\; (\alpha \beta -1/2)\right\} >0\), \(\alpha >0\) is defined in Proposition 2.1, \(r>0\) and \(s>0\) are given in Assumption 5.1, and \(\beta >0\) and \(\nu \in \mathbb {N}\) as in Definition 2.3.
When the power spectral density \(\gamma \) is known to be analytic over \([0,\lambda _{\max }]\) (meaning in particular that in Definition 2.3 any \(\nu \in \mathbb {N}\) works), the polynomial approximation error can be shown to decrease at an exponential rate. The resulting overall error between the random field \(\mathscr {Z}\) and its approximation \(\widehat{\mathscr {Z}}_{n,K}\) can then be upper bounded as stated in the next result.
Corollary 5.5
Let Assumptions 2.4 and 5.1 be satisfied and let \(\gamma \) be a power spectral density such that there exists some \(\chi >0\) such that the map \(z \in \mathbb {C} \mapsto \gamma (z)\) is holomorphic inside the ellipse \(E_\chi \subset \mathbb {C}\) centered at \(z=\lambda _{\max }/2\), with foci \(z_1=0\) and \(z_2=\lambda _{\max }\), and semi-major axis \(a_\chi =\lambda _{\max }/2+\chi \).
Then, the approximation error of the random field \(\mathscr {Z}\) by its Galerkin–Chebyshev approximation \(\widehat{\mathscr {Z}}_{n,K}\) of discretization order \(n\in \mathbb {N}\) big enough and polynomial order \(K\in \mathbb {N}\), satisfies
where \(C_{\text {Galer}}\). \({\tilde{C}}_{\text {pol}}\) and \({\widehat{C}}_{\text {pol}}\) are constants independent of n and K, \(\rho =\min \left\{ s;\; r;\; (\alpha \beta -1/2)\right\} >0\), \(\alpha >0\) is defined in Proposition 2.1, \(r>0\) and \(s>0\) are given in Assumption 5.1, and \(\beta >0\) as in Definition 2.3.
We prove these two error estimates by upper bounding the left-hand side by the sum of a discretization error and a polynomial approximation error, both of which are derived in the next two subsections. The discretization error is computed in the more general setting on spaces \(\dot{H}^\sigma \) defined in Sect. 2.3 (with \(\sigma =0\) giving the error on H). We also provide an interpretation of the terms composing this error estimate, as well as a result on the convergence of the covariance of the discretization scheme.
5.1 Error analysis of the discretized field
In this section, a convergence result of the discretized field \(\mathscr {Z}_n\) is derived in terms of a root-mean-squared error on the spaces \(\dot{H}^\sigma \) defined in Sect. 2.3.
Theorem 5.6
Let Assumptions 2.4 and 5.1 be satisfied. Then, there exists \(N_1\in \mathbb {N}\) such that for any \(n>N_1\), and \(\sigma \in [0, \alpha ^{-1}(2\alpha \beta -1))\), the approximation error of the random field \(\mathscr {Z}\) by its discretization \(\mathscr {Z}_n\) satisfies
where \(\alpha >0\) is defined in Proposition 2.1, \(q\ge 1\), \(r>0\) and \(s>0\) are given in Assumption 5.1, and \(\beta >0\) as in Definition 2.3.
Proof
Let \(n>\max \lbrace M_0; N_0\rbrace \), and let \(\mathscr {Z}^{(n)}\) be the truncated random field of \(\mathscr {Z}\) given by
We split the error with the triangle inequality into
and bound both terms in what follows.
\(\underline{\text {Truncation}~\text {error}~\text {term}}\) \(\Vert \mathscr {Z} - \mathscr {Z}^{(n)} \Vert _{L^2(\varOmega ; \dot{H}^\sigma )}\): Note that
which leads by Proposition 2.1 and Assumption 2.4 to
where the last inequality is derived using a Riemann sum associated with the integration of the function \(t\mapsto t^{-\alpha (2\beta -\sigma )}\) and using the assumption that \(\alpha (2\beta -\sigma )>1\).
\(\underline{\text {Discretization}~\text {error}}\) \(\Vert \mathscr {Z}^{(n)} - \mathscr {Z}_n \Vert _{L^2(\varOmega ; \dot{H}^\sigma )}\): We split the error further by the triangle inequality into
The first term satisfies
where for any \(i\in [\![1,n]\!]\), \(\sigma (i)=2\) if \(\lambda _i=0\) and \(\sigma (i)=\sigma \) otherwise. Hence, using the independence of the Gaussian random weights \(\lbrace W_j\rbrace _{j\in \mathbb {N}}\) and Assumption 5.1,
Following Remark 5.2, the first sum in \((\text {I})^2\) is 0. It then follows from Assumption 5.1, Proposition 2.1, and Assumption 2.4 that
And using the fact that \(\alpha q\le 2s\) (cf. Eq. (5.1)), we finally obtain
Bounding the sum again by the corresponding integral, we distinguish three cases:
-
if \(2s-(2\alpha \beta -\alpha \sigma )>-1\), then \(\sum _{j=1}^nj^{2s-(2\alpha \beta -\alpha \sigma )} \lesssim n^{2s-(2\alpha \beta -\alpha \sigma )+1} \);
-
if \(2s-(2\alpha \beta -\alpha \sigma )=-1\), then \(\sum _{j=1}^nj^{2s-(2\alpha \beta -\alpha \sigma )} \lesssim \log n \);
-
if \(2s-(2\alpha \beta -\alpha \sigma )<-1\), then \(\sum _{j=1}^nj^{2s-(2\alpha \beta -\alpha \sigma )} \lesssim 1 \).
Hence, we conclude
and continue with bounding
Following Remark 5.2, the first sum in \((\text {II})^2\) is 0. We then focus on the terms composing the second sum. The mean value theorem gives for any \(j\in [\![M_0+1,n]\!]\),
We have, for \(n>N_0\), \(\min \big \lbrace \lambda _k; \lambda _{k}^{(n)}\big \rbrace \ge l_\lambda \lambda _k \ge l_\lambda c_\lambda k^{\alpha }\) as a consequence of Proposition 2.1 and Assumption 5.1. We can therefore find \(N_1 > N_0\) such that for any \(n>N_1\) and any \(j\in [\![N_1, n]\!]\), \(\min \big \lbrace \lambda _j;\; \lambda _{j}^{(n)}\big \rbrace \ge l_\lambda c_\lambda k^{\alpha } \ge L_\gamma \), where \(L_\gamma \) is defined in Definition 2.3. Then, for any \(j\in [\![N_1, n]\!]\),
And for \(j<N_1\), we can take
where \(S_\gamma ' = \sup _{ [0, L_\gamma ]}\vert \gamma '\vert \). Therefore, using the last two inequalities (and applying again Proposition 2.1 and Assumption 5.1), we get
If \(q=1\), we have \((\text {II})^2 \lesssim n^{-2r}\) since \(2\alpha \beta -\alpha \sigma > 1\).
If \(q>1\), since \(\alpha (q-1) \le r\), we obtain
and using the same argument as for \((\text {I})^2\), we conclude that
Combining the terms \((\text {I})\) and \((\text {II})\) finally gives, if \(q>1\),
and if \(q=1\),
The proof is concluded by bounding Eqs. (5.5) to (5.7) by the smallest exponents.\(\square \)
This error estimate (5.4) yields the same convergence rate as the one derived in [5, 7] in their approximation of solutions to fractional elliptic SPDEs with spatial white noise, but our result differs from their result in three aspects. First, we defined our random fields on Riemannian manifolds. Then, the random fields covered by their result can be seen as those specific choices of \(\gamma \) such that \(\gamma \) is non-zero over \(\mathbb {R}_+\). Finally, we use slightly different assumptions on the discretization space: in Assumption 5.1, we do not assume that \(\lambda _{k}^{(n)}\ge \lambda _{k}\). This assumption holds in particular for finite element spaces associated with conforming triangulation and on domains of \(\mathbb {R}^d\) [49], and dropping it allows to open the way to the use of non-conforming methods.
We conclude this subsection by investigating the overall error in the covariance between the random field \(\mathscr {Z}\) and its discretized counterpart \(\mathscr {Z}_n\). This error is described in the next theorem and is derived using the same approach as in Theorem 5.6.
Theorem 5.7
Let Assumptions 2.4 and 5.1 be satisfied. Then, there exists some \(N_2\in \mathbb {N}\) such that for any \(n>N_2\), the covariance error between the random field \(\mathscr {Z}\) and its discretization \(\mathscr {Z}_n\) satisfies, for any \(\theta ,\varphi \in H\),
Proof
The proof of this theorem is similar to the proof of Theorem 5.6, and is available in Section SM3 of the Supplementary Materials.\(\square \)
5.2 Error analysis of the polynomial approximation
The Chebyshev polynomial approximation boils down to replacing the power spectral density \(\gamma \) by the polynomial \(P_{\gamma ,K}\) defined in (4.8), which approximates \(\gamma \) over a segment \([0, \lambda _n^{(n)}]\) containing all the eigenvalues of the discretized operator \(-\varDelta _n\) (or equivalently the eigenvalues of the matrix \(\varvec{S}\)). Hence, we have according to (3.5)
where \(\lbrace W_k\rbrace _{1\le k\le n}\) are the same random weights as the ones defining \(\mathscr {Z}_n\) in (3.5). The next result gives the root-mean-squared error between \(\mathscr {Z}_n\) and its approximation \(\widehat{\mathscr {Z}}_{n,K}\).
Theorem 5.8
Let Assumption 5.1 be satisfied, and let \(\nu \in \mathbb {N}\) be defined as in Definition 2.3, and let \(\lambda _{\max }=\lambda _n^{(n)}\). Then, there exists \(N_{\text {Cheb}}\in \mathbb {N}\) such that for any \(n> N_{\text {Cheb}}\), the root-mean-squared error between the discretized field \({\mathscr {Z}}_n\) and its polynomial approximation \(\widehat{\mathscr {Z}}_{n,K}\) of order \(K>\nu \) is bounded by
where \(\text {TV}(\gamma ^{(\nu )})\) denotes the total variation over \([0, \lambda _{\max }]\) of the \(\nu \)-th derivative of \(\gamma \) and \(\alpha >0\) and \(C_\lambda >0\) are defined in Proposition 2.1.
If \(\gamma \) satisfies that there exists some \(\chi >0\) such that the map \(z \in \mathbb {C} \mapsto \gamma (z)\) is holomorphic inside the ellipse \(E_\chi \subset \mathbb {C}\) centered at \(z=\lambda _{\max }/2\), with foci \(z_1=0\) and \(z_2=\lambda _{\max }\) and semi-major axis \(a_\chi =\lambda _{\max }/2+\chi \), then, there exists \(M_{\text {Cheb}}\in \mathbb {N}\) such that for any \(n> M_{\text {Cheb}}\),
Proof
Let \(\lambda _{\max }=\lambda _n^{(n)}\) and let \(K\in \mathbb {N}\). We observe first that
using the definition of \(\mathscr {Z}_n\) and \(\widehat{\mathscr {Z}}_{n,K}\). A rather crude upper bound of this quantity is given by
where
with \(\tilde{\gamma }\) defined in (4.7) and \(\mathscr {S}_K[\tilde{\gamma }]\) denoting the Chebyshev series of \(\tilde{\gamma }\) truncated at order K. If we take \(K>\nu \), the convergence properties of Chebyshev series (cf. Theorem A.1) imply that
Under Proposition 2.1, and Assumption 5.1, we have
which yields \(\lambda _{\max }=\mathscr {O}(n^{\alpha })\) (as \(n\rightarrow +\infty \)) since \(\alpha (q-1)\le r\). Hence, by defining \( N_{\text {Cheb}} = \min \lbrace n\in \mathbb {N}: C_1C_\lambda n^{\alpha (q-1)-r} <1\rbrace \), we obtain that for any \(n> N_{\text {Cheb}}\), \(\lambda _{\max }\le 2C_\lambda n^\alpha \), which in turn gives
For the second inequality, using a convergence result of Chebyshev series for analytic functions (cf. Theorem A.1) and the same reasoning as above, we get for any \(n, K\in \mathbb {N}\),
where \(\epsilon _\chi >0\) is given by \(\epsilon _\chi =2\lambda _{\max }^{-1}\big ( \chi +\sqrt{\chi (\lambda _{\max }+\chi )}\big )=h(\chi \lambda _{\max }^{-1})\), and for \(x>0\), \(h(x)=2(x+\sqrt{x(1+x)})\). In particular, for \(x\in (0,1)\), we have \( 2\sqrt{x}<h(x)< 2(1+\sqrt{2})\sqrt{x}\).
Following Proposition 2.1 and Assumption 5.1, \(\lambda _{\max }=\lambda _{n}^{(n)}\ge l_\lambda \lambda _{n} \ge l_\lambda c_\lambda n^\alpha \), which gives in particular \(\lambda _{\max }^{-1} \le (l_\lambda c_\lambda )^{-1} n^{-\alpha }\). Let \({\widehat{N}}_{\text {Cheb}} = \min \lbrace n\in \mathbb {N}: 4(1+\sqrt{2})^2\chi (l_\lambda c_\lambda )^{-1} n^{-\alpha } <1\rbrace \). Then, for any \(n> {\widehat{N}}_{\text {Cheb}}\), we have \(\chi \lambda _{\max }^{-1} \in (0,1)\) and
Taking \(n > M_{\text {Cheb}}= \max \lbrace N_{\text {Cheb}}, {\widehat{N}}_{\text {Cheb}}\rbrace \), we obtain
Using that \(x\mapsto x^{-1}(1+x)^{-K}\) is decreasing for \(x\in (0,1)\) and that \(\log (1+x)\ge x/2\) yields for any \(n> M_{\text {Cheb}}\),
where \(C_{\chi ,\lambda }=\sqrt{\chi (2C_\lambda )^{-1}}\). This in turn gives
\(\square \)
For a fixed number of degrees of freedom n in Theorem 5.8, the approximation error \(\Vert {\mathscr {Z}}_n-\widehat{\mathscr {Z}}_{n,K}\Vert _{L^2(\varOmega ;H)}\) converges to 0 as the order of the polynomial approximation K goes to infinity. Choosing K as a function of n that grows fast enough then allows to ensure the convergence of the approximation error as n goes to infinity. For instance, let us assume that \(\gamma \) is once differentiable with a derivative with bounded variations (i.e., \(\nu =1\) in Definition 2.3), and take for simplicity \(\lambda _{\max }=\lambda _{n}^{(n)}\). Assuming that Assumption 5.1 is satisfied, and following Proposition 2.1 yields \(\lambda _{\max }=\mathscr {O}(n^\alpha )\). Taking \(K=K(n)=f(n)n^{\alpha +1/2}\), where f denotes any function with \(\lim _{n\rightarrow \infty } f(n) = + \infty \), ensures that the approximation error \(\Vert {\mathscr {Z}}_n-\widehat{\mathscr {Z}}_{n,K}\Vert _{L^2(\varOmega ;H)}\) goes to 0 at least as fast as f goes to infinity. In Sect. 6.3, we provide another example for the choice of K for an analytic power spectral density.
In practice though, the order K of the polynomial approximation is set differently, which allows to work with relatively small orders. It is suggested in [44] to set K by controlling the deviation in distribution between the samples obtained with and without the polynomial approximation. We propose an approach based on the numerical properties of Chebyshev series, and show in the numerical experiments that it allows to limit the approximation order.
Observe that the random weights (4.9) defining the Chebyshev polynomial approximation \(\widehat{\mathscr {Z}}_{n,K}\) are obtained by summing the random vectors given by
where \(\varvec{W} \sim \mathscr {N}(\varvec{0}, \varvec{I})\) and \(c_0, \dots , c_K\) are the Chebyshev series coefficients of the function \(\tilde{\gamma }\) defined in (4.7). The Chebyshev polynomials \(\lbrace T_k\rbrace _{k\in \mathbb {N}}\) have values in \([-1,1]\), meaning in particular that the eigenvalues of the matrices \(T_k((2/\lambda _{\max })\varvec{S}-\varvec{I})\) lie in the same interval. Consequently, we have for any \(k\in [\![0, K]\!]\),
Let \(c_{\max }=\max \lbrace \vert c_k\vert : 0\le k\le K\rbrace \). Since the coefficients \(c_k\) converge to 0 at least linearly for power spectral densities (cf. Theorem A.1), the order K can be chosen to ensure that the ratio \(c_K/c_{\max } \ll 1\) or that the bound \(\vert c_K \vert n^{1/2} \ll 1\). Then, in practice, adding more terms to the expansion only results in negligible perturbations of the solution.
6 Complexity analysis
Recall that the Galerkin–Chebyshev approximation \(\widehat{\mathscr {Z}}_{n,K}\) of discretization order \(n\in \mathbb {N}\) and polynomial order \(K\in \mathbb {N}\) of a random field \(\mathscr {Z}\) is defined as
where \(\widehat{\varvec{Z}}=({\widehat{Z}}_1, \dots , {\widehat{Z}}_n)^T\) is a Gaussian random vector with mean \(\varvec{0}\) and covariance matrix
which can be computed by solving the linear system
for \(\varvec{W} \sim \mathscr {N}(\varvec{0}, \varvec{I})\). We now discuss the computational and storage cost of sampling a GRF using this approximation. In a first part, we derive these costs for the the case where nothing further is assumed about the basis \(\lbrace \psi _k\rbrace _{1\le k\le n}\) used to discretize the field. In a second part, we then show how some particular choices of this basis can help to drastically improve these costs. The computational and storage costs obtained in each case are summarized in Table 1. Each time, we distinguish offline computational costs, linked to operations that can be reused to generate more samples, and online computational costs steps that are specific to the computation of a given sample. In particular, we observe that the spectral method seems to perform best, but as we will see this method is rarely applicable, and we will in practice prefer the method based on linear finite elements with a mass lumping approximation which still offers overall computational costs that grow linearly with the product Kn (see Sects. 6.2.1 and 6.2.2 for more details).
6.1 Efficient sampling: general case
Generating samples of the weights \(\widehat{\varvec{Z}}\) in (6.2) requires two steps:
-
first, one computes the vector \(\widehat{\varvec{X}}=P_{\gamma ,K}(\varvec{S})\varvec{W}\) for some \(\varvec{W} \sim \mathscr {N}(\varvec{0}, \varvec{I})\). Due to the fact that \(P_{\gamma ,K}\) is a polynomial, this step can be implemented as an iterative program involving at each step only one matrix–vector product between \(\varvec{S}\) and a vector;
-
then, one solves the linear system \(\big (\sqrt{\varvec{C}}\big )^{T} \widehat{\varvec{Z}} =\widehat{\varvec{X}}\).
In order to execute these two steps, one only needs to implement the following two sub-algorithms:
-
an algorithm \(\varvec{\varPi }_{\varvec{S}}\) taking as input a vector \(\varvec{x}\) and returning the product \(\varvec{\varPi }_{\varvec{S}}(\varvec{x})=\varvec{S} \varvec{x}\);
-
an algorithm \(\varvec{\varPi }_{(\sqrt{\varvec{C}})^{-T}}\) taking as input a vector \(\varvec{x}\) and returning the solution \(\varvec{y}=\varvec{\varPi }_{(\sqrt{\varvec{C}})^{-T}}(\varvec{x})\) to the linear system \(\big (\sqrt{\varvec{C}}\big )^{T} \varvec{y} = \varvec{x} .\)
We present in Algorithm 1 of the Supplementary Materials the overall algorithm leading to sampling the weights of the decomposition defined in (6.1) using this approach.
Following the definition of \(\varvec{S}\) in Corollary 3.2, \(\varvec{\varPi }_{\varvec{S}}\) does not require the matrix \(\varvec{S}\) to be computed explicitly and stored: a product by \(\varvec{S}\) boils down to solving a first linear system defined by \((\sqrt{\varvec{C}})^{T}\), multiplying the obtained solution by \(\varvec{R}\) and then solving a second linear system defined by \(\sqrt{\varvec{C}}\). Hence, both \(\varvec{\varPi }_{(\sqrt{\varvec{C}})^{-T}}\) and \(\varvec{\varPi }_{\varvec{S}}\) rely on solving linear systems involving a square-root of the mass matrix \(\varvec{C}\) (or its transpose). The cost associated with calls to \(\varvec{\varPi }_{(\sqrt{\varvec{C}})^{-T}}\) and \(\varvec{\varPi }_{\varvec{S}}\) should be kept minimal in order to reduce the overall computational complexity of the sampling algorithm.
Since the choice of this square-root is free, one could take it as the Cholesky factorization of \(\varvec{C}\) satisfying \(\sqrt{\varvec{C}} = \varvec{L}\) for some lower-triangular matrix \(\varvec{L}\). Solving a linear system involving \(\varvec{L}\) or \(\varvec{L}^T\) can be done at roughly the cost of a matrix–vector product using forward or backward substitution. The algorithms \(\varvec{\varPi }_{\varvec{S}}\) and \(\varvec{\varPi }_{(\sqrt{\varvec{C}})^{-T}}\) resulting from this choice are presented in Algorithms 2 and 3 of the Supplementary Materials. Regarding the computational complexity of these algorithms, since solving a linear system using forward or backward substitution can be done with a computational cost of the same order as a matrix–vector product (namely \(\mathscr {O}(n^2)\) operations), each call to \(\varvec{\varPi }_{\varvec{S}}\) or \(\varvec{\varPi }_{(\sqrt{\varvec{C}})^{-T}}\) amounts to \(\mathscr {O}(n^2)\) operations. This means that, if implementations of these two algorithms are available, the cost of computing the weights \(\widehat{\varvec{Z}}\) in (6.2) is of order \(\mathscr {O}(Kn^2)\), where K corresponds to the order of the polynomial approximation.
Finally, recall that one needs an upper bound \(\lambda _{\max }\) of the largest eigenvalue of \(\varvec{S}\) in order to define the polynomial \(P_{\gamma , K}\). This upper bound can be obtained with a limited computational cost (namely \(\mathscr {O}(n^2)\) operations) by combining the Gershgorin circle theorem [24] and a power iteration scheme (as described in Section SM4.1 of the Supplementary Materials).
Overall, the computational cost of sampling the weights of the Galerkin–Chebyshev approximation \(\widehat{\mathscr {Z}}_{n,K}\) in (6.1) can be summarized as follows. We can distinguish between offline and online steps. The offline steps are as follows. First, there is the computation of the coefficients of the Chebyshev approximation \(P_{\gamma , K}\), which requires \(\mathscr {O}(K\log K)\) operations as mentioned in the previous subsection. Then, there is the Cholesky factorization of \(\varvec{C}\), which requires \(\mathscr {O}(n^3)\) operations [46, Chapter 2]. And finally, there is the computation of the upper bound of the eigenvalues of \(\varvec{S}\), which requires \(\mathscr {O}(n^2)\) operations (dominated by the use of the power iteration scheme). The online step is the computation of the weights according to (6.2), which requires \(\mathscr {O}(Kn^2)\) operations. Storage-wise, this workflow only requires enough space to store the Cholesky factorization of the mass matrix \(\varvec{C}\), the stiffness matrix \(\varvec{R}\), the \(K+1\) coefficients of the Chebyshev polynomial approximation, and a few vectors of size n. In conclusion, the offline costs are of order \(\mathscr {O}(K\log K+n^3)\), the online costs are of order \(\mathscr {O}(Kn^2)\), and the storage needs are of order \(\mathscr {O}(n^2+K)\). As we will see in the next section, both computational and storage costs can be reduced for typical choices of the discretization space \(V_n\).
6.2 Efficient sampling: Particular cases
The choice of the space \(V_n\) used to discretize the random fields impacts heavily the mass and stiffness matrices, and can in relevant cases be leveraged to speed up the sampling process. We provide here two examples, which will be considered later on in the numerical experiments.
6.2.1 Spectral approximation
If we assume that the eigenvalues of the Laplace–Beltrami operator are known, we can use spectral methods, which correspond to the case where \(V_n\) is the set of eigenfunctions associated with the first n eigenvalues of the Laplace–Beltrami operator. Then, since the eigenfunctions are orthonormal, the mass matrix \(\varvec{C}\) is equal to the identity matrix. Besides, using Green’s theorem, we have that the stiffness matrix \(\varvec{R}\) is also diagonal, with entries equal to the operator eigenvalues. This gives that \(\varvec{S}=\varvec{R}\) is diagonal.
Thus, sampling the weights of \(\widehat{\mathscr {Z}}_{n,K}\) can be done without requiring any Cholesky factorization: calls to \(\varvec{\varPi }_{\varvec{S}}\) are replaced by multiplication by the diagonal matrix \(\varvec{R}\) containing the eigenvalues of the operator, calls to \(\varvec{\varPi }_{(\sqrt{\varvec{C}})^{-T}}\) are replaced by products with an identity matrix, and the upper bound \(\lambda _{\max }\) is replaced by the maximal entry of \(\varvec{R}\). In particular, the offline costs are reduced to the computation of the coefficients of \(P_{\gamma , K}\), and the online costs are reduced to \(\mathscr {O}(n)\). As for the storage needs, they would now be reduced to \(\mathscr {O}(n)\) (since both \(\varvec{C}\) and \(\varvec{R}\) are diagonal).
In practice though, the Chebyshev polynomial approximation is not necessary. One can directly use Theorem 3.4 to compute samples of \(\mathscr {Z}_n\) (and therefore there is no need to approximate it by \(\widehat{\mathscr {Z}}_{n,K}\)): \(\varvec{S}\) being now diagonal, the matrix \(\gamma ^2(\varvec{S})\) is the diagonal matrix obtained by directly applying \(\gamma ^2\) to the diagonal entries of \(\varvec{S}\). Samples of \(\mathscr {Z}_n\) are then obtained by taking the weights \(\varvec{Z}\) as a sequence of independent Gaussian random variables with variances given by the diagonal entries of \(\gamma ^2(\varvec{S})\) (since \(\varvec{C}\) is the identity matrix). In conclusion, no offline costs are needed for the spectral method, the online costs are of order \(\mathscr {O}(n)\), and the storage needs are of order \(\mathscr {O}(n)\).
These computational costs might seem ideal, but one should remember that the spectral method is only applicable when the eigenfunctions and eigenvalues of the Laplace–Beltrami operator are known. This is the case for instance when working on rectangular Euclidean domains, for which the eigenfunctions correspond to the Fourier basis, and we retrieve the classical spectral methods, or for the sphere, for which the eigenfunctions are the spherical harmonics, see Sect. 7 for more details). For other choices of compact Riemannian manifolds, these are unknown, which is why we propose the next method relying on the finite element method.
6.2.2 Linear finite element spaces
Consider the case where \(V_n\) is taken to be a finite element space of (piecewise) linear functions associated with a simplicial mesh of the manifold \(\mathscr {M}\). In this case, the basis functions composing \(V_n\) have a support limited to a few elements of the mesh, and the matrices \(\varvec{C}\) and \(\varvec{R}\) are therefore sparse. Besides, for uniform meshes, one can bound the number of nonzero entries in each row of these matrices. Such sparsity can be leveraged to reduce the cost associated with sample generation.
The cost \(\eta _{\text {Chol}}(\varvec{C})\) of the Cholesky factorization now depends on the number of nonzero entries of \(\varvec{C}\), and adequate permutations can be found to ensure that the factors are themselves sparse. This cost is of course upper-bounded by the cost associated with the Cholesky factorization of a dense matrix, i.e., \(\mathscr {O}(n^3)\), but in practice the sparsity of the matrix is leveraged to achieve a lower computational cost. Consequently, the costs associated with calling \(\varvec{\varPi }_{\varvec{S}}\) or \(\varvec{\varPi }_{(\sqrt{\varvec{C}})^{-T}}\) are reduced to an order \(\mathscr {O}(\mu n)\), where \(\mu \ll n\) denotes an upper bound for the mean number of nonzero entries in \(\sqrt{\varvec{C}}\) and \(\varvec{R}\). This means in particular that the computational cost of computing the weights through (6.2) drops to \(\mathscr {O}(K\mu n)\) operations. Similarly, using the same approach as the one described in Sect. 6.1, the upper bound \(\lambda _{\max }\) can be computed in \(\mathscr {O}(\mu n)\) operations. In conclusion, the offline costs are of order \(\eta _{\text {Chol}}(\varvec{C})+\mathscr {O}(\mu n +K\log K)\), the online costs are of order \(\mathscr {O}(K\mu n)\), and the storage needs are of order \(\mathscr {O}(\mu n+K)\).
In practice, an additional approximation can be made to further reduce the computational cost of the algorithm. As advocated by Lindgren et al. [38], the mass matrix \(\varvec{C}\) can be replaced by a diagonal approximation \(\widehat{\varvec{C}}\) whose entries are given by
This approach results in a Markovian approximation of the random field, and is inspired from the lumped mass approximation proposed by Chen and Thomée [13] for parabolic PDEs. On Euclidean domains, this approach introduces an error in the covariance of the resulting field of order \(\mathscr {O}(h^2)\) where h is the mesh size, which, for a uniform mesh, is linked to the dimension n of the finite element space as \(n=\mathscr {O}(h^{-d})\). We show in the numerical experiments in Sect. 7 that this additional error does not affect the theoretical convergence rates derived in Sect. 5.
Following the lumped mass approach, the square-root \(\sqrt{\varvec{C}}\) currently computed as a Cholesky factor, is replaced by the square-root \(\widehat{\varvec{C}}^{1/2}\) of \(\widehat{\varvec{C}}\), which is the diagonal matrix obtained by taking the square-root of the entries of \(\widehat{\varvec{C}}\). This completely eliminates the need for a Cholesky factorization. Also the linear system previously solved by substitution can be trivially solved in linear time since the matrix is diagonal. As for the upper bound \(\lambda _{\max }\) it can be computed directly without requiring a power iteration method. Then, the offline costs of our approach drop to \(\mathscr {O}(K\log K)\) and the online costs are of order \(\mathscr {O}(K\mu n)\). As for the storage needs, they are reduced to \(\mathscr {O}(\mu n)\) (since both \(\varvec{C}\) and \(\varvec{R}\) are sparse). These costs are drastically reduced compared to the costs associated with the naive approach presented at the beginning of Sect. 4, which consisted of a storage need of \(\mathscr {O}(n^2)\) and a computational complexity of \(\mathscr {O}(n^3)\) operations. The storage costs now grow linearly with n, and the computational costs grow linearly with K and n, hence rendering the algorithm much more scalable.
6.3 Application: Simulation of Whittle–Matérn fields
To conclude this section, we provide an application of the convergence results in Sect. 5 and of the computational complexities derived in this section to the approximation of Whittle–Matérn random fields, i.e., fields with a power spectral density given by (2.5)).
Corollary 6.1
Let Assumption 5.1 be satisfied, and let \(\gamma \) be given by (2.5). Then, the approximation error of the random field \(\mathscr {Z}\) by its Galerkin–Chebyshev polynomial approximation \(\widehat{\mathscr {Z}}_{n,K}\) of order \(K\in \mathbb {N}\), satisfies
where \(C_{\text {Galer}}\) is a constant independent of n and K, \(\rho =\min \left\{ s;\; r;\; (\alpha \beta -1/2)\right\} >0\) and \(C_{\kappa ,\lambda }=2C_\lambda ^{1/2}\kappa ^{-1}\), \(\alpha >0\) and \(C_\lambda >0\) are defined in Proposition 2.1, \(\kappa >0\) and \(\beta >0\) are as in (2.5), and \(r>0\) and \(s>0\) are given in Assumption 5.1.
In particular, there exist \(\epsilon _0, C_1, C_2>0\) (depending only on \(\gamma \), \(C_{\text {Galer}}\) and the constants defined in Proposition 2.1 and Assumption 5.1) such that for any \(\epsilon \in (0,\epsilon _0)\), taking \(n=(C_1)^{1/\rho }\;\epsilon ^{-1/\rho }\) and \(K=\big \lceil C_{2}\;\epsilon ^{-\alpha /2\rho }\vert \log \epsilon \vert \big \rceil \) yields
Proof
To ease the reasoning, let us consider once again that the upper-bound \(\lambda _{\max }\) corresponds exactly to the maximal eigenvalue of \(\varvec{S}\). The inequality (6.3) follows directly from Corollary 5.5, after noting that \(z\in \mathbb {C}\mapsto \gamma (z)\) is holomorphic in the ellipse centered at \(z=\lambda _{\max }/2\), with foci \(z_1=0\) and \(z_2=\lambda _{\max }\), and semi-major axis \(a=\lambda _{\max }/2+\kappa ^2/2\) (i.e., \(\chi =\kappa ^2/2\) in Corollary 5.5), and that \(\vert \gamma \vert \) can be bounded in this ellipse by \((\kappa ^{2}/2)^{-\beta }\).
The error \(\Vert \mathscr {Z} - \widehat{\mathscr {Z}}_{n,K} \Vert _{L^2(\varOmega ; H)}\) satisfies the inequality
where \(E_{\text {Galer}}=C_{\text {Galer}}\; n^{-\rho }\) denotes the contribution to the error estimate due to the Galerkin approximation, and \(E_{\text {Cheb}}\) the contribution due to the Chebyshev approximation, i.e.,
Let \(\epsilon \in (0,\epsilon _{\max })\) where \(\epsilon _{\max } =\sup \lbrace \epsilon \in (0,1): (C_{\text {Galer}})^{1/\rho }\;\epsilon ^{-1/\rho } > M_{\text {Cheb}} \rbrace \) and \(M_{\text {Cheb}}\) is defined in Theorem 5.8. Let \(n=\lceil (C_{\text {Galer}})^{1/\rho }\;\epsilon ^{-1/\rho }\rceil \). Then, \(n > M_{\text {Cheb}}\) and \(E_{\text {Galer}}=\epsilon \). Let \(r_{\rho ,\alpha }=(1+(2\rho )^{-1}(\alpha +1))\), \(C_{\kappa ,\lambda ,\text {Galer}}=C_{\kappa ,\lambda } (C_{\text {Galer}})^{\alpha /2\rho }r_{\rho ,\alpha }\), and take \(K=\big \lceil C_{\kappa ,\lambda ,\text {Galer}}\;\epsilon ^{-\alpha /2\rho }\vert \log \epsilon \vert \big \rceil \). Thus,
where \(C_{\text {Cheb}}=C_{\kappa ,\lambda }(2^{-1}\kappa ^{2})^{-\beta } \; (C_{\text {Galer}})^{(\alpha +1)/2\rho }\) and we used the fact the \(\epsilon \le 1\).
In conclusion, let \(\tilde{\epsilon } \in (0, \epsilon _0)\) where \(\epsilon _0=(1+C_{\text {Cheb}})\epsilon _{\max }\) and let \(\epsilon =\tilde{\epsilon }(1+C_{\text {Cheb}})^{-1}\). Then, \(\epsilon \in (0,\epsilon _{\max })\), and when taking \(\lceil (C_{\text {Galer}})^{1/\rho }\;\epsilon ^{-1/\rho }\rceil \) and \(K=\big \lceil C_{\kappa ,\lambda ,\text {Galer}}\;\epsilon ^{-\alpha /2\rho }\vert \log \epsilon \vert \big \rceil \), we end up with an error \(\Vert \mathscr {Z} - \widehat{\mathscr {Z}}_{n,K} \Vert _{L^2(\varOmega ; H)} \le (1+ C_{\text {Cheb}})\epsilon = \tilde{\epsilon }\). \(\square \)
As a consequence, we can derive the computational cost required to sample a GRF with root-mean-squared error \(\Vert \mathscr {Z} - \widehat{\mathscr {Z}}_{n,K} \Vert _{L^2(\varOmega ; H)}\) smaller than some small \(\epsilon \) by taking \(n=(C_1)^{1/\rho }\;\epsilon ^{-1/\rho }\) and \(K=\big \lceil C_{2}\;\epsilon ^{-\alpha /2\rho }\vert \log \epsilon \vert \big \rceil \) in the estimates in Table 1. We end up with the bounds in Table 2. We also provide the computational cost associated with the choice of a linear finite element and mass lumping approximation. This method introduces an additional error term due to the mass lumping approximation, which in practice does not seem to affect the theoretical convergence rates of the root-mean-squared error (as verified in the numerical experiments in Sect. 7). Hence, we conjecture that the results in Corollary 6.1 and therefore the estimates in Table 2, still hold when using the mass lumping approximation. We finally observe that a Galerkin–Chebyshev approximation of a Whittle–Matérn field with a root-mean-squared error bounded by \(\epsilon >0\) can be asymptotically obtained with a computational cost \(\mathscr {O}(\mu \epsilon ^{-(\alpha /2+1)/\rho }\vert \log \epsilon \vert )\) using linear finite elements with a mass lumping approximation.
7 Numerical experiments
In this section we confirm the convergence estimates derived in Sect. 5 using numerical experiments. In a first subsection, we restrict ourselves to the specific case where the Riemannian manifold of interest \((\mathscr {M}, g)\) is the 2-sphere endowed with its canonical metric, as in this case the eigenvalues and eigenvectors of the Laplace–Beltrami are known, and hence the exact solution can be computed and compared to the various approximations introduced in this work. In a second subsection, we investigate the case where the Riemannian manifold of interest is a hyperboloid, for which, even though the the eigenvalues and eigenvectors of the Laplace–Beltrami are not known, we are still able retrieve the error estimate for the covariance.
7.1 Numerical experiments on the sphere
Recall that the Laplace–Beltrami operator \(-\varDelta _{\mathscr {M}}\) on the 2-sphere has eigenvalues \(\lambda _{l,m}\) given by \(\lambda _{l,m}=l(l+1)\) for \(l\in \mathbb {N}\), \(m\in [\![-l, l]\!]\), with associated eigenfunctions given by the (real) spherical harmonics \(Y_{l,m}\) defined in spherical coordinates \(\theta \in [0,\pi ], \phi \in [0,2\pi )\) by the expression
where for \(l\in \mathbb {N}\), \(m\in [\![0, l]\!]\), \(P_l^m\) denotes the associated Legendre polynomial with indices l and m. In the remainder of this section, we use \(\alpha = 2/d=1\) by Weyl’s asymptotic law in Proposition 2.1.
On the sphere, the Gaussian random fields defined using functions of the Laplacian \(\gamma (-\varDelta _\mathscr {M})\) as in (2.4) are particular instances of the class of isotropic random fields on the sphere described in [35]. The covariance \(C(\theta )\) of such fields between any two points on the sphere is linked to the spherical distance \(\theta \) separating the points through the relation
where \(P_l\), \(l\in \mathbb {N}_0\), denotes the Legendre polynomial of order l.
Finally, we restrict our numerical experiments to Whittle–Matérn fields by considering power spectral densities of the form \(\gamma (\lambda )=\vert \kappa ^2 + \lambda \vert ^{-\beta }\) for \(\lambda \ge 0\) and some parameters \(\kappa >0\), \(\beta >1/2\). We introduce an additional parameter a, which we call practical range, and which is defined from the parameters \(\nu \) and \(\kappa \) by \(a = 3.6527\kappa ^{-1}\nu ^{0.4874}\). In the remainder of this section, the power spectral densities \(\gamma \) will be characterized by choices of the parameters \(\nu \) and a. The rationale behind the parameter a comes from numerical experiments conducted in [47] which showed that the correlation range of the Matérn covariance function (on \(\mathbb {R}^2\)) is very-well approximated by a, thus yielding a rule-of-thumb for choosing \(\kappa \).
We now present the result obtained when computed numerically the truncation error, and the covariance error. Results on the error due to the polynomial approximation can be found in Section SM4.3 of the Supplementary Materials.
7.1.1 Truncation error
We look at the truncation error \(\Vert \mathscr {Z} - \mathscr {Z}^{(n)} \Vert _{L^2(\varOmega ; H)}\) between the full expansion \(\mathscr {Z}\) and its truncation \(\mathscr {Z}^{(n)}\) at order \(n\in \mathbb {N}\), for various choices of n. This error corresponds to the error term derived in Theorem 5.6 when the discretization space \(V_n\) is the set of the first n eigenvalues of the Laplace–Beltrami operator (cf. Sect. 6.2.1). In this case, Assumption 5.1 holds for arbitrary large values of the exponents \(r,s>0\) and we therefore expect a convergence of order \(\alpha \beta -1/2=\nu /2\).
We compute truncation errors for the power spectral densities \(\gamma \) given by
-
\(\nu =0.75\), \(a\in \lbrace \pi /6, \pi /3\rbrace \), yielding an expected convergence of order 0.375;
-
\(\nu =1\), \(a\in \lbrace \pi /6, \pi /3\rbrace \), yielding an expected convergence of order 0.5;
and consider truncation orders \(n\in \lbrace 10^2, 10^3, 10^4, 5\cdot 10^4, 10^5\rbrace \). Samples of the corresponding truncated fields are generated using the approach presented in Sect. 6.2.1.
The error \(\Vert \mathscr {Z} - \mathscr {Z}^{(n)} \Vert _{L^2(\varOmega ; H)}\) is approximated by a Monte Carlo estimate taking the form
where for any k, \(\mathscr {Z}^{(N_{\max })}_k\) is an independent realization of the truncation of \(\mathscr {Z}\) at a very high order \(N_{\max }=10^6\), and \(\mathscr {Z}^{(n)}_k\) is a truncation of \(\mathscr {Z}^{(N_{\max })}_k\) at order n. The number of samples used for this study is \(N_{\text {simu}}=500\), which is sufficient as larger choices of \(N_{\max }\) have little impact on the results. The results are presented in Fig. 2 and show that the theoretical orders of convergence are systematically retrieved.

Truncation error \(\left\| \mathscr {Z} - \mathscr {Z}^{(n)} \right\| _{L^2(\varOmega ; H)}\) on the sphere
7.1.2 Covariance error and computational cost
The covariance error refers to the absolute error in covariance between the model random field and its approximation used in practice. We take here the discretization space \(V_n\) to be the finite element space of piecewise linear functions defined on a polyhedral approximation of the sphere with triangular faces, hence following the surface finite element (SFEM) approach [19].
We generate \(10^6\) samples of the random field \(\widehat{\mathscr {Z}}_{n,K}\) while considering finite element spaces defined on gradually refined polyhedral approximations of the sphere. For each choice of parameter defining the spectral density \(\gamma \), we set the order K of the polynomial approximation using the approach described in Sect. 5.2, with a criterion \(\vert c_K/c_{\max }\vert <10^{-12}\). The covariance error we compute is given as an error between the covariance functions of the field \(\mathscr {Z}\) and its approximation \(\widehat{\mathscr {Z}}_{n,K}\). The former is given in (7.1) and the latter is approximated by a Monte Carlo estimator. The overall error between both covariance functions is then evaluated as the maximum absolute error between their evaluations on a grid of 500 equispaced points in \((0,\pi )\) along a great circle. The covariance errors are presented in Fig. 3a, and show that the theoretical convergence rate \(2\alpha \beta -1 = \nu \) is confirmed.
Finally, we present the order of polynomial approximation in Fig. 3b and the associated computation time needed to generate the samples used to compute the covariance errors in Fig. 3c. We observe that although the order of the polynomial approximation grows, the computation time remains small with less than half a second.

Approximation order used and time needed to compute one sample of the (approximated) Gaussian random field
7.2 Numerical experiment on a hyperboloid
In this section we confirm the error estimate from Theorem 5.7 numerically on a hyperboloid surface. We consider the two-dimensional surface defined implicitly by the equation
We equip \(\mathscr {M}\) with its canonical metric to turn it into a compact Riemannian manifold of dimension 2 and consider once again the sampling of Whittle–Matérn fields using the Galerkin–Chebyshev approach. In particular, we take again the discretization space \(V_n\) to be the finite element space of piecewise linear functions defined on a polyhedral approximation of the surface with triangular faces.
As in Sect. 7.1.2, we consider the covariance error between the random field and its approximation. More specifically, we evaluate the covariance of the field along the curve \(\mathscr {C}= \lbrace (x,y,z)\in \mathscr {M}: y=0 \text { and } x>0\rbrace \). To do so, we generate samples of the field using the Galerkin–Chebyshev approach and compute the covariance between the point \((1,0,0)\in \mathscr {C}\) and the points \(\mathscr {P}=\lbrace (\sqrt{1+z^2}, 0, z): z=-2+0.04i, \quad i\in [\![0,100]\!]\rbrace \subset \mathscr {C}\). We generate \(2.5\times 10^6\) samples on these points and use a Monte Carlo estimator to estimate the covariances. Note that for each sample the order K of the polynomial approximation is set in the same way as in Sect. 7.1.2 and the mass lumping approximation is applied. We repeat the experiment with finite element spaces defined on gradually refined polyhedral approximations of the surface. An example of a sample of the Whittle–Matérn field on \(\mathscr {M}\) along with the sampled points \(\mathscr {P}\) is presented in Fig. 4.

Whittle–Matérn field on the hyperboloid \(\mathscr {M}\) along with the sampled points \(\mathscr {P}\) used to compute the covariances (in black). The point (1, 0, 0) is colored in red, and the colors on the surface stand for the value of taken by the field (colour figure online)
Finally, we compute the covariances with this same approach on a very fine polyhedral approximation of \(\mathscr {M}\) (with 540900 nodes) and use these values as the reference solution. We then compute, for each level of discretization of \(\mathscr {M}\), the maximal absolute error between the covariance values and the ground truth. The result of the numerical experiment is presented in Fig. 5. The parameters defining the power spectral density \(\gamma \) are \(\nu =1\) and \(a=0.5\) (defined as in Sect. 7) meaning that we expect convergence of rate \(\nu =1\). As can be observed, we retrieve that the maximal absolute error in the covariance decreases as \(n ^{-1}\).

Maximum absolute error in covariance between the Whittle–Matérn field on the hyperboloid and its Galerkin–Chebyshev approximation
References
Adler, R.J., Taylor, J.E.: Random Fields and Geometry. Springer, Berlin (2009)
Axelsson, O., Barker, V.A.: Finite Element Solution of Boundary Value Problems: Theory and Computation. SIAM, Philadelphia (2001)
Bachmayr, M., Djurdjevac, A.: Multilevel representations of isotropic Gaussian random fields on the sphere. arXiv:2011.06987 (2020)
Bérard, P.H.: Spectral Geometry: Direct and Inverse Problems. Springer, Berlin (2006)
Bolin, D., Kirchner, K.: The rational SPDE approach for Gaussian random fields with general smoothness. J. Comput. Graph. Stat. 29(2), 274–285 (2020)
Bolin, D., Kirchner, K., Kovács, M.: Weak convergence of Galerkin approximations for fractional elliptic stochastic PDEs with spatial white noise. BIT Numer. Math. 58(4), 881–906 (2018)
Bolin, D., Kirchner, K., Kovács, M.: Numerical solution of fractional elliptic stochastic PDEs with spatial white noise. IMA J. Numer. Anal. 40(2), 1051–1073 (2020)
Bonito, A., Demlow, A., Owen, J.: A priori error estimates for finite element approximations to eigenvalues and eigenfunctions of the Laplace-Beltrami operator. SIAM J. Numer. Anal. 56(5), 2963–2988 (2018)
Bonito, A., Guignard, D., Lei, W.: Numerical approximation of Gaussian random fields on closed surfaces. arXiv preprint arXiv:2211.13739 (2022)
Borovitskiy, V., Terenin, A., Mostowsky, P., Deisenroth, M.P.: Matérn Gaussian processes on Riemannian manifolds. arXiv:2006.10160 (2020)
Borovitskiy, V., Azangulov, I., Terenin, A., Mostowsky, P., Deisenroth, M., Durrande, N.: Matérn Gaussian processes on graphs. In: Banerjee, A., Fukumizu, K. (eds) Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, PMLR, Proceedings of Machine Learning Research, vol. 130, pp. 2593–2601 (2021)
Bouclet, J.M.: An Introduction to Pseudo-Differential Operators. http://www.math.univ-toulouse.fr/~bouclet. Lecture Notes (2012)
Chen, C.M., Thomée, V.: The lumped mass finite element method for a parabolic problem. ANZIAM J. 26(3), 329–354 (1985)
Chilès, J.P., Delfiner, P.: Geostatistics : Modeling Spatial Uncertainty, 2nd edn. Wiley Series in Probability and Statistics (2012)
Cleanthous, G., Georgiadis, A., Lang, A., Porcu, E.: Regularity, continuity and approximation of isotropic Gaussian random fields on compact two-point homogeneous spaces. Stochastic Processes Appl. 130(8), 4873–4891 (2020)
Cooley, J.W., Tukey, J.W.: An algorithm for the machine calculation of complex Fourier series. Math. Comput. 19(90), 297–301 (1965)
Creasey, P.E., Lang, A.: Fast generation of isotropic Gaussian random fields on the sphere. Monte Carlo Methods Appl. 24(1), 1–11 (2018)
Demlow, A.: Higher-order finite element methods and pointwise error estimates for elliptic problems on surfaces. SIAM J. Numer. Anal. 47(2), 805–827 (2009)
Dziuk, G.: Finite elements for the Beltrami operator on arbitrary surfaces. In: Partial Differential Equations and Calculus of Variations, pp. 142–155. Springer, Berlin (1988)
Dziuk, G., Elliott, C.M.: Finite element methods for surface PDEs. Acta Numer. 22, 289–396 (2013)
Emery, X., Porcu, E.: Simulating isotropic vector-valued Gaussian random fields on the sphere through finite harmonics approximations. Stoch. Env. Res. Risk Assess. 33(8), 1659–1667 (2019)
Estrade, A., Fariñas, A., Porcu, E.: Covariance functions on spheres cross time: beyond spatial isotropy and temporal stationarity. Statist. Probab. Lett. 151, 1–7 (2019)
Friedberg, S.H., Insel, A.J., Spence, L.E.: Linear Algebra. Featured Titles for Linear Algebra (Advanced) Series. Pearson Education, London (2003)
Gerschgorin, S.: Über die Abgrenzung der Eigenwerte einer Matrix. Bulletin de l’Académie des Sciences de l’URSS Classe des sciences mathématiques et na 6, 749–754 (1931)
Gneiting, T.: Strictly and non-strictly positive definite functions on spheres. Bernoulli 19(4), 1327–1349 (2013)
Harbrecht, H., Herrmann, L., Kirchner, K., Schwab, C.: Multilevel approximation of Gaussian random fields: covariance compression, estimation and spatial prediction. arXiv:2103.04424 (2021)
Herrmann, L., Lang, A., Schwab, C.: Numerical analysis of lognormal diffusions on the sphere. Stochast. Partial Differ. Equ. Anal. Comput. 6(1), 1–44 (2018)
Herrmann, L., Kirchner, K., Schwab, C.: Multilevel approximation of Gaussian random fields: fast simulation. Math. Models Methods Appl. Sci. 30(01), 181–223 (2020)
Huang, C., Zhang, H., Robeson, S.M.: On the validity of commonly used covariance and variogram functions on the sphere. Math. Geosci. 43(6), 721–733 (2011)
Jansson, E., Kovács, M., Lang, A.: Surface finite element approximation of spherical Whittle-Matérn Gaussian random fields. SIAM J. Sci, Comput (2022)
Jones, R.H.: Stochastic processes on a sphere. Ann. Math. Stat. 34(1), 213–218 (1963)
Jost, J.: Riemannian Geometry and Geometric Analysis. Springer, Berlin (2008)
Knyazev, A.V., Osborn, J.E.: New a priori FEM error estimates for eigenvalues. SIAM J. Numer. Anal. 43(6), 2647–2667 (2006)
Lablée, O.: Spectral Theory in Riemannian Geometry. EMS textbooks in Mathematics, European Mathematical Society (2015)
Lang, A., Schwab, C.: Isotropic Gaussian random fields on the sphere: regularity, fast simulation and stochastic partial differential equations. Ann. Appl. Probab. 25(6), 3047–3094 (2015)
Lantuéjoul, C., Freulon, X., Renard, D.: Spectral simulation of isotropic Gaussian random fields on a sphere. Math. Geosci. 51(8), 999–1020 (2019)
Lee, J.M.: Smooth manifolds. In: Introduction to Smooth Manifolds, pp 1–31. Springer, Berlin (2013)
Lindgren, F., Rue, H., Lindström, J.: An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach. J. R. Stat. Soc. B 73(4), 423–498 (2011)
Lototsky, S.V., Rozovsky, B.L., et al.: Stochastic Partial Differential Equations. Springer, Berlin (2017)
Marinucci, D., Peccati, G.: Random Fields on the Sphere: Representation. Limit Theorems and Cosmological Applications. Cambridge University Press, Cambridge (2011)
Mason, J.C., Handscomb, D.C.: Chebyshev Polynomials. CRC Press, Cambridge (2002)
Parlett, B.N.: The Symmetric Eigenvalue Problem. SIAM, Philadelphia (1998)
Pereira, M.: Generalized random fields on Riemannian manifolds: Theory and practice. Ph.D. thesis, Université Paris Sciences et Lettres (2019)
Pereira, M., Desassis, N.: Efficient simulation of Gaussian Markov random fields by Chebyshev polynomial approximation. Spatial Stat. 31(100), 359 (2019)
Porcu, E., Bevilacqua, M., Genton, M.G.: Spatio-temporal covariance and cross-covariance functions of the great circle distance on a sphere. J. Am. Stat. Assoc. 111(514), 888–898 (2016)
Press, W.H., Teukolsky, S.A., Vetterling, W.T., Flannery, B.P.: Numerical Recipes: The Art of Scientific Computing, 3rd edn. Cambridge University Press, Cambridge (2007)
Romary, T.: Inversion des modèles stochastiques de milieux hétérogènes. Ph.D. thesis, Université Pierre et Marie Curie-Paris VI (2008)
Sauter, S.A., Schwab, C.: Boundary Element Methods. Springer Series in Computational Mathematics. Springer, London (2011)
Strang, G., Fix, G.J.: An Analysis of the Finite Element Method. Prentice-Hall, London (1973)
Strichartz, R.S.: Analysis of the Laplacian on the complete Riemannian manifold. J. Funct. Anal. 52(1), 48–79 (1983)
Taylor, M.E.: Partial Differential Equations I: Basic Theory. Springer, Berlin (1996)
Trefethen, L.N.: Approximation Theory and Approximation Practice, Extended SIAM, Philadelphia (2019)
Funding
Open access funding provided by Chalmers University of Technology.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no potential conflict of interests.
Additional information
Communicated by Mihaly Kovacs.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was partially supported by the Swedish Research Council (VR) through Grant No. 2020-04170, by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by the Knut and Alice Wallenberg Foundation, by the Chalmers AI Research Centre (CHAIR), and by the Simons Foundation Award No. 663281 granted to the Institute of Mathematics of the Polish Academy of Sciences for the years 2021–2023. The authors thank Christoph Schwab for helpful comments.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendices
Appendix A Uniform convergence of Chebyshev series
The next theorem is proven in [52, Theorems 7.1, 7.2, 8.1, 8.2] and gives conditions for the uniform convergence of Chebyshev series.
Theorem A.1
Let \(\nu \in \mathbb {N}\). If \(f:[-1, 1] \rightarrow \mathbb {R}\) is such that its derivatives \(f, f', \dots , f^{(\nu -1)}\) are continuous and that \(f^{(\nu )}\) is of bounded variation, then the coefficients of the Chebyshev series of f satisfy for any \(k>\nu \),
and for any \(K>\nu \), the error of the Chebyshev approximation is bounded by
where \(\text {TV}(f^{(\nu )})\) denotes the total variation of \(f^{(\nu )}\) over \([-1, 1]\) and \(\Vert \cdot \Vert _{\infty }\) denotes the \(L^{\infty }\)-norm on the segment \([-1, 1]\).
Besides if there exists \(\rho >1\) such that the complex function \(z\in \mathbb {C}\mapsto f(z)\) is holomorphic inside the ellipse \(E_\rho \) centered at 0, with foci \(z=\pm 1\), and semi-major (resp. semi-minor) axis of length \((\rho +\rho ^{-1})/2\) (resp. \((\rho -\rho ^{-1})/2\)), then, for any \(K\ge 0\),
and
Appendix B Proof of Theorem 3.1
Proof
Take an eigenvalue \(\lambda \) of the GEP defined by the matrix pencil \((\varvec{R}, \varvec{C})\), and denote by \(\varvec{w} \ne \varvec{0}\) an associated eigenvector. Using (3.2), we have for any \(k \in [\![1, n]\!]\),
which, by definition of \(E_0\), gives for any \(k \in [\![1, n]\!]\),
Note that \(\lbrace \psi _k\rbrace _{1\le k\le n}\) is also a basis of \(V_n\) as it is a family of linearly independent functions spanning \(V_n\). Denote by \(\varvec{A}\in \mathbb {R}^{n\times n}\) the invertible change-of-basis matrix between \(\lbrace \psi _k\rbrace _{1\le k\le n}\) and the orthonormal basis \(\lbrace f_k \rbrace _{1\le k\le n}\) of \(V_n\) in (3.1). In particular, \(\varvec{A}\) satisfies, for any \(k \in [\![1, n]\!]\),
Injecting this last equality in (B.1) gives
Multiplying both members of this equality by \(\varvec{A}^{-1}\) yields that for any \(k\in [\![1, n]\!]\),
And so, given that \(E_0(\varvec{w})\in V_n\),
Therefore \(\lambda \) is an eigenvalue of \(-\varDelta _n\) and \(E_0\) maps the eigenvectors of \((\varvec{R}, \varvec{C})\) to the eigenfunctions of \(-\varDelta _n\).
Observe that for any \(\varvec{x}\in \mathbb {R}^n\),
Hence, given that it is also linear, \(E_0\) is an isometry between \((\mathbb {R}^n, \Vert \cdot \Vert _{\varvec{C}})\) and \((V_n, \Vert \cdot \Vert _0)\). Consequently, \(E_0\) is injective: for any \(\varvec{x}\in \mathbb {R}^n\), \(E_0(\varvec{x})=0\) implies that \(\Vert \varvec{x}\Vert _{\varvec{C}}^2=\Vert E_0(\varvec{x})\Vert _0^2=0\) and so that \(\varvec{x}=0\). Finally, using the rank-nullity theorem [23], \(E_0\) is bijective (as an injective linear mapping between two vector spaces with the same dimension).\(\square \)
Appendix C Proof of the eigenvalue estimates for SFEM
Assume that \(\mathscr {M}\) is a smooth compact 2-dimensional surface without boundary equipped with the metric g induced by the Euclidean metric on \(\mathbb {R}^3\). Following the SFEM approach, we consider a polyhedral approximation \(\mathscr {M}_h\) of \(\mathscr {M}\) with mesh size h such that the vertices of \(\mathscr {M}_h\) lie on \(\mathscr {M}\). Let \(V_h\) be the finite-dimensional space of functions obtained by “lifting” on \(\mathscr {M}\) the linear finite element space defined on the polyhedral mesh \(\mathscr {M}_h\). Note in particular that \(V_h\) is geometrically consistent in the sense that \(V_h \subset \dot{H}^1\). Denote then by \((\lambda _{k}, e_k)_{k\in \mathbb {N}}\) the eigenpairs of the Laplace–Beltrami operator \(-\varDelta _{\mathscr {M}}\) and by \((\lambda _{k}^{(n)}, e_k^{n})_{1\le k\le n}\) the eigenpairs of the Galerkin approximation of \(-\varDelta _{\mathscr {M}}\) on \(V_h\), as defined in Sect. 3.1 (where \(n=\dim V_h\)).
Following [33, Theorem 3.1] and the smoothness of the eigenfunctions of \(-\varDelta _{\mathscr {M}}\), there exists C (independent of h) such that for any \(k\in \lbrace 1, \dots , n\rbrace \),
(see [9, Lemma 4.1] for a complete proof). Reinserting this bound and using the growth of the eigenvalues yield
Note then that by an inverse inequality [18, Proposition 2.7], there exists \(C_{\text {INV}}>0\) independent of h such that, for h small enough,
Since \(\Vert \nabla _\mathscr {M} e_n^{(n)}\Vert _0^2=(\nabla _\mathscr {M} e_n^{(n)}, \nabla _\mathscr {M} e_n^{(n)})_0=\lambda _{n}^{(n)}(e_n^{(n)}, e_k^{(n)})_0=\lambda _{n}^{(n)}\), we get \(\lambda _{n}^{(n)} \le (C_{\text {INV}})^2\,h^{-2}\). Hence we can conclude that
where \(C'=C(1+C(C_{\text {INV}})^2)\) is a constant independent of k and h. Finally, assuming that the polyhedral approximations \(\mathscr {M}_h\) for different values of h are built from uniform refinements of an initial polyhedral surface, the size n of \(V_h\) can be linked to the mesh size h by \(nh^2 \lesssim 1\), which in turn gives
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lang, A., Pereira, M. Galerkin–Chebyshev approximation of Gaussian random fields on compact Riemannian manifolds. Bit Numer Math 63, 51 (2023). https://doi.org/10.1007/s10543-023-00986-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10543-023-00986-8
Keywords
- Gaussian random fields
- Compact Riemannian manifolds
- Galerkin approximation
- Chebyshev polynomials
- Strong convergence
- Weak convergence
- Laplace–Beltrami operator
- Whittle–Matérn random fields