
Abstract
In this paper we consider the problem of the approximation of definite integrals on finite intervals for integrand functions showing some kind of “pathological” behavior, e.g. “nearly” singular functions, highly oscillating functions, weakly singular functions, etc. In particular, we introduce and study a product rule based on equally spaced nodes and on the constrained mock-Chebyshev least squares operator. Like other polynomial or rational approximation methods, this operator was recently introduced in order to defeat the Runge phenomenon that occurs when using polynomial interpolation on large sets of equally spaced points. Unlike methods based on piecewise approximation functions, mainly used in the case of equally spaced nodes, our product rule offers a high efficiency, with performances slightly lower than those of global methods based on orthogonal polynomials in the same spaces of functions. We study the convergence of the product rule and provide error estimates in subspaces of continuous functions. We test the effectiveness of the formula by means of several examples, which confirm the theoretical estimates.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The paper deals with the numerical computation of integrals of the type
where f is a sufficiently smooth function, \(w(x)=(1-x)^\alpha (1+x)^\beta \) is a Jacobi weight of parameters \(\alpha ,\beta >-1\), and the kernel K(x, y) defined in \(D=\{(x,y): x\in [-1,1], \ y\in S\}\), contains some peculiar drawbacks. The topic is of interest in many applications, and in particular useful in numerical methods for functional equations (see e.g. [8, 16, 26, 29]), which model problems arising in a large variety of fields: mathematical physics, electrochemistry, crystal growth, biophysics, viscoelasticity, heat transfer model, etc. Because of the large variety of applications, great attention has been posed in literature and several numerical methods for solving these equations have been proposed (see [1, 4] and the references therein).
Weakly singular functions, such as \(\log |x-y|, \ |x-y|^\mu , \mu >-1,\) or highly oscillating functions, such as \(\sin (yx),\) \(\cos (yx)\) for \(\ |y|\gg 1\), are only examples of possible kernels for which the accurate computation of I(f, y) can be successfully performed by means of the so-called product integration rules, i.e. formulae based on the approximation of the “smooth” function f and the exact computation of the rules coefficients. Product rules of interpolation type based on the zeros of orthogonal polynomials are well known in literature, also for the case of unbounded intervals and/or double integrals (see e.g. [15, 18, 21,22,23,24,25, 28, 30, 33]). These methods produce very satisfactory results, since the quadrature error depends essentially on the smoothness of the function f, and usually behaves like the best approximation error by polynomials of the function f. However, in many applications f is known only on a set of equally spaced points, or more in general the integrals have to be computed starting from scattered data. In these cases other procedures involving composite quadrature rules can be used, but this approach leads to a low degree of approximation, showing saturation phenomena. In this setting, we propose a product integration rule, based on the approximation of f known on a set of equispaced nodes, by using the constrained mock-Chebyshev least squares linear operator \(\hat{P}_{r,n}(f)\) [9, 12]. Such operator has been recently used for deriving an efficient quadrature rule [10, 11] based on equidistant points, for integrals of the type (1), with \(K(x,y)\equiv 1\). As we will show, the product formula we introduce here is convergent in suitable subspaces of \(C([-1,1])\), providing in these cases estimates of the quadrature error.
The outline of the paper is the following. In Sect. 2 we briefly recall the main results concerning the product formula and the constrained mock-Chebyshev least squares interpolant. In Sect. 3 we introduce the constrained mock-Chebyshev product formula, with estimate of the error in Sobolev-type subspaces, and provide some implementation details for a selection of kernels. In Sect. 4 are given some numerical tests, and comparisons with the results achieved by the product rule on Chebyshev zeros.
2 Preliminaries
From now on, \(\mathcal {C}\) will denote any positive constant having different meanings at different occurrences and the writing \(\mathcal {C}\ne \mathcal {C}(a,b,\dots )\) has to be understood as \(\mathcal {C}\) not depending on \(a,b,\dots \). If \(A,B >0\) are quantities depending on some parameters, we write \(A \sim B,\) if there exists a constant \(\mathcal {C}\ \ne \mathcal {C}\ (A,B)\) such that \(\mathcal {C}\ ^{-1} B \le A \le \mathcal {C}\ B.\) Furthermore, we denote by \(\varPi _m\) the space of the algebraic polynomials of degree less than or equal to m. Finally, for any bivariate function h(x, y), we denote the projections of the function h(x, y) on one variable as \(h_y(x)\) and \(h_x(y)\) respectively.
2.1 Function spaces and orthogonal basis
Let us denote by \(C^0([-1,1])\) the space of continuous functions in \([-1,1]\) equipped with the norm \( \Vert f\Vert _{\infty }:=\max \limits _{x\in [-1,1]}|f(x)|\). For any \(f\in C^0([-1,1])\)
is the error of best polynomial approximation of f in uniform norm. As well-known, by the Weierstrass Theorem [6],
By denoting with \(\mathcal{A}\mathcal{C}(-1,1)\) the space of functions in \([-1,1]\) which are absolutely continuous on every closed subset of \((-1,1)\) and by setting \(\phi (x)=\sqrt{1-x^2}\), let
be the Sobolev space of order \(s\in \mathbb {N},\ s\ge 1\), endowed with the norm
To estimate the error of best polynomial approximation, we recall the Favard inequality [14], which holds for each \(f\in W_s,\)
We also set
and we denote by \(\left\{ {p}_i(w^C)\right\} _{i\in \mathbb {N}_0}\) the sequence of orthonormal polynomials w.r.t. the 1-st kind Chebyshev weight \(w^C\)
2.2 A product integration rule on the zeros of 1-st kind Chebyshev polynomials
Let \(\{z_1,\dots , z_{r+1}\}\) be the zeros of the \((r+1)\)-th orthonormal polynomial \(p_{r+1}(w^C,\cdot )\) with respect to the 1-st kind Chebyshev weight \(w^C(x)=\frac{1}{\sqrt{1-x^2}}\) and denote by \(\{\lambda _i\}_{i=1}^{r+1}\) the corresponding Christoffel numbers. Let \(\mathcal {L}_{r}(w^C,f)\in \varPi _r\) be the interpolating polynomial of f at the zeros \(\{z_i\}_{i=1}^{r+1}\) of \(p_{r+1}(w^C)\), i.e.
It can be represented as (see e.g. [22], Chapter 4)
A class of interpolating product rules is based on the approximation of the function f in (1) by \(\mathcal {L}_{r}(w^C,f)\) (see e.g. [22] and the references therein), i.e.
where
and
The rule is exact for polynomials of degree r, i.e.
As it is well known, the accuracy of the product rule is based on “exact” evaluation of the modified moments
Depending on the kernel K and on the weight function w, a standard computation of \(M_k(y),\,k=0,\ldots ,r\) can be obtained by recurrence relations (see, e.g., [32]). Besides this approach, other strategies can be thought, as long as modified moments are computed with high accuracy. About the error estimate, from a more general result by Nevai [27], the following theorem holds
Theorem 1
Let \(f \in C^0([-1,1])\). Under the assumption
the following estimate holds true
2.3 Constrained mock-Chebyshev least squares interpolant
Let \(X_n=\{ \xi _i\}_{i=0}^n\) be the set of \(n+1\) equally spaced nodes of \([-1,1]\), i.e.
and let the function f be known only at the points of \(X_n\). The main idea of the constrained mock-Chebyshev least squares method [9, 13] is to construct an interpolant of f on a proper subset of \(X_n\), formed by \(m+1\) nodes, chosen as “closest” to Chebyshev–Lobatto nodes, and use the remaining \(n-m\) points of \(X_n\) to improve the accuracy of approximation by a process of simultaneous regression of degree \(p\ge 0\). To be more precise, let \(m=\left\lfloor \pi \sqrt{\frac{n}{2}} \right\rfloor \), and denote by \(X_m^{CL}\) the set of Chebyshev–Lobatto nodes of order \(m+1\)
For any \(i=0,\dots ,m\), let us define the node \(\xi ^{\prime }_{i}\in X_n\) as
then \(X^\prime _m:=\{\xi ^{\prime }_{i}:i=0,\dots ,m\}\subset X_n\) is the mock-Chebyshev set of order m related to \(X_n\) [2, 19, 20]. Despite \( X_{n-m}^{\prime \prime }:=X_n\smallsetminus X^{\prime }_m\) is not an equispaced grid, in [9] it is proven that, for n sufficiently large, it is possible to approximate an equispaced grid of \(q=\lfloor n/6\rfloor \) internal nodes of \([-1,1]\) with nodes of \( X_{n-m}^{\prime \prime }\). We denote such grid of q elements by \(\tilde{X}_{n-m}^{\prime \prime }\). The degree \(p=\left\lfloor \pi \sqrt{\frac{n}{12}}\right\rfloor \) of the least-squares polynomial is selected so that there is a subset of cardinality \(p+1\) of the equispaced set which is close, in the mock-Chebyshev sense, to the \(p+1\) Chebyshev grid
Set \(r=m+p+1\) and let \(\mathcal {B}_r=\{u_0(x),\dots ,u_r(x)\}\) be a basis of \(\varPi _r\). The constrained mock-Chebyshev least squares interpolant \(\hat{P}_{r,n}(f)\in \varPi _r\) is
where the vector \(\varvec{a}=[a_0,a_1,\dots ,a_r]^{T}\) is computed by solving the KKT linear system [3, 12]
with
\(\varvec{b}=[f(\xi _0),\dots , f(\xi _n)]^T,\;\varvec{d}=[f(\xi _0),\dots , f(\xi _m)]^T\) and \(\varvec{z}=[\hat{z}_1,\dots ,\hat{z}_{m+1}]^T\) the Lagrange multipliers vector. In defining V and C in (11) the assumption is that the nodes \(\xi _i\) have been reordered so that \(\xi _i=\xi ^{\prime }_i,\,\) \(i=0,\dots ,m,\) and the polynomials \(u_0,\dots ,u_m\) span \(\varPi _m\). In the following we denote by
the KKT matrix and by \(\kappa (M)=\Vert M \Vert _1 \Vert M^{-1} \Vert _1 \) its condition number in \(l_1\)-norm.
Remark 1
We note that the approximant \(\hat{P}_{r,n}(f)\) is uniquely determined by the evaluations of the function f at the set of equispaced nodes \(X_n\). Consequently,
where
is the Lagrange polynomial interpolating f at the nodes of \(X_n\).
The constrained mock-Chebyshev least squares operator
reproduces polynomials of degree \(\le r\) (cf. [9]) and interpolates the function f at the mock-Chebyshev subset of nodes, that is
Denoting by
the approximation error by means of the constrained mock-Chebyshev least squares interpolant and by setting
where \(D:=\max \limits _{j=0,\dots ,r}\left\Vert u_j \right\Vert _{\infty }\), the following theorem holds [13]
Theorem 2
Let be \(f\in C^0([-1,1])\), then
where \(E_r(f)\), introduced in (2), is the error of best uniform approximation of f by polynomials of \(\varPi _r\).
Corollary 1
Let \(f\in C^k([-1,1])\), \(k=0,\dots ,r\). Then we have
where \(\omega _f(\cdot )\) is the modulus of continuity of the function f (cf. [5]).
Proof
The proof follows by combining Theorem 2 and Jackson Theorem (see for instance [5, Ch. 4]). \(\square \)
In what follows we are going to choose the basis \(\mathcal {B}_r\) as
and hence the constrained mock-Chebyshev least squares polynomial takes the form
Moreover, in [13] it has been shown that
3 The main result
From now on we assume that the function f is known only on the set of equispaced nodes \(X_n\). As we announced in the introduction, the product integration rule we are going to introduce is based on the approximation of the function f by \(\hat{P}^C_{r,n}(f)\) expressed in the Chebyshev polynomial basis as in (21) and on the “exact” evaluation of the coefficients of the quadrature method. Indeed, by (1) we get
where \(w(x)=(1-x)^\alpha (1+x)^\beta ,\;\alpha ,\beta >-1\),
are the modified moments defined in (5) and
is the quadrature error.
Theorem 3
The quadrature sum \(\varSigma _{r,n}(f,y)\) in (25) takes the following expression
where
Proof
By the property (13) we get
where \(L_n(f)\) is defined as in (14). By substituting (29) in (2324), we obtain
\(\square \)
Remark 2
Equation (27) and (28) show that the weights of the quadrature rule \(\varSigma _{r,n}(f,y)\) depends on y and therefore, changing y, they must be recomputed. Note that the dependence on y is typical of the product integration rules, that, in the face of fast convergent rules, requires more computational effort. The same happens in the case of product rules based on the zeros of orthogonal polynomials.
Remark 3
When \(K(x,y)\equiv 1\) the quadrature rule (27) with weights (28) reduces to the stable quadrature rule from \(n+1\) equispaced nodes with degree of exactness r already introduced in [11]. As well known, this formula is based on the approximation of the function f by \(\hat{P}^C_{r,n}(f)\) expressed in the Chebyshev polynomial basis as in (21) and on the exact evaluation of the coefficients of the quadrature method by a Gaussian–Christoffel quadrature formula of order m [17, Ch. 3]. It is worth noting that the use of Clenshaw–Curtis quadrature rules with algebraic degree of precision equal to r, for which fast algorithms for computing the weights are well known [34, 35], will produce another kind of quadrature formula from equispaced nodes, which is worth of investigation.
We observe that the construction of the proposed quadrature rule requires the same modified moments of the product rule (4), i.e. it employs the same computational effort. However, differently from the formula (4), the new rule (25) presents the main advantage of using samples of f at equally spaced nodes. About the convergence of the product rule, we are able to prove the following
Theorem 4
Under the assumption
for any \(y\in S\) the following error estimate holds true
Proof
From Theorem 2, in view of (26) and under the assumption (30), we have
\(\square \)
Remark 4
Since \(B_n \approx \mathcal {C}\ n^{2.03}\), taking into account (3), the convergence of the rule is assured for functions \(f\in W_3\). As one can deduce from (7), the “classical” product formula (4) converges under less restrictive assumptions on the function f, which is required to be only continuous in the integration interval. However, such a rule requires the samples of f at the zeros of the Chebyshev polynomial \(T_{r+1}\), and hence is not reliable if one works on experimental data, usually obtained on equally spaced nodes. For instance, in evolution equations of nonlocal diffusion type, the data can be given at equally spaced points. To solve such a kind of equation, in [26] the authors proposed a discretization procedure based on the application of the line method and on quadrature formulae over equally spaced points.
3.1 Implementation details
Now we provide some details about the effective computation of the coefficients of the product rule (25), for the following choices of kernels:
and \(w(x)=(1-x)^\alpha (1+x)^\beta .\)
Let us focus on the case \(K_1(x,y)\) in order to compute the modified moments \(\left\{ M_{i}^{(K_1)}(y)\right\} _{i=0}^r\), where
To this purpose we first split the integral as follows
Introducing the linear transformations
and setting \(z=\varPhi _j(x),\;j=1,2,\) we have
where both the above integrals can be evaluated with high precision by means of \(r-\)point Gaussian rules w.r.t. the weight \((1-z)^\lambda (1+z)^\beta \) and \((1-z)^\alpha (1+z)^\lambda \) in the first and second integrals, respectively. Note that the transformed integrand contains factors of the type \((1\pm \varPhi _j^{-1}(z))^\rho , \ \rho >-1\), which are analytical functions, so that the error of the Gaussian rule geometrically goes to zero.
Let us consider the modified moments
In this case the main problem is the oscillation of the integrand. In order to mitigate this phenomenon, we propose to use a dilation technique introduced in [7, 30]. Setting \(z=yx\), we have
Moreover, we consider the following partition of the integration interval \([-y,y]\) into \(s:=\lfloor y \rfloor \) subintervals of size \(d:=\frac{2y}{s}\)
Hence, the modified moments (32) take the following expression
By setting
and with the change of variable \(t=\varphi _j(z)\), we get
where
The above integrals are less oscillating and can be evaluated with high precision by means of \(r-\)point Gaussian rules w.r.t. the weight \((1+t)^\beta \) and \((1-t)^\alpha \) in the first and last integrals and w.r.t. the Legendre weight in the others, respectively. Note that the transformed integrand contains factors of the type \(g(\varphi _j^{-1}(t))\), \(w\left( \frac{\varphi _j^{-1}(t)}{y} \right) \) and \(\left( 1\pm \frac{\varphi _j^{-1}(t)}{y}\right) ^\rho , \ \rho >-1\), which are analytical functions, so that the error of the Gaussian rule geometrically goes to zero.
The same dilation technique has been applied for “nearly” singular kernels of the type \(K_3(x,y)\) [30, 31]. In this case, we consider the modified moments
and we set \(z=\frac{x}{y}\), obtaining
We fix the parameter \(s:=\left\lfloor \frac{1}{y} \right\rfloor \) also in this case, in order to have \(d \sim 2\) and divide the interval \(\left[ -\frac{1}{y},\frac{1}{y}\right] \) into s subintervals of size d. Hence, we get
and
Denoting by
and by setting \(t=\psi _j(z)\) in each integral, we have
with
Since the poles of the integrand functions are far away from the real axis, the above integrals can be evaluated by means of \(r-\)point Gaussian rules w.r.t. the weight \((1+t)^\beta \) and \((1-t)^\alpha \) in the first and last integrals and w.r.t. the Legendre weight in the others, respectively. Note that the transformed integrand contains factors of the type \(\frac{1}{((\psi _j^{-1}(t))^2+1)^\mu }\), \(w(y\psi _j^{-1}(t))\) and \((2\pm (\frac{t-1}{2})yd)^\rho , \ \rho >-1\), which are analytical functions, so that the error of the Gaussian rule geometrically goes to zero.
Remark 5
The computation of the modified moments for the considered kernels is attained by means of Gaussian rules. By doing so we introduce an error that is of the order of the machine precision. This choice doesn’t have an impact on the performance of our rule (25). For other choices of kernels the modified moments can be evaluated exactly by means of recurrence relations that however can become progressively unstable as r increases.
4 Numerical experiments
In this section we present some numerical experiments to analyze the performance of the constrained mock-Chebyshev product rule and compare it with other procedures. More in detail, we perform a direct comparison between the constrained mock-Chebyshev product rule (25) and the classical product formula (4). To this purpose, in each example, we consider the following functions
and we focus on a particular kernel for different choices of \(y\in S\).
Tables 1, 2, 3 display the absolute errors
being the constrained mock-Chebyshev product rule based on a grid of 1001 uniformly distributed nodes in the interval \([-1,1]\). In this setting, we have \(n=1000,\,r=98,\,m=70\). All the tests are carried out in MatlabR2022a on a MacBook Pro under the MacOS operating system and in each table we report the CPU time required to evaluate the considered integral in four different values of y. Moreover, since the exact value of the integrals is not known, we assume as exact the values provided in quadruple working precision by the built-in function NIntegrate of the Wolfram Mathematica 13 software.
In our numerical tests we considered the following integrals:
Example 1
in which \(K(x,y)=|x-y |^{\frac{3}{10}}\) is a weakly singular kernel function and \(w(x)=w^C(x)\).
Example 2
involving a nearly singular kernel function \(K(x,y)=\frac{1}{(x^2+y^2)^2}\) and \(w(x)=w^C(x).\)
Example 3
with the highly oscillating kernel \(K(x,y)=\sin (yx)\) and \(w(x)=w^C(x)\).
Example 4
where \(f(x)=\frac{1}{1+25x^2}\) is the Runge function, \(K(x,y)=\cos (yx)\) is a highly oscillating kernel and \(w(x)=\sqrt{1-x^2}\) is the 2-nd kind Chebyshev weight.
The results in Tables 1, 2, 3 highlight that the product rules (25) and (4) have comparable performances. Nevertheless, the constrained mock-Chebyshev product formula (25) is based on equally spaced data and this makes it the adequate tool to choose in many practical applications, differently from the classical product rule (4) requiring that the function f is known analytically or at least at the zeros of orthonormal polynomial w.r.t. the weight function w.
In Example 4 we test the performance of the constrained mock-Chebyshev rule for different choices of equispaced grids in the integration interval \([-1,1]\). In this context, Table 4 reports the relative errors
attained by the rule (25) for increasing values of n,\(\,m\) and p, namely for gradually more dense equispaced grids of \(n+1\) points in \([-1,1]\), and for different values of y.

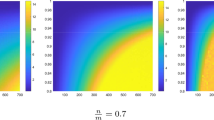
Benchmark analysis of the relative errors attained approximating the integral I(f, y) by means of the constrained mock-Chebyshev product rule based on different equispaced grids with \(f(x)=\frac{1}{1+25x^2}\) and \(K(x,y)=\cos (yx)\)
Table 4 and Fig. 1 show that the more dense the equispaced grid is, the more accurate is the constrained mock-Chebyshev rule (25). However, we also observe a slight loss of accuracy for increasing values of y. This can be attributed to the high oscillations of the kernel \(\cos (yx)\) and to the Runge phenomenon that occurs when using polynomial interpolation with polynomials of high degree over a set of equispaced interpolation points.
5 Conclusions and future works
In this paper we proposed a new product rule, based on equispaced points, through the constrained mock-Chebyshev least squares operator. Moreover, we provided an error estimate and many numerical examples which confirm the accuracy of the proposed formula. By the numerical results, the rule (27) on n nodes shows the same accuracy of the product rule (4) on \(m=\left\lfloor \pi \sqrt{\frac{n}{2}} \right\rfloor \) nodes. Based on these satisfactory results, it is our aim to extend this formula to the case of unbounded intervals or/and bivariate domains.
References
Atkinson, K. E.: The Numerical Solution of Integral Equations of the Second Kind. Cambridge Monographs on Applied and Computational Mathematics (1997)
Boyd, J.P., Xu, F.: Divergence (Runge phenomenon) for least-squares polynomial approximation on an equispaced grid and Mock-Chebyshev subset interpolation. Appl. Math. Comput. 210, 158–168 (2009)
Boyd, S., Vandenberghe, L.: Introduction to Applied Linear Algebra: Vectors, Matrices, and Least Squares. Cambridge University Press, Cambridge (2018)
Brunner, H.: Collocation Methods for Volterra Integral and Related Functional Differential Equations. Cambridge University Press, Cambridge (2004)
Cheney, E.W.: Introduction to Approximation Theory. Mcgraw-Hill Book Company, New York (1966)
Davis, P.J.: Interpolation and Approximation. Dover Publications, Illinois (2014)
De Bonis, M., Pastore, P.: A quadrature formula for integrals of highly oscillatory functions. Rend. Circ. Mat. Palermo 2, 279–303 (2010)
De Bonis, M.C., Stanić, M.P., Mladenović, T.V.T.: Nyström methods for approximating the solutions of an integral equation arising from a problem in mathematical biology. Appl. Numer. Math. 171, 193–211 (2022)
De Marchi, S., Dell’Accio, F., Mazza, M.: On the constrained mock-Chebyshev least-squares. J. Comput. Appl. Math. 280, 94–109 (2015)
Dell’Accio, F., Di Tommaso, F., Francomano, E., Nudo, F.: An adaptive algorithm for determining the optimal degree of regression in constrained mock-Chebyshev least squares quadrature. Dolomit. Res. Notes Approx. 15, 35–44 (2022)
Dell’Accio, F., Di Tommaso, F., Nudo, F.: Constrained mock-Chebyshev least squares quadrature. Appl. Math. Lett. 134, 108328 (2022)
Dell’Accio, F., Di Tommaso, F., Nudo, F.: Generalizations of the constrained mock-Chebyshev least squares in two variables: tensor product vs total degree polynomial interpolation. Appl. Math. Lett. 125, 107732 (2022)
Dell’Accio, F., Nudo, F.: Polynomial approximation of derivatives by the constrained mock-Chebyshev least squares operator (2023). Doi:https://doi.org/10.48550/arXiv.2209.09822
Ditzian, Z., Totik, V.: Moduli of Smoothness. SCMG Springer-Verlag, Berlin (1987)
Elliott, D., Paget, D.F.: The convergence of product integration rules. BIT Numer. Math. 18, 137–141 (1978)
Fermo, L., Occorsio, D.: Weakly singular linear Volterra integral equations: a Nyström method in weighted spaces of continuous functions. J. Comput. Appl. Math. 406, 114001 (2022)
Gautschi, W.: Numerical Analysis. Birkhäuser, Basel (2011)
Hasegawa, T., Sugiura, H.: Uniform approximation to Cauchy principal value integrals with logarithmic singularity. J. Comput. Appl. Math. 327, 1–11 (2018)
Ibrahimoglu, B.A.: A fast algorithm for computing the mock-Chebyshev nodes. J. Comput. Appl. Math. 373, 112336 (2020)
Ibrahimoglu, B.A.: A new approach for constructing mock-Chebyshev grids. Math. Methods Appl. Sci. 44, 14766–14775 (2021)
Lubinsky, D.S., Sidi, A.: Convergence of Product Integration Rules for Functions with Interior and Endpoint Singularities over Bounded and Unbounded Intervals. Math. Comput. 46, 229–245 (1986)
Mastroianni, G., Milovanovic, G.V.: Interpolation Processes Basic Theory and Applications. Springer, Berlin (2009)
Mastroianni, G., Monegato, G.: Nyström interpolants based on the zeros of Legendre polynomials for a non-compact integral operator equation. IMA J. Numer. Anal. 14, 81–95 (1994)
Mastroianni, G., Monegato, G.: Convergence of Product Integration Rules Over \((0, \infty )\) for Functions with Weak Singularities at the Origin. Math. Comput. 64, 237–249 (1995)
Mezzanotte, D., Occorsio, D.: Compounded Product Integration rules on \((0, +\infty )\). Dolomit. Res. Notes Approx. 15, 78–92 (2022)
Mezzanotte, D., Occorsio, D., Russo, M.G., Venturino, E.: A discretization method for nonlocal diffusion type equations. Annali dell’Università di Ferrara 68, 505–520 (2022)
Nevai, P.: Mean convergence of Lagrange interpolation III. Trans. Am. Math. Soc. 282, 669–698 (1984)
Occorsio, D., Russo, M.: A mixed scheme of product integration rules in \((-1,1)\). Appl. Numer. Math. 149, 113–123 (2020)
Occorsio, D., Russo, M.G.: Nyström methods for bivariate Fredholm integral equations on unbounded domains. Appl. Math. Comput. 318, 19–34 (2018)
Occorsio, D., Serafini, G.: Cubature formulae for nearly singular and highly oscillating integrals. Calcolo 55, 1–33 (2018)
Pastore, P.: The numerical treatment of love’s integral equation having very small parameter. J. Comput. Appl. Math. 236, 1267–1281 (2011)
Piessens, R., Branders, M.: The Evaluation and Application of Some Modified Moments. BIT Numer. Math. 13, 443–450 (1973)
Rathsfeld, A.: Quadrature methods for 2D and 3D problems. J. Comput. Appl. Math. 125, 439–460 (2000)
Sommariva, A.: Fast construction of Fejér and Clenshaw-Curtis rules for general weight functions. Comput. Math. Appl. 65, 682–693 (2013)
Trefethen, L.N.: Is Gauss quadrature better than Clenshaw-Curtis? SIAM Rev. 50, 67–87 (2008)
Acknowledgements
The authors are grateful to the anonymous reviewers for carefully reading the manuscript and for their precise and helpful suggestions which allowed to improve the work. This research has been achieved as part of RITA “Research ITalian network on Approximation” and as part of the UMI group “Teoria dell’Approssimazione e Applicazioni”. The research was supported by GNCS-INdAM 2022 projects “Metodi e software per la modellistica integrale multivariata” and “Computational methods for kernel-based approximation and its applications”. The authors are members of the INdAM Research group GNCS.
Funding
Open access funding provided by Università della Calabria within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dell’Accio, F., Mezzanotte, D., Nudo, F. et al. Product integration rules by the constrained mock-Chebyshev least squares operator. Bit Numer Math 63, 24 (2023). https://doi.org/10.1007/s10543-023-00968-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10543-023-00968-w