
Abstract
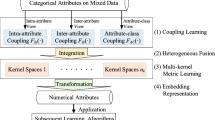
Mixed data containing categorical and numerical attributes are widely available in real-world. Before analysing such data, it is typically necessary to process (transform/embed/represent) them into high-quality numerical data. The conditional probability transformation method (CPT) can provide acceptable performance in the majority of cases, but it is not satisfactory for datasets with strong attribute association. Inspired by the one dependence value difference metric method, the concept of relaxing the attributes conditional independence has been applied to CPT, but this approach has the drawback of dramatically-expanding the attribute dimensionality. We employ the isometric embedding method to tackle the problem of dimensionality expansion. In addition, an attribute weighting method based on the must-link and cannot-link constraints is designed to optimize the data transformation quality. Combining these methods, we propose an attribute-weighted isometric embedding (AWIE) for categorical encoding on mixed data. Extensive experimental results obtained on 16 datasets demonstrate that AWIE significantly improves upon the classification performance (increasing the F1-score by 2.54%, attaining 6/16 best results, and reaching average ranks of 1.94/8), compared with 28 competitors.







Similar content being viewed by others

Data Availability
The experimental data of this paper is derived from the UCI (http://archive.ics.uci.edu/ml/index.php).
References
Ramírez-Gallego S, Krawczyk B, García S, Wozniak M, Herrera F (2017) A survey on data preprocessing for data stream mining: Current status and future directions. Neurocomputing 239:39–57. https://doi.org/10.1016/j.neucom.2017.01.078
García S, Luengo J, Herrera F (2015) Data preprocessing in data mining. Intell Syst Refer Libr. https://doi.org/10.1007/978-3-319-10247-4
Zhang Y, Cheung YM (2022) A new distance metric exploiting heterogeneous interattribute relationship for ordinal-and-nominal-attribute data clustering. IEEE Trans Cybern 52:758–771. https://doi.org/10.1109/TCYB.2020.2983073
Mousavi E, Sehhati M (2023) A generalized multi-aspect distance metric for mixed-type data clustering. Pattern Recognit 138:109353. https://doi.org/10.1016/j.patcog.2023.109353
Li Q, Xiong Q, Ji S, Yu Y, Wu C, Yi H (2021) A method for mixed data classification base on RBF-ELM network. Neurocomputing 431:7–22. https://doi.org/10.1016/j.neucom.2020.12.032
Zhang K, Wang Q, Chen Z, Marsic I, Kumar V, Jiang G, Zhang J (2015) From categorical to numerical: multiple transitive distance learning and embedding. 46–54. https://doi.org/10.1137/1.9781611974010.6
Kasif S, Salzberg S, Waltz DL, Rachlin J, Aha DW (1998) A probabilistic framework for memory-based reasoning. Artif Intell 104:287–311. https://doi.org/10.1016/S0004-3702(98)00046-0
Perlich C, Swirszcz G (2010) On cross-validation and stacking: building seemingly predictive models on random data. SIGKDD Explor 12:11–15. https://doi.org/10.1145/1964897.1964901
Mougan C, Masip D, Nin J, Pujol O (2021) Quantile encoder: tackling high cardinality categorical features in regression problems. CoRR abs/2105.13783:
Efron B, Morris C (1977) Stein’s paradox in statistics. Sci Am - SCI AMER 236:119–127. https://doi.org/10.1038/scientificamerican0577-119
Cestnik B, Bratko I (1991) On estimating probabilities in tree pruning. 138–150. https://doi.org/10.1007/BFb0017010
Micci-Barreca D (2001) A preprocessing scheme for high-cardinality categorical attributes in classification and prediction problems. SIGKDD Explor 3:27–32. https://doi.org/10.1145/507533.507538
Zdravevski E, Lameski P, Kulakov A (2011) Weight of evidence as a tool for attribute transformation in the preprocessing stage of supervised learning algorithms. 181–188. https://doi.org/10.1109/IJCNN.2011.6033219
Prokhorenkova LO, Gusev G, Vorobev A, Dorogush AV, Gulin A (2018) CatBoost: unbiased boosting with categorical features. 6639–6649
Zhang H, Jiang L, Yu L (2021) Attribute and instance weighted naive Bayes. Pattern Recognit 111:107674. https://doi.org/10.1016/j.patcog.2020.107674
Wang L, Xie Y, Pang M, Wei J (2022) Alleviating the attribute conditional independence and I.I.D. assumptions of averaged one-dependence estimator by double weighting. Knowl Based Syst 250:109078. https://doi.org/10.1016/j.knosys.2022.109078
Lopez-Arevalo I, Aldana-Bobadilla E, Molina-Villegas A, Galeana-Zapién H, Muñiz-Sánchez V, Gausin-Valle S (2020) A memory-efficient encoding method for processing mixed-type data on machine learning. Entropy 22. https://doi.org/10.3390/e22121391
Kunanbayev K, Temirbek I, Zollanvari A (2021) Complex encoding. Int Jt Conf Neural Netw (IJCNN) 2021:1–6. https://doi.org/10.1109/IJCNN52387.2021.9534094
Yan X, Chen L, Guo G (2021) Kernel-based data transformation model for nonlinear classification of symbolic data. Soft Comput 26:1249–1259. https://doi.org/10.1007/s00500-021-06600-9
Stanfill C, Waltz DL (1986) Toward memory-based reasoning. Commun ACM 29:1213–1228. https://doi.org/10.1145/7902.7906
Friedman N, Geiger D, Goldszmidt M (1997) Bayesian network classifiers. Mach Learn 29:131–163. https://doi.org/10.1023/A:1007465528199
Li C, Li H (2011) One dependence value difference metric. Knowl Based Syst 24:589–594. https://doi.org/10.1016/j.knosys.2011.01.005
Li Q, Xiong Q, Ji S, Wen J, Gao M, Yu Y, Xu R (2019) Using fine-tuned conditional probabilities for data transformation of nominal attributes. Pattern Recognit Lett 128:107–114. https://doi.org/10.1016/j.patrec.2019.08.024
Jiang L, Zhang H, Cai Z (2009) A novel Bayes model: hidden naive Bayes. IEEE Trans Knowl Data Eng 21:1361–1371. https://doi.org/10.1109/TKDE.2008.234
Li Q, Ji S, Hu S, Yu Y, Chen S, Xiong Q, Zeng Z (2022) A Multi-view deep metric learning approach for categorical representation on mixed data. Knowl-Based Syst 260:110161. https://doi.org/10.1016/j.knosys.2022.110161
Li Q, Xiong Q, Ji S, Gao M, Yu Y, Wu C (2020) Multi-view heterogeneous fusion and embedding for categorical attributes on mixed data. Soft Comput 24:10843–10863. https://doi.org/10.1007/s00500-019-04586-z
Cox MAA, Cox TF (2008) Multidimensional scaling. Handbook of Data Visualization 315–347. https://doi.org/10.1007/978-3-540-33037-0_14
Huo X, Smith A (2007) A survey of manifold-based learning methods. https://doi.org/10.1142/9789812779861_0015
Roweis S, Saul L (2001) Nonlinear dimensionality reduction by locally linear embedding. Science (New York, N.Y.) 290:2323–2326. https://doi.org/10.1126/science.290.5500.2323
Luo S, Miao D, Zhang Z, Zhang Y, Hu S (2020) A neighborhood rough set model with nominal metric embedding. Inf Sci 520:373–388. https://doi.org/10.1016/j.ins.2020.02.015
Yuan Z, Chen H, Li T (2022) Exploring interactive attribute reduction via fuzzy complementary entropy for unlabeled mixed data. Pattern Recognit 127:108651. https://doi.org/10.1016/j.patcog.2022.108651
Jiang L, Li C (2013) An augmented value difference measure. Pattern Recogn Lett 34:1169–1174. https://doi.org/10.1016/j.patrec.2013.03.030
Li C, Jiang L, Li H (2014) Naive Bayes for value difference metric. Front Comput Sci 8. https://doi.org/10.1007/s11704-014-3038-5
Jiang L, Wang D, Cai Z (2012) Discriminatively weighted naive bayes and its application in text classification. Int J Artif Intell Tools 21. https://doi.org/10.1142/S0218213011004770
Jiang L, Li C (2019) Two improved attribute weighting schemes for value difference metric. Knowl Inf Syst 60. https://doi.org/10.1007/s10115-018-1229-3
Jiang L, Li C, Wang S, Zhang L (2016) Deep feature weighting for naive Bayes and its application to text classification. Eng Appl Artif Intell 52:26–39. https://doi.org/10.1016/j.engappai.2016.02.002
Zhang H, Jiang L, Yu L (2020) Class-specific attribute value weighting for Naive Bayes. Inf Sci 508:260–274. https://doi.org/10.1016/j.ins.2019.08.071
Jiang L, Zhang L, Li C, Wu J (2019) A correlation-based feature weighting filter for Naive Bayes. IEEE Trans Knowl Data Eng 31:201–213 (https://ieeexplore.ieee.org/document/8359364)
Cerda P, Varoquaux G, Kégl B (2018) Similarity encoding for learning with dirty categorical variables. Mach Learn 107:1477–1494. https://doi.org/10.1007/s10994-018-5724-2
Li Q, Xiong Q, Ji S, Yu Y, Wu C, Gao M (2021) Incremental semi-supervised extreme learning machine for mixed data stream classification. Expert Syst Appl 185:115591. https://doi.org/10.1016/j.eswa.2021.115591
Rakotomamonjy A, Bach FR, Canu S, Grandvalet Y (2008) Simplemkl Alain Rakotomamonjy Stéphane Canu. http://jmlr.org/papers/v9/rakotomamonjy08a.html
Schölkopf B, Smola AJ (2002) Learning with Kernels: support vector machines, regularization, optimization, and beyond. Adaptive computation and machine learning series I-XVIII. https://ieeexplore.ieee.org/servlet/opac?bknumber=6267332
Popescu M-C, Balas V, Perescu-Popescu L, Mastorakis N (2009) Multilayer perceptron and neural networks. WSEAS Trans Circuits Syst 8.
Yang CC (2010) Search engines information retrieval in practice. J Assoc Inf Sci Technol 61:430. https://doi.org/10.1002/asi.21194
Nadeau C, Bengio Y (2003) Inference for the generalization error. Mach Learn 52:239–281. https://doi.org/10.1023/A:1024068626366
Li M-W, Xu D-Y, Geng J, Hong W-C (2022) A hybrid approach for forecasting ship motion using CNN–GRU–AM and GCWOA. Appl Soft Comput 114:108084. https://doi.org/10.1016/j.asoc.2021.108084
Demsar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Hoerl AE, Kennard RW (2000) Ridge regression: biased estimation for Nonorthogonal problems. Technometrics 42:80–86 (https://www.tandfonline.com/doi/abs/10.1080/00401706.2000.10485983)
Acknowledgements
The work was funded by the National Natural Science Foundation of China (grant no. 62166009), the Guizhou Provincial Natural Science Foundation of China (grant nos. ZK[2021]333 and ZK[2022]350), the Science and Technology Foundation of the Guizhou Provincial Health Commission (grant no. gzwkj2023-258), and the Ph.D. Research Startup Foundation of Guizhou Medical University (grant nos. 2020-051 and 2023-009).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Figures 7, 8, 9, 10, 11 and 12

Comparison between AWIE and the first category of encoding methods in terms of their F1 scores

Comparison between AWIE and the second category of encoding methods in terms of their F1 scores

Comparison between AWIE and the third category of encoding methods in terms of their F1 scores

F1 score comparison between our method and the first category of methods according to the Nemenyi test

F1 score comparison between our method and the second category of methods according to the Nemenyi test

F1 score comparison between our method and the third category of methods according to the Nemenyi test

Time cost comparison between our method and the first category of methods according to the Nemenyi test

Time cost comparison between our method and the second category of methods according to the Nemenyi test

Time cost comparison between our method and the third category of methods according to the Nemenyi test
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liang, Z., Ji, S., Li, Q. et al. An attribute-weighted isometric embedding method for categorical encoding on mixed data. Appl Intell 53, 26472–26496 (2023). https://doi.org/10.1007/s10489-023-04899-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-04899-5