
Abstract
Ensemble learning is an algorithm that utilizes various types of classification models. This algorithm can enhance the prediction efficiency of component models. However, the efficiency of combining models typically depends on the diversity and accuracy of the predicted results of ensemble models. However, the problem of multi-class data is still encountered. In the proposed approach, cost-sensitive learning was implemented to evaluate the prediction accuracy for each class, which was used to construct a cost-sensitivity matrix of the true positive (TP) rate. This TP rate can be used as a weight value and combined with a probability value to drive ensemble learning for a specified class. We proposed an ensemble model, which was a type of heterogenous model, namely, a combination of various individual classification models (support vector machine, Bayes, K-nearest neighbour, naïve Bayes, decision tree, and multi-layer perceptron) in experiments on 3-, 4-, 5- and 6-classifier models. The efficiencies of the propose models were compared to those of the individual classifier model and homogenous models (Adaboost, bagging, stacking, voting, random forest, and random subspaces) with various multi-class data sets. The experimental results demonstrate that the cost-sensitive probability for the weighted voting ensemble model that was derived from 3 models provided the most accurate results for the dataset in multi-class prediction. The objective of this study was to increase the efficiency of predicting classification results in multi-class classification tasks and to improve the classification results.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Currently, the problem of Multiclass classification with decision making processes is a fundamental problem in supervised learning which is an important problem in classify results by multiple label-classes [1,2,3]. For example, the works [4,5,6] applied to real-life situations such as text categorization, entity recognition, and disease diagnose respectively. Therefore, finding an appropriate method or strategy to solve the multi-class classification problem is important. However, it is difficult to solve multi-class classification problems in order to the scope of a decision for a problem is the decision-making process probably be more complex than the problems of binary classifications [7]. The decision-making process [4, 8,9,10] is another problem that has been studied in this research. Part of the decision to classify the result class of the data set. There is often a problem with multi-class dataset data due to improper classification of results due to the large collection and distribution of class results. From the increasing number of multi-class data sets Therefore, new machine learning algorithms [11,12,13] need to be developed to improve the efficiency of the results class prediction and find that there are multiple learning models that can be used to solve the same problem [14,15,16]. Ensemble learning is a machine learning process to improve the efficiency of predictions [17,18,19]., [20] using a strategy to combine multiple learning predictions and helps to reduce the problem of inappropriate model selection by combining all models. This method is popular and widely used to improve performance than individual models [13, 21, 22]. According to the effectiveness of the ensemble learning method, it is necessary to create Creating a new ensemble model to improve the model’s accuracy and stability [16, 20, 23]. The main challenges of creating a new ensemble model are how to combine strategy and methods. Determine the assigning weight probability, which is the method preceding the final class result classification process for multi-class data. In aspect of designing an efficient new ensemble model method [24,25,26], there are 4 key points to be considered: dataset, based model, combination strategy and method of assigning probability weight. According to previous studies [16, 27, 28] the researcher tends to not pay much attention to multi-class data sets due to the multi-class classification. There is a complex decision-making class classification results that are difficult to manage [29]. To deal with this important problem, there are 2 main methods that are used to create classification methods for multi-class data: The traditional base model method and the ensemble model method. At the traditional base model method [30,31,32,33,34,35,36,37,38,39,40], the model used to classify the resultant class, such as classifying the resultant class The nature of the decision tree, which is the decision tree method [41], is used to predict the pattern recognition class of the individual base model. [5, 42,43,44] Accuracy depends on the factors of the prediction of the result of class [45]. Although the traditional base model method can classify the result class in the case of multi-class data sets, it has difficulty in the decision of classifying the correct results class without information bias is greater than the ensemble model. Therefore, the ensemble learning model [46], is considered to be more appropriate for managing Multi-class classification, complex results in which they can improve the classification performance by using the combination method (multiple classifier) in machine learning [47,48,49]. Decision-making, the method of assigning weight (assigning weight probability to class result) is one of the challenges for classifying new result classes in multi-class data. [50,51,52] Therefore, ensemble learning methodology has been considered for reducing class bias occurrence from classification results [4, 53]. Maintaining good classification performance comes from combining result classes. By determining the appropriate probability weight and obtaining a higher classification accuracy for multi-class data [54, 55]. The latest techniques for the combination method are selection base model and assigning method. Many studies [40, 56,57,58] attempt to optimize the probability weight obtained from the prediction of the class results from the ensemble model. It focuses on the combination strategy process, which is a combination of weighted voting methods, which is a method for assigning appropriate weight values to classifications that do not affect the effectiveness of the model and the accuracy of the classification is derived from the improvement of assigning weight. In this step, the true positive value of the prediction of the resulting class increases and decreases. The misclassified data sets of multi-class data are compared to the base classification model and traditional ensemble model [42, 50, 59]. Another important problem is the lack of complete training samples in the data set, which causes training data insufficient data and the difficulty of using a combination strategy to combine models to create good classification methods for multi-class data. Therefore, recent work focuses on supervised machine learning methods, including cost-sensitive methods. Approach [57] in order to overcome the decision problem of classifying the appropriate outcomes. Most jobs that provide high accuracy (Measure the efficiency of the model by confusion matrix methods including Precision, Recall, F-measure, G-mean, and Accuracy). Only for multi-class data classification that has more than 2 result classes, the accuracy resulting from each the range of the number of classes. The result shows that even if the dataset has more classes, which should not be decrease the accuracy. While evaluating performance using the confusion matrix method of the base classification model and traditional ensemble model, the performance evaluation is lower than the new ensemble model. This is possible because of the information bias. The selection of the result class from a single pattern without randomization appropriate randomization results in incorrect results class predictions due to incorrect probability weight assignments. [5, 60, 61] Current work is trying to improve the efficiency of the method combination by setting cost new cost-sensitive weight (new assigning weight) for more accurate probability weight of class result.
In our research, we present a novel supervised cost-sensitive weighted based on Ensemble learning classification. For process resolution decision-making of multi-class classification. The framework that we have proposed is cost-sensitive probability weighted based on ensemble learning, which differs from the initial classification work [42, 62] that focuses on the pattern recognition of The classification of an individual base model that does not take into account the predisposition of the class result data obtained from predictions from the model may lead to information bias. Complex multi-class data without parameter adjustment prior to testing data, making cost-sensitive probability weighted methods stable in the process [63] while achieving accuracy It must be assessed by the efficiency of good classifying multi-class data. In addition, the cost-sensitive methods weighted based on ensemble learning that are presented are different from the traditional ones that are usually simple votes. [5, 20, 42, 64]. Who use the weight voting method in the assigning probability weight method because cost-sensitive weighted based on ensemble learning. The key principle is to determine the new weight of the final class result. It is used before the result class classification procedure to help reduce the risk of bias data management at the test samples from the base model integration, the proposed cost-sensitive weighted methods have been tested on multi-class benchmark datasets and have been implemented. The comparison of other state-of-the-art methods demonstrates the effectiveness of the framework presented in the areas of Precision, Recall, F-measure, G-mean and Accuracy.
To conclude, our main contributions are four folds:
-
1.
Our proposed method offers cost-sensitive weighted-based on ensemble learning, which is a novel supervised combination model based on Ensemble learning classification Based on machine learning methods to improve the classification of data from individual models to ensemble models for problem solving processes. The costed-weighted approach is to learn multi-class samples without adjusting the parameters of the base model, providing a good evaluation of the model. Than the base model method and the traditional ensemble model.
-
2.
Our proposed method presents the novel supervised learning of the cost-sensitive probability weighting ensemble learning method, where the combination strategy eliminates information bias from the decision to classify wrong outcomes, which is a good way of consolidating when that strategy gives value misclassified by decreasing.
-
3.
The methods is used TPrate-weight, which is a novel combination strategy from the improvement of the probability weight to combine the base model to provides a better classification performance compared to the many existing methods that are tested using benchmarks dataset.
-
4.
In this research, our proposed method present efforts to improve the process decision-making for multi-class data sets by suggesting the combination methods in the constructing ensemble model of the framework
2 Literature review
2.1 Ensemble model
The ensemble learning approach employs diverse classification models to enhance the prediction efficiency on various datasets. Although the individual models provide satisfactory prediction accuracy and precision on the dataset, they are sometimes confronted with the problem of bias when specifying the dataset that is obtained from the prediction or specifying the parameter. One of the approaches to resolving the bias is the joint decision approach, which is called ensemble learning with one additional base classification model. The decision is later combined via voting [64]. In this study, weighted voting was deployed to enhance the efficiency in predicting the classification model. Ensemble learning was utilized in various research studies to enhance the prediction efficiency. Reference [42] applied ensemble learning to multi-class ensemble classification and proposed the Kalman-filter-based heuristic ensemble (KFHE). Based on this approach, ensemble learning was conducted during the final procedure. The data were deployed with Kalman filters to combine various individual models with multi-class classification. The experiment compared the KFHE and the original ensemble model and calculated the efficiency of KFHE for testing data without noise and data with noisy class labels. The KFHE realized a significantly better value.
Ensemble learning has also been used to enhance the efficiency of classifiers. In reference [5], natural language processing (NLP) was conducted via ensemble learning, which employed the voting technique to combine classifiers for named-entity recognition. This approach was crucial for NLP. This study recommended two solutions for generating the ensemble model, which differ in terms of their effects in enhancing the efficiency. It was hypothesized that the reliability of predicting each classifier differed among the output classes. Therefore, the ensemble system must search for each class that was most suitable for the classifier through voting, such as binary voting. Additionally, it must determine the number of votes for each class for the single classifiers, such as the real votes. The applied model classified and selected without domain knowledge or language-specific resources. The results for each language demonstrated that multi-objective optimization (MOO) with real voting could yield higher efficiency than the individual classifiers in the ensemble. For selecting a suitable weight, all the parameters should be set to the most suitable values at the same time. To realize this objective, multi-objective optimization was implemented to enhance the efficiency in evaluating the quality of one additional classification.
In addition to improving the efficiency of machine learning via ensemble learning, reference [20] deployed extreme learning machines to improve the efficiency of the classification model via an advanced ensemble with various models. Extreme learning was efficient in its general operation. However, overfitting of the training data could be likely. To resolve the problem of low efficiency, a heterogeneous ensemble was implemented. This study proposed the advanced ELM ensemble (AELME) for classification. This approach was comprised of the regularized ELM, the 2-norm-optimized ELM (ELML2), and the kernel ELM. The ensemble was generated by training the ELM classifier, which was randomly selected on a subset of the training data with resampling. The resampling subset was selected for the classification of the training data. Each classifier was learned for selecting the data subset randomly via the ELM algorithm. The AELM-Ensemble was developed using the objective function to increase the diversity and accuracy in the group of the final ensemble. The class labels of the unseen data were predicted via majority voting, which were combined with the predictions from ensembles in AELME. The results of the study demonstrate that AELME yielded higher accuracy than the other models on benchmark datasets. Classifying the training data of the subset and combining heterogeneous ELM classifiers yielded high accuracy in the overall operation.
Moreover, in multi-objective optimization, ensemble learning is typically used to increase the efficiency of the classifier. Reference [4] conducted a sentiment analysis. An ensemble was generated via the weighted voting of multi-objective methods that are based on the differential evolution algorithm for text sentiment classification with supervised machine learning. Most approaches that employ ensemble learning for sentiment analysis manage the features to enhance the prediction efficiency. The study attempted to develop a multi-objective method by increase the efficiency via a weighted voting scheme to fix the suitable weights for each classifier and output class to increase the prediction efficiency for all the algorithms and the sentiment classification. Thus, a multi-objective differential evolution algorithm (MODE) was implemented in this study. Several mutation operators were applied to enhance the efficiency of the differential evolution algorithm. The weight of each classifier for each output class was prescribed by the MODE algorithm, whereas the weight of each classifier for each output class was combined by the ensemble to yield the final prediction for each output class.
Ensemble learning is one of the learning algorithms that has the highest efficiency in supervised learning with groups of models. The prediction strategy is to combine the predictions that are derived from multiple learning algorithms to generate the final result [65] and to increase the prediction efficiency [17]. The ensemble learning model utilized the advantages of each base model when combining the models. Then, the resulting model was utilized to generate the final result by combining the subdivisions from the prediction [66]. The model that combines the learning models was regarded as an efficient approach for improving the classification performance, and it realized outclassed management with a small sample size, high dimensionality, and data with complicated structures, such as the individual models [67]. Furthermore, ensemble learning was one of the machine learning approaches that was deployed to combine models to improve the result of each individual model. This approach relies on the combination of the output of sets of learning models according to specified rules to obtain a better model than an individual learner [68]. Ensemble learning is regarded as an efficient machine learning technique, which is comprised of diverse components for a single task instead of various subtasks. Later, the base learning machines were combined to form ensemble learning machines. Compared to the individual algorithms, it was found that the ensemble techniques could reduce the error in determining the mean and combine the multiple classification models to reduce overfitting of the training data. Many research studies have demonstrated the efficiency of ensemble learning, which is an easy technique. In addition, they indicated that ensemble learning realizes higher efficiency than the individual algorithms with the same complexity [27]. Ensemble learning is the combination of the outputs of sets of learning models according to specified rules to obtain a better model than single learners. Ensemble learning has been widely implemented in applications such as image recognition, speech recognition, and industrial process monitoring. Ensemble learning consists of two main procedures: The first procedure involves training. The ensemble model is derived from the base learning algorithms. The second procedure involves prediction. The output of the model is combined to generate the decision. The selection of the ensemble model can be divided into two stages:: The first stage fixes the functions or criteria for evaluating and ranking the model. The second stage deploys a search algorithm to search the group for the best model. The performances of ensemble methods depend on the training data. A severe problem of the ensemble learning algorithm during the stage of learning is maintaining the performance without duplicating the base model. In generating a different model from the feature space, the base models did not reduce the accuracy compared to the individual model, whereas the efficiency of all the ensemble models was enhanced [69]. Regarding ensemble learning, six vital techniques have been employed for analysis. However, the homogenous model is used as a technique for ensemble learning by voting from the separation data. The traditional homogenous model is described as follows.
2.1.1 AdaBoost (adaptive boosting)
AdaBoost [31, 70, 71] is a machine learning algorithm and one of the approaches that has been derived from ensemble learning. The approach combines weak models from various classification models. The main strategy of the AdaBoost algorithm concerns the generation of the model weights and sample weights. Once in the process of repeated training, the model weights and sample weights were trained by the weak model. The weights of the samples, which were inaccurately predicted, would increase to focus on the next training step. The model weights were calculated based on the error rate of each weak model.
2.1.2 Bagging (bootstrap aggregating)
Bootstrap aggregating (bagging) [72,73,74,75] is one of the primary ensemble methods that uses bootstrap sampling. With bagging, the ensemble, as a homogeneous ensemble, was combined to generate the prediction model with data resampling. Bagging was used to generate a subset for resampling, and aggregating was used to generate a subset for bootstrapping. The main objective of bagging was to reduce the error from the variance of the unstable base classifier.
2.1.3 Stacking
Stacking [16, 76, 77] is an approach that combines models. Stacking was deployed to reduce the error rate by reducing the bias in the data. The main strategy of stacking is to combine the outputs of various prediction models.
2.1.4 Random forest
A random forest [29, 78,79,80] or a random decision forest is an ensemble learning method for classification and regression. Moreover, random forest was one of the most powerful and successful machine learning algorithms and combined the diversity of randomized decision trees and prediction via averaging.
2.1.5 Random subspace
Random subspace [28] was proposed in a decision forest. Random subspace consists of multiple decision trees that are generated in multiple random subspaces, which are combined to form a classifier. Random subspace was the approach of the classifier ensemble, which was deployed to resolve the problems of noise and more redundant data than the single classifier. The random subspace of the training dataset was improved similarly to bagging. This improvement was conducted in the feature space, especially in the instance space. This approach was derived from the random subspace for generating the base classifier when the dataset had complicated or irrelevant properties.
2.1.6 Voting
Voting [62] is regarded as the easiest approach for combining individual classification algorithms. To select the rules for combining the classifier ensemble, voting is the decision rule for selecting a single class out of several alternatives. Voting predicts the class via majority voting. Voting is the approach that is most frequently implemented in ensemble learning. The pattern of voting includes unweighted and weighted voting. Unweighted voting involves simple voting or majority voting, while weighted voting involves simple weighted voting.
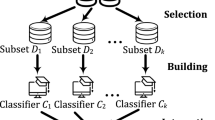
A literature review summary is presented in Table 1. The base learner model depends on the experimental data. For model combination, a strategy of combining the predictions of the classifications that are made is applied to the ensemble. There are two main types of ensembles: homogeneous ensembles and heterogeneous ensembles (Fig. 1).

Categories of Ensemble classifier models. (a) Homogeneous ensemble. (b) Hetorogeneous ensemble
Homogeneous ensembles used the same learning algorithm, whereas, heterogeneous ensembles use various learning algorithms, such as the classifier combination model. As an example of the research of Zhibin Wu et al. [73] in which the heterogeneous ensembles ensembles are constructed from two basic methods in comparing the model’s performance. Thus, creating models using the principles of a traditional ensemble model is the bagging method. By creating the ANN model as the 1st ensemble model and the SVM model as the 2nd ensemble model, these methods will be combined. A sample voting technique to create a new ensemble model, then compare to find the best method.
3 Proposed framework
Our proposed framework is a type of heterogeneous ensemble. This study focused on enhancing the efficiency of the data classification. Several classification models are typically employed for the test, such as the naive Bayes, multilayer perceptron, and decision tree models. These approaches were employed to evaluate the efficiency to identify the best approach. The model that was tested by those methods was called the base classifier model. The efficiency of the base classifier model was evaluated to identify the best approach. It was posited that best approach for the dataset depended on the attributes of the input dataset. Therefore, the strategy of testing the base models resulted in testing of the ensemble model, which is a combination of various models, to obtain a model with higher efficiency in testing the datasets and with higher accuracy. This study used a dataset with multiple data types to evaluate the efficiency and probability of the most suitable class and could encourage the dataset to realize the best accuracy. To combine the models, the base model was used to generate an ensemble model for obtaining the predicted class and the weights for calculating and combining the models. The weights from the probability of the class occurrence were calculated with the true positive (TP) rate, which measures the reliability of the class that was predicted by the model in comparison with the actual class. In addition, our purposed model uses the reliability rate as a parameter of the probability weight model to select a class. Before generating the model, the dataset was pre-processed. This procedure prepared the dataset before model testing. In this research study, the test for model efficiency was divided into three parts, namely, testing of the base model, the original ensemble model, and the proposed new ensemble model or the TPweight-voting ensemble model that consists of 3TP-Ensemble, 4TP-Ensemble, 5TP-Ensemble and 6TP-Ensemble. All the models, starting with the base model, consist of six models: the decision tree, k-nearest neighbours, support vector machine, multilayer perceptron, naive Bayes, and Bayesian network approaches. The base model was regarded as the beginning model for generating each new ensemble model. Next, the original ensemble model, which was comprised of another six approaches, namely, AdaBoost, bagging, random forest, random subspace, stacking, and voting, is presented. The models were combined via the traditional approach. Finally, the new ensemble model, namely, the TPweight-voting ensemble model, is presented. This model consists of four approaches: the 3TP-Ensemble model, the 4TP-Ensemble model, the 5TP-Ensemble model and the 6TP-Ensemble model. The TPweight-voting ensemble model consists of the base model and realizes improved prediction performance by combining various datasets into a new model to increase the prediction efficiency. This study aims at developing a more efficient model for multi-class classification datasets than the original individual models. In this study, the original ensemble models were compared.
Before the data are input for the test, they are pre-processed. The procedure for preparing the data before testing is as follows: First, various datasets that were derived from the UCI dataset (Center for Machine Learning and Intelligent Systems) were input for testing. Before testing the model with the datasets, the datasets were handled in two steps. The first step involved preparing the data. This step started with data cleaning, which involved cleaning the data and deleting the instances with large amounts of missing data. The second step replaced the missing values via imputation to make the data smoother. The final data preparation stage was data transformation. This stage transformed the data type according to the testing input pattern of the classification model. Part of the input data described the input attributes. Each dataset contains two or more classes to facilitate learning in multi-class classification problems. After adapting the datasets, the classification models were tested, and the obtained accuracy values were compared to identify the best approach for testing on the multiple datasets after the input data were suitably managed for testing with the classification model as the basis for generating the new ensemble model.
Figure 2 illustrates that the overall generation of the new ensemble model, which is comprised of two main parts: base model classification and ensemble model classification. The first part involves selecting a suitable model for combining and generating the new ensemble model. The second part generates the new ensemble model and is divided into two procedures. The notations that are used in this paper are presented in Table 2. The framework imported of multi-class dataset which has the data set divided into 2 sets, Training dataset and Testing dataset, then import and test with the based model. The reason why the proposed model used train and independent splitting in order to the training set is a set in which the model uses the imported dataset train to verify and assess the accuracy of the model. However, to measure error using data set is independent of all the data for choosing the best model which is simulation to real case study. The split independent train-test data has advantage with case of many attributes to be consider many classes in the experiment. The independent data splitting method will be not bias and overfitting when is considered and applied to real situation that shown the robustness of this methodology. In addition, it will be in the selection process based model. When preparation of testing data into the model, at this stage, the accuracy and predicted result will be obtained in Fig. 3.

Overview of the Newweight-voting ensemble model

Instance of corerectness TP rate
After obtaining the correctness, the next step will select the based model to create a new ensemble model and also will combine strategy with the base model that work together. Each model from the testing dataset have predicted class result of each model. The Classn value from this process is in the process of generating the heterogenous ensemble model, in which each classes are assigned a new Weight value for each class result. The equation is ProbCn*Combine strategyCn. This results in the Probability weight of the class result multiplied by the method or strategy used to combine the models. Combine strategyCn is divided into four methods: Combine strategyCn with TP rate, Recall, Precision, and Fmeasure. For example, the method presented by the research is Combine strategyCn with TP rate-weight, which details the creation of the heterogenous ensemble model and the calculation example as shown in Fig. 4.

Process of TP-rate weight ensemble model
Figure 4 shows the TP weight class calculation process, which contains a combination strategy by using TP rate, calculated with the probability of class result (probability weight). This method is caused by a combination of a variety of base models to achieve a new weight Class N. For example, the probability value of class N generated by a model M and multiplies with the TP rate of class N from model M.
The principle of TP-rate calculation is to calculate the value of the model that the class is actually accurately predicted value from 0 to 1. The true positive calculation of the class is divided by the total number of that class, where True positive is the relative value of the predicted class result and actual class result when the predicted class only meets the actual value. The result of class from the calculation was example that shown how to calculate the new weight of class as Fig. 5: Christian was calculated, the TP rate of 0.667 is derived from the predicted value of model1. In addition, model1 as bayse model was given the probability value that were from 0 to 1 which was 0.211. The new weight of model1 of class 1 as probability weigh of m1 mulplies with TP rate fo class1 as 0.141 approximatly.

Example of prediction with TP-rate weight ensemble model
After that the processes find the new weight class of all classes in that datasets when calculating to find all new weight classes that have occurred, therefore, The further calculated for the TP weight ensemble model method will be created a ensemble model, if the number of model N is 3 the new weight class of m1 to m3 shown 3 TP-weight Ensemble model in Fig. 6. The TP weight ensemble model is an example of a combination of 3 based models, which called the 3TP-weight ensemble model method. The 3TP-weight were composed of mlp, svm and bayes methods. The Christian class was calculated as new weight class of Christian from mlp model are combined with new weight class from Christian of svm model and new weight class of Christian from bayes model. For example, the 3TP-weight ensemble model is 0.287 by the 9th instances of classes: Christian with the 3TP-weight ensemble model was maximum value. Therefore, the TP weight is calculated of each class, which will be calculated as the WeightCn value of each class result from each model, the WeightCn value is the new probability weight for each class result and then use the weight averaging method to combine the WeightCn of each class from each model to get a NewWeight_Cn and select the class that has the maximum NewWeight_Cn to be the final class result of new ensemble model.

Process of the TP weight voting ensemble model
The process of creating a new ensemble model can be described in 4 steps as follows: Firstly, the models are combined by assigning weights to the predicted class. Secondly, a suitable class for generating another new ensemble model is identified in the voting stage. The overall procedure is described in Algorithm 1.

Algorithm 1 provides an overview of all the processes in the construction of the Newweight-voting ensemble learning model. First, the dataset was input. The dataset was divided into two parts: the training dataset, which is denoted by Tn, and the testing dataset, which is denoted by Ts. The process of generating the Newweight-voting ensemble learning model was divided into two main procedures: generating the base model and generating the Newweight model. Building the new ensemble model begins with the generation of the base model. The model set M = (m1, m2,…, mb), where b is the number of base models for testing, is generated. Another process involves selecting the model based on the accuracy on the testing dataset (Ts). Algorithm 2 presents the procedure for selecting the model for generating the new ensemble model, which results in the base model that is used in the process of combining the models. In the second procedure, the Newweight model was generated by generating a set of weights from the Newweight set W. In addition, a set of probabilities was generated, where the probability value set is P = (P1, P2,…, Pw) and w refers to the total number of instances in the testing dataset (Ts). Moreover, the set for the Newweight model (w1, w2,…, wd) was generated, and d refers to the number of generated New ensemble models. In Algorithm 3, the calculation function for the Newweight ensemble mode is implemented. The class with the largest Newweight was selected as the classification result of the Newweight-voting ensemble model, as presented in Algorithm 4. Then, the model obtains Newweight, which is the probability weight that is selected as the suitable weight of the new class for the New ensemble result in every sample set (Ts). The final result that is obtained from all the processes is the Newweight-voting ensemble learning model.

Algorithm 2 describes the selection of the base model for the process of combining the models. In this step, the training dataset was input, where the training sample set is N = (n1, n2,…, nu) and u is the total number of instances in the training dataset. The testing dataset contains the sample set S = (s1, s2,…, sw), where w is the total number of instances in the testing dataset from the class set C = (c1, c2,…, cm), in which m in the number of classes in each dataset that is generated from the testing samples (S) and the accepted accuracy value. In the step of selecting the model, the generated base model accepted the probability set P = (P1, P2,…, Pw) and the predicted result set D = (d1, d2,…, dw) that was derived from the probability of classifying the testing sample set (Ts). For generating the base model, the actual class and the predicted class from the samples in Ts were considered. The accuracy value is equal to the number true positives in the dataset multiplied by one hundred. Then, the obtained result is divided by the number of observations in the testing set (S). Having calculated the accuracy value of the base model, the model use to generate a new ensemble model, which was selected by sorting all the models in descending order of their accuracy values. The step of selecting the model for the combination involves deleting the base model that has the lowest accuracy. The base models were repeatedly deleted until three models remained; these models were combined. Thus, the model combination was the 3new-Ensemble, 4new-Ensemble, 5new-Ensemble and 6new-Ensemble model. After generating the base model and obtaining the accuracy value for selecting the base models, the final result was the various models for generating the Newweight-voting ensemble model.

Algorithm 3 presents a process for calculating weight in the new ensemble model. The traditional weight is replaced by the new weight from the combination strategy that consists of 4 methods for determining the new weight. Traditional base model combined with TP-weight method, Precision-weight, Recall-weight and Fmeasure-weight method.The input data in this process were the testing sample set S = (s1, s2,…, sw), which was calculated for generating the ensemble model with the class set (C) and probability set (P) that were derived from the testing sample set (Ts). Next, the base model set M = (m1, m2,…, mb) is accepted, where b is the number of tested base models. Algorithm 3 begins by calculating the probability values (P) of the sample set (S) via the measure for each model, and the values were between 0 and 1. The collection of probabilities is expressed in Eq. 1. The class result is predicted with the base model (M), and the prediction result set D = (d1, d2,…, dw) of the testing sample (Ts) is generated. This process results in the actual class and the predicted class.
True Positive rate-weight ensemble learning is a method in which various factors Comes from the rate that the class predicted correctly. The TP rate was calculated and used to determine the new weight of the new ensemble model, namely, TP-weight. The procedure for calculating the TPweight values by considering the probability of the class result from the prediction model multiplied by the weight, which was derived from the calculated TP rate (Trw) of each testing sample (Ts). The TP rate was calculated from the number of predicted classes that corresponded to the actual class in each sample set divided by the total number for all classes, as expressed in Eq. 2, from the confusion matrix in Table 3.
To combine the models, the TP-weight values of each class were combined through the average weight, which combined the TP-weight from each model to determine the suitable class with the largest TPweight. The class became the TP-weight class ensemble result. The TP-weight class can be calculated via Eq. 3.
For every class (C) in the TP-weight class ensemble result, an equation for the probability set P = (P1, P2,…, Pw) was obtained, where P was a set of probabilities of the class that were derived from the base model. The probability was multiplied by the weight from calculating the TP-weight values (Tr). The weight from the result that the model could correctly predict (D) was compared to the actual results of the testing samples (Ts), where w is the number of instances in the testing dataset (Ts) divided by the number in the base model set M = (m1, m2,…, mb), in which b is the number of base models that are used in the test to generate the ensemble model.
Precision-weight ensemble learning is a method in which various factors Comes from measuring the accuracy of the model by considering class by class. The Precision was calculated and used to determine the new weight of the new ensemble model, namely, Precision-weight. The procedure for calculating the Precision-weight values by considering the probability of the class result from the prediction model multiplied by the weight, which was derived from the calculated Precision (Pr) of each testing sample (Ts). Precision can be calculated from the ratio of the rows that the class predicted correctly based on the actual class. As for the total number of rows from the class result that is predicted correctly and incorrect prediction of the class being considered. Which will look for every class, the results in the import data set as in Eq. 4.
To combine the models, the Precision-weight values of each class were combined through the average weight, which combined the Prec-weight from each model to determine the suitable class with the largest Prec-weight. The class became the Prec-weight class ensemble result. The Prec-weight class can be calculated via Eq. 5.
For every class (C) in the Prec-weight class ensemble result, an equation for the probability set P = (P1, P2,…, Pw) was obtained, where P was a set of probabilities of the class that were derived from the base model. The probability was multiplied by the weight from calculating the Prec-weight values (Prr). The weight from the result that the model could correctly predict (D) was compared to the actual results of the testing samples (Ts), where w is the number of instances in the testing dataset (Ts) divided by the number in the base model set M = (m1, m2,…, mb), in which b is the number of base models that are used in the test to generate the ensemble model.
Recall-weight ensemble learning is a method in which various factors Comes from measuring the accuracy of the model by considering class by class. The Recall was calculated and used to determine the new weight of the new ensemble model, namely, Recall-weight. The procedure for calculating the Recall-weight values by considering the probability of the class result from the prediction model multiplied by the weight, which was derived from the calculated Recall (Rr) of each testing sample (Ts). The Recall value can be calculated from the ratio that the class predicts correctly to the actual class values. The total number of rows that the class predicts is incorrect and is not considered combined with all the correctly predicted rows, which will be finding the resulting class in the imported data set, as in Eq. 6.
To combine the models, the Recall-weight values of each class were combined through the average weight, which combined the Rec-weight from each model to determine the suitable class with the largest Rec-weight. The class became the Rec-weight class ensemble result. The Rec-weight class can be calculated via Eq. 7.
For every class (C) in the Rec-weight class ensemble result, an equation for the probability set P = (P1, P2,…, Pw) was obtained, where P was a set of probabilities of the class that were derived from the base model. The probability was multiplied by the weight from calculating the Rec-weight values (Rr). The weight from the result that the model could correctly predict (D) was compared to the actual results of the testing samples (Ts), where w is the number of instances in the testing dataset (Ts) divided by the number in the base model set M = (m1, m2,…, mb), in which b is the number of base models that are used in the test to generate the ensemble model.
Fmeasure-weight ensemble learning is a method in which various factors is derived from the weights of the probability of occurrence of the resulting class. The F-measure was calculated and used to determine the new weight of the new ensemble model, namely, Fm-weight. The procedure for calculating the Fm-weight values by considering the probability of the class result from the prediction model multiplied by the weight, which was derived from the calculated F-measure (Fr) of each testing sample (Ts). The F-measure can be calculated from the combination of the performance indicators of the two class result classification: precision and recall. The F-measure shows the average measurement of the accuracy and accuracy of that class can be calculated. Can be obtained from the following equation, where the F-measure is equal to the precision multiplied by the recall value multiplied by 2 times the precision combined with the recall value as in the 8th equation
To combine the models, the Fm-weight values of each class were combined through the average weight, which combined the Fm-weight from each model to determine the suitable class with the largest Fm-weight. The class became the Fm-weight class ensemble result. The Fm-weight class can be calculated via Eq. 9.
For every class (C) in the Fm-weight class ensemble result, an equation for the probability set P = (P1, P2,…, Pw) was obtained, where P was a set of probabilities of the class that were derived from the base model. The probability was multiplied by the weight from calculating the Fm-weight values (Fr). The weight from the result that the model could correctly predict (D) was compared to the actual results of the testing samples (Ts), where w is the number of instances in the testing dataset (Ts) divided by the number in the base model set M = (m1, m2,…, mb), in which b is the number of base models that are used in the test to generate the ensemble model. According to the equation, the number of classes with class n starts with n = 3, where n is the number of the class that was tested in the dataset, with at least three classes for the test with the objective of determining the multi-class classification results. Then, the class for which the combination strategy weight including the TP-weight, Prec-weight, the Rec-weight and the Fm-weight that exceeds α, which a threshold parameter that is set to 0.8 to yield the maximum accuracy rate in this study, was voted as the Newweight class of the Newweight -voting ensemble learning model.
After the calculation in Algorithm 3, the new weight was obtained. The combination strategy set T, was generated, and every sample set (Ts) in each model was calculated. Then, the models were combined by the new-weight ensemble model set T = (t1, t2,…,tj), where j refers to the total number of strategies. In the final process, The new weight ensemble was calculated continuously until the number of new weight ensemble values in the testing sample set S = (s1, s2,…, sw) was equal to the number in the testing dataset (Ts). The obtained Newweight ensemble was deployed to determine the Newweight ensemble class by the Newweight ensemble-voting maximum class. The results of this process were the Newweight ensemble values of each class, namely, each class of every model had a new weight that was derived from the new ensemble model.

Algorithm 4 describes the process of selecting the Newweight class that has the largest weight as the classification result of the Newweight -voting ensemble learning model. The input data consist of the testing samples (S) and the class (C) of the testing dataset (Ts). Moreover, the sets of the base model (M) and Newweight (W) were input. The procedure of selecting the weight started with the selection of the largest Newweight values that were calculated from every class compared to all the classes in the dataset and from every sample set (S). Next, the Newweight class set G = (g1, g2,…, gw) was generated. This procedure generates a new class ensemble result set (G), where g is the new class that is obtained by calculating the Newweight values and w is the number of instances in the testing dataset (Ts). This procedure results in new classes of ensemble models. Afterwards, a new ensemble model, namely, the Newweight-voting ensemble model, was generated, and the accuracy value was calculated from the testing samples (S) through the obtained Newweight class. Eventually, the results that were obtained by selecting the largest weight for the Newweight class were the sample classes in Ts or all classes in the testing dataset (Ts) from the new ensemble model.
4 Experimental results
This section describes the results of testing the model classifications. Ten datasets were considered in the test, which were derived from the UCI dataset (Center for Machine Learning and Intelligent Systems). Each dataset is detailed in Table 4. The table describes the attributes of the datasets. Moreover, for each of the ten datasets, it specifies the numbers of attributes, instances, and classes. The data were collected as integers and text files for the tests of the model. The largest dataset contained 8124 instances, and the smallest dataset contained 129 instances. The largest number of attributes was 148, and the smallest number was 5 attributes; hence, the test considers the model and the dataset that collected most and fewest attributes. Finally, the attributes of the classes were collected. It was a test of the multi-class classification performance, where the testing dataset with the most classes had 8 classes and that with the fewest classes had 3 classes. For testing of the model and the data, various datasets were considered. The datasets with the largest amount and the smallest amount of data generated the classifiers or predictors efficiently if there were many data instances to be considered in the test. Then, three types of classification models (the base model, the original ensemble model, and the TPweight-voting ensemble model) were tested. In this study, a test was administered to compare two ensemble models, namely, the original ensemble model and the new ensemble model. The obtained accuracy indicates that the Newweight ensemble model realized higher efficiency of the prediction class than the evaluation of the weight of the classification result using the combination strategy, which encouraged the probability of the class to have higher efficiency (Table 5).
5 Disscussion
The weight of cost-sensitive have divided into 4 weight measure as true-positive rate. True Positive rate-weight ensemble learning, Precision-weight ensemble learning, Recall-weight ensemble learning and Fmeasure-weight ensemble learning as Table 7. Each combination strategy is assessed by the overall performance measurements based on cost-sensitive learnings. The TP-rate cost-sensitive probability method was given the best performance measurement methods compared to other methods. The advantage of True positive rate-weight ensemble learning concept as expertise of models is used to able to predict only correct a class that is also high accuracy only each classes. Therefore, the experiment of TP weight will be better than other weighting measure. Our propose model focused on different weight measures is used for value combination from N ensemble methods. The overall performance as Precision, Recall, F-Measure, G-mean and Accuracy are measure repeatly that shown robustness of models definitely.
The overall performances of the classification models with between 3 and 7 classes are compared in Tables 6 and 7. This table compares the precision, recall, F-measure, G-measure and accuracy values of the base model classifications of all six models and six homogenous models. The proposed model with the best performance value was 3TP-ensemble model, as the values on nine datasets indicate that the 3TP-ensemble model yields the best results. On another dataset, the best results are obtained by the 6TP-ensemble, which is of the same type as the proposed model. The homogenous ensemble model that performed the best was the random forest model, whereas the approaches of stacking and voting yielded lower accuracy rates. The Bayes classification models realized satisfactory performance. Therefore, our proposed model was recently improved to enhance the efficiency in predicting the base classification results and to yield high precision, recall, F-measure and G-mean values in classifying the datasets, as shown in Fig. 7.

Evaluation measure (Precision, Recall, F-Measure, and G-Mean) performances of each data set and model
The multi-classes datasets in Fig. 8 were divided into three groups: First, the datasets with between 3 and 4 classes were grouped, which are balance scale, lymphographic, vehicle, grass grab, car evaluation, and user knowledge modelling. The best model is 3TP-ensemble, whereas the percentage accuracy rate is the same as those of classification models MLP and Bayes. Second, the datasets with 5 and 6 classes were grouped, which are eucalyptus soil and urban land cover. The highest accuracy rates are realized by 3TP and 6TP, respectively. This type of proposed model yields the best results. Finally, the datasets with 7 and 8 classes were grouped.

Accuracy performance versus the number of classes for multi-class classification
In addition, the F-measure performance of 3TP-ensemble is compared with those of other homogenous models in Reference [14], which proposed KFHE-e (noise 5%) and KFHE-1 (noise 5%), which were also based on the limitations of current multi-class classification ensemble algorithms. Our proposed model, namely, 3TP-ensemble, yields F-measure values of 0.909, 0.75, and 0.463 on the balance scale (3 classes), lymphography (4 classes) and flags (8 classes) datasets, as shown in Fig. 9. The percentage accuracy of 3TP-ensemble is the highest, namely, 85.74%, on the Lymphography dataset (4 classes) compared with mlp:NS ECOC V1, mlp:NS ECOC V2, svm: NS ECOC V1 and svm: NS ECOC V2 in reference [4] and NP-AVG and NP-MAX in reference [37], as shown in Fig. 10. The experimental results demonstrate the robustness and high performance measure values of the 3TP-Ensemble model.

F-measure performance comparison with other works

Accuracy performance comparison with other works (Lymphography dataset)
The TPweight ensemble could yield the most suitable predicted class among the new multi-classes of the classification result with increased accuracy. According to our approach, the model that provided the highest average accuracy value was the TPweight-voting ensemble model. Comparing the best accuracy values on each dataset between the homogenous ensemble model and the newly proposed ensemble model, the TPweight ensemble realized higher efficiency for predicting the result than the ten datasets and the original ensemble model. The TPweight-voting ensemble model was proposed for increasing the efficiency of predicting the classes in various datasets with multi-class labels in practice. The model encouraged the prediction in each sample set Ts to obtain the most suitable class, which was deriven by parameter α, which reflected the reliability of probability weight for each model, in combination with the TP rate. According to the experimental results for this approach, it could increase the accuracy value of the prediction to a higher value than those that were realized by other models of the original ensemble model.
6 Conclusions
In this research, we present a novel supervised cost-sensitive weighted based on Ensemble learning classification. By the framework of the method cost-sensitive probability weighted based on ensemble learning is introduced with the machine learning concept of cost-sensitive weighted ensemble learning which takes advantage of combining results to improve predictive performance -sensitive weighted is designed to reduce class bias occurring as a result of classification The focus is on the combination strategy that combines weighting with the method of weight voting, which is a method for determining the appropriate weight value. The method presented is based on instructional learning. That is, to learn the model first by dividing test data sets into training data and testing data in order to design a class result. For a multi-class dataset test data set, we demonstrate comprehensive results when compared to methods and apply it to 10 multi-class data sets. We clearly show that the method cost-sensitive probability. Our weighted based probability on ensemble learning has superior methods other state-of-the-art features in Accuracy, Recall, F-measure, G-mean and Accuracy, and reduce misclassified performance. And achieve accuracy values based on good evaluation of classifying multi-class data. Our methods are efficient and stable for problem sets in decision making processes. The multi-class dataset for future work will explore the management of selection base model for creating a new ensemble model to enhance the classification of data sets resulting from the combined prediction.
References
Agarwal N, Balasubramanian V, Jawahar C (2018) Improving multiclass classification by deep networks using DAGSVM and triplet loss. Pattern Recogn Lett 112:184–190
Eghbali N, Montazer G (2017) Improving multiclass classification using neighborhood search in error correcting output codes. Pattern Recogn Lett 100:74–82
Silva-Palacios D, Ferri C, Ramírez-Quintana M (2017) Improving performance of multiclass classification by inducing class hierarchies. Procedia Comput Sci 108:1692–1701
Onan A, Korukoğlu S, Bulut H (2016) A multiobjective weighted voting ensemble classifier based on differential evolution algorithm for text sentiment classification. Expert Syst Appl 62:1–16
Saha S, Ekbal A (2013) Combining multiple classifiers using vote based classifier ensemble technique for named entity recognition. Data Knowl Eng 85:15–39
Maron R, Weichenthal M, Utikal J, Hekler A, Berking C, Hauschild A, Enk A, Haferkamp S, Klode J, Schadendorf D, Jansen P, Holland-Letz T, Schilling B, Kalle C, Fröhling S, Gaiser M, Hartmann D, Gesierich A, Kähler K, Wehkamp U, Karoglan A, Bär C, Brinker T (2019) Systematic outperformance of 112 dermatologists in multiclass skin cancer image classification by convolutional neural networks. Eur J Cancer 119:57–65
Kang S, Cho S, Kang P (2015) Multi-class classification via heterogeneous ensemble of one-class classifiers. Eng Appl Artif Intell 43:35–43. https://doi.org/10.1016/j.engappai.2015.04.003
Webb C, Ferrari M, Lindström T, Carpenter T, Dürr S, Garner G et al (2017) Ensemble modelling and structured decision-making to support emergency disease management. Prev Vet Med 138:124–133
Goodarzi L, Banihabib M, Roozbahani A (2019) A decision-making model for flood warning system based on ensemble forecasts. J Hydrol 573:207–219
Wheaton M, Topilow K (2020) Maximizing decision-making style and hoarding disorder symptoms. Compr Psychiatry 101:152187
Silva-Palacios D, Ferri C, Ramirez-Quintana M (2017) Improving performance of multiclass classification by inducing class hierarchies. Procedia Comput Sci 108C:1692–1701
Vranjković V, Struharik R, Novak L (2015) Hardware acceleration of homogeneous and heterogeneous ensemble classifiers. Microprocess Microsyst 39(8):782–795
Chaudhary A, Kolhe S, Kamal R (2016) A hybrid ensemble for classification in multiclass datasets: an application to oilseed disease dataset. Comput Electron Agric 124:65–72
Xu J, Wang W, Wang H, Guo J (2020) Multi-model ensemble with rich spatial information for object detection. Pattern Recogn 99:107098
Yijinga L, Haixianga G, Xiaoa L, Yanana L, Jinlinga L (2016) Adapted ensemble classification algorithm based on multiple classifier system and feature selection for classifying multi-class imbalanced data. Knowl-Based Syst 94:88–104
Wang Y, Wang D, Geng N, Wang Y, Yin Y, Jin Y (2019) Stacking-based ensemble learning of decision trees for interpretable prostate cancer detection. Appl Soft Comput 77:188–204
Li Z, Wu D, Hu C, Terpenny J (2019) An ensemble learning-based prognostic approach with degradation-dependent weights for remaining useful life prediction. Reliab Eng Syst Saf 184:110–122
Bertini Junior J, Nicoletti M (2019) An iterative boosting-based ensemble for streaming data classification. Inf Fusion 45:66–78
Sabzevari M, Martínez-Muñoz G, Suárez A (2018) Vote-boosting ensembles. Pattern Recogn 83:119–133
Abuassba A, Zhang D, Luo X, Shaheryar A, Ali H (2017) Improving classification performance through an advanced ensemble based heterogeneous extreme learning machines. Comput Intell Neurosci 2017:1–11
Cai Y, Liu X, Zhang Y, Cai Z (2018) Hierarchical ensemble of extreme learning machine. Pattern Recogn Lett 116:101–106
Drotár P, Gazda M, Vokorokos L (2019) Ensemble feature selection using election methods and ranker clustering. Inf Sci 480:365–380
Moustafa S, ElNainay M, Makky N, Abougabal M (2018) Software bug prediction using weighted majority voting techniques. Alex Eng J 57(4):2763–2774
Samma H, Lahasan B (2020) Optimized two-stage ensemble model for mammography mass recognition. IRBM 41:195–204
La Cava W, Silva S, Danai K, Spector L, Vanneschi L, Moore J (2019) Multidimensional genetic programming for multiclass classification. Swarm Evol Comput 44:260–272
Brucker F, Benites F, Sapozhnikova E (2011) Multi-label classification and extracting predicted class hierarchies. Pattern Recogn 44:724–738
Mesquita D, Gomes JP, Rodrigues L, Oliveira S, Galvão R (2018) Building selective ensembles of randomization based neural networks with the successive projections algorithm. Appl Soft Comput 70:1135–1145
Gu J, Jiao L, Liu F, Yang S, Wang R, Chen P, Cui Y, Xie J, Zhang Y (2018) Random subspace based ensemble sparse representation. Pattern Recogn 74:544–555
Zhou Y, Qiu G (2018) Random forest for label ranking. Expert Syst Appl 112:99–109
Hamze-Ziabari S, Bakhshpoori T (2018) Improving the prediction of ground motion parameters based on an efficient bagging ensemble model of M5′ and CART algorithms. Appl Soft Comput 68:147–161
Hui Y, Shuli L, Rongxiu L, Jianyong Z (2018) Prediction of component content in rare earth extraction process based on ESNs-Adaboost. IFAC-Papersonline 51(21):42–47
Tang L, Tian Y, Pardalos P (2019) A novel perspective on multiclass classification: regular simplex support vector machine. Inf Sci 480:324–338
Benjumeda M, Bielza C, Larrañaga P (2019) Learning tractable Bayesian networks in the space of elimination orders. Artif Intell 274:66–90
Trabelsi A, Elouedi Z, Lefevre E (2019) Decision tree classifiers for evidential attribute values and class labels. Fuzzy Sets Syst 366:46–62
Zhang Y, Cao G, Wang B, Li X (2019) A novel ensemble method for k-nearest neighbor. Pattern Recogn 85:13–25
Heidari M, Shamsi H (2019) Analog programmable neuron and case study on VLSI implementation of multi-layer perceptron (MLP). Microelectron J 84:36–47
Jiang L, Zhang L, Yu L, Wang D (2019) Class-specific attribute weighted naive Bayes. Pattern Recogn 88:321–330
Guggari S, Kadappa V, Umadevi V (2018) Non-sequential partitioning approaches to decision tree classifier. Future Comput Inform J 3(2):275–285
Zhou X, Wang X, Hu C, Wang R (2020) An analysis on the relationship between uncertainty and misclassification rate of classifiers. Inf Sci 535:16–27
Kuncheva L, Rodríguez J (2012) A weighted voting framework for classifiers ensembles. Knowl Inf Syst 38(2):259–275
Rooney N, Patterson D (2007) A weighted combination of stacking and dynamic in- tegration. Pattern Recogn 40:1385–1388
Pakrashi A, Mac Namee B (2019) Kalman filter-based heuristic ensemble (KFHE): a new perspective on multi-class ensemble classification using Kalman filters. Inf Sci 485:456–485
Wang Z, Srinivasan R (2017) A review of artificial intelligence based building energy use prediction: contrasting the capabilities of single and ensemble prediction models. Renew Sust Energ Rev 75:796–808
Brembo E, Eide H, Lauritzen M, van Dulmen S, Kasper J (2020) Building ground for didactics in a patient decision aid for hip osteoarthritis. Exploring patient-related barriers and facilitators towards shared decision-making. Patient Educ Couns 103(7):1343–1350
Ding R, Palomares I, Wang X, Yang G, Liu B, Dong Y et al (2020) Large-scale decision-making: characterization, taxonomy, challenges and future directions from an artificial intelligence and applications perspective. Inf Fusion 59:84–102
Shortland N, Alison L, Thompson L (2020) Military maximizers: examining the effect of individual differences in maximization on military decision-making. Personal Individ Differ 163:110051
Yang X, Lo D, Xia X, Sun J (2017) TLEL: a two-layer ensemble learning approach for just-in-time defect prediction. Inf Softw Technol 87:206–220
Mesgarpour M, Chaussalet T, Chahed S (2017) Corrigendum to “ensemble risk model of emergency admissions (ERMER)”. Int J Med Inform 108:65–67
Lin L, Wang F, Xie X, Zhong S (2017) Random forests-based extreme learning machine ensemble for multi-regime time series prediction. Expert Syst Appl 83:164–176
Tan Y, Shenoy P (2020) A bias-variance based heuristic for constructing a hybrid logistic regression-naïve Bayes model for classification. Int J Approx Reason 117:15–28
Ceschi A, Costantini A, Sartori R, Weller J, Di Fabio A (2019) Dimensions of decision-making: an evidence-based classification of heuristics and biases. Personal Individ Differ 146:188–200
Trajdos P, Kurzynski M (2018) Weighting scheme for a pairwise multi-label classifier based on the fuzzy confusion matrix. Pattern Recogn Lett 103:60–67
Zhang L, Shah S, Kakadiaris I (2017) Hierarchical multi-label classification using fully associative ensemble learning. Pattern Recogn 70:89–103
Mao S, Jiao L, Xiong L, Gou S, Chen B, Yeung S-K (2015) Weighted classifier ensemble based on quadratic form. Pattern Recognit 48(5):1688–1706
Kim H, Kim H, Moon H, Ahn H (2011) A weight-adjusted voting algorithm for ensembles of classifiers. J Korean Stat Soc 40(4):437–449
Sun Z, Song Q, Zhu X, Sun H, Xu B, Zhou Y (2015) A novel ensemble method for classifying imbalanced data. Pattern Recogn 48(5):1623–1637
García V, Mollineda R, Sánchez J (2014) A bias correction function for classification performance assessment in two-class imbalanced problems. Knowl-Based Syst 59:66–74
Tao X, Li Q, Guo W, Ren C, Li C, Liu R, Zou J (2019) Self-adaptive cost weights-based support vector machine cost-sensitive ensemble for imbalanced data classification. Inf Sci 487:31–56
Rosdini D, Sari P, Amrania G, Yulianingsih P (2020) Decision making biased: how visual illusion, mood, and information presentation plays a role. J Behav Exp Financ 27:100347
Liu Y, Gunawan R (2017) Bioprocess optimization under uncertainty using ensemble modeling. J Biotechnol 244:34–44
Galicia A, Talavera-Llames R, Troncoso A, Koprinska I, Martínez-Álvarez F (2019) Multi-step forecasting for big data time series based on ensemble learning. Knowl-Based Syst 163:830–841
More S, Gaikwad P (2016) Trust-based voting method for efficient malware detection. Procedia Comput Sci 79:657–667
Guan D, Yuan W, Ma T, Lee S (2014) Detecting potential labeling errors for bioinformatics by multiple voting. Knowl-Based Syst 66:28–35
Cao J, Kwong S, Wang R, Li X, Li K, Kong X (2015) Class-specific soft voting based multiple extreme learning machines ensemble. Neurocomputing 149:275–284
Pérez-Gállego P, Castaño A, Ramón Quevedo J, José del Coz J (2019) Dynamic ensemble selection for quantification tasks. Inf Fusion 45:1–15
Wei Y, Sun S, Ma J, Wang S, Lai K (2019) A decomposition clustering ensemble learning approach for forecasting foreign exchange rates. J Manuf Sci Eng 4(1):45–54
Wang Z, Lu C, Zhou B (2018) Fault diagnosis for rotary machinery with selective ensemble neural networks. Mech Syst Signal Process 113:112–130
Zheng J, Wang H, Song Z, Ge Z (2019) Ensemble semi-supervised fisher discriminant analysis model for fault classification in industrial processes. ISA Trans 92:109–117
Alhamdoosh M, Wang D (2014) Fast decorrelated neural network ensembles with random weights. Inf Sci 264:104–117
Chen J, Yang C, Zhu H, Li Y, Gong J (2019) Simultaneous determination of trace amounts of copper and cobalt in high concentration zinc solution using UV–vis spectrometry and Adaboost. Optik 181:703–713
Barstuğan M, Ceylan R (2018) The effect of dictionary learning on weight update of AdaBoost and ECG classification. J King Saud Univ Comp Inf Sci. https://doi.org/10.1016/j.jksuci.2018.11.007
Hong H, Liu J, Bui D, Pradhan B, Acharya T, Pham B et al (2018) Landslide susceptibility mapping using J48 decision tree with AdaBoost, bagging and rotation Forest ensembles in the Guangchang area (China). CATENA 163:399–413
Wu Z, Li N, Peng J, Cui H, Liu P, Li H, Li X (2018) Using an ensemble machine learning methodology-bagging to predict occupants’ thermal comfort in buildings. Energ Build 173:117–127
Erdal H, Karahanoğlu İ (2016) Bagging ensemble models for bank profitability: an emprical research on Turkish development and investment banks. Appl Soft Comput 49:861–867
Sun J, Lang J, Fujita H, Li H (2018) Imbalanced enterprise credit evaluation with DTE-SBD: decision tree ensemble based on SMOTE and bagging with differentiated sampling rates. Inf Sci 425:76–91
Healey S, Cohen W, Yang Z, Kenneth Brewer C, Brooks E, Gorelick N et al (2018) Mapping forest change using stacked generalization: an ensemble approach. Remote Sens Environ 204:717–728
Sun W, Trevor B (2018) A stacking ensemble learning framework for annual river ice breakup dates. J Hydrol 561:636–650
Gong H, Sun Y, Shu X, Huang B (2018) Use of random forests regression for predicting IRI of asphalt pavements. Constr Build Mater 189:890–897
Shipway N, Barden T, Huthwaite P, Lowe M (2019) Automated defect detection for fluorescent penetrant inspection using random Forest. NDT&E Int 101:113–123
Partopour B, Paffenroth R, Dixon A (2018) Random forests for mapping and analysis of microkinetics models. Comput Chem Eng 115:286–294
Acknowledgments
This study was financially supported in part of the researcher development project of Department of Computer Science, Faculty of Science, Khon Kaen University, THAILAND. And we would like to thank you Asst.Prof.Dr. Mahasak Ketcham, Secretery of Artificial Intelligence Association of Thailand as advisory research.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rojarath, A., Songpan, W. Cost-sensitive probability for weighted voting in an ensemble model for multi-class classification problems. Appl Intell 51, 4908–4932 (2021). https://doi.org/10.1007/s10489-020-02106-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-020-02106-3