
Abstract
Hazardous healthcare waste (HCW) management system is one of the most critical urban systems affected by the COVID-19 pandemic due to the increase in waste generation rate in hospitals and medical centers dealing with infected patients as well as the degree of hazardousness of generated waste due to exposure to the virus. In this regard, waste network flow would face severe problems without taking care of hazardous waste through disinfection facilities. For this purpose, this study aims to develop an advanced decision support system based on a multi-stage model that was combined with the random forest recursive feature elimination (RF-RFE) algorithm, the indifference threshold-based attribute ratio analysis (ITARA), and measurement of alternatives and ranking according to compromise solution (MARCOS) methods into a unique framework under the Fermatean fuzzy environment. In the first stage, the innovative Fermatean fuzzy RF-RFE algorithm extracts core criteria from a finite set of initial criteria. In the second stage, the novel Fermatean fuzzy ITARA determines the semi-objective importance of the core criteria. In the third stage, the new Fermatean fuzzy MARCOS method ranks alternatives. A real-life case study in Istanbul, Turkey, illustrates the applicability of the introduced methodology. Our empirical findings indicate that “Pendik” is the best among five candidate locations for sitting a new disinfection facility for hazardous HCW in Istanbul. The sensitivity and comparative analyses confirmed that our approach is highly robust and reliable. This approach could be used to tackle other critical multi-dimensional problems related to COVID-19 and support sustainability and circular economy.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Waste Management (WM) is considered one of the major issues in modern urban communities that authorities and environmental organizations aim to address sustainably in order to minimize its adverse effects and achieve relevant environmental, social, and economic green targets (Tirkolaee et al., 2021; Torkayesh, Deveci, et al., 2021). With the high rate of urbanization and population growth, WM has become a complicated strategic problem for urban regions (Tirkolaee et al., in press). In addition, different characteristics of waste types, e.g., hazardous healthcare waste (HCW), industrial waste, construction waste, and municipal solid waste, have intensified the complexity of WM for large cities. Hence, the emergence of concepts such as circular economy also prioritised waste treatment (Paul et al., 2022).
In terms of the importance of appropriate treatment of different waste types, hazardous HCW is significant among all waste types due to its hazardous components that can have costly consequences on society, the environment, and the economy (Farrokhizadeh et al., in press). Moreover, most of the products used in healthcare centers are made of materials that can be reused through recycling, such as plastic-based products or even metal products. That is another reason for developing an appropriate treatment for hazardous HCW. A high degree of urbanization and population growth have significantly affected the material consumption rate in healthcare centers (Sazvar et al., in press). Additionally, the hazardous HCW generation rate has increased noticeably during recent decades (Pradenas et al., 2020). As a result, hazardous HCW generated in healthcare centers has a high potential for being recycled and reused in the secondary markets for similar purposes in healthcare centers or other industries.
Recently, the rise of the COVID-19 pandemic has triggered an increase in material consumption rate in healthcare centers due to high incidents of patients infected with the virus (Goodarzian et al., in press). Consequently, the hazardous HCW generation rate has also increased due to the higher utilization rate of plastic-based and other related materials such as face shields and face masks (Lofti et al., in press). However, the increase in material consumption rate in healthcare centers is not the only problem caused by the COVID-19 pandemic. COVID-19 has notoriously affected the degree of hazardous waste generated in healthcare centers due to the high exposure of material and staff to the infected patients (Das et al., 2021; Thakur, 2021). In this regard, the segregation process of hazardous HCW affected by COVID-19 becomes a risky, complicated, and costly task for all stakeholders (Klemeš et al., 2020; Zand & Heir, 2021). Empowering WM companies to treat hazardous HCW considering sustainability and circular practices and developing a disinfection facility to prepare affected hazardous HCW for the recycling, waste-to-energy, and disposal processes can bring positive results (Das et al., 2021; Singh et al., 2020). However, locating a disinfection facility on a waste network for a large city is a complicated, challenging, and multi-dimensional decision-making problem that requires state-of-the-art and reliable tools. Along with technical characteristics, such decision-making problems get into the big data framework (Mishra and Singh, in press) by considering economic, social, and environmental criteria. In this regard, appropriate decision-making tools should also consider the big data nature of the problem while making a decision.
Overall, this paper aims to address the following research questions:
-
(1)
What is the importance of disinfection facilities in waste network flow?
-
(2)
What are the required decision criteria to optimally locate a disinfection facility considering sustainability and circular economy concepts?
-
(3)
How to empower real-life decision-makers to address a multi-dimensional decision-making problem with a high number of decision criteria?
-
(4)
What is the possible way to empower real-life decision-makers to express their uncertain opinions within the decision-making processes?
In this regard, multi-criteria decision-making (MCDM) (Maghsoodi et al., 2018; Simic et al., 2021; Torkayesh, Malmir, et al., 2021) and machine learning algorithms (Bagheri et al., 2019; Chhay et al., 2018; Lu et al., 2021; Maghsoodi et al., 2020) are reliable tools that can unchain managers to tackle real-life multi-dimensional decision-making problems with a large number of decision criteria. Thus, this study develops a novel decision support system based on a multi-stage model that hybridizes the random forest recursive feature elimination (RF-RFE) algorithm, the indifference threshold-based attribute ratio analysis (ITARA), and the measurement of alternatives and ranking according to compromise solution (MARCOS) methods into a unique framework under the Fermatean fuzzy environment. This decision support system was utilized to locate a disinfection facility for hazardous HCW during the COVID-19 pandemic considering a large number of decision criteria under technical, social, economic, and environmental aspects.
1.1 The motivation for using random forest recursive feature elimination
One of the most common and applied approaches in many high-dimensional machine learning problems is applying various statistical and knowledge discovery in data (KDD) techniques to minimize noise and redundant data (Chen et al., 2020). One of the popular KDD and data mining methods used in machine learning problems to reduce the number of features is the recursive feature elimination (RFE) technique with various classifiers (Blum & Langley, 1997; Chen & Jeong, 2007). Rao and Rao (2021) described RFE as an effective method that selects a subset of the most relevant features to train the model and removes the weakest feature(s) until the specified number of features is reached. Evidence from the research studies showed that this method helps remove dependencies and co-linearity of any model (Guyon et al., 2002). One of the primary elements of the RFE method is the utilization of different classifiers such as support vector machines (Guyon et al., 2002; Rtayli & Enneya, 2020), partial least squares (You et al., 2014), Kernel Fisher discriminant analysis (Louw & Steel, 2006), Naïve Bayes (Artur, 2021), and random forest (RF) (Darst et al., 2018; Zhou et al., 2014). Research studies have previously used the RFE technique with different classifiers in various machine learning and data analytics problems (Guyon et al., 2002; Lin et al., 2018; Zhou et al., 2014). This study innovatively utilizes the RF-RFE algorithm as a pre-processing method to select core criteria of the analyzed disinfection facility location selection problem. To the best of the authors’ knowledge, practical applications of the RF-RFE algorithm in WM are unfortunately missing. None of the previous studies combined data mining and machine learning algorithms with FFS-based models into a unique framework. Furthermore, none of the previous studies used the RF-RFE algorithm as a pre-processing method for feature selection combined with MCDM methods. While developing a theoretical framework combining RF-RFE and MCDM methods is novel, this study has also applied this feature elimination technique to a real-world problem.
1.2 The motivation for using fermatean fuzzy sets
Senapati and Yager (2020) introduced the concept of Fermatean fuzzy sets (FFSs) as a generalization of intuitionistic fuzzy sets (IFSs) (Atanassov, 1999) and Pythagorean fuzzy sets (PFSs) (Yager & Abbasov, 2013) to deal with uncertainty. Compared to IFSs and PFSs, the FFS theory is an advanced approach in order to handle imprecise and vague information by expanding the spatial scope of membership and non-membership degrees (Yang et al., 2021). Additionally, IFSs and PFSs have shortcomings in contradictory decision-making environments in which the sum and quadratic sum of membership and non-membership degrees could exceed 1. Differently, FFSs can provide a higher precision by satisfying the criterion that the sum of cubes of membership and non-membership degrees is bounded by 1 (Yang et al., 2021). Therefore, the FFS theory is an exceptional approach for modelling complex human preferences in the decision-making process (Garg et al., 2020). FFS-based MCDM models have been used in diverse research areas, such as civil engineering (Senapati & Yager, ), economics (Sergi & Sari, 2021), environmental engineering (Shahzadi et al., 2021), logistics (Keshavarz-Ghorabaee et al., 2020), medicine (Akram et al., 2020; Garg et al., 2020), and transportation engineering (Sahoo, 2021). Unfortunately, available FFS-based models have not given any attention to complex WM problems. None of the previous studies combined data mining, and machine learning algorithms with FFS-based decision-making approaches into a unique framework. For the first time, this study proposes an approach based on Fermatean Fuzzy MCDM and RF-RFE algorithm and applies it to locate a disinfection facility for HCW.
1.3 The motivation for using the ITARA method
Hatefi (2019) developed the ITARA method and presented its substantial superiority over other weighting methods. The ITARA method directly obtains semi-objective quantitative criteria importance from an initial decision matrix. This simple and logical method assigns greater importance to the criteria with higher data dispersion since it is based on dispersion logic. Moreover, it innovatively utilizes the concept of the indifference threshold. The ITARA method has been applied for criteria importance determination in a few MCDM problems, such as material selection (Sofuoğlu, 2019), power grid dispatching (Du et al., 2020), water allocation management (Elshaboury et al., 2020), logistics equipment selection (Ulutaş et al., 2020), supplier selection (Chang et al., 2021), and risk assessment (Lo et al., 2021). Therefore, this unique method has not been applied for determining criteria importance in any WM problem. On the other hand, the ITARA method has been extended only under the intuitionistic standard cloud uncertain environment (Du et al., 2020). Hence, an extension of the ITARA method into the Fermatean fuzzy environment is still missing. This extension can be valuable for researchers and practitioners since the traditional ITARA method, which can only process deterministic data, may generate erroneous results under contradictory decision-making environments. As a result, to fill the previous research gaps, this study proposed the Fermatean fuzzy ITARA method and applied it to determine the importance of criteria for locating a disinfection facility for hazardous HCW.
1.4 The motivation for using the MARCOS method
MARCOS is one of the newest MCDM methods introduced by Stević et al. (2020), based on the ratio and reference point sorting approaches. The MARCOS method provides robust alternative ranking by definition of ideal/anti-ideal values, relationships between alternatives and reference points, and utility degrees. Its utilization increases the accuracy of decision-making systems and delivers valuable ranking outputs to practitioners. The MARCOS method is mainly utilized with crisp parameters, e.g., Stević and Brković (2020), and Stević et al. (2021). This method has been extended under various uncertain environments, such as D number (Chakraborty et al., 2020), fuzzy (Stanković et al., 2020), picture fuzzy (Simić et al., 2020), interval rough (Deveci et al., 2021), interval type-2 fuzzy (Gong et al., 2021), intuitionistic fuzzy (Ecer & Pamucar, 2021), and single-valued neutrosophic fuzzy (Pamucar, Ecer, et al., 2021). Unfortunately, the MARCOS method has not been extended before under the Fermatean fuzzy environment, significantly improving its applicability in real-life contradictory decision-making environments. On the other hand, the MARCOS method has been employed for solving various decision-making problems in agriculture (Maksimović et al., 2021), civil engineering (Celik & Gul, 2021), computer science (Torkayesh & Torkayesh, 2021), economics (Arsu & Ayçin, 2021), energy management (Deveci et al., 2021; Gong et al., 2021; Pamucar, Iordache, et al., 2021), human resources management (Stević & Brković, 2020), logistics (Chakraborty et al., 2020; Stević et al., 2020; Ulutaş et al., 2020), medicine (Biswas et al., in press), tourism (Mijajlović et al., 2020), and transportation engineering (Bakır et al., 2021; Bouraima et al., 2021; Pamucar, Ecer, et al., 2021; Simić et al., 2020; Stanković et al., 2020). However, not a single previous study utilized the MARCOS method in the WM research area. To fill these methodological and practical research gaps related to this unique MCDM method, this study introduces the Fermatean fuzzy MARCOS method and uses it to rank alternative candidate locations for a disinfection facility for hazardous HCW.
1.5 Contributions of the study
This is the first study that addresses the location problem for a disinfection facility for hazardous HCW during the COVID-19 pandemic. Moreover, it introduces a novel decision support system based on machine learning and MCDM. For the first time, this study integrates random forest recursive feature elimination for MCDM problems to extract core decision criteria. The RF-RFE algorithm has neither been coupled with any MCDM methods. Although various papers have used certain machine learning methods to extract core features (Huang et al., 2018; Ustebay et al., 2018), none of the previous studies have used RFE for core feature extraction. Also, none of the previous studies used RF-RFE for location selection of a disinfection facility for hazardous HCW. In terms of the MCDM, this study is the first to develop an integrated framework based on ITARA and MARCOS under the Fermatean fuzzy environment. Additionally, the Fermatean fuzzy ITARA and the Fermatean fuzzy MARCOS methods are proposed in this study. Finally, the Fermatean fuzzy ITARA-MARCOS model is used for the first time to solve a WM problem in the context of locating a disinfection facility.
1.6 Organization of the study
This research is structured as follows: Sect. 2 provides a review of related state-of-the-art research. Section 3 presents the approach based on the Fermatean fuzzy ITARA-MARCOS and RF-RFE algorithm. Section 4 defines the context definition and the proposed case study. Section 5 provides the results and discussion. Section 6 presents the conclusions of the study.
2 Literature review
This section is organized into three sub-sections; (a) available applications of data mining and machine learning in decision-making, (b) state-of-the-art decision-making approaches for HCW management, and (c) research gaps.
2.1 Applications of data mining and machine learning in waste management
Different WM operations have faced treatment organizations with severe challenges due to the high complexity of WM processes and the high amount of data. Data mining and machine learning methods have attracted specific attention in recent years due to the increasing influence of data on the optimal treatment of waste in different sectors. Table 1 summarizes applications of data mining and machine learning for WM problems. For a more detailed review of similar studies, readers can also refer to a recent literature review by Abdallah et al. (2020).
2.2 Decision-making approaches for healthcare waste management
HCW management has gained a significant research interest in recent years. Table 2 provides a comprehensive survey of the available decision-making approaches for HCW management.
Chauhan and Singh (2016) explored the sustainable location selection problem in the case of an HCW disposal site. Voudrias (2016) investigated systems for hazardous HCW treatment, including incineration, steam disinfection, microwave disinfection, chemical disinfection, and reverse polymerization. Hariz et al. (2017) explored suitable areas for sitting a centralized incinerator for HCW. Chauhan et al. (2018) ranked hospitals from the aspect of HCW management practices. Hinduja and Pandey (2019) evaluated incineration, steam sterilization, microwave disinfection, chemical disinfection, reverse polymerization, and pyrolysis to determine the best treatment technology for HCW. Ishtiaq et al. (2018) prioritized factors affecting the process of selecting an HCW disposal provider in developing countries.
Aung et al. (2019) assessed the performances of private and government hospitals in terms of HCW management practices. Nursetyowati et al. (2019) investigated reduction, sorting, storage, transportation, treatment, and burial management schemes for hazardous HCW generated in community hospitals. Mishra, Mardani, et al. (2020) analyzed the disposal assessment problem in the HCW context by considering microwave disinfection, incineration, steam sterilization, and landfilling. Mishra, Rani, et al. (2020) handled the facility location problem in the context of recycling centers for hazardous HCW. Li et al. (2020) performed a sustainability assessment of incineration, steam sterilization, landfilling, and microwave disinfection in developing countries.
Recently, Azizkhani et al. (2021) compared the suitability of irradiation, microwave disinfection, steam sterilization, chemical disinfection, landfilling, and incineration for managing HCW in rural and urban areas. Chauhan and Singh (2021) investigated the selection of an appropriate specialized HCW disposal firm in the single- and multi-sourcing contexts. Chauhan et al. (2021) explored the tendency and relationships of key drivers of intelligent HCW disposal planning in developing economies. Liu et al. (2021) benchmarked the suitability of incineration, chemical disinfection, microwave disinfection, steam sterilization, and reverse polymerization processes for treatments of regulated medical waste. Makan and Fadili (2021) assessed incineration and non-incineration systems for HCW. Thakur et al. (2021) explored the most critical factors influencing sustainable HCW management in developing countries.
3 Research gaps
The primary research gaps of the current are formulated as follows:
-
(i)
The design of contemporary HCW networks is a prerequisite for efficient management of this top-priority waste flow. However, the problem of locating a disinfection facility for hazardous HCW is not addressed and solved in the available studies. Although disinfection facilities are inevitable HCW network entities, especially in the COVID-19 era, the previous efforts only introduced decision-making approaches for locating landfill sites, waste-to-energy plans, or recycling centers.
-
(ii)
To the best of the authors’ knowledge, practical applications of the RF-RFE algorithm in WM are unfortunately missing. None of the previous studies hybridized data mining and machine learning algorithms with FFS-based models into a unique framework. Furthermore, none of the previous studies have used the RF-RFE algorithm as a pre-processing method for feature selection combined with MCDM methods.
-
(iii)
Various decision-making approaches for HCW management have been proposed in the literature. However, the available models can be employed only under crisp, fuzzy, intuitionistic fuzzy, or Pythagorean fuzzy environments. This significantly limits their applicability in real-life contradictory decision-making environments since they cannot efficiently represent complex, imprecise, and vague management preferences.
-
(iv)
The ITARA and MARCOS methods have not been utilized for solving any HCW management problem. Also, not a single study has integrated these two exceptional decision-making methods into a single framework under the Fermatean fuzzy environment.
This study proposes an approach based on the Fermatean fuzzy ITARA-MARCOS and RF-RFE algorithm for locating a disinfection facility for hazardous HCW in the COVID-19 era to address the research gaps.
4 Methodology
This section provides some preliminaries of FFSs; i.e., the geometric meaning, operational laws, the comparison method, score and accuracy functions as well as two advanced aggregation operators. Then, preliminaries of the RF-RFE algorithm are given. Finally, the approach based on the Fermatean fuzzy ITARA-MARCOS and RF-RFE algorithm is formulated and explained in detail. A comprehensive flowchart of the proposed three-stage approach is illustrated in order to increase the clarity of the presentation.
4.1 Preliminaries of Fermatean fuzzy sets
FFSs are a novel extension of IFSs and PFSs. Compared to IFSs and PFSs, FFSs provide a more general perspective for two-dimensional, i.e., membership and non-membership, information compared to IFSs and PFS since the sum of cubes of membership and non-membership degrees of FFSs is in the unit interval (Fig. 1).

The relationships between intuitionistic, Pythagorean, and Fermatean fuzzy sets
Definition 1
(Senapati & Yager, 2019a, 2019b, 2020). A Fermatean fuzzy set \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}\) in a universe X is an object having the form of:
where \(\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} \left( x \right) \in \left[ {0,\;1} \right]\) is the degree of membership of the element x in the set \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} ,\) \(\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} \left( x \right) \in \left[ {0,\;1} \right]\) in which the degree of non-membership of the element x in the set \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} ,\) and \(\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} \left( x \right)\) and \(\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} \left( x \right)\) satisfy the following condition:
The degree of indeterminacy of the element x in the set \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}\) is:
If X has only one element, then \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} = \left\{ {\left\langle {x,\;\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} \left( x \right),\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} \left( x \right)} \right\rangle \;\left| {\;x \in X} \right.} \right\}\) is called a Fermatean fuzzy number (FFN) in which \(\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} \in \left[ {0,\;1} \right],\) and \(0 \le \alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }}^{3} + \beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }}^{3} \le 1.\) For convenience, an FFN is denoted by \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} } \right).\)
Definition 2
(Garg et al., 2020). Let \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} } \right),\) \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{1} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{1} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{1} }} } \right),\) and \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{2} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{2} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{2} }} } \right)\) be three FFNs, the operational parameter η > 0, and τ > 0. The Yager T-norm and T-conorm operations of FFNs are defined as follows:
(a) Addition “ ⊕ ”
(b) Multiplication “ ⊗ ”
(c) Scalar multiplication
(d) Power
Definition 3
(Senapati & Yager, 2019a, 2019b, 2020). Let \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} } \right)\) be an FFN. The complement is defined as follows:
Definition 4
(Keshavarz-Ghorabaee et al., 2020). Let \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} } \right)\) be an FFN. The positive score function is defined as the following:
Definition 5
(Keshavarz-Ghorabaee et al., 2020). Let \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} }} } \right)\) be a FFN. The accuracy function \(acc\left( {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F} } \right) \in \left[ {0,\;1} \right]\) is distincted as follows:
Definition 6
(Senapati & Yager, 2019a, 2019b, 2020). Let \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{1} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{1} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{1} }} } \right)\) and \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{2} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{2} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{2} }} } \right)\) be two FFNs, and \(score\left( {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{i} } \right)\) and \(acc\left( {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{i} } \right)\) (i = 1, 2) be the score and accuracy functions of \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{1}\) and \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{2} ,\) respectively. The comparison method of FFNs \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{1}\) and \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{2}\) can be defined as:
Definition 7
(Garg et al., 2020). Let \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{l} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{l} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}_{l} }} } \right)\) (l = 1, …, p) be a number of FFNs, the operational parameter η > 0, and γ = (γ1, …, γp)T be the weight vector of them, with γl ∈ [0, 1] and \(\sum\nolimits_{l = 1}^{p} {\gamma_{l} } = 1.\) A Fermatean fuzzy Yager weighted average (FFYWA) operator is distincted as follows:
and a Fermatean fuzzy Yager weighted geometric (FFYWG) operator is defined as follows:
4.2 Preliminaries of the random forest recursive feature elimination algorithm
Random Forest (RF) is a well-known machine learning technique developed by Breiman (2001) that uses an ensemble of unpruned decision trees for classification or regression. The RF algorithm is built by a bootstrap sampling of the data, and at each split, the candidate set of variables is chosen randomly from all variables in a fixed number (Zhou et al., 2014). In the RF algorithm, the final result (or prediction) of an input sample is determined by the majority classification voting (classification) or averaging their outputs (regression) (Breiman, 2001; Zhou et al., 2014). It is important to note that the RF classifier can determine different measures of variable importance. Some input samples which are not used in the training process are labeled as Out-of-Bag (OOB) samples which is the data excluded in each tree. The excluded data are utilized to assess the generalization performance of classifiers and the OOB error estimation to provide an unbiased evaluation of the accuracy. Zhang et al. (2016) suggested while removing one feature at a time from the previous set, the subset of features is evaluated by the OOB error rate, and OOB error rates are stored to obtain the curve relating feature sets and OOB error rates. From the curves of the graph, the OOB error rate is almost not changed at the start because the excluded features are considered to not contribute to classification ability.
Recursive Feature Elimination (RFE) is regarded as a greedy algorithm based on feature ranking methods (Guyon et al., 2002; Zhou et al., 2014). For the RFE technique, the RF algorithm can be utilized as an efficient filter and classifier for the feature ranking algorithm, which runs fast and can scale to very high dimensional data. Although Zhang et al. (2016) drew attention to the fact that "…the feature importance threshold cannot be calculated, which decides how many features ranked ahead should be reserved. Since the threshold usually is determined by manual, it may affect the validity of feature selection", Zhou et al. (2014) suggested, "…according to a certain feature ranking standard, RFE starts from a complete set and then eliminates the least relevant feature one by one to select the most important features…". To describe the steps of the RF-RFE algorithm, the first step is to define the RF classifier.
According to Chen et al. (2020), a decision tree with \(M\) leaves can divide the feature space into \(M\) regions \({R}_{m}\) considering \(1\le m\le M\). In which \({R}_{m}\) is a region appropriate to \(m\), and \({c}_{m}\) is a constant suitable for that \(m\). The prediction function \(f\left(x\right)\) for each tree is defined as Eq. (16).
Each node of a decision tree will be split into two leaves, while a splitting attribute reduces the impurity of a node during the RF algorithm, which is measured by Gini importance (Breiman, 2001). Accordingly, in the node splitting procedure, \(i\) is the node impurity, and \(p\left(j\right)\) is the proportion of the \(j\) input sample in that node. Hence, Gini importance can be defined as Eq. (17).
Furthermore, considering the node splitting procedure and node impurity decline, for each feature \({F}_{i}\), the sum of the impurity decrement \(\alpha \Delta I\) in the \(k\) th (\(k=1, 2,\dots ,n\)) decision tree is the Gini importance of \({F}_{i}\). In which, \({i}_{left},{i}_{right},\) and \({i}_{parent}\) are Gini importance of parent, left child (leaf) and left child (leaf) node, and \({p}_{left}\mathrm{ and }{p}_{right}\) are sample proportion of left child node and left child node, respectively (Zhang et al., 2016). Then, the importance of every feature can be computed based on Eq. (18). \({F}_{i}^{*}\) calculates the optimal features, or the most important features.
Based on the mentioned preliminaries, the RF-RFE feature selection method to extract core features and attributes can be conducted based on the pseudocode presented in Algorithm 1.
Algorithm 1.
Main algorithm for RF-RFE feature selection method.

4.3 Approach Based on Fermatean Fuzzy ITARA-MARCOS and RF-RFE Algorithm
The proposed approach has three straightforward and logical stages (Fig. 2). In the first stage, the innovative Fermatean fuzzy RF-RFE algorithm extracts core criteria from a finite set of initial criteria. In the second stage, the novel Fermatean fuzzy ITARA determines the semi-objective importance of the core criteria. It utilizes the concept of dispersion logic to extract core criteria weights from a Fermatean fuzzy decision matrix. The Fermatean fuzzy ITARA assigns greater weights to core criteria with higher data dispersion and vice versa.

The flowchart of the approach based on the Fermatean Fuzzy ITARA-MARCOS and RF-RFE algorithm
Also, the concept of the indifference threshold is employed in this criteria weighting method to determine considerable ordered distances. In the third stage, the new Fermatean fuzzy MARCOS method ranks alternatives. This method extends the Fermatean fuzzy decision matrix by adding anti-ideal and ideal alternatives, and calculates utility degrees between the alternatives and two extreme reference points. Finally, alternative ranking is defined based on the utility functions of the alternatives. The FFS-based decision-making methodology is based on Yager T-norm and T-conorm enabling a more precise and flexible fusion of uncertain information.
Let us denote by m the number of alternatives, by k the number of initial criteria, and by h the number of experts. Let A = {A1, …, Ai, …, Am} (m ≥ 2) be a finite set of alternatives, V = {V1, …, Vs, …, Vk} (k ≥ 2) be a finite set of initial criteria, and D = {D1, …, De, …, Dh} (h ≥ 2) is a set of experts.
The approach mentioned above, based on the Fermatean fuzzy ITARA-MARCOS and RF-RFE algorithm, contains the following stages:
Stage 1: Fermatean fuzzy RF-RFE algorithm.
Step 1.1. Construct the Fermatean fuzzy initial decision matrices \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{{\Phi }}^{e} = \left[ {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\Phi }_{is}^{e} } \right]_{m \times k} :\)
where \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\Phi }_{is}^{e} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\Phi }_{is}^{e} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\Phi }_{is}^{e} }} } \right)\) (i = 1, …, m; s = 1, …, k; e = 1, …, h) is an FFN that represents the assessment of the alternative Ai under the initial criterion Vs given by the expert De. An initial decision matrix for each expert is defined by a Fermatean fuzzy linguistic assessment scale. Table 3 gives the nine-point Fermatean fuzzy linguistic scale to present alternative assessment preferences of experts.
Step 1.2. Aggregate the Fermatean fuzzy initial decision matrices:
where the aggregation is performed by the Fermatean fuzzy Yager weighted geometric operator (Definition 7) with the operational parameter η, \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\Psi }_{is} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\Psi }_{is} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\Psi }_{is} }} } \right)\) as the Fermatean fuzzy aggregated assessment of the alternative Ai under the initial criterion Vs, and \(\delta_{e} = {1 \mathord{\left/ {\vphantom {1 h}} \right. \kern-\nulldelimiterspace} h}\) (e = 1, …, h) is the weight of the expert De.
Step 1.3. Determine the score initial decision matrix \({\text{Q}} = [Q_{is} ]_{m \times k} :\)
where \(Q_{is}\) represents the score function of the Fermatean fuzzy aggregated assessment of the alternative Ai under the initial criterion Vs.
Step 1.4. Identify a set of k initial criteria V = {V1, …, Vs, …, Vk} (a subset of features\({F}_{i}:\left\{{F}_{1},{F}_{2},{F}_{3},\dots { ,F}_{n}\right\}\)) for RF-RFE input.
Step 1.5. Randomly sample 80% of the input data associated with the initial subset of features as the training dataset and the other 20% as the test dataset.
Step 1.6. Initialize the RF-RFE algorithm using a subset of features \({F}_{i}:\left\{{F}_{1},{F}_{2},{F}_{3},\dots ,{F}_{n}\right\}\) as the initial criteria \({V}_{s}\) for \(i\) in \(\{1: {p}_{1}\}\) rank \({F}_{i}\) using RF classifier \({\sum }_{m=1}^{M}{c}_{m}\prod \left(x,{R}_{m}\right)\) and compute the importance of the features \(\alpha \Delta I= \sum_{k}\Delta {i}_{k}\). Then, rank \(\left(p-i+1\right): {F}^{NP}\) and replace and update the list of the initial subset of features \({F}_{i}^{*}\leftarrow {F}_{i}^{*}-{F}^{NP}\). Exclude the feature with minimum criterion rank from \({F}_{i}^{*}\) and repeat until the threshold is satisfied.
Step 1.7. Extract a subset of core features \({F}_{i}^{*}\) as the core decision-making criteria, C = {C1, …, Cj, …, Cn} (n ≥ 2) with a list of orders and accuracy measures.
Stage 2: Fermatean fuzzy ITARA method.
Step 2.1. Construct the Fermatean fuzzy decision matrix \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\text{P}} = \left[ {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{P}_{ij} } \right]_{m \times n} :\)
where \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{P}_{ij} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{P}_{ij} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{P}_{ij} }} } \right)\) (i = 1, …, m; j = 1, …, n) is an FFN that represents the aggregated assessment of the alternative Ai under the core criterion Cj, and C = {C1, …, Cj, …, Cn} is the set of core criteria that are extracted from the set of initial criteria V = {V1, …, Vs, …, Vk} by using the Fermatean fuzzy RF-RFE algorithm, with \({\text{C}} \subseteq {\text{V}}{.}\).
Step 2.2. Determine the normalized decision matrix \({\text{R}} = \left[ {R_{ij} } \right]_{m \times n} :\)
where Rij denotes the normalized aggregated assessment of the alternative Ai under the core criterion Cj.
Step 2.3. Sort normalized aggregated assessments in increasing order:
where \(O_{(1)j}\) and \(O_{(m)j}\) denote the normalized aggregated assessments under the core criterion Cj with the lowest (order one) and highest (order m) values, respectively.
Step 2.4. Calculate the ordered distances:
where \(\Lambda_{tj}\) presents the ordered distance between adjacent normalized aggregated assessments \(O_{(t + 1)j}\) and \(O_{(t)j}\) under the core criterion Cj.
Step 2.5. Calculate the considerable ordered distances:
where \(\xi\) denotes the core criteria indifference threshold parameter. If \(\Lambda_{tj} > \xi\) then the corresponding ordered distance Gtj must augment the importance of the core criterion Cj. Otherwise, it is not seen as “considerable” and should be ignored by setting Gtj = 0.
Step 2.6. Determine the core criteria importance:
where \(\omega = \left( {\omega_{1} ,\; \ldots ,\;\omega_{j} ,\; \ldots ,\;\omega_{n} } \right)^{T}\) is the importance vector of the core criteria, with \(\omega_{j} \in \left[ {0,\;1} \right]\) (j = 1, …, n), and \(\sum\nolimits_{j = 1}^{n} {\omega_{j} } = 1.\) The distance measurement parameter λ represents the preferred metric. For instance, when λ is set to 1, 2, and ∞, the core criteria importance are based on the Manhattan, the Euclidian, and the Tchebycheff distances, respectively.
Stage 3: Fermatean fuzzy MARCOS method.
Step 3.1. Determine the Fermatean fuzzy extended decision matrix \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\text{W}} = \left[ {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{lj} } \right]_{(m + 2) \times n} :\)
where \({\text{A}}^{\prime} = \{ A_{0} ,\;A_{1} ,\;...,\;A_{l} ,\;...,\;A_{m} ,\;A_{m + 1} \}\) \((l = 0,\;...,\;m + 1)\) denotes the extended alternative set obtained by adding anti-ideal and ideal alternatives into the set of alternatives, and \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{lj} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{lj} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{lj} }} } \right)\) (l = 1, …, m; j = 1, …, n) is an FFN which denotes the aggregated assessment of the alternative Al under the core criterion Cj:
In this step, the Fermatean fuzzy decision matrix is extended by adding the worst and the best-aggregated assessment values to represent the anti-ideal and ideal alternatives, respectively. The comparison of FFNs is based on Definition 6.
(i) The anti-ideal alternative \(A_{0} = \{ \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{0\;1} ,\;...,\;\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{0\;j} ,\;...,\;\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{0\;n} \} \):
where \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{0j} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{0j} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{0j} }} } \right)\) (j = 1, …, n) is the collection of FFNs that represents anti-ideal aggregated assessments under each core criterion.
(ii) The ideal alternative \(A_{m + 1} = \{ \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{m + 1\;1} ,\;...,\;\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{m + 1\;j} ,\;...,\;\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{m + 1\;n} \} :\)
where \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{m + 1\;j} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{m + 1\;j} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{W}_{m + 1\;j} }} } \right)\) (j = 1, …, n) is the collection of FFNs that represents ideal aggregated assessments under each core criterion.
Step 3.2. Determine the Fermatean fuzzy normalized extended decision matrix \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\text{Y}} = [\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{Y}_{lj} ]_{{_{(m + 2) \times n} }} :\)
where only alternative assessments under the cost core criteria are transformed by the complement operation (Definition 3), \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{Y}_{lj} = (\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{Y}_{lj} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{Y}_{lj} }} )\) is the Fermatean fuzzy normalized aggregated assessment of the alternative Al under the core criterion Cj, \({\text{C}}^{ + } \subseteq {\text{C}}\) is the set of benefit core criteria, \({\text{C}}^{ - } \subseteq {\text{C}}\) is the set of cost core criteria, and \({\text{C}}^{ + } \cup {\text{C}}^{ - } = {\text{C}}{.}\).
Step 3.3. Weight the Fermatean fuzzy normalized extended decision matrix:
where the weighting is performed with the FFYWA operator (Definition 7) with the operational parameter η, and \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{B}_{l} = \left( {\alpha_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{B}_{l} }} ,\;\beta_{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{B}_{l} }} } \right)\) is the Fermatean fuzzy Yager weighted average score of the alternative Al.
Step 3.4. Calculate the utility degrees of each alternative.
(i) The first utility degree:
where \(U_{l}^{ - }\) denotes the utility degree of the alternative Al to the anti-ideal alternative \(A_{0} .\)
(ii) The second utility degree:
where \(U_{l}^{ + }\) represents the utility degree of the alternative Al to the ideal alternative \(A_{m + 1} .\)
Step 3.5. Calculate the utility functions.
(i) The first utility function:
where \(f\left( {U^{ - } } \right)\) presents the utility function of the anti-ideal alternative \(A_{0} .\)
(ii) The second utility function:
where \(f\left( {U^{ + } } \right)\) denotes the utility function of the ideal alternative \(A_{m + 1} .\)
Step 3.6. Calculate the utility function of each alternative:
where \(f\left( {U_{i} } \right)\) represents the utility function of the alternative Ai.
Step 3.7. Rank the alternatives. The alternatives should be ranked according to the decreasing values of their utility functions. The best alternative has the highest utility function.
5 Problem definition
This section presents detailed information on the problem and context description, goals, and targets. A case study in Istanbul is investigated to show the applicability of the proposed approach based on Fermatean fuzzy ITARA-MARCOS and RF-RFE algorithm in real-life practices, and information about the alternative locations and decision criteria were discussed.
5.1 Context definition
With the rise of COVID-19 around December 2019, industries around the world entered a new era of vagueness, dynamicity, and uncertainties. While urban management organizations such as municipalities were hardly hit by the effects of COVID-19 on different urban sectors, hospitals and medical centers are considered as top organizations that were negatively affected by COVID-19 due to their role in the treatment of infected patients. High incidence cases of COVID-19 faced medical centers with severe challenges in their capacity to address different problems. Consequently, it is evident that due to the high range of problems, strategic decisions should be taken to mitigate the irrecoverable effects of COVID-19 on human beings, society, environment, and the economy.
In this regard, WM in medical and healthcare centers turned out to be one of the crucial issues that both medical centers and other organizations had to deal with in order to decrease the effects of hazardous HCW. In the COVID-19 era, the performance of hospitals and healthcare centers dramatically deteriorated due to a sudden increase in material consumption and therefore increase in generated waste. Thus, real-life policymakers had to develop better pathways to address COVID-19 issues related to infectious waste, pathological waste, pharmaceutical waste, chemical waste, sharps, and other typical HCW such as genotoxic waste and pressurized containers and radioactive waste.
Along with the highly infectious nature of these waste types in business-as-usual situations, COVID-19 has doubled the concerns on their infectious degree. Therefore, healthcare centers and municipalities have faced a severe challenge of adequately eliminating such high hazardous and infectious waste. Endeavors on developing a proper framework to address hazardous waste rely on the fact that such waste types have a high potential to damage social health status, cause exposure to the environment, and bring up economic challenges. Considering the waste network flow, one of the leading tasks to dispose of hazardous HCW is to apply disinfection processes to mitigate the hazardousness to the minimum level. Nevertheless, one of the significant challenges that cities are facing nowadays is the capacity of the current disinfection facilities that are not suitable and enough for the treatment and disinfection of hazardous HCW. One of the strategic decision-making problems for both the healthcare sector and urban organizations is to establish a new disinfection facility in an appropriate location. However, locating a new disinfection facility is not a simple task and falls in the category of complicated urban planning decision-making affected by technical and sustainability criteria based on social, environmental, and economic perspectives. Therefore, the disinfection facility location selection problem for hazardous HCW under COVID-19 is a complicated and multi-dimensional task with many criteria requiring reliable and accurate tools to address. Figure 3 represents a network flow of HCW and the importance of disinfection facilities on the network.

HCW network flow
5.2 Case study
This section clarifies the background of the WM system and the case study of the current study in Istanbul, Turkey, in the recent year. A specific focus on HCW management and treatment statistics is deeply considered. Reasons to investigate Istanbul, Turkey, as the case study are elaborated below.
Istanbul is the biggest city in Turkey, with a population of over 15 million on both sides of the Bosphorus strait. Considering the high population, the HCW generation rate is noticeably high with a continuously growing trend. According to Atlas Waste,Footnote 1 more than 4 million tons of waste are generated per year in Istanbul, accounting for almost 416 kg per person per year. İSTAÇ,Footnote 2 one of the well-known local WM organizations in Istanbul, reports that roughly 28,000 tons of HCW are collected from 10,500 medical centers per year.
Turkey has passed a nonstable situation during the COVID-19 era with all its up and down. Considering the high population of Istanbul, the number of COVID cases increased to 31.000 around December 2020, and 61.000 around April 2021. Regarding these statistics of a city with such a high population, hospitals and medical centers dealing with infected patients face severe challenges, specifically in terms of increasing the demand rate for medical products. Along with the increase in demand for medical products in healthcare centers, the city faced another problem regarding medical face masks and face shields that people are obliged to put on outside. Due to their single-use nature, the daily amount of wasted masks and shields also has become another issue. Another source of medical waste related to COVID-19 is vaccination waste. An advantage of HCW is its high potential for recoverability and recyclability. However, a critical issue with waste from healthcare centers dealing with COVID-19 is its hazardous nature due to being directly exposed to the virus. Thus, treating these kinds of waste becomes more challenging from environmental, economic, and social perspectives. Hence, the necessity of a specialized disinfection facility for hazardous HCW of COVID-19 is highly significant for a populated city such as Istanbul, with a high incidence of cases. Disinfection facilities act as a critical entity in the network flow (Fig. 3), where hazardous HCW is treated with specific technologies before being transferred to recycling centers, waste-to-energy plants, or landfills.
5.2.1 Alternative candidate locations
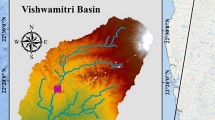
Four experts in the field of WM were invited to disclose potential locations for the instalment of a new disinfection facility for hazardous HCW generated from medical centers dealing with COVID-19 in Istanbul. Figure 4 presents five alternative candidate locations. These locations are “Beylikdüzü” (A1), “Eyüp” (A2), “Sarıyer” (A3), “Ümraniye” (A4), and “Pendik” (A5). The experts identify them based on the current status of HCW management in Istanbul and the geographical characteristics and positions of existing medical centers, collection centers, and recycling centers.

Location alternatives for a new disinfection facility for hazardous HCW in Istanbul
5.2.2 Identification of initial criteria
This section describes the initial criteria for locating a disinfection facility for hazardous HCW under COVID-19 based on technical, social, environmental, and economic aspects. Due to the high importance of a disinfection facility in HCW flow, a comprehensive review was conducted to derive a set of criteria for the analyzed location selection problem. The initial criteria are grouped based on technical, social, environmental, and economic perspectives.
-
(i)
Technical criteria
The technical aspect includes 12 criteria dealing with technical features of the disinfection facility location selection problem for hazardous HCW under COVID-19. Proximity to residential and urban areas (V1) measures the average distance of each alternative to the closest residential and urban living environment (cost criterion). Proximity to waste collection point (V2) assesses how close an alternative is to the closest and reachable collection points for HCW (benefit criterion). Proximity to waste segregation points (V3) indicates the average distance of each alternative to waste segregation centers (benefit criterion). Proximity to waste recovery sites (V4) indicates how far recovery centers are located from each alternative (benefit criterion). As HCW includes many recyclable products, the closeness to recovery centers is an advantage. Proximity to waste disposal sites (V5) measures the closeness of each alternative to disposal sites to handle waste that is not recyclable and must be treated differently (benefit criterion). Proximity to groundwater resources (V6) measures the suitability of alternatives based on the closeness of groundwater resources and water pipes (cost criterion).
In the same way, criterion proximity to underground water resources (V7) does the exact measurement against underground water resources (cost criterion). Proximity to environmentally protected zones (V8) assesses the average distance of location alternatives to the protected area based on environmental or animal protection acts (cost criterion). Land availability (V9) considers the average availability of required land for the facility's construction based on geographical and geological characteristics (benefit criterion). One of the major issues with waste network flow is the easiness of transportation routes between different entities. Logistics convenience (V10) shows the suitability of transportation and logistics for each location alternative (benefit criterion). In the same context, traffic congestion, rules, and controls around each alternative location are considered through traffic congestion (V11) (cost criterion). Professional workforce (V12) quantifies the easiness of finding and hiring a professional workforce in the new facility as soon as possible (benefit criterion).
-
(ii)
Social criteria
Social criteria cover five significant milestones within the social aspect of WM systems. Adherence to local rules and regulations (V13) is one of the most critical concerns of waste treatment companies and other related involved organizations in waste network flow. This criterion measures how much opening a facility is aligned with local rules and regulations of urban districts (benefit criterion). In the same context, the satisfaction level of residence around the site (V14) is another crucial matter considered when installing a new waste facility (benefit criterion). Regional job opportunities (V15) consider the possible average number of jobs created by opening a new facility (benefit criterion). Awareness level (V16) measures the knowledge and willingness of the people about sustainable WM practices and the necessity of appropriate treatment of infectious waste during the COVID-19 pandemic (benefit criterion). Health & safety (V17) quantifies health & safety levels in each location alternative (benefit criterion).
-
(iii)
Environmental criteria
Environmental criteria aim to consider the impacts of emission and pollution within the waste network flow. In this regard, three primary emission criteria and one pollution criterion were considered as follows. Air emission (V18) shows the possibility of the impact of air emission of a facility on the total air quality around each location alternative (cost criterion). In the same way, soil emission (V19) (cost criterion) and water emission (V20) (cost criterion) are used to evaluate location alternatives based on their possible roles and impacts on regional soil and water contamination, respectively. Finally, noise pollution (V21) is crucial for residential and industrial areas around location alternatives that should be considered when installing a new waste facility (cost criterion).
-
(iv)
Economic criteria
Nine critical economic criteria were also included in this category. Land price (V22) may be considered one of the important concerns for opening a new waste facility, including land price and construction costs (cost criterion). Transportation cost (V23) calculates the average transportation cost from collection points to the facility and from the facility to other entities in the network (cost criterion). Operations and maintenance costs (V24) ensemble all costs related to instalment, workforce cost, and periodic maintenance (cost criterion). Investment cost (V25) involves the costs related to technologies required for the disinfection process (cost criterion). Future expansion potential (V26) is one of the critical criteria considered during the installation process of a new facility. Future expansion potential is essential for large cities with a high waste generation rate (benefit criterion). Municipalities and environmental organizations may enact regulations and rules to support sustainability and a circular economy based on sustainable practices in large cities. Thus, regional financial incentives (V27) measure the relative level of financial incentives for such projects in each municipality where each alternative location is placed (benefit criterion). Due to the high importance of HCW flow among urban planning and sustainability practices, the system's resiliency has become an important measure. Therefore, three relevant resiliency factors are responsiveness (V28) which measures resiliency of the facility in terms of the quality of reacting quickly to any modification (benefit criterion), and flexibility (V29) which measures resiliency of the facility in terms of responding to disruptions as well as risks (benefit criterion), and robustness (V30) that assesses the resiliency of the facility to hold out against locational and natural disruptions (benefit criterion).
6 Results and discussion
6.1 Experimental results
This sub-section presents the results of the proposed approach based on the Fermatean fuzzy ITARA-MARCOS and RF-RFE algorithm for solving the disinfection facility location selection problem under COVID-19 in a real-life and practical case study in Istanbul. For this purpose, four experts (three male and one female) with an average of eight years of experience were invited to participate in the evaluation process. The expert team has been all involved in the managerial sector of WM systems of medical centers in Istanbul. Input data from the expert team were collected through an online questionnaire.
Stage 1: Fermatean fuzzy RF-RFE algorithm.
Step 1.1. Four invited experts in the field of WM used FFN linguistic variables defined in Table 3 to assess “Beylikdüzü” (A1), “Eyüp” (A2), “Sarıyer” (A3), “Ümraniye” (A4), and “Pendik” (A5) under 30 initial criteria. Their assessments of five alternative candidate locations for a disinfection facility for hazardous HCW under COVID-19 in Istanbul are given in Supplementary Table S1 (Online Resource). Then, the Fermatean fuzzy initial decision matrices (Supplementary Table S2) are constructed based on the experts’ input (Supplementary Table S1) and the Fermatean fuzzy linguistic scale (Table 3) considering Eq. (19).
Step 1.2. Four Fermatean fuzzy initial decision matrices (Supplementary Table S2) were aggregated by utilizing the FFYWG operator defined in Eq. (20) with the operational parameter \(\eta = 3.\) The aggregated Fermatean fuzzy initial decision matrix is provided in Table 4. For example, the Fermatean fuzzy assessments of the candidate location “Pendik” (A5) under the initial criterion “proximity to environmentally protected zones” (V8) given by the expert one, two, three, and four are (0.30, 0.80), (0.55, 0.50), (0.20, 0.90), and (0.10, 0.975), respectively (Supplementary Table S2). The Fermatean fuzzy aggregated assessment of the alternative A5 under the initial criterion V8 is computed as follows:
Step 1.3. The score initial decision matrix is given in Supplementary Table S3. It is determined with the help of Eq. (21) by taking into account the aggregated Fermatean fuzzy initial decision matrix (Table 4).
Step 1.4. A set of 30 initial criteria V = {V1, …, V15, …, V30} as a subset of features Fi: {F1, F2, F3, …, F30} were identified for RF-RFE input.
Step 1.5. Test and training samples were formed by randomly sampling 80% of the input data associated with the initial subset of features as the training dataset and the other 20% as the test dataset. To unify the random process of the RF-RFE technique, the random seed for random sampling is set as the 2021st.
Steps 1.6–1.7. The RF-RFE recursive algorithm using a subset of features Fi: {F1, F2, F3, …, F30} was utilized for the feature selection pre-processing procedures. The Classification And REgression Training (CARET) package (Kuhn, 2008; Kuhn et al., 2020) and the RF package (Breiman, 2001) in R programming language were used to conduct the RFE procedure in which cross-validation and bootstrap sampling techniques were used as the external resampling method. The performance measures were computed by CARET’s accuracy measure \(\mu_{{acc_{s} }}\) (s = 1, …, k) and Cohen's Kappa. Since the data gathered for the problem was from the experts, and random agreement among decision-makers is not available, this measure was not considered. Consequently, the results of the RF-RFE algorithm are summarized in Table 5. Furthermore, a graphical representation of the criteria accuracy measures was presented in Fig. 5. The core criteria are those with the highest importance measures considering accuracy values.

Performance measure of the cross-validated RF-RFE technique
Stage 2: Fermatean fuzzy ITARA method.
Step 2.1. The Fermatean fuzzy decision matrix is constructed using Eq. (22) by taking into account the aggregated Fermatean fuzzy initial decision matrix (Table 4) and the results of the Fermatean fuzzy RF-RFE algorithm (i.e., the core criteria for locating a disinfection facility that is extracted from the set of 30 initial criteria). This matrix is given in Supplementary Table S4.
Step 2.2. The normalized decision matrix is presented in Table 6. It is determined based on the Fermatean fuzzy decision matrix (Supplementary Table S4) with the help of Eq. (23). For example, under the core criterion “future expansion potential” (C11), the Fermatean fuzzy aggregated assessments of the candidate locations “Beylikdüzü” (A1), “Eyüp” (A2), “Sarıyer” (A3), “Ümraniye” (A4), and “Pendik” (A5) are (0.7872, 0.3458), (0.5113, 0.6053), (0.4732, 0.7978), (0.5911, 0.6871), and (0.9099, 0.1937), respectively (Supplementary Table S4). The normalized aggregated assessment of the alternative A2 under the core criterion C11 is calculated as follows: \(R_{{2{\kern 1pt} {\kern 1pt} 11}} = {{\left( {1 + 0.5113^{3} - 0.6053^{3} } \right)} \mathord{\left/ {\vphantom {{\left( {1 + 0.5113^{3} - 0.6053^{3} } \right)} {\left( {1 + 0.7872^{3} - 0.3458^{3} + 1 + 0.5113^{3} } \right.}}} \right. \kern-\nulldelimiterspace} {\left( {1 + 0.7872^{3} - 0.3458^{3} + 1 + 0.5113^{3} } \right.}}\)
Step 2.3. The sorted normalized aggregated assessments under the core criteria are provided in Supplementary Table S5. The normalized aggregated assessments (Table 6) are sorted in increasing order under each core criterion by employing Eq. (24). Supplementary Table S5 gives the sorting results.
Step 2.4. Table 7 provides the ordered distances under each core criterion. They were calculated by subtracting two normalized aggregated assessments with adjacent orders, as defined in Eq. (25).
Step 2.5. This step is built upon the concept of the indifference threshold to differentiate ordered distances into “considerable” and “non-considerable”. It is adopted that the core criteria indifference threshold ξ is 0.01. Table 7 provides the ordered distances under each core criterion calculated with the help of Eq. (26). In Table 7 (Columns 6–9), zero values denote “non-considerable” ordered distances that should be ignored, while non-zero values present “considerable” ordered distances.
Step 2.6. Equation (27) determines the core criteria importance based on the considerable ordered distances. The distance measurement parameter λ is set to 2 to use the Euclidean distance as the preferred metric. The calculated importance vector of the core criteria can be found in the last column of Table 7.
Stage 3: Fermatean fuzzy MARCOS method.
Step 3.1. The anti-ideal and ideal alternatives are determined by using Eqs. (30)–(31). Then, the Fermatean fuzzy decision matrix (Supplementary Table S4) is extended by adding them to the set of alternative locations. Table 8 presents the resulting matrix.
Step 3.2. The Fermatean fuzzy normalized extended decision matrix is given in Supplementary Table S6. It is determined with the help of Eq. (32) by taking into account the type of the core criteria and the Fermatean fuzzy aggregated assessments (Table 8). Cost-type core criteria are “proximity to residential and urban areas” (C1), “proximity to environmentally protected zones” (C5), “traffic congestion” (C6), “soil emission” (C7), “land price” (C8), “operations and maintenance costs” (C9), and “investment cost” (C10); i.e., C− = {C1, C5, C6, C7, C8, C9, C10}. The other seven core criteria are benefit-type.
Step 3.3. The FFYWA operator defined in Eq. (33) with the operational parameter \(\eta = 3\) is used to weight the Fermatean fuzzy normalized extended decision matrix (Supplementary Table S6) by taking into account the importance vector of the core criteria (Table 7). The FFYWA scores are provided in Table 8. For example, the FFYWA score of the location “Beylikdüzü” (A1) is: \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{B}_{1} = \left( {\sqrt[3]{{\min \left[ {1,\;\left( {0.0319 \cdot 0.4843^{9} + 0.0411 \cdot 0.8185^{9} + \cdots + 0.0590\, \cdot 0.7713^{9} } \right)^{1/3} } \right]}}} \right.,\)
Step 3.4. The utility degrees of the anti-ideal alternative and the ideal alternative are calculated using Eqs. (34) and (35), respectively. The obtained values are given in Table 9 (Columns 3–4).
Steps 3.5–3.6. Firstly, according to Eqs. (36)–(37) and the corresponding utility degrees from Table 9, the utility functions of the anti-ideal alternative and the ideal alternative are calculated as 0.285 and 0.715, respectively. Then, a utility function for each primary potential location (Table 9, Column 5) is determined with the help of Eq. (38).
Step 3.7. The assessed candidate locations are ranked according to the decreasing values of their utility functions. The generated ranking order is as follows (Table 9, Column 6): A5 (Pendik) \(\succ\) A1 (Beylikdüzü) \(\succ\) A4 (Ümraniye) \(\succ\) A2 (Eyüp) \(\succ\) A3 (Sarıyer). Therefore, the proposed approach determined “Pendik” as the best location for setting up a disinfection facility for hazardous HCW under COVID-19 in Istanbul since it has the highest utility function of 0.8733.
6.2 Sensitivity analyses
This sub-section provides comprehensive sensitivity analyses of the intrinsic parameters of the proposed methodology. High flexibility is one of the significant advantages of the introduced approach based on the Fermatean fuzzy ITARA-MARCOS and RF-RFE algorithm compared to the available decision-making approaches for HCW management. Our model has several built-in parameters that provide high flexibility to decision-makers when locating a disinfection facility for hazardous HCW in the COVID-19 era.
The operational parameter η of the FFYWA and the FFYWA operators represents the first built-in parameter of the formulated approach. The FFYWG operator is utilized to aggregate Fermatean fuzzy initial decision matrices in the first stage (i.e., the Fermatean fuzzy RF-RFE algorithm) of the developed methodology. On the other hand, the FFYWA operator is employed for weighting the Fermatean fuzzy normalized extended decision matrix in the Fermatean fuzzy MARCOS method. As a result, the first sensitivity analysis aims to explore the influence of this vital parameter on the results. In the base scenario, η is set to 3. Nine additional scenarios are created (Fig. 6).

Influence of the operational parameter η on the alternative utility functions
As shown in Fig. 6, the increase of the operational parameter produces a lower utility function only for “Beylikdüzü” (A1), which secures the top rank for “Pendik” (A5). The utility function of “Eyüp” (A2) grows much faster than the utility function of “Ümraniye” (A4). However, A2 stays the second-worst location for sitting a new disinfection facility for hazardous HCW in Istanbul because this growth is not sufficient to improve its ranking. The first sensitivity analysis confirmed the initial location ordering since changes in the operational parameter η do not produce any notable ranking variation in the additional scenarios.
The second sensitivity analysis aims to investigate the effects of the distance measurement parameter λ ∈ {1, 2, …, ∞}. This built-in parameter represents the preferred metric for determining the core criteria importance in the Fermatean fuzzy ITARA method. In the base scenario, the results are obtained using the Euclidean distance (λ = 2). Fifteen different scenarios are generated, including extreme instances based on the Manhattan distance (λ = 1) and the Tchebycheff distance (λ≈∞). Figure 7 shows the influence of the distance measurement parameter on the results. According to Fig. 7, it is found that the initial ordering of the alternative locations for opening a new disinfection facility for hazardous HCW remains unchanged under the variety of analyzed metrics.

Influence of the distance measurement parameter λ on the alternative utility functions
The core criteria indifference threshold ξ presents another intrinsic parameter of the formulated approach. It calculates the considerable ordered distances in the Fermatean fuzzy ITARA method. As a result, the concept of the indifference threshold is effectively integrated into the developed FFS-based methodology. The third sensitivity analysis aims to determine how the parameter ξ influences the results. In the base scenario, the core criteria indifference threshold parameter is set to 0.01. The values of ξ are varied in the interval [0, 0.1] with an increment value of 0.01. The effect of the third built-in parameter on the results is illustrated in Fig. 8. The increase of ξ generates a slightly higher utility function for “Beylikdüzü” (A1), “Ümraniye” (A4), and “Pendik” (A5). At the same time, it significantly deteriorates the utility functions of the two worst-ranked alternatives, i.e., “Eyüp” (A2) and “Sarıyer” (A3). Nevertheless, the initial location ordering A5 \(\succ\) A1 \(\succ\) A4 \(\succ\) A2 \(\succ\) A3 is preserved.

Influence of the indifference threshold parameter ξ on the alternative utility functions
According to the performed sensitivity analyses, it can be concluded that the initial ranking of five alternative candidate locations is successfully validated. Also, “Pendik” (A5) stands out as the best location for a new disinfection facility for hazardous HCW in Istanbul. Besides, three presented sensitivity analyses confirmed that the proposed approach based on the Fermatean fuzzy ITARA-MARCOS and RF-RFE algorithm could generate highly robust solutions in uncertain and contradictory real-life decision-making environments. On the other hand, the sensitivity analyses only explored robustness to changes in the intrinsic parameters. Robustness to changes in core criteria weights could also be checked. In this sense, additional scenarios could be simulated by changing the weight of the essential core criterion while adjusting the weights of the other core criteria.
6.3 Comparative analysis
This sub-section presents a comparison of the results obtained by the introduced approach based on the Fermatean fuzzy ITARA-MARCOS and RF-RFE algorithm with the three available state-of-the-art FFS-based approaches; i.e., FFS-WPM (Senapati & Yager, 2019b), FFS-WASPAS (Keshavarz-Ghorabaee et al., 2020), and FFS-TOPSIS (Senapati & Yager, 2020). The objectives of the comparative analysis are to check the reliability of our three-stage approach and outline its significant differences and advantages.
Figure 9 shows the ranks of five candidate locations for sitting a new disinfection facility for hazardous HCW in Istanbul generated by different Fermatean fuzzy approaches. The FFS-WPM approach provides a slightly different location ordering by putting “Beylikdüzü” (A1) in the first place and “Pendik” (A5) in the second place. The FFS-WASPAS and FFS-TOPSIS approaches provide the same ordering results as ours, i.e., A5 \(\succ\) A1 \(\succ\) A4 \(\succ\) A2 \(\succ\) A3.

Ranks of the alternative candidate locations are based on different approaches
The ranking similarity is investigated using Spearman’s rank correlation coefficient (rho) and the WS coefficient (Sałabun & Urbaniak, 2020). According to rho and WS coefficients, our approach has 97% and 93% of ranks matched. As a result, it can be outlined that the proposed three-stage approach can generate highly consistent ranking results.
The significant differences between our approach and three existing FFS-based approaches are as follows:
-
(a)
The framework proposed in this study and the FFS-WASPAS approach are applicable in the group decision-making context, while the FFS-WPM and FFS-TOPSIS approaches do not support the aggregation of multi-expert input preferences.
-
(b)
All existing FFS-based approaches utilize algebraic operations of FFNs. Differently, our approach is based on Yager T-norm and T-conorm operations to increase decision-making flexibility by adding an intrinsic parameter in both aggregation operators and providing a more precise fusion of uncertain information.
-
(c)
The FFS-WPM and FFS-TOPSIS approaches have low application flexibility since they do not have built-in parameters. The one-parametric FFS-WASPAS approach offers medium–low flexibility to decision-makers with its built-in balancing parameter. In contrast, the proposed approach of the current study offers high flexibility in real-life applications with three built-in parameters. The operational parameter η is for fine-tuning of the FFYWA and the FFYWA operators, the distance measurement parameter λ is for setting preferred metrics, and the parameter ξ is for selecting an indifference threshold value.
-
(d)
The FFS-WPM, FFS-WASPAS, and FFS-TOPSIS approaches assume that criteria weights are fully known in advance. Since this is not the case in most real-life applications, our three-stage approach can provide the semi-objective importance of criteria for decision-makes based on the newly developed Fermatean fuzzy ITARA method.
-
(e)
The existing approaches can hardly tackle multi-dimensional problems with a high number of criteria. These FFS-based approaches are unable to extract core features and efficiently reduce the computation burden of real-life problems. In contrast, the Fermatean fuzzy RF-RFE algorithm, which presents the first stage of the introduced methodology, offers an efficient method to screen out criteria having core importance. As a result, our approach can consider the big data nature of problems to empower researchers and practitioners when investigating real-life problems and making complex decisions.
6.4 Managerial implications
For a megacity like Istanbul, with a population of over 15 million, HCW management is among the top priorities of the provincial municipality and environmental organizations dealing with various types of waste. Considering the destructive effects of the COVID-19 pandemic on the healthcare sector, the hazardousness degree of HCW increased more and more due to exposure of medical materials and staff with the virus. Therefore, a crucial step in treating hazardous HCW rises due to negative social, healthcare, and environmental issues that such waste can bring up. In this regard, disinfection facilities in waste network flow become highly important in addressing issues and risks related to hazardous HCW during the pandemic. However, the complexity and dimension of the location selection problem for a disinfection facility increase considering concepts and standards such as sustainability and circular economy. Moreover, the recent rise of COVID-19 cases pointed out the significance of establishing adequate waste disinfection facilities to handle large waste mass medical centers. Since the beginning of the pandemic, Istanbul has been almost the top city with the highest number of COVID-19 cases and deaths. The establishment of a disinfection facility has higher importance for the city compared to other cities in Turkey.
Thus, we considered all required decision criteria in all dimensions to provide a reliable framework for addressing a large-scale decision-making problem for the city. Using the developed methodology, the core criteria were extracted based on experts’ opinions on the performance of five location alternatives under the initial criteria. Additionally, FFSs are used to provide a decision-making environment for experts to express their opinions with a specific degree of uncertainty. Five alternatives, “Beylikdüzü” (A1), “Eyüp” (A2), “Sarıyer” (A3), “Ümraniye” (A4), and “Pendik” (A5), are all evaluated to determine the best location to establish a disinfection facility to mitigate challenges and issues of hazardous HCW. The findings indicate that “Pendik” is the best option for locating a disinfection facility. Considering the real-life characteristics of the urban districts of Istanbul, “Pendik” can provide a very economic transportation process and a higher possibility of future expansion. This candidate location is also very far from the city center and high populated residential areas; therefore, establishing a waste facility would have the least social disadvantages.
6.5 Theoretical implications
While various methods have used different data mining and knowledge discovery in data methodologies to address multi-dimensional problems with a high number of criteria, this is the first study that used an RF-RFE algorithm as an efficient method to screen out criteria having core importance. Other research studies can use this method individually and/or combine it with other methodologies to tackle such big data problems for practical and real-world complex decision-making problems. Another theoretical implication is implementing different classifiers such as support vector machines, genetic algorithms, and simulated annealing algorithms instead of RF. Finally, one may develop the ITARA-MARCOS model under other well-known uncertain environments such as neutrosophic sets, fuzzy rough numbers, and Z-numbers.
7 Conclusions
This study introduced a three-stage approach for locating a disinfection facility for hazardous HCW in the COVID-19 era. In the first stage, the innovative Fermatean fuzzy RF-RFE algorithm extracted core criteria from a finite set of initial criteria. In the second stage, the novel Fermatean fuzzy ITARA determined the semi-objective importance of the core criteria. In the third stage, the new Fermatean fuzzy MARCOS method ranked alternatives. Three sensitivity analyses confirmed that the proposed approach could generate highly robust solutions in uncertain and contradictory real-life decision-making environments. The comparative analysis with the existing state-of-the-art Fermatean fuzzy approaches also approved its high reliability.
The major advantages of the developed approach are (a) the advanced aggregation of multi-expert input preferences, (b) the precise fusion of uncertain information, (c) high flexibility in real-life applications with three built-in parameters, (d) efficient generation of criteria weights when they are not fully known in advance, and (e) the ability to extract core features and reduce the computation burden of large-scale problems. Therefore, it can be concluded that it goes well beyond the available state-of-the-art FFS-based approaches.
A real-life case study for Istanbul to locate a disinfection facility for hazardous HCW during the COVID-19 pandemic showed the applicability and efficiency of the developed decision-making approach. Results of the developed methodology showed high accuracy and efficiency in handling the large-scale nature of the problem, uncertainties involved in the weight determination process, and ranking of alternatives. According to the results, “Pendik” is the top alternative for locating a disinfection facility in Istanbul, Turkey.
This study can be extended in several directions for future studies. The most plausible direction is to use the developed methodology for other large-scale decision-making problems in waste management, supply chain management, environmental planning, transportation planning, healthcare management, and sustainability assessment. Also, the proposed three-stage approach could be utilized to solve the addressed disinfection facility location selection problem under COVID-19 in different geographical contexts, e.g., other regions of Turkey and other countries.
Availability of data and materials
All authors consent when it is published.
References
Abbasi, M., Rastgoo, M. N., & Nakisa, B. (2019). Monthly and seasonal modeling of municipal waste generation using radial basis function neural network. Environmental Progress & Sustainable Energy, 38(3), e13033. https://doi.org/10.1002/ep.13033
Abdallah, M., Talib, M. A., Feroz, S., Nasir, Q., Abdalla, H., & Mahfood, B. (2020). Artificial intelligence applications in solid waste management: A systematic research review. Waste Management, 109, 231–246. https://doi.org/10.1016/j.wasman.2020.04.057
Akram, M., Shahzadi, G., & Ahmadini, A. A. H. (2020). Decision-making framework for an effective sanitizer to reduce COVID-19 under Fermatean fuzzy environment. Journal of Mathematics, 2020, 3263407. https://doi.org/10.1155/2020/3263407
Al-Ruzouq, R., Abdallah, M., Shanableh, A., Alani, S., Obaid, L., & Gibril, M. B. A. (2022). Waste to energy spatial suitability analysis using hybrid multi-criteria machine learning approach. Environmental Science and Pollution Research, 29, 2613–2628. https://doi.org/10.1007/s11356-021-15289-0
Arsu, T., & Ayçin, E. (2021). Evaluation of OECD countries with multi-criteria decision-making methods in terms of economic, social and environmental aspects. Operational Research in Engineering Sciences: Theory and Applications, 4(2), 55–78. https://doi.org/10.31181/oresta20402055a
Artur, M. (2021). Review the performance of the Bernoulli naïve Bayes classifier in intrusion detection systems using recursive feature elimination with cross-validated selection of the best number of features. Procedia Computer Science, 190, 564–570. https://doi.org/10.1016/j.procs.2021.06.066
Atanassov, K. T. (1999). Intuitionistic fuzzy sets. In K. T. Atanassov (Ed.), Intuitionistic fuzzy sets studies in fuzziness and soft computing (Vol. 35, pp. 1–137). Physica. https://doi.org/10.1007/978-3-7908-1870-3_1
Aung, T. S., Luan, S., & Xu, Q. (2019). Application of multi-criteria-decision approach for the analysis of medical waste management systems in Myanmar. Journal of Cleaner Production, 222, 733–745. https://doi.org/10.1016/j.jclepro.2019.03.049
Azizkhani, N. A., Gholami, S., Yusif, S., Moosavi, S., Miri, S. F., & Kalhor, R. (2021). Comparison of health-care waste management in urban and rural areas in Iran: Application of multi-criteria decision making method. Health Scope, 10(2), e113282. https://doi.org/10.5812/jhealthscope.113282
Bagheri, M., Esfilar, R., Golchi, M. S., & Kennedy, C. A. (2019). A comparative data mining approach for the prediction of energy recovery potential from various municipal solid waste. Renewable and Sustainable Energy Reviews, 116, 109423. https://doi.org/10.1016/j.rser.2019.109423
Bakır, M., Akan, Ş, & Özdemir, E. (2021). Regional aircraft selection with fuzzy PIPRECIA and fuzzy MARCOS: A case study of the Turkish airline industry. Facta Universitatis, Series: Mechanical Engineering, 19(3), 423–445. https://doi.org/10.22190/FUME210505053B
Biswas, S., Majumder, S., & Dawn, S. K. (in press). Comparing the socioeconomic development of G7 and BRICS countries and resilience to COVID-19: An entropy–MARCOS framework. Business Perspectives and Research. https://doi.org/10.1177/22785337211015406.
Blum, A. L., & Langley, P. (1997). Selection of relevant features and examples in machine learning. Artificial Intelligence, 97(1–2), 245–271. https://doi.org/10.1016/S0004-3702(97)00063-5
Bouraima, M. B., Stević, Ž, Tanackov, I., & Qiu, Y. (2021). Assessing the performance of Sub-Saharan African (SSA) railways based on an integrated Entropy-MARCOS approach. Operational Research in Engineering Sciences: Theory and Applications, 4(2), 13–35. https://doi.org/10.31181/oresta20402013b
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. https://doi.org/10.1023/A:1010933404324
Celik, E., & Gul, M. (2021). Hazard identification, risk assessment and control for dam construction safety using an integrated BWM and MARCOS approach under interval type-2 fuzzy sets environment. Automation in Construction, 127, 103699. https://doi.org/10.1016/j.autcon.2021.103699
Chakraborty, S., Chattopadhyay, R., & Chakraborty, S. (2020). An integrated D-MARCOS method for supplier selection in an iron and steel industry. Decision Making: Applications in Management and Engineering, 3(2), 49–69. https://doi.org/10.31181/dmame2003049c
Chang, T. W., Pai, C. J., Lo, H. W., & Hu, S. K. (2021). A hybrid decision-making model for sustainable supplier evaluation in electronics manufacturing. Computers & Industrial Engineering, 156, 107283. https://doi.org/10.1016/j.cie.2021.107283
Chauhan, A., Jakhar, S. K., & Chauhan, C. (2021). The interplay of circular economy with industry 4.0 enabled smart city drivers of healthcare waste disposal. Journal of Cleaner Production, 279, 123854. https://doi.org/10.1016/j.jclepro.2020.123854
Chauhan, A., & Singh, A. (2016). A hybrid multi-criteria decision making method approach for selecting a sustainable location of healthcare waste disposal facility. Journal of Cleaner Production, 139, 1001–1010. https://doi.org/10.1016/j.jclepro.2016.08.098
Chauhan, A., Singh, A., & Jharkharia, S. (2018). Healthcare waste management practices’ identification and evaluation to rank hospitals. International Journal of Operational Research, 33(3), 367–386. https://doi.org/10.1504/ijor.2018.095626
Chauhan, A., & Singh, S. P. (2021). Selection of healthcare waste disposal firms using a multi-method approach. Journal of Environmental Management, 295, 113117. https://doi.org/10.1016/j.jenvman.2021.113117
Chen, X., & Jeong, J. C. (2007). Enhanced recursive feature elimination. In Sixth international conference on machine learning and applications (ICMLA 2007), 13–15 December, Cincinnati, OH, USA (pp. 429–435). IEEE. https://doi.org/10.1109/ICMLA.2007.35.
Chen, R.-C., Dewi, C., Huang, S.-W., & Caraka, R. E. (2020). Selecting critical features for data classification based on machine learning methods. Journal of Big Data, 7, 52. https://doi.org/10.1186/s40537-020-00327-4
Chhay, L., Reyad, M. A. H., Suy, R., Islam, M. R., & Mian, M. M. (2018). Municipal solid waste generation in China: Influencing factor analysis and multi-model forecasting. Journal of Material Cycles and Waste Management, 20(3), 1761–1770. https://doi.org/10.1007/s10163-018-0743-4
Darst, B. F., Malecki, K. C., & Engelman, C. D. (2018). Using recursive feature elimination in random forest to account for correlated variables in high dimensional data. BMC Genetics, 19(1), 65. https://doi.org/10.1186/s12863-018-0633-8
Das, A. K., Islam, N., Billah, M., & Sarker, A. (2021). COVID-19 pandemic and healthcare solid waste management strategy—A mini-review. Science of the Total Environment. https://doi.org/10.1016/j.scitotenv.2021.146220
Deveci, M., Özcan, E., John, R., Pamucar, D., & Karaman, H. (2021). Offshore wind farm site selection using interval rough numbers based Best Worst Method and MARCOS. Applied Soft Computing. https://doi.org/10.1016/j.asoc.2021.107532
Du, P., Chen, Z., & Gong, X. (2020). Load response potential evaluation for distribution networks: A hybrid decision-making model with intuitionistic normal cloud and unknown weight information. Energy, 192, 116673. https://doi.org/10.1016/j.energy.2019.116673
Ecer, F., & Pamucar, D. (2021). MARCOS technique under intuitionistic fuzzy environment for determining the COVID-19 pandemic performance of insurance companies in terms of healthcare services. Applied Soft Computing, 104, 107199. https://doi.org/10.1016/j.asoc.2021.107199
Elshaboury, N., Attia, T., & Marzouk, M. (2020). Application of evolutionary optimization algorithms for rehabilitation of water distribution networks. Journal of Construction Engineering and Management, 146(7), 04020069. https://doi.org/10.1061/(asce)co.1943-7862.0001856
Farrokhizadeh, E., Seyfi-Shishavan, S. A., & Satoglu, S. I. (in press). Blood supply planning during natural disasters under uncertainty: A novel bi-objective model and an application for red crescent. Annals of Operations Research. https://doi.org/10.1007/s10479-021-03978-5.
Garg, H., Shahzadi, G., & Akram, M. (2020). Decision-making analysis based on Fermatean fuzzy Yager aggregation operators with application in COVID-19 testing facility. Mathematical Problems in Engineering, 2020, 7279027. https://doi.org/10.1155/2020/7279027
Golbaz, S., Nabizadeh, R., & Sajadi, H. S. (2019). Comparative study of predicting hospital solid waste generation using multiple linear regression and artificial intelligence. Journal of Environmental Health Science and Engineering, 17(1), 41–51. https://doi.org/10.1007/s40201-018-00324-z
Gong, X., Yang, M., & Du, P. (2021). Renewable energy accommodation potential evaluation of distribution network: A hybrid decision-making framework under interval type-2 fuzzy environment. Journal of Cleaner Production, 286, 124918. https://doi.org/10.1016/j.jclepro.2020.124918
Goodarzian, F., Ghasemi, P., Gunasekaren, A., Taleizadeh, A. A., & Abraham, A. (in press). A sustainable-resilience healthcare network for handling COVID-19 pandemic. Annals of Operations Research. https://doi.org/10.1007/s10479-021-04238-2.
Guyon, I., Weston, J., Barnhill, S., & Vapnik, V. (2002). Gene selection for cancer classification using support vector machines. Machine Learning, 46(1), 389–422. https://doi.org/10.1023/A:1012487302797
Hariz, H. A., Dönmez, C. Ç., & Sennaroglu, B. (2017). Siting of a central healthcare waste incinerator using GIS-based Multi-Criteria Decision Analysis. Journal of Cleaner Production, 166, 1031–1042. https://doi.org/10.1016/j.jclepro.2017.08.091
Hatefi, M. A. (2019). Indifference threshold-based attribute ratio analysis: A method for assigning the weights to the attributes in multiple attribute decision making. Applied Soft Computing, 74, 643–651. https://doi.org/10.1016/j.asoc.2018.10.050
Hinduja, A., & Pandey, M. (2019). Assessment of healthcare waste treatment alternatives using an integrated decision support framework. International Journal of Computational Intelligence Systems, 12(1), 318–333. https://doi.org/10.2991/ijcis.2018.125905685
Huang, X., Zhang, L., Wang, B., Li, F., & Zhang, Z. (2018). Feature clustering based support vector machine recursive feature elimination for gene selection. Applied Intelligence, 48(3), 594–607. https://doi.org/10.1007/s10489-017-0992-2
Hussain, A., Draz, U., Ali, T., Tariq, S., Irfan, M., Glowacz, A., et al. (2020). Waste management and prediction of air pollutants using IoT and machine learning approach. Energies, 13(15), 3930. https://doi.org/10.3390/en13153930
Ishtiaq, P., Khan, S. A., & Haq, M. U. (2018). A multi-criteria decision-making approach to rank supplier selection criteria for hospital waste management: A case from Pakistan. Waste Management & Research, 36(4), 386–394. https://doi.org/10.1177/0734242X18755894
Kannangara, M., Dua, R., Ahmadi, L., & Bensebaa, F. (2018). Modeling and prediction of regional municipal solid waste generation and diversion in Canada using machine learning approaches. Waste Management, 74, 3–15. https://doi.org/10.1016/j.wasman.2017.11.057
Keshavarz-Ghorabaee, M., Amiri, M., Hashemi-Tabatabaei, M., Zavadskas, E. K., & Kaklauskas, A. (2020). A new decision-making approach based on Fermatean fuzzy sets and WASPAS for green construction supplier evaluation. Mathematics, 8(12), 2202. https://doi.org/10.3390/math8122202
Klemeš, J. J., Van Fan, Y., Tan, R. R., & Jiang, P. (2020). Minimising the present and future plastic waste, energy and environmental footprints related to COVID-19. Renewable and Sustainable Energy Reviews, 127, 109883. https://doi.org/10.1016/j.rser.2020.109883
Kuhn, M. (2008). Building predictive models in R using the caret package. Journal of Statistical Software, 28(5), 1–26. https://doi.org/10.18637/jss.v028.i05
Kuhn, M., Wing, J., Weston, S., Williams, A., Keefer, C., et al. (2020). Package ‘caret.’ The R Journal, 223, 7.
Li, H., Li, J., Zhang, Z., Cao, X., Zhu, J., & Chen, W. (2020). Establishing an interval-valued fuzzy decision-making method for sustainable selection of healthcare waste treatment technologies in the emerging economies. Journal of Material Cycles and Waste Management, 22(2), 501–514. https://doi.org/10.1007/s10163-019-00943-0
Lin, X., Li, C., Zhang, Y., Su, B., Fan, M., & Wei, H. (2018). Selecting feature subsets based on SVM-RFE and the overlapping ratio with applications in bioinformatics. Molecules, 23(1), 52. https://doi.org/10.3390/molecules23010052
Liu, P., Rani, P., & Mishra, A. R. (2021). A novel Pythagorean fuzzy combined compromise solution framework for the assessment of medical waste treatment technology. Journal of Cleaner Production, 292, 126047. https://doi.org/10.1016/j.jclepro.2021.126047
Lo, H.-W., Hsu, C.-C., Huang, C.-N., & Liou, J. J. H. (2021). An ITARA-TOPSIS based integrated assessment model to identify potential product and system risks. Mathematics, 9, 239. https://doi.org/10.3390/math9030239
Lotfi, R., Kheiri, K., Sadeghi, A., & Tirkolaee, E. B. (in press). An extended robust mathematical model to project the course of COVID-19 epidemic in Iran. Annals of Operations Research. https://doi.org/10.1007/s10479-021-04490-6.
Louw, N., & Steel, S. J. (2006). Variable selection in kernel Fisher discriminant analysis by means of recursive feature elimination. Computational Statistics & Data Analysis, 51(3), 2043–2055. https://doi.org/10.1016/j.csda.2005.12.018
Lu, W., Lou, J., Webster, C., Xue, F., Bao, Z., & Chi, B. (2021). Estimating construction waste generation in the Greater Bay Area, China using machine learning. Waste Management, 134, 78–88. https://doi.org/10.1016/j.wasman.2021.08.012
Maghsoodi, A. I., Kavian, A., Khalilzadeh, M., & Brauers, W. K. (2018). CLUS-MCDA: A novel framework based on cluster analysis and multiple criteria decision theory in a supplier selection problem. Computers & Industrial Engineering, 118, 409–422. https://doi.org/10.1016/j.cie.2018.03.011
Maghsoodi, A. I., Riahi, D., Herrera-Viedma, E., & Zavadskas, E. K. (2020). An integrated parallel big data decision support tool using the W-CLUS-MCDA: A multi-scenario personnel assessment. Knowledge-Based Systems, 195, 105749. https://doi.org/10.1016/j.knosys.2020.105749
Makan, A., & Fadili, A. (2021). Sustainability assessment of healthcare waste treatment systems using surrogate weights and PROMETHEE method. Waste Management & Research, 39(1), 73–82. https://doi.org/10.1177/0734242X20947162
Maksimović, A., Puška, A., Šakić Bobić, B., & Grgić, Z. (2021). A model for supporting the decision of plum variety selection based on fuzzy logic. Journal of Central European Agriculture, 22(2), 450–461. https://doi.org/10.5513/JCEA01/22.2.2946
Meza, J. K. S., Yepes, D. O., Rodrigo-Ilarri, J., & Cassiraga, E. (2019). Predictive analysis of urban waste generation for the city of Bogotá, Colombia, through the implementation of decision trees-based machine learning, support vector machines and artificial neural networks. Heliyon, 5(11), e02810. https://doi.org/10.1016/j.heliyon.2019.e02810
Mijajlović, M., Puška, A., Stević, Ž, Marinković, D., Doljanica, D., Jovanović, S. V., et al. (2020). Determining the competitiveness of spa-centers in order to achieve sustainability using a fuzzy multi-criteria decision-making model. Sustainability, 12(20), 8584. https://doi.org/10.3390/su12208584
Mishra, A. R., Mardani, A., Rani, P., & Zavadskas, E. K. (2020). A novel EDAS approach on intuitionistic fuzzy set for assessment of health-care waste disposal technology using new parametric divergence measures. Journal of Cleaner Production, 272, 122807. https://doi.org/10.1016/j.jclepro.2020.122807
Mishra, A. R., Rani, P., Mardani, A., Pardasani, K. R., Govindan, K., & Alrasheedi, M. (2020). Healthcare evaluation in hazardous waste recycling using novel interval-valued intuitionistic fuzzy information based on complex proportional assessment method. Computers & Industrial Engineering, 139, 106140. https://doi.org/10.1016/j.cie.2019.106140
Mishra, S., & Singh, S. P. (in press). A stochastic disaster-resilient and sustainable reverse logistics model in big data environment. Annals of Operations Research. https://doi.org/10.1007/s10479-020-03573-0.
Nursetyowati, P., Nadifameidita, F. Q., Fairus, S., Irawan, D. S., & Rohajawati, S. (2019). Optimization of medical hazardous waste management in community health centers of depok city using analytical hierarchy process (AHP) method. Journal of Physics: Conference Series, 1364(1), 012040. https://doi.org/10.1088/1742-6596/1364/1/012040
Pamucar, D., Ecer, F., & Deveci, M. (2021). Assessment of alternative fuel vehicles for sustainable road transportation of United States using integrated fuzzy FUCOM and neutrosophic fuzzy MARCOS methodology. Science of the Total Environment, 788, 147763. https://doi.org/10.1016/j.scitotenv.2021.147763
Pamucar, D., Iordache, M., Deveci, M., Schitea, D., & Iordache, I. (2021). A new hybrid fuzzy multi-criteria decision methodology model for prioritizing the alternatives of the hydrogen bus development: A case study from Romania. International Journal of Hydrogen Energy, 46(57), 29616–29637. https://doi.org/10.1016/j.ijhydene.2020.10.172
Paul, A., Pervin, M., Roy, S. K., Maculan, N., & Weber, G. W. (2022). A green inventory model with the effect of carbon taxation. Annals of Operations Research, 309(1), 233–248. https://doi.org/10.1007/s10479-021-04143-8
Pradenas, L., Fuentes, M., & Parada, V. (2020). Optimizing waste storage areas in health care centers. Annals of Operations Research, 295(1), 503–516. https://doi.org/10.1007/s10479-020-03713-6
Rao, K. E., & Rao, G. A. (2021). Ensemble learning with recursive feature elimination integrated software effort estimation: A novel approach. Evolutionary Intelligence, 14(1), 151–162. https://doi.org/10.1007/s12065-020-00360-5
Rtayli, N., & Enneya, N. (2020). Enhanced credit card fraud detection based on SVM-recursive feature elimination and hyper-parameters optimization. Journal of Information Security and Applications, 55, 102596. https://doi.org/10.1016/j.jisa.2020.102596
Sahoo, L. (2021). A new score function based Fermatean fuzzy transportation problem. Results in Control and Optimization, 4, 100040. https://doi.org/10.1016/j.rico.2021.100040
Sałabun W., & Urbaniak K. (2020). A new coefficient of rankings similarity in decision-making problems. In ICCS 2020, vol 12138, 3–5 June, the Netherlands, Springer, Cham. https://doi.org/10.1007/978-3-030-50417-5_47.
Sazvar, Z., Zokaee, M., Tavakkoli-Moghaddam, R., Salari, S. A. S., & Nayeri, S. (in press). Designing a sustainable closed-loop pharmaceutical supply chain in a competitive market considering demand uncertainty, manufacturer’s brand and waste management. Annals of Operations Research. https://doi.org/10.1007/s10479-021-03961-0.
Senapati, T., & Yager, R. R. (2019a). Fermatean fuzzy weighted averaging/geometric operators and its application in multi-criteria decision-making methods. Engineering Applications of Artificial Intelligence, 85, 112–121. https://doi.org/10.1016/j.engappai.2019.05.012
Senapati, T., & Yager, R. R. (2019b). Some new operations over Fermatean fuzzy numbers and application of Fermatean fuzzy WPM in multiple criteria decision making. Informatica, 30(2), 391–412. https://doi.org/10.15388/Informatica.2019.211
Senapati, T., & Yager, R. R. (2020). Fermatean fuzzy sets. Journal of Ambient Intelligence and Humanized Computing, 11(2), 663–674. https://doi.org/10.1007/s12652-019-01377-0
Sergi, D., & Sari, I. U., et al. (2021). Fuzzy capital budgeting using Fermatean fuzzy sets. In C. Kahraman, S. Cevik Onar, & B. Oztaysi (Eds.), Intelligent and Fuzzy Techniques: Smart and Innovative Solutions (Vol. 1197, pp. 448–456). Cham: Springer. https://doi.org/10.1007/978-3-030-51156-2_52
Shahzadi, G., Muhiuddin, G., Arif Butt, M., & Ashraf, A. (2021). Hamacher interactive hybrid weighted averaging operators under Fermatean fuzzy numbers. Journal of Mathematics, 2021, 5556017. https://doi.org/10.1155/2021/5556017
Simic, V., Karagoz, S., Deveci, M., & Aydin, N. (2021). Picture fuzzy extension of the CODAS method for multi-criteria vehicle shredding facility location. Expert Systems with Applications, 175, 114644. https://doi.org/10.1016/j.eswa.2021.114644
Simić, V., Soušek, R., & Jovčić, S. (2020). Picture fuzzy MCDM approach for risk assessment of railway infrastructure. Mathematics, 8(12), 2259. https://doi.org/10.3390/math8122259
Singh, D., & Satija, A. (2018). Prediction of municipal solid waste generation for optimum planning and management with artificial neural network—Case study: Faridabad City in Haryana State (India). International Journal of System Assurance Engineering and Management, 9(1), 91–97. https://doi.org/10.1007/s13198-016-0484-5
Singh, N., Tang, Y., Zhang, Z., & Zheng, C. (2020). COVID-19 waste management: Effective and successful measures in Wuhan, China. Resources, Conservation, and Recycling, 163, 105071. https://doi.org/10.1016/j.resconrec.2020.105071
Sofuoğlu, M. A. (2019). Development of an ITARA-based hybrid multi-criteria decision-making model for material selection. Soft Computing, 23(15), 6715–6725. https://doi.org/10.1007/s00500-019-04056-6
Stanković, M., Stević, Ž, Das, D. K., Subotić, M., & Pamučar, D. (2020). A new fuzzy MARCOS method for road traffic risk analysis. Mathematics, 8(3), 457. https://doi.org/10.3390/math8030457
Stević, Ž, & Brković, N. (2020). A novel integrated FUCOM-MARCOS model for evaluation of human resources in a transport company. Logistics, 4, 4. https://doi.org/10.3390/logistics4010004
Stević, Ž, Das, D. K., & Kopić, M. (2021). A novel multiphase model for traffic safety evaluation: A case study of South Africa. Mathematical Problems in Engineering, 2021, 5584599. https://doi.org/10.1155/2021/5584599
Stević, Ž, Pamučar, D., Puška, A., & Chatterjee, P. (2020). Sustainable supplier selection in healthcare industries using a new MCDM method: Measurement of alternatives and ranking according to COmpromise solution (MARCOS). Computers & Industrial Engineering, 140, 106231. https://doi.org/10.1016/j.cie.2019.106231
Thakur, V. (2021). Framework for PESTEL dimensions of sustainable healthcare waste management: Learnings from COVID-19 outbreak. Journal of Cleaner Production, 287, 125562. https://doi.org/10.1016/j.jclepro.2020.125562
Thakur, V., Mangla, S. K., & Tiwari, B. (2021). Managing healthcare waste for sustainable environmental development: A hybrid decision approach. Business Strategy and the Environment, 30(1), 357–373. https://doi.org/10.1002/bse.2625
Thakur, V., & Ramesh, A. (2017). Healthcare waste disposal strategy selection using grey-AHP approach. Benchmarking: an International Journal, 24(3), 735–749. https://doi.org/10.1108/BIJ-09-2016-0138
Tirkolaee, E. B., Abbasian, P., & Weber, G. W. (2021). Sustainable fuzzy multi-trip location-routing problem for medical waste management during the COVID-19 outbreak. Science of the Total Environment, 756, 143607. https://doi.org/10.1016/j.scitotenv.2020.143607
Tirkolaee, E. B., Goli, A., Gütmen, S., Weber, G. W., & Szwedzka, K. (in press). A novel model for sustainable waste collection arc routing problem: Pareto-based algorithms. Annals of Operations Research. https://doi.org/10.1007/s10479-021-04486-2.
Torkayesh, A. E., Deveci, M., Torkayesh, S. E., & Tirkolaee, E. B. (2021). Analyzing failures in adoption of smart technologies for medical waste management systems: A type-2 neutrosophic-based approach. Environmental Science and Pollution Research. https://doi.org/10.1007/s11356-021-16228-9
Torkayesh, A. E., Malmir, B., & Asadabadi, M. R. (2021). Sustainable waste disposal technology selection: The stratified best-worst multi-criteria decision-making method. Waste Management, 122, 100–112. https://doi.org/10.1016/j.wasman.2020.12.040
Torkayesh, A. E., & Torkayesh, S. E. (2021). Evaluation of information and communication technology development in G7 countries: An integrated MCDM approach. Technology in Society, 66, 101670. https://doi.org/10.1016/j.techsoc.2021.101670
Ulutaş, A., Karabasevic, D., Popovic, G., Stanujkic, D., Nguyen, P. T., & Karaköy, Ç. (2020). Development of a novel integrated CCSD-ITARA-MARCOS decision-making approach for stackers selection in a logistics system. Mathematics, 8(10), 1672. https://doi.org/10.3390/math8101672
Ustebay, S., Turgut, Z., & Aydin, M. A. (2018). Intrusion detection system with recursive feature elimination by using random forest and deep learning classifier. In 2018 international congress on big data, deep learning and fighting cyber terrorism (IBIGDELFT), 3–4 December, Ankara, Turkey (pp. 71–76). IEEE. https://doi.org/10.1109/IBIGDELFT.2018.8625318.
Voudrias, E. A. (2016). Technology selection for infectious medical waste treatment using the analytic hierarchy process. Journal of the Air & Waste Management Association, 66(7), 663–672. https://doi.org/10.1080/10962247.2016.1162226
Yager, R. R., & Abbasov, A. M. (2013). Pythagorean membership grades, complex numbers, and decision making. International Journal of Intelligent Systems, 28(5), 436–452. https://doi.org/10.1002/int.21584
Yang, Z., Garg, H., & Li, X. (2021). Differential calculus of Fermatean fuzzy functions: Continuities, derivatives, and differentials. International Journal of Computational Intelligence Systems, 14(1), 282–294. https://doi.org/10.2991/ijcis.d.201215.001
You, W., Yang, Z., & Ji, G. (2014). PLS-based recursive feature elimination for high-dimensional small sample. Knowledge-Based Systems, 55, 15–28. https://doi.org/10.1016/j.knosys.2013.10.004
Zand, A. D., & Heir, A. V. (2021). Emanating challenges in urban and healthcare waste management in Isfahan, Iran after the outbreak of COVID-19. Environmental Technology, 42(2), 329–336. https://doi.org/10.1080/09593330.2020.1866082
Zhang, C., Li, Y., Yu, Z., & Tian, F. (2016). Feature selection of power system transient stability assessment based on random forest and recursive feature elimination. In 2016 IEEE PES Asia-Pacific power and energy engineering conference (APPEEC), 25–28 October, Xi'an, China (pp. 1264–1268). IEEE. https://doi.org/10.1109/APPEEC.2016.7779696.
Zhou, Q., Zhou, H., Zhou, Q., Yang, F., & Luo, L. (2014). Structure damage detection based on random forest recursive feature elimination. Mechanical Systems and Signal Processing, 46(1), 82–90. https://doi.org/10.1016/j.ymssp.2013.12.013
Acknowledgements
The authors are grateful for the valuable comments of the Editor-in-Chief, the Lead Guest Editor, and the four anonymous reviewers, who helped considerably improve the manuscript.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
VS: Conceptualization, Methodology, Software, Validation, Visualization, Writing—original draft, review and editing, Project administration. AET: Conceptualization, Investigation, Data Curation, Validation, Visualization, Writing—original draft, review and editing, Project administration. AIM: Methodology, Software, Validation, Visualization, Writing—original draft, review and editing.
Corresponding author
Ethics declarations
Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical approval
Not applicable.
Consent to participate
All authors consent.
Consent to publish
All authors consent when it is published.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Simic, V., Ebadi Torkayesh, A. & Ijadi Maghsoodi, A. Locating a disinfection facility for hazardous healthcare waste in the COVID-19 era: a novel approach based on Fermatean fuzzy ITARA-MARCOS and random forest recursive feature elimination algorithm. Ann Oper Res 328, 1105–1150 (2023). https://doi.org/10.1007/s10479-022-04822-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-022-04822-0