
Abstract
Gynaecological cancers encompass a spectrum of malignancies affecting the female reproductive system, comprising the cervix, uterus, ovaries, vulva, vagina, and fallopian tubes. The significant health threat posed by these cancers worldwide highlight the crucial need for techniques for early detection and prediction of gynaecological cancers. Preferred reporting items for systematic reviews and Meta-Analysis guidelines are used to select the articles published from 2013 up to 2023 on the Web of Science, Scopus, Google Scholar, PubMed, Excerpta Medical Database, and encompass AI technique for the early detection and prediction of gynaecological cancers. Based on the study of different articles on gynaecological cancer, the results are also compared using various quality parameters such as prediction rate, accuracy, sensitivity, specificity, the area under curve precision, recall, and F1-score. This work highlights the impact of gynaecological cancer on women belonging to different age groups and regions of the world. A detailed categorization of the traditional techniques like physical-radiological, bio-physical and bio-chemical used to detect gynaecological cancer by health organizations is also presented in the study. Besides, this work also explores the methodology used by different researchers in which AI plays a crucial role in identifying cancer symptoms at earlier stages. The paper also investigates the pivotal study years, highlighting the periods when the highest number of research articles on gynaecological cancer are published. The challenges faced by researchers while performing AI-based research on gynaecological cancers are also highlighted in this work. The features and representations such as Magnetic Resonance Imaging (MRI), ultrasound, pap smear, pathological, etc., which proficient the AI algorithms in early detection of gynaecological cancer are also explored. This comprehensive review contributes to the understanding of the role of AI in improving the detection and prognosis of gynaecological cancers, and provides insights for future research directions and clinical applications. AI has the potential to substantially reduce mortality rates linked to gynaecological cancer in the future by enabling earlier identification, individualised risk assessment, and improved treatment techniques. This would ultimately improve patient outcomes and raise the standard of healthcare for all individuals.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Gynaecological cancer is a noteworthy concern for women worldwide, encompassing a variety of cancers that primarily impact the female reproductive system. Timely detection and treatment are vital for obtaining the best outcomes (Maheshwari et al. 2016; Kruczkowski et al. 2022a). According to the National Cancer Institute, over 106,000 women in the US are projected to be diagnosed with gynaecological cancer by 2023, and a staggering 32,000 will succumb to this disease (Ch et al. 2022). In addition, an estimated 500,000 women are diagnosed with gynaecological cancer each year globally, with India alone reporting over a 100,000 new case (Penny 2020). Most women report their cancer at an advanced stage, due to lack of adequate screening facilities, awareness and diverse pathologies, which results in negative impact on the prognosis and clinical results (Maheshwari et al. 2016). Figure 1 shows the categorization of gynaecological cancer. Gynaecological cancers are a complex group of diseases with varying causes and symptoms. As women age, their risk of developing these cancers increases, indicating that age is a key factor. Recent research has focused on understanding the genetic and molecular aspects of these tumors, leading to insights into their development and more personalized treatments. Immunotherapy and targeted therapies have emerged as novel approaches, leveraging the body's immune system and targeting specific cancer-related molecules. The categorization of gynaecological cancer based on their area of occurrence is defined below:
-
(i)
Cervical cancer: Cervical cancer originates in the cervix, the lower segment of the uterus that links to the vagina, and is categorized as a type of gynaecological cancer (Kruczkowski et al. 2022a). It happens when uncontrolled growth of abnormal cervix cells leads to the development of a tumour. Human Papilloma Virus (HPV), a commonly transmitted sexual infection is the primary cause of cervical cancer in women body. Other factors responsible for causing cervical cancer includes smoking, a compromised immune system, a history of cervical cancer in the family, and certain genetic mutations (Ch et al. 2022).
-
(ii)
Ovarian cancer: Ovarian cancer is a distinctive type of cancer that initiates in the ovaries, which are the female reproductive organs accountable for egg production and the synthesis of female hormones. It is the fifth most common cancer among women and one of the most deadly gynaecological cancers (Penny 2020). Ovarian cancer is often termed as the "silent killer" because it does not show any signs in its early stages. But as the cancer advances, abdominal or pelvic pain, bloating, feeling full fast after eating, changes in bowel habits, unexplained weight loss or increase, frequent urination, exhaustion, and abnormal vaginal bleeding are among symptoms that may appear (Rooth 2013).
-
(iii)
Uterine cancer: Uterine cancer develops in the endometrium (uterus lining) and referred to as endometrial cancer. It is one of the most common cancer of the female reproductive system that typically occurs after menopause, but it can also affect women during their reproductive years (Filippova and Leitao 2020). Abnormal vaginal bleeding is the most prevalent sign of uterine cancer, especially after menopause. Atypical vaginal discharge, pelvic pain or discomfort, pain during sex, and unexpected weight loss are some more symptoms that could occur (Raglan et al. 2019).
-
(iv)
Vaginal cancer: A rare gynaecological cancer which develops in the tissue of vagina, the muscular canal that connects the uterus to the external genitals is known as vaginal cancer. It can develop at any age but women over the age of 60 are primarily affected by this cancer. Vaginal cancer can be classified into various forms based on the specific cells that are affected i.e., Adenocarcinoma, Clear cell Adenocarcinoma, Sarcoma, Squamous Cell Carcinoma. Weakened immune system, bloody, watery or foul-smelling vaginal discharge, pelvic pain, lump or mass in the vagina are some of the symptoms associated with this cancer.
-
(v)
Vulvar cancer: A relatively rare form of cancer that affects external genital area of women, known as the vulva is termed as vulvar cancer. The vulva comprises the outer lips (labia majora), clitoris, inner lips (labia minora), perineum and vaginal opening (Alkatout et al. 2015). Vulvar cancer typically develops slowly over a period and usually affects older women. Squamous cell carcinoma variant of the vulva cancer is the most prevalent group (95%), followed by sarcoma, melanoma, and basalioma histological variants (Günther et al. 2012).
-
(vi)
Fallopian tube cancer: An unusual type of gynaecological cancer that onsets in the fallopian tubes is referred as tubal cancer, commonly referred to as fallopian tube cancer. The fallopian tubes, which link the ovaries to the uterus, are integral parts of the female reproductive system. Even though fallopian tube cancer is not common, it is a dangerous ailment that needs medical attention. In its early stages, fallopian tube cancer has no symptoms. Some typical signs and symptoms of the condition may include abnormal bleeding or discharge from the cervix, pelvic discomfort or pain, modifications to bowel or bladder routines, bloating or swelling in the abdomen, eating until soon satisfied, unexplained loss of weight, drowsiness, or a lack of vitality etc. (Berek et al. 2018).

Categorization of gynaecological cancer
Figure 2 depicts the anatomical regions vulnerable to gynaecological cancer (Taylor et al. 2021), providing a visual depiction of both normal tissue cells and the corresponding affected reproductive structures.

Different regions of occurrence of gynaecological cancer (Taylor et al. 2021)
The present study aims to condense the abundance of information accumulated over the years, thereby providing a comprehensive survey of the present state of knowledge, diagnostic strategies, therapeutic modalities, and new trends in gynaecological cancer. It also investigates how efficiently AI based models can perform on the gynaecological cancer data and which data i.e., MRI, Pap scans, ultrasounds, demographic etc. are best suitable for these models for qualitative detection and prediction of gynaecological cancer. This review was motivated by a strong desire to enhance the life span of people affected by gynaecological cancer. The data presented in Fig. 3a, 4a and 5a for cervical (Cervix uteri cancer 2024), ovarian (Ovary cancer 2024), and uterine (Corpus uteri cancer 2024) cancer in 2022 reveals a clear age-related pattern in the number of deaths. For cervical cancer, mortality rates rise steadily with age, reaching a peak in the 65–69 age group. Similarly, ovarian cancer and uterine cancer follows a comparable pattern, with the highest mortality rates observed in the age group of 70–74. This age-specific distribution highlights the importance of early detection and emphasizes that gynaecological cancers become more prevalent and life-threatening as women age. The significantly higher number of deaths in older age groups underscores the urgency for effective screening and preventive measures, especially for post-menopausal women.

a Cervical cancer mortality rate by age (2022). b Cervical cancer mortality rate by region (2022)

a Ovarian cancer mortality rate by age (2022). b Ovarian cancer mortality rate by region (2022)

a Uterine cancer mortality rate by age (2022). b Uterine cancer mortality rate by region (2022)
The region-wise data for gynaecological cancers in 2022 reveals distinct patterns in occurrence across continents as presented in Fig. 3b, 4b and 5b. Cervical (Cervix uteri cancer 2024), Ovarian (Ovary cancer 2024), and Uterine (Corpus uteri cancer 2024) cancers show varying impact, with Europe consistently emerging as highly affected by all three types of cancer. Europe has high rates of cervical, uterine and ovarian cancer, followed by North America and the Caribbean, highlighting the importance of focused preventive efforts and significance of early detection in healthcare. Oceania requires comprehensive measures for early identification and prevention of all three malignancies due to high incidence of these diseases there. Although incidences are lower in Africa, early detection is still essential for reducing overall mortality rates. To mitigate the burden of gynaecological cancers and improvement in overall mortality rate, a comprehensive approach for early identification and prevention is essential, considering the problems faced by each location. By analysing the extensive body of literature and highlighting the nuances of these diseases, we seek to facilitate more informed clinical decision-making, elevate scientific research, and ultimately improve patient care. Detection of gynaecological cancers at earlier stages when they are more curable, early identification can significantly reduce the risk of death and improve the prognosis for those who are affected.
The paper is organised as such to facilitate the readability of the paper. The first section begins with the introduction of gynaecological cancer and its various types determined on the basis of region of occurrence of cancer cells. Motivation and contribution of the study are also described in Sect. 1. The material and methodology used in the study is presented in Sect. 2. Section 3 describes the traditional approaches to Gynaecological cancer study focusing on the physical-radiological, bio-physical and bio-chemical methods of cancer detection. The basic AI approach for gynaecological cancer detection and prediction is presented in Sect. 4. Related literature about the various approaches used in machine learning and deep learning by various researchers over the years has been discussed in Sect. 5. Section 6 explores the answers to the questions posed in the beginning of the study. Finally, the paper concludes in Sect. 7.
2 Material and method
The systematic review presented in this study is conducted using the PRISMA (Preferred Reporting Items for Systematic reviews and Meta-Analyses) guidelines (Moher et al. 2009). An efficient search has been carried out for selecting the research articles pertaining to gynaecological cancer from different electronic databases, i.e., Pubmed, Springer Open, Science Direct. Since gynaecological cancer is an umbrella term for different areas of gynaecology, an extensive search needs to be done for different cancers using various search query as discussed in Sect. 5. The inclusion and exclusion criteria such as year of publication, cancer class, technique used, language, research design, exploration, and search terms used in our systematic review are presented in Table 1.
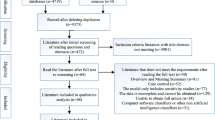
Figure 6 illustrates the PRISMA flowchart, which outlines the four phases utilized for thorough screening of the collected papers. The first phase begins with identification where various repositories are accessed for the identified research area. Also, the duplicate research work is also identified and removed from the final set. In the second phase screening is done, a transparent process wherein the papers are chosen by evaluating the recommendations made at various phases of the systematic review. After that eligibility is determined by evaluating the full-length articles (Page et al. 2021) and finally, the selected articles chosen for the review paper are identified in the included phase. Articles published between 2013 and 2023 are incorporated into this investigation. After eliminating duplicate research from the total of 567 papers that were chosen, 358 studies were retained. The research on illnesses other than cancer, treatment and surgery, and papers written in other than English language were subsequently eliminated from the final selection of 109 papers. Following this phase, research publications utilizing methodologies other than AI-based techniques were also excluded from further analysis, which entailed evaluating the entirety of the articles. The study's analysis concluded with the 93 chosen publications.

PRISMA for gynaecological cancer study
2.1 Investigations
To navigate the critical insights in gynaecological cancer prediction, we have formulated a set of fundamental questions, each designed to unravel distinct facets of the field. Following are the research questions which we tend to investigate in our study:
-
(i)
In which year were most of the gynaecological cancer prediction studies published?
-
(ii)
What are the challenges faced by researchers in constructing AI-based gynaecological cancer prediction models?
-
(iii)
Which gynaecological cancer has a higher mortality rate and is considered more dangerous?
-
(iv)
What are the most suitable features and representations to extract from medical imaging data (e.g., MRI, ultrasound, Pap smear images) for effective gynaecological cancer detection using deep learning algorithms?
Through these investigations, we aim to enhance our understanding and significantly contribute to the ongoing research on the prognosis and diagnosis of gynaecological cancer.
3 Traditional approaches to gynaecological cancer detection
The traditional approaches to gynaecological cancer diagnosis often use a combination of physical exam, diagnostic testing, and evaluation of medical history. Some of the most common procedures used for detection of gynaecological cancer is presented in this section. Broadly, the gynaecological cancer screening can be categorized into three types (Nyengidiki and Nyengidiki 2015):
3.1 Physical-radiological
Physical-radiological tests are diagnostic procedures that use physical examination and imaging methods to evaluate and diagnose a range of medical disorders. To give a more thorough assessment, these tests combine the use of physical examination findings with radiological imaging. Various physical-radiological tests used for detection of gynaecological cancer are:
-
(a)
X-rays: X-rays employ ionising radiation to produce images of the body's interior organs, however they are ineffective at capturing soft tissues, such as the pelvic reproductive organs. However, in some rare situations, X-rays might be employed as an additional imaging technique to assess certain characteristics of gynaecological tumours. Ovarian cancer is one such example of gynaecological cancer which can spread to lungs and a chest X-ray can assist in identification of abnormalities in the lung field in such case.
-
(b)
Ultrasound: Gynaecological malignancies are frequently detected and evaluated using ultrasound as an imaging method. Using high-frequency sound waves, it creates images of the pelvic organs that provide crucial information on their dimensions, structure, and anomalies. Doppler, Transvaginal, Endovaginal, and Pelvic ultrasounds are a few of the region-specific ultrasounds that are used to find gynaecological malignancy (Levi 1997).
-
(c)
Magnetic Resonance Imaging (MRI) Scan: MRI creates accurate images of the pelvic region by using radio waves and strong magnets (Peungjesada et al. 2009). It offers crucial information about the dimensions, position, and severity of gynaecological tumours and other abnormalities (Pesapane et al. 2018). Cervical, Uterine, and Ovarian malignancies can all be evaluated with MRI.
-
(d)
Computed Tomography (CT) Scans: CT scans are widely used in the detection, staging, and assessment of gynaecological cancers. With the use of state-of-the-art computer technology and X-rays, CT scans generate fine-grained cross-sectional images of the body (Pesapane et al. 2018; Brett and Brown 2015). They provide crucial information on the size, location, and characteristics of tumours as well as the involvement of nearby structures and potential metastases.
-
(e)
Positron Emission Tomography (PET) Scan: PET scanning is an advanced imaging technique which is used to identify, evaluate, and stage gynaecological cancers. PET scans reveal the metabolic activity of tissues and can be used to identify areas of abnormal cell growth. A little amount of radioactive tracer that emits positrons is injected during a PET scan. Gamma rays are subsequently released when these positrons collide with body electrons. The PET scanner detects these gamma rays and uses them to create exact images of the body's metabolic activity.
3.2 Biophysical
Biophysical tests are diagnostic techniques that quantify and assess the body's physical traits and properties. These tests provide valuable information for treatment and diagnosis and are intended to assess facets related to the reproductive organs. Gynaecological malignancies are detected and assessed using a variety of biophysical tests such as:
-
(a)
Pap Smears: Pap smears, also referred to as cervical cytology or Pap tests, is a standard screening technique used for detection of precancerous abnormalities in the cervix region. As part of the Pap smear procedure, cells are removed from the cervix and analysed under a microscope to search for any abnormal or possibly cancerous cells. The purpose of Pap smears is to detect precancerous cervix changes and cervical cancer. This test is not suitable for screening for other gynaecological cancers, such as ovarian or uterine cancer.
-
(b)
Colposcopy: The process of a colposcopy involves visually inspecting the cervix, vagina, and vulva with a colposcope, a magnifying instrument. It makes it possible to examine abnormal areas in more detail and to take tissue samples (biopsies) for further analysis. Colposcopy is commonly used to detect precancerous or cancerous abnormalities in the cervix or to evaluate bad results from Pap tests.
-
(c)
Laparoscopy: Laparoscopy is a minimally invasive surgical technique used to identify and treat gynaecological malignancies. A laparoscope, a thin, lit tube, is placed through small abdominal incisions to view and access the pelvic and abdominal organs. Laparoscopic removal of lymph nodes, uterine, fallopian tube, or ovarian cancer are among the options for treating gynaecological cancer.
-
(d)
Endometrial Biopsy: An endometrial biopsy involves taking a small sample of tissue for microscopic examination from the endometrium (lining of the uterus). It is often used to detect various uterine problems, evaluate irregular uterine bleeding, and diagnose endometrial cancer.
-
(e)
Vulva and Vaginal Smears: An alternative to the Pap test for detecting vulvar and vaginal cancers is a vulva and vaginal smear. These smears entail removing cells from the vulva or vaginal walls and examining them under a microscope in order to find any aberrant or maybe cancerous cells.
3.3 Bio-chemical
A "biochemical test" is a diagnostic technique that looks for different biochemical markers and parameters by analysing biological samples such as blood, urine, or tissue. Blood or laboratory tests are common terms used to describe biochemical tests. Many biochemistry-based assays are used to identify and evaluate gynaecological cancers. These tests search for substances or markers in biological samples, such as blood, that may indicate the existence of cancer or provide information about the disease. Different types of bio-chemical tests used for identification of gynaecological cancers are discussed below:
-
(a)
CA-125: A tumour marker called CA-125 is frequently employed in the detection and follow-up of ovarian cancer. It gauges the blood's concentration of a protein known as CA-125. Although elevated CA-125 levels are not only associated with ovarian cancer but can also be present in other illnesses, they can indicate the existence of ovarian cancer.
-
(b)
Human Chorionic Gonadotropin (hCG): During pregnancy, the Human Chorionic Gonadotropin hormone is generated. Rarely, some gynaecological malignancies, like ovarian germ cell tumours or gestational trophoblastic neoplasia, can generate hCG. These kinds of malignancies may be identified and followed up on using hCG blood testing.
-
(c)
CA 19–9: A tumour marker called CA 19–9 may be increased in some ovarian cancer instances. Additionally, it aids in the detection and follow-up of gastrointestinal tumours including pancreatic cancer. CA 19–9, however, is not only high in ovarian cancer; it can also occur in other diseases.
-
(d)
Alpha-fetoprotein (AFP): The protein AFP is normally made by the growing foetus. Elevated AFP levels, however, can be brought on by specific gynaecological malignancies, such as ovarian germ cell tumours or hepatocellular carcinoma (a liver cancer that can spread to the ovaries). These cancers may be diagnosed more quickly with the help of AFP testing.
-
(e)
BRCA 1 and 2: The BRCA 1 and BRCA 2 tests are genetic tests that are used for determination of potential risk of development of gynaecological cancers, particularly ovarian and breast cancer. These tests specifically target gene mutations in BRCA1 and BRCA2, which correlate with a heightened susceptibility to developing these cancers. Mutations in BRCA1 and BRCA2 are associated with an increased likelihood of developing fallopian tube cancer and primary peritoneal cancer.
Different type of tests used for different classes of gynaecological cancer is presented in Fig. 7.

Traditional approaches for gynaecological cancer study
4 AI techniques for gynaecological cancer detection and prediction
Various facets of medical research, diagnosis, therapy, and patient care have been revolutionised by machine/deep learning, making important contributions to the healthcare industry. The interpretation of medical images data such as X-rays, CT scans, and mammograms has greatly benefited from the application of machine learning algorithms. Whereas deep learning algorithms have demonstrated outstanding performance in the analysis of histopathology, MRI, and other types of medical pictures. From electronic health records, including patient demographics, lab findings, and medical histories, machine learning algorithms can infer useful insights. They aid in pattern recognition, disease risk prediction, and enhanced clinical judgement. DL/ML architectures have shown promising results in predicting gynaecologic cancers. A visual representation of the gynaecological cancer recognition model using practical machines and deep learning classification techniques is shown in Fig. 8. Various stages envisaged in detecting gynaecological cancer are as follows:
-
(a)
Data Collection: Commencing with the data collection stage, this first stage includes the inclusion of an extensive spectrum of data sources, including but not limited to laboratory results, medical imaging, examination reports, in-patient records, and patient-specific health data, all of which are crucial elements of this comprehensive investigation. Medical imaging and lab results play crucial roles in the global dissemination of AI models, acting as key components in both the development and execution of these sophisticated systems (Barragán-Montero et al. 2021; Currie et al. 2019).
-
(b)
Data Pre-processing: It is the crucial step that involves cleaning, transformation, and preparation of collected data into a format suitable for real analysis and model training. This phase directly influences the accuracy and reliability of the learning models considered under study. Various AI models employ one or combination of different techniques as stated below to get the data standardized according to the AI model. Few data pre-processing techniques used are as follows:
-
(i)
Removing Duplicates: The process of finding and removing records or entries that are identical or extremely similar inside a dataset is known as "removing duplicates from a dataset." This often entails comparing one or more dataset characteristics (columns) to determine if they have the same values. Programming languages and libraries like Python with Pandas, SQL for database operations, or specialised data cleaning tools can all be used to achieve duplicate removal.
-
(ii)
Fix Structural Errors: Errors in the basic structure or format of the data that make it unusable for the intended analysis or modelling are known as structural errors. It ensures that every column contains data of the same kind and transforms data types as needed. For example, changing text data into numerical or category representations. It also standardises the formatting across the whole dataset. Verifying that the column names and content match the intended structure is also checked in this process.
-
(iii)
Handle Outliers: Managing outliers in a dataset to keep them from negatively impacting statistical research or machine learning models is an essential component of data pre-processing. Statistical approaches, data visualisation, or domain expertise are employed to identify data points that exhibit significant discrepancies from the overall trend. By employing data transformation techniques like logarithmic or square root transformations, the influence of extreme values can be avoided by making the data less sensitive to outliers. The mathematical formula for logarithmic and square root transformation is presented in Eqs. 1 and 2 respectively.
$$y = \frac{{\log_{10} x}}{\ln x}$$(1)$$y = \sqrt x$$(2)
-
(i)

Methodology for detection of gynaecological cancer using AI techniques
Where x represents the original data point and y represent the transformed value.
-
(iv)
Type Conversion: Type conversion is an important aspect of data pre-processing when working with datasets that contain a variety of data types or when preparing data for analysis or modelling. Employing one or a combination of these techniques can help ensuring data integrity and accomplishment of planned tasks related to data analysis or machine learning. Convert columns to the proper types, including text-to-number conversion, date-and-time data handling, numerical category encoding (e.g., one-hot encoding), and uniformity scaling of numerical features are some of the examples of application of this technique.
-
(v)
Dealing with missing value: There are two main methods for handling missing values in a dataset: removal and filling. The removal strategy involves removing from the dataset any rows or columns that have missing values. This method works best with huge datasets when the overall amount of data lost is negligible when a relatively small number of rows or columns with missing data are removed. The filling approach entails substituting estimated or imputed values for missing values using statistical approaches, such as mean, median, mode, or more sophisticated imputation procedures. When the dataset is modestly sized and the information lost from eliminating data would be substantial, this method is preferred.
-
(vi)
Feature Scaling: The method of feature scaling entails converting numerical features into a standard range or distribution to make sure they all contribute equally to learning or analysis. Typical feature scaling methods employed are as follows:
-
Min–Max Scaling: This technique scales the features in the range of 0 to 1, while maintaining the relative relationships between the data points (Amorim et al. 2023). The min–max scaling is calculated using the following Eq. 3.
$$X_{sc} = \frac{{X - X_{min} }}{{X_{max} - X_{min} }}$$(3)where \({X}_{sc}\) is the scaled valued, \(X\) is the original value and \({X}_{min}\) and \({X}_{max}\) represents the minimum and maximum value of the feature in the dataset.
-
Standardization (Z-score scaling): Standardization adjusts features to possess a mean of 0 and a standard deviation of 1, enhancing the data's compatibility with algorithms that assume a Gaussian distribution (Amorim et al. 2023). The standardisation formula is expressed mathematically as follows in Eq. 4:
$$Z = \frac{X - \mu }{\sigma }$$(4)where Z stands for the scaled valued, \(\mu\) stands for mean and \(\sigma\) stands for standard deviation.
-
Normalization: Normalization scales features to have a Euclidean norm of 1. It is frequently employed in algorithms like k-nearest neighbours that rely on distance measures (Aksu et al. 2019). The Normalisation formula is as follows in Eq. 5:
$$X_{norm} = {X \mathord{\left/ {\vphantom {X {X_{2} }}} \right. \kern-0pt} {X_{2} }}$$(5)where \({X}_{norm}\) is the normalized feature value, \(X\) is the original value and \({\Vert X\Vert }_{2}\) is the L2 norm of the feature vector, calculated as \(\sqrt{{\sum }_{i=1}^{n}{X}_{i}^{2}}\), where n is the number of elements.
-
-
(vii)
Data Encoding: Data encoding involves converting text, categorical variables, and other non-numeric data into a numerical format, enabling ML algorithms to process and analyze the information effectively. Label encoding, One-Hot Encoding (Hackeling 2017), Binary Encoding, Count Encoding (Avati et al. 2017), etc. are some of the commonly used data encoding methods.
-
(c)
Feature Selection/Extraction: Feature selection (FS) is referred to as the method of choosing an efficient subset of features from the given set of features (Guyon and Elisseeff 2003; Weston et al. 2000) while maintaining the integrity of the dataset. Various feature selection methods used are:
-
(i)
Chi-Square Method: It is a statistical technique used for feature selection. It assesses the relationship between categorical variables in a dataset. The Eq. 6 for calculating Chi Square is:
$$\chi_{c}^{2} = \sum \frac{{\left( {O_{i} - E_{i} } \right)^{2} }}{{E_{i} }}$$(6)where c denotes degree of freedom, Oi refers to observed value and Ei is expected value. High value denotes that the independence hypothesis is false, while low value denotes that it is true (Vikas and Kaur 2021).
-
(ii)
Lasso Regression: The LASSO approach uses a shrinkage (regularisation) procedure to carry out regularisation and feature selection (Mohammed et al. 2021; Ai 2022). The penalty term, or L1 regularisation, is added to the cost function in lasso regression and represents the absolute sum of the coefficient values. The lasso cost function that needs to be reduced is presented in Eq. 7:
$$J\left( \beta \right) = Least\, Square \,Loss + \lambda \mathop \sum \limits_{i = 1}^{p} \left| {\beta_{i} } \right|$$(7)where \(J\left(\beta \right)\) is the cost to be minimized, more feature selection results from a greater value of the regularisation parameter, \(\lambda\), which regulates the severity of the penalty and coefficient of predictor variable is represented by \({\beta }_{i}.\)
-
(iii)
(iii) Principal Component Analysis (PCA): PCA is a statistical method employed for minimizing the dimensionality of dataset while preserving its principal components (Wold et al. 1987; Greenacre et al. 2022). To accomplish this, it projects high-dimensional data into a new subspace with fewer dimensions by determining the directions of highest variance. The new subspace defined by the set of orthogonal vectors is called as principal components. The principal components are calculated using the following Eq. 8.
$$Projected\, Data = X^{*} .V$$(8)where V is the matrix formed by stacking the selected eigenvectors as columns and \({X}^{*}\) is the centred value of variable, calculated for each variable as given in Eq. 9.
-
(i)
-
(d)
Data Splitting: To forecast the presence or advancement of cancer, a variety of characteristics (such as genetic markers, imaging data, and patient history) are analyzed to look for patterns. Splitting data properly ensures that the model's efficacy is evaluated on notional data, demonstrating how well the model could be extrapolated to new patient instances. Data Splitting helps prevent overfitting so that the prediction model captures the meaningful patterns rather than memorizing the training data. Various methods that can be applied for data splitting are as follows:
-
(i)
Train-Test Split: The most common splitting pattern used in the prediction model is train-test splitting where a specified percentage is kept for training and the other part is reserved for testing. Most used ratios are 70:30 or 80:20.
-
(ii)
Stratified Splitting: Stratified splitting ensures that the proportions of classes remain consistent across the splits to maintain representation which is important for cancer prediction as it can take care of all possible cases as defined in the study (Prusty et al. 2022).
-
(iii)
K-fold Cross-Validation: The dataset is partitioned into 'k' folds, or subsets. The model is evaluated on the remaining fold after being trained on 'k-1' folds 'k' times (Chakradeo et al. 2019; Mahesh et al. 2022). This guarantees comprehensive examination and lowers variability in the assessment of model performance.
-
(iv)
Nested Cross-Validation: The inner loop is used for training of hyperparameters whereas the outer loop is used for model evaluation (Zhong et al. 2023). This method works well for large-scale hyperparameter optimization or for limited datasets.
-
(i)
-
(e)
Model Selection and Prediction: The precise diagnosis and prognosis of cancer depend not only on the careful selection of strong predictive models but also on a sophisticated analysis of a variety of patient data. These models are extremely useful tools that predict the existence or advancement of cancer by using complex patterns found in genetic markers, imaging data, and clinical characteristics. The appropriate model is crucial for risk assessment, which enables tailored interventions. It also helps with early identification, improving treatment efficacy and patient survival rates. Support Vector Machine (Wu and Zhou 2017; Deng et al. 2018; Al Mudawi and Alazeb 2022), Logistic Regression (Laios et al. 2020; Stark et al. 2019), Decision Tree (Tanimu et al. 2021; Akter et al. 2021; Asadi et al. 2020; Alam et al. 2019), Random Forest (Al Mudawi and Alazeb 2022; Tanimu et al. 2021), Neural Networks (Ghoneim et al. 2020; Hussain et al. 2020; Chandran, et al. 2021; Khamparia et al. 2021), ADABoost (Sharma 2019), XGBoost (Akter et al. 2021; Kucukakcali et al. 2023; Hsiao et al. 2021; Jha et al. 2021), K-Nearest Neighbour (Laios et al. 2020; Wibowo et al. 2021; Karamti et al. 2023; Chen et al. 2023), Naïve Bayes (Kruczkowski et al. 2022b; Setiawan et al. 2021) are some of the models used by the researchers for identification and prediction of gynaecological cancer. A good model can be built by utilizing the best features and considering the limitations of these models.
-
(f)
Model Evaluation: Finally, the performance and effectiveness of predictive/classification model is accessed for understanding how well the model performs its intended task. Several metrics and techniques have been developed to evaluate the proposed models. Few common metrics that are used to evaluate the ML/DL models for cancer detection and prediction is presented in Table 2.
5 Related work
Researchers are embarking on a journey to effectively utilise artificial intelligence to tackle the problems caused by gynaecological cancer, hoping to provide precise and timely diagnoses, optimising treatment regimens, while improving patient outcomes. They are doing this by leveraging the power of DL and ML techniques. The work of few researchers in various areas of gynaecological cancer is discussed here.
5.1 Advancing machine learning models for gynaecological cancer prediction
Globally, cervical cancer is a common gynaecological malignancy, and early detection is essential to reduce the disease's burden. Utilising a voting technique, a data rectification mechanism, and a gene-assistance module, the research proposed by Lu et al. (2020) proposes a novel ensemble approach to forecast the possibility of cervical cancer. Five classifiers i.e., LR, SVM, KNN, MLP and DT are used as the base classifiers for two class classification. The voting strategy works as follows:
where, \({f}_{i}(x)\) indicates the base classifier which gives probability of each class i.e., \({f}_{i}(x)=({p}_{1}, {p}_{2})\) for binary classification and T represents the threshold. Multiple evaluations reveal that the voting system accurately forecasts the likelihood of cervical cancer, making it more scalable and useful. Another study by Jahan et al. (2021) focused on combining feature selection techniques i.e., Random Forest, SelectBest, and Chi-square to select top features on eight classification algorithms, namely Decision Tree, Gradient Boosting, Multilayer Perceptron (MLP), k-NN, Random Forest, SVC, LR, and AdaBoost. On several top feature sets, MLP beat rest of classification models, whereas Decision Tree had the lowest rate. MLP achieved the maximum accuracy accounting to 98.10% on the top 30 and 98.00% accuracy on the top 15. The error rate of weak models is evaluated using following Eq. 12.
A machine learning method is being used by Sun et al. (2017) to analyse Pap smear cervical cell pictures, with a random forest classifier with ReliefF (Robnik-Šikonja and Kononenko 2003) feature selection being applied. The Herlev data set was employed in the study, which classified 917 Pap smear pictures as normal or abnormal. The findings showed that the RF classifier has the maximum performance with top 13 characteristics, with an accuracy of 94.44% and an AUC value of 0.9804. The research also verified the utility of cytoplasm characteristics in categorization. Another study proposed by Nithya and Ilango (2019) analysed the risk factors and developed a feature selection model using ML techniques in R. For predicting cervical cancer, the model employs the C5.0, RF, RPART, KNN, and SVM algorithms. Various feature selection techniques explored in the present study are Boruta algorithm, Recursive Feature Elimination (RFE), simulated annealing, and feature selection with ML algorithms. According to the findings, C5.0 and random forest classifiers are effective at spotting women who are exhibiting clinical indications of cervical cancer.
The study done by Al Mudawi and Alazeb (2022) investigates the use of ML and DL in predicting cervical cancer, with the goal of early detection and prevention. Various classic machine learning techniques are compared, with Gradient boosting, DT, RF and adaptive boosting methods achieving the highest accuracy. The support vector machine performed exceptionally as well, achieving 99% accuracy. A survey of Saudi Arabian participants is also conducted as part of the project to measure their views on computer-assisted cervical cancer prediction. Five ML classification algorithms such as DT, RF, LR, MLP, and NB were utilised by Devi et al. (2023) to analyse the unbalanced input and target datasets. The results showed that the LR and DT algorithms performed the finest for discovering relevant predictors. ML classification algorithms were employed by Asadi et al. (2020) in his study. Data from 145 Iranian patients were analysed, and algorithms such as SVM, RBF, MLP, C&R tree, and QUEST were evaluated. Personal health, marital status, education, contraception, and caesarean deliveries were crucial predictors. Decision Tree algorithms were excellent in predicting key indicators for cervical cancer, showing the potential of ML in refining prediction and prevention efforts.
The study proposed by Priya and Karthikeyan (2020) utilized a Synthetic Minority Oversampling Technique (SMOTE) for improving accuracy in data pre-processing phase. The Eq. 13 is used to perform data oversampling through SMOTE.
"\({X}_{knn}\)" represents the k nearest neighbour of x, determined by computing Euclidean distance of "\({X}_{i}\)" and every other sample in class set A. The sampling rate "S" is determined based on the number of samples needed to balance the dataset. For each X in A, synthetic samples X1, X2, …, Xs are created, resulting in the final set A1. To eliminate irrelevant attributes, a filter-based feature selection approach is employed, followed by genetic-based feature selection to identify the best optimal features. The model is predicted using a Linear Support Vector Machine (SVM) classifier, which has an accuracy of 93.82%. DL method backpropagation is employed for classification, increasing accuracy to 97.25%. The output function of the deep learning model for n nodes in layer m is computed as follows in Eq. 14.
Some studies diagnosed the recurrence of cervical cancer. For instance, advanced machine learning methods are used in the study conducted by Tseng et al. (2014) to discover critical recurrence factors in cervical cancer. The C5.0 model emphasises critical prognostic markers, recommending randomised trials and enhanced post-treatment surveillance for better outcomes.
Three feature transformation algorithms i.e., log, sine and z-score were utilised on a Kaggle dataset comprising biopsy, cytology, Hinselmann, and Schiller attributes by Ali (2021). Different machine learning algorithms were examined, with Random Tree outperforming for biopsy and cytology, and Random Forest and Instance-Based K-nearest Neighbour excelling Hinselmann and Schiller, respectively. Feature selection techniques were used, demonstrating the study's efficacy in diagnosing cervical cancer in its early stages using clinical data and machine learning. A pertinent study carried out by Akazawa and Hashimoto (2020) has employed 5 ML algorithms to predict the class of ovarian cancer I.e., benign, borderline and malignancy from preoperative examination. 16 features have been derived from the diagnostic results. Highest accuracy of 0.80 is achieved using the XGBoost algorithm.
A study proposed by Lu et al. (2020) analyzed 349 Chinese patients and 49 characteristics such as demographics, blood routine testing, general chemistry, and tumour markers etc. To pick relevant features, a machine learning method MRMR (Minimum Redundancy-Maximum Relevance) proposed by Ding and Peng (2011) was used, and a decision tree model was built. The minimum redundancy condition is calculated using the Eq. 15 as presented below.
where S is the subset of features selected, mutual information function of variable I and variable j is denoted by I(i, j), with h representing the target variable. The mutual information I between variables x and y is computed on their joint probability distribution p(x, y) and their marginal probabilities p(x) and p(y):
The model discovered two key features: Human Epididymis Protein 4 (HE4) (Namini et al. 2021) and Carcinoembryonic Antigen (CEA), which are significant predictors of ovarian cancer. The model surpassed conventional OC prediction approaches, revealing machine learning's promise for predictive modelling of complex disorders.
95 individuals with ovarian cancer and 33 cysts were included in the study led by Chen et al. (2022), along with 79 healthy samples which gathered to about 174 blood samples. The study discovered that Raman spectroscopy of blood was appropriate for classifying patients into three health states: cancer, cyst, and normal. It was discovered that sequential 2-step binary classifications worked better for recognising these samples. The study additionally found that significant aspects for identifying cancer, cyst, and normal instances were provided by emission lines from main metal elements like magnesium, potassium, and sodium. Clinical applications for LIBS and Raman spectroscopies both appeared to be promising. Combining the two methodologies could enhance classification performance, however the ideal combination for improved classification performance should take correlation behaviours across characteristics into account.
In order to predict ovarian cancer recurrence using pathologic status and medical records from the Chung Shan Medical University Hospital Tumour Registry dataset, the study proposed by Tseng et al. (2017) integrates 5 data mining methodologies and ensemble learning. When incorporating specific risk factors as predictors, the integrated C5.0 model performs better at predicting the recurrence of ovarian cancer. The study discovered that the four most important risk variables for ovarian cancer recurrence were age, Pathologic M, Pathologic T and FIGO. The study proposed by Jing et al. (2023) used regression-based statistics and machine learning techniques to create a preoperative prediction model for ovarian lesions in China. Five classifiers were employed in the model: Lasso-Logistics prediction model (LLRM), MLP, KNN, XGB, RF and SVC. While the RFM model was successful in detecting ovarian serous adenocarcinoma and endometriosis cysts, the RF model was successful in predicting malignant and benign ovarian illness.
The study proposed by Erdemoglu et al. (2023) investigated artificial intelligence technologies to assist clinical decision-making and predict the risks of endometrial cancer and endometrial intraepithelial neoplasia in pre- and post-menopausal women. 564 women of various ages who had a history of breast cancer, hypertension, diabetes mellitus, menopause, obesity, endometrial thickness, and premenopausal irregular bleeding were included in the study. An uneven class distribution was found in the results, and an F1 score indicated the possibility of false positives and negatives. The study had a number of benefits, such as the removal of intra- and interobserver variability and the use of a reference test for every patient. Using the Ensemble technique for Clustering Cancer Data (EACCD) unsupervised technique (Chen et al. 2009), a precision prognostication system was created by Praiss et al. (2020) for endometrial cancer. The system's survival rates ranged between 37.9 and 99.8% and were based on grade, age, and TNM stage. The six highest-ranking survival groups were consolidated into three new prognostic groups as part of a modified EACCD grouping. The method showed enhanced prognostic prediction for patients with endometrial cancer, indicating the potential of machine learning for creating accurate prognostic systems.
According to the study proposed by Farzaneh et al. (2023), AI-based algorithms could be used as a non-invasive screening technique to detect endometrial cancer. With sensitivity and specificity values of 100% and 98% and 98.83% and 98.7%, the logistic regression model performed the best in predicting endometrial cancer. By identifying at-risk patients and implementing preventive measures, the models can be used to lower the likelihood of endometrial cancer. Accessing electronic records and locating medical professionals with artificial intelligence expertise are challenges for the study.
The study proposed by Stanzione et al. (2021) assessed a deep myometrial invasion (DMI) detection machine learning algorithm for endometrial cancer patients. The model produced an accuracy of 86% and 91% using feature extraction from preoperative MRI data. When employing ML, radiologist's performance rises from 82 to 100%. The study demonstrated the viability of an ML model powered by radiomics for DMI identification on MR T2-w images, potentially assisting radiologists in performing their jobs more effectively. Zhu et al. (2021) suggested a new computerised technique that focuses on the corpus uteri region rather than the tumour location to identify deep myometrial invasion (DMI) on MRI. The approach describes the irregularity of tissue structure within the corpus uteri caused by endometrial cancer (EC) using a geometric feature known as LS. LS is calculated using
Recursive feature elimination is used to automatically extract and select texture features. The ensemble model EPSVM, which is evaluated using leave-one-out cross-validation (LOOCV) (Hsu et al. 2003), is created by combining many probabilistic support vector machines (Probst et al. 2018). The findings demonstrate that EPSVM outperforms widely used classifiers and models that rely just on LS or textural characteristics. The suggested EPSVM can offer more accurate prediction by fusing LS and textural information, supporting radiologists in correctly classifying DMI on MRI. Dong et al. (2020) focused on using deep learning technique on MRI to demonstrate the precision of artificial intelligence (AI) for determining degree of myometrial invasion. 4896 contrast-enhanced T1-weighted images from 72 patients who had been given a surgico-pathological stage I endometrial cancer diagnosis were used to train the AI. Contrast-enhanced T1w (79.2%) had a greater accuracy rate for AI interpretation than T2w (70.8%). The study discovered that patients with concurrent benign leiomyomas or polypoid tumours had a higher likelihood of receiving inaccurate interpretations from AI. Although AI might not be able to completely replace doctors' knowledge, it might be useful for doctors to get a "second opinion" from AI before making important decisions about endometrial cancer.
5.2 Gynaecological cancer prediction using deep learning
CervDetect proposed by Mehmood et al. (2021) is a ground-breaking technology that uses deep learning to assess the risk of malignant cervical cancer. CervDetect accurately predicts cancer risk variables by merging random forest (RF) and shallow neural networks, outperforming previous studies with a remarkable 93.6% accuracy. CervDetect improves detection rates and has the potential for larger medical diagnostic applications by using Pearson correlation for data pre-processing and RF feature selection. Waly et al. (2022) presents an intelligent deep convolutional neural network (IDCNN-CDC) model for detecting and classifying cervical cancer using biomedical pap smear pictures. The Gaussian filter (GF) technique improves data by removing noise, whilst picture segmentation is determined by the Tsallis entropy technique (Lee et al. xxxx) with dragonfly optimisation (TE-DFO) algorithm. The Tsallis entropy is expanded to a non-extensive module utilising a broad entropy formation using numerous fractal concepts as given in Eq. 18:
where k represents the number of likelihoods of the scheme and q reflects the degree of non-extensiveness of the technique known as Tsallis variable or entropic index. The SqueezeNet model collects deep-learned characteristics from pictures, which are then used to detect and categorise cervix cells using the weighted ELM classification model. Herlev University Hospital's Herlev database is utilised for experimental validation. A unique convolutional neural network approach with 94% accuracy was presented by Ziyambe et al. (2023) for predicting and detecting ovarian cancer. This method solves the problems of human expert assessment, such as increased misclassification rates and longer analysis durations. Another study proposed by Christiansen et al. (2021) compared deep neural network (DNN)-based computerised ultrasound picture analysis to subjective assessment (SA) by an ultrasound expert. Based on all photos, an ensemble of three DNNs were employed to evaluate the likelihood of malignancy. DNN ensemble identified tumours as benign or malignant (Ovry-Dx1 model) or as benign, inconclusive, or malignant (Ovry-Dx2 model).
Another study by Gao et al. (2022) aimed to create a sophisticated Deep Convolutional Neural Network (DCNN) model that could automatically assess ultrasound images. On previously processed pelvic ultrasound images, a Dense Convolutional Network with 121 layers (DenseNet-121) (Chauhan et al. 2021) was trained with the goals of enhancing feature propagation, preventing gradient vanishing, and minimising the number of parameters. The Focal Loss approach was used to increase the accuracy of the DCNN model, which produced continuous prediction scores between 0 and 1 for each image. The malignancy score was determined as follows in Eq. 19:
On a study comprising 438 consecutive patients with adnexal lesions on ultrasonography, the diagnostic performance of the DCNN model was compared with that of radiologists. In the internal validation dataset, the DCNN model outperformed the typical diagnostic performance of radiologists with respect to accuracy, sensitivity, and specificity whereas in the external validation dataset it outperformed in terms of accuracy and specificity.
In another study by Wu et al. (2018), ovarian tumours were automatically classified from cytological pictures using DCNN based on AlexNet. Two groups of input data, original picture data and augmented image data, were used to train the DCNN, which consists of five convolutional layers, three max pooling layers, and two full reconnect layers. Using augmented photos as training data, the classification model's accuracy increased from 72.76 to 78.20%. The DCNN can identify most ovarian cancer cells without prior pathology or cryobiology knowledge, as shown by the accuracy of the model trained with enhanced data, which was close to that of a pathologist's diagnosis level. The study suggested by Ravishankar et al. (2023) built an automated ovarian cyst detection system that makes use of ultrasound imagery and machine learning methods. For cyst detection and classification, the system employs features that were retrieved from the images. The system carries out tasks such as feature extraction, feature selection, and classification using a Fuzzy Rule-Based Convolutional Neural Network (FCNN) (Hsu et al. 2020). The system has produced 98.37% accurate results in tests using benchmark datasets. Fuzzy rules can be used to handle incomplete, ambiguous, and uncertain information since they undertake qualitative reasoning to handle uncertainty.
The research, Hong et al. (2021) describes Panoptes, a multi-resolution deep convolutional neural network that uses digitised H&E-stained pathological pictures to predict endometrial cancer histological subtypes, molecular subtypes, and 18 frequent gene alterations. The model performs well on different datasets and generalises effectively, indicating promise for therapeutic use without sequencing. Panoptes employs an InceptionResnet-based CNN architecture (Szegedy et al. 2016) with several resolutions to capture features on H&E slides of varied sizes. Three branches of the architecture process sample from the same location at different resolutions concurrently. The multi-resolution design allows for both large-scale features at the level of the tissue and tiny details at the cellular level of the same region, collecting more detailed properties of the slides. The study examined four distinct Panoptes designs, two varieties of InceptionResnet, and three varieties of Inception, both with and without the clinical feature branch.
Researchers have also worked on the pre-processing techniques to make AI models more effective in predicting the uterine cancer. Hodneland et al. (2021) for the purpose of automatically segmenting tumours in endometrial cancer patients and extracting their volume and textural properties, a convolutional neural network has been built. Based on preoperative pelvic imaging, the network was trained, validated, and tested on a cohort of 139 patients. The algorithm was able to recover tumour volumes at a level comparable to that of a person expert, and it was able to deliver segmentation masks with human agreement comparable to that of a human expert's inter-rater agreement. This strategy is a potentially fruitful way for automatic radiomic tumour profiling and could produce prognostic signals that could lead to more specialised treatment. Another study by Urushibara et al. (2022) examined the accuracy of endometrial cancer diagnosis comparing radiologists and deep learning models using convolutional neural networks (CNN). According to the study, endometrial cancer has a lower contrast effect on CE-T1WI than myometrium, which makes it simpler for radiologists and CNN to detect the presence of cancer. For deep learning investigations of tumour diagnosis, it is crucial to consider the possibility of enhanced diagnostic performance by including alternative sequences and cross-sections. To create the ideal picture settings for deep learning utilising MRI with varied sequences and cross-sections, additional verification using different combinations of images in different locations is required.
A comprehensive representation of the work carried out by various researchers in the field of Gynaecological cancer with the help of AI tools and techniques is presented in Table 3.
6 Discussion
Research Question 1: In which year were most of the gynaecological cancer prediction studies published?
We searched four credible academic databases—PubMed, Web of Science, Scopus, and Google Scholar—with focus on studies published during the years 2017–2023. The databases mentioned above have been searched using the following search terms:
Search Term 1: “Gynaecological Cancer Prediction”.
Search Term 2: “AI for Gynaecological Cancer Prediction”.
Search Term 3: “ML/DL techniques used to predict Gynaecological cancer”.
Search term 4: “Ovarian/Cervical/Uterine/Endocrinal/Vaginal/Vulvar/Fallopian Tube Cancer detection and prediction”.
Search Term 5: “Detection of Female Reproductive Cancer using predictive modelling”.
With all these search terms, various papers have been identified and the papers which make to our research study based on the type and year of study are presented in Fig. 9 below:

Gynaecological cancer paper distribution by year
From the graph presented in Fig. 9, it is evident that maximum research work for identification and prediction of various types of gynaecological cancers have been published during the year 2021 and 2022 whereas in the year 2018 least number of papers on gynaecological study have been published. It is also evident from the graph that with each passing year more emphasis has been laid on the development of AI models for gynaecological cancer detection and prediction as they have yielded good accuracy in identifying this deadly disease at an early stage. Early detection is crucial for saving valuable life of the patients suffering from these types of life-threating diseases.
Research Question 2: What are the challenges faced by researchers in constructing AI-based gynaecological cancer prediction models?
For improving early detection, diagnosis, and treatment of gynaecological cancer, the incorporation of artificial intelligence (AI) into research and clinical practise is extremely promising. However, it has become clear through a comprehensive analysis of research papers and studies in this area that developing AI-based gynaecological cancer prediction models poses various complex difficulties. To realise the potential of AI in enhancing gynaecological cancer care, these issues must be resolved. Here, we list some of the major issues that have been repeatedly raised in the literature and serve as the main subject of this study.
-
(i)
Imbalanced Data: Many researchers have highlighted the pervasive problem of class imbalance in gynaecological cancer datasets, which results in biased model performance and decreased sensitivity in detecting cancer patients (Devi et al. 2023; Tseng et al. May 2017; Waly et al. 2022; Tanimu et al. 2022; Kaushik, et al. 2022).
-
(ii)
Resource Constraint: Limited budget, resources for computing, and experience are the constraints that affect the performance of AI model for prediction and detection of gynaecological cancer. Model development is hampered in smaller healthcare facilities by a lack of specialised equipment and diverse teams. Securing research funding, adhering to healthcare standards, and acquiring and maintaining a varied, high-quality dataset collection are difficult challenges. Cloud computing, data sharing efforts, open-source software, and collaboration with academic institutes can all provide cost-effective solutions to these problems (Akter et al. 2021; Lu et al. 2020; Lu et al. 2020; Jing et al. 2023; Urushibara et al. 2022; Sorayaie Azar et al. 2022; Elhoseny et al. 2019).
-
(iii)
Data Heterogeneity: Integrating and preparing data from several sources, such as medical records, imaging, and genetic data, can be challenging because the formats and quality of the data may vary (Asadi et al. 2020; Lu et al. 2020; Christiansen et al. 2021; Gonzalez-Bosquet et al. 2022).
-
(iv)
Clinical Validation: A crucial but challenging task in developing AI-based gynaecological cancer prediction models is clinical validation. To assure dependability and relevance, it entails meticulously testing and assessing model performance in actual healthcare settings. Clinical validation requires collaboration from healthcare experts, access to clinical facilities, and patient data. Researchers need to address issues such as changes in patient demographics and disease features while also demonstrating the model's efficacy, accuracy, and safety. Effectively bridging the gap between research and clinical practise requires careful planning, data exchange, and collaboration between AI scientists and healthcare providers (Erdemoglu et al. 2023; Ziyambe, et al. 2023; Ravishankar et al. 2023; Sorayaie Azar et al. 2022; Chaudhuri et al. 2021).
Data Accessibility and Quality: Data fragmentation and privacy problems might make it difficult to access extensive, varied, and well-curated datasets from different healthcare systems. For a model to be effective, the quality, accuracy, and relevance of the data must be guaranteed. Predictions can be less accurate when the data is incomplete or noisy. To overcome these obstacles, careful data preparation methods, data privacy laws, and cooperative data-sharing programmes may be necessary. To fully utilise AI in enhancing gynaecological cancer detection and therapy, it is imperative to address data accessibility and quality (Praiss et al. Dec. 2020; Farzaneh et al. 2023; Zhu et al. Jul. 2021; Urushibara et al. Dec. 2022).
Research Question 3: Which gynaecological cancer has a higher mortality rate and is considered more dangerous?
As per the data available from International Agency for Research on Cancer by WHO (Bray et al. 2018), the mortality rate of different types of gynaecological cancer for females around the world is presented in Figs. 10 and 11 below. From the Fig. 10, it is clearly visible that the African sub-continent has the highest mortality rate followed by the Asian and South American continent. The female of all age-groups is considered i.e., females aging between 0 to 85 + . The incidence rate of different gynaecological cancers has also been identified and from Fig. 11, it is evident that the average incidence rate is 55.605, referring that in a population of 1,00,000, the new cases which arises is approximately 56. Also, the highest rate is of 105.38 and that too is concentrated in the African sub-continent. European countries like Latvia, Lithuania, and Estonia show moderate to high incidence rates. The incidence rates in the Americas vary widely, with countries like Haiti and Honduras having lower rates, while countries like Barbados and Jamaica have higher rates. The data suggests a need for targeted public health interventions in countries with very high incidence rates to address underlying causes and improve health outcomes. As far as mortality rate is concerned, in 2022, Eswatini in the African continent reported the highest mortality rate at 71.12, while Yemen recorded the lowest mortality rate at 4.41. Sub-Saharan Africa has the highest mortality rates, with Eswatini, Malawi, Zimbabwe, and Zambia topping the list. Middle Eastern countries like Yemen and Saudi Arabia, along with East Asian countries like South Korea and Iran, have notably low mortality rates. Developed countries in Europe such as Switzerland, and some in the Middle East like Bahrain and Qatar, also have low mortality rates. Some relatively developed countries have higher-than-expected mortality rates, such as the Bahamas (28.05) and Guyana (20.68). Conversely, some developing countries show lower mortality rates, such as Yemen (4.41).

Region wise estimated mortality rate (World) in 2022, females (Bray et al. Nov. 2018)

Region wise estimated incidence rates (World) in 2022, females (Bray et al. Nov. 2018)
Figure 12 represents the incidence and mortality rates of different types of gynaecological cancers i.e., cervical, uterine, ovary, vulva, and vaginal cancers. It is evident from the figure, that cervical cancer tops the incidence rate followed by uterine and ovary cancer in terms of incidence rate. Whereas, the mortality rate of ovarian cancer is higher as compared to the uterine cancer. Cervical cancer has the highest mortality and incidence rate as per data of WHO as presented in Fig. 13 (Bray et al. 2018).

Estimated age-standardized incidence and mortality rates (World) in 2022, World, females

New cases of gynaecological cancer (2022)
The data for the number of new cases and the number of deaths by the gynaecological cancer suggest that cervical cancer causes maximum deaths accounting to a total of 54% among all gynaecological cancers followed by the ovarian cancer with 32% death rate as presented in Fig. 14. Cervical, Uterine and Ovarian cancer are the top three cancers among gynaecological cancers to report new cases every year with 45%, 22% and 29% new cases. Uterine cancer has a relatively low death rate as compared to cervical and ovarian cancer whereas vulvar and vaginal cancer have very low presence on both the number of new cases and deaths. However, vaginal, and vulvar cancers have very low occurrence rates of 3% and 1% respectively and 3% and 0% death rate as of data of 2022. Fallopian tube cancer is a very rare gynaecological cancer and as of the data of 2022 suggests it has no presence in the gynaecological cancer category.

Death rate of gynaecological cancer (2022)
Research Question 4: What are the most suitable features and representations to extract from medical imaging data (e.g., MRI, ultrasound, Pap smear images) for effective gynaecological cancer detection using AI algorithms?
Gynaecological cancer detection that is both accurate and efficient is crucial for women's healthcare since early diagnosis considerably enhances patient outcomes. The use of medical imaging techniques such as Pap smears, MRIs, and ultrasounds is crucial for the study. However, manual interpretation of these images is time-consuming and subject to variability. Feature extraction and representation are crucial for effective AI based prediction modelling for gynaecological cancer detection. Features are crucial traits extracted from medical images that allow algorithms to distinguish between malignant and benign tissues. It is crucial to choose the right characteristics since they should record essential details regarding texture, shape, and intensity. Based on the study as depicted in Fig. 15, it is evident that demographic data has been used widely for detection of cancer followed by pap smear tests. Ultrasound imaging is used for ovarian and uterine cancer detection. Whereas MRI are only used for detection of uterine cancer. The study also suggests that good quality Pap smear images can be of utmost importance for accurate prediction and detection of these types of cancers.

Diagnostics used for different gynaecological cancers
7 Addressing challenges: potential solutions
In this section, we present the potential solutions and recommendations to the challenges faced by the researchers in constructing AI-based gynaecological cancer prediction models. The identified issues can be overcome by adopting some of these solutions/recommendations.
7.1 Imbalanced data
Solution: Data Augmentation Techniques such as SMOTE (Ijaz et al. 2020; Karamti, et al. 2023), GANs (Ojo and Zahid 2023) etc. combined with algorithmic strategies could help in creating a more balanced dataset, enhancing the sensitivity of the AI models.
7.2 Resource constraint
Solution: To overcome the challenge of resource constraint, several strategies can be employed. Leveraging pre-trained models (Karani et al. 2022) and utilizing cloud-based AI services and platforms (Xue et al. 2022) can enhance scalability and computational efficiency. Employing open-source AI frameworks and software can streamline model development (Tan et al. 2021). Encouraging data sharing initiatives and partnerships can facilitate access to diverse datasets. Additionally, pursuing grants and fundings can reduce the financial burden, enabling broader innovation in AI-driven gynaecological cancer prediction models.
7.3 Data heterogeneity
Solution: Due to varying formats and quality, integrating data from different sources such as genetic, demographic, imaging, and pathological can be very challenging. Standardizing data formats and adopting data integration platforms can streamline this process (Xue et al. 2022; Shrestha et al. 2022). Robust pre-processing techniques (Mehmood et al. 2021) are essential to clean, normalize, and harmonize data from multiple sources, in order to ensure consistency and reliability.
7.4 Clinical validation
Solution: To enhance model’s acceptability and accuracy, it is crucial that AI models are clinically validated for their implementation in real world scenario. AI researchers and healthcare professionals must work together to make sure that the proposed models meet clinical needs and standards (Xue et al. 2022). The safety, efficacy, and long-term adaptability of AI models can be assured by following mandatory standards for clinical studies and continuous model monitoring.
7.5 Data accessibility and quality
Solution: Quality of data and access to the data is one of the major challenges faced by AI researchers as quality of data is of utmost importance while designing the AI models. Factors like privacy and data fragmentation often make it difficult to ensure access to big, diversified, and well-curated databases. Respecting ethical standards and data privacy regulations is essential for safeguarding patient information. Engaging in collaborative data-sharing initiatives promotes data exchange and improves institutional access to high-quality datasets.
8 Limitations
Although the study aimed to provide a detailed systematic review of the AI based models for early detection and prevention of gynaecological cancers but the study suffers from the following limitations:
(i) Research coverage: Most of the papers presented in the current study predominantly focuses on cervical, ovarian, and endometrial cancers as there is a notable paucity of studies on fallopian tube, vaginal and vulvar cancer papers. This disparity highlights the significant gap in the literature and underscores the need for more comprehensive studies encompassing all gynaecological cancers.
(ii) Data variability: It has also been identified that different researchers use different sets of data for training of models like some studies rely on MRI, Pap smears, and Ultrasounds images, while some models are dependent on the demographic, genetic and pathological data, leading to heterogeneous results. This poses a challenge in replicating and validating study findings, thereby affecting the reliability and generalizability of AI models for prediction and prognosis of gynaecological cancer.
(iii) Data dependence and standardization: The performance of AI models is dependent on the quality and quantity of the data available for training sets. However, it has been recognized during the study that no standard datasets are available, leading to inconsistencies and variations in the research outcomes.
9 Conclusion and future directions
93 studies between the year 2013–2023 were chosen from three digital libraries that can be accessed online and four questions were investigated in this study. The paper underscores the pivotal role of AI techniques in the early detection and prediction of gynaecological cancers. By analysing a range of research and techniques, we have elucidated the noteworthy advancements achieved in utilising AI to enhance diagnostic precision and prognosis skills in diverse imaging modalities (MRI, pap smear, Ultrasound, etc.). Our review's insights like 54% deaths are alone contributed by cervical cancer with 45% new cases followed by ovarian cancer whose death rate accounts to 32% emphasise the value of early identification and prediction in reducing the toll that gynaecological malignancies take on women's health. Our research also identifies several challenges and restrictions that researchers must overcome to create and apply AI-based methods for the identification of gynaecological cancer. These include problems with data quality, interpretability of models, ethical quandaries, and inadequate access to resources for healthcare and technology. It is essential that stakeholders involved in the healthcare system collaborate in order to proactively and constructively address these issues going forward. Through research funding, interdisciplinary teamwork, data sharing, and standardisation initiatives, we could potentially accelerate the rate at which AI advancements are applied in healthcare settings. The review highlights how AI has the potential to revolutionise the treatment of gynaecological cancers.
Future research should focus on broadening the scope of study in order to include the vaginal and vulvar cancers also. Collaborative efforts to create high quality datasets should be worked upon for improvising standardization of data. Frameworks should be developed for continuous monitoring and updating of AI moles to ensure accuracy and relevance of designed AI models. Interpretable AI models like explainable AI (XAI) should be developed for increasing the transparency of AI decision-making process for building trust among healthcare professionals and patients. We may work towards a future where all women have access to prompt and efficient interventions, thereby lowering the incidence of gynaecological cancers and enhancing the health of women everywhere by utilising technology and group effort.
Data availability
No datasets were generated or analysed during the current study.
References
Ai C (2022) A method for cancer genomics feature selection based on LASSO-RFE. Iran J Sci Technol Trans A 46(3):731–738
Akazawa M, Hashimoto K (2020) Artificial intelligence in ovarian cancer diagnosis. Anticancer Res 40(8):4795–4800
Aksu G, Güzeller CO, Eser MT (2019) The effect of the normalization method used in different sample sizes on the success of artificial neural network model. Int J Assess Tools Educ 6(2):170–192
Akter L, Ferdib-Al-Islam MM, Al-Rakhami MS, Haque MR (2021) Prediction of cervical cancer from behavior risk using machine learning techniques. SN Comput Sci 2(3):1–10
Al Mudawi N, Alazeb A (2022) A model for predicting cervical cancer using machine learning algorithms. Sensors (basel) 22(11):4132
Alam TM, Milhan M, Khan A, Iqbal MA, Wahab A, Mushtaq M (2019) Cervical cancer prediction through different screening methods using data mining. Int J Adv Comput Sci Appl 10(2)
Ali MM et al (2021) Machine learning-based statistical analysis for early stage detection of cervical cancer. Comput Biol Med 139:104985
Alkatout I et al (2015) Vulvar cancer: epidemiology, clinical presentation, and management options. Int J Womens Health 7:305–313
Asadi F, Salehnasab C, Ajori L (2020) Supervised algorithms of machine learning for the prediction of cervical cancer. J Biomed Phys Eng 10(4):513–522
Avati A, Jung K, Harman S, Downing L, Ng A, Shah NH (2017) Improving palliative care with deep learning. In: International conference on bioinformatics and biomedicine (BIBM), pp 311–316
Azar AS et al (2022) Application of machine learning techniques for predicting survival in ovarian cancer. BMC Med Inform Decis Mak 22(1):345
Barragán-Montero A et al (2021) Artificial intelligence and machine learning for medical imaging: a technology review. Phys Medica 83:242–256
Berek JS, Kehoe ST, Kumar L, Friedlander M (2018) Cancer of the ovary, fallopian tube, and peritoneum. Int J Gynaecol Obstet 143(Suppl 2):59–78
Bray F, Ferlay J, Soerjomataram I, Siegel RL, Torre LA, Jemal A (2018) Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin 68(6):394–424
Brett AD, Brown JK (2015) Quantitative computed tomography and opportunistic bone density screening by dual use of computed tomography scans. J Orthop Transl 3(4):178
Cervix uteri cancer. https://platform.who.int/mortality/themes/theme-details/topics/indicator-groups/indicator-group-details/MDB/cervix-uteri-cancer. Accessed 18 Jan 2024
Ch N, Sai PP, Madhuri G, Reddy KS, Reddy DVB (2022) Artificial intelligence based cervical cancer risk prediction using M1 algorithms. In: 2022 international conference on emerging smart computing and informatics (ESCI 2022)
Chakradeo K, Vyawahare S, Pawar P (2019) Breast cancer recurrence prediction using machine learning. In: 2019 IEEE conference on information & communication technologies (CICT 2019)
Chandran V et al (2021) Diagnosis of cervical cancer based on ensemble deep learning network using colposcopy images. Biomed Res Int. https://doi.org/10.1155/2021/5584004
Chaudhuri AK, Ray A, Banerjee DK, Das A (2021) A multi-stage approach combining feature selection with machine learning techniques for higher prediction reliability and accuracy in cervical cancer diagnosis. Int J Intell Syst Appl 13(5):46–63
Chauhan T, Palivela H, Tiwari S (2021) Optimization and fine-tuning of DenseNet model for classification of COVID-19 cases in medical imaging. Int J Inf Manag Data Insights 1(2):100020
Chen D, Xing K, Henson D, Sheng L, Schwartz AM, Cheng X (2009) Developing prognostic systems of cancer patients by ensemble clustering. J Biomed Biotechnol 2009:632786
Chen F et al (2022) Screening ovarian cancers with Raman spectroscopy of blood plasma coupled with machine learning data processing. Spectrochim Acta Part A 265:120355
Chen X et al (2023) Cervical cancer detection using K nearest neighbor imputer and stacked ensemble learningmodel. DIGIT Health. https://doi.org/10.1177/20552076231203802
Christiansen F, Epstein EL, Smedberg E, Åkerlund M, Smith K, Epstein E (2021) Ultrasound image analysis using deep neural networks for discriminating between benign and malignant ovarian tumors: comparison with expert subjective assessment. Ultrasound Obstet Gynecol 57(1):155–163
Corpus uteri cancer. https://platform.who.int/mortality/themes/theme-details/topics/indicator-groups/indicator-group-details/MDB/corpus-uteri-cancer. Accessed 18 Jan 2024
Currie G, Hawk KE, Rohren E, Vial A, Klein R (2019) Machine learning and deep learning in medical imaging: intelligent imaging. J Med Imaging Radiat Sci 50(4):477–487
de Amorim LBV, Cavalcanti GDC, Cruz RMO (2023) The choice of scaling technique matters for classification performance. Appl Soft Comput 133:109924
Deng X, Luo Y, Wang C (2019) Analysis of risk factors for cervical cancer based on machine learning methods. In: Proceedings of 2018 5th IEEE international conference on cloud computing and intelligence systems (CCIS 2018), pp 631–635
Devi S, Gaikwad SR, Harikrishnan R (2023) Prediction and detection of cervical malignancy using machine learning models. Asian Pac J Cancer Prev 24(4):1419–1433
Ding C, Peng H (2011) Minimum redundancy feature selection from microarray gene expression data. J Bioinform Comput Biol 3(2):185–205
Dong HC, Dong HK, Yu MH, Lin YH, Chang CC (2020) Using deep learning with convolutional neural network approach to identify the invasion depth of endometrial cancer in myometrium using MR images: a pilot study. Int J Environ Res Public Health 17(16):1–18
Elhoseny M, Bian GB, Lakshmanaprabu SK, Shankar K, Singh AK, Wu W (2019) Effective features to classify ovarian cancer data in internet of medical things. Comput Netw 159:147–156
Erdemoglu E et al (2023) Artificial intelligence for prediction of endometrial intraepithelial neoplasia and endometrial cancer risks in pre- and postmenopausal women. AJOG Glob Rep 3(1):100154
Farzaneh F et al (2023) Endometrial cancer in women with abnormal uterine bleeding: data mining classification methods. Casp J Int Med 14(3):526
Filippova OT, Leitao MM (2020) The current clinical approach to newly diagnosed uterine cancer. Expert Rev Anticancer Ther 20(7):581–590
Gao Y et al (2022) Deep learning-enabled pelvic ultrasound images for accurate diagnosis of ovarian cancer in China: a retrospective, multicentre, diagnostic study. Lancet Digit Heal 4(3):e179–e187
Ghoneim A, Muhammad G, Hossain MS (2020) Cervical cancer classification using convolutional neural networks and extreme learning machines. Futur Gener Comput Syst 102:643–649
Gonzalez-Bosquet J et al (2022) Using genomic variation to distinguish ovarian high-grade serous carcinoma from benign fallopian tubes. Int J Mol Sci 23(23):14814
Greenacre M, Groenen PJF, Hastie T, Denza AI, Markos A, Tuzhilina E (2022) Principal component analysis. Nat Rev Methods Prim 2(1):1–21
Günther V et al (2012) Malignant melanoma of the urethra: a rare histologic subdivision of vulvar cancer with a poor prognosis. Case Rep Obstet Gynecol 2012:1–6
Guyon I, Elisseeff A (2003) An introduction to variable and feature selection. J Mach Learn Res 3:1157–1182
Hackeling G (2017) Mastering machine learning with scikit-learn, 2nd edn. Packt Publishing, Birmingham
Hodneland E et al (2021) Automated segmentation of endometrial cancer on MR images using deep learning. Sci Rep 11(1):1–8
Hong R, Liu W, DeLair D, Razavian N, Fenyö D (2021) Predicting endometrial cancer subtypes and molecular features from histopathology images using multi-resolution deep learning models. Cell Rep Med 2(9):100400
Hsiao YW, Tao CL, Chuang EY, Lu TP (2021) A risk prediction model of gene signatures in ovarian cancer through bagging of GA-XGBoost models. J Adv Res 30:113–122
Hsu C-W, Chang C-C, Lin C-J (2003) A practical guide to support vector classification. 1396–1400
Hsu MJ, Chien YH, Wang WY, Hsu CC (2020) A convolutional fuzzy neural network architecture for object classification with small training database. Int J Fuzzy Syst 22(1):1–10
Hussain E, Mahanta LB, Das CR, Talukdar RK (2020) A comprehensive study on the multi-class cervical cancer diagnostic prediction on pap smear images using a fusion-based decision from ensemble deep convolutional neural network. Tissue Cell 65:101347
Ijaz MF, Attique M, Son Y (2020) Data-driven cervical cancer prediction model with outlier detection and over-sampling methods. Sensors 20(10):2809
Jahan S et al (2021) Automated invasive cervical cancer disease detection at early stage through suitable machine learning model. SN Appl Sci 3(10):1–17
Jha M, Gupta R, Saxena R (2021) Cervical cancer risk prediction using XGboost classifier. In: 2021 7th International Conference on Signal Processing and Communications (ICSC) 2021:133–136
Jing B et al (2023) Development of prediction model to estimate future risk of ovarian lesions: a multi-center retrospective study. Prev Med Rep 35:102296
Karamti H et al (2023) Improving prediction of cervical cancer using KNN imputed SMOTE features and multi-model ensemble learning approach. Cancers 15(17):4412
Karani H, Gangurde A, Dhumal G, Gautam W, Hiran S, Marathe A (2022) Comparison of performance of machine learning algorithms for cervical cancer classification. In: 2022 2nd advances in electrical, computing, communication and sustainable technologies (ICAECT 2022)
Kaushik K et al (2022) A machine learning-based framework for the prediction of cervical cancer risk in women. Sustain 14(19):11947
Khamparia A, Gupta D, Rodrigues JJPC, de Albuquerque VHC (2021) DCAVN: cervical cancer prediction and classification using deep convolutional and variational autoencoder network. Multimed Tools Appl 80(20):30399–30415
Kruczkowski M, Drabik-Kruczkowska A, Marciniak A, Tarczewska M, Kosowska M, Szczerska M (2022a) Predictions of cervical cancer identification by photonic method combined with machine learning. Sci Rep 12(1):1–11
Kruczkowski M, Drabik-Kruczkowska A, Marciniak A, Tarczewska M, Kosowska M, Szczerska M (2022b) Predictions of cervical cancer identification by photonic method combined with machine learning. Sci Rep 12(1):1–11
Kucukakcali Z, Ozhan O, Kucukakcali Z, Cicek IB (2023) Machine learning-based ovarian cancer prediction with XGboost and stochastic gradient boosting models. Med Sci 12(1):231–238
Laios A, Gryparis A, Dejong D, Hutson R, Theophilou G, Leach C (2020) Predicting complete cytoreduction for advanced ovarian cancer patients using nearest-neighbor models. J Ovarian Res 13(1):1–8
Lee K, Kim S, Lim S, Choi S, Oh S (2019) Tsallis reinforcement learning: a unified framework for maximum entropy reinforcement learning. arXiv:1902.00137
Levi S (1997) The history of ultrasound in gynecology 1950–1980. Ultrasound Med Biol 23(4):481–552
Lu M et al (2020a) Using machine learning to predict ovarian cancer. Int J Med Inform 141:104195
Lu J, Song E, Ghoneim A, Alrashoud M (2020b) Machine learning for assisting cervical cancer diagnosis: an ensemble approach. Futur Gener Comput Syst 106:199–205
Mahesh TR, Kaladevi AC, Balajee JM, Vivek V, Prabu M, Muthukumaran V (2022) An efficient ensemble method using K-fold cross validation for the early detection of benign and malignant breast cancer. Int J Integr Eng 14(7):204–216
Maheshwari A, Kumar N, Mahantshetty U (2016) Gynecological cancers: a summary of published Indian data. South Asian J Cancer 5(3):112–120
Mehmood M, Rizwan M, Gregusml M, Abbas S (2021) Machine learning assisted cervical cancer detection. Front Public Heal 9:1–14
Mohammed M, Mwambi H, Mboya IB, Elbashir MK, Omolo B (2021) A stacking ensemble deep learning approach to cancer type classification based on TCGA data. Sci Rep 11(1):1–22
Moher D, Liberati A, Tetzlaff J, Altman DG (2009) Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. J Clin Epidemiol 62(10):1006–1012
Namini NM, Abdollahi A, Movahedi M, Razavi AE, Saghiri R (2021) HE4, a new potential tumor marker for early diagnosis and predicting of breast cancer progression. Iran J Pathol 16(3):284
Nithya B, Ilango V (2019) Evaluation of machine learning based optimized feature selection approaches and classification methods for cervical cancer prediction. SN Appl Sci 1(6):1–16
Nyengidiki TK, Nyengidiki TK (2015) Screening methods for gynaecological cancers. Contemp Gynecol Pract. https://doi.org/10.5772/58947
Ojo MO, Zahid A (2023) Improving deep learning classifiers performance via preprocessing and class imbalance approaches in a plant disease detection pipeline. Agron 13(3):887
Ovary cancer. https://platform.who.int/mortality/themes/theme-details/topics/indicator-groups/indicator-group-details/MDB/ovary-cancer. Accessed 18 Jan 2024
Page MJ et al (2021) Updating guidance for reporting systematic reviews: development of the PRISMA 2020 statement. J Clin Epidemiol 134:103–112
Penny SM (2020) Ovarian cancer: an overview. Radiol Technol 91(6):561–575
Pesapane F, Codari M, Sardanelli F (2018) Artificial intelligence in medical imaging: threat or opportunity? Radiologists again at the forefront of innovation in medicine. Eur Radiol Exp 2(1):1–10
Peungjesada S, Bhosale PR, Balachandran A, Iyer RB (2009) Magnetic resonance imaging of endometrial carcinoma. J Comput Assist Tomogr 33(4):601–608
Praiss AM et al (2020) Using machine learning to create prognostic systems for endometrial cancer. Gynecol Oncol 159(3):744–750
Priya S, Karthikeyan NK (2020) A heuristic and ANN based classification model for early screening of cervical cancer. Int J Comput Intell Syst 13(1):1092–1100
Probst P, Boulesteix AL, Bischl B (2018) Tunability: importance of hyperparameters of machine learning algorithms. J Mach Learn Res 20:1–32
Prusty S, Patnaik S, Dash SK (2022) SKCV: stratified K-fold cross-validation on ML classifiers for predicting cervical cancer. Front Nanotechnol 4:972421
Raglan O et al (2019) Risk factors for endometrial cancer: an umbrella review of the literature. Int J Cancer 145(7):1719–1730
Ravishankar TN, Jadhav HM, Kumar NS, Ambala S, Pillai M (2023) A deep learning approach for ovarian cysts detection and classification (OCD-FCNN) using fuzzy convolutional neural network. Meas Sensors 27:100797
Robnik-Šikonja M, Kononenko I (2003) Theoretical and empirical analysis of ReliefF and RReliefF. Mach Learn 53(1–2):23–69
Rooth C (2013) Ovarian cancer: risk factors, treatment and management. Br J Nurs 22(17):S23–S30
Setiawan QS, Rustam Z, Pandelaki J (2021) Comparison of Naive Bayes and support vector machine with grey wolf optimization feature selection for cervical cancer data classification. In: 2021 International Conference on Decision Aid Sciences and Application (DASA) 2021:451–455
Sharma M (2019) Cervical cancer prognosis using genetic algorithm and adaptive boosting approach. Health Technol (berl) 9(5):877–886
Shrestha P et al (2022) A systematic review on the use of artificial intelligence in gynecologic imaging—background, state of the art, and future directions. Gynecol Oncol 166(3):596–605
Stanzione A et al (2021) Deep myometrial infiltration of endometrial cancer on MRI: a radiomics-powered machine learning pilot study. Acad Radiol 28(5):737–744
Stark GF, Hart GR, Nartowt BJ, Deng J (2019) Predicting breast cancer risk using personal health data and machine learning models. PLoS ONE 14(12):e0226765
Sun G, Li S, Cao Y, Lang F (2017) Cervical cancer diagnosis based on random forest. Int J Perform Eng 13(4):446
Szegedy C, Ioffe S, Vanhoucke V, Alemi AA (2016) Inception-v4, inception-ResNet and the impact of residual connections on learning. In: Thirty-First AAAI Conference on Artificial Intelligence 2017:4278–4284
Tak A, Parihar PM, Fatehpuriya DS, Singh Y (2022) Optimised feature selection and cervical cancer prediction using Machine learning classification. Scr Med (brno) 53(3):205–211
Tan X et al (2021) Automatic model for cervical cancer screening based on convolutional neural network: a retrospective, multicohort, multicenter study. Cancer Cell Int 21(1):1–10
Tanimu JJ, Hamada M, Hassan M, Ilu SY (2021) A contemporary machine learning method for accurate prediction of cervical cancer. SHS Web Conf 102:04004
Tanimu JJ, Hamada M, Hassan M, Kakudi H, Abiodun J (2022) A machine learning method for classification of cervical cancer. Electronics 11:463
Taylor AH, Tortolani D, Ayakannu T, Konje JC, Maccarrone M (2020) (Endo)cannabinoids and gynaecological cancers. Cancers 13(1):37
Tseng CJ, Lu CJ, Chang CC, Den Chen G (2014) Application of machine learning to predict the recurrence-proneness for cervical cancer. Neural Comput Appl 24(6):1311–1316
Tseng CJ, Lu CJ, Chang CC, Den Chen G, Cheewakriangkrai C (2017) Integration of data mining classification techniques and ensemble learning to identify risk factors and diagnose ovarian cancer recurrence. Artif Intell Med 78:47–54
Urushibara A et al (2022) The efficacy of deep learning models in the diagnosis of endometrial cancer using MRI: a comparison with radiologists. BMC Med Imaging 22(1):1–14
Vikas, Kaur P (2021) Lung cancer detection using chi-square feature selection and support vector machine algorithm. Int J Adv Trends Comput Sci Eng 10(3):2050–2061
Waly MI, Sikkandar MY, Aboamer MA, Kadry S, Thinnukool O (2022) Optimal deep convolution neural network for cervical cancer diagnosis model. Comput Mater Contin 70(2):3297–3309
Weston J, Mukherjee S, Chapelle O, Pontil M, Poggio T, Vapnik V (2000) Feature selection for SVMs. Adv Neural Inf Process Syst 13
Wibowo VVP, Rustam Z, Hartini S, Maulidina F, Wirasati I, Sadewo W (2021) Ovarian cancer classification using K-nearest neighbor and support vector machine. J Phys Conf Ser 1821(1):012007
Wold S, Esbensen K, Geladi P (1987) Principal component analysis. Chemom Intell Lab Syst 2(1–3):37–52
Wu W, Zhou H (2017) Data-driven diagnosis of cervical cancer with support vector machine-based approaches. IEEE Access 5:25189–25195
Wu M, Yan C, Liu H, Liu Q (2018) Automatic classification of ovarian cancer types from cytological images using deep convolutional neural networks. Biosci Rep 38(3):20180289
Xue P et al (2022) Deep learning in image-based breast and cervical cancer detection: a systematic review and meta-analysis. NPJ Digit Med 5(1):19
Zhong Y, Chalise P, He J (2023) Nested cross-validation with ensemble feature selection and classification model for high-dimensional biological data. Commun Stat 52(1):110–125
Zhu X, Ying J, Yang H, Fu L, Li B, Jiang B (2021) Detection of deep myometrial invasion in endometrial cancer MR imaging based on multi-feature fusion and probabilistic support vector machine ensemble. Comput Biol Med 134:104487
Ziyambe B et al (2023) A deep learning framework for the prediction and diagnosis of ovarian cancer in pre- and post-menopausal women. Diagnostics 13(10):1703
Acknowledgements
This study is supported via funding from Prince Sattam bin Abdulaziz University Project Number (PSAU/2024/R/1445).
Funding
The grant funded by the Korea government (MSIT) through the National Research Foundation of Korea (NRF) (No. 2022R1C1C1004590) provided support for this study.
Author information
Authors and Affiliations
Contributions
Sonam Gandotra, Yogesh Kumar, Nandini Modi: Conceptualization, Methodology, Investigation, Writing-original draft, Writing-review and editing. Jaeyoung Choi, Jana Shafi, Muhammad Fazal Ijaz: Writing-review and editing, Project administration, Funding acquisition. Jaeyoung Choi, Jana Shafi, Muhammad Fazal Ijaz: Writing-review and editing., preparing figures. Sonam Gandotra, Yogesh Kumar, Nandini Modi, Jaeyoung Choi, Jana Shafi, Muhammad Fazal Ijaz: Writing-original draft, Investigation, Supervision. Jaeyoung Choi, Jana Shafi, Muhammad Fazal Ijaz: Writing-review and editing, Supervision. Sonam Gandotra, Yogesh Kumar, Nandini Modi, Jaeyoung Choi, Jana Shafi, Muhammad Fazal Ijaz: Conceptualization, formal analysis.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gandotra, S., Kumar, Y., Modi, N. et al. Comprehensive analysis of artificial intelligence techniques for gynaecological cancer: symptoms identification, prognosis and prediction. Artif Intell Rev 57, 220 (2024). https://doi.org/10.1007/s10462-024-10872-6
Published:
DOI: https://doi.org/10.1007/s10462-024-10872-6