
Abstract
Accurate and rapid disease detection is necessary to manage health problems early. Rapid increases in data amount and dimensionality caused challenges in many disciplines, with the primary issues being high computing costs, memory costs, and low accuracy performance. These issues will arise since Machine Learning (ML) classifiers are mostly used in these fields. However, noisy and irrelevant features have an impact on ML accuracy. Therefore, to choose the best subset of features and decrease the dimensionality of the data, Metaheuristics (MHs) optimization algorithms are applied to Feature Selection (FS) using various modalities of medical imaging or disease datasets with different dimensions. The review starts by giving a general overview of the many approaches to AI algorithms, followed by a general overview of the various MH algorithms for healthcare applications, an analysis of MHs boosted AI for healthcare applications, and using a wide range of research databases as a data source for access to numerous field publications. The final section of this review discusses the problems and challenges facing healthcare application development.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The quadruple objective for healthcare is to enhance population health, patient experience of treatment, caregiver experience, and lower the steadily rising cost of care, which presents considerable challenges to healthcare systems around the world. Governments, payers, regulators, and providers are under pressure to innovate and alter healthcare delivery models as the world’s population ages, the prevalence of chronic diseases increases, and healthcare costs increase. Furthermore, healthcare systems today face the challenge of having to "perform" (provide efficient, high-quality care) and "transform" (improve) care on a scale by integrating real-world data-driven insights into patient care. The global pandemic has intensified this challenge (Davis 2019). Evaluation and treatment of primary diseases and prompt detection of sequelae that develop due to or accompany the basic ailment are essential components of successful patient care in a clinical context. Modern medical advancements have made a significant contribution to computer technology and other cutting-edge tools that can benefit people in a variety of ways. Variable uses include helping with surgery, testing, and the formulation of numerous drugs, and using a variety of instruments for instruction and training at other medical universities (Kaur and Kumar 2020). Each type of physical examination performed in the medical field uses various computing tools in one way or another. Using computer-aided automated processes for all evaluation procedures used to diagnose various diseases would enhance performance and treatment (Khan and Algarni 2020).
As is well known, the amount of data generated and extracted from the healthcare industry is enormous, and the rate of storing all the various healthcare data in databases associated with clinics is increasing at a much faster rate. Therefore, it is essential to process this data efficiently so that the extracted data can assist in the diagnosis and treatment of various diseases in patients (Dubey 2021). Today, many researchers are working on automating the diagnosis and prognosis of various diseases using multiple ML algorithms to enhance the successful treatment of all diseases (Li et al. 2021). Researchers are currently using various ML and data mining algorithms for disease diagnosis (Qiao and Yang 2019). Various data mining, Artificial Intelligence (AI), and MH techniques can be used to develop an automated and intelligent system for disease detection (Kulkarni et al. 2021).
In particular, cloud computing is making it possible for efficient and secure AI systems to become part of the standard healthcare delivery system. Compared to the historical "on-premises" architecture of healthcare organizations, cloud computing offers computational capacity for the analysis of appreciably large amounts of data at faster speeds and lower costs. We find that many IT companies are looking to collaborate more and more with healthcare organizations to advance AI-driven medical innovations made possible by cloud computing and the technological revolution (Wyld 2022).
Creating medical diagnoses based on images is a task that AI is equally adept at as a human professional. AI has the potential to enhance healthcare by reducing resource usage, freeing up time for doctor-patient interactions, and even assisting in the creation of customized treatments. The use of AI to understand medical images is one of the applications that is developing. This field depends on Deep Learning (DL), a complex form of ML in which a sequence of labeled images is fed into algorithms that pick out patterns within them and learn how to classify similar images. The identification of diseases ranging from cancer to eye disorders has shown potential using this method (Berwick et al. 2008).
AI and ML have become more common in healthcare environments. Artificial neural networks (ANNs), for example, have been used to enhance clinical diagnostic accuracy by learning and eventually identifying patterns in digital images (Varghese et al. 2010). Extreme Gradient Boosting is one of the ML methods used to improve disease prediction models (Chen et al. 2018; Commandeur et al. 2020). In the healthcare industry, computers are used for a variety of tasks, such as hospital information systems, medical data processing, and laboratory computing (Mehta et al. 1994). The brains of many diagnostic and monitoring equipment are computers and electronic chips. A computer is made up of various hardware parts and software that integrate and manage the operation of every physical part. An algorithm is a collection of diagrammed suggestions and instructions that describe a series of activities. MHs (Osman and Kelly 1996) were developed to provide optimal results for difficult data processing jobs more quickly than traditional techniques. MHs are governing systems for the pursuit of interaction. The inquiry space analysis is intended to quickly identify almost optimal solutions. There are many applications for MH computations, ranging from straightforward local search techniques to intricate learning metrics. The specialized approach technique and strategy can be employed to solve optimization problems.
A heuristic process is the foundation of an MH strategy. While the second type of MH method is based on a single solution approach (local search), the first type is based on population (random search) (Osman and Kelly 1996). Some MH calculations can be used to locate an ideal or a nearly ideal solution. They include a Genetic Algorithm (GA) that is based on genetic mechanisms (Reeves 2010), Artificial Bee Colony (ABC) that is based on bee behavior (Karaboga and Basturk 2007), Neural Networks (NNs) (Potvin and Smith 2003), ant colonies that are based on ant behavior (Dorigo and Stützle 2003), and simulated annealing (Henderson et al. 2003). In this review, an effective search has been conducted in which publications from various research databases, including Scopus (Elsevier 2004), PubMed, Web of Science, and others, have been deemed important for detecting research using AI and MH techniques in the recent decade [2014–2023].
1.1 Contribution
In this section, we discuss the value of MH algorithms for identifying different diseases. The method is new in that it applies MH algorithms to Decision Support Systems (DSS) for the single purpose of detecting different diseases or as a component of a large and hybrid system. The review discusses revolutionary MH algorithms and how they could be used to diagnose diseases. The review covers articles published in the last decade [2014–2023] for various disorders for which MH algorithms have been used. In this work, four key research questions are addressed:
-
1.
Which research used MH techniques and are they used to diagnose diseases?
-
2.
Which various diseases have used MH algorithms?
-
3.
What types of AI and MH techniques are currently used to diagnose diseases?
-
4.
What are the issues and limitations in each research area?
-
5.
What measurement criteria are used to evaluate the effectiveness of classification models?
-
6.
In what additional healthcare fields could MH techniques be applied in the future?
This is a summary of the primary contributions provided by this paper:
-
1.
Analysis of the current research methodologies on MHs and AI techniques.
-
2.
Provide an overview of DL and ML techniques currently applied to classifying diseases using different modalities of medical imaging or disease datasets with different dimensions.
-
3.
Provide MHs currently applied to FS using different modalities of medical imaging or disease datasets with different dimensions.
-
4.
Illustrate the modalities of medical imaging used for disease diagnosis.
-
5.
Present the datasets used in the classification models for medical images or disease datasets with different dimensions.
-
6.
Analysis of MHs boosted AI for healthcare applications.
1.2 Proposed model
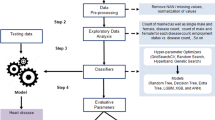
The proposed model that will be introduced in this review will involve the following steps, as shown in Fig. 1:
-
Datasets: Use different disease datasets with varying sizes of dimensions extracted from the official repositories [University of California Irvine (UCI) (Frank 2010), Kaggle (Alphabet 2010), INSPIRE Datasets (The University of Iowa 1925), etc.].
-
Data cleaning and pre-processing: done on the training dataset.
-
Feature extraction (FE): Extract the disease features.
-
FS: Help select the best-performed features of the FE.
-
Classification: FS is given as input to the classification process (classifier) and is used to analyze the disease dataset.
-
Statistical Validation: Nonparametric statistics, such as the Friedman mean rank, Kruskal-Wallis test, and Wilcoxon sign rank test.
-
Performance evaluation: The effectiveness of the performance of the proposed technique is evaluated using an evaluation metric and statistical analysis.

Classification model of healthcare applications
1.3 Paper structure
An overview of various AI and MH Optimization Algorithms utilized in healthcare applications is provided in this review. The remainder of this review is organized as follows: The basics and background for AI and MH techniques will be covered in Sect. 2, AI will be covered in Subsect. 2.1, and MH in Subsect. 2.2. Healthcare applications will be covered in Sect. 3, AI applications for healthcare applications will be covered in Subsect. 3.1, MH applications in Subsect. 3.2, AI and MH applications in Subsect. 3.3, research issues of healthcare applications in Sect. 4, future trends and challenges are covered in Sect. 5. Section 6 represents the conclusion of the review.
2 Basics and background
2.1 AI overview
AI is the science of building intelligent computers using algorithms that the computer follows to mimic human cognitive processes. With the ability to foresee issues as they arise, AI systems can act with intention, intelligence, and adaptability. The strength of AI lies in its capacity to recognize patterns and relationships in vast multidimensional and multi-modal datasets. For example, AI systems may be able to distill the entirety of a patient’s medical history into a single number that indicates a likely diagnosis (Shubhendu and Vijay 2013). AI is not a single technology but contains various subfields (such as ML and DL) that, on their own or in combination, provide applications with more intelligence (Saw and Ng 2022).
AI is being utilized in healthcare applications. Figure 2a displays statistics for AI and healthcare applications research from 2014 to 2023 based on a Scopus search. The distribution of AI in the field of healthcare research is shown in Fig. 2b. The use and implementation of AI in clinical practice remains limited after more than a decade of intense concentration, and many AI products for healthcare are still in the design and development stages. Although there are different approaches to developing AI systems for healthcare applications, far too frequently attempts are made to fit square pegs into round holes, that is, identify healthcare issues and utilize AI solutions without giving the local context (such as clinical workflows, user needs and ethical implications) the attention it deserves (Topol 2019).

The AI Techniques for Healthcare researches performed in the last decade (2014–2023)
2.1.1 ML overview
ML is one of the most prevalent types of AI. It is a statistical technique that allows models to be fitted to the data and ’learn’ by training on the data (Mitchell 1997). Precision medicine, which determines which treatment protocols are likely to be effective in a patient according to a variety of patient features and the treatment environment, is the most widely used use of classical ML in healthcare (Lee et al. 2018). A training dataset for which the outcome variable is known is necessary for the vast majority of ML and precision medicine applications; this process is known as supervised learning.
Different algorithms can be chosen for training the model. One approach is to use various relevant algorithms to train the model, and then use the confusion matrix and the Receiver Operating Curve (ROC) to assess how well it performed (Kendale et al. 2018). An iterative procedure creates the final model. To provide the model with the most predictive power, the optimum method with a combination of parameters is chosen. To reduce the amount of time and computational work required for hyperparameter adjustment, certain methodologies have provided default settings for different parameters (Probst et al. 2019).
ML is being utilized in healthcare applications. Figure 3a shows statistics for the research on ML and healthcare applications from 2014 to 2023 based on a Scopus search. The distribution of ML in the field of healthcare research is shown in Fig. 3b.

The ML Techniques for Healthcare research performed in the last decade (2014–2023)
ML algorithms used in healthcare research performed in the last decade (2014–2023) as shown in Table 1.
There are numerous instances in which ML algorithms are utilized to develop DSS that assist physicians. One instance is the stratification of the mortality risk of patients with infection using an ensemble model made up of four separate models, namely NN, a gradient-boosted DT, SVM, and LR algorithms COVID-19 (Gao et al. 2020). Furthermore, the greater ability to handle data using a variety of hardware and cloud solutions has improved our ability to employ sophisticated algorithms for big data (McKendrick 2021). Some examples of how ML is used to improve community health (Sally et al. 2022).
2.1.1.1 Logistic regression (LR)
In cases where the result has two levels, the LR classification algorithm, which is frequently used, predicts a categorical result (Brownlee 2016). The drawback of LR is that interactions must be manually inserted. Regression using more than two layers of a multinomial logistic function can predict categorical variables (Molnar 2020).
2.1.1.2 Support vector machine (SVM)
SVM algorithms are vital algorithms with the potential to solve health issues with precise computing. SVM processes data using regression, classification, and outlier identification. Numerous studies have used medical data analytics to demonstrate the ability of SVM to identify a wide range of health issues, including diabetes, blood pressure, and cancer. With increased usage in issues related to global health, SVM is anticipated to undergo a major revolution (Drucker et al. 1999). SVM is a reliable algorithm that is essential for the diagnosis and prognosis of many cancers. Training datasets and independent testing are initially applied to the pre-processed database. To develop SVM classifiers with the highest classification accuracy, data is used (Vatsa et al. 2005; Doucet et al. 2007).
The accuracy of SVM is one of the key arguments for using it in health evaluation. Its simplicity, clarity, and memory effectiveness are further benefits (Shen et al. 2016). SVM can be used; however, it has drawbacks such as the dependency on parameter precision and the inability to handle big datasets. By more accurately diagnosing ailments, SVM is a crucial algorithm that can improve healthcare applications. (Tharwat et al. 2017).
2.1.1.3 Decision tree (DT)
DT uses recursive partitioning, a technique that further divides the decision space into smaller and smaller parts before labeling it, to predict a categorical variable. The DT’s simplicity in adjusting to a clinical setting and its superior interpretability in comparison to other algorithms are both significant advantages. DT makes the prediction and informs the decision maker of the precise justification for it in a healthcare environment. It is also useful for categorizing unfamiliar datasets (Witten and Frank 2002). It is compared with other DT algorithms including C4.5. A more reliable version of C4.5, called EC4.5, was first introduced by (Ruggieri 2002). EC4.5 offers five times greater efficiency than C4.5 for identical DT. It shares the same decision-making tree as C4.5.
2.1.1.4 Naïve Bayes (NB)
Based on the Bayes theorem (Leung 2007), NB is employed. With more than two levels of prediction, this technique works well (Wickramasinghe and Kalutarage 2021). Less training data are needed compared to the LR algorithm in cases where the assumption of independence is true (Chen et al. 2020). The predictor variables are presumed to be independent, but in most circumstances, this is not the case. NB is a straightforward but effective algorithm with numerous real-world uses, from managing driverless vehicles to making product suggestions and medical diagnoses (Wickramasinghe and Kalutarage 2021).
2.1.1.5 Artificial neural network (ANN)
ANNs or Simulated Neural Networks (SNNs) are other names for Neural Networks, which are a subset of ML and the basis of DL techniques. They replicate the way that actual neurons communicate with each other, drawing inspiration from the human brain for both its name and its form Ripley et al. (1998). Three layers make up an ANN node layer: an input layer, one or more hidden levels, and an output layer. Each node, or artificial neuron, has a weight and threshold associated with it and is connected to other nodes. Any node whose output exceeds the specified threshold value is activated and starts sending data to the network’s top layer (Fan et al. 2021).
2.1.1.6 DL overview
ANNs are the foundation of the ML idea known as DL. DL models outperform standard data analysis techniques and shallow ML models in many applications (Akkus et al. 2017). DL is technically the use of NN with more than one or two layers. A parametric, non-linear change of input often makes up a "layer" in a neural network. To map high-dimensional inputs to outputs, these transformations are stacked to develop a statistical data structure. Optimizing the parameters allows for the execution of this mapping. This optimization uses gradient descent as its preferred method. When utilizing gradient descent, each parameter is updated to minimize the loss function by computing the partial derivative of the loss function concerning that parameter. As a result of stacking multiple of these layers, DL is given the label "Deep". "Learning" refers to the parameter optimization in the second component of the name (Janiesch et al. 2021). DL models typically include 50 to 200 layers and about 100 to 10 billion parameters. There are 600 and 175 billion parameters combined in two of the largest models officially described (Brown et al. 2020; Lepikhin et al. 2020). In recent years, the size of these models has increased incredibly quickly (Ahmed and Wahed 2020). Convolution Neural Networks (CNN), deep neural networks, and deep Boltzmann machines are some examples of common DL techniques (Yap et al. 2017). DL is being utilized in healthcare applications. Based on data from Scopus databases, Fig. 4a shows the statistics for the research on ML and healthcare applications from 2014 to 2023. The distribution of ML in the field of research on healthcare applications is shown in Fig. 4b.
DL was used in research on healthcare applications performed in the last decade (2014–2023) as shown in Table 2.

The DL Techniques for Healthcare applications research performed in the last decade (2014–2023)
CNN: Due to CNN’s simple architecture, it is used to solve complex image-driven pattern recognition issues and offers an efficient approach to begin using ANNs. Yap et al. (2017). As with traditional ANNs, CNNs are composed of neurons that can adapt to their environment. Each neuron, the core component of countless ANNs, will continue to process information and perform an action. The entire network will still only express one perceptive score function (the weight), from the input raw image vectors to the final output of the class score. The final layer will include loss functions related to the classes and all the standard advice developed for conventional ANNs still holds "true" value (O’Shea and Nash 2015). The main significant distinction between CNNs and traditional ANNs is that CNNs are predominantly employed in the field of image pattern recognition. This enables us to add image-specific characteristics while reducing the number of parameters needed to develop the model (Li et al. 2021).
CNNs include three different types of layers: convolutional, pooling, and fully connected. Each layer serves a certain purpose (Stenroos 2017):
-
1.
Convolutional layer: calculates the scalar product between the weights of the input volume-connected region and the neurons whose output is related to the particular areas of the input. The goal of the Rectified Linear Unit (ReLu) is to activate the output of the previous layer’s activation by utilizing an activation function.
-
2.
Pooling layer: downsamples along the spatial dimensionality of the input, resulting in activation with fewer parameters.
-
3.
Fully-connected layers: carry out the identical tasks as in conventional ANNs and derive class scores from the activations, which can then be applied to classification. Additionally, it is proposed that ReLu be utilized between these layers to enhance performance.
CNNs were utilized with excellent success in image classification and segmentation (Russakovsky et al. 2015).
The most popular CNN architectures are shown in Table 3 with their configuration.
2.2 MH optimization algorithms overview
In the world of computers today, there is a need for different techniques to solve various issues. One method that can offer workable answers to such problems is the use of MH algorithms. Because they are effective, MH algorithms are now used in healthcare data to diagnose diseases more effectively than conventional techniques.
When faced with a high number of input features, a usual approach is to employ MH approaches to lower the dimensionality of the original problem, which can occasionally improve learning performance. FS and Feature FE techniques are the two main categories of dimensionality reduction approaches. The key distinction between the two is that FE selects a subset of the original features, while FS combines the original features to produce a new set of features (Remeseiro and Bolon-Canedo 2019), as illustrated in Fig. 5.

FS and FE techniques
FS techniques can also be divided into filters, embedded methods, and wrappers based on how they interact with the learning technique (Guyon et al. 2008). Because the emphasis is on the general features of the data, the filters are independent of any learning methodology. Both wrappers and embedded techniques need a learning approach to carry out FS. An induction approach assesses potential feature candidate subsets for wraps. Wrappers are more computationally expensive than filters because of interactions with the classifier. Because selection is a step in the induction method’s training process, embedded techniques fall between filters and wrappers. Because the classifier is trained while looking for the best subset of features, embedded approaches are less computationally expensive than wrappers.
The techniques that have gained popularity among researchers for FS are Correlation-Based FS (CFS) (Hall 1999), INTERACT (Zhao and Liu 2009), Recursive Feature Elimination for SVM (SVM-RFE) (Guyon et al. 2002), ReliefF (Kononenko 1994), and consistency-based filter (Dash and Liu 2003).
MHs (Blum and Roli 2003) are generally considered a component of ML and soft computing technologies. The primary property of MHs is that they repeatedly perform the transition, evaluation, and determination operators in addition to input and output until the search process converges or satisfies the predetermined stopping condition (Tsai and Rodrigues 2013). We have noticed that some recent research on healthcare applications has employed MHs to solve data mining challenges, such as clustering for unknown data, classification for part of unknown data, and the association rule for intriguing patterns.
MHs are being utilized in healthcare applications. Based on data from Scopus databases, Fig. 6a shows statistics for the research of MH and healthcare applications from 2014 to 2023. The distribution of MH in the field of research for healthcare applications is shown in Fig. 6b.
Different classifications of MHs have been submitted according to how exploration and exploitation are used and the metaphor of search procedures, as shown in Table 4.

The MHs techniques for healthcare applications research performed in the last decade [2014–2023]
There are five main paradigms, as illustrated in Table 4.
2.2.1 Bio-stimulated algorithms
Bio-inspired algorithms tackle application issues in decision-making, information management, and optimization across various scientific fields. It is anticipated that in the coming years, more strategies will be developed in fields where intelligent optimization algorithms will be more efficient at tackling different problems in anomaly and failure detection regions (Mishra et al. 2011). This section provides a concise overview of bio-inspired algorithms.
Grey wolf optimization (GWO):
The GWO algorithm (Mirjalili et al. 2014) is an MH and bio-inspired methodology inspired by grey wolves in nature. The four types of grey wolves in a wolf pack are denoted as \(\alpha\), \(\beta\), \(\delta\), and \(\omega\). Among them, \(\alpha\) is regarded as the group’s leader. \(\beta\) wolves support \(\alpha\) in making decisions and hunting, and they are the next candidates to become the leader if \(\alpha\) reaches the point of retirement or passes away while hunting. \(\delta\) senior wolves, \(\alpha\) former wolves, sentinels, or scouts who guard the group’s boundaries. If the \(\alpha\) wolf reaches the point of retirement or passes away while hunting, the \(\beta\) wolves are considered the next contender eligible to become the leader. Elder wolves, former \(\alpha\) wolves, sentinels, or scouts known as \(\delta\) wolves guard the group’s boundaries. \(\omega\) wolves must be subordinate to all other dominant wolves and must follow all other categories of wolves, making them the least important wolf (Seyed et al. 2014). Medjahed et al. (2016) also adopted a straightforward update to GWO to convert it to a binary version. For FS for hyperspectral band selection, their binary version was used. The GWO was transformed into binary form Medjahed et al. (2016) using a straightforward threshold.
Artificial immune system (AIS):
AIS algorithms (Timmis et al. 2004) are essential tools in the ML framework, based on computational intelligence and inspired by the concepts and procedures of the vertebrate immune system. The AIS technique imitates the human immune system in some ways. According to Timmis’ 2008 summary (Timmis et al. 2008), the goal of AIS is to close the gap between immunology and engineering. To this end, a variety of research methods, abstraction from those models into algorithm design, and implementation in the context of engineering (Chanal et al. 2021). In Periasamy et al. (2022), AIS allows medical professionals to take preventive action at the appropriate time to prevent osteoporosis from developing early. Trials showed 94% prediction accuracy, demonstrating its value in identifying those at risk of osteoporosis in the future. Effective plan and schedule home care while taking into account factors including the patient’s preferences, the availability of caregivers, and their qualifications. An AIS is suggested as a route generator to overcome this issue, and a multi-agent method is built to ensure the best coordination and communication between all involved parties (Haitam et al. 2022).
2.2.2 Nature-inspired algorithms
Nature-Inspired Optimization Algorithms (NIOA) are influenced by the way things behave in the natural world. Biological processes, chemical processes, and other phenomena have all served as inspiration for NIOAs. Solutions in engineering, medicine, etc. have been made possible by this (Kumar et al. 2023). It is simple to break down natural processes into numerous intricately layered sub-processes. As a result, the algorithms become distinctive and powerful. The goal of the study of NIOAs is to improve the efficiency of nature-inspired algorithms by addressing algorithm selection, parameter tuning, and algorithm adaptation to changing environments (Dhal et al. 2019). These Nature-inspired algorithms are commonly used in medical applications for classification based on characteristics, and the relevant research is discussed below.
Invasive weed optimization (IWO):
IWO algorithm (Xing et al. 2014) is inspired by the way weeds naturally colonize and choose an area that is conducive to growth and reproduction. Invasive weed colonization served as a model for this technique. Weeds have shown remarkable resilience and adaptability. Therefore, they are not suitable for use in agriculture. According to Razmjooy and Razmjooy (2020), the filtered image is subjected to the suggested optimized NN based on the Quantum IWO algorithm to separate the regions of skin lesions. The DermIS and the Dermquest databases have both been used to analyze system performance. According to experimental results, the suggested approach is effective in segmenting skin lesions. The IWO method in Soulami et al. (2019) determines the ideal threshold for the extraction of questionable regions in mammograms. The Smallest Univalue Segment Assimilating Nucleus (SUSAN) algorithm is then applied to the selected threshold to find dense anomalies. The results indicate that this method outperforms other methods in terms of accuracy when it comes to identifying worrisome breast tissue, particularly dense breast tissue.
Cuckoo search algorithm (CSA):
The CSA is based on some cuckoo species’ brood parasitism. Additionally, the so-called Levy flights (Pavlyukevich 2007), as opposed to straightforward isotropic random walks, improve this technique. Some species use shared nests to lay their eggs, but they may also remove the eggs of other species to increase the chance that their eggs will hatch. Obligate brood parasitism is practiced by various species, which deposit their eggs in the nests of other host birds (Yang and Deb 2009). The deep cuckoo-based deep convolutional Long-Short Term Memory (convLSTM) classifier in Kumar et al. (2022) is tuned using CS to predict diseases. A training percentage of 97.591% for accuracy was obtained using the suggested strategy, which outperformed traditional techniques. The comparative investigation demonstrated that the suggested method produced greater accuracy than other techniques. Utilizing optimization algorithms such as CSA can help DL approaches become even more accurate (Zargar et al. 2020; Jain et al. 2021).
2.2.3 Physics-based algorithms
MH and computational intelligence are the two fields in which physics-based algorithms often belong (Can and Alataş 2015). Metalworking, music, the interaction of culture and development, and complicated dynamic systems like avalanches are a few examples of inspirational physical systems. They often combine local (neighborhood-based) and global search approaches with stochastic optimization algorithms.
High-dimensional issues can be solved efficiently and effectively using physics-based algorithms (Can and Alataş 2015). MH techniques based on physics are effective and reliable for dealing with complex, high-dimensional situations. Although 23 MH algorithms have roots in physics, few academics in the field are aware of them (Can and Alataş 2015). These physics-based algorithms are frequently utilized in medical applications to classify based on features, and the relevant research is discussed below.
Gravitational search algorithm (GSA):
The second rule of motion and Newton’s law of gravitation both served as inspiration for GSA (Rashedi et al. 2009). Each potential solution in the search space is viewed as an object whose fitness is determined by its mass. Compared to lighter objects, heavier ones are thought to be fit. Due to the gravitational attraction between the objects, they move around in the search space. The entire population eventually gravitates towards the heaviest object, also known as the global best solution, because the heavier objects attract other objects with greater power. GSA and SVM were used (Shirazi and Rashedi 2016) to study a model for spotting breast cancer on mammography images. The pre-processing was first performed and then ROI was derived. Once the features had been extracted, the Grey-Level Co-occurrence Matrix (GLCM) model was applied. After choosing the features, the key goal was to decrease the features and improve the classification accuracy using the mixed GSA. To overcome the curse of dimensionality, pyramid GSA (PGSA), a hybrid approach in which the number of genes is cyclically lowered, has been developed. Two components comprise PGSA: a filter and an iterative wrapper approach (influenced by GSA). To further minimize the dimension, the genes chosen in each cycle are carried over to the following rounds. By utilizing the most insightful genes while using fewer genes, PGSA seeks to maximize classification accuracy. Results from a multi-class microarray gene expression dataset for breast cancer are provided. To make a fair comparison, various FS algorithms have been put into practice. With 73 genes, the PGSA had the highest accuracy (84.5%) (Tahmouresi et al. 2022).
Sine cosine algorithm (SCA):
One of the most recent and promising population-based MH optimization techniques was SCA (Mirjalili 2016), which was first presented by Mirjalili in 2016. The inspiration for the SCA is very distinct. To discover the global optimum, it searches the space using two sine and cosine functions that update the positions of the solutions (Mirjalili 2016). Because of its straightforward implementation and comparatively good performance in solving difficult problems, SCA has been extensively explored and applied in different domains. SCA, for instance, was used to address the scheduling issue in Das et al. (2018). To address the FS problem, Sindhu et al. (2017) proposed an Improved SCA (ISCA) that integrates SCA with a new position update method and an elitism technique. Ten benchmark datasets from the medical and non-medical fields were used to validate the efficacy of ISCA. It was shown that ISCA was superior to well-known MHs.
To prevent early convergence of SCA, the random parameters \(r_1\), \(r_2\), and \(r_3\) in ISCA are dynamically modified. Based on the test systems for the IEEE 30-Bus and IEEE 118-Bus, the performance of ISCA was assessed.
2.2.4 Evolutionary algorithms
Evolutionary Algorithm (EA) employs naturalistic techniques and solves issues by mimicking the actions of living things. Evolving AI is a part of both bio-inspired and evolutionary computing (Eiben et al. 2015). EAs are motivated by Darwinian evolutionary ideas. The solutions act as distinct creatures in an ecosystem in EAs. The problem is first filled with a random mixture of viable solutions. Following that, the population’s fitness-or how quickly and effectively it solves problems-is tested. Then, only those who are physically fit are chosen to reproduce. The cycle repeats itself as the population’s fitness is assessed and the least fit people are removed (Vikhar 2016).
Genetic Algorithm (GA):
A search-based optimization technique called a GA (Mirjalili and Mirjalili 2019) is based on the ideas of natural selection and genetics. It is routinely utilized to identify ideal or almost ideal answers to challenging issues that would otherwise take a lifetime to resolve. GA is one of the most widely used algorithms in the medical field. In several research (Lee et al. 2007; Oztekin et al. 2010; Nalini et al. 2008), GA has been used to solve scheduling issues in the healthcare industry, such as reducing patient waiting times, because the answer to an optimization problem can be expressed as integers or binary numbers. The goal of Yeh and Lin (2007) is to use GA to solve the problem of nurse scheduling to find a better schedule that will improve the flow of the emergency room and, as a result, reduce patient waiting times compared to manually planned schedules. To improve patient care, a subsequent study (Nalini et al. 2008) took multiple goals into account at once (such as total patient waiting time and doctor scheduling), maximizing the impact of medical resources and reducing unnecessary spending. The use of GA to identify better weights to update or train classifiers is a promising method of employing MH for classification challenges in healthcare applications. For example, in Oztekin et al. (2010), the six most crucial features for predicting heart disease were chosen from thirteen features using GA. Because the FS technique can greatly reduce the complexity of the data, it is clear that this results in a savings of more than 50% in calculation time for the same data.
Differential evolution (DE):
DE (Storn 1996), a well-known EA that was motivated by Darwin’s theory of evolution, has been thoroughly researched to address different optimization problems and engineering applications. Meta DE was suggested in the medical field by Koutny (2016). With the help of diabetic patients from the Jaeb Center for Health Research, they verified their results by continuously measuring blood glucose levels (Koutny 2016). Using a multi-objective DE to adjust the random forest technique’s parameters for many medical applications, the author (Kaur et al. 2019) developed an e-health data prediction approach.
2.2.5 Swarm-based algorithms
Swarm behavior is frequently seen in natural systems with socially organized biological species. Ants, bees, and locusts are just a few examples of colonial insects that demonstrate highly coordinated behavior, although each individual has a restricted ability to detect and respond (Beauty 2008). Similar behaviors are displayed by schools of migrating fish and birds exhibit similar behaviors (Brown and Cunningham 2007). When fighting parasites, white blood cells act in swarms (Majno and Joris 2004).
Swarm Intelligence (SI) (Eberhart et al. 2001), and particularly swarm-based optimization algorithms, have in common with neural networks the crucial feature of being made up of numerous processing units, each of which has a finite amount of computational resources. However, when combined, these parts can develop effective information processing systems. Simply expressed, this means that a form of collective intelligence develops due to interactions between several non-intelligent entities.
Particle swarm optimization (PSO):
PSO (Venter and Sobieszczanski-Sobieski 2003) begins with a population of random solutions, or particles. Each particle in PSO also has a velocity, unlike in the other evolutionary computation methods. With velocities that are dynamically changed based on their past behaviors, particles move around the search space. As a result, throughout the search process, the particles tend to fly towards the better and better search area. PSO produced many successful results (Gandhi et al. 2010; Shyh-Jong et al. 2013) when it comes to classifying problems in a healthcare system. Using PSO as a classification algorithm to identify breast cancer is another encouraging research trend (Gandhi et al. 2010; Yeh et al. 2009). The study (Yeh et al. 2009) used statistical techniques to choose useful features before using PSO to divide the population into two groups: those who have breast cancer and those who do not. Therefore, the healthcare system discovers some helpful decision-making guidelines that would help physicians detect breast cancer. The accuracy rate of a classification algorithm can be increased by using PSO to select the most helpful features of the data or to decide how much weight to give each feature. In Chowdhury et al. (2009), the author used the PSO to establish the ideal pathophysiological parameter weights for a diagnosis system, which was later implemented in an FPGA. The study presented in Chowdhury et al. (2009) utilized an adaptive approach to dynamically alter the perception range of each PSO particle, which can be used to increase the classification accuracy rate.
Ant colony optimization (ACO):
The ACO (Dorigo et al. 2006) uses a unique technique to mimic the behavior of ants in the wild to identify an effective solution to the optimization problem in healthcare applications. Although ACOs are not often used in research to improve healthcare applications, the studies (Kuo and Shih 2007; Kuo et al. 2007) do show that it has a wide range of potential benefits. The association rules for the health insurance data were discovered using ACO in Kuo and Shih (2007). These results demonstrate how ACO can be utilized for different healthcare data mining tasks.
Studies (Bergholt et al. 2011; Madhusudhanan et al. 2010; Uma and Kirubakaran 2012) revealed that ACO can enhance classification in healthcare applications. ACO and a fuzzy rule were coupled in Madhusudhanan et al. (2010) to classify the components of hepatitis. ACO and Linear Discriminant Analysis (LDA) were used in a later study (Bergholt et al. 2011) to better understand the data from gastric cancer endoscopies. More specifically, LDA performs the function of data clustering, and ACO performs the function of classification in this hybrid method, known as ACO-LDA.
ACO can be used to predict cardiac disease, according to a recent study (Uma and Kirubakaran 2012). To choose the best features of a classification algorithm, this work coupled ACO and GA and performed these two MHs at each iteration of the convergence process.
2.3 Datasets
This section provides a summary of publicly available datasets that were utilized in different healthcare classification research. We use different disease datasets with varying sizes of dimensions extracted from the official repositories [UCI (Frank 2010), Kaggle (Alphabet 2010), INSPIRE Datasets (The University of Iowa 1925),… etc.]. These datasets include Arrhythmia, Primary Tumor, Lymphography,…, etc. that contain different feature types (categorical, integer, and real) as shown in Table 5. Table 5 shows different disease datasets with reference, relevance to healthcare, different numbers of features, number of patients, and feature type.
2.4 Medical imaging
The discipline of healthcare applications depends heavily on the analysis of images and the identification of disease patterns. Image-guided decision support is the gold standard for accurately diagnosing any condition in the medical industry. On the other hand, achieving high performance in accurately diagnosing the condition is still a difficult challenge. Consequently, MH algorithms can be utilized to enhance the functionality of the model, giving us the best results in terms of accurate disease prediction (Kumar and Gupta 2023; Kaur et al. 2022).
These medical imaging include white blood cells, chest X-rays, etc., as shown in Table 6.
2.5 Performance evaluation
Table 7) shows performance metrics, where FP, TP, TN, and FN denote False-Positive, True-Positive, True-Negative, and False-Negative cases.
3 Healthcare applications
This section discusses in detail the important applications of AI and MH in medicine and public health.
3.1 AI algorithms for healthcare applications
Big data and ML are influencing the majority of aspects of contemporary life, including entertainment, business, and healthcare applications. All of this data may be used to create an extremely detailed personal profile, which can forecast trends in healthcare applications and be very valuable for understanding and marketing behavior. There is much hope that the use of AI will significantly advance all aspects of healthcare applications, from diagnosis to therapy. There is already a lot of evidence that AI algorithms outperform humans in a variety of activities, such as analyzing medical images or connecting symptoms with the description and prognosis of disease (Douglas Miller and Brown 2018). The prevailing consensus is that AI techniques will support and enhance human work rather than, as some have suggested, completely replace it. AI is prepared to help medical professionals with a range of duties, including administrative workflow, clinical documentation, and specialized support like image analysis and patient monitoring.
AI algorithms for healthcare applications are summarized in Table 8. Table 8 contains the used dataset, publishing year, the type of algorithms used (either ML or DL), and the experimental results.
3.2 MH optimization algorithms for healthcare applications
In the world of computing today, there is a need for different techniques to address different issues. One method that can offer workable answers to these problems is the use of MH algorithms. Due to its effectiveness, MH algorithms are currently employed in healthcare data to diagnose diseases more effectively than conventional techniques. Furthermore, there is a wide range of MH applications in the field of healthcare applications, including improved classification systems, efficient detection systems, and an increase in the rate of disease diagnosis (Nassif et al. 2022).
In medical applications, FS has been utilized successfully to both reduce the dimensionality and enhance understanding of the root causes of disease. We outline some fundamental ideas about medical applications and offer crucial foundation knowledge on FS. We examine the most recent FS techniques developed for and used for medical issues.
Various MH algorithms are very helpful for FE and FS for various types of disease diagnosis and early detection. MH Algorithms for healthcare applications are summarized in Table 9.
Table 9 contains the used dataset, publishing year, the used algorithms, Purpose FS or Classification (Calssif.)), and experimental results.
3.3 MH and AI algorithms for healthcare applications
Many of the MH algorithms have been used as diagnostic tools. These MH algorithms are designed and utilized to diagnose approaches and are inspired by numerous typical natural observations or phenomena, including the behaviors of fish, birds, insects, animals, plants, and people. Better accuracy is obtained due to the FS process, which narrows down a vast array of features while maintaining system performance. Numerous techniques employing MH algorithms have been developed to handle the difficulty of shrinking the large feature space by deleting inessential and unnecessary features due to the inclusion of numerous features in ML tasks.
The FS has a single aim that needs to be optimized in single-objective FS tasks. No matter how many features there are or how much it costs to train a model, single-objective FS seeks to find the greatest classification performance. The FS task is handled by Multi-Objective FS (MOFS) which contains several evaluation criteria, as illustrated in Table 7, which transforms it into a multi-objective optimization problem to deal with the optimization of two objectives. The performance of categorization and the number of features are the goals. The result is that the answer to the MOFS optimization issue is a series of non-dominated solutions, each of which is a vector consisting of the best fitness. Table 10 contains the used disease dataset, publishing year, the use of hybrid MH and AI algorithms, purpose (FS or Classification), and experimental results.
4 Research issues
The development of computer and network technology has given us many options on how to build an effective information system for our daily lives. Healthcare information systems have advanced significantly in recent years, just as other information systems. A more comprehensive, more accurate, and reliable healthcare system can be developed using modern computers, networks, and intelligent technologies, as demonstrated by previous successful results of healthcare applications (Shehab et al. 2022). We can now offer doctors and patients monitoring, detection, and alarming services that are much more effective and efficient thanks to the application of ML technologies such as data analytics, as noted in Shehab et al. (2022).
4.1 Issues of healthcare
Five levels can be used to categorize recent research on healthcare applications (Koch 2006):
-
1.
International level: International organizations frequently assist in analyzing large-scale healthcare data on a global basis, such as when examining infectious diseases that are common in multiple nations. One of the crucial questions in today’s healthcare data analysis is how to predict the patterns of infectious diseases. Google is an illustrative example, which predicts flu scenarios based on user search keywords (Dugas et al. 2013).
-
2.
National and regional level: A potential research trend in recent years has been the ability of a data analytic system to validate an assumption and identify intriguing patterns in a large enough set of data from a national or regional medical center’s data (Kuo et al. 2007).
-
3.
Hospital level: The primary focus of hospital management is on how to maximize medical resources. Several of the earlier research (Nalini et al. 2008) tried to utilize MHs to address the hospital’s scheduling issue.
-
4.
Home/family level: The system can quickly identify human activity to offer the appropriate services, such as preventing elder persons from getting into accidents (Doukas and Maglogiannis 2008).
-
5.
Personal level: In Milenković et al. (2006), an attempt was made to extract physiological data and integrate it so that the data could be analyzed to offer the wearer of the appliances or sensors appropriate recommendations and services.
4.2 Issues of AI techniques
The major issues of AI techniques in healthcare applications are as follows:
-
When an ML model is employed to predict a health result in the event of a potential error, legal processes are not optimized. In actuality, it might be challenging to put this idea into practice because of the diversity of legal systems found around the world. The DT algorithm becomes increasingly difficult to interpret as the number of elements rises, while the LR algorithm has the limitation that interactions must be manually implemented (Nusinovici et al. 2020).
-
Unless models such as DT that allow intuitive interpretation are used, predictions based on ML typically do not provide explanations for the forecast (Nicholson Price et al. 2019).
-
Splits in variables with multiple levels are frequently favored by these models. It responds quickly to slight modifications in the training data (Patel and Prajapati 2018), and the kNN algorithm becomes slower (Cunningham and Delany 2021) as the number of predictor variables increases.
-
DL algorithms are nearly hard to understand or interpret. Patients may want to know why they were diagnosed with cancer if they are told it was because of a picture. Even doctors who are usually knowledgeable about DL algorithms’ workings might not be able to explain them.
-
Overfitting can occur when an algorithm discovers irrelevant correlations between patient features and results. It occurs when there are an excessive number of variables affecting the results, which causes the algorithm to forecast things incorrectly (Gama et al. 2022).
4.3 Issues of MH optimization algorithms
The major issues of MH techniques in healthcare applications are as follows:
-
Large-scale global optimization (LSGO) problems, which require the solution of a large number of decision variables, are usually computationally expensive for MAs algorithms.
-
The absence of mathematical analysis. As of yet, no compelling theoretical idea exists that gets around this restriction.
-
The MHs might not always locate the global optimum solution. There is no assurance that the algorithm will identify the optimal answer because of its random nature (Almufti 2019).
-
The use of data expansion strategies in some papers to prevent overfitting rather than learning transfer.
5 Future trends and challenges
To enhance the effectiveness of disease diagnosis, significant efforts must be made. This section shows future directions that can be employed in healthcare applications. Although the examined literature produced encouraging results, there are still some restrictions and difficulties that need to be resolved to use AI and MH approaches for healthcare application detection and classification. The following is a discussion of the primary difficulties, underlying trends, suggested research directions, and challenges of the review.
-
1.
The effectiveness of the DL classifier heavily relies on the size and type of the dataset; hence, DL necessitates a vast amount of training data. Additionally, creating significant amounts of medical imaging data is challenging, as eliminating human errors requires a lot of time and effort from many experts and one individual.
-
2.
Most of the examined studies evaluated these using various datasets that were privately gathered by healthcare application research organizations. The main flaw in this argument is how difficult it is to compare the performance of such models across different studies.
-
3.
The increasing adoption of wireless AI devices in healthcare necessitates the development of new technologies, including cloud computing and the Internet of Things, to address the processing and storage capacities of these devices. On the other hand, there is a chance that AI gadgets relying on the cloud could compromise the security of patient information (Sajid and Abbas 2016).
-
4.
Exploration and exploitation are two fundamental ideas in the MAs. Since they are completely opposed to one another, how do you balance between them to get the greatest results? (Črepinšek et al. 2013).
-
5.
Techniques for classifying healthcare applications using unsupervised grouping. Most of the research from the chosen source classified diseases using the supervised learning methodology. These techniques have produced better results when labeled training images are used. However, it can be challenging to find real-world examples of diseases with accurate symptoms that trained medical professionals have identified. Various grouping strategies can be used to train the disease classification model, which is urgently needed.
-
6.
The classification of diseases using reinforcement learning. At the same time, a major problem is building an ML model capable of learning from its surroundings. The main issue is the lack of sufficient disease image samples to accurately represent all types of healthcare applications. Thus, the application can significantly enhance the effectiveness of techniques for the classification of healthcare applications using images from the medical field.
-
7.
Although AI has advanced significantly in healthcare, human input, and monitoring are still necessary. Because no machine can detect behavioral observations or empathize with patients the way that humans can, humans are unique in this regard.
-
8.
Robustness compared to data-gathering techniques. To gradually add new datasets, the robustness issue of various clinical and technological scenarios must be resolved. The diverse presenting qualities of the coloring and enlargement variables are among these variances.
In addition to the previously mentioned points, further work should include:
-
To enable the classification job depending on the size and feature type of different datasets, generic image datasets with a variety of image modalities will be employed. A fall DNA case series might be interesting.
-
Instead of relying solely on these image modalities, other disease-related images can be employed to enhance the effectiveness of disease classification models, such as Computed Tomography (CT) images or thermal imaging. MRI or CT scans for the same patient are required.
-
To assess the generalizability of the model findings in a concealed or invisible collection of data, cross-validation is a technique for model validation. The goal is to categorize a dataset to test the model during training, to solve issues such as underfitting and overfitting, and to demonstrate how the learned model generalizes to a different dataset.
-
Technological research is developing a variety of encryption methods and de-identification or anonymization systems that remove identity information. The CDM-based distributed research network is a well-known example. Moreover, other data mining techniques that protect privacy; include homomorphic encryption and federated learning (You et al. 2017).
-
MH algorithms boosted AI techniques to find the optimal solution.
6 Conclusion
The most recent research on disease diagnosis and classification using MH and AI algorithms in various disease datasets is reviewed in this review. Section 3.1 categorizes AI applications into ML and DL categories; Sect. 3.2 shows the MH techniques used for FS or classification of diseases, and Sect. 3.3 presents the hybrid MH and AI techniques used in disease diagnosis.
The review’s strengths include the inclusion of six well-known ML approaches in AI, including LR, SVM, DT, kNN, NB, and ANN. The review also focuses on CNN and its DL architectures used to identify and categorize diseases by utilizing various modalities of medical imaging or disease datasets with different dimensions. MH techniques are classified into Bio-stimulated Algorithms, Nature-inspired Algorithms, Physics-based Algorithms, Evolutionary Algorithms, and Swarm-based Algorithms.
The architecture also detects and categorizes diseases from various disease datasets. Several datasets of diseases are used in the classification models for medical images or disease datasets with different dimensions, taken from official repositories [UCI (Frank 2010), Kaggle (Alphabet 2010), INSPIRE Datasets (The University of Iowa 1925), etc.]. Also in this review, an explanation of medical imaging is described, including mammograms, ultrasound, magnetic resonance imaging, histological and thermography images. Finally, the study illustrates research issues in healthcare and discusses future trends and challenges in healthcare applications.
Data availability
Data sharing is not applicable to this article as no data sets were generated or analyzed during the current study.
References
Ahmed N and Wahed M (2020) The de-democratization of ai: Deep learning and the compute divide in artificial intelligence research. arXiv preprint arXiv:2010.15581
Akkus Z, Galimzianova A, Hoogi A, Rubin DL, Erickson BJ (2017) Deep learning for brain MRI segmentation: state of the art and future directions. J Digit Imaging 30(4):449–459
Al-Tashi Q, Rais H, Abdulkadir SJ (2018) Hybrid swarm intelligence algorithms with ensemble machine learning for medical diagnosis. In 2018 4th international conference on computer and information sciences (ICCOINS), 1–6. IEEE
Alexandre Spanhol F, Oliveira LS, Petitjean C, Heutte L (2016) Breast cancer histopathological image classification using convolutional neural networks. In 2016 international joint conference on neural networks (IJCNN), 2560–2567. IEEE
Ali AA, Mishra S, Dappuri B (2020) Breast cancer classification using tetrolet transform based energy features and k-nearest neighbor classifier. Recent trends and advances in artificial intelligence and internet of things, 39–46
Almufti SM (2019) Historical survey on metaheuristics algorithms. Int J Sci World 7(1):1
Alphabet Inc (2010) The home of data science. https://www.kaggle.com/
Alweshah M (2014) Firefly algorithm with artificial neural network for time series problems. Res J Appl Sci Eng Technol 7(19):3978–3982
Anand S, Gayathri S (2015) Mammogram image enhancement by two-stage adaptive histogram equalization. Optik 126(21):3150–3152
Anandajayam P, Aravindkumar S, Arun P, Ajith A (2019) Prediction of chronic disease by machine learning. In 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), 1–6. IEEE
Arora S, Singh H, Sharma M, Sharma S, Anand P (2019) A new hybrid algorithm based on grey wolf optimization and crow search algorithm for unconstrained function optimization and feature selection. Ieee Access 7:26343–26361
Arora S, Sharma M, Anand P (2020) A novel chaotic interior search algorithm for global optimization and feature selection. Appl Artif Intell 34(4):292–328
Bahaddad AA, Ragab M, Bahaudien Ashary E, Khalil EM et al (2022) Metaheuristics with deep learning-enabled parkinson’s disease diagnosis and classification model. J Healthcare Eng 1:9276579
Beauty E (2008) Strangeness of insect societies
Bergholt MS, Zheng W, Lin K, Ho KY, Teh M, Yeoh KG, So JBY, Huang Z (2011) In vivo diagnosis of gastric cancer using Raman endoscopy and ant colony optimization techniques. Int J Cancer 128(11):2673–2680
Berwick DM, Nolan TW, Whittington J (2008) The triple aim: care, health, and cost. Health Aff 27(3):759–769
Binder A, Bockmayr M, Hägele M, Wienert S, Heim D, Hellweg K, Ishii M, Stenzinger A, Hocke A, Denkert C et al (2021) Morphological and molecular breast cancer profiling through explainable machine learning. Nat Mach Intell 3(4):355–366
Blum C, Roli A (2003) Metaheuristics in combinatorial optimization: overview and conceptual comparison. ACM Comput Survey (CSUR) 35(3):268–308
Böhle M, Eitel F, Weygandt M, Ritter K (2019) Layer-wise relevance propagation for explaining deep neural network decisions in MRI-based Alzheimer’s disease classification. Front Aging Neurosci 11:194
Bowyer K, Kopans D, Kegelmeyer WP, Moore R, Sallam M, Chang K, Woods K (1996) The digital database for screening mammography. In Third international workshop on digital mammography 58:27
Brown J, Cunningham S (2007) A history of ACM Siggraph. Commun ACM 50(5):54–61
Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A et al (2020) Language models are few-shot learners. Adv Neural Inf Process Syst 33:1877–1901
Brownlee J (2016) Logistic regression for machine learning. Machine Learning Mastery, 1
Can Ü, Alataş B (2015) Physics based metaheuristic algorithms for global optimization. Am J Inf Sci Comput Eng 1:94–106
Canayaz M (2021) Mh-covidnet: diagnosis of covid-19 using deep neural networks and meta-heuristic-based feature selection on X-ray images. Biomed Signal Process Control 64:102257
Cao YJ, Wu QH (1997) Evolutionary programming. In Proceedings of 1997 IEEE International Conference on Evolutionary Computation (ICEC’97), 443–446. IEEE
Chanal PM, Kakkasageri MS, Manvi SKS (2021) Security and privacy in the internet of things: computational intelligent techniques-based approaches. In Recent Trends in Computational Intelligence Enabled Research, 111–127. Elsevier
Chang V, Bhavani VR, Ariel Qianwen X, Hossain MA (2022) An artificial intelligence model for heart disease detection using machine learning algorithms. Healthcare Anal 2:100016
Chauhan U, Kumar V, Chauhan V, Tiwary S, Kumar A (2019) Cardiac arrest prediction using machine learning algorithms. In 2019 2nd international conference on intelligent computing, instrumentation and control technologies (ICICICT), volume 1, 886–890. IEEE
Chen X, Huang L, Xie D, Zhao Q (2018) Egbmmda: extreme gradient boosting machine for Mirna-disease association prediction. Cell Death Dis 9(1):3
Chen S, Webb GI, Liu L, Ma X (2020) A novel selective naïve bayes algorithm. Knowl-Based Syst 192:105361
Chereda H, Bleckmann A, Menck K, Perera-Bel J, Stegmaier P, Auer F, Kramer F, Leha A, Beißbarth T (2021) Explaining decisions of graph convolutional neural networks: patient-specific molecular subnetworks responsible for metastasis prediction in breast cancer. Genome Med 13:1–16
Chittora P, Chaurasia S, Chakrabarti P, Kumawat G, Chakrabarti T, Leonowicz Z, Jasiński M, Jasiński Ł, Gono R, Jasińska E et al (2021) Prediction of chronic kidney disease-a machine learning perspective. IEEE Access 9:17312–17334
Chollet F (2017) Xception: deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1251–1258
Chowdhury SR, Chakrabarti D, Saha H (2009) Medical diagnosis using adaptive perceptive particle swarm optimization and its hardware realization using field programmable gate array. J Med Syst 33:447–465
Clore K, John (2014) Diabetes 130-US Hospitals for Years 1999-2008. UCI Machine Learning Repository. https://doi.org/10.24432/C5230J
Commandeur F, Slomka PJ, Goeller M, Chen X, Cadet S, Razipour A, McElhinney P, Gransar H, Cantu S, Miller RJH et al (2020) Machine learning to predict the long-term risk of myocardial infarction and cardiac death based on clinical risk, coronary calcium, and epicardial adipose tissue: a prospective study. Cardiovasc Res 116(14):2216–2225
Črepinšek M, Liu S-H, Mernik M (2013) Exploration and exploitation in evolutionary algorithms: a survey. ACM Comput Surveys (CSUR) 45(3):1–33
Cunningham P, Jane Delany S (2021) k-nearest neighbour classifiers-a tutorial. ACM Computing Surveys (CSUR) 54(6):1–25
Dahiwade D, Patle G, Meshram E (2019) Designing disease prediction model using machine learning approach. In 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), 1211–1215. IEEE
Das S, Bhattacharya A, Chakraborty AK (2018) Solution of short-term hydrothermal scheduling using sine cosine algorithm. Soft Comput 22:6409–6427
Dash M, Liu H (2003) Consistency-based search in feature selection. Artif Intell 151(1–2):155–176
Davis N (2019) AI equal with human experts in medical diagnosis, study finds. The Guardian 24:20
Deepika D, Balaji N (2022) Effective heart disease prediction using novel MLP-EBMDA approach. Biomed Signal Process Control 72:103318
Dhal KG, Ray S, Das A, Das S (2019) A survey on nature-inspired optimization algorithms and their application in image enhancement domain. Arch Comput Methods Eng 26:1607–1638
Dhiman G, Kumar V (2017) Spotted hyena optimizer: a novel bio-inspired based metaheuristic technique for engineering applications. Adv Eng Softw 114:48–70
Dorigo M and Stützle T (2003) The ant colony optimization metaheuristic: algorithms, applications, and advances. Handbook of metaheuristics, pages 250–285
Dorigo M, Birattari M, Stutzle T (2006) Ant colony optimization. IEEE Comput Intell Mag 1(4):28–39
Doucet J-P, Barbault F, Xia H, Panaye A, Fan B (2007) Nonlinear SVM approaches to QSPR/QSAR studies and drug design. Curr Comput Aided Drug Des 3(4):263–289
Douglas Miller D, Brown EW (2018) Artificial intelligence in medical practice: the question to the answer? Am J Med 131(2):129–133
Doukas C, Maglogiannis I (2008) Advanced patient or elder fall detection based on movement and sound data. In 2008 Second International Conference on Pervasive Computing Technologies for Healthcare, 103–107. IEEE
Drucker H, Donghui W, Vapnik VN (1999) Support vector machines for spam categorization. IEEE Trans Neural Netw 10(5):1048–1054
Dubey AK (2021) Optimized hybrid learning for multi disease prediction enabled by lion with butterfly optimization algorithm. Sādhanā 46(2):63
Dugas AF, Jalalpour M, Gel Y, Levin S, Torcaso F, Igusa T, Rothman RE (2013) Influenza forecasting with google flu trends. PLoS ONE 8(2):e56176
Duggal P, Shukla S (2020) Prediction of thyroid disorders using advanced machine learning techniques. In 2020 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), 670–675. IEEE
Eberhart RC, Shi Y, Kennedy J (2001) Swarm intelligence. Elsevier, Amsterdam
Eiben AE, Smith JE, Eiben AE, Smith JE (2015) What is an evolutionary algorithm? Introduction to evolutionary computing, 25–48
Elsevier (2004) Elsevier’s abstract and citation database. www.scopus.com
Emam MM, Abdel Samee N, Jamjoom MM, Houssein EH (2023) Optimized deep learning architecture for brain tumor classification using improved hunger games search algorithm. Comput Biol Med 160:106966
Emary E, Zawbaa HM, Hassanien AE (2016) Binary grey wolf optimization approaches for feature selection. Neurocomputing 172:371–381
Fallahzadeh O, Dehghani-Bidgoli Z, Assarian M (2018) Raman spectral feature selection using ant colony optimization for breast cancer diagnosis. Lasers Med Sci 33(8):1799–1806
Fan F-L, Xiong J, Li M, Wang G (2021) On interpretability of artificial neural networks: a survey. IEEE Trans Radiat Plasma Med Sci 5(6):741–760
FEDESORIANO. Stroke prediction dataset (2021) https://www.kaggle.com/datasets/fedesoriano/stroke-prediction-dataset
Figueroa KC, Song B, Sunny S, Li S, Gurushanth K, Mendonca P, Mukhia N, Patrick S, Gurudath S, Raghavan S et al (2022) Interpretable deep learning approach for oral cancer classification using guided attention inference network. J Biomed Opt 27(1):015001–015001
Frank (2010) Machine learning repository. https://archive.ics.uci.edu/ml/index.php
Gama F, Tyskbo D, Nygren J, Barlow J, Reed J, Svedberg P (2022) Implementation frameworks for artificial intelligence translation into health care practice: scoping review. J Med Internet Res 24(1):e32215
Gao Y, Cai G-Y, Fang W, Li H-Y, Wang S-Y, Chen L, Yang Yu, Liu D, Sen X, Cui P-F et al (2020) Machine learning based early warning system enables accurate mortality risk prediction for covid-19. Nat Commun 11(1):5033
Ghoneim A, Muhammad G, Shamim Hossain M (2020) Cervical cancer classification using convolutional neural networks and extreme learning machines. Futur Gener Comput Syst 102:643–649
Gidde PS, Prasad SS, Singh AP, Bhatheja N, Prakash S, Singh P, Saboo A, Takhar R, Gupta S, Saurav S et al (2021) Validation of expert system enhanced deep learning algorithm for automated screening for covid-pneumonia on chest x-rays. Sci Rep 11(1):23210
Greensmith J (2007) The dendritic cell algorithm. PhD thesis, Citeseer
Guyon I, Weston J, Barnhill S, Vapnik V (2002) Gene selection for cancer classification using support vector machines. Mach Learn 46:389–422
Guyon I, Gunn S, Nikravesh M, Zadeh LA (2008) Feature extraction: foundations and applications, vol 207. Springer, Cham
Habib M, Aljarah I, Faris H, Mirjalili S (2020). Multi-objective particle swarm optimization: theory, literature review, and application in feature selection for medical diagnosis. Evolut Mach Learn Tech: Algorithms Appl, 175–201
Haitam E, Ayoub A, Najat R, Jaafar A (2022) An approach based on multi-agent and artificial immune algorithm for the vehicle routing problem in home-health care. In Advances in Information, Communication and Cybersecurity: Proceedings of ICI2C’21, pages 425–436. Springer
Hall MA (1999) Correlation-based feature selection for machine learning. PhD thesis, The University of Waikato
Hans R, Kaur H (2020) Hybrid binary sine cosine algorithm and ant lion optimization (Scalo) approaches for feature selection problem. Int J Comput Mater Sci Eng 9(01):1950021
Hatamlou A (2013) Black hole: a new heuristic optimization approach for data clustering. Inf Sci 222:175–184
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778
Henderson D, Jacobson SH, Johnson AW (2003) The theory and practice of simulated annealing. Handbook of metaheuristics, pages 287–319
Hepatitis. UCI Machine Learning Repository, (1988). https://doi.org/10.24432/C5Q59J
Hong ZQ, Yang JY (1992) Lung Cancer. UCI Machine Learning Repository. https://doi.org/10.24432/C57596
Houssein EH, Sayed A (2023) Dynamic candidate solution boosted beluga whale optimization algorithm for biomedical classification. Mathematics 11(3):707
Houssein EH, Sayed A (2023) A modified weighted mean of vectors optimizer for chronic kidney disease classification. Comput Biol Med 155:106691
Houssein EH, Saber E, Ali AA, Wazery YM (2021) Opposition-based learning tunicate swarm algorithm for biomedical classification. In 2021 17th International Computer Engineering Conference (ICENCO), pages 1–6. IEEE
Houssein Essam H, Mohamed Gaber M, Samee Nagwan Abdel, Alkanhel Reem, Ibrahim Ibrahim A, Wazery Yaser M (2023) An improved search and rescue algorithm for global optimization and blood cell image segmentation. Diagnostics 13(8):1422
Houssein EH, Abdel Samee N, Mahmoud NF, Hussain K (2023) Dynamic coati optimization algorithm for biomedical classification tasks. Comput Biol Med 164:107237
Houssein EH, Hosney ME, Mohamed WM, Ali AA, Younis EMG (2023) Fuzzy-based hunger games search algorithm for global optimization and feature selection using medical data. Neural Comput Appl 35(7):5251–5275
Hussein Alkeshuosh A, Zomorodi Moghadam M, Mansoori IA, Abdar M (2017) Using PSO algorithm for producing best rules in diagnosis of heart disease. In 2017 international conference on computer and applications (ICCA), 306–311. IEEE
Iam P, de Sousa Marley, Rebuzzi VMB, Eduardo C, da Silva (2019) Local interpretable model-agnostic explanations for classification of lymph node metastases. Sensors 19(13):2969
Ieracitano C, Mammone N, Versaci M, Varone G, Ali A-R, Armentano A, Calabrese G, Ferrarelli A, Turano L, Tebala C et al (2022) A fuzzy-enhanced deep learning approach for early detection of covid-19 pneumonia from portable chest X-ray images. Neurocomputing 481:202–215
Ilter N, Guvenir H (1998) Dermatology. UCI Machine Learning Repository. https://doi.org/10.24432/C5FK5P
Ismail Sayed G, Darwish A, Ella Hassanien A, Pan AJ-S (2017) Breast cancer diagnosis approach based on meta-heuristic optimization algorithm inspired by the bubble-net hunting strategy of whales. In Genetic and Evolutionary Computing: Proceedings of the Tenth International Conference on Genetic and Evolutionary Computing, November 7-9, 2016 Fuzhou City, Fujian Province, China 10, pages 306–313. Springer
Jain PK, Yekun EA, Pamula R, Srivastava G (2021) Consumer recommendation prediction in online reviews using cuckoo optimized machine learning models. Comput Electr Eng 95:107397
Janiesch C, Zschech P, Heinrich K (2021) Machine learning and deep learning. Electron Mark 31(3):685–695
Janosi R, Andras (1988) Heart disease. UCI Machine Learning Repository. https://doi.org/10.24432/C52P4X
Kamel SR, Yaghoubzadeh R (2021) Feature selection using grasshopper optimization algorithm in diagnosis of diabetes disease. Inf Med 26:100707
Karaboga D (2010) Artificial bee colony algorithm. Scholarpedia 5(3):6915
Karaboga D, Basturk B (2007) A powerful and efficient algorithm for numerical function optimization: artificial bee colony (ABC) algorithm. J Global Optim 39:459–471
Kaur K and Kumar Y (2020) Swarm intelligence and its applications towards various computing: a systematic review. In 2020 International conference on intelligent engineering and management (ICIEM), 57–62. IEEE
Kaur M, Gianey HK, Singh D, Sabharwal M (2019) Multi-objective differential evolution based random forest for E-health applications. Mod Phys Lett B 33(05):1950022
Kaur I, Sandhu AK, Kumar Y (2022) Artificial intelligence techniques for predictive modeling of vector-borne diseases and its pathogens: a systematic review. Arch Comput Methods Eng 29(6):3741–3771
Kavitha P, Prabakaran S (2019) A novel hybrid segmentation method with particle swarm optimization and fuzzy c-mean based on partitioning the image for detecting lung cancer. Preprints
Kendale S, Kulkarni P, Rosenberg AD, Wang J (2018) Supervised machine-learning predictive analytics for prediction of postinduction hypotension. Anesthesiology 129(4):675–688
Khalid AM, Hamza HM, Mirjalili S, Hosny KM (2022) Bcovidoa: a novel binary coronavirus disease optimization algorithm for feature selection. Knowl-Based Syst 248:108789
Khan MA and Algarni F (2020) A healthcare monitoring system for the diagnosis of heart disease in the IOMT cloud environment using MSSO-ANFIS. IEEE Access 8:122259–122269
Koch S (2006) Home telehealth—current state and future trends. Int J Med Informatics 75(8):565–576
Kononenko I (1994) Estimating attributes: Analysis and extensions of relief. In European conference on machine learning, 171–182. Springer
Koutny T (2016) Using meta-differential evolution to enhance a calculation of a continuous blood glucose level. Comput Methods Programs Biomed 133:45–54
Koza JR et al (1994) Genetic programming II, vol 17. MIT Press Cambridge, Cambridge
Krizhevsky A, Sutskever I, and Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, 1097–1105
Kulkarni AJ, Mezura-Montes E, Wang Y, Gandomi AH, Krishnasamy G (2021) Constraint handling in metaheuristics and applications. Springer, Cham
Kumar Y, Gupta S (2023) Deep transfer learning approaches to predict glaucoma, cataract, choroidal neovascularization, diabetic macular edema, drusen and healthy eyes: an experimental review. Arch Comput Methods Eng 30(1):521–541
Kumar Arora Y, Tandon A, Nijhawan R (2019) Hybrid computational intelligence technique: Eczema detection. In TENCON 2019-2019 IEEE Region 10 Conference (TENCON), 2472–2474. IEEE
Kumar A, Sai Satyanarayana Reddy S, Baig Mahommad G, Khan B, Sharma R, et al (2022) Smart healthcare: disease prediction using the cuckoo-enabled deep classifier in IOT framework. Scientific Programming, 2022
Kumar A, Nadeem M, Banka H (2023) Nature inspired optimization algorithms: a comprehensive overview. Evol Syst 14(1):141–156
Kuo RJ, Shih CW (2007) Association rule mining through the ant colony system for national health insurance research database in Taiwan. Comput Math Appl 54(11–12):1303–1318
Kuo RJ, Lin SY, Shih CW (2007) Mining association rules through integration of clustering analysis and ant colony system for health insurance database in Taiwan. Expert Syst Appl 33(3):794–808
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Lee Y-M, Choi C-S, Hwang S-G, Dong Kim H, Hong Min C, Park J-H, Lee H, Seon Kim T, Lee C-H (2007) Ubiquitous evolvable hardware system for heart disease diagnosis applications. In Reconfigurable Computing: Architectures, Tools and Applications: Third International Workshop, ARC 2007, Mangaratiba, Brazil, March 27-29, 2007. Proceedings 3, 283–292. Springer
Lee S-I, Celik S, Logsdon BA, Lundberg SM, Martins TJ, Oehler VG, Estey EH, Miller CP, Chien S, Dai J et al (2018) A machine learning approach to integrate big data for precision medicine in acute myeloid leukemia. Nat Commun 9(1):42
Lepikhin D, Lee H, Xu Y, Chen D, Firat O, Huang Y, Krikun M, Shazeer N, Gshard Z (2020) Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668
Li X, Zhang J, and Safara F (2021) Improving the accuracy of diabetes diagnosis applications through a hybrid feature selection algorithm. Neural Processing Letters, pages 1–17
Li Z, Liu F, Yang W, Peng S, and Zhou J (2021) A survey of convolutional neural networks: analysis, applications, and prospects. IEEE Trans Neural Netw Learn Syst
Little M (2008) Parkinsons. UCI Machine Learning Repository. https://doi.org/10.24432/C59C74
Liz H, Sánchez-Montañés M, Tagarro A, Domínguez-Rodríguez S, Dagan R, Camacho D (2021) Ensembles of convolutional neural network models for pediatric pneumonia diagnosis. Futur Gener Comput Syst 122:220–233
Lobato FS, Steffen V Jr (2014) Fish swarm optimization algorithm applied to engineering system design. Latin Am J Solids Struct 11:143–156
Lodha P, Talele A, Degaonkar K (2018) Diagnosis of Alzheimer’s disease using machine learning. In 2018 fourth international conference on computing communication control and automation (ICCUBEA), 1–4. IEEE
Lubicz R (2013) Konrad. Thoracic Surgery Data. UCI Machine Learning Repository. https://doi.org/10.24432/C5Z60N
Madhusudhanan S, Karnan M, Rajivgandhi K (2010) Fuzzy based ant miner algorithm in datamining for hepatitis. In 2010 International Conference on Signal Acquisition and Processing, 229–232. IEEE
Mafarja M, Mirjalili S (2018) Whale optimization approaches for wrapper feature selection. Appl Soft Comput 62:441–453
Magesh PR, Myloth RD, Tom RJ (2020) An explainable machine learning model for early detection of Parkinson’s disease using lime on Datscan imagery. Comput Biol Med 126:104041
Majno G, Joris I (2004) Cells, tissues, and disease: principles of general pathology. Oxford University Press, Oxford
Masud M, Singh P, Gaba GS, Kaur A, Alroobaea R, Alrashoud M, Alqahtani SA (2021) Crowd: crow search and deep learning based feature extractor for classification of parkinson‒s disease. ACM Trans Internet Technol (TOIT) 21(3):1–18
McKendrick J (2021) AI adoption skyrocketed over the last 18 months. Harvard Business Review
Medjahed SA, Ait Saadi T, Benyettou A, Ouali M (2016) Gray wolf optimizer for hyperspectral band selection. Appl Soft Comput 40:178–186
Mehta VK, Deb PS, Subba RD (1994) Application of computer techniques in medicine. Med J Armed Forces India 50(3):215–218
Milenković A, Otto C, Jovanov E (2006) Wireless sensor networks for personal health monitoring: issues and an implementation. Comput Commun 29(13–14):2521–2533
Ming Leung K, et al (2007) Naive bayesian classifier. Polytechnic University Department of Computer Science/Finance and Risk Engineering, 2007:123–156
Mirjalili S (2016) SCA: a sine cosine algorithm for solving optimization problems. Knowl-Based Syst 96:120–133
Mirjalili S, Mirjalili S (2019) Genetic algorithm. Evolutionary Algorithms and Neural Networks: Theory and Applications, 43–55
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61
Mishra KK, Tiwari S, Misra AK (2011) A bio inspired algorithm for solving optimization problems. In 2011 2nd International Conference on Computer and Communication Technology (ICCCT-2011), 653–659. IEEE
Mishra S, Kumar Thakkar H, Singh P, Sharma G (2022) A decisive metaheuristic attribute selector enabled combined unsupervised-supervised model for chronic disease risk assessment. Comput Intell Neurosci 2022(1):8749353
Mitchell TM (1997) Machine learning
Molnar C (2020) Interpretable machine learning. Lulu. com
Moreira IC, Amaral I, Domingues I, Cardoso A, Cardoso MJ, Cardoso JS (2012) Inbreast: toward a full-field digital mammographic database. Acad Radiol 19(2):236–248
Moura Daniel C, Guevara Miguel A, López (2013) An evaluation of image descriptors combined with clinical data for breast cancer diagnosis. Int J Comput Assist Radiol Surg 8(4):561–574
MRSANTOS (2019) Hepatocellular carcinoma dataset. The Home of Data Science. https://www.kaggle.com/datasets/mrsantos/hcc-dataset
Muntasir Nishat M, Faisal F, Rahman Dip R, Nasrullah SM, Ahsan R, Shikder F, Asfi-Ar-Raihan Asif M, Ashraful Hoque M (2021) A comprehensive analysis on detecting chronic kidney disease by employing machine learning algorithms. EAI Endorsed Trans Pervasive Health Technol 7(29):e1
Nagajyothi D, Addagudi R, Gunda T, Santhoshi Logitla S (2020) Detection of lung cancer using SVM classifier. Int J Emerg Trends Eng Res. https://doi.org/10.30534/ijeter/2020/113852020
Nalini Priya G, Anandhakumar P, Maheswari KG (2008) Dynamic scheduler-a pervasive healthcare system in smart hospitals using rfid. In 2008 International Conference on Computing, Communication and Networking, 1–6. IEEE
Nanglia P, Kumar S, Mahajan AN, Singh P, Rathee D (2021) A hybrid algorithm for lung cancer classification using SVM and neural networks. ICT Express 7(3):335–341
Nassif AB, Talib MA, Nasir Q, Afadar Y, Elgendy O (2022) Breast cancer detection using artificial intelligence techniques: a systematic literature review. Artif Intell Med 127:102276
Neves I, Folgado D, Santos S, Barandas M, Campagner A, Ronzio L, Cabitza F, Gamboa H (2021) Interpretable heartbeat classification using local model-agnostic explanations on ECGS. Comput Biol Med 133:104393
Nicholson Price W, Gerke S, Glenn Cohen I (2019) Potential liability for physicians using artificial intelligence. JAMA 322(18):1765–1766
Nusinovici S, Tham YC, Chak MY, Yan DS, Ting W, Li J, Sabanayagam C, Wong TY, Cheng C-Y (2020) Logistic regression was as good as machine learning for predicting major chronic diseases. J Clin Epidemiol 122:56–69
Oliveira JEE, Gueld MO, de A Araújo A, Ott B, Deserno TM (2008) Toward a standard reference database for computer-aided mammography. In Medical Imaging 2008: Computer-Aided Diagnosis, volume 6915, page 69151Y. International Society for Optics and Photonics
O’Shea K and Nash R (2015) An introduction to convolutional neural networks. arXiv preprint arXiv:1511.08458
Osman IH and Kelly JP (1996) Meta-heuristics
Oztekin A, Pajouh FM, Delen D, Swim LK (2010) An RFID network design methodology for asset tracking in healthcare. Decis Support Syst 49(1):100–109
Panigrahi A, Bhutia S, Sahu B, Galety MG, Nandan Mohanty S (2022) Bpso-PSO-SVM: an integrated approach for cancer diagnosis. In Disruptive Technologies for Big Data and Cloud Applications: Proceedings of ICBDCC 2021, 571–579. Springer
Pashaei E, Pashaei E (2020) Gene selection for cancer classification using a new hybrid of binary black hole algorithm. In 2020 28th Signal Processing and Communications Applications Conference (SIU), 1–4. IEEE
Patel HH, Prajapati P (2018) Study and analysis of decision tree based classification algorithms. Int J Comput Sci Eng 6(10):74–78
Patel V, Shah S, Trivedi H, Naik U (2020) An analysis of lung tumor classification using SVM and ANN with GLCM features. In Proceedings of First International Conference on Computing, Communications, and Cyber-Security (IC4S 2019), 273–284. Springer
Pavlyukevich I (2007) Lévy flights, non-local search and simulated annealing. J Comput Phys 226(2):1830–1844
Periasamy K, Periasamy S, Velayutham S, Zhang Z, Ahmed ST, Jayapalan A (2022) A proactive model to predict osteoporosis: an artificial immune system approach. Expert Syst 39(4):e12708
Peterson LE (2009) K-nearest neighbor. Scholarpedia 4(2):1883
Potvin J-Y and Smith KA (2003) Artificial neural networks for combinatorial optimization. In Handbook of metaheuristics, pages 429–455. Springer
Probst P, Boulesteix A-L, Bischl B (2019) Tunability: importance of hyperparameters of machine learning algorithms. J Mach Learn Res 20(1):1934–1965
Qiao W, Yang Z (2019) Solving large-scale function optimization problem by using a new metaheuristic algorithm based on quantum dolphin swarm algorithm. IEEE Access 7:138972–138989
Quan C, Ren K, Luo Z (2021) A deep learning based method for Parkinson’s disease detection using dynamic features of speech. IEEE Access 9:10239–10252
Quinlan R (1987) Thyroid Disease. UCI Machine Learning Repository. https://doi.org/10.24432/C5D010
Ragab DA, Attallah O, Sharkas M, Ren J, Marshall S (2021) A framework for breast cancer classification using multi-DCNNS. Comput Biol Med 131:104245
Rajiv Gandhi K, Karnan M, Kannan S (2010) Classification rule construction using particle swarm optimization algorithm for breast cancer data sets. In 2010 International Conference on Signal Acquisition and Processing, 233–237. IEEE
Ramadan A, Wajeeh Jasim Mohammed, El-Bakry Hazem M, Mohamed Hamed N, Taha Khalifa EM (2020) Breast and colon cancer classification from gene expression profiles using data mining techniques. Symmetry 12(3):408
Rashedi E, Nezamabadi-Pour H, Saryazdi S (2009) Gsa: a gravitational search algorithm. Inf Sci 179(13):2232–2248
Razmjooy N, Razmjooy S (2020) Skin melanoma segmentation using neural networks optimized by quantum invasive weed optimization algorithm. In Metaheuristics and optimization in computer and electrical engineering, 233–250. Springer
Reeves CR (2010) Genetic algorithms. Handbook of Metaheuristics, pages 109–139
Remeseiro B, Bolon-Canedo V (2019) A review of feature selection methods in medical applications. Comput Biol Med 112:103375
Ripley RM, Harris AL, Tarassenko L (1998) Neural network models for breast cancer prognosis. Neural Comput Appl 7(4):367–375
Rubini S (2015) Chronic kidney disease. UCI Machine Learning Repository. https://doi.org/10.24432/C5G020
Ruggieri S (2002) Efficient c4.5 [classification algorithm]. IEEE Trans Knowl Data Eng 14(2):438–444
Russakovsky O, Deng J, Hao S, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M et al (2015) Imagenet large scale visual recognition challenge. Int J Comput Vision 115(3):211–252
Sahu B, Mohanty S, Rout S (2019) A hybrid approach for breast cancer classification and diagnosis. EAI Endorsed Trans Scalable Inf Syst. https://doi.org/10.4108/eai.19-12-2018.156086
Sajid A, Abbas H (2016) Data privacy in cloud-assisted healthcare systems: state of the art and future challenges. J Med Syst 40(6):155
Sally L, Christie GA, Nguyen TT, Freeman JD, Hsu EB (2022) Applications of artificial intelligence and machine learning in disasters and public health emergencies. Disaster Med Public Health Prep 16(4):1674–1681
Saroja T, Kalpana Y (2023) Adaptive weight dynamic butterfly optimization algorithm (adboa)-based feature selection and classifier for chronic kidney disease (ckd) diagnosis. Int J Comput Intell Appl 22(01):2341001
Saw SN, Ng KH (2022) Current challenges of implementing artificial intelligence in medical imaging. Physica Medica 100:12–17
Shafiq S, Sabbir Ahmed M, Kaiser S, Mufti Mahmud Md, Hossain S, Andersson K (2022) Comprehensive analysis of nature-inspired algorithms for Parkinson’s disease diagnosis. IEEE Access 11:1629–1653
Shanmugam S, Preethi J (2019) Improved feature selection and classification for rheumatoid arthritis disease using weighted decision tree approach (react). J Supercomput 75:5507–5519
Shehab M, Abualigah L, Shambour Abu-Hashem MA, Yousef Shambour MK, Alsalibi AI, Gandomi AH (2022) Machine learning in medical applications: a review of state-of-the-art methods. Comput Biol Med 145:105458
Shen L, Chen H, Zhe Yu, Kang W, Zhang B, Li H, Yang B, Liu D (2016) Evolving support vector machines using fruit fly optimization for medical data classification. Knowl-Based Syst 96:61–75
Shirazi F, Rashedi E (2016) Feature weighting for cancer tumor detection in mammography images using gravitational search algorithm. In 2016 6th International Conference on Computer and Knowledge Engineering (ICCKE), 310–313. IEEE
Shukla Shubhendu S, Vijay J (2013) Applicability of artificial intelligence in different fields of life. Int J Sci Eng Res 1(1):28–35
Shyh-Jong W, Chuang L-Y, Lin Y-D, Ho W-H, Chiang F-T, Yang C-H, Chang H-W (2013) Particle swarm optimization algorithm for analyzing SNP-SNP interaction of renin-angiotensin system genes against hypertension. Mol Biol Rep 40:4227–4233
Simonyan K and Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
Sindhu R, Ngadiran R, Yacob YM, Zahri NAH, Hariharan M (2017) Sine-cosine algorithm for feature selection with elitism strategy and new updating mechanism. Neural Comput Appl 28:2947–2958
Singh RK, Pandey R, Babu RN (2021) Covidscreen: explainable deep learning framework for differential diagnosis of covid-19 using chest X-rays. Neural Comput Appl 33:8871–8892
Soulami KB, Ghribi E, Saidi MN, Tamtaoui A, Kaabouch N (2019) Breast cancer: segmentation of mammograms using invasive weed optimization and susan algorithms. In 2019 IEEE International Conference on Electro Information Technology (EIT), 1–7. IEEE
Stenroos O, et al (2017) Object detection from images using convolutional neural networks. Aalto University
Storn R (1996) On the usage of differential evolution for function optimization. In Proceedings of North American fuzzy information processing, 519–523. IEEE
Suan Mung P, Phyu S (2020) Effective analytics on healthcare big data using ensemble learning. In 2020 IEEE Conference on Computer Applications (ICCA), 1–4. IEEE
Suckling P (1994) The mammographic image analysis society digital mammogram database. Digital Mammo, 375–386
SVETLANA ULIANOVA (2019) Cardiovascular disease dataset. The Home of Data Science. https://www.kaggle.com/datasets/sulianova/cardiovascular-disease-dataset
Swain PH, Hauska H (1977) The decision tree classifier: design and potential. IEEE Trans Geosci Electron 15(3):142–147
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1–9
Szegedy C, Ioffe S, Vanhoucke V, Alemi AA (2017)Inception-v4, inception-resnet and the impact of residual connections on learning. In Thirty-first AAAI conference on artificial intelligence, 4278–4284
Tahmouresi A, Rashedi E, Yaghoobi MM, Rezaei M (2022) Gene selection using pyramid gravitational search algorithm. PLoS ONE 17(3):e0265351
Tharwat A, Hassanien AE, Elnaghi BE (2017) A Ba-based algorithm for parameter optimization of support vector machine. Pattern Recogn Lett 93:13–22
The University of Iowa. University of Iowa health care. https://medicine.uiowa.edu/eye/inspire-datasets, 1925
Timmis J, Knight T, de Castro LN, Hart E (2004) An overview of artificial immune systems. Computation in cells and tissues: perspectives and tools of thought, 51–91
Timmis J, Hone A, Stibor T, Clark E (2008) Theoretical advances in artificial immune systems. Theoret Comput Sci 403(1):11–32
Toğaçar M, Ergen B, Cömert Z (2020) Covid-19 detection using deep learning models to exploit social mimic optimization and structured chest x-ray images using fuzzy color and stacking approaches. Comput Biol Med 121:103805
Too J, Mirjalili S (2021) A hyper learning binary dragonfly algorithm for feature selection: a covid-19 case study. Knowl-Based Syst 212:106553
Topol EJ (2019) High-performance medicine: the convergence of human and artificial intelligence. Nat Med 25(1):44–56
Tsai C-W, Rodrigues JJPC (2013) Metaheuristic scheduling for cloud: a survey. IEEE Syst J 8(1):279–291
Tubishat M, Idris N, Shuib L, Abushariah MAM, Mirjalili S (2020) Improved SALP swarm algorithm based on opposition based learning and novel local search algorithm for feature selection. Expert Syst Appl 145:113122
Uddin MZ, Soylu A (2021) Human activity recognition using wearable sensors, discriminant analysis, and long short-term memory-based neural structured learning. Sci Rep 11(1):16455
Uddin MZ, Dysthe KK, Følstad A, Brandtzaeg PB (2022) Deep learning for prediction of depressive symptoms in a large textual dataset. Neural Comput Appl 34(1):721–744
Uma S, Kirubakaran E (2012) Intelligent heart diseases prediction system using a new hybrid metaheuristic algorithm. Int J Eng Res Technol 1(8):1–7
Varghese SA, Powell TB, Janech MG, Budisavljevic MN, Stanislaus RC, Almeida JS, Arthur JM (2010) Identification of diagnostic urinary biomarkers for acute kidney injury. J Investig Med 58(4):612–620
Vatsa M, Singh R, Noore A (2005) Improving biometric recognition accuracy and robustness using DWT and SVM watermarking. IEICE Electron Express 2(12):362–367
Venter G, Sobieszczanski-Sobieski J (2003) Particle swarm optimization. AIAA J 41(8):1583–1589
Vikhar PA (2016) Evolutionary algorithms: a critical review and its future prospects. In 2016 International conference on global trends in signal processing, information computing and communication (ICGTSPICC), 261–265. IEEE
Wazery YM, Saber E, Houssein EH, Ali AA, Amer E (2021) An efficient slime mould algorithm combined with k-nearest neighbor for medical classification tasks. IEEE Access 9:113666–113682
Wickramasinghe I, Kalutarage H (2021) Naive bayes: applications, variations and vulnerabilities: a review of literature with code snippets for implementation. Soft Comput 25(3):2277–2293
Witten IH, Frank E (2002) Data mining: practical machine learning tools and techniques with java implementations. ACM SIGMOD Rec 31(1):76–77
Wolberg W (1995) William. Breast Cancer Wisconsin (Diagnostic). UCI Machine Learning Repository. https://doi.org/10.24432/C5DW2B
Wolberg WH, Mangasarian OL (1990) Multisurface method of pattern separation for medical diagnosis applied to breast cytology. Proc Natl Acad Sci USA 87(23):9193–9196
Wolberg WH, Nick Street W, Mangasarian OL (1992) Breast cancer wisconsin (diagnostic) data set. UCI Machine Learning Repository, http://archive.ics.uci.edu/ml/
Wyld DC (2022) The black swan of the coronavirus and how American organizations have adapted to the new world of remote work. Euro J Business Manag Res 7(1):9–19
Xie S, Girshick R, Dollár P, Tu Z, and He K (2017) Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1492–1500
Xie W, Wang L, Kun Yu, Shi T, Li W (2023) Improved multi-layer binary firefly algorithm for optimizing feature selection and classification of microarray data. Biomed Signal Process Control 79:104080
Xin-She Yang (2009) Harmony search as a metaheuristic algorithm. Music-inspired harmony search algorithm: theory and applications, 1–14
Xin-She Yang (2012) Flower pollination algorithm for global optimization. In International conference on unconventional computing and natural computation, pages 240–249. Springer
Xing B, Gao W-J, Xing B, Gao W-J (2014) Invasive weed optimization algorithm. Innovative Computational Intelligence: A Rough Guide to 134 Clever Algorithms, pages 177–181
Yang XS, Deb S (2009) Cuckoo search via lévy flights, proceeings of world congress on nature & biologically inspired computing (nabic 2009, India)
Yang X-S, He X (2013) Bat algorithm: literature review and applications. Int J Bio-Inspired Comput 5(3):141–149
Yap MH, Pons G, Martí J, Ganau S, Sentís M, Zwiggelaar R, Davison AK, Martí R (2017) Automated breast ultrasound lesions detection using convolutional neural networks. IEEE J Biomed Health Inform 22(4):1218–1226
Yeh J-Y, Lin W-S (2007) Using simulation technique and genetic algorithm to improve the quality care of a hospital emergency department. Expert Syst Appl 32(4):1073–1083
Yeh W-C, Chang W-W, Ying Chung Y (2009) A new hybrid approach for mining breast cancer pattern using discrete particle swarm optimization and statistical method. Expert Syst Appl 36(4):8204–8211
You SC, Lee S, Cho S-Y, Park H, Jung S, Cho J, Yoon D, Park RW (2017) Conversion of national health insurance service-national sample cohort (NHIS-NSC) database into observational medical outcomes partnership-common data model (OMOP-CDM). In MEDINFO 2017: Precision Healthcare through Informatics, 467–470. IOS Press
Zamani H, Nadimi-Shahraki M-H (2016) Feature selection based on whale optimization algorithm for diseases diagnosis. Int J Comput Sci Inf Secur 14(9):1243
Zargar G, Tanha AA, Parizad A, Amouri M, Bagheri H (2020) Reservoir rock properties estimation based on conventional and NMR log data using ann-cuckoo: a case study in one of super fields in Iran southwest. Petroleum 6(3):304–310
Zhao Z, Liu H (2009) Searching for interacting features in subset selection. Intell Data Anal 13(2):207–228
Zwitter M, Soklic M (1988) Primary Tumor. UCI Machine Learning Repository, https://doi.org/10.24432/C5WK5Q
Zwitter M, Soklic M (1988) Lymphography. UCI Machine Learning Repository, https://doi.org/10.24432/C54598
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
Essam H. Houssein: Supervision, Methodology, Conceptualization, Software, Formal analysis, Visualization, Validation, Writing—review & editing. Eman Saber: Validation, Visualization, Data curation, Resources, Writing—original draft, Writing—review & editing, Conceptualization, Resources, Writing—original draft, Writing—review & editing. Abdelmgeid A. Ali: Supervision. Yaser M. Wazery: Supervision. All authors read and approved the final paper.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no Conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Houssein, E.H., Saber, E., Ali, A.A. et al. Integrating metaheuristics and artificial intelligence for healthcare: basics, challenging and future directions. Artif Intell Rev 57, 205 (2024). https://doi.org/10.1007/s10462-024-10822-2
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-024-10822-2