
Abstract
Data mining and analysis are critical for preventing or mitigating natural hazards. However, data availability in natural hazard analysis is experiencing unprecedented challenges due to economic, technical, and environmental constraints. Recently, generative deep learning has become an increasingly attractive solution to these challenges, which can augment, impute, or synthesize data based on these learned complex, high-dimensional probability distributions of data. Over the last several years, much research has demonstrated the remarkable capabilities of generative deep learning for addressing data-related problems in natural hazards analysis. Data processed by deep generative models can be utilized to describe the evolution or occurrence of natural hazards and contribute to subsequent natural hazard modeling. Here we present a comprehensive review concerning generative deep learning for data generation in natural hazard analysis. (1) We summarized the limitations associated with data availability in natural hazards analysis and identified the fundamental motivations for employing generative deep learning as a critical response to these challenges. (2) We discuss several deep generative models that have been applied to overcome the problems caused by limited data availability in natural hazards analysis. (3) We analyze advances in utilizing generative deep learning for data generation in natural hazard analysis. (4) We discuss challenges associated with leveraging generative deep learning in natural hazard analysis. (5) We explore further opportunities for leveraging generative deep learning in natural hazard analysis. This comprehensive review provides a detailed roadmap for scholars interested in applying generative models for data generation in natural hazard analysis.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Natural hazards are commonly referred to as geophysical, atmospheric, and hydrological events, arising from complex interactions within the Earth system across various spatial-temporal scales. These hazards, including floods, droughts, heatwaves, cyclones, volcanic eruptions, earthquakes, rockfalls, landslides, and avalanches, have led to significant economic and environmental impacts (Merz et al. 2020; McPhillips et al. 2018). Over the past decade, the escalation of these events has been notable. For example, in the period from 2010 to 2019, with an average annual economic loss of more than $187 billion attributed to natural hazards and a total economic loss of $2.98 trillion, which is $1.19 trillion higher than the loss incurred during the period from 2000 to 2009, and displacing an annual average of 24 million people. In 2020 alone, the economic toll reached approximately $268 billion. Furthermore, climate change is intensifying these hazards in frequency and severity, as exemplified by increasingly frequent and intense extreme heat events, prolonged droughts, and coastal flooding, leading to more severe consequences (Hirabayashi et al. 2013; Meehl and Tebaldi 2004).
Mitigating the adverse global impacts of natural hazards is therefore attracting increasing interest. There has been extensive research devoted to a comprehensive analysis of natural hazards, including the investigation of natural hazard mechanisms, risk assessment of natural hazards, prediction and warning of natural hazards, and emergency responses to natural hazards, which cover various scenarios before, during, and after natural hazard events (Cui et al. 2021).
Specifically, a deep understanding of natural hazards, including accurate attribution, is a prerequisite. For example, analyzing the dynamics of nonstationary multivariate processes facilitates assessing the risk of compound coastal flooding due to climate change-induced sea level rise (Bevacqua et al. 2021). Then, assessing the risk of potential hazard events can provide meaningful insights into their impacts. For example, landslide susceptibility assessment consists of estimating risk levels to enable the implementation of appropriate mitigation practices when risk levels are unacceptable, which presents the probability of landslides (Dai et al. 2002). Moreover, forecasts focus on the physical characteristics of upcoming natural hazard events, including the magnitude, spatial extent, and duration of the impending event (Merz et al. 2020). For example, active volcano forecasting focuses on unrest and eruptions (Ma et al. 2022d). Storm surge forecasting provides information about future trends in surge heights or total water levels (Rego and Li 2009; Dullaart et al. 2020). Based on forecasting results, an early warning system disseminates hazard-related information in advance of events that could pose threats. An earthquake early warning system, for example, may alert a target location between seconds and minutes before ground shaking is caused by an earthquake. In the event of a hazard, emergency responses involve assessments of the extent, severity, and socioeconomic effects to facilitate effective and efficient rescue operations, including evacuations. For example, conducting change detection to identify and map post-event damaged areas (Esposito et al. 2020; Mondini et al. 2021b; Mazzanti et al. 2022).
Data are integral to the aforementioned natural hazard analysis, facilitating the understanding, forecasting, and investigating a range of natural hazards, such as floods, volcanoes, earthquakes, wildfires, and landslides. Varied data sources are involved, ranging from remote sensing data obtained via different sensors and platforms (e.g., satellites, UAVs) to in situ observations, encompassing meteorological and climatological models.
Typically, data inform physics-based and data-driven models and characterize events, thus achieving attribution and prediction. Here, we have categorized the relevant data into two groups to delineate their diverse roles in natural hazard analysis: (i) general information about influencing factors and (ii) specific information characterizing the hazard itself. General information encompasses environmental and contextual data that contribute to or trigger hazard events, including meteorological data (e.g., rainfall, temperature, wind speed) and geophysical data (e.g., seismic records). Specific information quantifies the hazard event’s physical properties, spatiotemporal extent, and impact, including hazard magnitude (e.g., earthquake magnitude, hurricane wind speed, flood water level), spatial footprint (e.g., inundation area, landslide extent), temporal evolution (e.g., progression of a hurricane), impact data (e.g., damage assessments), and direct observations (e.g., satellite imagery).
Both general and specific information can provide insights into the underlying processes and physical phenomena for hazard evolutions, thus further facilitating versatile natural hazard analysis. However, the availability of data essential for natural hazard analysis is currently facing severe limitations due to environmental, economic, and technological factors. These limitations primarily manifest as low resolution, missing, noise, and scarcity, posing significant challenges in developing accurate and reliable models for advancing understanding, forecasting, and risk assessment of natural hazards.
First, the low resolution of data is a significant limitation in analyzing natural hazards at the local and regional levels. For example, due to insufficient computational resources, physical limitations, or incomplete information, publicly available remote sensing datasets and raw climate forecasts from weather and climate models tend to have an insufficient resolution.
Second, missing data prevents a sufficient description or accurate estimate of natural hazards, mainly due to inherent deficiencies or external influences of various devices that collect data. For example, outdoor monitoring devices are prone to environmental damage during in situ monitoring.
Third, noise tends to contaminate information available to analyze natural hazards, thereby reducing the signal-to-noise ratio and ultimately limiting data availability. Seismic networks, for example, record seismic signals with various noises. Random noise and surface waves may submerge the effective signal to an almost complete extent.
Fourth, scarce data may prevent the analysis of natural hazards (Grezio et al. 2017). Due to a lack of financial resources to support observation networks, it is difficult to operate and maintain monitoring devices that collect data for natural hazard analysis (Sun et al. 2018). Furthermore, the relative rarity of natural hazards causes data imbalances in label datasets employed for natural hazard analysis, which causes data scarcity.
Furthermore, the data uncertainty can be attributed to the quality, completeness, and availability of the data, which can affect the reliability of natural hazard analysis. For example, in flood modeling, uncertain data may result from the accuracy and spatial distribution of rainfall data, the reliability of river flow data, and the accuracy of terrain and land use data, which adversely affect flood models and flood risk assessments.
Analyzing natural hazards is impeded by the aforementioned limitations. In particular, over the past few years, integrating evolving data-driven paradigms, such as deep learning, into natural hazard analysis underscores a pressing challenge: the scarcity of adequate training data. Without sufficient training datasets, the effectiveness of data-driven models in detecting or predicting natural hazards is significantly compromised. This is the crux of the issue: the motivation for using advanced methodologies, such as deep learning, is their ability to discern complex patterns in hazard data, but their improvement heavily depends on access to large-scale, labeled datasets (Ma and Mei 2021).
Several approaches previously explored hold the potential to mitigate the aforementioned data availability limitations. For instance, crowdsourcing can provide essential information for natural hazard analysis through low-cost sensors or social media databases. Nevertheless, the privacy of collected data from this approach is not guaranteed (Zheng et al. 2018). Moreover, crowdsourcing only serves as a complementary data source for solving the problem of missing data and does not solve, for example, other limitations in data quality. Other solutions attempt to enhance data but may also have inherent limitations. For example, empirical-statistical downscaling methods in climate models may include a significant element of bias correction (Sonnewald et al. 2021).
In recent years, generative deep learning, a rapidly evolving subfield within deep learning, has emerged as a remarkably potent solution for analyzing natural hazards. Deep generative models typically generate data based on the probability distributions of existing datasets. By leveraging neural networks and advanced training strategies, these models have demonstrated exceptional performance in various fields, including in addressing the limitations related to data availability in natural hazard analysis.
The multifaceted advantages of deep generative models are significant: they enhance data quality, provide additional data at a relatively low cost, and reduce uncertainty (Camps-Valls et al. 2021). Hence, these models are instrumental in generating both general and specific information for natural hazard analysis. For general information, improving the resolution of meteorological data via deep generative models strengthens the identification of extreme precipitation events and facilitates the analysis of related natural hazards. For example, enhancing spatial resolution to a certain scale enables a more accurate capture of anomalies related to storm events (Zheng et al. 2018; Muller et al. 2015; Vosper et al. 2023).
In terms of specific details about hazards, deep generative models can generate diverse synthetic samples of hazard scenarios that maintain observational consistency with physical phenomena. These samples can enhance the training of deep learning models, thereby addressing the challenge of insufficient training data. For example, when using data-riven method, additional samples can be generated to overcome data scarcity and imbalance in landslide susceptibility assessments. We have highlighted and discussed this challenge and corresponding generative modeling solution in a previous survey on deep learning applications for geological hazards analysis (Ma and Mei 2021).
Overall, climate change is escalating the impacts of natural hazards worldwide. Thus, data generation has emerged as a critical necessity to address the significant challenges presented by hazard analysis, primarily due to limited data availability at various stages of hazard development. Recognizing the urgency of this issue, our review investigates the potential of generative deep learning as a transformative approach. We explore how it can be employed to enhance data in natural hazard analysis, thereby addressing the limitations caused by restricted data availability. Notably, given the crucial importance of various natural hazard applications (e.g., forecasting, early warning), a key concern regarding applying deep generative models for data generation is the reliability of the outputs, including their physical consistency.
Herein, we present a detailed survey of generative deep learning for data generation for natural hazard analysis, especially from motivations, advances, challenges, and opportunities. Scholars interested in generative deep learning will benefit from this review, which discusses how deep generative models can be developed or utilized for similar purposes. The remainder of this paper is organized into five sections that cover its major contributions.
-
(1)
The motivation behind using generative deep learning for data generation in natural hazard analysis is introduced. The common data sources involved in natural hazard analysis are summarized. Limitations of data availability in these sources are then discussed.
-
(2)
Generative deep learning is investigated as a potential solution. There is a brief introduction to generative deep learning, including several common deep generative models and the application scenarios in which they specialize.
-
(3)
The advances in generative deep learning for data generation in natural hazard analysis are reviewed. There is an emphasis on the input, utilization or development, and evaluation of deep generative models. This issue of developing more effective and physically reliable deep generative models that can be adapted to the inherent data characteristics for natural hazard analysis is explored.
-
(4)
The challenges involved in increasing the reliability of deep generative models are discussed since improving reliability will enable the results from these models to be more effectively applied to real-world natural hazard analysis.
-
(5)
Further opportunities are discussed, including the possibility of integrating deep generative models into the Digital Twin Earth project. This combination potentially allows this project to use higher and more realistic quality data, providing more accurate and real-time estimates of natural hazards.
2 Motivation: data availability in natural hazard analysis
A hazard is a physical event that potentially causes a significant negative impact on humans, infrastructure, or the environment (Li et al. 2020d). The term “natural hazard” is applied to describe numerous different physical phenomena, which can be broadly categorized into four groups (Merz et al. 2020), namely, geophysical hazards such as earthquakes, tsunamis, volcanic eruptions, and landslides; atmospheric hazards such as storm surges and tornadoes; hydrogeological hazards such as floods; and biophysical hazards such as wildfires.
Analyzing natural hazards can contribute to investigating the mechanisms of natural hazards, revealing the dynamic processes involved in causing natural hazards, assessing natural hazard risks, forecasting natural hazards, issuing early warnings, and providing emergency responses when natural hazards occur (Cui et al. 2021; Zheng et al. 2018). The reliable analysis of natural hazards can facilitate decision-making, which improves the development and implementation of risk management strategies, eventually reducing the vulnerability of human communities. Typically, natural hazard analysis focuses on mapping, characterizing, and modelling hazards and determining which factors impact the occurrence and scale of specific hazards (McPhillips et al. 2018).
Data are fundamental to natural hazard analysis; they can serve a variety of purposes either directly or through sophisticated statistical or modelling tools. Directly, data describe and assess hazards intuitively. Indirectly, data enable the development of physics-based or data-driven models, furthering hazard analysis.
Therefore, natural hazard analysis typically involves a broad array of data sources, covering an enormous amount of diverse information. Herein, we focus on two common information types utilized in natural hazard analysis: general information on influencing factors of natural hazards and specific information about the natural hazard event.
First, general information can reveal the dynamic processes of hazards relevant to various influencing factors and thus contribute to investigating the formation and evolution of natural hazards in the context of different physical processes in the Earth system, such as meteorological and geophysical data. In most cases, this information can also be provided as important variables in physics-based or data-driven models for improving forecasting methods and warning techniques for natural hazards (Whiteley et al. 2019).
Second, specific information can characterize hazard events, including the scale, spatial scope, and duration of a hazard event. For example, landslide investigations allow the acquisition of data on its essential characteristics, including landslide geomorphology, movement type, and velocity rate (Whiteley et al. 2019). This specific information is the basis for assessing natural hazards or for further research on natural hazards. In the context of assessment, these specific descriptions of hazards can be utilized to assess natural hazard risks based on dynamic processes and the social and environmental impacts associated with natural hazards.
Both of the aforementioned information could serve as input for physical-based or data-driven predictive models, which would facilitate the investigation of natural hazard evolution and improve the ability to forecast natural hazards. It is important to note that though data science has brought data-driven models to the forefront of natural hazards analysis, not all types of natural hazards can be effectively analyzed using these models alone. Natural hazards may require a more thorough mechanistic analysis, where physics-based models may be more appropriate. Validation and refinement of physics-based models can be enhanced by incorporating general information about environmental characteristics and specific information about hazards. Several recent reviews have discussed data-driven and physically-based modeling (Shen et al. 2023; Tsai et al. 2021; Bergen et al. 2019). We focus here on data used for natural hazard analysis modeling, regardless of whether these models are data-driven or physical.
Arguably, to enable accurate descriptions and deeper investigations of hazard events and to improve the performance of models developed for hazards, available data are essential to reliably solve problems by contributing sufficient information in temporal terms (dynamics or evolution of natural hazards) and spatial (area scale of natural hazards) terms (Knüsel et al. 2019).
However, there are currently substantial limitations in providing data for natural hazard analysis due to economic, technical, and environmental factors, which have been exacerbated by climate change and urbanization. Due to these limitations, natural hazard analysis will be hindered, thereby creating much uncertainty in hazard response and management. It has become essential to address these limitations for data generation in natural hazard analysis.
In this section, we discuss the limitations of data availability in natural hazard analysis as a motivation behind this survey. First, we introduce common data sources applied in natural hazard analysis. Second, we will explore four major limitations concerning the availability of data gathered from these different sources (Fig. 1).

An illustration of the motivation for data generation for natural hazard analysis. a The innermost layer describes the evolution of natural hazards caused by the interaction of various physical phenomena in the Earth system; the middle layer is the natural hazards discussed in this paper and their categories; the outermost layer is a typical natural hazard analysis. b There are common data sources that can provide data for analyzing natural hazards. This paper discusses both general and specific information related to analyzing natural hazards. c This paper discusses four limitations to data availability in natural hazard analysis
2.1 Data sources for natural hazard analysis
In this section, we review data sources involved in different natural hazard analyses, which contribute to a wide range of products for natural hazard analysis.
Several data sources are commonly involved in natural hazard analysis, including remote sensing platforms, and in situ measurements. Remote sensing technologies can produce optical and synthetic aperture radar (SAR) images related to surface observations (Hao et al. 2018). In situ measurements can record variations in multiple natural hazard-related variables overtime at a regional scale; for instance, seismic sensors can provide seismic waves for analyzing landslides and earthquakes (Whiteley et al. 2019). Moreover, reanalysis data can provide climate-related insights for natural hazards by combining irregularly observed data with numerical models that incorporate various physical and dynamical processes (Sun et al. 2018).
It is common for an analysis of a specific natural hazard to combine data from various sources since natural hazards are impacted by a variety of factors. For example, physical flood models require data involving several variables, including topography and land cover, high water marks for calibration and validation, and water levels derived from measurements of flood area boundaries (Assumpção et al. 2018). A common factor can also be applied to the analysis of different natural hazards, which involves a variety of data sources (Steptoe et al. 2018). For example, precipitation is the most critical and active variable in analyzing most natural hazards, and it can be obtained from various data sources, including satellite observations, in-situ measurements, and reanalysis systems (Sun et al. 2018).
In the following, we discuss the common data sources for analyzing different types of natural hazards.
2.1.1 Data sources for geophysical hazards analysis
2.1.1.1 Landslides
The occurrence of landslides is a consequence of various interacting factors that can be broadly categorized into controlling factors, predisposing conditions, and triggering factors. The controlling factors, which include soil and rock, mainly influence the location of landslide occurrences. Predisposing conditions (e.g., weathering, morphology) typically refer to slowly changing processes that tend to keep the slope marginally stable; triggering factors influence the time of landslide occurrence, including rainfall, earthquake shaking, and rising groundwater levels (Tanyas et al. 2021).
There are two categories of critical information involved in the analysis of landslides. In the first category, characteristics of the study area, such as geology and geomorphology, can be considered controlling factors. The second category includes the characteristics of landslide events, mainly covering the number, type, and scale of landslides and the aforementioned landslide triggering factors (Mondini et al. 2021a).
Landslide inventory mapping describes landslide information in the form of a map, one of the most common data for landslide analysis (Duman et al. 2005; Guzzetti et al. 2005). Remote sensing technologies have been developed recently that enable satellite, airborne, and ground-based data to be utilized for producing landslide maps. Corresponding data include optical satellite imagery, SAR imagery, and topographical information (van Westen et al. 2008; Guzzetti et al. 1996, 2008; Parker et al. 2011; Guzzetti et al. 2012; Malamud et al. 2004).
Optical images are important data for mapping landslides, including very high resolution (VHR) satellite images and multispectral imagery. VHR satellite images are applicable for mapping new landslides in forested areas, especially those triggered by a single driver such as heavy rainfall. Multispectral images can be employed for landslides mapping, derived images, and maps. Furthermore, geophysical surveys can also be applied to identify landslide extent and surface morphology.
An important part of landslide analysis is prediction. Prediction results can be improved by incorporating information about the environmental characteristics of landslides and the dynamics of landslide triggering factors.
First, the investigation of subsurface landslide characteristics contributes to landslide prediction. For example, geophysical data such as subsurface profiles or cross-sections can be employed to detect the formation and progression of antecedent failure conditions and serve as input for predictive modelling of potential damage events. Several geophysical techniques can collect characteristics and features of the landslide environment, thus producing static maps regarding the distribution of physical properties in the interior of the landslide body. For example, seismic reflection can be applied to investigate sliding surfaces produced by variations in the density and water content within landslides.
Second, the investigation of triggering factors can contribute to landslide prediction. A predominant factor is rainfall, which allows measurement and forecasting with adequate spatial and temporal accuracy for predicting the occurrence of landslides. Typically, rainfall fields can be obtained from rain gauges, weather radar, or satellite estimates, which proxy for the rainfall conditions and history at the landslide site before and during a landslide. Furthermore, global circulation models (GCMs) can also provide rainfall information for landslide prediction, which simulates complex weather patterns and climatic interactions that impact rainfall distribution. The downscaled synthetic rainfall sequences derived from GCM simulations are vital data inputs that provide a nuanced understanding of climatic influences on landslides. These sequences serve as an essential input to landslide prediction models, thereby assessing the long-term behaviors of landslides based on existing and future climate scenarios (Comegna et al. 2013).
2.1.1.2 Earthquake
Performing earthquake analysis requires geophysical data, which include observations, measurements, and estimates related to seismic sources, seismic waves, and their propagation medium.
Seismic networks are the primary source of seismic data, where seismic signals are continuously captured, collected, and stored as seismograms. The seismic data recorded reflects ground motions caused by seismic waves. In most cases, these recorded ground motions occur in three directions: north–south, east–west, and vertical. In exploration seismology, seismic signals are recorded by seismic reflection methods, where artificial vibrations using dynamite shots are transmitted through strata with varying seismic responses. An ordered collection of seismic traces constitutes a seismogram, which records the result of a shot.
Furthermore, there has been a dramatic increase in products from satellite platforms, which can be applied to measure Earth surface deformation caused by earthquakes and thus significantly enhance the current capabilities of earthquake analysis. A promising data source is SAR satellites, which produce InSAR data that can image earthquake deformation and strengthen earthquake detection (Biggs and Wright 2020; Liu et al. 2021b; Ahmad Abir et al. 2015). For example, several seismic studies based on InSAR time series analysis, including the measurement of small-amplitude, shallow creep, and postseismic deformation and the determination of earthquake source parameters, have been performed (Fialko 2006; Ryder et al. 2007; Dawson and Tregoning 2007).
2.1.1.3 Volcano eruptions
Most volcanoes experience signs of unrest prior to eruptions, including increased seismic activity and ground deformation (Potter et al. 2015; Reath et al. 2016; Caricchi et al. 2021; Loughlin et al. 2015; Brown et al. 2014). Therefore, volcano analysis emphasizes how to detect these signs of unrest and their anomalies, and an optimal approach is to perform multiple monitoring techniques.
Conventionally, in situ measurements of seismic activity and ground deformation have contributed critical information for tracking volcanic unrest. For example, installing a seismic network consisting of multiple seismic stations within a certain distance from an active crater enables the rapid acquisition and processing of volcanic seismic signals. However, this traditional approach of in-situ measurements entails vast limitations in terms of maintenance costs, especially for active volcanoes located in remote areas. In recent years, an alternative and considerably promising data source for volcano analysis have been remote sensing (Marchese et al. 2010).
According to the function of specific sensors deployed on satellites, these satellite products can deliver information about ground deformation, gas emissions or thermal anomalies of volcanoes (Reath et al. 2019). For example, InSAR images from satellites carrying synthetic aperture radar sensors are commonly employed to analyze the evolution of volcanic morphology. When Mount Merapi in Indonesia erupted in 2010, InSAR data were utilized to evaluate the lava dome, allowing evacuations to be planned effectively (Pallister et al. 2013).
2.1.1.4 Tsunamis
Submarine earthquakes can cause tsunamis (Astafyeva 2019). Accordingly, seismic data are commonly employed to analyze tsunamis, assess their impact, and forecast them before they strike the coast. For example, after significant tsunami events, teleseismic measurements are applied to estimate the magnitude of earthquakes and the propagation of tsunami waves (Titov et al. 2005; Melgar et al. 2016).
Tsunami forecasting is typically derived from physics-based simulations, where the seismic parameters required for the initial conditions of the forecasting model are typically derived from global navigation satellite system (GNSS) measurements and rapidly available source information from seismic stations. New observations from land-based and sea-based observing devices continuously update the forecast results. The three most commonly available observation devices are tide gauges, run-up gauges, and deep water pressure sensors. For example, tsunami surface elevation data can be inferred from deep water pressure sensors or directly measured by a tide gauge (Liu et al. 2021a).
2.1.2 Data sources for atmospheric hazards analysis
Atmospheric hazards comprise various physical phenomena occurring at the surface of the Earth, for example, tropical cyclones, which encompass cyclones, hurricanes, and typhoon equivalents and can cause storm surges. Extreme precipitation, wind speed, and temperature are associated with these phenomena (Steptoe et al. 2018). For example, the sea surface temperature (SST) is teleconnection to numerous localized atmospheric hazards.
Atmospheric hazards analysis emphasizes the knowledge of these teleconnections and the description and forecasting of climate and meteorological conditions at different spatial scales. Currently, continuously expanding satellite systems, combined with in situ monitoring systems, contribute a large amount of important information for either understanding the major climate and meteorological drivers and their teleconnections related to climate indices or directly identifying and tracking atmospheric hazards.
Satellite systems are an important data source for regular global measurements of variables related to atmospheric hazards. Typically, satellites carrying a wide range of sensors allow for large-scale and high-frequency monitoring of these variables. For example, AMSR-E with advanced microwave scanning radiometer-EOS can conduct continuous monitoring through clouds for variables including SST, wind speed, and rainfall through clouds. Its products are employed to forecast atmospheric hazards such as hurricanes. Furthermore, a single variable can be sourced from sensors on different satellites. For example, rainfall is typically obtained from three sensors: visible/infrared sensors, passive microwave sensors, and active microwave sensors (Sun et al. 2018). On the other hand, products from satellite systems can also be applied to describing and forecasting climate hazards. For instance, satellite images can predict typhoons by observing roughly large round clouds caused by typhoons and their surrounding smaller clouds (Li et al. 2020a).
Considering that variables related to atmospheric hazards tend to possess high spatial and temporal variability, measurements from in situ sources are also required for atmospheric hazard analysis. For example, precipitation is measured at the land surface by employing rain gauges, disdrometers, and radar. Storm surges are monitored by utilizing tide gauges to acquire real-time water level observations for forecasting and warning purposes (Needham et al. 2015).
Reanalysis data, critically used to analyze atmospheric hazards, combine observations from in situ monitoring systems and satellite systems with physics-based numerical models. This often involves a data assimilation process to produce an integrated and consistent estimate of the atmospheric state over extended periods. By offering a comprehensive view of various climate variables, reanalysis data enable the identification and tracking of atmospheric hazards. For example, storms are captured in the ERA5 reanalysis data by leveraging pressure, wind, and precipitation variables.
2.1.3 Data sources for hydrological hazards analysis
2.1.3.1 Floods
A major driver of flooding is rainfall, including short-duration, high-intensity, and long duration (Merz and Blöschl 2003). Temperature, wind speed, and soil moisture indirectly influence flooding (Kumar et al. 2021). Therefore, the data sources involved in analyzing floods are mainly related to surface water and the corresponding factors.
The observation of surface water contributes to the investigation of floods. Satellite platforms furnish effective remote sensing products for observing surface water dynamics, including optical and SAR imagery (Yu et al. 2005; Li et al. 2019). For example, the SAR system on Sentinel-1 can be applied to delineate water extent during flood events (Liang and Liu 2020). In situ measurements are another reliable data source for acquiring flood-related hydrological data, which contribute important information, including daily discharge and water levels.
On the other hand, the measurement of factors influencing flooding also contributes to flooding analysis. Over time, the variation in factors, including temperature, wind speed, relative humidity and soil moisture, can be collected through in situ monitoring to investigate flood generation mechanisms. Real-time access to rainfall information is crucial to flooding forecasting and warning. Typically, a flood warning is predicated on precipitation forecasts, and its lead time depends on the forecast horizon. Depending on the forecast horizon, rainfall information from different data sources can provide multiscale information. A common data source of rainfall information is a rain gauge from in situ monitoring.
2.1.3.2 Droughts
The occurrence of drought involves various factors that determine the type of drought. Common droughts include meteorological droughts, typically associated with persistent anomalies in atmospheric circulation patterns caused by SST anomalies (Dai 2011).
Therefore, the analysis of drought is commonly performed based on indicators derived from meteorological/hydrological data or weather/climate model data. Conventionally, the variables involved in calculating indicators are derived from in situ observations. With advances in remote sensing technology, satellite platforms have also emerged as a major data source for drought analysis, providing meteorological data for indicator calculations and observations of Earth’s surface conditions such as vegetation health and water levels (West et al. 2019). For example, rain data from different satellites can be used to calculate indicators such as normalized precipitation index (SPI) for detecting meteorological droughts on a large scale. Furthermore, the NDVI can be applied to assess soil moisture by monitoring the health of plants.
2.1.4 Data sources for biophysical hazards analysis
Wildfires are uncontrolled fires fueled by wild vegetation that widely impact the environment, including climate, carbon cycling, and ecosystem distribution. Analysis of wildfires emphasizes wildfire detection, which documents the location of wildfires, and area burned estimation, which quantifies the area burned by wildfires. Traditionally, these analyses were performed by field surveys. Recently, satellite platforms have contributed to the availability of a large and diverse range of products for wildfire analysis (Oliva and Schroeder 2015). Furthermore, wildfire prediction entails the analysis of complex dynamics among various factors, for example, meteorological or climatic factors. These variables can be obtained from reanalysis data (Chowdhury et al. 2021).
2.2 Limitations of data availability in natural hazard analysis
Currently, significant limitations exist in the quality and quantity of the data required to analyze natural hazards. Extracting meaningful information from these limited data is exceedingly challenging. Among the most effective solutions to this challenge is data enhancement. Exploring the limitations of data used for natural hazard analysis will facilitate the development of more effective methods for enhancing data. Therefore, here we analyze the limitations of the data available for natural hazard analysis across five perspectives: low-resolution data, missing data, noisy data, scarce data and uncertain data.
2.2.1 Limitations from low-resolution data
The resolution, defined as the amount of detail in data in temporal and spatial terms, impacts the observable information in data and is essential for natural hazard analysis (Goodchild and Proctor 1997). Typically, high-resolution data can better capture interactions between various physical phenomena associated with natural hazards, thus improving local forecasting accuracy significantly.
Arguably, improved data resolution has considerable importance for natural hazard analysis. The availability of high-resolution data has emerged as the most pressing need for many natural hazard analyses. For example, for landslide mapping, high-resolution imagery allows the classification of landslides by type and the identification of landslide sources and depositional areas (Tanyaş et al. 2017).
In this paper, “low” resolution is applied to describe the limitations encountered with data for natural hazard analysis, where “low” is a relative degree that indicates that the available resolution of the data does not satisfy the current requirements in natural hazard analysis due to the large variability of geophysical processes in both space and time. For example, precipitation intensity during an identical storm event can differ up to 30% in a spatial region ranging from 3 to 5 km, and most existing data do not adequately capture anomalies at this scale (Zheng et al. 2018; Muller et al. 2015).
Data sources influence the resolution of data for natural hazard analysis. For data from satellite platforms or in situ monitoring, the resolution tends to be determined by the sensors utilized to collect the data. Several sensors from satellite platforms have relatively low temporal and spatial resolutions, which may prevent their products from capturing small-scale, temporary natural hazard events. For example, passive microwave sensors can produce frequent observations. Still, their spatial resolution is relatively coarse, typically 25–70 km, which would impede their products from being employed to observe flooded inundation zones. In the last decade, many new sensors have produced images with a spatial resolution of meters or even the submeter level. However, the lower revisit frequency of these sensors makes a lower temporal resolution, thereby limiting intensive temporal monitoring of natural hazards (Huang et al. 2018).
In the seismic data acquisition process of reflection seismology, the spatial resolution often depends on the device’s location and number. For example, in a tomographic image, the resolution is dependent on the density of rays and the degree of ray crisscrossing, both of which depend on the location of seismic stations (Zhao 2021). Typically, the fewer the measurement points of the system, the lower the spatial resolution is, while the temporal resolution depends on the sampling frequency of the devices. Due to physical or economic limitations, the locations of geophones are commonly irregular, or the sampling spacing along the receivers falls short of the spatial sampling requirements at times, thus decreasing the resolution of the seismic data (Wei et al. 2021a; Gray 2013). Furthermore, seismic waves travelling to large depths will decrease in frequency while increasing in velocity and wavelength, thereby causing a decrease in seismic resolution (Kearey and Brooks 1991; Halpert 2019).
Furthermore, computational capabilities also limit the availability of high-resolution data. Higher-resolution data tend to require more computational resources.
Low temporal and spatial resolution will significantly hinder natural hazard analysis, decreasing the likelihood that small-scale natural hazards are detected and increasing the imprecision and uncertainty in natural hazard forecasting. For example, the low resolution of satellite products can cause small-scale and small-area volcanic activity to be unavailable for detection (Furtney et al. 2018). Similarly, the low resolution of satellite products can compromise landslide inventory mapping, which ideally should contain all detectable landslides down to 1–5 m in length (Tanyaş et al. 2017). Most soil moisture products from satellite platforms have a spatial resolution of approximately tens of kilometers, which is hardly sufficient for regional drought monitoring of several kilometers or even tens of meters (Peng et al. 2017). Relatively low resolution reanalysis data (e.g., resolution of less than 2 km) will hinder the monitoring and forecasting of storm surges (Merz et al. 2020; Roelvink et al. 2009). These low resolution reanalysis climate models also hinder agricultural and hydrological drought forecasting (Hao et al. 2018). Furthermore, low resolution data derived from inundation models probably cause inaccurate and even misleading descriptions of tsunamis (Grezio et al. 2017).
The aforementioned examples show that it is imperative to solve low-resolution limitations of data for natural hazard analysis. Progress in Earth observation techniques and physically-based modelling techniques provides many solutions. The increase in resolution is accompanied by substantial costs in data acquisition and handling, which means significant investment is needed. Furthermore, most conventional methods suffer from computational or hypothetical limitations. For example, statistical downscaling methods applied to improve the resolution of climate models substantially depend on specific statistics and struggle to address the inherent stochasticity in the relationships between two spatial scales (Groenke et al. 2020). Most methods for increasing seismic resolution require a priori information and can potentially yield unrealistic smoothing results (Li and Luo 2020). Low-cost methods that can address the limitations of conventional methods are preferable.
2.2.2 Limitations from missing data
In Earth observation systems that observe a wide range of variables associated with natural hazards by employing extensive devices, observation records inevitably suffer from missing data. Complicated, large-scale and inevitably missing data prevent further analysis of natural hazards and could obscure physical consistency across variables (Bessenbacher et al. 2021).
For example, during flood events, optical sensors impacted by cloud cover can also lead to missing information, thus hindering the correct estimation of crucial emission records (Huang et al. 2018). With regard to in situ monitoring, outdoor devices are susceptible to environmental damage, as occurred during Hurricane Katrina in 2005, when high magnitude tropical surges damaged and malfunctioned tide gauges (Needham et al. 2015). Damage to in-situ devices will interrupt the early warning of natural hazards (Zheng et al. 2018).
2.2.3 Limitations from noisy data
Noisy data typically refers to corrupted, distorted, or low signal-to-noise ratio observations, which are common in natural hazard analysis, especially in seismology-related investigations. Seismic data are vulnerable to contamination by different types of noise. This noise is defined as all unnecessary recorded energy that contaminates seismic data. For example, seismic stations record a variety of noises. The noises may be misinterpreted as seismic signals, resulting in false alarms from seismic warnings (Meier et al. 2019). Many denoising methods have been developed. The effectiveness of these approaches depends on a large amount of prior knowledge or numerous assumptions (Candès et al. 2006; Donoho 2006; Liu et al. 2016).
2.2.4 Limitations from scarce data
Data scarcity is defined as the limited or complete lack of available data, thus presenting difficulties in analyzing natural hazards. For example, the lack of available landslide inventory maps limits further insight into the causality of landslide distribution under different conditions, thus undermining the rapid assessment of landslide susceptibility, hazard, vulnerability, and risk (Guzzetti et al. 2012).
In natural hazard analysis, a significant reason for the scarcity of data is the lack of observations. Over the past 20 years, the number of in situ high-quality monitoring systems worldwide has been drastically reduced due to a shortage of public funding for operation and maintenance. This reduction in situ observing systems is particularly evident at weather stations (Jaffrés et al. 2018). Furthermore, many areas lack seismic instruments or are inadequately equipped with seismic instruments, including large areas of the Pacific Forearc region, which has placed these regions last for seismological investigations (Zhao 2021).
From the perspective of natural hazard analysis, reducing weather stations, an essential component of most natural hazard early warning systems, will hinder accurate short-term forecasting of natural hazards and real-time warnings. Similarly, the absence of other in situ monitoring methods can hinder natural hazard analysis. For example, the lack of stream gauges will prevent the collection of river system data on flow velocity and runoff volume, thus potentially underestimating flash floods due to extreme rainfall events (Jaffrés et al. 2018). Sparsely distributed tide gauges cannot capture the peak levels of tropical storm surges (Needham et al. 2015; Haigh et al. 2014). The scarcity of observational data will limit the initialization and updating of physically-based models. For example, the lack of gauging stations makes updating hydrological models, both offline and in real-time, impossible (Troin et al. 2021). A lack of seismic instruments can hinder the investigation of causal mechanisms and the locations of sources of seismic events (Zhao 2021).
On the other hand, the scarcity of natural hazard events is likely to cause a scarcity of corresponding data. For example, tsunamis infrequently occur, rendering the small number of available tsunami events only a small sample of thousands or millions of possible observation scenarios (Grezio et al. 2017). To describe this form of data scarcity, we introduce the second definition of data scarcity in computer science, i.e., data scarcity can also refer to a lack of data (e.g., hazard events) for a particular label, which is also referred to as data imbalance. Another example is the reanalysis data for detecting tornadoes, where the scarcity of tornadoes causes an imbalance in the data regarding tornado and no-tornado labels. This data imbalance tends to compromise the performance of machine learning developed to detect natural hazards.
A solution to the scarcity of data due to the lack of observations is to employ data substitution from other sources, such as crowdsourcing (Zheng et al. 2018). However, the data from these methods are typically available only for additional information. They are not substitutes for a more accurate and reliable description of natural hazards from in-situ observations. For the data imbalance problem, common solutions consist of oversampling and undersampling. Common data augmentation methods, including horizontal flipping and random cropping, can be applied as solutions for image data. Essentially, the above methods do not generate new samples and can potentially degrade the quality of the data (Rui et al. 2021).
Furthermore, solutions to the sample imbalance of hazard events have been developed in deep learning, such as weakly supervised learning (Zhou et al. 2022; He et al. 2022a). Through weakly labeled datasets, such as post-event remote sensing imagery, weakly supervised learning has been demonstrated to enable damage detection with a high degree of efficacy (Ali et al. 2020). Several recent studies have shown the feasibility of employing weakly supervised learning for detecting natural hazards, an example of which is flood mapping. These studies improved flood identification despite the limited number of labeled datasets available (Wang et al. 2020; Ma et al. 2022a). Integrating physical models into weakly supervised learning frameworks can potentially enhance the performance of flood segmentation, particularly without labeled data (He et al. 2022b). While falling outside the specific focus of this review on generative deep learning for data generation in natural hazard analysis, weakly supervised learning could provide a broader context for understanding the landscape of data-driven approaches in natural hazard analysis. Weakly supervised learning in Earth observational data has been reviewed by Yue et al. (2022).
2.2.5 Limitations from uncertain data
Although the Earth observation system provides information on the spatial and temporal evolution of hazards based on a wide array of variables, these records are subject to several uncertainties (Xu et al. 2021). Measurement error is the most common source of uncertainty, typically resulting from external conditions, instrument malfunctions, and methodological errors. External conditions such as precipitation could limit observations and affect the accuracy of data collection. Further, systematic errors are caused by factors inherent to the system. For example, in landslide deformation prediction, uncertainties may arise from the inherent variability of geotechnical materials, leading to unreliability in the parameters used to construct data-driven models (Chen et al. 2022; Min et al. 2023).
Furthermore, uncertainties may also be introduced through processing methods, including subjective analysis, interpolation techniques, and data fusion methods. For example, in landslide susceptibility mapping, the division of the number of attribute intervals (AINs) of continuous environmental factors is not standardized but subjectively determined, introducing significant uncertainty in constructing data-based models (Huang et al. 2021). Furthermore, when applying statistical relationships to obtain precipitation estimates from infrared signals, large uncertainties arise due to indirect correlations (Wang et al. 2021a).
A solution to data uncertainty would be to perform probabilistic natural hazards analysis. In this regard, Monte Carlo methods (MC) have been widely used to rigorously account for the uncertainties involved. For example, the uncertainty simulation method, which generates randomized samples to represent the uncertainty of the data, involves creating possible earthquake scenarios and generating randomized samples based on uncertainty in geological material properties (Du and Wang 2013; Ma et al. 2022b; Chen et al. 2022). A simulation process typically involves two steps: the first step involves sampling pseudo-random numbers, and the second step involves transforming them into simulated events. Nevertheless, these simulations are computationally intensive and have limited capabilities for precisely defining the properties of the events they generate. Typical event generators generate a large number of events and then select the most interesting ones from them with a low level of efficiency. The potential events not selected in that procedure may be discarded (Otten et al. 2021).
3 Generative deep learning
Generative deep learning has been an emerging deep learning paradigm in recent years, which relies on the same principles as deep learning, in which deep neural networks are used to learn data representations and complete the learning process according to objective functions. In generative deep learning, an essential characteristic of deep generative models is that they are fundamentally probabilistic, meaning they learn an approximate probability distribution from given samples and then generate new samples similar to the original sample (Ruthotto and Haber 2021).
Most recently, in the context of the rapid growth of deep learning and the demand for interdisciplinary applications, research into deep generative models has expanded rapidly.
The field of deep learning has given birth to a wide array of state of the art neural network architectures and training strategies. These advancements enabled deep generative models to break new ground in generating high-fidelity or diverse data and improving execution times, especially for image generation. Deep generative models also bring compelling application prospects for data enhancement in natural hazard analysis (Ravuri et al. 2021). Since deep generative models can handle diverse, heterogeneous, and highly correlated data, they have enormous potential for enhancing the data used to analyze natural hazards, leading to further improvements in hazard analysis effectiveness.
Several common deep generative models include Variational Autoencoders (VAE), Generative Adversarial Networks (GAN), Normalizing Flows (NF), and Diffusion model (DM), which have been employed to improve data availability in natural hazard analysis, e.g., GANs are utilized to generate a remote sensing image of a tropical cyclone, or normalized flow is utilized to downscale climate variables.
Before introducing the aforementioned deep generative models individually, we will discuss the necessary background related to these models, including the theoretical foundations of deep learning and architectural elements commonly used in deep generative models. It is essential to understand these concepts before developing or utilizing deep generative models to obtain satisfactory performance. The deep neural network architecture design and the customization of the training objectives are particularly important.
3.1 Theoretical foundations of deep learning
3.1.1 Neural networks
Neural networks consist of a series of neurons that serve as fundamental units. Each neuron is a function for performing two mathematical operations for one or more inputs x, then performing a nonlinear mapping \(y=f\left( \sum _{i} w_{i} x_{i}+b\right)\), and finally outputs y, where w and b are trainable parameters, referred to as weights and biases. f denotes the activation function for nonlinear mapping. Most deep neural networks have more than one hidden layer, with arbitrary numbers of neurons in each layer. Depending on the layer, the number of neurons may vary, and neurons may be connected differently, leading to various architectures.
The combination of neurons, layers and architectures further extends the flexibility of deep learning by enabling it to capture meaningful representations more readily. These combinations can be applied as neural network blocks to implement more complex representation learning. A neural network block can be a single layer, a component composed of multiple architectures, or an entire deep learning model.
The training of a neural network is an optimization process. The weights are iteratively tuned during training to drive the input–output relationships in the neural network toward the specified relationships in the training objective, which is regarded as a search or optimization problem. The training of a neural network can maximize or minimize the objective function (or loss function). A loss derived from the loss function measures the discrepancy between input and output (Jiang et al. 2021).
The loss function determines specifically what neural networks optimize, varying according to the particular task in deep learning. The most common loss functions, such as cross-entropy, mean absolute error (MAE), mean squared error (MSE), and root mean square error (RMSE), are also widely used in the intersection of deep learning and earth sciences.
Nevertheless, recent studies increasingly suggest that typical loss functions might not fully address the diverse requirements of physical processes in earth sciences. This realization opens up significant opportunities for developing more tailored and relevant loss functions. One particularly promising direction is to integrate known physical constraints in the Earth system into the loss function, thus enabling the addition of expert knowledge to difficult-to-interpret deep learning and giving physically consistent outputs. The design of loss functions for deep learning in the Earth system is a promising research topic but beyond the scope of this review. Here, we recommend the work of Ebert-Uphoff et al. (2021) as a preliminary summary, and they provide a discussion and tutorial on how to customize loss functions for deep learning in the environmental sciences.
3.1.2 Architectures
A wide variety of deep neural network architectures are proliferating, which aim to capture more valuable representations from data and thus achieve the corresponding tasks. The progression of these architectures has contributed to the evolution of deep generative models, allowing them to break new ground in generating high-fidelity or diverse data or improving execution time. The two most common deep neural network architectures currently employed in deep generative models for data generation in natural hazard analysis are fully connected neural networks and convolutional neural networks (CNN), and several other common architectures include recurrent neural networks (RNNs), autoencoders.
Fully connected neural networks are the most basic neural network architectures, in which information flows according to the order of input, hidden, and output layers. Stacking fully connected neural networks can yield more meaningful representations and benefit from the nonlinear activation functions applied in each layer (Jiang et al. 2021).
Convolutional neural networks (CNN) excel in processing spatial information, especially in image-based data, using a combination of convolutional layers and pooling layers. In these layers, filters perform convolutions to capture local spatial features, which facilitates extracting meaningful features by detecting local connections in the data (Pallister et al. 2013).
CNNs have a large number of variants. U-Net, a popular variant for processing satellite imagery and seismic signal data, comprised of three main blocks: (i) an encoder, (ii) a decoder, and (iii) the skip connection. Its encoder-decoder architecture is particularly effective in reconstructing seismic data (Park et al. 2020a).
Recurrent neural networks (RNN) are appropriate for handling time series data or other sequential data, where layers connect the output of a unit at one time step to its input at the next step, resulting in certain hidden states. RNNs can leverage historical and current input data, thus updating the current state based on earlier information in a sequence. Long short-term memory (LSTM) and GRU are common variants of RNNs.
Autoencoder (AE) involves mainly encoders and decoders connected by a bottleneck, which can reconstruct the original input data from latent representation. However, the latent space in the original AE is irregular. Decoding samples collected by an irregular latent space can generate meaningless data (Eigenschink et al. 2021).
One solution is constructing a latent space with sufficient regularity and enforcing the latent distribution to match a certain prior distribution. Variational autoencoder (VAE) emerge, which can be considered an important category of deep generative models. We will describe it in detail in Sect. 3.2.1.
The attention mechanism is typically applied to determine the relevance of input elements by computing their weight distributions. Through attention mechanisms, deep neural networks can extract more valuable information from input data by giving more weight to some features, resulting in improved performance.
Residual blocks in deep neural networks involve stacking layers with skip connections. One layer’s output is added to subsequent layers’ input, enhancing performance and preventing degradation in networks with multiple hidden layers (Fig. 2).

An illustration of the theoretical foundations of generative deep learning. a Common neural network architectures and their variants. b Depending on the deep neural network, data can be considered as different representations. c Visualisation of common operations in deep learning, with examples of convolution and attention. d A typical training paradigm for deep learning. Here, the loss function is employed to drive the input–output relationship in the neural network towards the specified relationship in the training target. e The theoretical basis of generative deep learning, i.e., modelling data distributions using deep neural network architecture to learn their probability distributions to generate data with similar distributions. f Three common deep generative models
3.2 Common deep generative models
A generative model aims to learn a data distribution \({\mathcal {X}} \in \mathbb {R}^{n}\) by a generator \(g: \mathbb {R}^{q} \rightarrow \mathbb {R}^{n}\). In a mapping process of the generator, samples from a latent distribution \({\mathcal {Z}} \in \mathbb {R}^{q}\) are mapped to points in distribution \({\mathcal {X}}\) that are similar to the given data. Deriving g is essential to generative models. In conventional generative models, this is considerably difficult. For example, for remote sensing image data, it is not feasible to derive \({\varvec{g}}\) by first principles, leading to an infeasible transformation of a sample from a univariate Gaussian to a desirable remote sensing image (Ruthotto and Haber 2021).
A new paradigm of deep learning, generative deep learning, offers a nuanced and flexible solution to this challenge, in which deep generative models are developed by deep neural network architecture, which can approximate high-dimensional functions with high accuracy. Differences between deep generative models and traditional generative methods lie in how the underlying distribution of the data is captured and represented. In traditional methods such as Monte Carlo simulations, strict assumptions, and priors are required for modeling, which means they can only be applied to specific and limited problems (Otten et al. 2021; Gao and Ng 2022). In situations where complex data, multidimensionality, and non-linear, interdependent relationships among variables are involved, these methods are often subject to the curse of dimensionality. By contrast, deep generative models are implicitly trained to understand the data distribution, making them particularly suitable for modeling complex, high-dimensional data for natural hazards analysis, in which relationships between variables can be highly non-linear and interdependent (Jahangir and Quilty 2024).
It is essential to develop the appropriate deep neural network architecture and loss functions in deep generative models, which will affect the ability of deep generative models to learn and solve problems. In deep generative models, the loss function introduces the concept of similarity to measure the difference between two distributions, i.e., the observed distribution and the generated distribution (Sanchez-Lengeling and Aspuru-Guzik 2018).
Four common existing deep generative models are VAEs, GANs, normalizing flows, and diffusion models, which have been introduced for data generation in natural hazard analysis. In the following, we will introduce and discuss both VAE and GAN in more detail, which are two more dominant models for improving data availability in natural hazard analysis. Furthermore, our introduction will also cover the normalizing flows and diffusion model, which has considerable potential.
3.2.1 Variational autoencoders (VAE)
VAE was proposed in 2013 as a variant of AE, which improves structural and regularity problems in AE. Instead of deterministically mapping the input to a specific point, VAE maps the unknown distribution of each input to the distribution in latent space (typically a Gaussian distribution) and then to the original distribution (Jiang et al. 2021). This improvement enables VAE to have generation ability.
VAE has been extensively applied in image generation. Recently, VAE has been demonstrated for data generation for natural hazard analysis. For example, VAE has been applied to meteorological data output by physical models to learn how their simulations behave, leading to better estimates of the future state of the Earth’s climate (Camps-Valls et al. 2021).
A potential limitation is that the images generated by VAE are not sufficiently sharp, which may explain their limited application in handling image data that can be utilized for natural hazard analysis. Many corresponding variants have been developed to address this concern. Similar to other generative models, the main improvements of VAE are embodied in two aspects, the deep neural network architecture employed by the encoder and decoder and the loss function.
A typical VAE variant is the \(\beta\)-VAE. Compared to VAE, \(\beta\)-VAE can discover disentangled representations, which is one where changes in a single latent variable are sensitive to changes in one feature/property of the training set while remaining relatively invariant to changes in another property. The disentangled representations contribute to better performance of \(\beta\)-VAE, thus rendering it applicable for data generation in natural hazard analysis. For example, \(\beta\)-VAE was used to process low-resolution, noisy, incorrectly migrated seismic images and then demonstrated its excellent reconstruction capabilities for such low-quality seismic images (Sen et al. 2020).
3.2.2 Generative adversarial networks (GAN)
3.2.2.1 Overview
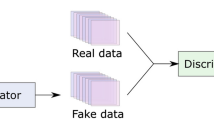
The Generative Adversarial Network (GAN), which was first proposed in 2014, is dominant among deep generative models. GAN adopts a unique method to generate data, which typically consists of two deep neural network architectures that work against each other: a generator G aims to transform the noise vector \(z \sim p_{z}\) into the output of the original data space, and a discriminator aims to distinguish the generator output G(z) from the original data x. A GAN is trained in an alternating pattern to achieve Nash equilibrium between generator and discriminator.
Although vanilla GAN has achieved impressive performance, it retains several loss function and architecture limitations. To address these problems, a number of variants of GAN have been proposed to improve its performance in various application scenarios.
According to the different improvements, these variants can be mainly grouped into three categories (Wang et al. 2021f):
-
(1)
Variants with improvements in the architecture. Vanilla GAN employs only the simplest fully connected networks, which implies that the more powerful and complex deep neural network architectures that have been developed have tremendous potential for GAN improvement. Extensive work has demonstrated that it is more effective to utilize particular deep neural network architectures targeting different data structures. For example, it may be more effective to leverage CNN-related architectures in a GAN to generate image data. Similarly, it may be more effective to employ RNN-related architectures in a GAN to generate sequence data.
-
(2)
Variants with improvements on loss functions. Loss functions are critical in GAN training because they allow for more stable training of the GAN and allow for more diverse samples to be generated.
-
(3)
Variants with improvements for specific application scenarios. Customizing the architecture and loss function of GAN for different application scenarios can better solve particular problems. For example, in computer vision, various GAN variants have emerged for better performing various image synthesis tasks, which involve image super-resolution and image-to-image translation.
3.2.2.2 GAN variants with improvements on the architecture
In this section, we mainly discuss two GAN variants, CGAN and DCGAN, which are commonly employed for data generation in natural hazard analysis.
The essential idea behind CGAN is to guide the data generation process with additional information. Building on the vanilla GAN, CGAN introduces additional auxiliary information y associated with the input samples as conditions for the generator G and discriminator D, including class labels, text, or images, to generate conditional real data. These additional auxiliary information y, as an extension of the latent space, can provide improved guidance to the GAN for generating and discriminating data.
DCGAN incorporate a deconvolutional neural network architecture into the generator G as the main architecture. This design enables G to be spatially upsampled with deconvolutional operations. DCGAN has been widely applied for data generation in natural hazard analysis. An exciting application is to address the class imbalance problem that exists in natural hazards data, where the data from non-hazard events far exceeds the data from the hazard events. The class imbalance problem tends to impact the performance of other deep neural networks that are modelled by utilizing these data. One example is the application of DCGAN to synthesize tornado-related remote sensing data to address the limitations of class imbalance caused by the sparsity of tornado events when analyzing tornado data (Barajas et al. 2020). In this preliminary work, tornado data generated by DCGAN are indistinguishable from real tornado data. These generated image data can be leveraged to train predictable deep learning models to predict real storms.
3.2.2.3 GAN variants with improvements on loss functions
The improvements in the loss function are primarily aimed at overcoming the challenges of GAN in terms of convergence. The minimax property of GAN training tends to result in training divergence, or convergence towards a degenerate optimum, where the generator maps all inputs to only one or a few specific images and the discriminator fails to differentiate from the original data, thereby rendering generated data lacking in diversity and practicality (Eigenschink et al. 2021).
WGAN, a typical variant, can effectively solve gradient vanishing and pattern collapse problems arising from GAN training by replacing the Jensen–Shannon (JS) divergence in vanilla GAN with the Wasserstein distance. A challenge remains in minimizing the Wasserstein distance. To further improve WGAN, several WGAN-based models have been developed.
For example, an improvement is adding gradient clipping, where the discriminator’s weights were limited to a certain range defined by the hyperparameter c. The method has been applied to improve the training of GAN when implementing the interpolation of seismic data. By clipping the weights in the discriminator D to a fixed range, the GAN enhances the stability of the training and generates high-quality geophysical data (Wei et al. 2021a).
However, the training performance of WGAN is highly sensitive to this hyperparameter c. A value of c that is too small or too large can result in instabilities when training WGAN. A further improvement would be to penalize the model when the gradient norm is far from 1. A corresponding variant is called WGAN-GP, which improves stability performance for training GAN.
3.2.2.4 GAN variants with improvements for specific application scenarios
The increasingly wide range of applications has encouraged variants of GAN to focus more on solving specific problems in different application scenarios. In particular, in image data synthesis, a large number of GAN variants have been developed to address several common problems in this field, including image super-resolution and image-to-image translation (Wang et al. 2021f). These GAN variants also have the potential for data generation for natural hazard analysis. To achieve this, the task of data generation for natural hazard analysis should be viewed as similar to the aforementioned task in image synthesis. Here we focus on how the task of data generation for natural hazard analysis corresponds to that of image super-resolution and image-to-image translation.
Image super-resolution refers to generating high-resolution images from low-resolution images through upsampling. Such super-resolution is somewhat analogous to improving low-resolution data involved in natural hazard analysis. In this regard, improving low-resolution remote sensing data has been considered a super-resolution problem (White et al. 2019). Regional downscaling of global weather and climate products can also correspond to the image super-resolution problem. More specifically, downscaling of spatial precipitation also means increasing the resolution of the original coarse precipitation dataset (Chen et al. 2020).
Consequently, variants specifically developed for super-resolution tasks in computer vision are appropriate for these similar application scenarios in natural hazard analysis, such as generating high-resolution meteorological data (Watson et al. 2020). The two most common variants are SRGAN and ESRGAN.
SRGAN employs residual networks as its generators, allowing for recovering finer textures from images. The discriminator consisting of multiple convolutional layers is applied to discriminate the real HR image from the generated SR image. ESRGAN has implemented several improvements to SRGAN. In ESRGAN, the architecture of the generator employs the Residual-in-residual Dense Block (RRDB); the discriminator is utilized to determine "whether an image is more real than another”, instead of "whether an image is real or fake”; the perceptual loss \(L_{\text{ percep } }\) are modified to allow the generated images to preserve brightness consistency and texture recovery.
Image-to-image translation refers to learning the mapping between the output and the input by training using a set of aligned image pairs, which allows the conversion of different image contents. These advantages are especially beneficial in data generation for natural hazard analysis. For example, extensive application scenarios in seismic image processing can be considered image-to-image translation.
In an attempt to explore GAN applications in geophysical imaging, the effectiveness of the GAN variants developed for an image to image translation is demonstrated in two application scenarios, where GAN generates different types of outputs by using seismic migration images as input. In the first application, the output is a higher quality migrated image, which indicates that a low quality seismic migrated image is "translated" into a high quality seismic migrated image. In the second application, the output becomes the corresponding dissociated reflectivity image, which means that the seismic migration image is "translated" into a dissociated reflectivity image (Picetti et al. 2019). Therefore, a key to better applying the GAN variant that was developed for image-to-image translation for data generation in natural hazard analysis is to identify such a pair of data, which can be served as input and output.
The field of computer science has supplied well developed and available GAN variants for image-to-image conversion. Two of the most typical variants are Pix2Pix and CycleGAN.
Pix2Pix is an early model of image-to-image translation that learns input and output mappings from pairs of images. In Pix2Pix, the model takes a pair of image datasets from different domains and then translates them from one domain to another. The generator G in Pix2Pix receives a source image as input and generates a translated result of that image. When a discriminator D receives a source image and a real or generated paired image, it determines whether it is a reasonable translation of the source image by determining whether or not the paired image is real or fake. Taking advantage of their advantages, Pix2Pix can generate synthetic seismic images by simply applying simple sketches (Ferreira et al. 2020)
Pix2Pix has improved the deep neural network architecture and loss function in several aspects to better solve the generic image-to-image translation problem. In terms of architectural improvements, Pix2Pix utilizes U-Net as the generator and provides noise in the form of dropout in a few layers during training and testing. Pix2Pix utilizes a discriminator known as PatchGAN that distinguishes between patches rather than the entire image. PatchGAN enforces more constraints, thus allowing Pix2Pix to focus more on sharp, high-frequency details in data.
The limitation of Pix2Pix is not being able to handle unpaired cross-domain data, which is common in real-world applications, especially for Earth observation data for analyzing natural hazards. Earth observation data from different regions or devices tend to have quite different distributions. A promising variant CycleGAN has been proposed to bridge such domain-to-domain gaps in the data as a solution.
CycleGAN has been applied to generate data related to natural hazard analysis, typical is to solve the class imbalance problem that other deep neural network architectures experience in training. For example, in the context of cyclone intensity estimation, most existing deep learning methods utilized for cyclone intensity estimation fail to achieve satisfactory performance due to data missing. CycleGAN has been employed to synthesize CNN features for classes lacking samples, thus addressing the problem of highly scarce cyclone data for specific intensities (Xu et al. 2019) (Fig. 3).

An overview of generative adversarial networks for data generation in natural hazard analysis. a A typical adversarial training process for generative adversarial networks. b Schematic of DCGAN, which has been demonstrated to generate tornado images (Barajas et al. 2020). c Schematic of CGAN, which has been demonstrated to improve meteorological data quality (Gómez-Gonzalez and Serradell Maronda 2021; Leinonen et al. 2021). d Schematic of WGAN, which modifies the loss function of the original GAN. The Wasserstein distance allows a smoother gradient to be calculated when training the GAN. WGAN, therefore, typically performs better. e Schematic of Pix2Pix, which allows excellent image-to-image translation. As an example, Pix2Pix can convert a sketch into a seismic image (Ferreira et al. 2020). f A schematic illustrating two GANs that can perform super-resolution. In the row below, the seismic image is the output of experiments conducted by the authors using ESRGAN
3.2.3 Normalizing flows (NF)
NF was developed in 2015, transforming a simple probability distribution (e.g., the standard normal distribution) into a more complicated distribution through a chain of invertible and fine-tunable mappings. In contrast to the aforementioned VAE and GAN, NF explicitly learns the data distribution, and its loss function is simply negative log-likelihood. Explicit here implies that these distributions are described by analytical expressions (Jiang et al. 2021). Although NF is a fascinating deep generative model, it has not been extensively applied in data generation for natural hazard analysis.
One advantage of NFs is to provide a solution to the intractable likelihood (probability density) problem in the VAEs and GANs. A significant difference is that VAEs and GANs represent low-dimensional data manifolds embedded in the data space and learn mappings between these spaces. In contrast, NFs are based on same-dimensional latent space. Thus, the tractable density of NF extends throughout the entire data space and is not limited to low-dimensional surfaces.
Theoretically, NF can provide latent distributions with infinite expressive power for probabilistic modelling. When applications that increase data availability in natural hazard analysis involve simulation-based inference environments, domain knowledge requires precise representations of the dimensions of the data manifolds, and NFs have great potential in this regard. The flexible density allows NF to be employed in application scenarios involving highly complex posteriors, e.g., downscaling tasks in climate science (Groenke et al. 2020).
3.2.4 Diffusion models (DM)
Most recently, a significant advance in deep generative models is the diffusion models, which originated in 2020 and were inspired by non-equilibrium thermodynamics (Ho et al. 2020). The deep generative models involves introducing random noise incrementally into data using a Markov chain of diffusion steps and learning to reverse this process (Yang et al. 2023). This reverse diffusion constructs data samples from noise, leveraging a Gaussian distribution as a starting point. The iterative denoising approach of diffusion models simplifies the task of generating samples from a target distribution compared to direct noise-to-distribution mapping.
Diffusion models hold significant promise for data generation due to their unique architecture and learning process. These models feature a fixed learning procedure and high-dimensional latent variables that closely match the dimensionality of the original data. This architecture allows them to reconstruct information-rich samples by progressively denoising corrupted versions of the data (Bond-Taylor et al. 2021). Diffusion models have demonstrably generated high-quality results in various tasks, including image super resolution (Li et al. 2022a), and 3D cloud generation (Luo and Hu 2021). Continuous advancements are further enhancing their capabilities. For example, diffusion models incorporating pixel constraints have shown improved adeptness at capturing subtle details in remote sensing imagery, leading to more refined super-resolution reconstructions (Liu et al. 2022).
Diffusion models are also excellent at conditional generation, capable of integrating text, class labels, and other modalities to generate controlled and diverse outputs. The conditional generation of diffusion models in natural hazard analysis can thus incorporate physical constraints and various modalities, enhancing the relevance and accuracy of generated scenarios. In addition to describing and predicting a wide range of natural hazard phenomena, this capability allows the generation of diverse scenarios capable of considering extreme situations. For example, using anticipated precipitation intensity as knowledge control, a diffusion model can capture the distribution of the future and be flexible in focusing on possible extreme weather events such as rainstorms and droughts (Gao et al. 2023).
4 Advances in data generation for natural hazard analysis with generative deep learning
In this section, we summarize the recent advances in generative deep learning for data generation in natural hazard analysis from two perspectives.
First, we summarize advances in data generation for general information in natural hazard analysis by applying deep generative models. General information, also referred to as ’explanatory variables’, pertain to common factors influencing natural hazards. These factors, such as meteorological and geophysical data, play a significant role in the occurrence and evolution of natural hazards. They typically serve as common input variables in natural hazard modelling, with their generation often leading to improved model performance.
A typical example is rainfall, which is an important variable in analyzing floods, landslides, droughts, storms, and other hazards. Increasing the availability of rainfall data can improve the predictability of related natural hazards. Here, we focus on meteorological and geophysical data, which encompass most of the influencing factors of natural hazards.
Second, we survey the advances of deep generative models in data generation for specific information, also refer to as ’outcome variables’, employed for natural hazard analysis. Outcome variables are detailed characteristics of specific natural hazard events. For example, satellite images are employed to exhibit typhoons, reanalysis products are employed to describe storms, and broadband seismic signals are recorded from seismic networks worldwide. For most natural hazard analysis tasks, specifically prediction, such specific information is essential for achieving accurate results.
For example, a data-driven classifier is commonly trained using a labelled dataset containing half of the samples with hazard event-specific information and half of the samples without hazard event-specific information. Well-trained classifiers can accurately and quickly determine whether an input dataset contains a hazard event to enable the application of prediction. With the increasing availability of class-balanced labelling datasets, tools for predicting natural hazards, especially data-driven models, will become more accurate and effective.
The following part focuses on how representative studies solve several questions. For example, how can the data be processed to be more suitable for deep generative models? According to natural hazard analysis data, how can deep neural network architectures and loss functions be designed or applied? How should the generated data be evaluated? We believe that discussing these questions can inspire further improvements based on the current work.
4.1 Data generation of general information in natural hazard analysis
4.1.1 Meteorological data
Meteorological data provide essential weather-related and climate-related information for natural hazard analysis, which are fundamental to understanding the processes of natural hazards, performing accurate hazard forecasting, and issuing timely hazard warnings. In most cases, a wide range of high-impact, weather-related natural hazards result from various physical processes at various spatial and temporal scales, which involve complex interactions among multiple meteorological factors or between meteorological factors and other influences. For example, abnormal rainfall and temperature can induce drought, certain levels of wind speed and humidity variability are likely to trigger storms, and intense rainfall often causes flooding. Common meteorological factors in natural hazard analysis include rainfall, temperature, and wind speed.
Meteorological data describe the dynamics of these meteorological factors at different spatial and temporal scales. They are typically adopted in models developed to investigate the evolution of natural hazards or to forecast them. Meteorological data are essential for enabling early warning systems for natural hazards. For example, rainfall is the most common weather trigger for landslides. Thus rainfall data are widely employed in modelling for the analysis of the occurrence and magnitude of slope damage. Most landslide early warning systems worldwide integrate rainfall information, including in-situ measurements from rain gauges, numerical weather forecasting forecasts, forecasts from weather radar, and estimations from satellite-based rainfall (Guzzetti et al. 2020).
The availability of meteorological data for natural hazard analysis substantially depends on the quality and quantity of meteorological data. First, the insufficient resolution is one of the major limitations of the quality of meteorological data involved in natural hazard analysis. Regarding spatial resolution, it is desirable to obtain data at finer scales with more local information. It is desirable to obtain precipitation time series with the sub-daily temporal resolution with regard to temporal resolution. For example, sub-daily precipitation data are required to accurately simulate flood peaks. Regarding spatial-temporal resolution, meteorological drought forecasts typically employ seasonal climate forecasts as indicators of droughts for modelling, which are commonly available at monthly time scales and \(1^{\circ }\) spatial resolution. Windstorm forecasts emphasize mesoscale correlation winds and gusts and are available on NWP models with grid sizes of tens of kilometres and lead times of 1-2 weeks (Merz et al. 2020). As promising solutions for increasing meteorological data’s spatial and temporal resolution, deep generative models have been demonstrated to be highly effective and efficient.
Second, regarding the quantity of meteorological data, data scarcity is one of the significant limitations of the availability of meteorological data for natural hazard analysis. For example, rainfall datasets are imbalanced due to the rarity of extreme rainfall events. A solution is generating more samples of rare events in meteorological datasets using deep generative models.
In the following part, we discuss how deep generative models can enhance meteorological data from the viewpoint of increasing both meteorological data quality and meteorological data quantity.
4.1.1.1 Increasing the quality of meteorological data
Spatial resolution Downscaling methods are applied to extrapolate local and regional-scale weather information from global climate models to increase the spatial resolution of meteorological data. For example, global climate models typically have a resolution of tens or hundreds of kilometres, while precipitation considerably varies at spatial scales of 1 km or less. This gap can be narrowed by downscaling, which offers finer resolutions and thus enables the forecasting of natural hazards associated with extreme rainfall.
This process of downscaling meteorological data is somewhat similar to superresolution in computer vision. Therefore, downscaling meteorological data can be characterized as an image superresolution task in computer vision, which will enable deep generative models specifically designed for image superresolution tasks to be utilized to provide a generated spatial resolution of meteorological data.
As introduced in Sect. 2, many deep generative models have been specifically developed for superresolution problems. The most common deep generative models are SRGAN and ESRGAN. Can these deep generative models have a role in downscaling meteorological data, and to what extent can they increase the resolution of meteorological data? In exploring these questions, Annau et al. (2023) has utilized frequency separation to resolve the inherent conflict between content loss and adversarial loss when downscaling from LR climate model scales to HR scales using original SRGAN models. After dividing high-resolution (HR) wind fields into high and low frequency components, adversarial loss is applied to one set of frequencies and content loss to the other. An 8\(\times\) increase in the resolution of the surface wind field was achieved with the enhanced SRGAN model by incorporating additional covariates.
Similarly, White et al. (2019) employed a modified ESRGAN to increase wind field resolution. For the adaptation of ESRGAN to wind velocity fields obtained from numerical simulations of WRF model grid data, a loss term was removed from the loss function of the original ESRGAN. The data generated by this improved ESRGAN recover more spatial details compared to baselines. Specifically, their spectra are more similar to real data than the SRGAN and the traditional bicubic upsampling, which indicates that the ESRGAN can capture the high-frequency information in the wind field by learning the data distribution at all scales.
To better apply the precipitation data from WRF, Watson et al. (2020) improved the original ESRGAN by replacing two upsampling blocks with three upsampling blocks in the neural network architecture and removing the VGG or GAN loss terms from the loss function. The improved ESRGAN achieved inspiring results, increasing the precipitation field resolution up to 9\(\times\) and capturing specific events in detail.
As a rule of thumb, 16\(\times\) is considered the extreme upsampling factor in superresolution. Therefore, can deep generative models achieve higher upsampling factors? For example, downscaling 100 km of grid data to 5 km using a 20\(\times\) upsampling factor would significantly improve the accuracy of seasonal forecasts related to meteorological variables. To achieve this outcome, Gómez-Gonzalez and Serradell Maronda (2021) developed deep generative models based on improvements to the CGAN architecture for increasing the resolution of temperature-gridded fields, where residual blocks mainly stack the generator. By exploiting the advantage that the CGAN can be conditioned by employing additional information, they have connected topographical maps and land-ocean binary masks to the temperature field data. It can be observed from experimental results that additional condition information can improve the reconstruction of high-frequency details and eventually achieve a 20\(\times\) upsampling factor.
An attempt to achieve a larger superresolution jump was conducted by Stengel et al. (2020), who trained deep generative models with a two-step method. Both steps, low-resolution to medium-resolution and medium-resolution to high-resolution, are implemented using a slightly improved SRGAN. This improvement in the training strategy increases the oversampling factor for the wind speed grid data derived from the climate system model to 50\(\times\). In this case, generated high-resolution wind speed data can recover highly sharp gradients or much finer small-scale characterizations and exhibit physical consistency with real wind data, including similar patterns and flow directionality.
Other deep generative models, such as VAEs, have been employed to increase the spatial resolution of meteorological data. The VAE can learn potentially relevant latent representations of data, which allows it to be ideally suited to dynamic discovery and understanding. Other applications for the VAE in atmospheric dynamics have demonstrated its ability to learn and extract hidden details from meteorological data (Reimers et al. 2018; Krinitskiy et al. 2019).
To demonstrate the ability of VAEs to reconstruct high-resolution meteorological data accurately, Mooers et al. (2020) applied a VAE that had a covariance constraint term added to the loss function to the reconstruction of the vertical velocity field. The VAE, with an improved loss function, successfully reconstructed the spatial structure of convection and detected the development of small-scale storms that may have escaped detection by conventional methods. Moreover, there is an interesting assumption that more thermodynamic information might enable VAEs to achieve more satisfying physical clustering in latent space. Adding convection-related variables to the input should improve the VAE. Mangipudi et al. (2021) successfully verified this hypothesis by including temperature, water vapour, and primitive vertical velocity fields in the input of a similar VAE.
The VAE has another advantage due to its unique sampling strategy in its latent space: it can maintain the spatial and temporal consistency of high-resolution fields during downscaling. This advantage was demonstrated by González-Abad et al. (2021), who successfully applied a CVAE to generate Europe’s high-resolution precipitation field. This study employed five thermodynamic variables as predictors to provide high-resolution precipitation data. After passing through the encoder of the CVAE, the complex interactions among these meteorological variables are represented by the latent space. The CVAE generated spatially consistent stochastic precipitation fields by sampling from this latent distribution.
Another generative model, NF, has been utilized to solve the inherent stochasticity of the relationships among spatial scale problems most downscaling methods confront.
More specifically, due to the stochastic nature of the data, the two scales may be inconsistent even when high-resolution data are paired with low-resolution data. As a solution, Groenke et al. (2020) conceived statistical downscaling as a domain alignment task, thus achieving downscaling for meteorological variables, including temperature or precipitation, by using NF. In this study, the low- and high-resolution fields are considered two different variables corresponding to two domains. Theoretically, NF can construct a bijection in the domains corresponding to the low- and high-resolution fields and thus can align the two variables according to a shared latent variable space. According to their experimental results, in the absence of paired low/high-resolution training data, NF employed successfully achieves the desired downscaling effectiveness.
Temporal resolution Natural hazard analysis will also benefit from the improved temporal resolution of meteorological data. Subdaily precipitation time series, for example, can render depicting rainfall variability more accurate, thus improving natural hazard prediction and warning. With the growing need for accurate precipitation nowcasting for early warning systems, including systems for floods and landslides, nowcasting based on radar data is expected to be a promising application scenario for deep generation models.
To utilize deep generation models, such as Pix2Pix, forecasting with radar data can be described as an image-to-image translation process, where forecasts based on past radar data are "translated" into forecasts for future radar data. As an example, Kim and Hong (2022) applied Pix2Pix to a short-term rainfall prediction, in which the real radar observational rain rate at time step t serves as the conditional input x. The real radar observational rain rate at time \(t+\Delta t\) serves as the target y, and the fake radar observational rain rate at time \(t+\Delta t\), G(x) is output by the generator. As x and y represent the real continuous data, while x and G(x) represent the fake continuous data, both pairs are fed to the discriminator to improve classification performance, thus forcing the generator to produce data closer to the ground truth. Within two hours, this well-trained Pix2Pix can accurately predict precipitation, thereby assisting in detecting sudden weather changes.
Similarly, based on Pix2Pix, Choi and Kim (2021) developed a Rad-cGAN that can perform forecasting within 10 min. Here, the conditional input x contains more sequence information, which comprises four consecutive radar reflectance data (\(t - 30\) min, \(t -20\) min, \(t - 10\) min and t min). The discriminator determines whether the continuous input data (from \(t - 30\) min to \(t + 10\) min) contain real radar reflectivity data y at \(t + 10\) min or fake radar reflectivity data generated by the generator from input x at \(t + 10\) min. Compared with U-Net and ConvLSTM, Rad-cGAN has a more accurate and efficient forecasting performance in different regions.
With the high dimensionality and uncertainty in meteorological data, generating spatially coherent rainfall patterns with high temporal resolution from lower temporal resolution data is challenging. In this regard, it seems plausible that the probability distribution models could provide a wide range of possible distributions, which implies that deep generative models that inherently estimate the probability distribution of images would be promising candidates for generating these distributions. By capturing multiple plausible futures, this probabilistic modeling method generates diverse results that better reflect real-world conditions.
Building on this idea, Scher and Peßenteiner (2021) combined DCGAN and WGAN to develop a deep generative model termed RainDisaggGAN, which can generate hourly precipitation field scenarios based on precipitation radar data. These results are almost visually indistinguishable from actual rainfall patterns. Arguably, RainDisaggGAN can approximate the probability distribution of spatiotemporal precipitation patterns. However, the preliminary research highlights two fundamental limitations. First, the authenticity of the generated data depends on the training data representing the same climatic conditions as the input data. Second, expert judgment is still necessary in determining when the training of the GAN should be terminated, as the quality of the generated pattern has diminished over time.
An alternative solution would be to directly integrate physical constraints into deep generative models, since diffusion models can produce controlled and diverse outputs. For example, Gao et al. (2023) incorporates prior knowledge into diffusion models, resulting in controllable rainfall patterns and simulations of potential extreme weather events.In particular, anticipated precipitation intensities are utilized in the diffusion model to provide knowledge-based control. At each denoising step, explicit knowledge control mechanisms are established to assess deviations from the imposed constraints and adjust the transition distribution accordingly. Guided by this knowledge control, the proposed diffusion model adeptly captures the probability distribution of future weather patterns and demonstrates flexibility in capturing potential extreme scenarios, such as rainstorms and droughts.
Moreover, high-resolution meteorological data for natural hazard analysis are not always immediately available. For example, geostationary satellites offer infrared images every three hours, which are sufficient for rain estimation and can thus provide early detection and warning of atmospheric hazards with a wide range of effects, such as tropical cyclones. However, the infrared signal is highly vulnerable to obscuration by thick clouds and can only measure cloud top features that are indirectly related to rainfall. Passive microwave data, which can pass through clouds, has insufficient temporal resolution for any real-time assessment of atmospheric hazards.
It would be interesting to convert infrared imagery to passive microwave rainfall. Meng et al. (2022) successfully achieved this conversion in image-to-image translation by applying an improved Pix2Pix (TCR-GAN) to the constructed benchmark dataset, which contained more than 70,000 paired infrared images passive microwave rainfalls. As a result, the rainfall data generated by TCR-GAN have a high temporal resolution, which allows for detecting spiralling rain bands and the eyes of typhoons.
There have also been attempts to develop deep generative models for a wider range of meteorological variables. For example, Pan et al. (2022) applied the CVAE to improve probabilistic seasonal predictions of precipitation and air temperature at the global scale, where snapshots of variables from climate simulations were adopted as predictors \({\textbf{X}}\) and \({\textbf{Y}}\). The CVAE models approximate the conditional probability distribution \(P({\textbf{Y}} \mid {\textbf{X}})\) associated with a pair of predictors \({\textbf{X}}\) and \({\textbf{Y}}\). By comparing the CVAE with several common, dynamic, seasonal prediction systems, it is demonstrated that CVAE predictions can achieve a higher level of certainty and probability. In this case, the CVAE significantly mitigated the limitations of dynamic forecasting, particularly in terms of initialization errors, model formulation errors, and internal climate variability, illustrating its promise for validating and diagnosing complex dynamic forecasting systems.
To further explore the ability of the GAN to learn the underlying conditional distributions of a variety of meteorological variables, Bihlo (2021) employed GAN models to separately forecast the geopotential height, two-meter temperature, and total precipitation in ERA5 reanalysis data. To better model the dynamics of meteorological variables, they correspond the weather prediction problem to the video-to-video mapping problem in computer vision, thus introducing the Pix2Pix variant that was developed to solve the video prediction problem as a solution. Here, the past meteorological field corresponds to the input frame, and the future meteorological field corresponds to the output frame, i.e., the prediction target. The impressive performance of the developed model, termed Vid2Vid, in several metrics demonstrates its potential ability as a purely data-driven paradigm for learning underlying physical processes. Additionally, it can capture certain uncertainties inherent in the evolution of the atmospheric system, thus enabling the detection of atmospheric hazards such as storms.
Limited by the spatial resolution of the ERA5 reanalysis data, Vid2Vid fails to achieve better performance in forecasting rainfall variables. As an improvement, Ravuri et al. (2021) developed a GAN model for instantaneous forecasting based on radar data, aiming to improve the skilful probabilistic forecasting ability of the deep generative model in rainfall variables, where the generator produces 18 future radar observations that represent rainfall forecasts based on the conditional distribution in four consecutive, historical radar observations.
The distinctive feature of this GAN model is the inclusion of two discriminators: a spatial discriminator and a temporal discriminator. These two discriminators correspond to a loss function, allowing the model to maintain consistency on both the spatial and temporal scales during training. Additionally, a regularization term is a critical constraint during model training, which allows the model to generate more accurate location predictions. By adding these constraints, the model significantly improves the accuracy and reliability of precipitation nowcasting (Fig. 4).

Replication results for increasing the temporal resolution of radar precipitation data by implementing a deep generative model (Ravuri et al. 2021). The following grid shows 30 predictive frames generated by a deep generative model, enhancing the temporal resolution of radar-based precipitation forecasts. Six rows (frames) allow for a detailed analysis of rainfall evolution within a single prediction sequence, each serving as a snapshot of 20 min. The five columns illustrate five different scenarios, visually capturing the inherent uncertainty and variability in weather forecasting. The colormap, transitioning from blues for low intensity to reds for high intensity. The horizontal (X) axis extends across the east–west spatial dimension, while the vertical (Y) axis denotes the north–south spatial dimension
Considering the consistency of meteorological data in terms of time evolution is interesting. In this regard, Leinonen et al. (2021) developed a stochastic superresolution GAN to improve the spatial resolution of precipitation fields. By utilizing ConvGRU, which is a deep neural network demonstrated to learn the temporal evolution of precipitation fields, the proposed GAN model integrating the CGAN and WGAN can generate an ensemble of high-resolution outputs for low-resolution radar rainfall field data in the same domain. In this ensemble, high-resolution radar rainfall fields can evolve consistently over time. The spread among these generated high-resolution data represents the uncertainty in downscaling by applying the superresolution GAN.
Spatial-temporal resolution Another interesting challenge is improving the resolution of meteorological data simultaneously in both the temporal and spatial dimensions. Deep generative models can be a promising solution. For example, utilizing deep generative models is expected to mitigate the problem of ambiguous radar echoes effectively.
Typically, crisp radar observations can provide details on future atmospheric evolution with the high spatial and temporal resolution, facilitating the assessment of hazards such as storms during their developmental stages, dynamics, and evolutionary trends. However, most conventional radar echo extrapolation techniques underestimate radar echoes, rendering them lacking in small-scale detail, thus further limiting their availability to analyse severe convective hazards.
To solve the blur problem in radar echo extrapolation, Hu et al. (2022) developed a spatial GAN and spectral GAN to introduce different constraints into the spatial domain and spectral domain. The spatial GAN involves reducing differences between the generated and real images in object shape, colour, and pattern. The spectral GAN reduces the spectral differences between the generated and real images, especially at high frequencies. The extrapolated radar sequences are further enhanced by adding the texture ("style") of future ground truth radar sequences by using style loss functions. This is a similar process to style transfer in computer vision. Furthermore, a neural network architecture for extracting spatiotemporal representations, ConvLSTM, was applied to the generator and enabled better temporal consistency of the extrapolated results.
The complexity of radar data poses a challenge when modelling it with GAN-based models. With the increasing dimensionality of radar data, the space for the results generated by the GAN-based model will dramatically increase, hindering convergence. Wang et al. (2021b) pointed out that it is difficult to simultaneously and accurately predict radar echoes’ location and intensity with a high resolution by applying GAN alone. As a solution, they developed a two-stage approach. A GAN model that combines CGAN and WGAN was applied in the second stage to improve the accuracy of a deep learning model from the first stage for estimating the radar intensity distribution. In this two-stage approach, the GAN is fed a feature map from the last decoding block of the first-stage deep learning model that contains more valuable representation than the radar image. A radar image with more details is then generated by this GAN, which has more details at small scales and is more consistent with the structural characteristics of radar echo.
Similarly, applying GAN to CNN-based models for increasing the resolution of data can also be applied to reanalysis productions. For example, Wang et al. (2021d) developed a CGAN to train CNN-based models to increase the resolution of two datasets from regional climate model (RCM) simulations. This CGAN maps input patches of coarse data to relevant patches of high-resolution data by using conditional variables such as vertically integrated water vapour and air temperature variables and actual precipitation amounts. With this approach, physically realistic, small-scale features can be generated, and extreme rainfall events can be effectively captured. As the images for each time step are separately processed, it is difficult for this approach to allow the generated output to evolve consistently, as occurs in several aforementioned methods.
4.1.1.2 Improving the scarcity of meteorological data
Data imbalance is a common limitation in meteorological data, especially in rainfall data, thus impacting the accuracy of numerical forecast models or machine learning-based forecasting models. For example, the deterministic global model of the European Centre for Medium-Range Weather Forecasts (ECMWF) tends to overestimate when the observed rainfall is minor. As common solutions, resampling methods typically alter the sample distribution, resulting in bias or overfitting of the forecast model.
Deep generative models have been proposed as alternatives to conventional resampling methods since they generate minority samples directly from the data rather than by resampling existing data. For example, Xie et al. (2021) applied a vanilla GAN to generate a short-term, intensive rainfall sample set, addressing the extremely imbalanced data distribution in the original dataset. GAN-enhanced data were utilized for short-term, intensive rainfall forecasting performed in a classified manner, thus improving accuracy.
Furthermore, the data imbalance resulting from the rarity of extreme rainfall events is also common in radar data. To increase the radar sequences of extreme precipitation, Zhang et al. (2020a) considered the generation of radar data as a video-generation problem, focusing on the spatial and temporal dependence of radar data. Motivated by MoCoGAN, a deep generative model specifically developed for video generation, they developed TsGAN to generate radar reflectance data for extreme precipitation. During the generative adversarial training phase, each frame of the radar image is decomposed into the cloud’s shape, which represents content information, and the flow direction, which represents motion information. Two discriminators are applied to distinguish whether these two types of information are from real images or random vectors. In particular, the fake motion information is generated from a series of random vectors by an RNN-based architecture, and the corresponding motion discriminator employs a spatiotemporal CNN architecture to capture temporal features. The resulting radar image sequences of extreme precipitation contain content details and motion details.
In the real world, meteorological data exhibit multimodal, heterogeneous distribution patterns and spatial and temporal dependencies, distinguishing them from general video data. For the generated meteorological data to display spatial and temporal properties that are physically consistent with the real world, integrating a priori information into the deep generative model can be a promising solution. Relevant physical knowledge, for example, can be introduced as conditional information input into the deep generative model. Building on this idea, Klemmer et al. (2021) embedded an extreme event mask into the context vector of COT-GAN (another deep generative model specifically developed for video generation), allowing the model to produce more realistic weather patterns in both space and time. In each of the time steps, a segmentation mask with the same shape as the input contains binary values, in which pixels are assigned a value of 1 when extreme events occur and 0 otherwise. Furthermore, they modified the loss function, thus adding physical information to the training process.
Specifically, a metric SPATE is introduced into the loss function of COT-GAN, which can measure spatial-temporal autocorrelation by detecting space-time clusters and homogeneous areas in the data. When applied to turbulence, logarithmic Gaussian-Cox processes, and global weather data, the additional SPATE loss term significantly improved the performance of COT-GAN, especially when simulating spatiotemporal dynamics.
Similarly, by using loss functions that reflect domain knowledge, Manepalli et al. (2019) imposed additional constraints on Pix2Pix to "translate" the meteorological data from the reanalysis dataset into physically consistent snow equivalents. These additional constraints include a severe penalty for waters in the study area, such as the Pacific Ocean, where snow is unlikely to accumulate. This physics-based Pix2Pix generated consistent results with physical laws, such as yielding an SWE that was almost zero during the summer.
In addition to focusing on capturing features in temporal and spatial dimensions to generate more realistic intense rainfall data, another interesting alternative is to control data generation by manipulating the distribution in latent space, thus providing a larger sample size to represent relatively rare scenarios. Building on this idea, Oliveira et al. (2021) controlled the latent representation of a vanilla VAE by sampling from the tails of the normal distribution, thus allowing it to generate more samples for describing rare events such as intense rainfall. In this study, a threshold was defined to determine the sampling location in the normal distribution. By mapping CHIRPS data characterized by complex spatiotemporal patterns to this identified latent representation, the vanilla VAE generated heavier rainfall patterns similar to the real data. The higher the threshold is, the more unusual the scenarios described by the generated samples are likely to be.
Similarly, this distribution-based method can also be implemented in a GAN. For the simulation of rare climate events, Boulaguiem et al. (2022) developed an evtGAN based on extreme value theory. Through the decomposition of a high-dimensional distribution into its marginal distributions and their dependence structures, evtGAN is able to simulate extreme temperatures and precipitation in gridded spatial fields adequately.
For meteorological data, data scarcity is also associated with computational costs. The majority of physically-based models, such as GCMs, require highly demanding computing environments, and thus, it is challenging to provide data products relevant to natural hazard analysis when computing resources are limited. Reducing the computational complexity of traditional modelling techniques is a challenge in improving the data scarcity of meteorological data. As a data-driven paradigm, deep generative models are demonstrated to be a potential way to reduce computational costs.
For example, to solve the stochastic parameterization problem in complex GCMs, Gagne et al. (2020) applied a GAN to sample from subgrid trend distributions that had the resolved state as the condition and thus obtained well-approximated results for the joint distribution of state and trends. With this integration of a GAN into the parameterization framework, there is no need to develop stochastic representations of model uncertainty retroactively. Similarly, Besombes et al. (2021) developed a WGAN capable of creating global atmospheric multivariate states. Here, a generator learns constraints that are physically consistent with the climate state and converts a Gaussian randomly distributed sample into a multivariate state in nonlinear latent space. Since there is no need to run a completed simulation as with the GCM, the computational time for this deep generative model is drastically reduced when running a 100-year daily simulation.
Furthermore, Schmidt et al. (2020) exploited a CGAN to generate a cloud reflectance field (CRF) by utilizing meteorological variables as conditions, reducing the computational time required to directly model the physical processes related to cloud composition and evolution by employing the GCM. By including additional conditions such as SST and relative humidity, the CGAN captures the set of possible scenarios under the initial conditions, thus enabling it to handle the chaotic nature of meteorological data. Although the model generates a clearer and more realistic reflectance map when using the L1 matching loss, the possibility of a mode collapse during training could hinder further exploration of the data pattern.
To solve this mode collapse problem when modelling chaotic meteorological data, Gupta et al. (2020) utilized a LOGAN-based StyleGAN that combines annealing optimization of the latent space and feature matching loss. By performing annealing, the StyleGAN can balance low bias and low variance, thus enabling a more accurate sampling of the representation space. It has been demonstrated in experiments with datasets from turbulent, chaotic systems relevant for weather and climate modelling that the model can generate high-fidelity data while preventing model collapse (Fig. 5).

Generative deep learning for increasing the availability of meteorological data in natural hazard analysis. a A schematic diagram for increasing the spatial resolution of meteorological data by applying SRGAN. LR low-resolution data, SR high-resolution data generated by applying SRGAN, HR original high-resolution data. Redrawn from Stengel et al. (2020). b A schematic diagram of increasing the temporal resolution of meteorological data by applying Pix2pix. The historical data and the predicted results constitute an input image pair. Redrawn from Choi and Kim (2021). c A schematic illustrates how sophisticated methods involving two GANs can increase spatial-temporal resolution of meteorological data. This approach minimizes the discrepancy between the generated meteorological data and the real data in terms of shape, colour, etc. by using a spatial GAN, and minimizes the spectral discrepancy between the generated meteorological data and the real data by using a spectral GAN. Redrawn from Hu et al. (2022). d A schematic diagram of how physical information can be encoded into GANs to generate more realistic weather patterns. A mask is prepared to represent extreme events here. Redrawn from Klemmer et al. (2021). e A schematic diagram of the spatially coherent stochastic precipitation field was generated using CVAE. These high-resolution predictors are five thermodynamic variables, predictand fields is precipitation data, and the complex interactions between them can be represented in the latent space of VAE. Redrawn from González-Abad et al. (2021). f A schematic diagram of the data generation is controlled by manipulating the distribution of the VAE latent space. This approach allows for the generation of a larger number of samples representing rare events such as heavy rainfall. Redrawn from Oliveira et al. (2021)
4.1.1.3 Preparation, customization, and evaluation of deep generative models for meteorological data generation
How to prepare meteorological data for the input of deep generative models?. Various methods exist for processing meteorological data for input to deep generative models, which depend on the data structure employed to represent the input data. Similar to images, most meteorological data are inherently characterized by rich spatial dependency (Wang et al. 2021d). Accordingly, image data structures are appropriate for representing meteorological data from different sources.
Most grid data from different sources can be considered two-dimensional images with dimensions of H (Height) \(\times\) W (Width). For example, a 15-year wind velocity field from a numerical simulation of the Southern California WRF model is considered an image. Each pixel corresponds to a grid representing the average wind speed in a 1.5 km \(\times\) 1.5 km region. These grid data are employed to train an ESR-GAN model (White et al. 2019). Furthermore, for modelling atmospheric convection by applying a VAE, spatial snapshots of the vertical velocity field from the 30-level by 128 Cloud Resolution Model (CRM) columns can be formatted as 30 \(\times\) 128 two-dimensional images. The fully convolutional architecture in the VAE is employed to retain local information about these grid data (Mooers et al. 2020).
Providing additional information will be beneficial. A common approach for this purpose is to input other variables into the model as different channels of an image. A colour image typically consists of red, green, and blue channels. Similarly, meteorological data can also be represented as a three-dimensional structure of H \(\times\) W \(\times\) N, where N denotes the number of variables (Vandal et al. 2018). The effectiveness of this approach of considering multivariate meteorological data as three-dimensional image structures was demonstrated (Bihlo 2021). For example, compared with simply using single variables, the VAE achieved better results when more variables were input in a multichannel manner, resulting in higher resolution meteorological data (Mangipudi et al. 2021). By connecting topographical maps and land-ocean binary masks to all input samples as image channels, the CGAN was better able to recover high-frequency details of the coarse resolution temperature field (Gómez-Gonzalez and Serradell Maronda 2021).
When using data from a physics-based model, the components for each variable at different atmospheric levels can also be considered channels (Wang et al. 2021d; Schmidt et al. 2020). Likewise, different wind components can be considered different channels (Stengel et al. 2020). A priori information can be added to the deep generative model as conditions. To incorporate conditional information about multiple extreme events into the GAN, the segmentation masks associated with each extreme event are assigned to separate input channels, with each extreme event corresponding to its channel (Klemmer et al. 2021).
As meteorological data are dynamic, numerous deep generative models require their temporal information. As a strategy for depicting temporal correlation, meteorological data can be represented as a T \(\times\) H \(\times\) W three-dimensional structure, where T denotes the temporal dimension. This video representation-like structure is particularly applicable to applications that increase the temporal resolution of forecast products (Ravuri et al. 2021; Wang et al. 2021b; Zhang et al. 2020a). For example, the data from ECMWF can be input into a time \(\times\) longitude \(\times\) latitude structure, which allows the deep generation model to predict the entire sequence at once, thus improving the prediction efficiency (Bihlo 2021). In some cases, meteorological data can also be represented as a three-dimensional structure of H \(\times\) W \(\times\) T, where the time dimension is considered the number of input channels (Oliveira et al. 2021). However, spatial-temporal dependencies may be neglected when a 2DCNN is applied to these representations (Wang et al. 2021b).
How can deep generative models be customized to generate meteorological data?. Most deep generative models are developed for handling image data. As discussed in Sect. 2, these deep generative models are generally based on CNNs and their variants to extract meaningful information from images. By considering meteorological data as images, these well-known, deep generative models can be directly applied to modelling meteorological data and extracting abstract features from it.
Considering the high dimensionality of meteorological data, many deep generative models employ encoder-decoder architectures that allow these features to be encoded as compact latent feature representations, thus making them more efficient to extract. For example, the U-Net architecture, typically employed as a generator in GANs, allows meteorological data to be contracted and then expanded, thus retaining both the global context and local details in the input data. The extraction of local information by U-Net also benefited from the skip connection in the architecture. The skip connection enables U-Net to share low-level features of contraction and expansion paths while avoiding the loss of input details.
Although deeper network architectures theoretically allow for more accurate extraction of meteorological data representations, they are computationally expensive. Residual blocks involving skipped connections are thus employed to efficiently build deeper architectures in deep generative models, which improve the capture of meteorological data features (Meng et al. 2022; Besombes et al. 2021). For example, in a GAN that utilizes multiple CNN layers to improve the resolution of meteorological data, residual blocks were introduced to both generators and discriminators to allow them to extract more high-level features (Leinonen et al. 2021). In particular, residual blocks have been superior in recovering high-frequency details (Gómez-Gonzalez and Serradell Maronda 2021).
In certain cases, deep generative models also consider the dynamic nature of meteorological data. Theoretically, RNN-based architectures specifically developed to handle sequence data are capable of capturing the temporal correlation in meteorological sequence data. With regard to handling spatiotemporal sequences, ConvLSTM is a highly applicable architecture that adopts convolution operators in the input-to-state and state-to-state transitions.
With ConvLSTM, there has been satisfactory performance in modelling the spatiotemporal correlation of meteorological data. For example, radar-based rainfall predictions obtained by ConvLSTM are superior to traditional, optical flow-based precipitation nowcasting models (Kim et al. 2017). The advantages of ConvLSTM have enabled it to be applied in deep generative models that consider the temporal correlation of meteorological data, especially GANs. An example is to apply ConvLSTM in generators to improve the motion features of the generated data (Zhang et al. 2020a).
Additionally, when a GAN is employed to improve the resolution of meteorological data, ConvGRU, a variant that is quite similar to ConvLSTM, was applied to ensure temporal consistency, which enables the generator to model the temporal evolution of the meteorological data and enables the discriminator to evaluate the plausibility of image sequences (Leinonen et al. 2021).
Another essential element of deep generative models, especially GANs, is their loss function. Inherently, GANs attempt to replicate the probability distribution of the input meteorological data. The loss function measures the difference between the generated meteorological data distribution and the real meteorological data distribution. There is a critical question at play here, which is as follows: How can the difference between the two distributions be effectively captured in the loss function?
In the field of computer vision, various solutions have been proposed. These methods or loss functions have been introduced to modelling meteorological data. For example, as a GAN variant that improves the loss function, the WGAN has been positively exploited in several models of meteorological data, commonly in conjunction with other GAN variants, thus solving the notoriously difficult problem of training a GAN. Another interesting application is style loss. When performing the style transfer task, style loss is applied to penalize differences among image styles, such as colour, texture, and pattern. When applied to radar data to increase its spatiotemporal resolution, style loss transfers detailed textures from future ground truth radar sequences to extrapolated radar sequences (Hu et al. 2022).
Different losses were most often combined to improve the quality of the generated meteorological data (Choi and Kim 2021). For example, a regularization term was incorporated into the loss function, which penalized the deviation between the real radar sequence and the predicted mean at the grid cell level, thus improving the accuracy of the position prediction (Ravuri et al. 2021). Furthermore, regularization terms facilitate capturing physical properties. For example, adding a statistically constrained loss function to the VAE allowed it to capture the variance and magnitude of different convective regimes (Mooers et al. 2020).
However, not all loss functions from computer vision are applicable to meteorological data. Perceptual loss, for example, has been demonstrated to generate more realistic images in SRGAN than traditional MSE loss. Nevertheless, this loss has been considered not applicable to characterizing critical features in meteorological data (Stengel et al. 2020). This problem can be solved by either removing the perceptual loss or altering the landscape of the loss function by adding an adversarial term (White et al. 2019; Stengel et al. 2020). To solve this problem, either the perceptual loss can be removed, or the landscape of the loss function can be changed by adding an adversarial term. The adversarial loss was demonstrated to generate more realistic and more physically relevant results (Ravuri et al. 2021; Stengel et al. 2020).
Are there more computer vision-inspired loss functions that enable deep generative models to be more effective for modelling meteorological data? How can loss functions impose penalties on the physical inconsistencies arising from deep generative models when modelling meteorological data? It would be interesting to explore these challenges further. An example is the loss function SPATE characterized by spatial-temporal autocorrelation that identifies homogeneous regions with similar behaviours and anomalous behaviours that differ from neighbouring areas, which may allow the GAN better to reflect the complexity spatiotemporal dynamics (Klemmer et al. 2021). Arguably, customizing loss functions is an excellent opportunity to develop more effective, deep generative models for increasing the availability of meteorological data.
How to evaluate the quality of meteorological data generated by deep generative models?. Numerous qualitative and quantitative approaches have been utilized to evaluate deep generative models developed to increase the availability of meteorological data.
From a qualitative analysis perspective, the most visual method is to directly observe the generated meteorological data, especially observing the content of the images to determine the quality of the data (Chen et al. 2020). For example, the texture on radar data can reflect rainfall distribution. By observing these textures, a GAN can be evaluated for its ability to infer the type and size of precipitation cells based on low-resolution images (Leinonen et al. 2021). Data from other sources can also be evaluated with similar observations. For example, when examining the velocity field of VAE output, the size, proper height, and structure of deep convective, shallow convective, and non-convective systems can be visually observed (Mooers et al. 2020).
In the case of deep generative models that generate image sequences, visual observation can effectively determine how the content changes between two frames. For example, by observing the motion differences between adjacent frames of a generated 15-frame image sequence, the GAN was demonstrated to generate dynamic data with more realistic and detailed motions (Zhang et al. 2020a).
Building on visual observations, determinations from experienced experts can contribute to a more reliable evaluation regarding the performance of deep generation models, thereby increasing their applicability in the real world. For example, when comparing the capability of the GAN and other nowcasting models to generate high-resolution rainfall nowcasting, expert forecasters exhibit a preference for the results generated by deep generative models (Ravuri et al. 2021).
From a quantitative analysis perspective, a common approach is to statistically analyze the generated data. Common metrics that are utilized to examine the statistical distribution of the generated meteorological data include mean square error (MSE) (White et al. 2019; Wang et al. 2021d; Zhang et al. 2020a), mean absolute error (MAE) (White et al. 2019), quantile-quantile (QQ) plot (Oliveira et al. 2021), Pearson correlation coefficient (Choi and Kim 2021; Pan et al. 2022), root mean square error (RMSE) (Choi and Kim 2021; Bihlo 2021; Leinonen et al. 2021), Kullback-Leibler (KL) divergence (Leinonen et al. 2021), Jensen-Shannon (JS) divergence (Wang et al. 2021d), normalized root mean square error scores (NRMSE) (Pan et al. 2022), and probability density function (PDF) (Stengel et al. 2020; Wang et al. 2021d; Gagne et al. 2020).
Among them, the long tail of the PDF is derived from the strong data variability, which allows an evaluation of the quality of the high-resolution data improved by the deep generative model. For generated data with grid cells, these metrics can be both evaluable at the level of a single grid cell for meteorological variables and aggregated at a regional scale for all information. For example, spatial patterns of generated rainfall can be observed by comparing the mean, standard deviation, and precipitation extremes in overall grid cells (Wang et al. 2021d).
Several evaluation methods from computer vision are also utilized to evaluate the picture quality of the generated data, including peak signal-to-noise ratio (PSNR), structural similarity (SSIM) and multiscale SSIM for measuring the structural similarity between two images (Leinonen et al. 2021; Hu et al. 2022; Zhang et al. 2020a). Note that SSIM and PSNR may not adequately capture the generated meteorological data’s dynamics and may be inconsistent with human judgment (White et al. 2019; Hu et al. 2022). An alternative is the recently proposed Learned Perceptual Image Patch Similarity (LPIPS), which can measure the perceived similarity between two images and has been demonstrated to be more compatible with human judgment (Hu et al. 2022).
Additionally, to improve the temporal resolution of meteorological data, one major application scenario for deep generative models is the generation of rainfall forecasts. Therefore, several common metrics in rainfall forecasting can be utilized to evaluate the performance of these deep generative models, for example, the critical success index (CSI) (Ravuri et al. 2021; Choi and Kim 2021; Hu et al. 2022), which is widely employed in evaluating the accuracy of models for precipitation event detection, and the Nash-Sutcliffe efficiency (NSE), which is widely employed for evaluating hydrological models (Choi and Kim 2021). A more comprehensive discussion of rainfall forecasting metrics is provided in Ravuri et al. (2021) and Chen et al. (2020).
Two methods generally evaluated for rainfall forecasting, the rank statistics method and continuously ranked probability score, are also applicable to evaluating the ensemble of high-resolution images generated by a deep generative model (Bihlo 2021; Leinonen et al. 2021). The former evaluates whether the deep generative model can generate the correct amount of variation, while the latter can be utilized as a metric for the entire prediction ensemble to evaluate the image quality. Based on the evaluation results for the ensemble of high-resolution atmospheric fields generated by CRPS, it seems promising to evaluate deep generative models that generate image sequences related to meteorological variables (Leinonen et al. 2021).
Furthermore, to solve the limitations of visual observations, one approach is to transform the generated data and real data into frequencies by utilizing the Fourier transform and then comparing them (Schmidt et al. 2020). For example, by performing a Fourier transform on the average turbulent kinetic energy in turbulent flows to calculate the energy spectrum, it is possible to determine whether the generative model can generate the physical properties of the meteorological data, including turbulent flow characteristics (Stengel et al. 2020; Gupta et al. 2020). Power spectral density, another critical metric that indicates the spatial resolution and higher moments of the data distribution, is also utilized to measure the ability of the deep generative model to capture high-frequency information from meteorological data (Ravuri et al. 2021; White et al. 2019; Mooers et al. 2020; Gupta et al. 2020). By improving the power spectral density, a novel metric, the power spectral density score, which measures the perceptual quality of the radar data from a spectral perspective, is proposed (Hu et al. 2022).
Deep generative models are inherently deep learning models, which implies that analyzing deep generative models from the perspective of interpretability will create more opportunities to evaluate their performance in meteorological data modelling. In this regard, several preliminary attempts have been made. For example, saliency map analysis has been proposed as an effective method for identifying forecast sources in deep generative models.
Specifically, saliency map analysis visualizes the neural network gradients to reveal how each predictor part affects the forecast. In the CVAE for rainfall forecasting, saliency map analysis explains the impact of physical patterns on rainfall forecasting. For example, significance plot analysis indicates that the top ocean potential temperature in the east-central equatorial Pacific negatively influences CVAE precipitation forecasts (Pan et al. 2022). k-Means clustering was also performed to analyze the latent representations derived from the VAE-based models. According to the clustering results, the variability of convective regimes in the latent space of two different VAEs can be detected (Mangipudi et al. 2021). The extensive evaluation methods described above have demonstrated the superior performance of deep generative models in meteorological data enhancement.
A further evaluation is to consider whether meteorological data enhanced by deep generative models can contribute to natural hazard analysis.
First, deep generative models can directly augment meteorological datasets for natural hazard analysis. For example, the VAE can be leveraged to generate samples with more extreme events in the Climate Hazards Group Infrared Precipitation and Stations V2.0 (CHIRPS) dataset, inherently a dataset for seasonal drought monitoring (Oliveira et al. 2021).
Second, it is interesting to evaluate whether the data that have been enhanced by deep generative models can be employed to detect abnormal events that might be associated with natural hazards. For instance, many extreme convective events can be detected from the generated data (Bihlo 2021; Wang et al. 2021b). A high-resolution dataset reconstructed with a VAE can also be exploited to simulate small-scale storm formation and morphology, capturing the evolution of abnormal storms that may not have been captured by other methods (Mooers et al. 2020).
4.1.2 Geophysical data
Geophysical data, especially seismic data, can reflect geological features’ depth extension and mantle dynamics’ influence and control on lithospheric processes (Zhao 2021). Seismic data are typically associated with several vital processes in exploration geophysics, including data processing (e.g., denoising and interpolation), inversion (e.g., imaging and migration), and interpretation (e.g., fault detection).
Seismic data can provide a large amount of valuable information for analyzing geophysical-related natural hazards, such as earthquakes, volcanic activity, tsunamis, and landslides (Yu and Ma 2021). In earthquake hazards, tomography imaging and waveform inversion based on seismic data can be employed to investigate causal mechanisms and source locations of deep earthquakes, where waveform inversion can demonstrate the complex rupture processes of that deep earthquake, and tomography images can be exploited to interpret anomaly amplitudes (Kuge 2017; Chen et al. 2018; Obayashi et al. 2017; Zhang et al. 2019; Oswald et al. 2021; Tsai and Hirth 2020). Furthermore, the recent activity of faults in the study area can be investigated by interpreting seismic data, and the seismic hazard in these areas can be evaluated (Tallini et al. 2019).
In landslide investigations, subsurface profiles acquired from geophysical data can be employed as static maps of the distribution of physical properties within the landslide body to characterize the landslide setting, such as the geological materials and geomorphology (Whiteley et al. 2019; Oswald et al. 2021; Gross et al. 2018). Moreover, geophysical data can also be utilized to determine the variations in subsurface physical parameters. For example, seismic waveform inversion techniques can provide the time evolution (force-time function) of the forces exerted on the ground surface by landslides (Moretti et al. 2015). Tomography imaging techniques can detect variations in moisture content over time, which can be exploited to monitor the response of the hydrological environment within a landslide to rainfall events (Travelletti et al. 2012; Palis et al. 2017; Merritt et al. 2016).
Geophysical data for natural hazard analysis substantially depend on their quality and quantity. However, the quality and quantity of geophysical data tend to be limited by environmental or economic aspects.
In terms of geophysical data quality, common limitations include noisy data, low-resolution data, and missing data. For example, in certain cases, seismic data acquisition processes fail to meet the requirements of space sampling, which leads to reduce the resolution. In terms of the quantity of geophysical data, the major limitation is data scarcity. For example, data-driven methods require numerous labelled geophysical data. These data often involve high-cost manual interpretation.
Among the promising solutions in geophysical data generation, deep generative models have been demonstrated to improve the quality and quantity of geophysical data substantially. Furthermore, deep generative models are applied in geophysical inversion to transform geophysical data into accurate subsurface information, increasing their availability for natural hazard analysis. Extensive studies have demonstrated that deep generative models can capture high-level features in geophysical data and maintain physical consistency with the real world.
Accordingly, we will discuss in the following part how deep generative models can enhance geophysical data, including increasing the quality of geophysical data, increasing the quality of geophysical inversions, and improving the scarcity of geophysical data.
4.1.2.1 Increasing the quality of geophysical data
Interpolation Different from common methods of interpolating geophysical data based on linearity and sparsity, Deep Generative Models are nonlinear models capable of learning to sample from high-dimensional distributions of probabilities. With its adversarial training process, a GAN could learn high-level features from complete seismic data to reconstruct missing data.
In an exploratory study, Ovcharenko and Hou (2020) developed a U-net-based GAN. They demonstrated this GAN ability to interpolate large seismic data gaps and reconstruct spatially aliased seismic events. Siahkoohi et al. (2018) added a reconstruction term to the loss function of a GAN and further increased the accuracy and efficiency of interpolation. By minimizing this reconstructed loss function, the GAN maps the distribution of partially sampled data to the distribution of fully sampled data. Once the seismic data with the missing term are fed to the trained GAN, an accurate interpolation can be performed in a few hundred milliseconds.
GANs can also learn additional features, thus contributing to geophysical data reconstruction. For example, considering both the time and frequency domain of geophysical data, Chang et al. (2021) developed a CGAN-based variant for interpolation. This variant consists of five generators and two discriminators. First, generator G1 is fed to the seismic samples, and generator G2 is used to transform the input sample into the frequency domain. Generators G1 and G2 generate features in the time and frequency domains, and their results are fed to a third generator G3. Last, generator G4 receives the features from generator G1, while generator G5 receives the features that are output by generators G2 and G3. A discriminator D1 is applied to distinguish between the interpolated sample by generator G4 and the real sample. Discriminator network D2 is applied to distinguish the frequency domain interpolated sample generated by generator G5 from the real spectral sample. This sophisticated training enables seismic data interpolation to achieve impressive performance in reconstructing features.
In some cases, an interpolation process can also be considered an image-to-image translation, in which an image that contains missing seismic traces may be "translated" into a complete seismic image by applying deep generative models. For example, Oliveira et al. (2018) employed Pix2Pix to handle missing seismic data. An image x with missing seismic traces is fed to generator G, which then generates image G(x) with synthesized seismic traces in missing regions. Discriminator D determines the classification of a false data pair consisting of x and the generated complete data G(x) and a real data pair consisting of x and the real complete data y. In terms of reflection continuity and amplitude magnitudes, the interpolated seismic data generated by the trained Pix2Pix in the missing regions of the seismic images are highly consistent with the neighboring seismic traces.
However, the original Pix2Pix is susceptible to modal collapse and vanishing gradients during training. To address this problem, Wei et al. (2021b) fixed the vanishing gradients in the discriminator of Pix2Pix by adding a Gaussian noise layer. As a result of this improvement, Pix2Pix trained from synthetic data can reconstruct irregular field seismic data more accurately, further improving its generalization and applicability.
Furthermore, when interpolating seismic data by utilizing the original Pix2Pix, the distribution of the generated complete seismic data G(x) will be as close to the distribution of the real seismic data y as possible by minimizing the JS divergence between the two distributions. A limit is that the JS divergence is not continuous everywhere. An effective alternative measure is the Wasserstein distance. By combining WGAN and Pix2Pix, a Pix2Pix-based GAN (WcGAN) is developed for dealiasing seismic data, where x is seismic data with aliasing and G(x) is seismic data without spatial aliasing. WcGAN has been demonstrated to be effective in providing more dense seismic data (Wei et al. 2021a).
Another popular deep learning model commonly applied to address image-to-image translation tasks, CycleGAN, is a promising candidate. When CycleGAN is applied to seismic data interpolation, seismic data with missing entries and complete seismic data can correspond to the source domain and target domain, respectively. Similar to sparsity-based algorithms, CycleGAN performs compression in the transform domain, allowing learning the relationships among the data across domains. Building on this idea, Kaur et al. (2021) modified the original CycleGAN by adding additional loss functions as constraints. This improved model can effectively interpolate 2-D and 3-D missing seismic data and recover steeply dipping, low amplitude diffraction, and complex moveout events.
Increasing Resolution:. Interpolation can also be considered an increase in resolution, owing to increasing the density of geophysical data. Consequently, geophysical data interpolation can be considered a "translation" from low resolution to high resolution, which is possible through Pix2Pix. For example, Oliveira et al. (2019) applied Pix2Pix to poststack seismic data interpolation, where x is a low-resolution seismic image and the data G(x) generated by the generator is a high-resolution image. Compared with traditional methods for 4\(\times\) downscaling, Pix2Pix is better able to increase the resolution of seismic images, increase the spatial density of seismic sections, and preserve high-frequency information.
A more appropriate solution should be to view the acquisition of more dense seismic data as a image super-resolution problem. In an exploratory study, SRGAN specifically developed for image superresolution has been proven to generate high-resolution seismic data (i.e., interpolated data) (Alwon 2019). Here, low-resolution input data were converted to 2-D seismic data after 2:1 trace decimation. Considering that seismic data are typically 3-D, Lu et al. (2018) applied a superresolution GAN for interpolation in the inline direction and crossline direction, yielding supersampled data that contain three times the inline and crossline densities.
Similarly, in the context of improving geophysical data quality through image superresolution, other studies have considered extending deep generated models from 2-D to 3-D data to increase their suitability. For example, Halpert (2019) applied an SREZ model to increase the resolution of 2-D and 3-D seismic data. By improving the loss function of DCGAN, this deep generative model achieves a 4\(\times\) improvement in low-resolution images, resulting in enhanced event discrimination and interpretation with seismic data at low frequencies.
Furthermore, Dutta et al. (2019) developed an SRGAN-based variant to improve the quality of 2-D slices and 3-D cube partitioning from 3-D seismic cubes by incorporating physical constraints into the model architecture and loss function. Specifically, in this improved SRGAN, pixel-level lithological information is added to the model architecture in the form of additional image channels to determine the lithologic class assigned to each pixel. Similarly, a joint distribution based on lithology classes is added to the loss function to ensure consistency in the manifold of seismic data. Such improvements reduce the uncertainty in the SRGAN. To further enhance the capability of the SRGAN in improving the seismic data quality, the low-resolution data for training were injected with 50% random noise. These noises have also been removed in the high-quality data improved by SRGAN.
Denoise In geophysical data denoising, deep generative models have proven promising solutions. An early exploration attempted to directly translate noisy seismic data into denoised seismic data by applying Pix2Pix. However, the method can only be applied in limited situations and cannot cancel out strong swell noise underwater (Alwon 2019).
Alternatively, VAE-based variants have been applied to handle geophysical data with high noise levels. As a component of the CNN-based deep learning model employed for semantic segmentation, \(\beta\)-VAE achieved adaptive denoising for seismic data. In this workflow, denoised seismic data generated by \(\beta\)-VAE can only be provided to a deep learning model for further processing and cannot be distinguished by human analysts (Sen et al. 2020).
More research has recently focused on developing deep generative models for the removal of various forms of noise, including desert noise. In open deserts, sand concentrates noise in seismic data at low frequencies, where the effective signal is typically concentrated.
As a result, the spectral aliasing of desert seismic data is aggravated, making conventional denoising methods ineffective. Several deep generative models have been specifically developed to separate effective signals from low-frequency noise in desert seismic data to address this problem. For example, Wang et al. (2021c) developed a DnGAN to map noisy input data to denoised data. With its powerful feature extraction capabilities, the RED-Net architecture serves as a generator for denoising. By adding an adversarial loss term based on WGAN-GP, DnGAN can better eliminate seismic low-frequency noise and recover desert seismic events (Fig. 6).

a A schematic diagram of a GAN for denoising seismic data. In many cases, RED-Net can be employed as a generator (denoiser) (Wang et al. 2021c; Dong and Li 2021). Redrawn from Wang et al. (2021c). b A schematic diagram of a diffusion model for denoising seismic data. Redrawn from Durall et al. (2023)
In several cases, desert seismic noise suppression is also regarded as a process of image-to-image translation to achieve a mapping of noisy seismic data domains to clean seismic data domains. For example, Li et al. (2022b) implemented desert data denoising by exploiting a GAN variant that integrates the attention mechanism. In this variant known as U-GAT-IT, the attention module in the generator assigns weights to parts that are critical for generating denoised signals. In contrast, the attention module of the discriminator focuses on determining whether a signal is effective or not.
Furthermore, in terms of image-to-image translation, another interesting variant of the GAN is RelGAN, which can control the attributes of the generated image data by encoding specific attributes while preserving other attributes. With these advantages, this GAN-based model can be a promising solution for suppressing low-frequency noise while simultaneously preserving seismic signals.
Building on this idea, Ma et al. (2022c) proposed RAGAN for desert seismic denoising, primarily built upon RelGAN. In this study, the attributes of seismic data are encoded as two-dimensional vectors, such that seismic data with no reflected signal and only noise are represented by the vector [1 0]. Seismic data with only signal without noise are denoted by the vector [0 1], and seismic data with reflected signal and noise are represented by the vector [1 1]. The attributes of input data x represent the original domain, and the attribute vector [0 1] of the noise-free seismic data is considered the target domain. The relative attribute v is the difference between these two attributes. By conditioning on the relative attribute, the generator of RAGAN generates fake data G(x, v) that corresponds to the target attribute. The well-trained RAGAN yielded output data that closely matched the target attribute vector [0 1] and, therefore, suppressed low-frequency background noise in seismic data and retained seismic events.
Additionally, deep generative models have been employed to eliminate the noise caused by geophysical data acquisition. For example, in assessing geophysical hazards, distributed acoustic sensing (DAS) provides fast and high-resolution aftershock information by determining dynamic strain (Li et al. 2021; Jousset et al. 2018).
As a result of poor coupling to the surroundings, DAS seismic data are inevitably contaminated by large amounts of background noise. To address this problem, Dong and Li (2021) developed a convolutional adversarial denoising network (CADN) that uses the generator in GAN as a denoiser and denoises DAS seismic a process for generating denoised data from noisy data. The backbone of the denoiser is a CNN-based network named RED-Net, which is applied to generate denoised DAS seismic records from synthesized noisy seismic records (superposition of theoretically pure DAS seismic records and real DAS noise). CADN has demonstrated excellent performance for signal preservation, noise suppression, and event recovery of DAS seismic records compared with conventional methods.
Recent research has explored the application of diffusion models to the denoising of seismic data (Durall et al. 2023). Through a forward diffusion process and subsequent parametric inversion, these models learn the probability distribution of the input data. Specific diffusion models gradually add controlled noise to the input data (forward diffusion), transforming it into a latent space that exhibits well-defined statistical properties. Following this, the model learns how to reverse this process by denoising the corrupted data. In the process, unwanted noise in seismic data can be removed, while retaining the underlying signals.
4.1.2.2 Increasing the quality of geophysical inversion
Typically, the complexity of physical phenomena, the high computational costs, and the limitations pertaining to the acquisition of seismic data hinder conventional inversion methods, which lead to substantial degradation of seismic image quality. Incorrect velocity models provided by inversion, for example, can yield inferior quality images, where reflectors are misplaced and seismic energy is defocused. To address this problem, Akhmadiev and Kanfar (2019) employed CycleGAN and Pix2Pix to "translate" defocused images into focused images, thus correcting the errors in the velocity model derived from the inversion.
To further improve the quality of images obtained through inversion, Picetti et al. (2019) a developed an improved version of Pix2Pix, improving its convergence properties and generality. Specifically, they integrated the prior information into a Pix2Pix by an additional regularization loss. The improved Pix2Pix achieved impressive results in two application cases: (1) turning a low-quality image with coarse migration into a high-quality image with dense migration, and (2) turning depth-migrated images into the respective deconvolved reflectivity images.
In other studies, seismic inversion was considered a mapping process that can be achieved using deep generative models. Theoretically, mapping geophysical data to high-quality images with subsurface attributes can be described as an image-to-image translation process. Deep generative models that are capable of learning forward and backward mapping relationships between two high-dimensional domains, such as CycleGAN, are therefore expected to be promising alternatives. CycleGAN has recently been successfully applied to learn stochastic partial differential equations, achieving bidirectional mapping of state parameters (Sun 2018).
Similarly, Mosser et al. (2018) applied a CycleGAN to implement cross-domain mapping during forward and backward inversion of seismic data, where data in a model domain with different velocities/impedances and thicknesses are mapped to a seismic amplitude domain, which are subsequently mapped to that model domain. This study demonstrated that a well-trained CycleGAN could generate realistic velocity fields and geological structures within seconds, with results that maintain faults and exhibit a certain velocity continuity across faults.
The applications of CycleGAN in inversion can be extended by defining domains \({\mathcal {X}}\) and \({\mathcal {Y}}\). For example, in addition to learning the nonlinear relationships between seismic attributes and subsurface attributes, CycleGAN can map the variations of these attributes across domains, which can avoid the effects of uncertain initial conditions and potential systematic errors. Building on this idea, Zhong et al. (2020a) applied CycleGAN and achieved rapid identification of changes in subsurface fluid properties based on time-lapse seismic data by corresponding domain \({\mathcal {X}}\) and domain \({\mathcal {Y}}\) to variations in seismic attributes and reservoir attributes, respectively. In this study, the training dataset implicitly represents physical knowledge by involving the computation of multiple physical variables (e.g., porosity distribution, lithology, and corresponding mineral composition and composition), which can serve as physical constraints in inversions involving deep generative models to further reduce uncertainty.
Typically, uncertainty is also a significant challenge in geophysical inversion. To reduce uncertainty, prior information can constrain the inversion process. However, in traditional inversion methods, handcrafted priors tend to involve sparsity assumptions or Gaussian distribution assumptions, thus hardly reflecting geological reality.
Recently, the application of samples generated by deep generative models to replace handcrafted prior information has been demonstrated to be a promising solution. Several studies have revealed that applying a GAN to provide prior information can improve the resolution and accuracy of inversion results. For example, Li and Luo (2020) modelled the distribution of seismic data using a GAN consisting of fully connected networks. They then fed its generated samples to a projected gradient descent algorithm. Compared with conventional least-squares error inversion, the inversion results from the GAN exhibit more high-frequency content. Furthermore, Mosser et al. (2020) parameterized a set of geological features by employing a WGAN for stochastic realizations of the possible model parameters. In this study, the GAN can provide the probability distribution of the model parameters by sampling from a low-dimensional, normally distributed latent variable, which represents differentiable priors.
Another solution to reduce uncertainty is to apply deep generative models with physical information in inversion workflows. In these models, physical constraints are typically imposed through their loss functions. For example, Song et al. (2022) designed a condition-based loss function for mapping uncertain geophysical data to geological data. This loss function that incorporates physical information can minimize the inconsistencies between geophysical and geological data and thus forces the generator in the GAN to learn to produce a facies model that is consistent with the input conditions.
Similarly, Yang et al. (2022) added an extra loss term to the VAE loss function representing the physical perception error between the real velocity map and the generated velocity map. The Gram matrix is applied to construct physical representations in the feature maps of several intermediate layers of the pre-trained neural network. Based on these presentations, physics perception is quantified. This integration of physical information increases VAE performance in geophysical inversion, particularly when recreating rare events.
Furthermore, in a method that involves the CGAN for inversion seismic impedance, Wu et al. (2021) employed a CNN as a forward model to learn seismic traces from impedance and then integrated the geophysical properties acquired by this deep neural network into the adversarial training of the CGAN. Specifically, two loss functions govern the training process of this CGAN, including the impedance loss between the generated impedance and the labelled seismic traces and the seismic loss between the output of the frozen CNN-based forward model and the unlabeled seismic traces. By employing these constraints of labelled data and the forward models, the discriminator endeavours to distinguish as accurately as possible the generated impedance corresponding to the input seismic traces from the actual impedance. A well-trained generator is developed that produces inversion results that are more consistent with reality.
4.1.2.3 Improving the scarcity of geophysical data
As data-driven methods are increasingly being applied to analyze geophysical hazards, limitations remain: data-driven method training requires large amounts of high-quality data with annotated labels, which would be labour intensive to label manually. These limitations can typically be addressed from two perspectives. (1) A limited dataset of labelled geophysical data can be applied to synthesize additional data for training data-driven models. (2) More automated methods are available to reduce the costs associated with manual annotation. Deep generative models have demonstrated impressive performances in both application aspects.
First, more geophysical data with labels can be obtained by utilizing deep generative models. For example, Ferreira et al. (2020) "translates" a relatively simple sketch into a seismic image by applying Pix2Pix, where edges with the same colours and sizes in the sketch are transformed into different textures and amplitudes in the real seismic image.
Additionally, deep generative models can generate more infrequent categories in labelled geophysical data, thus avoiding the impact of class imbalance problems on data-driven models. For example, classifying geophysical data according to quality facilitates extracting available information from them, while these quality categories tend to be unevenly distributed or have a severe class imbalance.
To generate rare classes in geophysical data classified according to quality, Milidiú and Müller (2020) developed a flow-based generation model, SeismoFlow, allowing accurate latent variable inference log-likelihood assessment without approximation, thus achieving more accurate synthetic results. It has been demonstrated that SeismoFlow achieves significant performance improvements in low-frequency class synthesis over datasets that are rated good, moderate, or bad. Furthermore, considering that SeismoFlow can generate high-quality synthetic samples with realistic appearances, it has the potential to improve the quality of geophysical data.
Deep generative models can also facilitate the annotation of geophysical data. For example, by utilizing VAEs that have the advantages of both encoding and decoding, Li et al. (2020c) performed the annotation of geophysical data in deep feature space. Specifically, an encoder in VAE maps seismic waveforms as labelled samples to the distribution of deep features. Then a decoder reconstitutes the deep feature as a high-dimensional waveform to produce pseudolabeled samples. When utilizing an SVM to classify seismic waveforms, the data generated by this VAE are added to the training dataset, thus improving the classification results for real fracture distributions.
Furthermore, to provide labelled data for the deep neural network to interpret geophysical data, Henriques et al. (2021) applied a VAE and a flow-based model to generate a pair of seismic image patches and their accompanying binary masks. In this case, the VAE estimates the distribution of a given attribute in the sample and thereby learns how it was stochastically generated. By using the VAE, binary masks may be produced from inferred distributions of the dataset and then applied to a normalizing flow model to generate associated seismic image patches. Annotated data generated by the method improved the performance of several semantic segmentation deep learning models.
4.1.2.4 Preparation, customization, and evaluation of deep generative models for geophysical data generation
How to prepare geophysical data for the input of deep generative models?. Deep generative models require effective given samples to learn distributions, similar to the training data employed in deep learning models. Numerous public datasets, such as the Netherlands F3 seismic survey, currently exist to meet this demand (Oliveira et al. 2018, 2019). Additionally, physical models in geophysics can be utilized to supply reliable synthetic data. Extensive studies have demonstrated that deep generative models trained with synthetic data from physical models can be applied to improve the availability of geophysical field data (Wang et al. 2021c; Li et al. 2022b). For instance, a well-trained GAN may effectively interpolate seismic field data by leveraging seismic data synthesized through the finite-difference approach based on a velocity model (Wei et al. 2021a).
Several common physical models can synthesize training data for deep generative models, including the 3-D overthrust model (Picetti et al. 2019; Siahkoohi et al. 2018), thin-layer geologic models (Wei et al. 2021b), and finite difference forward model (Dutta et al. 2019). When conducting geophysical inversion, data from physical models can impose implicit physical constraints on deep generative models to reduce uncertainty and develop physically coherent deep generative models (Zhong et al. 2020b).
Data from geophysical surveys are typically represented in 2-D images or as 3-D cubes, mainly depending on how they are acquired. These 2-D and 3-D data can be considered image representations in computer vision, where traces denote the content of an image containing deep features that neural networks may extract. Therefore, architectures with CNNs are appropriate for processing these data.
Most deep generative models are currently developed for 2-D geophysical data, which typically derive from cubes and contain inlines or crosslines (Mooers et al. 2020). Note that deep generative models may differently perform when constructing inlines or crosslines. For example, Pix2Pix is less robust to interpolation of inlines than to interpolate crosslines (Oliveira et al. 2019).
To expand the applicability of deep generative models to 3-D data, more deep generative models, which can improve the quality of 2-D slices and 3-D seismic cubes, have been developed (Kaur et al. 2021; Dutta et al. 2019). A few studies have also developed deep generative models to handle 4-D geophysical data with time-related attributes, thus modelling variations in the variables of interest rather than their actual values. By learning mappings among 4-D data, deep generative models effectively reduce the uncertainty of geophysical inversions (Zhong et al. 2020b).
For better feeding data into deep generation models, it is typically required to crop these image-like data into patches of specified pixel size. Common sizes include 64 \(\times\) 64, 80 \(\times\) 80, 128 \(\times\) 128, and 256 \(\times\) 256. Although larger sizes can accommodate more geophysical information, they are more computationally expensive. Another factor that can increase the computing cost is the data dimensions. Adding extra dimensions to the data will significantly increase the cost (Halpert 2019). In this regard, it might be interesting to decide how to balance the cost of computational processing with the processing of input data.
On the other hand, when applying a deep generative model to improve geophysical data quality, high-quality data tend to demand their low-quality counterparts, thus providing a reference for the models. For example, in the case of image-to-image translation, it is typically required to provide deep generative models with both a data pair consisting of low-quality data x and high-quality data y and a data pair consisting of low-quality data x and synthetic high-quality data G(x).
An important problem is how to obtain realm low-quality data x. The most common solution is to manually craft low-quality data in the training data. For example, the effect of missing traces can be simulated by randomly removing a certain number of seismic traces from a fully sampled original dataset (Kaur et al. 2021). Most deletion rates fall between 40% and 60% (Chang et al. 2021). Furthermore, the effect of spatial aliasing on synthetic training data can be created by adding one or more zero-valued seismic traces between every two traces, thus training a deep generative model that can eliminate spatial aliasing of seismic field data (Wei et al. 2021a). In most cases, by utilizing standard image processing tools, seismic images can be filtered to a lower resolution (Halpert 2019). Several other techniques are available to reduce the image resolution, including selecting an individual seismic trace from multiple seismic traces in the original seismic image (Oliveira et al. 2019) or employing low-pass frequency filtering on the original data (Halpert 2019; Dutta et al. 2019).
Handcrafting low-quality input x has the advantage of allowing the creation of varying degrees of low-quality data and an investigation of the extent to which deep generation models may increase geophysical data availability. For example, missing data columns can be manually created by erasing data within a specific width of the original seismic image. Deep generative models are less able to fill in the gaps of data when the gap is larger (Oliveira et al. 2018). By setting a certain number of seismic traces in the dataset to 0, a varying amount of random missing data can be obtained. Well-trained deep generative models demonstrated robust interpolation on geophysical data with different missing rates (Wei et al. 2021b).
In cases where improving the quality of geophysical data involves denoising, another problem must be considered. How can pure data that does not contain noise be obtained? Due to noise interference, a clean seismic record is almost impossible in actual seismic surveys. Typically, forward modelling with physical models can yield clean seismic signals (Wang et al. 2021c; Li et al. 2022b; Ma et al. 2022c; Dong and Li 2021; Alwon 2019).
How can deep generative models be customized to generate geophysical data?. When applying or developing deep generative models to increase the availability of geophysical data, a primary concern is how to efficiently and adequately extract nonlinear features from the original geophysical data, which is typically determined by the configuration of a neural network.
As discussed in Sect. 2, most of the existing deep generative models have well-designed configurations of neural networks that allow them to be robust and generalizable for application in a wide variety of domains. As a result, most studies aimed at increasing the availability of geophysical data have achieved satisfactory results either by directly applying existing deep generative models or by slightly altering them.
For example, Pix2Pix is commonly applied in seismic interpolation either directly or with minor modifications. The U-net in the Pix2Pix generator allows the output to be approximately aligned with the input, thus enabling it to only interpolate the missing seismic traces without changing the existing traces (Alwon 2019). Pix2Pix can also be modified to generate more reliable interpolation results for geophysical data. An example is to discard the random noise in the original Pix2Pix, which is commonly employed to enable the generated images with different styles under identical conditions (Wei et al. 2021a).
CycleGAN is another well-designed, deep generative model that can be directly deployed, which involves an encoding and decoding process and is analogous to sparsity-based algorithms in geophysics (Kaur et al. 2021). CycleGAN learns the relationships between two different qualities or types of geophysical data by compressing them in the transform domain and can thus better implement conversions between them (Fig. 7).

An overview of image-to-image translation in geophysical data using GAN. a A description of the Pix2Pix architecture. b A description of the CycleGAN architecture. c A schematic illustrating the input data for Pix2Pix and CycleGAN. Pix2Pix requires data pairs as input, thus enabling it to convert data \(x_{i}\) to data \(y_{i}\). When data \(x_{i}\) and data \(y_{i}\) are seismic image with missing traces and complete seismic image, Pix2Pix interpolates the geophysical data (first row on the left) (Oliveira et al. 2018). In the case where \(x_{i}\) and \(y_{i}\) are low-resolution seismic image and high-resolution seismic image, Pix2Pix can increase the resolution of the geophysical data (second row from the left) (Oliveira et al. 2019). CycleGAN does not require paired data and can map across \({\mathcal {X}}\) and \({\mathcal {Y}}\) domains due to its sophisticated cycle-consistent training mechanism. For CycleGAN, seismograms with missing traces can be considered data x in domain \({\mathcal {X}}\), and complete seismograms can be considered data y in domain \({\mathcal {Y}}\). Then, cycleGAN can perform seismic interpolation by mapping seismic image with missing traces x across domains to complete seismic image y (Kaur et al. 2021). Similarly, this cross-domain mapping also enables CycleGAN to perform the seismic inversion (Mosser et al. 2018). d The application of image-to-image translation is expected to cover a broader range of tasks, emphasising how to prepare the appropriate input data for each task
Furthermore, the application of other state-of-the-art models is interesting since they contain sophisticated neural network architectures that can more efficiently capture features from geophysical data. For example, U-GAT-IT utilizes the attention module in its generator and discriminator, enabling it to focus on the crucial information in the geophysical data more adequately. Thus, it is well suited for effective signals and removing noise. With U-GAT-IT, even the most detailed dynamic characteristics of effective signals can be preserved (Li et al. 2022b).
The integration of more effective deep neural network architectures into deep generative models, including CNNs and their variants, has further enabled deep generative models to learn important features from geophysical data. Deep generative models that take advantage of CNN-based architectures such as Pix2Pix have demonstrated satisfactory results in geophysical data generation, which suggests that CNN and their variants are well suited to capturing high-level features in geophysical data (Oliveira et al. 2018).
Recently, an increasing number of state-of-the-art CNN-based architectures have emerged off-the-shelf in computer vision, which can directly be incorporated into deep generative models developed to enhance geophysical data availability. For example, in the case of geophysical data denoising, a sophisticated CNN-based architecture named RED-Net has demonstrated excellent performance when it serves as the generator of deep generative models (Jiang et al. 2018). In RED-Net, multiple convolutional layers can simultaneously extract abstract features of the input signal and remove noise, and multiple deconvolutional layers can recover more details of the effective signal and increase event continuity by compensating for a portion of the information loss resulting from the convolutional layers. RED-Net-based generators have achieved impressive results in removing different types of geophysical data noise, including noise in desert areas and noise from DAS data (Wang et al. 2021c; Dong and Li 2021).
Another advantage of RED-Net is the employment of skip connections. By utilizing symmetric skip connections, this RED-Net-based generator is able to directly transfer low-dimensional features from the convolutional layer to the deconvolutional layer, thus improving the recovery of the effective signal. Similarly, in a GAN developed for the interpolation of geophysical data, the skip connection allows the data to maintain high-level features as it flows through the generator (Alwon 2019). Arguably, skip connections to the neural network structure facilitate the extraction of more complex nonlinear correlations from geophysical data by deep generative models without incurring the high computational costs associated with directly stacked deep structures (Chang et al. 2021; Kaur et al. 2021).
Furthermore, physical information can be incorporated into the deep generative model to output geophysical data with physical properties. Several preliminary attempts have been conducted to introduce physical constraints as conditional information into the deep generative model by adding channels to the input layers. For example, as prior knowledge, spatial probability maps of geological facies can be incorporated in GANs as input channels (Song et al. 2022). This approach has also been employed in an SRGAN, in which lithological category information can be fused with additional image channels at different locations of the neural network architecture (Dutta et al. 2019).
Another alternative is to incorporate a priori information into the loss function to introduce physical information into training deep generative models. For instance, both of the aforementioned deep generative models that add physical constraints to their architectures add corresponding physical information to the loss function, thereby further reducing the uncertainty in adversarial training. With the GAN conditioned on a geophysically interpreted probability map, additional loss functions are added to the original loss function, allowing it to learn the implicit patterns of geological facies. The SRGAN that incorporates physical information introduces lithology classes into the loss function by conditioning a joint distribution, enabling the generator to produce data more consistent with the original seismic image in terms of the manifold.
The design of loss functions for deep generative models has enormous potential in capturing geophysical properties. Through physical perception error and L1 error, for instance, a VAE embeds observable perceptual and real-world physical phenomena into the loss function, thus generating more physically meaningful data. Specifically, a physical perceptual error forces the data generated by this VAE to behave similarly to real geophysical data physically. Furthermore, by computing the difference between two velocity maps in continuous time, the L1 norm enables the data generated by this VAE to be consistent with the spatiotemporal dynamic pattern of the physical phenomenon that is being investigated (Yang et al. 2022).
Furthermore, the complex nature of geophysical data may enable training GANs to be more vulnerable to problems such as modal collapse and vanishing gradients. To address these problems, loss functions, including the Wasserstein distance or Wasserstein distance with gradient penalty, are employed to replace the original loss function in these GANs, thus stabilizing training and avoiding overly narrow distributions of output values (Alwon 2019; Mosser et al. 2020; Wu et al. 2021).
In a deep generative model, the loss function tends to be a weighted sum of multiple loss terms. If weight settings are inappropriate, deep generative models may fail to generate the expected geophysical data. For example, as observed from the parameter sensitivity analysis experiments from DD-GAN, when the weight governing the smoothness of the interpolation results is overly high, the interpolation results are oversmoothed, causing them to be inconsistent with fully sampled data (Chang et al. 2021).
A good trade-off among these losses should be achieved to obtain a well-trained, deep generative model. The optimal weighting configuration can be identified in the training process by repeatedly tuning the weights (Dong and Li 2021). Note that "optimal" is a relative concept. The search for better weighting requires more calculations of the deep generative model, which can be computationally expensive.
How to evaluate the quality of geophysical data generated by deep generative models?. Similar to applying deep generative models in other fields, deep generative models for geophysical data generation involve qualitative and quantitative evaluations.
From a qualitative perspective, the most common approach is to observe the visual results of geophysical data from deep generation models and thus evaluate their visual similarity to the original geophysical data. Visually observing the seismic data according to the overall structure, reflection amplitude, phase, and coherence of the deep generative model enables geoscience experts to determine whether it has achieved the desired results in terms of denoising, interpolating, and removing spatial aliasing in geophysical data (Picetti et al. 2019; Ferreira et al. 2020; Dutta et al. 2019).
For example, it can be observed that seismic images generated by Pix2Pix exhibit patterns consistent with the desired seismic structure, including the retention of reflection continuity and significant amplitude magnitudes similar to those of the original data (Oliveira et al. 2019; Alwon 2019). Additionally, it can be observed that the visual serration effects in spatial aliasing are eliminated in the seismic images generated by Pix2Pix (Wei et al. 2021a; Ovcharenko and Hou 2020). Observations of denoised seismic data obtained by different methods revealed that RAGAN was more effective than other methods in suppressing noise in desert seismic data and yielding clear and coherent event axes. In contrast, other methods still exhibited significant residual noise (Ma et al. 2022c).
To further evaluate the details in the geophysical data generated by the deep generation model, a common method is to transform the geophysical data into F-K spectra and thus extend the evaluation to the frequency domain (Chang et al. 2021; Kaur et al. 2021; Wang et al. 2021c). For example, a comparison of the F-K spectrum of denoised seismic data has demonstrated that DnGAN achieves excellent amplitude retention performance in desert denoising (Wang et al. 2021c). Similarly, CADN has been demonstrated to effectively suppress noise from DAS techniques while recovering the effective signal (Dong and Li 2021). Furthermore, power spectrum periodograms were utilized to evaluate denoised geophysical data generated by deep generative models from the frequency range perspective (Ma et al. 2022c).
From quantitative perspectives, statistical metrics are typically employed to quantify the differences between the geophysical data from the deep generative model and the original geophysical data. Specifically, the histogram is utilized to evaluate the denoising and inversion performance of the deep generative model (Oliveira et al. 2018; Zhong et al. 2020a). The Pearson correlation coefficient and \(R^{2}\) are employed to measure the similarity between the original seismic data and the generated seismic data (Oliveira et al. 2018; Kaur et al. 2021). MSEs and RMSEs are employed to evaluate the denoising performances of deep generative models (Li et al. 2022b; Ma et al. 2022c; Dong and Li 2021).
As a commonly evaluated metric in computational vision, the MSE has also been employed to evaluate the pixel-level distance between the generated seismic image and the original seismic image (Ferreira et al. 2020). However, MSE is pixel-based and thus has minimal relation to human perception. As a solution, another common evaluation metric in computer vision, structural similarity (SSIM), has been employed to measure the perceived changes of the generated seismic images, which can incorporate structural information through variance (Oliveira et al. 2019; Dutta et al. 2019). To further evaluate the complex patterns in seismic sections, evaluation metrics such as DSSIM and LBP, which to varying degrees consider the texture information on the images, have been utilized in computer vision (Oliveira et al. 2019).
A few quantitative metrics common to geophysics have also been applied to evaluate whether the generated geophysical data achieve the desired results in specific applications. An important metric in this regard is the signal-to-noise ratio. Increases in the signal-to-noise ratio indicate better performance of a deep generative model in terms of increasing the geophysical data quality (Wei et al. 2021a, b; Wang et al. 2021c). In geophysical data, the denoising performance of the deep generative model can be demonstrated by a significant increase in the S/N ratio (Dong and Li 2021). The S/N ratio is also utilized in determining the reliability of seismic data interpolated by deep generative models (Siahkoohi et al. 2018).
Moreover, it is crucial to investigate whether deep generative models can be applied in the real world. Most studies have applied the proposed deep generative models to field datasets with satisfactory results, thus demonstrating their generalization (Li et al. 2022b; Mosser et al. 2018)
Another interesting problem is whether the geophysical data generated by deep generative models can be applied to other data-driven models. Studies have demonstrated that deep generative models are capable of improving the performance of data-driven models by generating geophysical data. For example, in semantic segmentation of seismic images, the IoU metrics of several deep learning models, including DeeplabV3+ and Xception, were improved by augmenting the training dataset with GAN-generated masks and image patches (Henriques et al. 2021). The extended data generated by VAE significantly improved the classification results of the SVM for seismic waveforms (Li et al. 2020c).
4.2 Data generation of specific information in natural hazard analysis
To perform natural hazard analysis effectively, sufficient specific information about hazard events is essential. This could include the timing, location, intensity, and type of a hazard event, among other things. This information can increase the scientific understanding of natural hazards, enhance the accuracy and effectiveness of hazard detection and predictions, and provide reliable early warnings of natural hazards. For example, to reduce the impact of volcanic unrest and eruptions on nearby communities, continuous monitoring records containing raw signal events from volcanoes are utilized for training machine learning classifiers to recognize patterns associated with specific information about volcanic event signals, enabling effective prediction and timely warning (Grijalva et al. 2021).
There has been a recent trend toward developing data-driven models with high accuracy and efficiency as promising and popular tools for natural hazard analysis. An effective data-driven model in natural hazard analysis depends on large, well-labelled datasets available for training. There is a balanced distribution of samples with specific information about natural hazard events and samples without such information.
However, due to the rarity of natural hazard events or the prohibitively high costs of manual labelling, the availability of such class-balanced large labelled datasets has a variety of limitations. Typical limitations include insufficient numbers of quality instances, a lack of labels, and class imbalance, which yields less than desirable results for data-driven models in natural hazard analysis. For example, the lack of specific intensity cyclone data has prevented most existing data-driven models, particularly deep learning models, from achieving satisfactory performance in estimating cyclone intensity (Xu et al. 2019).
Deep generative models have provided effective solutions to these limitations based on two main aspects. First, deep generative models can be trained unsupervised, which reduces the dependence on high-quality large, labelled datasets for the detection process, thus increasing the availability of original unlabeled data. Furthermore, deep generative models can be applied to generate additional data containing specific hazard event information, thereby addressing problems such as insufficient numbers or class imbalance in datasets utilized for natural hazard analysis. For example, in the spatial prediction of landslides, deep generative models can typically generate scarcer classes that contain landslide events, thus solving the imbalance problem in landslide databases (Al-Najjar and Pradhan 2021).
In the following part, we discuss how deep generative models are applied for data generation for specific information in natural hazard analysis from these two perspectives (Fig. 8).

a In implementing VAE for the detection of hazard events in an anomaly detection manner, utilizing the inherent variations in the data to identify potential risks, the requirement for large, labeled datasets can be eliminated, improving the availability of original data that is not labeled. The process begins with an input sample being encoded into a latent space representation, capturing the essential features of the data. The VAE then attempts to reconstruct the input from this compressed form. The reconstruction error, the discrepancy between the original input and its reconstructed output, is a critical indicator of normalcy or anomaly. Inputs that yield a reconstruction error exceeding a predetermined threshold based on the error distribution of typical, "normal" data are flagged as potential hazards. b Deep generative models can generate additional data containing information on specific hazard events. Additional data can be used to solve the problem of insufficient numbers or imbalanced categories in the datasets available for natural hazard analysis
4.2.1 Increasing the availability of original data
Natural hazard event detection can be considered an anomaly detection task, where a hazard event can be defined as an "anomaly". Therefore, in cases of limited labelled data, deep generative models typically employed for anomaly detection can detect rare natural hazard events from unlabeled or few labelled original datasets. The primary reason for this is their unsupervised training paradigm. Data-driven models based on supervised learning require manual annotation of the original data. Deep generative models that are based on unsupervised learning, by contrast, do not require manual annotation of the original data. In this sense, deep generative models can increase the availability of original data and provide significant generalizations when detecting new events.
One of the most commonly employed deep generative models for anomaly detection tasks is the VAE with an encoder-decoder architecture, which learns the reliable representation of normal class data by compressing and reconstructing them. Typically, using a VAE to detect anomalies requires an appropriate threshold for defining the range of reconstruction error. When the decoder attempts to reconstruct the anomaly value, its performance will exceed this threshold, which indicates that the reconstruction failed and that the anomaly in the data will be correctly identified.
More recently, the VAE has been applied in avalanche detection to address the lack of specific information about avalanches by making existing SAR data more available. Due to harsh environments and rare occurrences, in-situ observations of avalanches are uncommon. SAR-based avalanche detection often requires expert manual annotations. As a solution, Sinha et al. (2020) regarded avalanches as anomalous phenomena. They exploited the VAE to detect avalanche debris in unlabeled SAR images, which would be difficult by using other change detection methods. By utilizing limited labelled avalanche data, the authors determined an optimal threshold for reconstruction error, which enabled the VAE anomaly detection process to be more suited to avalanche detection.
Furthermore, as a lightweight deep generative model, a VAE can be readily deployed on the hardware. Since a VAE is capable of rapidly and accurately detecting natural hazards rapidly, it can be implemented in remote sensing platforms to overcome the difficulties associated with delayed availability of data and inefficient utilization due to limited downlink capability and speed. Building on this idea, Ruzicka et al. (2021) developed RaVAEn, which can detect multiple natural hazards in multispectral imagery. By deploying RaVAEn on hardware that simulates resources available on a small satellite, they have demonstrated that the model can directly preprocess collected data on the satellite and label changing regions. This feature significantly improves the availability of original data and reduces response times for hazard events such as hurricanes, landslides, and floods. Additionally, the model uses the change detection novelty score as a reconstruction error, which can be calculated from the difference between two input image sequences from the same locations, thus improving the ability to detect hazard events.
Alternatively, GANs, which also utilize unsupervised training strategies, can be applied to increase the availability of original data. Different from the reconstruction-based unsupervised training of VAEs, the unsupervised training of GANs is inherently adversarial. For natural hazard analysis tasks such as earthquake early warning, unsupervised GANs can be trained to identify hazard-specific information from original data and thus provide an optimal discriminator that can quickly and accurately detect hazard events such as earthquakes.
For example, because seismic stations record many nuisance signals that behave similarly to real seismic signals, it is difficult to detect local seismic signals and provide reliable early warning of earthquakes by only a few seconds of seismic waveform data. Several studies have employed the GAN generator to learn waveform features such as peak amplitudes and dominant frequencies of P-waves to achieve better real-time seismic early warning. Thus, they used discriminators to distinguish them from other impulsive noises. In adversarial training, the generator generates increasingly realistic synthetic P-waves, forcing the discriminator to become more adept at identifying real waves. A well-trained discriminator can extract critical features from seismic P-waves and feed them to a random forest classifier, eliminating tedious manual annotation in traditional seismic detection (Meier et al. 2019; Li et al. 2018b).
4.2.2 Generating additional data with specific information of natural hazards
Numerous data-driven models have been applied to various natural hazard analyses to achieve accurate and efficient tasks in recent years. Nonetheless, as previously discussed, the effectiveness of these data-driven models, especially deep learning models, is dependent on obtaining large amounts of high-quality labelled training data, which tends to be expensive. When there are insufficient data to train effective data-driven models, deep generative models can be a viable solution since they can generate additional data that can provide specific information about natural hazards.
Two steps are typically involved in these types of solutions, driven by the task of analyzing natural hazards. Data generation is the first step. Here, deep generative models are trained to generate additional fidelity synthetic data from existing data. The second step involves the application of the generated data to the relevant task. The generated labelled dataset is utilized here to train the data-driven model and to enable it to achieve satisfactory results.
Such solutions that leverage deep generative models to obtain additional data are now being applied to different categories of natural hazard analysis, including atmospheric hazards analysis, hydrological hazards analysis, geophysical hazards analysis, and biological hazards analysis, to address the problem of limited data available for training data-driven models.
4.2.2.1 Atmospheric and hydrological hazards analysis
In atmospheric hazard analysis, a challenge is the prediction of cyclone destructiveness by estimating cyclone intensity, which is defined as the wind speed maximum at the centre of cyclones and is the most crucial parameter of cyclones. Recently, deep learning models have been demonstrated to successfully detect cyclone intensity labels and predict cyclone intensity values without the subjective bias inherent in traditional estimation methods. However, most existing training datasets exhibit a highly imbalanced distribution of cyclone intensity classes, with several classes containing only a few instances. When a dataset is imbalanced, deep learning models, such as CNNs, disregard the influences from these few cyclone classes during training, decreasing detection performance.
To overcome the problem of a lack of cyclone data with specific intensities that appears when CNN-based models are applied, Xu et al. (2019) employed CycleGAN to learn the evolution features of adjacent cyclone classes in cyclone images through fixed contextual intervals, i.e., the discrepancy of features over each fixed interval of cyclone intensity, and then utilized these evolution features to generate the features of the desired rare classes. A context-aware learning process is analogous to cross-domain mapping in CycleGAN, where the source domain \({\mathcal {X}}\) involves the CNN features of the input real specific cyclone samples and the target domain \({\mathcal {Y}}\) involves the desired CNN features of a few classes. The performance of data-driven classifiers in cyclone intensity estimation has been further improved as a consequence of utilizing the features of a few rare classes generated by this CycleGAN. Nonetheless, a synthesis of features from unpaired classes based on surrounding cyclone intensities might not capture the full range of cyclone characteristics.
Similarly, due to the rarity of atmospheric hazard events, other atmospheric hazard analyses encounter limitations from class imbalances in the training dataset. Theoretically, data-driven models can facilitate rapid and accurate tornado weather pattern classifications, enabling more accurate and timely warnings. However, in the available training dataset, there is an imbalance between tornado data and nontornado data, which tends to cause data-driven models to fail to predict the occurrence of tornadoes. To solve this problem, Barajas et al. (2020) applied DCGAN to generate sample datasets with image-based information about tornadoes. Tornado features generated by DCGAN are highly consistent with those observed in real data.
For atmospheric hazard analysis, missing data are also a concern. For example, prior to numerically estimating storm surges by using data-driven and surrogate models, it is common to interpolate the dry nearshore nodes by providing a pseudosurge. Conventional interpolation methods can incur high computational costs and disregard missing data’s spatial and temporal correlation. Moreover, the complex local geomorphology of the study area can contribute to incorrect interpolation outcomes.
To solve these problems, Adeli et al. (2021) developed Conv-GAIN, inspired by GAIN, which can interpolate missing data and was specifically designed for surge interpolation. The training mechanism is one of the significant advantages of the original GAIN. In training, GAIN employs a predicting mask and hint mechanism to maximize the discrimination of whether the data are obtained from a generator or real observation, thus forcing the generator to yield more realistic interpolation results. Conv-GAIN inherits the training mechanisms of the original GAIN and further enhances the architecture of the generator and discriminator of the original GAIN by replacing the FCNN with the CNN. With this improvement in architecture, Conv-GAIN can capture the spatiotemporal correlation of the data and perform reliable interpolation of storm surge datasets with structurally missing data. In datasets with extensive missing data, GAIN suffers due to weakened correlations in regions with large gaps, hampering convolutional learning.
Furthermore, in the aftermath of a storm surge event, satellite images are typically utilized to investigate street views, which are beneficial for assessing flood hazards caused by storm surges. However, storm surge is commonly accompanied by cloud cover over the affected areas, which prevents the availability of satellite imagery. Deep generation models appear to be a viable solution to this problem.
Recent advances indicate that deep generative models can provide more realistic and physically consistent data, which increases their ability to generate visual depictions of floods induced by storm surges. To achieve this outcome, incorporating physical laws into training is essential. A solution is to integrate flood hazard maps derived from storm surge physical models into deep generative models. For example, by combining the output of the SLOSH storm surge model, Lütjens et al. (2020) attempted to generate physics-based images of flood maps by implementing a Pix2Pix variant named Pix2PixHD. Specifically, the authors introduced physical conditions associated with the dynamics of a hurricane pushing water onto land by adding binary flood extent masks (flood vs. nonflood) to the postflood images. Next, image-to-image processes by Pix2PixHD translate preflood remote sensing images into postflood remote sensing images.
Indeed, incorporating additional information holds notable potential for improving flood simulations. do Lago et al. (2023) have demonstrated, utilizing localized catchment characteristics like elevation, impervious surfaces, and flow accumulation can significantly enhance the generation process. Hydrodynamic models such as HEC-RAS provide ground truth data that are leveraged to ensure high-fidelity simulations. In their modified Pix2Pix model, the above features are used as conditioning inputs, reducing reliance on random noise and guiding the model toward more physically plausible and accurate flood simulations. As a result, the model generates scenarios more rapidly than traditional models and allows accurate predictions of flood extent and depth in unseen catchments, which is a testament to the generalizability of the model. However, the spatial resolution of the current version may be a limitation.
Could flood modeling be improved by incorporating knowledge in addition to observed variables? An intriguing study currently incorporates auxiliary information with a priori knowledge into a diffusion model with an improved sampling strategy by employing a coupled heterogeneous mapping tensor decomposition algorithm (Shao et al. 2024). Furthermore, the study integrates the physical laws of hydrology by transforming control equations into penalty terms within the loss function, thereby enforcing flood physics constraints. With these physics constraints, output results that are not consistent with the common sense of flood physics are effectively "filtered," the model is guided to converge in a direction more consistent with the physical laws of floods, thereby increasing the accuracy of flood forecasts.
4.2.2.2 Geophysical hazards analysis
Landslide susceptibility assessment, which depends on landslide inventory maps to identify areas that must be surveyed in detail, is a major task in landslide analysis. Recently, landslide susceptibility assessments have been substantially improved with various state-of-the-art techniques, especially data-driven models. There is, however, one significant limitation to be addressed. Due to economic or environmental constraints, landslide inventory data are lacking in numerous regions. The lack of landslide information prevents data-driven models from achieving satisfactory results.
GANs have been considered promising solutions since they can generate additional samples to complement the limited number of landslide inventory datasets, thus training satisfactory data-driven models. To investigate this potential, Al-Najjar and Pradhan (2021) utilized additional landslide inventory data generated by a vanilla GAN for training several data-driven models, including the ANN, SVM, DT, and RF, and concluded that the inclusion of GAN-generated data improved the accuracy of landslide susceptibility assessments for most models, with the notable exception of RF.
A further study by the authors also applied a vanilla GAN to generate more landslide information in the grid data with more realistic distributions to address another limitation related to the landslide inventory dataset regarding class imbalance (Al-Najjar et al. 2021). The grid of event inventory maps for documenting the geographic distribution and scale of landslides consists of a positive class that reflects landslide occurrences and a negative class that reflects nonoccurrences. Typically, the latter distribution dominates, causing the data-driven model to preferentially categorize pixels as nonlandslide pixels, thus preventing the accurate identification of landslide pixels. The study results illustrate that a vanilla GAN can contribute to a more balanced distribution of landslide datasets and thus significantly improve the prediction performance of different data-driven models for spatial prediction of landslides, such as the ANN, RF, DT, kNN, and SVM.
While the results are promising, it is crucial to acknowledge the limitations. Physical plausibility and representativeness of the samples generated in both studies were not investigated extensively, raising concerns about potential biases. In the case of generated data deviating significantly from real-world landslide characteristics, such biases could undermine the reliability of data-driven models, particularly in critical applications such as risk assessment. To maintain the effectiveness of landslide susceptibility models, it is essential to assess the quality of the data generated rigorously.
An evaluation method could include examining the consistency of generated data with a known physical law or empirical observation. For example, Min et al. (2023) applied the Conditional Tabular GAN (CTGAN), based on a Gaussian mixture model, to oversample geotechnical properties, including soil cohesion, slope angle, soil density, soil depth, and friction angle. According to comparison results, while traditional methods such as Kriging and SMOTE yielded soil cohesion and depth values closely related to those of measured data, CTGAN-generated samples demonstrated distributions indicating divergence, highlighting the potential risks associated with using GANs to generate landslide sampling data for application in future studies. Even though they can generate many new samples, it is important to examine further the fidelity of these samples to the properties contained in real-world data.
This means that, regardless of whether the generated data is incorporated into a physically-based model or a data-driven model, a rigorous and careful evaluation must be conducted prior to implementation to ensure they accurately reflect the conditions they are intended to represent, ensuring not just statistical validity, but also physical plausibility.
In addition to generating samples to cope with data scarcity, another potential use of deep generative models is to improve existing landslide inventory mapping techniques to produce high-quality maps. Here, GANs can correct and augment existing landslide image data, allowing an intuitive evaluation of the plausibility and physical consistency of the generated samples. A typical example of such a generative approach is the application to improve the traditional change detection method, a commonly used technique for landslide mapping using bi-temporal optical remote sensing images. Despite the fact that the method of detecting changes is effective, other areas of change may be misidentified as landslides due to the complexity and uncertainty of landslides (Fan et al. 2019).
To address this, Fang et al. (2021) applied a Pix2Pix-based deep generative model to refine landslide inventory maps. Their approach involved preparing dual spatiotemporal images as input pairs and inputting them into a Pix2Pix-based model, effectively providing continuous and smooth contours of the landslide areas. It is interesting that the landslide image is converted to the post-landslide image as an image-to-image translation. A cross-domain mapping technique from Pix2Pix is capable of reducing the difference between unchanged and changed areas in bi-temporal remote sensing images and highlighting the changed areas simultaneously, thereby reducing the complexity and uncertainty of contextual information. Although the Pix2Pix model offers a promising approach for the refinement of landslide inventory maps, it is dependent on paired data, which presents a significant challenge. Obtaining high-quality, perfectly aligned images of pre- and post-landslides can be an expensive and time-consuming endeavor.
An alternative is to use cycleGAN, which generates similar translations without paired training data. CycleGAN facilitates the creation of non-landslide images from a dataset containing both landslide and non-landslide images without the need for accurately matched before-and-after pairs, while maintaining the integrity of the original domain’s key attributes. Accordingly, Zhou et al. (2022) utilized cycleGAN-generated images for their landslide segmentation method, which capitalizes on the differences between landscapes with and without landslides and contrasts them with the original, landslide-containing images. The segment method used in this study uses a weakly supervised learning framework, which only requires information about whether an image contains a landslide or not rather than detailed pixel-level information on where the landslide is located within the image. However, this method has limitations. The cycleGAN model itself may introduce artifacts or fail to capture subtle but critical features of the landscape.
To further mitigate the potential risks connected with geophysical hazards, an important and effective solution is an early warning system that can provide valuable information before hazard events occur. Recent trends have increased interest in earthquake early warning systems, which are being deployed worldwide to reduce risk and improve urban resiliency (Cremen and Galasso 2020). An ideal earthquake early warning system would issue alerts promptly or in real-time and provide information prior to an earthquake causing ground movement in a specific area. As a result, people can either evacuate dangerous buildings or move to safer locations inside a building in time to avoid severe casualties.
Typically, an early earthquake warning begins by detecting seismic events and by estimating their location, which is challenging. Data-driven models are increasingly effective and accurate solutions, but their potential is conditional on the availability of sufficient, high-quality, labelled training data.
To obtain accurate and efficient data-driven models for earthquake detection with limited labelled data, Wang et al. (2021e) developed a DCGAN-based variant that can generate realistic waveforms corresponding to seismic or nonseismic events. The authors improved DCGAN by reconfiguring the network architecture to be more compatible with seismic time series data, thus better capturing the important features of different waveforms. For example, the generator can generate three components of seismic signals separately.
By modifying the original GAN’s network architecture, synthetic seismic waveform data could be generated more efficiently. Therefore, Li et al. (2020e) has designed a variant of the GAN, enabling it to focus on features from earthquake events. In this improved GAN architecture, a gated CNN was utilized to extract specific features of the seismic signals from each component and those that exist across components without having to set up a separate pipeline. A deep neural network-based seismic event classifier, ConvQuakeNet, was used in the discriminator architecture, which can extract seismic features efficiently and accurately. These improvements allow the GAN variant to generate synthetic samples that exhibit diverse features consistent with real samples in both the temporal and frequency domains. According to the evaluation results in classification, the synthetic earthquake event samples significantly improve the performance of data-driven models in detecting seismic events.
Similarly, to ensure timely and reliable early warning of volcanic unrest and eruptions, it is also important to be able to accurately and efficiently identify and classify volcanic seismic events. In this respect, the data-driven models can be applied as a classifier to detect volcanic seismic events and thus improve, accelerate, and automate the monitoring and warning of volcanic activity.
In existing volcanic seismic data, the high complexity of waveforms and the scarcity of labelled data limit the application of data-driven models. To increase the training data available for data-driven models, Grijalva et al. (2021) developed a variant of the DCGAN named ESeismic-GAN that can generate long-period and volcano tectonic seismic event signals.
By transforming original volcano temporal domain signals to frequency-domain representations, this DCGAN-based variant can generate new amplitude-frequency responses. These generated frequency domain data are then converted back to the temporal domain by postprocessing. Several architectural improvements are implemented in ESeismic-GAN to address the difficult handling of complex seismic data from the original DCGAN. For example, the backbone of the generator and discriminator is modified to a 1-D convolutional layer, which is thus more compatible with the input 1-D data. By mixing the generated synthetic volcano signals with training data, the performances of data-driven classifiers have been significantly improved for detecting volcanic events.
It should be noted that the aforementioned approach is fundamentally data-driven, and does not consider the fact that earthquakes, and the seismic waves they broadcast, adhere to the physical constraints of the governing equations and constitutive laws of dynamic rupture and seismic wave propagation. This limitation stimulates the development of hybrid, physics-informed generative models that incorporate physical principles explicitly. For example, Yang and Ma (2023) developed FWIGAN, which integrates a physics-based generator (i.e., 2D constant density acoustic wave equation) with GAN, enabling direct incorporation of physical laws governing wave propagation into seismic data generation, thus estimating seismic velocity models within the context of distribution. However, this physics-informed paradigm has a certain degree of sensitivity to the initial model and may be adversely affected by scenarios where the initial model significantly differs from the true model.
4.2.2.3 Biophysical hazards analysis
Climate change has amplified in recent years, exacerbating the damage from wildfires on private and public property. An early detection is an important approach to mitigating wildfire damage. Conventional human wildfire detection is often inefficient, discontinuous, and subjective. Data-driven models, particularly deep learning models, can increasingly be integrated into automated wildfire detection systems to enable continuous and accurate monitoring of wildfires.
Well-trained deep learning models depend on class-balanced, wildfire labelled datasets. However, available training datasets are limited by data imbalance, where fire or smoke image data for wildfires are scarce since they require installed surveillance cameras or operational drones at wildfire sites. As a solution, Park et al. (2020b) considered transforming images of mountains without fire into images of mountains with wildfire as an image-to-image translation process. They generated diverse and realistic wildfire images from the mountain dataset by leveraging CycleGAN. With a training dataset consisting of the generated wildfire images and the real images, the accuracy of the deep learning model DenseNet in wildfire detection was significantly improved.
Another significant way to reduce the damage caused by wildfires is to predict the occurrence of fire events accurately. A typical example is predicting potential fires in certain locations by modelling the relationship between wildfires and their corresponding contributing factors. Before performing predictive modelling, geographical points are labelled "fire" or "no-fire", and details concerning these points, such as weather parameters, vegetation indices, and topography, are compiled into tabular datasets. In such wildfire tabular datasets, a significant discrete column is typically employed to provide specific information about wildfires, i.e., fire and no-fire labels.
In recent years, data-driven models have been expected to capture dynamic relationships between wildfire occurrence and its contributing factors by training on these datasets. A limitation arises regarding the amount of tabular data, which may not be sufficient for the training of these models. To solve this problem, Chowdhury et al. (2021) applied CTGAN, which has been applied in landslide oversampling as mentioned above, to generate reliable tabular data for wildfires, such as temperature, precipitation, surface pressure, wind direction and speed, and humidity, which improved the performance of different data-driven models for predicting wildfire locations. This model was specifically developed to generate tabular data. A mode-specific normalization is applied to prevent gradient vanishing when generating data for continuous columns. A conditional generator is utilized to learn the distribution accurately when generating data for discrete columns.
It is important to note, however, that despite these advancements, there continue to be inherent limitations and concerns regarding the reliability of the metrics generated by CTGANs. A major challenge lies in ensuring the authenticity and representativeness of the synthesized data, especially when dealing with rare or unprecedented wildfire events.
4.2.3 Customization and evaluation of deep generative models for generating specific information about natural hazards
How to customize deep generative models for generating specific information about natural hazards?. To extract the corresponding features from data containing specific information about natural hazard events more effectively and adequately, an appropriate deep generative model architecture is essential, which is substantially dependent on the data representation. For example, images derived from remote sensing or reanalysis systems exhibit structural and translational invariance similar to common image data. Deep generative models that have achieved impressive performance in computer vision, such as CycleGAN, can be directly applied to generating both these data and specific natural hazards information within these data.
CycleGAN excels at transforming content in images by cross-domain mapping, including transforming day into night, even without paired inputs. These advantages make it possible to convert remote sensing data without hazard events to remote sensing data that contain hazard events, thereby addressing the class imbalance problem in datasets utilized to analyze natural hazards. In this regard, CycleGAN has been successfully utilized to produce remote sensing image datasets for wildfires (Park et al. 2020b). Similarly, Pix2Pix, well-known for image-to-image translation, can transform prehazard images into posthazard images. With pairs of bitemporal remote sensing images of pre- and posthazards, Pix2Pix can suppress changes in unchanged regions while highlighting changes in hazard-affected regions, allowing it to detect hazards with minimal interference from other regions (Fang et al. 2021).
Generally, deep generative models can be effectively applied to handle various data representations with a well-designed architecture. For example, while pixels in image data follow a Gaussian distribution, continuous values in tabular data do not; thus, a vanilla GAN cannot be applied to the continuous columns of the multimodal distribution in the wildfire tabular dataset. As an alternative, CTGAN, which implements variational Gaussian mixture models to estimate values in continuous columns, can generate tabular data that follow the distributions of real data.
Furthermore, the generator and discriminator of CTGAN are constructed from the FCNN, which provides the capability to capture all possible correlations among all column values. The advantages of CTGAN allowed it to be leveraged to provide additional tabular data on wildfires. These data were utilized for training several data-driven wildfire prediction models, resulting in significantly improved performance (Chowdhury et al. 2021).
In certain cases with more complex Earth observation data, existing network architectures in generative models may not be able to capture their more complex features. Adapting the network architecture of existing deep generative models according to the data involved would be a promising solution.
For example, grid data, which contain specific information about natural hazards, typically have temporal and spatial correlations, but these relationships tend to be disregarded by the FCNN. CNNs can be utilized to address this problem. Against the backdrop of generating missing values for storm surge data using GAIN’s capabilities for data interpolation, the FCNN in GAIN’s original architecture was replaced by a CNN (Adeli et al. 2021). The improved GAIN effectively captures spatiotemporal correlations in 2-D grid datasets and thus can well interpolate on datasets with structurally missing data.
Note that deep generative models developed for image processing do not seem well suited for processing waveforms in seismic data. DCGANs, for example, have difficulty generating realistic waveforms from seismic signals despite being able to generate realistic tornadoes from image data. DCGANs, for example, have difficulty generating realistic waveforms from seismic signals despite their ability to generate realistic tornadoes from image data (Barajas et al. 2020; Grijalva et al. 2021; Li et al. 2018b). As experimentally demonstrated, the original DCGAN generated almost identical three-component waveforms, which are ineffective for seismic detection (Wang et al. 2021e).
A modification of DCGAN’s network architecture is necessary to handle seismic signal records that contain seismic or volcanic activity events. For example, the 2DCNN in the original DCGAN is replaced by a 1DCNN, and a neural network is commonly employed to generate sequence data such as audio and speech. It has been demonstrated that the 1DCNN can capture the comprehensive relationships and directions of seismic time series without affecting their temporal structure. Note that the kernel size in the 1DCNN, an important hyperparameter, can affect learning waveform features from the DCGAN. When the kernel size is set too small, the DCGAN may have difficulty generating sudden arrivals of P- and S-waves (Wang et al. 2021e).
Furthermore, when handling seismic signal data, the batch normalization (BN) layer, which follows the convolutional layer, is considered to cause overfitting and convergence problems. For this reason, when generating volcanic events, the BN layer is removed from the generator and discriminator (Grijalva et al. 2021).
Another interesting improvement for GAN architecture is the addition of a GLU into generators, thus efficiently and adequately capturing the order and hierarchy in the seismic time series. With this improvement, a GAN can better reproduce the time- and frequency-domain features in a seismic signal (Li et al. 2020e).
Moreover, it is interesting to explore the effectiveness of GAN discriminators in handling seismic signals. A discriminator can be considered a seismic feature extractor. In several studies, a GAN was employed to develop a well-trained discriminator that could be applied to extract waveform features, thereby enabling data-driven seismic classifiers to more rapidly and accurately identify seismic events.
The deep learning model developed for earthquake detection, which has an architecture that allows rapid and accurate earthquake classification, can be incorporated into GANs as a discriminator. A good example is ConvNetQuake, which employs a set of nonlinear local filters to analyze waveforms and has achieved excellent results in terms of both efficiency and accuracy (Perol et al. 2018). The accurate and efficient classification performance of the ConvNetQuake-based discriminator, which has been implemented in the GAN, can force the generator to yield more realistic seismic waveforms (Li et al. 2020e).
For the loss function, a common improvement is the integration of the WGAN into the application of the GAN. In theory, the WGAN can solve problems commonly observed during GAN training, such as vanishing gradients and mode collapse, thus achieving more stable convergence results (Barajas et al. 2020). However, the WGAN does not invariably ensure the best performance. In experiments involving the development of a GAN-based model for seismic event generation, Li et al. (2020e) observed that the original loss function provided the best performance gains compared with the least square loss function and Wasserstein loss function.
How to evaluate deep generative models for generating natural hazards information?. When evaluating the performance of deep generative models, qualitative and quantitative methods can be applied to examine whether these models provide realistic, specific information about natural hazard events.
Quantitative evaluations are typically performed with a visual inspection. For instance, when observing images generated by the DCGAN, noteworthy tornado characteristics such as shape, size, intensity, and centre have been identified (Barajas et al. 2020). In addition, a comparison of generated seismic signals with the original seismic signals can determine whether the GAN-based model generates waveform features that have similar visual features to the original waveform, including the P-wave onset and the coda wave decay after the first arrival (Li et al. 2018b). The qualitative evaluation of synthetic seismic event samples has been extended to the frequency domain. By comparing the spectrograms, Li et al. (2020e) observed that the frequency information in the synthetic seismic signals generated by the GAN-based model remained different from the original data.
In quantitative evaluation, several metrics employed include the F1 score (Sinha et al. 2020; Park et al. 2020b), precision-recall curve (Ruzicka et al. 2021), MAE, RMSE, Frechet distance (FD) (Grijalva et al. 2021), Frechet incidence distance (FID), and KL divergence (Ruzicka et al. 2021).
Although deep generative models, particularly GANs, have shown promise in improving natural hazard analyses by providing specific information, a question remains: Can their effectiveness in addressing different hazard problems be rigorously evaluated and quantified?
As discussed in Sect. 3.2.2.1, the primary application of specific information from deep generative models in natural hazards analysis has been addressing the limitations of data scarcity and class imbalance, particularly for rare events like volcanic eruptions and landslides. This approach involves generating realistic synthetic samples to augment existing datasets, which could lead to the development of data-driven models that can perform various tasks in natural hazard analysis and facilitate a more comprehensive understanding of the relationships between key factors and hazards. It is crucial that rigorous evaluation and validation should be conducted to confirm how generated data impacts the performance of data-driven models and their generalizability.
The performance of these data-driven models, when evaluated by common evaluation metrics, can, to some extent, reflect the applicability of synthematic sample from deep generation models. For example, by comparing the common statistical metric AUROC, the landslide inventory generated by GAN significantly improves several data-driven models’ performance for landslide susceptibility assessment (Al-Najjar and Pradhan 2021). The AUROC of the volcanic event classifier is significantly improved after GAN-based models are applied to seismic datasets to achieve class balance (Grijalva et al. 2021). Several data-driven models for predicting wildfire locations have improved precision-recall and F1 scores by utilizing wildfire data generated by CTGAN (Chowdhury et al. 2021). While this suggests the indirect effectiveness of deep generative models, exploring direct metrics for their performance remains rare research.
Beyond data augmentation, deep generative models are increasingly used to simulate realistic natural hazard scenarios, test mitigation strategies, predict the impact of future events, and investigate hazard characteristics. For example, flood inundation maps generated by deep generative models were used to evaluate flood protection infrastructure and identify vulnerable areas (do Lago et al. 2023). The advantage of deep generative models is that the data can be customized to meet specific research requirements, allowing for targeted investigations of specific hazards or conditions. The opportunity section includes more discussion.
Despite the promise, understanding potential biases in generated data and adapting models to different hazard types remain challenges. Developing specialized evaluation metrics and customizing models appropriate for the physical process involved in natural hazards is necessary to ensure physical consistency and rationality for generating specific information about natural hazards.
Several studies are being conducted to incorporate domain knowledge from geophysics and other relevant disciplines into generative deep learning to enhance physical plausibility (Wang et al. 2022; Gan et al. 2022; Meng et al. 2023b, a). There are several ways in which this can be done, including constraining the loss functions with physical laws or incorporating domain-specific data. Accordingly, domain-specific evaluation metrics should be developed to evaluate aspects such as physical consistency, agreement with established models, and sensitivity to biases. Using established physical models as validation tools for scenarios generated by deep generative models may be beneficial. For example, in the context of simulating flood wave propagation, established 2D shallow water models can be employed to generate reference water depth and unit discharge norm fields. These reference fields can then serve as a benchmark for evaluating the physical consistency and plausibility of generated flood scenarios (Carreau and Naveau 2023).
5 Challenges of deep generative learning for data generation in natural hazard analysis
Reliability is the foundation of all scientific studies. Data reliability here is the extent to which data generated by deep generative models accurately and consistently represent real-world natural hazard phenomena and can be reliably used for analysis and decision-making in natural hazard assessments. It involves statistical fidelity to actual events, physical consistency and plausibility, and usefulness for downstream tasks such as prediction or detection in a natural hazard analysis context.
A lack of reliable data may result in misguided scientific conclusions and cascade through subsequent analysis, resulting in inaccurate forecasts and misleading guidance, which could have severe consequences for public safety and emergency management. The issue of ensuring that the results produced by deep generative models in natural hazard analysis are reliable arises.
To alleviate the doubt held by the scientific community regarding the effectiveness of deep generative models with data generation for natural hazard analysis, a range of challenges must be addressed. For example, it is challenging to identify reliable methods for evaluating the trustworthiness of data generated by deep generative models. Further, ensuring that the proposed deep generative models can be applied to reproduce the same results based on published or new data is challenging.
Herein, we suggest that deep generative learning should be cautiously employed to provide more reliable data, thus allowing natural hazard analysis into real-world decision-making systems. When data generated by such deep generative models are utilized to analyze natural hazards, these data must be trustworthy. The following discussion will address the challenges of enhancing the reliability and trustworthiness of deep generative models, including evaluation and reproducibility.
5.1 Better evaluation for deep generative models
Deep generative models are notoriously difficult to evaluate. There are no uniform standards or guidance, and more ideal metrics are still being explored. The field of deep learning has developed various evaluation methods to determine if deep generative models are producing approximations that are close enough to the real approximations.
These methods are primarily divided into qualitative metrics and quantitative metrics. In natural hazard analysis, deep generative models for data generation can be evaluated with evaluation methods from deep learning. These common qualitative and quantitative evaluation methods have been discussed in Sect. 4. Here, we will further discuss the potential challenges of evaluating deep generative models qualitatively and quantitatively.
Qualitative evaluation typically considers the visual quality of generated data (especially image data) from the viewpoint of human perception. The fidelity and consistency of synthesized data can be determined by human visual inspection in computer vision. Such human evaluations tend to be constrained by the subjectivity of the researcher or designer. The subjectivity reduction may be partially achieved by inviting more participants into the evaluation process. For example, 12 participants were asked to respond "false" or "true" when they were shown photos of faces generated by training GANs. These responses were recorded and compiled into a summary of the accuracy and reliability of GANs (Wang et al. 2021f). Because these synthetic data are mere photos or digital images from large benchmark datasets, such as CelebA, nonspecialist judgment can serve as an adequate qualitative evaluation.
It is more challenging to evaluate natural hazard analysis data since they contain various physical meanings that have to be evaluated using specialized expertise. Experienced analysts are essential for checking the quality of the generated data for natural hazard analysis. For example, when analyzing seismic data for interpolation accuracy, specialized analysts can determine whether the deep generation model generates visually convincing and spatially aliased seismic events (Ovcharenko and Hou 2020). However, researchers in computer science or other fields may develop deep generative models for data generation to analyze natural hazards.
Improving the qualitative analysis of natural hazard data is to improve interdisciplinary communication. This approach will allow better determination of the decision value and operational utility of these generated data. For instance, the DeepMind team utilized expert forecasters’ preferences for generated precipitation fields to demonstrate the effectiveness and utility of its deep generative model’s radar precipitation probability forecasts. To reduce the subjectivity of individual expert evaluations, they invite additional experts to carry out evaluations. By combining the results of diverse experts in a statistically sound manner, a more reliable evaluation of the accuracy and value of data generated by deep generative models has been established. More information about this Expert Forecaster Assessment method in this study by DeepMind is available (Ravuri et al. 2021).
Quantitative evaluation is relatively less subjective than the qualitative evaluation (Eigenschink et al. 2021). Most quantitative metrics in the computer science area are derived from statistics. Statistically, data generated by a deep generative model should produce results similar to the original data. In cases where the visual inspection metrics are fulfilled and the data distributions are inconsistent, the generated data may provide a biased representation of the original distribution of data and omit information that may be critical.
Even though the generated data are statistically consistent with the real data, this does not guarantee that they are trustworthy or reliable. A solution is to add more quantitative metrics to evaluate the generated data, such as quantifying the visual quality of images produced by deep generative models. Many quantitative metrics that attempt to mimic human judgment have been developed in computer vision. Despite the surge in metrics, it remains a challenge to determine how better to measure the similarity of generated images with original images. Furthermore, these quantitative metrics are not always applicable to data involved in natural hazard analysis. In the case of image quality evaluation, the FID may not be able to properly estimate the underlying distribution of the high-resolution fields generated by the GAN (Leinonen et al. 2021).
Data for natural hazard analysis are complex, nonlinear, and dynamic. It is challenging to evaluate whether data generated by deep generative models exhibit physical properties. Statistical consistency of perception fidelity of the generated data, measured by other quantitative metrics, is not sufficient to determine whether the underlying physical laws are obeyed.
More diverse, physics-based, problem-specific methods for evaluation may be necessary (Hao et al. 2018). The situation has improved somewhat in this regard. For example, when applying deep generative models to generate high-resolution wind speed fields, the turbulent kinetic energy spectrum was utilized to evaluate the energy distribution. The probability density function was utilized to evaluate the longitudinal velocity gradient. These evaluations revealed that deep generative models could produce wind fields with turbulence-like physical properties (Stengel et al. 2020).
Furthermore, one often overlooked aspect of quantitative evaluation involves quantifying the uncertainty. For a natural hazard analysis to be reliable and effective, the data derived from deep generative models should minimize any uncertainty. Recent reviews from the field of computer science provide comprehensive summaries and comparative analyses of uncertainty quantification methods (Abdar et al. 2021). These methods can serve as references.
When deep generative models are applied to provide specific information about natural hazard events, further evaluation can be conducted by applying this generated data to train data-driven models that analyze natural hazards and then evaluate these data-driven models. Several challenges are involved in investigating how the generated data can improve data-driven models. For example, one common approach requires mixing generated data with real data and feeding it into the data-driven model. The performance of a data-driven model could be affected when the ratio of generated data to real data in the training dataset differs. Determining the optimal ratio presents an interesting challenge.
It is also necessary to interpret how generative data can improve the performance of data-driven models in natural hazard analysis. There are two potential solutions: quantifying the uncertainty in data-driven models and adopting more interpretive data-driven models.
Training more data-driven models to evaluate the effectiveness of generated data is a solution with both opportunities and challenges. Different data-driven models can benefit from generated data to varying degrees. In the case of generating grid data with landslide events, for example, the generated data contribute the most significant to the performance gain of the random forest model compared with other data-driven models. This finding implies a data-driven model that can most effectively capture the features of generated data, thereby enabling the best performance for natural hazard analysis. Note that finding such a model could involve high computational costs.
5.2 Overcoming hallucinations in deep generative models
Recent research increasingly scrutinizes the reliability of outputs from deep generative models, questioning whether they accurately reflect reality or merely constitute hallucinations (Yuan et al. 2023; Vaghefi et al. 2023). Concerns have been raised about the inherent nature of generative deep learning, particularly the possibility of producing hallucinatory information. This leads to a crucial inquiry: Do the outputs of deep generative models genuinely represent natural hazard scenarios, or are hallucinations? In this context, ’hallucinations’ suggest that the model’s outputs lack meaning or are fundamentally flawed (Li et al. 2024). Given the high-risk nature of natural hazard analysis, the potential severe consequences of using trained deep generative models in this domain should be carefully considered (Nava et al. 2023).
To effectively utilize deep generative models in natural hazard analysis, the factors to be considered are multifaceted and depend on the type of hazard, the geographical, hydrological, and atmospheric contexts, available data resources, and the specific analysis stage. For example, in scenarios where deep generative models are employed to generate scarce hazard data samples for training data-driven models, the emphasis should be on the diversity of these samples (Ivek and Vlah 2023). Conversely, when these models are used to enhance resolution or fill in gaps in data, the critical factor is ensuring that the generated data consistently aligns with real-world observations (Oyama et al. 2023; Vosper et al. 2023).
As previously discussed, to ensure that models trained for natural hazard analysis align closely with the ideal data distribution, three critical aspects are typically emphasized: input data, model architecture, and training methodologies. The input data determines what information can be effectively extracted and represented by approximating meaningful features. The model architecture and training methodologies determine how deep generative models acquire the ideal distribution to accommodate the specific data generation tasks relevant to various natural hazard analyses. Further exploration of residual architectures, activation functions, and network depth could yield interesting insights. For example, recent research has found that without explicit constraints on the maximum value, the Softplus activation allows deep generative models to produce more realistic extreme precipitation estimates (Harris et al. 2022).
A fundamental question arises: How can the specific data generation tasks in natural hazard analysis effectively align with the capabilities of existing deep generative models, such as input data formats, model architectures, and training methodologies? Recent research is increasingly focusing on the interesting direction. For example, an innovation in meteorological data generation utilizing a diffusion model. Researchers ingeniously adapted a Vision Transformer (ViT), a powerful computer vision model, for this purpose. Here, atmospheric data are conceptualized as time-dependent snapshots akin to images. Each snapshot comprised "pixels" representing various atmospheric conditions encoded in different "color" channels. Then, the score function of a diffusion model was leveraged to capture the statistical relationships between these atmospheric variables effectively (Li et al. 2024).
Nevertheless, this approach cannot completely rule out the possibility of hallucinations in individual samples. Assessing physical consistency remains a challenge. In light of recent advancements, leveraging domain knowledge as a guiding principle could be a promising solution (Zhang et al. 2020b; Liu et al. 2024a).
The common knowledge-guided framework includes supplementing the input information with additional data sources, such as satellite imagery, in-situ sensors, and reanalysis datasets, to capture the multimodal nature of the data (Duan et al. 2024; Kim et al. 2023). Integrating auxiliary variables like geographic coordinates, elevation, meteorological variables, and other contextual information into the generative model helps ensure the physical plausibility of the generated outputs (Ge et al. 2022).
To address the concern that data-driven models may overlook the physical significance of underlying dynamic processes, an interesting potential direction is to assimilate physical information from numerical methods into the model inputs as a guiding principle. This would enable the generative process to follow the fundamental laws of physics. Such physically informed generative paradigms have been employed in the context of geophysical and meteorological data generation (Meng et al. 2021; Hess et al. 2022; Gatti and Clouteau 2020a). Recent research has indicated that this paradigm could also be leveraged to characterize the deformation process of landslides (Liu et al. 2024b).
Controlling the sampling process in a deep generative model is another knowledge-informed paradigm. Typically, in models like VAE, the organization of the latent space significantly influences generation quality. Studies have focused on aiding models in accurately learning the data distribution relevant to natural hazard analysis by controlling latent factors through the incorporation of prior knowledge. One example is generating more extreme hazard scenarios by constraining the sampling space of a deep generative model to produce such rarefied samples (Szwarcman et al. 2024; Mooers et al. 2020, 2023).
Knowledge can also guide the training process by embedding physical equations representing real-world processes, enabling the model to learn a data distribution that mirrors natural phenomena (Liu et al. 2024b). For example, a recent study explored landslide dynamics’ temporal and spatial evolution using ordinary differential equations (ODEs). The variational inference optimization process incorporated temporal and spatial constraints by integrating ODE modules into a normalizing flow (NF) model. This approach approximates complex distributions and ensures that the characterized landslide deformation processes adhere to known landslide kinetics (Xu et al. 2024).
Furthermore, recent studies highlight the need for interdisciplinary, team science-based approaches in training deep learning models, a principle we believe extends to deep generative models (Wander et al. 2024). Maximizing the integration of tools and knowledge across various fields and incorporating expert input in the model generation process can mitigate the creation of illusory data in natural disaster scenarios. Employing such interdisciplinary methods may help ensure that models more accurately reflect real-world conditions and generate meaningful information for natural hazard analysis, thereby providing logically sound and plausible insights.
5.3 Improving reproducibility of deep generative models
In scientific research, reproducibility is a major principle that demonstrates the correctness of experimental results obtained with new methods and ensures their transparency. The lower the risk of errors, the more likely the new method is to be reliable. The reproducibility of a new method depends on whether others can reproduce its results within a reasonable range. The process must be based on the implementation details reported by the original authors.
In the context of natural hazard analysis, generative deep learning is a new approach to providing available data for natural hazard analysis. Therefore, the reproducibility of the deep generative models should be improved to demonstrate that their results are trustworthy. In other words, the reproducibility is a prerequisite for adopting data generated by these models in real-world natural hazard analysis.
For deep learning models, reproducibility refers to running a model on the same dataset in a particular environment and reproducing the original study’s results, which substantially depends on the training dataset and model configurations. Similarly, as a branch of deep learning models, the reproducibility of deep generative models also depends on both crucial factors. Ideally, a third party should obtain results equivalent to or similar to the results obtained by the original author by utilizing the data and code published by the original author in a similar environment (Heil et al. 2021). However, deep generative models developed for data generation in natural hazard analysis are prone to reproducibility challenges. In the case of insufficient information in reports about experiments, their critical results might be challenging to replicate.
From a data perspective, in natural hazard analysis, datasets that have been employed to obtain a well-trained, deep generative model are typically not publicly released due to data use agreements or concerns about confidentiality. Without published data from the original study, third parties are limited to training the model by utilizing alternative data. In the case of different data, the different distributions are likely to impact how a deep generative model is weighted during training, ultimately influencing its performance and reproduction of the original results.
There are some promising solutions here, including using publicly available datasets and increasing the generalization performance of deep generative models applied to other training datasets. Furthermore, a lack of transparency regarding the data processing steps could also pose a challenge to reproducibility in deep generative models. This challenge could be addressed by providing more detail on data processing methods, such as data normalization, dataset splitting, and how data could be processed with domain knowledge.
To improve the reproducibility of deep generative models from a modelling perspective, three approaches can be generally employed: providing more detailed information about the model, publishing the full source code, and sharing well-trained models. Each approach reveals varying degrees of insight into how models were constructed and run.
A detailed report should be a fundamental requirement, including the specific architecture of the model and all hyperparameters involved. The training process may involve changing the hyperparameters. The experimental results will vary when the default hyperparameters are changed. Appropriately documenting these parameter changes will be challenging. Some implementation details may not be obvious from method descriptions or experimental reports in certain cases. These details may be necessary.
When a deep generative model is reproduced, a slight bias from omitting these details may produce different behaviour, thus yielding different results. The source code, which contains more information about configuring and running deep generative models, can be published as a solution. Despite this progress, challenges remain. After running the source code of the deep generative model provided by the original author, uncertainties introduced by random initialization, random noise introduction, and random gradient descent were encountered, which complicated the replication of the results in the original report. Setting random seeds is a common way to reduce randomness.
Most deep generative models are computationally intensive, which can cause a significant increase in computing costs when third parties run the source code and attempt to obtain similar results. A solution is to share the well-trained models and the weights and outputs of the training process, which will enable the third party to save considerable amounts of time and computational resources.
6 Opportunities of deep generative learning for data generation in natural hazard analysis
In this section, we will discuss three promising and interesting opportunities, thus facilitating the more versatile and effective utilization or development of deep generative models for data in natural hazard analysis.
First, we discuss more possible applications and the development of deep generative models for further data generation in natural hazard analysis. The focus here is addressing missing values and noise in remote sensing data since it is common for challenges in remote sensing data also to affect natural hazard analysis. Second, we discuss potential applications of deep generative models in the Digital Twin Earth program.
6.1 More potential utilizations and developments of deep generative models for data generation in natural hazard analysis
As discussed in Sect. 2, natural hazard analysis involves multiple data sources, which may also provide important information for purposes other than natural hazard analysis. For example, remote sensing data can be utilized to describe the evolution of a landscape over time or urban growth patterns. Due to similar environmental, economic, and technical constraints, these data employed for other purposes face the same limitations as those used for natural hazards analyses. Deep generative models are demonstrated to be effective in solving these challenges.
Similar applications could be extended to more closely related datasets to natural hazard analysis, thus exploring additional potential utilization and development of deep generative models in further data generation for natural hazard analysis.
Cloud removal from satellite images Remote sensing techniques for Earth observation are highly effective in observing natural hazards. However, they can be restricted by missing data, such as dead pixels and thick clouds, due to operational constraints and atmospheric conditions (Zhang et al. 2018). In particular, approximately 70% of the Earth’s surface is covered by clouds, which will obscure a large amount of remote sensing data (Schroeder et al. 2008; Gao et al. 2010). Considering this limitation, most natural hazard analyses, such as flood mapping, prioritize cloud removal as the initial step to ensure real-time responsiveness in emergency response (Li et al. 2018a; Zhao et al. 2023).
Cloud occlusions lead to information loss, failing to characterize natural hazard evolution processes accurately and severely reducing the availability of remote sensing imagery in real-time monitoring systems, hindering timely hazard detection and thereby missing opportunities for early intervention. A typical case is exemplified by the 6 km long landslide in Villa Santa Lucia, central Chile, triggered by heavy rainfall and snowmelt on December 16, 2017. This event was not detected by optical satellites until January 2018, thereby hindering effective emergency response (Mondini et al. 2019). This case underscores the imperative of cloud removal for remote sensing imaging to ensure real-time monitoring for effectively detecting landslides.
Furthermore, cloud obscuration can also hinder the timely observation of volcanic activity by thermal sensors on satellites. In observations of the multiyear erupting Reventador volcano in Ecuador, only two cloudless images recorded by thermal sensors were available, severely limiting the ability to observe small-scale eruptions in real-time (Furtney et al. 2018). Given that cloud cover can rapidly obscure the view and prevent the timely detection of eruptions and other dynamic changes, cloud removal would be a feasible strategy for ensuring real-time monitoring of volcanic activity using satellite data.
To address the problem of missing data caused by cloud obscuration on satellite observations that are available for natural hazard detection, the most common solution is to remove the cloud from these satellite products. In most cases, cloud-free features can be recovered by applying cloud removal methods from cloud-contaminated satellite images. Typical cloud removal methods include spectral characteristic-based, spatial characteristic-based, and frequency characteristic-based methods (Rasti et al. 2014; Liang et al. 2001; Tan 2008; He et al. 2011). Most cloud removal fills the areas missing from satellite products due to cloud obscuration with more realistic shapes and textures, which remains a challenging task.
As a solution, generating cloud-free, spatial remote sensing data from cloud-obscured, remote sensing data can be described as the translation of images. Pix2Pix can be directly applied to translate cloud-corrupted multispectral images into haze-free multispectral images. An enhanced version of Pix2Pix, named SAR-Opt-cGAN, was developed, which further improved the cloud removal ability by adding additional long-wavelength SAR information to the input channel (Grohnfeldt et al. 2018).
The removal of cloud occlusions from spatial remote sensing data is often considered an image complement/restoration problem. Image completion/restoration refers to filling missing or covered areas in an image with generated samples. Therefore, when deep generative models are utilized to address this problem, modified network architecture and loss function contribute to more efficient and accurate extraction of critical contextual information from remote sensing images and thus better recovery of the background content covered by cloud cover. For example, spatial attention is incorporated into the generator of the GAN, which was able to achieve a local to a global focus on the cloud area, thus enhancing the information recovery in these areas. Adding a corresponding attention loss term to the loss function, this attention-based GAN, named the SpA GAN, generated better quality cloud-free images (Pan 2020).
CR-GAN-PM is another GAN variant that adds an adversarial loss function corresponding to an additional removal network R, which can transform multicloud images into cloud-free images without distorting the background information (Li et al. 2020b). Compared with other benchmark models, the CR-GAN-PM maximized the recovery of the original background information of the cloudy Sentinel-2A images when there were no paired images available.
The deep generative models can also be improved by adjusting the input information. For example, the YUV color space, which independently represents luminance and chrominance information, can be utilize to avoid colour distortion during thin cloud removal. In the GAN variant named YUV-GAN, an adversarial loss term is applied within the YUV color space to preserve details that have a higher correlation with human color perception, thereby improving cloud-free Sentinel-2A image reconstruction (Wen et al. 2021).
In the case of remote sensing data that describe sea surface temperatures, the scenario is much more complicated. Note that the aforementioned cloud removal approach for extracting surrounding information from one remote sensing image does not apply to uncertain cloud occlusion in sea surface temperature images. Therefore, a variant of DCGAN, which can recover cloud-obscured sea surface temperature images from historical image records, was, developed (Dong et al. 2019). This DCGAN-based variant features a novel loss function, which involves the corrupted image, an average image from several days around the corrupted image, and a mask that sets the missing part to zero. In low-dimensional space, the additional loss function contributes to obtaining the closest vector representation of the uncorrupted image by the input corrupted image. In atmospheric hazard analysis, this method is expected to provide a reference for removing clouds over remote sensing data.
SAR image denoising Noisy signals can also distort satellite products and thus complicate their interpretation. For example, the speckle noise induced by the coherence of scattering prevents the better performance of SAR images in mapping hazards such as landslides or floods (Liang and Liu 2020; Herrera et al. 2009; Squarzoni et al. 2003). Conventional denoising of remote sensing products also relies on a priori knowledge to explore and exploit image correlations, limiting the number of captured image features (Liu et al. 2020). Recently, the GAN has demonstrated the ability to map speckle-contaminated images (input SAR images with speckles) into speckle-free, clean SAR images without prior knowledge. By adding a variation loss function, the GAN can capture edge details in the SAR image and generate denoised images with clearer textures (Liu et al. 2020).
Low-light image enhancement A further concern regarding remote sensing data that may be available for natural hazard analysis is the lack of nighttime coverage for many satellite platforms, making it difficult to respond to natural hazards that occur at night. Fortunately, Pix2Pix specializes in the translation of daytime images into nighttime images. Therefore, this popular deep generative model is applied to generate nighttime visible images by adopting three infrared bands and the difference in brightness temperature between two single bands (Kim et al. 2020). A visual evaluation of nighttime virtual images generated by Pix2Pix shows a typhoon’s clear eye and continuous motion. The impressive results emphasize Pix2Pix’s potential to bridge the temporal gap between daytime images and nighttime images, thereby allowing a more accurate estimation of typhoon paths at nighttime.
Spatial-temporal interpolation Natural hazards are characterized by changes in both space and time throughout their evolution and are therefore typically considered as spatio-temporal continuous phenomena (Senogles et al. 2023). Nevertheless, incomplete and sparse observation data tend to limit hazard investigations. For example, limited monitoring points in large landslides could make it challenging to analyze and forecast the landslide deformation trends accurately. Spatial-temporal interpolation provides a solution. Most current interpolation algorithms are based on weighted averaging of neighboring sampled points, resulting in a smoothing effect. Furthermore, most traditional spatial interpolation methods have difficulty modeling complex data or a large number of missing values (Liu et al. 2018; Huang et al. 2023; Jiang et al. 2023).
In terms of emerging solutions, one recent trend has been to employ deep generative models to interpolate missing data by learning complex high-dimensional data distributions and then extrapolating these from those distributions. One of the most popular is the GAN, which is similar to the principle of multi-point geostatistics and can generate data randomly using deep-level distribution features from training samples to address the variability of missing types and missing rates between data sets. Furthermore, some explorations have involved VAE and NF and, more recently, diffusion models (Mulyadi et al. 2022; Tashiro et al. 2021; Liu et al. 2023).
Unlike other applications for spatial-temporal interpolation, natural hazards involve the complex nature of metaphysical fields. For example, landslides vary in displacement in response to multiple factors, including but not limited to geology, groundwater, and surface morphology. The magnitude and pattern of landslide displacement can change over time due to various factors, including weather patterns, seismic activity, temperature, and surface erosion. Given the complexity of these processes, interpolating landslide displacements spatially or temporally is a potentially tricky task.
Conditional deep generative models may solve this problem since these models involve integrating auxiliary information into the interpolation process, thus improving the physical realism of the interpolated outputs. An interesting work, for example, considers the advantages of the diffusion model in parsing through the noise to identify underlying patterns in different applications, which entirely use the explicit and implicit spatial-temporal relationships (Liu et al. 2023). Before analyzing conditional features, the model first interpolates observations and models the global context. Then, it uses dependent information to predict noise with the noise estimation module, utilizing global spatiotemporal correlations and geographical context to effectively handle high sensor failure rates and missing rates.
6.2 Use of deep generative models in establishing the digital twin of earth
The world is currently experiencing dramatic increases in natural hazards and major changes in technology. The urgency of climate change and advances in computational science have heightened the critical need for integrated information systems capable of enabling technology crossover, resource sharing, and functional integration.
The concept and applications of the digital twin of earth A promising avenue for addressing this need is the development of a digital twin of Earth. This open and interactive system would seamlessly integrate Earth system models with diverse observation data, leveraging advanced analysis tools, artificial intelligence, and intuitive visualization interfaces. Such an ensemble facilitates an in-depth exploration of the Earth’s current systemic state, enables prediction of future conditions, and supports the execution of hypothetical scenarios, thus comprehensively understanding the potential responses of the Earth system to various assumptions and interventions (Huang et al. 2022). Thus, the system can provide comprehensive estimates of Earth’s state that can serve as a crucial knowledge base for guiding human societies in meeting significant challenges, such as climate change mitigation and adaptation (Li et al. 2023).
It is envisioned that the digital twin of the Earth will be able to (1) continuously perform high-accuracy, real-time, and highly detailed, more realistic Earth system simulations; (2) obtain as much observational data as possible from Earth observation sources; and (3) estimate uncertain model parameters and missing details about surrogate processes. This process allows the system (1) to integrate into all sectors of impact and thus enable the transformation of scientific data into decisions and (2) to provide optimal data analysis performance while allowing users to interact with the data. For example, a digital twin of the Earth-structure system can include seismic sources and entire cities (Poursartip et al. 2020; Gatti and Clouteau 2020b).
While ambitious and still under development, efforts toward an Earth twin system are already underway globally. The European Union’s "Destination Earth" initiative is a leading example, aiming to create a high-resolution (1 km real-time) digital twin simulating the atmosphere, ocean, ice, and land. This system is designed to provide forecasts of floods, droughts, and fires on timescales ranging from days to years (Bauer et al. 2021). Similarly, NVIDIA has announced plans to develop Earth-2, a digital twin driven by artificial intelligence and dedicated to the prediction of climate change. Additional projects, such as NASA’s Earth System Digital Twin (ESDT), further demonstrate the growing international momentum behind this transformative concept.
Recent explorations are actively pursuing specific applications for Digital Twins of Earth. One example is the Joint UK Land Environment Simulator (JULES) project (Zhong et al. 2023). This project applies a unique approach that combines reduced-order modeling, machine learning prediction models, and data on Light Absorbing Aerosols (LA). Data generated from fire and emissions simulations serve as training data for the machine learning component within the digital twin model. Subsequently, the trained model receives a time series of wildfire-related data as input and attempts to estimate the risk of wildfire occurrence in future years.
Currently, the realization of a digital twin of the Earth remains an enormous challenge due to a range of factors, including uncertainty about the dynamics of the coupled Earth system itself, the lack of available observations, and the high computational costs associated with data processing and analytical models. These challenges create opportunities to apply deep generative models. As a bridge between data and simulations, deep generative models hold considerable promise to enable the digital twin of the Earth to simulate natural hazard impacts and climate change scenarios. These simulations will permit policy-makers to evaluate future hazard mitigation and prevention options and increase public awareness about natural hazards.
The Digital Twin Earth program involves various numerical models that are assumed to be computationally efficient, reliable, and lightweight, thus allowing more accurate reference data to be provided for policy and decision-making. Physical models provide high-precision approximations of various phenomena occurring on Earth through numerical optimization, typically ideal for achieving this vision. However, uncertainty and computational costs may prevent these models from being implemented in a digital twin of the Earth. These challenges offer an opportunity for deep generative models, which can be trained to learn input–output mappings at a relatively low computational cost. Several studies have indicated that deep generative models have great potential to facilitate uncertainty quantification and numerical simulation in a digital twin of the Earth.
The potential of deep generative models to advance the digital twin of earth development. The recent progress made in developing a deep generative model for the generation of natural hazards data has led to several interesting directions for a digital earth twin that might emerge in the near future.
First, deep generative models have been demonstrated to be able to describe uncertainty without involving structural assumptions. For example, by framing stochastic parameterization as sampling from a distribution of subgrid trends conditioned on the resolved state, a CGAN can approximate the joint distribution of the resolved state and subgrid trends. Using CGAN to stochastically parameterize weather and climate models has improved weather forecasts (Gagne et al. 2020). Moreover, a well-trained stochastic generator can generate broadband seismic signals based on fake experimental responses by defining a nonlinear stochastic process to train a GAN. In this case, synthetic signals from the GAN can be integrated into the digital twin of the Earth (Gatti and Clouteau 2020b).
Second, deep generative models have been demonstrated to be more efficient and less computationally expensive than full physical models. The GCM PLASIM requires 50 min to simulate weather conditions involving temperature, wind speed, relative humidity, vertical velocity, divergence, and geopotential height. In comparison, a well-trained generator of WGAN on the NVIDIA V-100 generates 36,500 samples corresponding to a 100-year simulation in only 3 min (Besombes et al. 2021).
Computationally intensive physical models also challenge providing high-resolution, real-time predictions for natural hazards, such as coastal storm surges and floods. Flood dynamics, for instance, are typically governed by shallow water equations, which originate from the Navier–Stokes equation and are widely applied in environmental flow simulations. Unfortunately, SWE solvers are computationally slow and require considerable time to provide detailed predictions of flood events in urban areas. Simplifying the assumptions can accelerate the process but yield inaccurate predictions.
An interesting solution would be to apply a deep generative model to extract flood dynamics from the data simulated by the solver. In this manner, a CGAN has been demonstrated to provide more accurate, real-time flood development predictions, where samples from the initial state of the flooding are employed to condition inputs and outputs (Qian et al. 2019). The training paradigm here is physics-based, integrating physical meaning into the model training through input data.
Similarly, in another GAN-based model for coastal flood visualization, the physical information from the storm surge model output is introduced through input channels. It was observed that images generated by this GAN could accurately reflect the physical laws of the hurricane pushing water onto land. Increasing physical consistency allows deep generative models to produce more reliable results for a digital twin of the Earth, thus facilitating critical decision-making (Lütjens et al. 2020).
Moreover, it would be very interesting to apply deep generative models to generate realistic hazard scenarios, heightening public awareness of natural hazards. Behavioural science studies have consistently demonstrated that interactions with images can affect the behaviours and attitudes of populations. Additionally, numerous geoscience studies demonstrate that the public can be more effectively engaged with topics such as climate change and hazard management through direct interaction with scientific elements. For example, when combined with real-world observation data, a simulation of a flash flood scenario allows people to observe the changes caused by such events and learn more about the reasons for its unpredictable properties (Skinner 2020).
More realistic simulation scenarios will heighten public awareness of natural hazards. Being aware of the risks associated with hazards allows people to take appropriate action when hazards occur. Another potential benefit of more realistic simulation scenarios is that increased public awareness facilitates the collection of crowdsourced data containing specific information about natural hazards.
To evoke the public’s imagination, several deep generative models have been developed for generating virtual simulations of real-world natural hazard risks. For example, a VAE has been employed to generate volcanic images depicting lava flows with training data from YouTube videos (Yamaguchi and Cabatuan 2018). Furthermore, deep generative models have been considered for simulating extreme events under climate change to enable a more intuitive visualization of climate change-induced hazards. Several works have demonstrated that variants of GAN that aim to solve image-to-image translation problems are sufficiently robust for simulating the effects of climate change in the real world by using real and simulated data and predicting the locations of floods (Cosne et al. 2020; Luccioni et al. 2021).
A promising variant in this respect is CycleGAN, which benefits from cross-domain training that could convert street images to flood-damaged street images (Schmidt et al. 2019). A well-trained CycleGAN that can generate photorealistic flood damage scenarios when given the address of a house or the name of a street has been demonstrated. Simulations created by CycleGAN will provide the public with a clear picture of the potential calamity that climate change can cause in their own home, in their neighbourhood, or on the street where they live. Compared with the original CycleGAN, this CycleGAN incorporates more prior knowledge in the input, which allows it to generate more realistic flood scenarios. Specifically, a binary flood map, which is based on the output from a climate model, is fed to the CycleGAN as additional information about whether a given house is inundated.
In addition to physical models, the Unity3D game engine is another source of additional information. For example, to provide input for the GauGAN variant referred to as ClimateGAN, the Unity3D game engine was utilized to obtain scene geometry annotations and semantic segmentation labels of the virtual world (Schmidt et al. 2021). The semantic data of the geometric and segmentation map can contribute to a more realistic flood mask for ClimateGAN, enabling realistic texture reproduction in water bodies. The well-trained ClimateGAN can make convincing projections of flood visualizations onto selected photos.
Similarly, in a variant of the Multimodal Unsupervised image-to-image Translation (MUNIT) framework, the Unity3D game engine is employed to simulate a realistic flood’s reflection and create paired images of a location before and after flooding (Cosne et al. 2020). In this example, the MUNIT-based variant generates realistic flood textures by limiting the cycle consistency loss and introducing a semantic consistency loss. It is not possible to address these methods in full detail considering the limitations of space. Further details can be obtained from the corresponding references if desired.
7 Discussion and summary
Data play an essential role in natural hazard analysis, which can support decision-making regarding the prevention and mitigation of hazards and facilitate a better understanding and management of hazards. However, economic costs and environmental constraints severely limit data availability in natural hazard analysis.
A promising deep learning-based solution has emerged in the wake of the recent boom in artificial intelligence. This novel paradigm, known as generative deep learning, allows for the generation of data from distributions of arbitrary complexity. In numerous fields, generative deep learning has achieved excellent performance in solving problems with both quantity of data and quality of data by utilizing state-of-the-art deep neural networks and deep learning training strategies. The ability of deep generative models to improve data quality or produce more data, as well as their relatively low computational cost and uncertainty, renders them increasingly attractive to a wide variety of Earth science applications, including natural hazards analysis. With the continuous and rapid development of deep learning in recent years, it is expected to further improve natural hazards analysis through data generation.
A comprehensive survey of generative deep learning related to data generation for natural hazard analysis is presented herein, particularly from the standpoint of motivations, advances, challenges, and opportunities. This review discusses an important topic: how generative deep learning can be utilized for data generation in natural hazard analysis and, in particular, how deep generative models can be developed and utilized for similar purposes. The discussion will be beneficial to scholars who are interested in deep generative models. This review addressed the following aspects.
First, a summary of the major data sources involved in natural hazards and the limitations of the data collected is given. Second, generative deep learning is also introduced as a potential solution. The concepts involved with generative deep learning and several common deep generative models are described. Third, the advances in generative deep learning for data generation in natural hazard analysis are reviewed. Fourth, challenges associated with the reliability of generative deep learning are discussed. Finally, further opportunities for leveraging generative deep learning for data generation in natural hazard analysis are discussed.
The following major conclusions are summarized from two perspectives: data and models.
From the perspective of data, direct application of existing deep generative models can provide realistic data with general information relating to natural hazard analysis, for example, radar reflectance for describing meteorological conditions. These data can be regarded as image data, which may explain why deep generative models perform well with these data. In contrast, deep generative models do not always provide specific information about hazard events, especially for seismic signal.
Several solutions effectively enable deep generative models to learn important natural hazard features from data. The data input processing can be improved. In the case of seismic data, the time domain can be converted to the frequency domain. Additional information can be added to the deep generative model, which can be conditioned to direct the model to capture more significant features from the original data. Another related approach is to use the output from the physical model as additional information, thus developing physical constraints that can be added to deep generative models, which increases the physical meaning of the deep generative models and reduces the uncertainty.
From the perspective of models, deep generative models such as SRGAN and ESRGAN designed for superresolution tasks are usually applied to meteorological data to enhance their resolution. At the same time, Pix2Pix and CycleGAN developed for image-to-image translation tasks are widely applied to geophysical data for denoising and interpolation. There are several ways that the DCGAN can be improved to generate earthquake events for seismic records.
The most common improvements are based on the network architecture and loss function. Typically, the performance of a deep generative model can be significantly enhanced by rationally modifying the network architecture based on the characteristics of the data. On the other hand, defining the loss function is crucial to enhancing the performance of the deep generative model. For deep generative models that aim to improve the availability of natural hazard data, the WGAN is typically applied to improve the training of these models but may not always be effective.
Another emerging, challenging, and attractive direction is introducing physical implications to the training of deep generative models by loss functions, which enable dramatic improvement in the physical consistency between their generated results and the results of real-world phenomena. It would be interesting to explore the design of deep generative models based on the characteristics of Earth observation data. The development of new deep generative models that are more customized to describe the physical processes of natural hazards realistically is expected.
Reliability remains a significant challenge for generative deep learning. Defining and exploring more metrics and standards is necessary to evaluate deep generative models objectively. Better interdisciplinary communication during qualitative evaluations would be beneficial. Experts from the field of Earth science can evaluate whether the data provided by a deep generative model contain meaningful information that can describe physical phenomena, helping to ensure the fidelity of the data and the utility of the model. Quantifying uncertainty is important. Adding uncertainty quantification to the evaluation of deep generative models may increase the reliability of the generated results. Ideally, a deep generative model with appropriate metrics should achieve the best performance and be easily replicated.
An appealing project, known as Digital Twin Earth, offers a tremendous opportunity for developing generative deep learning, thus providing optimal estimations of Earth’s physical phenomena. Establishing a digital twin of the Earth is extremely challenging due to the high cost of computations and the complexity of the Earth system. Deep generative models have been demonstrated to deliver solutions to various challenges faced by a digital twin of the Earth. It is expected that generative deep learning will continue to advance alongside the Digital Twin Earth program, enabling it to provide excellent scientific foundations for a variety of decision-making regarding natural hazards.
This paper primarily focuses on a review of deep generative models applied for data generation in several common natural hazard analysis, the methods, challenges, and future directions derived from it may provide inspiration to other fields with similar data issues.
References
Abdar M, Pourpanah F, Hussain S et al (2021) A review of uncertainty quantification in deep learning: techniques, applications and challenges. Inf Fusion 76:243–297. https://doi.org/10.1016/j.inffus.2021.05.008
Adeli E, Zhang J, Taflanidis AA (2021) Convolutional generative adversarial imputation networks for spatio-temporal missing data in storm surge simulations. arXiv preprint abs/2111.02823:1–32. arXiv:2111.02823
Ahmad Abir I, Khan S, Ghulam A et al (2015) Active tectonics of western potwar plateau-salt range, northern Pakistan from INSAR observations and seismic imaging. Remote Sens Environ 168:265–275. https://doi.org/10.1016/j.rse.2015.07.011
Akhmadiev R, Kanfar RS (2019) Subsurface imaging using GANS. Np URL: http://cs229stanfordedu/proj2019aut pp 1–6
Al-Najjar H, Pradhan B (2021) Spatial landslide susceptibility assessment using machine learning techniques assisted by additional data created with generative adversarial networks. Geosci Front 12(2):625–637. https://doi.org/10.1016/j.gsf.2020.09.002
Al-Najjar H, Pradhan B, Sarkar R et al (2021) A new integrated approach for landslide data balancing and spatial prediction based on generative adversarial networks (GAN). Remote Sens 13:1–30. https://doi.org/10.3390/rs13194011
Ali MU, Sultani W, Ali M (2020) Destruction from sky: weakly supervised approach for destruction detection in satellite imagery. ISPRS J Photogramm Remote Sens 162:115–124. https://doi.org/10.1016/j.isprsjprs.2020.02.002
Alwon S (2019) Generative adversarial networks in seismic data processing. pp 1991–1995, https://doi.org/10.1190/segam2018-2996002.1
Annau NJ, Cannon AJ, Monahan AH (2023) Algorithmic hallucinations of near-surface winds: statistical downscaling with generative adversarial networks to convection-permitting scales. Artif l Earth Ssyst. https://doi.org/10.1175/AIES-D-23-0015.1
Assumpção T, Popescu I, Jonoski A et al (2018) Citizen observations contributing to flood modelling: opportunities and challenges. Hydrol Earth Syst Sci 22(2):1473–1489. https://doi.org/10.5194/hess-22-1473-2018
Astafyeva E (2019) Ionospheric detection of natural hazards. Rev Geophys 57(4):1265–1288. https://doi.org/10.1029/2019RG000668
Barajas CA, Gobbert MK, Wang J (2020) Tornado storm data synthesization using deep convolutional generative adversarial network: Related works and implementation details. pp 1–6, https://doi.org/10.13016/M2GGLO-BTJ5
Bauer P, Stevens B, Hazeleger W (2021) A digital twin of earth for the green transition. Nat Clim Change 11:80–83. https://doi.org/10.1038/s41558-021-00986-y
Bergen KJ, Johnson PA, de Hoop MV et al (2019) Machine learning for data-driven discovery in solid earth geoscience. Science. https://doi.org/10.1126/science.aau0323
Besombes C, Pannekoucke O, Lapeyre C et al (2021) Producing realistic climate data with generative adversarial networks. Nonlinear Processes Geophys 28(3):347–370. https://doi.org/10.5194/npg-28-347-2021
Bessenbacher V, Seneviratne SI, Gudmundsson L (2021) Climfill: a framework for intelligently gap-filling earth observations. Geosci Model Dev Discuss. https://doi.org/10.5194/GMD-2021-164
Bevacqua E, De Michele C, Manning C et al (2021) Guidelines for studying diverse types of compound weather and climate events. Earth’s Future 9(11):1–23. https://doi.org/10.1029/2021EF002340
Biggs J, Wright T (2020) How satellite INSAR has grown from opportunistic science to routine monitoring over the last decade. Nat Commun 11:1–4. https://doi.org/10.1038/s41467-020-17587-6
Bihlo A (2021) A generative adversarial network approach to (ensemble) weather prediction. Neural Netw 139:1–16. https://doi.org/10.1016/j.neunet.2021.02.003
Bond-Taylor S, Leach A, Long Y et al (2021) Deep generative modelling: a comparative review of VAES, GANS, normalizing flows, energy-based and autoregressive models. IEEE Trans Pattern Anal 44:1–20. https://doi.org/10.1109/TPAMI.2021.3116668
Boulaguiem Y, Zscheischler J, Vignotto E, et al (2022) Modeling and simulating spatial extremes by combining extreme value theory with generative adversarial networks. Environmental Data Science abs/2104.12469:1–24. arXiv:2111.00267
Brown SK, Sparks R, Mee K, et al (2014) Regional and country profiles of volcanic hazard and risk: Report iv of the gvm/iavcei contribution to the global assessment report on disaster risk reduction 2015. United Nations Office for Disaster Risk Reduction pp 1–40
Camps-Valls G, Tuia D, Zhu XX et al (2021) Deep learning for the earth sciences: a comprehensive approach to remote sensing, climate science and geosciences. Wiley, Hoboken
Candès E, Romberg J, Tao T (2006) Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. IEEE Trans Inf Theory 52(2):489–509. https://doi.org/10.1109/TIT.2005.862083
Caricchi L, Townsend M, Rivalta E et al (2021) The build-up and triggers of volcanic eruptions. Nat Rev Earth Environ 2(7):458–476. https://doi.org/10.1038/s43017-021-00174-8
Carreau J, Naveau P (2023) A spatially adaptive multi-resolution generative algorithm: application to simulating flood wave propagation. Weather Clim Extremes 41:100580. https://doi.org/10.1016/j.wace.2023.100580
Chang D, Yang W, Yong X et al (2021) Seismic data interpolation using dual-domain conditional generative adversarial networks. IEEE Geosci Remote Sens Lett 18(10):1856–1860. https://doi.org/10.1109/LGRS.2020.3008478
Chen X, Feng K, Liu N, et al (2020) Rainnet: A large-scale dataset for spatial precipitation downscaling. arXiv preprint abs/2012.09700:1–18. arXiv:2012.09700
Chen X, Hu X, Ma G et al (2022) Predictive model of regional coseismic landslides permanent displacement considering uncertainty. Landslides 19:2513–2534. https://doi.org/10.1007/s10346-022-01918-3
Chen Y, Meng L, Zhang A et al (2018) Source complexity of the 2015 mw 7.9 bonin earthquake. Geochem Geophys Geosyst 19(7):2109–2120. https://doi.org/10.1029/2018GC007489
Choi S, Kim Y (2021) Rad-cgan v.10: Radar-based precipitation nowcasting model with conditional generative adversarial networks for multiple domains. Geosci Model Dev Discuss. https://doi.org/10.5194/gmd-2021-405
Chowdhury SM, Zhu K, Zhang YS (2021) Mitigating greenhouse gas emissions through generative adversarial networks based wildfire prediction. arXiv preprint abs/2108.08952:1–6. arXiv:2108.08952
Comegna L, Picarelli L, Bucchignani E et al (2013) Potential effects of incoming climate changes on the behaviour of slow active landslides in clay. Landslides 10(4):373–391. https://doi.org/10.1007/s10346-012-0339-3
Cosne G, Juraver A, Teng M, et al (2020) Using simulated data to generate images of climate change. arXiv preprint abs/2001.09531:1–9. arXiv:2001.09531
Cremen G, Galasso C (2020) Earthquake early warning: recent advances and perspectives. Earth Sci Rev 205:1–15. https://doi.org/10.1016/j.earscirev.2020.103184
Cui P, Peng J, Shi P et al (2021) Scientific challenges of research on natural hazards and disaster risk. Geogr Sustain 2(3):216–223. https://doi.org/10.1016/j.geosus.2021.09.001
Dai A (2011) Drought under global warming: a review. Wiley Interdiscip Rev Clim Change 2(1):45–65. https://doi.org/10.1002/wcc.81
Dai F, Lee C, Ngai Y (2002) Landslide risk assessment and management: an overview. Eng Geol 64(1):65–87. https://doi.org/10.1016/S0013-7952(01)00093-X
Dawson J, Tregoning P (2007) Uncertainty analysis of earthquake source parameters determined from INSAR: a simulation study. J Geophys Res Solid. https://doi.org/10.1029/2007JB005209
Dong J, Yin R, Sun X et al (2019) Inpainting of remote sensing SST images with deep convolutional generative adversarial network. IEEE Geosci Remote Sens Lett 16(2):173–177. https://doi.org/10.1109/LGRS.2018.2870880
Dong X, Li Y (2021) Denoising the optical fiber seismic data by using convolutional adversarial network based on loss balance. IEEE Trans Geosci Remote Sens 59(12):10544–10554. https://doi.org/10.1109/TGRS.2020.3036065
Donoho D (2006) Compressed sensing. IEEE Trans Inf Theory 52(4):1289–1306. https://doi.org/10.1109/TIT.2006.871582
Du W, Wang G (2013) Fully probabilistic seismic displacement analysis of spatially distributed slopes using spatially correlated vector intensity measures. Earthq Eng Struct Dyn 43:661–679. https://doi.org/10.1002/eqe.2365
Duan S, Song Z, Shen J et al (2024) Prediction for underground seismic intensity measures using conditional generative adversarial networks. Soil Dyn Earthq Eng 180:108619. https://doi.org/10.1016/j.soildyn.2024.108619
Dullaart J, Muis S, Bloemendaal N et al (2020) Advancing global storm surge modelling using the new era5 climate reanalysis. Climate Dyn 54(1–2):1007–1021. https://doi.org/10.1007/s00382-019-05044-0
Duman T, Çan T, Emre O et al (2005) Landslide inventory of northwestern Anatolia, Turkey. Eng Geol 77(1–2):99–114. https://doi.org/10.1016/j.enggeo.2004.08.005
Durall R, Ghanim A, Fernandez MR et al (2023) Deep diffusion models for seismic processing. Comput Geosci 177:105377. https://doi.org/10.1016/j.cageo.2023.105377
Dutta P, Power B, Halpert AD, et al (2019) 3d conditional generative adversarial networks to enable large-scale seismic image enhancement. arXiv preprint abs/1911.06932:1–8. arXiv:1911.06932
Ebert-Uphoff I, Lagerquist R, Hilburn K, et al (2021) Cira guide to custom loss functions for neural networks in environmental sciences - version 1. ArXiv abs/2106.09757:1–37. arXiv:2106.09757
Eigenschink P, Vamosi S, Vamosi R, et al (2021) Deep generative models for synthetic data. ACM Comput Surv pp 1–27
Esposito G, Marchesini I, Mondini AC et al (2020) A spaceborne SAR-based procedure to support the detection of landslides. Nat Hazards Earth Syst Sci 20(9):2379–2395. https://doi.org/10.5194/nhess-20-2379-2020
Fan X, Scaringi G, Domènech G et al (2019) Two multi-temporal datasets that track the enhanced landsliding after the 2008 Wenchuan earthquake. Earth Syst Sci Data 11:35–55. https://doi.org/10.5194/essd-11-35-2019
Fang B, Chen G, Pan L et al (2021) Gan-based siamese framework for landslide inventory mapping using bi-temporal optical remote sensing images. IEEE Geosci Remote Sens Lett 18(3):391–395. https://doi.org/10.1109/LGRS.2020.2979693
Ferreira R, Noce J, Oliveira D et al (2020) Generating sketch-based synthetic seismic images with generative adversarial networks. IEEE Geosci Remote Sens Lett 17(8):1460–1464. https://doi.org/10.1109/LGRS.2019.2945680
Fialko Y (2006) Interseismic strain accumulation and the earthquake potential on the southern SAN Andreas fault system. Nature 441(7096):968–971. https://doi.org/10.1038/nature04797
Furtney M, Pritchard M, Biggs J et al (2018) Synthesizing multi-sensor, multi-satellite, multi-decadal datasets for global volcano monitoring. J Volcanol Geotherm Res 365:38–56. https://doi.org/10.1016/j.jvolgeores.2018.10.002
Gagne D, Christensen H, Subramanian A et al (2020) Machine learning for stochastic parameterization: generative adversarial networks in the Lorenz ’96 model. J Adv Model Earth Syst 12(3):1–20. https://doi.org/10.1029/2019MS001896
Gan H, Pan X, Tang K et al (2022) EWR-NET: earthquake waveform regularization network for irregular station data based on deep generative model and resnet. J Geophys Res Solid Earth. https://doi.org/10.1029/2022jb024122
Gao Y, Ng MK (2022) Wasserstein generative adversarial uncertainty quantification in physics-informed neural networks. J Comput Phys 463:111270. https://doi.org/10.1016/j.jcp.2022.111270
Gao Y, Xie H, Yao T et al (2010) Integrated assessment on multi-temporal and multi-sensor combinations for reducing cloud obscuration of modis snow cover products of the pacific northwest USA. Remote Sens Environ 114(8):1662–1675. https://doi.org/10.1016/j.rse.2010.02.017
Gao Z, Shi X, Han B, et al (2023) Prediff: Precipitation nowcasting with latent diffusion models. In: Thirty-seventh Conference on Neural Information Processing Systems
Gatti F, Clouteau D (2020) Towards blending physics-based numerical simulations and seismic databases using generative adversarial network. Computer Methods Appl Mech Eng 372:113421. https://doi.org/10.1016/j.cma.2020.113421
Gatti F, Clouteau D (2020) Towards blending physics-based numerical simulations and seismic databases using generative adversarial network. Comput Methods Appl Mech Eng 372:1–27. https://doi.org/10.1016/j.cma.2020.113421
Ge X, Yang Y, Chen J et al (2022) Disaster prediction knowledge graph based on multi-source spatio-temporal information. Remote Sens 14:1214. https://doi.org/10.3390/rs14051214
Gómez-Gonzalez C, Serradell Maronda K (2021) Super-resolution for downscaling climate data. Barcelona Supercomputing Center pp 1–2
González-Abad J, Baño-Medina J, Heredia I (2021) On the use of deep generative models for "perfect" prognosis climate downscaling. In: NeurIPS 2021 Workshop on Tackling Climate Change with Machine Learning, pp 1–4, https://doi.org/10.20350/DIGITALCSIC/14013
Goodchild M, Proctor J (1997) Scale in a digital geographic world. Geogr Environ Modell 1(1):5–23
Gray S (2013) Spatial sampling, migration aliasing, and migrated amplitudes. Geophysics 78(3):157–164. https://doi.org/10.1190/GEO2012-0451.1
Grezio A, Babeyko A, Baptista M et al (2017) Probabilistic tsunami hazard analysis: multiple sources and global applications. Rev Geophys 55(4):1158–1198. https://doi.org/10.1002/2017RG000579
Grijalva F, Ramos W, Perez N et al (2021) Eseismic-gan: a generative model for seismic events from cotopaxi volcano. IEEE J Sel Top Appl Earth Obs Remote Sens 14:7111–7120. https://doi.org/10.1109/JSTARS.2021.3095270
Groenke B, Madaus L, Monteleoni C (2020) Climalign: Unsupervised statistical downscaling of climate variables via normalizing flows. pp 60–66, https://doi.org/10.1145/3429309.3429318
Grohnfeldt C, Schmitt M, Zhu X (2018) A conditional generative adversarial network to fuse SAR and multispectral optical data for cloud removal from sentinel-2 images. pp 1726–1729, https://doi.org/10.1109/IGARSS.2018.8519215
Gross F, Mountjoy J, Crutchley G et al (2018) Free gas distribution and basal shear zone development in a subaqueous landslide insight from 3d seismic imaging of the Tuaheni landslide complex, New Zealand. Earth Planet Sci Lett 502:231–243. https://doi.org/10.1016/j.epsl.2018.09.002
Gupta R, Mustafa M, Kashinath K (2020) Climate-stylegan: Modeling turbulent climate dynamics using style-gan. In: NeurIPS AI for Earth Sciences Workshop, pp 1–5
Guzzetti F, Cardinali M, Reichenbach P (1996) The influence of structural setting and lithology on landslide type and pattern. Environ Eng Geosci 2(4):531–555. https://doi.org/10.2113/gseegeosci.ii.4.531
Guzzetti F, Reichenbach P, Cardinali M et al (2005) Probabilistic landslide hazard assessment at the basin scale. Geomorphology 72(1–4):272–299. https://doi.org/10.1016/j.geomorph.2005.06.002
Guzzetti F, Ardizzone F, Cardinali M et al (2008) Distribution of landslides in the upper Tiber river basin, central Italy. Geomorphology 96(1–2):105–122. https://doi.org/10.1016/j.geomorph.2007.07.015
Guzzetti F, Mondini A, Cardinali M et al (2012) Landslide inventory maps: new tools for an old problem. Earth Sci Rev 112(1–2):42–66. https://doi.org/10.1016/j.earscirev.2012.02.001
Guzzetti F, Gariano S, Peruccacci S et al (2020) Geographical landslide early warning systems. Earth Sci Rev 200:1–29. https://doi.org/10.1016/j.earscirev.2019.102973
Haigh I, Wijeratne E, MacPherson L et al (2014) Estimating present day extreme water level exceedance probabilities around the coastline of Australia: tides, extra-tropical storm surges and mean sea level. Climate Dyn 42(1–2):121–138. https://doi.org/10.1007/s00382-012-1652-1
Halpert A (2019) Deep learning-enabled seismic image enhancement. pp 2081–2085, https://doi.org/10.1190/segam2018-2996943.1
Hao Z, Singh V, Xia Y (2018) Seasonal drought prediction: advances, challenges, and future prospects. Rev Geophys 56(1):108–141. https://doi.org/10.1002/2016RG000549
Harris L, McRae ATT, Chantry M et al (2022) A generative deep learning approach to stochastic downscaling of precipitation forecasts. J Adv Model Earth Syst. https://doi.org/10.1029/2022ms003120
He K, Sun J, Tang X (2011) Single image haze removal using dark channel prior. IEEE Trans Pattern Anal Mach Intell 33(12):2341–2353. https://doi.org/10.1109/TPAMI.2010.168
He W, Jiang Z, Kriby M, et al (2022a) Quantifying and reducing registration uncertainty of spatial vector labels on earth imagery. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. https://doi.org/10.1145/3534678.3539410
He W, Sainju AM, Jiang Z et al (2022) Earth imagery segmentation on terrain surface with limited training labels: a semi-supervised approach based on physics-guided graph co-training. ACM Trans Intell Syst Technol 13:1–22. https://doi.org/10.1145/3481043
Heil B, Hoffman M, Markowetz F et al (2021) Reproducibility standards for machine learning in the life sciences. Nat Methods 18(10):1132–1135. https://doi.org/10.1038/s41592-021-01256-7
Henriques LFM, Colcher S, Milidi’u RL, et al (2021) Generating data augmentation samples for semantic segmentation of salt bodies in a synthetic seismic image dataset. ArXiv abs/2106.08269:1–15. arXiv:2106.08269
Herrera G, Fernández-Merodo J, Mulas J et al (2009) A landslide forecasting model using ground based SAR data: the Portalet case study. Eng Geol 105(3–4):220–230. https://doi.org/10.1016/j.enggeo.2009.02.009
Hess P, Drüke M, Petri S et al (2022) Physically constrained generative adversarial networks for improving precipitation fields from earth system models. Nat Mach Intell 4:828–839. https://doi.org/10.1038/s42256-022-00540-1
Hirabayashi Y, Mahendran R, Koirala S et al (2013) Global flood risk under climate change. Nat Climate Change 3(9):816–821. https://doi.org/10.1038/nclimate1911
Ho J, Jain A, Abbeel P (2020) Denoising diffusion probabilistic models. https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf
Hu Y, Chen L, Wang Z et al (2022) Towards a more realistic and detailed deep-learning-based radar echo extrapolation method. Remote Sens 14:1–24. https://doi.org/10.3390/rs14010024
Huang C, Chen Y, Zhang S et al (2018) Detecting, extracting, and monitoring surface water from space using optical sensors: a review. Rev Geophys 56(2):333–360. https://doi.org/10.1029/2018RG000598
Huang F, Ye Z, Jiang SH et al (2021) Uncertainty study of landslide susceptibility prediction considering the different attribute interval numbers of environmental factors and different data-based models. CATENA 202:105250. https://doi.org/10.1016/j.catena.2021.105250
Huang L, Huang J, Li H et al (2023) Robust spatial temporal imputation based on spatio-temporal generative adversarial nets. Knowl Based Syst 279:110919. https://doi.org/10.1016/j.knosys.2023.110919
Huang T, David C, Oadia C, et al (2022) An earth system digital twin for flood prediction and analysis. In: IGARSS 2022 - 2022 IEEE International Geoscience and Remote Sensing Symposium, 9, pp 4735–4738, https://doi.org/10.1109/IGARSS46834.2022.9884830
Ivek T, Vlah D (2023) Reconstruction of incomplete wildfire data using deep generative models. Extremes 26:251–271. https://doi.org/10.1007/s10687-022-00459-1
Jaffrés J, Cuff C, Rasmussen C et al (2018) Teleconnection of atmospheric and oceanic climate anomalies with Australian weather patterns: a review of data availability. Earth Sci Rev 176:117–146. https://doi.org/10.1016/j.earscirev.2017.08.010
Jahangir MS, Quilty J (2024) Generative deep learning for probabilistic streamflow forecasting: conditional variational auto-encoder. J Hydrol 629:130498. https://doi.org/10.1016/j.jhydrol.2023.130498
Jiang J, Zheng L, Luo F, et al (2018) Rednet: Residual encoder-decoder network for indoor rgb-d semantic segmentation. arXiv preprint abs/1806.01054:1–14. arXiv:1806.01054
Jiang J, Chen M, Fan J (2021) Deep neural networks for the evaluation and design of photonic devices. Nat Rev Mater 6(8):679–700. https://doi.org/10.1038/s41578-020-00260-1
Jiang X, Wang X, Liu Y et al (2023) Spatial extrapolation of downscaled geochemical data using conditional GAN. Comput Geosci 179:105420. https://doi.org/10.1016/j.cageo.2023.105420
Jousset P, Reinsch T, Ryberg T et al (2018) Dynamic strain determination using fibre-optic cables allows imaging of seismological and structural features. Nat Commun 9(1):1–7. https://doi.org/10.1038/s41467-018-04860-y
Kaur H, Pham N, Fomel S (2021) Seismic data interpolation using deep learning with generative adversarial networks. Geophys Prospect 69(2):307–326. https://doi.org/10.1111/1365-2478.13055
Kearey P, Brooks M (1991) An introduction to geophysical exploration, 2nd edn. Blackwell Publications, Oxford
Kim J, Kim T, Ryu JG (2023) Multi-source deep data fusion and super-resolution for downscaling sea surface temperature guided by generative adversarial network-based spatiotemporal dependency learning. Int J Appl Earth Observ Geoinf 119:103312. https://doi.org/10.1016/j.jag.2023.103312
Kim JH, Ryu S, Jeong J et al (2020) Impact of satellite sounding data on virtual visible imagery generation using conditional generative adversarial network. IEEE J Sel Top Appl Earth Obs Remote Sens 13:4532–4541. https://doi.org/10.1109/JSTARS.2020.3013598
Kim S, Hong S, Joh M, et al (2017) Deeprain: Convlstm network for precipitation prediction using multichannel radar data. arXiv preprint abs/1711.02316:1–4. arXiv:1711.02316
Kim Y, Hong S (2022) Very short-term rainfall prediction using ground radar observations and conditional generative adversarial networks. IEEE Trans Geosci Remote Sens 60:1–8. https://doi.org/10.1109/TGRS.2021.3108812
Klemmer K, Saha S, Kahl M, et al (2021) Generative modeling of spatio-temporal weather patterns with extreme event conditioning. ArXiv abs/2104.12469:1–6. arXiv:2104.12469
Knüsel B, Zumwald M, Baumberger C et al (2019) Applying big data beyond small problems in climate research. Nature Climate Change 9(3):196–202. https://doi.org/10.1038/s41558-019-0404-1
Krinitskiy M, Zyulyaeva YA, Gulev SK, et al (2019) Clustering of polar vortex states using convolutional autoencoders. In: EGU General Assembly Conference Abstracts, pp 1–8
Kuge K (2017) Seismic observations indicating that the 2015 ogasawara (bonin) earthquake ruptured beneath the 660 km discontinuity. Geophys Res Lett 44(21):10855–10862. https://doi.org/10.1002/2017GL074469
Kumar P, Debele S, Sahani J et al (2021) An overview of monitoring methods for assessing the performance of nature-based solutions against natural hazards. Earth Sci Rev 217:1–26. https://doi.org/10.1016/j.earscirev.2021.103603
do Lago CA, Giacomoni MH, Bentivoglio R et al (2023) Generalizing rapid flood predictions to unseen urban catchments with conditional generative adversarial networks. J Hydrol 618:129276. https://doi.org/10.1016/j.jhydrol.2023.129276
Leinonen J, Nerini D, Berne A (2021) Stochastic super-resolution for downscaling time-evolving atmospheric fields with a generative adversarial network. IEEE Trans Geosci Remote Sens 59(9):7211–7223. https://doi.org/10.1109/TGRS.2020.3032790
Li H, Gao S, Liu G et al (2020) Visual prediction of typhoon clouds with hierarchical generative adversarial networks. IEEE Geosci Remote Sens Lett 17(9):1478–1482. https://doi.org/10.1109/LGRS.2019.2950687
Li H, Yang Y, Chang M et al (2022) Srdiff: single image super-resolution with diffusion probabilistic models. Neurocomputing 479:47–59. https://doi.org/10.1016/j.neucom.2022.01.029
Li J, Wu Z, Hu Z et al (2020) Thin cloud removal in optical remote sensing images based on generative adversarial networks and physical model of cloud distortion. ISPRS J Photogramm Remote Sens 166:373–389. https://doi.org/10.1016/j.isprsjprs.2020.06.021
Li K, Chen S, Hu G (2020) Seismic labeled data expansion using variational autoencoders. Artif Intell Geosci 1:24–30. https://doi.org/10.1016/j.aiig.2020.12.002
Li L, Tan J, Schwarz B et al (2020) Recent advances and challenges of waveform-based seismic location methods at multiple scales. Rev Geophys 58(1):1–47. https://doi.org/10.1029/2019RG000667
Li L, Carver R, Lopez-Gomez I et al (2024) Generative emulation of weather forecast ensembles with diffusion models. Sci Adv. https://doi.org/10.1126/sciadv.adk4489
Li Q, Luo Y (2020) Using gan priors for ultrahigh resolution seismic inversion. pp 2453–2457, https://doi.org/10.1190/segam2019-3215520.1
Li S, Sun D, Goldberg MD et al (2018) Automatic near real-time flood detection using SUOMI-NPP/VIIRS data. Remote Sens Environ 204:672–689. https://doi.org/10.1016/j.rse.2017.09.032
Li X, Feng M, Ran Y et al (2023) Big data in earth system science and progress towards a digital twin. Nat Rev Earth Environ 4:319–332. https://doi.org/10.1038/s43017-023-00409-w
Li Y, Martinis S, Wieland M (2019) Urban flood mapping with an active self-learning convolutional neural network based on terrasar-x intensity and interferometric coherence. ISPRS J Photogramm Remote Sens 152:178–191. https://doi.org/10.1016/j.isprsjprs.2019.04.014
Li Y, Ku B, Kim G, et al (2020e) Seismic signal synthesis by generative adversarial network with gated convolutional neural network structure. pp 3857–3860, https://doi.org/10.1109/IGARSS39084.2020.9323670
Li Y, Luo X, Wu N et al (2022) The application of semisupervised attentional generative adversarial networks in desert seismic data denoising. IEEE Geosci Remote Sens Lett 19:1–5. https://doi.org/10.1109/LGRS.2021.3073419
Li Z, Meier MA, Hauksson E et al (2018) Machine learning seismic wave discrimination: application to earthquake early warning. Geophys Res Lett 45(10):4773–4779. https://doi.org/10.1029/2018GL077870
Li Z, Shen Z, Yang Y et al (2021) Rapid response to the 2019 ridgecrest earthquake with distributed acoustic sensing. AGU Adv 2:1–9. https://doi.org/10.1029/2021AV00039
Liang J, Liu D (2020) A local thresholding approach to flood water delineation using sentinel-1 SAR imagery. ISPRS J Photogramm Remote Sens 159:53–62. https://doi.org/10.1016/j.isprsjprs.2019.10.017
Liang S, Fang H, Chen M (2001) Atmospheric correction of landsat ETM+ land surface imagery-part I: methods. IEEE Trans Geosci Remote Sens 39(11):2490–2498. https://doi.org/10.1109/36.964986
Liu C, Rim D, Baraldi R et al (2021) Comparison of machine learning approaches for tsunami forecasting from sparse observations. Pure Appl Geophys 178(12):5129–5153. https://doi.org/10.1007/s00024-021-02841-9
Liu F, Elliott J, Craig T et al (2021) Improving the resolving power of INSAR for earthquakes using time series: a case study in Iran. Geophys Res Lett 48(14):1–12. https://doi.org/10.1029/2021GL093043
Liu J, Yuan Z, Pan Z et al (2022) Diffusion model with detail complement for super-resolution of remote sensing. Remote Sens 14:34–48. https://doi.org/10.3390/rs14194834
Liu L, Zhou W, Guan K et al (2024) Knowledge-guided machine learning can improve carbon cycle quantification in agroecosystems. Nat Commun 15:357. https://doi.org/10.1038/s41467-023-43860-5
Liu M, Huang H, Feng H, et al (2023) Pristi: A conditional diffusion framework for spatiotemporal imputation. IEEE 39th International Conference on Data Engineering (ICDE) pp 1927–1939. https://doi.org/10.1109/icde55515.2023.00150
Liu R, Li Y, Jiao L (2020) Sar image specle reduction based on a generative adversarial network. pp 1–6, https://doi.org/10.1109/IJCNN48605.2020.9206847
Liu W, Cao S, Gan S et al (2016) One-step slope estimation for dealiased seismic data reconstruction via iterative Seislet thresholding. IEEE Geosci Remote Sens Lett 13(10):1462–1466. https://doi.org/10.1109/LGRS.2016.2591939
Liu Y, Chen Z, Hu B et al (2018) A non-uniform spatiotemporal kriging interpolation algorithm for landslide displacement data. Bull Eng Geol Environ 78:4153–4166. https://doi.org/10.1007/s10064-018-1388-1
Liu Y, Long J, Li C et al (2024) Physics-informed data assimilation model for displacement prediction of hydrodynamic pressure-driven landslide. Comput Geotech 167:106085. https://doi.org/10.1016/j.compgeo.2024.106085
Loughlin S, Sparks S, Brown S et al (2015) Global volcanic hazards and risk. Cambridge University Press, Cambridge. https://doi.org/10.1017/CBO9781316276273
Lu P, Morris M, Brazell S et al (2018) Using generative adversarial networks to improve deep-learning fault interpretation networks. Leading Edge 37(8):578–583. https://doi.org/10.1190/tle37080578.1
Luccioni A, Schmidt V, Vardanyan V et al (2021) Using artificial intelligence to visualize the impacts of climate change. IEEE Comput Graphics Appl 41(1):8–14. https://doi.org/10.1109/MCG.2020.3025425
Luo S, Hu W (2021) Diffusion probabilistic models for 3d point cloud generation. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp 2836–2844. https://api.semanticscholar.org/CorpusID:232092778
Lütjens B, Leshchinskiy B, Requena-Mesa C, et al (2020) Physics-informed gans for coastal flood visualization. arXiv preprint abs/2010.08103:1–10. arXiv:2010.08103
Ma F, Xiang D, Yang K et al (2022) Weakly supervised deep soft clustering for flood identification in SAR images. IEEE Geosci Remote Sens Lett 19:1–5. https://doi.org/10.1109/LGRS.2022.3150778
Ma G, Rezania M, Mousavi Nezhad M et al (2022) Uncertainty quantification of landslide runout motion considering soil interdependent anisotropy and fabric orientation. Landslides 19:1231–1247. https://doi.org/10.1007/s10346-021-01795-2
Ma H, Sun Y, Wu N et al (2022) Relative attributes-based generative adversarial network for desert seismic noise suppression. IEEE Geosci Remote Sens Lett 19:1–5. https://doi.org/10.1109/LGRS.2021.3135034
Ma Q, Li S, Cottrell G (2022) Adversarial joint-learning recurrent neural network for incomplete time series classification. IEEE Trans Pattern Anal Mach Intell 44(4):1765–1776. https://doi.org/10.1109/TPAMI.2020.3027975
Ma Z, Mei G (2021) Deep learning for geological hazards analysis: data, models, applications, and opportunities. Earth Sci Rev 223:1–33. https://doi.org/10.1016/j.earscirev.2021.103858
Malamud B, Turcotte D, Guzzetti F et al (2004) Landslides, earthquakes, and erosion. Earth Planet Sci Lett 229(1–2):45–59. https://doi.org/10.1016/j.epsl.2004.10.018
Manepalli A, Albert A, Rhoades A, et al (2019) Emulating numeric hydroclimate models with physics-informed CGANS. In: NeurIPS 2019 Workshop on Tackling Climate Change with Machine Learning, pp 1–4
Mangipudi H, Mooers G, Pritchard MS, et al (2021) Analyzing high-resolution clouds and convection using multi-channel vaes. arXiv preprint abs/2112.01221:1–4. arXiv:2112.01221
Marchese F, Ciampa M, Filizzola C et al (2010) On the exportability of robust satellite techniques (RST) for active volcano monitoring. Remote Sens 2(6):1575–1588. https://doi.org/10.3390/rs2061575
Mazzanti P, Scancella S, Virelli M et al (2022) Assessing the performance of multi-resolution satellite SAR images for post-earthquake damage detection and mapping aimed at emergency response management. Remote Sens 14:2210–2210. https://doi.org/10.3390/rs14092210
McPhillips L, Chang H, Chester M et al (2018) Defining extreme events: a cross-disciplinary review. Earth’s Future 6(3):441–455. https://doi.org/10.1002/2017EF000686
Meehl G, Tebaldi C (2004) More intense, more frequent, and longer lasting heat waves in the 21st century. Science 305(5686):994–997. https://doi.org/10.1126/science.1098704
Meier MA, Ross Z, Ramachandran A et al (2019) Reliable real-time seismic signal/noise discrimination with machine learning. J Geophys Res Solid 124(1):788–800. https://doi.org/10.1029/2018JB016661
Melgar D, Allen R, Riquelme S et al (2016) Local tsunami warnings: perspectives from recent large events. Geophys Res Lett 43(3):1109–1117. https://doi.org/10.1002/2015GL067100
Meng F, Song T, Xu D (2022) Simulating tropical cyclone passive microwave rainfall imagery using infrared imagery via generative adversarial networks. IEEE Geosci Remote Sens Lett 19:1–5. https://doi.org/10.1109/LGRS.2022.3152847
Meng Y, Rigall E, Chen X et al (2021) Physics-guided generative adversarial networks for sea subsurface temperature prediction. IEEE Trans Neural Netw Learn Syst 8:1–14. https://doi.org/10.1109/TNNLS.2021.3123968
Meng Y, Gao F, Rigall E et al (2023) Physical knowledge-enhanced deep neural network for sea surface temperature prediction. IEEE Geosci Remote Sens Lett 61:1–13. https://doi.org/10.1109/TGRS.2023.3257039
Meng Y, Rigall E, Chen X et al (2023) Physics-guided generative adversarial networks for sea subsurface temperature prediction. IEEE Trans Neural Netw Learn Syst 34(7):3357–3370. https://doi.org/10.1109/TNNLS.2021.3123968
Merritt A, Chambers J, Wilkinson P et al (2016) Measurement and modelling of moisture-electrical resistivity relationship of fine-grained unsaturated soils and electrical anisotropy. J Appl Geophys 124:155–165. https://doi.org/10.1016/j.jappgeo.2015.11.005
Merz B, Kuhlicke C, Kunz M et al (2020) Impact forecasting to support emergency management of natural hazards. Rev Geophys 58(4):1–52. https://doi.org/10.1029/2020RG000704
Merz R, Blöschl G (2003) A process typology of regional floods. Water Resour Res 39(12):510–520. https://doi.org/10.1029/2002WR001952
Milidiú RL, Müller L (2020) Seismoglow - data augmentation for the class imbalance problem. ArXiv abs/2007.12229:1–10. arXiv:2007.12229
Min DH, Kim YS, Kim S et al (2023) Strategy of oversampling geotechnical parameters through geostatistical, smote, and ctgan methods for assessing susceptibility of landslide. Landslides. https://doi.org/10.1007/s10346-023-02166-9
Mondini A, Santangelo M, Rocchetti M et al (2019) Sentinel-1 SAR amplitude imagery for rapid landslide detection. Remote Sens 11(7):1–27. https://doi.org/10.3390/rs11070760
Mondini A, Guzzetti F, Chang KT et al (2021) Landslide failures detection and mapping using synthetic aperture radar: past, present and future. Earth Sci Rev 216:1–33. https://doi.org/10.1016/j.earscirev.2021.103574
Mondini AC, Guzzetti F, Chang KT et al (2021) Landslide failures detection and mapping using synthetic aperture radar: past, present and future. Earth Sci. Rev. 216:103574. https://doi.org/10.1016/j.earscirev.2021.103574
Mooers G, Tuyls J, Mandt S, et al (2020) Generative modeling of atmospheric convection. pp 98–105, https://doi.org/10.1145/3429309.3429324
Mooers G, Pritchard M, Beucler T et al (2023) Comparing storm resolving models and climates via unsupervised machine learning. Sci Rep 13:22365. https://doi.org/10.1038/s41598-023-49455-w
Moretti L, Allstadt K, Mangeney A et al (2015) Numerical modeling of the mount meager landslide constrained by its force history derived from seismic data. J Geophys Res Solid 120(4):2579–2599. https://doi.org/10.1002/2014JB011426
Mosser L, Kimman W, Dramsch J, et al (2018) Rapid seismic domain transfer: Seismic velocity inversion and modeling using deep generative neural networks. pp 1–5, https://doi.org/10.3997/2214-4609.201800734
Mosser L, Dubrule O, Blunt M (2020) Stochastic seismic waveform inversion using generative adversarial networks as a geological prior. Math Geosci 52(1):53–79. https://doi.org/10.1007/s11004-019-09832-6
Muller C, Chapman L, Johnston S et al (2015) Crowdsourcing for climate and atmospheric sciences: current status and future potential. Int J Climatol 35(11):3185–3203. https://doi.org/10.1002/joc.4210
Mulyadi AW, Jun E, Suk HI (2022) Uncertainty-aware variational-recurrent imputation network for clinical time series. IEEE Trans Cybern 52(9):9684–9694. https://doi.org/10.1109/TCYB.2021.3053599
Nava L, Carraro E, Reyes-Carmona C et al (2023) Landslide displacement forecasting using deep learning and monitoring data across selected sites. Landslides 20:2111–2129. https://doi.org/10.1007/s10346-023-02104-9
Needham H, Keim B, Sathiaraj D (2015) A review of tropical cyclone-generated storm surges: global data sources, observations, and impacts. Rev Geophys 53(2):545–591. https://doi.org/10.1002/2014RG000477
Obayashi M, Fukao Y, Yoshimitsu J (2017) Unusually deep Bonin earthquake of 30 May 2015: a precursory signal to slab penetration? Earth Planet Sci Lett 459:221–226. https://doi.org/10.1016/j.epsl.2016.11.019
Oliva P, Schroeder W (2015) Assessment of VIIRS 375m active fire detection product for direct burned area mapping. Remote Sens Environ 160:144–155. https://doi.org/10.1016/j.rse.2015.01.010
Oliveira D, Ferreira R, Silva R et al (2018) Interpolating seismic data with conditional generative adversarial networks. IEEE Geosci Remote Sens Lett 15(12):1952–1956. https://doi.org/10.1109/LGRS.2018.2866199
Oliveira D, Ferreira R, Silva R et al (2019) Improving seismic data resolution with deep generative networks. IEEE Geosci Remote Sens Lett 16(12):1929–1933. https://doi.org/10.1109/LGRS.2019.2913593
Oliveira DAB, Diaz JG, Zadrozny B, et al (2021) Controlling weather field synthesis using variational autoencoders. In: ICML Climate Change AI Workshop, pp 1–5, arXiv:2108.00048
Oswald P, Strasser M, Hammerl C et al (2021) Seismic control of large prehistoric rockslides in the eastern alps. Nat Commun 12:1–8. https://doi.org/10.1038/s41467-021-21327-9
Otten S, Caron S, de Swart W et al (2021) Event generation and statistical sampling for physics with deep generative models and a density information buffer. Nat Commun 12:2985. https://doi.org/10.1038/s41467-021-22616-z
Ovcharenko O, Hou S (2020) Deep learning for seismic data reconstruction: opportunities and challenges. Euro Assoc Geosci Eng. https://doi.org/10.3997/2214-4609.202032054
Oyama N, Ishizaki NN, Koide S et al (2023) Deep generative model super-resolves spatially correlated multiregional climate data. Sci Rep 13:5992. https://doi.org/10.1038/s41598-023-32947-0
Palis E, Lebourg T, Tric E et al (2017) Long-term monitoring of a large deep-seated landslide (la Clapiere, south-east French alps): initial study. Landslides 14(1):155–170. https://doi.org/10.1007/s10346-016-0705-7
Pallister J, Schneider D, Griswold J et al (2013) Merapi 2010 eruption-chronology and extrusion rates monitored with satellite radar and used in eruption forecasting. J Volcanol Geotherm Res 261:144–152. https://doi.org/10.1016/j.jvolgeores.2012.07.012
Pan B, Anderson G, Goncalves A et al (2022) Improving seasonal forecast using probabilistic deep learning. J Adv Model Earth Syst 14(3):1–24. https://doi.org/10.1029/2021MS002766
Pan H (2020) Cloud removal for remote sensing imagery via spatial attention generative adversarial network. arXiv preprint abs/2009.13015:1–7. arXiv:2009.13015
Park J, Yoon D, Seol S, et al (2020a) Reconstruction of seismic field data with convolutional u-net considering the optimal training input data. pp 4650–4654, https://doi.org/10.1190/segam2019-3216017.1
Park M, Tran D, Jung D et al (2020) Wildfire-detection method using densenet and cyclegan data augmentation-based remote camera imagery. Remote Sens 12(22):1–16. https://doi.org/10.3390/rs12223715
Parker R, Densmore A, Rosser N et al (2011) Mass wasting triggered by the 2008 Wenchuan earthquake is greater than orogenic growth. Nat Geosci 4(7):449–452. https://doi.org/10.1038/ngeo1154
Peng J, Loew A, Merlin O et al (2017) A review of spatial downscaling of satellite remotely sensed soil moisture. Rev Geophys 55(2):341–366. https://doi.org/10.1002/2016RG000543
Perol T, Gharbi M, Denolle M (2018) Convolutional neural network for earthquake detection and location. Sci Adv 4(2):1–8. https://doi.org/10.1126/sciadv.1700578
Picetti F, Lipari V, Bestagini P et al (2019) Seismic image processing through the generative adversarial network. Interpretation (United Kingdom) 7(3):15–26. https://doi.org/10.1190/INT-2018-0232.1
Potter S, Scott B, Jolly G et al (2015) Introducing the volcanic unrest index (VUI): a tool to quantify and communicate the intensity of volcanic unrest. Bull Volcanol 77(9):1–15. https://doi.org/10.1007/s00445-015-0957-4
Poursartip B, Fathi A, Tassoulas J (2020) Large-scale simulation of seismic wave motion: a review. Soil Dyn Earthquake Eng 129:1–35. https://doi.org/10.1016/j.soildyn.2019.105909
Qian K, Mohamed AA, Claudel CG (2019) Physics informed data driven model for flood prediction: Application of deep learning in prediction of urban flood development. arXiv preprint abs/1908.10312:1–34. arXiv:1908.10312
Rasti B, Sveinsson J, Ulfarsson M (2014) Wavelet-based sparse reduced-rank regression for hyperspectral image restoration. IEEE Trans Geosci Remote Sens 52(10):6688–6698. https://doi.org/10.1109/TGRS.2014.2301415
Ravuri SV, Lenc K, Willson M et al (2021) Skilful precipitation nowcasting using deep generative models of radar. Nature 597:672–677. https://doi.org/10.1038/s41586-021-03854-z
Reath K, Ramsey M, Dehn J et al (2016) Predicting eruptions from precursory activity using remote sensing data hybridization. J Volcanol Geotherm Res 321:18–30. https://doi.org/10.1016/j.jvolgeores.2016.04.027
Reath K, Pritchard M, Poland M et al (2019) Thermal, deformation, and degassing remote sensing time series at the 47 most active volcanoes in Latin America: implications for volcanic systems. J Geophys Res Solid 124(1):195–218. https://doi.org/10.1029/2018JB016199
Rego J, Li C (2009) On the importance of the forward speed of hurricanes in storm surge forecasting: a numerical study. Geophys Res Lett 36(7):1–5. https://doi.org/10.1029/2008GL036953
Reimers SC., Tibau Alberdi XA, Requena-MEsa SC., et al (2018) SupernoVAE: Using deep learning to find spatio-temporal dynamics in Earth system data. In: AGU Fall Meeting Abstracts, pp 1–4
Roelvink D, Reniers A, van Dongeren A et al (2009) Modelling storm impacts on beaches, dunes and barrier islands. Coastal Eng 56(11–12):1133–1152. https://doi.org/10.1016/j.coastaleng.2009.08.006
Rui X, Cao Y, Yuan X et al (2021) Disastergan: generative adversarial networks for remote sensing disaster image generation. Remote Sens 13:1–18. https://doi.org/10.3390/rs13214284
Ruthotto L, Haber E (2021) An introduction to deep generative modeling. arXiv preprint abs/2108.08952:1–26. arXiv:2103.05180
Ruzicka V, Vaughan A, Martini D, et al (2021) Unsupervised change detection of extreme events using ml on-board. ArXiv abs/2111.02995:1–5. arXiv:2111.02995
Ryder I, Parsons B, Wright T et al (2007) Post-seismic motion following the 1997 Manyi (Tibet) earthquake: INSAR observations and modelling. Geophys J Int 169(3):1009–1027. https://doi.org/10.1111/j.1365-246X.2006.03312.x
Sanchez-Lengeling B, Aspuru-Guzik A (2018) Inverse molecular design using machine learning: generative models for matter engineering. Science 361(6400):360–365. https://doi.org/10.1126/science.aat2663
Scher S, Peßenteiner S (2021) Temporal disaggregation of spatial rainfall fields with generative adversarial networks. Hydrol Earth Syst Sci 25(6):3207–3225. https://doi.org/10.5194/hess-25-3207-2021
Schmidt V, Luccioni AS, Mukkavilli SK, et al (2019) Visualizing the consequences of climate change using cycle-consistent adversarial networks. arXiv preprint abs/1905.03709:1–7. arXiv:1905.03709
Schmidt V, Muhammed MA, Sankaran K, et al (2020) Modeling cloud reflectance fields using conditional generative adversarial networks. In: ICLR 2020 Workshop on Tackling Climate Change with Machine Learning, pp 1–9, arXiv:2002.07579
Schmidt V, Luccioni AS, Teng M, et al (2021) Climategan: Raising climate change awareness by generating images of floods. arXiv preprint abs/2110.02871:1–27. arXiv:1905.03709
Schroeder W, Csiszar I, Morisette J (2008) Quantifying the impact of cloud obscuration on remote sensing of active fires in the Brazilian amazon. Remote Sens Environ 112(2):456–470. https://doi.org/10.1016/j.rse.2007.05.004
Sen S, Kainkaryam S, Ong C, et al (2020) Saltseg: A ß-variational autoencoder constrained encoder-decoder architecture for accurate geologic interpretation. pp 2493–2497, https://doi.org/10.1190/segam2019-3216875.1
Senogles A, Olsen MJ, Leshchinsky B (2023) Ladi: landslide displacement interpolation through a spatial-temporal Kalman filter. Comput Geosci 180:105451. https://doi.org/10.1016/j.cageo.2023.105451
Shao P, Feng J, Lu J et al (2024) Data-driven and knowledge-guided denoising diffusion model for flood forecasting. Expert Syst Appl 244:122908. https://doi.org/10.1016/j.eswa.2023.122908
Shen C, Appling AP, Gentine P et al (2023) Differentiable modelling to unify machine learning and physical models for geosciences. Nat Rev Earth Environ 4:552–567. https://doi.org/10.1038/s43017-023-00450-9
Siahkoohi A, Kumar R, Herrmann F (2018) Seismic data reconstruction with generative adversarial networks. pp 1–5, https://doi.org/10.3997/2214-4609.201801393
Sinha S, Giffard-Roisin S, Karbou F, et al (2020) Variational autoencoder anomaly-detection of avalanche deposits in satellite SAR imagery. pp 113–119, https://doi.org/10.1145/3429309.3429326
Skinner C (2020) Flash flood!: a serious geogames activity combining science festivals, video games, and virtual reality with research data for communicating flood risk and geomorphology. Geosci Commun 3(1):1–17. https://doi.org/10.5194/gc-3-1-2020
Song S, Mukerji T, Hou J (2022) Bridging the gap between geophysics and geology with generative adversarial networks. IEEE Trans Geosci Remote Sens 60:1–12. https://doi.org/10.1109/TGRS.2021.3066975
Sonnewald M, Lguensat R, Jones D et al (2021) Bridging observations, theory and numerical simulation of the ocean using machine learning. Environ Res Lett 16(7):1–36. https://doi.org/10.1088/1748-9326/ac0eb0
Squarzoni C, Delacourt C, Allemand P (2003) Nine years of spatial and temporal evolution of the la Valette landslide observed by SAR interferometry. Eng Geol 68(1–2):53–66. https://doi.org/10.1016/S0013-7952(02)00198-9
Stengel K, Glaws A, Hettinger D et al (2020) Adversarial super-resolution of climatological wind and solar data. Proc Natl Acad Sci USA 117(29):16805–16815. https://doi.org/10.1073/pnas.1918964117
Steptoe H, Jones S, Fox H (2018) Correlations between extreme atmospheric hazards and global teleconnections: implications for multihazard resilience. Rev Geophys 56(1):50–78. https://doi.org/10.1002/2017RG000567
Sun A (2018) Discovering state-parameter mappings in subsurface models using generative adversarial networks. Geophys Res Lett 45(20):11137–11146. https://doi.org/10.1029/2018GL080404
Sun Q, Miao C, Duan Q et al (2018) A review of global precipitation data sets: data sources, estimation, and intercomparisons. Rev Geophys 56(1):79–107. https://doi.org/10.1002/2017RG000574
Szwarcman D, Guevara J, Macedo MMG et al (2024) Quantizing reconstruction losses for improving weather data synthesis. Sci Rep 14:3396. https://doi.org/10.1038/s41598-024-52773-2
Tallini M, Spadi M, Cosentino D et al (2019) High-resolution seismic reflection exploration for evaluating the seismic hazard in a Plio-quaternary intermontane basin (l’aquila downtown, central Italy). Quat Int 532:34–47. https://doi.org/10.1016/j.quaint.2019.09.016
Tan R (2008) Visibility in bad weather from a single image. pp 1–7, https://doi.org/10.1109/CVPR.2008.4587643
Tanyaş H, van Westen C, Allstadt K et al (2017) Presentation and analysis of a worldwide database of earthquake-induced landslide inventories. J Geophys Res: Earth Surf 122(10):1991–2015. https://doi.org/10.1002/2017JF004236
Tanyas H, Kirschbaum D, Lombardo L (2021) Capturing the footprints of ground motion in the spatial distribution of rainfall-induced landslides. Bull Eng Geol Environ 80:4323–4345. https://doi.org/10.1007/s10064-021-02238-x
Tashiro Y, Song J, Song Y, et al (2021) Csdi: Conditional score-based diffusion models for probabilistic time series imputation. In: Ranzato M, Beygelzimer A, Dauphin Y, et al (eds) Advances in Neural Information Processing Systems, vol 34. Curran Associates, Inc., pp 24804–24816, https://proceedings.neurips.cc/paper_files/paper/2021/file/cfe8504bda37b575c70ee1a8276f3486-Paper.pdf
Titov V, González F, Bernard E et al (2005) Real-time tsunami forecasting: challenges and solutions. Nat Hazards. https://doi.org/10.1007/1-4020-3607-8_3
Travelletti J, Sailhac P, Malet JP et al (2012) Hydrological response of weathered clay-shale slopes: water infiltration monitoring with time-lapse electrical resistivity tomography. Hydrol Processes 26(14):2106–2119. https://doi.org/10.1002/hyp.7983
Troin M, Arsenault R, Wood A et al (2021) Generating ensemble streamflow forecasts: a review of methods and approaches over the past 40 years. Water Resour Res 57(7):1–48. https://doi.org/10.1029/2020WR028392
Tsai V, Hirth G (2020) Elastic impact consequences for high-frequency earthquake ground motion. Geophys Res Lett 47(5):1–8. https://doi.org/10.1029/2019GL086302
Tsai WP, Feng D, Pan M et al (2021) From calibration to parameter learning: harnessing the scaling effects of big data in geoscientific modeling. Nat Commun. https://doi.org/10.1038/s41467-021-26107-z
Vaghefi SA, Stammbach D, Muccione V et al (2023) Chatclimate: grounding conversational AI in climate science. Commun Earth Environ 4:1–13. https://doi.org/10.1038/s43247-023-01084-x
Vandal T, Kodra E, Ganguly S, et al (2018) Generating high resolution climate change projections through single image super-resolution: An abridged version. pp 5389–5393, https://doi.org/10.24963/ijcai.2018/759
Vosper E, Watson P, Harris L et al (2023) Deep learning for downscaling tropical cyclone rainfall to hazard-relevant spatial scales. J Geophys Res Atmos. https://doi.org/10.1029/2022jd038163
Wander HL, Farruggia MJ, Fuente SL et al (2024) Using knowledge-guided machine learning to assess patterns of areal change in waterbodies across the contiguous united states. Environ Sci Technol 58:5003–5013. https://doi.org/10.1021/acs.est.3c05784
Wang C, Tang G, Gentine P (2021) Precipgan: merging microwave and infrared data for satellite precipitation estimation using generative adversarial network. Geophys Res Lett. https://doi.org/10.1029/2020gl092032
Wang C, Wang P, Wang P et al (2021) Using conditional generative adversarial 3-d convolutional neural network for precise radar extrapolation. IEEE J Sel Top Appl Earth Obs Remote Sens 14:5735–5749. https://doi.org/10.1109/JSTARS.2021.3083647
Wang H, Li Y, Dong X (2021) Generative adversarial network for desert seismic data denoising. IEEE Trans Geosci Remote Sens 59(8):7062–7075. https://doi.org/10.1109/TGRS.2020.3030692
Wang J, Liu Z, Foster I et al (2021) Fast and accurate learned multiresolution dynamical downscaling for precipitation. Geosci Model Dev 14(10):6355–6372. https://doi.org/10.5194/gmd-14-6355-2021
Wang S, Chen W, Xie SM et al (2020) Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens 12:207. https://doi.org/10.3390/rs12020207
Wang T, Trugman D, Lin Y (2021) Seismogen: seismic waveform synthesis using GAN with application to seismic data augmentation. J Geophys Res Solid 126(4):1–31. https://doi.org/10.1029/2020JB020077
Wang Y, Herron L, Tiwary P (2022) From data to noise to data for mixing physics across temperatures with generative artificial intelligence. Proc Natl Acad Sci USA. https://doi.org/10.1073/pnas.2203656119
Wang Z, She Q, Ward T (2021) Generative adversarial networks in computer vision: a survey and taxonomy. ACM Comput Surv 54(2):1–41. https://doi.org/10.1145/3439723
Watson CD, Wang C, Lynar TM, et al (2020) Investigating two super-resolution methods for downscaling precipitation: Esrgan and car. arXiv preprint abs/2012.01233:1–5. arXiv:2012.01233
Wei Q, Li X, Song M (2021) De-aliased seismic data interpolation using conditional Wasserstein generative adversarial networks. Comput Geosci 154:1–13. https://doi.org/10.1016/j.cageo.2021.104801
Wei Q, Li X, Song M (2021) Reconstruction of irregular missing seismic data using conditional generative adversarial networks. Geophysics 86:471–488. https://doi.org/10.1190/geo2020-0644.1
Wen X, Pan Z, Hu Y et al (2021) Generative adversarial learning in YUV color space for thin cloud removal on satellite imagery. Remote Sens 13(6):1–22. https://doi.org/10.3390/rs13061079
West H, Quinn N, Horswell M (2019) Remote sensing for drought monitoring and impact assessment: progress, past challenges and future opportunities. Remote Sens Environ 232:1–14. https://doi.org/10.1016/j.rse.2019.111291
van Westen C, Castellanos E, Kuriakose S (2008) Spatial data for landslide susceptibility, hazard, and vulnerability assessment: an overview. Eng Geol 102(3–4):112–131. https://doi.org/10.1016/j.enggeo.2008.03.010
White B, Singh A, Albert A (2019) Downscaling numerical weather models with gans. pp 1–4
Whiteley J, Chambers J, Uhlemann S et al (2019) Geophysical monitoring of moisture-induced landslides: a review. Rev Geophys 57(1):106–145. https://doi.org/10.1029/2018RG000603
Wu B, Meng D, Zhao H (2021) Semi-supervised learning for seismic impedance inversion using generative adversarial networks. Remote Sens 13(5):1–17. https://doi.org/10.3390/rs13050909
Xie H, Wu L, Xie W et al (2021) Improving ECMWF short-term intensive rainfall forecasts using generative adversarial nets and deep belief networks. Atmos Res. https://doi.org/10.1016/j.atmosres.2020.105281
Xu L, Chen N, Chen Z et al (2021) Spatiotemporal forecasting in earth system science: methods, uncertainties, predictability and future directions. Earth Sci Res 222:103828–103828. https://doi.org/10.1016/j.earscirev.2021.103828
Xu X, Zhong T, Zhou F et al (2024) Learning spatiotemporal manifold representation for probabilistic land deformation prediction. IEEE Trans Cybern 54(1):572–585. https://doi.org/10.1109/TCYB.2023.3291049
Xu Y, Yang H, Cheng M, et al (2019) Cyclone intensity estimate with context-aware cyclegan. pp 3417–3421, https://doi.org/10.1109/ICIP.2019.8803598
Yamaguchi A, Cabatuan M (2018) Generative model based frame generation of volcanic flow video. pp 1–5, https://doi.org/10.1109/HNICEM.2017.8269503
Yang F, Ma J (2023) Fwigan: full-waveform inversion via a physics-informed generative adversarial network. J Geophys Res Solid Earth. https://doi.org/10.1029/2022jb025493
Yang L, Zhang Z, Song Y et al (2023) Diffusion models: a comprehensive survey of methods and applications. ACM Comput Surv 56:1–39. https://doi.org/10.1145/3626235
Yang Y, Zhang X, Guan Q et al (2022) Making invisible visible: data-driven seismic inversion with spatio-temporally constrained data augmentation. IEEE Trans Geosci Remote Sens 60:1–13. https://doi.org/10.1109/TGRS.2022.3144636
Yu S, Ma J (2021) Deep learning for geophysics: current and future trends. Rev Geophys 59(3):1–36. https://doi.org/10.1029/2021RG000742
Yu Y, Privette J, Pinheiro A (2005) Analysis of the NPOESS VIIRS land surface temperature algorithm using MODIS data. IEEE Trans Geosci Remote Sens 43(10):2340–2349. https://doi.org/10.1109/TGRS.2005.856114
Yuan J, Liu T, Xia H et al (2023) A novel dense generative net based on satellite remote sensing images for vehicle classification under foggy weather conditions. IEEE Trans Geosci Remote Sens 61:1–10. https://doi.org/10.1109/TGRS.2023.3336546
Yue J, Fang L, Ghamisi P et al (2022) Optical remote sensing image understanding with weak supervision: concepts, methods, and perspectives. IEEE Trans Geosci Remote Sens 10(2):250–269. https://doi.org/10.1109/MGRS.2022.3161377
Zhang C, Yang X, Tang Y et al (2020) Learning to generate radar image sequences using two-stage generative adversarial networks. IEEE Geosci Remote Sens Lett 17(3):401–405. https://doi.org/10.1109/LGRS.2019.2922326
Zhang H, Wang F, Myhill R et al (2019) Slab morphology and deformation beneath IZU-Bonin. Nat Commun 10:1–8. https://doi.org/10.1038/s41467-019-09279-7
Zhang Q, Yuan Q, Zeng C et al (2018) Missing data reconstruction in remote sensing image with a unified spatial-temporal-spectral deep convolutional neural network. IEEE Trans Geosci Remote Sens 56(8):4274–4288. https://doi.org/10.1109/TGRS.2018.2810208
Zhang R, Liu Y, Sun H (2020) Physics-guided convolutional neural network (phycnn) for data-driven seismic response modeling. Eng Struct 215:110704. https://doi.org/10.1016/j.engstruct.2020.110704
Zhao D (2021) Seismic imaging of northwest pacific and east Asia: New insight into volcanism, seismogenesis and geodynamics. Earth Sci Rev 214:1–22. https://doi.org/10.1016/j.earscirev.2021.103507
Zhao M, Olsen P, Chandra R (2023) Seeing through clouds in satellite images. IEEE Trans Geosci Remote Sens 61:1–16. https://doi.org/10.1109/TGRS.2023.3239592
Zheng F, Tao R, Maier H et al (2018) Crowdsourcing methods for data collection in geophysics: state of the art, issues, and future directions. Rev Geophys 56(4):698–740. https://doi.org/10.1029/2018RG000616
Zhong C, Cheng S, Kasoar M et al (2023) Reduced-order digital twin and latent data assimilation for global wildfire prediction. Nat Hazards Earth Syst Sci 23:1755–1768. https://doi.org/10.5194/nhess-23-1755-2023
Zhong Z, Sun A, Wu X (2020) Inversion of time-lapse seismic reservoir monitoring data using cyclegan: a deep learning-based approach for estimating dynamic reservoir property changes. J Geophys Res Solid 125(3):1–23. https://doi.org/10.1029/2019JB018408
Zhou Y, Wang H, Yang R et al (2022) A novel weakly supervised remote sensing landslide semantic segmentation method: combining cam and Cyclegan algorithms. Remote Sens 14:3650. https://doi.org/10.3390/rs14153650
Acknowledgements
This research was jointly supported by Postdoctoral Fellowship Program of CPSF (Grant No. GZB20230685) and the National Science Foundation of China (Grant Nos. 42277161 and 42230709).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ma, Z., Mei, G. & Xu, N. Generative deep learning for data generation in natural hazard analysis: motivations, advances, challenges, and opportunities. Artif Intell Rev 57, 160 (2024). https://doi.org/10.1007/s10462-024-10764-9
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-024-10764-9