
Abstract
In many circumstances, decisions are based on subjective experience. However, some views can be vague, meaning that policymakers do not know exactly how they should express their opinions. Therefore, it is necessary for researchers to provide scientific decision frameworks, among which the multi-criteria decision making (MCDM) method in the linguistic environment is gradually favored by scholars. A large body of literature reports relevant approaches with regard to linguistic term sets, but existing approaches are insufficient to express the subjective thoughts of policymakers in a complex and uncertain environment. In this paper, we address this problem by introducing the concept of evidential linguistic term set (ELTS). ELTS generalizes many other uncertainty representations under linguistic context, such as fuzzy sets, probabilities, or possibility distributions. Measures on ELTS, such as uncertainty measure, dissimilarity measure and expectation function, provide general frameworks to handle uncertain information. Modeling and reasoning of information expressed by ELTSs are realized by the proposed aggregation operators. Subsequently, this paper presents a novel MCDM approach called evidential linguistic ELECTRE method, and applies it to the case of selection of emergency shelter sites. The findings demonstrate the effectiveness of the proposed method for MCDM problems under linguistic context and highlight the significance of the developed ELTS.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
In recent years, the rapid development of global urbanization and the economy has led to gradually increasing losses caused by natural disasters (Kılcı et al. 2015; Fei and Wang 2022). This is particularly true in densely populated and disaster-prone areas, where natural disasters deplete and destroy the material resources essential for human survival, thereby hindering societal development Şenik and Uzun (2021). A series of emergencies have highlighted that urban public spaces, especially crowd gathering places, are fraught with various risks and significant hidden dangers. In the event of an accident, if the safe evacuation of people cannot be guaranteed, the consequences can be even more catastrophic Wei et al. (2020). Therefore, in the context of disaster prevention and mitigation, ensuring safe evacuation is of paramount importance, with emergency shelters playing a crucial role Hosseini et al. (2022); Liu (2022). An emergency shelter is a pre-designated site equipped with specific functional facilities, enabling people to avoid direct or indirect harm from disasters and ensuring their basic needs are met for a period post-disaster Aydin and Cetinkale (2023). For effective disaster risk reduction, emergency shelters must possess certain characteristics, such as safety, accessibility, and effectiveness. This underscores the significance of their site selection, a key aspect of emergency management Zou et al. (2023).
As an important facility for post-disaster evacuation and resettlement of people, the location of emergency shelters is related to the efficiency of disaster relief and the level of evacuation services. Numerous scholars have extensively researched this area. Commonly used methods are single-objective model Kocatepe et al. (2018); Horner et al. (2018), multiobjective model Xu et al. (2018); Zhao et al. (2017) and hierarchical model Li et al. (2017). The literature focuses on the study of emergency shelter siting models throughout the analysis of goals, constraints, hazard types, and solutions Ma et al. (2019). Studies on location problems have offered us enlightenment. For instance, Mohammadi and his colleagues Arabahmadi et al. (2023) proposed strategies for optimizing facility locations under uncertain circumstances, while Rabbani Hirbod et al. (2023) explored the multi-treatment location arc routing problem with vehicle capacity constraints and considerations for waste separation. Furthermore, they established a hybrid integer nonlinear programming model for routing and location selection Moghaddasi et al. (2023). These contributions have provided valuable insights and inspired our approach to the location problem addressed in this study.
Another significant perspective involves studying emergency shelter site selection using multi-criteria decision-making (MCDM) methods. Liu Liu (2022) proposed a comprehensive framework to guide the site selection of post-earthquake medical service points, using the TOPSIS method to evaluate the suitability of alternative sites and rank them according to the evaluation results. Failures are given precedence through the application of Multi-Objective Optimization using Ratio Analysis, which is rooted in the Z-number theory outlined in Ghoushchi et al. (2021). This serves as a valuable reference for addressing the site selection issues discussed in this article. The literature Mishra et al. (2023) introduced a decision-making framework designed to assess sustainable wastewater treatment technology in an environment characterized by interval-valued intuitionistic fuzzy sets. This innovative approach has provided valuable insights and served as a source of inspiration for the present study. In Junian and Azizifar’s study Junian and Azizifar (2018), AHP was used as a MCDM method, considering principles such as vulnerable areas, access roads, fire centers, densely populated areas, and medical centers to determine the optimal site of temporary shelters in disaster-prone areas in northern Iran. Geng et al. Geng et al. (2021) employed Fuzzy-VIKOR to evaluate the performance of emergency shelters, determined the most ideal site of the shelter through multiple criteria. Taking Chengdu, Sichuan Province, China as an example, they provided a series of reliable solutions for the government. Song et al. Song et al. (2019) provided a rough QUALIFLEX method that combines the advantages of the QUALIFLEX method in manipulating multiple evaluation criteria with heterogeneity and the advantages of interval-rough numbers in fuzzy environments to solve the location problem of emergency shelters.
From the above analysis, it can be seen that the current emergency shelter site selection based on the MCDM method often involves a combination of specific technologies, such as AHP or TOPSIS, while overlooking the expression of evaluation information. To model the objective world from a mathematical point of view, a multitude of methodologies that conform to human cognition have been proposed. Fuzzy set theory Zadeh (1965) was put forward by Zadeh in 1965. It is an effective methodology that can quantitatively study and deal with inaccuracy, inconsonant and incomplete data and knowledge. As extensions, intuitionistic fuzzy sets Atanassov (1986); Hezam et al. (2023), Pythagorean fuzzy sets Yager (2013); Rani et al. (2023), and their related interval methods Pan et al. (2023); Zeng and Xiao (2023) were subsequently developed. However, these theories only work in the context of finite sets, considering a scenario in which decision makers are forced to choose between multiple possible values to accommodate existing approaches, often with unsatisfactory results. Hesitant fuzzy set was proposed by Torra Torra (2010) to model thus situation using multisets. However, it seems that humans are more accustomed to employing linguistic sets to give evaluations than to provide quantitative information. Inspired by this, Rodriguez et al. Rodriguez et al. (2011) extended HFS to linguistic contexts, which is widely concerned because it allows decision makers (DMs) to show the opinions in multiple linguistic terms. For example, the quietness of an engine is evaluated as “very poor” and “poor” and the safety of a car is described as “at least not low”. However, the hesitant fuzzy linguistic term set assigns equal weight or importance to each linguistic term, which is not in accordance with the reality Liu et al. (2023); Fei and Wang (2022). Consequently, probabilistic linguistic term set (PLTS) Pang et al. (2016) was developed to express the importance degrees of linguistic terms by probability distribution in a more general form. Going back to the example above, when a decision maker is \(50\%\) sure that the quietness is “bad” and \(50\%\) sure that it is “good”, his evaluation can be expressed as \(\{bad(0.5),good(0.5)\}\) by the PLTS. In addition, one hundred buyers expressed their feelings about the comfortable degree of the vehicle, of which 50 consider it is “low”, 30 state it is “fair”, and 20 express it is “high”. This information could be expressed as \(\{low(0.5)\),fair(0.3),\(high(0.2)\}\) with PLTS.
The PLTS, which has received extensive attention in the field of MCDM Liu et al. (2023); Li et al. (2023, 2022), is flexible enough to represent information containing all possible values with an importance weight. However, information from the real world is affected by plenty of sources of uncertainty. Quite a few cases are found where PLTS cannot be used, such as
-
(1)
The information is incomplete. Taking the evaluation of vehicle comfort as an example, suppose 40 out of 100 consumers consider it is “low”, 30 state it is “fair”, and 20 express it is “high”. PLTS fails in this case because the sum of all possibilities is less than 1, i.e., \(0.4+0.3+0.2<1\), where the information is identified to be incomplete. A suitable rule or mechanism is required to addresses the problem robustly.
-
(2)
When decision makers vacillate between two or more possible values. Continuing with the car comfort evaluation example, if 50 consumers state it is “low”, 40 express it is “fair”, and others hesitate between “fair” and “high” and cannot make a decision. If decision makers are forced to choose one by a hard assignment, unsatisfactory results might be obtained. Again, a new solution is required, and
-
(3)
A complete multi-criteria decision making problem involves numerous aspects, such as the expression of evaluation information [would be solved in 1) & 2)], calculation of criteria weight, aggregation of multiple opinions, ranking among alternatives, and so forth. The appropriate aggregation operator, comparison method, and several measures, such as uncertain measure and dissimilarity measure, are needed in applications.
Accordingly, the concept of evidential linguistic term set is developed, in this study, which would be capable of dealing with various types of uncertainties. An indispensable part of an outstanding MCDM approach is the ranking technique Wu et al. (2018), especially in the problem of emergency shelter site selection. The original outranking method called ELECTRE I was developed by Roy Roy (1968), followed by other methods of the ELECTRE family Roy (1978); Paelinck (1978); Roy and Hugonnard (1982). A distinctive aspect of ELECTRE techniques is their consideration of ordinal scales, which are transformed into abstract ranges while preserving their original verbal significance Jagtap and Karande (2023a). Additionally, ELECTRE methods excel at incorporating preference and indifference relations when modeling incomplete information, an advantage not found in other MCDM methodologies Jagtap and Karande (2023b); Jagtap et al. (2022). Nevertheless, despite the demonstrated utility of outranking methods in handling linguistic terms, there has been limited research exploring their application in this context Jagtap and Karande (2022).
This study focuses on employing outranking methods to address MCDM issues (primarily for emergency shelter site selection) in the evidential linguistic context. The main contributions are summarized below.
-
(1)
We define a new linguistic term set (LTS) that extends the traditional LTS to the power set. We assign unit degree of belief to elements in the new LTS to express the subjective opinion of the DMs. The proposed LTS and its belief distribution constitute the novel concept of evidential linguistic term set (ELTS). ELTS is a generalized uncertain LTS, which degrades to the PLTS when all degree of belief is assigned to single sets, and further, to the hesitant fuzzy LTS if the probability values are equal.
-
(2)
In conjunction with ELTS, some measures are developed, including uncertainty measure, dissimilarity measure and expectation function. Some properties related to them have been studied and proved. The aggregation operators between ELTSs are put forward, further, the weighted aggregation operators are developed considering the reliability of ELTSs. The reliability of ELTS is measured from two perspectives, i.e. inner and outer, where inner reliability measures the certainty of ELTSs and outer reliability measures the compatibility between ELTSs.
-
(3)
In this paper, a new approach to MCDM is introduced, which integrates ELTSs with the ELECTRE methodology. When dealing with decisions amidst uncertainty, the suggested technique not only innovates in how information is conveyed but also leverages the ELECTRE method’s strength in assessing the dominance relationships among various options.
-
(4)
The proposed method of evidence language MCDM is applied to the problem of emergency shelter location selection, the application of the proposed method is demonstrated, and the effectiveness of the method is demonstrated through sensitivity analysis and comparative experiments.
We arrange the rest of this paper in the following way: In Sect. 2, we introduce PLTS, the theory of belief function, and the concept of evidential linguistic term set. In Sect. 3, we give some measures of ELTSs, including uncertainty measure and dissimilarity measure. In Sect. 4, we present several aggregation operators of ELTSs. In Sect. 5, the expectation function of ELTSs is defined to enhance the computational power. In Sect. 6, we propose an MCDM method based on evidential linguistic term sets. In Sect. 7, a case study is conducted about selecting an emergency shelter site. Finally, in Sect. 8, some conclusions and future research focuses are given.
2 Evidential linguistic term set
We first review the basic concepts of PLTS Pang et al. (2016). We then provide an overview of belief function theory (BFT) Dempster (1967); Shafer (1976). Accordingly, the concept of evidential linguistic term set is presented.
2.1 Probabilistic linguistic term set
The basic definition of probabilistic linguistic term set is described below.
Definition 1
Pang et al. (2016) Let \(S=\{s_\alpha \vert \alpha =0,1,...,\tau \}\) be a linguistic term set, a PLTS is formulated as
in which \(L^{(k)}(p^{(k)})\) is the linguistic term \(L^{(k)}\) with the probability \(p^{(k)}\), and \(\#L(p)\) is the number of linguistic terms in L(p).
The theory of PLTS is highly useful in addressing MCDM issues, allowing DMs to express their opinions using linguistic terms. However, it does have some shortcomings in information expression. For example, while it permits the existence of partial ignorance, it upholds certain probabilistic properties at the expense of normalization. Additionally, it is only effective when probabilities are assigned to a single set of linguistic terms, but it becomes inadequate when experts express hesitation over multiple sets of linguistic terms.
2.2 Theory of belief function
The theory of belief function gives a remarkable framework for addressing issues involving uncertainty and/or ambiguity Shafer (1976); Dempster (1967). As an effective tool for uncertainty modeling, BFT has attracted the attention of scholars in divers fields including information fusion Zhou and Deng (2023), multicriteria decision analysis Qi et al. (2023), etc. Recently, some scholars combined BFT with linguistic terms Liu et al. (2023, 2023); Xue et al. (2024), which makes significant contributions to coping with MCDM issues under uncertain linguistic environment. The basics of BFT are introduced briefly as follows.
The frame of discernment (FoD) in BFT is defined as a finite discrete set \(\Theta = \{\theta _1,\theta _2,\ldots ,\theta _n\}\), which includes n mutually exclusive and exhaustive hypotheses. All the propositions of interest are contained in the power set of \(\Theta \), expressed as \(2^{\Theta } = \{\phi , \theta _1,\theta _2,\ldots ,\theta _n,\theta _1\cup \theta _2,\theta _1\cup \theta _3,\ldots ,\Theta \}\). The mapping \(m: 2^\Theta \rightarrow [0,1]\) is defined as a belief function or basic probability assignment for \(\Theta \) if it satisfies \(m(\phi ) = 0\), \(\sum _{A\in 2^\Theta }m(A)=1\). For \(A\subseteq \Theta \), its belief function is defined as \(Bel(A) = \sum _{B\subseteq A}m(B)\), and its plausibility function is defined as \(Pl(A) = \sum _{B\cap A\ne \phi }m(B)\). From these concepts we can conclude that, for \(A\subseteq \Theta \), its degree of support is represented by m(A), the degree of support of its all subsets is measured by Bel(A), and the degree to which A is credible is identified by Pl(A).
Another significant application of BFT is to obtain more reliable decision basis through information fusion. This process can be realized based on Dempster’s rule Dempster (1967). Two belief functions \(m_1\) and \(m_2\) can be combined as \((m_1\oplus m_2)(A)=\frac{1}{1-\kappa }\sum _{B\cap C=A}m_1(B)m_2(C)\), \(\forall A \subseteq \Theta \), in which \(\kappa = \sum _{B\cap C=\phi }m_1(B)m_2(C)\) is considered the degree of conflict between \(m_1\) and \(m_2\).
2.3 The concept of evidential linguistic term set
This study deals with limitations of PLTS listed above based upon the major ideological that derives from belief functions Shafer (1976). The philosophical contribution of BFT lies in the proposal of a multivalued mapping from one space S to another space \(2^S\) Dempster (1967), which allows the extension of the basic event space in probability theory to its power set. This points of view is significant for applying the concept of multivalued mapping to linguistic context, where the basic event space in probability theory is replaced by linguistic term sets (shown in Fig. 1), and propositions are of the form \(L^{(k)}(e^{(k)})\) meaning that the mass of belief of \(L^{(k)}\) is \(e^{(k)}\).

Illustration of the mapping from linguistic term sets S to \(2^S\)
Consequently, the concept of evidential linguistic term set (ELTS) can be introduced by the following definition:
Definition 2
Fei and Wang (2022); Fei and Feng (2021) Let \(S =\{s_\alpha \vert \alpha =-\tau ,...,-1,0,1,...,\tau \}\) be a LTS, an ELTS is represented by the form
where \(L^{(k)}(e^{(k)})\) is the linguistic term \(L^{(k)}\) associated with the mass of belief \(e^{(k)}\), and \(\#2^{S}\) is the number of elements in \(2^{S}\). Note that \(e^{(k)} = 0\) if \(L^{(k)} = \phi \). For convenience, in this paper, L(e) is called the evidential linguistic element (ELE).
3 Some measures of the ELTSs
In this section, we propose two measures for ELTSs, which are the uncertainty measure and the dissimilarity measure.
3.1 Uncertainty measure of ELEs
No matter the type of decision environment, introducing some level of uncertainty in the process of information expression is inevitable. Effectively capturing and quantifying this uncertainty is crucial to enhancing the reliability of decision making. We define an entropy function for ELEs to measure their uncertainty.
Definition 3
Let L(e) be an ELE on LTS S, the entropy function of L(e) is defined as:
where \(Pl\_P_{L(e)}\) indicates plausibility transform given by the following equations
where \(K = \sum _{L^{(A)}\subseteq S}Pl_{L(e)}(L^{(A)})\) and \(Pl_{L(e)}\) is the plausibility function of L(e) defined as:
The properties and proofs of the entropy of ELTS can be found in Appendix B.
3.2 Dissimilarity measure between ELEs
Dissimilarity or distance assessment is a crucial issue in BFT, therefore, the difference in information content between ELEs should be measured for further study.
Definition 4
Let \(L_1(e)\) and \(L_2(e)\) be two ELEs on LTS S, the dissimilarity between them can be calculated as:
where \(\overrightarrow{L_1(e)}=e_1^{(k)}\) and \(\overrightarrow{L_2(e)}=e_2^{(k)}\) \((k = 1,2,..., \#2^{S})\) are the vector representations of ELEs \(L_1(e)\) and \(L_2(e)\), and \({\underline{\underline{D}}}\) is a \(2^S \times 2^S\)-dimensional matrix with elements
where \(L^{(A)}\), \(L^{(B)}\) \(\in \) \(2^S\).
The properties and proofs of dissimilarity measure can be found in Appendix C.
4 Aggregation operators of ELTSs
To maximize the advantages of ELTSs in decision-making, a novel aggregation operator for ELTSs is developed firstly, followed by a weighted aggregation operator considering the importance of ELTSs.
4.1 Aggregation operators
In this section, a novel aggregation operator for ELTSs is developed by utilizing the Dempster’s rule, a couple of whose prominent characteristic are provided.
Definition 5
Let \(L_1(e)\) and \(L_2(e)\) be two ELEs on LTS S, the aggregation operator denoted by L(e) = \(L_1(e) \oplus L_2(e)\) is defined as:
with
where \(L^{(A)}\), \(L_1^{(B)}\), and \(L_2^{(C)}\) \(\in \) \(2^S\). Note that \(e^{(k)} = 0\) if \(L^{(k)} = \phi \).
Definition 6
Let \(L_1(e)\), \(L_2(e)\),..., \(L_n(e)\) be n ELEs on LTS S, the aggregation operator denoted by L(e) = \(L_1(e) \oplus L_2(e) \oplus \cdots \oplus L_n(e)\) is defined as:
with
where \(L^{(A)}\), \(L_1^{(A_i)}\), \(L_2^{(A_j)}\), and \(L_n^{(A_k)}\) \(\in \) \(2^S\). Note that \(e^{(k)} = 0\) if \(L^{(k)} = \phi \).
Based on literature Shafer (1976), it is easy to obtain the two properties of the proposed aggregation operator, namely, the commutative law and the associative law, which are expressed as \(L_1(e)\oplus L_2(e) = L_2(e)\oplus L_1(e)\) and \((L_1(e)\oplus L_2(e))\oplus L_3(e) = L_1(e)\oplus (L_2(e)\oplus L_3(e))\). In addition, specifically, when ELTSs degenerates to PLTSs, according to Defs. 5 and 6, we can get the following definitions.
Definition 7
If two given ELEs \(L_1(e)\) and \(L_2(e)\) on LTS S degrade to PLEs \(L_1(p)\) and \(L_2(p)\), the aggregation operator denoted by L(p) = \(L_1(p) \oplus L_2(p)\) is defined as:
where \(L_1^{(B)}\) and \(L_2^{(C)}\) \(\in \) S.
Definition 8
If n given ELEs \(L_1(e)\), \(L_2(e)\),..., \(L_n(e)\) on LTS S degrade to PLEs \(L_1(p)\), \(L_2(p)\),..., \(L_n(p)\), the aggregation operator denoted by L(p) = \(L_1(p) \oplus L_2(p) \oplus \cdots \oplus L_n(p)\) is defined as:
where \(L_1^{(A_i)}\), \(L_2^{(A_j)}\), and \(L_n^{(A_k)}\) \(\in \) S.
4.2 Weighted aggregation operators considering reliability
Due to the limited nature of cognition and experience, subjective judgments derived from human beings are often inaccurate, incomplete and unreliable. In what follows, we first define the reliability measure of ELEs and propose the weighted aggregation operators based on it.
4.2.1 The reliability of ELEs
Two aspects are taken into account in the definition of reliability of ELEs, i.e., certainty degree and compatibility that are called inner and outer reliability, respectively, in this paper.
In our previous related studies Xia et al. (2018); Fei and Wang (2022), the evidential reliability indicator (ERI) were defined to measure the reliability of the belief functions. In this work, based on which, the reliability of ELEs will be introduced. The inner reliability of ELEs will be proposed firstly based on the defined entropy function of ELEs in Sect. 3.1 as follows.
Definition 9
(Positive ideal ELE) Let \(S =\{s_\alpha \vert \alpha =-\tau ,...,-1,0,1,...,\tau \}\) be a LTS, the positive ideal ELE \(L^*(e)\) is one of ELEs on S that satisfies:
where \(H(\cdot )\) is the entropy function of ELEs, and min means \(L^*(e)\) is the ELE with minimum entropy on S. Following, the definition of negative ideal ELE \(L_*(e)\) can be given below.
Definition 10
(Negative ideal ELE) Suppose a LTS \(S =\{s_\alpha \vert \alpha =-\tau ,...,-1,0,1,...,\tau \}\), the negative ideal ELE \(L_*(e)\) is one of ELEs on S that satisfies:
where max denotes \(L_*(e)\) is one of ELEs on S with the maximum entropy.
Motivated by TOPSIS method Hwang and Yoon (1981), the inner reliability of ELEs, i.e., closeness index, is given by the following definition.
Definition 11
Suppose an ELE L(e) on LTS S, the inner reliability of ELE L(e) can be calculated as
where \(D^-(L(e))\) (\(D^+(L(e))\)) is the dissimilarity measure between L(e) and the negative ideal ELE \(L_*(e)\) (positive ideal ELE \(L^*(e)\)), which is defined in Sect. 3.2. It is obvious that for a given ELE, the smaller the similarity \(D^+(L(e))\), the closer it is to \(L^*(e)\), which means the higher the reliability. And the smaller the dissimilarity \(D^-(L(e))\), the closer it is to \(L_*(e)\), which means the lower the reliability.
Note that \(\mathcal {I}(L(e)) = 0\) iff \(L(e) = L_*(e)\), and \(\mathcal {I}(L(e)) = 1\) iff \(L(e) = L^*(e)\), so we have \(\mathcal {I}(\cdot ) \in [0,1]\) for all ELEs.
The inner reliability of ELEs has been defined above, then an interesting issue should be discussed, that is, how to get the positive and negative ideal ELEs. By Def. 9, the positive ideal ELE on LTS S is the one with minimum entropy. Based on Def. 3, the entropy of ELE L(e) would be the minimum when it satisfies \(L(e)=\{s_\varpi (1)\}\), where \(s_\varpi \in S\). Now we are interested in how to determine the special \(s_\varpi \). The following definition is presented to obtain \(s_\varpi \) that allows L(e) to achieve the minimum entropy.
Definition 12
Let L(e) be an ELE on LTS S, the single element \(s_\varpi \) that generates the positive ideal ELE \(L^*(e)\) is defined as
where \(ELE\_P(\cdot )\) is the pignistic probability transform (PPT) function defined in Def. 16. Note that if there are two or multiple elements in S with the same pignistic probability, then \(s_\varpi \) could be any of them.
According to Def. 10, the negative ideal ELE on LTS S is the one with maximum entropy. Based on the maximum entropy property proved in Def. 3, for ELE L(e) on S, the maximum entropy could be achieved when all the mass of belief is assigned to LTS S, i.e., \(L(e)=\{S(1)\}\), so the negative ideal ELE can be determined as \(L_*(e) = \{S(1)\}\).
With regard to a given ELE, the outer reliability of it takes into account its compatibility with other ELEs. In other words, the outer reliability of an ELE is denoted by the conflict between distinct ELEs to be aggregated, which is formalized as follows.
Definition 13
Let \(L_1(e)\), \(L_2(e)\),..., \(L_n(e)\) be n ELEs on LTS S, the support degree of ELE \(L_i(e)\) can be calculated as
where \(Sim(L_i(e),L_j(e)) = 1- d(L_i(e),L_j(e))\), and d is the dissimilarity measure defined in Sec. 3.2. Following, the credibility degree of ELE \(L_i(e)\) can be obtained as
based on which, the outer reliability of ELE \(L_i(e)\) can be calculated as
Consequently, the comprehensive reliability of ELEs is defined by using the following equation
Definition 14
Let \(L_1(e)\), \(L_2(e)\),..., \(L_n(e)\) be n ELEs on LTS S, the reliability of ELE \(L_i(e)\) can be obtained as
in which \(\beta \) is taken as a tuning parameter.
4.2.2 Weighted aggregation operation
In the last section, we developed the definition of ELE’s reliability from two aspects: the uncertainty of ELE itself and the compatibility among ELEs. The obtained reliability index can be regarded as the weight of ELE, based on which the weighted aggregation operation is defined as follows.
Definition 15
Let \(L_1(e)\), \(L_2(e)\),..., \(L_n(e)\) be n ELEs on LTS S, the weighted aggregation operator considering reliability can be defined as:
where \(\oplus \) is the aggregation operation defined in Def. 6, and \(\widetilde{L}(e)\) is the arithmetic mean value of \(L_1(e)\), \(L_2(e)\),..., \(L_n(e)\) that can be calculated as:
where \(w_l\) is the weight of \(L_l(e)\), which can be calculated by \(w_l = \mathcal {R}(L_l(e))/\sum _{l=1}^n\mathcal {R}(L_l(e))\).
5 Expectation function of ELTSs
In the context of linguistic terms, it is important enhance the computational power and scope among ELTSs Wu et al. (2018), so we define the expected function of ELTSs, which can map the ELEs to the unit interval [0, 1].
Definition 16
Let \(L(e) = \{L^{(k)},(e^{(k)})\vert L^{(k)} \in 2^{S}, k = 1,2,..., \#2^{S}\}\) be an ELE on LTS \(S =\{s_\alpha \vert \alpha = -\tau ,...,-1,0,1,...,\tau \}\), the PPT function of L(e) is given as
where \(\vert L^{(A)}\vert \) is the cardinality of element \(L^{(A)}\).
Consequently, the expected value function of L(e) is defined as
where \(\alpha ^{(l)}\) means the subscript of \(L^{(l)}\). For instance, \(\alpha ^{(1)} = -\tau \) corresponds to the linguistic term \(L^{(1)} = s_{-\tau }\).
The relevant remark can be found in Remark 2 of Appendix E. A few properties can be found in Appendix D.
The presented expectation function could be employed as a scoring function to compare different ELEs. With regard to two ELEs \(L_1(e)\) and \(L_2(e)\), if \(E(L_1(e)) > E(L_2(e))\), then \(L_1(e)\) is superior to \(L_2(e)\), denoted by \(L_1(e) \succ L_2(e)\); if \(E(L_1(e)) < E(L_2(e))\), then \(L_1(e)\) is inferior to \(L_2(e)\), denoted by \(L_1(e) \prec L_2(e)\); However, if \(E(L_1(e)) = E(L_2(e))\), then in which case, they cannot be distinguished. To address this issue, the deviation degree of an ELE is defined as follows.
Definition 17
Let \(L(e) = \{L^{(k)},(e^{(k)})\vert L^{(k)} \in 2^{S}, k = 1,2,..., \#2^{S}\}\) be an ELE on LTS S, the variance value function of L(e) can be calculated as
where \(\alpha ^{(l)}\) represents the subscript of \(L^{(l)}\), \(E(\cdot )\) is L(e)’s expectation function. \(ELE\_P(\cdot )\) is the pignistic probability function of L(e).
The relevant remark can be found in Remark 3 of Appendix E.
For two ELEs \(L_1(e)\) and \(L_2(e)\) with \(E(L_1(e)) = E(L_2(e))\), if \(\sigma (L_1(e)) > \sigma (L_2(e))\), then \(L_1(e) \prec L_2(e)\); if \(\sigma (L_1(e)) < \sigma (L_2(e))\), then \(L_1(e) \succ L_2(e)\); and if \(\sigma (L_1(e)) = \sigma (L_2(e))\), then \(L_1(e)\) is identical with \(L_2(e)\), denoted by \(L_1(e) \sim L_2(e)\);
6 An evidential linguistic ELECTRE method
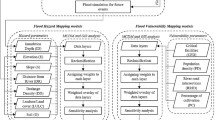
The proposed methodology employs ELTS in conjunction with the ELECTRE method to select the optimal alternative under multiple criteria. Firstly, we describe the MCDM problem in an evidential linguistic context, then put forward the approach to determine the decision matrix, followed by the method to obtain the criteria weight. Finally, we provide the concrete steps of the evidential linguistic ELECTRE method. The flowchart is shown in Fig. 2.

The flowchart of the evidential linguistic ELECTRE method
6.1 Introduction of the evidential linguistic ELECTRE issue
An MCDM issue can be described as containing m alternative \(A=\{a_1,a_2,...,a_m\}\), n criteria \(C=\{c_1,c_2,...,c_n\}\) with the weight vector \(W=(w_1,w_2,...,w_n)^T\), and q experts can be represented as \(\mathcal {E}=\{\epsilon _1,\varepsilon _2,...,\epsilon _q\}\) in a group decision issue. The evaluation of expert \(\epsilon _\kappa \) of alternative \(a_i\) under criterion \(c_j\) is expressed as \(x_{ij}^\kappa \) that could also be denoted as ELE \(L_{ij}^\kappa (e)\) in evidential linguistic environment. Therefore, the evaluation values provided by DMs can be expressed by evidential linguistic decision matrices as \(E^\kappa = (L_{ij}^\kappa (e))_{m\times n}\), \(\{i=1,2,...,m;j=1,2,...,n;\kappa =1,2,...,q\}\). Further, a group evidential linguistic individual decision matrix of DM \(\epsilon _\kappa \) can be determined as
where \(L_{ij}^\kappa (e)=\{L_{ij}^{\kappa (k)}(e_{ij}^{\kappa (k)})\vert L_{ij}^{\kappa (k)}\in 2^S\}\), and S is the specified LTS.
6.2 Determination of the aggregated decision matrix
The evaluation information from expert panel has been prepared. For each alternative, evaluations from diverse DMs should be combined to reflect his overall performance. To achieve it, the weighted aggregation operation proposed in Def. 15 is employed to combine evidential linguistic evaluations of multiple experts.
The evaluation values of alternative \(a_i\) with regard to criterion \(c_j\) from DMs \(\{\epsilon _1,\epsilon _2,...,\epsilon _p\}\) can be aggregated by Eq. (22) as \(L_{ij}(e) = L_{ij}^1(e) \widetilde{\oplus } L_{ij}^2(e) \widetilde{\oplus } \cdots \widetilde{\oplus } L_{ij}^p(e)\) (see Sect. 4.2.2 for details). So the aggregated evidential linguistic decision matrix of different experts can be calculated as
where \(L_{ij}(e)=\{L_{ij}^{(k)}(e_{ij}^{(k)})\vert L_{ij}^{(k)}\in 2^S\}\) on LTS S.
The obtained aggregated evidential linguistic decision matrix will be converted to numerical form to get the final decision matrix. The expectation values of evidential linguistic evaluations \(L_{ij}(e)\), \(\{i=1,2,...,m;j=1,2,...,n\}\) will be got using Def. 16 as \(\mathbb {E}_{ij}=E(L_{ij}(e))\). Therefore, the numerical decision matrix of evaluations from expert panel can be determined as
where \(\mathbb {E}_{ij}\) is the expectation value of ELE \(L_{ij}(e)\) associated with alternative \(a_i\) under criterion \(c_j\).
6.3 Obtainment of the criteria weight
The criteria weight will be obtained, in this paper, considering two aspects: objectivity and subjectivity. To determine objective weights, the Shannon entropy weight method is employed in conjunction with the obtained matrix D. First, standardize matrix \(\mathbb {E}_{ij}\) as
in which \({\widetilde{\mathbb {E}}}_{ij}\) is the standard matrix that needs to be further normalized to apply entropy weight method as
then the entropy value of each criterion can be calculated as
then, the divergence of the intrinsic information associated with \(c_j (j = 1, 2,\ldots ,n)\) can be determined as
where \(\zeta _j\) indicates the inherent contrast intensity of \(c_j\). We have that the larger this value is, the more crucial \(c_j\) is. Finally, the objective weight of \(c_j\) can be calculated as
From the subjective perspective, the importance weights of different criteria would be provided by DMs in the form of evidential linguistic elements. As a consequence, the subjective weight matrix is expressed by
where \(\underline{L}_{\kappa j}(e)=\{L_{\kappa j}^{(k)}(e_{\kappa j}^{(k)})\vert L_{\kappa j}^{(k)}\in 2^S\}\) on LTS S.
For a given criterion \(c_j\), the evaluation values of p DMs should be combined by Def. 15 as
where \(\underline{L}_{j}(e)\) is the evidential linguistic representation of \(c_j\).
Further, the expectation values of criteria weights represented by ELEs will be calculated based on Def. 16 as
The subjective weights of criteria can be determined by normalization as
To describe the subjective preference of DMs and consider the objective characteristics of crtieria, the subjective weight and objective weight are combined to obtain the comprehensive weight of \(c_j\) as
6.4 Evidential linguistic ELECTRE method
The ELECTRE method is known for the using of “outranking relations” to sort a large body of actions with MCDM problems. Several crucial definitions of ELECTRE I are summarized below Fei et al. (2019).
Definition 18
The preference relation of ELECTRE method is represented by a binary relation \(\lhd \), which indicates “not inferior to”. Given two variables \(\varphi \) and \(\psi \), their relation might be
-
(1)
\(\varphi \) \(\lhd \) \(\psi \) & \(\lnot \)(\(\psi \) \(\lhd \) \(\varphi \)), which means \(\varphi \) is completely superior to \(\psi \).
-
(2)
\(\psi \) \(\lhd \) \(\varphi \) & \(\lnot \)(\(\varphi \) \(\lhd \) \(\psi \)), which means \(\psi \) is completely superior to \(\varphi \).
-
(3)
\(\varphi \) \(\lhd \) \(\psi \) & \(\psi \) \(\lhd \) \(\varphi \), which means \(\varphi \) is not different from \(\psi \).
-
(4)
\(\lnot \)(\(\varphi \) \(\lhd \) \(\psi \)) & \(\lnot \)(\(\psi \) \(\lhd \) \(\varphi \)), which means \(\varphi \) and \(\psi \) are incompatible.
Definition 19
In ELECTRE method, The relation between \(\varphi \) and \(\psi \) is mainly reflected by two concepts, namely concordance and discordance, and their interpretation is given below.
-
(1)
Concordance: if enough criteria support this assertion, \(\varphi \) \(\lhd \) \(\psi \) can be verified.
-
(2)
Discordance: when (1) is true, none of the few criteria can strongly disagree with \(\varphi \) \(\lhd \) \(\psi \).
In view of the advantages of ELECTRE method in dealing with MCDM problems, in this paper, we extend it to the linguistic context, and the specific steps are manifested below.
Step 1. Normalize the decision matrix \(({\widetilde{\mathbb {E}}}_{ij})_{m\times n}\).
Matrix \(({\widetilde{\mathbb {E}}}_{ij})_{m\times n}\) has been obtained by Eq. (30).
Step 2. Determine the weighted normalized matrix \(({\widetilde{\mathbb {E}}}^w_{ij})_{m\times n}\).
The weighted normalized decision matrix is calculated based on the weights of criteria
Step 3. Construct concordance and discordance sets.
For alternative pairs \((a_{\mu },a_{\nu })\), the subscript set \(J = \{1,2,\ldots ,n\}\) of criteria \(\{c_1,c_2,\ldots ,c_n\}\) can be divided into two unintersected subsets \(\mathcal {Q}_{\mu \nu }\) and \(\mathcal {T}_{\mu \nu }\). \(\mathcal {Q}_{\mu \nu }\) is made up of criteria where \(a_\mu \) is superior than or equal to \(a_\nu \) (i.e., \(a_\mu \) S \(a_\nu \)), which is called concordance set. \(\mathcal {T}_{\mu \nu }\) consists of criteria where \(a_\mu \) is inferior to \(a_\nu \), which is called discordance set. The concordance and discordance sets can be determined as
Step 4. Get concordance and discordance matrices.
Employing the weights of different criteria and constructed concordance set \(\mathcal {Q}\), the concordance index can be calculated as \(\texttt {c}_{\mu \nu } = \sum _{j\in Q_{\mu \nu }}w_j\) that indicates the importance of \(a_\mu \) over \(a_\nu \). It is obvious that \(\texttt {c}_{\mu \nu }\in [0,1]\), and the larger the \(\texttt {c}_{\mu \nu }\), the greater the degree to which \(a_\mu \) is superior to \(a_\nu \). Consequently, the concordance matrix is determined as
Using the weighted normalized matrix \({\widetilde{\mathbb {E}}}^w_{ij}\) and constructed discordance set \(\mathcal {T}\), the discordance index can be calculated as \(\texttt {d}_{\mu \nu } = \frac{max_{j\in \mathcal {T}_{\mu \nu }}\vert {\widetilde{\mathbb {E}}}_{\mu j}-{\widetilde{\mathbb {E}}}_{\nu j}\vert }{max_{j\in J}\vert {\widetilde{\mathbb {E}}}_{\mu j}-{\widetilde{\mathbb {E}}}_{\nu j}\vert }\) that indicates the degree to which \(a_\mu \) is inferior to \(a_\nu \). We can easily get \(\texttt {d}_{\mu \nu }\in [0,1]\), and the greater \(\texttt {d}_{\mu \nu }\) is, the larger the degree to which alternative \(a_\mu \) is inferior to \(a_\nu \). Therefore, the discordance matrix is determined as
The conclusion can be drawn that information is complementary between \(\mathcal {C}\) and \(\mathcal {D}\). Specifically, the comparison between the criteria is denoted by \(\mathcal {C}\), and the comparison between evaluation values is manifested by \(\mathcal {D}\).
Step 5. Construct the concordance and discordance dominance matrices.
We use \(\mathcal {C}^{d}\) to represent the concordance dominance matrix that is defined as a Boolean matrix. The dominance of alternative \(a_\mu \) over \(a_\nu \) can be denoted by \(\mathcal {C}^{d}_{\mu \nu }\) and calculated as
in which \(\alpha \) is a threshold defined as \(\alpha = \sum _{\mu =1}^n\sum _{\nu =1}^n\texttt {c}_{\mu \nu }/n(n-1)\). \(\mathcal {C}^{d}_{\mu \nu } = 1\) indicates alternative \(a_\mu \) dominating \(a_{\nu }\).
The discordance dominance matrix \(\mathcal {D}^{d}\) is also a Boolean matrix, which is calculated as
in which \(\beta \) is a threshold that indicates the discordance level, which is calculated by \(\beta = \sum _{\mu =1}^n\sum _{\nu =1}^n\texttt {d}_{\mu \nu }/n(n-1)\). \(\mathcal {D}^{d}_{\mu \nu } = 1\) demonstrates alternative \(a_\mu \) dominating \(a_{\nu }\).
Step 6. Obtain the comprehensive dominance matrix.
The comprehensive dominance matrix \(\Phi \) could be calculated by peer to peer multiplication of the elements in matrices \(\mathcal {C}^{d}\) and \(\mathcal {D}^{d}\) as
in \(\Phi \), element \(\Phi _{\mu \nu }\) can be computed as \(\Phi _{\mu \nu } = \mathcal {C}^{d}_{\mu \nu } \mathcal {D}^{d}_{\mu \nu }\).
Step 7. Identify the optimal compromise alternative.
The outranking relation would be used to determined as small as possible a subset of alternatives as the optimal solutions. An illustrative graph \(G = (V, E)\) could be constructed to manifest the outranking relation among alternatives, in which V stands for the collection of alternatives and E is the collection of their relation. There is an arc between \(v_\mu \) and \(v_\nu \) if either \(a_\mu \) is superior to \(a_{\nu }\) or \(a_\mu \) is indifferent to \(a_\nu \). Alternative \(a_\mu \) is identified as preferred to \(a_{\nu }\) if an arc exists between \(v_\mu \) and \(v_\nu \) and the arrow goes from \(v_\mu \) to \(v_\nu \) (i.e., \(\Phi _{\mu \nu } = 1\)). The relation is incomparable between \(a_\mu \) and \(a_\nu \) if no arc exists between \(a_\mu \) outranks \(a_{\nu }\) (i.e., \(\Phi _{\mu \nu } = 0\)). \(a_\mu \) and \(a_\nu \) are indifferent if an arc exists between \(v_\mu \) and \(v_\nu \) and two arrows exist in both directions (i.e., \(\Phi _{\mu \nu } = 1\) and \(\Phi _{\mu \nu } = 1\)). The outranking relation could be expressed illustratively by a graph, where the binary relations \((i.e.,>, >^{-1}, \approx , ?)\) is shown in Fig. 3Fei et al. (2019),[58].

The graphical expression of the binary relations (>,\(>^{-1}\),\(\approx \),?)
7 Emergency shelter site selection using the evidential linguistic ELECTRE method
An emergency shelter is a facility that provides various services, such as medical assistance and food supply, to people affected by natural disasters. This can effectively alleviate the casualties caused by such events Ma et al. (2019). In this section, the proposed evidential linguistic ELECTRE method is further demonstrated by addressing an emergency shelter site selection problem. In what follows, both sensitivity analysis and comparative analysis are conducted to emphasize the validity of the evidential linguistic ELECTRE approach.
7.1 Case description
The site selection of emergency shelters is an important part of emergency management Kılcı et al. (2015). A reasonable decision regarding the site selection of emergency shelters contributes to efficiently dealing with emergencies, and it helps in reducing losses and hazards caused by secondary disasters Wei et al. (2020). In recent years, with the continuous attention of the national government to emergency management, scholars have proposed new theoretical methods Ma et al. (2019). However, in the context of practical application, more complexity and uncertainty are inevitably involved Wu et al. (2018). In the case of inaccurate and fuzzy information, people tend to use linguistic evaluation rather than precise numerical methods Pang et al. (2016). Therefore, emergency shelter site selection can be subdivided into the MCDM domain Liu (2022).
In this part, the evidential linguistic approach is employed to the problem of emergency shelter site selection. The five main elements are extracted and processed to measure the performance of the emergency shelter, which constitute the criteria set \(C=\{c_1, c_2, c_3, c_4, c_5\}\) of the decision. The meaning of each element is explained as follows. Safety \((c_1)\) is the most basic and important principle in the selection of the emergency shelter, which is to ensure the safety of the shelter, so as to avoid secondary harm to the refugees Wei et al. (2020); Liu (2022). Accessibility \((c_2)\) reflects the efficiency of emergency shelters to communicate with the outside world, including the distance to the main road, the distance to the transportation hub, the distance to the potential landing point and so on Liu (2022). Equilibrium \((c_3)\) means that the shelters should be distributed evenly, that is, the spatial distribution of the shelters should match the population density Hosseini et al. (2022). Effectiveness \((c_4)\) requires that the shelter needs to be of a certain size, and the number of refugees cannot exceed the capacity of the shelter Liu et al. (2022); Zhang et al. (2019). Environment \((c_5)\) directly affects the health of refugees, so necessary supplies such as clean air, water, and medical resources should be guaranteed Çetinkaya et al. (2021); Şenik and Uzun (2021).
Five emergency shelter sites (\(A = \{a_1,a_2,a_3,a_4,a_5\}\)) will participate in the evaluation according to the above criteria. To assess the sites’ performance effectively, the opinions of experts from different emergency departments are collected. The expert group is expressed as \(\mathcal {E}=\{\epsilon _1,\varepsilon _2,\varepsilon _3,\varepsilon _4,\varepsilon _5\}\). The evaluation information of sites from experts is represented by means of ELEs based on the LTS S = \(\{s_{-3}\) = very bad, \(s_{-2}\) = bad, \(s_{-1}\) = somewhat bad, \(s_0\) = medium, \(s_1\) = somewhat good, \(s_2\) = good, \(s_3\) = very good\(\}\). The evaluation results of sites are shown in Table 1.
7.2 Evidential linguistic ELECTRE method for the case
In this section, we will demonstrate the decision-making process step by step. Step 1. For each site, evaluations from different experts are shown in Table 1. Step 2. The proposed weighted aggregation operations is used to combine the evaluations of each expert on the same site with regard to different criteria. Based on the definitions in Sect. 4.2, the aggregated evaluations from different experts can be calculated, and are shown in Table 2. Step 3. Based on the obtained aggregated decision matrix, the expectation values of evidential linguistic evaluations will be calculated using Def. 16 to determine the numerical decision matrix of evaluations.
Step 4. The weights of criteria will be computed based on the definitions in Sect. 6.3 from two aspects, i.e., objective and subjective. To determine objective weights, the Shannon entropy weight method is employed based on Eqs. (30–34), and the objective weights of criteria \(\{c_1\ldots c_5\}\) are \(w_1^o = 0.3166\), \(w_2^o = 0.1196\), \(w_3^o = 0.0699\), \(w_4^o = 0.2984\), and \(w_5^o = 0.1955\). To determine subjective weights, the subjective weight matrix \(W^s\) is provided by DMs in Eq. (49). Based on Eqs. (36–38), the subjective weights of criteria can be obtained as \(w_1^j = 0.2521\), \(w_2^j = 0.2076\), \(w_3^j = 0.1854\), \(w_4^j = 0.1650\), and \(w_5^j = 0.1899\). The comprehensive weight is got using Eq. (39) as \(w_1 = 0.2917\), \(w_2 = 0.1627\), \(w_3 = 0.1175\), \(w_4 = 0.2291\), and \(w_5 = 0.1989\).
Step 5. The evidential linguistic ELECTRE method can be employed to determine the ranking of the alternatives. First, the normalized decision matrix should be calculated by matrix D by Eq. (30) as
Second, the weighted normalized matrix can be determined by Eq. (40) as
Third, the concordance and discordance sets is got by means of Eqs. (41 and 42), and the outputs are manifested in Tables 3 and 4.
Fourth, the concordance and discordance matrices is got by means of Eqs. (43 and 44), and the outputs are manifested in Tables 5 and 6.
Fifth, the concordance and discordance dominance matrices can be constructed based on Eqs. (45 and 46). Assume that the threshold \(\alpha \) and \(\beta \) of concordance and discordance indexes are 0.5 and 0.5, respectively (sensitivity analysis of the threshold will be given below). The results are manifested in Tables 7 and 8.
Sixth, the comprehensive dominance matrix can be determined by Eq. (47) as manifested in Table 9.
Finally, in Fig. 4 we give the decision graph, and based on which the alternatives are ranked. Some conclusions about the relationship between \(\{a_1, \ldots ,a_5\}\) can be obtained according to Fig. 4. \(a_5\) is preferred to other alternatives, so \(a_5\) is identified as the emergency shelter best site. \(a_4\) is worse than all the sites, so it is identified as the worst. \(a_1\) is preferred to \(a_3\). \(a_1\) is incompatible with \(a_2\). \(a_2\) is incompatible with \(a_3\).

The decision graph for the case study of emergency shelter site selection
7.3 Sensitivity analysis
In this section, the sensitivity analysis of the proposed method is performed using two experiments.
To demonstrate the sensitivity of parameters \(\alpha \) (threshold of concordance index) and \(\beta \) (threshold of discordance index) to the selection result, a few tests are conducted on the above performance selection problem of emergency shelter sites. In the experiment, we take all possible values of parameters \(\alpha \) and \(\beta \) (step size 0.2) to observe the change of the selection result. The output consists of three items: the best site, the worst site, and other relations (Preference only), which are given in Table 10.
Some conclusions and analysis from Table 10 are as follows:
-
(1)
During the whole experiment, regardless of the values of \(\alpha \) and \(\beta \), the optimal alternative is always \(a_5\).
-
(2)
Except when \(\alpha \) reaches the maximum value of 1, the worst alternative is \(a_4\).
-
(3)
Except in a few cases where the relation cannot be determined, \(a_3\) is always better than \(a_2\) and \(a_1\).
-
(4)
In several cases where the relation can be determined, \(a_2\) is superior to \(a_3\).
From the above findings, it can be concluded that for different parameters \(\alpha \) and \(\beta \), the overall ranking result is relatively stable, but there are some fluctuations simultaneously. ELECTRE is a flexible ranking method by using outranking relations, where thresholds \(\alpha \) and \(\beta \) can be considered as parameters to reflect the attitude of DMs. For threshold of concordance index \(\alpha \), the smaller \(\alpha \) is, the lower the requirement of the DM for concordance is, that is, the more optimistic the DM is, and vice versa. For threshold of discordance index \(\beta \), the larger \(\beta \) is, the lower the requirement of the DM for concordance is, that is, the more optimistic the DM is, and vice versa.
Additionally, it is crucial to analyze how changes in attribute weights impact decision outcomes Ghorui et al. (2023); Bitarafan et al. (2023); Puška et al. (2023). For this purpose, we design six scenarios, each corresponding to six different configurations of attribute weights, to observe their effects on decision results. As shown in Table 11, under different weight distributions, the final decision outcomes exhibit similarities. Specifically, the results of Scenarios 1, 2, 4, and 6 are consistent with the conclusions of our study. Notably, Scenario 3, besides validating our conclusions, further reveals that when the weight of accessibility is higher, \(a_1\) has a higher priority compared to \(a_2\). Similarly, Scenario 5, while confirming the research conclusions, also indicates that when the weight of effectiveness increases, \(a_2\) becomes more preferred than \(a_3\). Through this series of sensitivity analyses, we can clearly see that the impact of changes in attribute weights on the ranking of options is minimal.
7.4 Comparison and discussion
In this section, we will compare the method proposed in this paper with the existing methods from two aspects, namely information expression and decision-making process, respectively. With regard to decision/assessment information representation in a linguistic context, various extended forms of LTS Rodriguez et al. (2011); Wang et al. (2014); Chen et al. (2016); Pang et al. (2016); Gou et al. (2017) have been developed. These extensions each have their own unique characteristics. By examining the sequence of their development, we can discern a gradual process of improvement. To compare these methods, we conduct an analysis from the perspectives of syntactic form, semantic comprehension, strengths, and weaknesses. The comparison results are presented in Table 12.
As shown in Table 12, HFLTS was proposed to solve MCDM problems in uncertain linguistic environment based on hesitant fuzzy sets Rodriguez et al. (2011). As a direct extension, IVHFLTS was developed by Wang et al. Wang et al. (2014). However, the methods on account of hesitant fuzzy sets treats the weight of criteria in the decision as equal, which is obviously inconsistent with the reality. To address the above issue, probabilistic linguistic sets have been proposed, starting with PHFLTS Chen et al. (2016), which includes the proportional information of each generalized linguistic term. Followed by PLTS Pang et al. (2016) and DHHFLTS Gou et al. (2017), which can express complex linguistic terms more accurately, but their common shortcomings are that they cannot express multi-subset linguistic information, which is extremely important in uncertain MCDM problems. To overcome such limitations, the concept of ELTS is introduced in this paper, and then an evidential linguistic ELECTRE approach is proposed.
For decision methods, we compare ELECTRE method used in this paper with TOPSIS method Hwang and Yoon (1981) and VIKOR method Shen and Wang (2018), which are well-known in MCDM field. Because they are utility value-based ranking methods, the normalized decision matrix in Eq. (50) and comprehensive weight w serve as the basis for subsequent decisions. The ranking results from diverse approaches are provided in Table 13. We can discover that TOPSIS and VIKOR methods get the same ranking result, which is somewhat distinguish from our method. The main difference lies in the ranking of \(a_2\), which led to the three possible ranking results. However, for the determination of the best and worst alternatives, the conclusions of the three methods are consistent.
We further emphasize the advantage of the approach proposed in this paper, in that it is not limited to giving a simple ranking of alternatives, but rather reveals the outranking relation between them, i.e., preference, indifference, or incomparability. This can provide more valuable information, which is critical for analyzing the interrelationships between alternatives.
8 Conclusions and future work
This study is dedicated to the proposing and developing of an innovative methodology: evidential linguistic term sets. The application of LTSs to MCDM problems has gone through a process from considering simplicity to including complexity, for example, from HFLTS to PHFLTS to PLTS. Although a large number of excellent works have been presented to handle the uncertainty of the decision-making environment, they are far from being sufficient conditions for the objective decision of DMs. For example, HFLTS considers that the criteria weights are equal, and PLTS assigns unit belief to each LTS. Even PHFLTS can only partially express the uncertainty of DMs. In this paper, by introducing the concept of evidential LTS, the opinion of DMs is characterized by the power set of LTS, which is a philosophical advance of uncertain MCDM in the linguistic environment. We axiomatize several measures of ELTSs, such as uncertainty measure, dissimilarity measure, and expectation function. The aggregation operations for ELTSs are also developed and strengthened by taking into account the reliability.
On account of the above theoretical basis, we propose a MCDM approach in an evidential linguistic environment with the ELECTRE method. The advantages of this method can be summarized as follows: (1) the opinions of the DMs can be more easily expressed correctly, as it is compatible with greater uncertainty, (2) the (weighted) aggregation operators among ELEs are put forward based on Dempster’s rule, which implies its function as an uncertain inference tool, (3) the ELECTRE method is well known for analyzing the outranking relation between alternatives so that more valuable information can be revealed. A case study applied to the selection of an emergency shelter site fully confirms the above discussion through comparisons and analyses. These findings in this study have significant implications for modeling uncertainty in the field of emergency management and decision analysis.
While this study has made strides in formally proposing and establishing the concept and usage framework of the ELTS, and in expanding the application of the ELECTRE decision-making method, it is not without its limitations and potential directions for future research. Currently, a comprehensive linguistic decision framework underpinned by the theory of belief function has yet to be fully developed. Moreover, the exploration of MCDM in this study, based solely on ELTS within the ELECTRE context, remains limited. Future research should more broadly focus on various MCDM methods to fully leverage the potential of ELTS in decision-making. Additionally, the application of this study to the selection of emergency shelters is only a numerical case study and has not yet been validated in real-world scenarios, leaving room for future practical applications. Given these considerations, we put forward several perspectives to track the current work: improve the theoretical framework of ELTS, and carry out research from the perspectives of upper and lower probability intervals, namely, belief function and plausibility function; apply current theories and properties in other interesting MCDM methods, such as MOORA, SMART, and MULTIMOORA; Dedicated to theoretical contributions in more applications, such as emergency capability evaluation, emergency plan selection, etc.
Data availability
No datasets were generated or analysed during the current study.
Abbreviations
- MCDM:
-
Multi-criteria decision making
- ELTS:
-
Evidential linguistic term set
- ELECTRE:
-
Elimination and choice translating reality
- PLTS:
-
Probabilistic linguistic term set
- DMs:
-
Decision makers
- LTS:
-
Linguistic term set
- BFT:
-
Belief function theory
- FoD:
-
Frame of discernment
- ELE:
-
Evidential linguistic element
- ERI:
-
Evidential reliability indicator
References
Arabahmadi R, Mohammadi M, Samizadeh M, Rabbani M, Gharibi K (2023) Facility location optimization for technical inspection centers using multi-objective mathematical modeling considering uncertainty. J Soft Comput Decis Anal 1(1):181–208
Atanassov KT (1986) Intuitionistic fuzzy sets. Fuzzy Sets Syst 20(1):87–96
Aydin N, Cetinkale Z (2023) Simultaneous response to multiple disasters: integrated planning for pandemics and large-scale earthquakes. Int J Disaster Risk Reduct 86:103538
Bitarafan M, Hosseini KA, Zolfani SH (2023) Identification and assessment of man-made threats to cities using integrated grey bwm-grey Marcos method. Decis Making: Appl Manag Eng 6(2):581–599
Çetinkaya C, Özceylan E, İşleyen SK (2021) Emergency shelter site selection in Maar Shurin community of Idlib (Syria). Transp J 60(1):70–92
Chen Z, Chin KS, Li Y, Yang Y (2016) Proportional hesitant fuzzy linguistic term set for multiple criteria group decision making. Inform Sci 357:61–87
Dempster AP (1967) Upper and lower probabilities induced by a multivalued mapping. Ann Math Stat 38(2):325–339
Fei L (2022) Demand prediction of emergency materials using case-based reasoning extended by the dempster-shafer theory. Socio-Econ Plann Sci 84:101386
Fei L, Feng Y (2021) Modeling interactive multiattribute decision-making via probabilistic linguistic term set extended by Dempster–Shafer theory. Int J Fuzzy Syst 23(2):599–613
Fei L, Wang Y (2022) An optimization model for rescuer assignments under an uncertain environment by using Dempster–Shafer theory. Knowl Based Syst 255:109680
Fei L, Xia J, Feng Y, Liu L (2019) An ELECTRE-based multiple criteria decision making method for supplier selection using Dempster–Shafer theory. IEEE Access 7:84701–84716
Geng S, Hou H, Zhou Z (2021) A hybrid approach of Vikor and bi-objective decision model for emergency shelter location–allocation to respond to earthquakes. Mathematics 9(16):1897
Ghorui N, Mondal SP, Chatterjee B, Ghosh A, Pal A, De D, Giri BC (2023) Selection of cloud service providers using mcdm methodology under intuitionistic fuzzy uncertainty. Soft Comput 27(5):2403–2423
Ghoushchi SJ, Gharibi K, Osgooei E, Ab Rahman MN, Khazaeili M (2021) Risk prioritization in failure mode and effects analysis with extended Swara and Moora methods based on z-numbers theory. Informatica 32(1):41–67
Gou X, Liao H, Xu Z, Herrera F (2017) Double hierarchy hesitant fuzzy linguistic term set and multimoora method: a case of study to evaluate the implementation status of haze controlling measures. Inform Fusion 38:22–34
Hatami-Marbini A, Tavana M (2011) An extension of the electre i method for group decision-making under a fuzzy environment. Omega 39(4):373–386
Hezam IM, Basua D, Mishra AR, Rani P, Cavallaro F (2023) Intuitionistic fuzzy gained and lost dominance score based on symmetric point criterion to prioritize zero-carbon measures for sustainable urban transportation. Kybernetes. https://doi.org/10.1108/K-03-2023-0380/full/html
Hirbod F, Karimi T, Mohammadnazari Z, Rabbani M, Aghsami A (2023) Municipal solid waste management using multiple disposal location-arc routing and waste segregation approach: a real-life case study in England. J Ind Product Eng 41:81
Horner MW, Ozguven EE, Marcelin JM, Kocatepe A (2018) Special needs hurricane shelters and the ageing population: development of a methodology and a case study application. Disasters 42(1):169–186
Hosseini KA, Tarebari SA, Mirhakimi S (2022) A new index-based model for site selection of emergency shelters after an earthquake for Iran. Int J Disaster Risk Reduct 77:103110
Hwang CL, Yoon K (1981) Methods for multiple attribute decision making. Multiple attribute decision making. Springer, London, pp 58–191
Jagtap M, Karande P (2022) Effect of normalization methods on rank performance in single valued m-polar fuzzy electre-i algorithm. Mater Today: Proc 52:762–771
Jagtap M, Karande P (2023) The m-polar fuzzy set electre-i with revised Simos’ and ahp weight calculation methods for selection of non-traditional machining processes. Decis Making: Appl Manag Eng 6(1):240–281
Jagtap M, Karande P (2023) The m-polar fuzzy electre-i integrated ahp approach for selection of non-traditional machining processes. Cogent Eng 10(1):2181737
Jagtap M, Karande P, Patil P (2022) Modified m-polar fuzzy set electre-i approach. Fuzzy Comput Data Sci: Appl Chall. https://doi.org/10.1002/9781394156887.ch7
Jiroušek R, Shenoy PP (2018) A new definition of entropy of belief functions in the Dempster–Shafer theory. Int J Appr Reason 92:49–65
Junian J, Azizifar V (2018) The evaluation of temporary shelter areas locations using geographic information system and analytic hierarchy process. Civil Eng J 4(7):1678–1688
Kılcı F, Kara BY, Bozkaya B (2015) Locating temporary shelter areas after an earthquake: a case for turkey. Eur J Oper Res 243(1):323–332
Kocatepe A, Ozguven EE, Horner M, Ozel H (2018) Pet-and special needs-friendly shelter planning in south Florida: a spatial capacitated p-median-based approach. Int J Disaster Risk Reduct 31:1207–1222
Li H, Zhao L, Huang R, Hu Q (2017) Hierarchical earthquake shelter planning in Urban areas: a case for Shanghai in China. Int J Disaster Risk Reduct 22:431–446
Li C-C, Dong Y, Liang H, Pedrycz W, Herrera F (2022) Data-driven method to learning personalized individual semantics to support linguistic multi-attribute decision making. Omega 111:102642
Li C-C, Gao Y, Dong Y (2023) Managing missing preference values through consistency and consensus in distributed linguistic preference relations: a two-stage method based on personalized individual semantics. Group Decis Negot 32(1):125–146
Liu K (2022) Gis-based mcdm framework combined with coupled multi-hazard assessment for site selection of post-earthquake emergency medical service facilities in Wenchuan, China. Int J Disaster Risk Reduct 73:102873
Liu J, Cao L, Zhang D, Chen Z, Lian X, Li Y, Zhang Y (2022) Optimization of site selection for emergency medical facilities considering the Seir model. Comput Intell Neurosci. https://doi.org/10.1155/2022/1912272
Liu R, Fei L, Mi J (2023) Amulti-attribute decision-making method using belief-based probabilistic linguistic term sets and its application in emergency decision-making. CMES-Comput Model Eng Sci. https://doi.org/10.32604/cmes.2023.024927
Liu F, Liao H, Wu X, Al-Barakati A (2023) Evaluating internet hospitals by a linguistic z-number-based gained and lost dominance score method considering different risk preferences of experts. Inform Sci 630:647–668
Liu P, Dong X, Wang P (2023) Limited budget-based consensus model for large group decision making with hesitant fuzzy linguistic information. Appl Soft Comput 142:110368
Liu P, Dang R, Wang P, Wu X (2023) Unit consensus cost-based approach for group decision-making with incomplete probabilistic linguistic preference relations. Inform Sci 624:849–880
Ma Y, Xu W, Qin L, Zhao X (2019) Site selection models in natural disaster shelters: a review. Sustainability 11(2):399
Mishra AR, Rani P, Cavallaro F, Alrasheedi AF (2023) Assessment of sustainable wastewater treatment technologies using interval-valued intuitionistic fuzzy distance measure-based Mairca method. Facta Univ Ser: Mech Eng 21(3):359–386
Moghaddasi B, Majid ASG, Mohammadnazari Z, Aghsami A, Rabbani M (2023) A green routing-location problem in a cold chain logistics network design within the balanced score card pillars in fuzzy environment. J Comb Optim 45(5):1–33
Paelinck J (1978) Qualiflex: a flexible multiple-criteria method. Econ Lett 1(3):193–197
Pan L, Deng Y, Cheong KH (2023) Quaternion model of pythagorean fuzzy sets and its distance measure. Expert Syst Appl 213:119222
Pang Q, Wang H, Xu Z (2016) Probabilistic linguistic term sets in multi-attribute group decision making. Inform Sci 369:128–143
Puška A, Štilić A, Stojanović I (2023) Approach for multi-criteria ranking of Balkan countries based on the index of economic freedom. J Decis Anal Intell Comput 3(1):1–14
Qi G, Li J, Kang B, Yang B (2023) The aggregation of z-numbers based on overlap functions and grouping functions and its application on group decision-making. Inform Sci 623:857–899
Rani P, Alrasheedi AF, Mishra AR, Cavallaro F (2023) Interval-valued pythagorean fuzzy operational competitiveness rating model for assessing the metaverse integration options of sharing economy in transportation sector. Appl Soft Comput 148:110806
Rodriguez R, Martinez L, Herrera F (2011) Hesitant fuzzy linguistic term sets for decision making. IEEE Trans Fuzzy Syst 20(1):109–119
Roy B (1968) Classement et choix en présence de points de vue multiples. Revue française d’informatique et de recherche opérationnelle 2(8):57–75
Roy B (1978) Electre III: un algorithme de classements fondé sur une représentation floue des préférences en présence de critères multiples. Cahiers Du CERO 20(1):3–24
Roy B, Hugonnard J (1982) Ranking of suburban line extension projects on the Paris metro system by a multicriteria method. Transp Res Part A: General 16(4):301–312
Şenik B, Uzun O (2021) An assessment on size and site selection of emergency assembly points and temporary shelter areas in düzce. Nat Hazards 105(2):1587–1602
Shafer G et al (1976) A mathematical theory of evidence. Princeton University Press, Princeton
Shen K, Wang J (2018) Z-VIKOR method based on a new comprehensive weighted distance measure of Z-number and its application. IEEE Trans Fuzzy Syst 26(6):3232–3245
Song S, Zhou H, Song W (2019) Sustainable shelter-site selection under uncertainty: a rough Qualiflex method. Comput Ind Eng 128:371–386
Torra V (2010) Hesitant fuzzy sets. Int J Intell Syst 25(6):529–539
Wang J, Wu J, Wang J, Zhang H, Chen X (2014) Interval-valued hesitant fuzzy linguistic sets and their applications in multi-criteria decision-making problems. Inform Sci 288:55–72
Wei Y, Jin L, Xu M, Pan S, Xu Y, Zhang Y (2020) Instructions for planning emergency shelters and open spaces in China: lessons from global experiences and expertise. Int J Disaster Risk Reduct 51:101813
Wu X, Liao H, Xu Z, Hafezalkotob A, Herrera F (2018) Probabilistic linguistic multimoora: a multicriteria decision making method based on the probabilistic linguistic expectation function and the improved Borda rule. IEEE Trans Fuzzy Syst 26(6):3688–3702
Xia J, Feng Y, Liu L, Liu D, Fei L (2018) An evidential reliability indicator-based fusion rule for Dempster–Shafer theory and its applications in classification. IEEE Access 6:24912–24924
Xu W, Ma Y, Zhao X, Li Y, Qin L, Du J (2018) A comparison of scenario-based hybrid bilevel and multi-objective location-allocation models for earthquake emergency shelters: a case study in the central area of Beijing, China. Int J Geogr Inf Sci 32(2):236–256
Xue P, Fei L, Ding W (2024) A volunteer allocation optimization model in response to major natural disasters based on improved Dempster–Shafer theory. Expert Syst Appl 236:121285
Yager RR (2013) Pythagorean membership grades in multicriteria decision making. IEEE Trans Fuzzy Syst 22(4):958–965
Zadeh LA (1965) Fuzzy sets. Inf Control 8(3):338–353
Zeng Z, Xiao F (2023) A new complex belief entropy of \(\chi \)2 divergence with its application in cardiac interbeat interval time series analysis. Chaos, Solitons Fract 172:113542
Zhang H, Wang F, Tang H, Dong Y (2019) An optimization-based approach to social network group decision making with an application to earthquake shelter-site selection. Int J Environ Res Public Health 16(15):2740
Zhao X, Xu W, Ma Y, Qin L, Zhang J, Wang Y (2017) Relationships between evacuation population size, earthquake emergency shelter capacity, and evacuation time. Int J Disaster Risk Reduct 8(4):457–470
Zhou Q, Deng Y (2023) Belief extropy: measure uncertainty from negation. Commun Stat Theory Methods 52(11):3825–3847
Zou F, Jiang H, Che E, Wang J, Wu X (2023) Quantitative evaluation of emergency shelters in mountainous areas among multiple scenarios: evidence from Biancheng, China. Int J Disaster Risk Reduct 90:103665
Acknowledgements
The authors greatly appreciate the reviewers suggestions and the editors encouragement. This research was supported by the grants from the Natural Science Foundation of Shandong Province of China (Grant No. ZR2023QG099), Guangxi Social Science Fund (22BGL005), and the Social Risk Governance Research of Huangdao Second Jiaozhou Bay Tunnel Construction (SK210471).
Funding
This study was funded by Natural Science Foundation of Shandong Province of China (ZR2023QG099), Social Risk Governance Research of Huangdao Second Jiaozhou Bay Tunnel Construction (SK210471), Guangxi Social Science Fund (22BGL005).
Author information
Authors and Affiliations
Contributions
LF conceptualized and designed the study, and wrote the main manuscript text. XL collected and analyzed the data. CZ contributed to data analysis and interpretation, and provided critical revisions to the manuscript. All authors performed final checks on the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
1.1 Examples
Example 1
Let \(L_1(e)\) \(=\) \(\{s_{1}(1)\}\), \(L_2(e)\) \(=\) \(\{s_1(0.3),s_2(0.5),\{s_1,s_2\}(0.2)\}\) and \(L_3(e)\) \(=\) \(\{s_0(0.45),s_1(0.1),s_2(0.45)\}\) be three ELEs on LTS \(S =\{s_\alpha \vert \alpha = -2,-1,0,1,2\}\). By Eq. (15), the negative ideal ELE of \(L_{1,2,3}(e)\) is \(L_*(e)\) \(=\) \(\{S(1)\}\) \(=\) \(\{\{s_{-2},s_{-1},s_{0},s_1,s_2\}(1)\}\). By Eq. (14), the positive ideal ELE of \(L_{1}(e)\), \(L_{2}(e)\) and \(L_{3}(e)\) are \(L_1^*(e)=\) \(\{s_{1}(1)\}\), \(L_2^*(e)=\) \(\{s_{2}(1)\}\) and \(L_3^*(e)=\) \(\{s_{0}(1)\}\), respectively. Then the dissimilarity measures can be obtained by Eq. (6) as \(D^-(L_1(e))=0.8944\), \(D^-(L_2(e))=0.7280\), \(D^-(L_3(e))=0.7124\) and \(D^+(L_1(e))=0\), \(D^+(L_2(e))=0.4123\), \(D^+(L_3(e))=0.5074\). By Eq. (16), the inner reliability of \(L_{1}(e)\), \(L_{2}(e)\), and \(L_{3}(e)\) are \(\mathcal {I}(L_1(e))=1\), \(\mathcal {I}(L_2(e))=0.6384\), and \(\mathcal {I}(L_3(e))=0.5840\). The outer reliability of \(L_{1}(e)\), \(L_{2}(e)\), and \(L_{3}(e)\) are calculated as follows. First, the similarity matrix is obtained by dissimilarity measure (Eq. (6)) as
Second, the support degree of each ELE is calculated by Eq. (18) as \(Sup(L_1(e)) = 1.6123\), \(Sup(L_2(e)) = 1.9824\), and \(Sup(L_3(e)) = 1.8113\). Third, the credibility degree of each ELE is obtained by Eq. (19) as \(Crd(L_1(e)) = 0.2982\), \(Crd(L_2(e)) = 0.3667\), and \(Crd(L_3(e)) = 0.3351\). Finally, the outer reliability of each ELE is determined by Eq. (20) as \(\mathcal {O}(L_1(e)) = 0\), \(\mathcal {O}(L_2(e)) = 1\), and \(\mathcal {O}(L_3(e)) = 0.2945\). In this case, we let \(\beta = 0.5\), then the comprehensive reliability of ELEs \(L_1(e)\), \(L_2(e)\) and \(L_3(e)\) can be determined as \(\mathcal {R}(L_1(e)) = 0.5\), \(\mathcal {R}(L_2(e)) = 0.8192\) and \(\mathcal {R}(L_3(e)) = 0.392\). The weighted aggregation operator will be employed to combine the three ELES. The arithmetic mean value of \(L_1(e)\), \(L_2(e)\) and \(L_3(e)\) can be obtained by Eq. (23) as \(\widetilde{L}(e) = \{s_0(0.103),s_1(0.459),s_2(0.096),\{s_1,s_2\}(0.342)\}\). The aggregated ELE \(L(e) = L_1(e) \widetilde{\oplus } L_2(e) \widetilde{\oplus } L_3(e) = \widetilde{L}(e) \oplus \widetilde{L}(e) \oplus \widetilde{L}(e) = \{s_0(0.002),s_1(0.8477),s_2(0.0788),\{s_1,s_2\}(0.0715)\}\).
Example 2
(Continued to Example 1) Based on Def. 16, the expected values of \(L_1(e)\), \(L_2(e)\) and \(L_3(e)\) in Example 1 can be calculated as \(E(L_1(e)) = 0.75\), \(E(L_2(e)) = 0.9\), and \(E(L_3(e)) = 0.75\).
Example 3
(Continued to Example 2) Since \(E(L_1(e)) = E(L_3(e)) = 0.75\), their variance value can be calculated by Def. 17 as \(\sigma (L_1(e)) = 0\) and \(\sigma (L_3(e)) = 0.24\). So the ranking of these three ELEs is \(L_2(e) \succ L_1(e) \succ L_3(e)\).
Appendix B
1.1 The properties of the entropy of ELTSs
According to \(Jirou\check{s}ek\) and ShenoyJiroušek and Shenoy (2018), the entropy function of ELEs consists of two components, the conflict in L(e) is measured by the first one, and the non-specificity in L(e) is measured by the second one. The entropy H(L(e)) for ELE L(e) on S defined in Eq. (3) satisfies several outstanding properties, such as nonnegativity, maximum entropy, monotonicity, and probability consistency.
(I) Nonnegativity: \(H(L(e))\ge 0\), and \(H(L(e))=0\) iff there is a \(s\in S\) such that \(L(e) = \{s(1)\}\).
(II) Maximum entropy: H(L(e)) gets the maximum \(H_\uparrow (L(e))\) iff \(L(e) = \{S(1)\}\).
(III) Monotonicity: for two ELEs \(L_1(e)\) and \(L_2(e)\) on distinct LTSs \(S_1\) and \(S_2\), if \(\vert S_1\vert < \vert S_2\vert \), \(H_\uparrow (L_1(e))<H_\uparrow (L_2(e))\).
(IV) Probability consistency: if an ELE L(e) degrades to a PLE L(p), then \(H(L(e)) = H(L(p))\).
Proof
Let L(e), \(L_1(e)\) and \(L_2(e)\) be three ELEs on S, \(S_1\), and \(S_2\), respectively.
(I) based on Eqs. (3), (4), and (5), for L(e) on S, it is easy to have \(H_s(Pl\_P_{L(e)})\ge 0\) and \(H_d(L(e))\ge 0\), so \(H(L(e))\ge 0\). When \(L(e) = \{s(1)\}\), \(H_s(Pl\_P_{L(e)})=0\) and \(H_d(L(e))=0\), so \(H(L(e))=0\). Thus, \(H(\cdot )\) satisfies the nonnegativity property.
(II) let \(\vert S\vert = \#S\), then \(Pl\_P_{L(e)}(L^{(A)}) = \frac{1}{\#S}\) for all \(L^{(A)}\in S\), and therefore \(H_s(Pl\_P_{L(e)})=log(\#S)\), which is the maximum of all PLEs defined on S. We also have \(H_d(L(e))=log(\#S)\). Thus, \(H(\cdot )\) satisfies the maximum entropy property.
(III) based on the proof (II), we have \(H_\uparrow (L(e)) = 2log(\#S)\). Thus, since it is monotonic in \(\vert S\vert \), \(H_\uparrow (\cdot )\) satisfies the monotonicity property.
(IV) when ELE L(e) degrades to PLE L(p), it can be easily obtained that \(H_d(L(e))=0\), then \(H(L(e))=H(L(p))\), Thus, \(H(\cdot )\) satisfies the probability consistency property.
\(\square \)
Appendix C
1.1 The properties of dissimilarity measure of ELTSs
Theorem 1
Nonnegativity: \(d(L_1(e),L_2(e)) \ge 0\).
Proof
Since \({\underline{\underline{D}}}_{ij}>0\), \({{[{\overrightarrow{L_1(e)}} - {\overrightarrow{L_2(e)}}]}^T}=[e_1^{(k)}-e_2^{(k)}]^T\ge 0\), and \([{\overrightarrow{L_1(e)}} - {\overrightarrow{L_2(e)}}]\) \(=\) \([e_1^{(k)}-e_2^{(k)}] \ge 0\), based on Eq. (6), it is easy to have \(d(L_1(e),L_2(e))\ge 0\). \(\square \)
Theorem 2
Nondegeneracy: \(L_1(e) = L_2(e) \Longleftrightarrow d(L_1(e),L_2(e)) = 0\).
Theorem 3
Symmetry: \(d(L_1(e),L_2(e)) = d(L_2(e),L_1(e))\).
The proof of Theorems 2 and 3 is obvious and has been omitted here.
Note that when \(L_1(e)\) and \(L_2(e)\) degrades to two PLEs denoted as \(P_1(e)\) and \(P_2(e)\), that is, \({\underline{\underline{D}}}(L^{(A)},L^{(B)}) = \frac{{\vert L^{(A)} \cap L^{(B)}\vert }}{{\vert L^{(A)} \cup L^{(B)}\vert }}={\textbf {1}}_{\#S}\), so the dissimilarity measure can be represented as
Appendix D
1.1 The properties of expectation function of ELTSs
Property 1: For a given ELE \(L^{\vee }(e) = \{s_{-\tau }(1)\}\), we have \(E(L^{\vee }(e)) = 0\).
Proof
By Def. 16, \(E(L^{\vee }(e)) = \frac{-\tau +\tau }{2\tau }\times 1=0\). \(\square \)
In this case, \(L^{\vee }(e)\) is called minimum ELE.
Property 2: For a given ELE \(L^{\wedge }(e) = \{s_{\tau }(1)\}\), we have \(E(L^{\wedge }(e)) = 0\).
Proof
By Def. 16, \(E(L^{\wedge }(e)) = \frac{\tau +\tau }{2\tau }\times 1=1\). \(\square \)
In this case, \(L^{\wedge }(e)\) is called maximum ELE.
Property 3: For a given ELE L(e), we have \(E(L(e)) \in [L^{\vee }(e),L^{\wedge }(e)] = [0,1]\).
Proof
Since \(\alpha ^{(l)}\in [-\tau ,\tau ]\), we have \(\frac{\alpha ^{(l)}+\tau }{2\tau }\in [\frac{-\tau +\tau }{2\tau },\frac{\tau +\tau }{2\tau }]=[0,1]\). And since \(ELE\_P(L^{(l)})\ge 0\) and \(\sum _{l=1}^{\#S}ELE\_P(L^{(l)})=1\), we have \(\sum _{l=1}^{\#S}(\frac{\alpha ^{(l)}+\tau }{2\tau }ELE\_P(L^{(l)}))\) \(\in [\sum _{l=1}^{\#S}(0\times ELE\_P(L^{(l)})),\sum _{l=1}^{\#S}(1\times ELE\_P(L^{(l)}))]\) \(=[0,1]\). \(\square \)
An example is given in Example 2 of Appendix A.
Appendix E
1.1 Remarks
Remark 1
Various versions of LTS are used by scholars, such as \(\tilde{S} =\{\tilde{s}_\alpha \vert \alpha = 0,1,...,\tau \}\) and \(\tilde{\tilde{S}} =\{\tilde{s}_\alpha \vert \alpha = 1,...,\tau \}\). In this paper, we refer to LTS \(S =\{s_\alpha \vert \alpha =-\tau ,...,-1,0,1,...,\tau \}\) without any special instructions.
Remark 2
When LTSs \(\tilde{S} =\{\tilde{s}_\alpha \vert \alpha = 0,1,...,\tau \}\) and \(\tilde{\tilde{S}} =\{\tilde{\tilde{s}}_\alpha \vert \alpha = 1,...,\tau \}\) associated to the ELTS is concerned, in which cases, the expected values functions of \(\tilde{L}(e)\) and \(\tilde{\tilde{L}}(e)\) could be defined as \(E(\tilde{L}(e))=\sum _{l=1}^{\#\tilde{S}}(\frac{\alpha ^{(l)}}{\tau }ELE\_P(\tilde{L}^{(l)}))\) and \(E(\tilde{\tilde{L}}(e))=\sum _{l=1}^{\#\tilde{\tilde{S}}}(\frac{\alpha ^{(l)}}{\tau }ELE\_P(\tilde{\tilde{L}}^{(l)}))\). In this paper, if not specified, we refer to LTS S. If the ELE degrades to PLE, the expectation function would be consistent with the one in literature Wu et al. (2018).
Remark 3
With regard to LTS \(\tilde{S} =\{\tilde{s}_\alpha \vert \alpha = 0,1,...,\tau \}\), the variance value function of \(\tilde{L}(e)\) could be defined as
Note that if the mass of belief is entirely assigned to the singleton set, i.e. ELE degrades to PLE, the variance value function would be consistent with the form in literature Wu et al. (2018).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fei, L., Liu, X. & Zhang, C. An evidential linguistic ELECTRE method for selection of emergency shelter sites. Artif Intell Rev 57, 81 (2024). https://doi.org/10.1007/s10462-024-10709-2
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-024-10709-2