
Abstract
Genebanking, the process of preserving genetic resources, is a central practice in the modern management of crop genetics, especially for the species used for food and agriculture. Closely interrelated networks of local, national and global actors are responsible for ex situ conservation. They all seek to make plant genetic resources accessible for all and now face new challenges arising from digitisation. Plant sciences are entering the postgenomic era, moving fast from initially providing a single reference genome for each species (genomics), to harnessing the extent of diversity within crop species (pangenomics) and among their relatives (referred to as postgenomics). This paper describes the extent to which ex situ collections have already undergone a digital shift, or are planning to do so, and the potential impact of this postgenomic-induced dematerialisation on the global governance of plant genetic resources. In turn, digitising material (seed) collection changes the relationship between genebanks and genomic databases. Comprehensive genomic characterisation of genebank accessions is ongoing, and I argue here that these efforts may provide a unique opportunity for genebanks to further embrace the moral, ethical and ultimately political principles on which they were built. Repurposing genebanks as decentralised digital biocentres could help relocate capabilities and stewardship over genetic resources. Empowering local farmers by providing access, promoting the use and unlocking benefits from state-of-the-art tools of modern plant breeding may allow bridging the breeding divide. However, to accomplish such a paradigm shift, genebanks require a strong political mandate that must primarily originate from the access and benefit-sharing framework. Only so may the global challenges associated with the loss of biodiversity and food insecurity be addressed.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
In 2011, the contemporary artist Ai Weiwei filled the Tate Modern Museum with millions of small hand-crafted porcelain sunflower seeds. While the artwork may allow several layers of interpretation, one could imagine those seeds as a metaphoric genebank: static for the centuries to come, while still paying a tribute to the individuals that produced them. Genebanking of plant genetic resources is a central practice of modern agriculture aiming at the ex situ conservation of crop and wild plant genetic diversity. It aims to limit the erosion of genetic diversity with the aid of a variety of global, national and local genebanks storing seeds, DNA, tissue cultures, germplasm and other reproductive propagules (FAO 2010; Belanger and Pilling 2019; Pilling et al. 2020). Globally, several commitments have been established to try to improve the quantity and quality of ex situ conservation: under the United Nations Sustainable Development Goal no 2, the aim of Target 2.5 is “By 2020, maintain the genetic diversity of seeds, cultivated plants and farmed and domesticated animals and their related wild species, including through soundly managed and diversified seed and plant banks” (UN 2015). Ex situ conservation is important not only for PGRFA but also as a tool to support the conservation of biodiversity at large: Target 8 of the Global Strategy for Plant Conservation of the Convention for Biological Diversity (CBD) aims for the conservation of at least 75% of threatened species by 2020 (CBD 2002). The recently agreed post-2020 Global Biodiversity Framework also mentions the role of ex situ conservation to achieve its “30 by 30”Footnote 1 objectives.
Ex situ conservation is generally complementary to in situ conservation, which comprises various protected areas and focuses more on the population and ecosystem levels (FAO 2010). Worldwide, some 1750 genebanks hold around 7.4 million samples (or 4.9 million accessions) from over 6900 species relevant to agriculture (FAO 2010; Paton et al. 2020). The largest genebank network, also responsible for most ex situ conservation efforts, is coordinated by the Consultative Group for International Agricultural Research (CGIAR). The CGIAR played a central role in policy design and provided technical inputs that framed the governance framework over ex situ conservation (Frison 2018). They apply the provisions of Article 15Footnote 2 of the International Treaty on Plant Genetic Resources for Food and Agriculture (ITPGRFA 2004). Significantly, a small number of key players in ex situ conservation—such as the Millennium Seed Bank and the Svalbard Global Seed Vault—hold a large proportion of all samples. While objectives and derived policies may vary from one site to another, genebanks are responsible for “collecting, maintaining, characterising, documenting and distributing” various plant varieties, which can be landraces, bred varieties or wild ancestors (FAO 2011; Anglin et al. 2018). Genebanks thus not only play a central role in the conservation of PGRFA but also determine the extent of access to and hence the potential for sharing of benefits derived from these resources. The structure of ex situ conservation underlies a precise normative ideal defining how, when and by whom PGRFA can be accessed, commodified and the modalities of their future use (Peres 2016; Curry 2017). They are indeed central both to the ITPGRFA and to the Nagoya Protocol of the CBD, which regulates the access to and benefit-sharing for a large proportion of terrestrial biodiversity (ITPGRFA 2004, CBD-NP 2010).
To address major challenges such as food security, climate change and loss of biodiversity, crop breeding is under strong pressure from the current global governance frameworks to deliver adapted crops for future resilient agroecosystems. To access the diversity of genebanks for improving crops, some have advocated systematic genotyping and phenotyping of all conserved accessionsFootnote 3 (McCouch et al. 2013; Halewood et al. 2018a; Bohra et al. 2022).
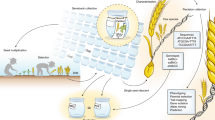
To make use of the genebank’s diversity, crop breeders, researchers and farmers need to describe the accessions that are stored. This process aims eventually at predicting how DNA variability is associated with plant phenotypes (in other words, everything that links the plant to its environment). Now, genebank’s curators and administrators considered the promise of genebank postgenomics,Footnote 4 i.e. using high-throughput genomics on genebank accessions to promote plant breeding. This is also a way to improve the cost-efficiency and effectiveness of collections (McCouch et al. 2012). For example, the Second Report on the State of the World’s PGRFA estimates that about a third of all PGRFA accessions are duplicates (FAO 2010; Curry 2022). In addition, the digitisationFootnote 5 of collections would be an appropriate response to ongoing calls for improvement in the standardisation of genebanks’ sampling, storing and regeneration procedures (FAO 2014). Interestingly, the role of duplication in ex situ collections has been recently questioned (Curry 2022). Digitizing genebanks can be considered as some sort of additional layer of duplication and raises similar questions towards the actual consequences on crop genetic resources conservation.
In this paper, I argue that the comprehensive digitisation of PGRFA collections may also ultimately lead to a major shift in the stewardship role of genebanks and their relationship to scientists, breeders and farmers. First, through collecting and merging plant genomics data, I describe the ongoing shift from genomics to post-genomics. I then gathered the current plant genomics literature and my experience as a genebank curator and national representative involved in various negotiations concerning genetic resources, to draw over the implications of this shift for genebanks. I also argue that the digitisation of PGRFA collections will have a major impact on genebanking.
Genebanks’ activities may shift from the general management of genetic resources (seeds) to the distribution of (digital) information (van Treuren and van Hintum 2014; Wambugu et al. 2018; Mascher et al. 2019). Sharing data will mechanically increase their involvement in post-banking activities: pre-breeding and breeding (for example to allow genomic selectionFootnote 6). But to embrace their new role fully, several challenges remain: like data governance, North/South imbalance, capacity building and standardization. In turn, I try here to evaluate how digitizing genebanks will have consequences on the global politics of genetic resources. Ultimately, empowering farmers and favouring their role as primary data producers (being genomic or phenotypic) will be central to future agricultural systems (MacPherson et al. 2022), and genebanks can be essential tools in that respect. Future developments in the access and benefit-sharing framework will hopefully avoid increasing an omics-driven breeding divide.
Making sense of sequence diversity: the rise of plant genomics
With an estimated 391,000 species worldwide, plants (of which 85% are seed plants) are among the most diverse and genetically complex biological phyla on Earth (Antonelli et al. 2020; Marks et al. 2021). Several ambitious genomic projects aim at comprehensive sequencings of plant diversity, such as the Earth Biogenome project (Lewin et al. 2018), the 10KP project (Cheng et al. 2018), or more focused initiatives, such as the sequencing of an entire botanical garden (Liu et al. 2019). As of the end of 2022, the NCBI genome database (https://www.ncbi.nlm.nih.gov/genome/) includes 1028 reference genomes of varying depth and quality, which are published in various open-access repositories (including NCBI, Ensembl Plants, and Phytozome). The field of plant genomics remains largely dominated by China, the USA and Europe, accounting for about three-quarters of genomes published to date (Marks et al. 2021; Kersey 2019).
Perhaps fortunately for plant geneticists and breeders, a relatively small subset of species is relevant to agriculture. To assess the extent of genomic advances in these species, I have compiled a list of 102 major crops, including 72 key crops covered in the Second Report on the State of the World’s PGRFA (FAO 2010) (Supplementary Table 1). However, this is a limited proportion of the estimated 7039 edible plants identified (Ulian et al. 2020). This short list largely coincides with a previously published list of common commodity crops (Castañeda-Álvarez et al. 2016) and the species listed in Annex 1 to the ITPGRFA. In addition, 30 key neglected and underutilised crops were also considered. The number of accessions in gene banks correlated well with the extent of genomic description (Supplementary Table 1). Of the 102 species selected, 83 have reference genome sequences of varying degrees of completeness, with about a third of these genomes completed to the chromosome level. Notably, 16 of the 19 species without publicly available genomes are part of the African Orphan Crops Consortium and are partially completed, together with another 100 species relevant to Africa (Hendre et al. 2019; Ulian et al. 2020; Ye and Fan 2021). The chronology of sequencing is closely related to technical advances, with an increasing number of increasingly diverse crops sequenced as sequencing techniques improved from Sanger and short-read to long-read Next Generation Sequencing and optical mapping (Figs. 1, 2).

Number of plant species and the various crop genome sequences available. While a very small proportion of species are used in agriculture (102 major crops), the list could be extended if Crop Wild Relatives are being considered and sequenced in so-called “super-pangenome” studies

The rise of postgenomics in crop species. A chronology of crop genome’s publication according to data from NCBI (https://www.ncbi.nlm.nih.gov/genome/) shows a recent rise in pangenomes and sequencing of underutilized crops. The shift from a unique reference genome per species to the sequencing of intraspecific diversity (pangenomes) is referred to here as the postgenomic shift. The data used to draw this figure are summed up in Supplementary Table 1
The simultaneous increase in throughput and decrease in prices recently allowed a surge of resequencing, moving from unique reference genomes to larger pangenomes.Footnote 7 As first observed after the Human Genome Project (Thacker 2005; Shaw 2016), as more and more whole genomes are completed and technology evolves, there is a natural movement towards the characterisation of allelic diversity performed by studying pangenomes of varieties within one species (Golicz et al. 2016; Bayer et al. 2020). In other words, after comparing variations across species (with only a single reference genome for any given species), sequencing allows now for comparing genomes within species (for example for presence/absence of genes). At least 21 pangenomes have been published—i.e. species with multiple reference genomes available (Guignon et al. 2020; Della et al. 2021), mostly from major crops such as rice (Schatz et al. 2014; Wang et al. 2018; Zhao et al. 2018), wheat (Montenegro et al. 2017; Walkowiak et al. 2020), maize (Lu et al. 2015), canola (Hurgobin and Edwards 2017), grapes (Liang et al. 2019), barley and chickpea (Monat et al. 2019; Gao et al. 2020; Jayakodi et al. 2020)—with a lot more still to come (Supplementary Table 1). Three groups of crops were distinguished with decreasing levels of description: first, cash crops with many accessions available in genebanks, and whole genomes as well as pangenomes described (rice, wheat and canola, but also banana and grapes); second, intermediate crops, with diversity reasonably well covered, but with a single reference genome available (typically vegetables); and third, some crops with few accessions and partial or ongoing genome sequencing, which are mostly orphan crops (Supplementary Table 1).
Thus, for the vast majority of key crops, whole genome sequences are available, though of varying quality and depth (Yuan et al. 2017). Modern breeding and plant sciences are generally increasingly data-rich and are now entering a postgenomic era, with a “rising deluge of data” (Stephens et al. 2015; Kelly 2019). Description of pangenomes by resequencing within varieties of the same crop—from single nucleotide polymorphism detection up to larger structural variants—will be highly beneficial for allele identification in breeding programs and genomic selection (Tao et al. 2019; Williamson and Leonelli 2023).
In addition, the portion of genetic diversity accessible by sequencing can be expanded by an order of magnitude with a third level of complexity: mining diversity outside the crop genus, in what has been referred to as the super-pangenome (Khan et al. 2020). In other words, sequencing the gene pools of crop wild relatives (Brozynska et al. 2016). Indeed, during domestication and breeding, a vast proportion of naturally occurring genetic variability has been lost. There are several examples of successful use of crop wild relatives in (pre-)breeding programs, such as Pm21 from the wheat relative Haynaldia villosa, which conferred resistance to powdery mildew in some wheat cultivars, or resistance to late blight (Phytophthora infestans) derived from the wild potato Solanum demissum (Dempewolf et al. 2017; Gao et al. 2020). It may be interesting to consider crop wild relatives from a PGRFA perspective, as it blurs the boundary between conventional biodiversity conservation and utilitarian mining of diversity for breeding purposes (Montenegro de Wit 2017).
Meanwhile, the gradual increase in the complexity and diversity of genomic data, resulting from improvements in sequencing technologies (Bevan et al. 2017; Yuan et al. 2017) and in data analysis (Schneeberger et al. 2009; Chaudhari et al. 2016; Sun et al. 2017; Brinton et al. 2020; Khan et al. 2020), will require dedicated new frameworks, which can be very challenging. Some databases have already tried to address challenges associated with comparative genomics (Guignon et al. 2020). For example, a rice pangenome study allowed the identification of 12,000 new genes that were initially absent from the rice reference genome (Schatz et al. 2014). Similarly, significant variations in gene numbers among 22,000 barley accessions were observed (Jayakodi et al. 2020). These two examples illustrate the significant differences observed between single reference genomes and their actual variability within species. Ultimately, this progress will possibly translate into more/better traits to be integrated into crop breeding programs. Maybe one of the most compelling cases illustrating the capacities of large-scale sequencing and subsequent digitisation is the chickpea, a relatively poorly documented crop until recently, where a single study sequenced more than 3000 accessions and wild relatives (Varshney et al. 2021). This study aimed to directly use the data for streamlining high-throughput phenotyping, allele identification and genomic selection (Varshney et al. 2021; Bohra et al. 2022). Many genebanks, including CGIAR, genotype their collections to better harness the genetic potential they contain (Halewood et al. 2018b). For example, the collection of grapes accessions of the Swiss national genebanks has been recently sequenced to allow a better understanding of their complex relationship with the rest of the continent. Better characterization of rice accessions from the International Rice Institute allowed identifying among rice accessions, traits for flood resistance or enhanced micronutrient contents (Halewood et al. 2018b). The examples of the successful harnessing of digitization in breeding are numerous (Aubry 2019; Aubry et al. 2022; Gaffney et al. 2022). The discovery of new alleles is central to crop breeding, and the study of pangenomes is surely the next logical step and signals entry into the postgenomic era.
So far, the very large majority of the data published in the literature are stored outside genebanks in dedicated omics repositories (like the INSDC databases). Meanwhile, as it becomes standard, it remains to be seen whether and how existing genebanks will have to accommodate these data and their constant increase in volumes. Some scholars anticipate a switch from germplasm collections to “biological digital centres” (Mascher et al. 2019). The ultimate step for genebanks, yet to be performed, will be to build the necessary links between causal alleles and phenotypic traits, like layers from phenomic, epigenetic, proteomic and metabolomic studies (Gebhardt 2013; Anglin et al. 2018; Nguyen and Norton 2020). This is potentially transformative for breeders, who will simply have to browse these databases to obtain an estimate of the genetic value of any given accession, a proper genebank-to-phenotype link (Mascher et al. 2019). Therefore, digitisation of germplasm collections can improve collection efficiency, in terms of both resource management—tracking accessions, avoiding duplication, and building a core collection (Glaszmann et al. 2010; McCouch et al. 2012)—and utilisation. But the real impact of this profound shift in genebank functions has yet to be seen in a more global context, not only for direct users (plant breedersFootnote 8) but also more generally for all other stakeholders involved: farmers, researchers and civil society organizations.
Challenges of repurposing gene banking for big data
Given the complex relationship between genebanks and food systems (Pistorius and van Wijk 1999), genebanks may be considered a good example of “hybrid objects” (Latour 1993). Latour describes hybrids as complex networks between science, economy and politics. Governance of hybrids is often challenging, as it is hard to consider these aspects comprehensively. For a long time, genebanks have been considered solely a pool of resources. However, their integration into various international legally binding instruments (Art. 15; ITPGRFA 2004) and global objectives (SDG, Target 2.5; Commission on Genetic Resources for Food and Agriculture, Second Global Plan of Action for PGRFA) closely link their function to political, social and ethical values (Esquinas-Alcázar 2005). This hybridity makes genebank management and policy complex, involving a wide variety of stakeholders (e.g. scientists, breeders, farmers, indigenous communities…).
The challenges associated with the digitisation of genetic resources and their progressive dematerialisationFootnote 9 bring a new set of stakeholders into play (e.g. database managers, sequencing firms, bioinformaticians), somehow destabilising the existing political consensus (Aubry 2019; Hartmann Scholz et al. 2021). Given the rise of fully dematerialised ubiquitous (cheap, portable and quick) sequencing (Erlich 2015), the current governance and operations of genebanks may have to be reassessed. A perfect example of fully decentralised data generation is the use of portable sequencers, such as Oxford Nanopore devices, which not only allow sequencing in the field but also offer a cloud-based analytic pipeline (Kono and Arakawa 2019; Cozzuto et al. 2020). The spread of such tools may have a strong impact on the economics of digital sequence information (DSI), especially in the context of growing genome editing capacities (Zhu et al. 2020), and genebanks will therefore need to adapt.
Meanwhile, it is not clear to what extent the few key providers of sequencing devices and data analysis (Illumina, Oxford Nanopore and PacBio have the largest market share) could influence conservation policy at large. There are well-known examples of hardware industries progressively shifting their business model to embrace big data, and there is no reason why the development of genomics should be any different. Digitisation of genebanks may profoundly change their position within food systems and will be confronted with similar challenges that affect other digital assets managers in a digital economy (Stuermer et al. 2017; Rohden et al. 2019). It may thus be necessary to evaluate the influence of all the stakeholders concerned by digitising the seed banks: the old ones (farmers, breeders, indigenous communities) as well as the new (bioinformaticians, data scientists and managers). New policies are needed to ensure that some of the most fundamental objectives of genebanks are met: protecting crop genetic diversity for the environment, food security and sustainable development. While repurposing genebanks to match the standards of modern science (and breeding) sounds logical and probably irreversible, in the next section, I try to assess the possible consequences of that shift and who is the most likely to profit from it.
Digitising genebanks or banking digital assets?
The growing reliance on genomic and phenotypic data in plant conservation and breeding has created some uncertainty regarding the management of plant genetic resources. In the late 2010s, some ambiguity arose within the legal framework for the information derived from various germplasms (CBD 2016; Aubry 2019). This controversy coincided with the rise of genome editing techniques, which opened up unprecedented possibilities for writing/synthesising DNA and modifying genomes (Chari and Church 2017). Referring again to the chickpea example (von Wettberg et al. 2018; Bohra et al. 2022), sequencing (i.e. digitisation of the genomes) of wild parents identified alleles responsible for low shattering important for chickpea cultivation. While these wild parents do not necessarily cross with cultivated chickpeas, it could be technically possible to genetically modify this locus.
As omics progress, the legal definition of plant genetic resources appears more and more ambiguous, with a two-components: physical (e.g. seeds, propagules) and informational (DSI) (Aubry et al. 2022). This (possibly) new dichotomy has created obstacles for most fora dealing with genetic resources, especially the internationally legally binding instruments dealing with access and benefit-sharing (ABS). Many scholars commented on this controversy, which appeared to reveal some underlying fragilities in the ABS framework design (Halewood et al. 2018b; Aubry 2019; Laird et al. 2020; Bond and Scott 2020; Nehring 2022). CGIAR centres took a proactive stance, seeking to integrate big data into their collections—for example, by generalising the use of digital object identifiers (DOI) in the global information system of the ITPGRFA (Halewood et al. 2018b). While many research programmes are using genebank infrastructure to access, extract and mine data (DSI), it appears that, without a quick and comprehensive integration of contemporary genomics practices, not only the treaties but also the public collections may become obsolete. Noteworthy, in the early days of human sequencing, (which could be considered the very first omics data wave), some questions were raised: about data access, databases governance, and the extent to which genomics databases could be considered as global public goods or protected commons (Chadwick and Wilson 2004). While the human data field does not consider access and benefit sharing per se, the ethical considerations that drove the governance of biobanks and their associated databases could be inspiring the management of digital data from non-human biodiversity.
Uploading the vault: from ex situ to in silico conservation
Interestingly, not long after the inception of the CBD, the challenges of digitisation were already apparent, as noted by Pistorius and Van Wijk (1999): “the collection and storage of genetic information in the form of data on DNA sequences is much more attractive than in the form of seed”. From a historical perspective, genebanks originated with the efforts of the Soviet plant geneticist Nikolai Vavilov to build a “universal store of genes” (Bonneuil 2019), a move subsequently revitalised by Otto Frankel to become an essential part of modern agriculture (Harlan 1975; Hawkes 2002; Scarascia-Mugnozza and Perrino 2002; Curry 2017). As socio-scientific hybrids, genebanks are embedded in food systems and are therefore strongly dependent on policy changes, levels of funding and parallel waves of privatisation in the plant breeding sector (Pistorius and van Wijk 1999; Nehring 2022). Notably, this may have a long-term impact not only on breeders or farmers but also on food security.
In a broader context of the biodiversity crisis, the regime complex governing genetic resources, in the first place the FAO Seed Treaty (ITPGRFA 2004), calls for improvement of the efficiency of gene banking (Curry 2022). Considering digitisation as part of the default gene banking process also underlies preexisting political views and values for the future of food systems (Alpsancar 2016; Fenzi and Bonneuil 2016; Peres 2016). In the long run, an inherent risk of mass-scale digitisation of genebanks might be that, if they are considered exclusively as instruments for the rational development of plant science, there is ground for gradually making genebanks redundant. Genebanks are costly and complicated structures while building new biological digital centres (i-genebanks) would presumably be cheaper (and therefore more efficient). The value of DNA information long-anticipated by Pistorius and Van Wijk could thus be considered as the ultimate stage of depoliticisation (and subsequent commodification) of PGRFA: when removed from their physical shell, genetic resources as “building blocks of biological crop diversity” (Bonneuil 2019) are more easily stored and managed, but they are also even more unlikely to be related to the farmers that initially grow and breed them (van Dooren 2009). Without further pursuing this extreme, prospective in silico scenario, it remains that genebanks still need to respond to the legal and ethical commitments from which they originate. Could genebank’s digitisation bring more equity to the food system?
Genebanks may indeed take advantage of the genomic revolution to embrace the human component constitutive of crop breeding and its resulting seeds/resources/accessions. The rise of omics technology could then possibly enhance participatory breeding (Jarvis et al. 2008; Williamson and Leonelli 2023) and in turn, help consider genetic resources more holistically: as constitutive elements of specific social and cultural organisation (Leclerc and Coppens d’Eeckenbrugge 2011). The future of bio-digital resources and their repositories are also tightly linked to scientific development: the relatively broad consensus over open access to genetic data in the biosciences (Amann et al 2019) and the developments of data sharing standards (e.g. FAIR: Findable, Accessible, Interoperable, Re-usable and CARE: Collective benefit, Authority to control, Responsibility, and Ethics, Reiser et al. 2018; Carroll et al. 2021), will influence the way digital data (DSI) originating from PGRFA could be managed, and mechanically impact on genebank practices. However, openly circulating data is not necessarily free of any economic interests, and open access is not fair access (Bezuidenhout et al. 2017; Aubry 2019). To move from the axiom “breeding uniformity and banking diversity” (Curry 2017), genebanks will need to actively integrate all stakeholders involved in PGRFA conservation and carefully consider their respective interests. But moving from physical genebanks as we know them, to participatory bio-digital biocenters is a paradigm shift that does not naturally align with the concept of genetic resources as it historically developed (Curry 2017; Bonneuil 2019). This will therefore require ambitious organisational and governance adjustments. This transformation requires first moving away from big centres and vaults towards polycentric farm networks managing local genetic commons (Ostrom 1999; Nehring 2022), which would ultimately be more focused on farmers. Again here, digitisation allows facilitated access to postgenomic-derived (big) data, which in turn can be translated into added value for breeding programs. Meanwhile, to make that possible, a strong effort towards capacity building and standardization across collections and datasets will be needed.
Ultimately, I argue here that, with sufficient political support, digitising genebanks could be a unique opportunity to significantly enhance the role of farmers in maintaining diversity and future-proof breeding.
Conclusion
With an estimated less than 1% of PGRFA genebank accessions used for crop improvement (Sharma et al. 2013), there is a general call for the genebanks to surf the wave of omics data to improve conservation efficiency and facilitate access to and use of their resources. However, as illustrated by the tense debates over the digitisation of genetic resources in the ABS instruments, digitisation is not merely improving genebank practice, but rather producing a major shift in their position within the food systems. They are considered not only as simple providers of seeds, cryogenic tissue cultures or propagules but rather as bio-digital centres, more effectively meeting the needs of breeders and farmers. Digitisation will improve their capacities for prediction in breeding. While most crop genomes are being sequenced and plant science is now entering the postgenomic era, the benefits that will emerge and the actors most likely to profit from them remain open. The observed bias in sequencing towards cash crops indicates that global industrialised economies are leading the postgenomics revolution and most probably feeding the breeding divide. Genebanks are at a crossroads: either driving the path to what could be referred to as digital biopiracy (Nehring 2022) and ultimately enhancing both breeding (Aubry 2019) and digital divide (Bezuidenhout et al. 2017) or using this probably unique opportunity to adapt practices, promote capacity building and ultimately improve access to their resources. This may, in turn, empower local and smallholder farmers to participate actively in storing, sharing and breeding local agrobiodiversity.
The key questions are: what happens when all crop diversity has been sequenced? To what extent could the genomic revolution help close the current gap in conservation and sequencing between cash and neglected crops? Will contemporary genebanks help to bridge the breeding divide, and what role can they play in conserving or extending genescapes? Interestingly, calls for a more inclusive plant genomic community are starting to rise from the research side (Marks et al. 2021).
The digitisation of genetic resources may offer a unique opportunity to reshape genebank-centric PGRFA conservation. Notably, there is a strong need to broaden the scope of conservation to promote and finance in situ and on-farm conservation. However, in situ conservation is significantly more complex and in direct tension with agricultural practices. Although it could also allow the maintenance of functioning agroecosystems which contain, among other elements, many crop wild relatives. Similar issues concerning the extent of digitisation of collections arise for (non-agricultural) biodiversity—e.g. in the development of the Extended Specimen Network in the US, which interestingly considers DSI on a much broader basis than purely genomic sequences (Lendemer et al. 2020). Other scholars evolving within the Commons conceptual framework, suggested alternative crop diversity management systems (Louafi et al. 2021). In this framework, shifting relationships between farmers, multipliers, breeders and genebanks are proposed to help address the stewardship and capabilities imbalance in the seed systems (Wynberg et al. 2021). Addressing the postgenomic digital shift can be central to promoting a new relationship between farmers and genebanks.
For genetic resources considered within the scope of the ABS framework, without waiting for hypothetical trickle-down benefits of the use (and commercialization) of digitised information derived from their accessions, genebanks could grasp the unique opportunity created by the genomic revolution. Like Ai Weiwei’s porcelain sunflower seeds, moving away from the representation of an impressive collective investment, genebanks may convey a particular vision for the seed systems, and their digitisation is a unique opportunity to enforce this vision, particularly the equity and fairness it conveys.
While a shift toward a hybrid of gene bank/genomic database might be perceived as a change in the division of labour: departing from their initial physical storage function to a more proactive role in the food systems, digital genebanks will help tackle the global loss of biodiversity and food insecurity. This will certainly only become a viable option if dedicated funds are allocated to scale up infrastructures, mobilise experts and deploy inclusive research programmes dealing with state-of-the-art conservation and sustainable use of PGRFA. But ultimately, empowering genebanks depends on political choices that are deeply rooted in how our seed/food systems are structured.
Notes
“30 by 30” refers to the latest engagements of the Convention of the Parties of the UN Convention for Biological Diversity in December 2022 to agree on 30% of Earth’s land and oceans being protected by 2030.
Article 15 of the ITPGRFA provides a legal mandate to the CGIAR centers to hold and manage ex situ collections of plant genetic resources for food and agriculture.
The basic unit of the genebank is the “accession”: a unique sample that has been collected and recorded in the genebank. The amount and quality of the information can vary between accessions and can be sometimes even duplicates of the same plants.
Genomics is a subset of genetics that concentrate on analysing large (high-throughput) data that describes large portions of genomes. Omics is a term used to refer at other domains of biology that have also been scaling up the amounts of data they produced (and digitised), like for example transcriptomics or metabolomics. The increase in available data from a unique reference genome per species to the sequencing of intraspecific diversity (pangenomes) is referred to here as the postgenomic shift.
Here, I refer to digitisation in a relatively narrow sense that applies for genebanks: the action to sequence and collect genome’s sequence of physical materials (so called accessions: seeds, propagules…). Being de facto high-throughput data, these data are stored digitally, often in repositories that are separate entities from genebanks.
Genomic selection is the process taking advantage of the comprehensive genetic variability of genomes (after high-throughput sequencing) of a population to associate in a quantifiable manner to certain traits: it defines the breeding value of individuals in a population. Genomic selection is meant to facilitate/speed up the breeding process.
The pangenome is define as the entire set of genes within a species: it entails not only one reference from one organism, but the entire variability contained within that clade.
Plant breeders refer here to a broad representation: from individual breeders, local networks, SMEs, up to large transnational breeding companies.
Dematerialisation is referring here to the fact that specific genetic resources contained in genebanks (accessions) could be sequenced and later accessed without the actual need for their “physical” shell (being a seed or a propagule).
Abbreviations
- ABS:
-
Access and Benefit Sharing
- CGIAR:
-
Consultative Group for International Agricultural Research
- DSI:
-
Digital Sequence Information
- FAO:
-
Food and Agriculture Organization
- ITPGRFA:
-
International Treaty on PGRFA
- NCBI:
-
National Center for Biotechnology Information
- PGRFA:
-
Plant Genetic Resources for Food and Agriculture
References
Alpsancar, S. 2016. Plants as digital things the global circulation of future breeding options and their storage in Gene Banks. Italian Journal of Science and Technology Studies 7: 44–66.
Amann, A., R.I. Rudolf, Baichoo, B.J. Blencowe, P. Bork, M. Borodovsky, et al. 2019. Toward unrestricted use of public genomic data. Science 363: 350–352. https://doi.org/10.1126/science.aaw1280.
Anglin, N.L., A. Amri, Z. Kehel, and D. Ellis. 2018. A case of need: Linking traits to genebank accessions. Biopreservation and Biobanking 16: 337–349. https://doi.org/10.1089/bio.2018.0033.
Antonelli, A., C. Fry, R.J. Smith, M.S.J. Simmonds, P.J. Kersey, H.W. Pritchard, M.S. Abbo, et al. 2020. State of the world’s plants and fungi 2020. Kew: Royal Botanic Gardens.
Aubry, S. 2019. The future of digital sequence information for plant genetic resources for food and agriculture. Frontiers in Plant Science 10: 1–10. https://doi.org/10.3389/fpls.2019.01046.
Aubry, S., C. Frison, J.C. Medaglia, E. Frison, M. Jaspars, M. Rabone, A. Sirakaya, D. Saxena, and E. Zimmeren. 2022. Bringing access and benefit sharing into the digital age. Plants, People, Planet 4: 5–12. https://doi.org/10.1002/ppp3.10186.
Bayer, P.E., A.A. Golicz, A. Scheben, J. Batley, and D. Edwards. 2020. Plant pan-genomes are the new reference. Nature Plants 6: 914–920. https://doi.org/10.1038/s41477-020-0733-0.
Belanger, J, and D. Pilling. 2019. The state of the world’s biodiversity for food and agriculture. Rome. https://www.fao.org/3/CA3129EN/CA3129EN.pdf. Accessed 10 Jan 2023.
Bevan, M.W., C. Uauy, B.B.H. Wulff, J. Zhou, K. Krasileva, and M.D. Clark. 2017. Genomic innovation for crop improvement. Nature 543: 346–354. https://doi.org/10.1038/nature22011.
Bezuidenhout, L.M., S. Leonelli, A.H. Kelly, and B. Rappert. 2017. Beyond the digital divide: Towards a situated approach to open data. Science and Public Policy 44: 464–475. https://doi.org/10.1093/scipol/scw036.
Bohra, A., K.C. Bansal, and A. Graner. 2022. The 3366 chickpea genomes for research and breeding. Trends in Plant Science 27: 217–219. https://doi.org/10.1016/j.tplants.2021.11.017.
Bond, M.R., and D. Scott. 2020. Digital biopiracy and the (dis)assembling of the Nagoya Protocol. Geoforum. https://doi.org/10.1016/j.geoforum.2020.09.001.
Bonneuil, C. 2019. Seeing nature as a ‘universal store of genes’: How biological diversity became ‘genetic resources’, 1890–1940. Studies in History and Philosophy of Science Part C: Studies in History and Philosophy of Biological and Biomedical Sciences. https://doi.org/10.1016/j.shpsc.2018.12.002.
Brinton, J., R.H. Ramirez-Gonzalez, J. Simmonds, L. Wingen, S. Orford, S. Griffiths, et al. 2020. A haplotype-led approach to increase the precision of wheat breeding. Communications Biology 3: 712. https://doi.org/10.1038/s42003-020-01413-2.
Brozynska, M., A. Furtado, and R.J. Henry. 2016. Genomics of crop wild relatives: Expanding the gene pool for crop improvement. Plant Biotechnology Journal 14: 1070–1085. https://doi.org/10.1111/pbi.12454.
Carroll, S.R., E. Herczog, M. Hudson, K. Russell, and S. Stall. 2021. Operationalizing the CARE and FAIR principles for indigenous data futures. Scientific Data 8: 108. https://doi.org/10.1038/s41597-021-00892-0.
Castañeda-Álvarez, N.P., K.K. Colin, H.A. Achicanoy, V. Bernau, H. Dempewolf, R.J. Eastwood, L. Guarino, et al. 2016. Global conservation priorities for crop wild relatives. Nature Plants 2: 16022. https://doi.org/10.1038/nplants.2016.22.
CBD. 2002. Global strategy plan for conservation. https://www.cbd.int/doc/meetings/cop/cop-09/media/cop9-press-kit-gspc-en.pdf. Accessed 10 Jan 2023.
CBD/COP/DEC/XIII/16. 2016. The decision adopted by the conference of the parties to the convention on biological diversity. https://www.cbd.int/decisions/. Accessed 10 Jan 2023.
CBD-NP Nagoya Protocol. 2010. https://www.cbd.int/abs/. Accessed 10 Jan 2023.
Chadwick, R., and S. Wilson. 2004. Genomic databases as global public goods? Res Publica 10: 123–134. https://doi.org/10.1023/B:RESP.0000034637.15364.11.
Chari, R., and G.M. Church. 2017. Beyond editing to writing large genomes. Nature Reviews Genetics 18: 749–760. https://doi.org/10.1038/nrg.2017.59.
Chaudhari, N.M., V.K. Gupta, and C. Dutta. 2016. BPGA- an ultra-fast pan-genome analysis pipeline. Scientific Reports 6: 24373. https://doi.org/10.1038/srep24373.
Cheng, S., M. Melkonian, S.A. Smith, S. Brockington, J.M. Archibald, P. Delaux, F. Li, et al. 2018. 10KP: A phylodiverse genome sequencing plan. GigaScience 7: 013. https://doi.org/10.1093/gigascience/giy013.
Cozzuto, L., H. Liu, L.P. Pryszcz, T. Hermoso Pulido, A. Delgado-Tejedor, J. Ponomarenko, and E.M. Novoa. 2020. MasterOfPores: A workflow for the analysis of Oxford nanopore direct RNA sequencing datasets. Frontiers in Genetics 11: 211. https://doi.org/10.3389/fgene.2020.00211.
Curry, H.A. 2017. Breeding uniformity and banking diversity: The genescapes of industrial agriculture, 1935–1970. Global Environment 10: 83–113. https://doi.org/10.3197/ge.2017.100104.
Curry, H.A. 2022. The history of seed banking and the hazards of backup. Social Studies of Science 52: 664–688. https://doi.org/10.1177/03063127221106728.
Della, C., R.Y. Qiu, S. Ou, M.B. Hufford, and C.N. Hirsch. 2021. How the pan-genome is changing crop genomics and improvement. Genome Biology 22: 3. https://doi.org/10.1186/s13059-020-02224-8.
Dempewolf, H., G. Baute, J. Anderson, B. Kilian, C. Smith, and L. Guarino. 2017. Past and future use of wild relatives in crop breeding. Crop Science 57: 1070. https://doi.org/10.2135/cropsci2016.10.0885.
Erlich, Y. 2015. A vision for ubiquitous sequencing. Genome Research 25: 1411–1416. https://doi.org/10.1101/gr.191692.115.
Esquinas-Alcázar, J. 2005. Science and society: Protecting crop genetic diversity for food security: Political, ethical and technical challenges. Nature Reviews Genetics 6: 946–953. https://doi.org/10.1038/nrg1729.
FAO. 2010. The second report on the state of the world’s plant genetic resources for food and agriculture. Rome. https://www.fao.org/agriculture/crops/thematic-sitemap/theme/seeds-pgr/sow/sow2/en/. Accessed 10 Jan 2023.
FAO. 2011. Second global plan of action for plant genetic resources for food and agriculture. Rome. https://www.fao.org/policy-support/tools-and-publications/resources-details/en/c/453631/. Accessed 10 Jan 2023.
FAO. 2014. Genebank standards for plant genetic resources for food and agriculture. https://www.fao.org/agriculture/crops/thematic-sitemap/theme/seeds-pgr/gbs/en/. Accessed 10 Jan 2023.
Fenzi, M., and C. Bonneuil. 2016. From “genetic resources” to “ecosystems services”: A century of science and global policies for crop diversity conservation. Culture, Agriculture, Food and Environment 38: 72–83. https://doi.org/10.1111/cuag.12072.
Frison, C. 2018. Redesigning the global seed commons law and policy for agrobiodiversity and food security. London: Routledge.
Gaffney, J., D. Girma, N.A. Kane, V. Llaca, E. Mace, N. Taylor, and R. Tibebu. 2022. Maximizing value of genetic sequence data requires an enabling environment and urgency. Global Food Security 33: 100619. https://doi.org/10.1016/j.gfs.2022.100619.
Gao, S., J. Wu, J. Stiller, Z. Zheng, M. Zhou, Y. Wang, and C. Liu. 2020. Identifying barley pan-genome sequence anchors using genetic mapping and machine learning. Theoretical and Applied Genetics. 133: 2535–2544. https://doi.org/10.1007/s00122-020-03615-y.
Gebhardt, C. 2013. Bridging the gap between genome analysis and precision breeding in potato. Trends in Genetics 29: 248–256. https://doi.org/10.1016/j.tig.2012.11.006.
Glaszmann, J.C., B. Kilian, H.D. Upadhyaya, and R.K. Varshney. 2010. Accessing genetic diversity for crop improvement. Current Opinion in Plant Biology 13: 167–173. https://doi.org/10.1016/j.pbi.2010.01.004.
Golicz, A.A., J. Batley, and D. Edwards. 2016. Towards plant pangenomics. Plant Biotechnology Journal 14: 1099–1105. https://doi.org/10.1111/pbi.12499.
Guignon, V., A. Toure, G. Droc, J. Dufayard, M. Conte, and M. Rouard. 2020. GreenPhylDB v5: A comparative pangenomic database for plant genomes. Nucleic Acids Research. https://doi.org/10.1093/nar/gkaa1068.
Halewood, M., T. Chiurugwi, R. Sackville Hamilton, B. Kurtz, E. Marden, E. Welch, F. Michiels, et al. 2018a. Plant genetic resources for food and agriculture: Opportunities and challenges emerging from the science and information technology revolution. The New Phytologist 217: 1407–1419. https://doi.org/10.1111/nph.14993.
Halewood, M., I. Lopez Noriega, D. Ellis, C. Roa, M. Rouard, and R. Sackville Hamilton. 2018b. Using genomic sequence information to increase conservation and sustainable use of crop diversity and benefit-sharing. Biopreservation and Biobanking 16: 368–376. https://doi.org/10.1089/bio.2018.0043.
Harlan, J.R. 1975. Our vanishing genetic resources. Science (New York) 188: 617–621. https://doi.org/10.1126/science.188.4188.617.
Hartmann Scholz, A., M. Lange, P. Habekost, P. Oldham, I. Cancio, G. Cochrane, and J. Freitag. 2021. Myth-busting the provider-user relationship for digital sequence information. GigaScience 10: 085. https://doi.org/10.1093/gigascience/giab085.
Hawkes, J.G. 2002. The evolution of plant genetic resources and the work of O.H. Frankel. In Managing plant genetic diversity, ed. A.H.D. Brown, J. Engels, M. Jackson, and V. Ramanatha Rao, 520. Wallingford: CABI Press.
Hendre, P.S., S. Muthemba, R. Kariba, A. Muchugi, Y. Fu, Y. Chang, B. Song, et al. 2019. African Orphan Crops Consortium (AOCC): Status of developing genomic resources for African orphan crops. Planta 250: 989–1003. https://doi.org/10.1007/s00425-019-03156-9.
Hurgobin, B., and D. Edwards. 2017. SNP discovery using a pangenome: Has the single reference approach become obsolete? Biology 6: 21. https://doi.org/10.3390/biology6010021.
ITPGRFA. 2004. International treaty on plant genetic resources for food. FAO. https://www.fao.org/plant-treaty/en/. Accessed 10 Jan 2023.
Jarvis, D.I., A.H.D. Brown, P.H. Cuong, L. Collado-Panduro, L. Latournerie-Moreno, S. Gyawali, T. Tanto, et al. 2008. A global perspective of the richness and evenness of traditional crop-variety diversity maintained by farming communities. Proceedings of the National Academy of Sciences 105: 5326–5331. https://doi.org/10.1073/pnas.0800607105.
Jayakodi, M., S. Padmarasu, G. Haberer, V.S. Bonthala, H. Gundlach, C. Monat, T. Lux, et al. 2020. The barley pan-genome reveals the hidden legacy of mutation breeding. Nature. https://doi.org/10.1038/s41586-020-2947-8.
Kelly, S. 2019. Editorial overview: Harvesting the fruits of plant genomics. Current Opinion in Plant Biology 48: A1–A2. https://doi.org/10.1016/j.pbi.2019.05.001.
Kersey, P.J. 2019. Plant genome sequences: Past, present, future. Current Opinion in Plant Biology 48: 1–8. https://doi.org/10.1016/j.pbi.2018.11.001.
Khan, A.W., V. Garg, M. Roorkiwal, A.A. Golicz, D. Edwards, and R.K. Varshney. 2020. Super-pangenome by integrating the wild side of a species for accelerated crop improvement. Trends in Plant Science 25: 148–158. https://doi.org/10.1016/j.tplants.2019.10.012.
Kono, N., and K. Arakawa. 2019. Nanopore sequencing: Review of potential applications in functional genomics. Development, Growth & Differentiation 61: 316–326. https://doi.org/10.1111/dgd.12608.
Laird, S., R. Wynberg, M. Rourke, F. Humphries, M. Ruiz Muller, and C. Lawson. 2020. Rethink the expansion of access and benefit sharing. Science 367: 1200–1202. https://doi.org/10.1126/science.aba9609.
Latour, B. 1993. We have never been modern. Harvard: Harvard University Press.
Leclerc, C., and G. Coppens d’Eeckenbrugge. 2011. Social organization of crop genetic diversity. The G × E × S interaction model. Diversity 4: 1–32. https://doi.org/10.3390/d4010001.
Lendemer, J., B. Thiers, A.K. Monfils, J. Zaspel, E.R. Ellwood, A. Bentley, K. LeVan, et al. 2020. The extended specimen network: A strategy to enhance US biodiversity collections, promote research and education. BioScience 70: 23–30. https://doi.org/10.1093/biosci/biz140.
Lewin, H.A., G.E. Robinson, W.J. Kress, W.J. Baker, J. Coddington, K.A. Crandall, Richard Durbin, et al. 2018. Earth BioGenome Project: Sequencing life for the future of life. Proceedings of the National Academy of Sciences of the United States of America 115: 4325–4333. https://doi.org/10.1073/pnas.1720115115.
Liang, Z., S. Duan, J. Sheng, S. Zhu, X. Ni, J. Shao, C. Liu, et al. 2019. Whole-genome resequencing of 472 Vitis accessions for grapevine diversity and demographic history analyses. Nature Communications 10: 1190. https://doi.org/10.1038/s41467-019-09135-8.
Liu, H., J. Wei, T. Yang, W. Mu, B. Song, T. Yang, Y. Fu, et al. 2019. Molecular digitization of a botanical garden: High-depth whole genome sequencing of 689 vascular plant species from the Ruili Botanical Garden. GigaScience. https://doi.org/10.1093/gigascience/giz007.
Louafi, S., M. Thomas, E.T. Berthet, F. Pélissier, K. Vaing, F. Jankowski, D. Bazile, J. Pham, and M. Leclercq. 2021. Crop diversity management system commons: Revisiting the role of genebanks in the network of crop diversity actors. Agronomy 11: 1893. https://doi.org/10.3390/agronomy11091893.
Lu, F., M.C. Romay, J.C. Glaubitz, P.J. Bradbury, R.J. Elshire, T. Wang, Y. Li, et al. 2015. High-resolution genetic mapping of maize pan-genome sequence anchors. Nature Communications 6: 6914. https://doi.org/10.1038/ncomms7914.
MacPherson, J., A. Voglhuber-Slavinsky, M. Olbrisch, P. Schöbel, E. Dönitz, I. Mouratiadou, and K. Helming. 2022. Future agricultural systems and the role of digitalization for achieving sustainability goals. A review. Agronomy for Sustainable Development 42: 70. https://doi.org/10.1007/s13593-022-00792-6.
Marks, R.A., S. Hotaling, P.B. Frandsen, and R. VanBuren. 2021. Representation and participation across 20 years of plant genome sequencing. Nature Plants 7: 1571–1578. https://doi.org/10.1038/s41477-021-01031-8.
Mascher, M., M. Schreiber, U. Scholz, A. Graner, J.C. Reif, and N. Stein. 2019. Genebank genomics bridges the gap between the conservation of crop diversity and plant breeding. Nature Genetics 51: 1076–1081. https://doi.org/10.1038/s41588-019-0443-6.
McCouch, S.R., G.J. Baute, J. Bradeen, P. Bramel, P.K. Bretting, E. Buckler, J.M. Burke, et al. 2013. Agriculture: Feeding the future. Nature 499: 23–24. https://doi.org/10.1038/499023a.
McCouch, S.R., K.L. McNally, W. Wang, and R. Sackville Hamilton. 2012. Genomics of gene banks: A case study in rice. American Journal of Botany 99: 407–423. https://doi.org/10.3732/ajb.1100385.
Monat, C., M. Schreiber, N. Stein, and M. Mascher. 2019. Prospects of pan-genomics in barley. Theoretical and Applied Genetics 132: 785–796. https://doi.org/10.1007/s00122-018-3234-z.
Montenegro, J.D., A.A. Golicz, P.E. Bayer, B. Hurgobin, H. Lee, C.K. Chan, P. Visendi, et al. 2017. The pangenome of hexaploid bread wheat. The Plant Journal 90: 1007–1013. https://doi.org/10.1111/tpj.13515.
Montenegro de Wit, M. 2017. Stealing into the wild: Conservation science, plant breeding and the makings of new seed enclosures. The Journal of Peasant Studies 44: 169–212. https://doi.org/10.1080/03066150.2016.1168405.
Nehring, R. 2022. Digitising biopiracy? The global governance of plant genetic resources in the age of digital sequencing information. Third World Quarterly 43: 1970–1987. https://doi.org/10.1080/01436597.2022.2079489.
Nguyen, G.N., and S.L. Norton. 2020. Genebank phenomics: A strategic approach to enhance value and utilization of crop germplasm. Plants 9: 817. https://doi.org/10.3390/plants9070817.
Ostrom, E. 1999. Polycentricity, complexity, and the commons. The Good Society 2: 37–41.
Paton, A., A. Antonelli, M. Carine, R. Campostrini Forzza, N. Davies, S. Demissew, G. Dröge, et al. 2020. Plant and fungal collections: Current status, future perspectives. Plants, People, Planet 2: 499–514. https://doi.org/10.1002/ppp3.10141.
Peres, S. 2016. Saving the gene pool for the future: Seed banks as archives. Studies in History and Philosophy of Science Part C: Studies in History and Philosophy of Biological and Biomedical Sciences 55: 96–104. https://doi.org/10.1016/j.shpsc.2015.09.002.
Pilling, D., J. Bélanger, and I. Hoffmann. 2020. Declining biodiversity for food and agriculture needs urgent global action. Nature Food 1: 144–147. https://doi.org/10.1038/s43016-020-0040-y.
Pistorius, R.J., and J.C. van Wijk. 1999. The exploitation of plant genetic information: Political strategies in crop development. Thesis, fully internal, Universiteit van Amsterdam, Netherlands.
Reiser, L., L. Harper, M. Freeling, B. Han, and S. Luan. 2018. FAIR: A call to make published data more findable, accessible, interoperable, and reusable. Molecular Plant 11: 1105–1108. https://doi.org/10.1016/j.molp.2018.07.005.
Rohden, F., S. Huang, G. Dröge, and A. Hartman Scholz. 2019. Combined study on DSI in public and private databases and DSI traceability. https://www.cbd.int/abs/DSI-peer/Study-Traceability-databases.pdf. Accessed 10 Jan 2023.
Scarascia-Mugnozza, G.T., and P. Perrino. 2002. The history of ex situ conservation and use of plant genetic resources. In Managing plant genetic diversity, ed. V.R. Rao, A.H.D. Brown, and M. Jackson, 520. Cambridge: CABI Press.
Schatz, M.C., L.G. Maron, J.C. Stein, A.H. Wences, J. Gurtowski, E. Biggers, H. Lee, et al. 2014. Whole genome de novo assemblies of three divergent strains of rice, Oryza sativa, document novel gene space of aus and indica. Genome Biology 15: 506. https://doi.org/10.1186/PREACCEPT-2784872521277375.
Schneeberger, K., J. Hagmann, S. Ossowski, N. Warthmann, S. Gesing, O. Kohlbacher, and D. Weigel. 2009. Simultaneous alignment of short reads against multiple genomes. Genome Biology 10: R98. https://doi.org/10.1186/gb-2009-10-9-r98.
Sharma, S., H.D. Upadhyaya, R.K. Varshney, and C.L.L. Gowda. 2013. Pre-breeding for diversification of primary gene pool and genetic enhancement of grain legumes. Frontiers in Plant Science 4: 309. https://doi.org/10.3389/fpls.2013.00309.
Shaw, J. 2016. Documenting genomics: Applying archival theory to preserving the records of the Human Genome Project. Studies in History and Philosophy of Science Part C: Studies in History and Philosophy of Biological and Biomedical Sciences 55: 61–69. https://doi.org/10.1016/j.shpsc.2015.08.005.
Stephens, Z.D., S.Y. Lee, F. Faghri, R.H. Campbell, C. Zhai, M.J. Efron, R. Iyer, M.C. Schatz, S. Sinha, and G.E. Robinson. 2015. Big data: Astronomical or genomical? PLoS Biology 13: e1002195. https://doi.org/10.1371/journal.pbio.1002195.
Stuermer, M., G. Abu-Tayeh, and T. Myrach. 2017. Digital sustainability: Basic conditions for sustainable digital artifacts and their ecosystems. Sustainability Science 12: 247–262. https://doi.org/10.1007/s11625-016-0412-2.
Sun, C., Z. Hu, T. Zheng, K. Lu, Y. Zhao, W. Wang, J. Shi, et al. 2017. RPAN: Rice pan-genome browser for ∼ 3000 rice genomes. Nucleic Acids Research 45: 597–605. https://doi.org/10.1093/nar/gkw958.
Tao, Y., X. Zhao, E. Mace, R. Henry, and D. Jordan. 2019. Exploring and exploiting pan-genomics for crop improvement. Molecular Plant 12: 156–169. https://doi.org/10.1016/j.molp.2018.12.016.
Thacker, E. 2005. The global genome. Boston: The MIT Press.
Ulian, T., M. Diazgranados, S. Pironon, S. Padulosi, U. Liu, L. Davies, M.R. Howes, et al. 2020. Unlocking plant resources to support food security and promote sustainable agriculture. Plants, People, Planet 2: 421–445. https://doi.org/10.1002/ppp3.10145.
United Nations. 2015. The sustainable development goals. https://sdgs.un.org/goals. Accessed 10 Jan 2023.
van Dooren, T. 2009. Banking seed: Use and value in the conservation of agricultural diversity. Science as Culture 18: 373–395. https://doi.org/10.1080/09505430902873975.
van Treuren, R., and T.J.L. van Hintum. 2014. Next-generation genebanking: Plant genetic resources management and utilization in the sequencing era. Plant Genetic Resources 12: 298–307. https://doi.org/10.1017/S1479262114000082.
Varshney, R.K., A. Bohra, J. Yu, A. Graner, Q. Zhang, and M.E. Sorrells. 2021. Designing future crops: Genomics-assisted breeding comes of age. Trends in Plant Science 26: 631–649. https://doi.org/10.1016/j.tplants.2021.03.010.
von Wettberg, E.J.B., P.L. Chang, F. Başdemir, N. Carrasquila-Garcia, L.B. Korbu, S.M. Moenga, G. Bedada, et al. 2018. Ecology and genomics of an important crop wild relative as a prelude to agricultural innovation. Nature Communications 9: 649. https://doi.org/10.1038/s41467-018-02867-z.
Walkowiak, S., L. Gao, C. Monat, G. Haberer, M.T. Kassa, J. Brinton, R.H. Ramirez-Gonzalez, et al. 2020. Multiple wheat genomes reveal global variation in modern breeding. Nature. https://doi.org/10.1038/s41586-020-2961-x.
Wambugu, P.W., M. Ndjiondjop, and R.J. Henry. 2018. Role of genomics in promoting the utilization of plant genetic resources in genebanks. Briefings in Functional Genomics 17: 198–206. https://doi.org/10.1093/bfgp/ely014.
Wang, W., R.M.Z. Hu, D. Chebotarov, S. Tai, Z. Wu, M. Li, et al. 2018. Genomic variation in 3,010 diverse accessions of Asian cultivated rice. Nature 557: 43–49. https://doi.org/10.1038/s41586-018-0063-9.
Williamson, H.F., and S. Leonelli. 2023. Cultivating responsible plant breeding strategies: Conceptual and normative commitments in data-intensive agriculture. In Towards responsible plant data linkage: Data challenges for agricultural research and development, ed. H.F. Williamson and S. Leonelli, 301–317. Cham: Springer.
Wynberg, R., R. Andersen, S. Laird, K. Kusena, C. Prip, and O.T. Westengen. 2021. Farmers’ rights and digital sequence information: Crisis or opportunity to reclaim stewardship over agrobiodiversity? Frontiers in Plant Science 12: 686728. https://doi.org/10.3389/fpls.2021.686728.
Ye, C., and L. Fan. 2021. Orphan crops and their wild relatives in the genomic era. Molecular Plant 14: 27–39. https://doi.org/10.1016/j.molp.2020.12.013.
Yuan, Y., P.E. Bayer, J. Batley, and D. Edwards. 2017. Improvements in genomic technologies: Application to crop genomics. Trends in Biotechnology 35: 547–558. https://doi.org/10.1016/j.tibtech.2017.02.009.
Zhao, Q., Q. Feng, H. Lu, Y. Li, A. Wang, Q. Tian, Q. Zhan, et al. 2018. Pan-genome analysis highlights the extent of genomic variation in cultivated and wild rice. Nature Genetics 50: 278–284. https://doi.org/10.1038/s41588-018-0041-z.
Zhu, H., C. Li, and C. Gao. 2020. Applications of CRISPR–Cas in agriculture and plant biotechnology. Nature Reviews Molecular Cell Biology 21: 661–677. https://doi.org/10.1038/s41580-020-00288-9.
Acknowledgements
The author would like to thank Emile Frison for his comments on the early version of the manuscript. The views and opinions expressed in this article are those of the author and do not necessarily reflect the official policies or positions of his affiliated institutions. My sincerest appreciation to the anonymous AHUM reviewers for comments and suggestions that strengthened my argument.
Funding
Open access funding provided by University of Zurich.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aubry, S. Genebanking plant genetic resources in the postgenomic era. Agric Hum Values 40, 961–971 (2023). https://doi.org/10.1007/s10460-023-10417-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10460-023-10417-7