
Abstract
For the provision of various ecosystem services in steep terrain, such as protection against natural hazards, a forest must be managed, which often requires the use of cable yarders. The design of a cable road is a complex and demanding task that also includes the search for appropriate support and anchor trees. The aim of this study was to evaluate whether and with what reliability potential support trees for cable yarding can be detected using remote sensing data. The detection of potential support trees was tested using 48 method combinations on 10 test plots of the Experimental Forest Management project in cable yarder terrain in the Swiss Alps in the Canton of Grisons. The most suitable method combinations used a Gaussian filter and a local maxima algorithm. On average, they had an extraction rate of 108.9–124.5% (root mean square, RMS) and a mean commission error of 66.0–67.2% (RMS). The correctly detected trees deviated horizontally by an average of 1.8 to 1.9 m from the position of the reference trees. The difference in tree heights was 1.1 to 1.6 m. However, for the application of single tree detection to support cable road planning in steep and complex terrain, too few potential support trees were detected. Nonetheless, the accuracy of the extracted tree parameters would already be sufficient for cable road planning.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
Introduction
Sustainable forest management includes not only the production of the raw material wood, but also the promotion of biodiversity and the provision of multiple important ecosystem services, such as recreational and leisure space, protection against gravity-induced natural hazards, drinking water provision, and carbon storage to mitigate the effects of climate change. To meet all of these demands, forest management is required. Especially in steep terrain, where forests fulfill major protective functions, forest operations can be very labor intensive, and dangerous at the same time, and are mostly carried out by cable- and air-based extraction methods. In Switzerland, cable yarders are used for extraction on about a quarter of the forest area (Brändli et al. 2020). The design of a cable yarder operation has to meet safety, economic and environmental framework conditions and is therefore a complex and demanding task. To simplify this process, several tools have been developed, such as those introduced by Chung et al. (2004), Bont and Heinimann (2012) and Dupire (2014). Most of the tools calculate a cable road layout according to several input parameters and propose the location and height of intermediate supports (e.g., Bont et al. 2022a, b). However, the workflows lack information about whether suitable trees, so-called support trees, on which a saddle and pully can be fixed, are actually available at the calculated positions. The suitability of a support tree depends on several criteria (Litscher and Rigling 1996): height, diameter at breast height (DBH), tree species, stability and vitality, orientation and inclination, anchoring characteristics, and position in the terrain. For gathering this missing information, remote sensing data might offer great potential.
Since the late 1980s, various approaches for the detection of individual trees from both orthophotos and airborne laser scanning (ALS) point clouds have been published. Probably the best-known detection method is local maximum detection, in which pixels in a canopy height model are identified as tree tops if they have the maximum height value in a defined neighborhood. Once the location of the local maximum is determined, the height above ground can be calculated. The reference value for ground level can be determined by a digital terrain model from remote sensing data. This detection method has been adapted and refined in several studies and combined with various filtering methods (Koch et al. 2006; Kaartinen et al. 2012; Eysn et al. 2015; Schardt et al. 2015). Recently, research has been conducted on new methods, such as clustering algorithms for isolating individual trees from point clouds (Parkan 2019), which, however, require data with a much higher resolution (> 70 points/m2) than needed with previous methods. In addition to tree position and tree height, various research studies have also been focused on other relevant parameters such as tree species (Holmgren and Persson 2004) and vitality (Hernández-Clemente et al. 2017).
Most of the detection methods have been developed for inventory purposes. Work dedicated specifically to identifying potential cable road support trees using remote sensing data is rare, because outside of Central Europe cable yarder use is geared toward clear-cutting operations. Thus, there are sufficient support trees in the usually even-aged stands and the logs can be dragged on the ground (Visser and Harril 2017; Bont and Church 2018). In Switzerland, where there is a long tradition of continuous cover forest management in Alpine forests, but also increasingly in other regions in Central Europe, stands are often smaller and more structured. In terms of climate change, foresters are further promoting structural diversity, similar to that found in the Swiss Alpine forests with mostly uneven-aged stands of mixed species. Therefore, it is more difficult to find stable support trees of the required strength and height. Dietsch et al. (2020) tested the use of drones for support tree detection. The results were promising, but obtaining drone data involves additional time and economic effort. Various remote sensing data sets, on the other hand, are open access and often cover a large area.
The aim of this study was to evaluate whether and to what degree of reliability potential support trees for cable-based forest operations can be detected using universal remote sensing data that cover a large area. The study focuses on three of the suitability criteria for support trees: position, height and strength (measured as DBH). For this purpose, the following research questions were formulated:
-
(i)
Which methods can be used to process remote sensing data to detect potential support trees in cable-based terrain?
-
(ii)
Which combinations of methods are best suited for the identification of potential support trees in terms of position, height and strength (DBH)?
-
(iii)
Is the accuracy of the extracted tree parameters sufficient for application in practice?
Material and methods
Study area
To reach the objective, a case study was conducted in the Swiss canton of Grisons. This canton, which is located in the Alps, was well suited because most of the timber is extracted by cable yarders. Further, uniform and comprehensive remote sensing data are freely available.
Various single tree detection methods were tested on 10 different test plots that belong to the Experimental Forest Management (EFM) project (Forrester et al. 2018). On these plots, the Swiss Federal Institute for Forest, Snow and Landscape Research (WSL) has been recording structure-relevant data, such as DBH and tree height, every 5–12 years for several decades, with some data collection occurring for the past 100 years. This seemed a useful data source to verify the results of the individual tree detection on the basis of the measured tree parameters.
All plots of the EFM project that were used in this study are located in the canton of Grisons, have a slope of at least 20 degrees, and are therefore relevant for management by cable yarder (N = 20). Some plots had to be excluded (N = 8) due to silvicultural measures or natural disturbances. In addition, very young stands were excluded (N = 2) because they did not provide potential support trees. Thus, 10 suitable test plots remained on which the single tree detection methods were applied (Fig. 1, Appendix). The plots are located between 620 and 1760 m above sea level (m a.s.l.) and range in area size from 0.21 to 1.22 ha. Most of the plots are multistage coniferous stands, with a few deciduous trees mixed in. Only one plot has a noteworthy proportion of hardwoods (16%).

Geographical location of the 10 test plots in the Swiss canton of Grisons © swisstopo 2021. Coordinate System EPSG 21,781
Data basis
Terrestrial data
During the data collection in the frame of the EFM project, all trees with DBH > 8 cm were recorded on each plot (N = 1954) (Forrester et al. 2018). In addition, the 100 largest trees in terms of DBH (indicated in the remaining manuscript as “largest trees (DBH)”) per hectare and 20% of all remaining trees were defined as sample trees (N = 453). With the exception of one beech tree (Fagus sylvatica), these were exclusively conifers, predominantly spruce (Picea abies). The heights of these trees were furthermore determined using a Vertex Laser GEO (Haglöfs, Sweden). The sample trees were measured using the horizontal distance and azimuth from different fixpoints, i.e., clearly identifiable landmarks both in the field and on the aerial photo or national map, with known coordinates. Individual tree coordinates were calculated and transformed into coordinates from the 1903 national survey (LV03, EPSG 21,781; Forrester et al. 2018). The horizontal precision of the differential global positioning system (DGPS) measurements of the tree positions was reported to range from 0.6 m to 6.2 m (mean = 1.6 m, standard deviation = 0.9 m, median = 1.5 m), depending on the test plot (Nitzsche and Stillhard 2018). For test plots with repeated exposures, only the exposures closest to the time of the collection of the remote sensing data were used.
Remote sensing data
Normalized airborne laser scanning (ALS) data from 2003 were available for the entire canton of Grisons (Artuso et al. 2003). The ALS point clouds have a density of 1–3 points per square meter. From this data set, canopy height models (CHM) with a resolution of 0.3 m × 0.3 m were calculated with the LiDAR processing software LAStools (Rapidlasso GmbH, Gilching, Germany) in two different ways: (i) without the pitfree algorithm of Khosravipour (2014) (CHM RawLi) and (ii) with the pitfree algorithm (CHM Pitfree). The pitfree algorithm attempts to remove pits in the canopy (Khosravipour 2014). These occur when laser signals do not hit the highest point of the vegetation, but penetrate deep into the vegetation before being reflected by a surface for the first time (Khosravipour 2014). Thus, two ALS-CHMs from 2003 in the coordinate system LV95 (EPSG 2056) were available as input data for the further investigations. The height accuracy of the ALS data has been given as ± 0.5 m (Artuso et al. 2003).
Detection of potential support trees
Selection of single tree detection methods
The method for extracting potential support trees had to be applicable to the forest structures in the Alpine region (Vauhkonen et al. 2011). In addition, it needed to be designed for the appropriate tree species mixtures, as well as for slope gradients greater than 20 degrees (Wauer and Hamberger 2010). For support trees in yarding operations, the co- and especially predominant stable trees are of interest. Smaller trees and trees in the lower canopy layer, on the other hand, do not need to be detected. Accordingly, the method should detect the co- and predominant trees as accurately as possible. To ensure that the method can be easily applied in practice, it should be suitable for data available over large areas and require a practicable computation time. Last but not least, the method should be able to be further developed so that it can be adapted to the presumably rapidly changing technical advances.
To identify suitable methods for processing remote sensing data, single tree detection was divided into the three processing steps: (1) deriving CHMs from ALS data (data basis), (2) filtering the CHMs (filtering method), and (3) detecting the single trees (detection method). The literature search for these three processing steps led to an extensive collection of methods and findings. For the data processing steps, seven filtering and three detection methods were selected that meet the above-mentioned requirements for cable road design. Together with the two data processing variants (Sect. 2.2.2), this resulted in 48 possible combinations (Fig. 2). They were named according to the processing steps: detection method, filtering method and data basis. Their abbreviations are listed in Fig. 2 and described in Tables 1 and 2.

The selected processing steps from the areas of data basis, filtering method and detection method. A total of 48 combinations of methods is possible
Programming of selected methods and DBH calculation
The individual processing steps were programmed separately in Python 3.7 (Python Software Foundation 2018) to allow automated testing of different combinations of the methods. The CHMs were smoothed by means of filters. Based on the smoothed CHMs, individual trees were detected and tree heights were determined. The basic assumption of all detection methods is that the top of a single tree shows up as a local maximum in the CHM and the value of the CHM in the detected grid cell corresponds to the tree height. The respective python scripts have been released under the GNU General Public License v3.0 and can be downloaded freely from github (Ramstein 2021).
The DBH of the trees was determined using an allometric function. The parameters of the function were estimated from the terrestrial measurements using linear regression in R v3.5.1 (R Core Team 2017). Thus, only the conifer data were used. The best model was obtained using a logarithm transformation (Eq. 1 and Appendix). To prevent overfitting, the models were also evaluated using leave-one-out cross-validation and PRESS statistics (Allen 1974). The estimated parameters had values of a = 8.7965 × 10–1, b = 0.2056 × 10–4, and c = 3.0306. The response variable was transformed during model building. To avoid biased estimates of the mean value (“back transformation bias”), we applied a correction according to Flewelling and Pienaar (1981). Therefore, the parameter c is composed of the intercept and the mean square error/2 of the log-transformed model.
DBH: diameter at breast height in mm, H: tree height in m.
Suitability of the different combinations of methods
In order to determine which data processing method is most suitable for the detection of potential support trees, the single tree detection on the 10 test plots was performed using different combinations of methods. Each combination of methods included all three processing steps (data preparation, filtering method and detection method; see Fig. 2). All 48 technically possible combinations of methods were implemented. The results of all combinations of methods were then compared with the field data.
The assignment procedure according to Eysn et al. (2015) was used to assess whether the local maxima correspond to the sample trees. All sample trees above a certain tree height were included in the analysis (hereafter referred to as reference trees). The threshold for tree height varied between 20 and 29 m depending on the site, as only the 100 largest trees (DBH) per hectare were measured (Appendix). A total of N = 369 reference trees were included in the validation. Similar to Eysn (2015), detected trees were assigned to the reference trees according to two criteria: (1) a maximum horizontal distance of 3 m (between the detected tree and the reference tree) and (2) a maximum tree height difference of 5 m. If multiple trees met these two criteria, the closest tree in horizontal distance was assigned. A correctly detected tree was thus a maximum of 3 m away (horizontal distance) from the associated reference tree (hereafter referred to as assigned reference tree) and was a maximum of 5 m shorter or taller than the assigned reference tree (Appendix).
To compare the 48 combinations of methods, the same metrics were calculated as in Eysn et al. (2015) (Table 3 and Appendix). The average value (AVG) of all 10 test plots was assessed for each method combination. In addition, the standard deviation (STD) and root mean square (RMS, Formula 2) of each metric were calculated to assess the dispersion of the values and to ensure comparability with results from other studies.
xi: metric value (e.g., ER, MR, OE, CE) on test plot i, n: number of test plots.
The evaluation of the combinations of methods was based on the two metrics extraction rate and commission error. The extraction rate should be as close to 100% (RMS) as possible. A lower extraction rate means that many potential support trees were not captured. A higher extraction rate means that many additional but nonexistent trees would have been detected. The second metric assessed was the commission error (Table 3), which should be as low as possible. Since the proportion of unfeasible cable roads should be reduced as much as possible, a small commission error is more important than a small omission error (Table 3), i.e., it is better if the method detects no trees instead of false trees.
Accuracy of extracted tree parameters
In order to assess the accuracy of the extracted tree parameters of the most appropriate combinations of methods, the parameters tree height difference and distance between the positions of the correctly detected trees and their assigned reference trees were calculated (Appendix). To evaluate the results, the uncertainties associated with the data basis were estimated and the practicality of the results was discussed with forest practitioners.
Results
Detection of potential support trees
The most suitable combinations of methods were derived based on the average extraction rates and commission errors (averaged over all plots). Combinations with higher extraction rates tended to have higher commission errors and vice versa (Fig. 3). The combinations of methods with an extraction rate (RMS) close to 100% all included the detection method LM1 (Fig. 3C). They did not have the lowest commission error (RMS), but values were not more than 5–10% higher than the lowest values. The lowest commission errors (RMS) resulted from combinations of methods with a very low extraction rate (RMS) of around 30%. These results lead to the conclusion that the following four combinations of methods (referred to hereafter as “selected best method combinations”) are best suited for the identification of potential support trees:
-
Pitfree – F3 – LM1
-
RawLi – F3 – LM1
-
Pitfree – F1 – LM1
-
RawLi – F1 – LM1

Each point shows the extraction rate and the commission error of one combination of methods averaged over all test plots once evaluated according to the data basis (A), the filtering method (B), the detection method (C), and the selection of the best method combinations (D)
Using the combinations of the above-listed methods, an extraction rate (RMS) of 108.9–124.6% was achieved, which means that more trees were detected than exist in reality (Table 4). The commission error (RMS) was around 65%. Hence, about 65% of the detected trees were not assigned to a reference tree in all four of the above-listed combinations.
Other combinations of methods led to significantly worse extraction rates of < 34% (RMS) and > 142% (RMS), with the most extreme values resulting from the filtering methods F5 and F7. In combination with the data basis RawLi and the detection method LM2, these two filtering methods achieved the highest extraction rates and commission errors (extraction rate 1819.8% (RMS) for F5 and 1947.3% (RMS) for F7, commission error 93.6% (RMS) for F5 and 94.2% (RMS) for F7; Table 4).
Accuracy of extracted tree parameters
The positions of the correctly detected trees deviated, on average over all plots and methods, by 1.7 m from the positions of the assigned reference trees (Fig. 4). The tree height differences were, on average over all plots and methods, 1–1.5 m and thus mostly positive, i.e., the heights of the assigned reference trees tended to be underestimated by the CHM or overestimated by the terrestrial measurements. This shows the same effect as the comparison of the tree heights derived from the CHM and the sample trees (Appendix). The DBH differences were also predominantly positive and the mean value of the differences varied between − 14 and + 7 cm (Fig. 4). The results of the different detection methods show a similar scattering of positional accuracy, tree height difference and DBH difference.

(top panel) Each point represents the difference between the terrestrially measured tree height or position and the tree height or position derived from the canopy height model (CHM). The tree height differences and the distances between the detected trees and their assigned reference trees have been averaged over all test plots per combination of methods. (bottom panel) Each point represents the difference between the terrestrially measured tree height or DBH and the tree height or calculated DBH derived from the CHM. The differences between the measured and calculated tree heights, as well as between the measured and calculated DBH, are mostly positive
The four selected best method combinations (Table 4) did not have the best tree height and position accuracies compared with the other combinations of methods. They detected the trees with an average positional accuracy of 1.8–1.9 m and an average difference from the assigned reference tree heights of 1.1 m to 1.6 m (Table 5). The deviation of the calculated DBH was, on average, between 3.1 cm and 4.0 cm (Table 5). The standard deviations hardly differed among the four best combinations of methods: 2 m for tree height difference, 0.7 m for positional accuracy, and 8.9–9.5 cm for DBH difference.
Discussion
Detection of potential support trees
To enhance the comparability of the results, the assignment process was based on the conditions of the study by Eysn et al. (2015). A correctly detected tree is < 3 m away (horizontal distance) from the assigned reference tree and < 5 m taller or shorter than the assigned reference tree. These assignment conditions have a great influence on whether a detected tree is assigned to a reference tree and judged as correctly detected or not. Inaccuracies in the terrestrial measurements and remote sensing data (Appendix), as well as variability in the terrain conditions, can further complicate the assignment, e.g., effects of the terrain slope or heterogenous forest structures.
The slope, which is usually at least 20 degrees in cable yarder terrain, can influence the assignment of the detected trees to the reference trees. Depending on the slope and the crown shape of the tree, the tree top may be shifted in relation to the trunk position (Khosravipour et al. 2015). ALS points that are slightly upslope or downslope from the tree top are height-normalized with a digital elevation model pixel value that may be significantly higher or lower than the base of the trunk. Therefore, Khosravipour et al. (2015) suggested performing single tree detection with a digital surface model (DSM) and then reading the tree heights from the CHM. This displacement between the base of the trunk and the top of the tree may occur as a result of factors other than terrain slope and crown shape. Sloping trees are not uncommon in steep, mountainous terrain. When located at the edge of a test plot, the base of the trunk can be inside and the top of the tree outside the plot, or vice versa. It is therefore possible that a reference tree with the base of its trunk just inside the test plot (but the top outside) is not assigned to a detected tree, although it would actually have been detected correctly. The opposite situation leads to a correctly detected tree not being assigned to a reference tree. Furthermore, the stand structure of alpine forests with groups of trees is difficult to capture: if tree tops are intergrown, they cannot be clearly distinguished in the CHM and thus cannot be detected by means of the algorithm.
Due to the influencing factors mentioned above, it is very likely that some correctly detected trees were not assigned to a reference tree in our study. Applying a larger tolerance range, such as increasing the maximum horizontal distance to 5 m, led to better results. Thus, the four most suitable combinations of methods with a maximum horizontal distance of 5 m showed a slightly higher extraction rate (113.7–130.0% (RMS); Appendix) and a significantly lower commission error (49.2–53.0% (RMS); Appendix). A larger tolerance range, however, increases the chance that incorrectly detected trees are assigned to a different reference tree with a randomly similar tree height. For an improved assignment, the assignment process must be refined or a verification in the field must be carried out.
In this study, available remote sensing data were used as input for the detection measurements. Most areas of Switzerland have ALS data of varying quality. With the software LAStools, ALS-based CHMs could be created with different processing variants. The results based on the two ALS CHMs (without pitfree/with pitfree) differ only slightly, i.e., they are suitable for single tree detection to a similar extent. One possible reason for this is the filtering of the CHM before the single tree detection, which reduces the effect of the pitfree algorithm.
The best combinations of methods were achieved with the filtering methods F1 and F3, which smooth the CHM with a Gaussian filter dependent on the image resolution (Menk et al. 2017) and a closing filter with subsequent Gaussian filtering (Eysn et al. 2015). On the other hand, the filtering methods F5 and F7 performed poorly. The filtering method F5 smoothed the CHM with a closing filter without a subsequent Gaussian filter. The morphological filter creates plateaus of pixels with equal height values, which means that a tree is defined by a plateau with maximum values. Since the detection method LM2 finds all pixels with maximum height values, many neighboring pixels are defined as local maxima for each tree. This problem can be addressed either with an additional filtering stage comparable to filtering method F3 or with crown segmentation. In the latter method, individual crowns are first identified, e.g., with morphological operations, and then the local maxima are searched for within the crown polygons. Filtering method F7 (Kaartinen et al. 2012), which also uses a Gaussian filter, may have performed worse in our case because the associated detection method was replaced in this study with the three detection methods LM1, LM2 and LM3.
The results indicate that a filter is necessary for a meaningful detection result. At least for the remote sensing data and resolutions used here, the combinations of methods without filtering achieved significantly worse values than the best combination of methods (extraction rate 108.8 to 124.6 (RMS) with filter and 146.6 to 162.8 (RMS) without filter; Appendix). This is in line with the results from Menk et al. (2017), who showed that CHMs with a resolution higher than 1 m × 1 m achieved the best results with filtering (in our study we used only one resolution of 0.3 m × 0.3 m). In the pursuit of increasingly detailed data, this effect should be taken into account and the choice of method adapted. Classical single tree detection methods developed for lower resolutions give poorer results for input data with higher resolutions, as the higher resolution increases local heterogeneity (Jakubowski et al. 2013). Greater heterogeneity further complicates the problem of choosing the window size for the maxima search, an issue that is well known in the literature. Jakubowski et al. (2013) therefore proposed a change from pixel-based to object-based image analysis. Besides applying a filtering method adapted to the resolution of the input file, using the right combination of filtering and detection methods is certainly crucial for successful detection.
The statistical values of the combinations of methods evaluated in our study are similar to the values reported by Eysn et al. (2015). For all methods considered, the study by Eysn et al. (2015) gave an average match rate of 47% (RMSE), an average extraction rate of 95% (RMS), an average commission error of 60% (RMS), and an average omission error of 57% (RMS). Eysn et al. (2015) reported mean accuracies of 1.7 m (RMS) for tree position and 1.0 m for tree height. In the study by Eysn et al. (2015), as in the present study, the detection and allocation of trees was made challenging by steep slopes and heterogenous forest structures. Nevertheless, it must be noted that the values are, in our opinion, not yet sufficient for accurate cable road design in practice. On average, the methods detected < 50% of the reference trees. This means that in practice, too many potential support trees would be ignored or – even more unfavorable – trees that are too small or too thin to be suitable as support trees could be indicated as potential support trees.
In addition, the suitability of a tree as a support tree depends on factors other than position, DBH and tree height. Some of the other safety features defined by the Swiss National Accident Insurance Fund (Litscher and Rigling 1996), such as tree species, vitality, orientation and inclination, could also be read from remote sensing data. In further research, the code used in the present study could be refined and extended with methods for, e.g., tree species detection. This would further restrict the possible suitable support trees. Nevertheless, analyses from remote sensing data can never replace in-field inspection for deciding if a tree is stable enough for use as a support tree.
Accuracy of extracted tree parameters
In addition to the influencing factors discussed in the previous sections, the accuracy of the various derived parameters is crucial for cable road design. For the most suitable combinations of methods, the parameter tree position has, in relation to the cable yarder technique, a reasonable accuracy, with a mean deviation of 1.8–1.9 m (± 0.7 m). According to various forestry experts, a support tree that is 2–3 m away from the cable road can still be used as a support tree (Ken Flury and Fritz Frutig, personal communication, 27 Nov 2019 and 05 Dec 2019). The error in terrestrially measured tree positions is in a similar range and could explain the observed differences (Sect. 2.2.1). The parameter tree height is relevant for cable road design because tree height can be used for DBH estimation. The correlation between tree height and DBH depends on many factors, such as species, tree vitality and silvicultural measures, and the derived DBH can therefore only be used as a rough estimate. The inaccuracy in DBH estimation due to a 1 to 2 m inaccuracy in height measurement is, in our opinion, smaller than that caused by the inaccuracy of the allometric function. If, as in Pestal (1961) for example, one assumes an increase in DBH of one cm per one meter of additional tree height, then the error is 1 to 2 cm. More recent research (e.g., Sharma and Breidenbach 2015; Sharma et al. 2019; Ciceu et al. 2020) approximately confirms the assumption made by Pestal, but also points out that stem shape diameter varies more than the error caused by inaccurate height measurement. Height deviations in the range of 1 to 2 m could also have been caused by inaccuracies in the terrestrial tree height measurement. For example, the direction of the measurement and the view of the tree top influence the accuracy. Hirschmugl (2008) therefore suggested using devices for terrestrial tree height measurements with a tolerance of 5% for spruce trees and 10% for pine and deciduous trees. The accuracy of the derived DBH is also sufficient for cable road design. The diameter at the desired support saddle height (also sometimes referred to as jack or cable shoe height), which should be at least 30 cm according to Pestal (1961), is estimated based on the DBH using a rule of thumb widely used in forestry (minus 1 cm diameter per meter tree height; Pestal 1961). Deviations of about 3 cm in the DBH would thus correspond to a difference in saddle height of about 3 m.
Inaccuracies in the DBH are caused by the different allometric relationships of the various tree species. A prior tree species classification of the detected trees would make it possible to use a DBH formula adapted to the species of each individual tree. A second possibility to improve the DBH prediction accuracy could be to use tailored taper equations of a tree species in a certain area, such as described in Brassel and Lischke (2001). A third option could be the direct calculation of DBH via stem detection from 3D point clouds. Various algorithms can already isolate individual trees and tree trunks from point clouds, provided the ALS data have a sufficiently high point density (Lamprecht et al. 2015; Parkan 2019). This allows tree trunks to be abstracted in 3D based on the isolated point clouds. The accuracy of the extracted tree parameters thus meets the requirements of cable road design.
Conclusion
Single tree detection is used for a wide range of forestry problems in science and practice. In this study, we evaluated whether and to what extent selected methods for the detection of single trees from remote sensing data can support the cable road design process. Specifically, we investigated whether potential support trees, used for multi-span cable-yarding configurations, could be identified. This would support the whole design process, though notably cannot replace in-field inspections to assess trees visually.
Our study shows that the selected method combinations using a Gaussian filter and detecting the local maxima, or tree tops, were most suitable to detect potential support trees on the alpine test plots. The accuracy of these method combinations in extracting tree parameters is considered sufficient for application in cable road design. However, too few potential support trees were detected with the methods analyzed here.
In future research projects, the combinations of methods analyzed here could be further refined by developing models for different forest types. The forest types could differ, for example, in terms of elevation, slope, proportion of deciduous trees, and structure. Parameters that can be derived from remote sensing data and transferred to a model could be considered. Another possibility would be to create a small-scale dominant height and stem number map. This would give an indication of whether there is a selection of trees with a certain height in the area of the optimal support position for a planned cable road. The difficulty with the positional accuracy of the potential support trees would thus be eliminated. Last but not least, drone data could be used as a data basis instead of ALS point clouds (Dietsch et al. 2020). Drones can be used in steep, inaccessible and remote locations and thus provide valuable data in this terrain. Nonetheless, our study highlights that remote sensing offers great research potential and a wide range of possibilities to support forest operations and cable road design.
Data availability
Not applicable.
Code availability
The code can be found on github. https://github.com/lramstein/SingleTreeDetectionFunctions (GNU General Public License v3.0).
References
Allen DM (1974) The relationship between variable selection and data augmentation and a method for prediction. Technometrics 16(1):125–127. https://doi.org/10.1080/00401706.1974.10489157
Artuso R, Bovet S, Streilein A (2003) Practical methods for the verification of countrywide terrain and surface models. In Proceedings of the ISPRS Working Group III/3 Workshop XXXIV–3/W13. 3-D reconstruction from airborne laserscanner and InSAR data, Oct 8–10, 2003, Dresden, Germany
Bachmann P (1999) Skript für die Lehrveranstaltung Waldwachstum I/II (Script for the course forest growth I/II). Professorship Forest Management and Forest Growth ETH Zurich. https://www.wsl.ch/forest/waldman/vorlesung/ww_tk0.ehtml. Accessed 10 December 2018 (In German).
Bont LG, Heinimann HR (2012) Optimum geometric layout of a single cable road. Eur J Forest Res 131(5):1439–1448. https://doi.org/10.1007/s10342-012-0612-y
Bont LG, Heinimann HR, Church RL (2014) Optimizing cable harvesting layout when using variable-length cable roads in central Europe. Can J for Res 44(8):949–960. https://doi.org/10.1139/cjfr-2013-0476
Bont LG, Church RL (2018) Location set-covering inspired models for designing harvesting and cable road layouts. Eur J Forest Res 137(6):771–792. https://doi.org/10.1007/s10342-018-1139-7
Bont LG, Moll PE, Ramstein L, Frutig F, Heinimann HR, Schweier J (2022) SEILAPLAN, a QGIS plugin for cable road layout design. Croatian J Forest Eng 2:241-255. https://doi.org/10.5552/crojfe.2022.1824
Bont LG, Ramstein L, Frutig F, Schweier J (2022b) Tensile forces and deflections on skylines of cable yarders: comparison of measurements with close-to-catenary predictions. Int J For Eng. https://doi.org/10.1080/14942119.2022.2051159
Bont LG, Maurer S, Breschan JR (2019) Automated cable road layout and harvesting planning for multiple objectives in steep terrain. Forests 10(8):687. https://doi.org/10.3390/f10080687
Brändli UB, Abegg M, Allgaier Leuch B (Red.) (2020) Swiss National Forest Inventory Results of the fourth survey 2009–2017. Swiss Federal Research Institute WSL, Birmensdorf (In German)
Brassel P, Lischke H (eds) (2001) Swiss National Forest Inventory: Methods and Models of the Second Assessment. Swiss Federal Research Institute WSL, Birmensdorf
Burger W, Burge MJ (2006) Digitale Bildverarbeitung eine Einführung mit Java und ImageJ (2., überarb. Aufl. ed.) (Digital image processing an introduction with Java and ImageJ (2nd, ed.)). Springer, Berlin (In German)
Chung W, Sessions J, Heinimann HR (2004) An application of a heuristic network algorithm to cable logging layout design. Int J for Eng 15(1):11–24
Ciceu A, Garcia-Duro J, Seceleanu I, Badea O (2020) A generalized nonlinear mixed-effects height–diameter model for Norway spruce in mixed-uneven aged stands. For Ecol Manage 477:118507. https://doi.org/10.1016/j.foreco.2020.118507
Cleveland WS, Grosse E, Shyu WM (1992) Local regression models – Chapter 8. In: Statistical Models in S. Wadsworth & Brooks/Cole, Pacific Grove (CA)
Dietsch P, Condrau C, Günter M, Dorren L, Ziesak M (2020) Seillinienplanung: Genauigkeit der Einzelbaumdetektion mit drohnengenerierten Luftbildern (Cable road planning: Accuracy of single tree detection with drone generated aerial imagery). Swiss For J 171(1):28–35 ((In German)). https://doi.org/10.3188/szf.2020.0028
Dupire S, Bourrier F, Berger F (2014) A new numerical tool to optimize the set-up of a standing skyline and improve cable yarding planning. XXIV IUFRO World Congress, Oct 5–11, 2014, Salt Lake City, United States (pp 14)
Eysn L, Hollaus M, Lindberg E, Berger F, Monnet JM, Dalponte M, Pfeifer N (2015) A benchmark of lidar-based single tree detection methods using heterogeneous forest data from the alpine space. Forests 6(12):1721–1747. https://doi.org/10.3390/f6051721
Flewelling JW, Pienaar LV (1981) Multiplicative regression with lognormal errors. For Sci 27(2):281–289
Forrester D, Nitzsche J, Schmid H (2018) The Experimental Forest Management project: An overview and methodology of the long-term growth and yield plot network. Swiss Federal Research Institute WSL, Birmensdorf
Ginzler C, Hobi ML (2015) Countrywide stereo-image matching for updating digital surface models in the framework of the Swiss National Forest Inventory. Remote Sens 7(4):4343–4370. https://doi.org/10.3390/rs70404343
Heinimann HR (2003) Holzerntetechnik zur Sicherstellung einer minimalen Schutzwaldpflege. ETH Zürich, Zürich
Hernández-Clemente R, North PR, Hornero A, Zarco-Tejada PJ (2017) Assessing the effects of forest health on sun-induced chlorophyll fluorescence using the FluorFLIGHT 3-D radiative transfer model to account for forest structure. Remote Sens Environ 193:165–179. https://doi.org/10.1016/j.rse.2017.02.012
Hirschmugl M (2008) Derivation of forest parameters from UltracamD data. Dissertation, TU Graz
Holmgren J, Persson Å (2004) Identifying species of individual trees using airborne laser scanner. Remote Sens Environ 90(4):415–423. https://doi.org/10.1016/S0034-4257(03)00140-8
Jakubowski MK, Li WK, Guo QH, Kelly M (2013) Delineating individual trees from lidar data: a comparison of vector- and raster-based segmentation approaches. Remote Sens 5(9):4163–4186. https://doi.org/10.3390/rs5094163
Kaartinen H, Hyyppa J, Yu XW, Vastaranta M, Hyyppa H, Kukko A, Wu JC (2012) An international comparison of individual tree detection and extraction using airborne laser scanning. Remote Sens 4(4):950–974. https://doi.org/10.3390/rs4040950
Khosravipour A, Skidmore AK, Isenburg M, Wang T, Hussin YA (2014) Generating pit-free canopy height models from airborne lidar. Photogramm Eng Remote Sens 80(9):863–872. https://doi.org/10.14358/pers.80.9.863
Khosravipour A, Skidmore AK, Wang TJ, Isenburg M, Khoshelham K (2015) Effect of slope on treetop detection using a LiDAR Canopy Height Model. ISPRS J Photogramm Remote Sens 104:44–52. https://doi.org/10.1016/j.isprsjprs.2015.02.013
Koch B, Heyder U, Weinacker H (2006) Detection of individual tree crowns in airborne lidar data. Photogramm Eng Remote Sens 72(4):357–363
Lamprecht S, Stoffels J, Dotzler S, Haß E, Udelhoven T (2015) aTrunk—an ALS-sased trunk detection algorithm. Remote Sens 7(8):9975–9997. https://doi.org/10.3390/rs70809975
Litscher R, Rigling L (1996) Forestry cable yarder systems; standards, rules, tables. SUVA (In German)
Menk J, Dorren L, Heinzel J, Marty M, Huber M (2017) Evaluation automatischer Einzelbaumerkennung aus luftgestützten Laserscanning-Daten (Evaluation of automatic single tree detection from airborne laser scanning data). Schweizerische Zeitschrift für Forstwesen 168(3):151–159 (In German). https://doi.org/10.3188/szf.2017.0151
Mustafic S, Kainer A, Schardt M (2014) Einzelbaumdetektion anhand von Ebenenschnitten (Single tree detection based on plane intersections). In: Strobl J, Blaschke T, Griesebner G, Zagel B (eds) Angewandte Geoinformatik (Applied geoinformatics). Herbert Wichmann Verlag, Berlin, pp 21–26 (In German)
Nitzsche J, Stillhard J (2018) Georeferencing Permanent Plot. Swiss Federal Research Institute WSL, Birmensdorf
Parkan MJ (2019) Combined use of airborne laser scanning and hyperspectral imaging for forest inventories. Dissertation, EPFL Lausanne
Pestal E (1961) Seilbahnen und Seilkrane für Holz-und Materialtransport (Cable cars and cable yarders for timber and material transport). Georg Fromme & Co, Vienna and Munich (In German)
Python Software Foundation. Python Language Reference, version 3.7. http://www.python.org. Accessed 05 November 2018
Ramstein L (2021) Github: SingleTreeDetectionFuctions (Version 1) [Computer software]. https://github.com/lramstein/SingleTreeDetectionFunctions
R Core Team (2017) R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/. Accessed 01 November 2018
Schardt M, Granica K, Hirschmugl M, Deutscher J, Mollatz M, Steinegger M, Linser S (2015) The assessment of forest parameters by combined LiDAR and satellite data over Alpine regions–EUFODOS Implementation in Austria. For J 61(1):3–11. https://doi.org/10.1515/forj-2015-0008
Schneider B (2016) Datenerfassungsprogramm STANDINV für Ertragskunde und Naturwaldreservate (Data collection program STANDINV for yield study and natural forest reserves). Swiss Federal Research Institut WSL, Birmensdorf (In German)
Sharma RP, Breidenbach J (2015) Modeling height-diameter relationships for Norway spruce, Scots pine, and downy birch using Norwegian national forest inventory data. For Sci Technol 11:44–53. https://doi.org/10.1080/21580103.2014.957354
Sharma RP, Vacek Z, Vacek S, Kučera M (2019) Modelling individual tree height–diameter relationships for multi-layered and multi-species forests in central Europe. Trees 33:103–119. https://doi.org/10.1007/s00468-018-1762-4
Swisstopo (2007) Koordinatenänderung LV95 - LV03 (Coordinate change LV95–LV03). https://www.swisstopo.admin.ch/de/home/meta/search.detail.document.html/swisstopo-internet/de/documents/geo-documents/koordinatenaenderungde.pdf.html. Accessed 07 December 2018 (In German).
Vauhkonen J, Ene L, Gupta S, Heinzel J, Holmgren J, Pitkanen J, Maltamo M (2011) Comparative testing of single-tree detection algorithms under different types of forest. Forestry 85(1):27–40. https://doi.org/10.1093/forestry/cpr051
Visser R, Harrill H (2017) Cable yarding in North America and New Zealand: a review of developments and practices. Croatian J For Eng 38(2):209–217
Wauer A, Hamberger O (2010) Merkblatt 13 - Holzernte in steilen Hanglagen (Leaflet 13 – Timber harvesting on steep slopes). The Bavarian State Institute of Forestry: https://www.waldwissen.net/de/technik-und-planung/forsttechnik-und-holzernte/waldarbeit/lwf-merkblatt-nr-13. Accessed 27 November 2018 (In German)
Acknowledgements
The authors would like to thank David Forrester (WSL) for providing the field data and the Office of Forests and Natural Hazards of the Canton of Grisons for supplying the logging data from recent years in the study area, as well as Fritz Frutig (WSL), Anton Karlon (Mayr-Melnhof Holz Holding AG) and Ken Flury (Untervaz forestry enterprise) for providing valuable information and assessments from practice. Finally, we thank Melissa Dawes for English editing assistance.
Funding
Open Access funding provided by Lib4RI – Library for the Research Institutes within the ETH Domain: Eawag, Empa, PSI & WSL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have influenced the work reported in this paper.
Additional information
Communicated by Eric R. Labelle.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Test plots
See Table 6.
Filtering methods

Output raster file of the different filtering methods
Residual plots
Call:
-
lm(formula = fmla.best.log, data = ds_NH_ohnena)
Residuals:
-
Min 1Q Median 3Q Max
-
− 0.85023 − 0.13058 0.00688 0.12696 0.88582
Coefficients:
-
Estimate Std. Error t value Pr( >|t|)
-
(Intercept) 2.981e+00 8.915e−02 33.437 < 2e−16 ***
-
log(htot_m) 8.797e−01 3.734e−02 23.559 < 2e−16 ***
-
I(htot_m^2) 2.206e−04 4.515e−05 4.885 1.26e−06 ***
-
–-
-
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘’ 1
-
Residual standard error: 0.2231 on 783 degrees of freedom
-
Multiple R-squared: 0.8418,Adjusted R-squared: 0.8414
-
F-statistic: 2083 on 2 and 783 DF, p-value: < 2.2e−16
See Fig. 6.

Residual plots of the allometric equation used to calculate DBH from tree height
Detailed description of the assignment process
The assignment of the detected trees to the reference trees was done in two steps (Fig. 7):
-
(1)
On every plot, tree height (H) and DBH were measured for the 100 largest trees (DBH) per hectare and for 20% of the remaining trees (randomly), which required the recording of DBH for all trees in an earlier step. Based on the trees (for which DBH and H were known), an estimation was made, above which tree height threshold all the trees in the plot were recorded. The estimation of this threshold was based on the tree height distribution of all trees (for which DBH and H were known) on the plot. Since tree height was only measured for the 100 largest trees (DBH) and for 20% of the remaining trees, there was a ‘kink’ in an otherwise smooth height distribution curve. The corresponding tree height at the ‘kink’ was identified visually for each plot and defined as the threshold value. Depending on the stand structure of the respective plot, the threshold was between 20 and 29 m height. The assignment process was then carried out for all trees above the defined tree height threshold (we refer these trees as reference trees). For the detected trees, the threshold value was lowered by the defined tolerance range of 5 m. Thus, for example, with a tree height threshold of 20 m, a detected tree of 18 m could be assigned to a nearby (< 3 m) reference tree of 21 m height.
-
(2)
For each reference tree the following procedure was carried out. First, all detected trees within 3 m horizontal distance and a tree height difference < 5 m to the reference tree were selected. Second, the combination (reference tree – detected tree) with the shortest horizontal distance was selected as assigned, so that no tree was assigned more than once.
Fig. 7 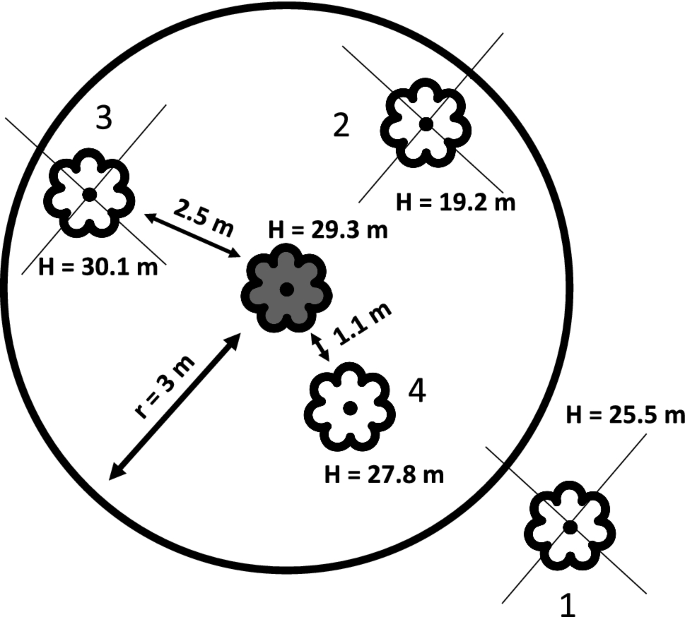
Example of the assignment process, in which a detected tree (in white) is assigned to the reference tree (gray middle tree). Tree 1 is more than 3 m away from the reference tree, tree 2 has a tree height difference of more than 5 m, and tree 3 is further away from the reference tree than tree 4, which is thus assigned to the reference tree

Definitions of additionally calculated metrics
See Table 8.
Detailed results of the selected best method combinations
Matching of remote sensing and terrestrial data
Methods
To find out how closely the remote sensing data matched the terrestrial data, the heights of the sample trees were compared with the height data from the ALS-CHM at the same location. Therefore, a buffer with a radius of 3 m was created around each sample tree according to Eysn et al. (2015), starting from the stem base coordinate (Fig. 8). This corresponds approximately to an average crown size, within which the tree top, i.e., the highest point of the CHM, should be located. Within the buffer, the highest value from the CHM was compared with the terrestrially recorded tree height. For all overlapping tree buffers, only the tallest sample tree was included in the analysis. In total, 276 sample trees were analyzed. A locally averaged regression curve (Loess method) was calculated for the evaluation.

The agreement of the remote sensing data with the terrestrial data was assessed with the following three steps: (1) creating a buffer with radius 3 m around each sample tree (terrestrially measured tree height Hterr), (2) searching for the maximum value of the CHM (HCHM) within the buffer of a sample tree, and (3) comparing the values Hterr and HCHM for each sample tree
Results
Both data processing variants (without or with pitfree algorithm) resulted in the same derived tree height values (HCHM), except for a few sample trees (Fig. 9). A comparison of the remote sensing data (HCHM) with the terrestrial data (Hterr) showed different behavior depending on the tree height. For tree heights < = 25 m (N = 39), those derived from the remote sensing data were taller than those derived from terrestrial measurements, as shown by the local mean according to the Loess method (Cleveland et al. 1992). The smaller the trees, the greater the difference between HCHM and Hterr. For tree heights > 25 m (N = 237), the CHM-derived tree heights were smaller than the terrestrially measured tree heights. The local mean (Loess method) showed a difference of up to 5 m, with the difference increasing with increasing tree height.

The heights of 276 reference trees are plotted against the maximum height values of the ALS canopy height models within a radius of 3 m around a reference tree. For better readability, the points of the two data series were slightly shifted against each other with the R function ‘position_jitter’. For both CHM variants (pitfree / non-pitfree), the local mean according to the Loess method is plotted
Discussion
Tree height values derived from the CHM overestimated the height of small sample trees, while they tended to slightly underestimate the height of larger sample trees. The overestimation of the small trees most likely results from cases where the laser signal hit a branch of a taller tree during the flight and thus appeared in the CHM as the highest point at this location. This problem was addressed by excluding the smaller sample trees in overlapping buffers, which explains why the number of trees with height ≤ 25 m was also significantly smaller.
A possible reason for the underestimation of the height of large trees may be the flattening of the maximum values through interpolation of the ALS points. It can also happen that the top of the crown is not directly hit by any laser signal during the aerial survey and thus another crown point is defined as the local maximum. In addition, the difference in height could be partially explained by the temporal distance between the aerial survey in 2003 and the field surveys conducted in 2014 and 2016. The trees are estimated to have grown 2–4 m in these 11–13 years (Bachmann 1999). Part of the difference could also be attributed to the inaccuracy of the tree height measurement. Hirschmugl (2008) found differences of up to 4.5 m for conifers in tree height measurements from different perspectives. Ginzler and Hobi (2015) calculated a RMSE of 1.55 m for the measurement accuracy of conifers based on double measurements conducted as part of the Swiss National Forest Inventory (NFI) (N = 441).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ramstein, L., Bont, L.G., Ginzler, C. et al. Comparison of single tree detection methods to extract support trees for cable road planning. Eur J Forest Res 141, 1121–1138 (2022). https://doi.org/10.1007/s10342-022-01495-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10342-022-01495-z