
Abstract
Analyses of distribution patterns and genetic structures of forest stands can address distinct family structures and provide insights into the association of genetic and phenotypic variation patterns. In this study, point pattern analysis and spatial autocorrelation were used to examine the spatial and genetic structures in two naturally generated beech stands, which differ in age, trunk morphology, and stand management. Significant tree clumping was observed at distances up to 20 m in the young forest stand, whereas dispersion at distances under 10 m was observed in the old stand. The spatial analysis based on Ripley’s k function of the two different groups of trees showed that the non-forked trees match in both stands the spatial pattern of all trees while the forked were randomly distributed. Additionally, according to the bivariate analysis, forked trees in both stands were randomly distributed as related to non-forked tree positions. Finally, Moran’s I values were not very high, though significant genetic autocorrelation was identified at distances up to 20 m in the young stand, suggesting the existence of distinct family structures. However, no significant genetic structuring was observed in the old stand. Our findings suggest that spatial genetic patterns are impacted by stand age, environmental factors and human activities. The spatial distribution of forked trees was not clearly associated to family structures. Random effects and also micro-environmental variation could be additional factors explaining forking of beech individuals.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The spatial pattern of genetic variation within populations is an important aspect of tree genetics since most of the genetic variation of forest tree species has been found to reside within than between populations (Merzeau et al. 1994). Limited seed and pollen dispersal increases the level of inbreeding, thereby raising the probability that neighbouring individuals possess the same seed parent of the previous generation (Marquardt and Epperson 2004; Wright 1943). Hence, local genetic structuring or “kinship structuring” easily results from the spatial clustering of individuals that are more closely related than would be expected under spatial random processes (Heywood 1991). Spatial genetic structures as a result of restricted pollen and seed dispersal have been reported in a population of the endangered plant Anthericum liliago (Peterson et al. 2002). Furthermore, landscape variables can also influence genetic structures as it is shown for different plant and animal populations (Kuss et al. 2008; Murphy et al. 2008). Different genetic structures were found in reproductive and juvenile plants of the same populations of the perennial herb Trillium camschatcense, depending also on the fragmentation of the populations (Yamagishi et al. 2007). In this case, the reproductive stage was more structured than the juvenile.
Effects of the age structures of stands on their family structures were examined by Neale and Adams (1985) for Douglas-fir and Yazdani et al. (1985) for mountain pines. In particular, their results indicated that spatial correlations, observed among seedlings, were mainly due to family structures and were often eliminated due to competition among genetically similar seedlings. Additionally, Neale and Adams (1985) showed that genetic structure in Douglas-fir populations is likely to remain unaffected by silvicultural treatments, as there was no significant difference in multilocus outcrossing estimates between treatments. This was not the case for European beech (Fagus sylvatica L.), where higher levels of genetic variation could be noted prior to thinning (Dounavi et al. 2002). How human influence affects the spatial characteristics of the next generation was demonstrated by Takahashi et al. (2000) for Japanese beech (Fagus crenata Blume). In this study, the decreased density of mother trees reduced mixing of seeds, thereby increasing the level of genetic clustering in thinned populations. Similarly, clustering was observed in Japanese beech after several anthropogenic influences (Kitamura et al. 2005). Using autocorrelation analysis, Bacilieri et al. (1994) found that oak populations exhibited significant genetic structure due to limited dispersal of pollen and/or seeds. In this study, family structures were present, while their patterns were different among loci.
Genetic studies on beech populations (Fagus sylvatica L.) have shown that the greater part of gene flow via seed is limited to a maximum distance of ~50 m (Müller-Starck 1996). Therefore, for natural regenerated stands, distinct family structures can be expected as a result of restricted pollen and seed dispersal. The existence of family structures has been confirmed already as a result of barochorous seed dispersal (Vornam et al. 2004). However, low spatial autocorrelation was detected in 14 Italian beech populations with a study at 11 enzyme gene loci (Leonardi and Menozzi 1996), presenting no clear delineation of different families. Similarly, low spatial genetic structuring was found in three French beech stands using isoenzyme loci. This result implies as well no stable genetic structuring in space and time which suggests less limited gene flow than expected (Merzeau et al. 1994). Thus far, few attempts have been made which identify family structures in natural beech forests based on genetic markers and make use of this knowledge for investigating phenotypic variation patterns.
Provenance trials established for beech have suggested that a strong genetic component influences structural morphology, either forked or non-forked (Hansen et al. 2003). However, no detailed conclusions regarding the genetic control of this phenotypic trait were made. Turok (1996) analysed populations of forked and non-forked beech individuals based on isoenzyme markers and found a slightly higher genetic variation in the group of forked trees. Hosius et al. (2003) confirmed the evident clumping of forked trees in a beech stand at the age of 125 years. This spatial clustering suggests that such trees are often members of the same family.
Furthering our knowledge of family structures and the association between genetic and phenotypic variation are important for forest management and conservation of genetic resources. Therefore, the aim of this study was to characterize the spatial distribution of forked trees in the two study stands and explain their existence either by identifying genetic families or by posing them to external environmental or anthropogenic factors. Specifically, the objectives of our study were as follows: (a) to characterize the spatial distribution of both, forked and non-forked, trees in the stands by using univariate and bivariate Ripley’s k function, (b) to characterize the spatial structure of the forked and non-forked trees by using Moran’s I index of spatial autocorrelation, (c) to identify spatial structures of genetic information by using Moran’s I index of spatial autocorrelation on genetic markers, and (d) to explore the spatial distribution of forked and non-forked trees in respect to genetic, demographic, or environmental mechanisms.
Materials and methods
Study areas
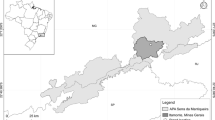
The investigated beech stands were chosen according to their trunk morphology, respectively, the forking character. The first stand is located in Bovenden (Central Germany) and the second in Schmallenberg (western Germany; Fig. 1). Both stands were naturally regenerated, contain trees ranging in age, and offer a good quality of wood. The Bovenden stand is predominately composed of Fagus sylvatica L. trees, is elevated at 400 m with a north-eastern aspect, and covers an area of 26.3 ha. The age of the stand ranges between 20 and 60 years and also includes natural regeneration. The Schmallenberg stand is a pure beech stand at an elevation of 500 m with a northern aspect and covers an area of 10.1 ha. It is ~140 years old and contains no natural regeneration.

Location of the study areas
Both stands experienced different intensities of silvicultural treatment. The Bovenden stand is relatively young and represents a structure which obviously preserved spatial characteristics of natural regeneration and indicates no effects of selective thinning. The Schmallenberg stand has undergone traditional thinning procedures which would generally affect the spatial appearance of forking. However, as reported by Turok (1996) especially for this stand, the proportion of forked trees is still untypically large for such an age. Hence, it can be argued that there was less room for selective thinning based on forking characteristics.
Spatial data
Survey plots of 2,500 and 13,000 m2 were delineated within the Bovenden and Schmallenberg stands, and the coordinates of all individuals in these plots were recorded. Additionally, the crown of each tree was categorized according to Krahl-Urban (1962), Hengst (1964), and Hussendoerfer et al. (1996). The group of the forked trees includes individuals of which the main trunk is divided into two equal forks (double leaders) and the side branches also show the equally divided form (Fig. 2); the forked form was not the result of a trunk injury (Hussendoerfer et al. 1996). The group of individuals with straight (monocormic) trunks are defined based on whether the axis of the main trunk is straight (Fig. 2); all other axes are inferior side axes and only one straight dominant shoot exists (Hussendoerfer et al. 1996). The spatial distribution of both forked and non-forked individual trees in the study areas is presented in Fig. 3.

Trunk form of the forked and non-forked trees

Spatial distribution of the forked and the non-forked trees in the study plots in Bovenden and Schmallenberg
Genetic data
Winter buds were collected from all mapped trees and analysed using nine polymorphic enzyme loci by means of horizontal starch gel electrophoresis (according to the methodology described by Müller-Starck 1996). The enzyme systems analysed were as follows: AAT (EC 2.6.1.1), LAP (EC 3.4.11.1), PGI (EC 5.3.1.9), PGM (EC 2.7.5.1), MNR (EC 1.6.99.2), IDH (EC 1.1.1.42), MDH (EC 1.1.1.37), and 6PGDH (EC 1.1.1.44). The genetic interpretation of the zymograms was based on previous inheritance analysis of these enzyme systems in beech (Müller-Starck and Starke 1993). The genetic diversity within each group of trees with different crown morphology (forked and non-forked) was estimated by calculating the number of alleles for each locus (n), the mean number of alleles per locus (A/L), the allelic diversity (v), and the genetic differentiation (δT; Gregorius 1978; Gregorius 1987). All genetic parameters were calculated by using the software GSED 2.1 (Gillet 2008).
Spatial analysis
Univariate and bivariate Ripley’s analyses
Spatial analyses were performed for both beech stands based on Ripley’s k function (Ripley 1977) in which the centre of a circle with radius d is placed on each individual, and all other individuals within the circle are counted. Ripley’s k function uses the distances between all pairs of point observations inside a circular search window (Fortin et al. 2002) and therefore provides a method of exploring the spatial pattern across a range of spatial scales (Moeur 1997; Reader 2000).
Under complete spatial randomness (CSR), that is achieved from a homogeneous Poisson process, the expected number of point observations within a distance (d) of a randomly chosen point is λπd 2. Thus, under CSR K(d) = πd 2, where λ is the number of points per unit area (Gatrell et al. 1996). K(d) plotted against the distance (d) results in a non-linear plot (Levine 2007). Usually, a transformation L(d) replaces the K(d) function to linearize and stabilize its variance (Moeur 1997; Perry et al. 2002). An estimate of K(d) and L(d) function is given by the following formulas:
(Gatrell et al. 1996; Levine 2007; Reader 2000), where R is the area of the region under observation, N is the number of individuals, and I d (d ij ) is an indicator function, which equals 1 if the spatial distance d ij between two individuals at positions i and j (i ≠ j) is less than d and 0 otherwise.
Positive values of L indicate a tendency towards aggregation, whereas negative values indicate a tendency towards regularity (Barot et al. 1999). Under complete spatial randomness (K(d) = πd 2), L(d) drops to zero. Since the sampling distribution of L(d) is not known, a simulation by defining randomly distributed points over the study area is implemented. The empirical L(d) functions were compared with the expected under spatial randomness for distance classes from 2 m up to the half of the shortest axis of the study plots (Goreaud and Pélissier 1999; Lancaster and Downes 2004). Corrections are required because K(d) tends to be underestimated near the edge of the region because of the fewer number of observations; events outside of the study area are missed (Lancaster and Downes 2004; Perry et al. 2006). The weighted edge correction method (Ripley 1977) was selected to minimize edge effects.
In addition to univariate Ripley’s k function, a bivariate measure K 12(d) was used to describe the spatial arrangement of the forked trees relative to non-forked trees (Diggle 1983; Goreaud and Pélissier 2003; Ripley 1977). In this case, the centre of a circle of radius d is placed on the individuals of type 1, and all other individuals of type 2 within the circle are counted. The K 12(d) values were also transformed to L 12(d), and compared to the spatial randomness, as described earlier for K(d).
where R is the area of region, N 1 are N 2 are the number of individuals of type 1 and 2, respectively, I d (d ij ) is an indicator function, which equals 1 if d ij (i ≠ j) is less than d and 0 otherwise, and w ij is a weighting factor to account for edge effects.
Positive values of bivariate L function indicate aggregation while negative values indicate segregation of the different kinds of points (Dale et al. 2002). Two null hypotheses exist for bivariate spatial patterns: independence and random labelling. Spatial independence presumes processes that determine the patterning of the two types of events a priori while random labelling a posteriori (Goreaud and Pélissier 2003; Perry et al. 2006). In our case, random labelling is more appropriate null hypothesis since the process affects the trees that are already established in the region. In this case, Monte Carlo simulation is implemented by maintaining the observed event positions and randomly relabelling each event into one of the two types (Perry et al. 2006). Univariate and bivariate Ripley’s k function was estimated by ADS in ADE-4 (available at http://pbil.univ-lyon1.fr/ADE-4-old/ADSWebUS.html; (Thioulouse et al. 1997).
Moran’s I index of spatial autocorrelation
Spatial autocorrelation reflects the degree to which the data values of one property are similar to other data values of the same property located nearby (Goodchild 1986). On a global level, it describes as an average the way and the degree to which a (trait) variable is correlated with itself in space (Hoekert et al. 2002). The existence of spatial autocorrelation gives evidence of spatial dependence; data values of the feature at one place depend on the data values of the feature at other places (Moyer et al. 2005). Positive spatial autocorrelation indicates that similar features tend to be located nearby forming a clustered pattern, whereas negative spatial autocorrelation indicates that similar features tend to be located far away forming a scattered pattern. On the absence of statistically significant spatial autocorrelation, the distribution of the data values of the feature presents neither a clustered nor a dispersed spatial pattern but rather a random spatial independent distribution (Dale et al. 2002).
Moran’s I coefficient (Moran 1950) is a conventional measure of autocorrelation, and it is estimated by using the following computing formula:
(Fortin et al. 2002; Hoekert et al. 2002; Levine 2007), where N is the sample number, x i and x j are the variable values at positions i and j (i ≠ j), respectively. \( \bar{x} \) is the mean value of the variable x, and w ij is a weight applied to the comparison between location i and location j, resulting in 1 for a distance within lag interval h and 0 otherwise.
The plot that results when the autocorrelation I(h) is plotted against the lag distance h is known as a correlogram. It visually presents the spatial structure of the property being under consideration and helps to determine some properties of the scale and pattern of spatial variability (Gardner 1998; Gustafson 1998; Oliver 2001). According to Odland (1988), the correlogram provides information for explaining processes that are responsible for spatial patterns. However, unlike identical patterns which correspond to identical correlograms, different patterns may or may not correspond to different correlograms. According to Turner et al. (1991), Sokal and Oden (1978b) suggested that similar correlograms of different patterns indicate similar underlying explanatory mechanisms for generating those patterns.
Spatial phenotypic structures
Spatial phenotypic structures were explored using Moran’s I coefficient of spatial autocorrelation. To express the forking and non-forking character of individuals, a bivariate variable was created: values of 0 and 1 were assigned to forked and non-forked individuals, respectively. Correlograms were calculated to show spatial phenotypic structures and the size of possible grouping of forked and non-forked individuals. Significant deviation from random distribution denotes spatial clustering which may be the result of either environmental or genetic control. All computations have been made in CrimeStat III (Levine 2007). Confidence intervals were estimated by Monte Carlo simulations (Manly 1997). Observed values in each lag distance were compared with the values obtained after 1,000 permutations. Each permutation was based on the rearrangement of the trunk morphology (forked/non-forked characters) of the trees over the spatial location of sampled individuals. The percentiles of 2.5 and 97.5 created an ~5% confidence interval for testing against randomness (Bacilieri et al. 1994; Kevin et al. 2004; Streiff et al. 1998).
Spatial genetic structures
Spatial genetic structure within the stands was analysed also using Moran’s I coefficient of spatial autocorrelation (Moran 1950). Correlograms were calculated to present spatial genetic distribution and indicate the size of family structures (Sokal and Oden 1978a; Sokal and Wartenberg 1983). These calculations were performed by using the software Spatial Genetic Software (SGS; (Degen et al. 2001). The genotypes of each individual tree were transformed to 0 if the corresponding allele is absent, 1 if they were heterozygous, or 2 if they were homozygous.
Rare alleles (frequency < 5%) are not very informative when identifying spatial processes, since they can be highly affected by the random effects of sampling (Sokal and Oden 1978b). Thus, Moran’s I values were calculated only for alleles with frequencies exceeding 5% at each locus. For diallelic loci, only the Moran’s I value of the most common allele is taken into account, since the autocorrelation coefficients are, in this case, identical. To summarize information provided by alleles, the mean of individual Moran’s I values was calculated over all alleles to produce consensus correlograms. According to the recommendation of Streiff et al. (1998), I(h) for multiple locus genetic structures is based on sums of the corresponding numerators and denominators over the alleles.
Significant deviation from random distribution of each calculated measure was tested using Monte Carlo simulations (Manly 1997). Each permutation was based on the rearrangement of multilocus genotypes over the spatial location of sampled individuals. Observed values in each distance class were compared with the values obtained after 1,000 permutations. A 95% confidence interval was estimated for testing against randomness (Bacilieri et al. 1994; Kevin et al. 2004; Streiff et al. 1998).
Results and discussion
Genetic variability
The allozyme markers displayed moderate levels of polymorphism, with a slightly larger mean number of alleles per locus in the forked trees when compared to the non-forked trees (Table 1). For most enzyme gene loci, forked trees also showed slightly higher allelic diversity (v) and total genetic differentiation (δT), when compared with non-forked. These findings are in accordance with Turok (1996) who had found slightly superior average allelic multiplicity at the same nine allozyme loci among forked trees (2.6) in comparison with non-forked individuals (2.1). Hosius et al. (2003) also confirmed small allelic distance between the forked and the non-forked trees, but also slightly higher diversity in forked individuals.
The genetic control of forking has only rarely been studied. Hussendoerfer et al. (1996) analysed pair comparisons and found no genetic differentiation with respect to stem morphology. Turok (1996) found a significant difference between allelic frequencies of forked trees and their nearest neighbour only at one among nine allozyme loci analysed, i.e. the gene locus 6GPDH-A. However, average genetic distance of 0.06 among forked trees and their nearest monocormic neighbour, an average allelic distance of 0.07 and genotypic distance of 0.10 between 45 forked and 51 non-forked trees, was reported. These distances are not significant but they still considerably exceed the differentiation among German beech stands ranging up to 0.03. Hosius et al. (2003) reported a highly significant difference at the gene locus MDH-C due to greater frequency of the allele MDH-C1 in the forked trees.
Krahl-Urban (1962) had studied three types of crown form of adult trees and young progeny beeches in their close neighbourhood, which had originated from natural regeneration and found no consistent similarity. These findings may have been due to low heritability or moderate seed dispersal distances. It is of importance to note that under the premise of genetic control of crown form, the sole causal interpretation of clumped occurrence of forked trees by family structures is restricted seed and/or pollen dispersal. However, Wang and Hattemer (2001) found that for beech stands (with density comparable to the two studied stands), 25% of the seeds were transferred further than 20 m. In an analysis of three series of field trials laid out by J. Krahl-Urban between 1951 and 1959, comprising 133 stand progenies, Kleinschmit and Svolba (1996) have reported on pronounced variation in stem curvature. Unfortunately, they did not mention stem forking, since, at that time, they considered those experiments still too young for reliably recording the expression of this important trait.
Spatial analysis
Univariate and bivariate Ripley’s analyses
The point pattern analysis in the Bovenden stand showed significant spatial aggregation for all trees at distances under 20 m (Fig. 4a). The spatial arrangement of all trees in the Schmallenberg stand appeared uniform up to a distance of about 10 m (Fig. 4b). For both stands, forked trees were spatially distributed randomly (Fig. 5c, d). The non-forked trees in Bovenden exhibited an aggregated spatial distribution up to a distance of ~20 m, whereas the non-forked trees in Schmallenberg were uniformly distributed up to 10 m whereby they exhibited a random distribution pattern.

Univariate Ripley’s k function of all trees in the beech stands a Bovenden, b Schmallenberg (dotted lines represent Monte Carlo randomization test)

Univariate Ripley’s k function of the forked and the non-forked trees in the two beech stands: a non-forked trees Bovenden, b non-forked trees Schmallenberg, c forked trees Bovenden, d forked trees Schmallenberg (dotted lines represent Monte Carlo randomization test)
The different spatial arrangement of the trees in the two stands may be a result of their different age structures. Specifically, competition and natural selection are in progress in the Bovenden stand where natural regeneration exists, while competition and natural selection in the Schmallenberg stand have already been completed. Consequently, long-term intraspecific competition between beech individuals in Schmallenberg revealed negative associations, which resulted to uniform spatial patterns. In contrast, young natural regeneration accumulates in space resulting to clumped spatial patterns in Bovenden. Similar results have been reported for the spatial distribution of Scots pine and oak in natural mixed forests in central Europe (Kint 2005).
In contrast, forked trees are randomly distributed in space, even if these come from populations where their spatial arrangement is either aggregated (Bovenden) or uniform (Schmallenberg). This suggests that there are less distinct family structures in the group of forked trees and a more possible micro-environmental influence and random effects in the formation of forked trunks. In contrast, the spatial distribution of the non-forked trees matches in both sampling areas the spatial distribution of all trees, reflecting thus the spatial pattern of all the trees in the stand.
Bivariate analysis indicated a random distribution of the one type of trees in relation to the other type, since bivariate L 12 values were not statistically different than the expected one under spatial randomness in both stands (Fig. 6). This means that there is no spatial association of one type of trees on the other, and subsequently no direct information about neighbouring preferences of the two types and unique spatial requirements.

Bivariate Ripley’s k function of the forked trees in relation to non-forked trees in: a Bovenden and b Schmallenberg, and non-forked trees in relation to forked trees c Bovenden, and d Schmallenberg (dotted lines represent Monte Carlo randomization test)
Spatial phenotypic patterns
Spatial autocorrelation of phenotypic characters was estimated by calculating Moran’s I values for each lag distance. Based on the correlograms presented in Fig. 7, Moran’s I values of the phenotypic character of the trees in each stand were not statistically different that what could be expected under spatial randomness. This result is in accordance with the spatial pattern observed from the bivariate Ripley’s analysis, suggesting that the trunk morphology of the trees in both stands is random in space.

Moran’s I spatial autocorrelation of forked and non-forked trees in: a Bovenden and b Schmallenberg
Spatial genetic structures
It is known that the main factors that influence the spatial structure of the genetic variation within populations are the condition of the mating system, gene flow, and natural selection. In general, the autocorrelation analysis conducted showed that there was a low correlation between the spatial and the genetic distances and that different patterns of genetic structures exist within the two stands. The results are presented in correlograms in Fig. 8.

Moran’s I spatial autocorrelation of the genetic data for a Bovenden and b Schmallenberg
Despite restricted correlations (Moran’s I values of less than 0.1 were found in both stands), significant clumping of genotypes for distance classes up to about 18 m were observed in the Bovenden stand (Fig. 8a). Moran’s I maximum values were observed in the first distance class of 0–5 m (I = 0.068), while at a distance of ~18 m and more presented no statistical difference than zero. The Schmallenberg stand did not present any clear spatial genetic structure in any distance class (Fig. 8b), although Moran’s I value approximates the upper limit of the confidence level up to a distance of about 20 metres. Relatively low autocorrelation was also found by Merzeau et al. (1994) and Leonardi and Menozzi (1996) in beech stands in France. Similar results have also been reported for other tree species including Acer saccharum, Quercus petraea, and Quercus robur (Bacilieri et al. 1994; Leonardi and Menozzi 1996; Perry and Knowles 1991).
The fine-scale genetic structures at short distance classes in the Bovenden stand suggest that micro-environmental selection was not the reason for this spatial structuring of genotypes, but instead a result of kinship. This finding is consistent with the expectation that beech offspring were clustered around parents, since seed dispersal in beech stands is limited (Müller-Starck 1996). On the other hand, in the old beech stand without natural regeneration (Schmallenberg), spatial autocorrelation was not evident. The explanation for the differences in genetic structures between stands could be related to their different age structures. Thus, genetic structures in the old stand (Schmallenberg) could have been eliminated over time due to density reduction. Possible spatial autocorrelations among seedlings, mainly as family structures, could have been eliminated due to competition among genetically more similar seedlings. Therefore, only some of the seedlings from each family reached the age of reproduction. Likewise, similar results were obtained in the isoenzymatic analysis and demographical study of spatial distribution of genetic variation within populations of the Japanese beech species Fagus crenata (Kitamura et al. 2005; Takahashi et al. 2000). These results indicate a spatial grouping of the seedlings under the presumable mother tree, whereby the young plants later showed a random spatial distribution. According to Epperson and Clegg (1986), the distance at which the Moran’s I value is closest to zero varies depending on the population density. These findings are consistent with the different sizes of genetically similar groups observed in our study, taking into consideration the different age structures of the stands.
Even in fairly old stands with low tree density where only part of the trees were sampled by use of a grid system, significantly positive genetic correlations were found at distances almost beyond those studied here and depending on gene locus (Ziehe and Hattemer 2004). The small-scale spatial genetic patterns and autocorrelations observed in Bovenden are more likely the result of family structures as a result of restricted gene flow; whereas for the Schmallenberg stand, large-scale adaptational effects at particular gene loci may have also contributed to random spatial patterns.
Another explanation for the different forms of the I-correlograms is the effect of human activities, such as forest management strategies, particularly thinning. Such anthropogenic factors could modify the distribution of the trees through the removal of individuals with economically undesired forked stem forms. The slightly clumped spatial distribution of genetic information and the random distribution of forked trees in the Bovenden stand support the notion that human activities have played an important role on the spatial patterns of the trees.
Similar studies have shown strong family structures by using nuclear microsatellites in a naturally regenerated but very old beech stand in Germany (Vornam et al. 2004). Microsatellites exhibit generally higher levels of genetic diversity and from that can be recommended to study family structures, although they are hardly related to crown form.
Quantitative vs. genetic structures
The comparison of the fine-scale genetic structure of quantitative traits with isoenzyme markers within a natural population of Centaurea jacea s.l. showed that allozyme markers and the genetic component of quantitative traits have similar patterns of spatial autocorrelation (Hardy et al. 2000). On the other hand, differences in spatial patterns among characters were observed in a study of microgeographic structure of Impatiens capensis, suggesting that forces other than drift may have also influenced the genetic structures of the populations (Argyres and Schmitt 1991). These results are in accordance with the findings of more pronounced difference of the F ST – Q ST for allozyme markers and morphological traits than for other kinds of molecular markers and life-history traits (Merila and Crnokrak 2001).
Our results show that the quantitative traits, forking and non-forking, have no significant spatial structure for their genetic component. This leads to the conclusion that the enzyme markers analysed are not associated with this morphological character.
Conclusions
This study has shown that genetic variability within forked trees was slightly higher than non-forked trees. Moreover, genetic variability was higher in the younger stand with higher density (Bovenden) than in the older stand (Schmallenberg). However, no clear genetic differentiation between the forked and non-forked trees was identified, and there was no further indication that particular enzymatic genotypes promote the formation of forked stems. These results provide no evidence about participation of the investigated loci in the genetic control of this trunk phenotypic character and also provide no clear indication about the existence of family structures with members of similar trunk morphology.
Clumping of trees and genetic structuring may be the result of the regeneration system and limited gene flow. With natural regeneration, a large amount of clumping and genetic autocorrelation at a small scale may be expected among the juvenile trees, reflecting mainly family structures. During stand development with a natural reduction in the density, family structures are partially dissolved and could be superimposed by adaptational effects at particular gene loci leading eventually to non-significant spatial characteristics. Hence, comparisons of stands with different regeneration systems, different age structures, or densities could be problematic if such stand characteristics are ignored.
The possible effect of human activities, such as forest management strategies, especially thinning could also lead to a more uniform distribution of trees, as observed for the Schmallenberg stand. The slightly clumped spatial distribution of genetic information and the random distribution of forked trees in Bovenden stand support the assumption that human activities modify the spatial pattern by the removal of individuals with economically undesired forked stem forms.
The data of those two stands suggest that their age, environmental factors and human activities can substantially affect spatial patterns and genetic structures of trees in beech stands, but further analysis of more beech stands by using similar approaches is necessary to approve and generalize our findings.
References
Argyres AZ, Schmitt J (1991) Microgeographic genetic structure of morphological and life history traits in a natural population of Impatiens capensis. Evolution 45:178–189
Bacilieri R, Labbe T, Kremer A (1994) Intraspecific genetic structure in a mixed population of Quercus petraea (Matt.) Leibl and Q. robur L. Heredity 73:130–141
Barot S, Gignoux J, Menaut JC (1999) Demography of a savanna palm tree: predictions from comprehensive spatial pattern analyses. Ecology 80:1987–2005
Dale MRT, Dixon P, Fortin M-J, Legendre P, Myers DE, Rosenberg MS (2002) Conceptual and mathematical relationships among methods for spatial analysis. Ecography 25:558–577
Degen B, Petit RJ, Kremer A (2001) SGS—spatial genetic software: a computer program for analysis of spatial genetic and phenotypic structures of individuals and populations. J Hered 92:447–449
Diggle PJ (1983) Statistical analysis of spatial point patterns. Academic Press, London
Dounavi K, Steiner W, Maurer WD (2002) Effects of different silvicultural treatments on the genetic structure of European beech populations (Fagus sylvatica L.). In: Gadow KV, Nagle J, Saborowski J (eds) Continuous cover forestry. Kluwer, Dordrecht
Epperson BK, Clegg MT (1986) Spatial-autocorrelation analysis of flower color polymorphisms within substructured populations of morning glory (Ipomoea-purpurea). Am Nat 128:840–858
Fortin MJ, Dale MRT, Ver Hoef J (2002) Spatial analysis in ecology. In: El-Shaarawi AH, Piegorsch WW (eds) Encyclopedia of environmetrics. Wiley, Chichester, pp 2051–2058
Gardner RH (1998) Pattern, process, and the analysis of spatial scales. In: Peterson DL, Parker VT (eds) Ecological scale: theory and applications. Columbia University Press, New York, pp 17–34
Gatrell AC, Bailey TC, Diggle PJ, Rowlingsont BS (1996) Spatial point pattern analysis and its application in geographical epidemiology. Trans Inst Br Geogr 21:256–274
Gillet E (2008) Genetic structures from electrophoresis data. GSED. 2.1. http://www.uni-goettingen.de/de/67064.html
Goodchild MF (1986) Spatial autocorrelation. Geo Books, Norwich
Goreaud F, Pélissier R (1999) On explicit formulas of edge effect correction for Ripley’s K-function. J Veg Sci 10:433–438
Goreaud F, Pélissier R (2003) Avoiding misinterpretation of biotic interactions with the intertype K 12 -function: population independence vs. random labelling hypotheses. J Veg Sci 14:681–692
Gregorius HR (1978) Concept of genetic diversity and its formal relationship to heterozygosity and genetic distance. Math Biosci 41:253–271
Gregorius HR (1987) The relationship between the concepts of genetic diversity and differentiation. Theor Appl Genet 74:397–401
Gustafson EJ (1998) Quantifying landscape spatial pattern: what is the state of the art. Ecosystems 1:143–156
Hansen JK, Jorgense BB, Stoltze P (2003) Variation of quality and predicted economic returns between European beech (Fagus sylvatica L.) provenances. Silvae Genet 52:185–197
Hardy OJ, Vanderhoeven S, Meerts P, Vekemans X (2000) Spatial autocorrelation of allozyme and quantitative markers within a natural population of Centaurea jacea (Asteraceae). J Evol Biol 13:656–667
Hengst E (1964) Der Kronenbau der Buche im Herzgebirge. Forstwiss Centralbl 83:79–87
Heywood JS (1991) Spatial analysis of genetic variation in plant populations. Annu Rev Ecol Syst 22:335–355
Hoekert WEJ, Neuféglise H, Schouten AD, Menken SBJ (2002) Multiple paternity and female-biased mutation at a microsatellite locus in the olive ridley sea turtle (Lepidochelys olivacea). Heredity 89:107–113
Hosius B, Leinemann L, Bergmann F, Maurer WD, Tabel U (2003) Genetische Untersuchungen zu Familienstrukturen und zur Zwieselbildung in Buchenbeständen. Forst und Holz 58:51–54
Hussendoerfer E, Schuetz J-P, Scholz F (1996) Genetische Untersuchungen zu physiologischen Merkmalen an Buche (Fagus sylvatica L.). Schweizerische Zeitschrift fuer Forstwesen 147:785–802
Kevin KS, Lee SL, Koh CL (2004) Spatial structure and genetic diversity of two tropical tree species with contrasting breeding systems and different ploidy levels. Mol Ecol 13:657–669
Kint V (2005) Structural development in ageing temperate Scots pine stands. Forest Ecol Manag 214:237–250
Kitamura K, Tachida H, Takenaka K, Furubayashi K, Kawano S (2005) Demographic genetics of Siebold’s beech (Fagaceae, Fagus crenata Blume) populations in the Tanzawa Mountains, central Honshu, Japan. II. Spatial differentiation and estimation of immigration rates using a stepping-stone structure. Plant Species Biol 20:133–144
Kleinschmit J, Svolba J (1996) Ergebnisse der Buchenherkunftsversuche von Krahl-Urban. AFZ/Der Wald 51:780–782
Krahl-Urban J (1962) Buchen-Nachkommenschaften. Allg Forst- und Jagdz 133:29–38
Kuss P, Pluess AR, Ægisdóttir HH, Stöcklin J (2008) Spatial isolation and genetic differentiation in naturally fragmented plant populations of the Swiss Alps. J Plant Ecol 1:149–159
Lancaster J, Downes BJ (2004) Spatial point pattern analysis of available and exploited resources. Ecography 27:94–102
Leonardi S, Menozzi P (1996) Spatial structure of genetic variability in natural stands of Fagus sylvatica L (beech) in Italy. Heredity 77:359–368
Levine N (2007) CrimeStat III: a spatial statistics program for the analysis of crime incident locations (v 3.1). http://www.icpsr.umich.edu/CRIMESTAT/
Manly BFJ (1997) Randomization, bootstraps and Monte Carlo methods in biology. Chaphall & Hall, London
Marquardt PE, Epperson B (2004) Spatial and population genetic structure of microsatellites in white pine. Mol Ecol 13:3305–3315
Merila J, Crnokrak P (2001) Comparison of genetic differentiation at marker loci and quantitative traits. J Evol Biol 14:892–903
Merzeau D, Comps B, Thiebaut B, Cuguen J, Letouzey J (1994) Genetic-structure of natural stands of Fagus sylvatica L (Beech). Heredity 72:269–277
Moeur M (1997) Spatial models of competition and gap dynamics in old-growth Tsuga heterophylla Thuja plicata forests. Forest Ecol Manag 94:175–186
Moran PAP (1950) Notes on continuous stochastic phenomena. Biometrika 37:17–23
Moyer GR, Osborne M, Turner TF (2005) Genetic and ecological dynamics of species replacement in an arid-land river system. Mol Ecol 14:1263–1273
Müller-Starck R (1996) Genetische Aspekte der Reproduktion der Buche (Fagus sylvatica L.) unter Berücksichtigung waldbaulicher Gegebenheiten. Berichte des Forschungszentrums Waldökosysteme, Reihe A: Bd. 135, Göttingen
Müller-Starck G, Starke R (1993) Inheritance of isoenzymes in European beech (Fagus sylvatica L). J Hered 84:291–296
Murphy MA, Evans JS, Cushman SA, Storfer A (2008) Representing genetic variation as continuous surfaces: an approach for identifying spatial dependency in landscape studies. Ecography 31:685–697
Neale DB, Adams WT (1985) The mating system in natural and shelterwood stands of Douglas-fir. Theor Appl Genet 71:201–207
Odland J (1988) Spatial autocorrelation. SAGE Publications, Newbury Park
Oliver MA (2001) Determining the spatial scale of variation in environmental properties using the variogram. In: Tate NJ, Atkinson PM (eds) Modelling scale in geographical information science. Wiley, Chichester, pp 191–219
Perry DJ, Knowles P (1991) Spatial genetic-structure within 3 sugar maple (Acer-saccharum Marsh) Stands. Heredity 66:137–142
Perry JN, Liebhold AM, Rosenberg MS, Dungan J, Miriti M, Jakomulska A, Citron-Pousty S (2002) Illustrations and guidelines for selecting statistical methods for quantifying spatial pattern in ecological data. Ecography 25:578–600
Perry GLW, Miller BP, Enright NJ (2006) A comparison of methods for the statistical analysis of spatial point patterns in plant ecology. Plant Ecol 187:59–82
Peterson A, Bartish IV, Peterson J (2002) Genetic structure detected in a small population of the endangered plant Anthericum liliago (Anthericaceae) by RAPD analysis. Ecography 25:677–684
Reader S (2000) Using survival analysis to study spatial point patterns in geographical epidemiology. Soc Sci Med 50:985–1000
Ripley BD (1977) Modelling spatial patterns. J R Stat Soc B 39:172–212
Sokal RR, Oden NL (1978a) Spatial autocorrelation in biology 2: some biological implications and four applications of evolutionary and ecological interest. Biol J Linnean Soc 10:199–228
Sokal RR, Oden NL (1978b) Spatial autocorrelation in biology. 1. Methodology. Biol J Linnean Soc 10:199–228
Sokal RR, Wartenberg DE (1983) A test of spatial auto-correlation analysis using an isolation-by-distance model. Genetics 105:219–237
Streiff R, Labbe T, Bacilieri R, Steinkellner H, Glössl J, Kremer A (1998) Within-population genetic structure in Quercus robur L. and Quercus petraea (Matt.) Liebl. assessed with isozymes and microsatellites. Mol Ecol 7:317–328
Takahashi M, Mukouda M, Koono K (2000) Differences in genetic structure between two Japanese beech (Fagus crenata Blume) stands. Heredity 84:103–115
Thioulouse J, Chessel D, Doledec S, Olivier JM (1997) ADE-4: a multivariate analysis and graphical display software. Stat Comput 7:75–83
Turner SJ, O’Neill RV, Conley W, Conley MR, Humphries HC (1991) Pattern and scale: statistics for landscape ecology. In: Turner MG, Gardner RH (eds) Quantitative methods in landscape ecology: the analysis and interpretation of landscape heterogeneity. Springer, New York, pp 17–49
Turok J (1996) Genetische Untersuchungen bei der Buche—Genetische Anpassungsprozesse und die Erhaltung von Genressourcen in Buchenwäldern (Fagus sylvatica L.), Landesanstalt fuer Oekologie, Bodenordnung und Forsten/Landesamt für Agrarordnung NRW
Vornam B, Decarli N, Gailing O (2004) Spatial distribution of genetic variation in a natural beech stand (Fagus sylvatica L.) based on microsatellite markers. Conserv Genet 5:561–570
Wang K, Hattemer HH (2001) Dispersal of seed and effective pollen in small stands of European beech (Fagus sylvatica L.). In: Müller-Starck G, Schubert R (eds) Genetic response of forest systems to changing environmental conditions. Kluwer, Dordrecht, The Netherlands, pp 259–269
Wright S (1943) Isolation by distance. Genetics 28:114–138
Yamagishi H, Tomimatsu H, Ohara M (2007) Fine-scale spatial genetic structure within continuous and fragmented populations of Trillium camschatcense. J Hered 98:367–372
Yazdani R, Lindgren D, Rudin D (1985) Gene dispersion and selfing-frequency in a seed tree stand of Pinus sylvestris (L.). Lect Notes Biomath 60:1139–1154
Ziehe M, Hattemer HH (2004) Auswirkungen räumlicher Verteilungen genetischer Varianten in Buchenbeständen auf dort geerntetes Saatgut. In: Maurer WD (ed) Mitteilungen aus der Forschungsanstalt fuer Waldökologie und Forstwirtschaft Rheinland-Pfalz: Zwei Jahrzehnte Genressourcen Forschung in Rheinland Pfalz, pp 102–120
Acknowledgments
We thank G. Dinkel and T. Seliger for their assistance by sampling and their help in the laboratory and R. Hood for the language revision and helpful comments on the manuscript. This study was financially supported from DFG (Deutsche Forschungsgemeinschaft) with grant Ha 501/26-1.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by K. Puettmann.
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License ( https://creativecommons.org/licenses/by-nc/2.0 ), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Dounavi, A., Koutsias, N., Ziehe, M. et al. Spatial patterns and genetic structures within beech populations (Fagus sylvatica L.) of forked and non-forked individuals. Eur J Forest Res 129, 1191–1202 (2010). https://doi.org/10.1007/s10342-010-0409-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10342-010-0409-9