
Abstract
We simplified Kozak’s taper model by setting the inflection point at 1.3 m (dbh) without losing accuracy and precision. The simplification was required to facilitate the estimation of the covariance parameters when using a mixed-effects method. This method was necessary to take into account the correlation among multiple diameter measurements on an individual stem. The simple stem taper model was fitted to an extended data set collected across the province of Quebec, Canada. Comparison of the predicted stem taper and the derived stem volume with those obtained using existing models showed a comparable predictive power for the simple model. Including a prediction of the tree random effects based on supplementary diameter measurements of the bole improves the predictive ability of the model around the extra diameter observation. This model offers welcome simplicity as a means of predicting tree taper at coarse resolution for planning tree harvesting.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Knowledge of tapering in a stem is of great value to primary log breakdown because it affects grade yield. Moreover, in the context of integrating timber harvest with product recovery, it is necessary to develop mathematical models that predict stem taper from (1) tree-level covariates such as dbh, height, and crown length, and (2) stand attributes such as those available from forest polygon maps. For tree level, several models have been proposed with more or less detail to assess the generality of taper equations as well as the effect of diverse tree attributes on taper variation. So far no study has investigated the simplification of taper equations for facilitating the quantification of current and eventual stand-level attributes on the variation of stem form. This simplification approach is justified for planning tree harvesting.
In Canada, boreal black spruce (Picea mariana (Mill.) B.S.P.) is a major commercial species. The use of taper equations can improve estimates of standing timber value and help schedule harvesting as a function of its current market demand. However, the existing stem taper equations are limited in their extended applications by the small number of trees used for their parameterization and by their inability to take into consideration the correlation among repeated measurements on individual trees (e.g., Newnham 1988; Bonnor and Boudewyn 1990; Sharma and Zhang 2004). Within this context, the objective of this paper was to develop a more general taper equation, which would apply over larger areas of black spruce stands. This was done by combining data sets from past studies into a larger database. The correlations among the data were taken into account through a mixed-effects model. Moreover, we tested the effect of measuring additional diameters along the bole over the predictive ability of the model by predicting the random effects using measured upper diameters as pre information. Like existing taper equations for black spruce, the mathematical formulation of stem taper was based on Kozak’s variable-exponent equation (1988).
Data
We used data from six studies containing 947 trees and covering all ecological domains where black spruce is present: the western and eastern black spruce-moss forest, and the western and eastern balsam fir-yellow birch forest (MRNF 2003). Since the data set was largely sufficient for the parameterization, 30% of the trees from each ecological domain were randomly kept apart for validation. dbh and height ranges are shown in Table 1 for partitions and study sites. Large ranges of dbh and heights were covered, and these ranges were similar for the parameterization and validation partitions.
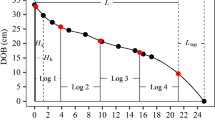
Ouellet (1983) measured outside bark diameter from the stump up to merchantable height (9-cm diameter outside the bark). Between both limits, outside bark diameter was measured at 0.15, 0.80, and 1.30 m, at 0.05 m below the first live whorl as well as at each third of merchantable height. The same sampling was used in Ung and Ouellet (1993) and in Bonnet and Pastor (1997). In Ung (1990), Beaumont et al. (1999) and Ruel et al. (2003), outside bark diameter was measured at 0.15, 1.30, and thereafter, at each meter up to the first live whorl. Also, diameter measurements were taken at each whorl up to the tip of the crown. Rycabel (personal communication, 2002) used a more regular pattern with measurements at 0.15, 0.65, 1.15 , 1.30, 2.15 m, and thereafter, at each meter up to the apex. For each sampled tree, total height and dbh (measured at 1.3 m) were also recorded.
Method
Three steps were followed: simplification of Kozak’s equation, model specification, and model verification with wood volume comparison.
Model simplification
Let i and j be the tree and the along-bole measurement position indices, respectively, such that i = 1, 2,…, n and j = 1, 2,…, m i . Kozak’s original equation can then be represented as follows:
where y ij is the inside bark diameter for section j in tree i, dbh i is the outside bark diameter at breast height, p is the relative height of the inflection point, h ij is the height of the measurement, ht i is the total height of the tree, ε ij is the random error term, and A, B and C ij are parameters to be estimated. The inflection point is where the stem profile changes from neiloid to paraboloid, and its relative height is thought to be constant within a given species, regardless of tree size (Demaerschalk and Kozak 1977). Parameters A and B, which deal with the conversion from outside to inside bark diameter, are assumed to be constant within a given species, and can be estimated with any appropriate data set (e.g., Garber and Maguire 2003). Parameter C ij represents the core of model 1a as it makes it possible to fit the various forms all along the bole. In fact, the bole form is considered to vary according to the relative height of the section (g ij ) and tree characteristics.
By only addressing outside bark diameter, which is required for wood product estimates at the preharvest planning stage and during harvest for optimum bucking, Eq. 1a can be simplified by dropping not only A but also B. Further simplification was carried out on term C ij , which represents the variable exponent. In the original model, C ij involved a complex linear function that included seven parameters and incorporated g ij under many forms, such as linear, square, inverse, square root, and logarithmic. First, C ij was relocated as an exponent of both g ij and p. Then, we reduced the linear function to three parameters as follows:
where a, b and c are the general parameters of the model. Through Eq. 2c, we lose the classical notion of inflection point by setting it at breast height, or 1.3 m. Although this is a strong assumption, preliminary trials revealed no major bias. Like most stem taper equations, Eq. 2a is mathematically consistent. At the apex of the tree, diameter y ij converges to 0. At breast height, the ratio involving g ij and p i yields 1 and y is equal to dbh i plus an error term so it is equal to dbh in expectation.
Model specification
When parameterizing a stem taper model, regular statistical estimators, such as ordinary or nonlinear least squares, rely on the assumptions of independently and normally distributed error terms with homogeneous variances (Steel et al. 1997, § 7.10). Besides, stem taper data are often autocorrelated as we can reasonably assume that diameter measurements are not entirely independent within the same tree. Departures from the assumption of independent errors result in biased statistical inferences (Sullivan and Clutter 1972), which hinder the selection of appropriate explanatory variables (Gregoire et al. 1995). Over the last three decades, the mixed-effects method has become increasingly popular in the forestry literature for this kind of analysis. This method makes it possible to relax the assumption of homogeneous variances and independent error terms. Recently, it has been used for modeling stem taper (e.g., Garber and Maguire 2003; Leites and Robinson 2004; Trincado and Burkhart 2006).
In general terms, model 2a can be expressed as follows:
where x ij is a vector of explanatory variables; δ i is a vector of unobserved tree random effects for tree i; β is a vector of unknown fixed-effect parameters; and ε ij is the residual error term. The vector of tree random effects and the vector of within-tree residual error terms (ε i ) are both assumed to be multivariate normally distributed, i.e., \( {\varvec{\updelta}}_{i} \mathop \sim \limits^{{_{{{\text{i}} . {\text{i}} . {\text{d}} .}} }} {\text{MVN}}({\mathbf{0}},{\varvec{\Upsigma}}) \) and \( {\mathbf{\varepsilon }}_{i} \mathop \sim \limits^{{_{{{\text{i}} . {\text{i}} . {\text{d}} .}} }} {\text{MVN}}({\mathbf{0}},{\mathbf{R}}_{i} ) \). The variance–covariance matrix of the within-tree error terms (R i ) is usually set to \( {\mathbf{R}}_{i} = \sigma^{2} {\mathbf{I}}_{{m_{i} }} \) under the assumption of independence. However, the distribution of ε i becomes multivariate when R i is assumed to have a correlation structure.
Due to the nonlinear form of Eq. 3, estimating the variance–covariance matrix Σ for the tree random effects is tedious. One way to obtain a more convenient form is to approximate model 3 through a first-degree Taylor expansion around the random effects (Pinheiro and Bates 2000, p. 312):
where z ij is a matrix of partial derivatives of the model with respect to the random effects.
From Eq. 4, the variance for the vector of within-tree diameters can be estimated as:
where matrix Z i consists of the appropriate z ij stacked and T is a matrix transposition. In addition to random effects, a correlation structure and a variance function can be specified for R i . Details on correlation structures and variance functions are available in Davidian and Giltinan (1995), Littell et al. (2006), and Pinheiro and Bates (2000, § 5.3.3). In a general context, the covariance matrix R i can be expressed as (Pinheiro and Bates 2000, p. 205):
where Γ i is a diagonal matrix whose elements are the residual variances \( \sigma_{ij}^{2} \) and Φ i is a correlation matrix whose off-diagonal elements are the correlations ρ ijj′.
In this case study, the parameters of model 2a were expressed through a mixed model adjustment as linear functions of one or many fixed effects as well as of the single tree random effect:
where β 1, β 2, β 3, β 4, β 5, and β 6 are the elements of the column vector of fixed-effect parameters (β), and δ 1,i , δ 2,i , and δ 3,i are the elements of the vector of tree-level random effects (δ i). We assumed that this vector had an unstructured covariance structure, i.e., there was no structure specified for the 3 × 3 matrix Σ. Moreover, matrix R i was modeled through a first-order autoregressive correlation structure and a power-of-the-mean variance function, which provided the best fit. The power-of-the-mean variance function and the continuous autoregressive correlation structure that were fitted are defined as follows:
where \( E(y_{ij} |{\varvec{\updelta}}_{i} ) \) is the mean predicted value conditional on the tree random effects, and σ2, θ and ρ are parameters to be estimated. Note that Eqs. 8a and 8b completely specify matrices Γ i and Φ i in Eq. 6. The adequacy of the random effects, the variance function, and the correlation structure were assessed through likelihood ratio tests and parsimony criteria (AIC and BIC).
The parameterization of nonlinear mixed models relies on likelihood estimation. Because the maximization of the likelihood function involves a complex integral, some approximations have been proposed in the statistical literature. Some of them consist in linearizing the model through a first-order Taylor expansion around the expected value zero of the random effects as shown in Eq. 4 and applying the linear mixed-model theory (e.g., Lindstrom and Bates 1990; Vonesh and Carter 1992). Model (2a) with all the aforementioned features was parameterized using the nlme package (Pinheiro et al. 2008) available in R software (R Core team 2008), which is based on this type of approximation.
Model validation
In addition to likelihood ratio tests and parsimony criteria (AIC and BIC), normalized residuals were used to check the fit of the model. Considering the variance–covariance matrix of the error terms, a vector of within-tree normalized residuals (r i ) can be approximated from the linear mixed-model theory (cf., Pinheiro and Bates 2000, p. 239) as
Normalized residuals can be seen as standardized residuals for mixed models because they account for the modeled covariances. If the mixed model is properly parameterized with regard to its covariance features, we can expect the elements of r i to be independently and normally distributed with mean 0 and variance 1, i.e., \( {\mathbf{r}}_{i} \mathop \sim \limits^{{_{{{\text{i}} . {\text{i}} . {\text{d}} .}} }} N({\mathbf{0}},{\mathbf{I}}) \) (SAS Institute 2008). These normalized residuals were used to check residual correlations.
Once model 2a was parameterized, mean predictions were generated for each observation of the validation partition. Because the random effects do not occur linearly in the model, these predicted values did not correspond to the mathematical expectation for the population, i.e., \( E[y_{ij} ] \ne f({\mathbf{x}}_{ij} ,{\mathbf{0}},\hat{\mathbf{\varvec{\upbeta}}}) \). In fact, the population-averaged predictions, i.e., the mathematical expectation of y ij without prior knowledge of the random effects, were obtained by integrating the marginal prediction of the model with respect to the random effects (e.g., McCulloch and Searle 2001, p. 65). In this case study, these population-averaged predictions would be obtained through \( E[y_{ij} ] = \int {f({\mathbf{x}}_{ij} ,{\varvec{\updelta}}_{i} ,\hat{\mathbf{\varvec{\upbeta}}})} \cdot {\text{pr}}({\varvec{\updelta}}_{i} ) \cdot {\text{d}}{\varvec{\updelta}}_{i} \). However, there was no closed-form solution to this integral and therefore, it was computed numerically.
Let \( \hat{y}_{ij} \) be the population-averaged predicted values for section j of tree i. The validity of the model was assessed through the average bias and the root mean square error (RMSE), which were computed as follows:
Relative biases and RMSE were obtained by dividing Eqs. 10a and 10b by the average observed diameter. Average biases and RMSE were calculated by classes of tenths of relative height as is done in most of the studies on the stem profile modeling (e.g., Garber and Maguire 2003; Sharma and Zhang 2004). Moreover, the trees were grouped into 5-cm dbh classes to check if bias was related to tree size.
Predicted stem tapers were also used to compute tree-level volume estimates. Estimated and observed volumes for trees of the validation data set were compared with assessed volume prediction bias. Observed volumes were calculated using two outside bark round-end diameters: a 0-cm limit, which provided the total volume, and a 9.1-cm limit, which is considered as the merchantable limit in the province of Quebec. The volumes were calculated with Smalian’s formula (Avery and Burkhart 1983, p. 30). Biases and RMSE were then computed.
Finally, like Lappi (2006) and Kublin et al (2008), the simplified model was also used to evaluate the number and best location of supplementary diameter measurements. According to the mixed model theory (Littell et al. 2006), additional diameters along the bole can be considered as prior knowledge of the stem taper, and can be used to predict the vector of tree random effects as:
Using the predicted \( \hat{\mathbf{\varvec{\delta}}}_{i} \) is known to reduce the variance of the model predictions (e.g., Hall and Bailey 2001). To test this effect in this case study, the validation data set was divided into ten relative height classes again. Like Trincado and Burkhart (2006), the root mean square error (RMSE) within each relative height class was obtained using the predicted random effect parameter. The evaluation was conducted with two different scenarios. The first used only one supplementary diameter at absolute heights of 0.0001 m (stump height), 3.5, 7, and 10 m. The second used two supplementary diameters at absolute heights of 3.5 m, with 7 m and at 3.5 m with 10 m.
Results
We parameterized the model several times keeping the fixed-effect specification constant. We first included the variance function, then the random effects and finally the correlation structure. According to AIC and BIC statistics, every additional covariance feature, i.e., the random effects, the variance function, and the correlation structure significantly improved the maximum likelihood of the model (Table 2). The maximum log-likelihood (LLK) value increased from −6,237 for the model including the variance function only to −4,175 for the complete model (model 5 in Table 2).
The normalized residuals were normally distributed with homogeneous variance. Empirical correlations were computed for height classes along the bole. The residuals exhibited low but persistent correlations for some distances between the diameter measurements (Fig. 1). Most correlations did not exceed the [−0.2, 0.2] range. The parameter estimation yielded the following parameter estimates (all significant at α = 0.01):
Note that the parameter estimates in Eqs. 11e, 11f, and 11g refer to the correlation structure and the variance function. The 95% confidence intervals of the fixed-effect parameters are annexed to this paper.

Empirical correlations against distance classes between height sections along the bole (dashed lines represent the 95% confidence intervals under the null hypothesis H0: \( {\text{Corr}}(r_{ij} ,r_{{ij^{\prime } }} ) = 0 \))
The estimates of the fixed-effect parameters and the variance–covariance matrix Σ were used in turn to generate a population-averaged mean predicted stem profile for each tree of the validation data set. The biases and RMSE were calculated for each 5-cm dbh class. Results are shown in Table 3. Two diameter classes (2.5–7.5 and 27.5–32.5 cm) were omitted from this table because they had too few trees.
The model tends to underestimate the diameters in the lower and upper sections, whereas the mid-section diameters are overestimated. For sections below 0.8 in relative height, most biases are smaller than or close to 0.4 cm in absolute value, and the RMSE ranges from 0.2 to 1.1 cm (Table 3). These biases are relatively low, with absolute relative values ranging from 0 to 6.5% which are similar to those obtained by Garber and Maguire (2003) and Sharma and Zhang (2004). For the upper sections, the biases are larger and range from 0.5 to 0.7 cm like those obtained by Garber and Maguire (2003) and Sharma and Zhang (2004). The pattern is similar for all diameter classes. With an average bias of 0.1 cm for all the validation data pooled, the model predictions can be considered nearly unbiased on average (Table 3).
The volume estimates show average biases that range from 0.1 to 3.2 dm3 in absolute values (Table 4). These biases are relatively small, representing less than 1% of the average observed volumes. RMSE tends to increase with the diameter. However, the relative root mean square error is rather constant, ranging from 5.4 to 10%. For most diameter classes, bias and RMSE are slightly larger for the merchantable volume.
When only one supplementary diameter measurement was considered at stump height (0.0001 m), 3.5, 7, and 10 m each time, Fig. 2 shows that: (1) the corrected curve is better than the mean response, (2) the correction cannot improve the accuracy of the whole stem; instead, the part around the supplementary diameter measurement is improved significantly, (3) the correction can hardly improve the prediction if the supplementary diameter is measured at the very bottom of the bole. Thus, the best placement depends on which part of the stem is considered to be more important. When two supplementary diameter measurements were considered, Fig. 3 shows that: (1) in general, the prediction is better than supplemented by only one extra diameter measurement, and (2) compared with the mean response, the improvement is less significant.

Root mean square error [RMSE (cm)] for the mean and calibrated responses using one supplementary diameter measurement

Root mean square error [RMSE (cm)] for the mean and calibrated responses using two supplementary diameter measurements
Discussion
The stem taper equation obtained represents a simplified version of Kozak’s original variable-exponent equation. It has three general parameters when the outside bark diameter is considered as the dependent variable. The use of random effects with a variance function and a correlation structure represents two advantages over the ordinary least square estimators. First, if the covariance features are adequate, the estimators for the vector of fixed-effect parameters and the variance components of the model are thought to be unbiased, although this property is derived from linear theory and has not been extended to the nonlinear case (Pinheiro and Bates 2000, p. 314). Therefore, the appropriate explanatory variables either at the tree scale or the stand scale can be selected according to their significance level. In this case study, tree height and the height/dbh ratio (h i /dbh i ) were significant variables in the prediction of stem taper.
Second, the mixed-effects method ensures some consistency among model predictions through the estimation of distinct error components. In this case study, four error components were found to be significant. Three were related to tree level, i.e., the three random effects (δ 1,i , δ 2,i , and δ 3,i ), whereas the last one was the residual error, which is associated with diameter measurements (ε ij ). The result obtained is more satisfying than what would be obtained using least square estimators in which the single error term is assumed to be entirely independent from one section to the other along the bole. Actually, such a least square-based model is likely to have a lower maximum log-likelihood when compared with a model with a variance function only (model 1 in Table 2), which in turn has a much lower maximum log-likelihood when compared with the proposed model (model 5 in Table 2).
An alternative to the simplification of Kozak’s equation is a linearization through a logarithmic transformation, which reduces the magnitude of the numerical problem of estimating its parameters. However, the logarithmic transformation induces a bias when the predicted values have to be back-transformed (Duan 1983). Moreover, the log-transformed diameter did not respect the assumption of normality in this case study. For these reasons, the nonlinear approach was preferable.
In terms of accuracy, the proposed model shows biases that are similar in range to those of other studies. Biases in the upper sections are particularly large, as in Garber and Maguire (2003) and Sharma and Zhang (2004). In our context, the low reliability in the upper bole section can be explained by the cylindrical assumption whose effect is exaggerated by the lack of diameter measurements in the upper bole sections. Also, the model is constrained to pass through the tip of the tree, and to be equal to the dbh at 1.3 m. Consequently, there is less flexibility near these points than anywhere else along the bole. However, the effects of these upper section biases on volume calculation are small. Actually, biases on the estimated volumes are relatively low (Table 4), and the numerical integration of the taper function yields a reliable mean prediction for the different volumes of a particular tree.
The mathematical consistency of the model, i.e., y ij = 0 when h ij = ht i and y ij = dbh i when h ij = 1.3, brings up some considerations about the heteroscedastic pattern of the residuals. In fact, the variance of the prediction error increases with the increase in the predicted value. This statement is logical, since we can reasonably expect the diameters at but swell to be more variable than those at the tip of the tree. However, because of the mathematical consistency of the model, the variance of the prediction error should decrease as sections get closer to breast height. For instance, there should not be a great variability in diameter predictions 10 cm above or below breast height. This statistical constraint has not been taken into account in this case study in a direct manner because it would have required a complex variance function, while a good compromise between complexity and efficiency is required for operational applications.
The evaluation of the supplementary diameter measurements showed that estimating the tree random effects improves the predictive capability of the simplified model. The corrected curve is better than the mean response. However, the correction cannot improve the accuracy of the whole stem; instead, the part around the extra diameter measurement is improved significantly. So the best placement depends on which part of the stem is considered more important. The prediction can be minimally improved by adding diameter measurements at both ends of the bole.
The model does not include any plot covariates because information at the plot level was not available. Consequently, the model relies on the assumption of within-plot tree independence. This can be a strong assumption, considering that some studies have already demonstrated that some plot attributes may have an effect on stem taper (e.g., Garber and Maguire 2003; Sharma and Zhang 2004). We also tested some plot random effects in the model, but convergence could not be achieved because of the complexity of the covariance features. However, the empirical correlation (an indirect evaluation of this plot random effect) was close to 0 (analysis not shown), indicating that the variance of the potential stand-level random effects might be low in this case study. This low random effect may be explained by the inclusion of the height/dbh ratio in the model. The ratio is a surrogate of tree density at the plot scale.
Conclusion
We have shown that a simplified version of Kozak’s equation can be applied to stem taper data of boreal black spruce using the mixed-effects method with a proposed correlation structure. The simplified equation was obtained by fixing the inflection point at dbh. The proposed correlation structure makes it possible to apply the mixed-effects method for adequately addressing the variability of stem taper at the tree scale. The low validation error based on the wide gradient of collected black spruce stem taper data provides the first evidence that this simplified variable-exponent taper equation can reliably predict black spruce tree taper over large areas. Related to the mean response, predicting the random effects through additional diameter measurements improves the predictive capability of the obtained model around the extra diameter observation.
To further improve the model, the first step will be to develop a variance function that is more consistent with the model. This function should induce a decrease in the variance as the sections get closer to breast height. The second step will be to link tree scale with plot scale. Plot scale is represented by forest polygon attributes based on aerial photos or remote sensing. Also it is necessary to clarify the limits of applicability of the proposed taper equation because the assumption of the model may be violated in other species and at other observations. Nevertheless, the model offers welcome simplicity as a means of predicting tree taper at coarse resolution from standard tree attribute measurements and from eventual polygon attributes available on any forest map that can be used for the primary log breakdown.
References
Avery TE, Burkhart HE (1983) Forest measurements, 3rd edn. McGraw-Hill Book Company, Princeton, NJ
Beaumont JF, Ung C-H, Bernier-Cardou M (1999) Relating site index to ecological factors in black spruce stands: tests of hypotheses. For Sci 45(4):484–491
Bonnet P-A, Pastor M (1997) Utilisation de la dimension fractale du houppier pour la vérification de la loi d’auto-éclaircie. Rapport de stage non publié. Centre de foresterie des Laurentides, Sainte-Foy, Québec
Bonnor GM, Boudewyn P (1990) Taper-volume equations for major tree species of the Yukon territory. Information Report BC-X-323, Forestry Canada, Pacific Forestry Centre, Victoria, BC
Davidian M, Giltinan DM (1995) Nonlinear models for repeated measurement data. Chapman & Hall, Boca Raton, FL
Demaerschalk JP, Kozak A (1977) The whole-bole system: a conditioned dual-equation system for precise prediction of tree profiles. Can J Res 7:488–497. doi:10.1139/x77-063
Duan N (1983) Smearing estimate: a nonparametric retransformation method. J Am Stat Assoc 78:605–610. doi:10.2307/2288126
Garber SM, Maguire DA (2003) Modeling stem taper of three central Oregon species using nonlinear mixed effects models and autoregressive error structures. For Ecol Manage 179:507–522
Gregoire TG, Schabenberger O, Barrett JP (1995) Linear modelling of irregularly spaced, unbalanced, longitudinal data from permanent-plot measurements. Can J Res 25:137–156
Hall DB, Bailey RL (2001) Modeling and prediction of forest growth variables based on multilevel nonlinear mixed models. For Sci 47(3):311–321
Kozak A (1988) A variable-exponent taper equation. Can J Res 18:1363–1368. doi:10.1139/x88-213
Kublin E, Augustin NH, Lappi J (2008) A flexible regression model for diameter prediction. Eur J For Res 127:415–428. doi:10.1007/s10342-008-0225-7
Lappi J (2006) A multivariate, non parametric stem-curve prediction method. Can J Res 36:1017–1027. doi:10.1139/X05-305
Leites LP, Robinson AP (2004) Improving taper equations of loblolly pine with crown dimensions in a mixed-effects modeling framework. For Sci 50:204–212
Lindstrom MJ, Bates DM (1990) Nonlinear mixed-effects models for repeated measures data. Biometrics 46:673–687. doi:10.2307/2532087
Littell RC, Milliken GA, Stroup WW, Wolfinger RD, Schabenberger O (2006) SAS for mixed models, 2nd edn. SAS Institute Inc, Cary, NC
McCulloch CE, Searle SR (2001) Generalized, linear, and mixed models. Wiley, New York
MRNF (2003) Vegetation zones and bioclimatic domains in Québec. Gouvernement du Québec. Ministère des Ressources naturelles et de la Faune. Available at: http://www.mrn.gouv.qc.ca/english/forest/quebec/quebec-environment-zones.jsp
Newnham RM (1988) A variable-form taper function. Information Report PI-X-83, Canadian Forestry Service, Petawawa National Forest Institute, Petawawa, ON
Ouellet D (1983) Biomass equations for black spruce in Quebec. Information Report LAU-X-60E, Canadian Forestry Service, Laurentian Forestry Centre, Sainte-Foy, QC
Pinheiro JC, Bates DM (2000) Mixed-effects models in S and S-PLUS. Springer, New York
Pinheiro JC, Bates DM, DebRoy S, Sarkar D, the R Core team (2008) The nlme package. Available at: http://cran.stat.sfu.ca/. Revised on June 23, 2008
R Core team (2008) The R project for statistical computing. Available at: http://www.r-project.org/. Revised on June 23, 2008
Ruel J-C, Horvàth R, Ung C-H, Munson A (2003) Comparing height growth and biomass production of black spruce trees in logged and burned stands. For Ecol Manage 193:371–384
SAS Institute (2008) SAS online doc 9.1.3. SAS Institute Inc. Available at: http://support.sas.com/onlinedoc/913/docMainpage.jsp (last revised on July 31, 2008)
Sharma M, Zhang SY (2004) Variable-exponent taper equations for jack pine, black spruce, and balsam fir in eastern Canada. For Ecol Manage 198:39–53
Steel RGD, Torrie JH, Dickey DA (1997) Principles and procedures of statistics: a biometrical approach. McGraw-Hill, New York
Sullivan AD, Clutter JL (1972) A simultaneous growth and yield model for loblolly pine. For Sci 18:76–86
Trincado G, Burkhart HE (2006) A generalized approach for modeling and localizing stem profile curves. For Sci 52:670–682
Ung C-H (1990) Tarifs de cubage paramétrés: application à l’épinette noire de Lebel-sur-Quévillon. Can J Res 20:1471–1478. doi:10.1139/x90-194
Ung C-H, Ouellet D (1993) Croissance et branchaison de l’épinette noire Picea mariana (Mill.) B.S.P. In: Ung C-H (ed) Les modèles de croissance forestière et leurs utilisations. Colloque international tenu les 18 et 19 novembre 1993, Centre municipal des Congrès, Québec (Canada) Canadian Forest Service, Laurentian Forestry Centre, Sainte-Foy, Q, pp 45–57
Vonesh EF, Carter RL (1992) Mixed-effects nonlinear regression for unbalanced repeated measures. Biometrics 48:1–17. doi:10.2307/2532734
Acknowledgments
The first author received financial support from NSERC, Grant No. 234774. Dr. Steen Magnussen of the Canadian Forest Service helped to make the paper more concise. The comments and suggestions of two anonymous reviewers have contributed to clarifying its scope.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by T. Seifert.
Appendix
Appendix
The 95% confidence intervals of the parameters are given in the following table (Table 5).
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Lejeune, G., Ung, CH., Fortin, M. et al. A simple stem taper model with mixed effects for boreal black spruce. Eur J Forest Res 128, 505–513 (2009). https://doi.org/10.1007/s10342-009-0300-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10342-009-0300-8