
Abstract
In Fennoscandia, the Glacial Isostatic Adjustment (GIA) causes intraplate deformations that affect the national static reference frames. The GNSS-determined velocities are important data for constraining the GIA models, which are necessary for maintaining the national reference frames. The Nordic Geodetic Commission (NKG) has published a dense and consistent GNSS station velocity solution in 2019, and we present now an update of the solution covering additional 3.5 years of data. Undetected positional offsets are the main factor decreasing the accuracy of the velocity estimates. We developed a method for the semi-automatic offset detection to improve the quality of our solution. The results show that we could correctly detect 74% of the manually determined offsets, and the undetected offsets would have caused a median 0.1 mm/y bias in trend. The method pointed out some otherwise unnoticed offsets and will decrease the need for manual analysis in the future. The updated velocity solution especially improves the velocity estimates of the newly established stations and the quality of the velocity estimates in Baltic countries. The formal uncertainties estimated using the power-law plus white noise model were at a median of 0.06 and 0.15 mm/y for horizontal and vertical velocities, respectively. However, we concluded that the systematic velocity uncertainties due to the reference frame alignment were approximately at the same level.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
GNSS-determined velocity fields are widely used in geodetic and geophysical studies locally, regionally, and globally. In Fennoscandia, the Glacial Isostatic Adjustment (GIA) process causes intraplate deformations that affect the national static reference frames, and the GNSS-determined velocities are important data for their maintenance. For example, they constrain GIA models and align the models to a geodetic reference frame to produce the required deformation models.
Today, the increased number of GNSS stations enables more detailed analysis of intraplate deformations. In Europe, Kenyeres et al. (2019) have published a dense velocity field by integrating long-term national solutions computed according to the current processing standards. Much effort has been expended on homogenizing and cross-checking the input solutions and on visual inspection of time series. However, the total of nearly 2000 stations set limits on the manual analysis. In the Nordic and Baltic countries, the densest sets of station velocities have been estimated under the Baseline Inferences for Fennoscandian Rebound, Sea-level, and Tectonics (BIFROST) project, of which the latest solution includes data until 2015.0 (Kierulf et al. 2021). This solution does not have equal station density in all Nordic and Baltic countries, and the focus has been on geodynamic studies. The GNSS Analysis Centre (AC) of the Nordic Geodetic Commission (NKG) was launched in 2011 to improve the station coverage and to estimate both positions and velocities utilizing the local knowledge of the stations. The methods of the NKG GNSS AC were presented by Lahtinen et al. (2018), and the first dense position and velocity solution was published by Lahtinen et al. (2019). This solution included velocities for 252 stations computed from the daily positional solutions between 1997 and 2017.1.
Abrupt positional changes, called offsets, are the main cause of the degrading of the GNSS velocity estimates. They can relate to equipment or processing changes, earthquakes, or remain unknown. The effect of the offsets depends on their size and position in the time series and its noise content. The GNSS position time series contain temporally correlated noise that has a spectrum of the power-law: \(f^{-n}\), where \(f\) is the frequency and \(n\) is the spectral index. White noise (\(n = 0\)), flicker noise (\(n = 1\)), and random walk (\(n = 2\)) are special cases of the power-law noise. The spectral index describes the stability of the time series. The white noise is very stable, whereas the flicker noise, which has typically been used to describe the GNSS data, may have offset-like behavior by its nature. The possibility that undetected offsets may cause random walk noise in the time series has also been discussed by Williams et al. (2003). Therefore, the power-law nature of the time series makes the offset detection challenging, as the noise itself can mimic small real offsets very well.
In the NKG GNSS AC, we have relied on manual offset analysis, which has thus far performed better than the automatic methods. However, manual analysis of hundreds of stations is very time-consuming, and more automatic routines are needed. The (semi)automatic methods can also ideally reveal small offsets that were not found in the manual analysis. The manual analysis also includes human factors, and a more automatic method may therefore homogenize the results.
Many offset detection methods have been developed during the past two decades. The performance is typically evaluated by the ratios between correctly found offsets (true positives, TP), false positives (FP), and false negatives (FN). The FPs correspond to false alarms and the FNs to undetected offsets. Gazeaux et al. (2013) reported on the results of the Detection of Offsets in GPS Experiment (DOGEx), in which different methods were blind tested on the same synthetic data set. The best performance rates were achieved with the manually analyzed solutions, and they achieved approximately 40% for TPs. The best performing automatic solution achieved approximately 35% for TPs. Later, Bruni et al. (2014) presented the results of the Sequential t test Analysis of Regime Shifts (STARS) procedure, achieving a ratio of 48% for TPs. Recently, Amiri-Simkoeii et al. (2018) achieved approximately 30% for TPs with the univariate method and approximately 75% with the multivariate method. The north, east, and up components were analyzed separately in univariate method and simultaneously in multivariate method. Here, a predefined maximum number of offsets was used that affected the number of FPs. Additionally, the offsets were added to the same epoch for all components, which may produce an optimistic figure for the performance of the multivariate solution.
Khazraei and Amiri-Simkoeii (2020) improved the method of Amiri-Simkoeii et al. (2018) by adding splines to the functional model. The results showed 53% for TPs with the old method without any predefined number of offsets and 61% for TPs with the improved model. Khazraei and Amiri-Simkoeii also tested the method on the DOGEx data set and achieved 33% for TPs. This was a little higher than the best automatic solutions submitted to DOGEx. Khazraei and Amiri-Simkoeii had used a different assumption for TPs than Gazeaux et al. (2013), and therefore lower TP ratios were achieved for the best models. In general, this indicates that the performance metrics are very dependent on the time series on which they have been tested on, how the assumption for TPs is defined, and whether an automatic or manually defined criterion for stopping the iterative offset search has been used. All these synthetic data sets included many offsets, and their performance with real data is difficult to evaluate.
From the perspective of operational work, we cannot obtain perfect results by using any method. The power-law noise can always mimic or hide a small offset. The methods presented in the literature typically do not use any metadata in decision making, but it plays a major role in the operative offset analysis. We want to add an offset if we can link it to a known change, though the size of the offset may be at a millimeter level. On the other hand, we want to avoid over-segmenting the data with unknown offsets. The use of metadata, therefore, enables the automating of the procedures of the manual offset detection.
This study presents an update of the NKG position and velocity solution covering 23.5 years of data. In the next chapter, we present the offset detection approach that we have developed and utilized in the pre-analysis of the time series. In the third chapter, we describe the methodology used for the computation of the cumulative position and velocity solution. In the fourth chapter, we show the results of the performance of the offset detection approach and evaluate the updated velocity solution with uncertainties. Finally, we discuss the developed methodology and the results and conclude the study.
Automatic offset detection
First, we present the methodology of our offset detection method. Second, we study its performance, using synthetic data to define a limit for minimum unknown offsets that can be found sufficiently reliably. The offset detection method has been empirically developed, mainly utilizing data from Finnish stations that included different types of offset.
Offset detection method
The aim is to detect millimeter level offsets, and such small changes may not be visible in all coordinate components. We, therefore, do the offset detection separately for the north, east, and up components of the time series. We model the time series using linear velocity, annual and semi-annual periodical signals, plus known offsets. We call it a standard linear trajectory model by Bevis and Brown (2014).
We utilize the findoffset program of the Hector software (Bos et al. 2013) to search for potential offset positions and estimate their sizes. Hector uses the maximum likelihood method to estimate the parameters of the standard linear trajectory model and the noise. It thus also enables the use of different noise models in offset detection. First, the parameters of the standard linear trajectory model and the noise of the time series are estimated. Second, for each epoch in the time series, an offset is added. The parameters of the model and noise, and the corresponding log-likelihood are recomputed using the fixed covariance matrix C from the first step. This produces the Bayesian Information Criterion (BIC) time series with fixed C: BICC. It is proportional to \(-2\mathrm{ln}L(\theta |x)\), where \(\mathrm{ln}L\) is the log-likelihood, \(\theta\) the estimated parameters, and \(x\) the observations. The implementation of the BICC computation in the findoffset program includes additional penalty parameters used for iterative offset detection, but they are not used in nor affected by our method and are therefore not described here. The BICC describes the model’s goodness of fit, so we assume that we find the most probable offset at the epoch of minimum BICC.
Figure 1 shows an example time series with an antenna change offset at 2019.5 and the computed BICC time series. In the case of using the white noise model, we see a clear minimum of the BICC time series at the antenna change epoch, whereas in the case of the power-law plus white noise, there are only single epochs with smaller BICC values. The BICC values range to approximately 30 units for the power-law-based BICC time series compared to the 400 units for the white noise. Therefore, the use of the power-law noise model is not, in this case, sufficiently sensitive to detect the rather clear offset. The method is simplified to the standard least squares solution with the white noise model because no noise model parameters are to be estimated using the maximum likelihood method. However, the iterative penalty parameter method of Hector is not sufficiently powerful if only white noise is used, leading to over-segmentation. A new criterion for the significance analysis of a potential offset is therefore needed.

An example residual time series (top) and the BICC time series (bottom) using white noise and power-law plus white noise models
The pattern of the BICC time series varies depending on the nature of the time series. It can be as clear and sharp as in Fig. 1, but it can also be smoother without a sharp minimum epoch. By studying the BICC time series of the NKG GNSS AC solutions, we identified that the difference of the median and minimum BICC values were linked to the existence of a real known offset. We define \(\Delta\)BIC as a measure of the significance of a potential offset.
We computed the ΔBICC for all the Finnish stations of the NKG GNSS AC solution with observations between 2 and 23.5 years. Figure 2 shows that the ΔBICC is larger than 100 for all manually detected offsets. On the other hand, as the absolute value of BICC grows as a function of the number of observations, the fixed absolute limit prevents the unwanted false positives in case of short time series. We can detect about 90% of the offsets of the data set using only the fixed ΔBICC limit. Therefore, we use the ΔBICC as an efficient measure to find the potential time series for subsequent offset analysis.

Computed ΔBICC values for each time series as a function of time series length. The color of the dots describes whether an offset has been detected or not in manual analysis. The unknown cases describe a potential unknown offset that should be studied in more detail
We introduce three parameters for the decision making. The time window defines the time span that we use in search of matching equipment or other known changes. In the case of small offsets in noisy time series, the minimum BICC may not occur exactly at the epoch of equipment change. Additionally, we set limits for minimum sizes of known and unknown offsets. The limit for minimum known offsets is used to avoid unrealistically small offsets being matched with known changes. The limit for minimum unknown offsets can be set based on the performance of the method analyzed using synthetic data (see next chapter).
We formulate the strategy of the ΔBICC offset detection with real data as follows:
-
1.
Compute the BICC time series for the time series.
-
2.
If the ΔBICC > 100, compute the size of the offset added to the epoch of the minimum BICC.
-
3.
Then try to match the epoch with the station’s metadata. If a match within a set time window is found, and the offset is larger than the minimum limit for known offsets, add an offset according to the metadata.
-
4.
Otherwise, if the size is larger than the minimum limit for unknown offsets, suggest that it be checked.
-
5.
Iterate steps 1–4 if an offset has been added or suggested in step 3 or 4.
Limit for minimum unknown offset
The aim is to set the limit of the size for unknown offsets so that only very probable unknown offsets are suggested to be set. Therefore, we studied the performance of the ΔBICC method with synthetic data in which the true offset positions were known. We created data using the simulatenoise program of the Hector software and parameters summarized in Table 1. The parameters were selected based on the median values of the power-law plus white noise estimates of the time series presented in Lahtinen et al. (2019). For the median case, the estimated fraction for white noise was zero. We, therefore, used only the power-law noise model. We added one offset for a random epoch of each time series. We repeated the setup with fifty time series and varying offset sizes ten times for six data sets: horizontal and vertical time series with lengths of 2000, 3000, and 5000 days. A true positive was achieved if the found offset was within 60 days of the correct day. This corresponds to our experience with the test data set. We set the limit for minimum size of an offset to 0.1 mm smaller than the STD of the noise, and we did not set any limit for the sizes of the known offsets.
Figure 3 shows the success rates of the ΔBICC method. The success rate increases as a function of the offset size as expected, but flattens when the rate reaches a minimum of 80%. It corresponds to offset sizes of 1.8 mm in the horizontal and 6.0 mm in the vertical, and factors of 2.5 and 2.2 of the noise amplitudes. The used spectral index was 0.1 unit higher for the vertical time series, meaning a slightly more stable time series, and we could therefore detect slightly smaller offsets relative to the amplitude of the noise. The length of the time series did not significantly affect the success rates. The detection accuracy, i.e., the number of days between the correct and detected offset date, improved as a function of increasing offset size. It was at maximum six days for 90% of the time series with 1.8/6.0 mm offset size. The results indicate that there is a risk of up to 20% for a false offset if we use the 1.8/6.0 mm as the minimum unknown offset. We consider this a good tradeoff between perfect results and potential FPs and FNs. We applied the ΔBICC method on our NKG GNSS AC time series, and the results are shown in the Results chapter.

Offset size versus the success rate of the offset detection with 2000, 3000, and 5000 days of observations for horizontal (top) and vertical (bottom) time series. The positions of the dots in the offset size axis have been shifted slightly to avoid the datasets overlapping
Methods of the cumulative solution
This updated GNSS station velocity solution follows mostly the same methods that were used in Lahtinen et al. (2019). We focus here on the changes and improvements that we have applied. We describe the input data, the pre-analysis with semi-automatic offset detection approach, and the methods of the velocity and uncertainty estimation.
Data
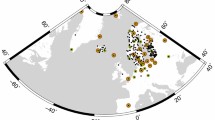
We used the daily position time series of the NKG GNSS AC covering the years 1997–2020.5. Nine local analysis centers (LAC) processed their subnet solutions that were combined to daily NKG solutions (Lahtinen et al. 2018). The daily processing was done with the Bernese GNSS software (Dach et al. 2015) and the combination using the CATREF software (Altamimi et al. 2018). The solutions until 2017.1 were from the reprocessing of the historical GPS-only data (NKG Repro1), described in detail in Lahtinen et al. (2019). These solutions were corrected with the IGN antenna model correction from IGS08 to IGS14 to avoid the positional shifts due to the antenna model change in 2017.1. The remaining solutions were from the operational processing with a similar setup as in the reprocessing, but GPS/GLONASS data have been used until 2019.4 and GPS/GLONASS/Galileo thereafter. Figure 4 shows an overview of all included stations. We have 323 stations in total and 41 co-located stations. The length of the time series varied from very new stations up to 23.5 years.

An overview of all the stations included in the NKG GNSS AC solution. The orange circles represent the stations used in the reference frame alignment
Pre-analysis of the time series
We pre-analyzed the position time series before velocity estimation to smooth the computationally heavy stacking of the cumulative solution. We searched for the offsets and rejected the snow-affected data. In this study, we did the offset analysis both manually and with the automatic ΔBICC method described in the previous section.
The manual time series analysis was based on visual interpretation by local analysis centers with existing information of the stations, like site log files and case studies. The analysis was done using mainly the Tsview software (Herring 2003), which enables the easy testing of the effect of different actions. The manual analysis of the BICC time series also indicated some otherwise undetected small offsets. In the case of a questionable offset, its effect on the trend was also evaluated. Although we analyzed the coordinate components separately, we set up offsets at the same epochs for all components in the station velocity estimation. Therefore, the effect of a potential offset needs to be analyzed for all components. We may skip adding an offset due to a small jump visible only in one component, if it changes significantly the velocity of another component. This may happen with unstable or short time series. In general, our principle was to define the offsets utilizing the best possible local knowledge of the stations. We used the manually defined offsets as true values in the performance analysis of the automatic ΔBICC method, and in the velocity estimation.
Position, velocity, and uncertainty estimation
The cumulative position and velocity solution was computed by combining the daily solutions with full covariance information using the least-squares methods of the CATREF software. The combination model is based on a seven-parameter similarity transformation, where each of the daily NKG solutions is transformed into the combined solution at the reference epoch (Altamimi et al. 2016, 2018). We aligned our solution to the EPN cumulative release of the IGb14 that covered the data until GPS week 2115 (Bruyninx et al. 2019; Legrand 2020). The reference stations are shown in Fig. 4. The other potential solutions could not be used: the IERS release of the ITRF2014 (Altamimi et al. 2016) is incompatible with the IGS14 antenna models, and the IGS14/IGb14 realizations of the ITRF2014 included too few usable stations in our area.
We constrained the velocities of the co-located stations to be the same for all co-located stations except in Sweden. We found significant velocity differences between some of the Swedish co-located stations in Lahtinen et al. (2019), and the differences remained at the same level for this updated solution. The stations have different monument types (concrete pillars versus steel grid mast) that may behave differently. We modeled the large post-seismic deformations of the Icelandic stations FJOC, INTA, and KALF due to earthquakes in late 2014 using the exponential model and approximated relaxation times.
The uncertainties were computed from the position residual time series of the CATREF solution using Hector software, which includes power-law-based noise modeling. The residuals were modeled using the standard linear trajectory model. We introduced the same discontinuities that had been used in the CATREF solution. The uncertainties of the co-located and constrained stations were computed from Hector’s uncertainty estimates using the formula derived in Lahtinen et al. (2019).
The Hector software uses the Generalized Gauss Markov (GGM) model by Langbein (2004) to approximate the flicker and general power-law noise. The (1 − Φ) term describes the flattening of the power spectral curve at low frequencies. In Lahtinen et al. (2019), the flicker plus white noise estimates were computed using the individually estimated flattening term (1 − Φ) due to computational issues with the very small (1 − Φ) terms. This resulted mostly in a better fit of the model with the data. However, the fit varied from time series to time series. We therefore re-analyzed the spectral properties of the time series to choose the model on the basis of the varying spectral properties of the time series.
Results
We first summarize the performance of the offset detection approach in the NKG time series. Second, we evaluate the updated velocity solution and present the estimated uncertainties.
Performance of offset detection approach
The performance of the ΔBICC offset detection method was tested on the daily position time series of 268 stations included in NKG GNSS AC. We excluded the stations in Greenland, Iceland, and Svalbard, because they typically include nonlinear trends that are not considered in this approach. Additionally, we did not analyze a few stations because we decided to reject data instead of adding an offset. These were typically stations where the gradual tree growth was seen as a changed or nonlinear trend, and tree-cutting causes a jump in the time series (see example in Lahtinen et al. 2019). The reprocessed data were rather clear of gross errors or systematical outliers due to snow, as they had already been pre-analyzed for the NKG Repro1 solution. The operational data since the 2017.1 epoch were added to the time series without any pre-analysis. A standard residual screening was performed within the offset detection process, using the limit of three times the interquartile range.
In the manual analysis, we identified small offsets at the epoch of the switch from reprocessed to operational data, despite the antenna model correction. We, therefore, added the 2017.1 epoch as a known epoch in addition to the information of the receiver and antenna changes. We used the 1.8 mm and 6.0 mm limits for the minimum unknown offsets based on the tests with the synthetic data. We set the time window to match the potential offsets to known equipment changes to ± 60 days, and for the switch from repro to operational to ± 30 days, based on our experience of the data.
Table 2 summarizes the results of the offset detection. Our ΔBICC method detected on average 74% of the manually defined offsets. The results vary a little among the countries depending on the number of stations and the quality of the time series. On the other hand, the method could not detect 26% of the manually detected offsets. Those were typically cases, in which the iteration stopped to some unknown-but-insignificant offset, and the smaller known offsets was not detected. This is typical for unstable time series. In addition, offsets that do not significantly affect the trend, may have been missed. Such cases included several small consecutive offsets, and offsets at the very end of the time series. The FNs were linked to 21 stations, and their effect on the estimated trends were for 90% of the stations below 0.15, 0.09, and 0.41 mm/y for north, east, and up respectively.
The ratios of the TPs, FNs, and FPs were split into 49%, 16%, and 35%, respectively. The FPs were typically offsets that were considered insignificant in the manual analysis. The method found several potential small offsets close to the dates of receiver changes in the past. However, we considered some of them insignificant. The number of false positives can be considered reasonable because it also provides useful information concerning the potential offsets or nonlinearities in the time series. The epoch of an offset may also be detected incorrectly just outside the search window despite our rather loose limits. In the performance analysis, this will cause an FN because the known offset was missed and an FP because the offset was detected outside the search window.
We obtained notifications, either true or false positives, from 15% of the number of analyzed time series. Thus, most of the time series did not include potential offsets, and with this approach, we could reduce and homogenize the manual pre-analysis of the time series. The offset detection performs very well with good quality stations, and the most anomalous time series with potential offsets can be identified from the residual time series.
Cumulative position and velocity solution
Our cumulative position and velocity solution, NKG_Repro1_IGb14_C2111, includes 275 stations with a minimum of three years of data. The means of the weighted RMS of the daily positions were 1.0 and 3.3 mm for horizontal and vertical components, respectively. We achieved a good agreement with the EPN C2115 cumulative reference frame release. The WRMS were 0.3, 0.6, and 1.9 mm for the positions and 0.0, 0.1, and 0.2 mm/year for the velocities in NEU respectively. The REYK and NYA1 stations were included in the datum, although they were not included in the highest-class stations defined by the EPN. The REYK improved the reference frame alignment in Iceland, and the NYAL prevented the north–south tilt compared to the results of the corresponding IGS cumulative solution.
Figures 5 and 6 show the estimated horizontal and vertical velocities in IGb14 for the stations with a minimum of three years of data. The vertical velocities show the common land uplift pattern, whereas the horizontal velocities mostly reflect the plate tectonics. The station coverage has improved in Finland, although we excluded about 25 recently installed stations. We also excluded many lower-class stations in Estonia to improve the quality over the station density in the area. The numerical dataset of the NEU velocities is given in the electronic supplement.

Estimated vertical velocities for the Nordic and Baltic countries. Smaller circles have been used for the newer Swedish co-located stations that were not constrained to the old ones. The Eurasian/North American plate border splitting Iceland is shown with a gray line

Estimated horizontal velocities for the Nordic and Baltic countries. The color of the circles shows the magnitude of the velocity, and the vectors show the direction. The vectors are shown only for a part of the stations for clarity
Figure 7 shows the velocity differences from the previous results by Lahtinen et al. (2019). The largest differences are mostly linked to the stations with the shortest time series plotted with smaller circles, where the amount of data increased relatively most. We could improve velocity estimates of several stations by adding previously undetected offsets, rejecting anomalous data and modeling the large post-seismic deformations. We also see approximately 0.1 mm/y systematic difference in an east–west direction due to the different reference frame realization. In general, we could improve the quality of the velocity estimates for the short or otherwise unstable time series.

Velocity differences from the previous results by Lahtinen et al. (2019). The vectors show the horizontal velocity differences, and the circles show the vertical velocity differences. The size of the circles changes with respect to the length of the time series
Figure 8 shows the velocity difference to the EPN densification solution D2100 by Kenyeres et al. (2019). We see a systematic difference of − 0.3 mm/y on the median in the up component and large discrepancies at several stations, both horizontally and vertically. The systematic difference results from the different sets of stations used in the reference frame alignment. The largest differences at individual stations are a sum of several reasons. Our solution includes data since 1997, but the EPN’s D2100 solution includes only data since 2008. This affects some of the stations with the longest time series due to their nonlinear changes. Furthermore, the velocity constraints of the co-located stations have been set up based on the site ID in the EPN densification solution, whereas we have made some exceptions based on our view of the stations. Finally, the different modeling of stations in Iceland causes large differences in velocity estimates.

The comparison of the velocities to the EPN densification solution D2100. The vectors show the horizontal velocity differences, and the circles show the vertical velocity differences. There are both systematic and random differences
Uncertainties
Table 3 summarizes the spectral indexes of the north, east, and up time series describing the stability of the position time series. The median values were − 0.8 for horizontal components and − 0.7 for the up component. The vertical time series were, therefore, on average, slightly more stable than the horizontal components, though the standard deviation of the noise was typically larger. However, the spectral indexes were between − 0.4 and − 1.0, showing variability in the power spectral properties of the stations. The spatial distribution of the spectral indexes is similar to the figures shown in Lahtinen et al. (2019). Especially in the east component, the spectral indexes for the stations in the eastern part of the network were closer to flicker noise, and in the western part, they were at a level of − 0.5.
The large variation in spectral indexes shows that the flicker noise assumption is too pessimistic for most of the stations. In general, the individually estimated power spectral index produces a much better fit of the model to the data. We can see a flattening of the power spectrum in low frequencies for the most stable stations, as Fig. 9 shows. However, the estimation of the flattening term cannot be reliably done with the short time series. We, therefore, selected the power-law plus white noise model for the final uncertainty estimation.

Example of a power spectral density of a station (15 years’ data, up component) showing the flattening of the spectrum in low frequencies
The uncertainty differences between this updated solution and the NKG Repro1 solution by Lahtinen et al. (2019) were mostly negligible in the horizontal components. Figure 10 shows differences in the up component. In general, we expect lower uncertainties for the updated solution with more data, but the change of the noise model from the flattened flicker noise to power-law noise affects the uncertainty estimates. The largest positive and negative differences were linked to the short time series plotted with smaller circles. They are affected most, as the estimation of the noise model parameters is more uncertain when we lack the samples in low frequencies.

Differences of the estimated uncertainties of the vertical velocities compared to the Repro1 solution. A positive value means an increase, and a negative value a decrease in the uncertainty estimate. The size of the circle changes with respect to the length of the time series
Table 4 describes the estimated uncertainties. The median uncertainties were 0.06, 0.07, and 0.15 mm/y for north, east, and up, respectively. They describe the internal uncertainty of the time series. However, we see the same sizes of systematic velocity differences in Fig. 7 between our solutions. The systematic differences typically originate from the differences in the reference frame alignment. The comparison of the station velocity estimates between IGS and EPN cumulative solutions shows that the accuracy of the station velocities is not at the level of 0.1 mm/y. This means that depending on the purpose, one may need to estimate and add other uncertainty factors to get the total uncertainty budget for the GNSS station velocities.
Discussion
We achieved high performance rates with our ΔBICC offset detection method. A comparison of the results with the other methods is not feasible due to the different data sets and assumptions for the TPs. However, the existing methods of Hector and Amiri-Simkoeii et al. (2018) could not detect small offsets similar to Fig. 1. We could detect even millimeter level true offsets in the high-quality time series. However, our method is not sensitive to many small consecutive offsets, especially if they cancel out each other’s effect on the trend. Furthermore, the offsets at the very end of the time series can also remain undetected, as they do not significantly affect the trend but should be taken into account for the position estimates. To detect these cases as well, a similar approach to the STARS methodology by Bruni et al. (2014) could be useful, in which offsets are searched with sliding segments of the time series.
We allowed a loose search window in the offset detection compared to the other methods, in which TPs were assumed only when an offset had been detected within a few days of the known date. However, several reasons support the use of the loose limits for GNSS time series. First, when we lower the limit for the smallest detectable offset, the estimation of the offset epoch becomes more inaccurate due to the power-law noise. Second, the GNSS stations may have monument, software, or hardware related issues, that show up earlier in the time series than the actual documented change. Third, the data gaps and the snow-effects in the time series may affect the automatically estimated epoch of an offset. We also recognize that the small offsets may become detectable some years after the offset epoch. Therefore, the analysis should be repeated for the full time series when new data are added to the time series.
We set the limit for the minimum unknowns based on the performance analysis of the method. The test data were created using the median spectral indexes of the NKG time series. The reasonable number of false positives and negatives showed that the limits worked well. However, there are variability in the properties of the time series, for example, in the spectral indexes. With more simulation, we could probably derive the limit as a function of some of the parameters.
We could improve the velocity estimates of several stations with the aid of the developed offset detection method. The time series of Iceland would further benefit from a more in-depth analysis of post-seismic deformations. We only modeled the most significant cases. A thorough analysis of the time series also resulted in differences in the offsets compared to the reference frame solution, which reduced the number of usable stations in the reference frame alignment. Therefore, it would be important to improve the offset analysis in the reference frame solutions by EPN and IGS. Preferably, this would be done in a coordinated and inclusive way, utilizing the local knowledge while harmonizing the methodology.
Conclusions
We developed an automatic offset detection method for the time series analysis to improve the quality of our velocity estimates and increase the efficiency of the time series analysis. Our study showed that the use of a power-law noise model in the offset detection could not detect small offsets at a level of 1–2 times the noise amplitude. These undetected offsets increase the instability of the time series, which leads to spectral indexes closer to flicker noise. Therefore, we used the white noise model and developed a BIC-based stopping criterion to avoid the increase in false alarms. Our ΔBICC method is easy to implement on top of the open-source software Hector, and only non-heavy scripting is needed. We achieved a 74% detection rate compared to the manual analysis, and the velocity biases due to the undetected offsets remained at a median below 0.1 mm/y.
Our updated position and velocity solution for Nordic and Baltic countries now covers up to 23.5 years of data. The new solution improves velocity estimates for several stations in all countries as a result of more data and the better modeling of individual stations. We estimated a median uncertainty of 0.06, 0.07, and 0.15 mm/y for north, east and up components, respectively, using the power-law plus white noise model. The uncertainties increased for some of the stations due to the noise model change compared to the NKG Repro1 solution by Lahtinen et al. (2019). The uncertainties due to the reference frame realization were approximately at the same level and should be considered in the total uncertainty budget when appropriate. The comparison with the EPN densification solution showed large differences in the station velocities despite the same input LAC solutions, demonstrating the importance of this regional solution for the maintenance of the Nordic–Baltic reference frames affected by the GIA. In the future, we will focus on the regular updates of our cumulative solution and the next reprocessing effort to strengthen the solution further.
Data Availability
The synthetic time series can be obtained upon request by the author. The daily input SINEX solutions can be obtained upon request from the NKG FTP server.
References
Altamimi Z, Rebischung P, Metivier L, Collilieux X (2016) ITRF2014: A new release of the International terrestrial reference Frame modeling nonlinear station motions. J Geophys Res Solid Earth. https://doi.org/10.1002/2016JB013098
Altamimi Z, Boucher C, Sillard P, Collilieux X, Rebischung P (2018) CATREF Software Combination and Analysis of Terrestrial Reference Frames. User manual, April 19, 2018
Amiri-Simkoeii AR, Hosseini-Asi M, Asgari J, Zangeneh-Nejad F (2018) Offset detection in GPS position time series using multivariate analysis. GPS Solut 23:13. https://doi.org/10.1007/s10291-018-0805-z
Bevis M, Brown A (2014) Trajectory models and reference frames for crustal motion geodesy. J Geodesy 88:283–311. https://doi.org/10.1007/s00190-013-0685-5
Bos MS, Fernandes RMS, Williams SDP, Bastos L (2013) Fast error analysis of continuous GNSS observations with missing data. J Geod. https://doi.org/10.1007/s00190-012-0605-0
Bruni S, Zerbini S, Raicich F, Errico M, Santi E (2014) Detecting discontinuities in GNSS coordinate time series with STARS: case study, the Bologna and Medicina GPS sites. J Geodesy 88(12):1203–1214. https://doi.org/10.1007/s00190-014-0754-4
Bruyninx C, Legrand J, Fabian A et al (2019) GNSS metadata and data validation in the EUREF permanent network. GPS Solut 23:106. https://doi.org/10.1007/s10291-019-0880-9
Dach R, Lutz S, Walser P, Fridez P (Eds) (2015) Bernese GNSS Software Version 5 2 User manual, Astronomical Institute, University of Bern, Bern Open Publishing. https://doi.org/10.7892/boris.72297; ISBN 978–3–906813–05–9.
Gazeaux J et al (2013) Detecting offsets in GPS time series: first results from the detection of offsets in GPS experiment. J Geophys Res Solid Earth 118(5):2397–2407. https://doi.org/10.1002/jgrb.50152
Herring T (2003) MATLAB Tools for viewing GPS velocities and time series. GPS Solut 7:194–199. https://doi.org/10.1007/s10291-003-0068-0
Kenyeres A et al (2019) Regional integration of long-term national dense GNSS network solutions. GPS Solut 23:122. https://doi.org/10.1007/s10291-019-0902-7
Khazraei SM (2020) Amiri-Simkoeii A R (2020) Improving offset detection algorithm of GNSS position time-series using spline function theory. Geophys J Int 224:257–270. https://doi.org/10.1093/gji/ggaa453
Kierulf HP, Steffen H, Barletta VR, Lidberg M, Johansson J, Kristiansen O (2021) Tarasov L (2021) A GNSS velocity field for geophysical applications in Fennoscandia. J Geodyn 146:101845. https://doi.org/10.1016/j.jog.2021.101845
Lahtinen S, Häkli P, Jivall L et al (2018) First results of the Nordic and Baltic GNSS analysis centre. J Geod Sci 8(1):34–42. https://doi.org/10.1515/jogs-2018-0005
Lahtinen S, Jivall L, Häkli P et al (2019) Densification of the ITRF2014 position and velocity solution in the Nordic and Baltic countries. GPS Solut 23:95. https://doi.org/10.1007/s10291-019-0886-3
Langbein J (2004) Noise in two-color electronic distance meter measurements revisited. J Geophys Res 109:B04406. https://doi.org/10.1029/2003JB002819
Legrand J. (2020) EPN multi-year position and velocity solution C2115, Available from Royal Observatory of Belgium. https://doi.org/10.24414/ROB-EUREF-C2115
Wessel P, Smith WHF, Scharroo R, Luis J, Wobbe F (2013) Generic mapping tools: improved version released. EOS Trans AGU 94:409–410. https://doi.org/10.1002/2013EO450001
Williams SDP (2003) The effect of coloured noise on the uncertainties of rates from geodetic time series. J Geodesy 76:483–494. https://doi.org/10.1007/s00190-002-0283-4
Acknowledgements
We thank all the NKG GNSS AC operators for the processing and time series analysis efforts. We thank Danish Agency for Data Supply and Efficiency for hosting the data server for the needs of the project. The maps of this paper were generated using the Generic Mapping Tools (GMT, Vessel et al. 2013).
Funding
Open Access funding provided by National Land Survey of Finland.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lahtinen, S., Jivall, L., Häkli, P. et al. Updated GNSS velocity solution in the Nordic and Baltic countries with a semi-automatic offset detection method. GPS Solut 26, 9 (2022). https://doi.org/10.1007/s10291-021-01194-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10291-021-01194-z