
Abstract
Introduction
For the analysis of clinical effects, multiple imputation (MI) of missing data were shown to be unnecessary when using longitudinal linear mixed-models (LLM). It remains unclear whether this also applies to trial-based economic evaluations. Therefore, this study aimed to assess whether MI is required prior to LLM when analyzing longitudinal cost and effect data.
Methods
Two-thousand complete datasets were simulated containing five time points. Incomplete datasets were generated with 10, 25, and 50% missing data in follow-up costs and effects, assuming a Missing At Random (MAR) mechanism. Six different strategies were compared using empirical bias (EB), root-mean-squared error (RMSE), and coverage rate (CR). These strategies were: LLM alone (LLM) and MI with LLM (MI-LLM), and, as reference strategies, mean imputation with LLM (M-LLM), seemingly unrelated regression alone (SUR-CCA), MI with SUR (MI-SUR), and mean imputation with SUR (M-SUR).
Results
For costs and effects, LLM, MI-LLM, and MI-SUR performed better than M-LLM, SUR-CCA, and M-SUR, with smaller EBs and RMSEs as well as CRs closers to nominal levels. However, even though LLM, MI-LLM and MI-SUR performed equally well for effects, MI-LLM and MI-SUR were found to perform better than LLM for costs at 10 and 25% missing data. At 50% missing data, all strategies resulted in relatively high EBs and RMSEs for costs.
Conclusion
LLM should be combined with MI when analyzing trial-based economic evaluation data. MI-SUR is more efficient and can also be used, but then an average intervention effect over time cannot be estimated.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Decisions about the implementation and/or reimbursement of new healthcare interventions increasingly rely on evidence of their cost-effectiveness compared to one or more alternative interventions, preferably usual care, to optimize the use of scarce healthcare resources [1, 2]. Economic evaluations seek to provide this information by relating the difference in costs between healthcare interventions to the difference in effects [2]. In many cases, economic evaluations are performed alongside clinical trials, which are then referred to as trial-based economic evaluations [3]. Important advantages of trial-based economic evaluations include the prospective collection of cost and effect data as well as the use of patient-level information to draw inferences about the cost-effectiveness of healthcare interventions [3].
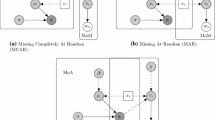
Missing data are common in clinical trials as participants may skip questions, follow-up assessments, and/or drop out of the study [4]. In trial-based economic evaluations, costs are calculated as the sum of numerous cost components that are measured at different time points. Thus, if one cost component is missing, costs cannot be calculated [2, 3, 5]. In the literature, three different missing data mechanisms are distinguished that describe the association between missing data and observed and unobserved variables [6]. Missing Completely At Random (MCAR) assumes missing data to occur by chance. Hence, the missing data are not associated with observed or unobserved variables. Missing At Random (MAR) occurs when the missing data are associated with observed variables, but not with unobserved variables. Missing Not At Random (MNAR) occurs when missing data sre associated with unobserved variables [6].
Historically, missing data in trial-based economic evaluations were handled by simply deleting participants with missing values (i.e., complete-case analysis). However, deleting missing cases from the analysis potentially biases estimates, as systematic differences may exist between subjects with missing and complete data [5,6,7]. Other methods to account for missing data in trial-based economic evaluations include “naïve” imputation methods, such as mean imputation and last observation carried forward. The use of “naïve” imputation methods is discouraged, because these methods do not account for the uncertainty related to filling in the missing values like other more advanced methods do [7,8,9,10,11]. Advanced methods, such as Multiple Imputation (MI) and Longitudinal Linear Mixed-model analysis (LLM) with maximum likelihood estimation are therefore considered more valid and are increasingly used for handling missing data [7,8,9,10, 12, 13].
The advantage of MI is that it estimates the total variance of the summary statistic considering the within- and between-imputation variance, reflecting the uncertainty around estimated missing values [13]. Another key advantage of MI is the possibility to include auxiliary variables in the imputation model that may be not relevant for the analysis model. This can help in improving the precision of the estimates and adjust for important missingness predictors. A possible disadvantage of such an approach, however, is the change of mis-specifying the imputation model, which may in turn lead to incorrect results. Another possible disadvantage of MI is the added computational complexity, because outcomes need to be estimated for all imputed datasets an then they are pooled to obtain overall estimates. Also, MI may lead to unstable results when no sufficient imputations are performed [14].
Previous studies have shown that when opting for LLM, in case of reasonably normally distributed outcomes, MI is not necessary to obtain unbiased estimates, because the maximum likelihood function uses all observed data and produces unbiased estimates under the MAR assumption [14, 15]. Faria et al. [5] suggested that MI is not required prior to LLM in trial-based economic evaluations either, but this has never been empirically tested. This is important because there are three distinct statistical challenges to trial-based economic evaluations that may affect the performance of LLM to deal with missing data: 1) costs are typically heavily right-skewed; 2) costs are cumulative sums over time, and 3) costs and effects are correlated [15]. This study aimed to bridge this gap in knowledge by assessing whether MI of missing variables prior to LLM increases its performance when analyzing longitudinal cost and effect data. Additionally, the impact of using either one of these approaches on cost-effectiveness estimates was assessed using empirical data.
Methods
To assess whether MI of missing values is required prior to LLM, a simulation study was conducted. SUR and mean imputation were added as analytic strategies to assess the relative performance of the main models (i.e., LLM and MI-LLM) versus (simpler) alternative approaches. Mean imputation was added because the results of Sullivan et al. [17] suggest that MI is not the only acceptable way to handle missing data in RCTs and that simpler approaches, such as mean imputation, may also have satisfactory performance. SUR was added, because with LLM the possible correlation between costs and effects is neglected, whereas SUR can account for this correlation through correlated error terms [16, 17]. In total, we compared six different methodological strategies; (i) LLM alone (LLM), (ii) mean imputation combined with LLM (M-LLM), (iii) MI combined with LLM (MI-LLM), (iv) seemingly unrelated regression alone (SUR-CCA), (v) mean imputation combined with SUR (M-SUR), and (vi) MI combined with SUR (MI-SUR). Additionally, two empirical datasets were used to evaluate the external validity of the results [18, 19].
Simulated datasets
Complete data generation
Two thousand complete datasets were generated using the Simstudy R package (R statistical software–version 3.5.2) [20]. The parameters used for generating variables were based on previous trial-based economic evaluations [21, 22] and the empirical datasets [18, 19], and are summarized in Table 1. The R code for data generation can be found in Supplementary material 1.
A total of 600 subjects per dataset was generated. An intervention to control ratio of 52:48 was simulated to resemble slightly unbalanced empirical datasets using a binomial distribution. A complete set of baseline variables was generated, including age, gender, costs (cT0), and utility values (uT0; i.e. a measure of health-related quality of life, HRQoL) [23]. Age was generated using a normal distribution, gender using a binomial distribution, while costs and utility values were generated with a gamma distribution (Table 1) [24]. At baseline, age and gender were positively related with costs and utility values, indicating that we assumed older subjects and men to have higher costs and utility values than younger subjects and women, respectively. To create a plausible MAR assumption, age and gender were slightly imbalanced, but we made sure that these imbalances were small and in line with those encountered in previous trial-based economic evaluations [19, 21, 22, 25]. Additionally, we assumed the correlation between costs and utility values to be about − 0.50 [26, 27]. Such a negative correlation might appear when subjects with a lower health-related quality of life (i.e. lower utility values) have higher treatment costs, because they were less healthy to begin with [27].
Follow-up cost and utility values were simulated, with a true total cost and quality-adjusted life-year (QALY) difference during the complete-duration of follow-up of 250 euros and 0.04 QALY, respectively (Table 1, Supplementary material 1). This was done by first generating costs and utility values at 3-month follow-up (i.e., cT1 and uT1), based on the subjects’ baseline cost and utility values (i.e., cT0 and uT0) as well as their age, gender, and treatment allocation (trt). Then, all other follow-up cost and utility values (i.e., 6, 9, and 12-month follow-up) were extrapolated from the subjects’ 3-month follow-up values, using a correlation between time points of 0.7 for costs and 0.9 for utility values and a compound symmetry correlation structure (i.e., correlations between subsequent time-points were assumed to be the same).
Missing data generation
We assumed baseline data to be completely observed for all subjects, which is often the case in trial-based economic evaluations [19, 21, 22, 25]. Missing follow-up cost and utility values were generated under the assumption that the missingness of data was solely due to drop-out, resulting in monotone missing data patterns only (Supplementary material 2). This means that subjects were assumed to either complete the study, and hence all follow-up assessments, or to drop-out after 3, 6, 9, or 12-months and have missing data from that time point on. We acknowledge that intermittent missingness patterns (e.g., non-monotone) may also exist in empirical data. However, for the sake of simplicity, and considering previous literature [28, 29], we opted to simulate monotone missing data patterns only.
To generate follow-up missing values, a missing data indicator \({m}_{ij}\) was generated for every subject i (i = 1, …, N = 600) at time point j (j = 1, …, 4) using a binomial distribution and a logit link function to model the linear dependence between the probability of missing data and its predictive variables (i.e., age, gender, cT0, uT0, trt).
where \({\pi }_{mij}\) is the probability of a subject i having missing data at time point j. The intercept (\({\beta }_{0})\) and coefficients (\({\beta }_{1, }{\beta }_{2, }{\beta }_{3, }{\beta }_{4, } {\beta }_{5})\) of covariates were tweaked to generate a plausible MAR assumption and datasets with 10, 25, and 50% missings. \({\varepsilon }_{i}\) is the error term (Supplementary material 2) [28]. Then, at the respective time point j, all complete follow-up cost and utility values were replaced by missing values according to \({m}_{ij}\). This process was repeated for all consecutive time points amongst the subset of individuals still in the study [28]. Thus, the “missingness” of costs and utility values at all time points was conditional on age, gender, as well as their baseline values. Subjects in the intervention group were assumed to be 4, 2, and 1 times more likely to have missing values compared to their control group counterparts for the datasets with 10, 25, and 50% missing data, respectively. This was done to strengthen the MAR assumption. The MAR assumption in our simulation differs from the MNAR assumption, because the \({\pi }_{mj}\) was independent of the partially observed follow-up cost and utility values [6, 7].
Number of simulations
The number of required simulated data sets (nsim) was calculated using the Monte Carlo standard error of the expected coverage rate [30]. The Monte Carlo standard error quantifies simulation uncertainty and provides an estimate of the standard error for simulation performance measures when using a finite number of simulations [30]. The coverage rate of the confidence intervals, that uses information of the Monte Carlo standard error represents the probability that a confidence interval contains the ‘true’ value. To estimate the coverage rate with an acceptable degree of imprecision, a total of 1900 simulated datasets (rounded up to 2000) was found to be needed based on a maximal Monte Carlo standard error of 0.5 and an expected coverage rate of 95%.
Data analyses
Data analyses were performed in StataSE 16® (StataCorp LP, CollegeStation, TX, US). All Stata codes can be found in Supplementary material 2, 3, and 4.
Methodological strategies
Longitudinal Linear Mixed-model analysis (LLM)–Two separate LLMs were performed, including one for costs and one for utility values:
where \({Costs}_{ij}\) and \({Utility}_{ij}\) represent the cost and utility values of subject i (i = 1, …, N = 600) at time point j (j = 1, …, 4). The model parameters include the coefficients \({{\beta }_{1, \dots , }\beta }_{9}\) of covariates, including various – by \({time}_{j}\) interactions. Moreover, \({\omega }_{ci}\) and \({\omega }_{ui}\) represent the random intercepts and \({\varepsilon }_{cij}\) and \({\varepsilon }_{cij}\) the error terms at each time point j for costs and utility, respectively. Both \({\omega }_{i}\) and \({\varepsilon }_{ij}\) follow a normal distribution [28, 31, 32].
To calculate the total cost difference between treatment groups, information was extracted on the average cost differences per time point, after which all follow-up cost differences were summed. To estimate the difference in QALY between treatment groups, information was extracted on the average utility differences per time point, after which the area under the curve method was applied[23]. Detailed information on model specification can be found in Supplementary material 3.
Mean Imputation combined with LLM (M-LLM)–In this strategy, missing cost and utility values were replaced by the mean values from the available cases at each time point (i.e., unconditional mean imputation) [5]. Subsequently, two separate LLMs were fitted as outlined under LLM (Supplementary material 3).
Multiple imputation combined with LLM (MI-LLM): in this strategy, missing cost and utility values were first imputed using Multivariate Imputation by Chained Equations (MICE; FCS-standard) [33] with Predictive Mean Matching (PMM) [34]. With PMM, a case with one or more missing values is matched with a number of cases with complete data (i.e., donor observations) [34]. The characteristics used to match an observation with missing values with donor observations are the variables specified in the imputation model, which in our case included age, gender, cT0, and uT0. Subsequently, a value is randomly drawn from the donor observations that have an observed value for that variable [34]. The MICE algorithm then uses this random value to fill in missing data in an iterative process until the pre-specified imputation model converges [33]. A set of 5 donors with complete data was used for the matching (i.e., a k-nearest neighbor [knn] of 5) [34]. The imputation model was stratified by treatment group (i.e., trt) [17]. In total, 10 datasets were imputed for datasets with 10% and 25% missing data, and 20 for datasets with 50% missing data. This was done to ensure that the loss-of-efficiency was smaller than 0.05 [33]. Subsequently, two separate LLMs were fitted per imputed dataset as outlined under LLM, after which pooled estimates were obtained using Rubin’s rules [6] (Supplementary material 3).
Seemingly Unrelated Regressions—Complete Case Analysis (SUR-CCA) – In this strategy, total costs and QALY were calculated by adding costs at each time point and using the area under the curve method, respectively [23]. Subsequently, a seemingly unrelated regressions (SUR) model was fitted. A SUR model consists of two separate regression equations, e.g. one for total costs and one for QALY, while simultaneously correcting for their possible correlation through correlated error terms [16, 35]. With the current strategy, only subjects with completely observed data were analyzed (i.e., a complete-case analysis).
where \({Costs}_{i}\) and \({QALY}_{i}\) are the observed total costs and QALY during follow-up of subject i (i = 1, …, N). \({\beta }_{0c}\) and \({\beta }_{0e}\) represent the models’ intercept,\({\beta }_{1c}\) and \({\beta }_{1q}\) represent the regression coefficients of the independent variable ‘treatment group’ (trt). \({\beta }_{2c}\dots {\beta }_{4c}\) and \({\beta }_{2q}\dots {\beta }_{4q}\) represent the regression coefficients for baseline values, age, and gender, \({\varepsilon }_{ci}\) and \({\varepsilon }_{ei}\) represent the correlated error terms for costs and QALY, respectively [16, 35].
Mean Imputation combined with SUR (M-SUR): in this strategy, follow-up missing cost and utility data were replaced by the mean values from the available cases at each time point (i.e., unconditional mean imputation) [5]. Subsequently, total costs and QALYs were calculated, and SUR analyses were performed as outlined under SUR (Supplementary material 3).
Multiple imputation combined with SUR (MI-SUR) – In this strategy, follow-up missing cost and utility data were first imputed using multivariate imputation by chained equations (MICE) as outlined under MI-LLM [33]. Then, total costs and QALYs were calculated and a SUR was fitted per imputed dataset as outlined under SUR, after which pooled estimates were obtained using Rubin’s rules (Supplementary material 3) [33].
Comparison of the methodological strategies
The performance of the methodological strategies was assessed with regard to costs and QALY differences using the following performance measures: empirical bias (EB), root-mean-square error (RMSE) and coverage rate (CR) [30]. Performance measures were calculated by comparing the ‘true’ values (i.e., estimand, [\(\theta\)]) with the estimated values \(\left(\widehat{\theta }\right)\) obtained from the methodological strategies conducted over the 2000 simulated datasets. Monte Carlo standard errors were estimated for each performance measure to quantify the uncertainty of these measures due to using 2000 simulated datasets [30] (Supplementary material 3).
(i) Empirical bias (EB) represents the average difference between \(\widehat{\theta }\) and \(\theta\). This performance measure estimates whether a method targets θ on average and must, therefore, be small.
(ii) Root-mean-square error (RMSE) represents the square root of the difference between \(\widehat{\theta }\) and \(\theta\).
The mean-square error (MSE) is a measure of accuracy that combines the bias and variance in a single measure [36]. For easier interpretation, we report the square root of the MSE, to express it on the same scale as costs and QALYs [36].
(iii) Coverage rate (CR) represents the percentage of times that the \(\theta\) is covered by the estimated 95% CI of \(\widehat{\theta }\).
The Monte Carlo standard error distance from the nominal value of 0.95 was used as a criterion of poor coverage [37]. It is worth to note that CR alone may mislead conclusions about the accuracy of methodological strategies, because high variances in estimates can lead to high CR [30, 38]. Therefore, in this study, CR was evaluated jointly with the other two performance measures [30].
In addition to assessing the performance of the methodological strategies for handling missing data (see Sect. 2.2.1), we assessed the performance of LLM and SUR in the complete datasets. This was done to have a better understanding of their performance in the context of a trial-based economic evaluation in general. That is, before examining their performance for handling missing data).
Empirical datasets
Description of the datasets
Data from two pragmatic randomized controlled trials were used in addition to the simulated data. In the first trial (empirical dataset 1), the cost-effectiveness of early rehabilitation after lumbar disc surgery was compared to no referral [18]. For the current study, utility values collected at baseline, 12, and 26 weeks and costs collected at 6, 12, and 26 weeks were used. For all scenarios, mean imputation was used to impute missing values at baseline [5]. Of the 169 participants used in our study, 13% (n = 22) had missing cost and/or utility data at one or more follow-up time points (Supplementary material 4). Stepwise backwards regression models with p < 0.05, were used to identify baseline variables that were predictive of the missingness of data and/or the cost-effectiveness outcomes. The identified variables were added to the imputation model as auxiliary variables (i.e. age, level of education, utility values, Oswestry Disability Index [ODI], pain intensity, Örebro Musculoskeletal Pain Screening Questionnaire [OMPSQ], and the credibility and expectancy surgery [CEQ]) [18]. Missing cost and utility data were imputed using multivariate imputation by chained equations (MICE; FCS-standard) [33] with PMM, stratified by treatment group [34]. Ten datasets were imputed to guarantee a loss of efficiency < 0.05. SUR and LLM were then fitted to the imputed data. The LMM models (i.e., M-LLM and MI-LLM) and SUR models (i.e., SUR-CCA, M-SUR, and MI-SUR) did not include auxiliary variables, and only were corrected for confounders (i.e. baseline utility values, ODI, OMPSQ, and CEQ). The LLM analysis model included both, auxiliary variables and confounders as, in doing so, it should lead to similar results when compared to MI-LL [5] (Supplementary material 4).
In the second trial (empirical dataset 2), the cost-effectiveness of an interpersonal psychotherapy for older adults with major depression was compared to care as usual (i.e., control). For this study, utility values collected at baseline, 6, and 12 months and costs collected at 2, 6, and 12 months were used [19]. Mean imputation was used to impute missing values at baseline [5]. Of the 143 participants, 68% (n = 98) of cost and utility data were missing at one or more follow-up time points (Supplementary material 4). Stepwise backwards regression models with p < 0.05, were used to identify baseline variables that were predictive of the missingness of data and/or the cost-effectiveness outcomes. The identified variables were added to the imputation model as auxiliary variables (i.e., age, activity daily living [ADL], utility values, alcohol-induced disorder, and mental health problems utility values, marital status, and household composition) [19]. Missing cost and utility data were imputed using multivariate imputation by chained equations (MICE; FCS-standard) [33] with PMM by treatment group[34]. Twenty datasets were imputed to guarantee a loss of efficiency < 0.05. SUR and LLM were then fitted to the imputed data. The LMM models (i.e., M-LLM and MI-LLM) and SUR models (i.e., SUR-CCA, M-SUR, and MI-SUR) did not include auxiliary variables and only were corrected for confounders (i.e., baseline utility values, marital status, and household composition). The LLM analysis model included both, auxiliary variables and confounders [5] (Supplementary material 4).
Cost-effectiveness analysis of the empirical datasets
Cost-effectiveness analyses were performed using the differences in costs and QALY between treatment groups estimated by all of the methodological strategies described under 2.2.1. to both empirical datasets. Cost-effectiveness acceptability curves (CEACs) were estimated using the parametric Incremental Net Benefit (INB) approach, where the estimate of acceptability was obtained as the probability that INB > 0 for every value of the willingness-to-pay threshold (WTP) [39, 40]. The INB is defined as \(INB=\lambda \times {\Delta }_{q}-{\Delta }_{c}\) and the probability (Pr) of the INB being positive conditional to \(\lambda\) is estimated as:
where λ is the WTP, \(\Phi\) is the cumulative standard normal distribution, and \({\Delta }_{q}\), \({\Delta }_{c}\) are the differences in QALY and total costs between the intervention and control, respectively. \(Var\left({\Delta }_{q}\right), Var\left({\Delta }_{c}\right)\), are the variances around differences in QALY and total costs, and \(Cov({ \Delta }_{q},{\Delta }_{c})\) is the covariance. To facilitate interpretation of the results, the probability of cost-effectiveness was also reported for willingness-to-pay thresholds of 10,000, 20,000 and 50,000 € per QALY gained [41].
Results
Comparison of methodological strategies
Simulated datasets
For costs, LLM, MI-LLM and MI-SUR resulted in lower EBs and RMSEs compared to M-LLM, SUR-CCA, and M-SUR for all proportions of missing data. For 10 and 25% of missing data, MI-LLM and MI-SUR resulted in lower EBs and RMSEs compared to LLM. Moreover, LLM and MI-LLM were associated with relatively high levels of overcoverage for 10% and 25% of missing data, whereas for MI-SUR CR was closest to the nominal value. For 50% of missing data, all methodological strategies resulted in relatively higher EBs and RMSEs compared to those found in 10 and 25% of missing data. For LLM, CR were closest to the nominal value compared to the other methodological strategies at 50% of missing data.
For QALY, LLM, MI-LLM, and MI-SUR resulted in lower EBs and RMSEs compared to M-LLM, SUR-CCA, and M-SUR for all proportions of missing data. For LLM, EBs and RMSEs were similar or slightly lower than for MI-LLM and MI-SUR for all proportions of missing data. For 10 and 25% of missing data, LLM and MI-LLM were associated with small levels of overcoverage, while MI-SUR was associated with small levels of undercoverage. For 50% of missing data, LLM, MI-LLM, and MI-SUR presented small levels of undercoverage (Table 2, Fig. 1). For both, costs and QALY outcomes, LLM, MI-LLM, and MI-SUR has similar performance measure compared to the LLM and SUR models based on complete datasets.

Plots showing root-mean-square error (RMSE) and empirical bias (EB) associated with the six methodological strategies (Method) at different proportions of missing data (i.e., low: 10%, medium: 25%, and high: 50%) for costs (A) and QALY (B). QALY: quality-adjusted life-year. LLM: longitudinal mixed-model. M-LLM: Mean imputation combined with LLM. MI-LLM: Multiple imputation combined with LLM. SUR-CCA: Seemingly unrelated regressions—complete case analysis. M-SUR: mean imputation combined with SUR. MI-SUR: multiple imputation combined with SUR
Empirical datasets
In empirical dataset 1, LLM, MI-LLM, and MI-SUR resulted in similar point estimates for QALYs, but not for costs. The 95%CIs around the cost and QALY differences were somewhat wider for LLM and MI-LLM compared to MI-SUR, but all 95%CIs showed that both differences were not statistically significant. Similar ICERs and probabilities of cost-effectiveness were found for LLM, MI-LLM, and MI-SUR. The mean imputation methods (M-LLM and M-SUR) resulted in narrower 95%CIs compared to LLM MI-LLM, and MI-SUR, but similar probabilities of cost-effectiveness. SUR-CCA resulted in very different point estimates, ICER, and probabilities of cost-effectiveness compared to all others methodological strategies (Table 3; Fig. 2).

Cost-effectiveness acceptability curves (CEACs) showing the probability of the intervention being cost-effective (x-axis) for different willingness-to-pay thresholds per unit of quality-adjusted life-year (QALY) gained (y-axis) in empirical datasets 1 and 2 with 9% and 53% of missing data in costs and QALY, respectively. LLM: longitudinal mixed-model. M-LLM: Mean imputation combined with LLM. MI-LLM: Multiple imputation combined with LLM. SUR-CCA: Seemingly unrelated regressions—complete case analysis. M-SUR: mean imputation combined with SUR. MI-SUR: multiple imputation combined with SUR. €: Euros
In empirical dataset 2, as in empirical dataset 1, similar point estimates for QALY, but not for costs were found for LLM, MI-LLM, and MI-SUR. Results of SUR-CCA, M-SUR, and M-LLM were most different from those of LLM, MI-LL, and MI-SUR (Table 3). Figure 2 shows that the probabilities of cost-effectiveness of the LLM, M-LLM, MI-LLM, M-SUR, and MI-SUR somewhat differed, particularly at lower WTP thresholds.
Discussion
Main findings
Our findings suggest that MI prior to LLM does improve the method’s performance for costs. However, at 50% missing data, all methods had a relatively high level of bias for costs. For QALY, LLM alone already has an acceptable level of performance. Furthermore, the performance of MI-LLM and MI-SUR was similar for costs as well as QALY. Finally, LLM, MI-LLM, and MI-SUR were found to perform considerably better than both mean imputation approaches (i.e., M-LLM, M-SUR) and SUR-CCA for costs and QALY. In empirical datasets, we found LLM, MI-LLM, and MI-SUR to result in similar point estimates for QALY, but not for costs, while the results of SUR-CCA, M-SUR and M-LLM were extensively different.
Interpretation of findings and comparison with the literature
Previous studies suggest that when using LLM, MI of missing values is not necessary to obtain unbiased effect estimates regardless of the missing data mechanism [14, 15]. In line with these studies, we found MI-LLM and LLM to perform equally well for QALY [14, 15]. For costs, however, we found MI prior to LLM to perform better than LLM alone. This difference in performance is likely because costs are typically associated with higher levels of skewness, kurtosis, within-subject variability, and between-subject variability compared with QALY. This phenomenon was also observed in our simulated as well as our empirical datasets. The LLM Stata command we used in our study assumes multivariate normality, whereas the PMM method used to impute data assumes that the distribution of missing values is the same as the observed one, which may result in more robustness to normality violations than maximum likelihood-based methods. According to Dong et al. (2013), this is so because violation of the multivariate normality assumption may cause convergence problems for maximum likelihood-based methods, while the posterior distribution in MI is approximated by a finite mixture of the normal distributions, enabling MI to capture non-normal features (e.g., skewness) [42]. To the best of our knowledge, however, systematic comparisons of MI and maximum likelihood-based methods in terms of their sensitivity to the violation of the multivariate normality assumption are lacking [42,43,44]. Recently, Gabrio et al. [31] assessed the applicability of LLM in one empirical trial-based economic evaluation showing similar point estimates for costs and QALY between LLM and MI-LLM [31]. In another study, Gabrio et al. [28] showed that a longitudinal model alone resulted in unbiased estimates under MAR in the context of a trial-based economic evaluation. Gabrio et al. [28], however, considered Bayesian joint longitudinal models, rather than mixed effects models, and did not assess their methods’ performance for costs and QALY separately [28]. In contrast to Gabrio et al. [28] we did not consider any correlation between costs and QALY in our maximum likelihood-based models, whereas costs and effects are typically correlated in trial-based economic evaluations. In a post-hoc analysis we, therefore, assessed whether our maximum likelihood-based models would perform better when specifying them according to the suggestion of Faria et al. (2014). That is, after rescaling costs to the same scale as utility values (i.e. 0–1), both outcomes were stacked on top of each other and simultaneously regressed upon the various covariates in the model using a three-level structure (i.e. subject, outcome, time)(see Supplementary material 5) [5]. However, even though we did find that such a joint estimation of total costs and QALY slightly improved the models’ bias, their coverage rates were found to be highly sensitive to an incorrect rescaling of costs, which makes the approach hard to apply in practice (Supplementary material 5). We also found MI-LLM to perform equally well as MI-SUR, while the former does not consider the possible correlation between costs and QALY and the latter does. This is in line with the results of Mutubuki et al. [45] who found accounting for the correlation between costs and effects not to have a large impact on cost and QALY estimates in two empirical datasets, nor on the statistical uncertainty surrounding both outcomes [45].
Strengths and limitations
To the best of our knowledge, our study is the first to assess whether it is necessary to perform MI before LLM to account for missing data in trial-based economic evaluations. Another strength of this study was the use of simulated data, which means that we know the ‘true’ outcomes and can, therefore, assess the statistical performance of the methods. In addition, we calculated the number of simulated datasets needed to draw valid conclusions and the simulated datasets resembled empirical data as closely as possible [30].
This study also has some limitations. First, as previously discussed, LLM assumes multivariate normality, an assumption that is typically violated for costs. Future research should therefore assess whether Bayesian joint longitudinal models are better suited for analyzing longitudinal trial-based economic evaluation data than the methods assessed in our study [28]. This might be because Bayesian models enable the joint estimation of costs and effects, while also allowing the use of different distributions for both outcomes (e.g. Gamma for costs and Beta for QALY) [28, 46]. Second, generating a strong MAR mechanism in simulated datasets with a longitudinal structure is relatively complex because a modification in one parameter impacts on all other parameters. To partially overcome this issue, slight baseline imbalances were introduced for age and gender. This, however, is in contrast with the theoretical advantage of RCTs, namely that the randomization of participants allows researchers the confidence that–on average–treatment groups are similar and that the only difference between both groups is the intervention to be assessed for its (cost-)effectiveness [47]. Nonetheless, every individual trial–by definition–exhibits some form of imbalance with respect to measured prognostic variables, especially smaller trials. Moreover, when generating the imbalances we made sure that they were small and in line with the slight baseline imbalances encountered in our empirical datasets [47]. Third, LLM can only deal with missing values at the aggregate level (i.e., total costs and utility values), which might make it less suitable when values are missing at the item level (e.g., number of GP visits, EQ-5D mobility dimension). Further research is therefore needed to assess whether the current results would hold when data are missing at the item-level. Fourth, four follow-up time points were simulated with equal time intervals (i.e., 3, 6, 9, and 12-months follow-up), whereas this is not necessarily the case in trial-based economic evaluations [48]. Further research is needed to assess the impact of varying time intervals on the performance of the methods assessed in this study. Fifth, in this study, we looked at MAR conditional on baseline values, whereas MAR can also be conditional on other values in the dataset. However, we do not expect our conclusion to change for MAR conditional at other values, because such other values can easily be included in an imputation model as well. Sixth, another limitation of the study is that results have only been assessed under MAR mechanisms, while MNAR is also possible. Since it is never possible to distinguish between MAR and MNAR from the data at hand, the robustness of deviations from the MAR assumption is ideally assessed in trial-based economic evaluations using sensitivity analyses. In doing so, the magnitude and direction of the departures from MAR are ideally defined based on external information (e.g. expert opinion) [5, 7]. Seventh, it is also relevant to mention that despite simulating skewed cost and effect data, we assumed that with the current sample size (i.e. 600 subjects), LMM estimates would be robust to non-normal distribution [49]. Amongst others, we did so because using bootstrapping to deal with skewed data made our simulations slower and time consuming. In addition, we wanted to ensure that the differences in performance could be attributed to the use of MI and/or LLM, and not to bootstrapping, and consensus does not currently exist as to how MI ought to be combined with bootstrapping [50, 51].
Implications for practice and research
MI-LLM was found to perform better than LLM in the simulated datasets and equally well as MI-SUR. Therefore, if researchers want to use LLM for analyzing trial-based economic evaluation data they are advised to multiply impute missing values first. Next to the identified improved performance of LLM, MI also allows to include values in the imputation model that may be not relevant for the analysis model (i.e., auxiliary variables), allows to impute missing values at the item-level, and allows for a wider range of regression models to be used in the analysis (e.g., SUR) [23]. From an efficiency standpoint, one might also opt for MI-SUR instead of MI-LLM, because it is computationally more efficient, while having similar EBs and RMSEs and CRs that are closer to the nominal value. Nevertheless, one should bear in mind, that SUR does not allow for the estimation of the average intervention effect over time, whereas LLM does. On the other hand, SUR account for the correlation between costs and effects, whereas LLM does not. Another important point is that variables included in the LLM model should have complete data at baseline otherwise, the model will exclude missing observations from the analysis. To facilitate researchers in using either one of these methods, software codes are included to this manuscript as Supplementary materials 3, and 5. Moreover, as the methods’ performance was found to be considerably less with 50% missing data, researchers are advised to extensively assess the robustness of their results to the methods applied for handling missing data, particularly with high percentages of missing data.
As previously discussed, it should be noted that the presence of item-level missingness highly depends on the measures used to collect the data. For example, it is rarely the case to observe item-level missingness in short questionnaires, such as the EQ-5D, which almost always exhibits monotone patterns [29]. On the contrary, resource use questionnaires often present item-level missingness in trial-based economic evaluations, which makes non-monotone pattern likely to be more relevant for costs. In the current study, we only simulated monotone patterns, hence further investigation is needed to assess whether the current results hold when data are missing at the item level and/or when time intervals vary over time.
Further research is also needed to assess whether Bayesian joint longitudinal models are preferred over the frequentist models evaluated in the current study. Among others, the relevance of exploring the performance of Bayesian models are that they can encode missingness assumptions via prior distributions (e.g., MNAR) and quantify uncertainty without the need to implement bootstrapping methods [52, 53].
Conclusion
Our findings suggest that if researchers want to use LLM for analyzing trial-based economic evaluation data, it is advisable to multiply impute missing values first. One might also opt for a combination of MI and SUR. MI-SUR is computationally more efficient than MI-LLM, but it does not allow for the estimation of average intervention effects over time while having the advantage of accounting for the correlation between costs and effects. Our findings also underscore the importance of extensively assessing the robustness of results to the methods applied for handling missing data, particularly with high percentages of missing data. Further research should assess the relative performance of MI-LLM and MI-SUR versus Bayesian joint longitudinal models, under MAR and MNAR assumptions and assess whether the current results hold when data are missing at the item-level and/or when time intervals vary over time.
References
WHO: 2015 Global Survey on Health Technology Assessment by National Authorities, https://www.who.int/health-technology-assessment/examples/en/, (2015)
Drummond, M.F., Sculpher, M.J., Torranc, G.W.: Methods for the economic evaluation of health care programmes. Oxford University Press, Oxford (2005)
Petrou, S., Gray, A.: Economic evaluation alongside randomised controlled trials: design, conduct, analysis, and reporting. The BMJ (2011). https://doi.org/10.1136/bmj.d1548
Rubin, D.B.: Multiple Imputation for Nonresponse in Surveys. John Wiley & Sons (2004)
Faria, R., Gomes, M., Epstein, D., White, I.R.: A guide to handling missing data in cost-effectiveness analysis conducted within randomised controlled trials. Pharmacoeconomics 32, 1157 (2014). https://doi.org/10.1007/s40273-014-0193-3
Little, R.J.A., Rubin, D.B.: Statistical Analysis with Missing Data. John Wiley & Sons Inc, New York, NY, USA (2014)
Gabrio, A., Mason, A.J., Baio, G.: Handling missing data in within-trial cost-effectiveness analysis: a review with future recommendations. PharmacoEconomics - Open. 1, 79–97 (2017). https://doi.org/10.1007/s41669-017-0015-6
Lipsitz, S.R., Fitzmaurice, G.M., Ibrahim, J.G., Sinha, D., Parzen, M., Lipshultz, S.: Joint generalized estimating equations for multivariate longitudinal binary outcomes with missing data: an application to AIDS data. J. R. Stat. Soc. Ser. A Stat. Soc. 172, 3–20 (2009). https://doi.org/10.1111/j.1467-985X.2008.00564.x
Noble, S.M., Hollingworth, W., Tilling, K.: Missing data in trial-based cost-effectiveness analysis: the current state of play. Health Econ. 21, 187–200 (2012). https://doi.org/10.1002/hec.1693
Díaz-Ordaz, K., Kenward, M.G., Cohen, A., Coleman, C.L., Eldridge, S.: Are missing data adequately handled in cluster randomised trials? A systematic review and guidelines. Clin. Trials Lond. Engl. 11, 590–600 (2014). https://doi.org/10.1177/1740774514537136
Zhang, Z.: Missing data imputation: focusing on single imputation. Transl. Med, Ann (2016). https://doi.org/10.3978/j.issn.2305-5839.2015.12.38
Gomes, M., Grieve, R., Nixon, R., Edmunds, W.J.: Statistical methods for cost-effectiveness analyses that use data from cluster randomized trials: a systematic review and checklist for critical appraisal. Med. Decis. Making. 32, 209–220 (2012). https://doi.org/10.1177/0272989X11407341
Sterne, J.A.C., White, I.R., Carlin, J.B., Spratt, M., Royston, P., Kenward, M.G., Wood, A.M., Carpenter, J.R.: Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls. BMJ 338, b2393 (2009). https://doi.org/10.1136/bmj.b2393
Twisk, J., de Boer, M., de Vente, W., Heymans, M.: Multiple imputation of missing values was not necessary before performing a longitudinal mixed-model analysis. J. Clin. Epidemiol. 66, 1022–1028 (2013). https://doi.org/10.1016/j.jclinepi.2013.03.017
Peters, S.A.E., Bots, M.L., den Ruijter, H.M., Palmer, M.K., Grobbee, D.E., Crouse, J.R., O’Leary, D.H., Evans, G.W., Raichlen, J.S., Moons, K.G.M., Koffijberg, H.: Multiple imputation of missing repeated outcome measurements did not add to linear mixed-effects models. J. Clin. Epidemiol. 65, 686–695 (2012). https://doi.org/10.1016/j.jclinepi.2011.11.012
Willan, A.R., Briggs, A.H., Hoch, J.S.: Regression methods for covariate adjustment and subgroup analysis for non-censored cost-effectiveness data. Health Econ. 13, 461–475 (2004). https://doi.org/10.1002/hec.843
Sullivan, T.R., White, I.R., Salter, A.B., Ryan, P., Lee, K.J.: Should multiple imputation be the method of choice for handling missing data in randomized trials? Stat. Methods Med. Res. 27, 2610–2626 (2018). https://doi.org/10.1177/0962280216683570
Oosterhuis, T., Ostelo, R.W., van Dongen, J.M., Peul, W.C., de Boer, M.R., Bosmans, J.E., Vleggeert-Lankamp, C.L., Arts, M.P., van Tulder, M.W.: Early rehabilitation after lumbar disc surgery is not effective or cost-effective compared to no referral: a randomised trial and economic evaluation. J. Physiother. 63, 144–153 (2017). https://doi.org/10.1016/j.jphys.2017.05.016
Bosmans, J.E., van Schaik, D.J.F., Heymans, M.W., van Marwijk, H.W.J., van Hout, H.P.J., de Bruijne, M.C.: Cost-effectiveness of interpersonal psychotherapy for elderly primary care patients with major depression. Int. J. Technol. Assess. Health Care. 23, 480–487 (2007). https://doi.org/10.1017/S0266462307070572
Goldfeld, K.: simstudy: Simulation of Study Data, https://CRAN.R-project.org/package=simstudy, (2019)
Wit, M., Rondags, S.M.P.A., Tulder, M.W., Snoek, F.J., Bosmans, J.E.: Cost-effectiveness of the psycho-educational blended (group and online) intervention HypoAware compared with usual care for people with Type 1 and insulin-treated Type 2 diabetes with problematic hypoglycaemia: analyses of a cluster-randomized controlled trial. Diabet. Med. 35, 214–222 (2018). https://doi.org/10.1111/dme.13548
Pols, A.D., van Dijk, S.E., Bosmans, J.E., Hoekstra, T., van Marwijk, H.W.J., van Tulder, M.W., Adriaanse, M.C.: Effectiveness of a stepped-care intervention to prevent major depression in patients with type 2 diabetes mellitus and/or coronary heart disease and subthreshold depression: a pragmatic cluster randomized controlled trial. PLoS ONE (2017). https://doi.org/10.1371/journal.pone.0181023
Whitehead, S.J., Ali, S.: Health outcomes in economic evaluation: the QALY and utilities. Br. Med. Bull. 96, 5–21 (2010). https://doi.org/10.1093/bmb/ldq033
Schouten, R.M., Lugtig, P., Vink, G.: Generating missing values for simulation purposes: a multivariate amputation procedure. J. Stat. Comput. Simul. 88, 2909–2930 (2018). https://doi.org/10.1080/00949655.2018.1491577
Apeldoorn, A.T., Bosmans, J.E., Ostelo, R.W., de Vet, H.C.W., van Tulder, M.W.: Cost-effectiveness of a classification-based system for sub-acute and chronic low back pain. Eur. Spine J. 21, 1290–1300 (2012). https://doi.org/10.1007/s00586-011-2144-4
El Alili, M., van Dongen, J.M., Goldfeld, K.S., Heymans, M.W., van Tulder, M.W., Bosmans, J.E.: Taking the Analysis of Trial-Based Economic Evaluations to the Next Level: The Importance of Accounting for Clustering. Pharmacoeconomics (2020). https://doi.org/10.1007/s40273-020-00946-y
Flynn, T., Peters, T.: Conceptual issues in the analysis of cost data within cluster randomized trials. J. Health Serv. Res. Policy. 10, 97–102 (2005). https://doi.org/10.1258/1355819053559065
Gabrio, A., Hunter, R., Mason, A.J., Baio, G.: Joint longitudinal models for dealing with missing at random data in trial-based economic evaluations. Value Health. 24, 699–706 (2021). https://doi.org/10.1016/j.jval.2020.11.018
Simons, C.L., Rivero-Arias, O., Yu, L.-M., Simon, J.: Multiple imputation to deal with missing EQ-5D-3L data: should we impute individual domains or the actual index? Qual. Life Res. 24, 805–815 (2015). https://doi.org/10.1007/s11136-014-0837-y
Morris, T.P., White, I.R., Crowther, M.J.: Using simulation studies to evaluate statistical methods. Stat. Med. 38, 2074–2102 (2019). https://doi.org/10.1002/sim.8086
Gabrio, A., Plumpton, C., Banerjee, S., Leurent, B.: Linear mixed models to handle missing at random data in trial-based economic evaluations. Health Econ. 31, 1276–1287 (2022). https://doi.org/10.1002/hec.4510
Twisk, J.W.R.: Applied Longitudinal Data Analysis for Epidemiology: A Practical Guide. Cambridge University Press (2013)
White, I.R., Royston, P., Wood, A.M.: Multiple imputation using chained equations: issues and guidance for practice. Stat. Med. 30, 377–399 (2011). https://doi.org/10.1002/sim.4067
Morris, T.P., White, I.R., Royston, P.: Tuning multiple imputation by predictive mean matching and local residual draws. BMC Med. Res. Methodol. 14, 75 (2014). https://doi.org/10.1186/1471-2288-14-75
Zellner, A.: Estimators for seemingly unrelated regression equations: some exact finite sample results. J. Am. Stat. Assoc. 58, 977–992 (1963). https://doi.org/10.1080/01621459.1963.10480681
Collins, L.M., Schafer, J.L., Kam, C.-M.: A comparison of inclusive and restrictive strategies in modern missing data procedures. Psychol. Methods. 6, 330–351 (2001). https://doi.org/10.1037/1082-989X.6.4.330
Pederson, S.P., Forster, R.A., Booth, T.E.: Confidence interval procedures for Monte Carlo transport simulations. Nucl. Sci. Eng. 127, 54–77 (1997)
Yucel, R.M., Demirtas, H.: Impact of non-normal random effects on inference by multiple imputation: a simulation assessment. Comput. Stat. Data Anal. 54, 790–801 (2010). https://doi.org/10.1016/j.csda.2009.01.016
Fenwick, E., O’Brien, B.J., Briggs, A.: Cost-effectiveness acceptability curves – facts, fallacies and frequently asked questions. Health Econ. 13, 405–415 (2004). https://doi.org/10.1002/hec.903
Löthgren, M., Zethraeus, N.: Definition, interpretation and calculation of cost-effectiveness acceptability curves. Health Econ. 9, 623–630 (2000)
Ministerie van Volksgezondheid, W. en S.: Evaluatie van eHealth-technologie - Publicatie - Zorginstituut Nederland. Ministerie van Volksgezondheid, Welzijn en Sport, https://www.zorginstituutnederland.nl/publicaties/publicatie/2017/05/17/evaluatie-van-ehealth-technologie
Dong, Y., Peng, C.-Y.J.: Principled missing data methods for researchers. Springerplus 2, 222 (2013). https://doi.org/10.1186/2193-1801-2-222
Schafer, J.L.: Multiple imputation: a primer. Stat. Methods Med. Res. 8, 3–15 (1999). https://doi.org/10.1177/096228029900800102
Knorr-Held, L.: Analysis of Incomplete Multivariate Data. J. L. Schafer, Chapman & Hall, London, 1997. No. of pages: xiv+430. Price: £39.95. ISBN 0–412–04061–1. Stat. Med. 19, 1006–1008 (2000). https://doi.org/10.1002/(SICI)1097-0258(20000415)19:7<1006::AID-SIM384>3.0.CO;2-T
Mutubuki, E.N., El Alili, M., Bosmans, J.E., Oosterhuis, T., Snoek, J., et al.: The statistical approach in trial-based economic evaluations matters: get your statistics together! BMC Health Serv. Res. 21, 475 (2021). https://doi.org/10.1186/s12913-021-06513-1
Manca, A., Lambert, P.C., Sculpher, M., Rice, N.: Cost-effectiveness analysis using data from multinational trials: the use of bivariate hierarchical modeling. Med. Decis. Mak. Int. J. Soc. Med. Decis. Mak. 27, 471–490 (2007). https://doi.org/10.1177/0272989X07302132
Ciolino, J.D., Palac, H.L., Yang, A., Vaca, M., Belli, H.M.: Ideal vs real: a systematic review on handling covariates in randomized controlled trials. BMC Med. Res. Methodol. 19, 136 (2019). https://doi.org/10.1186/s12874-019-0787-8
Huque, M.H., Carlin, J.B., Simpson, J.A., Lee, K.J.: A comparison of multiple imputation methods for missing data in longitudinal studies. BMC Med. Res. Methodol. 18, 168 (2018). https://doi.org/10.1186/s12874-018-0615-6
Nixon, R.M., Wonderling, D., Grieve, R.D.: Non-parametric methods for cost-effectiveness analysis: the central limit theorem and the bootstrap compared. Health Econ. 19, 316–333 (2010). https://doi.org/10.1002/hec.1477
Schomaker, M., Heumann, C.: Bootstrap inference when using multiple imputation. Stat. Med. 37, 2252–2266 (2018). https://doi.org/10.1002/sim.7654
Brand, J., van Buuren, S., le Cessie, S., van den Hout, W.: Combining multiple imputation and bootstrap in the analysis of cost-effectiveness trial data. Stat. Med. 38, 210–220 (2019). https://doi.org/10.1002/sim.7956
Gabrio, A., Daniels, M.J., Baio, G.: A Bayesian parametric approach to handle missing longitudinal outcome data in trial-based health economic evaluations. J. R. Stat. Soc. Ser. A Stat. Soc. 183, 607–629 (2020). https://doi.org/10.1111/rssa.12522
Mason, A.J., Gomes, M., Carpenter, J., Grieve, R.: Flexible Bayesian longitudinal models for cost-effectiveness analyses with informative missing data. Health Econ. 30, 3138–3158 (2021). https://doi.org/10.1002/hec.4408
Coretti, S., Ruggeri, M., McNamee, P.: The minimum clinically important difference for EQ-5D index: a critical review. Expert Rev. Pharmacoecon. Outcomes Res. 14, 221–233 (2014). https://doi.org/10.1586/14737167.2014.894462
Walters, S.J., Brazier, J.E.: Comparison of the minimally important difference for two health state utility measures: EQ-5D and SF-6D. Qual. Life Res. 14, 1523–1532 (2005)
Funding
This work was funded by the Amsterdam Public Health Research Institute, grant number: 2019075/MdB/EdB, 2019. The authors have no financial interests and non-financial interests to disclose.
Author information
Authors and Affiliations
Contributions
AJB obtained the funding for this research project. JEB, JMvD, JLMV, MEA, and AJB have contributed to the design of the study. AJB and MEA conducted the analysis. Analysis was supervised by JEB and JMvD. The first draft of the manuscript was written by AJB. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ben, Â.J., van Dongen, J.M., Alili, M.E. et al. The handling of missing data in trial-based economic evaluations: should data be multiply imputed prior to longitudinal linear mixed-model analyses?. Eur J Health Econ 24, 951–965 (2023). https://doi.org/10.1007/s10198-022-01525-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10198-022-01525-y