
Abstract
Efficient asset maintenance is key for delivering services such as transport. Current rail maintenance processes have been mostly reactive with a recent shift towards exploring proactive modes. The introduction of new ubiquitous technologies and advanced data analytics facilitates the embedding of a ‘predict-and-prevent’ approach to managing assets. Successful, user-centred integration of such technology is still, however, a sparsely understood area. This study reports results from a set of interviews, based on critical decision method, with rail asset maintenance and management experts regarding current procedural aspects of asset management and maintenance. We analyse and present the results from a human-centric sensemaking timeline perspective. We found that within a complex socio-technical environment such as rail transport, asset maintenance processes apply not only just at local levels, but also at broader, strategic levels that involve different stakeholders and necessitate different levels of expertise. This is a particularly interesting aspect within maintenance that has not been discussed as of yet within a process-based and timeline-based models of asset maintenance. We argue that it is important to consider asset maintenance activities within both micro (local)- and macro (broader)-levels to ensure reliability and stability in transport services. We also propose that the traditionally distinct notions of individual, collaborative and artefact-based sensemaking are in fact all in evidence in this sensemaking context, and argue that a more holistic view of sensemaking is therefore appropriate by placing these results within an amended recognition-primed decision-making model.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Asset management has been widely explored within different domains in industry (Vanier 2001). According to European Maintenance Standards (EN 13306:2001 2001), maintenance constitutes all the actions necessary during an asset’s operational lifecycle. These actions can be technical, managerial or administrative and aim to either sustain, fix or replace an asset so that it is in a state to deliver its function successfully. These actions span both specific maintenance work for the assets themselves, as well as strategic approaches to ensure the appropriate work programmes, technologies and procedures are in place for reliable maintenance. Maintenance management, for example, entails a number of activities such as inventory and procurement, computerised maintenance systems, operational involvement, total productive maintenance (TPM), technical and interpersonal training, statistical financial optimisation, reliability maintenance and, more recently, preventive and proactive maintenance (Marquez and Gupta 2006).
Without appropriate asset maintenance, services run high risks of failure with knock-on effects for user satisfaction and asset professionals’ performance (Markeset and Kumar 2003). Considering that all the factors contributing to the degeneration of assets (e.g. usage, weather, finances) and that maintenance spans both technical and managerial levels, asset maintenance can be expensive and may absorb the largest part of operations budget in a company (Garg and Deshmukh 2006). If a malfunction occurs, asset professionals are notified (e.g. via a phone call) and are requested to inspect and resolve the problem. In this case, asset treatment occurs if and only if an asset failure is detected and appropriately acknowledged. Therefore, reactive maintenance approaches require speedy reaction and diagnosis of the failure in order to recover service as soon as possible, but by this time costly service disruption may already have occurred (Golightly and Dadashi 2017).
Historically, the means to prevent failure has been scheduled inspection or renewal; however, this involves much manual labour to inspect assets, can involve redundant inspection and even unnecessary renewal, and may still not identify assets that might fail due to unexpectedly rapid deterioration (Åhrén and Parida 2009). Empirically driven maintenance can potentially increase the speed of diagnosis and maintenance reactions. This goes beyond simple remote condition monitoring of an asset, to analyse patterns of performance and degradation over time and over classes of assets. Not only does this lead to a better understanding of asset’s lifecycle and health status, it supports the adaptation of maintenance regimes to reflect the needs of the asset, rather than inefficient fixed schedules, thus saving cost and ensuring service continuity. Longer-term, greater knowledge of asset performance can be fed back into the supply chain as they redesign assets to better reflect operational conditions (Golightly et al. 2017).
Effective user-centred design of computerised asset maintenance systems becomes mandatory if technology is to support new ways for providing asset maintenance understanding (Dadashi et al. 2014; Houghton and Patel 2015). Associated challenges include not only initial increased costs and resources, but also understanding and defining performance metrics that are both historically and empirically driven, and setting up new standards and expectations for the reliability, safety and affordability of the railway services (Zoeteman 2006).This may be particularly challenging when, as with rail, technologies are being retrofitted onto existing assets and into existing working practices and culture (Ciocoiu et al. 2015). Given the strategic nature of maintenance, decision-making from planning, strategy and collaboration is just as important in human factors consideration of predictive maintenance as human–machine interface design (Golightly et al. 2017).
Prior asset maintenance models focused on mapping processes across the asset lifecycle. Within the rail network setting, key themes for asset maintenance include: strategy and planning, decision-making, asset knowledge, delivery planning, organisation and people, review and improvement (Office of Rail Regulation Report 2012). We argue that to improve the above processes, we first need to identify how human asset operators and managers understand and interpret asset data and what process stages are involved in that. It is these aspects that attempt to model in regard to asset maintenance in railways within this paper.
The work presented in this paper contributed to research developing a predictive maintenance architecture that could encompass a number of specific predictive maintenance technologies within a single, flexible platform for an urban metro system (Myers et al. 2016). The specific aim of the human factors work reported in this paper was to understand current maintenance decision-making stages and processes, with a view to informing use cases and requirements that would both support human–machine interface design, and inform the wider project of typical decisions and the operational context in which the architecture would be embedded. An approach based on sensemaking (Kefalidou and Houghton 2016) and recognition-primed decision-making (Baber and McMaster 2016; Klein 1993) was used to ground the analysis of decision-making, as this draws on how asset professionals use their prior experiences and expertise shape both how they respond to specific asset failures, and how they approach more strategic questions of effective maintenance.
The contributions of this paper are:
-
Identifying a set of decisions for both current, small-scale, individual maintenance activities (micro) and larger maintenance programmes and processes (macro).
-
Describing a set of cognitive activities associated with these decisions that would need to be reflected in future predictive maintenance solutions
-
Discussing, in sensemaking terms, both the advantages of predictive over reactive maintenance, and those aspects of current decision-making that must be reflected in future predictive maintenance solutions.
2 Background
2.1 Maintenance models and frameworks
A number of maintenance models have been generated that are either based on performance, empirical, theoretical, and process-based approaches in an attempt to track down maintenance processes to minimise costs and challenges. The majority of such process models usually focus on information provision and information flow in maintenance. Asset-related information is necessary to establish a baseline understanding of what an asset’s expected lifecycle is, what the available budget is and what the associated actions would need to be. Jones and Sharp (2007) provided an example of such a cyclic process in built maintenance where policy plays a start-up role in triggering the maintenance process, which mainly consists of information collection, modelling and planning activities. Other maintenance models focus on mapping the process activities that emphasise on the interoperability, necessary to be established in-between the different maintenance phases. Hassanain et al. (2001) proposed a performance requirements model that incorporates measuring, planning and managing activities (Hassanain et al. 2001). Other models are based more on processing failure modes and knock-on effects from a reliability maintenance perspective (e.g. Braaksma et al. 2013).
It is understood that existing maintenance process models focus on sequential task-oriented processes (Hassanain et al. 2001; Braaksma et al. 2013; Zoeteman 2006). Few of them only (see Jones and Sharp 2007), acknowledge the importance of human factors within assets maintenance process lifecycle or recognise potential iterative steps embedded within identified processes. This seems to be rather counter-intuitive considering that it is human actors (operators and asset managers) who formulate and execute asset maintenance plans and actions.
Existing asset maintenance frameworks focus either on operations management and decision-making (e.g. Pintelon and Gelders 1992) or on developing maintenance management toolkits that support advanced computations based on asset failure occurrences, optimising actions and in-house policies (e.g. Pintelon and Van Wassenhove (1990) or on maintenance performance analyses (e.g. Vanneste and van Wassenhove 1995). Madu (2000) approached asset maintenance management from an organizational perspective based on which effective maintenance and reliability can be offered only when all the organisation departments (and not only asset maintenance and management groups) work together towards a common goal (e.g. a highly reliable, safe and robust system is maintained). Chang (1998) acknowledged that in order to manage and support a wider maintenance goal network (e.g. through a more free and extended provision of information flow), more powerful computational tools and infrastructure are needed (Chang 1998).
More recently, Too (2010) posits the need to link asset management and asset maintenance processes more strongly. Within the proposed framework, decision-making plays a fundamental role in creating business value (e.g. capital investments such as finding the funds and sponsoring new asset projects), in making decisions on maintenance requirements (e.g. decisions made by asset managers) and on target service levels [e.g. Lost Customer Hours (LCH) within a rail service context]. Rail infrastructure appears to be moving from reactive models of asset maintenance to more ‘predict-and-prevent’ models where intelligent systems are embedded within the complex socio-technical transport network (Al-Douri et al. 2016; Zoeteman 2001, 2006; Bousdekis et al. 2015; Moore and Starr 2006). Such intelligent infrastructure incorporates the use of remote sensors that provide condition-based maintenance approaches whereby the sensors attached to the assets track asset health data continuously (Bousdekis et al. 2015; Campos 2009; Garcí et al. 2003; Wang et al. 2007). Ollier (2006) discusses the implications of transitioning from a legacy-based maintenance approach to more condition-based monitoring approaches within the context of monitoring assets continuously. Increased complexity within the network is a clear implication, opening up new challenges and opportunities for handling new asset data (Ollier 2006; Brickle et al. 2008). For example, overlaying and matching disparate asset information poses new challenges for data analytics and data interpretation, both necessary for enhancing maintenance decision-making and for reducing associated maintenance costs—however, new opportunities arise for obtaining and calculating dynamic asset health thresholds that provide more accuracy and reliability in understanding asset status (Ollier 2006; Brickle et al. 2008).
In railways particularly, the ‘Intelligent Infrastructure’ (II) model incorporates a set of new maintenance support interventions such as forecasting algorithms, distributed sensors, live CCTV and head-mounted cameras that facilitate ‘live’ monitoring of maintenance conditions and assets’ health status (Network Rail 2007). The purpose of II is to provide a framework to synthesise ‘live’ empirical assets’ data to improve maintenance regimes, increase reliability and stability in services as well as increase operational and human performance. Dadashi et al. (2014) argued that II in rail networks demand for new ways to understand the raw asset data, process it accordingly to transform it to information and intelligence to provide an appropriate proactive infrastructure for asset maintenance. According to Dadashi et al. (2014), this data processing—necessary for supporting II—has a serial nature that builds up gradually from raw data to business intelligence. We argue that in order to develop appropriate interoperable technological infrastructure that facilitate II needs, we need to understand first how engineers understand asset data and how they interact with it. To do so, within this paper we draw insights from existing theories in sensemaking.
2.2 Sensemaking processes
Asset maintenance entails complex processes, especially during the phases of understanding what the asset failure is, what caused it and how to resolve it. A large part of the process of understanding what the asset failure is relies upon the existing knowledge and expertise of individual operators. This prior knowledge is synthesised with current knowledge and intelligence and formulates a coherent, plausible account for a given situation (e.g. an asset failure). This process is known as individual sensemaking. Sense in its core can take two forms: the impasse of a subjective individual understanding of the environment and the more objective product (or artefact) which facilitates the understanding and sharing of a situation description (Baber and McMaster 2016). Individual sensemaking makes use of one’s own prior experience and knowledge through appropriate cognitive structures called schemas—according to Klein et al. (2007), the process of individual sensemaking takes place in dynamic environments to guide both understanding and action. Prior literature considers sensemaking as a Recognition-Primed Decision model (RPD) (Klein 1993). Klein and Crandall (1995) proposed an RPD model based on expert interviews conducted with experienced commanders in fire brigade which was later further developed to address more dynamic contexts (e.g. Klein 2011). According to this model (Fig. 1 below), expert decision-makers assess a given situation that for example, disrupted their goal (e.g. in rail asset maintenance that would involve tracking down what has happened and a service was disrupted), and then they extract appropriate cues that will lead them to a phase of pattern recognition (Baber and McMaster 2016). Identifying patterns within a given situation will activate action scripts that will in turn initiate an internal mental simulation utilising their existing mental models. Mental simulation, which is an evaluation stage where the course of action is assessed (as per Klein 1993), feeds back into the action scripts that determine the decided actions, which will in turn affect (and/or change) the given situation (e.g. in rail maintenance that would involve dispatching the individual ground engineer to investigate and fix the asset).

The Data-Frame Model (Klein et al. 2006a, b) fits within the RPD Model (Baber and McMaster 2016). According to Klein et al. (2006a, b), frames constitute conceptual constructs that can be explanatory structures accounting for the data (where data can be interpreted as events and stimuli such as maps, stories, diagrams). Frames can also shape the data within a closed-loop transition sequence between mental models (representing explanatory backward-looking processes) and mental simulation (representing anticipatory forward-looking processes) (Fig. 1). Within this process, individuals that engage in sensemaking attempt to place data into frames, structures and contexts to gain meaning. In that sense, the Data-Frame Model aligns with RPD Model but emphasises different processes and interactions. For example, the RPD Model focuses on how people derive a series of patterns through their experiences in an attempt to provide a description of the causal factors of a given ambiguous situation. On the other hand, the Data-Frame Model focuses on investigating the interactions and relationships between the data (e.g. maps, diagrams, stories) and the frames (i.e. explanatory structures).
Apart from individual sensemaking processes, sensemaking can be assisted through the use of artefacts. Artefacts can be anything that exist within the situational environment (internal and external) of a sensemaker (e.g. an actor or operator) and can take the form of either cognitive aids (which people can use to offload the information they process during their sensemaking activity—e.g. language and speech) or physical aids (with which people can interact and sensemake). Within this context, artefacts in sensemaking can facilitate a link between internal representations of a situation (e.g. mental models) and external representations of a situation (e.g. physical models and objects) (Attfield and Blandford 2011). Furthermore, artefacts in sensemaking can play the role of task-relevant information representations that are amenable to progressive transformations that take place through data combinations, representations and interpretations. Indeed, such combinations and interpretations are a product of a joint processing approach that involves artefacts, individuals, work flows, information flows and system components that interact with each other to provide a system-level cognition (Perry 2003, 2013).
Extending the notion of sensemaking with artefacts and the need to establish a ‘common ground’, sensemaking—as a process—can manifest strong collaborative elements. Sensemaking according to Weick (1995) constitutes a collaborative, intrinsically social process whereby a set of different ideas are developed that entail a set of explanatory possibilities aiming to facilitate and explain different understandings through the construction of a shared meaning. Collaborative sensemaking aims to construct socially shared cognitions and co-construct shared meanings within systemic environments and amongst the people/agents that lie and interact in them. According to Weick (1995), collaborative search lies at the heart of collaborative sensemaking and can have a number of different attributes such as: (1) characteristics of identity; (2) retrospective reflection; (3) enactment; (4) shared meaning; (5) continuity; (6) cues extraction from the environment; and (7) action orientation as a goal rather than accuracy. We note the similarities between sensemaking and situation awareness (Endsley 1995), in that both are concerned with interpretation of the world and, particularly for asset maintenance, the prediction of future states. Much work in Situation Awareness emphasises the role of a knowledge product, or state of awareness, while sensemaking is more concerned with the ongoing process of framing and reframing information (Klein et al. 2006a). However, alternative accounts (see Stanton et al. 2017) emphasise the dynamic nature of situation awareness that is both ‘framed’ by prior expectation, and is distributed between people as individuals and teams, and artefacts.
Within the context of rail asset maintenance, the given situation would relate to an asset failure and more specifically the cause of the asset failure. In such incidents, information about the asset, associated assets, the network and service need to be acquired as much as possible and as fast as possible in order to recover the service. Sometimes, factors that result in asset failure are known or expected—usually such factors are controlled via planned asset maintenance processes that occur periodically within the socio-technical system. However, in reactive maintenance modes when an unexpected failure occurs, such factors are often unknown and an expert (e.g. operation and ground engineer) investigation is needed to understand and resolve the issue. This may involve reference back to technical systems as artefacts, and cross-referencing with other experts and staff. As such, there seems to be a process akin of sensemaking within asset maintenance.
2.3 Research scope
While current investigations in asset maintenance have dealt with frameworks and models orientating towards processes, activities and information flow (e.g. Jones and Sharp 2007; Pintelon and Gelders 1992; Pintelon and Van Wassenhove 1990; Vanneste and van Wassenhove 1995; Hassanain et al. 2001; Braaksma et al. 2013; Zoeteman 2006), there is limited research that has unpacked notions of sensemaking that aim to enhance the way that asset professionals understand and interact with asset data (Sergeeva 2014; Mardiasmo et al. 2008; Schippera and Gerritsb 2017). Approaching asset maintenance with such a lens can provide a further insight as to human-centric needs and requirements that emerge within asset maintenance. For example, it can show how currently the transition from information to intelligence, identified in Dadashi et al. (2014), takes place in current practice and could be supported in future.
The research questions of this paper are therefore:
-
What are the current context, practices and processes for asset maintenance?
-
What is the associated decision-making that takes place within these asset maintenance processes?
-
What sensemaking behaviours are present that inform decision-making within current asset maintenance practices?
-
Can these sensemaking behaviours be described within an adapted recognition-primed decision-making model?
3 Methods
3.1 Design
We conducted light critical decision method (CDM) interviews, which lasted for approximately 1 h. CDM is a retrospective Cognitive Task Analysis (CTA) technique during which professionals are prompted to discuss decision-making key points and experienced incidents in an attempt to acquire information regarding their regimes, working patterns and challenges (Klein et al. 1989).
The reason for choosing CDMs to elicit important information is that they offer opportunities to acquire deeper and richer insights from the experts’ perspective in regard to their work tasks while maintaining a flexibility based on their responses as our experts came from a quite wide background (e.g. ground operators, managers and control operators). More importantly, CDMs allow the experts interviewed to identify for themselves those incidents they believe are critical or representative in terms of outcome, staff involvement and knock-on effects on the service [e.g. service disruption and Lost Customer Hours (LCHs)]. Furthermore, CDMs have been widely used across different domains and themes illustrating the depth of enquiries that elicits to identify criticalities and human behaviour (e.g. medicine—Galanter and Patel 2005; driving—Walker et al. 2009; emergencies—Mendonça 2007; accidents—Salmon 2011). CDMs offer interviewees the opportunity to narrate and discuss real-case incidents as they occurred within the natural eco-system, while the interviewer can guide through the narration (through the CDM probes) to aspects interesting to the incident decision-making and sensemaking process. This study employed a light version of the prompts provided by Klein et al. (1989)—the used prompts are shown in Table 2. By adopting a light version of the CDM prompts, we allowed flexibility in participants’ responses. For example, we provided affordances for participants to provide some responses to all the prompts, without necessarily following the standardised serial nature of the prompts but rather maintaining flexibility in discussion.
One could argue that CDMs, by being retrospective recollections of critical incidents, can be subject to memory retrieval alterations or post-event biases and subjectivity, which in turn can pose challenges in reproducing or replicating findings. However, CDMs provide an established method for eliciting expert knowledge in a structured yet flexible way that allow for gathering in-depth understandings regarding expert knowledge and experience (in this case, that of asset maintenance professionals in Rail). Furthermore, the main aim of the present paper was to acquire subjective expert knowledge in regard to how maintenance professionals experienced and recalled themselves critical incidents in asset maintenance to understand own sensemaking processes and not to compare the different incidents with each other. We acknowledge that each maintenance incident entails particularities and individual characteristics compared to other similar incidents due to differences in context complexities (e.g. natural environment characteristics, time of incident and people involved). As such, a CDM interview technique was adopted to obtain the aforementioned knowledge. All interviews were audio-recorded after participants’ permission using an Olympus digital voice recorder.
3.2 Participants
Ten Rail professionals (all male but one) were interviewed at their business premises. All professionals have worked for many years within Rail. Participants were recruited based on their business’s recommendations and had variable seniority roles. Table 1 shows the family of roles our participants belong to and their codings. From now on within this paper, we utilise these codings (i.e. participant 1, participant 2) to map the presented data to the expertise and job role of each individual participant.
As shown in Table 1, professionals currently in managerial and operational positions took part in our interviews. In addition, all participants apart from two (i.e. participant 10 and 3) have experience in frontline maintenance and engineering operational roles, before moving on to more senior positions. As such, all participants were able to provide both strategic and incident (operational)-based perspectives.
3.3 Procedure
The study was granted ethics approval by the Faculty of Engineering Ethics Committee, The University of Nottingham. Professionals were selected and recruited through suggestions provided by the corresponding transport infrastructure’s Assets Maintenance department. Participants were first introduced to the purpose of the study and signed the consent form for agreeing to participate. The session began with eliciting some background information and demographics from participants in regard to their training/educational studies, expertise and length of current and previous posts (if any) within their rail employee and/or in other organisations. Professionals were asked to describe a routine day in an attempt to get them discussing about their everyday work activities and demands. They were then prompted to recall interesting incidents from their experience up to date. The next stages involved (1) identifying key incidents (as volunteered by the professionals) and (2) examine them on a deeper level together (incident identification selection stage). The identified key incidents were subjective and drawn from participants’ own interpretations of maintenance incident severities. The severity of incidents were judged by participants themselves during CDM interview sessions and corresponded to (1) severity and impact of knock-on effects on service provision and to them individually for their professional career and development and (2) on communication and execution of maintenance tasks. More particularly, professionals were asked to describe the incident, being probed for further information whenever necessary (sensemaking of situation and ‘what-if’ queries). During this process, the researcher was constructing an incident timeline based on participants’ discourses. In the end, the researcher and the professionals went through the timeline to verify it (timeline construction and verification). The questions asked within these stages retained a level of flexibility in terms of the depth that they aimed at or acquired due to individuals’ different levels of expertise and domain of work. The CDM interview protocols allow for such key incidents identification through the standard prompts employed during the interview as part of the CDM protocol. For example, the standard CDM probes (see Table 2) unpacked criticalities in the decisions that participants had to make when important (according to their subjective evaluation) incidents occurred within the professional life. These probes aimed to elicit details in regard to participants’ needs given their discussed critical incident contexts in asset maintenance. While questions retained their overall thread theme, they were adjusted accordingly based on the flow of the CDM interview. However, depending on the issues that each professional brought forward, certain CDM probes overpowered others. Table 2 shows the stages of the CDM interview process alongside with example questions per each stage. Specific CDM stages relevant to the key incident identification stage are highlighted in light grey colour. These stages particularly are the ones eliciting useful information in regard to participants’ decision-making and sensemaking approaches. For example, the ‘timeline construction and verification’ CDM stage (Table 2) was the phase where the interviewer and the interviewee were co-constructing the key maintenance incident timelines followed by a cross-validation and verification of the identified stages and their sequence with the interviewee. During this particular stage, the timeline results presented later in the present paper were generated.
The CDM interview probes as presented in Table 2 are standard in CDMs (please see Klein et al. 1989; Hoffman et al. 1998) and have been previously used successfully to identify expert knowledge within the context of cognition, technology and work (see for examples Tichon 2007; Ross et al. 2014; Hoffman et al. 2009; Okoli et al. 2016; Rankin et al. 2016).
3.3.1 Data analysis
All expert interview sessions were transcribed. Timelines were identified from each of the participant responses, corresponding to the maintenance processes that they described. Both the transcripts and the resulting timelines were reviewed by both first and second author for validation. A thematic analysis was then utilised across all transcripts to identify core themes within professionals’ responses. Thematic analysis was chosen as the analytic approach because it is not bound to a particular pre-determined theoretical framework allowing for a ‘free style’ themes and pattern recognition across all the available dataset while maintaining flexibility (Braun and Clarke 2006). While these were identified and defined by the first author, they were reviewed and validated by the second author who also reviewed transcripts in the light of this coding.
4 Results and analysis
Results are presented in two sections—Sect. 4.1 presents asset maintenance timelines, and Sect. 4.2 presents decision-making themes.
4.1 Asset maintenance timelines
Considering the subjectivity that a CDM technique may pose as discussed within Methodology section, the results presented here constitute approximations of the reported case studies and incidents that aimed to identify key sensemaking and maintenance process stages including decision-making.
For the purpose of this paper, we present here two major exemplary sets of asset maintenance timelines as identified within our CDM interviews with the maintenance professionals (construction of a key incident timeline has been one of the key stages for the adopted CDM interview protocol—please see corresponding section in Sect. “3”). It is important to note at this point that within all the interviews, participants discussed about a number of different maintenance incidents and issues. However, for the purpose of this paper, we present two representative case studies and their associated timelines (as generated and cross-validated with the professionals at the time of the interview).
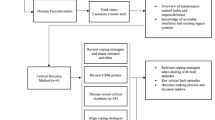
Participant data demonstrated the existence of different types of asset maintenance timelines depending on the context of application, processes and business priorities. For example, while there is a standard set of maintenance steps that need to take place to recover a service, the quality and quantity of these steps may vary depending on the application horizon, the time and place of the maintenance incident and of course depending on the nature of the maintenance goal. Figure 2 depicts an example of a representative timeline co-constructed with participant 7, discussing a localised operational asset maintenance incident. This incident related to drainage issues due to water logs, which was a recurrent issue appearing periodically within the operational life of the asset (i.e. tracks and signals).
4.1.1 Broadly, two types of process were highlighted
A micro-maintenance process (i.e. localised and operational) These are processes in response to the maintenance of individual assets, normally in the form of a repair or replacement in response to a specific asset failure. These are micro-processes in that they describe operational processes specific to ground repairs or replacements. These are often taking place to rectify current, or approaching, failures as identified by visual inspection. Also, they may be in response to actual failures identified in service, or approaching risks due to changes in context and environment—for example, an approaching storm means there is a risk of flooding that requires pumps to be preventatively checked. As a result, micro-processes can be, though are not always, reactive in their nature and typically operate at a short application horizon—such as hours or days—leading to decision-pressure and need to interpret and integrate environmental/contextual information to make a judgement. Figure 2 gives an example of a micro-process timeline elicited during the interview. As Fig. 2 also demonstrates, communication and cross-validation processes amongst the service’s and third-party professionals are absolutely necessary to ensure high levels of situation, context and process awareness. These types of awareness are necessary to be maintained throughout the asset maintenance lifecycle.

Example micro-context timeline
A macro-maintenance process (i.e. global and strategic) The other type of timeline was a maintenance process that was more strategic in that it covered a wider geographic area (e.g. a complete line), or a whole category of an asset. Also, this type of process was often triggered in response to strategic analysis of emerging asset behaviour and faults. It might also be triggered in response to much larger contextual events. For example, the London 2012 Olympics was given as a major trigger to assessing asset performance in order to ensure complete asset availability. Another trigger was strategic efforts to improve capacity overall by improving signalling performance. These processes may encompass many smaller micro-maintenance processes, and therefore we have termed them macro-maintenance. An example macro-context timeline is presented in Fig. 3. As Fig. 3 shows, communication amongst colleagues and third parties is critical in planning and reacting to maintenance needs independently on whether they are short-term and long-term. Considering the macro-timeline presented in Fig. 3, it is evident that the number of decision-making and associated maintenance processes increases and the involvement and dependencies on other external and internal parties and stakeholders increases as well. Expertise (or lack of) is critical to understand the volume of new asset data that comes into the system and when in-house expertise needs to be complemented, it becomes even more mandatory to discuss, identify risks and plan mitigations.

Example macro-context timeline
Furthermore, the timeline presented in Fig. 3 covers maintenance processes that are relevant when applying corrective planned maintenance rather than when reacting to an unexpected incident of service failure.
4.2 Nature of cognition in asset maintenance
What follows next is a thorough walkthrough of identified overarching cognitive elements in asset maintenance. The data presented below is also coded in such a manner to demonstrate associated sensemaking processes as per RPD model. The presented codes below are formulated on two layers: (1) type of sensemaking (i.e. collaborative, individual and artefact-based) and (2) sensemaking stages (e.g. situation, data/cue extraction, pattern recognition, action scripts, mental stimulation and mental models). Table 3 shows the sensemaking codes utilised for analysing what professionals reported.
Key decision-making processes as identified within our CDMs, which are shared on an operational (micro) and strategic (macro) level in asset maintenance are described below in detail providing professionals’ quotes. Furthermore, we map identified themes within professionals’ quotes to demonstrate the emergence of these themes within sensemaking and asset maintenance processes.
-
1.
Tasks definition Deciding what strategic maintenance tasks are relevant to promote putting organisational service forward is an important first step that needs to take into account the needs and requests of external stakeholders. Usually asset managers and professionals placed on managerial roles are responsible for setting the themes of asset management and maintenance tasks to be completed on a strategic and cultural level. Participant 1 below outlines their managerial role and responsibilities over a team for technical assistance. Participant 1 is responsible for defining their team’s priorities, core tasks and expectations:
“I’m responsible for a team for technical assistance and they look after… well, all of the technical matters. They’ll look after all of the … defect database [ARTE], which is quite important on the X Line.” [participant 1]
Participant 2, despite being in a completely different post from participant 1, is responsible for defining and determining the business cases within asset maintenance, and is also responsible for assigning sponsors to their business cases approved by the business higher ranks:
“I may do the high level business case (INDI) and if the business (COLL) wants it then I will decide (ACT), ok here is a sponsor (COLL) I need this project delivering to a party (ACT)” [participant 2]
It is clear that there is a strong hierarchical responsibilities approach within asset maintenance and indeed in task definition. Each layer of hierarchy maintains a level of control and management, yet it accepts input on task definition matters from higher in the hierarchy. Furthermore, as it can be seen within our quotes, professionals (independently of the type and core of their responsibilities) engage in both individual and collaborative activities that lead to action (e.g. maintenance actions such as constructing the business case, assigning sponsors and providing the ‘green light’ for project delivery). The data also suggest the utilisation of artefacts such as defect databases with which professionals interact with as part of monitoring and maintaining asset maintenance data as part of their routine work.
-
2.
Understand current asset Deciding upon what the current (and forecasted) asset issues, priorities and in-between interdependencies are, constitutes a fundamental decision-making phase that needs to take place as early as possible. It is part of a sensemaking process, the aim of which is to solidify strategic priorities as to what assets need to be tracked and maintained to secure a long-term service provision across the whole network. Identifying and acknowledging interdependencies is absolutely critical for the smoother operation of the whole network. This decision-making can take place on two levels: managerial and operational as participants 1 and 3 highlight below:
“And we just talk about the issues and raise (COLL)… we talk about any problems we’ve had or any accidents (COLL) (REFL). Well, the first thing is accidents or injuries, then failures and delays and so on (SITU)… And usually the first bit I get involved in would be rail defect reports (ARTE) and then any changes to our plans (ACT). We discuss them (COLL) and [perform] necessary changes to our plans (ACT), we’ll discuss them on the conference call (COLL).” [participant 1]
the idea of the process (COLL) is that at the end of it I should have information at my disposal (ARTE) that tells me right…this asset isn’t directly straight (CUE)…I need to do something about it (CONN)(EVAL) [participant 3]
As part of understanding current assets, professionals take part in a number of collaborative processes with other professionals to discuss, reflect upon, solidify and action their interpretations of asset statuses. As part of this process, they rely on the availability of generated maintenance artefacts such rail defect reports. They study these artefacts and they adjust their plans and actions based on the discussions they have about them. Particular asset maintenance professionals, e.g. managers, rely on such maintenance artefacts (e.g. periodic reports) to provide indicators to them and cues insofar as asset health behaviour and potential failure.
-
3.
Business process Within a complex socio-technical system setting, where different parties co-operate and co-ordinate for the continuous provision of transport services, an overarching strategic aim does not exclude a number of emerging sub-strategies coming from all associated parties. Decisions need to be made to harmonise the different strategies and to cross-validate how they contribute to achieving the overarching business strategy. This decision step is usually coordinated by asset managerial staff but also communicated to more operational staff as part of performing asset maintenance tasks. Participant 1 provides an example below on how experts aim to utilise different means (e.g. visual inspection and observation highlighting that traditional (and perhaps more intuitive) maintenance approaches may not always be the most appropriate. To evaluate and decide whether an action is appropriate for a particular asset, professionals need to know the asset characteristics and nature very well. Usually, such knowledge is being drawn from existing technical knowledge, expertise and experience in the field.
“you can follow that up with a visual inspection (ACT), but the visual inspection rarely gives you very much more information. You can’t see an internal crack in the rail (KNOW).” – [participant 1]
-
4.
Data Analytics (Data definition) To perform asset maintenance (especially considering the strategic shift to more ‘predict-and-prevent’ maintenance approaches) is necessary to decide upon what asset data are needed to support such a maintenance model and how can that be defined appropriately to minimise inconsistencies and misunderstandings. This decision-making can be performed by both managerial (e.g. asset manager) and sponsor staff. Participant 2 highlights how important was for them to communicate and link up with other engineers in order to ‘sensemake’, understand and define what data they have available and what data they are missing in order to perform their planning tasks.
“the upgrade was going to deliver the technical stuff nine months before we wanted to implement the final plan (PLAN) so didn’t already fit so we re-engineered (ACT) in terms of the process so that we can push stuff as late as possible or so that we can get the actual performance data (PLAN)(COLL)…we did a lot of really good work with the [3rd party] engineers (COLL) to understand what we did know what we didn’t know what we were confident (REFL) about what we needed to measure” – [participant 2]
In this instance, participant 2 (and their colleagues) was collaboratively planning and replanning for delivering innovations and fitting them into the existing infrastructure. This included jointly identifying and reflecting upon what knowledge and confidence levels they had available before proceeding with extra measurements.
-
5.
Data Analytics (Understanding Data) Part of understanding what asset data are already available within the system, is deciding what data to process at which stage and which data to exclude from processing. This stage links strongly with stage 4. To be able to make such a decision, an understanding of what these data represents is necessary. Participants 6 and 3 below demonstrate in their discussions some examples of the processes they adopt to reach an understanding of the data they have available:
“It depends on the action code (SITU)(ARTE)(KNOW). We have ultrasonic inspections carried out throughout the week (ARTE). That’s managed by an external [tech mark](INDI)(COLL), another team. It’s managed by [external team]. They have a programme to work to (SITU), so they report to us each night on what has been done (ARTE) (COLL) and we have to keep a record of all of the defects they’re reporting (ARTE). The defects will have a response code (ARTE). And that code is alphanumeric. The number indicates the immediate action that needs to be taken, so if it’s a ‘1’, it means a speed restriction has to be applied, generally speaking (SITU) (KNOW) (CUE) (INDI). ‘2’ means the defect has to be clamped (CUE) (KNOW) (INDI). And a ‘3’ is no action (CUE) (KNOW) (INDI). And then the letter determines the follow-up action that’s required (CUE) (KNOW) (INDI)(ACT). An ‘IE’ defect would mean it has to be removed from the track within 48 hours. And a ‘B’ defect within 7 days. And then there are some defects that can remain in the track and be monitored (CUE) (KNOW) (INDI)(ACT). And the monitoring period will vary depending on the location (SITU)(ARTE)(KNOW).” – [participant 6]
In this first case, professional 6 requires information to be passed to them by a third external party in regard to all the defects recorded. At this point, the two teams act in collaboration and are dependent on each other’s actions and results. Once they get the generated artefacts (e.g. reports and defect records) then they need to engage with another sensemaking process; that of going through the coding of the reported defects. Defect coding follows current situation standards and constitutes a ‘lexicon’ that professionals (as individuals) need to know in order to ‘decipher’ it. Each defect is coded in a way that can be semantically associated with the nature of the defect. This process is part of cue extracting and placing meaning in asset defects.
However, understanding information provided by third parties can prove to be challenging to interpret. The problematic situation they have to deal with is the lack of coding scheme for the logs (artefacts) provided by the third party leading participant 3 to be unable to decipher the asset information provided. For this process, they rely heavily on appropriate artefact-based and individual-based sensemaking through cue extraction.
“the problem (SITU) we had was the logs (ARTE) have been produced by [external company/3rd party] for diagnostic purposes (INDI) and the log format (ARTE) (CUE) was not documented there was no technical documentation (ARTE) (CUE) we could go to explain (INDI)” [participant 3]
-
6.
Data Meta-Analytics (Data needs and gaps definitions) Alongside understanding the nature of the available asset data, deciding upon what further data are needed becomes necessary to optimise the associated data processing. For example, asset data that third parties may hold may need to be available to be able to proceed with asset maintenance planning and modelling. Participant 8 provides below an example of how they identified misalignments between action codes and standards within analyses reports provided by others. The example below highlights how experience in spotting such flags is critical in ensuring robust asset maintenance.
“Sometimes (EVAL) we have to check the action code against the standards (REFL) (KNOW) (INDI). Generally their [inspectors] action code is correct but sometimes (EVAL) (…) there is something there when you look through the details (CUE), there’s often something that doesn’t quite tie up (CUE) (KNOW), and it flags up (CUE) that it needs to be checked (ACT).” – [participant 8]
As participant 8 suggests, the process of looking through externally provided artefacts (e.g. failure reports) includes evaluating the mapping of actions codes against the available standards and extracting cues on whether this process has been performed correctly (or aligns with team B’s evaluations). Part of these evaluations relies on individual’s and group’s existing knowledge (including presence of appropriate standards).
-
7.
Post-analytics and Coordination (thresholds identification) The decision on which asset performance thresholds constitute healthy behaviour and which not, needs to be collaborative and often relies heavily on training, expertise and personal experience—it is also a learning process. Asset behaviour may change over time due to a number of reasons including environmental and natural degradation. Nevertheless, within a ‘predict-and-prevent’ model of maintenance that relies heavily on empirical data, asset health thresholds need to be revisited and revised ‘as and when needed’. Participant 4, for example, looks upon the provided standards to identify when to remove or replace a degraded asset. However, they also utilise their own expertise and experience on performing this removal or replacement (there are either no or limited standards in certain areas within asset maintenance on how to perform asset maintenance tasks—however, there are standards on when to perform such tasks). The way that certain asset maintenance tasks take place is decided by the asset maintenance expert responsible at the given moment.
“So it’s checked (ACT). We decide (COLL)… the standards (INFO)(ARTE) will say it has to be removed within a certain time frame (INFO). It doesn’t say how it’s to be removed (INFO). So many of the defects, the smaller defects, we can weld repair (EVAL). Some of them (EVAL), we have to re-route (ACT), but that’s our decision (EVAL)(ACT)(COLL)” – [participant 4]
-
8.
Determine Asset Status Uncertainties can occur in relation to data quality, data validity and asset priorities at a given moment. At the same time, deciding upon what status an asset maintains and what the appropriate maintenance regime is for that particular asset is a critical process. On a strategic/macro-contextual level, determining uncertainties, asset status and regime is a strongly collaborative decision-making step that can take place over a period of time and rather than momentarily (e.g. as it may occur within a reactive maintenance incident context). Participant 2 below gives an example of the ‘negotiation’ and communication process they had to go through themselves to reduce their uncertainties in regard to the information they were given in an asset maintenance report:
“[got hold] of these two conflicting (EVAL) (CUE) pieces of information (ARTE)(INFO) with me (INDI) so when I queried (COLL)(ARTE) [I found that] would last a bit longer (INFO),” [participant 2]
In this case, the report was related to the determination of the timeline lifecycle of a particular type of asset proposing a ‘replacement’ date. The sensemaking process (in resolving their identified mismatch) included individually evaluating the information and artefacts they had available (drawing from their own knowledge and expertise portfolio) and then querying about further information collaboratively. Similarly, in the case of participant 3 below, the rationale of the data that is being provided on asset maintenance reports is questioned as a means for-not necessarily challenging the data given but more so as a means for understanding, digesting and processing the data to transform it to information and intelligence—furthermore, detail can be critical in asset maintenance especially in cases of critical services provision and planning:
“because there were uncertainties (EVAL) about what the detail was for something like the upgrade (SITU) we cared about the seconds (…) we cared about fractions of seconds really cause it all add up and makes a difference (EVAL)” – [participant 3]
-
9.
Board/Organisational Evaluations (decision-making on feasibility) When all the above set of decision-making processes take place, a feasibility asset maintenance report is generated and taken to the Board to decide upon whether the proposed maintenance strategy is feasible and viable. Participant 10 below links explicitly this notion of board decision-making to the level of quality the business (and consequently the service) offers. Transparency is critical for transport services as they can get public and/or private funds that necessitate compliance and clarity on how these funds get spend for the good of the service. The feasibility of asset maintenance projects that get the ‘green light’ to go ahead go through a scrutinising process where a number of factors are discussed that can determine the success or failure of the project—certain transparency processes are in place to guard this checkup (see example below):
“the business, it is like a level of quality, isn’t it, that we are transparent and obviously because of our level of our business (…)we get funded and all the rest of it (…) we have to be compliant and transparent and one of this is reviewing process that’s my understanding of the process (KNOW) (SITU) (INDI)- we -as a business (COLL) have this reviewing (INFO) to achieve a certain level or to pass we have to prove (COLL) (ACT) below how we do things in lots of layers” [participant 10]
Participant 10 demonstrates how business and service work on layers. This hierarchical structure leads to an individual sensemaking approach where individual professionals create their own understanding of business levels and processes embedded within the overarching business ethos. Participant 10 further elaborates on how collaboratively now (as opposed to individually before) have to prove (through action) the quality of their processes to their funders.
-
10.
Board/Organisational Evaluations (internal iterative discussions) Once a verdict on the asset maintenance regime report is generated by the Board, it is then communicated to asset maintenance teams (e.g. sponsors and operations). Following that, available maintenance options are internally discussed and decisions upon how they are going to be realised take place. Participant 3, for example, discussed the internal discussions they (as a team) went through as a result of the strategic shift to using empirical asset data rather than experience. Acknowledging that acquiring such data can be time-consuming, they (as a team again) engaged in a discussion to identify available options to optimise empirical data acquisition (this is a process that links strongly with the next step (i.e. point 11)).
“so I was in support team and to say what our options for accelerating this whole process what can we do and I worked with the existing upgrades team (COLL) to work through that and got into saying “but we want empirical data but we want it really quickly” (SITU)(EVAL) so whereas normally it would take weeks or months to collect the x data actually “how soon could we get as accurate data as possible” we looked a few options (COLL) (CUE)… actually looking at the data (ARTE) was the last option (EVAL) because it wasn’t that source we knew (PATT)(KNOW) and so knew we have to do work to build an interpreting data (ACT)” – [participant 3]
The sensemaking situation outlined above has to do with an uncertainty as to how/whether they can get accurate empirical data within a strict limited time constraint. They engage into a collaborative evaluation process to look through the different options. Within this process, they evaluate each option individually and they prioritise them based on what patterns they identify regarding feasibility—these patterns appear to be drawn from their already existing knowledge and experience.
-
11.
Fixing Asset (Preparing maintenance activities): Part of putting the decisions made (as outlined above) into action includes deciding what preparatory activities are needed in order to put the maintenance plan in place. In particular, within an empirical data-processing perspective, it is necessary to define what filtering is needed to streamline the agreed asset maintenance protocol before moving to the next stage of asset maintenance. Participant 3 continued this discussion by going through the different steps they went through to filter out the raw asset data they were getting from the external party engineers—part of this filtering was to identify meaningful from non-meaningful data and useful from non-useful data:
“we built (COLL) we … our engineers extract the information (ARTE) from them (CUE) and we built a lot of analysing to work through all of that (INFO)(KNOW) (…) threw most of it away (EVAL) (ACT) because it wasn’t stuff we were interested in (EVAL) but extracted from there (CUE)” [participant 3]
As the participant above discusses, they work collaboratively to make sense of the information (artefact) they have available through cue extraction. They also suggest an iterative evaluation process for their sensemaking that results in a number of actions such as disregarding analysed data acknowledging no use for them.
-
12.
Fixing Asset (Maintenance strategy shifts) In particular, within ‘hybrid’ maintenance provision models (e.g. incorporating both proactive and reactive elements), it is necessary to decide upon what and when it is needed to perform asset maintenance strategy shifts to maximise the quality of asset data collected and to ensure the service is running safely, reliably and robustly. Maintenance strategy shifts can be dependent not only on the nature of the asset (e.g. type and built) but also on their location as participant 8 outlines below. Furthermore, scheduled and reactive asset maintenance within the general lifecycle are approaches the constantly interplay with each other. As participant 8 mentions below, it is about understanding the circumstances and prioritising accordingly:
“It depends on the location (EVAL)(ARTE)(KNOW). Generally speaking, at the moment, 3 times a week. Some locations, twice a week. We are looking to change some of those[regime] (COLL), but that change process has been long and drawn out and difficult…to reduce it. To extend the time between inspections. (…) It’s been involved in lots of discussions (ARTE) (COLL) with trade union and health and safety reps, and it’s lagged on for… well actually, for years. (…) If we find something that needs to be dealt with straight away (EVAL) (…)it just becomes an urgent job (PROC)(CONN) and we deal with it as it needs to (ACT). I suppose, the most critical thing we have to deal with would be something like a broken rail” – [participant 8]
Extending time elapsed between inspections constitutes a long-term goal acknowledging the difficulties in achieving this. The process of identifying and applying the most appropriate asset maintenance regime is a complex decision depending on a number of different and diverse parameters, e.g. asset location and business needs. It is a collaborative process that involves a series of periodic discussions (artefacts), intra- and inter-group communications that realise both on horizontal and vertical layers within the business hierarchy. On a localised and micro-context level, asset maintenance professionals need to evaluate a maintenance situation on a one-to-one basis and prioritise the criticality of the incident accordingly. If it is urgent, then their actions will be immediate (reactive maintenance and asset data collection as an action of asset maintenance).
-
13.
Asset Data Collection Once strategy shifts are decided, the asset maintenance protocol is ready and available for execution. Its execution involves collecting asset data to start constructing empirically driven performance models that can potentially be used for service planning activities such as timetabling. Asset data are being collected by operational stuff and fed into the system for further processing. Participant 5 below demonstrates how the use of technology can change the way asset data are collected and transmitted to themselves and other associated experts.
”And then there are a number of other specialist inspections (ACT). And then of course there’s the track recording vehicle (ARTE), which gives us data on track geometry (ARTE). Both of those things will feed into our maintenance plans (ACT) (…) my technical team will be managing some of the manual interventions (ARTE) will just be done by the local supervisors (ACT) and they’ll arrange that themselves. (…) It all goes into [the database] via handheld devices (ARTE). Track recording information (INFO) comes as a series of different reports (ARTE). Well they’re emailed to us now, but then there’s the analogue trace is paper (ARTE). That’s still in that format.” – [participant 5]
-
14.
Determine new Asset status This further data processing is currently being performed by operation professionals based on their knowledge base, expertise and experience and may involve a series of collaborative steps with other associated professionals. However, within a proactive maintenance shift, it is anticipated that this decision-making task will be assisted by appropriately designed algorithmic approaches for handling complex asset Big Data. Understanding asset status (i.e. determining whether it is healthy, borderline failed/close to failure) is an iterative decision stage that needs to be monitored throughout a proactive and reactive maintenance cycle. There are, however, some differences as to how these stages develop depending on whether the asset maintenance mode is reactive or proactive. For example, within a reactive mode, understanding an asset’s status is dependent on a shorter turnaround timeline (e.g. decisions need to be made fast and potentially ‘on the fly’ as demonstrated earlier on through our professionals’ discussions). On the contrary, within a proactive mode, an extended decision-making timeline is supported as new asset-related information regarding asset health becomes available at earlier stages within the asset maintenance lifecycle.
“They do some analysis offline (CONN), directly off the train itself.(…) There were operating staff there as well, as they would always be. So they clamped the defect (ACT), we put the speed restriction on (ACT), and they had to move the chair (ACT)… a route chair because the defect was close to the chair (EVAL). So the support had been removed so they had to put wedges in as well (ACT). I wasn’t confident that the wedges would stay there all day (REFL) (KNOW), so even though we had a speed restriction on, I arranged for a couple of inspections to take place through the day (EVAL) (ACT).” – [participant 7]
Analyses of maintenance data occur both online and offline and with the presence of additional professionals. Proceeding analyses, maintenance actions follow, and this is not a static process. For example, formative asset data analyses completion does not necessarily mean that asset evaluation finishes; instead, it is a continuous process that gets evaluated and re-evaluated periodically and for the duration of the maintenance regime.
5 Discussion and limitations
The work presented in this paper aimed to apply a sensemaking approach to the processes of asset maintenance with a view to informing predictive asset maintenance strategy and technology. In practice, decision-making, sensemaking and process activities often intermingle in such a way that it is difficult to separate them when mapping asset maintenance processes. We found that asset maintenance processes incorporate a strong element of maintenance management. This management and strategic maintenance can manifest within both localised maintenance processes [e.g. planning and executing asset maintenance on particular parts of the rail network—localised operational (micro)-context] and within more global and strategic maintenance processes [e.g. planning and executing asset maintenance on a single line(s)—strategic global (macro) context]. Furthermore, different modes of sensemaking (e.g. individual, collaborative and artefact-based) interplay through a typical planned (routine) or reactive asset maintenance process whether this occurs on a localised or strategic setting. Instead of observing isolated sensemaking processes within the asset lifecycle (as have been theorised and empirically concluded in other research domains (e.g. firefighting Dyrks et al. 2008; crime investigation Baber et al. 2013; rail accidents Busby and Hibberd 2004), we found that all these different modes of sensemaking emerge and develop within asset maintenance lifecycles independently of whether maintenance processes are localised and operational (micro) or strategic (macro). We found that participants acknowledge heavily the importance of strategic maintenance and that ground operators need to be aware of these strategies and business priorities in order to make sense of the incident situation and in order to perform efficiently their day-to-day operational asset maintenance. As such, we propose to view rail asset maintenance sensemaking processes from a holistic point of view where both individual, collaborative and artefact-based approaches synergise to support and enhance effective and safe rail asset maintenance on both a strategic (global and macro) and localised operational (micro) levels. The above are core findings and contributions within this paper as existing asset maintenance models approach maintenance from either one perspective or another, with a lesser emphasis on the how strategic global asset maintenance aspects intermingle with localised ones.
We found that there is a strong timeline element when identifying asset maintenance activities, which are often characterised by iterations and not necessarily concrete sequential activities. Dadashi et al. (2014), suggested that within a Railway II setting, data collected goes through a series of processing stages. These stages start from raw data (as collected via, e.g. sensors), moving towards an information stage (in which data is filtered and matched to prior data). This leads to the construction of a knowledge base that transforms raw data to intelligence incorporating aspects from organisational culture, human automation interactions, user engagements and work organisation. Within our work in asset maintenance we found that these stages intermingle and do not necessarily follow a serial process. Professionals, depending on their role, expertise, mind set and personal style, engage into data processing in different ways through a series of iterative loops that involve the engagement of both internal and third-party experts and incorporating both individual, collaborative and artefact-based sensemaking.
A ground operator, for example, will interpret raw asset data with a different motivation, mind-set and knowledge base from an asset maintenance engineer—the same applies for asset managers and operations engineers. We found that this process of interpreting and understanding asset data benefits heavily from the engineer’s own prior experience and working culture. We posit that this finding has strong similarities to processes defined within the sensemaking literature and indeed, maintenance processes embed sensemaking processes on a multi-level context. For example, as seen in the literature (e.g. Weick 1995; Baber and McMaster 2016; Klein et al. 2007, Klein 2011; Perry 2003, 2013) sensemaking can be individual, collaborative and/or utilising environmental artefacts (internal or external). Within asset maintenance processes, understanding maintenance problem, asset status and interdependencies can be both individual (e.g. one operator’s) and collaborative (e.g. across different engineers) sensemaking processes that can also rely on artefacts (e.g. own’s experience, expertise, mind set, maintenance reports, meeting minutes, third-party knowledge), often at the same time. We found that within a standard asset maintenance lifecycle, all these different sensemaking processes intermingle and occur iteratively.
We also found that business culture, business strategy, in-house expertise and third parties play each of them a fundamental role in interpreting data, in synthesising data into useful information (e.g. sensemaking and identifying ‘cause and effect’) and transforming it to intelligence that can be put in context.
5.1 Theoretical implications
Building upon the RPD model of sensemaking (Klein and Crandall 1995; Klein 2011), we have adapted the model to fit in the rail asset maintenance context as we found that operators, ground engineers and asset managers utilise their own experiences to reach to fast decisions under uncertain, constrained and stressful environments (e.g. asset failures, budget constraints, maintenance planning).
We propose an adapted RPD model consisting of five core phases: (1) situation setting; (2) data or cue extraction; (3) Cues/Hints Schemas construction; (4) Connection-Making, (5) Decision-Making and Action Scripts (Fig. 4). This adapted RPD sensemaking model for asset maintenance focusses on four principles (acronym SENSE PLAN) which are the following: SENSE—this involves sensing asset status and contextual factors (including connection-making and processing); PLAN—this involves planning maintenance activities and strategies (including making plans based on existing knowledge and prior experience); ACTION—this involves performing asset maintenance actions depending on the role of the professional in each case such as making a phone call to fetch the most appropriate ground operator (e.g. if the professional is an incident response and command manager) or fixing the asset on the ground (e.g. if a ground engineering)—as such, this stage can include both decision-making and action tasks; and NEED—this involves identifying the operational and strategic needs to perform asset maintenance in the short and long-term (including interdependencies amongst assets, expertise and need for additional artefacts).

RPD sensemaking model of rail asset maintenance (the colour-coding used maps onto the four principles SENSE PLAN; the blue sections correspond to SENSE; the red section to PLAN and ACTION and the orange section to NEED) (color figure online)
During the data/cue extraction, certain artefacts can be used to assist the asset maintenance process such as asset raw data, environment and service data (e.g. notes, weather and asset reports, maps, asset logs, calls, discussions, videos, spreadsheets). These artefacts constitute and contribute to the development of both cognitive (e.g. internal) and social toolkits (e.g. external such as communication and collaboration with others) that asset maintenance professionals can employ during the asset maintenance lifecycle whether this is reactive of planned. Following data/cue extraction, professionals engage with available information and existing intelligence (acquired through their experiences and expertise) and formulate a joint knowledge base that feeds into the schematization of hints in regard to how to react and maintain an asset.
What professionals need to perform next is to make connections amongst the different information and intelligence they have at their disposal, which will lead to adapting their existing mental models of asset maintenance situations. This iterative process involves evaluating and re-evaluating the new and emerging information, data, knowledge and intelligence connections. This connection-making will inform the decision-making necessary to trigger the action scripts relevant to asset maintenance (e.g. dispatch appropriate personnel, resume service, halt service, identify criticalities and minimise knock-on effects). This decision-making stage feeds back to the situation setting with the aim to change and improve it (in rail maintenance, that would be to recover the service and/or fix the asset that failed).
We also found that training (or lack of training) and data processing can potentially increase complexity (or perceived complexity) independently of the mode of that asset maintenance (reactive or predictive). When using empirical data to inform and construct performance models or plan timetables, the ability to process asset data to inform decision-making becomes even more demanding. We found that sometimes interpretation of empirical raw data may need to be outsourced to third parties leading to increased complexity in the process. This process moves from being an individual (or company-based) sensemaking process towards a more collaborative one as both company’s and third-party’s experts work together to understand the new asset data. This is further evidence of the importance of cross-organisational factors affecting the success of predictive maintenance solutions identified by Golightly et al. (2017).
5.2 Practical implications
We anticipate that after the maintenance shift towards a more ‘predict-and-prevent’ model of maintenance, higher level sensemaking data processes (e.g. knowledge and intelligence) and Experts–Data Interactions (EDI) will have to be distributed across all data-processing stages as understanding asset data becomes more complex and bigger. The higher number of raw data facilitators (e.g. sensors) are introduced into the asset network system (and consequently into the service) the lower are going to be the levels of raw data processing that need to take place to facilitate higher levels of sensemaking. For example, within the context of modern intelligent decision-support tools for asset maintenance, technologies should support and facilitate enhanced communication interactions amongst all the relevant parties (external and internal stakeholders) as our participants highlighted within our data. Mapping this need to our proposed sensemaking model, such a technological facilitation would support ‘data/cue extraction’ using historical, empirical and ‘live (through remote sensors) data through a ‘socio-cognitive toolkit’ which would be comprised of a number of technological and interactive ‘artefacts’ to which both managerial and ground asset maintenance professionals could have access to. In effect, this could act as an ‘artefacts’ interactive database that would be updated continuously as new asset data are dropped into the system (e.g. via the remote sensors) or calculated (e.g. via the predictive mechanisms and algorithms at the back end). The processing facilitated through the ‘socio-cognitive toolkit’ would generate ‘cues/hints schemas’ that would interact with another knowledge database (i.e. ‘Reflective Practice’ database), the purpose of which is to provide a physical and cognitive space for sharing joint knowledge and prior experiences on processes, procedures, standards and meta-analyses of external sources. Again, this reinforces the importance of knowledge management, both within a given organisation, and across the supply chain, for predictive maintenance (Golightly et al. 2017). This database would need to incorporate both operational and strategic joint knowledge and would act as a ‘feeder’ to the ‘cues/hints schemas’ construction. The generated schemata of the asset maintenance situation would be passed on to a ‘connection-making planner’ that would act as a platform to formulate a ‘common operation picture’ for both operational and strategic maintenance levels. Once this common picture and the shared understanding is visualised, then a decision-support tool takes this visualisation and ‘translates’ it to a set of ‘action plan scripts’, which can take the form of a suggestions list of maintenance actions mapped to severity and priority levels. Within a proactive maintenance mode (e.g. using remote diagnostics), such a sensemaking model (and a technological innovation based on it) would need to be supported by a strong technological infrastructure that offers high predictive algorithmic power at the back end and appropriate hardware and database management that can handle the volumes of Big asset Data that is being constantly generated through the remote sensors. While remote sensing can provide a more realistic depiction of an asset’s health (and thus, more reliable sensemaking on its condition based on our proposed adapted sensemaking model), it would necessitate strong interpretive capabilities to analyse such Big Data and to be able to construct valid or appropriate ‘cues/hints schemas’ that will lead to efficient connection-making. In effect, by introducing new assets (i.e. remote sensors) attached to the ‘legacy’ assets, the complexity of the rail network increases, and this complexity needs to be addressed and managed accordingly through analytics and new types of planned maintenance.
Furthermore, within a proactive maintenance mode, knowledge integration to an intelligence hub (e.g. planning maintenance) can occur within a different timescale (e.g. allowing more time to plan for maintenance cycles to run rather than plan ‘on-the-fly’ maintenance actions as happens within a reactive maintenance mode). It seems that a separate (or even adaptive) and personalised data infrastructure is needed to not only support future proactive asset maintenance but also to accommodate and support the shift and transition from a reactive maintenance mode as well as facilitating the coexistence of both legacy and ubiquitous systems.
6 Conclusions
In this paper, we presented results from our investigation of rail asset maintenance processes with asset maintenance and management experts. We found that asset maintenance lifecycle is influenced strongly by human-centric factors such as experience, mind set and knowledge and that a lot of these processes are intrinsically sensemaking processes that are individual-based, collaborative and artefact-based at the same time. Furthermore, our work here emphasised the need to approach and understand asset maintenance from both a strategic global (macro) level and a more localised operational (micro) level. This is because our data suggests that all professionals independent of their seniority, current position and expertise, are acknowledging the importance of syncing and adjusting to the strategic maintenance levels even when operating within a localised context. It seems that strategic priorities are more intrinsically embedded within operational maintenance processes than it was believed before. Identifying human factors and sensemaking processes in asset maintenance can change the way that asset maintenance engineers approach and execute processes, procedures and standards when maintaining assets and can promote a more enhanced awareness of strategic and operational priorities.
We also identified a series of different process timelines that highlight core stages within asset maintenance and management within a localised operational (micro) and global strategic (macro) complex socio-technical system settings. We particularly found that these micro- and macro-context timelines share both similarities and differences. For example, while information input is necessary to trigger and sustain the asset maintenance cycle in both cases, the type of information—and indeed the source of that information—varies (e.g. understanding a maintenance issue necessitate input internally from within the operating team and associated teams [i.e. horizontal layer—team(s) across the business organisation] on a micro-context; on the other hand, on a macro-context level, information can come as, e.g. externally defined tasks from the higher levels of the organisation). We think this is a really useful contribution for user-centred design, because most people are just designing for the operational/reactive situation, and not thinking about the strategic. A second really useful outcome of the paper is the emphasis on collaborative sensemaking. This is somewhat apparent in the operational, but within the strategic, which involves group decision-making and board level strategy, is again something that is lost in the typical HCI research that one might draw on for RCM systems.
Furthermore, the step of understanding an asset (e.g. on a micro-context) extends to a broader need to understand asset issues and interdependencies on a more strategic and long-term level when on a macro-context. As asset maintenance and management shifts more towards the utilisation of empirical asset data to perform planning and maintenance tasks, more asset data becomes available for analyses and meta-analyses (e.g. Big Data analytics and post-analytics). Such a stage becomes strongly apparent when performing asset maintenance on a macro-level as more aspects and parts of the transport network and processes become dependent on it. Furthermore, macro-context process timelines encompass inevitably more process steps as their individual lifecycle extends further in the maintenance horizon. This can potentially have technological implications as to how to support best both longer-term and shorter-term asset maintenance procedures and processes. For example, under a ‘predict-and-prevent’ maintenance approach, processes change to become heavily supervisory and monitoring sensemaking on a longer lifespan while under a ‘reactive’ approach processes tend to become more of emergent sensemaking and within a shorter lifespan. Future steps to expand this investigation could include ethnomethodological in situ observations to validate and enrich current insights.
Despite the insights in asset maintenance that our research has provided, our present study has some limitations as well. For example, while our current participant sample incorporated maintenance professionals from managerial, sponsor-based and operational-based backgrounds, it has been limited in terms of numbers. A next step would be to conduct a study with a wider sample size that incorporates professionals from third parties and external individuals that contribute to the asset maintenance processes of Rail. In that way, we can gain further insights as to what strategic and operational priorities the other stakeholders (e.g. third parties) entail and how they fit within the strategic and operational maintenance priorities of Rail transport. Furthermore, the current methodological approach adopted within the present research focused on a CDM approach in data collection that prompted participants to discuss key asset maintenance incidents within their career. While the timelines of these key incidents were cross-validated with participants at the moment of the data collection, they may have not captured a full range of key maintenance incidents due to time and resource limitations and constraints. A next step would be to ‘cross-validate’ and expand these key incidents through the utilisation of additional research data collection approaches that complement CDMs. Examples of such could be observational methods and ethnomethodology that would help capturing incidents and experiences ‘as-and-when’ they occur within the natural operational and strategic environment (as opposed to CDMs recollection and reflection approaches). Furthermore, employing questionnaires would assist in capturing experiences and insights from a bigger sample size of asset maintenance professionals.
References
Åhrén T, Parida A (2009) Maintenance performance indicators (MPIs) for benchmarking the railway infrastructure: a case study. Benchmark Int J 16(2):247–258
Al-Douri YK, Tretten P, Karim R (2016) Improvement of railway performance: a study of Swedish railway infrastructure. J Modern Transp 24(1):22–37
Attfield S, Blandford A (2011) Making sense of digital footprints in team-based legal investigations: the acquisition of focus. Hum Comput Interact 26(1–2):38–71
Baber C, Attfield S, Wong W, Rooney C (2013) Exploring sensemaking through an intelligence analysis exercise. In: Proceedings of the 11th International Conference on Naturalistic Decision Making (NDM 2013), Marseille, France
Baber C, McMaster R (2016) Grasping the moment: sensemaking in response to routine incidents and major emergencies. CRC Press, Boca Raton
Bousdekis A, Magoutas B, Apostolou D, Mentzas G (2015) A proactive decision making framework for condition-based maintenance. Ind Manag Data Syst 115(7):1225–1250
Braaksma AJJ, Klingenberg W, Veldman J (2013) Failure mode and effect analysis in asset maintenance: a multiple case study in the process industry. Int J Prod Res 51(4):1055–1071
Braun V, Clarke V (2006) Using thematic analysis in psychology. Qual Res Psychol 3(2):77–101
Brickle B, Morgan R, Smith E, Brosseau J, Pinney C (2008) Identification of existing and new technologies for wheelset condition monitoring. RSSB report for task no. T607, TTCI (UK) Ltd., Rail Safety and Standards Board, London
Busby JS, Hibberd RE (2004) Artefacts, sensemaking and catastrophic failure in railway systems. In: Proccedings Systems, Man and Cybernetics, 2004 IEEE International Conference, Vol. 7, pp 6198–6205, IEEE
Campos J (2009) Development in the application of ICT in condition monitoring and maintenance. Comput Ind 60(1):1–20
Chang T (1998) Computers spur maintenance-management concepts. Oil Gas J 96(30):86–87
Ciocoiu L, Siemieniuch CE, Hubbard EM (2015) The changes from preventative to predictive maintenance: the organisational challenge. In: Proceedings of 5th international rail human factors conference, London, September 2015
Dadashi N, Wilson JR, Golightly D, Sharples S (2014) A framework to support human factors of automation in railway intelligent infrastructure. Ergonomics 57(3):387–402
Dyrks T, Denef S, Ramirez L (2008) An empirical study of firefighting sensemaking practices to inform the design of ubicomp technology. In: Sensemaking Workshop of the SIGCHI Conference on Human Factors in Computing Systems (CHI 2008). https://things.fit.fraunhofer.de/wp-content/uploads/2008/03/dyrks_sensemaking_chi2008.pdf. Accessed 15 Jan 2018
Endsley MR (1995) Toward a theory of situation awareness in dynamic systems. Hum Factors 37(1):32–64
Galanter CA, Patel VL (2005) Medical decision making: a selective review for child psychiatrists and psychologists. J Child Psychol Psychiatry 46(7):675–689
Garcí FP, Schmid F, Collado JC (2003) A reliability centered approach to remote condition monitoring. A railway points case study. Reliab Eng Syst Saf 80(1):33–40
Garg A, Deshmukh SG (2006) Maintenance management: literature review and directions. J Qual Maint Eng 12(3):205–238
Golightly D, Dadashi N (2017) The characteristics of railway service disruption: implications for disruption management. Ergonomics 60(3):307–320
Golightly D, Kefalidou G, Sharples S (2017) A cross-sector analysis of human and organisational factors in the deployment of data-driven predictive maintenance. Inf Syst e Bus Manag 1–22. https://doi.org/10.1007/s10257-017-0343-1
Hassanain MA, Froese TM, Vanier DJ (2001) Development of a maintenance management model based on IAI standards. Artif Intell Eng 15(2):177–193
Hoffman RR, Crandall B, Shadbolt N (1998) Use of the critical decision method to elicit expert knowledge: a case study in the methodology of cognitive task analysis. Hum Factors 40(2):254–276
Hoffman RR, Neville K, Fowlkes J (2009) Using cognitive task analysis to explore issues in the procurement of intelligent decision support systems. Cogn Technol Work 11(1):57–70
Houghton RJ, Patel H (2015, August). Interface design for prognostic asset maintenance. In: Proceedings 19th triennial congress of the IEA, vol 9, p 14
Jones K, Sharp M (2007) A new performance-based process model for built asset maintenance. Facilities 25(13/14):525–535
Kefalidou G, Houghton RJ (2016). How can a horse be in two places at once? Group sensemaking using diverse and ambiguous information. In: Ergonomics and human factors 2016
Klein GA (1993) A recognition-primed decision (RPD) model of rapid decision making. Ablex Publishing Corporation, New York, pp 138–147
Klein GA (2011) Streetlights and shadows: searching for the keys to adaptive decision making. MIT Press, Cambridge
Klein GA, Crandall BW (1995) The role of mental simulation, in naturalistic decision-making. In: Hancock P, Flach J, Caird J, Vincente K (eds) Local applications of the ecological approach to human-machine systems, vol 2. Erlbaum, Hillsdale, NJ, pp 324–358
Klein GA, Calderwood R, Macgregor D (1989) Critical decision method for eliciting knowledge. IEEE Trans Syst Man Cybern 19(3):462–472
Klein G, Moon B, Hoffman RR (2006a) Making sense of sensemaking 2: a macrocognitive model. IEEE Intell Syst 21(5):88–92
Klein G, Moon B, Hoffman RR (2006b) Making sense of sensemaking 1: alternative perspectives. IEEE Intell Syst 21(4):70–73
Klein G, Phillips JK, Rall EL, Peluso DA (2007) A data-frame theory of sensemaking. In: Expertise out of context: proceedings of the sixth international conference on naturalistic decision making. Lawrence Erlbaum, New York, pp 113–155
Madu CN (2000) Competing through maintenance strategies. Int J Qual Reliab Manag 17(9):937–949
Maintenance European Standards—EN 13306 (2001) Maintenance terminology. european standard. CEN (European Committee for Standardization), Brussels, AFNOR
Mardiasmo D, Tywoniak S, Brown KA, Burgess J (2008) Asset management and governance: analysing vehicle fleets in asset-intensive organisations. In: Brown KA, Mandell M, Furneaux, Craig W, Beach S (eds), Proceedings Contemporary Issues in Public Management: The Twelfth Annual Conference of the International Research Society for Public Management (IRSPM XII), pp. 1–20, Brisbane, Australia
Markeset T, Kumar U (2003) Design and development of product support and maintenance concepts for industrial systems. J Qual Maint Eng 9(4):376–392
Marquez AC, Gupta JN (2006) Contemporary maintenance management: process, framework and supporting pillars. Omega 34(3):313–326
Mendonça D (2007) Decision support for improvisation in response to extreme events: learning from the response to the 2001 world trade center attack. Decis Support Syst 43(3):952–967
Moore WJ, Starr AG (2006) An intelligent maintenance system for continuous cost-based prioritisation of maintenance activities. Comput Ind 57(6):595–606
Myers A, Tickem D, Evans J (2016) People Centred Intelligent Predict and Prevent (PCIPP) A novel approach to Remote Condition Monitoring. In: Proccedings 7th IET Conference on Railway Condition Monitoring 2016 (RCM 2016), p 9–6
Network Rail (2007) Strategic business plan control period 4. www.networkrail.co.uk
Office of Rail and Road (2012) Office of rail regulation report. http://www.orr.gov.uk/rail/publications/reports
Okoli JO, Weller G, Watt J (2016) Information processing and intuitive decision-making on the fireground: towards a model of expert intuition. Cogn Technol Work 18(1):89–103
Ollier BD (2006, November). Intelligent Infrastructure the business challenge. In: The institution of engineering and technology international conference on railway condition monitoring, 2006. IET, pp 1–6
Perry M (2003) Distributed cognition. In: Carroll JM (ed), HCI, models, theories, and frameworks. Morgan Kaufman, London
Perry M (2013) Socially distributed cognition in loosely coupled systems. In: Cowley S, Vallée-Tourangeau F (eds), Cognition beyond the brain. Springer, London, pp 147–169
Pintelon LM, Gelders LF (1992) Maintenance management decision making. Eur J Oper Res 58:301–317
Pintelon LM, Van Wassenhove LN (1990) A maintenance management tool. Omega 18(1):59–70
Rankin A, Woltjer R, Field J (2016) Sensemaking following surprise in the cockpit—a re-framing problem. Cogn Technol Work 18(4):623–642
Ross AJ, Anderson JE, Kodate N, Thompson K, Cox A, Malik R (2014) Inpatient diabetes care: complexity, resilience and quality of care. Cogn Technol Work 16(1):91–102
Salmon PM (2011) Human factors methods and accident analysis: practical guidance and case study applications. Ashgate Publishing Ltd, Farnham
Schippera D, Gerritsb L (2017) Communication and Sensemaking in the Dutch Railway System: explaining coordination failure between teams using a mixed methods approach. Complex Gov Netw 3(2):31–53
Sergeeva N (2014) Understanding of labelling and sustaining of innovation in construction: a sensemaking perspective. Eng Proj Organ J 4(1):31–43
Stanton NA, Salmon PM, Walker GH, Salas E, Hancock PA (2017) State-of-science: situation awareness in individuals, teams and systems. Ergonomics 60(4):449–466
Tichon JG (2007) Using presence to improve a virtual training environment. CyberPsychol Behav 10(6):781–788
Too EG (2010) A framework for strategic infrastructure asset management. In: Amadi-Echendu J, Brown K, Willett R, Mathew J (eds), Definitions, concepts and scope of engineering asset management, vol 1. Springer, London, pp 31–62
Vanier DD (2001) Why industry needs asset management tools. J Comput Civil Eng 15:35–43 (How adaptive systems fail. In: Hollnagel, E, Paries, J, Woods, DD, Wreathall, J (eds) Resilience Engineering in Practice. Ashgate, Aldershot)
Vanneste SG, Van Wassenhove LN (1995) An integrated and structured approach to improve maintenance. Eur J Oper Res 82:241–257
Walker GH, Stanton NA, Kazi TA, Salmon PM, Jenkins DP (2009) Does advanced driver training improve situational awareness? Appl Ergon 40(4):678–687
Wang W, Peter WT, Lee J (2007) Remote machine maintenance system through internet and mobile communication. Int J Adv Manuf Technol 31(7–8):783–789
Weick KE (1995) Sensemaking in organizations, vol 3. Sage, London
Zoeteman A (2001) Life cycle cost analysis for managing rail infrastructure. Eur J Transp Infrastruct Res EJTIR 1(4):391–413
Zoeteman A (2006) Asset maintenance management: state of the art in the European railways. Int J Crit Infrastruct (IJCIS) 2(2/3):2006
Acknowledgements
This work was funded by the Innovate UK-funded project PCIPP: People-Centred Infrastructure for Intelligent, Proactive and Predictive Assets Maintenance with Condition Monitoring project number 101698. Many thanks are due to all the professionals that assisted in the interviews planning and participation.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Kefalidou, G., Golightly, D. & Sharples, S. Identifying rail asset maintenance processes: a human-centric and sensemaking approach. Cogn Tech Work 20, 73–92 (2018). https://doi.org/10.1007/s10111-017-0452-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10111-017-0452-0