
Abstract
Aimed at limitations in the description and expression of three-dimensional (3D) physical information in two-dimentsional (2D) medical images, feature extraction and matching method based on the biomedical characteristics of skeletons is employed in this paper to map the 2D images of skeletons into a 3D digital model. Augmented reality technique is used to realize the interactive presentation of skeleton models. Main contents of this paper include: Firstly, a three-step reconstruction method is used to process the bone CT image data to obtain its three-dimensional surface model, and the corresponding 2D–3D bone library is established based on the identification index of the 2D image and the 3D model; then, a fast and accurate feature extraction and matching algorithm is developed to realize the recognition, extraction, and matching of 2D skeletal features, and determine the corresponding 3D skeleton model according to the matching result. Finally, based on the augmented reality technique, an interactive immersive presentation system is designed to achieve visual effects of the virtual human bone model superimposed and rendered in the world scenes, which improves the effectiveness of information expression and transmission, as well as the user's immersion and embodied experience.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
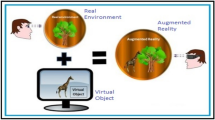
Materials such as paper books and e-books are still the main media for knowledge dissemination in the field of education, but there are some limitations in the description and expression of physical information by means of text and two-dimensional images. The two-dimensional skeleton illustrations in biomedical-related books have some drawbacks. For example, local medical features are abstract and difficult to be understood, it is difficult to distinguish similar images, and there are differences between images and physical information. The readability of those two-dimensional skeleton illustrations is poor, and it is easy to cause difficulties for readers to learn and understand. Aiming at the above-mentioned problems, a biomedical feature-based bone image augmented reality (Al-Ansi et al. 2023) presentation system, based on image feature extraction and matching technology and augmented reality presentation technology, is developed in this paper (as shown in Figs. 1 and 2). Its main point lies in the superposition of virtual skeleton models in real-world scenes and real-time interactive rendering of users. The crucial technologies include accurate three-dimensional reconstruction of the virtual skeleton model (Cheng et al. 2017), fast and accurate feature extraction and matching algorithm design, and interactive immersive skeleton rendering system development based on augmented reality technology.

Three-dimensional skeleton model augmented reality presentation based on a two-dimensional image

The key steps of virtual skeleton model rendering based on augmented reality
1.1 Traditional 3D reconstruction
Reconstruction of three-dimensional continuous skeleton surface model based on human CT images and constructing a human skeleton model database is the foundation for the overlaying presentation of virtual bone models and world scenes. As shown in Fig. 3, the traditional reconstruction methods (Wu et al. 2022) mainly include analytic method and iterative method. The analytical reconstruction method is based on the Projection-slice theorem and Fourier transform theory to process the CT image projection data to obtain the skeleton surface model. The reconstruction model has a higher resolution and faster reconstruction speed, but it is sensitive to noise (Zeng 2010), such as the Filtered Back Projection (Umar et al. 2021) (FBP) structural reconstruction algorithm proposed by Talha, the Back Projection Filtered (Pan et al. 2004a) (BFP) structural reconstruction algorithm proposed by Pan by deforming the Katsevich reconstruction algorithm, and the FDK (Pan et al. 2004b), the most famous cone-beam 3D image reconstruction algorithm proposed by FeldKamp. Iterative reconstruction minimizes the objective function to obtain a bone surface model by solving a system of linear equations about all pixel values in the CT image in an iterative approximation. For example, the most classical algebraic reconstruction algorithm (Gordon et al. 1970) (ART) proposed by Gordon, Simultaneous Algebra Reconstruction Technique (Andersen and Kak 1984) (SART) proposed by Andersen based on ART algorithm as well as a priori constraint-based feature dictionary (Xu et al. 2012), dual dictionary (Lu et al. 2012), 3D feature dictionary (Liu et al. 2018), Fast clustering dictionary (Zheng et al. 2018), and classical full variance constrained iterative reconstruction (Tan and Yang 2023). The reconstructed initial image is repeatedly modified during the iterative computation process until it satisfies the convergence criterion, and this process is more complicated, so the use of iterative method for 3D reconstruction leads to a significant increase in the reconstruction time and slower operation speed.

CT image three-dimensional reconstruction algorithm
1.2 Deep learning based 3D reconstruction
Deep learning (Litjens et al. 2017) technology is essentially through the simulation of the structure and working principle of the human brain neural network to achieve data learning and representation learning, in recent years, the rapid popularization of the Internet has made the acquisition of large-scale data more convenient, and the rapid development of GPUs and other specialized hardware makes the computer able to parallel processing of large-scale matrix operations, and these factors together promote the rapid development of deep learning technology. Currently, deep learning techniques have been widely used in several fields. For example, Kerdvibulvech et al. and Yamauchi et al. successfully introduced deep learning-based biometrics for reconstruction and recognition of 3D human motion analysis (Kerdvibulvech and Yamauchi 2014; Kerdvibulvech et al. 2014; Ye et al. 2018; Kao et al. 2019). As shown in Fig. 3, Deep learning technology has also become a powerful tool for solving complex problems in the process of medical 3D model reconstruction. Deep learning can be further divided into supervised learning and unsupervised learning according to the training objectives and the presence or absence of labels on the training data.
Supervised learning calculates the loss value to obtain the learning model based on the difference between the projected and true values of the data, and deep CT 3D reconstruction based on supervised learning can be categorized into domain transformation class, model class, and iterative unfolding class according to the way deep learning is used in the reconstruction process. The deep neural network in the domain transformation class of reconstruction methods fuses the learned knowledge into the inference model through feature extraction and representation learning, and uses the structural features extracted in the projection to reconstruct directly from the original data to the target model, such as the popular reconstruction network based on Automated Transform by Manifold Approximation (Zhu et al. 2018) (AUTOMAP) proposed by Zhu, and the iCT-Net (Li et al. 2019) method proposed by Li by adding a convolutional neural layer to the traditional FBP-based imaging method. The core of model-based reconstruction methods is to use deep neural networks to construct learnable a priori constraints and extract complex image features and a priori information that are difficult to characterize in a data-driven manner for 3D reconstruction of models, such as the plug-and-play a priori reconstruction proposed by Venkatakrishnan, the parametric plug-and-play (Venkatakrishnan et al. 2013) ADMM (He et al. 2019) reconstruction proposed by He, the BCD-Net (Chun and Fessler 2018) methods, etc. Iterative unfolding class reconstruction methods disassemble the iterative operations into different layers of the network model and combine the learned prior knowledge to reconstruct the model. For example, Zhang proposed a MetaInv-Net (Zhang et al. 2021) with self-learning features, Hu proposed a deep iterative optimization algorithm PRIOR (Hu et al. 2022a) based on residual learning, and Su proposed the DIR (Su et al. 2021) reconstruction method.
Compared with supervised learning, unsupervised learning needs to discover the intrinsic correlations among data from unlabeled training data, and reveal the hidden structural features among data through clustering, dimensionality reduction and other operations. In 3D deep reconstruction of medical images, unsupervised learning is further divided into the self-supervised learning class of deep reconstruction and the generative modeling class of 3D reconstruction, and the self-supervised learning class of reconstruction is based on the Noise2Inverse (Hendriksen et al. 2020) reconstruction framework proposed by Hendriksen, the Noise2Filter (Lagerwerf et al. 2020) reconstruction framework proposed by Lagerwerf, the IntraTomo (Zang et al. 2021) reconstruction framework proposed by Zang, and Noise2Projection (Choi et al. 2022) reconstruction framework proposed by Zhou. The generative model class of 3D reconstruction methods generates a model capable of generating expected new samples through unsupervised learning, and the two common generative models are implicit probabilistic models such as variational self-encoder, and explicit probabilistic models such as generative adversarial networks.
In summary, whether supervised or unsupervised learning, CT three-dimensional reconstruction based on deep-learning obtains a deep-learning neural network by calculating the loss value through the difference between the predicted value and the sample value, or finds hidden structures in unlabeled data by using statistical learning to obtain a learning model, which requires a large amount of high quality data for pre-training. It is difficult to guarantee the accuracy of the reconstruction model, and the interpretability is poor (Cheng et al. 2020; Han et al. 2021).
1.3 Image feature extraction and matching
For image feature extraction (Liu et al. 2021) and matching (Gu et al. 2022), the traditional method mainly relies on manually designed feature detectors to extract points with specific properties in the image, and calculates the distance between high-dimensional vectors using the distance function for similarity retrieval to achieve retrieval matching of the image. Traditional image feature extraction has three types of methods based on edge detection, corner detection and speckle detection. Edge-based detection is to detect the contours or edges of objects in an image, the edges are usually the places in the image where the color or brightness changes are more obvious, and are the boundaries between different objects in the image. Common edge detection methods include Canny (Canny 2009), LOG (Marr and Hildreth 1979), Sobel (Sobel and Feldman 1990), Robert (Wei 2021) and Prewitt (Saeed and Hossein 2022). The so-called corner detection is to find the point in the image where the pixel value or curvature value changes significantly, the basic idea is to use the corner detection operator to compute the response function for each pixel in the image and threshold the response function, and to obtain the non-zero point as the corner point by the way of non-extremely large inhibition, such as the usual Moravec (1980), Harris and Stephens (1988), Fast (Rosten and Drummond 2006), etc. Speckle-based image feature detection is to detect the region in the image that has a large difference in the gray value with its surrounding region, usually there are two implementations of derivative-based differential methods and local value-based watershed algorithms. Compared to corner detection methods, speckle as a local feature contains more regional features and is more robust to image distortions and illumination changes, such as DOG (Lowe 2004), SIFT (Lowe 2004), SURF (Bay et al. 2008), KAZE (Alcantarilla et al. 2012) and other algorithms have been widely used in many fields such as image alignment, target recognition and tracking. The commonly used methods for retrieval matching of image features are Brute-Force (Jakubović and Velagić 2018), Fast Library for Approximate Nearest Neighbors (FLANN), Random Sample Consensus (RANSAC) (Bian et al. 2017), Grid-based Matching Score (Ke and Sukthankar 2004) (GMS), etc., which are algorithms designed to efficiently process large-scale datasets in order to improve the performance of image retrieval matching.
1.4 Deep learning based image feature extraction and matching
Deep learning based image feature extraction and matching usually uses convolutional neural network (Krizhevsky et al. 2012) as a feature extractor, while initializing the model parameters with the help of transfer learning (Ciobotaru et al. 2023) to speed up the convergence of the model. As a commonly used deep learning model, convolutional neural network is a neural network structure consisting of structures such as convolutional layers, pooling layers, and fully connected layers, while transfer learning is a network model that applies knowledge learned in other solved tasks to new tasks. In the process of image feature extraction and matching, the image to be detected is fed into the pre-trained CNN model to detect the edges and textures in the image data through convolutional operations to obtain the image feature vectors, and to measure the similarity between the features by calculating the Euclidean distance or cosine similarity between the feature vectors. As shown in Fig. 4, deep learning based image feature extraction network models are TILDE (Verdie et al. 2015), KeyNet (Laguna et al. 2019) based on keypoint detection, L2-Net (Tian et al. 2017), HardNet (Mishchuk et al. 2017), SOSNet (Tian et al. 2019) based on local descriptor detection and BoVW (Ebel et al. 2019), NextVLAD (Arandjelović et al. 2018), REMAP (Husain and Bober 2019) based on global descriptor detection, which are combined with feature matching networks such as SuperGlue (DeTone et al. 2018) etc. to achieve retrieval matching of images. There are also network models for end-to-end detection such as LIFT (Yi et al. 2016), LF-Net (Ono et al. 2018), D2-Net (Dusmanu et al. 2019), RF-Net (Shen et al. 2019), GLM-Net (Jiang et al. 2022), GCNs (Wang et al. 2019, 2023a), etc. and multi-task fusion matching network models DELF (Noh et al. 2017), ContextDesc (Luo et al. 2019), HF-Net (Sarlin et al. 2019), etc. Although convolutional neural networks can be applied to different image feature extraction and matching tasks with the help of transfer learning, the model training requires a large amount of image data and high computational resources, but it does not have a significant advantage in detection and matching performance compared with traditional methods (Jing et al. 2023).

Image feature extraction and matching algorithm
The Oriented FAST and Rotated BRIEF (ORB) (Rublee et al. 2011) algorithm used in this paper combines oFAST corner detection and binary feature descriptor rBRIEF for feature extraction. The corner detection algorithm of oFAST determines the direction of feature points by intensity centroid, and solves the problem that FAST corner points do not have scale invariance by constructing an image scale pyramid. The rBRIEF descriptor adds the same rotation angle as the image to all matching point pairs in the neighborhood of the feature points to solve the problem that the BRIEF descriptor does not have rotation invariance. At the same time, statistical learning is used to improve the distinguishability of the descriptor. Grid-based motion statistics (GMS) (Alcantarilla et al. 2012) algorithm is used for image feature matching, and the correctness of the matching pair is verified according to the neighborhood features to support estimator of the matching pair, to reduce the probability of mismatching and improve the accuracy and robustness of the matching.
2 Construction of bone library
2.1 Skeleton surface model reconstruction
Efficient and accurate target image retrieval and matching is an essential prerequisite for the correct invocation of the human bone model, and the surface quality of virtual models can directly affect the rendering effect of augmented reality. Therefore, a high-quality human skeleton surface model is one of the key factors affecting the effect of augmented reality (Chen 2023). In this paper, CT reconstruction technology is employed to construct a human skeleton surface model. As shown in Fig. 5, Human CT images are used as the original data, and the threshold segmentation (Xiong et al. 2022) and region growth (Lin 2022) algorithms are carried out to accurately extract the skeletal tissue data in the CT image. The initial skeleton surface model is visualized by implicit surface reconstruction. Based on the ShrinkWrap (Overveld and Wyvill 2004) algorithm, the triangular mesh on the surface of the skeleton model is reconstructed to restore the surface morphology of the skeleton model and form a natural and continuous skeleton surface model with high quality.

Human skeleton model reconstruction process: a Original CT data, b threshold segmentation to extract skeletal tissue, c regional growth to extract skeletal tissue, d initial skeleton surface model, e optimized skeleton surface model
2.1.1 Bone tissue data extraction
A CT image is presented in grayscale, and the grayscale value of its pixel points reflects the absorption of X-rays by tissues and organs, i.e. the tissue density. Threshold segmentation is divided based on the grayscale value of each pixel in the CT image, and the image pixels are divided into two or more categories to realize the segmentation and extraction of different tissue and organ data. As shown in Fig. 6, if the lower limit of the threshold is too small or the upper limit is too high, the threshold range is too large, and the extracted skeletal tissue data has redundant tissue data adhesion; if the lower limit of the threshold is too high or the upper limit is too small, the threshold range is too small. The surface contour data of skeletal tissue can be extracted, but the internal data of bone tissue is gradually lost. The Hounsfield (HU) value range of human skeletal tissue is about [230, 1000].

Schematic diagram of threshold division of human bone tissue
When threshold segmentation is used to extract the skeletal tissue data, the tissue data similar to the density of the skeletal tissue will be extracted together. A better segmentation result can be obtained by specifying the seed point and performing iterative operations through region growth. Taking the specified seed point as the starting point for growth, the pixels in its neighborhood that meet regional growth conditions are added to the growth area according to growth rules, and complete segmentation of the target area data can be achieved by iterative calculation until the termination growth condition is reached (As shown in Fig. 7).

Regional growth extraction of hip bone tissue data: a Skeletal tissue data, b Hip bone tissue data separated by region growing method, c Hip bone tissue sampling point data
2.1.2 Reconstruction of bone surface model
The specified bone tissue data from the CT image data can be extracted with the threshold segmentation and region-growth algorithm, and the skeletal tissue data is visualized in the form of surface models by surface reconstruction technology. For each pixel x in the target region Ω, the Sign Distance Function (Osher et al. 2003) (SDF) is used to calculate the distance from the pixel x to the boundary of the target region ∂ to generate a signed distance field. The point outside (or inside) the boundary of the target region is positive (negative), and 0 on the boundary of the target region. The signed distance field is defined as
where \(a_{x}\) is the distance value of pixel point \(x\) in the target region and \(a\) is the distance value of boundary ∂ in the target region. The distance value in the symbolic distance field represents the distance between the pixel point and the nearest boundary, and the symbol represents the positional relationship between the pixel point and the target area. Through traversing all pixels in the space, the implicit function can be constructed by marking the points inside the target area and the points on the boundary of the target area
When cst = 0, the implicit surface itself is obtained, which is the zero-order iso-surface (Li et al. 2009). The implicit surface is sampled and can be represented by a smooth polygon through polygonization technology and polygon mesh optimization. The intersection of the surface and the voxel and the linear difference (3) and the central difference (4) are used to determine the coordinates and directions of the intersection of the implicit surface and the voxel cube edge by means of marching cubes (MC) (Lorensen and Cline 1987) surface reconstruction algorithm.
where \(P_{m} ,P_{n}\) are the vertex coordinates of the edge of the voxel cube, \(t_{m} ,t_{n}\) are the pixel values at the active edge vertices \(P_{m} ,P_{n}\), \(\vartriangle x,\vartriangle y,\vartriangle z\) are the unit lengths of the voxel cube in the \(x,y,z\) directions, respectively. According to the vertices and faces of the extracted mesh, the topological (Qin et al. 2011) relationship is constructed by calculating the adjacency relationship and boundary information to form triangular mesh of the model surface after connection. In the process of implicit surface polygonization, GPU parallel (Sun et al. 2007) calculation is employed to determine the vertices of the generated mesh, construct the topological relationship to generate triangular mesh of the model surface. The GPU model used is NVIDIA GeForce RTX2060, and the video memory size is 6.0 GB of dedicated GPU memory and 8.0 GB of shared GPU memory. The regularity of the distribution of the extracted network triangles and the reconstruction speed of the bone surface model are also continuously improved.
2.1.3 Optimization of model surface
The MC surface reconstruction algorithm generates a skeleton surface model based on the voxel grid method. There are irregular internal hollows and holes on the surface of the model, which seriously affect the quality of the skeleton surface model. The Shrink Wrapping surface reduction algorithm uses the surface deformation technology in image processing technology to simulate the shrinkage and wrapping process of the surface of the three-dimensional model, and regenerates the surface of the skeleton model based on the difference between the original model and the skeleton surface model to be generated. The initial skeleton surface model generated by MC algorithm consists of convex polygon patches composed of intersection points of the iso-surface and the voxel cube, and the iso-surface is formed by points in the three-dimensional space that satisfy the given function \(F(q) = cst\).
Here, R is the position of the geometric elements such as points, lines, or convex polygons that make up the reference surface, and \(\rho\) is the weight of each geometric element that makes up the iso-surface. The target surface can be regarded as an offset surface with a cylinder with hemispherical caps (Wang et al. 2021) at both ends as the original model. During the shrinkage process of the target surface wrapped by the original model, the Newton–Raphson iterative algorithm is used to determine the new vertex position instead of the original vertex to approach the target surface. The first-order Taylor expansion is used in the Newton–Raphson iterative algorithm to approximate the new point position on the original model. The Taylor expansions at the new vertex \(r + \varepsilon\) and the new position are as follows.
where \(\varepsilon\) is an arbitrary small displacement vector, and \(\nabla V(r)\) is the gradient of \(V(r)\). But we don't know the direction of \(\varepsilon\), so we can set a variable \(\lambda\), whose relation to \(\varepsilon\) is
The Taylor expansions at the new vertex \(r + \varepsilon\) and the new position are as follows
where \(\varepsilon\) is an arbitrary small displacement vector, and \(\nabla V(r)\) is the gradient of \(V(r)\). Under the premise of considering the topological structure of the original model, the appearance and quality of the model are improved by optimizing the surface position, and the new point is moved to the position closest to the surface of the original model to eliminate geometric defects and noises that may exist in the original model. Under the situation that the basic shape and structure of the model remain unchanged, the surface of the model is made smoother, more continuous, and more accurate. The Wrap operation is used to optimize the reconstructed initial hip bone surface model by Materialize Mimics V20.0, and the results are shown in the following Figs 8 and 9.

Sectional contour and surface model of hip bone model: a The initial cross-sectional contour and surface model of the hip bone, b Smallest detail = 1 mm, Gap closing distance = 2 mm, the cross-sectional contour of the hip bone and the surface model after contraction wrapping, c Smallest detail = 1 mm, Gap closing distance = 4 mm, the cross-sectional contour of the hip bone and the surface model after contraction wrapping, d Smallest detail = 1 mm, Gap closing distance = 6 mm, the cross-sectional contour of the hip bone and the surface model after contraction wrapping, e Smallest detail = 1 mm, Gap closing distance = 8 mm, the cross-sectional contour of the hip bone and the surface model after contraction wrapping

The surface model of hip bone before and after optimization: a Initial surface model of the hip bone. b The surface model of the hip bone after Shrink Wrapping optimization
2.2 Database construction
In order to realize the rapid presentation of human skeletal models based on augmented reality, a complete set of 3D digitized human skeletal models is first constructed, which is used for the subsequent realization of virtual human skeletal model calling and augmented reality presentation. In this experiment, a complete set of human CT data is used as the original data, and a smooth, continuous and accurate bone surface model is reconstructed by CT 3D reconstruction and surface optimization techniques, as shown in Fig. 10a. Second, a human bone model image database was constructed for testing the comprehensiveness of the algorithm and for subsequent target image retrieval and matching. (As shown in Fig. 10b). In this experiment, human skeletal image data were extracted from the university medical textbook "Colour Atlas of Human Anatomy", and random noise, random illumination, rotation, and scaling were added to the extracted human skeletal image data to verify the comprehensive performance of the image feature retrieval and matching algorithm. In order to further validate the rotational invariance and scale invariance of the algorithm, different rotation angles and different scaling scales are added to the human skeletal image data to generate image data for validating the rotational invariance and scale invariance of the algorithm. The two-dimensional human skeleton image is rotated at random angles of 30° intervals in clockwise and counterclockwise directions respectively, and image data at different rotation angle ranges are generated to test if the image feature extraction and matching algorithm has rotation invariance. The two-dimensional human skeleton image is scaled to generate image data with different scaling size to test if the image feature extraction and matching algorithm has scale invariance. In this experiment, the 3D digitized human skeleton database includes 206 bones, and the human skeleton image database contains a total of 1120 human skeleton image data with original images, added random noise, random illumination, rotation, and scaling.

The database of skeleton models and images: a three-dimensional human skeleton model database. b Partial images of two-dimensional human skeleton image database
3 Image feature extraction and matching
3.1 Image feature extraction based on ORB algorithm
3.1.1 Feature point detection
Image feature points are the points that contain local information in an image, such as corners of the image contour, points with dramatic texture change, dark points in the bright area and bright points in the dark area. The improved oFAST corner detection algorithm is used in ORB (Rublee et al. 2011) algorithm to extract image feature points. The central point of the original FAST algorithm is to determine whether a candidate point is a corner point through comparing its grayscale value with surrounding pixels. When there is a certain number of pixels around the candidate point and its grayscale value is significantly different, the candidate pixel point is identified as the feature point.
The FAST (Rosten and Drummond 2006) algorithm detects feature points, selects a candidate pixel \(P\) in the image and calculates its grayscale value \(M\). On the circle with candidate point \(P\) as the center and \(r = 3\) (pixel number) as the radius, 16 pixels are selected as the basis for determining whether the candidate pixel \(P\) is a corner point. Chooses an appropriate threshold \(\sigma\), when the absolute value of the difference between the gray value of a pixel around the candidate pixel \(P\) and that of the candidate pixel is less than or equal to \(\sigma\), it is determined that the pixel is similar to the candidate pixel. Otherwise, it is determined that the pixel is not similar to the candidate pixel. If 12 consecutive points in the 16 pixels are not similar to the pixel \(P\), the point \(P\) is determined as the feature point. At the same time, in order to further accelerate the speed of corner detection, 16 pixels are numbered 0–15 clockwise, and the grayscale value of the candidate pixel \(P\) is compared with that of the four equidistant pixels on the circle (such as 0, 4, 8, 12). If there are three or more pixels that are not similar to the point \(P\), the process is continued to determine whether the remaining pixels are similar to the point \(P\). Otherwise, the point \(P\) is directly judged as a non-feature point. (As shown in Fig. 11)

Image feature point extraction schematic diagram
Among them, \(C(p)\) is the pixel point on the circumference with the candidate pixel point \(p\) as the center,\(I(p)\) is the grayscale value of the candidate pixel \(P\) and \(I(x)\) is the grayscale value of the pixel at any point on the circumference \(C\). In order to avoid corner points being too dense, unstable feature points are eliminated by means of non-maximum suppression (Table 1).
Fast detection speed is the advantage of the FAST corner detection algorithm, but the extracted feature points have no direction and do not satisfy scale invariance. The improved oFAST algorithm extracts corners in different scale spaces to meet the requirements of image scale changes by constructing the scale pyramid of the image, and endows the feature points with scale invariance. To solve the problem that the corner feature has no direction, the oFAST algorithm uses intensity centroid to determine the main direction of feature points. The intensity centroid of its neighborhood is calculated with the feature point as the origin. The vector direction with the feature point as the starting point and the intensity centroid as the endpoint is the main direction of the feature point, and the brightness of the feature point in the neighborhood is enhanced in this direction. The formula for the calculation of the neighborhood matrix and the centroid coordinates of the neighborhood are
where C is the neighborhood interval of the feature point, and \(I(x,y)\) is the gray value of the pixel at the point \((x,y)\). Therefore, the main direction of the feature points are
3.1.2 Feature points description
In the process of feature description, BRIEF (Calonder et al. 2010) is used to randomly selects N pairs of points \((i_{n} ,j_{n} )\) with in the neighborhood of \(31 \times 31\) (pixel) with feature points as the center, and to determine the value of the binary string through comparing the grayscale value at the midpoint of random point pairs \(i_{n} ,j_{n}\).
in which \(I(i)\) and \(I(j)\) are the pixel grayscale values at random points \(i(u_{i} ,v_{i} )\) and \(j(u_{j} ,v_{j} )\). When the grayscale value of the first point \(i\) in the selected random point pair is greater than that of the second point \(j\), the value of the binary coding string is set to 1, otherwise set to 0. \(f_{nd}\) is the binary feature descriptor string of the feature point \(P\).
In the process of feature description, since the position of the selected random point pair does not have rotation invariance, the BRIEF descriptor does not have rotation invariance. Therefore, when using image feature points described by the BRIEF descriptor for image retrieval and matching, the accuracy of image matching will decrease sharply with the increasement of image rotation angle. The improved Steered BRIEF (sBRIEF) descriptor rotates all feature point pairs in the neighborhood of the key point according to the main direction of the key point, ensuring that the direction of the random point pair is consistent with the direction of the key point, so that the feature points extracted by the ORB algorithm have rotation invariance. Meanwhile, the random feature point pair \((i_{n} ,j_{n} )\) is replaced by a pair of \(5 \times 5\) sub-windows, and the pixel value of a single point is replaced by the sum of the grayscale value of the pixels in the sub-window to eliminate noise effect.
Here, \(A\) represents the \(N\) pairs of sub-window randomly selected in the neighborhood of the feature point \(P\), and \(R_{\theta }\) is the rotation matrix corresponding to the main direction angle \(\theta\) of the feature point. Although the sBRIEF descriptor has rotation invariance, the discriminability of the descriptor is poor and it is easy to cause mismatch. Due to this reason, ORB uses statistical learning method to re-select the set of point pairs around the neighborhood of key points. There are \(n = (31 - 5 + 1) \times (31 - 5 + 1)\) sub-windows in the neighborhood, and \(m = C_{n}^{2} = 265356265356\) methods to select sub-window pair randomly. The Rotation-Aware Brief (rBRIEF) descriptor selects 256 sub-window pairs from m sub-window pairs by Greedy search according to the principle of maximizing variance, and performs binarization calculation to obtain a feature point descriptor with scale invariance, rotation invariance and good discrimination.
3.2 Image feature matching based on GMS algorithm
Accurate matching of feature points is the basis and premise for image retrieval and model invocation. In applications, most of the incorrect image matching is not due to the lack of correct feature matching pairs. It is induced by the difficulty to distinguish the correctness of the matches. To solve this problem, Bian proposed a feature-matching filtering algorithm (Alcantarilla et al. 2012) based on grid motion estimation on the basis of the theory of movement smoothness. According to the movement smoothness constraint, pixels in the small neighborhood around the feature point will move along with the movement of the feature point. As shown in Fig. 12, correct matching has similar spatial positions, which means that a correct matching pair will be surrounded by the same correct matching with high probability. However, there are almost no identical mismatching pairs around the mismatching pair. According to the Bayesian theorem, the probability of correct matching is high if the matching with more matching pairs in its neighborhood.

GMS feature point pair matching diagram. Red represents the correct matching pair, and there are many similar matching pairs in its neighborhood as support matching (green). Blue represents the wrong matching pair, and there is no similar matching pair in its neighborhood as support matching
As shown in Fig. 13, assuming there are m matching feature points in the input image \(A\) and n matching feature points in the input image \(B\), the set \(C = \left\{ {c_{1} ,c_{2} , \cdot \cdot \cdot ,c_{m} } \right\}\) is defined as the feature matching relationship from image \(A\) to image \(B\), and \(c_{i}\) is the matching between the feature point \(a_{i}\) in image \(A\) and the feature point \(b_{i}\) in image \(B\). The neighborhood of matching \(c_{i}\) can be expressed as

Grid smooth motion estimation
Then the adjacent neighborhood of the matching \(c_{i}\) between images \(A\) and \(B\) can be expressed as
where \(d( \cdot , \cdot )\) represents the distance between two points, \(r\) is the distance threshold, and the number of elements in the set \(S_{i}\) is the motion support for matching \(c_{i}\).
where, \(t\) represents the probability that the correct matching supports matching in a neighborhood window, \(E_{t}\) represents the expectation value of the correct matching, \(V_{t}\) represents the variance of the correct matching, \(f\) represents the probability that the wrong matching supports matching in a neighborhood window, \(E_{f}\) represents the expectation value of the wrong matching, \(V_{f}\) represents the variance of the wrong matching, \(|N_{i} |\) is the number of matching pairs in the neighborhood \(N_{i}\). Furthermore, correct matching and error matching can be distinguished by expectation and variance.
In order to reduce repeated calculations, non-overlapping square grid area is used instead of the circular neighborhood. The image is divided into \(20 \times 20\) unit grids, and each unit grid \({{\text{w}}}_{i}\) is used as a small neighborhood to do the calculation to support the estimator. When the cell mesh is large, the overall matching calculation takes less time, but the grid may contain more mismatches, which affects the accuracy of feature matching. However, if the grid is small, the omission of correct matching pairs can also affect the accuracy of matching. Thus, a motion kernel approach is used to include the neighborhood information, and the unit grid and its adjacent 8 unit grids are combined into a larger grid \(W\) for the calculation of the feature support estimator. This speeds up the distinction between correct and wrong matchings. Where \(W = w_{1} \cup w_{2} \cup \cdot \cdot \cdot \cup w_{9}\), the set \(C\) can be further defined as \(C_{W} = C_{{{\text{w}}_{A}^{1} w_{B}^{1} }} \cup C_{{w_{A}^{2} w_{B}^{2} }} \cup \cdot \cdot \cdot \cup C_{{w_{A}^{9} w_{B}^{9} }}\). The adjacent neighborhoods of the matching feature \(c_{i}\) between images \(A\) and \(B\) are
The neighborhood feature support estimator of the matching pair can be expressed as
where \(k = 9\) is the parameter of the recombined grid computing neighborhood feature support estimator, \(X_{{a^{k} b^{k} }}\) is the matching pair of features between the unit grid \(a^{k}\) and \(b^{k}\), \(- 1\) is the original feature point removed from the summation of the feature support estimators. Furthermore, according to the empirical threshold function \(\tau \approx \alpha \sqrt n\), the feature point matching pairs can be divided into correct and error matching sets
3.3 Comparison of algorithm experiments
In this experiment, four different algorithms, SIFT, SURF, AKAZE, and ORB, are used to extract features from human skeleton images. The SIFT algorithm aims at extracting key points in an image that have invariant properties. The algorithm constructs an image pyramid, i.e., generates image data at different scales by downsampling operations, detects stable extreme points from them with the help of image difference pyramid and assigns positional information to these feature points. Further, based on the localized gradient direction of the image, SIFT assigns orientation information to each feature point. This equips each keypoint with multidimensional information such as position, scale and orientation. The keypoints found by SIFT usually exhibit salient features that are invariant to factors such as illumination, affine transformations and noise. The algorithm remains invariant to some extent to rotation, scale scaling and luminance changes, while showing some stability to viewpoint changes, affine transformations and noise (Jia et al. 2023). However, SIFT has poor real-time performance and is relatively weak in extracting feature points for smooth-edged targets (Xia et al. 2023).
The SURF algorithm, in contrast to SIFT, uses an approximation of the Hessian matrix determinant image instead of the Gaussian difference image in order to traverse all the pixel points in the image. The algorithm generates feature point detection response maps and localizes the feature points by means of non-maximal value suppression. Finally, the principal direction of the feature point is determined by Haar wavelet features based on the domain of the feature point and feature descriptors are created in this direction (OuYang et al. 2017). The SURF algorithm is known for its faster feature extraction and certain scale invariance. However, its invariance in terms of rotation is relatively poor compared to SIFT. This is because in determining the principal orientation of feature points, SURF relies too much on the gradient direction of the pixels in the local region (Ma et al. 2014), which may lead to inaccurate principal orientation of feature points. This means that the feature points extracted by the SURF algorithm may not be matched correctly when the image is rotated.
The AKAZE feature extraction algorithm constructs the scale space for Gaussian blurring that may lead to the loss of image edge information when constructing the image pyramid. To overcome this drawback, AKAZE uses nonlinear diffusion filtering (Yan and Zhang 2019) to construct the scale space to better preserve the edge features of the image. The localization of feature points is achieved by finding local maxima that are normalized at different scales. Further, the principal directions (Wu and Chen 2021) of the feature points were determined based on the Haar wavelet features in the domain of the feature points. To describe the image feature points, AKAZE uses the Modified Local Difference Binary Descriptor (M-LDB) (Zhao et al. 2022), which reduces the amount of computation while ensuring the scale invariance of the descriptor (Zhou 2021).
Four different image feature extraction algorithms are experimented with the image data in the constructed image database, including the original image data and the image data with added random interference factors. The experimental results in Table 2 show that in terms of the speed of feature extraction, the SIFT feature extraction algorithm runs the slowest, with an average processing time of about 0.038 s for one image. This is followed by the SURF and AKAZE algorithms, while the ORB feature extraction algorithm shows the highest operating efficiency with an average detection speed of about 0.009 s per image.
Further, the feature points extracted in human skeletal image data using different feature extraction algorithms are analyzed. As shown in Fig. 14, the ORB algorithm extracts relatively few feature points, but the texture features around the feature points are relatively rich, making these feature points more robust. Comparatively speaking, the AKAZE algorithm extracts relatively more feature points with uniform distribution, but this will lead to problems such as increased computation and slower operation speed in the subsequent target image retrieval matching. As for the SIFT and SURF algorithms, their extracted feature points are mainly distributed in the corners of the image where the texture varies greatly, which may face certain challenges when applied to images lacking obvious surface texture such as human bones. In summary, the ORB algorithm shows a more suitable performance for feature extraction of human bone images covered in this paper. Despite the relatively small number of feature points extracted, its robustness and accurate capture of texture features make the ORB algorithm more advantageous for the application of human bone images.

Image feature point extraction: a Image feature points extracted by SIFT algorithm, b Image feature points extracted by SURF algorithm, c Image feature points extracted by AKAZE algorithm, d Image feature points extracted by ORB algorithm
To verify the robustness of the feature points extracted by the ORB algorithm, rotational transformation and deflation transformation are added to the image data used for the experiments, and further feature extraction and matching tests are performed. The results of the experiment are shown in Fig. 15, there is a low probability of mismatching when the rotation angle is [60°, 90°) and [150°, 180°), and the mismatching rate is about 1.25%. Considering the interference factors such as noise and illumination, the error rate can be ignored, which meets the requirements of rotation invariance. When the scale of an image changes greatly, there is a certain degree of decrease in the accuracy of target image matching. However, when the scale of an image changes within a certain range, the feature points extracted by the ORB algorithm have good scale invariance.

Analysis of rotation invariance and scale invariance of ORB algorithm
The accuracy of image matching and running speed are important factors to evaluate the performance of image feature matching algorithms. They are used to determine the efficiency and effectiveness of different algorithms in practical applications. The accuracy of image matching means the ability of the algorithm to accurately find the corresponding features in different images. Reflected in image matching, it is the accuracy of finding the target image in the image database. On the other hand, running speed of the algorithm determines the efficiency of the feature matching algorithm, which shows the time required for the algorithm to perform the matching process, including three main aspects which are image feature detection, feature description and feature matching.
In this study, the widely used feature extraction algorithm is combined with feature matching algorithm and analyzed experimentally (Fig. 16). Experimental results in Fig. 17 show that when ORB feature extraction algorithm is combined with Brute Force feature matching algorithm, the program running speed is the fastest, and the matching time for a single image is about 0.019 s. But the accuracy of image matching is not ideal, with an accuracy rate of only 77.5%. For the combination of SIFT feature extraction algorithm with GMS feature matching algorithm, and the combination of SIFT feature extraction algorithm with FLANN feature matching algorithm, they lead to the highest image matching accuracy. There is no mismatch even when the image to be detected is added with illumination. However, due to the low running speed of SIFT feature extraction algorithm, it is not suitable for real-time or batch data processing. Considering multiple factors such as program running speed and the accuracy of graph feature matching, the image feature detection and matching algorithm combining the ORB algorithm with the GMS method is the optimal algorithm combination for real-time object detection.

Image feature detection and matching efficiency

Image feature detection and matching accuracy
4 Augmented reality presentation of bone model
A virtual model augmented reality rendering system for human skeletons is developed preliminarily in our study. As shown in Fig. 18, the system contains three main modules: image feature extraction and matching, virtual model rendering and virtual model interaction. The image feature extraction and matching module retrieves the image that is most similar to the image frame in the video stream in the two-dimensional image database, and determines its index value through image feature extraction and matching. According to the index value of the target image provided by the image feature extraction and matching module, the corresponding three-dimensional digital skeleton model is retrieved from the three-dimensional model database. After the virtual model is rendered, it is superimposed on the world scene and presented on the display terminal. For the virtual skeleton model presented on the display terminal, real-time interaction module can be used to realize effects such as model movement, scaling and rotation, and achieve multi-angle observation of the virtual model.

Augmented reality technology system architecture diagram
The image feature extraction and matching module is mainly used to realize the extraction of image features in video stream frames and the retrieval matching of target images in the two-dimensional image database. This module collects real-time video streams by calling a USB camera, and a series of consecutive image frames in the video stream is used as the initial input data for the module. As shown in Fig. 19, the ORB feature extraction algorithm is used to detect feature points in the image and to calculate the feature descriptor of each feature point to represent the image information around the feature point. The target image that matches the skeleton image in the two-dimensional image database is determined through Brute-force matching and error matching filtering algorithm based on motion estimation, and the index value of the target image is determined as the output data of this module. As shown in Fig. 20, the combination of the ORB image feature extraction algorithm and GMS feature matching algorithm for image feature matching has certain stability in image rotation, scaling, light changes and occlusion.

Feature point extraction of image frame in video stream: a The feature points of the skull images extracted from the video stream, b The feature points of the pelvis images extracted from the video stream, c The feature points of the vertebral column images extracted from the video stream, d The feature points of the sternum images extracted from the video stream, e The feature points of the foot images extracted from the video stream, f The feature points of the tibia and fibula images extracted from the video stream

Feature extraction and matching of images in video stream and database: a feature extraction and matching of thorax skeleton images in video stream and database, b Feature extraction and matching of thorax skeleton images rotated at a certain angle in the video stream and in the database, c feature extraction and matching of partially occluded thorax skeleton images in video stream and database
The index values output by the image feature extraction and matching module used as the input. The corresponding skeleton model from the three-dimensional human skeleton model database according to the input index value, which is rendered by VTK visualization tool and superimposed into the video stream for presentation in the display interface, as can be seen in Figs. 21a, e, i, m. The main loop of the system binds the user's interaction events with the callback function to achieve real-time interaction between the user and the model. When users interact with the model in the intelligent display interface, the system updates the model status in real-time by calling the corresponding callback function.

Augmented reality interaction and presentation of virtual skeleton model: a Augmented reality presentation of skull model, b Augmented reality presentation of skull model rotation interaction, c Augmented reality presentation of skull model scaling interaction (reduction), d Augmented reality presentation of skull model scaling interaction (amplification), e Augmented reality presentation of hip model, f Augmented reality presentation of hip model rotation interaction, g Augmented reality presentation of hip model scaling interaction (reduction), h Augmented reality presentation of hip model scaling interaction (amplification), i Augmented reality presentation of vertebral column model, j Augmented reality presentation of vertebral column model rotation interaction, (k) Augmented reality presentation of vertebral column model scaling interaction (reduction), l Augmented reality presentation of vertebral column model scaling interaction (amplification), m Augmented reality presentation of scapula model, n Augmented reality presentation of scapula model rotation interaction, o Augmented reality presentation of scapula model scaling interaction (reduction), p Augmented reality presentation of scapula model scaling interaction (amplification)
5 Conclusion
In this study, the augmented reality presentation technology of virtual human skeleton model in the real world is taken as the research object. A three-step reconstruction method is used to reconstruct the human skeleton surface model as the three-dimensional skeleton model database. Meanwhile, human skeleton model pictures are sorted out to construct the two-dimensional image database. The key technologies such as feature extraction and image feature matching in the implementation process of the system are theoretically analyzed and experimentally compared. The optimal combination of algorithms for image retrieval matching is determined through the comprehensive consideration of multiple factors, such as program running speed and accuracy. Finally, based on the two-dimensional image database of human skeleton model, the three-dimensional skeleton model database and the augmented reality technology, an interactive immersive skeleton model rendering system is designed to achieve the visual effect of the virtual human skeleton model in the world scene.
In response to the problem that 2D images have certain limitations in describing and expressing 3D physical information, 3D digital modeling software, such as SolidWorks, CATIA, Rhino, etc., has been widely used in the traditional mechanical industry to replace the traditional 2D engineering drawings. However, in professional fields such as medicine and biology, which require in-depth understanding of irregular skeletal model data, traditional solid models suffer from the problems of shortage of resources and are not easy to save and carry (Jia et al. 2023). Meanwhile, in the education and learning of specialized disciplines, teachers and students have increasing demands for interactivity, immersion and diversity in teaching (Huang et al. 2023; Lin et al. 2022). Although augmented reality technology has been applied in clinical medicine, the main research direction is to provide surgical navigation services (Wang et al. 2023b, c) in clinical surgery with the help of AR glasses such as HoloLens, which is costly and limited in application. The augmented reality rendering system of skeletal images based on biomedical features studied in this paper focuses on the easy application in the classroom of medicine, biology and other professional learning. The system realizes multi-directional observation and real-time interaction of virtual models, breaks through the ambiguous limitations of traditional two-dimensional data information transfer and expression, and enriches the learning mode. It is worth noting that the system is easy to realize and has a wide range of applications, which can be further promoted and applied to other disciplines and digital museums, etc., and has a high value of application and promotion.
Data availability
This declaration is not applicable.
References
Al-Ansi AM, Jaboob M, Garad A, Al-Ansi A (2023) Analyzing augmented reality (AR) and virtual reality (VR) recent development in education. Soc Sci Hum Open 8:100532. https://doi.org/10.1016/J.SSAHO.2023.100532
Alcantarilla PF, Bartoli A, Davison AJ (2012) KAZE features. In: European conference on computer vision
Andersen AH, Kak A (1984) Simultaneous algebraic reconstruction technique (SART): a superior implementation of the art algorithm. Ultrason Imaging 6(1):81–94
Arandjelović R, Gronat P, Torii A, Pajdla T, Sivic J (2018) NetVLAD: CNN architecture for weakly supervised place recognition. IEEE Trans Pattern Anal Mach Intell 40:1437–1451. https://doi.org/10.1109/TPAMI.2017.2711011
Bay H, Ess A, Tuytelaars T, Gool LV (2007) Speeded-up robust features (SURF). J Comput vis Image Understand 110(3):346–359
Bian J, Lin WY, Matsushita Y, Yeung SK, Nguyen TD, Cheng MM (2017) GMS: grid-based motion statistics for fast, ultra-robust feature correspondence. In: IEEE conference on computer vision and pattern recognition (CVPR), pp 2828–2837
Calonder M, Lepetit V, Strecha C, Fua P (2010) BRIEF: binary robust independent elementary features. In: European Conference on Computer Vision
Canny JF (2009) Canny edge detection
Chen Z (2023) HoloLens augmented reality-based navigational control study of brain hematoma removal robot. Harbin University Of Science And Technology. https://doi.org/10.27063/d.cnki.ghlgu.2023.000192
Cheng B, Zhao W, Luo W, Wang H, Liu F (2017) The application of CT-based 3D reconstruction model in digital orthopaedic research. Sch Mech Power Eng North Univ China 39:89–94
Cheng K, Wang N, Shi W, Zhan Y (2020) Research advances in the interpretability of deep learning. J Comput Res Dev 57:1208–1217
Choi K, Lim JS, Kim S (2022) Self-supervised inter- and intra-slice correlation learning for low-dose CT image restoration without ground truth. Expert Syst Appl 209:118072. https://doi.org/10.1016/j.eswa.2022.118072
Chun IY, Huang Z, Lim H, Fessler JA (2023) Momentum-Net: fast and convergent iterative neural network for inverse problems. IEEE Trans Pattern Anal Mach Intell 45:4915–4931. https://doi.org/10.1109/TPAMI.2020.3012955
Chun Y, Fessler JA (2018) Deep BCD-net using identical encoding-decoding CNN structures for iterative image recovery. In: 2018 IEEE 13th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), pp 1–5
Chun IY, Zheng X, Long Y, Fessler JA (2019) BCD-net for low-dose ct reconstruction: acceleration, convergence, and generalization. CoRR. http://arxiv.org/1908.01287
Ciobotaru A, Bota MA, Goța DI, Miclea LC (2023) Multi-instance classification of breast tumor ultrasound images using convolutional neural networks and transfer learning. J Bioeng 10:1419
DeTone D, Malisiewicz T, Rabinovich A (2018) SuperPoint: self-supervised interest point detection and description, pp 337–33712
Dusmanu M, Rocco I, Pajdla T, Pollefeys M, Sivic J, Torii A, Sattler T (2019) D2-Net: a trainable cnn for joint description and detection of local features, pp 8084–8093
Ebel P, Trulls E, Yi KM, Fua P, Mishchuk A (2019) Beyond cartesian representations for local descriptors, pp 253–262
Ghani MU, Karl WC (2021) Data and image prior integration for image reconstruction using consensus equilibrium. IEEE Trans Comput Imaging 7:297–308. https://doi.org/10.1109/TCI.2021.3062986
Gordon R, Bender R, Herman G (1970) Algebraic reconstruction techniques (ART) for three-dimensional electron microscopy and X-ray photography. J Theor Biol 29:471
Gu X, Ma G, Zhou S, Liu Q (2022) An improved image matching method combined with edge processing of outer points. Laser J 43(03):82–86. https://doi.org/10.14016/j.cnki.jgzz.2022.03.082
Gupta H, Jin KH, Nguyen HQ, McCann MT, Unser M (2018) CNN-based projected gradient descent for consistent CT image reconstruction. IEEE Trans Med Imaging 37:1440–1453. https://doi.org/10.1109/TMI.2018.2832656
Han X, Laga H, Bennamoun M (2021) Image-based 3D object reconstruction: state-of-the-art and trends in the deep learning era. IEEE Trans Pattern Anal Mach Intell 43:1578–1604. https://doi.org/10.1109/TPAMI.2019.2954885
Harris CG, Stephens MJ (1988) A combined corner and edge detector. In: Alvey vision conference. https://doi.org/10.5244/C.2.23
He J, Yang Y, Wang YB, Zeng D, Bian ZY, Zhang H, Sun J, Xu Z, Ma JH (2019) Optimizing a parameterized plug-and-play ADMM for iterative low-dose CT reconstruction. J IEEE Trans Med Imaging 38:371–382
Hendriksen AA, Pelt DM, Batenburg KJ (2020) Noise2Inverse: self-supervised deep convolutional denoising for tomography. IEEE Trans Comput Imaging 6:1320–1335. https://doi.org/10.1109/TCI.2020.3019647
Hu D, Zhang Y, Liu J, Luo S, Chen Y (2022a) DIOR: deep iterative optimization-based residual-learning for limited-angle CT reconstruction. IEEE Trans Med Imaging 41:1778–1790. https://doi.org/10.1109/TMI.2022.3148110
Hu D, Zhang Y, Liu J, Zhang Y, Coatrieux JL, Chen Y (2022b) PRIOR: prior-regularized iterative optimization reconstruction for 4D CBCT. IEEE J Biomed Health Inform 26:5551–5562. https://doi.org/10.1109/JBHI.2022.3201232
Huang Z, Zhang W, Li S, Li J, Wang W, Jiang B (2023) Prospects of clinical medical education teaching applications based on the metaverse. J China Higher Med Edu 9:1–4
Husain SS, Bober M (2019) REMAP: multi-layer entropy-guided pooling of dense CNN features for image retrieval. IEEE Trans Image Process 28:5201–5213. https://doi.org/10.1109/TIP.2019.2917234
Jakubović A, Velagić JJISE (2018) Image feature matching and object detection using brute-force matchers, pp. 83-86
Jia Z, He R, Jiang L, Zhang K (2023) Application of 3D visualization model in surgical clinical teaching. J Contin Med Educ 37:97–100
Jiang B, Sun P, Luo B (2022) GLMNet: graph learning-matching convolutional networks for feature matching. Pattern Recogn 121:108167. https://doi.org/10.1016/j.patcog.2021.108167
Jing J, Gao T, Zhang W, Gao Y, Sun C (2023) Image feature information extraction for interest point detection: a comprehensive review. IEEE Trans Pattern Anal Mach Intell 45:4694–4712. https://doi.org/10.1109/TPAMI.2022.3201185
Kao JY, Ortega A, Tian D, Mansour H, Vetro A (2019) Graph based skeleton modeling for human activity analysis. In: 2019 IEEE international conference on image processing (ICIP), pp 2025–2029
Ke Y, Sukthankar RJPotICSCoCV, Pattern Recognition C (2004) PCA-SIFT: a more distinctive representation for local image descriptors. https://doi.org/10.1109/CVPR.2004.1315206
Kerdvibulvech C, Yamauchi K (2014) Structural human shape analysis for modeling and recognition, pp 282–290
Kerdvibulvech C, Yamauchi K (2014) 3D Human motion analysis for reconstruction and recognition. In: Perales FJ, Santos-Victor J (eds) Articulated motion and deformable objects. Springer, Cham, pp 118–127
Krizhevsky A, Sutskever I, Hinton E (2012) ImageNet classification with deep convolutional neural networks. Commun ACM 60:84–90
Lagerwerf MJ, Hendriksen AA, Buurlage J-W, Joost Batenburg KJAE-P (2020) Noise2Filter: fast, self-supervised learning and real-time reconstruction for 3D Computed Tomography, http://arxiv.org/abs/arXiv:2007.01636
Laguna AB, Riba E, Ponsa D, Mikolajczyk K (2019) Key.Net: keypoint detection by handcrafted and learned CNN filters. CoRR. http://arxiv.org/abs/1904.00889
Li Z, Zou B, Wang L, Peng X (2009) lmplicit surfaces triangulation method with boundary preserved. J Comput Eng Des 30:1432–1434+1463. https://doi.org/10.16208/j.issn1000-7024.2009.06.019
Li Y, Li K, Zhang C, Montoya J, Chen GH (2019) Learning to reconstruct computed tomography images directly from Sinogram data under A variety of data acquisition conditions. IEEE Trans Med Imaging 38:2469–2481. https://doi.org/10.1109/TMI.2019.2910760
Li M, Huang X, Kuang Y, Liang X, Li Q, Zan T (2022) The Value of extended reality technology in microsurgery and its teaching applications. J Chin J Aesthet Plast Surg 33:504–507+515
Lin J (2022) Research on improved region growth method for CT image segmentation and 3D reconstruction. lnner Mongolia University of Science and Technology. https://doi.org/10.27724/d.cnki.gnmgk.2022.000492
Litjens G, Kooi T, Bejnordi BE, Setio A, Ciompi F, Ghafoorian M, van der Laak JAWM, van Ginneken B, Sánchez CI (2017) A survey on deep learning in medical image analysis. Med Image Anal 42:60–88. https://doi.org/10.1016/j.media.2017.07.005
Liu J, Hu Y, Yang J, Chen Y, Shu H, Luo L, Feng Q, Gui Z, Coatrieux G (2018) 3D feature constrained reconstruction for low-dose CT imaging. IEEE Trans Circuits Syst Video Technol 28:1232–1247. https://doi.org/10.1109/TCSVT.2016.2643009
Liu T et al (2021) lmproved algorithm for high-resolution image stitching based on ORB features. Laser Optoelectron Progress 58:85–92
Lorensen WE, Cline HE (1987) Marching cubes: A high resolution 3D surface construction algorithm. Paper presented at the Proceedings of the 14th annual conference on Computer graphics and interactive techniques
Lowe DG (2004) Distinctive image features from scale-invariant keypoints. J Int J Comput vis 60(2):91–110
Lu Y, Zhao J, Wang G (2012) Few-view image reconstruction with dual dictionaries. Phys Med Biol 57:173–189
Luo Z, Shen T, Zhou L, et al. (2019) ContextDesc: local descriptor augmentation with cross-modality context. J CoRR. http://arxiv.org/abs/1904.04084
Ma X, Yu G, Li C (2017) A data processing algorithm for unmanned aerial vehicle images based on SURF and SVM [D]. Henan Polytech Univ 36(06):69–74. https://doi.org/10.16186/j.cnki.1673-9787.2017.06.011
Marr D, Hildreth E (1980) Theory of edge detection. Proc R Soc Lond Ser B Biol Sci 207(1167):187–217
Mishchuk A, Mishkin D, Radenovic F, Matas J (2017) Working hard to know your neighbor's margins: Local descriptor learning loss. In: Neural Information Processing Systems
Moravec HP (1980) Obstacle avoidance and navigation in the real world by a seeing robot rover
Nie W, Zhao Y, Song D, Gao Y (2021a) DAN: deep-attention network for 3D shape recognition. IEEE Trans Image Process 30:4371–4383. https://doi.org/10.1109/TIP.2021.3071687
Noh H, Araujo A, Sim J, Weyand T, Han B (2017) Large-scale image retrieval with attentive deep local features. IEEE Int Conf Comput vis (ICCV) 2017:3476–3485
Ono Y, Trulls E, Fua PV, Yi KM (2018) LF-Net: learning local features from images. In: Neural information processing systems
Osher S, Fedkiw R (2003) Signed distance functions. In: Osher S, Fedkiw R (eds) Level set methods and dynamic implicit surfaces. Springer, New York, pp 17–22
OuYang J, Bu L, Wang T (2017) Binocular vision fire location method based on improved SURF algorithm. Fire Sci Technol 36(11):1613–1616
Pan X, Xia D, Yu Z, Li Y (2004a) A unified analysis of FBP-based algorithms in helical cone-beam and circular cone- and fan-beam scans. J Phys Med Biol 49:4349–4369. https://doi.org/10.1088/0031-9155/49/18/011
Pan X, Xia D, Yu Z, Yu L (2004b) A unified analysis of FBP-based algorithms in helical cone-beam and circular cone- and fan-beam scans. Phys Med Biol 49(18):4349–4369. https://doi.org/10.1016/j.ijrobp.2010.07.195
Qin Y, Lin H, Xian C, Gao S (2011) Rendering and Polygonization of Implicit Surface by Interval Analysis Based on GPU. J Comput Aided Des Comput Graph 23:763–770
Rosten E, Drummond T (2006) Machine learning for high-speed corner detection. In: European conference on computer vision
Rublee E, Rabaud V, Konolige K, Bradski G (2011) ORB: an efficient alternative to SIFT or SURF. Int Conf Comput vis 2011:2564–2571
Saeed B, Hossein B (2022) Edge detection on noisy images using Prewitt operator and fractional order differentiation. J Multimedia Tools Appl 81:9759–9770
Sarlin PE, Cadena C, Siegwart R, Dymczyk M (2019) From coarse to fine: robust hierarchical localization at large scale. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 12708–12717
Shen X, Wang C, Li X, Yu Z, Li J, Wen C, Cheng M, He Z (2019) RF-Net: an end-to-end image matching network based on receptive field, pp 8124–8132
Sobel I, Feldman GM (1990) An Isotropic 3 × 3 image gradient operator
Su T, Cui Z, Yang J, Zhang Y, Liu J, Zhu J, Gao X, Fang S, Zheng H, Ge Y (2021) Generalized deep iterative reconstruction for sparse-view CT imaging. J Phys Med Biol 67:025005
Sun W, Zhang C, Yang X (2007) Research view on marching cubes algorithm. J Comput Aided Des Graph 7:947–952
Tan Z, Yang H (2023) Total variation regularized multi-matrices weighted Schatten p-norm minimization for image denoising. Appl Math Model 124:518–531. https://doi.org/10.1016/j.apm.2023.08.002
Tian Y, Fan B, Wu F (2017) L2-Net: deep learning of discriminative patch descriptor in Euclidean space. In: IEEE conference on computer vision and pattern recognition (CVPR), vol 21-26, pp 6128–6136
Tian Y, Yu X, Fan B, Wu F, Heijnen H, Balntas V (2019) SOSNet: second order similarity regularization for local descriptor learning, pp 11008–11017
Umar TSM, Tariq M, Bin YW (2021) Novel FBP based sparse-view CT reconstruction scheme using self-shaping spatial filter based morphological operations and scaled reprojections. J Biomed Signal Process Control 64:102323
van Overveld K, Wyvill B (2004) Shrinkwrap: an efficient adaptive algorithm for triangulating an iso-surface. Vis Comput 20:362–379. https://doi.org/10.1007/s00371-002-0197-4
Venkatakrishnan SV, Bouman CA, Wohlberg B (2013) Plug-and-play priors for model based reconstruction. IEEE Global Conf Signal Inf Process 2013:945–948
Verdie Y, Yi KM, Fua P, Lepetit V (2014) TILDE: a temporally invariant learned DEtector. CoRR. http://arxiv.org/abs/1411.4568
Wang L, Han J, Lu S, Tang H, Qi Q, Feng N, Tang S (2021) Fast reconstruction algorithm of point cloud implicit surface. J Laser Optoelectron Prog 58(4):339–348
Wang R, Yan J, Yang X (2023a) Combinatorial Learning of robust deep graph matching: an embedding based approach. IEEE Trans Pattern Anal Mach Intell 45:6984–7000. https://doi.org/10.1109/TPAMI.2020.3005590
Wang J, Zhu H, Hu Y, Song Y, Chen S (2023b) Accurate fusion overlay method of augmented reality surgical navigation system based on hololens. J Mech Electr Eng Technol 52:6–13
Wang Q, Zhao K, Song G, Zhao Y, Zhao X (2023c) Augmented reality-based navigation system for minimally invasive spine surgery. J Robot 45:546–553. https://doi.org/10.13973/j.cnki.robot.220300
Wang R, Yan J, Yang X (2019) Learning combinatorial embedding networks for deep graph matching, pp 3056–3065
Wei Y (2021) Detection of lane line based on Robert operator. J Meas Eng 9:156–166
Wu L, Chen X (2021) An image stitching algorithm based on improved AKAZE feature and RANSAC. Comput Eng 47(01):246–254. https://doi.org/10.19678/j.issn.1000-3428.0056874
Wu D, Kim K, Fakhri GE, Li Q (2017) Iterative low-dose CT reconstruction with priors trained by artificial neural network. IEEE Trans Med Imaging 36:2479–2486. https://doi.org/10.1109/TMI.2017.2753138
Wu F, Liu J, Zhang Y, Chen Y, Lu Z (2022) Research on the Progress of Deep Reconstruction Algorithm for CT Imaging 27(04):387–404. https://doi.org/10.13505/j.1007-1482.2022.27.04.007
Xia X, Zhao Q, Xiang H, Qin X, Yue P (2023) SlFT feature extraction method for the defocused blurred area of multifocus images. J Opt Precis Eng 31:3630–3639
Xiang J, Dong Y, Yang Y (2021) FISTA-Net: learning a fast iterative shrinkage thresholding network for inverse problems in imaging. IEEE Trans Med Imaging 40:1329–1339. https://doi.org/10.1109/TMI.2021.3054167
Xiong F, Zhang Z, Ling Y, Zhang J (2022) Image thresholding segmentation based on weighted Parzen-window and linear programming techniques. Sci Rep 12:13635. https://doi.org/10.1038/s41598-022-17818-4
Xu Q, Yu H, Mou X, Zhang L, Hsieh J, Wang G (2012) Low-dose X-ray CT reconstruction via dictionary learning. IEEE Trans Med Imaging 31(9):1682–1697. https://doi.org/10.1109/TMI.2012.2195669
Yan L, Zhang T (2019) Feature points matching method based on improved A-KAZE algorithm. Microelectron Comput 36(12):64–68. https://doi.org/10.19304/j.cnki.issn1000-7180.2019.12.013
Ye Q, Qu C, Zhang YJIJAPR (2018) Human motion analysis based on extraction of skeleton and dynamic time warping algorithm using RGBD camera. Int J Appl Pattern Recognit 5:261–269
Yi KM, Trulls E, Lepetit V, Fua PVJA (2016) LIFT: learned invariant feature transform. http://arxiv.org/abs/1603.09114
Zang G, Idoughi R, Li R, Wonka P, Heidrich W (2021) IntraTomo: self-supervised learning-based tomography via sinogram synthesis and prediction, pp 1940–1950
Zeng G (2010) Medical image reconstruction. Springer, Berlin
Zhang Y, Yu H (2018) Convolutional neural network based metal artifact reduction in X-ray computed tomography. IEEE Trans Med Imaging 37(6):1370–1381. https://doi.org/10.1109/TMI.2018.2823083
Zhang H, Liu B, Yu H, Dong B (2021) MetaInv-net: meta inversion network for sparse view CT image reconstruction. IEEE Trans Med Imaging 40:621–634. https://doi.org/10.1109/TMI.2020.3033541
Zhao W, Liu J, Wang M, Li D (2023) Fast image registration method based on improved AKAZE algorithm [J/OL]. Adv Laser Optoelectron 60(06):90–96
Zheng X, Ravishankar S, Long Y, Fessler JA (2018) PWLS-ULTRA: an efficient clustering and learning-based approach for low-dose 3D CT image reconstruction. IEEE Trans Med Imaging 37:1498–1510. https://doi.org/10.1109/TMI.2018.2832007
Zhou R (2021) Research on mobile phone image stitching based on improved AKAZE-GMS and grid optimization [D]. Central China Normal Univ. https://doi.org/10.27159/d.cnki.ghzsu.2021.001305
Zhu B, Liu JZ, Cauley SF, Rosen BR, Rosen MS (2018) Image reconstruction by domain-transform manifold learning. Nature 555(7697):487–492
Funding
This work was supported by the National Natural Science Foundation of China [Grant Number 62262007] and [Grant Number 51705183].
Author information
Authors and Affiliations
Contributions
SY and TY developed the systems described herein and wrote the main manuscript text. YW, QS and ZH adjust the overall structure of the article, and further modify and optimize the content of the article. JD provides the image data required by this article.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare there is no conflict of interest.
Ethical approval
This declaration is not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sun, Y., Yuan, T., Wang, Y. et al. Augmented reality presentation system of skeleton image based on biomedical features. Virtual Reality 28, 98 (2024). https://doi.org/10.1007/s10055-024-00976-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10055-024-00976-3