
Abstract
Although conduct problems in childhood are stably associated with problem outcomes, not every child who presents with conduct problems is at risk. This study extends previous studies by testing whether childhood conduct problem trajectories are predictive of a wide range of other health and behavior problems in early adulthood using a general population sample. Based on 7,218 individuals from the Avon longitudinal study of parents and children, a three-step approach was used to model childhood conduct problem development and identify differences in early adult health and behavior problems. Childhood conduct problems were assessed on six occasions between age 4 and 13 and health and behavior outcomes were measured at age 18. Individuals who displayed early-onset persistent conduct problems throughout childhood were at greater risk for almost all forms of later problems. Individuals on the adolescent-onset conduct problem path consumed more tobacco and illegal drugs and engaged more often in risky sexual behavior than individuals without childhood conduct problems. Levels of health and behavior problems for individuals on the childhood-limited path were in between those for stable low and stable high trajectories. Childhood conduct problems are pervasive and substantially affect adjustment in early adulthood both in at-risk samples as shown in previous studies, but also in a general population sample. Knowing a child’s developmental course can help to evaluate the risk for later maladjustment and be indicative of the need for early intervention.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Conduct problem (CP) development across childhood varies between individuals: while the majority of children display stable low levels of problem behavior, some engage in stealing, lying, and fighting from an early age and continue to do so. Moreover, individuals on a childhood-limited CP pathway show early problem behavior, but desist upon entering adolescence while those on an adolescent-onset path only “kick off” in early adolescence [1]. Employing a measure that captures developmental patterns to assess the risk of future adjustment problems also responds to a methodological issue in developmental psychology: Whereas most adult offenders displayed externalizing behavior already in childhood, not all children with behavioral problems grow up to be antisocial adults [2, 3]. Generally, predicting future from childhood behavior is difficult. Focusing on one behavioral assessment in childhood—as often done—contributes to this lack of predictive validity as it neglects developmental within-person variance. Relying on one measurement results in assigning similarity to children with temporarily similar levels, but substantially different developmental histories.
Several studies have focused on predicting individual pathways from risk antecedents, but knowledge on the range of health and behavior outcomes of developmental trajectories is still limited to a few studies. Using groupings based on six assessments of antisocial behavior between ages 5 and 18, Moffitt and colleagues [4] analyzed data from the Dunedin (New Zealand) study and reported that at age 26 males on the stable high path offended and got into fights more frequently than those on the adolescent limited path and had more often been convicted for drug-related and violent offenses. While there is no doubt that this study is informative given that age span between antisocial trajectories and outcome assessment (>10 years), the analyses are based on a relatively small sample (n < 500) and trajectory membership was assigned “by hand” using cut-off methods. Odgers et al. [5] extended this study to include females and age 32 outcomes. Overcoming prior limitations, this study was based on a larger number of individuals (n ~ 1,000) and utilized computerized trajectory estimation methods. Despite substantially diverging problem trajectories in childhood and adolescence, few differences were found between those on stable low and childhood-limited pathways. Compared to individuals on the stable low path, those on the life-course persistent path were at greater risk for depression and substance use, and more violent. Notably, individuals on the adolescent-onset path were more likely to experience substance use problems than those on a low antisocial behavior trajectory. Generally, Odgers et al. [5] concluded that those on an early-onset persistent antisocial pathway fared the worst with regard to mental and physical health problems and economic situation at age 32. While both studies have added valued information to our understanding of the sequelae of conduct problem trajectories, they were conducted on only one New Zealand sample and cross-cultural validation of findings is needed. Another study that linked developmental pathways and problem outcomes comes from Roisman et al. [6] who reported differences between early-onset persistent and never antisocial youth with regard to externalizing behavior, depression/anxiety, affiliation with deviant peers, and illegal drug use at age 23. Since this study relied on data of a relatively small sample of high-risk children, it is unclear whether these findings also apply to a general population sample.
Only few studies of childhood CP trajectories have focused on outcomes in adolescence or early adulthood: Miller and colleagues [7] identified four developmentally distinct groups (non-problem, increasing, desisting, and chronic) based on self-reported delinquency assessed from grade 7 to 12, whose outcomes were compared at age 19. Adolescents in the increasing and chronic groups were more likely to report risky sex and partner violence than those in the non-problem class. This study was based on a sample drawn from high-risk schools, relied on self-reports of both conduct problems and outcomes and was restricted to a small and specific range of outcomes (intimate partner violence, risky sexual behavior, reported pregnancies, and depression). Thompson et al. [8] estimated CP trajectories across middle childhood and compared age 12 substance use and violent/delinquent behavior. Children in the stable high CP class were almost four times more likely to use substances at age 12 than the stable low group, but no differences with regard to violent/delinquent behavior were found between both trajectories. However, children on moderate and increasing-high CP trajectories showed significantly more violent and delinquent behavior than the stable low group. Again, this study was based on a specific sample as children were recruited based on history of or risk for maltreatment.
The reviewed studies show clearly that the developmental course of young people’s conduct problems is predictive of outcomes in early [8] and late adolescence [7] and adulthood [4–6]. However, the findings are only partly supportive of theoretical models of antisocial behavior development (used here as an umbrella term to include conduct problems in childhood, delinquency in adolescence, and criminality and offending in adulthood) that propose the existence of distinct groups with substantially different developmental pathways [1]. That is, individuals who show an early onset and remain on stable high levels of antisocial behavior throughout childhood and adolescence typically present with a unique set of risk factors that comprise early deprivation, a harsh family environment, and neurodevelopmental deficits and are at much greater risk to offend and grow up to become criminal adults [1].
In contrast, the adolescent-onset group is assumed to fare substantially better with regard to later development. That is, while minor antisocial activities may be observed, the prognosis for this group is more positive than for individuals who display early-onset and stable high antisocial behavior. The (assumed) transitory [9] nature of adolescent-onset antisocial behavior is mirrored in the absence of clear theoretical accounts of risk factors. That is, Moffitt [1] proposed that many adolescents feel trapped in a “maturity gap”, which describes the discrepancy between biological maturity and continued social dependence. Antisocial activities, particularly those that are conducive to increased adult status, are thought to resolve negative effect resulting from the maturity gap. Naturally, once adolescents transition into early adulthood, the discrepancy between biological and social maturity ceases, thus antisocial behavior should not be a mean to an end anymore. Presented differently, individuals on the adolescent-onset antisocial path are hypothesized to show much lower rates of externalizing behavior such as substance use and delinquency than individuals on the early-onset persistent trajectory in adulthood.
As noted above, not all previous studies showed this pattern [7, 8]. Importantly, the majority of studies on the topic is based on high-risk samples (bar Moffitt et al. and Odgers et al. [4, 5]), which opens the possibility that associations between developmental trajectories and problem outcomes are both consequences of (earlier) risk or otherwise confounded and limited in generalizability. While Moffitt et al. and Odgers et al. [4, 5] examined cohort data without emphasis on specific risk groups, their studies were based on a particular region. New Zealand has a considerably higher proportion of inhabitants aged 15 years or younger than the UK (23.2 % compared to 12.9 % in 2010), more children growing up in poor households (5.0 % compared to 10.1 %; defined as <50 % of median household income) and overcrowded conditions (31.0 compared to 21.5 %; defined as lower number of rooms than family members). In contrast, male unemployment is higher in the UK compared to New Zealand (8.6 % compared to 6.2 %). Notably, suicide rates are double as high in New Zealand compared to the UK (6.4 compared to 3.0 per 100.000 population). This difference is even more pronounced when youths between ages 14 and 19 are considered (15.9 compared to 3.0 per 100.000 population) [10]. Moreover, the legal systems in both countries differ with age of criminal responsibility being 10 years in the UK and 14 years in New Zealand (expect for very serious offenses). Whether or not an 11-year old will be charged for a minor offense such as shoplifting or fare-dodging will likely have a crucial impact on their further (criminal) development. Thus, replication of associations between antisocial behavior trajectories and later outcomes in other samples than the Dunedin study is needed.
In addition, both Moffitt et al. and Odgers et al. [4, 5] focused on adult outcomes. However, the critical transition period from adolescence to adulthood requires adjustment to various changes in social contexts, roles, and expectations [11] such as engagement in stable romantic relations and entering the labor market. Mastering these tasks is more difficult for individuals who present with adjustment problems, hence identifying antecedents that increase the risk of late adolescent and early adult maladjustment is of crucial importance. The current study, therefore, examines whether childhood CP trajectories predict age 18 functioning in a wide range of domains that cover both health and behavioral problems. We aim to replicate findings of previous studies, that is, show that developmental pathways of conduct problems are differently associated with problem outcomes and used a large UK cohort sample to overcome limitations of generalizability posed by the specific samples used in prior studies.
Current study
Previously developed trajectories of childhood CP (ages 4–13 [12]) were used to examine associations with a wide range of symptomatology, including use of legal and illegal substances, offending and criminal involvement, risky sexual behavior, gambling, depression, anxiety, and self-harm in early adulthood. The four trajectory classes differed with regard to predictive risk factors—those in the early-onset persistent high CP class showed greater rates of maternal anxiety during pregnancy, partner cruelty to the mother in early childhood, and harsh parenting and higher levels of undercontrolled temperament measured at 2 years of age than those in the childhood-limited class [12]. Moreover, differences in internalizing and externalizing diagnoses in middle childhood and with regard to the development of hyperactivity, emotional difficulties, peer problems, and prosocial behavior were observed between the trajectory classes with those in the early-onset persistent high CP class showing substantially more problems than those in the childhood-limited and adolescent-onset classes who, in turn, showed greater problems than those on a stable low CP trajectory [13]. Notably, the present study is the first to examine the extent to which these CP class differences persist into early adulthood. Given theoretical accounts of continuity of externalizing problems for some and discontinuity for others [1], we examined associations between childhood CP trajectories and a wide range of externalizing problems in early adulthood. Moreover, spurred by previously reported trajectory differences in emotional difficulties [13], depression [5], and anxiety [6], we further examined associations between childhood CP trajectories and internalizing problems. We predicted that those in an early-onset persistent high CP class fared substantially worse in all outcomes, followed by those who show adolescent-onset CP. No differences were anticipated between abstainers and adolescents whose CP had subsided in late childhood.
Method
Participants
Data were drawn from the Avon longitudinal study of parents and children (ALSPAC), an ongoing population-based study designed to investigate the effects of a wide range of influences on the health and development of children. Pregnant women residing in the south-west of England who had an estimated date of delivery between April 1, 1991, and December 31, 1992, were invited to participate. The initial study cohort consisted of 14,062 pregnancies and 13,978 (52 % boys and 48 % girls) singletons/twins still alive at 12 months of age. Compared to the 1991 UK National Census Data, the sample showed a slightly higher proportion of house owner-occupiers, and a smaller proportion of mothers from ethnic minorities [14]. As described in Boyd et al. [15], children enrolled in ALSPAC were more educated at 16 compared to the national average, were more likely to be white (reflecting the ethnical composition of the area from which the sample was drawn) and less likely to be eligible for free school meals (an indicator of low income in the UK). Ethical approval for the study was obtained from the ALSPAC Law and Ethics Committee and local Research Ethics Committees. Detailed information about ALSPAC is available online (http://www.bris.ac.uk/alspac). Please note that the study website also contains details of all the data that are available through a fully searchable data dictionary (http://www.bristol.ac.uk/alspac/researchers/data-access/data-dictionary/).
Measures
Conduct Problem trajectories
The derivation of CP trajectories has been reported previously [12]. Briefly, latent class growth analysis (LCGA) models were applied to six assessments (spanning the age period from 4 to 13 years) of mother-reported CP using the ‘conduct problem’ subscale of the Strengths and Difficulties Questionnaire [16, 17]. The sum-score of each assessment was dichotomized at the standard threshold of scores of 4 or more [16], yielding six binary indicators for the latent growth classes. The four resulting trajectories were described as low (70.1 %), childhood-limited (CL 12.1 %), adolescent-onset (AO 8.5 %) and early-onset persistent (EOP 9.2 %). Rates quoted are following modal class assignment. Entropy for this model was moderate at 0.689 and the average assignment probabilities under modal class assignment were as follows: low = 0.889, AO = 0.681, CL = 0.718 and EOP = 0.820.
Outcomes
Data for all outcome measures were obtained in computer-assisted interviews during the “Teen Focus 4” (TF4) hands-on assessment clinic held at the ALSPAC premises in Bristol, UK. The median age at attendance was 17 years and 9 months (IQR = 17 years and 7 months to 17 years and 11 months). Alcohol use: Respondents completed the ten-item alcohol use disorders identification test (AUDIT) [18]. We used a cut-off of 16 points and above on the AUDIT scale to indicate harmful use. Smoking: Following positive responses to “having ever smoked” and “having smoked in the last 30 days”, respondents indicated whether they smoked every week. The response to this question was used as binary indicator. Cannabis use: Respondents completed the six item cannabis abuse screen test [19] asking about cannabis use in the previous 12 months. The sum-score was derived by assigning 1 to the responses “fairly often” and “often” and 0 to the other response options and summing the responses. This scale was then dichotomized to indicate those scoring one or more points. We opted for this cut-off to yield an adequate number of problem users. Illicit drugs: A series of questions was asked about the use of cocaine, amphetamines, inhalants, sedatives, hallucinogens or opioids in the previous 12 months. Respondents were assigned a score of 1 if they had used any of the drugs listed. Self-reported offenses: Items similar to the core offenses in the 2005 Offending, Crime, and Justice Survey (mugging, shoplifting, break and enter, selling drugs, fire setting, selling, buying stolen goods [20]) were presented to respondents who indicated whether or not they had engaged in these behaviors in the past year. A score of 1 was assigned following a positive response to one or more of the items. Criminal involvement: Respondents indicated whether they had been arrested (in trouble with the police in the last year) or convicted of a criminal offense (on trial in court, got police caution, got court fine, got community service order, received an ASBO (antisocial behavior order) been in a secure unit, been in prison, been in mediation as offender). Respondents were assigned a score of 1 if their response was positive to one or more of the items. Self-harm: An indicator of self-harm in the last year was derived from the following two questions: “Have you ever hurt yourself on purpose in any way (e.g., by taking an overdose of pills, or by cutting yourself)?” If yes, “How many times have you harmed yourself in the last year?” (not in the past year/once/2–5 times/6–10 times/more than 10 times). The response was dichotomized into 0 = not self-harmed in the past year and 1 = self-harmed at least once in the past year. Risky sexual behavior: Respondents were asked how many sexual partners they had had in the last year and were assigned a score of 1 if they reported three or more different partners. Gambling: The problem gambling severity index (PGSI, derived from the longer Canadian Problem Gambling Inventory; [21] was administered to those who reported engagement in any of 16 types of gambling (e.g., lottery/horse racing/fruit machines) in the past year. For the current analysis, a problem gambler was defined as someone at low, moderate or high risk (e.g., a PGSI score of 1 or more).Footnote 1 Depression and Anxiety: Depression and anxiety were measured using the clinical interview schedule-revised (CIS-R), a self-administered computerized interview which derives diagnoses based on ICD-10 criteria for depression and anxiety disorder (GAD, panic, phobia, social anxiety). The computerized version shows close agreement with the interviewer administered version [22, 23]. A binary variable indicating a primary diagnosis of major depression was taken as the depression outcome measure. A binary variable indicating a primary or secondary diagnosis of anxiety was taken as the anxiety outcome measure.
Confounders
Models were adjusted for a number of potential confounding factors preceding the CP assessment and previously shown to be associated with CP trajectories [12]: Family characteristics: Socioeconomic status, marital status/cohabitation, maternal education, and age of the mother when first pregnant, drinking during pregnancy (≥2 units per day) and maternal family history of alcohol use, smoking during pregnancy, any maternal contact with the police during child’s first 4 years of life. Birth information: Child birth weight, gestational age, parity and a single indicator for any birth complications (e.g., abruption, preterm rupture, cervical suture). Child characteristics: Language development [24] and child temperament (activity, adaptability, intensity, and mood subscales [25] at 24 months postpartum. Child experiences: Maternal depression [26, 27] and anxiety [28, 29] assessed at 32 weeks antenatal and 8 weeks postnatal. Harsh parenting assessed at 24 months and partner emotional and/or physical cruelty to the mother during child’s first 4 years of life. Low emotional and practical support for the mother during child’s first 4 years of life. Indication of child head injury during child’s first 4 years of life. Maternal attitude toward the child (e.g., “I really enjoy this child”) measured at 33 months postpartum.
Analytic procedure
A ‘three-step’ approach [30] was chosen for the current analysis. For the first step, LCGA was used within Mplus to derive CP classes as described previously [12]. In the second step, posterior probabilities from the LCGA model were used to assign each respondent to the most-likely class (known as modal class assignment). In the third step, a set of logistic regression models were estimated with the latent class measure as the exposure with outcomes consisting of each of the binary variables described above. This third step incorporated Vermunt’s correction for classification errors (details below). Each regression model was adjusted for the confounders described above. Complete case estimates were compared with those obtained following a multiple imputation routine.
Correcting for classification errors
Estimating the effect of covariates on a latent class measure can bias parameter estimates unless a one-stage model is performed in which covariate effects are estimated at the same time as the latent class measurement [30]. However, Vermunt has described a number of instances in which the one-stage model is not ideal and has proposed a method which uses the classification errors from the original latent class model to adjust for the bias within subsequent regression analyses. This approach is very similar in most respects to the three-step method regularly utilized by LCGA modelers with the difference that uncertainty in the estimation of the latent class measure is incorporated into the final regression model. In Vermunt’s method, the level of agreement between the underlying latent class measure and its predicted (manifested) counterpart forms a set of cell-weights which correct the parameter estimates for the bias mentioned above. This classification-error matrix can be calculated for any 2nd stage class-assignment procedure (e.g., modal class assignment, proportional assignment, random assignment) and furthermore, in the case of modal class assignment, the required matrix can easily be derived from that given in Mplus’ standard output for a latent class model. All regression analyses were carried out in Latent Gold version 4.5.0.11145 [31].
Attrition analyses and imputation of missing data
The starting sample for this analysis was the 7,218 participants previously assigned to a CP class. Of these, 3,860 (53.5 %) provided information on one or more outcome measures within the TF4 clinic. Unsurprisingly, there was strong evidence (p < 0.001) of an association between modal class and availability of outcome data with 56.0 % of low cases providing follow-up data compared to 50.4 % of CL cases and 45.5 % of both EOP and AO cases. Table 1 depicts further analysis of the relationship between baseline demographics and the availability of CP and outcome data, showing clear evidence of social patterning both in the sample providing data for the longitudinal modeling of CP as well as those who remained part of the study to provide age 18 data. In addition to outcome non-response, not every child included in the LCGA model had complete data on confounders. Preliminary univariable logistic regression models employed listwise deletion resulting in sample ranging from 3,000 to 3,500 cases. Incorporating potential confounders led to a further attenuation of these already depleted sample sizes, hence fully adjusted models will only be shown following missing data imputation.
To address the problem of partial non-response among outcomes and confounders, missing data were imputed by chained equations [32] using the Stata ice routine [33] to restore sample size to 7,218 for all analyses. The imputation model contained the CP class assignment, outcomes and confounders described above, as well as several auxiliary variables known to be related to missingness and to key variables in our models. Including auxiliary variables to assist imputation of substantial amounts of missing data reduces bias. 100 datasets were imputed, with 20 cycles of regression switching, and these data exported to Latent Gold which applies the same model to each data set and pools the final results using Rubin’s rules [34].
Results
Outcome frequencies by class
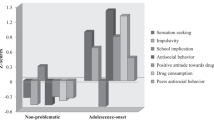
Prior to the fitting of the three-step logistic regression models, outcome rates were compared across the four CP classes (Table 2). There was strong evidence for an association between CP class and the majority of the outcomes (p ~0.001), but considerably weaker evidence for illicit drugs (p = 0.021), self-harm (p = 0.011) and gambling (p = 0.148). For all eleven outcomes, prevalence was highest among the EOP class and usually lowest for the low class. The ranking of CL and AO was more variable with AO >CL for substance use outcomes and CL >AO for ASB/criminal outcomes.
Prediction of outcomes by CP class
Tables 3 and 4 contain parameter estimates for the three-step logistic regression models. Table 3 contains univariable (unadjusted) estimates while Table 4 contains estimates adjusted for the potential confounding effects of the covariates described earlier. Both sets of results were obtained following missing data imputation (note that web table 1 shows unadjusted results using the complete case samples). For each binary outcome in turn, CP class was treated as a four-category nominal independent variable yielding three regression estimates, each with reference to the low class (CL, AO and EOP each versus low) and a single omnibus p value assessing evidence of differences for any of these three comparisons (final column of Table 3). To allow a more thorough exploration of the differences between CP classes, each model was re-parameterized to allow differences between the non-low classes to be quantified (EOP versus CL, EOP versus AO, and AO versus CL). In each instance, the reference category was chosen so that an odds ratio greater than one would be expected.
For the unadjusted results (Table 3), p values indicate variation across CP groups (p ~ 0.001) for ten out of the 11 outcomes considered, with gambling being an exception. Among those outcomes for which clear differences are apparent, the picture is far from consistent both in terms of the magnitude of the effects and also in terms of the individual post hoc differences. As expected, there are highly consistent differences between EOP and low CP classes (column 3) ranging from an approximately 50 to 80 % increase in odds for gambling and self-harm, to an over 300 % increase in odds for smoking and cannabis use. Moreover, compared with the low class, there is evidence of greater odds of smoking for those in CL and AO classes (columns 1 and 2). Those in the AO class are also at increased odds for use of illicit drugs and engaging in risky sexual behavior. Further post hoc comparisons (columns 4–6) indicate a number of differences between EOP and CL classes in the form of cannabis and alcohol use, smoking and self-reported offenses, however there was little clear separation apparent between AO and neither CL nor EOP. The pattern of results was generally consistent for the complete case unadjusted results (web table 1).
Table 4 shows the multivariable regression results, again derived from the 100 imputed datasets. As anticipated, parameter estimates have attenuated following adjustment for the wide range of confounders chosen. However, there remain a number of strong differences, primarily when comparing the EOP to the low class, but also for AO who remain at greater odds of smoking, illicit drug use and risky sexual behavior compared with the low class. In addition, compared to CL, individuals in the EOP class are at increased odds of alcohol, smoking, cannabis use, and both outcomes related to antisocial behavior.
Discussion
We examined whether developmental CP classes are predictive of a wide range of behavioral and health problems in early adulthood using a large UK cohort sample and thereby providing support to many of the findings of previous studies that used high-risk or geographically confined samples. Regardless of whether we used complete or imputed data, the EOP class was at substantially greater risk for most problems. Even when adjusting for a wide range of covariates, the EOP class was three times more likely than the low class to consume cannabis, and twice as likely as the low class to engage in risky sexual behavior—a result also yielded for those in the AO class. Similarly, adolescents in the AO and EOP classes were twice as likely to smoke than those in the low class. Taken together, our results support previous findings of a life-course persistent group of individuals with stable high problem behavior that crosses contexts and life stages [4–8]. Their involvement in practically all forms of problem behaviors will have a significant and serious negative impact on how these individuals master the important transition from adolescence to adulthood. It is likely that their entrance into the labor market and establishment of stable romantic relations will be less smooth than for others. Our results show that such difficulties are predictable from conduct problems at age 4, thus clearly underline the importance of very early and potentially repeated interventions to assist those who are at highest risk for a wide spectrum of problems. Although such substantial differences in risk may be expected with regard to externalizing problems [7, 35] our and other recent studies (Stringaris, Lewis, and Maughan, under review) are informative with regard to a broad range of internalizing problems.
Importantly, our findings also show that what is commonly understood as adolescence-limited problem behavior [1] is not entirely temporary. Not only did adolescents in the AO class report higher consumption of tobacco and illegal drugs, they also engaged more often in risky sexual behavior than their counterparts in the low class. The health and social risks associated with these behaviors are remarkable [36]. For instance, treatment of consequences of tobacco accounts costs the British National Health Service several billion pound sterling each year [37]. Unwanted pregnancies and increasing rates of sexually transmitted diseases are common consequences of risky sexual behavior and more prevalent in the UK than other Western European countries [38]. Our findings suggest that those who show increasing CP levels in late childhood are at high risk for these behaviors. Although our study did not focus on particular mechanisms through which early childhood conduct problems translate into this wide range of problem outcomes in late adolescence and several intermediate processes that involve adolescents’ peers are feasible. That is, adolescent-onset problem behavior is associated with delinquent peer involvement [39, 40] and such peer groups may also conduce other forms of problem behavior such as substance use and risky sex [41, 42]. Our findings are also in line with suggestions that individuals on an adolescent-onset path may get “trapped” in ensnaring behaviors (e.g., substance use, early pregnancy) that aggravate desistance from problem behavior and eventually lead to maladjustment and stable future problems [5, 35, 43, 44].
Finally, neither those in the CL nor AO class transition into young adulthood with levels of health and behavior problems that are comparably low to those observed in the low class. Theory and previous research suggest that individuals on a CL path should have desisted from problem behavior and be more or less indistinguishable from low group individuals [45]. A similar expectation may be had for the AO group, who should have “grown out” of problem behavior [1]. However, both groups were at risk for health and behavior problems that ranged between the low and EOP classes. Childhood CP indeed have a long reach and those who show elevated behavior problem levels at any point in their childhood may need attention from practitioners to ensure that such risks can be diminished.
Study limitations
The findings presented here are based on multiple reporter data and portray development across a substantial period of time. We used sophisticated longitudinal methodology that accounts for developmental variability in behavior when predicting outcome risks. Had we taken snapshots of conduct problems in childhood, we would have assigned low scores to those on the adolescent-onset and childhood-limited paths at one point in time and high scores at other points. It is likely that particularly the risks for substance use and risky sexual behavior of those in the adolescent-onset class would have gone unnoticed. Although we confined our outcome measures to snapshots, we focused on a transition period that is of crucial importance for a smooth start of adulthood.
Nonetheless, a number of limitations need to be acknowledged. First, our assessment of outcomes is based on self-reports, hence subject to response bias. Secondly, similar to many other longitudinal studies, ALSPAC has faced attrition over time. Because predictors of attrition [15] are also predictors of the outcome measures examined here, our sample is likely to under-represent individuals who show severe problem behavior. This, however, also means that risk associations found in this study are likely to have been attenuated. Third, the estimation of CP classes in our study did not yield perfect assignments, increasing the amount of uncertainty especially for the CL and AO classes. It is possible that this decreased the sensitivity of our CP measure to detect differences between both groups. Fourth, we examined associations between CP trajectories that reflected behavior up to age 13 and outcomes at age 19. Thus, we cannot draw conclusion about processes and factors during adolescence that may have acted as intermediate mechanisms or proxies, linking CP class to a particular outcome. Although self-reported antisocial behavior data are available, these differ considerably in response format from the mother-reported conduct problems on which the CP classes are based, we thus refrained from estimating new trajectories that would range until mid-adolescence. In addition, it was our aim to depict how childhood development has a long reach and can be used to assess risk for early adult internalizing and externalizing problems. Future studies are needed that elucidate the mechanisms underlying these associations in greater detail. Finally, while many outcomes in this study were frequent enough to use strict cut-offs, this was not the case for gambling. It is likely that access to gambling is more difficult than to other problem behaviors (e.g., tobacco) before legal age, which would explain the low frequencies yielded for problem gambling. Further assessments at later time points are required to draw informed conclusions about presence or absence of associations between CP and this outcome.
Despite these limitations, this study is unique in assessing a wide and varied range of outcomes of CP trajectories for an age group thus far neglected in similar studies (for an exception see [7]). Our findings show that elevated childhood CP levels are predictive of health problems and behavioral maladjustment at the transition from adolescence to adulthood. Identifying those at risk early enough is thus a key task for researchers and practitioners who work with young people.
Notes
Note that we also created groups using a stricter cut-off to indicate a higher level of problem gambling. While this resulted in significant modal class differences, group sizes were too small to be used in multivariate analyses.
References
Moffitt TE (1993) Adolescence-limited and life-course-persistent antisocial behavior: a developmental taxonomy. Psychol Rev 100:674–701
Piquero AR (2011) Invited address: James Joyce, Alice in Wonderland, the rolling stones, and criminal careers. J Youth Adolesc 40:761–775
Robins LN (1978) Sturdy childhood predictors of adult antisocial behaviour: replications from longitudinal studies. Psychol Med 8:611–622
Moffitt TE, Caspi A, Harrington H, Milne BJ (2002) Males on the life-course-persistent and adolescence-limited antisocial pathways: follow-up at age 26 years. Dev Psychopathol 14:179–207
Odgers CL, Moffitt TE, Broadbent JM, Dickson N, Hancox RJ, Harrington H, Poulton R, Sears MR, Thomson WM, Caspi A (2008) Female and male antisocial trajectories: from childhood origins to adult outcomes. Dev Psychopathol 20:673–716
Roisman GI, Aguilar B, Egeland B (2004) Antisocial behavior in the transition to adulthood: the independent and interactive roles of developmental history and emerging developmental tasks. Dev Psychopathol 16:857–871
Miller S, Malone PS, Dodge KA (2010) Developmental trajectories of boys’ and girls’ delinquency: sex differences and links to later adolescent outcomes. J Abnorm Child Psychol 38:1021–1032
Thompson R, Tabone JK, Litrownik AJ, Briggs EC, Hussey JM, English DJ, Dubowitz H (2011) Early adolescent risk behavior outcomes of childhood externalizing behavioral trajectories. J Early Adolesc 31:234–257
Le Blanc M (2011) An integrative personal control theory of deviant behavior: answers to contemporary empirical and theoretical developmental criminology issues. In: Farrington DP (ed) Integrated developmental and life-course theories of offending. Transaction Publishers, New Brunswick, pp 125–164
OECD (2013) Child Well-Being. OECD Social and Welfare Statistics (database).doi:10.1787/data-00666-en. Accessed 21 August 2013
Schulenberg JE, Sameroff AJ, Cicchetti D (2004) The transition to adulthood as a critical juncture in the course of psychopathology and mental health. Dev Psychopathol 16:799–806
Barker E, Maughan B (2009) Differentiating early-onset persistent versus childhood-limited conduct problem youth. Am J Psychiatry 166:900–908
Barker ED, Oliver BR, Maughan B (2010) Co-occurring problems of early onset persistent, childhood limited, and adolescent onset conduct problem youth. J Child Psychol Psychiatry 51:1217–1226
Golding J, Pembrey M, Jones R (2001) ALSPAC-the avon longitudinal study of parents and children. I. Study methodology. Paediatr Perinat Epidemiol 15:74–87
Boyd A, Golding J, Macleod J, Lawlor DA, Fraser A, Henderson J, Molloy L, Ness A, Ring S, Davey Smith G (2013) Cohort profile: the ‘children of the 90 s’—the index offspring of the avon longitudinal study of parents and children. Int J Epidemiol 42:111–127
Goodman R (2001) Psychometric properties of the strengths and difficulties questionnaire. J Am Acad Child Adolesc Psychiatry 40:1337–1345
Goodman R, Scott S (1999) Comparing the Strengths and Difficulties Questionnaire and the child behavior checklist: is small beautiful? J Abnorm Child Psychol 27:17–24
Babor TF, Higgins-Biddle JC, Saunders JB, Monteiro MG (2001) The alcohol use disorders identification test. Guidelines for use in primary care, 2nd edn. World Health Organization, Geneva
Legleye S, Karila L, Beck F, Reynaud M (2007) Validation of the CAST, a general population Cannabis abuse screening test. J Subst Use 12:233–242
Wilson D, Sharp C, Patterson A (2006) Young people and crime: findings from the 2005 offending, crime and justice survey, Statistical Bulletin 17/06. Home Office, London
Ferris J, Wynne H (2001) The Canadian problem gambling index. Canadian Centre on Substance Abuse, Ottawa
Bell T, Watson M, Sharp D, Lyons I, Lewis G (2005) Factors associated with being a false positive on the General Health Questionnaire. Soc Psychiatry Psychiatr Epidemiol 40:402–407
Patton G, Coffey C, Posterino M, Carlin J, Wolfe R, Bowes G (1999) A computerised screening instrument for adolescent depression: population-based validation and application to a two-phase case-control study. Soc Psychiatry Psychiatr Epidemiol 34:166–172
McCarthy D (1972) McCarthy scales of children’s abilities. Psychological Corporation, New York
Carey WB, McDevitt SC (1978) Stability and change in individual temperament diagnoses from infancy to early childhood. J Am Acad Child Psychiatry 17:331–337
Cox JL, Holden JM, Sagovsky R (1987) Detection of postnatal depression. Development of the 10-item Edinburgh Postnatal Depression Scale. Br J Psychiatry 150:782–786
Murray L, Carothers AD (1990) The validation of the Edinburgh Post-natal Depression Scale on a community sample. Br J Psychiatry 157:288–290
Birtchnell J, Evans C, Kennard J (1988) The total score of the crown-crisp experiential index: a useful and valid measure of psychoneurotic pathology. Br J Med Psychol 61(Pt 3):255–266
O’Connor TG, Heron J, Golding J, Beveridge M, Glover V (2002) Maternal antenatal anxiety and children’s behavioural/emotional problems at 4 years. Report from the avon longitudinal study of parents and children. Br J Psychiatry 180:502–508
Vermunt JK (2010) Latent class modeling with covariates: two improved three-step approaches. Political Anal 18:450–469
Vermunt JK, Magidson J (2005) Technical guide for Latent GOLD 4.0: basic and advanced. Statistical Innovations Inc, Belmont
Van Buuren S, Boshuizen HC, Knook DL (1999) Multiple imputation of missing blood pressure covariates in survival analysis. Stat Med 18:681–694
Royston P (2005) Multiple imputation of missing values: update of ice. Stata J 5:527–536
Little RJA, Rubin DB (1987) Statistical analysis with missing data. Wiley, New York
Moffitt TE, Caspi A (2005) Life-course persistent and adolescence-limited antisocial males: longitudinal follow-up to adulthood. Dev Psychobiol Aggress 14:161–186
Moffitt TE, the E-Risk Study Team (2002) Teen-aged mothers in contemporary Britain. J Child Psychol Psychiatry 43:727–742
Allender S, Balakrishnan R, Scarborough P, Webster P, Rayner M (2009) The burden of smoking-related ill health in the UK. Tob Control 18:262–267
Avery L, Lazdane G (2008) What do we know about sexual and reproductive health of adolescents in Europe? Eur J Contracept Reprod Healthc 13:58–70
Haynie DL (2001) Delinquent peers revisited: does network structure matter? Am J Sociol 106:1013–1057
Haynie DL, Osgood DW (2005) Reconsidering peers and delinquency: how do peers matter? Soc Forces 84:1109–1130
Kotchick BA, Shaffer A, Miller KS, Forehand R (2001) Adolescent sexual risk behavior: a multi-system perspective. Clin Psychol Rev 21:493–519
Schaefer DR, Haas SA, Bishop NJ (2012) A dynamic model of US adolescents’ smoking and friendship networks. Am J Public Health 102:e12–e18
Hussong AM, Curran PJ, Moffitt TE, Caspi A, Carrig MM (2004) Substance abuse hinders desistance in young adults’ antisocial behavior. Dev Psychopathol 16:1029–1046
Moffitt TE, Arseneault L, Belsky D, Dickson N, Hancox RJ, Harrington H, Houts R, Poulton R, Roberts BW, Ross S (2011) A gradient of childhood self-control predicts health, wealth, and public safety. Proc Natl Acad Sci 108:2693–2698
Veenstra R, Lindenberg S, Verhulst FC, Ormel J (2009) Childhood-limited versus persistent antisocial behavior why do some recover and others do not? The TRAILS study. J Early Adolesc 29:718–742
Acknowledgments
We are extremely grateful to all the families who took part in this study, the midwives for their help in recruiting them and the whole ALSPAC team, which includes interviewers, computer and laboratory technicians, clerical workers, research scientists, volunteers, managers, receptionists and nurses.
The UK Medical Research Council (Grant: 74882) the Wellcome Trust (Grant: 076467) and the University of Bristol provide core support for ALSPAC. This publication is the work of the authors who will serve as guarantors for the contents of this paper.
JH is supported by the UK Medical Research Council (Grants: G0800612 and G0802736) and the Wellcome Trust (Grant: 086684).
MRM is a member of the UK Centre for Tobacco Control Studies, a UKCRC Public Health Research: Centre of Excellence. Funding from British Heart Foundation, Cancer Research UK, Economic and Social Research Council, Medical Research Council, and the National Institute for Health Research, under the auspices of the UK Clinical Research Collaboration, is gratefully acknowledged.
Conflict of interest
None.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Kretschmer, T., Hickman, M., Doerner, R. et al. Outcomes of childhood conduct problem trajectories in early adulthood: findings from the ALSPAC study. Eur Child Adolesc Psychiatry 23, 539–549 (2014). https://doi.org/10.1007/s00787-013-0488-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00787-013-0488-5