
Abstract
Objective
To qualitatively and quantitatively assess integrated segmentation of three convolutional neural network (CNN) models for the creation of a maxillary virtual patient (MVP) from cone-beam computed tomography (CBCT) images.
Materials and methods
A dataset of 40 CBCT scans acquired with different scanning parameters was selected. Three previously validated individual CNN models were integrated to achieve a combined segmentation of maxillary complex, maxillary sinuses, and upper dentition. Two experts performed a qualitative assessment, scoring-integrated segmentations from 0 to 10 based on the number of required refinements. Furthermore, experts executed refinements, allowing performance comparison between integrated automated segmentation (AS) and refined segmentation (RS) models. Inter-observer consistency of the refinements and the time needed to create a full-resolution automatic segmentation were calculated.
Results
From the dataset, 85% scored 7–10, and 15% were within 3–6. The average time required for automated segmentation was 1.7 min. Performance metrics indicated an excellent overlap between automatic and refined segmentation with a dice similarity coefficient (DSC) of 99.3%. High inter-observer consistency of refinements was observed, with a 95% Hausdorff distance (HD) of 0.045 mm.
Conclusion
The integrated CNN models proved to be fast, accurate, and consistent along with a strong interobserver consistency in creating the MVP.
Clinical relevance
The automated segmentation of these structures simultaneously could act as a valuable tool in clinical orthodontics, implant rehabilitation, and any oral or maxillofacial surgical procedures, where visualization of MVP and its relationship with surrounding structures is a necessity for reaching an accurate diagnosis and patient-specific treatment planning.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
One of the recent trends for diagnostics and pre-surgical planning in orthodontics, orthognathic surgery, and oral implant placement has been the introduction of simplified digital workflows [1]. The solid basis of such workflows can often be accomplished by three-dimensional (3D) imaging, mainly cone-beam computed tomography (CBCT), which offers volumetric anatomical data of orofacial structures.
Segmentation of the imaging data acquired from CBCT is essential for generating 3D models of patient-specific anatomical structures, which is a prerequisite for virtual treatment planning and 3D manufacturing [1]. However, current segmentation techniques, either manual or semi-automatic, are time-consuming, suffer from human variability, and are hampered by metal and motion artifacts [2]. Besides, segmentation of CBCT images requires more time than traditional multi-slice computed tomography (MSCT), as MSCT images have a superior contrast resolution and lower noise which facilitate achieving a time-efficient segmentation [2,3,4]. Nevertheless, CBCT acts as the modality of choice in oral healthcare, considering its low cost, relatively lower dose, and increased accessibility [2, 5].
Considering these limitations of CBCT imaging in relation to segmentation, there is a need for automation of the current digital workflows by the application of artificial intelligence (AI)-based techniques. Recently, a convolutional neural network (CNN), a class of artificial neural networks, has dominated the field of medical image analysis, as it is specialized for processing data with defined, grid-like topology, such as two-dimensional (2D) and 3D images [6, 7]. CNNs have the ability to outperform standard image processing algorithms with high computational speed and correlate with other data such as clinical information or response to therapy. This provides an improvement in the quality of image processing and helps clinicians to extract and analyze relevant information in a concise format [7].
So far, the authors of several studies have focussed on the segmentation of individual craniomaxillofacial anatomical structures using CNN models [8,9,10,11]. However, no evidence exists about the integration of these multiple anatomical structures as a single unit. A combination of AI models specialized in segmenting different structures with variable densities simultaneously could pave the way towards the creation of a virtual patient with high performance in a time-efficient approach. This virtual patient could be applied for digital virtual planning of several treatment procedures, not only in general dentistry but also in maxillofacial surgery; Ear, Nose, and Throat (ENT); neurosurgery; and ophthalmology. Therefore, we aimed to assess the qualitative and quantitative performance of integrated CNN models of three previously validated individual networks for the creation of a segmented maxillary virtual patient (MVP) consisting of maxillary skeletal complex, maxillary sinuses, and teeth from CBCT images [8, 12, 13]. We hypothesized that the three integrated CNN models would reveal a similar performance as the individuals’ ones, along with a strong interobserver agreement in terms of time-efficiency and consistency for creating a segmented MVP.”
Materials and methods
This study was approved by the Research Ethics Committee of the University Hospitals Leuven (reference number: S65708) and was conducted in compliance with the World Medical Association Declaration of Helsinki on medical research. Patient-specific information was anonymized.
Dataset
The sample size was calculated based on previous comparable studies using a priori power analysis in G* power 3.1, with a power of 80% and a significance level of 5%[9, 11]. In this way, a total dataset of 40 scans of two devices (20 Accuitomo 3D; 20 Newtom VGi evo) was selected, consisting of 560 teeth, 80 sinuses, and 40 maxillofacial complexes acquired with different scanning parameters (Table 1). Inclusion criteria were scans with permanent dentition, including teeth with coronal and/or root fillings. Exclusion criteria were patients with a history of maxillofacial trauma, skeletal or dental malformation, post-orthognathic surgery patients with mini-plates and screws, presence of dental implants, and missing teeth in proximity to the sinus floor.
All CBCT images were saved in Digital Imaging and Communication in Medicine (DICOM) format and uploaded to an online cloud-based platform called Virtual Patient Creator (creator.relu.eu, version December 2021, Relu BV, Leuven, Belgium), which allowed combined automatic segmentation of maxillary complex, maxillary sinuses, and teeth, referred to as MVP.
Qualitative assessment
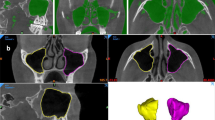
Two dentomaxillofacial radiologists (FNR and NM) clinically evaluated the automatic segmentation of the integrated structures by visually observing their corresponding colors on orthogonal planes of the CBCT images (Fig. 1). The three individual CNN models of maxillofacial complex, maxillary sinuses, and teeth have been previously validated, where they were proved to be highly accurate, requiring only minor refinements (slight over or under segmentation in each structure) (Fig. 2). Hence, a score from 0 to 10 was given for each segmentation based on the number of required minor refinements, where 0 represented ten refinements or more, 1 represented 9 refinements, 2 represented 8 refinements, and successively up to 10 that referred to a perfect segmentation without the need for any refinement. Inter-observer agreement was assessed for the scoring between the two observers. Additionally, needed refinements were performed for assessing the performance of the integrated models in comparison to the refined ones, and the consistency between observers.

3D views and their respective colored segmentations on CBCT slices on Virtual Patient Creator (creator.relu.eu, Relu BV, Version December 2021): a all structures combined showing the maxillary virtual patient, b maxillofacial complex, c maxillary sinuses, and d upper dentition

Borderline definition of the automatic segmentation of integrated structures (version 23.0, Materialise N.V., Leuven, Belgium)
Smart correction tools
Following visual assessment, both observers performed the required refinements using the newly developed tools on the virtual patient creator platform: normal and smart brushes, contour, and livewire tools. The normal brush is a simple cylindrical brush, which is used for adding brush strokes to refine small inadequacies between multiple image slices. The smart brush uses voxel intensities to group them by analyzing the voxel’s intensity below the cursor and selecting all voxels at a certain depth that have intensities within the selected voxel’s tolerance range. Both tools are unidirectional, causing only the slices above or below to be changed. Hence, there was no issue of overwriting slices that have already been corrected.
The contour tool automatically interpolates the inter-slice region between upper and lower selected contours. The livewire tool is an intelligent version of the contour tool, whose main principle of inter-slice interpolation remains the same. However, it connects the added points in a path that automatically follows the grey values of the image. Consequently, allowing the user to outline contours more quickly with a fewer number of points compared to a contour tool. Tutorials on how to use these tools are available as supplementary material (online resources 1–4).
Quantitative assessment
Timing
The time required to have a full-resolution automatic segmentation (AS) was measured directly by an automated algorithm. As for the refined segmentation (RS), it was calculated by summing up the time required for automatic segmentation and refinements. Finally, the average time for each segmentation technique was calculated.
Automatic versus refined segmentations
The automatic segmentation was compared to the manual refined segmentation, and the metrics used to assess its similarity included dice similarity coefficient (DSC), 95% Hausdorff distance (HD), and root mean square (RMS) (Table 2). The performance of the AI models for MVP segmentation was calculated using the following expression, where x is the comparison metric of interest (e.g., DSC) between automatic and refined segmentation.
The dentition metric was defined as the average overall individual tooth types:
Consistency of refined segmentations
The three CNN models have already proven to be 100% consistent at an individual level, hence AI consistency was not further investigated. The interobserver consistency of refined segmentations was assessed by overlapping the DICOM and resultant STL files of the segmentations performed by each observer. Thereafter, corresponding evaluation metrics were calculated.
Statistical analysis
Data were analyzed with IBM SPSS version 28.0.1.0 software (Armonk, NY). The weighted Kappa test (95%CI) was performed for the inter-observer agreement of the qualitative assessment. For quantitative data, the mean value and standard deviation of each evaluation metric were calculated.
Results
Based on the visual assessment, there was no overlap between the three structures (Fig. 2). From the entire dataset, 85% showed a score of 7 or more by both observers, and 15% were within the range of 3–6. Furthermore, there were no cases with scores of 0–2 (Fig. 3). In total, 40 scans required minor corrections, mainly due to mucosal thickening in the sinus, closed foramina and canals, small bone discontinuities in the palate and maxilla, and bone over-segmentation of zygomaticotemporal sutures (Table 3). Figure 4 illustrates some examples of the regions requiring refinements. The weighted Kappa test showed a strong inter-observer agreement (K = 0.832, 95% CI [0.704;0.960]) based on Landis and Koch’s classification [14].

Score frequency based on the number of corrections needed given by two observers (n = 80)

3D models and axial sections of CBCT scans illustrating the necessary refinements most often detected in qualitative analysis. a Mucosal thickening in the upper cortical of the right maxillary sinus. b MVP in a view showing bone discontinuity around palatine foramina. c Closed right infraorbital foramen in a lateral view of the MVP
The average timing for the automated segmentation of 40 cases was 1.7 min, ranging from 1.1 to 2.4 min. The average time required for refinements by the first and seconds was 3.4 min (1.2 to 15 min) and 2.5 min (1.0 to 11 min), respectively.
The performance metrics (Table 4) indicated an excellent overlap between automatic and refined segmentation with a DSC of 99.3% for both observers, implying that minimal refinements were required. The RMS value was 0.289 mm and 0.286 mm, and the 95% HD was 0.210 mm and 0.228 mm for each observer, respectively.
Interobserver consistency of refinements (Table 4) showed a high DSC of 99.8%. A close to zero 95% HD of 0.045 was detected with a low RMS value of 0.053. Additionally, the STL overlap comparison map also observed a similar pattern, hence suggesting a substantial agreement between both observers.
Discussion
An accurate 3D segmentation of orofacial structures is the first essential step in most digital dental workflows. It is crucial for precise delineation and outlining of normal anatomy, variations, differentiation from accompanied pathological lesions, and volumetric estimation of anatomical structures. If segmentation of multiple anatomical structures is performed simultaneously, it provides a clinician with a complete picture and focused approach towards studying the relation with the surrounding structures. Therefore, the present study investigated the performance of integrated CNN models for creating the MVP consisting of combined automatic segmentation of the maxillary complex, sinus, and teeth as a single unit.
For qualitative assessment, since only minor corrections were needed, the quality of integration was assessed based on the number of refinements and the required time. The results showed a strong agreement between both observers. A score equal to 7 or more (85% of the dataset) was considered a high-quality segmentation, while a score ranging from 3 to 6 (15% of the dataset) an above-average quality. Segmentations in Table 3 illustrate the types of required refinements per segmented structure. According to previous validation studies’ classification [12, 13], minor refinements have no or slight clinical relevance, and the present qualitative analysis assumes that this clinical impact depends on the number of minor refinements needed. In daily practice, the clinical relevance of such refinements might differ depending on the task at hand, such as visualization, diagnosis, treatment planning, and patient education. Moreover, each type of refinement might be more relevant in a specific clinical specialty compared to another one. For instance, mucosal sinus thickness is more relevant for treatment planning in oral and maxillofacial surgical procedures involving maxillary sinus floor elevation [15] compared to a routine dental examination or patient education.
The quantitative assessment revealed that the sum of mean time required for automatic MVP segmentation (1.7 min) was slightly higher compared to the sum of the previously documented timing for each structure segmentation which totaled 1.3 min (maxillofacial complex: 39.1, maxillary sinus: 24.4, all teeth: 13.7 s) [8, 12, 13]. This minimal difference could be attributed to some technical variabilities, such as nonuser active processes, which impact the segmentation time even if the same AI tool is run several times, making it a challenge to keep the time constant [16]. Another reason could be the large field of view (FOV) of the included sample, which could have increased the processing time. The previous studies used fewer testing samples with large FOVs because they covered only one region of interest.
We did not investigate the clinical accuracy of automated segmentation, which has previously been reported to have a high DSC score (maxillary complex: 92.6%, maxillary sinus: 98.4%, teeth: 90%), when compared to the reference ground truth generated by skilled human operators using a manual or semi-automatic approach. Rather, the relevant performance of the combined structural segmentation was compared to the manually refined one. The findings showed no change in performance following post-integration. A DSC score of 99.3% was observed compared to refined segmentation for both observers, hence implying high segmentation quality even for the scans requiring many refinements. Additionally, the interobserver consistency showed almost perfect overlap with a DSC of 99.8%, indicating that the integrated model could provide an automated ground that increases consistency between observers overcoming high observer variability in other segmentation techniques.
The presented CNN model overcame the issue of manual threshold selection required with semi-automatic approaches. Moreover, the main benefit of the model is the simultaneous segmentation of anatomical structures with different densities using a single platform, as shown in the coronal slice of Fig. 1a. This type of combined segmentation is not possible with the available semi-automatic segmentation software programs, where each structure has a different threshold requiring manual adjustment separately by the operator [17]. Clinically, this integrated segmentation could be a valuable tool in clinical orthodontics and maxillofacial surgical procedures, such as implant planning, bone grafting, and orthognathic and reconstructive surgery [18,19,20,21], where visualization of MVP and its relationship with surrounding structures is a necessity for reaching an accurate diagnosis and patient-specific treatment planning.
An additional advantage of the proposed approach was that no third-party software was required to refine the automated segmentations, which was not the case in the previous individual CNN model-based validation studies. As newly developed tools have been employed on the platform, which also let the clinicians directly refine the segmentations. However, lack of data heterogeneity remains a limitation, and there is a need to incorporate data from other CBCT devices with varying scanning parameters to justify the generalizability of the tool. In the near future, we plan to integrate other validated individual anatomical regions, such as the mandible, inferior alveolar canal, and pharyngeal airway [9,10,11]. It is also expected to expand the tool’s ability by integrating data from intra-oral scanners and facial scanners for the creation of a complete virtual patient, which could enhance the delivery of personalized dental care [22]. Furthermore, additional CBCT scans from various institutions, CBCT scanner brands, and the variability of patient anatomy and pathology should be integrated in the near future to increase the generalizability further. The application of AI tools and personalized data in clinical and research fields could support positive clinical protocols changes, help create predictive population models [23], and act as a visual educational tool for both clinicians and patients.
Conclusion
The three integrated CNN models proved to be fast and accurate for simultaneous segmentation of maxillary anatomical structures with different densities. Both the qualitative and the quantitative assessments revealed a strong interobserver consistency. The integrated MVP could act as a feasible tool for visualization, diagnostics, and treatment planning in daily clinical practice.
References
Shujaat S, Bornstein MM, Price JB, Jacobs R (2021) Integration of imaging modalities in digital dental workflows - possibilities, limitations, and potential future developments. Dentomaxillofac Radiol 50:20210268. https://doi.org/10.1259/dmfr.20210268
Jacobs R, Salmon B, Codari M, Hassan B, Bornstein MM (2018) Cone beam computed tomography in implant dentistry: recommendations for clinical use. BMC Oral Health 18:88. https://doi.org/10.1186/s12903-018-0523-5
Minnema J, van Eijnatten M, Kouw W, Diblen F, Mendrik A, Wolff J (2018) CT image segmentation of bone for medical additive manufacturing using a convolutional neural network. Comput Biol Med 103:130–139. https://doi.org/10.1016/j.compbiomed.2018.10.012
Vandenberghe B, Luchsinger S, Hostens J, Dhoore E, Jacobs R (2012) The influence of exposure parameters on jawbone model accuracy using cone beam CT and multislice CT. Dentomaxillofac Radiol 41:466–474. https://doi.org/10.1259/dmfr/81272805
Wang L, Chen KC, Gao Y, Shi F, Liao S, Li G, Shen SGF, Yan J, Lee PKM, Chow B, Liu NX, Xia JJ, Shen D (2014) Automated bone segmentation from dental CBCT images using patch-based sparse representation and convex optimization. Med Phys 41:043503. https://doi.org/10.1118/1.4868455
Hagan MT, Demuth HB, Beale MH, de Jesús O (2006) Neural networks in a softcomputing framework. Springer-Verlag, London
Leite AF, de Vasconcelos KF, Willems H, Jacobs R (2020) Radiomics and machine learning in oral healthcare. Proteomics Clin Appl 14:1900040. https://doi.org/10.1002/prca.201900040
Shaheen E, Leite A, Alqahtani KA, Smolders A, Van Gerven A, Willems H, Jacobs R (2021) A novel deep learning system for multi-class tooth segmentation and classification on cone beam computed tomography. A validation study. J Dent 115:103865. https://doi.org/10.1016/j.jdent.2021.103865
Verhelst P-J, Smolders A, Beznik T, Meewis J, Vandemeulebroucke A, Shaheen E, Van Gerven A, Willems H, Politis C, Jacobs R (2021) Layered deep learning for automatic mandibular segmentation in cone-beam computed tomography. J Dent 114:103786. https://doi.org/10.1016/j.jdent.2021.103786
Lahoud P, Diels S, Niclaes L, Van Aelst S, Willems H, Van Gerven A, Quirynen M, Jacobs R (2022) Development and validation of a novel artificial intelligence driven tool for accurate mandibular canal segmentation on CBCT. J Dent 116:103891. https://doi.org/10.1016/j.jdent.2021.103891
Shujaat S, Jazil O, Willems H, Van Gerven A, Shaheen E, Politis C, Jacobs R (2021) Automatic segmentation of the pharyngeal airway space with convolutional neural network. J Dent 111:103705. https://doi.org/10.1016/j.jdent.2021.103705
Morgan N, Van Gerven A, Smolders A, Vasconcelos KF, Willems H, Jacobs R (2022) Convolutional neural network for automatic maxillary sinus segmentation on cone-beam computed tomographic images. Sci Rep 12:7523. https://doi.org/10.1038/s41598-022-11483-3
Preda F, Morgan N, Van Gerven A, Nogueira-Reis F, Smolders A, Wang X, Nomidis S, Shaheen E, Willems H, Jacobs R (2022) Deep convolutional neural network-based automated segmentation of the maxillofacial complex from cone-beam computed tomography - a validation study. J Dent 124:104238. https://doi.org/10.1016/j.jdent.2022.104238
Landis JR, Koch GG (1977) The measurement of observer agreement for categorical data. Biometrics 33:159. https://doi.org/10.2307/2529310
Hung KF, Ai QYH, King AD, Bornstein MM, Wong LM, Leung YY (2022) Automatic detection and segmentation of morphological changes of the maxillary sinus mucosa on cone-beam computed tomography images using a three-dimensional convolutional neural network. Clin Oral Investig 26:3987–3998. https://doi.org/10.1007/s00784-021-04365-x
Nogueira PE, Matias R (2015) A quantitative study on execution time variability in computing experiments. In: 2015 Winter Simulation Conference (WSC): 529–540. https://doi.org/10.1109/WSC.2015.7408193
Friedli L, Kloukos D, Kanavakis G, Halazonetis D, Gkantidis N (2020) The effect of threshold level on bone segmentation of cranial base structures from CT and CBCT images. Sci Rep 10:7361. https://doi.org/10.1038/s41598-020-64383-9
Ma H, Van Dessel J, Bila M, Sun Y, Constantinus P, Jacobs R (2021) Application of three-dimensional printed customized surgical plates for mandibular reconstruction: report of consecutive cases and long-term postoperative evaluation. J Craniofac Surg 32:e663–e667. https://doi.org/10.1097/SCS.0000000000007835
Li B, Wei H, Jiang T, Qian Y, Zhang T, Yu H, Zhang L, Wang X (2021) Randomized clinical trial of the accuracy of patient-specific implants versus cad/cam splints in orthognathic surgery. Plast Reconstr Surg 148:1101–1110. https://doi.org/10.1097/PRS.0000000000008427
Mathew N, Gandhi S, Singh I, Solanki M, Bedi NS (2020) 3D models revolutionizing surgical outcomes in oral and maxillofacial surgery: experience at our center. J Maxillofac Oral Surg 19:208–216. https://doi.org/10.1007/s12663-019-01275-0
Palomo JM, El H, Stefanovic N, Bazina M (2019) Diagnostic value of 3D imaging in clinical orthodontics. Craniofacial 3D Imaging. Springer International Publishing, Cham, pp 113–139. https://doi.org/10.1007/978-3-030-00722-5_7
Bornstein MM (2022) The crucial role of dentomaxillofacial radiology for AI research in dental medicine – why it’s time for our specialty to lead the way! Dentomaxillofac Radiol 51:20229001. https://doi.org/10.1259/dmfr.20229001
Joda T, Bornstein MM, Jung RE, Ferrari M, Waltimo T, Zitzmann NU (2020) Recent trends and future direction of dental research in the digital era. Int J Environ Res Public Health 17:1987. https://doi.org/10.3390/ijerph17061987
Funding
Open access funding provided by Karolinska Institute. This study was supported by the Development Project of VLAIO (Flanders Innovation & Entrepreneurship). This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – Brasil (CAPES) – Finance Code 001.
Author information
Authors and Affiliations
Contributions
FNR, NM, SN, AVG, RJ, and CT contributed to the study conception and design. Data collection, image assessment, and segmentation refinements were performed by FNR and NM. SN and AVG provided the results of the evaluation metrics. FNR, NM, SN, AVG, RJ, and CT curated and analyzed the data and participated in writing the manuscript. RJ provided resources. RJ and CT supervised the project. NOS performed formal analysis and visualization of data curation during the peer review process. All authors reviewed the manuscript. The authors agreed with the final version of the manuscript.
Corresponding author
Ethics declarations
Ethical approval
All procedures performed were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. The study protocol was submitted to and approved by the Research Ethics Committee of the University Hospitals Leuven (reference number: S65708).
Informed consent
For this type of study (retrospective study), formal consent is not required.
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary file1 (MP4 96032 KB)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nogueira-Reis, F., Morgan, N., Nomidis, S. et al. Three-dimensional maxillary virtual patient creation by convolutional neural network-based segmentation on cone-beam computed tomography images. Clin Oral Invest 27, 1133–1141 (2023). https://doi.org/10.1007/s00784-022-04708-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00784-022-04708-2