
Abstract
Purpose
To develop a machine learning algorithm, using patient-reported data from early pregnancy, to predict later onset of first time moderate-to-severe depression.
Methods
A sample of 944 U.S. patient participants from a larger longitudinal observational cohortused a prenatal support mobile app from September 2019 to April 2022. Participants self-reported clinical and social risk factors during first trimester initiation of app use and completed voluntary depression screenings in each trimester. Several machine learning algorithms were applied to self-reported data, including a novel algorithm for causal discovery. Training and test datasets were built from a randomized 80/20 data split. Models were evaluated on their predictive accuracy and their simplicity (i.e., fewest variables required for prediction).
Results
Among participants, 78% identified as white with an average age of 30 [IQR 26–34]; 61% had income ≥ $50,000; 70% had a college degree or higher; and 49% were nulliparous. All models accurately predicted first time moderate-severe depression using first trimester baseline data (AUC 0.74–0.89, sensitivity 0.35–0.81, specificity 0.78–0.95). Several predictors were common across models, including anxiety history, partnered status, psychosocial factors, and pregnancy-specific stressors. The optimal model used only 14 (26%) of the possible variables and had excellent accuracy (AUC = 0.89, sensitivity = 0.81, specificity = 0.83). When food insecurity reports were included among a subset of participants, demographics, including race and income, dropped out and the model became more accurate (AUC = 0.93) and simpler (9 variables).
Conclusion
A relatively small amount of self-report data produced a highly predictive model of first time depression among pregnant individuals.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Perinatal depression is one of the most prevalent pregnancy complications in the US. Approximately 15% of individuals report depressive symptoms at some point in their pregnancy (Dietz et al. 2007), with instances of major depression occurring among roughly 12% of pregnancies (Le Strat et al. 2011) and in the postpartum period (Evans et al. 2001). Depression rates are lowest in the first trimester and tend to spike in the second trimester and again postpartum (Yu et al. 2020). Early adulthood, when many first pregnancies occur, is a time of particular vulnerability to depression onset (Rohde et al. 2005). Perinatal depression is associated with adverse outcomes for mother and infant (Chung et al. 2001), including preterm delivery (Grigoriadis et al. 2013), delayed infant/child development (Madigan et al. 2018), decreased quality of life (Lagadec et al. 2018), and poor maternal-child attachment (Santoro and Peabody 2010).
The American College of Obstetricians and Gynecologists (ACOG Committee Opinion No. 757 Summary: Screening for Perinatal Depression 2018), the US Preventive Services Taskforce (U. S. Preventive Services Task Force et al. 2019), and other professional organizations recommend early and routine perinatal screening for depression risk. Established perinatal depression screening tools, such as the Edinburgh Postnatal Depression Scale (EPDS) (Cox et al. 1987) and PHQ-9 (Spitzer et al. 1999), are effective at detecting current depressive symptoms. However, these screening tools are inconsistently administered during the course of pregnancy, with common practice being to screen once during early pregnancy and not again until the postpartum period (Long et al. 2020; Sidebottom et al. 2021). As such, many instances of active depression may be missed during routine care. Moreover, these screening tools are not intended for the identification of future depression risk (Cox 2017; Kroenke et al. 2001). Both for prevention and intervention, there is a need for screeners that can be administered early in pregnancy to identify those who are likely to develop new depressive symptoms at a future stage of pregnancy.
Studies of perinatal depression trajectories find heterogeneity in both symptoms and the risk factors associated with the timing and duration of those symptoms (Ahmed et al. 2018; Bayrampour et al. 2016; Mora et al. 2009). Depression symptoms in pregnancy are consistently associated with postpartum depression occurrence. History of depression prior to pregnancy is, in turn, one of the strongest predictors of depression during pregnancy (Guintivano et al. 2018a; Lancaster et al. 2010; O’Hara and Swain 1996). Consequently, depression history is an extremely useful cue for identifying those who may experience recurrent depression part way through their pregnancy and into the postpartum period. However, approximately 50% of individuals experiencing depression in pregnancy report no prior depression history, necessitating use of other risk cues for those individuals (McCall-Hosenfeld et al. 2016). Other documented perinatal depression risk factors that can be measured in early pregnancy include having an unplanned pregnancy (Abajobir et al. 2016; Cheng et al. 2009; Orr et al. 2008), previous pregnancy complications (Blackmore et al. 2011; Egan et al. 2017; Silverman et al. 2017; Zhang et al. 2020), other concurrent mental health conditions, such as anxiety, (Korja et al. 2018; Putnam et al. 2017), stressful life events (Guintivano et al. 2018b; Nunes and Phipps 2013; Qobadi et al. 2016), and health-related social needs, including a lack of social or financial support (O’Hara and Swain 1996; Robertson et al. 2004). Still, little is known about how to use these risk factors concurrently to identify who is likely to experience first time depression in their pregnancy.
As the field of perinatal mental health moves towards precision medicine, machine learning can play a powerful role in shaping care delivery and risk phenotyping, including digital phenotyping, offering an opportunity for earlier intervention (Hurwitz et al. 2023; Osborne et al. 2019; Torous et al. 2015). Machine learning algorithms have shown promise in their ability to predict maternal depression (Cellini et al. 2022; Zhong et al. 2022). A 2021 review by Ramakrishnan et al. found that the majority of perinatal depression models have focused on prediction of depression in the postpartum period and include individuals with a prior history of depression (Ramakrishnan et al. 2021; Robertson et al. 2004). Other review studies show that perinatal depression algorithms have largely been built on data mined from big data sources, such as electronic health records or social media data (Zhong et al. 2022). While these models perform well, they may fail to incorporate the kinds of contextual social factors that influence mental health outcomes, and which can only be elicited through patient self-report, such as stressful life events. Often these machine learning models are considered to be a ‘black box,’ using methods that obscure which data is being used or how the algorithm actually works with the data to identify risk factors. When machine learning models are difficult – if not impossible – to interpret, they pose a challenge to providers that are trying to understand the underlying triggers of depression risk (Rudin 2019; Schmude et al. 2023). Moreover, such ‘black box’ algorithms cannot be easily translated into the kind of screening tool that can be administered directly to a patient. As such, algorithms implemented into clinical workflows without process transparency may risk non-engagement from healthcare providers (Cutillo et al. 2020; Kelly et al. 2019; Liefgreen et al. 2023; MacKay et al. 2023). Developing algorithms for new depression onset in pregnancy that include self-reported data on social or contextual risk factors, while remaining simple to understand and relevant to the clinicians managing patients, is a critical need in healthcare.
In this secondary analysis of patient-reported data collected through a prenatal smartphone app, we applied machine learning methods to develop an algorithmic model from data collected early in pregnancy (during first trimester app-use) to predict subsequent onset of first time depression in pregnancy. To identify a predictive model that could ultimately be translated into a patient-facing screener in the early prenatal care workflow, we compared a set of machine learning methods chosen for their ability to reduce the number of variables required in the model and their ease of interpretation. All models were used to predict new moderate-to-severe depressive symptoms among individuals with no prior depression history.
Methods
Study sample
Data was collected using the MyHealthyPregnancy™ (MHP) smartphone app from September 2019 to April 2022. Patients of the University of Pittsburgh Medical Center (UPMC) healthcare system were prescribed MHP during their first prenatal visit (8 +/- 2 weeks’ gestation) as part of a quality improvement initiative to supplement routine prenatal care with a digital support (ethics board approval project number: 1684). Patients were eligible for inclusion in this study if they were 18 + years of age, had no self-reported history of depression, completed a first trimester screener for potential risk factors and voluntarily completed at least one subsequent EPDS through the MHP app. All study procedures were approved by the University of Pittsburgh’s Institutional Review Board (STUDY2207002). Data analyses were performed in 2023.
App-collected patient-report data
MyHealthyPregnancy (MHP) is an evidence-based mHealth tool for use during pregnancy (Bohnhoff et al. 2021; Castillo et al. 2022a, b; Krishnamurti et al. 2017, 2021, 2022a, b, c; Mora et al. 2020). It provides education organized by the user’s week of gestation and connection to relevant resources within and outside the healthcare system. MHP also offers pregnancy tracking tools, such as a daily assessment of mood and symptoms, a diary to document the user’s pregnancy experiences, a fetal movement counter and contraction timer, and routine screenings for psychosocial risks. In addition, the app uses patient-entered data to alert providers to possible risks during pregnancy.
Upon first use of MHP, patients were asked a baseline (early first trimester) questionnaire consisting of demographics (e.g. “Which best describes your household income in the past 12 months?”), medical history (e.g., “Is this your first pregnancy?”), and psychosocial questions (e.g., “Have you recently been feeling unusually stressed about going into labor and giving birth?”). Patients could also volunteer self-reported experiences of health-related social needs (e.g., “Within the last 12 months, have you worried you would run out of food, or did you run out of food, before being able to buy more?”) throughout their pregnancy. All patients were subsequently prompted once a trimester on the app’s home screen to use the app-embedded EPDS for depression self-screening. From July 2021 onwards, the EPDS was available in the app for voluntary self-screening for depression symptoms at any point during the pregnancy. A cutoff EPDS score of 13 or more (moderate to severe depression risk) reported at any time during the pregnancy, but after the initial early first-trimester baseline questionnaire administration, was used to define new perinatal depression symptom onset (Cox et al. 1987; Hewitt et al. 2009; Levis et al. 2020).
Machine learning
Six machine learning models were trained and applied to patient-provided app data shared in the early first trimester baseline questionnaire to predict instances of new-onset perinatal depression symptoms (EPDS ≥ 13) later in pregnancy among participants with no self-reported history of depression. Three models were chosen to prioritize a smaller set of variables: Least Absolute Shrinkage and Selection Operator (LASSO) (Tibshirani 1996), Forward Stepwise Selection (FSS) (Kutner et al. 2005), and Shallow Decision Trees (SDT) (Breiman 2017; Ripley 2007). Two models were chosen to ensure that potential nonlinear relationships, which might not otherwise have been identified in the other models, were captured: Random-Forest (Breiman 2001) and Extreme Gradient Boosting (XGBoost) (Chen and Guestrin 2016). Lastly, a novel method, a nonparametric graph learning approach (Stable P-C) (Colombo and Maathuis 2012; Spirtes et al. 2000) using Kernel-based Conditional Independence (Zhang et al. 2012) (PC-KCI) (Mesner et al. 2019), was chosen to capture potential non-linear relationships while also using a smaller set of variables. All models allow for simple, interpretable output.
Each model was built iteratively, with data being randomly split into 80% for training, withholding 20% for testing, which is aligned with best practice recommendations (Gholamy et al. 2018). Missing data was handled using the dropout method, so only participants with complete data were included in the modeling. As expected, the number of participants in the study cohort who experienced first time depression in their pregnancy was smaller than the number of those who did not experience depression, leading to an unbalanced dataset. To address this, we balanced the training data using random oversampling from among those with first time moderate-severe depression symptoms. Five-fold cross-validation was used to determine which features were retained in each model within the training set. The held-out test data was then used to assess the predictive accuracy of those models. This approach allowed us to develop accurate models while increasing the generalizability of results to future data (Preis et al. 2022).
Evaluation
Models were evaluated for accuracy (i.e. how well the model distinguishes depression)on the test set using AUC values for predicting moderate-severe (EPDS ≥ 13) depression symptoms. Confidence intervals for the AUC values were calculated using 2,000 stratified bootstrap replicates. To accurately identify at least 80% of cases with first time moderate-severe depression in pregnancy, we set a sensitivity (i.e. the probability of identifying an individual as ‘depressed’ if they have depression) and specificity (i.e. the probability of a identifying an individual as ‘not-depressed’, if they do not have depression) threshold of at least 0.80 using the highest performing model. Consistent with existing literature, sensitivity and specificity were determined with a predicted value threshold of 11 (Alvarado-Esquivel et al. 2006; Horáková et al. 2022; Levis et al. 2020; Teissèdre and Chabrol 2004). Diagnostic Odds Ratios (DORs) were used to measure a model’s ability to discriminate between positive and negative cases at the sensitivity/specificity threshold, with a higher value indicating more successful discrimination. To assess the average point-wise difference between actual and predicted EPDS scores, root mean squared error (RMSE) was calculated for each machine learning model. We considered the number of risk variables retained in each model – or the number of variables required for prediction – to be a measure of the model’s simplicity for clinical utility. The model’s predictive accuracy (AUC) and simplicity for were compared for all six models. DeLong’s test was used for determining statistical differences in AUC values between compared models.
The novel PC-KCI algorithm was implemented using Python v3.10.7. All other modeling and analyses were conducted using R v4.2.2.
Results
Demographics
During the study period, a sample of 944 (from a cohort of 5,223) patients using MHP were eligible for study inclusion. Median age was 30 years [IQR 26–34], 70% had at least a college degree, the majority self-identified as white (77.8%), and 61% had a yearly household income of at least $50,000. Population characteristics are shown in Table 1, including differences in baseline characteristics between those with and without new onset depression in the sample.
All patients using the MHP app at the time of the study completed baseline clinical and psychosocial risk questions upon initiation of app use. Of these, 4,313 (82.6%) reported having no history of depression. Of the individuals with no depression history, 944 (18.1%) also self-screened for depression throughout their pregnancyFootnote 1 and were eligible for inclusion in the study. A subset of 603 of the 944 eligible participants also self-reported their experiences of health-related social needs prior to completing a depression screener and were included in a sub-analysis to understand the additional role of social needs in predicting first time depression onset. Figure 1 shows the data collection flow from initiation of app use to model inclusion.

STROBE flow diagram of enrollment in study and eligibility criteria for modeling
Of the patients included in our modeling, 110 (11.7%) met the threshold cut-off for moderate-to-severe depression symptoms (EPDS ≥ 13). Patients were more likely to be eligible for inclusion (no reported history of depression and self-screened using EPDS) if they identified as non-white (OR = 1.22, p = 0.03) or were over the age of 35 (OR = 1.22, p = 0.03). They were less likely to be eligible if they had a history of anxiety (OR = 0.40, p < 0.01). Otherwise, there were no demographic differences between those who were eligible for inclusion and those who were not.
Model performance
Table 2 shows the comparison of predictive performance among the 6 different machine learning models.
Model performance ranged from an AUC value of 0.74 [Shallow Decision Trees] up to an AUC value of 0.89 [PC-KCI], DORs ranged from 4.18 [Shallow Decision Trees] to 20.36 [PC-KCI], while RMSEs ranged from 3.94 [Random-Forest] to 5.17 [Shallow Decision Trees]. Online Resource 1 shows pairwise comparisons of model AUCs to evaluate meaningful differences in accuracy. The AUC achieved by PC-KCI was significantly higher than all other baseline models.
The number of possible risk variables out of the total number of variables was used as a measure of simplicity. Variable-selection models retained anywhere from 24% [Decision Trees] − 82% [LASSO] of the possible risk variables. Shallow Decision Trees retaining the fewest variables (24% or 13/55). PC-KCI and Shallow Decision Trees were both simpler (i.e., require fewer variables for prediction) than LASSO and Forward Stepwise Selection.
Figure 2 shows a graphical representation of the accuracy and simplicity among the machine learning models. Despite XGBoost having the second highest level of accuracy (AUC = 0.80), neither XGBoost nor Random-Forest achieved high enough accuracy to offset the models’ lack of simplicity. Shallow Decision Trees selected slightly fewer variables than PC-KCI (26% or 14/53). However, PC-KCI was the optimal model overall, maximizing predictive accuracy, while simultaneously minimizing the number of variables required to make that prediction.

Accuracy (AUC) and simplicity (percent of variables retained) of machine learning models predicting first time depression in pregnancy from patient-reported data
Risk predictors
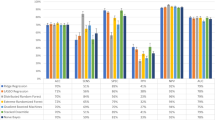
Across all 6 models, variables that were retained from the original 55 variables fell into the broad categories of demographics, family medical history, personal medical history, pregnancy-specific stressors, other psychosocial factors, and substance use. Figure 3 shows the distribution of variables within each broad category that were selected by each of the models.

Distribution of selected variables in each variable category by machine learning model
Online Resource 2 displays those variables retained across the majority of models from each of these categories. Reporting a non-specific but negative change in mood (i.e., feeling “unusually blue”), childhood emotional neglect, stress specific to labor and delivery concerns, and interpersonal relationship stress were all retained as predictive psychosocial variables, regardless of the machine learning model used.
The relative role of health-related social needs
Online Resource 3 shows the comparison of predictive performance among the machine learning models when health-related social needs were included for that subset of participants that voluntarily reported them prior to completing a depression screener. With the inclusion of health-related social needs, most models became both simpler and more predictive. Almost all models showed improved accuracy when health-related social needs were included in the model, except for two variable-selection models, Forward Stepwise Selection and LASSO. Shallow Decision Trees showed the greatest improvement in accuracy (AUC = 0.92), while remaining simple in structure (only 14 variables required out of 60). PC-KCI and Random-Forest had the highest predictive accuracy, which was not significantly different (p = 0.97), although Random Forest achieved a low level of sensitivity (0.20). PC-KCI was, again, the simplest model, only requiring 9 variables for prediction, whereas Random-Forest, by design, requires all variables for prediction. Thus, when including health-related social needs as a risk factor, PC-KCI remained the optimal model (AUC = 0.93, with sensitivity of 0.90, specificity of 0.81, DOR of 38.50, and RMSE of 4.71).
Figure 4a and b shows a visualization of the variables retained by the PC-KCI algorithm in the larger sample and in the subset of participants for whom health-related social needs were reported.

Visualizations of variables retained by the PC-KCI algorithm
Notably, the inclusion of reports of health-related social needs resulted in the retention of food insecurity, as the only health-related social need predictive of depression. Moreover, when food insecurity was included, demographic variables, such as race and income, were dropped from the model. The specific self-report variables included in the PC-KCI model are found in Table 3.
Discussion
Principal findings
This study used patient-reported data collected early in pregnancy with a smartphone app to develop several machine learning models for predicting subsequent first time depression onset later in the pregnancy. When comparing approaches that had intentionally been selected for their ability to decrease the number of variables required for predictive accuracy or for their ability to identify non-linear relationships between risk factors, one algorithm, PC-KCI, was optimal in terms of both accuracy and simplicity. The findings from this study suggest that a small amount of patient-reported data collected early in the first trimester of pregnancy – 14 questions in total – can be used to identify, with substantial accuracy, who will later develop new moderate-to-severe depression onset. Notably, when health-related social needs – specifically, food insecurity – were included for a subset of individuals that reported them prior to first time depression onset, the model became both more predictive and simpler, and no longer included demographic variables. This highlights the critical role that social risk factors play in instances of first time depression, as well as the revealing risks that may be more present among specific demographic groups.
Machine learning methods have been effective at predicting perinatal depression in the prior literature with most published models achieving AUCs of at least 0.70 (e.g., Cellini et al. 2022). The most accurate models tend to be the most complex as they are maximizing accuracy by using all possible data (Kelly et al. 2019). To have practical clinical utility, however, models should be explainable and, ideally, simple enough to implement (MacKay et al. 2023). In previous models of perinatal depression prediction, non-linear machine learning models tend to perform the best (Andersson et al. 2021; Preis et al. 2022; Shin et al. 2020) and are the most common choice across studies (Zhong et al. 2022); indicating the complexity of the relationship between risk factors and depression. Similarly, in the present analysis, non-linear models performed well in predicting first time depression. However, when additionally considering simplicity for the purpose of clinical utility, only one model was optimal – PC-KCI. This finding highlights the opportunity to consider the selection of algorithms, including graph learning methods like PC-KCI, to prioritize their practical use for clinicians and to glean new insights on the relationships between potential clinical risk factors.
Consistent with existing studies, our optimal model identified factors related to previously documented domains of risk, such as demographic factors (e.g., income), clinical history (e.g., prior anxiety), and experiences of stressful events (Augusto et al. 2020; Preis et al. 2022; Robertson et al. 2004; Yu et al. 2020; Zhong et al. 2022). However, the best-performing model also shed light on pregnancy-specific stressors that might uniquely contribute to first time instances of perinatal depression onset, such as concerns regarding labor and delivery and negative perceptions of the pregnancy affecting physical appearance or future health. The findings also point to the relative strength that underlying, non-specified poor mood may play in first time depression onset in pregnancy. This non-specified poor mood could be an early indicator of sadness, which is a key symptom of depression, though more typically associated with depression occurring among those who are not pregnant or in the postpartum period (Bernstein et al. 2008). Sadness is not conceptualized as feeling “unusually blue” in current screening instruments (Cox et al. 1987; Spitzer et al. 1999) and additional research is needed to understand if feeling ‘unusually blue’ is a precursor or a proxy of early feelings of sadness or is itself a unique risk factor. Lastly, these findings point to identification of a population at particular risk for new-onset depression. The optimal predictive model may be used to direct greater scrutiny for diagnosing and consideration of preventive intervention.
From a health systems and public health standpoint, identifying high-risk but asymptomatic individuals has the potential to change the framework of care delivery through prevention, but also poses challenges in referrals and resource utilization in the face of significant shortages in mental health services (Butryn et al. 2017). Future investigation should focus on approaches to address depression-related risk factors (e.g., hunger prevention, provision of social support, sleep optimization), as well as strategies to prevent or mitigate the onset and effects of depression, while also considering health care utilization and availability of resources. Perinatal mental health providers (e.g., psychiatrists, psychologists, pharmacists, and/or OBGYNs) should consider incorporating these predictive modeling tools into electronic medical records and clinical workflows in a way that is least impeding to front-line staff. Our best performing model used a small number of variables that can be inputted by patients, allowing for ease in implementation in routine care.
Limitations
One primary limitation to this study is participation bias as data were limited to those patients in our healthcare system who were willing to engage with a pregnancy app prescribed by their obstetrical provider and were willing to self-screen for depression at least once throughout their use. Although the majority of women of reproductive age have smartphones (Pew Research Center 2021) and the majority of pregnant people do use pregnancy apps during their pregnancy (Lee and Moon 2016), the risk factors present for the patient population in our dataset may not be generalizable to all pregnant individuals. In particular, populations that tend to have lower access to the internet and smartphone capabilities also tend to have less access to healthcare resources more generally (Eyrich et al. 2021; Kan et al. 2022; Roberts and Mehrotra 2020). Moreover, while the demographic distribution of individuals included in our dataset is reflective of the greater patient population of our healthcare system, there is limited representation from racially diverse groups that are not well-represented in our regional geography. Similarly, our sample showed some response bias. All participants completed baseline screening, but only 60% volunteered information about health-related social needs, whether due to stigma around disclosure of these issues or limited engagement with the app. As a result, food insecurity - a key variable for predicting new depression – was inconsistently measured across the sample.
To focus on prediction of first-time depression onset in pregnancy, we chose to limit data to those who had no history of depression. We did, however, include those with a history of anxiety, as it is diagnostically and symptomatically distinct from depression and is an established depression risk factor. This decision allowed us to consider anxiety history, which may be missed as a risk factor when not concurrent with depression. Furthermore, although anxiety symptoms often co-occurs with depression symptoms, over 40% of individuals experiencing increasing depression do not experience increasing anxiety (Korja et al. 2018). Participants in this study were not asked to disclose use of specific medications, so it is possible some individuals with a history of anxiety might have been taking antidepressants as part of their treatment. Antidepressant use, not captured by our analysis, could introduce noise in our specificity signal. If this were the case, false-positive predictions would be more likely to occur among those who would otherwise be experiencing depression if not already using medication. Future work will incorporate prescription medication use, among other treatments, to improve the specificity of the screening model.
Lastly, while our analysis includes a consideration of the trade-off of accuracy and simplicity, we do not explicitly measure the interpretability of this algorithm to those individuals who would implement it as a screening approach. In planned future work, we will refine this algorithm in partnership with clinical research partners, such as perinatal mental health care providers and administrators, as well as with perinatal individuals, incorporating their perspectives on the relevance of the questions for screening purposes, discussion of what may be missing, and any potential implementation barriers (Jeyaraman et al. 2023).
Conclusions
This work demonstrates an approach to developing a machine learning risk prediction model, built from patient-reported data, that can be used in the first trimester to identify those individuals likely to develop first time moderate-severe depression later in their pregnancy. The variables selected by the best-performing model encompass a simple set of questions that could be administered to patients early in pregnancy to support tailored resource provision and early intervention for depression risk. The model also identified some novel pregnancy-specific stressors that may play a unique role in depression risk during the perinatal period and underscore the importance of considering the psychosocial and environmental context in which an individual is navigating their pregnancy.
Notes
Although the vast majority of EPDS screenings occurred in the 2nd or 3rd trimester, 2.8% of maximum EPDS scores did occur late in the first trimester (i.e., at 11 or 12 weeks). These individuals were not removed from analyses, as sensitivity analyses conducted by removing these individuals show no change in AUCs.
References
Abajobir AA, Maravilla JC, Alati R, Najman JM (2016) A systematic review and meta-analysis of the association between unintended pregnancy and perinatal depression. J Affect Disord 192:56–63. https://doi.org/10.1016/j.jad.2015.12.008
ACOG Committee Opinion No (2018) Obstet Gynecol 132(5):1314–1316. https://doi.org/10.1097/aog.0000000000002928. 757 Summary: Screening for Perinatal Depression
Ahmed A, Feng C, Bowen A, Muhajarine N (2018) Latent trajectory groups of perinatal depressive and anxiety symptoms from pregnancy to early postpartum and their antenatal risk factors. Arch Womens Ment Health 21(6):689–698. https://doi.org/10.1007/s00737-018-0845-y
Alvarado-Esquivel C, Sifuentes-Alvarez A, Salas-Martinez C, Martínez-García S (2006) Validation of the Edinburgh Postpartum Depression Scale in a population of puerperal women in Mexico. Clin Pract Epidemiol Ment Health 2:33. https://doi.org/10.1186/1745-0179-2-33
Andersson S, Bathula DR, Iliadis SI, Walter M, Skalkidou A (2021) Predicting women with depressive symptoms postpartum with machine learning methods. Sci Rep 11(1):7877. https://doi.org/10.1038/s41598-021-86368-y
Augusto ALP, de Abreu Rodrigues AV, Domingos TB, Salles-Costa R (2020) Household food insecurity associated with gestacional and neonatal outcomes: a systematic review. BMC Pregnancy Childbirth 20(1):229. https://doi.org/10.1186/s12884-020-02917-9
Bayrampour H, Tomfohr L, Tough S (2016) Trajectories of Perinatal depressive and anxiety symptoms in a community cohort. J Clin Psychiatry 77(11):e1467–e1473. https://doi.org/10.4088/JCP.15m10176
Bernstein IH, Rush AJ, Yonkers K, Carmody TJ, Woo A, McConnell K, Trivedi MH (2008) Symptom features of postpartum depression: are they distinct? Depress Anxiety 25(1):20–26. https://doi.org/10.1002/da.20276
Blackmore ER, Cote-Arsenault D, Tang W, Glover V, Evans J, Golding J, O’Connor TG (2011) Previous prenatal loss as a predictor of perinatal depression and anxiety. Br J Psychiatry 198(5):373–378. https://doi.org/10.1192/bjp.bp.110.083105
Bohnhoff J, Davis A, de Bruin WB, Krishnamurti T (2021) COVID-19 information sources and health behaviors during pregnancy: results from a prenatal app-embedded survey. Jmir Infodemiology 1(1):e31774. https://doi.org/10.2196/31774
Breiman L (2001) Random forests. Mach Learn 45:5–32
Breiman L (2017) Classification and regression trees. Routledge, New York. https://doi.org/10.1201/9781315139470
Butryn T, Bryant L, Marchionni C, Sholevar F (2017) The shortage of psychiatrists and other mental health providers: causes, current state, and potential solutions. Int J Acad Med 3(1):5–9. https://doi.org/10.4103/ijam.Ijam_49_17
Castillo AF, Davis AL, Krishnamurti T (2022a) Adapting a Pregnancy App to Address Disparities in Healthcare Access Among an Emerging Latino Community: Qualitative Study using Implementation Science Frameworks. https://doi.org/10.1186/s12905-022-01975-9
Castillo AF, Davis AL, Krishnamurti T (2022b) Using implementation science frameworks to translate and adapt a pregnancy app for an emerging latino community. BMC Womens Health 22(1):1–12. https://doi.org/10.1186/s12905-022-01975-9
Cellini P, Pigoni A, Delvecchio G, Moltrasio C, Brambilla P (2022) Machine learning in the prediction of postpartum depression: a review. J Affect Disord 309:350–357. https://doi.org/10.1016/j.jad.2022.04.093
Chen T, Guestrin C, Xgboost A scalable tree boosting system. In: Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016. pp 785–794. https://doi.org/10.1145/2939672.2939785
Cheng D, Schwarz EB, Douglas E, Horon I (2009) Unintended pregnancy and associated maternal preconception, prenatal and postpartum behaviors. Contraception 79(3):194–198. https://doi.org/10.1016/j.contraception.2008.09.009
Chung TK, Lau TK, Yip AS, Chiu HF, Lee DT (2001) Antepartum depressive symptomatology is associated with adverse obstetric and neonatal outcomes. Psychosom Med 63(5):830–834. https://doi.org/10.1097/00006842-200109000-00017
Colombo D, Maathuis MH (2012) A modification of the PC algorithm yielding order-independent skeletons. CoRR, abs/12113295. doi:https://doi.org/10.48550/arXiv.1211.3295
Cox J (2017) Use and misuse of the Edinburgh postnatal depression scale (EPDS): a ten point ‘survival analysis’. Arch Women Ment Health 20(6):789–790. https://doi.org/10.1007/s00737-017-0789-7
Cox JL, Holden JM, Sagovsky R (1987) Detection of postnatal depression. Development of the 10-item Edinburgh postnatal depression scale. Br J Psychiatry 150:782–786. https://doi.org/10.1192/bjp.150.6.782
Cutillo CM, Sharma KR, Foschini L, Kundu S, Mackintosh M, Mandl KD, Beck T, Collier E, Colvis C, Gersing K, Gordon V, Jensen R, Shabestari B, Southall N, Group MIiHWW (2020) Machine intelligence in healthcare—perspectives on trustworthiness, explainability, usability, and transparency. Npj Digit Med 3(1):47. https://doi.org/10.1038/s41746-020-0254-2
Dietz PM, Williams SB, Callaghan WM, Bachman DJ, Whitlock EP, Hornbrook MC (2007) Clinically identified maternal depression before, during, and after pregnancies ending in live births. Am J Psychiatry 164(10):1515–1520. https://doi.org/10.1176/appi.ajp.2007.06111893
Egan AM, Dunne FP, Lydon K, Conneely S, Sarma K, McGuire BE (2017) Diabetes in pregnancy: worse medical outcomes in type 1 diabetes but worse psychological outcomes in gestational diabetes. QJM 110(11):721–727. https://doi.org/10.1093/qjmed/hcx106
Evans J, Heron J, Francomb H, Oke S, Golding J (2001) Cohort study of depressed mood during pregnancy and after childbirth. BMJ 323(7307):257–260. https://doi.org/10.1136/bmj.323.7307.257
Eyrich NW, Andino JJ, Fessell DP (2021) Bridging the Digital divide to avoid leaving the most vulnerable behind. JAMA Surg 156(8):703–704. https://doi.org/10.1001/jamasurg.2021.1143
Gholamy A, Kreinovich V, Kosheleva O (2018) Why 70/30 or 80/20 relation between training and testing sets. A pedagogical explanation
Grigoriadis S, VonderPorten EH, Mamisashvili L, Tomlinson G, Dennis CL, Koren G, Steiner M, Mousmanis P, Cheung A, Radford K, Martinovic J, Ross LE (2013) The impact of maternal depression during pregnancy on perinatal outcomes: a systematic review and meta-analysis. J Clin Psychiatry 74(4):e321–341. https://doi.org/10.4088/JCP.12r07968
Guintivano J, Manuck T, Meltzer-Brody S (2018a) Predictors of Postpartum Depression: a Comprehensive Review of the last decade of evidence. Clin Obstet Gynecol 61(3):591–603. https://doi.org/10.1097/GRF.0000000000000368
Guintivano J, Sullivan PF, Stuebe AM, Penders T, Thorp J, Rubinow DR, Meltzer-Brody S (2018b) Adverse life events, psychiatric history, and biological predictors of postpartum depression in an ethnically diverse sample of postpartum women. Psychol Med 48(7):1190–1200. https://doi.org/10.1017/S0033291717002641
Hewitt C, Gilbody S, Brealey S, Paulden M, Palmer S, Mann R, Green J, Morrell J, Barkham M, Light K, Richards D (2009) Methods to identify postnatal depression in primary care: an integrated evidence synthesis and value of information analysis. Health Technol Assess 13(36):1–145. https://doi.org/10.3310/hta13360
Horáková A, Nosková E, Švancer P, Marciánová V, Koliba P, Šebela A (2022) Accuracy of the Edinburgh Postnatal Depression Scale in screening for major depressive disorder and other psychiatric disorders in women towards the end of their puerperium. Ceska Gynekol 87(1):19–26. https://doi.org/10.48095/cccg202219
Hurwitz E, Butzin-Dozier Z, Master H, O’Neil ST, Walden A, Holko M, Patel RC, Haendel MA (2023) Harnessing consumer wearable digital biomarkers for individualized recognition of postpartum depression using the all of us Research Program dataset. https://doi.org/10.1101/2023.10.13.23296965. medRxiv
Jeyaraman M, Balaji S, Jeyaraman N, Yadav S (2023) Unraveling the ethical Enigma: Artificial Intelligence in Healthcare. Cureus 15(8):e43262. https://doi.org/10.7759/cureus.43262
Kan K, Heard-Garris N, Bendelow A, Morales L, Lewis-Thames MW, Davis MM, Heffernan M (2022) Examining Access to Digital Technology by Race and Ethnicity and Child Health Status among Chicago Families. JAMA Netw Open 5(8):e2228992–e2228992. https://doi.org/10.1001/jamanetworkopen.2022.28992
Kelly CJ, Karthikesalingam A, Suleyman M, Corrado G, King D (2019) Key challenges for delivering clinical impact with artificial intelligence. BMC Med 17(1):195. https://doi.org/10.1186/s12916-019-1426-2
Korja R, Nolvi S, Kataja E-L, Scheinin N, Junttila N, Lahtinen H, Saarni S, Karlsson L, Karlsson H (2018) The courses of maternal and paternal depressive and anxiety symptoms during the prenatal period in the FinnBrain Birth Cohort study. PLoS ONE 13(12):e0207856. https://doi.org/10.1371/journal.pone.0207856
Krishnamurti T, Davis AL, Wong-Parodi G, Fischhoff B, Sadovsky Y, Simhan HN (2017) Development and testing of the myhealthypregnancy app: a behavioral decision research-based tool for assessing and communicating pregnancy risk. JMIR mHealth uHealth 5(4):e7036. https://doi.org/10.2196/mhealth.7036
Krishnamurti T, Davis AL, Quinn B, Castillo AF, Martin KL, Simhan HN (2021) Mobile remote monitoring of intimate partner violence among pregnant patients during the COVID-19 shelter-in-place order: quality improvement pilot study. J Med Internet Res 23(2):e22790. https://doi.org/10.2196/22790
Krishnamurti T, Allen K, Hayani L, Rodriguez S, Davis AL (2022a) Identification of maternal depression risk from natural language collected in a mobile health app. Procedia Comput Sci 206:132–140. https://doi.org/10.1016/j.procs.2022.09.092
Krishnamurti T, Birru Talabi M, Callegari LS, Kazmerski TM, Borrero S (2022b) A framework for Femtech: guiding principles for developing digital reproductive health tools in the United States. J Med Internet Res 24(4):e36338. https://doi.org/10.2196/36338
Krishnamurti T, Davis AL, Rodriguez S, Hayani L, Bernard M, Simhan HN (2022c) Use of a Smartphone App to explore potential underuse of prophylactic aspirin for Preeclampsia. Obstet Gynecol Surv 77(4):206–208. https://doi.org/10.1001/jamanetworkopen.2021.30804
Kroenke K, Spitzer RL, Williams JB (2001) The PHQ-9: validity of a brief depression severity measure. J Gen Intern Med 16(9):606–613. https://doi.org/10.1046/j.1525-1497.2001.016009606.x
Kutner MH, Nachtsheim CJ, Neter J, Li W (2005) Applied linear statistical models, vol 5. McGraw-Hill Irwin, Boston
Lagadec N, Steinecker M, Kapassi A, Magnier AM, Chastang J, Robert S, Gaouaou N, Ibanez G (2018) Factors influencing the quality of life of pregnant women: a systematic review. BMC Pregnancy Childbirth 18(1):455. https://doi.org/10.1186/s12884-018-2087-4
Lancaster CA, Gold KJ, Flynn HA, Yoo H, Marcus SM, Davis MM (2010) Risk factors for depressive symptoms during pregnancy: a systematic review. Am J Obstet Gynecol 202(1):5–14. https://doi.org/10.1016/j.ajog.2009.09.007
Le Strat Y, Dubertret C, Le Foll B (2011) Prevalence and correlates of major depressive episode in pregnant and postpartum women in the United States. J Affect Disord 135(1–3):128–138. https://doi.org/10.1016/j.jad.2011.07.004
Lee Y, Moon M (2016) Utilization and content evaluation of Mobile applications for pregnancy, birth, and Child Care. Healthc Inf Res 22(2):73–80. https://doi.org/10.4258/hir.2016.22.2.73
Levis B, Negeri Z, Sun Y, Benedetti A, Thombs BD, Group DESDE (2020) Accuracy of the Edinburgh Postnatal Depression Scale (EPDS) for screening to detect major depression among pregnant and postpartum women: systematic review and meta-analysis of individual participant data. BMJ 371:m4022. https://doi.org/10.1136/bmj.m4022
Liefgreen A, Weinstein N, Wachter S, Mittelstadt B (2023) Beyond ideals: why the (medical) AI industry needs to motivate behavioural change in line with fairness and transparency values, and how it can do it. AI & SOCIETY. https://doi.org/10.1007/s00146-023-01684-3
Long MM, Cramer RJ, Bennington L, Morgan FG, Wilkes CA, Fontanares AJ, Sadr N, Bertolino SM, Paulson JF (2020) Perinatal depression screening rates, correlates, and treatment recommendations in an obstetric population. Fam Syst Health 38(4):369–379. https://doi.org/10.1037/fsh0000531
MacKay C, Klement W, Vanberkel P, Lamond N, Urquhart R, Rigby M (2023) A framework for implementing machine learning in healthcare based on the concepts of preconditions and postconditions. Healthc Analytics 3:100155. https://doi.org/10.1016/j.health.2023.100155
Madigan S, Oatley H, Racine N, Fearon RMP, Schumacher L, Akbari E, Cooke JE, Tarabulsy GM (2018) A Meta-analysis of maternal prenatal depression and anxiety on child Socioemotional Development. J Am Acad Child Adolesc Psychiatry 57(9):645–657e648. https://doi.org/10.1016/j.jaac.2018.06.012
McCall-Hosenfeld JS, Phiri K, Schaefer E, Zhu J, Kjerulff K (2016) Trajectories of depressive symptoms throughout the Peri- and Postpartum Period: results from the First Baby Study. J Women’s Health 25(11):1112–1121. https://doi.org/10.1089/jwh.2015.5310
Mesner O, Davis A, Casman E, Simhan H, Shalizi C, Keenan-Devlin L, Borders A, Krishnamurti T (2019) Using graph learning to understand adverse pregnancy outcomes and stress pathways. PLoS ONE 14(9):e0223319. https://doi.org/10.1371/journal.pone.0223319
Mora PA, Bennett IM, Elo IT, Mathew L, Coyne JC, Culhane JF (2009) Distinct trajectories of perinatal depressive symptomatology: evidence from growth mixture modeling. Am J Epidemiol 169(1):24–32. https://doi.org/10.1093/aje/kwn283
Mora AC, Krishnamurti T, Davis A, Simhan H (2020) 930: a culturally appropriate mobile health application for pregnancy risk communication to latino women. Am J Obstet Gynecol 222(1):S575–S576. https://doi.org/10.1016/j.ajog.2019.11.941
Nunes AP, Phipps MG (2013) Postpartum depression in adolescent and adult mothers: comparing prenatal risk factors and predictive models. Matern Child Health J 17(6):1071–1079. https://doi.org/10.1007/s10995-012-1089-5
O’Hara MW, Swain AM (1996) Rates and risk of postpartum depression—a meta-analysis. Int Rev Psychiatry 8(1):37–54. https://doi.org/10.3109/09540269609037816
Orr ST, James SA, Reiter JP (2008) Unintended pregnancy and prenatal behaviors among urban, black women in Baltimore, Maryland: the Baltimore preterm birth study. Ann Epidemiol 18(7):545–551. https://doi.org/10.1016/j.annepidem.2008.03.005
Osborne LM, Betz JF, Yenokyan G, Standeven LR, Payne JL (2019) The role of Allopregnanolone in pregnancy in Predicting Postpartum anxiety symptoms. Front Psychol 10:1033. https://doi.org/10.3389/fpsyg.2019.01033
Pew Research Center (2021) Mobile Fact Sheet. https://www.pewresearch.org/internet/fact-sheet/mobile/
Preis H, Djurić PM, Ajirak M, Chen T, Mane V, Garry DJ, Heiselman C, Chappelle J, Lobel M (2022) Applying machine learning methods to psychosocial screening data to improve identification of prenatal depression: implications for clinical practice and research. Arch Women Ment Health 25(5):965–973. https://doi.org/10.1007/s00737-022-01259-z
Preventive Services Task US, Force, Curry SJ, Krist AH, Owens DK, Barry MJ, Caughey AB, Davidson KW, Doubeni CA, Epling JW Jr., Grossman DC, Kemper AR, Kubik M, Landefeld CS, Mangione CM, Silverstein M, Simon MA, Tseng CW, Wong JB (2019) Interventions to prevent Perinatal Depression: US Preventive Services Task Force Recommendation Statement. JAMA 321(6):580–587. https://doi.org/10.1001/jama.2019.0007
Putnam KT, Wilcox M, Robertson-Blackmore E, Sharkey K, Bergink V, Munk-Olsen T, Deligiannidis KM, Payne J, Altemus M, Newport J, Apter G, Devouche E, Viktorin A, Magnusson P, Penninx B, Buist A, Bilszta J, O’Hara M, Stuart S, Brock R, Roza S, Tiemeier H, Guille C, Epperson CN, Kim D, Schmidt P, Martinez P, Di Florio A, Wisner KL, Stowe Z, Jones I, Sullivan PF, Rubinow D, Wildenhaus K, Meltzer-Brody S (2017) Clinical phenotypes of perinatal depression and time of symptom onset: analysis of data from an international consortium. Lancet Psychiatry 4(6):477–485. https://doi.org/10.1016/s2215-0366(17)30136-0
Qobadi M, Collier C, Zhang L (2016) The Effect of Stressful Life events on Postpartum Depression: findings from the 2009–2011 Mississippi pregnancy risk Assessment Monitoring System. Matern Child Health J 20(Suppl 1):164–172. https://doi.org/10.1007/s10995-016-2028-7
Ramakrishnan R, Rao S, He JR (2021) Perinatal health predictors using artificial intelligence: a review. Womens Health (Lond) 17:17455065211046132. https://doi.org/10.1177/17455065211046132
Ripley BD (2007) Pattern recognition and neural networks. Cambridge University Press
Roberts ET, Mehrotra A (2020) Assessment of disparities in Digital Access among Medicare beneficiaries and implications for Telemedicine. JAMA Intern Med 180(10):1386–1389. https://doi.org/10.1001/jamainternmed.2020.2666
Robertson E, Grace S, Wallington T, Stewart DE (2004) Antenatal risk factors for postpartum depression: a synthesis of recent literature. Gen Hosp Psychiatry 26(4):289–295. https://doi.org/10.1016/j.genhosppsych.2004.02.006
Rohde P, Lewinsohn PM, Klein DN, Seeley JR (2005) Association of parental depression with psychiatric course from adolescence to young adulthood among formerly depressed individuals. J Abnorm Psychol 114(3):409–420. https://doi.org/10.1037/0021-843x.114.3.409
Rudin C (2019) Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat Mach Intell 1(5):206–215. https://doi.org/10.1038/s42256-019-0048-x
Santoro K, Peabody H (2010) Identifying and treating maternal depression: strategies and considerations for health plans. National Institute of Health Care Management, Washington, DC, pp 1–28
Schmude T, Koesten L, Möller T, Tschiatschek S On the Impact of Explanations on Understanding of Algorithmic Decision-Making. In, 2023 2023. ACM. https://doi.org/10.1145/3593013.3594054
Shin D, Lee KJ, Adeluwa T, Hur J (2020) Machine learning-based predictive modeling of Postpartum Depression. J Clin Med 9(9):2899
Sidebottom A, Vacquier M, LaRusso E, Erickson D, Hardeman R (2021) Perinatal depression screening practices in a large health system: identifying current state and assessing opportunities to provide more equitable care. Arch Womens Ment Health 24(1):133–144. https://doi.org/10.1007/s00737-020-01035-x
Silverman ME, Reichenberg A, Savitz DA, Cnattingius S, Lichtenstein P, Hultman CM, Larsson H, Sandin S (2017) The risk factors for postpartum depression: a population-based study. Depress Anxiety 34(2):178–187. https://doi.org/10.1002/da.22597
Spirtes P, Glymour CN, Scheines R (2000) Causation, prediction, and search. MIT Press
Spitzer RL, Kroenke K, Williams JB (1999) Validation and utility of a self-report version of PRIME-MD: the PHQ primary care study. Primary care evaluation of Mental disorders. Patient Health Questionnaire JAMA 282(18):1737–1744. https://doi.org/10.1001/jama.282.18.1737
Teissèdre F, Chabrol H (2004) Detecting women at risk for postnatal depression using the Edinburgh postnatal depression scale at 2 to 3 days postpartum. Can J Psychiatry 49(1):51–54. https://doi.org/10.1177/070674370404900108
Tibshirani R (1996) Regression shrinkage and Selection Via the Lasso. J Roy Stat Soc: Ser B (Methodol) 58(1):267–288. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x
Torous J, Staples P, Onnela JP (2015) Realizing the potential of mobile mental health: new methods for new data in psychiatry. Curr Psychiatry Rep 17(8):602. https://doi.org/10.1007/s11920-015-0602-0
Yu M, Li H, Xu D, Wu Y, Liu H, Gong W (2020) Trajectories of perinatal depressive symptoms from early pregnancy to six weeks postpartum and their risk factors—a longitudinal study. J Affect Disord 275:149–156. https://doi.org/10.1016/j.jad.2020.07.005
Zhang K, Peters J, Janzing D, Schölkopf B (2012) Kernel-based conditional independence test and application in causal discovery. arXiv Preprint arXiv 12023775. https://doi.org/10.48550/arXiv.1202.3775
Zhang L, Wang L, Cui S, Yuan Q, Huang C, Zhou X (2020) Prenatal depression in women in the third trimester: prevalence, predictive factors, and Relationship with maternal-fetal attachment. Front Public Health 8:602005. https://doi.org/10.3389/fpubh.2020.602005
Zhong M, Zhang H, Yu C, Jiang J, Duan X (2022) Application of machine learning in predicting the risk of postpartum depression: a systematic review. J Affect Disord 318:364–379. https://doi.org/10.1016/j.jad.2022.08.070
Funding
This study was funded by a grant from the National Institute of Mental Health (5R34 MH130950).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Data collection was performed by Tamar Krishnamurti and Hyagriv Simhan. Data analysis was performed by Samantha Rodriguez. The first draft of the manuscript was written by Tamar Krishnamurti. All authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethical approval
This research study was conducted retrospectively from data obtained for clinical purposes. The University of Pittsburgh IRB approved the secondary data analyses presented in this manuscript (STUDY2207002).
Competing interests
Authors TK and HS hold equity ownership in Naima Health LLC. The remaining authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Krishnamurti, T., Rodriguez, S., Wilder, B. et al. Predicting first time depression onset in pregnancy: applying machine learning methods to patient-reported data. Arch Womens Ment Health (2024). https://doi.org/10.1007/s00737-024-01474-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00737-024-01474-w