
Abstract
Downscaling of daily precipitation from Global Circulation Models (GCMs)-predictors at a station level, especially in arid and semi-arid regions, has remained a formidable challenge yet. The current study aims at proposing a coupled model of Discrete Wavelet Transform (DWT), Artificial Neural Networks (ANNs), and Quantile Mapping (QM) for statistical downscaling of daily precipitation. Given the historic (1978–2005) and future (2006–2100) predictors of eight-selected GCMs under Representative Concentration Pathways (RCPs) 2.6, 4.5, and 8.5, a viable DWT-ANN model was developed for each station. Subsequently, we linked QM to DWT-ANN for bias correction and drizzle effect postprocessing of the DWT-ANN-historic/future projected precipitation. The skill of DWT-ANN-QM was demonstrated using various evaluation metrics, including Taylor diagram, Quantile–Quantile plot, Empirical Cumulative Distribution Function, and wet/dry spell analysis. We appraise the efficacy of the coupled model at 12 weather stations over the Gharehsoo River Basin (GRB) in northwestern Iran. Compared to the observed wet/dry spells, the dry-spells were better simulated via DWT-ANN-QM rather than the wet-spells wherein length and exceedance probability of the spells were overestimated. Results indicated that the future precipitation across the GRB will rise, on average, from 10 to 17% depending on weather station. Seasonal spatial distribution of the middle future (2041–2070) precipitation illustrated that an increase for fall and winter, especially, is expected, whereas the amount of the future spring and summer precipitation is projected to be declined. Having been developed and tested in a semi-arid basin, the efficacy of the coupled model should be further assessed in more humid climates.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The acceleration of anthropogenic greenhouse gas emissions, ensued from a rapid population growth and economic development, accounts for a major contribution to the global warming in the recent decades (IPCC 2014). In consequence, the hydrological cycle and thereafter availability of water resources across different areas of the world have been endangered (Kouhestani et al. 2016).
Precipitation as the driver of the hydrological cycle has been substantially influenced as a result of climate change (Tryhorn and DeGaetano 2011; Yang et al. 2023). Because of these already considerable changes in precipitation patterns over the past decades, water resources managers and planners in many regions have started to prepare and take measures to withstand or mitigate imminent changes in the climate conditions.
The first step to do this properly is to have accurate future climate predictions for a specific region. To that end, the so-called General Circulation Models (GCMs) are used. They are based on the theories underlying the atmospheric/oceanic physics. The GCMs simulation outcome is greatly affected by plausible realizations of future Greenhous Gas (GHG) concentrations (Sachindra et al. 2014) and for that reason they are usually driven by emission scenarios, which include the former Special Report on Emission Scenarios (SRES), and the more recent Representative Concentration Pathways (RCPs) that range from the relatively mild RCP2.6 to the most extreme RCP8.5, where the number expresses the power of the forcing global radiation in \(W/{m}^{2}\).
However, while GCMs provide reasonable simulations of hydro-climate variables at global scales with grid sizes of 1–3 degrees (~ 100-300 km), they still suffer from the resolution needed for generating local climate as required for water resources impacts studies at the watershed scale (Chen and Zhang 2021; Iizumi et al. 2011; Mandal et al. 2016). To overcome this inherent resolution limitation of most GCMs, the so-called downscaling techniques are used to derive predictand(s) at small scale from coarse-resolution predictors for being further used in local impact studies.
Downscaling methods are widely classified as either dynamic or statistical. Dynamic downscaling is based on some sort of nesting a finer scale regional climate model (RCM) (from a few kilometers to as much as 50 km) within the large-scale grid of a GCM (Wood et al. 2004) and drive the RCM with the boundary forcing of the parent GCM. The serious disadvantages of dynamic downscaling tools are high computational requirements, model complications, and their dependence on boundary conditions obtained from GCMs. Therefore, they are not as widely used as the class of statistical downscaling methods. The main assumption in statistical downscaling is that a stochastic or deterministic relationship, called a transfer model, exists between a GCM-predictor, e.g. geopotential height, moisture fluxes, sea surface temperatures, etc. and a local or regional predictand such as temperature and/or precipitation (Canon et al. 2011). Nonetheless, the extent to which the derived transfer function’s skill may change when applied to future climate projections has been a question of research (Dixon et al. 2016). Statistical downscaling is more adaptable and flexible owing to low computational demand, simple modeling structure, and easy modifications for application at various locations.
Statistical downscaling techniques developed until now, recognized as perfect prognosis (“prog”, PP) algorithms (Legasa et al. 2023), can be categorized into three groups: (1) classification/weather typing methods (Haberlandt et al. 2015; Hay et al. 1991; Hughes and Guttorp 1994; Mehrotra and Sharma 2010); (2) regression/ transfer function approaches (Kannan and Ghosh 2013; Maraun et al. 2010; von Storch et al. 1993; Wilby et al. 2002, 1999); and (3) weather generators (Caron et al. 2008; Eum and Simonovic 2012; King et al. 2015; Sharif and Burn 2006; Wilks 1999; Wilks and Wilby 1999). Among these PPs, regression/transfer functions model class, as epitomized in the well-known SDMS-software (Wilby et al. 2002, 1999), is probably the most widely used downscaling model. In spite of its countless applications in climate impact studies, SDSM and other statistical downscaling methods, in general, have serious limitations when it comes to the downscaling of daily precipitation, required as an input into almost all hydrological models, particularly with the purpose of local climate impact assessment on water resources. This is because daily precipitation exhibits spatiotemporal intermittence, highly skewed distribution, complex stochastic dependencies, and discrete characteristic reflected by wet and dry spells, particularly, in arid and semi-arid areas (Ramana et al. 2013). Additionally, precipitation is a highly uncertain and heterogeneous spatial phenomenon, occurring because of interwoven interactions between different climate variables.
As the climate variables simulated by the numerical models as well as downscaled precipitation often show a distinct systematic deviation from the true observed climate, postprocessing of the climate model outputs in such a manner to match the observed climate is inevitable (Christensen et al. 2008). Recognized as a postprocessing approach, bias correction methods (BCMs) that fall into the category of model output statistics (MOS) have been developed over the last decade (Gudmundsson et al. 2012) and increasingly being used in climate impact studies (Emami and Koch 2017; Fereidoon and Koch 2018).
The core methodology of this class of MOS is to apply some statistical transformations to the GCM/RCM predictors/outputs to correct for the named systematic biases. Even though bias correction methods have been criticized for being dependent on non-physical bases (Ngai et al. 2017), various statistical adjustment techniques have been developed and fine-tuned over the recent years thus far, including the delta change model (Hay et al. 1991), multiple linear regression (Hay and Clark 2003), local intensity scaling (Schmidli et al. 2006), monthly mean correction (Fowler and Kilsby 2007), gamma-gamma transformation (Sharma et al. 2007), fitted histogram equalization (Piani et al. 2010a), and quantile mapping (QM) (Ngai et al. 2017; Sachindra et al. 2014; Themeßl et al. 2012). Particularly, the latter has demonstrated to be an effective bias correction approach, as it can be used for all types of statistical distributions and can successfully adjust the biases in the quantiles, the mean, as well as the standard deviation and, in case of precipitation, wet/dry-spell frequency (Fang et al. 2015). As such, QM appears to outperform other methods to effectively adjust the systematic biases of RCM and GCM-simulated precipitation (Chen et al. 2013; Sun et al. 2011; Themeßl et al. 2012). Despite the fact that the viability of QM has been widely reported in the literature, instead, Maraun (2013) has asserted that the drizzle effect for areal means are overcorrected and area-mean extremes are overestimated as well as trends are affected by the QM algorithm. Nonetheless, different QM approaches have been developed to resolve the deficiencies of the classic QM algorithm (Adeyeri et al. 2020; Cannon et al. 2015).
There have been further developments regarding nonparametric statistical downscaling models over the last decades. Among the several conceptual and black box models developed over this period, coupled Discrete Wavelet Transforms (DWT) and Artificial Neural Network (ANN)-based models appear to be the most promising for simulating hydrologic processes and specifically for precipitation forecasting (Nourani et al. 2014).
Thus, nowadays, DWT has been gaining more attention as a versatile analysis tool, because of its capability to elucidate simultaneously both spectral and temporal information within a time-signal (Adeyeri and Ishola 2021; Adeyeri et al. 2019). Indeed, DWT resolves the basic drawbacks of classical Fourier analysis — which delivers only globally time-averaged frequency information (Markovic and Koch 2005) — by decomposing a time series into its sub-components at different scales (periods), producing a good local representation of the signal in both time and frequency domains, thereby providing further information about the structure of the physical process to be modelled (Partal and Cigizoglu 2009).
ANN has shown superiority over nonlinear regression techniques, because it can elicit complex patterns and relationships between predictors and predictand (Baghanam et al. 2018). The viable skill of ANN in simulation of the nonlinear and time-varying properties of atmospheric predictors at different scales has been demonstrated by downscaling studies in the literature (Chadwick et al. 2011; Dibike and Coulibaly 2006; Nourani et al. 2018; Okkan and Fistikoglu 2014; Okkan and Kirdemir 2016; Wilby and Wigley 1997).
A step further is to combine DWT and ANN to a so-called coupled DWT-ANN model that benefits from multi-scale signals as input data, thus providing a better forecast that would be possible with a single pattern input (Nourani et al. 2009a). A Wavelet-ANN coupled model was firstly developed by Aussem et al. (1998) for financial time series forecasting. For the purpose of rainfall prediction at different temporal scales, i.e. daily and monthly, Wavelet-ANN has been applied to some studies (Goyal 2014; Nourani et al. 2009b; Partal and Cigizoglu 2009; Shafaei et al. 2016). Underlying multi-resolution seasonality extracted by wavelet transforms (e.g. DWT, Wavelet-entropy) as being latter fed into an ANN has enhanced the capability of ANN in extracting various features of a time series (Baghanam et al. 2018).
As successful applications of QM have been well documented (Chen et al. 2013; Sun et al. 2011; Themeßl et al. 2012), we appointed QM to be linked to the DWT-ANN model for postprocessing of the daily future projected precipitation.
Moreover, successful applications of DWT have been well reported, for instance, for downscaling and forecasting of evapotranspiration (Kaheil et al. 2008), detecting and downscaling of wet areas (Kaheil and Creed 2009), spatial downscaling of radar-derived rainfall field (Nourani et al. 2020), and downscaling of daily precipitation (Kumar et al. 2021).
Likewise, ANN (Ahmed et al. 2015), and QM (Lafon et al. 2013) models have been already applied per se or in a coupled manner (i.e. DWT-ANN) (Baghanam et al. 2022; Nourani et al. 2009a) to simulate as well as to bias correct the simulated/downscaled precipitation data. Nonetheless, according to the authors’ best knowledge, they have not been used as a coupled model for statistical downscaling of daily precipitation.
Therefore, the objective of this study is to introduce and test a hybrid model of DWT, ANNs, and QM for the statistical downscaling of daily precipitation. For that purpose, we use historical (1978–2005) and future (2006–2100) data from eight selected GCMs, including NorESM1-M, CNRM-CM5, CSIRO-Mk3-6, GFDL-ESM2G, GFDL-ESM2M, HadGEM2-AO, HadGEM2-ES, and MPI-ESM-MR from the newest version of the Fifth Assessment Report (AR5) under Representative Concentration Pathways (RCPs) 2.6, 4.5, and 8.5.
The effectiveness of the DWT-ANN-QM approach is to be assessed through diverse evaluation criteria, encompassing Taylor diagrams, Quantile–Quantile plots, Empirical Cumulative Distribution Functions, and wet/dry spell analysis.
2 Study area
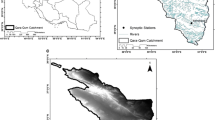
The Gharehsoo River Basin (GRB), located in northwestern Iran, covers an area about 4193 \({km}^{2}\) and extends between latitude 37° 46ʹ-38° 36ʹ N and longitude 47° 46ʹ- 48° 42 ʹ E (Fig. 1). As a semi-arid region, dry and wet seasons of the GRB are in the periods of May through October and November through April, respectively. According to historical daily records collected from synoptic meteorology stations of the Iran Meteorological Organization and rain gauge stations of the Iran Ministry of Energy in the study area (Table 1), 12 weather stations (Fig. 1b), distributed over the basin for the historic period 1978–2005, were selected.

(a) Map of world including the countries; (b) Iran’s map including the Gharehsoo River Basin (GRB); (c) spatial distribution of the average precipitation across the GRB for the reference period (1978–2005); (d) the digital elevation model (DEM) of the GRB
Being equal to about one-third of the world’s average precipitation, the average annual precipitation in the GRB (Table 1), depending on weather station, varies from 267 to 357 mm that falls mainly in the winter months (November to April). According to the Köppen climate classification, the prevailing climate is cold and semi-arid (BSk).
The GRB presents a challenging environment for precipitation statistical downscaling due to its heterogeneous wet and dry spells and frequent extreme precipitation events. These characteristics often lead to deviations of precipitation from a Gaussian distribution, which is a fundamental assumption of many parametric statistical downscaling methods. Consequently, classical statistical transformation techniques like Box-Cox are inadequate for this region.
Moreover, being a mountainous area with a semi-arid climate, the GRB is particularly vulnerable to the impacts of climate change, as noted by Beniston (2003). Projections from the Intergovernmental Panel on Climate Change (IPCC) suggest a potential decrease in precipitation for the mid-latitude and subtropical dry regions such as the GRB (IPCC 2014). This anticipated decline in precipitation raises significant concerns about the future availability of water resources in the basin. As the precipitation of this basin varies greatly from the upstream to its downstream, providing a statistical downscaling that can effectively downscale the daily precipitation at a station level for such a complex terrain would be a stepping stone for perspective statistical downscaling studies aiming at downscaling of precipitation in semi-arid regions with highly complex terrains.
In light of these challenges, downscaling future daily precipitation at the local station becomes crucial. This downscaling process provides essential input data, allowing hydrological models to project future water yield accurately. In turn, this information empowers local authorities and decision-makers to devise effective strategies for water resource management, both in terms of mitigation and adaptation to the effects of climate change (Taie Semiromi and Koch 2020).
3 Methodology
3.1 Large-scale GCM/NCEP- datasets
In the current study, the climate predictors of eight GCMs, as listed in Table 2, including NorESM1-M, CNRM-CM5, CSIRO-Mk3-6, GFDL-ESM2G, GFDL-ESM2M, HadGEM2-AO, HadGEM2-ES, and MPI-ESM-MR from the newest version of the Fifth Assessment Report (AR5) of Intergovernmental Panel on Climate Change (IPCC) were employed.
These eight GCMs were chosen according to their better performance over Iran and the near neighbour countries such as Pakistan and Iraq and distant neighbour countries such as India (Afshar et al. 2017; Babar et al. 2015; Latif et al. 2018; Lee and Wang 2014; Mahmood et al. 2018; Prasanna 2015; Salman et al. 2018b; Xuan et al. 2017).
Considering that most of climate change impact assessments conducted in Iran, particularly those undertaken in the GRB (Javan et al. 2015), have benefited from large-scale predictors of the National Centers for Environmental Prediction and National Center for Atmospheric Research (NCEP/NCAR) reanalysis dataset 1 (Kalnay et al. 1996; Kistler et al. 2001), to draw a comparison between the results anticipated from this study with other studies undertaken in this region, we utilize this dataset on the eight-selected GCMs grid box (Table 3). NCEP-predictors are a global set of gridded weather data at a 2.5° by 2.5° horizontal resolution for the historic period available from 1948 until present.
Due to the availability of the measured precipitation at the 12 weather stations for the period 1978–2005, the NCEP-predictors for the same period were employed. All predictors have been standardized before being screened by subtracting the long-term mean and dividing by the long-term standard deviation (Liu et al. 2011). GCM-predictors for the historic period 1978–2005 and future period 2006–2100 have been acquired from the CMIP5 data archive (https://esgf-data.dkrz.de/projects/esgf-dkrz/). The first ensemble member (r1i1p1) of each of the models has been chosen in this study. We used Climate Data Operator (CDO) program to remap the selected GCMs using a bilinear interpolation approach, which results in a smooth transformation (Salman et al. 2018a), to match the resolution of the NCEP/NCAR reanalysis predictors. The recent climate change studies are based on RCPs rather than SRES. The CMIP5-based scenarios produce a sustained combination of future population growth, technological advances, and socioeconomic parameters (Taylor et al. 2012). Three radiative forcing scenarios were used in the present study that consist of 1) RCP2.6 representing a rise in the radiative forcing to 2.6 (\(W/{m}^{2}\)) by year 2100, 2) RCP4.5, in which an increase of 4.5 \(W/{m}^{2}\) will be expected, and 3) RCP8.5, representing 8.5 \(W/{m}^{2}\) rise in the radiative forcing, as will be experienced by the end of the century (Kouhestani et al. 2016).
Thus, with the purpose of calibrating the proposed downscaling model, the potential NCEP-predictor-set consisting of 26 atmospheric variables (Table 3) was employed to be later processed for selecting the most suitable predictor(s) at each weather station. As the size of the basin covers approximately one NCEP grid box, only one grid-point of the NCEP-predictors was required.
3.2 Screening of the predictors
Choosing the most suitable large-scale predictors is known as the most crucial step in all kinds of statistical downscaling approaches (Huang et al. 2011; Wilby et al. 2002); as is the case especially for the downscaling of precipitation. According to recommendations of Khan et al. (2006), Huang et al. (2011b), and Mahmood and Babel (2014), some major considerations should be considered while screening the potential predictors, including (1) the monthly percentage of variance explaining the locally observed precipitation; (2) physical interconnection between predictors and local precipitation; (3) the predictor’s capability to carry climate change information; and (4) accurate representation of the potential predictors by climate models. Screening the most suitable predictors, we have adopted the stepwise approach following Mahmood and Babel (2014):
-
(1)
A correlation matrix between a predictand at a weather station, i.e. precipitation and NCEP-predictors (as listed in Table 3) was established and then highly correlated predictors, as indicated by a p-value < 0.05, were chosen and arranged in descending order.
-
(2)
The predictor with the strongest correlation with the predictand at a station, known as the Master/Super Predictor (MP/SP), was identified.
-
(3)
Each predictand and the MP were correlated with the remainder of the selected predictors to compute the partial correlation and correlation coefficients. Moreover, the correlation coefficients between individual selected predictors were computed. In this step, to calculate the partial correlation, depending on the number of the selected predictors, the following Equations (Eq. 1a and 1b) were used:
Partial correlation formula when there are two predictors (independent predictor, i.e. x and z as control predictor):
Partial correlation formula when there are more than two predictors:
where \({\mathrm{r}}_{\mathrm{xy}.{\mathrm{z}}_{1}\dots {\mathrm{z}}_{\mathrm{n}}}\) is partial correlation between \(\mathrm{x}\) and \(\mathrm{y}\) (predictand or dependent variable) in case of removing the correlation effects of the other independent variables or control predictors (\({\mathrm{z}}_{1}\dots {\mathrm{z}}_{\mathrm{n}}\)). \({\mathrm{P}}_{\mathrm{x},\mathrm{y}}\) is the inverse correlation between predictors x and y. \({\mathrm{P}}_{\mathrm{xi }}{\mathrm{and P}}_{\mathrm{yi}}\) show the inverse correlations of \(\mathrm{x}\) and \(\mathrm{y}\) predictors with themselves, respectively (Baba et al. 2004). In the present study, at weather stations with two selected predictors, the MP was used as a control predictor (Eq. 1a) and then we calculated the partial correlation for the other predictor. The same was applied to the other predictor for computing the partial correlation of the MP. However, at weather stations with more than two selected predictors, all predictors except one were considered as the control predictors (Eq. 1b) whereby the partial correlation was calculated for the predictor of interest. This procedure was repeated for the other predictors. Thus, the partial correlations were computed for all selected predators.
-
(4)
The predictors with high individual mutual correlation between 0.5 and 0.7, as suggested by Pallant (2007), were left out to eliminate any multicollinearity.
-
(5)
Finally, the percentage reduction (PR) was calculated (Eq. 2) for identification of the second most suitable predictor.
$$\mathrm{PR}=\left(\frac{{P}_{r}-\mathrm{R}}{\mathrm{R}}\right)\times 100$$(2)
Where \({P}_{r}\) is the absolute partial correlation and \(\mathrm{R}\) indicates the absolute correlation coefficient.
The second most suitable predictor has only a very small multicollinearity with the MP. The third, fourth, and following-order suitable predictor can then be ascertained by calculating \(\mathrm{PR}\) for the remainder of the predictor-set. Likewise to most applications of statistical downscaling methods, between one to three predictors were identified to satisfactorily explain the predictand in calibration, while removing any existing multicollinearity (Mahmood and Babel 2013). The predictor-set chosen in this way was then used as input into the DWT.
3.3 Model development
3.3.1 Discrete Wavelet Transform (DWT)
In hydrological applications, discrete-time signal is the much more prevalent than a continuous-time signal process. Due to its localization properties in both time and scale, the DWT follows tracking of the time evolution of processes at different scales possible in the signal (Nourani et al. 2009a). The wavelet transform of a time series f (t) is expressed as:
where φ (t) states the original wavelet with effective length (t) that is normally quite shorter than the target time series f (t). The variable “\(\mathrm{a}\)” is the scale factor that demonstrates the properties of frequency as its variation escalates a spectrum and “\(\mathrm{b}\)” shows the translation in time so that its variation resembles the “sliding” of the wavelet over f (t). The wavelet spectrum is thus generally indicated in time–frequency domain. For low scales namely once |a|< < 1, the wavelet function is highly concentrated with frequency contents mostly in the higher frequency bands. On the contrary, if |a|> > 1, the wavelet is lengthened and, therefore consists of mostly low frequencies. Hence, for small scales, a more detailed view of the signal with a higher resolution is achieved, while for larger scales a more general view of the signal structure is resulted. The initial signal X (n) passes through two filters including low pass and high pass (Fig. S1) and as a result, two signals as Approximations (A) and Details (D) are emerged. The approximations are considered as the high-scale, low frequency elements of the signal, while the details are the low-scale, high frequency components. Customarily, the low frequency content of the signal (approximation, A) is the most prominent part. It shows the signal identity. The high frequency component (detail, D) is nuance. The decomposition process can be repeated, with successive approximations being decomposed in turn, so that one signal is broken down into many lower resolution components (Ramana et al. 2013).
The selection of appropriate mother wavelet is of paramount importance to decompose the signal. On this matter, Daubechies and Morlet wavelet transforms are known as the most commonly used mother wavelets in engineering applications. Daubechies wavelets represent a good balance between parsimony and information richness; they generate homogeneous events over the signal and findings have shown that most of prediction models can clearly identify them (Benaouda et al. 2006). In the current study, the Daubechies wavelet of order 4 (db4) was employed.
The decomposition level L = \({j}_{max}\) is determined as \(\mathrm{L}=\mathrm{int}[\mathrm{log}\left(\mathrm{N}\right)]\), where N is the time series length, respectively (Nourani et al. 2009a). In the current study N = 10,227, thus L = 4. As such, d1, d2, d3 and d4 are then the details and a4 denotes the low-scale approximation of the time series at that level (see Fig. S1, see Supplementary). These details and the approximation are then fed into the ANN-model.
For instance, the multiresolution decomposition of the NCEP standardized specific humidity at 500 hPa during 1978–2005, as one of the selected predictors for the downscaling of the precipitation, is illustrated (Fig. S2, see Supplementary). One can clearly notice how high frequency noise is filtered out in the a4-approximation, which should make the calibration of the ANN-QM downscaling process easier.
3.3.2 Artificial neural network model
In this study, Multi-layer Perceptrons (MLPs), which have been widely considered as the simplest and most commonly used neural network architectures, was employed. MLPs can be trained using several learning algorithms. In the present study, the Levenberg–Marquardt (LM) or damped Gauss–Newton method was used. It has often been found to be superior compared to other nonlinear optimization methods, like the classical back-projection method, although it needs more computer memory than other algorithms (Adamowski and Sun 2010).
When constructing an ANN model, the principal objective is to reach the optimum architecture of the ANN in a way that a satisfactory relationship between the input and output variables is obtained (Mislan et al. 2015). Deciding the number of layers and number of neurons in the hidden layers is then an important task of establishing the overall neural network architecture (Heaton 2008).
The selection of an appropriate architecture, i.e. number of hidden layers and neurons for the neural network will come down to trial and error. In practice, in most ANN engineering applications, the number of hidden layers is one (Heaton 2008) and this number was also used in this study. However, the number of neurons is more variable, as it depends also on the number of input signals used in the coupled DWT-ANN model, as discussed below.
3.4 Coupled wavelet and artificial neural network (DWT-ANN) model
The coupled wavelet and neural network (DWT-ANN) model developed here is an ANN model that benefits from the sub-series components of the DWT-multiresolution analysis of the original selected climate predictors. The different DWT-ANN models were then created using the approximations (a) and details (d) of the decomposed selected predictors (signals) – as mentioned, ranging between 1 and 3 at a weather station as input and the observed precipitation (predictand) as output (Fig. S3, see Supplementary). In other words, with the decomposition at level 4, favored here (Fig. S1, see Supplementary), 5 sub-signals, i.e. the a4 and the details d1, d2, d3 and d4 (see Eq. 1) were generated. Accordingly, depending on the weather station, the number of inputs ranges from 5 to 15. The skeleton of the 12 DWT-ANN models obtained conclusively for the different weather stations is described in Table 4.
Likewise to other hydrological studies (e.g. Zare and Koch 2018), for creating the training and validation sub-sets, the historic period (1978–2005) at each weather station was divided into two parts, namely a training set (70% of the historic period) and a validation set (30% of the historic period). The model was fit to the training set and the fitted model was used to simulate the responses for the observations in the validation set. The resulting validation set error rate is typically assessed using Mean Squared Error (MSE) (James et al. 2013). In the light of benefiting from a long historical data record (e.g. 1978–2005), the developed DWT-ANN models can be adequately trained by capturing the extreme events that exist in the output layer (daily precipitation), implying that the extreme events for the future scenarios might be well projected accordingly. The 12 trained and validated DWT-ANN models were then forced with the approximations (a) and details (d) of the decomposed selected future predictors of the 8 GCMs and under 3 RCPs 2.6, 4.5, and 8.5, resulting in projecting the daily precipitation at the 12 stations for the future period 2006–2100.
3.5 Bias correction using quantile mapping (QM)
In the present study, the biases reflected in the historic- and future-simulated/projected precipitation by the 12 DWT-ANN models were then bias-corrected using quantile mapping based on empirical quantiles, which is available in the”qmap” R package (https://cran.r-project.org/web/packages/qmap/qmap.pdf). It should be noted that we used QM for correction of the mean, standard deviation, quantiles, and drizzle effects of the daily downscaled precipitation resulted from DWT-ANN.
The QM algorithm is resulted from the empirical transformation (Themeßl et al. 2012). The practical formidable problem of QM is to find a good approximation (transfer function h) for projecting simulated climate predictors \({P}_{m}\) onto observed ones \({P}_{o}\), i.e. (Piani et al. (2010b)
Different methods have been provided in the literature to find an appropriate h (Gudmundsson et al. 2012). The most commonly used technique to approximate h is to apply empirical cumulative distribution functions (ECDFs) to the two sets of predictors which hopefully can be described by some known parametric distributions. As this is practically often not possible for different precipitation time series of a wide variety of climates (Gudmundsson et al. 2012; Themeßl et al. 2011; Wood et al. 2004), statistical transformations as an application of the probability integral transform (Angus 1994) are employed to get the biased corrected-simulated precipitation of \({\widehat{x}}_{m,p}\left(t\right)\) for a time period, expressed as follow:
where \({F}_{o,h}\) and \({F}_{m,h}\) are the CDFs of observed (\({x}_{o,h}\)) and modeled (\({x}_{m,h}\)) data, respectively for the historical period, denoted by the subscript h (Cannon et al. 2015). Thus, the empirical CDFs are then estimated using tables of the empirical percentiles (Boe et al. 2007).
As the empirical CDFs, estimated from the calibration set (1978–1996), were approximated by tables of empirical percentiles, following the procedure of Boe et al. (2007), the values falling between the percentiles were approximated using a cubic interpolation approach.
Nonetheless, when the values of the projection scenarios (2006–2100), as simulated by DWT-ANN, were larger than the calibration values used to train the QM model, the maximum quantile of the empirical percentiles range, provided for the calibration period, was employed to correct these larger amounts of precipitation for the projection period (Boe et al. 2007; Gudmundsson et al. 2012; Themeßl et al. 2012). This possibility can somewhat allow flexibility to the QM model to correct the values that are higher than those not seen during the calibration period.
Afterwards, using the estimated parameters of the empirical QM transfer function (Eq. 5), obtained from the historical period (1978–2005), the future (up to year 2100) DWT-ANN projected daily precipitation data was bias-corrected. It should be noted that since there are different statistical distributions of wet and dry spells for the different months of the year, this bias correction was repeated for each month, i.e. 12 times and was used for the corresponding future projections for that month.
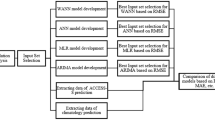
To evaluate the skill of QM in bias correction of the DWT-ANN-simulated precipitation, the historic period was systematically split into two sub-sets, out of which two-third of the dataset (1978–1996) was used for the calibration purpose and the remainder (1997–2005) was employed for the validation. Nonetheless, to procure the parameters of QM for bias correction of the daily future projected precipitation under the 8 GCMs, we trained QM using the whole historic period (1978–2005). The flow chart of the proposed methodology for simulation and prediction of daily precipitation, i.e. the working of the coupled DWT-ANN-QM model is illustrated in Fig. 2.

Flowchart of the DWT-ANN-QM coupled model for precipitation downscaling
4 Results and discussion
4.1 Assessment of the DWT-ANN-QM model’s skill in downscaling and bias correction of the historic precipitation
As listed in Table 4, the performance of DWT-ANN and DWT-ANN-QM models is demonstrated in both calibration/training and validation/test steps in simulating and bias-correcting of daily precipitation at 12 weather stations and under the 8 GCMs. As RMSE, the objective function used for assessment, is directly proportional to the magnitude of the precipitation at each station, one can notice that the maximum and minimum RMSE were found for the stations with the maximum (e.g. Namin, Nir, and Pole Almas) and minimum (e.g. Samian, Abi Biglou, and Hir) of the precipitation, on average (see Table 1). It should be noted that RMSE of DWT-ANN-simulated precipitation for both training and test subsets under all GCMs at all stations is smaller than that of DWT-ANN-QM-simulated and bias corrected precipitation. The reason for this is that the objective function through which DWT-ANN is trained is RMSE, while the same is not true for the DWT-ANN-QM model in which QM was coupled to DWT-ANN. Therefore, a lower RMSE of DWT-ANN-simulated precipitation should not be seen as outperformance of DWT-ANN over DWT-ANN-QM. Due to the high-skill postprocess implemented using QM, the mean, standard deviation, and drizzle effects, as well as quantiles of uncorrected/simulated daily precipitation were rigorously corrected.
To better illustrate the skill of DWT-ANN-QM in downscaling of the historic precipitation, we employed the Taylor diagram (Taylor 2001), enabling us to draw an comparison between the historic precipitation (1978–2005) and the downscaled precipitation resulted from the 8 GCMs at each weather station. As illustrated in Fig. 3, all of the 8 GCM models manifested almost identical output, distributing within a specific region of the Taylor diagram. Nonetheless, based on the three statistics of the Taylor diagram, MPI-ESM-MR outperformed the other GCMs at 4 weather stations, including Abi Biglou, Ardebil, Nir, and Shams Abad. The same holds true for HadGEM2-AO at 3 stations, including Gilandeh, Hir, and Namin. Similarly, NorESM1-M yielded a better result at two stations, which are Kouzeh and Samian. CSIRO-Mk3-6, GFDL-ESM2G, and HadGEM2-ES could surpass the other GCMs at stations: Lay, Pole Almas, and Yamchi Olya, respectively. The remainder of GCMs, namely CNRM-CM5 and GFDL-ESM2M could not prove superiority over all other GCMs at all stations. Afshar et al. (2017) drew a comparison among 14 GCMs across the northeast of Iran via 4 statistical metrics \(.\) Their findings revealed that NorESM1-M and GFDL-ESM2G demonstrated a noticeable superiority over the other 12 GCMs, while CSIRO-Mk3-6 and HadGEM2-ES showed unsatisfactory results. Therefore, our results are partially corroborated by the study of Afshar et al. (2017). The discrepancy spotted between two studies can be attributed to two different prevailing climates of application areas, namely the GRB in the northwest of Iran (see Fig. 1a) and Kashafrood basin in the northeast of Iran, where Afshar et al. (2017) conducted their studies.

Taylor diagrams for the monthly downscaled precipitation using DWT-ANN-QM for the historic period (1978–2005) at the 12 weather stations under the 8 GCMs. Note that for each GCM, three statistics are plotted: (1) the Pearson correlation coefficient (demonstrating similarity in pattern between the historic and GCM-downscaled precipitation) is associated with the azimuthal angle (dotted black lines); (2) the centered RMSE in the GCM-downscaled precipitation is proportional to the distance from the hollow circle on the x-axis identified as “observed” (red contours); and (3) the standard deviation of the GCM-downscaled precipitation is proportional to the radial distance from the origin (dotted blue contours). The observed/historic standard deviation at each station is represented by the hollow circle on the x-axis joining to the y-axis using a solid black contour
Compared with other state-of-the-art methods for statistical downscaling of precipitation, in particular the study conducted by Rashid et al. (2016), in which continuous wavelet transform (CWT) was employed in conjunction with Generalized Additive Model in Location, Scale and Shape (GAMLSS), a higher \({R}^{2}\) for both calibration (0.64) and validation (0.62) subsets was obtained. This is mainly ascribed to the fact that they forced the GAMLSS model with reanalysis NCEP/NCAR to downscale the historic period (1960–2010). Since the NCEP predictors resemble the observed data, GAMLSS could better simulate the historic precipitation. But in the present study, we aimed at projecting the precipitation in a changing climate for the future period. Thus, we forced DWT-ANN-QM with the selected historic predictors of the 8 GCMs that contain systematic bias. A meaningful comparison, however, between these two models can be only undertaken when both studies take advantage of the same dataset and application area.
To pinpoint the skill of QM in postprocessing the daily DWT-ANN-simulated precipitation, as driven by the 8 GCMs, in comparison with the daily historic precipitation, Quantile–quantile (Q-Q) plot (Gibbons and Chakraborti 2014) was deployed at each station and for both calibration (1978–1996) and validation (1997–2005) subsets. For the calibration period (Fig. 4), the quantiles of the corrected precipitation lie essentially on the slope-one line (R2 = 1), irrespective of the GCM used, indicating that the distributions of observed data on the one hand and those of the 8 GCMs on the other hand were practically identical. However, the quantiles of the uncorrected daily precipitation are highly deviated from the slope-one line (R2 = 1), indicating the viable effect of postprocessed made via QM (Chen et al. 2013; Themeßl et al. 2012). For the validation period (Fig. 5), the quintiles of the daily corrected precipitation are partially deviated from the 45-degree line, in particular for larger precipitation values, yet the R2 –values are close to one, again suggesting a promising implication of the QM model.

Q-Q plot of the daily observed, uncorrected-simulated (DWT-ANN), and corrected-simulated (DWT-ANN-QM) precipitation as driven by the 8 GCMs for the calibration period (1978–1996) at the 12 weather stations

As in Fig. 4, but for the validation period (1997–2005). Note that R1-R8 denote the Pearson correlation between the quantiles of the observed precipitation (1997–2005) and that of the daily corrected-simulated precipitation (DWT-ANN-QM) as driven by the 8 GCMs for the same period
As displayed in Fig. 5, a distinct deviation can be noticed for reproduction of the heavier amounts of precipitation for the validation set. For instance, this deviation, irrespective of overestimation and underestimation, from the observed precipitation occurred somewhere between 15 to 20 mm (e.g. 20 mm in Abi Biglou; 15 mm in Yamchi Olya), thus implying QM was not well trained for heavier amounts of precipitation. Owing to the fact that the GRB is located in a semi-arid region, length of wet spells is not generally so long that leads to a higher amount of precipitation. As a consequence, due to a low frequency of great amounts of precipitation witnessed during such a short period of validation subset (1997–2005), the QM algorithm could not well correct the larger values of daily precipitation. This deviation was demonstrated by the partial GCMs overestimation at Ardebil, Gilandeh, Lay, Namin, Nir, Pole Almas, Samian, Shams Abad, and Yamchi Olya stations and similarly by the partial GCMs underestimation at Abi Biglou, Hir, and Kouzeh stations. Therefore, it is of paramount importance to assess the skill of QM for correcting the daily simulated precipitation of humid climates, where sustained wet spells are frequent and so a great amount of precipitation is expected, which may result in a better training of QM.
In addition, as an inherent uncertainty of GCM outputs, tendency to overestimate wet days (Goddard et al. 2001; Nyunt et al. 2016) might be another reason why this apparent discrepancy between the observed and simulated-bias corrected precipitation was identified for higher amount of the precipitation.
As earlier mentioned, to hone the skill of QM for correction of the future projected precipitation (2006–2100) of DWT-ANN, we trained it using the complete historic period (1978–2005) instead, leading to capture more frequent heavier precipitation events while being trained.
4.2 Assessment of the DWT-ANN-QM model’s skill in reproduction of empirical cumulative distribution functions (ECDFs)
The empirical cumulative distribution functions (CDFs) of the daily historic precipitation, the daily uncorrected-simulated precipitation of DWT-ANN, and the daily corrected-simulated precipitation of DWT-ANN-QM, were illustrated for the calibration (1978–1996) (Fig. 6) and validation (1997–2005) (Fig. 7) subsets. As illustrated in Fig. 6, the ECDFs of the corrected-simulated precipitation for the calibration and validation periods, as driven by the eight GCMs, imitate closely those of the historic period. As shown, all of the corrected ECDS are very well matched to the observed ECDF so that they can be hard distinguished from each other; this is especially the case for the precipitation amounts exceeding 15–20 mm. By contrast, the uncorrected ECDFs are partially deviated from the observed ECDFs. Therefore, the positive effect of the bias correction with the QM algorithm is clearly demonstrated. Similarly, a comparison was drawn between the ECDFs of the historic precipitation and those of the projected by the precipitation driven by the eight future GCMs (Figs. S4-S6; see Supplementary) under RCPs 2.6, 4.5, and 8.5. As shown in Fig. S4, an overestimation of the projected precipitation resulted from increasing the projected wet spells (Fig. 8), relative to the historic precipitation, can be seen under RCP2.6 at all weather stations. The lowest discrepancy was found at Samian station, whereas the highest discrepancy was identified at Kouzeh and Gilandeh stations. Interestingly, Gilandeh, Kouzeh, and Samian stations indicated the lowest standard deviations (SDs) as calculated for the historic period (Table 1) amounting to 60, 65, and 67 mm, respectively. Nonetheless, the best match was recognized for Samian (Fig. S4j) that can be ascribed to a lower percentage reduction (PR) (Eq. 2) as listed in Table S1 (see Supplementary) for the two selected predictors rather than PR calculated for Kouzeh having one selected predictor and Gilandeh consisting of three selected predictors. The same holds true for the ECDFs of the precipitation projected under RCP4.5 (Fig. S5). As displayed for RCP8.5 (Fig. S6), at all stations, due to a considerable increase in wet days and thus precipitation amounts, a longer tail for the projected ECDFs can be discerned.

Empirical cumulative distribution functions (ECDFs) for the historic precipitation, uncorrected-simulated of DWT-ANN and corrected-simulated precipitation of DWT-ANN-QM for the calibration period (1978–1996), as driven by the 8 GCMs at the 12 weather stations

As in Fig. 6, but for the validation period (1997–2005)

Exceedance probability of the dry spells for the daily observed precipitation and historic corrected-simulated precipitation of DWT-ANN-QM as driven by the 8 GCMs
4.3 Assessment of the DWT-ANN-QM model’s skill in simulation of dry and wet spells
Wet and dry spells analysis should also be taken into account for the assessment of the reliability of the proposed downscaling approach. Indeed, knowledge of the wet and dry spell lengths and frequencies are important in water resource planning and management, particularly, in countries relying on hydropower generation (She et al. 2016).
Throughout the literature, several definitions of wet/dry spell lengths are given; in this study the maximum number of consecutive days with precipitation greater/less than 0.1 mm/day, recommended for arid and low precipitation regions (Pervez and Henebry 2014), was considered as the threshold.
In Figs. 8 and 9, the empirical occurrence/exceedance probabilities of the dry and wet spell lengths fallowing Kannan and Ghosh (2013) were plotted, respectively at each weather station for both the historic and the DWT-ANN-QM simulated-bias corrected daily precipitation under all historic GCMs. The general pattern of the curves is typical for some hydrological extreme distribution observed in both figures. One may notice that the dry spells were better reproduced relative to the wet spells, although an overall overestimation of the exceedance probability and the lengths of the spells were nearly witnessed under all GCMs. The greatest mismatch can be seen for CNRM-CM5 (e.g. Ardebil, Hir, Kouzeh, Namin, Yamchi Olya), CSIRO-Mk3-6 (e.g. Abi Biglou, Nir), and GFDL-ESM2G (e.g. Gilandeh).

As Fig. 8, but for the wet spells
Similarly, as shown in Fig. S7-S9 (see Supplementary), an overestimation for the exceedance probability and the length of dry spells were projected for RCP2.6, 4.5 and 8.5, respectively. The discrepancy between the historic wet spells and that of the future GCMs is much higher (Fig. S10-S12; see Supplementary). The reason for this peculiar behavior, which has also been reported in previous studies particularly in arid or semi-arid regions with often short rainfall bursts (Hu et al. 2013; Hughes and Guttorp 1994; Liu et al. 2011), may be due to the very short temporal dependence/small lag-correlation of the more extreme precipitation process (Hu et al. 2013). In addition, as precipitation tends to typify a Markov process (Katz 1977) in which a short memory or low temporal dependency is represented, especially in arid and semi-arid regions where the dry-spells constitute a quite longer length of a precipitation time series, thereby resulting in a higher occurrence probability.
As a consequence, the proposed coupled model could surpass reproduction of the dry spells rather than wet spells owing to this considerable probability of occurrence, while there are a much higher systematic overestimation between the historic and corrected-simulated wet spell occurrence probability (Fig. 9). This discrepancy can be also attributed to the poor skill of the QM model at correcting higher amount of precipitation because these events are exceptional and thus cannot adequately train the parameters of the QM model. As a result, QM cannot properly increase the amount of precipitation for the extreme events of the DWT-ANN simulated precipitation, but only an increase in the number of the wet days can counterbalance the underestimated extreme events in order to ensure a mean and standard deviation as witnessed for the historic period. Thus, the skill of QM in correction of storm events typifying intrinsic characteristic of precipitation in arid and semi-arid regions should be carefully taken into consideration.
In addition, as explained earlier for the mismatches witnessed for Fig. 5, GCM outputs have a propensity to over predict wet spells (Goddard et al. 2001; Nyunt et al. 2016). Hence, the longer tail of the projected wet spell over that of the observed wet spells in the present study may be explained by such an intrinsic uncertainty induced by the used GCMs. The poor performance of two statistical downscaling methods used by Liu et al. (2011) for simulation of wet spells has been also documented.
Based on our best knowledge, it is the first time that QM using empirical quantiles was fused with DWT-ANN. Nonetheless, for future studies, other QM approaches such as the quantile delta mapping, suggested by Cannon et al. (2015), may be used in combination with DWT-ANN for bias correction of downscaled precipitation in comparison with the QM using empirical quantiles, which was used in this study.
It should be noted, however, due to the internal variability of GCMs and RCMs, noticeable systematic biases can be expected, which most of bias correction methods suffer from shortcomings to resolve these biases (Adeyeri et al. 2020; Cannon 2016; Maraun 2012).
4.4 Projection of future precipitation via the DWT-ANN-QM model
We forced the DWT-ANN-QM model to downscale and bias correct the future precipitation (2006–2100) with the selected predictors of the 8 GCMs under the three emission scenarios RCP2.6, 4.5, and 8.5 at the 12 weather stations. The results of the middle future projection (2041–2070), however, in comparison with historic period (1978–2005) are here presented (Figs. 10, 11, 12, 13, 14, 15, 16). The projections of the near and distant future (2006–2040 and 2071–2100, respectively) are provided in Supplementary (Fig. S13-S18).

Averages of the monthly precipitation for the historic and the future GCMs-driven projections for the middle future (2041–2070) under the emission scenario RCP2.6

As Fig. 10, but under the emission scenario RCP4.5

As Fig. 10, but under the emission scenario RCP8.5

Spatial distributions of relative change of the winter mean precipitation for the future time slice 2041–2070 in comparison with the reference period 1978–2005 under the 8 GCMs. Note that a positive and negative percentage indicate an increase and decline of the future winter precipitation compared with the reference period, respectively

As in Fig. 13, but for spring

As in Fig. 13, but for summer

As in Fig. 13, but for fall
Figure 10, 11, 12 illustrate, depending on the GCM used, the future monthly precipitation may increase or decrease relative to the historic period (1978–2005). These variabilities are much pronounced in wet seasons, i.e. from January to May. Overall, the average of the monthly precipitation will increase, particularly during wet months (e.g. November, December, January, and February) under RCP2.6 at all stations (Fig. 10). Under RCP4.5 (Fig. 11) the averages of the monthly precipitation will be less raised rather than that of RCP2.6. Nonetheless, a benevolent increase in the monthly average of the precipitation is projected under RCP8.5 (Fig. 12).
The reason for this peculiar behavior could be attributed to higher temperatures usually anticipated under RCP8.5, which in turn can lead to a higher amount of evapotranspiration, resulting in more precipitable water in the atmosphere. Hence, it will cause more propensity for precipitation occurrence (Huang et al. 2014), counteracting the generally witnessed decline in the precipitation during the historic period in the GRB (Ardabil Regional Water Authority 2013). Our findings are corroborated by Pendergrass et al. (2017) in which on basis of comparing RCP8.5 projections for the end of the twenty-first century with recent decades, precipitation variability rises 3–4% \({K}^{-1}\) globally, 4–5% \({K}^{-1}\) across land, and 2–4% \({K}^{-1}\) over ocean and is considerably robust on a range of time scales from daily to decadal. Furthermore, their results demonstrated that this increase in variability can be as high as the average of precipitation and lower than moisture and extreme precipitation as shown by nearly all models, areas, and time scales. The changes can be associated with rising in the atmospheric moisture, although it has been partially mitigated by weakening circulations. Thus, the discrepancy spotted between RCP4.5 and RCP8.5 in the current study can be attributed as a natural variability, even under a warmer climate.
The spatial variability of the middle future projected precipitation under the 8 GCMs relative to the historic precipitation at a seasonal scale has also been illustrated by Figs. 13, 14, 15, 16. Overall, the average of winter precipitation will rise under most of the GCMs and scenarios, although a decline in the future winter of 2041–2070 is anticipated for CSIRO-Mk3-6 (RCP2.6), GFDL-ESM2G (RCP4.5), GFDL-ESM2M (RCP8.5), and at some areas of the GRB under GFDL-ESM2G (RCP8.5), GFDL-ESM2M (RCP2.6), and GFDL-ESM2M (RCP4.5) (Fig. 13).
The maximum increase of the future winter is to be expected for CNRM-CM5 (RCP8.5), whereas the maximum decline for the same season covering the whole basin is anticipated to occur for CSIRO-Mk3-6 (RCP2.6).
The increase in the future precipitation, including the winter (September, December, January, February, March,) across the GRB has also been projected by Javan et al. (2015) in the light of employing the PRECIS (Providing REgional Climates for Impacts Studies) climate model and considering B2 as a SRES (Special Report on Emissions Scenarios) scenario.
The future spring precipitation is expected to be diminished, rather than the historic spring period of 1978–2005, under 16 GCMs/scenarios combinations (out of maximum possibilities: 8 GCMs × 3 RCPs), while a rise in the future spring precipitation has been projected under 8 GCMs/scenarios combinations (Fig. 14). The maximum rise and decline have been witnessed for GFDL-ESM2G (RCP4.5 and 8.5, yet with a partial difference in spatial distribution (see Fig. 14k-l)) and HadGEM2-ES (RCP8.5), respectively. In contrast to the future winter (Fig. 13), the future summer precipitation is projected to be considerably reduced under 20 GCMs/scenarios combinations, though 4 GCMs/scenarios show a rise in the precipitation (Fig. 15). The maximum reduction and increase relative to the historic summer period 1978–2005 are anticipated for CSIRO-Mk3-6 (RCP4.5) and HadGEM2-ES (RCP2.6), respectively. Compared with the historic precipitation of fall for the period 1978–2005, the future projected fall precipitation for 2041–2070 has been prognosticated to be increased and decreased under 16 and 2 GCMs/scenarios combinations, respectively (Fig. 16). Nonetheless, the future fall precipitation may increase or decrease, depending on the spatial distribution as projected for 6 GCMs/scenarios combinations, including NorESM1-M (RCP2.6), CNRM-CM5 (RCP8.5), GFDL-ESM2G (RCP2.6), HadGEM2-AO (RCP8.5), and HadGEM2-ES (RCP4.5 and RCP8.5).
In general, compared to our spatial analysis conducted for the four seasons hinting a rise in the future precipitation on average, the results of a large scale spatial projection of future precipitation (2020–2050) undertaken by Terink et al. (2013) are counterintuitive. They used nine GCMs and SRES A1B reflecting two time slices (2020–2030 and 2040–2050) to project different hydro-climate variables, including precipitation across the Middle East and North Africa (MENA). Having statistically downscaled the precipitation in the light of the GCMs, they have found that under the aforementioned future periods the annual precipitation is anticipated to be reduced around 5 to 10% across the GRB.
Corroborating partially our findings, the study performed by Modarres et al. (2018) indicated that some increases in precipitation, particularly maximum rainfall has been projected. They projected the variability of the maximum daily rainfall across the north and North West of Iran for the future period 2020–2049 under 6 GCMs and two scenarios A2 and B1. Their results showed that a change between -16 to 7% under scenario A2 can be expected for this region. Similarly, depending on the used GCM, maximum rainfall can vary from -16 to 10% under scenario B1, compared to the historic period (1981–2010). However, it should be noted that only one GCM grid covers the GRB as compared to the study of Modarres et al. (2018) where a quite larger region in size was investigated.
Moreover, to better spot the differences between the future scenarios and the historic precipitation, the averages of the annual projected precipitation at all weather stations and for all time slices under the 8 GCMs, relative to that of the historic period are provided in Table S2 (see Supplementary).
4.5 Limitations and considerations
The current research was undertaken in accordance with the historic and future climate predictors of 8 GCMs under climate change scenarios of RCPs 2.6, 4.5, and 8.5. Nonetheless, it is necessary to assess the validity and effectiveness of the proposed statistical downscaling approach, i.e. DWT-ANN-QM with more recent climate change scenarios, namely Shared Socioeconomic Pathways (SSPs), which represent climate change scenarios of projected socioeconomic global changes up to 2100 as per the IPCC Sixth Assessment Report on climate change in 2021. In this study, we employed the NCEP reanalysis parameters in order to ascertain the most important atmospheric parameters influencing daily precipitation in the GRB. As several newer reanalysis datasets have emerged such as ECMWF (European Centre for Medium-Range Weather Forecasts), MERRA-2 (), JRA-55 (Japanese 55-year Reanalysis), CFSR (Climate Forecast System Reanalysis), and 20CR (Twentieth Century Reanalysis), the efficacy of this statistical downscaling method should be further evaluated based on the predictor screening procedure applied to the predictors of the aforementioned reanalysis atmospheric parameters. In addition, as the simulation of dry-spells outperformed that of the wet-spells, we advise caution when using the proposed approach for the projection of the future wet-spells, which is of great importance in water resources management plans in a changing climate.
5 Conclusion
Despite substantial efforts in developing advanced statistical downscaling models, downscaling of daily precipitation from global climate models (GCMs) at the local/station level, particularly in arid and semi-arid regions, remains a significant challenge for climate change impact assessments. In this study, we proposed a novel nonparametric statistical downscaling model that integrates discrete wavelet transform (DWT), artificial neural networks (ANNs), and quantile mapping (QM) algorithms to both downscale and bias-correct historic (1978–2005) and future (2006–2100) daily precipitation at 12 weather stations in the Gharehsoo River Basin (GRB), northwestern Iran.
Our proposed coupled downscaling algorithm, DWT-ANN-QM, was rigorously assessed using various statistical measures, including Taylor diagrams, Q-Q plot analyses for calibration and validation subsets, and empirical cumulative distribution functions (ECDFs). Additionally, the model's performance in reproducing dry and wet spells for both historic and future periods was evaluated.
Findings revealed significant improvements in simulated precipitation with the implementation of the QM algorithm, particularly evidenced by Q-Q plot analyses and ECDF comparisons. While the coupled model satisfactorily reconstructed dry spells, there was a systematic overestimation of the exceedance probability and length of wet spells, attributed to insufficient training of the QM model for extreme precipitation events.
Overall, projections indicate an increase in future precipitation across the GRB, ranging from 10 to 17% depending on the weather station. Notably, the seasonal spatial distribution of future precipitation suggests increases in fall and winter, with declines projected for spring and summer.
The present study investigated historical and future climate predictors from 8 GCMs across RCP scenarios 2.6, 4.5, and 8.5. However, it is essential to evaluate the validity and efficacy of our proposed statistical downscaling approach, DWT-ANN-QM, using more recent climate change scenarios, particularly Shared Socioeconomic Pathways (SSPs). We utilized the NCEP reanalysis parameters to identify the most influential atmospheric parameters affecting daily precipitation in the GRB. With the emergence of newer reanalysis datasets such as ECMWF, MERRA-2, JRA-55, CFSR, and 20CR, further assessment of this statistical downscaling method is warranted, employing the given predictor screening procedure on the predictors of these reanalysis atmospheric parameters. Additionally, given the superior performance in simulating dry spells compared to wet spells, caution is advised when using our approach to project future wet spells, which holds significant implications for water resources management plans in a changing climate.
From a water resource management perspective, it is advisable to devise strategies for retaining floodwaters via enhancing sponge function of landscape and implementing managed aquifer recharge systems due to wetter winter and fall months as anticipated for the future in the GRB, thereby sustaining streamflow during anticipated drier spring and summer months.
Data Availability
The daily precipitation data can be requested from the Iran Meteorological Organization and rain gauge stations of the Iran Ministry of Energy and the datasets analyzed are available from the corresponding author.
Code availability
The codes used in this study can be shared up on a reasonable request.
References
Adamowski J, Sun KR (2010) Development of a coupled wavelet transform and neural network method for flow forecasting of non-perennial rivers in semi-arid watersheds. J Hydrol 390(1–2):85–91
Adeyeri OE, Ishola KA (2021) Variability and Trends of Actual Evapotranspiration over West Africa: The Role of Environmental Drivers. Agric for Meteorol 308–309:108574
Adeyeri OE, Laux P, Lawin AE, Ige SO, Kunstmann H (2019) Analysis of hydrometeorological variables over the transboundary Komadugu-Yobe basin, West Africa. J Water Climate Chang 11(4):1339–1354
Adeyeri OE, Laux P, Lawin AE, Oyekan KSA (2020) Multiple bias-correction of dynamically downscaled CMIP5 climate models temperature projection: a case study of the transboundary Komadugu-Yobe river basin, Lake Chad region West Africa. SN Appl Sci 2(7):1221
Afshar AA, Hasanzadeh Y, Besalatpour AA, Pourreza-Bilondi M (2017) Climate change forecasting in a mountainous data scarce watershed using CMIP5 models under representative concentration pathways. Theor Appl Climatol 129(1–2):683–699
Ahmed K, Shahid S, Haroon SB, Xiao-jun W (2015) Multilayer perceptron neural network for downscaling rainfall in arid region: A case study of Baluchistan Pakistan. J Earth Syst Sci 124(6):1325–1341
Angus JE (1994) The Probability Integral Transform and Related Results. Siam Rev 36(4):652–654
Ardabil Regional Water Authority 2013 Investigation of Groundwater Balance in Ardabil Plain, p. 179, Ardabil Regional Water Authority, Ardabil, Iran.
Aussem A, Campbell J, Murtagh F (1998) Wavelet-based feature extraction and decomposition strategies for financial forecasting. J Comput Intell Finance 6(2):5–12
Baba K, Shibata R, Sibuya M (2004) Partial correlation and conditional correlation as measures of conditional independence. Aust N Z J Stat 46(4):657–664
Babar ZA, Zhi XF, Fei G (2015) Precipitation assessment of Indian summer monsoon based on CMIP5 climate simulations. Arab J Geosci 8(7):4379–4392
Baghanam AH, Norouzi E, Nourani V (2022) Wavelet-based predictor screening for statistical downscaling of precipitation and temperature using the artificial neural network method. Hydrol Res 53(3):385–406
Baghanam AH, Nourani V, Keynejad M-A, Taghipour H, Alami M-T (2018) Conjunction of wavelet-entropy and SOM clustering for multi-GCM statistical downscaling. Hydrol Res 50(1):1–23
Benaouda D, Murtagh F, Starck JL, Renaud O (2006) Wavelet-based nonlinear multiscale decomposition model for electricity load forecasting. Neurocomputing 70(1):139–154
Beniston, M.J.C.C. 2003. Climatic Change in Mountain Regions: A Review of Possible Impacts. 59(1), 5-31
Boe J, Terray L, Habets F, Martin E (2007) Statistical and dynamical downscaling of the Seine basin climate for hydro-meteorological studies. Int J Climatol 27(12):1643–1655
Cannon AJ (2016) Multivariate Bias Correction of Climate Model Output: Matching Marginal Distributions and Intervariable Dependence Structure %J Journal of Climate. 29(19), 7045–7064
Cannon AJ, Sobie SR, Murdock TQ (2015) Bias Correction of GCM Precipitation by Quantile Mapping: How Well Do Methods Preserve Changes in Quantiles and Extremes? J Climate 28(17):6938–6959
Canon J, Dominguez F, Valdes JB (2011) Downscaling climate variability associated with quasi-periodic climate signals: A new statistical approach using MSSA. J Hydrol 398(1–2):65–75
Caron A, Leconte R, Brissette F (2008) An Improved Stochastic Weather Generator for Hydrological Impact Studies. Can Water Resour J 33(3):233–255
Chadwick R, Coppola E, Giorgi F (2011) An artificial neural network technique for downscaling GCM outputs to RCM spatial scale. Nonlin Processes Geophys 18(6):1013–1028
Chen, J. and Zhang, X.J. 2021. Challenges and potential solutions in statistical downscaling of precipitation. Climatic Change 165(3–4).
Chen ZS, Chen YN, Li BF (2013) Quantifying the effects of climate variability and human activities on runoff for Kaidu River Basin in arid region of northwest China. Theor Appl Climatol 111(3–4):537–545
Christensen JH, Boberg F, Christensen OB, Lucas-Picher P (2008) On the need for bias correction of regional climate change projections of temperature and precipitation. Geophys Res Lett 35(20)
Dibike YB, Coulibaly P (2006) Temporal neural networks for downscaling climate variability and extremes. Neural Netw 19(2):135–144
Dixon KW, Lanzante JR, Nath MJ, Hayhoe K, Stoner A, Radhakrishnan A, Balaji V, Gaitán CF (2016) Evaluating the stationarity assumption in statistically downscaled climate projections: is past performance an indicator of future results? Clim Change 135(3):395–408
Emami F, Koch M (2017) Evaluating the water resources and operation of the Boukan Dam in Iran under climate change. European Water 59:17–24
Eum HI, Simonovic SP (2012) Assessment on variability of extreme climate events for the Upper Thames River basin in Canada. Hydrol Process 26(4):485–499
Fang GH, Yang J, Chen YN, Zammit C (2015) Comparing bias correction methods in downscaling meteorological variables for a hydrologic impact study in an arid area in China. Hydrol Earth Syst Sc 19(6):2547–2559
Fereidoon M, Koch M (2018) SWAT-MODSIM-PSO optimization of multi-crop planning in the Karkheh River Basin, Iran, under the impacts of climate change. Sci Total Environ 630:502–516
Fowler HJ, Kilsby CG (2007) Using regional climate model data to simulate historical and future river flows in northwest England. Clim Change 80(3–4):337–367
Gibbons JD, Chakraborti S (2014) Nonparametric Statistical Inference, Fourth Edition: Revised and Expanded, Taylor & Francis
Goddard L, Mason SJ, Zebiak SE, Ropelewski CF, Basher R, Cane MA (2001) Current approaches to seasonal to interannual climate predictions. 21(9), 1111-1152
Goyal MK (2014) Monthly rainfall prediction using wavelet regression and neural network: an analysis of 1901–2002 data, Assam India. Theor Appl Climatol 118(1–2):25–34
Gudmundsson L, Bremnes JB, Haugen JE, Engen-Skaugen T (2012) Technical Note: Downscaling RCM precipitation to the station scale using statistical transformations - a comparison of methods. Hydrol Earth Syst Sc 16(9):3383–3390
Haberlandt U, Belli A, Bardossy A (2015) Statistical downscaling of precipitation using a stochastic rainfall model conditioned on circulation patterns - an evaluation of assumptions. Int J Climatol 35(3):417–432
Hay LE, Clark MP (2003) Use of statistically and dynamically downscaled atmospheric model output for hydrologic simulations in three mountainous basins in the western United States. J Hydrol 282(1–4):56–75
Hay LE, Mccabe GJ, Wolock DM, Ayers MA (1991) Simulation of Precipitation by Weather Type Analysis. Water Resour Res 27(4):493–501
Heaton J (2008) Introduction to Neural Networks for C#, Heaton Research, Inc
Hu YR, Maskey S, Uhlenbrook S (2013) Downscaling daily precipitation over the Yellow River source region in China: a comparison of three statistical downscaling methods. Theor Appl Climatol 112(3–4):447–460
Huang AN, Zhou Y, Zhang YC, Huang DQ, Zhao Y, Wu HM (2014) Changes of the Annual Precipitation over Central Asia in the Twenty-First Century Projected by Multimodels of CMIP5. J Climate 27(17):6627–6646
Huang J, Zhang J, Zhang Z, Xu C, Wang B, Yao J (2011) Estimation of future precipitation change in the Yangtze River basin by using statistical downscaling method. Stoch Env Res Risk Assess 25(6):781–792
Hughes JP, Guttorp P (1994) A class of stochastic models for relating synoptic atmospheric patterns to regional hydrologic phenomena. Water Resour Res 30(5):1535–1546
Iizumi T, Nishimori M, Dairaku K, Adachi SA, Yokozawa M (2011) Evaluation and intercomparison of downscaled daily precipitation indices over Japan in present-day climate: Strengths and weaknesses of dynamical and bias correction-type statistical downscaling methods. J Geophys Res: Atmospheres 116(D1), n/a-n/a
IPCC 2014 Climate Change 2014: Synthesis Report. Contribution of Working Groups I, II and III to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change Pachauri, R.K. and Meyer, L.A. (eds), p. 151, Geneva, Switzerland
James G, Witten D, Hastie T, Tibshirani R (2013) An Introduction to Statistical Learning with Applications in R. Springer-Verlag, New York
Javan K, Fallah Haghgoo Lialestani MR, Ashouri H, Moosavian N (2015) Assessment of the impacts of nonstationarity on watershed runoff using artificial neural networks: a case study in Ardebil, Iran. Modeling Earth Systems and Environment 22(1)
Kaheil YH, Creed IF (2009) Detecting and Downscaling Wet Areas on Boreal Landscapes. IEEE Geosci Remote Sens Lett 6(2):179–183
Kaheil YH, Rosero E, Gill MK, McKee M, Bastidas LA (2008) Downscaling and Forecasting of Evapotranspiration Using a Synthetic Model of Wavelets and Support Vector Machines. IEEE Trans Geosci Remote Sens 46(9):2692–2707
Kalnay E, Kanamitsu M, Kistler R, Collins W, Deaven D, Gandin L, Iredell M, Saha S, White G, Woollen J, Zhu Y, Chelliah M, Ebisuzaki W, Higgins W, Janowiak J, Mo KC, Ropelewski C, Wang J, Leetmaa A, Reynolds R, Jenne R, Joseph D (1996) The NCEP/NCAR 40-Year Reanalysis Project. 77(3), 437–472
Kannan S, Ghosh S (2013) A nonparametric kernel regression model for downscaling multisite daily precipitation in the Mahanadi basin. Water Resour Res 49(3):1360–1385
Katz RW (1977) Precipitation as a Chain-Dependent Process. 16(7), 671-676
Khan MS, Coulibaly P, Dibike Y (2006) Uncertainty analysis of statistical downscaling methods using Canadian Global Climate Model predictors. Hydrol Process 20(14):3085–3104
King LM, McLeod AI, Simonovic SP (2015) Improved Weather Generator Algorithm for Multisite Simulation ofPrecipitation and Temperature. J Am Water Resour as 51(5):1305–1320
Kistler R, Kalnay E, Collins W, Saha S, White G, Woollen J, Chelliah M, Ebisuzaki W, Kanamitsu M, Kousky V, Dool Hvd, Jenne R, Fiorino M (2001) The NCEP–NCAR 50-Year Reanalysis: Monthly Means CD-ROM and Documentation. 82(2), 247–268
Kouhestani S, Eslamian SS, Abedi-Koupai J, Besalatpour AA (2016) Projection of climate change impacts on precipitation using soft-computing techniques: A case study in Zayandeh-rud Basin Iran. Global Planet Chang 144:158–170
Kumar YP, Maheswaran R, Agarwal A, Sivakumar B (2021) Intercomparison of downscaling methods for daily precipitation with emphasis on wavelet-based hybrid models. J Hydrol 599
Lafon T, Dadson S, Buys G, Prudhomme C (2013) Bias correction of daily precipitation simulated by a regional climate model: a comparison of methods. Int J Climatol 33(6):1367–1381
Latif M, Hannachi A, Syed FS (2018) Analysis of rainfall trends over Indo-Pakistan summer monsoon and related dynamics based on CMIP5 climate model simulations. Int J Climatol 38:E577–E595
Lee JY, Wang B (2014) Future change of global monsoon in the CMIP5. Clim Dyn 42(1–2):101–119
Legasa MN, Thao S, Vrac M, Manzanas R (2023) Assessing Three Perfect Prognosis Methods for Statistical Downscaling of Climate Change Precipitation Scenarios. Geophys Res Lett 50(9)
Liu Z, Xu Z, Charles SP, Fu G, Liu L (2011) Evaluation of two statistical downscaling models for daily precipitation over an arid basin in China. Int J Climatol 31(13):2006–2020
Mahmood R, Babel MS (2013) Evaluation of SDSM developed by annual and monthly sub-models for downscaling temperature and precipitation in the Jhelum basin Pakistan and India. Theor Appl Climatol 113(1–2):27–44
Mahmood R, Babel MS (2014) Future changes in extreme temperature events using the statistical downscaling model (SDSM) in the trans-boundary region of the Jhelum river basin. Weather and Climate Extremes 5–6:56–66
Mahmood R, Jia SF, Tripathi NK, Shrestha S (2018) Precipitation Extended Linear Scaling Method for Correcting GCM Precipitation and Its Evaluation and Implication in the Transboundary Jhelum River Basin. Atmosphere 9(5)
Mandal S, Srivastav RK, Simonovic SP (2016) Use of beta regression for statistical downscaling of precipitation in the Campbell River basin, British Columbia, Canada. J Hydrol 538:49–62
Maraun D (2012) Nonstationarities of regional climate model biases in European seasonal mean temperature and precipitation sums. 39(6)
Maraun D (2013) Bias Correction, Quantile Mapping, and Downscaling: Revisiting the Inflation Issue. J Climate 26(6):2137–2143
Maraun D, Wetterhall F, Ireson AM, Chandler RE, Kendon EJ, Widmann M, Brienen S, Rust HW, Sauter T, Themeßl M, Venema VKC, Chun KP, Goodess CM, Jones RG, Onof C, Vrac M, Thiele-Eich I (2010) Precipitation downscaling under climate change: Recent developments to bridge the gap between dynamical models and the end user. Reviews of Geophysics 48(3), n/a-n/a
Markovic D, Koch M (2005) Wavelet and scaling analysis of monthly precipitation extremes in Germany in the 20th century: Interannual to interdecadal oscillations and the North Atlantic Oscillation influence. Water Resour Res 41(9), n/a-n/a
Mehrotra R, Sharma A (2010) Development and Application of a Multisite Rainfall Stochastic Downscaling Framework for Climate Change Impact Assessment. Water Resour Res 46
Mislan H, Hardwinarto S, Sumaryono, Aipassa M (2015) Rainfall Monthly Prediction Based on Artificial Neural Network: A Case Study in Tenggarong Station, East Kalimantan - Indonesia. Procedia Comput Sci 59, 142-151
Modarres R, Ghadami M, Naderi S, Naderi M (2018) Future extreme rainfall change projections in the north of Iran. Meteorol Appl 25(1):40–48
Ngai ST, Tangang F, Juneng L (2017) Bias correction of global and regional simulated daily precipitation and surface mean temperature over Southeast Asia using quantile mapping method. Global Planet Change 149:79–90
Nourani V, Alami MT, Aminfar MH (2009a) A combined neural-wavelet model for prediction of Ligvanchai watershed precipitation. Eng Appl Artif Intell 22(3):466–472
Nourani V, Baghanam AH, Adamowski J, Kisi O (2014) Applications of hybrid wavelet-Artificial Intelligence models in hydrology: A review (vol 514, pg 358, 2014). J Hydrol 517:1189–1189
Nourani V, Baghanam AH, Gokcekus H (2018) Data-driven ensemble model to statistically downscale rainfall using nonlinear predictor screening approach. J Hydrol 565:538–551
Nourani V, Farshbaf A, Adarsh S (2020) Spatial downscaling of radar-derived rainfall field by two-dimensional wavelet transform. Hydrol Res 51(3):456–469
Nourani V, Komasi M, Mano A (2009b) A Multivariate ANN-Wavelet Approach for Rainfall-Runoff Modeling. Water Resour Manag 23(14):2877–2894
Nyunt CT, Koike T, Yamamoto A (2016) Statistical bias correction for climate change impact on the basin scale precipitation in Sri Lanka, Philippines, Japan and Tunisia. Hydrol Earth Syst Sci Discuss 2016:1–32
Okkan U, Fistikoglu O (2014) Evaluating climate change effects on runoff by statistical downscaling and hydrological model GR2M. Theor Appl Climatol 117(1):343–361
Okkan U, Kirdemir U (2016) Downscaling of monthly precipitation using CMIP5 climate models operated under RCPs. 23(3), 514–528
Pallant J (2007) SPSS Survival Manual: A step by step guide to data analysis using the SPSS for windows
Partal T, Cigizoglu HK (2009) Prediction of daily precipitation using wavelet-neural networks. Hydrolog Sci J 54(2):234–246
Pendergrass AG, Knutti R, Lehner F, Deser C, Sanderson BM (2017) Precipitation variability increases in a warmer climate. Scientific Reports 7
Pervez MS, Henebry GM (2014) Projections of the Ganges-Brahmaputra precipitation Downscaled from GCM predictors. J Hydrol 517:120–134
Piani C, Haerter JO, Coppola E (2010a) Statistical bias correction for daily precipitation in regional climate models over Europe. Theor Appl Climatol 99(1–2):187–192
Piani C, Weedon GP, Best M, Gomes SM, Viterbo P, Hagemann S, Haerter JO (2010b) Statistical bias correction of global simulated daily precipitation and temperature for the application of hydrological models. J Hydrol 395(3–4):199–215
Prasanna V (2015) Regional climate change scenarios over South Asia in the CMIP5 coupled climate model simulations. Meteorol Atmos Phys 127(5):561–578
Ramana RV, Krishna B, Kumar SR, Pandey NG (2013) Monthly Rainfall Prediction Using Wavelet Neural Network Analysis. Water Resour Manag 27(10):3697–3711
Rashid MM, Beecham S, Chowdhury RKJT, Climatology A (2016) Statistical downscaling of rainfall: a non-stationary and multi-resolution approach. 124(3), 919-933
Sachindra DA, Huang F, Barton A, Perera BJC (2014) Statistical downscaling of general circulation model outputs to precipitation—part 2: bias-correction and future projections. Int J Climatol 34(11):3282–3303
Salman S, Shahid S, Ismail T, Ahmed K, Wang X (2018a) Selection of climate models for projection of spatiotemporal changes in temperature of Iraq with uncertainties. Atmos Res 213
Salman SA, Shahid S, Ismail T, Ahmed K, Wang XJ (2018b) Selection of climate models for projection of spatiotemporal changes in temperature of Iraq with uncertainties. Atmos Res 213:509–522
Schmidli J, Frei C, Vidale PL (2006) Downscaling from GCM precipitation: a benchmark for dynamical and statistical downscaling methods. Int J Climatol 26(5):679–689
Shafaei M, Adamowski J, Fakheri-Fard A, Dinpashoh Y, Adamowski K (2016) A wavelet-SARIMA-ANN hybrid model for precipitation forecasting. J Water Land Dev I-II I(28):27–36
Sharif M, Burn DH (2006) Simulating climate change scenarios using an improved K-nearest neighbor model. J Hydrol 325(1–4):179–196
Sharma D, Das Gupta A, Babel MS (2007) Spatial disaggregation of bias-corrected GCM precipitation for improved hydrologic simulation: Ping River Basin Thailand. Hydrol Earth Syst Sc 11(4):1373–1390
She DX, Mishra AK, Xia J, Zhang LP, Zhang X (2016) Wet and dry spell analysis using copulas. Int J Climatol 36(1):476–491
Sun FB, Roderick ML, Lim WH, Farquhar GD (2011) Hydroclimatic projections for the Murray-Darling Basin based on an ensemble derived from Intergovernmental Panel on Climate Change AR4 climate models. Water Resour Res 47
Taie Semiromi M, Koch M (2020) How Do Gaining and Losing Streams React to the Combined Effects of Climate Change and Pumping in the Gharehsoo River Basin, Iran? Water Resour Res 56(7), e2019WR025388
Taylor KE (2001) Summarizing multiple aspects of model performance in a single diagram. J Geophys Res Atmos 106(D7):7183–7192
Taylor KE, Stouffer RJ, Meehl GA (2012) An Overview of CMIP5 and the Experiment Design. Bull Am Meteor Soc 93(4):485–498
Terink W, Immerzeel WW, Droogers P (2013) Climate change projections of precipitation and reference evapotranspiration for the Middle East and Northern Africa until 2050. 33(14), 3055–3072.
Themeßl MJ, Gobiet A, Heinrich G (2012) Empirical-statistical downscaling and error correction of regional climate models and its impact on the climate change signal. Clim Change 112(2):449–468
Themeßl MJ, Gobiet A, Leuprecht A (2011) Empirical-statistical downscaling and error correction of daily precipitation from regional climate models. Int J Climatol 31(10):1530–1544
Tryhorn L, DeGaetano A (2011) A comparison of techniques for downscaling extreme precipitation over the Northeastern United States. Int J Climatol 31(13):1975–1989
von Storch H, Zorita E, Cubasch U (1993) Downscaling of Global Climate-Change Estimates to Regional Scales - an Application to Iberian Rainfall in Wintertime. J Climate 6(6):1161–1171
Wilby RL, Dawson CW, Barrow EM (2002) SDSM - a decision support tool for the assessment of regional climate change impacts. Environ Modell Softw 17(2):147–159
Wilby RL, Hay LE, Leavesley GH (1999) A comparison of downscaled and raw GCM output: implications for climate change scenarios in the San Juan River basin. Colorado J Hydrol 225(1–2):67–91
Wilby RL, Wigley TML (1997) Downscaling general circulation model output: a review of methods and limitations. 21(4), 530-548
Wilks DS (1999) Multisite downscaling of daily precipitation with a stochastic weather generator. Climate Res 11(2):125–136
Wilks DS, Wilby RL (1999) The weather generation game: a review of stochastic weather models. Prog Phys Geog 23(3):329–357
Wood AW, Leung LR, Sridhar V, Lettenmaier DP (2004) Hydrologic implications of dynamical and statistical approaches to downscaling climate model outputs. Clim Change 62(1–3):189–216
Xuan WD, Ma C, Kang LL, Gu HT, Pan SL, Xu YP (2017) Evaluating historical simulations of CMIP5 GCMs for key climatic variables in Zhejiang Province. China Theor Appl Climatol 128(1–2):207–222
Yang H, Yang K, Qin J, Ding BH, Jiang YZ, Chen YY, Zhou X, Wang Y, Sharma S (2023) Adaptive Statistical Spatial Downscaling of Precipitation Supported by High-Resolution Atmospheric Simulation Data for Mountainous Areas of Nepal. J Meteorol Res-Prc 37(4):508–520
Zare M, Koch M (2018) Groundwater level fluctuations simulation and prediction by ANFIS- and hybrid Wavelet-ANFIS/Fuzzy C-Means (FCM) clustering models: Application to the Miandarband plain. J Hydro-Environ Res 18:63–76
Acknowledgements
Authors would like to thank Regional Water Company of Ardabil, Iran for providing meteorological data. Moreover, we would like to extend our special gratitude to Dr. Hussein Akbari who greatly assisted in collecting the data used in this study. In addition, we would like to express our gratitude to Dr. Tobias Stacke from the Max-Planck-Institute for Meteorology for his useful comments while working on the manuscript. Finally, we are grateful to Deutscher Akademischer Austauschdienst (DAAD) for awarding scholarship to the first co-author for conducting this research.
Funding
Open Access funding enabled and organized by Projekt DEAL. The authors did not receive support from any organization for the submitted work.
Author information
Authors and Affiliations
Contributions
MTS devised the research methodology and wrote the initial draft of the manuscript. MK reviewed and edited the draft of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Taie Semiromi, M., Koch, M. Statistical downscaling of precipitation in northwestern Iran using a hybrid model of discrete wavelet transform, artificial neural networks, and quantile mapping. Theor Appl Climatol (2024). https://doi.org/10.1007/s00704-024-05033-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00704-024-05033-2