
Abstract
Statistical analysis of extreme values is applied to wind data from National Centers for Environmental Prediction and National Center for Atmospheric Research reanalysis grid points over the ocean region bounded at 23°S and 40°W and 42°W towards the south and southeastern Brazilian coast. The period of analysis goes from 1975 to 2006. The generalized extreme value and generalized Pareto distributions are employed for annual and daily maxima, respectively. The Pareto–Poisson point process characterization is also used to analyze peaks over threshold. Return levels for 10, 25, 50, and 100 years are calculated at each grid point. However, most of the reanalysis data fall within 1–10-year return periods, suggesting that hazardous wind speed with low probability (return periods of 50–100) have rarely measured in this period. Wide confidence intervals on these levels show that there is not enough information to make predictions with any degree of certainty to return periods over 100 years. Low extremal index (θ) values are found for excess wind speeds over a high threshold, indicating the occurrence of consecutively high peaks. In order to obtain realistic uncertainty information concerning inferences associated with threshold excesses, a declustering method is performed, which separates the excesses into clusters, thereby rendering the extreme values more independent.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The knowledge of extreme wind patterns associated with speed and direction is important for studies on climatology, hydrology, and engineering applications in structural projects related to onshore and offshore activities, wind farms, and oil and gas exploitation (Holmes and Moriarty 1999; Cheng and Yeung 2002; Rajabi and Modarres 2008; Michler-Cieluch et al. 2009).
The south and southeastern coast of Brazil is constantly affected by the passage of cold fronts with cyclones developing throughout the region. These meteorological systems can cause severe storms with risk of damages along the coastline.
Extratropical cyclones, which are considered to be the most severe events that reach the region between 40° and 25°S, can eventually cause considerable damages in onshore and offshore structures. de Oliveira (2004, 2009) and de Oliveira et al. (2008, 2009) verified that the sea level rising (storm surges) was caused by extratropical cyclones located in these geographic positions, affecting the south and southeastern Brazilian coastline.
de Oliveira (2009) analyzed tide gauge series from the southeast coast and wind speed from reanalysis grid points 0, 1, and 2 (Fig. 1), verifying high energy values around 7.5- and 5-day periods. These periods are related to the intervals of frontal system passages over the cyclogenetic region.

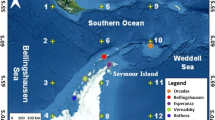
The map shows part of South America with the track of the most cold fronts that reach the south and southeast Brazilian coast. This track is represented by the grid points of the wind components obtained from the NCEP/NCAR reanalysis data set. The respective grid points are: grid0_40°56′S/52°30′W, grid1_35°14′S/50°38′W, grid2_29°31′S/45°00′W, grid3_25°42′S/45°00′W, grid4_25°42′S/46°52′W, and grid5_23°481 S/43°07′W
South and southeastern Brazilian oceanic areas are characterized by cyclogenetic activities with cold fronts moving in the southwest–northeast direction (Gan and Rao 1991). The authors found that the extratropical cyclones over South America are more frequent in winter than in any other season. Earlier, Satyamurty et al. (1990) found that the highest cyclogenesis frequency was obtained for the summer season. Both studies agreed on one of the most active cyclogenetic areas, namely the Gulf of San Mathias (42.5°S, 62°W) during summer and over Uruguay (around 31°S, 55°W) during winter. Sinclair (1995) and Simmonds and Keay (2000) observed that the east region of Argentina, Uruguay, and southern Brazil have a larger density of cyclogenesis resulting in more frequent occurrence of the phenomenon during winter and fewer during summer. Mendes (2006) verified that cyclones also travel longer distances during winter. Extratropical cyclones that reach the South Atlantic Ocean near the Brazilian coast occasionally become stronger in the Uruguayan and Argentinean coasts generating extreme winds that eventually reach the south and southeast coast of Brazil (Seluchi 1995; Gonçalves 2007). Mendes et al. (2010) verified that the predominant tracks of the extratropical cyclones, and their interannual variability, affect weather in South America. Fedorova et al. (2007) verified that the extreme wind speeds over this region are related to large-scale systems such as cold fronts associated with low pressure systems, instability lines, as well as mesoscale convective systems. de Oliveira (2009) verified that there is a positive tendency on occurrence number of extreme wind speed events in the South Atlantic Ocean region between 40°S and 23°S (from north Argentina to southeast Brazil), using six grid points of the National Centers for Environmental Prediction and National Center for Atmospheric Research (NCEP/NCAR) reanalysis data set (Kistler et al. 2001) from 1975 to 2006 period.
In the South Atlantic Ocean, the time series for wind speed are too sparse in spatial and temporal scales to analyze and simulate storms. The limited number of these series, with uninterrupted long periods (between 30 and 50 years or more), raises difficulties for characterizing the behavior of severe events in these region as well as for extrapolating return levels with long return periods.
Extreme value analysis (EVA) informs about the tails of time series of random processes through the statistical study of the inherent properties of these extremes (Fisher and Tippett 1928). This approach can be used for risk analysis to estimate eventual losses, through the modeling of the behavior of less frequent or even rare of certain phenomena (Embrecht et al. 1997).
Some problems are expected when we apply EVA to meteorological variables because they are rarely independent, as the theory requires. But it is possible if there are a large number of observations, the variables are identically distributed, and there is no serial correlation between successive occurrences of extreme values (Sen 1997).
The use of the generalized extreme value (GEV) and generalized Pareto distributions (GPD) have several applications for environmental data because of their appropriateness for modeling extremes (Brabson and Palutikof 1999; Katz et al. 2002; Ramesh and Davison 2002; Assumpção 2004; Bautista et al. 2004; Bazán 2005; Silva and Zocchi 2006). Application of the GEV distribution implies the use of long annual extreme value series (more than 30 years of observation) but, even so, a considerable loss of information can occur. The GPD presents an advantage over the GEV distribution because it uses more relevant information of extreme using the excesses over a threshold (peaks over threshold, POT) instead of only maxima taken typically over long blocks of time. This method considers, instead of annual maxima, excess over a sufficiently high threshold in the time series (Mendes 2004). Hence, the data set is enlarged to decrease the sampling uncertainty. This method has gained wide acceptance in the extreme value estimation due to Pickands’ (1975) work in 1975—the year when the GPD was proved to be the limiting distribution of peaks (An and Pandey 2005). As the meteorological variables tend to present successive dependent extreme values, the technique of declustering was applied, which considers successive extremes as belonging at the same event.
The aim of this work is to apply extreme value analysis to the wind data set from NCEP/NCAR reanalysis to estimate extreme wind speeds over the oceanic region between 40°S and 23°S. These latitudes are continuously affected by the passage of cold fronts with cyclones. We used the software extRemes, developed at NCAR, to select the best fitting extreme value distributions for each grid point and then to search climatological characteristics of the extreme distributions in this area.
The next section presents the data and methodology, Section 3 presents the results and discussion, and Section 4 summarizes the major findings.
2 Data and methodology
2.1 Data
Long-term series of meteorological experimental data on the South Atlantic Ocean region next to the Brazilian coast, necessary for research on extremes, are scarce. Thus, in this work, we decided to use the reanalysis data set from the NCEP/NCAR. The climatological series utilized is based on the 32 years (1975–2006) of zonal (U) and meridional (V) wind components on 10-m height level at 00, 06, 12, and 18 UTC. It was obtained over the ocean region bounded at 23°S and 40°S and 42°W towards the south and southeastern Brazilian coast. The wind data are considered to be from the most accurate class of data in the NCEP/NCAR reanalysis data set (Kalnay et al. 1996). They are considered type A variables (except in the Tropics), being strongly influenced by the available observations, rendering them more reliable (Kistler et al. 2001).
The quality of this data set pre-1979, before the assimilation of satellite data, is questionable in the southern hemisphere (Tennant and Reason 2005). However, in this work, the period of January 1, 1975 to December 31, 2006 was used to develop extreme analysis modeling. de Oliveira (2009) used basic statistics for the 1975–1979 period, confirming the stationarity of the series with respect to other periods. Several researches use NCEP/NCAR reanalysis data set to study the behavior of extreme meteorological variables, as can be seen in (Brooks et al. 2003; Zolina et al. 2004; Fang et al. 2008).
The wind speed and direction time series are calculated from these data for the six grid points throughout the meridional coast from north of Argentina to southeast of Brazil. This region is related to the main direction of the passage of frontal systems that affect the Brazilian coastline and these grid points represent the main track of these meteorological systems. Thus, our domain in searching to identify the wind extreme values, in the area, is bounded at 23°S and 40°S and 42°W towards the Brazilian coast. Figure 1 shows the study area and the grid points utilized in this work.
2.2 Methodology
EVA is the application of results from extreme value theory to investigations concerning extreme or rare phenomena. The theory states that under certain regularity conditions, if the maximum of random variables taken over suitably large blocks have a non-degenerate distribution, then that distribution must be the GEV distribution. Similarly, for excesses over a suitably high threshold, analogous results state that their distribution is the GPD. A point process model can also be adapted, which can be used to demonstrate the connection between the GEV and GPD. The theory is well established, and more details can be found in numerous texts (e.g., Coles 2007). It is helpful here to show the log-likelihoods for the various models used here because different texts use different parameterizations. The log-likelihood function for the GEV distribution (1) is given by
Note that the GEV is a family of distributions where the shape parameter determines the type of distribution that results; specifically, the reverse Weibull (bounded upper tail), Gumbel (light tail), or the Frechet (heavy tail). The case for the Gumbel (ξ = 0) requires special treatment because it is a single point in a continuous parameter space, and therefore, will not be estimated by maximizing the log-likelihood (1) above with probability 1. The log-likelihood for the Gumbel case is
The log-likelihood for the GPD is given by
where k represents the number of excesses over the threshold u.
For the case where ξ = 0,
Finally, for the PP, there are two approaches for estimating the parameters: the orthogonal and GEV re-parameterization methods. The orthogonal approach involves fitting the data to the rate parameter and intensity separately. In other words, the GPD is simply fitted using the likelihood (3) or (4). The maximum likelihood estimation (MLE) for the rate parameter in the stationary case is the mean of the excess times. For the latter approach, the likelihood function to maximize is
where n y is the number of observations per year (or other desired time period), and N(A) is the number of threshold excesses.
The R software package, extRemes, from the NCAR, is used to perform the extreme modeling following Gilleland and Katz (2005, 2006). The methods used for each grid point are described below:
-
Generalized extreme value distribution (GEV) and Pareto distribution (GPD) are applied to annual and daily data, considering block maxima for the GEV distribution and peaks over a threshold for the GPD, respectively. As the interest of the present research is to model absolute excesses, thresholds are considered to be constant.
-
The Pareto–Poisson distribution (GPD-P) is also fit to daily excesses over a threshold. This model will give similar results to the GPD alone, but also incorporates information about the frequency of extreme events (Gilleland and Katz 2006).
-
Threshold selection is purely a statistical process. Extreme value distributions are justified only for the excesses over a high threshold, so the chosen threshold needs to be high enough that the assumptions for the GPD are valid. However, it also needs to be low enough so that there are enough data that subsequent confidence intervals will not be too wide. This is not an issue here because the chosen threshold is low enough as to be able to make meaningful inferences for meteorological purposes, in this case pertaining to extreme winds. In this work, the methods of the mean excess or mean residual life plot and the plots of scale and shape parameters against thresholds are used to choose the best ones (Coles 2007).
-
MLE is used to estimate the distribution parameters.
-
Probability and quantile plots are used to evaluate the validity of the assumptions for applying the extreme value distributions used here.
-
Return levels associated with 1/p return periods are calculated. Confidence intervals are estimated by the delta method, which assumes that the return levels are normally distributed. For shorter return periods, this assumption is generally valid; but for longer return periods, the distributions are typically fairly skewed generally leading to intervals that are too wide, particularly for the lower bounds.
-
The extremal index (θ), which measures the degree of independence among excesses, is calculated for the wind extremes, and the higher its value, the greater the independence of excesses over a threshold.
-
Declustering–independent storm method is used to obtain excess data that are more likely to be independent than the raw excesses.
-
Specifically, the runs declustering method is employed, which defines clusters as starting at the first occurrence of an excess and ending after r consecutive values drop below the threshold. Different choices for r are investigated here on cluster identification. In this paper, the GPD and GPD-P approaches are fit without and with the runs declustering method.
3 Results and discussion
3.1 GEV
The Weibull distribution presented the best fit for wind annual maximum speeds for the grid points 0, 1, 2, and 4. However, for grid points 2 and 4, confidence intervals for the shape parameter include zero so that the Gumbel hypothesis cannot be rejected. The shape parameter values for grid points 3 and 5 are very close to zero, with zero firmly inside confidence intervals. Therefore, the Gumbel distribution fits best to the annual maximum series at these grid points. Table 1 shows the best fitting model for each grid point with the respective standard deviation. Table 1 also shows the return levels associated with the 100-year return period (estimated from the best fitting distribution for each), as well as their maxima and mean values (estimated from the series themselves). Note that the predicted 100-year return levels are close to the maxima that already occurred in the region.
As can be seen in Fig. 2, most reanalysis data fall within the 1–10-year return periods suggesting that strong wind with low probability (high-return periods of 50–100) have rarely measured in the region. The limits of the confidence interval for return period values over 100 years show a curve very distant from the straight line, mainly for values related to grid point 3. The large confidence intervals for extreme return levels show that there is not enough information to make predictions with any degree of certainty to return periods over 100 years (Coles 2007). The Weibull distribution has a bounded upper tail leading to a convex return level plot with return levels reaching a plateau at this upper bound.

Return level plots of return period of annual maximum wind speed with 95% confidence intervals calculated by the delta method for each grid point
Figure 3 shows the probability and quantile plots for the GEV fitted to annual maxima. The plots show that the assumptions necessary to justify using the GEV are met because the lines are reasonably straight in all cases, with the exception of grid points 3 and 5, which show some curvature.

Plots of probability and quantile of annual maximum wind speed for each grid points
3.2 Excess over threshold—POT model and the GPD model
Table 2 shows the thresholds selected above which the excesses were fitted to the GPD with the number of excesses over the respective thresholds for each grid point. The number of occurrences of those extreme values per year corresponds to the Poisson process rate parameter (λ). The GPD is fit to the tails of daily maxima wind speeds using thresholds around 13 to 15 m/s (45 to 55 km/h) for grid points 0 and 1 yielding λ between 25 and 32 occurrences per year. Those values represent independent events and are in agreement with the values found by Gan and Rao (1991) for cyclogenesis in the region.
The parameters of the distributions fit by the GPD model for excesses with the respective standard errors are also shown. Shape parameter (ξ) values indicate that data were best fitted by the beta distribution at all grid points. In points 0, 2, and 4, values are closer to zero, indicating that the hypothesis that this parameter is zero (i.e., the exponential distribution) cannot be rejected.
In Fig. 4, it is possible to verify that very few wind speeds with longer return periods than 10 years have measured in the available period as is also found for the GEV case (cf. Fig. 2). However, return period curves for wind speed extreme values appear less accentuated than for GEV fitting, tending to linearity with confidence intervals much closer to the straight line for longer return periods. This is in concordance with not being able to reject the exponential case, which would have a straight-line return value curve. Because more data are used in fitting the GPD than the GEV distribution, there is more certainty in the estimates, resulting in confidence intervals that are narrower. However, if there is strong dependence in the excesses over the threshold, then these intervals will be unrealistically narrow. Therefore, such dependence is investigated in the next section.

Plots of return period of wind speed excess over a threshold fitted by GPD distribution with 95% confidence interval for each grid points
The quantile–quantile plots between the data, where excesses above the threshold are arranged and plotted against the values of the respective distribution for each grid point follow perfectly straight lines (not shown in this paper), indicating that the assumptions for using the GP distribution functions are reasonable.
3.3 Extremal index and declustering
The extremal index (θ) calculated using thresholds at the 90th percentile of the data at each grid point resulted in a mean value around 0.58. Those θ values characterize a relative dependence between excesses over their respective thresholds, indicating the occurrence of consecutive days of severe storms. Thus, those values could be associated with transient systems as cold fronts, with a period of 3–5 days between passages (Gan and Rao 1991).
Table 3 presents θ values for percentiles above 90%, and the wind speed values for the return periods of 10, 25, 50, and 100 years with their respective 95% confidence intervals, in parenthesis.
The declustering method is performed for r = 2 and 3, considering the length of these intervals to be consistent with the passage of frontal systems over the region, thereby keeping the independence of severe events. The best GPD fittings relating to the distribution parameters were reached using r = 3. In Fig. 5 (a) and (b), we can see that for each grid point, the number of excesses vary more with increasing thresholds when declustering is not performed. We can observe in Fig. 5 (b) the number of the cluster is less sensitive when the threshold increases. As the threshold increases, fewer excesses remain, and subsequently, fewer clusters, which may suggest that more severe excesses are associated with shorter durations. The great number of the peaks related to each cluster is in agreement with the severe events that caused sea level rising along the south and southeastern coasts of Brazil.

a Number of excesses over several thresholds using the POT model and b number of clusters after the declustering alternative method with r = 3
4 Conclusions
The main conclusions in the present EV analysis refer to comparison between the GEV and GPD models, through probability and quantile plots using wind reanalysis data set in grid points over South Atlantic region from north of Argentina to southeast Brazil. GPD fits appear more satisfactory than those for the GEV, showing better results for the return levels of the return period of 100 years. GEV fitting shows that the Weibull distribution is more suitable at points between 40° and 25° of latitude, whereas the Gumbel distribution appears to be a better model for latitudes between 25° and 23°.
The best fitting GPD is found to be the beta distribution at all locations, and the return levels for 100 years are exceeded in some points, standing, on average, close to the already occurred peaks. The GPD and PP are similar methods and present harmonious results. So, apart from small differences that result from having to estimate the parameters of the two formulations, they should be (nearly) the same by definition. Return levels for periods up to 100 years for both GEV and GPD distributions yield values very close to the maxima already registered, indicating rare strong winds occurred during the analyzed period.
The extremal index values indicate permanence of excesses in consecutive days, characterizing that the extreme wind speeds are related to the passage of transient systems. The technique of declustering is a useful tool to recognize, through the clusters, the severity of such meteorological events.
The methodology presented in this paper to analyze temporal and spatially the extreme wind speeds in grid points over the southeast ocean region of the South America was useful to identify the extreme distributions of that variable in a region where the climatological information are scarce. The use of reanalysis data in grid points over the Atlantic Ocean, from north Argentina to southeast Brazil, covering the main track of the passage of cold fronts, made it possible to analyze the statistics of wind speed behavior. In addition to analyzing the extreme distribution, it was possible to identify that the occurrence of extremes is better correlated with the passage of cold fronts than with convective systems, likewise near the southeast coast of Brazil.
The mean values were also verified for 32-year period and they presented values around 8.0 to 5.0 m/s on 10-m height level from higher to lower latitudes respectively, being considered suitable values for wind farms in agreement with Pimenta et al. (2008). Then the south and southeast Brazilian coastlines have wind resources suitable for economically attractive offshore activities.
References
An T, Pandey MD (2005) A comparision of methods of extreme wind speed estimation. Techinical note. J Wind Eng Ind Aerodyn 93:535–545
Assumpção CNB (2004) Bayesian analysis of extreme events with threshold estimation, D. Sc. thesis. Federal University of Rio de Janeiro—COPPE/UFRJ, Brazil
Bautista EAL, Zocchi SS, Angelocci LR (2004) A Distribuição Generalizada de Valores Extremos Aplicada ao Ajuste dos Dados de Velocidade Máxima do Vento em Piracicaba, São Paulo, Brasil. Revista de Matemática e Estatística 22:95–111
Bazán FAV (2005) Bootstrap techinique applied to the evaluation of statistical uncertainties in extreme analysis, M. Sc. Thesis, Federal University of Rio de Janeiro—COPPE/UFRJ, Rio de Janeiro, Brazil
Brabson BB, Palutikof JP (1999) Tests of the generalized Pareto distribution for predicting extreme wind speeds. J Appl Meteorol 39:1627–1640
Brooks HE, Lee JW, Craven JP (2003) The spatial distribution environments from global reanalysis data. Atmos Res 67–68:73–94
Cheng E, Yeung C (2002) Generalized extreme gust wind speeds distribution. J Wind Eng Ind Aerodyn 90:1657–1669
Coles S (2007) An introduction to statistical modeling of extreme values. Springer, London
de Oliveira MMF (2004) Artificial neural network to predict the meteorological tide in Paranaguá—PR, M. Sc. Thesis, Federal University of Rio de Janeiro—COPPE/UFRJ, Rio de Janeiro, Brazil
de Oliveira MMF (2009) Statistical analysis of environment data set with application of the EVT and sea level forecasting by means artificial neural network, D. Sc. Thesis, Federal University of Rio de Janeiro—COPPE/UFRJ, Rio de Janeiro, Brazil
de Oliveira MMF, Ebecken NFF, de Lima BSL, Santos IA, de Oliveira JLF (2008) EVT application to study the sea level variations and cyclones near the southeast coast of South America. In: International Meeting on South Atlantic Cyclones, Track Prediction and Risk Evolution, Rio de Janeiro, RJ, Brazil
de Oliveira MMF, Ebecken NFF, de Oliveira JLF, Santos IA (2009) Neural network to predict a storm surge. J Appl Meteorol Climatol 48:143–155
Embrecht P, Klüppelberg C, Mikosch T (1997) Modelling extremal events for insurance and finance. Springer-Verlag, Berlin
Fang X, Wang A, Fong S-K, Lin W, Lui J (2008) Changes of reanalysis-derived Northern Hemisphere summer warm extreme indices during 1948–2006 and links with climate variability. Glob Planet Change 63:67–78
Fedorova N, Levit V, de Carvalho MH (2007) Precipitation events in Pelotas-RS associated to the processes and synoptic systems. Braz J Meteorol 22:134–160
Fisher RA, Tippett LH (1928) Limiting forms of the frequency distribution of the largest or smallest member of a sample. Proc Camb Phylos Soc 24:180–190
Gan MA, Rao VB (1991) Surface cyclogenesis over South America. Mon Weather Rev 119:1293–1302
Gilleland E, Katz RW (2005) Extremes Toolkit (extremes): Weather and climate applications of extreme value statistics, national center foundation (NSF)—National Center for Atmospheric Research (NCAR)
Gilleland E, Katz RW (2006) Analyzing seasonal to interannual extreme weather and climate variability with the extremes toolkit, Research Applications Laboratory National Center for Atmospheric Research
Gonçalves RF (2007) Regional frequency analysis of extreme winds in Paraná, M. Sc., Thesis, Federal University of Paraná, Paraná, Brazil
Holmes JD, Moriarty WW (1999) Application of the generalized Pareto distribution to extreme value analysis in wind engineering. J Wind Eng Ind Aerodyn 83:1–10
Kalnay et al (1996) The NCEP/NCAR 40 year reanalysis project. Bull Am Meteorol Soc 177:437–471
Katz RW, Parlange MB, Naveau P (2002) Statistics of extremes in hydrology. Adv Water Resour 25:1287–1304
Kistler R et al (2001) The NCEP-NCAR 50-year reanalysis: monthly means CD-ROM and documentation. Bull Am Meteorol Soc 82:247–267
Mendes BVM (2004) Introduction to analysis of extreme events, 1ªth edn. Rio de Janeiro, E-papers Publisher Services Ltda, p 232
Mendes D (2006) Regimes de circulação no Atlântico Sul e sua relação com a localização e intensidade de sistemas activos e com o balanço de vapor na região, PhD. Thesis. Universidade de Lisboa, Portugal
Mendes D, Souza EP, Marengo JA, Mendes MCD (2010) Climatology of extratropical cyclones over the South American-southern oceans sector. Theor Appl Climatol 100:239–250
Michler-Cieluch T, Krause G, Buck BH (2009) Reflections on integrating operation and maintenance activities of offshore wind farms and mariculture. Ocean Coast Manage 52:57–68
Pickands J (1975) Statistical inference using order statistics. Ann Stat 3:119–131
Pimenta F, Kempton W, Garvine R (2008) Combining meteorological stations and satellite data to evaluate the offshore wind power resource of Southeastern Brazil. Renewable Energy 33:2375–2387
Rajabi MR, Modarres R (2008) Extreme value frequency analysis of wind data from Isfaham, Iran. J Wind Eng Ind Aerodyn 96:78–82
Ramesh NI, Davison AC (2002) Local models for exploratory analysis of hydrological extremes. J Hydrol 256:106–119
Satyamurty P, Ferreira CC, Gan MA (1990) Cyclonic vortices over South America. Tellus 42:194–201
Seluchi ME (1995) Diagnóstico y pronóstico de situaçiones sinópticas conducentes a ciclogénesis sobre el este de Sudamérica. Geofísica Internacional 34:171–186
Sen Z (1997) Na alternative approach for extreme values statistics of climatologic dependent variables in small samples. Theor Appl Climatol 58:169–173
Silva RR, Zocchi SS (2006) A distribuição generalizada de Pareto–Poisson no estudo da precipitação pluvial total diária máxima em Piracicaba, SP. Revista de Matemática Estatística 24:77–94
Simmonds I, Keay K (2000) Mean southern hemisphere extratropical cyclone behavior in the 40-year NCEP-NCAR reanalysis. J Climate 13:873–885
Sinclair MR (1995) A climatology of cyclogenesis for the Southern Hemisphere. Mon Weather Rev 123:1601–1619
Tennant WJ, Reason CJC (2005) Associations between the global energy cycles and regional rainfall in South Africa and Southwest Australia. J Climate 18:3032–3047
Zolina O, Kapala A, Simmer C, Gulev SK (2004) Analysis of extreme precipitation over Europe from different reanalysis: a comparative assessment. Glob Planet Change 44:129–161
Acknowledgments
The first author would like to thank the support provided by the Brazilian agency (CNPq). The extremes software package is supported by the Weather and Climate Impacts Assessment Science Program (http://www.assessment.ucar.edu), which is funded by the U.S. National Science Foundation (NSF).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License ( https://creativecommons.org/licenses/by-nc/2.0 ), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
de Oliveira, M.M.F., Ebecken, N.F.F., de Oliveira, J.L.F. et al. Generalized extreme wind speed distributions in South America over the Atlantic Ocean region. Theor Appl Climatol 104, 377–385 (2011). https://doi.org/10.1007/s00704-010-0350-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-010-0350-3