
Abstract
Aim
Diabetes health economic (HE) models play important roles in decision making. For most HE models of diabetes 2 diabetes (T2D), the core model concerns the prediction of complications. However, reviews of HE models pay little attention to the incorporation of prediction models. The objective of the current review is to investigate how prediction models have been incorporated into HE models of T2D and to identify challenges and possible solutions.
Methods
PubMed, Web of Science, Embase, and Cochrane were searched from January 1, 1997, to November 15, 2022, to identify published HE models for T2D. All models that participated in The Mount Hood Diabetes Simulation Modeling Database or previous challenges were manually searched. Data extraction was performed by two independent authors. Characteristics of HE models, their underlying prediction models, and methods of incorporating prediction models were investigated.
Results
The scoping review identified 34 HE models, including a continuous-time object-oriented model (n = 1), discrete-time state transition models (n = 18), and discrete-time discrete event simulation models (n = 15). Published prediction models were often applied to simulate complication risks, such as the UKPDS (n = 20), Framingham (n = 7), BRAVO (n = 2), NDR (n = 2), and RECODe (n = 2). Four methods were identified to combine interdependent prediction models for different complications, including random order evaluation (n = 12), simultaneous evaluation (n = 4), the ‘sunflower method’ (n = 3), and pre-defined order (n = 1). The remaining studies did not consider interdependency or reported unclearly.
Conclusions
The methodology of integrating prediction models in HE models requires further attention, especially regarding how prediction models are selected, adjusted, and ordered.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Global healthcare expenditure for diabetes showed a more than threefold increase from $232 billion in 2007 to $727 billion in 2017 for individuals aged 20–79 [1]. To help decision makers efficiently and explicitly allocate scarce resources across many interventions, health economic (HE) models, which evaluate the lifetime costs and benefits of interventions using a quantitative analysis framework, are widely used [2].
More than 90% of individuals with diabetes are diagnosed as type 2 diabetes (T2D) [3], and T2D affected nearly half a billion people worldwide in 2018 [4]. For T2D, several HE models exist and have been repeatedly applied in a wide range of settings to support decision making [5,6,7], such as the reimbursement of medications [8], prevention programs [9], and treatment strategies [10].
To simulate complications, HE models usually incorporate prediction models that mathematically combine multiple predictors to estimate the risk of diabetes-related events. For example, the UK Prospective Diabetes Study (UKPDS) risk engine [11] formulated mathematical models, with covariates such as diabetes duration, age, gender, body mass index, and glycated hemoglobin A1c (HbA1c) to estimate the probability of macrovascular and microvascular complications, such as myocardial infarction (MI), stroke, and ulcer. T2D affects multiple organ systems, resulting in numerous interdependent complications in nearly 20% of individuals [12, 13]. For example, the risk of atrial fibrillation is substantially higher following an MI [14], and a fourfold risk of stroke follows atrial fibrillation [15]. The common approach to considering this interdependency in simulations with HE models is to first properly estimate the prediction models one by one—for instance, stroke history is used as a covariate for MI—and then integrate the interdependent prediction models in the HE models, most often using random ordering of the prediction models to reduce bias [11]. Despite the simplicity of random ordering, this approach might ignore the causal relations of T2D pathology and result in inaccuracy [16], so it is important to evaluate alternative approaches for the integration of multiple prediction models for complications within HE models.
Several systematic reviews focusing on HE models or prediction models in T2D have been published, but none of them investigated the methodology of ordering prediction models. Those focused on the HE models mainly aimed to summarize [7], compare [17], and assess the available HE models [18,19,20]. Despite the availability of many prediction models [21,22,23,24], few have been applied in HE models. The most commonly used prediction models are the UKPDS [11, 25] and Framingham risk equations [26,27,28], but the selection criteria for prediction models remain unclear [29].
Therefore, the objective of this study is to assess how prediction models are incorporated into HE models for T2D and answer research questions regarding the selection and integration of prediction models in HE models. As a scoping review, we do not aim to identify and compare all HE models or prediction models for T2D or to declare one as the best. Instead, our goal is to understand how and why existing HE models incorporate prediction models as they do and to discuss challenges and possible solutions in the application of prediction models. This will inform existing and future HE models by providing insight into possible further improvements to incorporating prediction models.
Methods
This study was conducted and reported following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews (PRISMA-ScR) [30,31,32] (Table S1) and registered with the Open Science Framework (https://osf.io/8bmjc).
Literature search
A literature search was performed in PubMed, Web of Science, Embase, and Cochrane to identify published HE models for T2D since January 1, 1997 (the publication year of the model by Eastman et al. [33]). The last search was performed on November 15, 2022. The search strategy (Appendix S1) combined three elements indicating T2D, HE models and prediction models. In addition, the Diabetes Simulation Modeling Database [34] was screened to include its registered models, and all models participating in one or more past Mount Hood challenges were included based on challenge reports (Table S2).
Inclusion and exclusion criteria
Studies were included if they described HE models that estimated future health outcomes for individuals with T2D by applying prediction models. Evidence-based transition probabilities were recognized as prediction models when there was at least one independent variable as a predictor, e.g., diabetes duration or HbA1c, otherwise the paper was excluded. Papers that re-applied existing HE models without adjustment were excluded. Additionally, papers concerning other types or stages of diabetes (e.g., type 1 diabetes or pre-diabetes), particular complications of diabetes (e.g., neuropathy), or a subgroup of individuals (e.g., overweight individuals) were excluded. Finally, papers were excluded if they were not in English or their full texts were not publicly accessible. The same screening criteria were used for title, abstract, and full text.
Extracted information
A data extraction form including three key themes was constructed to collect and summarize information in a consistent and standardized format (Table S3). The three themes consist of:
1) Main HE models structure: Basic model structure, time horizon, cycle length, and taxonomy [35] based on (a) cohort- or individual-level, (b) continuous- or discrete-time, and (c) discrete event simulation or state transition model or otherwise, were summarized.
2) Complications and mortality: Health states or events, prediction models applied for each macrovascular and microvascular complication and mortality were extracted, including their characteristics, as well as the selection criteria used for the choice of prediction models, if any.
3) Methods of integrating prediction models: No taxonomy exists to categorize the methods used to integrate prediction models, so we considered the following key question when summarizing approaches: are the prediction models interdependent? If so, were prediction models run (a) simultaneously; (b) in a specific predetermined order or (c) in some other combination?
Additionally, we extracted information describing the various prediction models that were identified in the HE models, including their statistical model structure (e.g., Cox-regression or parametric regression), follow-up time, population, predictors, outcomes and methods for modeling treatment effects (Table S4).
Two reviewers (X.L. and F.L.) independently extracted and summarized information. Disagreements were resolved through discussion or consultation with a third reviewer (A.G.).
Results
The selection process yielded 1923 citations from PubMed, Embase, Cochrane, and Web of science, and 34 citations from the Mount Hood Diabetes Simulation Modeling Database or challenges. After removing duplicates, screening based on title, abstract, and full text was performed and we identified 42 papers reporting on 34 key HE models (Fig. 1 and Table 1). Some models required more than one paper to understand and fully extract their information. All extracted information can be found in Table S3 and is summarized in Tables 2–4.

Abbreviations: HE, Health economic
PRISMA flow chart for the literature review.
Model classification and the use of prediction models within different model structures
Developing HE models for diabetes is an iterative process, and many upgraded models have been built based on previous versions (Fig. 2). Many models consequently show a similar model structure (Tables 2 and 3).

Abbreviations: Cardiff, The Cardiff Diabetes Model; Caro, an economic evaluation model published by Caro et al.; CDC, an economic evaluation model published by The CDC Diabetes Cost-effectiveness Group; Eastman, an economic evaluation model published by Eastman et al.; JADE, the Januvia Diabetes Economic model; ODEM, Ontario Diabetes Economic Model; RCT, Randomized Control Trials; Tilden, an economic evaluation model published by Tilden et al.; TTM, the Treatment Transitions Model; UKPDS-OM, The UK Prospective Diabetes Study Outcomes Model
Development of some health economic models for type 2 diabetes.
Table 3 distinguishes four different model structures, including one continuous-time individual-level object-oriented model, 11 discrete-time individual-level state transition models, 15 discrete-time individual-level discrete event simulation models, and seven discrete-time cohort-level state transition models. The object-oriented model, Archimedes, applied differential equations as prediction models at the biological level. State transition models defined complications as states, with transition probabilities informed by prediction models, and thus the movement of an individual to another state indicates an event occurs in the current cycle. Discrete-time discrete event simulation models defined complications as events. Prediction models indicate the probability of event occurrence in a given time cycle. In the model simulation, these probabilities are compared with a random number drawn from a uniform distribution ranging from 0 to 1 to indicate whether an event occurs in the current cycle.
The most common states or events included in HE models were myocardial infarction (n = 23, 68%), heart failure (n = 21, 62%), and stroke (n = 14, 41%) for macrovascular complications, and retinopathy (n = 21, 62%), nephropathy (n = 19, 56%), and neuropathy (n = 18, 53%) for microvascular complications (Table S3).
Application of prediction models
Tables 4, 5 and 6, Fig. 3, and Table S4 provide an overview of prediction models that were employed in the HE decision models. Figure 4 indicates in general where and how the prediction models were applied in the HE models.

Abbreviations:ADVANCE, model for cardiovascular risk prediction in Action in Diabetes and Vascular Disease: Preterax and Diamicron Modified-release Controlled Evaluation; BMI, Body Mass Index; BRAVO, the prediction models of Building, Relating, Assessing, and Validating Outcomes diabetes microsimulation model; CHD, Congenital Heart Disease; CHIME, Chinese Hong Kong Integrated Modeling and Evaluation; CVD, Cardiovascular Disease; Framingham, Framingham risk models; HbA1c, Hemoglobin A1c; HF, Heart Failure; JJRE, Japanese Elderly Diabetes Intervention Trial risk engine; MI, Myocardial Infarction; NDR, prediction models from Swedish National Diabetes Register; QRisk, Cardiovascular Risk Score; RECODe, Risk Equations for Complications of Type 2 Diabetes; SBP, Systolic Blood Pressure; UKPDS, The UK Prospective Diabetes Study risk engine.
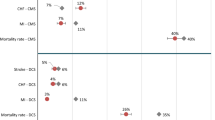
Characteristics of prediction models in type 2 diabetes health economic models.

Abbreviations:HbA1c, Hemoglobin A1c; MI, Myocardial Infarction
Flowchart of a general individual-level model structure.
Older HE models estimated their own prediction models (e.g., Eastman, Archimedes, UKPDS and EAGLE), and newer HE models used or re-estimated existing prediction models, with a few exceptions (e.g., BRAVO and JJCEM). The UKPDS risk engine (n = 20, 59%) is the most frequently used set of prediction models (Table 2), followed by the Framingham, BRAVO, NDR, RECODe models. Updated versions of HE models tend to incorporate UKPDS risk engines rather than Framingham, which was developed 20 years ago, because UKPDS is more recent (published in 2013) and has a longer follow-up (1977–2007). The most recent prediction models are CHIME (cohorts observed from 2006 to 2017 and models published in 2021), RECODe, and BRAVO (both applied the Action to Control Cardiovascular Risk in Diabetes trial cohorts observed from 2001 to 2009 and published around 2018). The rationale for choosing particular existing prediction models is unclear in most HE models. Only the SPHR model explained that this was based on discussion with the stakeholder group regarding the suitability of settings, such as country, cohort characteristics, and covariate selection.
Many HE models applied different prediction models for macrovascular and microvascular disease risks (Table S3). Some existing prediction models (e.g., Framingham, ADVANCE and QRisk2) were only applicable for macrovascular disease. In many models, microvascular disease was estimated using diabetes duration stratified constant hazard ratios, assuming implicit exponential survival models. For example, Eastman calculated transition probabilities for various microvascular health states using published evidence-based diabetes duration-related hazard ratios (Algorithms see Appendix S2). Nine subsequent models (GDM, DiDACT, CDC, Cardiff, Sheffield, TTM, IHE, MICADO, and ECHO) also applied the Eastman transition rates or adjusted rates with the same algorithm, using newly published clinical evidence.
Most HE models split mortality into two components: cardiovascular disease (CVD) mortality and other mortality (Table S3). CVD mortality was informed by prediction models (e.g., Framingham, UKPDS, and RECODe), and other mortality was either derived from local mortality statistics (e.g., national life tables) or informed by mortality prediction models. Competing risk models were often applied to avoid overestimation of the mortality risk (e.g., DiDACT, CDC, and Michigan). As an exception, GDM applied one prediction model to estimate all-cause mortality, with a random number to define whether it was CVD or other mortality.
Two methods of re-calibrating prediction models to a specific setting were identified, either adjusting the default risk (e.g., EAGLE) or reconciling the transition probability in an iterative process until reproducing findings from an external population (e.g., Grima). Another adjustment option was providing users with choices of several prediction models (e.g., IQVIA-CORE, EAGLE, IHE, and ECHO). For example, ECHO enables the users’ choice between UKPDS, ADVANCE and NDR-CVD risk equations. Finally, rather than choosing between prediction models, PRIME implemented a model averaging approach based on the “distance” between the derivation cohort and the simulated cohort to evaluate individual-level risk informed by multiple risk models, including the UKPDS and BRAVO risk engines.
Dealing with multiple complications and prediction models
Integrating selected and adjusted prediction models into a HE decision model is related to the HE model’s time cycle (Table S3). A fixed annual cycle was applied in the majority of models (n = 27, 79%), in which shorter cycles may be enabled for certain complications, such as a one-month cycle for neuropathy for COMT. Only DiDACT applied a 5-year cycle to simplify the model. A six-month cycle was applied in Tilden, JADE, and Syreon, and a one-month cycle in TTM and PREDICT. These shortened time cycles serve to ensure consistency with clinical trial data’s follow-up. Two methods were identified for incorporating prediction models with an original follow-up time other than the time cycle needed for the HE models. This was done either via algebraic compression and a constant risk assumption (e.g., GDM, RAMP, and PREDICT) or using the proportional hazard assumption and applying hazard ratios from the prediction models to survival over the duration of the time cycle from the HE model (e.g., SPHR), see Appendix S3 for algorithms.
Table 2 summarizes the methods of the combination of the prediction models. Many early HE models, especially those built before 2004, assumed no interdependence between different complications. GDM was the first model seen to assume interdependency of CVD events using the sunflower method. This method first predicted the occurrence of the next CVD event of any kind and used additional equations to predict which CVD event it would be, including combined events. This process was then repeated during the next cycle to estimate the order of events. For example, in SPHR, the QRisk2 equation estimated the CVD probability, and its nature (e.g., stroke or myocardial infarction, etc.) was determined separately by the published age- and gender-specific CVD distribution. ECHO also adopted this method as an optional choice for users.
An alternative approach is random order evaluation with interdependency. For example, IQVIA-CORE and UKPDS-OM tackled interactions among multiple complications by recording individuals’ event history in tracker variables and adjusting the risk of other complications accordingly, using dummies reflecting pre-existing complications in prediction models. To avoid possible bias, during simulations, the order of prediction models is randomly assigned for each time cycle.
A third approach is the simultaneous evaluation by lagged events information to inform on interdependencies. This approach avoids considering the interdependency of events occurring in the current cycle (e.g., MICADO). A predefined order, as the fourth approach, was applied in only JJCEM, in which the prediction model of amputation, which included retinopathy as a predictor, was run as the final model.
Treatment effects
Prediction models might be estimated from data with different treatments in place. Treatment effects were either included explicitly as a dummy variable, or implicitly as impact on risk factors. Most prediction models identified in health economic HE models only used dummy variables to reflect the use of antihypertensive medication (Framingham-stroke, ADVANCE, and QRisk2), while the effect of glucose control treatment was consistently modeled implicitly via impact on risk factors (e.g., UKPDS and JJRE). Two exceptions are that CHIME risk equations and RECODe include both antihypertensives and oral diabetes drug as dummy variables (Table S4). Statin use was also included in only these two risk equations (CHIME and RECODe), though ADVANCE included statin in the variable selection phase but it was finally dropped by stepwise approach.
Two methods were identified for modeling treatment effects while applying prediction models that do not explicitly consider treatment effects as dummy variables. One method applies relative risks or conditional probabilities (e.g., treatment-specific states and transition probabilities applied in IMIB). The other method estimates the effect of treatment on underlying risk factors (e.g., in Cardiff, the effect of medication on HbA1c was modeled via an update of HbA1c levels in a treatment module that, in turn, altered the probabilities of events, see Fig. 4). Treatment modules may also allow treatment switches, mimicking clinical practice. The trigger for this switch depended on an evidence-based transition matrix (e.g., DiDACT) or on individuals’ clinical indicators, such as a specific HbA1c level or diabetes duration (e.g., JADE).
Treatment compliance was considered in 6 (18%) models (Eastman, GDM, Michigan model, Tilden, Syreon, ECHO), by specifying the rate of individual compliance or simulating HbA1c levels between standard care (e.g., 10%) and comprehensive care (e.g., 7.2%).
Discussion
We found four solutions for dealing with the interdependency of prediction models in HE simulation models. All approaches required several assumptions, and no new approaches were introduced in recent years. For many models, it was difficult to determine the exact methods applied because of the lack of transparency in reporting and the ambiguity of the terminology applied.
The pros and cons of various HE modeling structures have been widely discussed [7, 36, 37]. Our study investigated HE models from the perspective of incorporating prediction models. Individual-level discrete event simulation models would be the most straightforward structure, because individual-level models can be well informed directly by common prediction models, while cohort-level models require extra implementation steps (e.g., converting information from prediction models into relative risks or using mean risk factor values to inform prediction models). Additionally, as a result of Markov property assumptions, state transition models usually cannot easily accommodate prediction models that explicitly include duration, while discrete event simulation models can easily keep track of time as an attribute and hence directly use time-to-event prediction models.
Confirming previous studies [38, 39], we did not find a clear preference for certain prediction models. The likely explanation of UKPDS risk engine being the most commonly used prediction model, is that it is the first risk engine developed in a T2D population, covers most T2D complications, and has a high degree of transparency in describing its algorithm and coefficients [25]. However, the rationale for adopting specific prediction models in HE models has been underreported.
Being referenced or recommended in clinical guidelines could be one rationale for incorporating specific prediction models into HE models [40]. For instance, a risk calculator [41] is recommended for estimating the risk of ASCVD in American diabetes guidelines [42] and the UKPDS risk engine is referenced to measure CVD risk in European diabetes guidelines [43]. Since clinical prediction models have higher calibration requirements than HE models [44], such inclusion in guidelines could be seen as support for these prediction models. However, clinical prediction models and HE models may deviate in requirements regarding variable selection. Clinical prediction models often prefer including fewer predictors, which are available in routine care, whereas HE models may want to cover all of their modeled risk factors. When using clinical trials as main source of input this might be a wider range of predictors than those in routine care. In addition, for clinical application, discrimination next to calibration is very important [45], while for HE models, with their focus on aggregate outcomes, calibration-in-the-large will be the most important [46]. Due to these distinct scopes and requirements, clinical guideline-recommended prediction models are not always the best fit for HE models. For example, NDR performed better than UKPDS risk model for well-treated individuals, whereas UKPDS risk model performed better for the older UK cohort, indicating that the choice should reflect the specifics of the application [47].
In our opinion, several criteria could help select suitable prediction models as follows (multiple sets of prediction models can be chosen at the same time):
-
1.
Time period: The UKPDS risk engine allows to validate modeling a population for a long-time horizon (17.6-year median follow-up), but covers a somewhat older time period (1977–2007). CHIME risk model suits well with short-term and recent time horizons (4-year mean follow-up until 2017).
-
2.
Population: JJRE, CHIME, and the Chinese Hong Kong registry risk models suit well with an Asian population; NDR suits well with a European population; QRisk and UKPDS were developed in UK populations; BRAVO and RECODe were developed in US populations. If a mixture of multiple ethnic groups is of interest, UKPDS, EAGLE, QRisk, RECODe, and BRAVO which consider ethnic groups as a predictor, are suitable.
-
3.
The available predictors are listed in Table 5 and could guide choice of prediction model(s). Of note, unavailable risk factors, such as white blood cell counts, may be imputed, enlarging the applicability of prediction models [48]. If information about both events and medication use is available, CHIME and RECODe are suitable.
-
4.
Outcomes of interest can be found in Table 6. NDR, ADVANCE, and QRisk predict the aggregate CVD, while UKPDS, BRAVO, CHIME, and RECODe predict each separate CVD event (i.e., MI, stroke and others). For prediction of subsequent events (i.e., the second or next time of occurring), NDR and UKPDS offer most details. If microvascular diseases are of interest, UKPDS, EAGLE, BRAVO, and CHIME suit well.
Once prediction models are selected, properly incorporating them into HE models requires attention to recalibration and adjustment. When data are available, recalibrating prediction models is important if the cohort of deriving prediction models differs from that of the application at hand in a HE model. For example, UKPDS-OM2 poorly predicted the CANVAS program outcomes, but recalibrating intercepts and refitting the coefficients, while preserving the UKPDS-OM2 structure, substantially improved the fit [49]. That is, the recalibration of the prediction models based on available data or characteristics to the setting of interest involves adjusting the intercept (for logistic regression models) or the baseline survival function (for survival regression models) and adjusting regression coefficients for prediction models [24, 50,51,52]. Furthermore, especially when data for recalibration are unavailable, applying different sets of prediction models in HE models for the same outcome might help to overcome differences between populations. The weighted model averaging approach [53] could be applied to summarize multiple predictions. Alternatively, different prediction models could inform best-case or worst-case risk predictions and enable quantifying the structural uncertainty caused by prediction model choice [54,55,56]. This would inform HE model users better than a single prediction model.
Interdependency is increasingly incorporated when combining prediction models in HE models, but the order problem currently shows only four solutions: random ordering, the sunflower method, using lagged events or using a predefined order. Random ordering is the most common approach for recent HE models in T2D. Despite its advantage of simplicity, it might ignore potential biologically more plausible sequences of T2D complications. Alternative approaches therefore deserve further investigation, and we recommended to use them in different study designs accordingly and compare results to random ordering, to check which works best:
-
1.
When the HE model is defined in continuous time: Use the vertical modeling approach [57, 58], as the continuous-time version of the sunflower method in the statistical analysis to derive prediction models. Both methods decompose the joint probability by looking first at the time of the event and then its cause at the time of failure based on observable quantities, such as relative cause-specific hazards [16, 57, 58]. However, vertical modeling is a continuous-time model that integrates time-proportional hazards and logistic regression with covariates [57, 58]. The sunflower method is a discrete-time method that compares the estimated time-related incidence rate to the relative event frequency [16].
-
2.
When the HE model is defined in discrete time, and the event progression is moderate during one cycle: Use linked-equations with a time-lagging structure to minimize the effects of endogeneity, like this has been applied in HE models of chronic obstructive pulmonary disease [59].
-
3.
When pathology and an estimation of the sequence of events are of interest: Use directed acyclic graphs [60, 61] or the network approach [62] which unravel the pathological sequence of complications to find a causal diagram to guide interdependencies.
-
4.
When running time is not a major concern, the most straightforward method is to reduce the cycle length (to, e.g., monthly cycles). As all health statuses will then be more frequently updated, the bias introduced by ordering will be reduced [15].
The distinct methods of treatment effect integration we identified (either by the change of risk factors or dummy variables) may influence what sources of evidence can be handled. Treatment effects as indicated by risk factors, could use effect estimates from either randomized control trials or real-world evidence, and enable relatively straightforward updates of such effects. However, they risk underestimating effects that run via routes other than risk factor levels. For example, the effect of sodium-glucose cotransporter-2 inhibitors on the risk of cardiovascular complications may be underestimated when modeled based on risk factor levels alone, and trial-observed hazard ratios may provide the best fit [63]. Therefore, we recommend future HE models to adopt a hybrid approach which supplement surrogate risk factors with directly observed event rate changes [64], by incorporating both event rate changes resulting from treatment-induced risk-factor-level changes through prediction models and direct event rate changes indicated by direct evidence from observations (e.g., hazard ratios from trials). Of note, double counting should be avoided by estimating the gap between the risk-factor induced and observed event rate changes, and adjusting estimated to observed event rate changes for the trial follow-up period only. Any assumptions regarding treatment effects beyond the trial follow-up period should be clearly and transparently reported [65].
Treatment switches were modeled using a transition matrix or threshold-levels of risk factors. However, switches might also be triggered by events (e.g., CVD) regardless of past medication [66]. Therefore, future studies might consider treatment switches triggered by events or tracker variables. Furthermore, many HE models did not adequately integrate treatment compliance and persistence, which potentially affects the estimated cost-effectiveness of treatment. Future studies might incorporate compliance by establishing rates of disease progression (e.g., transition probabilities) or risk factor levels as functions of individual compliance [67].
HE models are becoming increasingly complicated and have integrated more interdependent prediction models, so transparency has become more difficult and important to achieve. Although the continuous-time model, Archimedes, was successfully validated with 18 trials (correlation = 0.99) [68], it has been criticized because of its high complexity and low transparency [37], indicating the necessity of balancing transparency and complexity when incorporating prediction models. Although there are reporting and transparency guidelines or checklists for HE models [69], prediction models [70], and diabetes modeling in particular [65], these guidelines neglect aspects valuable in estimating prediction models with the purpose of subsequently using them in HEs. These aspects include the order and interdependency of prediction models (i.e., how to order the interdependent prediction models to reflect causal relations of diabetes complications). The Diabetes Modelling Input Checklist [65] might be applied to improve model transparency. This requires clearly describing the assumption of treatment effect and the source of the risk equations for the model. Additionally, reporting the method of integrating prediction models and possible recalibration might be helpful. Furthermore, attending networks, such as the Mount Hood Diabetes Challenge Network; maintaining model registries; and reporting results from reference case simulations will improve transparency and confidence in models and ultimately improve decision-making [71].
Despite the study’s strengths, it has limitations. First, only one reviewer screened searches and selected papers. However, compared to other reviews, we did not miss any models to the best of our knowledge. Second, contrary to other reviews, we did not assess HE models’ quality but rather focused on the methodology. To get overview of all methods and prediction models applied, we did not restrict the time of publishing or the HE model’s validity. Most HE models we investigated were validated internally and externally with a satisfactory quality [7, 20, 37]. Previous studies could be consulted if the validity [7, 20, 37], quality [7, 20, 37], and suitability [20] of T2D HE models are the primary areas of interest. Finally, we could not identify an existing categorization of methods to combine prediction models into HE models and hence had to use our own terminology.
In conclusion, descriptions of prediction model integration methods in HE models tend to be ambiguous, while methods used to combine them seemed somewhat outdated, creating the need for clarification and improvement. We sought to mitigate this need by addressing the gap in assessing how prediction models that calculate complication risks are incorporated in T2D HE models. Currently, an increasing number of T2D HE models are being developed and updated for a wide range of countries, populations, complications, treatments, and indicators, enhancing the need for proper integration of prediction models. Thus, more attention should be focused on the methodology of choosing, adjusting, and ordering prediction models and the transparency of these approaches.
References
Standl E, Khunti K, Hansen TB, Schnell O (2019) The global epidemics of diabetes in the 21st century: current situation and perspectives. Eur J Prevent Cardiol 26(2_suppl):7–14. https://doi.org/10.1177/2047487319881021
Aalabaf-Sabaghi M (2007) Decision modelling for health economic evaluation. J Epidemiol Commun Health. https://doi.org/10.1136/jech.2007.059576
IDF Diabetes Atlas 10th edition. Available from https://diabetesatlas.org/atlas/tenth-edition/?dlmodal=active&dlsrc=https%3A%2F%2Fdiabetesatlas.org%2Fidfawp%2Fresource-files%2F2021%2F07%2FIDF_Atlas_10th_Edition_2021.pdf. Accessed 25th May 2022
Roglic G (2016) WHO global report on diabetes: a summary. Int J Noncommun Dis 1(1):1–3
Chen J, Alemao E, Yin D, Cook J (2008) Development of a diabetes treatment simulation model: with application to assessing alternative treatment intensification strategies on survival and diabetes-related complications. Diabet Obes Metab 10:33–42. https://doi.org/10.1111/j.1463-1326.2008.00885.x
van Giessen A, Peters J, Wilcher B et al (2017) Systematic review of health economic impact evaluations of risk prediction models: stop developing, start evaluating. Value Health 20(4):718–726. https://doi.org/10.1016/j.jval.2017.01.001
Govan L, Olivia W, Lindsay R, Briggs A (2015) How do diabetes models measure up? a review of diabetes economic models and ADA guidelines. J Health Econ Outcomes Res 3(2):132–152. https://doi.org/10.36469/9831
Pawaskar M, Bilir SP, Kowal S, Gonzalez C, Rajpathak S, Davies G (2019) Cost-effectiveness of intensification with sodium-glucose co-transporter-2 inhibitors in patients with type 2 diabetes on metformin and sitagliptin vs direct intensification with insulin in the United Kingdom. Diabetes Obes Metab 21(4):1010–1017. https://doi.org/10.1111/dom.13618
Gilmer T, O’Connor PJ, Schiff JS et al (2018) Cost-effectiveness of a community-based diabetes prevention program with participation incentives for Medicaid beneficiaries. Health Serv Res 53(6):4704–4724. https://doi.org/10.1111/1475-6773.12973
Hellgren M, Svensson AM, Franzen S et al (2021) The burden of poor glycaemic control in people with newly diagnosed type 2 diabetes in Sweden: A health economic modelling analysis based on nationwide data. Diabetes Obes Metab 23(7):1604–1613. https://doi.org/10.1111/dom.14376
Hayes AJ, Leal J, Gray AM, Holman RR, Clarke PM (2013) UKPDS Outcomes Model 2: a new version of a model to simulate lifetime health outcomes of patients with type 2 diabetes mellitus using data from the 30 year united kingdom prospective diabetes study: UKPDS 82. Diabetologia 56(9):1925–1933. https://doi.org/10.1007/s00125-013-2940-y
American Diabetes Association Consensus Panel (2004) Guidelines for computer modeling of diabetes and its complications. Diabetes Care 27(9):2262–2265
Morgan CL, Currie CJ, Stott NCH, Smithers M, Butler CC, Peters JR (2000) The prevalence of multiple diabetes-related complications. In. 17:146–151
Jabre P, Jouven X, Adnet F et al (2011) Atrial fibrillation and death after myocardial infarction a community study. Circulation 123(19):2094–2100. https://doi.org/10.1161/Circulationaha.110.990192
Kazemian P, Wexler DJ, Fields NF, Parker RA, Zheng A, Walensky RP (2019) Development and validation of PREDICT-DM: a new microsimulation model to project and evaluate complications and treatments of type 2 diabetes mellitus. Diabet Technol Therapeut 21(6):344–355. https://doi.org/10.1089/dia.2018.0393
Brown JB, Russell A, Chan W, Pedula K, Aickin M (2000) The global diabetes model: user friendly version 3.0. Diabet Res Clin Pr. https://doi.org/10.1016/S0168-8227(00)00215-1
Charokopou M, Sabater FJ, Townsend R, Roudaut M, McEwan P, Verheggen BG (2016) Methods applied in cost-effectiveness models for treatment strategies in type 2 diabetes mellitus and their use in Health technology assessments: a systematic review of the literature from 2008 to 2013. Curr Med Res Opin 32(2):207–218. https://doi.org/10.1185/03007995.2015.1102722
Rinaldi G, Hijazi A, Haghparast-Bidgoli H (2019) Cost and cost-effectiveness of mHealth interventions for the prevention and control of type 2 diabetes mellitus: a protocol for a systematic review. BMJ Open 9(4):e027490–e027490. https://doi.org/10.1136/bmjopen-2018-027490
Becker C, Langer A, Leidl R (2011) The quality of three decision-analytic diabetes models: a systematic health economic assessment. Exp Rev Pharmacoecon Outcomes Res 11(6):751–762. https://doi.org/10.1586/erp.11.68
Li JY, Bao Y, Chen XD, Tian LM (2021) Decision models in type 2 diabetes mellitus: a systematic review. Acta Diabetol 58(11):1451–1469. https://doi.org/10.1007/s00592-021-01742-6
Van Dieren S, Beulens JWJ, Kengne AP et al (2012) Prediction models for the risk of cardiovascular disease in patients with type 2 diabetes: a systematic review. Heart 98(5):360–369. https://doi.org/10.1136/heartjnl-2011-300734
Lagani V, Koumakis L, Chiarugi F, Lakasing E, Tsamardinos I (2013) A systematic review of predictive risk models for diabetes complications based on large scale clinical studies. J Diabet Complicat 27(4):407–413. https://doi.org/10.1016/j.jdiacomp.2012.11.003
Collins GS, Mallett S, Omar O, Yu LM (2011) Developing risk prediction models for type 2 diabetes: a systematic review of methodology and reporting. BMC Med. https://doi.org/10.1186/1741-7015-9-103
Abbasi A, Peelen LM, Corpeleijn E et al (2012) Prediction models for risk of developing type 2 diabetes: systematic literature search and independent external validation study. BMJ. https://doi.org/10.1136/bmj.e5900
Clarke PM, Gray AM, Briggs A, Farmer AJ, Fenn P, Stevens RJ, Matthews DR, Stratton IM, Holman RR (2004) A model to estimate the lifetime health outcomes of patients with Type 2 diabetes: the United Kingdom Prospective diabetes study (UKPDS) outcomes model (UKPDS no. 68). Diabetologia 47(10):1747–1759. https://doi.org/10.1007/s00125-004-1527-z
Anderson KM, Odell PM, Wilson PWF, Kannel WB (1991) Cardiovascular disease risk profiles. Am Heart J. https://doi.org/10.1016/0002-8703(91)90861-B
D’Agostino RB, Wolf PA, Belanger AJ, Kannel WB (1994) Stroke risk profile: Adjustment for antihypertensive medication the framingham study. Stroke. https://doi.org/10.1161/01.STR.25.1.40
Wilson PWF, D’Agostino RB, Levy D, Belanger AM, Silbershatz H, Kannel WB (1998) Prediction of coronary heart disease using risk factor categories. Circulation. https://doi.org/10.1161/01.CIR.97.18.1837
Watson P, Preston L, Squires H, Chilcott J, Brennan A (2014) Modelling the economics of type 2 diabetes mellitus prevention: a literature review of methods. Appl Health Econ Health Policy 12(3):239–253. https://doi.org/10.1007/s40258-014-0091-z
Moher D, Liberati A, Tetzlaff J, Altman DG (2009) Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. PLoS Med 6(7):e1000097. https://doi.org/10.1371/journal.pmed.1000097
Tricco AC, Zarin LE, O’Brien KKE, Colquhoun H, Levac D (2018) Preferred reporting items for systematic reviews and meta-analyses extension for scoping reviews (PRISMA-ScR) checklist. Ann Intern Med 169(7):11–12. https://doi.org/10.7326/M18-0850.2
Vrabel M (2015) Preferred reporting items for systematic reviews and meta-analyses. Oncol Nurs Forum 42(5):552–554. https://doi.org/10.1188/15.ONF.552-554
Eastman RC, Javitt JC, Herman WH et al (1997) Model of complications of NIDDM: I Model construction and assumptions. Diabet Care 20(5):725–734. https://doi.org/10.2337/diacare.20.5.725
mthooddiabeteschallenge.com. Available from https://www.mthooddiabeteschallenge.com/registry
Experiments N (2008) A taxonomy of model structures for economic evaluationof health technologies. 1131(2007): 1127-1131. https://doi.org/10.1002/hec
Yi Y, Philips Z, Bergman G, Burslem K (2010) Economic models in type 2 diabetes. Curr Med Res Opin 26(9):2105–2118. https://doi.org/10.1185/03007995.2010.494451
Dadwani RS, Laiteerapong N (2020) Economic simulation modeling in type 2 diabetes. Curr Diabet Rep. https://doi.org/10.1007/s11892-020-01306-y
Palmer AJ (2013) Computer modeling of diabetes and its complications: A report on the fifth mount Hood challenge meeting. Value Health 16(4):670–685. https://doi.org/10.1016/j.jval.2013.01.002
Palmer AJ, Roze S, Valentine WJ et al (2007) Computer modeling of diabetes and its complications: a report on the fourth Mount Hood challenge meeting. Diabet Care 30(6):1638–1646. https://doi.org/10.2337/dc07-9919
Betts MB, Milev S, Hoog M et al (2019) Comparison of recommendations and use of cardiovascular risk equations by health technology assessment agencies and clinical guidelines. Value Health 22(2):210–219. https://doi.org/10.1016/j.jval.2018.08.003
Association TACoCAH ASCVD risk calculator Available from https://tools.acc.org/ascvd-risk-estimator-plus/#!/calculate/estimate/. Accessed 11 Nov 2022
American Diabetes Association Professional Practice C (2022) 10. Cardiovascular Disease and Risk Management: Standards of Medical Care in Diabetes-2022. Diabetes Care 45(Suppl 1): S144-S174. https://doi.org/10.2337/dc22-S010
Grant PJ, Cosentino F (2019) The 2019 ESC Guidelines on diabetes, pre-diabetes, and cardiovascular diseases developed in collaboration with the EASD. Eur Heart J 40(39):3215–3217. https://doi.org/10.1093/eurheartj/ehz687
Tripepi G, Heinze G, Jager KJ, Stel VS, Dekker FW, Zoccali C (2013) Risk prediction models. Nephrol Dial Transpl 28(8):1975–1980. https://doi.org/10.1093/ndt/gft095
Alba AC, Agoritsas T, Walsh M et al (2017) Discrimination and calibration of clinical prediction models users’ guides to the medical literature. Jama-J Am Med Assoc 318(14):1377–1384. https://doi.org/10.1001/jama.2017.12126
Emamipour S, Pagano E, Di Cuonzo D et al (2022) The transferability and validity of a population-level simulation model for the economic evaluation of interventions in diabetes: the MICADO model. Acta Diabetol 59(7):949–957. https://doi.org/10.1007/s00592-022-01891-2
Lundqvist A, Carlsson KS, Johansen P, Andersson E, Willis M (2014) Validation of the IHE cohort model of type 2 diabetes and the impact of choice of macrovascular risk equations. PLoS ONE 9(10):e110235. https://doi.org/10.1371/journal.pone.0110235
Pagano E, Konings SRA, Di Cuonzo D et al (2021) Prediction of mortality and major cardiovascular complications in type 2 diabetes: external validation of UK Prospective diabetes study outcomes model version 2 in two European observational cohorts. Diabetes Obes Metab 23(5):1084–1091. https://doi.org/10.1111/dom.14311
Willis M, Asseburg C, Slee A, Nilsson A, Neslusan C (2021) Macrovascular risk equations based on the CANVAS program. PharmacoEconomics 39(4):447–461. https://doi.org/10.1007/s40273-021-01001-0
Van Houwelingen HC (2000) Validation, calibration, revision and combination of prognostic survival models. Statistics Med 19(24):3401–3415
Vergouwe Y, Moons KGM, Steyerberg EW (2010) External validity of risk models: Use of benchmark values to disentangle a case-mix effect from incorrect coefficients. Am J Epidemiol 172(8):971–980. https://doi.org/10.1093/aje/kwq223
Janssen KJM, Moons KGM, Kalkman CJ, Grobbee DE, Vergouwe Y (2008) Updating methods improved the performance of a clinical prediction model in new patients. J Clin Epidemiol. https://doi.org/10.1016/j.jclinepi.2007.04.018
Pollock RF, Norrbacka K, Boye KS, Osumili B, Valentine WJ (2022) The PRIME Type 2 Diabetes Model: a novel, patient-level model for estimating long-term clinical and cost outcomes in patients with type 2 diabetes mellitus. J Med Econ 25(1):393–402
McEwan P, Ward T, Bennett H, Bergenheim K (2014) Comparing the event prediction capability of the UKPDS68 and Hong Kong diabetes risk equations within a type 2 diabetes simulation model. Value Health 17(7):A729–A730. https://doi.org/10.1016/j.jval.2014.08.074
Olivieri AV, Ramos M, Altrabsheh E, Monteiro S, Gurjar K, Lamotte M (2019) PDB26 contrasting three type 2 diabetes cardiovascular risk equations for east Asia with ukpds82 using the IQVIA core diabetes model. Value Health 22:S144. https://doi.org/10.1016/j.jval.2019.04.576
Asseburg C, Johansen P, Nilsson A, Willis M (2015) Impact of the Framingham offspring study (FOS) vs Kaiser Permanente NorthWest (KPNW) prediction equations for diabetes mellitus in economic modelling of type 2 diabetes mellitus. Diabetologia 58(1):S481. https://doi.org/10.1007/s00125-015-3687-4
Nicolaie MA, Van Houwelingen HC, Putter H (2010) Vertical modeling: a pattern mixture approach for competing risks modeling. Stat Med. https://doi.org/10.1002/sim.3844
Nicolaie MA, Taylor JMG, Legrand C (2019) Vertical modeling: analysis of competing risks data with a cure fraction. Lifetime Data Anal. https://doi.org/10.1007/s10985-018-9417-8
Exuzides A, Colby C, Briggs AH et al (2017) Statistical modeling of disease progression for chronic obstructive pulmonary disease using data from the ECLIPSE study. Med Decis Making 37(4):453–468. https://doi.org/10.1177/0272989x15610781
Siriwardhana C, Lim E, Davis J, Chen JJ (2018) Progression of diabetes, ischemic heart disease, and chronic kidney disease in a three chronic conditions multistate model. BMC Public Health 18(1):1–14. https://doi.org/10.1186/s12889-018-5688-y
Hoogenveen RT, Feenstra TL, van Baal PHM, Baan CA (2005) A conceptual framework for budget allocation in the RIVM Chronic Disease Model. A case study of Diabetes mellitus. 1-66
Hossain ME, Uddin S, Khan A, Moni MA (2020) A framework to understand the progression of cardiovascular disease for type 2 diabetes mellitus patients using a network approach. Int J Env Res Pub He 17(2):596. https://doi.org/10.3390/ijerph17020596
Si L, Willis MS, Asseburg C et al (2020) Evaluating the ability of economic models of diabetes to simulate new cardiovascular outcomes trials: a report on the ninth Mount Hood diabetes challenge. Value Health 23(9):1163–1170. https://doi.org/10.1016/j.jval.2020.04.1832
McEwan P, Bennett H, Khunti K et al (2020) Assessing the cost-effectiveness of sodium-glucose cotransporter-2 inhibitors in type 2 diabetes mellitus: a comprehensive economic evaluation using clinical trial and real-world evidence. Diabetes Obes Metab 22(12):2364–2374. https://doi.org/10.1111/dom.14162
Palmer AJ, Si L, Tew M et al (2018) Computer modeling of diabetes and its transparency: a report on the eighth mount hood challenge. Value Health 21(6):724–731. https://doi.org/10.1016/j.jval.2018.02.002
Association AD (2021) 9. Pharmacologic approaches to glycemic treatment: Standards of Medical Care in Diabetes—2021. Diabetes Care 44(Supplement 1): S111-S124
Hughes D, Cowell W, Koncz T, Cramer J (2007) Methods for integrating medication compliance and persistence in pharmacoeconomic evaluations. Value Health 10(6):498–509. https://doi.org/10.1111/j.1524-4733.2007.00205.x
Eddy DM, Schlessinger L (2003) Validation of the archimedes diabetes model. Diabet Care 26(11):3102–3110. https://doi.org/10.2337/diacare.26.11.3102
Husereau D, Drummond M, Augustovski F et al (2022) Consolidated health economic evaluation reporting standards 2022 (CHEERS 2022) statement: updated reporting guidance for health economic evaluations. Value Health 25(1):3–9. https://doi.org/10.1016/j.jval.2021.11.1351
Moons KGM, Altman DG, Reitsma JB et al (2015) Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): Explanation and elaboration. Ann Internal Med. https://doi.org/10.7326/M14-0698
Kent S, Becker F, Feenstra T et al (2019) The challenge of transparency and validation in health economic decision modelling: a view from mount hood. Pharmacoeconomics 37(11):1305–1312. https://doi.org/10.1007/s40273-019-00825-1
Schlessinger L, Eddy DM (2002) Archimedes: a new model for simulating health care systems—The mathematical formulation. J Biomed Inf 35(1):37–50. https://doi.org/10.1016/S1532-0464(02)00006-0
Eddy DM, Schlessinger L (2003) Archimedes—a trial-validated model of diabetes. Diabet Care 26(11):3093–3101. https://doi.org/10.2337/diacare.26.11.3093
Shao H, Fonseca V, Stoecker C, Liu S, Shi L (2018) Novel Risk engine for diabetes progression and mortality in USA: building, relating, assaessing, and validating outcomes (BRAVO). PharmacoEconomics 36(9):1125–1134. https://doi.org/10.1007/s40273-018-0662-1
McEwan P, Peters JR, Bergenheim K, Currie CJ (2006) Evaluation of the costs and outcomes from changes in risk factors in type 2 diabetes using the Cardiff stochastic simulation cost-utility model (DiabForecaster). Curr Med Res Opin 22(1):121–129. https://doi.org/10.1185/030079906X80350
Caro JJ, Klittich WS, Raggio G et al (2000) Economic assessment of troglitazone as an adjunct to sulfonylurea therapy in the treatment of type 2 diabetes. Clin Therapeut 22(1):116–127. https://doi.org/10.1016/S0149-2918(00)87983-7
Caro JJ, Ward AJ, O’Brien JA (2002) Lifetime costs of complications resulting from type 2 diabetes in the US. Diabet Care 25(3):476–481. https://doi.org/10.2337/diacare.25.3.476
The CDCDC-ESG (1998) The Cost-effectiveness of Screening for Type 2 Diabetes
Group CDCDC-E (2002) Cost-effectiveness of intensive glycemic and serum cholesterol level reduction for type 2 diabetes. Jama 287(19): 2542-2551
Press R (2009) Validation of the CDC-RTI Diabetes Cost-Effectiveness Model. Published online
Quan J, Ng CS, Kwok HHY et al (2021) Development and validation of the CHIME simulation model to assess lifetime health outcomes of prediabetes and type 2 diabetes in Chinese populations: a modeling study. PLoS Med 18(6):e1003692. https://doi.org/10.1371/journal.pmed.1003692
Wu B, Ma J, Zhang S, Zhou L, Wu H (2018) Development and validation of a Health Policy Model of Type 2 diabetes in Chinese setting. J Comp Effectiveness Res 7(8):749–763. https://doi.org/10.2217/cer-2018-0001
Su ZT, Bartelt-Hofer J, Brown S et al (2020) The use of computer simulation modeling to estimate complications in patients with type 2 diabetes mellitus: comparative validation of the cornerstone diabetes simulation model. PharmacoEcon Open 4(1):37–44. https://doi.org/10.1007/s41669-019-0156-x
Bagust A, Hopkinson PK, Maier W, Currie CJ (2001) An economic model of the long-term health care burden of type II diabetes. Diabetologia 44(12):2140–2155. https://doi.org/10.1007/s001250100023
Brändle M, Azoulay M, Greiner RA (2011) Cost-effectiveness of insulin glargine versus NPH insulin for the treatment of Type 2 diabetes mellitus, modeling the interaction between hypoglycemia and glycemic control in Switzerland. Int J Clin Pharmacol Therapeut 49(3):217–230. https://doi.org/10.5414/CPP49217
Mueller E, Maxion-Bergemann S, Gultyaev D et al (2006) Development and validation of the economic assessment of glycemic control and long-term effects of diabetes (EAGLE) model. Diabet Technol Therapeut 8(2):219–236
Eastman RC, Javitt JC, Herman WH et al (1997) Model of complications of NIDDM: II analysis of the health benefits and cost-effectiveness of treating NIDDM with the goal of normoglycemia. Diabet Care 20(5):735–744
Willis M, Johansen P, Nilsson A, Asseburg C (2017) Validation of the economic and health outcomes model of type 2 diabetes mellitus (ECHO-T2DM). PharmacoEconomics 35(3):375–396. https://doi.org/10.1007/s40273-016-0471-3
Grima DT, Thompson MF, Sauriol L (2007) Modelling cost effectiveness of insulin glargine for the treatment of type 1 and 2 diabetes in Canada. PharmacoEconomics 25(3):253–266. https://doi.org/10.2165/00019053-200725030-00007
Steen Carlsson K, Persson U (2014) Cost-effectiveness of add-on treatments to metformin in a Swedish setting: liraglutide vs sulphonylurea or sitagplitin. J Med Econ 17(9):658–669. https://doi.org/10.3111/13696998.2014.933110
Palmer AJ, Brandt A, Gozzoli V, Weiss C, Stock H, Wenzel H (2000) Outline of a diabetes disease management model: principles and applications. Diabetes Res Clin Pr 50(SUPPL. 3):47–56. https://doi.org/10.1016/S0168-8227(00)00216-3
Palmer AJ, Weiss C, Sendi PP et al (2000) The cost-effectiveness of different management strategies for type I diabetes: a Swiss perspective. Diabetologia 43(1):13–26. https://doi.org/10.1007/s001250050003
Palmer AJ, Roze S, Valentine WJ et al (2004) The CORE Diabetes Model: Projecting long-term clinical outcomes, costs and cost-effectiveness of interventions in diabetes mellitus (types 1 and 2) to support clinical and reimbursement decision-making. Curr Med Res Opin 20(Suppl 1):S5-26. https://doi.org/10.1185/030079904X1980
Tanaka S, Langer J, Morton T et al (2021) Developing a health economic model for Asians with type 2 diabetes based on the Japan diabetes complications study and the Japanese elderly diabetes intervention trial. BMJ Open Diabet Res Care 9(1):e002177. https://doi.org/10.1136/bmjdrc-2021-002177
van der Heijden AA, Feenstra TL, Hoogenveen RT et al (2015) Policy evaluation in diabetes prevention and treatment using a population-based macro simulation model: the MICADO model. Diabet Med 32(12):1580–1587. https://doi.org/10.1111/dme.12811
Baan CA, Bos G, Jacobs-van der Bruggen MAM (2005) Modeling chronic diseases: the diabetes module justification of (new) input data. pp. 1–33
Zhou H, Isaman DJM, Messinger S et al (2005) A computer simulation model of diabetes progression, quality of life, and cost. Diabet Care 28(12):2856–2863. https://doi.org/10.2337/diacare.28.12.2856
Medical Advisory S (2009) Application of the ontario diabetes economic model (ODEM) to determine the cost-effectiveness and budget impact of selected type 2 diabetes interventions in ontario. Ont Health Technol Assess Ser 9(25):1–21
Schramm W, Sailer F, Pobiruchin M, Weiss C open source disease models for diabetes mellitus. Available from https://www.prosit.de/index.php/Main_Page
Jiao F, Wan EYF, Fung CSC et al (2019) Cost-effectiveness of a primary care multidisciplinary risk assessment and management program for patients with diabetes mellitus (RAMP-DM) over lifetime. Endocrine 63(2):259–269. https://doi.org/10.1007/s12020-018-1727-9
Gillett M, Dallosso HM, Dixon S et al (2010) Delivering the diabetes education and self management for ongoing and newly diagnosed (DESMOND) programme for people with newly diagnosed type 2 diabetes: cost effectiveness analysis. BMJ 341:7770. https://doi.org/10.1136/bmj.c4093
Breeze PR, Thomas C, Squires H et al (2017) The impact of Type 2 diabetes prevention programmes based on risk-identification and lifestyle intervention intensity strategies: a cost-effectiveness analysis. Diabet Med A J Br Diabet Assoc 34(5):632–640. https://doi.org/10.1111/dme.13314
Nagy B, Zsolyom A (2016) Cost-effectiveness of a risk-based secondary screening programme of type 2 diabetes. Diabet Metab Res Rev 32(7):710–729
Tilden DP, Mariz S, O’Bryan-Tear G, Bottomley J, Diamantopoulos A (2007) A lifetime modelled economic evaluation comparing pioglitazone and rosiglitazone for the treatment of type 2 diabetes mellitus in the UK. Pharmacoeconomics 25:39–54
Smolen HJ, Murphy DR, Gahn JC, Yu X, Curtis BH (2014) The evaluation of clinical and cost outcomes associated with earlier initiation of insulin in patients with type 2 diabetes mellitus. J Manag Care Pharm 20(9):968–984
Kengne AP, Patel A, Marre M et al (2011) Contemporary model for cardiovascular risk prediction in people with type 2 diabetes. Eur J Cardiovasc Prevent Rehabili. https://doi.org/10.1177/1741826710394270
Yang X, So WY, Kong APS et al (2007) Development and validation of stroke risk equation for Hong Kong Chinese patients with type 2 diabetes—The Hong Kong diabetes registry. Diabet Care 30(1):65–70. https://doi.org/10.2337/dc06-1273
Yang XL, Ma RC, So WY et al (2008) Development and validation of a risk score for hospitalization for heart failure in patients with Type 2 diabetes mellitus. Cardiovasc Diabetol 7:9. https://doi.org/10.1186/1475-2840-7-9
Yang X, So WY, Kong APS et al (2008) Development and validation of a total coronary heart disease risk score in type 2 diabetes mellitus. Am J Cardiol 101(5):596–601. https://doi.org/10.1016/j.amjcard.2007.10.019
Tanaka S, Tanaka S, Iimuro S et al (2013) Predicting macro- and microvascular complications in type 2 diabetes: The japan diabetes complications study/the japanese elderly diabetes intervention trial risk engine. Diabet Care 36(5):1193–1199. https://doi.org/10.2337/dc12-0958
Zethelius B, Eliasson B, Eeg-Olofsson K, Svensson AM, Gudbjörnsdottir S, Cederholm J (2011) A new model for 5-year risk of cardiovascular disease in type 2 diabetes, from the Swedish national diabetes register (NDR). Diabet Res Clin Pr. https://doi.org/10.1016/j.diabres.2011.05.037
Kiadaliri AA, Gerdtham UG, Nilsson P, Eliasson B, Gudbjornsdottir S, Carlsson KS (2013) Towards renewed health economic simulation of type 2 diabetes: risk equations for first and second cardiovascular events from swedish register data. Plos One 8(5):e62650. https://doi.org/10.1371/journal.pone.0062650
Hippisley-Cox J, Coupland C, Vinogradova Y, Robson J, May M, Brindle P (2007) Derivation and validation of QRISK, a new cardiovascular disease risk score for the United Kingdom: Prospective open cohort study. Br Med J. https://doi.org/10.1136/bmj.39261.471806.55
Hippisley-Cox J, Coupland C, Brindle P (2017) Development and validation of QRISK3 risk prediction algorithms to estimate future risk of cardiovascular disease: prospective cohort study. BMJ 357:j2099. https://doi.org/10.1136/bmj.j2099
Basu S, Sussman JB, Berkowitz SA, Hayward RA, Yudkin JS (2017) Development and validation of risk equations for complications of type 2 diabetes (RECODe) using individual participant data from randomised trials. Lancet Diabet Endocrinol 5(10):788–798. https://doi.org/10.1016/S2213-8587(17)30221-8
Stratton IM, Adler AI, Neil HAW et al (2000) Association of glycaemia with macrovascular and microvascular complications of type 2 diabetes (UKPDS 35): prospective observational study. Bmj-Brit Med J 321(7258):405–412. https://doi.org/10.1136/bmj.321.7258.405
Stevens RJ, Kothari V, Adler AI, Stratton IM, Holman RR (2001) The UKPDS risk engine: A model for the risk of coronary heart disease in type II diabetes (UKPDS 56). Clin Sci. https://doi.org/10.1042/CS20000335
Kothari V, Stevens RJ, Adler AI et al (2002) UKPDS 60: risk of stroke in type 2 diabetes estimated by the UK prospective diabetes study risk engine. Stroke. https://doi.org/10.1161/01.STR.0000020091.07144.C7
Stevens RJ, Coleman RL, Adler AI, Stratton IM, Matthews DR, Holman RR (2004) Risk factors for myocardial infarction case fatality and stroke case fatality in type 2 diabetes: UKPDS 66. Diabetes Care. https://doi.org/10.2337/diacare.27.1.201
Acknowledgements
The authors thank Ina Vrolijk, University of Groningen, for helping with developing search terms of this review, and Freek van Delft, MSc, University of Twente, for discussing the article and providing scientific suggestions during Lowlands Health Economic Study Group conference 2021.
Funding
There is no relevant funding to disclose.
Author information
Authors and Affiliations
Contributions
XL, AG, and TLF contributed to the study concept and plan development. XL, AG, and FL contributed to the data collection. All authors contributed to the data interpretation and manuscript preparation, and critical revision for intellectual content. All authors approved the final draft of the manuscript for submission.
Corresponding author
Ethics declarations
Conflict of interest
There is no relevant funding or conflicts of interest to disclose.
Ethical standard statement
This study is a scoping review. Data are collected from related articles, and all of them are referenced in the manuscript. No studies involving human or animal participants were conducted by the authors specifically for the preparation of this article.
Additional information
Managed By Antonio Secchi .
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, X., Li, F., Wang, J. et al. Prediction of complications in health economic models of type 2 diabetes: a review of methods used. Acta Diabetol 60, 861–879 (2023). https://doi.org/10.1007/s00592-023-02045-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00592-023-02045-8