
Abstract
A brain tumor is one of the most lethal diseases that can affect human health and cause death. Invasive biopsy techniques are one of the most common methods of identifying brain tumor disease. As a result of this procedure, bleeding may occur during the procedure, which could harm some brain functions. Consequently, this invasive biopsy process may be extremely dangerous. To overcome such a dangerous process, medical imaging techniques, which can be used by experts in the field, can be used to conduct a thorough examination and obtain detailed information about the type and stage of the disease. Within the scope of the study, the dataset was examined, and this dataset consisted of brain images with tumors and brain images of normal patients. Numerous studies on medical images were conducted and obtained with high accuracy within the hybrid model algorithms. The dataset's images were enhanced using three distinct local binary patterns (LBP) algorithms in the developed model within the scope of the study: the LBP, step-LBP (nLBP), and angle-LBP (αLBP) algorithms. In the second stage, classification algorithms were used to evaluate the results from the LBP, nLBP and αLBP algorithms. Among the 11 classification algorithms used, four different classification algorithms were chosen as a consequence of the experimental process since they produced the best results. The classification algorithms with the best outcomes are random forest (RF), optimized forest (OF), rotation forest (RF), and instance-based learner (IBk) algorithms, respectively. With the developed model, an extremely high success rate of 99.12% was achieved within the IBk algorithm. Consequently, the clinical service can use the developed method to diagnose tumor-based medical images.
Similar content being viewed by others
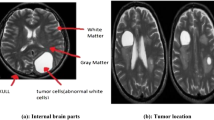

1 Introduction
More than half of all cases of brain tumors are caused by gliomas [1]. Glioma primary brain tumors are divided into four groups according to symptoms: low-grade I and II gliomas (LGG) and high-grade III and IV gliomas (HGG) [2]. This extremely lethal tumor can occur at any age in various histological subregions. Additionally, a glioma tumor is an invasive tumor [3]. The glioblastoma (GBM) cells that cause the tumor can grow and spread very rapidly as they immerse in the healthy brain parenchyma and infiltrate into the surrounding tissues. In this circumstance, it increases the significance of the early diagnosis of brain tumor disease. A brain tumor can be detected with computed tomography (CT), positron emission tomography (PET), and magnetic resonance imaging (MRI) [4]. Among the brain’s soft tissue imaging methods, MRI imaging produces better outcomes compared to other methods. The fact that there are billions of active cells in the brain tissue complicates the detection and treatment of the tumoral region in the event that a possible tumor forms. One of the leading causes of death in people recently is due to tumors in brain tissue. It has been determined that approximately 300,000 people worldwide apply to hospitals with complaints of brain tumors every year. More than 150 types of brain tumors have been identified in humans [5].
Approximately 700,000 people in the USA currently have a primary brain tumor, and another is expected to be diagnosed in 2022. Brain tumors can cause death, have a significant impact on quality of life, and alter everything for the patient and their relatives. Without distinction, brain tumors impact both sexes and all racial and ethnic groups of people [6]. A primary brain or spinal cord tumor originates from the brain or spinal cord. An estimated 25,050 adults (14,170 men and 10,880 women) in the USA were diagnosed with primary cancerous tumors in the brain and spinal cord in 2022. It is less than 1% of the probability of catching this type of tumor in a person’s lifetime. Brain tumors account for 85 to 90% of all primary central nervous system (CNS) tumors. An estimated 308,102 people were diagnosed with a primary brain or spinal cord tumor in 2020. About 4170 children under the age of 15 were diagnosed with brain or CNS tumors in 2020 in the USA. This occurs when a tumor develops outside of the brain and spreads to other parts of the body. Leukemia, lymphoma, melanoma, breast, kidney, and lung cancers are the most typical tumors that spread to the brain. Cancer in the brain and other nervous systems is the 10th leading cause of death for men and women. Globally, primary CNS and brain tumors were estimated to have been the leading cause of 251,329 fatalities in 2020.
The percentage of people who live for at least five years after the tumor is found is called the 5-year survival rate. It is almost 36% of the 5-year survival rate for people with a cancerous brain or CNS tumor in the USA. The 10-year survival rate is almost 31%. Age is a factor in overall survival rates after being diagnosed with a cancerous brain or CNS tumor. For those under the age of 15, the 5-year survival rate is almost 75%. For those between the ages of 15 and 39, the 5-year survival rate is close to 72%. The 5-year survival rate for people aged 40 and over is 21%. The type of brain or spinal cord tumor does, however, have a substantial effect on predicting survival rates. The consequences of your diagnosis should be discussed with your doctor. It is critical to remember that estimates of patients with brain tumors' chances of survival exist [7].
The fact that the brain tumor, which has a significant risk of death, is so dangerous makes it essential for early diagnosis and rapid initiation of treatment. Identification of the tumor area is extremely important. When the studies conducted in this case were analyzed, deep learning-based studies obtained very remarkable results. Among these studies conducted with deep learning, convolutional neural network methods such as AlexNet, VGG-Net, RestNet, and Google-Net draw attention [8]. The most prominent feature of the studies carried out with deep learning methods is that they have a strong feature extraction capacity [9,10,11]. Fuzzy edge detection and U-Net CNN classifications outperform traditional machine learning approaches, particularly when it comes to segmenting brain tumors [12]. Brain tumor components are primary and secondary metastases. Primary tumors occur in the CNS, while secondary tumors occur in the extracranial regions. The most common of the primary tumors is the GBM tumor. Secondary tumors occur when cancer cells, particularly those from the lung, breast, or kidney, metastasize to the brain [13].
The authors of the [14] study examined MRI images of brain tumor patients. The dataset used consisted of 86 images from the study. The obtained MRI images were applied separately to the LBP and Gabor wavelet transform methods, and impressive results were obtained. In the study, 0.93 foreground pixel precision and 0.98 background pixel precision results were obtained. In the study conducted by Sharif et al., the detection and segmentation of the tumor area in the brain soft tissue and the classification of the grades of the existing tumor areas were performed, respectively. A high success rate of 99% was obtained from the complex datasets used in this study [14]. In another study, a dataset of brain tumor images was first processed with the LBP method and then re-evaluated with the multilayered support vector machine (ML-SVM). In the study, the accuracy rate was as high as 99.23% [15]. In 2016, another study was conducted to automate the detection of gliomas in 3D images. It obtained a high success accuracy rate and also performed the segmentation of the glioma tumor in 3D MRI images in the study in 2016 [16]. In another study carried out in 2020, a brain tumor detection study was carried out on MRI images. In this study, the gray-level run length matrix (GLRLM) method was initially applied to the images, and then, the center-symmetric local binary pattern (CS-LBP) method was applied. As a result of the study, a great example of success was revealed, with an accuracy rate of 94% [17].
The study, conducted by Gupta et al. in 2018, was on a classified glioma brain tumor. Within the scope of the study, the boundaries of the tumor were determined on 3D images by applying the discrete wavelet transform (DWT) and LBP methods together. In this study, a high success rate was obtained with an accuracy of 96% [18]. In another study conducted in 2019, feature extraction examined MRI images of brain tumor patients. Feature extraction was used together with the LBP method and the steerable pyramid (SP) method. In the conducted study, a high success rate was obtained with an accuracy rate of 97.67% [19]. Sharif et al. obtained quite remarkable results in 2019. Within the scope of the study, the tumor image dataset obtained from MRI imaging was subjected to a series of algorithms. Among the algorithms applied, there is also the LBP algorithm, and with the developed method, the researchers attained a high success rate of 98% [20]. In the study conducted in 2022, Başaran first evaluated the MRI dataset containing brain tumors with the gray-level co-occurrence matrix (GLCM) method. After the first evaluation, the images were enhanced with the LBP method. The results were re-evaluated with a fully connected layer of AlexNet, VGG16, EfficientNet, and ResNet50. A remarkable success rate of 98.22% was achieved in this study [21]. Researchers carried out another study in 2022 for extraction. Together, they used MRI tumor images to extract the texture, intensity, and shape features of brain tumors using the LBP and hybrid local directional pattern with Gabor filter (HLDP-GF) methods. In this study, a high success rate of 99.5% was achieved [22]. In another study conducted in 2022, a brain tumor dataset was obtained from two different hospitals in China: Nanfang Hospital in Guangzhou and Tianjin Medical University General Hospital in Tianjin. The dataset images were first enhanced with fine-tuned convolutional neural networks (FT-CNN) and LBP methods, which were applied separately. A high success rate of 98.7% was obtained in this study [23].
Within the scope of the conducted study, literature studies were carried out in the early diagnosis of brain tumors, and the diagnosis of brain tumors was successfully conducted with LBP algorithms. In this study, two new LBP algorithms were proposed based on the classical LBP method. The results obtained with the proposed LBP methods were re-evaluated with some classification algorithms, and all the results were compared. The study continues as Material and Methods, Results and Discussion, and Conclusion.
2 Material and methods
2.1 Dataset
The brain tumor dataset images were obtained from the public Kaggle website [24]. When the images of the dataset are examined, 45% of the images belong to healthy individuals, while the rest contain images of diseased individuals. Not all images in the dataset have certain resolution. Of the images with different image resolutions, 19% have a resolution of 512 × 512 pixels, 8% have a resolution of 225 × 225 pixels, and the remaining images have different pixel resolutions. Although the dataset containing brain tumors contains a large number of images, the images have different resolutions. In addition, 97% of the images in the dataset are in three color format (red green blue–RGB) while the rest are in gray format. The most important factor in achieving high success in deep learning-based applications is that the datasets included contain a large number of images. The dataset considered within the scope of the study includes 4600 brain MRI images of diseased and healthy individuals. The number of images in the dataset is considerable when some other studies in this field are examined. For example, the brain tumor segmentation (BraTS) challenge is the most common dataset used in studies on brain tumors. While the BraTS2021 challenge includes approximately 8000 MRI images, the BraTS2020 challenge includes approximately 2640 MRI images. This shows that there is a significant number of images in the dataset considered within the scope of the study. This situation is also important for our study (Fig. 1).

Block Diagram
2.2 Block diagram of study
First, the dataset's brain tumor images were converted to 256 × 256 pixel sizes. The color presence of the images was checked, and if the images were in RGB format, they were converted to grayscale. After checking and conversion, the images were then converted to binary format. The binary format images in the dataset were then applied to the LBP algorithms (LBP, nLBP and αLBP respectively). For that process, MATLAB software was used. The frequency values and features of the images enhanced with LBP methods were extracted. Following the frequency extraction process, the values of the retrieved images were applied to the resample function in the Weka software. Finally, some selected classification algorithms were applied for analysis in Weka software.
2.3 Feature extraction methods
Feature extraction is especially important for detecting and classifying the hidden details in the image. The feature extraction process helps maximize the similarity within the class and minimize the similarity between classes. At this point, important information about the image is revealed. Vectors are obtained by subtracting the features. After this stage, vectors are used to train and test the data in the classification step [25].
2.3.1 Local binary pattern
To extract textural characteristics, one uses the local binary pattern (LBP) technique. There are numerous advantages obtained from the LBP method. At the beginning of these is a simple algorithm feature. It requires less computation compared to other algorithms. On the other hand, its insensitivity to different lighting intensities can be defined as another advantage [26]. The examination of texture has a critical place in the image processing process. In the process of texture analysis, it is of particular importance to be able to adapt between different traditional statistical and structural models. This harmony can be provided by the LBP method. It is a fairly successful technique, especially when used to combat grayscale shifts brought on by things like variations in lighting in an image. Additionally, the LBP approach has a straightforward computational feature [27]. The LBP method’s formula (1) is as follows:
P depicts as the neighbors of central pixel, R represents the radius of neighborhood, \({g}_{i}\) is neighboring pixel intensity, and \({g}_{c}\) is center pixel value.
The binary equivalent of the sub-image image calculated in Fig. 2 is (10,111,001)2. When the binary equivalent is calculated as decimal, the equivalent of the Pc value in the sub-image is 185.

Original LBP method calculation
2.3.2 Local binary pattern with relationship of distance neighbors
Since the first use of the LBP method, numerous variations of LBP methods have been developed. The first of the two LBP algorithms that are proposed in this study operates on the fundamental principle of considering the eight adjacent pixels around the central pixel sequence. If Pc = P0, P1, P2, P3, P4, P5, P6, and P7 pixels around the center pixel are bounced and processed instead of sequentially, a result different from the original LBP method will result.
In Fig. 3, it is shown according to the number of bounces. Instead of comparing according to the \({P}_{c}\) center pixel in the sub-image, in the developed nLBP method, a relationship was established between eight pixels around the \({P}_{c}\).

Sub-image enhanced by step-LBP algorithm
According to Fig. 3, if the step parameter is one, then Pc = S(P0 > P1), S(P1 > P2), S(P2 > P3), S(P3 > P4), S(P4 > P5), S(P5 > P6), S(P6 > P7), S(P7 > P0) relation is performed.
If the step parameter is two, then Pc = S(P0 > P2), S(P1 > P3), S(P2 > P4), S(P3 > P5), S(P4 > P6), S(P5 > P7), S(P6 > P0), S(P7 > P1) relation is performed.
If the step parameter is three, then Pc = S(P0 > P3), S(P1 > P4), S(P2 > P5), S(P3 > P6), S(P4 > P7), S(P5 > P0), S(P6 > P1), S(P7 > P2) relation is performed.
If the step parameter is four, then Pc = S(P0 > P4), S(P1 > P5), S(P2 > P6), S(P3 > P7), S(P4 > P0), S(P5 > P1), S(P6 > P2), S(P7 > P3) relation is performed.
Thus, some changes were introduced in the classical LBP calculation;
was recalculated.
Considering the sub-image in Fig. 1 above as an example, the binary equivalent of step 1:
Pc = S(36 > 221), S(221 > 129), S(129 > 80), S(80 > 145), S(145 > 190), S(190 > 219), S(219 > 168), S(168 > 36) = 01100011; the decimal equivalent of the obtained value is 99.
Considering the sub-image in Fig. 1 above as an example, the binary equivalent of step 2:
Pc = S(36 > 129), S(221 > 80), S(129 > 145), S(80 > 190), S(145 > 219), S(190 > 168), S(219 > 36), S(168 > 221) = 01000110; the decimal equivalent of the obtained value is 70.
Considering the sub-image in Fig. 1 above as an example, the binary equivalent of step 3:
Pc = S(36 > 80), S(221 > 145), S(129 > 190), S(80 > 219), S(145 > 168), S(190 > 36), S(219 > 221), S(168 > 129) = 01000101; the decimal equivalent of the obtained value is 69.
Considering the sub-image in Fig. 1 above as an example, the binary equivalent of step 4:
Pc = S(36 > 145), S(221 > 190), S(129 > 219), S(80 > 168), S(145 > 36), S(190 > 221), S(219 > 129), S(168 > 80) = 01001011; the decimal equivalent of the obtained value is 75.
2.3.3 Local binary pattern with relationship of angle parameters
The main purpose of the LBP method is to perform texture analysis on the image. Different variants of the LBP method were developed during the tissue analysis process, and different results were obtained with the developed variants. In the scope of the study, the second method we will consider within the variant studies is the LBP method, which depends on the angle value. In Fig. 4, the angle-LBP (αLBP) approach is illustrated.

The sub-image is enhanced by angle-LBP algorithm
In the classical LBP method, the center pixel is compared with the eight neighboring pixels around it, while in the αLBP method, the calculation is performed on the two-way neighbor values above the determined angle value of the selected center pixel. The calculation formula of this developed approach is as follows:
If it is performed an example calculation;
3 adjacent pixels considered for the value of α = 0
Pc = S(48 > 244), S(48 > 128), S(48 > 157), S(48 > 37), S(48 > 29), S(48 > 17), S(48 > 148), S(48 > 36).
is in the form. The binary equivalent of the obtained Pc value is 00011101 and the decimal equivalent corresponds to the Pc = 29 value.
4 adjacent pixels considered for the value of α = 45
Pc = S(48 > 228), S(48 > 178), S(48 > 49), S(48 > 187), S(48 > 166), S(48 > 83), S(48 > 72), S(48 > 176).
is in the form. The binary equivalent of the obtained Pc value is 00000000 and the decimal equivalent corresponds to the Pc = 0 value.
5 adjacent pixels considered for the value of α = 90
Pc = S(48 > 12), S(48 > 69), S(48 > 83), S(48 > 193), S(48 > 59), S(48 > 59), S(48 > 23), S(48 > 44).
is in the form. The binary equivalent of the obtained Pc value is 10,000,011 and the decimal equivalent corresponds to the Pc = 131 value.
6 adjacent pixels considered for the value of α = 135
Pc = S(48 > 129), S(48 > 28), S(48 > 146), S(48 > 250), S(48 > 173), S(48 > 49), S(48 > 54), S(48 > 125).
is in the form. The binary equivalent of the obtained \({P}_{c}\) value is 01000000 and the decimal equivalent corresponds to the \({P}_{c}\) = 64 value. In this way, each time the angle changes, the αLBP method gives us a new pattern.
6.1 Classification methods
Weka software was another used software within the scope of this study. Weka software was developed by the University of Waikato and takes its name from the initials of the words "Waikato Environment for Knowledge Analysis." Many of the most commonly used machine learning classification algorithms can be used on Weka software. Weka software was developed in Java language and also Java projects prepared can especially be easily uploaded. Weka software contains a series of comprehensive algorithms primarily for the purpose of data mining. These algorithms are especially used for feature selection, clustering, association rule learning, classification, and regression purposes [28]. In this section, a number of classification methods used on Weka software, especially within the scope of this study, are listed.
6.1.1 Instance-based learner
The instance-based learner (IBk) algorithm used in the Weka software corresponds to the K-nearest neighbor (KNN) algorithm used in other machine learning or deep learning software. The KNN algorithm identifies the training samples in the dataset with n-dimensional numerical features. Basically, when the KNN algorithm explores any sample in the dataset, it searches the pattern space for the k training samples closest to the sample being considered. In this way, the most common class assignment is performed among the k-nearest neighbors of the sample under consideration [29, 30]. Within the scope of this study, the K-nearest neighbor value was analyzed with the IBk algorithm. Each sample that did not appear in the features extracted with the IBk algorithm used was compared with the existing ones using a distance criterion.
6.1.2 Random forest
The random forest algorithm is a substantial statistical training model. It performs well, particularly in small- and medium-sized datasets. It does not need large datasets like neural network algorithms. The bagging operation performs the averaging of the noisy but approximately unbiased models in the dataset, thus reducing its variance. Each tree in the random forest algorithm can capture any complex interaction structure in the data. Each tree benefits greatly from the average, as it has a noisy nature. On the other hand, when each tree produced by bagging is similarly distributed, the average expectation for all trees distributed is the same. Therefore, the goal of bagged and evenly dispersed trees is to have comparable distributions and aim to minimize variance. The only way to overcome this undesirable situation for the outcome is by reducing the variance [31].
6.1.3 Optimized forest
The optimized forest algorithm is based on the decision forest algorithm from the genetic algorithm family. In this manner, optimized forest selection with high accuracy and diversity is carried out to improve the optimized forest algorithm’s overall accuracy. Using the chromosome structure of the genetic algorithm, it is coded to form a population of 20 chromosomes. Furthermore, the generated chromosomes are also subjected to crossover and mutation processes using the roulette wheel technique. After the first stage, the elitist approach is used to successfully pick chromosomes. The top 20 chromosomes are chosen from a pool of 40 to avoid the algorithm’s chromosomes degrading. As a result of all these processes, a sequential search process is applied to obtain the best ensemble accuracy [32].
6.1.4 Rotation forest
The rotation forest algorithm is significantly different from the random forest algorithm, despite both being based on trees. The main difference is that a rotation forest transforms attributes into sets of principal components and uses a C4.5 decision tree. Unlike the rotation forest algorithm, where the features are sampled at the node for each tree, the rotation forest algorithm uses all the attributes for each tree. The features are randomly divided into a certain f dimension and the transformation is generated independently for each feature set. However, some of the samples can be discarded and then sampled, modified to include a particular case forest. On a smaller dataset, a PCA model is created. The created model is then applied to all samples to create a new feature f, and the dataset is combined [33].
6.1.5 J48 decision tree
Classification is the process of constructing a class model from a set of records containing class labels. The decision tree algorithm, on the other hand, performs the process of finding out how the feature vector of a set of samples behaves. The class is created for each newly created example on the basis of training examples. This approach, which creates estimate criteria for the target variables, makes the critical distribution easy to understand. J48 is the development of ID3, an implementation of the C4.5 algorithm. In cases of possible overfitting, pruning is used as a firming tool. The purity of each leaf is prioritized in other classification algorithms, while in this method, rules are made to provide the precise identification of the data. The aim here is to gradually generalize a decision tree until the algorithm achieves a balance between adaptability and precision [34].
6.1.6 Multilayer perceptron
It is the best-known and most commonly used neural network algorithm. There is no loop in this example. Usually, signals are only transferred in one direction inside the network, from input to output. The output of each neuron does not affect the neuron itself; however, forward data flows. This type of architecture is called feedforward, and there are hidden layers that are not directly connected to the environment. It can be in a feedback structure that incorporates reaction connections and provides data transmission in both directions due to its network structure. Such networks have the potential to be incredibly powerful and complicated. The network is dynamic until it reaches equilibrium. Multiple layers may indicate that decision areas need to be more sophisticated. A single-layer, single-input sensor creates decision regions in the form of half-planes. Each neuron in another layer added to the network serves as a standard sensor for the outputs of the front-layer neurons. In this case, the output of the network can predict the convex decision regions formed by the intersection of the half-planes formed by the neurons [35].
6.1.7 Simple logistic
This algorithm, sometimes referred to as "logit regression" or "logit model," is a mathematical method that uses algebra to determine the likelihood of an occurrence based on statistical data. Logistic regression assigns 1 to event occurrence and 0 to non-occurrence. A value of 1 is indicated for an event's occurrence and 0 for its non-occurrence. For instance, a student receives a score of 1 for passing the exam and a score of 0 for failing it. This situation is also known as binomial logistic regression [36].
6.1.8 Multilayer perceptron
It is a feedforward neural network algorithm that is used to distinguish data that cannot be separated linearly. Moreover, complicated functions can be modeled with this algorithm, and it is a widely used supervised learning method that does not ignore irrelevant inputs or noise. Its structure allows for the possibility of several layers. Each node represents a neuron with a nonlinear activation function. As it is most commonly known, it consists of an input layer, a hidden layer, and an output layer. The movement is only in a forward direction, from input nodes to hidden nodes and then to output nodes [37].
6.1.9 Sequential minimal optimization
Sequential minimal optimization (SMO) is a simple algorithm that solves any SVM quadratic programming (QP) problem without the need for extra matrix storage. Its sensitivity is thus lower than that of digital cutoff probes. It also has the ability to quickly solve problems without using any numerical QP optimization steps. The SMO algorithm uses Osuna's theorem to perform the convergence operation. In this method, a general QP problem is decomposed into smaller QP problems. Unlike the more commonly used methods, SMO chooses to solve even the smallest possible optimization problem at every step. Rather than calling an entire QP library routine, the inner loop of the algorithm helps to accomplish this in a relatively short amount of C code. Even though the algorithm method solves more optimization sub-problems, the QP problem is solved quickly because each sub-problem is solved so quickly. Aside from this, SMO does not require additional matrix storage. As a result, large-scale issues like very large SVM training difficulties may be accommodated on any normal workstations or PC RAM [38].
6.1.10 Radial basis function
The radial basis function (RBF) classifier is an algorithm with a feedforward network structure used as a supervised training algorithm. The activation function is typically configured with a single layer of hidden units selected from a class of functions called core functions. Although the RBF algorithm has many characteristics with regard to back propagation, it also has several advantages. Although it trains more quickly than backpropagation networks, the behavior of the single hidden layer is the key differentiator between the two. Instead of using the RBF algorithm's sigmoidal or S-shaped activation function, the hidden units in the RBF network use a Gaussian or other fundamental kernel function. Each created hidden unit generates a rating score to be able to match between its weights or centers associated with the input vector [39].
6.1.11 Decision table
This method enables the information in the tables to be used in an algorithmic way. The table may contain more than one land state. This situation changes according to the needs and expectations of the users. Even though decision tables are a traditional approach, they may be transformed into a unique, practical, and efficient tool that aids in decision making when coupled with contemporary design and management techniques. It is easy and understandable to define the actions to be taken after the conditions in the tables are met. The most fundamental function of the tables is to provide a solution to a problem. Tables demonstrate how cause (conditions) and effect (actions) are related. The biggest advantage of decision tables is the possibility of presenting complex relationships in a clear and transparent way. The most basic condition for the creation of decision tables is “If…, then…” [40].
6.2 Experimental test
The confusion matrix was used in the performance evaluation of the results of the experimental study. In the confusion matrix, the target attribute estimations and actual values are compared. The matrix used is summarized with the numerical values of the correct and incorrect prediction numbers. The actual values are represented by the columns in the generated matrix, while the rows represent a predicted class. In the resultant matrix, true positive (TP) and true negative (TN) are correctly predicted values in the model, while false positive (FP) and false negative (FN) are incorrectly predicted values in the model. Accuracy, sensitivity, specificity, precision, and F-Score values are calculated from this matrix. The following equations show the calculations of TP, TN, FP, and FN, respectively. The harmonic average of the F-Score precision and recall values is produced once all these values have been received.
7 Results and discussion
7.1 Results
The images in the dataset are required to preprocess because the images in the dataset are not all the same size or in the same color format. After the preprocessing step, the images in the dataset had a dimension of 256 × 256 pixels. The images' color formats were converted to grayscale formats. After all the preprocessing steps, the images were altered to the proper size and format. The images were converted into a single-color format and uniform size. After that, these were processed by the LBP methods. All images obtained from the dataset were first preprocessed and then subjected to two LBP algorithms developed alongside the classic LBP algorithm.
Sample images of patients with brain tumor disease and healthy individuals from the raw images in the dataset are given below. The images of the sample images handled in the dataset, which are formed as a result of image processing, are also shown in Fig. 5.

The sample image in the dataset
Within the scope of the study, the images of the brain tumor dataset obtained from the Kaggle website were enhanced with three different LBP methods. First, the results were obtained from the images processed with the classical LBP method, and then, the images were improved again with the newly developed nLBP and αLBP methods.
When the results in Table 1 are examined in detail, there are two different LBP algorithms developed by taking the classical LBP algorithm as a reference. Separately, quite impressive outcomes were produced in the current algorithms built. Within the scope of the study, the highest success rate was obtained by re-evaluating the results obtained from the nLBP algorithm with the IBk classification algorithm used in Weka software. In general, it can be seen that the IBk algorithm performs successful classification in re-evaluating the results obtained from all three algorithms. When examined in general terms, it was determined that the results obtained with random forest and optimized forest classification algorithms were the second most successful classification algorithm. The rotation forest and J48 classification algorithms produced results with a success rate of more than 90%. The DT classification method produced the worst successful classification result in the investigation. Among the other categorization algorithms tested in the experimental investigation, success rates ranged between 80 and 90 percent.
Image classification was applied to all the results obtained as a result of all three studies. After the preprocessing stage, different results were obtained by changing the four angle values in the αLBP algorithm. The fifth result was obtained from the dataset subjected to the classical LBP algorithm. In the last stage, four different result values were obtained from four different values in the nLBP algorithm. The sample results are shown in Fig. 6. On the other hand, it is shown that there are nine different results for the healthy individual MRI image in the dataset in Fig. 7. All nine LBP and developed LBP results obtained were subjected to 11 different classification algorithms separately.

Images created by the αLBP method according to different α value

Images created by the nLBP method according to different d values. a meningioma, b glioma, c pituitary
The four classification algorithms that give the best results are the random forest, optimized forest, IBk and rotation forest algorithms, respectively. All nine results obtained were subjected to 11 different algorithms, and a total of 99 different results are given in Table 1.
When all the results obtained within the scope of the study were examined, the most successful results were obtained from the nLBP algorithm derived from the LBP algorithm. Among the 11 algorithms used for classification, the highest evaluation result was obtained with the IBk classification algorithm. Other successful results obtained by evaluating the nLBP algorithm values, such as ROC, recall and f-measure, are given in Table 2.
The results of this study are shown in Fig. 8. In the confusion matrix, the actual and predicted values are displayed. The power of the proposed method in confusion matrix is shown from another perspective.

Confusion matrix
7.2 Discussion
The results obtained from other studies using the same dataset are shown in Table 3. Table 3 shows the obtained results with the same dataset. The CNN algorithm was used in two different studies, and the results were close. High success results were obtained in these studies, especially those developed using the CNN algorithm and deep convolutional networks. Within the scope of the study, the images in the dataset containing brain tumors obtained from the Kaggle webpage were enhanced with the LBP, nLBP and αLBP algorithms. The highest accuracy rate was obtained with the nLBP algorithm in step 1. The highest accuracy rate obtained in the study was 99.12%. The study was written in MATLAB software, and the results were re-evaluated via Weka software.
Four different results were obtained by each nLBP and αLBP according to variables. The last result was obtained by the LBP algorithm. The variables of αLBP are 0, 45, 90 and 135 degrees, and the variables of nLBP are 1 to 4. Within the scope of the study, nine different evaluation results were obtained. The experimental results obtained with MATLAB software were preprocessed via Weka software by resample algorithm. After preprocessing, it was subjected to 11 different algorithms. Out of 11 different classification algorithms, it was chosen four that gave the most successful results that were determined. All the results obtained are shown in Table 1. The purpose of doing this is to perform the experimental work that will achieve the highest accuracy.
The results were obtained from the four successful classification algorithms that gave the highest results after the preprocess was evaluated. When the results were examined, the best results were obtained from the IBk classification algorithm; these ones are close to each other between the step 1 parameter in the nLBP and the classical LBP algorithm. While the result obtained from the classical LBP algorithm was subjected to the IBk classification, the success rate was 99.09%, while the success rate obtained by subjecting the results obtained from the nLBP algorithm to the IBk classification was 99.12%. The results obtained as a result of the study were preprocessed in Weka software and subjected to classification algorithms. The most successful classification result in the study was obtained with the IBk algorithm (Table 4).
8 Conclusion
Within the scope of the study, analysis was carried out on a comprehensive dataset containing images of brain tumor patients and images of healthy individuals. The main purpose of the analysis is to accurately identify images of brain tumor patients at an early stage with deep learning and machine learning-based algorithms. In this study, MRI images obtained on the dataset were enhanced with nLBP and αLBP algorithms based on the classical LBP algorithm. Since its development, the local binary pattern algorithm has developed numerous variants that have gained ground in image enhancement studies. Although there are many different algorithms developed based on the local binary patterns algorithm, it is reported that impressive results are obtained in many of these algorithms. The results obtained with the nLBP and αLBP algorithms developed within the scope of the study were re-evaluated using Weka software, which uses machine learning algorithms especially for data mining tasks. The images were first preprocessed and then re-evaluated with other classification algorithms. An extremely high success rate was achieved in the reclassification process. It was determined that IBk, random forest, optimized forest and rotation forest algorithms contributed positively to the feature results obtained with LBP, nLBP and αLBP algorithms. When the results obtained were examined, the most successful result was obtained by determining the first step of the nLBP algorithm and using the IBk classification algorithm. One of the most important outcomes of the study is the further development of the successful results obtained within its scope. As part of future research, model training will be carried out with various datasets of MR images of brain tumors and efforts will be made to develop it further.
Data availability
The datasets generated during and/or analyzed during the current study are available in the Kaggle repository [24].
Abbreviations
- LBP:
-
Local binary patterns
- nLBP:
-
Step local binary patterns
- αLBP:
-
Angle local binary patterns
- RF:
-
Random forest
- OF:
-
Optimized forest
- rf:
-
Rotation forest
- IBk:
-
Instance-based learner
- LGG:
-
Low-grade gliomas
- HGG:
-
High-grade gliomas
- GBM:
-
Glioblastoma
- CT:
-
Computed tomography
- PET:
-
Positron emission tomography
- MRI:
-
Magnetic resonance imaging
- CNS:
-
Central nervous system
- RF-EMF:
-
Radiofrequency electromagnetic fields
- ML-SVM:
-
Multilayered support vector machine
- GLRLM:
-
Gray-level run length matrix
- CS-LBP:
-
Center-symmetric local binary pattern
- DWT:
-
Discrete wavelet transform
- SP:
-
Steerable pyramid
- GLCM:
-
Gray-level co-occurrence matrix
- HLDP-GF:
-
Hybrid local directional pattern with Gabor filter
- FT-CNN:
-
Fine-tuned convolutional neural networks
- RGB:
-
Red green blue
- SMO:
-
Sequential minimal optimization
- RBF:
-
Radial basis function
- TP:
-
True positive
- TN:
-
True negative
- FP:
-
False positive
- FN:
-
False negative
References
Nie J et al (2009) Automated brain tumor segmentation using spatial accuracy-weighted hidden Markov Random Field. Comput Med Imaging Graph 33(6):431–441. https://doi.org/10.1016/j.compmedimag.2009.04.006
Bakas S, et al. (2018). Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv preprint arXiv:1811.02629..
Essadike A, Ouabida E, Bouzid A (2018) Brain tumor segmentation with Vander Lugt correlator based active contour. Comput Methods Programs Biomed 160:103–117. https://doi.org/10.1016/j.cmpb.2018.04.004
Havaei M et al (2017) Brain tumor segmentation with deep neural networks. Med Image Anal 35:18–31. https://doi.org/10.1016/j.media.2016.05.004
Nayak DR, Padhy N, Mallick PK, Zymbler M, Kumar S (2022) Brain tumor classification using dense efficient-net. Axioms 11(1):34. https://doi.org/10.3390/axioms11010034
Pichaivel M, Anbumani G, Theivendren P, Gopal M (2022) An overview of brain tumor, in brain tumors. IntechOpen. https://doi.org/10.5772/intechopen.100806
Siegel RL, Miller KD, Fuchs HE, Jemal A (2022) Cancer statistics, 2022. CA Cancer J Clin 72(1):7–33. https://doi.org/10.3322/caac.21708
Jiang Y, Zhang Y, Lin X, Dong J, Cheng T, Liang J (2022) SwinBTS: a method for 3D multimodal brain tumor segmentation using swin transformer. Brain Sci 12(6):797. https://doi.org/10.3390/brainsci12060797
Esteva A et al (2017) Dermatologist-level classification of skin cancer with deep neural networks. Nature 542(7639):115–118. https://doi.org/10.1038/nature21056
Gulshan V et al (2016) Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 316(22):2402. https://doi.org/10.1001/jama.2016.17216
Hu J, Shen L, Sun G (2018). Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7132-7141).
Maqsood S, Damasevicius R, Shah FM (2021). An efficient approach for the detection of brain tumor using fuzzy logic and U-NET CNN classification. In: Computational Science and Its Applications–ICCSA 2021: 21st International Conference, Cagliari, Italy, September 13–16, 2021, Proceedings, Part V 21 (pp. 105-118). Springer International Publishing.https://doi.org/10.1007/978-3-030-86976-2_8.
Schaettler MO et al (2022) Characterization of the genomic and immunologic diversity of malignant brain tumors through multisector analysis. Cancer Discov 12(1):154–171. https://doi.org/10.1158/2159-8290.CD-21-0291
Amin J, Sharif M, Raza M, Saba T, Anjum MA (2019) Brain tumor detection using statistical and machine learning method. Comput Methods Programs Biomed 177:69–79. https://doi.org/10.1016/j.cmpb.2019.05.015
Kolla M, Mishra RK, Zahoor Ul Huq S, Vijayalata Y, Gopalachari MV, Siddiquee KA (2022) CNN-based brain tumor detection model using local binary pattern and multilayered SVM classifier. Comput Int Neurosci 2022:9015778–9015778. https://doi.org/10.1155/2022/9015778
Abbasi S, Tajeripour F (2017) Detection of brain tumor in 3D MRI images using local binary patterns and histogram orientation gradient. Neurocomputing 219:526–535. https://doi.org/10.1016/j.neucom.2016.09.051
Mudda M, Manjunath R, Krishnamurthy N (2022) Brain tumor classification using enhanced statistical texture features. IETE J Res 68(5):3695–3706. https://doi.org/10.1080/03772063.2020.1775501
Gupta M, Rajagopalan V, Rao BVVSNP (2019) Glioma grade classification using wavelet transform-local binary pattern based statistical texture features and geometric measures extracted from MRI. J Exp Theor Artif Intell 31(1):57–76. https://doi.org/10.1080/0952813X.2018.1518997
Kale VV, Hamde ST, Holambe RS (2019) Brain disease diagnosis using local binary pattern and steerable pyramid. Int J Multimed Inf Retr 8(3):155–165. https://doi.org/10.1007/s13735-019-00174-x
Sharif M, Amin J, Nisar MW, Anjum MA, Muhammad N, Ali Shad S (2020) A unified patch based method for brain tumor detection using features fusion. Cogn Syst Res 59:273–286. https://doi.org/10.1016/j.cogsys.2019.10.001
Başaran E (2022) A new brain tumor diagnostic model: Selection of textural feature extraction algorithms and convolution neural network features with optimization algorithms. Comput Biol Med 148:105857. https://doi.org/10.1016/j.compbiomed.2022.105857
Sasank VVS, Venkateswarlu S (2022) Hybrid deep neural network with adaptive rain optimizer algorithm for multi-grade brain tumor classification of MRI images. Multimed Tools Appl 81(6):8021–8057. https://doi.org/10.1007/s11042-022-12106-9
Zahoor MM, Qureshi SA, Khan A, Rehman AU, Rafique M (2022). A novel dual-channel brain tumor detection system for MR images using dynamic and static features with conventional machine learning techniques. Waves in Random and Complex Media, https://doi.org/10.1080/17455030.2022.2070683.
“Brian Tumor Dataset,” https://www.kaggle.com/datasets/preetviradiya/brian-tumor-dataset.
Ningtyas AD, Nababan EB, Efendi S (2022) Performance analysis of local binary pattern and k-nearest neighbor on image classification of fingers leaves. Int J Nonlinear Anal Appl 13(1):1701–1708
Haghnegahdar AA, Kolahi S, Khojastepour L, Tajeripour F (2018) Diagnosis of tempromandibular disorders using local binary patterns. J Biomed Phys Eng 8(1):87–96
Ojala T, Pietikäinen M, Harwood D (1996) A comparative study of texture measures with classification based on featured distributions. Pattern Recognit 29(1):51–59. https://doi.org/10.1016/0031-3203(95)00067-4
E Frank et al., (2009) Weka-A Machine Learning Workbench for Data Mining, In: Data Mining and Knowledge Discovery Handbook, Boston, MA: Springer US, https://doi.org/10.1007/978-0-387-09823-4_66.
Rahman Ahad MdA, Islam MdN, Jahan I (2016) Action recognition based on binary patterns of action-history and histogram of oriented gradient. J Multimodal User Interfaces 10(4):335–344. https://doi.org/10.1007/s12193-016-0229-4
Han J, Kamber M, and Pei J, Data Mining Concepts and Techniques, 3rd ed. 2012.
Ionita I (2016) Data mining technique for e-learning. J Appl Comput Sci Math 10(2):26–31. https://doi.org/10.4316/JACSM.201602004
R Caruana A Niculescu-Mizil, (2006) An empirical comparison of supervised learning algorithms. In: Proceedings of the 23rd international conference on Machine learning - ICML ’06, New York, New York, USA: ACM Press, 161–168, https://doi.org/10.1145/1143844.1143865.
Adnan MN, Islam MZ (2016) Optimizing the number of trees in a decision forest to discover a subforest with high ensemble accuracy using a genetic algorithm. Knowl Based Syst 110:86–97. https://doi.org/10.1016/j.knosys.2016.07.016
IA Jimoh, I Ismaila, M Olalere, (2019) Enhanced decision Tree-J48 With SMOTE machine learning algorithm for effective botnet detection in imbalance dataset. In: 2019 15th International Conference on Electronics, Computer and Computation (ICECCO), IEEE, 1–8. https://doi.org/10.1109/ICECCO48375.2019.9043233.
Gardner MW, Dorling SR (1998) Artificial neural networks (the multilayer perceptron)—a review of applications in the atmospheric sciences. Atmos Environ 32(14–15):2627–2636. https://doi.org/10.1016/S1352-2310(97)00447-0
Hsieh FY, Bloch DA, Larsen MD (1998) A simple method of sample size calculation for linear and logistic regression. Stat Med 17(14):1623–1634. https://doi.org/10.1002/(SICI)1097-0258(19980730)17:14%3c1623::AID-SIM871%3e3.0.CO;2-S
Tang J, Deng C, Huang G-B (2016) Extreme learning machine for multilayer perceptron. IEEE Trans Neural Netw Learn Syst 27(4):809–821. https://doi.org/10.1109/TNNLS.2015.2424995
Nakanishi KM, Fujii K, Todo S (2020) Sequential minimal optimization for quantum-classical hybrid algorithms. Phys Rev Res 2(4):043158. https://doi.org/10.1103/PhysRevResearch.2.043158
Buhmann MD (2000) Radial basis functions. Acta Numer 9:1–38. https://doi.org/10.1017/S0962492900000015
Baesens B, Setiono R, Mues C, Vanthienen J (2003) Using neural network rule extraction and decision tables for credit-risk evaluation. Manage Sci 49(3):312–329. https://doi.org/10.1287/mnsc.49.3.312.12739
Kaggle, “novel dual-channel brain tumor detection system for MR images .”
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest, financial or otherwise.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gül, M., Kaya, Y. Comparing of brain tumor diagnosis with developed local binary patterns methods. Neural Comput & Applic 36, 7545–7558 (2024). https://doi.org/10.1007/s00521-024-09476-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-024-09476-6