
Abstract
Judgments are taken in a structured way; both human and business management decisions involve a hierarchical process that requires a level of compromise between risk, cost, reward, experience and knowledge. This article proposes a management decision structure that emulates the human brain approach based on genetic and deep learning cluster algorithms and the random neural network. Reinforcement learning takes quick and specific local decisions, deep learning clusters enables identity and memory, and deep learning management clusters make final strategic decisions. The presented genetic algorithm transmits the learned information to future generations in the network weights rather than the neurons. Because the subject’s information, a combination of memory, identity and decision data, is never lost but transmitted, the genetic algorithm provides immortality. The management decision structure has been applied and validated in a smart investment Fintech application: an intelligent banker that makes buy and sell asset decisions with an associated market and risk that entirely transmits itself to a future generation. Results are rewarding; the management decision structure with genetics and machine learning based on the random neural network algorithm that emulates the human brain and biology transmits information to future generations and learns autonomously, gradually and continuously while adapting to the environment.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The brain takes decisions in a structured way, and the striatum is a fundamental area essential in decision making formed of different sections that have distinct roles: the dorsolateral striatum functions in typical actions, the dorsomedial striatum in goal-directed actions and the ventral striatum in motivation [1]; although these three different regions have independent functions, they coordinate between each other during the different stages of decision-making process based on hierarchical reinforcement learning. Similar structured decision-making approach is also applied in business management, company and institution operations and emergency services that require a level of compromise between risk, cost, reward, experience and knowledge.
In addition to our brain hierarchical decision process, biological organisms autonomously learn in a gradual and continuous approach while adapting to the environment using genetic changes to generate new complex structures in organisms [2]. The current structure of the organisms defines the type and level of the future genetic variation that will provide a better adaption to the environment or increased reward to a goal function. Random genetic changes have more probability to be successful in organisms that change in a systematic and modular manner where the new structures acquire the same set of subgoals in different combinations. This approach enables organisms not only to remember their reward evolution but also to generalize goal functions to successfully adapt to future environments [3]. The adaptations learned from the living organisms affect and guide evolution, even though the characteristics acquired are not transmitted to the genome [4]; however, its gene functions are altered and transmitted to the new generation. This method enables learning organisms to evolve much faster.
Successful machine learning and artificial intelligence models have been based on biology emulating the structures provided by nature during the learning, adaptation and evolution when interacting with the external environment. Neural networks and deep learning are based on brain structure which is formed of dense local clusters of the same neurons. Dense clusters perform different functions which are connected between each other with numerous very short paths and few long distance connections [5]. The brain retrieves a large amount of data obtained from the senses; analyzes the material and finally selects the relevant information [6] where the cluster of neurons specialization occurs due to their adaption when learning tasks.
1.1 Research proposal
This article proposes a management decision structure that emulates the brain functions using reinforcement learning and deep learning clusters based on the random neural network. Information in the presented model is learned through the interaction and adaptation to the environment using reinforcement and deep learning. Decisions are taken in a hierarchical way with different learnings specialized in different stages of the decision process:
Reinforcement learning [7,8,9] takes quick and specific local decisions;
Deep learning clusters [10,11,12] enable identity and memory;
Deep learning management clusters [13,14,15,16] make final strategic decisions.
In addition, this article presents a genetic learning algorithm based on the genome and evolution applying extreme learning machine methods [17,18,19,20,21]. Information in the proposed genetic algorithm is transmitted to future generations in the network weights through the combinations of four different nodes rather than the value of nodes themselves. The four nodes represent the genome nucleotides (C, G, A or T) that form the double helix of the DNA where the output layer of nodes replicates the input layer as the genome reproduces replicas of organisms. The genetic learning algorithm fixes the output to four neuron values that represent the four different nucleoids, and it also fixes the network weights to generate four different types of neurons rather than random values as proposed by the ELM theory. Genetic algorithm provides immortality: the entire subject’s information, defined as the combination of memory, identity and decision data, is never lost but transmitted to future generations.
The proposed management decision structure has been applied and validated in a smart investment application: an intelligent banker that makes buy and sell asset decisions with an associated market and risk that entirely transmits itself to a future generation.
The results presented by this article are rewarding and promising: the intelligent banker takes the right decisions, learns the variable asset price, makes profits on specific markets at minimum risk and finally efficiently transmits the information learned to future generations.
1.2 Research structure
This article presents the research background that consists on the genome, artificial neural networks, machine learning, genetic algorithms and extreme machine learning in Sect. 2. The random neural network with reinforcement learning, deep learning clusters, deep learning management clusters and genetic algorithm are defined in Sect. 3. The management decision structure and its application to smart investment in an intelligent banker are presented in Sect. 4, whereas its implementation is described in Sect. 5. The experimental results are shown in Sect. 6 with a cryptocurrency evaluation in Sect. 7. Finally, conclusions and future work are shared in Sect. 8.
2 Research background and literature review
Artificial neural networks, machine learning and genetic algorithms have been applied in economics and finance to make predictions where extreme machine learning have improved the performance of classic neural network models.
2.1 Genome
The genome is the genetic material of an organism; it consists of 23 pairs of chromosomes (1–22, X and Y) for a human cell formed of genes (approximately 21,000 in total) that code for a molecule that has a function or instruction to make proteins as presented by Pellegrini et al. [22]. Furthermore, genes are formed of base pairs (approximately 3 billion in total). The DNA is a double helix formed by the combination of only four nucleotides (cytosine [C], guanine [G], adenine [A] or thymine [T]) where each base pair consists of the combination of two nucleoids G-C and A-T. The genetic code is formed of codons; a sequence consisted of three nucleotides or three-letter words. Proteins that have similar combination of base pairs tend to have a related functionality determination of protein functions from genetic sequences following the research of Suzuki [23].
2.2 Artificial neural networks
Artificial neural networks have been applied to make financial predictions and represent financial models. The bankruptcy prediction capability of several neural network architectures based on different training sets and number of iterations was evaluated by Leshno and Spector [24]; the neural networks are trained with data obtained from different firm’s financial reports where the prediction capability of the neural network is compared against classical discriminant analysis models. Artificial neural networks for a financial distress prediction model are used by Chen and Du [25]; the back propagation learning algorithm is trained with a dataset obtained from the Taiwan Stock Exchange Corporation where the inputs to the neural network are 37 model factor ratios. An artificial neural network with back propagation gradient descent learning algorithm to predict the direction of stock market index movement for the Istanbul Stock Exchange is applied by Kara et al. [26]; the inputs of the feedforward network correspond to ten technical indicators such as moving average or momentum and the output neuron represents the direction of the index movement.
The effectiveness of neural network models in stock market predictions was evaluated by Guresen et al. [27]; the models analyzed are multilayer perceptron, dynamic artificial neural network and hybrid neural networks where the mean square error and mean absolute deviate metrics are used to compare each model. Different artificial neural networks in bankruptcy prediction against traditional Bayesian classification theory are analyzed by Zhang et al. [28]; the method of cross-validation is applied to examine the sample variation between neural networks. Different ways to use prior knowledge such as newspaper headlines and neural networks to improve multivariate prediction ability is investigated by Kohara et al. [29]; the topics are chief Tokio stock exchange price index, exchange rate dollar-yen, interest rate, crude oil price and New York Dow Jones where the inputs to the neural network are the relative topic difference. Regression, artificial neural networks and support vector machines for predicting the S&P 500 Stock Market Price Index are compared by Sheta et al. [30]; they use 27 potential financial and economic variables that impact the stock movement; these variables are used as the input nodes whereas the output node gives the predicted next week value. Artificial neural networks and fuzzy logic for market predictions are included by Khuat et al. [31] where the input layer contains 30 neurons corresponding to 30 close days and the output node is the close price of the next day.
A feedforward multilayer perceptron to predict a company’s stock value is used by Naeini et al. [32]; the network predicts the next day stock value of a company listed in the Tehran Stock Exchange Corporation only based on its stock trade history and without any information of the current market. A hybrid system based on a multiagent architecture to analyze stock market behavior is created by Iuhasz et al. [33] to improve the profitability in a short or medium time period investment; the proposed system compares the results of feed forward and recurrent neural network in terms of accuracy and time performance. The use of neural networks as an alternative to classical statistical techniques for forecasting within the framework of arbitrage pricing theory model for stock ranking is examined by Nicholas et al. [34]; the training and test sets consist of data presented as factors extracted from the balance sheets of the companies in the UK stocks, and the resultant outperformance Y is the output.
A comparative survey of artificial intelligence applications in Finance is presented by Bahrammirzaee [35] that covers artificial neural networks, expert system and hybrid intelligent systems in financial markets, credit evaluation, portfolio management and financial prediction and planning. The use of artificial neural networks in accounting and finance is reviewed by Coakley and Brown [36]; it includes modeling issues and applicability guidelines such as the selection of the learning algorithm, error and transfer functions, architecture and network training. The applications of neural networks in finance are analyzed by Fadlalla and Lin [37]; in particular, the common characteristics of these applications are examined and compared against applications based on statistical and econometrics models. The use of neural networks in finance and economics forecasting is reviewed by Huang et al. [38]; input variables, type of neural network models and performance comparisons are analyzed for the prediction of foreign exchange rates, stock market index and economic growth. Li et al. [39] summarize different applications of artificial intelligence technologies such as neural networks, deep learning and machine leaning in several domains of business administration including finance, retail, manufacturing and management consultancy.
Machine learning has been applied to solve nonlinear models in continuous time in macroeconomics and finance by Duarte [40] where the problem of solving the corresponding nonlinear partial differential equations can be reformulated as a sequence of supervised learning problems. A single variable time-series model that combines two financial volatility metrics to predict and forecast one of them is proposed by Stefani et al. [41]; the method is based on artificial neural networks with a multilayer perceptron in a single-hidden-layer configuration, the k-nearest neighbors as a local nonlinear model used for classification and regression and finally support vector machine in a regression methodology. Deep learning has also been incorporated in long–short-term memory neural networks for financial market predictions by Fischer and Krauss [42] where day returns are calculated for each day at defined stocks. Hasan et al. [43] investigate how to apply hierarchical deep learning models for the problems in finance such as stock market prediction and classification; the deep learning models are based on neural networks, recurrent neural networks with big data finance datasets.
2.3 Genetic algorithms
Genetic algorithms (GA) have been proposed as method to increase learning performance. Overlapping generations (OLG) economies in which agents use genetic algorithms to learn correct decision rules are studied by Arifovic [44]; the results of an OLG model with GA learning against the results of the same model where the agents form expectations via either the sample average of past prices or least squares adaptive algorithms are compared in terms of on equilibrium within inflationary economies. A genetic algorithm to feature discretization in artificial neural networks for the prediction of stock market index was proposed by Kim and Han [45]; the GA is applied to improve the learning algorithm and to reduce the complexity in feature space.
A hybrid model based on genetic algorithm and neural networks to forecast tax collection is applied by Ticona et al. [46]; endogenous and exogenous variables are used as input variables of the neural network for the multistep time series to forecast a hybrid model based on lags of the value of the time series, differences and moving averages. A genetic algorithm-based deep learning method is presented by Hossain and Capi [47]; the GA is used to optimize the deep learning parameters such as the number of hidden units, the number of epochs, learning rates and momentum in learning stage of the hidden layers. A genetic algorithm assisted method for deep learning that improves the performance of a deep autoencoder producing a sparser neural network is presented by David and Greental [48]; the GA population of each chromosome is a set of weights for the autoencoder. The latest deep learning structures and evolutionary algorithms that can be used to train them are reviewed by Tirumala [49]; these include convolutional neural networks, deep belief networks, stacked autoencoders, generative neuroevolution and deep learning using genetic algorithm.
2.4 Extreme learning machine
The learning speed of feedforward neural networks is in general slower than required due to the slow gradient-based learning algorithm that adjusts iteratively the parameters of the networks. A new learning algorithm called extreme learning machine (ELM) for single-hidden-layer feedforward neural networks (SLFNs) which randomly chooses hidden nodes and analytically determines its output weight is proposed by Huang et al. [17]. The output weights linking the hidden layer to the output layer of SLFNs can be analytically determined through simple generalized inverse operation of the hidden layer output matrices; Huang et al. [18] proves that SLFNs work as universal approximators by randomly choose hidden nodes and then only adjusting the output weights linking the hidden layer and the output layer. An ELM architecture for multilayer perceptron is proposed by Tang et al. [19]; the ELM is divided into two main components: self-taught feature extraction followed by supervised feature classification which they are connected by random initialized hidden weights. ELM provides a unified learning platform with extensive methods of feature mappings that can be applied in regression and multiclass classification applications directly, as demonstrated by Huang et al. [20]. An extreme learning machine-based autoencoder is introduced by Kasun et al. [21] which learns feature representations using singular values.
Reservoir computing consists on an input signal that is fed into a fixed or random dynamical system, or reservoir, where the dynamics of the reservoir map the input to a higher dimension, then a retrieval method is trained to read the state of the reservoir and map it to the desired output [50]; the main benefit is that the reservoir is fixed and training is performed only at the retrieval stage therefore the complexity of the computationally demanding neural networks learning algorithms is reduced. An empirical analysis of deep recurrent neural network architectures with stacked layers develops and improves hierarchical dynamics in deep recurrent architectures within the efficient reservoir computing approach [51]; a deep layering of recurrent models provides an effective diversification of temporal representations in the layers of the hierarchy. Deep Echo State Network models consist of a stack of multiple nonlinear reservoir layers that potentially allow the exploitation of the advantages of a hierarchical temporal feature representation at different levels of abstraction while preserving the training efficiency typical of the reservoir computing methodology [52]; however, adding layers to a deep reservoir architecture affects the regime of network’s dynamics toward equally or less stable behaviors. A new architecture, reservoir with random static projections is proposed to improve the performance of Echo State Networks based on the compromise between the amount of nonlinear mapping and short-term memory when applied to time-series data which are highly nonlinear [53]; a similar method is also applied using an ELM whose input is presented through a time delay.
Radial basis function (RBF) networks that have one hidden layer are capable of universal approximation [54]; RBF networks with the same smoothing factor in each kernel node is broad enough for universal approximation. ELMs can be also extended to a RBF network case, which allows the centers and impact widths of RBF kernels to be randomly generated and the output weights to be simply analytically calculated instead of iteratively tuned [55]; the ELM algorithm for RBF networks can complete learning at very fast speed and produce generalization performance very close to support vector machines in many artificial and real benchmarking function approximation and classification applications. The RBF network applies a nonmonotonic transfer function based on the Gaussian density function [56]; while producing robust decision surfaces, the RBF also provides an estimate of how close a test instance is to the original training data, allowing the classifier to identify that a test instance potentially represents a new class while still presenting the most probable classification. Feedforward neural networks using RBF assume that the patterns of the learning environment are separable by hyperspheres [57]; it is demonstrated that their related cost function is local minima free with respect to all the network weights.
3 The random neural network genetic deep learning model
3.1 The random neural network
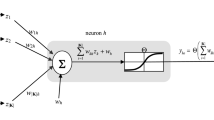
The random neural network (RNN) [7,8,9] represents more closely how signals are transmitted in many biological neural networks where they travel as spikes or impulses, rather than as analogue signal levels. The RNN is a spiking recurrent stochastic model for neural networks. Its main analytical properties are the “product form” and the existence of the unique network steady state solution. The random neural network has also been applied in different genetic models [58,59,60,61,62,63,64,65,66,67].
The RNN is composed of M neurons each of which receives excitatory (positive) and inhibitory (negative) spike signals from external sources which may be sensory sources or neurons (Fig. 1). These spike signals occur following independent Poisson processes of rates λ+ (m) for the excitatory spike signal and λ− (m) for the inhibitory spike signal, respectively, to cell \(m \in \left\{ {1, \ldots M} \right\}\).

The random neural network
Neurons interact with each other by interchanging signals in the form of spikes of unit amplitude:
A positive spike is interpreted as excitation signal because it increases by one unit the potential of the receiving neuron;
A negative spike is interpreted as inhibition signal decreasing by one unit the potential of the receiving neuron or has no effect if the potential is already zero.
Each neuron accumulates signals and it will fire if its potential is positive. Firing will occur at random, and spikes will be sent out at rate r(i) with independent, identically and exponentially distributed inter-spike intervals:
Positive spikes will go out to neuron j with probability p+(i, j) as excitatory signals;
Negative spikes with probability p−(i, j) as inhibitory signals.
A neuron may send spikes out of the network with probability d(i). We have:
Neuron potential decreases by one unit when the neuron fires either an excitatory spike or an inhibitory spike. External (or exogenous) excitatory or inhibitory signals to neuron i will arrive at rates Λ(i), λ(i), respectively, by stationary Poisson processes. The random neural network weight parameters w+(j, i) and w−(j, i) are the nonnegative rate of excitatory and inhibitory spike emission, respectively, from neuron i to neuron j:
Information is transmitted by the rate or frequency at which spikes travel. Each neuron i, if it is excited, behaves as a frequency modulator emitting spikes at rate w(i, j) = w+(i, j) + w−(i, j) to neuron j. Spikes will be emitted at exponentially distributed random intervals. Each neuron acts as a nonlinear frequency demodulator transforming the incoming excitatory and inhibitory spikes into potential.
In this model, each neuron is represented at time t ≥ 0 by its internal state km(t) which is a nonnegative integer. If km(t) ≥ 0, then the arrival of a negative spike to neuron m at time t results in the reduction of the internal state by one unit: km(t+) = km(t) − 1. The arrival of a negative spike to a neuron has no effect if km(t) = 0. On the other hand, the arrival of an excitatory spike always increases the neuron’s internal state by 1; km(t+) = km(t) + 1.
The random neural network defines qi as the probability a neuron i is excited:
where the λ+(i), λ−(i) for i = 1, …, n satisfy the system of nonlinear simultaneous equations:
3.2 Reinforcement learning algorithm
A random neural network (RNN) [7,8,9] with at least as many nodes as the number of decisions to be taken is generated where neurons are numbered 1, …, j, …, n; therefore, for any decision i, there is some neuron i. Decisions in this RL algorithm with the RNN are taken by selecting the decision j for which the corresponding neuron is the most excited, the one which has the largest value of qj.
The state qj is the probability that it is excited, these quantities satisfy the following system of nonlinear equations:
The reinforcement learning algorithm used in this model is based on the cognitive packet network presented by Gelenbe [68,69,70,71,72]. Given some Goal G that the agent has to achieve as a function to be optimized and reward R as a consequence of the interaction with the environment, successive measured values of the R are denoted by Rl, l = 1, 2, … and these are used to compute a decision threshold:
where α is some constant 0 < α < 1 that can be statically assigned or dynamically updated based on the external observations.
The agent takes the lth decision which corresponds to neuron j and then the lth reward Rl is measured and its associated Tl−1 is calculated where the network weighs are updated as follows for all neurons i ≠ j.
if Tl−1 ≤ R1:
$$\begin{aligned} & w^{ + } \left( {i,j} \right) \, = \, w^{ + } \left( {i,j} \right) \, + \, R_{1} \\ & w^{ - } \left( {i,k} \right) \, = \, w^{ - } \left( {i,k} \right) \, + \frac{{R_{l} }}{n - 2}\quad {\text{if }}k \, \ne \, j \\ \end{aligned}$$(7)else if Rl < Tl−1:
$$\begin{aligned} & w^{ + } \left( {i,k} \right) \, = \, w^{ + } \left( {i,k} \right) \, + \frac{{R_{l} }}{n - 2}\quad {\text{if}}\,k \, \ne \, j \\ & w^{ - } \left( {i,j} \right) \, = \, w^{ - } \left( {i,j} \right) \, + \, R_{l} \\ \end{aligned}$$(8)
This research uses reinforcement learning to make binary decisions with only two neurons (Fig. 2).
where
On the above equations, w+ij is the rate at which neuron i transmits excitation spikes to neuron j and w−ij is the rate at which neuron i transmits inhibitory spikes to neuron j in both situations when neuron i is excited. Λi and λi are the rates of external excitatory and inhibitory signals, respectively.

Reinforcement learning algorithm
3.3 The random neural network with multiple clusters
Deep learning with random neural networks is described by Gelenbe and Yin [10,11,12]. This model is based on the generalized queuing networks with triggered customer movement (G-networks) where customers or tasks are either “positive” or “negative” and customers or tasks can be moved from queues or leave the network. G-networks are introduced by Gelenbe [73, 74]; an extension to this model is developed by Gelenbe et al. [75] where synchronized interactions of two queues could add a customer in a third queue.
The model considers a special network M(n) that contains n identically connected neurons, each which has a firing rate r and external inhibitory and excitatory signals λ− and λ+, respectively (Fig. 3). The state of each cell is denoted by q, and it receives an inhibitory input from the state of some cell u which does not belong to M(n); therefore, for any cell \(i \, \in \, M\left( n \right)\), there is an inhibitory weight w−(u) ≡ w−(u,i) > 0 from u to i.

Clusters of neurons
For any \(i,j \, \in \, M\left( n \right)\), we have w+(i,j) = w−(i,j) = 0, but all whenever one of the neurons fires, it triggers the firing of the other neurons with the following values. As presented in [14,15,16], the potential for each identical neuron is calculated as:
where (10) is a second-degree polynomial in q:
3.4 Deep learning clusters
The deep learning architecture presented in [10,11,12] is composed on C multiple clusters, each of which is made up of a M(n) cluster each with n hidden neurons (Fig. 4). For the cth such cluster, c = 1, …, C, the state of each of its identical cells is denoted by qc. In addition, there are U input cells which do not belong to these C clusters, and the state of the uth cell u = 1, …, U is denoted by \(\bar{q}_{u}\). The cluster network has U input cells and C clusters.

The random neural network with multiple clusters
The deep learning clusters model defines:
I = (idl1, idl2, …, idlu), a U-dimensional vector \(I \, \in \, \left[ {0,1} \right]^{U}\) that represents the input state \(\overline{{q_{u} }}\) for the cell u;
w−(u, c) is the U × C matrix of inhibitory weights from the U input cells to the cells in each of the C clusters;
Y = (ydl1, ydl2, …, ydlc), a C-dimensional vector \(Y \, \in \, \left[ {0,1} \right]^{C}\) that represents the cell state qc for the cluster c.
Each hidden neuron in the clusters c, with \(c \, \in \, \left\{ {1, \ldots ,C} \right\}\) receives an inhibitory input from each of the U input neuron. Thus, for each neuron in the cth cluster, we have inhibitory weights w−(u, c) > 0 from the uth input neuron to each neuron in the cth cluster; the uth input neuron will have a total inhibitory “exit” weight, or total inhibitory firing rate \(\overline{{r_{u} }}\) to all the clusters which is of value:
As calculated in (10), the potential for each neuron qc in cluster C is:
The activation function of the cth cluster is defined as:
where
We have:
The network learns the U × C weight matrix w−(u, c) by calculating new values of the network parameters for the input I and output Y using gradient descent learning algorithm which optimizes the network inhibitory weight parameters w−(u, c) from a set of input–output pairs (iu, yc).
3.5 Deep learning management cluster
The deep learning management cluster was proposed by Serrano et al. [13,14,15,16]. It takes management decisions based on the inputs from different deep learning clusters (Fig. 5). The deep learning management cluster defines:

The random neural network with a management cluster
Imc, a C-dimensional vector \(I_{\text{mc}} \in \left[ {0,1} \right]^{C}\) that represents the input state \(\overline{{q_{c} }}\) for the cluster c;
w−(c) is the C-dimensional vector of inhibitory weights from the C input clusters to the cells in the management cluster mc;
Ymc, a scalar \(Y_{\text{mc}} \in \left[ {0,1} \right]\), the cell state qmc for the management cluster mc.
The activation function of the management cluster mc is defined as:
where
we have:
3.6 Genetic learning algorithm model
The proposed genetic learning algorithm on this article is an autoencoder based on the extreme learning machine (ELM) presented by Huang et al. [17,18,19,20,21] for single-layer feedforward networks (SLFN). For N arbitrary distinct samples (xi, ti), where xi = [xi1, xi2, … xin]T\(\in\)Rn and ti = [ti1, ti2, … tim]T\(\in\)Rm, an standard SLFN with \(N^{{\prime }}\) hidden nodes and activation function g(x) is mathematically modeled as:
where wi = [wi1, wi2, … win]T is the weight vector connecting the ith hidden node and the input nodes, βi = [βi1, βi2, … βim]T is the weight vector connecting the ith hidden node and the output nodes, bi is the threshold of the ith hidden node and g(x) activation function of hidden nodes. The above N equations can be written as:
where T = [ti1, ti2, … tim]T are the target outputs and H = [gi(w1·x1 + b1), gi(w2·x2 + b2), … gi(wn′·xn′ + bn′)]T. The output weights β can be calculated by Eq. 6:
where H† is the Moore–Penrose generalized inverse of matrix H.
Extreme learning machine [17,18,19,20,21] proves that the input weights and hidden layer biases of SLFNs can be randomly assigned if the activation functions in the hidden layer are infinitely differentiable. In addition, SLFNs can be considered as a linear system where the output weights can be analytically determined through simple generalized inverse operation of the hidden layer output matrices.
The proposed genetic learning algorithm is based on an ELM auto encoder that models the genome as it codes the replica of the organism that contains it. It consists of two instances of the network described in Sect. 3.4. Network 1 is formed of U input neurons and C clusters, and network 2 has C input neurons and U clusters (Fig. 6). The organism is represented as a set of data X which is a U vector \(X \, \in \, \left[ {0,1} \right]^{U}\). The genetic learning algorithm fixes C to 4 neurons that represent the four different nucleoids G, C, A and T and it also fixes W1 to generate four different types of neurons rather than random values as proposed by the ELM theory. The operational complexity of the proposed algorithm is O(n2).

Genetic learning algorithm
Network 1 encodes the organism, and it is defined as:
q1 = (q11, q12, …, q1u), a U-dimensional vector \(q_{1} \in \left[ {0,1} \right]^{U}\) that represents the input state qu for neuron u;
W1 is the U × C matrix of weights w−1(u,c) from the U input neurons to the neurons in each of the C clusters;
Q1 = (Q11, Q12, …, Q1c), a C-dimensional vector \(Q^{1} \in \left[ {0,1} \right]^{C}\) that represents state qc for the cluster c where \(Q^{1} \, = \,\zeta \left( {W_{1} X} \right)\).
Network 2 decodes the genome, as the pseudoinverse of Network 1, it is defined as:
q2 = (q21, q22, …, q2c), a C-dimensional vector \(q_{2} \in \left[ {0,1} \right]^{C}\) that represents the input state qc for neuron c with the same value as Q1 = (Q11, Q12, …, Q1c);
W2 is the C × U matrix of weights w−2(c,u) from the C input neurons to the neurons in each of the U cells;
Q2 = (q21, q22, …, q2u), a U-dimensional vector \(Q^{2} \in \, \left[ {0,1} \right]^{U}\) that represents the state qu for the cell u where Q2 = ζ(W2Q1) or Q2 = ζ(W2ζ(XW1)).
The learning algorithm is the adjustment of W1 to code the organism X into the four different neurons or nucleoids and then calculate W2 so that resulting decoded organism Q2 is the same as the encoded organism X:
Following the extreme learning machine model, W2 is calculated as:
we have:
where pinv is the Moore–Penrose pseudoinverse:
4 Management decision structure: smart investment
The management decision structure combines in a hierarchal way the four presented different learnings: reinforcement learning, deep learning, deep learning management clusters and genetic learning (Fig. 7). This approach enables structured decisions based on shared information where different learnings are specialized in a decision area. Final decisions are taken collaboratively to achieve a bigger reward that includes the entire decision-making chain.

Management decision structure: smart investment
The smart investment model, named “GoldAI Sachs,” is formed of clusters of intelligent bankers that take local fast binary decisions “buy or sell” on a specific asset based on reinforcement learning (RL) through the interactions and adaptations with the environment where the reward is the profit made. Each asset banker has an associated deep learning (DL) cluster that learns asset identity such as price and reward.
Asset bankers are dynamically clustered to different properties such as investment reward, risk or market type being managed by a market banker deep learning management cluster that selects the best performing asset bankers. The market bankers specialize in learning which asset banker will take the best decision, rather than directly the asset properties.
Finally, a CEO banker deep learning management cluster manages the different market bankers and takes the final structured investment decisions based on the market reward and associated risk prioritizing markets that generate more reward at a lower risk, as any banker would do. The CEO banker genetic algorithm provides immortality: the entire subject’s information, defined as the combination of memory, identity and decision data, is never lost but transmitted to future generations.
4.1 Asset banker reinforcement learning
The asset banker reinforcement learning algorithm used in the proposed model takes only two fast binary local asset investment decisions. Each intelligent banker is formed of two interconnected neurons where the investment decision is taken according to the neuron that has the maximum potential.
“GoldAI Sachs” asset banker reinforcement learning is defined as:
q0, neuron 0 for a buy decision
q1, neuron 1 for a sell decision
The reward R is based on the economic profit that the asset bankers achieve with the decisions they make, successive measured values of the R are denoted by Rl, l = 1,2…; these are used to compute the predicted reward:
where α represents the investment reward memory that can be statically assigned or dynamically updated based on the external observations.
If the observed measured reward is greater than the associated predicted reward; reinforcement learning rewards the decision taken by increasing the network weight that point to it; otherwise; it penalizes it:
if Rl > PR1:
$$\begin{aligned} & {\text{Reward}}\,{\text{Buy}}\,{\text{decision:}}\,w^{ + }_{10} = \, w^{ + }_{10} + \left| R \right| \\ & {\text{or}}\,{\text{Reward}}\,{\text{Sell}}\,{\text{decision:}}\,w^{ + }_{01} = \, w^{ + }_{01} + \left| R \right| \\ \end{aligned}$$(25)Otherwise, if Rl < PR1:
$$\begin{aligned} & {\text{Penalise}}\,{\text{Buy}}\,{\text{decision:}}\,w^{ - }_{10} = \, w^{ - }_{10} + \, \left| R \right| \\ & {\text{or}}\,{\text{Penalise}}\,{\text{Sell}}\,{\text{decision:}}\,w^{ - }_{01} = \, w^{ - }_{01} + \, \left| R \right| \\ \end{aligned}$$(26)
In addition to the reinforcement leaning, asset bankers make prediction price assets (PPA) based on the previous prediction (PAP) and current price asset (CPA):
where γ represents the asset price prediction memory.
4.2 Asset banker deep learning cluster
Deep learning is used to learn key investment values that generate asset identity. The smart investment model assigns a deep learning cluster per asset banker. Each different deep learning cluster learns the asset reward or profit prediction, the asset price and the asset price prediction.
“GoldAI Sachs” groups asset bankers dynamically into market sectors according to their risk, profit or type. The model defines a set of x asset banker deep learning clusters as:
IBanker-x = (iBanker-x1, iBanker-x2, …, iBanker-xu) a U-dimensional vector where iBanker-x1, iBanker-x2, and iBanker-xu are the same banker number x;
w−Banker-x(u, c) is the \(U \times C\) matrix of weights of the deep learning cluster for banker x;
YBanker-x = (yBanker-x1, yBanker-x2, …, yBanker-xc) a C-dimensional vector where yBanker-x1 is the reinforcement learning reward prediction, yBanker-x2 is the dynamic reward prediction, yBanker-x3 is the transaction price, and yBanker-xc is the price prediction for banker number x.
4.3 Market banker deep learning management cluster
The market banker deep learning management cluster analyzes the predicted reward from its respective asset banker deep learning clusters, prioritizes their values based on local market knowledge and finally reports to the CEO banker deep learning management cluster the total predicted profit that its market can make.
“GoldAI Sachs” model defines a set of x market banker deep learning management clusters as:
IMarketBanker-x, a C-dimensional vector \(I_{{{{\rm MarketBanker}\text{-}}x}} \in \, \left[ {0,1} \right]^{C}\) with the values of the predicted rewards from asset banker x;
w−MarketBanker-x (c) is the C-dimensional vector of weights that represents the priority of each asset banker x;
YMarketBanker-x, a scalar \(Y_{{{{\rm MarketBanker}\text{-}}x}} \in \, \left[ {0,1} \right]\) that represents the predicted profit the market banker deep learning management cluster can make.
4.4 CEO banker deep learning management cluster
The CEO banker deep learning management cluster, “AI Morgan” takes the final investment management decision based on the inputs from the market bankers and the associated. The CEO banker selects the markets that can generate better reward at lower risk where the maximum risk is defined as β by the “GoldAI Sachs” board of directors, or other user, where the higher the value the higher risk. β can be statically assigned or dynamically updated based on the external observations.
“GoldAI Sachs” model defines the CEO banker deep learning management cluster:
ICEO-Banker, a X-dimensional vector \(I_{{{{\rm CEO}}\text{-}{{\rm Banker}}}} \in \, \left[ {0,1} \right]^{X}\) with the values of the set x banker DL management clusters;
w−CEO-Banker (c) is the C-dimensional vector of weights that represents the risk associated to each market;
YCEO-Banker, a scalar \(Y_{{{{\rm CEO}\text{-}{\rm Banker}}}} \in \left[ {0,1} \right]\) that represents the final investment decision.
4.5 CEO banker genetic algorithm
Genetic learning transmits entirely the knowledge acquired from the CEO banker, defined as the combination of memory, identity and decision data, to future banker generations when “AI Morgan” considers itself no longer valid due energy limitations or cybersecurity attacks. Because the CEO banker information is never lost but transmitted to future generations, genetic algorithm provides immortality rather than reinforcement learning applied in fast local decisions or deep learning in identity (Fig. 8).

“GoldAI Sachs” smart investment model definition
“GoldAI Sachs” model defines genetic learning as an autoencoder where:
XGenetic = (xGenetic1, xGenetic2, …, xGenteticu) a U-dimensional vector where xGenetic1, xGenetic2, and xGeneticu are outputs of the x banker deep learning clusters;
w−Genetic−1 (u, c) is the U × C matrix of weights of the genetic encoder;
YNucleoid = (yNucleoid1, yNucleoid2, …, yNucleoidc) a C-dimensional vector where yNucleoid1, …, yNucleoidc is the value of the nucleoid
w−Genetic−2(c, u) is the C × U matrix of weights of the genetic decoder;
YGeneration = (yGeneration1, yGeneration2, …, yGenerationc) a C-dimensional vector where yGeneration1, …, yGenerationc is the value of the new banker generation.
5 Smart investment implementation
“GoldAI Sachs” is implemented in Java with eight asset bankers clustered in two different markets; bond market is low reward and therefore low risk, whereas risk market is high reward and high risk.
5.1 Asset banker reinforcement learning and deep learning clusters
Each asset banker has a two-node reinforcement learning algorithm to make local fast decisions “buy or sell” trade on different assets. the banker DL cluster learns the asset properties to create asset identity; it has four inputs cells (u = 4) and four output clusters (c = 4) where the input cell is the normalized value of the x asset banker identification: x (iBanker-x1 = 0·x, iBanker-x2 = 0·x, iBanker-x3 = 0·x, iBanker-x4 = 0·x) and the output clusters are the normalized asset properties: (yBanker-x1 = reinforcement learning reward prediction, yBanker-x2 = dynamic reward prediction, yBanker-x3 = transaction price, yBanker-x4 = price prediction as shown in Table 1. “GoldAI Sachs” normalizes the DL clusters; the inputs to: x/10 and the outputs to (reward or price/100) + 0.5, respectively, to keep the learning algorithm within the stable region.
5.2 Market banker deep learning management clusters
“GoldAI Sachs” has two market banker DL management clusters for the bond and commodities market, respectively. The inputs of the market bankers are the predicted asset banker rewards, whereas the output is the predicted reward the market can make. The network weighs are the asset banker priority; i.e., the best asset banker only to be considered with the maximum banker set at 1.0 and others at 0.0 or the four Bankers with the same priority; with all the network weights set at 0.25 as shown in Table 2.
5.3 CEO banker deep learning management clusters
The input of the CEO banker deep learning management cluster is the market profit provided by the market bankers and its network weight is the risk associated to each market. The smart investment model considers that market risk level is related to the reward the market can generate. The CEO banker, “AI Morgan” starts gradually assessing the reward increasing the risk β from 0.1 up to the maximum risk limit permissible by “GoldAI Sachs” owner or manager. “AI Morgan” then takes the final decision based on a greater predicted reward at the lowest risk β as represented in Table 3.
5.4 CEO banker genetic algorithm
Genetic learning algorithm is an autoencoder where the Market’s properties, identity and decisions learned by the banker deep learning clusters are codified into four neurons that represent the 4 nucleoids of the Genome: (cytosine [C], guanine [G], adenine [A] or thymine [T]). These values are transmitted to the next generation in a daily basis.
The input XGenetic to the genetic algorithm corresponds to a 32-dimensional vector where xGenetic1, xGenetic2, … xGenetic32 correspond to the 4 outputs of the 8 asset bankers YBanker-xYGene a is 4-dimensional vector where yNucleoid,1 …, yNucleoid4 is the value of the four different nucleoids. The output of the genetic algorithm YGeneration corresponds to the input XGenetic as shown in Table 4.
6 Smart investment experimental results
“GoldAI Sachs” is evaluated with eight different assets to assess the adaptability and performance of our proposed smart investment solution for 11 days. The assets are split into the bond market with low risk and slow reward and the derivative market with high risk and fast reward (Fig. 9). Experiments are carried out with reinforcement learning first initialized with a buy decision.

Smart investment data model
6.1 Asset banker reinforcement learning validation
The profit that each asset banker makes when buying or selling 100 assets for 11 days with the maximum profit, the ratio between both the number of winning decisions against the losing ones and the number of buy decisions against the sell, is shown in Tables 5 and 6. The validation covers three different values of investment reward memory α.
The simulation results are almost independent from the value of the investment reward memory α, this is due the reduced complexity in asset price variation. The reinforcement learning algorithm adapts very quickly to variable asset prices where asset 6 shows that the lowest investment memory, α = 0.1, is the optimum value. The profit made in assets that start downward such as asset 2, asset 4, asset 6 and asset 8 is worse than the upward ones because the asset bankers are initialized with a buy decision.
6.2 Asset banker deep learning cluster validation
The asset banker deep learning cluster validation for the eight different assets during the 11 different days is shown in Table 7. The learning algorithm error threshold is set at 1.0E−25. The first value is the final iteration number for learning algorithm number, and the second is the normalized error at 1.0E−26.
The learning algorithm of the deep learning clusters is very stable; it achieves a minimum error 1.0E−25 with very reduced iterations.
6.3 Market banker deep learning management cluster validation
The profits generated by the market bankers are shown in Tables 8 and 9 and Figs. 10 and 11. The market bankers take market decisions rather than individual asset decisions form the asset bankers. Market bankers invest 400 assets which is the combination of the four asset bankers purchasing power. The combined profits that the asset bankers can make independently and the profits the bond market manager can obtain are presented; in addition, the maximum values are also shown.

Bond market banker accumulative profits; α = 0.1

Derivative market banker accumulative profits; α = 0.1
The addition of a specialized market banker deep learning management cluster increases the profits almost to the maximum value. Tables 10 and 11 represent the bond and derivative market bankers deep learning management clusters values.
6.4 CEO banker deep learning management cluster validation
The CEO banker, “AI Morgan,” profited at different risks ratios with a total of investment of 800 assets is represented in Table 12. A low risk value β = 0.2 represents 640 assets in the bond market (B) and 160 is the derivative market (D), whereas a high risk value β = 0.8 is 160 assets in the bond market and 640 in the derivative market, respectively.
The more risk the CEO banker “AI Morgan” takes, the more profit is able to generate as the investment decisions are directed to the derivative market reaching nearly optimum values. Table 13 and Fig. 12 represent the CEO banker deep learning management clusters values at different risks with the final risk decision.

CEO banker accumulative profits; α = 0.1
6.5 CEO banker genetic algorithm validation
The genetic algorithm validation for the four different nucleoids (C, G, A, T) during the 10 different days is shown in Tables 14 and 15 with the genetic algorithm error.
The genetic algorithm codifies the CEO banker and transmits this information to the next generations with a residual error with only one iteration at a minimum time.
7 Cryptocurrency evaluation
“GoldAI Sachs” is evaluated with seven different assets to assess the adaptability and performance of our proposed smart investment solution for 664 days, from 07/08/2015 to 31/05/2017. The assets are split into the Bitcoin exchange market (BITSTAMP, BTCE, COINBASE, KRAKEN) and the currency market (Bitcoin, Ethereum, Ripple). Reinforcement learning is first initialized with a buy decision.
Cryptocurrency evaluation data has been produced though datasheets obtained from Kraggle; only three different currencies were found (Fig. 13). The values of the different assets within the Bitcoin exchange market are very similar as they trade the same currency, whereas the currency market presents a more disperse set of values.

Cryptocurrency investment data model
7.1 Asset banker reinforcement learning validation
The profit that each asset banker makes when buying or selling 100 assets for 664 days from year 2015 to 2017 with the maximum profit, the ratio between both the number of winning decisions against the losing ones and the number of buy decisions against the sell, is shown in Tables 16, 17 and 18. The validation covers three different values of investment reward memory α.
The RNN reinforcement learning algorithm adapts very quickly to variable asset prices and makes profits; although not to optimum values. The value of the investment reward memory does not have a mayor impact in the overall profit due to the great adaptation of reinforcement learning algorithm though a high value of investment reward memory generates more profits (Fig. 14).

Asset banker reinforcement learning validation; α = 0.1; α = 0.5; α = 0.9
7.2 Asset banker deep learning cluster validation
The asset banker deep learning cluster validation for the seven different assets during the 664 different days from year 2015 to 2017 is shown in Table 19. The learning algorithm error threshold is set at 1.0E−25. The first value is the final iteration number for learning algorithm number, and the second is the normalized error at 1.0E−26.
7.3 Market banker deep learning management cluster validation
The profit the market bankers can make for the 664 days from year 2015 to 2017 is shown in Tables 20, 21 and 22 where the validation includes three different values of investment reward memory α. The market bankers take market decisions rather than individual asset decisions form the asset bankers. Bitcoin exchange market banker invests 400 assets which is the combination of the four asset bankers purchasing power whereas currency market banker invests 300 assets as there are only three asset bankers.
The Bitcoin exchange market banker does not increase the profits of the market; this is mostly due to the fact that the four Bitcoin exchange asset bankers perform very similarly on almost equal asset conditions therefore with the addition of a market banker, the independent knowledge acquired by each asset banker is lost. However, when the currency asset bankers operate under diverse asset conditions, the addition of a currency market banker increases the market profit due to the right selection of the best performing asset banker. Different values of investment reward memory have an impact on the final profit where a balanced investment reward memory (α = 0.5) between previous and last investment provides optimum results (Figs. 15, 16).

Exchange market banker profits; α = 0.5

Currency market banker profits; α = 0.5
Table 23 represents the bond and derivative market bankers deep learning management clusters average values for the 664 days from year 2015 to 2017.
7.4 CEO banker deep learning management cluster validation
The CEO banker, “AI Morgan,” profits at different risks ratios β with a total of investment of 700 assets for different investment reward memories α is shown in Tables 24, 25 and 26 for the 664 days from year 2015 to 2017. A risk value β = 0.2 represents 560 assets in the exchange market and 140 in the currency market whereas a risk value β = 0.8 is 140 assets in the exchange market and 560 in the currency market, respectively. This research considers the exchange market as low risk and the currency market as high risk.
The results are consisted with the previous validation the best reward is at α = 0.5. The CEO banker takes the right decisions where the profits increase as the risk increases. Table 27 represents the CEO banker deep learning management clusters values at different risk decisions (Figs. 17, 18).

CEO banker maximum profits; α = 0.5

CEO banker profits; α = 0.5
7.5 CEO banker genetic algorithm validation
The genetic algorithm validation for the four different nucleoids (C, G, A, T) average value during the 664 different days from year 2015 to 2017 is shown in Table 28 with the genetic algorithm error. The genetic algorithm codifies the CEO banker with a residual error.
8 Conclusions
This article has presented a management decision structure based on the human brain with its hierarchical decision process. In addition, this article has defined a new learning genetic algorithm based on the genome where the information is transmitted in the network weights rather than through the neurons. The management decision structure has been implemented in a Fintech application: smart investment model that simulates the human brain with reinforcement learning for fast decisions, deep learning to learn properties to create asset identity, deep learning management clusters to make global decisions and genetic to transmit learned information and decisions to future generations.
In the smart investor model, “GoldAI Sachs” asset banker reinforcement learning algorithm takes the right investment decisions; with great adaptability to asset price changes whereas asset banker deep learning learns asset properties and identity. Market bankers success to increase the profit by selecting the best performing asset bankers and the CEO banker, “AI Morgan,” increases the profits considering the associated market risks, prioritizing low risk investment decision at equal profit.
Genetic learning transmits entirely the knowledge acquired from the CEO banker, defined as the combination of memory, identity and decision data, to future banker generations at a minimum error and time. Because the CEO banker information is never lost but transmitted to future generations, genetic algorithm provides immortality. Future work will analyze different methods to improve the performance or increase the profits, of the proposed deep learning cluster structure.
References
Ito M, Doya K (2015) Distinct neural representation in the dorsolateral, dorsomedial, and ventral parts of the striatum during fixed- and free-choice tasks. J Neurosci 35(8):3499–3514
Kirschner M, Gerhart J (2005) The plausibility of life resolving Darwin’s dilemma. Yale University Press, New Haven, pp 1–336
Parter M, Kashtan N, Alon U (2008) Facilitated variation: how evolution learns from past environments to generalize to new environments. Public library of science. Comput Biol 4(11):1–15
Hinton G, Nowlan S (1996) How learning can guide evolution. Complex Syst 1:495–502
Smith D, Bullmore E (2007) Small-world brain networks. Neuroscientist 12:512–523
Sporns O, Chialvo D, Kaiser M, Hilgetag C (2004) Organization, development and function of complex brain networks. Trends Cogn Sci 8(9):418–425
Gelenbe E (1989) Random neural networks with negative and positive signals and product form solution. Neural Comput 1:502–510
Gelenbe E (1993) Learning in the recurrent random neural network. Neural Comput 5:154–164
Gelenbe E (1993) G-networks with triggered customer movement. J Appl Probab 30:742–748
Gelenbe E, Yin Y (2016). Deep learning with random neural networks. In: International joint conference on neural networks, pp 1633–1638
Yin Y, Gelenbe E (2016) Deep learning in multi-layer architectures of dense nuclei, pp 1–10. CoRR arXiv: https://arxiv.org/abs/1609.07160
Yin Y, Gelenbe E (2017) Single-cell based random neural network for deep learning. In: International joint conference on neural networks, pp 86–93
Serrano W, Gelenbe E (2016) An intelligent internet search assistant based on the random neural network. In: Artificial intelligence applications and innovations, pp 141–153
Serrano W (2016) A big data intelligent search assistant based on the random neural network. In: International neural network society conference on big data, pp 254–261
Serrano W, Gelenbe E (2017) Intelligent search with deep learning clusters. In: Intelligent systems conference, pp 254–267
Serrano W, Gelenbe E (2017) The deep learning random neural network with a management cluster. In: International conference on intelligent decision technologies, pp 185–195
Huang G, Zhu Q, Siew C (2006) Extreme learning machine: theory and applications. Neurocomputing 70(1–3):489–501
Huang G, Chen L, Siew C (2006) Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans Neural Netw 17(4):879–892
Tang J, Deng C, Huang G (2016) Extreme learning machine for multilayer perceptron. IEEE Trans Neural Netw Learn Syst 27(4):1–13
Huang G, Zhou H, Ding X, Zhang R (2012) Extreme learning machine for regression and multiclass classification. IEEE Trans Syst Man Cybern 42(2):513–529
Kasun L, Zhou H, Huang G (2013) Representational learning with extreme learning machine for big data. IEEE Intell Syst 28(6):31–34
Pellegrini M, Marcotte E, Thompson M, Eisenberg D, Yeates T (1999) Assigning protein functions by comparative genome analysis: protein phylogenetic profiles. Proc Natl Acad Sci USA 96:4285–4288
Suzuki M (1994) A framework for the DNA protein recognition code of the probe helix in transcription factors: the chemical and stereo chemical rules. Structure 2(4):317–326
Leshno M, Spector Y (1996) Neural network prediction analysis: the bankruptcy case. Neurocomputing 10(2):125–147
Chen W, Du Y (2009) Using neural networks and data mining techniques for the financial distress prediction model. Expert Syst Appl 36:4075–4086
Kara Y, Acar M, Kaan Ö (2011) Predicting direction of stock price index movement using artificial neural networks and support vector machines: the sample of the Istanbul Stock Exchange. Expert Syst Appl 38:5311–5319
Guresen E, Kayakutlu G, Daim T (2011) Using artificial neural network models in stock market index prediction. Expert Syst Appl 38:10389–10397
Zhang G, Hu M, Patuwo B, Indro D (1999) Artificial neural networks in bankruptcy prediction: general framework and cross-validation analysis. Eur J Oper Res 116:16–32
Kohara K, Ishikawa T, Fukuhara Y, Nakamura Y (1997) Stock price prediction using prior knowledge and neural networks. Intell Syst Account Finance Manag 6:11–22
Sheta A, Ahmed S, Faris H (2015) A comparison between regression, artificial neural networks and support vector machines for predicting stock market index. Int J Adv Res Artif Intell 4(7):55–63
Khuat T, Le M (2017) An application of artificial neural networks and fuzzy logic on the stock price prediction problem. Int J Inf Visual 1(2):40–49
Naeini M, Taremian H, Hashemi H (2010) Stock market value prediction using neural networks. In: International conference on computer information systems and industrial management applications, pp 132–136
Iuhasz G, Tirea M, Negru V (2012) Neural network predictions of stock price fluctuations. In: International symposium on symbolic and numeric algorithms for scientific computing, pp 505–512
Nicholas A, Zapranis A, Francis G (1994) Stock performance modeling using neural networks: a comparative study with regression models. Neural Netw 7(2):375–388
Bahrammirzaee A (2010) A comparative survey of artificial intelligence applications in finance: artificial neural networks, expert system and hybrid intelligent systems. Neural Comput Appl 19:1165–1195
Coakley J, Brown C (2000) Artificial neural networks in accounting and finance: modeling issues. Int J Intell Syst Account Finance Manag 9:119–144
Fadlalla A, Lin C (2001) An analysis of the applications of neural networks in finance. Interfaces 31(4):112–122
Huang W, Lai K, Nakamori Y, Wang S, Yu L (2007) Neural networks in finance and economics forecasting. Int J Inf Technol Decis Mak 6(1):113–140
Li Y, Jiang W, Yang L, Wu T (2018) On neural networks and learning systems for business computing. Neurocomputing. 275:1150–1159
Duarte V (2017) Macro, finance, and macro finance: solving nonlinear models in continuous time with machine learning. Sloan School of Management, Massachusetts Institute of Technology, Cambridge, pp 1–27
Stefani J, Caelen O, Hattab D, Bontempi G (2017) Machine learning for multi-step ahead forecasting of volatility proxies. In: Workshop on mining data for financial applications, pp 1–12
Fischer T, Krauss C (2017) Deep learning with long short-term memory networks for financial market predictions. In: Florida Atlantic University discussion Papers in Economics, vol 11, pp 1–32
Hasan A, Kalıpsız O, Akyokuş S (2017) Predicting financial market in big data: deep learning. In: International conference on computer science and engineering, pp 510–515
Arifovic J (1995) Genetic algorithms and inflationary economies. J Monet Econ 36:219–243
Kim K, Han I (2000) Genetic algorithms approach to feature discretization in artificial neural networks for the prediction of stock price index. Expert Syst Appl 19:125–132
Ticona W, Figueiredo K, Vellasco M (2017) Hybrid model based on genetic algorithms and neural networks to forecast tax collection: application using endogenous and exogenous variables. In: International conference on electronics, electrical engineering and computing, pp 1–4
Hossain D, Capi G (2017) Genetic algorithm based deep learning parameters tuning for robot object recognition and grasping. Int Sch Sci Res Innov 11(3):629–633
David O, Greental I (2014) Genetic algorithms for evolving deep neural networks. In: ACM genetic and evolutionary computation conference, pp 1451–1452
Tirumala S (2014) Implementation of evolutionary algorithms for deep architectures. In: Artificial intelligence and cognition, pp 164–171
Schrauwen B, Verstraeten D, Campenhout J (2007) An overview of reservoir computing: theory, applications and implementations. In: Proceedings of the European symposium on artificial neural networks, pp 471–482
Gallicchio C, Micheli A, Pedrelli L (2017) Deep reservoir computing: a critical experimental analysis. Neurocomputing. 268:87–99
Gallicchio C, Micheli A (2017) Echo state property of deep reservoir computing networks. Cogn Comput 9(3):337–350
Butcher JB, Verstraeten D, Schrauwen B, Day CR, Haycock PW (2013) Reservoir computing and extreme learning machines for non-linear time-series data analysis. Neural Netw 38:76–89
Park J, Sandberg IW (1991) Universal approximation using radial-basis-function networks. Neural Comput 3(2):246–257
Huang G, Siew C (2004) Extreme learning machine: RBF network case. In: IEEE control, automation, robotics and vision conference, pp 1–8
Leonard JA, Kramer MA (1991) Radial basis function networks for classifying process faults. IEEE Control Syst Mag 11(3):31–38
Bianchini M, Frasconi P, Gori M (1995) Learning without local minima in radial basis function networks. IEEE Trans Neural Netw 6(3):749–756
Gelenbe E (1997) A class of genetic algorithms with analytical solution. Robot Auton Syst 22(1):59–64
Gelenbe E (2007) Steady-state solution of probabilistic gene regulatory networks. Phys Rev 76(1):031903
Gelenbe E, Liu P, Laine J (2006) Genetic algorithms for route discovery. IEEE Trans Syst Man Cybern 36(6):1247–1254
Gelenbe E (2007) Dealing with software viruses: a biological paradigm. Inf Secur Tech Rep 12:242–250
Gelenbe E (2008) Network of interacting synthetic molecules in equilibrium. Proc R Soc A Math Phys Sci 464:2219–2228
Kim H, Gelenbe E (2009) Anomaly detection in gene expression via stochastic models of gene regulatory networks. Comput Biol 10(3):S26
Kim H, Gelenbe E (2012) Stochastic gene expression modeling with hill function for switch-like gene responses. IEEE/ACM Trans Comput Biol Bioinf 9(4):973–979
Kim H, Gelenbe E (2012) Reconstruction of large-scale gene regulatory networks using bayesian model averaging. IEEE Trans Nanobiosci 11(3):259–265
Gelenbe E (2012) Natural computation. Comput J 55(7):848–851
Kim H, Park T, Gelenbe E (2014) Identifying disease candidate genes via large-scale gene network analysis. Int J Data Min Bioinform 10(2):175–188
Gelenbe E (2004) Cognitive packet network. Patent US 6804201 B1
Gelenbe E, Xu Z, Seref E (1999) Cognitive packet networks. In: International conference on tools with artificial intelligence, pp 47–54
Gelenbe E, Lent R, Xu Z (200) Networks with cognitive packets. In: IEEE international symposium on the modeling, analysis, and simulation of computer and telecommunication systems, pp 3–10
Gelenbe E, Lent R, Xu Z (2001) Measurement and performance of a cognitive packet network. Comput Netw 37(6):691–701
Gelenbe E, Lent R, Montuori A, Xu Z (2002) Cognitive packet networks: QoS and performance. In: IEEE international symposium on the modeling, analysis, and simulation of computer and telecommunication systems, pp 3–9
Gelenbe E (1993) G-networks: a unifying model for neural nets and queueing networks. In: Modelling analysis and simulation of computer and telecommunications systems, pp 3–8
Fourneau J, Gelenbe E, Suros R (1994) G-networks with multiple class negative and positive customers. In: Modelling analysis and simulation of computer and telecommunications systems, pp 30–34
Gelenbe E, Timotheou S (2008) Random neural networks with synchronized interactions. Neural Comput 20(9):2308–2324
Funding
This article was not funded or received any grants, except the academic support of Imperial College London.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that he has no conflict of interest against any company or institution.
Ethical standards
This research has not involved human participants and/or animals, except for the author contribution.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Smart investment model—neural schematic
Appendix: Smart investment model—neural schematic

Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Serrano, W. Genetic and deep learning clusters based on neural networks for management decision structures. Neural Comput & Applic 32, 4187–4211 (2020). https://doi.org/10.1007/s00521-019-04231-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-019-04231-8