
Abstract
Noise prediction is important for crew comfort in an offshore platform such as oil drilling rig. A deep neural network learning on the oil drilling rig is not widely studied. In this paper, a deep belief network (DBN) with the last layer initialized with trained DBN (named DBN-DNN) is used to model the sound pressure level (SPL) in the compartments of the oil drilling rig. The method finds an optimal number of the hidden neurons in restricted Boltzmann machine by using a normalized Euclidean distance from the worst possible error for each hidden layer progressively. The dataset used for experimental results is obtained via vibroacoustics simulation software such as VA-One and actual site measurements. The results show that output parameters such as spatial SPL, average spatial SPL, structure-borne SPL and airborne SPL improve the testing root mean square error to around 20% as compared to randomly assigning the number of neurons for each hidden layer. The testing RMSE in the output parameters has improved when compared with a multi-layer perceptron, sparse autoencoder, Softmax, self-taught learning and extreme learning machine.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Due to rapid technology advancement, the industries aim to reduce the manpower by incorporating artificial intelligence (AI) in a different domain. For example, adding intelligence in the sense of having conscious thought in the systems allows them to make decisions that impact performance in the maritime industry. There are many applications of AI in electric vehicle (Elassad et al. 2020), optimal path planning for research vessels (Liang and Wang 2019) and fault diagnosis of marine diesel engine (Hou et al. 2019). In addition, a deep evolutionary modeling was applied to marine propulsion systems (Diez-Olivan et al. 2019). It helped to predict temperatures related to a marine propulsion system, detecting anomalies in operating conditions.
It was followed by using neural network for collision avoidance system (Praczyk 2020), motion planning and task assignment (Zadeh et al. 2018) in an autonomous underwater vehicle. A broader application of the fuzzy neural network for condition maintenance of marine electric propulsion system (Liang et al. 2014) was demonstrated. The results improved the operational efficiency and maintenance ability of ship. In addition, machine-learning-based approach was used in marine environment (Li et al. 2019). The approach combined cross-recurrence plot and statistical analysis. It gives visualization of marine time series and the degree of similarity between different marine factors.
The knowledge-based engineering methods (Yang et al. 2012) involved an intelligent method for ship deck design used to provide suitable suggestions to reduce design cycle time and improve work efficiency. Monte Carlo simulation (Cui and Wang 2013) was applied on container ship. Reliability analysis using the uncertainty in the design variables subjected to seawater corrosion was performed. The approach applied on a ship structural design problem had resulted in a more robust design approach. Another paper Abramowski (2013) used simulated annealing and genetic algorithm to model the cargo ship effective power that helps in the power prediction on-board the ship.
In addition, the neural network approach was used to predict marine traffic (Daranda 2016) under different disturbances and geographical structures. The successful prediction on the turning regions led to a future application to predict the marine traffic situation. The estimation of the main engine power of a container ship was performed using multiple linear regressions (Cepowski 2017). The approach was applied to the engine power data collected from 4414 container ships over 10 years. The results obtained were more accurate than using a simple linear regression.
Despite the successes of the neural network on marine engineering and naval architecture involving ship, the AI applications on offshore industry such as oil drilling rig are still quite limited. Recently, there is a growing interest in noise control on the oil rig platform where crews are staying on board for an extended period. The noise affects their well-being especially at night where they require rest hour in the crew accommodation block while drilling is still ongoing. A new SOLAS regulation II-1/3-12 (Resolution MSC.337 (91)) requires new ships to reduce on-board noise and to protect personnel from noise.
The mandatory maximum noise level limits in different locations such as machinery spaces, accommodation and other spaces on board ships are imposed. For example, crew members without hearing protection should not expose to noise levels, exceeding 85 dB(A) for less than eight hours. In the event of more than eight hours in spaces with high noise, it should not exceed 80 dB(A). However, at least one-third of a day, they should subject to a noise level of below 75 dB(A).
In order to tackle the problem at the early design stage, a paper was first published using intelligent method (instead of expensive commercial software). A multiple generalized regression neural network model using fuzzy c-means with principal component analysis (PCA) (Chin et al. 2017) was used to reduce the size of the input parameters before predicting the sound pressure level (SPL) in different compartments on the oil rig platform. However, the method was quite computationally exhaustive as pre-processing using the fuzzy c-means and PCA was required. Hence, another paper suggested an adaptive online sequential extreme learning machine (ELM) (Chin and Ji 2018) for solving the same problem where the noise data were only available in batches. The ELM-based approach requires less training time as the parameters of the hidden layers are randomly generated without tuning. However, it exhibited a higher root mean square error over time than its counterpart such as multi-layer perceptron.
A deep neural network based on stacked autoencoder (Essien and Giannetti 2020) was also proposed. It consists of multiple layers of sparse autoencoders (AE) where outputs of each layer are connected to successive input layers. The first layer is usually meant to learn lower features, and it progresses to learn even higher-order features at a higher layer. In addition, a multilayer perceptron (MLP) (Fan et al. 2020) combined with other approaches can be used. However, it is still a class of feedforward neural network that consists of more than three layers where the input node consists of a nonlinear activation function. The updating of weight is still performed using the classical back-propagation (BP).
An extension from the single-layered neural network to multiple-layered neural networks to overcome the higher testing RMSE at the expense of reasonable training time was proposed. A deep architecture consists of several levels of nonlinear neural nets with various hidden layers (LeCun et al. 2015). Boltzmann machine (BM) is a log-linear Markov random field (MRF) (Fischer and Igel 2012). A restricted Boltzmann machine (RBM) is BM without connections between hidden–hidden and visible–visible. However, the RBM is the basic block used in the deep architectures in deep belief network (DBN) (Hinton et al. 2006) and deep Boltzmann machine (DBM). The DBN trains numerous layers of RBM via a greedy algorithm. After training the stack of RBMs, it can initialize a multi-layer neural network. On the other hand, the deep neural network (DNN) is stacked by including the last layer where it is initialized with trained DBN. The proposed network is sometimes called DBN-DNN (Tanaka and Okutomi 2014). The DBN-DNN is fine-tuned in a supervised manner using the classical back-propagation (BP) algorithm (Rumelhart et al. 1986).
In this paper, the DBN-DNN of 5-layer is used and compared with other networks such as MLP and AE to predict the four outputs, namely spatial sound pressure level (SPL), spatial average SPL, structure-borne noise and airborne noise at different octave frequencies (from 125 to 8000 Hz) using 13 input variables obtained from experiments and numerical results from the commercial software. However, issue related to the network structure such as finding the number of optimal neurons used in each hidden layer is still quite challenging in the AI research. Thus, a method to determine an optimal number of the hidden neurons in DBN-DNN is proposed. It uses a normalized Euclidean distance from the worst possible error across each hidden layer to determine the optimal number of neurons. The optimization moves progressively from first hidden layer to last hidden layer. The results using the optimized neuron number exhibit improvement in the testing root mean square error (RMSE) as compared to the DBN-DNN without the optimal search for the number of neurons or using the random number of neurons.
Most of the noise prediction uses sound spectrum and log-mel (Su et al. 2019) for subsequent CNN training. As the log-mel inputs are color images, the computation time and resources can be quite intensive to perform the CNN for different locations on the oil drilling rig. Furthermore, they are mainly for classification tasks. In this paper, the sound pressure level (SPL) at different frequencies and spatial locations as inputs to model the sound pressure level is proposed. This paper contributes to the area of deep learning for noise prediction of spatial SPL, spatial average SPL, structure-borne noise and airborne noise at different octave frequencies on the offshore platform during the initial design stage where design data or information such as sound spectrum is limited. In addition, the paper also contributes to the finding of optimal number of neurons for each hidden layer that is still an active research areas, particularly for the frequency- and spatial-dependent data. Lastly, the overall approach eliminates the use of expensive commercial noise simulation software during the preliminary design stage of offshore rig design. Similar approach can be applied to other applications of interest.
This paper consists of the following sections. Section 2 describes the frequency-dependent noise dataset from the oil drilling rig for training: Sect. 3 reviews DBN fundamental that is essential to understand the topic. Section 4 describes the proposed neurons optimization algorithm for the hidden layers. Section 5 demonstrates the deep neural networks and comparisons with other approaches. Section 6 concludes the paper.
2 Frequency-dependent noise dataset
The frequency-dependent noise data used in this paper were obtained from the previous works (Chin et al. 2017; Chin and Ji 2018). The compartments or rooms in the oil rig can be affected by airborne, structure-borne and transmission noise. The main sound pressure level (SPL) parameters in dB(A) are mainly: output spatial SPL (or localized SPL measurement), structure-borne SPL (due to structural vibration), average spatial SPL (average of different SPL measurements within the compartment) and airborne (transmitted through the air from the noise source) SPL which can be predicted using the following input variables in Table 1. The data and related information can be downloaded from the following link: https://github.com/mcschin1/deeplearning_noise_offshoreplatform
-
1.
total sound power level (SWL) or sound source
-
2.
room type (NORSOK S-002 (Resolution MSC.337 (91)) administrated by Norwegian Technology Standards Institution for Norwegian offshore sector) for eight different room types based on the permitted noise levels on the board of the oil-rig
-
(a)
Type 1- unmanned machinery room (maximum allowable 110dBA)
-
(b)
Type 2- unmanned machinery room (maximum allowable 90 dBA)
-
(c)
Type 3- manned machinery room (maximum allowable 85dBA)
-
(d)
Type 4- unmanned instrument room (maximum allowable 75 dBA)
-
(e)
Type 5- store, workshop and instrument room (maximum allowable 70 dBA)
-
(f)
Type 6- living quarter public area, change room, corridor and toilets (maximum allowable 65 dBA)
-
(g)
Type 7- living quarter public area, laboratory, local control room, galley, mess room, office, gymnasium, lobby (maximum allowable 60 dBA)
-
(h)
Type 8- cabin, hospital, central control room (maximum allowable 45dBA)
-
(a)
-
3.
room surface area
-
4.
room volume
-
5.
first nearest source sound power levels
-
6.
source–receiver distance from the first source
-
7.
second nearest source sound power levels
-
8.
source–receiver distance from the second source
-
9.
room mean absorption coefficient
-
10.
the maximum sound power level of adjacent rooms
-
11.
panel or insulation thickness
-
12.
room type (refers to item 2) of the adjacent room
-
13.
number of decks to the main deck

Typical compartment (top) and model of oil drilling rig (bottom) (Chin and Ji 2018)
The hull dimensions of the jack-up rig involved in the study can be shown in Fig. 1. The proposed approach uses dataset (Chin and Ji 2018) to train the DBN-DNN model. There are not more than 215 observations in the thirteen input variables (Table 1) across the octave frequencies (i.e., 125 Hz, 250 Hz, 500 Hz, 1000 Hz, 2000 Hz, 4000 Hz and 8000 Hz) for predicting the SPL of the oil drilling rig. Data for each input variables were obtained from different rooms on the offshore platform (Table 1) using both the commercial VA-One software and site measurements. There are around 19565 data for all seven octave frequencies where 50% of it will be used for training and remaining for testing. As shown in Table 1, all data are continuous variables except for the data used for the room types which is a discrete variable. All data are normalized to the range from 0 to 1 before the machine learning.
3 Deep belief network
A graphical representation of an RBM used to form stacked RBM is shown in Fig. 2. The RBM is pre-trained using the training data via contrastive divergence (CD) (Hinton 2002) training algorithm of the RBMs. Then, the states of the hidden binary units of the trained RBM are utilized as the training data for the next layer of the RBM. This process is repeated for other layers. The deep belief network (DBN) is constructed by stacking the trained RBMs. Adding a final decision layer to the DBN gives the DBN-DNN. The supervised training of the DBN-DNN by the back-propagation algorithm is called fine-tuning. The details of RBM to final DBN-DNN construction can be found in the following reference (Tanaka and Okutomi 2014).
The joint probabilities of visible units v and hidden units h of RBM (Fig. 2) can be denoted by
where E is the energy function, Z is the partition function, W represents the weights connecting hidden and visible units and a and b are the biases of the visible and hidden layers, respectively. For example, v =1 (or h =1) when b (or c) will be positive or vice versa. The partition function Z is defined as
The energy function E in (2) can be expressed as
where a and b are the biases of the visible (v) and hidden (h) layers, respectively, and W represents the weights connecting v and h.
The conditional probabilities of the hidden (visible) state given the visible (hidden) state are written as Eq. (4) and (5), respectively. The given visible and hidden states are both random binary variable. Hence,
where \(\sigma \) is the sigmoid function defined as \(\sigma (W^{\mathrm{T}}{} \mathbf{v} +\mathbf{b} )=\frac{1}{1+\exp [-(\mathbf{W} ^{\mathrm{T}}{} \mathbf{v} +\mathbf{b} )]}\) , b is the bias and W represents the weights connecting v and h.
Similarly, the conditional probabilities of the visible state given the hidden state are
where \(\sigma \) is the sigmoid function defined as \(\sigma (\mathbf{W} {} \mathbf{h} +\mathbf{a} )=\frac{1}{1+\exp [-(\mathbf{W} {} \mathbf{h} +\mathbf{a} )]}\),a is the bias and W represents the weights connecting v and h.
The set of visible and hidden units are conditionally independent in RBMs. The block Gibbs sampling by simultaneously sampling visible (or hidden) units with fixed values of hidden (visible) units can be performed. A single step of Markov chain can be expressed as shown in Eqs. (6) and (7).
where \(\mathbf{h} ^{n}\) is the set of all hidden units at n-th step of the Markov chain, a and b are the biases of the visible (v) and hidden(h) layers, respectively, and \(\sigma \) is the sigmoid function.

Graphical representation of stacked RBM, DBN and DBN-DNN

Input data and reconstruction during CD training
However, the update of each parameter in the process needs one such chain to convergence. It can be quite computationally exhaustive. The principle of CD can reduce the sampling process to just a single-step CD (known as CD-1). As seen in Fig. 3, it consists of the positive phase where the input sample went into the input layer \(\mathbf{v} _{1}\) and propagated to the hidden layer to give \(\mathbf{h} _{1}\) via Eq. (4). The result of the hidden layer \(\mathbf{h} _{1}\) propagates down to a new or reconstructed visible layer \(\mathbf{v} _{2 }\) via Eq. (5) Then to \(\mathbf{h} _{2}\) again. The change of the parameters in the CD training can be expressed as
where \(\epsilon \) is the training rate, the superscripts of 1 and 2 of \(h_{j}^ {}\)and \(v_{i}^ {}\) are used to denote the step in the sampling process and the angle bracket refers to the average training data.
The inference Tanaka and Okutomi (2014) of the RBM by taking expectation after the activation function is defined as
where \(\sigma \) is the sigmoid function, E is the expectation of the probability P(.), \(\varsigma _{l}^ {}\) is the input, \(\mathbf{b} _{l}^ {}\) is the bias and \(\mathbf{W} _{l}^{\mathrm{T}}\mathrm{\;}\) represents the weights.
The conditional probabilities of the (l+1)-th node given all possible combinations of binary states of the l-th node are computed. It is followed by evaluating the expectation of conditional probabilities. The eventual closed-form approximation (Tanaka and Okutomi 2014) of (9) can be expressed as
where E is the expectation, \(w_{l}^{j}\) is the j-th column vector of the matrix \(\mathbf{W} _{l}^ {}\), \(b_{l}^{j}\) is the j-th column vector of the matrix \(\mathbf{b} _{l}^ {}\), \(\varsigma _{l}^ {}\) is the input, \(\sigma \) is the sigmoid function, \(\rho ^{2}\) is the variance and \(\mu \) is the mean.
Here, the mean \(\mu \) and variance \(\rho ^{2}\) Tanaka and Okutomi (2014) in (10) can be defined as follows.

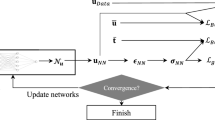
Overall flow of optimizing number of neurons from first to last hidden layer in DBN-DNN
where P(.) is the probability, \(w_{l}^{ij}\) is the (i,j)-th element of the matrix \(\mathbf{W} _{l}^ {}\), \(b_{l}^{ij}\) is the ij-th column vector of the matrix \(\mathbf{b} _{l}^ {}\), \(\varsigma _{l}^ {}\) is the input and \(V[\varsigma _{l+1}^{j}]\) represents the variance of \(\varsigma _{l+1}^{j}\).
The forward inference of the DBN-DNN with the inference is easy. For the fine-tuning of the DBN-DNN, back-propagation two sets of partial derivatives (Wang and Manning 2013) are required. The back-propagation process can be obtained similarly using classical BP. The details can be found in Tanaka and Okutomi (2014), and its potential application can be seen in Zhang et al. (2017), Sun et al. (2018) and Xiong et al. (2018).
4 Neuron optimization algorithm for hidden layers
Problems related to the network structure such as the number of neurons for each hidden layer are still a challenging task within the AI research. In this paper, the optimal number of neurons used in the three hidden layers is based on the idea of Euclidean Distance. The method finds an optimal number of the hidden neurons in DBN-DNN by using a normalized Euclidean distance between the current RMSE and the worst possible error. The approach applies on the first hidden layer and propagates to the last hidden layer progressively as seen in Fig. 4 before validating the final set of hidden neurons.
In the process of finding the optimal number of hidden neurons in one layer, the remaining hidden layer is set to one. A final validation using the optimal set of hidden neuron is performed to ensure the RMSE is indeed smaller than the worst-case value.
In summary, the procedure of finding the optimal neurons for one hidden layer is as follows.
-
1.
The root mean square error (RMSE) of the test sample \((E_{ij})\) consisting of four actual SPL outputs (j), namely spatial SPL, average spatial SPL, structure-borne SPL and airborne SPL across different sets of neuron numbers (i), is computed. For clarity, only ten different numbers of neurons starting from 2 to 11 are used. The RMSE matrix can be tabulated in Table 2
-
2.
The best-case (equal to 0) and worst-case (equal to 80dBA as it should not exceed this value under SOLAS regulation II-1/3-12 [14]) RMSE value for each SPL output are also provided in the RMSE matrix as seen in Table 2.
-
3.
The RMSE matrix is then normalized by the root mean square (RMS) value for each SPL output in Eq. (13). The normalized values can be seen in Table 3.
$$\begin{aligned} R_{ij}=\frac{E_{ij}}{\sqrt{\sum _{j=1}^{m}{E_{ij}^2}}},\forall i=1,...,n;j=1,...,m \end{aligned}$$(13)where RMS \(\sqrt{\sum _{j=1}^{m}{E_{ij}^2}}\) is computed as \([85.773 \quad 86.510 88.174 \quad 87.937] \)
-
4.
The Euclidean distance between the current and the best-case value of RMSE for the SPL outputs is given in Eq. (14). The values for the Euclidean distance are tabulated in Table 4.
$$\begin{aligned} S_{j}^{+}={\sqrt{\sum _{i=1}^{n}{(E_{ij}-R_{i}^{+})^2}}},\forall j=1,...,m \end{aligned}$$(14) -
5.
The Euclidean distance between the current and the worst-case value of RMSE for the SPL outputs is given in Eq. (15). The values for the Euclidean distance can be seen in Table 5.
$$\begin{aligned} S_{j}^{-}={\sqrt{\sum _{i=1}^{n}{(E_{ij}-R_{i}^{-})^2}}},\forall j=1,...,m \end{aligned}$$(15)
-
6.
Calculate the closeness or distance to the best value by computing the ratio of the worst-case RMSE value over the sum of both the worst-case and the best-case values of the RMSE for the SPL outputs in Eq. (16). The values can be seen in Table 6.
$$\begin{aligned} C_{j}^{+}=\frac{S_{j}^{-}}{S_{j}^{-} +S_{j}^{+} },\forall j=1,...,m \end{aligned}$$(16) -
7.
Finally, perform ranking on the ratio obtained from Eq. (16). As seen in Table 6, the optimal number of neurons is the higher value that is closer to the best case, \(S_{j}^{+}\). In this case, the highest ratio or the optimal number of neuron is \(11\mathrm{th}\) neuron. Note that \(R^{+}\) (or \(R^{-}\)) is not included as it is always the highest (or the lowest).
-
8.
The optimal number of neurons for first hidden layer is used and the same procedure repeats for the \(2\mathrm{nd}\) until it reaches the last hidden layer. During the process of finding the optimal number of the hidden neurons in one layer, the remaining hidden layer is set to 1.
-
9.
The final optimal number of neurons for all hidden layers is then used. The testing RMSE of the SPL outputs is validated to ensure that the optimal neuron numbers (Table 7\([11-3-2]\)) give the lower RMSE values than the worst case (see Table 8 equal to \([5-11-8]\)).
The results of the neuron optimization algorithm for all hidden layers can be seen in the next section.
5 Experimental results
5.1 Neuron optimization algorithm for hidden layers at different frequencies
The neuron optimization algorithm is applied to DBN-DNN. The optimal number of neurons can be seen in Table 7 for 125 Hz. It is found that the optimal number of neurons is 11, 3 and 2 . The average RMSE for the testing using the proposed optimal neuron number is approximately \(20\%\) less than the random assignment of the number of neurons. Similar phenomena can be seen in Fig. 5 where the SPL outputs have a closer match to the actual outputs as compared to other number of neurons.
Instead of using the same number of neurons for other frequencies, namely 250 Hz, 500 Hz, 1000 Hz, 2000 Hz, 4000 Hz and 8000 Hz, the results of the neuron optimization algorithm can be seen in Table 9. The average RMSE of the SPL outputs using different optimal numbers of neurons is higher than its counterpart that uses the same number of neurons \([11-3-2]\). In addition to the more training time required as a result of more number of optimization, the results for optimizing the number of neurons for each frequency do not show prominent improvement. In fact, the RMSE is slightly higher than the constant optimal number of neurons. Hence, the constant optimal number of neurons \([11-3-2]\) is used for all frequencies.

SPL output responses using optimal and random number of neurons for DBN-DNN
5.2 Comparisons with other neural networks
Next, the DBN-DNN with the optimal number of neurons is then compared with the MLP, sparse autoencoder (AE), Softmax, self-taught learning (STL) and extreme learning machine (ELM). The results of other approaches tabulated in Tables 10 and 11 can be found in the paper Chin and Ji (2018). The sigmoid function was used except for ELM that used sinusoidal activation function. The number of neurons used for MPL, AE, Softmax, STL and ELM is as follows: 65, 25, 15, 200 and 2, respectively. The details can be seen in Tables 10 and 11.
The hardware environment includes a laptop with Intel 2.40 GHz CPU and 16G Memory. A total of 215 data for each input parameters for all octave frequency: 125 Hz, 250 Hz, 500 Hz, 1000 Hz, 2000 Hz, 4000 Hz and 8000 Hz, were used for machine learning. The thirteen input data can be seen in Table 1. As such, a total of 19565 points were used for the noise prediction. Around 50% of the dataset was utilized for training and remaining was for testing. The performance was evaluated using the root mean square error (RMSE) of the four outputs: spatial SPL, average spatial SPL, structure-borne SPL and airborne SPL. The time spent on training is tabulated in Tables 10 and 11 for all the octave frequency. A three-hidden-layer DBN-DNN (excluding the input and output layer) was used.
The number of hidden units or neurons for the three-layer is configured as \([11-3-2]\). All the RBMs used in DBN-DNN are Bernoulli–Bernoulli RBMs. The maximum iteration was set to 500 that can be adjusted to fine-tune the results. The momentum value is between 0 and 1. To jump from local minima, the momentum value has to be high. If it becomes too large, the learning rate needs to be smaller. A substantial momentum causes a faster convergence. With both momentum and learning rate at high values, it will skip the minimum with a large step.
Conversely, a small momentum can increase the training time and can trap in local minimal. However, it can help to smooth out the variations for changing gradient. In this paper, the right value of momentum was obtained through trial and error. The initial momentum was set to 0.5 for the first five iterations followed by 0.9. The weight cost was set to 0.0002. It is used to decrease the cost function. By dropping out units (both hidden and visible), it helps to reduce overfitting issue. A dropout rate of 0.5 was used. The learning step size was set to 0.035. The inputs were normalized to 0 to 1 in order to reduce the training time and the risk of the local optima.
As observed in Tables 10 and 11, the DBN-DNN has the lowest testing RMSE among MLP, AE, Softmax, STL and ELM in all the selected octave frequency. However, the time taken to complete the training is moderately faster than MLP and Softmax. However, the DBN-DNN is slower than the ELM. The ELM is faster as it is based on a straightforward formula or structure that can achieve quite a fast training speed with only one hidden layer (not trained via a constant weight on the incoming connections). The training time for DBN-DNN is around 20 s. Although ELM has a simple structure such as less neurons can be used for the hidden layer, the RMSE of ELM is not sufficiently small. Hence, a multi-layer neural network such as DBN-DNN is proposed to reduce the testing RMSE.
As shown in Figs. 6, 7, 8,9, 10,11 and 12, the mean outputs of each neuron in the hidden layers of the DBN-DNN were plotted. As observed, each hidden layer is trying to learn the features of the thirteen input parameters. The first hidden layer is usually meant to learn lower features, and it progresses to learn even higher-order features at a higher layer. Unlike face recognition, each layer can learn edges and face features such as nose, eyes and mouth. In noise prediction, each hidden layer will learn the importance of the input parameters such as level of the noise source, the volume of the room, distance from the noise source and noise insulation or absorption coefficient of the room. However, the outputs of the neurons may not coincide with the input parameters, and the image plots may not provide information such as edge and features of the face (in the case of face recognition problem). Nevertheless, some insights into the performance of DBN-DNN in each hidden layer can be obtained.
For example, in Fig. 6 (for 125 Hz), more emphasis is placed on first and second hidden neurons to achieve the targeted spatial SPL, average spatial SPL, structure-borne SPL and airborne SPL. As the training continues to the next layer, the mean activation outputs become more prominent. The \(4\mathrm{th}\) layer gives the outputs of DBN-DNN in the range of 0 to 1 that are then converted back to the actual SPL values. As seen in Fig. 6, 7, 8, 9, 10, 11 and 12, the mean activation value of each neuron is quite different in each layer. In general, higher activation outputs can be found in spatial SP and average spatial SPL. On the other hand, the structure-borne SPL has the smallest activation output as compared to the rest. From the training, it can observe that a few layers are required to train the dataset in order to learn the necessary features that affect the SPL. Increasing the hidden layer beyond three does not have much improvement on the testing RMSE.

Mean activation function outputs for each layer for 125 Hz using DBN-DNN

Mean activation function outputs for each layer for 250 Hz using DBN-DNN

Mean activation function outputs for each layer for 500 Hz using DBN-DNN

Mean activation function outputs for each layer for 1000 Hz using DBN-DNN

Mean activation function outputs for each layer for 2000 Hz using DBN-DNN

Mean activation function outputs for each layer for 4000 Hz using DBN-DNN

Mean activation function outputs for each layer for 8000 Hz using DBN-DNN

Spatial, average spatial, structure-borne and airborne SPL for 125 Hz using DBN-DNN

Spatial, average spatial, structure-borne and airborne SPL for 250 Hz using DBN-DNN

Spatial, average spatial, structure-borne and airborne SPL for 500 Hz using DBN-DNN

Spatial, average spatial, structure-borne and airborne SPL for 1000 Hz using DBN-DNN

Spatial, average spatial, structure-borne and airborne SPL for 2000 Hz using DBN-DNN

Spatial, average spatial, structure-borne and airborne SPL for 4000 Hz using DBN-DNN

Spatial, average spatial, structure-borne and airborne SPL for 8000 Hz using DBN-DNN
As observed from Figs. 13, 14, 15, 16, 17, 18 and 19, the responses of the noise prediction in each frequency can be plotted. In general, the RMSE of the SPL outputs is not more than 10dBA. The prediction of the overall SPL, in particular the airborne noise, performs better at a higher frequency of 2000 Hz and beyond. It is due to the fact that the airborne noise is characterized by higher frequency. As observed, there exist some deviations between the actual and prediction by DBN-DNN. It is due to the presence of both continuous and discrete variables in the dataset. Although the normalization was performed to have the same range of values for each of the inputs to guarantee stable convergence of weight and biases, the normalization can cause errors in the training of the data (with outliers) when they are passed through the nonlinearities in each layer before the outputs. However, the testing RMSE can further be improved by fine-tuning the hyper-parameters of DBN-DNN such as step size and momentum values, but at the expense of higher computation time in training and testing if the number of neurons or layer increases. Moreover, it may not reduce the RMSE.
6 Conclusion
The deep belief network (DBN) including the last layer where it was initialized with trained DBN called DBN-DNN was used to model the sound pressure level (SPL) of the compartments in the oil drilling rig. The supervised pre-training changed the weights in a greedy layer-wise fashion. The two layers at a time were trained as a restricted Boltzmann machine (RBM) where one of the hidden layers acted as the visible layer for the next. It was followed by the supervised pre-tuning that adjusted these parameters using the standard back-propagation.
To improve on the neural network structure, the normalized Euclidean distance from the worst possible error for each hidden layer was used to determine the optimal number of the hidden neurons in RBM. It was performed in a progressive manner from the first to the last hidden layer. The results indicated that the spatial SPL, average spatial SPL, structure-borne SPL and airborne SPL improved the testing root mean square error (RMSE) to approximately 20% as compared to its counterpart using the random assignment of number of neurons.
In addition, as compared with the other machine learning approaches such as multilayer perceptron (MLP), sparse autoencoder (AE), Softmax, self-taught learning (STL) and extreme learning machine (ELM), the experimental results showed that the RMSE in the spatial SPL, average spatial SPL, structure-borne SPL and airborne SPL had improved.
In the future, more dataset will be sought for training, and further adaptive-based fine-tuning will be incorporated into the DBN-DNN to reduce the testing RMSE.
References
Abramowski T (2013) Application of artificial intelligence methods to preliminary design of ships and ship performance optimization. Naval Eng J 125(3):101
Cepowski T (2017) Prediction of the main engine power of a new container ship at the preliminary design stage. Manag Syst Prod Eng 2(26):97–99
Chin CS, Ji X (2018) Adaptive online sequential extreme machine learning for frequency dependent noise data on offshore oil rig. Eng Appl Artif Intel 74:226–241
Chin CS, Ji X, Woo WL, Kwee TJ, Yang WX (2017) Modified multiple generalized regression neural network models using fuzzy C-means with principal component analysis for noise prediction of offshore platform. Neural Comput Appl 2017:1–16
Cui J, Wang D (2013) Application of knowledge-based engineering in ship structural design and optimization. Ocean Eng 72:124–139
Daranda A (2016) A neural network approach to predict marine traffic. Technical Report MII-DS-07T-16-9-16. Vilnius University Institute of Mathematics and Informatics, Lithuania
Diez-Olivan A, Pagan JA, Sanz R, Sierra B (2019) Deep evolutionary modeling of condition monitoring data in marine propulsion systems. Soft Comput 23:9937?9953
Elassad ZEA, Mousannif H, Moatassime HA, Karkouch A (2020) The application of machine learning techniques for driving behavior analysis: a conceptual framework and a systematic literature review. Eng Appl Artif Intell 87:103312
Essien AE, Giannetti C (2020) A deep learning model for smart manufacturing using convolutional LSTM neural network autoencoders. IEEE Trans Ind Inf 99:1
Fan Y, Xu K, Wu H, Zheng Y, Tao B (2020) Spatiotemporal modeling for nonlinear distributed thermal processes based on KL decomposition, MLP and LSTM network. IEEE Access 8:25111
Fischer A, Igel C (2012) An Introduction to Restricted Boltzman machine, progress in pattern recognition, image analysis. Comput Vis Appl 7441:14–36
Hinton GE (2002) Training products of experts by minimizing contrastive divergence. Neural Comput 14(8):1771–1800
Hinton GE, Osindero S, Teh Y (2006) A fast learning algorithm for deep belief nets. Neural Comput 18:1527–1554
Hou L, Zou J, Du C, Zhang J (2019) A fault diagnosis model of marine diesel engine cylinder based on modified genetic algorithm and multilayer perceptron. Soft Comput
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521:436–444
Li Z, Cai D, Wang J, Li Y, Gui G, Sun X, Wang N, Zhang J, Liu H, Wang G (2019) Machine learning based dynamic correlation on marine environmental data using cross-recurrence strategy. IEEE Access 7:17
Liang S, Yang J, Wang Y, Wang M (2014) Fuzzy neural network in condition maintenance for marine electric propulsion system, 2014 IEEE Conference and Expo Transportation Electrification Asia-Pacific, August 31 ?Sept 3. Beijing, China
Liang Y, Wang L (2019) Applying genetic algorithm and ant colony optimization algorithm into marine investigation path planning model. Soft Comput
Praczyk T (2020) Neural collision avoidance system for biomimetic autonomous underwater vehicle. Soft Comput 24:1315?1333
Resolution MSC.337 (91). Code on noise levels on board ships. http://www.imo.org/en/KnowledgeCentre/IndexofIMOResolutions/Maritime-Safety-Committee-(MSC)/Documents/MSC.337(91).pdf. Accessed 27 Feb 2020
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning representations by back-propagating errors. Nature 323:533–536
Su Y, Zhang K, Wang J, Madani K (2019) Environment sound classification using a two-stream CNN based on decision-level fusion. Sensors 19(7):1733
Sun X, Zhang H, Meng W, Zhang R, Li K, Peng T (2018) Primary resonance analysis and vibration suppression for the harmonically excited nonlinear suspension system using a pair of symmetric viscoelastic buffers. Nonlinear Dyn 94(2):1243–1265
Tanaka M, Okutomi M (2014) A novel inference of a restricted Boltzmann machine. In: 22nd International conference on pattern recognition, pp 1526-1531
Wang S, Manning C (2013) Fast dropout training. ICML 2013:118–126
Xiong H, Zhu X, Zhang R (2018) Energy recovery strategy numerical simulation for dual axle drive pure electric vehicle based on motor loss model and big data calculation, complexity, 2018, Article ID 4071743, 14 pages
Yang HZ, Chen JF, Ma N, Wang DY (2012) Implementation of knowledge-based engineering methodology in ship structural design. Comput Aided Des 44:196–202
Zadeh SM, Powers DMW, Sammut K, Yazdani AM (2018) A novel versatile architecture for autonomous underwater vehicle? Motion planning and task assignment. Soft Comput 22:1687?1710
Zhang R, He Z, Wang H, You F, Li K (2017) Study on self-tuning tyre friction control for developing main-servo loop integrated chassis control system. IEEE Access 5:6649–6660
Acknowledgements
The authors would like to thanks Newcastle University in Singapore and National Natural Science Foundation of China for the support. This study was funded by National Natural Science Foundation of China (Grant No. 51775565).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There is no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Communicated by V. Loia.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chin, C.S., Zhang, R. Noise modeling of offshore platform using progressive normalized distance from worst-case error for optimal neuron numbers in deep belief network. Soft Comput 25, 495–515 (2021). https://doi.org/10.1007/s00500-020-05163-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-020-05163-5