
Abstract
Accurate reference evapotranspiration (ET0) estimation has an effective role in reducing water losses and raising the efficiency of irrigation water management. The complicated nature of the evapotranspiration process is illustrated in the amount of meteorological variables required to estimate ET0. Incomplete meteorological data is the most significant challenge that confronts ET0 estimation. For this reason, different machine learning techniques have been employed to predict ET0, but the complicated structures and architectures of many of them make ET0 estimation very difficult. For these challenges, ensemble learning techniques are frequently employed for estimating ET0, particularly when there is a shortage of meteorological data. This paper introduces a powerful super learner ensemble technique for ET0 estimation, where four machine learning models: Extra Tree Regressor, Support Vector Regressor, K-Nearest Neighbor and AdaBoost Regression represent the base learners and their outcomes used as training data for the meta learner. Overcoming the overfitting problem that affects most other ensemble methods is a significant advantage of this cross-validation theory-based approach. Super learner performances were compared with the base learners for their forecasting capabilities through different statistical standards, where the results revealed that the super learner has better accuracy than the base learners, where different combinations of variables have been used whereas Coefficient of Determination (R2) ranged from 0.9279 to 0.9994 and Mean Squared Error (MSE) ranged from 0.0026 to 0.3289 mm/day but for the base learners R2 ranged from 0.5592 to 0.9977, and MSE ranged from 0.0896 to 2.0118 mm/day therefore, super learner is highly recommended for ET0 prediction with limited meteorological data.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
Due to the water scarcity that many countries around the world are currently facing as a result of climate change, it was necessary to reduce water consumption, especially in agriculture. One of the best solutions for reducing water losses in agricultural irrigation is to determine the crop water requirements accurately. Evapotranspiration (ET) is considered as the main ingredient in crop water demand calculations.ET is the process of mislaying water from both the soil surface and the plant.in reality, the ET value for a specific crop can be estimated by using the corresponding crop coefficient (KC) with ET0 which can be estimated using different climate data under conventional underlying surface conditions (Wu et al. 2021a, b, c).
ET0 is the fundamental component of water resource management for increasing water productivity (Hu et al. 2022). The availability of a precise instrument for calculating ET0 is essential for irrigation managers and water researchers (Tikhamarine et al. 2020). The Food and Agriculture Organization (FAO) has been suggested that the FAO Penman–Monteith (PM) model is the most widely used method for estimating ET0 (Nema et al. 2017; Wu et al. 2021a, b, c). The PM model is applied to different climates and environments without any adjustments being made, and the resulting estimates are reliable. That's why it's regarded as a standard for checking other models against (Wu et al. 2021a, b, c). However, there are significant drawbacks for using the PM method because it needs access to a variety of meteorological data, such as air temperature, relative humidity, solar radiation, and wind speed as shown in Fig. 1 as model inputs (Chen et al. 2020; Yamaç 2021).

Meteorological factors, including sunshine duration, wind velocity, humidity, and air temperature, have an impact on evapotranspiration, which refers to both transpiration and evaporation. This process involves the loss of water from both the soil surface and plant
Many studies have adopted a variety of empirical techniques to compute ET0 including temperature-based, radiation-based, humidity-based, water budget-based, mass transfer-based, and pan-based techniques when all meteorological parameters are not available (Chen et al. 2020; Yamaç 2021). However, because of complex and dynamic processes, it is challenging to estimate ET0 using empirical equations, and to do so, high-quality, site-appropriate meteorological data are required (Yamaç 2021).Therefore, a simplified model must be developed in order to estimate ET0 with high precision while using fewer meteorological data.
Due to the above constraint, researchers developed modeling methodologies to estimate ET0 over the world when meteorological data is restricted or insufficient (Laaboudi and Slama 2020; Valipour et al. 2019). When it came to estimating ET0, machine learning took into consideration more than any other method. In order to model ET0, several researchers have switched from empirical modeling to black-box modeling utilizing machine learning tools where, the use of machine learning to estimate, predict, and forecast ET0 related indicators has been the subject of hundreds of research articles published in the past ten years (Chia et al. 2021).
In the agricultural domain, big data analytic technologies such as generalized neuro-fuzzy models, artificial neural network, adaptive neuro-fuzzy inference system, multi-layer perceptron neural network (MLPNN), extreme learning machine, M5 tree model, least square-support vector regression, multivariate adaptive regression splines have been provided for ET0 estimation (Saggi and Jain 2019). Despite the fact that Big Data analysis plays an important role in data management in digital agriculture, most countries find it difficult to adopt digital agriculture due to a lack of essential technologies, such as effective mobile cellular infrastructure and facilities (Wanniarachchi and Sarukkalige 2022).
Over the past twenty years, diverse artificial intelligence models have been utilized across multiple scientific and engineering domains to address a range of scientific challenges, including modeling, optimization, and prediction. This is due to the capacity of artificial intelligence to effectively address non-linear relationships between variables (Tikhamarine et al. 2020). In order to precisely estimate ET0 scientists have turned to artificial intelligence methods like neural networks and fuzzy logic because they can handle large amounts of data, performs calculations quickly and accurately, and delivers high accuracy. However, these techniques can have complex architectures and structures that make simulation challenging (Ehteram et al. 2019).
Despite the increasing popularity of utilizing AI methods for estimating ET0, these techniques are often implemented without considering the fundamental physical processes that govern ET. This oversight may lead to imprecise outcomes. Moreover, based on current understanding, endeavors to estimate ET0 using AI models have revealed that optimal input combinations do not consistently remain the same, even when subjected to identical climatic conditions. This is attributed to the stochastic and indeterminate selection of meteorological parameters (Yu et al. 2020).
Enhancing prediction accuracy and developing models that give more accurate results is one of the main problems of machine learning but, this can be done by giving the model more data to train on, introducing large architectures, and providing more computer resources (Ravindran et al. 2021). Researchers studying evapotranspiration have recently become interested in ensemble based approaches since these systems are typically more reliable, perform better, and require less computing power (Martín et al. 2021). For the purpose of forecasting ET0 in a variety of climate zones across the globe, it has been suggested that various machine-learning ensemble models be utilized (Salam and Islam 2020). The main goals of using ensembles are to decrease prediction variance, bias, and/or enhance performance where, the major advantages of it are that it can be carried out either through parallel or sequential approach, and it has historically shown a good behavior dealing with outliers and the negative impacts of imperfect data (Kar et al. 2021; Martín et al. 2021).
Ensemble learning techniques are commonly categorized into three main types: bagging, boosting, and stacking/blending. The ensemble technique of bagging involves the process of sampling from the training data with replacement, also known as bootstrap, and subsequently performing averaging or voting over the class labels; Boosting produces ensemble by merging low-performing learners in order to have the possibility that later models would compensate for mistakes made by previous models; In stacking, one learning algorithm uses the results of the others to make predictions about the correct values in the test set. Every approach possesses its own set of advantages and disadvantages. Bagging is known to primarily reduce variance as opposed to bias. However, it may not be as effective when applied to relatively simplistic models. Boosting, on the other hand, aims to reduce both bias and variance by iteratively combining weak learners. It is important to note that boosting is sensitive to noisy data and outliers, and may result in over-fitting. Lastly, stacking is a technique that aims to reduce both variance and bias by addressing errors made by base learners. This is achieved by fitting one or more meta-models on the predictions made by the base learners (Shahhosseini et al. 2022).
In the domain of ensemble learning, it is important to note that Bagging and Boosting are commonly recognized as homogeneous ensembles, while Stacking stands out as a heterogeneous ensemble. Homogeneous ensembles are characterized by the inclusion of models constructed using a singular machine learning algorithm. On the other hand, heterogeneous ensembles encompass models derived from a diverse range of algorithms. In the context of performance prediction, it has been observed that a heterogeneous ensemble holds a distinct advantage over a homogeneous combination (Li et al. 2021; Mienye and Sun 2022).
Stacking technique shows the capability of combining the benefits of various fundamental models and has been demonstrated to be superior in the domains of intrusion detection, short-term electricity consumption prediction, and automatic cataract detection and grading. To date, there has been no additional progress in utilizing stacking and blending techniques to estimate daily ET0 in the context of ensemble models (Wu et al. 2021a, b, c). The stacking approach typically involves a set of base learners at (level 0), along with a Meta learner at (level 1). The base learners generate outputs that are then utilized as inputs for the Meta learner.
The super learner methodology is an extension of the stacking technique, which generates an ensemble model through cross-validation. The super learner is constructed by combining a variety of potential learners, which have been created utilizing multiple algorithms, through a weighted combination (Lankford and Grimes 2021). This approach has been investigated by theoretical examination and has been recommended by scholarly research. The super learner has the potential to outperform the constituent algorithms that were employed in its construction by minimizing a cross-validation loss function (Taghizadeh-Mehrjardi et al. 2021). The utilization of the super learner offers numerous advantages due to its ability to provide flexibility in terms of the variety and quantity of predictive models employed for constructing the super learner. Additionally, it takes into consideration the variations in the predictive capabilities of each individual model. Furthermore, this article outlines a strategic methodology to effectively mitigate the risk of over-fitting during the training process. This is achieved by using cross-validation (Kabir and Ludwig 2019; Taghizadeh-Mehrjardi et al. 2021).In addition it is highly suitable for the field of parallel programming. The various candidate estimators can perform their respective tasks independently, and the utilization of these estimators on distinct training sets can also be isolated (Hastie et al. 2009). However, when dealing with large or streaming data, the current super learning approach is constrained by the computational cost of conducting cross-validated estimator selection from scratch for every incoming batch of data (Benkeser et al. 2018).
From this viewpoint, this paper represents high performance ensemble learning method which has the ability to overcome the complexity of the PM model and the drawbacks of other ensemble learning methods where, limited meteorological data will be used as input for the proposed model. The objectives of this work clarify on the following points:
-
Employing the super learner ensemble learning approach in conjunction with the cross validation theory employing 12 folds to estimate ET0. This will be carried out by utilizing various combinations of limited meteorological data as inputs, thereby addressing the limitation of the PM model which requires a diverse range of meteorological data that may not be readily available in different regions across the world.
-
The PM model and four machine learning models were compared to the suggested model. Our framework's output was compared to competitors to assess our model's ability to estimate ET0 accurately with little meteorological data.
2 Related work
Predicting ET0 accurately is important in many areas like irrigation planning and scheduling, plant water requirements, hydrology, water resource allocation and drainage planning (Chia et al. 2022). For the importance of this variable many researchers have made great time and effort to find solutions to overcome the obstacles that face the estimation of it, especially, in the case of insufficient meteorological data. Many papers have been published to find solutions for the difficulties facing the estimation of ET0.
Seifi and Riahi (2020) have been used three hybrid models called least square support vector machine-gamma test (LSSVM-GT), artificial neural network-gamma test (ANN-GT) and Adaptive neuro fuzzy inference system- gamma test (ANFIS-GT) which have been evaluated and compared with each other to estimate ET0 under arid conditions of Zahedan station, Iran where the results indicated the ability of the developed LSSVM-GT approach to predict ET0 accurately rather than other approaches and can be utilized to generate efficient irrigation strategies with the purpose of preserving available water sources.
Zhu et al. (2020) employed the particle swarm optimization (PSO) algorithm to effectively ascertain the parameters of the extreme learning machine (ELM) model. Consequently, a pioneering hybrid PSO-ELM model was introduced to estimate the daily evapotranspiration. In comparison to equivalent empirical models using the same inputs, the results showed that machine learning models provided more accurate ET0 estimates. It was advised to use the PSO-ELM model, which outperformed other machine learning and empirical models, to predict daily ET0 in the dry Northwest China region with few inputs.
Wu et al. introduced three hybrid models that combine the extreme learning machine model (ELM) with biological heuristic algorithms: the Particle Swarm Optimization algorithm (PSO), the Genetic Algorithm (GA), and the Artificial Bee Colony (ABC) For daily ET0 forecasting across China's varying climate zones, the result showed the ability of PSO-ELM to estimate the ET0 with high precision using limited meteorological data.
Wu et al. (2019) used a five-fold cross-validation approach to assess the performance of four bio-inspired algorithm optimized extreme learning machine ( ELM) models for predicting daily ET0 across China: ELM with genetic algorithm (ELM-GA), ELM with ant colony optimization (ELM-ACO), Elm with cuckoo search algorithm (CSA), and ELM with flower pollination algorithm (ELM-FPA). The findings supported the ability of bio-inspired optimization algorithms, particularly the FPA and CSA algorithms, to enhance the daily ET0 prediction accuracy of the traditional ELM model in China’s various climates.
Mokari et al. (2022) compared four machine learning (ML) models, extreme learning machine (ELM), genetic programming (GP), random forest (RF), and support vector regression (SVR), for estimating daily ET0 with different limited climatic data as inputs in New Mexico using ten fold cross-validation method where, the results showed that SVR and ELM were the best ML models for all input scenarios in the analyzed climate zones, showing the best stability in testing.
Mangalath Ravindran et al. (2022) proposed an innovative approach to estimating daily ET0 through the implementation of an Automated Machine Learning (Auto ML) solution. This is the first instance in which such a methodology has been applied to ET0 prediction in a scenario characterized by limited input parameters, representing a significant contribution to the field of ET0 estimation research. The study implemented two distinct Auto ML frameworks, namely Auto Gluon-Tabular (AGT) and H2O Auto ML, which are automated machine learning tools designed for tabular data. AGT is a novel open-source AutoML methodology developed by Amazon Web Service, while H2O AutoML is built on the scalable and open-source H2O ML platform. The study utilized daily meteorological data from a humid tropical climatic region in Kerala, India, and assessed the performance of these frameworks against radiation-based empirical methods and conventional ML methods. Where, the results showed the AGT’s superiority in ET0 prediction at all weather stations.
Wu et al. (2021a, b, c) used the artificial bee colony (ABC) algorithm, the differential evolution (DE) algorithm, and the particle swarm optimization (PSO) algorithm to calibrate the Hargreaves model, commonly referred to as HG, is widely acknowledged as the most efficient and uncomplicated method for estimating ET0 where, PSO-HG model was found to have the most accurate ET0 estimation on daily and monthly scales, and it can be recommended as the preferred model to predict ET0 in humid regions in southwest China.
Mattar and Alazba (2019) involved the modeling of ET0 as a significant component of hydrological applications, utilizing diverse combinations of climatic variables through two distinct methodologies: gene expression programming (GEP) and multiple linear regression (MLR).The findings suggest that the GEP and MLR models have a more significant impact on the mean relative humidity and wind speed at a height of 2 m than other variables. Incorporating temperature data into models, solar radiation exhibits a marginal impact on enhancing the precision of ET0 estimation. Furthermore, the GEP models' lower statistical error criteria values have substantiated their superior performance in comparison to MLR models and other empirical equations.
Ehteram et al. (2019) developed a new approach for modeling monthly ET0 at Indian weather station by employing a modified support vector machine (SVM) based on the cuckoo algorithm (CA). The SVM-CA results were compared with those from empirical models, genetic programming (GP), a tree model (M5T), and an adaptive neuro-fuzzy inference system (ANFIS) where, a positive outcomes proved that the suggested SVM-CA model outperforms the GP, M5T, and ANFIS models in predicting ET0.
This study (Feng and Tian 2021) aimed to explore the ability of the k-Nearest Neighbor algorithm (KNN) as a data mining technique for estimating ET0 in a semi-arid region of China, despite the limited availability of climatic data. Furthermore, an ET0 forecast model based on the KNN algorithm was evaluated in comparison to the PM-56 equation. Where, the results indicated that KNN model was shown to have the highest accuracy in case of using max, min temperature and relative humidity as inputs.
Zhang et al. (2022) proposed six machine learning algorithms for the estimation of daily ET0. Data pertaining to meteorological conditions, encompassing the uppermost and lowermost temperatures, radiation levels, relative humidity, and wind velocity, spanning the temporal range from 1960 to 2019, were procured from a total of eighteen monitoring stations situated in the northeastern region of Inner Mongolia, China. Three different combinations of inputs were used to train and test the proposed models. These combinations were compared with corresponding empirical equations, which included two equations based on temperature, three equations based on radiation, and two equations based on humidity. The results indicated that when the characteristics of radiation or humidity were added to the given temperature characteristics, all of the proposed machine learning models were able to estimate ET0. Furthermore, the accuracy of these models was higher than that of the calibrated empirical equations that were external to the training study area. This suggests that it would be feasible to construct an ET0 prediction algorithm for cross-station information with similar meteorological characteristics, in order to achieve an acceptable ET0 estimation for a specific station.
This study (Dong et al. 2022) examined the spatiotemporal fluctuations in ET0 (evapotranspiration) in China and enhance the precision of ET0 estimations across several spatiotemporal dimensions. In this study, three machine learning models, namely convolutional neural nets (CNN), extreme learning machines (ELM), and multiple adaptive regression splines (MARS), were evaluated alongside seven empirical models calibrated using the mind evolutionary algorithm (MEA). The objective was to determine the most appropriate models for estimating ET0 across various spatiotemporal scales in China. The findings indicate that machine learning models had superior performance compared to empirical models across various spatiotemporal scales. CNN demonstrated superior performance in terms of both model correctness and stability when calculating ET0.
The objective of this study (Abdallah et al. 2022a) was to assess the efficacy of a D-vine Copula-based quantile regression (DVQR) algorithm for estimating daily evapotranspiration (ET0) in two hyper-arid locations, specifically the Atbara and Kassala stations, located in Sudan. The study focused on the period from 2000 to 2015 and examined the performance of the DVQR model using different input structures. Additionally, the DVQR model was compared to other statistical models including Multivariate Linear Quantile Regression (MLQR), Experimental Models (EMMs), Bayesian Model Averaging Quantile Regression (BMAQR), and Classical Machine Learning (CML). In addition, many computational intelligence models were utilized in this study, namely random forests (RF), support vector machines (SVM), Extreme Learning Machines (ELM), extreme gradient booster (XGBoost), and M5 Models Tree (M5Tree). The findings indicate that the first EMMs exhibited subpar performance, but demonstrated improvement following the implementation of calibrating methodologies. The DVQR, MLQR, & BMAQR models exhibited superior performance in comparison to the calibrated EMMs. In comparison to the MLQR & BMAQR models, the DVQR model demonstrated superior accuracy across both study sites. The M5Tree, Support Vector Machine (SVM), and Extreme Gradient Boosting (XGBoost) models exhibited superior performance compared to the Extreme Learning Machine (ELM) and Random Forest (RF) algorithms at both testing sites.
The objective of this study (Elbeltagi et al. 2023) was to develop a model for estimating evapotranspiration (ETo) in Egypt's key agricultural governorates, namely Al Buhayrah, Alexandria, Ismailiyah, and Minufiyah. This was achieved through the utilization of four machine learning (ML) algorithms, namely a linear regression approach (LR), random subspace (RSS), reduced error pruning tree (REPTree),and additive regression (AR). The study identified maximum temperature (Tmax), minimum temperature (Tmin), and solar radiation (SR) as the three input variables that exerted the most significant influence on the results of subset regression and sensitivity analysis. The outcome achieved through the process of performing an action or task. The results of a comparison investigation of machine learning models demonstrated that REPTree exhibited superior performance compared to its competitors, as evidenced by reaching the highest values across multiple performance metrics in both the training and evaluation stages.
The integration of the forecasting models of the top estimation techniques is one of the most efficient methods to provide accurate predictions; this is called ensemble learning approach (Roy et al. 2020). Ensemble learning combines weak learners to develop a new strong model to decrease deviation, lowering variance, or enhance predictive accuracy where, bagging, boosting, and stacking are popular ensemble learning approaches (Wu et al. 2021a, b, c). Ponraj and Vigneswaran (2020) used employed various machine learning algorithms (i.e. multiple linear regression, random forest, and gradient boost regression) to estimate ET0 with and without preprocessing approaches, and the findings show that the preprocessed gradient boost model outperformed the other two models.
Wu et al. (2020a, b) assessed the potential usability of the random forest (RF) prediction model, which is used to replicate daily ET0 where, the results demonstrate that the RF model is a superior way to predict ET0 for the dry oasis area with fewer data. Huang et al. (2019) investigated the capability of CatBoost algorithm for effectively forecasting daily ET0 with minimal meteorological data in humid parts of China, where, CatBoost performances were compared with random forest (RF) and support vector machine (SVM) performances. The results indicated that CatBoost data processing took less time and memory than RF and SVM also; it improved accuracy, stability, and computational cost over RF but, SVM produced the best prediction accuracy and stability with partial meteorological parameter combinations, whereas CatBoost performed best with complete combinations.
Wu et al. (2020a, b) evaluated and compared the efficiency of five Boosting-based models, namely Adaptive Boosting (ADA), Gradient Boosting Decision Tree (GBDT), Extreme Gradient Boosting (XGB), Light Gradient Boosting Decision Machine (LGB), and Gradient boosting with categorical features support (CAT), in the estimation of daily ET0 across ten stations situated in the eastern monsoon zone of China. Where, the result showed the utilization of CAT models is highly advisable for the estimation of ET0 and can be advocated to enhance the efficiency of the model with restricted meteorological parameters in the eastern monsoon region of China.
In this research (Başakın et al. 2023) the authors employed stochastic gradient boost (SGB), a widely utilized soft computing technique, for estimating reference evapotranspiration (ET0) in the Adiyaman region of southeastern Turkey. The ET0 (reference evapotranspiration) was calculated using the FAO-56-Penman–Monteith technique. Subsequently, we approximated the ET0 using the SGB (Simplified Surface Energy Balance) approach, incorporating maximum and minimal temperature, wind speed, solar radiation, and relative humidity data received from a meteorological station. The findings indicate that the hybrid SSA-SGB method produced more precise results in comparison to the predictions made using the stand-alone SGB method.
This work (Heramb et al. 2023) aimed to optimize various machine learning techniques, including random forest model (RF), intense gradient boosting (XGB), & light gradient boost (LGB), using the grey wolf optimizer (GWO), specifically GWORF, GWOXGB, and GWOLGB for ET0 estimation. The findings indicate that the hybrid machine learning (ML) models outperformed traditional and empirical models in accurately predicting outcomes at all stations. Additionally, the random forest (RF) models demonstrated significantly better accuracy when utilizing the Grey Wolf Optimizer (GWO) compared to the LightGBM (LGB) and XGBoost (XGB) models.
The objective of this study (Jayshree et al. 2023) was to examine the efficacy of four ensemble strategies in accurately estimating the daily ET0 values at chosen locations in 10 agro climatic regions in Karnataka, India, spanning the time period from 1979 to 2014. The evaluation of these models was conducted by employing various combinations of meteorological variables as inputs through the use of tenfold cross-validation. The results demonstrated that the ensemble models, including all climatic variables, yielded the most precise estimates of ET0 when compared to alternative input combinations. Additionally the random forest regressor demonstrated superior performance compared to the other three models across all evaluated metrics. Nevertheless, the model in question resulted in the most significant computational expenditure, while the computational cost associated with the bagging approach for the linear regression was the most minimal. The performance for the extreme gradient-boosting algorithm was shown to be the most stable when trained on a modified dataset.
On the other hand, evapotranspiration studies have ignored other ensemble methods, such as Stacking, despite the significant benefits, which include the ability to simultaneously develop ensembles from a variety of learning models and benefit from each one’s advantages while avoiding its drawbacks. Furthermore, when dealing with outliers and noise, Stacking ensembles have typically performed well (Martín et al. 2021). The term "stacked ensemble" refers to a specific type of ensemble approach in which multiple machine learning models are assembled in layers, with data moving from the input to the outcome (Petinrin and Saeed 2019; Vidyarthi et al. 2020).
Wu et al. (2021a, b, c) presents the initial assessment of stacking and blending ensemble models for the purpose of estimating daily ET0. The stacking and blending models utilized a two-tiered architecture. The first layer, or level-0, consisted of basic models such as random forest (RF), support vector regression (SVR), multilayer perceptron neural network (MLP), and K-Nearest Neighbor regression (KNN). The second layer, or level-1, produced the ultimate outcome through linear regression (LR). The findings suggest that the stacking and blending models exhibited superior performance compared to the basic and empirical models, irrespective of the input combination. In contrast to basic models, the stacking and blending models exhibited greater portability across stations situated in diverse climate zones. Regarding computational expenses, stacking and blending models outperformed basic models in terms of accuracy within a reasonable time frame and with a smaller training dataset. However, blending models were able to achieve comparable high accuracy to stacking models in less time after expanding the size of the training dataset. Hence, the utilization of stacking and blending ensemble models is highly recommended for the estimation of ET0, particularly in cases where the training dataset or meteorological variables are restricted.
Even though the performance of an ensemble or combining learners in multiple ways performed much better than a single-candidate learner, there is concern that these methods may over fit the data and may not be the best way to combine the candidate learners (Kabir and Ludwig 2019). From the previous literature review, it's evident that researchers have tried to improve ET0 prediction approaches, and that work in this field is currently in progress. This study introduces the super learner technique, an ensemble approach to get over the limitations of the PM model and other machine learning models to estimate ET0 precisely.
3 Materials and methods
The study area and dataset, the meteorological input combinations, the proposed model's flowchart, the super learner technique's structure, the machine learning models employed in this investigation are all included in this section, model evaluation metrics and PM model.
3.1 Study area and data collection
In light of recent climate changes and population growth in Egypt, the country is facing a significant water shortage. Consequently, it is imperative to devise solutions to address this issue. The Egyptian government is currently focused on improving water resource management, particularly by mitigating water loss in the agricultural sector. This research aims to assist the government in developing an accurate model for estimating reference evapotranspiration, particularly in regions lacking sufficient meteorological data.
The Arab Republic of Egypt has a landmass of approximately 1,002,000 square kilometers and a location in the northeastern part of the African continent. Its latitudes range from 22 to 32 degrees north, while its longitudes range from 25 to 37 degrees east.
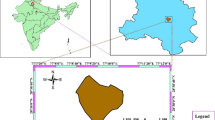
The 32 Egyptian weather stations that contributed to the dataset utilized in this investigation are depicted in Fig. 2. These stations are part of the United Nations Food and Agriculture Organization's (UN-FAO) CLIMWAT database, which has been used in the vast majority of ET0 estimation research (Smith et al., 1993). the dataset covers the period from 1971 to 2000 and includes Long-term monthly mean values of maximum and lowest air temperature (Tmax, Tmin) [°C], relative humidity (RH) (%), solar radiation (Rs) (MJ/m2/day), wind speed (U) at 2 m height (km/day), sunshine hours (H) as inputs and ET0 (mm/day) estimated with the PM model as target.

Geographical distribution of weather stations in Egypt that were selected from the CLIMWAT database
3.2 Data splitting
The dataset consists of 384 records, which have been divided into two subsets. The training set contains 80% of the data, while the testing set contains the remaining 20%. The descriptive statistics of the characteristics of the dataset are presented in Table 1. In this table, the variables Xmin, Xmean, Xmax, and Sx represent the minimum, mean, maximum, and standard deviation, respectively. Additional to this, Fig. 3 depicted the boxplot which illustrated the distribution of each variable in the dataset employed in the current study.

Box plot illustrates the distribution of each variable employed in the current study's dataset
3.3 Proposed model workflow
The stages involved in the application of the suggested model to this research, beginning with the creation of the dataset and ending with the prediction of ET0, are shown in Fig. 4.

The proposed model workflow involves generating a dataset by combining meteorological data and ET0, which is calculated using PM model data. The dataset is then split into training and testing sets, comprising 80% and 20% of the data, respectively. A super learner model is trained using the training set, and the proposed model is evaluated using five statistical indices, namely \({R}^{2}\), RMSE, MAE,MAPE and MSE, on the testing set
3.4 Super Learner model (SL)
The concept of stacking was introduced by David Wolpert in the past 15 years. The implementation details, which were previously considered an "art" by Wolpert in 1992, were transformed into a scientific approach in 1996 by Leo Breiman. Breiman showcased the effectiveness of non-negative least squares (NNLS) regression in amalgamating predictions from algorithms that were fitted to the same dataset, also known as meta-learning. The theory proposed by Mark van der Laan, Sandrine Dudoit, and Aad van der Vaart in 2007 was further expanded to demonstrate that, in the case of large samples, the stacking approach is an optimal method for acquiring knowledge about two variables.
The aforementioned algorithm acquired an alternative terminology, namely "Super Learner" (Phillips et al. 2023). SL model, commonly known as the model ensemble, is a loss-based learning system developed and studied by Lin et al. (2019). The present model is categorized as a stacking ensemble learning methodology, which amplifies the accuracy of the model by means of selecting and amalgamating multiple models (Lee et al. 2022). The SL model will asymptotically outperform all other candidate learners, according to theoretical findings where a Meta learner is learned using the outcomes of a number of base learners. Utilizing cross-validation, the outputs from base learners, also known as the level-one data, can be produced (Kabir and Ludwig 2019).
Consequently, this methodology not only delineates the associations between predictors and the modeling outcomes generated through penalized regression, but also possesses the capability to depict the non-linear connections and interplay through the utilization of spline algorithms or decision trees (Taghizadeh-Mehrjardi et al. 2021). The framework of SL model according to Lee et al. (2022) that used in this study is illustrated in Fig. 5, where, it demonstrates the SL model's workflow, as well as the base learners that were employed in this study. The MLEns (Flennerhag & jlopezpena 2018) (http://ml-ensemble.com) module was used to create the SL model.

Super Learner's Architecture which involves partitioning the entire dataset into folds, with each fold being further divided into a training set and a verification set (V). Four base learner models, namely ETR, SVR, KNN, and ADA, are then trained on the training set and evaluated on the verification set for each fold to generate predictions. These predictions are used to create a new dataset consisting of both Z and V, which is then used to train the Meta learner and ultimately generate predictions
The methodology for constructing the SL model as illustrated in Lee et al. (2022) can be succinctly outlined as follows. The objective of analyzing a dataset through observation Dn = (Xn, Yn), n = 1, 2, 3… k, is to make an estimation of the regression Ψ0 (X) = E (Y|X) where X is a vector of the variables that go into the model, and Y is the outcome that is of interest to us. The SL method comprises a set of distinct principles, which are outlined as follows:
-
(1)
Minimizing the predicted loss E [L (D, \(\Psi \))] is a good way to think about the regression problem as follows:
$${\Psi }_{0} (X) = arg min E [L (D,\Psi )]$$(1)with L being a loss function.
-
(2)
The entire data set χ is divided into k subsets using a k-fold cross-validation approach. Each subset is comprised of verification and training samples V(v) (v = 1,2,3,….,n), T(v) (v = 1,2,3,….,n), correspondingly. Consider a set of algorithms that produce j base learners denoted by \(\widehat{\Psi}\) i (i = 1, 2, 3… j).In the v-th iteration, every base model is trained on the training set T(v). Additionally, the predictions for the respective verification sample can be determined by:
$${\widehat{\Psi}}_{\mathrm{i},\mathrm{T}\left(\mathrm{v}\right) }(\mathrm{V}\left(\mathrm{v}\right),(\mathrm{i}=1, 2, 3\dots \mathrm{ j}))$$(2) -
(3)
The individual predictions generated by each base learner are aggregated through a stacking process, resulting in the formation of a prediction matrix Z = \({\widehat{\Psi}}_{\mathrm{i},\mathrm{T}\left(\mathrm{v}\right) }(\mathrm{V}\left(\mathrm{v}\right)\). The proposed approach involves a set of candidate base learners that are combined using a weight vector α to form a family of weighted combinations which can determine by:
$$\mathrm{m}(\mathrm{z}|\mathrm{\alpha })=\sum_{\mathrm{i}=1}^{\mathrm{j}}{\mathrm{\alpha }}_{\mathrm{i }}{\widehat{\Psi }}_{\mathrm{i},\mathrm{T}\left(\mathrm{v}\right) }(\mathrm{V}\left(\mathrm{v}\right), \quad \sum_{\mathrm{i}=1}^{\mathrm{j}}{\mathrm{\alpha }}_{\mathrm{i }}=1$$(3) -
(4)
The weight vector α is determined by minimizing the cross-validated errors between the permissible weight vector combinations and the actual output Y. This is achieved through the calculation of:
$$\widehat{\mathrm{\alpha }}=\text{ arg min }\sum_{\mathrm{c}=1}^{\mathrm{n}}{\left({\mathrm{Y}}_{\mathrm{c}}-\mathrm{m}({\mathrm{z}}_{\mathrm{c}}|\mathrm{\alpha })\right)}^{2}$$(4) -
(5)
The final super learner is produced by combining the optimal weight vector \(\widehat{\mathrm{\alpha }}\) with \(\widehat{\Psi}\) i (X) according to\(\mathrm{m}(\mathrm{z}|\mathrm{\alpha })\), where:
$${\widehat{\Psi }}_{\mathrm{SL}}(\mathrm{X})=\sum_{\mathrm{i}=1}^{\mathrm{j}}{\widehat{\mathrm{\alpha }}}_{\mathrm{i }}{\widehat{\Psi }}_{\mathrm{i }}(\mathrm{X})$$(5)
3.5 Base learners
Base learners refer to algorithms that are not completely specified but establish a specific learning approach. It's best to consider a variety of base learners and create various versions of the same base learner with different tuning criteria. Incorporating a low-performing learner in the library setting does not pose any detrimental effects, as their performance will be assigned a value of zero (Phillips et al. 2023).
It has been decided to use the machine learning algorithms Extra Tree Regressor (ETR), Support Vector Regressor (SVR), K-Nearest Neighbors (KNN), and AdaBoost Regressor (ADA) as base learners in the Super Learner's model, where the Scikit-learn package (Pedregosa et al. 2011) (https://scikit-learn.org) in Python 3.8 was used to implement the models that were employed in this study. The selected machine learning algorithms can be described as follows:
(1) Extra Tree Regressor (ETR)
As first proposed by Geurts et al., the Extra Tree Regressor (ETR) method is a refined strategy that expands on the strengths of the Random Forest model (Hameed et al. 2021). Extra-Trees are appealing due to their computational efficiency during learning and their ability to compete with other set approaches in terms of accuracy, all while being extremely quick thanks to their extreme randomness (Berrouachedi et al. 2019). ETR's greatest advantage is that it does not necessitate intensive focus on the choice of hyper parameter values while implementation (Saeed et al. 2021).
There are primarily two significant differences between the ETR and Random Forest systems. First, the ETR uses every possible cutting point and randomly selects one to use for dividing nodes. Two, it grows trees using the complete training set (Hameed et al. 2021; Jamei et al. 2021). Figure 6 provides an illustration of the architecture of ETR. With a dataset in hand, ETR chooses a split rule at the root node at random, using a combination of feature selection and cutoff point selection. Until you reach a leaf node, this process will be repeated in all of the nodes below the current one. More specifically, the number of trees in the ensemble, the number of attributes/features to randomly choose, and the minimum number of samples/instances required to divide a node are the three most critical parameters of ETR (Saeed et al. 2021).

The architectural design of the ETR is the subject of discussion. Upon obtaining a dataset, ETR employs a randomized approach to select a split rule for the root node, utilizing a combination of feature selection (N) and cutoff point selection. The aforementioned procedure will be iterated in all nodes situated beneath the present one, until a leaf node is reached
(2) Support Vector Regressor (SVR)
Vapnik was the one who initially suggested using a support vector machine, also known as the SVM approach (Üne et al. 2020; Yamaç, 2021). Owing to its high ability to focus on the complex nonlinear relationships between inputs, SVM is employed for regression and classification issues (Chia et al. 2020; Üne et al. 2020; Yamaç 2021). However, according to current studies on SVM model implementation, the key difficulty is optimizing internal parameters (Ehteram et al. 2019). For the ET0 prediction, which is more likely to be a regression problem than a classification problem, the support vector regression (SVR), which is a version of the support vector machine, is the type of model that is typically utilized (Chia et al. 2020). The accuracy of SVR models is determined by the appropriate selection of kernels and their corresponding parameters. Typically, the radial basis function (RBF) is the preferred kernel due to its superior efficiency in estimating ET0, as supported by prior research findings (Abdallah et al. 2022b; Hebbalaguppae Krishnashetty et al. 2021; Svm et al. 2022).
(3) K-Nearest Neighbors (KNN)
Cover and Hart (1967) created the k-nearest neighbor (KNN) approach, which is widely used in data mining models today (Yamaç 2021). As a result of its efficiency, ease of use, adaptability, and performance, this technique is capable of addressing issues with classification and regression (Yamaç, 2021; Yamaç and Todorovic 2020). The KNN approach does have certain drawbacks, despite the many benefits that were just discussed. Due to the need to calculate the distance between each query example and all training samples, the KNN algorithm might have a slow running time when dealing with large training datasets. Nevertheless, kd-trees can be utilized to improve KNN searches for large amounts of data (Feng and Tian 2021; Yamaç and Todorovic 2020).
Choosing the appropriate "K" value is an important step in applying the KNN algorithm. If the K value is low, the algorithm will become increasingly difficult to understand and will be vulnerable to overfitting. On the other hand, if the K value is high, the model is going to be quite easy to understand (Liu et al. 2021).The steps of KNN technique (Qaddoura and Younes 2022) can be summarized in the following as shown in Fig. 7:
-
(1)
Determine the value of k, as shown in the figure k = 3
-
(2)
Using Euclidean distance, calculate the distance between the aqua-colored point and each red-colored point.
-
(3)
Based on k = 3, the three dots with red color inside the circle represent the three nearest neighbors.
-
(4)
The predicted value can be determined by taking the average value of the three red point values.

KNN for regression problems, where the predicted value can be determined by taking the average of the values of the 3 nearest points based on the distance between the aqua-colored point and each red-colored point
(4) AdaBoost Regression (ADA)
The ADA model quickly rose to prominence as one of the most effective ways to machine learning recognition (Asadollah et al. 2021; Wang et al. 2022; Yamaç and Todorovic 2020). AdaBoost is well recognized as the first effective boosting algorithm, wherein the base learners consist of decision trees that possess a solitary split. Decision trees that consist of only a few nodes and branches are commonly referred to as decision stumps (Mienye and Sun 2022). In the present study, decision tree regressors are utilized as the base learners of ADA model.
ADA's key benefits are that it is more stable with noisy data and has a low impact on the overfitting problem (Jin et al. 2020). In addition to this, the ADA is a well-liked boosting strategy due to the high estimation precision it offers and the ease with which it can be implemented in code (Yamaç and Todorovic 2020). The ADA is a meta-estimator that fits a regression to the entire data and then fits multiple copies of the regression to the corresponding dataset, adjusting the weight of the instances based on the errors of the current prediction as presented in Fig. 8 (Jin et al. 2020).

Schematic of AdaBoost Regression, where all data points in the dataset denoted as (Dm) are assigned uniform weights. The determination of whether a sample will be taken or not is contingent upon the weight of the sample. Sampling with replacement is employed to generate a training set (Dm1) from the dataset (Dm) based on weight considerations. The training set is subsequently utilized to train a regressor. The objective of conducting a prediction loss evaluation is to assess the efficacy of the trained regressor and ascertain an appropriate weight (w1) for the regressor
For the sake of clarity, we will refer to the data set as (Dm). As can be seen, each of the data in (Dm) is given an equal weight to begin with. The weight is what determines whether or not a sample will be taken. In accordance with the weight, we take a sample from the dataset (Dm) using replacement in order to produce a training set (Dm1), and we then make use of the training set in order to train a regressor. The purpose of a prediction loss evaluation is to evaluate the trained regressor and determine a weight (w1) for the regressor, as is illustrated in Fig. 8 (Min and Luo 2016).
3.6 Meta learner
A meta-learner is an algorithm with a defined set of inputs that has been taught to make predictions about a new collection of variables. Therefore, the meta-learner is a learner that learns from the knowledge of other learners. Dataset used to fit the meta-learner, including cross-validated prediction values and validation set outcomes from base learners (Van Der Laan et al. 2007). The Multilayer Perceptron, sometimes known as MLP, is a popular artificial neural network (ANN) architecture that is frequently employed in the field of hydrological modeling (Achite et al. 2022). MLP model has been extensively utilized in the examination of diverse complicated problems (Wu et al. 2021a, b, c). MLP is inspired by neurons in the human central nervous system. It also features straightforward coding and, in most situations, accurate ET0 calculations (Bellido-Jiménez et al. 2022). Due of the aforementioned benefits, MLP will be utilized as a Meta learner in the current investigation. The parameter configurations for the base learners, Meta learner, and Super Learner models employed in the current study are presented in Table 2.
3.7 Penman–Monteith FAO 56 equation (PM model)
The FAO Penman–Monteith model has served as the foundation for numerous prior comparative evaluations due to its wide applicability across geographic regions with little to no modification of its parameters. The Penman–Monteith (P-M) model was initially formulated by Monteith to approximate the rate of evapotranspiration. This model takes into consideration the potential evaporation that occurs over water surfaces and the transpiration process, while assuming that the vegetation canopy functions as a single uniform cover or "big-leaf". The P-M model got standardization by the Food and Agriculture Organization (FAO) and the World Meteorological Organization (WMO) (Abeysiriwardana et al. 2022). The PM model is presented in Chen et al. (2020), Hu et al. (2022), Üneş et al. (2020), Wu et al. (2021a, b, c) and Zhu et al. (2020) as:
where ET0 reference evapotranspiration [mm/day], Rn net radiation at the crop surface [Mj/m2 /day], G soil heat flux density [Mj/m2/day], T mean daily air temperature at 2 m height [oC], U2 wind speed at 2 m height [m/s], es saturation vapour pressure [KPa], ea actual vapour pressure [KPa], es − ea saturation vapour pressure deficit [KPa], Δ Slope vapour pressure curve [KPa/oC], γ Psychrometric constant [KPa/ o C].
The FAO-56 document should be reviewed for further information regarding the computation of each of the variables listed above (Allen et al. 1998).
3.8 Input combinations
As stated in Table 3, this study examined six different combinations of meteorological data as inputs for the suggested model.
3.9 Model performance evaluation
All of the models' performances were assessed with using five well-known metrics: root mean square error (RMSE), mean absolute error (MAE), mean squared error (MSE), mean absolute percentage error (MAPE) (Vaz et al. 2023),and coefficient of determination (\({R}^{2}\)) (Sharma et al. 2022) as the following:
-
(1)
$$RMSE = { }\sqrt {\frac{1}{N}{ }\mathop \sum \limits_{i = 1}^{N} \left( {ET_{i}^{act} - ET_{i}^{pred} } \right)^{2} }$$(7)
where \(ET_{i}^{act}\) and \(ET_{i}^{pred}\) are ET0 values estimated by FAO-56 PM and models respectively.
-
(2)
$$MAE = { }\frac{{\mathop \sum \nolimits_{i = 1}^{N} \left| {ET_{i}^{act} - { }ET_{i}^{pred} } \right|}}{N}$$(8)
where \(ET_{i}^{act}\) and \(ET_{i}^{pred}\) are ET0 values estimated by FAO-56 PM and models respectively.
-
(3)
$$R^{2} = { }\frac{{\left[ {\mathop \sum \nolimits_{i = 1}^{N} \left( {ET_{i}^{act} - { }\overline{{ET_{O}^{act} }} } \right)\left( {ET_{i}^{{pred{ }}} - \overline{{ET_{o}^{pred} }} } \right)} \right]^{2} }}{{\mathop \sum \nolimits_{i = 1}^{N} \left( {ET_{i}^{act} - { }\overline{{ET_{O}^{ACT} }} } \right)^{2} { }\mathop \sum \nolimits_{i = 1}^{N} \left( {ET_{i}^{pred} - { }\overline{{ET_{O}^{pred} }} } \right)^{2} }}$$(9)
where \(ET_{i}^{act}\) and \(ET_{i}^{pred}\) are ET0 values estimated by FAO-56 PM and models and \(\overline{{{\text{ET}}_{{\text{o}}}^{{{\text{pred}}}} }}\) , \(\overline{{{\text{ET}}_{{\text{O}}}^{{{\text{ACT}}}} }}\) are the mean values estimated by models and FAO-56 PM respectively.
-
(4)
$$MSE = { }\frac{1}{{N{ }}}\mathop \sum \limits_{i = 1}^{N} \left( {ET_{i}^{act} - ET_{i}^{pred} } \right)^{2}$$(10)
where \(ET_{i}^{act}\) and \(ET_{i}^{pred}\) are ET0 values estimated by FAO-56 PM and models respectively.
-
(5)
$$MAPE = \frac{1}{N}{\text{~}}\mathop \sum \limits_{{i = 1}}^{N} \frac{{\left| {ET_{i}^{{act}} - {\text{~}}ET_{i}^{{pred}} } \right|}}{{ET_{i}^{{act}} }}{\text{*}}100$$
where \(ET_{i}^{act}\) and \(ET_{i}^{pred}\) are ET0 values estimated by FAO-56 PM and models respectively.
4 Experimental results
This section relies on the experiment results obtained from the proposed model to assess its effectiveness in utilizing diverse restricted meteorological data as inputs. Subsequently, a comparative analysis is presented between the results obtained from our proposed model and the base learners. Ultimately, a comparative analysis is presented between the results obtained from our proposed model and those of other models in the same field. The present investigation utilized five distinct statistical metrics, namely RMSE, MAE, MSE, MAPE and \({R}^{2}\), in conjunction with diverse input meteorological variables to assess the study's objectives.
The \({R}^{2}\) is a statistical measure utilized to assess the correlation and concurrence between the actual and predicted daily ET0. \({R}^{2}\) value of 1 is considered to be excellent and indicates a positive correlation. While the metrics of MAE, RMSE, MAPE, and MSE are utilized to quantify the level of error that is linked with the estimated models. These metrics are characterized by a numerical range that spans from 0 to ∞, with the ideal value being 0 (Vaz et al. 2023).
Initially, a correlation analysis was conducted utilizing a seaborn heatmap (Waskom 2021) to examine the relationship between meteorological input parameters, specifically maximum and minimum temperature (Tmax and Tmin), relative humidity (RH), solar radiation (RS), wind speed (U), sun shine hours (H), and the output variable, namely reference evapotranspiration (ET0). As indicated in Fig. 9, the results of the correlation analysis demonstrate that RS exerts the most substantial impact on ET0, whereas U exhibits the least significant effect. This justification is also supported by previous investigations (Yildirim et al. 2023).

Correlation analysis of selected variables and ET0, where the result demonstrate that RS exerts the most substantial impact on ET0, whereas U exhibits the least significant effect
Additionally, the correlation between relative humidity and ET0 was found to be strong and negative. The observed negative correlation indicates that there exists an inverse association between ET0 and relative humidity. As per the given information, an increase in relative humidity would result in a decrease in the reference evapotranspiration variable. This phenomenon is evidenced by the fact that increased relative humidity results in reduced water loss from both the Earth's surface and plant cells to the atmosphere. This is due to the presence of elevated atmospheric humidity, which is supported by the findings of study (Seifi & Riahi 2020).
4.1 Performance analysis of super learner
The study compared the performance of the SL model with that of the PM model during testing period, using various combinations of meteorological data. The findings as shown in Table 4 indicated that the model with complete meteorological variable inputs (M1) demonstrated the best performance of RMSE, MAE and MSE (0.0512, 0.0358 and 0.0026 mm/day), and MAPE of 0.9148% across all input conditions. Previous research provides support to this argument as well (Wu et al. 2021a, b, c; Yu et al. 2020). In cases where the solar radiation variable is substituted with sunshine hours (M2), the statistical indicators exhibit lower performance (0.2717, 0.2239 and 0.0738 mm/day for RMSE, MAE and MSE, respectively), and MAPE of 5.6145% compared to the M1 inputs. However, the performance is higher than the other combination models (M3, M4, M5, and M6) inputs.
Furthermore, in the context of reducing input variables, there exists a degree of similarity between the model that employs input combinations of temperatures, wind speed, and humidity (M3) inputs and the model that utilizes combinations of humidity, solar radiation, and wind speed (M6) inputs. The former model yields RMSE, MAE, and MSE values of 0.4141, 0.3338, and 0.1715 mm/day, respectively and MAPE of 8.1670%, while the latter model produces RMSE, MAE, and MSE values of 0.4186, 0.3345, and 0.1753, respectively, and MAPE of 8.0131%. Conversely, the utilization of solely temperature and wind speed (M5) inputs resulted in the least optimal performances in comparison to all other input combinations, with respective RMSE, MAE, and MSE values of 0.5735, 0.4575, and 0.3289 respectively, and MAPE of 11.5706%.
The \({R}^{2}\) values for various super learner models utilizing distinct meteorological data as inputs are presented in Figs. 10, 11 and 12 as per the analysis. The most optimal SL was executed in the M1 inputs, exhibiting a high coefficient of determination (\({R}^{2}\) = 0.9994), while the least favorable SL was conducted in the M5 inputs, demonstrating a relatively lower coefficient of determination (\({R}^{2}\) = 0.9279). Furthermore, it can be observed that there is a certain level of resemblance between the \({R}^{2}\) values obtained for SL when utilizing M3 (temperature, humidity, and wind speed) and M6 (humidity, wind speed, and solar radiation) inputs, with \({R}^{2}\) values of 0.9624 and 0.9616, respectively. Furthermore, the study found that substituting Rs in M1 inputs with sunshine hours (M2) inputs resulted in a decrease of 1.56% in \({R}^{2}\) values. Specifically, the \({R}^{2}\) values were 0.9994 and 0.9838 for M1 and M2, respectively.

Scatter plots comparison based on statistical metric \({\mathrm{R}}^{2}\) between predicted ET0 values by employed models against ET0 estimated by standard PM model for M1 and M2 input combinations

Scatter plots comparison based on statistical metric \({\mathrm{R}}^{2}\) between predicted ET0 values by employed models against ET0 estimated by standard PM model for M3 and M4 input combinations

Scatter plots comparison based on statistical metric \({\mathrm{R}}^{2}\) between predicted ET0 values by employed models against ET0 estimated by standard PM model for M5 and M6 input combinations
Additionally, incorporating Rs variable into M5 inputs (M4) led to an improvement of 3.09% in \({\mathrm{R}}^{2}\) values. The \({\mathrm{R}}^{2}\) values were 0.9575 and 0.9279 for M4 and M5, respectively. Finally, replacing Rs in M4 inputs with RH variable (M3) resulted in a slight improvement of 0.5% in \({\mathrm{R}}^{2}\) values. The \({\mathrm{R}}^{2}\) values were 0.9575 and 0.9624 for M4 and M3, respectively. The preceding findings indicate that RH has a substantial impact and are more effective in approximating ET0 using SL models. Previous results demonstrated that RH have significant influence on ET0 estimation (Ferreira et al. 2019).
4.2 Comparison of performance analysis of SL and base learners across Input Combinations
Table 4 demonstrates that the base learners' performance varied depending on the input conditions. Specifically, the models utilizing complete meteorological variables (M1) exhibited the best performance in terms of RMSE, MSE, MAE, and MAPE across all input conditions, with the exception of the ADA model for M6 inputs, which included RH, Rs, and U, and outperformed the other ADA models in terms of MAE and MAPE. Moreover, the models using M5 inputs demonstrated lower performance across all input conditions for RMSE, MSE, MAE and MAPE, except for the ADA model using M3 inputs, which exhibited lower RMSE and MSE than the M5 inputs, and the KNN model using M6 inputs, which exhibited lower MAE and MAPE than the M5 inputs.
Furthermore, Table 4 showed that among the various base learners, SVR models exhibited the most superior performance in terms of RMSE, MSE, MAE and MAPE across M1 inputs, which utilized complete meteorological data, and this finding is in agreement with prior research (Yu et al. 2020), M2 inputs, which replaced the Rs in M1 inputs with H, and M3 inputs, which included temperature, wind speed, and relative humidity. Specifically, the RMSE values were 0.1025, 0.2994, and 0.4416 mm/day for M1, M2, and M3, respectively. The MSE values were 0.0105, 0.0896, and 0.1950 mm/day for M1, M2, and M3, respectively, and the MAE values were 0.0442, 0.2382, and 0.3696 mm/day for M1, M2, and M3, respectively. Finally, the MAPE values were 1.2088, 6.3108 and 9.4351, respectively. However the observation of a larger root mean square error (RMSE) compared to the mean absolute error (MAE) in the support vector machine (SVM) models suggests the presence of outliers or significant errors, but to a lesser degree than in the other base learner models. This finding is consistent with previous research (Chia et al. 2020). Additionally, SVR model is effective in addressing the intricate nonlinear association between ET0 and meteorological factors. Furthermore, it demonstrates notable precision and computational efficiency when estimating ET0 (Hou et al. 2023).
Additionally, The ETR models shown enhanced performance when incorporating the Tmax, Tmin, and U (M5) inputs, except for the MAPE metric, which revealed lower values compared to SVR. Furthermore, the M4 inputs, which encompassed the M5 inputs and Rs, in conjunction with the M6 inputs, comprising the RH, Rs, and U combinations, also yielded favorable results. RMSE and MSE values obtained were 0.4515 and 0.6313, and 0.4747 mm/day for RMSE, and 0.2039, 0.3986, and 0.2253 mm/day for M4, M5, and M6, respectively. The MAE values yielded the highest performance for the M4 and M5 inputs, with respective values of 0.5128 and 0.3769. Furthermore, the MAPE values obtained from the M4 input combinations were 9.2724, which were lower than the MAPE values obtained from SVR model when utilizing the M5 and M6 input combinations. Specifically, the MAPE values for the ETR were 13.4573 and 9.5639 for M5 and M6, respectively, while the MAPE values for the SVR model were 13.4412 and 9.1261 for M5 and M6, respectively. The ETR model demonstrated superiority in terms of accuracy compared to the KNN and ADA models. This advantage can be attributed to the ETR model's ability to effectively simulate outlier values, which is a challenging task for any AI model (Hameed et al. 2021). The ADA and KNN models exhibited inferior performance across all input combinations, as evidenced by their lower RMSE, MSE, MAE and MAPE results as shown in Table 4 relative to the other base learner models. However, ADA outperformed KNN, which demonstrated the poorest results in comparison to the remaining base learner models. The K-nearest neighbors (KNN) model exhibits the least favorable performance compared to the other base learners, indicating a limited capacity to effectively capture nonlinear relationships between weather conditions and ET0 (Zhang et al. 2022).
In contrast, the results depicted in Figs. 10, 11 and 12 indicate that the \({R}^{2}\) value of SVR models ranged from 0.8926 to 0.9977. Notably, the SVR approach exhibited superior performance compared to all other base learner models when utilizing complete meteorological data as inputs (M1), as well as when using M2, M3, and M6 inputs. Conversely, the \({R}^{2}\) value of ETR models ranged from 0.9127 to 0.9570, with ETR demonstrating the best performance among all base learner models when using M4 and M5 inputs. Furthermore, it was observed that KNN models exhibited the least \({R}^{2}\) outcomes compared to all other fundamental learner models. The \({R}^{2}\) values ranged from 0.5592 to 0.7629.
Based on the preceding outcomes of the base learner models in contrast to the results of the SL models, it can be concluded that the SL models exhibited superior performance across all input combinations. The evaluation metrics, namely RMSE, MSE, MAE, and \({R}^{2}\), ranged from 0.0512, 0.0026, 0.0358 mm/day, and 0.9279 to 0.5735, 0.3289, 0.4575 mm/day, and 0.9994, respectively. Furthermore, the MAPE exhibited a range of values, spanning from 0.9148 to 11.5706. The superiority of SL models over other base learner models in estimating ET0 can be attributed to their smaller values of RMSE, MSE, MAE, and MAPE, as well as their higher \({R}^{2}\) values. Moreover, it possesses the capability to provide precise outcomes even with restricted meteorological information, such as M3, M4, M5, and M6.
4.3 Comparison with related work
To evaluate the effectiveness of our proposed model, we employed performance metrics on the testing set and compared its results with those of other techniques that have been applied to the same dataset. The objective of the aforementioned research (Mattar 2018) was to create and assess a gene expression programming (GEP) model that could estimate the average monthly evapotranspiration (ET0) with limited climatic data. The dataset utilized in the analysis was sourced from the CLIMWAT database comprising of data, collected from 32 weather stations located in Egypt.
A comparative analysis has been conducted between our proposed model and the GEP model, utilizing four distinct input combinations, namely Tmax, Tmin, and U, Tmax, Tmin, RH, and U, Tmax, Tmin, Rs, and U, RH, Rs, and U. The comparison has been evaluated based on two metrics. The statistical metrics \({R}^{2}\) and RMSE are commonly used in data analysis and modeling to evaluate the accuracy and goodness of fit of a given model.
Table 5 displays the RMSE and \({R}^{2}\) outcomes of our proposed model and the GEP model results shown in Mattar (2018) for all input combinations utilized in the comparison. The results indicated that our proposed model's RMSE values achieved the lowest errors than those of the GEP models. Specifically, our proposed and GEP model's RMSE values were 0.582 and 0.573 mm/day when utilizing Tmax, Tmin, and U inputs, 0.430 and 0.414 mm/day when using Tmax, Tmin, RH, and U inputs, 0.476 and 0.440 mm/day when using Tmax, Tmin, Rs, and U inputs, and 0.546 and 0.418 mm/day when using RH, Rs, and U inputs, respectively. The lowest RMSE values indicate a superior fit and serve as a metric for the precision of our proposed model in forecasting ET0.
On the contrary, Table 5 displays \({R}^{2}\) values indicating slight variations in performance between the utilization of Tmax, Tmin, and U inputs, Tmax, Tmin, RH, and U inputs and Tmax, Tmin, Rs, and U. The \({R}^{2}\) values for our proposed model and GEP models were marginally different, with 0.9279 and 0.929 for Tmax, Tmin, and U inputs, 0.9624 and 0.962 for Tmax, Tmin, RH, and U inputs, and 0.9575 and 0.953 for Tmax, Tmin, Rs, and U respectively. However, when considering alternative input combinations utilizing RH, Rs, and U as inputs, the \({R}^{2}\) values for our proposed model exhibited a 2.45% increase. Specifically, the \({R}^{2}\) values for our proposed model and the GEP model were 0.9616 and 0.938, respectively.
Overall, our proposed model exhibited superior performance compared to the GEP models across all input combinations utilized in the comparison, except for the Tmax, Tmin, and U inputs, where the \({R}^{2}\) value of the GEP model was marginally higher than that of our proposed model. The present findings suggest that the proposed model exhibits a high degree of accuracy and can be effectively utilized for the purpose of modeling ET0.
A different methodology (Mattar and Alazba 2019) which employed multiple linear regressions (MLR) to model reference evapotranspiration (ET0) using the identical dataset that we employed, and its performance was compared to that of our proposed model using two statistical metrics: RMSE and MAE utilizing four distinct input combinations, namely Tmax, Tmin, and U, Tmax, Tmin, RH, and U, Tmax, Tmin, Rs, and U, RH, Rs, and U.
Table 6 displays the RMSE and MAE results of both our proposed model and the MLR model, as reported in (Mattar & Alazba 2019), across all input combinations that were compared. The findings suggest that the RMSE and MAE values of our proposed model exhibited superior performance compared to the MLR models, as they yielded the lowest errors. The RMSE values of our proposed MLR model were determined to be 0.573 and 0.701 mm/day when incorporating Tmax, Tmin, and U inputs. When utilizing Tmax, Tmin, RH, and U inputs, the RMSE values were found to be 0.414 and 0.502 mm/day. Similarly, when using Tmax, Tmin, Rs, and U inputs, the RMSE values were determined to be 0.440 and 0.668 mm/day. Lastly, the RMSE values were found to be 0.418 and 0.685 mm/day when utilizing RH, Rs, and U inputs. The MAE values of our proposed MLR model were computed to be 0.457 and 0.503 mm/day when utilizing Tmax, Tmin, and U inputs. When using Tmax, Tmin, RH, and U inputs, the MAE values were 0.333 and 0.411 mm/day. Similarly, when using Tmax, Tmin, Rs, and U inputs, the MAE values were 0.320 and 0.478 mm/day. Lastly, when using RH, Rs, and U inputs, the MAE values were computed to be 0.334 and 0.528 mm/day. The superior fit of our proposed model in forecasting ET0, as compared to MLR, is evidenced by the lowest RMSE and MAE values obtained across all input combinations utilized in the comparison. These values serve as a metric for the precision of our model.
5 Discussion
The objective of this work is to examine the utilization of the SL approach for estimating reference evapotranspiration. There are a wide range of standard and non-traditional techniques that can be employed for the estimation of ET0. Several research have also demonstrated that machine learning methods outperformed conventional empirical formulas, such as temperature-based and radiation-based approaches, for ET0 estimating (Chia et al. 2020; Rahman et al. 2020). The accuracy of machine learning models in predicting ET0 is primarily determined by the combination of input climatic variables (Zhu et al. 2020).
Ensemble modeling is highly appealing due of its ability to improve model performance with low exertion (Chia et al. 2021). The three primary categories of ensemble learning methods are bagging, stacking, and boosting. It is essential to have a comprehensive understanding of each technique and to take them into account while conducting any kind of predictive modeling (Jayshree et al. 2023).
The Penman–Monteith approach is considered the most accurate among conventional methods for estimating ET0, while it requires a high level of parameterization. Due to the unavailability of some characteristics and stations in certain regions, it is not feasible to estimate ET0 using this approach for all regions (Fan et al. 2018a; T R et al. 2023). To address this problem, this study utilized a heterogeneous ensemble method known as the super learner. This method is a version of the stacking technique and offers flexibility in terms of the range and number of predictive models used to construct the super learner.
At the first part of the current study, the results of SL model have been compared to the results of the four base learner models over different input combinations wherein the outcomes of all models are compared to those of the PM model. The results based on five statistical indexes: RMSE, MAE, R2, MAPE and MSE demonstrated that the Super Learner model outperformed the four base learner models across six different input combinations. The results of this study indicate that the utilization of stacking models for ET0 estimate is superior, which aligns with the findings of earlier research and further strengthens this conclusion (Wu et al. 2021a, b, c). Furthermore, the utilization of all possible input combinations yielded the most optimal performance across all other input combinations. This finding supports previous research indicating that the accuracy of the model improves as the number of inputs increases (Fan et al. 2018b; Heramb et al. 2023; Jayshree et al. 2023). In addition, the models which utilized four input combinations, produced adequate estimates of ET0 that align with the findings reported in reference (Jayshree et al. 2023). Furthermore, the suggested model, which utilized three input combinations (namely RH, Rs, and U), shown a higher level of accuracy in estimating ET0 compared to the model that employed four input combinations (Tmin, Tmax, Rs, and U). This finding suggests that the former model exhibits superior accuracy in estimating ET0 while utilizing a reduced set of meteorological data. This finding is consistent with the studies conducted by previous scholars (Fan et al. 2018a).
Also, the findings of the study indicate that the inclusion of relative humidity (RH) and solar radiation (Rs) significantly affect the estimation of ET0.The argument has been strengthened by previous research (Zhang et al. 2022). This is evident in the results of the SL model, which demonstrate a decrease in performance when replacing Rs in M1 inputs with H in M2 inputs. Specifically, the SL model's performance decreased by 81.15% based on RMSE metric, by 84.01% based on MAE, by 4.69% based on MAPE and by 1.56% based on \({R}^{2}\).
Furthermore, upon the removal of RH and Rs from M1 resulting in M5 inputs, the performance of the SL model exhibited a decrease of 91.07% in terms of RMSE, 92.17% in terms of MAE, 10.65% in terms of MAPE and 7.15% in terms of \({R}^{2}\). Additionally, the inclusion of relative humidity (RH) as an input parameter alongside temperature and wind speed resulted in a 27.79% improvement in the performance of the SL model as determined by RMSE. MAE and MAPE also showed a 27.03% and 3.4% improvement, respectively, while \({R}^{2}\) increased by 3.58%. Furthermore, the inclusion of Rs to M5 inputs, specifically temperature and wind speed, resulted in a 23.20% improvement in the performance of the SL model as measured by RMSE, a 30.01% and 3.17% improvement as measured by MAE and MAPE, respectively, and a 3.09% improvement as measured by \({R}^{2}\). These findings suggest that the variables used are effective in estimating ET0.
In the second section of the study, a comparative analysis was conducted to assess the effectiveness of the proposed model. Specifically, the proposed model was compared to two related works, namely the GEP model utilized in Mattar (2018) and the MLR model employed in Mattar and Alazba (2019). This comparison aimed to determine the superiority of the proposed model over its counterparts.
The initial study involved a comparison between our proposed model and the GEP model. The results indicated that our model exhibited a performance improvement of 2.45% in terms of \({R}^{2}\) and 23.44% in terms of RMSE when utilizing RH, Rs, and U inputs. Furthermore, the model we have put out has demonstrated an enhancement in performance by 0.46% in terms of \({R}^{2}\) and by 7.56% in terms of RMSE, specifically when utilizing Tmax, Tmin, Rs, and U inputs. Furthermore, the model we proposed exhibited an enhancement in performance of 0.04% in terms of \({R}^{2}\) and 3.72% in terms of RMSE, when utilizing inputs of Tmax, Tmin, RH, and U inputs. On the other hand, the utilization of Tmax, Tmin, and U inputs in the GEP model resulted in a performance enhancement of 0.11% in terms of \({R}^{2}\) and 1.54% in terms of RMSE. The results of this study indicate that the proposed model demonstrates a significant level of precision and can be efficiently employed for the purpose of ET0 modeling.
Conversely, in the second study, a comparison was conducted between our proposed model and the MLR model. The results demonstrated that SL outperformed MLR in terms of minimizing errors, as determined by the RMSE and MAE metrics, across all input combinations utilized in the analysis. The performance of SL was enhanced by 18.25% and 9.14% for RMSE and MAE, respectively, when utilizing Tmax, Tmin, and U inputs. Similarly, when incorporating Tmax, Tmin, RH, and U inputs, the performance of SL was improved by 17.52% and 18.97% for RMSE and MAE, respectively. Furthermore, the utilization of Tmax, Tmin, Rs, and U inputs resulted in a 34.13% and 33.05% improvement in RMSE and MAE, respectively. Finally, the incorporation of RH, Rs, and U inputs led to a 38.97% and 36.74% improvement in RMSE and MAE, respectively. The results of this study demonstrate the efficiency of the SL model in enhancing the accuracy of ET0 estimation with restricted meteorological data by minimizing the discrepancies between the projected and observed ET0 values.
Subsequently based on the above findings, the optimal result for estimating ET0 was observed when using the M1 input combination. The argument is additionally strengthened by previous research (Wu et al. 2021a, b, c; Yu et al. 2020). This observation is supported by Fig. 13, which illustrates the optimal structure of the SL models suggested in this study for ET0 estimation. Furthermore, we proposed the utilization of the M3 model, which encompasses temperatures, humidity, and wind speed. Additionally, we recommended the adoption of the M6 model, which incorporates humidity, solar radiation, and wind speed. Moreover, we suggested the implementation of the M4 model, which comprises temperatures, solar radiation, and wind speed, as it has demonstrated superior performance in accurately estimating ET0. These models were chosen due to their exceptional performance and ability to reduce the number of input combinations required for estimation.

The optimal configuration of SL models for estimating ET0
6 Conclusions and future work
The Penman–Monteith (PM) method requires a greater amount of meteorological observation data for the estimation of ET0, rendering its application challenging in countries or regions where the necessary observation equipment is not readily accessible. Scholars have initiated research into the integration of intelligent algorithms with conventional estimation techniques to enhance the accuracy and efficiency of ET0 estimation, in light of the proliferation of machine learning technology. For these reasons this study was implemented to offer a high performance ensemble learning model that has been suggested for daily ET0 estimation using limited meteorological data.
The ensemble method which called Super Learner technique is based on the cross-validation theory and includes four base learner models ETR, SVR, KNN, and ADA. According to the preceding, the Super Learner model is a preferred technique for ET0 estimation, particularly in the situation of insufficient meteorological data, which may be lacking in some parts of the world. However, it is crucial to take into account the time cost associated with big datasets when considering the cross-validation theory. This is particularly relevant when employing multiple levels of base learners, especially if these base learners are complicated. The aforementioned factors can potentially restrict the effectiveness of the suggested model. we still need to improve the results, and this can be done in a number of ways:
-
Employing various input combinations in an attempt to attain the optimal input combination that results in a precise estimation of ET0.
-
Exploring alternative base learner models or scaling up their quantity to improve the accuracy of the model is being attempted.
-
The utilization of hyper parameter tuning techniques enables the attainment of optimal parameters for individual base learners, thereby enhancing the overall performance of the model.
-
The utilization of data preparation techniques has the potential to improve the overall performance of the model. Furthermore, the exploration of various cross-validation folds has the potential to enhance the ultimate accuracy of the model.
-
Investigating the impact of varying dataset sizes on the performance of the super learner model.
-
Investigating the efficacy of employing bio-inspired algorithms, including Particle Swarm Optimization (PSO), Whale Optimization Algorithm (WOA), Ant Colony Optimization Algorithm (ACO), Artificial Bee Colony Algorithm, and Bacterial Foraging Optimization Algorithm (BFO), as feature selection techniques to improve the accuracy of a super learner model.
References
Abdallah M, Mohammadi B, Modathir MA, Omer A, Cheraghalizadeh M, Eldow MEE, Duan Z (2022a) Reference evapotranspiration estimation in hyper-arid regions via D-vine copula based-quantile regression and comparison with empirical approaches and machine learning models. J Hydrol: Region Stud 44(October):101259. https://doi.org/10.1016/j.ejrh.2022.101259
Abdallah M, Mohammadi B, Modathir MA, Omer A, Cheraghalizadeh M, Eldow MEE, Duan Z (2022b) Reference evapotranspiration estimation in hyper-arid regions via D-vine copula based-quantile regression and comparison with empirical approaches and machine learning models. J Hydrol: Region Stud 44(September):101259. https://doi.org/10.1016/j.ejrh.2022.101259
Abeysiriwardana HD, Muttil N, Rathnayake U (2022) A comparative study of potential evapotranspiration estimation by three methods with FAO Penman–Monteith method across Sri Lanka. Hydrology. https://doi.org/10.3390/hydrology9110206
Achite M, Jehanzaib M, Sattari MT, Toubal AK, Elshaboury N, Wałęga A, Krakauer N, Yoo JY, Kim TW (2022) Modern techniques to modeling reference evapotranspiration in a semiarid area based on ANN and GEP models. Water (switzerland). https://doi.org/10.3390/w14081210
Allen RG, Pereira LS, Raes D, Smith M (1998) FAO Irrigation and Drainage Paper No. 56 - Crop Evapotranspiration. November 2017
Asadollah SBHS, Khan N, Sharafati A, Shahid S, Chung ES, Wang XJ (2021) Prediction of heat waves using meteorological variables in diverse regions of Iran with advanced machine learning models. Stochastic Environmental Research and Risk Assessment, 0123456789 (2009). https://doi.org/10.1007/s00477-021-02103-z
Başakın EE, Ekmekcioğlu Ö, Stoy PC, Özger M (2023) Estimation of daily reference evapotranspiration by hybrid singular spectrum analysis-based stochastic gradient boosting. MethodsX, 10(February). https://doi.org/10.1016/j.mex.2023.102163
Bellido-Jiménez JA, Estévez J, García-Marín AP (2022) A regional machine learning method to outperform temperature-based reference evapotranspiration estimations in Southern Spain. Agric Water Manag. https://doi.org/10.1016/j.agwat.2022.107955
Benkeser D, Ju C, Lendle S, Vander Laan M (2018) Online cross-validation-based ensemble learning. Stat Med 37(2):249–260. https://doi.org/10.1002/sim.7320
Berrouachedi A, Jaziri R, Bernard G (2019) Deep extremely randomized trees. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 11953 LNCS(December), pp 717–729. https://doi.org/10.1007/978-3-030-36708-4_59
Chen Z, Zhu Z, Jiang H, Sun S (2020) Estimating daily reference evapotranspiration based on limited meteorological data using deep learning and classical machine learning methods. J Hydrol 591(July):125286. https://doi.org/10.1016/j.jhydrol.2020.125286
Chia MY, Huang YF, Koo CH (2020a) Support vector machine enhanced empirical reference evapotranspiration estimation with limited meteorological parameters. Comput Electron Agric. https://doi.org/10.1016/j.compag.2020.105577
Chia MY, Huang YF, Koo CH, Fung KF (2020b) Recent advances in evapotranspiration estimation using artificial intelligence approaches with a focus on hybridization techniques—A review. Agronomy. https://doi.org/10.3390/agronomy10010102
Chia MY, Huang YF, Koo CH (2021) Improving reference evapotranspiration estimation using novel inter-model ensemble approaches. Comput Electron Agric 187(December 2020):106227. https://doi.org/10.1016/j.compag.2021.106227
Chia MY, Huang YF, Koo CH, Ng JL, Ahmed AN, El-Shafie A (2022) Long-term forecasting of monthly mean reference evapotranspiration using deep neural network: a comparison of training strategies and approaches. Appl Soft Comput 126:109221. https://doi.org/10.1016/j.asoc.2022.109221
Dong J, Zhu Y, Jia X, Shao M, Han X, Qiao J, Bai C, Tang X (2022) Nation-scale reference evapotranspiration estimation by using deep learning and classical machine learning models in China. J Hydrol 604(October 2021):127207. https://doi.org/10.1016/j.jhydrol.2021.127207
Ehteram M, Singh VP, Ferdowsi A, Mousavi SF, Farzin S, Karami H, Mohd NS, Afan HA, Lai SH, Kisi O, Malek MA, Ahmed AN, El-Shafie A (2019) An improved model based on the support vector machine and cuckoo algorithm for simulating reference evapotranspiration. PLoS ONE 14(5):1–25. https://doi.org/10.1371/journal.pone.0217499
Elbeltagi A, Srivastava A, Al-Saeedi AH, Raza A, Abd-Elaty I, El-Rawy M (2023) Forecasting long-series daily reference evapotranspiration based on best subset regression and machine learning in Egypt. Water (switzerland). https://doi.org/10.3390/w15061149
Fan J, Yue W, Wu L, Zhang F, Cai H, Wang X, Lu X, Xiang Y (2018a) Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China. Agric for Meteorol 263(July):225–241. https://doi.org/10.1016/j.agrformet.2018.08.019
Fan J, Yue W, Wu L, Zhang F, Cai H, Wang X, Lu X, Xiang Y (2018b) Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China. Agric for Meteorol 263(September):225–241. https://doi.org/10.1016/j.agrformet.2018.08.019
Feng K, Tian J (2021) Forecasting reference evapotranspiration using data mining and limited climatic data. Eur J Remote Sens 54(sup2):363–371. https://doi.org/10.1080/22797254.2020.1801355
Ferreira LB, da Cunha FF, de Oliveira RA, Fernandes Filho EI (2019) Estimation of reference evapotranspiration in Brazil with limited meteorological data using ANN and SVM – A new approach. J Hydrol 572(March):556–570. https://doi.org/10.1016/j.jhydrol.2019.03.028
Flennerhag S, Jlopezpena (2018) flennerhag/mlens: 0.2.3. https://doi.org/10.5281/ZENODO.1475440
Hameed MM, Alomar MK, Khaleel F, Al-Ansari N (2021) An extra tree regression model for discharge coefficient prediction: novel, practical applications in the hydraulic sector and future research directions. Math Probl Eng. https://doi.org/10.1155/2021/7001710
Hastie T, Tibshirani R, Friedman J (2009) Springer Series in Statistics. In: The elements of statistical learning, vol 27, issue 2. https://doi.org/10.1007/b94608
Hebbalaguppae Krishnashetty P, Balasangameshwara J, Sreeman S, Desai S, Bengaluru Kantharaju A (2021) Cognitive computing models for estimation of reference evapotranspiration: a review. Cogn Syst Res 70(July):109–116. https://doi.org/10.1016/j.cogsys.2021.07.012
Heramb P, Ramana Rao KV, Subeesh A, Srivastava A (2023) Predictive modelling of reference evapotranspiration using machine learning models coupled with grey wolf optimizer. Water (switzerland) 15(5):1–32. https://doi.org/10.3390/w15050856
Hou W, Yin G, Gu J, Ma N (2023) Estimation of spring maize evapotranspiration in semi-arid regions of Northeast China using machine learning: an improved SVR Model based on PSO and RF algorithms. Water (switzerland). https://doi.org/10.3390/w15081503
Hu Z, Bashir RN, Rehman AU, Iqbal S, Shahid MMA, Xu T (2022) Machine learning based prediction of reference evapotranspiration (ET0) using IoT. IEEE Access 10(June):70526–70540. https://doi.org/10.1109/ACCESS.2022.3187528
Huang G, Wu L, Ma X, Zhang W, Fan J, Yu X, Zeng W, Zhou H (2019) Evaluation of CatBoost method for prediction of reference evapotranspiration in humid regions. J Hydrol 574(December 2018):1029–1041. https://doi.org/10.1016/j.jhydrol.2019.04.085
Jamei M, Karbasi M, Adewale Olumegbon I, Moshraf-Dehkordi M, Ahmadianfar I, Asadi A (2021) Specific heat capacity of molten salt-based nanofluids in solar thermal applications: A paradigm of two modern ensemble machine learning methods. J Mol Liq 335:116434. https://doi.org/10.1016/j.molliq.2021.116434
Jayashree TR, Reddy NS, Acharya UD (2023) Modeling daily reference evapotranspiration from climate variables: assessment of bagging and boosting regression approaches. Water Resour Manag 37(3):1013–1032. https://doi.org/10.1007/s11269-022-03399-4
Jin X, Li S, Zhang W, Zhu J, Sun J (2020) Prediction of soil-available potassium content with visible near-infrared ray spectroscopy of different pretreatment transformations by the boosting algorithms. Appl Sci (switzerland). https://doi.org/10.3390/app10041520
Kabir MF, Ludwig SA (2019) Enhancing the performance of classification using super learning. Data-Enabled Discov Appl 3(1):1–13. https://doi.org/10.1007/s41688-019-0030-0
Kar S, Purbey VK, Suradhaniwar S, Korbu LB, Kholová J, Durbha SS, Adinarayana J, Vadez V (2021) An ensemble machine learning approach for determination of the optimum sampling time for evapotranspiration assessment from high-throughput phenotyping data. Comput Electron Agric. https://doi.org/10.1016/J.COMPAG.2021.105992
Laaboudi A, Slama A (2020) Using neuro-fuzzy and linear models to estimate reference evapotranspiration in south region of Algeria (A comparative study). Ital J Agrometeorol 2020(2):55–64. https://doi.org/10.13128/ijam-971
Lankford S, Grimes D (2021) Enhanced neural architecture search using super learner and ensemble approaches. In: ACM international conference proceeding series, pp 137–143. https://doi.org/10.1145/3456126.3456133
Lee S, Nguyen NH, Karamanli A, Lee J, Vo TP (2022) Super learner machine-learning algorithms for compressive strength prediction of high performance concrete. Struct Concrete. https://doi.org/10.1002/suco.202200424
Li G, Shen M, Li M, Cheng J (2021) Personal credit default discrimination model based on super learner ensemble. Math Probl Eng. https://doi.org/10.1155/2021/5586120
Lin H, Zou W, Li T, Feigenberg SJ, Teo BKK, Dong L (2019) A super-learner model for tumor motion prediction and management in radiation therapy: development and feasibility evaluation. Sci Rep 9(1):1–12. https://doi.org/10.1038/s41598-019-51338-y
Liu Y, Zhang S, Zhang J, Tang L, Bai Y (2021) Assessment and comparison of six machine learning models in estimating evapotranspiration over croplands using remote sensing and meteorological factors. Remote Sens. https://doi.org/10.3390/rs13193838
Mangalath Ravindran S, Moorakkal Bhaskaran SK, Ambat K, S., Balakrishnan, K., & Manguttathil Gopalakrishnan, M. (2022) An automated machine learning methodology for the improved prediction of reference evapotranspiration using minimal input parameters. Hydrol Process 36(5):1–21. https://doi.org/10.1002/hyp.14571
Martín J, Sáez JA, Corchado E (2021) On the suitability of stacking-based ensembles in smart agriculture for evapotranspiration prediction. Appl Soft Comput 108:107509. https://doi.org/10.1016/J.ASOC.2021.107509
Mattar MA (2018) Using gene expression programming in monthly reference evapotranspiration modeling: a case study in Egypt. Agric Water Manag 198:28–38. https://doi.org/10.1016/j.agwat.2017.12.017
Mattar MA, Alazba AA (2019) GEP and MLR approaches for the prediction of reference evapotranspiration. Neural Comput Appl 31(10):5843–5855. https://doi.org/10.1007/s00521-018-3410-8
Mienye ID, Sun Y (2022) A survey of ensemble learning: concepts, algorithms, applications, and prospects. IEEE Access 10(August):99129–99149. https://doi.org/10.1109/ACCESS.2022.3207287
Min H, Luo X (2016) Calibration of soft sensor by using Just-in-time modeling and AdaBoost learning method. Chin J Chem Eng 24(8):1038–1046. https://doi.org/10.1016/j.cjche.2016.05.015
Mokari E, DuBois D, Samani Z, Mohebzadeh H, Djaman K (2022) Estimation of daily reference evapotranspiration with limited climatic data using machine learning approaches across different climate zones in New Mexico. Theor Appl Climatol 147(1–2):575–587. https://doi.org/10.1007/s00704-021-03855-y
Nema MK, Khare D, Chandniha SK (2017) Application of artificial intelligence to estimate the reference evapotranspiration in sub-humid Doon valley. Appl Water Sci 7(7):3903–3910. https://doi.org/10.1007/s13201-017-0543-3
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay É (2011) Scikit-learn: machine learning in python. J Mach Learn Res 12(May 2014):2825–2830
Petinrin OO, Saeed F (2019) Stacked ensemble for bioactive molecule prediction. IEEE Access 7:153952–153957. https://doi.org/10.1109/ACCESS.2019.2945422
Phillips RV, van der Laan MJ, Lee H, Gruber S (2023) Practical considerations for specifying a super learner. Int J Epidemiol. https://doi.org/10.1093/ije/dyad023
Ponraj AS, Vigneswaran T (2020) Daily evapotranspiration prediction using gradient boost regression model for irrigation planning. J Supercomput 76(8):5732–5744. https://doi.org/10.1007/s11227-019-02965-9
Qaddoura R, Younes MB (2022) Temporal prediction of traffic characteristics on real road scenarios in Amman. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-022-03708-0
Rahman ATMS, Hosono T, Kisi O, Dennis B, Imon AHMR (2020) A minimalistic approach for evapotranspiration estimation using the Prophet model. Hydrol Sci J 65(12):1994–2006. https://doi.org/10.1080/02626667.2020.1787416
Ravindran SM, Bhaskaran SKM, Ambat SKN (2021) A deep neural network architecture to model reference evapotranspiration using a single input meteorological parameter. In: Environmental processes (vol 8, issue 4). Springer International Publishing. https://doi.org/10.1007/s40710-021-00543-x
Roy DK, Barzegar R, Quilty J, Adamowski J (2020) Using ensembles of adaptive neuro-fuzzy inference system and optimization algorithms to predict reference evapotranspiration in subtropical climatic zones. J Hydrol 591(March):125509. https://doi.org/10.1016/j.jhydrol.2020.125509
Saeed U, Jan SU, Lee YD, Koo I (2021) Fault diagnosis based on extremely randomized trees in wireless sensor networks. Reliab Eng Syst Saf 205(October 2020):107284. https://doi.org/10.1016/j.ress.2020.107284
Saggi MK, Jain S (2019) Reference evapotranspiration estimation and modeling of the Punjab Northern India using deep learning. Comput Electron Agric 156(December 2018):387–398. https://doi.org/10.1016/j.compag.2018.11.031
Salam R, Islam ARMT (2020) Potential of RT, bagging and RS ensemble learning algorithms for reference evapotranspiration prediction using climatic data-limited humid region in Bangladesh. J Hydrol 590(January):125241. https://doi.org/10.1016/j.jhydrol.2020.125241
Seifi A, Riahi H (2020) Estimating daily reference evapotranspiration using hybrid gamma test-least square support vector machine, gamma test-ann, and gamma test-anfis models in an arid area of Iran. J Water Clim Change 11(1):217–240. https://doi.org/10.2166/wcc.2018.003
Shahhosseini M, Hu G, Pham H (2022) Optimizing ensemble weights and hyperparameters of machine learning models for regression problems. Mach Learn Appl 7(December 2021):100251. https://doi.org/10.1016/j.mlwa.2022.100251
Sharma G, Singh A, Jain S (2022) DeepEvap: Deep reinforcement learning based ensemble approach for estimating reference evapotranspiration. Appl Soft Comput 125:109113. https://doi.org/10.1016/j.asoc.2022.109113
Smith M, Food and Agriculture Organization of the United Nations. Research and Technology Development Division. Agrometeorological Group, & Food and Agriculture Organization of the United Nations (1993) CLIMWAT for CROPWAT: a climatic database for irrigation planning and management. 113. http://www.fao.org/nr/water/infores_databases_climwat.html
Svm VM, Learning E, Elm M, Iv-a R (2022) Modeling reference crop evapotranspiration using support vector machine (SVM) and extreme learning machine (ELM) in Region IV-A. Philippines Water 14(5):754. https://doi.org/10.3390/w14050754
Taghizadeh-Mehrjardi R, Hamzehpour N, Hassanzadeh M, Heung B, Ghebleh Goydaragh M, Schmidt K, Scholten T (2021) Enhancing the accuracy of machine learning models using the super learner technique in digital soil mapping. Geoderma 399:115108. https://doi.org/10.1016/J.GEODERMA.2021.115108
Tikhamarine Y, Malik A, Souag-Gamane D, Kisi O (2020) Artificial intelligence models versus empirical equations for modeling monthly reference evapotranspiration. Environ Sci Pollut Res 27(24):30001–30019. https://doi.org/10.1007/s11356-020-08792-3
Üne F, Kaya YZ, Mamak M (2020) Daily reference evapotranspiration prediction based on climatic.pdf, pp 763–773
Üneş F, Kaya YZ, Mamak M (2020) Daily reference evapotranspiration prediction based on climatic conditions applying different data mining techniques and empirical equations. Theoret Appl Climatol 141(1–2):763–773. https://doi.org/10.1007/s00704-020-03225-0
Valipour M, Sefidkouhi MAG, Raeini-Sarjaz M, Guzman SM (2019) A hybrid data-driven machine learning technique for evapotranspiration modeling in various climates. Atmosphere. https://doi.org/10.3390/atmos10060311
Van Der Laan MJ, Polley EC, Hubbard AE (2007) Super learner. Stat Appl Genet Mol Biol 6(1):1–10. https://doi.org/10.2202/1544-6115.1309
Vaz PJ, Schutz G, Guerrero C, Cardoso PJS (2023) Hybrid neural network based models for evapotranspiration prediction over limited weather parameters. IEEE Access 11(December 2023):963–976. https://doi.org/10.1109/ACCESS.2022.3233301
Vidyarthi SK, Tiwari R, Singh SK (2020) Stack ensembled model to measure size and mass of almond kernels. J Food Process Eng. https://doi.org/10.1111/jfpe.13374
Wang L, Guo Y, Fan M, Li X (2022) Wind speed prediction using measurements from neighboring locations and combining the extreme learning machine and the AdaBoost algorithm. Energy Rep 8:1508–1518. https://doi.org/10.1016/j.egyr.2021.12.062
Wanniarachchi S, Sarukkalige R (2022) A review on evapotranspiration estimation in agricultural water management: past, present, and future. Hydrology 9(7):1–12. https://doi.org/10.3390/hydrology9070123
Waskom M (2021) Seaborn: statistical data visualization. J Open Source Software 6(60):3021. https://doi.org/10.21105/joss.03021
Wu L, Zhou H, Ma X, Fan J, Zhang F (2019) Daily reference evapotranspiration prediction based on hybridized extreme learning machine model with bio-inspired optimization algorithms: application in contrasting climates of China. J Hydrol 577(April):123960. https://doi.org/10.1016/j.jhydrol.2019.123960
Wu M, Feng Q, Wen X, Deo RC, Yin Z, Yang L, Sheng D (2020a) Random forest predictive model development with uncertainty analysis capability for the estimation of evapotranspiration in an Arid Oasis region. Hydrol Res 51(4):648–665. https://doi.org/10.2166/NH.2020.012
Wu T, Zhang W, Jiao X, Guo W, Hamoud YA (2020b) Comparison of five Boosting-based models for estimating daily reference evapotranspiration with limited meteorological variables. PLoS ONE 15(6):1–28. https://doi.org/10.1371/journal.pone.0235324
Wu T, Zhang W, Jiao X, Guo W, Alhaj Hamoud Y (2021a) Evaluation of stacking and blending ensemble learning methods for estimating daily reference evapotranspiration. Comput Electron Agric 184(March 2020):106039. https://doi.org/10.1016/j.compag.2021.106039
Wu Z, Cui N, Hu X, Gong D, Wang Y, Feng Y, Jiang S, Lv M, Han L, Xing L, Zhu S, Zhu B, Zhang Y, Zou Q, He Z (2021b) Optimization of extreme learning machine model with biological heuristic algorithms to estimate daily reference crop evapotranspiration in different climatic regions of China. J Hydrol 603(PC):127028. https://doi.org/10.1016/j.jhydrol.2021.127028
Wu Z, Cui N, Zhu B, Zhao L, Wang X, Hu X, Wang Y, Zhu S (2021c) Improved hargreaves model based on multiple intelligent optimization algorithms to estimate reference crop evapotranspiration in humid areas of southwest china. Atmosphere 12(1):1–20. https://doi.org/10.3390/atmos12010015
Yamaç SS (2021) Artificial intelligence methods reliably predict crop evapotranspiration with different combinations of meteorological data for sugar beet in a semiarid area. Agric Water Manag 254(9):106968. https://doi.org/10.1016/j.agwat.2021.106968
Yamaç SS, Todorovic M (2020) Estimation of daily potato crop evapotranspiration using three different machine learning algorithms and four scenarios of available meteorological data. Agric Water Manag 228(October 2019):105875. https://doi.org/10.1016/j.agwat.2019.105875
Yildirim D, Küçüktopcu E, Cemek B, Simsek H (2023) Comparison of machine learning techniques and spatial distribution of daily reference evapotranspiration in Türkiye. Appl Water Sci 13(4):1–16. https://doi.org/10.1007/s13201-023-01912-7
Yu H, Wen X, Li B, Yang Z, Wu M, Ma Y (2020) Uncertainty analysis of artificial intelligence modeling daily reference evapotranspiration in the northwest end of China. Comput Electron Agric. https://doi.org/10.1016/j.compag.2020.105653
Zhang H, Meng F, Xu J, Liu Z, Meng J (2022) Evaluation of machine learning models for daily reference evapotranspiration modeling using limited meteorological data in Eastern Inner Mongolia, North China. Water (switzerland). https://doi.org/10.3390/w14182890
Zhu B, Feng Y, Gong D, Jiang S, Zhao L, Cui N (2020) Hybrid particle swarm optimization with extreme learning machine for daily reference evapotranspiration prediction from limited climatic data. Comput Electron Agric 173(March):105430. https://doi.org/10.1016/j.compag.2020.105430
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB). The authors have not disclosed any funding.
Author information
Authors and Affiliations
Contributions
The corresponding author is responsible for ensuring that the descriptions are accurate and agreed by all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aly, M.S., Darwish, S.M. & Aly, A.A. High performance machine learning approach for reference evapotranspiration estimation. Stoch Environ Res Risk Assess 38, 689–713 (2024). https://doi.org/10.1007/s00477-023-02594-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-023-02594-y