
Abstract
The notion of generalized rank in the context of multiparameter persistence has become an important ingredient for defining interesting homological structures such as generalized persistence diagrams. However, its efficient computation has not yet been studied in the literature. We show that the generalized rank over a finite interval I of a \(\textbf{Z}^2\)-indexed persistence module M is equal to the generalized rank of the zigzag module that is induced on a certain path in I tracing mostly its boundary. Hence, we can compute the generalized rank of M over I by computing the barcode of the zigzag module obtained by restricting to that path. If M is the homology of a bifiltration F of \(t\) simplices (while accounting for multi-criticality) and I consists of \(t\) points, this computation takes \(O(t^\omega )\) time where \(\omega \in [2,2.373)\) is the exponent of matrix multiplication. We apply this result to obtain an improved algorithm for the following problem. Given a bifiltration inducing a module M, determine whether M is interval decomposable and, if so, compute all intervals supporting its indecomposable summands.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In Topological Data Analysis (TDA) one of the central tasks is that of decomposing persistence modules into direct sums of indecomposables. In the case of a persistence module M over the integers \(\textbf{Z}\), which implies that M is isomorphic to a direct sum of interval modules \(\mathbb {I}([b_\alpha ,d_\alpha ])\), for integers \(b_\alpha \le d_\alpha \) and \(\alpha \) in some index set A [1, 2]. The multiset of intervals \(\{[b_\alpha ,d_\alpha ],\,\alpha \in A\}\) that appear in this decomposition constitutes the persistence diagram, or equivalently, the barcode of M—a central object in TDA [3, 4].
There are many situations in which data naturally induce persistence modules over posets which are different from \(\textbf{Z}\) [5,6,7,8,9,10,11,12,13,14]. Unfortunately, the situation already becomes ‘wild’ when the domain poset is \(\textbf{Z}^2\). In that situation, one must contend with the fact that a direct analogue of the notion of persistence diagrams may not exist [8], namely it may not be possible to obtain a lossless up-to-isomorphism representation of the module as a direct sum of interval modules.
Much energy has been put into finding ways in which one can extract incomplete but still stable invariants from persistence modules \(M:\textbf{Z}^d\ \text{(or } \textbf{R}^d \text{) }\rightarrow \textbf{vec}\) (which we will refer to as a \(\textbf{Z}^d\)-module). Biasotti et al. [15] considered the restriction of an \(\textbf{R}^d\)-module to lines with direction vectors in the positive orthant.Footnote 1 This was further developed by Lesnick and Wright in the RIVET project [16] which facilitates the interactive visualization of \(\textbf{Z}^2\)-modules. Cai et al. [17] considered a certain elder-rule on the \(\textbf{Z}^2\)-modules which arise in multiparameter clustering. Other efforts have attempted to identify algebraic conditions guaranteeing that M can be decomposed into interval modules of varying degrees of complexity. This has been fully realized in [18, 19] in the case when the intervals in question are rectangles. The case of more complicated intervals has been approached in [20,21,22] through the lens of Möbius inversion.

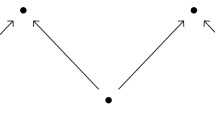
Generalized rank via zigzag persistence. Let M be a \(\textbf{Z}^2\)-module. (A) Standard rank: Let \(p\le q\) in \(\textbf{Z}^2\). The rank of the structure map from p to q coincides with the multiplicity of full bars (red) over the diagonal path, which is three. (B) Generalized rank: Let I be an interval of \(\textbf{Z}^2\). Let us consider the zigzag poset \(\partial I:p_1\le (p_0\vee p_1) \ge p_0\le q_0 \ge (q_0\wedge q_1) \le q_1\). The generalized rank of M over I is equal to the multiplicity of full bars (red) in the zigzag module \(M_{\partial I}\), which is two (Theorem 3.12) (note: by definition, the zigzag poset \(\partial I\) does not fully inherit the partial order on \(\textbf{Z}^2\). For example, the partial order on \(\partial I\) does not contain the pair \((p_1,q_1)\) whereas \(p_1\le q_1\) in \(\textbf{Z}^2\))
The notion of Möbius inversion was first explicitly recognized in the TDA literature by Patel in [23] through the reinterpretation of the persistence diagram of a \(\textbf{Z}\)-module as the Möbius inversion of its rank function. Patel’s work was then extended by Kim and Mémoli [22] to the setting of modules defined over any suitable locally finite poset. They generalized the rank invariant via the limit-to-colimit map over subposets and then conveniently expressed its Möbius inversion. In fact the limit-to-colimit map was suggested by Amit Patel to the authors of [22] who in [24] used it to define a notion of rank invariant for zigzag modules. Chambers and Letscher [25] also considered a notion of persistent homology over directed acyclic graphs using the limit-to-colimit map. Asashiba et al. [20] study the case of modules defined on an \(m\times n\) grid and propose a high-level algorithm for computing both their generalized rank function and their Möbius inversions with the goal of providing an approximation of a given module by interval decomposables. Asashiba et al. [26] tackle the interval decomposability of a given \(\textbf{Z}^d\)-module via quiver representation theory.
One fundamental algorithmic problem is that of determining whether a given \(\textbf{Z}^2\)-module is interval decomposable, and if so, computing the intervals. There are some existing solutions to this problem in the literature. Suppose that the input \(\textbf{Z}^2\)-module is induced by a bifiltration (Definition 4.1) comprising insertions of at most t simplices on a grid of cardinality O(t). First, the decomposition algorithm by Dey and Xin [27] can produce all indecomposables from such a module in \(O(t^{2\omega +1})\) time (see [28] for comments about its implementation) where \(\omega \in [2,2.373)\) is the exponent of matrix multiplication. Given these indecomposables, one could then test whether they are indeed interval modules. However, the algorithm requires that the input module be such that no two generators or relations in the module have the same grade. Then, Asashiba et al. [26] give an algorithm which requires enumerating an exponential number (in t) of intervals. Finally, the algorithm by Meataxe sidesteps both of the above issues, but incurs a worst-case cost of \(O(t^{18})\) as explained in [27].
See also [29,30,31,32,33] for related recent work.
Contributions.
One of our key results is as follows. Let M be a \(\textbf{Z}^2\)-module. We prove that the generalized rank of M over any finite interval I in \(\textbf{Z}^2\) can be computed using the zigzag persistence barcode of the restriction of M to a certain zigzag path within I (Theorem 3.12). See Fig. 1 for an illustration. By utilizing this theorem, we establish two algorithms described subsequently.
Assume that the input is a filtration \(\mathcal {F}\) of a simplicial complex K over an interval I of \(\textbf{Z}^2\) such that I and K consist of O(t) points and simplices, respectively. The filtration can be multicritical, i.e. for any simplex \(\sigma \in K\), the subset of points in I at which \(\sigma \) is present can admit multiple minimal points. When the filtration \(\mathcal {F}\) is multicritical, we assume that \(\sum _{\sigma \in K}n(\sigma )=O(t)\) where \(n(\sigma )\) is the number of minimal points in I at which \(\sigma \) is present.
Let \(M_{\mathcal {F}}\) be the persistence module that is obtained by applying the homology functor to the filtration \(\mathcal {F}\).
-
Given that \(M_{\mathcal {F}}\) is interval decomposable, we provide an algorithm Interval (page 19) to compute the barcode of \(M_{\mathcal {F}}\) in time \(O(t^{\omega +2})\) (Proposition 4.15).
-
We provide an algorithm IsIntervalDecomp (page 23) to decide the interval decomposability of \(M_{\mathcal {F}}\) in time \(O(t^{3\omega +2})\) (Proposition 4.17).
2 Preliminaries
In Sect. 2.1, we review the notion of interval decomposability of persistence modules. In Sect. 2.2, we review the notions of generalized rank invariant and generalized persistence diagram. In Sect. 2.3, we discuss how to compute the limit and the colimit of a given functor \(P\rightarrow \textbf{vec}\).
2.1 Persistence Modules and Their Decompositions
We fix a certain field \(\mathbb {F}\) and every vector space in this paper is over \(\mathbb {F}\). Let \(\textbf{vec}\) denote the category of finite dimensional vector spaces and linear maps.
Let \(P\) be a poset. We regard \(P\) as the category that has points of \(P\) as objects. Also, for any \(p,q\in P\), there exists a unique morphism \(p\rightarrow q\) if and only if \(p\le q\). For a positive integer d, let \(\textbf{Z}^d\) be given the partial order defined by \((a_1,a_2,\ldots ,a_d)\le (b_1,b_2,\ldots ,b_d)\) if and only if \(a_i\le b_i\) for \(i=1,2,\ldots ,d\).
A (\(P\)-indexed) persistence module is any functor \(M:P\rightarrow \textbf{vec}\) (which we will simply refer to as a P-module). In other words, to each \(p\in P\), a vector space \(M_p\) is associated, and to each pair \(p\le q\) in \(P\), a linear map \(\varphi _{M}(p,q):M_p\rightarrow M_q\) is associated. Importantly, whenever \(p\le q\le r\) in \(P\), it must be that \(\varphi _M(p,r)=\varphi _M(q,r)\circ \varphi _M(p,q)\).
We say that a pair of \(p,q\in P\) is comparable if either \(p\le q\) or \(q\le p\).
Definition 2.1
([34]) An interval I of \(P\) is a subset \(I\subseteq P\) such that:
-
(i)
I is nonempty.
-
(ii)
If \(p,q\in I\) and \(p\le r\le q\), then \(r\in I\).
-
(iii)
I is connected, i.e. for any \(p,q\in I\), there is a sequence \(p=p_0, p_1,\cdots ,p_\ell =q\) of elements of I with \(p_i\) and \(p_{i+1}\) comparable for \(0\le i\le \ell -1\).
By \(\textbf{Int}(P)\) we denote the set of all finite intervals of \(P\). When \(P\) is finite and connected, \(P\in \textbf{Int}(P)\) will be referred to as the full interval.
For an interval I of \(P\), the interval module \(\mathbb {I}_I:P\rightarrow \textbf{vec}\) is defined as
Definition 2.2
Let M be any \(P\)-module. A submodule N of M is defined by subspaces \(N_p\subseteq M_p\) such that \(\varphi _M(p,q)(N_p)\subseteq N_q\) for all \(p,q\in P\) with \(p\le q\). These conditions guarantee that N itself is a \(P\)-module, with the structure maps given by the restrictions \(\varphi _M(p,q)\vert _{N_p}\). In this case we write \(N \le M\).
A submodule N is a summand of M if there exists a submodule \(N'\) which is complementary to N, i.e. \(M_p=N_p\oplus N'_p\) for all p. In that case, we say that M is a direct sum of \(N,N'\) and write \(M\cong N\oplus N'\). Note that this direct sum is an internal direct sum.
The (external) direct sum \(M_1\oplus M_2\) of given P-modules \(M_1\) and \(M_2\) is the \(P\)-module where \((M\oplus N)_p=M_p\oplus N_p\) for \(p\in P\) and \(\varphi _{M\oplus N}(p,q)=\varphi _{M}(p,q)\oplus \varphi _{N}(p,q)\) for \(p\le q\) in \(P\). A nonzero \(P\)-module M is indecomposable if whenever \(M=M_1\oplus M_2\) for some \(P\)-modules \(M_1\) and \(M_2\), either \(M_1=0\) or \(M_2=0\).
Definition 2.3
A \(P\)-module M is called interval decomposable if M is isomorphic to a direct sum of interval modules, i.e. there exists an indexing set \(\mathcal {J}\) such that \(M\cong \bigoplus _{j\in \mathcal {J}}\mathbb {I}_{I_{j}}\) (external direct sum). In this case, the multiset \(\{I_j: j\in \mathcal {J}\}\) is called the barcode of M, which will be denoted by \(\textrm{barc}(M)\).
The Azumaya–Krull–Remak-Schmidt theorem [35] guarantees that \(\textrm{barc}(M)\) is well-defined, i.e. the multiset \(\{I_j: j\in \mathcal {J}\}\) is unique.
Consider a zigzag poset of n points, \( \bullet _{1}\leftrightarrow \bullet _{2} \leftrightarrow \ldots \bullet _{n-1} \leftrightarrow \bullet _n\) where \(\leftrightarrow \) stands for either \(\le \) or \(\ge \). A functor from a zigzag poset to \(\textbf{vec}\) is called a zigzag module [6]. Any zigzag module is interval decomposable [1] and thus admits a barcode.
The following proposition directly follows from the Azumaya–Krull–Remak–Schmidt theorem and will be useful in Sect. 4.
Proposition 2.4
Let \(M:P\rightarrow \textbf{vec}\) be interval decomposable and let \(N\le M\) be a summand of M (Definition 2.2). Then, M/N is interval decomposable.
Proof
It suffices to show that \(M\cong N\oplus (M/N)\) (since M is interval decomposable, this isomorphism and Azumaya-Krull-Remak-Schmidt’s theorem [35] guarantee that M/N is also interval decomposable). Let \(\iota :N\hookrightarrow M\) be the canonical inclusion. Since N is a summand of M, there exists a complementary submodule \(N'\le M\) with \(M=N\oplus N'\) (internal direct sum). For the inclusion \(\iota :N'\hookrightarrow M\) and the projection \(\pi :M\rightarrow M/N\), the composition \(\pi \circ \iota \) is an isomorphism, completing the proof. \(\square \)
2.2 Generalized Rank Invariant and Generalized Persistence Diagrams
Throughout this section, let \(P\) be a finite connected poset. Consider any \(P\)-module M. Then M admits a limit \(\varprojlim M=(L, (\pi _p:L\rightarrow M_p)_{p\in P})\) and a colimit \(\varinjlim M =(C, (i_p:M_p\rightarrow C)_{p\in P})\); see Appendix 1. For every \(p\le q\) in \(P\), we have
By the connectedness of P, we have \(i_p \circ \pi _p=i_q \circ \pi _q:L\rightarrow C\) for any \(p,q\in P\). This equality ensures the validity of the following definition.
Definition 2.5
([22]) The canonical limit-to-colimit map \(\psi _M:\varprojlim M\rightarrow \varinjlim M\) is the linear map \(i_p\circ \pi _p\) for any \(p\in P\). The generalized rank of M is \(\textrm{rank}(M):=\textrm{rank}(\psi _M)\).
The rank of M counts the multiplicity of the fully supported interval modules in a direct sum decomposition of M.
Theorem 2.6
([25, Lem. 3.1]) The rank of M is equal to the number of indecomposable summands of M which are isomorphic to the interval module \(\mathbb {I}_{P}\).
Definition 2.7
The \((\textbf{Int})\)-generalized rank invariant of M is the map \(\textrm{rk}_{\mathbb {I}}(M):\textbf{Int}(P)\rightarrow \textbf{Z}_{\ge 0}\) defined as \(I\mapsto \textrm{rank}(M\vert _I)\), where \(M\vert _I\) is the restriction of M to I.
Remark 2.8
(Additivity) Given any P-modules M and N, it is not hard to show that \(\textrm{rank}(M\oplus N)=\textrm{rank}(M)+\textrm{rank}(N)\). This implies that \(\textrm{rk}_{\mathbb {I}}(M\oplus N)=\textrm{rk}_{\mathbb {I}}(M)+\textrm{rk}_{\mathbb {I}}(N)\).
Definition 2.9
The \((\textbf{Int})\)-generalized persistence diagram of M is the uniqueFootnote 2 function \(\textrm{dgm}_{\mathbb {I}}(M):\textbf{Int}(P)\rightarrow \textbf{Z}\) that satisfies, for any \(I\in \textbf{Int}(P)\),
The following is a slight variation of [22, Thm. 3.14] and [20, Thm. 5.10].
Theorem 2.10
If a given \(M:P\rightarrow \textbf{vec}\) is interval decomposable, then for all \(I\in \textbf{Int}(P)\), \(\textrm{dgm}_{\mathbb {I}}(M)(I)\) is equal to the multiplicity of I in \(\textrm{barc}(M)\).
Proof
It is not hard to verify that for any \(I,J\in \textbf{Int}(P)\),
For \(J\in \textbf{Int}(P)\), let \(\mu _J\in \textbf{Z}_{\ge 0}\) be the multiplicity of J in \(\textrm{barc}(M)\). We have \(\displaystyle M\cong \bigoplus _{J\in \textbf{Int}(P)}\mathbb {I}_J^{\mu _J}\) where \(\mathbb {I}_J^{\mu _J}\) is the direct sum of \(\mu _J\) copies of \(\mathbb {I}_J\). Then, by Theorem 2.6 and Remark 2.8, we have that for all \(I\in \textbf{Int}(P)\)
By the uniqueness of \(\textrm{dgm}_{\mathbb {I}}(M)\) mentioned in Definition 2.9, \(\textrm{dgm}_{\mathbb {I}}(M)(I)=\mu _I\) for all \(I\in \textbf{Int}(P)\). \(\square \)
In the rest of this subsection, we consider \(P\) to be a finite interval of the product poset \(\textbf{Z}^2\). Recall that \(\textbf{Int}(\textbf{Z}^2 )\) denotes the set of finite intervals of \(\textbf{Z}^2\).
Definition 2.11
For any \(I\in \textbf{Int}(\textbf{Z}^2)\), we define \(\textrm{nbd}_{\mathbb {I}}(I):=\{p\in \textbf{Z}^2{\setminus } I: I\cup \{p\}\in \textbf{Int}(\textbf{Z}^2)\}.\)
Note that \(\textrm{nbd}_{\mathbb {I}}(I)\) is nonempty [20, Prop. 3.2]. When \(A\subseteq \textrm{nbd}_{\mathbb {I}}(I)\) contains more than one point, \(A\cup I\) is not necessarily an interval of \(\textbf{Z}^2\). However, there always exists a unique smallest interval that contains \(A\cup I\), which is denoted by \(\overline{A\cup I}\). See Fig. 2 for an illustrative example.

A For the given interval I of \(\textbf{Z}^2\), we have \(\textrm{nbd}_{\mathbb {I}}(I)=\{p,p'\}\). For \(A=\{p,p'\}\), the set \(A\cup I\) is not an interval of \(\textbf{Z}^2\). B The points in the shaded region form \(\overline{A\cup I}\)
Remark 2.12
([20, Thm. 5.3]) If in Definition 2.9 we assume that \(P\) is a finite interval of \(\textbf{Z}^2\), then we have that for every \(I\in \textbf{Int}(P)\),Footnote 3
2.3 Canonical Constructions of Limits and Colimits
Let M be any P-module.
Notation 2.13
Let \(p,q\in P\) and let \(v_{p}\in M_p\) and \(v_{q}\in M_q\). We write \(v_p\sim v_q\) if p and q are comparable, and either \(v_p\) is mapped to \(v_q\) via \(\varphi _M(p,q)\) or \(v_q\) is mapped to \(v_p\) via \(\varphi _M(q,p)\).
The following proposition gives a standard way of constructing a limit and a colimit of a P-module M. Since it is well-known, we do not prove it (see for example [38, Chap. 5]).
Proposition 2.14
-
(i)
The limit of M is (isomorphic to) the pair \(\left( W,(\pi _p)_{p\in P}\right) \) where
$$\begin{aligned} W:=\left\{ (v_p)_{p\in P}\in \prod _{p\in P} M_p:\ \forall p\le q \text{ in } P,\ v_{p}\sim v_{q} \right\} \end{aligned}$$(2)and for each \(p\in P\), the map \(\pi _p:W\rightarrow M_p\) is the canonical projection. An element of W is called a section of M.Footnote 4
-
(ii)
The colimit of M is (isomorphic to) the pair \(\left( U, (i_p)_{p\in P}\right) \) described as follows: For \(p\in P\), let the map \(j_p:M_p\hookrightarrow \bigoplus _{p\in P}M_p\) be the canonical injection. U is the quotient \(\left( \bigoplus _{p\in P}M_p\right) /T\), where T is the subspace of \(\bigoplus _{p\in P} M_p\) that is generated by the vectors of the form \(j_p(v_p)-j_q(v_q), \ v_p\sim v_{q},\) the map \(i_p:M_p\rightarrow U\) is the composition \(\rho \circ j_p\), where \(\rho \) is the quotient map \(\bigoplus _{p\in P} M_p\rightarrow U\).

3 Computing Generalized Rank via Boundary Zigzags
In Sect. 3.1 we introduce the notions of lower and upper fences of a poset. In Sect. 3.2, we introduce the notion of boundary cap \(\partial I\) of a finite interval I of \(\textbf{Z}^2\), which is a path, a certain sequence of points in I. In Sect. 3.3, we show that the rank of any functor \(M:I\rightarrow \textbf{vec}\) can be obtained by computing the barcode of the zigzag module over the path \(\partial I\).
3.1 Lower and Upper Fences of a Poset
Let P be any connected poset. Given any \(p\in P\), by \(p^{\downarrow }\), we denote the set of all elements of P that are less than or equal to p. Dually \(p^{\uparrow }\) is defined as the set of all elements of P that are greater than or equal to p.
Definition 3.1
A subposet \(L\subset P\) (resp. \(U\subset P\)) is called a lower (resp. upper) fence of P if L is connected, and for any \(q\in P\), the intersection \(L\cap q^{\downarrow }\) (resp. \(U\cap q^{\uparrow }\)) is nonempty and connected.
The following proposition is a crucial milestone towards establishing our main result, Theorem 3.12.
Proposition 3.2
Let L and U be a lower and an upper fences of a connected poset P respectively. Given any P-module M, we have \(\varprojlim M \cong \varprojlim M\vert _{L}\) and \(\varinjlim M \cong \varinjlim M\vert _{U}\).
Although this proposition directly follows from the fact that the inclusions \(L\hookrightarrow P\) and \(U\hookrightarrow P\) are respectively initial and final functors (see [38, Sect. 9.3]), an elementary and tangible proof is given below, which utilizes the following proposition.
Proposition 3.3
Let M be a P-module and let \(L\subset P\) be a lower fence. Let \(\textbf{v}\in \bigoplus _{p\in I}{M_p}\). The tuple \(\textbf{v}\) belongs to \(\varprojlim M\) if and only if for every \(p\in P\), it holds that \(\textbf{v}_p=\varphi _M(q,p)(\textbf{v}_q)\) for every \(q\in L\) such that \(q\le p\).
Proof
The forward direction is straightforward from the description of \(\varprojlim M\) given in Proposition 2.14 (i). Let us show the backward direction. Again, by Proposition 2.14 (i) it suffices to show that for all \(r\le p\) in P it holds that \(\textbf{v}_p=\varphi _M(r,p)(\textbf{v}_r)\). Fix \(r\le p\) in P. Since L is a lower fence, there exists \(q\in L\) such that \(q\le r\le p\). Then, by assumption and by functoriality of M, we have
as desired. \(\square \)
Proof of Proposition 3.2
We only prove \(\varprojlim M \cong \varprojlim M\vert _L\). It suffices to prove that the section extension map \(e:\varprojlim M\vert _L \rightarrow \varprojlim M\) in (3) is bijective. The injectivity is clear by definition. The surjectivity follows from the forward direction of the statement in Proposition 3.3. \(\square \)
The canonical isomorphism \(\varprojlim M \cong \varprojlim M\vert _{L}\) in Proposition 3.2 is given by the canonical section extension \(e:\varprojlim M\vert _{L} \rightarrow \varprojlim M\). Namely,
where for any \(q\in P\), the vector \(\textbf{w}_q\) is defined as \(\varphi _M(p,q)(\textbf{v}_p)\) for any \(p\in L\cap q^{\downarrow }\); the connectedness of \(L\cap q^{\downarrow }\) guarantees that \(\textbf{w}_q\) is well-defined. Also, if \(q\in L\), then \(\textbf{w}_q=\textbf{v}_q\). The inverse \(r:=e^{-1}\) is the canonical section restriction. The other isomorphism \(\varinjlim M \cong \varinjlim M\vert _{U}\) in Proposition 3.2 is given by the map \(i:\varinjlim M\vert _U\rightarrow \varinjlim M\) defined by \([v_p]\mapsto [v_p]\) for any \(p\in U\) and any \(v_p\in M_p\); the fact that this map i is well-defined will become clear from Proposition 3.10. Let us define \(\xi : \varprojlim M\vert _{L} \rightarrow \varinjlim M\vert _{U}\) by \(i^{-1}\circ \psi _M\circ e\). By construction, the following diagram commutes

where \(\psi _M\) is the canonical limit-to-colimit map of M. Hence we have the fact
which is useful for proving Theorem 3.12.
3.2 Boundary Cap of an Interval in \(\textbf{Z}^2\)
Let \(I\in \textbf{Int}(\textbf{Z}^2)\), i.e. I is a finite interval of \(\textbf{Z}^2\) (Definition 2.1). By \(\min (I)\) and \(\max (I)\), we denote the collections of minimal and maximal elements of I, respectively. In other words,
Note that \(\min (I)\) and \(\max (I)\) are nonempty and that \(\min (I)\) and \(\max (I)\) respectively form an antichain in I, i.e. any two different points in \(\min (I)\) (or in \(\max (I)\)) are not comparable.
Remark 3.4
-
(i)
The least upper bound and the greatest lower bound of \(p,q\in \textbf{Z}^2\) are denoted by \(p\vee q\) and \(p\wedge q\) respectively. Let \(p=(p_x,p_y)\) and \(q=(q_x,q_y)\) in \(\textbf{Z}^2\). Then,
$$\begin{aligned} p\vee q= (\max \{p_x,q_x\}, \max \{p_y,q_y\}),\hspace{3mm}p\wedge q= (\min \{p_x,q_x\}, \min \{p_y,q_y\}). \end{aligned}$$ -
(ii)
Let \(I\in \textbf{Int}(\textbf{Z}^2)\). Since \(\min (I)\) is a finite antichain, we can list the elements of \(\min ( I)\) in ascending order of their x-coordinates, i.e. \(\min (I):=\{p_0,\ldots ,p_k\}\) and such that for each \(i=0,\ldots ,k,\) the x-coordinate of \(p_i\) is less than that of \(p_{i+1}\). Similarly, let \(\max (I):=\{q_0,\ldots ,q_\ell \}\) be ordered in ascending order of \(q_j\)’s x-coordinates. We have that \(p_0\le q_0\) (Fig. 3).

Five different intervals I of \(\textbf{Z}^2\). Relations in \(\min _{\textbf{ZZ}}(I)\) and \(\max _{\textbf{ZZ}}(I)\) are indicated by green and red arrows, respectively. The inequality \(p_0\le q_0\) is indicated by blue arrows unless \(p_0=q_0\). Notice that \(\partial I\), as defined in equation (8), has cardinality 2, 2, 6, 6, 6 in that order ((A),(B),(C),(D),(E))
Based on Remark 3.4 (ii) above, we define the following:
Definition 3.5
(Lower and upper zigzags of an interval) Let I, \(\min (I)\), and \(\max (I)\) be as in Remark 3.4 (ii). We define the following two zigzag posets (Fig. 3):
Note that \(\min _{\textbf{ZZ}} (I)\) and \(\max _{\textbf{ZZ}} (I)\) are lower and upper fences of I respectively.
For \(p,q\in P\), let us write \(p\triangleleft q\) if \(p<q\) and there is no \(r\in P\) such that \(p<r<q\). Similarly, we write \(p\triangleright q\) if \(p>q\) and there is no \(r\in P\) such that \(p>r>q\).
Definition 3.6
Given a poset \(P\), a path \(\Gamma \) between two points \(p,q\in P\) is a sequence of points \(p=p_0,\ldots , p_k=q\) in \(P\) such that either \(p_i\le p_{i+1}\) or \(p_i\ge p_{i+1}\) for every \(i\in [1,k-1]\) (note that there can be a pair \(i\ne j\) such that \(p_i=p_j\)). The path \(\Gamma \) is said to be monotonic if \(p_i\le p_{i+1}\) for each i. The path \(\Gamma \) is called faithful if either \(p_i\triangleleft p_{i+1}\) or \(p_i\triangleright p_{i+1}\) for each i.
Definition 3.7
(Boundary cap of an interval) We define the boundary cap \(\partial I\) of \(I\in \textbf{Int}(\textbf{Z}^2)\) as the path obtained by concatenating \(\min _{\textbf{ZZ}}(I)\) and \(\max _{\textbf{ZZ}}(I)\) in Eqs. (6) and (7).
We remark that \(\partial I\) can contain multiple copies of the same point. Namely, there can be \(i\in [0,k]\) and \(j\in [0,\ell ]\) such that either \(p_i=q_j\) (Fig. 3 (A)), \(p_i=q_j\wedge q_{j+1}\) (Fig. 3 (C)), \(p_i\vee p_{i+1}=q_j\) (Figure 3 (C)), or \(p_i\vee p_{i+1}=q_{j}\wedge q_{j+1}\) (Fig. 3 (D)).
Consider the following zigzag poset of the same length as \(\partial I\):
Still using the notation in Eqs. (8) we have the following order-preserving map
whose image is \(\partial I\): \(\bullet _1\) is sent to \(p_k\), \(\bullet _2\) is sent to \(p_k\vee p_{k-1}\), \(\ldots \), and \(\circ _{2\ell +1}\) is sent to \(q_\ell \).
3.3 Generalized Rank Invariant via Boundary Zigzags
The goal of this section is to establish one of our main results, Theorem 3.12. Let P be a poset and let M be any P-module.
Definition 3.8
Let \(\Gamma :p_0,\ldots ,p_k\) be a path in P. A \((k+1)\)-tuple \(\textbf{v}\in \bigoplus _{i=0}^k M_{p_i}\) is called the section of M along \(\Gamma \) if \(\textbf{v}_{p_i}\sim \textbf{v}_{p_{i+1}}\) for each i (Notation 2.13).
We remark that a path \(\Gamma \) can contain multiple copies of the same point in P. The next example shows that a section \(\textbf{v}\) of M along \(\Gamma :p_0,\ldots ,p_k\) does not necessarily belong to the limit of the restriction of M to the subposet \(\{p_0,\ldots ,p_k\}\subseteq P\).
Example 3.9
Consider \(M:\{(1,1),(1,2),(2,2),(2,1)\}(\subset \textbf{Z}^2)\rightarrow \textbf{vec}\) given as follows.

Consider the path \(\Gamma :(1,1),(1,2),(2,2),(2,1)\) which contains all points in the indexing poset. Then, \(\textbf{v}:=(1,1,1,(0,1))\in M_{(1,1)}\oplus M_{(1,2)}\oplus M_{(2,2)}\oplus M_{(2,1)}\) is a section of M along \(\Gamma \), while \(\textbf{v}\not \in \varprojlim M\).
By Proposition 2.14 (ii), we directly have:
Proposition 3.10
Let \(p,q\in P\). For any vectors \(v_{p}\in M_{p}\) and \(v_q\in M_q\), \([v_{p}]=[v_q]\) inFootnote 5 the colimit \(\varinjlim M\) if and only if there exist a path \(\Gamma :p=p_0,p_1,\ldots ,p_n=q\) in P and a section \(\textbf{v}\) of M along \(\Gamma \) such that \(\textbf{v}_{p}=v_{p}\) and \(\textbf{v}_{q}=v_q\).

Definition 3.11
(Zigzag module along \(\partial I\)) For the map \(\iota _I:\textbf{ZZ}_{\partial I}\rightarrow I\) in Eq. (10), we define the zigzag module \(M_{\partial I}:\textbf{ZZ}_{\partial I}\rightarrow \textbf{vec}\) by the composition \(M\circ \iota _I\).
We remark that, by Setup 1 and Definition 3.8, each \(\textbf{v}=(\textbf{v}_{x})_{x\in \textbf{ZZ}_{\partial I}}\in \varprojlim M_{\partial I}\) is an element of \(\bigoplus _{x\in \textbf{ZZ}_{\partial I}} M_{ \iota _I(x)}\) that is a section M along \(\partial I\).
One of our main results is the following.
Theorem 3.12
\(\textrm{rank}(M)\) is equal to the multiplicity of the full interval in \(\textrm{barc}(M_{\partial I})\).
Proof
By Theorem 2.6, it suffices to show that
Let \(L:=\min _{\textbf{ZZ}}(I)\) and \(U:=\max _{\textbf{ZZ}}(I)\) which are lower and upper fences of I respectively. Let us define the maps e, r, i and \(\xi \) as described in the paragraph after Proposition 3.2. Then, by equation (5), it suffices to prove that the rank of \(\xi \) equals the rank of \(\psi _{M_{\partial I}}\). To this end, we show that there exist a surjective linear map \(f:\varprojlim M_{\partial I}\rightarrow \varprojlim M\vert _L\) and an injective linear map \(g:\varinjlim M\vert _U \rightarrow \varinjlim M_{\partial I}\) such that \(\psi _{M_{\partial I}}=g\circ \xi \circ f\). We define f as the canonical section restriction \((\textbf{v}_q)_{q\in \partial I}\mapsto (\textbf{v}_{q})_{q\in L}\). We define g as the canonical map, i.e. \([v_{q}]\mapsto [v_q]\) for any \(q\in U\) and any \(v_q\in M_q\). By Proposition 3.10 and by construction of \(M_{\partial I}\), the map g is well-defined.
We now show that \(\psi _{M_{\partial I}}=g\circ \xi \circ f\). Let \(\textbf{v}:=(\textbf{v}_q)_{q\in \partial I}\in \varprojlim M_{\partial I}\). Then, by definition of \(\psi _{M_{\partial I}}\) (Setup 1), the image of \(\textbf{v}\) via \(\psi _{M_{\partial I}}\) is \([\textbf{v}_{q_0}]\) where \(q_0\in U\) is defined as in Remark 3.4 (ii). Also, we have
which proves the equality \(\psi _{M_{\partial I}}=g\circ \xi \circ f\).
We claim that f is surjective. Let \(r':\varprojlim M \rightarrow \varprojlim M_{\partial I}\) be the canonical section restriction map \((\textbf{v}_q)_{q\in I}\mapsto (\textbf{v}_{q})_{q\in \partial I}\). Then, the restriction \(r:\varprojlim M \rightarrow \varprojlim M\vert _L\), can be seen as the composition of two restrictions \(r=f\circ r'\). Since r is the inverse of the isomorphism e in diagram (4), r is surjective and thus so is f.
Next we claim that g is injective. Let \(i':\varinjlim M_{\partial I}\rightarrow \varinjlim M\) be defined by \([v_q]\mapsto [v_q]\) for any \(q\in \partial I\) and any \(v_q\in M_q\). By Proposition 3.10 and by construction of \(M_{\partial I}\), the map \(i'\) is well-defined. Then, for the isomorphism i in diagram (4), we have \(i=i'\circ g\). This implies that g is injective. \(\square \)
Remark 3.13
In Definition 3.7 one may consider the “lower” boundary cap \(\widehat{\partial I}\), as an alternative to \(\partial I\):
The value \(\textrm{rank}(M)\) also equals the multiplicity of the full interval in the barcode of the zigzag module induced over \(\widehat{\partial I}\).
By Theorem 3.12, we can utilize algorithms for zigzag persistence in order to compute the generalized rank invariant and the generalized persistence diagram of any \(\textbf{Z}^2\)-module that is obtained by applying the homology functor to a simplicial filtration \(\mathcal {F}\) over (a subset of) \(\textbf{Z}^2\). For this, we complete the boundary cap of a given interval to a faithful path (i.e. we put the missing monotonic paths between every pair of consecutive points) and then simply run a zigzag persistence algorithm. Notice that, if \(\mathcal {F}\) satisfies the condition in Setup 3 below, the above mentioned faithful path admits only O(t) insertions and deletions of simplices in the zigzag filtration and hence the zigzag persistence algorithms of Milosavljevic et al. [39] and of Dey and Hou [40] run in time \(O(t^\omega )\).
Remark 3.14
To compute \(\textrm{dgm}_{\mathbb {I}}(M)(I)\) by the formula in (1), one needs to consider terms whose number depends exponentially on the number of neighbors of I. However, for any interval that has at most \(O(\log t)\) neighbors, we have \(2^{O(\log t)}=t^c\) terms for some constant \(c>0\). It follows that using \(O(t^{\omega })\) zigzag persistence algorithm for computing generalized ranks, we obtain an \(O(t^{\omega +c})\) algorithm for computing generalized persistence diagrams of intervals that have at most \(O(\log t)\) neighbors.
4 Computing Intervals and Detecting Interval Decomposability
When a persistence module M admits a summand N that is isomorphic to an interval module, N will be called an interval summand of M. In this section, we apply Theorem 3.12 for computing generalized rank via zigzag to different problems that ask to find interval summands of an input finite \(\textbf{Z}^2\)-module: Problems 4.3, 4.6, and 4.16.
Let K be a finite abstract simplicial complex and let \(\textrm{sub}(K)\) be the poset of all subcomplexes of K, ordered by inclusion.
Definition 4.1
Given any poset \(P\), an order-preserving map \(\mathcal {F}:P\rightarrow \textrm{sub}(K)\) is called a (simplicial) filtration (of K over \(P\)). When P is either \(\textbf{Z}^2\) or an interval of \(\textbf{Z}^2\), we call \(\mathcal {F}\) a bifiltration.

Computing the dimension function.
In all algorithms below, we utilize a subroutine Dim\(({{\mathcal {F}}},P)\), which computes the dimension of the vector space \((M_{{\mathcal {F}}})_p\) for every \(p\in P\).
Proposition 4.2
Dim\(({{\mathcal {F}}},P)\) can be executed in \(O(t^4)\) time.
Proof
To implement Dim, we maintain a set C which we initialize to be the empty set. We consider each \(p\in \min (P)\) iteratively and proceed as follows. We reach all points \(q\in p^{\uparrow }\backslash C\) from p in a depth first search over paths that are both monotonic and faithful (Definition 3.6). These paths form a directed tree Q rooted at p (where the arrows do not zigzag). We run the standard persistence algorithm on the filtration \({\mathcal {F}}\) restricted to Q with a slight modification so that the branchings in the tree are taken care of. We traverse the tree Q in a depth first manner and each time we come to a branching node, we start with the matrix which was computed during the previous visit of this node. This means that we leave a copy of the reduced matrix at each node that we traverse. Let \(t_p\) equal the maximum of the cardinality of \(p^\uparrow \backslash C\) and the number of insertions of simplices over a monotonic path in the directed tree Q. Then, it is easy to see that \(t_p=O(t)\) by our assumption on t (based on the description in Setup 3). At each node q we spend \(O(t_p^2)\) time to copy a matrix of size \(O(t_p)\times O(t_p)\). Also, for each simplex insertion, we spend \(O(t_p^2)\) time to reduce this matrix. Therefore, in total, each simplex insertion takes \(O(t_p^2)=O(t^2)\) time. Considering all minimal points, we see that, in total we insert only \(O(t^2)\) simplices. This is because the input filtration consists of \(O(t^2)\) insertions (each simplex in the complex K is inserted at most O(t) times in the filtration) and each insertion is processed only once over all minimal points. This gives us a total complexity of \(O(t^2)\times O(t^2)=O(t^4)\). \(\square \)
4.1 Detecting Interval Modules
We consider the following problem. Recall that \(P\) is a finite interval of \(\textbf{Z}^2\).
Problem 4.3
Determine whether \(M_{\mathcal {F}}\) is isomorphic to the direct sum of a certain number of copies of \(\mathbb {I}_P\) and if so, report the number of such copies.
Algorithm IsInterval solves Problem 4.3. The correctness of the algorithm follows from Proposition 4.4. Below, for \(m\in \textbf{Z}_{\ge 0}\) let \(\mathbb {I}_P^{m}:=\underbrace{\mathbb {I}_P\oplus \mathbb {I}_P\oplus \cdots \oplus \mathbb {I}_P}_{m}\). In particular, \(\mathbb {I}_P^0\) is defined to be the trivial module. Let us recall that \((M_{{\mathcal {F}}})_{\partial P}\) denotes the zigzag module along the boundary cap \(\partial P\) (Definition 3.11).
Algorithm IsInterval(\({\mathcal {F}}\), \(P\))
-
Step 1. Compute zigzag barcode \(\textrm{barc}((M_{{\mathcal {F}}})_{\partial P})\) and let m be the multiplicity of the full interval.
-
Step 2. Call Dim\(({{\mathcal {F}}},P)\) (Computes \(\dim (M_{{\mathcal {F}}})_p\) for every \(p\in P\))
-
Step 3. If \(\dim (M_{{\mathcal {F}}})_p=m\) for each point \(p\in P\) return m, otherwise return 0 indicating \(M_{{\mathcal {F}}}\) has a summand which is not an interval module supported over \(P\).
Recall that \(\textbf{vec}\) denotes the category of finite dimensional vector spaces and linear maps.
Proposition 4.4
Assume that a given \(M:P\rightarrow \textbf{vec}\) has the indecomposable decomposition \(M\cong \bigoplus _{i=1}^m M_i\). Then, every summand \(M_i\) is isomorphic to the interval module \(\mathbb {I}_{P}\) if and only if \(\textrm{rk}_{\mathbb {I}}(M)(P)=\dim M_p=m\) for all \(p\in P\).
Proof
By Theorem 2.6, the forward direction is straightforward. Let us show the backward direction. Since \(\textrm{rk}_{\mathbb {I}}(M)(P)=m\), by Theorem 2.6, we have that \(M\cong \mathbb {I}_{P}^m \oplus M'\) where \(M'\) admits no summand that is isomorphic to \(\mathbb {I}_P\). Fix any \(p\in P\). Then, \(m=\dim (M_p)=\dim ((\mathbb {I}_{P}^m )_p)+\dim (M'_p)=m+\dim (M'_p)\), and hence \(\dim (M'_p)=0\). Since p was chosen arbitrarily, \(M'\) must be trivial. \(\square \)
Proposition 4.5
Algorithm IsInterval can be run in \(O(t^4)\) time.
Proof
As we commented earlier, Step 1 computing the zigzag barcode \(\textrm{barc}((M_{\mathcal {F}})_{\partial P})\) can be implemented to run in \(O(t^\omega )\) time because it runs on a filtration comprising \(O(t)\) insertions and deletions of simplices over an index set of size \(O(t)\). Step 2 takes \(O(t^4)\) time (Proposition 4.2). Step 3 takes only time \(O(t)\). This implies that the overall complexity is \(O(t^4)\) given that \(\omega <2.373\). \(\square \)
4.2 Interval Decomposable Modules and Its Summands
Setup 3 still applies in Sect. 4.2. Next, we consider the problem of computing all indecomposable summands of \(M_\mathcal {F}\) under the assumption that \(M_\mathcal {F}\) is interval decomposable (Definition 2.3).
Problem 4.6
Assume that \(M_{\mathcal {F}}:P\rightarrow \textbf{vec}\) is interval decomposable. Find \(\textrm{barc}(M_{\mathcal {F}})\).
We present algorithm Interval to solve Problem 4.6 in \(O(t^{\omega +2})\) time. This algorithm is eventually used to detect whether a given module is interval decomposable or not (Problem 4.16). Before describing Interval, we first describe another algorithm TrueInterval. The outcomes of both Interval and TrueInterval are the same as the barcode of \(M_\mathcal {F}\) in Problem 4.6 (Propositions 4.10 and 4.14). Whereas TrueInterval is more intuitive, real implementation is accomplished via Interval.
Definition 4.7
Let \(\mathcal {I}(M_{\mathcal {F}}):=\{I\in \textbf{Int}(P):\,\textrm{rk}_{\mathbb {I}}(M_{\mathcal {F}})(I)>0\}\). We call \(I\in \mathcal {I}(M_{\mathcal {F}})\) maximal if there is no \(J\supsetneq I\) in \(\textbf{Int}(P)\) such that \(\textrm{rk}_{\mathbb {I}}(M_{\mathcal {F}})(J)\) is nonzero.
Proposition 4.8
Assume that \(M_\mathcal {F}\) is interval decomposable and let \(I\in \mathcal {I}(M_{\mathcal {F}})\) be maximal. Then, I belongs to \(\textrm{barc}(M_{\mathcal {F}})\) and the multiplicity of I in \(\textrm{barc}(M_{\mathcal {F}})\) is equal to \(\textrm{rk}_{\mathbb {I}}(M_{\mathcal {F}})(I)\).
Proof
By assumption, all summands in the sum
corresponding to the second term of (1) are zero. Hence, \(\textrm{dgm}_{\mathbb {I}}(M_{{\mathcal {F}}})(I)=\textrm{rk}_{\mathbb {I}}(M_{{\mathcal {F}}})(I)>0\). Since \(M_{{\mathcal {F}}}\) is interval decomposable, by Theorem 2.10, \(\textrm{dgm}_{\mathbb {I}}(M_{{\mathcal {F}}})(I)\) is equal to the multiplicity of I in \(\textrm{barc}(M_{{\mathcal {F}}})\). Therefore, not only does I belong to \(\textrm{barc}(M_{{\mathcal {F}}})\), but also the value \(\textrm{rk}_{\mathbb {I}}(M_{{\mathcal {F}}})(I)\) is equal to the multiplicity of I in \(\textrm{barc}(M_{{\mathcal {F}}})\).
\(\square \)
Corollary 4.9
Assume that \(M_\mathcal {F}\) is interval decomposable and let \(I\in \mathcal {I}(M_{\mathcal {F}})\) be maximal. Let \(\mu _I:=\textrm{rk}_{\mathbb {I}}(M_{\mathcal {F}})(I)\). Then, \(M_\mathcal {F}\) admits a summand N which is isomorphic to \(\mathbb {I}_I^{\mu _I}\).
Let us now describe a procedure TrueInterval that outputs all indecomposable summands of a given interval decomposable module. It uses ‘true’ quotient operation justifying the name. For computational efficiency, we will implement TrueInterval differently with the algorithm Interval avoiding the quotient operation.
Let \(M:=M_{{\mathcal {F}}}\). First we compute \(\dim M_p\) for every point \(p\in P\). Iteratively, we choose a point p with \(\dim M_p\not = 0\) and compute a maximal interval \(I\in \mathcal {I}(M)\) containing p. Since M is interval decomposable, by Proposition 4.8 and Corollary 4.9 we have that \(I\in \textrm{barc}(M)\) and that there is a summand \(N\cong \mathbb {I}_{I}^{\mu _I}\) of M. Consider the quotient module \(M':= M/N\). Clearly, this ‘peeling off’ of N reduces the total dimension of the input module. Namely, \(\dim M'_p= {\left\{ \begin{array}{ll} \dim M_p-\mu _I,&{}p\in I \\ \dim M_p,&{}p\notin I. \end{array}\right. }\) We continue the process by replacing M with \(M'\) until there is no point \(p\in P\) with \(\dim M_p\not = 0\) (note that \(M'\) is interval decomposable by Proposition 2.4). Since \(\dim M:=\sum _{p\in P}\dim M_p\) is finite, this process terminates in finitely many steps. By Proposition 2.4 and Corollary 4.9, the outcome of TrueInterval is a list of all intervals in \(\textrm{barc}(M)\) with accurate multiplicities:
Proposition 4.10
Assume that \(M_{\mathcal {F}}\) is interval decomposable. Let \(I_i\), \(i=1,\ldots , k\) be the intervals computed by TrueInterval. For each \(i=1,\ldots , k\), let \(\mu _{I_i}:=\textrm{rk}_{\mathbb {I}}(M_\mathcal {F})({I_i})\). Then, we have \(M_\mathcal {F}\cong \bigoplus _{i=1}^k \mathbb {I}_{I_i}^{\mu _{I_i}}\).
Next, we describe an algorithm Interval that simulates TrueInterval while avoiding explicit quotienting of \(M_{{\mathcal {F}}}\) by its summands.
We associate two variables d(p) and \(\texttt{ptlist}(p)\) with each point \(p\in P\). Their roles are described below.
The variable d(p) is a number that equals the original dimension of \((M_{{\mathcal {F}}})_p\) minus the number of intervals peeled off so far (counted with their multiplicities) which contained p. It is initialized to \(\dim (M_{{\mathcal {F}}})_p\). Each time we compute a maximal interval \(I\in \mathcal {I}(M_\mathcal {F})\) with multiplicity \(\mu _I\) that contains p, we update \(d(p):=d(p)-\mu _I\). This current value of d(p) keeps track of how many more intervals that contain p still need to be peeled off by TrueInterval.
The variable \(\texttt{ptlist}(p)\) is a list that maintains the set of the intervals containing p that have been output so far. So, if we have already output intervals, say \(I_1,\ldots , I_k\), which contain p, then \(\texttt{ptlist}(p)=\{I_1,\ldots ,I_k\}\). While searching for a maximal interval I, we maintain a variable \(\texttt{idlist}\) for I that contains the set of intervals common to all points in I. So, if \(I=\{p_1,\ldots ,p_m\}\), then \(\texttt{idlist}=\texttt{ptlist}(p_1)\cap \ldots \cap \texttt{ptlist}(p_m)\) at the end of the search. Initializing \(\texttt{idlist}\) with \(\texttt{ptlist}(p)\) of the initial point p, we update it as we explore expanding I. Every time we augment I with a new point q, we update \(\texttt{idlist}\) by taking its intersection with \(\texttt{ptlist}(q)\) associated with q.
We assume a routine Count that takes an idlist as input and gives the total number of intervals in the idlist counted with their multiplicities. This means that if \(\texttt{idlist}=\{I_1,\ldots ,I_k\}\), then Count(\(\mathtt idlist\)) returns the number \(c:= \mu _{I_1}+\cdots +\mu _{I_k}\).
Notice that, while searching for a maximal interval starting from a point, we keep considering the original given module \(M_{{\mathcal {F}}}\) since we do not implement the true ‘peeling’ (i.e. quotient \(M_{\mathcal {F}}\) by a submodule). However, we modify the condition for checking the maximality of an interval I. We check whether \(\textrm{rk}_{\mathbb {I}}(M_{\mathcal {F}})(I)>c\), that is, whether the generalized rank of \(M_{\mathcal {F}}\) over I is larger than the total number of intervals containing I that would have been peeled off so far by TrueInterval. This idea is implemented in the following algorithm.
Algorithm Interval (\({\mathcal {F}}\): Filtration, \(P\):Poset)
-
Step 1. Call Dim(\({\mathcal {F}}\),\(P\)) and set \(d(p):=\dim (M_{{\mathcal {F}}})_p\); \(\texttt{ptlist}(p):=\emptyset \) for every \(p\in P\)
-
Step 2. While there exists a \(p\in P\) with \(d(p)> 0\) do
-
Step 2.1 Let \(I:=\{p\}\); \(\texttt{idlist}:=\texttt{ptlist}(p)\); unmark every \(q\in P\)
-
Step 2.2 If there exists unmarked \(q\in \textrm{nbd}_{\mathbb {I}}(I)\) with \(d(q)>0\),Footnote 6 then
-
i.
\(\texttt{templist}:=\texttt{idlist}\cap \texttt{ptlist}(q)\); \(c:=\) Count(\(\mathtt templist\))
-
ii.
If \(\textrm{rk}_{\mathbb {I}}(M_{{\mathcal {F}}})(I\cup \{q\})>c\) thenFootnote 7 mark q; set \(I:=I\cup \{q\}\); \(\texttt{idlist}:=\texttt{idlist}\cap \texttt{ptlist}(q)\)
-
iii.
go to Step 2.2
-
i.
-
Step 2.3 Output I with multiplicity \(\mu _I:=\textrm{rk}_{\mathbb {I}}(M_{{\mathcal {F}}})(I)-c\)
-
Step 2.4 For every \(q\in I\) set \(d(q):=d(q)-\mu _I\) and \(\texttt{ptlist}(q):=\texttt{ptlist}(q)\cup \{I\}\)
-
The output of Interval can be succinctly described as:
Output: \(\{(I_i,\mu _{I_i}):i=1,\ldots ,k\}\) where \(I_i\in \textbf{Int}(P)\) and \(\mu _i\) is a positive integer for each i.
Remark 4.11
For each \(p\in P\), we have that \(\dim ({M_\mathcal {F}})_p=\displaystyle \sum _{I_i\ni p} \mu _i\). This equality holds even when \(M_\mathcal {F}\) is not interval decomposable.
We will show that if \(M_\mathcal {F}\) is interval decomposable, then the output of Interval coincides with the barcode of \(M_{\mathcal {F}}\) (Propositions 4.10 and 4.14).
Example 4.12
(Interval with interval decomposable input) Suppose that \(M_{\mathcal {F}}\cong \mathbb {I}_{I_1}\oplus \mathbb {I}_{I_2}\oplus \mathbb {I}_{I_3}\) as depicted in Fig. 4 (A). The algorithm Interval yields \(\{(I_1,1),(I_2,1),(I_3,1)\}\). In particular, since \(I_1\supset I_2 \supset I_3\), Interval outputs \((I_1,1)\), \((I_2,1)\), and \((I_3,1)\) in order, as depicted in Fig. 5 (A).
Details for Example 4.12
We illustrate how the barcode of \(M_{\mathcal {F}}\) is obtained as the output of Interval. In Step 1, for \(p=(2,2)\), we have \(d(p)=3\) and \(\texttt{ptlist}(p)=\emptyset \). For the first round of the while loop in Step 2, note that \(q=(2,1)\) belongs to \(\textrm{nbd}_{\mathbb {I}}(\{p\})\) and thus q can be added to \(I=\{p\}\). After several rounds of the while loop, we obtain \(I_1\) with \(\mu _{I_1}=1\), and for every \(q\in I_1\) (including \(p=(2,2)\)), d(q) is decreased by 1. Next, suppose that another search begins at \(I=\{p\}\) and it tries to include \(q=(2,1)\). We obtain \(\textrm{rk}_{\mathbb {I}}(M_{\mathcal {F}})(I\cup \{q\})=1\) as in the previous round, but now Count\((\texttt{ptlist}(p)\cap \texttt{ptlist}(q))\) also returns 1 in Step 2.2(i) because the previously detected interval \(I_1\) contains both p and q. Then, the test \(\textrm{rk}_{\mathbb {I}}(M_{\mathcal {F}})(I\cup \{q\})> (c=1)\) in Step 2.2(ii) fails and the search proceeds with other points. Again, after several iterations of successful and unsuccessful attempts to expand I, we obtain the interval \(I_2\) with \(\mu _{I_2}=1\). After obtaining \((I_2,\mu _2)\), only \(p=(2,2)\) has \(d(p)=1\) because of which another round of while loop starting at p outputs the interval \(I_3=\{p\}\). \(\square \)
The algorithm Interval outputs the barcode of an input module \(M_{\mathcal {F}}\) when \(M_{\mathcal {F}}\) is interval decomposable. If \(M_{\mathcal {F}}\) is not interval decomposable, the output of the algorithm Interval may not be unique and may not include some interval I even if the interval module \(\mathbb {I}_I\) is a summand of \(M_\mathcal {F}\).
Example 4.13
(Interval with non-interval-decomposable input) Consider the persistence module N depicted in Fig. 4, which is indecomposable and not isomorphic to an interval module.
-
(i)
When \(M_{\mathcal {F}}\cong N\) is the input to Interval, two possible final outputs of Interval are \(\{(J_1,1),(J_2,1)\}\) and \(\{(J_1',1),(J_2',1)\}\) depicted in Fig. 5 (B) and (C).
-
(ii)
Let \(M_{\mathcal {F}}\cong N\oplus \mathbb {I}_{I_2}\) be the input to Interval, where \(\mathbb {I}_{I_2}\) is depicted in Fig. 4 (A). Then, one possible final output of Interval is \(\{(L_1,1),(L_2,1),(L_3,1)\}\) as depicted in Fig. 5 (D). Note that the output does not contain interval \(I_2\), even though \(\mathbb {I}_{I_2}\) is a summand of \(M_{\mathcal {F}}\).

Modules \(M,N:\{1,2,3\}\times \{1,2\}\rightarrow \textbf{vec}\). M is interval decomposable, but N is not

Details for Example 4.13(ii)
In Step 1 of Interval, for \(p=(2,2)\), we have \(d(p)=3\) and \(\texttt{ptlist}(p)=\emptyset \). In Step 2.2, \(q=(1,2)\) belongs to \(\textrm{nbd}_{\mathbb {I}}(\{p\})\) and thus q can be added to \(I=\{p\}\). Once I becomes \(\{p,q\}\), after multiple iterations within Step 2.2, I will expand to \(L_1\) in Fig. 5 (D). Since \(\textrm{rk}_{\mathbb {I}}(M_\mathcal {F})(L_1)=1\) and \(L_1\) is a maximal interval (Definition 4.7), the pair of \(L_1\) and \(\mu _{L_1}=1\) will be a part of the output. By continuing this process, one possible final output is \(\{(L_1,1),(L_2,1),(L_3,1)\}\) as depicted in Fig. 5 (D). \(\square \)
Proposition 4.14
If \(M_{{\mathcal {F}}}\) is interval decomposable, Interval\(({\mathcal {F}}\), \(P)\) computes all and only intervals in \(\textrm{barc}(M_{\mathcal {F}})\) with correct multiplicities.
Proof
We prove that Interval computes an interval I with multiplicity \(\mu _I\) if and only if TrueInterval\(({\mathcal {F}}\), \(P)\) computes it with the same multiplicity.
(‘if’): We induct on the list of intervals in the order they are computed by TrueInterval. We prove two claims by induction: (i) TrueInterval can be run to explore the points in \(P\) in the same order as Interval while searching for maximal intervals, (ii) if \(I_i\), \(i=1,\cdots , k\), are the intervals computed by TrueInterval with this chosen order, then Interval also outputs these intervals with the same multiplicities. Clearly, for \(i=1\), Interval computes the maximal interval on the same input module \(M_{{\mathcal {F}}}\) as TrueInterval does. So, clearly, TrueInterval can be made to explore \(P\) as Interval does and hence their outputs are the same. Assume inductively that the hypotheses hold for \(i\ge 1\). Then, TrueInterval operates next on the module \(M_{i+1}:=M_{{\mathcal {F}}}/(\mathbb {I}_{I_1}^{\mu _{I_1}}\oplus \cdots \oplus \mathbb {I}_{I_i}^{\mu _{I_i}})\) (here each \(\mathbb {I}_{I_i}^{\mu _{I_i}}\) stands for a summand of \(M_{\mathcal {F}}\) that is isomorphic to \(\mathbb {I}_{I_i}^{\mu _{I_i}}\) by Corollary 4.9). We let TrueInterval explore \(P\) in the same way as Interval does. This is always possible because the outcome of the test for exploration remains the same in both cases as we argue. The variable d(p) at this point has the value \(\dim (M_{i+1})_p\) and thus both TrueInterval and Interval can start exploring from the point p if \(d(p)>0\). So, we let TrueInterval compute the next maximal interval \(I_{i+1}\) starting from the point p if Interval starts from p.
Now, when Interval tests for a point q to expand the interval I, we claim that the result would be the same if TrueInterval tested for q. First of all, the condition whether \(I\cup \{q\}\) is an interval or not does not depend on which algorithm we are executing. Second, the list supplied to Count in Step 2.2 (i) exactly equals the list of intervals containing \(I\cup \{q\}\) that Interval has already output. By the inductive hypothesis, this list is exactly equal to the list of intervals that TrueInterval had already ‘peeled off’. Therefore, the test \(\textrm{rk}_{\mathbb {I}}(M_{{\mathcal {F}}})(I\cup \{q\})>c\) that Interval performs in Step 2.2 (ii) is exactly the same as the test \(\textrm{rk}_{\mathbb {I}}(M_{i+1})(I\cup \{q\})>0\) that TrueInterval would have performed for the module \(M_{i+1}\). This establishes that Interval computes the same interval \(I_{i+1}\) with the same multiplicity as TrueInterval would have computed on \(M_{i+1}\) using the same order of exploration as the inductive hypothesis claims.
(‘only if’): We already know that Interval computes all intervals that TrueInterval computes. We claim that it does not compute any other interval. For intervals computed by TrueInterval, one has that \(\dim (M_{{\mathcal {F}}})_p=\sum _i(\mathbb {I}_i^{\mu _{I_i}})_p\), or equivalently \(\dim (M_{{\mathcal {F}}})_p=\sum _{I\in \{I_1,\ldots ,I_k\} s.t. I\ni p} \mu _I\). The algorithm Interval decreases the variable d(p) exactly by the amount on the right-hand side of the equation and is intialized to \(\dim (M_{{\mathcal {F}}})_p\). Therefore, every d(p) becomes equal to \(\dim (M_{{\mathcal {F}}})_p\) after Interval computes the intervals that TrueInterval computes. The condition \(d(p)>0\) in the while loop prohibits Interval to compute any other interval. \(\square \)
Proposition 4.15
Interval\(({\mathcal {F}}\), \(P)\) runs in \(O(t^{\omega +2})\) time.
Proof
Each iteration in the while loop executes a traversal of the graph underlying the poset \(P\) starting from a point p. Each time, we reach a new point q in this traversal, we execute a zigzag persistence computation on the boundary cap \(\partial (I\cup \{q\})\). This means, the number of times a zigzag persistence is computed equals the number of times a point in the poset is considered by the while loop. We claim that this number is \(O(t^2)\). Each time a point p is considered by the while loop, either we include it in an interval that is output (a successful attempt), or we don’t include it in the expansion of the current interval (unsuccessful attempt) and q appears as a point in the neighborhood of an interval that is output. The number of times a point is involved in a successful attempt is at most \(t\) because a point can be contained in at most \(t\) intervals (\(\dim (M_{{\mathcal {F}}})_p\le t\)). Similarly, the number of times a point is involved in an unsuccessful attempt is at most \(4t\) because the point can be in the neighborhood of at most \(4t\) intervals (at most \(t\) intervals for each of its \(\le 4\) neighbors). Therefore, each point participates in at most \(O(t)\) computations of zigzag persistence over the entire while loop. Each zigzag computation takes time \(O(t^{\omega })\) since the filtration \({{\mathcal {F}}}\vert _{\partial (I\cup \{q\})}\) restricted to the boundary cap has length at most \(t\) comprising at most t insertions and deletions of simplices. It follows that the total cost due to zigzag persistence computation is bounded by \(O(t^{\omega +2})\).
Now, we analyze the cost of maintaining the lists with each point and with the intervals under construction. Notice that \(\dim (M_{{\mathcal {F}}})=\sum _{p\in P} \dim (M_{{\mathcal {F}}})_p=O(t^2)\) because there are at most t points in \(P\) with \(\dim (M_{{\mathcal {F}}})_p\le t\) for each \(p\in P\) since \({\mathcal {F}}\) has at most \(t\) simplices. Each while loop iteration maintains a global list, calls Count on this list, and updates \(\texttt{ptlist}(q)\) for some points \(q\in P\). The cost of this counting and updates cannot be more than the order of the final total size \(\sum _p \texttt{ptlist}(p)\) of the lists, which in turn is no more than \(\dim (M_{{\mathcal {F}}})=O(t^2)\). Thus, over the entire while loop we incur \(O(t^4)\) cost for maintenance of the lists and for the counting based on them. Also, step 1 takes \(O(t^4)\) time to compute the dimensions. Thus, we have a worst-case complexity of \(O(t^4+t^{\omega +2})=O(t^{\omega +2})\) because it is known that \(\omega \ge 2\).
\(\square \)
4.3 Interval Decomposability
Setup 3 still applies in Sect. 4.3. We consider the following problem.
Problem 4.16
Determine whether the module \(M_{{\mathcal {F}}}\) is interval decomposable or not.
If the input module \(M_{{\mathcal {F}}}\) is interval decomposable, then the algorithm Interval computes all intervals in the barcode. However, if the module \(M_{{\mathcal {F}}}\) is not interval decomposable, then the algorithm is not guaranteed to output all interval summands. We show that Interval still can be used to solve Problem 4.16. For this we test whether each of the output intervals I with multiplicity \(\mu _I\) indeed supports a summand \(N\cong \mathbb {I}_I^{\mu _I}\) of \(M_{{\mathcal {F}}}\).
To do this we run Algorithm 3 in Asashiba et al. [26] for each of the output intervals of Interval. Call this algorithm TestInterval which with an input interval I, returns \(\mu _I>0\) if the module \(\mathbb {I}_I^{\mu _I}\) is a summand of M and 0 otherwise.
For each of the intervals I with multiplicity \(\mu _I\) returned by Interval(\({\mathcal {F}}\), \(P\)) we test whether TestInterval(I) returns a non-zero \(\mu _I\). The first time the test fails, we declare that \(M_{{\mathcal {F}}}\) is not interval decomposable. This gives us a polynomial time algorithm (with complexity \(O(t^{3\omega +2})\)) to test whether a module induced by a given bifiltration is interval decomposable or not. It is a substantial improvement over the result of Asashiba et al. [26] who gave an algorithm for tackling the same problem. Their algorithm cleverly enumerates the intervals in the poset to test, but still tests exponentially many of them and hence may run in time that is exponential in \(t\). Because of our algorithm Interval, we can do the same test but only on polynomially many intervals.
Algorithm IsIntervalDecomp (\({\mathcal {F}}\), \(P\))
-
Step 1. \({{\mathcal {I}}=\{(I_i,\mu _{I_i})\}}\leftarrow \) Interval(\({\mathcal {F}}\), \(P\))
-
Step 2. For every \(I_i\in {{\mathcal {I}}}\) do
-
Step 2.1 \(\mu \leftarrow \) TestInterval(\(M_{{\mathcal {F}}}\),\(I_i\))
-
Step 2.2 If \(\mu \not = \mu _{I_i}\) then output false; quit
-
-
Step 3. output true
Proposition 4.17
IsIntervalDecomp\(({\mathcal {F}}\), \(P)\)
-
1.
returns true if and only if \(M_{{\mathcal {F}}}\) is interval decomposable, and
-
2.
takes \(O(t^{3\omega +2})\) time.
Proof
By the contrapositive of Proposition 4.10, if for any of the computed interval(s) \(I_i\), \(i=1,\cdots ,k\) by Interval, \(\mathbb {I}_{I_i}^{\mu _{I_i}}\) is not a summand of \(M_{{\mathcal {F}}}\), then \(M_{{\mathcal {F}}}\) is not interval decomposable. On the other hand, if every such interval module is a summand of \(M_{{\mathcal {F}}}\), then we have that \(M_{{\mathcal {F}}}\cong \bigoplus _{i=1}^k \mathbb {I}_{I_i}^{\mu _{I_i}}\) because \(\dim (M_{\mathcal {F}})_p= \sum _i^k \dim (\mathbb {I}_{I_i}^{\mu _{I_i}})_p\) for every \(p\in P\).
Time complexity By Proposition 4.15, Step 1 runs in time \(O(t^{\omega +2})\). We claim that \(\dim (M_{\mathcal {F}})=O(t^2)\) (see Proof of Proposition 4.15). Therefore, Interval returns at most \(O(t^2)\) intervals. According to the analysis in Asashiba et al. [26], each test in Step 2.1 takes \(O(((\dim M_{\mathcal {F}})^\omega + t)t^{\omega })=O(t^{3\omega })\) time and thus \(O(t^{3\omega +2})\) in total over all \(O(t^2)\) tests which dominates the time complexity of IsIntervalDecomp. \(\square \)
4.4 Interval Produces Partial Sections of Indecomposable Summands
The algorithm Interval produces all intervals of an input interval decomposable module. A natural question is what does the algorithm Interval return on a module that is not interval decomposable (Fig. 5 (B)). We show that the intervals returned by the algorithm support “partial” sections of indecomposable summands:
Proposition 4.18
Let \({\mathcal {I}}\) be the set of intervals computed by Interval(\({\mathcal {F}}\),P). Then, for every \(I\in {{\mathcal {I}}}\), there exists a section supported over I of an indecomposable summand of \(M_{\mathcal {F}}\).
The above result follows from the proposition below since Interval outputs an interval I only if \(\textrm{rk}(M_{{\mathcal {F}}})(I)> 0\).
Proposition 4.19
Let P be a finite connected poset. Let M be a P-module with an indecomposable decomposition \(M\cong \bigoplus _{j\in L} M_j\) for some finite set L. Let \(I\in \textbf{Int}(P)\). If \(\textrm{rk}(M)(I)=c>0\), there are \(j_1,\ldots ,j_c\in L\) such that for each \(t=1,\ldots , c\), there exists a section \(\textbf{v}\) of \(M_{j_t}\vert _I\) that is fully supported, i.e. \(\textbf{v}_p\ne 0\) for all \(p\in I\).Footnote 8
Proof
By the assumption, we have
Note that \(M_j\vert _I\) can be decomposable for each j. Let \(M_j\vert _I\) have an indecomposable decomposition
i.e. each \(M_{jk}\) is an indecomposable I-module. Then \(M\vert _I\) has an indecomposable decomposition
Since I is a finite poset and \(M_p\) is finite dimensional for each \(p\in P\), we have that \(\varprojlim M\vert _I\) is finite dimensional. Hence the notions of direct product and direct sum coincide in the category of I-indexed modules. This implies that \(\varprojlim (N_1\oplus N_2)\cong \varprojlim N_1 \oplus \varprojlim N_2\) (and it is a standard fact that \(\varinjlim (N_1\oplus N_2)\cong \varinjlim N_1 \oplus \varinjlim N_2\) [38, Thm. V.5.1]). Therefore, we have that
Since each \(M_{jk}\) is indecomposable, by Theorem 2.6,
Therefore, there exist exactly c distinct pairs (j, k) such that \(M_{jk}\cong \mathbb {I}_I\). Hence, for each of such (j, k), we can find a section \(\textbf{v}:=\textbf{v}^{jk}\) of \(M_{jk}\) that is fully supported over I. Since \(M_{jk}\) is a summand of \(M_j\vert _I\), \(\textbf{v}\) is also a section of \(M_j\vert _I\), as desired. \(\square \)
4.5 Barcode Ensemble from Interval
Fix a P-module M \(=M_{\mathcal {F}}\) as an input to the algorithm Interval. Recall that an output of Interval with the input M is a collection \(\{(I_i,\mu _{I_i})\}_i\). This collection may change with different choices available during the exploration for computing maximal intervals. The collection \(\textbf{E}(M)\) of all possible outputs of Interval will be called the barcode ensemble of M. Proposition 4.14 implies:
Corollary 4.20
If \(\textbf{E}(M)\) contains more than one collection, then M is not interval decomposable.
Suppose that a collection \(\mathcal {C}:=\{(I_i,\mu _{I_i})\}_i\) belongs to \(\textbf{E}(M)\). We consider the interval decomposable module \(\mathbb {I}_\mathcal {C}:=\bigoplus _i \mathbb {I}_{I_i}^{\mu _i}\) corresponding to \(\mathcal {C}\). Fix any interval \(J\subset P\). We define
We remark that \(\textrm{rk}(\mathbb {I}_{\mathcal {C}})(J)\) is equal to \(\sum _{i} \mu _i\) where the sum is taken over all i such that \(I_i\supseteq J\).
A single output of the algorithm Interval may fail to capture the generalized rank invariant of M; for instance, in Example 4.13 (i), the generalized rank invariant of the module \(M_{\mathcal {F}}(\cong N)\) is different from the generalized rank invariants of \(\bigoplus _{i=1}^2\mathbb {I}_{J_i}\) or \(\bigoplus _{i=1}^2\mathbb {I}_{J_i'}\). Nevertheless, the barcode ensemble \(\textbf{E}(M)\) recovers the generalized rank invariant of the input module M:
Proposition 4.21
For every interval \(J\subseteq P\), we have
By the design of the algorithm Interval, the above equality is clearly true when \(\textrm{rk}(M)(J)=0\).
Proof
(\(\ge \)) Let \(m:=\textrm{rk}(M)(J)\) and pick any \(\mathcal {C}=\{(I_i,\mu _i))\}_i\) in \(\textbf{E}(M)\). By the design of the algorithm Interval, it is not possible for the sum \(\displaystyle \sum _{\begin{array}{c} i \\ I_i\supset J \end{array}} \mu _i\) (\(=\textrm{rk}(\mathbb {I}_{\mathcal {C}})\)) to be greater than m. Since \(\mathcal {C}\) was arbitrarily chosen in \(\textbf{E}(M)\), we have \(\textrm{rk}(M)(J)\ge \textbf{E}(M)(J)\).
(\(\le \)) Assume that \(m:=\textbf{E}(M)(J)\). This implies that there exists \(\mathcal {C}=\{(I_i,\mu _i)\}_i\) in \(\textbf{E}(M)\) such that \(\textrm{rk}(\mathbb {I}_\mathcal {C})(J)=m\). We prove the desired inequality by contradiction. Suppose that \(n:=\)\(\textrm{rk}(M)(J)>m\). This implies that we can run the while loop (Step 2) at least n times starting from the singleton interval \(I=\{p\}\) for any point \(p\in J\). Let \(\mathcal {C}'\) be any final output obtained in this strategy. Then, the output \(\mathcal {C}'\) contains intervals \(I'_j\) containing J with multiplicity \(\mu '_j\) and we have \(n=\sum _{j}\mu '_j\). Then, by Theorem 2.6, we have that \(\textrm{rk}(\mathbb {I}_{\mathcal {C}'})(J)\ge n>m\), contradicting the definition of \(\textbf{E}(M)(J)\). \(\square \)
5 Discussion
Some open questions that follow are:(i) Can we generalize Theorem 3.12 to d-parameter persistent homology for \(d>2\)? One obstacle is that, for \(d>2\), the (minimal) lower and upper fences of an interval \(I\in \textbf{Int}(\textbf{Z}^d)\) are generally not zigzag posets. (ii) Can the complexity of the algorithms be improved? (iii) In particular, can we improve the interval decomposability testing by improving TestInterval which currently uses an algorithm of Asashiba et al.? (iv) Finally, it would be interesting to see the use of our results in applications, see e.g. [41] for an application in machine learning.
Data Availability
Data sharing not applicable to this article.
Code Availability
Code sharing not applicable to this article.
Notes
When \(d=2\) this means lines with positive slope.
When P is finite, \(\prod _{p\in P} M_p= \bigoplus _{p\in P} M_p\).
For simplicity, we write \([v_{p}]\) and \([v_q]\) instead of \([j_p(v_p)]\) and \([j_q(v_q)]\) respectively where \(j_p:M_p\rightarrow \bigoplus _{r\in P}M_r\) and \(j_q:M_q\rightarrow \bigoplus _{r\in P}M_r\) are the canonical inclusion maps.
When the input \(M_{\mathcal {F}}\) is interval decomposable, the algorithm outputs the barcode of \(M_\mathcal {F}\) even without the condition “with \(d(q)>0\)". But, when \(M_{\mathcal {F}}\) is not interval decomposable, the condition “with \(d(q)>0\)" ensures that the equality in Remark 4.11 holds.
We remark that these sections can be further extended using the structure maps to submodules which may have larger supports than the original sections.
References
Gabriel, P.: Unzerlegbare darstellungen i. Manuscr. Math. 6, 71–103 (1972)
Crawley-Boevey, W.: Decomposition of pointwise finite-dimensional persistence modules. J. Algebra Appl. 14(05), 1550066 (2015)
Dey, T.K., Wang, Y.: Computational Topology for Data Analysis. Cambridge University Press, Cambridge, UK (2022)
Edelsbrunner, H., Harer, J.: Computational Topology: An Introduction. American Mathematical Society, Providence, RI (2010)
Bauer, U., Botnan, M.B., Oppermann, S., Steen, J.: Cotorsion torsion triples and the representation theory of filtered hierarchical clustering. Adva. Math. 369, 107171 (2020)
Carlsson, G., de Silva, V.: Zigzag persistence. Found. Comput. Math. 10(4), 367–405 (2010)
Carlsson, G., Mémoli, F.: Multiparameter hierarchical clustering methods. In: Classification as a Tool for Research, pp. 63–70. Springer, Heidelberg (2010)
Carlsson, G., Zomorodian, A.: The theory of multidimensional persistence. Discrete Comput. Geom. 42(1), 71–93 (2009)
Dey, T.K., Hou, T.: Updating zigzag persistence and maintaining representatives over changing filtrations. CoRR arxiv:2112.02352 (2021)
Escolar, E.G., Hiraoka, Y.: Persistence modules on commutative ladders of finite type. Discrete Comput. Geom. 55(1), 100–157 (2016)
Kim, W., Mémoli, F.: Spatiotemporal persistent homology for dynamic metric spaces. Discrete Comput. Geom. 66(3), 831–875 (2021)
Lesnick, M.: Multidimensional interleavings and applications to topological inference. PhD thesis, Stanford University (2012)
Lesnick, M.: The theory of the interleaving distance on multidimensional persistence modules. Found. Comput. Math. 15(3), 613–650 (2015)
Miller, E.: Modules over posets: commutative and homological algebra. arXiv preprint arXiv:1908.09750 (2019)
Biasotti, S., Cerri, A., Frosini, P., Giorgi, D., Landi, C.: Multidimensional size functions for shape comparison. J. Math. Imaging Vis. 32(2), 161–179 (2008)
Lesnick, M., Wright, M.: Interactive visualization of 2-d persistence modules. arXiv preprint arXiv:1512.00180 (2015)
Cai, C., Kim, W., Mémoli, F., Wang, Y.: Elder-rule-staircodes for augmented metric spaces. SIAM J. Appl. Algebra Geom. 5(3), 417–454 (2021)
Botnan, M., Lebovici, V., Oudot, S.: On Rectangle-Decomposable 2-Parameter Persistence Modules. In: 36th International Symposium on Computational Geometry (SoCG 2020), vol. 164 (2020). https://doi.org/10.4230/LIPIcs.SoCG.2020.22
Cochoy, J., Oudot, S.: Decomposition of exact pfd persistence bimodules. Discrete Comput. Geom. 63(2), 255–293 (2020)
Asashiba, H., Escolar, E.G., Nakashima, K., Yoshiwaki, M.: On approximation of \(2d\)-persistence modules by interval-decomposables. arXiv preprint arXiv:1911.01637 (2019)
Clause, N., Kim, W., Memoli, F.: The discriminating power of the generalized rank invariant. arXiv preprint arXiv:2207.11591 (2022)
Kim, W., Mémoli, F.: Generalized persistence diagrams for persistence modules over posets. J. Appl. Comput. Topol. 5(4), 533–581 (2021)
Patel, A.: Generalized persistence diagrams. J. Appl. Comput. Topol. 1(3), 397–419 (2018)
Kim, W., Mémoli, F.: Rank invariant for zigzag modules. arXiv preprint arXiv:1810.11517v1 (2018)
Chambers, E., Letscher, D.: Persistent homology over directed acyclic graphs. In: Research in Computational Topology, pp. 11–32. Springer, (2018)
Asashiba, H., Buchet, M., Escolar, E.G., Nakashima, K., Yoshiwaki, M.: On interval decomposability of 2d persistence modules. Comput. Geom. 105, 101879 (2022)
Dey, T.K., Xin, C.: Generalized persistence algorithm for decomposing multiparameter persistence modules. J. Appl. Comput. Topol. 9, 1–52 (2022)
Kerber, M.: Multi-parameter persistent homology is practical. In: NeurIPS 2020 Workshop on Topological Data Analysis and Beyond (2020)
Betthauser, L., Bubenik, P., Edwards, P.B.: Graded persistence diagrams and persistence landscapes. Discrete Comput. Geom. 8, 1–28 (2021)
Botnan, M., Oppermann, S., Oudot, S.: Signed barcodes for multi-parameter persistence via rank decompositions and rank-exact resolutions. arXiv preprint arXiv:2107.06800 (2021)
Bubenik, P., Elchesen, A.: Virtual persistence diagrams, signed measures, and wasserstein distance. arXiv preprint arXiv:2012.10514 (2020)
Kim, W., Moore, S.: Bigraded betti numbers and generalized persistence diagrams. arXiv preprint arXiv:2111.02551v3 (2021)
McCleary, A., Patel, A.: Edit distance and persistence diagrams over lattices. arXiv preprint arXiv:2010.07337 (2020)
Botnan, M., Lesnick, M.: Algebraic stability of zigzag persistence modules. Algebraic Geometric Topol. 18(6), 3133–3204 (2018)
Azumaya, G.: Corrections and supplementaries to my paper concerning Krull–Remak–Schmidt’s theorem. Nagoya Math. J. 1, 117–124 (1950)
Rota, G.C.: On the foundations of combinatorial theory i. theory of Möbius functions. Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete 2(4), 340–368 (1964)
Stanley, R.P.: Enumerative Combinatorics. Cambridge Studies in Advanced Mathematics, vol. 1, 2nd edn. Cambridge University Press, Cambridge (2011)
Mac Lane, S.: Categories for the Working Mathematician, vol. 5. Springer, New York (2013)
Milosavljević, N., Morozov, D., Skraba, P.: Zigzag persistent homology in matrix multiplication time. In: Proceedings of the Twenty-seventh Annual Symposium on Computational Geometry, pp. 216–225 (2011)
Dey, T.K., Hou, T.: Fast computation of zigzag persistence. In: 30th Annual European Symposium on Algorithms, ESA 2022. LIPIcs, vol. 244 (2022). https://doi.org/10.4230/LIPIcs.ESA.2022.43
Xin, C., Mukherjee, S., Samaga, S., Dey, T.K.: GRIL: a 2-parameter persistence based vectorization for machine learning. CoRR arXiv:2304.04970 (2023)
Acknowledgements
The authors thank the anonymous reviewers for constructive feedback and suggesting ideas that shortened the proof of Theorem 3.12. This work is supported by NSF Grants CCF-2049010, CCF-1740761, DMS-1547357, and IIS-1901360.
Funding
This work is supported by NSF grants CCF-2049010, CCF-1740761, DMS-1547357, and IIS-1901360.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Editor in Charge: Kenneth Clarkson
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Limits and Colimits
Appendix A: Limits and Colimits
We recall the notions of limit and colimit from category theory [38]. Recall that a poset \(P\) can be viewed as a category whose objects are the elements of \(P\) and morphisms are the comparable pairs \(p\le q\) in \(P\). Although limits and colimits are defined for functors indexed by small categories we restrict our attention to poset-indexed functors. Let \(\mathcal {C}\) be any category.
Definition A.1
(Cone) Let \(F:P\rightarrow \mathcal {C}\) be a functor. A cone over F is a pair \(\left( L,(\pi _p)_{p\in P}\right) \) consisting of an object L in \(\mathcal {C}\) and a collection \((\pi _p)_{p\in P}\) of morphisms \(\pi _p:L \rightarrow F(p)\) that commute with the arrows in the diagram of F, i.e. if \(p\le q\) in \(P\), then \(\pi _q= F(p\le q)\circ \pi _p\) in \(\mathcal {C}\), i.e. the diagram below commutes.

In Definition A.1, the cone \(\left( L,(\pi _p)_{p\in P}\right) \) over F is sometimes denoted simply by L, suppressing the collection \((\pi _p)_{p\in P}\) of morphisms if no confusion can arise. A limit of \(F:P\rightarrow \mathcal {C}\) is a terminal object in the collection of all cones over F:
Definition A.2
(Limit) Let \(F:P\rightarrow \mathcal {C}\) be a functor. A limit of F is a cone over F, denoted by \(\left( \varprojlim F,\ (\pi _p)_{p\in P} \right) \) or simply \(\varprojlim F\), with the following terminal property: If there is another cone \(\left( L',(\pi '_p)_{p\in P} \right) \) of F, then there is a unique morphism \(u:L'\rightarrow \varprojlim F\) such that \(\pi _p'=\pi _p\circ u\) for all \(p\in P\).
It is possible that a functor does not have a limit at all. However, if a functor does have a limit then the terminal property of the limit guarantees its uniqueness up to isomorphism. For this reason, we sometimes refer to a limit as the limit of a functor.
Cocones and colimits are defined in a dual manner:
Definition A.3
(Cocone) Let \(F:P\rightarrow \mathcal {C}\) be a functor. A cocone over F is a pair \(\left( C,(i_p)_{p\in P}\right) \) consisting of an object C in \(\mathcal {C}\) and a collection \((i_p)_{p\in P}\) of morphisms \(i_p:F(p)\rightarrow C\) that commute with the arrows in the diagram of F, i.e. if \(p\le q\) in \(P\), then \(i_p= i_q\circ F(p\le q)\) in \(\mathcal {C}\), i.e. the diagram below commutes.

In Definition A.3, a cocone \(\left( C,(i_p)_{p\in P}\right) \) over F is sometimes denoted simply by C, suppressing the collection \((i_p)_{p\in P}\) of morphisms. A colimit of \(F:P\rightarrow \mathcal {C}\) is an initial object in the collection of cocones over F:
Definition A.4
(Colimit) Let \(F:P\rightarrow \mathcal {C}\) be a functor. A colimit of F is a cocone, denoted by \(\left( \varinjlim F,\ (i_p)_{p\in P}\right) \) or simply \(\varinjlim F\), with the following initial property: If there is another cocone \(\left( C', (i'_p)_{p\in P}\right) \) of F, then there is a unique morphism \(u:\varinjlim F\rightarrow C'\) such that \(i'_p=u\circ i_p\) for all \(p\in P\).
It is possible that a functor does not have a colimit at all. However, if a functor does have a colimit then the initial property of the colimit guarantees its uniqueness up to isomorphism. For this reason, we sometimes refer to a colimit as the colimit of a functor. It is well-known that if P is finite, then any functor \(F:P\rightarrow \textbf{vec}\) admits both limit and colimit in \(\textbf{vec}\). Assume that \(P\) is also connected. Then, by the commutativity in (11) and (12), once a cone and a cocone of F are specified, there exists the canonical map from the cone to the cocone, leading to Definition 2.5.
Remark A.5
Let \(P\) be a finite and connected poset. Let Q be a finite and connected subposet of \(P\). Let us fix any \(F:P\rightarrow \textbf{vec}\).
-
(i)
For any cone \(\left( L', (\pi _p')_{p\in P}\right) \) over F, its restriction \(\left( L', (\pi _p')_{p\in Q}\right) \) is a cone over the restriction \(F\vert _Q:Q\rightarrow \textbf{vec}\). Therefore, by the terminal property of the limit \(\left( \varprojlim F\vert _{Q}, (\pi _q)_{q\in Q}\right) \), there exists the unique morphism \(u:L' \rightarrow \varprojlim F\vert _{Q}\) such that \(\pi _q'=\pi _q\circ u\) for all \(q\in Q\).
-
(ii)
For any cocone \(\left( C', (i_p')_{p\in P}\right) \) over F, its restriction \(\left( C', (i_p')_{p\in Q}\right) \) is a cocone over the restriction \(F\vert _Q:Q\rightarrow \textbf{vec}\). Therefore, by the initial property of \(\varinjlim F\vert _{Q}\), there exists the unique morphism \(u:\varinjlim F\vert _{Q} \rightarrow C'\) such that \(i'_q=u\circ i_q\) for all \(q\in Q\).
-
(iii)
By the previous two items, there exist linear maps \(\pi :\varprojlim F\rightarrow \varprojlim F\vert _{Q}\) and \(\iota :\varinjlim F\vert _{Q}\rightarrow \varinjlim F\) such that \(\psi _F=\iota \circ \psi _{F\vert _{Q}} \circ \pi .\)
Therefore, \(\textrm{rank}(F)=\textrm{rank}(\psi _{F})\le \textrm{rank}(\psi _{F\vert _{Q}})=\textrm{rank}(F\vert _{Q})\).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dey, T.K., Kim, W. & Mémoli, F. Computing Generalized Rank Invariant for 2-Parameter Persistence Modules via Zigzag Persistence and Its Applications. Discrete Comput Geom 71, 67–94 (2024). https://doi.org/10.1007/s00454-023-00584-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00454-023-00584-z
Keywords
- Persistence diagram
- Persistent homology
- Möbius inversion
- Quiver representations
- Multiparameter persistence