
Abstract
Consider a branching Markov process with values in some general type space. Conditional on survival up to generation N, the genealogy of the extant population defines a random marked metric measure space, where individuals are marked by their type and pairwise distances are measured by the time to the most recent common ancestor. In the present manuscript, we devise a general method of moments to prove convergence of such genealogies in the Gromov-weak topology when \(N \rightarrow \infty \). Informally, the moment of order k of the population is obtained by observing the genealogy of k individuals chosen uniformly at random after size-biasing the population at time N by its kth factorial moment. We show that the sampled genealogy can be expressed in terms of a k-spine decomposition of the original branching process, and that convergence reduces to the convergence of the underlying k-spines. As an illustration of our framework, we analyse the large-time behavior of a branching approximation of the biparental Wright–Fisher model with recombination. The model exhibits some interesting mathematical features. It starts in a supercritical state but is naturally driven to criticality. We show that the limiting behavior exhibits both critical and supercritical characteristics.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
1.1 A branching process with a self-organized criticality behavior
The original motivation of the present article is the branching approximation of a classical model in population genetics. It can be formulated as a branching process in discrete time where each individual carries a subinterval of (0, R), for some fixed parameter \(R > 0\). At generation \(t = 0\), the population is made of a single individual carrying the full interval (0, R). At each subsequent generation, individuals reproduce independently and an individual carrying an interval I with length \(|I|\) gives birth to K(I) children, where
and \(N \ge R\) is another fixed parameter. Each of these K(I) children inherits independently an interval which is either the full parental interval I, or a fragmented version of it. More precisely, with probability
we say that a recombination occurs: a random point is sampled uniformly on I which breaks I into two subintervals. The child inherits either the left or the right subinterval with equal probability. With probability \(1 - r_N\) no recombination occurs and the child inherits the full parental interval I. We refer to this process as the branching process with recombination.
One of the most interesting aspect of the present model is a self-organized criticality property. While the process is “locally” supercritical, since \(\mathbb {E}[K(I)] > 1\), intervals are broken via recombination and the process is naturally driven to criticality. Under the regime \(N \gg R \gg 1\), we will prove that some features are reminiscent of a critical branching process (for instance, it satisfies a type of Yaglom’s law) but also bears similarities to supercritical branching processes. In particular, one striking feature is related to the genealogy of the process conditioned on survival at a large time horizon. In the natural time scale, the genealogy of the extant population is indistinguishable from the supercritical case, that is, it converges to a star tree. However, if we zoom in on the root by rescaling time in a logarithmic way, the genealogy converges to the celebrated Brownian Coalescent Point Process and becomes indistinguishable from a critical branching process.
From a biological standpoint, our process was first introduced in [3] and corresponds to a branching approximation of a more complicated model of population genetics, named the biparental Wright–Fisher model with recombination. The connection between the two models and their biological significance are discussed in greater details in Sect. 2.
1.2 Convergence of types and genealogy
In order to analyse the previous model, we introduce a general framework and provide simple criteria for the convergence of random genealogies. Although the branching process that we consider is interesting in its own right, our study aims at giving a concrete illustration of a general approach that could presumably be relevant in many other settings.
It is quite common that individuals in a branching process are endowed with a “type”, which is heritable and can in turn influence the reproductive success of individuals. Let us denote by E the set of types. For instance, in our work E is the set of subintervals of (0, R), for branching random walks \(E = \mathbb {R}^d\) [44], or for multi-type Galton–Watson processes E is often chosen as finite [1, Chapter 5]. In the absence of types or when the reproduction law does not depend on types (as for standard branching random walks in \(\mathbb {R}^d\)), the scaling limits of the tree structure and of the distribution of types have received quite a lot of attention [12, 30, 39]. In this particular setting, one can make use of an encoding of the tree as the excursion of a stochastic process, the so-called contour process, or height process. Convergence is then obtained by showing that the corresponding excursion converges.
When the reproduction law may depend on the types, some attempts to extend the excursion approach exist in the literature [40] but as far we know a systematic and amenable approach is still missing. In this work we follow a different approach, and extend the seminal work of [18] to prove convergence in the Gromov-weak topology. Proving convergence in distribution for this setting is very similar in spirit to the method of moments for real random variables, where one proves convergence in distribution by showing that all moments of the tree structure converge. In the context of trees and metric spaces, the moments of order k are obtained by summing over all k-tuples of individuals at some generation, and considering a functional of the subtree spanned by these k individuals. Informally, this amounts to picking k individuals at random in a size biased population, and then proving convergence of the genealogy of the sample. One contribution of our work is that, analogously to the method of moments in the real setting, we only need to prove convergence of the moments with no need to identify the limit. This relies on a de Finetti-like representation of exchangeable coalescents that was developed in [17]. See Theorem 4 for our main convergence result.
1.3 Spinal decomposition of Markov branching processes
To compute the moments of branching process, we make use of a second set of tools called spinal decompositions [22, 31, 44]. One of the main insight of the present manuscript lies in the observation that an ingenious random change of measure allows us to reduce the computation of a polynomial of order k to a computation on a single tree with k leaves, called the k-spine tree. Since this type of manipulation allows one to reduce a computation involving the whole tree to a computation involving only k individuals, this type of results have been called many-to-few formula. While many-to-one formula have been extensively explored in the literature since the seminal work of Lyons et al. [31], spinal decompositions of higher order are more sparse. One formulation has been exposed in [22] (see also [4, 21, 24, 41]) where the k-spine is constructed from a system of branching particles evolving according to a prescribed Markov dynamics. While the main result in [22] could be in principle applied to our setting, the computation rapidly proved to be intractable. Another contribution of our work, that we want to emphasize, is a derivation of new general many-to-few formula that was better suited to our case. Let us describe it briefly here, and refer to Sect. 3 for a complete account.
The k-spine tree in our work is constructed iteratively as a coalescent point process (CPP in short). Starting from a single branch of length N, at each step a new branch is added to the right of the tree. Branch lengths are assumed to be i.i.d., and the procedure is stopped when the tree has k leaves, see Fig. 4. Given this tree, types need to be assigned to vertices of the k-spine tree. For \(k = 1\), the tree is made of a single branch, and the sequence of types observed from the root to the unique leaf is a Markov chain. This Markov chain is the usual sequence of types along the spine that arises in many versions of the many-to-one formula [7, 44]. It is obtained as the Doob harmonic transform of the offspring type, see Sect. 3.1. For a general k, the previous chain is duplicated independently at each branch point. The distribution of the resulting tree is connected to the original distribution of the branching process through a random change of measure \(\Delta _k\) given in (3). The latter factor accounts for the fact that individuals located at the branch points are more likely to have a large offspring and a favorable type.
While our spinal decomposition result bears similarities with that in [22], our formulation allows for a more general distribution of the k-spine tree, which can be any discrete CPP. This additional degree of freedom proved very valuable in our application, where the introduction of a well-chosen ansatz for the genealogy of the process, see (17), simplified considerably earlier versions of our proofs. More generally, we believe that our approach is particularly amenable to the study of near-critical branching processes, since the scaling limit of their genealogy can also be described as a continuous CPP. Nevertheless, see [21, 24] for successful applications of the techniques in [22] to study the genealogy of a sample from a Galton–Watson tree.
1.4 Outline
Overall, the contribution of our work is three-fold. We have (1) derived a new type of many-to-few formula based on a CPP tree, (2) combined it with the framework of the Gromov-weak topology to produce an effective way of studying the scaling limit of types and genealogies in branching processes, and (3) applied it to study a complex model from population genetics, the branching process with recombination.
The rest of our work is laid out as follows. Section 2 provides more details on the biological motivation of the branching process with recombination and a statement of our main results concerning this model. Those results will be proved using a general framework that will be developed in the subsequent sections.
In Sect. 3 we construct the k-spine tree and prove our spinal decomposition result. In Sect. 4, we show that the convergence of the genealogy of branching processes can be reduced to the convergence of the associated k-spines. This approach relies on a previous work [17] where we provide a de Finetti-like representation of ultrametric spaces that allows us to extend previous convergence criteria for the Gromov-weak topology.
In the last two sections, we apply the previous framework to the model at hand. In Sect. 5, we characterize the 1-spine associated to the branching process with recombination, and prove our convergence results in Sect. 6.
2 Branching process with recombination
2.1 Biological motivation
In the context of this work, genetic recombination is the biological mechanism by which an individual can inherit a chromosome which is not a copy of one of its two parental chromosomes, but a mix of them. An idealized version of this mechanism is illustrated in Fig. 1. Due to recombination, the alleles carried by an individual at different loci, that is, locations on the chromosome, are not necessarily transmitted together. At the level of the population, this creates a complex correlation between the gene frequencies at different loci which is hard to study mathematically.

When a recombination occurs, a point is chosen along the sequence, called the crossover point and represented by a dashed line. Two new chromosomes are formed by swapping the parts of the parental chromosomes on one side of the crossover point. The offspring inherits one of these two chromosomes (color figure online)
When focusing on a finite number of loci it is possible to express the dynamics of these frequencies as a set of non-linear differential equations or stochastic differential equations [2, 36]. However, one needs to keep track of the frequencies of all possible combinations of alleles. As the number of such combinations grows exponentially fast with the number of loci, it leads to expressions that rapidly become cumbersome, providing little biological insight. Another very fruitful approach is to trace backward-in-time the set of potential ancestors of the population. This gives rise to a mathematical object named the ancestral recombination graph (ARG) [19], or see [13, Chapter 3]. However, the ARG is quite complicated both from a mathematical and a numerical point of view. Nevertheless, see [28] for some recent mathematical results, and [32, 33] for approximations of the ARG that have proved very successful in application.
In this work we consider a third approach to this question, which is to envision the chromosome as a continuous segment. At each reproduction event recombination can break this segment into several subintervals, a subset of which is transmitted to the offspring, as in Fig. 1. The genetic contribution of an individual is now described by a collection of intervals, which are delimited by points called junctions. This point of view has long-standing history dating back to the work of Fisher [16], see for instance [23] and references therein. Let us discuss the specific model that we consider, and how the branching process with recombination approximates it.
2.2 Connection to the Wright–Fisher model
Consider a population of fixed size N where individuals are endowed with a continuous chromosome represented by the interval (0, R). At each generation, individuals pick independently two parents uniformly from the previous generation. Assume that these parents can be distinguished, so that there is a left and a right parent. Then, independently for each individual:
-
with probability \(1 - R/N\), it inherits the chromosome of one of its two parents, say the left one;
-
with probability R/N, a recombination occurs. A crossover point U is sampled uniformly on (0, R), and the offspring inherits the part of the chromosome to the left of U from its left parent, and that to the right of U from its right parent.
Suppose that at some focal generation, labeled generation \(t = 0\), each chromosome in the population is assigned a different color. Due to recombination, new chromosomes are formed that are mosaics of the initial colors. We are ultimately interested in describing the long-term distribution of these mosaics in the population. This is illustrated in Fig. 2.

Illustration of the Wright–Fisher model with recombination. A line is drawn between each individual and its parents. It is dotted if no genetic material is inherited from this parent. The right panel focuses on the genetic material left by the red individual. Note that each individual only carries an interval before the first reproduction event involving two descendants of the focal ancestor (color figure online)
In this work, we consider a simpler but related problem. Fix a focal ancestor, and say that its chromosome is red. We trace the individuals in the population that have inherited some genetic material from this focal ancestor, that is, the set of individuals that have some red on their chromosome as well as the location of the red color. To recover the branching approximation that we study, consider an individual in the population at some generation t carrying a red interval I. Its offspring size distribution is
Each of these children has another parent in the population. As long as the number of individuals with a red piece of chromosome is small compared to N, this other parent does not have any red part on its chromosome.
Therefore, there are only four possible outcomes for each child:
-
With probability \(1 - R/N\) no recombination occurs and
-
with probability 1/2 it inherits I;
-
with probability 1/2 the interval I is lost.
-
-
With probability R/N a recombination occurs and
-
if \(U \not \in I\) the interval I is transmitted or lost with probability 1/2;
-
if \(U \in I\), the child inherits the subinterval of I to the left or to the right of U with probability 1/2.
-
By combining the previous cases, we recover that the number of descendants that carry some red of an individual with red interval I is approximately distributed as a \(\textrm{Poisson}\big (1 + \tfrac{|I|}{N} \big )\) r.v., and that the probability of inheriting a fragmented interval is
This is the description of the branching process with recombination.
2.3 Limiting behavior
Let \(\textbf{P}_R\) denote the distribution of the branching process with recombination started from a single individual with interval (0, R). The following asymptotic expression for the survival probability of this process was already derived in [3].
Proposition 1
[3] Let \(Z_N\) denote the population size at generation N in the branching process with recombination. The limit
exists. Moreover it fulfills
Let \(T_N\) denote the set of individuals at generation N in the branching process with recombination. For an individual \(u \in T_N\), we denote by \(I_u\) the interval that it carries. For \(u, v \in T_N\), let \(d_T(u,v)\) denote the genealogical distance between u and v, that is, the number of generations that need to be traced backward in time before u and v find a common ancestor.
Our first result provides the joint limit of the interval lengths and of the genealogy of the population. To derive this limit, we will envision the population as a marked metric measure space and work with the marked Gromov-weak topology [10]. The definition of this topology is recalled in Sect. 4.1.
Let us consider the measure \(\mu _N\) on \(T_N \times \mathbb {R}_+\) defined as
The triple \([T_N, d_T, \mu _N]\) is the marked metric measure space corresponding to the branching process with recombination. Let us finally define the rescaling
and define the rescaled distance as
which is the distance obtained by rescaling time according to \(F_R\).
Theorem 1
Fix \(t > 0\). Conditional on survival at time \(\lfloor Nt\rfloor \) the following limit holds in distribution for the marked Gromov-weak topology,
where \([(0,Y), d_P]\) is a Brownian coalescent point process, and \(\textrm{Exp}(t)\) is the exponential distribution with mean 1/t.
A stronger version of this result is proved in Sect. 6.3. Let us now briefly discuss several consequences of the previous result.
2.3.1 Convergence of the empirical measure
As mentioned in the introduction, the branching process at hand is naturally driven to criticality through recombination. Recall that if the offspring distribution of a (standard) critical branching processes has finite second moment, the celebrated Yaglom law states that conditional on survival up to time Nt, the rescaled population size \(Z_{\lfloor Nt\rfloor }/N\) converges to an exponential random variable. In contrast, the convergence of \(\frac{\mu _{\lfloor Nt\rfloor }}{t N \log R}\) entails that the rescaled population size at time Nt converges to an exponential random variable, but the population size is of order \(N\log R\) instead of N. In words, the local supercritical character of the process translates into an extra \(\log R\) factor for the population size.
Secondly, the convergence of the random measure \(\frac{\mu _{\lfloor Nt\rfloor }}{t N \log R}\) also implies that the length of the interval carried by a typical individual in the population is exponentially distributed with mean 1/t. Since the limiting random measure is deterministic, the intervals carried by k typical individuals in the populations are independent (propagation of chaos). Note that, although the length of the initial interval R goes to infinity, the intervals at any finite time t remain of finite length. This phenomenon is usually referred to as coming down from infinity. In our work, it originates from the existence of an entrance law at infinity for the spine, which turns out to be connected to the existence of such entrance laws for positive self-similar Markov processes with negative index of self-similarity [5, 6].
2.3.2 Convergence of the genealogy
Let us first comment on the rescaling \(F_R\). Although the expression of \(F_R\) appears a bit daunting at first, it essentially boils down to first rescaling time by N (as expected), and then measuring time from the origin in the log-scale. The first consequence is that the genealogy of the population in the natural scale (that is, if we only rescale time by N) converges to a star tree so that the genealogy becomes indistinguishable from the one of a supercritical branching process at the limit.
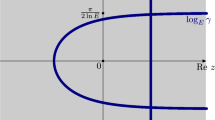
A second consequence of this result is that, after rescaling time according to \(F_R\), the genealogy of the branching process with recombination converges to a limiting metric space named the Brownian coalescent point process (CPP). It is constructed out of a Poisson point process P on \((0,\infty ) \times (0, 1)\) with intensity \(\textrm{d}t \otimes \frac{1}{x^2} \textrm{d}x\). Let
The Brownian CPP is the random metric space \([(0,Y), d_P]\), where Y is an exponential r.v. with mean 1, independent of P, see Fig. 3 for a graphical construction. It corresponds to the limit of the genealogy of a critical Galton–Watson process with finite variance [39].
2.3.3 Chromosomic distance
The previous result provides a complete description of the interval lengths in the population, but does not provide any insight into their distribution over (0, R). We will encode the latter information by picking a reference point belonging to each interval in the population and considering the usual distance on the real line between these points. More precisely, for each \(u \in T_N\), pick a reference point \(M_u\) uniformly on \(I_u\). We define a new metric
We will refer to the \(D_N\) as the chromosomic distance.
The quadruple \([T_N, d_N, D_N, \mu _N]\) can be seen as a random “bi-metric” measure space with marks. We can define a straightforward extension of the marked Gromov-weak topology for such objects, see the end of Sect. 4.1. The correct rescaling for \(D_N\) is to set
In Sect. 6.3, we prove the following refinement of Theorem 1.
Theorem 2
Fix \(t > 0\). Conditional on survival of the process at \(\lfloor tN\rfloor \), the following limit holds in distribution for the marked Gromov-weak topology,
where \([(0,Y), d_P]\) is a Brownian coalescent point process, and \(\textrm{Exp}(t)\) is the exponential distribution with mean 1/t.
It is important to note that, in the limit, the two metrics coincide. This result is quite interesting from a biological point of view. It shows that there is a correspondence between the genealogical distance between two individuals, and the chromosomic distance between the genetic material that they carry. Indeed, the latter two quantities are correlated: two individuals inherit intervals that are subsets of the interval carried by their most-recent common ancestor. If this ancestor is recent, its interval is smaller, and so is their chromosomic distance. Our result shows that, in the limit, the two distances become identical when considered on the right scale. This result is illustrated in Fig. 3.

Top: simulation of a Brownian CPP. The black vertical lines represent to the atoms of P, and the corresponding tree is pictured in grey. Bottom: geometry of the blocks of ancestral material corresponding to the top CPP. Each block is represented by a black stripe. The correspondence between the blocks and the tree are shown for some blocks by grey segments joining the two. The distance between two consecutive stripes is the logarithm of their distance on the chromosome. Note that this induces a strong deformation of the intuitive linear scale
Remark 1
Define the point process
which corresponds to the CPP tree “viewed from the individual with the left-most interval”. Using elementary properties of Poisson point processes shows that \(\vartheta \) can also be written as
where \(\mathcal {P}\) is a Poisson point process on \((0,\infty ) \times (0, \infty )\) with intensity \(\frac{1}{x^2} e^{-x/y} \textrm{d}x \textrm{d}y\).
The same expression was obtained in [28, Theorem 1.5] to describe the set of loci that share the same ancestor as the left-most locus in the fixed haplotype of a Wright–Fisher model with recombination, under a limiting regime similar to ours. This connection is quite surprising. We are considering a branching approximation where all intervals belong to distinct individuals and its chromosome carries at most one block of ancestral genome, whereas in [28] all intervals belong to a single chromosome, which has reached fixation in the population.
3 The k-spine tree
3.1 The many-to-few formula
The objective of this first section is to introduce the k-spine tree and state our many-to-few formula, that relates the expression of the polynomials of a branching process to the k-spine tree. All the random variables introduced here are more formally defined in the forthcoming sections, where the proof of the many-to-few formula is carried out. A formal statement of our result requires some preliminary notation.
3.1.1 Assumption and notation
Consider a Polish space \((E, d_E)\), and a collection \((\Xi (x);\, x \in E)\) of random point measures on E. This collection can be used to construct a branching process with type space E, such that the atoms of a realization of \(\Xi (x)\) provide the types of the children of an individual with type x. The distribution of the resulting branching process is denoted by \(\textbf{P}_x\).
Let K(x) denote the number of atoms of \(\Xi (x)\), and set
for the distribution of K(x). The nth factorial moment of K(x) is denoted by \(m_{n}(x)\), that is,
where we have used the notation \(k^{(n)}\) for the nth descending factorial of k,
Our results are more easily formulated under the assumption that, conditional on K(x), the locations of the atoms are i.i.d. with distribution \(p(x, \cdot )\). That is, we assume that
where \((\xi _i(x);\, i \ge 1)\) is an i.i.d. sequence distributed as \(p(x, \cdot )\) and is independent of K(x). We make the further simplifying assumption that all distributions \(p(x, \cdot )\) have a density w.r.t. some common measure \(\Lambda \) on E. With a slight abuse of notation, the density of \(p(x,\cdot )\) is denoted by \((p(x,y);\, y \in E)\).
3.1.2 Harmonic function
We say that a map \(h :E \rightarrow [0,\infty )\) is (positive) harmonic if
where we used the notation \(\langle \mu , f\rangle = \int f \textrm{d}\mu \), see for instance [7]. A harmonic function can be used to define a new probability kernel on E, defined as
The fact that this is a probability measure follows from the harmonicity of h.
3.1.3 The k spine tree
We are now ready to define the k-spine tree. Let \(\nu = (\nu _n;\, n \in \{0, \dots , N-1\})\) be a probability distribution and let \((W_1, \dots , W_{k-1})\) be i.i.d. random variables with distribution \(\nu \). Define
There is a unique tree with k leaves labeled by \(\{1,\dots ,k\}\) such that the tree distance between the leaves is \(d_T\). We denote it by S and call it the \(\nu \)-CPP tree. This tree is constructed inductively by grafting a branch of length \(N-W_i\) on the tree constructed at step i, as illustrated in Fig. 4.
We now assign marks on the tree such that along each branch of the tree, marks evolve according to a Markov chain with transition kernel \((q(x,y);\, x,y \in E)\) defined in (2). More formally construct a collection of processes \((X_1, \dots , X_k)\) such that
-
the process \((X_1(n);\, n \ge 0)\) is a Markov chain with transition \((q(x,y);\, x,y \in E)\) started from x;
-
conditional on \((X_1, \dots , X_i)\),
$$\begin{aligned} \forall n \ge 0,\quad X_{i+1}(n) = {\left\{ \begin{array}{ll} X_i(n) &{}\text { if }n < W_i\\ X'(n-W_i) &{}\text { if }n \ge W_i \end{array}\right. } \end{aligned}$$for some independent Markov chain \(X'\) with transition \((q(x,y);\, x,y \in E)\) started from \(X_i(W_i)\).
By thinking of \((X_i(n);\, n \ge 0)\) as giving the sequence of marks along the branch of S starting from the root and going to the ith leaf, we can assign to each vertex \(u \in S\) a mark \(Y_u\).

Illustration of the construction of a CPP tree. The vector \((W_1,\dots ,W_{k-1})\) branching times between successive leaves. In this example, this vector is (6, 4, 1, 5, 5). The tree is recovered from these times by grafting for each i a branch of length \(N-W_i\) to the right-most vertex of the tree at generation \(W_i\)
Definition 1
The k-spine tree is the random marked tree \([S, (Y_u;\, u \in S)]\) encoded by the variables \((W_1, \dots , W_{k-1})\) and \((X_1, \dots , X_k)\). The distribution of the latter variables is denoted by \(\textbf{Q}^{k,N}_x\).
We are now ready to state our many-to-few formula. It can be described informally as follows. Suppose that the branching process with law \(\textbf{P}_x\) is biased by the kth factorial moment of its size at generation N and that k individuals are chosen uniformly for that generation. Then the law of the subtree spanned by these individuals is \(\textbf{Q}^{k,N}_x\) biased by a random factor \(\Delta _k\) that can be expressed as
where \(d_u\) denotes the degree of a vertex \(u \in S\) and \(Y_u\) its mark. Note that the left product in (3) has at most \(k-1\) terms, which correspond to the branch points in S.
Lemma 1
Assume that for every \(x\in E\), the offspring number K(x) is Poisson (for some given parameter \(\lambda (x)>0\) that may depend on x). Then
Proof
This simply follows from the well known fact that the kth factorial moment of a Poisson random variable with parameter \(\lambda >0\) is \(\lambda ^k\). \(\square \)
Finally, let \(T_N\) denote the labels of the Nth generation of a branching process with distribution \(\textbf{P}_x\), for \(u \in T_N\) let \(X_u\) denote its type, and let \(d_T\) denote the tree distance on \(T_N\).
Proposition 2
(Many-to-few) For any test function \(\varphi \),
where \(\sigma \) is an independent uniform permutation of \(\{1, \dots , k\}\).
Remark 2
-
(i)
In our construction of the k-spine, the distribution of the tree is independent of the marking. The term \(\Delta _k\) captures the interplay between the genealogy and the types as a function of the marking at “topological” points.
-
(ii)
Compare Proposition 2 to the many-to-few formula in [22]. Both expressions relate the distribution of a k-sample from the branching process (l.h.s. of the equality) to that of a simpler k-spine tree (r.h.s. of the equality) at the expense of a bias term, here denoted by \(\Delta _k\).
-
(iii)
In [22], the k-spine tree only depends on the moments of the reproduction law. Our formulation has one extra degree of freedom, since the k-spine tree is constructed out of an a priori genealogy, the \(\nu \)-CPP tree.
-
(iv)
In many situations, including the model at hand, the bias term in [22] becomes degenerate in the limit so that the distribution of the limiting genealogy is singular with respect to that of the original k-spine tree. For instance, for near-critical processes conditioned on survival at generation N, the first split time of the k-spine tree in [22, Sect. 8] remains of order 1, whereas the most-recent common ancestor of the whole population is known to live at a time of order N. In contrast, one advantage of our approach is that \(\nu \) can be well-chosen so that the bias \(\Delta _k\) converges to a non-degenerate limit. This amounts to finding a good ansatz for the limiting genealogy. In our example this ansatz is given in (17), and the limit of the bias \(\Delta _k\) is independent of the genealogy. This indicates that the limit of the genealogy does not depend on the types in the population.
The rest of the section is dedicated to the proof of the many-to-few formula. Our strategy to prove this result is to define a new tree with distribution \(\bar{\textbf{Q}}^{k,N}_x\) by grafting on the k-spine tree independent subtrees distributed as the original branching process. The many-to-few formula will then follow from the more precise spinal decomposition theorem, which states that \(\bar{\textbf{Q}}^{k,N}_x\) and \(\textbf{P}_x\) are connected through the random change of measure \(\Delta _k\). It is proved in Sect. 3.4. The remaining sections provide a rigorous construction of the measures \(\textbf{P}_x\) and \(\bar{\textbf{Q}}_x^{k,N}\) and the proof of the spinal decomposition theorem.
3.2 Tree construction of the branching process
Let us recall some common notation on trees.
3.2.1 Trees
Following the usual Ulam–Harris labeling convention, all trees will be encoded as subsets of
Let us consider an element \(u = (u(1), \dots , u(n)) \in \mathscr {U}\). We denote by \(|u| = n\) its length, interpreted as the generation of u. Moreover, its ith child is denoted by
and its ancestor in the previous generation as
The set \(\mathscr {U}\) is naturally endowed with a partial order \(\preceq \), where \(u \preceq v\) if u is an ancestor of v, that is,
The most-recent common ancestor of u and v can then be defined as
In the tree interpretation of \(\mathscr {U}\), we can define a metric \(d_T\) corresponding to the graph distance as
Finally, as a consequence of the Ulam–Harris encoding, trees are planar in the sense that the children of each vertex are endowed with a total order. Accordingly let us denote by \(\le \) the lexicographical order on \(\mathscr {U}\), which we will call the planar order. Note that \(\le \) extends \(\preceq \).
A subset \(\tau \subseteq \mathscr {U}\) is called a tree if
-
(i)
\(\varnothing \in \tau \);
-
(ii)
if, for some j, \(uj \in \tau \), then \(u \in \tau \);
-
(iii)
for any \(u \in \tau \), there exists \(k_u \in \mathbb {N}\) such that
$$\begin{aligned} ui \in \tau \iff i \le k_u, \end{aligned}$$where \(k_u\) is the number of children of u, also called the (out-)degree of u.
The set of all trees is denoted by \(\Omega \). For a tree \(\tau \in \Omega \), define its restriction to the nth generation as
and that to the first n generations as
Furthermore, let us denote by \(\Omega _n\) the set of trees of height at most n, where the height of a tree is defined as the generation of the oldest individual in the tree.
3.2.2 Marked trees and definition of \(\textbf{P}_x\)
A marked tree is a tree \(\tau \in \Omega \) with a collection \((x_u;\, u \in \tau )\) of marks with values in E. Let us define a random marked tree \([T, (X_u;\, u \in T)]\) inductively as follows, that corresponds to the branching process with offspring reproduction point processes \((\Xi (x);\, x \in E)\).
Start from a single individual \(\varnothing \) with mark \(X_\varnothing = x\). Conditional on the first n generations \(T_{[n]}\) and their marks \((X_u;\, u \in T_{[n]})\), consider a collection of independent point processes \((\Xi _u;\, u \in T_n)\), where
Let us write
for the atoms of \(\Xi _u\). Then define the next generation as
with marks given by
Let \(T = \cup _{n \ge 1} T_n\) be the whole tree, and define define \(\textbf{P}_x\) as the law of the random marked tree \([T, (X_u;\, u \in T)]\) obtained through the previous procedure, and \(\textbf{P}^N_x\) the law of its restriction to the first N generations.
3.3 Ultrametric trees
From now on, we consider a fixed, focal generation N. In this section we construct the measure \(\bar{\textbf{Q}}^{k,N}_x\) obtained by grafting some independent subtrees on the k-spine tree. This construction relies on the notion of (discrete) ultrametric trees.
3.3.1 Ultrametric trees
A tree \(\tau \in \Omega _N\) with height N is called ultrametric if all of its leaves lie at height N, that is
The set of all ultrametric trees of height N with k leaves is denoted by \(\mathbb {U}^{k,N}\). For \(\tau \in \mathbb {U}^{k,N}\), let us denote by \((\ell _1, \dots , \ell _k)\) the leaves of \(\tau \) in lexicographical order, that is, such that
The previous description of an ultrametric tree as an element of \(\Omega _N\) is not suitable to describe the large N limit of the k-spine tree. To derive such a limit, we need to encode elements of \(\mathbb {U}^{k,N}\) as a sequence \((g_1,\dots , g_{k-1})\) giving the branch times between successive leaves in the tree. This construction is sometimes referred to as a coalescent point process (CPP) [29, 39].
More precisely, define the map
The following straightforward result shows that the tree \(\tau \) can be recovered from the vector of coalescence times \(\Phi (\tau )\).
Lemma 2
The map \(\Phi \) is a bijection from the set of ultrametric trees \(\mathbb {U}^{k,N}\) to the set of vectors \(\{0, \dots , N-1\}^{k-1}\).
3.3.2 The k-spine tree
Let \((W_1,\dots , W_{k-1})\) and \((X_1,\dots ,X_k)\) have distribution \(\textbf{Q}^{k,N}_x\). We formally define the \(\nu \)-CPP tree illustrated in Fig. 4 as the random tree \(S {:}{=}\Phi ^{-1}(W_1, \dots , W_{k-1})\). Note that the CPP tree associated to the uniform distribution is uniform on \(\mathbb {U}^{k,N}\). The processes \((X_1,\dots ,X_k)\) can now be used to construct a collection of marks \((Y_u;\, u \in S)\) as follows. Each \(u \in S\) is of the form
for some leaf \(\ell _i\) and \(n \le N\). Define the mark of such a u as
(It is not hard to see that \(Y_u\) is well-defined in that it does not depend on the choice of \(\ell _i\) if u is ancestral to several leaves.) The marked tree \([S, (Y_u)]\) is the k-spine tree encoded by the r.v. \((W_1,\dots ,W_{k-1})\) and \((X_1,\dots ,X_k)\).
3.3.3 Construction of \(\bar{\textbf{Q}}^{k,N}_x\)
Let \([S, (Y_u)]\) be the k-spine tree constructed above. We attach to S some subtrees distributed as \(\textbf{P}_x\) to define a larger marked tree \([T, (X_u)]\). This yields a random tree with k spines originated from the k leaves of S at generation N. The distribution of these random variables will be denoted by \(\bar{\textbf{Q}}^{k,N}_x\).
To construct T from the spine, we first specify the number of subtrees that need to be attached to each vertex u of the spine. We will distinguish the degree of a vertex in S and that in the larger tree T. We denote by \(d_u\) the number of children in S of u. (The degree of u in T will be denoted by \(k_u\) as previously.) We work conditional on \([S, (Y_u)]\) and assume them to be fixed. Let \((K_u;\, u \in S, |u| < N)\) be independent variables such that \(K_u\) has the distribution of \(K(Y_u)\), biased by its \(d_u\)th factorial moment. That is,
Among the \(K_u\) children of u in T, \(d_u\) are distinguished as they correspond to the children of u in S. Let \(C_{u1}< \dots < C_{ud_u}\) be the labels of these distinguished children, and let us assume that they are uniformly chosen among the \(\left( {\begin{array}{c}K_u\\ d_u\end{array}}\right) \) possibilities. We can now define the subtree corresponding to S in the larger tree T by an inductive relabelling of the nodes. For \(u \in S\), define \(\Psi (u)\) inductively as follows
with corresponding marks
Finally, let us attach the subtrees to \([S, (Y_u)]\). For \(u \in S\), consider a sequence \([T_{ui}, (X_{ui,v};\, v);\, i \ge 1]\) of i.i.d. marked trees with the original distribution \(\textbf{P}_{X_{ui,\varnothing }}\), but with random initial mark \(X_{ui, \varnothing }\) distributed as \(p(Y_u, \cdot )\). The final tree T is defined as
and for \(v \in T_{ui}\), the mark of \(\Psi (u)iv\) is
Informally, for each of the \(K_u - d_u\) children of u that are not in S, we realize one step of the Markov chain with kernel \((p(x,y);\, x,y \in E)\) and then attach a whole subtree \(T_{ui}\) to that child.
The resulting tree T has k distinguished leaves, \(\Psi (\ell _1), \dots , \Psi (\ell _k)\), corresponding to the k leaves of S. Let us finally define
for an independent uniform permutation \(\sigma \) of \(\{1,\dots , k\}\). The distribution of the triple \([T_{[N]}, (X_u), (V_i)]\) is denoted by \(\bar{\textbf{Q}}^{k,N}_x\), where \(T_{[N]}\) is the restriction of T to the first N generations.
3.4 The spinal decomposition theorem
Our final objective in this section is to connect \(\textbf{P}_x\) and \(\bar{\textbf{Q}}^{k,N}_x\) to derive our many-to-few formula. We assume \(\nu _n > 0\) for all \(n \in \{ 0, \dots , N-1 \}\). Recall the expression of \(\Delta _k\) from (3). Our spinal decomposition theorem states that, if \(\textbf{P}_x\) is biased by the kth factorial moment of its size at generation N and k uniformly chosen individuals \((V_1,\dots ,V_k)\) are distinguished from that generation, the corresponding marked tree \([T_N, (X_u), (V_i)]\) is distributed as \(\bar{\textbf{Q}}^{k,N}_x\) biased by \(\Delta _k\).
Theorem 3
(Spinal decomposition) Consider a tree \(\tau \) with height N and k distinct vertices \((v_1, \dots , v_k) \in \tau _N\). Let h be a harmonic function for the branching process with law \((\textbf{P}_x;\, x \in E)\). Then, for any test function \(\varphi \), we have
Proof
It is enough to prove the result for the uniform CPP by noting that \(\prod _{u\in S}\frac{1}{N\nu _u}\) is the Radon–Nykodim derivative of the uniform CPP with respect to the \(\nu \)-CPP.
The natural state space for \(\textbf{P}^N_x\) is the space of all marked trees with height at most N, that is,
Using that the offspring distribution on E has a density w.r.t. some measure \(\Lambda \), it is clear that \(\textbf{P}^N_x\) has a density w.r.t. a dominating measure defined as
which is given by
where \(k_u\) stands for the number of children of u.
Let \(\textbf{s}\) denote the subtree spanned by \((v_1,\dots ,v_k)\), that is
We can decompose (5) into a product on \(\textbf{s}\) and on the subtrees attached to \(\textbf{s}\). The branching property shows that
For \(u \in \textbf{s}\), let \(d_u\) denote the number of children of u that belong to \(\textbf{s}\), that is,
Let us make the following change in the previous equality
Let us also write the second term in the product as
Putting both expressions together, we obtain that
The result now follows upon identifying each term in this product. The first term is \(\Delta _k\). The second term is the density of the marks \((x_u;\, u \in \textbf{s})\) along the k-spine. The last product is made of three terms. The first is the probability that the \(d_u\) children of u that belong to \(\textbf{s}\) have a given birth rank. The second is the probability that the final degree of u is \(k_u\) given that it has \(d_u\) children in \(\textbf{s}\) (see (4)). The last is the density of the marked trees attached to u. The \(N^{k-1}k!\) term in the statement of theorem is simply the probability of observing a given ultrametric tree and labeling of the leaves. \(\square \)
Proof of Proposition 2
Let \(\tau \) be some fixed tree and \(v_1,\dots ,v_k\) be distinct vertices at height N of \(\tau \). Using Theorem 3 yields
Summing over all \((v_1,\dots ,v_k)\) first, then over all \(\tau \), and recalling that \(V_i = \ell _{\sigma _i}\) for an independent uniform permutation \(\sigma \) of \(\{1,\dots ,k\}\) proves the result. \(\square \)
4 Convergence of marked branching processes
4.1 The marked Gromov-weak topology
Deriving the scaling limit of the genealogy and types in a branching process requires one to envision it as a random marked metric measure space. In this work we equip the set of all such spaces with the marked Gromov-weak topology [10]. This section is a brief remainder of the basic properties of this topology, a more thorough account can be found in [10, 18]. We do not restrict our attention to trees and try to follow as much as possible the notation in [10], so that some notation in this section might be inconsistent with the rest of the paper.
Let \((E, d_E)\) be a fixed complete separable metric space, referred to as the mark space. In our application, \(E = [0, \infty )\) is endowed with the usual distance on the real line. A marked metric measure space (mmm-space for short) is a triple \([X, d, \mu ]\), where (X, d) is a complete separable metric space, and \(\mu \) is a finite measure on \(X \times E\).
To define a topology on the set of mmm-spaces, for each \(k \ge 1\) consider the map
that maps k points in \(X \times E\) to the matrix of pairwise distances and vector of marks. We denote by \(\nu _{k, X} = \mu ^{\otimes k} \circ R_k^{-1}\), the kth marked distance matrix distribution of \([X, d, \mu ]\), which is the pushforward of \(\mu ^{\otimes k}\) by the map \(R_k\). (Note that \(\mu \) is not necessarily a probability distribution.) For some \(k \ge 1\) and some continuous bounded test function
let us define a functional
Functionals of the previous form are called polynomials (k is the degree or order of the polynomial), and the set of all polynomials, obtained by varying k and \(\varphi \), is denoted by \(\Pi \).
Definition 2
The marked Gromov-weak topology is the topology on mmm-spaces induced by \(\Pi \). A random mmm-space is a r.v. with values in the set of (equivalence classes of) mmm-spaces, endowed with the Gromov-weak topology and the associated Borel \(\sigma \)-field.
Remark 3
Formally, the marked Gromov-weak topology should be defined on equivalence classes of mmm-spaces, where two spaces belong to the same class if f there is a measure preserving isometry between the supports of their measures that also preserves marks, see [10, Definition 2.1]. This distinction has little consequences in practice so that we often omit it.
There is a unique equivalence class of all mmm-spaces with a null sampling measure, which acts as the null mmm-space and that we denote by \(\textbf{0}\). It follows from the definition of the Gromov-weak topology that a sequence of mmm-spaces \(([X_n, d_n, \mu _n];\, n \ge 1)\) converges to \(\textbf{0}\) if f \(\mu _n(X_n \times E) \rightarrow 0\). If \([X,d,\mu ]\) is a random mmm-space, the expectation of a polynomial evaluated at \([X,d,\mu ]\), namely \(\mathbb {E}[\Phi (X,d,\mu )]\), is called a moment of \([X,d,\mu ]\).
Remark 4
(Polar decomposition) An mmm-space \([X,d,\mu ] \ne \textbf{0}\) can be seen as a pair \((\bar{\mu }, [X,d,\hat{\mu }])\) where \(\bar{\mu } = \mu (X \times E)\) is the total mass of \(\mu \) and \(\hat{\mu } = \mu / \bar{\mu }\) is the renormalized probability measure. This is the so-called polar decomposition of \([X,d,\mu ]\) [9]. The space of all polar decompositions is naturally endowed with the product topology, where the space of all probability mmm-spaces is endowed with the more standard marked Gromov-weak topology restricted to probability mmm-spaces [10]. It is not hard to see that the map taking non-null mmm-spaces to their polar decompositions is an homeomorphism.
An important consequence of this remark is that the convergence in distribution of a sequence of mmm-spaces \([X_n, d_n, \mu _n]\) implies that of \([X_n, d_n, \hat{\mu }_n]\), provided that the limit mmm-space is a.s. non-null. In particular, for ultrametric spaces, it implies the convergence in distribution of the genealogy of k individuals sampled from \([X_n,d_n,\mu _n]\) according to \(\hat{\mu }_n\).
Many properties of the marked Gromov-weak topology are derived in [10] under the further assumption that \(\mu \) is a probability measure. Relaxing this assumption to account for finite measures is quite straightforward but requires some caution, as the total mass of \(\mu \) can now drift to zero or infinity. In particular, the following result shows that \(\Pi \) forms a convergence determining class only when the limit satisfies a moment condition, which is a well-known criterion for a real variable to be identified by its moments, see for instance [14, Theorem 3.3.25]. This result was already stated for metric measure spaces without marks in [9, Lemma 2.7].
Proposition 3
Suppose that \([X,d,\mu ]\) is a random mmm-space verifying
Then, for a sequence \([X_n, d_n, \mu _n]\) of random mmm-spaces to converge in distribution for the marked Gromov-weak topology to \([X,d,\mu ]\) it is sufficient that
for all \(\Phi \in \Pi \).
Proof
Let us prove this result carefully. Fix a polynomial \(\Phi \) of degree k associated to a non-negative continuous bounded functional \(\varphi \). Recall the notation \(\bar{\mu }_n\) for the total mass of \([X_n, d_n, \mu _n]\), which is a r.v. with values in \([0, \infty )\), and \(\hat{\mu }_n = \mu _n / \bar{\mu }_n\). Introduce a new measure \(M_n^\Phi \) on \([0, \infty )\) such that for any continuous bounded function \(f :[0, \infty ) \rightarrow \mathbb {R}\)
The key observation is now that, applying Fubini’s theorem, \([X, d, \mu ] \mapsto \bar{\mu }^p \Phi (X,d,\mu )\) is again a polynomial of the form (6) (of degree \(p+k\)). Therefore, our assumption entails that, for any integer \(p \ge 0\),
where we have defined \(M^\Phi \) is a similar way to \(M^\Phi _n\) using the limiting random variable \([X,d,\mu ]\). Now, the usual method of moments on \([0, \infty )\), see for instance [14, Theorem 3.3.26], entails that for any continuous bounded function f
We have used that \(M^\Phi \) fulfills the moment growth condition of [14, Theorem 3.3.26] since
and (7) holds. By taking linear combinations, (8) holds for any polynomials, not only non-negative ones.
Let \(f :[0, \infty ) \rightarrow \mathbb {R}\) be continuous bounded and have its support bounded away from 0. Since \(x \mapsto f(x) / x^k\) is continuous bounded, applying (8) to this map and using that \(\Phi (X_n, d_n, \mu _n) = \bar{\mu }_n^k \Phi (X_n, d_n, \hat{\mu }_n)\) shows
Standard arguments show that the above convergence also holds for \(f(x) = g(x) \textbf{1}_{\{x \ge \varepsilon \}}\) for any continuous bounded g and \(\varepsilon > 0\) such that \(\mathbb {P}(\bar{\mu } = \varepsilon ) = 0\). Since [10, Theorem 5] ensures that polynomials are convergence determining on mmm-spaces with a probability sampling measure, we can use [15, Proposition 4.6, Chapter 3] to obtain that for any continuous bounded functional F on the space of mmm-spaces,
(Here we have applied the result to the polar decomposition of the mmm-space, and used that the polar decomposition defines an homeomorphism.)
To end the proof, we note that by Portmanteau’s theorem
Finally, we write
take a limit \(n \rightarrow \infty \) first, then \(\varepsilon \rightarrow 0\), and use (9) to estimate the first term and (10) to control the second one to obtain
which is the desired result. \(\square \)
4.1.1 Bi-metric measure spaces
The branching process with recombination is naturally endowed with two metrics: the genealogical distance and the chromosomic distance. Therefore, for the purpose of this application only, let us say that \([X, d, D, \mu ]\) is a marked bi-metric measure space if both d and D are metric that make (X, d) and (X, D) Polish spaces, and if \(\mu \) is a finite measure on \(X \times E\), where X is endowed with the \(\sigma \)-field induced by reunion of the open balls of d and D.
A polynomial of a marked bi-metric measure space is a functional of the form
for some k and some \(\varphi \). Accordingly we define the Gromov-weak topology for these spaces as the topology induced by the polynomials. It is straightforward to check that all the results stated for mmm-spaces carry on to marked bi-metric measure spaces, up to replacing the polynomials in (6) by that in (11).
4.2 Convergence of ultrametric spaces
Using Proposition 3 requires one to have prior knowledge of the limit \([X,d,\mu ]\). A stronger version of this result would be that the convergence of each \((\mathbb {E}[ \Phi (X_n,d_n,\mu _n) ];\, n \ge 1)\) implies the existence of a random mmm-space to which \((X_n, d_n, \mu _n)\) converges in distribution (under a moment condition similar to (7)). Such a result cannot hold in the current formulation of the marked Gromov-weak topology. This is a consequence of the fact that some limits of distance matrix distributions cannot be expressed as the distance matrix distribution of a separable metric space, see for instance [18, Example 2.12 (ii)]. To overcome this issue, it is necessary to relax the separability assumption in the definition of an mmm-space.
Deriving a meaningful extension of the Gromov-weak topology to non-separable metric spaces is not a straightforward task, since it raises many measure theoretic difficulties. However, when restricting our attention to genealogies, as is the purpose of this work, the specific tree structure of these objects can be used to define such an extension. We follow the framework introduced in [17, Sect. 4], but see also [20]. The results contained in this section are not necessary for the analysis of the branching process with recombination and can be possibly skipped.
Definition 3
(Marked UMS, [17]) A marked ultrametric measure space (marked UMS) is a collection \([U, d, \mathscr {U}, \mu ]\) where \(\mathscr {U}\) is a \(\sigma \)-field and
-
(i)
The metric d is \(\mathscr {U} \otimes \mathscr {U}\)-measurable and is an ultrametric:
$$\begin{aligned} \forall x,y,z \in X,\quad d(x,y) \le \max \{ d(x,z), d(z,y) \}. \end{aligned}$$ -
(ii)
The \(\sigma \)-field \(\mathscr {U}\) verifies:
$$\begin{aligned} \sigma \big ( B(x,t);\, x \in U, t > 0\big ) \subseteq \mathscr {U} \subseteq \mathscr {B}(U) \end{aligned}$$where B(x, t) is the open ball of radius t and center x, and \(\mathscr {B}(U)\) is the Borel \(\sigma \)-field associated to (U, d);
-
(iii)
The measure \(\mu \) is a finite measure on \(U \times E\), defined on the product \(\sigma \)-field \(\mathscr {U} \otimes \mathscr {B}(E)\).
Remark 5
While this definition might be surprising at first sight, note that if (U, d) is separable and ultrametric, points (i) and (ii) of the definition are fulfilled when \(\mathscr {U}\) is chosen to be the usual Borel \(\sigma \)-field. Therefore, a separable marked UMS in the sense of Definition 3 is an ultrametric mmm-space in the sense of Sect. 4.1. When no \(\sigma \)-field is prescribed, \(\mathscr {U}\) is assumed to be the Borel \(\sigma \)-field. Using a naive definition of a marked UMS as a complete metric space with a finite measure on the corresponding Borel \(\sigma \)-field raises some deep measure theoretic issues related to the Banach–Ulam problem, that are avoided by Definition 3, see [17, Sect. 4] for a discussion.
Point (i) of the above definition ensures that each map \(R_k\) is measurable, so that we can define the marked distance matrix distribution \(\nu _{k,U}\) and the polynomials \(\Phi (U, d, \mathscr {U}, \mu )\) of a marked UMS \((U,d,\mathscr {U},\mu )\) as in the previous section. Analogously to mmm-spaces, we define the marked Gromov-weak topology on the set of marked UMS as the topology induced by the set of polynomials.
Remark 6
Again, for the topology to be separated we need to work with equivalence classes of marked UMS. For non-separable spaces, the correct notion of equivalence is that of weak isometry provided in [17, Definition 4.11]. We do not make the distinction between marked UMS and their equivalence class in practice.
We can now state a stronger version of Proposition 3 for ultrametric spaces. In the statement of the theorem we will need a mild tightness conditions. For a marked UMS \([U,d,\mathscr {U}, \mu ]\), define the maps r and \(\pi _E\) as
and the corresponding pushforward measures
If \([U,d,\mathscr {U},\mu ]\) is random, these are random measures, and we denote their intensity measures by \(\mathbb {E}[w_U]\) and \(\mathbb {E}[m_U]\), which are deterministic measures on \(\mathbb {R}_+\) and E respectively.
Theorem 4
Let \((U_n, d_n, \mathscr {U}_n, \mu _n)\) be a sequence of random marked UMS such that for any polynomial \(\Phi \in \Pi \),
exists, and fulfill (compare with (7))
Suppose also that the sequences \((\mathbb {E}[w_{U_n}];\, n \ge 1)\) and \((\mathbb {E}[m_{U_n}];\, n \ge 1)\) are relatively compact, as measures on \(\mathbb {R}_+\) and E. Then there exist a random marked UMS, \([U, d, \mathscr {U}, \mu ]\) such that \((U_n, d_n, \mathscr {U}_n, \mu _n)\) converges to that limit in the marked Gromov-weak topology. Moreover the limit is characterized by
Remark 7
The previous result suggests the following simple method to prove convergence in distribution in the (usual) sense of separable ultrametric mmm-spaces. First prove that the conditions of Theorem 4 are fulfilled, then check that the limiting marked UMS is a.s. separable. The two compactness conditions on \((\mathbb {E}[w_{U_n}])\) and \((\mathbb {E}[m_{U_n}])\) ensure, in combination with the convergence of the moments, that the sequence of mmm-spaces is tight. Compare this to checking, on top of the previous assumptions, the tightness criterion in [18, Theorem 2 (ii)] that ensures that no mass of the sampling measure is accumulating on isolated points. This condition is not needed here because we have enlarged the state space of mmm-spaces to include non-separable metric spaces.
The proof of the above result is based on a characterization of all exchangeable ultrametric matrices. We call a random pair \((d_{ij};\, i,j \ge 1)\) and \((Y_i;\, i \ge 1)\) a marked exchangeable ultrametric matrix if
-
each \(Y_i\) has values in E;
-
\((d_{ij};\, i, j \ge 1)\) is a.s. an ultrametric on \(\mathbb {N}\);
-
its distribution is invariant by the action of any permutation \(\sigma \) of \(\mathbb {N}\) with finite support:
$$\begin{aligned} \big ( (d_{\sigma _i\sigma _j};\, i, j \ge 1), (Y_{\sigma _i};\, i \ge 1) \big ) \overset{\mathrm {(d)}}{=} \big ( (d_{ij};\, i, j \ge 1), (Y_i;\, i \ge 1) \big ). \end{aligned}$$
A typical way to obtain such an ultrametric matrix is to consider an i.i.d. sample \((X_i, Y_i;\, i \ge 1)\) from a marked UMS \((U,d,\mathscr {U},\mu )\) with \(\mu (U) = 1\) a.s., and define
The next result shows that all exchangeable marked matrices are obtained in this way. It can be seen as a version of Kingman’s representation theorem of exchangeable partitions [26] for ultrametric matrices.
Theorem 5
[17] Let \((d_{ij};\, i,j \ge 1)\) and \((Y_i;\, i \ge 1)\) be an exchangeable marked ultrametric matrix. There exists a random marked probability UMS \([U, d, \mathscr {U}, \mu ]\) (that is, \(\mu (U)=1\) a.s.) such that the exchangeable marked ultrametric matrix obtained by sampling from it as in (13) is distributed as \((d_{ij};\, i,j \ge 1)\) and \((Y_i;\, i \ge 1)\). Moreover this marked UMS is unique in distribution.
Proof
This result is a straightforward extension of [17, Theorem 1.8] that deals with the case without marks. To guide the reader, let us mention the crucial modification that need to be made. The proof relies on encoding some marginals of \((d_{ij};\, i,j \ge 1)\) as an exchangeable sequence of r.v. \((\xi ^{(0)}_i, \dots , \xi _i^{(p)};\, i \ge 1)\) in \([0, 1]^p\) and using a de Finetti-type argument, see [17, Appendix B]. The same argument should be applied to the exchangeable sequence of r.v. \((\xi ^{(0)}_i,\dots ,\xi ^{(p)}_i, Y_i;\, i \ge 1, )\). \(\square \)
Proof of Theorem 4
We prove the result by a tightness and uniqueness argument. To prove tightness, we embed the space of marked UMS into a space of measures, using the marked distance matrices, and use known tightness arguments for random measures. More precisely, the map \(\iota :[U, d, \mathscr {U}, \mu ] \mapsto (\nu _{k,U};\, k \ge 1)\) is an injection. This is a consequence of the uniqueness part of Theorem 5. For each \(k \ge 1\), \(\nu _{k,U}\) lives in the space of finite measures on \(\mathbb {R}_+^{k^2} \times E^k\), which can be endowed with the weak topology. If the space of sequences \((\nu _{k,U};\, k \ge 1)\) is endowed with the product topology, it follows readily from the definition of the Gromov-weak topology that \(\iota \) is a homeomorphism from the space of marked UMS to its image. We claim that the image of \(\iota \) is closed in this product topology. If this is the case, the space of marked UMS is homeomorphic to a closed subset of the space of sequences of measures, and clearly,
where in the right-hand side each \(\nu _{k,Un}\) is a random measure, and tightness is with respect to the weak topology. For the collection of random measures \((\nu _{k,U_n};\, n \ge 1)\) to be tight it is sufficient that the collection of intensity measures \((\mathbb {E}[\nu _{k,U_n}];\, n \ge 1)\) is relatively compact [8, Lemma 3.2.8]. For \(y = ((d_{ij}), u_i;\, i,j \le k) \in \mathbb {R}^{k^2} \times E^k\), let \(p_{ij}(y) = d_{ij}\) and \(p'_i(y) = u_i\) be the projection maps. It is sufficient to show that the pushforward of \(\mathbb {E}[\nu _{k,U_n}]\) through each projection is relatively compact. By definition, for a Borel set \(A \subseteq \mathbb {R}_+\) and \(i \ne j\), by exchangeability,
The relative compactness of \((\mathbb {E}[\nu _{k,U_n}] \circ p_{ij}^{-1};\, n \ge 1)\) now follows from that of \((\mathbb {E}[w_{U_n}];\, n \ge 1)\) and from the uniform integrability of \(\bar{\mu }_n^{k-2}\). In a similar way, for a Borel set \(B \in E\),
The desired compactness follows form that of \((\mathbb {E}[m_{U_n}];\, n \ge 1)\) and from the uniform integrability of \(\bar{\mu }_n^{k-1}\).
We now go back to our claim that the image of \(\iota \) is closed. For each \(k, n \ge 1\), let \(\nu _{k,n}\) be the kth marked distance matrix distribution of some marked UMS \([U_n, d_n, \mathscr {U}_n, \mu _n]\), and assume that it converges as \(n \rightarrow \infty \) to some \(\nu _k\). We need to show that the limiting sequence of distance matrices can be obtained by sampling from a marked UMS. We can assume without loss of generality that \(\nu _k \ne 0\). Let \(\hat{\nu }_k\) be the probability measure obtained by renormalizing \(\nu _k\), and define similarly \(\hat{\nu }_{k,n}\). Since the projection of \(\hat{\nu }_{k+1,n}\) on \(\mathbb {R}_+^{k^2} \times E^k\) is equal to \(\hat{\nu }_{k,n}\), the same property holds for \(\hat{\nu }_{k+1}\) and \(\hat{\nu }_k\). Using Kolmogorov’s extension theorem, we can extend consistently the measures \((\hat{\nu }_k;\, k \ge 1)\) to a measure \(\hat{\nu }_\infty \) on \(\mathbb {R}_+^{\mathbb {N}\times \mathbb {N}} \times E^{\mathbb {N}}\) whose projections on finite-dimensional spaces are given by the measures \((\hat{\nu }_k;\, k \ge 1)\). Quite clearly, \(\hat{\nu }_\infty \) is the law of a marked exchangeable ultrametric matrix. (Exchangeability and almost sure ultrametricity hold for a fixed n, and pass to the limit.) Theorem 5 shows that we can find a marked UMS \([U, d, \mathscr {U}, \hat{\mu }]\) whose kth marked distance matrix distribution is \(\hat{\nu }_k\). Denote by \(\bar{\mu }\) the limit of the total mass of \(\nu _{1,n}\), and by \(\mu = \bar{\mu } \hat{\mu }\). The kth marked distance matrix distribution of the marked UMS \([U, d, \mathscr {U}, \mu ]\) is \(\bar{\mu }^k \hat{\nu }_k = \nu _k\). This proves the claim.
Finally, we prove uniqueness. Let \([U, d, \mathscr {U}, \mu ]\) and \([U', d', \mathscr {U}', \mu ']\) be two random marked UMS, that are limits in distribution of a subsequence of \(([U_n, d_n, \mathscr {U}_n, \mu _n];\, n \ge 1)\). We want to show that they have the same distribution. For any polynomial \(\Phi \in \Pi \), since \(\Phi \) is continuous and \((\Phi (U_n, d_n, \mathscr {U}_n, \mu _n);\, n \ge 1)\) is uniformly integrable (it has uniformly bounded moments of all orders), the moments of the two limiting marked UMS coincide and verify (12), namely,
Introducing the same measure \(M^\Phi \) as in the proof of Proposition 3, the method of moments on \(\mathbb {R}_+\) shows that, for any continuous bounded \(f :\mathbb {R}_+ \rightarrow \mathbb {R}\) and any polynomial \(\Phi \),
so that if \(f(0) = 0\), we have
On the event \(\{ \bar{\mu } > 0 \}\), let \((d_{ij}, Y_i;\, i,j \ge 1)\) be the marked exchangeable ultrametric matrix obtained from an i.i.d. sample from \([U, d, \mathscr {U}, \hat{\mu }]\), and define \((d'_{ij}, Y'_i;\, i,j \ge 1)\) similarly from \([U', d', \mathscr {U}', \hat{\mu }']\). The identity (14) can be written as
This equation shows that \(\bar{\mu }\) and \(\bar{\mu }'\) have the same distribution, and for \(\bar{\mu }\)-a.e. x, the law of \((d_{ij}, Y_i;\, i,j \le k)\) conditional on \(\bar{\mu } = x\) is the same as that of \((d'_{ij}, Y'_i;\, i,j \le k)\) conditional on \(\bar{\mu }' = x\). The uniqueness part of Theorem 5 shows that the law of \([U, d, \mathscr {U}, \hat{\mu }]\) conditional on \(\bar{\mu } = x\) is the same as that of \([U', d', \mathscr {U}', \hat{\mu }']\) conditional on \(\bar{\mu }'\). Combining this with the fact that \(\bar{\mu }\) and \(\bar{\mu }'\) have the same distribution and that the polar decomposition is a homeomorphism proves that the two marked UMS have the same distribution. \(\square \)
4.3 Moments of some continuous trees
In this section we compute the moments of some usual random tree models, namely CPP trees and \(\Lambda \)-coalescents, to illustrate the type of expression that can arise for the limiting mmm-space of Proposition 3.
4.3.1 Continuous coalescent point processes
Coalescent point process trees are a class of continuous random trees that correspond to the scaling limit of the genealogy of various branching processes [11, 27, 39]. Of particular interest is the Brownian CPP described in Sect. 2.3 that corresponds to the scaling limit of critical Galton–Watson processes, and also corresponds to the limit of the rescaled genealogy of the branching process with recombination.
Consider a Poisson point process P on \([0, \infty ) \times (0, \infty )\), with intensity \(\textrm{d}t \otimes \nu (\textrm{d}x)\). We make the further assumptions that
For some \(x_0 > 0\), let Y denote the first atom of P whose second coordinate exceeds \(x_0\), that is,
The CPP tree at height \(x_0\) associated to \(\nu \) is the random metric measure space \([(0, Y), d_P, {{\,\textrm{Leb}\,}}]\) with
Proposition 4
Let \([(0,Y), d_P, {{\,\textrm{Leb}\,}}]\) be the CPP tree at height \(x_0\) associated to the measure \(\nu \). Then for any continuous bounded function \(\varphi \) with associated polynomial \(\Phi \), we have
where for \(i < j\),
the r.v. \((H_1, \dots , H_{k-1})\) are i.i.d. with c.d.f.
and \(\sigma \) is an independent uniform permutation of \(\{1, \dots , k\}\).
Proof
According to (6), we need to study the distance of k variables sampled uniformly from [0, Y], after having biased \(([0, Y], d_P, {{\,\textrm{Leb}\,}})\) by the kth moment of its mass.
Since Y is independent of the restriction of P to \([0,\infty ) \times [0, x_0]\), the distribution of \(([0, Y], d_P, {{\,\textrm{Leb}\,}})\) biased by the kth moment of Y is simply that of \(([0, Z], d_P, {{\,\textrm{Leb}\,}})\), where Z is distributed as Y, biased by its kth moment. Let us use the notation \(\theta {:}{=}\nu ((x_0, \infty ))\). It is well known that Z follows a \(\textrm{Gamma}(\theta , k+1)\) distribution, that is, Z has density
Conditional Z, let \((U_1,\dots , U_k)\) be i.i.d. uniform variables on [0, Z], and denote by \((U^*_1,\dots , U^*_k)\) their order statistics. Let us also denote \(U^*_0 = 0\) and \(U^*_{k+1} = Z\). It is standard that
are independent exponential variables with mean \(1/\theta \). Define
As the restriction of P to \([0, \infty ) \times [0, x_0]\) is independent of the vector \((U^*_0, \dots , U^*_{k+1})\), \((H_0,\dots ,H_k)\) are i.i.d. and distributed as
The following direct computation shows that this has the required distribution,
It is clear from the definition of \(d_P\) that for \(i < j\),
Therefore, if \(\sigma \) denotes the unique permutation of [k] such that \(U_i = U^*_{\sigma _i}\),
\(\square \)
In this work, the scaling limit of the genealogy is given by the Brownian CPP, which is the CPP with height 1 associated to the measure
Corollary 1
The moments of the Brownian CPP are given by
where for \(i < j\),
the r.v. \((H_1, \dots , H_{k-1})\) are i.i.d. uniform on (0, 1), and \(\sigma \) is an independent uniform permutation of \(\{1, \dots , k\}\).
Proof
A direct computation shows that
so that the variables \(H_i\) in Proposition 4 are uniform on [0, 1]. \(\square \)
4.3.2 Metric measure spaces with independent types
In our model and in many other settings, the types in the population become independent of the genealogy in the limit of large population size. Typically, this situation arises when the time between the ancestors of two typical individuals in the population is large, so that the dynamics of the types along the lineages has time to reach some form of equilibrium and to forget about its starting point (the type of the ancestor).
For a mmm-space \([X, d, \mu ]\), the independence between the types and the genealogy corresponds to having a product sampling measure of the form \(\mu = \mu _X \otimes \mu _E\), where \(\mu _X\) is a measure on X, and \(\mu _E\) a probability measure on the type space E. The moments of such product mmm-spaces are easily expressed in terms of the (unmarked) metric measure space \([X, d, \mu _X]\).
Proposition 5
Let \([X,d,\mu ]\) be a random mmm-space with a sampling measure of the form \(\mu = \mu _X \otimes \mu _E\), where \(\mu _E\) is a deterministic probability measure on E. Then, for any polynomial \(\Phi \in \Pi \), we have
where \((Y_1, \dots , Y_k)\) are i.i.d., distributed as \(\mu _E\), and independent of \([X,d,\mu _X]\).
Proof
By definition of a polynomial and applying Fubini’s theorem for a.s. all realizations of the random measure,
\(\square \)
4.3.3 \(\Lambda \)-coalescents
A \(\Lambda \)-coalescent is a process with values in the partitions of \(\mathbb {N}\) such that for any n, its restriction to \(\{1, \dots , n\}\) is a Markov process with the following transitions. When the process has b blocks, any k blocks merge at rate \(\lambda _{b,k}\) where
for some finite measure \(\Lambda \). These processes were introduced in [38, 42], and provide the limit of the genealogy of several celebrated population models with fixed population size [34, 43].
A \(\Lambda \)-coalescent can be seen as a random ultrametric space on \(\mathbb {N}\). It is possible to take an appropriate completion of this space to define an ultrametric \(d_\Lambda \) on (0, 1) that encodes the metric structure of the coalescent, see [18, Sect. 4] for the separable case, and [17, Sect. 3] for the general case. More precisely, there exists a random ultrametric \(d_\Lambda \) such that if \((V_i;\, i \ge 1)\) is an independent sequence of i.i.d. uniform r.v. on (0, 1), and \(\Pi _t\) is the partition defined through the equivalence relation
then \((\Pi _t;\, t \ge 0)\) is distributed as a \(\Lambda \)-coalescent. In particular, this leads to the following expression for the moments of the metric measure space \([(0,1), d_\Lambda , {{\,\textrm{Leb}\,}}]\).
Proposition 6
Let \([(0, 1), d_\Lambda , {{\,\textrm{Leb}\,}}]\) be a \(\Lambda \)-coalescent tree. Then
where
for a realization \((\Pi _t;\, t \ge 0)\) of a \(\Lambda \)-coalescent.
4.4 Relating spine convergence to Gromov-weak convergence
Let \([T, (X_u)]\) be the random marked tree with distribution \(\textbf{P}_x\) constructed in Sect. 3.2, and let \(Z_N = |T_N|\) denote the population size at generation N. Recall that T can be endowed with the graph distance \(d_T\), and that \(T_N\) denotes the Nth generation of the process. The metric \(d_T\) restricted to \(T_N\) encodes the genealogy of the population, and has the simple expression
Define the mark measure on \(T_N \times E\) as
The triple \([T_N, d_T, \mu _N]\) is the mmm-space associated to the branching process \([T, (X_u)]\). The polynomial of degree k corresponding to a functional \(\varphi \) can be written as
The aim of this section is to provide a general convergence criterion for a rescaling of the sequence of mmm-spaces \([T_N, d_T, \mu _N;\, N \ge 1]\) that only involves computation on the k-spine tree. For each \(N \ge 1\), consider a rescaling parameter \(\alpha _N\) for the population size, \(\beta _N :E \rightarrow E\) for the mark space, and \(\gamma _N :\mathbb {R}_+ \rightarrow \mathbb {R}_+\) for the genealogical distances. We assume that \(\gamma _N\) is increasing so that \(\gamma _N\circ d_T\) is also an ultrametric, and that \(\alpha _N \rightarrow \infty \).
Theorem 6
Suppose that for any \(k \ge 1\) and any continuous bounded function \(\varphi \), the sequence
converges and that the limit fulfills (12). Then there exists a random marked UMS \([U,d,\mathscr {U},\mu ]\) such that conditional on \(Z_N > 0\),
holds in distribution for the marked Gromov-weak topology.
Proof
According to Theorem 4 it is sufficient to prove that the following moments converge,
Let us denote by
By the many-to-few formula, Proposition 2,
for an independent uniform permutation \(\sigma \) of [k]. Taking \(\varphi \equiv 1\), the assumption of the result readily implies that
Therefore, since
the convergence of each \(M_N\) follows from that of \(\widetilde{M}_N\) and the result is proved. \(\square \)
4.5 Convergence of the k-spine
Theorem 6 shows that convergence of the branching process in the Gromov-weak topology can be deduced from the convergence of some functionals of the k-spine tree. We now provide a general convergence result for the k-spine tree that will be used to compute the limit of (15) for the branching process with recombination.
We work under the measure \(\textbf{Q}^{k,N}_x\) and define
Since our work involves working under various measures, for a sequence \((P_n;\, n \ge 1)\) of probability measures and a sequence \((Y_n;\, n \ge 1)\) of r.v., we will use the notation
to mean that the distribution of \(Y_n\), under the measure \(P_n\), converges to the distribution of Y.
Assumption 1
(A1)
-
(i)
There exists a limiting r.v. W such that
$$\begin{aligned} W^N_1 \xrightarrow [\,N \rightarrow \infty \,]{\,\textbf{Q}^{1,N}_x\,} W. \end{aligned}$$ -
(ii)
There exists a limiting Feller process X such that, if \(X^N_1(0) \rightarrow X(0)\),
$$\begin{aligned} X^N_1 \xrightarrow [\,N \rightarrow \infty \,]{\,\textbf{Q}^{1,N}_x\,} X \end{aligned}$$in the Skorohod topology.
There exist equivalent formulations of the second point involving generators or semigroups, see for instance [25, Theorem 19.28]. In the next result, we use the notation
for the concatenation of f and g at time t.
Proposition 7
Suppose that (A1) holds. Then
where,
-
the r.v. \((W_1, \dots , W_{k-1})\) are i.i.d. copies of the limiting r.v. W;
-
\(X_1\) is distributed as X started from x and is independent of \((W_1,\dots , W_{k-1})\);
-
for each i, conditional on \((W_1, \dots , W_{k-1})\) and \((X_1, \dots , X_i)\),
$$\begin{aligned} X_{i+1} = [X_i; W_i; X'] \end{aligned}$$where \((X'(t);\, t \ge 0)\) is distributed as X started from \(X_i(W_i)\).
Proof
Let us work inductively, and assume that the convergence holds for some \(k \ge 1\). Let \(\widetilde{X}^N_{k+1}\) be distributed as X, started from \(X^N_k(W^N_k)\).
Obviously, \(W^N_k\) converges to \(W_k\), a copy of W independent of \((W_1,\dots ,W_{k-1})\) and of \((X_1,\dots ,X_k)\). Then it follows from the fact that X has no fixed time discontinuity that \(X^N_k(W^N_k)\) converges to \(X_k(W_k)\). Using the assumption (A1), this entails that \(\widetilde{X}^N_{k+1}\) converges to a limiting process \(\widetilde{X}_{k+1}\), which is distributed as X started from \(X_k(W_k)\).
Recalling that, by definition of the discrete spine under \(\textbf{Q}^{k,N}_x\),
the claim is a consequence of the a.s. continuity of the concatenation map, which is proved in Lemma 6. \(\square \)
5 The recombination spine
We now focus on the branching process with recombination. In this first section we derive the properties of its 1-spine.
Using the formalism of the previous section, the branching process with recombination can be constructed as a random marked tree, where the mark space is the set of intervals of \(\mathbb {R}\). According to the description of the branching process with recombination, an individual with mark \(I = [a,b]\) gives birth to K(I) children, with
Then, each newborn experiences a recombination event with probability
In the case of a recombination, the offspring inherits the interval [a, U] or [U, b] with equal probability, where U is uniformly distributed over I. As in the previous section, we denote by \(\Xi (I)\) the offspring point process of a mother with interval I. The objective of this section is to compute and characterize the distribution \(\textbf{Q}^{1,N}_I\) of the intervals along the 1-spine and its large N limit \(\textbf{Q}^1_I\).
5.1 The h-transformed mark process
Defining \(\textbf{Q}^{1,N}_I\) first requires one to find an adequate harmonic function for the branching process. In the branching process with recombination, a simple calculation shows that the length of the intervals is harmonic.
Lemma 3
The function \(h :I \mapsto |I|\) is harmonic for the family of point processes \((\Xi (I))\).
Let us now compute the distribution \(\textbf{Q}^{1,N}_I\) of the h-transformed process. According to (2), under \(\textbf{Q}^{1,N}_I\), the probability of experiencing no recombination in one time-step when carrying interval I is
When experiencing a recombination event, according to (2) the resulting interval is biased by h, that is, biased by its length. This leads to the following description of the distribution of the intervals along the spine.
Definition 4
The distribution \(\textbf{Q}^{1,N}_I\) of the intervals along the 1-spine in the branching process with recombination is that of the discrete-time Markov chain \((I(n);\, n \ge 0)\) verifying \(I(0) = I\), and conditional on \(I(n) = [a,b]\),
where \(U^*\) has the size-biased uniform distribution on \([0, b-a]\). For convenience, \(\textbf{Q}^{1,N}_R\) refers to \(\textbf{Q}^{1,N}_{[0,R]}\).
5.2 Large N convergence of the spine
As in the previous section, let \(I^N\) denote the rescaled process
We show that its large N limit is given by the following process.
Definition 5
Let \(\textbf{Q}^1_I\) denote the distribution of the continuous-time Markov process \((I(t);\, t \ge 0)\) started from I and such that jumps:
-
from [a, b] to \([a, a+U^*]\) at rate \((b-a)/2\);
-
from [a, b] to \([b-U^*, b]\) at rate \((b-a)/2\).
Again, \(\textbf{Q}^1_R\) corresponds to \(\textbf{Q}^1_{[0,R]}\).
Proposition 8
The process \((I^N(t);\, t \ge 0)\) under \(\textbf{Q}^{1,N}_I\) converges in distribution for the Skorohod topology to \((I(t);\, t \ge 0)\) under \(\textbf{Q}^1_I\).
Proof
The two processes \((I^N(t);\, t \ge 0)\) and \((I(t);\, t \ge 0)\) visit the same sequence of states, in distribution. Therefore, convergence in the Skorohod topology amounts to convergence of the jump times. Started from [a, b], the time before the first jump of \((I^N(t);\, t \ge 0)\) is distributed as \(T^N / N\), where \(T^N\) is geometrically distributed with success probability \((b-a) / N\). It is clear that \(T^N / N\) converges in distribution to an exponentially distributed variable with mean \(1/(b-a)\). Applying this convergence to the successive jump times of \((I^N(t);\, t \ge 0)\) readily proves the result. \(\square \)
5.3 Poisson construction of \(\textbf{Q}^1_R\)
We are interested in the large R properties of the spine. In this section, we prove that the spine has a unique entrance law at infinity, which can be constructed from a homogeneous Poisson point process. This construction will also provide a coupling for the distribution of \((I(t);\, t \ge 0)\) started from any initial condition. It is illustrated in Fig. 5.
First, for an interval \(I = [a,b]\), it will be convenient to use the notation
for any reals \(\lambda , \mu \).
Consider a homogeneous Poisson point process P on \([0, \infty ) \times \mathbb {R}\). For any \(t \ge 0\), consider the point process \(P_t\) on \(\mathbb {R}\) of atoms of P with time coordinate in [0, t] defined as
The atoms of \(P_t(A)\) split the real line into infinitely many subintervals. We are interested in the subinterval covering the origin. More precisely, let \((x_i;\, i \in \mathbb {Z})\) be the atoms of \(P_t\), labeled in such a way that
and define \(I_P(t) = [x_0, x_1]\).

Illustration of the Poisson construction of \(\textbf{Q}^1_R\). Atoms of P are represented with dark circles. At each time t, the vertical slice of the shaded region gives \(I_R(t)\)
The following proposition shows that \((I_P(t);\, t \ge 0)\) corresponds to the distribution of \((I(t);\, t \ge 0)\), started from infinity.
Proposition 9
Let M be uniformly distributed on [0, 1] and independent of P. Then, for any \(R \ge 0\), the process \((I_R(t);\, t \ge 0)\) defined as
has distribution \(\textbf{Q}^1_R\). Moreover, for any t, M is uniformly distributed on \(I_R(t)\).
The proposition will follow from the next simple result.
Lemma 4
Let U and V be independent uniform r.v. on [0, 1]. Define the interval
Then \(|I|\) is independent of the event \(\{V \le U\}\), \(|I|\) is a size-biased uniform r.v. on [0, 1], and V is uniformly distributed on I.
Proof
Let \(A = \{ V \le U \}\) and \(\bar{A} = \{ V > U \}\). For any test function \(\varphi \) and \(\psi \), we can directly compute
and
\(\square \)
Proof of Proposition 9
It is clear that \(I_R(0) = [0, R]\). Let us consider the sequence of jumps times \((T_i;\, i \ge 0)\) of \(I_R\). By definition of the process, \(T_{i+1}\) is the smallest time after \(T_i\) such that there exists \(X_{i+1}\) with \((T_{i+1}, X_{i+1}) \in P\) and \(X_{i+1} \in I_R(T_i)\). Then, if \(I_R(T_i) = [a,b]\),
By the properties of homogeneous Poisson processes, \(T_{i+1}-T_i\) is exponentially distributed with parameter \(|I_R(T_i)|\), and \(X_{i+1}\) is uniformly distributed over \(I_R(T_i)\).
Using that UR is uniformly distributed over [0, R], a straightforward induction using Lemma 4 proves that for any i, UR is uniformly distributed on \(I_R(T_i)\), and that \(|I_R(T_{i+1})|\) is a size-biased r.v. uniform on \(I_R(T_i)\). This corresponds to the description of the transition mechanism of \((I(t);\, t\ge 0)\) under \(\textbf{Q}^1_R\) and proves the result. \(\square \)
Define
The coupling provided by the previous representation can be used to study the behavior of \((X(t);\, t \ge 0)\) as \(R \rightarrow \infty \).
Corollary 2
As \(R \rightarrow \infty \), the process \((X(t);\, t \ge 0)\) under \(\textbf{Q}^1_R\) converges in distribution to \((X_P(t);\, t \ge 0)\) for the topology of uniform convergence on every set \([\varepsilon , \infty )\), \(\varepsilon > 0\). For any \(t > 0\), \(X_P(t)\) follows a \(\textrm{Gamma}(2, t)\) distribution, that is
Proof
By the Poisson construction, if \(X_R(t) {:}{=}|I_R(t)|\), then \((X_R(t);\, t \ge 0)\) is distributed as \((X(t);\, t \ge 0)\) under \(\textbf{Q}^1_R\). It is straightforward to see that for any \(\varepsilon > 0\), for large enough R we have \(X_R(t) = X_P(t)\) for any \(t \ge \varepsilon \), proving the convergence part of the result.
By well-known properties of Poisson point processes, \(P_t\) is a homogeneous Poisson point process with rate t. Moreover both the first positive and negative atom of \(P_t\) follow an exponential distribution with parameter t, and are independent. This proves that \(X_P(t)\) is gamma distributed with the right parameters. \(\square \)
5.4 Self-similarity
From the transition mechanism of \((I(t);\, t \ge 0)\), we see that \((X(t);\, t \ge 0)\) is also a Markov process. Under \(\textbf{Q}^1_R\) it starts from R and, conditional on X(t), it jumps at rate X(t) to \(X(t) U^*\), where \(U^*\) is a size-biased uniform r.v. on [0, 1]. As the jump rate of \((X(t);\, t \ge 0)\) at time t is X(t), the process \((X(t);\, t \ge 0)\) is self-similar with index \(-1\), in the sense that for any constant \(c > 0\), the following identity in law holds
Positive Markov processes fulfilling the previous property are called positive self-similar Markov processes (pssMp), see [37] for an introductory exposition.
Remark 8
In this work we will not make use of this connection with pssMp since all computations can be carried out directly from the Poisson construction. However this link could be used to generalize our results to a larger class of branching processes on the intervals, with more general fragmentation rules for the offspring distribution.
5.5 Convergence of the rescaled spine
Recall the definition of \(F_R\) and \(F_R^{-1}\) from (1). The following result provides the limit of the spine after rescaling time according to \(F_R^{-1}\).
Proposition 10
Let \(0< u_1< \dots < u_n \le 1\). Then
where the \(\gamma _i\)’s are independent Gamma r.v.’s with parameter (2, 1).
Proof
We show the result by induction on n. Recall that \(X(F^{-1}_R(u))\) has the same distribution as \(Y_1\wedge RU + Y_2 \wedge R(1-U)\) where \(Y_1\), \(Y_2\) are independent and exponentially distributed with mean \(1/F^{-1}_R(u)\) and U is uniform on [0, 1]. For every \(u\in (0,1]\), \(1/F^{-1}_R(u) \sim R^{1-u} = o(R)\) so that \(Y_1\wedge RU + Y_2 \wedge R(1-U) = Y_1+Y_2\) with a probability going to 1. This establishes the result at stage 1.
Let us now assume that the property is satisfied at stage n. Conditional on the process X up to time \(F_R^{-1}(u_n)\), the Markov property implies that the spine at \(F^{-1}_R(u_{n+1})\) is distributed as \(Y_1 \wedge R_n U + Y_2 \wedge R_n(1-U)\) where \(R_n = X(F_R^{-1}(u_n))\), and \(Y_1\), \(Y_2\) are independent and exponentially distributed with mean \(\big (F^{-1}_R(u_{n+1}) - F^{-1}_R(u_n)\big )^{-1}\). Since we have
as in the case \(n = 1\), this implies that \(F^{-1}_R(X(u_{n+1}))\) is converging to an independent \(\gamma _{n+1}\) random variable. \(\square \)
6 The recombination k-spine tree
In the previous section we have characterized the large N, large R behavior of the process giving the marks along a single spine. We now provide a similar characterization for the k-spine tree. We start with the following definition.
Definition 6
Let us denote by \(\textbf{Q}^k_I\) the law of some r.v. \((I_1,\dots ,I_k)\) and \((W_1,\dots , W_{k-1})\) such that:
-
\((W_1,\dots , W_{k-1})\) are i.i.d. r.v.’s on [0, 1] with c.d.f. \(F_R\);
-
\(I_1\) has distribution \(\textbf{Q}^1_I\) and is independent of \((W_1,\dots , W_{k-1})\);
-
\(I_{i+1} = [I_i; W_i; I']\), where conditional on \((W_1,\dots , W_i)\) and \((I_1,\dots , I_i)\), \(I'\) has distribution \(\textbf{Q}^1_{I_i(W_i)}\).
We also use the shorter notation \(\textbf{Q}^k_R\) for \(\textbf{Q}^k_{[0,R]}\).
6.1 Convergence of the tree
According to Proposition 10, it is natural to rescale time using \(F_R\) as follows.
Definition 7
We consider the rescaled k-spine measure as
in the sense that under \(\mathcal {Q}^k_R\)
-
The branch times are distributed as \((F_R(W_1), \dots , F_R(W_{k-1}))\);
-
The spatial processes are distributed \((I_1 \circ F_R^{-1}, \dots , I_k \circ F_R^{-1})\);
where \((W_1,\dots , W_{k-1})\) and \((I_1,\dots , I_k)\) are distributed respectively as the branch times and the spatial processes under \(\textbf{Q}^k_R\).
The following result is a straightforward extension of Proposition 10.
Proposition 11
Under the rescaled k-spine measure \(\mathcal {Q}_R^k\):
-
(i)
The branch times \((W_1,\dots , W_{k-1})\) are distributed as i.i.d. uniform random variables on [0, 1].
-
(ii)
Conditional on the \(W_i\)’s
$$\begin{aligned} \Big ( \big ( F_R^{-1}(W_1) X_1(W_1),\dots , F^{-1}_R(W_{k-1}) X_{k-1}(W_{k-1}) \big ), \big ( X_1(1),\dots , X_{k}(1) \big ) \Big ) \\ \xrightarrow [\,R\rightarrow \infty \,]{\,\mathcal {Q}_R^{k}\,} \big ( (\gamma _1,\dots , \gamma _{k-1}), (\bar{\gamma }_1,\dots , \bar{\gamma }_{k}) \big ) \end{aligned}$$where the \(\gamma _i\)’s and \(\bar{\gamma }_i\)’s are independent Gamma r.v.’s with parameter (1, 2).
Proof
The proof goes along the same line the one of Proposition 10 and is left to the interested reader. \(\square \)
6.2 Convergence of the chromosomic distance
In this section, we prove that the genealogical distance and the rescaled chromosomic distance coincide in the large R limit under \(\mathcal {Q}^k_R\). For \(i < j\), set
to be the time at which branches i and j split. Define
which is the genealogical distance between the leaves of the k-spine tree.
Conditional on \((I_1, \dots , I_k)\) and \((W_1, \dots , W_{k-1})\), let \(M_i\) be uniformly distributed on \(I_i(1)\). We define
which is the chromosomic distance between the leaves. For later purpose, we also introduce the corresponding rescaled distance,
The next result provides an interesting relation between the genealogy of the branching process and the “geography” along the chromosome. Namely, on a logarithmic scale, the distance between two segments on the chromosome is directly related to the genealogy of the two segments.
Lemma 5
We have
Proof
Let us work under \(\textbf{Q}^k_R\) and let \(i < j\). By construction of the k-spine, conditional on \(I_i(W_{i,j})\), \((I_i(t+W_{i,j});\, t \ge 0)\) and \((I_j(t+W_{i,j});\, t \ge 0)\) are independent and distributed as \(\textbf{Q}^1_{I_i(W_{i,j})}\). We know from the Poisson construction that, conditional on \(I_i(W_{i,j})\), \(M_i\) and \(M_j\) are independent uniform variables on that interval. Therefore,
is a \(\textrm{Beta}(1,2)\) r.v. Write
From the previous point and Proposition 10,
Moreover
so that
The result follows by noting that the r.v. on the left-hand side has the same distribution under \(\textbf{Q}^k_R\) as
under \(\mathcal {Q}^k_R\). \(\square \)
6.3 Proof of the main result
We can now proceed to the proof of our main result.
Proof of Theorem 2
In order to ease the exposition, we only prove the result for \(t = 1\), but the proof is easily adapted for general \(t > 0\).
Recall that \(\textbf{Q}^{1,N}_R\) denotes the distribution of the 1-spine provided in Definition 5. Let \(\textbf{Q}^{k,N}_R\) be the corresponding k-spine distribution, with i.i.d. branch times \((W_1, \dots , W_{k-1})\) such that
for the function \(F_R\) defined in (1).
Set
where the \(M_i\) are uniformly distributed on the \(I_i(N)\). In order to use Theorem 6, we need to compute the limit of
where for the branching process with recombination,
with
According to Proposition 8, under \(\textbf{Q}^{1,N}_R\) the process \(I^N\) converges to the limiting process with distribution \(\textbf{Q}^1_R\) introduced in Definition 5. Therefore, Proposition 7 proves that
where the limiting variables have distribution \(\textbf{Q}^k_R\). Since the variables \((W_1,\dots ,W_{k-1})\) are a.s. distinct under \(\textbf{Q}^k_R\), it entails that
Corollary 3 provides enough uniform integrability to conclude that
where the last line follows by rescaling time according to (1) and the distances are defined in (16). The first observation is that, a.s.,
The second observation is that conditional on \((W_1, \dots , W_{k-1})\), according to Proposition 11,
where the limiting r.v. are \(\textrm{Gamma}(2,1)\) distributed and independent. Let \(\beta \in (1,2)\) and define
By reverting the previous change of variable
By Corollary 3, the r.h.s. is uniformly bounded in R. This provides enough uniform integrability to get
where \(\gamma _i\) are i.i.d. \(\textrm{Gamma}(2,1)\) r.v., \(Y_i\) are i.i.d. standard exponential random variable, and we have used Lemma 5 for the convergence of the distances.
We can now apply Theorem 6 with
Recall that \(Z_N\) denotes the population size and that from Proposition 1
exists and that
Therefore,
exists and we have
Applying Theorem 6 for the large N limit, then Proposition 3 for the large R limit, and finally Propositions 5 and 4 for the polynomials of the Brownian CPP with independent marks proves the result. Note that since the total mass of the Brownian CPP is exponentially distributed, it fulfills the moment condition (7). For the large N limit, the size of the branching process with recombination is stochastically dominated by a Galton–Watson process with \(\textrm{Poisson}(1 + R/N)\) offspring distribution. The size of this process, conditional on survival at time N and rescaled by N, is well-known to converge to an exponential distribution, see for instance [35, Theorem 2.1]. This readily shows that (12) is also fulfilled by the large N limit, for each fixed R. \(\square \)
Remark 9
In the above proof we have made use of Theorem 4 to identify the large N limit of the genealogy. It is possible to prove the result without relying on our extension of the Gromov-weak topology by constructing the branching process with recombination by superimposing on a Galton–Watson tree with \(\textrm{Poisson}(1+R/N)\) offspring distribution a process along the branches describing the recombination events as in [3]. The large N limit could then be expressed by means of the superprocess limit associated to that branching model.
References
Athreya, K.B., Ney, P.E.: Branching Processes. Grundlehren der Mathematischen Wissenschaften, Springer, Berlin (1972)
Baake, E., Herms, I.: Single-crossover dynamics: finite versus infinite populations. Bull. Math. Biol. 70, 603–624 (2008)
Baird, S.J.E., Barton, N.H., Etheridge, A.M.: The distribution of surviving blocks of an ancestral genome. Theor. Popul. Biol. 64, 451–471 (2003)
Bansaye, V., Delmas, J.-F., Marsalle, L., Tran, V.C.: Limit theorems for Markov processes indexed by continuous time Galton–Watson trees. Ann. Appl. Probab. 21, 2263–2314 (2011)
Bertoin, J., Caballero, M.-E.: Entrance from \(0+\) for increasing semi-stable Markov processes. Bernoulli 8, 195–205 (2002)
Bertoin, J., Yor, M.: The entrance laws of self-similar Markov processes and exponential functionals of Lévy processes. Potential Anal. 17, 389–400 (2002)
Biggins, J.D., Kyprianou, A.E.: Measure change in multitype branching. Adv. Appl. Probab. 36, 544–581 (2004)
Dawson, D.A.: Measure-Valued Markov Processes. Lecture Notes in Mathematics, Springer, Berlin (1993)
Depperschmidt, A., Greven, A.: Tree-valued Feller diffusion. arXiv:1904.02044 (2019)
Depperschmidt, A., Greven, A., Pfaffelhuber, P.: Marked metric measure spaces. Electron. Commun. Probab. 16, 174–188 (2011)
Duchamps, J.-J., Lambert, A.: Mutations on a random binary tree with measured boundary. Ann. Appl. Probab. 28, 2141–2187 (2018)
Duquesne, T., Le Gall, J.-F.: Random trees, Lévy processes and spatial branching processes. Astérisque 281, 153 (2002)
Durrett, R.: Probability Models for DNA Sequence Evolution. Probability and its Applications, 2nd edn. Springer, New York (2008)
Durrett, R.: Probability: Theory and Examples. Cambridge Series in Statistical and Probabilistic Mathematics, 5th edn. Cambridge University Press, Cambridge (2019)
Ethier, S.N., Kurtz, T.G.: Markov Processes: Characterization and Convergence. Wiley Series in Probability and Statistics, Wiley, New York (1986)
Fisher, R.A.: A fuller theory of “junctions’’ in inbreeding. Heredity 8, 187–197 (1954)
Foutel-Rodier, F., Lambert, A., Schertzer, E.: Exchangeable coalescents, ultrametric spaces, nested interval-partitions: a unifying approach. Ann. Appl. Probab. 31, 2046–2090 (2021)
Greven, A., Pfaffelhuber, P., Winter, A.: Convergence in distribution of random metric measure spaces (\(\Lambda \)-coalescent measure trees). Probab. Theory Relat. Fields 145, 285–322 (2009)
Griffiths, R.C., Marjoram, P.: An ancestral recombination graph. In: Progress in Population Genetics and Human Evolution, pp. 257–270. Springer (1997)
Gufler, S.: A representation for exchangeable coalescent trees and generalized tree-valued Fleming–Viot processes. Electron. J. Probab. 23, 42 (2018)
Harris, S.C., Johnston, S.G.G., Roberts, M.I.: The coalescent structure of continuous-time Galton–Watson trees. Ann. Appl. Probab. 30, 1368–1414 (2020)
Harris, S.C., Roberts, M.I.: The many-to-few lemma and multiple spines. Ann. Inst. Henri Poincaré Probab. Stat. 53, 226–242 (2017)
Janzen, T., Miró Pina, V.: Estimating the time since admixture from phased and unphased molecular data. Mol. Ecol. Resour. 22, 908–926 (2021)
Johnston, S.G.G.: The genealogy of Galton–Watson trees. Electron. J. Probab. 24, 35 (2019)
Kallenberg, O.: Foundations of Modern Probability. Probability and its Applications, 2nd edn. Springer, New York (2002)
Kingman, J.F.C.: The representation of partition structures. J. Lond. Math. Soc. 18, 374–380 (1978)
Lambert, A.: The contour of splitting trees is a Lévy process. Ann. Probab. 38, 348–395 (2010)
Lambert, A., Miró Pina, V., Schertzer, E.: Chromosome painting: how recombination mixes ancestral colors. Ann. Appl. Probab. 31, 826–864 (2021)
Lambert, A., Popovic, L.: The coalescent point process of branching trees. Ann. Appl. Probab. 23, 99–144 (2013)
Le Gall, J.-F.: Brownian excursions, trees and measure-valued branching processes. Ann. Probab. 19, 1399–1439 (1991)
Lyons, R., Pemantle, R., Peres, Y.: Conceptual proofs of \(L\log L\) criteria for mean behavior of branching processes. Ann. Probab. 23, 1125–1138 (1995)
Marjoram, P., Wall, J.D.: Fast “coalescent’’ simulation. BMC Genet. 7, 16 (2006)
McVean, G.A.T., Cardin, N.J.: Approximating the coalescent with recombination. Philos. Trans. R. Soc. B: Biol. Sci. 360, 1387–1393 (2005)
Möhle, M., Sagitov, S.: A classification of coalescent processes for haploid exchangeable population models. Ann. Probab. 29, 1547–1562 (2001)
O’Connell, N.: The genealogy of branching processes and the age of our most recent common ancestor. Adv. Appl. Probab. 27, 418–442 (1995)
Ohta, T., Kimura, M.: Linkage disequilibrium due to random genetic drift. Genet. Res. 13, 47–55 (1969)
Pardo, J.C., Rivero, V.: Self-similar Markov processes. Bol. Soc. Mat. Mex.: Terc. Ser. 19, 201–235 (2013)
Pitman, J.: Coalescents with multiple collisions. Ann. Probab. 27, 1870–1902 (1999)
Popovic, L.: Asymptotic genealogy of a critical branching process. Ann. Appl. Probab. 14, 2120–2148 (2004)
Popovic, L., Rivas, M.: The coalescent point process of multi-type branching trees. Stoch. Process. Appl. 124, 4120–4148 (2014)
Ren, Y.-X., Song, R., Sun, Z.: A 2-spine decomposition of the critical Galton–Watson tree and a probabilistic proof of Yaglom’s theorem. Electron. Commun. Probab. 23, 1–12 (2018)
Sagitov, S.: The general coalescent with asynchronous mergers of ancestral lines. J. Appl. Probab. 36, 1116–1125 (1999)
Schweinsberg, J.: Coalescent processes obtained from supercritical Galton–Watson processes. Stoch. Process. Appl. 106, 107–139 (2003)
Shi, Z.: Branching Random Walks. Lecture Notes in Mathematics, Springer, Cham (2015)
Acknowledgements
We greatly thank Amaury Lambert for initiating this project, for very helpful discussions, and for his interest in this work.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A. Appendix
A. Appendix
1.1 A.1. Continuity of the concatenation map
For two càdlàg functions x and y and a positive real r, recall that
denotes the concatenation of x and y at time r.
Lemma 6
Suppose that we have two sequences of càdlàg functions \((x_n)\) and \((y_n)\) that converge to x and y respectively in the Skorohod topology. Moreover, suppose that \((r_n)\) converges to \(r > 0\), and that x is continuous at r. Then
Proof
Recall that a sequence \((z_n)\) converges to some z in the Skorohod topology if f for each \(T \ge 0\), we can find a sequence of continuous increasing maps \(\lambda _n\) such that
and
see for instance [15, Proposition 5.3].
Fix \(T > r\), and let \((\lambda _n)\) and \((\mu _n)\) fulfill (18) and (19) with \((z_n)\) replaced by \((x_n)\) and \((y_n)\) respectively. For \(\varepsilon > 0\), let \(\delta \) be such that
Using that
we know that for n large enough \(\lambda _n(r-\delta )< r_n < \lambda _n(r+\delta )\). Define
which is continuous, increasing, and is designed so that \(\lambda '_n(r) = r_n\) and coincides with \(\lambda _n\) outside of \((r-\delta , r+\delta )\). Now,
Therefore, up to modifying \(\lambda _n\) in this way and extracting a subsequence, we can always assume that, in addition to (18) and (19), we have \(\lambda _n(r) = r_n\).
Let us now denote
and define
to be the concatenation of the two increasing maps. Clearly \((\nu _n)\) fulfills (18), and using that \(\nu _n(t) < r_n\) if f \(t < r\), we obtain
from which it follows that
proving the result. \(\square \)
1.2 A.2. Uniform integrability results
The aim of this technical section is to prove the uniform integrability of the inverse of the k-spine.
Lemma 7
For any \(\alpha < 1\) and \(t > 0\), there exists a constant C such that
There also exists a constant \(C'\) such that for N sufficiently large
Proof
As \(X^N\) and X are non-increasing, we have
and
It is a direct consequence of the Poisson construction that X(t) under \(\textbf{Q}^1_R\) is stochastically dominated by X(t) under \(\textbf{Q}^1_{R'}\) if \(R \le R'\). Therefore
Moreover, by self-similarity,
Together, these two identities yields that
The first part of the result is proved provided that
Recalling that X(t) has the same distribution as \(Y_1 \wedge U + Y_2 \wedge (1-U)\) where \(Y_1\) and \(Y_2\) are exponentially distributed with mean 1/t and U uniformly distributed on [0, 1], a direct computation shows that
The second part of the result follows from the fact that, for any \(c > 1\), for large enough N,
To see this note that \(X^N\) and X visit the same sequence of states in distribution. Thus stochastic domination follows if \((X(ct);\, t \ge 0)\) jumps faster than \((X^N(t);\, t \ge 0)\). Started from \(\rho \), the process \(X^N\) jumps after a time \(T^N / N\) whereas X jumps after a time T with
A direct computation shows that, provided \(1-\exp (-c\rho / N) \le \rho / N\), T/c is stochastically dominated by \(T^N / N\). The latter condition clearly holds for all \(\rho \le R\) for large enough N. \(\square \)
We now apply the previous estimate inductively to the k-spine, first to be able to take the large N limit, then to take the large R limit. Recall the notation \(X^N_i\) for the rescaled marks along branch i and the notation \(W^N_i\) for the rescaled ith branch time, and the notation
Corollary 3
For any \(R > 1,k \ge 1\), and \(\beta \in (1,2)\),
Further,
Proof
We only prove the result in the continuum setting. The discrete case can be proved along the same lines. Applying the Markov property to \(X_{k+1}\) at time \(W_k\) and using Lemma 7 yields
where in the last inequality, we used the fact that \(\Phi (u)\le 2\) for every \(u \in [0,1]\). Let \(p, q \ge 0\) such that \(\frac{1}{p} + \frac{1}{q} = 1\) and take q close enough to 1 such that \(q \beta \in (1,2)\). By Hölder’s inequality, the second term on the r.h.s. is bounded from above by
Further,
Finally, \(W_1 X_1(W_1)\) is a \(\textrm{Gamma}(2,1)\) r.v. under \(\textbf{Q}^k_\infty \). The result follows by a straightforward induction since the case \(k=1\) was proved in Lemma 7. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Foutel-Rodier, F., Schertzer, E. Convergence of genealogies through spinal decomposition with an application to population genetics. Probab. Theory Relat. Fields 187, 697–751 (2023). https://doi.org/10.1007/s00440-023-01223-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-023-01223-7
Keywords
- Spinal decomposition
- Many-to-few formula
- Convergence of genealogies
- Yaglom’s law
- Recombination
- Population genetics