
Abstract
During their lifetimes, individuals in populations pass through different states, and the notion of an occupancy time describes the amount of time an individual spends in a given set of states. Questions related to this idea were studied in a recent paper by Roth and Caswell for cases where the environmental conditions are constant. However, it is truly important to consider the case where environments are changing randomly or in directional way through time, so the transition probabilities between different states change over time, motivating the use of time-dependent stage-structured models. Using absorbing inhomogenous Markov chains and the discrete-time McKendrick–von Foerster equation, we derive explicit formulas for the occupancy time, its expectation, and its higher-order moments for stage-structured models with time-dependent transition rates. The results provide insights into the dynamics of long lived plant or animal populations where individuals transition in both directions between reproductive and non reproductive stages. We apply our approach to study a specific time-dependent model of the Southern Fulmar, and obtain insights into how the number of breeding attempts depends on external conditions that vary through time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The study of structured populations in ecology often is focused on organisms with a life history with distinct yearly events. A seminal contribution to this work was that of Leslie in the 1940’s (Leslie 1945) who represented the dynamics of age-structured populations using a discrete-time model formulated as a vector with entries representing the number of individuals at different, equally spaced, ages, and a matrix representing yearly transitions with the entries in the top row representing births and the sub-diagonal elements representing the year to year survival probabilities. Similar representations can be used to study spatially structured populations, and more commonly stage-structured populations (Caswell 2001, Lefkovitch 1965). In the latter case, entries represent yearly transition probabilities between different stages in the population. For some stage-structured populations, individuals transition back and forth between reproductive and nonreproductive states, and of great interest is the overall time individuals spend in reproductive states during their lifetime. This behavior typically occurs in organisms where successful reproduction represents a substantial expenditure of energy. Examples of organisms that do these kind of transitions are plants, with orchids a prominent example Shefferson et al. (2019). The importance of focusing on these transitions for understanding the dynamics of plant populations, especially in variable environments, has been emphasized Gremer et al. (2012), Alahuhta et al. (2017). Other organisms that move between breeding and nonbreeding states are large birds such as the Southern Fulmar Jenouvrier et al. (2015) and the California condor Meretsky et al. (2000) where individuals transition between breeding and nonbreeding states.
Although ecologists typically think of stage-structured modeling approaches as focusing on the numbers of individuals in different states, a different interpretation is possible if we break up the model into two pieces: one representing reproduction, and the other representing transitions among states not involving reproduction. This separation of the description of reproduction from the description of transitions between states by organisms (see e.g. Cushing (1998)) is a standard approach that is often useful. Interpretations of these stage-structured models usually assume that the matrix entries representing these transition rates are constant, ignoring both any effects of density dependence or any influence of environmental changes through time. Consequently, the state vector in the submodel that does not include reproduction could equivalently be considered as the probability that a single organism is at a particular state. The initial condition for this view is not the number of individuals in different states, but the probability distribution for the states that a focal individual starts in. Another feature is that organisms are not immortal, so an additional state could be included representing death.
Under this alternate interpretation, the discrete-time model can be viewed as a finite state inhomogeneous absorbing Markov chain. The different states of the Markov chain correspond to reproductive states or physical location. A new view that emerges from this interpretation is that it makes sense to consider the amount of time (number of years) that an organism spends in some subset of the states in the model. For example, an organism may move in and out of breeding states, if breeding one year moves the organism to a nonbreeding state the following year. Observations may easily be able to tell if an organism is breeding or non-breeding, or clearly flowering or nonflowering for plants. Thus it makes sense to consider how much time an individual spends in the breeding state. More generally, for a given set of states, the amount of time an individual spends in that set over its lifetime is called the occupancy time.
This intriguing view of dynamics of individuals has been explored theoretically in a recent paper by Roth and Caswell (2018). The key assumption that the probabilities of transitions between different states are constant through time produces a resulting Markov chain that is homogeneous. Then, using ideas from the theory of Markov chains they develop formulas to calculate various quantities of biological interest including the expected occupancy time of an individual in a target set as well as other aspects.
Yet, environments, and hence transition probabilities between states for an individual, are not constant through time. On shorter time scales, there is important environmental variability, such as El Ninos and the Pacific decadal oscillation, with similar cycles in other locations around the globe. Perhaps more importantly, global change is leading to dramatic longer term secular changes in the life histories of individual organisms. Thus, an important feature to include in demographic models for ecological populations is possible changes in the environment through time, representing either short or long term environmental fluctuations. In this case, the resulting demographic models lead to inhomogeneous Markov chains. In this article, we derive formulas for the distribution and moments of occupancy times for inhomogeneous Markov chains which will highlight the role that environmental variability can play. We will also demonstrate how to calculate and interpret these quantities with a specific application, given by breeder states of the Southern Fulmar bird population.
2 Occupancy times for inhomogeneous Markov chains
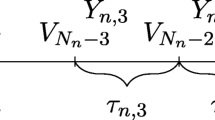
The transition probabilities among states for living organisms at any fixed time can be represented by a column sub-stochastic matrix, as no individuals are created, but death is possible. Since we allow for changes in these rates through time, we use a sequence of column sub-stochastic matrices through time to represent transition probabilities between states for individuals during their lifetime. Thus, let \(\{B(n)\}_{n\in {\mathbb {N}}_0}\) be a sequence of column sub-stochastic matrices in \({\mathbb {R}}^{d\times d}\), i.e. for all \(n\in {\mathbb {N}}_0=\{0,1,2,\dots \}\), all entries of B(n) are non-negative, and for \(j\in \{1,\dots ,d\}\), we have \(\sum _{i=1}^dB_{ij}(n)\le 1\). The matrix element \(B_{ij}(n)\) describes the probability an individual moves from state j to state i at the discrete time step from time n to time \(n+1\). Thus, the sum of the entries in the columns are less than one because we allow transition to death, which is not explicitly included as a state. Accordingly, the probabilities describing the evolution from time m to time \(n>m\) are given by the elements of the transition operator
corresponding to the linear nonautonomous difference equation \(x_{n+1}=B(n)x_n\), see Kloeden and Rasmussen (2011), Pötzsche (2010).
Although the question of occupancy times can be analysed in a purely deterministic nonautonomous setting, we aim at a stochastic description in order to make the analysis of statistical quantities more convenient. Let \(\{{\bar{X}}_n\}_{n \in {\mathbb {N}}_0}\) be the corresponding inhomogeneous absorbing Markov chain on the finite state space \(S=\{1,\dots , d\}\) that starts in the probability vectorFootnote 1\(v\in [0,1]^d\), and note that we have
and
We now extend our model to include death. We define the absorption probabilities at time \(n\in {\mathbb {N}}_0\) by \(b(n) = ({\text {Id}}-B(n))^T\mathbb {1}_d\), where \(\mathbb {1}_d = (1,\dots ,1)^T\in {\mathbb {R}}^{d}\). Here, \({\text {Id}}\) denotes the identity matrix. It is convenient to explicitly include an additional state representing death, and hence we can extend our absorbing Markov chain \(\{{\bar{X}}_n\}_{n\in {\mathbb {N}}_0}\) to obtain a full Markov chain \(\{X_n\}_{n\in {\mathbb {N}}_0}\), which is generated using the transition matrices
We note that the Markov chain \(\{X_n\}_{n\in {\mathbb {N}}_0}\) has values in the extended state space \(S\cup \{d+1\}\). We define the lifetime of the Markov chain \(\{X_n\}_{n\in {\mathbb {N}}_0}\) by
Note that the lifetime N describes the random time that an individual enters the absorbing state \(d+1\), that is the time until death. Its probability distribution can be calculated explicitly.
Proposition 1
The probability distribution of the lifetime is given by
Proof
For all \(n\in {\mathbb {N}}\), we have
which finishes the proof of this proposition. \(\square \)
We are now interested in the random amount of time an individual spends in a subset, such as the breeding state, of the state space consisting of all possible individual states, up to a certain time.
Definition 1
For \(R\subset S\), we define the R-occupancy time at time n by
where \(\#\) denotes the number of elements of the set, and we define \(A_R(0)=0\). The lifetime R-occupancy time
is the amount of time a individual spends in R over its lifetime.
In order to compute the distribution of the lifetime R-occupancy time and its moments, it is useful to consider the joint distribution of the R-occupancy time and the state of the Markov chain at time n, given by
We note that this is not a probability distribution since there is a nonzero probability of death. In fact, the total mass available at time \(n\in {\mathbb {N}}\) is given by \(\sum _{j=1}^d \sum _{a=0}^{\infty } p_j^{R}(a,n) = (1,\dots , 1) \Phi (n,0)v\), which is less than 1 in general.
The following proposition shows that this joint distribution evolves according to a partial difference equation, which is a generalisation of the discretised McKendrick–von Foerster equation for age dependent population dynamics (McKendrick 1926).
Proposition 2
The time evolution of the distribution \(p^{R}_j(a,n)\) is governed by the partial difference equation
for any \(a\in {\mathbb {N}}\) and \(n\in {\mathbb {N}}_0\), with initial conditions

and boundary conditions governed by
Proof
For the evolution equation, we have for all \(a\in {\mathbb {N}}\) and \(n\in {\mathbb {N}}_0\) that
which proves (3). The initial conditions are satisfied by definition, and the validity of the boundary conditions follows from
for all \(j\in S\) and \(n\in {\mathbb {N}}\). \(\square \)
We define \(p^{ R}(a,n):=(p_1^{ R}(a,n),\dots ,p_d^{ R}(a,n))^T\) for all \(a,n\in {\mathbb {N}}_0\). Note that one can write Eq. (3) more compactly in matrix form
where we have allowed R to also stand for the diagonal binary matrix describing the subset \(R\subset S\), defined by

The following theorem explains how to calculate the distribution and moments of the lifetime R-occupancy time \(\tau _R\).
Theorem 1
For any \(R\subset S\), the distribution of the lifetime R-occupancy time \(\tau _R\) is given by
for all \(a\in {\mathbb {N}}\). The moments of \(\tau _{R}\) are given by
where \(m^{R}_k(n) = \sum _{a=0}^{\infty }a^k p^{ R}(a,n)\in {\mathbb {R}}^d\) for all \(k\in {\mathbb {N}}_0\). We demonstrate how to efficiently calculate the terms \(m_k^R(n)\) below in Proposition 3.
Proof
For all \(a\in {\mathbb {N}}\), we have
Note that from the second to the third line, we used conditional independence of the random variables \(X_{n}\) and \(A_R(n)\) given \(X_{n-1}\). This proves (4). To prove (5) we observe
\(\square \)
We now demonstrate how to calculate the terms \(m^{R}_k(n) = \sum _{a=0}^{\infty }a^k p^{ R}(a,n)\) without having to solve Eq. (3). Fundamental is the observation that for a fixed \(k\in {\mathbb {N}}\), the sequence \(n\mapsto m^R_k(n)\) solves a difference equation, involving also terms \(m^R_\ell (n)\), where \(\ell <k\).
Proposition 3
Consider \(R\subset S\). Then the sequence \(n\mapsto m_0^R(n)\) satisfies the difference equation
For \(k\in {\mathbb {N}}\), the sequence \(n\mapsto m_k^{ R}(n)\) satisfies the difference equation
The initial conditions are given by \(m_0^R(0)=v\) and \(m_k^R(0)=0\) for all \(k\in {\mathbb {N}}\).
Proof
Firstly, the definition of \(m_0^R\) and (2) imply that \(m_0^R(n) = \Phi (n-1,0)v\), which proves that it satisfies the above difference equation. Next, for \(k\in {\mathbb {N}}\), we use the matrix form
of (3) and obtain
This finishes the proof of this proposition. \(\square \)
The pseudo code presented in Fig. 1 describes how to efficiently implement the formulas in Theorem 1 and Proposition 3 to approximate the first K moments of the lifetime R-occupancy time for a given set of transition matrices \(\{B(n)\}_{n\in {\mathbb {N}}_0}\). The idea is to iteratively solve the set of difference equations described in Proposition 3 while simultaneously building up the sums in (5) for finitely many natural numbers \(n=0,\dots ,N\).

We close this section by a short discussion how the analysis is simplified when looking at certain special cases.
We first consider the special case of determining the future life of an organism, \(R=S\). If we assume that \(X_n=j\) for some \(n\in {\mathbb {N}}_0\) and \(j\in S\), then this implies that \(A_S(n)=n\), and hence, \(p_j^S(n,n)={\mathbb {P}}\{X_n = j\} = (\Phi (n,0)v)_j\), and we have \(p_j^S(a,n)=0\) whenever \(a\not =n\). A consequence of this is that the partial difference Eq. (3) from Proposition 2 reduced to a (non-partial) difference equation of the form
with \(p^S(0,0)=v\). Formula (4) in Theorem 1 then simplifies to
and the formulas in Proposition 3 simplify slightly, since the matrix R is the identity matrix and can be removed. Also note that this becomes identical to the probability distribution of the lifetime given in Proposition 1.
Now consider the special case that the transition probabilities between stages are constant through time, so the Markov chain is homogeneous, which has been treated in Roth and Caswell Roth and Caswell (2018) using a different approach. Since the matrix B(n) and the vector b(n) do not depend on \(n\in {\mathbb {N}}_0\) in this case, the probability distribution of the lifetime is given in this special case by
which is known as a phase-type distribution (Neuts 1981). The formulas in Theorem 1 and Proposition 3 do not simplify, except that the matrix B and the vector b do not depend on time.
Finally, in case the Markov chain is homogeneous and \(R=S\), the above discrete-time phase-type distribution is also the distribution of the occupancy time \(\tau _S\), and respective quantities for expectation and higher-order moments can be obtained more easily from Neuts (1981); see also Metzler and Sierra (2018), where the continuous-time case is treated via absorbing Markov processes.
3 Occupancy times in breeder stages of the Southern Fulmar
We illustrate our theory of occupancy times for inhomogeneous Markov chains using a stage-structured model describing the life cycle of the Southern Fulmar. The Southern Fulmar is a sea bird with colonies along the coast of Antarctica. There are four states that the bird can be in, the structure of the model is shown in Fig. 2.

Shows the four states of the Southern Fulmar model and how they are connected. Pre-breeder refers to birds which have yet to breed for the first time. Successful breeders have raised a chick that year. Failed breeders have found a mate but either failed to hatch an egg or the chick died. Finally non-breeders refers to birds who have previously bred but have no mate that year
The rates of transition between these four states depend on the ice conditions in that year. In Jenouvrier, Péron, and Weimerskirch Jenouvrier et al. (2015), the years are classified as favorable, ordinary and unfavorable. In favorable years the colony is close to the edge of the sea ice. This means foraging trips are shorter and more likely to be successful.
In Sect. 3.1, we first consider deterministic, but time-dependent, rates that describe transitions between these four states, and in Sect. 3.2, we use a random model to describe changes in the external environment.
3.1 Deterministic external environments
In Jenouvrier et al. (2015), the transition rates between the four different states have been obtained using satellite data between 1979 and 2010. This involved classification of the three different ice conditions (favorable, ordinary, unfavorable), see Fig. 3, and three different transition matrices (\(U_f\), \(U_o\), \(U_u\)) corresponding to the possible ice conditions:

Shows the sequence of ice conditions between 1979 and 2010. The favorability of a year is determined by the distance between the ice edge and the colony, and the total sea ice area. The average life expectancy of a bird is around 12 years
We are interested in how many years of a bird’s life it attempts to breed. Note that a breeding attempt occurs if the bird is either in the Successful Breeder or Failed Breeder state. This means that, using the notation of the previous section, we are interested in the set \(R=\{2,3\}\) and the lifetime R-occupancy time \(\tau _R\) is the number of breeding attempts a bird makes in its life. In Fig. 4 we use Equ. (5) to calculate the expected value and co-efficient of variation for \(\tau _R\) for four different scenarios (as explained in the caption of this figure). In Fig. 5, we use Equ. (4) to calculate the distribution of \(\tau _R\) for the four scenarios.

Compares the expected value a and the co-efficient of variation b of the lifetime R-occupancy time \(\tau _R\) for different initial states. We compare the three autonomous scenarios of constant conditions with the time varying conditions described in Fig. 3

Panel a shows the full probability distribution \(a\mapsto {\mathbb {P}}\{\tau _R=a\}\) of the lifetime R-occupancy time for individuals initialised in the successful breeder state. We compare the distribution for the time-dependent scenario shown in Fig. 3 with constant conditions. Panel b shows the expected value of the lifetime R-occupancy time as a function of the year they first entered the successful breeder state
We conclude that for the time-dependent scenario shown in Fig. 3, the statistical properties of the lifetime R-occupancy time is quite similar to the scenario where all the years are ordinary. The effects of the occasional favorable and unfavorable years approximately balance each other out, but such a conclusion would not have been possible using a purely time-independent analysis of a homogeneous Markov chain.
3.2 Randomly varying external environments
The formulas and algorithm presented in Sect. 2 are valid for an arbitrary sequence of time-dependent transition matrices \(B=\{B(n)\}_{n\in {\mathbb {N}}_0}\). A particularly relevant source of such time-dependence arises from a Markov chain with transition probabilities varying randomly through time. In this subsection, we formulate this mathematically and apply it to the Southern Fulmar example.
In order to treat the case of a randomly varying environment we need to specify a probabilistic model of the environment. This is obtained by specifying a probability distribution on the set consisting of sequences of transition matrices. Below we describe a very simple model which is tailored to our Southern Fulmar example. However, the ideas described remain valid for any application and for more complicated probabilistic models. This could involve, for example, temporal correlations or an infinite set of possible transition matrices.
For the Southern Fulmar example, we have chosen a particularly simple probabilistic model by assigning probabilities \(P_f\), \(P_u\), \(P_o\in [0,1]\) for favorable, unfavorable and ordinary years, respectively. We clearly must have
We can generate a random sequence of transition matrices by picking the matrices \(U_f\), \(U_u\), \(U_o\) according to the probabilities \(P_f\), \(P_u\), \(P_o\) independently at each time-step. We use \(\mu \) to denote the probability measure on the set of sequences of matrices which is described above. For example we have
We note that there are now two separate sources of randomness contributing to lifetime R-occupancy time, see also Shoemaker et al. (2020), Brett (2008).
-
1.
The demographic stochasticity modelled by the Markov chain, as used in the first part of the paper. Different individuals born at the same time take different demographic paths due to this level of randomness. We use \({\mathbb {E}}_{{\mathbb {P}}_B}\) to denote expectations taken over only this level of randomness. Here we emphasise the dependence on the specific sequence of matrices B.
-
2.
The environmental stochasticity from the varying conditions. All individuals in the population at a given time experience the same randomly changing conditions. We use \({\mathbb {E}}_{\mu }\) to denote expectation taken over only this level of randomness.
As ecologists have emphasized Shoemaker et al. (2020), Brett (2008), demographic stochasticity is the dominant stochastic force in small populations, while environmental stochasticity is more important in larger populations, so it is important to examine the effects of both. We additionally note that climate change is expected to have large effects not only on means but on variability van der Wiel and Bintanja (2021), which is a further reason for focusing on the effect of variability on population dynamics.
The method described in Sect. 2 allows us to efficiently calculate the moments and distribution of the lifetime R-occupancy time for a specific sequence of transition matrices. This means we can obtain averages over the demographic stochasticity as described in the pseudo code in Fig. 1, so we do not need to resort to Monte Carlo simulation. However, to numerically obtain expected values over the environmental stochasticity we do have to randomly generate many sequences of matrices, apply the algorithm explained in Fig. 1 for each of the randomly generated sequences, and then take the average.
In Fig. 6 we show how the expected value and the co-efficient of variation of the lifetime R-occupancy time taken over both levels of randomness depend on the probabilities \(P_f\), \(P_u\) and \(P_o\) of the three different ice conditions. Unsurprisingly, we see in Fig. 6a that an increased probability of favorable years results in a large increase in the expected number of breeding attempts. We also see that a high probability of unfavorable years causes more relative variability in the number of breeding attempts.

a expected value and b coefficient of variation of the lifetime R-occupancy time as a function of the probabilities \((P_f, P_o, P_u)\). Here the expectation are taken over both the demographic and environmental stochasticity. For each \((P_f, P_o, P_u)\) we sample 2000 random sequences of matrices. For each random sequence of transition matrices we use the formulas in the previous section to calculate the demographic level expected value and variance. Then we average over the 2000 samples to approximate the statistics. Individuals are initialised in the pre-breeder state. It is helpful in understanding this figure to note that the three corners of the triangle correspond to constant deterministic conditions as shown in Fig. 4
It is interesting to consider how much the two levels of stochasticity contribute to the uncertainty expressed by the co-efficient of variation shown in Fig. 6b. We can decompose the variance to show the contribution of the two sources of randomness and obtain
The total variance is the sum of the environmental expected value of the demographic variance and the environmental variance of the demographic expected value. In Fig. 7, we see that, for our model, almost all of the observed variance is explained by the demographic stochasticity rather than the environmental stochasticity.

Shows the contributions of the two sources of variance in the lifetime R-occupancy time. The expected value of the demographic level variance (a) is much larger than the variance of the demographic level expected value (b). The computations are done in the same way as Figure 6
4 Conclusions
We have presented extensions to the analysis of occupancy times for states in a compartmental model such as a stage-structured demographic model from the case of constant transition rates through time previously analyzed by Roth and Caswell Roth and Caswell (2018) to the important case of time-varying transition rates. For demographic models, understanding how the amount of time individuals will spend in different states as environmental conditions change, either randomly or on a longer term from global change, is an important question in conservation biology, as exemplified by the demography of the California condor Meretsky et al. (2000) and plants with dormant states Gremer et al. (2012), Alahuhta et al. (2017). We have illustrated this with specific calculations showing how random variations in the environment affect the expected time spent as a breeder in Southern Fulmar populations. Using these ideas in an applied context does bring up questions about the meaning of occupancy time.
We would like to emphasise that there are a number of interpretations of occupancy times for time-dependent compartmental processes, and this has been explored only very recently in the literature Sierra et al. (2017), Metzler (2020). Firstly, it makes a difference whether one considers only a single individual organism or particle, or whether one is interested in dynamical processes that involve a lot of organisms or particles. In this article, we focused on single organisms or particles, and we used a stochastic model. When considering many organisms or particles, the law of large numbers can be used to derive a deterministic model describing the evolution of mass accurately. In our context, the deterministic evolution is given by the difference equation \(x_{n+1}=B(n)x_n\) and solved using the transition operator from (1), via \(\Phi (n,m)v\), where v is a probability vector describing the initial mass distribution. The occupancy time \(\tau _R\) we have developed here carries over naturally to that setting, and the distribution of \(\tau _R\) has the same interpretation, meaning that in particular Theorem 1 applies for \(k=1\), giving the expected occupancy time. We note that higher-order moments for \(k>1\) do not have a meaning in this large particle limit.
For large particle systems, a different analysis is possible for time-dependent compartmental processes, in either discrete or continuous time, that also have inputs. These are modelled in the linear case either as a nonautonomous linear difference equation \(x_{n+1}=B(n)x_n + s_n\) or differential equation \(\dot{x} = B(t)x +s(t)\). The theory developed here also applies to this setting with the interpretation that the initial mass probability distribution v is determined by the input vector \(s_n\) or s(t) at time n or t, respectively. This yields a (time-dependent) occupancy time describing this quantity for all particles that enter the system at a particular time, but a different perspective is possible here and was first explored in Rasmussen et al. (2016). Instead of considering the future of all particles that come into the system at some time n or t, one can also look at for how long particles leaving the system at a particular time have spent in a certain subset, which essentially covers the past of the system. We note that for autonomous systems at equilibrium, these two approaches are the same. These two approaches yield different answers not only for nonautonomous systems, but also for autonomous systems that have not yet reached equilibrium.
As an example of where these different definitions of occupancy times for subsets of the states could be important in understanding dynamics, a discrete-time version of the carbon cycle models considered in Rasmussen et al. (2016) is illustrative. These models look at the expected time that carbon is in various pools. The approaches we have outlined in this paper could be used, for example, to determine the expected time a molecule spends in the litter pool (as opposed to the soil or vegetation pools).
We finally note that the methods we have developed here, as well as the variations discussed in the preceding paragraphs, are not only relevant for ecology, but can be applied to different settings such as systems biology, pharmacokinetics Anderson (1983), epidemiology Jacquez and Simon (1993) and biogeochemistry Sierra et al. (2017). Despite the fact that some of these applications can naturally be modeled effectively by autonomous dynamical systems, many applications such as the carbon cycle depend on changing environmental conditions, which are either of deterministic or random nature, and thus in the setting of this article.
Notes
The sum of the entries of a probability vector v is equal to 1, i.e. \(\sum _{i=1}^d v_i=1\)
References
Alahuhta Kirsi, Crone Elizabeth, Ettinger Ailene, Hens Hilde, Jäkäläniemi Anne, Tuomi Juha (2017) Instant death, slow death and the consequences of assumptions about prolonged dormancy for plant population dynamics. J Ecol 105(2):471–483
Anderson DH (1983) Compartmental modeling and tracer kinetics, vol 50. Lecture Notes in Biomathematics. Springer, Berlin
Caswell H (2001) Matrix Population Models, 2nd edn. Sinauer Associates, Sunderland, Massachusetts, USA
Cushing JM (1998) An introduction to structured population dynamics, SIAM
Gremer Jennifer R, Crone Elizabeth E, Lesica Peter (2012) Are dormant plants hedging their bets? Demographic consequences of prolonged dormancy in variable environments., The American Naturalist 179(3), 315–327 PMID: 22322220
Jacquez JA, Simon CP (1993) Qualitative theory of compartmental systems. SIAM Rev 35(1):43–79
Jenouvrier S, Péron C, Weimerskirch H (2015) Extreme climate events and individual heterogeneity shape life-history traits and population dynamics. Ecol Monogr 85(4):605–624
Kloeden PE, Rasmussen M (2011) Nonautonomous dynamical systems, mathematical surveys and monographs, vol 176. American Mathematical Society, Providence, RI
Lefkovitch LP (1965) The study of population growth in organisms grouped by stages. Biometrika 35:183–212
Leslie PH (1945) The use of matrices in certain population mathematics. Biometrika 33(3):183–212
McKendrick AG (1926) Applications of mathematics to medical problems. Proc Edinb Math Soc 40:98–130
Brett A (2008) Melbourne and Alan Hastings, extinction risk depends strongly on factors contributing to stochasticity. Nature 454(7200):100–103
Meretsky VJ, Snyder NFR, Beissinger SR, Clendenen DA, Wiley JW (2000) Demography of the california condor: implications for reestablishment. Conserv Biol 14(4):957–967
Metzler H (2020) Compartmental systems as Markov chains: age, transit time, and entropy, Ph.D. thesis, Friedrich-Schiller-Universität Jena
Metzler H, Sierra CA (2018) Linear autonomous compartmental models as continuous-time Markov chains: transit-time and age distributions. Math Geosci 50:1–34
Neuts MF (1981) Matrix-geometric solutions in stochastic models: an algorithmic approach, The Johns Hopkins University Press,
Pötzsche C (2010) Geometric theory of nonautonomous discrete dynamical systems and discretizations, Springer lecture notes in mathematics, vol 1907. Springer, Berlin, Heidelberg, New York
Rasmussen M, Hastings A, Smith MJ, Agusto FB, Chen-Charpentier BM, Hoffman FM, Jiang J, Todd-Brown KEO, Wang Y, Wang Y-P, Luo Y (2016) Transit times and mean ages for nonautonomous and autonomous compartmental systems. J Math Biol 73(6–7):1379–1398
Roth G, Caswell H (2018) Occupancy time in sets of states for demographic models. Theor Popul Biol 120:62–77
Shefferson RP, Jacquemyn H, Kull T, Hutchings MJ (2019) The demography of terrestrial orchids: life history, population dynamics and conservation. Bot J Linnean Soc 192(2):315–332
Shoemaker Lauren G, Sullivan Lauren L, Donohue Ian, Cabral Juliano S, Williams Ryan J, Mayfield Margaret M, Chase Jonathan M, Chu Chengjin, Harpole W. Stanley, Huth Andreas, HilleRisLambers Janneke, James Aubrie R. M, Kraft Nathan J. B, May Felix, Muthukrishnan Ranjan, Satterlee Sean, Taubert Franziska, Wang Xugao, Wiegand Thorsten, Yang Qiang, Abbott Karen C (2020) Integrating the underlying structure of stochasticity into community ecology. Ecology 101(2):e02922
Sierra CA, Müller M, Metzler H, Manzoni S, Trumbore SE (2017) The muddle of ages, turnover, transit, and residence times in the carbon cycle. Glob Change Biol 23(5):1763–1773
van der Wiel K, Bintanja R (2021) Contribution of climatic changes in mean and variability to monthly temperature and precipitation extremes. Commun Earth Environ 2:1
Acknowledgements
Alan Hastings was supported by the US NSF Grant DMS-1817124. Martin Rasmussen was supported by funding from the European Union’s Horizon 2020 research and innovation programme for the ITN CRITICS under Grant Agreement Number 643073. George Chappelle’s work was funded through the EPSRC CDT in Mathematics for Planet Earth. The authors are grateful to Holger Metzler and an anonymous referee for comments leading to an improvement of the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chappelle, G., Hastings, A. & Rasmussen, M. Occupancy times for time-dependent stage-structured models. J. Math. Biol. 84, 16 (2022). https://doi.org/10.1007/s00285-022-01713-7
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00285-022-01713-7