
Abstract
Background
Accurately predicting which patients are most likely to benefit from massive transfusion protocol (MTP) activation may help patients while saving blood products and limiting cost. The purpose of this study is to explore the use of modern machine learning (ML) methods to develop and validate a model that can accurately predict the need for massive blood transfusion (MBT).
Methods
The institutional trauma registry was used to identify all trauma team activation cases between June 2015 and August 2019. We used an ML framework to explore multiple ML methods including logistic regression with forward and backward selection, logistic regression with lasso and ridge regularization, support vector machines (SVM), decision tree, random forest, naive Bayes, XGBoost, AdaBoost, and neural networks. Each model was then assessed using sensitivity, specificity, positive predictive value, and negative predictive value. Model performance was compared to that of existing scores including the Assessment of Blood Consumption (ABC) and the Revised Assessment of Bleeding and Transfusion (RABT).
Results
A total of 2438 patients were included in the study, with 4.9% receiving MBT. All models besides decision tree and SVM attained an area under the curve (AUC) of above 0.75 (range: 0.75–0.83). Most of the ML models have higher sensitivity (0.55–0.83) than the ABC and RABT score (0.36 and 0.55, respectively) while maintaining comparable specificity (0.75–0.81; ABC 0.80 and RABT 0.83).
Conclusions
Our ML models performed better than existing scores. Implementing an ML model in mobile computing devices or electronic health record has the potential to improve the usability.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Over the last few decades, a massive transfusion protocol (MTP) has become a widespread tool in the management of severely injured patients to help ensure that blood products are coordinated and delivered in an expeditious manner while adhering to an optimal ratio of each component of transfusion therapy. There is good evidence that these protocols help clinicians provide earlier and more balanced resuscitation and their use has been associated with improved patient survival [1, 2]. However, MTP activations are resource-intensive events. Not only do they consume large amounts of blood products, but they may also require the allocation of specific human resources, such as blood bank technologists or porters, for hours. Thus, there is a special interest in accurately determining which patients are most likely to benefit from activation of MTP.
Several scoring systems have been created to help clinicians determine when MTP should be activated [3]. The ideal tool would balance sensitivity and specificity for the need for massive blood transfusion (MBT) so that all patients whose outcome depends on the timely activation of MTP would receive it, while excluding patients who would not benefit. Generally, these existing scores were derived from small- to medium-sized trauma patient cohorts. Inputs vary between scores, with some using only vital signs, some relying only on variables available at the bedside in the Emergency Department (ED), and others requiring laboratory values that would need some time process [4,5,6,7]. The calculation complexity also varies between these scores and this added burden may explain why the most cited score, the Assessment of Bleeding Consumption (ABC), is also one of the simplest [6].
Several factors have changed in the past decade which justifies another approach at predicting need for MBT. The number of trauma centers with MTPs has continued to increase [8] and even many small centers now have MTPs [9]. Clinicians in these smaller centers, where MTP is activated more rarely, are more likely to benefit from decision aids. In addition, the ubiquity of intelligent electronic health records (EHR) and stand-alone smartphone applications means that more complex tools may now be practical. Finally, in the last two decades, machine learning (ML) techniques have become increasingly sophisticated, accessible, and reported in medical applications. ML, broadly, uses a number of mathematical methods to process input data and create an output, commonly a prediction or classification. [10]. The purpose of this study was to investigate whether modern ML methods can be used to create a more accurate tool to predict the need for MTP. We hypothesized that ML models using only variables available in the period of the initial trauma assessment can predict the need for MBT more accurately compared to the currently used scoring systems.
Methods
Study design and patients
This is a retrospective study conducted at a high-volume, urban Level 1 Trauma Center. After approved by the Institutional Review Board, the institutional trauma registry was queried to identify eligible patients and retrieve the data between June 1, 2015 and August 31, 2019. Further information was collected from the EHR and digital picture archiving system. The study population included all patients (age ≥ 16 years) who presented as trauma team activations (TTA). The TTA criteria at our institution are included in Supplemental Table 1. Patients were excluded if they presented without any signs of life or if they had missing Glasgow Coma Scale (GCS) or ED vital sign values.
Data collection
Variables available during the initial trauma assessment in the ED were collected (age, sex, body mass index [BMI], mechanism of injury, pre-hospital and ED vital signs, and GCS). Results of the extended focused assessment with sonography for trauma (eFAST) were extracted from the EHR including the location of any positive results (thorax, pericardium, abdomen). Portable pelvis x-ray was reviewed by board-certified surgeons (MS, KM) and assessed for presence of visible pelvic fractures. In the primary analysis, pelvis x-ray was not used in the models because it was not routinely performed. In a sensitivity analysis, pelvis x-ray results were included to evaluate for changes in prediction model performances. Finally, blood transfusion data were obtained including number of units and timing of transfusions, type of product transfused, and whether MTP was activated.
Statistical analysis
The outcome of interest was need for MBT which was defined as the need for ≥10 units of packed red blood cells (PRBC) in the first 24 h after arrival. We tested commonly used ML techniques including regression (simple and penalized) and decision trees (single tree and random forest) which are the generally interpretable models. We expanded our assessment of ML algorithms by implementing support vector machines (SVMs), naïve Bayes, boosting techniques such as XGBoost and AdaBoost, and neural networks.
All models were validated using a fivefold cross validation process. Under a fivefold cross validation, the data were split into five partitions. The full analysis was then run five times where during each run, a different partition was used as the testing data while the remaining partitions were used as the training data. A model that performs well should show similar performance results across each of the five runs. Some models required a threshold value for classification (e.g., logistic regression). In those cases, we present each model’s performance when we selected a threshold value that minimizes the distance from the receiver operating characteristics (ROC) curve to perfect sensitivity and specificity. In practice, different thresholds can be selected to reflect the local preferences for higher sensitivity or specificity. We evaluated model performance by looking at the following metrics of interest across our cross validation: area under the curve (AUC), sensitivity, specificity, positive predicted value (PPV) and negative predicted value (NPV). In addition to comparing our prediction models to each other, we also compared our models’ performance to the ABC score [6] and the Revised Assessment of Bleeding and Transfusion (RABT) score [7], when applied to our patient set.
Results
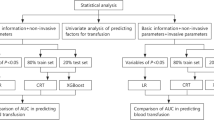
During the study period, 4102 TTA patients were identified in our trauma registry. After excluding patients under age 16 years, with no signs of life upon arrival, and with missing information, a total of 2,483 patients were included for analysis (Fig. 1). The median age was 37 years, median SBP of 135 mmHg, and DBP of 90 mmHg (Table 1). The mean injury severity score was 13. Approximately 98% of the patients had an eFAST examination performed with 15.7% of those results being positive. Only 37% of the patients underwent a pelvis x-ray, and after verifying against patient charts, 11.7% of those patients had positive results. While MTP was activated 233 times (9.4%), only 121 (4.9%) required MBT within the first 24 h of arrival. Full descriptive statistics are shown in Table 2.

Patient flow diagram. GCS: Glasgow Coma Scale
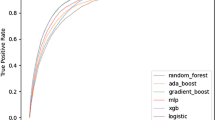
In our study population, we observed that the ABC score had a sensitivity of 0.36, specificity of 0.80, PPV of 0.08, and NPV of 0.96. The RABT score had values of 0.55, 0.83, 0.14, and 0.23 for sensitivity, specificity, PPV, and NPV, respectively. Compared with these scores, all ML models had comparable or higher sensitivity. All models, except for SVM. Naïve Bayes, and Neural networks had comparable specificity, PPV, and NPV. Full performance metrics with mean and standard errors from the cross-validation results are shown in Table 3. The ROC curves for all tested models are shown in Fig. 2. In a sensitivity analysis where all ML models are re-run using the pelvis X-ray information, we find that our model performance generally improves with logistic regression reaming as a high performing model. Model performance metrics for the sensitivity analysis are presented in the supplementary document in Supplemental Table 2.

Comparison of ML models using ROC curves. ML: machine learning, ROC: receiver operating characteristics, ABC: Assessment of Blood Consumption, RABT: Revised Assessment of Bleeding and Transfusion
Discussion
The current study showed that most ML methods outperform the ABC score and RABT score in predicting the need for MBT in TTA patients. We used a large patient dataset, approximately five times larger than those used by other groups to develop scoring systems and limited our inclusion to objective data available early in the initial trauma assessment. A machine learning framework was then used to evaluate numerous ML tools and compare them in terms of test characteristics. Although one other study has used a modern ML method [11], we report the first multi-method approach, searching to optimize prediction over a broad range of techniques.
Predicting who will require MBT has been an area of ongoing research for nearly two decades. Early activation of MTP is associated with improved mortality in several studies [1, 2] and, as these protocols have become widespread, the need for decision aids has presumably increased. At least 15 scoring systems predicting MBT requirement have been described and the pros and cons of each of these have also been reviewed [12, 13]. Notably, most of these scoring systems are derived retrospectively from single-center experiences. Prior work has demonstrated that, in general, the more variables are considered, the better the score performs. The simplest scores use only physiologic data or a combination of physiologic data and information about mechanism [14, 15]. More comprehensive scores use data obtained from the FAST exam, laboratory results, and plain radiography [5,6,7, 16]. While additional variables tend to improve score performance in terms of predictive power, waiting for laboratory studies to result or medical imaging may lead to delays in MTP activation which ultimately could erode the benefit of early activation. In this study, we therefore focused on patient characteristics that are readily available early upon arrival to the trauma center, to preclude delay for laboratory results. The number of variables, while more comprehensive than the simplest, most popular scores currently in use, was also selected to not be too large so as to become onerous to use in a trauma setting with the help of an electronic app.
The majority of existing scoring systems were derived by using regression methods and relatively small populations. The ABC score, for example, was derived from a cohort of 596 patients with 77 massive transfusion events [6]. The RABT score used a population of 380 patients and 102 massive transfusions [7]. Many of the existing scores dichotomize the input variables to make calculation simpler, at the expense of accuracy. As an example, the ABC score assigns one point for SBP ≤ 90 mmHg which means that, all other factors being equal, a patient with SBP of 91 mmHg is regarded the same way as a patient with an SBP of 120 mmHg. This desire for simplicity is pervasive among risk scores. This was a necessary feature of classic scores such as Ranson’s criteria for acute pancreatitis mortality or the Child–Pugh score for cirrhosis mortality where clinicians simply did not have access to computing power to perform more sophisticated calculations [17, 18]. With the widespread availability of smartphones, tables, and other mobile devices in the clinical setting and the increased adoption of EHR systems, modern scoring systems may benefit from more complex models. Our group has been working on the development of a mobile app to be used by clinicians in real time without increasing their workload. Given the paucity of data on the use of mobile apps in a highly stressful medical environment, future studies should evaluate usability of the prediction app in the acute trauma setting.
In contrast to existing scoring systems, the current study explored different ML techniques for MBT prediction. ML has brought standardized techniques by which to evaluate and compare statistical models beyond those which were traditionally used. AUC, sensitivity, specificity, PPV, and NPV are widely used and understood metrics by which multiple models can be transparently compared. It has also increased the acceptance of cross validation and other methods to identify over- and underfitting, which may be particularly valuable when data comes from a single center and may not be generalizable a priori. In this work, we examine the performance of existing methods (such as ABC score, etc.) against ML methods on these metrics using fivefold cross validation to provide multiple perspectives in understanding how this data might perform in a real-world setting.
Our results identified 3 ML models that were comparable or outperformed the well-accepted ABC score and RABT score across all metrics: logistic regression, Random Forest, and AdaBoost. The remaining models still perform better in terms of sensitivity but have noticeably lower specificity. Given that many of these models performed very similarly, choosing the optimal model to build into production depends in part on human factors and the costs of over- or under-classifying. Ultimately, the final model we would recommend is the complete simple logistic regression without applying any variable selection or regularization. We identify this as the most preferable model for three reasons: (1) The complete simple logistic regression performance is as good as, if not better, than the other ML approaches tested, (2) A simple logistic regression is highly interpretable and more familiar to clinicians, which will assist in future efforts toward implementation. For example, our regression results confirm that a higher heart rate is an indicator of increased need for MBT, (3) Removing variables that a physician may deem to be significant can result in skepticism regarding the model, and translate to further challenges in implementation. Additionally, as previously discussed, we left out pelvic x-ray results because it is not consistently performed in our study cohort, thus rendering the model useless if pelvic results were required. Sensitivity analysis did however show that incorporating pelvic x-ray results can improve predictive performance.
Our study has several limitations. First, our training and validation datasets were composed of retrospective data collected at discrete points in time. Although this remains how data are stored in trauma registries, clearly some information was lost through this simplification. Having multiple sets of physiologic data or even continuous information, for example, might lead to better prediction as has been demonstrated in other ML applications [19]. Second, we included all patient data accessible retrospectively, but other streams available to the clinician at the point of care were not included. These include subtleties about the mechanism, patient medications, and the patient’s general appearance which, especially to expert clinicians, may carry strong predictive value. Third, we had to handle some variables cautiously because of associated information that would erode at the generalizability of our results. At our center, for example, pelvic x-ray is not routinely performed because our time to computed tomography (CT) is sufficiently low that we consider it unnecessary in most patients. Thus, plain film is often reserved for patients who are particularly unwell and who, in the trauma attending’s opinion, may not be stable enough for CT. In early iterations of our algorithms, this resulted in a strong positive association between merely receiving a pelvic X-ray and need for massive transfusion. The result is that we had to exclude an important potential source of data because of this confounding effect. Finally, like most studies attempting to create a prediction tool, there is the risk of overtraining to our data set and not being able to reproduce our results on another population of patients.
Conclusions
Our results suggest that the use of modern ML methods can significantly improve the accuracy in predicting the need for MBT. However, this improvement must be validated and the feasibility of implementing these algorithms in the trauma bay environment must be explored in future studies.
References
Dente CJ, Shaz BH, Nicholas JM et al (2009) Improvements in early mortality and coagulopathy are sustained better in patients with blunt trauma after institution of a massive transfusion protocol in a civilian level I trauma center. J Trauma 66:1616–1624
Riskin DJ, Tsai TC, Riskin L et al (2009) Massive transfusion protocols: the role of aggressive resuscitation versus product ratio in mortality reduction. J Am Coll Surg 209:198–205
Cantle PM, Cotton BA (2017) Prediction of massive transfusion in trauma. Crit Care Clin 33:71–84
McLaughlin DF, Niles SE, Salinas J et al (2008) A predictive model for massive transfusion in combat casualty patients. J Trauma 64:S57-63
Schreiber MA, Perkins J, Kiraly L et al (2007) Early predictors of massive transfusion in combat casualties. J Am Coll Surg 205:541–545
Nunez TC, Voskresensky IV, Dossett LA et al (2009) Early prediction of massive transfusion in trauma: simple as ABC (assessment of blood consumption)? J Trauma 66:346–352
Joseph B, Khan M, Truitt M et al (2018) Massive transfusion: the revised assessment of bleeding and transfusion (RABT) score. World J Surg 42:3560–3567
Etchill E, Sperry J, Zuckerbraun B et al (2016) The confusion continues: results from an American Association for the Surgery of Trauma survey on massive transfusion practices among United States trauma centers. Transfusion 56:2478–2486
Chin V, Cope S, Yeh CH et al (2019) Massive hemorrhage protocol survey: marked variability and absent in one-third of hospitals in Ontario, Canada. Injury 50:46–53
Liu Y, Chen PC, Krause J et al (2019) How to read articles that use machine learning: users’ guides to the medical literature. JAMA 322:1806–1816
Mina MJ, Winkler AM, Dente CJ (2013) Let technology do the work: Improving prediction of massive transfusion with the aid of a smartphone application. J Trauma Acute Care Surg 75:669–675
Shih AW, Al Khan S, Wang AY et al (2019) Systematic reviews of scores and predictors to trigger activation of massive transfusion protocols. J Trauma Acute Care Surg 87:717–729
Tonglet ML (2016) Early prediction of ongoing hemorrhage in severe trauma: presentation of the existing scoring systems. Arch Trauma Res 5:e33377
Mitra B, Cameron PA, Mori A et al (2011) Early prediction of acute traumatic coagulopathy. Resuscitation 82:1208–1213
Rau CS, Wu SC, Kuo SC et al (2016) Prediction of massive transfusion in trauma patients with shock index, modified shock index, and age shock index. Int J Environ Res Public Health 13:683
Rainer TH, Ho AM, Yeung JH et al (2011) Early risk stratification of patients with major trauma requiring massive blood transfusion. Resuscitation 82:724–729
Ranson JH, Rifkind KM, Roses DF et al (1974) Prognostic signs and the role of operative management in acute pancreatitis. Surg Gynecol Obstet 139:69–81
Pugh RN, Murray-Lyon IM, Dawson JL et al (1973) Transection of the oesophagus for bleeding oesophageal varices. Br J Surg 60:646–649
Reyna MA, Josef CS, Jeter R et al (2019) Early prediction of sepsis from clinical data: the physionet/computing in cardiology challenge 2019. Crit Care Med 48:210–217
Funding
Open access funding provided by SCELC, Statewide California Electronic Library Consortium. Neither internal nor external financial support was used for this study.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors deny any potential conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Strickland, M., Nguyen, A., Wu, S. et al. Assessment of Machine Learning Methods to Predict Massive Blood Transfusion in Trauma. World J Surg 47, 2340–2346 (2023). https://doi.org/10.1007/s00268-023-07098-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00268-023-07098-y