
Abstract
The purpose of this paper is to provide a systematic discussion of a generalized barycenter based on a variant of unbalanced optimal transport (UOT) that defines a distance between general non-negative, finitely supported measures by allowing for mass creation and destruction modeled by some cost parameter. They are denoted as Kantorovich–Rubinstein (KR) barycenter and distance. In particular, we detail the influence of the cost parameter to structural properties of the KR barycenter and the KR distance. For the latter we highlight a closed form solution on ultra-metric trees. The support of such KR barycenters of finitely supported measures turns out to be finite in general and its structure to be explicitly specified by the support of the input measures. Additionally, we prove the existence of sparse KR barycenters and discuss potential computational approaches. The performance of the KR barycenter is compared to the OT barycenter on a multitude of synthetic datasets. We also consider barycenters based on the recently introduced Gaussian Hellinger–Kantorovich and Wasserstein–Fisher–Rao distances.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Over the past decade, optimal transport (OT) based concepts for data analysis (for a thorough treatment of the mathematical foundations of optimal transport see e.g. [59, 60, 72]) have seen increasing popularity. This is mainly due to the fact that OT based methods respect important features of the data’s geometric structure. Furthermore, noteworthy advances have been achieved in various areas, such as optimisation [7, 32, 74], machine learning [24, 56, 75], computer vision [25, 66, 69] and statistical inference [34, 54, 67], among others. This methodological and computational progress recently also paved the way to novel areas of applications including genetics [20, 62] and cell biology [29, 39, 70, 73], to cite but a few. Of particular importance from a data analysis point of view are extensions to compare more than two measures, a prominent proposal being the Fréchet mean [22], in the present context known as Wasserstein barycenter [1]. Wasserstein barycenters allow for a notion of average on the space of probability measures, which is well-adapted to the geometry of the data [3, 4]. With recent progress on their computation [9, 12, 19, 28, 36, 41] they establish themselves even further as a promising tool in many fields of data analysis, such as texture mixing [58], distributional clustering [76], histogram regression [10], domain adaptation [51] and unsupervised learning [63], among others.
However, a well known drawback of the Wasserstein distance and its barycenters in various applications is their limitation to measures with equal total mass. In fact, in many real world instances the difference in total mass intensity is of crucial importance. Employing vanilla Wasserstein based tools on general positive measures necessitates the usage of a normalisation procedure to enforce mass equality between the measures. This approach is, by design, oblivious to the mass differences between the original measures and can limit its use in applications. Exemplary, we mention that normalisation destroys stoichiometric features in the analysis of protein interaction and pathways as pointed out in Tameling et al [70]. Overall, this might lead to incorrect conclusions on specific applications. An illustrative example is given in Fig. 1.

(Unbalanced) OT between two measures (support in blue and brown, respectively) with weights equal to one at each support point. Top-Left: OT plan (red) between normalised versions of the two measures. Rest: UOT plans (red/purple) between non-normalised measures. From top-left to bottom-right C is decreasing. The edges, which have been removed most recently due to the reduction of C, are shown in green. Edges which have been added to the UOT graph due to the most recent reduction of C are marked in purple (Color figure online)
1.1 Prior Work
The limitation of OT based concepts dealing only with measures of equal total mass has opened a wealth of approaches to account for more general measures. As an early proposal of this idea, the partial OT formulation [11, 21] suggests to fix the total mass of the OT plan in advance, while relaxing the marginal constraints. Comparably more recent are entropy transport formulationsFootnote 1. This general framework removes the marginal constraints and instead uses a divergence functional to measure the deviation between the transport marginals and the input measures. The entropy transport framework encompasses the Hellinger–Kantorovich distance [15, 45], also known as Wasserstein–Fisher–Rao distance [14] and the Gaussian Hellinger–Kantorovich distance [45]. Inherent to all of these models is their dependency on parameters whose exact influence on the models’ properties is generally not well understood. An alternative idea is based on extending the well-studied dynamic formulation of OT [5] to measures with different total masses. With a focus on its geodesic properties, this approach has been studied in several works [14, 16, 26].
In this paper, we rely on a simple and intuitive idea based on the seminal work of Kantorovich and Rubinstein [37]. This accounts for mass construction and deletion at a cost modeled by some prespecified parameter (for details see also [33, 35]). It leads to the Kantorovich–Rubinstein distance (KRD) which curiously has been revisited several times under different names by various authors. For \(p=1\), it has been referred to as Earth Mover’s Distance [55], and generalized Wasserstein distance [57], while for general \(p\ge 1\) common terminology includes Kantorovich distance [31], generalized KRD [61], transport-transform metric [53] and robust optimal transport distance [52].
1.2 Contributions
In this work, we define barycenters with respect to the KRD and investigate their fundamental properties from a data analysis point of view. This extends the popular notion of Wasserstein barycenters to unbalanced barycenters (UBCs), i.e., barycenters of measures of different total masses. Similary, UBCs have been considered explicitly for the Hellinger–Kantorovich distance [17, 23] and for the partial OT distance for absolutely continuous measures [38]. Notably, the well-known approach of matrix scaling algorithms has been shown to provide a general framework to approximate any UBC based on entropy optimal transport [15] of finitely supported measures. Closely related to our approach is the work by Müller et al [53] approximating the KR barycenter in the special case of point patterns.
The KR distance: Let \((\mathcal {X},d)\) be a finite metric space, where \(\mathcal {X}=\{ x_1,\dots ,x_N \}\) and
is the set of non-negative measuresFootnote 2 on \(\mathcal {X}\). For a measure \(\mu \in \mathcal {M}_+(\mathcal {X})\) its total mass is defined as \(\mathbb {M}(\mu ){:}{=}\sum _{x\in \mathcal {X}}\mu (x)\) and the subset of non-negative measures with total mass equal to one is the set of probability measures \(\mathcal {P}(\mathcal {X})\). If \(\pi \in \mathcal {M}_+(\mathcal {X}\times \mathcal {X})\) is a measure on the product space \(\mathcal {X}\times \mathcal {X}\) its marginals are defined as \(\pi (x,\mathcal {X}){:}{=}\sum _{x^\prime \in \mathcal {X}} \pi (x,x^\prime )\) and \(\pi (\mathcal {X},x^\prime ){:}{=}\sum _{x \in \mathcal {X}}\pi (x,x^\prime )\), respectively. For two measures \(\mu ,\nu \in \mathcal {M}_+(\mathcal {X})\) we define the set of non-negative sub-couplings as
Similarly, we denote the set of couplings between \(\mu \) and \(\nu \) as \(\Pi _=(\mu ,\nu )\), where the inequality constraints in (1) are replaced by equalities. For \(p\ge 1\) and a parameter \(C>0\), unbalanced optimal transport (UOT) between two measures \(\mu ,\nu \in \mathcal {M}_+(\mathcal {X})\) is defined as
Notably, \(\text {UOT}_{p,C}(\mu ,\nu )\) is finite for all measures \(\mu ,\nu \in \mathcal {M}_+(\mathcal {X})\) with possibly different total masses and a solution of (2) always exists. Here, the parameter C penalizes deviation of mass from the marginals of \(\pi \) with respect to the input measures \(\mu ,\nu \in \mathcal {M}_+(\mathcal {X})\). In particular and unlike the (balanced) OT problem
defined only for measures \(\mu ,\nu \in \mathcal {M}_+(\mathcal {X})\) with equal total mass \(\mathbb {M}(\mu )=\mathbb {M}(\nu )\), UOT in (2) relaxes the marginal constraint and allows optimal solutions to have more flexible marginals. Based upon UOT we define the p-th order Kantorovich-Rubinstein distance between two measures \(\mu ,\nu \in \mathcal {M}_+(\mathcal {X})\) as
For any \(p\ge 1\), it defines a distance on the space of non-negative measures \(\mathcal {M}_+(\mathcal {X})\) and it is an extension of the well-known p-Wasserstein distance \(W_p(\mu ,\nu ){:}{=}\left( \text {OT}_p(\mu ,\nu )\right) ^{\nicefrac {1}{p}}\) defined only for measures of equal total mass. Indeed, the KRD is shown to interpolate in-between OT on small scales and point-wise comparisons on large scales (Theorem 2.2) relative to the parameter C. This allows for an intuitive interpretation of the KRD. More precisely, in Lemma 2.1, we detail a clear geometrical connection between the value of C and the structure of the UOT. In particular, this contrasts the closely related partial OT problem [21] mentioned above. Employing Lagrange multipliers one can see that for any choice of C, there exists a fixed mass m of the partial OT problem, such that these two problems are equivalent. However, finding this value of m requires to solve the UOT problem. We stress that the influence of m on the resulting transport is in general hard to determine, while the impact of C is intuitively clear. Thus, this perspective seems better suited to many applications. For the specific case of measures supported on ultrametric trees (Sect. 2.1.1) we prove (Theorem 2.3) an analogue of the well-known closed formula for the p-Wasserstein distance [40]. Additionally, the computation of the KRD is known to be equivalent to solving a related balanced OT problem [33], allowing to apply any state-of-the-art solver with minimal modifications to compute the KRD and plan.
The KR barycenter: The KRD also lends itself to define a notion of a barycenter for a collection of measures as a generalization of the p-Wasserstein barycenter defined for probability measures \(\mu _1,\ldots ,\mu _J\in \mathcal {P}(\mathcal {X})\) as

Here, \((\mathcal {X},d)\) is assumed to be embedded in some ambient space \((\mathcal {Y},d)\), e.g., an Euclidean space with \(\mathcal {X}\subset \mathcal {Y}\). The distance d on \(\mathcal {X}\) is understood to be the distance on \(\mathcal {Y}\) restricted to \(\mathcal {X}\). For  , any measure
, any measure

is said to be a (p, C)-Kantorovich–Rubinstein barycenter or (p, C)-barycenter for shortFootnote 3. We refer to the objective functional \(F_{p,C}\) as (unbalanced) (p, C)-Fréchet functional. Notably, (p, C)-barycenters’ support is not restricted to the finite space \(\mathcal {X}\) which raises fundamental questions on its structural properties. In the following, we establish that there exists a finite set containing the support of any (p, C)-barycenter (Sect. 2.2). Indeed, this set can be explicitly constructed from the support of the individual \(\mu _i\)’s, but its size grows exponentially in the number of individual measures. However, we prove that there always exists a sparse (p, C)-barycenter whose support size is at most linear in the number of measures (Theorem 2.5). We note that these properties are analogs of well-known properties of Wasserstein barycenters [4], that we re-establish for the unbalanced setting.
Comparably, employing more general entropy transport distances, we are not aware of any similar structural description of their barycenters in terms of the input measures and the parameter. Notably, the entropy optimal transport barycenter of dirac measures is not necessarily finitely supported itself (for an example see [23]). In contrast, our explicit structural description of the support of KR barycenters provides an immediate understanding of its properties for a given choice of C. This clear link between C and the (p, C)-barycenter also allows to incorporate previous knowledge of the measures or the ground space into the choice C. The (p, C)-barycenter can be tuned to be more flexible and provide superior performance compared to its p-Wasserstein counterpart by avoiding to normalise each measure. An illustrative example is included in Fig. 2, where the (p, C)-barycenter detects all clusters correctly, while the Wasserstein barycenter does not provide any structural information on the underlying measures. This showcases potentially superior robustness and flexibility of the (p, C)-barycenter compared to the Wasserstein barycenter. We study this comparison in more detail on multiple synthetic data sets in Sect. 4. Here, the computational resultsFootnote 4 are based on the fact that, due to our structural analysis of the support of the (p, C)-barycenter, it is straightforward to modify any given state-of-the-art solver for the Wasserstein barycenter problem to solve the (p, C)-barycenter problem (Sect. 4.1).

Upper two rows: An excerpt of eight instances of a dataset of \(N=100\) nested ellipses at up to 5 different clusters in \([0,1]^2\). The number of ellipses in each cluster follows a Poisson distribution. For the cluster in the center the intensity is 2 and for the four outer clusters the intensity is 1. Each ellipse is discretized into 50 points with mass 1 at each location. For details on the computational methods refer to Sect. 4. Bottom-Left: The Wasserstein barycenter of the normalized versions of these measures (runtime about 15 hours). Bottom-Right: The (2, 0.2)-barycenter of these measures (runtime about 30 minutes). The (2, C)-barycenter for different values of C can be seen in Fig. 8
2 Kantorovich–Rubinstein Distance and \(\mathbf {(p,C)}\)-Barycenter
In this section, we provide some theoretical analysis of the structural properties inherent in the UOT in (2) and as a consequence to the KRD in (3). We also focus on the variational formulation defining the (p, C)-barycenter in (5).
2.1 KR Distance
In this subsection, we focus on structural properties of minimizers for UOT in (2) and their consequences for the KRD. Notably, one can equivalently restate the penalization of total mass in (2) as
While in (2) the parameter \(C>0\) controls the deviation of the total mass of \(\pi \), the alternative representation (6) demonstrates its marginal characterization. Indeed, the parameter C specifies the maximal distance (scale) for which transportation is cheaper than creation or destruction of mass. More precisely, each optimal solution \(\pi _C\) for (2) induces a directed transportation graph \(G(\pi _C)\) between the support points of \(\mu \) (source points) and the support points of \(\nu \) (sink points). By definition, the graph \(G(\pi _C)\) contains a directed edge \((x,x^\prime )\) if and only if \(\pi _C(x,x^\prime )>0\). For a directed path \(P=(x_{i_1},\ldots ,x_{i_k})\) in \(G(\pi _C)\) its path length is defined as \(\mathcal {L}(P)=\sum _{j=1}^{k-1} d^p(x_{i_j},x_{i_{j-1}})\). The parameter \(C>0\) determines the maximal path length for any path in \(G(\pi _C)\) as the following statement demonstrates.
Lemma 2.1
For \(p\ge 1\), parameter \(C>0\) and measures \(\mu ,\nu \in \mathcal {M}_+(\mathcal {X})\) consider the UOT (2) with an optimal solution \(\pi _C\). The length of any directed path P from the corresponding transport graph \(G(\pi _C)\) is bounded by
In particular, if \(d(x,x^\prime )> C\) then for any optimal solution of 2 it holds \(\pi _C(x,x^\prime )=0\).
A proof is included in Appendix A.2. Lemma 2.1 shows that the underlying transportation graph has maximal path length \(C^p\) which limits the interaction between source and sink points. It will be of crucial importance for closed formulas on ultra-metric trees in the following subsection. As an immediate consequence we obtain some important statements on the KRD in (3) along with its metric property.
Theorem 2.2
For any \(p\ge 1\) and parameter \(C>0\) the following statements hold:
-
(i)
The p-th order KRD in (3) defines a metric on the space of non-negative measures \(\mathcal {M}_+(\mathcal {X})\).
-
(ii)
If \(C\le \min _{x\ne x^\prime } d(x,x^\prime )\), then it holds that
$$\begin{aligned} \text {KR}_{p,C}^p(\mu ,\nu )=\frac{C^p}{2}\text {TV}(\mu ,\nu ), \end{aligned}$$where \(TV(\mu ,\nu ){:}{=}\nicefrac {1}{2}\sum _{x\in \mathcal {X}}|\mu (x)-\nu (x) |\) is the total variation distance. The same equality holds for all \(C>0\) if \(\mu (x)\ge \nu (x)\) for all \(x\in \mathcal {X}\) or if \(\mu (x)\le \nu (x)\) for all \(x\in \mathcal {X}\).
-
(iii)
If \(C\ge \max _{x,x^\prime }d(x,x^\prime )\) and \(\mathbb {M}(\mu )=\mathbb {M}(\nu )\), then it holds that
$$\begin{aligned} \text {KR}_{p,C}^p(\mu ,\nu )=W_p^p(\mu ,\nu ). \end{aligned}$$ -
(iv)
If \(C_1\le C_2\), then it holds
$$\begin{aligned} \text {KR}_{p,C_1}^p(\mu ,\nu )\le \text {KR}_{p,C_2}^p(\mu ,\nu ). \end{aligned}$$
We stress that the metric property of the KRD in Theorem 2.2 (i) has already been established in specific instances, e.g., for \(p=1\) [57]. Our proof follows that of Theorem 2 in Müller et al [53] for uniform measures on point patterns with minor modifications.
Theorem 2.2 demonstrates how two measures \(\mu ,\nu \in \mathcal {M}_+(\mathcal {X})\) are compared with respect to KRD. Depending on the parameter \(C>0\) the optimal value interpolates between p-th order Wasserstein distance on small scales and total variation on larger scales with respect to C. Equivalently, these properties can be shown by considerations of the dual program for UOT in (2) given by

where the equality holds due to strong duality. For \(p=1\) this can be further specified to
which reveals its relation to the flat metric [8] as observed in Lellmann et al [44]; Schmitzer and Wirth [65]. As in general \(\mathbb {M}(\mu )\ne \mathbb {M}(\nu )\), the bound \(f,g\le C^p/2\) on dual feasible solutions f, g is necessary for the dual to be finite. However, if the measures \(\mu ,\nu \in \mathcal {M}_+(\mathcal {X})\) have equal total mass \(\mathbb {M}(\mu )=\mathbb {M}(\nu )\) and \(C\ge \max _{x,x^\prime } d(x,x^\prime )\), then the bound on dual feasible solutions is redundant and we obtain the dual of the usual OT problem

2.1.1 KR Distance on Ultrametric Trees
For OT, the approximations of the underlying distance by a tree metric are common tools for theoretical and practical purposes. The former is usually employed for rates of convergence for the expectation of empirical OT costs [68] while in the latter tree approximations serve to reduce the computational complexity inherent in OT [42]. OT on ultramatric trees is also applied for the analysis of phylogenetic trees [27]. For an efficient computational implementation of UOT on tree metrics we refer to Sato et al [61]. Notably, while OT with tree metric costs has a closed form solution, this fails to hold for its UOT counterpart. An exception is given in terms of ultrametric trees for which not only OT [40] but also UOT admits a closed form solution, which we establish in this subsection.
To this end, consider a tree \(\mathcal {T}\) with nodes V, edges E attached with (non-negative) weights w(e) for \(e\in E\) and a designated root r. Two nodes \(\textsf {v},\textsf {w}\in V\) are connected by a unique path denoted \(\mathcal {P}(\textsf {v},\textsf {w})\) either represented by a sequence of nodes or as a sequence of edges. The distance \(d_\mathcal {T}(\textsf {v},\textsf {w})\) is equal to the sum of the weights of those edges contained in \(\mathcal {P}(\textsf {v},\textsf {w})\). A leaf of \(\mathcal {T}\) is any node such that its degree (number of edges attached to the node) is equal to one and the set of all leaf nodes is denoted as \(L\subset V\). A node \(\textsf {v}^\star \) is termed parent of node \(\textsf {v}\) denoted by \(\text {par}(\textsf {v})=\textsf {v}^\star \) if both are connected by a single edge but \(\textsf {v}^\star \) is closer to the root than \(\textsf {v}\). The parent of the root node is set to \(\text {par}(\textsf {r})=\textsf {r}\). For a node \(\textsf {v}\) its children are the elements of the set \(\mathcal {C}(\textsf {v})=\left\{ \textsf {w}\in V \,\mid \, \textsf {v}\in \mathcal {P}(\textsf {w},\textsf {r})\right\} \). Notice that with this definition \(\textsf {v}\) is a child of itself (Fig. 3a for an illustration).

General Tree Structures: a A tree graph \(\mathcal {T}\) with root r (orange), internal nodes (black) and leaf nodes L (green). By definition \(\text {par}(\textsf {v}_5)=\text {par}(\textsf {v}_{6})=\textsf {v}_2\) and the children of \(\textsf {v}_1\) are equal \(\mathcal {C}(\textsf {v}_1)=\{\textsf {v}_1,\textsf {v}_3,\textsf {v}_4,\textsf {v}_7,\textsf {v}_8\}\). The distance from each leaf node to the root may vary. b An ultrametric tree \(\mathcal {T}\) with height function h (red) such that \(0=h_43<h_3<h_2<h_1<h_0\). Edge weights are defined by the the difference of consecutive height values, e.g. \(w(e_1)=h_0-h_1\). Each leaf node (green) is at the same distance to the root r (orange) (Color figure online)
A tree \(\mathcal {T}\) is termed ultrametric tree if all its leaf nodes are at the same distance to the root. Equivalently, there exists a height function \(h:V \rightarrow \mathbb {R}_+\) that is monotonically decreasing meaning that \(h(\text {par}(\textsf {v}))\ge h(\textsf {v})\) and such that \(h(\textsf {v})=0\) for \(\textsf {v}\in L\). The distance is set to \(d_\mathcal {T}(\textsf {v},\text {par}(\textsf {v}))=\left| h(\textsf {v})-h(\text {par}(\textsf {v}))\right| \) and extended on the full tree (Fig. 3b for an illustration).
Consider an ultrametric tree \(\mathcal {T}\) with height function h and measures \(\mu ^L,\nu ^L\) supported on the leaf nodes \(L\subset V\). We prove that the p-th order KRD admits a closed formula for such a setting. Intuitively, the parameter C restricts transportation of mass up to a certain threshold allowing to decompose \(\mathcal {T}\) into subtrees. Mass transportation is restricted solely within each subtree whereas mass abundance or deficiency is penalized with parameter C for each particular subtree (Fig. 4 for an illustration). We define the set
with the convention that \(\mathcal {R}(C)=\lbrace \textsf {r} \rbrace \) if \(\nicefrac {C}{2}\ge h(\textsf {r})\) and for a node \(\textsf {v}\in V\) set

Closed formula for the KRD on ultrametric trees: a Depending on the regularization \(C>0\) and the underlying height function h the ultrametric tree \(\mathcal {T}\) introduced in Fig. 3b is decomposed into two subtrees. Each node in the set \(\mathcal {R}(C)=\left\{ \textsf {v}_1,\textsf {v}_2\right\} \) (orange) serves as a new root and corresponding subtrees \(\mathcal {T}(\textsf {v}_1){:}{=}\mathcal {C}(\textsf {v}_1)\) and \(\mathcal {T}(\textsf {v}_2){:}{=}\mathcal {C}(\textsf {v}_2)\) are equal their respective set of children with corresponding edges. b The p-th height transformation \(\mathcal {T}_p(\textsf {v}_1)\) and \(\mathcal {T}_p(\textsf {v}_2)\) of the induced subtrees \(\mathcal {T}(\textsf {v}_1)\) and \(\mathcal {T}(\textsf {v}_2)\), respectively. Each subtree is extended by a new root (blue) with an edge (lightblue) whose distance is equal the difference of regularization \(\nicefrac {C^p}{2}\) and the p-th height transformed value of the former root
Theorem 2.3
(KR on ultrametric trees) Consider an ultrametric tree \(\mathcal {T}\) with leaf nodes L and height function \(h:V\rightarrow \mathbb {R}_+\) inducing the tree metric \(d_\mathcal {T}\). For any \(p\ge 1\) and two measures \(\mu ^L,\nu ^L\in \mathcal {M}_+(L)\) supported on the leaf nodes of \(\mathcal {T}\) it holds that
The closed formula in Theorem 2.3 decomposes the underlying UOT into two tasks. While summing over subtrees carried out by the outer sum, the inner sum consists of two terms. The first considers OT within each subtree whereas the second accounts for mass deviation on that particular subtree.
The proof of this formula is given in Appendix A.2.1.
2.2 \(\mathbf {(p,C)}\)-Barycenters
In the finite setting considered in this work a (p, C)-barycenter as defined in (5) always exists, but is not necessarily unique. Moreover, the location and structure of the support of the (p, C)-barycenter are not fixed and hence unknown. For the Wasserstein barycenter there exists a finitely supported, sparse barycenter in this context [4, 43]. We establish analog properties of the (p, C)-barycenter.
Definition 2.4
Let \((\mathcal {Y},d)\) be a metric space, \(p\ge 1\) and \(J\in \mathbb {N}\). A Borel barycenter application \(T^{J,p}\) associates to any points \((y_1,\dots ,y_J)\in \mathcal {Y}^J\) a minimum \(y^\star \in \mathcal {Y}\) of \(\sum _{i=1}^J d^p(y_i,y)\), i.e.,


Centroid sets and barycenters: The support points of three (\(J=3)\) measures (yellow, brown and blue dots) with unit mass at each position. Top: Different centroid sets \(\mathcal {C}_{KR}(3,2,C)\) (red squares) with increasing value of C from left to right. Bottom-Left: The centroid set \(\mathcal {C}^{W}(3,2)\) (dark green squares) corresponding to the 2-Wasserstein barycenter. Bottom-Center: Circles corresponding to \(C^p\) (for two different choices of C) balls around the support points. The grey colouring indicates that there is no overlap of at least two circles in this area and thus no (2, C)-barycenter can have mass in this area. Conversely, the green colouring indicates overlap and thus the potential support area of the barycenter. Bottom-Right: The (2, C)-barycenter (red squares) for a specific choice of C and the 2-Wasserstein barycenter (dark green squares) (Color figure online)
A Borel barycenter application is in general not a function since the minimum does not need to be unique. In particular, \(y=T^{J,p}(y_1,\dots ,y_J)\) only means that y is one of the minima of the average distance function. As the measures \(\mu _1,\ldots ,\mu _J\) are defined on \(\mathcal {X}\) we usually restrict the Borel barycenter application to inputs from the space \(\mathcal {X}\subset \mathcal {Y}\). We define the full centroid set of the measures \(\mu _1,\ldots ,\mu _J\in \mathcal {M}_+(\mathcal {X})\) as
and the restricted centroid set
We stress that for each L-tupel \((x_1,\dots ,x_L)\) one fixed representative of \(T^{L,p}(x_1,\dots ,x_L)\) is chosen for the construction of the centroid set \(C_{KR}(J,p,C)\). To streamline the presentation any statement concerning \(\mathcal {C}_{KR}(J,p,C)\) in the following theorem is to be understood in the sense that there exists a choice of \(\mathcal {C}_{KR}(J,p,C)\) such that the statement holds true.
Theorem 2.5
Let \(\mu _1,\dots ,\mu _J \in \mathcal {M}_+(\mathcal {X})\) be a collection of non-negative measures on the finite discrete space \(\mathcal {X}\subset \mathcal {Y}\). For any \(C>0\) it holds that
-
(i)
$$\begin{aligned} \inf _{\mu \in \mathcal {M}_+(\mathcal {Y})}F_{p,C}(\mu )=\inf _{\begin{array}{c} \mu \in \mathcal {M}_+(\mathcal {Y})\\ \text {supp}(\mu )\subseteq \mathcal {C}_{KR}(J,p,C) \end{array}}F_{p,C}(\mu ). \end{aligned}$$
Moreover, any (p, C)-barycenter \(\mu ^\star \) satisfies \(\text {supp}(\mu ^\star )\subseteq \mathcal {C}_{KR}(J,p,C)\) and its total mass is bounded by
$$\begin{aligned} 0\le \mathbb {M}(\mu ^\star )\le \frac{2}{J}\sum _{i=1}^J \mathbb {M}(\mu _i). \end{aligned}$$ -
(ii)
For any (p, C)-barycenter \(\mu ^*\) and any point \(y \in \text {supp}(\mu ^*)\), there exist UOT plans \(\pi _i\) between \(\mu ^*\) and \(\mu _i\) for \(i=1,\dots ,J\), respectively, such that if \(\pi _i(y,x)>0\), then there exists \(L\ge \lceil J/2 \rceil \), \(x_l\in \text {supp}(\mu _{i_l})\) for \(l=2,\dots ,L\), \((i_2,\dots ,i_L)\subset \{1,\dots ,J\}\) and \(i_l\ne i\) for \(l=2,\dots ,L\) with \(y=T^{L,p}(x,x_{i_2},\dots ,x_{i_L})\), \(\pi _{j}(y,x_{j})>0\) if \(j \in \{i_2,\dots ,i_L \}\).
Additionally, if for any \((x_1,\dots ,x_L)\in \mathcal {Y}^L\) it holds that
$$\begin{aligned} T^{L,p}(x_1,\dots ,x_L)=T^{L,p}(y_1,x_2,\dots ,x_L) \Leftrightarrow x_1=y_1, \end{aligned}$$(10)then \(\pi _i(y,x)\in \{0,\mu ^*(y)\}\) for \(i=1,\dots ,J\).
-
(iii)
If \(M_i{:}{=}\vert \text {supp}(\mu _i)\vert \) for \(1\le i\le J\) then there exists a (p, C)-barycenter \(\mu ^\star \) such that
$$|\text {supp}(\mu ^\star ) |\le \min \left\{ |\mathcal {C}_{KR}(J,p,C) |, \sum _{i=1}^J M_i \right\} .$$ -
(iv)
If \(C_1\le C_2\), then it holds
$$\begin{aligned} \inf _{\mu \in \mathcal {M}_+(\mathcal {Y})}F_{p,C_1}(\mu )\le \inf _{\mu \in \mathcal {M}_+(\mathcal {Y})}F_{p,C_2}(\mu ). \end{aligned}$$ -
(v)
Furthermore, set \(\mathcal {Z}{:}{=}\bigcup _{i=1}^J \text {supp}(\mu _i)\cup \mathcal {C}_{KR}(J,p)\) and define
$$\begin{aligned} d_{\min }^\prime {:}{=}\min _{x\in \mathcal {Z}\setminus \mathcal {C}_{KR}(J,p), \ y\in \mathcal {C}_{KR}(J,p)} d(x,y). \end{aligned}$$If \(C\le d_{\min }^\prime \), then the (p, C)-barycenter \(\mu ^\star \) is given by
$$\begin{aligned} \mu ^\star =\underset{x \in \mathcal {X}}{\overset{}{\sum }} med(\mu _1(x),\dots ,\mu _J(x))\delta _{x}. \end{aligned}$$ -
(vi)
Let \(C>J^{1/p}\text {diam}(\mathcal {Z})\) and let \(\mu _1,\dots ,\mu _J\) be ordered such that \(\mathbb {M}(\mu _i)\le \mathbb {M}(\mu _j)\) for \(i\le j\). Suppose that J is odd or there there exists no point \(y \in \mathcal {Y}\) contained in at least J/2 different support sets. Then, for any (p, C)-barycenter \(\mu ^\star \) it holds that \(\mathbb {M}(\mu ^\star )= \mathbb {M}\left( \mu _{\lceil J/2 \rceil }\right) \). Else, there exists at least one (p, C)-barycenter with this total mass.
The proof is based on the fact that finding a (p, C)-barycenter can be proven to be equivalent to solving a multi-marginal optimal transport problem (Sect. 3.2). Statement (i) provides insights into the structure of the support of any (p, C)-barycenter and its dependency with respect to the magnitude of C. The definition of \(\mathcal {C}_{KR}(J,p,C)\) can be understood as a joint restriction on \(\sum _{i=1}^{L}d^p(x_i,y)\) combined with an individual restriction on each \(d^p(x_i,y)\) of the original centroid points of \(\mathcal {C}_{KR}(J,p)\). The joint restriction ensures that simply deleting any mass at a given centroid point (and thus reducing the total mass of the measure) does not improve the objective value. This is a minimal feasibility assumption on the considered centroid point, as otherwise no measure containing this point can be optimal. The second restriction concerns each point individually. If a point \(x_i\) has a distance larger than \(C^p\) from a point y, then, by Lemma 2.1, there is no transport between y and \(x_i\). Thus, centroids which have have a larger distance to one of the points \(x_1,\dots ,x_L\) they are constructed from can not be in the support of any (p, C)-barycenter. This also gives rise to some helpful intuition for the support structure of any (p, C)-barycenter. Considering all \(C^p\)-neighbourhoods around any of the support points of the \(\mu _i\), then a (p, C)-barycenter can only have support in regions where at least balls from \(\lceil J/2 \rceil \) different measures intersect. A visual representation of this is given in the center of bottom row of Fig. 5. By definition, the sets \(\mathcal {C}_{KR}(J,p,C)\) are equipped with a natural ordering in the sense that if \(C_1\le C_2\) then \(\mathcal {C}_{KR}(J,p,C_1)\subseteq \mathcal {C}_{KR}(J,p,C_2)\). Moreover, if C is large enough then \(\mathcal {C}_{KR}(J,p,C)=\mathcal {C}_{KR}(J,p)\). We illustrate these sets in the top row Fig. 5. We observe that the cardinality of the restricted centroid set in (9) decreases with decreasing C. In the extremes for large C the restricted centroid sets coincides with the full centroid sets in (8) that is independent of C. For small C, if there is no point which is contained in the support of at least J/2 measures, the restricted centroid set is empty. For an illustration we refer to the top row of Fig. 5.
Property (ii) is an analogue to a well-known characterization [4] of the p-Wasserstein barycenter on \(\mathbb {R}^d\) with Euclidean distance \(d_2\), where the transport from the barycenter to the underlying measures is characterized by a transport map. The corresponding statement for the (p, C)-barycenter holds true as well in this context. Indeed, on \((\mathbb {R}^d,d_2)\) condition (10), which can be understood as an injectivity-type assumption on the barycentric application, is satisfied due to the fact that \(T^L(x_1,\dots ,x_L)=\frac{1}{L}\sum _{l=1}^Lx_l\). However, for \((\mathbb {R}^d,d_1)\) this assertion does not hold. Consider \(x_1<x_2<x_3<x_4\in \mathbb {R}\) and measures \(\mu _1=\delta _{x_1}+\delta _{x_2}, \mu _2=\delta _{x_3}+\delta _{x_4}\), then any measure of the form \(\mu ^*=2\delta _{y}\) for any \(y \in [x_2,x_3]\) is a (p, C)-barycenter for \(C>2|x_1-x_4|\). Thus, there only exist mass-splitting UOT plans between \(\mu ^*\) and \(\mu _1,\mu _2\) and the transport is not characterized by a transport map. On more general spaces such as a tree \(\mathcal {T}\) rooted at r, three leaves \(x_1,x_2,x_3\) and positive edge weights \(e_1,\dots , e_3\in (0,1)\) the barycenter on \(\mathcal {T}\) of any two leafs \(x_i\ne x_j\), is the root r. In particular, in this example, or in fact in any tree \(\mathcal {T}=(V,E)\) which has a vertex y with degree of at least threeFootnote 5 condition (10) fails. The unique (2, 2)-barycenter of two measures \(\mu _1=\delta _{x_1}+\delta _{x_2}\) and \(\mu _2=\delta _{x_2}+\delta _{x_3}\) is given by \(\mu ^*=2\delta _r\). Thus, there are again only mass-splitting UOT plans between \(\mu ^*\) and \(\mu _1\) and \(\mu _2\). However, for the unit circle \(\mathcal {S}^1\) equipped with its natural arc-length distance property (10) does hold. Assume \(a_0=T^L(x_1,\dots ,x_L)=T^{L,p}(y_1,\dots ,x_L)\), \(a_1=T^{L-1,p}(x_2,\dots ,x_L)\) and for each \(x\in \mathcal {S}_1\) denote \(H_r(x)\) and \(H_l(x)\) as the halfcircle right and left of x, respectively. It is straightforward to see by contraposition that if it holds \(a_1\in H_r(a_0)\), then this implies \(x_1,y_1\in H_l(a_1)\) and \(x_1,y_1\in H_l(a_0)\). However, it also holds \(d(x_1,a_0)=d(y_1,a_0)\), and thus \(\langle x_1-y_1,a_0 \rangle =0\). In particular, this implies that either \(x_1\in H_l(a_0)\) and \(y_1\in H_r(a_0)\) or vice versa and hence \(x_1=y_1\). The case \(a_1\in H_l(a_0)\) is analog and the case \(a_0=a_1\) clear.
Property (iii) guarantees the existence of sparse (p, C)-barycenters. For large C the size \(\mathcal {C}_{KR}(J,p,C)\) scales as \(\prod _{i=1}^{J} M_i\), growing essentially exponentially in J. However, here we see that there always exists a (p, C)-barycenter supported on a sparse subset of \(\mathcal {C}_{KR}(J,p,C)\) which has cardinality growing only linearly in J. Part (iv) simply extends the montonicity of the (p, C)-KRD to the (p, C)-Fréchet functional. Statement (v) yields a critical point after which decreasing C does no longer change the resulting (p, C)-barycenter and provides a closed form characterisation of the (p, C)-barycenter in this context. Finally, statement (vi) enables control on the total mass of the (p, C)-barycenter for large values of C. In particular, since the total mass is close to the median of the total masses of the \(\mu _i\), we point out that the total mass of the (p, C)-barycenter in this setting is robust against outliers. A small amount of measures with unreasonably high mass has no impact on the total mass of the (p, C)-barycenter.
Naturally, we compare the (p, C)-barycenter to its popular Wasserstein analogue in (4). As proven in Le Gouic and Loubes [43] (and initially for \(p=2\) for \(\mathbb {R}^d\) by [4]) the support of any p-Wasserstein barycenter is contained in
Compared to the p-Wasserstein barycenter of the probability measures \(\mu _1,\ldots ,\mu _J\) the restricted centroid set \(\mathcal {C}_{KR}(J,p,C)\) allows more flexibility for specific cases and can provide a more reasonable representation of the data. We illustrate this in Fig. 5 (bottom-left/right) where the (2, C)-barycenter clearly represents all clusters while the 2-Wasserstein barycenter fails to capture them. Nevertheless, if C is large enough and all measures have equal total mass both barycenters coincide.
Corollary 2.6
If \(C> 2^{\frac{1}{p}}\text {diam}(\mathcal {Z})\) and \(\mathbb {M}(\mu _1)=\mathbb {M}(\mu _2)=\dots =\mathbb {M}(\mu _J)\), then any p-Wasserstein barycenter is also a (p, C)-barycenter and vice versa.
While this shows that the (p, C)-barycenter is a strict generalisation of the usual p-Wasserstein barycenter as the solutions coincide for large C, for smaller values of C there can be significant differences. One such striking difference between the p-Wasserstein barycenter and the (p, C)-barycenter comes in the form of a localization property. Let \(B_1,\dots ,B_R \subset \mathcal {Y}\) such that \(\text {supp}(\mu _i)\subset \cup _{r=1}^{R}B_r\) with \(\text {diam}(B_r)\le C\) for all \(r=1,\dots ,R\) and \(d(B_k,B_l)>2^{1/p} C\) for all \(k\ne l\). Here, the \((p,C)-\)barycenter tends to place mass between the clusters \(B_1,\dots ,B_R\). However, a (p, C)-barycenter is obtained by combining R barycenters of the measures restricted to the \(B_1,\dots ,B_R\), respectively.
Lemma 2.7
Let \(\mu _1,\dots ,\mu _J \in \mathcal {M}_+(\mathcal {X})\) such that for all \(i=1,\dots ,J\) it holds \(\text {supp}(\mu _i)\subset \cup _{r=1}^{R}B_r\) for some \(B_1,\dots ,B_R \subset \mathcal {Y}\) with \(\text {diam}(B_r)\le C\) for all \(r=1,\dots ,R\) and \(d(B_k,B_l)> 2^{1/p}C\) for all \(k\ne l\). For \(r=1,\dots ,R\), let

where \(conv(B_r)\) is the convex hull of \(B_r\) for \(r=1,\dots ,R\). Then, the measure \(\underset{r=1}{\overset{R}{\sum }} \mu _r^*\) is a (p, C)-barycenter of \(\mu _1,\dots ,\mu _J\).
In particular, Lemma 2.7 implies that the (p, C)-barycenter respects the cluster structure within the supports of the measures if the clustered are sufficiently separated and C is adapted according to the cluster size. Examples of this setting can be seen in Fig. 2 and Fig. 5.
3 A Lift to Optimal Transport, Wasserstein Barycenters and Multi-marginal Optimal Transport
In this section, we provide the necessary tools and framework to establish our results in the previous section. Following the ideas of Guittet [33] we state UOT in (2) as an equivalent balanced OT problem. We extend this idea to the (p, C)-barycenter, showing it to be equivalent to a specific Wasserstein barycenter problem as well as a balanced multi-marginal optimal transport problem.
3.1 A Lift to Optimal Transport
We fix a parameter \(C>0\), introduce an additional dummy point \(\mathfrak {d}\) and define the augmented space \(\tilde{\mathcal {X}}{:}{=}\mathcal {X}\cup \{\mathfrak {d}\}\) with metric cost
Notably, \(\tilde{d}_C:\tilde{\mathcal {X}}\times \tilde{\mathcal {X}}\rightarrow \mathbb {R}_+\) defines a metric on \(\tilde{\mathcal {X}}\) [53, Lemma A1]. Consider the subset \(\mathcal {M}_+^B(\mathcal {X}){:}{=}\left\{ \mu \in \mathcal {M}_+(\mathcal {X})\, \mid \, \mathbb {M}(\mu )\le B\right\} \subset \mathcal {M}_+(\mathcal {X})\) of non-negative measures whose total mass is bounded by B. Setting \(\tilde{\mu }{:}{=}\mu + (B-\mathbb {M}(\mu ))\delta _\mathfrak {d}\), any measure \(\mu \in \mathcal {M}_+^B(\mathcal {X})\) defines an augmented measure \(\tilde{\mu }\) on \(\tilde{\mathcal {X}}\) such that \(\mathbb {M}(\tilde{\mu })=B\). Hence, for two measures \(\mu ,\nu \in \mathcal {M}_+^B(\mathcal {X})\) we can define the OT problem on \(\tilde{\mathcal {X}}\) between their augmented measures \(\tilde{\text {OT}}_{\tilde{d}_C^p}(\tilde{\mu },\tilde{\nu })\). In fact, it holds that
where the first equality follows by Lemma 2.1 as for any optimal solution \(\pi _C\) it holds \(\pi _C(x,x^\prime )=0\) if \(d^p(x,x^\prime )> C^p\) and the second follows by [33, Lemma 3.1]. The same equalities remain valid replacing B by an arbitrarily large constant as summarized by the following lemma.
Lemma 3.1
Consider \(\mu ,\nu \in \mathcal {M}_+^B(\mathcal {X})\) with extended versions \(\tilde{\mu },\tilde{\nu }\). Then for any \(a>0\) it holds that
Proof
For \(p=1\), the result is trivial since by duality \(\tilde{\text {OT}}_{\tilde{d}_C}(\tilde{\mu },\tilde{\nu })\) only depends on the difference of the measures. For \(p>1\) we invoke \(\tilde{d}_C\)-cyclical monotonicity [72, Thm. 5.10] of any OT plan \(\pi \) and use the property that \(\tilde{d}_C^p(x,\mathfrak {d})=\nicefrac {C^p}{2}\). This yields that \((\mathfrak {d},\mathfrak {d})\in \text {supp}(\pi )\) which leads to the desired conclusion. \(\square \)
3.2 A Lift to Wasserstein Barycenters
We can also lift the optimization problem defining a (p, C)-barycenter to an equivalent p-Wasserstein barycenter formulation (4). Augmentation of the underlying measures, however, is not straightforward as the total mass of the (p, C)-barycenter is unknown. A first crude upper bound on its total mass leads to a feasible approach.
Lemma 3.2
Consider \(\mu _1,\dots ,\mu _J \in \mathcal {M}_+(\mathcal {X})\) and let \(F_{p,C}\) be their associated unbalanced Fréchet functional. Then it holds that

More precisely, any (p, C)-barycenter \(\mu ^\star \) of \(\mu _1,\ldots ,\mu _J\) satisfies \(\mathbb {M}(\mu ^\star )\le \sum _{i=1}^J \mathbb {M}(\mu _i)\).
Proof
Assume first that there exists a measure \(\mu \in \mathcal {M}_+(\mathcal {Y})\) such that \(\mu =\nu _1+\nu _2\) where no transport between \(\nu _2\) and any \(\mu _i\) occurs in the optimal solution of \(\text {UOT}_{p,C}(\mu ,\mu _i)\) for \(1\le i \le J\) and it holds \(\mathbb {M}(\nu _2)>0\). Thus it holds
and we improve the objective value of \(\mu \) by removing \(\nu _2\). Hence, let \(\mu \in \mathcal {M}_+(\mathcal {Y})\) be any measure such that \(\nu _2\equiv 0\). Consider \(\pi _i\) the optimal solution for \(\text {UOT}_{p,C}(\mu ,\mu _i)\) for each \(1\le i \le J\). Decompose the measure \(\mu =\sum _{i=1}^J \tau _i\), where \(\tau _i\) is the mass of \(\mu \) transported to \(\mu _i\) according to \(\pi _i\) and which is not yet included in any \(\tau _j\) for \(j<i\). Clearly, \(\mathbb {M}(\mu )=\sum _{i=1}^J \mathbb {M}(\tau _i)\le \sum _{i=1}^J \mathbb {M}(\mu _i)\) and we conclude that
By our first considerations the claim follows. \(\square \)
Given the upper bound on the total mass of any (p, C)-barycenter at our disposal we can formulate a lift of the (p, C)-barycenter problem to a related p-Wasserstein barycenter problem. For this, let \(\tilde{\mathcal {Y}}{:}{=}\mathcal {Y}\cup \{\mathfrak {d}\}\) endowed with the metric \(\tilde{d}_C\) in (12) (replace \(\mathcal {X}\) by \(\mathcal {Y}\) and recall that \(\mathcal {X}\subset \mathcal {Y}\)) and augment the measures \(\mu _1,\ldots ,\mu _J\) to \(\tilde{\mu }_1,\ldots ,\tilde{\mu }_J\) where \(\tilde{\mu }_i=\mu _i+\sum _{j\ne i} \mathbb {M}(\mu _j) \delta _\mathfrak {d}\) for \(1\le i\le J\). In particular, \(\mathbb {M}(\tilde{\mu }_i)=\sum _{j=1}^J \mathbb {M}(\mu _j)\) and we can define the augmented p-Fréchet functional
where by definition \(\tilde{F}_{p,C}\) is restricted to measures \(\mu \) with mass \(\mathbb {M}(\mu )=\sum _{i=1}^J \mathbb {M}(\mu _i)\).
Lemma 3.3
For \(1\le i \le J\) consider measures \(\mu _i\in \mathcal {M}_+(\mathcal {X})\) and their augmented versions \(\tilde{\mu }_i{:}{=}\mu _i+\sum _{j\ne i}\mathbb {M}(\mu _j)\delta _\mathfrak {d}\), respectively. Then it holds that
for all \(\mu \in \mathcal {M}_+(\mathcal {Y})\) such that \(\mathbb {M}(\mu )\le \sum _{i=1}^J \mathbb {M}(\mu _i)\) and in particular
The proof of this Lemma is given in Appendix A.1.
Remark 3.4
(Optimal (p, C)-barycenters) Lemma 3.3 states that the optimal objective value for the (p, C)-barycenter is equal the related p-Wasserstein barycenter problem on the augmented space. In particular, the proof also reveals that if \(\tilde{\mu }^\star \) is a p-Wasserstein barycenter for the augmented measures \(\tilde{\mu }_1,\ldots ,\tilde{\mu }_J\) then \(\mu ^\star {:}{=}\tilde{\mu }^\star -\tilde{\mu }^\star (\mathfrak {d})\delta _\mathfrak {d}\) is a (p, C)-barycenter for the measures \(\mu _1,\ldots ,\mu _J\). Vice versa, if \(\mu ^\star \) is a (p, C)-barycenter for the measures \(\mu _1,\ldots ,\mu _J\) then \(\tilde{\mu }^\star {:}{=}\mu ^\star +\left( \sum _{i=1}^J \mathbb {M}(\mu _i)-\mathbb {M}(\mu ^\star )\right) \delta _\mathfrak {d}\) is a p-Wasserstein barycenter for the augmented measures \(\tilde{\mu }_1,\ldots ,\tilde{\mu }_J\).
3.3 A Lift to Multi-Marginal Optimal Transport
On the augmented space \(\tilde{\mathcal {Y}}{:}{=}\mathcal {Y}\cup \{\mathfrak {d}\}\) equipped with metric \(\tilde{d}_C\) in (12), we define for \(p\ge 1\) and \(J\in \mathbb {N}\) a Borel barycenter application \(\tilde{T}^{J,p}_C:\tilde{\mathcal {Y}}^J\rightarrow \tilde{\mathcal {Y}}\) that takes as input \((y_1,\ldots ,y_J)\in \tilde{\mathcal {Y}}\) and outputs any minimizer \(y\in \tilde{\mathcal {Y}}\) of the function
Of particular interest to us is the barycentric application restricted to inputs from \(\tilde{\mathcal {X}}\). However, we collect some of its key properties for general input \((y_1,\ldots ,y_J)\in \tilde{\mathcal {Y}}^J\). For this, we define the index set
If clear from the context, then the dependence on \(y_1,\dots ,y_J\) is suppressed and the set is simply denoted as \(\mathcal {B}\).
Lemma 3.5
Fix some parameter \(C>0\) and consider the space \(\tilde{\mathcal {Y}}\) with metric \(\tilde{d}_C\) as defined in (12). For points \((y_1,\ldots ,y_J)\in \tilde{\mathcal {Y}}^J\) it holds that
-
(i)
\(\tilde{T}^{J,p}_C(y_1,\dots ,y_J)=\mathfrak {d}\) if and only if \(\underset{i \not \in \mathcal {B}}{\overset{}{\sum }} \tilde{d}_C^p(y_i,y) \ge (J-2|\mathcal {B}|)C^p/2\) for any \(y\in \tilde{\mathcal {Y}}\). In particular, if strict inequality holds then \(\tilde{T}^{J,p}_C(y_1,\dots ,y_J)=\mathfrak {d}\) is unique.
-
(ii)
If \(2|\mathcal {B}|\ge J\) then it holds \(\tilde{T}^{J,p}(y_1,\dots ,y_J)=\mathfrak {d}\) with uniqueness if \(2|\mathcal {B}|> J\).
-
(iii)
If \(\tilde{T}^{J,p}(y_1,\dots ,y_J)\ne \mathfrak {d}\) then it holds

-
(iv)
If \(C>2^{\frac{1}{p}}\text {diam}(\mathcal {Y})\), then for any points \(y_1,\ldots ,y_J\in \mathcal {Y}\) with \(|\mathcal {B}|=0\) it holds that \(\tilde{T}^{J,p}_C(y_1,\dots ,y_J)=T^{J,p}(y_1,\dots ,y_J)\) where the latter one is defined with respect to the usual metric \(d^p\) on \(\mathcal {Y}\).

A proof of this result is provided in Appendix A.1. Lemma 3.5 allows to characterize the centroid sets of the augmented measures \(\tilde{\mu }_1,\ldots ,\tilde{\mu }_J\) defined as

Remark 3.6
We point out that computing \(\tilde{T}^{J,p}_C\) is in general a difficult optimisation problem. While for squared euclidean distance, computing the barycentric application simply amounts to taking the mean of the \(x_i\), even on the non-augmented space, there are no closed form solutions available for most choices of distances and values of p. This problem is exacerbated by the truncation of the distance \(\tilde{d}\) at \(C^p\) (as also pointed out in [53]), since it implies that disregarding a certain subset of points and just computing the barycenter with respect to the remaining \(x_i\) might in fact be optimal. However, initially it is not clear which \(x_i\) to choose, turning this into a difficult combinatorial problem.
Recall that for any measure \(\mu \) its support is contained in \(\mathcal {X}\) a subset of \(\mathcal {Y}\). The augmented measure \(\tilde{\mu }\) is extended by an additional support point at \(\{\mathfrak {d}\}\). In particular, while the centroid set is a subset of \(\tilde{\mathcal {Y}}\) it only depends on the support of the measures \(\tilde{\mu }_i\) contained in \(\tilde{\mathcal {X}}{:}{=}\mathcal {X}\cup \{\mathfrak {d}\}\).
Corollary 3.7
For the centroid sets of the augmented measures \(\tilde{\mu }_i\in \mathcal {M}_+(\tilde{\mathcal {X}})\) with \(1\le i \le J\) it holds
Proof
The first inclusion follows by statements (i) and (iii) in Lemma 3.5 and the observation that \(|\mathcal {B}|=J-L\). The second by applying \(\mathcal {C}_{KR}(J,p,C)\subset \mathcal {C}_{KR}(J,p)\). \(\square \)
Remark 3.8
One could define \(\mathcal {C}_{KR}(J,p,C)\) in terms of \(\tilde{d}_C\) instead of d to obtain equality in the first inclusion. Replacing \(T^{L,p}\) by \(\tilde{T}^{L,p}_C\) in the definition of the centroid set would not alter any of the related proofs and yield slightly sharper control on the support of (p, C)-barycenter. However, as we consider the given definition to be more intuitive, we omit this improvement in the statement of the theorem.
Let \(\Pi (\tilde{\mu }_1,\dots ,\tilde{\mu }_J)\) be the set of measures on \(\tilde{\mathcal {Y}}\times \ldots \times \tilde{\mathcal {Y}}\) whose i-th marginal is equal to \(\tilde{\mu }_i\) for all \(1\le i \le J\). We refer to the elements of this set as multi-couplings of \(\tilde{\mu }_1,\dots ,\tilde{\mu }_J\). For \(p\ge 1\) define the augmented multi-marginal transport problem as
where
The relation between the augmented multi-marginal transport formulation (14) and the (p, C)-barycenter is as follows.
Proposition 3.9
Let \(\mu _1,\dots ,\mu _J \in \mathcal {M}_+(\mathcal {X})\) and \(\tilde{\mu }_1,\ldots ,\tilde{\mu }_J\) be their augmented counterparts. If \(\pi \in \Pi (\tilde{\mu }_1,\dots ,\tilde{\mu }_J)\) is a solution to the augmented multi-marginal problem (14), then the measure \(\mu ^\star {:}{=}(\tilde{T}_C^{J,p} \# \pi )_{\vert \mathcal {Y}}\in \mathcal {M}_+(\mathcal {Y})\) is a (p, C)-barycenter of the measures \(\mu _1,\dots ,\mu _J\), where \(\tilde{T}_C^{J,p} \# \pi \) denotes the pushforward of \(\pi \) under \(\tilde{T}_C^{J,p}\). Moreover, for every (p, C)-barycenter \(\mu ^\star \), there exists a solution \(\pi \) to the augmented multi-marginal transport problem, such that
In particular, it holds that
The proof follows straightforwardly along the lines of related statements for the multi-marginal optimal transport problem ([43, Theorem 8]; [49, Lemma 8] or [54, Proposition 3.1.2]). This correspondence between the (p, C)-barycenter problem and a balanced multi-marginal optimal transport serves as one of the key components in the proof of Theorem 2.5.
4 Computational Issues and Numerical Experiments
We present approaches to compute the (p, C)-barycenter problem by solving related OT problems. Based on this, we investigate the performance of the Wasserstein and (p, C)-barycenters on multiple synthetic datasets. For reference, we also report on results for two related concepts of unbalanced barycenters (UBCs), namely the Gaussian-Hellinger–Kantorovich and Wasserstein–Fisher–Rao barycenter.
4.1 Algorithms
Theorem 2.5 and Proposition 3.9 both allow to pose the augmented problem (recall Sect. 3) as a linear program and using Lemma 3.3 one can obtain a solution to the original problem by solving the augmented one. Using any linear program solver this enables the direct computation of an exact solution of this problem. However, the number of variables in this approach scales as the size of \(\mathcal {C}_{KR}(J,p,C)\) and hence it turns out to be infeasible already for relatively small instance sizes. To compute (p, C)-barycenters at larger scales we revisit iterative methods to solve the (balanced) Wasserstein barycenter problem and give instructions how to use modifications of them to compute (p, C)-barycenters. In particular, we detail a multi-scale method which solves successive fixed-support (p, C)-barycenter LPs on increasingly refined support sets. This provides a meta-framework to adjust state-of-the-art solvers for the Wasserstein barycenter for (p, C)-barycenter computations.
To construct the augmented problem we add the dummy point \(\mathfrak {d}\) to the support of the \(\mu _i\)’s, while setting its distance to all other locations to be \(C^p/2\). Note, that by Lemma 2.1 and Lemma 3.1 the truncation of \(\tilde{d}\) at \(C^p\) can be omitted if \(\mathbb {M}(\tilde{\mu }_i)>3\max _{i=1,\dots ,J} \mathbb {M}(\mu _i)\). If this is not the case, we can enforce it by adding additional mass at \(\mathfrak {d}\) in all augmented measures without changing the optimal value.
4.1.1 LP-Formulation for the \(\mathbf {(p,C)}\)-Barycenter
Using property (i) from Theorem 2.5, we can rewrite the augmented (p, C)-barycenter problem as a linear program similarly to the usual p-Wasserstein barycenter problem (4). However, compared to the latter one, we replace the standard centroid set \(\mathcal {C}_W(J,p)\) from (11), by the centroid set \(\tilde{\mathcal {C}}_{KR}(J,p,C)\) of the augmented measures from (13). This yields
where \(M_i=|\tilde{\mathcal {X}}_i |\) is the cardinality of the support of the augmented measure \(\tilde{\mu }_i\). Here, \(c^i_{jk}\) denotes the distance between the j-th point of \(|\tilde{\mathcal {C}}_{KR}(J,p,C) |\) and the k-th point in the support of \(\tilde{mu}_i\), while \(b^i\) is the vector of masses corresponding to \(\tilde{\mu }_i\). For practical purposes it may be advantageous to solve the multi-marginal problem instead of the (p, C)-barycenter problem. This changes the number of variables from \(|\tilde{\mathcal {C}}_{KR}(J,p,C) |(1+\sum _{i=1}^J M_i\)) to \(\prod _{i=1}^J M_i\) and the number of constraints from \(J|\tilde{\mathcal {C}}_{KR}(J,p,C) |+\sum _{i=1}^J M_i\) to \(\sum _{i=1}^J M_i\). Depending on the value of C, and hence the cardinality of \(\tilde{\mathcal {C}}_{KR}(J,p,C)\), it is possible to pick the problem with the smaller complexity.
While this formulation is appealing for proving theoretical statements as provided in Theorem 2.5, it quickly becomes computationally infeasible even for small scale problems as the number of variables in the LP grows potentially as \(\prod M_i\). However, it still enables exact computations of (p, C)-barycenters for small scale examples, which is currently impossible for general UBCs. Though, while there has been some recent advancement for the 2-Wasserstein barycenter in special cases [2] these LP-based algorithms ultimately do not scale to large instance sizes.
4.2 Iterative Algorithms and the Multi-scale Approach

An illustration of the multi-scale approach on two different datasets. The fixed-support solutions are shown on grids of the sizes \(8 \times 8\), \(16\times 16\), \(32\times 32\), \(64\times 64\) and \(128 \times 128\) increasing from left to right. The corresponding run-times on a single core of an Intel Core i7 12700K in the first/second row were 2.5/5 seconds, 14/16 seconds, 145/42 seconds, 13/3 minutes and 143/22 minutes. Top: The dataset of nested ellipses from Fig. 7. Bottom: The dataset of ellipses with clustered support structure from Fig. 2
For the Wasserstein barycenter, iterative methods computing approximate barycenters, with a per iterations complexity only linear in the number of measures, enjoy great popularity. Most well known is the fixed-support Wasserstein barycenter [28, 46, 75] approach, aiming to find the best approximation of the barycenter on a pre-specified support set, for which a variety of methods is available. We utilise this fixed-support approach for the augmented (p, C)-barycenter problem by adding the dummy point \(\mathfrak {d}\) to the given support and constructing the cost as described above. This yields a meta-framework which allows to employ fixed-support Wasserstein barycenter algorithms for fixed-support (p, C)-barycenter computation. One can also modify more general free support methods [19, 28, 48], which usually alternate between updating the support set of the barycenter and its weights on this set, to provide approximate (p, C)-barycenters. However, the necessary position updates usually explicitly or implicitly rely on being able to compute the barycentric application \(\tilde{T}^{J,p}\) efficiently. Recalling Remark 3.6, this is in general not tractable for the augmented problem, which severely hinders the use of these approaches. Thus, it is tempting to avoid these issues by approximating \(\mathcal {Y}\) with a large finite space, i.e., by taking a grid of high-resolution, and solving the fixed support (p, C)-barycenter problem on this set. However, solving the fixed-support problem on this large space requires significant computational effort. We advovate an alternative by adapting the ideas of multi-scale methods for the Wasserstein distance/barycenter [30, 50, 64] to the (p, C)-barycenter setting. The idea of this approach is to start with a coarse version of the problem and then successively solve refined problems, while using the knowledge of the coarse solution to reduce the complexity of the finer ones.
Thus, we initialise the support set of the barycenter as a fixed grid of size \(K_1 \times \dots \times K_d\) in \(\mathbb {R}^d\). In the j-th step of the algorithm, after solving the fixed-support problem, we remove the grid points which have zero mass and replace the remaining ones with its \(2^d\) closest points in a refined version of the original grid of size \(2^jK_1 \times \dots \times 2^jK_d\). This can be understood as solving the fixed-support problem on successively finer grids, while incorporating information provided by having already solved a coarser solution of the problem. We terminate the method once a pre-specified resolution has been reached. This allows to obtain fixed-support approximation of the (p, C)-barycenter on fine grids without having to optimise over the full support set.
We point out that this approach, while inspired by multi-scale approaches is more closely related to the formerly mentioned free-support methods. As such it does in general not yield a globally optimal fixed-support (p, C)-barycenter at the finest resolution. Instead it converges to a local minimum of the unbalanced Fréchet functional depending on the resolution of the initial grid. This is a common problem among alternating procedures for the free-support barycenter problem and can be attributed to the fact that the Fréchet functional is non-convex in the support locations of the measures. However, we stress that with this approach we observe reasonable approximations of the (p, C)-barycenter while avoiding the inherent problems of generalising usual position update procedures discussed above. In particular, we do not have to solve the \(\tilde{T^{J,p}_C}\) barycenter problem at any point. Additionally, we note that the initial grid size should be chosen at least fine enough that the distance between two adjacent grid points is smaller than C. Otherwise it is possible that support points lying between two grid points, having distance larger C to both, are not accounted for. For a visual illustration of the algorithm we refer to Fig. 6.
4.3 Synthetic Data Simulations
We test the performance of the (p, C)-barycenter as a data analytic tool compared to the usual p-Wasserstein barycenter on a multitude of datasets. We base our computations on the MAAIPM method [28], which allows for high-precision approximations of barycenters up to moderate data sizes. The algorithm has been deployed to solve the fixed-support (p, C)-barycenter problems arising in the multi-scale method detailed above. For all experiments, the initial grid size as been set to \(16\times 16\) and the refinement is terminated at a gridsize of \(128\times 128\). Values below \(10^{-5}\) have been considered as zero for the purposes of grid refinement. All experiments have been carried out on a single core of an Intel Core i7 12700K. Implementations of our used method and some alternatives can be found as part of the R-package WSGeometry (on CRAN).

An excerpt of a dataset of \(N=100\) discretized ellipses. Each measure contains between 1 and 3 ellipses with equal probability. Each ellipse consists of 50 points with mass 1 in \([0,1]^2\). Left: In darkgreen the 2-Wasserstein barycenter, where all measures are normalized to be probability measures (runtime about 8 hours). Right: In red, the (2, 1.5)-barycenter (runtime about 30 minutes) (Color figure online)
4.4 Mismatched Shapes
This first set of examples mainly serves as starting point to illustrate improved performance of the (p, C)-barycenter compared to the p-Wasserstein barycenter. A prototypical benchmark for the p-Wasserstein barycenter are two nested ellipses as popularized in Cuturi and Doucet [19]. For our example of nested ellipses, we assume that the support of each measure consists of nested ellipses, but the number of ellipses varies between the individual underlying measures. Specifically, we assume that for each \(\mu _i\) the number of ellipses is uniformly random in \(\{1,2,3\}\) and that each ellipse is discretised onto M support points with unit mass, respectively. This can be seen in Fig. 7. We observe that while the p-Wasserstein barycenter recovers the elliptic shape of the underlying measures, it fails to produce distinct ellipses and instead produces something akin to a ring. In contrast, the (p, C)-barycenter yields two distinct ellipses, which coincides with the expected number of ellipses in one of the measures. This aligns well with intuition that the (p, C)-barycenter will simply disregard any additional structures which are not present in a sufficient amount of underlying measures. In contrast, the p-Wasserstein barycenter does not allow for this flexibility which enforces additional support points.

The (2, C)-barycenters for the measures in Fig. 2 for different values of C. From top-left to bottom-right the values of \(C/{\text {runtime in minutes}}\) are equal to 0.1/28, 0.15/28, 0.2/26, 0.25/28, 0.275/27, 0.3/33, 0.35/59, 0.4/132, 0.45/156, 0.5/160, 0.55/160, 0.6/155, respectively
4.5 Local Scale Cluster Detection
Recall the setting of Fig. 2. In the following class of examples, we are interested in datasets which possesses a natural cluster structure. Let \(B_1,\dots ,B_R\subset \mathbb {R}^D\) be convex, disjoint sets and assume that \(\text {supp}(\mu _i)\subset \cup _{r=1}^{R}B_r\) for all \(i=1,\dots ,J\). If the diameter of all \(B_r\) is bounded from above by C and that the distance between each two \(B_r,B_s\) is at least \(2^{1/p} C\), then Lemma 2.7 guarentees that the (p, C)-barycenter detects all of the R clusters in which at least J/2 measures have positive mass. In particular, by Theorem 2.5 (v) the (p, C)-barycenter will have mass in all of those clusters. Intuitively, this setting is reasonable if, for instance, it is already known that any interactions between support points of different measures are limited to scales below a certain threshold, which should then be chosen as C. The lower bound on the inter-cluster distance ensures that any pair of two clusters is well-separated, ensuring that it is always possible to distinguish between two different clusters, as they can not be arbitrarily close to each other.
In Fig. 2 the p-Wasserstein barycenter completely fails to capture the geometric data structure. Most of its mass is between the clusters and the outer clusters have nearly no mass. Moreover, the elliptic structure within each cluster is clearly not captured. In contrast, the (p, C)-barycenter not only captures all clusters, it also distinguishes between the difference in intensity (expected number of ellipses) in the clusters, matching the theoretical guarantees of Lemma 2.7. We stress that for this example the choice of C is of particular importance. If we choose C too large, the (p, C)-barycenter will fail to recover the data’s support structure (for an illustration of the (p, C)-barycenter in this example over a range of values of C see Fig. 8). Consequently, it is crucial to choose C appropriately. In this example, the barycenter appears to be stable and detect all clusters for \(C\in [0.1,0.275]\). Notably, if the locations of the clusters are already known, this setting also allows for parallel computations of the (p, C)-barycenter, where the problems are solved separately on each cluster and recombined at the end (Lemma 2.7).
4.6 Randomly Distorted Measures
In a statistical context it is important to investigate the stability of the (p, C)-barycenter under random distortions. We fix a reference measure \(\mu _0\) on \(\mathbb {R}^d\) and generate a set of measures by random modifications of \(\mu _0\). We then attempt to recover \(\mu _0\) by computing the p-Wasserstein and (p, C)-barycenter of these measures, respectively.
In the following, let B(p) denote a Bernoulli random variable with mean p, \(Poi(\lambda )\) a Poisson distribution with mean \(\lambda \) and U[a, b] a uniform distribution on [a, b]. We generate \(\mu _1,\dots ,\mu _J\) as follows:
For \(i=1,\dots ,J\) initialise \(\mu _i=\mu _0\), then succesively modify \(\mu _i\) based on the four following steps.
-
(i)
Point Deletion: Fix \(p_{del}\in [0,1]\) and \(\lambda _{del} \in \mathbb {R}_+\). We draw a Ber(\(p_{del})\) random variable. If it takes the value 1, then we draw \(D\sim Poi(\lambda _{del})\) and select \(\min (D,|\text {supp}(\mu _0)|)\) points in the support of \(\mu _0\) uniformly by drawing without replacement. These points (and their mass) are not contained in \(\mu _i\), since they have been deleted.
-
(ii)
Point Addition: We fix parameters \(p_{add}\in [0,1],\lambda _{add}\in \mathbb {R}_+, m_{add}\in \mathbb {R}^2, \sigma _{add}\in \mathbb {R}^{2\times 2},u_0,u_1\in \mathbb {R}\). Draw a Ber(\(p_{add}\)) random variable. If it takes the value 1, draw a Poi(\(\lambda _{add}\)) random variable \(\alpha \). Then, generate \(\alpha \) random variables following a normal distribution with mean \(m_{add}\) and covariance matrix \(\sigma _{add}\). Add these support points to \(\mu _i\), where the weight of each of these points is determined by independent \(U[u_0,u_1]\) random variables.
-
(iii)
Position Change: Fix parameters \(a_1,a_2,b_1,b_2\in \mathbb {R}\) with \(a_1 \le b_1\) and \(a_2\le b_2\). For each \(x_0\) in the support of \(\mu _i\), we draw a \(U([a_1,b_1]\times [a_2,b_2])\) random variable and shift the position of \(x_0\) by it.
-
(iv)
Weight Change: Fix parameters \(l,u\in \mathbb {R}\) with \(l\le u\). For each support point \(x_0\) of \(\mu _0\) with weight \(w_0\), we draw a U[l, u] random variable U and change the weight of \(x_0\) in \(\mu _i\) to be \(w_0+U\).
An example of this setting can be seen in Fig. 9. Comparing the two barycenters displayed there to the original measure reveals that, while the rough shape of the 2-Wasserstein barycenter is correct, its mass is spread out over a larger area and it has a significantly larger number of support points. Since all measures have been normalised, we have also lost all information on the mass of \(\mu _0\). Contrary to that, the (p, C)-barycenter retrieves the original measures recovering the location and number of the of support points closely. Additionally, it also has a mass which only deviates from the original mass by about \(0.23\%\). If one is only interested in recovering the general shape of the data, both approaches provide comparable performance. However, if the measures total mass and more detailed support structure are of importance the (p, C)-barycenter appears to be preferable.

An excerpt from a dataset of \(N=100\) noisy nested ellipses supported in \([0,1]^2\). The parameters are \(p_{del}=1/3\), \(\lambda _{del}=75\), \(p_{add}=1/3\), \(\lambda _{add}=25\), \(m_{add}=(0.5,0.5)^T\), \(\sigma _{add}=0.15I_{2}\), \(u_0=0.9\), \(u_1=1.1\), \(a_1=a_2=-0.025\), \(b_1=b_2=0.025\), \(l=u=0.1\). Left: The 2-Wasserstein barycenter in dark green (runtime about 4 hours). Center: The original measure \(\mu _0\) (black). Right: The (2, 1.5)-barycenter in red (runtime about 20 min) (Color figure online)
4.7 Total Mass Intensity

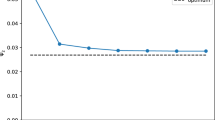
The mass of a (p, C)-barycenter for three sets of measures relative to the median of the total mass intensities of these measures. The green line corresponds to \(J=25\) measures from the same class as considered in Fig. 2. The red line corresponds to the same measures where the four outer clusters have been moved closer to the central one, such that their distance has been halved. The blue line corresponds to \(J=5\) measures with the same cluster structure as in Fig. 2, where the total number of ellipses in all clusters is fixed to be equal to four for all J measures (Color figure online)
While the p-Wasserstein barycenter of J probability measures has mass one, the mass of the (p, C)-barycenter depends on C as well as the geometry of the measures \(\mu _1,\dots ,\mu _J \in \mathcal {M}_+(\mathcal {X})\). Exact values for the mass of a (p, C)-barycenter without detailed computations, are only available in the limiting scenarios where C is extremely small or large relative to the other distances in \(\mathcal {X}\). For the former, we know by Theorem 2.5 (v) that the barycenter has mass zero for disjoint measures and for the latter, Theorem 2.5 (vi) yields that there exists a (p, C)-barycenter with total mass intensity equal to the median of \(\mathbb {M}(\mu _1),\dots ,\mathbb {M}(\mu _J)\). For intermediate values of C, Theorem 2.5 (i) yields the upper bound by \(2J^{-1}\sum _{i=1}^J\mathbb {M}(\mu _i)\). To highlight some possible behaviours of the total mass intensity of (p, C)-barycenter we consider three specific examples in Fig. 10. We note that in all three cases at about \(C=0.6\) the mass of the barycenters is at the median of their respective \(\mu _1,\dots ,\mu _J\) and does no longer change with increasing C. This is significantly smaller than the requirement in Theorem 2.5 (vi), which underlines the fact that while in the worst case, this lower bound is sharp, in many examples the total mass of the (p, C)-barycenter stabilises significantly earlier. Moreover, none of the three curves is monotone. Instead the total mass of the barycenter is increasing up to a certain point, after which it decreases until it reaches the median of the masses. This makes intuitive sense, as the measures are disjoint, thus for small C the barycenter is empty and starts to grow in mass quickly as the points within the clusters can be matched. In particular, the differences in intensity between clusters might lead to a total mass over the median \(\mathbb {M}(\mu _1),\dots ,\mathbb {M}(\mu _J)\), as by Lemma 2.7 the total mass intensity of the (p, C)-barycenter is \(\sum _{r=1}^R med(\mathbb {M}(\mu _{1_{\vert B_r}}),\dots ,\mathbb {M}(\mu _{J_{\vert B_r}}) \), where \(B_1,\dots ,B_5\) denote the respective cluster locations. For larger C these clusters start to merge and support points between the clusters reduce the total mass. In particular, these points can be seen clearly in the plot. Up until about \(C=0.1\), which is the cluster size, the mass of the barycenters rises sharply, before stabilising until the intercluster distance is reached. This is about 0.3 for the green and blue lines and about 0.15 for the red line (since the measures in this example are generated by halving the intercluster distance from the green one). This behaviour highlights the sensitivity of the mass of the (p, C)-barycenter to the geometry of the measures. It is therefore impossible to infer the total mass of the (p, C)-barycenter from the magnitude of C alone without accounting for the specific measures. However, analysing the structural properties of the support sets of the measures might provide a good indication at what values of C changes in drastic behaviour of the total mass are to be expected.
4.8 Comparison with Related Unbalanced Barycenter Concepts
We compare the (p, C)-barycenter with two alternative UBC approaches.
The Gaussian-Hellinger–Kantorovich Barycenter: This example falls in the general framework of optimal entropy transport problems. Measuring deviation between a feasible solution and the input marginals is carried out via the Kullback-Leibler divergence defined for \(\mu \ll \nu \)Footnote 6 as
If \(\mu \not \ll \nu \) the value of KL is set to be \(+\infty \). For a parameter \(\lambda >0\), the Gaussian-Hellinger–Kantorovich Distance [45] is defined as
where \(\pi _1\) and \(\pi _2\) denote the respective marginals of \(\pi \). The \(GHK_\lambda \) barycenter is defined as

The Hellinger–Kantorovich Barycenter: The Hellinger–Kantorovich distance, also known as Wasserstein–Fisher–Rao distance [14, 45], is closely related to the Gaussian-Hellinger–Kantorovich distance. For fixed parameter \(\sigma \in (0,\pi /2]\), referred to as the cut-locus, it is defined as
where \(cos_\sigma : z\mapsto \cos (\min (z,\sigma ))\). For a fixed cut-off locus \(\sigma \), the \(HK_\sigma \) barycenter is defined as

Comparing the barycenters: As the resulting barycenters vary significantly in all three cases, depending on the parameters \(C,\lambda ,\sigma \), we compare their behaviour upon change of parameter.

Comparison of the three unbalanced barycenters when varying their parameter. All measures are supported on an equidistant \(64\times 64\) grid in \([0,1]^2\). First row: The four underlying measures. Second row: The Gaussian-Hellinger–Kantorovich barycenter for \(\lambda =0.01,0.15,\dots ,1.83,1.97\). Third row: The Hellinger–Kantorovich barycenter for \(\sigma =0.01,0.08,\dots ,0.64,0.71\). Fourth row: The KR barycenter for \(C=0.01,0.08,\dots ,0.64,0.71\)
As a simple example, we consider four measures supported on subsets of a grid on \([0,1]^2\), displayed in Fig. 11. To ensure fair comparison, we deploy the same method based on the general scaling method [15] to approximate the UBC in all three cases. However, we point out that this implies disregarding the ambient space and instead taking the minimum over all positive measures supported on a prespecified grid in \([0,1]^2\).
For high parameter values all three approaches yield similar results. This is, of course, to be expected, since these distances interpolate between p-Wasserstein distance and total variation/Kullback-Leibler distance and large parameters correspond to a setting being close to the Wasserstein distance. The KR barycenter has mass zero for small choice of C by Theorem 2.5 (iv), since the four measures have disjoint support. After reaching a threshold of \(C\approx 0.1\), the mass in the (2, C)-barycenter starts to increase as mass is added in the center of the unit square until at \(C\approx 0.3\) the mass of an individual data measure is reached.
For small \(\lambda \) the \(GHK_\lambda \) barycenter has small mass and its support is close to that of a linear mean of the four measures, though the total mass intensity is significantly lower than for the original measures. With increasing \(\lambda \) the mass starts to increase and to smear into the middle of the unit square, until a large square, encompassing all four data supports, is formed. After this point increasing \(\lambda \) causes the square to contract while its mass increases. Finally, we approach a single square at roughly the same size as the squares in the underlying measures for large \(\lambda \).
The \(HK_\sigma \) barycenter is close to a linear mean of the four measures for small cut-off. Increasing \(\sigma \) initially reduces the mass at each of the square locations. At a threshold of \(\sigma \approx 0.34\), we observe a change, where part of the mass is moved vertically or horizontally to the mid points between the squares in a rectangular shape. Until \(\sigma \approx 0.43\) all mass is shifted to these "middle-rectangles", at which point a second shift occurs, where the mass from these rectangles starts to move towards a square in the center. At \(\sigma \approx 0.6\), all mass has been shifted towards a square in the center and there is no further change in the HK barycenter, when increasing \(\sigma \).

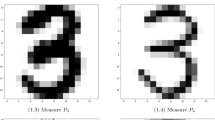
Images displaying the underlying measures used for barycenter computation in Fig. 13. Each row corresponds to a dataset of ten elements of the classical MNIST dataset which have been randomly rescaled and shifted within a \(50\times 50\) grid in \([0,1]^2\). Their total mass intensities have not been normalised

Comparison of the three unbalanced barycenters when varying their parameter. The set of underlying measures for a is the first row of Fig. 12. For b it is the second for c the third. For each class of examples the three different UOT barycenter models are considered in different rows: First row: The Gaussian-Hellinger–Kantorovich barycenter for \(\lambda = 0.01, 0.12, 0.23,\dots ,1\). Second row: The Hellinger–Kantorovich barycenter for \(\sigma =0.01,0.08,\dots ,0.64\). Third row: The KR barycenter for \(C=0.1,0.2,\dots ,1\)
Additionally, we consider Figs. 12 and 13, where the three unbalanced barycenter models are compared on three exemplary classes based on the MNIST dataset. Here, the original \(28\times 28\) images have been rescaled to sizes between \(14\times 14\) and \(42\times 42\) and embedded in a random subgrid of a \(50\times 50\) image. In this setting, there is a notable distinction between the GHK barycenter and the KR and HK barycenters. While for the former, the overall shape is recovered even for small parameter values, the latter two barycenters produce unstructured results for small parameters. The GHK distance is not constructed to have a maximal transport distance comparable to the impact of C or \(\sigma \) in the other two cases, which allows to transport across larger distance and recover the correct shape for smaller values of \(\lambda \). However, the mass of the GHK barycenter is significantly smaller than that of the original measures for small values of \(\lambda \) and only increases to the correct magnitude for larger penalty values. The HK and KR barycenters consist of fragments of the final shape which move towards a joint location for increasing parameters. For large penalties all three models are nearly identical and display the corresponding number correctly. This makes sense, as in this setting the minimisation in any individual term of the (p, C)-Fréchet functional is driven by minimising an OT term. We point out that for the (p, C)-barycenter this regime is guaranteed to be reached by choosing C larger than the diameter of the space, while for the other two models the suitable parameter choice for this example is ambiguous without actually computing the result for specific values.
Overall, for large parameter values all considered UBCs perform similarly. In small parameter regimes we observe significant differences. This difference in behavior is to be expected as the dependence of the UOT models on their parameters varies significantly. One key advantage of the KR barycenter is that its connection between the choice of C and the properties of the resulting barycenter is immediate and intuitive. While the cut-off locus \(\sigma \) for the HK barycenter fulfils a similar role, imposing control at the maximum scale at which transport does occur, the consequences of changing \(\sigma \) from one value to another are far less immediate due to the involved structure of the cost functional in this setting. Similarly to the KR barycenter, it is worth noticing that the HK barycenter does allow for mass at locations given by centroids of support points of \(L<N\) measures. Though, while for the KRD a feature of the underlying measures is only contained in the barycenter if it is present in more than \(L=N/2\) measures, the HK barycenter also allows for mass at locations constructed from less support points. Thus, the HK barycenter is prone to being more susceptible to errors due to noise within the data. Compared to the other two choices, the parameter \(\lambda \) of the GHK barycenter does appear to have less interpretation, with the only clear connection being that increasing \(\lambda \) increases the mass of the GHK barycenter. There does also not appear to be any well-founded method how to approach the choice of \(\lambda \) for a given dataset.
Notes
A non-negative measure on a finite space \(\mathcal {X}\) is uniquely characterized by the values it assigns to each singleton \(\{ x\}\). To ease notation we write \(\mu (x)\) instead of \(\mu (\{x\})\). The corresponding \(\sigma \)-field is always to be understood as the powerset of \(\mathcal {X}\).
For the sake of readability, the weights in this definition are fixed to 1/J, though it is easy to adapt all instances of their occurrence in this work to arbitrary positive weights \(\lambda _1,\dots ,\lambda _J\), summing to 1.
An implementation can be found in the R package WSGeometry on CRAN.
The degree of a vertex in a graph is the number of vertices which are adjacent to it.
A measure \(\mu \in \mathcal {M}_+(\mathcal {X})\) is said to be absolutely continuous (denoted \(\mu \ll \nu \)) with respect to another measure \(\nu \in \mathcal {M}_+(\mathcal {X})\) if \(\nu (A)=0\) implies \(\mu (A)=0\) for any measurable set A.
If \(\textsf {v},\textsf {w}\in L\) are leaf nodes their common ancestor is defined as the node included in the path from \(\textsf {v}\) to \(\textsf {w}\) closest to the root.
References
Agueh, M., Carlier, G.: Barycenters in the Wasserstein space. SIAM J. Math. Anal. 43(2), 904–924 (2011)
Altschuler, J.M., Boix-Adsera, E.: Wasserstein barycenters can be computed in polynomial time in fixed dimension. J. Mach. Learn. Res. 22, 44–1 (2021)
Álvarez-Esteban, P.C., Del Barrio, E., Cuesta-Albertos, J., et al.: A fixed-point approach to barycenters in Wasserstein space. J. Math. Anal. Appl. 441(2), 744–762 (2016)
Anderes, E., Borgwardt, S., Miller, J.: Discrete Wasserstein barycenters: optimal transport for discrete data. Math. Methods Oper. Res. 84(2), 389–409 (2016)
Benamou, J.D., Brenier, Y.: A computational fluid mechanics solution to the Monge-Kantorovich mass transfer problem. Numerische Mathematik 84(3), 375–393 (2000)
Benamou, J.D., Carlier, G., Cuturi, M., et al.: Iterative Bregman projections for regularized transportation problems. SIAM J. Sci. Comput. 37(2), A1111–A1138 (2015)
Bertsimas, D., Tsitsiklis, J.N.: Introduction to Linear Optimization, vol. 6. Athena Scientific, Belmont (1997)
Bogachev, V.I.: Measure Theory, vol. 1. Springer, Berlin (2007)
Bonneel, N., Rabin, J., Peyré, G., et al.: Sliced and Radon Wasserstein barycenters of measures. J. Math. Imaging Vis. 51(1), 22–45 (2015)
Bonneel, N., Peyré, G., Cuturi, M.: Wasserstein barycentric coordinates: histogram regression using optimal transport. ACM Trans. Gr. 35(4), 71–1 (2016)
Caffarelli, L.A., McCann, R.J.: Free boundaries in optimal transport and Monge-Ampere obstacle problems. Ann. Math. pp. 673–730 (2010)
Carlier, G., Oberman, A., Oudet, E.: Numerical methods for matching for teams and Wasserstein barycenters. ESAIM: Math. Model. Numer. Anal. 49(6), 1621–1642 (2015)
Carlier, G., Duval, V., Peyré, G., et al.: Convergence of entropic schemes for optimal transport and gradient flows. SIAM J. Math. Anal. 49(2), 1385–1418 (2017)
Chizat, L., Peyré, G., Schmitzer, B., et al.: An interpolating distance between optimal transport and Fisher-Rao metrics. Found. Comput. Math. 18(1), 1–44 (2018)
Chizat, L., Peyré, G., Schmitzer, B., et al.: Scaling algorithms for unbalanced optimal transport problems. Math. Comput. 87(314), 2563–2609 (2018)
Chizat, L., Peyré, G., Schmitzer, B., et al.: Unbalanced optimal transport: dynamic and Kantorovich formulations. J. Funct. Anal. 274(11), 3090–3123 (2018)
Chung, N.P., Phung, M.N.: Barycenters in the Hellinger–Kantorovich space. Appl. Math. Optim., pp. 1–30 (2020)
Cuturi, M.: Sinkhorn distances: lightspeed computation of optimal transport. Adv. Neural Inf. Process. Syst. 26, 2292–2300 (2013)
Cuturi, M., Doucet, A.: Fast computation of Wasserstein barycenters. In: International Conference on Machine Learning, PMLR, pp. 685–693 (2014)
Evans, S.N., Matsen, F.A.: The phylogenetic Kantorovich-Rubinstein metric for environmental sequence samples. J. R. Stat. Soc.: Ser. B (Stat. Methodol.) 74(3), 569–592 (2012)
Figalli, A.: The optimal partial transport problem. Arch. Ration. Mech. Anal. 195(2), 533–560 (2010)
Fréchet, M.: Les éléments aléatoires de nature quelconque dans un espace distancié. In: Annales de l’institut Henri Poincaré, pp. 215–310 (1948)
Friesecke, G., Matthes, D., Schmitzer, B.: Barycenters for the Hellinger-Kantorovich distance over \(\mathbb{R}^d\). SIAM J. Math. Anal. 53(1), 62–110 (2021)
Frogner, C., Zhang, C., Mobahi, H., et al.: Learning with a Wasserstein loss. Adv. Neural Inf. Process. Syst. 28, 2053–2061 (2015)
Gangbo, W., McCann, R.J.: Shape recognition via Wasserstein distance. Q. Appl. Math., pp. 705–737 (2000)
Gangbo, W., Li, W., Osher, S., et al.: Unnormalized optimal transport. J. Comput. Phys. 399(108), 940 (2019)
Gavryushkin, A., Drummond, A.J.: The space of ultrametric phylogenetic trees. J. Theor. Biol. 403, 197–208 (2016)
Ge, D., Wang, H., Xiong, Z. et al.: Interior-point methods strike back: Solving the wasserstein barycenter problem. In: Advances in Neural Information Processing Systems, vol. 32 (2019)
Gellert, M., Hossain, M.F., Berens, F.J.F., et al.: Substrate specificity of thioredoxins and glutaredoxins—towards a functional classification. Heliyon 5(12), e02,943 (2019)
Gerber, S., Maggioni, M.: Multiscale strategies for computing optimal transport. J. Mach. Learn. Res. 18, 1–32 (2017)
Gramfort, A., Peyré, G., Cuturi, M.: Fast optimal transport averaging of neuroimaging data. In: International Conference on Information Processing in Medical Imaging, pp. 261–272. Springer, Berlin (2015)
Grötschel, M., Lovász, L., Schrijver, A.: Geometric Algorithms and Combinatorial Optimization, vol. 2. Springer, Berlin (2012)
Guittet, K.: Extended Kantorovich norms: a tool for optimization. Tech. rep., Technical Report 4402, INRIA (2002)
Hallin, M., Mordant, G., Segers, J.: Multivariate goodness-of-fit tests based on Wasserstein distance. Electron. J. Stat. 15(1), 1328–1371 (2021)
Hanin, L.G.: Kantorovich-Rubinstein norm and its application in the theory of Lipschitz spaces. Proc. Am. Math. Soc. 115(2), 345–352 (1992)
Heinemann, F., Munk, A., Zemel, Y.: Randomized Wasserstein barycenter computation: resampling with statistical guarantees. SIAM J. Math. Data Sci. 4(1), 229–259 (2022)
Kantorovich, L.V., Rubinstein, S.: On a space of totally additive functions. Vestnik St Petersbg. Univ.: Math. 13(7), 52–59 (1958)
Kitagawa, J., Pass, B.: The multi-marginal optimal partial transport problem. In: Forum of Mathematics, Sigma, Cambridge University Press (2015)
Klatt, M., Tameling, C., Munk, A.: Empirical regularized optimal transport: statistical theory and applications. SIAM J. Math. Data Sci. 2(2), 419–443 (2020)
Kloeckner, B.R.: A geometric study of Wasserstein spaces: ultrametrics. Mathematika 61(1), 162–178 (2015)
Kroshnin, A., Tupitsa, N., Dvinskikh, D., et al.: On the complexity of approximating Wasserstein barycenters. In: International Conference on Machine Learning, PMLR, pp. 3530–3540 (2019)
Le, T., Yamada, M., Fukumizu, K., et al.: Tree-sliced variants of Wasserstein distances. In: Advances in Neural Information Processing Systems, pp. 12304–12315 (2019)
Le Gouic, T., Loubes, J.M.: Existence and consistency of Wasserstein barycenters. Probab. Theory Relat. Fields 168(3), 901–917 (2017)
Lellmann, J., Lorenz, D.A., Schonlieb, C., et al.: Imaging with Kantorovich-Rubinstein discrepancy. SIAM J. Imaging Sci. 7(4), 2833–2859 (2014)
Liero, M., Mielke, A., Savaré, G.: Optimal entropy-transport problems and a new Hellinger-Kantorovich distance between positive measures. Inventiones Mathematicae 211(3), 969–1117 (2018)
Lin, T., Ho, N., Chen, X., et al.: Fixed-support Wasserstein barycenters: computational hardness and fast algorithm. Adv. Neural Inf. Process. Syst. 33 (2020)
Luenberger, D.G., Ye, Y., et al.: Linear and Nonlinear Programming, vol. 2. Springer, Berlin (1984)
Luis, G., Salzo, S., Pontil, M., et al.: Sinkhorn barycenters with free support via frank-wolfe algorithm. Adv. Neural Inf. Process. Syst. 32 (2019)
Masarotto, V., Panaretos, V.M., Zemel, Y.: Procrustes metrics on covariance operators and optimal transportation of Gaussian processes. Sankhya A 81(1), 172–213 (2019)
Mérigot, Q.: A multiscale approach to optimal transport. In: Computer Graphics Forum, Wiley Online Library, pp. 1583–1592 (2011)
Montesuma, E.F., Mboula, F.M.N.: Wasserstein barycenter for multi-source domain adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16785–16793 (2021)
Mukherjee, D., Guha, A., Solomon, J.M., et al.: Outlier-robust optimal transport. In: International Conference on Machine Learning, PMLR, pp. 7850–7860 (2021)
Müller, R., Schuhmacher, D., Mateu, J.: Metrics and barycenters for point pattern data. In: Statistics and Computing, pp. 1–20 (2020)
Panaretos, V.M., Zemel, Y.: An Invitation to Statistics in Wasserstein Space. Springer, Berlin (2020)
Pele, O., Werman, M.: A linear time histogram metric for improved SIFT matching. In: European Conference on Computer Vision, pp. 495–508. Springer (2008)
Peyré, G., Cuturi, M., et al.: Computational optimal transport: with applications to data science. Found. Trends® Mach. Learn. 11(5–6), 355–607 (2019)
Piccoli, B., Rossi, F.: Generalized Wasserstein distance and its application to transport equations with source. Arch. Ration. Mech. Anal. 211(1), 335–358 (2014)
Rabin, J., Peyré, G., Delon, J., et al.: Wasserstein barycenter and its application to texture mixing. In: International Conference on Scale Space and Variational Methods in Computer Vision, pp. 435–446, Springer (2011)
Rachev, S.T., Rüschendorf, L.: Mass Transportation Problems: Volume I: Theory, vol. 1. Springer, Berlin (1998)
Santambrogio, F.: Optimal Transport for Applied Mathematicians, vol. 55. Springer, Berlin (2015)
Sato, R., Yamada, M., Kashima, H.: Fast unbalanced optimal transport on a tree. Adv. Neural Inf. Process. Syst. 33, 19039–19051 (2020)
Schiebinger, G., Shu, J., Tabaka, M., et al.: Optimal-transport analysis of single-cell gene expression identifies developmental trajectories in reprogramming. Cell 176(4), 928–943 (2019)
Schmitz, M.A., Heitz, M., Bonneel, N., et al.: Wasserstein dictionary learning: optimal transport-based unsupervised nonlinear dictionary learning. SIAM J. Imaging Sci. 11(1), 643–678 (2018)
Schmitzer, B.: Stabilized sparse scaling algorithms for entropy regularized transport problems. SIAM J. Sci. Comput. 41(3), A1443–A1481 (2019)
Schmitzer, B., Wirth, B.: A framework for Wasserstein-1-type metrics. J. Convex Anal. 26(2), 353–396 (2019)
Solomon, J., De Goes, F., Peyré, G., et al.: Convolutional Wasserstein distances: efficient optimal transportation on geometric domains. ACM Trans. Gr. 34(4), 1–11 (2015)
Sommerfeld, M., Munk, A.: Inference for empirical Wasserstein distances on finite spaces. J. R. Stat. Soc. Ser. B 80(1), 219–238 (2018)
Sommerfeld, M., Schrieber, J., Zemel, Y., et al.: Optimal transport: Fast probabilistic approximation with exact solvers. J. Mach. Learn. Res. 20(105), 1–23 (2019)
Su, Z., Zeng, W., Wang, Y., et al.: Shape classification using Wasserstein distance for brain morphometry analysis. In: International Conference on Information Processing in Medical Imaging, pp. 411–423. Springer (2015)
Tameling, C., Stoldt, S., Stephan, T., et al.: Colocalization for super-resolution microscopy via optimal transport. Nat. Comput. Sci. 1(3), 199–211 (2021)
Villani, C.: Topics in Optimal Transportation, vol. 58, American Mathematical Society (2003)
Villani, C.: Optimal Transport: Old and New, vol. 338. Springer, Berlin (2008)
Wang, S., Yuan, M.: Revisiting colocalization via optimal transport. Nat. Comput. Sci. 1(3), 177–178 (2021)
Wolsey, L.A., Nemhauser, G.L.: Integer and Combinatorial Optimization, vol. 55. Wiley, New York (1999)
Xie, Y., Wang, X., Wang, R., et al.: A fast proximal point method for computing exact Wasserstein distance. In: Uncertainty in Artificial Intelligence, PMLR, pp. 433–453 (2020)
Ye, J., Wu, P., Wang, J.Z., et al.: Fast discrete distribution clustering using Wasserstein barycenter with sparse support. IEEE Trans. Signal Process. 65(9), 2317–2332 (2017)
Acknowledgements
F. Heinemann and M. Klatt gratefully acknowledge support from the DFG Research Training Group 2088 Discovering structure in complex data: Statistics meets optimization and inverse problems. A. Munk gratefully acknowledges support from the DFG CRC 1456 Mathematics of the Experiment A04, C06 and the Cluster of Excellence 2067 MBExC Multiscale bioimaging–from molecular machines to networks of excitable cells. We kindly thank two anonymous referees for their helpful comments and suggestions.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interest
The authors have not disclosed any competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The funding was provided by Deutsche Forschungsgemeinschaft (Grant Nos. CRC 1456, Cluster of Excellence MBExC 2067, RTG 2088).
A Proofs
A Proofs
1.1 A.1 Proofs of Section 3
Proof of Lemma 3.3
Let \(\mu \in \mathcal {M}_+(\mathcal {Y})\) be such that \(\mathbb {M}(\mu )\le \sum _{i=1}^J \mathbb {M}(\mu _i)\). Then
where (i) follows from the lift to an OT problem (Sect. 3.1) and (ii) follows from Lemma 3.1 by adding mass \(\sum _{j\ne i} \mathbb {M}(\mu _j)-\mathbb {M}(\mu )\) at \(\mathfrak {d}\). We then have that
and
Combining both inequalities and using Lemma 3.2 then finishes the proof.
Proof of Lemma 3.5
(i) By definition, the objective value for \(\tilde{T}^{J,p}_C(y_1,\ldots ,y_J)\) at \(\mathfrak {d}\) is equal to \((J-|\mathcal {B}|)C^p/2\). Thus, \(\tilde{T}_C^{J,p}\) outputs \(\mathfrak {d}\) if and only if for any \(y \in \mathcal {Y}\) it holds
which is equivalent to
In particular, if all inequalities are strict \(\mathfrak {d}\) is the unique output for \(\tilde{T}^{J,p}_C(y_1,\ldots ,y_J)\). Statement (ii) is a direct consequence of (i). For statement (iii) we again use that by definition \(\tilde{d}^p_C(y,\mathfrak {d})=\nicefrac {C^p}{2}\) for any \(y\in \mathcal {Y}\) and hence
Proving (iv), let \(C>2^{\nicefrac {1}{p}}\text {diam}(\mathcal {Y})\), pick points \(y_1,\ldots ,y_J\in \mathcal {Y}\) and observe that for any \(y\in \mathcal {Y}\) it holds that
Thus, \(\tilde{T}_C^{J,p}(x_1,\ldots ,x_J)\ne \mathfrak {d}\) and since \(|\mathcal {B}|=0\), the claim follows from (iii). \(\square \)
1.2 A.2 Proofs of Section 2
Proof for Lemma 2.1
Suppose that \(\pi _C\) is optimal but its induced graph \(G(\pi _C)\) contains a path \(P=(x_{i_1},\ldots ,x_{i_k})\) such that \(\mathcal {L}(P)>C^p\). By definition of \(G(\pi _C)\) it holds that \(\pi _C(x_{i_j},x_{i_{j+1}})>0\) for all \(1\le j \le k-1\). We define a new transport plan with augmented transport along the path P. For this, define \(\epsilon {:}{=}\min _{1\le j \le k-1}\pi _C(x_{i_j},x_{i_{j+1}})\) and construct the new plan
Compared to \(\pi _C\) the transportation cost for \(\tilde{\pi _C}\) is reduced by \(\epsilon \mathcal {L}(P)\) while the marginal deviation is increased by \(\epsilon C^p\). In particular, it holds that
As \(\epsilon >0\) and \(\mathcal {L}(P)>C^p\) this contradicts the optimality for \(\pi _C\). Consequently, any path P in the induced graph \(G(\pi _C)\) necessarily has path length at most \(C^p\). If \(d(x,x^\prime )>C\) this implies that \(d^p(x,x^\prime )>C^p\) and hence by the statement on induced graphs that \(\pi _C(x,x^\prime )=0\). \(\square \)
Proof for Theorem 2.2
We first establish the metric properties (i). It is straightforward to show \(\text {KR}_{p,C}(\mu ,\nu )=0\) if and only if \(\mu =\nu \) and that \(\text {KR}_{p,C}\) is symmetric. For the triangle inequality let \(\mu ,\nu ,\tau \in \mathcal {M}_+(\mathcal {X})\) and choose \(B\ge \max \{\mathbb {M}(\mu ),\mathbb {M}(\nu ),\mathbb {M}(\tau )\}\). Then by augmenting the measures accordingly (Sect. 3.1) we find that
where the inequality follows by the triangle inequality for the Wasserstein distance [71, Theorem 7.3]. Statement \({\textbf {(ii)}}\) follows from Lemma 2.1 by noting that there exists at least one optimal solution \(\pi _C\) equal to zero except on the diagonal for which \(\pi _C(x,x)=\mu (x)\wedge \nu (x)\). Plugging into the objective of (2) yields the claim. Additionally, suppose that w.l.o.g. \(\mu (x)\ge \nu (x)\) for all \(x\in \mathcal {X}\). Then independent to the choice of \(C>0\) and \(p\ge 1\) the unique optimal solution is to remain all shared mass at its common place and to delete surplus material which is exactly the solution \(\pi _C(x,x)=\mu (x)\wedge \nu (x)\) described before. Statement \({\textbf {(iii)}}\) follows by noting that for \(C\ge \max _{x,x^\prime }d(x,x^\prime )\) the dual formulation in (\(\text {DUOT}_{p,C}\)) and in (\(\text {DOT}_{p}\)) coincide.
Finally, for statement (iv) we note that by construction it holds \(\tilde{d}_{C_1}^p(x,y)\le \tilde{d}_{C_2}^p(x,y)\) for all \(x,y\in \tilde{\mathcal {Y}}\). Hence, for any coupling \(\pi \) of the augmented measures \(\tilde{\mu },\tilde{\nu }\) it holds
Taking the minimum over all couplings of \(\tilde{\mu }\) and \(\tilde{\nu }\) on both sides completes the proof. \(\square \)
1.2.1 A.2.1 Proof for Theorem 2.3
Using the lift to the OT problem, we can now start to prove the closed formula on ultra-metric trees. For this, consider an ultrametric tree \(\mathcal {T}\) with height function \(h:V\rightarrow \mathbb {R}_+\) and define its p-height transformed tree denoted \(\mathcal {T}_p{:}{=}\mathcal {T}\) as the same tree but with height function \(h_p(\textsf {v})=2^{p-1}h(\textsf {v})^p\). An illustration is given in Fig. 4. Notice that by monotonicity \(\mathcal {T}_p\) is again an ultrametric tree.
Lemma A.1
Let \(\mathcal {T}\) be an ultrametric tree with height function \(h:V\rightarrow \mathbb {R}_+\) and consider its p-height transformed tree \(\mathcal {T}_p\). Then it holds that
for all leaf nodes \(\textsf {v},\textsf {w}\in L\subset V\).
Proof
Let \(\textsf {v},\textsf {w}\in L\) be two leaf nodes in the ultrametric tree \(\mathcal {T}\) with height function h and let a be their common ancestorFootnote 7. Since paths between any two vertices are unique and all leaf nodes have the same distance to the root, it holds that
Hence,
where we use that \(h(\textsf {v})=0\). Repeating the argument for the ultrametric tree \(\mathcal {T}_p\) we conclude that \(d_{\mathcal {T}_p}(\textsf {v},\textsf {w})=2d_{\mathcal {T}_p}(\textsf {v},\textsf {a})=2^ph(\textsf {a})^p\).
Equipped with this result we are now able to prove the closed formula from Theorem 2.3.
Proof for Theorem 2.3
Let \(\text {KR}^p_{p,C}(\mu ,\nu )=\text {UOT}_{p,C}(\mu ,\nu )\) refer to UOT w.r.t. the distance on \(\mathcal {T}\), which only depends on the distance between individual leaf nodes. Considering the p-th height transformed tree \(\mathcal {T}_p\) and applying Lemma A.1 we conclude that
The linear optimization problem can be decomposed on several subtrees. For this recall that by Lemma 2.1 (i) there exists an optimal solution such that mass transportation is only considered on metric scales between two leaf nodes \(\textsf {v},\textsf {v}^\prime \in L\) such that \(d_{\mathcal {T}_p}(\textsf {v},\textsf {v}^\prime )\le C^p\). If \(\textsf {v}_0\) is the common ancestor of \(\textsf {v},\textsf {v}^\prime \) then by the ultrametric tree properties of \(\mathcal {T}\) (see also the proof of Lemma A.1) the inequality \(d_{\mathcal {T}_p}(\textsf {v},\textsf {v}^\prime )\le C^p\) is equivalent to the height function \(h(\textsf {v}_0)\le \frac{C}{2}\). Consider the set \(\mathcal {R}(C)\) in (7) and for each \(\textsf {v}\in \mathcal {R}(C)\) define subtrees \(\mathcal {C}(\textsf {v})\) consisting of the children of \(\textsf {v}\) and the subset of corresponding edges. By construction if \(\textsf {v}_i,\textsf {v}_j\in \mathcal {R}(C)\) with \(\textsf {v}_i \ne \textsf {v}_j\) then the subtrees are disjoint \(\mathcal {C}(\textsf {v}_i)\cap \mathcal {C}(\textsf {v}_j)=\emptyset \) (Fig. 4a for an illustration). In particular, the linear optimization problem \(\text {KR}_{p,C}^p(\mu ^L,\nu ^L)\) is decomposed on each individual subtree \(\mathcal {C}(\textsf {v})\) for each \(\textsf {v}\in \mathcal {R}(C)\). The distance on individual subtrees is set to be the p-th height transformed tree distance \(d_{\mathcal {T}_p}\) which exactly captures the pairwise p-th power distance between leaf nodes belonging to the same subtree (Lemma A.1). For an element \(\textsf {v}\in \mathcal {R}(C)\) consider its subtree \(\mathcal {C}(\textsf {v})\) with distance \(d_{\mathcal {T}_p}\). By definition the maximal distance between its leaf nodes is bounded by \(\nicefrac {C^p}{2}\). We augment the subtree \(\mathcal {C}(\textsf {v})\) with a dummy node \(\tilde{\textsf {v}}\) and introduce an edge \(e=(\textsf {v},\tilde{\textsf {v}})\) with edge weight \(\frac{C^p}{2}-2^{p-1}h(\textsf {v})^p\) (Fig. 4b for an illustration). Denote the augmented tree by \(\tilde{\mathcal {C}}(\textsf {v})\). Considering the measures \(\mu ^L,\nu ^L\) restricted to \(\mathcal {C}(\textsf {v})\) we augment \(\mu ^L\) adding mass \(\left( \mu ^L(\mathcal {C}(\textsf {v}))-\nu ^L(\mathcal {C}(\textsf {v}))\right) _+\) at \(\tilde{\textsf {v}}\) and vice versa augment \(\nu ^L\) adding mass \(\left( \nu ^L(\mathcal {C}(\textsf {v}))-\mu ^L(\mathcal {C}(\textsf {v}))\right) _+\) at \(\tilde{\textsf {v}}\). This construction defines an equivalent OT problem on \(\tilde{\mathcal {C}}(\textsf {v})\) [33]. Hence, applying the closed formula for OT on general metric trees [20, p.575] yields
Summing over all subtrees indexed by the set \(\mathcal {R}(C)\) finishes the proof. \(\square \)
1.2.2 Proofs for the Barycenter
Proof of Theorem 2.5
(ii) Let \(\mu \) be a (p, C)-barycenter and \(\tilde{\mu }\) its augmented counterpart. Then, by Proposition 3.9 there exists an optimal multi-coupling \(\pi \), such that it holds \(\mu =\tilde{\mu }_{\vert \mathcal {Y}}=(\tilde{T}_C^{J,p}\# \pi )_{|\mathcal {Y}}\). Hence, for each \(y\in \text {supp}(\tilde{\mu })\) there exists \(K_y\ge 1\) and \(K_y\) J-tupels \((x^1_{y,1},\dots ,x^J_{y,1}),\dots ,(x^1_{y,K_y},\dots ,x^J_{y,K_y})\) such that for \(k=1,\dots ,K_y\) it holds
and \(\mu (y)=\sum _{k=1}^{K_y}a^y_k\), where \(a_k^y=\pi (x^1_{y,k},\dots ,x^J_{y,k})\). For \(i=1,\dots ,J\) define \(\tilde{\pi }_i\in \mathcal {M}_+(\mathcal {Y}\times \mathcal {Y})\) by \(\tilde{\pi }_i(y,x^i_{y,k})=a_k^y\) for all \(y\in \text {supp}(\tilde{\mu })\), \(i=1,\dots ,J\) and \(k=1,\dots ,K_y\). Set \(\tilde{\pi }_i\) to be zero everywhere else for \(i=1,\dots ,J\). By construction, \(\tilde{\pi }_i\) defines an OT plan between \(\tilde{\mu }\) and \(\tilde{\mu }_i\) for \(i=1,\dots ,J\). It holds
where the first equality follows from Proposition 3.9 and the third and fourth by construction. Since \(\tilde{\pi }_i\) is an OT plan between \(\tilde{\mu }\) and \(\tilde{\mu }_i\) it holds for all \(i=1,\dots ,J\) that
Thus, it follows together with the previous equations that
i.e. \(\tilde{\pi }_i\) is optimal. Lemma 3.5 now yields the first part of the statement.
For the second part assume that for any \((x_1,\dots ,x_L)\in \mathcal {Y}^L\) it holds that \(T^{L,p}(x_1,\dots ,x_L)=T^{L,p}(y_1,x_2,\dots ,x_L)\) is equivalent to \(x_1=y_1\). Let \(y\in \text {supp}(\tilde{\mu })\) and consider OT plans \(\tilde{\pi }^1,\dots ,\tilde{\pi }^J\) between \(\tilde{\mu }\) and \(\tilde{\mu }_i\), respectively. For \(i=1,\dots ,J\) consider \(x^i\) such that \(\tilde{\pi }_i(y,x^i)=a_i>0\). Assume that it holds \(y\ne \tilde{T}_C^{J,p}(x_1,\dots ,x_J)\). Denote the minimum of the \(a_i\) as \(a_0=\min _{i=1,\dots ,J} a_i\). By construction, it follows that
which is a contradiction to \(\tilde{\mu }\) being a barycenter of \(\tilde{\mu }_1,\dots ,\tilde{\mu }_J\). Thus, it holds \(y=\tilde{T}_C^{J,p}(x_1,\dots ,x_J)\). Now, assume w.l.o.g. there exists \(x_1,z_1\in \mathcal {Y}\), such that it holds \(\pi ^1(y,x_1)>0\) and \(\pi ^1(y,z_1)>0\). However, by the previous argument this implies
By assumption this is equivalent to \(x_1=z_1\), thus it holds for all \(x,y\in \mathcal {Y}\) and \(i=1,\dots ,J\) that \(\pi ^i(y,x)\in \{0,\mu (y) \}\).
(i) By Proposition 3.9 the objective value of the balanced multi-marginal and (p, C)-barycenter problem coincide and a (p, C)-barycenter is obtained as the push-forward of an optimal balanced multi-coupling under the map \(\tilde{T}_C^{J,p}\) restricted to \(\mathcal {Y}\). By construction and Corollary 3.7 any such measure is supported in \(\mathcal {C}_{\text {KR}}(J,p,C)\). Thus, there always exists a (p, C)-barycenter whose support is restricted to \(\mathcal {C}_{\text {KR}}(J,p,C)\) and the minimum over Y and \(\mathcal {C}_{\text {KR}}(J,p,C)\) coincide.
The second part is similar and we let \(\tilde{\mu }\) be any p-Wasserstein barycenter. Then by Proposition 3.9, there exists a multi-coupling of \(\tilde{\mu }_1,\dots ,\tilde{\mu }_J\), such that \(\tilde{\mu }=\tilde{T}_C^{J,p}\# \tilde{\pi }\). Since any such push-forward measure can only have support in \(\mathcal {C}_{\text {KR}}(J,p,C)\cup \{\mathfrak {d}\}\), it holds for \(\mu =\tilde{\mu }_{\vert \mathcal {Y}}\) that \(\text {supp}(\mu )\subset \mathcal {C}_{\text {KR}}(J,p,C)\). It remains to show the upper bound on the total mass. By the equivalence to the multi-marginal problem and by Lemma 3.5 (ii) any (p, C)-barycenter \(\mu \) cannot have mass on a point which is constructed from a set of points \((x_1,\dots ,x_J)\) for which \(2|\mathcal {B}(x_1,\dots ,x_J)|\ge J\). Additionally, by part (ii) we know that there exists UOT plans, such that the mass of each (p, C)-barycenter support point is fully transported to points it is constructed from. Let \((a_1,\dots , a_K)\) be the weight vector of the support points of the (p, C)-barycenter, then it holds that
since by the previous argument and Lemma 3.5, any (p, C)-barycenter support point \(x_k\) reduces the maximum available mass by at least \(\lceil J/2 \rceil a_k\) and by Lemma 3.2, the total mass of the (p, C)-barycenter is bounded by the sum of the total masses of the \(\mu _i\). Therefore it holds that
(iii) The multi-marginal problem between \(\tilde{\mu }_1,\dots ,\tilde{\mu }_J\) is a balanced problem, thus we can pose this as a linear program with a total of \(\prod _{i=1}^JM_i\) variables and \(\sum _{i=1}^N M_i+J\) constraints. As all measures have the same total mass, we can drop one arbitrary marginal constraint for each measure besides the first. Thus, the rank of the constraint matrix in the corresponding constraint is bounded by \(\sum _{i=1}^N M_i +1\). Hence, each basic feasible solution of the linear program has at most \(\sum _{i=1}^N M_i + 1\) non-zero entries (see [47] for details). Let \(\pi \) be such a solution. By Proposition 3.9 the measure \(\tilde{\mu }=\tilde{T}_C^{J,p}\# \pi \) is a p-Wasserstein barycenter and by construction it has at most \(\sum _{i=1}^N M_i +1\) support points. Due to the upper bound on the total mass of the (p, C)-barycenter in property (i), we can guarantee that there is non-zero mass at \(\mathfrak {d}\) for \(J>2\), hence in this case, restricting the measure to \(\mathcal {Y}\) reduces the support size by one. For \(J=2\), we note that the multi-marginal problem is just the augmented UOT problem. By construction we either have a point x in the support of one of the two measures, such that there is transport between x and \(\mathfrak {d}\) or both measures have equal mass at \(\mathfrak {d}\) and it is optimal to leave this mass in place. In the first case, we have mass at \(\tilde{T}^{J,p}_C(x,\mathfrak {d})=\mathfrak {d}\), thus the support size can be reduced by one and in the second the problem is equivalent to the OT problem and thus the barycenter has at most \(M_1+M_2-1\) support points. Finally, by property (i) the support of any (p, C)-barycenter is contained in \(\mathcal {C}_{KR}(J,p,C)\), thus the cardinality of this set also provides a trivial upper bound on the support size of any (p, C)-barycenter. Taking the minimum over both quantities, we conclude
(iv) For any \(\mu \in \mathcal {M}_+(\mathcal {Y})\), it holds
where the inequality follows from Theorem 2.2 (iv). Taking the infimum over all measures in \(\mathcal {M}_+(\mathcal {Y})\) on both sides completes the proof.
(v) Let \(C\le d_{\min }^\prime \), then by Theorem 2.2 (ii) it holds

where the change in the  in the second line follows from the fact that the total variation can only increase if we place mass outside of the support of the measures. Thus it suffices to consider measures supported on the union of the supports. Now, we note that the K summands are independent to each other, thus we can minimise them separately. Hence, for the k-th entry of a it holds that
in the second line follows from the fact that the total variation can only increase if we place mass outside of the support of the measures. Thus it suffices to consider measures supported on the union of the supports. Now, we note that the K summands are independent to each other, thus we can minimise them separately. Hence, for the k-th entry of a it holds that

which yields the claim.
(vi) Let \(\mathbb {M}_i=\mathbb {M}(\mu _i)\) for \(i=1,\dots ,J\) and set \(\mathbb {M}_0=0\). Assume that J is odd. Let \(\mu \) be a (p, C)-barycenter of \(\mu _1,\dots ,\mu _J\) with \(\mu (\mathcal {Y})\in [\mathbb {M}_{k-1},\mathbb {M}_k]\). In particular, \(\mu \) fulfills the non-mass-splitting property in (ii). Let \(a\in (0,\mathbb {M}_k-\mathbb {M}(\mu )]\) and \(\tilde{\mu }\) the augmented measure for \(\mu \). By construction, we can find support points \(x_k,\dots ,x_J\ne \mathfrak {d}\) of the augmented measures \(\tilde{\mu }_k,\dots ,\tilde{\mu }_J\) from which w.l.o.g. mass a is transported to \(\mathfrak {d}\) in \(\mu \). If one of the points has mass smaller a, we can just replace a with the minimum of the masses of the points and repeat the argument until we have considered a total mass of a. Set \(x_0=\tilde{T}_C^{J,p}(\mathfrak {d},\dots , \mathfrak {d},x_k,\dots ,x_J)\) and notice that if \(x_0=\mathfrak {d}\), we do not change the objective function in the augmented problem (Lemma 3.1) by adding this point which means w.l.o.g. \(x_0\ne \mathfrak {d}\). In this case, we have

Now, the objective cost of not having mass a at \(x_0\) is \(aC^p(J-k)/2\), while the cost of adding \(a\delta _{x_0}\) to \(\mu \) is equal to \(a(kC^p/2 + \sum _{i=k}^{J}\tilde{d}_C^p(x_i,x_0))\). Hence, adding the point improves the value of the Fréchet functional, if
For \(2k>J\), the right hand side will always be negative, so we can not improve. Thus, we assume \(2k<J\). By assumption it holds \(C\ge J^{\frac{1}{p}} \text {diam}(\mathcal {Z})\). Hence,
Therefore, for \(2k<J\) the objective value of \(\mu \) can always be improved by increasing its mass by a, as long as \(k < \lceil J/2 \rceil \). Thus, since \(\mu \) is a barycenter it holds \(\mathbb {M}(\mu )\ge \mathbb {M}\mu _{\lceil J/2 \rceil }\).
An analog, converse argument yields that if \(k>J/2\), we can always improve the objective value of \(\mu \), since removing and then re-adding any mass to \(\mu \) increases the objective value by the previous argument. Hence, it holds \(\mathbb {M}(\mu )= \mathbb {M}\mu _{\lceil J/2 \rceil }\).
Now, assume J is even. For \(2k\ne J\) nothing in the previous argument changes. However, for \(2k=J\) (note that this can only hold now that J is even), the right hand side is zero, however, if all the \(x_i\) for \(i=k,\dots , J\), are identical to \(x_0\) (in particular, there exists a point contained in the support of at least half of the measures), then the left hand side will also be zero. In this case, the presence of this point does not change the objective value and there are (p, C)-barycenters of different total masses. However, we can still always choose to not place mass in such cases, to obtain a (p, C)-barycenter of the desired total mass.
Proof for Lemma 2.7
It suffices to show that there is no centroid point, which is constructed from points from two or more different sets \(B_r\). Assume there is a point \(y_0 \in \mathcal {C}_{KR}(J,p,C)\), such that \(y_0\) is constructed, among others, from \(x_1 \in B_r\) and \(x_2\in B_s\) for \(r\ne s\). We distinguish two cases. Assume \(y_0 \in B_r\), then it holds \(d^p(x_1,y_0)>2^{p-1}C^p\ge C^p\) and \(y_0\) would not be in the restricted centroid set. The analogue argument holds for \(y_0 \in B_s\). Now, assume \(y_0\) is neither in \(B_r\) nor \(B_S\). Since \(d(B_r,B_S)>2^{1/p}C\), it holds either \(d^p(B_r,y_0)>C^p\) or \(d^p(B_s,y_0)>C^p\). Thus, we obtain another contradiction to \(y_0\in \mathcal {C}_{KR}(J,p,C)\). Hence, \( \mathcal {C}_{KR}(J,p,C)\) only contains centroids constructed from points within one \(B_r\) and by convexity of the \(B_r\), any centroid point constructed from points within \(B_r\) is again in \(B_r\). Theorem 2.5 (ii) yields that there will always be an optimal solution which only transports within each \(B_r\), thus the R problems are in fact independent and we can separate them without changing the objective value. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Heinemann, F., Klatt, M. & Munk, A. Kantorovich–Rubinstein Distance and Barycenter for Finitely Supported Measures: Foundations and Algorithms. Appl Math Optim 87, 4 (2023). https://doi.org/10.1007/s00245-022-09911-x
Accepted:
Published:
DOI: https://doi.org/10.1007/s00245-022-09911-x
Keywords
- Unbalanced optimal transport
- Kantorovich–Rubinstein
- Wasserstein
- Barycenter
- Multi-marginal transport
- Ultrametric trees