
Abstract
We define a state space and a Markov process associated to the stochastic quantisation equation of Yang–Mills–Higgs (YMH) theories. The state space \(\mathcal{S}\) is a nonlinear metric space of distributions, elements of which can be used as initial conditions for the (deterministic and stochastic) YMH flow with good continuity properties. Using gauge covariance of the deterministic YMH flow, we extend gauge equivalence ∼ to \(\mathcal{S}\) and thus define a quotient space of “gauge orbits” \(\mathfrak {O}\). We use the theory of regularity structures to prove local in time solutions to the renormalised stochastic YMH flow. Moreover, by leveraging symmetry arguments in the small noise limit, we show that there is a unique choice of renormalisation counterterms such that these solutions are gauge covariant in law. This allows us to define a canonical Markov process on \(\mathfrak {O}\) (up to a potential finite time blow-up) associated to the stochastic YMH flow.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
The purpose of this paper is to construct and study the Langevin dynamic associated to the Euclidean Yang–Mills–Higgs (YMH) measure on the torus \(\mathbf{T}^{d}\), for \(d=3\). Postponing precise definitions to Sect. 1.3, the YMH measure should be the probability measure formally given by

where \(\mathrm {d}A\) (resp. \(\mathrm {d}\Phi \)) is a formal Lebesgue measure on the space of principal \(G\)-connections on a principal bundle \(\mathcal{P}\to \mathbf{T}^{d}\) (resp. associated vector bundle \(\mathcal{V}\)), for \(G\) a compact Lie group with Lie algebra \(\mathfrak {g}\). The YMH action  is given by
is given by

where \(F_{A}\) is the curvature 2-form of \(A\) and \(\mathrm {d}_{A}\) denotes the covariant derivative defined by the connection \(A\). In particular, this includes the pure Yang–Mills (YM) action, in which the Higgs field \(\Phi \) is absent (i.e., the associated vector bundle has dimension 0).
The YMH action is an important component of the Standard Model Lagrangian, and the mathematical study of the YMH measure on various manifolds has a long history. Much work has been done to give a meaning to (1.1) for the pure YM theory in \(d=2\), including \({\mathbf {R}}^{2}\) and compact surfaces. These works are primarily based on an elegant integrability property of 2D YM; a sample list of contributions is [38, 41, 52, 67, 72, 81]. In the Abelian case \(G=U(1)\) on \({\mathbf {R}}^{d}\) the measure (1.1) is essentially a Gaussian measure (e.g. [49]), and [48] and [37] proved convergence of the \(U(1)\) lattice Yang–Mills theory to the continuum theory in \(d=3\) and \(d=4\) respectively. Still in the Abelian case, one can also make sense of the full YMH theory in \(d=2\) [13–15] and \(d=3\) [64, 65]. A form of ultraviolet stability in finite volume (i.e. on \(\mathbf{T}^{d}\)) was also shown for the pure YM theory in \(d=4\) using a continuum regularisation in [71] and in \(d=3,4\) using renormalisation group methods on the lattice in a series of works by Balaban culminating in [2–4]. The above list of works is far from exhaustive and we refer to the surveys [26, 62, 69] for further references and history. We mention that the construction of the pure YM measure in \(d=3\) and of the non-Abelian YMH measure in \(d=2\) (and \(d=3\)), even in finite volume, is open.
In this paper we will always assume that the bundles \(\mathcal{P}\) and \(\mathcal{V}\) are trivial. Upon fixing a global section of \(\mathcal{P}\), we can therefore identify a connection \(A\) with a \(\mathfrak {g}\)-valued 1-form and a section of \(\mathcal{V}\) with a function \(\Phi \colon \mathbf{T}^{d}\to \mathbf{V}\), where \(\mathbf{V}\) is a real finite-dimensional inner product space carrying an orthogonal representation \(\boldsymbol{\varrho }\) of \(G\). We will often drop \(\boldsymbol{\varrho }\) from our notation and simply write \(g\phi \) for \(\boldsymbol{\varrho }(g)\phi \), and similarly \(h\phi \) for \(h\in \mathfrak {g}\) will denote the derivative representation of \(\mathfrak {g}\) on \(\mathbf{V}\).
Besides the non-existence of the Lebesgue measure on infinite-dimensional spaces and the usual divergencies which arise from the non-quadratic terms in an action, a major problem when trying to give a meaning to (1.1) is the fact that it is (formally) invariant under the action of an infinite-dimensional group of transformation. Indeed, assuming for now that all the objects are smooth, a gauge transformation \(g \) is an element \(g \in \mathfrak {G}^{\infty }\stackrel {{\tiny \mathrm {def}}}{=}\mathcal {C}^{\infty}(\mathbf{T}^{d},G)\) which acts on \((A,\Phi )\) by
Geometrically, gauge transformations are automorphisms of the principal bundle \(\mathcal{P}\), so \((A^{g},\Phi ^{g})\) can be interpreted as representing \((A,\Phi )\) in a new coordinate system i.e., using a different global section of \(\mathcal{P}\). An important feature of gauge theory is that all coordinate systems should give rise to the same physical quantities. In particular, one can verify that

which suggests that  should be invariant under the action of any gauge transformations \(g\). Since the group of all gauge transformations is infinite-dimensional, such a measure cannot exist as a bona fide \(\sigma \)-additive probability measure.
should be invariant under the action of any gauge transformations \(g\). Since the group of all gauge transformations is infinite-dimensional, such a measure cannot exist as a bona fide \(\sigma \)-additive probability measure.
A potential way to make rigorous sense of (1.1) is through stochastic quantisation, which was introduced in the physics literature for gauge theories by Parisi–Wu [78]. In this approach, one aims to construct  as the invariant measure of the Langevin dynamic associated to the action
as the invariant measure of the Langevin dynamic associated to the action  . Formally, this is given by
. Formally, this is given by
where \(\mathrm {d}_{A}^{\ast}\) denotes the adjoint of \(\mathrm {d}_{A}\), and \(\mathbf{B}\colon \mathbf{V}\otimes \mathbf{V}\rightarrow \mathfrak{g}\) is the unique \({\mathbf {R}}\)-linear form such that

for all \(u,v \in \mathbf{V}\) and \(h \in \mathfrak {g}\). The noises \(\xi \) and \(\zeta \) are independent space-time white noises with respect to our metrics, i.e. for \(\xi = \xi _{i} \mathrm {d}x_{i}\),
Here \(\mathord{\mathrm{Cas}}\in \mathfrak {g}\otimes _{s} \mathfrak {g}\) is the quadratic Casimir element and \(\mathrm{Cov}\in \mathbf{V}\otimes _{s} \mathbf{V}\) is identity map if we identify \(\mathbf{V}\simeq \mathbf{V}^{*}\) using the metric on \(\mathbf{V}\). We normalise the Casimir similarly and note that these covariances satisfy the invariant properties \((\mathrm {Ad}_{g} \otimes \mathrm {Ad}_{g}) \mathord{\mathrm{Cas}}=\mathord{\mathrm{Cas}}\) and \((g \otimes g) \mathrm{Cov}=\mathrm{Cov}\) for every \(g\in G\). The dynamic (1.4) is formally invariant in law under any time-independent gauge transformation \(g\) by (1.3), namely, if \((A,\Phi )\) a solution to (1.4) then, for any fixed time-independent gauge transformation \(g\) we have that \((A^{g},\Phi ^{g})\) solves (1.4) with \((\xi ,\zeta )\) replaced by the rotated noise \((\mathrm {Ad}_{g} \xi ,g \zeta )\) which is equal in law. In particular, the bilinear form \(\mathbf{B}\) satisfies the covariance property \(\mathrm {Ad}_{g} \mathbf{B}(u\otimes v) = \mathbf{B}(gu\otimes gv)\).
In spatial coordinates, (1.4) reads
for \(i\in [d] = \{1,\ldots , d\}\) with the summation over \(j\) implicit. A major problem with this equation is the lack of parabolicity in the equations for \(A\), which is a reflection of the invariance of the action  under the gauge group. As discussed in [22], this problem can be circumvented by taking any sufficiently regular time-dependent 0-form \(\omega \colon [0,T]\to \mathcal{C}^{\infty}(\mathbf{T}^{d},\mathfrak {g})\) and consider instead of (1.4) the equation
under the gauge group. As discussed in [22], this problem can be circumvented by taking any sufficiently regular time-dependent 0-form \(\omega \colon [0,T]\to \mathcal{C}^{\infty}(\mathbf{T}^{d},\mathfrak {g})\) and consider instead of (1.4) the equation
Then, at least formally, solutions to (1.8) are gauge equivalent in law to those of (1.4) under a time-dependent gauge transformation. To get a parabolic flow for \(A\) in (1.8) a convenient choice of \(\omega \) is \(\omega = -\mathrm {d}^{*} A=\partial _{j}A_{j}\) which yields the so-called DeTurck–Zwanziger term [34, 35, 88] in the first equation of (1.8). After making this choice our main focus will be the stochastic Yang–Mills–Higgs (SYMH) flow which in coordinates reads
The system (1.9) is formally gauge covariant in the following sense: if \((A,\Phi )\) is a solution to (1.9) then, given a time evolving gauge transformation \(g\) solving \(g^{-1} \partial _{t}g = -\mathrm {d}_{A}^{*} (g^{-1} \mathrm {d}g)\), \((A^{g},\Phi ^{g})\) solves the same equation with \((\xi ,\zeta )\) replaced by \((\mathrm {Ad}_{g}\xi ,g\zeta )\) which, since \(g\) is adapted, is equal in law to \((\xi ,\zeta )\).
1.1 Outline of the paper
In Sects. 1.3 and 1.4 we introduce important notation and summarise the main theorems.
In Sect. 2 we construct a nonlinear metric space \(\mathcal{S}\) of distributions which serves as the state space for SYMH on \(\mathbf{T}^{3}\). By using the regularising and gauge covariant properties of the deterministic YMH flow (with DeTurck–Zwanziger term), we define regularised gauge-invariant observables on \(\mathcal{S}\) which have good continuity properties and show that gauge equivalence ∼ extends to \(\mathcal{S}\) in a canonical way. Furthermore sufficiently regular gauge transformations \(g\in \mathcal {C}^{\varrho }(\mathbf{T}^{3},G)\) act on \(\mathcal{S}\) and preserve ∼. The main idea in the definition of \(\mathcal{S}\) is to specify how the heat semigroup \(t\mapsto \mathcal{P}_{t} X\) behaves on elements \(X\in \mathcal{S}\); the space \(\mathcal{S}\) is nonlinear because we force control on quadratic terms of the form \(\mathcal{P}_{t} X \cdot \nabla \mathcal{P}_{t} X\) arising from the most singular terms in (1.9). In Sect. 3 we show that the stochastic heat equation defines a continuous stochastic process with values in \(\mathcal{S}\).
In Sect. 4 we build on the “basis free” regularity structures framework in [22] to show that certain symmetries are preserved by BPHZ renormalisation. This is then used in Sect. 5 to show that SYMH can be renormalised with mass counterterms to admit local solutions through mollifier approximations, which defines a continuous stochastic process with values in \(\mathcal{S}\) (possibly with blow-up).
In Sect. 6 we show that there exists a choice for the mass renormalisation so that SYMH is genuinely (not only formally) gauge covariant in law. That is, the pushforwards to \(\mathfrak {O}= \mathcal{S}/{\sim}\) of the laws of two solutions \((A(t),\Phi (t))\) and \((\bar{A}(t),\bar{\Phi}(t))\) to SYMH for \(t>0\) with initial conditions \((A(0),\Phi (0))=(a,\phi )\) and \((\bar{A}(0),\bar{\Phi}(0))=(a^{g},\phi ^{g})\) respectively are equal (modulo subtleties involving restarting the equation). This is done through an argument based on preservation of gauge symmetry in the small noise limit, which is inspired by [12]. In Sect. 7 we show that there exists a Markov process on the space of “gauge orbits” \(\mathfrak {O}\), which is unique in a suitable sense and onto which the solution to SYMH from Sect. 6 projects.
Finally in Appendix A we collect some results concerning modelled distributions with singular behaviour at \(t=0\), which allows us to construct solutions to our SPDEs starting from suitable singular initial conditions. In Appendix B we collect some results on the deterministic YMH flow which are useful for defining gauge equivalence ∼ on \(\mathcal{S}\) regularised observables. In Appendix C, we extend the well-posedness result for \((A,\Phi )\) in Sect. 5 to a coupled \((A,\Phi ,g)\) system which is used in Sects. 6 and 7. In Appendix D we prove that our solution maps are injective in law as functions of renormalisation constants, which is useful in showing gauge covariance in Sect. 6.
1.2 Related works and open problems
Let us mention several other works related to this one. The idea to use the regularising properties of the deterministic YMH flow to define regularised gauge-invariant observables for singular gauge fields was advocated in [23, 24] and more recently in [17, 18]; see also [7, 33, 42, 70, 76] for related ideas in the physics literature. The results in [17, 18] are closely related to those obtained in Sects. 2 and 3; see Remarks 2.8, 2.14, and 3.16 for a brief comparison.
In further work, Gross established a solution theory for the YM flow with initial conditions in \(H^{1/2}\) in [50, 51]. This space is natural since it is scaling critical for the YM flow in three dimensions. (This is in the sense that it has small-scales scaling exponent \(\alpha = -1\), so that \(\Delta u\), \(u\cdot Du\) and \(u^{3}\) all have the same scaling exponent \(\alpha -2 = 2\alpha -1 = 3\alpha = -3\).) Note however that the solution to the stochastic YM flow does not belong to that space. Instead, it belongs to \(\mathcal{C}^{-\frac{1}{2}-\kappa}\) for any \(\kappa > 0\) (but not to \(\mathcal{C}^{-\frac{1}{2}}\)) which, although it is a space of rather badly behaved distributions, has scaling exponent \(-\frac{1}{2}-\kappa \) which is subcritical for the YM flow. Unfortunately, these spaces are sufficiently badly behaved so that there do exist vector-valued \(X \in \mathcal{C}^{-\frac{1}{2}}\) for which the map \(t \mapsto \mathcal{P}_{t} X \otimes \nabla \mathcal{P}_{t} X\) fails to be locally integrable at \(t=0\) (this does not happen when \(u \in H^{\frac{1}{2}}\)). In fact, there exists no Banach space of distributions supporting the 3D Gaussian free field to which the YM flow extends continuously [31].
There are also number of recent results, from a probability theory perspective, on lattice gauge theories in \(d=3\) and \(d=4\) and their scaling limits. Some works in this direction include [25] on the YM free energy, [16, 27, 43, 44] on the analysis of Wilson loops with discrete gauge group and [19, 46] with \(G=U(1)\), and [28] on the confinement problem. See also [84–86] for work on lattice gauge theory using Langevin dynamics.
The idea of stochastic quantisation was introduced in the physics literature by Nelson [77] and Parisi–Wu [78]. With the development of regularity structures [56] and paracontrolled distributions [55] to solve singular SPDEs (see also [20, 39, 66]), this idea has been applied to the rigorous construction and study of scalar quantum fields, especially the \(\Phi ^{4}_{3}\) theory [1, 53, 59, 73, 74]. See also [5, 6, 54] for another stochastic analytic approach.
We finally mention some earlier works of the authors. In [22] we studied the Langevin dynamic on for the pure YM measure on \(\mathbf{T}^{2}\) (though the results therein carry over without fundamental problems to the YMH theory). Because the equations in \(d=2\) are much less singular than in \(d=3\), we were able to obtain stronger results with different methods. Namely,
-
The state space constructed in [22] was a linear Banach space and came with an action of a gauge group which determined completely the “gauge equivalence” relation ∼; we do not know here if there exists a gauge group acting on \(\mathcal{S}\) which determines ∼ (we suspect it does not with the current definitions).
-
Gauge covariance of the SYM process in [22] was shown through a direct computation of the renormalisation constants coming from just three stochastic objects. Here such a computation is infeasible by hand due to the presence of a large number of logarithmic divergences, which is why we rely on more subtle symmetry arguments.
-
The SYMH (1.9) for \(d=2\) (and its deterministic version for any \(d\)) admits arbitrary initial conditions in the Hölder–Besov space \(\mathcal{C}^{\eta}\) only for \(\eta >-\frac{1}{2}\), and the state space considered in [22] embeds into such a Hölder–Besov space. Here \(\mathcal{S}\) embeds at best into \(\mathcal{C}^{\eta}\) for \(\eta <-\frac{1}{2}\), which causes significant complications in the short-time analysis. This problem becomes even worse for the multiplicative noise versions of (1.9) considered in Sect. 6 to the extent that we require a substantial change to the fixed point problem when restarting the equation, in particular solving for a suitable ‘remainder’, in order to obtain maximal solutions.
We also mention that the first work to study the stochastic quantisation of a gauge theory using regularity structures is [83] (using a lattice regularisation of \(\mathbf{T}^{2}\) with \(G=U(1)\) and a Higgs field), and the first work to give a representation of the YM measure on \(\mathbf{T}^{2}\) as a random variable taking values in a (linear) state space of distributional connections for which certain Wilson loops are defined pathwise is [30]. The state space in [30] served as the basis for that in [22], and part of the definition of \(\mathcal{S}\) in the present work is inspired by these works (see Sects. 2.3 and 2.5).
We close with some open problems. One of the main questions is whether the Markov process on \(\mathfrak {O}\) constructed in this paper admits an invariant measure, which should then be unique due to the strong Feller [57] and full support [58] properties of the solution. We do conjecture that such an invariant measure exists, which then yields a reasonable candidate for the YMH measure on \(\mathbf{T}^{3}\). Unfortunately, we do not even know how to show the weaker statement that the Markov process survives for all times. For the pure YM measure and Langevin dynamic on \(\mathbf{T}^{2}\), this question was recently answered in [32].
Another question is whether one can strengthen or change the construction of \((\mathcal{S},\sim )\) in such a way that there exists a topological group \(\bar {\mathfrak {G}}\) containing \(\mathfrak {G}^{\infty }= \mathcal{C}^{\infty}(\mathbf{T}^{3},G)\) as a dense subgroup, acting on \(\mathcal{S}\), having closed orbits, and such that ∼ is given by its orbits. For \(d=2\), it was shown in [22] that (the closure of smooth functions in) \(\mathcal{C}^{\alpha}(\mathbf{T}^{2},G)\), for some \(\alpha \in (\frac{1}{2},1)\) is such a group; this is both aesthetically pleasing and a tool to simplify a number of arguments. The lack of a nice gauge group in \(d=3\), for example, leads to difficulties in studying the topology of \(\mathfrak {O}\) (we only know it is separable and completely Hausdorff here as opposed to Polish in [22]), and complicates the construction of the Markov process on \(\mathfrak {O}\).
We finally mention that it would be of interest to extend the results of this paper to \({\mathbf {R}}^{3}\), but this problem is entirely open. In fact, this problem is open even in the 2D setting of [22, 32]. Regarding global-in-time solutions, see the very recent progress [9] for Abelian-Higgs on \(\mathbf{T}^{2}\).
1.3 Notation and conventions
We collect some conventions and notations used throughout the article. Part of this notation follows [22]. We equip the torus \(\mathbf{T}^{3}={\mathbf {R}}^{3}/{\mathbf {Z}}^{3}\) with the geodesic distance denoted by \(|x-y|\), and \({\mathbf {R}}\times \mathbf{T}^{3} \) the parabolic distance \(|(t,x)-(s,y)|=\sqrt{|t-s|}+|x-y|\). We will tacitly identify \(\mathbf{T}^{3}\) with the set \([-\frac{1}{2},\frac{1}{2})^{3}\).
Throughout the article we fix a compact Lie group \(G\), with associated Lie algebra \(\mathfrak {g}\), endowed with an adjoint invariant metric denoted by \(\langle \;,\;\rangle _{\mathfrak {g}}\). We will often assume \(G\) to be embedded into a space of matrices. Let \(\mathbf{V}\) be a real vector space of finite dimension \(\dim \mathbf{V}\ge 0\) endowed with a scalar product \(\langle \;,\;\rangle _{\mathbf{V}}\) and an orthogonal representation \(\boldsymbol{\varrho }\) of \(G\). As mentioned before, we often drop \(\boldsymbol{\varrho }\) from our notation and simply write \(g\phi \equiv \boldsymbol{\varrho }(g)\phi \) and \(h\phi \equiv \boldsymbol{\varrho }(h)\phi \) for \(g\in G\), \(h\in \mathfrak {g}\), and \(\phi \in \mathbf{V}\), where \(\boldsymbol{\varrho }(h)\phi \) is understood as the derivative representation.
Remark 1.1
Even if \(\mathbf{V}\) is a complex vector space endowed with a Hermitian inner product \(\langle \;,\;\rangle _{\mathbf{V}}\), and the representation of \(G\) on \(\mathbf{V}\) is unitary, we instead view \(\mathbf{V}\) as a real vector space with \(\dim _{{\mathbf {R}}}(\mathbf{V}) = 2\dim _{{\mathbf {C}}}(\mathbf{V})\) endowed with the Euclidean inner product given by \(\operatorname{Re}\langle \;,\;\rangle _{\mathbf{V}}\) and view the representation as an orthogonal representation on \(\mathbf{V}\). In fact, the definition of the YMH action (1.2), the deterministic part of the SPDE (1.4) which is its gradient flow, and the definition of white noise in (1.6) all only depend on \(\operatorname{Re}\langle \;,\;\rangle _{\mathbf{V}}\) and not on \(\operatorname{Im}\langle \;,\;\rangle _{\mathbf{V}}\).
A “gauge field” \(A\) is an equivariant connection on the trivialFootnote 1 principal bundle \(\mathcal{P}\simeq \mathbf{T}^{3}\times G\) viewed as a 1-form \(A=(A_{1},A_{2},A_{3})\colon \mathbf{T}^{3}\to \mathfrak {g}^{3}\), which determines a covariant derivative \(\mathrm {d}_{A}\) on the associated bundle \(\mathcal{V}=\mathcal{P}\otimes _{\boldsymbol{\varrho }}\mathbf{V}\simeq \mathbf{T}^{3}\times \mathbf{V}\) by \(\mathrm {d}_{A}\Phi =\mathrm {d}\Phi +A\Phi = (\partial _{i}\Phi +A_{i}\Phi )\, \mathrm {d}x_{i}\) (see e.g. [36, Sect. 2.1.1]). A “Higgs field” is a section of \(\mathcal{V}\), viewed simply as a function \(\Phi \colon \mathbf{T}^{3}\to \mathbf{V}\). The curvature of a gauge field \(A\) is the \(\mathfrak {g}\)-valued 2-form \((F_{A})_{ij}=\partial _{i}A_{j} -\partial _{j}A_{i}+[A_{i},A_{j}]\).
A space-time mollifier \(\chi \) is a compactly supported smooth function on \({\mathbf {R}}\times {\mathbf {R}}^{3}\) such that \(\int \chi = 1\) and for every \(i\in \{1,2,3\}\), \(\chi \) is invariant under \(x_{i} \mapsto -x_{i}\) along with \((x_{1},x_{2},x_{3}) \mapsto (x_{\sigma (1)},x_{\sigma (2)},x_{ \sigma (3)})\) for any permutation \(\sigma \) on \(\{1,2,3\}\). \(\chi \) is called non-anticipative if it is supported in the set \(\{(t,x): t \geq 0\}\).
Assume that we are given a finite-dimensional normed space \((E, |\cdot |)\) and a metric space \((F,d)\). For \(\alpha \in (0,1]\), we define as usual
where \(|f|_{\alpha\mbox{-H{\"{o}}l}} \stackrel {{\tiny \mathrm {def}}}{=}\sup _{x\neq y\in F} \frac{|f(x)-f(y)|}{d(x,y)^{\alpha}} < \infty \) denotes the Hölder seminorm and \(|f|_{\infty }= \sup _{x\in F} |f(x)|\) denotes the sup norm.
For \(\alpha >1\), we define \(\mathcal {C}^{\alpha}(\mathbf{T}^{3},E)\) (resp. \(\mathcal {C}^{ \alpha}({\mathbf {R}}\times \mathbf{T}^{3},E)\)) to be the space of \(k\stackrel {{\tiny \mathrm {def}}}{=}\lceil \alpha \rceil -1\) times differentiable functions (resp. \(k_{0}\)-times differentiable in \(t\) and \(k_{1}\)-times differentiable in \(x\) for all \(2k_{0}+k_{1}\le k\)), with \((\alpha -k)\)-Hölder continuous \(k\)-th derivatives.
For \(\alpha <0\), let \(r \stackrel {{\tiny \mathrm {def}}}{=}-\lceil \alpha -1 \rceil \) and we define

where \(\mathcal {B}^{r}\) denotes the set of all smooth functions \(\psi \in \mathcal {C}^{\infty}(\mathbf{T}^{3})\) with \(|\psi |_{\mathcal {C}^{r}} \leq 1\) and support in \(\{z\in \mathbf{T}^{3}\,:\,|z|\leq \frac{1}{4}\}\) and where \(\psi ^{\lambda}_{x}(y) \stackrel {{\tiny \mathrm {def}}}{=}\lambda ^{-3}\psi (\lambda ^{-1}(y-x))\).
For \(\alpha =0\), we define \(\mathcal {C}^{0}\) to simply be \(L^{\infty}(\mathbf{T}^{3},E)\), and use \(\mathcal {C}(\mathbf{T}^{3},E)\) to denote the space of continuous functions, both spaces being equipped with the sup norm. For any \(\alpha \in {\mathbf {R}}\), we denote by \(\mathcal {C}^{0,\alpha}\) the closure of smooth functions in \(\mathcal {C}^{\alpha}\). We drop \(E\) from the notation whenever it is clear from the context.
If ℬ is a space of \(\mathfrak {g}\)-valued distributions equipped with a (semi-)norm \(|\cdot |\), then \(\Omega \mathcal{B}\) denotes the space of \(\mathfrak {g}\)-valued distributional 1-forms \(A= A_{i}\, \mathrm {d}x_{i}\) where \(A_{i}\in \mathcal{B}\), equipped with the corresponding (semi-)norm \(|A|\stackrel {{\tiny \mathrm {def}}}{=}\sum _{i=1}^{3} |A_{i}|\). When ℬ is of the form \(\mathcal {C}(\mathbf{T}^{3},\mathfrak {g})\), \(\mathcal {C}^{\alpha}(\mathbf{T}^{3},\mathfrak {g})\), etc., we write simply \(\Omega \mathcal {C}\), \(\Omega \mathcal {C}^{\alpha}\), etc. for \(\Omega \mathcal{B}\). For \(\varrho \in [0,\infty ]\), we write \(\mathfrak {G}^{\varrho }\stackrel {{\tiny \mathrm {def}}}{=}\mathcal{C}^{\varrho }(\mathbf{T}^{3},G)\) and let \(\mathfrak {G}^{0,\varrho }\) denote the closure of smooth functions in \(\mathfrak {G}^{\varrho }\), where we understand \(G\) as embedded into a space of matrices. We often call \(\mathfrak {G}^{\varrho }\) a gauge group and its elements gauge transformations.
In the remainder of the article, unless otherwise stated, we denote \(E=\mathfrak {g}^{3}\oplus \mathbf{V}\). This implies \(\mathcal{D}'(\mathbf{T}^{3},E)\simeq \Omega \mathcal{D}'\oplus \mathcal{D}'(\mathbf{T}^{3},\mathbf{V})\) and, for \(X\in \mathcal{D}'(\mathbf{T}^{3},E)\), we write \(X=(A,\Phi )\) for the corresponding decomposition. In particular, the configuration space of smooth (connection-Higgs) pairs \((A,\Phi )\) is \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\).
We similarly combine noises into a single variable \(\xi = ((\xi _{i})_{i=1}^{3},\zeta )\), which in view of (1.6) has covariance \(\mathbf{E}[\xi (t,x) \otimes \xi (s,y)] = \delta (t-s)\delta (x-y) \mathbf{Cov}\), with
Note that \(E\) carries a representation of \(G\) given for \(g\in G\) by
If \(g\) and \(x\) are functions (or distributions) with values in \(G\) and \(E\) respectively, we let \(g\xi \) denote the above operation pointwise whenever it makes sense.
For \(X,Y\in \mathcal{C}^{\infty}(\mathbf{T}^{3},E)\) we write \(X\sim Y\) if there exists \(g\in \mathfrak {G}^{\infty}\) such that \(X^{g}=Y\), where \(X^{g}=(A^{g},\Phi ^{g})\) is defined in (1.3). Recall that \(X\mapsto X^{g}\) defines a left group action of \(\mathfrak {G}^{\infty}\) on \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\). We denote by \(\mathfrak {O}^{\infty }\stackrel {{\tiny \mathrm {def}}}{=}\mathcal{C}^{\infty}(\mathbf{T}^{3},E)/{\sim}\) the corresponding quotient space. (The action \(X\mapsto X^{g} = gX\) of \(\mathfrak {G}^{\infty}\) on \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\) should not be confused with the action of \(\mathfrak {G}^{\infty}\) on \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\) given by (1.11).)
We will often use the following streamlined notation for writing the nonlinear terms of our equations. For any \(X\in E\) and \(i \in \{1,2,3\} \), we write \(X |_{\mathfrak {g}_{i}} \in \mathfrak {g}\) and \(X |_{\mathbf{V}} \in \mathbf{V}\) to be the projections of \(X\) onto the \(i\)-th component of \(X\) which is a copy of \(\mathfrak {g}\) and the last component of \(X\) which is a copy of \(\mathbf{V}\) respectively. Given any \(X\in E\) and \(\partial X = (\partial _{1} X,\partial _{2} X,\partial _{3} X)\in E^{3}\), where \(\partial _{i} X\) is just a generic element in \(E\) (which does not necessarily mean a derivative in general), and similarly \(\bar{X}\in E\) and \(\partial \bar{X}\), we introduce the shorthand notation \(X\partial \bar{X}, X^{3} \in E\) defined as
where, as above, the summation over \(j\) is implicit and we have written
and \(\bar{A}_{i}, \partial _{j} \bar{A}_{i}, \bar{\Phi}, \partial _{j} \bar{\Phi}\) are understood in the analogous way.
Recall the following notation from [22, Sect. 1.5.1]. Given a metric space \(F\), we extend it with a cemetery state  by setting
by setting  and postulating that the complement of every closed ball in \(F\) is a neighbourhood of
and postulating that the complement of every closed ball in \(F\) is a neighbourhood of  in \(\hat{F}\). We then recall the definition of the metric space \(F^{{\mathop{\mathrm{sol}}}}\) from [22, Sect. 1.5.1], which should be thought of as the space of continuous trajectories with values in \(\hat{F}\) which can blow up in finite time but cannot be “reborn”. The purpose of the rather convoluted definition of the metric of \(F^{{\mathop{\mathrm{sol}}}}\) is to guarantee that it is separable and complete (provided that \(F\) is).
in \(\hat{F}\). We then recall the definition of the metric space \(F^{{\mathop{\mathrm{sol}}}}\) from [22, Sect. 1.5.1], which should be thought of as the space of continuous trajectories with values in \(\hat{F}\) which can blow up in finite time but cannot be “reborn”. The purpose of the rather convoluted definition of the metric of \(F^{{\mathop{\mathrm{sol}}}}\) is to guarantee that it is separable and complete (provided that \(F\) is).
1.4 Main theorems
We first collect our results on the state space of our 3D stochastic YMH process, with references to more precise statements in later sections. Here, we will use the notation \(\mathcal{F}_{t}\) for the DeTurck–YMH flow (the solution to (1.9) with \(\xi = \zeta = 0\) and the \(\Phi |\Phi |^{2}\) term droppedFootnote 2) at time \(t\). Standard parabolic PDE theory shows that this is well-posed for short times for all initial conditions in \(\mathcal{C}^{\nu}(\mathbf{T}^{3},E)\) as soon as \(\nu > -\frac{1}{2}\). In other words, writing \(\mathcal{O}_{t} \subset \mathcal{C}^{\nu}\) for the set of initial conditions admitting a solution up to time \(t\), these are a decreasing family of open sets with \(\bigcup _{t \in (0,\varepsilon ]}\mathcal{O}_{t} = \mathcal{C}^{\nu}\). On the other hand, the projection \(\tilde {\mathcal{F}}_{t}\) of the DeTurck–YMH flow onto \(\mathfrak {O}^{\infty}\) is globally well-posed for all initial conditions in \(\mathcal{C}^{\nu}\). (This allows for a time-dependent gauge transformation which doesn’t change the projection of the flow to \(\mathfrak {O}^{\infty}\) but can prevent it from blowing up, see Appendix B, in particular Corollary B.5.) Recalling that \(E=\mathfrak {g}^{3}\oplus \mathbf{V}\), we can state our results regarding the state space \(\mathcal{S}\) (see Definition 2.22 below) as follows.
Theorem 1.2
State space
For every \(\eta \in (-\frac{1}{2}-\kappa ,-\frac{1}{2})\), where \(\kappa >0\) is sufficiently small, there exists a complete (nonlinear) metric space \((\mathcal{S},\Sigma )\) of \(E\)-valued distributions satisfying the following properties.
-
(i)
There is a canonical embedding \(\mathcal{S}\hookrightarrow \mathcal{C}^{\eta}(\mathbf{T}^{3},E)\) and there exists \(\bar{\nu}< 0\) such that \(\mathcal{C}^{\bar{\nu}}(\mathbf{T}^{3},E) \hookrightarrow \mathcal{S}\) densely. Furthermore, \(\mathcal{S}\) is closed under scalar multiplication when viewed as a space of distributions. See Lemmas 2.25and 2.35(ii).
-
(ii)
The deterministic DeTurck–YMH flow \(X \mapsto \mathcal{F}_{t}(X)\in \mathcal{C}^{\infty}(\mathbf{T}^{3},E)\) extends continuously to the closure of \(\mathcal{O}_{t+s}\) in \(\mathcal{S}\) for every \(s,t>0\). It follows that \(t \mapsto \mathcal{F}_{t}(X)\) is well-posed for every \(X \in \mathcal{S}\) and every sufficiently small \(t\) (depending on \(X\)) and the flow on gauge orbits \(X\mapsto \tilde{\mathcal{F}}_{t}\in \mathfrak {O}^{\infty}(X)\) extends continuously to all of \(\mathcal{S}\) for every \(t>0\). One furthermore has
$$\begin{aligned} \lim _{t\to 0} \Sigma (\mathcal {F}_{t}(X),X)=0 \qquad \forall X \in \mathcal{S}\;. \end{aligned}$$ -
(iii)
Define the equivalence relation on \(\mathcal{S}\) by \(X\sim Y \Leftrightarrow \tilde{\mathcal{F}}(X) = \tilde{\mathcal{F}}(Y)\). Then ∼ extends the notion of gauge-equivalence defined for smooth functions. Moreover, the quotient space \(\mathfrak {O}\stackrel {{\tiny \mathrm {def}}}{=}\mathcal{S}/{\sim}\) is a separable completely Hausdorff space. See Proposition 2.51.
-
(iv)
There exists \(\varrho \in (\frac{1}{2},1)\) and a continuous left group action \(\mathfrak {G}^{\varrho }\times \mathcal{S}\ni (g,X)\mapsto X^{g} \in \mathcal{S}\) for which \(X\sim X^{g}\) and which agrees with the action (1.3) for smooth \(g\) and \(X\). See Proposition 2.28.
-
(v)
There exist \(\nu \in (0,\frac{1}{2})\) and \(C,q>0\) such that, for all \(g \in \mathfrak {G}^{\varrho }\) and \(X \in \mathcal{S}\), one has \(|g|_{\mathcal{C}^{\nu}} \leq C(1+\Sigma (X,0)+\Sigma (X^{g},0))^{q}\). See Theorem 2.39.
Remark 1.3
A consequence of Theorem 1.2(iii) is that classical gauge-invariant observables (Wilson loops, string observables, etc) have “smoothened” analogues defined on \(\mathfrak {O}\) obtained by precomposing the classical observable with \(\tilde{\mathcal{F}}_{t}\) for some (typically small) \(t>0\). These smoothened observables are sufficient to separate points in \(\mathfrak {O}\), see Sect. 2.8.
Remark 1.4
The significance of point (v) may seem unclear at this stage. However, this estimate is crucial in the construction of the Markov process on \(\mathfrak {O}\) in Sect. 7.
Remark 1.5
The definition of the metric \(\Sigma \) is given in two parts: \(\Sigma (X,Y)=\Theta (X,Y)+{|\!|\!| X-Y |\!|\!|}\). The metric \(\Theta \) is defined in Sect. 2.1 and guarantees continuity of \(\tilde{\mathcal{F}}_{t}\) with respect to the initial condition. The norm \({|\!|\!| \cdot |\!|\!|}\) is defined in Sect. 2.5 and implies point (v). Both metrics come with several parameters, the final values of which are given at the beginning of Sect. 5.
Fix i.i.d. \(\mathfrak {g}\)-valued white noises \((\xi _{i})_{i=1}^{3}\) on \({\mathbf {R}}\times \mathbf{T}^{3}\) and an independent \(\mathbf{V}\)-valued space-time white noise \(\zeta \) on \({\mathbf {R}}\times \mathbf{T}^{3}\) and write \(\xi ^{\varepsilon }_{i} \stackrel {{\tiny \mathrm {def}}}{=}\xi _{i} * \chi ^{\varepsilon }\) along with \(\zeta ^{\varepsilon }\stackrel {{\tiny \mathrm {def}}}{=}\zeta * \chi ^{\varepsilon }\). Here \(\chi \) is a mollifier as in Sect. 1.3 and \(\chi ^{\varepsilon }(t,x) =\varepsilon ^{-5} \chi (\varepsilon ^{-2}t,\varepsilon ^{-1}x)\). For each \(\varepsilon \in (0,1]\) consider the system of SPDEs on \({\mathbf {R}}_{+} \times \mathbf{T}^{3}\) with \(i \in \{1,2,3\}\)Footnote 3
where the summation over \(j\) is again implicit, and we fix some choice of \((C_{\mbox{A}}^{\varepsilon }, C_{\Phi}^{\varepsilon }: \varepsilon \in (0,1])\) with
Here \(L_{G}(\mathbf{V},\mathbf{V})\) (resp. \(L_{G}(\mathfrak {g},\mathfrak {g})\)) is the space of all the linear operators from \(\mathbf{V}\) (resp. \(\mathfrak {g}\)) to itself which commute with the action of \(G\) (resp. adjoint action of \(G\)). Recall also that \(\mathbf{B}\colon \mathbf{V}\otimes \mathbf{V}\rightarrow \mathfrak{g}\) is the bilinear form determined by (1.5). In view of the notation introduced in Sect. 1.3, we may also write (1.14) as
where for any \(C \in L(\mathfrak {g},\mathfrak {g}) \) we write \(C^{\oplus 3}\) for \(C\oplus C\oplus C\in L(\mathfrak {g}^{3},\mathfrak {g}^{3})\).
Remark 1.6
One particular example in our setting is that \(\mathcal{V}\) is the adjoint bundle, i.e. \(\mathbf{V}=\mathfrak {g}\), and \(G\) acts on \(\mathbf{V}\) by adjoint action. In this case, \(\Phi \) is also \(\mathfrak {g}\)-valued and the bilinear form is simply given by the Lie bracket \(\mathbf{B}(\mathrm {d}_{A}\Phi \otimes \Phi ) = - [\mathrm {d}_{A}\Phi , \Phi ]\).
Recall the definition of \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\) from Sect. 1.3 (see \(F^{{\mathop{\mathrm{sol}}}}\) below (1.13) for any metric space \(F\)).
Theorem 1.7
Local existence
Consider any \(\mathring{C}_{\mbox{A}} \in L_{G}(\mathfrak {g},\mathfrak {g}) \) and a space-time mollifier \(\chi \). Then there exist  with
with  and
and  and which depend only on \(\chi \), such that the following statements hold.
and which depend only on \(\chi \), such that the following statements hold.
-
(i)
The solution \((A,\Phi )\) to the system (1.14) where

converges in \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\) in probability as \(\varepsilon \to 0\).
-
(ii)
The limit in item (i) depends only on \(\mathring{C}_{\mbox{A}}\) and not on \(\chi \).

Remark 1.8
See Theorem 5.1 for a slightly more general version of Theorem 1.7. The operators  and
and  will be determined by the BPHZ character that deforms the canonical lift of \(\xi ^{\varepsilon }\) into the BPHZ lift of \(\xi ^{\varepsilon }\).
will be determined by the BPHZ character that deforms the canonical lift of \(\xi ^{\varepsilon }\) into the BPHZ lift of \(\xi ^{\varepsilon }\).
While the equation (1.14) does fall under the “blackbox” local existence theory of [10, 11, 21, 56] and the vectorial regularity structures of [22], this theory does not directly give us Theorem 1.7. There are three issues we must overcome: (i) we want our solution to take values in the non-standard state space \(\mathcal{S}\), (ii) we want to start the dynamic from arbitrary, rough (not necessary “modelled”) initial data in \(\mathcal{S}\), and (iii) we must verify that the renormalisation counter-term is given by  for some
for some  and
and  which is not obvious from the formulae for counterterms provided in [11, 22].
which is not obvious from the formulae for counterterms provided in [11, 22].
Our next result is about gauge covariance of the limiting solution, provided that the operator \(\mathring{C}_{\mbox{A}}\) is suitably chosen. See [22, Sect. 2.2] for a discussion in the 2D case (which extends mutatis mutandis to the 3D case) on gauge covariance, and lack thereof before the limit, from a geometric perspective. To formulate this result, we consider a gauge transformation \(g(0)\) acting on the initial condition \((a,\phi )\) of \((A,\Phi )\) as in (1.14), and define a new dynamic \((B,\Psi )\) with initial condition \(g(0)(a,\phi )\) such that \((B,\Psi )=g(A,\Phi )\) for some suitable time-dependent gauge-transformation \(g\). The transformation \(g\) is chosen in such a way as to ensure that \((B,\Psi )\) converges in law to the solution to SYMH with initial condition \(g(0)(a,\phi )\), provided that \(\mathring{C}_{\mbox{A}}\) is suitably chosen. The resulting dynamics \((B,\Psi )\) and \(g\) satisfy the equations
Above and for the rest of this section, we let \(\varrho \in (\frac{1}{2},1)\) be as in Theorem 1.2(iv).
As mentioned above, for this choice of \((B,\Psi )\) and \(g\), one has \((B,\Psi )=g(A,\Phi )\) for any fixed \(\varepsilon > 0\). Furthermore, \(g\) as given by the solutions to (1.16) also solves
Note that (1.17) with \(A\) given as in Theorem 1.7 is also classically ill-posed as \(\varepsilon \downarrow 0\) but can be shown to converge using regularity structures (however, it might blow up before \(A\) does). Since the products in \(g (A, \Phi )\) are well defined in the spaces where convergence takes place, this gives one way of seeing that the solutions to (1.16) also converge as \(\varepsilon \downarrow 0\).
For any \(\mathring{C}_{\mbox{A}} \in L(\mathfrak {g},\mathfrak {g})\), let \(\mathcal{A}_{\mathring{C}_{\mbox{A}}}\colon \mathcal{S}\rightarrow \mathcal{S}^{ {\mathop{\mathrm{sol}}}}\) be the solution map taking initial data \((a,\phi ) \in \mathcal{S}\) to the limiting maximal solution of (1.14) promised by Theorem 1.7. Our main result on the construction of a gauge covariant process can be stated as follows.
Theorem 1.9
Gauge covariance
There exists a unique \(\mathring{C}_{\mbox{A}} \in L_{G}(\mathfrak {g},\mathfrak {g})\), independent of our choice of mollifier \(\chi \), with the following properties.
-
(i)
For all \(g(0) \in \mathfrak{G}^{\varrho }\) and \((a,\phi ) \in \mathcal{S}\), one has, modulo finite time blow-up
$$ g\mathcal{A}_{\mathring{C}_{\mbox{A}}}(a,\phi ) \stackrel {{\tiny \mathrm {law}}}{=}\mathcal{A}_{ \mathring{C}_{\mbox{A}}} \big(g(0)(a,\phi ) \big) \quad \quad \quad $$where \(g\) is given by (1.17) with \(A\) therein given by the corresponding component of \(\mathcal{A}_{\mathring{C}_{\mbox{A}}}(a,\phi )\) and initial condition \(g(0)\). See Theorem 6.1for a precise statement.
-
(ii)
There exists a unique Markov process \(\mathscr{X}\) on \(\mathfrak {O}\) such that, for every \((a,\phi ) \in \mathcal{S}\), if \(\mathscr{X}\) is started from \([(a,\phi )]\) then there exists a random time \(t > 0\) such that, for all \(s \in [0,t]\), \(\mathscr{X}_{s} = [\mathcal{A}_{\mathring{C}_{\mbox{A}}}(a,\phi )_{s}]\). See Theorem 7.5.
Remark 1.10
One reason why statement (i) above is not precise is that it is not clear that \(g\mathcal{A}_{\mathring{C}_{\mbox{A}}}(a,\phi )\) as given above belongs to \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\) –we cannot exclude that both \(g\) and \(\mathcal{A}_{\mathring{C}_{\mbox{A}}}(a,\phi )\) blow up at some finite time \(T\) but in such a way that \(g\mathcal{A}_{\mathring{C}_{\mbox{A}}}(a,\phi )\) converges to a finite limit at \(T\).
2 State space and gauge-invariant observables
We construct in this section the metric space \((\mathcal{S},\Sigma )\) described in Theorem 1.2. As mentioned in Remark 1.5, we first define a metric space \((\mathcal{I},\Theta )\) in Sect. 2.1 which will serve as the space of initial conditions for the (stochastic and deterministic) YMH flow. The final state space \((\mathcal{S}, \Sigma )\) is defined in Sect. 2.3 using an additional norm on ℐ. The definitions of the spaces ℐ and \(\mathcal{S}\) will depend on several parameters, and we will formulate a condition (ℐ) (which stands for initial) for the parameters under which we can solve the deterministic initial value problem in the space ℐ, and a condition (\(\mathcal {G}\mathcal {I}\)) (resp. (\(\mathcal {G}\mathcal {S}\))) under which we have a continuous left group action of \(\mathfrak {G}^{0,\varrho }\) on ℐ (resp. on \(\mathcal{S}\)).
Remark 2.1
All the results of this section hold with \(\mathbf{T}^{3}\) replaced by \(\mathbf{T}^{d}\) for \(d=2,3\). Furthermore, the only result which requires \(d\leq 3\) is the global existence of the deterministic YMH flow without DeTurck term ℰ from Appendix B, which is used in Definition 2.11 (and even this could be disposed of by redefining ∼ in Definition 2.11 to use only local in time solutions). Note that long-time existence in \(d=4\) of the YM flow (i.e. no Higgs component) was recently shown in [87]. However, the state space ℐ in Definition 2.4 below would not support the Gaussian free field in dimension \(d \geq 4\) (or distributions of similar regularity). Furthermore, the results of all subsequent sections break down badly in \(d\ge 4\).
We write “Let \(\eta =\alpha -\), \(\beta =\nu +\), etc. Then …” to indicate that there exists \(\varepsilon >0\) such that for all \(\eta \in (\alpha -\varepsilon ,\alpha )\), \(\beta \in (\nu ,\nu +\varepsilon )\), etc. “…” holds. If “…” involves a statement of the form “there exists \(\varrho =\gamma -\)”, this means that there exists \(\varrho < \gamma \) and \(\varrho \to \gamma \) as \(\eta \to \alpha \), \(\beta \to \nu \), etc., and similarly for “\(\varrho =\gamma +\)”.
We will also use the shorthands \(x\leq \mathop{\mathrm{Poly}}(K)y\) and \(x\lesssim y\) to denote that \(x\leq C (K+1)^{q} y\) and \(x\leq C y\) respectively for some \(C,q>0\) which, unless otherwise stated, depend only the Greek letters \(\alpha \), \(\beta \), etc.
2.1 Space of initial conditions
Definition 2.2
Recall the notation \(E=\mathfrak {g}^{3}\oplus \mathbf{V}\). For \(X\in \mathcal{D}'(\mathbf{T}^{3},E)\), define
the solution to the heat equation with initial condition \(X\), and
For \(\delta \), \(\beta \in {\mathbf {R}}\), let \(\mathcal{B}^{\beta ,\delta}\) denote the Banach space of continuous functions \(Y\colon (0,1]\to \mathcal{C}^{\beta}(\mathbf{T}^{3},E\otimes E^{3})\) for which
For \(\eta \in {\mathbf {R}}\), we define the space \(D(\mathcal{N}) \stackrel {{\tiny \mathrm {def}}}{=}\{X\in \mathcal{C}^{\eta}(\mathbf{T}^{3},E) \,:\, \mathcal{N}(X)\in \mathcal{B}^{ \beta ,\delta}\}\) endowed with the topology induced from \(\mathcal{C}^{\eta}\). Although, for the parameters \(\eta \), \(\beta \), \(\delta \) in the regime we care about, the function \(\mathcal{N}\colon D(\mathcal{N}) \to \mathcal{B}^{\beta ,\delta}\) is not continuous, the continuity of \(\mathcal{C}^{\eta}(\mathbf{T}^{3},E)\ni X\mapsto \mathcal{N}_{t}(X)\in \mathcal{C}^{\beta}(\mathbf{T}^{3},E \otimes E^{3})\) for each \(t>0\) easily yields the following:
Lemma 2.3
For every \(\eta \), \(\beta \), \(\delta \in {\mathbf {R}}\), the graph of \(\mathcal{N}\colon D(\mathcal{N})\to \mathcal{B}^{\beta ,\delta}\) is closed. □
Definition 2.4
For \(X,Y\in \mathcal{D}'(\mathbf{T}^{3},E)\) and \(\delta ,\beta ,\eta \in {\mathbf {R}}\), define the (extended) pseudometric and (extended) metric

Let \(\mathcal{I}=\mathcal{I}_{\eta ,\beta ,\delta}\) denote the closure of smooth functions under the metric \(\Theta \equiv \Theta _{\eta ,\beta ,\delta}\). We define the shorthands  and \(\Theta (X)\stackrel {{\tiny \mathrm {def}}}{=}\Theta (X,0)\). We will often drop the reference to \(\eta ,\beta ,\delta \) in the notation \((\mathcal{I},\Theta )\). Unless otherwise stated, we equip ℐ with the metric \(\Theta \).
and \(\Theta (X)\stackrel {{\tiny \mathrm {def}}}{=}\Theta (X,0)\). We will often drop the reference to \(\eta ,\beta ,\delta \) in the notation \((\mathcal{I},\Theta )\). Unless otherwise stated, we equip ℐ with the metric \(\Theta \).
Remark 2.5
By Lemma 2.3, ℐ can be identified with a subset of \(\mathcal{C}^{0,\eta}\).
Remark 2.6
We will later choose \(\eta \), \(\beta \), \(\delta \) such that the additive stochastic heat equation defines a continuous ℐ-valued process. An (essentially optimal) example is \(\eta =-\frac{1}{2}-\), \(\delta \in (\frac{3}{4},1)\), and \(\beta = -2(1-\delta )-\).
For a (possibly time-dependent) distribution \(X\) taking values in \(E\), we will often write \(X=(A,\Phi )\) to denote the two components of \(X\) in the decomposition \(\mathcal{D}'(\mathbf{T}^{3},E)\simeq \Omega \mathcal{D}'\oplus \mathcal{D}'(\mathbf{T}^{3},\mathbf{V})\).
Definition 2.7
We say that \((\eta ,\beta ,\delta )\in {\mathbf {R}}^{3}\) satisfies condition (ℐ) if

Remark 2.8
The space ℐ is essentially the same as the space of possible initial conditions appearing in [17, Thm. 2.9], provided that the exponents \(\gamma _{i}\) appearing there are identified with \(\gamma _{1} = -\eta /2\), \(\gamma _{2} = \delta -1-\beta /2\). In particular, the condition \(\eta +\hat{\beta}>-1\) in (ℐ) (guaranteeing that the initial data is scaling subcritical) corresponds to their condition \(\gamma _{1} + \gamma _{2} < 1/2\).
Proposition 2.9
Local well-posedness of YMH flow
Suppose that \((\eta ,\beta ,\delta )\) satisfy (ℐ). For \(T>0\), let \(B\) denote the Banach space of functions
for which
Then for all \(X=(A,\Phi )\in \mathcal{I}\) and \(T\leq \mathop{\mathrm{Poly}}(\Theta (X)^{-1})\), there exists a unique function \(\mathcal{R}(X)\in B\) such that
solves the YMH flow (with DeTurck term)

with initial condition \(X\) in the sense that \(\lim _{t\to 0} |\mathcal{R}_{t}(X)|_{\mathcal{C}^{\hat{\beta}}} = 0\). Furthermore,

where the proportionality constant depends only on \(\eta ,\beta ,\delta \), and the map \(\mathcal{I}\ni X\mapsto \mathcal{R}(X)\in B\) is locally Lipschitz continuous.
Remark 2.10
In coordinates, (2.2) reads
with implicit summation over \(j\). We will use the flow induced by this equation to define our space of “gauge orbits” in Sect. 2.6. For this purpose, we could equally have used any regularising and gauge covariant flow with nonlinearities of the same order, such as the deterministic analogue of (1.9).
Proof
For \(X\in \mathcal{I}\), consider any map \(\mathcal{M}^{X}\colon B \to B\) of the form
where \(P\colon E\times E\to E\) is a polynomial of degree at most 3 such that \(P(0)=0\). Observe that \(|\mathcal{P}_{s} X|_{\infty} \lesssim s^{\frac{\eta}{2}}|X|_{\mathcal{C}^{\eta}}\) and \(| \partial \mathcal{P}_{s}X|_{\infty}\lesssim s^{\frac{\eta}{2}-\frac{1}{2}}|X|_{ \mathcal{C}^{\eta}}\). Furthermore, since \(\frac{\beta -\hat{\beta}}{2}=-(1-\delta )\),

and the same bound holds with \(|\cdot |_{\mathcal{C}^{\hat{\beta}}}\) replaced by \(|\cdot |_{\infty}\) and \(|\cdot |_{\mathcal{C}^{1}}\), \((t-s)^{-(1-\delta )}\) replaced by \((t-s)^{\frac{\beta}{2}}\) and \((t-s)^{-\frac{1}{2} +\frac{\beta}{2}}\), and the final  replaced by
replaced by  and
and  respectively.
respectively.
It readily follows that for \(\kappa =\frac{1}{2}\min \{\eta +\hat{\beta}+1,2\hat{\beta}+1,3\eta +2 \}\) and all \(R\in B\)

and for \(\bar{X}\in \mathcal{I}\), \(\bar{R} \in B\), and denoting \(Q(x)\stackrel {{\tiny \mathrm {def}}}{=}x^{2}+x\),

(The terms \(\mathcal{P}_{s} X \partial R_{s}\), \(R_{s} \partial \mathcal{P}_{s}X\) account for the condition \(\eta +\hat{\beta}>-1\), \(R_{s} \partial R_{s}\) accounts for \(\hat{\beta}> - \frac{1}{2}\), and \((\mathcal{P}_{s}X)^{3}\) accounts for \(\eta >-\frac{2}{3}\).) It follows that for \(T\leq \mathop{\mathrm{Poly}}(\Theta (X)^{-1})\) sufficiently small, \(\mathcal{M}^{X}\) stabilises the ball in \(B\) of radius  , is a contraction on this ball, and the unique fixed point of \(\mathcal{M}^{X}\) is a locally Lipschitz function of \(X\in \mathcal{I}\). Moreover, since ℐ is the closure of smooth functions,
, is a contraction on this ball, and the unique fixed point of \(\mathcal{M}^{X}\) is a locally Lipschitz function of \(X\in \mathcal{I}\). Moreover, since ℐ is the closure of smooth functions,
and thus \(\lim _{t\to 0} |\mathcal{M}^{X}_{t}(R)|_{\mathcal{C}^{\hat{\beta}}} = 0\) for all \(R\in B\). It remains to observe that the desired \(\mathcal{R}(X)\) is the fixed point of a map \(\mathcal{M}^{X}\) of the above form. □
Definition 2.11
Let \((\eta ,\beta ,\delta )\) satisfy (ℐ). For \(X\in \mathcal{I}\), let \(\mathcal{F}(X)\in \mathcal{C}^{\infty}((0,T_{X})\times \mathbf{T}^{3},E)\) denote the solution to (2.2) with initial condition \(X\) where \(T_{X}\) denotes the maximal existence time of the solution in \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\). We write \(\mathcal{F}_{t}(X)=(\mathcal{F}_{A,t}(X),\mathcal{F}_{\Phi ,t}(X))\) for its decomposition in \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\simeq \Omega \mathcal{C}^{\infty}\oplus \mathcal{C}^{ \infty}(\mathbf{T}^{3},\mathbf{V})\).
Define \(\tilde{\mathcal{F}}(X)\colon (0,\infty )\to \mathfrak {O}^{\infty}\) by
where ℰ is the flow of the YMH equation without the DeTurck and \(\Phi ^{3}\) terms, see Definition B.3.
We define an equivalent relation ∼ on ℐ by \(X\sim Y \Leftrightarrow \tilde{\mathcal{F}}(X)=\tilde{\mathcal{F}}(Y)\). Let \([X]\) denote the equivalence class of \(X\in \mathcal{I}\).
Remark 2.12
We will see below in Proposition 2.15 that ∼ extends the notion of gauge equivalence for smooth functions.
Remark 2.13
By Lemma B.4, \(\mathcal{F}_{t}(X)\in \tilde{\mathcal{F}}_{t}(X)\) for all \(t\in (0,T_{X})\). This allows us interpret \(\tilde{\mathcal{F}}\) as an extension of ℱ to all times modulo gauge equivalence.
Remark 2.14
In [18], the authors introduce a topological space \(\mathcal {X}\) as a candidate state space of the 3D Yang–Mills measure. Roughly speaking, \(\mathcal {X}\) contains all functions \(X\colon (0,\infty )\to \mathfrak {O}^{\infty}\) which solve the YM flow ℱ with the DeTurck–Zwanziger term modulo gauge equivalence (with no restrictions at \(t=0\) although some restrictions could easily be added). They furthermore show in [17] that the Gaussian free field has a natural representative as a probability measure on \(\mathcal {X}\). Note that we will use a space we call \(\mathcal {X}\) in Sect. 2.3 which is unrelated to the space \(\mathcal {X}\) in [18].
The space \(\mathcal{I}/{\sim}\) (and thus also the smaller space \(\mathfrak {O}= \mathcal{S}/{\sim}\) that we ultimately work with) embeds canonically into \(\mathcal {X}\). The main difference is that ℐ and \(\mathcal{S}\) are actual spaces of distributional connections that are not themselves defined in terms of the flow ℱ, although the analytic conditions we impose control how fast \(\mathcal{F}_{t}\) can blow up at time \(t=0\). One advantage is that this yields a large number of continuous operations on the state space \(\mathfrak {O}\). Furthermore, we later show that the SHE takes values in \(\mathcal{C}({\mathbf {R}}_{+},\mathcal{S})\), thus effectively recovering the main result of [17]; see Remark 3.16.
A result in [18] that we do not consider here is a tightness criterion for \(\mathcal {X}\) although it is possible in principle to formulate such criteria for ℐ and \(\mathcal{S}\) using the compact embedding results in Sect. 2.7.
2.2 Backwards uniqueness on gauge orbits for the YMH flow
In this subsection we show a backwards uniqueness property for the YMH flow which will be a key step in defining our space of “gauge orbits”. For \(\varrho \in (\frac{1}{2},1]\), recall from [22, Sect. 3] the spaces \(\Omega _{ \varrho \mbox{-gr}}\) and \(\Omega ^{1}_{ \varrho \mbox{-gr}}\), the closure of \(\mathfrak {g}\)-valued 1-forms in \(\Omega _{ \varrho \mbox{-gr}}\). More precisely, \(\Omega _{ \varrho \mbox{-gr}}\) is equipped with a norm \(|\cdot |_{ \varrho \mbox{-gr}}\), defined in the same way as in [22, Def. 3.7] except that \(\mathbf{T}^{2}\) is replaced by \(\mathbf{T}^{3}\). In Sect. 2.21 we will introduce a generalisation of it, but for this subsection we only need \(\Omega ^{1}_{ \varrho \mbox{-gr}}\). Here we only recall that \(\Omega ^{1}_{ \varrho \mbox{-gr}}\) is embedded into \(\mathcal{C}^{\varrho -1}\), see e.g. (2.9) below. For
we say that \(X\sim \bar{X}\) in \(\Omega ^{\varrho }\) if there exists \(g\in \mathfrak {G}^{\varrho }\) such that \(\bar{X}=X^{g} \stackrel {{\tiny \mathrm {def}}}{=}(\mathrm {Ad}_{g} A - (\mathrm {d}g)g^{-1},g\Phi )\). (Here, we recall the action of \(\mathfrak {G}^{\varrho }\) on \(\Omega ^{1}_{ \varrho \mbox{-gr}}\) in [22, Sect. 3.4, Definition 3.26]; in particular the formal expression \(A^{g}=\mathrm {Ad}_{g} A - (\mathrm {d}g)g^{-1}\) is defined there as an element of \(\Omega ^{1}_{ \varrho \mbox{-gr}}\).) Remark that ∼ in \(\Omega ^{\varrho }\) extends the usual notion of gauge equivalence of smooth functions. Remark also that \(\Omega ^{\varrho }\) embeds into ℐ for some parameters satisfying (ℐ), so that the YMH flow ℱ is well-defined on \(\Omega ^{\varrho }\). The following is the main result of this subsection.
Proposition 2.15
Let \(\varrho \in (\frac{1}{2},1]\) and \(X, Y \in \Omega ^{\varrho }\). The following statements are equivalent.
-
(i)
\(X\sim Y\) in \(\Omega ^{\varrho }\).
-
(ii)
\(\tilde{\mathcal{F}}(X)=\tilde{\mathcal{F}}(Y)\), i.e. \(X\sim Y\) in ℐ.
-
(iii)
\(\tilde{\mathcal{F}}_{t}(X) = \tilde{\mathcal{F}}_{t}(Y)\) for some \(t >0\).
Remark 2.16
In the setting of Proposition 2.15, it also holds that if \(\mathcal{F}_{t}(X)=\mathcal{F}_{t}(Y)\) for some \(t \in (0,T_{X}\wedge T_{Y})\), then \(X=Y\). This follows from Lemma 2.17 below or from classical backwards uniqueness statements for parabolic PDEs, e.g. [29, Thm. 2.2].
The proof of Proposition 2.15, which is based on analytic continuation and the YMH flow without DeTurck term, is given at the end of this subsection. Denote by \(\mathcal{K}_{0}\) the real Banach space of pairs \((A,\Phi )\in \mathcal{I}\) which are continuously differentiable and write \(\mathcal{K}\) for the complexification of \(\mathcal{K}_{0}\). Note that even if \(\mathbf{V}\) happens to have a complex structure already, we view it as real in this construction, so that the \(\Phi \)-component of an element of \(\mathcal{K}\) takes values in \(\mathbf{V}\oplus \mathbf{V}\) endowed with its canonical complex structure. A similar remark applies to \(\mathfrak {g}\). We also write \(\mathcal{L}_{0} \subset \mathcal{K}_{0}\) and \(\mathcal{L}\subset \mathcal{K}\) for the subspaces consisting of twice continuously differentiable functions, endowed with the corresponding norms.
For the remainder of the subsection, fix \(\alpha <\pi /2\) and \(T>0\) and define the sector \(S_{\alpha }= \{t \in {\mathbf {C}}\,:\, \operatorname{Re}(t) \in [0,T] \,\&\, |{\arg t}| \le \alpha \}\). Write \(\mathcal{B}\mathcal{K}\) for the set of holomorphic functions \(X \colon S_{\alpha }\to \mathcal{K}\) such that
and similarly for \(\mathcal{B}\mathcal{L}\).
Lemma 2.17
Let \(X_{0}\in \mathcal{L}_{0}\). Then, for \(T\) sufficiently small, \(\mathcal{F}(X_{0})\colon [0,T]\to \mathcal{L}_{0}\) admits a (necessarily unique) analytic continuation to an element of \(\mathcal{B}\mathcal{L}\).
Proof
Note that \(X\stackrel {{\tiny \mathrm {def}}}{=}\mathcal{F}(X_{0})\) solves
for a holomorphic function \(F \colon \mathcal{L}\to \mathcal{K}\) (see [75] for a definition) that is bounded on bounded sets. This is equivalent to the integral equation
which we now interpret as a fixed point problem on a space of holomorphic functions on \(S_{\alpha}\). Recall that \(\|e^{t\Delta} u\|_{\mathcal{L}} \lesssim |t|^{-1/2}\|u\|_{\mathcal{K}}\) for all \(t \in S_{\alpha}\) as can easily be seen from the explicit expression of the heat kernel. It immediately follows that the operator \(\mathcal{M}\colon Y \mapsto (t \mapsto t \int _{0}^{1} e^{tu\Delta}Y_{t(1-u)} \mathrm {d}u)\) is bounded from \(\mathcal{B}\mathcal{K}\) into \(\mathcal{B}\mathcal{L}\) with norm of order \(T^{1/2}\), and therefore that the fixed point problem (2.4) admits a unique solution in \(\mathcal{B}\mathcal{L}\). □
Lemma 2.18
Let \(H \in \mathcal{B}\mathcal{K}\) and let \(g\) denote the solution to
with some initial condition \(g_{0}\in \mathcal{C}^{1}\). Set \(h_{i} = g^{-1}\partial _{i} g\) and \(U = \boldsymbol{\varrho }(g)\) for some finite-dimensional representation \(\boldsymbol{\varrho }\) of \(G\). Then, \(h_{i}\) and \(U\) can be extended uniquely to holomorphic functions \(S_{\alpha }\to \mathcal{C}\) and \(S_{\alpha }\to \mathcal{C}^{1}\) respectively.
Proof
It suffices to note that \(h_{i}\) and \(U\) solve pointwise the ODEs
We can interpret these as ODEs in \(\mathcal{C}\) and \(\mathcal{C}^{1}\) respectively, which admit solutions since the right-hand sides are holomorphic functions of \(H\), \(h\) and \(U\). These solutions are global since the equations are linear. □
Recall that \(\mathcal{E}(X)\) denotes the solution of the YMH flow without DeTurck term and with initial condition \(X\).
Lemma 2.19
For \(X \in \mathcal{C}^{\infty}(\mathbf{T}^{3},E)\), \(\mathcal{E}(X)\) is real analytic on \({\mathbf {R}}_{+}\) with values in \(\mathcal{C}\).
Proof
Denoting \(\mathcal{F}(X)= (a,\phi )\), by Lemma B.4, if \(g\) solves the ODE
then \(\mathcal{E}(X) = \mathcal{F}(X)^{g}= U(\mathcal{F}(X) - h)\) where \(h\) (understood as \((h_{1},h_{2},h_{3},0)\)) and \(U\) are defined from \(g\) as in Lemma 2.18 but with \(\boldsymbol{\varrho }\) replaced by \(\mathrm {Ad}^{3}\oplus \boldsymbol{\varrho }\) on \(\mathfrak {g}^{3} \oplus \mathbf{V}\). Lemma 2.17 implies that \(\mathcal{F}(X)\) is real analytic with values in \(\mathcal{C}^{2}\) for short times, and Lemma 2.18 implies that \(h\) and \(U\) are real analytic with values in \(\mathcal{C}\) and \(\mathcal{C}^{1}\) respectively. It follows that \(\mathcal{E}(X)\) is real analytic for short times (with a lower bound on these times depending only on its \(\mathcal{C}^{2}\) norm) and thus on \({\mathbf {R}}_{+}\) since \(\mathcal{E}(X)\) exists globally by Lemma B.1. □
Lemma 2.20
Let \(\varrho \in (\frac{1}{2},1]\). The set \(\{(X,Y)\in \Omega ^{\varrho }\times \Omega ^{\varrho }\,:\,X\sim Y \mbox{ in } \Omega ^{\varrho }\}\) is closed in \(\Omega ^{\varrho }\times \Omega ^{\varrho }\).
Proof
Suppose \((X_{n},Y_{n})\to (X,Y)\) in \(\Omega ^{\varrho }\times \Omega ^{\varrho }\) with \(X_{n}^{g_{n}} = Y_{n}\). Consider \(\bar{\varrho }\in (\frac{1}{2},\varrho )\). By the estimate \(|g|_{ \varrho \mbox{-H{\"{o}}l}}\lesssim |A|_{ \varrho \mbox{-gr}}+|A^{g}|_{ \varrho \mbox{-gr}}\) (see [22, Prop. 3.35]) and the compact embedding \(\mathfrak {G}^{\varrho }\hookrightarrow \mathfrak {G}^{\bar{\varrho }}\), it follows that \(g_{n} \to g\) in \(\mathfrak {G}^{\bar{\varrho }}\) along a subsequence with \(g\in \mathfrak {G}^{\varrho }\). Furthermore, by continuity of the maps
(see [22, Lem. 3.30, 3.32] for the first; the second is obvious), we have \(X^{g} - Y_{n} \to 0\) in \(\Omega ^{\bar{\varrho }}\), which implies \(X^{g} = Y\). □
Proof of Proposition 2.15
The implication (ii)⇒(iii) is trivial. To show (i)⇒(ii), suppose \(X^{g}=Y\) for some \(g\in \mathfrak {G}^{\varrho }\). Then \(\mathcal{F}_{t}(X)^{h_{t}}=\mathcal{F}_{t}(Y)\) for all sufficiently small \(t>0\), where \(h\) solves a parabolic PDE with initial condition \(g\) (see [22, Sect. 2.2] or Remark 2.44 below). Hence (i)⇒(ii). For the final implication (iii)⇒(i), suppose first that \(X, Y\in \mathcal{C}^{\infty}(\mathbf{T}^{3},E)\). By Lemma B.4, \(\mathcal{E}_{t}(X)\sim \mathcal{F}_{t}(X)\), and likewise for \(Y\), hence \(\mathcal{E}_{t}(X)\sim \mathcal{E}_{t}(Y)\). By Lemma B.6, there exists \(g\in \mathfrak {G}^{\infty}\) such that \(\mathcal{E}_{s}(X)^{g} = \mathcal{E}_{s}(Y)\) for all \(s \geq t\). By Lemma 2.19 and uniqueness of analytic continuations, it follows that \(\mathcal{E}_{s}(X)^{g} = \mathcal{E}_{s}(Y)\) for all \(s \geq 0\), in particular \(X\sim Y\). The case of general \((X,Y)\in \Omega ^{\varrho }\) follows by Lemma 2.20 and the fact that \(\lim _{s\to 0}\mathcal{F}_{s}(X) = X\) in \(\Omega ^{\bar{\varrho }}\) for any \(\bar{\varrho }\in (\frac{1}{2},\varrho )\). Indeed, if \(\tilde{\mathcal{F}}_{t}(X) = \tilde{\mathcal{F}}_{t}(Y)\) for some \(t >0\), since \(\mathcal{F}_{s}(X)\) and \(\mathcal{F}_{s}(Y)\) are \(\mathcal{C}^{\infty}\) for all \(s\in (0,T_{X} \wedge T_{Y} \wedge t)\), one has \(\mathcal{F}_{s}(X)\sim \mathcal{F}_{s}(Y)\) by the \(\mathcal{C}^{\infty}\) case proved above, and in particular \((\mathcal{F}_{s}(X), \mathcal{F}_{s}(Y))\) is in the set defined in Lemma 2.20. One then has \(X\sim Y\) in \(\Omega ^{\varrho }\) by sending \(s\to 0\). Hence (iii)⇒(i). □
2.3 Final state space
In this subsection, we introduce the “second half” of our state space \((\mathcal{S},\Sigma )\). We do this by introducing an additional norm \({|\!|\!| \cdot |\!|\!|}_{\alpha ,\theta}\). The role of this norm will become clear in Sect. 2.5 where it will be used to control the Hölder norm of any gauge transformation \(g\) in terms of \(X\) and \(X^{g}\) (Theorem 2.39 below).
Let \(\mathcal {X}\) denote the set of oriented line segments in \(\mathbf{T}^{3}\) of length at most \(\frac{1}{4}\), i.e.
where \(B_{r} \stackrel {{\tiny \mathrm {def}}}{=}\{v \in {\mathbf {R}}^{3} \,:\, |v| \leq r\}\), (the first coordinate of \(\mathcal {X}\) is the initial point, the second coordinate is the direction). We say that \(\ell = (x,v)\) and \(\bar{\ell}= (\bar{x}, \bar{v})\) are joinable if \(\bar{x} = x+v\), there exists \(c \in {\mathbf {R}}\) such that \(\bar{v} = c v\), and \(|v+\bar{v}| \le 1/4\). In that case, we define \(\ell \sqcup \bar{\ell}= (x, v+\bar{v})\).
Let \(\Omega \) denote the space of additive \(\mathfrak {g}\)-valued functions on \(\mathcal {X}\) (see [22, Def. 3.1] for the definition in 2D –precisely the same definition applies here with \(\mathbf{T}^{2}\) and \({\mathbf {R}}^{2}\) replaced by \(\mathbf{T}^{3}\) and \({\mathbf {R}}^{3}\)). Observe that every \(A\in \Omega \mathcal{B}\), where ℬ denotes the space of bounded measurable \(\mathfrak {g}\)-valued functions, canonically defines an element of \(\Omega \) by
Definition 2.21
For \(A\in \Omega \), \(\alpha \in (0,1]\), and \(t>0\), define
where the supremum is taken over all lines \(\ell \in \mathcal {X}\) of length less than \(t\). For \(A\in \Omega \mathcal{D}'\) and \(\theta \in {\mathbf {R}}\), define the (extended) norm
For \(\eta ,\beta ,\delta \in {\mathbf {R}},\alpha \in (0,1],\theta \in {\mathbf {R}}\), recalling Definition 2.4 and the notational convention \(X=(A,\Phi )\), define on \(\mathcal{D}'(\mathbf{T}^{3},E)\) the (extended) metric \(\Sigma \equiv \Sigma _{\eta ,\beta ,\delta ,\alpha ,\theta}\) by
Similar to before, we use the shorthand \(\Sigma (X) \stackrel {{\tiny \mathrm {def}}}{=}\Sigma (X,0)\) and will often drop the reference to \(\eta ,\beta ,\delta ,\alpha ,\theta \) in the notation \(\Sigma \).
Definition 2.22
For \(\alpha \in (0,1]\) and \(\theta \in {\mathbf {R}}\), let \(\mathcal{S}\equiv \mathcal{S}_{\eta ,\beta ,\delta ,\alpha ,\theta}\subset \mathcal{I}_{\eta ,\beta ,\delta}\) denote the closure of smooth functions under \(\Sigma \). Unless otherwise stated, we equip \(\mathcal{S}\) with the metric \(\Sigma \).
Lemma 2.25 below provides a basic relation between \({|\!|\!| \cdot |\!|\!|}_{\alpha ,\theta}\) and the Hölder–Besov spaces \(|\cdot |_{\mathcal{C}^{\eta}}\) that generalises the estimates
(which hold for all \(A\in \Omega \mathcal{C}\) and \(\alpha \in (0,1]\), see [30, Prop. 3.21]). We first state the following lemma.
Lemma 2.23
For all \(\alpha \in (0,1]\), \(t\in (0,1)\), and \(A\in \Omega \),
Proof
Identical to [45, Ex. 4.24]. □
The proof of the following lemma is obvious.
Lemma 2.24
For all \(0<\alpha \leq \beta \leq 1\), \(t\in (0,1)\), and \(A\in \Omega \),
We now have the ingredients in place for the generalisation of (2.9) we just announced.
Lemma 2.25
For \(A\in \Omega \mathcal{D}'\), \(\alpha \in (0,1]\), and \(\theta \geq 0\),
where the proportionality constants depend only on \(\alpha ,\theta \).
Proof
Denoting \(\eta \stackrel {{\tiny \mathrm {def}}}{=}(1+2\theta )(\alpha -1)\),
where we used (2.9) in the first line, Lemma 2.23 in the second line, and Lemma 2.24 in the third line. □
2.4 Gauge transformations
Throughout this subsection, let us fix
Recall that \(\mathcal{C}^{0,\eta}\) denotes the closure of smooth functions in \(\mathcal{C}^{\eta}\). Since \(\varrho +\eta >0\), \(2\varrho -1>0\), and \(\eta \leq \varrho -1\), the group \(\mathfrak {G}^{0,\varrho }\) (resp. \(\mathfrak {G}^{\varrho }\)) acts continuously on \(\mathcal{C}^{0,\eta}(\mathbf{T}^{3},E)\) (resp. \(\mathcal{C}^{\eta}( \mathbf{T}^{3},E)\)) via \((A,\Phi ) \mapsto (A,\Phi )^{g} \stackrel {{\tiny \mathrm {def}}}{=}(\mathrm {Ad}_{g} A - (\mathrm {d}g) g^{-1},g \Phi )\). The following result shows that, under further conditions, the action of \(\mathfrak {G}^{0,\varrho }\) extends to ℐ.
Definition 2.26
We say that \((\varrho ,\eta ,\beta ,\delta )\in {\mathbf {R}}^{4}\) satisfies condition (\(\mathcal {G}\mathcal {I}\)) if

We say that \((\varrho ,\eta ,\beta ,\delta ,\alpha ,\theta ) \in {\mathbf {R}}^{6}\) satisfies condition (\(\mathcal {G}\mathcal {S}\)) if

Remark 2.27
The conditions (2.10) stated at the start of this subsection together with \(\eta \geq 2-2\delta -\varrho \) and \(\delta <1\) are equivalent to (\(\mathcal {G}\mathcal {I}\)).
Proposition 2.28
Suppose \((\varrho ,\eta ,\beta ,\delta )\) satisfies (\(\mathcal {G}\mathcal {I}\)). Then \((g,X) \mapsto X^{g}\) defines a continuous left group action \(\mathfrak {G}^{0,\varrho }\times \mathcal{I}\to \mathcal{I}\) which is uniformly continuous on every ball in \(\mathfrak {G}^{0,\varrho }\times \mathcal{I}\). If in addition \((\eta ,\beta ,\delta )\) satisfies (ℐ), then \(X^{g} \sim X\) for all \((g,X)\in \mathfrak {G}^{0,\varrho }\times \mathcal{I}\). Finally, if \((\varrho ,\eta ,\beta ,\delta ,\alpha ,\theta )\) satisfies (\(\mathcal {G}\mathcal {S}\)), then \((g,X) \mapsto X^{g}\) defines a continuous left group action \(\mathfrak {G}^{0,\varrho }\times \mathcal{S}\to \mathcal{S}\) which is uniformly continuous on every ball in \(\mathfrak {G}^{0,\varrho }\times \mathcal{S}\).
We break up the proof into several lemmas.
Lemma 2.29
Let \(g\in \mathcal{C}^{\varrho }(\mathbf{T}^{3})\), \(h\in \mathcal{C}^{\eta}(\mathbf{T}^{3})\), which we identify with periodic distributions on \({\mathbf {R}}^{3}\). For every Schwartz function \(\phi \in \mathcal{S}({\mathbf {R}}^{3})\)

where \(\phi ^{\lambda}_{x} = \lambda ^{-3}\phi (\frac{\cdot -x}{\lambda})\) and the proportionality constant depends only on \(\varrho ,\eta ,\phi \).
Proof
The reconstruction theorem, using a modification of the proof of [56, Prop. 4.14], implies that

To extend this to a Schwartz function \(\phi \), we can decompose \(\phi =\sum _{k\in {\mathbf {Z}}^{3}}\phi _{k}(\cdot -k)\) where \(\phi _{k}\) has support in a ball of radius \(\sqrt {d}\) centered at 0 and \(|\phi _{k}|_{\mathcal{C}^{1}}\lesssim |k|^{-d-1-\varrho }\). Then \(\phi ^{\lambda}_{x}=\sum _{k\in {\mathbf {Z}}^{3}}(\phi _{k})_{x+\lambda k}^{ \lambda}\) and (2.12) implies

Furthermore

from which (2.11) follows by taking the sum over \(k\in {\mathbf {Z}}^{3}\). □
Corollary 2.30
Consider \(g,h\) as in Lemma 2.29. Then for all \(t\in (0,1)\)
and
where the proportionality constants depend only on \(\varrho ,\eta \).
Proof
Apply Lemma 2.29 with \(\phi = \mathcal{P}_{1}\) and \(\phi =\nabla \mathcal{P}_{1}\), where we interpret \(\mathcal{P}_{t}\) as the heat kernel at time \(t>0\). □
For \(g\in G\) and \((a,\phi )\in E\), let us denote \(g(a,\phi ) \stackrel {{\tiny \mathrm {def}}}{=}(\mathrm {Ad}_{g} a, g\phi )\in E\). We extend this action to \(G\times E^{3}\to E^{3}\) diagonally. In particular, \(gX\) is well-defined as an element of \(\mathcal{C}^{\eta}(\mathbf{T}^{3},E)\) (resp. \(\mathcal{C}^{\eta}(\mathbf{T}^{3},E^{3})\)) provided \(g\in \mathfrak {G}^{\varrho }\) and \(X\in \mathcal{C}^{\eta}(\mathbf{T}^{3},E)\) (resp. \(X \in \mathcal{C}^{\eta}(\mathbf{T}^{3},E^{3})\)). Similarly for the spaces \(\mathcal{C}^{0,\eta}\) and \(\mathfrak {G}^{0,\varrho }\). Denote further
Lemma 2.31
For \(X,Y\in \mathcal{C}^{\eta}(\mathbf{T}^{3},E)\), \(g\in \mathfrak {G}^{\varrho }\), and \(t\in (0,1)\)
where the proportionality constant depends only on \(\eta ,\varrho \).
Proof
We use the shorthand \(a_{i},b_{i}\) for \(i=1,2\) to denote \(g\mathcal{P}_{t} X, g\mathcal{P}_{t} Y\) if \(i=1\) and \(g\nabla \mathcal{P}_{t}X, g\nabla \mathcal{P}_{t} Y\) if \(i=2\), and \(\bar{a}_{i},\bar{b}_{i}\) to denote the same symbols except with the \(g\) inside the \(\mathcal{P}_{t}\), e.g. \(\bar{a}_{1} = \mathcal{P}_{t}gX,\bar{b}_{2} = \nabla \mathcal{P}_{t} gY\). With this notation, and henceforth dropping ⊗, the quantity we aim to bound is \(|(a_{1}a_{2}-b_{1}b_{2})-(\bar{a}_{1} \bar{a}_{2} - \bar{b}_{1} \bar{b}_{2})|_{ \infty}\).
By Corollary 2.30,
and
with similar inequalities for the “\(b\)” terms. It follows that
where in the first line we used the fact that multiplication by \(g\) on \(E\) preserves the \(L^{\infty}\) norm, and in the second line Young’s theorem for \(\mathcal{C}^{\varrho }\times \mathcal{C}^{\eta}\) by \(\eta >-\varrho \). In the same way
It remains to observe that \((a_{1}a_{2}-b_{1}b_{2})-(\bar{a}_{1} \bar{a}_{2} - \bar{b}_{1} \bar{b}_{2})\) is the sum of the previous four terms inside the norms \(|\cdot |_{\infty}\). □
Lemma 2.32
Suppose \(\eta + \frac{\varrho -1}{2} \geq -\delta \). Then for \(X,Y\in \mathcal{C}^{\eta}(\mathbf{T}^{3},E)\) and \(g\in \mathfrak {G}^{\varrho }\)

where the proportionality constant depends only on \(\eta ,\beta ,\varrho ,\delta \).
Proof
For \(Z \in \mathcal{C}^{\beta}(\mathbf{T}^{3},E\otimes E^{3})\) and \(g\in \mathfrak {G}^{\varrho }\),
The conclusion now follows by applying (2.13) to \(Z=\mathcal{N}_{t}(X)-\mathcal{N}_{t}(Y)\) together with Lemma 2.31. □
Lemma 2.33
Suppose \(\eta + \frac{\varrho -1}{2} \geq -\delta \). For \(X\in \mathcal{C}^{\eta}(\mathbf{T}^{3},E)\) and \(g\in \mathfrak {G}^{\varrho }\),

where the proportionality constant depends only on \(\eta ,\varrho ,\beta ,\delta \).
Proof
For \(Z \in \mathcal{C}^{\beta}(\mathbf{T}^{3},E\otimes E^{3})\) and \(g\in \mathfrak {G}^{\varrho }\),
The conclusion follows by combining (2.14) with Lemma 2.31. □
Lemma 2.34
Consider \(\bar{\eta},\eta \leq 0\), \(t\in (0,1)\), and \(X,Y,\bar{X},\bar{Y}\in \mathcal{D}'(\mathbf{T}^{3},E)\). Then
where the proportionality constant depends only on \(\bar{\eta}\) and \(\eta \).
Proof
Using \(|\mathcal{P}_{t}X|_{\infty} \lesssim t^{\eta /2}|X|_{\mathcal{C}^{\eta}}\) and \(|\nabla \mathcal{P}_{t}X|_{\infty} \lesssim t^{(\eta +1)/2}|X|_{\mathcal{C}^{\eta}}\), we obtain
as claimed. □
Lemma 2.35
Consider \(\bar{\eta}\leq 0\) and \(X,Y,\bar{X},\bar{Y}\in \mathcal{D}'(\mathbf{T}^{3},E)\).
-
(i)
Suppose \(\eta +\bar{\eta}\geq 1-2\delta \). Then

-
(ii)
Suppose \(\bar{\eta}\ge \frac{1}{2}-\delta \). Then



The proportionality constants in both statements depend only on \(\eta ,\bar{\eta},\beta ,\delta \).
Proof
(i) follows from applying Lemma 2.34 and the embedding \(L^{\infty}\hookrightarrow \mathcal{C}^{\beta}\) to the two “cross terms” and from the fact that \(\frac{\eta +\bar{\eta}-1}{2} \geq -\delta \Leftrightarrow \eta + \bar{\eta}\geq 1-2\delta \). (ii) follows directly from Lemma 2.34 with \(\eta =\bar{\eta}\). □
Lemma 2.36
Suppose \(\eta \geq 2-2\delta -\varrho \) and \(X,Y\in \mathcal{C}^{\eta}(\mathbf{T}^{3},E)\) and \(g\in \mathfrak {G}^{\varrho }\). Then

and

where the proportionality constants depend only on \(\eta ,\beta ,\varrho ,\delta \).
Proof
Recall our assumption (2.10) on the parameters. Observe that \(\eta \in (-\varrho ,\varrho -1]\), \(\varrho \le 1\), and \(\eta +\varrho \ge 2-2\delta \) together imply \(\eta + \frac{\varrho -1}{2} \geq -\delta \) and \(\varrho \ge \frac{3}{2}-\delta \). Writing \(\mathrm {d}g g^{-1}\in \mathcal{C}^{\varrho -1}(\mathbf{T}^{3},E)\) as the element with zero second component in \(E=\mathfrak {g}^{3}\oplus \mathbf{V}\),

where we used Lemma 2.35(i) with \(\bar{\eta}=\varrho -1\) (using \(\eta +\varrho \ge 2-2\delta \)). We then obtain (2.15) from Lemmas 2.33 and 2.35(ii) again with \(\bar{\eta}=\varrho -1\) (using \(\varrho \geq \frac{3}{2}-\delta \)). In a similar way

where we used Lemma 2.35(i) with \(\bar{\eta}=\varrho -1\) in the first bound (using again \(\eta +\varrho > 2-2\delta \)) and Lemma 2.32 in the second bound. □
Lemma 2.37
Let \(\alpha \in (0,1]\) and \(\theta \geq 0\) such that \(\varrho \geq 1+2\theta (\alpha -1)\). Then for all \(g\in \mathfrak {G}^{\varrho }\)
where the proportionality constant depends only on \(\varrho ,\alpha ,\theta \).
Proof
Since \(\varrho >\frac{1}{2}\), \(|(\mathrm {d}g) g^{-1}|_{\mathcal{C}^{\varrho -1}}\lesssim |g|_{\mathcal{C}^{\varrho }}|g|_{ \varrho \mbox{-H{\"{o}}l}}\). Since \(\varrho -1\geq 2\theta (\alpha -1)\), the conclusion follows by Lemma 2.25. □
Lemma 2.38
Let \(\alpha \in (0,1]\) and \(\theta \geq 0\) such that \(\varrho \geq -\tilde{\eta} \stackrel {{\tiny \mathrm {def}}}{=}-(1+2\theta )(\alpha -1)\). Let \(A\in \Omega \mathcal{C}^{\eta}\) and \(g\in \mathfrak {G}^{\varrho }\). Then
where the proportionality constant depends only on \(\varrho ,\alpha ,\theta \).
Proof
By Lemma 2.25, \(|A|_{\mathcal{C}^{\tilde{\eta}}} \lesssim {|\!|\!| A |\!|\!|}_{\alpha ,\theta}\). Since \(\tilde{\eta}+\varrho >0\), by Corollary 2.30, for all \(t\in (0,1)\)
On the other hand, \(-\tilde{\eta}\geq 1-\alpha \), hence \(\varrho +\alpha >1\), and thus for all \(t\in (0,1)\)
(this follows by restricting the proof of [22, Lem. 3.32] to lines of length less than \(t^{\theta}\)), from which the conclusion follows. □
Proof of Proposition 2.28
For \(X,Y\in \mathcal{I}\) and \(g\in \mathfrak {G}^{\varrho }\), by (2.15) and the fact that \(|g|_{ \varrho \mbox{-H{\"{o}}l}} \leq |g-1|_{\mathcal{C}^{\varrho }}\),

as \((g,Y) \to (1,X)\) in \(\mathfrak {G}^{\varrho }\times \mathcal{I}\). Furthermore, for \(h\in \mathfrak {G}^{\varrho }\), clearly \(|X^{g} - Y^{h}|_{\mathcal{C}^{\eta}} \to 0\) as \((g,X)\to (h,Y)\). Therefore, by (2.16),

as \((g,X)\to (h,Y)\). It follows that, if \(g\in \mathfrak {G}^{0,\varrho }\), then \(X^{g}\in \mathcal{I}\). Furthermore \((g,X) \mapsto X^{g}\) is a continuous left group action \(\mathfrak {G}^{0,\varrho }\times \mathcal{I}\to \mathcal{I}\) and it is easy to see from the explicit form of the estimates (2.15) and (2.16) that this map is uniformly continuous on every ball in \(\mathfrak {G}^{0,\varrho }\times \mathcal{I}\).
Suppose further that \((\eta ,\beta ,\delta )\) satisfies (ℐ). Then \(X^{g} \sim X\) for all smooth \((g,X)\in \mathfrak {G}^{0,\varrho }\times \mathcal{I}\). The fact that \(X^{g} \sim X\) for all \((g,X)\in \mathfrak {G}^{0,\varrho }\times \mathcal{I}\) now follows from Proposition 2.15 together with the density of smooth functions in \(\mathfrak {G}^{0,\varrho } \times \mathcal{I}\) and continuity of ℱ on ℐ by Proposition 2.9.
Finally, suppose further that \((\varrho ,\eta ,\beta ,\delta ,\alpha ,\theta )\) satisfies (\(\mathcal {G}\mathcal {S}\)). Fix \((g,X) \in \mathfrak {G}^{\varrho }\times \mathcal{S}\). Then for \((h,Y) \in \mathfrak {G}^{\varrho }\times \mathcal{S}\), by Lemmas 2.37 and 2.38
as \(|h-1|_{\mathcal{C}^{\varrho }} +{|\!|\!| X-Y |\!|\!|}_{\alpha ,\theta} \to 0\). Furthermore, by Lemma 2.38, \({|\!|\!| X^{g}-Y^{g} |\!|\!|}_{\alpha ,\theta}\to 0\) as \({|\!|\!| Y- X |\!|\!|}_{\alpha ,\theta}\to 0\), and therefore
as \(|h-g|_{\mathcal{C}^{\varrho }} +{|\!|\!| X-Y |\!|\!|}_{\alpha ,\theta} \to 0\). It follows that \((g,X) \mapsto X^{g}\) is a continuous left group action \(\mathfrak {G}^{0,\varrho }\times \mathcal{S}\to \mathcal{S}\) and uniform continuity on every ball in \(\mathfrak {G}^{0,\varrho }\times \mathcal{S}\) is clear again from the explicit form of the estimates in Lemmas 2.37 and 2.38. □
2.5 Estimates on gauge transformations
Recall that, by Proposition 2.28, if \((\varrho ,\eta ,\beta ,\delta )\) satisfies (\(\mathcal {G}\mathcal {I}\)), then \((g,X)\mapsto X^{g}\) is a continuous group action \(\mathfrak {G}^{0,\varrho }\times \mathcal{I}\to \mathcal{I}\).
Theorem 2.39
Let \(\theta =0+\), \(\alpha =\frac{1}{2}-\), \(\delta \in (\frac{3}{4},1)\), \(\beta =-2(1-\delta )-\), and \(\eta =-\frac{1}{2}-\). There exists \(\nu =\frac{1}{2}-\) such that \(|g|_{\mathcal{C}^{\nu}} \leq \mathop{\mathrm{Poly}}(\Sigma (X)+\Sigma (X^{g}))\) for all \(g\in \mathfrak {G}^{0,\varrho }\), \(X\in \mathcal{I}\), and \(\varrho \in (\frac{1}{2},1]\) such that \((\varrho ,\eta ,\beta ,\delta )\) satisfies (\(\mathcal {G}\mathcal {I}\)).
Remark 2.40
The conditions on \((\eta ,\beta ,\delta )\) in the above theorem ensure that they satisfy (ℐ) and that there exists \(\varrho \in (\frac{1}{2},1]\) such that \((\varrho ,\eta ,\beta ,\delta )\) satisfies (\(\mathcal {G}\mathcal {I}\)). On the other hand, we do not suppose in this subsection that \((\varrho ,\eta ,\beta ,\delta ,\alpha ,\theta )\) satisfies (\(\mathcal {G}\mathcal {S}\)) since the continuity of the group action \(\mathfrak {G}^{0,\varrho }\times \mathcal{S}\to \mathcal{S}\) will not be needed.
We prove the theorem at the end of this subsection. The main ingredients are Lemma 2.46(b), which provides an estimate on \(|g|_{\mathcal{C}^{\nu}}\) in terms of a nonlinear PDE \(\mathcal{H}^{X}(g)\) with initial condition \(g\) (this is rather generic and similar to how the heat flow characterises Hölder spaces), and Lemma 2.45, which estimates the (spatial) Hölder norm of \(\mathcal{H}^{X}(g)\) in terms of \(\mathcal{F}(X)\) and \(\mathcal{F}(X^{g})\) (this estimate is based on holonomies and Young ODE theory, and was used extensively in [22]).
We first require several lemmas and definitions. Recall the notation \(\mathcal{F}(X)=(\mathcal{F}_{A}(X),\mathcal{F}_{\Phi}(X))\) from Definition 2.11.
Definition 2.41
Let \((\eta ,\beta ,\delta )\) satisfy (ℐ), \(X\in \mathcal{I}\) and \(g\in \mathfrak {G}^{\nu}\) for some \(\nu >0\). We denote by \(\mathcal{H}^{X}(g)\colon (0,T_{X,g})\to \mathfrak {G}^{\infty}\) the solution to
where \(T_{X,g}\) is the minimum between \(T_{X}\) and the blow up time of \(\mathcal{H}^{X}(g)\) in \(\mathfrak {G}^{\infty}\).
Remark 2.42
Using the bound \(\sup _{t\in (0,T)}t^{-\frac{\eta \wedge \hat{\beta}}{2}}|\mathcal{F}_{t}(X)|_{ \infty}<\infty \) for some \(T>0\), standard arguments show that, if \(g \in \mathfrak {G}^{\nu}\) for some \(\nu >0\), then indeed a classical solution to (2.17) exists and is continuous with respect to \(g \in \mathfrak {G}^{\nu}\) (cf. Lemma 2.46(a)).
Remark 2.43
“ℋ” stands for “harmonic” since, if \(\mathcal{F}_{A}(X)=0\), then \(\mathcal{H}^{X}(g)\) is the harmonic map flow with initial condition \(g\).
Remark 2.44
The significance behind Definition 2.41 is the identity
which is valid for all smooth \((g,X)\) and therefore for all \(X\in \mathcal{I}\) and \(g\in \mathfrak {G}^{0,\varrho }\) whenever \((\varrho ,\eta ,\beta ,\delta )\) satisfies both (ℐ) and (\(\mathcal {G}\mathcal {I}\)). In particular, \(\mathcal{H}^{X}(g)\) also solves
which follows from \([\mathrm {Ad}_{H}(\mathcal{F}_{A}(X)_{j}),(\partial _{j} H) H^{-1}]= [ \mathcal{F}_{A}(X)^{H}_{j},(\partial _{j} H) H^{-1}]\) in (2.17) and then (2.18). Moreover, a direct computation shows that \(\mathcal{H}^{X}_{t}(g)^{-1}=\mathcal{H}^{X^{g}}_{t}(g^{-1})\) for all \(t\in [0,T_{X,g}\wedge T_{X^{g},g^{-1}})\).
The relation (2.18) yields the following lemma.
Lemma 2.45
Let \((\varrho ,\eta ,\beta ,\delta )\) satisfy (ℐ) and (\(\mathcal {G}\mathcal {I}\)), \(g\in \mathfrak {G}^{0,\varrho }\), and \(X\in \mathcal{I}\). Then \(T_{X,g}=T_{X^{g},g^{-1}} = T_{X}\wedge T_{X^{g}}\), and, for all \(t\in (0,T_{X,g})\) and \(\gamma \in (\frac{1}{2},1]\),
where the proportionality constant depends only on \(\gamma \).
Proof
The bound (2.19) follows from (2.18) and [22, Prop. 3.35, Eq. 3.24]. Then \(T_{X}\wedge T_{X^{g}} \leq T_{X,g}\) follows from the fact that, for any given \(k > 0\), \(\|\mathcal{H}^{X}(g)\|_{\mathcal{C}^{k}}\) only blows up if \(|\mathcal{H}^{X}(g)|_{\mathcal{C}^{\nu}}\) does for all \(\nu >0\). Since \(T_{X,g}\leq T_{X}\) by definition, it remains only to show that \(T_{X,g} \leq T_{X^{g}}\) (which will show \(T_{X,g}=T_{X}\wedge T_{X^{g}}\) and the fact that \(T_{X^{g},g^{-1}} = T_{X}\wedge T_{X^{g}}\) follows by symmetry). But this follows from the facts that, for all \(\gamma \in (\frac{1}{2},1]\), \(\mathcal{F}(X)\) can only blow up if \(|\mathcal{F}_{A}(X)|_{\gamma\mbox{-gr}}+|\mathcal{F}_{\Phi}(X)|_{\mathcal{C}^{\gamma -1}}\) does and that \(|A^{g}|_{\gamma\mbox{-gr}}+|g\Phi |_{\mathcal{C}^{\gamma -1}} \leq K(|A|_{ \gamma\mbox{-gr}}+|\Phi |_{\mathcal{C}^{\gamma -1}}+|g|_{\gamma\mbox{-H{\"{o}}l}})\) for some increasing function \(K\colon {\mathbf {R}}_{+}\to {\mathbf {R}}_{+}\). □
For \(\eta \in {\mathbf {R}}\), \(T>0\), a normed space \(B\), and \(X\colon (0,T) \to \mathcal {C}(\mathbf{T}^{3},B)\), denote
Lemma 2.46
Let \((\eta ,\beta ,\delta )\) satisfy (ℐ), \(\nu \in (0,1]\), \(g\in \mathfrak {G}^{\nu}\), \(X\in \mathcal{I}\), and \(T>0\).
-
(i)
Let \(\gamma \in [\nu ,2)\), and define \(\kappa \stackrel {{\tiny \mathrm {def}}}{=}\frac{1}{2}\min \{\eta +1,\nu \}\). Then there exists \(c>0\) such that for all \(S\in (0,T)\) such that \(0< S^{\kappa }\le c |g|_{\mathcal {C}^{\nu}}^{-2}(|\mathcal{F}_{A}(X)|_{\eta ;T}+1)^{-1}\),
$$\begin{aligned} |\mathcal{H}^{X}(g)|_{\gamma ,\nu ;S} \stackrel {{\tiny \mathrm {def}}}{=}\sup _{t\in (0,S)} t^{(\gamma - \nu )/2}|\mathcal{H}^{X}_{t}(g)|_{\mathcal {C}^{\gamma}} \lesssim |g|_{\mathcal {C}^{\nu}} \;, \end{aligned}$$(2.20)where the proportionality constant depends only on \(\eta ,\nu ,\gamma \).
-
(ii)
Conversely, if \(\gamma -\nu \in [0,\frac{2\kappa}{3})\), then
$$\begin{aligned} |g|_{\mathcal {C}^{\nu}}\leq \mathop{\mathrm{Poly}}( |\mathcal{F}_{A}(X)|_{\eta ;T} + |\mathcal{H}^{X}(g)|_{ \gamma ,\nu ;T}+T^{-1} )\;, \end{aligned}$$where the relevant constants depend only on \(\eta ,\nu ,\gamma \).
Proof
(a) Observe that \(h\stackrel {{\tiny \mathrm {def}}}{=}\mathcal{H}^{X}(g)\) solves a fixed point of the form
It is easy to check that, for the given values of \(S\) and for \(c\) small enough, ℳ stabilises the ball of radius \(2 |g|_{\mathcal{C}^{\nu}}\) in the Banach space \(\mathcal{C}_{\gamma ,\nu ;S}\cap \mathcal{C}_{1,\nu ;S}\cap \mathcal{C}_{\nu ,\nu ;S}\) (using the notation obvious from (2.20)) and is a contraction on this ball.
(b) Observe that, for all \(S>0\) and \(t\in (0,S)\)
and
By part (a), \(|h|_{\nu ,\nu ;S}+|h|_{1,\nu ;S}\lesssim |g|_{\mathcal {C}^{\nu}}\) whenever \(S\leq \mathop{\mathrm{Poly}}(|\mathcal{F}_{A}(X)|_{\eta ;S}^{-1}) |g|_{\mathcal{C}^{\nu}}^{-2/ \kappa}\), and thus
On the other hand,
and, for all \(t\geq S\), \(|e^{t\Delta}g|_{\mathcal {C}^{\gamma}}\leq |e^{S\Delta}g|_{\mathcal {C}^{\gamma}}\). Therefore, denoting \(\bar{\kappa} \stackrel {{\tiny \mathrm {def}}}{=}\kappa -\frac{\gamma -\nu}{2}\in ( \frac{2\kappa}{3},\kappa )\),
Hence, whenever \(S \leq \mathop{\mathrm{Poly}}(|\mathcal{F}_{A}(X)|_{\eta ;S}^{-1}) |g|_{\mathcal {C}^{\nu}}^{-2/ \bar{\kappa}}\),
If \(T\leq \mathop{\mathrm{Poly}}(|\mathcal{F}_{A}(X)|_{\eta ;T}^{-1}) |g|_{\mathcal {C}^{\nu}}^{-2/ \bar{\kappa}}\), then the conclusion follows. Otherwise, we can choose \(S\in (0,T)\) such that \(S \asymp (|\mathcal{F}_{A}(X)|_{\eta ;T}+1)^{q} |g|_{\mathcal {C}^{\nu}}^{-2/ \bar{\kappa}}\) for some \(q<0\) and such that (2.21) holds, and thus
Since \(\gamma -\nu \in [0,\frac{2\kappa}{3}) \Leftrightarrow (\gamma -\nu )/ \bar{\kappa}\in [0,1)\), the conclusion follows. □
The proof of the following lemma is routine.
Lemma 2.47
Interpolation
For \(\alpha ,\zeta \in (0,1]\), \(\kappa \in [0,1]\), and \(A\in \Omega \),
We will apply the following lemma with \(\alpha =\frac{1}{2}-\) and \(\gamma =\frac{1}{2}+\).
Lemma 2.48
For all \(\eta \leq 0\), \(\alpha \in (0,1]\), \(\gamma \in [\alpha ,1]\), \(\theta \geq 0\), and \(A\in \Omega \mathcal{D}'\),
where \(\kappa \stackrel {{\tiny \mathrm {def}}}{=}\frac{\gamma -1}{\alpha -1}\in [0,1]\) and the proportionality constant depends only on \(\eta \).
Proof
Observe that \(|\mathcal{P}_{t}A|_{1\mbox{-gr}} \lesssim |\mathcal{P}_{t}A|_{\infty }\lesssim t^{\eta /2}|A|_{ \mathcal{C}^{\eta}}\), and, by Lemma 2.23, \(|\mathcal{P}_{t} A|_{\alpha\mbox{-gr}} \leq t^{-\theta (1-\alpha )}{|\!|\!| A |\!|\!|}_{ \alpha ,\theta}\). Since \(\gamma =\kappa \alpha +(1-\kappa )\), it follows from Lemma 2.47 that
as claimed. □
Proof of Theorem 2.39
Take \(\gamma =\frac{1}{2}+\) and denote \(X=(A,\Phi )\). Then, for all \(T\leq \mathop{\mathrm{Poly}}(\Theta (X)^{-1})\) and \(t\in (0,T)\),

where \(\kappa =\frac{\gamma -1}{\alpha -1}\) and \(\omega =0-\), and where we used Lemma 2.48 and Proposition 2.9 in the second bound along with the trivial bound \(|\cdot |_{\gamma\mbox{-gr}}\leq |\cdot |_{1\mbox{-gr}}\asymp |\cdot |_{\infty}\).
Define \(\nu \stackrel {{\tiny \mathrm {def}}}{=}\gamma +2\omega \). Observe that \(\nu =\frac{1}{2}-\) for our choice of parameters. It follows from Lemma 2.45 that
Since \(|\mathcal{F}_{A}(X)|_{\eta ;T} \lesssim \Theta (X)+1\) by Proposition 2.9, it follows from Lemma 2.46(b) that \(|g|_{\mathcal{C}^{\nu}}\leq \mathop{\mathrm{Poly}}(\Sigma (A)+\Sigma (A^{g}) )\). □
2.6 Gauge orbits
Let us fix \((\eta ,\beta ,\delta )\) satisfying (ℐ) for the rest of the subsection. Recall the relation ∼ on ℐ from Definition 2.11 which extends the usual notion of gauge equivalence. Recall also the space \(\mathcal{S}\) in Definition 2.22.
Definition 2.49
Define the quotient space under ∼ by \(\mathfrak {O}\stackrel {{\tiny \mathrm {def}}}{=}\mathcal{S}/{\sim}\).
Lemma 2.50
The set \(\{(X,Y)\in \mathcal{I}^{2}\,:\,X\sim Y\}\) is closed in \(\mathcal{I}^{2}\).
Proof
Suppose \((X_{n},Y_{n})\to (X,Y)\) in \(\mathcal{I}^{2}\) with \(X_{n}\sim Y_{n}\). Then, by Proposition 2.9,
for some \(t>0\) sufficiently small, and similarly for \(Y_{n},Y\). The conclusion now follows from Lemma 2.20. □
Proposition 2.51
With the quotient topology, \(\mathfrak {O}\) is separable and completely Hausdorff.
Proof
Separability follows from the fact that \(\mathcal{S}\) is separable. The relation ∼ is of the form \(X\sim Y \Leftrightarrow f(X) = f(Y)\) for a continuous function \(f \colon \mathcal{S}\to \mathfrak {U}\), where \(\mathfrak {U}\) a metric space; for instance, \(f=\tilde{\mathcal{F}}_{t}\) for \(t>0\) (recall Proposition 2.15) and \(\mathfrak {U}=\mathfrak {O}_{\alpha}\) for \(\alpha \in (\frac{2}{3},1]\) as defined in [22, Sect. 3.6]. Since \(\mathfrak {U}\) is completely Hausdorff, so is \(\mathfrak {O}\). □
Remark 2.52
In addition to the quotient topology, another natural topology on \(\mathfrak {O}\) is given by taking one of the functions \(f\colon \mathcal{S}\to \mathfrak {U}\) mentioned in the proof of Proposition 2.51, which necessarily induces a bijection \(f\colon \mathfrak {O}\to f(\mathfrak {O})\subset \mathfrak {U}\), and equip \(\mathfrak {O}\) with the corresponding subspace topology. This leads to a weaker topology than the quotient topology but which is metrisable and separable. One loses, however, continuity of solutions to SYMH (modulo gauge equivalence) with respect to the initial condition under this topology, and it is not clear whether there is a choice for \(f\) (or some family of such functions) for which this weaker topology is completely metrisable.
Recall (see the last paragraph of Sect. 1.3) the metrisable space  . We extend ∼ to \(\hat{\mathcal{S}}\) by
. We extend ∼ to \(\hat{\mathcal{S}}\) by  . In particular, we identify \(\hat{\mathfrak {O}}\stackrel {{\tiny \mathrm {def}}}{=}\hat{\mathcal{S}}/{\sim}\) with
. In particular, we identify \(\hat{\mathfrak {O}}\stackrel {{\tiny \mathrm {def}}}{=}\hat{\mathcal{S}}/{\sim}\) with  . Equip \(\hat{\mathfrak {O}}\) with the quotient topology.
. Equip \(\hat{\mathfrak {O}}\) with the quotient topology.
Proposition 2.53
A strict subset \(O\subsetneq \hat{\mathfrak {O}}\) is open if and only if  and \(O\) is open as a subset of \(\mathfrak {O}\).
and \(O\) is open as a subset of \(\mathfrak {O}\).
Proof
Consider the collection \(\tau \stackrel {{\tiny \mathrm {def}}}{=}\{\hat{\mathfrak {O}}\}\cup \{O\subset \mathfrak {O}\,:\,O\text{ is open} \}\). It is easy to verify that \(\tau \) is a topology on \(\hat{\mathfrak {O}}\). Let \(\sigma \) denote the quotient topology on \(\hat{\mathfrak {O}}\). We claim that the projection \(\pi \colon \hat{\mathcal{S}}\to (\hat{\mathfrak {O}},\tau )\) is continuous, from which it follows that \(\tau \subset \sigma \). Indeed, for \(O\in \tau \), either \(O=\hat{\mathfrak {O}}\) in which case \(\pi ^{-1}(O)=\hat{\mathcal{S}}\), or \(O\subset \mathfrak {O}\) is open in which case \(\pi ^{-1}(O)\) is an open subset of \(\mathcal{S}\) and therefore also an open subset in \(\hat{\mathcal{S}}\). Hence \(\pi \colon \hat{\mathcal{S}}\to (\hat{\mathfrak {O}},\tau )\) is continuous as claimed.
We now claim that also \(\sigma \subset \tau \), which then completes the proof. Indeed, every equivalence class \([A]\in \mathfrak {O}\) contains a sequence which converges to  in \(\hat{\mathcal{S}}\) (see [22, Lem. 3.46] for the proof of a similar statement). Therefore, if \(O\in \sigma \) and
in \(\hat{\mathcal{S}}\) (see [22, Lem. 3.46] for the proof of a similar statement). Therefore, if \(O\in \sigma \) and  , then \(O=\hat{\mathfrak {O}}\in \tau \) since \(\pi ^{-1}(O)\) is open by definition of the quotient topology and contains
, then \(O=\hat{\mathfrak {O}}\in \tau \) since \(\pi ^{-1}(O)\) is open by definition of the quotient topology and contains  , so that it must contain some element of every equivalence class \([A]\in \mathfrak {O}\). On the other hand, suppose \(O\in \sigma \) and
, so that it must contain some element of every equivalence class \([A]\in \mathfrak {O}\). On the other hand, suppose \(O\in \sigma \) and  . Then \(\pi ^{-1}(O)\subset \mathcal{S}\) and \(\pi ^{-1}(O)\) is open as a subset of \(\hat{\mathcal{S}}\) (by definition of \(\sigma \)). It is easy to see that every open subset of \(\hat{\mathcal{S}}\) which does not contain
. Then \(\pi ^{-1}(O)\subset \mathcal{S}\) and \(\pi ^{-1}(O)\) is open as a subset of \(\hat{\mathcal{S}}\) (by definition of \(\sigma \)). It is easy to see that every open subset of \(\hat{\mathcal{S}}\) which does not contain  is also open in \(\mathcal{S}\). Hence \(\pi ^{-1}(O)\) is also open in \(\mathcal{S}\), and therefore \(O\) is open in \(\mathfrak {O}\), thus \(O\in \tau \). Hence \(\sigma \subset \tau \) as claimed. □
is also open in \(\mathcal{S}\). Hence \(\pi ^{-1}(O)\) is also open in \(\mathcal{S}\), and therefore \(O\) is open in \(\mathfrak {O}\), thus \(O\in \tau \). Hence \(\sigma \subset \tau \) as claimed. □
2.7 Embeddings and heat flow
In this subsection, we study compact embeddings for the spaces ℐ and \(\mathcal{S}\) and the effect of the heat flow. We first record the following lemma, the proof of which is straightforward.
Lemma 2.54
Lower semi-continuity
Let \(\eta ,\beta ,\delta ,\theta ,\kappa \in {\mathbf {R}}\), \(\alpha \in (0,1]\). The functions

are lower semi-continuous.
Lemma 2.55
-
(i)
For all \(\eta ,\beta \in {\mathbf {R}}\) and \(\delta \geq 0\), there exists \(C>0\) such that, for all \(h\in [0,1]\) and \(X\in \mathcal{D}'(\mathbf{T}^{3},E)\), \(\Theta (\mathcal{P}_{h}X)\leq (1+Ch)\Theta (X)\).
-
(ii)
For all \(\alpha \in (0,1]\), \(A\in \Omega \mathcal{D}'\), and \(t,s\geq 0\), \(|\mathcal{P}_{s}A|_{\alpha \mbox{-gr};< t} \leq |A|_{\alpha \mbox{-gr};< t}\). In particular, \(\mathcal{P}_{s}\) is a contraction for \({|\!|\!| \cdot |\!|\!|}_{\alpha ,\theta}\) for any \(\alpha \in (0,1]\) and \(\theta \in {\mathbf {R}}\).
Proof
(i) Note that \(|\mathcal{P}_{h}X|_{\mathcal{C}^{\eta}} \leq (1+Ch)|X|_{\mathcal{C}^{\eta}}\). Furthermore

where we used that \(\sup _{t\in [1,1+h)}|\mathcal{N}_{t}X-\mathcal{N}_{1} X|_{\mathcal{C}^{\beta}}\leq C h |X|_{ \mathcal{C}^{\eta}}^{2}\) to get the last bound. (ii) Consider \(\ell =(x,v)\) with \(|\ell |< t\). Then, by the definition (2.7),
where we used that \(|A(x-y,v)|\leq |A|_{\alpha \mbox{-gr};< t}|\ell |^{\alpha}\) and \(\int _{\mathbf{T}^{3}}\mathcal{P}_{s}(y)\mathrm {d}y=1\). □
The proof of the following lemma is obvious.
Lemma 2.56
For \(s\in (0,1)\), \(0<\alpha \leq \bar{\alpha}\leq 1\), \(\theta \geq 0\), and \(A\in \Omega \mathcal{D}'\),
Proposition 2.57
Compact embeddings
Let \(\eta <\bar{\eta},\bar{\delta}<\delta \), \(\beta ,\kappa \in {\mathbf {R}}\), \(0<\alpha <\bar{\alpha}\leq 1\), and \(\theta ,R>0\).
-
(i)
If \(X_{n}\to X\) in \(\mathcal{C}^{\kappa}(\mathbf{T}^{3},E)\) and \(\sup _{n} \Theta _{\bar{\eta},\beta ,\bar{\delta}}(X_{n})<\infty \), then \(\Theta (X_{n},X)\to 0\). In particular, \(\{X\in \mathcal{D}'(\mathbf{T}^{3},E)\,:\, \Theta _{\bar{\eta},\beta ,\bar{\delta}}(X) \leq R\}\) is a compact subset of \((\mathcal{I},\Theta )\).
-
(ii)
If \(A_{n}\to A\) in \(\Omega \mathcal{C}^{\kappa}\) and \(\sup _{n} {|\!|\!| A_{n} |\!|\!|}_{\bar{\alpha},\theta}<\infty \), then \({|\!|\!| A_{n}-A |\!|\!|}_{\alpha ,\theta}\to 0\). In particular, \(\{A\in \Omega \mathcal{D}'\,:\, {|\!|\!| A |\!|\!|}_{\bar{\alpha},\theta} \leq R\}\) is a compact subset of the closure of smooth functions under \({|\!|\!| \cdot |\!|\!|}_{\alpha ,\theta}\).
-
(iii)
\(\{X\in \mathcal{D}'(\mathbf{T}^{3},E)\,:\, \Sigma _{\bar{\eta},\beta ,\bar{\delta}, \bar{\alpha},\theta}(X) \leq R\}\) is a compact subset of \((\mathcal{S},\Sigma )\).
Proof
(i) Recall the compact embedding \(\mathcal{C}^{\bar{\eta}}\hookrightarrow \mathcal{C}^{0,\eta}\). Furthermore, for every \(s\in (0,1)\)

The first term is bounded above by  due to the lower semi-continuity of
due to the lower semi-continuity of  (Lemma 2.54) and can therefore be made arbitrarily small by choosing \(s\) sufficiently small, while the second term converges to 0 as \(n\to \infty \) for any fixed \(s\in (0,1)\) since the operator norm of \(\mathcal{P}_{t} \colon \mathcal{C}^{\kappa }\to \mathcal{C}^{1}\) is bounded uniformly in \(t>s\). It follows that \(\Theta (X_{n},X)\to 0\). The final claim in (i) now follows from Lemma 2.54.
(Lemma 2.54) and can therefore be made arbitrarily small by choosing \(s\) sufficiently small, while the second term converges to 0 as \(n\to \infty \) for any fixed \(s\in (0,1)\) since the operator norm of \(\mathcal{P}_{t} \colon \mathcal{C}^{\kappa }\to \mathcal{C}^{1}\) is bounded uniformly in \(t>s\). It follows that \(\Theta (X_{n},X)\to 0\). The final claim in (i) now follows from Lemma 2.54.
(ii) In a similar way, for every \(s\in (0,1)\)
The first term is bounded above by \(2s^{\theta (\bar{\alpha}-\alpha )}\sup _{n}{|\!|\!| A_{n} |\!|\!|}_{ \bar{\alpha},\theta}\) by Lemma 2.56 and lower semi-continuity of \({|\!|\!| \cdot |\!|\!|}_{\alpha ,\theta}\) (Lemma 2.54) and can therefore be made arbitrarily small, while the second term converges to 0 as \(n\to \infty \). Hence \({|\!|\!| A_{n}-A |\!|\!|}_{\alpha ,\theta}\to 0\). The final claim in (ii) now follows from Lemma 2.54.
(iii) This claim is a consequence of (i) and (ii). □
Proposition 2.58
Let \(\beta ,\eta ,\theta \in {\mathbf {R}}\), \(\delta \geq 0\), and \(\alpha \in (0,1]\).
-
(i)
\(\lim _{h\downarrow 0}\Theta (\mathcal{P}_{h}X,X)=0\) for all \(X\in \mathcal{I}\).
-
(ii)
\(\lim _{h\downarrow 0}\Sigma (\mathcal{P}_{h}X,X)=0\) for all \(X\in \mathcal{S}\).
Proof
To prove (i), observe that for all \(h\in [0,1]\)

for a proportionality constant depending only on \(\eta ,\beta ,\delta \). It readily follows that the set of \(X\in \mathcal{I}\) such that  is closed in ℐ. Furthermore, this set contains all smooth functions, from which (i) follows. The claim (ii) follows in the same way once we remark that \({|\!|\!| \mathcal{P}_{h}A |\!|\!|}_{\alpha ,\theta} \leq {|\!|\!| A |\!|\!|}_{\alpha ,\theta}\) by Lemma 2.55(ii) and therefore the set of \(X\in \mathcal{S}\) for which \(\lim _{h\downarrow 0}\Sigma (\mathcal{P}_{h}X,X)=0\) is closed in \(\mathcal{S}\) and contains the smooth functions. □
is closed in ℐ. Furthermore, this set contains all smooth functions, from which (i) follows. The claim (ii) follows in the same way once we remark that \({|\!|\!| \mathcal{P}_{h}A |\!|\!|}_{\alpha ,\theta} \leq {|\!|\!| A |\!|\!|}_{\alpha ,\theta}\) by Lemma 2.55(ii) and therefore the set of \(X\in \mathcal{S}\) for which \(\lim _{h\downarrow 0}\Sigma (\mathcal{P}_{h}X,X)=0\) is closed in \(\mathcal{S}\) and contains the smooth functions. □
Lemma 2.59
Let \(0<\bar{\alpha}\leq \alpha \leq 1\), \(\theta \geq 0\), \(\kappa \in (0,1)\), \(h>0\), and \(A\in \Omega \mathcal{D}'\). Then
where the proportionality constant depends only on \(\bar{\alpha},\alpha ,\theta ,\kappa \).
Proof
We can assume that \(h\in (0,1)\). For all \(0< t\leq s<1\)
where we used Lemma 2.24 in the first bound and Lemma 2.55(ii) in the second bound. On the other hand, denote \(\eta \stackrel {{\tiny \mathrm {def}}}{=}(1+2\theta )(\alpha -1)\) so that \(|A|_{\mathcal{C}^{\eta}}\lesssim {|\!|\!| A |\!|\!|}_{\alpha ,\theta}\) by Lemma 2.25. Then, for \(0< s< t<1\) and \(\bar{\eta}\leq \eta \),
Optimising over \(s\in (0,1)\) so that \(s^{\theta (\alpha -\bar{\alpha})}=s^{\bar{\eta}/2}h^{(\eta -\bar{\eta})/2} \Leftrightarrow s = h^{\gamma}\) where \(\gamma = \frac{\eta -\bar{\eta}}{2\theta (\alpha -\bar{\alpha})-\bar{\eta}}\), we see that
Note that \(\eta \leq 2\theta (\alpha -\bar{\alpha})\) (with strict inequality if \(\theta >0\) and \(\bar{\alpha}<1\)), hence \(\gamma \nearrow 1\) as \(\bar{\eta}\to -\infty \), from which the conclusion follows. □
Lemma 2.60
Let \(\kappa ,h\in (0,1)\), \(\beta ,\eta \leq 0\), \(\delta <\bar{\delta}\) with \(\bar{\delta}\geq 0\), and \(X\in \mathcal{D}'(\mathbf{T}^{3},E)\). Then

where the proportionality constant depends only on \(\eta ,\kappa \).
Proof
For all \(0< t\leq s<1\)

On the other hand, for \(0< s< t<1\) and any \(\bar{\eta}\leq \eta \)
where we used Lemma 2.34 in the second bound. Optimising over \(s\in (0,1)\) so that \(s^{\bar{\delta}-\delta}=s^{(\bar{\eta}+\eta -1)/2}h^{(\eta -\bar{\eta})/2} \Leftrightarrow s = h^{\gamma}\) where \(\gamma = \frac{\eta -\bar{\eta}}{2(\bar{\delta}-\delta )+1-\eta -\bar{\eta}}\), we see that

Note that \(\eta < 2(\bar{\delta}-\delta )+1-\eta \), hence \(\gamma \nearrow 1\) as \(\bar{\eta}\to -\infty \), from which the conclusion follows. □
Remark 2.61
One could sharpen Lemma 2.60 by not immediately dropping \(t^{\bar{\delta}}\) in (2.23), but this only improves the result in the case \(2\eta \geq 1-2\delta \), which is not the case in which we will apply this lemma.
2.8 Smoothened gauge-invariant observables
We conclude this section with a discussion on the gauge-invariant observables defined on the space ℐ (and therefore on \(\mathcal{S}\)).
Definition 2.62
A function \(\mathcal{O}\colon \mathcal{C}^{\infty}(\mathbf{T}^{3},E)\to {\mathbf {R}}\) is called gauge-invariant if \(\mathcal{O}\) factors through a function \(\mathcal{O}\colon \mathfrak {O}^{\infty}\to {\mathbf {R}}\) (which we denote by the same symbol), i.e. if \(\mathcal{O}(X)=\mathcal{O}(Y)\) whenever \(X\sim Y\). A collection \(\{\mathcal{O}^{i}\}_{i\in I}\) of gauge-invariant observables on \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\) is called separating if for all \(X,Y\in \mathcal{C}^{\infty}(\mathbf{T}^{3},E)\)
The same definitions apply with \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\) replaced by ℐ.
If \(\mathcal{O}\colon \mathcal{C}^{\infty}(\mathbf{T}^{3},E)\to {\mathbf {R}}\) is a gauge-invariant observable then, recalling the YMH flow \(\tilde{\mathcal{F}}\colon (0,\infty )\to \mathfrak {O}^{\infty}\) from Definition 2.11, we define its “smoothened” version \(\mathcal{O}_{t}\colon \mathcal{I}\to {\mathbf {R}}\) for \(t>0\) by
For \(X,Y\in \mathcal{I}\), recall that \(X\sim Y\) if and only if \(\tilde {\mathcal{F}}_{t}(X)=\tilde {\mathcal{F}}_{t}(Y)\) for some \(t>0\) due to Proposition 2.15. Hence, given a separating collection \(\{\mathcal{O}^{i}\}_{i\in I}\) of gauge-invariant observables on \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\) and any \(t>0\), \(\{\mathcal{O}^{i}_{t}\}_{i\in I}\) is a separating collection of gauge-invariant observables on ℐ.
In the rest of this subsection, we describe a natural separating collection of gauge-invariant observables on \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\).Footnote 4 For \(x\in \mathbf{T}^{3}\) denote by \(\mathcal{P}_{x}\) the set of piecewise smooth paths \(\gamma \colon [0,1]\to \mathbf{T}^{3}\) such that \(\gamma _{0}=x\) and by \(\mathcal{L}_{x}\subset \mathcal{P}_{x}\) the subset of loops, i.e. those \(\gamma \in \mathcal{P}_{x}\) such that \(\gamma _{1}=x\).
Given \(\gamma \in \mathcal{P}_{x}\) for some \(x\in \mathbf{T}^{3}\) and \(A\in \Omega \mathcal{C}^{\infty}\), the holonomy of \(A\) along \(\gamma \) is defined as \(\mbox{hol}(A,\gamma )\stackrel {{\tiny \mathrm {def}}}{=}y_{1}\) where \(y\) satisfies the ODE \(\mathrm {d}y_{t} = y_{t} A(\gamma _{t})\dot{\gamma}_{t}\) with \(y_{0}=\mathrm{id}\) (in fact \(A\in \Omega _{\alpha}\) for \(\alpha \in (\frac{1}{2},1]\) suffices to define the holonomy as shown in [22, Thm. 2.1(i)].
Definition 2.63
For \(n\geq 1\) let \(\mathcal{A}_{n}\) denote the set of all continuous functions \(f\colon G^{n}\times \mathbf{V}^{n}\to {\mathbf {R}}\) such that for all \(g,h_{1},\ldots , h_{n}\in G\) and \(\phi _{1},\ldots ,\phi _{n}\in \mathbf{V}\)
Then, for any \(x\in \mathbf{T}^{3}\), let \(\mathbf {W}_{x}\) denote the set of all functions on \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)\) of the form
where \(n\geq 1\), \(f\in \mathcal{A}_{n}\), \(\ell ^{1},\ldots ,\ell ^{n}\in \mathcal{L}_{x}\), and \(\gamma ^{1},\ldots ,\gamma ^{n}\in \mathcal{P}_{x}\).
Remark 2.64
Every \(\mathcal{O}\in \mathbf {W}_{x}\) is gauge-invariant due to the identity \(\mbox{hol}(A^{g},\gamma )=g(\gamma _{0})\mbox{hol}(A,\gamma )g(\gamma _{1})^{-1}\). In the absence of the Higgs field (i.e. \(\mathbf{V}=\{0\}\) or when \(f\) is independent of its \(\mathbf{V}^{n}\)-argument), \(\mathbf {W}_{x}\) is a separating collection for \(\Omega \mathcal{C}^{\infty}/{\sim}\), see [79, Prop. 2.1.2].
Remark 2.65
Elements of \(\mathbf {W}_{x}\) of the form \((A,\Phi )\mapsto f(\mbox{hol}(A,\ell ))\), where \(\ell \in \mathcal{L}_{x}\) and \(f\colon G\to {\mathbf {R}}\) is a class function, are known as Wilson loops. For many choices of \(G\), Wilson loops also form a separating collection for \(\Omega \mathcal{C}^{\infty}\), but this is harder to show than for \(\mathbf {W}_{x}\); see [40, 68, 80] where this question is investigated.
Remark 2.66
Elements of \(\mathbf {W}_{x}\) of the form  are known as string observables.
are known as string observables.
We now show that \(\mathbf {W}_{x}\) is a separating collection for all of \(\mathcal{C}^{\infty}(\mathbf{T}^{3},E)/{\sim}\).
Proposition 2.67
Consider \(x\in \mathbf{T}^{3}\) and \((A,\Phi ),(B,\Psi )\in \mathcal{C}^{\infty}(\mathbf{T}^{3},E)\). The following statements are equivalent.
-
(i)
\((A,\Phi )\sim (B,\Psi )\).
-
(ii)
\(\mathcal{O}(A,\Phi )=\mathcal{O}(B,\Psi )\) for all \(\mathcal{O}\in \mathbf {W}_{x}\).
Proof
This is similar to [79, Prop. 2.1.2]. The direction (i)⇒(ii) is Remark 2.64. Suppose now that (ii) holds. For \(\gamma \in \mathcal{P}_{x}\) define \(\Gamma _{\gamma} \stackrel {{\tiny \mathrm {def}}}{=}\{g\in G\,:\,g\mbox{hol}(A,\gamma )\Phi (\gamma _{1})= \mbox{hol}(B,\gamma )\Psi (\gamma _{1})\}\), and for \(\ell \in \mathcal{L}_{x}\) define \(\Lambda _{\ell} \stackrel {{\tiny \mathrm {def}}}{=}\{g\in G\,:\,g\mbox{hol}(A,\ell )g^{-1}=\mbox{hol}(B, \ell )\}\). Then (ii) implies

for any finite subsets \(I\subset \mathcal{P}_{x}\), \(J\subset \mathcal{L}_{x}\). This is due to the fact that if
then there exists \(g\in G\) such that \(h_{i}=g \bar{h}_{i} g^{-1}\) and \(\phi _{i} = g\bar{\phi}_{i}\) for all \(1\le i\le n\). Since \(\Gamma _{\gamma}\) and \(\Lambda _{\ell}\) are compact, (2.24) holds for any countable \(I\subset \mathcal{P}_{x}\), \(J\subset \mathcal{L}_{x}\) by Cantor’s intersection theorem. Since all objects are smooth and \(\mathcal{P}_{x}\) and \(\mathcal{L}_{x}\) are separable (say in the \(C^{1}\)-metric), one can choose \(I\subset \mathcal{P}_{x}\), \(J\subset \mathcal{L}_{x}\) to be countable dense subsets, and it follows that there exists \(g\in (\bigcap _{\gamma \in \mathcal{P}_{x}}\Gamma _{\gamma})\cap (\bigcap _{ \ell \in \mathcal{L}_{x}}\Lambda _{\ell})\).
Define \(h\in \mathcal{C}^{\infty}(\mathbf{T}^{3},G)\) by the identity \(g\mbox{hol}(A,\gamma )=\mbox{hol}(B,\gamma )h(y)\), where \(\gamma \) is any path in \(\mathcal{P}_{x}\) such that \(\gamma _{1}=y\) (note that \(h(y)\) is independent of the choice of \(\gamma \)). Then \(\mbox{hol}(B,\gamma )h(\gamma _{1})\Phi (\gamma _{1})=g\mbox{hol}(A,\gamma ) \Phi (\gamma _{1})=\mbox{hol}(B,\gamma )\Psi (\gamma _{1})\) for all \(\gamma \in \mathcal{P}_{x}\), and thus \(\Psi =\Phi ^{h}\). Similarly \(h(z)\mbox{hol}(A,\gamma )h(y)^{-1}=\mbox{hol}(B,\gamma )\) for all \(z,y\in \mathbf{T}^{3}\) and \(\gamma \in \mathcal{P}_{z}\) with \(\gamma _{1}=y\), from which it follows that \(A^{h}=B\). □
3 Stochastic heat equation
The main goal of this section is to show that the stochastic heat equation (SHE) is a continuous process with values in \((\mathcal{S},\Sigma )\). We analyse separately the two parts \(\Theta \) and \({|\!|\!| \cdot |\!|\!|}_{\alpha ,\theta}\) which add to give \(\Sigma \).
3.1 The first half
Throughout this subsection, let \(\xi \) denote either the \(E\)-valued space-time white noise \(((\xi _{i})_{i=1}^{3},\zeta )\) on \({\mathbf {R}}\times \mathbf{T}^{3}\) or its smoothened version \(((\xi _{i}^{\varepsilon })_{i=1}^{3},\zeta ^{\varepsilon })\). Then there exists \(C_{\xi }> 0\) such that  for all smooth compactly supported \(\phi \colon {\mathbf {R}}\times \mathbf{T}^{3}\to E\). Let \(\Psi \) solve \((\partial _{t} - \Delta ) \Psi = \xi \) on \({\mathbf {R}}_{+} \times \mathbf{T}^{3}\) with initial condition \(\Psi (0)\in \mathcal{D}'(\mathbf{T}^{3},E)\). We will often write \(\Psi _{t}=\Psi (t)\) for short.
for all smooth compactly supported \(\phi \colon {\mathbf {R}}\times \mathbf{T}^{3}\to E\). Let \(\Psi \) solve \((\partial _{t} - \Delta ) \Psi = \xi \) on \({\mathbf {R}}_{+} \times \mathbf{T}^{3}\) with initial condition \(\Psi (0)\in \mathcal{D}'(\mathbf{T}^{3},E)\). We will often write \(\Psi _{t}=\Psi (t)\) for short.
Definition 3.1
We say that \((\eta ,\beta ,\delta )\in {\mathbf {R}}^{3}\) satisfies condition (\(\mathcal {I}'\)) if

We introduce the homogenous version of the metric \(\Theta \) by

Proposition 3.2
Assume (\(\mathcal {I}'\)) and that \(\Psi _{0}\in \mathcal{I}_{\eta ,\beta ,\delta}\). Then for all \(T > 0\), there is a modification of \(\Psi \) such that \(\Psi \in \mathcal{C}([0,T],\mathcal{I}_{\eta ,\beta ,\delta})\) and, for every \(\bar{\eta}<\eta \), \(\bar{\beta}<\beta \) and \(\bar{\delta}>\delta \) there exists \(\kappa >0\) such that \(p\in [1,\infty )\),

and
For the proof, we require several lemmas. Below we denote by \(\mathbin{\hat{*}}\) the spatial convolution (in contrast with ∗ for space-time convolution). Below we write \(G\) for the heat kernel associated to the heat semigroup \(\mathcal{P}\).Footnote 5
Lemma 3.3
Let \(d\geq 1\), \(\gamma \in (0,d)\) and \(\alpha \in (0,\gamma )\). Let \(\mathcal{P}_{t}^{(k)}\) be the \(k\)th spatial derivative of the heat semigroup \(\mathcal{P}\) for multiindex \(|k|\le 1\). Let \(f\in \mathcal{D}'(\mathbf{T}^{d})\) which is smooth except for the origin, and satisfy the bound \(|f(x)|\lesssim |x|^{-\gamma}\) uniformly in \(x\in \mathbf{T}^{d}\backslash \{0\}\). Then for any \(\omega \in \big(0,\min (\frac{\alpha}{2},\frac{1}{2}) \big)\) one has
uniformly in \(t\in (0,1)\) and \(x\in \mathbf{T}^{d}\setminus \{0\}\).
Proof
By the bound \(|G^{(k)}(t,x)|\lesssim \big(|x|+\sqrt{t}\big)^{-d-|k|} \) one has
uniformly in \(t\in (0,1)\), where in the last step we applied [56, Lem. 10.14]. The second bound follows in the same way using the bound on \(\partial _{t} G^{(k)}(t,x)\) by \(\big(|x |+\sqrt{t}\big)^{-d-|k|-2}\) and interpolation. □
Lemma 3.4
Suppose that \(\tilde{\Psi}\) solves SHE with initial condition \(\tilde{\Psi}(0)=0\). Let \(T>0\), \(\delta \in (\frac{1}{2},1)\), and \(\beta < 2(\delta -1)\). Then for \(\kappa \stackrel {{\tiny \mathrm {def}}}{=}\min \{2(\delta -1)-\beta ,\frac{1}{2}\}\), one has
uniformly in \(t,\bar{t}\in (0,1)\), \(r,s\in [0,T]\), and \(\lambda \in (0,1)\), where \(\phi ^{\lambda }= \lambda ^{-3}\phi (\cdot / \lambda )\) and \(\phi \in \mathcal{C}^{\infty}(\mathbf{T}^{3})\) with support in \(\{z\in \mathbf{T}^{3}\,:\,|z|\leq \frac{1}{4}\}\).
Proof
Define \(C_{r,s}(x) = \mathbf{E}\langle \tilde{\Psi}(r,0),\tilde{\Psi}(s,x)\rangle _{E}\). For any \(t,\bar{t}, r,s\ge 0\) and \(x\in \mathbf{T}^{3}\), recalling \([3]=\{1,2,3\}\), we write
Here note that \(\mathcal{N}_{t} (\tilde{\Psi}_{r})\) has zero mean thanks to the spatial derivative in its definition (2.1). By Wick’s theorem for \(x,\bar{x}\in \mathbf{T}^{3}\) one has
It is easy to check that
uniformly in \(r,s\in [0,T]\) and \(x\in \mathbf{T}^{3}\setminus \{0\}\). Since \(\kappa \in (0,\frac{1}{2}]\), interpolation between the two bounds in (3.5) implies
Applying Lemma 3.3 twice, with \(\gamma =1\) and then with \(\gamma =1-\alpha \) for any \(\alpha \in (0,\frac{1}{2})\) therein, one has, for any \(\tau ,\bar{\tau}\in \{t,\bar{t}\}\), \(\iota ,\bar{\iota}\in \{r,s\}\), \(i,j \in \{0,1\}\),
Here \(G^{(0)}=G\) and \(G^{(1)}\) denotes \(\partial _{k} G\) for a generic \(k\in [3]\). Choose \(\alpha \stackrel {{\tiny \mathrm {def}}}{=}\delta -\frac{1}{2}\). By these bounds and obvious telescoping, one then has the bound
for \(\ell \in \{1,2\}\). The same bound holds with \(r,s\) and \(t,\bar{t}\) swapped and thus holds for (3.4).
It remains to integrate this bound on (3.4) against the test functions \(\phi ^{\lambda}\). Bounding \(\phi ^{\lambda}\) by constant \(\lambda ^{-3}\) over its support which has diameter proportional to \(\lambda \), one obtains that the integral of \(\text{(3.4)} \) against \(\phi ^{\lambda}(x)\phi ^{\lambda}(\bar{x})\) is bounded above by a multiple of \(C_{\xi}^{2} (|t-\bar{t}|+|r-s|)^{\kappa} \) times \(\lambda ^{4\delta -4-2\kappa} \leq \lambda ^{2\beta}\), where used that \(\kappa \leq 2(\delta -1)-\beta \) in the final bound. □
Lemma 3.5
Let \(\beta ,\eta \leq 0\), \(\delta <\bar{\delta}\) with \(\bar{\delta}\geq 0\), and \(\Psi _{0}\in \mathcal{D}'(\mathbf{T}^{3},E)\). Then for \(\kappa \in (0,2(\bar{\delta}-\delta ))\), writing
one has

where the proportionality constant depends only on \(\beta ,\eta ,\delta ,\bar{\delta},\kappa \).
Proof
By Lemma 2.60,

for any \(\tilde{\kappa}\in (0,1)\) and \(\delta <\bar{\delta}\), where we used  and similarly for the \(\mathcal{C}^{\eta}\) norm. By assumption on the indices, \(|r-s|^{\tilde{\kappa}(\bar{\delta}-\delta )}\lesssim |r-s|^{ \frac{\kappa}{2}}\) for \(\tilde{\kappa}\) sufficiently close to 1, where we used \(\kappa <2(\bar{\delta}-\delta )\). Similarly,
and similarly for the \(\mathcal{C}^{\eta}\) norm. By assumption on the indices, \(|r-s|^{\tilde{\kappa}(\bar{\delta}-\delta )}\lesssim |r-s|^{ \frac{\kappa}{2}}\) for \(\tilde{\kappa}\) sufficiently close to 1, where we used \(\kappa <2(\bar{\delta}-\delta )\). Similarly,

Finally, assuming \(t\le \bar{t}\) without loss of generality,

where we again used \(\kappa <2(\bar{\delta}-\delta )\) in the last bound. Combining the above three bounds we obtain (3.8). □
Lemma 3.6
Assume (\(\mathcal {I}'\)) and that \(\delta <\bar{\delta}< 1\) and \(\beta > \bar{\beta}>-\frac{1}{2}\). Let \(0<\kappa < \min (2(\bar{\delta}-\delta ),\eta -\beta +2\delta -3/2)\), and \(T>0\). Then for all \(r,s\in [0,T]\) and \(p\in [1,\infty )\)

where the proportionality constant depends only on \(\eta ,\beta ,\bar{\beta},\delta ,\bar{\delta},\kappa ,T\).
Proof
Write \(\Psi _{s}=\tilde{\Psi}_{s}+ \mathcal{P}_{s} \Psi _{0}\) where \(\tilde{\Psi}\) solves SHE with \(\tilde{\Psi}(0)=0\), and assume \(r>s\). Since \(\tilde{\Psi}\) and \(\mathcal{N}_{t} (\tilde{\Psi}_{r})\) are mean-zero, it is straightforward to check that
where in the first term on the right-hand side we replace \(\delta \) in (3.4) by \(\bar{\delta}\), and \(\mathcal{M}_{t,\bar{t},r,s,\bar{\delta}}(\Psi _{0})\) is as in (3.7). Here for \(i,j\in \{0,1\}\) we define
where \(\mathcal{P}^{(i)}\) denotes the \(i\)-th spatial derivative of \(\mathcal{P}\) as in the proof of Lemma 3.4.
By Lemma 3.4, the integral of (3.4) against \(\phi ^{\lambda}(x)\phi ^{\lambda}(\bar{x})\) satisfies the bound (3.3). By Lemma 3.5, the integration of the second term on the right-hand side of (3.9) against \(\phi ^{\lambda}(x)\phi ^{\lambda}(\bar{x})\) is bounded by

It remains to bound the last term in (3.9). We can prove for each \(i,j\in \{0,1\}\),
Indeed, if \(\bar{t}\notin (\frac{t}{2},2t)\), we bound the two terms on the left-hand side of (3.11) separately, and by the first inequality in (3.6) (with \(\alpha =\beta +\frac{1}{2}\)) and \(|\mathcal{P}_{t+r}^{(i)} \Psi _{0}|_{\infty }\lesssim t^{ \frac{\eta -|i|}{2}} |\Psi _{0}|_{\mathcal{C}^{\eta}}\), we have
This is then bounded by the right-hand side of (3.11) since \(\bar{\delta}-\frac{\beta}{2}-\frac{3}{4}+\frac{\eta}{2}>0\) by (\(\mathcal {I}'\)) and \((t\vee \bar{t})^{\kappa }\lesssim |t-\bar{t}|^{\kappa}\) by our assumption on \(t,\bar{t}\). The other term \(J_{t,t,x,\bar{x}}^{(i,j)}(r,r) \) is bounded in the same way. On the other hand, if \(\bar{t} \in (\frac{t}{2},2t)\), we bound the left-hand side of (3.11) by obvious telescoping. Using (3.6) (with \(\alpha =\beta +\frac{1}{2}\) or \(\alpha =\beta +\frac{1}{2}+\kappa \)), \(|\mathcal{P}_{t+r}^{(i)} \Psi _{0}|_{\infty }\lesssim t^{ \frac{\eta -|i|}{2}} |\Psi _{0}|_{\mathcal{C}^{\eta}}\), and
we obtain a bound by
where \(q,\bar{q}\in {\mathbf {R}}\) are such that \(q+\bar{q}=2\bar{\delta}-\beta -\frac{3}{2}+\eta -\kappa \). By our assumption on \(t,\bar{t}\), one has \(t^{q} \, \bar{t}^{\bar{q}} \lesssim (t\vee \bar{t})^{q+\bar{q}}\), so we obtain (3.11). Here we recall again that \(\eta -\beta +2\bar{\delta}-3/2>0\) by (\(\mathcal {I}'\)), and we assume \(\kappa < \eta -\beta +2\delta -3/2\). So one has \((t\vee \bar{t})^{2\bar{\delta}-\beta -\frac{3}{2}+\eta -\kappa} \le 1\). The same bound holds with \(r,s\) and \(t,\bar{t}\) swapped. So the last line of (3.9) is bounded by
The integration of the last line of (3.9) against test functions \(\phi ^{\lambda}(x)\phi ^{\lambda}(\bar{x})\) is then bounded by \(C_{\xi}\) times (3.10). The lemma then follows by collecting the above bounds and using the equivalence of Gaussian moments. □
or Proposition 3.2
It is standard to show that for all \(\bar{\eta}\in (-\frac{2}{3}, \eta )\), \(0<\kappa <\frac{\eta -\bar{\eta}}{2}\), \(p\geq 1\) and \(T > 0\)
where the proportionality constant depends only on \(p,\eta ,\bar{\eta},\kappa ,T\). Recalling Def. 2.4, it remains to bound the moments of, for a suitable modificaiton of \(\Psi \) and for \(\delta <\bar{\delta}< 1\) and \(\kappa >0\) sufficiently small,

By Lemma 3.6 below and the classical Kolmogorov continuity theorem over \((0,1)\times [0,T]\), one has, for every \(p\in [1,\infty )\) and \(\kappa \in (0,(\bar{\delta}-\delta )\wedge \frac{\eta -\beta +2\delta -3/2}{2})\),

where the proportionality constant depends only on \(p,\eta ,\bar{\eta},\beta ,\delta ,\bar{\delta},\kappa ,T\), which in particular bounds the moments of (3.12) by restricting to \(t=\bar{t}\) and proves (3.1).
To prove (3.2), writing \(\Psi _{r} = \mathcal{P}_{r}\Psi _{0} + \tilde{\Psi}_{r}\) as in the proof of Lemma 3.6, we have
which has finite moments of all orders for \(\kappa >0\) sufficiently small. Moreover

By Lemma 3.4, Kolmogorov’s theorem, and equivalence of Gaussian moments, we have
Furthermore, by (3.11),
and likewise with \(\mathcal{P}_{t}\tilde{\Psi}_{r}\otimes \nabla \mathcal{P}_{t+r} \Psi _{0}\) replaced by \(\mathcal{P}_{t+r}\Psi _{0}\otimes \nabla \mathcal{P}_{t} \tilde{\Psi}_{r}\). Restricting to \(s=0\) and combining with (3.13) concludes the proof of (3.2).
For the final claim that \(\Psi \) is in \(\mathcal{C}([0,T],\mathcal{I})\), remark that \([0,T]\ni r\mapsto \Psi _{r} \in \mathcal{I}\) is continuous at 0 due to (3.2) and due to continuity of \([0,T]\ni r\mapsto \mathcal{P}_{r}\Psi _{0} \in \mathcal{I}\) (Proposition 2.58(i)). Continuity at \(r>0\) follows from the fact that \(\tilde{\Psi}\in \mathcal{C}([0,T],\mathcal{I})\) due to (3.1) and from Lemma 2.35(i) once we write \(\Psi _{r} = \tilde{\Psi}_{r} + \mathcal{P}_{r}\Psi _{0}\) where \(\mathcal{P}\Psi _{0}\in \mathcal{C}((0,T],L^{\infty})\). □
3.2 The second half
Throughout this subsection, let \(\xi \) be an \(\mathfrak {g}^{3}\)-valued Gaussian random distribution on \({\mathbf {R}}\times \mathbf{T}^{3}\). Suppose there exists \(C_{\xi }> 0\) such that

for all smooth compactly supported \(\phi \colon {\mathbf {R}}\times \mathbf{T}^{3}\to \mathfrak {g}^{3}\). Let \(\Psi \) solve \((\partial _{t} - \Delta ) \Psi = \xi \) on \({\mathbf {R}}_{+} \times \mathbf{T}^{3}\) with initial condition \(\Psi (0)\in \mathcal{D}'(\mathbf{T}^{3},\mathfrak {g}^{3})\).
Proposition 3.7
Let \(0 < \bar{\alpha}< \alpha < \frac{1}{2}\), \(\theta \in (0,1]\), and \(0<\kappa <\theta \min \{\alpha -\bar{\alpha},\frac{1-2\bar{\alpha}}{4} \}\). Then for all \(p\geq 1\) and \(T > 0\)
where the proportionality constant depends only on \(p,\alpha ,\bar{\alpha},\theta ,\kappa ,T\).
We give the proof at the end of this subsection after several preliminary results. Recall the space of line segments \(\mathcal {X}\) defined by (2.6). For a line \(\ell = (x,v)\in \mathcal {X}\), define the line integral along \(\ell \) as the distribution

Lemma 3.8
For all \(\kappa \in (\frac{1}{2},1)\), there exists \(C>0\) such that for all \(t\in (0,1)\) and \(\ell \in \mathcal{X}\)
Proof
By translation and rotationFootnote 6 invariance, we can assume \(\ell =(0,r e_{1})\). Then for \(k = (k_{1},k_{2},k_{3}) \in {\mathbf {Z}}^{3}\) with \(k\neq 0\)

Therefore
If \(|k|\geq t^{-1}\), then \(e^{-2t|k|^{2}}\leq e^{-2|k|}\), which is summable so that these values of \(k\) make a contribution to the sum of order at most \(r^{2}\) which in turn is bounded by \(rt^{2\kappa -2}\) since \(r,t \le 1\). For the rest of the sum we simply bound the exponential by 1, so that is bounded above by
as required. Here the second inequality holds since when \(r\le t\), the sum of \(r^{2} \wedge k^{-2}\) over \(0< k< t^{-1}\) is bounded by \(r^{2} t^{-1}\le r\), and when \(r> t\), this sum is bounded by \(\sum _{0< k\le r^{-1}} r^{2} \) plus \(\sum _{r^{-1}< k< t^{-1}} k^{-2}\) which is bounded by \(r+(r-t)\lesssim r\). The first inequality follows by splitting the sum into the regime \(|k_{1}|\ge |k_{2}|+|k_{3}|\) where we first sum over \(k_{2},k_{3}\) and use \(|k_{1}|\asymp |k|\), and the regime \(|k_{1}|\le |k_{2}|+|k_{3}|\) where we first sum over \(k_{1}\) and use \(|k_{2}|+|k_{3}|\asymp |k|\). □
For a triangle \(P=(x,v,w)\), \(x\in \mathbf{T}^{3}\), \(v,w\in {\mathbf {R}}^{3}\) with \(|v|,|w|\leq \frac{1}{4}\), define the surface integral along \(P\) as the distribution

Lemma 3.9
For all \(\kappa >0\), \(t\in (0,1)\), and triangles \(P\)
where the first proportionality constant depends on \(\kappa \) and the second is universal.
Remark 3.10
The bound \(|e^{t\Delta}\delta _{P}|_{L^{2}}^{2} \lesssim |P|t^{-\frac{1}{2}}\) is likely optimal. On the other hand, the bound \(|e^{t\Delta}\delta _{P}|_{H^{\kappa}}^{2}\lesssim |P|t^{-\frac{1}{2}- \kappa}\) is likely suboptimal but suffices for our purposes.
Proof
The first bound follows from the heat flow estimate \(|e^{t\Delta}f|_{H^{\kappa}}^{2} \lesssim t^{-\kappa}|f|_{L^{2}}\), so it remains to show that \(|e^{t\Delta}\delta _{P}|_{L^{2}}^{2} \lesssim |P|t^{-1/2}\). Moreover, it suffices to consider right-angled triangles, in which case we can assume \(P=(0,re_{1},he_{2})\). Note that \(|e^{t\Delta}\delta _{P}|_{L^{2}} \leq |e^{t\Delta}\delta _{R}|_{L^{2}}\) where  is the surface integral along the rectangle with sides \(re_{1}\) and \(he_{2}\). Then for \(k \in {\mathbf {Z}}^{3}\)
is the surface integral along the rectangle with sides \(re_{1}\) and \(he_{2}\). Then for \(k \in {\mathbf {Z}}^{3}\)

and therefore
The sum over \(k_{1}\) splits into \(|k_{1}|\leq r^{-1}\) and \(|k_{1}|>r^{-1}\), each of which are of order at most \(r\), and likewise for \(k_{2}\), which shows that \(|e^{t\Delta}\delta _{R}|_{L^{2}}^{2}\lesssim rht^{-1/2} =2|P|t^{-1/2}\). □
Lemma 3.11
Suppose \(\Psi (0)=0\) and let \(T>0\). Then for all \(s\in [0,T]\), \(t\in (0,1)\), \(\kappa \in (0,\frac{1}{2})\), and \(\ell \in \mathcal {X}\)
and for all \(\kappa \in (0,1)\) and triangles \(P\)
where \(A(\partial P)\) denotes the line integral of \(A\in \Omega \mathcal{C}^{\infty}\) around the boundary of \(P\) under an arbitrary orientation (see [22, Def. 3.10]) and where the proportionality constants depend only on \(\kappa \) and \(T\).
Proof
Observe that, for any \(A\in \Omega \mathcal{C}^{\infty}\),  . Furthermore,
. Furthermore,

Hence, by (3.14),

Since \(|e^{(t+u)\Delta}\delta _{\ell}|_{L^{2}}^{2} \lesssim u^{\kappa -1} |e^{t \Delta}\delta _{\ell}|_{H^{\kappa -1}}^{2} \lesssim u^{\kappa -1}| \ell | t^{-2\kappa}\), where we used Lemma 3.8 in the final bound, we obtain

from which (3.15) follows. To show (3.16), we can suppose that \(P\) is in the \((x_{1},x_{2})\)-plane. Then, by Stokes’ theorem,

Furthermore,

and thus by (3.14), Lemma 3.9, and the bound \(|e^{u\Delta}\partial _{i}f|_{L^{2}}^{2} \lesssim u^{\kappa -1}|f|_{H^{ \kappa}}^{2}\),

The same applies to  , from which the conclusion follows. □
, from which the conclusion follows. □
Lemma 3.12
Let \(A\) be a \(\mathfrak {g}\)-valued stochastic process indexed by \(\mathcal{X}\) such that, for all joinable \(\ell ,\bar{\ell}\in \mathcal{X}\), \(A(\ell \sqcup \bar{\ell}) = A(\ell )+A(\bar{\ell})\) almost surely. Suppose that there exist \(r,s\in (0,1)\), \(p,M>0\), and \(\alpha \in (0,1]\) such that for all \(\ell \in \mathcal{X}\) with \(|\ell |< r\)
and for all triangles \(P\) with \(|P| < s\)
Then there exists a modification of \(A\) (which we denote by the same letter) which is a.s. a continuous function on \(\mathcal{X}\). Furthermore, for every \(\bar{\alpha}\in (0,\alpha -\frac{24}{p})\), there exists \(\lambda > 0\), depending only on \(p,\alpha ,\bar{\alpha}\), such that
Proof
For \(\ell =(x,v)\in \mathcal {X}\), let us denote \(\ell _{i}\stackrel {{\tiny \mathrm {def}}}{=}x\) and \(\ell _{f}\stackrel {{\tiny \mathrm {def}}}{=}x+v\), and define the metric \(d\) on \(\mathcal {X}\) by
Recall that \(\ell ,\bar{\ell}\in \mathcal {X}\) are called far if \(d(\ell ,\bar{\ell}) > \frac{1}{4} (|\ell | \wedge |\bar{\ell}|)\). For \((\ell ,\bar{\ell})\in \mathcal {X}^{2}\), let \(T(\ell ,\bar{\ell})= |P_{1}|+|P_{2}|\) where \(P_{1},P_{2}\) are the triangles \(P_{1} = (\ell _{i},\ell _{f},\bar{\ell}_{f})\) and \(P_{2}=(\ell _{i},\bar{\ell}_{f},\bar{\ell}_{i})\). Let \(\mbox{Area}(\ell _{i},\bar{\ell}_{i}) = T(\ell ,\bar{\ell})\wedge T( \bar{\ell},\ell )\). Similar to [22, Def. 3.3], we now define \(\varrho \colon \mathcal {X}^{2} \to [0,\infty )\) by
By the same argument as in [22, Remark 3.4], note that there exists \(C>0\) such that \(\varrho (a,b)\leq C(\varrho (a,c)+\varrho (c,b))\).
By definition, for any \(\ell ,\bar{\ell}\in \mathcal {X}\), there exist \(a,b\in \mathcal {X}\) and triangles \(P_{1},P_{2}\) such that \(A(\ell )-A(\bar{\ell})=A(\partial P_{1})+A(\partial P_{2}) + A(a) - A(b)\) and \(|P_{1}|+|P_{2}| \leq \varrho (\ell ,\bar{\ell})^{2}\) and \(|a|+|b|\leq \varrho (\ell ,\bar{\ell})\) (if \(\ell ,\bar{\ell}\) are far, then \(a=\ell \), \(b=\bar{\ell}\), and \(P_{1},P_{2}\) are empty; if \(\ell ,\bar{\ell}\) are not far, then \(a\) is the chord from \(\ell _{f}\) to \(\bar{\ell}_{f}\) and \(b\) is the chord from \(\bar{\ell}_{i}\) to \(\ell _{i}\)). It follows that for all \(\ell ,\bar{\ell}\in \mathcal {X}\) with \(\varrho (\ell ,\bar{\ell})<\sqrt {s} \wedge r\)
where the proportionality constant depends only on \(p,\alpha \).
Let \(\mathcal{X}_{< r}\) denote the set of line segments of length less than \(r\). For \(N \geq 1\) let \(D_{N;< r}\) denote the set of line segments in \(\mathcal {X}_{< r}\) whose start and end points have dyadic coordinates of scale \(2^{-N}\), and let \(D_{< r}=\cup _{N\geq 1} D_{N;< r}\). For any \(\ell \in D_{< r}\) and \(L \geq 1\), we can write \(A(\ell ) = A(\ell _{0}) + \sum _{i=1}^{m} A(\ell _{i})-A(\ell _{i-1})\) for some finite \(m \geq 1\) and where \(\ell _{i}\in D_{2(L+i);< Kr}\) and \(\varrho (\ell _{i},\ell _{i-1}) \leq K2^{-(L+i)}\) for a constant \(K>0\). Moreover, the first \(\ell _{i}\) which has non-zero length satisfies \(|\ell _{i}|\asymp |\ell |\). Taking \(L\) as the smallest positive integer such that \(2^{-L} < \sqrt {s} \wedge r\), it follows that, for any \(\bar{\alpha}\in (0,1]\),
where the proportionality constant depends only on \(\bar{\alpha}\). Observe that \(|D_{2N}| \asymp 2^{12N}\). Therefore, raising both sides of (3.18) to the power \(p\) and replacing the suprema on the right-hand side by sums, we obtain from (3.17)
where the proportionality constant depends only on \(p,\bar{\alpha}\). Since \(24-p(\alpha -\bar{\alpha})<0 \Leftrightarrow \bar{\alpha}\in (0, \alpha -\frac{24}{p})\), the conclusion follows as in the classical Kolmogorov criterion, see e.g. the proof of [63, Thm. 4.23]. □
Lemma 3.13
Suppose \(\Psi (0)=0\). Let \(\alpha \in (0,\frac{1}{2})\), \(\bar{\alpha}\in (0,\alpha -\frac{24}{p})\), \(\theta \in (0,1]\), and \(T>0\). Then for all \(p \geq p_{0}(\alpha ,\bar{\alpha},\theta )>0\) is sufficiently large,
where the proportionality constant depends only on \(\alpha ,\bar{\alpha},\theta ,p,T\).
Proof
Take \(\kappa \stackrel {{\tiny \mathrm {def}}}{=}\theta (\frac{1}{2}-\alpha )\in (0,\frac{1}{2})\). Then \(|\ell |t^{-2\kappa}\leq |\ell |^{2\alpha}\) whenever \(|\ell |< t^{\theta}< 1\) and \(|P|t^{-\frac{1}{2}-\kappa} \leq |P|^{\alpha}\) whenever \(|P|< t<1\), in which case Lemma 3.11 and equivalence of Gaussian moments imply
and
Applying Lemma 3.12 (with \(r,s\) therein equal to \(t^{\theta},t\) respectively) and taking \(p\) sufficiently large so that \(\sup _{t\in (0,1)}(t^{-6}+t^{-12\theta})t^{\theta p(\alpha - \bar{\alpha})}\leq 2\), we obtain for all \(\beta \in (0,\alpha -\frac{24}{p})\)
It is easy to see that for all \(A\in \Omega \mathcal{D}'\)
where the proportionality constant depends only on \(\bar{\alpha},\theta \). Combining (3.20), (3.19), and the fact that \(|A|_{\bar{\alpha}\mbox{-gr};< t^{\theta}} \leq t^{\theta (\beta -\bar{\alpha})}|A|_{ \beta \mbox{-gr};< t^{\theta}}\) for \(\beta \in [\bar{\alpha},1]\) (Lemma 2.24) we eventually obtain
as claimed. □
Proof of Proposition 3.7
Let \(0 \leq s \leq t \leq T\) and observe that
where \(\tilde{\Psi}\colon [0,s] \to \Omega \mathcal{D}'\) and \(\hat{\Psi}\colon [s,t] \to \Omega \mathcal{D}'\) solve the SHE driven by \(\xi \) with \(\tilde{\Psi}(0)=0\) and \(\hat{\Psi}(s)=0\). By Lemmas 2.55(ii) and 2.59, for any \(\gamma \in (0,1)\),
Likewise, by Lemmas 2.59 and 3.13, for any \(\zeta \in (\alpha +\frac{24}{p},\frac{1}{2})\) and \(\gamma \in (0,1)\),
Finally, by Lemma 3.13, for any \(\beta \in (\bar{\alpha}+\frac{24}{p},\frac{1}{2})\),
Taking \(\gamma \in (0,1)\), \(\beta \in (\bar{\alpha}+\frac{24}{p},\frac{1}{2})\), and denoting \(\bar{\kappa} \stackrel {{\tiny \mathrm {def}}}{=}\theta \min \{\gamma (\alpha -\bar{\alpha}), \frac{1-2\beta}{4}\}\), we obtain
We can choose \(p\) sufficiently large and \(\gamma \in (0,1)\) sufficiently close to 1 such that \(\kappa <\bar{\kappa}\) for some \(\beta \in (\bar{\alpha}+\frac{24}{p},\frac{1}{2})\), and the conclusion follows by Kolmogorov’s continuity theorem. □
3.3 Convergence of mollifications
We conclude this section with a corollary on the convergence of mollifications of the SHE in \(\mathcal{C}([0,T],\mathcal{S})\) (albeit with no quantitative statement).
Lemma 3.14
Let \(\eta <\bar{\eta},\bar{\delta}<\delta \), \(\beta \in {\mathbf {R}}\), \(0<\alpha <\bar{\alpha}\leq 1\), and \(\theta ,R>0\). Denote \(\bar{\Sigma} \stackrel {{\tiny \mathrm {def}}}{=}\Sigma _{\bar{\eta},\beta ,\bar{\delta},\bar{\alpha}, \theta}\) and define the set \(B_{R}\stackrel {{\tiny \mathrm {def}}}{=}\{Y\in \mathcal{S}\,:\, \bar{\Sigma}(Y)\leq R\}\). Then for every \(c>0\) there exists \(\bar{c}>0\) such that for all \(X,Y\in B_{R}\), \(|X-Y|_{\mathcal{C}^{\eta}}<\bar{c} \Rightarrow \Sigma (X,Y)<c\).
Proof
By Proposition 2.57(iii), \(B_{R}\) is compact in \(\mathcal{S}\). The metric \(\Sigma \) is stronger than \(|\cdot |_{\mathcal{C}^{\eta}}\) so the identity map \(\mathrm{id}\colon (B_{R},\Sigma )\to (B_{R},|\cdot |_{\mathcal{C}^{\eta}})\) is continuous. In particular, \(B_{R}\) is compact also in \(\mathcal{C}^{\eta}\). Recall that if \(\tau ,\sigma \) are Hausdorff topologies on a set \(A\) such that (i) \(\tau \) is stronger than \(\sigma \) and (ii) \((A,\tau )\) and \((A,\sigma )\) are both compact, then \(\tau =\sigma \). It follows that the identity map \(\mathrm{id}\colon (B_{R},|\cdot |_{\mathcal{C}^{\eta}})\to (B_{R},\Sigma )\) is also continuous and thus uniformly continuous by the Heine–Cantor theorem. □
Corollary 3.15
Let \(\xi \) be as in Sect. 3.1. Let \(\chi \) be a mollifier and \(\xi ^{\varepsilon }= \chi ^{\varepsilon }* \xi \). Suppose that \(\Psi ^{\varepsilon }\) (resp. \(\Psi \)) solves SHE driven by \(\xi ^{\varepsilon }\) (resp. \(\xi \)), with \(\Psi ^{\varepsilon }_{0}=\Psi _{0} \in \mathcal{S}\). Suppose (\(\mathcal {I}'\)) and let \(\theta \in (0,1]\), \(\alpha \in (0,\frac{1}{2})\), \(T>0\). Then \(\Psi ^{\varepsilon }\to \Psi \) in probability in \(\mathcal{C}([0,T],\mathcal{S})\) as \(\varepsilon \to 0\).
Proof
By Propositions 3.2 and 3.7, \(\Psi \) and \(\Psi ^{\varepsilon }\) a.s. take values in \(\mathcal{C}([0,T],\mathcal{S})\). Let \(\bar{\eta}\in (\eta ,-\frac{1}{2})\), \(\bar{\delta}\in (0,\delta )\), and \(\bar{\alpha}\in (\alpha ,\frac{1}{2})\) such that \((\bar{\eta},\beta ,\bar{\delta})\) satisfies (\(\mathcal {I}'\)), denote \(\bar{\Sigma} \stackrel {{\tiny \mathrm {def}}}{=}\Sigma _{\bar{\eta},\beta ,\bar{\delta},\bar{\alpha}, \theta}\). Then, for every \(c,R>0\), by Lemma 3.14, there exists \(\bar{c}>0\) such that
By (3.2), the first probability on the right-hand side can be made arbitrarily small, uniformly in \(\varepsilon \in (0,1)\), by taking \(r\) small. On the other hand, for any fixed \(r>0\), the final probability, by (3.1) and Proposition 3.7, converges to 0 uniformly in \(\varepsilon \in (0,1)\) as \(R\to \infty \), while the second probability converges to 0 as \(\varepsilon \to 0\), see e.g. [56, Prop. 9.5]. □
Remark 3.16
The main result of [17] is that the YM flow ℱ started from smooth approximations of the Gaussian free field (GFF) converges locally in time to a process which one can interpret as the flow started from the GFF. We recover essentially the same result from Proposition 2.9 and Corollary 3.15 once we start the SHE from the GFF, which is its invariant measure.
In fact, after showing that ℱ is a locally Lipschitz function on \(\mathcal{I}\supset \mathcal{S}\) in Proposition 2.9, the claim that ℱ is well-defined on the GFF reduces to showing that the latter takes values in ℐ, which is a Gaussian moment computation similar and simpler to that of Sect. 3.1.
A minor difference with the results of [17] is that therein convergence is shown in \(L^{p}\) while we only show convergence in probability; it would not be difficult to modify our arguments to show convergence in \(L^{p}\) but we refrain from doing so since it is not needed in the sequel.
4 Symmetry and renormalisation in regularity structures
In this section we formulate algebraic arguments which verify that the symmetries of a system of equations are preserved by the BPHZ renormalisation procedure.
For what follows we are in the setting of [22, Sect. 5]; we fix a collection of solution types \(\mathfrak {L}_{+}\), noise types \(\mathfrak {L}_{-}\), a target space assignment \(W = (W_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}}\) and a kernel space assignment \(\mathcal{K} = (\mathcal{K}_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}_{+}}\), with \(\mathfrak {L}=\mathfrak {L}_{+}\sqcup \mathfrak {L}_{-}\). We assume that all of these space assignments are finite-dimensional.
We then fix a corresponding space assignment \(V = (V_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}}\) as in [22, Eq. 5.25], that is
The symmetries that we study are simultaneous transformations of the target spaces where the solution and the noise take values in and transformations on the underlying (spatial) base space \(\Lambda \subset {\mathbf {R}}^{d}\). We assume that \(\Lambda \) is invariant under reflections across coordinate axes and permutations of canonical basis vectors –to keep our presentation simpler we will only consider transformations of the base space that are compositions of such reflections and permutations.
Definition 4.1
Let \(\mathrm{Tran}\) be the collection of quartets \(\mathbf{T} = (T,O,\sigma ,r)\) where
-
\(T = (T_{\mathfrak {b}})_{\mathfrak {b}\in \mathfrak{L}}\) with \(T_{\mathfrak {b}}\in L(W_{\mathfrak {b}},W_{\mathfrak {b}})\) invertible. \(T\) determines our transformation of the target spaces for the noise and solution.
-
\(O = (O_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}_{+}}\) with \(O_{\mathfrak {t}}\in L(\mathcal{K}_{\mathfrak {t}})\) invertible. The role of \(O\) is to specify transformations of our kernels.
-
\(\sigma \in S_{d}\) where \(S_{d}\) is the set of permutations of the set \([d]\), and \(r \in \{-1,1\}^{d}\). The role of \(\sigma \) and \(r\) is to determine our transformation of the base space –we also overload notation and, for \(\sigma \) and \(r\) as above, define \(\sigma ,r \in L({\mathbf {R}}^{d},{\mathbf {R}}^{d})\) by setting \((r x)_{i} = r_{i}x_{i}\) and \((\sigma x)_{i} = x_{\sigma ^{-1}(i)}\) for \(i=1\ldots d\). We have \(\sigma ,r\colon \mathbf{T}^{d} \rightarrow \mathbf{T}^{d}\) and also view them as maps on our space-time domain \({\mathbf {R}}_{+} \times \mathbf{T}^{d}\) by acting on the spatial coordinates only.
One should view an element \(\mathbf{T} = (T,O,\sigma ,r) \in \mathrm{Tran}\) as acting on solutions/noises \(A_{\mathfrak {t}}\) and kernels \(K_{\mathfrak {t}}\) by mapping
We endow \(\mathrm{Tran}\) with a group structure compatible with the above: given \(\mathbf{T} = (T,O,\sigma ,r)\) and \(\mathbf{T}' = (T',O',\sigma ',r')\) we set \(\mathbf{T} \mathbf{T}' = (T T',OO',\sigma \sigma ',\sigma r' \sigma ^{-1} r)\).
As above, we have a left group action of \(S_{d}\) on multi-indices \({\mathbf {N}}^{d+1}\) by setting \(\sigma (p_{0},\ldots ,p_{d}) = (p_{0},p_{\sigma ^{-1}(1)},\dots ,p_{ \sigma ^{-1}(d)})\), yielding an action on the set of edge types \(\mathcal{E}= \mathfrak{L}\times {\mathbf {N}}^{d+1}\). It also yields an action of \(S_{d}\) on \({\mathbf {N}}^{\mathcal{E}}\), viewed as multi-sets of elements of ℰ, given by applying \(\sigma \) to each element of any given multiset in \({\mathbf {N}}^{\mathcal{E}}\). We then fix a rule \(R\) that is \(S_{d}\)-invariant in the sense that, for any \(\sigma \in S_{d}\), \(\mathfrak {t}\in \mathfrak{L}\), and \(\mathcal{N}\in R(\mathfrak {t}) \subset {\mathbf {N}}^{\mathcal{E}}\), we have \(\sigma \mathcal{N}\in R(\mathfrak {t})\).
Recall that a rule \(R\) assigns a subset of \({\mathbf {N}}^{\mathcal{E}}\) to each \(\mathfrak {t}\in \mathfrak{L}\) and determines a set of conforming trees \(\mathfrak{T}\) and forests \(\mathfrak{F}\). Our trees have edge decorations \(e \mapsto (\mathfrak {t}(e),\mathfrak {n}(e)) \in \mathcal{E}\) and node decorations \(v \mapsto \mathfrak {n}(v) \in {\mathbf {N}}^{d+1}\), the latter also being referred to as “polynomial decorations”. Loosely speaking, such a decorated tree conforms to the rule \(R\) if, given any inner node, if \(\mathfrak {t}\in \mathfrak{L}\) is the type of the unique edge leaving \(v\), the multiset given by the decorations of the edges entering \(v\) belongs to \(R(\mathfrak {t})\). Combining this with a space-assignment \(V\) yields a regularity structure  which admits a decomposition into subspaces
which admits a decomposition into subspaces  indexed by trees \(\tau \in \mathfrak{T}\) (and an algebra
indexed by trees \(\tau \in \mathfrak{T}\) (and an algebra  decomposing into linear subspaces
decomposing into linear subspaces  indexed by \(f \in \mathfrak{F}\)). We refer to [10, Definition 5.8] and [22, Sect. 5.5] for more details.
indexed by \(f \in \mathfrak{F}\)). We refer to [10, Definition 5.8] and [22, Sect. 5.5] for more details.
In order to formulate our arguments we now define a right action  by specifying three transformations on
by specifying three transformations on  : one that encodes \(T\) and \(O\), one that encodes \(\sigma \), and one that encodes \(r\).
: one that encodes \(T\) and \(O\), one that encodes \(\sigma \), and one that encodes \(r\).
For encoding the transformation of the target space we use [22, Remark 5.19]. Given an “operator assignment”
that remark says that, for any \(\mathfrak{L}\)-typed symmetric set  , we can apply \(L\) “component-wise” to obtain a linear operator
, we can apply \(L\) “component-wise” to obtain a linear operator  . Since
. Since  decomposes as a direct sum of such spaces, this defines a linear operator
decomposes as a direct sum of such spaces, this defines a linear operator  .
.
Example 4.2
We present a simple example of the above construction. We work with \(\mathfrak{L}_{-} = \{\mathfrak {l}\}\), \(\mathfrak{L}_{+} = \{\mathfrak {t}\}\). Suppose we fix some linear transformation acting on the target space of our noise, that is some \(U \in L(W_{\mathfrak {l}},W_{\mathfrak {l}})\), and define an operator assignment \(L\) by \(L_{\mathfrak {t}} = \mathrm{id}\in L(V_{\mathfrak {t}},V_{\mathfrak {t}})\) and \(L_{\mathfrak {l}} = U^{\ast} \in L(V_{\mathfrak {l}},V_{\mathfrak {l}})\). Then, to demonstrate the corresponding linear transformation on our regularity structure, we look at the \(\mathfrak{L}\)-typed symmetric set  associated to the tree
associated to the tree  . We have
. We have  and, given \(u,v \in V_{\mathfrak {l}}\), we have
and, given \(u,v \in V_{\mathfrak {l}}\), we have  and
and

Given \(\mathbf{T} \in \mathrm{Tran}\), we define the operator assignment
We write  for the corresponding linear operator given by [22, Remark 5.19] which encodes the transformation of our target space on
for the corresponding linear operator given by [22, Remark 5.19] which encodes the transformation of our target space on  .
.
Remark 4.3
It is natural that the operators \((T_{\mathfrak {t}}: \mathfrak {t}\in \mathfrak{L}_{+})\) do not play a role in how we transform the regularity structure because the regularity structure is constructed to study the structure of the noise and does not depend on our choice of the spaces \((W_{\mathfrak {t}}: \mathfrak {t}\in \mathfrak{L}_{+})\). The role of the operators \((T_{\mathfrak {t}}: \mathfrak {t}\in \mathfrak{L}_{+})\) will be to act on the \(W_{\mathfrak {t}}\)-valued modelled distributions with \(\mathfrak {t}\in \mathfrak{L}_{+}\) that describe the solution.
Given \(r \in \{-1,1\}^{d}\) we define  by setting, for each \(f \in \mathfrak {F}\),
by setting, for each \(f \in \mathfrak {F}\),

where for any \(q = (q_{i})_{i=0}^{d} \in {\mathbf {N}}^{d+1}\) we write \(r^{q} =\prod _{i=1}^{d} r_{i}^{q_{i}}\) and \(n(f) \in {\mathbf {N}}^{d+1}\) is given by
Here \(E_{f}\) is the set of edges of \(f\), \(N_{f}\) is the set of nodes of \(f\), and \(\mathfrak {n}\) denotes the edge and polynomial decorations.
We define a left group action \((\sigma ,f) \mapsto \sigma f\) of \(S_{d}\) on \(\mathfrak {F}\) by setting \(\sigma f\) to be the forest obtained by performing the replacement \(\mathfrak {n}(a) \mapsto \sigma \mathfrak {n}(a)\) for any edge or node \(a \in E_{f} \sqcup N_{f}\). Note that, for any \(f \in \mathfrak {F}\), there is a canonical isomorphism  since the edges of \(\sigma ^{-1} f\) are in natural correspondence with those of \(f\). We write
since the edges of \(\sigma ^{-1} f\) are in natural correspondence with those of \(f\). We write  .
.
We then set  . Note that, as elements of
. Note that, as elements of  , \(I(\mathbf{T})^{\ast}\) commutes with \(r^{\ast}\) and with \(\sigma ^{\ast}\). We abuse notation and write
, \(I(\mathbf{T})^{\ast}\) commutes with \(r^{\ast}\) and with \(\sigma ^{\ast}\). We abuse notation and write  for the adjoints of the operators we just introduced.
for the adjoints of the operators we just introduced.
We also have a natural left action of \(\mathrm{Tran}\) on  given by setting, for \(\mathbf{T} = (T,O,\sigma ,r) \in \mathrm{Tran}\) and \(\mathbf{A} = (A_{(\mathfrak {b},p)})_{(\mathfrak {b},p) \in \mathcal{E}}\),
given by setting, for \(\mathbf{T} = (T,O,\sigma ,r) \in \mathrm{Tran}\) and \(\mathbf{A} = (A_{(\mathfrak {b},p)})_{(\mathfrak {b},p) \in \mathcal{E}}\),
We now define the various ways in which we impose that a given system should respect a given transformation.
Definition 4.4
Fix \(\mathbf{T} \in \mathrm{Tran}\), with \(\mathrm{Tran}\) defined as in Definition 4.1.
-
Given a nonlinearity \(F(\cdot ) = \bigoplus _{\mathfrak {t}\in \mathfrak{L}} F_{\mathfrak {t}}(\cdot )\) we say \(F\) is \(\mathbf{T}\)-covariant if, for every \(\mathfrak {l}\in \mathfrak{L}_{-}\), \(F_{\mathfrak {l}}(\cdot ) = \mathrm{id}_{W_{\mathfrak {l}}}\) and, for every \(\mathfrak {t}\in \mathfrak{L}_{+}\),
$$ (O_{\mathfrak {t}}^{\ast} \otimes T_{\mathfrak {t}}^{-1}) F_{\mathfrak {t}}(\mathbf{T} \mathbf{A}) = F_{\mathfrak {t}}(\mathbf{A}) \;. $$where on the left-hand side we are using the action (4.4).
-
Given a kernel assignment \(K = (K_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}_{+}}\) we say \(K\) is \(\mathbf{T}\)-invariant if for every \(\mathfrak {t}\in \mathfrak{L}_{+}\) and \(z \in {\mathbf {R}}\times \mathbf{T}^{d}\), \(O_{\mathfrak {t}} K_{\mathfrak {t}}(\sigma ^{-1} r z) = K_{\mathfrak {t}}(z)\).
-
Given a random noise assignment \(\zeta = (\zeta _{\mathfrak {l}})_{\mathfrak {l}\in \mathfrak{L}_{-}}\) we say \(\zeta \) is \(\mathbf{T}\)-invariant if the tuple of random fields \(\big( \zeta _{\mathfrak {l}}(\cdot ) \big)_{\mathfrak {l}\in \mathfrak{L}_{-}}\) and \(\big( T_{\mathfrak {l}} \zeta _{\mathfrak {l}}( \sigma ^{-1} r \cdot ) \big)_{\mathfrak {l}\in \mathfrak{L}_{-}}\) have the same probability law.
-
Given
 orFootnote 7
orFootnote 7 , we say that \(\ell \) is \(\mathbf{T}\)-invariant if \(\mathbf{T}\ell \stackrel {{\tiny \mathrm {def}}}{=}\ell \circ \mathbf{T}^{\ast} = \ell \).
, we say that \(\ell \) is \(\mathbf{T}\)-invariant if \(\mathbf{T}\ell \stackrel {{\tiny \mathrm {def}}}{=}\ell \circ \mathbf{T}^{\ast} = \ell \).
 or
or , we say that
, we say that We then have the following lemma, where the canonical lift is defined as in [10, Sect. 6.3], and the corresponding BPHZ character is defined as in [10, Thm 6.18] (see also [22, Sect. 5.7.2]).
Lemma 4.5
Fix \(\mathbf{T} \in \mathrm{Tran}\). Suppose we are given a kernel assignment \(K\) and a smooth, random noise assignment \(\zeta \) which are both \(\mathbf{T}\)-invariant. Let  be the corresponding canonical lift and
be the corresponding canonical lift and  its BPHZ character. Then both \(\bar{\boldsymbol{\Pi}}_{\mbox{\scriptsize can}}\) and
its BPHZ character. Then both \(\bar{\boldsymbol{\Pi}}_{\mbox{\scriptsize can}}\) and  are \(\mathbf{T}\)-invariant.
are \(\mathbf{T}\)-invariant.
Proof
To show that \(\bar{\boldsymbol{\Pi}}_{\mbox{\scriptsize can}}\) is invariant it suffices to show that, for any \(\tau \in \mathfrak {T}\), one has \((\mathbf{T} \bar{\boldsymbol{\Pi}}_{\mbox{\scriptsize can}})[\tau ] = \bar{\boldsymbol{\Pi}}_{\mbox{\scriptsize can}}[\sigma ^{-1} \tau ] \circ \mathbf{T}^{\ast}[\tau ] = \bar{\boldsymbol{\Pi}}_{\mbox{\scriptsize can}}[\tau ]\) –this is because both \(\mathbf{T}\) and \(\bar{\boldsymbol{\Pi}}_{\mbox{\scriptsize can}}\) “factorise” over forests appropriately.
Using the same notation convention as used in [22, Eq. 5.31], one has that \(\bar{\boldsymbol{\Pi}}_{\mbox{\scriptsize can}}[\sigma ^{-1} \tau ] \circ \mathbf{T}[\tau ]\) is given by
By cancelling powers of \(r\), using the \(\mathbf{T}\)-invariance of \(K\) and \(\zeta \) we see that the last line is precisely \(\bar{\boldsymbol{\Pi}}_{\mbox{\scriptsize can}}[\tau ]\).
To prove the statement regarding  we observe that
we observe that  where
where  is the negative twisted antipode defined in [10, Eq. 6.8]. From the definition of \(\Delta ^{-}\) as in [22, Sect. 5.5], it is straightforward to verify recursively that \((\mathbf{T}^{\ast} \otimes \mathbf{T}^{\ast}) \Delta ^{-} = \Delta ^{-} \mathbf{T}^{\ast}\) and, combining this with the inductive definition of
is the negative twisted antipode defined in [10, Eq. 6.8]. From the definition of \(\Delta ^{-}\) as in [22, Sect. 5.5], it is straightforward to verify recursively that \((\mathbf{T}^{\ast} \otimes \mathbf{T}^{\ast}) \Delta ^{-} = \Delta ^{-} \mathbf{T}^{\ast}\) and, combining this with the inductive definition of  , it follows that
, it follows that  , so that
, so that

concluding the proof. □
Note that, for the linear operator  (see [22, Sect. 5.8.2] for its definition) we have, for any \(\mathbf{T} \in \mathrm{Tran}\), the identity
(see [22, Sect. 5.8.2] for its definition) we have, for any \(\mathbf{T} \in \mathrm{Tran}\), the identity

Lemma 4.7 below shows how covariance of our nonlinearity propagates through coherence. We refer to [22, Sect. 5.8.2] for the notion of coherence, as well as the definitions of the maps \(\boldsymbol{\Upsilon}\) and \(\bar{\boldsymbol{\Upsilon}}\) which basically describe the coefficient in front of \(\tau \) in the expansion of the solution as a modelled distribution. (See also [11, Sect. 2] where the notion of coherence and the maps \(\boldsymbol{\Upsilon}\) and \(\bar{\boldsymbol{\Upsilon}}\) are discussed in more details.) For our purposes it suffices to recall that these maps \(\boldsymbol{\Upsilon}\) and \(\bar{\boldsymbol{\Upsilon}}\) satisfy the following inductive property: if \(\tau \) is of the form

where \(m \geq 0\), \(\tau _{i} \in \mathfrak {T}\), and \(o_{i} \in \mathcal{E}\), thenFootnote 8

where
and \(S(\tau )\) is defined as in [22, Eq. 5.56]. More explicitly, if, for each \(i \in [m]\), we define \(\beta _{i} \in {\mathbf {N}}\) to be the multiplicity of  in \(\beta _{i} \in {\mathbf {N}}\) in (4.7), then
in \(\beta _{i} \in {\mathbf {N}}\) in (4.7), then
Remark 4.6
In what follows we will often suppress tensor products with an identity operator from our notation. For instance, given a tensor product of vector spaces \(H \otimes H'\) a third vector space \(\tilde{H}\), and operators on \(H \otimes H'\) of the form \((L \otimes \mathrm{id}_{H'})\) for \(L \in L(H, \tilde{H})\) or \((\mathrm{id}_{H} \otimes Q)\) for \(Q \in L(H',\tilde{H})\), we will often write, for \(v \in H \otimes H'\), \(Lv \in \tilde{H} \otimes H'\) or \(Q v \in H \otimes \tilde{H}\) where \(L\) and \(Q\) are only acting on the appropriate factor of the tensor product.
Lemma 4.7
Let \(\mathbf{T} \in \mathrm{Tran}\) and suppose that \(F\) is a \(\mathbf{T}\)-covariant nonlinearity. Then we have, for any \(\mathfrak {t}\in \mathfrak{L}\),

Proof
We will prove that, for every \(\tau \in \mathfrak {T}\), \(\mathfrak {t}\in \mathfrak{L}\), and \(q \in {\mathbf {N}}^{d+1}\), we have the identities

where we set \(T_{(\mathfrak {t},q)} = r^{q}T_{\mathfrak {t}}\). The desired claim then follows after summing over \(\tau \in \mathfrak {T}\).
We will prove the identities (4.10) by induction in \(|E_{\tau}| + \sum _{u \in N_{\tau}} |\mathfrak {n}(\tau )| \). We start by proving the first identity of (4.10) when \(\tau = \mathbf{1}\) and \(\mathfrak {t}= \mathfrak {l}\in \mathfrak{L}_{-}\). Fix some basis \((e_{i})_{i \in I}\) of \(W_{\mathfrak {l}}\), we then have

On the other hand, we have
When \(\tau = \mathbf{1}\) and \(\mathfrak {t}\in \mathfrak{L}_{+}\) we have
where, in the second equality above, we used the \(\mathbf{T}\)-covariance of \(F\). Note that in both computations above we are using the fact that \(\mathbf{T}^{\ast}[\mathbf{1}] = \mathrm{id}_{{\mathbf {R}}}\).
From (4.8), we immediately see that, for fixed \(\mathfrak {t}\in \mathfrak{L}\) and \(\tau \in \mathfrak {T}\), the second identity of (4.10) follows from the first and (4.6).
To finish our proof we just need to prove the inductive step for the first identity of (4.10) –for this we may assume that \(\mathfrak {t}\in \mathfrak{L}_{+}\). We then write, using (4.8),
Here the subscript \([ \cdot ]_{\mathbf{A}}\) indicates where the derivative is being evaluated. In the second equality of (4.11) we used that the operator \(\mathbf{T}^{\ast}\) is appropriately multiplicative and in the third equality we used our inductive hypothesis.
Using the \(\mathbf{T}\)-covariance of \(F\) we have \(I(\mathbf{T})^{\ast}_{\mathfrak {t}} \bar{\boldsymbol{\Upsilon}}_{\mathfrak {t}}[\mathbf{1}]( \mathbf{A}) = T_{\mathfrak {t}}\bar{\boldsymbol{\Upsilon}}_{\mathfrak {t}}[\mathbf{1}](\mathbf{T}^{-1} \mathbf{A})\). From this it follows that
Inserting (4.12) into the last line of (4.11) gives
and we are done since \(S(\tau ) = S(\sigma ^{-1} \tau )\). □
Let  be the collection of algebra homomorphisms \(\ell \) from
be the collection of algebra homomorphisms \(\ell \) from  to \({\mathbf {R}}\) that satisfy \(\ell [\tau ] = 0\) for any \(\tau \in \mathfrak {T}\setminus \mathfrak {T}_{-}\).Footnote 9 Recall that ℜ can be identified with the renormalisation group via an action
to \({\mathbf {R}}\) that satisfy \(\ell [\tau ] = 0\) for any \(\tau \in \mathfrak {T}\setminus \mathfrak {T}_{-}\).Footnote 9 Recall that ℜ can be identified with the renormalisation group via an action  and that [22, Prop. 5.68] describes an action of the renormalisation group on nonlinearities, which we write \(F \mapsto M_{\ell}F\).
and that [22, Prop. 5.68] describes an action of the renormalisation group on nonlinearities, which we write \(F \mapsto M_{\ell}F\).
We can then state the following proposition.
Proposition 4.8
Let \(\mathbf{T} \in \mathrm{Tran}\), let \(F\) be a \(\mathbf{T}\)-covariant nonlinearity, and let \(\ell \in \mathfrak{R}\) be \(\mathbf{T}\)-invariant. Then, for every \(\mathfrak {t}\in \mathfrak{L}_{+}\),
In particular, \(M_{\ell}F\) is \(\mathbf{T}\)-covariant.
Proof
Since \(F\) is already \(\mathbf{T}\)-covariant we see that the second statement follows from the first. Now observe that
where in the first equality we used Lemma 4.7 and the last equality we used the \(\mathbf{T}\)-invariance of \(\ell \). □
5 The stochastic Yang–Mills–Higgs equation
In this section we study the system (1.14) and prove Theorem 1.7. We will first formulate (1.14) in terms of the blackbox theory of [10, 11, 21] and vectorial regularity structures of [22], but in order to obtain our desired result we will need to handle the three issues described in Remark 1.8.
Throughout the rest of the paper, let us fix \(\eta \in (-\frac{2}{3},-\frac{1}{2})\), \(\delta \in (\frac{3}{4},1)\), \(\beta \in (-\frac{1}{2},-2(1-\delta ))\), \(\theta \in (0,1]\), and \(\alpha \in (0,\frac{1}{2})\) such that
and such that the conditions of Theorem 2.39 hold. Note that such a choice of parameters is always possible –we first choose \(\alpha ,\theta \), then choose \(\eta \) sufficiently close to \(-\frac{1}{2}\) such that \(2\theta (\alpha -1)<\eta +\frac{1}{2}\), then choose \(\delta \) sufficiently close to 1 such that \(\hat{\eta}<\eta +\frac{1}{2}\), and finally choose \(\beta \) such that \(\hat{\beta}\) satisfies (5.1)–(5.3). We also remark that the tuple \((\varrho ,\eta ,\beta ,\delta ,\alpha ,\theta )\in {\mathbf {R}}^{6}\) satisfies conditions (ℐ), (\(\mathcal {I}'\)) and (\(\mathcal {G}\mathcal {S}\)) for some \(\varrho \in (\frac{1}{2},1)\). We use these parameters to define the metric space \((\mathcal{S},\Sigma )\equiv (\mathcal{S}_{\eta ,\beta ,\delta ,\alpha , \theta},\Sigma _{\eta ,\beta ,\delta ,\alpha ,\theta})\) as in Definition 2.22.
We rewrite (1.14) as
Here we introduced constants \(\boldsymbol{\sigma}^{\varepsilon }\in {\mathbf {R}}\) which will be useful in Sect. 6.
Theorem 5.1
Fix any space-time mollifier \(\chi \). Then there exist

with  and
and  such that the following statements hold.
such that the following statements hold.
-
(i)
For any \((\mathring{C}_{\mbox{A}},\boldsymbol{\sigma}) \in L_{G}(\mathfrak {g},\mathfrak {g}) \times {\mathbf {R}}\) and any sequence \((\mathring{C}_{\mbox{A}}^{\varepsilon },\boldsymbol{\sigma}^{\varepsilon }) \rightarrow (\mathring{C}_{ \mbox{A}},\boldsymbol{\sigma})\) as \(\varepsilon \downarrow 0\), the solutions \(X\) to the system (5.4) where
 (5.5)
(5.5)converge in \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\) in probability as \(\varepsilon \to 0\).
-
(ii)
The limit of the solutions depends on the sequence \((\mathring{C}^{\varepsilon }_{\mbox{A}},\boldsymbol{\sigma}^{\varepsilon })\) only through its limit \((\mathring{C}_{\mbox{A}},\boldsymbol{\sigma})\).

Remark that Theorem 1.7 clearly follows from Theorem 5.1. The rest of this section is devoted to the proof of Theorem 5.1, which we give in Sect. 5.3. To set up the regularity structure, we represent the Yang–Mills–Higgs field \(X\) by a single type denoted as \(\mathfrak {z}\), and we set \(W_{\mathfrak {z}} =E\). The noise \(\xi \) is represented by a type \(\bar{\mathfrak {l}}\) and accordingly we set \(W_{\bar{\mathfrak {l}}} = E\). Our set of types is then specified as \(\mathfrak {L}=\mathfrak {L}_{+}\cup \mathfrak {L}_{-}\) with \(\mathfrak {L}_{+} = \{\mathfrak {z}\}\) and \(\mathfrak {L}_{-} = \{\bar{\mathfrak {l}}\}\). We write \(\mathcal{E}=\mathfrak{L}\times {\mathbf {N}}^{3+1}\), and \((e_{i})_{i=0}^{3}\) for the generators of \({\mathbf {N}}^{3+1}\).
Let \(\kappa \in (0,1/100]\).Footnote 10 The associated degrees are defined as \(\deg ( \mathfrak {z}) = 2 - \kappa \) and \(\deg (\bar{\mathfrak {l}}) =-5/2 - \kappa \), and the map \(\mathrm{reg}: \mathfrak{L}\rightarrow {\mathbf {R}}\) verifying the subcriticality of our system is given by \(\mathrm{reg}(\mathfrak {z}) = -1/2 - 4\kappa \) and \(\mathrm{reg}(\bar{\mathfrak {l}}) =-5/2 - 2\kappa \).
We also set our kernel space assignment by setting \(\mathcal{K}_{\mathfrak {z}} = {\mathbf {R}}\) and we define a corresponding space assignment \((V_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak {L}}\) according to (4.1) –this space assignment is then used for the construction of our concrete regularity structure via the functor \(\mathbf{F}_{V}\) as in [22, Sect. 5].
Remark 5.2
Here we have taken a smaller set of types, namely, if we followed the setting as in [22, Sect. 6] we would have to associate a type to each component of the connection and the Higgs field, and each component of the noises, and the target space \(W\) would be either \(\mathfrak {g}\) or \(\mathbf{V}\) depending on the specific component.
The form of (1.9) motivates us to consider the rule \(\mathring{R}\) given by  and
and
Here for any \(\mathfrak {t}\in \mathfrak{L}\) we write \(\mathfrak {t}= (\mathfrak {t},0)\) and \(\partial _{j} \mathfrak {t}= (\mathfrak {t},e_{j})\) as shorthand for edge types. We also write products to represent multisets, for instance \(\mathfrak {z}\partial _{j} \mathfrak {z}= \{ (\mathfrak {z},0), (\mathfrak {z},e_{j})\}\). It is straightforward to verify that \(\mathring{R}\) is subcritical, and has a smallest normal extension which admits a completion \(R\) in the sense of [10, Sect. 5] that is also subcritical and will be used to define our regularity structure.
We also obtain a corresponding set of trees \(\mathfrak {T}=\mathfrak {T}(R)\) conforming to \(R\). As in [22, Sect. 7], we write  , and write
, and write  for the corresponding \(E\)-valued modelled distribution. Recall that \(\boldsymbol{\Xi}= \mathrm{id}\), the identity map under the canonical identifications
for the corresponding \(E\)-valued modelled distribution. Recall that \(\boldsymbol{\Xi}= \mathrm{id}\), the identity map under the canonical identifications  . For this section and the rest of the paper, we will adopt the usual graphical notation (e.g. [22]) for trees: circles
. For this section and the rest of the paper, we will adopt the usual graphical notation (e.g. [22]) for trees: circles  for noises, thin and thick lines for
for noises, thin and thick lines for  and
and  for some \(j\in [3]\); see Sect. 5.1 for examples. We will also sometimes write
for some \(j\in [3]\); see Sect. 5.1 for examples. We will also sometimes write  for
for  .
.
For the kernel assignment, we set \(K_{\mathfrak {z}} = K\) where we fix \(K\) to be a truncation of the Green’s function \(G(z)\) of the heat operator as in [22, Sect. 6.2]. In particular we choose \(K\) so that it satisfies all the symmetries of the heat kernel so that, with the notation in Sect. 4, for any \(\sigma \in S_{3}\), \(r \in \{-1,1\}^{3}\) and \(z \in {\mathbf {R}}\times \mathbf{T}^{d}\), one has \(K_{\mathfrak {t}}(\sigma ^{-1} r z) = K_{\mathfrak {t}}(z)\). We also fix a random smooth noise assignment \(\xi _{\bar{\mathfrak {l}}} =\boldsymbol{\sigma}^{\varepsilon } \xi ^{\varepsilon } =\boldsymbol{\sigma}^{\varepsilon } \xi \ast \chi ^{\varepsilon }\).
Remark 5.3
Within the rest of this section, to lighten our notation, we will simply assume that \(\mathring{C}^{\varepsilon }_{\mbox{A}} =\mathring{C}_{\mbox{A}}\) and \(\boldsymbol{\sigma}^{\varepsilon } =\boldsymbol{\sigma}\) (except for the very end of the proof of Theorem 5.1). This will not affect any of the arguments in this section.
Following the notation in [22, Sect. 7], for  we write its components in the following way:
we write its components in the following way:

and  . We then define the nonlinearity as
. We then define the nonlinearity as  and, in the notation of (1.15),
and, in the notation of (1.15),

where \(\mathring{C}_{\mathfrak {z}} \stackrel {{\tiny \mathrm {def}}}{=}\mathring{C}_{\mbox{A}}^{\oplus 3} \oplus (-m^{2})\).
Remark 5.4
Here and below, we always use purple colour (see the colour version online) to identify elements  and their components.
and their components.
5.1 Mass renormalisation
Recall that \(\mathfrak{T}_{-}=\mathfrak{T}_{-}(R)\) is the set of all unplanted trees in \(\mathfrak{T}\) with vanishing polynomial label at the root and negative degree. Define the subset

where \(n(\tau ) = (n_{0}(\tau ),\dots , n_{3}(\tau )) \in {\mathbf {N}}^{3+1}\) is defined in (4.3), \(E_{\tau}\) denotes the set of edges of \(\tau \), and we write \(\mathfrak {t}:E_{\tau} \rightarrow \mathfrak{L}\) for the map that labels edges with their types.
Recall from [22, Prop. 5.68] that to find the renormalised equation, we aim to compute the counterterms

Thanks to Lemma 5.5 below, only trees in  will actually contribute to (5.10).
will actually contribute to (5.10).
Lemma 5.5
Let \(\tau \in \mathfrak {T}\), then  .
.
Proof
We first note that by convention  for \(\tau \in \mathfrak {T}\setminus \mathfrak {T}_{-}\).
for \(\tau \in \mathfrak {T}\setminus \mathfrak {T}_{-}\).
Now, if we define \(\mathbf{T} = (T,O,\sigma ,r)\in \mathrm{Tran}\) by setting \(T\), \(O\), and \(\sigma \) to be identity operators and \(r = (-1,-1,-1)\) then we have that \(\xi ^{\varepsilon }\) and \(K\) are both \(\mathbf{T}\)-invariant, so we have  by Lemma 4.5. On the other hand
by Lemma 4.5. On the other hand  . Therefore, if \(\sum _{i=1}^{3}n_{i}(\tau )\) is not even, we must have
. Therefore, if \(\sum _{i=1}^{3}n_{i}(\tau )\) is not even, we must have  .
.
The second constraint defining  can be argued similarly by setting \(T_{\bar{\mathfrak {l}}} = - \mathrm{id}_{W_{\bar{\mathfrak {l}}}}\) and then \(T_{\mathfrak {z}}\), \(S\), \(\sigma \), and \(r\) to be identity operators. □
can be argued similarly by setting \(T_{\bar{\mathfrak {l}}} = - \mathrm{id}_{W_{\bar{\mathfrak {l}}}}\) and then \(T_{\mathfrak {z}}\), \(S\), \(\sigma \), and \(r\) to be identity operators. □
Remark 5.6
Note that, since \(d=3\), the term \(\mathring{C}_{\mathfrak {z}} X\) leads to trees of the form  with degree \(-\kappa \). However, by Lemma 5.5, the BPHZ character vanishes on each of these trees since it has an odd number of derivatives. This is important because it is convenient for the constants
with degree \(-\kappa \). However, by Lemma 5.5, the BPHZ character vanishes on each of these trees since it has an odd number of derivatives. This is important because it is convenient for the constants  and
and  appearing below to be independent of the constant \(\mathring{C}_{\mathfrak {z}}\).
appearing below to be independent of the constant \(\mathring{C}_{\mathfrak {z}}\).
One of our key results for this section is the following proposition.
Proposition 5.7
Suppose  . Then, for any
. Then, for any  , there exists \(C_{v,\tau} \in L(W_{\mathfrak {z}},W_{\mathfrak {z}})\) such that
, there exists \(C_{v,\tau} \in L(W_{\mathfrak {z}},W_{\mathfrak {z}})\) such that

Furthermore, there exist  and
and  such that
such that

where  , and the linear maps
, and the linear maps  ,
,  have the forms
have the forms

where for \(j\in \{1,2\}\), the maps  and
and  are independent of \(\boldsymbol{\sigma}\).
are independent of \(\boldsymbol{\sigma}\).
Proof
The first statement, that the left-hand side is a linear function of  , is shown in Lemma 5.12. The second statement is proven in Lemma 5.13. □
, is shown in Lemma 5.12. The second statement is proven in Lemma 5.13. □
Before going into the proof of Proposition 5.7, we give an explicit calculation of (5.10) at the “leading order”. This will not be used elsewhere but demonstrates how the “basis-free” framework developed in [22, Sect. 5] applies to an SPDE where the nonlinearities are given by three intrinsic operations: the Lie brackets, the bilinear form \(\mathbf{B}\), and the natural action of \(\mathfrak {g}\) on \(\mathbf{V}\).
Until the start of Sect. 5.1.1, consider \(d=2,3\). As in [22, Eq. (6.7)],  consists of all the “leading order” trees, i.e. trees of degree \(-1-2\kappa \) for \(d=3\) (resp. \(-2 \kappa \) for \(d=2\)) that contribute to (5.10). Denoting \((t_{i})\) (resp. \((v_{\mu})\)) an orthonormal basis of \(\mathfrak {g}\) (resp. \(\mathbf{V}\)), our claim is that, at the leading order, the renormalisation is given by the following natural \(G\)-invariant linear operators:
consists of all the “leading order” trees, i.e. trees of degree \(-1-2\kappa \) for \(d=3\) (resp. \(-2 \kappa \) for \(d=2\)) that contribute to (5.10). Denoting \((t_{i})\) (resp. \((v_{\mu})\)) an orthonormal basis of \(\mathfrak {g}\) (resp. \(\mathbf{V}\)), our claim is that, at the leading order, the renormalisation is given by the following natural \(G\)-invariant linear operators:
with Einstein’s convention of summation.
Remark 5.8
The first map is indeed \(\mathrm {ad}_{\mathord{\mathrm{Cas}}}\) with \(\mathord{\mathrm{Cas}}=t_{i}\otimes t_{i} \in \mathfrak {g}\otimes _{s}\mathfrak {g}\) the Casimir element, see [22, Remark 6.8]. For the last map we note that by (1.5) and the fact that the representation is orthogonal,

We remark that \(\mathrm {ad}_{\mathord{\mathrm{Cas}}}\) is a multiple of \(\mathrm{id}_{\mathfrak {g}}\) when \(\mathfrak {g}\) is simple, and \(\boldsymbol{\varrho }(\mathord{\mathrm{Cas}})\) is a multiple of \(\mathrm{id}_{\mathbf{V}}\) when the representation is irreducible (see [60, Prop. 10.6] for a formula of this multiple). For the map \({\mathbf{C}}_{\mathord{\mathrm{Cas}}}\), one has

which is just the contraction of \(\mathord{\mathrm{Cas}}\) with \(A\in \mathfrak {g}\) using the Hilbert–Schmidt inner product on \(\mathrm {End}(\mathbf{V})\). It is easy to check their \(G\)-invariance.
Following the notation of [22, Sect. 6], but with dimension \(d\) and the Higgs field \(\Phi \), one hasFootnote 11

where \(\mathbf{Cov}\) is as in (1.10) and
Here, the index \(j \in [d]\) is fixed (no summation) and \(\hat{C}^{\varepsilon }\) is clearly independent of it.
Lemma 5.9
We have  where
where
Proof (Sketch)
By straightforward calculation one hasFootnote 12

Adding all these identities we obtain the claimed map \(\mathcal {L}_{\mbox{\tiny lead}}\). □
Remark 5.10
\(\bar{C}^{\varepsilon } -2d\hat{C}^{\varepsilon }\) converges to a finite value as \(\varepsilon \to 0\), which essentially follows from [22, Proof of Lemma 6.9]. So when \(d=3\), both the coefficients of \(\mathrm {ad}_{\mathord{\mathrm{Cas}}} \) and \({\mathbf{C}}_{\mathord{\mathrm{Cas}}}\) are divergent (at rate \(O(\varepsilon ^{-1})\)). Interestingly, if \(d=2\), the coefficients of \(\mathrm {ad}_{\mathord{\mathrm{Cas}}} \) and \({\mathbf{C}}_{\mathord{\mathrm{Cas}}}\) both converge to finite limits (which was shown in the case without Higgs field in [22, Sect. 6]). With this remark and Lemma 5.9 one should be able to extend the main results of [22] to the Yang–Mills–Higgs case in 2D by following the arguments therein.
Note that there are a large number of trees in  besides the ones in Lemma 5.9, for instance
besides the ones in Lemma 5.9, for instance

Below we develop more systematic arguments to find their contribution to the renormalised equation.
5.1.1 Linearity of renormalisation
We prove the first statement of Proposition 5.7, namely we only have linear renormalisation. Note that for each \(\tau \in \mathfrak {T}_{-}(R)\),  is polynomial in
is polynomial in  (namely, in
(namely, in  and its derivatives). Obviously it suffices to show that each term of the polynomial is linear in
and its derivatives). Obviously it suffices to show that each term of the polynomial is linear in  . Fixing such a term, we write \(p_{X}\) and \(p_{\partial }\) for the total powers of
. Fixing such a term, we write \(p_{X}\) and \(p_{\partial }\) for the total powers of  and derivatives respectively in this monomial, for instance for
and derivatives respectively in this monomial, for instance for  we have \(p_{X}=2\) and \(p_{\partial }=1\).
we have \(p_{X}=2\) and \(p_{\partial }=1\).
It turns out to be convenient to introduce a formal parameter \(\lambda \) and to write the nonlinear terms of our SPDEFootnote 13 as \(\lambda X\partial X + \lambda ^{2} X^{3}\). Since \(\bar{\boldsymbol{\Upsilon}}_{\mathfrak {z}}[\tau ]\) is generated by iterative substitutions with these nonlinear terms, each term of \(\bar{\boldsymbol{\Upsilon}}_{\mathfrak {z}}[\tau ]\) comes with a coefficient \(\lambda ^{n_{\lambda}}\) for some positive integer \(n_{\lambda}\). For instance  is associated with \(n_{\lambda}=4\).
is associated with \(n_{\lambda}=4\).
For a fixed tree \(\tau \) we also write \(k_{\xi }= |\{ e \in E_{\tau}: \mathfrak {t}(e) = \bar{\mathfrak {l}} \}|\) for the total number of noises and \(k_{\partial }= \sum _{i=1}^{3} |n_{i}(\tau )| \) for the total number of derivatives plus the total powers of \(\mathbf{X}\). (Recall (4.3) for relevant notation.) For instance for the tree  we have \(k_{\xi}=4\) and \(k_{\partial }=2\).
we have \(k_{\xi}=4\) and \(k_{\partial }=2\).
Lemma 5.11
Let \(\tau \in \mathfrak {T}_{-}(R)\). For each term of \(\bar{\boldsymbol{\Upsilon}}_{\mathfrak {z}}[\tau ]\) which is associated with numbers \((n_{\lambda}, k_{\partial }, k_{\xi},p_{X}, p_{\partial })\) as above, we have
Proof
For  where \(o_{i} \in \mathcal{E}\), recall our recursive definition
where \(o_{i} \in \mathcal{E}\), recall our recursive definition
where  . Since our SPDE has additive noise, we only need to consider the case \(o_{i} \in \mathfrak{L}_{+} \times {\mathbf {N}}^{d+1}\) for all \(i\in [m]\). By linearity it suffices to prove the lemma assuming that \(\bar{\boldsymbol{\Upsilon}}_{\mathfrak {z}} [\tau ] \) is monomial. Also note that it suffices to show the case \(q=0\), since increasing \(|q|\) by 1 amounts to increasing each of \(p_{\partial }, k_{\partial },\deg (\tau ) \) by 1, which preserves (5.12a)–(5.12c).
. Since our SPDE has additive noise, we only need to consider the case \(o_{i} \in \mathfrak{L}_{+} \times {\mathbf {N}}^{d+1}\) for all \(i\in [m]\). By linearity it suffices to prove the lemma assuming that \(\bar{\boldsymbol{\Upsilon}}_{\mathfrak {z}} [\tau ] \) is monomial. Also note that it suffices to show the case \(q=0\), since increasing \(|q|\) by 1 amounts to increasing each of \(p_{\partial }, k_{\partial },\deg (\tau ) \) by 1, which preserves (5.12a)–(5.12c).
We prove the lemma by induction. The base case of the induction is \(\tau = \Xi = \mathcal{I}_{\bar{\mathfrak {l}}} [\mathbf{1}]\) which has \(\deg (\tau ) = -5/2-\kappa \), and its associated five numbers \((n_{\lambda}, k_{\partial }, k_{\xi},p_{X}, p_{\partial }) = (0,0,1,0,0)\) obviously satisfy the three identities.Footnote 14
For each \(1\le i\le m\) denote by \((n_{\lambda}^{(i)}, k_{\partial }^{(i)}, k_{\xi}^{(i)} ,p_{X}^{(i)}, p_{\partial }^{(i)})\) the numbers associated to each \(\bar{\boldsymbol{\Upsilon}}_{o_{i}}[\tau _{i}]\), and our induction assumption is that they all satisfy (5.12a)–(5.12c). Denote by \((n_{\lambda}^{(0)}, k_{\partial }^{(0)}, k_{\xi}^{(0)} ,p_{X}^{(0)}, p_{\partial }^{(0)})\) the numbers associated to either the term  or the term
or the term  , which are \((1,0,0,2,1)\) and \((2,0,0,3,0)\) respectively. It is easy to check that these satisfy (5.12a)–(5.12c) since \(\deg (\mathbf {1})=0\).
, which are \((1,0,0,2,1)\) and \((2,0,0,3,0)\) respectively. It is easy to check that these satisfy (5.12a)–(5.12c) since \(\deg (\mathbf {1})=0\).
From the recursion (5.13) we observe that
and \(p_{\partial } + k_{\partial } = \sum _{i=0}^{m} (p_{\partial }^{(i)} + k_{\partial }^{(i)})\). Using these relations together with our induction assumption, one easily checks that (5.12a) and (5.12b) hold for \(\tau \).
Finally, observe that if the factor  in
in  is not substituted (i.e. \(o_{i}=(\mathfrak {z},0)\) for all \(i\in [m]\)), one has \(\deg (\tau ) = \sum _{i=1}^{m} \deg (\tau _{i}) + 2m\) and \(p_{\partial } = \sum _{i=0}^{m} p_{\partial }^{(i)}\), where the term \(2m\) arises from the increase of degree by the heat kernel. On the other hand if
is not substituted (i.e. \(o_{i}=(\mathfrak {z},0)\) for all \(i\in [m]\)), one has \(\deg (\tau ) = \sum _{i=1}^{m} \deg (\tau _{i}) + 2m\) and \(p_{\partial } = \sum _{i=0}^{m} p_{\partial }^{(i)}\), where the term \(2m\) arises from the increase of degree by the heat kernel. On the other hand if  is substituted by some \(\boldsymbol{\Upsilon}_{o_{i}}[\tau _{i}]\) (i.e. \(o_{i}=( \mathfrak {z},e_{j})\) for some \(i\in [m]\) and \(j\in \{1,2,3\}\)), one has \(\deg (\tau ) = \sum _{i=1}^{m} \deg (\tau _{i}) + 2m-1\) and \(p_{\partial } = (\sum _{i=0}^{m} p_{\partial }^{(i)}) -1\). Using these relations and (5.14) as well as our inductive assumption, we see that in both cases the last identity (5.12c) is preserved for \(\tau \). □
is substituted by some \(\boldsymbol{\Upsilon}_{o_{i}}[\tau _{i}]\) (i.e. \(o_{i}=( \mathfrak {z},e_{j})\) for some \(i\in [m]\) and \(j\in \{1,2,3\}\)), one has \(\deg (\tau ) = \sum _{i=1}^{m} \deg (\tau _{i}) + 2m-1\) and \(p_{\partial } = (\sum _{i=0}^{m} p_{\partial }^{(i)}) -1\). Using these relations and (5.14) as well as our inductive assumption, we see that in both cases the last identity (5.12c) is preserved for \(\tau \). □
The following lemma shows that we only have linear renormalisation.
Lemma 5.12
There exists \(\mathcal {L}\in L (E,E)\) such that

The map ℒ has the form \(\mathcal {L}= \boldsymbol{\sigma}^{2} \mathcal {L}_{1} +\boldsymbol{\sigma}^{4} \mathcal {L}_{2}\) where for each \(j\in \{1,2\}\), the map \(\mathcal {L}_{j} \in L(E,E)\) is independent of \(\boldsymbol{\sigma}\).
Proof
It suffices to prove that for each tree \(\tau \in \mathfrak {T}_{-}(R)\), we have either \((p_{X}, p_{\partial }) = (1,0)\) or  .
.
The proof easily follows from analysing each possible value of \(n_{\lambda}\) (which is the advantage of introducing this parameter). By the “parity” Lemma 5.5, both \(k_{\xi}\ge 2\) and \(k_{\partial }\) must be even, or  . Obviously we also have \(p_{X} = 0 \Rightarrow p_{\partial }=0\).
. Obviously we also have \(p_{X} = 0 \Rightarrow p_{\partial }=0\).
Let \(n_{\lambda}=2\). We look for solutions toFootnote 15
To have even \(k_{\xi}\ge 2\), by (5.12a) of Lemma 5.11, \(p_{X}\) must be odd. To have even \(k_{\partial }\), by (5.12b) \(p_{\partial }\) must be even. Thus we only have one solution \((p_{X}, p_{\partial }) = (1,0)\) to the above inequality. For this solution, by (5.12a), we have \(k_{\xi }=2\).
Let \(n_{\lambda}=3\) and we solve
As above, to have even \(k_{\xi}\ge 2\), \(p_{X} \in \{2,0\}\). To have even \(k_{\partial }\), the number \(p_{\partial }\) must be odd. Since whenever \(p_{X} = 0\) we must have \(p_{\partial }=0\) as mentioned above, there is then no solution to the above inequality.
Consider \(n_{\lambda}=4\) and
To have even \(k_{\xi}\ge 2\), \(p_{X} \in \{1,3\}\). To have even \(k_{\partial }\), the number \(p_{\partial }\) must be even. So the only solution is \((p_{X}, p_{\partial }) = (1,0)\). For this solution, by (5.12a), we have \(k_{\xi }=4\).
Consider \(n_{\lambda}=5\) and \(\deg (\tau ) = \frac{p_{X}}{2} + p_{\partial }\le 0\). To have even \(k_{\partial }\), the number \(p_{\partial }\) must be odd, so there is no solution. Finally for \(n_{\lambda}\ge 6\), \(\deg (\tau )>0\). Putting these together proves the first claim. Moreover, since we have shown above that \(k_{\xi}\) can only be 2 or 4, and \(\boldsymbol{\sigma}\) is the coefficient in front of the noise, the map ℒ has the claimed form. □
5.1.2 Symmetries of the renormalisation
Having proved that the renormalisation is linear in \(X\), we now show that ℒ is subject to a number of constraints by symmetries, allowing us to complete the proof of Proposition 5.7.
Lemma 5.13
For any \(\varepsilon > 0\), the linear map \(\mathcal {L}\in L(E,E) \) in Lemma 5.12has the form  with
with  and
and  . Moreover \(\mathcal {L}\in L_{G}(E,E) \), namely ℒ commutes with the action \(\mathrm {Ad}\oplus \boldsymbol{\varrho }\) of \(G\) on \(E\). In particular,
. Moreover \(\mathcal {L}\in L_{G}(E,E) \), namely ℒ commutes with the action \(\mathrm {Ad}\oplus \boldsymbol{\varrho }\) of \(G\) on \(E\). In particular,  and
and  .
.
Proof
Our proof will repeatedly reference Proposition 4.8, with various choices of \(\mathbf{T} = (T,O,\sigma ,r) \in \mathrm{Tran}\) to prove the various properties of ℒ. We will always choose \(T\) of the form \(T = T_{\mathfrak {z}} \oplus T_{\bar{\mathfrak {l}}} = \tilde{T} \oplus \tilde{T}\) for some \(\tilde{T} \in L(E,E)\) –recall that \(W_{\mathfrak {z}}\simeq W_{\bar{\mathfrak {l}}} \simeq E = \mathfrak {g}_{1} \oplus \mathfrak {g}_{2} \oplus \mathfrak {g}_{3}\oplus \mathbf{V}\) where each \(\mathfrak {g}_{i}\) is a copy of \(\mathfrak {g}\).
We first show that ℒ is appropriately block diagonal. Fix \(i\in \{1,2,3\}\) and choose \(\mathbf{T} = (T,O,\sigma ,r) \in \mathrm{Tran}\) as follows. The map \(\tilde{T}\) acts on \(E\) by flipping the sign of the \(i\)-th component, namely for every \(u\in E\), let \((\tilde{T} u) |_{\mathfrak {g}_{i}} = - u |_{\mathfrak {g}_{i}} \) and \((\tilde{T} u) |_{\mathfrak {g}_{i}^{\perp}} = u |_{\mathfrak {g}_{i}^{\perp}} \). We then also flip the sign of the \(i\)-th spatial coordinate, namely \(\sigma =\mathrm{id}\), \(O=\mathrm{id}\) and \(r_{j} =1_{j \neq i} - 1_{j=i} \) for every \(j\in \{1,2,3\}\).
Observe that our nonlinearity  is then \(\mathbf{T}\)-covariant, namely
is then \(\mathbf{T}\)-covariant, namely  ; this is because, in any term for the \(\mathfrak {g}_{i}\) component in (1.12), the spatial index \(j\) (appearing either as a subscript of
; this is because, in any term for the \(\mathfrak {g}_{i}\) component in (1.12), the spatial index \(j\) (appearing either as a subscript of  or as a partial derivative
or as a partial derivative  ) appears an even number of times if \(j \neq i\) and an odd number of times if \(j=i\). For instance, one of the terms in the \(\mathfrak {g}_{i}\) component
) appears an even number of times if \(j \neq i\) and an odd number of times if \(j=i\). For instance, one of the terms in the \(\mathfrak {g}_{i}\) component  flips sign when
flips sign when  is replaced by
is replaced by  , because according to the definition of
, because according to the definition of  given by (4.4), if \(j\neq i\),
given by (4.4), if \(j\neq i\),  is fixed and
is fixed and  flips sign, and if \(j= i\),
flips sign, and if \(j= i\),  flips sign and
flips sign and  is fixed.
is fixed.
Also, \(K\) and \(\xi _{\varepsilon }\) are both \(\mathbf{T}\)-invariant, so by Lemma 4.5, both \(\bar{\boldsymbol{\Pi}}_{\mbox{\scriptsize can}}\) and  are \(\mathbf{T}\)-invariant. Invoking Proposition 4.8 and Lemma 5.12 we conclude that \(\mathcal {L}X\) is \(\mathbf{T}\)-covariant. Since this holds for every \(i \in \{1,2,3\}\), one has
are \(\mathbf{T}\)-invariant. Invoking Proposition 4.8 and Lemma 5.12 we conclude that \(\mathcal {L}X\) is \(\mathbf{T}\)-covariant. Since this holds for every \(i \in \{1,2,3\}\), one has  with \(C_{\varepsilon }^{(1)},C_{\varepsilon }^{(2)},C_{\varepsilon }^{(3)} \in L(\mathfrak {g},\mathfrak {g})\) and
with \(C_{\varepsilon }^{(1)},C_{\varepsilon }^{(2)},C_{\varepsilon }^{(3)} \in L(\mathfrak {g},\mathfrak {g})\) and  .
.
We now show that the first three blocks are identical. Fixing \(i\neq j \in \{1,2,3\}\), we choose another \(\mathbf{T} = (T, O,\sigma ,r) \in \mathrm{Tran}\) where \(\sigma \in S_{3}\) is defined by swapping \(i\) and \(j\), \(r=1\), \(O=\mathrm{id}\), and \(T\) is given by swapping the \(\mathfrak {g}_{i}\) and \(\mathfrak {g}_{j}\) components, namely
It is easy to check that  is again \(\mathbf{T}\)-covariant, and the kernel \(K\) and noise \(\xi \) are both \(\mathbf{T}\)-invariant. Invoking Proposition 4.8 again it follows that \(\mathcal {L}X\) is \(\mathbf{T}\)-covariant which implies that
is again \(\mathbf{T}\)-covariant, and the kernel \(K\) and noise \(\xi \) are both \(\mathbf{T}\)-invariant. Invoking Proposition 4.8 again it follows that \(\mathcal {L}X\) is \(\mathbf{T}\)-covariant which implies that  .
.
To show \(\mathcal{L} \in L_{G}(E,E)\) we choose \(\mathbf{T} = (T, O,\sigma ,r) \in \mathrm{Tran}\) by taking \(r=1\), \(O=\mathrm{id}\) and \(\sigma =\mathrm{id}\), and, for any fixed \(g \in G\), define \(\tilde{T}\) to be the action by \(g\in G\) on \(E\). Note that  is \(\mathbf{T}\)-covariant (since each term in (1.9) is covariant), and the noise \(\xi _{\varepsilon }\) is \(\mathbf{T}\)-invariant. Since this holds for any \(g \in G\), we thus have \(\mathcal {L}\in L_{G}(E,E) \). □
is \(\mathbf{T}\)-covariant (since each term in (1.9) is covariant), and the noise \(\xi _{\varepsilon }\) is \(\mathbf{T}\)-invariant. Since this holds for any \(g \in G\), we thus have \(\mathcal {L}\in L_{G}(E,E) \). □
Remark 5.14
It is possible to show that ℒ in Lemma 5.12 – 5.13 is symmetric with respect to the inner product given on \(E\). Indeed, recalling that \(\mathbf{V}\cong \mathbf{V}^{*}\) is canonically given by the scalar product \(\langle \;,\;\rangle _{\mathbf{V}}\), the action (1.2) is invariant under \(\Phi \mapsto \Phi ^{*}\) (with connection replaced by its dual connection, which is locally still represented by \(A\)), and (1.9) is covariant i.e. the transformation \((\Phi ,\zeta ) \mapsto (\Phi ^{*},\zeta ^{*})\) just amounts to applying the dual operation to the second equation. A similar argument as above can show that \(\mathcal {L}^{*} \Phi ^{*} = (\mathcal {L}\Phi )^{*}\) which means that ℒ is symmetric. If \(\mathfrak {g}\) is simple and \(\boldsymbol{\varrho }\) is irreducible, and assuming \(\boldsymbol{\varrho }\) is surjective, then  commute with all the orthogonal transformations and therefore must be multiples of the identity on \(\mathfrak {g}\) and \(\mathbf{V}\) respectively.
commute with all the orthogonal transformations and therefore must be multiples of the identity on \(\mathfrak {g}\) and \(\mathbf{V}\) respectively.
Remark 5.15
One may wonder if our model “decouples” as \(\mathfrak {g}\) splits into simple and abelian components and \(\mathbf{V}\) decomposes into irreducible subspaces. The “pure YM” part (i.e. the first term in (1.2)) decouples under the decomposition of \(\mathfrak {g}\), as observed in [22, Remarks 2.8, 2.10]. The term \(|\mathrm {d}_{A} \Phi (x)|^{2}\) (and the corresponding terms in our SPDE) decouples into orthogonal irreducible components, but the \(|\Phi |^{4}\) term does not. On the other hand, assuming that \(\mathbf{V}\) is irreducible but \(\mathfrak {g}=\mathfrak {g}_{1}\oplus \mathfrak {g}_{2}\), by [82, Theorem 3.9], \(\mathbf{V}= \mathbf{V}_{1}\otimes \mathbf{V}_{2}\) for irreducible representations \(\mathbf{V}_{i}\) of \(\mathfrak {g}_{i}\). So for \(A_{j}\in \mathfrak {g}_{j}\) and \(\Phi _{j} \in \mathbf{V}_{j}\) we have \(\mathrm {d}_{A_{1}+A_{2}} (\Phi _{1}\otimes \Phi _{2}) = (\mathrm {d}_{A_{1}} \Phi _{1} )\otimes \Phi _{2} + \Phi _{1} \otimes (\mathrm {d}_{A_{2}} \Phi _{2})\); the two terms are generally not orthogonal, and one does not have any decoupling.
5.2 Solution theory
We now turn to posing the analytic fixed point problem in an appropriate space of modelled distributions for (5.8). A naive formulation would be
Here, \(\mathbf{1}_{+}\) is the restriction of modelled distributions to non-negative times,  where
where  is the abstract integration operator, and \(R\) the operator realising convolution with \(G - K\) as a map from appropriate Hölder–Besov functions into modelled distributions as in [56, Eq. 7.7], and \(\mathcal{P}X_{0}\) is the “harmonic extension” of \(X_{0}\) as in [56, Eq. 7.13]. However, (5.15) can not be closed in any \(\mathscr{D}^{\gamma ,\eta}_{\alpha}\) space, even for smooth initial data. This is because \(\mathbf{1}_{+} \boldsymbol{\Xi} \in \mathscr{D}^{\infty ,\infty}_{-5/2-}\), so \(\mathcal {X}\in \mathscr{D}^{\gamma ,\eta}_{\alpha}\) would require \(\eta , \alpha < -1/2\), but then \(\mathcal {X}\partial \mathcal {X}\in \mathscr{D}^{\gamma -\frac{3}{2}-, -2-}_{-2-}\) at best. Unfortunately, exponents below −2 represent a non-integrable singularity in the time variable so that we cannot apply the standard integration result [56, Prop. 6.16] (which requires \(\eta \wedge \alpha >-2\)) for the modelled distributions \(\mathbf{1}_{+} \boldsymbol{\Xi}\) and \(\mathcal {X}\partial \mathcal {X}\).Footnote 16
is the abstract integration operator, and \(R\) the operator realising convolution with \(G - K\) as a map from appropriate Hölder–Besov functions into modelled distributions as in [56, Eq. 7.7], and \(\mathcal{P}X_{0}\) is the “harmonic extension” of \(X_{0}\) as in [56, Eq. 7.13]. However, (5.15) can not be closed in any \(\mathscr{D}^{\gamma ,\eta}_{\alpha}\) space, even for smooth initial data. This is because \(\mathbf{1}_{+} \boldsymbol{\Xi} \in \mathscr{D}^{\infty ,\infty}_{-5/2-}\), so \(\mathcal {X}\in \mathscr{D}^{\gamma ,\eta}_{\alpha}\) would require \(\eta , \alpha < -1/2\), but then \(\mathcal {X}\partial \mathcal {X}\in \mathscr{D}^{\gamma -\frac{3}{2}-, -2-}_{-2-}\) at best. Unfortunately, exponents below −2 represent a non-integrable singularity in the time variable so that we cannot apply the standard integration result [56, Prop. 6.16] (which requires \(\eta \wedge \alpha >-2\)) for the modelled distributions \(\mathbf{1}_{+} \boldsymbol{\Xi}\) and \(\mathcal {X}\partial \mathcal {X}\).Footnote 16
Recall the local reconstruction operator \(\tilde{\mathcal{R}}\) and the global reconstruction operator ℛ described in Appendix A. The reason that the proof of [56, Prop. 6.16] fails in this case is that the modelled distributions \(\mathbf{1}_{+} \boldsymbol{\Xi}\) and \(\mathcal {X}\partial \mathcal {X}\) canonically only admit local (but not global) reconstructions \(\tilde{\mathcal{R}} \mathbf{1}_{+} \boldsymbol{\Xi}\) and \(\tilde{\mathcal{R}} (\mathcal {X}\partial \mathcal {X})\) which are defined as space-time distributions only away from the \(t=0\) hyperplane. However, Lemma A.4 allows us to bypass this difficulty if we also specify space-time distributions that extend \(\tilde{\mathcal{R}} \mathbf{1}_{+} \boldsymbol{\Xi}\) and \(\tilde{\mathcal{R}} (\mathcal {X}\partial \mathcal {X})\) to \(t=0\).
More precisely, for fixed \(\varepsilon > 0\), we can easily define such an extension for \(\tilde{\mathcal{R}} \mathbf{1}_{+} \boldsymbol{\Xi}\), and by linearising around the SHE we can similarly handle the product \(\mathcal {X}\partial \mathcal {X}\). Let
and consider

where, for a space-time distribution \(\omega \), the notation  is defined as in Appendix A. The space-time distributions in the superscripts here play the role of “inputs by hand” to the integration operators which replace the standard reconstructions that aren’t defined a priori. Pretending for now that the initial condition \(X_{0}\) is sufficiently regular, the fixed point problem (5.17) can be solved for \(\tilde{\mathcal {X}}\in \mathscr{D}^{3/2+,0-}_{0-}\) and we can apply Lemma A.4 once we check its condition, that is, \(1_{t > 0} \xi ^{\varepsilon }\) and \(\tilde{\mathcal{R}}(\mathbf {1}_{+} \boldsymbol{\Xi})\) agree away from \(t=0\) (which is obvious), and the same holds for \(\tilde{\Psi}_{\varepsilon } \partial \tilde{\Psi}_{\varepsilon }\) and \(\tilde{\mathcal{R}}\big( \tilde{\boldsymbol{\Psi}} \partial \tilde{\boldsymbol{\Psi}} \big)\). The fact that \(\mathcal{R}\mathcal {X}\) solves (5.4) then follows by combining [11] and [22, Sect. 5.8] along with Proposition 5.7.
is defined as in Appendix A. The space-time distributions in the superscripts here play the role of “inputs by hand” to the integration operators which replace the standard reconstructions that aren’t defined a priori. Pretending for now that the initial condition \(X_{0}\) is sufficiently regular, the fixed point problem (5.17) can be solved for \(\tilde{\mathcal {X}}\in \mathscr{D}^{3/2+,0-}_{0-}\) and we can apply Lemma A.4 once we check its condition, that is, \(1_{t > 0} \xi ^{\varepsilon }\) and \(\tilde{\mathcal{R}}(\mathbf {1}_{+} \boldsymbol{\Xi})\) agree away from \(t=0\) (which is obvious), and the same holds for \(\tilde{\Psi}_{\varepsilon } \partial \tilde{\Psi}_{\varepsilon }\) and \(\tilde{\mathcal{R}}\big( \tilde{\boldsymbol{\Psi}} \partial \tilde{\boldsymbol{\Psi}} \big)\). The fact that \(\mathcal{R}\mathcal {X}\) solves (5.4) then follows by combining [11] and [22, Sect. 5.8] along with Proposition 5.7.
Note that we are slightly outside of the setting of [11] because we have replaced the standard integration operators \(\mathcal{G}_{\mathfrak {z}}\) and  with non-standard ones with “inputs”. However the results of [11] still hold because \(\mathcal{X}\) is still coherentFootnote 17 with respect to the nonlinearity (5.8). Coherence is a completely local algebraic property and for each \((t,x)\) with \(t > 0\), \(\mathcal{X}(t,x)\) solves an algebraic fixed point problem of the form
with non-standard ones with “inputs”. However the results of [11] still hold because \(\mathcal{X}\) is still coherentFootnote 17 with respect to the nonlinearity (5.8). Coherence is a completely local algebraic property and for each \((t,x)\) with \(t > 0\), \(\mathcal{X}(t,x)\) solves an algebraic fixed point problem of the form

where \((\cdots )\) takes values in the polynomial sector of the regularity structure. The relation above is all that is needed to deduce that \(\mathcal{X}\) is coherent at \((t,x)\).
Remark 5.16
Note that there is a degree of freedom in the “\(t=0\) renormalisation” of (5.17) that could be exploited: one could add to the \(\tilde{\Psi}_{\varepsilon } \partial \tilde{\Psi}_{\varepsilon }\) appearing in the superscript any fixed distribution supported on \(t=0\). This does not affect at all the coherence of \(\mathcal{X}\) with the nonlinearity, but in fact changes our initial condition. The fact that we do not add such a distribution in the superscript means that \(\mathcal{R}\mathcal{X}\) really does solve (5.4) with the prescribed initial data.
Combining this with the probabilistic convergence of the BPHZ models and the distributions \(1_{t > 0} \xi ^{\varepsilon }\) and \(\tilde{\Psi}_{\varepsilon } \partial \tilde{\Psi}_{\varepsilon }\) in the appropriate spaces as \(\varepsilon \downarrow 0\), one also gets stability of the solution in this limit. However, the analysis above depends on having fairly regular initial data which is not sufficient for our purposes. In order to use this dynamic to construct our Markov process we will need to start the dynamic from an arbitrary \(X_{0} \in \mathcal{S}\).
As in our analysis of the deterministic equation (2.2) with rough initial data, the \(t=0\) behaviour of the term \(X \partial X\) requires us to linearise about \(\mathcal{P}X_{0}\) and take advantage of the control over \(\mathcal{N}(X_{0})\) given by the metric on \(\mathcal{S}\). We thus introduce the decomposition
where \(\tilde{\boldsymbol{\Psi}}\) is as in (5.17), and consider the fixed point problem
Instead of using the spaces \(\mathscr{D}^{\gamma ,\eta}_{\alpha}\) of [56], it will be convenient to use a slightly smaller class of “\(\hat{\mathscr{D}}\) spaces” with \(\hat{\mathscr{D}}^{\gamma ,\eta}_{\alpha} \subsetneq \mathscr{D}^{\gamma ,\eta}_{ \alpha}\) which impose a vanishing condition near \(t=0\). These spaces were introduced in [47] and used in [22] for the SYM in dimension \(d=2\). We collect their important properties in Appendix A.
Imposing \(X_{0} \in \mathcal{S}\) will give us control over the first term on the right-hand side of (5.20). We will see that the other products in the first and second lines of (5.20) will belong to \(\hat{\mathscr{D}}\) spaces with good enough exponents for Theorem A.5 (for non-anticipative kernels) to apply, thanks to Lemma A.3 which gives more refined power-counting for multiplication in \(\hat{\mathscr{D}}\) spaces than that of for instance [56, Prop. 6.12] for the usual \(\mathscr{D}\) spaces. While we choose to use \(\hat{\mathscr{D}}\) spaces here as a matter of convenience, it will serve as a warm-up for Sect. 6.4.2 where it is crucial.
Finally the products of modelled distributions in the last line of (5.20) give us non-integrable singularities, similarly as in our discussion for (5.17), but we can again appeal to the integration result Lemma A.4 instead of the standard result [56, Prop. 6.16]. Note that the distributions \(\mathcal{P}X_{0}\) and \(\tilde{\Psi}_{\varepsilon }\) are explicit objects, so we can again show by hand that \(\mathcal{P}X_{0} \partial \tilde{\Psi}_{\varepsilon }\) and \(\tilde{\Psi}_{\varepsilon }\partial \mathcal{P}X_{0}\) converge probabilistically as \(\varepsilon \downarrow 0\) to some well-defined distributions over the entire space-time. We can argue exactly as for (5.17) that \(\mathcal{R}\mathcal{X}\) solves (5.4) for every fixed \(\varepsilon > 0\) whenever \(\mathcal{X}\) solves (5.19)–(5.20).
Below we first prove the necessary probabilistic convergences mentioned above, and then close the analytic fixed point problem (5.19)–(5.20). This will complete the proof of Theorem 5.1.
5.2.1 Probabilistic estimates for solution theory
We start with the probabilistic convergence of models. Let  be the BPHZ models determined by the kernel and noise assignments as in the beginning of this section.
be the BPHZ models determined by the kernel and noise assignments as in the beginning of this section.
Lemma 5.17
The random models  converge in probability to a limiting random model
converge in probability to a limiting random model  as \(\varepsilon \downarrow 0\).
as \(\varepsilon \downarrow 0\).
Proof
We take a choice of scalar noise decomposition and check the criteria of [21, Theorem 2.15] which are insensitive to this choice. First, it is clear that for any scalar noise decomposition, the random smooth noise assignments here are a uniformly compatible family of Gaussian noises that converge to the Gaussian white noise. We then note that
and the minimum is achieved for \(\tau \) of the form  . Here \(N(\tau )\) is the set of vertices of \(\tau \) such that \(v \neq e_{-} \) for any \(e\) with \(\mathfrak {t}(e)\in \mathfrak{L}_{-}\), so the third criterion is satisfied. Combining this with the fact that \(\deg (\mathfrak {l}) = -5/2 - \kappa \) for every \(\mathfrak {l}\in \mathfrak{L}_{-}\) guarantees that the second criterion is satisfied. Finally, the worst case scenario for the first condition is for \(\tau \) of the form
. Here \(N(\tau )\) is the set of vertices of \(\tau \) such that \(v \neq e_{-} \) for any \(e\) with \(\mathfrak {t}(e)\in \mathfrak{L}_{-}\), so the third criterion is satisfied. Combining this with the fact that \(\deg (\mathfrak {l}) = -5/2 - \kappa \) for every \(\mathfrak {l}\in \mathfrak{L}_{-}\) guarantees that the second criterion is satisfied. Finally, the worst case scenario for the first condition is for \(\tau \) of the form  and \(A = \{a\}\) with \(\mathfrak {t}(a) = \mathfrak {l}\) for \(\mathfrak {l}\in \mathfrak{L}_{-}\) for which we have \(\deg (\tau ) + \deg (\mathfrak {l}) + |\mathfrak{s}| = 1 - 4\kappa > 0\) as required. □
and \(A = \{a\}\) with \(\mathfrak {t}(a) = \mathfrak {l}\) for \(\mathfrak {l}\in \mathfrak{L}_{-}\) for which we have \(\deg (\tau ) + \deg (\mathfrak {l}) + |\mathfrak{s}| = 1 - 4\kappa > 0\) as required. □
We now give the promised statement about the probabilistic definition of products involving the initial data and the solution to SHE. We skip proving the convergence of \(1_{t > 0} \xi ^{\varepsilon }\) since this follows by a straightforward application of Kolmogorov’s argument combined with second moment computations. In the next lemmas, we recall that \(G\) is the Green’s function of the heat operator and we let \((\Omega ^{\mathrm {noise}},\mathbf{P})\) denote the probability space on which \(\xi \) is defined.
Lemma 5.18
For each \(\kappa >0\) there exists \(\bar{\kappa}>0\) such that, for all \(T>0\) and \(p\in [1,\infty )\), \(G*(\tilde{\Psi}_{\varepsilon }\partial \tilde{\Psi}_{\varepsilon }) \) converges in \(L^{p}(\Omega ^{\mathrm {noise}};\mathcal{C}^{\bar{\kappa}}([0,T],\mathcal{C}^{-\kappa}(\mathbf{T}^{3})))\) to a limit denoted by \(G*(\tilde{\Psi}\partial \tilde{\Psi})\). In particular, \(\tilde{\Psi}_{\varepsilon }\partial \tilde{\Psi}_{\varepsilon }\) converges in \(L^{p}(\Omega ^{\mathrm {noise}};\mathcal{C}^{-2-\kappa}(\mathfrak{K}))\) to a limit denoted by \(\tilde{\Psi}\partial \tilde{\Psi}\) for any compact \(\mathfrak{K}\subset {\mathbf {R}}\times \mathbf{T}^{3}\).
Proof
By equivalence of Gaussian moments, it suffices to consider \(p=2\). Dropping reference to \(\varepsilon \) and denoting \({\mathcal {Y}} = G*(\tilde{\Psi}\partial \tilde{\Psi}) \), one has
Using [56, Lem. 10.14], followed by Lemma 3.3 (with \(\gamma =2\) and \(\alpha =2-2\kappa \) therein), one has
for \(\kappa >0\) arbitrarily small, where the first bound follows from Wick’s theorem, the fact that \(\mathbf{E}(\tilde{\Psi}\partial \tilde{\Psi})=0\) thanks to the derivative, and the uniform in \(\varepsilon >0\) bound
Here \(\phi ^{\lambda}\) is the rescaled spatial test function as in Lemma 3.4. Setting \(s=0\) one then has \(\mathbf{E}| \langle {\mathcal{Y}}_{t} ,\phi ^{\lambda }\rangle |^{2} \lesssim t^{\kappa }\lambda ^{-2\kappa} \). Therefore \(\mathbf{E}|( \mathcal{P}_{t-s}-1) {\mathcal{Y}}_{s} |^{2}_{\mathcal{C}^{-\kappa}} \lesssim s^{\kappa /4}|t-s|^{\kappa /4}\), which handles the first term on the right-hand side of (5.21). Since \(\mathcal{Y}_{r}=0\) for \(r\leq 0\), it follows from a Kolmogorov argument that \(\mathbf{E}|{\mathcal{Y}}|_{\mathcal{C}^{\bar{\kappa}}([0,T], \mathcal{C}^{-\kappa}(\mathbf{T}^{3}))}^{2}\) is bounded uniformly in \(\varepsilon >0\) for any \(T>0\) and \(\kappa >0\).
To show that \(\mathcal {Y}\) converges in \(\mathcal{C}^{\bar{\kappa}}([0,T], \mathcal{C}^{-\kappa}(\mathbf{T}^{3}))\) as \(\varepsilon \downarrow 0\), it suffices to extract a small power of \(\bar{\varepsilon }\) in the corresponding bounds on \(\mathcal{P}_{t-r} (\tilde{\Psi}_{\varepsilon }\partial \tilde{\Psi}_{\varepsilon }) -\mathcal{P}_{t-r} ( \tilde{\Psi}_{\bar{\varepsilon }}\partial \tilde{\Psi}_{\bar{\varepsilon }})\) for \(0<\varepsilon <\bar{\varepsilon }\).
The final claim follows by applying to \(\mathcal {Y}\) the heat operator, which is a bounded operator from \(\mathcal{C}([-T,T],\mathcal{C}^{-\kappa}(\mathbf{T}^{3}))\) to \(\mathcal{C}^{-2-\kappa}((-T,T)\times \mathbf{T}^{3})\) and remarking that \(\mathcal {Y}\) is continuous over \([-T,T]\) once we extend it by \(\mathcal {Y}_{t}=0\) for \(t<0\). □
Lemma 5.19
For every \(\kappa >0\) and \(\eta \in (-1,-\frac{1}{2})\), there exists \(\bar{\kappa}>0\) such that, for all \(T>0\), \(p\in [1,\infty )\), uniformly in \(0<\varepsilon <\bar{\varepsilon }<1\),
In particular, \(G*(\mathcal{P}X_{0} \partial \tilde{\Psi}_{\varepsilon })\) and \(G*(\tilde{\Psi}_{\varepsilon }\partial \mathcal{P}X_{0})\) converge in \(\mathcal{C}^{\bar{\kappa}}([0,T],\mathcal{C}^{\eta +\frac{1}{2}-\kappa})\) in \(L^{p}(\Omega ^{\mathrm {noise}},\mathbf{P})\) to limits denoted respectively by \(G*(\mathcal{P}X_{0} \partial \tilde{\Psi})\) and \(G*(\tilde{\Psi}\partial \mathcal{P}X_{0})\), and \(\mathcal{P}X_{0} \partial \tilde{\Psi}_{\varepsilon }\) and \(\tilde{\Psi}_{\varepsilon }\partial \mathcal{P}X_{0}\) converge in \(\mathcal{C}^{\eta -\frac{3}{2}-\kappa}(\mathfrak{K})\) in \(L^{p}(\Omega ^{\mathrm {noise}},\mathbf{P})\) to limits denoted respectively by \(\mathcal{P}X_{0} \partial \tilde{\Psi}\) and \(\tilde{\Psi}\partial \mathcal{P}X_{0}\) for any compact \(\mathfrak{K}\subset {\mathbf {R}}\times \mathbf{T}^{3}\). The maps sending \(X_{0}\) to any of these limits is a bounded linear map from \(\mathcal{C}^{\eta}\) to the corresponding \(L^{p}(\Omega ^{\mathrm {noise}},\mathbf{P})\) space.
Proof
We apply the same trick as (5.21). Dropping again reference to \(\varepsilon \), one has
Since \(r,\bar{r}\) are symmetric, we just consider the regime \(r\le \bar{r}\), so that \({\bar{r}}^{\eta /2} \le r^{\eta /2}\). By [56, Lem. 10.14] followed by Lemma 3.3 (with \(\gamma =1\) and \(\alpha =2\eta + 2 -2 \kappa \in (0,1)\) therein for \(\kappa \) sufficiently small), the above quantity is bounded by a multiple of
Setting \(s=0\) and denoting \({\mathcal {Y}} = G*(\mathcal{P}X_{0} \partial \tilde{\Psi}) \), one then has \(\mathbf{E}| \langle {\mathcal{Y}}_{t} ,\phi ^{\lambda }\rangle |^{2} \lesssim t^{\kappa}\lambda ^{2\eta +1-2\kappa} \). The claim for \(G*(\mathcal{P}X_{0} \partial \tilde{\Psi})\) and \(\mathcal{P}X_{0} \partial \tilde{\Psi}\) now follows in the same way as in the proof of Lemma 5.18.
The argument for \(\tilde{\Psi}\partial \mathcal{P}X_{0}\) is similar except we have
and instead of [56, Lem. 10.14] we use Lemma 3.3 twice (first with \(\gamma =1\) and \(\alpha =1+\eta \in (0,\frac{1}{2})\) and then with \(\gamma =-\eta \) and \(\alpha =\eta +1-2\kappa \in (0,-\eta )\) therein for \(\kappa \) sufficiently small) to bound the above quantity by a multiple of
The rest of the proof is again the same as that of Lemma 5.18. □
5.3 Proof of Theorem 5.1
Proof of Theorem 5.1
We first show that the fixed point problem (5.20) is well-posed, and then argue that the reconstructed solutions converge in \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\).
Fix \(\gamma \in (\frac{3}{2}+2\kappa ,2)\). Writing \(\mathcal{X}\) as (5.19), we will solve the fixed point problem (5.19) and (5.20) for \(\hat {\mathcal{X}}\) in \(\hat{\mathscr{D}}^{\gamma ,\hat{\beta}}_{-5\kappa}\) with \(\hat{\beta}> -1/2\) as in (ℐ). Note that
Moreover, since \(X_{0}\in \mathcal{I}\), we use the bound (2.3) with \(|\cdot |_{\mathcal{C}^{\hat{\beta}}}\) replaced by \(|\cdot |_{\mathcal{C}^{k}}\) (for \(|k|<\gamma \)) to concludeFootnote 18 that \(\mathcal{G}_{\mathfrak {z}} \big( \mathcal{P}X_{0} \partial \mathcal{P}X_{0} \big)\) is well-defined as an element of \(\hat{\mathscr{D}}^{\gamma ,\hat{\beta}}_{0}\).
For the other terms in the first line on the right-hand side of (5.20), since \(\partial \hat {\mathcal{X}}\in \hat{\mathscr{D}}^{\gamma -1,\hat{\beta}-1}_{-1-5 \kappa}\), by (5.25) and Lemma A.3 one has
where we took \(\kappa >0\) sufficiently small such that \(-5\kappa >\hat{\beta}\). Note that \(\hat{\beta}>-1/2\) due to (ℐ), and thus \(\min (\hat{\beta}+\eta -1,2\hat{\beta}-1) > -2\). Therefore, by Theorem A.5,
provided that \(\kappa >0\) is sufficiently small.
For the cubic and linear term on the second line of (5.20), by the definition of \(\tilde{\boldsymbol{\Psi}}\) in (5.17) and Lemma A.4, we have \(\tilde{\boldsymbol{\Psi}}\in \mathscr{D}^{\gamma ,-\frac{1}{2}-2\kappa}_{-\frac{1}{2}-2\kappa}\) and thus \(\tilde{\boldsymbol{\Psi}}\in \hat{\mathscr{D}}^{\gamma ,-\frac{1}{2}-2\kappa}_{-\frac{1}{2}-2\kappa}\). Then by the fact that \(\mathcal{P}X_{0} , \hat {\mathcal{X}}\) belong to the \(\hat{\mathscr{D}}\)-spaces with exponents stated above, and taking \(\kappa >0\) sufficiently small such that \(\eta <-\frac{1}{2}-2\kappa \), one has
By (ℐ), \(3\eta >-2\) so that Theorem A.5 applies, and we have \(\mathcal{G}_{\mathfrak {z}} \big( \mathcal{X}^{3} + \mathring{C}_{\mathfrak {z}} \mathcal{X}\big) \in \hat{\mathscr{D}}^{\gamma ,\hat{\beta}}_{-2\kappa}\). Moreover, one has
The condition (ℐ) again guarantees that Theorem A.5 applies to these terms provided that \(\kappa >0\) is small enough. This concludes our analysis for the second line of (5.20).
The terms in the third line of (5.20) require extra care. Indeed, applying Lemma A.3 for multiplication as before we have
and
but then the reconstruction Theorem A.2 and thus Theorem A.5 do not apply because \(-2-4\kappa < -2\) and \(\eta -\frac{3}{2}-\kappa < -2\). To control these terms in (5.20) we use instead Lemma A.4, for which we need to check that \(\omega \) is compatible with \(f\) for every term of the form \(\mathcal{G}^{\omega}(f)\).
For the last two terms this is immediate since for \(|k| \in \{0,1\}\) and \(t \neq 0\), \((\tilde{\mathcal{R}} \partial ^{k}\tilde{\boldsymbol{\Psi}})(t,x) = \partial ^{k} \tilde{\Psi}_{ \varepsilon }(t,x)\), and since renormalisation commutes with multiplication by polynomials, for any modeled distribution \(H\) taking values in the span of the polynomial sector, one has \(\tilde{\mathcal{R}} (H \partial ^{k}\tilde{\boldsymbol{\Psi}})(t,x) = (\tilde{\mathcal{R}}H)(t,x) ( \tilde{\mathcal{R}}\partial ^{k}\tilde{\boldsymbol{\Psi}})(t,x)\).
For the term \(\mathcal{G}^{\tilde{\Psi}_{\varepsilon }\partial \tilde{\Psi}_{\varepsilon }} (\tilde{\boldsymbol{\Psi}}\partial \tilde{\boldsymbol{\Psi}})\), since the action of the model on  is unaffected by BPHZ renormalisation (see Lemma 5.5), one has
is unaffected by BPHZ renormalisation (see Lemma 5.5), one has
for \(t \neq 0\). This verifies the conditions of Lemma A.4 which together with (5.29)–(5.30) shows that the fixed point problem (5.20) is well-posed for \(\varepsilon > 0\).
The stability of the fixed point problem (in modelled distribution space) as \(\varepsilon \downarrow 0\) for a short (random) time interval \([0,\tau ]\) then follows from the convergence of models (Lemma 5.17), Lemmas 5.18–5.19 and (A.1). Here \(\tau >0\) depends only on the size of model in the time interval \([-1,2]\) and the size of the initial condition in \(\mathcal{S}\).
We write \(X^{\varepsilon } = \mathcal{R}\mathcal{X}\) in the rest of the argument, where \(\mathcal{X}\) is given by (5.19) and \(\hat{\mathcal{X}}\) is the solution to the fixed point problem (5.20) for the model  over the interval \([0,\tau ]\).
over the interval \([0,\tau ]\).
We now show that \(X^{\varepsilon }\) converges as \(\varepsilon \downarrow 0\) in \(\mathcal{C}([0,\tau ],\mathcal{S})\). To this end, let \(\Psi ^{\varepsilon }\) (resp. \(\Psi \)) solve the stochastic heat equation driven by \(\xi ^{\varepsilon }\) (resp. \(\xi \)) with initial condition \((a,\phi ) \in \mathcal{S}\), and let us decompose \(X^{\varepsilon }= \Psi ^{\varepsilon }+ \hat{X}^{\varepsilon }\). By the above construction, \(\hat{X}^{\varepsilon }= \mathcal{R}\hat{\mathcal{X}}\) where ℛ is the reconstruction map for  . By convergence of models given by Lemma 5.17, and continuity of the reconstruction map ℛ, \(\hat{X}^{\varepsilon }\) converges in probability to a limit denoted by \(\hat{X}\) in \(\mathcal{C}^{-\kappa}((0,\tau )\times \mathbf{T}^{3})\).
. By convergence of models given by Lemma 5.17, and continuity of the reconstruction map ℛ, \(\hat{X}^{\varepsilon }\) converges in probability to a limit denoted by \(\hat{X}\) in \(\mathcal{C}^{-\kappa}((0,\tau )\times \mathbf{T}^{3})\).
We claim further that \(\hat{X}^{\varepsilon }\) converges to \(\hat{X}\) in \(\mathcal{C}([0,\tau ],\mathcal{C}^{\eta +\frac{1}{2}-\kappa}(\mathbf{T}^{3}))\). Indeed, one has \(\hat{X} = \mathcal{Y} + \hat{X}_{R}\) where \(\mathcal{Y} \stackrel {{\tiny \mathrm {def}}}{=}G*(\Psi \partial \Psi )\) with \(G\) the heat kernel and \(\Psi \) as above, and \(\hat{X}_{R} \in \mathcal{C}([0,\tau ],\mathcal{C}^{\frac{1}{2} - \kappa})\). Then writing \(\Psi =\mathcal{P}X_{0}+\tilde{\Psi}\) with \(X_{0}=(a,\phi )\) and \(\tilde{\Psi}\) the solution to SHE with 0 initial condition, we can split \(\mathcal {Y}\) into four terms. The term quadratic in \(\mathcal{P}X_{0}\) can be bounded as in the proof of Proposition 2.9, while the term quadratic in \(\tilde{\Psi}\) and the cross terms between \(\mathcal{P}X_{0}\) and \(\tilde{\Psi}\) converge in \(\mathcal{C}([0,T], \mathcal{C}^{\eta +\frac{1}{2}-\kappa})\) due to Lemmas 5.18 and 5.19 respectively. In conclusion, \(\mathcal {Y}^{\varepsilon }\to \mathcal {Y}\) in probability (even in \(L^{p}\) for any \(p\in [0,\infty )\)) in \(\mathcal{C}([0,T], \mathcal{C}^{\eta +\frac{1}{2}-\kappa}(\mathbf{T}^{3}))\), and therefore \(\hat{X}^{\varepsilon }\to \hat{X}\) in probability in \(\mathcal{C}([0,\tau ],\mathcal{C}^{\eta +\frac{1}{2}-\kappa})\) for any \(\kappa >0\) as claimed.
To show that \(X^{\varepsilon }\) converges as \(\varepsilon \downarrow 0\) in \(\mathcal{C}([0,\tau ],\mathcal{S})\), note that, by assumption (5.2) (and the condition for \(\beta \) therein), we can choose \(\kappa >0\) small enough such that \(\eta +(\eta +\frac{1}{2}-\kappa ) > 1-2\delta \) (which follows from (5.2)-(5.3)), \(\eta +\frac{1}{2}-\kappa >\frac{1}{2}-\delta \) (see above (5.1)), and \(\eta +\frac{1}{2}-\kappa >2\theta (\alpha -1)\) (see below (5.3)). Then, by items (i) and (ii) of Lemma 2.35 respectively, pointwise in \([0,\tau ]\),

and

and by Lemma 2.25,
Furthermore, by Corollary 3.15, for all \(T>0\)

in probability. It follows that there exists a random variable \(C_{\varepsilon }>0\) (with moments of all orders bounded uniformly in \(\varepsilon >0\)) such that, for all \(R>1\) and \(t\in [0,\tau ]\), on the event \(|\hat{X}_{t}|_{\mathcal{C}^{-\kappa}}+|\hat{X}^{\varepsilon }_{t}|_{\mathcal{C}^{-\kappa}} < R\), it holds that
-
\(\Sigma (X_{t})+\Sigma (X^{\varepsilon }_{t}) < C_{\varepsilon }R^{2}\), and
-
\(|\hat{X}_{t}-\hat{X}^{\varepsilon }_{t}|_{\mathcal{C}^{\eta +\frac{1}{2}-\kappa}} < \varepsilon \Rightarrow \Sigma (X_{t},X^{\varepsilon }_{t}) < c_{\varepsilon }R + C_{\varepsilon } \varepsilon \),
where \(c_{\varepsilon }\) is another random variable (with finite moments of all orders) such that \(c_{\varepsilon }\to 0\) in probability as \(\varepsilon \to 0\). Using that \(\hat{X}^{\varepsilon }\to \hat{X}\) in probability in \(\mathcal{C}([0,\tau ],\mathcal{C}^{\eta +\frac{1}{2}-\kappa})\), and using Proposition 2.58(ii) to handle continuity at time \(t=0\) for the stochastic heat equation, it follows that \(X^{\varepsilon }\to X\) in probability in \(\mathcal{C}([0,\tau ],\mathcal{S})\) as claimed.
Finally, we note that \(X^{\varepsilon }\) indeed solves equation (5.4) on the time interval \([0,\tau ]\), since for smooth initial data the equation (5.20) reconstructs to the same equation that (5.17) does.
After the initial time interval \([0,\tau ]\), we can restart the equation “close to stationarity” by solving for the remainder. More specifically, let \(V\) denote the solution in the space of modelled distributions for the remainder equation arising from the “generalised Da Prato–Debussche trick” in [11] and associated to the model  (we allow \(\varepsilon =0\)). Recall that this equation removes the stationary “distributional” objects, which in our case are
(we allow \(\varepsilon =0\)). Recall that this equation removes the stationary “distributional” objects, which in our case are  and
and  , and solves for the remainder in the space of modelled distributions \(\mathscr{U}^{\gamma ,\eta}_{+}\) specified in [11, Sect. 5.5, Eq. 5.16].
, and solves for the remainder in the space of modelled distributions \(\mathscr{U}^{\gamma ,\eta}_{+}\) specified in [11, Sect. 5.5, Eq. 5.16].
We start the equation from time \(\tau \) and with initial condition \(v^{\varepsilon }(\tau ) \stackrel {{\tiny \mathrm {def}}}{=}\hat{X}_{R}^{\varepsilon }(\tau ) + f^{\varepsilon }(\tau )\) where \(\hat{X}^{\varepsilon }_{R}\in \mathcal{C}([0,\tau ],\mathcal{C}^{\frac{1}{2}-\kappa})\) is defined as above and \(f^{\varepsilon }\) is defined by

where the symbols represent the stationary objects

Note that  converges in \(\mathcal{C}^{\infty}((0,\infty )\times \mathbf{T}^{3})\) and therefore
converges in \(\mathcal{C}^{\infty}((0,\infty )\times \mathbf{T}^{3})\) and therefore  converges in \(\mathcal{C}^{\frac{1}{2}-\kappa}((0,\infty )\times \mathbf{T}^{3})\) in probability as \(\varepsilon \downarrow 0\). Hence \(f^{\varepsilon }\) converges in probability in \(\mathcal{C}^{\frac{1}{2}-\kappa}((0,\infty )\times \mathbf{T}^{3}) \) as \(\varepsilon \downarrow 0\).
converges in \(\mathcal{C}^{\frac{1}{2}-\kappa}((0,\infty )\times \mathbf{T}^{3})\) in probability as \(\varepsilon \downarrow 0\). Hence \(f^{\varepsilon }\) converges in probability in \(\mathcal{C}^{\frac{1}{2}-\kappa}((0,\infty )\times \mathbf{T}^{3}) \) as \(\varepsilon \downarrow 0\).
Since the initial condition of \(V\) is Hölder continuous with exponent \(\frac{1}{2}-\kappa \), we obtain a maximal solution for \(V\) for which \(\mathcal{R}^{\varepsilon }V\) converges in \(\mathcal{C}^{\frac{1}{2}-\kappa}(\mathbf{T}^{3})^{{\mathop{\mathrm{sol}}}}\) to \(\mathcal{R}^{0} V\) (we use here that \(\mathcal{R}^{\varepsilon }V\) is continuous with respect to the initial data \(v^{\varepsilon }(\tau )\), and that \(v^{\varepsilon }(\tau )\to v^{0}(\tau )\)). Furthermore, \(f\) is chosen in such a way that

Finally, for \(\varepsilon >0\), it follows from coherence (specifically from [11, Thm. 5.7]) that  solves the equation (5.4) with initial condition \(X^{\varepsilon }(\tau )\) on \([\tau ,T^{*}_{\varepsilon })\), where \(T^{*}_{\varepsilon }\) is the maximal existence time of \(\mathcal{R}^{\varepsilon }V\). By the same argument as above concerning \(\hat{X}^{\varepsilon }\) and \(\Psi ^{\varepsilon }\) we further see that
solves the equation (5.4) with initial condition \(X^{\varepsilon }(\tau )\) on \([\tau ,T^{*}_{\varepsilon })\), where \(T^{*}_{\varepsilon }\) is the maximal existence time of \(\mathcal{R}^{\varepsilon }V\). By the same argument as above concerning \(\hat{X}^{\varepsilon }\) and \(\Psi ^{\varepsilon }\) we further see that  converges as \(\varepsilon \downarrow 0\) in probability in \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\) to
converges as \(\varepsilon \downarrow 0\) in probability in \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\) to  . This completes the proof of part (i).
. This completes the proof of part (i).
Part (ii) simply follows from the stability of the fixed point problem in space of modelled distributions with respect to coefficients in the fixed point problem. □
6 The gauge transformed system
We now formulate the first part of Theorem 1.9 precisely. Throughout the section, let \(\chi \) be a space-time mollifier. Define the mapping
by setting
Observe that (6.1) maps \(\mathfrak {G}^{0,\varrho }\) into \(\tilde{\mathfrak {G}}^{0,\varrho }\), the closure of smooth functions in \(\tilde{\mathfrak {G}}^{\varrho }\).
By Lemma C.1, for any \((x,g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\), if we write \((X^{\varepsilon },g^{\varepsilon })\) for the solution to (C.1)+(C.2) starting with initial data \((x,g_{0})\) and with \(c^{\varepsilon } = 0\) and \(\mathring{C}_{\mbox{A}}^{\varepsilon }\), \(\mathring{C}_{\Phi}^{\varepsilon }\) as in the statement of the lemma, then we have that \((X^{\varepsilon },g^{\varepsilon })\) converges in probability, as \(\varepsilon \downarrow 0\), in \((\mathcal{S}\times \mathfrak {G}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) to a limit \((X,g)\). We write  . We analogously write
. We analogously write  for the analogous construction, obtained via Lemma C.2 to take the limit of the solutions to (C.6)+(C.7) instead of (C.1)+(C.2).
for the analogous construction, obtained via Lemma C.2 to take the limit of the solutions to (C.6)+(C.7) instead of (C.1)+(C.2).
Theorem 6.1
Suppose \(\chi \) is non-anticipative and let  be as in (5.11) with \(\boldsymbol{\sigma}=1\). Fix \(\mathring{C}_{\mbox{A}}\in L_{G}(\mathfrak {g},\mathfrak {g})\), \((a,\phi ) \in \mathcal{S}\), and \(g(0)\in \mathfrak {G}^{0,\varrho }\). Let
be as in (5.11) with \(\boldsymbol{\sigma}=1\). Fix \(\mathring{C}_{\mbox{A}}\in L_{G}(\mathfrak {g},\mathfrak {g})\), \((a,\phi ) \in \mathcal{S}\), and \(g(0)\in \mathfrak {G}^{0,\varrho }\). Let  and
and  , and let \((B,\Psi ,g)\) be the solution to (1.16). Furthermore, for \(\check{C} \in L_{G}(\mathfrak {g},\mathfrak {g})\), let \((\bar{A},\bar{\Phi},\bar{g})\) be the solution to
, and let \((B,\Psi ,g)\) be the solution to (1.16). Furthermore, for \(\check{C} \in L_{G}(\mathfrak {g},\mathfrak {g})\), let \((\bar{A},\bar{\Phi},\bar{g})\) be the solution to
where we set \(\bar{g}\equiv 1\) on \((-\infty ,0)\).
-
(i)
For every \(\varepsilon >0\), there exists a smooth maximal solution to (6.3) in \((\mathcal{S}\times \mathfrak {G}^{0,\varrho })\) obtained by replacing \(\xi = \big( (\xi _{i})_{i=1}^{3}, \zeta \big)\) by \(\tilde{\xi}^{\delta} \stackrel {{\tiny \mathrm {def}}}{=}\xi \mathbf{1}_{t<0}+\mathbf{1}_{t\geq 0}\xi ^{ \delta}\) and taking the \(\delta \downarrow 0\) limit.
-
(ii)
There exists a unique operator \(\check{C}\in L_{G}(\mathfrak {g},\mathfrak {g})\) such that for all choices of \((B(0),\Psi (0), g(0)) = (\bar{A}(0),\bar{\Phi}(0), \bar{g}(0)) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\), \((B,\Psi ,U,h)\) and \((\bar{A},\bar{\Phi}, \bar{U},\bar{h})\) converge in probability to the same limit in \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) as \(\varepsilon \downarrow 0\). Here \(\bar{U},\bar{h}\) and \(U,h\) are determined by \(\bar{g}\) and \(g\) respectively via (6.2).
-
(iii)
The operator \(\check{C}\) above is independent of \(\mathring{C}_{\mbox{A}}\) and our choice of non-anticipative mollifier \(\chi \).
-
(iv)
\(\check{C}\) is the unique value of \(\mathring{C}_{\mbox{A}}\) for which the following property holds: for any \((x,g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\), if one writes
 and
and  , then \((g X, U,h) \stackrel {{\tiny \mathrm {law}}}{=}(\tilde{X},\tilde{U},\tilde{h}) \) in \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\), where \(\tilde{U},\tilde{h}\) and \(U,h\) are determined by \(\tilde{g}\) and \(g\) respectively via (6.2).
, then \((g X, U,h) \stackrel {{\tiny \mathrm {law}}}{=}(\tilde{X},\tilde{U},\tilde{h}) \) in \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\), where \(\tilde{U},\tilde{h}\) and \(U,h\) are determined by \(\tilde{g}\) and \(g\) respectively via (6.2).
 and
and  , then
, then The proof of Theorem 6.1 will be given at the end of this section. If \(\chi \) is non-anticipative, then \(\lim _{\delta \downarrow 0} \bar{U} \tilde{\xi}^{\delta} \) is equal in law to \(\xi \) by Itô isometry since \(\bar{U}\) is adapted and is orthogonal on \(E\). Therefore, when we choose \(\mathring{C}_{\mbox{A}}=\check{C}\), the law of \((\bar{A},\bar{\Phi})\) –which does not depend on \(\bar{g}\) anymore –is equal to the solution to (1.14) with initial condition \(g(0)(a,\phi )\), and Theorem 6.1 implies the desired property of gauge covariance described in Theorem 1.9(ii) –this property is illustrated in Fig. 1. The desired Markov process on gauge orbits in Sect. 7 will therefore be constructed from the \(\varepsilon \downarrow 0\) limit \(X=(A,\Phi )\) of the solutions to (1.14) where the constants are defined by (5.5) with \(\mathring{C}_{\mbox{A}}=\check{C}\) and \(\boldsymbol{\sigma}^{\varepsilon }=1\). Remark that, by Theorems 5.1(ii) and 6.1(iii), this \(X\) is canonical in that it does not depend on \(\chi \).

An illustration (see colour figure online) of the \((A,\Phi )\) system (blue) (1.14), the \((B,\Psi )\) system (red) (1.16), \(g\) (cyan) given by (1.16) (or equivalently (1.17)), and the \((\bar{A},\bar{\Phi})\) system (green) (6.3). The black curves stand for gauge orbits. With the choice \(\mathring{C}_{\mbox{A}}=\check{C}\), \((A,\Phi )\) and \((\bar{A},\bar{\Phi})\) have the same law modulo initial condition. As \(\varepsilon \downarrow 0\), the red and green curves on the right converge to the same limit
Remark 6.2
The non-anticipative assumption on the mollifier \(\chi \) is used in various places in the proof of Theorem 6.1(ii). We use it in Proposition 6.38 to relate (6.3) in law to an SPDE with additive noise, for which the short-time analysis is simpler. Furthermore, under this assumption, \(\check{C}\) defined by the limit in (6.113) is an \(\varepsilon \)-independent finite constant; this relies on Proposition 6.43 which requires a non-anticipative mollifier.
Before continuing we describe some of the important differences between the proof of Theorem 6.1 and the analogous theorem in \(d=2\), namely [22, Thm. 2.9]. For this comparison, the fact that [22] does not involve a Higgs field is an immaterial difference.
Firstly, the short-time analysis of the systems (1.16) and (6.3) is significantly more involved for \(d=3\) than \(d=2\). We therefore require control on more stochastic objects (in addition to the models) which arise from ill-defined products between terms involving the noise and the initial condition; some of these objects require non-trivial renormalisation not present in \(d=2\) (see (6.58) and (6.66)).
We furthermore require a more involved decomposition of the abstract fixed point problem due to these singularities than for \(d=2\). This is particularly the case in the analysis of the maximal solution to the system (6.3) performed in Proposition 6.39, where we require a new fixed point problem which solves for a suitable ‘remainder’. While a similar but simpler change in the fixed point problem was also required in [22, Sect. 7.2.4], the main difference here is that we need to leverage the fact that the fixed point for the ‘remainder’ has an improved initial condition. (We already met similar considerations in the proof of Theorem 5.1, where we used two different strategies for the time intervals \([0,\tau ]\) and \([\tau ,\infty )\) and were able to fall back on the results of [11] for the latter due to the additive nature of the noise – in the proof of Proposition 6.39, the results of [11] are not available because the noise is multiplicative.)
Next, note that the parameters \(\bar{C}\) appearing in [22, Thm 2.9] and \(\check{C}\) in Theorem 6.1 are related as follows: in \(d=2\), one has the convergence  where
where  is the BPHZ constant appearing in Theorem 1.7.Footnote 19 The parameter \(\bar{C}\) appearing in [22] would then correspond to
is the BPHZ constant appearing in Theorem 1.7.Footnote 19 The parameter \(\bar{C}\) appearing in [22] would then correspond to  .
.
The key difference in our arguments is the use of explicit formulae for renormalisation constants in \(d=2\) vs. small noise limits and injectivity arguments in \(d=3\) –without either of these the best one would be able to do in both \(d=2,3\) would be to obtain Theorem 6.1(ii) with the modification that \(\check{C}\) would have to be replaced by, say, \(\check{C}_{\varepsilon }\) which in principle would be allowed to diverge as \(\varepsilon \downarrow 0\).
In \(d=2\), \(\bar{C}_{\varepsilon }\) can be computed explicitly in terms of a small number of trees, and it can be shown that one has the convergence \(\lim _{\varepsilon \downarrow 0} \bar{C}_{\varepsilon } = \bar{C}\). This gives [22, Thm 2.9(i)]. Moreover one can directly verify that, for a non-anticipative mollifier,  is independent of the mollifier. This would prove Theorem 6.1(iii) in \(d=2\) since in the limit, BPHZ renormalisation removes all the dependence on the mollifier.
is independent of the mollifier. This would prove Theorem 6.1(iii) in \(d=2\) since in the limit, BPHZ renormalisation removes all the dependence on the mollifier.
In \(d=3\), \(\check{C}_{\varepsilon }\) has contributions from dozens of trees and explicit computation is not feasible. As mentioned earlier, by using small noise limits we can argue that \(\check{C}_{\varepsilon }\) remains bounded as \(\varepsilon \downarrow 0\) (Lemmas 6.36 and 6.37). Injectivity of our solution theory also provides some rigidity and prevents \(\check{C}_{\varepsilon }\) from having distinct subsequential limits (Propositions 6.41 and 6.43). This gives the convergence \(\lim _{\varepsilon \downarrow 0} \check{C}_{\varepsilon } = \check{C}\) which establishes Theorem 6.1(ii). These same propositions also show that the limiting \(\check{C}\) does not depend on our particular choice of non-anticipative mollifier which gives part of Theorem 6.1(iii).Footnote 20
Note that while \(\check{C}\) is independent of the mollifier in both \(d=2,3\) we do not claim that it is a universalFootnote 21 constant –our constant \(\check{C}\), as well as the constants  ,
,  , is fixed only once one has fixed a BPHZ lift of space-time white noise, but the latter is not canonical since we must prescribe a large-scale truncation of the heat kernel to perform this lift.
, is fixed only once one has fixed a BPHZ lift of space-time white noise, but the latter is not canonical since we must prescribe a large-scale truncation of the heat kernel to perform this lift.
6.1 Setting up regularity structures
As in [22, Sect. 7] we will replace the evolutions of gauge transformations in (1.16) and (6.3) with evolutions in linear spaces –to that end, recall the mapping (6.1). We next state a lemma about writing the dynamics (1.16) and (6.3) in terms of the variables (6.2).
Below it will be convenient to overload notation and sometimes write \(\boldsymbol{\varrho }\) for the direct sum of the adjoint representation of \(G\) on \(\mathfrak {g}\) and the representation of \(G\) on \(\mathbf{V}\). Note that we also write \(\boldsymbol{\varrho }\) for its derivative representation (except in the proof of Lemma 6.3 where we will use \(\bar{\boldsymbol{\varrho }}\) instead since the distinction is conceptually more important there), but the meaning of \(\boldsymbol{\varrho }\) will be clear from the context.
Lemma 6.3
Consider any smooth \(B\colon (0,T]\to \Omega \mathcal {C}^{\infty}\) and suppose \(g\) solves the third equation in (1.16). Then \(h\) and \(U\) defined by (6.2) satisfy
Proof
The derivation for the equation of \(h\) is exactly the same as in [22, Lem. 7.2] since it does not rely on any specific representation, and in particular the third equation in (1.16) for \(g\) can be rewritten as
Given any Lie group representation \(\boldsymbol{\varrho }: G \to GL(V)\) for a vector space \(V\) and its derivative representation \(\bar{\boldsymbol{\varrho }}: \mathfrak {g}\to L(V,V)\), (6.5) implies that the function \(U \colon \mathbf{T}^{3} \rightarrow GL(V)\) defined by \(U=\boldsymbol{\varrho }(g)\) satisfies (6.4).
Indeed if \(\bar{h}_{i} =(\partial _{i} g) g^{-1} \) for \(i\in \{0\}\cup [d]\), then \(\bar{\boldsymbol{\varrho }}(\bar{h}_{i}) = \partial _{i} (\boldsymbol{\varrho }(g)) \boldsymbol{\varrho }(g)^{-1} \) and so in particular \(\partial _{i} U = \bar{\boldsymbol{\varrho }}(\bar{h}_{i}) U\). This identity has two consequences:
These two identities together then yield the desired equation. □
Define \(U\) and \(h\) as in (6.2) using \(g\) from (1.16), and \(\bar{U}\) and \(\bar{h}\) as in (6.2) using \(\bar{g}\) from (6.3). We can then rewrite the “unrenormalised” equations of (1.16) and (6.3) respectively as
combined with (6.4) for the evolution of \((U,h)\) and
again combined with (6.4). Note that in the nonlinear terms such as \(B_{j}^{2} \Psi \) we are implicitly referencing the derivative representation of \(\mathfrak {g}\) on \(\mathbf{V}\).
To set up the regularity structure, as in the previous section, we combine the components of the connection and the Higgs field into a single variable: \(\bar{X} = ((\bar{A}_{i})_{i=1}^{3},\bar{\Phi})\) and \(Y = ((B_{i})_{i=1}^{3},\Psi )\). Recall the notation \(\xi \stackrel {{\tiny \mathrm {def}}}{=}((\xi _{i})_{i=1}^{3},\zeta )\). Our approach is to work with one single regularity structure to simultaneously study the systems (6.4)+(6.6) for \((Y,U,h)\) and (6.4)+(6.7) for \((\bar{X}, \bar{U}, \bar{h})\), allowing us to compare their solutions at the abstract level of modelled distributions. In fact, we will set it up in such a way that in the \(\varepsilon \downarrow 0\) limit, the two solution maps associated to each of these systems converge to the same limit as modelled distributions.
Let \(\kappa >0\). We introduce the label sets \(\mathfrak {L}_{+} \stackrel {{\tiny \mathrm {def}}}{=}\{\mathfrak {z}, \mathfrak {m}, \mathfrak {h}, \mathfrak {h}', \mathfrak {u}\} \) and \(\mathfrak {L}_{-} \stackrel {{\tiny \mathrm {def}}}{=}\{\mathfrak {l}, \bar{\mathfrak {l}} \}\) and set their degrees to
We briefly explain the roles of the types introduced above. Regarding noises, \(\bar{\mathfrak {l}}\) represents the noise \(\chi ^{\varepsilon } \ast \xi \) in the \((B,\Psi )\) equation (6.6), while \(\mathfrak {l}\) represents the noise \(\xi \) in the \((\bar{A},\bar{\Phi})\) equation (6.7).Footnote 22
To understand the roles of the types \(\mathfrak {z}\) and \(\mathfrak {m}\), observe that when writing (6.7) as an integral equation we are in an analogous situation to the one described in [22, Sect. 7.2], namely the term \(\bar{U} \xi = ( (\bar{U}_{\mathfrak {g}} \xi _{i})_{i=1}^{3}, \bar{U}_{ \mathbf{V}} \zeta )\) appearing on the right-hand side is convolved with a mollified heat kernel \(G \ast \chi ^{\varepsilon }\) while the remaining terms are convolved with an un-mollified heat kernel. This requires us to use two types to track the RHS of (6.7): we use \(\mathfrak {m}\) for the term \(\bar{U} \xi \) and \(\mathfrak {z}\) for everything else. As in [22, Sect. 7.2], we also use \(\mathfrak {z}\) to keep track of the entire RHS of (6.6).
One difference in our use of types versus what was done in [22, Sect. 7] is that here the RHS of the equation for \(h\) in (6.4) is also split into two pieces using the types \(\mathfrak {h}\) and \(\mathfrak {h}'\). Since we are working in dimension \(d=3\), power counting after an application of Leibniz rule would suggest that the terms \(\partial _{i} [B_{j},h_{j}]\) could generate a number of counterterms, but by keeping them written as total derivatives we can easily verify that no counterterms are generated. To implement this we use \(\mathfrak {h}'\) to keep track of the terms \([B_{j},h_{j}]\) with the understanding that in the integral equation for \(h\) coming from (6.4), the terms associated to \(\mathfrak {h}'\) should be integrated with the gradient of the heat kernel, while \(\mathfrak {h}\) tracks the rest of the RHS of the \(h\) equation in (6.4) while \(\mathfrak {u}\) tracks the \(U\) equation.
We will specify the corresponding rule \(R\) later, but it will be subcritical with respect to the map \(\mathrm{reg}: \mathfrak{L}\rightarrow {\mathbf {R}}\) given by
provided that \(\kappa < \frac{1}{100}\) (more stringent requirements on \(\kappa \) will be imposed for other purposes later). Our target space assignment \((W_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak {L}}\) is given by
and our kernel space assignment \((\mathcal{K}_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak {L}_{+}}\) is given by
The assignment \((V_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak {L}}\) used to build our regularity structure is then given by (4.1).
We now specify our ruleFootnote 23
It is straightforward to verify that \(\mathring{R}\) is subcritical with respect to deg (for \(\mathrm{reg}\) defined as above), and has a smallest normal extension which admits a completion \(R\) and that is also subcritical. We use \(R\) to define our regularity structure and write \(\mathfrak {T}\) for the corresponding set of trees conforming to \(R\). As in Sect. 5 we write  and
and  , and later we will also use the notations
, and later we will also use the notations  and
and  for the corresponding \(E\)-valued modelled distributions.
for the corresponding \(E\)-valued modelled distributions.
The kernel assignment \(K^{(\varepsilon )} = (K_{\mathfrak {t}}^{(\varepsilon )}: \mathfrak {t}\in \mathfrak{L}_{+})\) is given by
where \(K^{\varepsilon }= K \ast \chi ^{\varepsilon }\).
Our noise assignment \(\zeta ^{\delta ,\varepsilon } = (\zeta _{\mathfrak {l}}: \mathfrak {l}\in \mathfrak {L}_{-})\) is given by
Namely, \(\bar{\mathfrak {l}}\) indexes the noise \(\xi ^{\varepsilon }= \boldsymbol{\sigma}^{\varepsilon } \chi ^{\varepsilon }* \xi \) in (6.6), while \(\mathfrak {l}\) indexes the white noise \(\boldsymbol{\sigma}^{\varepsilon } \xi \) in (6.7) –we have replaced \(\xi \) with \(\xi ^{\delta}\) above since it is convenient to work with smooth models, we will later take, for \(\varepsilon >0\), the benign limit \(\delta \downarrow 0\) to obtain (6.7). The label \(\mathfrak {m}\) is used to track the term \(\bar{U} \xi \) in (6.7) –these terms are treated separately because they are hit by a mollified heat kernel, which is why we defined \(K_{\mathfrak {m}}^{(\varepsilon )} = K^{\varepsilon }\) above.
We now fix two nonlinearities \(F = \bigoplus _{\mathfrak {t}\in \mathfrak{L}} F_{\mathfrak {t}},\ \bar{F} = \bigoplus _{ \mathfrak {t}\in \mathfrak{L}} \bar{F}_{\mathfrak {t}} \) which encode the systems \((Y,U,h)\) and \((\bar{X},\bar{U}, \bar{h})\) separately. For \(\mathfrak {t}\in \mathfrak{L}_{-}\) we set \(F_{\mathfrak {t}}= \bar{F}_{\mathfrak {t}}= \mathrm{id}_{E}\) (recalling that  ), and set, similarly as in (5.7),
), and set, similarly as in (5.7),

We also write  and similarly decompose
and similarly decompose  .
.
Recalling the convention (1.12), overloading notation  and writing
and writing
we define

Moreover, writing  ,
,  , and
, and  , we define
, we define

where \((e_{k})\) is the canonical basis of \(V_{\mathfrak {h}'}={\mathbf {R}}^{3}\) and the index \(j\) is summed over \(\{1,2,3\}\); and finally

Remark 6.4
By [22, Sect. 5.8] the nonlinearity \(F_{\mathfrak {h}'} \) takes values in \(V_{\mathfrak {h}'} \otimes W_{\mathfrak {h}'} \cong {\mathbf {R}}^{3} \otimes \mathfrak {g}^{3} \cong \mathfrak {g}^{3\times 3}\), although it has a special diagonalFootnote 24 form with identical entries. This is because \(F_{\mathfrak {h}'} \) here describes a gradient of a \(\mathfrak {g}\)-valued function.
Regarding \(\bar{F}\), we set

and  ,
,  ,
,  in the same way as (6.13) above,
in the same way as (6.13) above,

and define \(\bar{F}_{\mathfrak {h}} \), \(\bar{F}_{\mathfrak {h}'}\), \(\bar{F}_{\mathfrak {u}} \) in the same way as \(F_{\mathfrak {h}}\), \(F_{\mathfrak {h}'}\), \(F_{\mathfrak {u}}\) except that  ,
,  ,
,  are replaced by
are replaced by  ,
,  ,
,  .
.
We write ℳ for the space of all models and, for \(\varepsilon \in [0,1]\), we write \(\mathscr{M}_{\varepsilon } \subset \mathscr{M}\) for the family of \(K^{(\varepsilon )}\)-admissible models. We also define  to be the BPHZ character associated to the kernel assignment \(K^{(\varepsilon )}\) and the noise assignment \(\zeta ^{\delta ,\varepsilon }\).
to be the BPHZ character associated to the kernel assignment \(K^{(\varepsilon )}\) and the noise assignment \(\zeta ^{\delta ,\varepsilon }\).
6.2 Renormalisation of the gauge transformed system
The following proposition is one of the main results of this section and describes the form of the BPHZ counterterms that appear in (6.6) and (6.7) after renormalisation. In order to write these counterterms in a clean form, we will want to impose a nonlinear constraint on  and
and  that is consistent with (6.2). Recalling that
that is consistent with (6.2). Recalling that  , we define
, we define
Definition 6.5
We define  to be the collection of
to be the collection of  such that
such that  and
and  for each \(i \in \{1,2,3\}\).Footnote 25
for each \(i \in \{1,2,3\}\).Footnote 25
Proposition 6.6
For \(\mathfrak {t}\in \{\mathfrak {u},\mathfrak {h},\mathfrak {h}'\}\) and any  one has
one has

Moreover, there exist operators  and
and  such that, for any
such that, for any  ,
,

where  and
and  are the same maps as in Proposition 5.7. One also has the convergence
are the same maps as in Proposition 5.7. One also has the convergence

Finally there are  and
and  for \(j\in \{1,2\}\) which are all independent of \(\boldsymbol{\sigma}\), such that
for \(j\in \{1,2\}\) which are all independent of \(\boldsymbol{\sigma}\), such that

where \(\bullet \in \{ \mbox{\footnotesize {YM, Gauge, Higgs}} \}\).
The proof of Proposition 6.6 requires many intermediate computations and is delayed to the end of Sect. 6.3. We note that the situation here is more complicated than Proposition 5.7, in particular the number of trees of negative degree that appear is much larger and power-counting arguments as in Lemma 5.11 do not get us quite as far because of the presence of components  and
and  of positive regularity. We will have to combine power-counting and parity arguments in a more sophisticated way.
of positive regularity. We will have to combine power-counting and parity arguments in a more sophisticated way.
As before, we define \(\mathfrak{T}_{-}\) the set of all unplanted trees in \(\mathfrak{T}\) with vanishing polynomial label at the root and negative degree. To impose parity constraints, we define the following sets of trees where we recall the definition of \(n(\tau )\) in (4.3) and write \(n(\tau ) = (n_{0}(\tau ),\dots ,n_{d}(\tau )) \in {\mathbf {N}}^{d+1}\):
The first set above enforces that a tree has “even parity in space” while the second enforces that a tree has “even parity in the noise”. We also define \(\mathfrak {T}^{\mathrm{od,sp}}\) and \(\mathfrak {T}^{\mathrm{od,noi}}\) analogously with “even” replaced by “odd”. We set  . Note that some of our notation in this section, like \(\mathfrak {T}\) and
. Note that some of our notation in this section, like \(\mathfrak {T}\) and  , collide with notation we used in Sect. 5 but which definition we are referring to should be clear from context –namely in this section we are, unless we explicitly say otherwise, always referring to the definitions made in this section.Footnote 26
, collide with notation we used in Sect. 5 but which definition we are referring to should be clear from context –namely in this section we are, unless we explicitly say otherwise, always referring to the definitions made in this section.Footnote 26
We have the following version of Lemma 5.5 which is proven in exactly the same way.
Lemma 6.7
Let \(\tau \in \mathfrak {T}\), then  . □
. □
Remark 6.8
A generalisation of Remark 5.6 also holds in the present setting. In particular, recalling \(\mathring{C}_{\mathfrak {z}}\) and \(\mathring{C}_{\mathfrak {h}}\) from (6.14), \(\mathring{C}_{\mathfrak {h}}\) cannot generate any new renormalisation by power counting and the counterterms generated by \(\mathring{C}_{\mathfrak {z}}\) are of the same type as in Remark 5.6, with the BPHZ characters vanishing on them by parity. This implies again that the constants on the right-hand side of (6.19) do not depend on \(\mathring{C}_{\mathfrak {z}}\) or \(\mathring{C}_{\mathfrak {h}}\).
In what follows, we will first show that the \((Y,U,h)\) system only requires renormalisation terms that are linear in \((Y,h)\) in the \(Y \) equation. We then point out how to get the same result for the \((\bar{X}, \bar{U}, \bar{h})\) system.
Remark 6.9
We overload our Lie bracket notation in various ways. For \((a_{i})_{i=1}^{d}\), \((b_{i})_{i=1}^{d} \in \mathfrak {g}^{d}\), we write \([a,b] \stackrel {{\tiny \mathrm {def}}}{=}\sum _{i=1}^{d} [a_{i},b_{i}] \in \mathfrak {g}\). For \(u = v \oplus w \in \mathfrak {g}^{d} \oplus \mathbf{V}= W_{\mathfrak {z}}\) and \(b \in \mathfrak {g}^{d}\) we set \([u,b] \stackrel {{\tiny \mathrm {def}}}{=}[v,b] \in \mathfrak {g}\). For \(h\in \mathfrak {g}\) and \(u\in \mathfrak {g}^{d}\), we define \([h,u] \in \mathfrak {g}^{d}\) componentwise.
The equations for \(h_{i}\) and \(U\) contain several products that are not classically defined, namely, the term \([h_{j},\partial _{j} h_{i}] \), and \([B_{j}, h_{j}]\) which appears three times. However, the following lemma shows that BPHZ renormalisation doesn’t generate any renormalisationFootnote 27 in the equations for \(h_{i}\) and \(U\).
Lemma 6.10
For every  one has \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {h}} [\tau ] =\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {h}'} [ \tau ]= \bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {u}}[\tau ]=0\).
one has \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {h}} [\tau ] =\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {h}'} [ \tau ]= \bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {u}}[\tau ]=0\).
Recall [22, Lemma 5.65, Remark 5.66] that the map \(\boldsymbol{\Upsilon}^{F}\) can be computed by an (algebraic) Picard iteration as follows. An element  , where
, where  is the space of expansions as in [22, Sect. 5.8], has the form
is the space of expansions as in [22, Sect. 5.8], has the form  where
where  ,Footnote 28 and if
,Footnote 28 and if  is coherent then (up to truncation at some order),
is coherent then (up to truncation at some order),

where  . Given
. Given  , we substitute it into the right-hand side of (6.23), and obtain an element \(\mathcal {A}^{R}\), which together with
, we substitute it into the right-hand side of (6.23), and obtain an element \(\mathcal {A}^{R}\), which together with  yields a new element
yields a new element  which is then substituted again into the right-hand side of (6.23). By subcriticality, this iteration stabilises after a finite number of steps to an element which gives
which is then substituted again into the right-hand side of (6.23). By subcriticality, this iteration stabilises after a finite number of steps to an element which gives  .
.
We will use a “substitution” notation to keep track of how terms are produced by expanding the polynomial \(F\) on the right-hand side of (6.23). As an example, we write

The notation  indicates that we replace
indicates that we replace  with the term on the left-hand side. Thus (6.24) corresponds to
with the term on the left-hand side. Thus (6.24) corresponds to

which is a contribution to  (since
(since  and
and  appears on the RHS for the equation for \(U\).)
appears on the RHS for the equation for \(U\).)
Note that above we are using the convention for Lie brackets given in Remark 6.9 and we set  . Below, when multiple factors are being substituted as in (6.26a)–(6.26b) the substitutions should be read from left to right on both sides.
. Below, when multiple factors are being substituted as in (6.26a)–(6.26b) the substitutions should be read from left to right on both sides.
Proof of Lemma 6.10
Denote \(\mathcal {Y}\stackrel {{\tiny \mathrm {def}}}{=}\mathcal {A}_{\mathfrak {z}}\) and \(\mathcal {H}\stackrel {{\tiny \mathrm {def}}}{=}\mathcal {A}_{\mathfrak {h}}+\mathcal {A}_{\mathfrak {h}'}\). We start with the coherent expansion  , where \(Y_{0} \) is obtained by substituting both
, where \(Y_{0} \) is obtained by substituting both  in
in  by
by  . Here \(q_{\le L}\) denotes the projection onto degrees \(\le L\). A substitution
. Here \(q_{\le L}\) denotes the projection onto degrees \(\le L\). A substitution  in the \(h\) equation yields
in the \(h\) equation yields  where
where

Considering the term  in the \(U\) equation: by a simple power counting the only substitutions relevant to \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {u}}[\tau ]\) with \(\tau \in \mathfrak {T}_{-}\) are
in the \(U\) equation: by a simple power counting the only substitutions relevant to \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {u}}[\tau ]\) with \(\tau \in \mathfrak {T}_{-}\) are

which only contribute to \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {u}}[\tau ]\) with \(\tau \in \mathfrak {T}^{\mathrm{od,noi}}\) and \(\tau \in \mathfrak {T}^{\mathrm{od,sp}}\) respectively. Thus the claim for \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {u}}\) holds.
We turn to the equation for \(h_{i}\). Considering the term  , by power counting the relevant substitutions are
, by power counting the relevant substitutions are  and
and

which only contribute to \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {h}}[\tau ]\) with \(\tau \in \mathfrak {T}^{\mathrm{od,noi}}\) or \(\tau \in \mathfrak {T}^{\mathrm{od,sp}}\). Concerning the term  , the substitution
, the substitution

gives an updated expansion  where
where

Now for the term  in the equation for \(h_{i}\), the relevant substitutions
in the equation for \(h_{i}\), the relevant substitutions

again lead to trees in \(\mathfrak {T}^{\mathrm{od,noi}}\) or \(\mathfrak {T}^{\mathrm{od,sp}}\), which proves the claim for \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {h}}\) and \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {h}'}\). □
We now prepare for our analysis of the renormalisation in the equation for  equation by keeping track of the key substitutions involved.
equation by keeping track of the key substitutions involved.
The main difference between renormalising the  equation versus renormalising the YMH equation of Sect. 5 comes from substituting for
equation versus renormalising the YMH equation of Sect. 5 comes from substituting for  . The coherent expansion (up to order \(5/2\)) for
. The coherent expansion (up to order \(5/2\)) for  is written as
is written as

where the subscripts indicate the degrees (minus some multiple of \(\kappa > 0\) which is taken to be arbitrarily small). Here the term \(U_{3/2}\) is obtained by (6.26a) and \(U_{2}\) is obtained by (6.26b). The term \(U_{5/2}\) is obtained by summing

Above we have listed parity information for the substitutions as well –recall that the parities of \(h_{1/2}\) and \(h_{1}\) are given in (6.25) and (6.27). Here \(Y_{1/2}\) is the degree \(\frac{1}{2} -\) term in the coherent expansion of \(\mathcal {Y}\stackrel {{\tiny \mathrm {def}}}{=}\mathcal {A}_{\mathfrak {z}}\), which arises from

To find all the relevant trees contributing to the renormalisation of the \((Y,U,h)\) system, we can simply take the trees for the YMH system discussed in Sect. 5 such as  and replace some of their noises by the trees that appear in
and replace some of their noises by the trees that appear in  . Intuitively one could think of the \(Y\) equation as driven by “additive noises” which are \(\xi \) multiplied by the terms in (6.28).
. Intuitively one could think of the \(Y\) equation as driven by “additive noises” which are \(\xi \) multiplied by the terms in (6.28).
Remark 6.11
Note that \(U_{2}\) depends on \(Y_{0}\), and \(U_{5/2}\) depends on \(Y_{0}\) and \(Y_{1/2}\). Fortunately, \(Y_{0}\) and \(Y_{1/2}\) only depend on the first two terms on the right-hand side of (6.28) (since \(Y_{r}\) depends on \(U_{s}\) if \(s-\frac{5}{2}+2 \le r\)). This makes some of the explicit calculations below not too difficult.
6.2.1 Grafting
In this section we make precise the statement above that we compute the renormalisation of the \(Y\) equation by using the trees for the simpler YMH equation of Sect. 5. The purpose of this subsection is to facilitate the proof of Lemma 6.22. Instead of trying to compute the renormalisation counterterms by hand, we instead use arguments that only leverage space and noise parity arguments and the relation of the \(Y\) equation to the YMH equation of Sect. 5.
Let \(\tilde{\mathfrak {T}}\) be the set of trees that was referred to as \(\mathfrak {T}\) in Sect. 5. Since our label set and rule is just an extension of what was introduced in Sect. 5, we have that \(\tilde{\mathfrak {T}} \subset \mathfrak {T}\) where \(\mathfrak {T}\) refers to the set of trees we introduced in this section. Since our target and kernel space assignments in this section are also just an extension of those introduced in Sect. 5, we also have canonical inclusions  . We also write
. We also write  and
and  for the corresponding maps for the YMH system which are defined on
for the corresponding maps for the YMH system which are defined on  .
.
We write  for the set of all trees \(\tau \in \tilde{\mathfrak {T}} \cap \mathfrak{T}_{-}\) with
for the set of all trees \(\tau \in \tilde{\mathfrak {T}} \cap \mathfrak{T}_{-}\) with  .
.
Remark 6.12
We make some observations about the structure of trees  . First, any
. First, any  cannot contain any instances of
cannot contain any instances of  for any \(p,k \in {\mathbf {N}}^{d+1}\). If this was the case then one would be able to replace an instance of
for any \(p,k \in {\mathbf {N}}^{d+1}\). If this was the case then one would be able to replace an instance of  in \(\tau \) with
in \(\tau \) with  to obtain a new tree
to obtain a new tree  for which \(\deg (\bar{\tau}) \le \deg (\tau ) + \deg (\bar{\mathfrak {l}})\). But since \(\deg (\tau ) < 0\), this would violate subcriticality.
for which \(\deg (\bar{\tau}) \le \deg (\tau ) + \deg (\bar{\mathfrak {l}})\). But since \(\deg (\tau ) < 0\), this would violate subcriticality.
Second, any  cannot have instances of
cannot have instances of  for \(k \neq 0\) –since
for \(k \neq 0\) –since  , this would force
, this would force  .
.
Putting these two observations together,  imposes that the leaves of \(\tau \) are given by noises, and there are no products of a polynomial with noises. This will be useful to keep in mind for some of the lemmas (and inductive proofs) to follow.
imposes that the leaves of \(\tau \) are given by noises, and there are no products of a polynomial with noises. This will be useful to keep in mind for some of the lemmas (and inductive proofs) to follow.
We define \(\mathfrak {T}_{g}\) (\(g\) stands for “grafting”) to be the collection of all the trees used to describe the RHS of (6.28), namely,

In particular \(\mathfrak {T}_{g}\) has as elements the abstract monomials,  , and
, and

which can be seen by the discussion below (6.28) (or (6.26a)–(6.26b)), and

which originate from (6.29a), (6.29b), (6.29c). Here, \(i,j \in \{1,2,3\}\) represent space indices which specify the directions of the derivatives appearing on the given symbol. Again, the subscripts indicate their degrees (modulo a multiple of \(\kappa \)). Our list of the \(\frac{5}{2}\) trees is not exhaustive; we listed only those in \(\mathfrak {T}^{\mathrm{ev,sp}} \cap \mathfrak {T}^{\mathrm{od,noi}}\) since the rest of them will turn out to be irrelevant in renormalisation.
As described earlier, we will modify the trees  by replacing an instance of \(\bar{\mathfrak {l}}\) in \(\bar{\tau}\) by \(\hat{\tau} \bar{\mathfrak {l}}\) where \(\hat{\tau} \in \mathfrak {T}_{g}\). We will also say that \(\hat{\tau}\) is “grafted” onto \(\bar{\mathfrak {l}}\) in the tree \(\bar{\tau}\). Note that grafting \(\mathbf{1}\) onto some
by replacing an instance of \(\bar{\mathfrak {l}}\) in \(\bar{\tau}\) by \(\hat{\tau} \bar{\mathfrak {l}}\) where \(\hat{\tau} \in \mathfrak {T}_{g}\). We will also say that \(\hat{\tau}\) is “grafted” onto \(\bar{\mathfrak {l}}\) in the tree \(\bar{\tau}\). Note that grafting \(\mathbf{1}\) onto some  yields \(\bar{\tau}\) itself. For instance, for \(j \in \{1,2,3\}\), we have
yields \(\bar{\tau}\) itself. For instance, for \(j \in \{1,2,3\}\), we have  and two modifications of the tree given by grafting
and two modifications of the tree given by grafting  are
are

For any  and \(\hat{\tau} \in \mathfrak {T}_{g}\), we define \(\mathfrak {T}[\hat{\tau};\bar{\tau}] \subset \mathfrak {T}\) to be the collection of all the trees \(\tau \in \mathfrak {T}\) which are obtained by precisely one grafting of \(\hat{\tau}\) onto an instance of \(\bar{\mathfrak {l}}\) in \(\bar{\tau}\). More precisely, \(\mathfrak {T}[\hat{\tau};\bar{\tau}]\) is defined inductively in the number of instances of \(\bar{\mathfrak {l}}\) in \(\bar{\tau}\). For the base case we have \(\bar{\tau} = \bar{\mathfrak {l}}\) and set \(\mathfrak {T}[ \hat{\tau}; \bar{\mathfrak {l}}] = \{ \hat{\tau}\bar{\mathfrak {l}} \}\). For the inductive step, we note that any
and \(\hat{\tau} \in \mathfrak {T}_{g}\), we define \(\mathfrak {T}[\hat{\tau};\bar{\tau}] \subset \mathfrak {T}\) to be the collection of all the trees \(\tau \in \mathfrak {T}\) which are obtained by precisely one grafting of \(\hat{\tau}\) onto an instance of \(\bar{\mathfrak {l}}\) in \(\bar{\tau}\). More precisely, \(\mathfrak {T}[\hat{\tau};\bar{\tau}]\) is defined inductively in the number of instances of \(\bar{\mathfrak {l}}\) in \(\bar{\tau}\). For the base case we have \(\bar{\tau} = \bar{\mathfrak {l}}\) and set \(\mathfrak {T}[ \hat{\tau}; \bar{\mathfrak {l}}] = \{ \hat{\tau}\bar{\mathfrak {l}} \}\). For the inductive step, we note that any  with \(\bar{\tau} \neq \bar{\mathfrak {l}}\) can be written
with \(\bar{\tau} \neq \bar{\mathfrak {l}}\) can be written

and we then set

Remark 6.13
Note that the parity in space / parity in the number of noises / degree of every tree in \(\mathfrak {T}[\hat{\tau};\bar{\tau}]\) is the sum of the corresponding quantities for \(\hat{\tau}\) and \(\bar{\tau}\). We also note that, for  , the condition \((\hat{\tau}_{1},\bar{\tau}_{1}) \neq (\hat{\tau}_{2},\bar{\tau}_{2} )\) forces \(\mathfrak {T}[ \hat{\tau}_{1} ; \bar{\tau}_{1}]\) and \(\mathfrak {T}[ \hat{\tau}_{2} ; \bar{\tau}_{2}]\) to be disjoint.
, the condition \((\hat{\tau}_{1},\bar{\tau}_{1}) \neq (\hat{\tau}_{2},\bar{\tau}_{2} )\) forces \(\mathfrak {T}[ \hat{\tau}_{1} ; \bar{\tau}_{1}]\) and \(\mathfrak {T}[ \hat{\tau}_{2} ; \bar{\tau}_{2}]\) to be disjoint.
We write \(\mathfrak {T}_{g}[\bar{\tau}] = \bigsqcup _{\hat{\tau} \in \mathfrak {T}_{g}} \mathfrak {T}[ \hat{\tau} ;\bar{\tau}]\), and define the following subspaces of 

We then have the following lemma which classifies the trees in  .
.
Lemma 6.14
Let  with \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {z}}[\tau ] \neq 0\), then \(\tau \in \mathfrak {T}_{g}[\bar{\tau}] \) for some
with \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {z}}[\tau ] \neq 0\), then \(\tau \in \mathfrak {T}_{g}[\bar{\tau}] \) for some  .
.
Moreover, precisely one of the following statements hold:
-
1.
 .
. -
2.
\(\tau \in \mathfrak{T}[\mathbf{X}_{j};\bar{\tau}]\) for some \(j \in \{1,2,3\}\) and
 (6.35)
(6.35) -
3.
 for some
for some  (6.36)
(6.36) -
4.
 for some \(\hat{\tau}\) given in (6.31).
for some \(\hat{\tau}\) given in (6.31). -
5.
 for some \(\hat{\tau}\) given in (6.32).
for some \(\hat{\tau}\) given in (6.32).
 .
.
 for some
for some 
 for some
for some  for some
for some Remark 6.15
Note that the assumption \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {z}}[\tau ] \neq 0\) is needed because the set of trees \(\mathfrak {T}\) includes many trees that don’t even appear in the coherent expansion of the  system (such as \(\mathfrak {l}\)) and the lemma would fail in these cases.
system (such as \(\mathfrak {l}\)) and the lemma would fail in these cases.
Remark 6.16
The trees satisfying (6.36) are  ,
,  ,
,  . Some examples of trees satisfying (6.35) are
. Some examples of trees satisfying (6.35) are

In fact, (6.35) implies that \(\bar{\tau}\) can only have 2 or 4 noises. Indeed, since  , in the notation of Lemma 5.11, \(k_{\xi}\) is even, so by (5.12a) \(n_{\lambda}-p_{X}\) must be odd; then using \(\deg (\bar{\tau}) \le -1\) and (5.12a), we see that the only solutions to (5.12a)–(5.12c) are \(k_{\xi}=2\) and \(k_{\xi}=4\).
, in the notation of Lemma 5.11, \(k_{\xi}\) is even, so by (5.12a) \(n_{\lambda}-p_{X}\) must be odd; then using \(\deg (\bar{\tau}) \le -1\) and (5.12a), we see that the only solutions to (5.12a)–(5.12c) are \(k_{\xi}=2\) and \(k_{\xi}=4\).
Proof
In this proof we keep in mind that parities and degrees are additive under grafting (Remark 6.13).
By the discussion in the beginning of this subsection, for every \(\tau \in \mathfrak {T}\) with \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {z}}[\tau ] \neq 0\), there is a unique way of obtaining \(\tau \) by choosing some \(\bar{\tau} \in \tilde{\mathfrak {T}}\) with  , \(m \ge 0\), and \(\hat{\tau}_{1},\dots ,\hat{\tau}_{m}\) with \(\hat{\tau}_{j} \neq \mathbf{1}\) and \(\boldsymbol{\Upsilon}^{F}_{\mathfrak {u}}[\hat{\tau}_{j}] \neq 0\), and then choosing \(m\) instances of \(\bar{\mathfrak {l}}\) in \(\bar{\tau}\) and replace them by \(\hat{\tau}_{1}\bar{\mathfrak {l}},\dots ,\hat{\tau}_{m}\bar{\mathfrak {l}}\). Recalling that each tree in \(\mathfrak {T}[\hat{\tau};\bar{\tau}]\) is obtained by only one grafting by definition, to prove the first statement we must show \(m=1\).
, \(m \ge 0\), and \(\hat{\tau}_{1},\dots ,\hat{\tau}_{m}\) with \(\hat{\tau}_{j} \neq \mathbf{1}\) and \(\boldsymbol{\Upsilon}^{F}_{\mathfrak {u}}[\hat{\tau}_{j}] \neq 0\), and then choosing \(m\) instances of \(\bar{\mathfrak {l}}\) in \(\bar{\tau}\) and replace them by \(\hat{\tau}_{1}\bar{\mathfrak {l}},\dots ,\hat{\tau}_{m}\bar{\mathfrak {l}}\). Recalling that each tree in \(\mathfrak {T}[\hat{\tau};\bar{\tau}]\) is obtained by only one grafting by definition, to prove the first statement we must show \(m=1\).
Now, since we impose \(\tau \in \mathfrak {T}_{-}\), then, for \(\kappa >0\) sufficiently small, one necessarily has \(\deg (\hat{\tau}_{j}) \ge 1\) for all \(j\in \{1,\ldots ,m\}\) and therefore one must have \(m \le 1\) unless  . This is because every \(\bar{\tau}\) satisfying the above condition with at least two noises has degree strictly larger than −2, except for
. This is because every \(\bar{\tau}\) satisfying the above condition with at least two noises has degree strictly larger than −2, except for  .
.
Suppose  , for which \(\deg (\bar{\tau})=-2-2\kappa \). Then since \(\tau \in \mathfrak {T}_{-}\), one must have \(m\le 2\). If \(m = 2\) then one must have \(\hat{\tau}_{j} = \mathbf {X}_{i_{j}}\) for both \(j=1,2\) (since, for \(\hat{\tau}_{j}\) not of this form, one has \(\deg (\hat{\tau}_{j}) \ge 3/2-\)). However, in this case \(\tau \notin \mathfrak {T}^{\mathrm{ev},\mathrm{sp}}\), therefore we must have \(m=1\). Since \(\tau \in \mathfrak {T}_{-}\) and \(\deg (\hat{\tau}) \ge 0\) furthermore imply \(\deg (\bar{\tau}) < 0\), one has
, for which \(\deg (\bar{\tau})=-2-2\kappa \). Then since \(\tau \in \mathfrak {T}_{-}\), one must have \(m\le 2\). If \(m = 2\) then one must have \(\hat{\tau}_{j} = \mathbf {X}_{i_{j}}\) for both \(j=1,2\) (since, for \(\hat{\tau}_{j}\) not of this form, one has \(\deg (\hat{\tau}_{j}) \ge 3/2-\)). However, in this case \(\tau \notin \mathfrak {T}^{\mathrm{ev},\mathrm{sp}}\), therefore we must have \(m=1\). Since \(\tau \in \mathfrak {T}_{-}\) and \(\deg (\hat{\tau}) \ge 0\) furthermore imply \(\deg (\bar{\tau}) < 0\), one has  , thus proving the first statement.
, thus proving the first statement.
We now prove the second statement. Note that the claim that we fall into precisely one of these cases follows from the disjointness statement in Remark 6.13. The key point to prove is that the sets in the statement of the lemma cover  . Write \(\tau \in \mathfrak {T}[\hat{\tau}; \bar{\tau}]\) with \(\hat{\tau} \in \mathfrak {T}_{g}\) and
. Write \(\tau \in \mathfrak {T}[\hat{\tau}; \bar{\tau}]\) with \(\hat{\tau} \in \mathfrak {T}_{g}\) and  .
.
-
If \(\hat{\tau} = \mathbf{1}\), then \(\tau = \bar{\tau}\) so
 .
. -
If \(\hat{\tau} = \mathbf {X}^{p}\) with \(|p|_{\mathfrak{s}} =2\) then we must have \(\deg (\bar{\tau}) \le -2\), which forces
 . But in both cases
. But in both cases  .
. -
If \(\hat{\tau} = \mathbf {X}^{p}\) for \(|p|_{\mathfrak{s}} = 1\) then we must have \(\bar{\tau}\) as in (6.35), since parity and degree are additive under grafting.
 .
. . But in both cases
. But in both cases  .
.Thus all that remains are the cases where \(\hat{\tau}\) belongs to the second set on the right-hand side of (6.30) so we assume this from now on.
-
There is a single such \(\hat{\tau}\) of minimal degree given by
 with \(\deg (\hat{\tau} )=3/2-\). This choice of \(\hat{\tau}\) forces \(\bar{\tau}\) to be as in (6.36).
with \(\deg (\hat{\tau} )=3/2-\). This choice of \(\hat{\tau}\) forces \(\bar{\tau}\) to be as in (6.36). -
If \(\deg (\hat{\tau}) = 2-\), it has to be one of the trees in (6.31), so we have \(\hat{\tau}\in \mathfrak {T}^{\mathrm{ev, noi}} \cap \mathfrak {T}^{\mathrm{od, sp}}\), which forces \(\bar{\tau}\) to be in \(\mathfrak {T}^{\mathrm{ev, noi}} \cap \mathfrak {T}^{\mathrm{od, sp}}\) as well and \(\deg (\bar{\tau})\le -2\), so
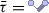 .
. -
If \(\deg (\hat{\tau}) = 5/2-\) then we must have
 in order for \(\deg (\tau ) < 0\). This in turn forces \(\hat{\tau} \in \mathfrak {T}^{\mathrm{od, noi}} \cap \mathfrak {T}^{\mathrm{ev, sp}}\), and all such \(\hat{\tau} \) are listed in (6.32).
in order for \(\deg (\tau ) < 0\). This in turn forces \(\hat{\tau} \in \mathfrak {T}^{\mathrm{od, noi}} \cap \mathfrak {T}^{\mathrm{ev, sp}}\), and all such \(\hat{\tau} \) are listed in (6.32).
 with
with 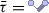 .
. in order for
in order for Thus we proved that \(\tau \) is in precisely one of the five cases claimed by the lemma. □
Below we study the effect of the \(\boldsymbol{\Upsilon}\) map acting on the trees that appeared in the previous proof.
The following lemma states that the contribution to the renormalised equation from trees in  is the same as what was observed in Sect. 5. In what follows, we overload notation and write
is the same as what was observed in Sect. 5. In what follows, we overload notation and write  for the operator constructed via [22, Remark 5.19] using the operator assignment \(L = (L_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}}\) given by setting
for the operator constructed via [22, Remark 5.19] using the operator assignment \(L = (L_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}}\) given by setting  if \(\mathfrak {t}\in \{ \bar{\mathfrak {l}},\mathfrak {l}\}\) and \(L_{\mathfrak {t}} = \mathrm{id}_{V_{\mathfrak {t}}}\) otherwise; namely,
if \(\mathfrak {t}\in \{ \bar{\mathfrak {l}},\mathfrak {l}\}\) and \(L_{\mathfrak {t}} = \mathrm{id}_{V_{\mathfrak {t}}}\) otherwise; namely,  acts on
acts on  by acting on each factor \(V_{\mathfrak {l}}\) and \(V_{\bar{\mathfrak {l}}}\).
by acting on each factor \(V_{\mathfrak {l}}\) and \(V_{\bar{\mathfrak {l}}}\).
We also note that, while  should take as an argument an element of \(\prod _{ o = (\mathfrak {z},p), (\bar{\mathfrak {l}},p)} W_{o}\), there is a natural projection to this space from
should take as an argument an element of \(\prod _{ o = (\mathfrak {z},p), (\bar{\mathfrak {l}},p)} W_{o}\), there is a natural projection to this space from  by dropping all other components, so below we write
by dropping all other components, so below we write  with arguments
with arguments  with this projection implicitly understood.
with this projection implicitly understood.
Lemma 6.17
For any  one has
one has

Proof
We can proceed by an induction in the number of instances of \(\bar{\mathfrak {l}}\) in the tree \(\tau \), appealing to the inductive definition (4.8). The base case of the induction is given by  in which caseFootnote 29
in which caseFootnote 29

where \(\bar{\boldsymbol{\Xi}} = \mathrm{id}_{W_{\mathfrak {z}}} \in V_{\bar{\mathfrak {l}}} \otimes W_{\mathfrak {z}}\). Now for the inductive step we write  as in (6.33) and we have, since \(m \ge 1\) and \(o_{j}= (\mathfrak {z},p_{j})\),
as in (6.33) and we have, since \(m \ge 1\) and \(o_{j}= (\mathfrak {z},p_{j})\),

Then by (4.8) one has

where in the second equality we used the induction hypothesis, and in the third equality we used the definition of  given before this lemma. □
given before this lemma. □
The above lemma shows that if we don’t expand \(U\) in the multiplicative noise \(U\xi \), the corresponding trees are the same as those seen for the YMH system in the last section, and the renormalisation they produce will be the same as that stated in Proposition 5.7. In the remainder of this subsection we will actually expand \(U\) (thus generalising Lemma 6.17), and performing a single such expansion can be formulated using the grafting procedure we described earlier. For each tree \(\tau \) that comes from grafting, i.e. \(\tau \in \mathfrak {T}[\hat{\tau};\bar{\tau}]\), we aim to describe \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {z}}[\tau ]\).
Before we proceed, a simple example may be helpful to motivate the upcoming lemmas. Consider \(\tau \in \mathfrak{T}[\hat{\tau}, \bar{\tau}]\) with  and
and  , as in (6.36). Pretending that we only have a nonlinearity \([B_{j},[B_{j},B_{i}]]\) in the equation for \(Y\) and ignoring the other terms, \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {z}}[\tau ]\) is given by
, as in (6.36). Pretending that we only have a nonlinearity \([B_{j},[B_{j},B_{i}]]\) in the equation for \(Y\) and ignoring the other terms, \(\bar{\boldsymbol{\Upsilon}}^{F}_{\mathfrak {z}}[\tau ]\) is given by

where  (recall (6.26a)). We can think of this as being obtained by the usual inductive construction of \(\bar{\boldsymbol{\Upsilon}}^{F}\) except for a tweak that one starts as the base case with not only \(\bar{\boldsymbol{\Xi}}\) but also
(recall (6.26a)). We can think of this as being obtained by the usual inductive construction of \(\bar{\boldsymbol{\Upsilon}}^{F}\) except for a tweak that one starts as the base case with not only \(\bar{\boldsymbol{\Xi}}\) but also  ; this will be made precise in Lemma 6.18. In order to factor out
; this will be made precise in Lemma 6.18. In order to factor out  (to eventually show that the renormalisation will not depend on
(to eventually show that the renormalisation will not depend on  ), note that (6.37) can be thought of as being obtained by taking
), note that (6.37) can be thought of as being obtained by taking  and inserting
and inserting  into each appropriate location, and finally applying
into each appropriate location, and finally applying  in the way explained above Lemma 6.17 –this will be formulated as a linear map which brings
in the way explained above Lemma 6.17 –this will be formulated as a linear map which brings  to (6.37); see Lemma 6.19 for the precise formulation.
to (6.37); see Lemma 6.19 for the precise formulation.
Given  and
and  we will define objects
we will define objects  . Our definition of
. Our definition of  is inductive in the number of \(\bar{\mathfrak {l}}\) edges in \(\bar{\tau}\). For the base case, we set
is inductive in the number of \(\bar{\mathfrak {l}}\) edges in \(\bar{\tau}\). For the base case, we set

For the inductive step, for \(\bar{\tau}\) as in (6.33), we set

where  . From this inductive definition it is clear that the mapping
. From this inductive definition it is clear that the mapping

is linear, and takes  into
into  for every \(\hat{\tau} \in \mathfrak {T}_{g}\).
for every \(\hat{\tau} \in \mathfrak {T}_{g}\).
In the next lemma we specify  to be the terms appearing in the expansion for \(U\) in (6.28). Recall the shorthand notation
to be the terms appearing in the expansion for \(U\) in (6.28). Recall the shorthand notation  for the components
for the components  of
of  .
.
Lemma 6.18
For any  and \(\hat{\tau} \in \mathfrak {T}_{g}\), we have the consistency relation
and \(\hat{\tau} \in \mathfrak {T}_{g}\), we have the consistency relation

where

Proof
The proof follows by induction in the number of \(\bar{\mathfrak {l}}\) edges in \(\bar{\tau}\). The base case is given by \(\bar{\tau} = \bar{\mathfrak {l}}\), then if \(\tau \in \mathfrak {T}_{g}[\bar{\mathfrak {l}}]\) one has \(\tau = \hat{\tau} \bar{\mathfrak {l}}\) for some \(\hat{\tau} \in \mathfrak {T}_{g}\) and the result follows by a straightforward computation: indeed recalling the definition of \(\mathfrak {T}_{g}\) in (6.30) and by (4.8) one has

which are consistent with (6.38). For the inductive step, we can assume that \(\bar{\tau}\) is of the form (6.33), and then the claim follows by combining the inductive definition (4.8), (6.34) and (6.39) along with the induction hypothesis. Indeed, by (4.8) and (6.34)

where \(\bar{\beta}_{j}\) denotes the multiplicity of  in \(\bar{\tau}\) –we need to divide by this number because our sum above is overcounting the elements of (6.34) when any
in \(\bar{\tau}\) –we need to divide by this number because our sum above is overcounting the elements of (6.34) when any  appears with multiplicity. Here on the right-hand side, we are writing
appears with multiplicity. Here on the right-hand side, we are writing  for every fixed \(j\) and \(\mathring{\tau}\). We then observe that \(\frac{\mathring{S}(\bar{\tau})}{\mathring{S}(\tau )} = \bar{\beta}_{j}\) since \(\mathring{S}\) introduced in (4.8)+(4.9) is precisely a product of factorials of multiplicities. Now using the inductive hypothesis which states that
for every fixed \(j\) and \(\mathring{\tau}\). We then observe that \(\frac{\mathring{S}(\bar{\tau})}{\mathring{S}(\tau )} = \bar{\beta}_{j}\) since \(\mathring{S}\) introduced in (4.8)+(4.9) is precisely a product of factorials of multiplicities. Now using the inductive hypothesis which states that

we obtain the claimed identity by (6.39). □
We now introduce the operator on our regularity structure that are related to the grafting procedure on trees we described earlier.
Lemma 6.19
There exists  with the following properties
with the following properties
-
1.
For any \(\hat{\tau} \in \mathfrak {T}_{g}\),
 , and
, and  ,
,  maps
maps  into
into  .
. -
2.
For any
 ,
, 
where
 is given by the relevant component of
is given by the relevant component of  . Here we are applying the convention of Remark 4.6so
. Here we are applying the convention of Remark 4.6so  and
and  act only on the left factor of
act only on the left factor of 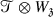 ; and the notation
; and the notation  denotes right multiplication /composition by
denotes right multiplication /composition by  , that is the mapping
, that is the mapping  .
.
 , and
, and  ,
,  maps
maps  into
into  .
. ,
, 
 is given by the relevant component of
is given by the relevant component of  . Here we are applying the convention of Remark
. Here we are applying the convention of Remark  and
and  act only on the left factor of
act only on the left factor of 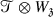 ; and the notation
; and the notation  denotes right multiplication /composition by
denotes right multiplication /composition by  , that is the mapping
, that is the mapping  .
.Proof
We first define, for fixed  ,
,  by defining
by defining  for
for  inductively in the number of \(\bar{\mathfrak {l}}\) edges in \(\bar{\tau}\). For the base case \(\bar{\tau} = \bar{\mathfrak {l}}\), we have, for any
inductively in the number of \(\bar{\mathfrak {l}}\) edges in \(\bar{\tau}\). For the base case \(\bar{\tau} = \bar{\mathfrak {l}}\), we have, for any  , \(\hat{\tau} \in \mathfrak {T}_{g}\), and
, \(\hat{\tau} \in \mathfrak {T}_{g}\), and  ,
,

Here, to interpret \(b^{\ast} v\), we note that \(W_{\mathfrak {u}}\) has an adjoint action on \(V_{\bar{\mathfrak {l}}} \simeq W_{\mathfrak {z}}^{\ast}\) and the product outside of the parentheses above is just the product in the regularity structure. This extends to arbitrary  by linearity.
by linearity.
For the inductive step, given \(\bar{\tau}\) as in (6.33) and  we define
we define

By the definition of the space  and the symmetry of the above expressions this suffices to define
and the symmetry of the above expressions this suffices to define  and the first statement of the lemma is easy to verify.
and the first statement of the lemma is easy to verify.
The second statement is a straightforward to verify by induction. For the base case \(\bar{\tau}=\bar{\mathfrak {l}}\), we note that for  ,
,

by (6.38), where the \(\{e_{i}\}_{i=1}^{\dim (E)}\) are a basis for \(E\) and \(i\) is summed implicitly. For the inductive step, by definition of  , the right-hand side of (6.41) equals
, the right-hand side of (6.41) equals

where in the last step we applied the inductive hypothesis and Lemma 6.17. This is precisely the left-hand side of (6.41) by definition (6.39). □
6.3 Computation of counterterms
Lemma 6.20
Suppose that \(\bar{\tau}\) is of the form  or
or  or satisfies (6.35) or (6.36). Then,
or satisfies (6.35) or (6.36). Then,  has no dependence on
has no dependence on  .
.
Proof
The cases of  or
or  follow trivially from a short, straightforward computation.
follow trivially from a short, straightforward computation.
To prove the lemma in the cases of (6.35) or (6.36) we invoke Lemma 5.11 and show that \(p_{X} = p_{\partial }=0\).
Suppose that \(\bar{\tau}\) satisfies (6.35). Since \(\deg (\bar{\tau}) \le -1\), \(k_{\xi }\) is even and \(k_{\partial }\) is odd, the only solutions to the equations in Lemma 5.11 are \((n_{\lambda},k_{\xi},k_{\partial }) = (1,2,1)\), \((n_{\lambda},k_{\xi},k_{\partial }) = (3,4,3)\), \((n_{\lambda},k_{\xi},k_{\partial }) = (3,4,1)\), and \((p_{X},p_{\partial })=(0,0)\) for all these three solutions.
Now suppose that \(\bar{\tau}\) satisfies (6.36). Since \(\deg (\bar{\tau}) \le -3/2\), \(k_{\xi }\) is odd and \(k_{\partial }\) is even, the only solutions to the equations in Lemma 5.11 are \((n_{\lambda},k_{\xi},k_{\partial }) = (0,1,0)\), \((n_{\lambda},k_{\xi},k_{\partial }) = (2,3,0)\), \((n_{\lambda},k_{\xi},k_{\partial }) = (2,3,2)\), and again \((p_{X},p_{\partial })=(0,0)\) for all these three solutions. □
In the next lemma we apply Lemma 6.19 to study the  introduced in (6.40).
introduced in (6.40).
Lemma 6.21
For every \(\hat{\tau}\in \{ \hat{\tau}_{3/2}, \hat{\tau}_{2}^{\bullet}, \hat{\tau}_{5/2}^{ \bullet} \}\) (see (6.31), (6.32)), writing  , we have
, we have

for some  which depends on
which depends on  only through a linear dependence on
only through a linear dependence on  .
.
Moreover, if  satisfies
satisfies  then (6.44) also holds for \(\hat{\tau} = \mathbf {X}_{i}\).
then (6.44) also holds for \(\hat{\tau} = \mathbf {X}_{i}\).
Proof
We start with the first statement of the lemma in which case \(\hat{\tau}\) is of the form  . If
. If  , since
, since  , by Lemma 6.17 one has
, by Lemma 6.17 one has  where, following as in Lemma 6.20,
where, following as in Lemma 6.20,  has no dependence on
has no dependence on  . Therefore for each \(\tilde{\tau}\) in this set,
. Therefore for each \(\tilde{\tau}\) in this set,

which is in the desired form. Moreover,

where  has no dependence on
has no dependence on  . Therefore for
. Therefore for  ,
,

which is also in the desired form. Finally the claim for  can be checked in an analogous way.
can be checked in an analogous way.
To prove the second statement of the lemma, we note that  so we have
so we have  which is of the desired form. □
which is of the desired form. □
To state the next lemma, for every \(g \in G\), one can define a natural action of \(\boldsymbol{\varrho }(g)\) on  as in [22, Remark 5.19] or as above Lemma 6.17, with the operator assignment \(L = (L_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}}\) with \(L_{\mathfrak {t}} = \boldsymbol{\varrho }(g)\) for \(\mathfrak {t}\in \mathfrak{L}_{-}\) and \(L_{\mathfrak {t}} = \mathrm{id}_{V^{\ast}_{\mathfrak {t}}}\) otherwise. The following lemma states that under certain conditions of
as in [22, Remark 5.19] or as above Lemma 6.17, with the operator assignment \(L = (L_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}}\) with \(L_{\mathfrak {t}} = \boldsymbol{\varrho }(g)\) for \(\mathfrak {t}\in \mathfrak{L}_{-}\) and \(L_{\mathfrak {t}} = \mathrm{id}_{V^{\ast}_{\mathfrak {t}}}\) otherwise. The following lemma states that under certain conditions of  (which in particular will be satisfied by
(which in particular will be satisfied by  ), the equation for \(Y\) only requires renormalisation that is linear in \(Y\) and \(h\):
), the equation for \(Y\) only requires renormalisation that is linear in \(Y\) and \(h\):
Lemma 6.22
Fix  . Suppose that \(\boldsymbol{\varrho }(g) \ell = \ell \) for every \(g \in G\), and that \(\ell [\tau ] = 0\) for every
. Suppose that \(\boldsymbol{\varrho }(g) \ell = \ell \) for every \(g \in G\), and that \(\ell [\tau ] = 0\) for every  .
.
Let \(C_{\ell ,\tau} \in L(E,E)\) be the same mapFootnote 30that appears in Proposition 5.7.
Then there exists \(C_{\ell} \in L(\mathfrak {g}^{3},E)\) such that, for any  ,
,

Proof
We first note that we have

Here we define  to consist of all of those \(\bar{\tau}\) as in (6.35) or (6.36), or of the form
to consist of all of those \(\bar{\tau}\) as in (6.35) or (6.36), or of the form  or
or  . We also define \(\mathfrak {T}_{g,h} \subset \mathfrak {T}_{g}\) to be given by all the symbols that we graft in Lemma 6.14, namely it consists of \(\mathbf {X}_{j}\) for \(j \in \{1,2,3\}\) and
. We also define \(\mathfrak {T}_{g,h} \subset \mathfrak {T}_{g}\) to be given by all the symbols that we graft in Lemma 6.14, namely it consists of \(\mathbf {X}_{j}\) for \(j \in \{1,2,3\}\) and  , along with all symbols appearing in (6.31) and (6.32).
, along with all symbols appearing in (6.31) and (6.32).
By Proposition 5.7 and Lemma 6.17, one has for each  ,
,

For the second contribution on the right-hand side of (6.46), by Lemma 6.18 and linearity,

where  . Now, by Lemma 6.21 we can write
. Now, by Lemma 6.21 we can write  for some
for some  which depends on
which depends on  only through a linear dependence on
only through a linear dependence on  .
.
By Lemma 6.19, the second term on the right-hand side of (6.46) then equals to

Using the fact that  is in the image of \(\boldsymbol{\varrho }(\cdot )\), one has
is in the image of \(\boldsymbol{\varrho }(\cdot )\), one has  . Recall that
. Recall that  has no dependence on
has no dependence on  thanks to Lemma 6.20. Therefore the last line is of the form
thanks to Lemma 6.20. Therefore the last line is of the form  as desired. □
as desired. □
We now turn to the renormalisation of the \((\bar{X}, \bar{U}, \bar{h})\) system. There are slight differences between our book-keeping for \((Y,U,h)\) versus \((\bar{X}, \bar{U}, \bar{h})\): (i) in the latter system we use the label \(\mathfrak {l}\) instead of the label \(\bar{\mathfrak {l}}\) to represent the noise; and (ii) the RHS of the equation for \(\bar{X}\) is broken as a sum of two terms –the first term being \(\bar{U} \xi \) which is labelled by \(\mathfrak {m}\) and the second term which contains everything else being labelled then by \(\mathfrak {z}\).
We write \(\mathfrak {T}^{F}\) for the collection of all \(\tau \in \mathfrak {T}\) that contain no instance of \(\mathfrak {l}\) or \(\mathfrak {m}\). We write \(\mathfrak {T}^{\bar{F}}\) for the collection of all \(\tau \in \mathfrak {T}\) which (i) contain no instance of \(\bar{\mathfrak {l}}\) and (ii) satisfy the constraint that in any expression of the form  we must have \(o \in \{\mathfrak {m}\} \times {\mathbf {N}}^{d+1}\). Trees generated by the \(F\) system belong to \(\mathfrak {T}^{F}\) and trees generated by the \(\bar{F}\) system belong to \(\mathfrak {T}^{\bar{F}}\). In particular, \(\tau \in \mathfrak {T}\setminus \mathfrak {T}^{F} \Rightarrow \bar{\boldsymbol{\Upsilon}}^{F}[ \tau ] = 0\) and \(\tau \in \mathfrak {T}\setminus \mathfrak {T}^{\bar{F}} \Rightarrow \boldsymbol{\Upsilon}^{ \bar{F}}[\tau ] = 0\).
we must have \(o \in \{\mathfrak {m}\} \times {\mathbf {N}}^{d+1}\). Trees generated by the \(F\) system belong to \(\mathfrak {T}^{F}\) and trees generated by the \(\bar{F}\) system belong to \(\mathfrak {T}^{\bar{F}}\). In particular, \(\tau \in \mathfrak {T}\setminus \mathfrak {T}^{F} \Rightarrow \bar{\boldsymbol{\Upsilon}}^{F}[ \tau ] = 0\) and \(\tau \in \mathfrak {T}\setminus \mathfrak {T}^{\bar{F}} \Rightarrow \boldsymbol{\Upsilon}^{ \bar{F}}[\tau ] = 0\).
Moreover, there is a natural bijection \(\theta \colon \mathfrak {T}^{\bar{F}} \rightarrow \mathfrak {T}^{F}\) obtained by replacing any edge of type \((\mathfrak {m},p)\) with \((\mathfrak {z},p)\) and noise edge of type \(\mathfrak {l}\) with one of type \(\bar{\mathfrak {l}}\). Moreover, there is an induced isomorphism  which maps
which maps  into
into  . We then have the following lemma.
. We then have the following lemma.
Lemma 6.23
Given any \(\tau \in \mathfrak {T}^{\bar{F}}\), one has, for any \(\mathfrak {t}\in \{\mathfrak {u},\mathfrak {h},\mathfrak {h}'\}\),

Proof
This is straightforward to prove by appealing to the inductive formulae for \(\boldsymbol{\Upsilon}^{\bar{F}}\) and \(\boldsymbol{\Upsilon}^{F}\). □
We can now give the proof of the main result of this subsection.
Proof of Proposition 6.6
Note that  satisfies the conditions of Lemma 6.22 (using Lemma 6.7 for the parity constraint and arguing similarly for the invariance of \(\ell \) under \(\boldsymbol{\varrho }(\cdot )\)). In particular, we see that (6.18) follows from Lemma 6.10; and we also have (6.45) by Lemma 6.22.
satisfies the conditions of Lemma 6.22 (using Lemma 6.7 for the parity constraint and arguing similarly for the invariance of \(\ell \) under \(\boldsymbol{\varrho }(\cdot )\)). In particular, we see that (6.18) follows from Lemma 6.10; and we also have (6.45) by Lemma 6.22.
We now turn to proving the first line of (6.19). We will now argue in a similar way as Lemma 5.13 to show that the right-hand side of (6.45) has a block structure of the form

with  , and
, and  .
.
Consider \(\mathbf{T} =(T,\sigma ,r,O)\in \mathrm{Tran}\) chosen by fixing \(i \in \{1,2,3\}\), and then choosing \(T\) to act on \(W_{\mathfrak {z}}\simeq W_{\mathfrak {m}} \simeq W_{\bar{\mathfrak {l}}} = \mathfrak {g}_{1} \oplus \mathfrak {g}_{2} \oplus \mathfrak {g}_{3}\oplus \mathbf{V}\), on \(W_{\mathfrak {h}} \simeq W_{\mathfrak {h}'} = \mathfrak {g}_{1} \oplus \mathfrak {g}_{2} \oplus \mathfrak {g}_{3}\) by flipping the sign of the \(\mathfrak {g}_{i}\) component, and act as the identity on \(W_{\mathfrak {u}}\). We set \(r\) which flips the \(i\)-th spatial coordinate, and set \(\sigma =\mathrm{id}\). For \(O = (O_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}_{+}}\), we have \(O_{\mathfrak {t}} = \mathrm{id}\) except for \(\mathfrak {t}= \mathfrak {h}'\) where \(\mathcal{K}_{\mathfrak {h}'} \simeq {\mathbf {R}}^{3}\) and we set \(O_{\mathfrak {h}'}\) to flip the sign of the \(i\)-th spatial component.
One can check that our nonlinearity  is then \(\mathbf{T}\)-covariant, and the kernels and noises are \(\mathbf{T}\)-invariant. Considering such transformations for every \(i \in \{1,2,3\}\) and applying Proposition 4.8 then implies that the linear renormalisation must be appropriately block diagonal.
is then \(\mathbf{T}\)-covariant, and the kernels and noises are \(\mathbf{T}\)-invariant. Considering such transformations for every \(i \in \{1,2,3\}\) and applying Proposition 4.8 then implies that the linear renormalisation must be appropriately block diagonal.
We then show that the blocks associated to different spatial indices are the same. Again as in Lemma 5.13, we consider \(\mathbf{T} =(T,\sigma ,r,O)\in \mathrm{Tran}\) chosen by fixing \(1 \le i < j \le 3\) and then choosing \(T\) to act on \(W_{\mathfrak {z}} \simeq W_{\mathfrak {m}} \simeq W_{\bar{\mathfrak {l}}} = \mathfrak {g}_{1} \oplus \mathfrak {g}_{2} \oplus \mathfrak {g}_{3}\oplus \mathbf{V}\) and \(W_{\mathfrak {h}} \simeq W_{\mathfrak {h}'} = \mathfrak {g}_{1} \oplus \mathfrak {g}_{2} \oplus \mathfrak {g}_{3}\) by swapping the \(\mathfrak {g}_{i}\) and \(\mathfrak {g}_{j}\) components, and act as an identity on \(W_{\mathfrak {u}}\). We also set \(r\) given by the identity, and \(\sigma \) exchanges \(i\) and \(j\). For \(O = (O_{\mathfrak {t}})_{\mathfrak {t}\in \mathfrak{L}_{+}}\), we have \(O_{\mathfrak {t}} = \mathrm{id}_{\mathcal{K}_{\mathfrak {t}}}\) except for \(\mathfrak {t}= \mathfrak {h}'\) where \(\mathcal{K}_{\mathfrak {h}'} \simeq {\mathbf {R}}^{3}\) and we set \(O_{\mathfrak {h}'}\) to swap the \(i\) and \(j\) spatial components. One can check that our nonlinearity  is then \(\mathbf{T}\)-covariant, and kernels and noises are \(\mathbf{T}\)-invariant. Considering such transformations for every \(1 \le i < j \le 3\) and applying Proposition 4.8, we conclude that the blocks indexed by different spatial indices must be identical.
is then \(\mathbf{T}\)-covariant, and kernels and noises are \(\mathbf{T}\)-invariant. Considering such transformations for every \(1 \le i < j \le 3\) and applying Proposition 4.8, we conclude that the blocks indexed by different spatial indices must be identical.
Finally, to show that the block operators all commute with the appropriate actions of \(G\), we again argue using Proposition 4.8, fixing \(g \in G\) and looking at \(\mathbf{T} \in \mathrm{Tran}\) where \(T\) acts on \(W_{\mathfrak {z}}\) and \(W_{\mathfrak {m}}\) as \(\boldsymbol{\varrho }(g)\), on \(W_{\mathfrak {u}}\) by right composition/multiplication with \(\boldsymbol{\varrho }(g)\), and on \(W_{\mathfrak {h}}\) and \(W_{\mathfrak {h}'}\) by \(\mathrm {Ad}_{g}\). We set \(r\), \(\sigma \), and \(O\) to be the appropriate identity operators.
To finish justifying the first line of (6.19), we note that our choice of kernel and noise assignments guarantee that, for any  one has
one has  where on the right-hand side we are referring to the character in (5.10) –this justifies replacing
where on the right-hand side we are referring to the character in (5.10) –this justifies replacing  and
and  with
with  and
and  . (Note that
. (Note that  and
and  are the same maps as that in Proposition 5.7, which follows from Lemma 6.22.) More generally, for any \(\tau \in \mathfrak {T}\) with \(\boldsymbol{\Upsilon}_{\mathfrak {z}}^{F}[\tau ] \neq 0\),
are the same maps as that in Proposition 5.7, which follows from Lemma 6.22.) More generally, for any \(\tau \in \mathfrak {T}\) with \(\boldsymbol{\Upsilon}_{\mathfrak {z}}^{F}[\tau ] \neq 0\),  does not depend on \(\delta > 0\), therefore
does not depend on \(\delta > 0\), therefore  does not depend on \(\delta > 0\) either, and we can just denote this map by
does not depend on \(\delta > 0\) either, and we can just denote this map by  as in the first line of (6.19).
as in the first line of (6.19).
Repeating the argument above combined with Lemma 6.23 gives us the second line of (6.19), although in this case the operators should be allowed to depend on \(\delta \). It then only remains to prove (6.20).
For the first two statements we note that, if \(\boldsymbol{\Pi}_{\delta ,\varepsilon }\) is the canonical lift of the kernel assignment \(K^{(\varepsilon )}\) and noise assignment \(\zeta ^{\delta ,\varepsilon }\) then for any \(\tau \in \mathfrak {T}^{\bar{F}}\) with  , one has
, one has
where \(\bar{\boldsymbol{\Pi}}_{\delta ,\varepsilon } = \mathbf{E}[\boldsymbol{\Pi}_{\delta ,\varepsilon }(0)]\) and the equality above is between elements of  . Here \(\theta \) and \(\Theta \) are as in the paragraph before (6.23). One can verify (6.48) with a straightforward computation. The key observation is that the condition
. Here \(\theta \) and \(\Theta \) are as in the paragraph before (6.23). One can verify (6.48) with a straightforward computation. The key observation is that the condition  means that the only way any instance of \(\mathfrak {l}\) appears in \(\tau \) is as
means that the only way any instance of \(\mathfrak {l}\) appears in \(\tau \) is as  for some \(p \in {\mathbf {N}}^{d+1}\), then to argue (6.48) one just observes that
for some \(p \in {\mathbf {N}}^{d+1}\), then to argue (6.48) one just observes that
Heuristically, as \(\delta \downarrow 0\), “ is the same as
is the same as  ”. Since the map \(\Theta \) interacts well with coproducts, it is easy to see that (6.48) holds if we replace \(\bar{\boldsymbol{\Pi}}_{\delta ,\varepsilon }[\cdot ]\) with
”. Since the map \(\Theta \) interacts well with coproducts, it is easy to see that (6.48) holds if we replace \(\bar{\boldsymbol{\Pi}}_{\delta ,\varepsilon }[\cdot ]\) with  .
.
To prove the last statement of (6.20), it suffices to show that for any \(\varepsilon > 0\) and \(\tau \in \mathfrak {T}^{\bar{F}}\) the limit

exists. Note that \(\tau \in \mathfrak {T}^{\bar{F}}\) implies that every noise in \(\tau \) not incident to the root is incident to an \(\varepsilon \)-regularised kernel. This then means that \(\mathbf{E}[ \boldsymbol{\Pi}_{\delta ,\varepsilon }[\tau ](\cdot )]\) remains smooth in the limit \(\delta \downarrow 0\). Indeed, if \(\tau \) doesn’t contain an instance of the noise \(\mathfrak {l}\) at the root then \(\boldsymbol{\Pi}_{\delta ,\varepsilon }[\tau ](\cdot )\) itself remains smooth in the \(\delta \downarrow 0\) limit. On the other hand, if \(\tau \) does contain an instance of \(\mathfrak {l}\) at the root, then one can write \(\mathbf{E}[\boldsymbol{\Pi}_{\delta ,\varepsilon }[\tau ](\cdot )]\) as a sum over Wick contractions. Each term in the sum can be written a convolution of kernels where each integration vertex is incident to at most one \(\delta \)-regularized kernel (the covariance of \(\xi ^{\delta}\) while the rest of the kernels are of the form \(D^{p} K^{\varepsilon }\) and smooth. It is then straightforward to argue that, as \(\delta \downarrow 0\), this convolution converges to one written completely in terms of the smooth kernels of the form \(D^{p} K^{\varepsilon }\). We then obtain (6.49) by expanding its RHS in terms of the negative twisted antipode and applying the above observations.
Finally, to show (6.21), it is enough to recall (5.11), and observe that the trees \(\tau \) in Lemma 6.14 all have 2 or 4 noises (in particular see Remark 6.16). Moreover, since the block structure of the operators in (6.19) holds for every choice of \(\boldsymbol{\sigma}\), all the blocks appearing must decompose into orders \(\boldsymbol{\sigma}^{2}\) and \(\boldsymbol{\sigma}^{4}\) in the same way. □
6.4 Solution theory
We start by trying to pose the analytic fixed point problems associated to (6.6) for the \(E \oplus \mathfrak {g}^{3} \oplus (L(\mathfrak {g},\mathfrak {g})\oplus L(\mathbf{V}, \mathbf{V}))\)-valued modelled distributions \((\mathcal{Y}, \mathcal{H},\mathcal{U})\).
As before, for each \(\mathfrak {t}\in \mathfrak{L}_{+}\) we write  for the corresponding abstract integration operator on modelled distributions realising convolution with \(K_{\mathfrak {t}}^{(\varepsilon )}\) in (6.11). We also sometimes write
for the corresponding abstract integration operator on modelled distributions realising convolution with \(K_{\mathfrak {t}}^{(\varepsilon )}\) in (6.11). We also sometimes write  and
and  for
for  and
and  respectively. Moreover, we write
respectively. Moreover, we write  for \(\mathfrak {t}\in \{\mathfrak {z},\mathfrak {h},\mathfrak {u}\}\) and
for \(\mathfrak {t}\in \{\mathfrak {z},\mathfrak {h},\mathfrak {u}\}\) and  , where \(R\) represents convolution with \(G-K\) as in Sect. 5.2. Recall the convention (1.12).
, where \(R\) represents convolution with \(G-K\) as in Sect. 5.2. Recall the convention (1.12).
In addition to the difficulties described in the beginning of Sect. 5.2, we now have a multiplicative noise term \(U\xi \) which requires additional treatments. First, note that the worst term in \(\mathcal{U}\boldsymbol{\bar{\Xi}}\) is of degree \(-\frac{5}{2}-\kappa \) which is below −2, so the general integration theorem [56, Prop. 6.16]Footnote 31 would not apply. The second problem is that, even if we could apply the integration operator on it, we would have  for \(\eta =-\frac{1}{2}-2\kappa \), but as in Sect. 5.2 having a closed fixed point problem requires us to work in \(\hat{\mathscr{D}}^{\gamma ,\hat{\beta}}\) with \(\hat{\beta}> -1/2\) due to the term \(Y\partial Y\).
for \(\eta =-\frac{1}{2}-2\kappa \), but as in Sect. 5.2 having a closed fixed point problem requires us to work in \(\hat{\mathscr{D}}^{\gamma ,\hat{\beta}}\) with \(\hat{\beta}> -1/2\) due to the term \(Y\partial Y\).
To handle these difficulties we start by decomposing \(\mathcal{U}= \mathcal{P}U_{0} + \hat{\mathcal{U}}\) and solve for \(\hat{\mathcal{U}}\in \hat{\mathscr{D}}^{\gamma ,\varrho }\) for suitable exponents \(\gamma ,\varrho \). The component \(\hat{\mathcal{U}}\) has improved behaviour near \(t=0\) since we have subtracted the initial condition \(U_{0}\), so that we are in the scope of Theorem A.5 for the term \(\hat{\mathcal{U}}\boldsymbol{\bar{\Xi}}\). On the other hand, \(\mathcal{P}U_{0} \bar{\boldsymbol{\Xi}}\) can be handled with Lemma A.4, since, thanks to Lemma 6.26 below,
probabilistically converges as \(\varepsilon \downarrow 0\) in \(\mathcal{C}^{-\frac{5}{2}-\kappa}\) on the entire space-time (not just \(t>0\)). For \(\varrho \in (1/2,1)\), we have \(\mathcal{P}U_{0} \in \mathscr{D}^{\infty ,\varrho }_{0}\), and since \(\bar{\boldsymbol{\Xi}}\in \mathscr{D}^{\infty ,\infty}_{-\frac{5}{2}-\kappa}\) one has \(\mathcal{P}U_{0} \bar{\boldsymbol{\Xi}}\in \mathscr{D}^{\infty ,\varrho -\frac{5}{2}- \kappa}_{-\frac{5}{2}-\kappa}\). So by Lemma A.4

(the compatibility condition of Lemma A.4 will be checked in Lemma 6.27 below). We write
We write \(\omega _{0}\) above instead of \(\boldsymbol{\sigma} \mathcal{P}U_{0}\xi ^{\varepsilon }\) not only as shorthand, but also because later in Lemma 6.31 we will consider \(\omega _{0}\) as part of a given deterministic input to a fixed point problem (which is necessary in the \(\varepsilon \downarrow 0\) limit).
Furthermore, analogously to Sect. 5.2, we will linearise \(\mathcal{Y}\) around \(\mathcal{P}Y_{0}\) and \(\boldsymbol{\Psi}^{U_{0}}\), and then apply Lemma A.4 with appropriate “input” distributions, in a similar way as we did for the last line of (5.20).
Putting things together, for fixed initial data
where we recall that \(\mathcal{S}\subset \mathcal{C}^{\eta}\) for \(\eta <-1/2\) and \(\varrho \in (1/2,1)\), we decompose
where we want
along with \(\mathcal{H}\in \mathscr{D}^{\gamma _{\mathfrak {h}},\eta _{\mathfrak {h}}}_{\alpha _{\mathfrak {h}}}\) for some appropriate exponents \(\gamma _{\mathfrak {h}},\eta _{\mathfrak {h}},\alpha _{\mathfrak {h}}\) (these exponents will be specified in (6.81); note that solving ℋ only requires a “standard” modelled distribution space as in [56]), and solve the fixed point problem
and

Here we have defined
The \(E\)-valued space-time distributions \(\omega _{1},\omega _{2},\omega _{3}\) are compatible with the respective modelled distributions and are part of the input to the fixed point problem. We will later take
where, writing \(\chi _{\varepsilon }^{(2)} \stackrel {{\tiny \mathrm {def}}}{=}\chi ^{\varepsilon }*\chi ^{\varepsilon }\),
Here the values of \(c_{1}^{\varepsilon }, c_{2}^{\varepsilon }\) clearly do not depend on \(i\in \{1,2,3\}\). Note that in (6.58) we use the convention (1.12) except for the term \(\mathcal{P}U_{0}\partial \mathcal{P}U_{0}\) for which that convention does not apply since \(\mathcal{P}U_{0}\) is not \(E\)-valued. To define \(\mathcal{P}U_{0}\partial \mathcal{P}U_{0}\), for any
we set \(u\partial v \in E=\mathfrak {g}^{3}\oplus \mathbf{V}\) as being given by

where \((e_{\alpha})_{\alpha}\) is an orthonormal basis of \(\mathfrak {g}\) and \((e_{a})_{a}\) is an orthonormal basis of \(\mathbf{V}\). Here \(\alpha \) and \(a\) are being summed as usual.
The reason to define the above space-time distributions will become clear in Lemmas 6.26 and 6.27. We will write \(\omega ^{\varepsilon }_{\ell}\) for \(\ell \in \{0,1,2,3\}\) when we wish to make the dependence of \(\omega _{\ell}\) on \(\varepsilon \) explicit.
The abstract fixed point problem for the \((\bar{X}, \bar{U},\bar{h})\) system (6.7) is given by (6.56) with \(\mathcal{U}=\mathcal{P}U_{0} + \hat{\mathcal{U}}\) as before but with \(\mathcal{Y}\) in (6.53) replaced by
where
and \(\mathcal{W}\in \mathscr{D}^{\frac{7}{4},-\frac{1}{2}-\kappa}\) is the canonical lift of a smooth function on \((0,\infty )\), and (6.55) replaced by
where  with \(\bar{R}\) defined just like \(R\) but with \(G - K\) replaced by \(G^{\varepsilon } - K^{\varepsilon }\). Here we define (recall from (6.11) that the kernel assigned to \(\mathfrak {m}\) is \(K^{\varepsilon }\))
with \(\bar{R}\) defined just like \(R\) but with \(G - K\) replaced by \(G^{\varepsilon } - K^{\varepsilon }\). Here we define (recall from (6.11) that the kernel assigned to \(\mathfrak {m}\) is \(K^{\varepsilon }\))

\(\bar{R}_{Q}\) is defined in the same way as \(R_{Q}\) in (6.57) with \(\boldsymbol{\Psi}^{U_{0}} \) replaced by \(\bar{\boldsymbol{\Psi}}^{U_{0}} \) and \(\mathcal{P}Y_{0}\) replaced by ℳ, and \(\bar{\omega}_{i}\) are distributions compatible with the respective modelled distributions. The modelled distribution \(\mathcal{W}\) is part of the input for the fixed point problem and we will later take
understood as \(\mathcal{W}=0\) if \(\varepsilon =0\). The role of \(\mathcal{W}\) is to encode the behaviour of \(\xi \) on negative times so as to obtain the correct reconstruction. We will also later take
where, similar to before, we write
Here \(c_{1}^{\varepsilon ,\delta} ,c_{2}^{\varepsilon ,\delta}\) are defined as in (6.59) except that \(K\) is replaced by \(K^{\varepsilon }\) and \(\chi _{\varepsilon }^{(2)}\) is replaced by \(\chi _{\delta}^{(2)}\). We will write \(\bar{\omega}_{0}^{\delta}\) and \(\bar{\omega}^{\varepsilon ,\delta}_{\ell}\) for \(\ell \in \{1,2,3\}\) and \(\bar{\omega}^{\varepsilon }_{4}\) when we wish to make the dependence of \(\bar{\omega}\) on \(\varepsilon ,\delta \) explicit (remark that \(\bar{\omega}^{\delta}_{0}\) and \(\bar{\omega}^{\varepsilon }_{4}\) are independent of \(\varepsilon \) and \(\delta \) respectively).
6.4.1 Probabilistic input
We write  to be the BPHZ models associated to the kernel assignment \(K^{(\varepsilon )}\) and random noise assignment \(\zeta ^{\delta ,\varepsilon }\). We will first take \(\delta \downarrow 0\) followed by \(\varepsilon \downarrow 0\). Recall that here \(\varepsilon \) is the mollification parameter in Theorem 6.1, and \(\delta \) is an additional mollification for the white noise in (6.3) which is introduced just for technical reasons, so that the models we explicitly construct are smooth models.
to be the BPHZ models associated to the kernel assignment \(K^{(\varepsilon )}\) and random noise assignment \(\zeta ^{\delta ,\varepsilon }\). We will first take \(\delta \downarrow 0\) followed by \(\varepsilon \downarrow 0\). Recall that here \(\varepsilon \) is the mollification parameter in Theorem 6.1, and \(\delta \) is an additional mollification for the white noise in (6.3) which is introduced just for technical reasons, so that the models we explicitly construct are smooth models.
Recall from [22, Sect. 7.2.2] that one can encode the smallness of \(K-K^{\varepsilon }\) and \(\xi -\xi ^{\varepsilon }\) by introducing \(\varepsilon \)-dependent norms on our regularity structure. We then have corresponding \(\varepsilon \)-dependent seminorms \(|\!|\!||\!|\!|_{\varepsilon }\) and pseudo-metrics \(d_{\varepsilon }(,) = |\!|\!|;|\!|\!|_{\varepsilon }\) on models as in Appendix A. We will write \(\varsigma \in (0,\kappa ]\) for the small parameter ‘\(\theta \)’ appearing in [22, Sect. 7.2.2] to avoid confusion with \(\theta \) as defined in Sect. 5. For the reader unfamiliar with [22, Sect. 7], we remark that all we need with these \(\varepsilon \)-dependent (semi)norms is that one can extract a factor \(\varepsilon ^{\varsigma}\) in an abstract Schauder estimate for \(K-K^{\varepsilon }\) (see Lemma A.6 and Lemma A.7) and, similarly, an estimate of the type \(|\!|\!|\boldsymbol{\Xi}- \bar {\boldsymbol{\Xi}} |\!|\!|_{\varepsilon }\lesssim \varepsilon ^{ \varsigma}\) encoding the corresponding bound on \(\xi -\xi ^{\varepsilon }\) at the level of models /modelled distributions (see (6.85) below).
We then also have \(\varepsilon \)-dependent seminorms on \(\mathscr{D}^{\gamma ,\eta} \ltimes \mathscr{M}_{\varepsilon }\) denoted by \(|\cdot |_{\mathscr{D}^{\gamma ,\eta ,\varepsilon }}\), and on \(\hat{\mathscr{D}}^{\gamma ,\eta} \ltimes \mathscr{M}_{\varepsilon }\) denoted by \(|\cdot |_{\hat{\mathscr{D}}^{\gamma ,\eta ,\varepsilon }}\). These seminorms are indexed by compact subsets of \({\mathbf {R}}\times \mathbf{T}^{3}\), which, as in Appendix A, we will always take of the form \(O_{\tau}=[-1,\tau ]\times \mathbf{T}^{3}\) for \(\tau \in (0,1)\) and will sometimes keep implicit.
Lemma 6.24
One has, for any \(p \ge 1\),

Moreover, there exist models  for \(\varepsilon \in (0,1]\) and a model
for \(\varepsilon \in (0,1]\) and a model  such that one has the following convergence in probability:
such that one has the following convergence in probability:


Proof
The proof follows in exactly the same way as [22, Lem. 7.24], by invoking [21, Thm. 2.15] and [21, Thm. 2.31] and checking the criteria of these theorems as in Lemma 5.17. The only tweak for the proof of [22, Lem. 7.24] is that the covariance of the noise \(\xi ^{\varepsilon }\) is measured in the \(\|\|_{-5-2\kappa ,k}\) kernel norm here since \(d=3\). □
The next lemma shows that \(\mathcal{W}\) in (6.62) vanishes as \(\varepsilon \downarrow 0\).
Lemma 6.25
Let \(\mathcal{W}\) be defined by (6.65) and denote by the same symbol its lift to the polynomial sector. Then, for all \(\kappa \in (0,1)\) and \(\tau >0\), there exists a random variable \(M\) with moments bounded of all orders such that
Proof
Recall that \(\sup _{s\in [0,\varepsilon ^{2}]}|\chi ^{\varepsilon }*(\xi \mathbf{1}_{-})(s)|_{L^{ \infty}} \leq M \varepsilon ^{-\frac{5}{2}-\kappa}\). Therefore, for all \(\gamma \in [0,2)\setminus \{1\}\) and \(t\in [0,2\varepsilon ^{2}]\)
Recall further that \(\sup _{s\in [0,\varepsilon ^{2}]}|\chi ^{\varepsilon }*(\xi \mathbf{1}_{-})(s)|_{\mathcal{C}^{- \frac{1}{2}-2\kappa}} \leq M \varepsilon ^{-2+\kappa}\). Therefore, for all \(\gamma \) as above and \(t\in (2\varepsilon ^{2},\tau ]\),
where it suffices to integrate from 0 to \(\varepsilon ^{2}\) since \(\chi ^{\varepsilon }*( \xi \mathbf{1}_{-})\) is supported on the time interval \((-\infty ,\varepsilon ^{2}]\). □
The next lemma gives the probabilistic convergence of the products that are ill-defined due to \(t=0\) singularities but are needed in the formulation of our fixed point problem. Recall \(\omega ^{\varepsilon }_{\ell}\) defined in (6.50) and (6.58) and \(\bar{\omega}_{\ell}^{\varepsilon ,\delta}\) defined in (6.66). In the definition of \(\bar{\omega}_{\ell}^{\varepsilon ,\delta}\) we take ℳ as in (6.62) where \(\mathcal{W}\) is defined by (6.65).
Lemma 6.26
For all \(0 < \delta \le \varepsilon < 1\), there exists a random variable \(M>0\), of which every moment is bounded uniformly in \(\varepsilon ,\delta \), and such that
and
where \(\alpha =\eta -\frac{3}{2},m=1,n=1\) for \(\ell \in \{1,2\}\) and \(\alpha =-2,m=0,n=2\) for \(\ell =3\), and
In particular, \(\omega ^{0}_{0}\stackrel {{\tiny \mathrm {def}}}{=}\lim _{\varepsilon \downarrow 0}\omega ^{\varepsilon }_{0}\) exists in probability in \(\mathcal{C}^{-\frac{5}{2}-\kappa}\), and \(\lim _{\varepsilon \downarrow 0}\bar{\omega}^{\varepsilon }_{4} = 0\) in probability in \(\mathcal{C}^{\eta -\frac{3}{2}-2\kappa}\).
Moreover \(\omega _{1}^{\varepsilon }\) and \(\omega _{2}^{\varepsilon }\) converge in probability as \(\varepsilon \to 0\) in \(\mathcal{C}^{\eta -\frac{3}{2}-\kappa}\), and \(\omega _{3}^{\varepsilon }\) converges in probability as \(\varepsilon \to 0\) in \(\mathcal{C}^{-2-\kappa}\). We denote their limits by \(\omega _{1}^{0},\omega _{2}^{0},\omega _{3}^{0}\). Finally, for \(\ell \in \{1,2,3\}\), the limit \(\bar{\omega}^{\varepsilon ,0}_{\ell} \stackrel {{\tiny \mathrm {def}}}{=}\lim _{\delta \downarrow 0} \bar{\omega}^{\varepsilon ,\delta}_{\ell}\) exists and \(\omega _{\ell}^{0} = \lim _{\varepsilon \downarrow 0} \bar{\omega}_{\ell}^{ \varepsilon ,0}\) under the same topologies as above.
Proof
Uniformly in \(\psi \in \mathcal {B}^{3}\), \(\lambda ,\varepsilon \in (0,1)\), and \(\delta \in (0,\varepsilon )\),

and

We thus obtain (6.71) by equivalence of Gaussian moments and Kolmogorov’s theorem.
The convergence of \(\omega _{1}^{\varepsilon }, \omega _{2}^{\varepsilon }\) follows in exactly the same way as Lemma 5.19 (for the special case \(U_{0}=1\)) except that in (5.23)-(5.24) one also uses \(|\mathcal{P}U_{0}|_{\infty} \lesssim 1\).
The convergence of the second Wiener chaos of \(\omega _{3}^{\varepsilon }\) also follows in the same way as Lemma 5.18 except that in (5.22) one simply bounds \(|\mathcal{P}U_{0}|_{\infty} \lesssim 1\). Regarding the zeroth chaos of \(\omega _{3}^{\varepsilon }\), we note that
where the first line should be understood with the notation (1.12) while the second line should be understood with the notation (6.60). In particular both sides are \(E\)-valued functions of \(z\). Indeed, (6.73) can be checked using (1.12)+(6.60) and the facts that the components of the white noise \(\xi \) are independent and the basis in (6.60) are orthogonal.
(6.73) would be zero if \(U_{0}=1\) (since the integrand would be odd in the spatial variable thanks to the derivative), but generally not. Write
and the same for \(\mathcal{P}U_{0} (\bar{w})\) for which we call the multiindex \(\bar{k}\) instead of \(k\). Fixing \(i\in [3]\), we consider the \(i\)-th component of (6.73). Below we write \(s,\bar{s}\) for the time variables of \(w, \bar{w}\) and \(z=(t,x)\).
We substitute (6.74) into (6.73). The contributions from terms with \(k_{i}+\bar{k}_{i}\in \{0,2\}\) all vanish since \(K\), \(\chi _{\varepsilon }^{(2)}\) are even and \(\partial _{i} K\) is odd in the \(i\)-th spatial variables.
The contributions from terms with \(k_{i}+\bar{k}_{i} =1\) combined with the renormalisation terms introduced in (6.58)-(6.59) converge in \(\mathcal{C}^{-2-\kappa}\). Indeed, consider the contribution of the case \((k_{i},\bar{k}_{i})=(0,1)\) to (6.73) minus the renormalisation term \(c_{2}^{\varepsilon }\mathcal{P}U_{0}\partial \mathcal{P}U_{0}\) (the argument for the other case is identical). Note that here \(s,\bar{s}\) need to be positive for the integrand in (6.73) to be non-zero, whereas in (6.59) \(s,\bar{s} \in {\mathbf {R}}\). Thus the contribution we consider here is bounded by \(|\mathcal{P}U_{0}(z)\partial \mathcal{P}U_{0}(z)|\) times
This implies that this part of contribution is in \(\mathcal{C}^{-1}\subset \mathcal{C}^{-2-\kappa}\).
All the other terms involve \(r_{u}\) and they converge in \(\mathcal{C}^{-2-\kappa}\). Indeed, one has that for \(s, \bar{s} \le t\), \(|r_{u}(w,z)|\lesssim s^{\frac{\varrho -5/2}{2}} |w-z|^{\frac{5}{2}} |U_{0}|_{ \mathcal{C}^{\varrho }}\). Then the “worst” terms are the two cross terms between \(\mathcal{P}U_{0} (z)\) (i.e. \(k=0\)) and \(r_{u}\), one of which (the other one is almost identical) is bounded by \(|U_{0}|_{\mathcal{C}^{\varrho }}^{2}\) times
since \(\varrho >1/2\), where the integration variables \(s \in [0, t]\). Regarding the cross terms between \((w-z)^{k} \mathcal{P}^{(k)}U_{0} (z)\) with \(|k|\in \{1,2\}\) and \(r_{u}\), one can bound \(|\mathcal{P}^{(k)}U_{0} (z)| \lesssim t^{\frac{\varrho -|k|}{2}}|U_{0}|_{\mathcal{C}^{ \varrho }}\), and then proceeding as above one obtains a better bound of the form
The cross terms between \(r_{u}(w,z)\) and \(r_{u}(\bar{w},z)\) are then even easier to bound. Finally, note that as a function of \(z\) (6.73) converges in \(\mathcal{C}^{\varrho -2}\subset \mathcal{C}^{-2-\kappa}\) as desired, using the fact that \(|\!|\!|\delta -\chi ^{\varepsilon }|\!|\!|_{-5-\kappa ;m} \lesssim \varepsilon ^{\kappa}\) in the notation of [56, Sect. 10.3].
By the same arguments one can show the desired convergences of \(\mathcal{P}Y_{0} \partial \bar{\Psi}^{U_{0}}_{\delta}\), \(\bar{\Psi}^{U_{0}}_{\delta} \partial \mathcal{P}Y_{0}\), and \(\bar{\omega}_{3}^{\varepsilon ,\delta}\). To prove the claimed convergences of \(\bar{\omega}_{1,2}^{\varepsilon ,\delta}\) it suffices to show that \(\mathcal{W}\partial \bar{\Psi}^{U_{0}}_{\delta}\) and \(\bar{\Psi}^{U_{0}}_{\delta} \partial \mathcal{W}\) vanish in the limit. Below we write \(w< z\) (resp. \(w\le z\)) for space-time variables \(w,z\) if the time coordinate of \(w\) is less than (resp. less or equal to) the time coordinate of \(z\).
Using the definitions of \(\mathcal{W}\) in (6.65) and \(\bar{\Psi}^{U_{0}}_{\delta}\) in (6.67), and non-anticipativeness of \(K\) and \(\chi \), the zeroth chaos of \(\mathcal{W}\partial \bar{\Psi}^{U_{0}}_{\delta}\) can be bounded by
where \(D\stackrel {{\tiny \mathrm {def}}}{=}\{(w_{1},w_{2},y_{1},y_{2}): w_{2}<0<w_{1}\le z, 0<y_{2}<y_{1} \le z\}\). For any \(\varepsilon >0\), as \(\delta \downarrow 0\), the integrand converges to a smooth function but \(D\) shrinks to an empty set, since \(\chi ^{\delta}\) has support size \(\delta \) and \(w_{2}<0<y_{2}\), so the above integral vanishes in the limit. The zeroth chaos of \(\bar{\Psi}^{U_{0}}_{\delta} \partial \mathcal{W}\) vanishes by the same argument, with the derivative in (6.75) taken on the first \(K\).
The second chaos of \(\mathcal{W}\partial \bar{\Psi}^{U_{0}}_{\delta}\) and \(\bar{\Psi}^{U_{0}}_{\delta} \partial \mathcal{W}\), as well as the term \(\mathcal{W}\partial \mathcal{W}\) in \(\bar{\omega}_{4}\), are bounded similarly as Lemma 5.18, except that instead of (5.22) one uses the bound
for \(|k|\in \{0,1\}\), where the time variables of \(w\) and \(\bar{w}\) are restricted to \([0,\varepsilon ^{2}]\), due to the cutoff functions \(\mathbf{1}_{t\geq 0}\), \(\mathbf{1}_{t<0}\) and the compact support of \(\chi ^{\varepsilon }\) in the definition of \(\mathcal{W}\). (Note that \(\mathcal{W}\) defined in (6.65) and \(\tilde{\Psi}_{\varepsilon }\) defined in (5.16) only differ by a cutoff function \(\mathbf{1}_{t<0}\).) Finally, regarding the terms \(\mathcal{P}Y_{0} \partial \mathcal{W}\) and \(\mathcal{W}\partial \mathcal{P}Y_{0}\) in the definition of \(\bar{\omega}_{4}\), they vanish by the same proof of Lemma 5.19, except that in (5.23)-(5.24), one obtains an extra factor \(\varepsilon ^{\kappa}\) thanks to (6.76).
The difference estimates (6.72) between \(\omega _{\ell}^{\varepsilon }\) and \(\bar{\omega}_{\ell}^{\varepsilon ,\delta}\) follow the same arguments using \(|\!|\!|K-K^{\varepsilon }|\!|\!|_{-3-\kappa ;m} \lesssim \varepsilon ^{\kappa}\) and \(|\!|\!|\chi ^{\delta}-\chi ^{\varepsilon }|\!|\!|_{-5-\kappa ;m} \lesssim (\varepsilon \vee \delta )^{\kappa}\). □
The next lemma ensures that the input distributions in our fixed point problem are compatible with the corresponding modelled distributions.
Lemma 6.27
Consider \(\varepsilon \in [0,1]\) and \(\delta \in [0,\varepsilon ]\). Then, for the model  , \(\omega ^{\varepsilon }_{0}\) and \(\bar{\omega}^{\delta}_{0}\) is compatible with \(\mathcal{P}U_{0}\bar{\boldsymbol{\Xi}}\) and \(\mathcal{P}U_{0}\boldsymbol{\Xi}\) respectively. Furthermore
, \(\omega ^{\varepsilon }_{0}\) and \(\bar{\omega}^{\delta}_{0}\) is compatible with \(\mathcal{P}U_{0}\bar{\boldsymbol{\Xi}}\) and \(\mathcal{P}U_{0}\boldsymbol{\Xi}\) respectively. Furthermore
is compatible with
respectively. Finally, \(\bar{\omega}^{\varepsilon ,\delta}_{4}\) is compatible with \(\mathcal{P}Y_{0} \partial \mathcal{W}+ \mathcal{W}\partial \mathcal{P}Y_{0} + \mathcal{W}\partial \mathcal{W}\).
Proof
We first consider \(\varepsilon ,\delta >0\). For \(\mathcal{P}U_{0} \bar{\boldsymbol{\Xi}}\), it is clear that for \(t>0\)
because for any modelled distribution \(f\) in the span of the polynomials, one has \(\tilde{\mathcal{R}} (f \bar{\boldsymbol{\Xi}})(t,x) = (\tilde{\mathcal{R}}f)(t,x) ( \tilde{\mathcal{R}} \bar{\boldsymbol{\Xi}})(t,x)\). This also proves the claim for \(\bar{\omega}^{\delta}_{0}\) since \(\bar{\omega}^{\delta}_{0}=\omega _{0}^{\delta}\). (Note that we required \(\varepsilon >0\) above since we cannot in general multiply arbitrary \(\xi \in \mathcal{C}^{-\frac{5}{2}-\kappa}\) and \(\mathcal{P}U_{0}\) for \(U_{0}\in \mathcal{C}^{\varrho }\) to obtain a distribution on all of \({\mathbf {R}}\times \mathbf{T}^{3}\).)
The case for \(\varepsilon =\delta =0\) follows from the fact that the first equality in (6.77) still holds on \((0,\infty )\times \mathbf{T}^{3}\) (in a distributional sense) and from the existence of \(\omega ^{0}_{0} \stackrel {{\tiny \mathrm {def}}}{=}\lim _{\varepsilon \to 0} \mathcal{P}U_{0} \xi _{\varepsilon }\) in probability in \(\mathcal{C}^{-\frac{5}{2}-\kappa}\) obtained in Lemma 6.26.
Consider again \(\varepsilon ,\delta >0\). For the same reason, we have for \(t>0\)
and similarly \(\tilde{\mathcal{R}}( \boldsymbol{\Psi}^{U_{0}} \partial \mathcal{P}Y_{0} )(t,x)=\omega _{2}^{ \varepsilon }(t,x)\). Moreover, we claim that for \(t>0\)
In fact, recalling the definition of \(\boldsymbol{\Psi}^{U_{0}}\) in (6.51) and writing the polynomial lift of \(\mathcal{P}U_{0} \) as \(u \mathbf{1}+ \langle \nabla u, \mathbf{{X} \rangle }\) plus higher order polynomials, one has

where \((\cdots )\) stands for trees which do not require renormalisation. Here a crossed circle  denotes \(\mathbf {X}_{j}\Xi \) with the index \(j \in \{1,2,3\}\) being equal to the derivative index for the derivative (thick line) of the tree. The BPHZ renormalisation of the two trees
denotes \(\mathbf {X}_{j}\Xi \) with the index \(j \in \{1,2,3\}\) being equal to the derivative index for the derivative (thick line) of the tree. The BPHZ renormalisation of the two trees  and
and  yields renormalisation constants that are precisely given by (6.59), and therefore one has (6.78).
yields renormalisation constants that are precisely given by (6.59), and therefore one has (6.78).
The corresponding claims for \(\bar{\omega}^{\varepsilon ,\delta}_{\ell}\) with \(\ell =1,2,3\) follow in an identical way, while the claim for \(\bar{\omega}_{4}\) is obvious. Finally, the case \(\varepsilon >0\) and \(\delta =0\) follows from the convergence of models (6.69) and the corresponding convergence \(\bar{\omega}^{\varepsilon ,0}_{\ell}=\lim _{\delta \downarrow 0}\bar{\omega}^{ \varepsilon ,\delta}_{\ell}\) in Lemma 6.26, and the case \(\varepsilon =\delta =0\) follows from (6.70) and the convergences
in Lemma 6.26. □
Remark 6.28
As in the discussion in Sect. 5.2, for each \(z=(t,x)\) with \(t > 0\), \(\mathcal{Y}(z)\) solves an algebraic fixed point problem of the form

where \((\cdots )\) takes values in the polynomial sector, and similarly for \(\mathcal{U}(z)\) and \(\mathcal{H}(z)\). From this we see that the solution \(\mathcal{Y}(z)\) must be coherent with respect to (6.15)–(6.17). Therefore, the renormalised equations are still given by Proposition 6.6. The appearance of the renormalisations in (6.58)-(6.59) are an artifact of our decomposition (6.53). Namely, they correspond to the BPHZ renormalisations of  and
and  (as pointed out in the proof of Lemma 6.27) which contribute to the term
(as pointed out in the proof of Lemma 6.27) which contribute to the term  in Proposition 6.6; even if one were to renormalise the decomposed equations, terms such as \((c_{1}^{\varepsilon }+c_{2}^{\varepsilon }) \hat{\mathcal{U}}\partial \hat{\mathcal{U}}\) would arise in addition to the ones in (6.58), which would still contribute to
in Proposition 6.6; even if one were to renormalise the decomposed equations, terms such as \((c_{1}^{\varepsilon }+c_{2}^{\varepsilon }) \hat{\mathcal{U}}\partial \hat{\mathcal{U}}\) would arise in addition to the ones in (6.58), which would still contribute to  . Also we note that the inputs \(\omega \)’s match the global reconstruction with the BPHZ model in the smooth setting, therefore the reconstructed solution satisfies the correct initial condition.
. Also we note that the inputs \(\omega \)’s match the global reconstruction with the BPHZ model in the smooth setting, therefore the reconstructed solution satisfies the correct initial condition.
6.4.2 Closing the analytic fixed point problem
In the rest of this subsection, we collect the deterministic analytic results needed to solve and compare (6.55)+(6.56) and (6.63)+(6.56). The input necessary to solve the two systems is a model \(Z\), initial condition (6.52), distributions \(\omega _{\ell}\) and \(\bar{\omega}_{\ell}\) compatible with the corresponding \(f\) in every term of the form \(\mathcal{G}^{\omega}(f)\), and the modelled distribution \(\mathcal{W}\) in (6.62) which takes values in the polynomial sector.
We say that an \(\varepsilon \)-input of size \(r>0\) over time \(\tau >0\) is a collection of such objects which furthermore satisfy

where \(\omega _{4}\stackrel {{\tiny \mathrm {def}}}{=}0\), \(\varsigma >0\) is the fixed parameter from Sect. 6.4.1 (which we later take sufficiently small), \(\boldsymbol{\Pi}^{Z}=\Pi _{0}\) where we denote as usual \(Z=(\Pi ,\Gamma )\), and
Above and until the end of the subsection we write

Note that the thick line in  and
and  represents a spatial derivative, so each of these really represents a collection of three basis vectors, one for each direction, indexed by \(j\). In (6.79), the corresponding norm should be interpreted as including a supremum over \(j\).
represents a spatial derivative, so each of these really represents a collection of three basis vectors, one for each direction, indexed by \(j\). In (6.79), the corresponding norm should be interpreted as including a supremum over \(j\).
Remark 6.29
The choice ‘0’ in the definition \(\boldsymbol{\Pi}^{Z}=\Pi _{0}\) is completely arbitrary since the structure group acts trivially on the set of symbols  and therefore \(\Pi _{0} = \Pi _{x}\) for all \(x\in {\mathbf {R}}\times \mathbf{T}^{3}\) when restricted to \(\mathcal {J}\).
and therefore \(\Pi _{0} = \Pi _{x}\) for all \(x\in {\mathbf {R}}\times \mathbf{T}^{3}\) when restricted to \(\mathcal {J}\).
Remark 6.30
The term on the left-hand side of (6.79) involving sup plays no role in Lemma 6.31, but will be important in Proposition 6.32 below.
We assume throughout this subsection that \(\chi \) is non-anticipative, which implies that \(K^{\varepsilon }\) is also non-anticipative.
Lemma 6.31
Consider \(r>0\), \(\varepsilon \in [0,1]\), and the bundle of modelled distributions
where
Then there exists \(\tau >0\), depending only on \(r\), such for all \(\varepsilon \)-inputs of size \(r\) over time \(\tau \) there exist solutions \(\mathscr{S}\) and \(\bar{\mathscr{S}}\) in (6.80) on the interval \((0,\tau )\) to (6.55)+(6.56) and (6.63)+(6.56) respectively. Furthermore
uniformly in \(\varepsilon \) and \(\varepsilon \)-inputs of size \(r\), where \(| |_{\vec{\gamma},\vec{\eta}, \varepsilon ;\tau} \) is the corresponding multi-component modelled distribution (semi)norm for (6.81) on the interval \((0,\tau )\). Finally, when the space of models is equipped with the metric \(d_{1;\tau}\), both \(\mathscr{S}\) and \(\bar{\mathscr{S}}\) are locally uniformly continuous with respect to the input.
Proof
We first prove well-posedness of the fixed point problem (6.55)+(6.56). For simplicity we write \(\gamma \) for \(\gamma _{\mathfrak {z}}\). As in the additive case (5.25), one has \(\mathcal{P}Y_{0} \in \hat{\mathscr{D}}^{\infty ,\eta}_{0} \), \(\partial \mathcal{P}Y_{0} \in \hat{\mathscr{D}}^{\infty ,\eta -1}_{0} \), and, since \(Y_{0}\in \mathcal{I}\), \(\mathcal{G}_{\mathfrak {z}} \big( \mathcal{P}Y_{0} \partial \mathcal{P}Y_{0} \big)\) is well-defined as an element of \(\hat{\mathscr{D}}^{\gamma ,\hat{\beta}}_{0}\) due to (2.3). Also, for \(\varrho \in (1/2,1)\), we recall that \(\mathcal{P}U_{0} \in \mathscr{D}^{\infty ,\varrho }_{0}\) and \(\bar{\boldsymbol{\Xi}}\in \mathscr{D}^{\infty ,\infty}_{-\frac{5}{2}-\kappa}\). Thus \(\mathcal{P}U_{0} \bar{\boldsymbol{\Xi}}\in \mathscr{D}^{\infty ,\varrho -\frac{5}{2}- \kappa}_{-\frac{5}{2}-\kappa}\) and, by Lemma A.4, we have (6.51), i.e., \(\boldsymbol{\Psi}^{U_{0}}\in \mathscr{D}^{\infty ,-1/2-2\kappa}_{-1/2-2\kappa}\).
Considering the terms in \(R_{Q}\) as defined in (6.57), Lemma A.3 implies
Since \((\eta +\hat{\beta}-1)\wedge (2\hat{\beta}-1) \wedge (\hat{\beta}- \frac{3}{2}-2\kappa )> -2\) by (ℐ), using Theorem A.5, one has \(\mathcal{G}_{\mathfrak {z}} \mathbf{1}_{+} R_{Q} \in \hat{\mathscr{D}}^{\gamma ,\hat{\beta}}_{- \frac{1}{2}-2\kappa}\).
On the other hand, by (6.51), one has
where \(\eta -\frac{3}{2}-2\kappa < -2\). Taking \(\kappa >0\) sufficiently small such that \(\eta +\frac{1}{2}<-2\kappa \), Lemma A.4 therefore implies that the first line on the right-hand side of (6.55) belongs to \(\mathscr{D}^{\infty , \eta +\frac{1}{2}-3\kappa}_{-5\kappa}\) and thus to \(\hat {\mathscr{D}}^{\infty , \eta +\frac{1}{2}-3\kappa}_{-5\kappa}\) by Remark A.1.
Moreover, using \(\eta <-\frac{1}{2}-2\kappa \), it follows from (6.51), (6.53), (6.54), and Remark A.1 that for \(\varrho \in (1/2,1)\)
so Theorem A.5 applies and one has \(\mathcal{G}_{\mathfrak {z}} \mathbf{1}_{+} \big( \mathcal{Y}^{3} + \mathring{C}_{\mathfrak {z}} \mathcal{Y}+ \mathring{C}_{\mathfrak {h}}\mathcal{H}\big) \in \hat{\mathscr{D}}^{\gamma ,\hat{\beta}}_{- \frac{1}{2}-2\kappa}\).
Finally, recalling that \(\gamma _{\mathfrak {u}}= \frac{5}{2}+2\kappa \), we have
Using our assumption \(\varrho >1/2\) one has \(\varrho -\frac{5}{2}-\kappa > -2\) for \(\kappa >0\) sufficiently small, so Theorem A.5 again applies and one has \(\mathcal{G}_{\mathfrak {z}} \big( \hat{\mathcal{U}}\bar{\boldsymbol{\Xi}} \big) \in \hat{\mathscr{D}}^{\gamma ,\hat{\beta}}_{-\frac{1}{2}-2\kappa}\).
Turning to the equation for ℋ, using our assumptions (6.81), we have
For the term \([\mathcal{H}_{j},\partial _{j} \mathcal{H}]\) above, we used that the lowest degree term appearing in the expansion for ℋ is  . Recalling that \(\varrho \in (\frac{1}{2},1)\) and \(\eta _{\mathfrak {h}}=\varrho -1\), as well as \(\eta +\varrho >0\) (since (\(\mathcal {G}\mathcal {I}\)) implies (2.10) by Remark 2.27), one has \(\eta +\eta _{\mathfrak {h}}>-1\) and \((2\eta _{\mathfrak {h}}-1) \wedge (\eta +2\eta _{\mathfrak {h}})>-2\). Thus the right-hand side of the equation for ℋ belongs to \(\mathscr{D}^{\gamma _{\mathfrak {h}},\eta _{\mathfrak {h}}}_{\alpha _{\mathfrak {h}}} \).
. Recalling that \(\varrho \in (\frac{1}{2},1)\) and \(\eta _{\mathfrak {h}}=\varrho -1\), as well as \(\eta +\varrho >0\) (since (\(\mathcal {G}\mathcal {I}\)) implies (2.10) by Remark 2.27), one has \(\eta +\eta _{\mathfrak {h}}>-1\) and \((2\eta _{\mathfrak {h}}-1) \wedge (\eta +2\eta _{\mathfrak {h}})>-2\). Thus the right-hand side of the equation for ℋ belongs to \(\mathscr{D}^{\gamma _{\mathfrak {h}},\eta _{\mathfrak {h}}}_{\alpha _{\mathfrak {h}}} \).
Regarding the equations for \(\mathcal{U}\) and \(\hat{\mathcal{U}}\), our assumption (6.81) on \(\hat{\mathcal{U}}\) and the fact that \(\mathcal{P}U_{0} \in \mathscr{D}^{\infty ,\varrho }_{0}\) implies \(\mathcal{U}\in \mathscr{D}^{\gamma _{\mathfrak {u}},\eta _{\mathfrak {u}}}_{0}\), so
where \(2\eta _{\mathfrak {h}}\in (-1,0)\), and \(\eta +\eta _{\mathfrak {h}}>-1\) as mentioned above. Noting that \((\gamma _{\mathfrak {h}}-\frac{1}{2}-2\kappa )+2-\kappa = \gamma _{\mathfrak {u}}\), Theorem A.5 then implies that the right-hand side of the equation for \(\hat{\mathcal{U}}\) belongs to \(\hat{\mathscr{D}}^{\gamma _{\mathfrak {u}},\eta _{\mathfrak {u}}}_{\alpha _{\mathfrak {u}}} \). The fact that these maps stabilise and are contractions on a ball follows from the short-time convolution estimates in Theorem A.5 as well as the refinement of [56, Thm. 7.1] given by [22, Prop. A.4]. Local uniform continuity of the unique fixed point with respect to the inputs follows in the same way as the proof of [56, Thm. 7.8].
The well-posedness for the other system (6.63)+(6.56) also follows in the same way, with the following differences.
-
\(\mathcal{M}\in \hat{\mathscr{D}}^{7/4,\eta}_{0}\) now plays the role of \(\mathcal{P}Y_{0}\) in \(\bar{R}_{Q}\). For the two corresponding terms in (6.83), by Lemma A.3,
$$\begin{aligned} \mathcal{M}\partial \hat{\mathcal{Y}}\in \hat{\mathscr{D}}^{\frac{1}{4}-2\kappa ,\eta + \hat{\beta}-1}_{-\frac{3}{2}-2\kappa}\;,\quad \text{and} \quad \hat{\mathcal{Y}} \partial \mathcal{M}\in \hat{\mathscr{D}}^{\frac{1}{4}-2\kappa ,\eta + \hat{\beta}-1}_{-\frac{1}{2}-2\kappa}\;. \end{aligned}$$Therefore \(\mathcal{G}_{\mathfrak {z}} \mathbf{1}_{+} \bar{R}_{Q} \in \hat{\mathscr{D}}^{\gamma , \hat{\beta}}_{-\frac{1}{2}-2\kappa}\) as before.
-
ℳ likewise plays the role of \(\mathcal{P}Y_{0}\) in the first two terms in (6.84), for which, using (6.64),
$$\begin{aligned} \mathcal{M}\partial \bar{\boldsymbol{\Psi}}^{U_{0}} \in \mathscr{D}^{\frac{1}{4}-2\kappa ,\eta - \frac{3}{2}-2\kappa}_{-\frac{3}{2}-2\kappa}\;, \quad \text{and} \quad \bar{\boldsymbol{\Psi}}^{U_{0}}\partial \mathcal{M}\in \mathscr{D}^{\frac{1}{4}-2\kappa ,\eta - \frac{3}{2}-2\kappa}_{-\frac{1}{2}-2\kappa}\;. \end{aligned}$$By Lemma A.4, the first line of the right-hand side of (6.63) is therefore in \(\mathscr{D}^{\gamma , \eta +\frac{1}{2}-3\kappa}_{-5\kappa}\) and thus in \(\hat {\mathscr{D}}^{\gamma , \eta +\frac{1}{2}-3\kappa}_{-5\kappa}\) by Remark A.1.
-
Since \(\mathcal{W}\in \hat{\mathscr{D}}_{0}^{7/4,-\frac{1}{2}-\kappa}\) and \(\mathcal{P}Y_{0}\in \hat{\mathscr{D}}^{\infty ,\eta}_{0}\), we have \(\mathcal{P}Y_{0} \partial \mathcal{W}\in \hat{\mathscr{D}}_{0}^{3/4,\eta -\frac{3}{2}- \kappa}\), \(\mathcal{W}\partial \mathcal{P}Y_{0} \in \hat{\mathscr{D}}_{0}^{7/4,\eta -\frac{3}{2}- \kappa}\), and \(\mathcal{W}\partial \mathcal{W}\in \hat{\mathscr{D}}_{0}^{3/4,-2-2\kappa}\). Therefore, for \(\kappa >0\) sufficiently small, the second line of (6.63) is in \(\hat{\mathscr{D}}^{\gamma ,\hat{\beta}}_{0}\) by Lemma A.4.
-
For the term \(\mathcal{G}_{\mathfrak {m}} \mathbf{1}_{+}\big( \hat{\mathcal{U}} \boldsymbol{\Xi} \big)\), we recall that
 is the abstract integration realising \(K_{\mathfrak {m}}^{(\varepsilon )} = K^{\varepsilon }= K*\chi ^{\varepsilon }\), and since \(K^{\varepsilon }\) is non-anticipative, we can use the statement in Theorem A.5 for non-anticipative kernels in the same way as for equation (6.55).
is the abstract integration realising \(K_{\mathfrak {m}}^{(\varepsilon )} = K^{\varepsilon }= K*\chi ^{\varepsilon }\), and since \(K^{\varepsilon }\) is non-anticipative, we can use the statement in Theorem A.5 for non-anticipative kernels in the same way as for equation (6.55).
 is the abstract integration realising
is the abstract integration realising It remains to compare the two systems and prove (6.82). First, by (6.51), (6.64), (A.1) and Lemma A.7,

Also, as in [22, Eq. (7.19)-(7.20)] one has
By (6.85) and Remark A.1 one then has
The same bounds hold for \(\partial (\boldsymbol{\Psi}^{U_{0}}-\bar{\boldsymbol{\Psi}}^{U_{0}})\) with \(-\frac{1}{2}-2\kappa \) replaced by \(-\frac{3}{2}-2\kappa \). Moreover, since
its \(\hat{\mathscr{D}}^{\gamma _{\mathfrak {z}},\eta _{\mathfrak {z}}}_{\alpha _{\mathfrak {z}}} \) norm is of order \(\varepsilon ^{\varsigma}\) using Theorem A.5, (6.85), and Lemma A.6.
Using (6.86), and again by Theorem A.5, the \(\hat{\mathscr{D}}^{\gamma _{\mathfrak {z}},\eta _{\mathfrak {z}}}_{\alpha _{\mathfrak {z}}} \) norm of
is also of order \(\varepsilon ^{\varsigma}\).
Turning to the first lines of (6.55) and (6.63), by (A.1) and Lemma A.7 we have
Therefore (6.88) is of order \(\varepsilon ^{\varsigma}\). The differences for the other two terms in the first lines of (6.55) and (6.63) are bounded in the same way. We readily obtain (6.82) from the above bounds and the short-time convolution estimates. □
With further assumptions on the models, we can obtain the following improved convergence. Recall the definition of \(\mathcal {Y}\) from (6.53).
Proposition 6.32
Suppose we are in the setting of Lemma 6.31. For every \(\tau \in (0,1)\), equip the space of models \(\mathscr{M}_{1}\) with the pseudo-metricFootnote 32

Let \(\lambda \in (0,1)\) and \(r>0\). Then there exists \(\tau \in (0,1)\), depending only on \(r\), such that \(I\mapsto \mathcal{R}\mathcal {Y}\in \mathcal{C}([\lambda \tau ,\tau ],\mathcal{S})\) is a uniformly continuous function on the set
The same statement holds with \(\mathcal {Y}\) replaced by \(\bar{\mathcal {Y}}\stackrel {{\tiny \mathrm {def}}}{=}\mathcal{P}Y_{0} + \bar{\boldsymbol{\Psi}}^{U_{0}} + \hat{\mathcal {Y}}\) i.e. by the \(\mathcal {Y}\)-component of \(\bar{\mathscr{S}}\), \(\omega \) replaced by \(\bar{\omega}\), and  and
and  replaced by
replaced by  and
and  .
.
Furthermore, as \(\varepsilon \downarrow 0\),
uniformly over all \(\varepsilon \)-inputs of size \(r\) over time \(\tau \) which satisfy

Proof
We prove first the statement regarding uniform continuity of \(I\mapsto \mathcal{R}\mathcal{Y}\). It follows from Lemma 6.31 and continuity of the reconstruction map that, for some \(\tau \in (0,1)\), \(\mathcal{R}\mathcal{U}\) is a uniformly continuous function into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{C}^{\frac{3}{2}-3\kappa})\) of the input. Truncating \(\mathcal{Y}\) at level \(\gamma =\frac{1}{2}-6\kappa \), we can write

where \(u = \mathcal{R}\mathcal{U}\) and \(v=u\otimes u\). Remark that the structure group acts trivially on  ,
,  , and \(\mathbf {1}\), and in particular \(b\) is a uniformly continuous function into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{C}^{\frac{1}{2}-6\kappa})\) of the input.
, and \(\mathbf {1}\), and in particular \(b\) is a uniformly continuous function into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{C}^{\frac{1}{2}-6\kappa})\) of the input.
The reconstruction of \(\mathcal{Y}\) on \([\lambda \tau ,\tau ]\times \mathbf{T}^{3}\) is then

Observe that  and
and  are uniformly continuous functions into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{S})\) and \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{C}^{-\kappa})\) respectively of the input due to our choice of metric on \(\mathscr{M}_{1}\). Hence
are uniformly continuous functions into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{S})\) and \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{C}^{-\kappa})\) respectively of the input due to our choice of metric on \(\mathscr{M}_{1}\). Hence  is a uniformly continuous function into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{C}^{-\kappa})\) of the input. Furthermore, it follows from Lemmas 2.32, 2.33, and 2.38 that \((g,Y) \mapsto gY\) is uniformly continuous from every ball in \(\mathfrak {G}^{\varrho }\times \mathcal{S}\) into \(\mathcal{S}\). Therefore
is a uniformly continuous function into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{C}^{-\kappa})\) of the input. Furthermore, it follows from Lemmas 2.32, 2.33, and 2.38 that \((g,Y) \mapsto gY\) is uniformly continuous from every ball in \(\mathfrak {G}^{\varrho }\times \mathcal{S}\) into \(\mathcal{S}\). Therefore  is a uniformly continuous functions into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{S})\) of the input. It follows from the same perturbation argument as in (5.31) that \(\mathcal{R}\mathcal{Y}\) is a uniformly continuous function into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{S})\) of the input. The proof of the analogous statement for \(I\mapsto \mathcal{R}\bar{\mathcal {Y}}\) is identical.
is a uniformly continuous functions into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{S})\) of the input. It follows from the same perturbation argument as in (5.31) that \(\mathcal{R}\mathcal{Y}\) is a uniformly continuous function into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{S})\) of the input. The proof of the analogous statement for \(I\mapsto \mathcal{R}\bar{\mathcal {Y}}\) is identical.
It remains to prove (6.89). Due to (6.82), \(|b-\bar{b}|_{\mathcal{C}([\lambda \tau ,\tau ],\mathcal{C}^{1/2-6\kappa})}\to 0\), and, combining with continuity of the reconstruction map, \(|\mathcal{R}\mathcal{U}-\mathcal{R}\bar{\mathcal{U}}|_{\mathcal{C}([\lambda \tau ,\tau ],\mathcal{C}^{3/2-3 \kappa})} \to 0\) as \(\varepsilon \downarrow 0\). Both convergences are uniform over all inputs of a given size. Then (6.89) follows from assumption (6.90) and a similar argument as above. □
Remark 6.33
Similar to [22, Rem. 7.16], one should be able to set \(\lambda =0\) in Proposition 6.32 once the initial conditions are taken appropriately (namely \(h_{0}= (\mathrm {d}g)g^{-1}\) for some \(g\in \mathfrak {G}^{0,\varrho }\)) and extra assumptions on \(\omega _{\ell},\bar{\omega}_{\ell}\) are made of the type \(G*\omega _{0}\in \mathcal{C}([0,1],\mathcal{S})\) and \(G*\omega _{\ell}\in \mathcal{C}([0,1],\mathcal{C}^{-\kappa})\) for \(\ell =1,2,3,4\). However, the weaker statement with \(\lambda >0\) suffices for our purposes.
6.5 Renormalised local solutions
The main result of this subsection is Proposition 6.38 which shows that the SPDEs (6.92) and (6.93) below, which we will later take to coincide with (6.3) (up to \(o(1)\)) and (1.16) respectively, converge to the same limit locally in time in \(\mathcal{C}([0,\tau ],\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })\).
We start by introducing some decomposition for our renormalisation constants. Recalling that we have fixed a space-time mollifier \(\chi \), Proposition 6.6 defines the renormalisation operators  and
and  , which depend on \(\boldsymbol{\sigma}^{\varepsilon }\in {\mathbf {R}}\). Recall from Propositions 5.7 and 6.6 that for \(j \in \{1,2\}\) there exist
, which depend on \(\boldsymbol{\sigma}^{\varepsilon }\in {\mathbf {R}}\). Recall from Propositions 5.7 and 6.6 that for \(j \in \{1,2\}\) there exist  and
and  which are all independent of \(\boldsymbol{\sigma}^{\varepsilon }\), such that for
which are all independent of \(\boldsymbol{\sigma}^{\varepsilon }\), such that for  ,
,
We first show in Proposition 6.34 that the SPDEs (6.92) and (6.93) converge (to the same limit) locally in time as space-time distributions in \(\mathcal{C}^{-\frac{1}{2}-\kappa}((0,\tau )\times \mathbf{T}^{3})\). This allows us to use a small noise limit argument in Lemmas 6.36 and 6.37 to show that  and
and  are bounded in \(\varepsilon \). This in turn allows us to improve the mode of convergence in Proposition 6.38 to \(\mathcal{C}([0,\tau ],\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })\) by comparing (6.92) and (6.93) to an SPDE with additive noise.
are bounded in \(\varepsilon \). This in turn allows us to improve the mode of convergence in Proposition 6.38 to \(\mathcal{C}([0,\tau ],\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })\) by comparing (6.92) and (6.93) to an SPDE with additive noise.
We define operators in \(L_{G} (E,E)\) given by

To state Proposition 6.34, we fix \(\boldsymbol{\sigma}\in {\mathbf {R}}\), and some choice of constants \((\boldsymbol{\sigma}^{\varepsilon } \in {\mathbf {R}}: \varepsilon \in (0,1])\) with \(\boldsymbol{\sigma}^{\varepsilon } \rightarrow \boldsymbol{\sigma}\). We also fix \(\mathring{C}_{\mbox{A}}, \mathring{C}_{\mbox{h}} \in L_{G}(\mathfrak {g},\mathfrak {g})\), and some choice of \(\mathring{C}^{\varepsilon }_{\mbox{A}}, \mathring{C}^{\varepsilon }_{\mbox{h}} \in L_{G}(\mathfrak {g}, \mathfrak {g})\) with \(\mathring{C}^{\varepsilon }_{\mbox{A}} \rightarrow \mathring{C}_{\mbox{A}}\), and \(\mathring{C}^{\varepsilon }_{\mbox{h}} \rightarrow \mathring{C}_{\mbox{h}}\) as \(\varepsilon \downarrow 0\), and then define as in (6.14)
Finally we will simply write \(\mathrm {d}g g^{-1}\) for \(\mathrm {d}g g^{-1}\oplus 0 \in E\) and recall the shorthand notation (1.15) and that \(\mathbf {F}\) is the filtration generated by the white noise.
Proposition 6.34
Suppose \(\chi \) is non-anticipative and fix any initial data \(\bar{x} = (\bar{a},\bar{\phi}) \in \mathcal{S}\) and \(g(0) \in {\mathfrak {G}}^{0,\varrho }\). Consider the system of equations for \(\bar{X}=(\bar{A},\bar{\Phi})\)
where \(\bar{g} \) solves the last equation in (6.3) with \(\bar{A}\) given by the first component of the \(\bar{X}\) from (6.92) and we define \(\bar{g} \xi \) as in (1.11) with \(\bar{g}\equiv 1\) on \((-\infty ,0)\). Consider further the system of equations for \(Y=(B,\Psi )\)
where \(g \) solves the last equation in (1.16) with \(B\) given by the first component of \(Y\), and \(g \xi ^{\varepsilon }\) is again defined by (1.11). Both systems are taken with initial conditions \(\bar{X}(0)=Y(0)=\bar{x}\) and \(\bar{g}(0) = g(0)\), and with renormalisation operators

Then, for \(\varepsilon >0\), the system (6.92) is well-posed in the same sense as Theorem 6.1(i).
Furthermore, let \((U,h)\) (resp. \((\bar{U},\bar{h})\)) be defined by \(g\) (resp. \(\bar{g}\)) as in (6.2). Then there exists \(\tau >0\), depending only on \(\sup _{\varepsilon \in (0,1)}(|\mathring{C}_{\mbox{A}}^{\varepsilon }|+ |\mathring{C}_{\mbox{h}}^{ \varepsilon }| +|\boldsymbol{\sigma}^{\varepsilon }|)\), the realisation of the noise on \([-1,2]\times \mathbf{T}^{3}\), and the size of \((\bar{x},g(0))\) in \(\mathcal{S}\times \mathfrak {G}^{\varrho }\), such that \(\tau \) is an \(\mathbf {F}\)-stopping time and such that \((\bar{X},\bar{U},\bar{h})\) and \((Y,U,h)\) converge in probability in \(\mathcal{C}^{-\frac{1}{2}-\kappa}((0,\tau )\times \mathbf{T}^{3})\) to the same limit as \(\varepsilon \downarrow 0\). More precisely, there exists a \(\mathcal{C}^{-\frac{1}{2}-\kappa}((0,\infty )\times \mathbf{T}^{3})\)-valued random variable \((X,V,f)\) such that
in probability as \(\varepsilon \downarrow 0\). Moreover, \((X,V,f)\) depends on the sequences \(\mathring{C}_{\mbox{A}}^{\varepsilon }\), \(\mathring{C}_{\mbox{h}}^{\varepsilon }\) and \(\boldsymbol{\sigma}^{\varepsilon }\) only through their limits \(\mathring{C}_{\mbox{A}}\), \(\mathring{C}_{\mbox{h}}\), and \(\boldsymbol{\sigma}\).
Proof
We first claim that (6.92) is well-posed and is moreover the renormalised equation satisfied by the reconstruction of \(\mathcal{Y}\) in (6.53) with respect to  , where \(\hat{\mathcal{Y}}\) solves the fixed point problem (6.63). The other inputs \(\bar{\omega}_{\ell}\) and \(\mathcal{W}\) for (6.63) are defined by (6.65) and (6.66). Since
, where \(\hat{\mathcal{Y}}\) solves the fixed point problem (6.63). The other inputs \(\bar{\omega}_{\ell}\) and \(\mathcal{W}\) for (6.63) are defined by (6.65) and (6.66). Since  is not a smooth model, the proof of the claim for (6.92) goes via obtaining the corresponding renormalised equation for the model
is not a smooth model, the proof of the claim for (6.92) goes via obtaining the corresponding renormalised equation for the model  and then taking the limit \(\delta \downarrow 0\), which is justified by the convergence (6.69) and Lemmas 6.26-6.27.
and then taking the limit \(\delta \downarrow 0\), which is justified by the convergence (6.69) and Lemmas 6.26-6.27.
By [11, Thm. 5.7] and [22, Prop. 5.68], together with the discussion in Sect. 6.4 (see in particular Remark 6.28), the reconstruction with respect to  of \((\mathcal{Y},\mathcal{U},\mathcal{H})\) yields \((\bar{X}, \bar{U}, \bar{h})\) where we write \(\bar{X}=(\bar{A},\bar{\Phi})\), and by (6.18) from Proposition 6.6, \((\bar{U},\bar{h})\) satisfies the “barred” versionFootnote 33 of (6.4) which is not renormalised.
of \((\mathcal{Y},\mathcal{U},\mathcal{H})\) yields \((\bar{X}, \bar{U}, \bar{h})\) where we write \(\bar{X}=(\bar{A},\bar{\Phi})\), and by (6.18) from Proposition 6.6, \((\bar{U},\bar{h})\) satisfies the “barred” versionFootnote 33 of (6.4) which is not renormalised.
We first claim that \(\bar{U}\) satisfies the conditions of Definition 6.5. Indeed, if \(\bar{g}\) solves (6.3) for the given \(\bar{A}\), then Lemma 6.3 with this given \(\bar{A}\) implies that \((\mathrm {d}\bar{g}) \bar{g}^{-1}\) and \(\boldsymbol{\varrho }(\bar{g})\) solve the “barred” version of (6.4) with the same initial condition as that of \((\bar{U},\bar{h})\), thus \((\bar{U},\bar{h})=(\boldsymbol{\varrho }(\bar{g}) ,(\mathrm {d}\bar{g}) \bar{g}^{-1})\).
We apply Proposition 6.6, and take the limit \(\delta \downarrow 0\) of the renormalisation constants to conclude that \(\bar{X}\) solves (6.92) but with \(\bar{g} \xi _{i} \) replaced by \(\bar{U}\xi _{i}\) and \((\mathrm {d}\bar{g}) \bar{g}^{-1}\) replaced by \(\bar{h}\). It remains to observe that if \((\bar{X}', \bar{g})\) is the solution to (6.92) and the last equation in (6.3), where \(\bar{g} \) is such that \(\boldsymbol{\varrho }(\bar{g}) = \bar{U}\) and \(\mathrm {d}\bar{g} \bar{g}^{-1}=\bar{h}\), then similarly as above using Lemma 6.3, we have \(\bar{X}=\bar{X}'\), which proves the claim that \(\bar{X}\) solves (6.92).
A similar argument shows that (6.93) is the renormalised equation satisfied by the reconstruction of \(\mathcal{Y}\) in (6.53) with respect to  , where \(\hat{\mathcal{Y}}\) solves the fixed point problem (6.55).
, where \(\hat{\mathcal{Y}}\) solves the fixed point problem (6.55).
The probabilistic input from Lemmas 6.24, 6.26, and 6.27, together with the deterministic Lemma 6.31, Remark 6.30, and continuity of the reconstruction map \(\mathcal{R}\colon \mathscr{D}^{\gamma _{\mathfrak {t}},\eta _{\mathfrak {t}}}_{\alpha _{\mathfrak {t}}} \to \mathcal{C}^{\alpha _{\mathfrak {t}}\wedge \eta _{\mathfrak {t}}}((0,\tau )\times \mathbf{T}^{3})\), prove the statement concerning convergence in probability as \(\varepsilon \downarrow 0\). The fact that \(\tau \) is a stopping time follows from the fact that, since \(\chi \) and \(K\) are non-anticipative, one only needs to know the noise up to time \(t>0\) to determine if the corresponding \(\varepsilon \)-input is of size \(r>0\) over time \(t\).
Finally, the fact that \((X,V,f)\) in the proposition statement can be chosen to depend only on the limits \(\mathring{C}_{\mbox{A}}\), \(\mathring{C}_{\mbox{h}}\), and \(\boldsymbol{\sigma}\) follows from the continuity of the fixed point problems (6.55)+(6.56) and (6.63)+(6.56) with respect to the coefficients of the non-linearity, and with respect to the input model  and distributions \(\omega ^{\varepsilon }_{\ell},\bar{\omega}^{\varepsilon ,0}_{\ell}\) which are multilinear functions of \(\boldsymbol{\sigma}^{\varepsilon }\). □
and distributions \(\omega ^{\varepsilon }_{\ell},\bar{\omega}^{\varepsilon ,0}_{\ell}\) which are multilinear functions of \(\boldsymbol{\sigma}^{\varepsilon }\). □
Our next goal is to show boundedness of \(C_{\mathfrak {z}}^{\varepsilon }- C^{\varepsilon }_{\mathfrak {h}}\) and \(\bar{C}^{\varepsilon }_{\mathfrak {h}}\) appearing in Proposition 6.34. This will allow us to relate \(\bar{X}\) and \(Y\) to a variant of equation (1.14), which we study in Appendix C, and for which continuity into \(\mathcal{S}\) at time \(t=0\) is simpler to show since the noise appears additively.
We now take advantage of the parameter \(\boldsymbol{\sigma}\). For clarity we include the following remark.
Remark 6.35
In Sects. 5 and 6, the parameter \(\boldsymbol{\sigma}^{\varepsilon }\) which multiplies the noise terms in (5.4) and (6.92)–(6.93) is incorporated into our noise assignment,Footnote 34 that is we look at the BPHZ lifts of the noise \(\boldsymbol{\sigma}^{\varepsilon } \xi ^{\varepsilon }\) in Sect. 5 (and \(\boldsymbol{\sigma}^{\varepsilon } \xi ^{\varepsilon }\), \(\boldsymbol{\sigma}^{\varepsilon }\xi \) in Sect. 6).
In the results below we perform small noise limits \(\lim _{\varepsilon \downarrow 0 } \boldsymbol{\sigma}^{\varepsilon } = 0\). An important fact is that in this limit the corresponding BPHZ lifts converge to the BPHZ lift of the “noise” 0 (which is just the canonical lift of 0, that is the unique admissible model that vanishes on any tree containing a label in \(\mathfrak{L}_{-}\)). In fact, the full “\(\varepsilon \)-inputs” converge to 0 (see the \(\boldsymbol{\sigma}\) dependence in the bounds of Lemma 6.26), which allows us to argue that the corresponding solutions converge (in the appropriate sense), as \(\varepsilon \downarrow 0\) to the solution we obtain from the zero noise.
Lemma 6.36
For \(j \in \{1,2\}\), let  . Then
. Then
Proof
We proceed by contradiction, supposing that we have a subsequence of \(\varepsilon \downarrow 0\) along which \(\lim _{\varepsilon \downarrow 0} r_{1}^{\varepsilon } + r_{2}^{\varepsilon } = \infty \) where \(r_{j}^{\varepsilon } \stackrel {{\tiny \mathrm {def}}}{=}|D_{j}^{\varepsilon }|^{\frac{1}{2j}}\). We then set \(\bar{\boldsymbol{\sigma}}^{\varepsilon } = (r_{1}^{\varepsilon } + r_{2}^{\varepsilon })^{-1}\). By passing to another subsequence we can assume that
It follows that we can find a constant \(z \in {\mathbf {R}}\) such that if we set \(\boldsymbol{\sigma}^{\varepsilon } \stackrel {{\tiny \mathrm {def}}}{=}z \bar{\boldsymbol{\sigma}}^{\varepsilon }\) and \(\hat{C}^{\varepsilon } \stackrel {{\tiny \mathrm {def}}}{=}(\boldsymbol{\sigma}^{\varepsilon })^{2} D_{1}^{\varepsilon }+ (\boldsymbol{\sigma}^{\varepsilon })^{4} D_{2}^{\varepsilon }\) then \(\hat{C}^{\varepsilon } \rightarrow \hat{C} = z^{2} \hat{C}_{1} + z^{4} \hat{C}_{2} \neq 0\) along the subsequence for which we have (6.95).
Now we set
as the constants in (6.91) and Proposition 6.34. We then note that the solution \(Y\) to (6.93) for initial data \((\bar{x},g(0)) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\), with renormalisation constants \(C^{\varepsilon }_{\mathfrak {z}},C^{\varepsilon }_{\mathfrak {h}}\) given by (6.94), namely the solution to

is equal to \(gX\) where \(X\) solves (5.4) with initial data \(x\stackrel {{\tiny \mathrm {def}}}{=}\bar{g}(0)^{-1}\bar{x}\), with constants (5.5) and \(\mathring{C}^{\varepsilon }_{\mbox{A}} = 0 \) and \(\boldsymbol{\sigma}^{\varepsilon }\) as above, namely \(X\) solves

The key fact is that with our choices of constants one has  .
.
As \(\varepsilon \downarrow 0 \) we have that \(\boldsymbol{\sigma}^{\varepsilon } \rightarrow 0\) and so, by Remark 6.35, the solutions to (6.98) converge (in the sense given by Proposition 6.34) to the solution of the deterministic PDE
(Recall that  .) On the other hand, as \(\varepsilon \downarrow 0\) along our subsequence, the solutions to (6.97) converge to the solution of the deterministic PDE
.) On the other hand, as \(\varepsilon \downarrow 0\) along our subsequence, the solutions to (6.97) converge to the solution of the deterministic PDE
where \(\mathrm {d}g g^{-1}= h\) solves the deterministic PDE (6.4), which is non-zero for generic initial conditions. We remind the reader that convergence as \(\varepsilon \downarrow 0\) of the solutions to (6.4) is a straightforward consequence of Lemma 6.31 and continuity of the reconstruction operator.
Since on the one hand the relation \(gX = Y\) is preserved under the limit \(\varepsilon \downarrow 0\) but on the other hand \(gX\) solves the same equation as \(X\) (i.e. without the last term appearing in the equation for \(Y\)), this gives us the desired contradiction.Footnote 35 □
Lemma 6.37
Suppose \(\chi \) is non-anticipative. Then

Proof
We proceed similarly to the proof of Lemma 6.36, except that now instead of comparing \(Y\) with a gauge transformation of \(X\), we compare \(\bar{X}\) with \(X\).
Arguing by contradiction, we suppose as in the proof of Lemma 6.36 that we have a subsequence \(\varepsilon \downarrow 0\) and \(\boldsymbol{\sigma}^{\varepsilon } \rightarrow 0\) with

This time, we consider \((\bar{X},\bar{g})\) as in Proposition 6.34 –namely, with \(\bar{X}= (\bar{A},\bar{\Phi})\) solving (6.92) and \(\bar{g}\) as in (6.3) –and choose

as the constants in (6.91). For any \(\varepsilon > 0\), define the transformation of the white noise \(T^{\varepsilon }\colon \xi \mapsto T^{\varepsilon }(\xi )\) by \(T^{\varepsilon }(\xi )=\bar{g} \xi \) on \([0,\tau ]\) and \(T^{\varepsilon }(\xi )=\xi \) on \({\mathbf {R}}\setminus [0,\tau ]\). Recall here that \(\tau >0\) is the \(\mathbf {F}\)-stopping time as in Proposition 6.34. In particular, since \(\chi \) is non-anticipative, \(\bar{g}\) is adapted to \(\mathbf {F}\), it follows that this operation is well defined and that moreover \(T^{\varepsilon }(\xi )\stackrel {{\tiny \mathrm {law}}}{=}\xi \).Footnote 36
Then, by definition, \(\bar{X}= \tilde{X}\stackrel {{\tiny \mathrm {def}}}{=}(\tilde{A},\tilde{\Phi})\) on \([0,\tau ]\) where \(\tilde{X}\) and \(\tilde{g}\) solve
(The reason why the term \(\bar{C}^{\varepsilon }_{\mathfrak {h}} \mathrm {d}\tilde{g} \tilde{g}^{-1}\) is absent is that \(\bar{C}^{\varepsilon }_{\mathfrak {h}} = 0\) thanks to our choice (6.99).) Remark that, for every \(\varepsilon >0\), the above equations are well-posed and \((\tilde{X},\tilde{g})\) are smooth for \(t>0\) since \(T^{\varepsilon }(\xi )\stackrel {{\tiny \mathrm {law}}}{=}\xi \), and thus \((\tilde{X},\tilde{g})\) can be extended to maximal solutions in \((\mathcal{S}\times \mathfrak {G}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\).
On the one hand, by Remark 6.35, \(\bar{X}\) converges in probability on \([0,\tau ]\) (in the sense given by Proposition 6.34) to the solution of the deterministic equation

where \(\bar{g}\) solves the relevant equation in (6.3). On the other hand, since \(T^{\varepsilon }(\xi )\stackrel {{\tiny \mathrm {law}}}{=}\xi \), it follows from Theorem 5.1 that \(\tilde{X}\) converges in law (and thus in probability) in \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\) to the solution of the deterministic equation
Since we can choose \(\bar{g}_{0}\) so that \(\mathrm {d}\bar{g}_{0} g_{0}^{-1} \neq 0\), we can find initial data for which the (deterministic) solution of (6.101) differs from that of (6.102) for all sufficiently small times, which gives the desired contradiction. □
We are now ready to improve the mode of convergence in Proposition 6.34.
Proposition 6.38
The conclusion of Proposition 6.34holds with the improvement that \((\bar{X},\bar{U},\bar{h})\) and \((Y,U,h)\) converge in probability in \(\mathcal{C}([0,\tau ],\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })\) as \(\varepsilon \downarrow 0\). More precisely, the random variable \((X,V,f)\) in Proposition 6.34takes values in \(\mathcal{C}([0,\tau ],\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })\) and
in probability as \(\varepsilon \downarrow 0\).
Proof
Continuing from the proof of Proposition 6.34 –Corollary 3.15 and Proposition 6.32 provide the additional probabilistic and deterministic input respectively to conclude the desired statement with \(\mathcal{C}([0,\tau ],\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })\) replaced by \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })\) for any fixed \(\lambda \in (0,1)\).
To lighten notation, we will only consider the \(\bar{X}\) and \(Y\) components henceforth; how to add back \(\bar{U},\bar{h}\) and \(U,h\) will be clear. We assume henceforth that \(\tau \in (0,1)\).
For \(\varepsilon >0\), we extend \(Y\) to a function in \(\mathcal{C}([0,1],\mathcal{S})\) by stopping it at \(\tau \). It follows from the above that there exists a \(\mathcal{C}((0,1],\mathcal{S})\)-valued random variable \(Z\) such that \(\sup _{t\in (\lambda ,1]}\Sigma (Z(t),Y(t))\to 0\) in probability as \(\varepsilon \downarrow 0\) for every \(\lambda >0\). We now claim that
and likewise for \(\bar{X}\). To prove (6.103), a similar calculation as in [22, Sect. 2.2] implies that \(Y=gX\) where \(X,g\) solve (C.1)-(C.2) with operator

and initial condition \(x= g(0)^{-1} \bar{x}\).
Observe that \(\sup _{\varepsilon \in (0,1]} |c^{\varepsilon }|<\infty \) due to Lemma 6.36. It follows from a similar proof to that of Theorem 5.1 with minor changes as indicated in the proof of Lemma C.1, that (6.103) holds with \(\Sigma (Y(t),Y(0))\) replaced by \(\Sigma (X(t),X(0)) + |g(t)-g(0)|_{\mathfrak {G}^{0,\varrho }}\). Recalling from Proposition 2.28 that \((g,X)\mapsto g X\) is a uniformly continuous function from every ball in \(\mathfrak {G}^{0,\varrho }\times \mathcal{S}\) into \(\mathcal{S}\), we obtain (6.103) from the identity \(Y=g X\).
Observe that (6.103) implies that \(Z\) can be extended to a \(\mathcal{C}([0,1],\mathcal{S})\)-valued random variable by defining \(Z(0)=Y(0)\) and \(\sup _{t\in [0,1]}\Sigma (Y(t),Z(t)) \to 0\) in probability as \(\varepsilon \downarrow 0\).
We now claim that (6.103) holds with \(Y\) replaced by \(\bar{X}\), where we also extend \(\bar{X}\) to a function in \(\mathcal{C}([0,1],\mathcal{S})\) by stopping it at \(\tau \). Recall that \(\tau >0\) is the \(\mathbf {F}\)-stopping time, which depends only on \(\xi \mathbin{\upharpoonright}_{[-1,2]\times \mathbf{T}^{3}}\) (through the size of its BPHZ model), for which \(\bar{X}\) is well-defined and converges in probability in \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{S})\) as \(\varepsilon \downarrow 0\) to the same limit \(Z\) as \(Y\) for all \(\lambda \in (0,1)\).
To prove the claim, for \(\varepsilon >0\), define as in the proof of Lemma 6.37 the transformation of the white noise \(T\colon \xi \mapsto T(\xi )\), where \(T(\xi )=\bar{g} \xi \) on \([0,\tau ]\) and \(T(\xi )=\xi \) on \({\mathbf {R}}\setminus [0,\tau ]\). Then \(\bar{X}=\tilde{X}\stackrel {{\tiny \mathrm {def}}}{=}(\tilde{A},\tilde{\Phi})\) on \([0,\tau ]\) where \((\tilde{X},\tilde{g})\in (\mathcal{S}\times \mathfrak {G}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) denotes the maximal solution to
Since \(\chi \) is non-anticipative, Lemma 6.37 yields \(\sup _{\varepsilon \in (0,1]}|\bar{C}^{\varepsilon }_{\mathfrak {h}}|<\infty \). Since \(T(\xi )\stackrel {{\tiny \mathrm {law}}}{=}\xi \), it follows again from the same proof as Theorem 5.1 with small changes as indicated in the proof of Lemma C.1/C.2 that (6.103) holds with \(Y\) replaced by \(\tilde{X}\). (In fact, if we knew that \(\bar{C}^{\varepsilon }_{\mathfrak {h}}\) converges to a finite limit as \(\varepsilon \downarrow 0\), then we would know that \((\tilde{X},\tilde{g})\) converges in \((\mathcal{S}\times \mathfrak {G}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\).) Since \(\bar{X}= \tilde{X}\) on \([0,\tau ]\), it also follows that (6.103) holds with \(Y\) replaced by \(\bar{X}\) as claimed.
Finally, recalling that \(\sup _{t\in (\lambda ,1]}\Sigma (\bar{X}(t),Y(t)) \to 0\) in probability as \(\varepsilon \downarrow 0\) for all \(\lambda \in (0,1)\), it follows that \(\sup _{t\in [0,1]}\Sigma (\bar{X}(t),Y(t))\to 0\) in probability as \(\varepsilon \downarrow 0\) as required. □
6.6 Convergence of maximal solutions
The main result of this subsection is the following.
Proposition 6.39
Suppose we are in the setting of Proposition 6.34. Then \((\bar{X},\bar{U}, \bar{h})\), obtained as in Theorem 6.1(i), converge in probability as maximal solutions in \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) as \(\varepsilon \downarrow 0\).
Remark 6.40
The proof of Proposition 6.39 applies with several changes to show convergence of \((Y,U,h)\) as maximal solutions. However, we will derive this result below more simply in Corollary 6.42 using pathwise gauge equivalence.
Proof
As in [22, Sect. 7.2.4], it will be convenient to consider a different abstract fixed point problem from (6.63), which solves instead for the ‘remainder’ of \(\bar{X}\). Like in [22], this new fixed point will encode information of \(\bar{U}\) on an earlier time interval which is necessary to make sense of the term \(\chi ^{\varepsilon }* (\bar{g} \xi )\). In addition to this, and unlike in [22], it is important that this new fixed point problem will have an improved regularity in the initial condition for \(\bar{X}\).
To motivate the new fixed point problem, consider the system of SPDEs given by (6.92)+(6.4). Note that if we start with an arbitrary initial condition at some earlier time \(t_{0} < 0\), then the solution at time 0 is necessarily of the form
where \(\tilde{X}_{0} \in \mathcal{C}^{-\kappa}\) (even in \(\mathcal{C}^{\frac{1}{2}-}\), but we don’t need to use this). Looking now at positive times, it is straightforward to see that \(X = \tilde{X} + Z_{1}+Z_{2}\) where \(Z_{1} = K^{\varepsilon }* (\bar{U}\xi )\), \(Z_{2} = K*(Z_{1}\partial Z_{1})\), and \(\bar{U}\) solves (6.2) for positive times and is equal to its previous value for negative times, and \(\tilde{X}\) solves the fixed point problem
We now lift this to a fixed point problem in a suitable space of modelled distributions. For this, assume that we are given \(\tilde{X}_{0} \in \mathcal{C}^{-\kappa}\), \(h_{0} \in \mathcal{C}^{\frac{1}{2}-3\kappa}\), and a modelled distribution \(\tilde {\mathcal{U}}\in \mathscr{D}^{\frac{5}{2}+2\kappa}\) defined on \([-T,0]\times \mathbf{T}^{3}\) for some \(T\in (0,1)\) and taking values in the corresponding sector of our regularity structure. One should think of \(\tilde{\mathcal{U}}\) as the ‘previous’ \(\bar{U}\) restricted to a sufficiently short interval \([-T,0]\).
As earlier, we decompose \(\mathcal{U}= \mathcal{P}\bar{U}_{0} + \hat {\mathcal{U}}\). We therefore extend \(\tilde {\mathcal{U}}\) to positive times by the Taylor lift of the harmonic extension of its reconstruction \(\bar{U}_{0}\) at time 0. Note that \(\bar{U}_{0}\) is simply given by the component of \(\tilde {\mathcal{U}}\) multiplying \(\mathbf{1}\) since the sector corresponding to \(\mathcal{U}\) is of function type. We also have \(\bar{U}_{0} \in \mathcal{C}^{\frac{3}{2}-3\kappa}\) which implies that, as a modelled distribution on \([-T,\infty )\times \mathbf{T}^{3}\), \(\tilde {\mathcal{U}}\in \bar {\mathscr{D}}^{\frac{5}{2}+2\kappa ,\frac{3}{2}-3\kappa}_{0}\).
Let us write now
where \(\mathcal{U}= \tilde{\mathcal{U}}+ \hat{\mathcal{U}}\). Here \(\hat{\mathcal{U}}\) and ℋ solve (6.56), and \(\mathcal{Y}\stackrel {{\tiny \mathrm {def}}}{=}\mathcal{Z}_{1}+\mathcal{Z}_{2}+\tilde {\mathcal{Y}}\) where \(\tilde {\mathcal{Y}}\) solves
We claim that we can solve for
Indeed, by Lemma A.3 and Theorem A.5, \(\mathcal{U}\boldsymbol{\Xi}\in \bar {\mathscr{D}}^{\kappa ,-1-4\kappa}_{-\frac{5}{2}-\kappa}\) and \(\mathcal{Z}_{1} \in \bar{\mathscr{D}}^{2-\kappa ,1-5\kappa}_{-\frac{1}{2}-2\kappa}\). Hence
Furthermore \(\tilde{X}_{0} \in \mathcal{C}^{-\kappa}\) and the ‘right-hand side’ is
Note how \(-\mathcal{Z}_{1}\partial \mathcal{Z}_{1}\) cancels the worst term in \(\mathcal{Y}\partial \mathcal{Y}\), so that the worst terms are now \(\mathcal{Z}_{1}^{3} \in \bar{\mathscr{D}}^{1-5\kappa ,-9\kappa}_{-\frac{3}{2}-6 \kappa}\) and \(\mathcal{Z}_{1} \partial \tilde {\mathcal{Y}}\in \bar{\mathscr{D}}^{\kappa , -\frac{3}{2}-3 \kappa}_{-\frac{3}{2}-2\kappa}\). Since \(\mathscr{D}^{\kappa ,-\frac{3}{2}-6\kappa}_{-\frac{3}{2}-6\kappa}\) is stable under multiplication by \(\mathbf{1}_{+}\), the fixed point problem (6.106) is well-posed.
Furthermore, under the same pseudo-metric on models as in Proposition 6.32, the reconstruction \((\bar{X},\tilde{X},Z_{1},Z_{2},\bar{U},\bar{h})\) of the solution \((\mathcal{Y},\tilde {\mathcal{Y}}, \mathcal{Z}_{1},\mathcal{Z}_{2},\mathcal{U},\mathcal{H})\) is a locally uniformly continuous function into \(\mathcal{C}([\lambda \tau ,\tau ],\mathcal{S}\times \mathcal{C}^{-\kappa}\times \mathcal{S}\times \mathcal{C}^{-5\kappa}\times \tilde{\mathfrak {G}}^{0,\varrho })\) (for any fixed \(\lambda >0\)) of the tuple
where \(\tau \) is locally uniform in the tuple. (Note how we do not require the input distributions \(\bar{\omega}\) any more because the initial condition is in \(\mathcal{C}^{-\kappa}\) instead of \(\mathcal{C}^{\eta}\) for \(\eta <-\frac{1}{2}\).)
For \(\varepsilon \in [0,1]\), the construction of the maximal solutions (modelled distributions) \((\mathcal{Y},\mathcal{U},\mathcal{H})\) is then similar to [22, Def. 7.20]. Namely, we begin by solving for \((\mathcal{Y},\mathcal{U},\mathcal{H})\) using the original equation (6.63)+(6.61)+(6.56) on an interval \([0,\sigma _{1}]\stackrel {{\tiny \mathrm {def}}}{=}[0,2\tau _{1}]\). The underlying model is  as in Lemma 6.24, \(\mathcal{W}\) is taken as in (6.65), and \(\bar{\omega}^{0}_{0}\), \(\bar{\omega}^{\varepsilon ,0}_{\ell}\) for \(\ell \in \{1,2,3\}\), and \(\bar{\omega}^{\varepsilon }_{4}\) are defined through (6.66) and Lemma 6.26.
as in Lemma 6.24, \(\mathcal{W}\) is taken as in (6.65), and \(\bar{\omega}^{0}_{0}\), \(\bar{\omega}^{\varepsilon ,0}_{\ell}\) for \(\ell \in \{1,2,3\}\), and \(\bar{\omega}^{\varepsilon }_{4}\) are defined through (6.66) and Lemma 6.26.
We then take \(T=\tau _{1}\) with time centred around \(\sigma _{1}\) and \(\mathcal{U}\mathbin{\upharpoonright}_{[\sigma _{1}-T,\sigma _{1}]}\) playing the role of \(\tilde {\mathcal{U}}\) above, and
Solving now (6.106)+(6.56) with this data (and the same model  ), we extend the solution to the interval \([0,\sigma _{2}]\stackrel {{\tiny \mathrm {def}}}{=}[0,2\tau _{1}+2\tau _{2}]\).
), we extend the solution to the interval \([0,\sigma _{2}]\stackrel {{\tiny \mathrm {def}}}{=}[0,2\tau _{1}+2\tau _{2}]\).
Then we set \(T=\tau _{2}\), centre time around \(\sigma _{2}\), and solve again (6.106)+(6.56) with \(\tilde {\mathcal{U}}= \mathcal{U}\mathbin{\upharpoonright}_{[\sigma _{2}-T,\sigma _{2}]}\), \(\tilde{X}_{0} = (\mathcal{R}\tilde {\mathcal{Y}})(\sigma _{2})\) and \(h_{0}=(\mathcal{R}\mathcal{H})(\sigma _{2})\). We thus extend the solution \((\mathcal{Y},\mathcal{U},\mathcal{H})\) to the interval \([0,\tau ^{*})\) where \(\tau ^{\star }= \sum _{k=1}^{\infty}\sigma _{k}\).
The proof of the proposition is then similar to that of [22, Prop. 7.23]. In particular, similar to [22, Remarks 7.21, 7.22], the reconstruction \((\bar{X}, \bar{U},\bar{h})\) solves the renormalised PDEs (6.92)+(6.4) on the interval \([0,\sigma _{n}]\) provided that \(\varepsilon ^{2} < \tau _{i}\) for all \(i=1,\ldots , n\). Moreover, by the convergence of models from Lemma 6.24 and Corollary 3.15, for every \(n\geq 1\), there exists \(\varepsilon _{n}\) such that we can choose the same \(\tau _{1},\ldots ,\tau _{n}\) for all \(\varepsilon \in [0,\varepsilon _{n}]\).
The final important remark is that for \(\varepsilon =0\), the reconstructions of the above maximal solutions on each interval \((\sigma _{k},\sigma _{k+1}]\) coincide with the reconstructions of the solutions to the original fixed point problem (6.63) with \(\mathcal{W}=0\) and \(\bar{\omega}_{\ell}\) defined again through (6.66) and Lemma 6.26 –note that, since we take \(\delta \downarrow 0\) first and then \(\varepsilon \downarrow 0\), the initial condition at each time step \(\sigma _{k}\) is independent of \(\xi \mathbin{\upharpoonright}_{[\sigma _{k},\infty )}\) (modulo centring time around \(\sigma _{k}\)), therefore the estimates and convergence results from Lemma 6.26 still hold since \(\sigma _{k}\) can be taken as a stopping time. In particular, the maximal solution for \(\varepsilon =0\) is in \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\), which, combined with Proposition 6.38, implies that \((\bar{X},\bar{U},\bar{h})\) converges as \(\varepsilon \downarrow 0\) in \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) (in probability). □
6.7 Gauge covariance
In this subsection we prove Theorem 6.1. We keep using the notation of Sect. 6.5. Following Proposition 6.38, we will use the main result of Appendix D to show that  and
and  both converge to finite limits as \(\varepsilon \downarrow 0\). This in turn will allow us to conclude the proof of Theorem 6.1.
both converge to finite limits as \(\varepsilon \downarrow 0\). This in turn will allow us to conclude the proof of Theorem 6.1.
Proposition 6.41
Suppose \(\chi \) is non-anticipative. With notation as in Lemma 6.36, there exists \((D_{1},D_{2}) \in L_{G}(\mathfrak {g},\mathfrak {g})^{2}\) such that
Moreover, \((D_{1},D_{2})\) does not depend on the choice of mollifier.
Proof
We start by proving the first statement regarding \(\varepsilon \downarrow 0\) convergence. Recalling that \(\sup _{\varepsilon \in (0,1]}\big( |D_{1}^{\varepsilon }| + |D_{2}^{\varepsilon }| \big)< \infty \) by Lemma 6.36, we argue by contradiction and suppose that there exist sequences \(\varepsilon _{n}, \tilde{\varepsilon }_{n} \downarrow 0\) along which we have distinct limits
as \(n \rightarrow \infty \). We will show that this gives rise to a contradiction with the results of Appendix D. We first note that we can find \(\boldsymbol{\sigma}\) such that, setting \(D = \boldsymbol{\sigma}^{2} D_{1} + \boldsymbol{\sigma}^{4} D_{2}\) and \(\tilde{D} = \boldsymbol{\sigma}^{2}\tilde{D}_{1} + \boldsymbol{\sigma}^{4} \tilde{D}_{2}\), we have \(D \neq \tilde{D}\). We fix \(g_{0} \in \mathfrak {G}^{0,\varrho }\) such that \(D^{\oplus 3} \mathrm {d}g_{0} g_{0}^{-1} \neq \tilde{D}^{\oplus 3} \mathrm {d}g_{0} g_{0}^{-1}\) and some arbitrary \(Y_{0} \in \mathcal{S}\).
Now for \(\varepsilon > 0\) let \((X^{\varepsilon },g^{\varepsilon })\) be the maximal solution to (5.4) (with \(\boldsymbol{\sigma}^{\varepsilon }=\boldsymbol{\sigma}\) and \(\mathring{C}^{\varepsilon }_{\mbox{A}} = \mathring{C}_{\mbox{A}} = 0\)) and (1.17), started from the initial data \((X_{0},g_{0})\) where \(Y_{0} = g_{0} X_{0}\). Observe that, by Lemma C.1, \((X^{\varepsilon },g^{\varepsilon })\) converges in probability in \((\mathcal{S}\times \mathfrak {G}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) as \(\varepsilon \downarrow 0\) to a limit we denote \((X,g)\). On the other hand, \(Y^{\varepsilon }\stackrel {{\tiny \mathrm {def}}}{=}g^{\varepsilon } X^{\varepsilon }\) solves
where in the definitions of \(C_{\mathfrak {z}}\stackrel {{\tiny \mathrm {def}}}{=}C_{\mathfrak {z}}^{\varepsilon }\) and \(C_{\mathfrak {h}}^{\varepsilon }\) one takes \(\mathring{C}^{\varepsilon }_{\mbox{A}} = \mathring{C}_{\mbox{A}} = 0\) and \(\mathring{C}^{\varepsilon }_{\mbox{h}} = \boldsymbol{\sigma}^{2} D^{\varepsilon }_{1} + \boldsymbol{\sigma}^{4} D^{ \varepsilon }_{2}\). Then, by (6.107), we have \(\mathring{C}^{\varepsilon _{n}}_{\mbox{h}} \rightarrow D\) and \(\mathring{C}^{\tilde{\varepsilon }_{n}}_{\mbox{h}} \rightarrow \tilde{D}\).
For the rest of the argument we recall the space of local solutions \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{lsol}}}}\) and local solution map  introduced in Remark D.8.
introduced in Remark D.8.
Then there exists some strictly positive \(\mathbf{F}\)-stopping time \(\tau \) such that, in probability, we have

Here \(U,h\) (resp. \(U^{\varepsilon _{n}}, h^{\varepsilon _{n}}\) /\(U^{\tilde{\varepsilon }_{n}}, h^{\tilde{\varepsilon }_{n}}\)) are obtained from \(g\) (resp. \(g^{ \varepsilon _{n}}\) /\(g^{\tilde{\varepsilon }_{n}}\)) via (6.2).
On the other hand, since \((X^{\varepsilon },g^{\varepsilon })\) does not depend on \(\mathring{C}^{\varepsilon }_{\mbox{h}}\) and by the continuity of the group action given in Proposition 2.28, it follows that
in probability, as random elements of \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{lsol}}}}\) –here \((\tau , X,U,h)\) is defined by stopping the maximal solution \((X,U,h) \in (\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) at \(\tau \).
By (D.13) and cancelling stochastic integrals and terms \(\big( 0^{\oplus 3} \oplus (- m^{2}) \big)X\) on either side, we have the almost sure equality
However, this is a contradiction since \(\lim _{t \downarrow 0} h(t) = \mathrm {d}g_{0} g_{0}^{-1}\) –this finishes the proof of the first statement of the proposition.
The statement about independence with respect to our choice of mollifier \(\chi \) can be proven with the same argument –the key point above was that the limit \((\tau , X,U,h)\) in (6.108) is independent of which \(\varepsilon \downarrow 0\) subsequence we choose, thanks to BPHZ convergence.Footnote 37 However, the BPHZ model that defines \((\tau ,X,U,h)\) is also insensitive to the choice of mollifier one uses when taking \(\varepsilon \downarrow 0\). Therefore the argument above to prove uniqueness of the limiting constants obtained with two different \(\varepsilon \downarrow 0\) subsequences and a single mollifier can be repeated when taking \(\varepsilon \downarrow 0\) with two different mollifiers. □
As a corollary of Proposition 6.41 and the proof of Proposition 6.38, we obtain convergence of \((Y,U,h)\) as maximal solutions.
Corollary 6.42
In the setting of Proposition 6.34, \((Y,U,h)\) converges in probability in \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) as \(\varepsilon \downarrow 0\).
Proof
Consider \(X,g\) as in the proof of Proposition 6.38. Since \(c^{\varepsilon }\) in (6.104) converges as \(\varepsilon \downarrow 0\) to a finite limit due to Proposition 6.41, \((X,g)\) converges in probability in \((\mathcal{S}\times \mathfrak {G}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) as \(\varepsilon \downarrow 0\) due to Lemma C.1. Since \(Y=gX\) and \((U,h)\) are defined from \(g\) by (6.2) for all positive times (until the blow-up of \((X,g)\)), the conclusion follows from the local uniform continuity of the group action (Proposition 2.28). □
The next proposition concerns the \(\varepsilon \downarrow 0\) limit of the renormalisation constants  which appear in the renormalised equations for \(\bar{X}\).
which appear in the renormalised equations for \(\bar{X}\).
Assume that the mollifier \(\chi \) is non-anticipative. For any fixed \(\varepsilon > 0\), after taking \(\delta \downarrow 0\), since \(\bar{g}\) is adapted one expects that the law of \(\bar{X}\) should remain the same if one replaces \(\bar{g} \xi \) by \(\xi \), in which case the equation for \(\bar{X}\) would simply become the equation for \(X\). Therefore one expects that  should vanish when the mollifier \(\chi \) is non-anticipative. However the following result is sufficient for our needs.
should vanish when the mollifier \(\chi \) is non-anticipative. However the following result is sufficient for our needs.
Proposition 6.43
Suppose \(\chi \) is non-anticipative. Then, for \(j\in \{1,2\}\), there exists  such that
such that

Moreover,  is independent of our choice of non-anticipative \(\chi \).
is independent of our choice of non-anticipative \(\chi \).
Proof
We first prove the limit as \(\varepsilon \downarrow 0\) for a fixed choice of mollifier. Recall that by Lemma 6.37 we have  . To prove convergence we again argue by contradiction and suppose that we have sequences \(\varepsilon _{n}\) and \(\tilde{\varepsilon }_{n}\) going to 0 along which we have the distinct limits
. To prove convergence we again argue by contradiction and suppose that we have sequences \(\varepsilon _{n}\) and \(\tilde{\varepsilon }_{n}\) going to 0 along which we have the distinct limits

We fix \(\boldsymbol{\sigma}\in {\mathbf {R}}\) such that, if we set  and
and  , one has \(D \neq \tilde{D}\). Fix \(\bar{g}_{0} \in \mathfrak {G}^{0,\varrho }\) such that
, one has \(D \neq \tilde{D}\). Fix \(\bar{g}_{0} \in \mathfrak {G}^{0,\varrho }\) such that
along with some arbitrary \(\bar{X}_{0} \in \mathcal{S}\).
Again, for \(\varepsilon > 0\), and this time making \(\varepsilon \)-dependence explicit, let \(\bar{X}^{\varepsilon },\bar{g}^{\varepsilon }\) be the maximal solution to (6.92) with \(\boldsymbol{\sigma}^{\varepsilon } = \boldsymbol{\sigma}\),  , and \(\mathring{C}^{\varepsilon }_{\mbox{A}} = 0\) started from initial data \((\bar{X}_{0},\bar{g}_{0})\). By Proposition 6.39 we have the convergence in probability
, and \(\mathring{C}^{\varepsilon }_{\mbox{A}} = 0\) started from initial data \((\bar{X}_{0},\bar{g}_{0})\). By Proposition 6.39 we have the convergence in probability

Here \(\bar{U}^{\varepsilon }, \bar{h}^{\varepsilon }\) are obtained from \(\bar{g}^{\varepsilon }\) as in (6.2) and  is the BPHZ solution map given in (D.1).
is the BPHZ solution map given in (D.1).
Now, let \((X^{\varepsilon },g^{\varepsilon })\) be the maximal solution to (C.6)–(C.7) with \(\mathring{C}^{\varepsilon }_{\mbox{A}} = 0\) and \(c^{\varepsilon } = 0\) started from initial data \((\bar{X}_{0},\bar{g}_{0})\). Due to our choice of renormalisation constants, \((X^{\varepsilon },g^{\varepsilon })\) is equal to \((\bar{X}^{\varepsilon },\bar{g}^{\varepsilon })\) in law. Moreover, by Lemma C.2, \((X^{\varepsilon },g^{\varepsilon })\) converges in probability as \(\varepsilon \downarrow 0\) to a limit \((X,g)\).
It follows that  but this combined with (6.110) gives a contradiction with Lemma D.1 since
but this combined with (6.110) gives a contradiction with Lemma D.1 since

The above argument finishes the proof of the first statement. The second statement, regarding independence of the limit with respect to our choice of non-anticipative mollifier \(\chi \), can be also be proven using the above argument –the relation between the first and second statement of this proposition mirrors what is explained in the final paragraph of the proof of Proposition 6.43 –again the limit \((X,g)\) of \((X^{\varepsilon },g^{\varepsilon })\) above does not depend on the choice of mollifier. Thus we can repeat the argument above for two sequences obtained by taking \(\varepsilon \downarrow 0\) for two different non-anticipative mollifiers. □
Proof of Theorem 6.1
Part (i) was already proven in Proposition 6.34.
We now prove part (ii). We will apply Proposition 6.38 (together with Proposition 6.39 and Corollary 6.42) with \(\boldsymbol{\sigma}_{\varepsilon }=\boldsymbol{\sigma}=1\). Note that Proposition 6.38 holds for any choice of converging sequence \((\mathring{C}_{\mbox{A}}^{\varepsilon }, \mathring{C}_{\mbox{h}}^{\varepsilon })\). We now find the claimed \(\varepsilon \)-independent \(\check{C}\), so that for any \(\mathring{C}_{\mbox{A}}\) as in Theorem 6.1, we can choose suitable \((\mathring{C}_{\mbox{A}}^{\varepsilon }, \mathring{C}_{\mbox{h}}^{\varepsilon })\) for the systems in Proposition 6.38 so that the two systems (1.16)+(6.3) being compared in Theorem 6.1 and the two systems (6.93)+(6.92) being compared in Proposition 6.38 match, at least up to order \(o(1)\). To match (1.16) and (6.93) we require

while to match (6.3) and (6.92) to order \(o(1)\) we require

To satisfy the first identities in (6.111)–(6.112), we take \(\mathring{C}_{\mbox{A}}^{\varepsilon }= \mathring{C}_{\mbox{A}}\).
For the second identities, by Proposition 6.41, one has convergence of  . We therefore set
. We therefore set

so that the second identity in (6.111) is satisfied and \(\lim _{\varepsilon \downarrow 0}\mathring{C}_{\mbox{h}}^{\varepsilon }\) exists. Furthermore, by Proposition 6.43 and the non-anticipative assumption on \(\chi \), one has convergence of  . We therefore set
. We therefore set

so that the second identity in (6.112) is satisfied. Since the difference between the constants in the two systems (6.3) and (6.92) vanishes, stability of the fixed point problem (6.63) with respect to \(\mathring{C}_{\mathfrak {h}}\) implies that the two systems converge in probability to the same limit.
The claimed convergence in probability in part (ii) therefore follows from Proposition 6.38 with the above choice of \((\mathring{C}_{\mbox{A}}^{\varepsilon }, \mathring{C}_{\mbox{h}}^{\varepsilon })\) together with Proposition 6.39 and Corollary 6.42. Indeed, Proposition 6.39 and Corollary 6.42 imply that the two systems converge separately as maximal solutions in probability in \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) as \(\varepsilon \downarrow 0\), while Proposition 6.38 implies the two limits are equal on an interval \([0,\tau ]\) where \(\tau >0\) is an \(\mathbf {F}\)-stopping time bounded stochastically from below by a distribution depending only on the size of the initial condition. Since both limits are (time-homogenous) \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })\)-valued strong Markov process with respect to \(\mathbf {F}\), it follows that they are equal almost surely as \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\)-valued random variables.
Furthermore, \(\check{C}\) is unique by the injectivity in law given by Lemma D.1 –any alternative choice of \(\check{C}\) would mean that each of the each of the two systems again converge to solutions of the form  , but now with distinct choices of \((\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}})\) for each of the systems. This completes the proof of part (ii).
, but now with distinct choices of \((\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}})\) for each of the systems. This completes the proof of part (ii).
For part (iii) of the theorem, observe that the right hand side of (6.113) is independent of \(\mathring{C}_{\mbox{A}}\) thanks to Remark 6.8 and independent of our specific choice of non-anticipative \(\chi \) thanks to the second statements in Propositions 6.41+6.43.
The final part (iv) of the theorem is mostly a reformulation of the other parts of the theorem. Note that \((g X, U, h)\) is almost surely equal to the maximal solution \((Y,U,h) = (B,\Psi ,U,h)\) (as given in part (ii) of the theorem) started from the initial data \((g_{0} x, \boldsymbol{\varrho }(g_{0}), \mathrm {d}g_{0} g_{0}^{-1})\). On the other hand, if \((\bar{X},\bar{U},\bar{h})\) (again, the limiting solution given in part (ii)) is started from initial data \((g_{0} x, \boldsymbol{\varrho }(g_{0}), \mathrm {d}g_{0} g_{0}^{-1})\) then we have \((Y,U,h) = (\bar{X},\bar{U},\bar{h})\) almost surely, in particular \((Y,U,h) \stackrel {{\tiny \mathrm {law}}}{=}(\bar{X},\bar{U},\bar{h})\).
Finally, we have that \((\bar{X},\bar{U},\bar{h}) \stackrel {{\tiny \mathrm {law}}}{=}(\tilde{X}, \tilde{U}, \tilde{h})\) for all choices of \((x,g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\) if and only if \(\mathring{C}_{\mbox{A}} = \check{C}\). To see that \(\mathring{C}_{\mbox{A}} = \check{C}\) is a sufficient condition for this equality in law, note that, for \(\varepsilon > 0\) and non-anticipative mollifiers, we have equality in law for the solutions of (6.3) and those of (C.6)+(C.7) (with \(c^{\varepsilon } = 0\)).
To see that \(\mathring{C}_{\mbox{A}} = \check{C}\) is a necessary condition for \((\bar{X},\bar{U},\bar{h}) \stackrel {{\tiny \mathrm {law}}}{=}(\tilde{X}, \tilde{U}, \tilde{h})\), note that, by the injectivity in law given by Lemma D.1, there exists a choice of \((g_{0} x, g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\) for which limits of the law of \((\bar{X},\bar{U},\bar{h})\) started from \((g_{0} x, g_{0})\) has a different law then that of the limit of the maximal solutions to a modification of (6.3) where one again starts from \((g_{0} x, g_{0})\) but drops the term \((\mathring{C}_{\mbox{A}} - \check{C})(\partial _{i} \bar{g} )\bar{g}^{-1}\). However, this latter law is equal to the law of \((\tilde{X}, \tilde{U}, \tilde{h})\) (again, since the dynamics only differ by a rotation of the noise by an adapted gauge transformation). This shows that if \(\mathring{C}_{\mbox{A}} \neq \check{C}\) then there exists initial data for which \((\bar{X},\bar{U},\bar{h}) \not \stackrel {{\tiny \mathrm {law}}}{=}(\tilde{X}, \tilde{U}, \tilde{h})\). □
7 Markov process on gauge orbits
We finally turn to the existence and uniqueness of a Markov process on the orbit space \(\mathfrak {O}\) associated to the SPDE (1.14), which is the second part of Theorem 1.9.
We first adapt to our setting the notion of a generative probability measure from [22] in order to specify the way in which a Markov process is canonical. Our definition differs slightly from that of [22] due to the different structure of the quotient space.
Definition 7.1
Unless otherwise stated, a white noise \(\xi =(\xi _{1},\xi _{2}, \xi _{3},\zeta )\) is understood to be an \(E=\mathfrak {g}^{3}\oplus \mathbf{V}\)-valued white noise on \({\mathbf {R}}\times \mathbf{T}^{3}\) defined on a probability space \((\Omega ^{\mathrm {noise}},\mathcal {F}, \mathbf{P})\). A filtration \(\mathbf {F}=(\mathcal {F}_{t})_{t \geq 0}\) is said to be admissible for \(\xi \) if \(\xi \) is adapted to \(\mathbf {F}\) and \(\xi \vert _{[t,\infty )}\) is independent of \(\mathcal {F}_{t}\) for all \(t \geq 0\). By the SYMH solution map (driven by \(\xi \)) we mean the random map
for which \(t\mapsto \Lambda _{s,t}(x)\) is the \(\varepsilon \downarrow 0\) limit in probability in \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\) of the solutions to (1.14) with initial condition \(x\) at initial time \(s\), and with a mollifier \(\chi \) and operators \((C^{\varepsilon }_{\mbox{A}},C^{\varepsilon }_{\Phi})\) defined by (5.5) with \(\mathring{C}_{\mbox{A}}=\check{C}\) and \(\boldsymbol{\sigma}^{\varepsilon }=1\), where \(\check{C}\) is the unique \(\chi \)-independent operator in Theorem 6.1(iii).
We will frequently say that \(X\) solves SYMH driven by \(\xi \) with initial condition \(x\in \hat{\mathcal{S}}\) and time \(s\geq 0\) to mean that \(X(t)=\Lambda _{s,t}(x)\). Remark that \(\Lambda _{s,s}(x)=x\) by construction. We will drop the reference to \(s\) whenever \(s=0\).
For fixed \(s,t,x\), note that \(\Lambda _{s,t}(x)\colon \Omega ^{\mathrm {noise}}\to \hat{\mathcal{S}}\) is a random variable and we make no claims about the \(\mathbf{P}\)-a.s. continuity in \(x\) (the difficulty here being the extra stochastic objects in Lemma 5.19 that need to be constructed from the initial data). Nonetheless, \(t\mapsto \Lambda _{s,t}(x)\) is \(\mathbf{P}\)-a.s. continuous since it is \(\mathbf{P}\)-a.s. in \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\). Moreover, \(\mathcal{S}\ni x\mapsto \Lambda _{s,s+\cdot}(x) \in L^{0}(\Omega ^{ \mathrm {noise}};\hat{\mathcal{S}})\) is continuous in probability for any \(s\geq 0\).
Furthermore, for an admissible filtration \(\mathbf {F}\) and an \(\mathbf {F}\)-stopping time \(\tau \), if \(X_{0}\) is an \(\mathbf {F}_{\tau}\)-measurable random variable, then \(t\mapsto \Lambda _{\tau ,\tau +t}(X_{0})\) is well-defined as a \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\)-valued random variable and is adapted to the filtration \(\{\mathcal {F}_{\tau +t}\}_{t\geq 0}\). Indeed, this follows from independence of \(\tilde{\Psi}_{\varepsilon } \) and \(X_{0}\) in the notation of Lemma 5.19. Furthermore, we can readily verify the flow property
for any \(\mathbf {F}\)-stopping times \(s\leq t\leq u\) and \(\mathbf {F}_{s}\)-measurable \(X_{0}\). Indeed, (7.1) follows from the analogous identity at the level of the mollification \(\xi ^{\varepsilon }\) combined with continuity of \(x\mapsto \Lambda _{s,t}(x)\) in probability.
For a metric space \(F\), denote by \(D({\mathbf {R}}_{+},F)\) the usual Skorokhod space of càdlàg functions. We extend the gauge equivalent relation ∼ to  by imposing that
by imposing that  .
.
Recall that we have fixed the parameters \(\eta ,\beta ,\delta ,\alpha ,\theta \) in the way described in the beginning of Sect. 5 which is required to define the space \((\mathcal{S},\Sigma )\equiv (\mathcal{S}_{\eta ,\beta ,\delta ,\alpha , \theta},\Sigma _{\eta ,\beta ,\delta ,\alpha ,\theta})\) as in Definition 2.22.
Consider \(\bar{\eta}\in (\eta ,-\frac{1}{2})\), \(\bar{\delta}\in (\frac{3}{4},\delta)\) such that \(\beta <-2(1-\bar{\delta})-\), and \(\bar{\alpha}\in (\alpha ,\frac{1}{2})\). Note that \((\bar{\eta},\beta ,\bar{\delta})\) also satisfies (ℐ). Denote \(\bar{\Sigma}\equiv \Sigma _{\bar{\eta},\beta ,\bar{\delta},\bar{\alpha}, \theta}\).
Definition 7.2
A probability measure \(\mu \) on \(D({\mathbf {R}}_{+},\hat{\mathcal{S}})\) is called generative if there exists a filtered probability space \((\Omega ^{\mathrm {noise}},\mathcal {F},(\mathcal {F}_{t})_{t \geq 0}, \mathbf{P})\) supporting a white noise \(\xi \) for which the filtration \(\mathbf {F}=(\mathcal {F}_{t})_{t \geq 0}\) is admissible and a \(D({\mathbf {R}}_{+},\hat{\mathcal{S}})\)-valued random variable \(X\) on \(\Omega ^{\mathrm {noise}}\) with the following properties.
-
1.
The law of \(X\) is \(\mu \) and \(X(0)\) is \(\mathcal {F}_{0}\)-measurable.
-
2.
Let \(\Lambda \) denote the SYMH solution map. There exists an non-decreasing sequence of \(\mathbf {F}\)-stopping times \((\varsigma _{j})_{j=0}^{\infty}\), such that a.s. \(\varsigma _{0}=0\) and, for all \(j \geq 0\),
-
(a)
one has \(X(t) = \Lambda _{\varsigma _{j},t}(X(\varsigma _{j}))\) for all \(t\in [\varsigma _{j},\varsigma _{j+1})\), and
-
(b)
the random variable \(X(\varsigma _{j+1})\) is \(\mathcal {F}_{\varsigma _{j+1}}\)-measurable and
$$\begin{aligned} X(\varsigma _{j+1}) \sim \Lambda _{\varsigma _{j},\varsigma _{j+1}}(X( \varsigma _{j}))\;. \end{aligned}$$
-
(a)
-
3.
Let
 . Then a.s. \(\lim _{j\to \infty}\varsigma _{j}=T^{*}\). Furthermore, on the event \(\{T^{*}<\infty \}\), almost surely
. Then a.s. \(\lim _{j\to \infty}\varsigma _{j}=T^{*}\). Furthermore, on the event \(\{T^{*}<\infty \}\), almost surely -
 on \([T^{*},\infty )\), and
on \([T^{*},\infty )\), and -
one has
$$\begin{aligned} \lim _{t\nearrow T^{*}} \inf _{\substack{Y\in \mathcal{S}\\Y\sim X(t)}} \bar{\Sigma}(Y,0) = \infty \;. \end{aligned}$$(7.2)
-
 . Then a.s.
. Then a.s.  on
on If there exists \(x\in \hat{\mathcal{S}}\) such that \(X(0)=x\) almost surely, then we call \(x\) the initial condition of \(\mu \).
Remark 7.3
The meaning of item 2 is that, before blow-up, the dynamic \(X\) runs on the interval \([\varsigma _{j},\varsigma _{j+1})\) according to SYMH, after which it jumps to a new point in its gauge orbit and restarts SYMH at time \(\varsigma _{j+1}\). The main point of item 3 is that the whole gauge orbit \([X(t)]\) “blows up” at time \(T^{*}\) provided we measure “size” in a slightly stronger sense than \(\Sigma \). We use \(\bar{\Sigma}\) in (7.2) due to technical issues with measurable selections; using \(\Sigma \) in (7.2) would be more natural, but we do not know if Theorem 7.5(i) below remains true in this case. The reason why this is nevertheless sensible is that even if we start with an initial condition in \(\mathcal{S}\) for which \(\bar{\Sigma}\) is infinite, it is immediately finite so that the infimum in (7.2) is almost surely finite for all \(t \in (0,T^{*})\).
Remark 7.4
In the setting of Definition 7.2, if \(Z\colon \Omega ^{\mathrm {noise}}\to \hat{\mathcal{S}}\) is \(\mathcal {F}_{s}\)-measurable, then \(t\mapsto \Lambda _{s,t}(Z)\) is adapted to \((\mathcal {F}_{t})_{t \geq s}\). Hence \(X\) is adapted to \(\mathbf {F}\), \(T^{*}\) is an \(\mathbf {F}\)-stopping time, the event (7.2) is \(\mathcal {F}_{T^{*}}\)-measurable, and \(T^{*}\) is predictable.
Define the quotient space \(\hat{\mathfrak {O}}\stackrel {{\tiny \mathrm {def}}}{=}\hat{\mathcal{S}}/{\sim}\), which we can readily identify, as a set, with  . Note that \(\hat{\mathfrak {O}}\) is not Hausdorff, but there is a simple description of its topology in terms of the (completely Hausdorff) topology of \(\mathfrak {O}\). Indeed, \(O\subset \hat{\mathfrak {O}}\) is open if and only if either (\(O= \hat{\mathfrak {O}}\)) or (
. Note that \(\hat{\mathfrak {O}}\) is not Hausdorff, but there is a simple description of its topology in terms of the (completely Hausdorff) topology of \(\mathfrak {O}\). Indeed, \(O\subset \hat{\mathfrak {O}}\) is open if and only if either (\(O= \hat{\mathfrak {O}}\)) or ( and \(O\subset \mathfrak {O}\) is open), see Proposition 2.53.
and \(O\subset \mathfrak {O}\) is open), see Proposition 2.53.
Let \(\pi \colon \hat{\mathcal{S}}\to \hat{\mathfrak {O}}\) denote the canonical projection map. If \(\mu \) is generative, then thanks to Definition 7.2, the pushforward \(\pi _{*}\mu \) is a probability measure on \(\mathcal{C}({\mathbf {R}}_{+},\hat{\mathfrak {O}})\), instead of just on \(D({\mathbf {R}}_{+},\hat{\mathfrak {O}})\). Our main result regarding the construction of a suitable Markov process on \(\mathfrak {O}\) is as follows.
Theorem 7.5
-
(i)
For every \(x\in \hat{\mathcal{S}}\), there exists a generative probability measure \(\mu \) with initial condition \(x\).
-
(ii)
For every \(z\in \hat{\mathfrak {O}}\), there exists a (necessarily unique) probability measure \(\mathbf{P}^{z}\) on \(\mathcal{C}({\mathbf {R}}_{+},\hat{\mathfrak {O}})\) such that, for every \(x\in z\) and generative probability measure \(\mu \) with initial condition \(x\), \(\pi _{*}\mu =\mathbf{P}^{z}\). Furthermore, \(\{\mathbf{P}^{z}\}_{z\in \hat{\mathfrak {O}}}\) define the transition functions of a time homogeneous Markov process on \(\hat{\mathfrak {O}}\).
The proof of Theorem 7.5 is postponed to Sect. 7.3. Before that, we provide a number of results showing how to exploit the gauge covariance obtained in Theorem 6.1 in this setting.
7.1 Coupling SYMH with gauge-equivalent initial conditions
Throughout this subsection, we fix a white noise \(\xi \) defined on a probability space \((\Omega ^{\mathrm {noise}},\mathcal{F},\mathbf{P})\) and let \(\mathbf {F}=(\mathcal {F}_{t})_{t\geq 0}\) denote its canonical filtration. Let furthermore \(x,\bar{x}\in \mathcal{S}\) and \(X=(A,\Phi )\in \mathcal{S}^{{\mathop{\mathrm{sol}}}}\) solve SYMH driven by \(\xi \) with initial condition \(X(0)=x\).
If \(\bar{x} = x^{g(0)}\) for some \(g(0)\in \mathfrak {G}^{1}\), it follows readily from Theorem 6.1 that \(\bar{X} \stackrel {{\tiny \mathrm {def}}}{=}X^{g}\) solves SYMH driven by \(g\xi = (\mathrm {Ad}_{g}\xi _{1},\mathrm {Ad}_{g}\xi _{2},\mathrm {Ad}_{g}\xi _{3},g\zeta )\) with initial condition \(\bar{x}\), where \(g\) is the \(\varepsilon \downarrow 0\) limit of the solutions to (1.17) with initial condition \(g(0)\) (and where \((A,\Phi )=X\)). The point of this subsection is to prove that if only \(\bar{x} \sim x\), then a similar statement still holds true. Namely, we have the following result.
Proposition 7.6
Suppose \(x\sim \bar{x}\). Then, on the same probability space \((\Omega ^{\mathrm {noise}},\mathcal{F},\mathbf{P})\), there exists a process \((\bar{X},g)\) and a white noise \(\bar{\xi}\), both adapted to \(\mathbf {F}\), such that \(\bar{X}\) solves SYMH driven by \(\bar{\xi}\) with initial condition \(\bar{x}\) and such that \(g(t)\in \mathfrak {G}^{\frac{3}{2}-}\) and \(\bar{X}(t) = X(t)^{g(t)}\) for all \(t>0\) inside the interval of existence of \((\bar{X}, g)\in \mathcal{S}\times \mathfrak {G}^{\frac{3}{2}-}\). Furthermore, \(g\) cannot blow up in \(\mathfrak {G}^{\frac{3}{2}-}\) before \(\Sigma (X)+\Sigma (\bar{X})\) does.
Remark 7.7
The proof of Proposition 7.6 will reveal that \(g\) solves (1.17) with some initial condition \(g^{(0)}\in \mathfrak {G}^{\frac{1}{2}-}\).
Lemma 7.8
For every \(x\in \mathcal{S}\),
-
(i)
\(\lim _{t\downarrow 0}\Sigma (\mathcal{F}_{t}(x),x)=0\),
-
(ii)
\(\lim _{s\downarrow 0}\sup _{t\in [0,T]} \Sigma (\mathcal{P}_{s} \mathcal{F}_{t} (x), \mathcal{F}_{t} (x)) = 0\), where \(T\leq \mathop{\mathrm{Poly}}(\Theta (x)^{-1})\) is a time of existence of \(\mathcal{F}_{t}(x)\) appearing in Proposition 2.9.
Proof
(i) Writing \(p_{t} \stackrel {{\tiny \mathrm {def}}}{=}\mathcal{P}_{t}x\) and \(\mathcal{F}_{t} x = p_{t} + r_{t}\), it follows from Proposition 2.58(ii) that \(\lim _{t\to 0}\Sigma (p_{t},x)=0\). Observe further that \(|r_{t}|_{\mathcal{C}^{\hat{\beta}}}\to 0\) by Proposition 2.9. Since \(\hat{\beta}\geq 2\theta (\alpha -1)\) by assumption (5.1), it follows from Lemma 2.25 that \(\lim _{t\to 0}{|\!|\!| r_{t} |\!|\!|}_{\alpha ,\theta}=0\). Furthermore \(|r_{t}|_{\mathcal{C}^{\eta}}\to 0\) since, by (5.2) and the conditions on \(\eta \) and \(\delta \) (which in particular imply that \(\eta + \delta < \frac{1}{2}\) and therefore \(\hat{\eta}> \eta \)), one has \(\eta <\hat{\beta}\). Finally, by Lemma 2.35(i),

with \(\hat{\eta}\) as in (5.2). As \(t\to 0\), the first term on the right-hand side converges to 0 since \(\Theta (p_{t},x)\to 0\), the second term converges to 0 since

by Lemma 2.35(ii) and since \(\hat{\beta}\geq \hat{\eta}>\frac{1}{2}-\delta \) by assumption (5.2), and the third term converges to 0 also because of (5.2).
(ii) As above, write \(\mathcal{F}_{t} x= p_{t}+r_{t}\). Since \(\mathcal{P}_{t}\) is a contraction for the norm \({|\!|\!| \cdot |\!|\!|}_{\alpha ,\theta}\) by Lemma 2.55(ii), it follows that
which converges to 0 as \(s\downarrow 0\) by Proposition 2.58(ii). By an identical argument,
Furthermore, by Proposition 2.9, \(\lim _{t\downarrow 0}|r_{t}|_{\mathcal{C}^{\hat{\beta}}}= 0\) and \(\sup _{t\in [\varepsilon ,T]}|r_{t}|_{L^{\infty}}<\infty \) for every \(\varepsilon >0\). Using that \(|\mathcal{P}_{s} f - f|_{\mathcal{C}^{\hat{\beta}}}\lesssim s^{-\hat{\beta}/2}|f|_{L^{ \infty}}\) and \(\hat{\beta}<0\), it follows from (7.5) that
Therefore, using \(\hat{\beta}\geq 2\theta (\alpha -1)\) and Lemma 2.25 to estimate \({|\!|\!| \mathcal{P}_{s} r_{t} - r_{t} |\!|\!|}_{\alpha ,\theta} \lesssim |\mathcal{P}_{s} r_{t} - r_{t}|_{\mathcal{C}^{\hat{\beta}}}\) we obtain
Since \(\eta <-\frac{1}{2}<\hat{\beta}\), (7.4) also implies \(\lim _{s\downarrow 0}\sup _{t\in [0,T]}|\mathcal{P}_{s} r_{t} - r_{t}|_{ \mathcal{C}^{\eta}}=0\).
It remains only to consider the terms with  . By Lemma 2.35(i), uniformly in \(t\geq 0\),
. By Lemma 2.35(i), uniformly in \(t\geq 0\),

for \(\hat{\eta}\) as in (5.2). Since \(\hat{\beta}\geq \hat{\eta}\), it follows from (7.3)-(7.4) that the final two terms converge to 0 as \(s\downarrow 0\) uniformly in \(t\in [0,T]\). For the first term, observe that, by (2.22),

Since \(\lim _{s\downarrow 0}\Theta (p_{s},x)=0\) by Proposition 2.58(i),

Furthermore, by Lemma 2.35(ii), uniformly in \(t\geq 0\),

The final term again converges to 0 as \(s\downarrow 0\) uniformly in \(t\in [0,T]\). □
Proof of Proposition 7.6
Let us define \(x_{n},\bar{x}_{n}\in \mathcal{C}^{\infty}(\mathbf{T}^{3},E)\) by
which exist for \(n\) sufficiently large. Let \(g_{n}(0) \in \mathfrak {G}^{\infty}\) such that \(x_{n}^{g_{n}(0)} = \bar{x}_{n}\). It follows from Lemma 7.8(i) and Theorem 2.39 that, for some \(\nu <\frac{1}{2}\),
In particular, passing to a subsequence, we can assume \(g_{n}(0)\to g(0)\) in \(\mathfrak {G}^{0,\nu -}\). Let \(X_{n}=(A_{n},\Phi _{n})\) solve SYMH driven by \(\xi \) with initial condition \(x_{n}\) and let \(g_{n}\) solve (1.17) driven by \(A_{n}\) with initial condition \(g_{n}(0)\).
Consider further the process \(\xi _{n}\) given by \(g_{n}\xi \) on \([0,T_{X_{n},g_{n}})\) and by \(\xi \) outside this interval, where we set, as in [22, Sect. 1.5.1],

Remark that \(\xi _{n}\) is a white noise by Itô isometry. Let \(\bar{X}_{n}\) solve SYMH driven by \(\xi _{n}\) with initial condition \(\bar{x}_{n}\). Observe that \(\bar{X}_{n}\) and \(X_{n}^{g_{n}}\) are strong Markov processes, for which, by Theorem 6.1, \(\bar{X}_{n} = X_{n}^{g_{n}} \) on an interval \([0,\tau ]\) where \(\tau \) is a stopping time bounded stochastically from below by the size of \((X_{n}(0), g_{n}(0))\) in \(\mathcal{S}\times \mathfrak {G}^{0,\varrho }\). It follows that
Next, we claim that
where \(g\) solves (1.17) with initial condition \(g(0)\) and where we define \(X^{g}(0) = \bar{x}\) (for \(t>0\), note that \(g(t)\in \mathfrak {G}^{\frac{3}{2}-}\) and thus \(X^{g}(t)\) makes sense by Proposition 2.28). To prove (7.7), remark that \(\Sigma (x_{n},x)\to 0\) by Lemma 7.8(i). It thus follows from Lemma C.1 with \(c^{\varepsilon }=0\) therein that \((X_{n},g_{n}) \to (X,g)\) in probability in \((\mathcal{S}\times \mathfrak {G}^{0,\nu -})^{{\mathop{\mathrm{sol}}}}\). Therefore, for any \(\lambda ,\delta >0\),
It follows by joint continuity of the group action from Proposition 2.28 and the estimates on gauge transformations from Theorem 2.39 (which ensures that \(|g|_{\mathcal{C}^{1/2-}}\) and thus \(|g|_{\mathcal{C}^{3/2-}}\) cannot blow up before \(\Sigma (X)+\Sigma (X^{g})\) does, hence \(T_{X,g}=T_{X,X^{g}}\)) that
It remains to handle the time interval \([0,\lambda ]\) for which we can proceed similar to the proof of Proposition 6.38. Specifically, it holds that
Indeed, this follows from \(X_{n}^{g_{n}} = \bar{X}_{n}\), which solves the SYMH driven by \(\xi _{n}\) with initial condition \(\bar{x}_{n}\), and \(\lim _{s\downarrow 0}\sup _{n}\Sigma (\mathcal{P}_{s} \bar{x}_{n},\bar{x}_{n}) \to 0\) by Lemma 7.8(ii), combined with the arguments from the proof of Theorem 5.1 to handle the remainder terms. The proof of (7.7) now follows from combining (7.8)-(7.9) and the facts that \(\Sigma (\bar{x},\bar{x}_{n})\to 0\) by Lemma 7.8(i) and that \(X_{n}\to X\) in probability in \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\).
Finally, since \(\xi _{n}\stackrel {{\tiny \mathrm {law}}}{=}\xi \) and \(\Sigma (\bar{x}_{n},\bar{x})\to 0\) by Lemma 7.8, \(\bar{X}_{n}\stackrel {{\tiny \mathrm {law}}}{\to }\bar{X}\) in \(\mathcal{S}^{{\mathop{\mathrm{sol}}}}\), where \(\bar{X}\) is equal in law to the solution to SYMH with initial condition \(\bar{x}\). By Remark D.7, there exists a white noise \(\bar{\xi}\) on the probability space \((\Omega ^{\mathrm {noise}},\mathcal{F},\mathbf{P})\) which is adapted to \((\mathcal{F}_{t})_{t \geq 0}\) such that \(\bar{X}\) solves SYMH driven by \(\bar{\xi}\) with initial condition \(\bar{x}\). Combining with (7.7) and (7.6), we obtain the first claim in the proposition statement.
For the second claim we first note that Theorem 2.39 gives control of \(|g|_{\mathcal{C}^{1/2-}}\) in terms of \(\Sigma (X)+\Sigma (\bar{X})\). Next we point out that, by Lemma C.1, for any \(\nu > 0\), we can start the limiting \(\varepsilon \downarrow 0\) dynamic (C.1)-(C.2) with initial data \(g \in \mathfrak {G}^{\nu}\). Moreover, the limiting dynamic has maximal solutions in a space where the \(g\) component belongs to \(\mathfrak {G}^{\frac{3}{2}-}\). Therefore, \(g\) can blow up in \(\mathfrak {G}^{\frac{3}{2}-}\) only if it blows up in \(\mathfrak {G}^{\nu}\) for every \(\nu >0\). □
7.2 Measurable selections
Define \(m\colon \mathcal{S}\to [0,\infty ]\) by
where ∼ is the equivalence relation on \(\mathcal{S}\subset \mathcal{I}\) defined in Definition 2.11. The following is the main result of this subsection.
Theorem 7.9
There exists a Borel function \(S\colon \mathcal{S}\to \mathcal{S}\) such that for all \(X\in \mathcal{S}\)
-
\(S(X)\sim X\),
-
\(\bar{\Sigma}(S(X)) \leq 2m(X)\) if \(m(X) < \infty \), and
-
\(S(X)=X\) if \(m(X)=\infty \).
Proof of Theorem 7.9
We start with the following preliminary statement.
Lemma 7.10
The function \(m\) given in (7.10) is lower semi-continuous on \(\mathcal{S}\).
Proof
Let \(X_{n}\to X\) in \(\mathcal{S}\) and consider \(Y_{n}\in \mathcal{S}\) such that \(Y_{n}\sim X_{n}\) and \(\bar{\Sigma}(Y_{n})-m(X_{n})<\frac{1}{n}\). Passing to a subsequence, we may suppose that \(\lim _{n\to \infty}m(X_{n})=\liminf _{n\to \infty}m(X_{n})\). If \(m(X_{n}) \to \infty \), then there is nothing to prove. Otherwise, \(\sup _{n} \bar{\Sigma}(Y_{n}) < \infty \), so by the compact embedding due to Proposition 2.57(iii), there exists \(Y\in \mathcal{S}\) such that \(\Sigma (Y_{n},Y)\to 0\) and \(\bar{\Sigma}(Y) \leq \liminf _{n} \bar{\Sigma}(Y_{n}) = \lim _{n} m(X_{n})\). Since \((X_{n},Y_{n})\to (X,Y)\) in \(\mathcal{S}^{2}\) and \(X_{n}\sim Y_{n}\), it follows that \(X\sim Y\) by Lemma 2.50. □
Consider the sets \(B \stackrel {{\tiny \mathrm {def}}}{=}\{X\in \mathcal{S}\,:\, \bar{\Sigma}(X) \leq 2m(X) < \infty \}\) and \(\Gamma \subset \mathcal{S}^{2}\) defined by the disjoint union
Lemma 7.11
For every \(X\in \mathcal{S}\), \(\{Y\in \mathcal{S}\,:\,(X,Y)\in \Gamma \}\) is non-empty and compact.
Proof
If \(m(X)=\infty \), the result is obvious. Otherwise the result follows from the invariance of \(m\) on \([X]\), the fact that \([X]\) is closed in \(\mathcal{S}\) by Lemma 2.50, and the fact that \(\{Y\in \mathcal{S}\,:\, \bar{\Sigma}(Y)\leq 2m(X)\}\) is compact in \(\mathcal{S}\) by Proposition 2.57(iii). □
We now have all the ingredients in place to complete the proof of Theorem 7.9. Since \(\bar{\Sigma},m\colon \mathcal{S}\to [0,\infty ]\) are lower semi-continuous (Lemmas 2.54 and 7.10), \(B\) is Borel in \(\mathcal{S}\). Moreover, \(\{(X,Y)\in \mathcal{S}^{2}\,:\, X\sim Y\}\) is closed in \(\mathcal{S}^{2}\) (Lemma 2.50) and thus \(\Gamma \) is Borel in \(\mathcal{S}^{2}\). The conclusion follows from Lemma 7.11 and [8, Thm 6.9.6] since \(\mathcal{S}\) is a Polish space. □
7.3 Proof of Theorem 7.5
Proof of Theorem 7.5
(i) We extend the function \(S\) in Theorem 7.9 to a Borel function \(S\colon \hat{\mathcal{S}}\to \hat{\mathcal{S}}\) by  . Let \(\xi \) be a white noise defined on a probability space \((\Omega ^{\mathrm {noise}},\mathcal {F},\mathbf{P})\) and let \(\mathbf {F}=(\mathcal {F}_{t})_{t\geq 0}\) be the canonical filtration generated by \(\xi \).
. Let \(\xi \) be a white noise defined on a probability space \((\Omega ^{\mathrm {noise}},\mathcal {F},\mathbf{P})\) and let \(\mathbf {F}=(\mathcal {F}_{t})_{t\geq 0}\) be the canonical filtration generated by \(\xi \).
Consider any \(x \in \hat{\mathcal{S}}\). We define a càdlàg process \(X\colon \Omega ^{\mathrm {noise}}\to D({\mathbf {R}}_{+}, \hat{\mathcal{S}})\) with \(X(0)=x\), and a sequence of \(\mathbf {F}\)-stopping times \((\varsigma _{j})_{j=0}^{\infty}\) as follows. The idea is to run the SYMH equation until the first time \(t\geq \varsigma _{j}\) such that \(\bar{\Sigma}(X(t)) \geq 1+4m(X(t))\), at which point we use \(S\) to jump to a new representative of \([X(t)]\) and then restart SYMH, setting \(\varsigma _{j+1}=t\). At time \(t=0\), however, it is possible that \(\bar{\Sigma}(x)=m(x)=\infty \), in which case this procedure does not work. We therefore treat \(t=0\) as a special case.
If  , we define
, we define  for all \(t\in {\mathbf {R}}_{+}\) and \(\varsigma _{j}=0\) for all \(j\geq 0\). Suppose now that
for all \(t\in {\mathbf {R}}_{+}\) and \(\varsigma _{j}=0\) for all \(j\geq 0\). Suppose now that  . Set \(\varsigma _{0} = 0\) and \(X(0)=x\). Define \(Y \in \mathcal {C}([0,\infty ),\hat{\mathcal{S}})\) by \(Y(t) = \Lambda _{0,t}(x)\) and \(R \in \mathcal {C}([0,\infty ),\hat{{\mathbf {R}}}_{+})\) by
. Set \(\varsigma _{0} = 0\) and \(X(0)=x\). Define \(Y \in \mathcal {C}([0,\infty ),\hat{\mathcal{S}})\) by \(Y(t) = \Lambda _{0,t}(x)\) and \(R \in \mathcal {C}([0,\infty ),\hat{{\mathbf {R}}}_{+})\) by
Define further
We then define \(X(t) = Y(t)\) for \(t\in (0,\varsigma _{1})\) and \(X(\varsigma _{1}) = S(Y(\varsigma _{1}))\). Observe that a.s.
and thus \(\bar{\Sigma}(X(\varsigma _{1}))<\infty \) because \(\Sigma (Y(t))<\infty \Rightarrow \bar{\Sigma}(Y(t))<\infty \) for all \(t>0\).
Having defined \(\varsigma _{1}\), consider now \(j \geq 1\). If \(\varsigma _{j}=\infty \), we set \(\varsigma _{j+1}=\infty \). Otherwise, if \(\varsigma _{j}<\infty \), suppose that \(X\) is defined on \([0,\varsigma _{j}]\). If  , then define \(\varsigma _{j}=\varsigma _{j+1}\). Suppose now that
, then define \(\varsigma _{j}=\varsigma _{j+1}\). Suppose now that  . Define \(Y \in \mathcal {C}([\varsigma _{j},\infty ),\hat{\mathcal{S}})\) by
. Define \(Y \in \mathcal {C}([\varsigma _{j},\infty ),\hat{\mathcal{S}})\) by
and
We then define \(X(t) = Y(t)\) for \(t\in (\varsigma _{j},\varsigma _{j+1})\) and \(X(\varsigma _{j+1}) = S(Y(\varsigma _{j+1}))\). Observe that the map \([\varsigma _{j},\infty )\to \hat{{\mathbf {R}}}_{+}\), \(t\mapsto \bar{\Sigma}(Y(t))\), is a.s. continuous. Furthermore, \(\bar{\Sigma}(Y(\varsigma _{j})) \leq 2m(Y(\varsigma _{j}))\) and the map \([\varsigma _{j},\infty ) \ni t \mapsto m(Y(t))\) is lower semi-continuous (Lemma 7.10). Therefore, a.s. \(\varsigma _{j+1}>\varsigma _{j}\).
Let \(T^{*}\stackrel {{\tiny \mathrm {def}}}{=}\lim _{j\to \infty}\varsigma _{j}\). If \(T^{*}<\infty \), we define  for all \(t\in [T^{*},\infty )\). We have now defined \(X(t)\in \hat{\mathcal{S}}\) for all \(t\in {\mathbf {R}}_{+}\) and, by construction,
for all \(t\in [T^{*},\infty )\). We have now defined \(X(t)\in \hat{\mathcal{S}}\) for all \(t\in {\mathbf {R}}_{+}\) and, by construction,  . Moreover, \(X\) takes values in \(D({\mathbf {R}}_{+},\hat{\mathcal{S}})\).
. Moreover, \(X\) takes values in \(D({\mathbf {R}}_{+},\hat{\mathcal{S}})\).
To prove (i), it remains to show that
Since, by construction, \(\bar{\Sigma}(X(t))\in [m(X(t)),1+4m(X(t))]\) for all \(t\geq \varsigma _{1}\), it suffices to prove that
To this end, consider \(M>1\). For any stopping time \(\tau < T^{*}\), on the event \(\bar{\Sigma}(X(\tau ))\leq M\), we have
where \(\delta \in (0,1)\) is random and depends on \(X(\tau )\) and the realisation of \(\xi \) on \([\tau ,\tau +1]\), but is stochastically bounded from below by a function of \(M\) in the sense that there exists \(\varepsilon =\varepsilon (M)\in (0,1)\) such that
Indeed, (7.13)-(7.14) follows from the fact that \(\bar{\Sigma}(\mathcal{P}_{r} Z) \leq (1+Cr)\bar{\Sigma}(Z)\) for any \(Z\in \mathcal{S}\) by Lemma 2.55, from the stochastic bounds on \(\sup _{r\in [0,h]}r^{-\kappa}\bar{\Sigma}(\Psi _{r},\mathcal{P}_{r}\Psi _{0})\) for the SHE \(\Psi \) from (3.2) and Proposition 3.7 and the stochastic bounds in Lemmas 5.18-5.19 (we use that \(\tau \) is a stopping time in all of these stochastic bounds), and from the perturbation argument similar to that in the proof of Theorem 5.1 that uses Lemma 2.35 (see (5.31)).
Consider the sequence of stopping times \(\tau _{j} = \inf \{t\geq \varsigma _{j} \,:\, \bar{\Sigma}(X(t)) \leq M\}\). For \(j\geq 2\), we have
and thus, if \(\tau _{j} <\varsigma _{j+1}\) and
then by the flow property (7.1) (which allows us to restart the dynamic at \(\tau _{j}\)), we have
Therefore, by (7.13)-(7.14), a.s.
Remark also that \(\bar{\Sigma}(X(\varsigma _{j+1}))\leq \bar{\Sigma}(X(\tau _{j}))/2\) implies \(\bar{\Sigma}(X(\varsigma _{j+1}))\leq M/2\) and thus \(\tau _{j+1}=\varsigma _{j+1}\). It now follows from the strong Markov property of \(\{X_{\tau _{1}+t}\}_{t\geq 0}\) that, for any integer \(q\geq 1\),
Finally, since \(\bar{\Sigma}(X(\varsigma _{k}))\geq 1\) for all \(k\geq 1\), by taking any \(q\) in (7.15) such that \(2^{-q}M<1/2\) and by (7.13)-(7.14), we obtain
It readily follows that, on the event \(T^{*}<\infty \), there are only finitely many \(j\) such that \(\tau _{j}< \varsigma _{j+1}\), which concludes the proof of (7.12) and thus of (7.11).
(ii) The idea, like in the proof of [22, Thm. 2.13(ii)], is to couple any generative probability measure \(\bar{\mu}\) to the law of the process \(X\) constructed in part (i). Consider \(x,\bar{x}\in \hat{\mathcal{S}}\) with \(x\sim \bar{x}\) and a generative probability measure \(\bar{\mu}\) on \(D({\mathbf {R}}_{+},\hat{\mathcal{S}})\) with initial condition \(\bar{x}\). Let \((\Omega ^{\mathrm {noise}},\mathcal {F},\mathbf {F}=(\mathcal {F}_{t})_{t \geq 0}, \mathbf{P})\), \(\bar{\xi}\), \(\bar{X}\colon \Omega ^{\mathrm {noise}}\to D({\mathbf {R}}_{+},\hat{\mathcal{S}})\), and \(\bar{T}^{*}\) denote respectively the corresponding filtered probability space, white noise, random variable, and blow-up time as in Definition 7.2.
It follows from Proposition 7.6 that there exists, on the same filtered probability space \((\Omega ^{\mathrm {noise}},\mathcal {F},\mathbf {F}, \mathbf{P})\), a càdlàg process \(X\colon {\mathbf {R}}_{+}\to \hat{\mathcal{S}}\) constructed as in part (i) using a white noise \(\xi \) for which \(\mathbf {F}\) is admissible and such that \(X \sim \bar{X}\) and \(X(0)=x\). In particular, the pushforwards \(\pi _{*}\bar{\mu}\) and \(\pi _{*}\mu \) coincide, where \(\mu \) is the law of \(X\).
To complete the proof, it remains to show that for the process \(X\) from part (i) with any initial condition \(x\in \hat{\mathcal{S}}\), the projected process \(\pi X\in \mathcal {C}({\mathbf {R}}_{+},\hat{\mathfrak {O}})\) is Markov. However, this follows from taking \(\bar{\mu}\) in the above argument as the law of \(X\) with initial condition \(\bar{x} \sim x\). □
Notes
We emphasise again that the case of non-trivial bundles is of course very interesting but will not be treated here.
One would have a term \(- m^{2} \Phi \) here in view of (1.2), but we absorb it into the term \(C^{\varepsilon }_{\Phi} \Phi \).
This construction is a simple adaptation of a well-known construction for pure gauge fields; for completeness, and since it is easy to do so, we give the details.
Writing \(G\) for both heat kernel and the Lie group will not cause any confusion since it is clear from the context.
There is a bijection between distributions on \(\mathbf{T}^{d}\) supported in a ball centered at zero of radius \(\frac{1}{4}\) and distributions on \({\mathbf {R}}^{d}\) (where Sobolev norms are rotation invariant) with the same property, and the corresponding Sobolev norms on \(\mathbf{T}^{d}\) and \({\mathbf {R}}^{d}\) are equivalent.
 is defined in [22, Sect. 5.5], and it is immediate that \(\mathbf{T}^{\star}\) leaves
is defined in [22, Sect. 5.5], and it is immediate that \(\mathbf{T}^{\star}\) leaves  invariant.
invariant.Recall from [22, Sect. 5.8.2] that \(\boldsymbol{\Upsilon}_{o}[\tau ] =\Upsilon _{o}[\tau ]/S(\tau )\) and recursive formulae for \(\Upsilon \) and \(S\) are given therein. Here, we instead give a recursive formula for \(\boldsymbol{\Upsilon}\). It is easy to check that these recursive formulae are consistent and one may be more convenient than the other for different purposes. The formula here involves a factor \(\mathring{S}(\tau )\) and we give a formula for it in (4.9).
As in [22] \(\mathfrak {T}_{-} \stackrel {{\tiny \mathrm {def}}}{=}\{\tau \in \mathfrak {T}\,:\, \deg \tau < 0,\ \mathfrak {n}(\varrho ) = 0,\ \tau \mbox{ unplanted}\}\) where \(\varrho \) is the root of \(\tau \).
We will impose additional, more stringent, smallness requirements on \(\kappa \) for other purposes later.
For instance, in the first identity, \(2 \hat{C}^{\varepsilon }{\mathbf{C}}_{\mathord{\mathrm{Cas}}}\) is obtained by “substituting”
 into \(\mathbf{B}(\partial _{i} \Phi \otimes \Phi )\) for \(\Phi \), and \(2 d \hat{C}^{\varepsilon }\boldsymbol{\varrho }(\mathord{\mathrm{Cas}}) \) is obtained by substituting
into \(\mathbf{B}(\partial _{i} \Phi \otimes \Phi )\) for \(\Phi \), and \(2 d \hat{C}^{\varepsilon }\boldsymbol{\varrho }(\mathord{\mathrm{Cas}}) \) is obtained by substituting  into \(2A_{j} \partial _{j} \Phi \) for \(A_{j}\).
into \(2A_{j} \partial _{j} \Phi \) for \(A_{j}\).One can eventually take \(\lambda =1\), but having these coefficients will be helpful for power counting: pretending that \(\lambda \) has “degree \(-1/2\)”, these nonlinear terms all have the same degree as white noise.
We do not start the induction from \(\tau =\mathbf{1}\) since it does not satisfy the last identity: \(\bar{\boldsymbol{\Upsilon}}_{\mathfrak {z}}[\mathbf{1}] \) has a term
 , for which \(n_{\lambda}=k_{\xi}=p_{X}=p_{\partial }=0\), and \(\deg (\mathbf{1})=0\), so (5.12c) would read \(0=-\frac{5}{2}\).
, for which \(n_{\lambda}=k_{\xi}=p_{X}=p_{\partial }=0\), and \(\deg (\mathbf{1})=0\), so (5.12c) would read \(0=-\frac{5}{2}\).In this proof we drop the term \(-k_{\xi} \kappa \) in (5.12c) since it is irrelevant after we have chosen \(\kappa >0\) sufficiently small.
Another way to bypass this problem is to let \(\Xi \) represent the noise restricted to positive times, that is we could put the indicator function for positive times inside the model instead of the fixed point problem for modelled distributions. However, working with a non-stationary noise would create serious technical difficulties since we would not be able to use [21] to control the given models –in general the trees in \(\mathfrak {T}_{-}\) would need time-dependent renormalisation counter-terms.
See [22, Def. 5.64].
Note that the bound (2.3) references classical Hölder-Besov spaces but the space of modelled distributions taking values in the polynomial sector coincides with these classical spaces.
This is not true for
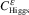 in \(d=2\) but again, this makes no difference as the Higgs doesn’t play an important role in this argument.
in \(d=2\) but again, this makes no difference as the Higgs doesn’t play an important role in this argument.That \(\check{C}\) doesn’t depend on \(\mathring{C}_{\mbox{A}}\) can be argued with power-counting and parity, see Remark 6.8.
Such as the \(1/24\) that appears in KPZ in \(d=1\).
The “bar” in the notation \(\bar{\mathfrak {l}}\) indicates the “mollification at scale \(\varepsilon \)”, and has nothing to do with the “bars” in \((\bar{A},\bar{\Phi})\).
The framework of Sect. 4 allows for cases where the nonlinearity would have a non-diagonal form and the “components mix”, for instance the Navier–Stokes equations with \(\text{div}(u\otimes u)\) where \(u\otimes u\) takes values in \({\mathbf {R}}^{3\times 3}\).
Here, when we write
 the notation \(\boldsymbol{\varrho }\) means the adjoint representation of
the notation \(\boldsymbol{\varrho }\) means the adjoint representation of 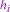 on \(\mathfrak {g}\).
on \(\mathfrak {g}\).This also holds in 2D, see [22, Lem. 7.28].
See [22, Sect. 5.8.2] for the definition of
 .
.Note that if \(p \neq 0 \) then the desired statement does not hold for
 but
but  .
.Here we also use the symbol \(\ell \) to refer to its restriction to
 .
.Recall the conditions \(\eta \wedge \alpha >-2\) and \(\bar{\eta}= \eta \wedge \alpha +\beta \) in [56, Prop. 6.16].
More precisely, we redefine \(\mathscr{M}_{1}\) to be the closure of smooth models under this pseudo-metric with \(\tau =1\).
That is with \(\bar{U}\) and \(\bar{h}\) instead of \(U\) and \(h\) and also with \(B\) replaced by \(\bar{A}\).
For instance, the noise term in the abstract fixed point problem in Sect. 5 is just \(\bar{\boldsymbol{\Xi}}\), not \(\boldsymbol{\sigma}^{\varepsilon }\bar{\boldsymbol{\Xi}}\).
Note that while Proposition 6.34 gives us convergence in a space where we don’t have continuity at \(t=0\), the limiting deterministic equations certainly have continuity at 0 for smooth initial data and therefore must be different as space-time distributions on \((0,T)\times \mathbf{T}^{3}\) for sufficiently small \(T>0\).
This equality in law follows from applying Itô’s isometry to \(T^{\varepsilon }(\xi )\), using that \(\bar{g}\) acts by an orthogonal representation, and then appealing to Lévy’s characterisation of Brownian motion.
This is clearly true for the maximal solution \((X,U,h)\). The stopping time \(\tau \) can also be chosen small enough in a way that only depends on the limiting BPHZ model and initial data \((X_{0},g_{0})\) and an a-priori bound on the constants \(\mathring{C}^{\varepsilon }_{\mbox{A}}\), \(\mathring{C}^{\varepsilon }_{\mbox{h}}\).
See Corollary 6.42.
Which we note are different from the solutions to the regularised equation.
Note that \(\hat{\pi}_{0}\) may not be an isomorphism because one may have
 , there will be some symmetrisation in the action of \(\hat{\pi}_{0}[\hat{\sigma }]\) when \(\hat{\pi}_{0}(\hat{\sigma })\) has more symmetries than \(\hat{\sigma }\).
, there will be some symmetrisation in the action of \(\hat{\pi}_{0}[\hat{\sigma }]\) when \(\hat{\pi}_{0}(\hat{\sigma })\) has more symmetries than \(\hat{\sigma }\).For independence with respect to \(\mathring{C}_{\mbox{A}}\) our particular choice of the renormalisation character plays a role here, see Remark 6.8.
 is defined in [
is defined in [ invariant.
invariant. into
into  into
into  , for which
, for which 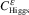 in
in  the notation
the notation 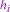 on
on  .
. but
but  .
. .
. , there will be some symmetrisation in the action of
, there will be some symmetrisation in the action of References
Albeverio, S., Kusuoka, S.: The invariant measure and the flow associated to the \(\Phi ^{4}_{3}\)-quantum field model. Ann. Sc. Norm. Super. Pisa, Cl. Sci. (5) 20(4), 1359–1427 (2020). https://doi.org/10.2422/2036-2145.201809_008
Balaban, T.: Ultraviolet stability of three-dimensional lattice pure gauge field theories. Commun. Math. Phys. 102(2), 255–275 (1985). https://doi.org/10.1007/BF01229380
Balaban, T.: Renormalization group approach to lattice gauge field theories. I. Generation of effective actions in a small field approximation and a coupling constant renormalization in four dimensions. Commun. Math. Phys. 109(2), 249–301 (1987). https://doi.org/10.1007/BF01215223
Balaban, T.: Large field renormalization. II. Localization, exponentiation, and bounds for the \(\mathbf{R}\) operation. Commun. Math. Phys. 122(3), 355–392 (1989). https://doi.org/10.1007/BF01238433
Barashkov, N., Gubinelli, M.: A variational method for \(\Phi ^{4}_{3}\). Duke Math. J. 169(17), 3339–3415 (2020). https://doi.org/10.1215/00127094-2020-0029
Barashkov, N., Gubinelli, M.: The \({\Phi _{3}^{4}}\) measure via Girsanov’s theorem. Electron. J. Probab. 26, 1–29 (2021). https://doi.org/10.1214/21-EJP635
Bern, Z., Halpern, M.B., Sadun, L., Taubes, C.: Continuum regularization of quantum field theory. II. Gauge theory. Nucl. Phys. B 284(1), 35–91 (1987). https://doi.org/10.1016/0550-3213(87)90026-5
Bogachev, V.I.: Measure Theory. Vol. I, II. Springer, Berlin (2007). https://doi.org/10.1007/978-3-540-34514-5.
Bringmann, B., Cao, S.: Global well-posedness of the stochastic Abelian-Higgs equations in two dimensions. ArXiv e-prints (2024). arXiv:2403.16878
Bruned, Y., Hairer, M., Zambotti, L.: Algebraic renormalisation of regularity structures. Invent. Math. 215(3), 1039–1156 (2019). https://doi.org/10.1007/s00222-018-0841-x
Bruned, Y., Chandra, A., Chevyrev, I., Hairer, M.: Renormalising SPDEs in regularity structures. J. Eur. Math. Soc. 23(3), 869–947 (2021). https://doi.org/10.4171/jems/1025
Bruned, Y., Gabriel, F., Hairer, M., Zambotti, L.: Geometric stochastic heat equations. J. Am. Math. Soc. 35(1), 1–80 (2021). https://doi.org/10.1090/jams/977
Brydges, D., Fröhlich, J., Seiler, E.: On the construction of quantized gauge fields. I. General results. Ann. Phys. 121(1–2), 227–284 (1979). https://doi.org/10.1016/0003-4916(79)90098-8
Brydges, D.C., Fröhlich, J., Seiler, E.: Construction of quantised gauge fields. II. Convergence of the lattice approximation. Commun. Math. Phys. 71(2), 159–205 (1980). https://doi.org/10.1007/BF01197918
Brydges, D.C., Fröhlich, J., Seiler, E.: On the construction of quantized gauge fields. III. The two-dimensional Abelian Higgs model without cutoffs. Commun. Math. Phys. 79(3), 353–399 (1981). https://doi.org/10.1007/BF01208500
Cao, S.: Wilson loop expectations in lattice gauge theories with finite gauge groups. Commun. Math. Phys. 380(3), 1439–1505 (2020). https://doi.org/10.1007/s00220-020-03912-z
Cao, S., Chatterjee, S.: The Yang-Mills heat flow with random distributional initial data. Commun. Partial Differ. Equ. 48(2), 209–251 (2023). https://doi.org/10.1080/03605302.2023.2169937
Cao, S., Chatterjee, S.: A state space for 3D Euclidean Yang–Mills theories. Commun. Math. Phys. 405(1), 3 (2024). https://doi.org/10.1007/s00220-023-04870-y
Chandra, A., Chevyrev, I.: Gauge field marginal of an Abelian Higgs model. ArXiv e-prints (2022). arXiv:2207.05443
Chandra, A., Ferdinand, L.: A flow approach to the generalized KPZ equation. ArXiv e-prints (2024). arXiv:2402.03101
Chandra, A., Hairer, M.: An analytic BPHZ theorem for regularity structures. ArXiv e-prints (2016). arXiv:1612.08138
Chandra, A., Chevyrev, I., Hairer, M., Shen, H.: Langevin dynamic for the 2D Yang-Mills measure. Publ. Math. Inst. Hautes Études Sci. 136, 1–147 (2022). https://doi.org/10.1007/s10240-022-00132-0
Charalambous, N., Gross, L.: The Yang-Mills heat semigroup on three-manifolds with boundary. Commun. Math. Phys. 317(3), 727–785 (2013). https://doi.org/10.1007/s00220-012-1558-0
Charalambous, N., Gross, L.: Neumann domination for the Yang-Mills heat equation. J. Math. Phys. 56(7), 073505 (2015). https://doi.org/10.1063/1.4927250
Chatterjee, S.: The leading term of the Yang-Mills free energy. J. Funct. Anal. 271(10), 2944–3005 (2016). https://doi.org/10.1016/j.jfa.2016.04.032
Chatterjee, S.: Yang-Mills for probabilists. In: Probability and Analysis in Interacting Physical Systems. Springer Proc. Math. Stat., vol. 283, pp. 1–16. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-15338-0_1
Chatterjee, S.: Wilson loops in Ising lattice gauge theory. Commun. Math. Phys. 377(1), 307–340 (2020). https://doi.org/10.1007/s00220-020-03738-9
Chatterjee, S.: A probabilistic mechanism for quark confinement. Commun. Math. Phys. 385(2), 1007–1039 (2021). https://doi.org/10.1007/s00220-021-04086-y
Chen, X.-Y.: A strong unique continuation theorem for parabolic equations. Math. Ann. 311(4), 603–630 (1998). https://doi.org/10.1007/s002080050202
Chevyrev, I.: Yang-Mills measure on the two-dimensional torus as a random distribution. Commun. Math. Phys. 372(3), 1027–1058 (2019). https://doi.org/10.1007/s00220-019-03567-5
Chevyrev, I.: Norm inflation for a non-linear heat equation with Gaussian initial conditions. Stoch. Partial Differ. Equ., Anal. Computat. (2023). https://doi.org/10.1007/s40072-023-00317-6
Chevyrev, I., Shen, H.: Invariant measure and universality of the 2D Yang-Mills Langevin dynamic. ArXiv e-prints (2023). arXiv:2302.12160
Del Debbio, L., Patella, A., Rago, A.: Space-time symmetries and the Yang-Mills gradient flow. J. High Energy Phys. 212, Article ID 212 (2013). https://doi.org/10.1007/JHEP11(2013)212
DeTurck, D.M.: Deforming metrics in the direction of their Ricci tensors. J. Differ. Geom. 18(1), 157–162 (1983). https://doi.org/10.4310/JDG/1214509286
Donaldson, S.K.: Anti self-dual Yang-Mills connections over complex algebraic surfaces and stable vector bundles. Proc. Lond. Math. Soc. (3) 50(1), 1–26 (1985). https://doi.org/10.1112/plms/s3-50.1.1
Donaldson, S.K., Kronheimer, P.B.: The Geometry of Four-Manifolds. Oxford Mathematical Monographs. The Clarendon Press, New York (1990)
Driver, B.K.: Convergence of the \({\mathrm{U}}(1)_{4}\) lattice gauge theory to its continuum limit. Commun. Math. Phys. 110(3), 479–501 (1987). https://doi.org/10.1007/BF01212424
Driver, B.K.: YM2: continuum expectations, lattice convergence, and lassos. Commun. Math. Phys. 123(4), 575–616 (1989). https://doi.org/10.1007/BF01218586
Duch, P.: Flow equation approach to singular stochastic PDEs. ArXiv e-prints (2021). arXiv:2109.11380
Durhuus, B.: On the structure of gauge invariant classical observables in lattice gauge theories. Lett. Math. Phys. 4(6), 515–522 (1980). https://doi.org/10.1007/BF00943439
Fine, D.S.: Quantum Yang-Mills on a Riemann surface. Commun. Math. Phys. 140(2), 321–338 (1991). https://doi.org/10.1007/BF02099502
Fodor, Z., Holland, K., Kuti, J., Nogradi, D., Wong, C.H.: The Yang-Mills gradient flow in finite volume. J. High Energy Phys. 2012(11), 007 (2012). https://doi.org/10.1007/JHEP11(2012)007
Forsström, M.P., Lenells, J., Viklund, F.: Wilson loops in finite Abelian lattice gauge theories. Ann. Inst. Henri Poincaré Probab. Stat. 58(4), 2129–2164 (2022). https://doi.org/10.1214/21-aihp1227
Forsström, M.P., Lenells, J., Viklund, F.: Wilson loops in the Abelian lattice Higgs model. Probab. Math. Phys. 4(2), 257–329 (2023). https://doi.org/10.2140/pmp.2023.4.257
Friz, P.K., Hairer, M.: A Course on Rough Paths. With an Introduction to Regularity Structures. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-08332-2
Garban, C., Sepúlveda, A.: Improved spin-wave estimate for Wilson loops in \(U(1)\) lattice gauge theory. Int. Math. Res. Not. 2023(21), 18142–18198 (2023). https://doi.org/10.1093/imrn/rnac356
Gerencsér, M., Hairer, M.: Singular SPDEs in domains with boundaries. Probab. Theory Relat. Fields 173(3–4), 697–758 (2019). https://doi.org/10.1007/s00440-018-0841-1
Gross, L.: Convergence of \({\mathrm{U}}(1)_{3}\) lattice gauge theory to its continuum limit. Commun. Math. Phys. 92(2), 137–162 (1983). https://doi.org/10.1007/BF01210842
Gross, L.: Lattice gauge theory; heuristics and convergence. In: Stochastic Processes—Mathematics and Physics (Bielefeld, 1984), Lecture Notes in Math., vol. 1158, pp. 130–140. Springer, Berlin (1986). https://doi.org/10.1007/BFb0080213
Gross, L.: Stability of the Yang-Mills heat equation for finite action. ArXiv e-prints (2017). arXiv:1711.00114
Gross, L.: The Yang-Mills heat equation with finite action in three dimensions. Mem. Am. Math. Soc. 275, 1349 (2022). https://doi.org/10.1090/memo/1349
Gross, L., King, C., Sengupta, A.: Two-dimensional Yang-Mills theory via stochastic differential equations. Ann. Phys. 194(1), 65–112 (1989). https://doi.org/10.1016/0003-4916(89)90032-8
Gubinelli, M., Hofmanová, M.: A PDE construction of the Euclidean \(\phi _{3}^{4}\) quantum field theory. Commun. Math. Phys. 384(1), 1–75 (2021). https://doi.org/10.1007/s00220-021-04022-0
Gubinelli, M., Meyer, S.-J.: The FBSDE approach to sine-Gordon up to \(6\pi \). ArXiv e-prints (2024). arXiv:2401.13648
Gubinelli, M., Imkeller, P., Perkowski, N.: Paracontrolled distributions and singular PDEs. Forum Math. Pi 3, e6 (2015). https://doi.org/10.1017/fmp.2015.2
Hairer, M.: A theory of regularity structures. Invent. Math. 198(2), 269–504 (2014). https://doi.org/10.1007/s00222-014-0505-4
Hairer, M., Mattingly, J.: The strong Feller property for singular stochastic PDEs. Ann. Inst. Henri Poincaré Probab. Stat. 54(3), 1314–1340 (2018). https://doi.org/10.1214/17-AIHP840
Hairer, M., Schönbauer, P.: The support of singular stochastic partial differential equations. Forum Math. Pi 10, e1 (2022). https://doi.org/10.1017/fmp.2021.18
Hairer, M., Steele, R.: The \(\Phi _{3}^{4}\) measure has sub-Gaussian tails. J. Stat. Phys. 186(3), 38 (2022). https://doi.org/10.1007/s10955-021-02866-3
Hall, B.: Lie groups, Lie Algebras, and Representations: An Elementary Introduction, 2nd edn. Graduate Texts in Mathematics, vol. 222. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-13467-3
Hong, M.-C., Tian, G.: Global existence of the m-equivariant Yang-Mills flow in four dimensional spaces. Commun. Anal. Geom. 12(1), 183–211 (2004). https://doi.org/10.4310/CAG.2004.V12.N1.A10
Jaffe, A., Witten, E.: Quantum Yang-Mills theory. In: The Millennium Prize Problems, pp. 129–152. Clay Math. Inst, Cambridge (2006)
Kallenberg, O.: Foundations of Modern Probability. Probability Theory and Stochastic Modelling, vol. 99. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-61871-1
King, C.: The \({\mathrm{U}}(1)\) Higgs model. I. The continuum limit. Commun. Math. Phys. 102(4), 649–677 (1986). https://doi.org/10.1007/BF01221651
King, C.: The \({\mathrm{U}}(1)\) Higgs model. II. The infinite volume limit. Commun. Math. Phys. 103(2), 323–349 (1986). https://doi.org/10.1007/BF01206942
Kupiainen, A.: Renormalization group and stochastic PDEs. Ann. Henri Poincaré 17(3), 497–535 (2016). https://doi.org/10.1007/s00023-015-0408-y
Lévy, T.: Yang-Mills measure on compact surfaces. Mem. Am. Math. Soc. 166, 790 (2003). https://doi.org/10.1090/memo/0790
Lévy, T.: Wilson loops in the light of spin networks. J. Geom. Phys. 52(4), 382–397 (2004). https://doi.org/10.1016/j.geomphys.2004.04.003
Lévy, T., Sengupta, A.: Four chapters on low-dimensional gauge theories. In: Stochastic Geometric Mechanics. Springer Proc. Math. Stat., vol. 202, pp. 115–167. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-63453-1_7
Lüscher, M.: Properties and uses of the Wilson flow in lattice QCD. J. High Energy Phys. 2010(8), 071 (2010). https://doi.org/10.1007/JHEP08(2010)071
Magnen, J., Rivasseau, V., Sénéor, R.: Construction of \({\mathrm{YM}}_{4}\) with an infrared cutoff. Commun. Math. Phys. 155(2), 325–383 (1993). https://doi.org/10.1007/BF02097397
Migdal, A.A.: Recursion equations in gauge theories. Sov. Phys. JETP 42, 413 (1975)
Moinat, A., Weber, H.: Space-time localisation for the dynamic \(\Phi ^{4}_{3}\) model. Commun. Pure Appl. Math. 73(12), 2519–2555 (2020). https://doi.org/10.1002/cpa.21925
Mourrat, J.-C., Weber, H.: The dynamic \(\Phi ^{4}_{3}\) model comes down from infinity. Commun. Math. Phys. 356(3), 673–753 (2017). https://doi.org/10.1007/s00220-017-2997-4
Mujica, J.: Holomorphic functions on Banach spaces. Note Mat. 25(2), 113–138 (2005)
Narayanan, R., Neuberger, H.: Infinite \(N\) phase transitions in continuum Wilson loop operators. J. High Energy Phys. 2006(3), 32 (2006). https://doi.org/10.1088/1126
Nelson, E.: Derivation of the Schrödinger equation from Newtonian mechanics. Phys. Rev. 150, 1079–1085 (1966). https://doi.org/10.1103/PhysRev.150.1079
Parisi, G., Wu, Y.S.: Perturbation theory without gauge fixing. Sci. Sin. 24(4), 483–496 (1981). https://doi.org/10.1360/ya1981-24-4-483
Sengupta, A.: The Yang-Mills measure for \(S^{2}\). J. Funct. Anal. 108(2), 231–273 (1992). https://doi.org/10.1016/0022-1236(92)90025-E
Sengupta, A.: Gauge invariant functions of connections. Proc. Am. Math. Soc. 121(3), 897–905 (1994). https://doi.org/10.2307/2160291
Sengupta, A.: Gauge theory on compact surfaces. Mem. Am. Math. Soc. 126, 600 (1997). https://doi.org/10.1090/memo/0600
Sepanski, M.R.: Compact Lie groups. Graduate Texts in Mathematics, vol. 235. Springer, New York (2007). https://doi.org/10.1007/978-0-387-49158-5
Shen, H.: Stochastic quantization of an Abelian gauge theory. Commun. Math. Phys. 384(3), 1445–1512 (2021). https://doi.org/10.1007/s00220-021-04114-x
Shen, H., Zhu, R., Zhu, X.: A stochastic analysis approach to lattice Yang-Mills at strong coupling. Commun. Math. Phys. 400(2), 805–851 (2023). https://doi.org/10.1007/s00220-022-04609-1
Shen, H., Smith, S.A., Zhu, R.: A new derivation of the finite N master loop equation for lattice Yang-Mills. Electron. J. Probab. 29 (2024). https://doi.org/10.1214/24-ejp1090
Shen, H., Zhu, R., Zhu, X.: Langevin dynamics of lattice Yang-Mills-Higgs and applications. ArXiv e-prints (2024). arXiv:2401.13299
Waldron, A.: Long-time existence for Yang-Mills flow. Invent. Math. 217(3), 1069–1147 (2019). https://doi.org/10.1007/s00222-019-00877-2
Zwanziger, D.: Covariant quantization of gauge fields without Gribov ambiguity. Nucl. Phys. B 192(1), 259–269 (1981). https://doi.org/10.1016/0550-3213(81)90202-9
Acknowledgements
We would like to thank Leonard Gross for helpful discussions. We are also very grateful to the referees whose many comments allowed to substantially improve the article. IC acknowledges support from the EPSRC via the New Investigator Award EP/X015688/1. MH gratefully acknowledges support from the Royal Society through a research professorship, grant RP\R1\191065. HS gratefully acknowledges support by NSF grants DMS-1954091 and CAREER DMS-2044415.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Singular modelled distributions
In this appendix we collect some useful results on singular modelled distributions. We write \(P = \{(t,x) \,:\, t=0\}\) for the time 0 hyperplane. Recall that the reconstruction operator \(\tilde {\mathcal{R}}\colon \mathscr{D}^{\gamma ,\eta}_{\alpha} \to \mathcal{D}'({\mathbf {R}}^{d+1} \setminus P)\) defined in [56, Sect. 6.1] is local, and there is in full generality no way of canonically extending \(\tilde {\mathcal{R}}\) to an operator \(\mathcal{R}\colon \mathscr{D}^{\gamma ,\eta}_{\alpha} \to \mathcal{D}'({\mathbf {R}}^{d+1})\). Here \(\alpha \) denotes the lowest degree of the modelled distribution as usual. [56, Prop. 6.9] provides such a unique extension under the assumption \(\alpha \wedge \eta >-2\) (which is then also required by the integration results [56, Prop. 6.16]) which is insufficient for our purposes in Sect. 5 and 6. Below we collect some results which require weaker conditions.
As in [22, Sect. 7], it will furthermore be important for us to have short-time convolution estimates on intervals \([0,\tau ]\) which depend only on the model up to time \(\tau \). This is used to ensure that a time \(\tau >0\) on which fixed point maps are contractions is a stopping time.
We write \(\bar {\mathscr{D}}^{\gamma ,\eta} = \mathscr{D}^{\gamma ,\eta} \cap \mathscr{D}^{\eta}\) as well as \(\hat {\mathscr{D}}^{\gamma ,\eta} \subset \bar {\mathscr{D}}^{\gamma ,\eta}\) for the subspace of those functions \(f\in \bar {\mathscr{D}}^{\gamma ,\eta}\) such that \(f(t,x) = 0\) for \(t \le 0\). Similarly to [56, Lem. 6.5] one can show that these are closed subspaces of \(\mathscr{D}^{\gamma ,\eta}\), so that we endow them with the usual norms \(|\!|\!|f|\!|\!|_{\gamma ,\eta}\). We also note that \(\mathbf{1}_{+} f= f\) for all \(f\in \hat{\mathscr{D}}^{\gamma ,\eta}\).
Remark A.1
If \(\eta \le \alpha \), then \(\hat{\mathscr{D}}^{\gamma ,\eta}_{\alpha}\) simply coincides with the space of all \(f \in \mathscr{D}^{\gamma ,\eta}_{\alpha}\) which vanish for \(t \le 0\).
Recall from [22, Appendix A] that \(\omega \in \mathcal{C}^{\alpha \wedge \eta}\) is called compatible with \(f\in \mathscr{D}^{\gamma ,\eta}_{\alpha}\), where \(\gamma >0\), if \(\omega (\psi )=\tilde{\mathcal{R}}f(\psi )\) for all \(\psi \in \mathcal{C}^{\infty}_{c}({\mathbf {R}}^{d+1}\setminus P)\). For the proofs of the following results, we refer to [22, Appendix A].
Theorem A.2
Let \(\gamma > 0\) and \(\eta \in (-2,\gamma ]\). There exists a unique continuous linear operator \(\mathcal{R}:\hat{\mathscr{D}}^{\gamma ,\eta}_{\alpha}\to \mathcal{C}^{\eta \wedge \alpha}\) such that \(\mathcal{R}f\) is compatible with \(f\).
Lemma A.3
For \(F_{i} \in \bar {\mathscr{D}}^{\gamma _{i},\eta _{i}}_{\alpha _{i}}\) with \(\alpha _{i} \le 0 < \gamma _{i}\) and \(\eta _{i} \le \gamma _{i}\), one has \(F_{1} \cdot F_{2} \in \bar{\mathscr{D}}^{\gamma , \eta}_{\alpha _{1}+\alpha _{2}}\) with \(\gamma = (\alpha _{1} + \gamma _{2})\wedge (\alpha _{2} + \gamma _{1})\) and \(\eta = (\alpha _{1} + \eta _{2})\wedge (\alpha _{2} + \eta _{1}) \wedge (\eta _{1} + \eta _{2})\). Furthermore, if \(F_{i} \in \hat {\mathscr{D}}^{\gamma _{i},\eta _{i}}_{\alpha _{i}}\), then \(F_{1} \cdot F_{2} \in \hat{\mathscr{D}}^{\gamma , \eta _{1} + \eta _{2}}_{ \alpha _{1}+\alpha _{2}}\).
Remark that the multiplication bound [56, Prop. 6.12] and Lemma A.3 also hold for the \(\varepsilon \)-dependent norms in Sect. 6.4.
Below we assume that we have an abstract integration map ℐ of order \(\beta \)Footnote 38 and admissible models \(Z,\bar{Z}\) realising a non-anticipative kernel \(K\) for ℐ. Following [47, Sect. 4.5] and [22, Appendix A.3], given a space-time distribution \(\omega \) and a modelled distribution \(f\), we write  for the modelled distribution defined as in [56, Sect. 5] but with \(\mathcal{R}f\) in the definition replaced by \(\omega \).
for the modelled distribution defined as in [56, Sect. 5] but with \(\mathcal{R}f\) in the definition replaced by \(\omega \).
Working henceforth in the periodic setting \({\mathbf {R}}\times \mathbf{T}^{d}\), we use the shorthand \(O_{T}=[-1,T]\times \mathbf{T}^{d}\) for \(T>0\). Recall from [22, Appendix A.1] the semi-norm \(|\!|\!|Z|\!|\!|_{T}\) defined as the smallest constant \(C\) such that, for all homogeneous elements \(\tau \) in our regularity structure,
for all \(\phi \in \mathcal{B}^{r}\), \(x \in O_{T}\), and \(\lambda \in (0,1]\) such that \(B_{\mathfrak{s}}(x,2\lambda ) \subset O_{T}\), and
for all \(x,y \in O_{T}\). The pseudo-metric \(|\!|\!|Z;\bar{Z}|\!|\!|_{T}\) is defined analogously. We will write \(||_{ \mathscr{D}^{\gamma ,\eta};T}\) for the modelled distribution semi-norm associated to the set \(O_{T}\), and likewise for \(\hat{\mathscr{D}}^{\gamma ,\eta}\). We similarly define \(|\omega |_{\mathcal{C}^{\alpha}_{T}}\) for \(\omega \in \mathcal{D}'({\mathbf {R}}\times \mathbf{T}^{d})\) and \(\alpha \in {\mathbf {R}}\) as the smallest constant \(C\) such that
for all \(\phi \in \mathcal{B}^{r}\), \(x \in O_{T}\), and \(\lambda \in (0,1]\) such that \(B_{\mathfrak{s}}(x,2\lambda ) \subset O_{T}\).
Lemma A.4
Fix \(\gamma >0\). Let \(f\in \mathscr{D}^{\gamma ,\eta}_{\alpha}\) and let \(\omega \in \mathcal{C}^{\eta \wedge \alpha}\) be compatible with \(f\). Set \(\bar{\gamma}=\gamma +\beta \), \(\bar{\eta}=(\eta \wedge \alpha )+\beta \), which are assumed to be non-integers, \(\bar{\alpha}=(\alpha +\beta )\wedge 0\) and \(\bar{\eta}\wedge \bar{\alpha}>-2\). Then  , and one has
, and one has  .
.
Furthermore, if \(\bar{f}\in \mathscr{D}^{\gamma ,\eta}_{\alpha}\) is a modelled distribution with respect to \(\bar{Z}\) and \(\bar{\omega}\in \mathcal{C}^{\eta \wedge \alpha}\) is compatible with \(\bar{f}\), then

locally uniformly in models, modelled distributions and space-time distributions \(\omega \), \(\bar{\omega}\). Finally, the above bound also holds uniformly in \(\varepsilon \) for the \(\varepsilon \)-dependent norms on models and modelled distributions defined in [22, Sect. 7.2].
For the spaces \(\hat {\mathscr{D}}^{\gamma ,\eta}\), we have the following version of Schauder estimate.
Theorem A.5
Let \(\gamma >0\), and \(\eta > -2\) such that \(\gamma +\beta \notin {\mathbf {N}}\) and \(\eta +\beta \notin {\mathbf {N}}\). Then, there exists an operator  which also maps \(\hat {\mathscr{D}}^{\gamma ,\eta}\) to \(\hat{\mathscr{D}}^{\gamma +\beta ,\eta +\beta}\) and such that
which also maps \(\hat {\mathscr{D}}^{\gamma ,\eta}\) to \(\hat{\mathscr{D}}^{\gamma +\beta ,\eta +\beta}\) and such that  with the reconstruction ℛ from Theorem A.2. Furthermore, for \(T\in (0,1)\) and \(\kappa \geq 0\)
with the reconstruction ℛ from Theorem A.2. Furthermore, for \(T\in (0,1)\) and \(\kappa \geq 0\)

where the first proportionality constant depends only on \(|\!|\!|Z|\!|\!|_{T}\) and the second depends on \(|\!|\!|Z|\!|\!|_{T}+|\!|\!|\bar{Z}|\!|\!|_{T}+|f |_{\mathscr{D}^{\gamma ,\eta};T}+| \bar{f} |_{ \mathscr{D}^{\gamma ,\eta};T}\).
Write  and
and  for integration operators on modelled distributions corresponding to \(\mathfrak {z}\) and \(\mathfrak {m}\). Recall from (6.11) that they represent the kernels \(K\) and \(K^{\varepsilon }= K \ast \chi ^{\varepsilon }\). We assume that \(\chi \) is non-anticipative and therefore so is \(K \ast \chi ^{\varepsilon }\). Recall the fixed parameter \(\varsigma \in (0,\kappa ]\) and the norms \(|\cdot |_{\hat{\mathscr{D}}^{\gamma ,\eta ,\varepsilon };T}\) in Sect. 6.4.1. The following results are from [22, Sect. 7].
for integration operators on modelled distributions corresponding to \(\mathfrak {z}\) and \(\mathfrak {m}\). Recall from (6.11) that they represent the kernels \(K\) and \(K^{\varepsilon }= K \ast \chi ^{\varepsilon }\). We assume that \(\chi \) is non-anticipative and therefore so is \(K \ast \chi ^{\varepsilon }\). Recall the fixed parameter \(\varsigma \in (0,\kappa ]\) and the norms \(|\cdot |_{\hat{\mathscr{D}}^{\gamma ,\eta ,\varepsilon };T}\) in Sect. 6.4.1. The following results are from [22, Sect. 7].
Lemma A.6
Fix \(\gamma > 0\) and \(\eta < \gamma \) such that \(\gamma + 2 - \kappa \notin {\mathbf {N}}\), \(\eta + 2 - \kappa \notin {\mathbf {N}}\), and \(\eta >-2\). Suppose that \(\chi ^{\varepsilon }\) is non-anticipative. Then, for fixed \(M > 0\), one has for all \(T\in (0,1)\)

uniformly in \(\varepsilon \in (0,1]\), \(Z \in \mathscr{M}_{\varepsilon }\) with \(|\!|\!|Z|\!|\!|_{\varepsilon ;T} \le M\), and \(f \in \hat{\mathscr{D}}^{\gamma ,\eta} \ltimes Z\).
Lemma A.7
Under the same assumptions as Lemma A.4with \(\beta =2-\kappa \) and for fixed \(M>0\) one has for all \(T\in (0,1)\)

uniformly in \(\varepsilon \in (0,1]\), \(Z \in \mathscr{M}_{\varepsilon }\) with \(|\!|\!|Z|\!|\!|_{\varepsilon ;T} \le M\), and \(f \in \mathscr{D}^{\gamma ,\eta} \ltimes Z\).
Appendix B: YMH flow without DeTurck term
In this appendix we collect some useful results on the YMH flow (without DeTurck and \(\Phi ^{3}\) term) which reads
or, in coordinates,
In this section we set \(E=\mathfrak {g}^{d}\oplus \mathbf{V}\) where \(d \in \{2,3\}\).
Lemma B.1
Theorems 2.6 and 3.7 of [61]
For \(d=2,3\) and any \((A_{0},\Phi _{0})\in \mathcal{C}^{\infty}(\mathbf{T}^{d},E)\), there exists a unique solution to (B.1) in \(\mathcal{C}^{\infty}({\mathbf {R}}_{+}\times \mathbf{T}^{d}, E)\) with initial condition \((A_{0},\Phi _{0})\).
Remark B.2
It is assumed in [61] that the Higgs bundle \(\mathcal{V}\) is the adjoint bundle, i.e. the setting of Remark 1.6, and that \(d=3\). The same proof, however, works in the case of a general Higgs bundle; the case \(d=2\) follows by considering fields \(X=(A,\Phi )\) with \(A_{3}=0\) and \(\partial _{3} X=0\).
Definition B.3
Let \(\mathcal{E}\colon \mathcal{C}^{\infty}(\mathbf{T}^{d},E)\to \mathcal{C}^{\infty}({\mathbf {R}}_{+} \times \mathbf{T}^{d}, E)\) be the map taking \(X = (A_{0},\Phi _{0})\) to the smooth solution of (B.1) with initial condition \(X\).
A classical way to obtain solutions to (B.1) is given by the following lemma, the proof of which is standard.
Lemma B.4
Let \(X\in \mathcal{C}^{\infty}(\mathbf{T}^{d},E)\) and \(\mathcal{F}(X)=(a,\phi )\in \mathcal{C}^{\infty}([0,T_{X})\times \mathbf{T}^{d},E)\) as defined in Definition 2.11 (the solution of the YMH flow with DeTurck term and initial condition \(X\)). Let \(g\colon [0,T_{X})\to \mathcal{C}^{\infty}(\mathbf{T}^{d},G)\) solve
Then \((A,\Phi )\stackrel {{\tiny \mathrm {def}}}{=}\mathcal{F}(X)^{g} \colon [0,T_{X}) \to \mathcal{C}(\mathbf{T}^{d},E)\) solves (B.1) with initial condition \(X\).
Corollary B.5
For every \(t\geq 0\), \(\mathcal{C}^{\infty}\ni X\mapsto \mathcal{E}_{t}(X)\in \mathcal{C}^{\infty}\) is continuous.
Proof
For \(X\in \mathcal{C}^{\infty}\), by Proposition 2.9 there exists \(t>0\) sufficiently small (depending, say, only on \(|X|_{L^{\infty}}\)) such that \(\mathcal{C}^{\infty}\ni Y\mapsto (\mathcal{F}_{t}(Y),g_{t}) \in \mathcal{C}^{\infty}\) is continuous at \(X\), where \(g\) solves (B.2) with \(\mathcal{F}(Y)=(a,\phi )\). Hence \(Y\mapsto \mathcal{E}_{t}(Y)\) is continuous at \(X\). Continuity for arbitrary \(t\geq 0\) follows from non-explosion of \(|X|_{L^{\infty}}\) (Lemma B.1) and patching together intervals. □
For \(\varrho \in (\frac{1}{2},1]\), recall the action of \(\mathfrak {G}^{0,\varrho }\) on \(\Omega ^{\varrho }\supset \mathcal{C}^{\infty}(\mathbf{T}^{d},E)\) from Sect. 2.2.
Lemma B.6
Suppose \(X,Y\in \mathcal{C}^{\infty}(\mathbf{T}^{d},E)\) and \(X^{g}=Y\) for some \(g\in \mathfrak {G}^{\varrho }\) and \(\varrho \in (\frac{1}{2},1]\). Then \(g\in \mathcal{C}^{\infty}(\mathbf{T}^{d},G)\) and \(\mathcal{E}_{t}(X)^{g} = \mathcal{E}_{t}(Y)\) for all \(t \geq 0\).
Proof
\(\mathcal{C}^{\alpha}\) control on \(g\) gives \(\mathcal{C}^{\alpha}\) control on \(\mathrm {d}g\) by writing \(\mathrm {d}g = (\mathrm {Ad}_{g} A - A^{g})g\) where \(X=(A,\Phi )\). Hence \(g\) is smooth. The fact that \(\mathcal{E}(X)^{g} = \mathcal{E}(Y)\) is clear. □
Appendix C: Evolving rough gauge transformations
In this appendix, we extend the analysis performed in Sect. 5 for the system (5.4) to the coupled system
and
where \(X=(A,\Phi )\), \(\nu >0\) and \(c^{\varepsilon }\in L(\mathfrak {g},\mathfrak {g})\). Note that (C.2) is identical to (1.17). The following result provides well-posedness and stability of \((X,g)\), which is used in Sects. 6 and 7.
Lemma C.1
Let \((X^{\varepsilon },g^{\varepsilon })\) solve (C.1)-(C.2) with \(\nu \in (0,\frac{3}{2})\), \(c^{\varepsilon }\in L(\mathfrak {g},\mathfrak {g})\) such that \(\lim _{\varepsilon \downarrow 0}c^{\varepsilon }\) exists, and \(C_{\mbox{A}}^{\varepsilon }, C_{\Phi}^{\varepsilon }\) as in Theorem 1.7. Then \((X^{\varepsilon },g^{\varepsilon })\) converges to a process \((X,g)\) in probability in \((\mathcal{S}\times \mathfrak {G}^{0,\nu})^{{\mathop{\mathrm{sol}}}}\). Furthermore, the solution map
is continuous, where \(L^{0}(\Omega ^{\mathrm {noise}};(\mathcal{S}\times \mathfrak {G}^{0,\nu})^{{\mathop{\mathrm{sol}}}})\) is the space of \((\mathcal{S}\times \mathfrak {G}^{0,\nu})^{{\mathop{\mathrm{sol}}}}\)-valued random variables defined on the underlying probability space \(\Omega ^{\mathrm {noise}}\) equipped with the topology of convergence in probability.
Proof
To circumvent the issue that the target space \(G\) is nonlinear, we can assume without loss of generality that for some \(n \in {\mathbf {N}}\), we embed \(G \subset O(n)\), \(\mathfrak {g}\subset \mathfrak {o}(n)\) (the Lie algebra of \(O(n)\)), and \(\mathbf{V}\subset {\mathbf {R}}^{n}\). Then \(A_{j}\) and \(g\) just take values in \({\mathbf {R}}^{n \times n}\) which is the linear space of \(n\) by \(n\) matrices. Therefore we can exchange the term \(c^{\varepsilon }g^{-1}\mathrm {d}g \oplus 0\) in (C.1) for \(c^{\varepsilon }g^{*}\mathrm {d}g \oplus 0\) and equation (C.2) for the equation
where \(g\) takes values in \({\mathbf {R}}^{n \times n}\) and we are using the fact that, for \(M \in O(n)\), \(M^{\ast} = M^{-1}\). Here the bracket is just the matrix commutator.
Since the solution theory for \((X,g)\) is similar to that of (5.4), we only sketch the main differences. We enlarge the regularity structure introduced in Sect. 5 to treat (C.1) and (C.4) together, and verify that the corresponding BPHZ character does not introduce any renormalisation into (C.4) nor any additional renormalisation into (C.1). This means that the dynamic for \(g\) remains compatible with (C.2), in particular it preserves \(G\) as the target space if the initial data is \(G\)-valued, and the dynamic for \(A_{j}\) also preserves the Lie subalgebra \(\mathfrak {g}\) as the target space if the initial data is \(\mathfrak {g}\)-valued. We then verify that the enlarged abstract fixed point problem is also well-posed. Arguing the convergence of the BPHZ models can be done in the same way as before.
To enlarge the regularity structure we introduce a new type \(\mathfrak {k}\), namely we set \(\mathfrak {L}_{+} = \{\mathfrak {z},\mathfrak {k}\}\). The target and kernel space assignments are enlarged by setting \(W_{\mathfrak {k}}= {\mathbf {R}}^{n\times n}\) and \(\mathcal{K}_{\mathfrak {k}} = {\mathbf {R}}\). We also set \(\deg ( \mathfrak {k}) = 2 \) and \(\mathrm{reg}(\mathfrak {k})= 3/2 - 5\kappa \). We also have an enlarged nonlinearity by reading off of the right-hand side of (C.4) and adding a term corresponding to \((c^{\varepsilon }g^{*}\mathrm {d}g ,0)\) to the nonlinearity (5.8) for \(X\).
We use the shorthand  for the component \(A_{(\mathfrak {k},0)}\) of
for the component \(A_{(\mathfrak {k},0)}\) of  . Writing ℋ for the coherent expansion for the solution to (C.4), we then have
. Writing ℋ for the coherent expansion for the solution to (C.4), we then have

Here and below \(q_{< L}\) denotes the projection onto degrees \(< L\), and we used the summation convention in the bracket as in Remark 6.9. We also have  . A simple power counting argument shows that the only trees \(\tau \) where one has both \(\deg (\tau ) < 0\) and \(\bar{\boldsymbol{\Upsilon}}_{\mathfrak {k}}[\tau ] \neq 0\) are
. A simple power counting argument shows that the only trees \(\tau \) where one has both \(\deg (\tau ) < 0\) and \(\bar{\boldsymbol{\Upsilon}}_{\mathfrak {k}}[\tau ] \neq 0\) are  ,
,  and
and  . The first two trees are planted and thus do not contribute to renormalisation. By parity (similarly to Lemma 5.5) the last one vanishes when hit by the BPHZ character.
. The first two trees are planted and thus do not contribute to renormalisation. By parity (similarly to Lemma 5.5) the last one vanishes when hit by the BPHZ character.
To see that no additional renormalisation appears in (C.1) beyond that already shown for (5.4), it suffices to observe that tree of lowest degree added to the expansion of \(X\) by the presence of \((c^{\varepsilon }g^{*}\mathrm {d}g,0)\) is  , which has positive degree.
, which has positive degree.
The fixed point problem
can be solved in \(\mathscr{D}^{\gamma ,\nu}\) with \(\gamma =1+\) since, for the term \(\partial _{j} \mathcal{H}\mathcal{H}^{\ast} \partial _{j} \mathcal{H}\) one has
and for the term \(\mathcal{H}[\mathcal{A}_{j},\mathcal{H}^{\ast}\partial _{j} \mathcal{H}]\) one has
Here \(2\nu -2 > -2\), and \(\nu -\frac{3}{2} > -\frac{3}{2}\), so [56, Prop. 6.16] applies. The abstract fixed point problem for the \(X\)-component is solved in essentially the same way as in the proof of Theorem 5.1.
We note that continuity at time \(t=0\) of \(\mathcal {R}\mathcal {H}\) follows from the fact that the initial condition \(g_{0}\) is in \(\mathfrak {G}^{0,\nu}\), on which the heat semigroup is strongly continuous, and the fact that the first term on the right-hand side of (C.5) goes to zero in \(\mathscr{D}^{\gamma +\frac{3}{2}-, \nu +\frac{1}{2}-}_{0}\) for short times by [56, Thm. 7.1].
The final claim on continuity of the map (C.3) follows from Lemma 5.19, which shows continuity (in \(L^{p}\) and thus in probability) with respect to \(X_{0}\) of the singular products of \(\mathcal{P}X_{0}\) and the SHE \(\tilde{\Psi}\) appearing in the fixed point problem, combined with standard arguments showing (pathwise) continuity of the solution in the initial data. □
We state the following straightforward variant of Lemma C.1 which is used in the proof of Propositions 6.38 and 6.43.
Lemma C.2
The statement of Lemma C.1stills holds with (C.1)-(C.2) replaced by
and
Remark C.3
It is natural to ask why we use two different approaches for formulating the evolution of our gauge transformation in linear spaces: for the proof of Lemma C.1 we view \(G\) as a group of matrices while in Sect. 6 we adopt the viewpoint of tracking the pair \((U,h)\) as in (6.2).
In Sect. 6, \((U,h)\) are the natural variables for tracking how our gauge transformations act on our gauge field (which makes \(h\) appear) and on our \(E\)-valued white noise (which makes \(U\) appear). This also makes them good variables for keeping track of the renormalisation in (6.6) and (6.7).
On the other hand, \(h\) as introduced in (6.2) is not well-defined for the initial data treated in Lemma C.1 when \(\nu \le \frac{1}{2}\), which is the class of initial data that is used in Proposition 7.6.
Appendix D: Injectivity of the solution map
Our objective in this appendix is to prove that one can recover, from the outputs of the limiting solution maps for (6.92) and (6.93), the values of the constants \((\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}}) \in L(\mathfrak {g}, \mathfrak {g})^{2}\). This tells us that these solution maps have injectivity properties as functions of these constants, and this is a key ingredient for the proof of the convergence statements in Propositions 6.41 and 6.43. Our arguments here are in the same in spirit as [12, Thm 3.5], but adapted to the present setting where our solution contains more singular components.
We introduce the same notations for the set of types \(\mathfrak{L}= \mathfrak{L}_{+} \sqcup \mathfrak{L}_{-}\), rule \(R\), kernel and target space assignments, corresponding regularity structure  , and kernel assignments \(K^{(\varepsilon )}\) and noise assignments \(\zeta ^{\delta ,\varepsilon }\) that we defined in Sect. 6.1. Recall (see [10]) that models can be described by non-recentred evaluation maps \(\boldsymbol{\Pi}\), and for the rest of this appendix we use this notation when referring to models. We then write \(\boldsymbol{\Pi}_{\delta ,\varepsilon }\) for the canonical lift of the kernel assignment \(K^{(\varepsilon )}\) from (6.11) and noise assignment \(\zeta ^{\delta ,\varepsilon }\) from (6.12),
, and kernel assignments \(K^{(\varepsilon )}\) and noise assignments \(\zeta ^{\delta ,\varepsilon }\) that we defined in Sect. 6.1. Recall (see [10]) that models can be described by non-recentred evaluation maps \(\boldsymbol{\Pi}\), and for the rest of this appendix we use this notation when referring to models. We then write \(\boldsymbol{\Pi}_{\delta ,\varepsilon }\) for the canonical lift of the kernel assignment \(K^{(\varepsilon )}\) from (6.11) and noise assignment \(\zeta ^{\delta ,\varepsilon }\) from (6.12),  for the corresponding BPHZ lift, and
for the corresponding BPHZ lift, and  for the BPHZ character that shifts \(\boldsymbol{\Pi}_{\delta ,\varepsilon }\) to
for the BPHZ character that shifts \(\boldsymbol{\Pi}_{\delta ,\varepsilon }\) to  . By BPHZ convergence (see Lemma 6.24) for the family of models
. By BPHZ convergence (see Lemma 6.24) for the family of models  , we obtain a limiting random model
, we obtain a limiting random model  , as well as a limit
, as well as a limit  .
.
Fix initial conditions \(\bar{x} = (\bar{a},\bar{\phi})\in \mathcal{S}\) and \(g_{0}\in \mathfrak {G}^{0,\varrho }\) as well as \(\mathring{C}_{\mbox{A}}, \mathring{C}_{\mbox{h}} \in L(\mathfrak {g},\mathfrak {g})\) and \(\boldsymbol{\sigma}\in {\mathbf {R}}\). We write \({\Omega}^{\mathrm {noise}}\) for the canonical probability space for the underlying white noise on which all the random models introduced above are defined. By Proposition 6.39, we have a mapping

where \(L^{0}_{{\mathop{\mathrm{sol}}}}\) is the space of equivalence classes (modulo null sets) of measurable maps from \({\Omega}^{\mathrm {noise}}\) to \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) and  is the corresponding maximal solution map for bothFootnote 39 (6.92) and (6.93) and the \((U,h)\) /\((\bar{U},\bar{h})\) obtained from their corresponding gauge transformations \(g\) /\(\bar{g}\) using (6.2).
is the corresponding maximal solution map for bothFootnote 39 (6.92) and (6.93) and the \((U,h)\) /\((\bar{U},\bar{h})\) obtained from their corresponding gauge transformations \(g\) /\(\bar{g}\) using (6.2).
Our main result for this section is the following lemma.
Lemma D.1
There exists a sequence of measurable maps \((O_{n})_{n \in {\mathbf {N}}}\) from \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) to  such that, for any \(\boldsymbol{\sigma}\in {\mathbf {R}}\), \(\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}} \in L(\mathfrak {g},\mathfrak {g})\), and \((\bar{x},g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\), one has
such that, for any \(\boldsymbol{\sigma}\in {\mathbf {R}}\), \(\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}} \in L(\mathfrak {g},\mathfrak {g})\), and \((\bar{x},g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\), one has

Above \(\mathring{C}_{\mathfrak {z}}\), \(\mathring{C}_{\mathfrak {h}}\) are defined from \(\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}}\) as in (6.14).
The abstract fixed point problem used in the proof of Proposition 6.39 will not be suitable for our analysis in this section and it will be preferable to use the abstract fixed point problem used to prove the \(\varepsilon \downarrow 0\) convergence of local solutions in Propositions 6.34+6.38.
For that reason, we give another construction of maximal solutions obtained by patching together the limits of local solutions. Fix again initial conditions \(\bar{x} = (\bar{a},\bar{\phi})\in \mathcal{S}\) and \(g_{0}\in \mathfrak {G}^{0,\varrho }\) as well as \(\mathring{C}_{\mbox{A}}, \mathring{C}_{\mbox{h}} \in L(\mathfrak {g},\mathfrak {g})\) and \(\boldsymbol{\sigma}\in {\mathbf {R}}\). Let \(\mathbf {F}\) denote the canonical filtration generated by the noise \(\xi \).
Let \(\tau _{1}\in (0,1)\) be the \(\mathbf {F}\)-stopping time from Proposition 6.38 corresponding to initial condition \(( \bar{x},g_{0})\), constants \(\mathring{C}^{\varepsilon }_{\mbox{A}}\equiv \mathring{C}_{\mbox{A}}\), \(\mathring{C}^{\varepsilon }_{\mbox{h}}\equiv \mathring{C}_{\mbox{h}}\), and \(\boldsymbol{\sigma}^{\varepsilon }=\boldsymbol{\sigma}\). We first define \((\bar{X},\bar{U},\bar{h})\) on \([0,\tau _{1}]\) as the \(\varepsilon \downarrow 0\) limit of the solution to (6.92) as in Propositions 6.34/6.38.
We now let \(\tau _{2}-\tau _{1}\in (0,1)\) be the stopping time from Proposition 6.38 corresponding to the new ‘initial time’ \(\tau _{1}\) and initial condition \((\bar{X},\bar{U}, \bar{h})(\tau _{1})\).Footnote 40 We then extend \((\bar{X},\bar{U},\bar{h})\) to \([\tau _{1},\tau _{2}]\) by defining it as the \(\varepsilon \downarrow 0\) limit of the corresponding solution to (6.92).
We proceed in this way defining \((\bar{X},\bar{U},\bar{h})\) as an element of \(\mathcal{C}([0,\tau ^{*}) , \mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })\) where \(\tau ^{*} = \lim _{n\to \infty} \tau _{n}\). We then extend \((\bar{X},\bar{U},\bar{h})\) to a function  by setting
by setting  for all \(t\geq \tau ^{*}\). We then have the following lemma.
for all \(t\geq \tau ^{*}\). We then have the following lemma.
Lemma D.2
With the above construction, one has \((\bar{X},\bar{U},\bar{h}) \in (\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{ {\mathop{\mathrm{sol}}}}\) and  .
.
Proof
For the first statement, observe that \(\tau _{n+1}-\tau _{n}\) is independent of \(\tau _{1},\tau _{2},\ldots , \tau _{n}\) when conditioned on \((\bar{X},\bar{U},\bar{h})(\tau _{n})\) and is stochastically bounded from below by a distribution depending only on \(\Sigma (\bar{X}(\tau _{n})) +|(\bar{U},\bar{h})(\tau _{n})|_{ \tilde{\mathfrak {G}}^{0,\varrho }}\). Furthermore, for any \(\mathbf {F}\)-stopping time \(\sigma <\tau ^{*}\), there exists another \(\mathbf {F}\)-stopping time \(\bar{\sigma}>\sigma \) such that \(\bar{\sigma}-\sigma \) is stochastically bounded from below by a distribution depending only on \(\Sigma (\bar{X}(\sigma )) +|(\bar{U},\bar{h})(\sigma )|_{\tilde{\mathfrak {G}}^{0, \varrho }}\) and such that
It follows that, on the event \(\tau ^{*}<\infty \), almost surely  and therefore \((\bar{X},\bar{U},\bar{h}) \in (\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{ {\mathop{\mathrm{sol}}}}\).
and therefore \((\bar{X},\bar{U},\bar{h}) \in (\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{ {\mathop{\mathrm{sol}}}}\).
The second statement follows from the last paragraph of the proof of Proposition 6.39. □
We now state a version of [12, Lemma 3.6].
Lemma D.3
Fix \((\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}}) \in L(\mathfrak {g},\mathfrak {g})^{2}\) and \((\bar{x} , g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\).
Let \((\mathcal{Y},\mathcal{U},\mathcal{H})\) be the local solution, associated to the model  along with the rest of the limiting \(\varepsilon \)-inputs, of the abstract fixed point problem (6.56)+(6.63) with constants \(\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}}\) and initial condition \((\bar{x},U_{0},h_{0})\) (the latter two are determined from \(g_{0}\) via (6.2)) promised by Lemma 6.31, and let \(\tau \) be the associated \(\mathbf {F}\)-stopping time given in the statement of that lemma. Let \((\bar{X}, \bar{U} ,\bar{h}) = \mathcal{R}(\mathcal{Y},\mathcal{U},\mathcal{H})\).
along with the rest of the limiting \(\varepsilon \)-inputs, of the abstract fixed point problem (6.56)+(6.63) with constants \(\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}}\) and initial condition \((\bar{x},U_{0},h_{0})\) (the latter two are determined from \(g_{0}\) via (6.2)) promised by Lemma 6.31, and let \(\tau \) be the associated \(\mathbf {F}\)-stopping time given in the statement of that lemma. Let \((\bar{X}, \bar{U} ,\bar{h}) = \mathcal{R}(\mathcal{Y},\mathcal{U},\mathcal{H})\).
Then, the (random) distribution  , where \(\tilde{\mathcal{R}}\) is the local (defined away from time \(t=0\)) reconstruction operator for the model
, where \(\tilde{\mathcal{R}}\) is the local (defined away from time \(t=0\)) reconstruction operator for the model  , admits an extension to a random element of
, admits an extension to a random element of  such that for every (deterministic) \(E\)-valued space-time test function \(\psi \),
such that for every (deterministic) \(E\)-valued space-time test function \(\psi \),

where the integral is in the Itô sense and \(\boldsymbol{\sigma}W\) is the \(L^{2}(\mathbf{T}^{3},E)\)-cylindrical Wiener process associated to the noise \(\boldsymbol{\sigma}\xi = \mathcal{R}\boldsymbol{\Xi}\).
Proof
First note that the quantity (D.2) is well-defined since \(s \mapsto U(s,\cdot )\) is continuous and adapted. To obtain (D.2), we approximate  with the models
with the models  (using a non-anticipative mollifier \(\chi \)) and let \(\eta ^{\varepsilon }\) be the analog of \(\eta \) but with the role of
(using a non-anticipative mollifier \(\chi \)) and let \(\eta ^{\varepsilon }\) be the analog of \(\eta \) but with the role of  replaced with
replaced with  along with the corresponding regularised \(\varepsilon \)-inputs.
along with the corresponding regularised \(\varepsilon \)-inputs.
Now, on the one hand, we have \(\lim _{\varepsilon \downarrow 0} \eta ^{\varepsilon }(\psi ) = \eta (\psi )\). On the other hand, thanks to [11], it follows that if we write \((\bar{X}^{\varepsilon },\bar{U}^{\varepsilon },\bar{h}^{\varepsilon })\) for the relevant objects defined from  along with the associated \(\varepsilon \)-inputs, one has the identity
along with the associated \(\varepsilon \)-inputs, one has the identity

where  is defined as in (6.49) –note that \(\boldsymbol{\bar{\Upsilon}}^{\bar{F}}_{\mathfrak {m}}[\sigma ]\) can be written as a function of the pointwise values of the smooth (until blow-up) functions \((\bar{X}^{\varepsilon },\bar{U}^{\varepsilon },\bar{h}^{\varepsilon })\).
is defined as in (6.49) –note that \(\boldsymbol{\bar{\Upsilon}}^{\bar{F}}_{\mathfrak {m}}[\sigma ]\) can be written as a function of the pointwise values of the smooth (until blow-up) functions \((\bar{X}^{\varepsilon },\bar{U}^{\varepsilon },\bar{h}^{\varepsilon })\).
Observe that \(\sigma \in \mathfrak {T}_{-}\) and \(\boldsymbol{\bar{\Upsilon}}_{\mathfrak {m}}^{\bar{F}}[\sigma ] \neq 0\) forces \(\sigma \) to have an occurrence of \(\mathfrak {l}\) at the root, so by Lemma D.4 below the second term above vanishes. The result then follows by the stability of the Itô integral. □
The above proof used the following lemma regarding properties of the renormalisation character  in (6.49).
in (6.49).
Lemma D.4
Suppose that \(\chi \) is non-anticipative and that  is given by (6.49). Then, for any \(\sigma \in \mathfrak {T}^{\bar{F}} \) that has an occurrence of \(\mathfrak {l}\) at the root, one has
is given by (6.49). Then, for any \(\sigma \in \mathfrak {T}^{\bar{F}} \) that has an occurrence of \(\mathfrak {l}\) at the root, one has  .
.
Proof
The action of the negative twisted antipode on \(\sigma \) generates a linear combination of forests, and each such forest must contain at least one tree of the form  where every noise in \(\tilde{\sigma }\) is incident to an \(\varepsilon \)-regularised kernel. For \(\delta > 0\) sufficiently small,
where every noise in \(\tilde{\sigma }\) is incident to an \(\varepsilon \)-regularised kernel. For \(\delta > 0\) sufficiently small,  by independence, and since
by independence, and since  the proof is completed. □
the proof is completed. □
The key step in constructing the \(O_{n}\)’s promised in Lemma D.1 is constructing, as function of the limiting \(\varepsilon \downarrow 0\) solution \((X,U,h)\) to (6.92), the nonlinear expression \(\mathcal{N}(X,U,h) = \text{ ``}X^{3} + X \partial X \text{ ''}\) –which are the limits of the corresponding terms on the right-hand side of (6.92)). We will have to define \(\mathcal{N}(X,U,h)\) in a renormalised sense, that is by regularising \((X,U,h)\) at a scale \(\hat{\varepsilon } > 0\) and defining a regularised and renormalised \(\mathcal{N}_{\hat{\varepsilon }}(\bullet , \bullet ,\bullet )\).
To do this we introduce modelled distributions that describe the regularisation of \((X,U,h)\),Footnote 41 and show that the reconstruction of \(\mathcal{N}\) applied to the regularised modelled distribution for \(X\) converges to the reconstruction of \(\mathcal{N}\) applied to the modelled distribution for the original, unregularised \(X\). At the algebraic level, this regularisation of \((X,U,h)\) is encoded by introducing new labels corresponding to regularised kernels. Intermediate quantities appearing when comparing the two reconstructions described above will involve both regularised kernels and unregularised kernels which makes adding labels necessary (as opposed to just modifying our assignment of kernels to labels).
Finally, to complete the argument one needs to know that reconstruction of our nonlinearity evaluated at these regularised modelled distributions makes sense as an observable on \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) –but this last point can be justified with arguments from [11].
Let ℳ be the set of models on  that are admissible with the kernel assignment \(K^{(0)}\) –note that
that are admissible with the kernel assignment \(K^{(0)}\) –note that  . We then define a larger set of labels by adding a duplicate type \(\hat{\mathfrak {t}}\) for each \(\mathfrak {t}\in \mathfrak{L}_{+}\). Our new set of kernel types is then \(\hat{\mathfrak {L}}_{+} = \mathfrak {L}_{+} \sqcup \{ \hat{\mathfrak {t}}: \mathfrak {t}\in \mathfrak{L}_{+} \}\), and our new set of types is \(\hat{\mathfrak {L}} = \hat{\mathfrak {L}}_{+} \sqcup \mathfrak {L}_{-}\). We also set, for each \(\mathfrak {t}\in \mathfrak{L}_{+}\), \(\deg (\hat{\mathfrak {t}}) = \deg (\mathfrak {t})\), \(W_{\hat{\mathfrak {t}}} \simeq W_{\mathfrak {t}}\), and \(\mathcal{K}_{\hat{\mathfrak {t}}} \simeq \mathcal{K}_{\mathfrak {t}}\).
. We then define a larger set of labels by adding a duplicate type \(\hat{\mathfrak {t}}\) for each \(\mathfrak {t}\in \mathfrak{L}_{+}\). Our new set of kernel types is then \(\hat{\mathfrak {L}}_{+} = \mathfrak {L}_{+} \sqcup \{ \hat{\mathfrak {t}}: \mathfrak {t}\in \mathfrak{L}_{+} \}\), and our new set of types is \(\hat{\mathfrak {L}} = \hat{\mathfrak {L}}_{+} \sqcup \mathfrak {L}_{-}\). We also set, for each \(\mathfrak {t}\in \mathfrak{L}_{+}\), \(\deg (\hat{\mathfrak {t}}) = \deg (\mathfrak {t})\), \(W_{\hat{\mathfrak {t}}} \simeq W_{\mathfrak {t}}\), and \(\mathcal{K}_{\hat{\mathfrak {t}}} \simeq \mathcal{K}_{\mathfrak {t}}\).
We extend the rule \(R\) to obtain a rule \(\hat{R}\) on \(\hat{\mathfrak {L}}\) as follows: for any \(\mathfrak {t}\in \mathfrak{L}\) we set \(\hat{R}(\mathfrak {t}) = R(\mathfrak {t})\) and, for any \(\mathfrak {t}\in \mathfrak{L}_{+}\), we set \(\hat{R}(\hat{\mathfrak {t}})\) to be the collection of all the node types \(\hat{N}\) that can be obtained by taking \(N \in R(\mathfrak {t})\) and replacing any number of instances of edge types \((\mathfrak {t},p) \in \mathfrak{L}_{+} \times {\mathbf {N}}^{d+1}\) with \((\hat{\mathfrak {t}},p)\).
We define the set of trees \(\hat{\mathfrak {T}} \supset \mathfrak {T}\) to be those that strongly conform to \(\hat{R}\) but where we also enforce that any edge of type \((\hat{\mathfrak {t}},p)\) has to be incident to the root. Since the latter constraint is preserved by coproducts, \(\hat{\mathfrak {T}}\) determines a regularity structure  .
.
Finally we introduce a parameter \(\hat{\varepsilon } \in [0,1]\) and define the kernel assignment \(K^{[\hat{\varepsilon }]} = (K^{[\hat{\varepsilon }]}_{\mathfrak {b}}: \mathfrak {b}\in \hat{\mathfrak {L}}_{+})\) by setting, for each \(\mathfrak {t}\in \mathfrak{L}_{+}\), \(K^{[\hat{\varepsilon }]}_{\mathfrak {t}} = K^{(0)}_{\mathfrak {t}}\) and \(K^{[\hat{\varepsilon }]}_{\hat{\mathfrak {t}}} = K^{(0)}_{\mathfrak {t}} \ast \chi _{ \hat{\varepsilon }}\). We write \(\hat{\mathscr{M}}_{\hat{\varepsilon }}\) for the collection of \(K^{[\hat{\varepsilon }]}\)-admissible models on  and then set \(\hat{\mathscr{M}} = \bigcup _{\hat {\varepsilon }} \hat{\mathscr{M}}_{\hat{\varepsilon }}\). We denote by \(\pi _{0}\) the natural restriction map \(\pi _{0}: \hat{\mathscr{M}} \rightarrow \mathscr{M}\).
and then set \(\hat{\mathscr{M}} = \bigcup _{\hat {\varepsilon }} \hat{\mathscr{M}}_{\hat{\varepsilon }}\). We denote by \(\pi _{0}\) the natural restriction map \(\pi _{0}: \hat{\mathscr{M}} \rightarrow \mathscr{M}\).
We define a mapping \(\hat{\mathfrak {T}} \ni \hat{\sigma } \mapsto \hat{\pi}_{0}(\hat{\sigma }) \in \mathfrak {T}\) by replacing, for every \(\mathfrak {t}\in \mathfrak{L}_{+}\) and \(p \in {\mathbf {N}}^{d+1}\), all edges of type \((\hat{\mathfrak {t}},p)\) in \(\hat{\sigma }\) with edges of type \((\mathfrak {t},p)\). Overloading notation, this mapping on trees also induces a linear mapFootnote 42 . We again denote by \(\hat{\pi}_{0}\) the corresponding linear map
. We again denote by \(\hat{\pi}_{0}\) the corresponding linear map  . Right composition by \(\hat{\pi}_{0}\) gives us another map \(\iota : \mathscr{M}\rightarrow \hat{\mathscr{M}}_{0}\) and we note that \(\pi _{0} \circ \iota = \mathrm{id}\).
. Right composition by \(\hat{\pi}_{0}\) gives us another map \(\iota : \mathscr{M}\rightarrow \hat{\mathscr{M}}_{0}\) and we note that \(\pi _{0} \circ \iota = \mathrm{id}\).
For every \(\hat{\varepsilon } > 0\) we define a map \(\mathcal{E}_{\hat{\varepsilon }}\colon \mathscr{M}\rightarrow \hat{\mathscr{M}}_{\hat{\varepsilon }}\) as follows. Given \(\boldsymbol{\Pi}\in \mathscr{M}\) we fix \(\mathcal{E}_{\hat{\varepsilon }}(\boldsymbol{\Pi})\) to be the unique model in \(\hat{\mathscr{M}}_{\hat{\varepsilon }}\) that satisfies
-
\(\mathcal{E}_{\hat{\varepsilon }}(\boldsymbol{\Pi}) [ \sigma ] = \boldsymbol{\Pi}[\sigma ]\) for \(\sigma \in \mathfrak {T}\)
-
For
 with \(\bar{\sigma },\sigma _{j} \in \mathfrak {T}\), one has $$\begin{aligned} \mathcal{E}_{\hat{\varepsilon }}(\boldsymbol{\Pi}) [ \sigma ] = \boldsymbol{\Pi}[\bar{\sigma }] \Big( \bigotimes _{j=1}^{n}\partial ^{p_{j}}K_{\mathfrak {t}_{j}} \ast \chi ^{ \hat{\varepsilon }} \ast \boldsymbol{\Pi}[\sigma _{j}] \Big)\;. \end{aligned}$$(D.3)
with \(\bar{\sigma },\sigma _{j} \in \mathfrak {T}\), one has $$\begin{aligned} \mathcal{E}_{\hat{\varepsilon }}(\boldsymbol{\Pi}) [ \sigma ] = \boldsymbol{\Pi}[\bar{\sigma }] \Big( \bigotimes _{j=1}^{n}\partial ^{p_{j}}K_{\mathfrak {t}_{j}} \ast \chi ^{ \hat{\varepsilon }} \ast \boldsymbol{\Pi}[\sigma _{j}] \Big)\;. \end{aligned}$$(D.3)
 with
with Note that \(\pi _{0} \circ \mathcal{E}_{\hat{\varepsilon }} = \mathrm{id}\). Below, we write \(\hat{\mathfrak{R}}\) for the renormalisation group for  . We can now state and prove our analog of [12, Lem 3.7].
. We can now state and prove our analog of [12, Lem 3.7].
Lemma D.5
There exists a sequence \(( \hat{M}_{\hat{\varepsilon }}: \hat{\varepsilon } \in (0,1])\) of elements of \(\hat{\mathfrak{R}}\) that all leave  invariant and such that the models
invariant and such that the models

converge in probability to  as \(\hat{\varepsilon } \downarrow 0\). Moreover, one has
as \(\hat{\varepsilon } \downarrow 0\). Moreover, one has  .
.
Proof
First note that the statement  will follow from showing that \(M_{\hat{\varepsilon }}\) leaves
will follow from showing that \(M_{\hat{\varepsilon }}\) leaves  invariant thanks to the identity (D.4).
invariant thanks to the identity (D.4).
The general idea is to define \(\hat{\boldsymbol{\Pi}}_{\hat{\varepsilon }}\) to be the BPHZ renormalisation of the random model  . However, we can not directly BPHZ renormalise the random model
. However, we can not directly BPHZ renormalise the random model  since
since  is not a smooth model (simply because
is not a smooth model (simply because  is not a smooth model). We can suppose, by regularising the noise, that we have a collection of smooth random BPHZ models
is not a smooth model). We can suppose, by regularising the noise, that we have a collection of smooth random BPHZ models  that converge to
that converge to  as \(\varepsilon \downarrow 0\) in every \(L^{p}\).
as \(\varepsilon \downarrow 0\) in every \(L^{p}\).
We then define \(\hat{\boldsymbol{\Pi}}_{\hat{\varepsilon },\varepsilon }\) to be the BPHZ renormalisation of  , and let \(M_{\hat{\varepsilon },\varepsilon }\) be the corresponding element in renormalisation group that satisfies
, and let \(M_{\hat{\varepsilon },\varepsilon }\) be the corresponding element in renormalisation group that satisfies

By stability of the BPHZ lift, \(\hat{\boldsymbol{\Pi}}_{\hat{\varepsilon },\varepsilon }\) converges to  whichever way one takes \(\varepsilon ,\hat{\varepsilon } \downarrow 0\).
whichever way one takes \(\varepsilon ,\hat{\varepsilon } \downarrow 0\).
Next, we argue that \(\hat{M}_{\hat{\varepsilon },\varepsilon }\) leaves  invariant. Writing \(\ell _{\hat{\varepsilon },\varepsilon }\) for the character that defines \(\hat{M}_{\hat{\varepsilon },\varepsilon }\), it suffices to verify that \(\sigma \in \mathfrak {T}_{-} \subset \mathfrak {T}\Rightarrow \ell _{\hat{\varepsilon },\varepsilon }[ \sigma ] = 0\). Recall that \(\ell _{\hat{\varepsilon },\varepsilon }\) is given by the composition of the negative twisted antipode with
invariant. Writing \(\ell _{\hat{\varepsilon },\varepsilon }\) for the character that defines \(\hat{M}_{\hat{\varepsilon },\varepsilon }\), it suffices to verify that \(\sigma \in \mathfrak {T}_{-} \subset \mathfrak {T}\Rightarrow \ell _{\hat{\varepsilon },\varepsilon }[ \sigma ] = 0\). Recall that \(\ell _{\hat{\varepsilon },\varepsilon }\) is given by the composition of the negative twisted antipode with  . The negative twisted antipode takes trees in \(\sigma \in \mathfrak {T}_{-} \) into forests of trees in \(\mathfrak {T}\) which contain at least one tree \(\tilde{\sigma } \in \mathfrak {T}_{-}\). Note that for \(\tilde{\sigma } \in \mathfrak {T}_{-}\) we have
. The negative twisted antipode takes trees in \(\sigma \in \mathfrak {T}_{-} \) into forests of trees in \(\mathfrak {T}\) which contain at least one tree \(\tilde{\sigma } \in \mathfrak {T}_{-}\). Note that for \(\tilde{\sigma } \in \mathfrak {T}_{-}\) we have  since
since  is a BPHZ model in ℳ. Therefore, \(\ell _{\hat{\varepsilon },\varepsilon }[\sigma ] = 0\).
is a BPHZ model in ℳ. Therefore, \(\ell _{\hat{\varepsilon },\varepsilon }[\sigma ] = 0\).
What remains to be shown is that, for fixed \(\hat{\varepsilon } > 0\), the limit \(M_{\hat{\varepsilon }}\stackrel {{\tiny \mathrm {def}}}{=}\lim _{\varepsilon \downarrow 0} M_{\hat{\varepsilon },\varepsilon } \) exists. Here, it suffices to show that for every \(\sigma \in \mathfrak {T}\),  converges as \(\varepsilon \downarrow 0\).
converges as \(\varepsilon \downarrow 0\).
Since the models  themselves converge, we have the convergence of
themselves converge, we have the convergence of  for \(\deg (\sigma ) > 0\) as \(\varepsilon \downarrow 0\). If \(\sigma \in \mathfrak {T}_{-}\) then we may assume that
for \(\deg (\sigma ) > 0\) as \(\varepsilon \downarrow 0\). If \(\sigma \in \mathfrak {T}_{-}\) then we may assume that  , where
, where  consists of all \(\sigma \in \hat{\mathfrak {T}}_{-}\) which have even parity in both space and noise, since otherwise the expectation vanishes.
consists of all \(\sigma \in \hat{\mathfrak {T}}_{-}\) which have even parity in both space and noise, since otherwise the expectation vanishes.
Now, if  has a vanishing polynomial label then
has a vanishing polynomial label then  is space-time stationary, and so for any fixed smooth space-time test function \(\phi \) integrating to 1, we have
is space-time stationary, and so for any fixed smooth space-time test function \(\phi \) integrating to 1, we have

Again, convergence of the random models  implies the convergence of the right-hand side above.
implies the convergence of the right-hand side above.
Now suppose that  has a non-vanishing polynomial label, then it must be the case that \(\sigma \) contains precisely one factor of \(\mathbf {X}_{j}\) for some \(j \in \{1,2,3\}\). Since
has a non-vanishing polynomial label, then it must be the case that \(\sigma \) contains precisely one factor of \(\mathbf {X}_{j}\) for some \(j \in \{1,2,3\}\). Since  is a “stationary model” in the sense of [10, Def 6.17] it follows that, for any \(h \in {\mathbf {R}}^{d+1}\), one has
is a “stationary model” in the sense of [10, Def 6.17] it follows that, for any \(h \in {\mathbf {R}}^{d+1}\), one has

are equal in law, where \(\bar{\sigma }\) is obtained from \(\sigma \) by removing the factor \(\mathbf {X}_{j}\). It follows that, for any fixed smooth space-time test function \(\phi \) integrating to 1 that satisfies \(\int _{{\mathbf {R}}^{d+1}} z_{j} \phi (z) = 0\), one again has (D.5). □
We can now state the key construction in our argument for proving Lemma D.1.
Lemma D.6
Let \(\tilde{\tau}\) be a stopping time with respect to the canonical filtration on \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\) dominated by the blow-up time \(\tau ^{\ast}\).
There exists a measurable map  with the following property.
with the following property.
Fix any \((\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}}) \in L(\mathfrak {g},\mathfrak {g})^{2}\) and \((\bar{x},g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\) and write  . Then
. Then
for almost every \(\xi \in {\Omega}^{\mathrm {noise}}\) where the random distribution \(\eta ^{\tilde{\tau}}\) is defined by setting, for any deterministic  ,
,

Above, \(W\) is the \(L^{2}(\mathbf{T}^{3},E)\)-cylindrical Wiener process associated to the noise \(\xi \).
Proof
Without loss of generality, we set \(\boldsymbol{\sigma}= 1\) and drop it from the notation. Heuristically we want to define \(O(\bar{X},\bar{U},\bar{h})\) as
where we are using the notation of (1.12) for the fourth and fifth terms on the right-hand side.
The first three terms on the right-hand side are canonically well-defined but the fourth and fifth are not. However, we know how to construct, for \((\bar{X},\bar{U},\bar{h})\) in the statement of the lemma, the renormalised nonlinearities \(\bar{X}^{3}\) and \(\bar{X} \partial \bar{X}\), and the crucial point is that the construction of these nonlinearities has no dependence on the choice of \(\mathring{C}_{\mbox{A}}\) and \(\mathring{C}_{\mbox{h}}\) because our renormalisation counter-terms do not depend on these constants.Footnote 43
Let \(\mathcal{X} = (\mathcal{X}_{\mathfrak {t}}: \mathfrak {t}\in \mathfrak{L}_{+})\) be the limiting modelled distributions that solve the fixed point problems (6.56) and (6.63) –in particular,
We perform a trivial enlargement of our fixed point problems by including a second set of components which represent the \(\hat{\varepsilon }\)-mollification of the first.
Note that, for \(\hat{\varepsilon } \ge 0\), one can pose and solve a fixed point problem for modelled distributions \(\mathcal{X}= (\mathcal{X}_{\mathfrak {t}}: \mathfrak {t}\in \mathfrak{L}_{+})\) and \(\mathcal{X}^{[\hat{\varepsilon }]} = (\mathcal{X}^{[\hat{\varepsilon }]}_{\hat{\mathfrak {t}}}: \mathfrak {t}\in \mathfrak{L}_{+})\) of the form
where what we wrote for the system for \(\mathcal{X}\) is a shorthand for the system appearing in Lemma 6.31, and \(\vec{\omega}\) represents the data regarding ill-defined products at \(t=0\) that is needed to pose the fixed point problem.
Then \(\mathcal{G}^{[\hat{\varepsilon }],\vec{\omega}}_{\hat{\mathfrak {t}}}\) is an analogous shorthand for the abstract lift of the kernel \(G \ast \chi ^{\hat{\varepsilon }}\) or \(\nabla G \ast \chi ^{\hat{\varepsilon }}\) with rough part \(K^{[\hat{\varepsilon }]}_{\hat{\mathfrak {t}}}\) and augmented by the same data as the \(\tilde{\mathcal{X}}\) –note that the same collection of products ill-defined at \(t=0\) appear in both equations above.
Furthermore, for any \(\hat{\varepsilon } \ge 0\), the fixed point problem above, augmented by the \(\varepsilon \)-inputs \(\omega \) built from \(\xi \) along with the model  , admits solutions in appropriate spaces of modelled distributions on \([0,\hat{\tau}) \times \mathbf{T}^{3}\) for some \(\hat{\tau} > 0\). Henceforth we use the notation \(\mathcal{X}\) and \(\mathcal{X}^{[\hat{\varepsilon }]}\) to refer to the solutions to these fixed point problems.
, admits solutions in appropriate spaces of modelled distributions on \([0,\hat{\tau}) \times \mathbf{T}^{3}\) for some \(\hat{\tau} > 0\). Henceforth we use the notation \(\mathcal{X}\) and \(\mathcal{X}^{[\hat{\varepsilon }]}\) to refer to the solutions to these fixed point problems.
We define \((\mathcal{Y}^{[\hat{\varepsilon }]}, \mathcal{U}^{[\hat{\varepsilon }]},\mathcal{H}^{[\hat{\varepsilon }]})\) analogously to (D.7) but with the role of \(\mathcal{X}\) replaced by \(\mathcal{X}^{[\hat{\varepsilon }]}\). We also set, for \(\mathring{\mathcal{Y}} \in \{\mathcal{Y}, \mathcal{Y}^{[\hat{\varepsilon }]}\}\),
For any model \(\hat{\boldsymbol{\Pi}} \in \hat{\mathscr{M}}\) which satisfies  , we have \(\mathcal{R} (\mathcal{Y},\mathcal{U},\mathcal{H}) = (\bar{X},\bar{U},\bar{h})\) on \([0,\hat{\tau}) \times \mathbf{T}^{3}\) since the equation for \(\mathcal{X}\) does not involve the trees of \(\hat{\mathfrak {T}} \setminus \mathfrak {T}\), and we also have the distributional identity
, we have \(\mathcal{R} (\mathcal{Y},\mathcal{U},\mathcal{H}) = (\bar{X},\bar{U},\bar{h})\) on \([0,\hat{\tau}) \times \mathbf{T}^{3}\) since the equation for \(\mathcal{X}\) does not involve the trees of \(\hat{\mathfrak {T}} \setminus \mathfrak {T}\), and we also have the distributional identity
where again \(\tilde{\mathcal{R}}\) is the local reconstruction operator (which avoids \(t=0\)). To finish our proof we would need to construct \(\tilde{\mathcal{R}} \mathfrak{N}(\mathcal{Y})\) as a functional of \((\bar{X},\bar{U},\bar{h})\).
If \(\hat{\boldsymbol{\Pi}} \in \hat{\mathscr{M}}\) is of the form \(\iota (\boldsymbol{\Pi})\) for \(\boldsymbol{\Pi}\in \mathscr{M}\) then one has \(\tilde{\mathcal{R}} \circ \hat{\pi}_{0} = \tilde{\mathcal{R}}\) and \(\hat{\pi}_{0} \mathcal{Y}^{[0]} = \mathcal{Y}\). In particular, we have \(\hat{\pi} \mathfrak{N}( \mathcal{Y}^{[0]} ) = \mathfrak{N}( \mathcal{Y})\) and \(\tilde{\mathcal{R}} \mathfrak{N}( \mathcal{Y}^{[0]} )= \tilde{\mathcal{R}} \mathfrak{N}( \mathcal{Y})\).
For each \(\hat{\varepsilon } > 0\), let \(\hat{\boldsymbol{\Pi}}_{\hat{\varepsilon }}\) be as given by (D.4) in Lemma D.5. We fix a subsequence \(\hat{\varepsilon }_{n} \downarrow 0\) such that the models \(\hat{\boldsymbol{\Pi}}_{\hat{\varepsilon }_{n}}\) converge almost surely as \(n \rightarrow \infty \).
By the observations above and Lemma D.5 we have that, as distributions on \((0,\hat{\tau}) \times \mathbf{T}^{3}\), \(\tilde{\mathcal{R}} \mathfrak{N}(\mathcal{Y}^{[\hat{\varepsilon }_{n}]})\) converges to \(\tilde{\mathcal{R}} \mathfrak{N}(\mathcal{Y})\) almost surely as \(n \rightarrow \infty \).
Moreover, we claim that there exist \(c_{\hat{\varepsilon },1}, c_{\hat{\varepsilon },2} \in L(\mathfrak {g}^{3},\mathfrak {g}^{3})\) and \(c_{\hat{\varepsilon },3} \in L(\mathfrak {g}^{3},E)\) such that
In order to justify this claim one can argue as in [11, Sect. 2.8.3] and include \(\mathfrak{N}(\mathcal{Y}^{[\hat{\varepsilon }]})\) as yet another component of our system associated to some new label \(\check{\mathfrak {z}}\), we write \(\check{F} = (\check{F}_{\mathfrak {t}} : \mathfrak {t}\in \hat{\mathfrak {L}} \sqcup \{ \check{\mathfrak {z}}\})\) the non-linearity for this bigger system. Since the model  is a multiplicative model on the sector that \(\mathfrak{N}(\mathcal{Y}^{[\hat{\varepsilon }]})\) lives in and
is a multiplicative model on the sector that \(\mathfrak{N}(\mathcal{Y}^{[\hat{\varepsilon }]})\) lives in and  agrees with \(\hat{\boldsymbol{\Pi}}_{\hat{\varepsilon }}\) on this same sector, the renormalised nonlinearity that allows us to calculate the left hand side of (D.9) is
agrees with \(\hat{\boldsymbol{\Pi}}_{\hat{\varepsilon }}\) on this same sector, the renormalised nonlinearity that allows us to calculate the left hand side of (D.9) is
where \(\ell _{\hat{\varepsilon }}\) is the character corresponding to the operator \(\hat{M}_{\hat{\varepsilon }}\) in Lemma D.5. To argue that the second term above agrees with the functional form seen in the bracketed term appearing in (D.9), one observes that the trees contributing to the above formula are obtained as graftings onto trees \(\tilde{\sigma }\) where \(\tilde{\sigma }\) is obtained from taking one of the trees in  and replacing all of its kernel edges \((\mathfrak {t},p)\) incident to the root in \(\theta (\hat{\sigma })\) with their \(\hat{\varepsilon }\)-regularised versions \((\hat{\mathfrak {t}},p)\) –here \(\theta \) is the map that “takes \((Y,U,h)\) trees to \((\bar{X},\bar{U},\bar{h})\) trees” described before Lemma 6.23. Note that changing edges in this way does not change noise, spatial parity, or degree. One can then by hand, work through the recursive formula that defines \(\boldsymbol{\bar{\Upsilon}}_{\check{\mathfrak {z}}}\) and afterwards take advantage of the fact that \(\boldsymbol{\Upsilon}^{\check{F}}_{\hat{\mathfrak {t}}} = \boldsymbol{\Upsilon}^{\check{F}}_{\mathfrak {t}} = \boldsymbol{\Upsilon}^{\bar{F}}_{\mathfrak {t}}\) for \(\mathfrak {t}\in \{\mathfrak {m}, \mathfrak {h}, \mathfrak {h}', \mathfrak {z}\}\) to apply the same arguments as in the proof of Lemma 6.22 to obtain the desired claim.
and replacing all of its kernel edges \((\mathfrak {t},p)\) incident to the root in \(\theta (\hat{\sigma })\) with their \(\hat{\varepsilon }\)-regularised versions \((\hat{\mathfrak {t}},p)\) –here \(\theta \) is the map that “takes \((Y,U,h)\) trees to \((\bar{X},\bar{U},\bar{h})\) trees” described before Lemma 6.23. Note that changing edges in this way does not change noise, spatial parity, or degree. One can then by hand, work through the recursive formula that defines \(\boldsymbol{\bar{\Upsilon}}_{\check{\mathfrak {z}}}\) and afterwards take advantage of the fact that \(\boldsymbol{\Upsilon}^{\check{F}}_{\hat{\mathfrak {t}}} = \boldsymbol{\Upsilon}^{\check{F}}_{\mathfrak {t}} = \boldsymbol{\Upsilon}^{\bar{F}}_{\mathfrak {t}}\) for \(\mathfrak {t}\in \{\mathfrak {m}, \mathfrak {h}, \mathfrak {h}', \mathfrak {z}\}\) to apply the same arguments as in the proof of Lemma 6.22 to obtain the desired claim.
The key takeaway from (D.9) is that \(N^{\hat{\varepsilon }}(\bar{X},\bar{U},\bar{h})\) is well-defined on all of \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\). Finally, we set \(O^{\tilde{\tau}}(\bar{X},\bar{U},\bar{h})\) to be the limit of
if this limit exists in  , otherwise we set \(O^{\tilde{\tau}}(\bar{X},\bar{U},\bar{h}) = 0\).
, otherwise we set \(O^{\tilde{\tau}}(\bar{X},\bar{U},\bar{h}) = 0\).
Now, by Lemma D.2,  can be obtained as the patching of the limits of local solutions obtained from Proposition 6.38. In particular, the argument above gives us (D.6) almost everywhere on \({\Omega}^{\mathrm {noise}}\) if one replaces \(\tilde{\tau}\) both in (D.6) and (D.10) with \(\tau _{1} \wedge \tilde{\tau}\) where \(\tau _{1} > 0\) is the \(\mathbf {F}\)-stopping time coming from Proposition 6.38 as described in the patching construction of \((\bar{X},\bar{U},\bar{h})\). However, the same argument can again be applied on every epoch \([\tau _{j} \wedge \tilde{\tau} ,\tau _{j+1} \wedge \tilde{\tau}]\) and patching the observables obtained on each epoch together gives us the desired result. □
can be obtained as the patching of the limits of local solutions obtained from Proposition 6.38. In particular, the argument above gives us (D.6) almost everywhere on \({\Omega}^{\mathrm {noise}}\) if one replaces \(\tilde{\tau}\) both in (D.6) and (D.10) with \(\tau _{1} \wedge \tilde{\tau}\) where \(\tau _{1} > 0\) is the \(\mathbf {F}\)-stopping time coming from Proposition 6.38 as described in the patching construction of \((\bar{X},\bar{U},\bar{h})\). However, the same argument can again be applied on every epoch \([\tau _{j} \wedge \tilde{\tau} ,\tau _{j+1} \wedge \tilde{\tau}]\) and patching the observables obtained on each epoch together gives us the desired result. □
Proof of Lemma D.1
Define
where \(\|(x,u,h)\|\) in (D.11) is shorthand for \(\Sigma (x) + |(u,h)|_{\tilde{\mathfrak {G}}^{0,\varrho }}\).
Given \(\psi \in \mathcal{C}^{\infty}(\mathbf{T}^{3},E)\) and \(Z \in (\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{sol}}}}\), we define
where we choose some \(\tilde{\psi}_{n} \in \mathcal{C}^{\infty}\big((1/n,2/n),{\mathbf {R}}\big)\) integrating to 1.
The desired result then follows by using that \(\eta ^{\tilde{\tau}}(\psi \tilde{\psi}_{n})\) has expectation 0 and that the \(\mathring{C}_{\mathfrak {z}} X + \mathring{C}_{\mathfrak {h}} h\) appearing on the right-hand side of (D.6) are actually functions of time with values in \(\mathcal{C}^{\eta}(\mathbf{T}^{3},E)\), are uniformly bounded over time and \({\Omega}^{\mathrm {noise}}\) by the definition of \(\tilde{\tau}\), and converge almost surely to the desired deterministic values as one takes \(t \downarrow 0\). □
Remark D.7
For fixed \((\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}}) \in L(\mathfrak {g},\mathfrak {g})^{2}\) and \((X_{0},g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\), Lemma D.6 allows us to recover \(\eta ^{\tilde{\tau}}\) directly from  . In particular,
. In particular,  , restricted to the \(X\) component, is a local solution map to (1.14) (where \(\mathring{C}_{\mbox{h}}\) plays no role). By applying Lemma D.6 with \(\tilde{\tau} = \tau ^{\ast}\), we have \(\tilde{\eta}^{\tilde{\tau}} = \xi \mathbin{\upharpoonright}_{(0, \tau ^{\star})}\) –this means that we can recover the noise \(\xi \) directly from the solution of (1.14) from positive times up to the blow-up time of \(X\).
, restricted to the \(X\) component, is a local solution map to (1.14) (where \(\mathring{C}_{\mbox{h}}\) plays no role). By applying Lemma D.6 with \(\tilde{\tau} = \tau ^{\ast}\), we have \(\tilde{\eta}^{\tilde{\tau}} = \xi \mathbin{\upharpoonright}_{(0, \tau ^{\star})}\) –this means that we can recover the noise \(\xi \) directly from the solution of (1.14) from positive times up to the blow-up time of \(X\).
Remark D.8
Our proof of Lemma D.6 can also be carried out for local solutions to (6.92) and (6.93). Indeed, one can define a space of stopped local solutions
Then Propositions 6.34+6.38 give us, for each fixed \(\boldsymbol{\sigma}\in {\mathbf {R}}\), a mapping

Here \(L^{0}_{{\mathop{\mathrm{lsol}}}}\) is the space of equivalence classes (modulo null sets) of measurable maps from \({\Omega}^{\mathrm {noise}}\) to \((\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{lsol}}}}\). Furthermore, writing  , we can enforce that \(\tau \) is an \(\mathbf {F}\)-stopping time.
, we can enforce that \(\tau \) is an \(\mathbf {F}\)-stopping time.
One can then replace the role of \(\tilde{\tau}\) with \(\tau \) coming from \((\tau ,Z) \in (\mathcal{S}\times \tilde{\mathfrak {G}}^{0,\varrho })^{{\mathop{\mathrm{lsol}}}}\) in the argument of Lemma D.6. This gives a measurable map  such that, for any \((\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}}) \in L(\mathfrak {g},\mathfrak {g})^{2}\) and \((\bar{x},g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\), if we write
such that, for any \((\mathring{C}_{\mbox{A}},\mathring{C}_{\mbox{h}}) \in L(\mathfrak {g},\mathfrak {g})^{2}\) and \((\bar{x},g_{0}) \in \mathcal{S}\times \mathfrak {G}^{0,\varrho }\), if we write  , then
, then

where \(W\) is the \(E\)-valued Wiener process associated to \(\xi \).
Appendix E: Symbolic index
We collect in this appendix commonly used symbols of the article.
Symbol | Meaning |
|---|---|
\({|\!|\!| |\!|\!|}_{\alpha ,\theta}\) | Extended norm on \(\Omega \mathcal{D}'\) |
\(|\!|\!||\!|\!|_{\varepsilon }\) | ε-dependent seminorm on models |
| BPHZ maximal solution map to SYM equation |
| BPHZ local solution map to gauge transformed system |
| Target space of jets of noise and solution |
\(\mathcal{B}^{\beta ,\delta}\) | Banach space for the lifted quadratic objects |
\(\mathring{C}_{\mbox{A}}\), \(m^{2}\), \(\mathring{C}_{\mbox{h}}\) | Parameters in unrenormalised equations |
| BPHZ mass renormalisation maps for (A,Φ) |
\(C_{\mbox{A}}^{\varepsilon }\), \(C_{\Phi}^{\varepsilon }\) | Masses in BPHZ renormalised equations for (A,Φ) |
| BPHZ mass renormalisation maps for (Ā,Φ̄) |
| BPHZ “h-renormalisation” in B or Ā equation |
Č | The crucial map for obtaining gauge covariance |
\(\hat{\mathscr{D}}^{\gamma ,\eta}\) | A subspace of \(\mathscr{D}^{\gamma ,\eta}\) |
\(d_{\varepsilon }(,)\) | ε-dependent metric on models (\(d_{1}\) is \(d_{\varepsilon }\) with ε = 1) |
E | Shorthand for \(E=\mathfrak {g}^{3}\oplus \mathbf{V}\) |
ℰ | The set of edge types \(\mathcal{E}= \mathfrak{L}\times {\mathbf {N}}^{d+1}\) |
\(\mathcal{E}_{t}(X)\) | Deterministic YMH flow without DeTurck term |
\(\mathcal{F}_{t}(X)\) | Deterministic YMH flow with DeTurck term |
F | Filtration \(\mathbf {F}=(\mathcal {F}_{t})_{t\geq 0}\) generated by the noise |
\(F^{{\mathop{\mathrm{sol}}}}\) | Functions into |
\(\mathfrak {G}^{\varrho }\) | The gauge group \(\mathcal{C}^{\varrho }(\mathbf{T}^{3},G)\) |
\(\mathfrak {G}^{0,\varrho }\) | Closure of smooth functions in \(\mathfrak {G}^{\varrho }\) |
\(\tilde{\mathfrak {G}}^{\varrho }\) | Space \(\mathcal{C}^{\varrho }\times \mathcal{C}^{\varrho - 1}\) “of (U,h)’s” |
\(\tilde{\mathfrak {G}}^{0,\varrho }\) | Closure of smooth functions in \(\tilde{\mathfrak {G}}^{\varrho }\) |




 ,
, 
 ,
, 
 ,
, 
 with finite-time blow up
with finite-time blow upRights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chandra, A., Chevyrev, I., Hairer, M. et al. Stochastic quantisation of Yang–Mills–Higgs in 3D. Invent. math. 237, 541–696 (2024). https://doi.org/10.1007/s00222-024-01264-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00222-024-01264-2