
Abstract
Following the theoretical notion that tools often extend one’s body, in the present study, we investigated whether imitation of hand or tool actions is modulated by effector-specific information. Subjects performed grasping actions toward an object with either a handheld tool or their right hand. Actions were initiated in response to pictures representing a grip at an object that could be congruent or incongruent with the required action (grip-type congruency). Importantly, actions could be cued by means of a tool cue, a hand cue, and a symbolic cue (effector-type congruency). For both hand and tool actions, an action congruency effect was observed, reflected in faster reaction times if the observed grip type was congruent with the required movement. However, neither hand actions nor tool actions were differentially affected by the effector represented in the picture (i.e., when performing a tool action, the action congruency effect was similar for tool cues and hand cues). This finding suggests that imitation of hand and tool actions is effector-independent and thereby supports generalist rather than specialist theories of imitation.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
In our daily lives, we often use objects that greatly extend our bodily action capabilities, such as writing with a pen, using a hammer, or driving a car. According to an extended view of cognition, such objects can be considered as an extension of the human body (Clark 2004). This notion is exemplified by upper limb amputees who can attain an amazing degree of control over neural prostheses and who often consider the prosthesis as a part of their own body (Schultz and Kuiken 2011).
In addition to these clinical achievements, a growing number of studies have provided insight into the functional and neural mechanisms underlying the extension of one’s body schema to include tools and external objects (for review, see: Arbib et al. 2009). For instance, in a monkey study, it was found that the response properties of visuotactile neurons in the anterior intraparietal sulcus (IPS) changed after the monkey acquired the skill to use a tool as a rake (Iriki et al. 1996). More specifically, whereas the initial receptive field of these neurons responded to stimuli near the hand, after training with the tool, the receptive field was found extended into more distant space surrounding the end of the tool. The authors suggested that the use of the tool extended the representation of the body, by including the area that could only be reached with the rake. In humans, comparable effects of tool use have been established as well by investigating cross-modal congruency effects for stimuli presented at the end of a tool (Maravita et al. 2002; Holmes et al. 2004, 2007). Together these studies suggest that tool use changes one’s peripersonal space—i.e., the space directly surrounding one’s body—via a process of multisensory integration of information related to the tool.
Whereas the relation between tool use and changes in the body schema has been an intensive topic of investigation, less is known about the mechanisms whereby we learn to use novel tools. Observational learning and imitation likely provide important mechanisms to learn novel tool use that would otherwise take a lot of time and effort (Massen and Prinz 2009). For instance, as children we learn how to eat with a knife and a fork by observing our parents or peers, and as adults we may learn how to operate the new espresso machine by carefully observing the actions of our colleagues. The ability to learn by observation and imitation has received much attention in recent years (Byrne and Russon 1998; Rizzolatti et al. 2001; Brass and Heyes 2005; van der Helden et al. 2010). A classical finding is that participants are faster to execute a movement after having observed an actor performing the same movement, even in cases where the observed movement is irrelevant to the subject’s task (Brass et al. 2000, 2001; Press et al. 2005; Jonas et al. 2007a). Several studies have suggested that an important network underlying imitation and observational learning is formed by the putative mirror neuron system and more specifically by the inferior frontal gyrus (IFG; Iacoboni et al. 1999; Kilner et al. 2003; Koski et al. 2003; Buccino et al. 2004; van der Helden et al. 2010). In contrast, other studies have argued for a more general involvement of the IFG in perception–action coupling—beyond imitation—(Dassonville et al. 2001; Newman-Norlund et al. 2007b, 2010). As a consequence, the precise functional significance of the neural mechanisms involved in imitation remains a matter of ongoing debate.
Different explanations have been suggested for these apparently contradictory findings. On the one hand, specialist theories of imitation suggest that imitation is subserved by a special purpose imitation system that evolved in order to relate observed biological movement to one’s own motor repertoire (Meltzoff and Moore 1989; Anisfeld 1991; Jones 2009). According to this theory, an important mechanism underlying imitation is the direct matching of observed movements unto one’s own motor repertoire. In other words, based on learned action-effect associations (i.e., the movement of our own hand results in a perceptual change in our visual field), the observation of the perceptual consequences of an action elicits to some extent the same motor program as used for bringing about the effect. Because the kinematics for bringing about a tool action are quite different from the kinematics of a manual action, observation of tool and hand actions should activate different motor programs. As a consequence, according to the specialist view of imitation, tool use imitation should be different from the imitation of biological actions, as both rely on different specialized neural systems and involve different action representations. On the other hand, generalist theories of imitation suppose that imitation is based on general cognitive mechanisms of associative learning and action control that are involved in other tasks as well (Anisfeld 1991; Brass and Heyes 2005). According to the generalist view, tool use imitation and biological imitation should be similar, as both rely on a common neural network involved in perception–action coupling.
The aims of this study were to distinguish between these two hypotheses and to extend our knowledge about the relation between tool use and imitation more generally. Therefore, subjects performed actions either with their hand or with a handheld tool in separate blocks. We manipulated the congruency of the grip type observed in the picture (grip congruency). Importantly, actions could be performed in response to a tool cue, a hand cue, or a symbolic cue (effector congruency). In this way, we were able to measure whether imitation of tool or hand actions is modulated by effector-specific information.
We used an experimental setup in which the subject was seated behind a table on which a graspable object was placed that could be grasped with a full grip or a precision grip at respectively the lower side or the upper side of the object. Subjects were instructed to always make a full grip or a precision grip in response to a color cue represented on a screen (e.g., green = grasp object at lower side with a full grip, red = grasp object at upper side with a precision grip). The color cue was superimposed on different effectors in the picture (i.e., a hand or a tool) that could be in a spatial position that was congruent or incongruent with respect to the required action. For instance, in congruent trials, the color cue was presented at the lower side of the object that could be grasped with a full grip and the color instructed the subject to actually grasp the lower side with a full grip. In incongruent trials, the color cue could for instance be presented at the upper side of the object that could be grasped with a precision grip, while the color instructed the subject to actually grasp the lower side with a full grip. In this way, we were able to measure the automatic interference effect of observing actions that could be congruent or incongruent with respect to the planned grip type and the effector displayed.
Methods
Participants
Twenty-four right-handed healthy adults participated in the experiment (7 men, mean age = 24.0 years) with normal or corrected-to-normal vision. Data from 3 participants were discarded from analysis, as the experiment could not be completed. In addition, data from 1 subject were excluded because of grasping the incorrect object part in more than 25% of all trials, leaving 19 participants for the final analysis.
Experimental setup and procedure
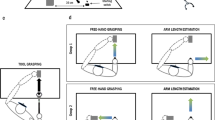
Participants were seated in front of a table facing a computer screen at a distance of approximately 100 cm. A centrally located response box was placed on the participant’s lap and served as a starting position for the grasping actions. A custom-made touch-sensitive manipulandum was attached to the table, consisting of a small cylinder (r = .08 cm, height = 1.80 cm) on top of a larger cylindrical base (r = 3.00 cm, height = 8.00 cm) that could be grasped with respectively a precision (upper part of object) and a power grip (lower part of object; see Fig. 1a).

a Experimental setup. Participants were seated behind a table on which the manipulandum and a screen were placed. Actions were performed with either the right hand (left picture) or with a handheld tool (right picture). Stimuli were presented on a screen directly in front of the participant. b Starting picture representing the manipulandum with the actor’s hands out of view (left side) and example stimuli (right side) used in the tool cue, the hand cue, and the symbolic cue conditions. Participants were instructed to grasp the manipulandum with either a precision or a power grip depending on the color of the stimuli
In half of all experimental blocks, subjects grasped the manipulandum by using a handheld mechanical tool (tool blocks); in the other half of all blocks, subjects grasped the manipulandum by using their right hand (hand blocks). The mechanical tool consisted of a handheld tool that could be held with a power grip (see Fig. 1 A; tool length = 78 cm; maximum distance between opened jaws = 8.5 cm). When using the tool to grasp the manipulandum, the movements of the hands differed from manual grasping in two ways: (1) The tool was always held with a full grip, and when closing the hand (i.e., making a full hand pincer grip), a handle was pulled resulting in the closing of the jaws. With hand extension, the handle was released, resulting in the opening of the jaws of the tool; and (2) The jaws of the tool were placed in 90° opposition relative to the position of the hand. During tool blocks, the chair on which the participant was seated had to be moved backwards, such that the jaws of the tool ended up in the same position as the initial position of the subjects’ hands during hand blocks (see Fig. 1a).
Each trial started with the participant holding the starting button of the response box, either by means of their index finger (hand blocks) or by means of the base of the tool (tool blocks). A starting picture appeared for 1,000–1,500 ms, representing the manipulandum and the actor with both hands out of view (see Fig. 1b). Then the target stimulus appeared which remained on the screen until the computer detected a grasping response or a return to the starting button.
Target stimuli consisted of static pictures representing a hand cue (hand grasping the manipulandum), a tool cue (tool grasping the manipulandum), or a symbolic cue (dots presented near the manipulandum; see Fig. 1b). For hand cues and tool cues, the effector (the hand or the jaws of the tool) was colored red or green, by adjusting the color balance using Photoshop CS5 (Adobe Systems, Inc, CA). Symbolic cues consisted of red or green dots near the manipulandum and were included as a control condition to establish a baseline measure of performing hand and tool actions in response to unambiguous visual cues. Thus, in the case of symbolic cues, no effector was represented in the picture: only the colored dots were visible. Hand cues, tool cues, and symbolic cues were randomly presented. Pictures were presented at a size of 1,280 × 1,024 pixels, resulting in a stimulus size on the screen that matched the experimental setup in size (i.e., the object, hand, and tool represented in the picture had a size comparable to their real counterparts).
The participants were instructed to perform either a precision or a power grip, based on the color of the cue. Half of all participants were required to perform a power grip in response to the color green and a precision grip in response to the color red. The other half of all participants received opposite instructions. In this way, participants were instructed to perform actions that were either congruent or incongruent with respect to the end location and grip type represented in the picture (e.g., grasping the upper part of the manipulandum, while observing a cue at the lower part of the manipulandum). Importantly, the manipulation to instruct actions based on color cues ensured that participants were attending both the grip type and the effector displayed in the picture, even though this information was task-irrelevant (i.e., the grip type displayed was not relevant to the action that the subject was required to perform). Participants were instructed only to initiate their movement when they were certain which part of the object they planned to grasp. All movements were made with the right hand, and following movement execution, participants were instructed to hold the object for about 1 s, without lifting or moving it, after which they returned to the starting position to initiate the next trial. No explicit instructions were given with respect to the fixation while performing the movement, but as it is generally known that the eyes are often ahead of the hand (Neggers and Bekkering 2000), subjects most likely fixated on the target object that they had to grasp. Participants performed 4 blocks of 120 trials each. These blocks consisted of a 2 (action: tool and hand) × 3 (stimulus: hand cue, tool cue, or symbolic cue) × 2 (movement: congruent and incongruent) design, and block order (i.e., tool or hand) was counterbalanced between participants. In total, the experiment took about 1 h.
The experiment was controlled using Presentation software version 12.2 (Neurobehavioral Systems, Davis, CA). The response box and the manipulandum were connected to a computer to detect (1) reaction times (time between target onset and release of the starting position), (2) movement times (time between release of the starting position and grasping the manipulandum), and (3) end position (power or precision grip).
Results
Trials with incorrect responses (i.e., grasping the incorrect part of the object; 3.4% of all trials), trials in which the subject did not hold the button at the onset of the picture (reaction times less than 100 ms; 1.1% of all trials), and trials exceeding a 2 SD cutoff for each subject’s mean RT (3.3% of all trials) were excluded from reaction time analysis. The averaged reaction times, movement times, and error rates were analyzed using a 2 × 3 × 2 repeated measures ANOVA with Action (tool and hand), Cue type (tool, hand, and symbolic) and Congruency (congruent and incongruent movements) as within-subjects factors. Reaction and movement times are represented in Fig. 2.

Reaction and movement times. Graphs at the left represent RTs and MTs to actions performed with the tool, and graphs at the right represent RTs and MTs to actions performed with the hand. Bars on the left represent actions in response to tool cues, bars in the middle represent actions in response to hand cues, and bars on the right represent actions in response to symbolic cues. Light bars represent congruent movements and dark bars incongruent movements. Error bars represent standard errors
For reaction times, a main effect of Congruency, F(1, 18) = 41.9, P < .001, η2 = .70, reflected slower reaction times for incongruent (457 ms, SE = 20) compared to congruent movement cues (441 ms, SE = 18). A main effect of Cue type, F(2,36) = 28.3, P < .001, η2 = .61, reflected faster reaction times to symbolic cues (433 ms, SE = 17) compared to hand cues (462 ms, SE = 20) and tool cues (452 ms, SE = 19). The main effect of Action was not significant (P = .25). No significant interactions were observed.
For movement times, a significant main effect of Action, F(1, 18) = 45.7, P < .001, η2 = .72, reflected that movement times were faster when the actions were performed with the hand (530 ms, SE = 18) than with the tool (789 ms, SE = 41). No other main effects or interactions were found significant for the analysis of movement times.
For the analysis of the error rates (i.e., grasping the manipulandum at the incorrect part), a significant main effect of Action, F(1, 18) = 9.0, P < .01, η2 = .72, reflected that subjects made slightly more errors (i.e., grasping the incorrect part of the object) when using the tool (4.9%) than when grasping with the hand (1.9%). No other effects were found significant for the analysis of error rates.
Discussion
The present study established a classical action congruency effect for hand actions and tool actions, reflected in faster responses if the observed movement was the same as the instructed movement, even though the observed movement was irrelevant to the subject’s task. Thereby this study extends previous findings that were based on finger lifting movements (Brass et al. 2000, 2001) and transitive hand movements (Newman-Norlund et al. 2007a, 2010; van Schie et al. 2008) to the domain of tool use.
Importantly, neither hand actions nor tool actions were differentially affected by the effector represented in the picture. Thus, when performing a tool action, the action congruency effect was comparable for cues representing a tool and a hand. Similarly, when performing a hand action, no difference was found in the action congruency effect between cues representing a hand or a tool. These findings are in line with previous studies that have reported comparable effects of biological and non-biological stimuli on action imitation (Press et al. 2005; Jansson et al. 2007; Newman-Norlund et al. 2010). Thereby these findings support generalist theories of imitation, according to which imitation is subserved by general cognitive mechanisms of associative learning and action control (Brass and Heyes 2005; Heyes 2011).
In addition, the finding that tool imitation is not modulated by effector-specific information is in line with several studies, suggesting that tool use training results in the acquisition of effector-independent action representations. For instance, grasping kinematics are often highly comparable between actions performed with the hand or with a tool (Gentilucci et al. 2004), and in a recent study, it was found that observational priming of an action with a physical device was not influenced by whether the action was performed with the left or the right arm (Massen 2009). In a recent fMRI study, a comparable activation was found in the brain’s parieto-frontal grasping network when subjects planned a hand grasping action or a grasping action with a handheld tool (Jacobs et al. 2010). In addition, in monkeys, it was found that grasping neurons in the ventral premotor cortex represented the outcome of a tool action rather than the precise kinematics by which the action was performed (Umilta et al. 2008).
Interestingly, some studies have shown tool-specific responses in the mirror neuron system (e.g., neurons are active both when viewing a tool action and executing a hand action; Ferrari et al. 2005) and during action observation in humans (Massen and Prinz 2009). One possibility is that representing tool actions in terms of the outcome requires a substantial amount of training with the tool—either by observation or by doing. In this context, it should be noted that most tool-responsive mirror neurons were observed in the later phases of the experiment, after which the monkey had already some experience with tool observation (Ferrari et al. 2005). Furthermore, grasping neurons were found similar responsive to the observation of a hand closure using a pair of normal pliers and a hand opening using a pair of “inverse pliers” (Umilta et al. 2008). Using a similar paradigm in humans, it was found that TMS-evoked motor potentials reflected the outcome of the action (e.g., the pliers opening or closing) rather than the actual hand kinematics involved (Cattaneo et al. 2009). Together these studies support the idea that tool actions are represented in an effector-independent fashion.
In the present experiment, the effector used for grasping was varied between blocks, whereas the grip type to be executed varied within blocks. This design was a logical consequence of the fact that it is difficult to vary the effector within blocks (i.e., subject alternating between hand and tool actions from trial to trial). One possible confound of this design could be that information about the grip type was more task-relevant as it varied from trial to trial, whereas the effector used for grasping remained the same. In other words, the finding that imitation of hand and tool actions is effector-independent could be a consequence of subjects paying more attention to the grip type than to the effector represented in the picture. Indeed, previous studies have shown that the saliency of the action feature observed plays an important role in facilitating imitation (Bird et al. 2007; Franz et al. 2007). However, in contrast to many previous imitation studies, it should be noted that in the present study, only the color of the action cue determined what action subjects were required to perform, whereas both the grip type and the effector represented in the picture were irrelevant to the subject’s task. In fact, the color cue was always superimposed on the effector, thereby ensuring that subjects implicitly attended to both the grip type and the effector. The finding that only information about the grip type interfered with action imitation, suggests that only task-irrelevant information about the grip but not about the effector can facilitate or inhibit imitation. In addition, it should be noted that several studies have shown that even when both the effector and the end location vary within blocks, imitation is mainly modulated by the end location of the observed action (Bekkering et al. 2000; Wohlschlager et al. 2003; Franz et al. 2007), thereby providing further support for the notion that the findings observed in the present study are not an artifact of the experiment setup.
In the present study, the end location of the action (up or down) was always concordant with a specific grip type (precision or full grip). Thus, based on the present study, it is difficult to determine whether the action congruency effect was driven mainly by the spatial location (up or down) or by the grip type (precision or full grip) of the observed effector. However, in a recent study using a similar setup (van Schie et al., in prep.), we showed that the planning of manual grasping actions was more efficient in response to cues representing information about the end location than in response to cues representing the grip type to be performed. In addition, several studies on action observation have shown that it is easier to attend to goal-related aspects (i.e., what is the end location of the action?) than to grip-related aspects of an observed action (i.e., which grip is used for grasping the object? Bach et al. 2005; van Elk et al. 2008). Similarly, in the present study, it is likely that the action congruency effect reflects the congruence between the observed end location and the planned end location of the action.
The present study shows that the imitation of tool actions is effector-independent, as measured with reaction times. In addition to reaction times, kinematic and/or EMG measures often provide valuable insight into the precise dynamics underlying action execution. For instance, with respect to tool use it has been shown that grasping kinematics are often highly comparable between actions performed with the hand or with a tool (Gentilucci et al. 2004). Although in the present study we did not measure kinematics, the finding of an action congruency effect in the reaction times but not in the movement times suggests that action congruency mainly affected the planning phase and not the execution phase of the action (see also: Chong et al. 2009). Typically, reaction times are considered a reliable measure of how plans for movement sequences are mentally represented (Rosenbaum et al. 1984), and faster reaction times often reflect a more efficient planning process. Thus, the finding that especially the reaction times were affected by the congruency of the observed action is in line with the action planning-control framework, according to which the planning phase of an action—which involves the incorporation of visual and cognitive information—occurs within the first few hundred milliseconds (Glover 2004).
Interestingly, both tool and hand actions were performed faster in response to symbolic cues compared to hand and tool cues. Although some previous studies have reported faster responses to biological compared to non-biological cues (Brass et al. 2000; Jonas et al. 2007a), in another imitation study, a comparable advantage of symbolic over biological cues was observed (Newman-Norlund et al. 2010). At a neural level, although some studies have suggested that motor-related areas respond preferentially to the observation of biological movements (Iacoboni et al. 1999; Perani et al. 2001; Heiser et al. 2003; Kilner et al. 2003; Tai et al. 2004), other studies have shown that biological and non-biological movements result in activation in overlapping brain areas (Gazzola et al. 2007; Jonas et al. 2007b). The apparent inconsistency between these studies may be related to the stimuli used. In the present experiment, the symbolic stimuli used were probably more salient than both the tool stimuli and the hand stimuli, thereby resulting in faster reaction times.
Previous studies have suggested that an important mechanism underlying imitation is spatial compatibility, i.e., the spatial congruence between a stimulus and a response results in faster reaction times (Aicken et al. 2007; Jansson et al. 2007; van Schie et al. 2008; Catmur and Heyes 2010). The present study is in line with this account, as the driving factor underlying the imitation of both hand and tool actions appears to be the spatial compatibility of the action cue with the prepared action, rather than the effector-specific information represented by the cue. The finding that both hand and tool actions showed comparable reaction time effects furthermore supports the idea that actions are planned primarily in terms of the end location (i.e., grasping the upper or lower part of the object) rather than the effector by which the action is performed. This interpretation is in accordance with the ideomotor principle according to which actions are represented primarily in terms of the effects they produce (Prinz 1997; Hommel et al. 2001; Massen and Prinz 2009; Shin et al. 2010) and fits will with the hierarchical view of the motor system according to which end locations are an organizing feature of action planning (Grafton and Hamilton 2007; Rosenbaum et al. 2007). The present study extends this view to tool actions as well, in line with the notion that tools often can be considered a natural extension of the human body (Arbib et al. 2009).
Conclusions
The main finding of the present study is that the imitation of hand and tool actions is not affected by effector-specific information. Thereby this study supports generalist rather than specialist theories of imitation and suggests that imitation is subserved by general cognitive mechanisms, such as spatial compatibility.
References
Aicken MD, Wilson AD, Williams JH, Mon-Williams M (2007) Methodological issues in measures of imitative reaction times. Brain Cogn 63:304–308. doi:10.1016/j.bandc.2006.09.005
Anisfeld M (1991) Neonatal imitation. Dev Rev 11:60–97. doi:10.1016/0273-2297(91)90003-7
Arbib MA, Bonaiuto JB, Jacobs S, Frey SH (2009) Tool use and the distalization of the end-effector. Psychol Res 73:441–462. doi:10.1007/s00426-009-0242-2
Bach P, Knoblich G, Gunter TC, Friederici AD, Prinz W (2005) Action comprehension: deriving spatial and functional relations. J Exp Psychol Hum Percept Perform 31:465–479. doi:10.1037/0096-1523.31.3.465
Bekkering H, Wohlschlager A, Gattis M (2000) Imitation of gestures in children is goal-directed. Q J Exp Psychol A 53:153–164
Bird G, Brindley R, Leighton J, Heyes C (2007) General processes, rather than “goals,” explain imitation errors. J Exp Psychol Hum Percept Perform 33:1158–1169. doi:10.1037/0096-1523.33.5.1158
Brass M, Heyes C (2005) Imitation: is cognitive neuroscience solving the correspondence problem? Trends Cogn Sci 9:489–495. doi:10.1016/j.tics.2005.08.007
Brass M, Bekkering H, Wohlschlager A, Prinz W (2000) Compatibility between observed and executed finger movements: comparing symbolic, spatial, and imitative cues. Brain Cogn 44:124–143. doi:10.1006/brcg.2000.1225
Brass M, Bekkering H, Prinz W (2001) Movement observation affects movement execution in a simple response task. Acta Psychol (Amst) 106:3–22. doi:10.1016/S0001-6918(00)00024-X
Buccino G, Vogt S, Ritzl A, Fink GR, Zilles K, Freund HJ, Rizzolatti G (2004) Neural circuits underlying imitation learning of hand actions: an event-related fMRI study. Neuron 42:323–334. doi:10.1016/S0896-6273(04)00181-3
Byrne RW, Russon AE (1998) Learning by imitation: a hierarchical approach. Behav Brain Sci 21:667–684; discussion 684–721
Catmur C, Heyes C (2010) Time course analyses confirm independence of imitative and spatial compatibility. J Exp Psychol Hum Percept Perform. doi:10.1037/a0019325
Cattaneo L, Caruana F, Jezzini A, Rizzolatti G (2009) Representation of goal and movements without overt motor behavior in the human motor cortex: a transcranial magnetic stimulation study. J Neurosci 29:11134–11138. doi:10.1523/JNEUROSCI.2605-09.2009
Chong TT, Cunnington R, Williams MA, Mattingley JB (2009) The role of selective attention in matching observed and executed actions. Neuropsychologia 47:786–795. doi:10.1016/j.neuropsychologia.2008.12.008
Clark A (2004) Natural-born cyborgs: minds, technologies and the future of human intelligence. Oxford University Press, Oxford
Dassonville P, Lewis SM, Zhu XH, Ugurbil K, Kim SG, Ashe J (2001) The effect of stimulus-response compatibility on cortical motor activation. Neuroimage 13:1–14. doi:10.1006/nimg.2000.0671
Ferrari PF, Rozzi S, Fogassi L (2005) Mirror neurons responding to observation of actions made with tools in monkey ventral premotor cortex. J Cogn Neurosci 17:212–226. doi:10.1162/0898929053124910
Franz EA, Ford S, Werner S (2007) Brain and cognitive processes of imitation in bimanual situations: Making inferences about mirror neuron systems. Brain Res 1145:138–149. doi:10.1016/j.brainres.2007.01.136
Gazzola V, van der Worp H, Mulder T, Wicker B, Rizzolatti G, Keysers C (2007) Aplasics born without hands mirror the goal of hand actions with their feet. Curr Biol 17:1235–1240. doi:10.1016/j.cub.2007.06.045
Gentilucci M, Roy AC, Stefanini S (2004) Grasping an object naturally or with a tool: are these tasks guided by a common motor representation? Exp Brain Res 157:496–506. doi:10.1007/s00221-004-1863-8
Glover S (2004) Separate visual representations in the planning and control of action. Behav Brain Sci 27:3–24; discussion 24–78
Grafton ST, Hamilton AF (2007) Evidence for a distributed hierarchy of action representation in the brain. Hum Mov Sci 26:590–616. doi:10.1016/j.humov.2007.05.009
Heiser M, Iacoboni M, Maeda F, Marcus J, Mazziotta JC (2003) The essential role of Broca’s area in imitation. Eur J Neurosci 17:1123–1128. doi:10.1046/j.1460-9568.2003.02530.x
Heyes C (2011) Automatic imitation. Psychol Bull 137:463–483. doi:10.1037/a0022288
Holmes NP, Calvert GA, Spence C (2004) Extending or projecting peripersonal space with tools? Multisensory interactions highlight only the distal and proximal ends of tools. Neurosci Lett 372:62–67. doi:10.1016/j.neulet.2004.09.024
Holmes NP, Sanabria D, Calvert GA, Spence C (2007) Tool-use: capturing multisensory spatial attention or extending multisensory peripersonal space? Cortex 43:469–489. doi:10.1016/S0010-9452(08)70471-4
Hommel B, Musseler J, Aschersleben G, Prinz W (2001) The Theory of Event Coding (TEC): a framework for perception and action planning. Behav Brain Sci 24:849–878; discussion 878–937
Iacoboni M, Woods RP, Brass M, Bekkering H, Mazziotta JC, Rizzolatti G (1999) Cortical mechanisms of human imitation. Science 286:2526–2528. doi:10.1126/science.286.5449.2526
Iriki A, Tanaka M, Iwamura Y (1996) Coding of modified body schema during tool use by macaque postcentral neurones. Neuroreport 7:2325–2330
Jacobs S, Danielmeier C, Frey SH (2010) Human anterior intraparietal and ventral premotor cortices support representations of grasping with the hand or a novel tool. J Cogn Neurosci 22:2594–2608. doi:10.1162/jocn.2009.21372
Jansson E, Wilson AD, Williams JH, Mon-Williams M (2007) Methodological problems undermine tests of the ideo-motor conjecture. Exp Brain Res 182:549–558. doi:10.1007/s00221-007-1013-1
Jonas M, Biermann-Ruben K, Kessler K et al (2007a) Observation of a finger or an object movement primes imitative responses differentially. Exp Brain Res 177:255–265. doi:10.1007/s00221-006-0660-y
Jonas M, Siebner HR, Biermann-Ruben K et al (2007b) Do simple intransitive finger movements consistently activate frontoparietal mirror neuron areas in humans? Neuroimage 36(Suppl 2):T44–T53. doi:10.1016/j.neuroimage.2007.03.028
Jones SS (2009) The development of imitation in infancy. Phil Trans R Soc Lond B Biol Sci 364:2325–2335. doi:10.1098/rstb.2009.0045
Kilner JM, Paulignan Y, Blakemore SJ (2003) An interference effect of observed biological movement on action. Curr Biol 13:522–525. doi:10.1016/S0960-9822(03)00165-9
Koski L, Iacoboni M, Dubeau MC, Woods RP, Mazziotta JC (2003) Modulation of cortical activity during different imitative behaviors. J Neurophysiol 89:460–471. doi:10.1152/jn.00248.2002
Maravita A, Spence C, Kennett S, Driver J (2002) Tool-use changes multimodal spatial interactions between vision and touch in normal humans. Cognition 83:B25–B34. doi:10.1016/S0010-0277(02)00003-3
Massen C (2009) Observing human interaction with physical devices. Exp Brain Res 199:49–58. doi:10.1007/s00221-009-1971-6
Massen C, Prinz W (2009) Movements, actions and tool-use actions: an ideomotor approach to imitation. Phil Trans R Soc Lond B Biol Sci 364:2349–2358. doi:10.1098/rstb.2009.0059
Meltzoff AN, Moore MK (1989) Imitation in newborn infants: exploring the range of gestures imitated and the underlying mechanisms. Dev Psychol 25:954–962. doi: 10.1037/0012-1649.25.6.954
Neggers SF, Bekkering H (2000) Ocular gaze is anchored to the target of an ongoing pointing movement. J Neurophysiol 83:639–651
Newman-Norlund RD, Noordzij ML, Meulenbroek RG, Bekkering H (2007a) Exploring the brain basis of joint action: co-ordination of actions, goals and intentions. Soc Neurosci 2:48–65. doi:10.1080/17470910701224623
Newman-Norlund RD, van Schie HT, van Zuijlen AM, Bekkering H (2007b) The mirror neuron system is more active during complementary compared with imitative action. Nat Neurosci 10:817–818. doi:10.1038/nn1911
Newman-Norlund RD, Ondobaka S, van Schie HT, van Elswijk G, Bekkering H (2010) Virtual lesions of the IFG abolish response facilitation for biological and non-biological cues. Front Behav Neurosci 4:5. doi:10.3389/neuro.08.005.2010
Perani D, Fazio F, Borghese NA, Tettamanti M, Ferrari S, Decety J, Gilardi MC (2001) Different brain correlates for watching real and virtual hand actions. Neuroimage 14:749–758. doi:10.1006/nimg.2001.0872
Press C, Bird G, Flach R, Heyes C (2005) Robotic movement elicits automatic imitation. Brain Res Cogn Brain Res 25:632–640. doi:10.1016/j.cogbrainres.2005.08.020
Prinz W (1997) Perception and action planning. J Cogn Psychol 9:129–154. doi:10.1080/713752551
Rizzolatti G, Fogassi L, Gallese V (2001) Neurophysiological mechanisms underlying the understanding and imitation of action. Nat Rev Neurosci 2:661–670. doi:10.1038/35090060
Rosenbaum DA, Inhoff AW, Gordon AM (1984) Choosing between movement sequences: A hierarchical editor model. J Exp Psychol Hum Percept Perform 113:372–393. doi:10.1037/0096-3445.113.3.372
Rosenbaum DA, Cohen RG, Jax SA, Weiss DJ, van der Wel R (2007) The problem of serial order in behavior: Lashley’s legacy. Hum Mov Sci 26:525–554. doi:10.1016/j.humov.2007.04.001
Schultz AE, Kuiken TA (2011) Neural interfaces for control of upper limb prostheses: the state of the art and future possibilities. PM R 3:55–67. doi:10.1016/j.pmrj.2010.06.016
Shin YK, Proctor RW, Capaldi EJ (2010) A review of contemporary ideomotor theory. Psychol Bull 136:943–974. doi:10.1037/a0020541
Tai YF, Scherfler C, Brooks DJ, Sawamoto N, Castiello U (2004) The human premotor cortex is ‘mirror’ only for biological actions. Curr Biol 14:117–120. doi:10.1016/j.cub.2004.01.005
Umilta MA, Escola L, Intskirveli I et al (2008) When pliers become fingers in the monkey motor system. Proc Natl Acad Sci USA 105:2209–2213. doi:10.1073/pnas.0705985105
van der Helden J, van Schie HT, Rombouts C (2010) Observational learning of new movement sequences is reflected in fronto-parietal coherence. PLoS One 5:e14482. doi:10.1371/journal.pone.0014482
van Elk M, van Schie HT, Bekkering H (2008) Conceptual knowledge for understanding other’s actions is organized primarily around action goals. Exp Brain Res 189:99–107. doi:10.1007/s00221-008-1408-7
van Schie HT, van Waterschoot BM, Bekkering H (2008) Understanding action beyond imitation: reversed compatibility effects of action observation in imitation and joint action. J Exp Psychol Hum Percept Perform 34:1493–1500. doi:10.1037/a0011750
Wohlschlager A, Gattis M, Bekkering H (2003) Action generation and action perception in imitation: an instance of the ideomotor principle. Phil Trans R Soc Lond B Biol Sci 358:501–515. doi:10.1098/rstb.2002.1257
Acknowledgments
We thank two anonymous reviewers for their helpful comments on a previous version of this manuscript. This work was supported by the Netherlands Organization for Scientific Research (grant 453-05-001 awarded to HB) and by the Marie Curie Intra European Fellowship within the Seventh European Community Framework Program (IEF grant 252713 to MVE).
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
van Elk, M., van Schie, H.T. & Bekkering, H. Imitation of hand and tool actions is effector-independent. Exp Brain Res 214, 539–547 (2011). https://doi.org/10.1007/s00221-011-2852-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-011-2852-3