
Abstract
We study geometric random graphs defined on the points of a Poisson process in d-dimensional space, which additionally carry independent random marks. Edges are established at random using the marks of the endpoints and the distance between points in a flexible way. Our framework includes the soft Boolean model (where marks play the role of radii of balls centered in the vertices), a version of spatial preferential attachment (where marks play the role of birth times), and a whole range of other graph models with scale-free degree distributions and edges spanning large distances. In this versatile framework we give sharp criteria for absence of ultrasmallness of the graphs and in the ultrasmall regime establish a limit theorem for the chemical distance of two points. Other than in the mean-field scale-free network models the boundary of the ultrasmall regime depends not only on the power-law exponent of the degree distribution but also on the spatial embedding of the graph, quantified by the rate of decay of the probability of an edge connecting typical points in terms of their spatial distance.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Background
An important topic in percolation theory and, more generally, the theory of geometrically embedded random graphs, is the comparison of Euclidean distances of two points with their graph distance, often called chemical distance. Starting with the work of Grimmett and Marstrand [20], this problem has been studied for Bernoulli percolation, for example by Antal and Pisztora [1] and Garet and Marchand [15, 16], but also for models with long range interactions, such as random interlacements, see Černý and Popov [8], its vacant set and the Gaussian free field, see Drewitz et al. [14]. In the supercritical phase of these models Euclidean and chemical distance of points on the unbounded connected component are typically of comparable order when the points are distant, see [14] for general conditions for percolation models on \(\mathbb {Z}^d\) to share this behaviour. The introduction of additional long edges can change this behaviour and the graph distance can be a power of the logarithm or even an iterated logarithm of the Euclidean distance. In the latter case the graph is called ultrasmall. The focus of this paper is to characterise ultrasmallness in geometric random graphs and provide a universal limit theorem for typical distances in such graphs.
We briefly review what is known on this problem. A classical scenario is long-range percolation. Here points x, y of a Poisson process in \({\mathbb {R}}^d\) or of the lattice \({\mathbb {Z}}^d\) are connected independently with probability
for some \(\delta >1\). Biskup [4, 5] has shown that if \(1<\delta <2\) then the chemical distance is
with high probability as x, y are fixed points on the infinite component with \(|x-y|\rightarrow \infty \), where \(\Delta =\frac{\log 2}{\log (2/\delta )}\). If \(\delta >2\) it was shown by Berger [3] that the chemical distance is at least linear in the Euclidean distance and for \(\delta =2\) there is recent progress by Ding and Sly [12], but in both cases the precise asymptotics is still an open problem. In general, ultrasmallness cannot occur in long-range percolation models.
Ultrasmallness is however a well established phenomenon in scale-free networks. These networks are typically not modelled as spatial graphs, so to compare the results to our scenario we restrict the graph to the vertices inside a ball of radius R, which now contains N lattice or Poisson points, with N of order \(R^d\). The mean-field nature of these models is reflected in the fact that connection probabilities do not depend on the spatial position of these points. Instead, points carry independent uniform marks and connections between points are established independently given the marks, with a probability \(1 \wedge \frac{1}{N} g(s,t)\) depending on the marks s, t of the vertices at the ends of a potential edge. Dependencies of interest are, for example,
-
(i)
\(g(s,t)=s^{-\gamma }t^{-\gamma },\)
-
(ii)
\(g(s,t)=(s\vee t)^{-\gamma }(s \wedge t)^{\gamma -1},\)
-
(iii)
\(g(s,t)= (s^{-\gamma /d}+ t^{-\gamma /d})^{d}.\)
For all these examples, the graphs have scale-free degree distributions with power-law exponent \(\tau =1+\frac{1}{\gamma }\). When \(\gamma <\frac{1}{2}\) (or, equivalently, \(\tau >3\)) the chemical distance of two randomly chosen points x, y in the largest component is of order \(\log N\) or, equivalently, \(\log |x-y|\), see Bollobas et al. [6]. If however \(\gamma >\frac{1}{2}\) (or, equivalently, \(2<\tau <3\)), then the graph is ultrasmall and there is a universal limit theorem for the chemical distance of two randomly chosen potints x, y, namely
where \(c=2\) for (i) and \(c=4\) for (ii), (iii), see Dommers et al. [13], van der Hofstad et al. [31] and Norros and Reittu [28] for the existence of an ultrasmall phase and Dereich et al. [11] for general lower bounds that match the upper bounds in the ultrasmall phase in all those examples.
Looking at spatially embedded graphs with a scale-free degree distribution, Deijfen et al. [9], Deprez et al. [10] and Bringmann et al. [7] investigated a range of spatial models where points are endowed with weights, which are heavy-tailed random variables corresponding loosely to negative powers \(t^{-\gamma }\) of uniformly chosen marks t. The connection probability of two marked points depends on the product of the weights and the spatial distance of the points, which is the case in models like scale-free percolation and hyperbolic random graphs. Behaviour analogous to kernel (i) in the non-spatial case is identified in [7] for these models, namely that the transition between ultrasmall and small world behaviour occurs at \(\gamma =\frac{1}{2}\) (equivalently, \(\tau =3\)) and in the former case a limit theorem as in (1) with \(c=2\) holds.
We shall see in the present paper that not only the proof techniques but also the results of [7, 9, 10] depend crucially on the fact that connections are considered that depend on the weights of points by taking the product. In fact, the situation changes radically when other, equally natural, ways of connecting vertices are considered, and we shall see that the novel behaviour that we unlock in this paper is also of a universal nature. We now discuss two natural examples, which constitute our main motivation. In both cases the vertices of the graph are the points of a standard Poisson process in \({\mathbb {R}}^d\) and every point is endowed with an independent mark, which is uniformly distributed on the unit interval (0, 1).
In the Boolean (graph) model on \({\mathbb {R}}^d\) the points carry random radii, which can be derived from the uniform marks t, for example as \(t^{-\gamma /d}\). In the hard version of the model two points are connected by an edge if the balls around them with the associated random radii intersect. In the more powerful soft version of the Boolean model independent, identically distributed positive random variables \(X=X(x,y)\) are associated with every unordered pair of vertices \(\{x,y\}\) and a connection is made iff
where s, t are the marks of the vertices. The choice \(X=1\) corresponds to the hard Boolean model, while the choice of \(\gamma =0\) and a heavy-tailed random variable X with decay
for some \(\delta >1\), replicates the long-range percolation model. While neither of these boundary cases is ultrasmall, we show that a choice of \(\gamma \in (0,1)\) and \(\delta >1\) gives
-
ultrasmallness if \(\gamma >\frac{\delta }{\delta +1}\) but,
-
no ultrasmallness if \(\gamma <\frac{\delta }{\delta +1}\).
Note that this boundary depends not only on the power-law exponent of the degree distribution, which is \(\tau =1+\frac{1}{\gamma }\), but also on \(\delta \), which is a geometric quantity related to the decay in the presence of long edges between typical vertices. In particular ultrasmallness does not occur when the variance of the degree distribution becomes infinite, but at a threshold that depends on spatial correlations influencing the graph topology beyond the degree distribution, a feature that is not present in the scale-free percolation or hyperbolic random graph models. In the ultrasmall case we also get a different form of the limit theorem for the chemical distance, namely
where the dependence of the limiting constant on \(\delta \) is another novel feature.
In our second example we look at the age-based random connection model, which was introduced in Gracar et al. [17]. Here the mark of a vertex is considered to be its birth time so that the model is intrinsically dynamical. At its birth time t a vertex is connected to all vertices born previously with a probability
where \(s<t\) is the birth-time of the older vertex and \(\varphi :(0,\infty )\rightarrow [0,1]\) is a non-increasing profile function. As \((t/s)^{\gamma }\) is the asymptotic order of the expected degree at time t of a vertex born at time \(s\downarrow 0\) this infinite graph model mimics the behaviour of spatial preferential attachment networks [2, 25]. An upper bound for the chemical distance for spatial preferential attachment is given by Hirsch and Mönch [24], but lower bounds are not known. Our results show that, as in the soft Boolean model, we have in the age-dependent random connection model that ultrasmallness fails if \(\gamma <\frac{\delta }{\delta +1}\). If \(\gamma >\frac{\delta }{\delta +1}\) we get a lower bound matching that of [24] and we get the precise asymptotics for the chemical distance as stated in (2).
The similarity in the behaviour of our examples is a strong hint that there is a large class of spatial graph models which displays universal behaviour markedly different from both the class of spatial scale-free graphs investigated in [7] and the non-spatial scale-free models studied, for example, in [30]. This idea is further supported by the recent paper by Gracar et al. [19] which investigates the existence of a subcritical percolation phase and reveals the same regime boundary depending on the parameters \(\gamma \) and \(\delta \). In the present paper we explore this universality class of spatial scale-free random graphs by providing general bounds for the chemical distance based only on upper and lower bounds on the connection probabilities between finitely many pairs of points. This approach is sufficiently flexible to yield the fine results described above for the entire range of models in this class, including of course both of the examples described above. The main difficulty here is to produce lower bounds larger than those obtainable for the non-spatial scale-free models by making substantial use of the restrictions coming from the underlying Euclidean geometry.
1.2 Framework
Suppose \({\mathscr {G}}\) is a graph with vertex set given by the points of a Poisson process \(\mathcal {X}\) of unit intensity on \(\mathbb {R}^d \times (0,1)\). We write the points of this process as \(\mathbf {x}=(x,t)\) and refer to x as the location and t as the mark of the vertex \(\mathbf {x}\). Small marks indicate powerful vertices. We write \(\mathbf {x}\sim \mathbf {y}\) if the vertices \(\mathbf {x}\), \(\mathbf {y}\) are connected by an edge in \(\mathscr {G}\).
We denote by \(\mathbb {P}_\mathcal {X}\) the law of \(\mathscr {G}\) conditioned on the Poisson process \(\mathcal {X}\) and by \(\mathbb {P}_{\mathbf {x_1},\ldots , \mathbf {x_n}}\) the law of \(\mathscr {G}\) conditioned on the event that \(\mathbf {x_1},\ldots , \mathbf {x_n}\) are points of the Poisson process \(\mathcal {X}\). The following assumption depends on parameters \(\delta >1\) and \(0\le \gamma <1\), it leads to lower bounds on chemical distances in the graph.
Assumption 1.1
There exists \(\kappa >0\) such that, for every finite set of pairs of vertices \(I\subset \mathcal {X}^2\) in which each vertex appears at most twice, we have
where \(\mathbf {x}_i = (x_i,t_i)\), \(\mathbf {y}_i=(y_i,s_i)\).
In Sect. 1.4 we shall see several natural examples of geometric random graphs which satisfy Assumption 1.1. Note that the assumption does not include conditional independence of the events \(\lbrace \mathbf {x}_i\sim \mathbf {y}_i \rbrace \), which makes several classical tools, such as the BK-inequality, unavailable in our proofs. Without the conditional independence one cannot give a precise description for the degree distribution. However, it is worth noting that Assumption 1.1 is formed in such a way that it implies the existence of a constant \(C>0\) for which the expected degree of a vertex with mark t is smaller than \(Ct^{-\gamma }\). The next assumption, which we use to give matching upper bounds on chemical distances in the ultrasmall regime, however, does contain a conditional independence assumption.
Assumption 1.2
Given \(\mathcal {X}\) edges are drawn independently of each other and there exists \(\alpha ,\kappa >0\) such that, for every pair of vertices \(\mathbf {x}=(x,t), \mathbf {y}=(y,s)\in \mathcal {X}\),
The weight dependent random connection model is a class of graphs introduced in [18, 19] as a general framework, which incorporates many (but not all) of our examples of spatial random graphs. In that context our assumptions roughly mean that the random graphs are stochastically dominated by the random connection model with preferential attachment kernel (Assumption 1.1) and dominate the random connection model with min kernel (Assumption 1.2). Note, that these models have a scale-free degree distribution with power-law exponent \(\tau = 1 + \frac{1}{\gamma }\). Hence, as previously mentioned these examples deviate from the behaviour of non-spatial models and scale-free percolation in that the emergence of ultrasmallness does not depend only on the power-law exponent.
1.3 Statement of the main results
We write \(\mathbf {x}{\mathop {\leftrightarrow }\limits ^{n}}\mathbf {y}\) if there exists a path of length n from \(\mathbf {x}\) to \(\mathbf {y}\) in \(\mathscr {G}\), i.e. there exist \(\mathbf {x}_1,\ldots ,\mathbf {x}_{n-1} \in \mathscr {G}\) such that
We denote by \(\mathbf {x}\leftrightarrow \mathbf {y}\) if \(\mathbf {x}{\mathop {\leftrightarrow }\limits ^{n}} \mathbf {y}\) holds for some n, i.e. if \(\mathbf {x}\) and \(\mathbf {y}\) are in the same connected component in \(\mathscr {G}\). The graph distance, or chemical distance, is given by
Our main results identify the regime where \({\mathscr {G}}\) is ultrasmall, i.e. where the graph distance behaves like an iterated logarithm of the Euclidean distance. Moreover in this regime we provide a precise limit theorem for the behaviour of the graph distance of remote points. The first and foremost result in this context are lower bounds for the chemical distance of two points at large Euclidean distance using only Assumption 1.1.
Theorem 1.1
Let \(\mathscr {G}\) be a general geometric random graph which satisfies Assumption 1.1 for some \(\gamma \in [0,1)\) and \(\delta >1\).
-
(a)
If \(\gamma < \frac{\delta }{\delta +1}\), then \(\mathscr {G}\) is not ultrasmall, i.e. for \(\mathbf {x},\mathbf {y}\in \mathbb {R}^d\times (0,1)\), under \({\mathbb {P}}_{\mathbf {x},\mathbf {y}}\), the distance \(\mathrm {d}(\mathbf {x},\mathbf {y})\) is of larger order than \(\log \log \left| x-y \right| \) with high probability as \(\left| x-y \right| \rightarrow \infty \).
-
(b)
If \(\gamma > \frac{\delta }{\delta +1}\), then for \(\mathbf {x},\mathbf {y}\in \mathbb {R}^d\times (0,1)\) we have
$$\begin{aligned} \mathrm {d}(\mathbf {x},\mathbf {y}) \ge \frac{4\log \log \left| x-y \right| }{{\log \big (\frac{\gamma }{\delta (1-\gamma )}\big )}} \end{aligned}$$under \({\mathbb {P}}_{\mathbf {x},\mathbf {y}}\) with high probability as \(\left| x-y \right| \rightarrow \infty \).
The second result provides a matching upper bound for the chemical distance in the ultrasmall regime under Assumption 1.2. Put together we get the following limit theorem for the chemical distance under Assumptions 1.1 and 1.2 in the ultrasmall regime.
Theorem 1.2
Let \(\mathscr {G}\) be a general geometric random graph which satisfies Assumptions 1.1 and 1.2 for some \(\gamma >\frac{\delta }{\delta +1}\). Then \(\mathscr {G}\) is ultrasmall and, for \(\mathbf {x},\mathbf {y}\in \mathbb {R}^d\times (0,1)\), we have
under \({\mathbb {P}}_{\mathbf {x},\mathbf {y}}(\cdot \mid \mathbf {x}\leftrightarrow \mathbf {y})\) with high probability as \(\left| x-y \right| \rightarrow \infty \).
Remarks
-
For the convergence in Theorem 1.2 we fix marks \(s,t\in (0,1)\) and add points \(\mathbf {x}=(x,s)\) and \(\mathbf {y}=(y,t)\) to the Poisson process. Then we show that
$$\begin{aligned} {\mathbb {P}}_{\mathbf {x},\mathbf {y}}\Big ( \Big |\frac{\mathrm {d}(\mathbf {x},\mathbf {y})}{\log \log \left| x-y \right| } - \frac{4}{\log \big (\frac{\gamma }{\delta (1-\gamma )}\big )}\Big | > \epsilon \, \Big | \, \mathbf {x}\leftrightarrow \mathbf {y}\Big ) \end{aligned}$$converges to zero if \(\left| x-y \right| \rightarrow \infty \).
-
Stronger results, like explicit lower bounds on \(\mathrm {d}(\mathbf {x},\mathbf {y})\) under Assumption 1.1 and upper bounds under Assumption 1.2 only will be formulated in Propositions 2.1 and 3.1 below.
-
The results continue to hold mutatis mutandis when the underlying Poisson process is replaced by the points of the lattice \({\mathbb {Z}}^d\) endowed with independent uniformly distributed marks.
1.4 Examples
1.4.1 The soft Boolean model
As explained in the introduction in the (soft) Boolean model on \({\mathbb {R}}^d\) the points x carry independent identically distributed random radii \(R_x\) and unordered pairs of points \(\{x,y\}\) carry independent identically distributed nonnegative random variables X(x, y). Given these variables two points x and y are connected iff
For a lower bound we assume that there are constants \(C_1, C_2>0\) such that
We can put this model into our framework by constructing the radius \(R_x\) of a point \(\mathbf {x}=(x,t)\) as \(R_x=F^{-1}(1-t)\) where F is the distribution function of the radius distribution and \(F^{-1}(t)=\inf \{ u :F(u)\ge t\}\) its generalised inverse. Given \({\mathcal {X}}\), the probability of a connection of \(\mathbf {x}\) and \(\mathbf {y}\) is
As \(F^{-1}(1-t)=\inf \{ u :1-F(u)\le t\}\le C_1^{\gamma /d} t^{-\gamma /d}\) we infer that the probability of a connection of \(\mathbf {x}\) and \(\mathbf {y}\) is bounded by \(\kappa (t\wedge s)^{-\delta \gamma } \left| x-y \right| ^{-\delta d}\) and hence, using conditional independence of edges, Assumption 1.1 holds. The assumption then implies no ultrasmallness if \(\gamma <\frac{\delta }{\delta +1}\), which holds in particular in the hard model for arbitrary \(0<\gamma <1\), as X(x, y) is constant and hence \(\delta \) can be chosen arbitrarily large. Similarly, if \(\gamma >\frac{\delta }{\delta +1}\) and for every small \(\epsilon >0\) there are constants \(c,C>0\) such that, for all \(r\ge 1\),
then Assumptions 1.1 and 1.2 hold for values arbitrarily close to \(\gamma \) and \(\delta \) and hence the full limit theorem in probability (3) holds.
1.4.2 Hirsch’s scale-free Gilbert graph
Hirsch [23] discusses a model which in its soft version connects every unordered pair of vertices \(\{x,y\}\) iff
where \(R_x, R_y\) and X(x, y) are as in Example 1.4.1. He gives a lower bound for the chemical distance of the hard model, which is of the from \( |x-y| /\log |x-y|\). Our result also shows that the hard model is not ultrasmall albeit with a much smaller lower bound of an order slightly below \(\log |x-y|\). However, this bound extends uniformly to the soft model if \(\delta >\frac{\gamma }{1-\gamma }\). This includes long-range percolation, which corresponds to the case \(\gamma =0\), in which we know from [4] that if \(\delta <2\) the chemical distance is indeed of the order of a power of a logarithm. Our results become best possible looking at the soft model with X heavy-tailed with \(\delta <\frac{\gamma }{1-\gamma }\). In that case we show that distances can be drastically smaller and satisfy the limit theorem in Theorem 1.2.
1.4.3 The age-dependent random connection model
This dynamical model was introduced in [17] as a simplification of the spatial preferential attachment model of Jacob and Mörters [25, 26]. A vertex \(\mathbf {x}=(x,t)\) is born at time t and at birth connects to all vertices \(\mathbf {y}=(y,s)\) born previously with probability
where \(\beta >0\) is a density parameter and \(\varphi :(0,\infty )\rightarrow [0,1]\) is a non-increasing profile function standardized to satisfy \(\int \varphi (|x|^d)\, dx=1\). It is easy to see that for \(t\gg s\) the expected degree at time t of a vertex born at time s is of asymptotic order \((t/s)^{\gamma }\), so that the model combines preferences of attachment to vertices of high degree and to nearby vertices in a balanced way. If \(\varphi (r) \le C r^{-\delta }\) we see that Assumption 1.1 holds so that ultrasmallness fails if \(\gamma <\frac{\delta }{\delta +1}\). But if \(\gamma >\frac{\delta }{\delta +1}\) and also, for every \(\epsilon >0\), there is \(c>0\) with \(\varphi (r) \ge c r^{-\delta +\epsilon }\) for all \(r\ge 1\), then ultrasmallness holds and we get the asymptotic chemical distance as stated in (2).
1.4.4 Scale-free percolation
As explained in Sect. 1.1 for the model of Deijfen et al. [9] and other models constructed by taking products of vertex weights and distances we do not expect our results to be relevant or even sharp. In fact, the dependence on the weights in these models is so strong that the geometry does not play a significant role and the techniques developed in this paper are not needed to understand the behaviour of the chemical distance. For these models Assumption 1.1 only holds for \(\gamma <\frac{1}{2}\) and in this case we recover from Theorem 1.1 the well-known result that the graph is not ultrasmall when the power-law exponent is \(\tau >3\). For recent results for the chemical distance when \(\gamma <\frac{1}{2}\), see [21].
1.4.5 The reinforced age-dependent random connection model
We consider a reinforced version of the age-dependent random connection model described above, where the connection probability between vertices is reinforced by additional weights of the nodes. Interestingly, although edges do not occur independently of each other due to the additional weights, our results still apply in full generality. Let the vertex set be a Poisson point process \(\mathcal {X}\) on \(\mathbb {R}^d\times (0,1)\) as before. We assign in addition to each point \(\mathbf {x}\in \mathcal {X}\) an independent identically distributed reinforcement weight \(W = W_\mathbf {x}\), for which we assume the second moment exists that it is almost surely bounded away from zero, i.e. there exists \(\alpha >0\) such that \({\mathbb {P}}(W\ge \alpha ) = 1\). Given \(\mathcal {X}\) and the reinforcement weights, edges are then formed independently between \(\mathbf {x}= (x,t)\) and \(\mathbf {y}= (y,s)\) with probability
where \(\varphi \) is as in Example 1.4.3. Let \(I \subset \mathcal {X}^2\) be a set of pairs of vertices where each vertex appears at most twice. If there is \(C>0\) such that \(\varphi (r) \le C r^{-\delta }\) for all \(r>0\),
where the second inequality holds since each reinforcement weight appears at most twice in the product and they are independent of \(\mathcal {X}\). As the second moment of the weights exists, Assumption 1.1 holds for an appropriately chosen \(\kappa \). Hence, ultrasmallness fails if \(\gamma <\frac{\delta }{\delta +1}\). On the other hand, we can easily couple the reinforced age-dependent random connection model to an age-dependent random connection model with a modified density parameter, such that the later is a subgraph of the former. Indeed, for each pair of vertices we draw an independent uniform random variable \(U(\mathbf {x},\mathbf {y})\). Given the Poisson process \(\mathcal {X}\), the reinforcement weights and the family \((U(\mathbf {x},\mathbf {y}))_{\mathbf {x},\mathbf {y}\in \mathcal {X}}\), we can construct the age-dependent random connection model and the reinforced model in the following way. First, add an edge between any pair of vertices when
This leads to the age-dependent random connection model with new density parameter \(\tilde{\beta } = \beta \alpha ^{-2/\delta }\). Since \(W\ge \alpha \) almost surely, each such edge is also added in the reinforced model. To get the full reinforced model, we add additional edges to hitherto unconnected pairs of vertices if
As the age-dependent random connection model is ultrasmall when \(\gamma >\frac{\delta }{\delta +1}\) and if for every \(\epsilon >0\), there exists \(c>0\) with \(\varphi (r) \ge c r^{-\delta +\epsilon }\) for all \(r\ge 1\), the reinforced model is ultrasmall as well and we get the asymptotic chemical distance as stated in (2) under both tail assumptions stated for \(\varphi \) in this section. Note that Examples 1.4.1 and 1.4.2 can similarly be reinforced, and similar conclusions can consequently be drawn.
1.4.6 Ellipses percolation
Teixeira and Ungaretti [29] introduce a model on \(\mathbb {R}^2\) as a collection of random ellipses centred on points of a Poisson process \(\mathcal {X}\) on \(\mathbb {R}^2\times (0,1)\) with uniform marks t, from which the size of the major half-axis is derived as \(t^{-\gamma /2}\) while its direction is sampled uniformly. The size of the minor half-axis is one. The random graph is then constructed by taking the Poisson process as the vertex set and forming edges given the collection of random ellipses between pairs of points of the point process if their ellipses intersect. Hilário and Ungaretti [22] show that, for \(\gamma \in (1,2)\), the model is ultrasmall.
We introduce a soft version of this model, where for each pair of vertices \(\mathbf {x},\mathbf {y}\) we consider copies of their ellipses where the size of the major axes are multiplied with independent, identically distributed positive heavy-tailed random variables \(X=X(\mathbf {x},\mathbf {y})\) with \({\mathbb {P}}(X>r)\sim r^{-2\delta }\) for some \(\delta >1\). An edge between \(\mathbf {x}\) and \(\mathbf {y}\) is then formed if the new ellipses intersect. Note that given \(\mathcal {X}\) edges are not drawn independently of each other, as the neighbourhood of each vertex depends on the orientation of the ellipses. Our results show that, for \(\gamma \in [0,1)\), the original model is never ultrasmall and the soft model is not ultrasmall if \(\gamma <\frac{\delta }{\delta +1}\). We see that if an edge is formed between \(\mathbf {x}= (x,t)\) and \(\mathbf {y}= (y,s)\), this implies that balls around x and y with radii \(X(\mathbf {x},\mathbf {y})t^{-\gamma /2}\) and \(X(\mathbf {x},\mathbf {y})s^{-\gamma /2}\) intersect. Thus, there exists \(\kappa > 0\) such that
Since the random variables \(X(\mathbf {x},\mathbf {y})\) are independent, Assumption 1.1 holds for \(\gamma \in [0,1)\) and \(\delta >1\) and the claimed result follows.
2 Proof of the Lower Bounds for the Chemical Distance
2.1 Truncated first moment method
To prove the lower bounds of Theorem 1.1 we find an upper bound for \({\mathbb {P}}_{\mathbf {x},\mathbf {y}}\lbrace \mathrm {d}(\mathbf {x}, \mathbf {y}) \le 2\Delta \rbrace \) and choose \(\Delta \) as large as possible while keeping the probability sufficiently small. Note that the definition of the graph distance \(\mathrm {d}\) can be reduced to the existence of self-avoiding paths, since if there exists a path of length n between two given vertices there also exists a self-avoiding path with shorter or equal length between those two. Hence, the paths considered throughout this section are assumed to be self-avoiding. The event \(\lbrace \mathrm {d}(\mathbf {x}, \mathbf {y}) \le 2\Delta \rbrace \) is equivalent to the existence of at least one path between \(\mathbf {x}\) and \(\mathbf {y}\) of length smaller than \(2\Delta \). Hence,
where \(\mathbf {x}= \mathbf {x}_0\), \(\mathbf {y}= \mathbf {x}_n\), \(\bigcup ^{\ne }\) (resp. \(\sum ^{\ne }\)) denotes the union (resp. sum) over all possible sets of pairwise distinct vertices \(\mathbf {x}_0,\ldots ,\mathbf {x}_n\) of the Poisson process and \({\mathbb {E}}\) is the expectation with respect to the law of a Poisson process with unit intensity on \(\mathbb {R}^d\times (0,1)\). To keep notation throughout the paper short we will abbreviate the previous notation and write \(\sum _{\mathbf {x}_1,\ldots ,\mathbf {x}_m}\) for the sum over all sets of m distinct vertices of the Poisson process. We get, by using Mecke’s equation [27] and Assumption 1.1 that
This bound is only good enough if \(\gamma <\frac{1}{2}\). If \(\gamma \ge \frac{1}{2}\) the expectation on the right is dominated by paths which are typically not present in the graph. These are paths which connect \(\mathbf {x}\) or \(\mathbf {y}\) quickly to vertices with small mark t. Our strategy is therefore to truncate the admissible mark of the vertices of a possible path between \(\mathbf {x}\) and \(\mathbf {y}\). We define a decreasing sequence \((\ell _k)_{k\in \mathbb {N}_0}\) of thresholds and call a tuple of vertices \((\mathbf {x}_0,\ldots ,\mathbf {x}_n)\) good if their marks satisfy \(t_k\wedge t_{n-k} \ge \ell _k\) for all \(k\in \lbrace 0,\ldots , n \rbrace \). A path consisting of a good tuple of vertices is called a good path. We denote by \(A^{_{(\mathbf {x})}}_k\) the event that there exists a path starting in \(\mathbf {x}\) which fails this condition after exactly k steps, i.e. a path \(((x,t),(x_1,t_1),\ldots (x_k,t_k))\) with \(t\ge \ell _0, t_1\ge \ell _1,\ldots , t_{k-1} \ge \ell _{k-1}\), but \(t_k<\ell _k\). Furthermore we denote by \(B^{_{(\mathbf {x},\mathbf {y})}}_n\) the event that there exists a good path of length n between \(\mathbf {x}\) and \(\mathbf {y}\). Then, for given vertices \(\mathbf {x}\) and \(\mathbf {y}\)
This decomposition is the same as for the mean-field models in [11]. The main feature of our proof is to show that the geometric restrictions and resulting correlations in our spatial random graphs make it much more difficult for a path to connect to a vertex with small mark. Hence a larger sequence \((\ell _k)\) of thresholds can be chosen that still makes the two first sums on the right of (TMB) small, allowing the third sum to be small for a larger choice of \(\Delta \). This requires a much deeper analysis of the graph and its spatial embedding.
2.2 Outline of the proof
The characteristic feature of the shortest path connecting two typical vertices is that, starting from both ends, the path contains a subsequence of increasingly powerful vertices. The two parts started at the ends meet roughly in the middle in a vertex of exceptionally high power depending on the distance between the starting vertices. In our framework powerful vertices are characterised by small marks. For geometric random graphs fulfilling Assumption 1.1 we show that arbitrary strategies connecting increasingly powerful vertices are dominated by an optimal strategy by which paths make connections between vertices of increasingly high power in a way depending on the parameters \(\gamma \) and \(\delta \) in our assumption:
-
If \(\gamma > \frac{\delta }{\delta +1}\) we connect two powerful vertices \(\mathbf {x}\) and \(\mathbf {y}\) via a connector, a single vertex with a larger mark which is connected to both \(\mathbf {x}\) and \(\mathbf {y}\);
-
if \(\gamma <\frac{\delta }{\delta + 1}\) we connect them by a single edge.
In both cases, we now sketch how our argument works on paths containing only the optimal type of connection between powerful vertices. The principal challenge of the proof will however be to show how these proposed optimal strategies dominate the entirety of other possible strategies. This is particularly hard in the former case, because a vast number of potential strategies leads to a massive entropic effect that needs to be controlled. Note also that at this point we need not show that the proposed optimal strategies actually work. This (easier) part of the proof requires Assumption 1.2 and is carried out in Sect. 3.

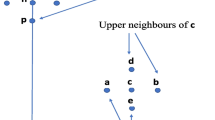
An example of a path with optimal connection type for \(\gamma >\frac{\delta }{\delta +1}\). The horizontal axis corresponds to the sequential numbering of vertices on the path, the vertical axis represents the mark space. Powerful vertices (indicated by black dots) alternate with connectors (indicated by grey dots)
In the case \(\gamma >\frac{\delta }{\delta +1}\) the optimal connection strategy is to follow a path of length 2n between \(\mathbf {x}\) and \(\mathbf {y}\), where we assume that n is even and that the vertices \(\mathbf {x}_1=(x_1,t_1),\ldots ,\mathbf {x}_{2n-1}=(x_{2n-1},t_{2n-1})\) of the path satisfy that \(t_{2(k+1)}<t_{2k}<t_{2k+1}\) and \(t_{2n-2(k+1)}<\) \(t_{2n-2k}<t_{2n-2k+1}\) for all \(k=0,\ldots ,n/2\), i.e. the vertices with even index can be seen as powerful vertices, while the ones with odd index represent the connectors between them, see Fig. 1. Note that at this point we make no assumptions on the locations of these vertices.
For arbitrary \(\varepsilon >0\), we now determine a truncation sequence \((\ell _k)_{k\in \mathbb {N}_0}\), such that paths starting in \(\mathbf {x}\), resp. \(\mathbf {y}\), which are not good, only exist with a probability smaller than \(\varepsilon \). To do so, we establish an upper bound for the probability of the event \(A_n^{_{(\mathbf {x})}}\) that there exists a path starting in \(\mathbf {x}\) whose n-th vertex is the first vertex which has a mark smaller than the corresponding \(\ell _n\). We denote by \(N(\mathbf {x},\mathbf {y},n)\) the number of paths of length n from \(\mathbf {x}=(x,t)\) to a vertex \(\mathbf {y}=(y,s)\) whose vertices \((x_1,t_1),\ldots (x_{n-1},t_{n-1})\) fulfill \(t_{2(k+1)}<t_{2k}<t_{2k+1}\) for all \(k=0,\ldots ,\lfloor n/2 \rfloor -1\) and which is one half of a good path, i.e. \(t\ge \ell _0, t_1\ge \ell _1,\ldots , t_{n-1} \ge \ell _{n-1}\). The mark of \(\mathbf {y}\) is not restricted in this definition and is therefore allowed to be smaller than \(\ell _n\). Hence, in this case the event \(A_n^{_{(\mathbf {x})}}\) can only occur for n even, since by definition a connector is less powerful than the preceding and following vertex and therefore has a mark larger than the corresponding \(\ell _n\). For n even we have by Mecke’s equation that
Since the existence of a path counted in \(N(\mathbf {x},\mathbf {y},n)\) is equivalent to the existence of vertices \(\mathbf {z}_1,\ldots , \mathbf {z}_{n/2-1}\) such that the marks are bounded from below by \(\ell _2,\ell _4,\ldots , \ell _{n-2}\), with \(\mathbf {z}_0=\mathbf {x}, \mathbf {z}_{n/2}=\mathbf {y}\) the marks \(u_0,\ldots , u_{n/2}\) of \(\mathbf {z}_0,\ldots , \mathbf {z}_{n/2}\) are decreasing, and \(\mathbf {z}_i, \mathbf {z}_{i+1}\) are connected via a single connector, Mecke’s equation yields
where \(K(\mathbf {z}_i,\mathbf {z}_{i+1},2)\) is the number of connectors between \(\mathbf {z}_i\) and \(\mathbf {z}_{i+1}\). Using Mecke’s equation and Assumption 1.1 we have
where
for \(\rho (x):=1\wedge x^{-\delta }\) and \(\mathbf {z}_i=(z_i,u_i)\), \(\mathbf {z}_{i-1}=(z_{i-1},u_{i-1})\). We see in Lemma 2.1 that there exists \(C>0\) such that, for two given vertices \(\mathbf {x}= (x,t)\) and \(\mathbf {y}= (y,s)\) far enough from each other,
This inequality holds for the optimal connection type between two powerful vertices of the path and we will see that this type of bound holds also for the case of multiple connectors between two powerful vertices (cf. Lemma 2.3). It also clearly displays the influence of the spatial embedding of the random geometric graph via the parameter \(\delta \). Assuming (5) for the moment, we obtain
where \(\mathbf {z}_i = (z_i,u_i)\) for \(i=0,\ldots n/2\) and where we without loss of generality integrate up to \(u_0\) in all but the last integral. When dealing with a general (rather than the optimal) connection strategy, we will use a classification of the strategies in terms of binary trees. Left-to-right exploration of the tree will reveal the structure of the decomposition that replaces the straightforward decomposition in (4) and additional information on the location of the vertices will be encoded in terms of colouring of the leaves. Figure 2 displays the classifying binary tree for the optimal connection type.

Representation of a path with optimal connection type by a binary tree. For a less trivial example resulting from a general connection strategy, see Fig. 5
For a sufficiently large constant \(c>0\) the right-hand side of (6) can be bounded by
as shown in Lemma 2.5 considering all paths. With \(\ell _0\) smaller than the mark of \(\mathbf {x}\) we choose the truncation sequence \((\ell _k)\) for \(\varepsilon >0\), such that
and we have
Writing \(\eta _n := \ell _n^{-1}\) we can deduce from (7) a recursive description of \((\ell _n)_{n\in \mathbb {N}_0}\) such that
Consequently there exist \(b>0\) and \(B>0\) such that \( \eta _n \le b\exp (B(\gamma /(\delta (1-\gamma )))^{n/2}). \) We close the argument with heuristics that leads from this truncation sequence to a lower bound for the chemical distance. Let \(\mathbf {x}\) and \(\mathbf {y}\) be two given vertices. If there exists a path of length \(n<\log \left| x-y \right| \) between them, there must exist at least one edge in this path which is longer than \(\frac{\left| x-y \right| }{\log \left| x-y \right| }\). For \(\left| x-y \right| \) large, this edge typically must have an endvertex whose mark is, up to a multiplicative constant, smaller than \(\left| x-y \right| ^{-d}\). Hence, if we choose
we ensure \(\ell _\Delta \) is of larger order than \(\left| x-y \right| ^{-d}\). Therefore there is no good path whose vertices are powerful enough to be an endvertex of an edge longer than \(\frac{\left| x-y \right| }{\log \left| x-y \right| }\) and consequently no good path of length shorter than \(2\Delta \) can exist between \(\mathbf {x}\) and \(\mathbf {y}\).
Turning to the case \(\gamma < \frac{\delta }{\delta +1}\), we consider paths whose powerful vertices are connected directly to each other. For a path of length n between two given vertices \(\mathbf {x}\) and \(\mathbf {y}\) we assume that n is even and for the vertices \(\mathbf {x}_1=(x_1,t_1),\ldots , \mathbf {x}_{n-1}=(x_{n-1},t_{n-1})\) of the path we assume that we have \(t_0>t_1>\cdots >t_{n/2}\) and \(t_n>t_{n-1}>\cdots >t_{n/2}\), where \(t_0\) is the mark of \(\mathbf {x}\) and \(t_n\) the mark of \(\mathbf {y}\). We again make no restrictions on the locations of those vertices. Restricting the paths described in \(A_n^{_{(\mathbf {x})}}\) and \(B_n^{_{(\mathbf {x},\mathbf {y})}}\) to paths with this structure we follow the same argumentation as above to establish sufficiently small bounds for the event \(A_n^{_{(x)}}\) for a given vertex \(\mathbf {x}= (x_0,t_0)\),
where we again without loss of generality integrate over a larger range. For \(c>0\) large enough, the right-hand side can be further bounded by
see Lemma 2.9. Choosing \(\ell _0 < t_0\) and \((\ell _n)_{n\in \mathbb {N}_0}\) for \(\epsilon >0\), such that the last displayed term equals \(\frac{\varepsilon }{\pi ^2n^2}\) ensures that \(\sum _n {\mathbb {P}}_\mathbf {x}(A_n^{\mathbf {x}})<\frac{\varepsilon }{6}\) and by induction we see that this choice is possible while for any \(p>1\) there exists \(B>0\) such that \( \eta _n \le B^{n\log ^p(n+1)}. \) Following the same heuristics as before leads to the choice
for some constant \(c>0\) such that paths between \(\mathbf {x}\) and \(\mathbf {y}\) with length shorter than \(2\Delta \) do not exist with high probability.
2.3 The ultrasmall regime
We now start the full proof in the case \(\gamma >\frac{\delta }{\delta +1}\) considering all possible connection strategies. We prepare this by first modifying the graph by adding edges between vertices which are sufficiently close to each other. We call a path step minimizing if it connects any pair of vertices on the path by a direct edge, if it is available. Note that the length of any path connecting two fixed vertices can be bounded from below by the length of a step mimimizing path connecting the two vertices. Two spatial constraints emerge from this: On the one hand, vertices on a step minimizing path in the modified graph that are not neighbours on the path cannot be near to each other. On the other hand, vertices connected by one of the added edges have to be near to each other. To make full use of these constraints we need to distinguish between original edges and edges added to the graph. This can be done efficiently by endowing every edge with a conductance, which is one for original and two for added edges.
More precisely, we consider a graph \(\tilde{\mathscr {G}}\) where edges are endowed with conductances as follows: First, create a copy of \(\mathscr {G}\) and assign to every edge conductance one. Then, between two vertices \(\mathbf {x}= (x,t)\) and \(\mathbf {y}= (y,s)\) of \(\tilde{\mathscr {G}}\) an edge is added to \(\tilde{\mathscr {G}}\) with conductance two whenever
Since all conductances and edges of \(\tilde{\mathscr {G}}\) are deterministic functionals of \(\mathscr {G}\), there exists an almost sure correspondence between \(\mathscr {G}\) and \(\tilde{\mathscr {G}}\), under which an edge with conductance one in \(\tilde{\mathscr {G}}\) implies the existence of the same edge in \(\mathscr {G}\). With conductances assigned to every edge of \(\tilde{\mathscr {G}}\), we define the conductance of a path \(P=(\mathbf {x}_0,\ldots ,\mathbf {x}_n)\) in \(\tilde{\mathscr {G}}\) as the sum over all conductances of the edges of P and denote it by \(w_P\).
We call a self-avoiding path \(P=(\mathbf {x}_0,\ldots ,\mathbf {x}_n)\) in \(\mathscr {G}\) or \(\tilde{\mathscr {G}}\) step minimizing
Note that a step minimizing path in \(\mathscr {G}\) is not necessarily step minimizing in \(\tilde{\mathscr {G}}\), since there could exist an edge of conductance two between two vertices of the path that would reduce the number of steps. But by removing the vertices connecting such a pair of vertices from the path we can shorten the path to a step minimizing path in \(\tilde{\mathscr {G}}\) whose length and conductance is no more than the length of the original path. Hence the chemical distance \(\mathrm {d}(\mathbf {x},\mathbf {y})\) between vertices \(\mathbf {x}\) and \(\mathbf {y}\) in \(\mathscr {G}\) is larger or equal than the conductance \(\mathrm {d}_w(\mathbf {x},\mathbf {y}) := \min \lbrace w_P: P\ \text {is a path between }\mathbf {x}\ \text {and}\ \mathbf {y} \rbrace \) between them in \(\tilde{\mathscr {G}}\).
To bound the probabilities occurring in (TMB), we express the events on \(\mathscr {G}\) with the help of corresponding events on \(\tilde{\mathscr {G}}\) by replacing the role of the length of a path by its conductance. The role of the conductance is crucial, as it allows us to distuingish newly added edges in a path, which is necessary to keep the bounds of the probabilities in (TMB) sufficiently small. We call a path \(P = (\mathbf {x}_0,\ldots ,\mathbf {x}_n)\) in \(\tilde{\mathscr {G}}\) good if its marks satisfy \(t_k\ge \ell _{w_P(k)}\) and \(t_{n-k}\ge \ell _{w_P-w_P(n-k)}\) for all \(k = 0,\ldots ,n\), where \(w_P(k)\) is the conductance of P between \(\mathbf {x}_0\) and \(\mathbf {x}_k\). We denote by \(\tilde{A}_k^{\mathbf {x}}\) the event that there exists a step minimizing path starting in \(\mathbf {x}\) in \(\tilde{\mathscr {G}}\) with conductance k which fails to be good on its last vertex. Notice that if there exists a path described by the event \(A_k^{\mathbf {x}}\), i.e. a path for which the k-th vertex is the first one whose mark is smaller than the corresponding truncation value \(\ell _k\), then due to the correspondence between \(\mathscr {G}\) and \(\tilde{\mathscr {G}}\) there also exists a step minimizing path P in \(\tilde{\mathscr {G}}\) with \(w_P\le k\) which also fails the condition on its last vertex. Hence, the first two summands of the right-hand side of (TMB) can be bounded from above by \(\sum _{n=1}^\Delta {\mathbb {P}}_{\mathbf {x}}(\tilde{A}^{(\mathbf {x})}_n)\) and \(\sum _{n=1}^\Delta {\mathbb {P}}_{\mathbf {y}}(\tilde{A}^{(\mathbf {y})}_n)\).
To bound \({\mathbb {P}}_{\mathbf {x}}(\tilde{A}^{(\mathbf {x})}_n)\), we count the expected number of paths occurring in the event \(\tilde{A}^{(\mathbf {x})}_n\). Note that if \({\left| x-y \right| ^d\le \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }}\) holds for vertices \(\mathbf {x}\) and \(\mathbf {y}\), there exist no step minimizing paths between \(\mathbf {x}\) and \(\mathbf {y}\) with conductance larger or equal three and there exists one step minimizing path with conductance two, since there exists an edge of conductance two between the two vertices. This property also holds for any of the subclasses of step minimizing paths introduced in the following.
For given vertices \(\mathbf {x}=(x,t)\) and \(\mathbf {y}=(y,s)\) define the random variable \(N(\mathbf {x},\mathbf {y},n)\) as the number of distinct step minimizing paths P between \(\mathbf {x}\) and \(\mathbf {y}\) with \(w_P=n\), whose connecting vertices \((x_1,t_1),\ldots (x_{m-1},t_{m-1})\) all have a larger mark than \(\mathbf {y}\) and fulfill \(t\ge \ell _0, t_1\ge \ell _{w_P(1)},\ldots , t_{m-1} \ge \ell _{w_P(m-1)}\). As \(\tilde{A}^{_{(\mathbf {x})}}_n\) is the event that there exists a path with conductance n, where the final vertex is the first and only one which has a mark smaller than the corresponding \(\ell _n\), the final vertex is also the most powerful vertex of the path. Hence, the number of paths described by the event \(\tilde{A}^{(\mathbf {x})}_n\) can be written as the sum of \(N(\mathbf {x},\mathbf {y},n)\) over all sufficiently powerful vertices \(\mathbf {y}\) of the graph and, by Mecke’s formula, we have
We now decompose \(N(\mathbf {x},\mathbf {y},n)\). For \(k=1,\ldots , n-1\), define \(N(\mathbf {x},\mathbf {y},n,k)\) as the number of step minimizing paths P between \(\mathbf {x}\) and \(\mathbf {y}\) with \(w_P=n\) and
-
whose connecting vertices \((x_1,t_1),\ldots (x_{m-1},t_{m-1})\) have marks larger than the corresponding thresholds \(\ell _{w_P(1)}, \ldots , \ell _{w_P(m-1)}\) and larger than the mark of \(\mathbf {y}\), and
-
there exists \(r \in \lbrace 1,\ldots ,m-1 \rbrace \) such that we have \(w_P(r) = n-k\) and the connecting vertex \(\mathbf {x}_{r} = (x_{r},t_{r})\) has the smallest mark among the connecting vertices and \(\mathbf {x}\).
The vertex \(\mathbf {x}_{r}\) can be understood as the powerful vertex of the path which connects to \(\mathbf {y}\) via a path of less powerful vertices with conductance k. Consequently, we write \(N(\mathbf {x},\mathbf {y},n,n)\) for the number of step minimizing paths of conductance n, which connect \(\mathbf {x}\) and \(\mathbf {y}\) via less powerful vertices. Then we have, for \(n\in \mathbb {N}\),
For \(k=1,\ldots ,n-1\), the existence of a path counted in \(N(\mathbf {x},\mathbf {y},n,k)\) implies the existence of a vertex \(\mathbf {z}\) such that a step minimizing path counted by \(N(\mathbf {x},\mathbf {z},n-k)\) exists which connects to \(\mathbf {y}\) via a path of less powerful vertices with conductance k. Hence
for \(n\in \mathbb {N}\) and \(k=1,\ldots , n-1\), where we denote by \(K(\mathbf {z},\mathbf {y},k)\) the number of step minimizing paths P between \(\mathbf {z}\) and \(\mathbf {y}\) with \(w_P = k\) whose vertices have marks larger than the marks of \(\mathbf {z}\) and \(\mathbf {y}\). Note that unlike \(N(\mathbf {x},\mathbf {y},n)\), this random variable is symmetric in its first two arguments and by definition we have that \(N(\mathbf {x},\mathbf {y},n,n) = K(\mathbf {x},\mathbf {y},n)\). Observe that \(K(\mathbf {z},\mathbf {y},1)\) is the indicator whether \(\mathbf {z}\) and \(\mathbf {y}\) are connected by an edge with conductance one. We turn our attention to \(K(\mathbf {z},\mathbf {y},k)\) in the case \(k\ge 2\), i.e. two powerful vertices are connected via one or more connectors or an edge with conductance two.
Connecting powerful vertices. First consider the random variable \(K(\mathbf {x},\mathbf {y},2)\). If \(\left| x-y \right| ^d\le \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }\), the vertices \(\mathbf {x}\) and \(\mathbf {y}\) are connected by an edge with conductance two and we infer that \(K(\mathbf {x},\mathbf {y},2) = 1\). In the other case, \(K(\mathbf {x},\mathbf {y},2)\) is equal to the number of connectors between \(\mathbf {x}\) and \(\mathbf {y}\), i.e the number of vertices with mark larger than the marks of \(\mathbf {x}\) and \(\mathbf {y}\), which form an edge of conductance one to \(\mathbf {x}\) and \(\mathbf {y}\). The following lemma shows the stated inequality (5) from Sect. 2.1 for this case. Recall that we write \(\rho (x) := 1\wedge x^{-\delta }\) and define \(I_\rho := \int _{\mathbb {R}^d}\mathrm {d}x \rho (\kappa ^{-1/\delta }\left| x \right| ^d)\).
Lemma 2.1
(Two-connection lemma). Let \(\mathbf {x}= (x,t), \mathbf {y}= (y,s)\) be two given vertices with \({\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }}\). Then
where \(C = \tfrac{I_\rho 2^{d \delta + 1}}{(\gamma - (1-\gamma )\delta )}\).
Proof
The first inequality follows directly by summing over all possible connectors and applying Assumption 1.1 and Mecke’s formula. Observe that for every vertex \(\mathbf {z}=(z,u)\) either \(\left| x-z \right| \ge \frac{\left| x-y \right| }{2}\) or \(\left| y-z \right| \ge \frac{\left| x-y \right| }{2}\), as the open sets \(B_{\frac{\left| x-y \right| }{2}}(x)\) and \(B_{\frac{\left| x-y \right| }{2}}(y)\) are disjoint. Hence, we have
\(\square \)
We consider the event that vertices \(\mathbf {x}\) and \(\mathbf {y}\) are connected by multiple vertices with larger marks. Recall that \(K(\mathbf {x},\mathbf {y},k)\) is the number of step minimizing paths P between \(\mathbf {x}\) and \(\mathbf {y}\) with \(w_P = k\) whose vertices have marks larger than the marks of \(\mathbf {x}\) and \(\mathbf {y}\). As before we call the vertices of such a path connectors. To control the number of such paths, notice that for any possible choice of connectors between \(\mathbf {x}\) and \(\mathbf {y}\), there exists an almost surely unique connector with smallest mark, i.e the most powerful connector. For \(i=1,\ldots ,k\), we denote by \(K(\mathbf {x},\mathbf {y},k,i)\) the number of step minimizing paths between \(\mathbf {x}\) and \(\mathbf {y}\) where the connectors have a larger mark than \(\mathbf {x}\) and \(\mathbf {y}\) and there is a vertex \(\mathbf {x}_r\) with \(w_P(r) = i\) which is the most powerful connector of those vertices. Then,
Assume now that the connector \(\mathbf {x}_r\) is the most powerful of all connectors and \(w_P(r)=i\). In this case, the possible connectors \(\mathbf {x}_1,\ldots , \mathbf {x}_{r-1}\) and \(\mathbf {x}_{r+1},\ldots , \mathbf {x}_{m-1}\) need to have larger mark than \(\mathbf {x}_r\). Hence, the paths between \(\mathbf {x}_r\) and \(\mathbf {x}\), resp. \(\mathbf {y}\), considered on their own have the same structure as the initial path and this leads to

Decomposing the path at the most powerful connector
We use this decomposition together with Assumption 1.1 to find an upper bound for \({\mathbb {E}}_{\mathbf {x},\mathbf {y}} K(\mathbf {x},\mathbf {y},k)\). Recall that, if \({\left| x-y \right| ^d\le \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }}\), we have \(K(\mathbf {x},\mathbf {y},k)= 0\) if \(k\ge 3\) and \(K(\mathbf {x},\mathbf {y},k) = 1\) if \(k= 2\) by definition. We now introduce a mapping
by \(e_K(\mathbf {x},\mathbf {y},1) = \rho (\kappa ^{-1/\delta }(t\wedge s)^{\gamma }(t\vee s)^{1-\gamma }\left| x-y \right| ^d),\) for \(\mathbf {x},\mathbf {y}\in \mathbb {R}^d\times (0,1],\) and, for \(k\ge 2\) under the assumption that \({\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }}\),
and otherwise \(e_K(\mathbf {x},\mathbf {y},2) = 1\) and \(e_K(\mathbf {x},\mathbf {y},k) = 0\) for \(k\ge 3\).
Lemma 2.2
Let \(\mathbf {x}, \mathbf {y}\in \mathbb {R}^d\times (0,1]\) be two given vertices. Then, for all \(k\in \mathbb {N}\), we have
Note that by Assumption 1.1 and Lemma 2.1, we have \({\mathbb {E}}_{\mathbf {x},\mathbf {y}}K(\mathbf {x},\mathbf {y},1)\le e_K(\mathbf {x},\mathbf {y},1)\) and \({\mathbb {E}}_{\mathbf {x},\mathbf {y}}K(\mathbf {x},\mathbf {y},2)\le e_K(\mathbf {x},\mathbf {y},2)\). We prove the result for general k by induction using (12), but to do so we need to classify the possible connection strategies according to the way in which powerful vertices are placed. This classification is done by means of coloured binary trees. We write \(\mathcal {T}_{k-1}\) for the set of all binary trees with \(k-1\) vertices. Here a binary tree is a rooted tree in which every vertex can have either no child, a right child, a left child or both. We colour the vertices of a tree \(T\in \mathcal {T}_{k-1}\) in such a way that the leaves of the tree can be either blue or red, and every other vertex is coloured blue. Thus, for each \(T\in \mathcal {T}_{k-1}\) there exist \(2^{\ell }\) different colourings, where \(\ell \) is the number of leaves of T. Let \(\mathcal {T}_{k-1}^c\) be the set of all coloured trees.
Before proceeding we outline the role of the tree and its coloured vertices in regard to the information they capture. We will construct the tree so as to describe the precise order of the connectors’ marks. In order to distuingish between connections of vertices that are sufficiently close to form an edge with conductance two and connections between vertices which are further apart, red vertices of the tree will represent the first case and blue the second.

a Classification of a connection strategy by means of a binary tree. Local minima of the path correspond to branchpoints and local maxima to blue leaves of the corresponding binary tree T. Matching labels in the tree on the right are obtained by left-to-right labelling. b One connector of the path in a is replaced by an edge of conductance two. This edge corresponds to the red vertex in the tree to which no label and hence no vertex of the path is attached
To each step minimizing path of conductance k between \(\mathbf {x}\) and \(\mathbf {y}\) we associate a coloured tree \(T\in \mathcal {T}_{k-1}^c\) in two steps, see Fig. 4a:
-
(1)
If the connectors of the step minimizing path P of conductance k are \(\mathbf {x}_1,\ldots ,\mathbf {x}_m\) with \(m\le k-1\), we associate a vector \(\mathbf {u} = (u_1,\ldots , u_{k-1})\) to the path defined as follows. We set \(u_{w_P(i)} := t_i\) for all \(i\in {1,\ldots ,m}\) and \(u_j = 1\) for all \(j\in \lbrace 1,\ldots ,k-1 \rbrace \backslash \lbrace w_P(1),\ldots ,w_P(m) \rbrace \). Then
$$\begin{aligned} \mathbf {u} \in \mathcal {U}_{k-1} := \lbrace \mathbf {u} = (u_1,\ldots ,u_{k-1}) \in (0,1]^{k-1} :u_i \not = 1\ \text {if}\ u_{i-1}=1 \rbrace . \end{aligned}$$ -
(2)
To \(\mathbf {u}\in \mathcal {U}_{k-1}\) we associate a coloured tree \(T \in \mathcal {T}_{k-1}^c\) as follows:
-
For \(k=2\) we have \(\mathbf {u} = (u_1)\) and the set \(\mathcal {T}_1^c\) contains two trees T, each consisting only of the root which may be coloured blue or red. If \(\mathbf {u} = (1)\), then \(\mathbf {u}\) is associated to the tree T with the red root and otherwise \(\mathbf {u}\) is associated to the tree with the blue root.
-
For \(k>2\), assume that to every tuple in \(\mathbf {u}\in \mathcal {U}_{j-1}\) with \(2\le j<k\) we have already associated a coloured tree \(T\in \mathcal {T}_{j-1}^c\). Let \(\mathbf {u} = (u_1,\ldots ,u_{k-1})\) and let \(u_i\) be the smallest value of \(\mathbf {u}\). Then, there exist trees \(T_1\in \mathcal {T}_{i-1}^c\) and \(T_2\in \mathcal {T}_{k-i-1}^c\) associated to \(\mathbf {u}_1 = (u_1,\ldots ,u_{i-1})\), resp. \(\mathbf {u}_2 = (u_{i+1},\ldots , u_{k-1})\). To \(\mathbf {u}\) we associate the tree \(T\in \mathcal {T}_{k-1}^c\), which has \(T_1\) as the left subtree of the root and \(T_2\) as the right subtree and colour the root blue.
-
Conversely, given a tree \(T\in \mathcal {T}_{k-1}^c\) let m be the number of blue vertices of the tree. We define a labelling
of the blue vertices in T by letting \(\sigma _T(i)\) be the ith vertex removed in a left-to-right exploration of the tree consisting of the blue vertices. This exploration starts with the vertex obtained by starting at the root and going left at any branching until this is no longer possible. Remove this vertex and repeat the procedure unless the removal disconnects a part from the tree or removes the root. If a part is disconnected explore this part (which is rooted in the right child of the last removed vertex) until it is fully explored and removed, and continue from there with the remaining tree. If the root is removed while it has a right child, explore the tree rooted in that child until it is fully explored and then stop. Similarly, define a bijection
by letting \(\tau _T(i)\) be the ith vertex seen by a left-to-right exploration of all vertices on the tree T. We also set \(\sigma _T^{-1}(\tau _T(0)):= 0\) and \(\sigma _T^{-1}(\tau _T(k)) := m+1\). Finally,
is defined recursively. For the root v of T, we set \(\varkappa _T(v) = (0,k)\). As before, removing v splits T into a left subtree \(T_1\) and a right subtree \(T_2\). If these trees are nonempty, set \(\varkappa _T(v_1) = \big (\varkappa _T^{{\scriptscriptstyle {({1}})}}(v),\tau _T^{-1}(v)\big )\) for the root \(v_1\) of \(T_1\), resp. \(\varkappa _T(v_2) = \big (\tau _T^{-1}(v),\varkappa _T^{{\scriptscriptstyle {({2}})}}(v)\big )\) for the root \(v_2\) of \(T_2\). Repeat this for the subtrees until \(\varkappa _T(v)\) is defined for all \(v\in T\). Thus, for each vertex \(v\in T\), its image \(\varkappa _T(v)\) captures
-
as its first entry the labelling \(\tau _T^{-1}\) of the last vertex seen by a left-to-right exploration before the first vertex of the subtree rooted in v (and set to 0 if there is no such vertex),
-
as its second entry the labelling \(\tau _T^{-1}\) of the first vertex seen by a left-to-right exploration after the last vertex of the subtree rooted in v (and set to k if there is no such vertex).
With these labelings at hand, we now describe four restrictions that are satisfied by the marks and locations of the connectors \(\mathbf {x}_1,\ldots , \mathbf {x}_m\) of every step-minimizing path connecting \(\mathbf {x}_0= (x_0,t_0)\) and \(\mathbf {x}_{m+1}=(x_{m+1},t_{m+1})\) to which the coloured tree T is associated, namely
-
(i)
if \(\sigma _T(i)\) is the root in T, then \(t_i>t_0,t_{m+1}\);
-
(ii)
if \(\sigma _T(i)\) is a child of \(\sigma _T(j)\) in T, then \(t_i>t_j\),
-
(iii)
if there is a red leaf v with \(i = \sigma _T^{-1}(\tau _T(\varkappa _T^{{\scriptscriptstyle {({1}})}}(v)))\) and \(j = \sigma _T^{-1}(\tau _T(\varkappa _T^{{\scriptscriptstyle {({2}})}}(v)))\), then
$$\begin{aligned} \left| x_i-x_j \right| ^d \le \kappa ^{1/\delta }(t_i\wedge t_j)^{-\gamma } (t_i\vee t_j)^{-\gamma /\delta }; \end{aligned}$$ -
(iv)
if there is a blue vertex v with \(i = \sigma _T^{-1}(\tau _T(\varkappa _T^{{\scriptscriptstyle {({1}})}}(v)))\) and \(j = \sigma _T^{-1}(\tau _T(\varkappa _T^{{\scriptscriptstyle {({2}})}}(v)))\), then
$$\begin{aligned} \left| x_i-x_j \right| ^d > \kappa ^{1/\delta }(t_i\wedge t_j)^{-\gamma } (t_i\vee t_j)^{-\gamma /\delta }. \end{aligned}$$
Note that whereas (i) and (ii) describe the order of the marks, (iii) and (iv) encode the spatial restrictions on the connectors via the colour of the tree vertices. In (iv), \(\mathbf {x}_i\) (resp. \(\mathbf {x}_j\)) is the first vertex to the left (resp. right) with a smaller mark than \(\mathbf {x}_{\sigma _T^{-1}(v)}\) and the inequality ensures that \(\mathbf {x}_i\) and \(\mathbf {x}_j\) are far enough apart that no edge with conductance two can exist between them. Conversely, the inequality in (iii) ensures the existence of an edge with conductance two. These conditions motivate the following definitions:
- \(\bullet \):
-
\(M_T\) as the set of vectors \((t_1,\ldots , t_m)\in (0,1)^m\) such that (i), (ii) hold,
- \(\bullet \):
-
\(I^{\mathrm {rl}}_T\) as the set of pairs \((i,j) \in \lbrace 0,\ldots ,m+1 \rbrace ^2\) for which a red leaf v of T exists such that \(i = \sigma _T^{-1}(\tau _T(\varkappa _T^{{\scriptscriptstyle {({1}})}}(v)))\) and \(j = \sigma _T^{-1}(\tau _T(\varkappa _T^{{\scriptscriptstyle {({2}})}}(v)))\),
- \(\bullet \):
-
\(I^{\mathrm {b}}_T\) as the set of pairs \((i,j) \in \lbrace 0,\ldots ,m+1 \rbrace ^2\) for which a blue vertex v of T exists such that \(i = \sigma _T^{-1}(\tau _T(\varkappa _T^{{\scriptscriptstyle {({1}})}}(v)))\) and \(j = \sigma _T^{-1}(\tau _T(\varkappa _T^{{\scriptscriptstyle {({2}})}}(v)))\),
- \(\bullet \):
-
and \(I^{\mathrm {bc}}_T\) as the set of pairs \((i,i+1) \in \lbrace 0,\ldots ,m+1 \rbrace ^2\) for which we have that \(\tau _T^{-1}(\sigma _T(i+1)) - \tau _T^{-1}(\sigma _T(i)) = 1\).
Whereas \(M_T\) captures the restrictions on the marks, \(I_T^{\mathrm {rl}}\) and \(I_T^{b}\) contain the indices to which the the spatial restrictions (iii) and (iv) apply, as for \((i,j)\in I_T^{\mathrm {b}}\) the vertices \(\mathbf {x}_i\) and \(\mathbf {x}_j\) cannot be near to each other and for \((i,j)\in I_T^{\mathrm {rl}}\) the vertices \(\mathbf {x}_i\) and \(\mathbf {x}_j\) have to be that near to each other so that an edge of conductance two exists between them. For each pair \((i,j)\in I_T^{\mathrm {rl}}\) we have \(j = i+1\) and \(I_T^{\mathrm {rl}}\), \(I_T^{\mathrm {bc}}\) form a partition of \(\lbrace (i,i+1):i = 0,\ldots ,m \rbrace \), because for any \((i,i+1)\in I_T^{\mathrm {bc}}\), there exists an edge of conductance one between the vertices \(\mathbf {x}_i\) and \(\mathbf {x}_{i+1}\).
Proof of Lemma 2.2
For \(T\in \mathcal {T}_{k-1}^c\), we define \(K_T(\mathbf {x},\mathbf {y})\) as the number of step minimizing paths P between \(\mathbf {x}\) and \(\mathbf {y}\) with \(w_P = k\) whose vertices have marks larger than the marks of \(\mathbf {x}\) and \(\mathbf {y}\) to which T is associated. Then
If \(k=1\) (or equivalently \(T=\emptyset \)) we have that \(K_T(\mathbf {x},\mathbf {y})\) is the indicator of the event that \(\mathbf {x}\) and \(\mathbf {y}\) are connected by an edge. For \(k=2\), if T is the tree consisting of the red root \( K_{T}(\mathbf {x},\mathbf {y}) = 1\{\left| x-y \right| ^d \le \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }\}\) and if T is the tree consisting of the blue root
For \(k\ge 3\) we split the tree at the root, i.e.
where \(T_1\) and \(T_2\) are the left, resp. right, subtree of T obtained by cutting the root. Repeat the step (15) by consecutively splitting the tree at the vertices as seen in the order of a depth first search of the blue vertices in the tree, reducing the product to terms corresponding to empty or single red vertex trees. We get
where \(\mathbf {x}_0=\mathbf {x}\), \(\mathbf {x}_{m+1}=\mathbf {y}\) and \(v_{(i,i+1)}\in T\) is the red leaf associated to (i, j) in the definition of \(I_T^{\mathrm {rl}}\). Note that the term \(K_{v_{(i,i+1)}}\) contains further spatial restrictions on \(\mathbf {x}_i\) and \(\mathbf {x}_{i+1}\), ensuring that these vertices are sufficiently close. Taking expectations yields
By Assumption 1.1, we have
Hence, using the Mecke formula for m points, we get
What remains to be seen is that when the right-hand side in (17) is denoted \(e^T_K(\mathbf {x}, \mathbf {y})\) and summed over all \(T\in \mathcal {T}_{k-1}^c\) we obtain \(e_K(\mathbf {x}, \mathbf {y}, k)\). This is clearly true when \(k=1\) and \(k=2\). Otherwise we use (13) to decompose \(e_K(\mathbf {x}, \mathbf {y}, k)\). By induction, the factors in this decomposition can be represented as in (17) and we obtain
Writing the terms \(e^{T_1}_K(\mathbf {x}, \mathbf {z})\) and \(e^{T_2}_K(\mathbf {z}, \mathbf {y})\) as in (17) as integrals over \(\mathbf {x}_1, \ldots , \mathbf {x}_{m_1}\) and \(\mathbf {x}_{m_1+2}, \ldots , \mathbf {x}_{m}\) we can insert \(\mathbf {z}\) as \(\mathbf {x}_{m_1+1}\) and note that the conditions and terms emerging in that integral are exactly the same as in (17) for the tree T with \(T_1\) and \(T_2\) as left and right subtree of the root. Indeed,
-
the vector \((t_1,\ldots ,t_m)\) of the marks of \(\mathbf {x}_1,\ldots ,\mathbf {x}_m\) is an element of \(M_T\) iff
\((t_1,\ldots ,t_{m_1})\in M_{T_1}\), \((t_{m_1+2},\ldots ,t_m)\in M_{T_2}\) and \(t_{m_1+1} > s\vee t\),
-
the spatial conditions described by \(I_T^{\mathrm {b}}\) are fulfilled iff \(x_1,\ldots ,x_{m_1}\) fulfills the ones decribed by \(I_{T_1}^{\mathrm {b}}\), \(x_{m_1+2},\ldots ,x_{m}\) the ones by \(I_{T_2}^{\mathrm {b}}\) and
$$\begin{aligned} {\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }}, \end{aligned}$$ -
\(I^{\mathrm {rl}}_T\) is the union of \(I^{\mathrm {rl}}_{T_1}\) and \(I^{\mathrm {rl}}_{T_2}\) where the values of the pairs of \(I^{\mathrm {rl}}_{T_2}\) have been increased by \(m_1+1\) and in the same way \(I^{\mathrm {bc}}_{T}\) directly emerges from \(I^{\mathrm {bc}}_{T_1}\) and \(I^{\mathrm {bc}}_{T_2}\).
Hence, \(e_K(\mathbf {x},\mathbf {y},k)\) can be obtained by summing \(e_K^T(\mathbf {x},\mathbf {y})\) over all \(T\in \mathcal {T}_{k-1}^c\). \(\square \)
Lemma 2.3
(k-connection lemma). Let \(\mathbf {x}= (x,t), \mathbf {y}= (y,s)\) be two given vertices with \({\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }}\) and \(0<\ell <\frac{1}{e}\) such that \(\ell <t\vee s\). Then there exists \(C>1\) such that, for \(k\ge 3\), we have
where \(k_*:= k \mod 2\).
Proof
Choose \(C>1\) such that C is larger than the constants appearing in Lemmas 2.1, A.1 and A.2 of the appendix. We now show by induction that
holds for all \(k\ge 2\), where \({{\,\mathrm{Cat}\,}}(k-1)\) is the \((k-1)\)-th Catalan number. Note that, for \(k\ge 2\), it holds \(e_K(\mathbf {x},\mathbf {y},k) \le 1\) for \({\left| x-y \right| ^d \le \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }}\). Thus, it remains to show (18) under the condition \({\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }}\). For \(k=2\), the bound (18) is already established by Lemma 2.1. If \(k=3\) and \(\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma }(t\vee s)^{-\gamma /\delta }\), by (13) we have
Using the bounds established in Lemma 2.1 together with Lemma A.2 leads to
Let \(k\ge 4\) and assume that (18) holds for all \(j = 2,\ldots , k-1\). For \(\mathbf {x}, \mathbf {y}\) such that \(\left| x-y \right| ^d > \kappa ^{1/\delta } (t\wedge s)^{-\gamma }(t \vee s)^{-\gamma /\delta }\), by (13),
With (18) we hence get,
Using Lemma A.1 and Lemma A.2 the last expression can be further bounded by
If k is even, i and \(k-i\) need to be either both even or both odd, for \(i=1,\ldots ,k-1\). Since \(\ell >0\) is chosen small enough that \(\log (\frac{1}{\ell })^2 < \ell ^{1-\gamma -\gamma /\delta }\), we have that in both cases
If k is odd, an analogous observation leads to
Hence, we have
and (18) holds for k. The observation that \({{\,\mathrm{Cat}\,}}(k)\le 4^k\) concludes the proof. \(\square \)
Probability bounds for bad paths. With Lemma 2.3 we can establish a bound for \({\mathbb {E}}_{\mathbf {x},\mathbf {y}}N(\mathbf {x},\mathbf {y},n)\), recall the definitions in Sect. 2.2. As in (10) and (11), we have
Here \(\mathbf {z}\) is the most powerful vertex of the path disregarding \(\mathbf {y}\) and connects to \(\mathbf {y}\) via less powerful vertices. As done for \(K(\mathbf {x},\mathbf {y},k)\) in the previous section we compare \({\mathbb {E}}_{\mathbf {x},\mathbf {y}}N(\mathbf {x},\mathbf {y},n)\) with a deterministic mapping
defined as
and for \(n\ge 2\)
for \(\mathbf {x},\mathbf {y}\in \mathbb {R}^d\times (0,1],\) if \({\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }}\), and otherwise \(e_N(\mathbf {x},\mathbf {y},2) = 1\) and \(e_N(\mathbf {x},\mathbf {y},n) = 0\) for \(n\ge 3\).
Lemma 2.4
Let \(\mathbf {x}, \mathbf {y}\in \mathbb {R}^d\times (0,1]\) be two given vertices. Then, for all \(n\in \mathbb {N}\), we have
Proof
First recall that for \({\left| x-y \right| ^d \le \kappa ^{1/\delta }(t\wedge s)^{-\gamma } (t\vee s)^{-\gamma /\delta }}\) we have \(N(\mathbf {x},\mathbf {y},n) = 0\) for \(n\ge 3\) and \(N(\mathbf {x},\mathbf {y},2) = 1\). Thus in this case \(N(\mathbf {x},\mathbf {y},n)\) is equal to \(e_N(\mathbf {x},\mathbf {y},n)\) and consequently their expectations are equal. Otherwise, the proof follows the same argument as in Lemma 2.2, where we again classify the possible connection strategies between \(\mathbf {x}\) and \(\mathbf {y}\) through coloured binary trees. We therefore only briefly present the required class of trees, explain the association of a path to the corresponding tree and the restrictions on marks and space which a step minimizing path that associates to T has to satisfy.
Let \(\mathcal {T}_{n}^{cb}\) be a class of coloured rooted binary trees with n vertices which are constructed as follows. For \(k\le n\), we have a backbone consisting of k vertices, starting with the root followed by \(k-1\) vertices, each a left child of the previous one. The last vertex in this line is coloured red, the others blue. Let \(i_1,\ldots ,i_k\in \mathbb {N}\) with \(i_1+\cdots + i_k = n-k\). A tree \(T\in \mathcal {T}_{n}^{cb}\) is formed by attaching to the j-th vertex (as seen by a left-to-right exploration of the backbone) a coloured subtree \(T_j\in \mathcal {T}_{i_j}^{c}\) rooted in its right child, for \(j=1,\ldots ,k\).
To any path \(P = (\mathbf {x}_0,\mathbf {x}_1,\ldots ,\mathbf {x}_{m+1})\) with \(\mathbf {x}_0 = \mathbf {x}\) and \(\mathbf {x}_{m+1} = \mathbf {y}\) where the connecting vertices have larger marks than \(\mathbf {y}\) we associate a tree \(T \in \mathcal {T}_n^{cb}\) as follows. We say \(\mathbf {x}_i\) is a powerful vertex of P if \(t_i\le t_j\) for all \(j=0,\ldots ,i-1\). By definition, the vertices \(\mathbf {x}_0\) and \(\mathbf {x}_m\) are always powerful vertices. We denote by \(\lbrace \mathbf {x}_{i_1},\ldots ,\mathbf {x}_{i_{k+1}} \rbrace \) the set of powerful vertices keeping the order in the path. Then two consecutive powerful vertices \(\mathbf {x}_{i_j}\) and \(\mathbf {x}_{i_{j+1}}\) are, by definition, connected via a path of connectors \(\mathbf {x}_{i_j+1},\ldots \mathbf {x}_{i_{j+1}-1}\) of conductance \(w_j:=w_P(i_{j+1})-w_P(i_j)\). If \(w_j\ge 2\), associate the connectors of the path connecting \(\mathbf {x}_{i_j}\) and \(\mathbf {x}_{i_{j+1}}\) to a non-empty coloured tree \(T_j \in \mathcal {T}_{w_j-1}^c\) as in the proof of Lemma 2.2. Let \(T \in \mathcal {T}_n^{cb}\) be the coloured tree which has a backbone of length k and where \(T_{j}\) is attached to the j-th vertex (as seen by a left-to-right exploration of the backbone) such that its right child is the root of \(T_j\), see Fig. 5 for an example.

Associating a coloured binary tree to a path. The powerful vertices of the path are indicated in black. We have \(k=3\) vertices on the backbone. The three trees attached to the backbone are constructed as in Fig. 4, where the vertices with the smallest mark on the connecting paths are the roots which are attached as right children to the backbone
Given a tree \(T\in \mathcal {T}_{n}^{cb}\), let m be the number of blue vertices of the tree and k the number of vertices of the backbone. As in the proof of Lemma 2.2, we define a labelling
by letting \(\sigma _T(0)\) be the red vertex on the backbone and \(\sigma _T(i)\) be the ith vertex seen by a left-to-right exploration of the blue vertices of T. Define the bijection
by letting \(\tau _T(0)\) be the red vertex on the backbone and \(\tau _T(i)\) be the \((i+1)\)st vertex seen by a left-to-right exploration of all other vertices of the tree. Denote by \(v_1,\ldots ,v_k\) the vertices of the backbone of T and \(T_1,\ldots ,T_k\) the subtrees rooted in their right child. Set \(i_j := \sigma ^{-1}(v_{j})\), for \(i=1,\ldots ,k\), and \(i_{k+1} := m+1\). Then, the following restrictions on marks and space are satisfied by the vertices \(\mathbf {x}_1,\ldots ,\mathbf {x}_{m}\) of any path connecting \(\mathbf {x}_0 = \mathbf {x}\) and \(\mathbf {x}_{m+1} = \mathbf {y}\) to which T is associated:
-
(i)
\(t_{i_{j}}>t_{i_{j+1}}\), for \(j=1,\ldots ,k\),
-
(ii)
if there exists a vertex \(v_j\) of the backbone with \(\tau _T^{-1}(v_j) \ge 2\), then
$$\begin{aligned} \left| x_0 - x_{i_j} \right| ^d > \kappa ^{1/\delta }(t_0\wedge t_{i_j})^{-\gamma } (t_0\vee t_{i_j})^{-\gamma /\delta }, \end{aligned}$$ -
(iii)
for \(j=1,\ldots ,k\), the vertices \(\mathbf {x}_{i_j+1},\ldots ,\mathbf {x}_{i_{j+1}-1}\) satisfy the four restrictions on marks and space given by the coloured tree \(T_i\) and \(\mathbf {x}_{i_j},\mathbf {x}_{i_{j+1}}\) as described prior to the proof of Lemma 2.2.
For \(T\in \mathcal {T}_{n}^{cb}\), we define \(N_T(\mathbf {x},\mathbf {y})\) as the number of step minimizing paths to which T is associated. Denote again by \(v_1,\ldots ,v_k\) the vertices of the backbone of T and set \(i_j := \sigma ^{-1}(v_j)\), \(i_{k+1} := m+1\). Splitting the tree at each blue vertex of the backbone leads to
where \(T_j\) is the subtree attached to the right child of \(v_j\). Proceeding for each \(K_{T_j}\) and using the iterative structure of \(e_N\) as in the proof of Lemma 2.2 yields the result. \(\square \)
As a path described by the event \(\tilde{A}_n^{_{(\mathbf {x})}}\) (recall the definition from Sect. 2.2) has a restriction on the mark but not on the location of its last vertex, we can use the integral
with \(\mathbf {y}= (y,s)\) and s smaller than some yet to be determined value to bound \({\mathbb {P}}_{\mathbf {x}}(\tilde{A}_n^{_{(\mathbf {x})}})\). Thus, we define for given \(\mathbf {x}= (x,t)\) and \(n\in \mathbb {N}\) the mapping \(\mu _n^\mathbf {x}:(0,t] \rightarrow [0,\infty )\) by
Recall that we write \(k_*:= k\pmod 2\) and \(I_\rho := \int \mathrm {d}x \, \rho (\kappa ^{-1/\delta }\left| x \right| ^d)\). By the definition of \(e_N(\mathbf {x},\mathbf {y},1)\) we have \(\mu _1^\mathbf {x}(s) \le I_\rho s^{-\gamma } t^{\gamma -1}\), for \(s\in (0,t]\), and, for \(n\ge 2\), with a short calculation using Lemma 2.3 we get the recursive property
where \(C>0\) is the constant from Lemma 2.3. Here, the first summand (24) corresponds to the first summand of (19), i.e. the number of paths with conductance n where the first vertex \(\mathbf {x}\) and the last vertex with mark s are the two most powerful vertices of the path. The summands (25) and (26) describe the second summand of (19), where (26) covers the case that the last vertex of a path is directly connected to the preceding most powerful vertex.
Using the recursive inequality in (24)–(26) we now establish bounds for \(\mu _n^{\mathbf {x}}\). To make the proof more transparent we continue working with a general sequence \((\ell _n)_{n\in \mathbb {N}_0}\) assuming only that it is at least exponentially decaying, i.e. for any \(b>0\) it holds that \(\ell _{n+2} < b \ell _n\). We choose \(b>0\) small enough such that \(\sum _{j=2}^\infty b^{(\gamma +\gamma /\delta -1)\frac{(j-3)(j-1)}{8}}\) converges. This choice is possible because in our regime \(\gamma +\gamma /\delta \) is larger than one. We denote the limit of the series by \(c_{b}>1\). As we have already seen for the optimal path structure in Sect. 2.1, the chosen sequence \((\ell _n)_{n\in \mathbb {N}_0}\) decays much faster than any exponential rate so that this assumption will not have any effect on the result. Without loss of generality we may additionally assume \(\ell _0<\frac{1}{e}\).
Lemma 2.5
Let \(\mathbf {x}= (x,t)\) be a given vertex and let the sequence \((\ell _n)_{n\in \mathbb {N}_0}\) be at least exponentially decaying with \(\ell _0<t\wedge \frac{1}{e}\). Then, there exists a constant c such that, for \(n\in \mathbb {N}\), we have
where
and
Proof
We choose the constant \(c>0\) such that it is larger than \(\frac{I_{\rho }c_b}{(\gamma + \gamma /\delta -1)\wedge 1}\) and larger than the constant C from Lemma 2.3. Since this also implies that \(c>I_{\rho }\), by the definition of \(\mu _1^\mathbf {x}\) we have
For \(n=2\), the recursive inequality for \(\mu _2^\mathbf {x}\) yields
Using the already established bound for \(n=1\) we have
Now let \(n\ge 3\) and we assume that (27) holds for all \(\tilde{n}\le n-1\). Then, using the already established bounds and the recursive inequality property we have
Assume for the moment that
holds. Then, as \(c>C\), the term \(\mu _n^\mathbf {x}(s)\) can be further bounded by
which by (28) is smaller than \(C_n s^{-\gamma }\) for \(s\in (0,t]\). Hence, by induction the stated inequality holds for all \(n\in \mathbb {N}\).
It remains to show that (29) holds. If k is even, a repeated application of (28) and \(\ell _{n+2} <b\ell _n\) yields
If k is odd a similar calculation leads to
Distinguishing whether n is even or odd, the second term of (29) can be bounded in a similar way and so the whole expression can be bounded by
where the two sums can be bounded by \(c_b\) which implies that (29) holds. \(\square \)
Notice that, as stated in Sect. 2.1, the inequality (29) shows us that the major contribution to the expected value of \(N(\mathbf {x},\mathbf {y},n)\) comes from the paths where the two most powerful vertices are connected via a single connector. To see why, notice that the right-hand side of (29) is, up to a constant, the same as the \(k=2\) term of the left-hand side. In fact, Lemma 2.5 shows that the dominant class of possible paths is the one described in Sect. 2.1.
We are now ready to bound the probability of the event \(\tilde{A}^{(\mathbf {x})}_n\), i.e. the event that there exists a path of conductance n where the final vertex is the first and only one which has a mark smaller than the corresponding \(\ell _n\). In particular the final vertex is the most powerful vertex of the path. By Mecke’s equation, we have
Hence, Fubini’s theorem and Lemma 2.5 yield
As in Sect. 2.1, with \(\ell _0 < t\wedge \frac{1}{e}\) we choose the sequence \((\ell _n)_{n\in \mathbb {N}_0}\) for \(\varepsilon >0\), such that
and we have
Since \(C_n\) is defined recursively, we can obtain a recursive representation of the sequence \((\ell _n)_{n\in \mathbb {N}_0}\). Let \(\eta _n := \ell _n^{-1}\) for \(n\in \mathbb {N}_0\). Then, we have
Hence, there exists a different constant \(c>0\) such that \(\eta _{n+2}^{1-\gamma } \le c\eta _n^{\gamma /\delta } + c\log (\eta _{n+1})\eta _{n+1}^{1-\gamma }\). By induction, we conclude that there exist \(b>0\) and \(B>0\) such that
and thus the rate of decay of \((\ell _n)_{n\in \mathbb {N}_0}\) is faster than exponential.
Probability bounds for good paths. We now proceed to establish a bound on the last summand \(\sum _{n=1}^{2\Delta }{\mathbb {P}}_{\mathbf {x},\mathbf {y}}(B^{_{(\mathbf {x},\mathbf {y})}}_n)\) of (TMB). To do so we consider the original graph \(\mathscr {G}\). Recall that \(B^{_{(\mathbf {x},\mathbf {y})}}_n\) is the event that there exists a good path of length n between \(\mathbf {x}\) and \(\mathbf {y}\). This can be bounded by the union of all possible good paths given by the vertices of the Poisson point process, i.e.
where \(\mathbf {x}= \mathbf {x}_0\), \(\mathbf {y}= \mathbf {x}_n\), \(\bigcup ^{\ne }\) denotes the union across all possible sets of pairwise distinct vertices \(\mathbf {x}_0,\ldots ,\mathbf {x}_n\) of the Poisson process. By Mecke’s equation the right-hand side can be bounded from above by

The following lemma reduces this bound to a non-spatial problem for paths of “reasonable” length which only depends on the marks of \(\mathbf {x}_1,\ldots ,\mathbf {x}_{n-1}\) but not on their location. This allows us to use a similar strategy as the one used by Dereich et al. [11], where lower bounds for the typical distance of non-spatial preferential attachment models are established.
Lemma 2.6
For given vertices \(\mathbf {x}=(x,t)\) and \(\mathbf {y}=(y,s)\), let \(\Delta \le c_\varepsilon \left| x-y \right| ^\epsilon \) for some \(1>\varepsilon >0\) and \(c_{\varepsilon }>0\). Then, there exist constants \(a>0\) and \(\tilde{\kappa } > 0\) such that, for \(n\le \Delta \), we have
where \(t_0=t\) resp. \(t_n=s\) are the marks of \(\mathbf {x}\) resp. \(\mathbf {y}\) and \(\mathbf {x}_i = (x_i, t_i)\) for \(i=1,\ldots ,n-1\).
Remark 2.1
The constants a and \(\tilde{\kappa }\) of Lemma 2.6 depend on the choice of \(\varepsilon \) and \(c_\varepsilon \). But for \(\Delta = O(\log \left| x-y \right| )\), for any \(\epsilon >0\) there exists a \(c_\epsilon >0\), such that, for \(\left| x-y \right| \) large enough, we have \(\Delta \le c_\varepsilon \left| x-y \right| ^\epsilon \). Thus, if \(\left| x-y \right| \) is large enough, the choice of a and \(\tilde{\kappa }\) does not depend on \(\left| x-y \right| \).
Proof
Let \(\lbrace \mathbf {x}, \mathbf {x}_1, \ldots , \mathbf {x}_{n-1}, \mathbf {y} \rbrace \) be a set of given vertices. By Assumption 1.1 we have
As \(n\le c_\varepsilon \left| x-y \right| ^\epsilon \), no matter the choice of vertices, there must exist at least one edge between two vertices \(\mathbf {x}_{k-1} = (x_{k-1},t_{k-1})\) and \(\mathbf {x}_k = (x_k,t_k)\) with \(\left| x_{k-1}-x_k \right| \ge c_\varepsilon ^{-1} \left| x-y \right| ^{1-\varepsilon }\). Hence, the expression above can be further bounded by
where the last inequality is achieved by integration over the location of the vertices. We choose \(\tilde{\kappa }>2c_\varepsilon ^{d}\kappa ^{1/\delta }\vee 2I_\rho \). Since \(\delta >1\), the term
can be bounded by \(c_\varepsilon ^{d}\kappa ^{1/\delta } (t_{k-1}\wedge t_k)^{-\gamma }(t_{k-1}\vee t_k)^{\gamma -1} \left| x-y \right| ^{-d(1-\varepsilon )}\) and therefore there exists a constant \(a>0\) such that we have
\(\square \)
By Remark 2.1, with Lemma 2.6 and Fubini’s theorem we obtain
where \(\mathbf {x}= (x,t_0)\) and \(\mathbf {y}= (y,t_n)\). We define,
and set \(\nu _0^\mathbf {x}(s) = \delta _0(t-s)\). Then, the inequality above can be rewritten as
Note that as defined, \(\nu _n^\mathbf {x}(s)\) can be written recursively as
This allows us to establish an upper bound for \(\nu _n^\mathbf {x}(s)\) analogous to the non-spatial case in [11]. The following lemma is a corollary of [11, Lemma 1].
Lemma 2.7
Let \((\ell _n)_{n\in \mathbb {N}}\) be a given non-increasing sequence and \(\nu _n^\mathbf {x}(s)\) be as defined in (33), where \(\mathbf {x}= (x,t)\) and \(s\in (0,1)\). Then, there exists a constant \(c>0\) such that, for all \(n\in \mathbb {N}\),
where
and \(\alpha _1 = \tilde{\kappa } t^{\gamma -1}\), \(\beta _1 = \tilde{\kappa } t^{-\gamma }\).
Proof
For \(n=1\), we have by (33) that

Assume (35) holds for \(n\in \mathbb {N}\). Then, by (34), we have that
Hence, by induction (35) holds for all \(n\in \mathbb {N}\). \(\square \)
Although Lemma 2.7 holds for an arbitrary sequence \((\ell _n)_{n\in \mathbb {N}}\), recall that we have chosen \((\ell _n)_{n\in \mathbb {N}}\) such that (30) holds. This implies by (31) that there exists a constant \(c_1>0\) such that
where \(\eta _n := \ell _n^{-1}\) as before. Additionally, notice that \((\alpha _n)_{n\in \mathbb {N}}\) and \((\beta _n)_{n\in \mathbb {N}}\) are non-decreasing sequences. By Lemma 2.7, we have that
It follows from the definition of \((\alpha _n)_{n\in \mathbb {N}}\) and \((\beta _n)_{n\in \mathbb {N}}\) that \(\beta _n \le c^{-1}\alpha _{n+1}\) and
where the second summand on the right-hand side is bounded by a multiple of the first. Therefore, there exists a constant \(c_2>0\) such that \(\beta _n^2 \le c_2 \alpha _{n+1}^2 \ell _{n+1}^{1-2\gamma }\). This and the monotonicity of the sequences \((\alpha _n)_{n\in \mathbb {N}}\) and \((\ell _n)_{n\in \mathbb {N}}\) gives that
Recall that the sequence \((C_n)_{n\in \mathbb {N}}\) from Lemma 2.5 is defined as
with \(C_1 = c\ell _0^{\gamma -1}\) and \(C_2 = c^2\ell _0^{-\gamma /\delta } + c\log (\tfrac{1}{\ell _1})C_1\). We compare this sequence to \((\alpha _n)_{n\in \mathbb {N}}\) in order to bound (38) further. By writing \(\alpha _{n+2}\) in terms of \(\alpha _n\) and \(\beta _n\) we have that
As all summands on the right-hand side are bounded by a multiple of \(\alpha _n \ell _n^{1-2\gamma }\log ({1/\ell _{n+1}})\) and \(\log ({1/\ell _{n+1}})\) is smaller than a multiple of \(\log (1/\ell _{n})\), there exists a constant \(c_3\) such that \(\alpha _{n+2} \le c_3 \alpha _n \ell _n^{1-2\gamma }\log ({1/\ell _n})\). To compare \((\alpha _n)_{n\in \mathbb {N}}\) and \((C_n)_{n\in \mathbb {N}}\), notice that, up to a constant, \(\alpha _1\) and \(\alpha _2\) are equal to \(C_1\) and \(C_2\). Moreover
Applying this inequality recursively and expressing \(\alpha _{n+2}\) we obtain that for some \(c_4>0\)
Hence, we have
where the second inequality follows by (30) and (37). Observe that, as \(\frac{\delta (1-\gamma )}{\gamma }<1\), the series \(\sum _{i=1}^{\infty } \left( \delta (1-\gamma )/\gamma \right) ^i\) converges. Hence, there exists a constant which is larger than \(c_1\) to the power \({\sum _{j=1}^i(\delta (1-\gamma )/\gamma )^i}\) for any \(i\in \mathbb {N}\) and a constant \(c_5>0\) such that
Furthermore since we have established that \(\eta _n\) is of the order displayed in (32) it follows directly that the left-hand side multiplied with the product above can also be bounded by \(\ell _{n+1}^{-c_5}\) for any sufficiently large constant \(c_5>0\). Hence, there exists a further constant \(c_6 >0\) such that \(\frac{4(1+c_2)}{2\gamma -1}\alpha _{n+1}^2 \ell _{n+1}^{1-2\gamma } \le \frac{c_6}{(n+1)^4}\ell _{n+1}^{-(1+c_5)}\). Therefore, we have by using (32) once more that
Let \(D>0\) such that \(B(1+c_5)(\gamma /(\delta (1-\gamma )))^{\frac{1-D}{2}}<a\) and choose \(\Delta \le \frac{2\log \log \left| x-y \right| }{\log \left( \gamma /\delta (1-\gamma ))\right) } - D\). Then the above expression is of order \(\mathcal {O}(\log \log \left| x-y \right| ^{-2})\). Hence, for our choice of \(\Delta \), we have
which implies the stated lower bound of Theorem 1.1(b).
2.4 The non-ultrasmall regime
In this section we consider the case \(\gamma <\frac{\delta }{\delta +1}\) and show that the graph is not ultrasmall, i.e. the chemical distance in the graph is not of double logarithmic order of the Euclidean distance. In particular, we show the following.
Proposition 2.1
Let \(\mathscr {G}\) be a geometric random graph which satisfies Assumption 1.1 for some \(\delta >1\) and \(0<\gamma <\frac{\delta }{\delta + 1}\). Then, for any \(p>1\), there exists \(c>0\) such that, for \(\mathbf {x},\mathbf {y}\in \mathbb {R}^d\times (0,1)\), we have
under \({\mathbb {P}}_{\mathbf {x},\mathbf {y}}\) with high probability as \(\left| x-y \right| \rightarrow \infty \).
The proof is structurally analogous to the ultrasmall case, but significantly easier due to the simpler nature of the dominating strategy. As in Sect. 2.2, we bound the probabilities in (TMB) using a suitable truncation sequence \((\ell _n)_{n\in \mathbb {N}_0}\) such that the probability that bad paths starting in a vertex \(\mathbf {x}\) exist can be made arbitrarily small. In this case, however, the truncation sequence decreases only exponentially. Similarly to the ultrasmall case, we construct a graph \(\tilde{\mathscr {G}}\) which contains a copy of \(\mathscr {G}\) and additionally an edge is added between two vertices \(\mathbf {x}=(x,t)\) and \(\mathbf {y}= (y,s)\) of \(\tilde{\mathscr {G}}\) whenever
Unlike done previously in Sect. 2.2, we assign no conductance to any edge in \(\tilde{\mathcal {G}}\) and therefore only consider the lengths of paths. We declare a self-avoiding path \(P = (\mathbf {x}_0,\ldots ,\mathbf {x}_n)\) in \(\tilde{\mathscr {G}}\) step minimizing if there exists no edge between \(\mathbf {x}_i\) and \(\mathbf {x}_j\) for all i, j with \(\left| i-j \right| \ge 2\) and denote by \(\tilde{A}^\mathbf {x}_n\) the event that there exists a step minimizing path starting in \(\mathbf {x}\) of length n in \(\tilde{\mathscr {G}}\), where the final vertex is the first vertex which has a mark smaller than the corresponding \(\ell _n\). Then the first two summands of the right-hand side of (TMB) can be bounded from above by \(\sum _{n=1}^\Delta {\mathbb {P}}_{\mathbf {x}}(\tilde{A}^{(\mathbf {x})}_n)\) and \(\sum _{n=1}^\Delta {\mathbb {P}}_{\mathbf {y}}(\tilde{A}^{(\mathbf {y})}_n)\), since for any path implying the event \(A^{(\mathbf {x})}_n\) there exists a step minimizing path in \(\tilde{\mathscr {G}}\) of smaller or equal length which also fails to be good on its last vertex.
To bound these probabilities, we define the random variable \(N(\mathbf {x},\mathbf {y},n)\) as the number of distinct step minimizing paths between \(\mathbf {x}\) and \(\mathbf {y}\) of length n, whose vertices \((x_1,t_1),\ldots (x_{n-1},t_{n-1})\) fulfill \(t\ge \ell _0, t_1\ge \ell _1,\ldots , t_{n-1} \ge \ell _{n-1}\) and which all have a larger mark than \(\mathbf {y}\). By Mecke’s equation we have that
As before, the paths counted in \(N(\mathbf {x},\mathbf {y},n)\) can be decomposed such that (19) holds, where \(K(\mathbf {x},\mathbf {y},k)\) is the number of step minimizing paths between \(\mathbf {x}\) and \(\mathbf {y}\) of length k such that the vertices \(\mathbf {x}_1,\ldots ,\mathbf {x}_{{k}-1}\) between them have marks larger than \(\mathbf {x}\) and \(\mathbf {y}\). We again refer to such vertices as connectors. Note that if \(\left| x-y \right| ^d\le \kappa ^{1/\delta }(t\wedge s)^{-\gamma }(t\vee s)^{\gamma - 1}\), there exists no step minimizing paths of length larger or equal two between \(\mathbf {x}\) and \(\mathbf {y}\). Hence, we have \(N(\mathbf {x},\mathbf {y},n) = K(\mathbf {x},\mathbf {y},n) = 0\) for \(n\ge 2\) under this assumption.
We now bound the expectation of \(K(\mathbf {x},\mathbf {y},k)\). As in Sect. 2.2, we define a mapping
where \(e_K(\mathbf {x},\mathbf {y},1) = \rho (\kappa ^{-1/\delta }(t\wedge s)^{\gamma }(t\vee s)^{1-\gamma }\left| x-y \right| ^d),\) for \(\mathbf {x},\mathbf {y}\in \mathbb {R}^d\times (0,1]\) and
if \({\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma }(t\vee s)^{\gamma - 1}}\) and otherwise \(e_K(\mathbf {x},\mathbf {y},k) = 0\). As before we use a binary tree to classify the connection strategies and use this together with Assumption 1.1 to obtain \({\mathbb {E}}_{\mathbf {x},\mathbf {y}} K(\mathbf {x},\mathbf {y},k) \le e_K(\mathbf {x},\mathbf {y},k)\), for \(k\in \mathbb {N}\).
Lemma 2.8
Let \(\mathbf {x}= (x,t), \mathbf {y}= (y,s)\) be vertices with \(\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma }(t\vee s)^{\gamma - 1}\). Then there exists \(C>1\) such that, for \(k\ge 2\), we have
Proof
By [19, Lemma 2.2] there exists a constant \(C>1\) such that if \(\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma }(t\vee s)^{\gamma - 1}\) we have
We now show by induction that
holds for all \(k\ge 2\). This is sufficient, since \({{\,\mathrm{Cat}\,}}(k)\le 4^{k}\). For \(k=2\) this follows from (39). Let \(k\ge 3\) and assume (40) holds for all \(j= 2,\ldots , k-1\). For \(\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma }(t\vee s)^{\gamma - 1}\) this, together with the definition of \(e_K(\mathbf {x},\mathbf {y},k)\), yields
With (39) the right-hand side can be further bounded by
As \(\sum _{i=1}^{k-1} {{\,\mathrm{Cat}\,}}(i-1){{\,\mathrm{Cat}\,}}(k-i-1) = {{\,\mathrm{Cat}\,}}(k-1)\) we get that (40) holds for k. \(\square \)
Probability bounds for bad paths Using Lemma 2.8 and (19) we find a suitable upper bound for \(\int _{\mathbb {R}^d}{\mathbb {E}}_{\mathbf {x},\mathbf {y}}N(\mathbf {x},\mathbf {y},n) \mathrm {d}y\), with \(\mathbf {y}= (y,s)\), which leads to a bound for \({\mathbb {P}}_{\mathbf {x}}(\tilde{A}_n^{\mathbf {x}})\). Recall that by (19) we have, for \(n\in \mathbb {N}\),
As in Sect. 2.2, to establish an upper bound on \({\mathbb {E}}_{\mathbf {x},\mathbf {y}}N(\mathbf {x},\mathbf {y},n)\), we define a mapping
by setting \(e_N(\mathbf {x},\mathbf {y},1) = \rho (\kappa ^{-1/\delta }(t\wedge s)^{\gamma }(t\vee s)^{1-\gamma }\left| x-y \right| ^d)\), for \(\mathbf {x},\mathbf {y}\in \mathbb {R}^d\times (0,1]\), and for \(n\ge 2\) if \({\left| x-y \right| ^d > \kappa ^{1/\delta }(t\wedge s)^{-\gamma }(t\vee s)^{\gamma - 1}}\) we set \(e_N(\mathbf {x},\mathbf {y},n)\) to be
and otherwise \(e_N(\mathbf {x},\mathbf {y},n) = 0\). As in Sect. 2.2 we have \({\mathbb {E}}_{\mathbf {x},\mathbf {y}} N(\mathbf {x},\mathbf {y},n) \le e_N(\mathbf {x},\mathbf {y},n)\), for \(n\in \mathbb {N}\). Thus, for a given vertex \(\mathbf {x}=(x,t)\) and \(n\in \mathbb {N}\), an upper bound of \(\int _{\mathbb {R}^d} \mathrm {d}y {\mathbb {E}}_{\mathbf {x},\mathbf {y}}N(\mathbf {x},\mathbf {y},n)\) is given by the mapping \(\mu _n^\mathbf {x}:(0,t] \rightarrow [0,\infty )\) defined by
where \(\mathbf {y}= (y,s)\). We interpret s as the mark of the last vertex of a path counted by the random variable \(N(\mathbf {x},\mathbf {y},n)\). With \(I_\rho = \int \mathrm {d}x \rho (\kappa ^{-1/\delta }\left| x \right| ^d)\) we can see by the definition of \(e_N(\mathbf {x},\mathbf {y},1)\) that \(\mu _1^\mathbf {x}(s) \le I_\rho s^{-\gamma }t^{\gamma -1}\) for \(s\in (0,t]\) and for \(n\ge 2\) it follows by a short calculation and Lemma 2.8 that
where \(C>1\) is the constant from Lemma 2.8. To establish a bound for \(\mu _n^\mathbf {x}\) no further assumptions on the truncation sequence \((\ell _n)_{n\in \mathbb {N}_0}\) are necessary. As discussed in Sect. 2.1 we will see that the major contribution to the mass of \(\mu _n^\mathbf {x}(s)\) comes from the paths where the two most powerful vertices are connected directly and not via one or more connectors. This is indicated by the definition of the sequence \((C_n)_{n\in \mathbb {N}_0}\) and the inequality (44) in the proof of the following lemma.
Lemma 2.9
Let \(\mathbf {x}= (x,t)\) be a given vertex and let the sequence \((\ell _n)_{n\in \mathbb {N}_0}\) be monotonically decreasing with \(\ell _0 <t\wedge \frac{1}{e}\). Then, there exists \(c>0\) such that, for \(n\in \mathbb {N}\),
where \(C_1 = c\ell _0^{\gamma -1}\) and \(C_{n+1} = c\log (\frac{1}{\ell _n})C_n\).
Proof
We choose the constant \(c>2(C\vee I_\rho )\), where C is as in Lemma 2.8. Then by definition of \(\mu _1^\mathbf {x}\) we have \(\mu _1^\mathbf {x}(s) = I_\rho s^{-\gamma }t^{\gamma -1} \le c s^{-\gamma }\ell _0^{\gamma -1} = C_1s^{-\gamma }\) for \(s\in (0,t]\). Let \(n\ge 2\) and assume that (43) holds for all \(\tilde{n} \le n-1\). Then, by (43),
We now want to show that
since assuming this leads to \(\mu _n^\mathbf {x}(s) \le 2I_\rho \log (\tfrac{1}{\ell _{n-1}}) C_{n-1}s^{-\gamma } \le c\log (\tfrac{1}{\ell _{n-1}}) C_{n-1}s^{-\gamma }\) \( = C_n s^{-\gamma }\), which completes the proof. By definition of the constants \(C_n\) we have that
As \(\log (\frac{1}{\ell _n})>1\), for all \(n\in \mathbb {N}_0\), we have \(C_{n+1}\ge cC_n\) by definition of \((C_n)_{n\in \mathbb {N}_0}\), and using that \(c>2C\), the right-hand side can be further bounded by
which shows (44). \(\square \)
Now we bound the probability of the event \(\tilde{A}_n^{(\mathbf {x})}\), i.e. the event that there exists a path of length n, where the last vertex is the only vertex which has a mark smaller than its truncation bound \(\ell _n\). As in Sect. 2.2, Mecke’s equation yields
where we have used Fubini’s theorem in the second inequality and Lemma 2.9 in the third one. With \(\ell _0 < t\wedge \frac{1}{e}\) we choose the sequence \((\ell _n)_{n\in \mathbb {N}}\) for \(\epsilon >0\), such that
and get \(P(\tilde{A}_n^{(\mathbf {x})})\le \frac{\varepsilon }{6}\). From the recursive definition of the sequence \((C_n)\) we obtain a recursive representation of \((\ell _n)_{n\in \mathbb {N}_0}\). Let \(\eta _n := \ell _n^{-1}\) for \(n\in \mathbb {N}_0\), then
Hence, there exists a new constant \(c>0\) such that \(\eta _{n+1}^{1-\gamma } \le c\log (\eta _{n+1})\eta _{n+1}^{1-\gamma }\) and by induction we get that for any \(p>1\) there exists \(B>1\) large enough such that
Probability bounds for good paths We now consider the existence of good paths between two given vertices \(\mathbf {x}\) and \(\mathbf {y}\). We focus on the case \(\gamma \in (\frac{1}{2}, \frac{\delta }{\delta +1})\), as the cases \(\gamma = \frac{1}{2}\) and \(\gamma <\frac{1}{2}\) follow with analogous or simpler arguments. As before we restrict the event \(B_n^{\mathbf {x},\mathbf {y}}\) to the existence of a step minimizing good path of length n connecting \(\mathbf {x}\) and \(\mathbf {y}\) in \(\tilde{\mathcal {G}}\). Deviating a bit from the method of Sect. 2.2 we relax the definition of \(B_n^{\mathbf {x},\mathbf {y}}\) by defining \(\tilde{B}_n^{\mathbf {x},\mathbf {y}}\) as the event that there exists a step minimizing path between \(\mathbf {x}\) and \(\mathbf {y}\) in \(\tilde{\mathscr {G}}\) where the most powerful vertex of the path has a mark larger than \(\ell _{\lfloor \frac{n}{2} \rfloor }\). Then the term \(\sum _{n=1}^{2\Delta } {\mathbb {P}}_{\mathbf {x},\mathbf {y}}(B_n^{\mathbf {x},\mathbf {y}})\) in (TMB) can be replaced by \(\sum _{n=1}^{2\Delta } {\mathbb {P}}_{\mathbf {x},\mathbf {y}}(\tilde{B}_n^{\mathbf {x},\mathbf {y}})\).
We characterize the paths used in \(\tilde{B}_n^{\mathbf {x},\mathbf {y}}\) by their powerful vertices, as done for regular paths in [19]. A vertex \(\mathbf {x}_k\) of a path \((\mathbf {x}_0,\ldots ,\mathbf {x}_n)\) is powerful if \(t_i\ge t_k\) for all \(i=0,\ldots , k-1\) or if \(t_i\ge t_k\) for all \(i=k+1,\ldots , n\). Note that by definition the vertices \(\mathbf {x}= \mathbf {x}_0\) and \(\mathbf {y}= \mathbf {x}_n\) are always powerful. The indices of the powerful vertices are a subset of \(\lbrace 0,\ldots ,n \rbrace \) which we denote by \(\lbrace i_0,i_1,\ldots ,i_{m-1},i_m \rbrace \), where \(m+1\) is the number of powerful vertices in a path and \(i_0=0\), \(i_m=n\). As the most powerful vertex of a good path fulfils the assumption above, there exists a \(k\in \{0,\ldots ,m\}\) such that \(\mathbf {x}_{i_k}\) is the most powerful vertex of the path. We decompose the good paths at the powerful vertices first and then proceed to decompose the path between powerful vertices \(\mathbf {x}_{i_j}\) and \(\mathbf {x}_{i_{j-1}}\) in the same way as done for the random variable \(K(\mathbf {x}_{i_{j-1}},\mathbf {x}_{i_j}, i_{j}-i_{j-1})\) in Sect. 2.2. Using Mecke’s equation, we get
Then, following the same arguments as in the proof of Lemma 2.6, there exists \(a>0\) and \(\tilde{\kappa }>0\) such that \({\mathbb {P}}_{\mathbf {x},\mathbf {y}}(\tilde{B}_n^{(\mathbf {x},\mathbf {y})})\) is bounded by
By a simple calculationFootnote 1 the sum over k on the right-hand side can be bounded by a constant multiple of
Since \(\sum _{k=1}^{m-1} \left( {\begin{array}{c}m-2\\ k-1\end{array}}\right) \le 2^{m-2}\) and the second summand can be bounded by a multiple of the first, there exists a constant \(c_1>0\) such that \({\mathbb {P}}_{\mathbf {x},\mathbf {y}}(\tilde{B}_n^{(\mathbf {x},\mathbf {y})})\) is bounded by
where we have used (45) for the second inequality and denoted \((-1)!=1\) and \(\tilde{\kappa }\) might have changed between the steps. Since
for all \(m=1,\ldots ,n\) and \(\sum _{m=1}^n \left( {\begin{array}{c}n-1\\ m-1\end{array}}\right) \le 2^n\), there exists a constant \(c_2\ge 2(C\vee \tilde{\kappa })\) such that the right-hand side above can be further bounded by
By Stirling’s formula we have that \(\frac{n^{n-2}}{(n-2)!}\le e^n\). Hence, there exists \(c_3>0\) such that
We can see that \(B^{(2\gamma -1)\Delta \log ^p(\Delta +1)}\) dominates the right-hand side in the sense that there exist constants \(c_4,c_5>0\) such that
We now set
Then, we have that
A second order Taylor expansion shows that the right-hand side converges to \(-\infty \) as \(\left| x-y \right| \rightarrow \infty \). Hence, for such a choice of \(\Delta \), we have \({\mathbb {P}}_{\mathbf {x},\mathbf {y}}\lbrace \mathrm {d}(\mathbf {x},\mathbf {y}) \le 2\Delta \rbrace \le \varepsilon + o(1)\) which implies the statement of Proposition 2.1.
3 Proof of the Upper Bound for the Chemical Distance
To prove the upper bound for the chemical distance, we show the following proposition.
Proposition 3.1
Suppose Assumption 1.2 holds for \(\gamma >\frac{\delta }{\delta + 1}\). Then for any vertex \(\mathbf {x}\) there exists a path with no more than
vertices connecting \(\mathbf {0}\) and \(\mathbf {x}\), with high probability under \({\mathbb {P}}_{\mathbf {0},\mathbf {x}}(\cdot \mid \mathbf {0} \leftrightarrow \mathbf {x})\) as \(\left| x \right| \rightarrow \infty \).
To prove this result, we rely on a strategy introduced in [24]. Since the vertices of \(\mathscr {G}\) are given by the points of a Poisson process, the most powerful vertex inside a box with volume of order \(\left| x \right| ^d\) around the midpoint between \(\mathbf {0}\) and \(\mathbf {x}\) typically has a mark smaller than \(\left| x \right| ^{-d}\log \left| x \right| \). Hence, it is sufficient to construct a short enough path from \(\mathbf {0}\) resp. \(\mathbf {x}\) to this most powerful vertex inside the box. Here, as in Sect. 2.1, the typical connection type between two powerful vertices is crucial. For \(\gamma >\frac{\delta }{\delta +1}\) we expect two powerful vertices to be connected via a vertex with larger mark, which we again call a connector. In fact, the following lemma shows that for a powerful vertex with mark t and a suitable vertex with a sufficiently smaller mark, the probability that there exist no connector which neighbours each of the two vertices is decaying exponentially fast as the mark t gets small. This is a corollary of [24] and follows with the same calculations as in [19, Lemma 3.1]. We now fix for the rest of the section
noting that our assumptions ensure that the intervals are nonempty.
Lemma 3.1
There exists \(c>0\) such that for two given vertices \(\mathbf {x}= (x,t), \mathbf {y}=(y,s) \in {\mathcal {X}}\) with \(t,s\le \frac{1}{4}\), \(s\le t^{\alpha _1}\) and \(\left| x-y \right| ^d\le t^{-\alpha _2}\) we have
Proof
We only consider connectors \(\mathbf {z}= (z,u)\) with \(u\ge \frac{1}{2}\) and \(\left| x-z \right| <t^{-\frac{\gamma }{d}}\). Then, by the thinning theorem [27, Theorem 5.2] and Assumption 1.2 the number of such connectors is Poisson distributed with its mean bounded from below by
where \(\rho (x) := 1\wedge x^{-\delta }\) as in the previous section. As \(\left| x-y \right| ^d < t^{-\alpha _2}\) and \(s<t^{\alpha _1}\) this can be bounded from below by \({c} t^{(\alpha _2-\alpha _1\gamma )\delta -\gamma } \), where \(c = ({{\alpha ^2}\rho (\kappa ^{-1/\delta })\kappa }{2^{-(d\delta +1)}})\wedge \) \(({\alpha ^2}\rho (\kappa ^{-1/\delta })/2)\). \(\square \)
We now look into a box \(H(x) = \frac{x}{2}+[-2\left| x \right| ,2\left| x \right| ]^d\) and introduce a hierarchy of layers \(L_1\subset L_2\subset \cdots \subset \mathcal {X} \cap H(x)\times (0,1)\) of vertices inside the box containing \(\mathbf {0}\) and \(\mathbf {x}\). While the layer \(L_1\) only contains vertices with very small mark, vertices with larger and larger marks are included in layers with larger index. More precisely, as in [24] we set
and
where \(\eta = (\gamma - (\alpha _2-\alpha _1\gamma )\delta )\wedge (\alpha _2-\alpha _1) >0\). As the vertex set \(\mathcal {X}\) is a Poisson process, by Lemma 3.1 for a given vertex in layer \(L_{k+1}\) there exists with high probability a suitable vertex in layer \(L_k\) such that both vertices are connected via a connector with high probability. As in [24, 26] we can use an estimate as in Lemma 3.1 to see that a vertex in \(L_1\) is either the most powerful vertex in the box or connected to it via a connector, with high probability as \(\left| x \right| \rightarrow \infty \). Hence we get that \({{\,\mathrm{diam}\,}}(L_K) \le 4K\).
Since K is of order \((1+o(1))\frac{\log \log \left| x \right| }{\log {\alpha _1}}\), to finish the proof it suffices to show that the vertices \(\mathbf {0}\) and \(\mathbf {x}\) are connected to the layer \(L_K\) in fewer than \(o(\log \log \left| x \right| )\) steps. To do so, we first show that \(\mathbf {0}\) (resp. \(\mathbf {x}\)) is connected to a vertex with sufficiently small mark and within distance smaller than \(\left| x \right| \) in finitely many steps. Then, we show that this vertex is connected to a vertex of \(L_K\) in \(o(\log \log \left| x \right| )\) steps. To keep the existence of these two paths sufficiently independent we rely on a sprinkling argument. For \(b<1\) we assign independently to each vertex in \({\mathcal {X}}\) the color black with probability b and red with probability \(r=1-b\). Then, we denote by \(\mathscr {G}^b\) the graph induced by restricting \(\mathscr {G}\) to the black vertices and the edges between them. In the same way we define \(\mathscr {G}^r\) for the black vertices. Note that \(\mathscr {G}^r \cup \mathscr {G}^b\) is a subgraph of \(\mathscr {G}\).
We use the black vertices to ensure the existence of the first part of the path in \(\mathscr {G}^b\). Thus, we define for \(\mathbf {0}\) (and similarly for \(\mathbf {x}\)) the event \(E^b(D,s,v)\) that there exists a black vertex \(\mathbf {z}\) with mark smaller than s and within distance shorter than v such that there exists a path in \(\mathscr {G}^b\) of length smaller D between \(\mathbf {0}\) and \(\mathbf {z}\). Then, given \(\mathbf {z}\), we use the red vertices to show that \(\mathbf {z}\) is connected to the layer \(L_K\) in sufficiently few steps. We denote by \(L_k^r\) the restriction of \(L_k\) to its red vertices. Observe that we still have \({{\,\mathrm{diam}\,}}(L_K^r) \le 4K\) in \(\mathscr {G}^r\), as Lemma 3.1 restricted to \(\mathscr {G}^r\) also holds if the constant c is multiplied by r. We define F to be the event that \(\mathbf {z}\) is connected by a path of length smaller than \(o(\log \log \left| x \right| )\) to \(L_K^r\) in \(\mathscr {G}^r\). Note that the event \(\mathbf {0} \leftrightarrow \mathbf {x}\) implies that with high probability \(\mathbf {0}\) and \(\mathbf {x}\) are part of the unique infinite component \(K_\infty \) of \(\mathscr {G}\), since \({\mathbb {P}}_{\mathbf {0},\mathbf {x}}(\lbrace \mathbf {0} \leftrightarrow \mathbf {x} \rbrace \backslash \lbrace \mathbf {0},\mathbf {x}\in K_\infty \rbrace )\) converges to zero as \(\left| x \right| \rightarrow \infty \). This is a consequence of the uniqueness of the infinite component \(K_\infty \) as \(\lbrace \mathbf {0} \leftrightarrow \mathbf {x} \rbrace \backslash \lbrace \mathbf {0},\mathbf {x}\in K_\infty \rbrace \) implies that \(\mathbf {0} \) and \(\mathbf {x}\) are part of the same finite component whose asymptotic proportion of vertices is zero. Thus, to prove Proposition 3.1 it is sufficient to show that for any \(s>0\) there exists a almost surely finite random variable D(s) such that
where \(\theta \) is the asymptotic proportion of vertices in the infinite component of \(\mathscr {G}\) and \(K_\infty ^b\) is the infinite component of \(\mathscr {G}^b\). Note that, as \(\gamma >\frac{\delta }{\delta + 1}\), the critical percolation parameter of the graph \(\mathscr {G}\) is 0 by [19], and therefore \(K_\infty ^b\) exists and is unique. Now the probability above can be bounded from below by
We show in the following two lemmas that the last two terms converge to 0 as \(s\rightarrow 0\) and \(\left| x \right| \rightarrow \infty \) as in [24], which yields
where \(\theta _b\) is the asymptotic proportion of vertices in the infinite component of \(\mathscr {G}^b\). As in [26, Proposition 7] it can be shown that the percolation probability \(\theta _b\) is continuous in b such that \(\theta _b\) converges to \(\theta \) as \(b\nearrow 1\), which completes the proof.
Lemma 3.2
Let \(b,s>0\). Then, there exists an almost surely finite random variable D(s) such that
Proof
Let \(E^b(D,s)\) be the event that there exists a black vertex \(\mathbf {z}\) with mark smaller than s which is connected to \(\mathbf {0}\) in less than D steps. If \(\mathbf {0} \in K_\infty ^b\) there exists a path connecting \(\mathbf {0}\) to at least one black vertex with mark smaller than s. This follows from the results in [19] where it is shown that vertices with arbitrarily small mark are contained in the infinite component \(K_\infty ^b\). In fact, the random variable \(D_\infty = \min \lbrace D:\ \text {the event}\ E^b(D,s)\ \text {occurs} \rbrace \) is finite. Hence, if \(\left| x \right| \) is large enough, \(E^b(D_\infty ,s,\left| x \right| )\) occurs if \(\mathbf {0} \in K_\infty ^b\) and thus \( \lim _{\left| x \right| \rightarrow \infty } {\mathbb {P}}_\mathbf {0}\left( \lbrace \mathbf {0} \in K_\infty ^b \rbrace \backslash E^b(D(s),s,\left| x \right| )\right) = 0 \). \(\square \)
Lemma 3.3
Let \(b>0\) and, on \(E^b(D(s),s,\left| x \right| )\), denote by \(\mathbf {z}\) the black vertex \((x_0,t_0)\) with \(t_0<s\) within graph distance D(s) from \(\mathbf {0}\) in \(\mathscr {G}^b\), which minimizes \(|x_0|\). Then,
Proof
Starting in \(\mathbf {z}=(x_0,t_0)\) we want to find a red vertex \(\mathbf {x}_1 = (x_1,t_1) \in \mathcal {X} \cap H(x)\times (0,1)\) with \(\left| x_0-x_1 \right| ^d\le t_0^{-\alpha _2}\) and \(t_1\le t_0^{\alpha _1}\) which is connected to \(\mathbf {z}\) via one connector. Since \(\left| x_0 \right| \le \left| x \right| \), we have that \(x_0 \in H(x)\). Note that the volume of the intersection of H(x) and the ball \(B_{t_0^{-\alpha _2/d}}(x_0)\) is a positive proportion of the ball volume. Hence, there exists \(c>0\) such that the number of red vertices inside the box H(x) with \(\left| x_0-x_1 \right| ^d\le t_0^{-\alpha _2}\) and \(t_1\le t_0^{\alpha _1}\) is Poisson-distributed with parameter larger than \(crt_0^{\alpha _1-\alpha _2}\) and thus the probability that such a vertex does not exist is bounded by
where the second summand is a consequence of Lemma 3.1 restricted to \(\mathscr {G}^r\). Repeating this strategy, the same arguments yield that for a vertex \(\mathbf {x}_{j-1} = (x_{j-1},t_{j-1})\) the probability that there does not exist a connection to a red vertex \(\mathbf {x}_j = (x_j,t_j)\) inside H(x) with \(\left| x_{j-1}-x_j \right| ^d\le t_{j-1}^{-\alpha _2}\) and \(t_j\le t_{j-1}^{\alpha _1}\) is bounded by
As \(\eta = (\gamma - (\alpha _2-\alpha _1\gamma )\delta )\wedge (\alpha _2-\alpha _1)\) and \(t_j\le t_{j-1}^{\alpha _1}\), the right-hand side can be further bounded such that \(p_j\le 2\exp (-ct_0^{_{{-\eta \alpha _1^{j-1}}}}).\) Applying a union bound, the probability of failing to reach \(L_K^r\) from \(\mathbf {z}\) is bounded by
which converges to 0 as \(s\searrow 0\), as shown in [24, Lemma A.4]. As \(t_j\le t_0^{\alpha ^j}\), it takes at most \(O(\log \log \log \left| x \right| )\) iterations of this strategy to arrive to a red vertex inside H(x) with mark smaller than \((\log \left| x \right| )^{-\eta ^{-1}}\). This completes the proof. \(\square \)
Notes
For details see the proof of [19, Lemma 2.5], which differs from this calculation only in the fact that the mark of the first and last vertex of a path is fixed in our setting.
References
Antal, P., Pisztora, A.: On the chemical distance for supercritical Bernoulli percolation. Ann. Probab. 24(2), 1036–1048 (1996)
Barabási, A.-L., Albert, R.: Emergence of scaling in random networks. Science 286(5439), 509–512 (1999)
Benjamini, I., Berger, N.: The diameter of long-range percolation clusters on finite cycles. Random Struct. Algorithms 19(2), 102–111 (2001)
Biskup, M.: On the scaling of the chemical distance in long-range percolation models. Ann. Probab. 32(4), 2938–2977 (2004)
Biskup, M., Lin, J.: Sharp asymptotic for the chemical distance in long-range percolation. Random Struct. Algorithms 55(3), 560–583 (2019)
Bollobás, B., Janson, S., Riordan, O.: The phase transition in inhomogeneous random graphs. Random Struct. Algorithms 31(1), 3–122 (2007)
Bringmann, K., Keusch, R., Lengler, J.: Average distance in a general class of scale-free networks with underlying geometry. arXiv:1602.05712 (2018)
Cerný, J., Popov, S.: On the internal distance in the interlacement set. Electron. J. Probab. 17(29), 25 (2012)
Deijfen, M., van der Hofstad, R., Hooghiemstra, G.: Scale-free percolation. Ann. Inst. Henri Poincaré Probab. Stat. 49(3), 817–838 (2013)
Deprez, P., Wüthrich, M.V.: Scale-free percolation in continuum space. Commun. Math. Stat. 7(3), 269–308 (2019)
Dereich, S., Mönch, C., Mörters, P.: Typical distances in ultrasmall random networks. Adv. Appl. Probab. 44(2), 583–601 (2012)
Ding, J., Sly, A.: Distances in critical long range percolation. arXiv:1303.3995 (2015)
Dommers, S., van der Hofstad, R., Hooghiemstra, G.: Diameters in preferential attachment models. J. Stat. Phys. 139(1), 72–107 (2010)
Drewitz, A., Ráth, B., Sapozhnikov, A.: On chemical distances and shape theorems in percolation models with long-range correlations. J. Math. Phys. 55(8), 083307 (2014)
Garet, O., Marchand, R.: Asymptotic shape for the chemical distance and first-passage percolation on the infinite Bernoulli cluster. ESAIM Probab. Stat. 8, 169–199 (2004)
Garet, O., Marchand, R.: Large deviations for the chemical distance in supercritical Bernoulli percolation. Ann. Probab. 35(3), 833–866 (2007)
Gracar, P., Grauer, A., Lüchtrath, L., Mörters, P.: The age-dependent random connection model. Queueing Syst. 93(3–4), 309–331 (2019)
Gracar, P., Heydenreich, M., Mönch, C., Mörters, P.: Recurrence versus transience for weight-dependent random connection models. Electron. J. Probab. 27, 1–31 (2022)
Gracar, P., Lüchtrath, L., Mörters, P.: Percolation phase transition in weight-dependent random connection models. Adv. Appl. Prob. 53(4), 1090–1114 (2021)
Grimmett, G.R., Marstrand, J.M.: The supercritical phase of percolation is well behaved. Proc. R. Soc. Lond. Ser. A 430(1879), 439–457 (1990)
Hao, N., Heydenreich, M.: Graph distances in scale-free percolation: the logarithmic case. arXiv:2105.05709 (2021)
Hilário, M., Ungaretti, D.: Euclidean and chemical distances in ellipses percolation. arXiv:2103.09786 (2021)
Hirsch, C.: From heavy-tailed Boolean models to scale-free Gilbert graphs. Braz. J. Probab. Stat. 31(1), 111–143 (2017)
Hirsch, C., Mönch, C.: Distances and large deviations in the spatial preferential attachment model. Bernoulli 26(2), 927–947 (2020)
Jacob, E., Mörters, P.: Spatial preferential attachment networks: power laws and clustering coefficients. Ann. Appl. Probab. 25(2), 632–662 (2015)
Jacob, E., Mörters, P.: Robustness of scale-free spatial networks. Ann. Probab. 45(3), 1680–1722 (2017)
Last, G., Penrose, M.: Lectures on the Poisson Process. Cambridge University Press, Cambridge (2017)
Norros, I., Reittu, H.: On a conditionally Poissonian graph process. Adv. Appl. Probab. 38(1), 59–75 (2006)
Teixeira, A., Ungaretti, D.: Ellipses percolation. J. Stat. Phys. 168(2), 369–393 (2017)
van der Hofstad, R.: Random Graphs and Complex Networks II. Cambridge University Press, Cambridge (2022)
van der Hofstad, R., Hooghiemstra, G., Znamenski, D.: Distances in random graphs with finite mean and infinite variance degrees. Electron. J. Probab. 12(25), 703–766 (2007)
Acknowledgements
This research was supported by Deutsche Forschungsgemeinschaft (DFG) as Project Number 425842117. No data or code was created as part of this research. We would also like to thank the anonymous referees for valuable comments which led to significant improvements in the paper.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by J. Ding.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Further Calculations for the Ultrasmall Regime
Further Calculations for the Ultrasmall Regime
Lemma A.1
Let \(x,y\in \mathbb {R}^d\), \(t,s\in (0,1]\) and \(\ell >0\) with \(\ell <t\vee s\). For \(\gamma > \frac{\delta }{\delta +1}\),
where \(\tilde{c}=\frac{2^{d \delta +1}I_\rho }{(\gamma +\gamma /\delta -1)} \vee 1\).
Proof
Assume \(t<s\), then we have
where we used for the first inequality that, for \(z\in \mathbb {R}^d\), either \(\left| x-z \right| \) or \(\left| y-z \right| \) is larger than \(\frac{\left| x-y \right| }{2}\) and for the third inequality that \(\gamma > \frac{\delta }{\delta +1}\) implies \(\gamma +\gamma /\delta -1 > 0\). \(\square \)
Lemma A.2
Let \(x,y\in \mathbb {R}^d\), \(t,s\in (0,1]\) and \(\frac{1}{e}>\ell >0\) with \(\ell <t\vee s\). For \(\gamma >\frac{\delta }{\delta +1}\),
where \(\tilde{c}=\frac{I_\rho 2^{d \delta + 1}}{(\delta - 1)(\gamma +\gamma /\delta -1)\wedge 1}\).
Proof
Since, for \(z\in \mathbb {R}^d\), either \(\left| x-z \right| \) or \(\left| y-z \right| \) is larger than \(\frac{\left| x-y \right| }{2}\), we have
As \(\gamma > \frac{\delta }{\delta + 1}\) and \(\delta >1\), we have \(-\gamma /\delta + (\gamma -1)\delta >-1\). Hence, the last expression can be further bounded by
since \(\log (\ell ^{-1})>1\). \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gracar, P., Grauer, A. & Mörters, P. Chemical Distance in Geometric Random Graphs with Long Edges and Scale-Free Degree Distribution. Commun. Math. Phys. 395, 859–906 (2022). https://doi.org/10.1007/s00220-022-04445-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00220-022-04445-3