
Abstract
We analyse the eigenvectors of the adjacency matrix of a critical Erdős–Rényi graph \({\mathbb {G}}(N,d/N)\), where d is of order \(\log N\). We show that its spectrum splits into two phases: a delocalized phase in the middle of the spectrum, where the eigenvectors are completely delocalized, and a semilocalized phase near the edges of the spectrum, where the eigenvectors are essentially localized on a small number of vertices. In the semilocalized phase the mass of an eigenvector is concentrated in a small number of disjoint balls centred around resonant vertices, in each of which it is a radial exponentially decaying function. The transition between the phases is sharp and is manifested in a discontinuity in the localization exponent \(\gamma (\varvec{\mathrm {w}})\) of an eigenvector \(\varvec{\mathrm {w}}\), defined through \(\Vert \varvec{\mathrm {w}} \Vert _\infty / \Vert \varvec{\mathrm {w}} \Vert _2 = N^{-\gamma (\varvec{\mathrm {w}})}\). Our results remain valid throughout the optimal regime \(\sqrt{\log N} \ll d \leqslant O(\log N)\).
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
1.1 Overview
Let A be the adjacency matrix of a graph with vertex set \([N]\!=\! \{1, \dots , N\}\). We are interested in the geometric structure of the eigenvectors of A, in particular their spatial localization. An \(\ell ^2\)-normalized eigenvector \(\varvec{\mathrm {w}} = (w_x)_{x \in [N]}\) gives rise to a probability measure \(\sum _{x \in [N]} w_x^2 \delta _x\) on the set of vertices. Informally, \(\varvec{\mathrm {w}}\) is delocalized if its mass is approximately uniformly distributed throughout [N], and localized if its mass is essentially concentrated in a small number of vertices.
There are several ways of quantifying spatial localization. One is the notion of concentration of mass, sometimes referred to as scarring [49], stating that there is some set \({{\mathcal {B}}} \subset [N]\) of small cardinality and a small \(\varepsilon > 0\) such that \(\sum _{x \in {{\mathcal {B}}}} w_x^2 = 1 - \varepsilon \). In this case, it is also of interest to characterize the geometric structure of the vertex set \({{\mathcal {B}}}\) and of the eigenvector \(\varvec{\mathrm {w}}\) restricted to \({{\mathcal {B}}}\). Another convenient quantifier of spatial localization is the \(\ell ^p\)-norm \(\Vert \varvec{\mathrm {w}} \Vert _p\) for \(2 \leqslant p \leqslant \infty \). It has the following interpretation: if the mass of \(\varvec{\mathrm {w}}\) is uniformly distributed over some set \({{\mathcal {B}}} \subset [N]\) then \(\Vert \varvec{\mathrm {w}} \Vert _p^2 = |{{\mathcal {B}}} |^{-1 + 2/p}\). Focusing on the \(\ell ^\infty \)-norm for definiteness, we define the localization exponent \(\gamma (\varvec{\mathrm {w}})\) through
Thus, \(0 \leqslant \gamma (\varvec{\mathrm {w}}) \leqslant 1\), and \(\gamma (\varvec{\mathrm {w}}) = 0\) corresponds to localization at a single vertex while \(\gamma (\varvec{\mathrm {w}}) = 1\) to complete delocalization.
In this paper we address the question of spatial localization for the random Erdős–Rényi graph \({\mathbb {G}}(N,d/N)\). We consider the limit \(N \rightarrow \infty \) with \(d \equiv d_N\). It is well known that \({\mathbb {G}}(N,d/N)\) undergoes a dramatic change in behaviour at the critical scale \(d \asymp \log N\), which is the scale at and below which the vertex degrees do not concentrate. Thus, for \(d \gg \log N\), with high probability all degrees are approximately equal and the graph is homogeneous. On the other hand, for \(d \lesssim \log N\), the degrees do not concentrate and the graph becomes highly inhomogeneous: it contains for instance hubs of exceptionally large degree, leaves, and isolated vertices. As long as \(d > 1\), the graph has with high probability a unique giant component, and we shall always restrict our attention to it.
Here we propose the Erdős–Rényi graph at criticality as a simple and natural model on which to address the question of spatial localization of eigenvectors. It has the following attributes.
-
(i)
Its graph structure provides an intrinsic and nontrivial notion of distance.
-
(ii)
Its spectrum splits into a delocalized phase and a semilocalized phase. The transition between the phases is sharp, in the sense of a discontinuity in the localization exponent.
-
(iii)
Both phases are amenable to rigorous analysis.
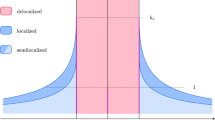
Our results are summarized in the phase diagram of Fig. 1, which is expressed in terms of the parameter b parametrizing \(d = b \log N\) on the critical scale and the eigenvalue \(\lambda \) of \(A / \sqrt{d}\) associated with the eigenvector \(\varvec{\mathrm {w}}\). To the best of our knowledge, the phase coexistence for the critical Erdős–Rényi graph established in this paper had previously not been analysed even in the physics literature.

The phase diagram of the adjacency matrix \(A / \sqrt{d}\) of the Erdős–Rényi graph \({\mathbb {G}}(N,d/N)\) at criticality, where \(d = b \log N\) with b fixed. The horizontal axis records the location in the spectrum and the vertical axis the sparseness parameter b. The spectrum is confined to the coloured region. In the red region the eigenvectors are delocalized while in the blue region they are semilocalized. The grey regions have width o(1) and are not analysed in this paper. For \(b > b_*\) the spectrum is asymptotically contained in \([-2,2]\) and the semilocalized phase does not exist. For \(b < b_*\) a semilocalized phase emerges in the region \((-\lambda _{\max }(b), -2) \cup (2, \lambda _{\max }(b))\) for some explicit \(\lambda _{\max }(b) > 2\)
Throughout the following, we always exclude the largest eigenvalue of A, its Perron–Frobenius eigenvalue, which is an outlier separated from the rest of the spectrum. The delocalized phase is characterized by a localization exponent asymptotically equal to 1. It exists for all fixed \(b > 0\) and consists asymptotically of energies in \((-2,0) \cup (0,2)\). The semilocalized phase is characterized by a localization exponent asymptotically less than 1. It exists only when \(b < b_*\), where
It consists asymptotically of energies in \((-\lambda _{\max }(b), -2) \cup (2, \lambda _{\max }(b))\), where \(\lambda _{\max }(b) > 2\) is an explicit function of b (see (1.14) below). The density of states at energy \(\lambda \in {\mathbb {R}}\) is equal to \(N^{\rho _b(\lambda ) + o(1)}\), where \(\rho _b\) is an explicit exponent defined in (1.14) below and illustrated in Fig. 2. It has a discontinuity at 2 (and similarly at \(-2\)), jumping from \(\rho _b(2^-) = 1\) to \(\rho _b(2^+) = 1 - b / b^*\). The localization exponent \(\gamma (\varvec{\mathrm {w}})\) from (1.1) of an eigenvector \(\varvec{\mathrm {w}}\) with associated eigenvalue \(\lambda \) satisfies with high probability
This establishes a discontinuity, in the limit \(N \rightarrow \infty \), in the localization exponent \(\gamma (\varvec{\mathrm {w}})\) as a function of \(\lambda \) at the energies \(\pm 2\). See Fig. 2 for an illustration; we also refer to Appendix A.1 for a simulation depicting the behaviour of \(\Vert \varvec{\mathrm {w}} \Vert _\infty \) throughout the spectrum. Moreover, in the semilocalized phase scarring occurs in the sense that a fraction \(1 - o(1)\) of the mass of the eigenvectors is supported in a set of at most \(N^{\rho _b(\lambda ) + o(1)}\) vertices.

The behaviour of the exponents \(\rho _b\) and \(\gamma \) as a function of the energy \(\lambda \). The dark blue curve is the exponent \(\rho _b(\lambda )\) characterizing the density of states \(N^{\rho _b(\lambda ) + o(1)}\) of the matrix \(A / \sqrt{d}\) at energy \(\lambda \). The entire blue region (light and dark blue) is the asymptotically allowed region of the localization exponent \(\gamma (\varvec{\mathrm {w}})\) of an eigenvector of \(A / \sqrt{d}\) as a function of the associated eigenvalue \(\lambda \). Here \(d = b \log N\) with \(b = 1\) and \(\lambda _{\max }(b) \approx 2.0737\). We only plot a neighbourhood of the threshold energy 2. The discontinuity at 2 of \(\rho _b\) is from \(\rho _b(2^-) = 1\) to \(\rho _b(2^+) = 1 - b / b^* = 2 - 2 \log 2\)
The eigenvalues in the semilocalized phase were analysed in [10], where it was proved that they arise precisely from vertices x of abnormally large degree, \(D_x \geqslant 2 d\). More precisely, it was proved in [10] that each vertex x with \(D_x \geqslant 2 d\) gives rise to two eigenvalues of \(A / \sqrt{d}\) near \(\pm \Lambda (D_x / d)\), where \(\Lambda (\alpha ) :=\frac{\alpha }{\sqrt{\alpha -1}}\). The same result for the O(1) largest degree vertices was independently proved in [54] by a different method. We refer also to [14, 15] for an analysis in the supercritical and subcritical phases.
In the current paper, we prove that the eigenvector \(\varvec{\mathrm {w}}\) associated with an eigenvalue \(\lambda \) in the semilocalized phase is highly concentrated around resonant vertices at energy \(\lambda \), which are defined as the vertices x such that \(\Lambda (D_x/d)\) is close to \(\lambda \). For this reason, we also call the resonant vertices localization centres. With high probability, and after a small pruning of the graph, all balls \(B_r(x)\) of a certain radius \(r \gg 1\) around the resonant vertices are disjoint, and within any such ball \(B_r(x)\) the eigenvector \(\varvec{\mathrm {w}}\) is an approximately radial exponentially decaying function. The number of resonant vertices at energy \(\lambda \) is comparable to the density of states, \(N^{\rho _b(\lambda ) + o(1)}\), which is much less than N. See Fig. 3 for a schematic illustration of the mass distribution of \(\varvec{\mathrm {w}}\).

A schematic representation of the geometric structure of a typical eigenvector in the semilocalized phase. The giant component of the graph is depicted in pale blue. The eigenvector’s mass (depicted in dark blue) is concentrated in a small number of disjoint balls centred around resonant vertices (drawn in white), and within each ball the mass decays exponentially in the radius. The mass outside the balls is an asymptotically vanishing proportion of the total mass
The behaviour of the critical Erdős–Rényi graph described above has some similarities but also differences to that of the Anderson model [11]. The Anderson model on \({\mathbb {Z}}^n\) with \(n \geqslant 3\) is conjectured to exhibit a metal-insulator, or delocalization-localization, transition: for weak enough disorder, the spectrum splits into a delocalized phase in the middle of the spectrum and a localized phase near the spectral edges. See e.g. [8, Figure 1.2] for a phase diagram of its conjectured behaviour. So far, only the localized phase of the Anderson model has been understood rigorously, in the landmark works [4, 39], as well as contributions of many subsequent developments. The phase diagram for the Anderson model bears some similarity to that of Fig. 1, in which one can interpret 1/b as the disorder strength, since smaller values of b lead to stronger inhomogeneities in the graph.
As is apparent from the proofs in [4, 39], in the localized phase the local structure of an eigenvector of the Anderson model is similar to that of the critical Erdős–Rényi graph described above: exponentially decaying around well-separated localization centres associated with resonances near the energy \(\lambda \) of the eigenvector. The localization centres arise from exceptionally large local averages of the potential. The phenomenon of localization can be heuristically understood using the following well-known rule of thumb: one expects localization around a single localization centre if the level spacing is much larger than the tunnelling amplitude between localization centres. It arises from perturbation theory around the block diagonal model where the complement of balls \(B_r(x)\) around localization centres is set to zero. On a very elementary level, this rule is illustrated by the matrix \(H(t) = \bigl ( {\begin{matrix}0 &{} t\\ t &{} 1\end{matrix}}\bigr )\), whose eigenvectors are localized for \(t = 0\), remain essentially localized for \(t \ll 1\), where perturbation theory around H(0) is valid, and become delocalized for \(t \gtrsim 1\), where perturbation theory around H(0) fails.
More precisely, it is a general heuristic that the tunnelling amplitude decays exponentially in the distance between the localization centres [25]. Denoting by \(\beta (\lambda ) > 1\) the rate of exponential decay at energy \(\lambda \), the rule of thumb hence reads
where L is the distance between the localization centres and \(\varepsilon (\lambda )\) the level spacing at energy \(\lambda \). For the Anderson model restricted to a finite cube of \({\mathbb {Z}}^n\) with side length \(N^{1/n}\), the level spacing \(\varepsilon (\lambda )\) is of order \(N^{-1}\) (see [57] and [8, Chapter 4]) whereas the diameter of the graph is of order \(N^{1/n}\). Hence, the rule of thumb (1.3) becomes
which is satisfied and one therefore expects localization. For the critical Erdős–Rényi graph, the level spacing \(\varepsilon (\lambda )\) is \(N^{-\rho (\lambda )+o(1)}\) but the diameter of the giant component is only \(\frac{\log N}{\log d}\). Hence, the rule of thumb (1.3) becomes
which is never satisfied because \(\frac{\log \beta (\lambda )}{\log d}\rightarrow 0\) as \(N \rightarrow \infty \). Thus, the rule of thumb (1.3) is satisfied in the localized phase of the Anderson model but not in the semilocalized phase of the critical Erdős–Rényi graph. The underlying reason behind this difference is that the diameter of the Anderson model is polynomial in N, while the diameter of the critical Erdős–Rényi graph is logarithmic in N. Thus, the critical Erdős–Rényi graph is far more connected than the Anderson model; this property tends to push it more towards the delocalized behaviour of mean-field systems. As noted above, another important difference between the localized phase of the Anderson model and the semilocalized phase of the critical Erdős–Rényi graph is that the density of states is of order N in the former and a fractional power of N in the latter.
Up to now we have focused on the Erdős–Rényi graph on the critical scale \(d \asymp \log N\). It is natural to ask whether this assumption can be relaxed without changing its behaviour. The question of the upper bound on d is simple: as explained above, there is no semilocalized phase for \(d > b_* \log N\), and the delocalized phase is completely understood up to \(d \leqslant N/2\), thanks to Theorem 1.8 below and [35, 42]. The lower bound is more subtle. In fact, it turns out that all of our results remain valid throughout the regime
The lower bound \(\sqrt{\log N}\) is optimal in the sense that below it both phases are disrupted and the phase diagram from Fig. 1 no longer holds. Indeed, for \(d \lesssim \sqrt{\log N}\) a new family of localized states, associated with so-called tuning forks at the periphery of the graph, appear throughout the delocalized and semilocalized phases. We refer to Sect. 1.5 below for more details.
Previously, strong delocalization with localization exponent \(\gamma (\varvec{\mathrm {w}}) = 1 + o(1)\) has been established for many mean-field models, such as Wigner matrices [1, 34,35,36,37], supercritical Erdős–Rényi graphs [35, 42], and random regular graphs [12, 13]. All of these models are homogeneous and only have a delocalized phase.
Although a rigorous understanding of the metal-insulator transition for the Anderson model is still elusive, some progress has been made for random band matrices. Random band matrices [23, 40, 47, 58] constitute an attractive model interpolating between the Anderson model and mean-field Wigner matrices. They retain the n-dimensional structure of the Anderson model but have proved somewhat more amenable to rigorous analysis. They are conjectured [40] to have a similar phase diagram as the Anderson model in dimensions \(n \geqslant 3\). As for the Anderson model, dimensions \(n > 1\) have so far seen little progress, but for \(n = 1\) much has been understood both in the localized [48, 50] and the delocalized [20,21,22, 28,29,30,31,32,33, 43, 51, 52, 59] phases. A simplification of band matrices is the ultrametric ensemble [41], where the Euclidean metric of \({\mathbb {Z}}^n\) is replaced with an ultrametric arising from a tree structure. For this model, a phase transition was rigorously established in [56].
Another modification of the n-dimensional Anderson model is the Anderson model on the Bethe lattice, an infinite regular tree corresponding to the case \(n = \infty \). For it, the existence of a delocalized phase was shown in [5, 38, 44]. In [6, 7] it was shown that for unbounded random potentials the delocalized phase exists for arbitrarily weak disorder. It extends beyond the spectrum of the unperturbed adjacency matrix into the so-called Lifschitz tails, where the density of states is very small. The authors showed that, through the mechanism of resonant delocalization, the exponentially decaying tunnelling amplitudes between localization centres are counterbalanced by an exponentially large number of possible channels through which tunnelling can occur, so that the rule of thumb (1.3) for localization is violated. As a consequence, the eigenvectors are delocalized across many resonant localization centres. We remark that this analysis was made possible by the absence of cycles on the Bethe lattice. In contrast, the global geometry of the critical Erdős–Rényi graph is fundamentally different from that of the Bethe lattice (through the existence of a very large number of long cycles), which has a defining impact on the nature of the delocalization-semilocalization transition summarized in Fig. 1.
Transitions in the localization behaviour of eigenvectors have also been analysed in several mean-field type models. In [45, 46] the authors considered the sum of a Wigner matrix and a diagonal matrix with independent random entries with a large enough variance. They showed that the eigenvectors in the bulk are delocalized while near the edge they are partially localized at a single site. Their partially localized phase can be understood heuristically as a rigorous (and highly nontrivial) verification of the rule of thumb for localization, where the perturbation takes place around the diagonal matrix. Heavy-tailed Wigner matrices, or Lévy matrices, whose entries have \(\alpha \)-stable laws for \(0< \alpha < 2\), were proposed in [24] as a simple model that exhibits a transition in the localization of its eigenvectors; we refer to [3] for a summary of the predictions from [24, 53]. In [18, 19] it was proved that for energies in a compact interval around the origin, eigenvectors are weakly delocalized, and for \(0< \alpha < 2/3\) for energies far enough from the origin, eigenvectors are weakly localized. In [3], full delocalization was proved in a compact interval around the origin, and the authors even established GOE local eigenvalue statistics in the same spectral region. In [2], the law of the eigenvector components of Lévy matrices was computed.
Conventions Throughout the following, every quantity that is not explicitly constant depends on the fundamental parameter N. We almost always omit this dependence from our notation. We use C to denote a generic positive universal constant, and write \(X = O(Y)\) to mean \(|X | \leqslant C Y\). For \(X,Y > 0\) we write \(X \asymp Y\) if \(X = O(Y)\) and \(Y = O(X)\). We write \(X \ll Y\) or \(X = o(Y)\) to mean \(\lim _{N \rightarrow \infty } X/Y = 0\). A vector is normalized if its \(\ell ^2\)-norm is one.
1.2 Results—the semilocalized phase
Let \({\mathbb {G}} = {\mathbb {G}}(N,d/N)\) be the Erdős–Rényi graph with vertex set \([N] :=\{1, \ldots , N\}\) and edge probability d/N for \(0 \leqslant d \leqslant N\). Let \(A = (A_{xy})_{x,y \in [N]} \in \{0,1\}^{N\times N}\) be the adjacency matrix of \({\mathbb {G}}\). Thus, \(A =A^*\), \(A_{xx}=0\) for all \(x \in [N]\), and \(( A_{xy} :x < y)\) are independent \({\text {Bernoulli}}(d/N)\) random variables.
The entrywise nonnegative matrix \(A/\sqrt{d}\) has a trivial Perron–Frobenius eigenvalue, which is its largest eigenvalue. In the following we only consider the other eigenvalues, which we call nontrivial. In the regime \(d \gg \sqrt{\log N/\log \log N}\), which we always assume in this paper, the trivial eigenvalue is located at \(\sqrt{d} (1 + o(1))\), and it is separated from the nontrivial ones with high probability; see [14]. Moreover, without loss of generality in this subsection we always assume that \(d \leqslant 3 \log N\), for otherwise the semilocalized phase does not exist (see Sect. 1.1).
For \(x \in [N]\) we define the normalized degree of x as
In Theorem 1.7 below we show that the nontrivial eigenvalues of \(A / \sqrt{d}\) outside the interval \([-2,2]\) are in two-to-one correspondence with vertices with normalized degree greater than 2: each vertex x with \(\alpha _x > 2\) gives rise to two eigenvalues of \(A / \sqrt{d}\) located with high probability near \(\pm \Lambda (\alpha _x)\), where we defined the bijective function \(\Lambda :[2,\infty ) \rightarrow [2,\infty )\) through
Our main result in the semilocalized phase is about the eigenvectors associated with these eigenvalues. To state it, we need the following notions.
Definition 1.1
Let \(\lambda >2\) and \(0 < \delta \leqslant \lambda - 2\). We define the set of resonant vertices at energy \(\lambda \) through
We denote by \(B_r(x)\) the ball around the vertex x of radius r for the graph distance in \({\mathbb {G}}\). Define
all of our results will hold provided \(c > 0\) is chosen to be a small enough universal constant. The quantity \(r_\star \) will play the role of a maximal radius for balls around localization centres.
We introduce the basic control parameters
which under our assumptions will always be small (see Remark 1.5 below). We now state our main result in the semilocalized phase.
Theorem 1.2
(Semilocalized phase). For any \(\nu > 0\) there exists a constant \({{\mathcal {C}}}\) such that the following holds. Suppose that
Let \(\varvec{\mathrm {w}}\) be a normalized eigenvector of \(A/\sqrt{d}\) with nontrivial eigenvalue \(\lambda \geqslant 2+{{\mathcal {C}}} \xi ^{1/2}\). Let \(0<\delta \leqslant (\lambda -2)/2\). Then for each \(x \in {{\mathcal {W}}}_{\lambda , \delta }\) there exists a normalized vector \(\varvec{\mathrm {v}}(x)\), supported in \(B_{r_\star }(x)\), such that the supports of \(\varvec{\mathrm {v}}(x)\) and \(\varvec{\mathrm {v}}(y)\) are disjoint for \(x \ne y\), and

with probability at least \(1 - {{\mathcal {C}}} N^{-\nu }\). Moreover, \(\varvec{\mathrm {v}}(x)\) decays exponentially around x in the sense that for any \(r \geqslant 0\) we have
Remark 1.3
An analogous result holds for negative eigenvalues \(-\lambda \leqslant -2 - {{\mathcal {C}}} \xi ^{1/2}\), with a different vector \(\varvec{\mathrm {v}}(x)\). See Theorem 3.4 and Remark 3.5 below for a precise statement.
Remark 1.4
The upper bound \(d \leqslant 3 \log N\) in (1.10) is made for convenience and without loss of generality, because if \(d > 3 \log N\) then, as explained in Sect. 1.1, with high probability the semilocalized phase does not exist, i.e. eigenvalues satisfying the conditions of Theorem 1.2 do not exist.
Theorem 1.2 implies that \(\varvec{\mathrm {w}}\) is almost entirely concentrated in the balls around the resonant vertices, and in each such ball \(B_{r_\star }(x)\), \(x \in {{\mathcal {W}}}_{\lambda ,\delta }\), the vector \(\varvec{\mathrm {w}}\) is almost collinear to the vector \(\varvec{\mathrm {v}}(x)\). Thus, \(\varvec{\mathrm {v}}(x)\) has the interpretation of the localization profile around the localization centre x. Since it has exponential decay, we deduce immediately from Theorem 1.2 that the radius \(r_\star \) can be made smaller at the expense of worse error terms. In fact, in Definition 3.2 and Theorem 3.4 below, we give an explicit definition of \(\varvec{\mathrm {v}}(x)\), which shows that it is radial in the sense that its value at a vertex y depends only on the distance between x and y, in which it is an exponentially decaying function. To ensure that the supports of the vectors \(\varvec{\mathrm {v}}(x)\) for different x do not overlap, \(\varvec{\mathrm {v}}(x)\) is in fact defined as the restriction of a radial function around x to a subgraph of \({\mathbb {G}}\), the pruned graph, which differs from \({\mathbb {G}}\) by only a small number of edges and whose balls of radius \(r_\star \) around the vertices of \({{\mathcal {W}}}_{\lambda ,\delta }\) are disjoint (see Proposition 3.1 below). For positive eigenvalues, the entries of \(\varvec{\mathrm {v}}(x)\) are nonnegative, while for negative eigenvalues its entries carry a sign that alternates in the distance to x. The set of resonant vertices \(\mathcal W_{\lambda ,\delta }\) is a small fraction of the whole vertex set [N]; its size is analysed in Lemma A.12 below.
Remark 1.5
Note that, by the lower bounds imposed on d and \(\lambda \) in Theorem 1.2, we always have \(\xi , \xi _{\lambda - 2} \leqslant 1/ {{\mathcal {C}}}\).
Using the exponential decay of the localization profiles, it is easy to deduce from Theorem 1.2 that a positive proportion of the eigenvector mass concentrates at the resonant vertices.
Corollary 1.6
Under the assumptions of Theorem 1.2 we have
with probability at least \(1 - {{\mathcal {C}}} N^{-\nu }\).
Next, we state a rigidity result on the eigenvalue locations in the semilocalized phase. It generalizes [10, Corollary 2.3] by improving the error bound and extending it to the full regime (1.4) of d, below which it must fail (see Sect. 1.5 below). Its proof is a byproduct of the proof of our main result in the semilocalized phase, Theorem 1.2. We denote the ordered eigenvalues of a Hermitian matrix \(M\in {\mathbb {C}}^{N\times N}\) by \(\lambda _1(M) \geqslant \lambda _2(M) \geqslant \cdots \geqslant \lambda _N(M)\). We only consider the nontrivial eigenvalues of \(A / \sqrt{d}\), i.e. \(\lambda _i(A / \sqrt{d})\) with \(2 \leqslant i \leqslant N\). For the following statements we order the normalized degrees by choosing a (random) permutation \(\sigma \in S_N\) such that \(i \mapsto \alpha _{\sigma (i)}\) is nonincreasing.
Theorem 1.7
(Eigenvalue locations in semilocalized phase). For any \(\nu > 0\) there exists a constant \({{\mathcal {C}}}\) such that the following holds. Suppose that (1.10) holds. Let
Then with probability at least \(1 - {{\mathcal {C}}} N^{-\nu }\), for all \(1\leqslant i\leqslant |{{\mathcal {U}}}|\) we have
and for all \(|{{\mathcal {U}}} | + 2 \leqslant i \leqslant N - |{{\mathcal {U}}} |\) we have
We remark that the upper bound on d from (1.10), which is necessary for the existence of a semilocalized phase, can be relaxed in Theorem 1.7 to obtain an estimate on \(\max _{2 \leqslant i \leqslant N} |\lambda _i(A / \sqrt{d}) |\) in the supercritical regime \(d \geqslant 3 \log N\), which is sharper than the one in [10]. The proof is the same and we do not pursue this direction here.
We conclude this subsection with a discussion on the counting function of the normalized degrees, which we use to give estimates on the number of resonant vertices (1.7). For \(b \geqslant 0\) and \(\alpha \geqslant 2\) define the exponent
Define \(\alpha _{\max }(b) :=\inf \{\alpha \geqslant 2 :\theta _b(\alpha ) = 0\}\). Thus, \(\theta _b\) is a nonincreasing function that is nonzero on \([0, \alpha _{\max }(b))\). Moreover, \(\theta _b(2) = [1 - b/b_*]_+\), so that \(\alpha _{\max }(b) > 2\) if and only if \(b < b_*\). From Lemma A.9 below it is easy to deduce that if \(d \gg 1\) then \(\alpha _{\sigma (1)} = \alpha _{\max }(d/\log N) + O(\zeta / d)\) with probability at least \(1 - o(1)\) for any \(\zeta \gg 1\). Thus, \(\alpha _{\max }(d/\log N)\) has the interpretation of the deterministic location of the largest normalized degree. See Fig. 4 for a plot of \(\theta _b\).

A plot of the exponent \(\theta _b(\alpha )\) as a function of \(\alpha \geqslant 2\) for the values \(b = 0.3\) (blue), \(b = 1.3\) (red), and \(b = 2.3\) (green). The graph hits the value 0 at \(\alpha _{\max }(b)\)
In Appendix A.4 below, we obtain estimates on the density of the normalized degrees \((\alpha _x)_{x \in [N]}\) and combine it with Theorem 1.2 to deduce a lower bound on the \(\ell ^p\)-norm of eigenvectors in the semilocalized phase. The precise statements are given in Lemma A.12 and Corollary A.13, which provide quantitative error bounds throughout the regime (1.10). Here, we summarize them, for simplicity, in simple qualitative versions in the critical regime \(d \asymp \log N\). For \(b < b_*\) we abbreviate
where \(\Lambda ^{-1}(\lambda ) = \frac{\lambda ^2}{2}(1 + \sqrt{1 - 4/\lambda ^2})\) for \(|\lambda | \geqslant 2\). Let \(d = b \log N\) with some constant \(b < b_*\), and suppose that \(2 + \kappa \leqslant \lambda \leqslant \lambda _{\max }(b) - \kappa \) for some constant \(\kappa > 0\). Then Lemma A.12 (ii) implies (choosing \(1/d \ll \delta \ll 1\))
with probability \(1 - o(1)\). From (1.15) and Theorem 1.2 we obtain, for any \(2 \leqslant p \leqslant \infty \),
with probability \(1 - o(1)\) (see Corollary A.13 below). In other words, the localization exponent \(\gamma (\varvec{\mathrm {w}})\) from (1.1) satisfies \(\gamma (\varvec{\mathrm {w}}) \leqslant \rho _b(\lambda ) + o(1)\). See Fig. 2 for an illustration of the bound (1.16) for \(p = \infty \). We remark that the exponent \(\rho _b(\lambda )\) also describes the density of states at energy \(\lambda \): under the above assumptions on b and \(\lambda \), for any interval I containing \(\lambda \) and satisfying \(\xi \ll |I | \ll 1\), the number of eigenvalues in I is equal to \(N^{\rho _b(\lambda ) + o(1)} |I |\) with probability \(1 - o(1)\), as can be seen from Lemma A.12 (i) and Theorem 1.7.
1.3 Results—the delocalized phase
Let A be the adjacency matrix of \({\mathbb {G}}(N,d/N)\), as in Sect. 1.2. For \(0< \kappa < 1/2\) define the spectral region
Theorem 1.8
(Delocalized phase). For any \(\nu >0\) and \(\kappa >0\) there exists a constant \({{\mathcal {C}}} > 0\) such that the following holds. Suppose that
Let \(\varvec{\mathrm {w}}\) be a normalized eigenvector of \(A / \sqrt{d}\) with eigenvalue \(\lambda \in {{\mathcal {S}}}_\kappa \). Then
with probability at least \(1 - \mathcal CN^{-\nu }\).
In the delocalized phase, i.e. in \({{\mathcal {S}}}_\kappa \), we also show that the spectral measure of \(A / \sqrt{d}\) at any vertex x is well approximated by the spectral measure at the root of \({\mathbb {T}}_{d\alpha _x,d}\), the infinite rooted \((d\alpha _x,d)\)-regular tree, whose root has \(d \alpha _x\) children and all other vertices have d children. This approximation is a local law, valid for intervals containing down to \(N^\kappa \) eigenvalues. See Remark 4.4 as well as Remark 4.3 and Appendix A.2 below for details.
Remark 1.9
In [42] it is shown that (1.19) holds with probability at least \(1 - \mathcal CN^{-\nu }\) for all eigenvectors provided that
This shows that the upper bound in (1.18) is in fact not restrictive.
Remark 1.10
(Optimality of (1.18) and (1.20)). Both lower bounds in (1.18) and (1.20) are optimal (up to the value of \({{\mathcal {C}}}\)), in the sense that delocalization fails in each case if these lower bounds are relaxed. See Sect. 1.5 below.
We note that the domain \({{\mathcal {S}}}_\kappa \) is optimal, up to the choice of \(\kappa > 0\). Indeed, as explained in Sect. 1.5 below, delocalization fails in the neighbourhood of the origin, owing to a proliferation highly localized tuning fork states. Similarly, we expect the delocalization to fail in the neighbourhoods of \(\pm 2\), where the masses of the eigenvectors become concentrated on vertices x with normalized degrees \(\alpha _x\) close to 2. The neighbourhoods of \(0, \pm 2\) are also singled out as the regions where the self-consistent equation used to prove Theorem 1.8 (see Lemma 4.16) becomes unstable. This instability is directly related to the appearance of singularities in the spectral measure of the tree \({\mathbb {T}}_{d \alpha _x,d}\) (see (4.11) and Fig. 8 for an illustration). The singularity near 0 occurs when \(\alpha _x\) is close to 0, and the singularities near \(\pm 2\) when \(\alpha _x\) is close to 2. See Fig. 10 for a simulation that demonstrates numerically the failure of delocalization outside of \({{\mathcal {S}}}_\kappa \).
1.4 Extension to general sparse random matrices
Our results, Theorems 1.2, 1.7, and 1.8, hold also for the following family of sparse Wigner matrices. Let \(A = (A_{xy})\) be the adjacency matrix of \({\mathbb {G}}(N,d/N)\) as above and \(W=(W_{xy})\) be an independent Wigner matrix with bounded entries. That is, W is Hermitian and its upper triangular entries \((W_{xy} :x \leqslant y)\) are independent complex-valued random variables with mean zero and variance one, \({\mathbb {E}}|W_{xy} |^2 = 1\), and \(|W_{xy} | \leqslant K\) almost surely for some constant K. Then we define the sparse Wigner matrix \(M = (M_{xy})\) as the Hadamard product of A and W, with entries \(M_{xy} :=A_{xy} W_{xy}\). Since the entries of \(M / \sqrt{d}\) are centred, it does not have a trivial eigenvalue like \(A / \sqrt{d}\).
Theorem 1.11
Let \(M = (M_{xy})_{x,y \in [N]}\) be a sparse Wigner matrix. Define
Theorems 1.2 and 1.8 hold with (1.21) if A is replaced with M, and Theorem 1.7 holds with (1.21) if \(\lambda _{i + 1}(A/\sqrt{d})\), \(\lambda _{N-i+1}(A/\sqrt{d})\), and \(\lambda _i(A/\sqrt{d})\) are replaced with \(\lambda _{i}(M / \sqrt{d})\), \(\lambda _{N-i+1}(M / \sqrt{d})\), and \(\lambda _i(M / \sqrt{d})\), respectively. Here, the constants \({{\mathcal {C}}}\) depend on K in addition to \(\nu \) and \(\kappa \).
The modifications to the proofs of Theorems 1.2 and 1.7 required to establish Theorem 1.11 are minor and follow along the lines of [10, Section 10]. The modification to the proof of Theorem 1.8 is trivial, since the assumptions of the general Theorem 4.2 below include the sparse Wigner matrix M. We also remark that, with some extra work, one can relax the boundedness assumption on the entries of W, which we shall however not do here.
1.5 The limits of sparseness and the scale \(d \asymp \sqrt{\log N}\)
We conclude this section with a discussion on how sparse \({\mathbb {G}}\) can be for our results to remain valid. We show that all of our results—Theorems 1.2, 1.7, and 1.8—are wrong below the regime (1.4), i.e. if d is smaller than order \(\sqrt{\log N}\). Thus, our sparseness assumptions—the lower bounds on d from (1.10) and (1.18)—are optimal (up to the factor \(\log \log N\) in (1.10) and the factor \({{\mathcal {C}}}\) in (1.18)). The fundamental reason for this change of behaviour will turn out to be that the ratio \(|S_2(x) | / |S_1(x) |\) concentrates if and only if \(d \gg \sqrt{\log N}\), where \(S_i(x)\) denotes the sphere in \({\mathbb {G}}\) of radius i around x. This can be easily made precise with a well-known tuning fork construction, detailed below.
In the critical and subcritical regime \(1 \ll d = O(\log N)\), the graph \({\mathbb {G}}\) is in general not connected, but with probability \(1 - o(1)\) it has a unique giant component \({\mathbb {G}}_{\mathrm {giant}}\) with at least \(N (1 - \mathrm {e}^{- d/4})\) vertices (see Corollary A.15 below). Moreover, the spectrum of \(A / \sqrt{d}\) restricted to the complement of the giant component is contained in the \(O\bigl (\frac{\sqrt{\log N}}{d}\bigr )\)-neighbourhood of the origin (see Corollary A.16 below). Since we always assume \(d \geqslant {{\mathcal {C}}} \sqrt{\log N}\) and we only consider eigenvalues in \({\mathbb {R}}\setminus [-\kappa ,\kappa ]\), we conclude that all of our results listed above only pertain to the eigenvalues and eigenvectors of the giant component.
For \(D = 0,1,2,\dots \) we introduce a starFootnote 1tuning fork of degree D rooted in \({\mathbb {G}}_{\mathrm {giant}}\), or D-tuning fork for short, which is obtained by taking two stars with central degree D and connecting their hubs to a common base vertex in \({\mathbb {G}}_{\mathrm {giant}}\). We refer to Fig. 5 for an illustration and Definition A.17 below for a precise definition.

A star tuning fork of degree 12 rooted in a graph. The tuning fork is highlighted in blue. Its base is filled with red and its two hubs are filled with blue
It is not hard to see that every D-tuning fork gives rise to two eigenvalues \(\pm \sqrt{D/d}\) of \(A / \sqrt{d}\) restricted to \({\mathbb {G}}_{\mathrm {giant}}\), whose associated eigenvectors are supported on the stars (see Lemma A.18 below). We denote by \(\Sigma :=\{\sqrt{D/d} :\text {a D-tuning fork exists}\}\) the spectrum of \(A / \sqrt{d}\) restricted to \({\mathbb {G}}_{\mathrm {giant}}\) generated by the tuning forks. Any eigenvector associated with an eigenvalue \(\sqrt{D/d} \in \Sigma \) is localized on precisely \(2D + 2\) vertices. Thus, D-tuning forks provide a simple way of constructing localized states. Note that this is a very basic form of concentration of mass, supported at the periphery of the graph on special graph structures, and is unrelated to the much more subtle concentration in the semilocalized phase described in Sect. 1.2.
For \(d > 0\) and \(D \in {\mathbb {N}}\) we now estimate the number of D-tuning forks in \({\mathbb {G}}(N,d/N)\), which we denote by F(d, D). The following result is proved in Appendix A.6.
Lemma 1.12
(Number of D-tuning forks). Suppose that \(1 \ll d = b \log N = O(\log N)\) and \(0 \leqslant D \ll \log N / \log \log N\). Then \(F(d,D) = N^{1 - 2b - 2b D + o(1)}\) with probability \(1 - o(1)\).
Defining \(D_* :=\frac{\log N}{2d} - 1\), we immediately deduce the following result.
Corollary 1.13
For any constant \(\varepsilon > 0\) with probability \(1 - o(1)\) the following holds. If \(D_* \leqslant -\varepsilon \) then \(\Sigma = \emptyset \). If \(D_* \geqslant \varepsilon \) then \(\Sigma = \{\pm \sqrt{D/d} :D \in {\mathbb {N}}, D \leqslant D_* (1 + o(1))\}\).
We deduce that if \(d \leqslant (1/2 - \varepsilon ) \log N\) then \(\Sigma \ne \emptyset \) and hence the delocalization for all eigenvectors from Remark 1.9 fails. Hence, the lower bound (1.20) is optimal up to the value of \({{\mathcal {C}}}\).
Similarly, for \(d \gg \sqrt{\log N}\) the set \(\Sigma \) is in general nonempty, but we always have \(\Sigma \subset [-\kappa , \kappa ]\) for any fixed \(\kappa > 0\), so that eigenvalues from \(\Sigma \) do not interfere with the statements of Theorems 1.2, 1.7, and 1.8. On the other hand, if \(d = \sqrt{\log N} / t\) for constant t, we find that \(\Sigma \) is asymptotically dense in the interval \([-t/\sqrt{2}, t / \sqrt{2}]\). Since the conclusions of Theorems 1.2, 1.7, and 1.8 are obviously wrong for any eigenvalue from \(\Sigma \), they must all be wrong for large enough t. This shows that the lower bounds d from (1.10) and (1.18) are optimal (up to the factor \(\log \log N\) in (1.10) and the factor \({{\mathcal {C}}}\) in (1.18)).
In fact, the emergence of the tuning fork eigenvalues of order one and the failure of all of our proofs has the same underlying root cause, which singles out the scale \(d \asymp \sqrt{\log N}\) as the scale below which the concentration of the ratio
fails for vertices x satisfying \(D_x \asymp d\). Clearly, to have a D-tuning fork with \(D \asymp d\), (1.22) has to fail at the hubs of the stars. Moreover, (1.22) enters our proofs of both the semilocalized and the delocalized phase in a crucial way. For the former, it is linked to the validity of the local approximation by the \((D_x,d)\)-regular tree from Appendix A.2, which underlies also the construction of the localization profile vectors (see e.g. (3.35) below). For the latter, in the language of Definition 4.6 below, it is linked to the property that most neighbours of any vertex are typical (see Proposition 4.8 (ii) below).
2 Basic Definitions and Overview of Proofs
In this preliminary section we introduce some basic notations and definitions that are used throughout the paper, and give an overview of the proofs of Theorems 1.2 (semilocalized phase) and 1.8 (delocalized phase). These proofs are unrelated and, thus, explained separately. For simplicity, in this overview we only consider qualitative error terms of the form o(1), although all of our estimates are in fact quantitative.
2.1 Basic definitions
We write \({\mathbb {N}}= \{0,1,2,\dots \}\). We set \([n] :=\{1, \ldots , n\}\) for any \(n \in {\mathbb {N}}^*\) and \([0] :=\emptyset \). We write \(|X |\) for the cardinality of a finite set X. We use \(\mathbb {1}_{\Omega }\) as symbol for the indicator function of the event \(\Omega \).
Vectors in \({\mathbb {R}}^N\) are denoted by boldface lowercase Latin letters like \(\varvec{\mathrm {u}}\), \(\varvec{\mathrm {v}}\) and \(\varvec{\mathrm {w}}\). We use the notation \(\varvec{\mathrm {v}} = (v_x)_{x \in [N]} \in {\mathbb {R}}^N\) for the entries of a vector. We denote by \({{\,\mathrm{supp}\,}}\varvec{\mathrm {v}} :=\{x \in [N] :v_x \ne 0\}\) the support of a vector \(\varvec{\mathrm {v}}\). We denote by  the Euclidean scalar product on \({\mathbb {R}}^N\) and by
the Euclidean scalar product on \({\mathbb {R}}^N\) and by  the induced Euclidean norm. For a matrix \(M \in {\mathbb {R}}^{N \times N}\), \(\Vert M \Vert \) is its operator norm induced by the Euclidean norm on \({\mathbb {R}}^N\). For any \(x \in [N]\), we define the standard basis vector \(\varvec{\mathrm {1}}_x :=(\delta _{xy})_{y \in [N]} \in {\mathbb {R}}^N\). To any subset \(S \subset [N]\) we assign the vector \(\varvec{\mathrm {1}}_S\in {\mathbb {R}}^N\) given by \(\varvec{\mathrm {1}}_S :=\sum _{x \in S} \varvec{\mathrm {1}}_x\). In particular, \(\varvec{\mathrm {1}}_{\{ x\}} = \varvec{\mathrm {1}}_x\).
the induced Euclidean norm. For a matrix \(M \in {\mathbb {R}}^{N \times N}\), \(\Vert M \Vert \) is its operator norm induced by the Euclidean norm on \({\mathbb {R}}^N\). For any \(x \in [N]\), we define the standard basis vector \(\varvec{\mathrm {1}}_x :=(\delta _{xy})_{y \in [N]} \in {\mathbb {R}}^N\). To any subset \(S \subset [N]\) we assign the vector \(\varvec{\mathrm {1}}_S\in {\mathbb {R}}^N\) given by \(\varvec{\mathrm {1}}_S :=\sum _{x \in S} \varvec{\mathrm {1}}_x\). In particular, \(\varvec{\mathrm {1}}_{\{ x\}} = \varvec{\mathrm {1}}_x\).
We use blackboard bold letters to denote graphs. Let \({\mathbb {H}} = (V({\mathbb {H}}), E({\mathbb {H}}))\) be a (simple, undirected) graph on the vertex set \(V({\mathbb {H}}) = [N]\). We often identify a graph \({\mathbb {H}}\) with its set of edges \(E({\mathbb {H}})\). We denote by \(A^{{\mathbb {H}}} \in \{0,1\}^{N \times N}\) the adjacency matrix of \({\mathbb {H}}\). For \(r \in {\mathbb {N}}\) and \(x \in [N]\), we denote by \(B_r^{{\mathbb {H}}}(x)\) the closed ball of radius r around x in the graph \({\mathbb {H}}\), i.e. the set of vertices at distance (with respect to \({\mathbb {H}}\)) at most r from the vertex x. We denote the sphere of radius r around the vertex x by \(S_r^{{\mathbb {H}}}(x) :=B_r^{{\mathbb {H}}}(x) \setminus B_{r - 1}^{{\mathbb {H}}}(x)\). We denote by \(D_x^{{\mathbb {H}}}\) the degree of the vertex x in the graph \({\mathbb {H}}\). For any subset \(V \subset [N]\), we denote by \({\mathbb {H}} \vert _V\) the subgraph induced by \({\mathbb {H}}\) on V. If \({\mathbb {H}}\) is a subgraph of \({\mathbb {G}}\) then we denote by \({\mathbb {G}} \setminus {\mathbb {H}}\) the graph on [N] with edge set \(E({\mathbb {G}}) \setminus E({\mathbb {H}})\). In the above definitions, if the graph \({\mathbb {H}}\) is the Erdős–Rényi graph \({\mathbb {G}}\), we systematically omit the superscript \({\mathbb {G}}\).
The following notion of very high probability is a convenient shorthand used throughout the paper. It simplifies considerably the probabilistic statements of the kind that appear in Theorems 1.2, 1.7, and 1.8. It also introduces two special symbols, \(\nu \) and \({{\mathcal {C}}}\), which appear throughout the rest of the paper.
Definition 2.1
Let \(\Xi \equiv \Xi _{N,\nu }\) be a family of events parametrized by \(N \in {\mathbb {N}}\) and \(\nu > 0\). We say that \(\Xi \) holds with very high probability if for every \(\nu > 0\) there exists \({\mathcal {C}}\equiv {\mathcal {C}}_\nu \) such that
for all \(N \in {\mathbb {N}}\).
Convention 2.2
In statements that hold with very high probability, we use the special symbol \({{\mathcal {C}}} \equiv {{\mathcal {C}}}_\nu \) to denote a generic positive constant depending on \(\nu \) such that the statement holds with probability at least \(1 - {{\mathcal {C}}}_\nu N^{-\nu }\) provided \(\mathcal C_\nu \) is chosen large enough. Thus, the bound \(|X | \leqslant {\mathcal {C}}Y\) with very high probability means that, for each \(\nu >0\), there is a constant \({\mathcal {C}}_\nu >0\), depending on \(\nu \), such that
for all \(N \in {\mathbb {N}}\). Here, X and Y are allowed to depend on N. We also write \(X = {{\mathcal {O}}}(Y)\) to mean \(|X | \leqslant {{\mathcal {C}}} Y\).
We remark that the notion of very high probability from Definition 2.1 survives a union bound involving \(N^{O(1)}\) events. We shall tacitly use this fact throughout the paper. Moreover, throughout the paper, the constant \({{\mathcal {C}}} \equiv {{\mathcal {C}}}_\nu \) in the assumptions (1.10) and (1.18) is always assumed to be large enough.
2.2 Overview of proof in semilocalized phase
The starting point of the proof of Theorem 1.2 is the following simple observation. Suppose that M is a Hermitian matrix with eigenvalue \(\lambda \) and associated eigenvector \(\varvec{\mathrm {w}}\). Let \(\Pi \) be an orthogonal projection and write \(\overline{\Pi } \!\,:=I - \Pi \). If \(\lambda \) is not an eigenvalue of \(\overline{\Pi } \!\,M \overline{\Pi } \!\,\) then from \((M - \lambda ) \varvec{\mathrm {w}} = 0\) we deduce
If \(\Pi \) is an eigenprojection of M whose range contains the eigenspace of \(\lambda \) (for instance \(\Pi = \varvec{\mathrm {w}} \varvec{\mathrm {w}}^*\) if \(\lambda \) is simple) then clearly both sides of (2.1) vanish. The basic idea of our proof is to apply an approximate version of this observation to \(M = A / \sqrt{d}\), by choosing \(\Pi \) appropriately, and showing that the left-hand side of (2.1) is small by estimating the right-hand side.
In fact, we chooseFootnote 2
where \({{\mathcal {W}}}_{\lambda ,\delta }\) is the set (1.7) of resonant vertices at energy \(\lambda \), and \(\varvec{\mathrm {v}}(x)\) is the exponentially decaying localization profile from Theorem 1.2. The proof then consists of two main ingredients:
-
(a)
\(\Vert \overline{\Pi } \!\,M \Pi \Vert = o(1)\);
-
(b)
\(\overline{\Pi } \!\,M \overline{\Pi } \!\,\) has a spectral gap around \(\lambda \).
Informally, (a) states that \(\Pi \) is close to a spectral projection of M, as \(\overline{\Pi } \!\,M \Pi = [M,\Pi ] \Pi \) quantifies the noncommutativity of M and \(\Pi \) on the range of \(\Pi \). Similarly, (b) states that \(\Pi \) projects roughly onto an eigenspace of M of energies near \(\lambda \). Plugging (a) and (b) into (2.1) yields an estimate on \(\Vert \overline{\Pi } \!\,\varvec{\mathrm {w}} \Vert \) from which Theorem 1.2 follows easily. Thus, the main work of the proof is to establish the properties (a) and (b) for the specific choice of \(\Pi \) from (2.2).
The construction of the localization profile \(\varvec{\mathrm {v}}(x)\) uses the pruned graph \({\mathbb {G}}_\tau \) from [10], a subgraph of \({\mathbb {G}}\) depending on a threshold \(\tau > 1\), which differs from \({\mathbb {G}}\) by only a small number of edges and whose balls of radius \(r_\star \) around the vertices of \({{\mathcal {V}}}_\tau :=\{x :\alpha _x \geqslant \tau \}\) are disjoint (see Proposition 3.1 below). Now we define the vector \(\varvec{\mathrm {v}}(x) :=\varvec{\mathrm {v}}^\tau _+(x)\), where, for \(\sigma = \pm \) and \(\tau > 1\),
The motivation behind this choice is explained in Appendix A.2: with high probability, the \(r_\star \)-neighbourhood of x in \({\mathbb {G}}_\tau \) looks roughly like that of the root of infinite regular tree \({\mathbb {T}}_{D_x, d}\) whose root has \(D_x\) children and all other vertices d children. The adjacency matrix of \({\mathbb {T}}_{D_x, d}\) has the exact eigenvalues \(\pm \sqrt{d} \Lambda (\alpha _x)\) with the corresponding eigenvectors given by (2.3) with \({\mathbb {G}}_\tau \) replaced with \({\mathbb {T}}_{D_x, d}\).
The central idea of our proof is the introduction of a block diagonal approximation of the pruned graph. Define the orthogonal projections
The range of \(\Pi \) from (2.2) is a subspace of the range of \(\Pi ^\tau \), i.e. \(\Pi \Pi ^\tau = \Pi \). The interpretation of \(\Pi ^\tau \) is the orthogonal projection onto all localization profiles around vertices x with normalized degree at least \(2 + o(1)\), which is precisely the set of vertices around which one can define an exponentially decaying localization profile. Now we define the block diagonal approximation of the pruned graph as
here we defined the centred and scaled adjacency matrix \(H^\tau :=A^{{\mathbb {G}}_\tau } / \sqrt{d} - E^\tau \), where \(E^\tau \) is a suitably chosen matrix that is close to \({\mathbb {E}}A^{{\mathbb {G}}} / \sqrt{d}\) and preserves the locality of \(A^{{\mathbb {G}}_\tau }\) in balls around the vertices of \({{\mathcal {V}}}_\tau \). In the subspace spanned by the localization profiles \(\{\varvec{\mathrm {v}}^\tau _\sigma (x) :\sigma = \pm , x \in {{\mathcal {V}}}_{2 + o(1)}\}\), \(\widehat{H}^\tau \) is diagonal with eigenvalues \(\sigma \Lambda (\alpha _x)\). In the orthogonal complement, it is equal to \(H^\tau \). The off-diagonal blocks are zero. The main work of our proof consists in an analysis of \(\widehat{H}^\tau \).
In terms of \(\widehat{H}^\tau \), abbreviating \(H :=(A^{{\mathbb {G}}} - {\mathbb {E}}A^{{\mathbb {G}}}) / \sqrt{d}\), the problem of showing (a) and (b) reduces to showing
-
(c)
\(\Vert H - \widehat{H}^\tau \Vert = o(1)\),
-
(d)
\(\Vert \overline{\Pi } \!\,^\tau H^\tau \overline{\Pi } \!\,^\tau \Vert \leqslant 2 + o(1)\).
Indeed, ignoring minor issues pertaining to the centring \({\mathbb {E}}A^{{\mathbb {G}}}\), we replace \(M = A^{{\mathbb {G}}} / \sqrt{d}\) with H in (a) and (b). Then (a) follows immediately from (c), since \(\overline{\Pi } \!\,H \Pi = \Vert \overline{\Pi } \!\,\widehat{H}^\tau \Pi \Vert + o(1) = o(1)\), as \(\overline{\Pi } \!\,\widehat{H}^\tau \Pi = 0\) by the block structure of \(\widehat{H}^\tau \) and the relation \(\Pi ^\tau \Pi = \Pi \). To show (b), we note that the \(\Pi ^\tau \)-block of \(\widehat{H}^\tau \), \(\Pi ^\tau \widehat{H}^\tau \Pi ^\tau = \sum _{x \in {{\mathcal {V}}}_{2 + o(1)}} \sum _{\sigma = \pm } \sigma \Lambda (\alpha _x) \varvec{\mathrm {v}}^\tau _\sigma (x) \varvec{\mathrm {v}}^\tau _\sigma (x)^*\), trivially has a spectral gap: \(\overline{\Pi } \!\,\Pi ^\tau H^\tau \Pi ^\tau \overline{\Pi } \!\,\) has no eigenvalues in the \(\delta \)-neighbourhood of \(\lambda \), simply because the projection \(\overline{\Pi } \!\,\) removes the projections \(\varvec{\mathrm {v}}^\tau _\sigma (x) \varvec{\mathrm {v}}^\tau _\sigma (x)^*\) with eigenvalues \(\sigma \Lambda (\alpha _x)\) in the \(\delta \)-neighbourhood of \(\lambda \). Moreover, the \(\overline{\Pi } \!\,^\tau \)-block also has such a spectral gap by (d) and \(\lambda > 2 + o(1)\). Hence, by (c), we deduce the desired spectral gap (b).
Thus, what remains is the proof of (c) and (d). To prove (c), we prove \(\Vert H - H^\tau \Vert = o(1)\) and \(\Vert H^\tau - \widehat{H}^\tau \Vert = o(1)\). The bound \(\Vert H - H^\tau \Vert = o(1)\) follows from a detailed analysis of the graph \({\mathbb {G}} \setminus {\mathbb {G}}_\tau \) removed from \({\mathbb {G}}\) to obtain the pruned graph \({\mathbb {G}}_\tau \), which we decompose as a union of a graph of small maximal degree and a forest, to which standard estimates of adjacency matrices of graphs can be applied (see Lemma 3.8 below). To prove \(\Vert H^\tau - \widehat{H}^\tau \Vert = o(1)\), we first prove that \(\varvec{\mathrm {v}}^\tau _\sigma (x)\) is an approximate eigenvector of \(H^\tau \) with approximate eigenvalue \(\sigma \Lambda (\alpha _x)\) (see Proposition 3.9 below). Then we deduce \(\Vert H^\tau - \widehat{H}^\tau \Vert = o(1)\) using that the balls \(B_{2r_\star }(x)\), \(x \in {{\mathcal {V}}}_{2 + o(1)}\), are disjoint and the locality of the operator \(H^\tau \) (see Lemma 3.11 below). Thus we obtain (c).
Finally, we sketch the proof of (d). The starting point is an observation going back to [10, 15]: from an estimate on the spectral radius of the nonbacktracking matrix associated with H from [15] and an Ihara–Bass-type formula relating the spectra of H and its nonbacktracking matrix from [15], we obtain the quadratic form inequality \(|H | \leqslant I + Q + o(1)\) with very high probability, where \(Q = {{\,\mathrm{diag}\,}}(\alpha _x :x \in [N])\), \(|H |\) is the absolute value of the Hermitian matrix H, and o(1) is in the sense of operator norm (see Proposition 3.13 below). Using (c), we deduce the inequality
To estimate \(\Vert \overline{\Pi } \!\,^\tau H^\tau \overline{\Pi } \!\,^\tau \Vert \), we take a normalized eigenvector \(\varvec{\mathrm {w}}\) of \(\overline{\Pi } \!\,^\tau H^\tau \overline{\Pi } \!\,^\tau \) with maximal eigenvalue \(\lambda > 0\). Thus, \(\varvec{\mathrm {w}} \perp \varvec{\mathrm {v}}^\tau _\pm (x)\) for all \(x \in {{\mathcal {V}}}_{2 + o(1)}\). We estimate \(\overline{\Pi } \!\,^\tau H^\tau \overline{\Pi } \!\,^\tau \) from above (an analogous argument yields an estimate from below) using (2.5) to get
Choosing \(\tau = 1 + o(1)\), we see that (d) follows provided that we can show that
since \(\max _x \alpha _x \leqslant {{\mathcal {C}}} \log N\) with very high probability.
The estimate (2.7) is a delocalization bound, in the vertex set \({{\mathcal {V}}}_\tau \), for any eigenvector \(\varvec{\mathrm {w}}\) of \(\widehat{H}^\tau \) that is orthogonal to \(\varvec{\mathrm {v}}_\pm ^\tau (x)\) for all \(x \in \mathcal V_{2 + o(1)}\) and whose associated eigenvalue is larger than \(2 \tau + o(1)\). It crucially relies on the assumption that \(\varvec{\mathrm {w}} \perp \varvec{\mathrm {v}}_\pm ^\tau (x)\) for all \(x \in {{\mathcal {V}}}_{2 + o(1)}\), without which it is false (see Proposition 3.14 below). The underlying principle behind its proof is the same as that of the Combes–Thomas estimate [25]: the Green function \(((\lambda - Z)^{-1})_{ij}\) of a local operator Z at a spectral parameter \(\lambda \) separated from the spectrum of Z decays exponentially in the distance between i and j, at a rate inversely proportional to the distance from \(\lambda \) to the spectrum of Z. We in fact use a radial form of a Combes–Thomas estimate, where Z is the tridiagonalization of a local restriction of \(\widehat{H}^\tau \) around a vertex \(x \in {{\mathcal {V}}}_\tau \) (see Appendix A.2) and i, j index radii of concentric spheres. The key observation is that, by the orthogonality assumption on \(\varvec{\mathrm {w}}\), the Green function \(((\lambda - Z)^{-1})_{i r_\star }\), \(0 \leqslant i < r_\star \), and the eigenvector components in the radial basis \(u_i\), \(0 \leqslant i < r_\star \), satisfy the same linear difference equation. Thus we obtain exponential decay for the components \(u_i\), which yields \(u_0^2 \leqslant o(1/\log N) \sum _{i = 0}^{r_*} u_i^2\). Going back to the original vertex basis, this implies that \(w_x^2 \leqslant o(1/\log N) \Vert \varvec{\mathrm {w}}|_{B_{2r_\star }^{{\mathbb {G}}_\tau }(x)}\Vert ^2\) for all \(x \in \mathcal V_\tau \), from which (2.7) follows since the balls \(B_{2r_\star }^{{\mathbb {G}}_\tau }(x)\), \(x \in {{\mathcal {V}}}_\tau \), are disjoint.
2.3 Overview of proof in delocalized phase
The delocalization result of Theorem 1.8 is an immediate consequence of a local law for the matrix \(A / \sqrt{d}\), which controls the entries of the Green function
in the form of high-probability estimates, for spectral scales \({{\,\mathrm{Im}\,}}z\) down to the optimal scale 1/N, which is the typical eigenvalue spacing. Such a local law was first established for \(d \gg (\log N)^6\) in [35] and extended down to \(d \geqslant {{\mathcal {C}}} \log N\) in [42]. In both of these works, the diagonal entries of G are close to the Stieltjes transform of the semicircle law. In contrast, in the regime (1.4) the diagonal entry \(G_{xx}\) is close to the Stieltjes transform of the spectral measure at the root of an infinite \((D_x,d)\)-regular tree. Hence, \(G_{xx}\) does not concentrate around a deterministic quantity.
The basic approach of the proof is the same as for any local law: derive an approximate self-consistent equation with very high probability, solve it using a stability analysis, and perform a bootstrapping from large to small values of \({{\,\mathrm{Im}\,}}z\) . For a set \(T \subset [N]\) denote by \(A^{(T)}\) the adjacency matrix of the graph \({\mathbb {G}}\) where the vertices of T (and all incident edges) have been removed, and denote by \(G^{(T)} = \bigl (A^{(T)} / \sqrt{d} - z\bigr )^{-1}\) the associated Green function. In order to understand the emergence of the self-consistent equation, it is instructive to consider the toy situation where, for a given vertex x, all neighbours \(S_1(x)\) are in different connected components of \(A^{(x)}\). This is for instance the case if \({\mathbb {G}}\) is a tree. On the global scale, where \({{\,\mathrm{Im}\,}}z\) is large enough, this assumption is in fact valid to a good approximation, since the neighbourhood of x is with high probability a tree. Then a simple application of Schur’s complement formula and the resolvent identity yield
Thus, on the global scale, using that G is bounded, we obtain the self-consistent equation
with very high probability.
It is instructive to solve the self-consistent equation (2.9) in the family \((G_{xx})_{x \in [N]}\) on the global scale. To that end, we introduce the notion of typical vertices, which is roughly the set \({{\mathcal {T}}} = \{x \in [N] :\alpha _x = 1 + o(1)\}\). (In fact, as explained below, the actual definition for local scales has to be different; see (2.12) below.) A simple argument shows that with very high probability most neighbours of any vertex are typical. With this definition, we can try to solve (2.9) on the global scale as follows. From the boundedness of G we obtain a self-consistent equation for the vector \((G_{xx})_{x \in {{\mathcal {T}}}}\) that reads
It is not hard to see that the equation (2.10) has a unique solution, which satisfies \(G_{xx} = m + o(1)\) for all \(x \in {{\mathcal {T}}}\). Here m is the Stieltjes transform of the semicircle law, which satisfies \(m = \frac{1}{-z - m}\). Plugging this solution back into (2.9) and using that most neighbours of any vertex are typical shows that for \(x \notin {{\mathcal {T}}}\) we have \(G_{xx} = m_{\alpha _x} + o(1)\), where \(m_\alpha :=\frac{1}{-z - \alpha m}\). One readily finds (see Appendix A.2 below) that \(m_{\alpha _x}\) is Stieltjes transform of the spectral measure of the infinite \((D_x,d)\)-regular tree at the root.
The first main difficulty of the proof is to provide a derivation of identities of the form (2.8) (and hence a self-consistent equation of the form (2.9)) on the local scale \({{\,\mathrm{Im}\,}}z \ll 1\). We emphasize that the above derivation of (2.8) is completely wrong on the local scale. Unlike on the global scale, on the local scale the behaviour of the Green function is not governed by the local geometry of the graph, and long cycles contribute to G in an essential way. In particular, eigenvector delocalization, which follows from the local law, is a global property of the graph and cannot be addressed using local arguments; it is in fact wrong outside of the region \(\mathcal S_\kappa \), although the above derivation is insensitive to the real part of z.
We address this difficulty by replacing the identities (2.8) with the following argument, which ultimately provides an a posteriori justification of approximate versions of (2.8) with very high probability, provided we are in the region \({{\mathcal {S}}}_\kappa \). We make an a priori assumption that the entries of G are bounded with very high probability; we propagate this assumption from large to small scales using a standard bootstrapping argument and the uniform boundedness of the density of the spectral measure associated with \(m_\alpha \). It is precisely this uniform boundedness requirement that imposes the restriction to \({{\mathcal {S}}}_\kappa \) in our local law (as explained in Remark 1.10, this restriction is necessary). The key tool that replaces the simpleminded approximation (2.8) is a series of large deviation estimates for sparse random vectors proved in [42], which, as it turns out, are effective for the full optimal regime (1.4). Thus, under the bootstrapping assumption that the entries of G are bounded, we obtain (2.8) (and hence also (2.9)), with some additional error terms, with very high probability.
The second main difficulty of the proof is that, on the local scale and for sparse graphs, the self-consistent equation (2.10), which can be derived from (2.9) as explained above, is not stable enough to be solved in \((G_{xx})_{x \in {{\mathcal {T}}}}\). This problem stems from the sparseness of the graphs that we are considering, and does not appear in random matrix theory for denser (or even heavy-tailed) matrices. Indeed, the stability estimates of (2.10) carry a logarithmic factor, which is usually of no concern in random matrix theory but is deadly for the sparse regime of this paper. This is a major obstacle and in fact ultimately dooms the self-consistent equation (2.10). To explain the issue, write the sum in (2.10) as \(\sum _y S_{xy} G_{yy}\), where S is the \({{\mathcal {T}}} \times {{\mathcal {T}}}\) matrix \(S_{xy} = \frac{1}{d} A_{xy}\). Writing \(G_{xx} = m + \varepsilon _x\), plugging it into (2.10), and expanding to first order in \(\varepsilon _x\), we obtain, using the definition of m, that \(\varepsilon _x = -m^2 ((I - m^2 S)^{-1} \zeta )_x\). Thus, in order to deduce smallness of \(\varepsilon _x\) from the smallness of \(\zeta _x\), we need an estimate on the normFootnote 3\(\Vert (I - m^2 S)^{-1} \Vert _{\infty \rightarrow \infty }\). In Appendix A.10 below we show that for typical S, \({{\,\mathrm{Re}\,}}z \in {{\mathcal {S}}}_\kappa \), and small enough \({{\,\mathrm{Im}\,}}z\),we have
for some universal constant C and some constant \(C_\kappa \) depending on \(\kappa \). In our context, where \(\zeta _x\) is small but much larger than the reciprocal of the lower bound of (2.11), such a logarithmic factor is not affordable.
To address this difficulty, we avoid passing by the form (2.10) altogether, as it is doomed by (2.11). The underlying cause for the instability of (2.10) is the inhomogeneous local structure of the matrix S, which is a multiple of the adjacency matrix of a sparse graph. Thus, the solution is to derive a self-consistent equation of the form (2.10) but with an unstructured S, which has constant entries. The basic intuition is to replace the local average \(\frac{1}{d} \sum _{y \in S_1(x)} G_{yy}^{(x)}\) in the first identity of (2.8) with the global average \(\frac{1}{N} \sum _{y \ne x} G_{yy}^{(x)}\). Of course, in general these two are not close, but we can include their closeness into the definition of a typical vertex. Thus, we define the set of typical vertices as
The main work of the proof is then to prove the following facts with very high probability.
-
(a)
Most vertices are typical.
-
(b)
Most neighbours of any vertex are typical.
With (a) and (b) at hand, we explain how to conclude the proof. Using (a) and the approximate version of (2.8) established above, we deduce the self-consistent equation for typical vertices,
which, unlike (2.10), is stable (see Lemma 4.19 below) and can be easily solved to show that \(G_{xx} = m + o(1) = m_{\alpha _x} + o(1)\) for all \(x \in {{\mathcal {T}}}\). Moreover, if \(x \notin {{\mathcal {T}}}\) then we obtain from (2.8) and (b) that
where we used that \(G_{yy} = m + o(1)\) for \(y \in {{\mathcal {T}}}\). This shows that \(G_{xx} = m_{\alpha _x} + o(1)\) for all \(x \in [N]\) with very high probability, and hence concludes the proof.
What remains, therefore, is the proof of (a) and (b); see Proposition 4.8 below for a precise statement. Using the bootstrapping assumption of boundedness of the entries of G, it is not hard to estimate the probability \({\mathbb {P}}(x \in {{\mathcal {T}}})\), which we prove to be \(1 - o(1)\), although \(\{x \in {{\mathcal {T}}}\}\) does not hold with very high probability (this characterizes the critical and subcritical regimes). Now if the events \(\{x \in {{\mathcal {T}}}\}\), \(x \in [N]\), were all independent, it would then be a simple matter to deduce (a) and (b).
The most troublesome source of dependence among the events \(\{x \in {{\mathcal {T}}}\}\), \(x \in [N]\), is the Green function \(G_{yy}^{(x)}\) in the definition of \({{\mathcal {T}}}\). Thus, the main difficulty of the proof is a decoupling argument that allows us to obtain good decay for the probability \({\mathbb {P}}(T \subset {{\mathcal {T}}})\) in the size of T. This decay can only work up to a threshold in the size of T, beyond which the correlations among the different events kick in. In fact, we essentially prove that
see Lemma 4.12. Choosing the largest possible T, \(T = o(d)\), we find that the first term on the right-hand side of (2.13) is bounded by \(N^{-\nu }\) provided that \(o(1) d^2 \geqslant \nu \log N\), which corresponds precisely to the optimal lower bound in (1.18). Using (2.13), we may deduce (a) and (b).
To prove (2.13), we need to decouple the events \(\{x \in {{\mathcal {T}}}\}\), \(x \in T\). We do so by replacing the Green functions \(G^{(x)}\) in the definition of \({{\mathcal {T}}}\) by \(G^{(T)}\), after which the corresponding events are essentially independent. The error that we incur depends on the difference \(G^{(T)}_{yy} - G_{yy}\), which we have to show is small with very high probability under the bootstrapping assumption that the entries of G are bounded. For T of fixed size, this follows easily from standard resolvent identities. However, for our purposes it is crucial that T can have size up to o(d), which requires a more careful quantitative analysis. As it turns out, \(G^{(T)}_{yy} - G_{yy}\) is small only up to \(|T | = o(d)\), which is precisely what we need to reach the optimal scale \(d \gg \sqrt{\log N}\) from (1.4).
3 The Semilocalized Phase
In this section we prove the results of Sect. 1.2–Theorems 1.2 and 1.7.
3.1 The pruned graph and proof of Theorem 1.2
The balls \((B_r(x))_{x \in {{\mathcal {W}}}_{\lambda , \delta }}\) in Theorem 1.2 are in general not disjoint. For its proof, and in order to give a precise definition of the vector \(\varvec{\mathrm {v}}(x)\) in Theorem 1.2, we need to make these balls disjoint by pruning the graph \({\mathbb {G}}\). This is an important ingredient of the proof, and will also allow us to state a more precise version of Theorem 1.2, which is Theorem 3.4 below. This pruning was previously introduced in [10]; it is performed by cutting edges from \({\mathbb {G}}\) in such a way that the balls \((B_r(x))_{x \in {{\mathcal {W}}}_{\lambda , \delta }}\) are disjoint for appropriate radii, \(r = 2 r_\star \), by carefully cutting in the right places, thus reducing the number of cut edges. This ensures that the pruned graph is close to the original graph in an appropriate sense. The pruned graph, \({\mathbb {G}}_\tau \), depends on a parameter \(\tau > 1\), and its construction is the subject of the following proposition.
To state it, we introduce the following notations. For a subgraph \({\mathbb {G}}_\tau \) of \({\mathbb {G}}\) we abbreviate
Moreover, we define the set of vertices with large degrees
Proposition 3.1
(Existence of pruned graph). Let \(1 + \xi ^{1/2} \leqslant \tau \leqslant 2\) and \(d \leqslant 3 \log N\). There exists a subgraph \({\mathbb {G}}_\tau \) of \({\mathbb {G}}\) with the following properties.
-
(i)
Any path in \({\mathbb {G}}_\tau \) connecting two different vertices in \({{\mathcal {V}}}_\tau \) has length at least \(4 r_{\star } +1\). In particular, the balls \((B_{2 r_{\star }}^{\tau }(x))_{x \in {{\mathcal {V}}}_\tau }\) are disjoint.
-
(ii)
The induced subgraph \({\mathbb {G}}_\tau |_{B_{2 r_{\star }}^{\tau }(x)}\) is a tree for each \(x \in {{\mathcal {V}}}_\tau \).
-
(iii)
For each edge in \({\mathbb {G}}\setminus {\mathbb {G}}_\tau \), there is at least one vertex in \({{\mathcal {V}}}_\tau \) incident to it.
-
(iv)
For each \(x \in {{\mathcal {V}}}_\tau \) and each \(i \in {\mathbb {N}}\) satisfying \(1 \leqslant i \leqslant 2 r_{\star }\) we have \(S_i^{\tau }(x) \subset S_i(x)\).
-
(v)
The degrees induced on [N] by \({\mathbb {G}}\setminus {\mathbb {G}}_\tau \) are bounded according to
$$\begin{aligned} \max _{x \in [N]} D_x^{{\mathbb {G}} \setminus {\mathbb {G}}_\tau } \leqslant {{\mathcal {C}}} \frac{\log N}{(\tau -1)^2d} \end{aligned}$$(3.1)with very high probability.
-
(vi)
Suppose that \(\sqrt{\log N} \leqslant d\). For each \(x \in {{\mathcal {V}}}_\tau \) and all \(2 \leqslant i \leqslant 2 r_\star \), the bound
$$\begin{aligned} |S_{i}(x)\setminus S_{i}^{\tau }(x)|\leqslant {\mathcal {C}}\frac{\log N}{(\tau -1)^2}d^{i-2} \end{aligned}$$(3.2)holds with very high probability.
The proof of Proposition 3.1 is postponed to the end of this section, in Sect. 3.5 below. It is essentially [10, Lemma 7.2], the main difference being that (vi) is considerably sharper than its counterpart, [10, Lemma 7.2 (vii)]; this stronger bound is essential to cover the full optimal regime (1.4) (see Sect. 1.5). As a guide for the reader’s intuition, we recall the main idea of the pruning. First, for every \(x \in {{\mathcal {V}}}_\tau \), we make the \(2 r_\star \)-neighbourhood of x a tree by removing appropriate edges incident to x. Second, we take all paths of length less than \(4 r_\star + 1\) connecting different vertices in \({{\mathcal {V}}}_\tau \), and remove all of their edges incident to any vertex in \({{\mathcal {V}}}_\tau \). Note that only edges incident to vertices in \({{\mathcal {V}}}_\tau \) are removed. This informal description already explains properties (i)–(iv). Properties (v) and (vi) are probabilistic in nature, and express that with very high probability the pruning has a small impact on the graph. See also Lemma 3.8 below for a statement in terms of operator norms of the adjacency matrices. For the detailed algorithm, we refer to the proof of [10, Lemma 7.2].
Using the pruned graph \({\mathbb {G}}_\tau \), we can give a more precise formulation of Theorem 1.2, where the localization profile vector \(\varvec{\mathrm {v}}(x)\) from Theorem 1.2 is explicit. For its statement, we introduce the set of vertices
around which a localization profile can be defined.
Definition 3.2
(Localization profile). Let \(1 + \xi ^{1/2} \leqslant \tau \leqslant 2\) and \({\mathbb {G}}_\tau \) be the pruned graph from Proposition 3.1. For \(x \in {{\mathcal {V}}}\) we introduce positive weights \(u_0(x), u_1(x), \dots , u_{r_\star }(x)\) as follows. Set \(u_0(x) > 0\) and define, for \(i = 1, \dots , r_\star - 1\),
For \(\sigma = \pm \) we define the radial vector
and choose \(u_0(x) > 0\) such that \(\varvec{\mathrm {v}}^\tau _\sigma (x)\) is normalized.
Remark 3.3
The family \((\varvec{\mathrm {v}}_\sigma ^\tau (x) :x \in {{\mathcal {V}}}, \,\sigma = \pm )\) is orthonormal. Indeed, if \(x,y \in {{\mathcal {V}}}\) are distinct, then by Proposition 3.1 (i) the vectors \(\varvec{\mathrm {v}}^\tau _{\sigma }(x)\) and \(\varvec{\mathrm {v}}^\tau _{{\tilde{\sigma }}}(y)\) are orthogonal for any \(\sigma , {\tilde{\sigma }} = \pm \) because they are supported on disjoint sets of vertices. Moreover, \(\varvec{\mathrm {v}}^\tau _+(x)\) and \(\varvec{\mathrm {v}}^\tau _-(x)\) are orthogonal by the choice of \(u_{r_\star }(x)\) from (3.4), as can be seen by a simple computation.
The following result restates Theorem 1.2 by identifying \(\varvec{\mathrm {v}}(x)\) there as \(\varvec{\mathrm {v}}_+^\tau (x)\) given in (3.5). It easily implies Theorem 1.2, and the rest of this section is devoted to its proof.
Theorem 3.4
The following holds with very high probability. Suppose that d satisfies (1.10). Let \(\varvec{\mathrm {w}}\) be a normalized eigenvector of \(A/\sqrt{d}\) with nontrivial eigenvalue \(\lambda \geqslant 2+ {{\mathcal {C}}} \xi ^{1/2}\). Choose \(0<\delta \leqslant (\lambda -2)/2\) and set \(\tau :=1 + (\lambda -2)/8\wedge 1\). Then

Remark 3.5
An analogous result holds for negative eigenvalues \(-\lambda \), where \(\lambda \) is as in Theorem 3.4 and \(\varvec{\mathrm {v}}_+^\tau (x)\) in (3.6) is replaced with \(\varvec{\mathrm {v}}_-^\tau (x)\).
For the motivation behind Definition 3.2, we refer to the discussion in Sect. 2.2 and Appendix A.2. As explained there, if \({\mathbb {G}}_\tau \) is sufficiently close to the infinite tree \({\mathbb {T}}_{D_x, d}\) in a ball of radius \(r_\star \) around x, and if \(r_\star \) is large enough for \(u_{r_\star }(x)\) to be very small, we expect (3.5) to be an approximate eigenvector of A. This will in fact turn out to be true; see Proposition 3.9 below. That \(r_\star \) is in fact large enough is easy to see: the definition of \(r_\star \) in (1.8) and the bound \(\xi \geqslant 1/d\) imply that, for \(\alpha _x\geqslant 2+ C (\log d)^2 / \sqrt{\log N}\), we have
This means that the last element of the sequence \((u_i(x))_{i=0}^{r_\star }\) is bounded by \(\xi \). Note that the lower bound on \(\alpha _x\) imposed above always holds for \(x \in {{\mathcal {V}}}\), since, by (1.10),

An illustration of the three sets of vertices of increasing size that enter into the proof of Theorem 3.4. Each vertex x is plotted as a dot at its normalized degree \(\alpha _x\). The largest set is \({{\mathcal {V}}}_{\tau }\) from Proposition 3.1, where \(1 + \xi ^{1/2} \leqslant \tau \leqslant 2\). It is used to define the pruned graph \({\mathbb {G}}_\tau \). The intermediate set is \({{\mathcal {V}}} \equiv {{\mathcal {V}}}_{2 + \xi ^{1/4}}\) from (3.3). It is the set of vertices for which we can define the localization profile vector \(\varvec{\mathrm {v}}(x)\) that decays exponentially around x. The smallest set \(\mathcal W_{\lambda ,\delta } = \Lambda ^{-1}([\lambda - \delta , \lambda + \delta ])\) is the set of resonant vertices at energy \(\lambda \)
As a guide to the reader, in Fig. 6, we summarize the three main sets of vertices that are used in the proof of Theorem 3.4. We conclude this subsection by proving Theorem 1.2 and Corollary 1.6 using Theorem 3.4.
Proof of Theorem 1.2
The first claim follows immediately from Theorem 3.4, with \(\varvec{\mathrm {v}}(x) = \varvec{\mathrm {v}}^\tau _+(x)\). To verify the claim about the exponential decay of \(\varvec{\mathrm {v}}\), we note that the graph distance in \({\mathbb {G}}\) is bounded by the graph distance in \({\mathbb {G}}_\tau \), which implies
from which the claim easily follows using the definition (3.4). \(\quad \square \)
Proof of Corollary 1.6
We decompose  , where
, where  and \(\varvec{\mathrm {e}}\) is orthogonal to \({{\,\mathrm{Span}\,}}\{\varvec{\mathrm {v}}_+^\tau (x) :x \in {{\mathcal {W}}}_{\lambda , \delta }\}\). By Theorem 3.4 we have \(\Vert \varvec{\mathrm {e}} \Vert \leqslant \frac{{{\mathcal {C}}} (\xi +\xi _{\tau -1})}{\delta }\) and
and \(\varvec{\mathrm {e}}\) is orthogonal to \({{\,\mathrm{Span}\,}}\{\varvec{\mathrm {v}}_+^\tau (x) :x \in {{\mathcal {W}}}_{\lambda , \delta }\}\). By Theorem 3.4 we have \(\Vert \varvec{\mathrm {e}} \Vert \leqslant \frac{{{\mathcal {C}}} (\xi +\xi _{\tau -1})}{\delta }\) and
Moreover, since \(\lambda - \delta \geqslant 2 \geqslant \tau \), we have \(\mathcal W_{\lambda ,\delta } \subset {{\mathcal {V}}}_\tau \), so that Proposition 3.1 (i) implies \((\varvec{\mathrm {v}}^\tau _+(x))_y = \delta _{xy} u_0(x)\) for \(x,y \in {{\mathcal {W}}}_{\lambda , \delta }\). Thus we have
Since \(u_0(y)\) was chosen such that \(\varvec{\mathrm {v}}_+^\tau (y) \) is normalized, we find
Define \(\alpha :=\Lambda ^{-1}(\lambda )\) for \(\alpha \geqslant 2\). Since \(|\Lambda (\alpha _y)-\lambda |\leqslant \delta \) for \(y\in \mathcal W_{\lambda , \delta }\), we obtain
where we used that \(\lambda \pm \delta - 2 \asymp \lambda - 2\). Since \(\frac{\mathrm {d}}{\mathrm {d}\alpha } \frac{\alpha - 2}{2 (\alpha - 1)} = \frac{1}{2(\alpha - 1)^2} \asymp \lambda ^{-4}\), we find
where we used (3.7) and the upper bound on \(\delta \) in the last step. By an elementary computation,
and the claim hence follows by recalling (3.7) and plugging (3.9) and (3.11) into (3.10). \(\quad \square \)
3.2 Block diagonal approximation of pruned graph and proof of Theorems 3.4 and 1.7
We now introduce the adjacency matrix of \({\mathbb {G}}_\tau \) and a suitably defined centred version. Then we define a block diagonal approximation of this matrix, called \(\widehat{H}^\tau \) in (3.16) below, which is the central construction of our proof.
Definition 3.6
Let \(A^\tau \) be the adjacency matrix of \({\mathbb {G}}_\tau \). Let \(H :=\underline{A} \!\, / \sqrt{d}\) and \(H^\tau :=\underline{A} \!\,^\tau / \sqrt{d}\), where
and \(\chi ^\tau \) is the orthogonal projection onto \({{\,\mathrm{Span}\,}}\{ \varvec{\mathrm {1}}_y :y \notin \bigcup _{x \in {{\mathcal {V}}}_\tau } B_{2 r_\star }^\tau (x)\}\).
The definition of \(\underline{A} \!\,^\tau \) is chosen so that (i) \(\underline{A} \!\,^\tau \) is close to \(\underline{A} \!\,\) provided that \(A^\tau \) is close to A, since the kernel of \(\chi ^\tau \) has a relatively low dimension, and (ii) when restricted to vertices at distance at most \(2 r_\star \) from \(\mathcal V_\tau \), the matrix \(\underline{A} \!\,^\tau \) coincides with \(A^\tau \). In fact, property (i) is made precise by the simple estimate
with very high probability (see [10, Eq. (8.17)] for details). Property (ii) means that \(\underline{A} \!\,^\tau \) inherits the locality of the matrix A, meaning that applying \(\underline{A} \!\,^\tau \) to a vector localized in space to a small enough neighbourhood of \(\mathcal V_\tau \) yields again a vector localized in space. This property will play a crucial role in the proof, and it can be formalized as follows.
Remark 3.7
Let \(i + j \leqslant 2 r_\star \). Then for any \(x \in {{\mathcal {V}}}_\tau \) and vector \(\varvec{\mathrm {v}}\) we have
The next result states that \(H^\tau \) is a small perturbation of H.
Lemma 3.8
Suppose that \(d \leqslant 3 \log N\). For any \(1 + \xi ^{1/2} \leqslant \tau \leqslant 2\) we have \(\Vert H - H^\tau \Vert \leqslant {{\mathcal {C}}} \xi _{\tau -1}\) with very high probability.
The next result states that \(\varvec{\mathrm {v}}_\sigma ^\tau (x)\) is an approximate eigenvector of \(H^\tau \).
Proposition 3.9
Let d satisfy (1.10). Let \(x \in [N]\) and suppose that \(1 + \xi ^{1/2} \leqslant \tau \leqslant 2\). If \(\alpha _x\geqslant 2+ C (\log d)^2 / \sqrt{\log N}\) then for \(\sigma = \pm \) we have
with very high probability.
The proofs of Lemma 3.8 and Proposition 3.9 are deferred to Sect. 3.3. The following object is the central construction in our proof.
Definition 3.10
(Block diagonal approximation of pruned graph) Define the orthogonal projections
and the matrix
That \(\Pi ^\tau \) and \(\overline{\Pi } \!\,^\tau \) are indeed orthogonal projections follows from Remark 3.3. Note that \(\widehat{H}^\tau \) may be interpreted as a block diagonal approximation of \(H^\tau \). Indeed, completing the orthonormal family \((\varvec{\mathrm {v}}^\tau _\sigma (x))_{x \in {{\mathcal {V}}}, \sigma = \pm }\) to an orthonormal basis of \({\mathbb {R}}^N\), which we write as the columns of the orthogonal matrix R, we have
The following estimate states that \(\widehat{H}^\tau \) is a small perturbation of \(H^\tau \).
Lemma 3.11
Let d satisfy (1.10). If \(1 + \xi ^{1/2} \leqslant \tau \leqslant 2\) then \(\Vert H^\tau - \widehat{H}^\tau \Vert \leqslant {\mathcal {C}}\xi \) with very high probability.
The proof of Lemma 3.11 is deferred to Sect. 3.3. The following result is the key estimate of our proof; it states that on the range of \(\overline{\Pi } \!\,^\tau \) the matrix \(H^\tau \) is bounded by \(2\tau + o(1)\).
Proposition 3.12
Let d satisfy (1.10). If \(1 + \xi ^{1/2} \leqslant \tau \leqslant 2\) then \(\Vert \overline{\Pi } \!\,^\tau H^\tau \overline{\Pi } \!\,^\tau \Vert \leqslant 2\tau + {{\mathcal {C}}} (\xi +\xi _{\tau -1})\) with very high probability.
The proof of Proposition 3.12 is deferred to Sect. 3.4. We now use Lemma 3.11 and Proposition 3.12 to conclude Theorems 3.4 and 1.7.
Proof of Theorem 3.4
Define the orthogonal projections
By definition, the orthogonal projections \(\Pi ^\tau \) and \(\Pi ^\tau _{\lambda ,\delta }\) commute. Moreover, under the assumptions of Theorem 3.4 we have the inclusion property
See also Fig. 6. To show (3.17), we note that the condition on \(\delta \) and the lower bound on \(\lambda \) in Theorem 3.4 imply \(\lambda - \delta \geqslant 2 + {{\mathcal {C}}} \xi ^{1/2}\). Using \(\Lambda (2 + x) - 2 \asymp x^2 \wedge x^{1/2}\) for \(x \geqslant 0\) we conclude that for any \(\alpha \geqslant 2\) we have the implication \(\Lambda (\alpha ) \geqslant \lambda - \delta \; \Rightarrow \; \alpha \geqslant 2 + \xi ^{1/4}\), which implies (3.17).
Next, we abbreviate \(E^\tau :=\chi ^\tau ({\mathbb {E}}A / \sqrt{d}) \chi ^\tau \) and note that \(\Pi ^\tau E^\tau = 0\) because \(\Pi ^\tau \chi ^\tau = 0\) by construction of \(\varvec{\mathrm {v}}_\sigma ^\tau (x)\). From (3.17) we obtain \(\overline{\Pi } \!\,^\tau _{\lambda ,\delta } = \overline{\Pi } \!\,^\tau _{\lambda ,\delta } \Pi ^\tau + \overline{\Pi } \!\,^\tau \), which yields
where we used that the cross terms vanish because of the block diagonal structure of \(\widehat{H}^\tau \).
The core of our proof is the spectral gap
To establish (3.19), it suffices to establish the same spectral gap for each term on the right-hand side of (3.18) separately, since the right-hand side of (3.18) is a block decomposition of its left-hand side. The first term on the right-hand side of (3.18) is explicit:
which trivially has no eigenvalues in \([\lambda - \delta , \lambda + \delta ]\).
In order to establish the spectral gap for the second term of (3.18), we begin by remarking that \(E^\tau \) has rank one and, by (3.13), its unique nonzero eigenvalue is \(\sqrt{d} + O(1/\sqrt{d})\). Hence, by rank-one interlacing and Proposition 3.12, we find
for some simple eigenvalue \(\mu = \sqrt{d} + O(1)\). Thus, to conclude the proof of the spectral gap for the second term of (3.18), it suffices to show that
To prove (3.21), we suppose that \(\lambda \geqslant 2 + 8 {{\mathcal {C}}} \xi ^{1/2}\) and, recalling the condition on \(\delta \) and the choice of \(\tau \) in Theorem 3.4, obtain
where in the last step we used that \(\xi _{\tau -1} < \xi ^{1/2}\) by our choice of \(\tau \) and the lower bound on \(\lambda \). This is (3.21).
For the following arguments, we compare \(A / \sqrt{d}\) with \(\widehat{H}^\tau + E^\tau \) using the estimate
with very high probability, which follows from Lemma 3.8, Lemma 3.11, (3.13) and \(d^{-1/2} \leqslant {{\mathcal {C}}} \xi \).
Next, we use (3.24) to conclude the proof of (3.22). The only nonzero eigenvalue of \(E^\tau \) is \(\sqrt{d}(1 + O(1/d))\), and from Proposition 3.12 and Remark 1.5 we have \(\Vert \widehat{H}^\tau \Vert \leqslant \Lambda (\max _{x \in {{\mathcal {V}}}} \alpha _x) + O(1)\) with very high probability, so that Lemma A.7 and the assumption (1.10) yield \(\Vert \widehat{H}^\tau \Vert \leqslant {{\mathcal {C}}} \sqrt{\frac{\log N}{d}}\) with very high probability. Hence, by first order perturbation theory (e.g. Weyl’s inequality), (1.10) and (3.24) imply that \(A/\sqrt{d}\) has one eigenvalue bigger than \(\sqrt{d} - O(1)\) and all other eigenvalues are at most \({{\mathcal {C}}} \sqrt{\frac{\log N}{d}}\). Since \(\lambda \) is nontrivial, we conclude that \(\lambda \leqslant {{\mathcal {C}}} \sqrt{\frac{\log N}{d}}\). By the upper bound \(\delta \leqslant (\lambda - 2)/2\) and the lower bound on d in (1.10), this concludes the proof of (3.22) and, thus, the one of the spectral gap (3.19).
Next, from (3.19), and (3.24), we conclude the spectral gap for the full adjacency matrix
Using (3.25) we may conclude the proof. The eigenvalue-eigenvector equation \((A/ \sqrt{d} - \lambda ) \varvec{\mathrm {w}} = 0\) yields
Assuming that \(\delta > {{\mathcal {C}}} (\xi + \xi _{\tau - 1})\), from (3.25) we get
Moreover, since \(\overline{\Pi } \!\,_{\lambda ,\delta }^\tau \widehat{H}^\tau \Pi _{\lambda ,\delta }^\tau = 0\) and \(E^\tau \Pi _{\lambda ,\delta }^\tau =0\), we deduce from (3.24) that
Plugging (3.27) and (3.28) into (3.26) yields
since \(\varvec{\mathrm {w}}\) is normalized. This concludes the proof if \(\delta > {{\mathcal {C}}} (\xi + \xi _{\tau - 1})\) (after a renaming of the constant \({{\mathcal {C}}}\)), and otherwise the claim is trivial. \(\quad \square \)
Proposition 3.12 is also the main tool to prove Theorem 1.7.
Proof of Theorem 1.7
The proof uses Proposition 3.12, Lemma 3.8, and Lemma 3.11 for \(\tau \in [1 + \xi ^{1/2}/3,2]\). Note that the lower bound \(1 + \xi ^{1/2}/3\) is smaller than the lower bound \(1 + \xi ^{1/2}\) imposed in these results, but their proofs hold verbatim also in this regime of \(\tau \).
We set \(E^\tau :=\chi ^\tau ({\mathbb {E}}A/\sqrt{d})\chi ^\tau \) with \(\chi ^\tau \) from Definition 3.6. We now compare \(A/\sqrt{d}\) and \(\widehat{H}^\tau + E^\tau \), as in the proof of Theorem 3.4, and use some estimates from its proof. For any \( \tau \in [1 + \xi ^{1/2}/3,2]\), we have
since \(\Pi ^\tau \chi ^\tau =0\). By first order perturbation theory and the choice \(\tau =2\), we get from (3.29), (3.20) and (3.24) that \(\lambda _1(A/\sqrt{d}) = \mu + O(\xi ) = \sqrt{d} + O(1)\) and \(\lambda _1(A/\sqrt{d})\) is well separated from the other eigenvalues of \(A/\sqrt{d}\) (see the proof of Theorem 3.4). Combining (3.29), (3.20), and (3.24), choosing \(\tau = 1 + \xi ^{1/2}/3\) as well as using \({{\mathcal {C}}}(\xi + \xi _{\tau - 1}) \leqslant \xi ^{1/2}/3\) for this choice of \(\tau \) imply (1.12).
Moreover, we apply first order perturbation theory to (3.29) using (3.20) and (3.24), and obtain
with very high probability for all \(\tau \in [1+\xi ^{1/2}/3,2]\) and all \(i \in [|{{\mathcal {U}}} |]\) satisfying
What remains is choosing \(\tau \equiv \tau _i\), depending on \(i \in [|{{\mathcal {U}}} |]\), such that the condition (3.31) is satisfied and the error estimate from (3.30) transforms into the form of (1.11). Both are achieved by setting
Note that \(\tau \in [1 + \xi ^{1/2}/3,2]\) as \(\sigma (i) \in {{\mathcal {U}}}\). From \(\Lambda (\alpha _{\sigma (i)})-2 \geqslant 3(\tau -1) \) due to (3.32) and \(\Lambda (\alpha _{\sigma (i)})-2 \geqslant \xi ^{1/2}\) by the definition of \({{\mathcal {U}}}\), we conclude that
where we used \(\tau - 1 \geqslant 3 \xi _{\tau - 1} \log d\) as \(\tau -1 \geqslant \xi ^{1/2}/3\). This proves (3.31) and, thus, (3.30) for any \(\sigma (i) \in {{\mathcal {U}}}\) with the choice of \(\tau \) from (3.32).
In order to show that the right-hand side of (3.30) is controlled by the one in (1.11), we now distinguish the two cases, \(\Lambda (\alpha _{\sigma (i)}) -2 \leqslant 3\) and \(\Lambda (\alpha _{\sigma (i)}) -2 > 3\). In the latter case, \(\tau = 2\) by (3.32) and (1.11) follows immediately from (3.30) as \(\xi _1 \leqslant \xi \). If \(\Lambda (\alpha _{\sigma (i)}) -2 \leqslant 3\) then \(\tau - 1 = (\Lambda (\alpha _{\sigma (i)}) -2)/3\) and, thus, \(\xi _{\tau - 1} = 3 \xi _{\Lambda (\alpha _{\sigma (i)}) -2}\). Hence, (3.30) implies (1.11). This concludes the proof of Theorem 1.7. \(\quad \square \)
3.3 Proof of Lemma 3.8, Proposition 3.9, and Lemma 3.11
Proof of Lemma 3.8
To begin with, we reduce the problem to the adjacency matrices by using the estimate (3.13). Hence, with very high probability,
where \(A^{{\mathbb {D}}_\tau }\) is the adjacency matrix of the graph \({\mathbb {D}}_\tau :={\mathbb {G}} \setminus {\mathbb {G}}_\tau \). Hence, since \(d^{-1/2} \leqslant C \xi _{\tau -1} \) by \(d \leqslant 3 \log N\) and the definition (1.9), it suffices to show that \(\Vert A^{{\mathbb {D}}_\tau } \Vert \leqslant {{\mathcal {C}}} \xi _{\tau -1} \sqrt{d}\).
We know from Proposition 3.1 (iii) and (v) that with very high probability \({\mathbb {D}}_\tau \) consists of (possibly overlapping) starsFootnote 4 around vertices \(x \in {{\mathcal {V}}}_\tau \) of central degree \(D_x^{{\mathbb {D}}_\tau } \leqslant {{\mathcal {C}}} d \xi _{\tau -1}^2\). Moreover, with very high probability,
-
(i)
any ball \(B_{2 r_\star }(x)\) around \(x \in {{\mathcal {V}}}_\tau \) has at most \({{\mathcal {C}}}\) cycles;
-
(ii)
any ball \(B_{2 r_\star }(x)\) around \(x \in {{\mathcal {V}}}_\tau \) contains at most \({{\mathcal {C}}} d \xi _{\tau -1}^2\) vertices in \({{\mathcal {V}}}_\tau \).
Claim (i) follows from [10, Corollary 5.6], the definition (1.8), and Lemma A.7. Claim (ii) follows from [10, Lemma 7.3] and \(h((\tau -1)/2) \asymp (\tau -1)^2\) for \(1 \leqslant \tau \leqslant 2\).
Let \(x \in {{\mathcal {V}}}_\tau \). We claim that we can remove at most \(\mathcal C\) edges of \({\mathbb {D}}_\tau \) incident to x so that no cycle passes through x. Indeed, if there were more than \({{\mathcal {C}}}\) cycles in \({\mathbb {D}}_\tau \) passing through x, then at least one such cycle would have to leave \(B_{2 r_\star }(x)\) (by (i)), which would imply that \(B_{2 r_\star }(x)\) has at least \(r_\star \) vertices in \({{\mathcal {V}}}_\tau \), which, by (ii), is impossible since \(r_\star \geqslant 2 {{\mathcal {C}}} d \xi _{\tau -1}^2\) by \(\tau \geqslant 1 + \xi ^{1/2}\). See Fig. 7 for an illustration of \({\mathbb {D}}_\tau \).
Thus, we can remove a graph \({\mathbb {U}}_\tau \) from \({\mathbb {D}}_\tau \) such that \({\mathbb {U}}_\tau \) has maximal degree \({{\mathcal {C}}}\) and \({\mathbb {D}}_\tau \setminus {\mathbb {U}}_\tau \) is a forest of maximal degree \(\mathcal Cd \xi _{\tau -1}^2\) (by (ii)). The claim now follows from Lemma A.4. \(\quad \square \)

An illustration of a connected component of \({\mathbb {D}}_\tau \). Vertices of \({{\mathcal {V}}}_\tau \) are drawn in white and the other vertices in black. The ball \(B_{2 r_\star }(x)\) around a chosen white vertex x is drawn in grey, where \(2 r_\star = 4\). The illustrated component of \({\mathbb {D}}_\tau \) has three cycles, two of which are in \(B_{2 r_\star }(x)\). The blue and red cycles pass through x. The purple edge is removed from the blue cycle, i.e. it is put into the graph \({\mathbb {U}}_\tau \). With very high probability, the red cycle cannot appear, because it leaves the ball \(B_{2 r_\star }(x)\) and therefore contains more white vertices in \(B_{2 r_\star }(x)\) than allowed by property (ii)
Proof of Proposition 3.9
We focus on the case \(\sigma = +\); trivial modifications yield (3.14) for \(\sigma = -\). The basic strategy is to decompose \((H^\tau - \Lambda (\alpha _x))\varvec{\mathrm {v}}_+^\tau (x)\) into several error terms that are estimated separately. A similar argument was applied in [10, Proposition 5.1] to the original graph \({\mathbb {G}}\) instead of \({\mathbb {G}}^\tau \), which however does not yield sharp enough estimates to reach the optimal scale \(d \gg \sqrt{\log N}\) (see Sect. 1.5).
We omit x from the notation in this proof and write \(u_i\), \(\varvec{\mathrm {v}}_+^\tau \) and \(S_i^\tau \) instead of \(u_i(x)\), \(\varvec{\mathrm {v}}^\tau _+(x)\) and \(S_i^\tau (x)\). We define
Note that \((\varvec{\mathrm {s}}^\tau _i)_{i=0}^{2r_\star }\) form an orthonormal system. Defining the vectors
a straightforward computation using the definition of \(\varvec{\mathrm {v}}^\tau _+\) yields
For a detailed proof of (3.34) in a similar setup, we refer the reader to [10, Lemma 5.2] (note that in the analogous calculation of [10] the left-hand side of (3.34) is multiplied by \(\sqrt{d}\)). The terms in (3.34) analogous to \(\varvec{\mathrm {w}}_0\) and \(\varvec{\mathrm {w}}_1\) in [10] vanish, respectively, because the projection \(\chi ^\tau \) is included in (3.12) and because \({\mathbb {G}}_\tau |_{B_{2r_\star }^\tau }\) is a tree by Proposition 3.1 (ii). The vector \(\varvec{\mathrm {w}}_4\) from (3.33) differs from the one in [10] due to the special choice of \(u_{r_\star }\) in (3.4).
We now complete the proof of (3.14) by showing that each term on the right-hand side of (3.34) is bounded in norm by \({\mathcal {C}} \xi \) with very high probability. We start with \(\varvec{\mathrm {w}}_3\) by first proving the concentration bound
with very high probability, for \(i = 1, \ldots , r_\star \). To prove this, we use Proposition 3.1 (iv) and (vi), as well as [10, Lemma 5.4], to obtain
with very high probability, where we used that \(\alpha _x \geqslant 1\), and the assumption [10, Eq. (5.13)] is satisfied by the definition (1.8). Therefore, invoking [10, Lemma 5.4] in the following expansion yields
with very high probability. Hence, recalling the lower bound \(\tau \geqslant 1 + \xi ^{1/2}\), we obtain (3.35).
We take the norm in the definition of \(\varvec{\mathrm {w}}_3\), use the orthonormality of \((\varvec{\mathrm {s}}_i^\tau )_{i=0}^{r_\star }\), and end up with
Consequently, (3.35) and \(\sum _{i=0}^{r_\star } u_i^2 =1\) yield the desired bound on \(\Vert \varvec{\mathrm {w}}_3 \Vert \).
In order to estimate \(\Vert \varvec{\mathrm {w}}_2 \Vert \), we use the definitions
and the Pythagorean theorem to obtain
with very high probability. Here, in the last step, we used (3.35), \(\sum _{i=0}^{r_\star } u_i^2 = 1\) and \(|d - {\mathbb {E}}[N_i(y) | B_{i-1}] | = d |B_{i-1} |/N \leqslant {\mathcal {C}}\) with very high probability due to [10, Eq. (5.12b)] and Lemma A.7.
Next, we claim that
with very high probability, for \(i = 2, \ldots , r_\star \). The proof of (3.39) is based on a dyadic decomposition analogous to the one used in the proof of [10, Eq. (5.26)]. We distinguish two regimes and estimate
with very high probability, where we introduced
In (3.40), we used that, with very high probability, \(\bigl (N_i(y)-{\mathbb {E}}[N_i(y) | B_{i-1}]\bigr )^2 \leqslant d^2 \bigl ((\tau - 1/2)^2 \vee 1\bigr ) \leqslant d^2 \mathrm {e}\), because \(y\in S_{i-1}^\tau \) implies the conditions \(0\leqslant N_i(y)\leqslant D_y\leqslant \tau d \) due to Proposition 3.1 (i) and \(d/2 \leqslant {\mathbb {E}}[N_i(y) |B_{i-1}] \leqslant d\) with very high probability. By Proposition 3.1 (iv), we have \({{\mathcal {N}}}_{i,k}^\tau \subset {{\mathcal {N}}}^{i-1}_k\), where \({{\mathcal {N}}}^{i-1}_k\) is defined as in the proof of [10, Eq. (5.26)]. (Note that, in the notation of [10], there is a one-to-one mapping between \(A_{( B_{i-1})}\) and \(B_i\).) In this proof it is shown that, with very high probability,
Using (3.36) and (3.37), and then plugging the resulting bound into (3.40) concludes the proof of (3.39).
Thus, we obtain \(\Vert \varvec{\mathrm {w}}_2 \Vert \leqslant {{\mathcal {C}}} \xi \) with very high probability, by starting from (3.38) and using (3.35), (3.39) and Proposition 3.1 (v) as well as the assumption \(1 + \xi ^{1/2} \leqslant \tau \leqslant 2\).
Finally, we estimate \(\varvec{\mathrm {w}}_4\). Since \(\alpha _x \geqslant 2\) and \(u_0 \leqslant 1\) we have that \(u_{r_\star } + u_{r_\star -1} \leqslant 3 (\alpha _x - 1)^{-(r_\star -2)/2}\). The other coefficients of \(\varvec{\mathrm {s}}_{r_\star -1}^\tau \), \(\varvec{\mathrm {s}}_{r_\star }^\tau \) and \(\varvec{\mathrm {s}}_{r_\star +1}^\tau \) are bounded by \({{\mathcal {C}}}\) with very high probability, due to \(\alpha _x \geqslant 2\) and (3.35), respectively. Therefore, (3.7) implies \(\Vert \varvec{\mathrm {w}}_4 \Vert \leqslant {{\mathcal {C}}} \xi \). This concludes the proof of Proposition 3.9. \(\quad \square \)
Proof of Lemma 3.11
We have to estimate the norm of
Each \(x \in {{\mathcal {V}}}\) satisfies the condition of Proposition 3.9 since \(\xi ^{1/4} \geqslant C (\log d)^2 / \sqrt{\log N}\) (see (3.8)). Hence, for any \(x \in {{\mathcal {V}}}\) and \(\sigma = \pm \), Proposition 3.9 yields
with very high probability, where the second statement follows from the first together with the definition (3.5) of \(\varvec{\mathrm {v}}_\sigma ^\tau (x)\) and Remark 3.7. By Proposition 3.1 (i), the balls \(B_{2r_\star }^\tau (x)\) and \(B_{2r_\star }^\tau (y)\) are disjoint for \(x, y \in {{\mathcal {V}}}_\tau \) with \(x \ne y\). Hence, in this case, \(\varvec{\mathrm {v}}_\sigma ^\tau (x),\varvec{\mathrm {e}}_\sigma ^\tau (x) \perp \varvec{\mathrm {v}}_{\sigma '}^\tau (y),\varvec{\mathrm {e}}_{\sigma '}^\tau (y)\). For any \(\varvec{\mathrm {a}} = \sum _{x\in {{\mathcal {V}}}} \sum _{\sigma = \pm } a_{x,\sigma } \varvec{\mathrm {v}}_\sigma ^\tau (x)\), we obtain
Thus, with very high probability, \(\Vert \overline{\Pi } \!\,^\tau H^\tau \Pi ^\tau \varvec{\mathrm {a}} \Vert ^2 \leqslant \sum _{x \in {{\mathcal {V}}}} \Vert \sum _{\sigma = \pm } a_{x,\sigma } \varvec{\mathrm {e}}_\sigma ^\tau (x)\Vert ^2 \leqslant 4 {{\mathcal {C}}}^2\sum _{x\in \mathcal V} \sum _{\sigma = \pm } a_{x,\sigma }^2 \xi ^2 = 4 {{\mathcal {C}}}^2 \xi ^2 \Vert \varvec{\mathrm {a}} \Vert ^2\) by orthogonality. Therefore, \(\Vert \overline{\Pi } \!\,^\tau H^\tau \Pi ^\tau \Vert \leqslant {{\mathcal {C}}} \xi \) with very high probability. Similarly, the representation
yields the desired estimate on the sum of the two first terms on the right-hand side of (3.41). \(\quad \square \)
3.4 Proof of Proposition 3.12
In this section we prove Proposition 3.12. Its proof relies on two fundamental tools.
The first tool is a quadratic form estimate, which estimates H in terms of the diagonal matrix of the vertex degrees. It is an improvement of [10, Proposition 6.1]. To state it, for two Hermitian matrices X and Y we use the notation \(X \leqslant Y\) to mean that \(Y - X\) is a nonnegative matrix, and \(|X |\) is the absolute value function applied to the matrix X.
Proposition 3.13
Let \(4 \leqslant d \leqslant 3 \log N\). Then, with very high probability, we have
where Q is the diagonal matrix with diagonal \((\alpha _x)_{x \in [N]}\).
The second tool is a delocalization estimate for an eigenvector \(\varvec{\mathrm {w}}\) of \(\widehat{H}^\tau \) associated with an eigenvalue \(\lambda > 2\). Essentially, it says that \(w_x\) is small at any \(x \in {{\mathcal {V}}}_\tau \) unless \(\varvec{\mathrm {w}}\) happens to be the specific eigenvector \(\varvec{\mathrm {v}}^\tau _\pm (x)\) of \(\widehat{H}^\tau \), which is by definition localized around x. Thus, in any ball \(B_{2 r_\star }^\tau (x)\) around \(x \in {{\mathcal {V}}}_\tau \), all eigenvectors except \(\varvec{\mathrm {v}}^\tau _\pm (x)\) are locally delocalized in the sense that their magnitudes at x are small. Using that the balls \((B_{2 r_\star }^\tau (x))_{x \in \mathcal V_\tau }\) are disjoint, this implies that eigenvectors of \(\overline{\Pi } \!\,^\tau H^\tau \overline{\Pi } \!\,^\tau \) have negligible mass on the set \(\mathcal V\).
Proposition 3.14
Let d satisfy (1.10). If \(1 + \xi ^{1/2} \leqslant \tau \leqslant 2\) then the following holds with very high probability. Let \(\lambda \) be an eigenvalue of \(\widehat{H}^{\tau }\) with \(\lambda >2\tau +{{\mathcal {C}}} \xi \) and \(\varvec{\mathrm {w}}=(w_x)_{x \in [N]}\) its corresponding eigenvector.
-
(i)
If \(x \in {{\mathcal {V}}}\) and \(\varvec{\mathrm {v}}_\pm ^{\tau }(x)\perp \varvec{\mathrm {w}}\) or if \(x \in {{\mathcal {V}}}_\tau \setminus {{\mathcal {V}}}\) then
$$\begin{aligned} \frac{|w_{x}|}{\Vert \varvec{\mathrm {w}}|_{B_{2r_\star }^\tau (x)}\Vert }\leqslant \frac{\lambda ^2}{(\lambda -2 \tau - {{\mathcal {C}}}\xi )^{2}}\bigg (\frac{2 \tau +{{\mathcal {C}}} \xi }{\lambda }\bigg )^{r_{\star }}\,. \end{aligned}$$ -
(ii)
Let \(\varvec{\mathrm {w}}\) be normalized. If \(\varvec{\mathrm {v}}_\pm ^{\tau }(x)\perp \varvec{\mathrm {w}}\) for all \(x \in {{\mathcal {V}}}\) then
$$\begin{aligned} \sum _{x\in {{\mathcal {V}}}_\tau }w_{x}^{2}\leqslant \frac{\lambda ^4}{(\lambda -2 \tau -{{\mathcal {C}}} \xi )^{4}}\bigg (\frac{2 \tau +{{\mathcal {C}}} \xi }{\lambda }\bigg )^{2r_{\star }}\,. \end{aligned}$$
Analogous results hold for \(\lambda < -2 \tau - {{\mathcal {C}}} \xi \).
We may now conclude the proof of Proposition 3.12.
Proof of Proposition 3.12
By Proposition 3.13, Lemma 3.11, and Lemma 3.8 we have
with very high probability, where we used \(\frac{\log N}{d^{2}}\vee d^{-1/2} \leqslant (\xi +\xi _{\tau -1})\).
Arguing by contradiction, we assume that there exists an eigenvalue \(\lambda > 2\tau + {{\mathcal {C}}}' (\xi +\xi _{\tau -1})\) of \(\overline{\Pi } \!\,^\tau H^\tau \overline{\Pi } \!\,^\tau \) for some \({{\mathcal {C}}}' \geqslant 2 {{\mathcal {C}}}\) to be chosen later. By the lower bound in (1.10), we may assume that \({{\mathcal {C}}}' \xi \leqslant 1\). Thus, by the definition of \(\widehat{H}^\tau \), there is an eigenvector \(\varvec{\mathrm {w}}\) of \(\widehat{H}^\tau \) corresponding to \(\lambda \), which is orthogonal to \(\varvec{\mathrm {v}}_\pm ^\tau (x)\) for all \(x \in {{\mathcal {V}}}\). From (3.42), we conclude
It remains to estimate the two sums on right-hand side of (3.43).
Since \(\varvec{\mathrm {w}} \perp \varvec{\mathrm {v}}^\tau _\pm (x)\) for all \(x \in {{\mathcal {V}}}\), we can apply Proposition 3.14 (ii). We find
where in the last step we recalled the definition (1.8) and used that \(\tau \leqslant 2\) and \({{\mathcal {C}}}' \xi \leqslant 1\). Using the estimate
combined with Proposition 3.14 (ii), (3.44) and Lemma A.7, yields
where the third step follows by choosing \({{\mathcal {C}}}'\) large enough, depending on \({{\mathcal {C}}}\).
Plugging this estimate into (3.43) and using \(\sum _x w_x^2\leqslant 1\) to estimate the first sum in (3.43), we obtain \(\lambda \leqslant 2\tau + 2 {\mathcal {C}} (\xi +\xi _{\tau -1})\). This is a contradiction to the assumption \(\lambda > 2\tau + {{\mathcal {C}}}' (\xi +\xi _{\tau -1})\). The proof of Proposition 3.12 is therefore complete. \(\quad \square \)
Proof of Proposition 3.13
We only establish an upper bound on H. The proof of the same upper bound on \(-H\) is identical and, therefore, omitted.
We introduce the matrices \(H(t) = (H_{xy}(t))_{x, y \in [N]}\) and \(M(t) = (\delta _{xy} m_x(t))_{x,y \in [N]}\) with entries
By the estimate on the spectral radius of the nonbacktracking matrix associated with H in [15, Theorem 2.5] and the Ihara–Bass-type formula in [15, Lemma 4.1] we have, with very high probability, \(\det (M(t)-H(t))\ne 0\) for all \(t\geqslant 1+{{\mathcal {C}}} d^{-1/2}\). Because \((M(t)-H(t))\rightarrow I\) as \(t\rightarrow \infty \), the matrix \(M(t)-H(t)\) is positive definite for large enough t. By continuity of the eigenvalues, we conclude that all eigenvalues of \(M(t)-H(t)\) stay positive for \(t\geqslant 1+\mathcal C d^{-1/2}\), and hence
for all \(t\geqslant 1+{{\mathcal {C}}} d^{-1/2}\) with very high probability. We now define the matrix \(\Delta = (\Delta _{xy})_{x,y \in [N]}\) with
It is easy to check that \(\Delta \) is a nonnegative matrix. We also have
where we used that \(|H_{xy} | \leqslant d^{-1/2}\) and \(\sum _{y'} H_{x y'}^2 \leqslant \alpha _x + \frac{d}{N}\) by definition of H. We use this to estimate the diagonal entries of \(\Delta \) and obtain
On the other hand, for the diagonal matrix M(t), we have the trivial upper bound
since \(\alpha _x \leqslant {\mathcal {C}} (\log N)/d\) with very high probability due to Lemma A.7. Finally, combining (3.45), (3.46) and (3.47) yields
and Proposition 3.13 follows by choosing \(t= 1+{{\mathcal {C}}} d^{-1/2}\). \(\quad \square \)
What remains is the proof of Proposition 3.14. The underlying principle behind the proof is the same as that of the Combes–Thomas estimate [25]: the Green function \(((\lambda - Z)^{-1})_{ij}\) of a local operator Z at a spectral parameter \(\lambda \) separated from the spectrum of Z decays exponentially in the distance between i and j, at a rate inversely proportional to the distance from \(\lambda \) to the spectrum of Z. Here local means that \(Z_{ij}\) vanishes if the distance between i and j is larger than 1. Since a graph is equipped with a natural notion of distance and the adjacency matrix is a local operator, a Combes–Thomas estimate would be applicable directly on the level of the graph, at least for the matrix \(H^\tau \). For our purposes, however, we need a radial version of a Combes–Thomas estimate, obtained by first tridiagonalizing (a modification of) \(\widehat{H}^\tau \) around a vertex \(x \in {{\mathcal {V}}}_\tau \) (see Appendix A.2). In this formulation, the indices i and j have the interpretation of radii around the vertex x, and the notion of distance is simply that of \({\mathbb {N}}\) on the set of radii. Since Z is tridiagonal, the locality of Z is trivial, although the matrix \(\widehat{H}^\tau \) (or its appropriate modification) is not a local operator on the graph \({\mathbb {G}}_\tau \).
To ensure the separation of \(\lambda > 2\tau + o(1)\) and the spectrum of Z, we cannot choose Z to be the tridiagonalization of \(\widehat{H}^\tau \), since \(\lambda \) is an eigenvalue of \(\widehat{H}^\tau \). In fact, Z is the tridiagonalization of a new matrix \(\widehat{H}^{\tau ,x}\), obtained by restricting \(\widehat{H}^\tau \) to the ball \(B^\tau _{2 r_\star }(x)\) and possibly subtracting a suitably chosen rank-two matrix, which allows us to show \(\Vert \widehat{H}^{\tau , x} \Vert \leqslant 2 \tau + o(1)\). By the orthogonality assumption on \(\varvec{\mathrm {w}}\), we then find that the Green function \(((\lambda - Z)^{-1})_{i r_\star }\), \(0 \leqslant i < r_\star \), and the eigenvector components in the radial basis \(u_i\), \(0 \leqslant i < r_\star \), satisfy the same linear difference equation. The exponential decay of \(((\lambda - Z)^{-1})_{i r_\star }\) in \(r_\star - i\) then implies that, for each \(x \in {{\mathcal {V}}}_\tau \), \(u_0^2 \leqslant o(1/\log N) \sum _{i = 0}^{r_*} u_i^2\). Going back to the original vertex basis, this implies that \(w_x^2 \leqslant o(1/\log N) \Vert \varvec{\mathrm {w}}|_{B_{2r_\star }^\tau (x)}\Vert ^2\) for all \(x \in {{\mathcal {V}}}_\tau \), from which Proposition 3.14 follows since the balls \(B_{2r_\star }^\tau (x)\), \(x \in {{\mathcal {V}}}_\tau \), are disjoint.
Proof of Proposition 3.14
For a matrix \(M \in {\mathbb {R}}^{N \times N}\) and a set \(V \subset [N]\), we use the notation \((M \vert _V)_{xy} :=\mathbb {1}_{x,y \in V} M_{xy}\).
We begin with part (i). We first treat the case \(x\in {{\mathcal {V}}}\). To that end, we introduce the matrix
We claim that, with very high probability,
To show (3.49), we begin by noting that, by Proposition 3.1 (i) and (ii), \({\mathbb {G}}_{\tau }\) restricted to \(B_{2r_{\star }}^{\tau }(x)\) is a tree whose root x has \(\alpha _x d\) children and all other vertices have at most \(\tau d\) children. Hence, Lemma A.5 yields \(\bigl \Vert H^{\tau }|_{B_{2r_{\star }}^{\tau }(x)} \bigr \Vert \leqslant \sqrt{\tau } \Lambda (\alpha _x /\tau \vee 2)\). Using Lemma 3.11 we find
with very high probability, and since \(\varvec{\mathrm {v}}_\pm ^\tau (x)\) is an eigenvector of \(\widehat{H}^\tau |_{B_{2r_{\star }}^{\tau }(x)}\) with eigenvalue \(\pm \Lambda (\alpha _x)\), we conclude
with very high probability. The estimate (3.51) is rough in the sense that the subtraction of the two last terms of (3.48) is not needed for its validity (since \(\Lambda (\alpha _x) \leqslant \sqrt{\tau } \Lambda (\alpha _x/\tau \vee 2)\)). Nevertheless, it is sufficient to establish (3.49) in the following cases, which may be considered degenerate.
If \(\alpha _x \leqslant 2 \tau \) then (3.51) immediately implies (3.49), since \(\sqrt{\tau } \leqslant \tau \). Moreover, if \(\alpha _x > 2 \tau \) and \(\Lambda (\alpha _x) \leqslant 2 \sqrt{\tau } + {{\mathcal {C}}} \xi \), then (3.51) implies
which is (3.49) after renaming the constant \({{\mathcal {C}}}\).
Hence, to prove (3.49), it suffices to consider the case \(\Lambda (\alpha _x) > 2 \sqrt{\tau } + {{\mathcal {C}}} \xi \). By Proposition 3.1 (i) and (ii), \({\mathbb {G}}_{\tau }\) restricted to \(B_{2r_{\star }}^{\tau }(x) \setminus \{x\}\) is a forest of maximal degree at most \(\tau d\). Lemma A.4 therefore yields \(\Vert H^{\tau }|_{B_{2r_{\star }}^\tau (x) \setminus \{x\}}\Vert \leqslant 2\sqrt{\tau }\). Moreover, the adjacency matrix of the star graph consisting of all edges of \({\mathbb {G}}_\tau \) incident to x has precisely two nonzero eigenvalues, \(\pm \sqrt{d \alpha _x}\). By first order perturbation theory, we therefore conclude that \(H^{\tau }|_{B_{2r_{\star }}^\tau (x)}\) has at most one eigenvalue strictly larger than \(2\sqrt{\tau }\) and at most one strictly smaller than \(-2\sqrt{\tau }\). Using (3.50) we conclude that \(\widehat{H}^{\tau }|_{B_{2r_{\star }}^\tau (x)}\) has at most one eigenvalue strictly larger than \(2\sqrt{\tau }+{{\mathcal {C}}} \xi \) and at most one strictly smaller than \(-2\sqrt{\tau }-{{\mathcal {C}}} \xi \). Since \(\varvec{\mathrm {v}}_+^{\tau }(x)\) (respectively \(\varvec{\mathrm {v}}_-^{\tau }(x)\)) is an eigenvector of \(\widehat{H}^{\tau }|_{B_{2r_{\star }}^\tau (x)}\) with eigenvalue \(\Lambda (\alpha _{x})\) (respectively \(-\Lambda (\alpha _{x})\)), and since \(\Lambda (\alpha _x) > 2 \sqrt{\tau } + {{\mathcal {C}}} \xi \), we conclude (3.49).
Next, let \((\varvec{\mathrm {g}}_i)_{i=0}^{r_\star }\) be the Gram–Schmidt orthonormalization of the vectors \(((\widehat{H}^{\tau ,x})^i \varvec{\mathrm {1}}_x)_{i=0}^{r_\star }\). We claim that
for \(i = 0, \ldots , r_\star \). The proof proceeds by induction. The base case for \(i =0\) holds trivially. For the induction step, it suffices to prove for \(0 \leqslant i < r_\star \) that if \({{\,\mathrm{supp}\,}}\varvec{\mathrm {g}}_i \subset B_{r_\star +i}^\tau (x)\) then
To that end, we note that by Proposition 3.1 (i) we have \(\widehat{H}^{\tau ,x} = \bigl (\overline{\Pi } \!\,^{\tau } H^\tau \overline{\Pi } \!\,^\tau \bigr ) |_{B_{2r_{\star }}^{\tau }(x)}\). Hence, by induction assumption, Proposition 3.1 (i), and Remark 3.7,
and we conclude (3.53), as \({{\,\mathrm{supp}\,}}\varvec{\mathrm {v}}_\sigma ^\tau (x) \subset B_{r_\star }^\tau (x)\).
Let  , be the tridiagonal representation of \(\widehat{H}^{\tau ,x}\) up to radius \(r_\star \) (see Appendix A.2 below). Owing to (3.49), we have
, be the tridiagonal representation of \(\widehat{H}^{\tau ,x}\) up to radius \(r_\star \) (see Appendix A.2 below). Owing to (3.49), we have
We set \(u_{i}:=\langle \varvec{\mathrm {g}}_{i},\varvec{\mathrm {w}}\rangle \) for any \(0 \leqslant i \leqslant r_\star \). Because \(\varvec{\mathrm {w}}\) is an eigenvector of \(\widehat{H}^{\tau }\) that is orthogonal to \(\varvec{\mathrm {v}}_\pm ^\tau (x)\), for any \(i<r_\star \), (3.52) implies
with the conventions \(u_{-1}=0\) and \(Z_{0,-1}=0\). Let \(G(\lambda ) :=(\lambda - Z)^{-1}\) be the resolvent of Z at \(\lambda \). Note that \(\lambda -Z\) is invertible since \(\lambda > \Vert Z \Vert \) by assumption and (3.54). Since \(\bigl ((\lambda - Z) G(\lambda )\bigr )_{i \, r_{\star }} = 0\) for \(i<r_\star \), we find
Therefore \((G_{i r_{\star }}(\lambda ))_{i\leqslant r_\star }\) and \(\left( u_{i}\right) _{i\leqslant r_\star }\) satisfy the same linear recursive equation (cf. (3.55)); solving them recursively from \(i = 0\) to \(i = r_\star \) yields
for all \(i\leqslant r_{\star }\). Moreover, as \(\lambda >\Vert Z\Vert \) by assumption and (3.54), we have the convergent Neumann series \(G(\lambda )= \frac{1}{\lambda }\sum _{k\geqslant 0}(Z / \lambda )^{k}\). Thus, the offdiagonal entries of the resolvent satisfy
Since Z is tridiagonal, we deduce that \(\bigl ((Z / \lambda )^k\bigr )_{0 r_\star } = 0\) if \(k < r_\star \), so that, by (3.54),
On the other hand, for the diagonal entries of the resolvent, we get, by splitting the summation over k into even and odd values,
where in the thid step we discarded the terms \(k > 0\) to obtain a lower bound using that \(I + Z/\lambda \geqslant 0\) by (3.54), and in the last step we used (3.54). Hence, the definition of \(u_i\) and (3.52) imply
Here, we used (3.56) in third step and (3.57) as well as (3.58) in the last step. This concludes the proof of (i) for \(x \in {{\mathcal {V}}}\).
In the case \(x\in {{\mathcal {V}}}_\tau \setminus {{\mathcal {V}}}\), we set \(\widehat{H}^{\tau ,x} :=\widehat{H}^{\tau } |_{B_{2r_{\star }}^{\tau }(x)}\). We claim that (3.49) holds. To see that, we use Proposition 3.1 (i) and (ii) as well as Lemma A.5 with \(p = d(2 + \xi ^{1/4})\) and \(q = d \tau \) to obtain
Here, the last step is trivial if \(\tau \geqslant 1 + \xi ^{1/4}/2\) and, if \(\tau \in [1 + \xi ^{1/2}, 1 + \xi ^{1/4}/2]\), we used that \(f(\tau ) :=\sqrt{\tau }\Lambda ((2 + \xi ^{1/4}) / \tau )/(2\tau )\) is monotonically decreasing on this interval and \(f(1 + \xi ^{1/2}) \leqslant 1\), as can be seen by an explicit analysis of the function f. Now we may take over the previous argument verbatim to prove (i) for \(x \in {{\mathcal {V}}}_\tau \setminus {{\mathcal {V}}}\).
Finally, we prove (ii). By (i) we have
where we used that the the balls \(\{B^\tau _{2r_\star }(x) :x \in {{\mathcal {V}}}_\tau \}\) are disjoint, which implies \(1=\Vert \varvec{\mathrm {w}}\Vert ^2 \geqslant \sum _{x\in {{\mathcal {V}}}_\tau } \Vert \varvec{\mathrm {w}}|_{B^\tau _{2r_{\star }}(x)}\Vert ^2\). \(\quad \square \)
3.5 Proof of Proposition 3.1
We conclude this section with the proof of Proposition 3.1.
Proof of Proposition 3.1
Parts (i)–(v) follow immediately from parts (i)–(iv) and (vi) of [10, Lemma 7.2]. To see this, we remark that the function h from [10] satisfies \(h((\tau - 1)/2) \asymp (\tau - 1)^2\) for \(1 < \tau \leqslant 2\). Moreover, by Lemma A.7 and the upper bound on d, we have \(\max _x D_x \leqslant {{\mathcal {C}}} \log N\) with very high probability. Hence, choosing the universal constant c small enough in (1.8) and recalling the lower bound on \(\tau - 1\), in the notation of [10, Equations (5.1) and (7.2)] we obtain for any \(x \in {{\mathcal {V}}}_\tau \) the inequality \(2 r_\star \leqslant (\frac{1}{4} r_x ) \wedge (\frac{1}{2} r(\tau ))\) with very high probability. This yields parts (i)–(v).
It remains to prove (vi), which is the content of the rest of this proof. From now on we systematically omit the argument x from our notation. Part (v) already implies the bound
with very high probability, which is (3.2) for \(i=1\).
From [10, Eq. (7.13)] we find
(As a guide to the reader, this estimate follows from the construction of \({\mathbb {G}}_\tau \) given in [10, Proof of Lemma 7.2], which ensures that if a vertex \(z \in S_i\) is not in \(S_i^\tau \) then any path in \({\mathbb {G}}\) of length i connecting z to x is cut in \({\mathbb {G}}_\tau \) at its edge incident to x.) Hence, in order to show (vi) for \(i \geqslant 2\), it suffices to prove
with very high probability, for all \(2 \leqslant i \leqslant 2 r_\star \).
We start with the case \(i=2\). We shall use the relation
where, for \(y \in S_1\), we introduced \(N_2(y) :=|S_{1}(y) \cap S_2 |\). Note that \(N_2(y)\) is the number of vertices in \(S_2\) connected to x via a path of minimal length passing through y. The identity (3.61) is a direct consequence of \(|S_1(y) | = |S_1(y) \cap S_2 | + |S_1(y) \cap S_1 | + |S_1(y) \cap S_0 |\) using the definition of \(N_2\) and \(|S_1(y) \cap S_0 | = |S_1(y) \cap \{x \} | = 1\).
The second and third terms of (3.61) are smaller than the right-hand side of (3.60) for \(i=2\) due to [10, Eq. (5.23)] and (3.59), respectively. Hence, it remains to estimate the first term on the right-hand side of (3.61) in order to prove (3.60) for \(i =2\).
To that end, we condition on the ball \(B_1\) and abbreviate \({\mathbb {P}}_{B_1}(\cdot ) :={\mathbb {P}}(\, \cdot \mid B_1)\). Since
we find that conditioned on \(B_1\) the random variables \((N_2(y))_{y \in S_1}\) are independent \({\text {Binom}}(N - |B_1 |, d/N)\) random variables. We abbreviate \(\Gamma :=\frac{\log N}{(\tau -1)^2}\). For given \({{\mathcal {C}}}, {{\mathcal {C}}}'\), we set \({{\mathcal {C}}}'' :={{\mathcal {C}}}' + 2 \mathcal C\) and estimate
In order to estimate the first term on the right-hand side of (3.63), we shall prove that if \(|B_1 | \leqslant N^{1/4}\) then
for all \(y\in S_1\) and \(t \leqslant 1/8\). To that end, we estimate
With Poisson approximation, Lemma A.6 below, we obtain (assuming that 2d is an integer to simplify notation)
By Stirling’s approximation we get
The term in the parentheses on the right-hand side is negative for \(t \leqslant 1/8\), and hence
for large enough d, which gives (3.64). Since the family \((N_2(y))_{y \in S_1}\) is independent conditioned on \(B_1\), we can now use Chebyshev’s inequality to obtain, for \(0 \leqslant t \leqslant 1/8\),
Now we set \(t = 1/8\), recall the bound \(\tau \leqslant 2\), plug this estimate back into (3.63), and take the expectation. We use Lemma A.7 to estimate \(|S_1 |\), which in particular implies that \(|B_1 | \leqslant N^{1/4}\) with very high probability; this concludes the estimate of the expectation of the first term of (3.63) by choosing \({{\mathcal {C}}}'\) large enough. Next, the expectation of the second term is easily estimated by Lemma A.7 since \(N_2(y)\) has law \({\text {Binom}}(N - |B_1 |, d/N)\) when conditioned on \(B_1\). Finally, the expectation of the last term of (3.63) is estimated by (3.59) by choosing \({{\mathcal {C}}}\) large enough. This concludes the proof of (3.60) for \(i = 2\).
We now prove (3.60) for \(i + 1\) with \(i\geqslant 2\) by induction. Using [10, Lemma 5.4 (ii)] combined with Lemma A.7, we deduce that
with very high probability for all \(y\in S_1\setminus S_1^{\tau }\) and all \(i \leqslant r_\star \). Therefore, using the induction assumption, i.e. (3.60) for i, we obtain
with very high probability, where we used the concavity of \(\sqrt{\,\cdot \,}\) in the second step, (3.59) and (3.60) for i in the last step. Since \(\sqrt{d^i \log N}\leqslant d^{i/2+1}\leqslant d^i\) for \(i\geqslant 2 \) and the sequence \((d^{1-i/2})_{i \in {\mathbb {N}}}\) is summable, this proves (3.60) for \(i+1\) with a constant \({{\mathcal {C}}}\) independent of i. This concludes the proof of Proposition 3.1. \(\quad \square \)
4 The Delocalized Phase
In this section we prove Theorem 1.8. In fact, we state and prove a more general result, Theorem 4.2 below, which immediately implies Theorem 1.8.
4.1 Local law
Theorem 4.2 is a local law for a general class of sparse random matrices of the form
where \(f \geqslant 0\) and \(\varvec{\mathrm {e}} :=N^{-1/2}(1,1,\dots ,1)^*\). Here H is a Hermitian random matrix satisfying the following definition.
Definition 4.1
Let \(0< d < N\). A sparse matrix is a complex Hermitian \(N\times N\) matrix \(H=H^* \in {\mathbb {C}}^{N \times N}\) whose entries \(H_{ij}\) satisfy the following conditions.
-
(i)
The upper-triangular entries (\(H_{ij}:1 \leqslant i \leqslant j\leqslant N\)) are independent.
-
(ii)
We have \({\mathbb {E}} H_{ij}=0\) and \( {\mathbb {E}} |H_{ij} |^2=(1 + O(\delta _{ij}))/N\) for all i, j.
-
(iii)
Almost surely, \(|H_{ij} | \leqslant K d^{-1/2}\) for all i, j and some constant K.
It is easy to check that the set of matrices M defined as in (4.1) and Definition 4.1 contains those from Theorem 1.8 (see the proof of Theorem 1.8 below). From now on we suppose that \(K = 1\) to simplify notation.
The local law for the matrix M established in Theorem 4.2 below provides control of the entries of the Green function
for z in the spectral domain
for some constant \(L \geqslant 1\). We also define the Stieltjes transform g of the empirical spectral measure of M given by
The limiting behaviour of G and g is governed by the following deterministic quantities. Denote by \({\mathbb {C}}_+ :=\{z \in {\mathbb {C}}:{{\,\mathrm{Im}\,}}z > 0\}\) the complex upper half-plane. For \(z \in {\mathbb {C}}_+\) we define m(z) as the Stieltjes transform of the semicircle law \(\mu _1\),
An elementary argument shows that m(z) can be characterized as the unique solution m in \({\mathbb {C}}_+\) of the equation
For \(\alpha \geqslant 0\) and \(z \in {\mathbb {C}}_+\) we define
so that \(m_1 = m\) by (4.6). In Lemma A.3 below we show that \(m_\alpha \) is bounded in the domain \(\varvec{\mathrm {S}}\), with a bound depending only on \(\kappa \).
For \(x \in [N]\) we denote the square Euclidean norm of the xth row of H by
which should be thought of as the normalized degree of x; see Remark 4.3 below.
Theorem 4.2
(Local law for M). Fix \(0 < \kappa \leqslant 1/2\) and \(L \geqslant 1\). Let H be a sparse matrix as in Definition 4.1, define M as in (4.1) for some \(0 \leqslant f \leqslant N^{\kappa /6}\), and define G and g as in (4.2) and (4.4) respectively. Then with very high probability, for d satisfying (1.18), for all \(z \in \varvec{\mathrm {S}}\) we have
Proof of Theorem 1.8
Under the assumptions of Theorem 1.8 we find that \(M :=A / \sqrt{d}\) is of the form (4.1) for some H and f satisfying the assumptions of Theorem 4.2. Now Theorem 1.8 is a well-known consequence of Theorem 4.2 and the boundedness of \(m_{\alpha }(z)\) in (A.4) below. For the reader’s convenience, we give the short proof. Denoting the eigenvalues of M by \((\lambda _i(M))_{i \in [N]}\) and the associated eigenvectors by \((\varvec{\mathrm {w}}_i(M))_{i \in [N]}\), setting \(z = \lambda + \mathrm {i}\eta \) with \(\eta = N^{-1 + \kappa }\), by (4.9) and (A.4) we have with very high probability

where in the last step we omitted all terms except i satisfying \(\lambda _i(M) = \lambda \). The claim follows by renaming \(\kappa \rightarrow \kappa / 2\). (Here we used that Theorem 4.2 holds also for random \(z \in \varvec{\mathrm {S}}\), as follows form a standard net argument; see e.g. [16, Remark 2.7].) \(\quad \square \)
Remark 4.3
(Relation between \(\alpha _x\) and \(\beta _x\)). In the special case \(M = d^{-1/2} A\) with A the adjacency matrix of \({\mathbb {G}}(N,d/N)\), we have
with very high probability, by Lemma A.7.
By definition, \(m_\alpha (z) \in {\mathbb {C}}_+\) for \(z \in {\mathbb {C}}_+\), i.e. \(m_\alpha \) is a Nevanlinna function, and \(\lim _{z \rightarrow \infty } z m_\alpha (z) = -1\). By the integral representation theorem for Nevanlinna functions, we conclude that \(m_\alpha \) is the Stieltjes transform of a Borel probability measure \(\mu _\alpha \) on \({\mathbb {R}}\),
Theorem 4.2 implies that the spectral measure of M at a vertex x is approximately \(\mu _{\beta _x}\) with very high probability.
Inverting the Stieltjes transform (4.11) and using the definitions (4.5) and (4.7), we find after a short calculation
where
The family \((\mu _\alpha )_{\alpha \geqslant 0}\) contains the semicircle law (\(\alpha = 1\)), the Kesten-McKay law of parameter d (\(\alpha = d / (d - 1)\)), and the arcsine law (\(\alpha = 2\)). For rational \(\alpha = p/q\), the measure \(\mu _{p/q}\) can be interpreted as the spectral measure at the root of the infinite rooted (p, q)-regular tree, whose root has p children and all other vertices have q children. We refer to Appendix A.2 for more details. See Fig. 8 for an illustration of the measure \(\mu _\alpha \).
Remark 4.4
Using a standard application the Helffer-Sjöstrand formula (see e.g. [16, Section 8 and Appendix C]), we deduce from Theorem 4.2 the following local law for the spectral measure. Denote by \(\varrho _x\) the spectral measure of M at vertex x. Under the assumptions of Theorem 4.2, with very high probability, for any inverval \(I \subset {{\mathcal {S}}}_\kappa \), we have
The error is smaller than the left-hand side provided that \(|I | \geqslant {{\mathcal {C}}} N^{\kappa - 1}\).

An illustration of the probability measure \(\mu _\alpha \) for various values of \(\alpha \). For \(\alpha > 2\), \(\mu _\alpha \) has two atoms which we draw using vertical lines. The measure \(\mu _\alpha \) is the semicircle law for \(\alpha = 1\), the arcsine law for \(\alpha = 2\), and the Kesten-McKay law with \(d = \frac{\alpha }{\alpha - 1}\) for \(1< \alpha < 2\). Note that the density of \(\mu _\alpha \) is bounded in \({{\mathcal {S}}}_\kappa \), uniformly in \(\alpha \). The divergence of the density near 0 is caused by values of \(\alpha \) close to 0, and the divergence of the density near \(\pm 2\) by values of \(\alpha \) close to 2
The remainder of this section is devoted to the proof of Theorem 4.2. For the rest of this section, we assume that M is as in Theorem 4.2. To simplify notation, we consistently omit the z-dependence from our notation in quantities that depend on \(z \in \varvec{\mathrm {S}}\). Unless mentioned otherwise, from now on all statements are uniform in \(z \in \varvec{\mathrm {S}}\).
For the proof of Theorem 4.2, it will be convenient to single out the generic constant \({{\mathcal {C}}}\) from (1.18) by introducing a new constant \({{\mathcal {D}}}\) and replacing (1.18) with
Our proof will always assume that \({{\mathcal {C}}} \equiv {{\mathcal {C}}}_\nu \) and \({{\mathcal {D}}} \equiv {{\mathcal {D}}}_\nu \) are large enough, and the constant \(\mathcal C\) in (1.18) can be taken to be \({{\mathcal {C}}} \vee \mathcal D\). For the rest of this section we assume that d satisfies (4.13) for some large enough \({{\mathcal {D}}}\), depending on \(\kappa \) and \(\nu \). To guide the reader through the proof, in Fig. 9 we include a diagram of the dependencies of the various quantities appearing throughout this section.

The dependency graph of the various quantities appearing in the proof of Theorem 4.2. An arrow from x to y means that y is chosen as a function of x. The independent parameters, \(\kappa \) and \(\nu \), are highlighted in blue
4.2 Typical vertices
We start by introducing the key tool in the proof of Theorem 4.2, a decomposition of vertices into typical vertices and the complementary atypical vertices. Heuristically, a typical vertex x has close to d neighbours and the spectral measure of M at x is well approximated by the semicircle law. In fact, in order to be applicable to the proof of Proposition 4.18 below, the notion of a typical vertex is somewhat more complicated, and when counting the number of neighbours of a vertex x we also need to weight the neighbours with diagonal entries of a Green function, so that the notion of typical vertex also depends on the spectral parameter z, which in this subsection we allow to be any complex number z with \({{\,\mathrm{Im}\,}}z \geqslant N^{-1 + \kappa }\). This notion is defined precisely using the parameters \(\Phi _x\) and \(\Psi _x\) from (4.18) below. The main result of this subsection is Proposition 4.8 below, which states, in the language of graphs when \(M = d^{-1/2} A\) with A the adjacency matrix of \({\mathbb {G}}(N,d/N)\), that most vertices are typical and most neighbours of any vertex are typical. To state it, we introduce some notation.
Definition 4.5
For any subset \(T \subset [N]\), we define the minor \(M^{(T)}\) with indices in T as the \((N-|T |) \times (N-|T |)\)-matrix
If T consists only of one or two elements, \(T = \{x\}\) or \(T=\{x,y\}\), then we abbreviate \(M^{(x)}\) and \(M^{(xy)}\) for \(M^{(\{x\})}\) and \(M^{(\{x,y\})}\). We also abbreviate \(M^{(Tx)}\) for \(M^{(T \cup \{ x\})}\). The Green function of \(M^{(T)}\) is denoted by
We use the notation
Definition 4.6
(Typical vertices). Let \(\mathfrak a> 0\) be a constant, and define the set of typical vertices
where
Note that this notion depends on the spectral parameter z, i.e. \({{\mathcal {T}}}_\mathfrak a\equiv {{\mathcal {T}}}_\mathfrak a(z)\). The constant \(\mathfrak a\) will depend only on \(\nu \) and \(\kappa \). It will be fixed in (4.23) below. The constant \({{\mathcal {D}}} \geqslant \mathfrak a^{3/2}\) from (4.13) is always chosen large enough so that \(\varphi _{\mathfrak a} \leqslant 1\).
The following proposition holds on the event \(\{\theta = 1\}\), where we introduce the indicator function
depending on some deterministic constant \(\Gamma \geqslant 1\). In (4.40) below, we shall choose a constant \(\Gamma \equiv \Gamma _\kappa \), depending only on \(\kappa \), such that the condition \(\theta = 1\) can be justified by a bootstrapping argument along the proof of Theorem 4.2 in Sect. 4.3 below.
Throughout the sequel we use the following generalization of Definition 2.1.
Definition 4.7
An event \(\Xi \) holds with very high probability on an event \(\Omega \) if for all \(\nu > 0\) there exists \({{\mathcal {C}}} > 0\) such that \({\mathbb {P}}(\Xi \cap \Omega ) \geqslant {\mathbb {P}}(\Omega ) - {{\mathcal {C}}} N^{-\nu }\) for all \(N \in {\mathbb {N}}\).
We now state the main result of this subsection.
Proposition 4.8
There are constants \(0 < q \leqslant 1\), depending only on \(\Gamma \), and \(\mathfrak a> 0\), depending only on \(\nu \) and q, such that, on the event \(\{\theta = 1\}\), the following holds with very high probability.
-
(i)
Most vertices are typical:
$$\begin{aligned} |{{\mathcal {T}}}_\mathfrak a^c | \leqslant \exp ( q \varphi _\mathfrak a^2 d ) + N \exp ( - 2 q \varphi _\mathfrak a^2 d). \end{aligned}$$ -
(ii)
Most neighbours of any vertex are typical:
$$\begin{aligned} \sum _{y \in {{\mathcal {T}}}_\mathfrak a^c}^{(x)}|H_{xy} |^2 \leqslant {{\mathcal {C}}} \varphi _\mathfrak a+ {\mathcal {C}}d^4 \exp (- q \varphi _\mathfrak a^2 d ) \end{aligned}$$uniformly for \(x \in [N]\).
For the interpretation of Proposition 4.8 (ii), one should think of the motivating example \(M = d^{-1/2} A\), for which \(d \sum _{y \in \mathcal T^c_\mathfrak a}^{(x)}|H_{xy} |^2\) is the number of atypical neighbours of x, up to an error term \({{\mathcal {O}}}\bigl (\frac{d^2 + d \log N}{N}\bigr )\) by Remark 4.3.
The remainder of Sect. 4.2 is devoted to the proof of Proposition 4.8. We need the following version of \({{\mathcal {T}}}_\mathfrak a\) defined in terms of \(H^{(T)}\) instead of H.
Definition 4.9
For any \(x \in [N]\) and \(T \subset [N]\), we define
and
Note that \(\Phi _x^{(\emptyset )} = \Phi _x\) and \(\Psi _x^{(\emptyset )} = \Psi _x\) with the definitions from (4.18), and hence \({{\mathcal {T}}}_\mathfrak a^{(\emptyset )} = {{\mathcal {T}}}_\mathfrak a\). The proof of Proposition 4.8 relies on the two following lemmas.
Lemma 4.10
There are constants \(0 < q \leqslant 1\), depending only on \(\Gamma \), and \(\mathfrak a> 0\), depending only on \(\nu \) and q, such that, for any deterministic \(X \subset [N]\), the following holds with very high probability on the event \(\{\theta = 1\}\).
-
(i)
\(|X \cap {{\mathcal {T}}}_{\mathfrak a/2}^c | \leqslant \exp ( q \varphi _\mathfrak a^2 d) + |X | \exp (- 2 q \varphi _\mathfrak a^2 d)\).
-
(ii)
If \(|X | \leqslant \exp ( 2 q \varphi _\mathfrak a^2 d)\) then \(|X \cap {{\mathcal {T}}}_{\mathfrak a/2}^c | \leqslant \mathcal \varphi _\mathfrak ad\).
For any deterministic \(x \in [N]\), the same estimates hold for \(\big ({{\mathcal {T}}}^{(x)}_{\mathfrak a/ 2}\big )^c\) instead of \({{\mathcal {T}}}^c_{\mathfrak a/2}\) and a random set \(X \subset [N] \setminus \{x\}\) that is independent of \(H^{(x)}\).
Lemma 4.11
With very high probability, for any constant \(\mathfrak a> 0\) we have
for all \(x,y \in [N]\).
Before proving Lemmas 4.10 and 4.11, we use them to establish Proposition 4.8.
Proof of Proposition 4.8
For (i), we choose \(X = [N]\) in Lemma 4.10 (i), using that \({{\mathcal {T}}}_{\mathfrak a/2} \subset \mathcal T_\mathfrak a\).
We now turn to the proof of (ii). By Lemma 4.11, on the event \(\{\theta = 1\}\) we have \({{\mathcal {T}}}^c_\mathfrak a\subset \big ({{\mathcal {T}}}^{(x)}_{\mathfrak a/2}\big )^c\) with very high probability and hence
with very high probability. Since \(|H_{xy} |^2 \leqslant 1 / d\) almost surely, we obtain the decomposition
where we defined
Since \(\sum ^{(x)}_y |H_{xy} |^2 \leqslant {{\mathcal {C}}} d\) with very high probability by Definition 4.1 and Bennett’s inequality, we conclude that
with very high probability.
We shall apply Lemma 4.10 to the sets \(X = X_k\) and \(({{\mathcal {T}}}_{\mathfrak a/ 2}^{(x)})^c\). To that end, note that \(X_k \subset [N] \setminus \{x\}\) is a measurable function of the family \((H_{xy})_{y \in [N]}\), and hence independent of \(H^{(x)}\). Thus, we may apply Lemma 4.10.
We define \(K :=\max \bigl \{k \geqslant 0 :{{\mathcal {C}}} d^{k + 3} \leqslant \mathrm {e}^{ 2q\varphi _\mathfrak a^2 d}\bigr \}\) and decompose the sum on the right-hand side of (4.20) into
with very high probability. Here, we used Lemma 4.10 (ii) to estimate the summands if \(k \leqslant K\) and Lemma 4.10 (i) and (4.21) for the other summands. Since \(\log N \leqslant d^2\), this concludes the proof of (ii). \(\quad \square \)
The rest of this subsection is devoted to the proofs of Lemmas 4.10 and 4.11. Let \(\theta \) be defined as in (4.19) for some constant \(\Gamma \geqslant 1\). For any subset \(T \subset [N]\), we define the indicator function
Lemma 4.10 is a direct consequence of the following two lemmas.
The first one, Lemma 4.12, is mainly a decoupling argument for the random variables \((\Psi _x)_{x \in [N]}\). Indeed, the probability that any fixed vertex x is atypical is only small, o(1), and not very small, \(N^{-\nu }\); see (4.31) below. If the events of different vertices being atypical were independent, we could deduce that the probability that a sufficiently large set of vertices are atypical is very small. However, these events are not independent. The most serious breach of independence arises from the Green function \(G^{(x)}_{yy}\) in the definition of \(\Psi _x\). In order to make this argument work, we have to replace the parameters \(\Phi _x\) and \(\Psi _x\) with their decoupled versions \(\Phi _x^{(T)}\) and \(\Psi _x^{(T)}\) from Definition 4.9. To that end, we have to estimate the error involved, \(|\Phi _x - \Phi _x^{(T)} |\) and \(|\Psi _x - \Psi _x^{(T)} |\). Unfortunately the error bound on the latter is proportional to \(\beta _x\) (see (4.32)), which is not affordable for vertices of large degree. The solution to this issue involves the observation that if \(\beta _x\) is too large then the vertex is atypical by the condition on \(\Phi _x\), which allows us to disregard the size of \(\Psi _x\). The details are given in the proof of Lemma 4.12 below.
The second one, Lemma 4.13, gives a priori bounds on the entries of the Green function \(G^{(T)}\), which shows that if the entries of G are bounded then so are those of \(G^{(T)}\) for \(|T | = o(d)\). For T of fixed size, this fact is a standard application of the resolvent identities from Lemma A.24. For our purposes, it is crucial that T can have size up to o(d), and such a quantitative estimate requires slightly more care.
Lemma 4.12
There is a constant \(0 < q \leqslant 1\), depending only on \(\Gamma \), such that, for any \(\nu >0\), there is \({\mathcal {C}}>0\) such that the following holds for any fixed \(\mathfrak a> 0\). If \(x \notin T \subset [N]\) are deterministic with \(|T | \leqslant \varphi _\mathfrak ad /{\mathcal {C}}\) then
Lemma 4.13
For any subset \(T \subset [N]\) satisfying \(|T | \leqslant \frac{d}{{{\mathcal {C}}} \Gamma ^2}\) we have \(\theta \leqslant \theta ^{(T)}\) with very high probability.
Before proving Lemma 4.12 and Lemma 4.13, we use them to show Lemma 4.10.
Proof of Lemma 4.10
Throughout the proof we abbreviate \({\mathbb {P}}_\theta (\Xi ) :={\mathbb {P}}(\Xi \cap \{ \theta = 1\})\). Let \({{\mathcal {C}}}\) be the constant from Lemma 4.12, and set
For the proof of (ii), we choose \(k = \varphi _\mathfrak ad /{\mathcal {C}}\) and estimate
where in the second step we used (4.22a). Thus, by our choice of \(\mathfrak a\), we have \({\mathbb {P}}_\theta (|X \cap {{\mathcal {T}}}_{\mathfrak a/ 2}^c | \geqslant k) \leqslant ({{\mathcal {C}}} + 1) N^{-\nu /2}\), from which (ii) follows after renaming \(\nu \) and \({{\mathcal {C}}}\).
To prove (i) we estimate, for \(t>0\) and \(l \in {\mathbb {N}}\),
Choosing \(l = \varphi _\mathfrak ad/{\mathcal {C}}\), regrouping the summation according to the partition of coincidences, and using Lemma 4.12 yield
Here, \(\mathfrak P_l\) denotes the set of partitions of [l], and we denote by \(k = |\pi |\) the number of blocks in the partition \(\pi \in \mathfrak P_l\). We also used that the number of partitions of l elements consisting of k blocks is bounded by \(\left( {\begin{array}{c}l\\ k\end{array}}\right) l^{l - k}\). The last step follows from the binomial theorem. Therefore, using \(l = \varphi _\mathfrak ad/{{\mathcal {C}}}\) and choosing \(t = \mathrm {e}^{q \varphi _\mathfrak a^2 d} + |X | \mathrm {e}^{- 2 q \varphi _\mathfrak a^2 d}\) as well as \({\mathcal {C}}\) and \(\nu \) sufficiently large imply the bound in Lemma 4.10 (i) with very high probability, after renaming \({\mathcal {C}}\) and \(\nu \). Here we used (4.13).
To obtain the same statements for \({{\mathcal {T}}}_{\mathfrak a/ 2}^{(x)}\) instead of \({{\mathcal {T}}}_{\mathfrak a/ 2}\), we estimate
For both parts, (i) and (ii), the conditional probability \({\mathbb {P}}\bigl ( |X \cap ({{\mathcal {T}}}_{\mathfrak a/ 2}^{(x)})^c | \geqslant t, \theta ^{(x)} = 1 \big \vert X \bigr )\) can be bounded as before using (4.22b) instead of (4.22a) since, by assumption on X, the set \({{\mathcal {T}}}_{\mathfrak a/ 2}^{(x)}\) and the indicator function \(\theta ^{(x)}\) are independent of X. The smallness of \({\mathbb {P}}(\theta ^{(x)} = 0, \theta = 1) \leqslant {\mathbb {P}}(\theta ^{(x)} < \theta )\) is a consequence of Lemma 4.13. This concludes the proof of Lemma 4.10. \(\quad \square \)
The rest of this subsection is devoted to the proofs of Lemmas 4.11, 4.12, and 4.13.
Lemma 4.14
There is \(\mathfrak c\equiv \mathfrak c_\nu >0\), depending on \(\nu \) and \(\kappa \), such that for any deterministic \(T \subset [N]\) satisfying \(|T | \leqslant \mathfrak cd / \Gamma ^2\) we have with very high probability
Moreover, under the same assumptions on T and for any \(u \in [N] \setminus T\), we have
with very high probability.
Before proving Lemma 4.14, we use it to conclude the proof of Lemma 4.13.
Proof of Lemma 4.13
The bound in (4.24) of Lemma 4.14 implies that \(\theta = \theta \theta ^{(T)}\) with very high probability. Since \(\theta \leqslant 1\), the proof is complete. \(\quad \square \)
Proof of Lemma 4.14
Throughout the proof we work on the event \(\{\theta = 1\}\) exclusively. After a relabelling of the vertices [N], we can suppose that \(T = [k]\) with \(k \leqslant cd/\Gamma ^2\). For \(k \in [N]\), we set
Note that \(\Gamma _0 \leqslant \Gamma \) by definition of \(\theta \).
We now show by induction on k that there is \({\mathcal {C}}>0\) such that
for all \(k \in {\mathbb {N}}\) satisfying \(k \leqslant \frac{d}{32 \, {\mathcal {C}}\Gamma ^2}\). Since \(1 + x \leqslant \mathrm {e}^x\), (4.26) implies that \(\Gamma _k \leqslant \mathrm {e}^{1/2} \Gamma _0 \leqslant 2 \Gamma \). This directly implies (4.24) by the definition of \(\theta \).
The initial step with \(k = 0\) is trivially correct. For the induction step \(k \rightarrow k+1\), we set \(T = [k]\) and \(u = k + 1\). The algebraic starting point for the induction step is the identities (A.32a) and (A.32b). We shall need the following two estimates. First, from Lemma A.23 and Cauchy–Schwarz, we get
where we used that \(\Gamma _{k+1} \geqslant 1\), \(f \leqslant N^{\kappa /6}\), and \({{\,\mathrm{Im}\,}}z\geqslant N^{-1 + \kappa }\). Second, the first estimate of (A.28) in Corollary A.21 with \(\psi = \Gamma _{k+1}/\sqrt{d}\) and \(\gamma = \sqrt{\Gamma _{k+1}/(N{{\,\mathrm{Im}\,}}z)}\), Lemma A.23, and \(\Gamma _{k+1} \geqslant 1\) imply
with very high probability.
Hence, owing to (A.32a) and (A.32b) with \(T = [k]\) and \(u = k + 1\), we get, respectively,
with very high probability.
By the induction assumption (4.26) we have \({{\mathcal {C}}} \Gamma _k / \sqrt{d} \leqslant 2 {{\mathcal {C}}} \Gamma / \sqrt{d} \leqslant 1/2\), so that the first inequality in (4.29) implies the rough a priori bound
with very high probability. From the second inequality in (4.29) and (4.30), we deduce that
where in the second step we used \(\Gamma _k \leqslant 2 \Gamma \), by the induction assumption (4.26). This concludes the proof of (4.26), and, hence, of (4.24).
For the proof of (4.25), we start from (A.32b) and use (4.27), (4.28) as well as (4.24). This concludes the proof of Lemma 4.14. \(\quad \square \)
The next result provides concentration estimates for the parameters \(\Phi _x\) and \(\Psi _x\).
Lemma 4.15
There is a constant \(0 < q \leqslant 1\), depending only on \(\Gamma \), such that the following holds. Let \(\mathfrak c>0\) be as in Lemma 4.14, and let \(x \in [N]\) and \(T \subset [N]\) be deterministic and satisfy \(|T | \leqslant \mathfrak cd / \Gamma ^2\). Then for any \(0 < \varepsilon \leqslant 1\) we have
and, for any \(u \notin T\),
with very high probability.
Before proving Lemma 4.15, we use it conclude the proof of Lemma 4.11.
Proof of Lemma 4.11
Using (A.27b), we find that \(\beta _x \leqslant {{\mathcal {C}}} (1 + \frac{\log N}{d})\) with very high probability. The claim now follows from (4.32) with \(T = \emptyset \) and the definition of \(\varphi _{\mathfrak a}\), choosing the constant \({{\mathcal {D}}}\) in (4.13) large enough. \(\quad \square \)
Proof of Lemma 4.15
Set \(q :=\frac{1}{2^{11}(\mathrm {e}\Gamma )^2}\). We get, using (A.27b) with \(r :=32 q \varepsilon ^2 d \leqslant d\), \({\mathbb {E}}|H_{xy} |^2 = 1/N\), and Chebyshev’s inequality,
with very high probability for any \(0 < \varepsilon \leqslant 1\). This proves the estimate on \(\Psi _x^{(T)}\) in (4.31), and the estimate for \(\Phi _x^{(T)}\) is proved similarly.
We now turn to the proof of (4.32). If \(x = u\) then the statement is trivial. Thus, we assume \(x \ne u\). In this case we have
and the claim for \(\Phi \) follows by Definition 4.1. Next,
The last term multiplied by \(\theta ^{(T)}\) is estimated by \(O(\Gamma / d)\) since \(\theta ^{(T)} |G_{uu}^{(Tx)} | \leqslant 4 \Gamma \) by (4.30). We estimate the first term using (4.25) in Lemma 4.14, which yields
with very high probability. This concludes the proof of Lemma 4.15. \(\quad \square \)
Proof of Lemma 4.12
Throughout the proof we abbreviate \({\mathbb {P}}_\theta (\Xi ) :={\mathbb {P}}(\Xi \cap \{ \theta = 1\})\). We have
where we defined the event
We have the inclusions
Defining the event
we therefore deduce by a union bound that
We begin by estimating the first term of (4.34). To that end, we observe that, conditioned on \(H^{(T)}\), the family \((\Omega _x^{(T)})_{x \in T}\) is independent. Using Lemma 4.13 we therefore get
and we estimate each factor using (4.31) from Lemma 4.15 as
where in the last step we used that \(\mathrm {e}^{-4 q \varphi _{\mathfrak a}^2 d} \leqslant 1/2\). We conclude that
Next, we estimate the second term of (4.34). After renaming the vertices, we may assume that \(T = [k]\) with \(k \leqslant \varphi _\mathfrak ad / {{\mathcal {C}}}\), so that we get from (4.32) from Lemma 4.15 (using that \(\varphi _\mathfrak ad / {{\mathcal {C}}} \leqslant \mathfrak cd / \Gamma ^2\) provided that \({{\mathcal {D}}}\) in (4.13) is chosen large enough, depending on \(\mathfrak a\)), by telescoping and recalling Lemma 4.13,
with very high probability on the event \(\{\theta = 1\}\), if the constant \({{\mathcal {C}}}\) in the upper bound \(\varphi _\mathfrak ad / {{\mathcal {C}}}\) on k is large enough.
The last term of (4.34) is estimated analogously, with the additional observation that, by definition of \(\Phi _x\) and since \(\varphi _{\mathfrak a/2} \leqslant 1/2\), on the event \(\{|\Phi _x | \leqslant \varphi _{\mathfrak a/ 2}\}\) we have \(\beta _x \leqslant 2\). Thus, on the event \(\{\theta = 1\} \cap \{|\Phi _x | \leqslant \varphi _{\mathfrak a/ 2}\}\) we have, by Lemma 4.13,
with very high probability, for large enough \({{\mathcal {C}}}\) in the upper bound on k. We conclude that the two last terms of (4.34) are bounded by \({{\mathcal {C}}} N^{-\nu }\), and the proof of (4.22a) is therefore complete.
The proof of (4.22b) is identical, replacing the matrix M with the matrix \(M^{(x)}\). \(\quad \square \)
4.3 Self-consistent equation and proof of Theorem 4.2
In this subsection, we derive an approximate self-consistent equation for the Green function G, and use it to prove Theorem 4.2. The key ingredient is Proposition 4.18 below, which provides a bootstrapping bound stating that if \(G_{xx} - m_{\beta _x}\) is smaller than some constant then it is in fact bounded by \(\varphi _\mathfrak a\) with very high probability. It is proved by first deriving and solving a self-consistent equation for the entries \(G_{xx}\) indexed by typical vertices \(x \in {{\mathcal {T}}}_\mathfrak a\), and using the obtained bounds to analyse \(G_{xx}\) for atypical vertices \(x \in {{\mathcal {T}}}^c_\mathfrak a\).
We begin with a simple algebraic observation.
Lemma 4.16
(Approximate self-consistent equation). For any \(x \in [N]\) and \(z \in {\mathbb {C}}_+\), we have
where we introduced the error term
Proof
The lemma follows directly from (A.31) and the definition (4.1). \(\quad \square \)
Let \(\theta \) be defined as in (4.19) with some \(\Gamma \geqslant 1\). The following lemma provides a priori bounds on the error terms appearing in the self-consistent equation.
Lemma 4.17
For all \(z \in {\mathbb {C}}\) with \({{\,\mathrm{Im}\,}}z \geqslant N^{-1 + \kappa }\), with very high probability,
Proof
We first estimate \(Y_x\). From Definition 4.1, the upper bound on f, and (4.13), we conclude that \(|H_{xx} | + f / N = O(d^{-1/2})\) almost surely. Moreover, the Cauchy–Schwarz inequality, Lemma A.23, (4.24) and the upper bound on f imply
for some constant \(C_\kappa \) depending only on \(\kappa \). Next, we use the first estimate of (A.28), Lemma A.23, and the upper bound on f to conclude that
with very high probability (compare the proof of (4.28)). Moreover, from Lemma A.23 and the second estimate of (A.28) we deduce that remaining term in (4.37) is \(\mathcal O(d^{-1}) = {{\mathcal {O}}}(d^{-1/2})\). This concludes the proof of (4.38a).
For the proof of (4.38b), we start from (A.29) and use \(M_{xa} = H_{xa} + f/ N \) to obtain
Similar arguments as in (4.28) and (4.27) show that the first and third term, respectively, are bounded by \({\mathcal {C}}d^{-1/2}\) with very high probability. The same bound for the second term follows from Definition 4.1 and (4.24) in Lemma 4.14. This proves (4.38b).
Finally, (4.38c) follows directly from (4.25). \(\quad \square \)
Proposition 4.18 below is the main tool behind the proof of Theorem 4.2. To formulate it, we introduce the z-dependent random control parameters
and, for some constant \(\lambda \leqslant 1\), the indicator function
Proposition 4.18 below provides a strong bound on \(\Lambda \) provided the a priori condition \(\phi = 1\) is satisfied. Each step of its proof is valid provided \(\lambda \) is chosen small enough depending on \(\kappa \). Note that, owing to (A.4), there is a deterministic constant \(\Gamma \), depending only on \(\kappa \), such that, for all \(z \in {\mathbf {S}}\), we have
In particular, if \(\Gamma \) in the definition (4.19) of \(\theta \) is chosen as in (4.40) then
Proposition 4.18
There exists \(\lambda > 0\), depending only on \(\kappa \), such that, for all \(z \in {\mathbf {S}}\), with very high probability,
For the proof of Proposition 4.18, we employ the results of the previous subsections to show that the diagonal entries \((G_{xx})_{x \in {{\mathcal {T}}}_\mathfrak a}\) of the Green function of M at the typical vertices satisfy the approximate self-consistent equation (4.42) below. This is a perturbed version of the relation (4.6) for the Stieltjes transform m of the semicircle law, which holds for all \(z \in {\mathbb {C}}_+\). The stability estimate, (4.43) below, then implies that \(G_{xx}\) and m are close for all \(x \in \mathcal T_\mathfrak a\). From this we shall, in a second step, deduce that \(G_{xx}\) is close to \(m_{\beta _x}\) for all x; this steps includes also the atypical vertices.
The next lemma is a relatively standard stability estimate of self-consistent equations in random matrix theory (compare e.g. to [27, Lemma 3.5]). It is proved in Appendix A.9.
Lemma 4.19
(Stability of the self-consistent equation for m). Let \({{\mathcal {X}}}\) be a finite set, \(\kappa >0\), and \(z \in {\mathbb {C}}_+\) satisfy \(|\mathrm {Re}\,z | \leqslant 2- \kappa \). We assume that, for two vectors \((g_x)_{x \in {{\mathcal {X}}}}\), \((\varepsilon _x)_{x \in {{\mathcal {X}}}} \in {\mathbb {C}}^{{{\mathcal {X}}}}\), the identities
hold for all \(x \in {{\mathcal {X}}}\). Then there are constants \(b, C \in (0,\infty )\), depending only on \(\kappa \), such that if \(\max _{x \in {{\mathcal {X}}}} |g_x -m(z) | \leqslant b\) then
where m(z) satisfies (4.6).
Proof of Proposition 4.18
Throughout the proof, we work on the event \(\{\phi = 1\}\), which, by (4.41), is contained in the event \(\{\theta = 1\}\). Fix \(\mathfrak a\) as in Proposition 4.8. Throughout the proof we use that \(d^{-1/2} \leqslant \varphi _\mathfrak a\) by the upper bound in (4.13). Owing to (4.38b), it suffices to estimate \(\Lambda _{\mathrm d}\). Let b be chosen as in Lemma 4.19, and set \(\lambda :=b/2\) in the definition (4.39) of \(\phi \).
For the analysis of \(G_{xx}\) we distinguish the two cases \(x \in {{\mathcal {T}}}_\mathfrak a\) and \(x \notin {{\mathcal {T}}}_\mathfrak a\).
If \(x \in {{\mathcal {T}}}_\mathfrak a\) then we write using Lemma 4.16 and the definition (4.18) of \(\Psi _x\) that
where the error term \(\varepsilon _x\) satisfies
with very high probability. Here, in the first step of (4.44) we used (4.38a), (4.38c), Proposition 4.8 (i), and the bound on \(\Psi _x\) in the definition (4.17) of \({{\mathcal {T}}}_\mathfrak a\), and in the second step of (4.44) we used that \(\varphi _\mathfrak a^2 d = \mathfrak a^2 (\log N)^{2/3} d^{-1/3}\) and (4.13) imply \((\log N)^{1/6} / {{\mathcal {C}}} \leqslant \varphi ^2_\mathfrak ad \leqslant {{\mathcal {C}}} (\log N)^{1/2}\), which yields
Thus, for \((G_{xx})_{x \in {{\mathcal {T}}}_\mathfrak a}\) we get the self-consistent equation in (4.42) with \(g_x = G_{xx}\) and \({{\mathcal {X}}} = {{\mathcal {T}}}_\mathfrak a\). Moreover, by the bound on \(\Phi _x\) in the definition (4.17) of \({{\mathcal {T}}}_\mathfrak a\), we have \(\beta _x = 1 + {{\mathcal {O}}}(\varphi _\mathfrak a)\). Hence, by (A.5), the assumption \(\phi = 1\) and \(d \geqslant {\mathcal {C}}\sqrt{\log N}\), we find that
choosing the constant \({{\mathcal {D}}}\) in (4.13) large enough that the right-hand side of (A.5), i.e. \(C |\beta _x - 1 |\), is bounded by b/2. Hence Lemma 4.19 is applicable and we obtain \(|G_{xx} - m | = O(\max _{y \in {{\mathcal {T}}}_\mathfrak a} |\varepsilon _y |)\). Therefore, we obtain
with very high probability. This concludes the proof in the case \(x \in {{\mathcal {T}}}_\mathfrak a\).
What remains is the case \(x \notin {{\mathcal {T}}}_\mathfrak a\). In that case, we obtain from Lemma 4.16 that
where the error term \(\varepsilon _x\) satisfies \(\varepsilon _x = {{\mathcal {O}}} ((1 + \beta _x) \varphi _\mathfrak a)\) with very high probability. Here we used (4.38a) as well as (4.38c), (4.45), (4.46) and Proposition 4.8 (ii) twice to conclude that
with very high probability. From (4.7) and (4.47) we therefore get
To estimate the right-hand side of (4.48), we consider the cases \(\beta _x \leqslant 1\) and \(\beta _x > 1\) separately.
If \(\beta _x \leqslant 1\) then, by (A.4), the first factor of (4.48) is bounded by C. Thus, by (4.7), the second factor is bounded by 2C provided that \(|\varepsilon _x | \leqslant 1/{2C}\) by choosing \({{\mathcal {D}}}\) in (4.13) large enough, and the third factor is bounded by \({{\mathcal {C}}} \varphi _\mathfrak a\). This yields the claim.
If \(\beta _x > 1\), we use that \({{\,\mathrm{Im}\,}}m \geqslant c\) for some constant \(c > 0\) depending only on \(\kappa \) and L. Thus, the right-hand side of (4.48) is bounded in absolute value, again using (A.4), by \(C \frac{1}{\beta _x c/2} {{\mathcal {C}}} \beta _x \varphi _\mathfrak a\), provided that \({{\mathcal {D}}}\) in (4.13) is chosen large enough. This yields the claim. \(\quad \square \)
Proof of Theorem 4.2
After possibly increasing L, we can assume that L in the definition of \({\mathbf {S}}\) in (4.3) satisfies \(L \geqslant 2/\lambda + 1\), where \(\lambda \) is chosen as in Proposition 4.18.
We first show that (4.10) follows from (4.9). Indeed, averaging the estimate on \(|G_{xx} - m_{\beta _x} |\) in (4.9) over \(x \in [N]\), using that \(m_{\beta _x} = m + O(\varphi _\mathfrak a)\) for \(x \in {{\mathcal {T}}}_\mathfrak a\) by (A.5) and estimating the summands in \({{\mathcal {T}}}_\mathfrak a^c\) by Proposition 4.8 (i) and (A.4) yield (4.10) due to (4.45).
What remains is the proof of (4.9). Let \(z_0 \in {\mathbf {S}}\), set \(J :=\min \{ j \in {\mathbb {N}}_0 :\mathrm {Im}\,z_0 + j N^{-3} \geqslant 2 / \lambda \}\), and define \(z_j :=z_0 + \mathrm {i}j N^{-3}\) for \(j \in [J]\). We shall prove the bound in (4.9) at \(z = z_j\) by induction on j, starting from \(j = J\) and going down to \(j = 0\). Since \(|G_{xy}(z) | \leqslant (\mathrm {Im}\,z)^{-1}\) and \(|m_{\beta _x}(z) | \leqslant (\mathrm {Im}\,z)^{-1}\) for all \(x,y \in [N]\), we have \(\max _x |G_{xx}(z_J) - m_{\beta _x}(z_J) | \leqslant \lambda \) and \(\phi (z_J) = 1\).
For the induction step \(j \rightarrow j - 1\), suppose that \(\phi (z_j) = 1\) with very high probability. Then, by Proposition 4.18, we deduce that \(\Lambda (z_j) \leqslant \mathcal C \varphi _\mathfrak a\) with very high probability. Since \(G_{xy}\) and \(m_{\beta _x}\) are Lipschitz-continuous on \({\mathbf {S}}\) with constant \(N^2\), we conclude that \(\Lambda (z_{j-1}) \leqslant {\mathcal {C}}\varphi _\mathfrak a+ N^{-1}\) with very high probability. If N is sufficiently large and \(\varphi _\mathfrak a\) is sufficiently small, obtained by choosing \({{\mathcal {D}}}\) in (4.13) large enough, then we deduce that \(\Lambda (z_{j-1}) \leqslant \lambda \) with very high probability and hence \(\phi (z_{j - 1}) = 1\) with very high probability. Using Proposition 4.18, this concludes the induction step, and hence establishes \(\Lambda (z_0) \leqslant {{\mathcal {C}}} \varphi _\mathfrak a\) with very high probability. Here we used that the intersection of J events of very high probability is an event of very high probability, since \(J \leqslant C N^3\), where C depends on \(\kappa \). \(\quad \square \)
Notes
For simplicity we only consider stars, but the same argument can be applied to arbitrary trees.
This projection \(\Pi \) is denoted by \(\Pi ^\tau _{\lambda ,\delta }\) in the proof of Theorem 3.4 below.
We write \(\Vert \cdot \Vert _{p \rightarrow p}\) for the operator norm on \(\ell ^p\).
A star around a vertex x is a set of edges incident to x.
The tridiagonalization algorithm that we use is the Lanczos algorithm. Tridiagonalizing matrices in numerical analysis and random matrix theory [26, 55] is usually performed using the numerically more stable Householder algorithm. However, when applied to the adjacency matrix \(X = A\) of a graph, the Lanczos algorithm is more convenient because it can exploit the sparseness and local geometry of A.
The assumption \(d \gg \log \log N\) in Lemma A.10 is tailored so that it covers the entire range \(\alpha \geqslant 2\), which is what we need in this paper. The assumption on d could also be removed at the expense of introducing a nontrivial lower bound on \(\alpha \).
References
Aggarwal, A.: Bulk universality for generalized Wigner matrices with few moments. Prob. Theor. Rel. Fields 173(1–2), 375–432 (2019)
Aggarwal, A., Lopatto, P., Marcinek, J.: Eigenvector statistics of Lévy matrices. Preprint arXiv:2002.09355 (2020)
Aggarwal, A., Lopatto, P., Yau, H.-T.: GOE statistics for Lévy matrices. Preprint arXiv:1806.07363 (2018)
Aizenman, M., Molchanov, S.: Localization at large disorder and at extreme energies: an elementary derivation. Commun. Math. Phys. 157, 245–278 (1993)
Aizenman, M., Sims, R., Warzel, S.: Absolutely continuous spectra of quantum tree graphs with weak disorder. Commun. Math. Phys. 264(2), 371–389 (2006)
Aizenman, M., Warzel, S.: Extended states in a Lifshitz tail regime for random Schrödinger operators on trees. Phys. Rev. Lett. 106(13), 136804 (2011)
Aizenman, M., Warzel, S.: Resonant delocalization for random Schrödinger operators on tree graphs. J. Eur. Math. Soc. 15(4), 1167–1222 (2013)
Aizenman, M., Warzel, S.: Random Operators, Graduate Studies in Mathematics. American Mathematical Society, Providence (2015)
Ajanki, O.H., Erdős, L., Krüger, T.: Quadratic vector equations on complex upper half-plane. Mem. Am. Math. Soc. 261(1261), v+133 (2019)
Alt, J., Ducatez, R., Knowles, A.: Extremal eigenvalues of critical Erdős–Rényi graphs. Ann. Prob. 49(3), 1347–1401 (2021)
Anderson, P.W.: Absence of diffusion in certain random lattices. Phys. Rev. 109(5), 1492 (1958)
Bauerschmidt, R., Huang, J., Yau, H.-T.: Local Kesten–McKay law for random regular graphs. Commun. Math. Phys. 369(2), 523–636 (2019)
Bauerschmidt, R., Knowles, A., Yau, H.-T.: Local semicircle law for random regular graphs. Commun. Pure Appl. Math. 70(10), 1898–1960 (2017)
Benaych-Georges, F., Bordenave, C., Knowles, A.: Largest eigenvalues of sparse inhomogeneous Erdős–Rényi graphs. Ann. Prob. 47(3), 1653–1676 (2019)
Benaych-Georges, F., Bordenave, C., Knowles, A.: Spectral radii of sparse random matrices. Ann. Inst. Henri Poincaré Probab. Stat. 56(3), 2141–2161 (2020)
Benaych-Georges, F., Knowles, A.: Local Semicircle Law for Wigner Matrices, Advanced Topics in Random Matrices, Panor. Synthèses, vol. 53, pp. 1–90. Soc. Math. France, Paris (2017)
Bollobás, B.: Random Graphs. Cambridge University Press, Cambridge (2001)
Bordenave, C., Guionnet, A.: Localization and delocalization of eigenvectors for heavy-tailed random matrices. Prob. Theor. Rel. Fields 157(3–4), 885–953 (2013)
Bordenave, C., Guionnet, A.: Delocalization at small energy for heavy-tailed random matrices. Commun. Math. Phys. 354(1), 115–159 (2017)
Bourgade, P., Erdős, L., Yau, H.-T., Yin, J.: Universality for a class of random band matrices. Adv. Theor. Math. Phys. 21(3), 739–800 (2017)
Bourgade, P., Yang, F., Yau, H.-T., Yin, J.: Random band matrices in the delocalized phase, II: generalized resolvent estimates. J. Stat. Phys. 174(6), 1189–1221 (2019)
Bourgade, P., Yau, H.-T., Yin, J.: Random band matrices in the delocalized phase, I: quantum unique ergodicity and universality. Commun. Pure Appl. Math. 73(7), 1526–1596 (2020)
Casati, G., Molinari, L., Izrailev, F.: Scaling properties of band random matrices. Phys. Rev. Lett. 64(16), 1851 (1990)
Cizeau, P., Bouchaud, J.-P.: Theory of Lévy matrices. Phys. Rev. E 50(3), 1810 (1994)
Combes, J.M., Thomas, L.: Asymptotic behaviour of eigenfunctions for multiparticle Schrödinger operators. Commun. Math. Phys. 34, 251–270 (1973)
Dumitriu, I., Edelman, A.: Matrix models for beta ensembles. J. Math. Phys. 43(11), 5830–5847 (2002)
Erdős, L., Yau, H.-T., Yin, J.: Bulk universality for generalized Wigner matrices. Prob. Theor. Rel. Fields 154(1–2), 341–407 (2012)
Erdős, L., Knowles, A.: Quantum diffusion and delocalization for band matrices with general distribution. Ann. H. Poincaré 12, 1227–1319 (2011)
Erdős, L., Knowles, A.: Quantum diffusion and eigenfunction delocalization in a random band matrix model. Commun. Math. Phys. 303, 509–554 (2011)
Erdős, L., Knowles, A.: The Altshuler-Shklovskii formulas for random band matrices II: the general case. Ann. H. Poincaré 16, 709–799 (2014)
Erdős, L., Knowles, A.: The Altshuler-Shklovskii formulas for random band matrices I: the unimodular case. Commun. Math. Phys. 333, 1365–1416 (2015)
Erdős, L., Knowles, A., Yau, H.-T.: Averaging fluctuations in resolvents of random band matrices. Ann. H. Poincaré 14, 1837–1926 (2013)
Erdős, L., Knowles, A., Yau, H.-T., Yin, J.: Delocalization and diffusion profile for random band matrices. Commun. Math. Phys. 323, 367–416 (2013)
Erdős, L., Knowles, A., Yau, H.-T., Yin, J.: The local semicircle law for a general class of random matrices. Electron. J. Probab. 18, 1–58 (2013)
Erdős, L., Knowles, A., Yau, H.-T., Yin, J.: Spectral statistics of Erdős–Rényi graphs I: local semicircle law. Ann. Prob. 41, 2279–2375 (2013)
Erdős, L., Schlein, B., Yau, H.-T.: Local semicircle law and complete delocalization for Wigner random matrices. Commun. Math. Phys. 287, 641–655 (2009)
Erdős, L., Yau, H.-T., Yin, J.: Rigidity of eigenvalues of generalized Wigner matrices. Adv. Math. 229, 1435–1515 (2012)
Froese, R., Hasler, D., Spitzer, W.: Transfer matrices, hyperbolic geometry and absolutely continuous spectrum for some discrete Schrödinger operators on graphs. J. Funct. Anal. 230(1), 184–221 (2006)
Fröhlich, J., Spencer, T.: Absence of diffusion in the Anderson tight binding model for large disorder or low energy. Commun. Math. Phys. 88, 151–184 (1983)
Fyodorov, Y., Mirlin, A.: Scaling properties of localization in random band matrices: a \(\sigma \)-model approach. Phys. Rev. Lett. 67(18), 2405 (1991)
Fyodorov, Y., Ossipov, A., Rodriguez, A.: The Anderson localization transition and eigenfunction multifractality in an ensemble of ultrametric random matrices. J. Stat. Mech. Theor Exper. 2009(12), L12001 (2009)
He, Y., Knowles, A., Marcozzi, M.: Local law and complete eigenvector delocalization for supercritical Erdős–Rényi graphs. Ann. Prob. 47(5), 3278–3302 (2019)
He, Y., Marcozzi, M.: Diffusion profile for random band matrices: a short proof. J. Stat. Phys. 177(4), 666–716 (2019)
Klein, A.: Absolutely continuous spectrum in the Anderson model on the Bethe lattice. Math. Res. Lett. 1(4), 399–407 (1994)
Lee, J.O., Schnelli, K.: Local deformed semicircle law and complete delocalization for Wigner matrices with random potential. J. Math. Phys. 54(10), 103504 (2013)
Lee, J.O., Schnelli, K.: Extremal eigenvalues and eigenvectors of deformed Wigner matrices. Prob. Theor. Rel. Fields 164(1–2), 165–241 (2016)
Mirlin, A.D., Fyodorov, Y.V., Dittes, F.-M., Quezada, J., Seligman, T.H.: Transition from localized to extended eigenstates in the ensemble of power-law random banded matrices. Phys. Rev. E 54(1), 3221–3230 (1996)
Peled, R., Schenker, J., Shamis, M., Sodin, S.: On the Wegner orbital model. Int. Math. Res. Not. 2019(4), 1030–1058 (2019)
Sarnak, P.: Arithmetic Quantum Chaos. The Schur lectures (1992)(Tel Aviv). Israel Math. Conf. Proc., vol. 8, pp. 183–236 (1995)
Schenker, J.: Eigenvector localization for random band matrices with power law band width. Commun. Math. Phys. 290, 1065–1097 (2009)
Shcherbina, M., Shcherbina, T.: Universality for 1 D random band matrices. Preprint arXiv:1910.02999 (2019)
Sodin, S.: The spectral edge of some random band matrices. Ann. Math. 172(3), 2223–2251 (2010)
Tarquini, E., Biroli, G., Tarzia, M.: Level statistics and localization transitions of Lévy matrices. Phys. Rev. Lett. 116(1), 010601 (2016)
Tikhomirov, K., Youssef, P.: Outliers in spectrum of sparse Wigner matrices. Random Struct. Algorithms 58(3), 517–605 (2021)
Trotter, H.F.: Eigenvalue distributions of large Hermitian matrices; Wigner’s semicircle law and a theorem of Kac, Murdock, and Szegő. Adv. Math. 54(1), 67–82 (1984)
von Soosten, P., Warzel, S.: The phase transition in the ultrametric ensemble and local stability of Dyson Brownian motion. Electr. J. Prob. 23, 1–70 (2018)
Wegner, F.: Bounds on the density of states in disordered systems. Z. Phys. B Cond. Mat. 44(1), 9–15 (1981)
Wigner, E.P.: Characteristic vectors of bordered matrices with infinite dimensions. Ann. Math. 62, 548–564 (1955)
Yang, F., Yin, J.: Random band matrices in the delocalized phase, III: averaging fluctuations. Probab. Theory Related Fields 179(1–2), 451–540 (2021)
Acknowledgements
The authors would like to thank Simone Warzel for helpful discussions. The authors gratefully acknowledge funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (Grant Agreement No. 715539_RandMat) and from the Swiss National Science Foundation through the NCCR SwissMAP grant.
Funding
Open Access funding provided by Université de Genève.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by L. Erdos
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
In the following appendices we collect various tools and explanations used throughout the paper.
1.1 Simulation of the \(\ell ^\infty \)-norms of eigenvectors
In Fig. 10 we depict a simulation of the \(\ell ^\infty \)-norms of the eigenvectors of the adjacency matrix \(A / \sqrt{d}\) of the Erdős–Rényi graph \({\mathbb {G}}(N,d/N)\) restricted to its giant component. We take \(d = b \log N\) with \(N = 10'000\) and \(b = 0.6\). The eigenvalues and eigenvectors are drawn using a scatter plot, where the horizontal coordinate is the eigenvalue and the vertical coordinate the \(\ell ^\infty \)-norm of the associated eigenvector. The higher a dot is located, the more localized the associated eigenvector is. Complete delocalization corresponds to a vertical coordinate \(\approx 0.01\), and localization at a single site to a vertical coordinate 1. Note the semilocalization near the origin and outside of \([-2,2]\). The two semilocalized blips around \(\pm 0.4\) are a finite-N effect and tend to 0 as N is increased. The Perron–Frobenius eigenvalue is an outlier near 2.8 with delocalized eigenvector.

A scatter plot of \((\lambda , \Vert \varvec{\mathrm {w}} \Vert _\infty )\) for all eigenvalue-eigenvector pairs \((\lambda , \varvec{\mathrm {w}})\) of the adjacency matrix \(A / \sqrt{d}\) of the critical Erdős–Rényi graph restricted to its giant component, where \(N = 10'000\) and \(d = 0.6 \log N\)
1.2 Spectral analysis of the infinite rooted (p, q)-regular tree
In this appendix we describe the spectrum, eigenvectors, and spectral measure of the following simple graph.
Definition A.1
For \(p,q \in {\mathbb {N}}^{*}\) we define \({\mathbb {T}}_{p,q}\) as the infinite rooted (p, q)-regular tree, whose root has p children and all other vertices have q children.
A convenient way to analyse the adjacency matrix of \({\mathbb {T}}_{p,q}\) is by tridiagonalizing it around its root. To that end, we first review the tridiagonalizationFootnote 5 of a general symmetric matrix \(X \in {\mathbb {R}}^{N \times N}\) around a vertex \(x \in [N]\); we refer to [10, Appendices A–C] for details. Let \(r \in {\mathbb {N}}\) and \(x \in [N]\). Suppose that the vectors \(\varvec{\mathrm {1}}_x, X \varvec{\mathrm {1}}_x, X^2 \varvec{\mathrm {1}}_x, \dots , X^r \varvec{\mathrm {1}}_x\) are linearly independent, and denote by \(\varvec{\mathrm {g}}_0, \varvec{\mathrm {g}}_1, \varvec{\mathrm {g}}_2, \dots , \varvec{\mathrm {g}}_r\) the associated orthonormalized sequence. Then the tridiagonalization of X around x up to radius r is the \((r + 1) \times (r+1)\) matrix \(Z = (Z_{ij})_{i,j = 0}^r\) with  . By construction, Z is tridiagonal and conjugate to X restricted to the subspace \({{\,\mathrm{Span}\,}}\{\varvec{\mathrm {g}}_0, \varvec{\mathrm {g}}_1, \dots , \varvec{\mathrm {g}}_r\}\).
. By construction, Z is tridiagonal and conjugate to X restricted to the subspace \({{\,\mathrm{Span}\,}}\{\varvec{\mathrm {g}}_0, \varvec{\mathrm {g}}_1, \dots , \varvec{\mathrm {g}}_r\}\).
Let now \(X = A \equiv A^{{\mathbb {T}}_{p,q}}\) be the adjacency matrix of \({\mathbb {T}}_{p,q}\), whose root we denote by o. Then it is easy to see that \(\varvec{\mathrm {g}}_i = \varvec{\mathrm {1}}_{S_i(o)} / \Vert \varvec{\mathrm {1}}_{S_i(o)} \Vert \) and the tridiagonalization of A around the root up to radius \(\infty \) is the infinite matrix \(\sqrt{q} Z(p/q)\), where
If \(\alpha > 2\), a transfer matrix analysis (see [10, Appendix C]) shows that \(Z(\alpha )\) has precisely two eigenvalues in \({\mathbb {R}}\setminus [-2,2]\), which are \(\pm \Lambda (\alpha )\). The associated eigenvectors are \(((\pm )^i u_i)_{i \in {\mathbb {N}}}\), where \(u_0 > 0\) and \(u_i :=\frac{\sqrt{\alpha }}{(\alpha - 1)^{i/2}} \, u_0\) for \(i \geqslant 1\). Note that the eigenvector components are exponentially decaying since \(\alpha > 2\), and hence \(u_0\) can be chosen so that the eigenvectors are normalized. Going back to the original vertex basis of \({\mathbb {T}}_{p,q}\), setting \(\alpha = p/q\), we conclude that the adjacency matrix A has eigenvalues \(\pm \sqrt{q} \Lambda (\alpha )\) with associated eigenvectors \(\sum _{i \in {\mathbb {N}}} (\pm )^i u_i \varvec{\mathrm {1}}_{S_i(o)} / \Vert \varvec{\mathrm {1}}_{S_i(o)} \Vert \).
Next, we show that the measure \(\mu _\alpha \) from (4.12) is the spectral measure at the root of \(A^{{\mathbb {T}}_{p,q}} / \sqrt{d}\) and the spectral measure at 0 of (A.1).
Lemma A.2
-
(i)
For any \(\alpha \geqslant 0\) the measure \(\mu _\alpha \) is the spectral measure of \(Z(\alpha )\) at 0.
-
(ii)
For any \(p,q \in {\mathbb {N}}^*\) the measure \(\mu _{p/q}\) is the spectral measure of the normalized adjacency operator \(A^{{\mathbb {T}}_{p,q}} / \sqrt{q}\) at the root.
Proof
For (i), define the vector \(\varvec{\mathrm {e}}_0 = (1,0,0,\dots ) \in \ell ^2({\mathbb {N}})\). The spectral measure of \(Z(\alpha )\) with respect to \(\varvec{\mathrm {e}}_0\) is characterized by its Stieltjes transform

Here, we used Schur’s complement formula on the Green function
\((Z(\alpha ) - z)^{-1}\), observing that the minor of
\(Z(\alpha )\) obtained by removing the zeroth row and column is Z(1). Setting
\(\alpha = 1\) in (A.2) and recalling the defining relation (4.6) of the Stieltjes transform m of the semicircle law, we conclude that
 and hence from (4.7) and (A.2) we get
and hence from (4.7) and (A.2) we get
 , as desired.
, as desired.
The proof of (ii) is analogous. Denote the root of \({\mathbb {T}}_{p,q}\) by o. Again using Schur’s complement formula to remove the oth row and column of \(H = A^{{\mathbb {T}}_{p,q}} / \sqrt{q}\), we deduce that

where we used that \({\mathbb {T}}_{p,q}\) from which o has been removed consists of p disconnected copies of \({\mathbb {T}}_{q,q}\). Setting \(p = q\) in (A.3) and comparing to (4.6) implies that the left-hand side of (A.3) is equal to m(z) if \(p = q\), and hence (ii) for general p follows from (4.7).
Finally, we remark that the equality of the spectral measures of Z(p/q) and \(A^{{\mathbb {T}}_{p,q}} / \sqrt{q}\) can also be seen directly, by noting that Z(p/q) is the tridiagonalization of \(A^{{\mathbb {T}}_{p,q}} / \sqrt{q}\) around the root o. \(\quad \square \)
We conclude with some basic estimates for the Stieltjes transform \(m_\alpha \) of \(\mu _\alpha \) used in Sect. 4.
Lemma A.3
For each \(\kappa >0\) there is a constant \(C>0\) depending only on \(\kappa \) such that for all \(z \in \varvec{\mathrm {S}}\) and all \(\alpha \geqslant 0\) we have
Proof
The simple facts follow directly from the corresponding properties of the semicircle law and its Stieltjes transform m (see e.g. [16, Lemma 3.3]). We leave the details to the reader. \(\quad \square \)
1.3 Bounds on adjacency matrices of trees
In this appendix we derive estimates on the operator norm of a tree. We start with a standard estimate on the operator norm of a graph.
Lemma A.4
Let \({\mathbb {T}}\) be a graph whose vertices have degree at most \(q+1\) for some \(q \geqslant 1\). Then \(\Vert A^{{\mathbb {T}}} \Vert \leqslant q+1\) and if in addition \({\mathbb {T}}\) is a tree then \(\Vert A^{{\mathbb {T}}} \Vert \leqslant 2 \sqrt{q}\).
Proof
The first claim is obvious by the Schur test for the operator norm. To prove the second claim, choose a root o and denote by \(C_x\) the set of children of the vertex x. Then for any vector \(\varvec{\mathrm {w}} = (w_x)\) we have

where in third step we used Young’s inequality and in the fourth step that each vertex in the sum appears once as a child and at most q times as a parent. This concludes the proof. \(\quad \square \)
The same proof shows that if \({\mathbb {T}}\) is a rooted tree whose root has at most p children and all other vertices at most q children, then \(\Vert A^{{\mathbb {T}}} \Vert \leqslant \sqrt{q} (p/q \vee 2)\). This bound is sharp for \(p \leqslant 2q\) but not for \(p > 2q\). The sharp bound in the latter case is established in the following result.
Lemma A.5
Let \(p,q \in {\mathbb {N}}^*\). Let \({\mathbb {T}}\) be a tree whose root has p children and all the other vertices have at most q children. Then the adjacency matrix \(A^{{\mathbb {T}}}\) of \({\mathbb {T}}\) satisfies \(\Vert A^{{\mathbb {T}}}\Vert \leqslant \sqrt{q} \Lambda (p/q \vee 2)\).
Proof
Let \(r \in {\mathbb {N}}\) and denote by \({\mathbb {T}}_{p,q}(r)\) the rooted (p, q)-regular tree of depth r, whose root x has p children, all vertices at distance \(1 \leqslant i \leqslant r\) from x have q children, and all vertices at distance \(r+1\) from x are leaves. For large enough r, we can exhibit \({\mathbb {T}}\) as a subgraph of \({\mathbb {T}}_{p,q}(r)\). By the Perron–Frobenius theorem,

for the some normalized eigenvector \(\varvec{\mathrm {w}}\) whose entries are nonnegative. We extend \(\varvec{\mathrm {w}}\) to a vector indexed by the vertex set of \({\mathbb {T}}_{p,q}(r)\) by setting \(w_y = 0\) for y not in the vertex set of \({\mathbb {T}}\). Clearly,

Abbreviating \(A \equiv A^{{\mathbb {T}}_{p,q}(r)}\), it therefore remains to estimate the right-hand side of (A.7) for large enough r. To that end, we define Z as the tridiagonalization of A around the root up to radius r (see Appendix A.2). The associated orthonormal set \(\varvec{\mathrm {g}}_0, \varvec{\mathrm {g}}_1, \dots , \varvec{\mathrm {g}}_r\) is given by \(\varvec{\mathrm {g}}_i = \varvec{\mathrm {1}}_{S_i(x)}/\Vert \varvec{\mathrm {1}}_{S_i(x)}\Vert \), and \(Z = \sqrt{q} Z_r(p/q)\), where \(Z_r(\alpha )\) is the upper-left \((r+1) \times (r+1)\) block of (A.1). We introduce the orthogonal projections \(P_0 :=\varvec{\mathrm {g}}_0 \varvec{\mathrm {g}}_0^*\) and \(P :=\sum _{i = 0}^r \varvec{\mathrm {g}}_i \varvec{\mathrm {g}}_i^*\). Clearly, \(P_0 P = P_0\) and hence \((1 - P) (1 - P_0) = 1 - P\). For large enough r the vectors \(\varvec{\mathrm {g}}_r\) and \(\varvec{\mathrm {w}}\) have disjoint support, and hence  , since \(A \varvec{\mathrm {g}}_i \subset {{\,\mathrm{Span}\,}}\{\varvec{\mathrm {g}}_{i-i}, \varvec{\mathrm {g}}_{i+1}\}\) for \(i < r\). Thus we have
, since \(A \varvec{\mathrm {g}}_i \subset {{\,\mathrm{Span}\,}}\{\varvec{\mathrm {g}}_{i-i}, \varvec{\mathrm {g}}_{i+1}\}\) for \(i < r\). Thus we have

From [10, Appendices B and C] we find
Moreover, the operator \((1 - P_0) A (1 - P_0)\) is the adjacency matrix of a forest whose vertices have degree at most q. By Lemma A.4, we therefore obtain \(\Vert (1 - P_0) A (1 - P_0) \Vert \leqslant 2 \sqrt{q}\). From (A.8) we therefore get

By (A.6) and (A.7), the proof is complete. \(\quad \square \)
1.4 Degree distribution and number of resonant vertices
In this appendix we record some basic facts about the distribution of degrees of the graph \({\mathbb {G}}(N,d/N)\), and use them to estimate the number of resonant vertices \({{\mathcal {W}}}_{\lambda , \delta }\).
The following is a quantitative version of the Poisson approximation of a binomial random variable.
Lemma A.6
(Poisson approximation) If D is a random variable with law \({\text {Binom}}(n,p)\) then for \(k\leqslant \sqrt{n}\) and \(p \leqslant 1 / \sqrt{n}\) we have
Proof
Plugging the estimates \((1-p)^{n-k}= \mathrm {e}^{(n-k)\log (1-p)} = \mathrm {e}^{-np + O(pk + p^2n)}\) and
into \({\mathbb {P}}(D_x = k) = \frac{n!}{k! (n-k)!} p^k (1-p)^{n-k}\) yields the claim, since \(pk \leqslant k^2/n + p^2 n\). \(\quad \square \)
Lemma A.7
For \({\mathbb {G}}(N,d/N)\) we have \(\alpha _x \leqslant {\mathcal {C}}\bigl (1 + \frac{ \log N}{d}\bigr )\) with very high probability.
Proof
This is a simple application of Bennett’s inequality; see [10, Lemma 3.3] for details. \(\quad \square \)
Next, we recall some standard facts about the distribution of the degrees. Define the function \(f_d : [1,\infty ) \rightarrow \big [\frac{1}{2} \log (2 \pi d), \infty \big )\) through
which is bijective and increasing. For its interpretation, we note that if \(Y \overset{\mathrm d}{=}{\text {Poisson}}(d)\) then by Stirling’s formula we have \({\mathbb {P}}(Y = k) = \exp \bigl (-f_d(k/d) + O \bigl (\frac{1}{k}\bigr )\bigr )\) for any \(k \in {\mathbb {N}}\). There is a universal constant \(C > 0\) such that for \(1 \leqslant l \leqslant \frac{N}{C \sqrt{d}}\) the equation \(f_d(\beta ) = \log (N/l)\) has a unique solution \(\beta \equiv \beta _l(d)\). The interpretation of \(\beta _l(d)\) is the typical location of \(\alpha _{\sigma (l)}\). By the implicit function theorem, we find that \(d \mapsto \beta _l(d)\) on the interval \(\bigl (0, \frac{N^2}{C l^2}\bigr ]\) is a decreasing bijective function.
Definition A.8
An event \(\Xi \equiv \Xi _N\) holds with high probability if \({\mathbb {P}}(\Xi ) = 1 - o(1)\).
The following result is a slight generalization of [10, Proposition D.1], which can be established with the same proof. We note that the qualitative notion of high probability can be made stronger and quantitative with some extra effort, which we however refrain from doing here.
Lemma A.9
If \(d \geqslant 1\) and \(l \geqslant 1\) satisfies \(\beta _l(d) \geqslant 3/2\) then
with high probability, where \(\zeta \) is any sequence tending to infinity with N.
The following resultFootnote 6 gives bounds on the counting function of the normalized degrees \((\alpha _x)_{x \in [N]}\).
Lemma A.10
Suppose that \(\zeta \) satisfies
for some large enough universal constant C. Then for any \(\alpha \geqslant 2\) we have with high probability
Proof
If \(d > 3 \log N\), then an elementary analysis using Bennett’s inequality shows that \(|\{x \in [N] :\alpha _x \geqslant \alpha \} | = 0\) with high probability. Since \(N \mathrm {e}^{-f_d(\alpha )} \leqslant 1\) for \(\alpha \geqslant 2\), the claim follows. Thus, for the following we assume that \(d \leqslant 3 \log N\).
Abbreviate \(\Upsilon :=\frac{3}{2} \frac{\zeta }{d}\), which is an upper bound for the right-hand side of (A.11). For the following we adopt the convention that \(\beta _0(d) = \infty \). Choose \(l \geqslant 0\) such that
and define
We shall show that
for \(\underline{k} \!\, \geqslant 1\),
and
Thus \(\beta _{\overline{k} \!\,}(d) \geqslant 3/2\) and, assuming \(\underline{k} \!\, \geqslant 1\), Lemma A.9 is applicable to the indices \(\overline{k} \!\,\) and \(\underline{k} \!\,\). We obtain, with high probability,
from which we deduce that
which also holds trivially also for the case \(\underline{k} \!\, = 0\). By applying the function \(f_d\) to (A.14) we obtain \(l \leqslant N \mathrm {e}^{-f_d(\alpha )} \leqslant l+1\), so that (A.19) yields (A.13).
Next, we verify (A.17). We consider the cases \(l = 0\) and \(l \geqslant 1\) separately. If \(l = 0\) then, by the definition of \(\beta _{\overline{k} \!\,}(d)\), for (A.17) we require \((\log N)^{2 \zeta } + 1 \leqslant N \mathrm {e}^{-f_d(3/2)}\), which holds by the assumption \(d \leqslant 3 \log N\) and the upper bound on \(\zeta \). Let us therefore suppose that \(l \geqslant 1\). By (A.14), \(\alpha \geqslant 2\), and the definition of \(\beta _l(d)\), we have \(l \leqslant N \mathrm {e}^{-f_d(2)}\), and we have to ensure that \((l+2) (\log N)^{2 \zeta } \leqslant N \mathrm {e}^{-f_d(3/2)}\). Since \(l \geqslant 1\), this is satisfied provided that \(3 \mathrm {e}^{-f_d(2)} (\log N)^{2 \zeta } \leqslant \mathrm {e}^{-f_d(3/2)}\), which holds provided that \(f_d(2) - f_d(3/2) \geqslant 3 \zeta \log \log N\). This inequality is true because \(f_d(2) - f_d(3/2) \geqslant f'_d(3/2) /2 \geqslant d/C\), where we used that \(f_d'(\alpha ) = d \log \alpha + \frac{1}{2 \alpha }\).
What remains, therefore, is the proof of (A.15) and (A.16). We begin with the proof of (A.15). We get from the mean value theorem that
The right-hand side of (A.20) is bounded from below by \(\Upsilon \) provided that
We estimate \(\beta _{\underline{k} \!\,}(d) \leqslant \beta _1(d)\) using the elementary bound \(f_d(\beta ) \geqslant \frac{d}{10} \beta \) for \(\beta \geqslant 2\), which yields \(\log N = f_d(\beta _1(d)) \geqslant \frac{d}{10} \beta _1(d)\). By assumption on d we therefore get
Thus, (A.21) holds by \(\underline{k} \!\, \leqslant l / (\log N)^{2 \zeta }\). This concludes the proof of (A.15).
Next, we prove (A.16). As in (A.20), we find
Together with \(\beta _{l+1}(d) \leqslant \beta _1(d) \leqslant \log N\) from (A.22), we deduce that the right-hand side of (A.23) is bounded from below by \(\Upsilon \) provided that \(\log \bigl (\frac{\overline{k} \!\,}{l+1}\bigr ) \geqslant 2 \zeta \log \log N\), which is true by definition of \(\overline{k} \!\,\). This concludes the proof of (A.16). \(\quad \square \)
The following result follows easily from Lemma A.10. Recall the definition (1.13) of the exponent \(\theta _b(\alpha )\).
Corollary A.11
Suppose that \(\zeta \) satisfies (A.12). Write \(d = b \log N\). Then for any \(\alpha \geqslant 2\) we have
with high probability.
Using the exponent \(\theta _b(\alpha )\) from (1.13) and \(\alpha _{\max }(b)\) defined below it, we may state the following estimate on the density of the normalized degrees and the number of resonant vertices.
Lemma A.12
The following holds for a large enough universal constant C. Suppose that \(\zeta \) satisfies (A.12). Write \(d = b \log N\).
-
(i)
For \(2 \leqslant \alpha < \beta \leqslant \alpha _{\max }(b)\) satisfying \(\beta - \alpha \geqslant C \frac{\zeta \log \log N}{d \log \alpha }\), with high probability we have
$$\begin{aligned} |\{x \in [N] :\alpha \leqslant \alpha _x \leqslant \beta \} | = N^{\theta _b(\alpha ) + \varepsilon }\,, \qquad \varepsilon = O \biggl (\frac{\zeta \log \log N}{\log N}\biggr )\,. \end{aligned}$$(A.24) -
(ii)
For \(\delta \geqslant C \frac{\zeta \log \log N}{d}\) and \(2 + \delta \leqslant \lambda \leqslant \Lambda (\alpha _{\max }(b))\), with high probability we have
$$\begin{aligned} |{{\mathcal {W}}}_{\lambda ,\delta } | = N^{\theta _b(\Lambda ^{-1}(\lambda - \delta )) + \varepsilon }\,, \qquad \varepsilon = O \biggl (\frac{\zeta \log \log N}{\log N}\biggr )\,. \end{aligned}$$
Note that, since \(\xi \geqslant d^{-1/2}\), if the conclusion of Theorem 1.2 is nontrivial then \(\delta \geqslant d^{-1/2}\), and hence the assumption on \(\delta \) in Lemma A.12 (ii) is automatically satisfied for suitably chosen \(\zeta \).
Proof of Lemma A.12
Part (i) follows Corollary A.11 below by noting that the assumption on \(\beta \) implies \(\theta _b(\alpha ) - \theta _b(\beta ) \geqslant C \frac{\zeta \log \log N}{\log N}\) by the mean value theorem.
Part (ii) follows from Part (i), using that \(\log (\lambda - \delta ) \geqslant \log 2\), that \(\Lambda '\) is bounded on \([2,\infty )\), and the mean value theorem. \(\quad \square \)
Corollary A.13
The following holds for large enough universal constants \(C, \mathcal C\). Suppose that (1.10) holds. Write \(d = b \log N\). Let \(\varvec{\mathrm {w}} = (w_x)_{x \in [N]}\) be a normalized eigenvector of \(A/\sqrt{d}\) with nontrivial eigenvalue \(2+{{\mathcal {C}}} \xi ^{1/2} \leqslant \lambda \leqslant \Lambda (\alpha _{\max }(b))\). Then with high probability for any \(2 \leqslant p \leqslant \infty \) we have
Proof
We choose \(\delta :=C (\xi + \xi _{\lambda - 2})\). Then by assumption on \(\lambda \) we have \(\delta \leqslant (\lambda - 2)/2\), and hence Theorem 1.2 yields, using that \(\varvec{\mathrm {v}}(x)\) is supported in \(B_{r_\star }(x)\), \(\sum _{x \in {{\mathcal {W}}}_{\lambda ,\delta }} \sum _{y \in B_{r_{\star }}(x)} w_y^2 \geqslant \frac{1}{2}\) with high probability. Using that for any vector \(\varvec{\mathrm {x}} \in {\mathbb {R}}^n\) we have \(\Vert \varvec{\mathrm {x}} \Vert _p^2 \geqslant n^{2/p - 1} \Vert \varvec{\mathrm {x}} \Vert _2^2\) (by Hölder’s inequality), with the choice \(n = \sum _{x \in \mathcal W_{\lambda ,\delta }} |B_{r_{\star }}(x) |\), we get
with high probability, where we used Lemma A.7 to estimate \(\max _{x \in [N]}|B_{r_\star }(x) | \leqslant N^{C \log \log N / \sqrt{\log N}}\) with high probability.
Next, using the mean value theorem and elementary estimates on the derivatives of \(\theta _b\) and \(\Lambda ^{-1}\), we estimate
Invoking Lemma A.12 (ii) with \(\zeta :=\log \log N\), and recalling (A.25), therefore yields the claim. \(\quad \square \)
1.5 Connected components of \({\mathbb {G}}(N,d/N)\)
In this appendix we give some basic estimates on the sizes of connected components of \({\mathbb {G}}(N,d/N)\). These are needed for the analysis of the tuning forks in Appendix A.6 below. The arguments are standard and are tailored to work well in the regime \(1 \ll d \leqslant \log N\) that we are interested in. For smaller values of d, see e.g. [17].
Lemma A.14
Let \(W_k\) be the number of connected components that have k vertices and \(\widehat{W}_k\) the number of connected components that have k vertices and are not a tree. Then for \(k \leqslant N/2\) we have
Proof
For a set \(X \subset [N]\), denote by \({{\mathcal {T}}}(X)\) the set of spanning trees of X. If X is a connected component of \({\mathbb {G}}\) then there exists \({\mathbb {T}} \in {{\mathcal {T}}}(X)\) a subgraph of \({\mathbb {G}}\) such that no vertex of X is connected to a vertex of \([N] \setminus X\). Hence,
Taking the expectation now easily yields the claim, using \(|\mathcal T(X) | = |X |^{|X | - 2}\) by Cayley’s theorem, that a tree on k vertices has \(k - 1\) edges, Stirling’s approximation, and \(1 - x \leqslant \mathrm {e}^{-x}\).
The argument to estimate \(\widehat{W}_k\) is similar, noting that in addition to a spanning tree \({\mathbb {T}}\) of X, we also have to have at least one edge not in \({\mathbb {T}}\) connecting two vertices of X. Thus,
and we may estimate the expectation as before. \(\quad \square \)
We call a connected component of \({\mathbb {G}}\) small if it is not the giant component. For the following statement we recall the definition of high probability from Definition A.8.
Corollary A.15
Suppose that \(d \gg 1\). All small components of \({\mathbb {G}}\) have at most \(O\bigl (\frac{\log N}{d}\bigr )\) vertices with very high probability. All small components of \({\mathbb {G}}\) are trees with high probability. The giant component of \({\mathbb {G}}\) has at least \(N (1 - \mathrm {e}^{-d/4})\) vertices with high probability.
Proof
Any small component has at most N/2 vertices. Using Lemma A.14 we therefore get that the probability that there exists a small component with at least K vertices is bounded by
by summing the geometric series. Since \(d/2 - \log d - 1 \geqslant c d\) for some universal constant c, we obtain the first claim. To obtain the second claim, we use Lemma A.14 to estimate the probability that there exists a small component that is not a tree by \(\sum _{k = 1}^{N/2} {\mathbb {E}}{\widehat{W}_k} \leqslant \mathrm {e}^{-d/3}\). To obtain the last claim, we estimate the expected number of vertices in small components by \({\mathbb {E}}\bigl [\sum _{k = 1}^{N/2} k W_k\bigr ] \leqslant N \sum _{k = 1}^\infty k \mathrm {e}^{-k (d/2 - \log d - 1)} \leqslant C N \mathrm {e}^{- d/3}\) using Lemma A.14, and the third claim follows from Chebyshev’s inequality. \(\quad \square \)
We may now estimate the adjacency matrix on the small components of \({\mathbb {G}}(N,d/N)\). The following result follows immediately from Corollary A.15 and Lemma A.4.
Corollary A.16
Suppose that \(d \gg 1\). Then the operator norm of \(A / \sqrt{d}\) restricted to the small components of \({\mathbb {G}}\) is bounded by \(O\bigl (\frac{\sqrt{\log N}}{d}\bigr )\) with high probability.
Corollary A.16 makes it explicit that Theorem 1.8 excludes all eigenvectors on small components of \({\mathbb {G}}\), whose eigenvalues lie outside \({{\mathcal {S}}}_\kappa \) precisely under the lower bound from (1.18).
1.6 Tuning forks and proof of Lemma 1.12
In this appendix we give a precise definition of the D-tuning forks from Sect. 1.5 and prove Lemma 1.12.
Definition A.17
A star of degree \(D \in {\mathbb {N}}\) consists of a vertex, the hub, and D leaves adjacent to the hub, the spokes. A star tuning fork of degree D is obtained by taking two disjoint stars of degree D along with an additional vertex, the base, and connecting both hubs to the base. We say that a star tuning fork is rooted in a graph \({\mathbb {H}}\) if it is a subgraph of \({\mathbb {H}}\) in which both hubs have degree \(D+1\) and all spokes are leaves.
Lemma A.18
If a star tuning fork of degree D is rooted in some graph \({\mathbb {H}}\), then the adjacency matrix of \({\mathbb {H}}\) has eigenvalues \(\pm \sqrt{D}\) with corresponding eigenvectors supported on the stars of the tuning fork, i.e. on \(2D + 2\) vertices.
Proof
Suppose first that \(D \geqslant 1\). Note first that the adjacency matrix of a star of degree D has rank two and has the two nonzero eigenvalues \(\pm \sqrt{D}\), with associated eigenvector equal to \(\pm \sqrt{D}\) at the hub and 1 at the spokes. Now take a star tuning fork of degree D rooted in a graph \({\mathbb {H}}\). Define a vector on the vertex set of \({\mathbb {H}}\) by setting it to be \(\pm \sqrt{D}\) at the hub of the first star, 1 at the spokes of the first star, \({\mp } \sqrt{D}\) at the hub of the second star, \(-1\) at the spokes of the second star, and 0 everywhere else. Then it is easy to check that this vector is an eigenvector of the adjacency matrix of \({\mathbb {H}}\) with eigenvalue \(\pm \sqrt{D}\). If \(D = 0\) the construction is analogous, defining the vector to be \(+1\) at one hub and \(-1\) at the other. \(\quad \square \)
We recall from Sect. 1.5 that F(d, D) denotes the number of star tuning forks of degree D rooted in \({\mathbb {G}}_{\mathrm {giant}}\).
Lemma A.19
Suppose that \(1 \ll d \ll \sqrt{N}\) and \(0 \leqslant D \ll \sqrt{N}\). Then
and \({\mathbb {E}}[F(d,D)^2] \leqslant {\mathbb {E}}[F(d,D)]^2 (1 + o(1))\).
Proof of Lemma 1.12
From Lemma A.19 we deduce that if \(1 \ll d = b \log N = O(\log N)\) and \(D \ll \log N / \log \log N\), then \({\mathbb {E}}[F(d,D)] = N^{1 - 2b - 2b D + o(1)}\). The claim then follows from the second moment estimate in Lemma A.19 and Chebyshev’s inequality. \(\quad \square \)
Proof of Lemma A.19
Let \(x_1,x_2 \in [N]\) be distinct vertices and \(R_1, R_2 \subset [N] \setminus \{x_1,x_2\}\) be disjoint subsets of size D. We abbreviate \(U = (x_1, x_2, R_1, R_2)\) and sometimes identify U with \(\{x_1, x_2\} \cup R_1 \cup R_2\). The family U and a vertex \(o \in [N] \setminus U\) define a star tuning fork of degree D with base o, hubs \(x_1\) and \(x_2\), and associated spokes \(R_1\) and \(R_2\). Let \(\mathscr {C}_k({\mathbb {H}})\) denote the vertex set of the kth largest connected component of the graph \({\mathbb {H}}\). Then \(F(d,D) = \frac{1}{2}\sum _U \sum _{o \in [N] \setminus U} \mathbb {1}_{o \in \mathscr {C}_1({\mathbb {G}})} S_{o,U}\), where
The factor \(\frac{1}{2}\) corrects the overcounting from the labelling of the two stars.
For disjoint deterministic U, we split the random variables \(A = (A', A'')\) into two independent families, where \(A' :=(A_{uv} :u \in U \text { or } v \in U)\) and \(A'' :=(A_{uv} :u,v \in [N] \setminus U)\). Note that \(S_{o,U}\) is \(A'\)-measurable. We define the event
which is \(A''\)-measurable. By Corollary A.15 and the assumption on D, the event \(\Xi \) holds with high probability. Moreover, we have \(\mathbb {1}_{\Xi } \mathbb {1}_{o \in \mathscr {C}_1({\mathbb {G}})} S_{o,U} = \mathbb {1}_{\Xi } \mathbb {1}_{o \in \mathscr {C}_1({\mathbb {G}} \vert _{[N] \setminus U})} S_{o,U}\), since the component of o in \({\mathbb {G}}\) and \({\mathbb {G}} \vert _{[N] \setminus U}\) differ by \(2D + 2\) vertices. Thus, for fixed \(o \in [N] \setminus U\), using the independence of \(A'\) and \(A''\), we get
We have \({\mathbb {P}}(\Xi ^c) = o(1)\) and \({\mathbb {P}}\bigl (o \in \mathscr {C}_1({\mathbb {G}} \vert _{[N] \setminus U})\bigr ) = 1 - o(1)\) by Corollary A.15 and the assumption on D. Computing \({\mathbb {E}}[S_{o,U}]\) and performing the sum over o and U, we therefore conclude that
from which (A.26) follows. The estimate of the second moment is similar; one can even disregard the restriction to the giant component by estimating \({\mathbb {E}}[F(d,D)^2] \leqslant \frac{1}{4} \sum _{U, {{\tilde{U}}}} \sum _{o,{{\tilde{o}}} \in [N]} {\mathbb {E}}[S_{o,U} S_{{{\tilde{o}}}, \tilde{U}}]\); we omit the details. \(\quad \square \)
1.7 Multilinear large deviation bounds for sparse random vectors
In this appendix we collect basic large deviation bounds for multilinear functions of sparse random vectors, which are proved in [42]. The following result is proved in Propositions 3.1, 3.2, and 3.5 of [42]. We denote by \(\Vert X \Vert _r :=({\mathbb {E}}|X |^r)^{1/r}\) the \(L^r\)-norm of a random variable X.
Proposition A.20
Let r be even and \(1 \leqslant d \leqslant N\). Let \(X_1, \ldots , X_N\) be independent random variables satisfying
for all \(i \in [N]\) and \(2 \leqslant k \leqslant r\). Let \(a_i \in {\mathbb {C}}\) and \(b_{ij} \in {\mathbb {C}}\) be deterministic for all \(i,j \in [N]\). Suppose that
and
for some \(\gamma , \psi \geqslant 0\). Then
The \(L^r\)-norm bounds in Proposition A.20 induce bounds that hold with very high probability.
Corollary A.21
Fix \(\kappa \in (0,1)\). Let the assumptions of Proposition A.20 be satisfied. If \(\psi /\gamma \geqslant N^{\kappa /4}\) then with very high probability
Remark A.22
Our proof of Corollary A.21 shows that \({\mathcal {C}}\) can be chosen as a linear function of \(\nu \) for the first estimate of (A.28) and as a quadratic function of \(\nu \) for the second estimate of (A.28).
Proof
Fix \(\nu \geqslant 1\). We choose \(r= \nu \log N\) in (A.27a) of Proposition A.20 and obtain from Cheybshev’s inequality that

as \(\kappa \in (0,1)\). Similarly, choosing \(r = \frac{1}{2} \nu \log N\) in (A.27c) yields

\(\square \)
1.8 Resolvent identities
In this appendix we record some well-known identities for the Green function (4.2) and its minors from Definition 4.5. We assume throughout that \(z \in {\mathbb {C}}\setminus {\mathbb {R}}\).
Lemma A.23
(Ward identity). For \(x \notin T \subset [N]\) we have
Proof
This is a standard identity for resolvents, see e.g. [16, Eq. (3.6)]. \(\quad \square \)
Lemma A.24
Let \(T \subset [N]\). For \(x, y \notin T\) and \(x \ne y\), we have
For \(x, y, a \notin T\) and \(x \ne a \ne y\), we have
For any \(x \in [N]\), we have
Proof
All identities are standard and proved e.g. in [16]: (A.29) in [16, Eq. (3.5)], (A.30) in [16, Eq. (3.4)] and (A.31) in [16, Lemma A.1 and (5.1)]. \(\quad \square \)
We recall (4.1) and derive two expansions used in Sect. 4. For any \(T \subset [N]\) and \(x,y, u \notin T\), \(x \ne u \ne y\), we have
which follows from (A.30) and (A.29). Under the same assumptions, applying (A.29) to (A.32a) yields
1.9 Stability estimate—proof of Lemma 4.19
In this appendix we prove Lemma 4.19. The estimate in [27, Lemma 3.5] corresponding to (4.43) has logarithmic factors, which are not affordable for our purposes: they have to be replaced with constants. The following proof of Lemma 4.19 is analogous to that of the more complicated bulk stability estimate from [9, Lemma 5.11].
Proof of Lemma 4.19
We introduce the vectors \(\varvec{\mathrm {g}} :=(g_x)_{x \in {{\mathcal {X}}}}\) and \(\varvec{\mathrm {\varepsilon }}:=(\varepsilon _x)_{x \in {{\mathcal {X}}}}\). Moreover, with the abbreviation \(m :=m(z)\) we introduce the constant vectors \(\varvec{\mathrm {m}} = (m)_{x \in {{\mathcal {X}}}}\) and \(\varvec{\mathrm {e}} :=|{{\mathcal {X}}} |^{-1/2} (1)_{x \in {{\mathcal {X}}}}\). We regard all vectors as column vectors. A simple computation starting from the difference of (4.6) and (4.42) reveals that
where \(B :=1 - m^2 \varvec{\mathrm {e}} \varvec{\mathrm {e}}^*\), and column vectors are multiplied entrywise. The inverse of B is
For a matrix \(R \in {\mathbb {C}}^{{{\mathcal {X}}} \times {{\mathcal {X}}}}\), we write \(\Vert R \Vert _{\infty \rightarrow \infty }\) for the operator norm induced by the norm \(\Vert \varvec{\mathrm {r}} \Vert _\infty = \max _{x \in {{\mathcal {X}}}} |r_x |\) on \({\mathbb {C}}^{{{\mathcal {X}}}}\). It is easy to see that there is \(c>0\), depending only on \(\kappa \), such that \(|1- m(w)^2 |\geqslant c\) for all \(w \in {\mathbb {C}}_+\) satisfying \(|\mathrm {Re}\,w | \leqslant 2 - \kappa \). Hence, owing to \(\Vert \varvec{\mathrm {e}} \varvec{\mathrm {e}}^* \Vert _{\infty \rightarrow \infty } = 1\), we obtain \(\Vert B^{-1} \Vert _{\infty \rightarrow \infty } \leqslant 1 + |1- m^2 |^{-1} \leqslant 1+ c^{-1}\). Therefore, inverting B in (A.33) and choosing b, depending only on \(\kappa \), sufficiently small to absorb the term quadratic in \(\varvec{\mathrm {g}} - \varvec{\mathrm {m}}\) into the left-hand side of the resulting bound yields (4.43) for some sufficiently large \(C>0\), depending only on \(\kappa \). This concludes the proof of Lemma 4.19. \(\quad \square \)
1.10 Instability estimate—proof of (2.11)
In this appendix we prove (2.11), which shows that the self-consistent equation (2.10) is unstable with a logarithmic factor, which renders it useless for the analysis of sparse random graphs. More precisely, we show that the norm \(\Vert (I - m^2 S)^{-1} \Vert _{\infty \rightarrow \infty }\) is ill-behaved precisely in the situation where we need it. For simplicity, we replace \(m^2\) with a phase \(\alpha ^{-1} \in S^1\) separated from \(\pm 1\), since for \({{\,\mathrm{Re}\,}}z \in {{\mathcal {S}}}_\kappa \) we have
by [33, Lemma 3.5]. Moreover, for definiteness, recalling that with very high probability most of the \(d (1 + o(1))\) neighbours of any vertex in \({{\mathcal {T}}}\) are again in \({{\mathcal {T}}}\), we assume that S is the adjacency matrix of a d-regular graph on \({{\mathcal {T}}}\) divided by d.
By the spectral theorem and because S is Hermitian, \(\Vert (\alpha - S)^{-1} \Vert _{2 \rightarrow 2}\) is bounded, but, as we now show, the same does not apply to \(\Vert (\alpha - S)^{-1} \Vert _{\infty \rightarrow \infty }\). Indeed, the upper bound of (2.11) follows from [34, Proposition A.2], and the lower bound from the following result.
Lemma A.25
(Instability of (2.10)). Let S be 1/d times the adjacency matrix of a graph whose restriction to the ball of radius \(r \in {\mathbb {N}}^*\) around some distinguished vertex is a d-regular tree. Let \(\alpha \in S^1\) be an arbitrary phase. Then
for some universal constant \(c > 0\).
In particular, denoting by N the number of vertices in the tree (which may be completed to a d-regular graph by connecting the leaves to each other), for \(d \asymp \log N\) and \(r \asymp \frac{\log N}{\log d}\) we find
which is the lower bound of (2.11).
Proof of Lemma A.25
After making r smaller if needed, we may assume that \(\frac{r}{\log r} \leqslant d\). We shall construct a vector \(\varvec{\mathrm {u}}\) satisfying \(\Vert \varvec{\mathrm {u}} \Vert _\infty = 1\) and \(\Vert (\alpha - S) \varvec{\mathrm {u}} \Vert _\infty = O\bigl (\frac{\log r}{r}\bigr )\), from which (A.35) will follow. To that end, we construct the sequence \(a_0, a_1, \dots , a_r\) by setting
A short transfer matrix analysis shows that \(|a_k | \leqslant \mathrm {e}^{C_1 k /d}\) for some constant \(C_1\). Now choose \(\mu :=C_2 \frac{\log r}{r}\) with \(C_2 :=2 \vee 2 C_1\), and define \(b_k :=\mathrm {e}^{-\mu k} a_k\). Calling o the distinguished vertex, we define \(u_x :=b_k\) if \(k = {{\,\mathrm{dist}\,}}(o,x) \leqslant r\) and \(u_x = 0\) otherwise. It is now easy to check that \(\Vert (\alpha - S) \varvec{\mathrm {u}} \Vert _\infty = O\bigl (\frac{\log r}{r}\bigr )\), by considering the cases \(k = 0\), \(1 \leqslant k \leqslant r - 1\), and \(k \geqslant r\) separately. The basic idea of the construction is that if \(\mu \) were zero, then \((\alpha - S) \varvec{\mathrm {u}}\) would vanish exactly on \(B_{r - 1}(o)\), but it would be large on the boundary \(S_r(o)\). The factor \(\mathrm {e}^{-\mu k}\) introduces exponential decay in the radius which dampens the contribution of the boundary \(S_r(o)\) at the expense of introducing errors in the interior \(B_{r - 1}(o)\). \(\quad \square \)
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Alt, J., Ducatez, R. & Knowles, A. Delocalization Transition for Critical Erdős–Rényi Graphs. Commun. Math. Phys. 388, 507–579 (2021). https://doi.org/10.1007/s00220-021-04167-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00220-021-04167-y