
Abstract
Time-domain Boundary Element Methods (BEM) have been successfully used in acoustics, optics and elastodynamics to solve transient problems numerically. However, the storage requirements are immense, since the fully populated system matrices have to be computed for a large number of time steps or frequencies. In this article, we propose a new approximation scheme for the Convolution Quadrature Method powered BEM, which we apply to scattering problems governed by the wave equation. We use \({\mathscr {H}}^2\)-matrix compression in the spatial domain and employ an adaptive cross approximation algorithm in the frequency domain. In this way, the storage and computational costs are reduced significantly, while the accuracy of the method is preserved.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The numerical solution of wave propagation problems is a crucial task in computational mathematics and its applications. In this context, BEM play a special role, since they only require the discretisation of the boundary instead of the whole domain. Hence, BEM are particularly favourable in situations where the domain is unbounded, as it is often the case for scattering problems. There, the incoming wave hits the object and emits a scattered wave, which is to be approximated in the exterior of the scatterer.
In contrast to Finite Element or Difference Methods, BEM are based on boundary integral equations posed in terms of the traces of the solution. For the classical example of the scalar wave equation, the occurring integral operators take the form of so called “retarded potentials” related to Huygen’s principle. In [2], Bamberger and Ha Duong laid the foundation for their analysis by applying variational techniques in the frequency domain. Since then, significant improvements have been made, which are explained thoroughly in the monograph of Sayas [59]. Recently, a unified and elegant approach based on the semi-group theory has been proposed in [34]. Besides, the articles [22] and [38] give an excellent overview of the broad topic of time-domain boundary integral equations.
There are three different strategies for the numerical solution of time-dependent problems with BEM. The classical approach is to treat the time variable separately and discretise it via a time-stepping scheme. This leads to a sequence of stationary problems, which can be solved with standard BEM [49]. However, one serious drawback is the emergence of volume terms even for vanishing initial conditions and right-hand side. Therefore, additional measures like the dual-reciprocity method [54] are necessary or otherwise the whole domain needs to be meshed, which undermines the main benefit of BEM.
In comparison to time-stepping methods, space-time methods regard the time variable as an additional spatial coordinate and discretise the integral equations directly in the space-time cylinder. To this end, the latter is partitioned either into a tensor grid or into an unstructured grid made of tetrahedral finite elements [41]. For that reason, space-time methods feature an inherent flexibility, including adaptive refinement in both time and space simultaneously as well as the ability to capture moving geometries [25, 26, 55]. However, the computational costs are high due to the increase in dimensionality and the calculation of the retarded potentials is far from trivial [56].
Finally, transformation methods like Lubich’s CQM [46, 47] present an appealing alternative. The key idea is to take advantage of the convolutional nature of the operators by use of the Fourier-Laplace transform and to further discretise via linear multi-step [48] or Runge-Kutta methods [6, 7]. Although the transition to the frequency domain comes with certain restrictions, e.g. the physical domain needs to be constant in time, it features some important advantages. Foremost, the approximation involves only spatial boundary integral operators related to Helmholtz problems. The properties of these frequency-dependent operators are well studied [50] and they are substantially easier to deal with than retarded potentials. Moreover, the CQM is applicable for several problems of poro- and visco-elasticity, where only the Fourier-Laplace transform of fundamental solution is explicitly known [61]. Higher order discretisation spaces [33] as well as variable time step sizes [45] are also supported. Apart from acoustics [8, 35, 58], CQM have been applied successfully to challenging problems in electrodynamics [1], elastodynamics [36, 39, 60] and quantum mechanics [51].
Regardless of the method in use, we face the same major difficulty: as BEM typically generate fully populated matrices, the storage and computational costs are huge. Since this is already valid for the stationary case, so called fast methods driven by low-rank approximations have been developed for elliptic equations, see the monographs [11, 28, 57]. The crucial observation is that the kernel function admits a degenerated expansion in the far-field, which can be exploited by analytic [19, 29] or algebraic compression algorithms [10, 14]. In this way, the numerical costs are lowered to almost linear in the number of degrees of freedom. For highly oscillatory kernel functions, so called multilevel or directional algorithms [13, 18, 21, 23, 24] feature nearly linear complexity. The situation becomes even more difficult when moving to time-domain BEM. In the CQM formulation, several system matrices per frequency need to be assembled, culminating in a large number of matrices overall. Because they stem from elliptic problems, it is straightforward to approximate them via standard techniques [40]. Based on the observation that the convolution weights decay exponentially, cut-off strategies [5, 30] have been developed to accelerate the calculations. Details on how to combine these two concepts and how to solve the associated systems efficiently are given in [4]. It is also possible to filter out irrelevant frequencies if a priori information about the solution is known [9].
In this article, we present a novel approach which relies on hierarchical low-rank approximation in both space and frequency. The main idea is to reformulate the problem of approximating the convolution weights as a tensor approximation problem [31]. By means of \({\mathscr {H}}^2\)-matrices in space and ACA in frequency, we manage to reduce the complexity to almost linear in the number of degrees of freedom as well as in the number of time steps. In other words, the numerical costs are significantly reduced, which makes the algorithm particularly fast and efficient.
The paper is structured as follows. In Sect. 2, we recall the boundary integral equations and their Galerkin formulation for the wave equation, which serves as our model problem throughout this article. Subsequently, we describe the numerical discretisation of the integral equations powered by CQM and BEM in Sect. 3. The next two Sects. 4 and 5 deal with the low-rank approximation of the associated matrices and tensors respectively. Afterwards, in Sect. 6, we analyse the hierarchical approximation and specify the algorithm in its entirety. Finally, we present numerical examples in Sect. 7 and summarise our results in Sect. 8.
2 Preliminaries
2.1 Formulation of the problem
Let \(\varOmega ^{\text {in}} \subset {\mathbb {R}}^3\) be a bounded domain with Lipschitz boundary \(\varGamma = \partial \varOmega \) and denote by \(\varOmega = {\mathbb {R}}^3 \setminus {\overline{\varOmega }}_{\text {in}}\) the exterior domain. Further, let n be the unit normal vector on \(\varGamma \) pointing into \(\varOmega \).

Visualisation of the scattering problem
We study the situation depicted in Fig. 1 where an incident wave \(u^{\text {in}}\) is scattered by the stationary obstacle \(\varOmega ^{\text {in}}\), causing a scattered wave u to propagate in the free space \(\varOmega \). In the absence of external sources, we may assume that u satisfies the homogeneous wave equation
Here, the coefficient c is the speed at which the wave travels in the medium. Using dimensionless units, we set \(c=1\). Moreover, \(\varDelta \) is the Laplacian in the spatial domain and \(T > 0\) is a fixed final time. Depending on the characteristics of the scatterer \(\varOmega ^\text {in}\) and the incoming wave \(u^\text {in}\), the scattered wave u is subject to boundary conditions posed on the surface \(\varGamma \). We prescribe mixed boundary conditions of the form
given either on the Dirichlet boundary \(\varGamma _D\) or the Neumann boundary \(\varGamma _N\) with
Furthermore, we assume that \(u^{\text {in}}\) has not reached \(\varOmega \) yet, which implies vanishing initial conditions for u,
Remark 1
Surprisingly enough, regularity results for hyperbolic problems of type (1) with non-homogeneous boundary conditions were not available until the fundamental works of Lions and Magenes [44]. By the use of sophisticated tools from functional analysis and the theory of pseudo-differential operators, they paved the way for the mathematical analysis of general second-order hyperbolic systems. Subsequently, their findings were substantially improved and we present two examples here. Let \(\varSigma = \varGamma \times [0,T]\) be the lateral boundary of the space-time cylinder \(Q = \varOmega \times [0,T]\). For the pure Dirichlet case, \(\varGamma _D = \varGamma \), it is shown in [42] that
In comparison, optimal regularity results for the Neumann problem, \(\varGamma = \varGamma _N\), are derived in [62] and are of the form
In [43] it is shown that this result cannot be improved, i.e. that for all \(\varepsilon >0\) there exist \(g_N \in L^2(\varSigma )\) such that \(u \not \in H^{3/4 + \varepsilon }(Q)\). From these findings, it becomes evident that the situation of mixed conditions like (2) is far from trivial and needs special treatment. An alternative approach involves the theory of boundary integral equations, which are introduced in Sect. 2.2. In combination with the semi-group theory [34] or Laplace domain techniques [2, 59], general transmission problems can be treated in a uniform manner. To keep things simple, we refrain from specifying the function spaces in the following sections and refer to the given publications instead.
2.2 Boundary integral equations
The fundamental solution of (1) is given by
where \(\delta \) is the Dirac delta distribution defined by
for smooth test functions \(\varphi \). Thus, the behaviour of the wave at position x and time t is completely determined by its values at locations y and earlier times \(\tau = t - \left|y - x\right|\). In other words, an event at (x, t) is only affected by actions that took place on the backward light cone
of (x, t) in space-time. Therefore, \(u^*\) is also known as retarded Green’s function and \(\tau =t - \left|y - x\right|\) is called retarded time [37]. This property becomes particularly important in the representation formula,
which expresses the solution by the convolution of the boundary data with the fundamental solution. Although formally specified on the lateral surface \(\varSigma \), the evaluation of the Dirac delta reduces the domain of integration to its intersection with the backward light cone,
Since the boundary data is only given on \(\varGamma _D\) or \(\varGamma _N\), we derive a system of boundary integral equations for its unknown parts. To this end, we define the trace operators \(\gamma _0\) and \(\gamma _1\) by
for sufficiently smooth v. Note that \(\gamma _1\) coincides with the normal derivative \(\partial / \partial n\). Now, we take the Dirichlet trace in (3) and obtain the first equation
for almost every \((x,t) \in \varSigma \). Similarly, application of the Neumann trace yields
We identify the terms above with so-called boundary integral operators,
and rewrite the boundary integral equations in matrix form,
Hence, the solution to the wave equation (1) is found by solving for the unknown boundary data in the system above and inserting it into the representation formula (3). For the mapping properties of the operators and the solvability of the equations, we refer to [34].
2.3 Galerkin formulation
We derive a Galerkin formulation of (6). Taking mixed boundary conditions (2) into account, we choose extensions \({\tilde{g}}_D\) and \({\tilde{g}}_N\) on \(\varGamma \) satisfying
Furthermore, we decompose the Dirichlet and Neumann traces as follows
and obtain for \(t \in [0,T]\)
Here, the right hand side is known and we have to solve for the unknown Neumann data \({\tilde{q}}\) on the Dirichlet boundary \(\varGamma _D\) and the Dirichlet data \({\tilde{u}}\) on the Neumann part \(\varGamma _N\), respectively. Hence, the Galerkin formulation is to find \({\tilde{q}}\) and \({\tilde{u}}\) such that
holds at every time \(t \in [0,T]\) and for all test functions w and v. The index of the duality product \(\left\langle \cdot ,\cdot \right\rangle \) indicates on which part of the boundary it is formed.
3 Numerical discretisation
In view of the numerical treatment of (7), we have to discretise both time and space. We start with the time discretisation.
3.1 Convolution quadrature method
The application of the integral operators in (5) requires the evaluation of the convolution in time of the form
where f is a distribution and g is smooth. In order to compute such convolutions numerically, we employ the Convolution Quadrature Method (CQM) introduced in [46]. It is based on the Fourier-Laplace transform defined by
and on the observation that we can replace f by the inverse transform of \({\hat{f}}\) and change the order of integration, i.e.
The integration is performed along the contour
where \(\sigma >0\) is greater than the real part of all singularities of \({\hat{f}}\). In further steps, the inner integral is approximated by a linear multi-step method and Cauchy’s integral formula is used. In this way, the CQM yields approximations of (8) at discrete time points
via the quadrature formula
For a parameter \(0<R<1\), the quadrature weights are defined by
and they are given in terms of \({\hat{f}}\) sampled at specific frequencies
which depend on the quotient \(\chi \) of the generating polynomials of the multi-step method [32]. Popular examples are the backward differentiation formulas (BDF) of order \(p\le 2\) with
which are A-stable. The parameter R controls the distribution of the frequencies and is subject to the numerical implementation of the method. If we assume that \({\hat{f}}(s_\ell )\) are approximated with an error bounded by \(\delta >0\), then the choice \(R=\delta ^{1/2N}\) guarantees that \(\omega _n\) are accurate up to \({\mathscr {O}}(\sqrt{\delta })\). For further details we refer to [46,47,48].
Returning to the setting of (7), we apply the CQM to approximate the expressions occurring in the Galerkin formulation, for instance \(h(t) = \left\langle w,{\mathscr {V}}{\tilde{q}}(t)\right\rangle _{\varGamma _D}\), at equidistant time steps \(t = t_n\). For the the single layer operator \({\mathscr {V}}\) we obtain
with quadrature weights
The transformed fundamental solution \({\hat{u}}^*\) is precisely the fundamental solution of the Helmholtz equation for complex frequencies \(s \in {\mathbb {C}}\),
and has the representation
In contrast to the retarded fundamental solution \(u^*\), its transform \({\hat{u}}^*\) defines a smooth function for \(x \ne y\) and all s. Hence, the CQM formulation has the advantage that distributional kernel functions are avoided. We set \({\tilde{q}}_k = {\tilde{q}}(\cdot ,t_k)\) and introduce the operator
which acts only on the spatial component. Finally, we end up with the approximation
where the continuous convolution is now replaced by a discrete one. Repeating this procedure for the other integral operators leads to the time-discretised Galerkin formulation: find \({\tilde{u}}_k\) and \(\tilde{q_k}\), \(k=0,\ldots ,N\), such that
holds for all test functions w and v and \(n=0, \ldots , N\).
From its Definition (13), we see that the single layer operator \(\widehat{\mathbf {V}}_{n-k}\) admits the representation
as a scaled discrete Fourier transform of the operators \(\mathbf {V}_\ell \),
These are exactly the single layer operators corresponding to the Helmholtz equations with frequencies \(s_\ell \). In the same manner, the other integral operators \(\widehat{\mathbf {K}}_{n-k}\), \(\widehat{\mathbf {K}}^\prime _{n-k}\) and \(\widehat{\mathbf {D}}_{n-k}\) may be written in terms of the respective operators \(\mathbf {K}_\ell \), \(\mathbf {K}_\ell ^\prime \), \(\mathbf {D}_\ell \) of the Helmholtz equations. Since \(\text {Re} (s_\ell ) \ne 0\), the single layer operator \(\mathbf {V}_\ell \) and hypersingular operator \(\mathbf {D}_\ell \) are elliptic [2, 53]. The operator \(\widehat{{\mathscr {I}}}_{n-k}\) on the other hand can be easily calculated,
Therefore, the spatial discretisation of (14) is equivalent to a spatial discretisation of a sequence of Helmholtz problems.
3.2 Galerkin approximation
We assume that the boundary \(\varGamma \) admits a decomposition into flat triangular elements, which belong either to \(\varGamma _D\) or \(\varGamma _N\). We define boundary element spaces of constant and linear order
and global variants
Then, we follow the ansatz
with \({\underline{q}}_n\in {\mathbb {R}}^{M_D}\), \({\underline{u}}_n\in {\mathbb {R}}^{M_N}\) to approximate the unknown Neumann and Dirichlet data. Likewise, the boundary conditions are represented by coefficient vectors \({\underline{g}}_n^N\in {\mathbb {R}}^{M_0}\) and \({\underline{g}}_n^D\in {\mathbb {R}}^{M_1}\), which are determined by \(L^2\)-projections onto \(S_h^i(\varGamma )\).
As pointed out before, we begin with the discretisation of the boundary integral operators of Helmholtz problems. For each frequency \(s_\ell \), \(\ell =0,\ldots ,N-1\), we have boundary element matrices
defined by
with \(i=1,\ldots ,M_0\), \(j=1,\ldots ,M_1\), \(m=1,\ldots ,M_D\), \(p=1,\ldots ,M_N\). Just as in (15), these auxiliary matrices are then transformed to obtain the integration weights of the CQM. In the case of the single layer operators this amounts to
such that
holds by linearity. Moreover, we identify sub-matrices
The Galerkin approximation of (14) is then equivalent to the system of linear equations
with right-hand side
While the first row in (18) corresponds to the right-hand side of (14), the second row contains the boundary values of the previous time steps and results from the convolutional structure of the CQM approximation. Since the left-hand side of the linear system stays the same for every time step, only one matrix inversion has to be performed throughout the whole simulation. To be more precise, system (17) is equivalent to the decoupled system
where S is the Schur complement
Since both \({\widehat{V}}_0\) and S are real symmetric and positive definite, we factorise them via LU decomposition once for \(n=0\) and use forward and backward substitution to solve the systems progressively in time.
Naturally, the assembly of the boundary element matrices and the computation of the right-hand side (18) for each step are the most demanding parts of the algorithm, both computational and storage wise. Due to the fact that the matrices are generally fully populated, sparse approximation techniques are indispensable for large scale problems. Compared to stationary problems, this is even more crucial here, as the amount of numerical work scales with the number of time steps. Therefore, it is necessary to not only approximate in the spatial but also in the frequency variable. It proves to be beneficial to interpret the array of matrices \(V_k\), \(k = 0, \ldots , N-1\), as a third order tensor
In this way, we can restate the problem within the frame of general tensor approximation and compression. To that end, we introduce low-rank factorisations which make use of the tensor product.
Definition 1
(Tensor Product) For matrices \(A^{(j)} \in {\mathbb {C}}^{r_j \times I_j}\), \(j = 1, \ldots , d\) and a tensor \(\varvec{\mathscr {X}} \in {\mathbb {C}}^{I_1 \times \cdots \times I_d}\), we define the tensor or mode product \(\times _j\) by
Because of the singular nature of the fundamental solution, a global low-rank approximation of \(\varvec{\mathscr {V}}\) is practically not achievable. Instead, we follow a hierarchical approach where we partition the tensor into blocks, which we approximate individually. Our scheme is based on \({\mathscr {H}}^2\)-matrix approximation in the spatial domain, i.e. in i and j, and ACA in the frequency, i.e. in k.
4 Hierarchical matrices
The boundary element matrices \(V_k\) are of the form
where \(\psi _i\) and \(\varphi _j\) are trial and test functions respectively with index sets I and J and g is a kernel function. We associate with each \(i\in I\) and \(j \in J\) sets \(X_i\) and \(Y_j\), which correspond to the support of \(\psi _i\) and \(\varphi _j\). For \(r \subset I\) and \(c \subset J\), we define
Moreover, we choose axis-parallel boxes \(B_r\) and \(B_c\) that contain the sets \(X_r\) and \(Y_c\), respectively.
Since g is non-local, the matrix G is typically fully populated. However, if \(X_r\) and \(Y_c\) are well separated, i.e. if they satisfy the admissibility condition
for fixed \(\eta >0\), then the kernel function admits the degenerated expansion
into Lagrange polynomials \(L_{r,\mu }\) and \(L_{c,\nu }\) on \(X_r\times Y_c\) . Here, we choose tensor products \(\xi _{r,\mu }\) and \(\xi _{c,\nu }\) of Chebyshev points in \(B_r\) and \(B_c\) as interpolation points. In doing so, the double integral reduces to a product of single integrals
which results in the low-rank approximation of the sub-block
with
By approximating suitable sub-blocks with low-rank matrices, we obtain a hierarchical matrix approximation of G. This approach leads to a reduction of both computational and storage costs for assembling G from quadratic to almost linear in \(\#I\) and \(\#J\), where \(\#I\) denotes the cardinality of the set I.
4.1 Matrix partitions
In the following, we give a short introduction on hierarchical matrices based on the monographs [11, 17]. Since only sub-blocks that satisfy the admissibility condition (20) permit accurate low-rank approximations, a partition of the matrix indices \(I \times J\) into admissible and inadmissible blocks is required. To this end, we define cluster trees for I and J.
Definition 2
(Cluster trees) Let \({\mathscr {T}}(I)\) be a tree with nodes \(\varnothing \ne r \subset I\). We call \({\mathscr {T}}(I)\) a cluster tree if the following conditions hold:
-
1.
I is the root of \({\mathscr {T}}(I)\).
-
2.
If \(r \in {\mathscr {T}}(I)\) is not a leaf, then r is the disjoint union of its sons
$$\begin{aligned} r = \bigcup _{r^\prime \in {{\,\mathrm{sons}\,}}(r)} r^\prime . \end{aligned}$$ -
3.
\(\# {{\,\mathrm{sons}\,}}(r) \ne 1\) for \(r \in {\mathscr {T}}(I)\).
We denote by \({\mathscr {L}}({\mathscr {T}}(I))\) the set of leaf clusters
Moreover, we assume that the size of the clusters is bounded from below, i.e.
in order to control the number of clusters and limit the overhead in practical applications.
There are several strategies to perform the clustering efficiently. For instance, the geometric clustering in [28] constructs the cluster tree recursively by splitting the bounding box in the direction with largest extent. Alternatively, the principal component analysis can be used to produce well-balanced cluster trees [11].
Since searching the whole index set \(I \times J\) for an optimal partition is not reasonable, we restrict ourselves to partitions which are based on cluster trees of I and J.
Definition 3
(Block cluster trees) Let \({\mathscr {T}}(I)\) and \({\mathscr {T}}(J)\) be cluster trees. We construct the block cluster tree \({\mathscr {T}}(I \times J)\) by
-
1.
setting \(I \times J\) as the root of \({\mathscr {T}}(I \times J)\),
-
2.
and defining the sons recursively starting with \(r \times c\) for \(r = I\) and \(c = J\):
$$\begin{aligned} {{\,\mathrm{sons}\,}}(r \times c) = \left\{ \begin{aligned}&{{\,\mathrm{sons}\,}}(r) \times c,&\text {if} {{\,\mathrm{sons}\,}}(r) \ne \varnothing \text { and } {{\,\mathrm{sons}\,}}(c) = \varnothing ,\\&r \times {{\,\mathrm{sons}\,}}(c),&\text {if} {{\,\mathrm{sons}\,}}(r) = \varnothing \text { and } {{\,\mathrm{sons}\,}}(c) \ne \varnothing ,\\&{{\,\mathrm{sons}\,}}(r) \times {{\,\mathrm{sons}\,}}(c),&\text {if} {{\,\mathrm{sons}\,}}(r) \ne \varnothing \text { and } {{\,\mathrm{sons}\,}}(c) \ne \varnothing ,\\&\varnothing ,&\text {if } r \times c \text { is admissible or}\\&{{\,\mathrm{sons}\,}}(r) = {{\,\mathrm{sons}\,}}(c) = \varnothing . \end{aligned} \right. \end{aligned}$$
Then, the set of leaves \({\mathscr {L}}({\mathscr {T}}(I \times J))\) is a partition in the following sense.
Definition 4
(Admissible partition) We call \({\mathscr {P}}\) a partition of \(I \times J\) with respect to the block cluster tree \({\mathscr {T}}(I \times J)\) if
-
1.
\({\mathscr {P}} \subset {\mathscr {T}}(I \times J)\),
-
2.
\(b, b^\prime \in {\mathscr {P}} \implies b \cap b^\prime = \varnothing \text { or } b = b^\prime \),
-
3.
\({\dot{\bigcup }}_{b \in {\mathscr {P}}}\, b = I \times J\).
Moreover, \({\mathscr {P}}\) is said to be admissible if every \(r \times c \in {\mathscr {P}}\) is either admissible (20) or
In this case, the near and far field of \({\mathscr {P}}\) are defined by
Thus, the near field \({\mathscr {P}}^-\) describes those blocks of G that are stored in full, because they are inadmissible or simply too small. On the other hand, the far field \({\mathscr {P}}^+\) contains admissible blocks only, which are approximated by low-rank matrices. In Fig. 2 a partition for the single layer potential is visualised.

Visualisation of a matrix partition. Green blocks are admissible, whereas red ones are inadmissible
Remark 2
Since evaluating the admissibility condition (20) is rather expensive, we use the alternative condition
which operates on the bounding boxes and is easier to check.
4.2 \({\mathscr {H}}^2\)-matrices
One special class of hierarchical matrices consists of \({\mathscr {H}}^2\)-matrices. They are based on the observation that the matrices \(U_b\) and \(W_b\) in the low-rank factorisation (22) of the far field block \(b =r\times c\) only depend on the respective row cluster r or column cluster c and not on the block b itself.
Definition 5
(\({\mathscr {H}}^2\)-matrices) Let \({\mathscr {P}}\) be an admissible partition of \(I \times J\).
-
1.
We call
$$\begin{aligned} {\left( U_r \right) }_{r \in {\mathscr {T}}(I)}, \quad U_r \in {\mathbb {C}}^{r \times k_r}, \quad k_r > 0, \end{aligned}$$(nested) cluster basis, if for all non-leaves \(r \in {\mathscr {T}}(I) \setminus {\mathscr {L}}({\mathscr {T}}(I))\) transfer matrices
$$\begin{aligned} E_{r^\prime ,r} \in {\mathbb {C}}^{k_{r^\prime } \times k_r}, \quad r^\prime \in {{\,\mathrm{sons}\,}}(r),\ \end{aligned}$$exist such that
$$\begin{aligned} U_r = \begin{pmatrix} U_{r_1} E_{r_1,r} \\ \dots \\ U_{r_p} E_{r_p,r} \end{pmatrix}, \quad {{\,\mathrm{sons}\,}}(r) = \left\{ r_1, \ldots , r_p \right\} . \end{aligned}$$ -
2.
G is called \({\mathscr {H}}^2\)-matrix with row cluster basis \({\left( U_r \right) }_{r \in {\mathscr {T}}(I)}\) and column cluster basis \({\left( W_c \right) }_{c \in {\mathscr {T}}(J)}\), if there are coupling matrices \(S_b \in {\mathbb {C}}^{k_r \times k_c}\) such that
$$\begin{aligned} G[b] = U_r\, S_b\, W_c^H \end{aligned}$$for each far field block \(b = r \times c\).
In view of our interpolation scheme, we observe that the Lagrange polynomials of the father cluster \(r \in {\mathscr {T}}(I)\) can be expressed by the Lagrange polynomials of its son clusters \(r^\prime \in {{\,\mathrm{sons}\,}}(r)\) via interpolation,
Hence, by choosing transfer matrices
the cluster basis becomes nested
Algorithm 1 describes the assembly of cluster bases and summarises the construction of an \({\mathscr {H}}^2\) -matrix by interpolation.

In the following, let \({\widetilde{G}}\) be the \({\mathscr {H}}^2\)-approximation of the dense Galerkin matrix G. Kernel functions like (12) are asymptotically smooth, i.e. there exist constants \(C_{as}>0,c_0\ge 1\) such that
for all multi-indices \(\alpha , \beta \in {\mathbb {N}}^3\). Together with the admissibility condition (23), this property implies exponential decay of the approximation error [17].
Theorem 1
(Approximation error) Let \(r \times c \in {\mathscr {P}}^+\) be admissible with \(\eta \in (0,2)\) and let \(g(\cdot ,\cdot )\) be an asymptotically smooth function. If we use a fixed number of m interpolation points in each direction, resulting in \(p = m^3\) points overall, the separable expansion
satisfies
for some constant \(C_{int}\) independent of m and
Consequently, the matrix approximation error is bounded by
where the constant \(C_\varGamma \) depends only on \(\varGamma \) and the clustering.
Remark 3
Following [20], the kernel function in (12) is asymptotically smooth for \(\text {Re}(s)>0\) with constants
where
is the quotient between imaginary and real part of the frequency s. Note that this estimate is not optimal and diverges for \(\text {Re}(s)\rightarrow 0\), although the kernel function is still asymptotically smooth for \(\text {Re}(s)=0\), see [11].
As the computation of the far field only requires the assembly of the nested cluster bases and coupling matrices, the storage costs are reduced drastically, as depicted in Fig. 3. The red boxes symbolise dense near-field blocks, whereas far-field coupling matrices are painted magenta. The blocks to the left and above the partition illustrate the nested row and column cluster bases. There, leaf matrices are drawn in blue, while transfer matrices are coloured in magenta.

Visualisation of the storage costs of an \({\mathscr {H}}^2\)-matrix
The \({\mathscr {H}}^2\)-matrix scheme scales linearly in the number of degrees of freedom [16].
Theorem 2
(Complexity estimates) Let \({\mathscr {T}}(I\times J)\) be sparse in the sense that a constant \(C_{sp}\) exists such that
for all \(r \in {\mathscr {T}}(I)\) and \(c \in {\mathscr {T}}(J)\). Then, the \({\mathscr {H}}^2\)-matrix \({\widetilde{G}}\) requires
units of storage and the matrix-vector multiplication can be performed in just as many operations.
The number of interpolation points \(p=m^3\) equals the rank of the low-rank factorisations in the far field. Due to Remark 3, we see that m scales linearly with \(\tan \alpha \) or, equivalently, m is of order \({\mathscr {O}}\left( \left|\text {Im}(s) / \text {Re}(s)\right|\right) \) for a fixed accuracy \(\varepsilon <1\) of the approximation. If \(\alpha \) is bounded by a constant, then p only depends on \(\varepsilon \) and grows like \({\mathscr {O}}(-{\log (\varepsilon )}^3)\). However, the frequencies \(s_\ell \) of (11) in the CQM depend on R and \(\chi \).
Example 1
For the BDF-2 method with \(\chi (R)=(R^2-4R+3)/2\) and \(R=\delta ^{1/2N}\), we obtain
since the real part takes its minimum at \(\theta =0\) and the imaginary part is less than 3. Due to
it follows that m is of order \({\mathscr {O}}(N)\).
Thus, we conclude that the interpolation order m may grow linearly with the number of time steps N, cf. [3]. Nonetheless, the exponential decay from the real part of the frequency significantly improves the situation in practical applications as we see in Sect. 7.
Remark 4
Similar results hold for the kernel functions of the double layer and hyper-singular operator as well, see [11, 17]. The approach is also not limited to polynomial interpolation but alternative techniques like fast multipole methods [21, 24] or methods based on algebraic compression [18, 52] exist, which may generate lower ranks.
5 Adaptive cross approximation
Returning to the setting of (19), namely the approximation of the tensor
we have the preliminary result that each slice \(V_k\) is given in form of an \({\mathscr {H}}^2\)-matrix. Since the geometry \(\varGamma \) is fixed for all times, we can construct a partition that does not depend on the particular frequency \(s_k\). Therefore, we can select the same set of clusters \({\mathscr {T}}(I)\) and \({\mathscr {T}}(J)\) for all \(V_k\). In this way, the partition \({\mathscr {P}}\) as well as the cluster bases \({\left( U_r \right) }_ {r \in {\mathscr {T}}(I)}\) and \({\left( W_c \right) }_{c \in {\mathscr {T}}(J)}\) have to be built only once and are shared between all \(V_k\). The latter only differ in the coupling matrices and near-field entries, which have to be computed separately for each frequency \(s_k\).
Since all \(V_k\) are partitioned identically, the tensor \(\varvec{\mathscr {V}}\) defined in (19) inherits their block structure in the sense that it can be decomposed according to \({\mathscr {P}}\) by simply ignoring the frequency index k.
Definition 6
Let \(K = \{0,\ldots ,N-1\}\) and \({\mathscr {T}}(K) = \{ K \}\). In the current context, we define \(\varvec{\mathscr {P}} \in {\mathscr {T}}(I \times J \times K)\) to be the tensor partition with blocks
which are admissible or inadmissible whenever \(r \times c \in {\mathscr {P}}\) is admissible or inadmissible, respectively.
Naturally, this construction implies that the far-field blocks of \(\varvec{\mathscr {V}}\) are given in low-rank format,
with \(S_{b,k}\) being the coupling matrix of b for the frequency \(s_k\). If we collect the matrices \(S_{b,k}\) in the tensor \(\varvec{\mathscr {S}}_b\) in the same manner as \(V_k\) in \(\varvec{\mathscr {V}}\), we can factor out the cluster bases \(U_r\) and \(W_c\) using the tensor product from Definition 7,
The coupling tensor \(\varvec{\mathscr {S}}_b\) consists of kernel evaluations of the transformed fundamental solution,
which is smooth in \(B_r \times B_c\) but also in the frequency \(s \in {\mathbb {C}}\). The latter holds true even for the near-field, whose entries are
Hence, it is feasible to compress the tensor even further with respect to the frequency index k. In particular, the above discussion shows that we may proceed separately for each block \(b \in \varvec{\mathscr {P}}\), which represents either a dense block \(\varvec{\mathscr {V}}[b]\) in the near-field or a coupling block \(\varvec{\mathscr {S}}_b\) in the far-field.
5.1 Multivariate adaptive cross approximation
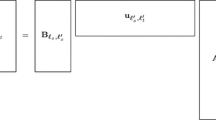
Let \(\varvec{\mathscr {G}} \in {\mathbb {C}}^{m \times n \times p}\) be a tensor. The multivariate adaptive cross approximation (MACA) introduced in [12] finds a low-rank approximation of rank \(r \le p\) of the form
with matrices \(C_\ell \in {\mathbb {C}}^{m \times n}\) and vectors \(d_\ell \in {\mathbb {C}}^p\) as illustrated in Fig. 4. When applied to the tensors \(\varvec{\mathscr {V}}[b]\) or \(\varvec{\mathscr {S}}_b\) of the CQM, \(C_\ell \) includes the spatial information whereas \(d_\ell \) contains the frequency part. The main idea of the ACA is to reuse the original entries of the tensor.

Visualisation of the low-rank factorisation
Starting from \(\varvec{\mathscr {R}}^{(0)} = \varvec{\mathscr {G}}\), we pick a non-zero pivot element in \(\varvec{\mathscr {R}}^{(\ell )}\) with index \((i_\ell , j_\ell , k_\ell )\) and select the corresponding matrix slice and fibre for our next low-rank update, i.e.
Then, we compute the residual \(\varvec{\mathscr {R}}^{(\ell +1)}\) by subtracting their tensor product,
The residual \(\varvec{\mathscr {R}}^{(\ell +1)} = \varvec{\mathscr {G}} - \varvec{\mathscr {G}}^{(\ell )}\) measures the accuracy of the approximation. After \(r=\ell \) steps we obtain the low-rank factorisation (25). By construction, the cross entries successively vanish, i.e.
which implies \(\varvec{\mathscr {R}}^{(p+1)} = 0\) and hence \(r \le p\). Figure 5 depicts one complete step of the MACA. We extract the cross consisting of \(C_\ell \) and \(d_\ell \) from \(\varvec{\mathscr {R}}^{(\ell )}\) and subtract the update \(C_\ell \times _3 d_\ell \), thereby eliminating the respective cross from \(\varvec{\mathscr {R}}^{(\ell +1)}\).

One step of the MACA
The choice of the pivoting strategy is the crucial part of the algorithm. On the one hand, it should lead to nearly optimal results, in the sense that high accuracy is achieved with relatively low rank. On the other hand, it should be reliable and fast, otherwise it would become a bottleneck of the algorithm. Different pivoting strategies are available [11], but we restrict ourselves to finding the maximum entries in \(C_\ell \) and \(d_{\ell -1}\), i.e. we choose \((i_\ell , j_\ell , k_\ell )\) such that
with \(k_{1} = 0\). Throughout the algorithm, only r slices and fibres of the original tensor \(\varvec{\mathscr {G}}\) are used. Thus, there is no need to build the whole tensor \(\varvec{\mathscr {G}}\) in order to approximate it and its entries are computed only on demand. This feature presents a clear advantage of the ACA, especially in BEM, where the generation of the entries is expensive. In this regard, the routine entry in Algorithm 2 is understood to be a call-back that computes the entries of \(\varvec{\mathscr {G}}\) at the time of its call. Moreover, the tensors \(\varvec{\mathscr {G}}^{(\ell )}\) are never formed explicitly but are stored in the low-rank format.

Here, we terminate the algorithm if the low-rank update \(C_\ell \times _3 d_\ell = \varvec{\mathscr {G}}_\ell - \varvec{\mathscr {G}}_{\ell -1}\) is sufficiently small compared to \(\varvec{\mathscr {G}}^{(\ell )}\). Likewise, this stopping criterion does not require the expansion of \(\varvec{\mathscr {G}}^{(\ell )}\) due to the identity
Neglecting the numerical work needed to compute the entries of \(\varvec{\mathscr {G}}\), the overall complexity of the MACA amounts to \({\mathscr {O}}(r^2 (n m + p))\).
If we collect the vectors \(d_\ell \) in the matrix \(D^{(r)}\in {\mathbb {C}}^{p\times r}\) and the matrices \(C_\ell \) in the tensor \(\varvec{\mathscr {C}}^{(r)} \in {\mathbb {C}}^{m \times n \times r}\), we obtain the short representation
which is equivalent to (25).
Remark 5
A tensor \(\varvec{\mathscr {X}} \in {\mathbb {C}}^{I_1 \times \cdots \times I_d}\) can be unfolded into a matrix by rearranging the index sets, which is called matricisation. For instance, the mode-j unfolding \({\mathscr {M}}_j(\varvec{\mathscr {X}}) \in {\mathbb {C}}^{I_j \times (\varPi _{k \ne j} I_k)}\) is defined by
With this in mind, it turns out that the MACA is in fact the standard ACA applied to a matricisation of the tensor. In our special case, it is the mode-3 unfolding.
Due to Remark 5, we can derive error bounds for the approximant \(\varvec{\mathscr {G}}^{(r)}\) based on standard results for the ACA.
Theorem 3
(Approximation error) Let \(\varvec{\mathscr {G}}\) be either a dense block \(\varvec{\mathscr {V}}[b]\) or a coupling block \(\varvec{\mathscr {S}}_b\). Then there exist \(0<\rho <1\) and \(C>0\) such that the residual satisfies
The constants C and \(\rho \) depend on the block b and on R, \(\chi \) and N of (11).
Proof
We parameterise s according to (11),
Then, the entries of \(\varvec{\mathscr {G}}\) are obtained by collocation of the functions
at \(\theta = k / N\), \(k=-N+1,\ldots ,N\). Because they are analytic in \(\theta \), we may use [15, Sect. 68 (76)] to bound the error of the best polynomial approximation of degree \(\ell \),
where \(f=F_{ij},G_{\mu \nu }\), \(0<\rho <1\) and M is chosen such that the absolute value of f is less than M within an ellipse in the complex plane whose foci are at \(-1\) and 1 and the sum of whose semi-axes is \(1 / \rho \). Since the equidistant sampling points form a unisolvent set for the approximating polynomials, the requirements of [11, Theorem 3.35] are satisfied and the desired bound follows. \(\square \)
Theorem 3 also justifies the choice of our stopping criterion. If we assume
then we obtain
by setting \(\varepsilon = \delta (1-\rho )/(1+\delta )\).
6 Combined algorithm
We are ready to state the complete algorithm, see Algorithm 3, for the low-rank approximation of the boundary element tensors from Sect. 3.2. In the first step, we build the cluster bases and construct a partition of the associated tensor (19) as outlined in Sect. 4 and Definition 6. In the second step, we apply the MACA from Sect. 5 to each block of the partition and obtain low-rank factorisations of the form (26). Eventually, we end up with a hierarchical tensor approximation, which reads
Besides the calls of the MACA routine, Algorithm 3 is identical to Algorithm 1.

6.1 Error analysis
Before we discuss computational aspects of this algorithm, we state a result for the approximation error.
Corollary 1
(Tensor Approximation Error) For every \(\varepsilon \ge 0\), we find an approximation \(\widetilde{\varvec{\mathscr {V}}}\) of \(\varvec{\mathscr {V}}\) generated by Algorithm 3 which satisfies
Proof
For admissible blocks \(b \in \varvec{\mathscr {P}}^+\) we observe that the first term in
is controlled by the \({\mathscr {H}}^2\)-approximation and the second one by the MACA. By virtue of Theorems 1 and 3 , we can prescribe accuracies \(\delta _b >0\) on the approximation error for every far-field block. Similarly, we can bound the error block-wisely in the near-field by \(\delta _b\). Hence, we obtain the desired bound by choosing \(\delta _b\) such that
is satisfied. \(\square \)
6.2 Complexity and fast arithmetics
For admissible blocks, the low-rank approximation is given in the so called Tucker format [27].
Definition 7
(Tucker format) For a tensor \(\varvec{\mathscr {X}} \in {\mathbb {C}}^{I_1 \times \cdots \times I_d}\) the Tucker format of tensor rank \((p_1,\ldots ,p_d)\) consists of matrices \(A^{(j)} \in {\mathbb {C}}^{p_j \times I_j}\), \(j = 1, \ldots , d\), and a core tensor \(\varvec{\mathscr {C}} \in {\mathbb {C}}^{p_1 \times \cdots \times p_d}\) such that
with the tensor product from Definition 1.
One of the main advantages of the approximation in the Tucker format is the reduction in storage costs. The Tucker representation requires
units of storage when compared with the dense block tensor. For (27) we deduce the following corollary.
Corollary 2
(Storage Complexity) Let p denote the rank of the \({\mathscr {H}}^2\)-matrix approximation and r the maximal rank of the MACA over all blocks. Under the assumptions of Theorem 2, the hierarchical tensor decomposition needs about
units of storage.
In addition, the low-rank structure allows us to substantially accelerate important steps of the CQM. We recall that the computation of the integration weights \({\widehat{V}}_n\) in (16) comprises a matrix-valued discrete Fourier transform of the auxiliary matrices \(V_\ell \). If we use representation (25) instead, we can factor out the frequency-independent matrices, i.e.
Therefore, the transform has to be performed solely on the vectors \(d_k\),
with the result that the tensor of integration weights \(\widehat{\varvec{\mathscr {V}}}\) inherits the hierarchical low-rank format of the original tensor \(\varvec{\mathscr {V}}\). In particular, the decomposition (27) still holds with \(D_b\) replaced by \({\widehat{D}}_b\), whose columns are precisely the transformed vectors \({\hat{d}}_k\). Thereby, we reduce the number of required FFTs to less than r per block. The other improvement concerns the computation of the right-hand side in (18). There, discrete convolutions of the form
need to be evaluated in each step. Once again, we insert (25) and obtain
This representation requires r matrix-vector multiplications, which amounts to \(r\, N\) matrix-vector multiplications in total. This is significantly less than the \(N^2/2\) multiplications needed by the conventional approach.
In combination with fast \({\mathscr {H}}^2\)-matrix arithmetics [16], the algorithm scales nearly linearly in the number of degrees of freedom M and time steps N. This is shown Table 1, where we compare the storage and operation counts of our algorithm with those of the traditional ones. The estimates follow from the observation that the algorithm essentially computes r \({\mathscr {H}}^2\)-matrices and additional r vectors per block. The discrete Fourier transform is applied only to the vectors \(d_k\) of length N which amounts to \({\mathscr {O}}(N\,\log (N))\) operations in each case. The algorithm performs r \({\mathscr {H}}^2\)-matrix-vector-multiplications, each of which takes \({\mathscr {O}}(p\,M)\) operations, for the computation of the right-hand side at a time step. Finally, the solution of the linear systems consists of one hierarchical LU-decomposition of complexity \({\mathscr {O}}(M^2)\) and N forward and backward substitutions with a cost of \({\mathscr {O}}(M)\) for each. If an efficient preconditioner is available, we may replace the direct solver by an iterative algorithm to eliminate the quadratic term \(M^2\). Note that the numerical effort for computing the tensor entries is not stated explicitly but is reflected in the storage complexity. Note that the ranks themselves depend not only on the prescribed accuracy but on N as well. The discussion at the end of Sect. 4 shows that the interpolation order m scales linearly with N and the numerical experiments in Sect. 7.1 indicate a logarithmic growth. Similarly, the tensor rank r displays a linear dependency on N. Nevertheless, the algorithm still performs quite well as we see in the next section.
7 Numerical examples
In this section, we present numerical examples which confirm our theoretical results and show the efficiency of our new algorithm. In all experiments, we set the parameter \(\eta \) in the admissibility condition (20) to 2.0 and use the backward differentiation formula of order 2 (BDF-2) with \(R = 10^{-5 / N}\) in the CQM. The core implementation is based on the H2Lib software.Footnote 1 The machine in use consists of two Intel Xenon Gold 6154 CPUs operating at 3.00 GHz with 376 GB of RAM.
7.1 Tensor approximation
The first set of examples concerns the performance and accuracy of the tensor approximation scheme.

Spherical geometry \(\varGamma \) used in the performance tests
Let \(\varGamma \) be the surface of a polyhedron \(\varOmega \), which approximates the sphere of radius 1 with M flat triangles, see Fig. 6. The time interval is set to (0, 5). We compare the dense tensor \(\varvec{\mathscr {V}}\) of single layer potentials with its low-rank factorisation \(\widetilde{\varvec{\mathscr {V}}}\) and study the impact of the interpolation order m as well as accuracy \(\varepsilon \) of the MACA on the approximation error, rank distribution, memory requirements and computation time.

Results for \(M=51,200\), \(N=256\), \(m=3,5,7\) and improving accuracy \(\varepsilon \) of the MACA
We first set the number of degrees of freedom to \(M = 51,200\) and time steps to \(N=256\), resulting in a Courant number of \(\varDelta t / h \approx 0.83\). In Fig. 7, the results for varying \(\varepsilon \) and fixed \(m=3,5,7\) are presented. Foremost, we observe that the relative error
in the Frobenius norm decreases with \(\varepsilon \) until it becomes constant for \(\varepsilon \ge 10^{-4}\). This behaviour can be explained by Corollary 1. Even if the coupling blocks are reproduced exactly by the MACA, the \({\mathscr {H}}^2\)-matrix approximation still dominates the total error. Moreover, the numerical results confirm that the maximal block-wise rank r of the MACA depends logarithmically on \(\varepsilon \) for fixed m. It stays below 30 in contrast to 256 time steps, which reveals the distinct low-rank character of the block tensors. Accordingly, our algorithm demands only for a small fraction of memory compared with the conventional dense approach. At worst, the compression rate reaches \(3\%\) of the original storage requirements for \(m=7\). For \(m=3,5\) and optimal choice of \(\varepsilon = 10^{-2},10^{-3}\), we further improve it to \(0.2\%\) and \(0.8\%\), respectively. Similarly, the computation time needed for the assembly of the tensor is drastically reduced. For the optimal values of \(\varepsilon \), the algorithm takes only a couple of seconds (\(m=3,5\)) or minutes (\(m=7\)) to compute the approximation of the single layer potentials. Furthermore, we report that both memory requirements and computation time scale logarithmically with \(\varepsilon \).

Storage requirements relative to the plain \({\mathscr {H}}^2\)-matrix approach for \(M=51{,}200\), \(N=256\), \(m=3,5,7\) and varying \(\varepsilon \)

Results for \(M=51{,}200\), \(N=256\), \(\varepsilon =10^{-m}\) and increasing interpolation order m

Results for constant courant number \(\varDelta t / h = 0.7\), \(m=7\), \(\varepsilon = 10^{-8}\) and increasing number of degrees of freedom M

Exemplary rank distribution of the tensor partition for \(M=51{,}200\) degrees of freedom and \(N=768\) time steps

Results for \(M=51{,}200\), \(m=7\), \(\varepsilon = 10^{-8}\) and increasing number of time steps N
To further demonstrate the benefits of the MACA, we consider the compression rate in comparison to the case when only \({\mathscr {H}}^2\)-matrices are used. In Fig. 8, the storage costs for the same test setup are presented. We notice that the inclusion of the MACA reduces the memory requirements to less than \(15\%\), while the same level of accuracy is achieved. If we modify the interpolation order m instead, Theorems 1 and 2 indicate that the approximation error decreases exponentially while the storage costs rise polynomially. This is confirmed by the findings in Fig. 9, where we set \(\varepsilon = 10^{-m}\) to ensure that MACA error is negligible. Indeed, we see that the error e is roughly halved whenever m is increased by one and reaches almost \(10^{-4}\) for \(m=8\). The upper right plot shows that the simultaneous change in \(\varepsilon \) and m leads to a linear growth of the MACA rank r in terms of m. Since the storage and computational complexity for fixed M and N is of order \({\mathscr {O}}(p\, r)\), where \(p = m^3\) is the interpolation rank, we observe that the memory and time consumption scale approximately as \({\mathscr {O}}(m^4)\). Note that in contrast to the prior example, the partition changes with different m, because the latter directly affects the clustering. Since the performance is more sensitive to a change in m, we recommend to select \(\varepsilon \) on the basis of m.
In the next two tests, we investigate the scaling of the algorithm in the number of degrees of freedom M and time steps N. First off, we fix the Courant number \(\varDelta t / h = 0.7\) and refine the mesh \(\varGamma \) successively. The parameters \(m=7\) and \(\varepsilon = 10^{-8}\) are chosen in such a way that the error e is of the magnitude \(10^{-3}\). Note that the approximation is more accurate for small M as the near-field still occupies a large part of the partition. The results are depicted in Fig. 10, where the number of time steps is added for the sake of completeness. First of all, we notice that the storage and computational complexity are linear in M in accordance with Corollary 2. Although the maximal rank r grows logarithmically at the same time, it does not influence the overall performance. This is probably due to the average rank staying almost constant in comparison. The rank distribution is visualised in form of a heat map in Fig. 11.
The dependence on the number of time steps N for constant \(M=51,200\) is illustrated in Fig. 12. We use the same values for the parameters as before, i.e., \(m=7\) and \(\varepsilon = 10^{-8}\), and now change the Courant number \(\varDelta t / h\) instead of M. As expected, the memory and time requirements scale linearly in N. The rise of the error e is attributed to the change in frequencies \(s_\ell \). From the discussion at the end of Sect. 4 we recall that the convergence rate of the interpolation error is controlled by the quotient \(\left|\text {Im}(s_\ell )/\text {Re}(s_\ell )\right|\) which itself depends on N. The numerical results here indicate that the error e grows linearly with N, so the interpolation order m and hence p scale logarithmically in N for fixed e. Note that the result in Example 1 only implies linear scaling for p. A more accurate estimate than the one provided in Remark 3 could potentially resolve this discrepancy. Finally, the rank r of the MACA exhibits linear growth in N for a fixed accuracy \(\varepsilon \). This is probably related to the change in frequencies as well. Yet, this seems to have no noticeable impact on the complexity of the method.
We summarise that the approximation scheme has almost linear complexity in both the number of degrees of freedom M and time steps N for fixed tolerance \(\varepsilon \) and interpolation order m.
7.2 Scattering problem
In this last section, we perform benchmarks for our fast CQM algorithm from Sect. 6 and study the effect of the tensor approximation on the solution of the wave problem.

Front view and back view of the obstacle
To that end, we switch settings to the model problem (1) posed in the exterior of the geometry pictured in Fig. 13. The spherical wave
serves as the exact solution. We shift the time variable such that u reaches the boundary \(\varGamma \) right after \(t=0\).

Results for constant courant number \(\varDelta t / h = 0.2\), \(m=5\), \(\varepsilon = 10^{-4}\) and increasing number of degrees of freedom M
The first part of tests concerns the fast arithmetics developed in Sect. 6.2. To simplify matters, we impose pure Dirichlet conditions on \(\varGamma _D = \varGamma \) and solve for the Neumann trace \(q_n\) in
as outlined in Sect. 3.2. We choose \(T=4.7\) as the final time. We identify three major stages of the algorithm, firstly the assembly of the tensors, secondly the inversion of \({\widehat{V}}_0\) and thirdly the step-by-step solution of the linear systems, which is also known as marching-in-on-time (MoT). In Fig. 14, we visualise how the running time is distributed among the stages and how they scale in N and M for fixed parameters \(m=5\) and \(\varepsilon =10^{-4}\). Overall, we see that the numerical results are consistent with the estimates from Table 1. Beginning with the tensor assembly, we once again observe linear complexity in M. The assembly comprises the fast transformation from (28) and is not explicitly listed, since it requires less than 2 seconds to perform in all cases. The LU decomposition of the matrix \({\widehat{V}}_0\) involves \({\mathscr {O}}(M^2)\) operations but it nevertheless poses the least demanding part of the algorithm for our problem size. On the other hand, the iterative solution of (30) takes the largest amount of time. However, the application of (29) allows for the fast computation of the right-hand sides in just \({\mathscr {O}}(M N)\). This presents a significant speed up over the conventional implementation. Taking into account that \(N \sim M^{1/2}\) for a constant Courant number, we expect the second stage to be the most expensive for very large M. Therefore, it might be advantageous to switch to iterative algorithms to solve the linear systems if efficient preconditioners are available.

Results for constant \(M=19{,}182\), \(N=235\), \(\varepsilon = 10^{-8}\) and increasing interpolation order m
For the last example, we split the boundary \(\varGamma \) in Neumann and Dirichlet parts \(\varGamma _N\) and \(\varGamma _D\) and replace the Dirichlet conditions by mixed conditions. The Neumann boundary \(\varGamma _N\) covers the upper half of \(\varGamma \) with positive component \(x_3>0\), while the rest of \(\varGamma \) accounts to the Dirichlet part. Furthermore, we consider the time interval (0, 1.7). We denote by \(u_n\) and \(q_n\) the exact solutions and compare them with the approximations \({\tilde{u}}_n\) and \({\tilde{q}}_n\) obtained by our fast CQM. We also include the reference solutions \({\tilde{u}}^\text {ref}_n\) and \({\tilde{q}}^\text {ref}_n\) provided by the dense version. In particular, we are interested in how the interpolation order m affects the quality of the approximations, which we estimate by computing the deviations
A value close to one indicates that the interpolation error does not spoil the overall accuracy of the algorithm. We select a mesh with \(M=19{,}182\) triangles and set the number of time steps to \(N=235\). The choice of \(\varepsilon =10^{-8}\) guarantees that the MACA does not deteriorate the interpolation quality. The results for varying m are depicted in Fig. 15. We observe that the approximations show the same level of accuracy for \(n\le 75\) regardless of the interpolation order. Then, the interpolation error becomes noticeable for \(m=4\) as \(e^D_n\) and \(e^N_n\) grow with n. The deviations from the reference solution are considerably smaller for \(m=6\) and our approximation scheme has almost no impact on the accuracy for \(m\ge 8\).
8 Conclusion
In this paper, we have presented a novel fast approximation technique for the numerical solution of wave problems by the CQM and BEM. We have given insights into the theoretical and practical aspects of our algorithm and have explained how it acts as a kind of hierarchical tensor approximation. Moreover, we have proposed fast arithmetics for the evaluations of the discrete convolutions in the CQM. In this way, we manage to reduce the complexity in terms of the number of spatial degrees of freedom M and number of time steps N: the storage costs from \({\mathscr {O}}(M^2 N)\) to \({\mathscr {O}}(r\,p\,M + r\,N)\) and the computational costs from \({\mathscr {O}}(M^2 N^2 +M^3)\) to \({\mathscr {O}}(r\,p\,M N + M^2)\), where p and r are the ranks of the \({\mathscr {H}}^2\)-matrix approximation and the MACA respectively. Therefore, we consider our work to be a step towards making large scale space-time simulations possible with BEM.
Notes
The source code is available at https://github.com/H2Lib/H2Lib.
References
Ballani, J., Banjai, L., Sauter, S., Veit, A.: Numerical solution of exterior Maxwell problems by Galerkin BEM and Runge–Kutta convolution quadrature. Numer. Math. 123(4), 643–670 (2013)
Bamberger, A., Ha Duong, T.: Formulation variationnelle espace-temps pour le calcul par potentiel retardé de la diffraction d’une onde acoustique. I. Math. Methods Appl. Sci. 8(3), 405–435 (1986)
Banjai, L.: Multistep and multistage convolution quadrature for the wave equation: algorithms and experiments. SIAM J. Sci. Comput. 32(5), 2964–2994 (2010)
Banjai, L., Kachanovska, M.: Fast convolution quadrature for the wave equation in three dimensions. J. Comput. Phys. 279, 103–126 (2014)
Banjai, L., Kachanovska, M.: Sparsity of Runge–Kutta convolution weights for the three-dimensional wave equation. BIT 54(4), 901–936 (2014)
Banjai, L., Lubich, C., Melenk, J.M.: Runge–Kutta convolution quadrature for operators arising in wave propagation. Numer. Math. 119(1), 1–20 (2011)
Banjai, L., Messner, M., Schanz, M.: Runge–Kutta convolution quadrature for the boundary element method. Comput. Methods Appl. Mech. Engrg. 245(246), 90–101 (2012)
Banjai, L., Rieder, A.: Convolution quadrature for the wave equation with a nonlinear impedance boundary condition. Math. Comp. 87(312), 1783–1819 (2018)
Banjai, L., Sauter, S.: Rapid solution of the wave equation in unbounded domains. SIAM J. Numer. Anal. 47(1), 227–249 (2009)
Bebendorf, M.: Approximation of boundary element matrices. Numer. Math. 86(4), 565–589 (2000)
Bebendorf, M.: Hierarchical matrices. Lecture Notes in Computational Science and Engineering, vol. 63. Springer, Berlin (2008)
Bebendorf, M.: Adaptive cross approximation of multivariate functions. Constr. Approx. 34(2), 149–179 (2011)
Bebendorf, M., Kuske, C., Venn, R.: Wideband nested cross approximation for Helmholtz problems. Numer. Math. 130(1), 1–34 (2015)
Bebendorf, M., Rjasanow, S.: Adaptive low-rank approximation of collocation matrices. Computing 70(1), 1–24 (2003)
Bernšteĭn, S.N.: Sobranie sočinenii. Tom I. Konstruktivnaya teoriya funkciĭ [1905–1930]. Izdat. Akad. Nauk SSSR, Moscow (1952)
Börm, S.: \({\cal{H}}^2\)-matrix arithmetics in linear complexity. Computing 77(1), 1–28 (2006)
Börm, S.: Efficient numerical methods for non-local operators, EMS Tracts in Mathematics, vol. 14. European Mathematical Society, Zürich (2010)
Börm, S., Börst, C.: Hybrid matrix compression for high-frequency problems. SIAM J. Matrix Anal. Appl. 41(4), 1704–1725 (2020)
Börm, S., Löhndorf, M., Melenk, J.M.: Approximation of integral operators by variable-order interpolation. Numer. Math. 99(4), 605–643 (2005)
Breuer, J.: Schnelle Randelementmethoden zur Simulation von elektrischen Wirbelstromfeldern sowie ihrer Wärmeproduktion und Kühlung. Ph.D. thesis, Universität Stuttgart (2005)
Cheng, H., Crutchfield, W., Gimbutas, Z., Greengard, L., Ethridge, J., Huang, J., Rokhlin, V., Yarvin, N., Zhao, J.: A wideband fast multipole method for the Helmholtz equation in three dimensions. J. Comput. Phys. 216(1), 300–325 (2006)
Costabel, M., Sayas, F.J.: Time-Dependent Problems with the Boundary Integral Equation Method, pp. 1–24. John Wiley & Sons, Inc., New York-London-Sydney (2017)
Darve, E.: The fast multipole method: numerical implementation. J. Comput. Phys. 160(1), 195–240 (2000)
Engquist, B., Ying, L.: Fast directional multilevel algorithms for oscillatory kernels. SIAM J. Sci. Comput. 29(4), 1710–1737 (2007)
Gimperlein, H., Maischak, M., Stephan, E.: Adaptive time domain boundary element methods with engineering applications. J. Integral Equations Appl. 29(1), 75–105 (2017)
Gimperlein, H., Özdemir, C., Stark, D., Stephan, E.: hp-version time domain boundary elements for the wave equation on quasi-uniform meshes. Comput. Methods Appl. Mech. Engrg. 356, 145–174 (2019)
Hackbusch, W.: Tensor spaces and numerical tensor calculus, Springer Series in Computational Mathematics, vol. 42. Springer, Heidelberg (2012)
Hackbusch, W.: Hierarchical Matrices: Algorithms and Analysis. Springer Series in Computational Mathematics, vol. 49. Springer, Heidelberg (2015)
Hackbusch, W., Börm, S.: Data-sparse approximation by adaptive \({\cal{ H}}^2\)-matrices. Computing 69(1), 1–35 (2002)
Hackbusch, W., Kress, W., Sauter, S.A.: Sparse convolution quadrature for time domain boundary integral formulations of the wave equation. IMA J. Numer. Anal. 29(1), 158–179 (2009)
Haider, A.M., Schanz, M.: Generalization of adaptive cross approximation for time-domain boundary element methods. PAMM 19(1), e201900072 (2019)
Hairer, E., Nørsett, S.P., Wanner, G.: Solving ordinary differential equations. I, Springer Series in Computational Mathematics, vol. 8, second edn. Springer, Berlin (1993)
Hassell, M., Sayas, F.J.: Convolution quadrature for wave simulations. In: Numerical Simulation in Physics and Engineering, SEMA SIMAI Springer Ser., vol. 9, pp. 71–159. Springer, Cham (2016)
Hassell, M.E., Qiu, T., Sánchez-Vizuet, T., Sayas, F.J.: A new and improved analysis of the time domain boundary integral operators for the acoustic wave equation. J. Integral Equations Appl. 29(1), 107–136 (2017)
Hassell, M.E., Sayas, F.J.: A fully discrete BEM-FEM scheme for transient acoustic waves. Comput. Methods Appl. Mech. Engrg. 309, 106–130 (2016)
Hsiao, G.C., Sánchez-Vizuet, T., Sayas, F.J., Weinacht, R.J.: A time-dependent wave-thermoelastic solid interaction. IMA J. Numer. Anal. 39(2), 924–956 (2019)
Jackson, J.: Classical Electrodynamics, 3rd edn. Wiley, New York-London-Sydney (1998)
Joly, P., Rodríguez, J.: Mathematical aspects of variational boundary integral equations for time dependent wave propagation. J. Integral Equ. Appl. 29(1), 137–187 (2017)
Kielhorn, L., Schanz, M.: Convolution quadrature method-based symmetric Galerkin boundary element method for 3-d elastodynamics. Internat. J. Numer. Methods Engrg. 76(11), 1724–1746 (2008)
Kress, W., Sauter, S.: Numerical treatment of retarded boundary integral equations by sparse panel clustering. IMA J. Numer. Anal. 28(1), 162–185 (2008)
Langer, U., Steinbach, O.: Space-Time Methods. De Gruyter, Berlin, Boston (2019)
Lasiecka, I., Lions, J.L., Triggiani, R.: Nonhomogeneous boundary value problems for second order hyperbolic operators. J. Math. Pures Appl. (9) 65(2), 149–192 (1986)
Lasiecka, I., Triggiani, R.: Sharp regularity theory for second order hyperbolic equations of Neumann type. I. \(L_2\) nonhomogeneous data. Ann. Mat. Pura Appl. (4) 157, 285–367 (1990)
Lions, J.L., Magenes, E.: Non-homogeneous boundary value problems and applications. Vol. I–III. Springer, New York-Heidelberg (1972–1973)
Lopez-Fernandez, M., Sauter, S.: Generalized convolution quadrature based on Runge–Kutta methods. Numer. Math. 133(4), 743–779 (2016)
Lubich, C.: Convolution quadrature and discretized operational calculus. I. Numer. Math. 52(2), 129–145 (1988)
Lubich, C.: Convolution quadrature and discretized operational calculus. II. Numer. Math. 52(4), 413–425 (1988)
Lubich, C.: On the multistep time discretization of linear initial-boundary value problems and their boundary integral equations. Numer. Math. 67(3), 365–389 (1994)
Mansur, W.: A time-stepping technique to solve wave propagation problems using the boundary element method. Ph.D. thesis, University of Southhampton (1983)
McLean, W.: Strongly elliptic systems and boundary integral equations. Cambridge University Press, Cambridge (2000)
Melenk, J.M., Rieder, A.: Runge-Kutta convolution quadrature and FEM-BEM coupling for the time-dependent linear Schrödinger equation. J. Integral Equations Appl. 29(1), 189–250 (2017)
Messner, M., Schanz, M., Darve, E.: Fast directional multilevel summation for oscillatory kernels based on Chebyshev interpolation. J. Comput. Phys. 231(4), 1175–1196 (2012)
Nédélec, J.C.: Acoustic and Electromagnetic Equations. Applied Mathematical Sciences, vol. 144. Springer, New York (2001)
Partridge, P., Brebbia, C., Wrobel, L.C.: The Dual Reciprocity Boundary Element Method. International Series on Computational Engineering. Springer, Dordrecht (1991)
Pölz, D., Gfrerer, M.H., Schanz, M.: Wave propagation in elastic trusses: an approach via retarded potentials. Wave Motion 87, 37–57 (2019)
Pölz, D., Schanz, M.: Space-time discretized retarded potential boundary integral operators: quadrature for collocation methods. SIAM J. Sci. Comput. 41(6), A3860–A3886 (2019)
Rjasanow, S., Steinbach, O.: The Fast Solution of Boundary Integral Equations. Mathematical and Analytical Techniques with Applications to Engineering. Springer, New York (2007)
Sauter, S.A., Schanz, M.: Convolution quadrature for the wave equation with impedance boundary conditions. J. Comput. Phys. 334, 442–459 (2017)
Sayas, F.J.: Retarded Potentials and Time Domain Boundary Integral Equations. Springer Series in Computational Mathematics, vol. 50. Springer, Cham (2016)
Schanz, M.: Wave Propagation in Viscoelastic and Poroelastic Continua: A Boundary Element Approach, Lecture Notes in Applied and Computational Mechanics, vol. 2, 1 edn. Springer, Berlin-Heidelberg (2001)
Schanz, M., Antes, H.: A new visco- and elastodynamic time domain: boundary element formulation. Comput. Mech. 20(5), 452–459 (1997)
Tataru, D.: On the regularity of boundary traces for the wave equation. Ann. Scuola Norm. Sup. Pisa Cl. Sci. (4) 26(1), 185–206 (1998)
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Seibel, D. Boundary element methods for the wave equation based on hierarchical matrices and adaptive cross approximation. Numer. Math. 150, 629–670 (2022). https://doi.org/10.1007/s00211-021-01259-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00211-021-01259-8