
Abstract
We study a boundedly rational model of imitation when payoff distributions of actions differ across types of individuals. Individuals observe others’ actions and payoffs, and a comparison signal. One of two inefficiencies always arises: (i) uniform adoption, i.e., all individuals choose the action that is optimal for one type but suboptimal for the other, or (ii) dual incomplete learning, i.e., only a fraction of each type chooses its optimal action. Which one occurs depends on the composition of the populations and how critical the choice is for different types of individuals. In an application, we show that a monopolist serving a populations of boundedly rational consumers cannot fully extract the surplus of high-valuation consumers, but can sell to consumers who do not value the good.



Similar content being viewed by others
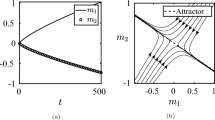
Notes
This example is inspired in the analysis of the adoption of high yielding varieties of rice and wheat among heterogeneous farmers in India (see, e.g., Munshi 2004).
The inefficiencies caused by heterogeneity are not confined to payoff-ordering decision rules. Indeed, it can be shown that a decision rule would lead both populations to converge to choose their respective optimal actions only if the problem is “trivial,” i.e., if for each individual, the revised probability of choosing her optimal action is one every time she observes both actions.
Since our benchmark model assumes uniform sampling and generates uniform adoption, and Ellison and Fudenberg (1993) assume non-uniform sampling and do not generate uniform adoption, one may ask whether uniform sampling is what leads to uniform adoption (when it occurs). Our extension to biased sampling, however, reveals that in our model uniform adoption is consistent with non-uniform sampling.
Since \(y+\delta -x\in [-2,2]\), we need \(\beta \in (0,1/4]\) so that the probabilities of switching are specified in [0, 1]. In general, when \((y+\delta -x)\in [-\overline{c},\overline{c}]\), with \(\overline{c}>0\), we need \(\beta \in \left( 0,\frac{1}{2\overline{c}}\right] \). Here \(\overline{c}=2\), but, for instance, the assumptions we make in the application of Sect. 5 yield a different value for \(\overline{{c}}\).
It may seem unintuitive that a payoff-ordering decision rule prescribes switching with positive probability even if the observed action earned a lower perceived payoff than the own action. Changing this feature of the decision rule, however, would not allow payoff-ordering as the decision would necessarily have to be nonlinear in observed payoffs and then the construction in the argument of sufficiency of the proof of Proposition 1 would not go through. To illustrate, consider an environment in which c gives a payoff of 0.1 to type A individuals with certainty, d gives a payoff of 0 with certainty for type B individuals, and the comparison signal observed by type A individuals observing type B individuals choosing d is equal to 0 with probability 4/5 and 0.9 with probability 1/5. In this case, \(\pi _{Ad}>\pi _{Ac}\). Nevertheless, a decision rule that never switches if the observed action’s perceived payoff is lower than the own would require a type A individual to stick with c with probability 4/5 when observing a type B individual who chose d.
There are measurability problems in invoking the law of large numbers for a continuum of random variables (see, e.g., Feldman and Gilles 1985; Judd 1985, and Alos-Ferrer 2002). We thank Carlos Alos-Ferrer for pointing this out and providing us with these references. In the last decade, a number of papers deal with this issue and with independent random matching in particular, using Fubini Extensions introduced in Sun (2006) (see, e.g., Duffie and Sun 2007, 2012). See also Podczeck and Puzzello (2012), who build on an earlier contribution by Alos-Ferrer (1999) to study independent random matching with a continuum of agents. We thank three anonymous referees for guiding us to this literature. In particular, the foundations for the dynamical system analyzed here are an application of the results of Duffie et al. (2016). In a related environment, with a different approach, Benaim and Weibull (2003) show that the deterministic path of dynamical systems yield a reasonable approximation of discrete-time stochastic adjustment in large populations and over finite time horizons (see also Sandholm 2003, 2010a).
As in most of the equations below, the time dependence of p and q have been omitted.
There are at least a couple of alternative ways to avoid bounding U and D away from 1. First, the distribution of the comparison signal could be allowed to depend on the payoff realization in such a manner that \(y+\delta -x\in [-1,1]\). This would allow \(U,D\in (1/2,1]\). Alternatively, as we discuss below, one could consider decision rules which are not payoff-ordering. The results of allowing \(U,D\in (1/2,1]\), however, are qualitatively similar to those of our benchmark case.
We only exclude \(\alpha =\underline{\alpha }\) and \(\alpha =\overline{\alpha }\), because the techniques that we use in the proof of the result applies only to hyperbolic rest points (see the proof of Theorem 1) and at \(\alpha =\underline{\alpha }\) and \(\alpha =\overline{\alpha }\) some of the rest points are not hyperbolic.
We cannot have complete learning for one type and partial learning for the other. For example, we have no rest points (1, q) with \(q>0\). Intuitively, since type A individuals occasionally observe action b in this point and switch with positive probability when they do, they would move away from action a. Similarly, we have no rest points (p, 1) with \(p>0\).
Whenever a rest point is a global attractor, it satisfies the second condition of asymptotic stability. In general, however, it does not necessarily satisfy the first part, i.e., it is possible that the dynamics move away from the rest point before eventually converging to it. Nevertheless, Theorem 1 reveals that a rest point of (5)–(6) is asymptotically stable if and only if it is a global attractor of the system.
There are, however, examples of decision rules and environments such that these conditions are met. For instance, consider decision rules such as a suitably modified version of “imitate if better” (see, e.g., Oyarzun and Ruf 2009), in which individuals switch (corresp. do not switch) with probability 1 if \(y+\delta >x\) (corresp. \(y+\delta <x\)), and randomize with a fair coin, otherwise. This decision rule yields \(L_{ab}(A,B)=L_{ba}(B,A)=0\) in the environment such that \(\pi _{Aa}=\pi _{Bb}=1\), \(\pi _{Ab}=\pi _{Ba}=0\), and the comparison signals within individuals of the same type (for all actions) are deterministic.
In formal terms, Proposition 4 of “Appendix 2” holds in the model with general intensities as well (with the natural necessary adjustment to the definition of \(\hat{\varDelta }(\varSigma )\) to accommodate for the dummy-sampling variable in the individual state).
The only possibilities we do not consider here are when \(\alpha _{A}=\overline{\alpha }_{A}(\alpha _{B})\) or \(\alpha _{B}=\overline{\alpha }_{B}(\alpha _{A})\), in which case some rest points may not be hyperbolic and hence may not be determined using the Jacobian of the system.
An implication of this result is that uniform adoption does not require uniform sampling. Furthermore, both types being heavily biased toward sampling individuals of their own type are not incompatible with uniform adoption. For instance, in Fig. 2, we just require \(\alpha _{B}<0.19\) for uniform adoption of a to occur for any \(\alpha _{A}\). More broadly, if we measure type B individuals’ bias to sample their own type by \(\psi _{B}:=\alpha _{B}(1-\alpha )^{-1}\), it is easy to see that we can have uniform adoption even if \(\psi _{B}\) is very high: if we fix \(\psi _{B}\), for sufficiently small \((1-\alpha )\) one obtains that \(\psi _{B}(1-\alpha )<0.54\) and hence uniform adoption of a (for high enough \(\alpha _{A}\)).
We normalize the physical payoffs to be in [0.5, 1] so that the total payoff of each choice, corresponding to the physical payoffs minus the price charged by the monopolist, fall in [0, 1], as in the benchmark model.
Our model is related to Spiegler’s (2006) model of markets for “quacks.” In his paper, the treatment is ineffective for all individuals in the populations, so he refers to the healer as a quack. In our model, the healer is not a quack since the treatment works for some individuals, although it is ineffective for others.
At prices above \(\varphi \), under full information, both type A and type B individuals prefer not to buy the treatment. In our setting, such prices would lead the populations to a state in which no individual buys the treatment. As we show below, prices larger than \(\varphi \) do not add anything to the analysis.
From footnote 11, we need \(\beta \in \left( 0,\frac{1}{2\overline{c}}\right] \) and here \(y+\delta -x\in \left[ -\overline{c},\overline{c}\right] =\left[ -1.5,1.5\right] \).
This simplifies the analysis significantly. We leave the alternative, in which the monopolist has a positive discount rate and maximizes the present value of all his future profits, for future research.
The statement of Theorem 1 does not include the cutoff values, which in this case correspond to \(r=\underline{r}(\varphi ,\alpha )\) and \(r=\overline{r}(\varphi ,\alpha )\), since the techniques used to prove Theorem 1 are valid for hyperbolic rest points and some rest points are non-hyperbolic at the cutoff values. Nevertheless, by directly applying the definition of asymptotic stability and constructing a straightforward \(\varepsilon -\gamma \) argument, it can be shown that for the prices \(r=\underline{r}(\varphi ,\alpha )\) and \(r=\overline{r}(\varphi ,\alpha )\), \((p^{*},q^{*})\) is equal to \(\left( 1,0\right) \) and (0, 1), respectively.
For the formal argument, see the working paper version, Hedlund and Oyarzun (2016).
Notice that since the payoff-ordering property has to hold for arbitrary finite sets \(X\subset [0,1]\) and \(\varDelta \subset [-1,1]\), the triplet \((x,y,\delta )\) can be chosen arbitrarily within \([0,1]\times [0,1]\times [-1,1]\) (as long as it satisfies the hypothesis of the corollary).
For a definition of super-atomless measures see Definition 5 and the appendix of Podczeck (2010).
The analysis also assumes a right-continuous filtration \(\{{\mathscr {F}}_{t}:t\in {\mathbb {R}}^{+}\}\) in the probability space \((\varOmega ,{\mathscr {F}},P)\), such that all null events are included in \({\mathscr {F}}_{0}\); but this filtration will not appear (explicitly) in our analysis.
Theorem 1 in Podczeck (2010) shows that a sufficient condition allowing \(\lambda \boxtimes P\) to be a rich Fubini extension (i.e., a proper extension of the product measure of \(\lambda \) and P on \(W\times \varOmega \) that allows for essentially pairwise independent random variables that are not essentially constant) is that the measure in the index probability space (\(\lambda \)) is super-atomless, which we have assumed from the outset.
As in most of the equations below, the time and state-of-the-world dependence of p and q have been omitted.
In the definition in Duffie et al. (2016), dynamical systems also depend on parameters describing mutation intensities and matching intensities. In our model, there are no mutations so these parameters are all zero and hence we omit them, and the matching intensities of our model are given by the fraction of the populations of the state of the individual to be sampled; thus, we omit these parameters as well. We only consider different intensities in Sect. 4 and “Appendix 4”.
Corollary 2 in Duffie et al. (2016) considers a slightly more general formulation of Definition 2 (that, as mentioned in footnote 39, allows for exogenous mutation rates of individual states and matching intensities functions where matching intensities of individuals of different states are not necessarily proportional to the fraction of the populations of the individual state of the sampled individual). For that more general formulation, this corollary establishes the existence of a Fubini Extension where a DS \((\rho ,\pi )\) can be defined. Their Corollary 1, which we use below, provides the differential equations describing the path of the expected value of the fraction of individuals in each individual state and establishes that the realization of this path is almost surely equal to its expected value.
In the rest of the proof, we omit the time and state-of-the-world dependence of \(p_{\sigma }\), p, and q, and their time derivatives.
To see why 1. holds observe that, from (17), we have \(\sum _{\sigma \in \varSigma :\tau =A,c=a,x=x_{0}}\dot{p}_{\sigma }\) is equal to \(\sum _{\sigma \in \varSigma :\tau =A,c=a,x=x_{0}} \sum _{\sigma ''\in \varSigma {\setminus }\{\sigma \}}p_{\sigma ''}\sum _{\sigma '\in \varSigma }p_{\sigma '}\varsigma _{\sigma ''\sigma '}(\sigma )-\sum _{\sigma \in \varSigma :\tau =A,c=a,x=x_{0}}p_{\sigma }\sum _{\sigma ''\in \varSigma {\setminus }\{\sigma \}}\sum _{\sigma '\in \varSigma }p_{\sigma '}\varsigma _{\sigma \sigma '}(\sigma '')\). From (1), the minuend is \(\mu _{Aa}(x_{0})\) times the minuend in (18). The initial conditions imply that, at time \(t=0\), the subtrahend is \(\mu _{Aa}(x_{0})\) times the subtrahend in (18). Thus, at \(t=0\), \(\sum _{\sigma \in \varSigma :\tau =A,c=a,x=x_{0}}\dot{p}_{\sigma }=\mu _{Aa}(x_{0})\alpha \dot{p}\). Therefore, at \(t=0\), the right derivative of \(\sum _{\sigma \in \varSigma :\tau =A,c=a,x=x_{0}}p_{\sigma }/(\alpha p)\) with respect to t is 0. Furthermore, the derivative of \(\sum _{\sigma \in \varSigma :\tau =A,c=a,x=x_{0}}p_{\sigma }/(\alpha p)\) with respect to t is negative (positive) when \(\sum _{\sigma \in \varSigma :\tau =A,c=a,x=x_{0}}p_{\sigma }>(<)\mu _{Aa}(x_{0})\). Thus, \(\sum _{\sigma \in \varSigma :\tau =A,c=a,x=x_{0}}p_{\sigma }/(\alpha p)\) is constant over time and equal to its value at \(t=0\), \(\mu _{Aa}(x_{0})\). The proof of the facts 2–4 is similar and it is omitted.
Dependence on time and state of the world are omitted in the notation.
References
Alos-Ferrer, C.: Dynamical systems with a continuum of randomly matched agents. J. Econ. Theory 86, 245–267 (1999)
Alos-Ferrer, C.: Individual Randomness in Economic Models with a Continuum of Agents. University of Vienna, Mimeo (2002)
Alos-Ferrer, C., Kirchsteiger, G., Walzl, M.: On the evolution of market institutions: the platform design paradox. Econ. J. 120, 215–243 (2010)
Alos-Ferrer, C., Schlag, K.: Imitation and learning. In: Anand, P., Pattanaik, P., Puppe, C. (eds.) Ch. 11, The Handbook of Rational and Social Choice, pp. 271–298. Oxford University Press, Oxford (2009)
Alos-Ferrer, C., Shi, F.: Imitation with asymmetric memory. Econ. Theory 49, 193–215 (2012)
Apesteguia, J., Huck, S., Oechssler, J.: Imitation: theory and experimental evidence. J. Econ. Theory 136, 217–235 (2007)
Banerjee, A.: A simple model of herd behavior. Q. J. Econ. 107, 797–817 (1992)
Benaim, M., Weibull, J.: Deterministic approximation of stochastic evolution in games. Econometrica 71, 873–903 (2003)
Bikhchandani, S., Hirshleifer, D., Welch, I.: A theory of fads, fashion, custom, and cultural change as information cascades. J. Polit. Econ. 100, 992–1026 (1992)
Borgers, T., Morales, A., Sarin, R.: Expedient and monotone learning rules. Econometrica 72, 383–405 (2004)
Cubitt, R., Sugden, R.: The selection of preferences through imitation. Rev. Econ. Stud. 65, 761–771 (1998)
Currarini, S., Jackson, M., Pin, P.: An economic model of friendship: homophily, minorities, and segregation. Econometrica 77, 1003–1045 (2009)
Duffie, D., Qiao, L., Sun, Y.: Continuous time random matching. Working Paper, Graduate School of Business, Stanford University (2016)
Duffie, D., Sun, Y.: Existence of independent random matching. Ann. Appl. Probab. 17, 386–419 (2007)
Duffie, D., Sun, Y.: The exact law of large numbers for independent random matching. J. Econ. Theory 147, 1105–1139 (2012)
Ellison, G., Fudenberg, D.: Rules of thumb for social learning. J. Polit. Econ. 101, 612–643 (1993)
Ellison, G., Fudenberg, D.: Word of mouth communication and social learning. Q. J. Econ. 110, 93–125 (1995)
Feldman, M., Gilles, C.: An expository note on individual risk without aggregate uncertainty. J. Econ. Theory 35, 26–32 (1985)
Fudenberg, D., Imhof, L.: Imitation processes with small mutations. J. Econ. Theory 131, 251–262 (2006)
Hedlund, J.: Imitation in Cournot oligopolies with multiple markets. Econ. Theory 60, 567–587 (2015)
Hedlund, J., Oyarzun, C.: Imitation in Heterogeneous Populations. AWI Discussion Paper 625, Department of Economics, University of Heidelberg (2016)
Hofbauer, J., Sandholm, W.: Survival of dominated strategies under evolutionary dynamics. Theor. Econ. 6, 341–377 (2011)
Hofbauer, J., Sigmund, K.: Evolutionary Games and Populations Dynamics. Cambridge University Press, Cambridge (1998)
Judd, K.: The law of large numbers with a continuum of IID random variables. J. Econ. Theory 35, 19–25 (1985)
Morales, A.: Absolutely expedient imitative behavior. Int. J. Game Theory 31, 475–492 (2002)
Munshi, K.: Social learning in a heterogeneous populations. J. Dev. Econ. 73, 185–213 (2004)
Neary, P.: Competing conventions. Game. Econ. Behav. 76, 301–328 (2012)
Offerman, T., Schotter, A.: Imitation and luck: an experimental study on social sampling. Game. Econ. Behav. 65, 461–502 (2009)
Oyarzun, C., Ruf, J.: Monotone imitation. Econ. Theory 41, 411–441 (2009)
Podczeck, K.: On existence of rich Fubini extensions. Econ. Theory 45, 1–22 (2010)
Podczeck, K., Puzzello, D.: Independent random matching. Econ. Theory 50, 1–29 (2012)
Sandholm, W.: Evolution and equilibrium under inexact information. Game. Econ. Behav. 44, 343–378 (2003)
Sandholm, W.: Populations Games and Evolutionary Dynamics. MIT press, Cambridge (2010a)
Sandholm, W.: Pairwise comparison dynamics and evolutionary foundations for Nash equilibrium. Games 1, 3–17 (2010b)
Santos-Pinto, L., Sobel, J.: A model of positive self-image in subjective assessments. Am. Econ. Rev. 95, 1386–1402 (2005)
Schlag, K.: Why imitate, and if so, how? A bounded rational approach to multi-armed bandits. J. Econ. Theory 78, 130–156 (1998)
Smith, L., Srensen, P.: Pathological outcomes of observational learning. Econometrica 68, 371–398 (2000)
Spiegler, R.: The market for quacks. Rev. Econ. Stud. 73, 1113–1131 (2006)
Spiegler, R.: Bounded Rationality and Industrial Organization. Oxford University Press, Oxford (2011)
Sun, Y.: The exact law of large numbers via Fubini extension and characterization of insurable risks. J. Econ. Theory 126, 31–69 (2006)
Suri, T.: Selection and comparative advantage in technology adoption. Econometrica 79, 159–209 (2011)
Sydsaeter, K., Hammond, P., Seierstad, A., Strom, A.: Further Mathematics for Economic Analysis. Pearson Education, Prentice Hall (2008)
Van den Steen, E.: Rational overoptimism (and other biases). Am. Econ. Rev. 94, 1141–1151 (2004)
Young, P.: Innovation diffusion in heterogeneous populations: contagion, social influence, and social learning. Am. Econ. Rev. 99, 1899–1924 (2009)
Author information
Authors and Affiliations
Corresponding author
Additional information
We thank Carlos Alos-Ferrer, Jose Apesteguia, Philipp Kircher, Antonio Morales, Michael Rapp, Javier Rivas, Adam Sanjurjo, Karl Schlag, Luis Ubeda, Amparo Urbano, and the seminar participants at Stockholm School of Economics, University of Alicante, University of Auckland, University of Guadalajara, University of Guanajuato, University of Heidelberg, the Australasian Economic Theory Workshop 2012, and SAET 2012 (Brisbane) for helpful comments and suggestions. We also thank four referees for constructive comments to improve the paper, and Darrel Duffie, Lei Qiao, and Yeneng Sun for providing us a preliminary version of one of their manuscripts. Financial support from the Ministerio de Ciencia e Innovacion and FEDER funds under Projects BES-2008-008040 (Hedlund) and SEJ-2007-62656 (Oyarzun), Spain, is gratefully acknowledged.
Appendices
Appendix 1: Proof of necessity in Proposition 1
We define the probability space \((\hat{\varOmega },\hat{{\mathscr {F}},}\hat{\mu })\) with \(\hat{\varOmega }=X^{2}\times \varDelta \), \(\hat{{\mathscr {F}}}=2^{X^{2}\times \varDelta }\), and the probability measure induced by \(\mu _{\tau c,\tau ^{\prime }d}\), which we call the environment. The (marginal) distribution functions \(\mu _{\tau c}\), \(\mu _{\tau 'd}\) and \(\mu _{\tau \tau 'd}\) are derived from \(\mu _{\tau c,\tau ^{\prime }d}\) in the usual way. Thus, the payoff distribution of a type \(\tau \) individual who chooses c is \(\mu _{\tau c}\) and the probability of the event \(\{x\in D\}\), with \(D\subseteq X\), is denoted by \(\mu _{\tau c}(D)\); and if D is a singleton \(\{x\}\), with \(x\in X\), then its probability is denoted by \(\mu _{\tau c}(x)\). The analogous notation conventions apply to the distributions of the comparison signal and the payoff distribution of a type \(\tau '\) individual who chooses d. Necessity in Proposition 1 is argued using the following lemmata.
Lemma 5
Suppose L is payoff-ordering. Then, \(\pi _{\tau d}=\pi _{\tau c}\) implies \(L_{cd}(\tau ,\tau ^{\prime })=\frac{1}{2}\) for all different actions c, d and types \(\tau ,\tau '\in T\).
Proof
Consider the environment induced by \(\mu _{\tau c,\tau ^{\prime }d}\) such that \(\pi _{\tau d}=\pi _{\tau c}\) and assume \(L_{cd}(\tau ,\tau ^{\prime })<\frac{1}{2}\) (the argument for the case \(L_{cd}(\tau ,\tau ^{\prime })>\frac{1}{2}\) is analogous). We will now consider a different environment induced by a slightly different probability mass, \(\widetilde{\mu }_{\tau c,\tau ^{\prime }d}\). Suppose that payoffs and comparison signals, in both environments, are independent. The modified version of \(\mu _{\tau d}\), denoted by \(\widetilde{\mu }_{\tau d}\), is such that for any set \(I\subset X{\setminus }\{1\}\) we have \(\widetilde{\mu }_{\tau d}(I)=(1-\varepsilon )\mu _{\tau d}(I)\) and \(\widetilde{\mu }_{\tau d}(1)=\mu _{\tau d}(1)+\varepsilon \mu _{\tau d}(X{\setminus }\{1\})\) for some \(\varepsilon \in (0,1]\). Thus, \(\widetilde{\pi }_{\tau d}=(1-\varepsilon )\pi _{\tau d}+\varepsilon \). The modified version of \(\mu _{\tau c}\), denoted by \(\widetilde{\mu }_{\tau c}\), is such that for any \(I\subset X{\setminus }\{0\}\) we have \(\widetilde{\mu }_{\tau c}(I)=(1-\varepsilon )\mu _{\tau c}(I)\) and \(\widetilde{\mu }_{\tau c}(0)=\mu _{\tau c}(0)+\varepsilon \mu _{\tau c}(X{\setminus }\{0\})\). Thus, \(\widetilde{\pi }_{\tau c}=(1-\varepsilon )\pi _{\tau c}\). The modified expected value of the comparison signal of a type \(\tau \) individual who observes a type \(\tau '\) individual choosing d, denoted by \(\widetilde{\pi }_{\tau \tau ^{\prime }d}\), is
where \(\pi _{\tau \tau ^{\prime }d}\) is the expected value of the comparison signal in the initial environment. Suppose that the distribution of this comparison signal in the modified environment is given by a compounded distribution which weights with probabilities \(1-\varepsilon \) and \(\varepsilon \) the distribution of the comparison signal in the initial environment and a degenerate distribution which assigns all the probability to \(1-\pi _{\tau ^{\prime }d}\), respectively. In all the other respects, the modified and initial environments are the same. Let \(\widetilde{L}_{cd}(\tau ,\tau ^{\prime })\) denote the expected value of the probability of switching to d when \(i\in \tau \) chooses c, observes \(j\in \tau ^{\prime }\) who chooses d and the comparison signal, in the modified environment. Then, \(\widetilde{L}_{cd}(\tau ,\tau ^{\prime })\) can be written as a continuous function of \(\varepsilon \) over the domain [0, 1] and when \(\varepsilon =0\), \(\widetilde{L}_{cd}(\tau ,\tau ^{\prime })=L_{cd}(\tau ,\tau ^{\prime })<\frac{1}{2}\). In order to see this, notice that
where the right-hand side is a polynomial function of \(\varepsilon \). Thus, for small enough \(\varepsilon \), \(\widetilde{L}_{cd}(\tau ,\tau ^{\prime })<\frac{1}{2}\) and, since \(\widetilde{\pi }_{\tau d}>\widetilde{\pi }_{\tau c}\), L is not payoff-ordering. \(\square \)
Corollary 2
If L is payoff-ordering, \(x,y\in [0,1]\), \(\delta \in [-1,1]\), and \(x=y+\delta \), then \(L(x,y,\delta )=\frac{1}{2}\).
Proof
Consider \(x,y,\delta \) which satisfy the hypothesis and an environment in which \(\mu _{\tau c}(x)=\mu _{\tau d}(y+\delta )=\mu _{\tau ^{\prime }d}(y)=\mu _{\tau \tau ^{\prime }d}(\delta )=1\).Footnote 34 In this environment, \(L_{cd}(\tau ,\tau ^{\prime })=L(x,y,\delta )\), and thus, Lemma 5 implies \(L(x,y,\delta )=\frac{1}{2}\). \(\square \)
Lemma 6
If L is payoff-ordering, then \(L(x,y,\delta )\) is an affine transformation of \(y+\delta -x\) for all \(x,y\in [0,1]\) and \(\delta \in [-1,1]\).
Proof
Consider arbitrary \(x,y\in [0,1]\) and \(\delta \in [-1,1]\). Consider an environment such that, with probability \(\frac{1}{2}\), a first event occurs in which the payoff received by type \(\tau \) when she chooses c is x, the payoff received by type \(\tau ^{\prime }\) individual when she chooses d is y, and the comparison signal observed by a type \(\tau \) individual when she observes the type \(\tau ^{\prime }\) individual is \(\delta \). Otherwise, a second event occurs in which the payoff received by a type \(\tau \) individual when she chooses c is y, the payoff received by a type \(\tau ^{\prime }\) individual when she chooses d is x, and the comparison signal observed by a type \(\tau \) individual when she observes a type \(\tau ^{\prime }\) individual is \(-\delta \). It follows that \(\pi _{\tau c}=\pi _{\tau d}=\frac{x+y}{2}\). If L is payoff ordering, then \(L_{cd}(\tau ,\tau ^{\prime })=\frac{1}{2}\), i.e.,
Now, consider a second environment that differs from the previous one only in that the first event is replaced by two events that occur with probability \(\frac{1}{2}\frac{y+\delta -x+2}{4}\) and \(\frac{1}{2}\left( 1-\frac{y+\delta -x+2}{4}\right) \), respectively. In the first of these events, the payoff received by a type \(\tau \) individual when she chooses c is 0, the payoff received by a type \(\tau ^{\prime }\) individual when she chooses d is 1, and the comparison signal observed by a type \(\tau \) individual when she observes a type \(\tau ^{\prime }\) individual is 1. In the second of these events, the payoff received by a type \(\tau \) individual when she chooses c is 1, the payoff received by a type \(\tau ^{\prime }\) individual when she chooses d is 0, and the comparison signal observed by a type \(\tau \) individual when she observes a type \(\tau ^{\prime }\) individual is \(-1\). As in the previous environment, \(\pi _{\tau c}=\pi _{\tau d}\) and, if L is payoff-ordering, then \(L_{cd}(\tau ,\tau ^{\prime })=\frac{1}{2}\), i.e.,
Subtracting (11) from (12), we obtain
It follows that L is a linear function of \(y+\delta -x\), and thus, from Corollary 2, L must satisfy \(L(x,y,\delta )=\frac{1}{2}+\beta (y+\delta -x)\) for some real number \(\beta \).
Finally, consider \(x,y\in [0,1]\) and \(\delta \in [-1,1]\) such that \(y+\delta >x\) and the environment F such that \(\mu _{\tau c}(x)=\mu _{\tau d}(y+\delta )=\mu _{\tau ^{\prime }d}(y)=\mu _{\tau \tau ^{\prime }d}(\delta )=1\). Since \(L_{cd}(\tau ,\tau ^{\prime })=L(x,y,\delta )=\frac{1}{2}+\beta (y+\delta -x)\), payoff-ordering implies that \(\beta >0\). \(\square \)
To close the proof of Proposition 1, since the range of L is [0, 1], \(x,y\in [0,1]\), and \(\delta \in [-1,1]\), we also need \(\beta \le \frac{1}{4}\).
Appendix 2: Formal derivation of the dynamic system
Probability space The populations is modeled as an index probability space \((W,{\mathscr {W}},\lambda )\) where W is the continuum of individuals, \({\mathscr {W}}\) is a \(\sigma -\)algebra of subsets of W, and \(\lambda \) is a super-atomless measure; in particular, \(\lambda (A)=\alpha \) and \(\lambda (B)=1-\alpha \).Footnote 35 Time is indexed by \(t\in {\mathbb {R}}^{+}\) with the Borel \(\sigma -\)algebra denoted by \({\mathscr {B}}\). The probability space that we use to model the random aspects of the imitation process is \((\varOmega ,{\mathscr {F}},P)\).Footnote 36
Dynamical system Our analysis is concerned with the fraction of type A individuals choosing a, \(p(\omega ,t)\), and the fraction of type B individuals choosing b, \(q(\omega ,t)\) for all \(\omega \in \varOmega \) and \(t\in {\mathbb {R}}^{+}\). In order to analyze the paths \(\left( p(\omega ,t),q(\omega ,t)\right) _{t\in {\mathbb {R}}^{+}}\), we define the state function \(\rho :W\times \varOmega \times {\mathbb {R}}^{+}\rightarrow \varSigma \) where \(\rho (i,\omega ,t)\) is the state of individual i in the state of the world \(\omega \), at time t. We also define the sampling function \(\pi :W\times \varOmega \times {\mathbb {R}}^{+}\rightarrow W\cup \{J\}\) specifying the individual \(\pi (i,\omega ,t)\) that the individual i samples at time t in the state of the world \(\omega \), where \(\pi (i,\omega ,t)=J\) means that individual i does not sample any other individual at time t in the state of the world \(\omega \). We assume that \(\pi (i,\omega ,t)\ne J\) implies \(\pi (\pi (i,\omega ,t),\omega ,t)=i\); that is, individuals sample each other.
The fraction of individuals whose state is \(\sigma \) at time t in the state of the world \(\omega \), denoted by \(p_{\sigma }(\omega ,t)\), is given by \(p_{\sigma }(\omega ,t)=\lambda \left( \left\{ i\in W:\rho (i,\omega ,t)=\sigma \right\} \right) \) for all \(\sigma \in \varSigma \), \(\omega \in \varOmega \), and \(t\in {\mathbb {R}}^{+}\). Therefore, we have the following version of Eq. (2), that express directly the state-of-the-world dependence of the fractions of individuals making optimal choices:
Differential equations of the system We now provide the differential equations governing the fractions of the populations making their optimal choices within each type.
Proposition 4
Fix the initial fractions of the populations in each individual state at \(\left( p_{\sigma }(0)\right) _{\sigma \in \varSigma }\in \hat{\varDelta }(\varSigma )\). There exists a Fubini Extension \((W\times \varOmega ,{\mathscr {W}}\boxtimes {\mathscr {F}},\lambda \boxtimes P)\) Footnote 37 in which the state and sampling function \((\rho ,\pi )\) are defined, such that: (i) \((p(\omega ,t),q(\omega ,t))\) is deterministic almost surely; and (ii) for \(P-\)almost all \(\omega \in \varOmega \), \((p(\omega ,\cdot ),q(\omega ,\cdot )):{\mathbb {R}}^{+}\rightarrow [0,1]^{2}\) is the solution of the system of differential equations
with initial conditionFootnote 38
Before providing the proof of Proposition 4, we need to introduce the following definition, which is adapted from Duffie et al. (2016).
Definition 2
Consider a pair of a state and a sampling function \((\rho ,\pi )\) defined on a Fubini Extension \((W\times \varOmega ,{\mathscr {W}}\boxtimes {\mathscr {F}},\lambda \boxtimes P)\), \(\left( p_{\sigma }(0)\right) _{\sigma \in \varSigma }\in \hat{\varDelta }(\varSigma )\), and \(\left( \left( \varsigma _{\sigma \sigma '}(\sigma '')\right) _{\sigma ''\in \varSigma }\right) _{(\sigma ,\sigma ')\in \varSigma ^{2}}\) with \(\left( \varsigma _{\sigma \sigma '}(\sigma '')\right) _{\sigma ''\in \varSigma }\in \varDelta (\varSigma )\) for all \((\sigma ,\sigma ')\in \varSigma ^{2}\). The pair \((\rho ,\pi )\) is said to be a continuous time dynamical system with independent random sampling and independent random state-changing with parameters Footnote 39 \(\left( p_{\sigma }(0)\right) _{\sigma \in \varSigma }\) and \(\left( \left( \varsigma _{\sigma \sigma '}(\sigma '')\right) _{\sigma ''\in \varSigma }\right) _{(\sigma ,\sigma ')\in \varSigma ^{2}}\) (denoted by DS) if: (i) \(\left( p_{\sigma }(\omega ,t)\right) _{\sigma \in \varSigma }\) is deterministic almost surely with given initial conditions \(\left( p_{\sigma }(\omega ,0)\right) _{\sigma \in \varSigma }=\left( p_{\sigma }(0)\right) _{\sigma \in \varSigma }\); (ii) for \(\lambda -\)almost every \(i\in W\), \(\rho (i,\cdot ,\cdot )\) is a continuous time Markov chain in \(\varSigma \) with transition intensity
for all two different states \(\sigma \) and \(\sigma ''\) in \(\varSigma \), and \(R_{\sigma \sigma }(\omega ,t)=-\sum _{\sigma '\in \varSigma {\setminus }\{\sigma \}}R_{\sigma \sigma '}(\omega ,t)\) for all \(\sigma \in \varSigma \), \(\omega \in \varOmega \), and \(t\in {\mathbb {R}}^{+}\); (iii) \(\rho (i,\omega ,t)\) is \(\left( {\mathscr {W}}\boxtimes {\mathscr {F}}\right) \otimes {\mathscr {B}}-\)measurable; and (iv) for \(\lambda -\)almost all \(i\in W\), \(\rho (i,\cdot ,t)\) and \(\rho (j,\cdot ,t)\) are independent for \(\lambda -\)almost all \(j\in W\).
Now, we are ready to provide the proof of Proposition 4.
Proof
From Corollary 2 in Duffie et al. (2016), there exists a Fubini Extension \((W\times \varOmega ,{\mathscr {W}}\boxtimes {\mathscr {F}},\lambda \boxtimes P)\) such that the pair of state and sampling function \((\rho ,\pi )\), defined on \((W\times \varOmega ,{\mathscr {W}}\boxtimes {\mathscr {F}},\lambda \boxtimes P)\), is a DS with parameters \(\left( p_{\sigma }(0)\right) _{\sigma \in \varSigma }\in \hat{\varDelta }(\varSigma )\) and \(\left( \left( \varsigma _{\sigma \sigma '}(\sigma '')\right) _{\sigma ''\in \varSigma }\right) _{(\sigma ,\sigma ')\in \varSigma ^{2}}\) with \(\left( \varsigma _{\sigma \sigma '}(\sigma '')\right) _{\sigma ''\in \varSigma }\in \varDelta (\varSigma )\) for all \((\sigma ,\sigma ')\in \varSigma ^{2}\).Footnote 40 From their Corollary 1, for \(P-\)almost all \(\omega \), \(\left( p_{\sigma }(\omega ,t)\right) _{\sigma \in \varSigma }\) is the solution of the system of differential equations
for all \(\sigma \in \varSigma \), with \(\left( p_{\sigma }(\omega ,0)\right) _{\sigma \in \varSigma }=\left( p_{\sigma }(0)\right) _{\sigma \in \varSigma }\). Therefore,Footnote 41
If \(\tau =A\) and \(\tau ''=B\), then \(\varsigma _{\sigma ''\sigma '}(\sigma )=\varsigma _{\sigma \sigma '}(\sigma '')=0\) for all \(\sigma '\in \varSigma \). Therefore, in both the minuend and subtrahend, the second summation is over \(\{\sigma ''\in \varSigma :\tau ''=A\}\); thus,
where the second equality is obtained canceling the terms appearing in the minuend and subtrahend out. Next, since \(c=a\) and \(c''=b\) we have \(\varsigma _{\sigma ''\sigma '}(\sigma )=0\) whenever \(c'=b\) and \(\varsigma _{\sigma \sigma '}(\sigma '')=0\) whenever \(c'=a\). Therefore, in the minuend, the third summation is over \(\{\sigma '\in \varSigma :c'=a\}\), and in the subtrahend, the third summation is over \(\{\sigma '\in \varSigma :c'=b\}\). Thus,
The minuend in the right-hand-side of (19), denoted by M, may be written as
where we have used the definition of \(\left( \left( \varsigma _{\sigma \sigma '}(\sigma '')\right) _{\sigma ''\in \varSigma }\right) _{(\sigma ,\sigma ')\in \varSigma ^{2}}\) in (1) and the fact that
Therefore,
where the second equality follows from the fact that
-
1.
\(\sum _{\sigma \in \varSigma :\tau =A,c=a,x=x_{0}}p_{\sigma }=\alpha p\mu _{Aa}(x_{0})\),
-
2.
\(\sum _{\sigma \in \varSigma :\tau =A,c=b,x=x_{0},\delta _{A}=\delta }p_{\sigma }=\alpha (1-p)\mu _{Ab}(x_{0})\mu _{AAa}(\delta )\),
-
3.
\(\sum _{\sigma \in \varSigma :\tau =B,c=a,x=x_{0}}p_{\sigma }=(1-\alpha )(1-q)\mu _{Ba}(x_{0})\), and
-
4.
\(\sum _{\sigma \in \varSigma :\tau =A,c=b,x=x_{0},\delta _{B}=\delta }p_{\sigma }=\alpha (1-p)\mu _{Ab}(x_{0})\mu _{ABa}(\delta )\),
for all \(x_{0}\in X\) and \(\delta \in \varDelta \).Footnote 42
Similarly, the subtrahend in (19) can be written as
thus,
The analogous argument yields (15). \(\square \)
Appendix 3: Proof of Theorem 1
Proof
First, we establish asymptotic stability. Define the Jacobian matrix of \((\dot{p},\dot{q})\)
where \(\dot{p}_{i}(p,q)\) and \(\dot{q}_{i}(p,q)\) denote the corresponding partial derivatives of \(\dot{p}(p,q)\) and \(\dot{q}(p,q)\) with respect to their \(i^{th}\) arguments, i.e., with respect to p or q. A rest point \((p^{*},q^{*})\) is asymptotically stable if the real part of the eigenvalues of \(J(p^{*},q^{*})\) are negative (see, e.g., Sydsaeter et al. 2008, Theorems 6.8.1 and 7.5.1). This is equivalent to \(Det(J(p^{*},q^{*}))>0\) and \(Tr(J(p^{*},q^{*}))<0\), where \(Det(J(p^{*},q^{*}))\) and \(Tr(J(p^{*},q^{*}))\) are the determinant and trace of \(J(p^{*},q^{*})\), respectively. Consider first (1, 0). We have \(Tr(J(1,0))=2D-(1+U)-\alpha (U+D-1)<0\). Next, \(Det(J(1,0))=U(1-2D)+\alpha (U+D-1)>0\) is equivalent to \(\alpha >\frac{U(1-2D)}{U+D-1}=\overline{\alpha }\). An analogous calculation holds for \(\,(0,1)\). Now, consider \((\hat{p},\hat{q})\). Note that
Next,
if \(\alpha >\frac{(1-U)(2D-1)}{(U+D-1)}=\underline{\alpha }\) and \(\alpha <\frac{U(2D-1)}{(U+D-1)}=\overline{\alpha }\).
In order to prove that the asymptotically stable points are global attractors, notice that \(\dot{p}_{2},\dot{q}_{1}<0\), hence \(\lim _{t\rightarrow \infty }(p(t),q(t))\in RP\) for all paths (see, e.g., Theorem 3.4.1 in Hofbauer and Sigmund 1998). It is easy to verify that all \((p,q)\in RP{\setminus }\{(p^{*},q^{*})\}\) are saddle-path stable with no stable arm in \([0,1]^{2}\). Hence, the system always converges to the asymptotically stable point. \(\square \)
Appendix 4: Proofs Section 4
1.1 Dynamical systems with biased sampling
In this subsection, we briefly sketch how to derive (9)–(10). The general version of Eq. (16), when we allow for general intensities, is
and the corresponding version of Eq. (17) isFootnote 43
Then, (20) and analogous derivations to those following Eq. (17) in “Appendix 2” yield (9)–(10).
1.2 Proofs of stable equilibria
First, we provide the proof of Lemma 2.
Proof of Lemma 2
(i) We use the determinant and trace of the Jacobian matrix of the system (3)–(4). Recall that (p, q) is asymptotically stable if and only if \(Det(J(p,q))>0\) and \(Tr(J(p,q))<0\). Now, \(Det(J(1,0))=U-D+\alpha _{B}D(1-2U)+\alpha _{A}(2D-1)(1-U))>0\) if and only if \(\alpha _{A}>\overline{\alpha }_{A}(\alpha _{B})\). \(\overline{\alpha }_{A}(\alpha _{B})\ge 1\) for all \(\alpha _{B}\ge \frac{1-D}{D}\), so if \(\alpha _{A}>\overline{\alpha }_{A}(\alpha _{B})\), then \(\alpha _{B}<\frac{1-D}{D}\). Finally, if \(\alpha _{B}<\frac{1-D}{D}\), then \(Tr(J(1,0))=\alpha _{A}-1-U(1+\alpha _{A})+D(1+\alpha _{B})<0\). (ii) is established analogously. (iii) follows from (i) and (ii) and the fact that \(\overline{\alpha }_{A}(\alpha _{B})>\left[ \overline{\alpha }_{B}^{-1}\right] (\alpha _{B})\) for all \(\alpha _{B}\in (0,1)\). \(\square \)
Proof of Corollary 1
Part (i) follows by observing that \(\overline{\alpha }_{A}(\alpha _{B})>1\) for all \(\alpha _{B}>\frac{1-D}{D}\), and if \(U>D\), then \(\overline{\alpha }_{A}(\alpha _{B})<0\) for all \(\alpha _{B}<\frac{U-D}{D(2U-1)}\). An analogous argument proves (ii). \(\square \)
Proof of Proposition 2
Since \(\dot{p}_{2}(p,q),\dot{q}_{1}(p,q)<0\) the system always converges to a rest point as \(t\rightarrow \infty \) (see, e.g., Theorem 3.4.1 in Hofbauer and Sigmund 1998). If \(\alpha _{A}>\overline{\alpha }_{A}(\alpha _{B})\), then, by Lemma 3, \(RP=\{(1,0),(0,1)\}\). By Lemma 2, (0, 1) is not asymptotically stable. Furthermore, (0, 1) has no stable arm in \([0,1]^{2}\). Hence, the system converges to (1, 0). Analogously if \(\alpha _{A}<\left[ \overline{\alpha }_{B}^{-1}\right] (\alpha _{B})\), then the system converges to (0, 1). If \(\left[ \overline{\alpha }_{B}^{-1}\right] (\alpha _{B})<\alpha _{A}<\overline{\alpha }_{A}(\alpha _{B})\), then by Lemma 3, \(RP=\{(1,0),(0,1),(\widetilde{p},\widetilde{q})\}\), for some \((\widetilde{p},\widetilde{q})\in (0,1)^{2}\). By Lemma 2, (1, 0) and (0, 1) are not asymptotically stable and, furthermore, have no stable arm in \([0,1]^{2}\). Hence, the system converges to \((\widetilde{p},\widetilde{q})\). \(\square \)
Appendix 5: Proofs of Section 5
Proof of Proposition 3
Since \(G(r)=0\) for all \(r\ge \varphi \) and G is continuous on \([0,\varphi ]\), it attains its maximum somewhere in this interval. Both Q and G are twice continuously differentiable on \((\underline{r}(\varphi ,\alpha ),\overline{r}(\varphi ,\alpha ))\). Let \(G^{\prime }(x^{+})\) and \(G^{\prime }(x^{-})\) (corresp. \(Q^{\prime }(x^{+})\) and \(Q^{\prime }(x^{-})\)) denote the right and left derivatives, respectively, of G (corresp. Q) for all \(x\in (\underline{r}(\varphi ,\alpha ),\overline{r}(\varphi ,\alpha ))\).
Suppose \(k\ge \overline{r}(\varphi ,\alpha )\). Then, \(G(r)<0\) for all \(r\in [0,\overline{r}(\varphi ,\alpha ))\) and \(G(r)=0\) for all \(r\ge \overline{r}(\varphi ,\alpha )\). Hence, in this case, the monopolist withdraws from the market.
Suppose \(k<\overline{r}(\varphi ,\alpha )\). Then,
Hence, in this case \(r^{*}<\overline{r}(\varphi ,\alpha )\). From Lemma 4, \(G^{\prime }(\underline{r}(\varphi ,\alpha )^{+})>0\) if \(k>\hat{k}\). Hence, if \(k>\hat{k}\), then \(r^{*}>\underline{r}(\varphi ,\alpha )\). This proves that \(r^{*}\in (\underline{r}(\varphi ,\alpha ),\overline{r}(\varphi ,\alpha ))\) if \(k\in (\hat{k},\overline{r}(\varphi ,\alpha ))\). In order to see that in this case, \(r^{*}\) is the unique solution to \(G^{\prime }(r)=0\), first note that \(G(r)<0\) for \(r<k\), and hence, \(r^{*}\ge k\). Next, for any k, r such that \(0\le k\le r\in (\underline{r}(\varphi ,\alpha ),\overline{r}(\varphi ,\alpha ))\), we have that
If \(Q^{\prime \prime }(r)\le 0\), this is obvious. Note that if \(k=0\) then
for \(r<\varphi \). Thus, if \(Q^{\prime \prime }(r)\ge 0\) then \(G^{\prime \prime }(r)=2Q^{\prime }(r)+(r-k)Q^{\prime \prime }(r)\le 2Q^{\prime }(r)+rQ^{\prime \prime }(r)<0\). G is therefore strictly concave on \((k,\overline{r}(\varphi ,\alpha ))\) which together with \(G^{\prime }(k)>0\) implies that \(r^{*}\) is the unique solution to \(G^{\prime }(r)=0\).
Suppose \(k\le \hat{k}\). Then, from Lemma 4, \(G^{\prime }(\underline{r}(\varphi ,\alpha )^{+})<0\) and G is strictly concave on \((\underline{r}(\varphi ,\alpha ),\overline{r}(\varphi ,\alpha ))\) given \(k\le \hat{k}<\underline{r}(\varphi ,\alpha )\). Since \(G^{\prime }(\underline{r}(\varphi ,\alpha )^{+})<0\), we have \(G^{\prime }(r)<0\) for all \(r\in (\underline{r}(\varphi ,\alpha ),\overline{r}(\varphi ,\alpha ))\). Finally, since G is increasing on \([0,\underline{r}(\varphi ,\alpha ))\), we obtain \(r^{*}=\underline{r}(\varphi ,\alpha )\). \(\square \)
Rights and permissions
About this article

Cite this article
Hedlund, J., Oyarzun, C. Imitation in heterogeneous populations. Econ Theory 65, 937–973 (2018). https://doi.org/10.1007/s00199-017-1044-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00199-017-1044-1