
Abstract
Due to the advent of powerful solvers, today linear programming has seen many applications in production and routing. In this publication, we present mixed-integer linear programming as applied to scheduling geodetic very-long-baseline interferometry (VLBI) observations. The approach uses combinatorial optimization and formulates the scheduling task as a mixed-integer linear program. Within this new method, the schedule is considered as an entity containing all possible observations of an observing session at the same time, leading to a global optimum. In our example, the optimum is found by maximizing the sky coverage score. The sky coverage score is computed by a hierarchical partitioning of the local sky above each telescope into a number of cells. Each cell including at least one observation adds a certain gain to the score. The method is computationally expensive and this publication may be ahead of its time for large networks and large numbers of VLBI observations. However, considering that developments of solvers for combinatorial optimization are progressing rapidly and that computers increase in performance, the usefulness of this approach may come up again in some distant future. Nevertheless, readers may be prompted to look into these optimization methods already today seeing that they are available also in the geodetic literature. The validity of the concept and the applicability of the logic are demonstrated by evaluating test schedules for five 1-h, single-baseline Intensive VLBI sessions. Compared to schedules that were produced with the scheduling software sked, the number of observations per session is increased on average by three observations and the simulated precision of UT1-UTC is improved in four out of five cases (\({6}~\upmu \text {s}\) average improvement in quadrature). Moreover, a simplified and thus much faster version of the mixed-integer linear program has been developed for modern VLBI Global Observing System telescopes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction and motivation
Through immense progress in the development of the respective solvers, today mixed-integer linear programming (MILP) has many applications in production and planning. In this publication, we demonstrate its applicability to the scheduling process of very-long-baseline interferometry (VLBI, Sovers et al. 1998) which has many similarities to routing but also complications beyond.
VLBI is a space geodetic technique used for the maintenance of the International Terrestrial Reference Frame (ITRF, Altamimi et al. 2016) and the International Celestial Reference Frame (ICRF, Fey et al. 2015). Both reference frames are essential for the determination of geophysical phenomena such as sea-level rise or plate tectonic movements, as well as for precise navigation on Earth and in space.
Furthermore, VLBI is the only technique able to determine without hypothesis all transformation parameters between the ICRF and the ITRF, i.e., the Earth orientation parameters (EOPs). VLBI is especially important for the determination of the Earth’s phase of rotation UT1 (Universal Time) which is commonly parameterized as the difference UT1-UTC with respect to Universal Time Coordinated (UTC) derived by atomic clocks (Lambeck 1980). To guarantee the availability of UT1-UTC results every day, the network sessions of 24-h duration carried out by the International VLBI Service for Geodesy and Astrometry (IVS, Nothnagel et al. 2017) are complemented by daily 1-h-long, so-called Intensive sessions (Nothnagel and Schnell 2008) that have the only purpose to determine UT1-UTC.
VLBI measurements need an active scheduling of the observations because it has to be guaranteed that two or more radio telescopes located on the Earth always simultaneously observe the same compact extragalactic radio sources, such as quasars, to form a radio interferometer. The radio telescopes are usually located as far apart as several thousand kilometers. Thus, the visible sky above each radio telescope is different, and only a subset of common radio sources can be observed by two or more telescopes at any time. VLBI scheduling is a combinatorial optimization problem determining which radio telescopes should observe which source at what time and for how long in order to achieve an optimal geometric stability and precision of the final data adjustment.
Existing scheduling approaches are all heuristic and sequential, lacking a view of the entire time period to be scheduled and the constantly changing optimal options which might be excluded because of previous decisions. In this paper, we present a new approach for a VLBI scheduling program which finds the schedule with the optimal sky coverage considering the geometries at the whole time period as a single decision entity using mixed-integer linear programming, i.e., we formalize the optimization problem as a linear objective function with a set of linear inequality constraints over a set of variables. In contrast to pure linear programming (LP), which requires that each variable receives a real number, in mixed-integer linear programming (MILP) we can require that a pre-defined set of variables receives integer values. This additional degree of freedom provides us with the possibility of formulating binary decisions problems, such as the selection of observations. On the other hand, this additional strength makes it NP-hardFootnote 1 to find a solution for a mixed-integer linear programming formulation, while for linear programming this is possible in polynomial time. Despite this computational hardness, highly specialized solvers (e.g., CPLEX (2015) and Gurobi Optimization (2019)) can be used for solving real-world instances of mixed-integer linear programming in adequate time (Bixby and Rothberg 2007). In particular, with the increasing computational power of servers and the ongoing development of the solvers, integer linear programming specifically and mathematical programming in general have become a powerful and generic tool for combinatoric optimization. One of our main contributions is the transfer of the corresponding scheduling problem with its manifold geometric and technical constraints into a mixed-integer programming formulation. We describe the general setup of this scheduling algorithm emphasizing the logic behind it. To that end, we focus on the test case of single-baseline sessions of only 1-hour duration for the determination of UT1-UTC (so-called Intensives). However, the basic concepts can be transferred to more general problem settings.
All existing and frequently used scheduling strategies have in common that they take a sequential approach. This means that the observations are scheduled chronologically and that a new observation is planned based on the already existing ones. The most commonly used software for producing geodetic schedules is currently the sked package (Gipson 2016) which has its origin in the early 1980s and which started off requiring that each scan was selected manually. In the following years, an automatic selection process was added featuring a rough sky coverage optimization option. The selection criterion was how well the observations were distributed on the local sky above each station. This is due to that a good local sky coverage is important for the determination of the delay caused by the wet part of the troposphere.
Later, Steufmehl (1994) extended sked with a dynamic method based on covariance analysis in analogy to the optimization of geodetic networks. New observations are chosen such that the average variance of the estimated parameters is minimized. In the approach of Sun et al. (2014), the observations are chosen so that each source in the list of candidate radio sources is observed in a well-balanced manner, optimizing the sampling of the complete celestial sphere. For short-duration, single-baseline sessions employing twin telescopes, Leek et al. (2015) developed a criterion based on impact factors. The impact factors depend on the Jacobian matrix and the covariance matrix of the observations and are used to find the most influential observations.
Mathematical programming formulations have been used for scheduling problems before (Williams 2013), for example, for the job shop scheduling problem (Błażewicz et al. 1996), in which the sequence of jobs on machines has to be determined. Furthermore, there are models for most forms of transportation (Barnhart and Laporte 2007) such as flight and crew schedules for airplanes (Ball et al. 2007), passenger railway transportation (Caprara et al. 2007; Fügenschuh et al. 2006) or maritime transportation (Christiansen et al. 2007). Further examples for integer linear programming (ILP) applied to scheduling problems are the scheduling of sport events (Nemhauser and Trick 1998; Durán et al. 2007) and the scheduling of physicians in the emergency room (Beaulieu et al. 2000). More related, mathematical programming has also been applied for scheduling Earth observations via satellites, e.g., Marinelli et al. (2011) and Wang et al. (2016). Moreover, several authors have presented approaches to scheduling the observations of astronomical telescopes. However, to the best of our knowledge mathematical programming has not been applied to scheduling problems in geodetic VLBI before.
Usually, heuristic methods have been proposed, such as iteratively choosing the observation that requires the telescope to slew as little as possible (Moser and van Straten 2018). Johnston and Adorf (1992) formalized the problem of scheduling the Hubble Space Telescope as a nonlinear 0-1 integer program and applied a heuristic neural network algorithm for computing solutions. Giuliano and Johnston (2008) presented a heuristic approach based on evolutionary algorithms for scheduling the James Webb Space Telescope.
Lampoudi and Saunders (2013) developed an ILP-based optimization approach for scheduling telescope networks, and Lampoudi et al. (2015) presented experimental results with the exact mathematical solver gurobi, which we also used for our work. However, while the general methodology of their work is similar to ours, the scheduling problems considered by them and by us are very different. More specifically, the method of Lampoudi et al. (2015) deals with requests of researchers for observation time, which would allow the researchers to conduct their experiments. Scheduling, in this sense, means to allocate a time slot for each request. The problem that we aim to solve, however, is to schedule every single measurement, each of which typically takes not longer than a few minutes, while considering geometric constraints that are specific for geodetic VLBI. A more detailed review of scheduling approaches in astronomy with a focus on scheduling networks of radio telescopes is provided by Buchner (2011), who notes that in typical applications it is ‘not a big deal to lose 15 min of observation,’ and thus, a rather coarse discretization of time is justifiable. This is very different in our application, however, in which a typical 24-h experiment incorporates several thousand observations.
The main challenge of scheduling geodetic VLBI experiments is that the problem is not purely combinatoric, but requires geometric constraints and objectives that are highly problem-specific. Most prominently, the solutions should maximize the geometric distributions of the observations optimizing the local sky coverage at each station. For that purpose, we present a new score that is developed based on existing approaches (Sun et al. 2014) and that is used for rating the sky coverage of the computed schedules. However, also other geometric and more technical constraints need to be taken into account. For example, due to the cables connecting the moving and non-moving part of the radio telescope, the degree of rotation is restricted. Further, the shading of each radio telescope caused by terrain, buildings and vegetation has to be considered when pointing the telescope. All these constraints make the problem of controlling the radio telescopes for geodetic VLBI to be a complex and nonstandard scheduling problem. We have tested the proposed approach on 1-h, single-baseline Intensive sessions for daily determinations of UT1-UTC. Compared to the software sked, more observations were found and the uncertainty of UT1-UTC was decreased in four out of the five sessions that we investigated.
The paper is structured as follows. In Sect. 2, we first present the VLBI scheduling problem in detail discussing all its requirements and constraints taken into account. Afterward, in Sect. 3 we introduce a newly developed formal definition of the score used for rating the sky coverage. For the convenience of readers who are not familiar with mathematical programming, we give a short and general introduction to this technique in Sect. 4. In Sect. 5, we then present a mathematical formalization of the scheduling problem, which we then use in Sect. 6 to give a basic mathematical programming formulation. This formulation comprises all constraints that are necessary to obtain a feasible scheduling and may be also used as starting point for future work for related problems. However, this formulation is not sufficient to be deployed in practice for the considered problem setting. Further extensions that can be plugged in to model technical details such as the cable wrap of the radio telescope are given in Appendix B. In Sect. 7, we introduce simplifications to our model that can be applied to modern VLBI Global Observing System (VGOS) telescopes. In Sect. 8, we then evaluate the approach by investigating the standard deviations of the estimated parameters, the sky coverage and the number of observations. Finally, in Sect. 9 we conclude the paper and give a short outlook on future work.

Sky plots with source transits on January 4, 2018, 18:30–19:30 UT. The blue transits are visible from both stations. The gray transits are only visible at the corresponding station. On the northern hemisphere, the sources are moving clockwise around the pole of the Earth rotation axis, which is marked with a black dot. The thick black lines are the station-specific horizon masks, and the orange line represents the transit of the Sun
2 Problem setting
In this section, we shortly describe the overall problem setting, emphasizing the technical challenges to be solved when creating a schedule for radio telescopes in the context of geodetic VLBI. We first note that the radio telescopes used for VLBI are directional antennas that need active control, i.e., their movements have to be scheduled. The scheduling process of VLBI sessions determines which radio telescopes observe which source at what time and for how long. It aims at finding the best possible observation sequence with respect to a specific criterion, such as the sky coverage or the variance of the target parameters. In this paper, we present an approach that optimizes a newly developed score for the local sky coverage (Sect. 3). A good sky coverage is the key to more accurate estimates of the target parameters, because it is representing the geometric configuration and the quality of the sampling of the troposphere.
In this paper, we focus on Intensive sessions for VLBI which means that each session takes one hour and only two telescopes are involved. In general, this implies that only sources that are visible from two stations simultaneously are possible candidates for an observation. As the radio telescopes are typically located far away from each other, the sky above each radio telescope is different and only a subset of all sources is visible from both stations at the same time.
Furthermore, the shading of each radio telescope caused by terrain, buildings and vegetation has to be taken into account when controlling the movement of the telescopes. For this purpose, the local horizon at each station is modeled with a horizon mask. The general elevation limit is set to some single-digit value depending on the type of the VLBI session. To keep our results comparable to the sked results, we fix this limit to 8\({^\circ }\). In Fig. 1, the transits of visible sources are illustrated exemplarily for one Intensive session.
The duration of an observation has to be long enough so that a specified signal-to-noise ratio (SNR) is exceeded. The latter depends on the observation time, the correlated flux density of the observed source, the combined sensitivity of each telescope and its receiver, and the total recorded bandwidth.
Another aspect is the duration required to slew the telescope from one source to another. This duration depends on the rotational speed of the telescopes. Additionally, the same source should not be observed in succession, because the same part of the sky would be observed again and no further geometric information is gathered. Thus, a specified time has to pass before the same source should be observed again.
Finally, a rather technical restriction is that the telescopes with an azimuth–elevation mount cannot rotate arbitrarily often in the same direction around their azimuth axis because of the cables connecting the movable part of the telescope with the fixed one. To prevent the cables from tearing, the telescope is restricted in its azimuthal movements, typically to one and a half turns around the axis. This means that it might be necessary to rotate the telescope in a certain direction, although the opposite direction comes with a smaller rotational angle. The mechanism routing the cable is called cable wrap. More details about geodetic VLBI scheduling are given by Nothnagel (2018) and Gipson (2016).
3 Sky coverage score
The amount of water vapor in the atmosphere, which is the driving element of refractive retardation of the signal, is unpredictable because it is highly variable in space and time (Davis et al. 1985). Thus, its impact on the delay cannot be modeled precisely enough, but has to be estimated in the data analysis process. The common parameter for all observations of a certain time period, say one hour, is the zenith wet delay (ZWD). It can best be estimated if observations with many different elevation angles contribute to the design (or Jacobian) matrix of the least squares adjustment. This is the motivation why we try to optimize the sky coverage of the observations already at the time of preparing the observing schedules.
In routine VLBI analysis, it is assumed that the atmosphere above each station is rotationally symmetric. Thus, the wet delay is estimated solely in zenith direction as a consolidating parameter employing a so-called mapping function to relate the observations at individual elevation angles to the zenith direction (Niell 1996). The tilt of the symmetry axis of the modeled atmosphere with respect to the zenith direction is often estimated in the form of gradient parameters, too (MacMillan 1995). To model the temporal variations, ZWDs are estimated with P-splines (Fahrmeir et al. 2013) using an interval length of around 15–60 min.
Apart from the ZWDs, additional parameters are estimated, such as relative station clocks and station coordinates. To distinguish between the impact of the station clocks and the ZWD, observations at all elevation angles, especially at low ones, are necessary.Footnote 2 Moreover, the partial derivatives of both the station height and the ZWD depend on the elevation in the same way (Nilsson et al. 2013). Therefore, observations with many different elevation angles de-correlate the station heights, the clocks and the ZWDs.
According to Steufmehl (1994), two limitations of the tropospheric delay modeling have to be considered. First, the mapping function does not transfer the delay from the direction of the observation into the zenith direction faultlessly. The impact of this inaccuracy can be reduced with uniformly spread observations in elevation in each P-spline interval. Furthermore, the neutral atmosphere is turbulent; that is, the atmosphere is never strictly rotationally symmetric. A good coverage of all azimuth directions reduces this effect. Thus, the systematic errors caused by the troposphere are reduced by a spatially and temporally uniform distribution of observations at each station, which is referred to as a good local sky coverage.
There is no standardized definition of the sky coverage. In many cases, the local sky is partitioned into a single set of cells of a certain geometric dimension and a count is performed of how many of these cells are covered with observations (e.g., Sun et al., 2014). A full score of the local sky coverage within a pre-defined time period (score = 1) may be given if in each cell at least one observation is located. Thus, the logic works in a way that for each cell with at least one observation \( \frac{1}{N} \) is added to the score where N is the number of cells.

In each partition, six out of thirteen cells are selected. Thus, they have the same score, although the sky coverage is clearly different in each sky plot
Unfortunately, this approach has the drawback that different observation constellations have the same score, although they should be rated differently; see Fig. 2. There are three ways in which the configuration can be altered without changing the score. First, the distribution of observations within a cell has no impact. For example, two observations in two adjacent cells that are located at the common cell border are rated exactly as two observations located in the middle of each cell. Secondly, the number of observations within a cell has no impact. Consider two distributions with the same number of observations as an example. One has two observations in each cell, and the other one has only one observation in each cell except for one containing the remaining observations. The latter distribution is clearly worse, but has the same score. Finally, the score is independent of the distribution of the cells with at least one observation. For example, three nearby occupied cells would result in the same score as three occupied cells which are far away from each other.
To avoid all these drawbacks, we propose a different scheme working with multiple levels of partitioning. We use several partitions simultaneously with an increasing number \(N_i \) of cells with \( N_i < N_{i+1}\). For each partition i, the score \(S_i\), which is the number of occupied cells \(n_i\) divided by the total number of cells \(N_i\), is computed. The total score S is then obtained by summing up the individual scores of each partition
where k is the number of partitions. To reach the highest possible score, each cell in each partition has to include at least one observation. The individual contribution of a cell belonging to the ith partition is \(\frac{1}{N_i}\). Thus, the cells of the roughest partition have the largest impact on the score. The cell’s impact of the finer partitions is getting smaller. This approach is rating the distribution of the observations on the entire sky, but also the local distribution in parts of the sky. The global distribution is rated by the roughest partition, whereas the local structures are rated by the finer partitions. To ensure that the entire sky is used, the roughest partition should not have more cells than observations. Making a rough estimate based on the permitted observation duration is satisfactory for this purpose.

The cells of each partition should be of equal surface area and similar shape to ensure equal weights. A method to achieve this is described by Beckers and Beckers (2012): A disk is divided into concentric rings, and each ring is subdivided into several cells. Given the number of cells per ring, the inner and outer radii can be computed for each ring such that each cell has the same surface area. These cells are projected with the Lambert azimuthal equal-area projection to the hemisphere. Beckers and Beckers (2012) describe how to choose the number of cells per ring to obtain a similar aspect ratio for each cell. Some examples are given in Fig. 3.
Since the atmosphere varies over time, we have to limit our ranking to specific time periods. We may call such a period the score period for which the score is computed according to Eq. 1. The duration of the score periods can be adapted to the interval length of the P-splines for the troposphere modeling to ensure a good estimation of all coefficients. It is also possible to create overlapping score periods to make the estimation more flexible. The total score for a newly generated observing schedule of full duration of the session considering the temporal and spatial sky coverage is
where u is the number of score periods.
4 Mixed-integer programming
For readers, who are not familiar with mathematical programming, we give a short introduction starting with linear programs (LPs) and integer linear programs (ILPs). Linear programming (Dantzig 1963; Papadimitriou and Steiglitz 1998; Robert 2007; Williams 2013) is a global optimization method that asks for a vector \(x \in \mathbb {R}\) minimizing the linear objective function
subject to linear inequality constraints:
In this context, n is the number of parameters, that is, the dimensionality of the problem, and m is the number of constraints. The vector \(\varvec{a}\) contains the coefficients forming the linear combination with the parameters \(\varvec{x}\). The linear coefficient linking the ith constraint with the jth parameter is denoted with \(c_{ij}\). Each of the constraints can be interpreted as a hyperplane dividing the solution space into two half spaces. The constraints are restricting the parameters to be within the so-called feasible region. In Fig. 4, this region, the constraints and the objective function are visualized with a two-dimensional example. The optimal solution is located at the intersection of two hyperplanes. This is exploited by algorithms solving linear programs (Dantzig 1963).
It is possible to restrict parameters to integer values, which leads to integer linear programs. A linear program containing integer and continuous parameters is called mixed-integer linear programming (MILP). A special case is the restriction of parameters to binary values. Binary parameters enable the modeling of logical conditions. MILPs require in general more computational resources than linear programs of the same size; in fact, solving MILP formulations is NP-hard (Garey and Johnson 1979) in general, while linear programming formulations can be solved in polynomial time (Williams 2013).
In this paper, we use an MILP for scheduling VLBI sessions. While linear programs can be solved efficiently, solvers for integer linear programs have a worst-case running time that is exponential in the problem size. On the other hand, integer linear programming has turned out to be a very versatile approach that has been successfully applied to a large range of combinatorial optimization problems.

Example of a 2D linear program. The objective function is \(x_1+x_2\) and its value is indicated by the color bar. The three inequality constraints are visualized with blue lines and the intersections with red points. The feasible region is marked with a blue pattern. The maximum is located at point B. There is no unique minimum, instead all points on the segment \(\overline{AC}\) are minimal
5 Formal model
In this section, we formalize the problem of scheduling VLBI sessions with multiple radio telescopes for integer programming. We are given a set \({Q = \{ q_1, q_2, \ldots , q_{u} \}}\) of sources that are possible candidates for observations. Further, we are given a set \({S = \{s_1, s_2, \ldots , s_v\}}\) of stations. Each station corresponds to one radio telescope located on Earth. We define our basic model such that it supports an arbitrary number of stations, while in our evaluation of the model we restrict ourselves to the special case of two radio telescopes. The sources are observed within a pre-defined session described by the time interval \(T\subseteq {\mathbb {R}}\). We assume that for each source we are given its exact trajectory, which allows us to pre-compute the times of its visibility for a given location on Earth. Hence, we can assume that for a station \(s\in S\) and a source \(q\in Q\) we are given the function \(v_{s,q}:T \rightarrow \{0,1\}\), which models the visibility of the source q from s. We say that a source q is visible from s at time \(t\in T\) if \(v_{s,q}(t)=1\) and it is not visible if \(v_{s,q}(t)=0\); for the computation of \(v_{s,q}\), we refer to Nothnagel (2018). A transit\(h_{s,q}\) of q over s is a maximally long time interval \(I\subseteq T\) such that for each point \(t\in I\) in time q is visible from s; that is, for all \(t \in I\) we have \(v_{s,q}(t)=1\). We denote the set of all transits of q over s by \(H_s\).
In order to observe a source, the telescope at a station rotates accordingly in the first step and then tracks the source in the second step. We call the first step slewing and the second step tracking. During tracking, the received signals are recorded. Both steps constitute one activity of a telescope forming a connected entity of the scheduling process. We call the point in time when the activity switches from the slewing step to the tracking step the switch time.
In our problem setting, we only consider observations of sources that are conducted by at least two stations simultaneously. Thus, we model an observation of a source q as a tuple \((a_1, a_2)\) of activities of two different stations such that two requirements are fulfilled:
- R1
both activities track the source q,
- R2
the tracking steps, being part of the respective activities, start at the same time and have the same duration.
A single observation o consists of two tracking steps being part of the respective activities. We observe that, by requirement R2, this is well defined. A schedule\(\mathcal {U}=(A,O)\) of a set Q of sources and a set S of stations consist of a set A of activities and a set \(O\subseteq A\times A\) of observations such that
- 1.
each station \(s\in {\mathcal {S}}\) executes at most one activity \(a\in A\) at the same time,
- 2.
for each observation \(o\in O\), the duration of its tracking step is longer than the minimal duration required to reach a certain SNR of o,
- 3.
for each activity A, the slewing duration is longer than the minimal duration required to rotate the telescope from the last observed source to the next one and
- 4.
only visible sources are observed.
For a given schedule \(\mathcal {U}\), we evaluate its sky coverage\(w(\mathcal {U})\), which we formalize as follows. Following the concepts of Sect. 3, we introduce k levels of granularity. For each level i, we partition the hemisphere above the station \(s\in S\) into a set \(C_i\) of cells with equal area; with increasing level, the number of cells in \(C_i\) increases. To keep the presentation easy, we consider only one score period for the entire session. It is straightforward to extend the objective function to evaluate multiple score periods. We denote the union of all those sets by \({\mathcal {C}}_s\). For each cell \(c \in {\mathcal {C}}_s\), we determine a score w(c) as described in Sect. 3. Here, w(c) corresponds to the fraction in Eq. 1. A cell \(c\in {\mathcal {C}}_s\) is occupied by an activity a of s if the observed source of the activity is located within the cell at the switch time of a. Hence, for a schedule \({\mathcal {U}}\) and a station \(s\in S\) we obtain a set \(L_s\subseteq {\mathcal {C}}_s\) of cells that are occupied by the activities of s in \({\mathcal {U}}\). We aim at finding a schedule that maximizes the sky coverage among all possible schedules, which is
Other common optimization criteria for scheduling are based on the covariance matrix of the estimated parameters, for example the trace of this matrix. However, computing the trace—or any other value based on the covariance matrix—using a linear combination of the (binary) parameters in a schedule \(\mathcal {U}\) is not possible because a matrix inversion is necessary to compute the covariance matrix. That is the reason for only using the sky coverage score.
We note that the presented formalization describes the core of our model, which can be used as starting point for further components (e.g., supporting constraints on cable wrap). In Sect. 6, we present an implementation of the formal model, and in Appendix B, we describe how to adapt this basic model such that it can be deployed in practice.
6 Optimization approach
In this section, we present the basic MILP model that we use to create a geodetic VLBI schedule. To keep the presentation simple, this model only comprises the most fundamental concepts and ideas. In Appendix B, we present further extensions that are necessary to apply the approach in practice, such as the model for the cable wrap.
Roughly speaking, we discretize the time interval T of the session into a finite set of subintervals. We chose these subintervals such that for each station each subinterval can contain at most one starting point of at most one candidate activity and such that a source leaves/enters a cell of a partition only at times that correspond to the boundaries of that subinterval. This allows us to structure the solution space by reformulating the problem as follows. We assign to each subinterval one candidate activity. The idea is that the switch time of the candidate activity lies in that interval. The task is then to select a subset of these candidate activities. This in particular means that for each selected candidate activity we also need to define its exact switch time as well as its start and end times. Further, for a selected candidate activity we need to specify the observed source (see Fig. 5). The selection is done in such a way that it maximizes the score of the sky coverage over all possible selections. We note that this is a mere reformulation of the optimization problem presented in Sect. 5, but the optimal solution is not lost by the applied discretization.

Illustration of the basic model. This simplified example involves three sources, two stations and 30 atomic intervals. Moreover, one possible schedule consisting of four observations is included. To each source, a different color is assigned. In the sky plots, the transit of the sources is shown as colored arcs. The observations are marked with red circles and enumerated chronologically. In the below timeline, the boundaries of the atomic interval are visualized with gray dotted vertical lines. There is a horizontal line for each station and each source. The time in which a source is visible from a station is highlighted by its color and an increased thickness. If the source is not visible, the corresponding horizontal line remains gray. The activities are marked on the timeline with colored rectangles. The switch times of the activities are labeled with the number of the corresponding observation and are marked with a black vertical bar which divides the rectangle. The left part of each rectangle represents the slewing phase and the right part the tracking phase. Observations are only possible if both stations can see the same source at the same time. (Corresponding horizontal lines are thick and colored.) In this illustration, only one possible schedule is shown; however, there are many possible schedules. For instance, the blue source could be observed before the orange one. To decide which sequence is the best, we use the MILP
We now formalize these ideas as MILP by starting with the discretization of the session interval T. Let \(T_{dt}\) be the set of the points in time that partition T into intervals of equal length dt, which is set to the shortest permitted scan duration. Further, for a station \(s\in S\), let \(T_s\) be the set of the points in time when a visible source leaves a cell \(c\in C_s\) and enters another cell \(c'\in C_s\). The points in time in the union of the set \(T_{dt}\) and the sets \(T_s\) (\(s\in S\)) partition the interval T into \(n\) intervals. These are the shortest and indivisible intervals which we call atomic intervals. They serve as the smallest units for the discretization of time intervals. For the deployment of the model in practice, we will simplify the atomic intervals to the set \(T_{dt}\) (see Appendix B). Further, to each atomic interval and each station, we assign a candidate activity whose tracking step starts within this interval; the actual selection of the activity is done by the MILP approach. We denote those activities of a station \(s\in S\) by \(a_s^{0}, a_s^{1} \ldots , a_s^{n-1}\) sorted in increasing chronological order and the set containing these activities by \(A_s\). Further, for an activity a, we denote its time interval by I(a).
Moreover, let \({B = \left\{ (s,s') \in S \times S \mid s \ne s' \right\} }\) be the set of all possible baselines between the given stations. We assign to each atomic interval and each baseline \(b\in B\) a possible observation whose tracking phase starts within this interval; the actual selection of the observation is done by the MILP approach. We denote those observations of a baseline \(b\in B\) by \(o_b^{0}, o_b^{1} \ldots , o_b^{n-1}\) sorted in increasing chronological order and the set containing these activities by \(O_b\).
In the following, we introduce the variables, constraints and the objective of the MILP model.
6.1 Variables

Example of time-related variables for one activity and one station. The variables in parentheses refer to the atomic interval containing the time-related variable
For each activity \(a\in A_s\), we introduce the following variables and constants.
- 1.
The binary variable \(a. \mathsf {isSelected} \in \{0,1\}\). We interpret the variable such that \(a. \mathsf {isSelected} =1\) if the activity is selected for the schedule and otherwise \(a. \mathsf {isSelected} =0\).
- 2.
For each source \(q\in Q\), the binary variable \(a. \mathsf {isTracked} (q)\in \{0,1\}\). We interpret the variable such that \(a. \mathsf {isTracked} (q)=1\) if q is observed by the station s during the tracking step of a.
- 3.
The continuous variable \(a. \mathsf {startTime} \in T\), which defines the starting time of the activity.
- 4.
The continuous variable \(a. \mathsf {switchTime} \in I(a)\), which defines the time when the activity switches from the slewing step to the tracking step.
- 5.
The continuous variable \(a. \mathsf {stopTime} \in T\), which defines the time when the activity stops.
If \(a. \mathsf {isSelected} =0\), the values of \(a. \mathsf {startTime} \), \(a. \mathsf {switchTime} \) and \(a. \mathsf {stopTime} \) do not have any meaning. The variables related to times are illustrated in Fig. 6.
For each baseline \(b \in B\) and each observation \(o\in O_b\), we introduce the binary variable \({o. \mathsf {isSelected} \in \{0,1\}}\). We interpret the variable such that \(o. \mathsf {isSelected} =1\) if the observation is selected for the schedule and otherwise \(o. \mathsf {isSelected} =0\).
Finally, for each cell \(c\in {\mathcal {C}}_s\) of each station we introduce the binary variable \(c. \mathsf {isOccupied} \in \{0,1\}\). We interpret the variable such that \(c. \mathsf {isOccupied} =1\) if the cell contains a selected activity of s.
6.2 Constraints
Next, we introduce the constraints of our basic MILP model and explain them in detail.
Constraints on a Single Activity. For each station s and for each activity \(a\in A_s\), we introduce the constraint
Constraint C1 enforces that each selected activity tracks exactly one source.
Moreover, we need to ensure that a station \(s\in S\) only tracks a source \(q\in Q\) that is visible. This particularly requires that we can formulate implications of the form
where \( condition1 \) and \( condition2 \) evaluate to zero or one expressing the truth values true and false, respectively. In order to ease the description in this section, we use that notation. In Appendix A.1, we explain in detail how such constraints can be systematically expressed in mixed-integer programming formulations. For each station \(s \in S\), each activity \(a \in A_s\) and each source \(q \in Q\), let \(h\in H_{s,q}\) be the transit that either starts in I(a), but does not end in I(a) or contains I(a). We introduce the following constraint if the transit h exists
with \(h. \mathrm {start} \) and \(h. \mathrm {end} \) being the start time and the end time of the transit h, respectively. Otherwise, if h does not exist, we introduce the following constraint that ensures that the station s does not track the source q during the activity a.
For the basic model, we assume a fixed minimal duration \(d_\mathrm {A}\) for the slewing step and a fixed minimal duration \(d_\mathrm {T}\) for the tracking step; in Appendix B, we explain how to relax this assumption. For each station s and for each activity \(a\in A_s\), we require
The duration \(d_\mathrm {A}\) and \( d_\mathrm {T}\) have to be positive; thus, Constraint C5 implies that \({a. \mathsf {startTime} < a. \mathsf {switchTime} }\) and Constraint C6 implies that \({a. \mathsf {switchTime} < a. \mathsf {stopTime} }\).
Constraints on Activities of the Same Station. We introduce a constraint that ensures that a station \(s\in S\) executes at most one activity at the same time. To that end, let \(a\in A_s\) and \(a'\in A_s\) be two activities such that the atomic interval of a precedes the atomic interval of \(a'\). We introduce
Constraints on Observations. For each baseline \(b \in B\) and each observation \(o \in O_b\), we introduce the following constraints. To that end, let a and \(a'\) be the activities of o.
Constraint C8 and Constraint C9 ensure that the corresponding activities are selected, if the observation is selected. Constraint C10 guarantees that both radio telescopes start the observation simultaneously. Further, for each source \(q \in Q\) we require:
Constraint C11 ensures that the observation is selected if both radio telescopes track the same source. To enforce that both stations track the same source, Constraint C12 is introduced.
If an activity is selected, there has to be at least one additional selected activity of another station in the same atomic interval to form a baseline for an observation. To formalize this requirement, we introduce the following constraint for each station \(s \in S \) and for each activity \(a \in A_s\):
with \(O_{s,a}\subseteq \{O_b |b \in B\}\) being the set of all observations that contain the activity a.
Constraints on Cells. Let \( Q_{c,a} \subseteq Q \) be the subset of sources that are located within the cell \(c \in {\mathcal {C}}_s\) during the activity \(a \in A_s\) at station s. For each activity \(a \in A_s\) and each cell \(c \in {\mathcal {C}}_s\) of station s, the following constraint is added.
This ensures \(c. \mathsf {isOccupied} = 0 \) if the sum is zero; that is, not a single cell contains an observation. Else \(c. \mathsf {isOccupied} \) can be one or zero.
6.3 Objective
Subject to Constraints C1–C14, we maximize
By reason of this objective, \(c. \mathsf {isOccupied} \) will always receive the highest possible value, which is 0 if c does not contain any observation due to Constraint C14 and otherwise 1. Therefore, it correctly measures the sky coverage. For a given input instance, consider the solution of the MILP formulation, which in particular assigns to each variable \(o. \mathsf {isSelected} \) with \(o\in O_b\) and to each variable \(a. \mathsf {isSelected} \) with \(a \in A_s\) the value 1 or 0. Let
and let
The tuple \((A_\mathrm {selected},O_\mathrm {selected})\) forms a valid schedule for the input instance maximizing the total sky coverage. Altogether, by construction we obtain the following theorem.
Theorem 1
The presented MILP formulation yields a valid schedule that maximizes the sky coverage.

The cable is illustrated with a spiral. In the gray highlighted area, the cable is overlapping. Depending on the source configuration, different ways to slew from one source to another are possible. In each example, the point of departure is marked with a black dot. In a, the telescope has to rotate counterclockwise, while in b it could rotate either clockwise or counterclockwise
7 Simplified model for modern VGOS telescopes
In Appendix B, we extend the basic model described in Sect. 6. In particular, Constraints C5 and C6 fixing the slewing and tracking duration to a constant value are replaced. The slewing duration is mutable and depends on the source positions, the slewing rates of the telescope and the cable wrap (see Appendix B.4). The tracking duration is determined based on the SNR (Appendix B.1). Those extensions enlarge the MILP significantly, leading to a longer runtime. Thus, we have also investigated simplifications of the MILP for modern VLBI telescopes.
The VLBI Global Observing System (VGOS) incorporates new telescopes that are smaller than the legacy telescopes and can move much faster. VGOS-compatible telescopes need only 30 s for a full rotation, while legacy telescopes need several minutes. For example, the legacy telescope at Wettzell needs 2 min for a full rotation and the legacy telescope at Kokee Park requires more than 3 min. In the following, we introduce simplifications that can be applied to VGOS telescopes by reason of their fast rotation speed. However, these simplifications limit the set of possible schedules, and only a subset of the schedules that are valid in the original model need to be examined.
We simplify the scheduling problem by introducing regular observations, i.e., all observations have the same duration and the lag between two subsequent observations is constant. Moreover, we fix the beginning of the first observation. Hence, the start time, stop time and switch time of all activities are pre-defined and are not determined by the LP, meaning we can remove the variable \( \mathsf {startTime} \), \( \mathsf {switchTime} \) and \( \mathsf {stopTime} \). Then there are only binary variables simplifying the MILP to a pure ILP.
In this setup, the slewing duration has to be fixed to the time required for a full rotation, to ensure a valid schedule. Due to the short maximal slewing duration of VGOS telescopes, we can do this without loosing too much potential observing time. This simplification should not be applied to legacy telescopes, though, because too much unnecessary time may have been reserved for the slewing of the telescopes when using a standard slewing duration. In order to specify the start times of the observation, we have to redefine the atomic intervals. Each atomic interval is exactly as long as the constant observation duration, and between two atomic intervals, there is a gap that corresponds to the slewing time. In Fig. 8, these atomic intervals are highlighted in gray. The observation durations (e.g. 30 s) match the atomic intervals, and the slewing phases match the gap between the atomic intervals. This leads to a schedule with regular observations; thus, here we automatically schedule one observation per minute. The first 30 s is reserved for the slewing of the telescopes, while the remaining 30 s is used for the tracking or rather the observation.

Illustration of atomic intervals for simplified VGOS model. The atomic intervals are highlighted in gray. The tracking phases are marked with blue solid arrows and match the atomic intervals. The slewing phases are marked with dashed red arrows and match the gaps between the atomic intervals. The activities are illustrated with black dotted arrows
As a consequence, the constraints involving the variables \( \mathsf {startTime} \), \( \mathsf {switchTime} \) or \( \mathsf {stopTime} \) can be removed from the model or have to be reformulated. To ensure that only visible sources are tracked, Constraint C4 has to be added if necessary, but Constraint C2 and Constraint C3, which constrain the switch and stop time, are not used. Moreover, Constraint C5, C6, C7 and C10 are not needed, because the start points of the observations are pre-defined.
Two of the features introduced in Appendix B, namely the consideration of the SNR (see Appendix B.1) and the constraint on subsequent observations of the same source (see Appendix B.2), are also used in the simplified model for VGOS telescopes.
To ensure that only sources are observed that reach a certain SNR within the fixed observation time, we have to apply Constraints C17 and C18, if necessary. Due to the fixed observing time, observations can have an SNR that is much higher than the specified minimal SNR.
To prevent that the same source is observed twice within a specified time, we add Constraint C20 with the variable \( \mathsf {switchTime} \) referring to the start of the corresponding atomic interval and not belonging to the parameters of the ILP.
Note that these simplifications are not reasonable, if the observation duration is significantly shorter than the maximal slewing duration. For example, if sources are observed only 10 s, three quarters of the session would be spent on the slewing and a lot of possible observation would be missed.
8 Evaluation
In this section, we evaluate the proposed MILP formulation through concrete test runs. After describing the setup (Sect. 8.1), we present the results of our evaluation (Sect. 8.2).
Apart from the following theoretical evaluation, four INT2 sessionsFootnote 3 were scheduled with a prototype of the presented MILP and were observed successfully. Thus, the presented approach is creating valid schedules. However, a bandwidth of 8 MHz was used, although current INT2 sessions already use 16 MHz. Thus, a comparison of these sessions with other recent INT2 sessions is not meaningful.
8.1 Setup for evaluation
The new scheduling approach was implemented in the Analysis Scheduling Combination Toolbox (ivg::ASCoT, Artz et al. 2016; Halsig et al. 2017) that has been developed by the VLBI Group at the University of Bonn. The MILP (Sect. 5) is solved with the Gurobi Optimizer,Footnote 4 which is freely available for academic purposes. The Gurobi Optimizer can speed up the solution of MILPs with parallel computations. Therefore, a computer with two processors with 12 cores each is used to compute the schedules. The solution of the MILP is CPU and memory-intensive: The scheduling of an Intensive session allocates about 80 GB RAM and lasts for several hours. Thus, regular 24-h IVS sessions are not considered in this section because of the limited hardware resources, and only Intensive sessions involving two stations are considered.

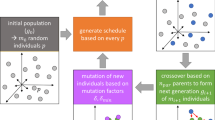
Flow diagram presenting the scheduling approach. The core of the approach is the MILP incorporating all possible schedules. It is highlighted dark gray in the diagram. In each iteration, the current value of the objective function and the upper bound of the objective function are computed. When both values coincide, the optimal solution is found
There are two stop criteria. If the solution lasts longer than a day, the optimization is stopped and the current best solution is used. The second criterion is the difference between the current lower bound of the objective function and the current value of the objective function. This difference is called gap and is given in percent. If the gap is zero, it is proved that the solution is optimal with respect to the applied objective function. If the gap is smaller than a specified value, the optimization is stopped, too. Note that a gap larger than zero does not necessarily mean that the current solution is not already optimal. The scheduling approach is summarized in Fig. 9.
Intensive sessions are usually analyzed with a least squares adjustment Koch (2013). By default, a clock offset, a clock rate and a second-order clock term are estimated for one of the two stations. Additionally, a ZWD offset for each station and UT1-UTC are estimated. We compute the covariance matrix of these parameters based on the schedules, which is possible without any observation. The stochastic model is based on the achieved SNR of each observation and does not consider correlations.
The schedules created with the MILP were compared with those created with the software sked (Gipson 2016). The criteria for the comparison were the score of the sky coverage, the number of observations and the standard deviation of UT1-UTC, which is included in the covariance matrix of the estimated parameters. For a meaningful comparison between sked and the MILP approach, the setup of both programs has to be the same. Thus, the schedules created with MILP were based on existing sked schedules. The following parameters were adopted from the sked schedules:
the involved stations including their sensitivity (system equivalent flux density) and recording setup (bandwidth, channels)
the source and flux catalogs
the minimal and maximal scan length
the minimal SNR for the X and S bands
the minimal allowed distance to the Sun
the minimal duration before a source is observed again
the horizon mask and the minimal allowed elevation
the start and end of the session
Three different setups for MILP were used. All setups used the three partitions visualized in Fig. 3 for the sky coverage score. They differed in the constraints on the number of observations and the number of score periods (see Sect. 3). The setups are labeled with ‘M’ and introduced in the following.
- M1
The number of observations was restricted to be equal to the number of observations found by sked. Only one score period was used for the computation of the sky coverage.
- M2
The number of observations was restricted to be equal to or larger than the number of observations found by sked. Again only one score period was used for the computation of sky coverage. The solution of M1 was used as start for this setup to speed up the solvers.
- M3
There were no constraints on the number of observations. Two score periods with a duration of half an hour were used for the computation of the sky coverage.
In order to evaluate the simplified model for VGOS telescopes (Sect. 7), we created two additional schedules for each session. The investigated sessions were INT1 sessions involving the baseline from Wettzell, Germany, to Kokee Park, Hawaii, USA. At both observatories, VGOS-compatible telescopes and legacy telescopes are available. We used the same time period for the schedules, but we replaced the legacy telescopes with the VGOS telescopes. According to the original/legacy schedules, we used the same SNR target (X band) and the same observation time of 40 s Footnote 5 The score periods lasted for 10 min and had a 5 min overlap. Moreover, we used a broadband setup with 32 channels (using only one polarization) with 32 MHz bandwidth each for the computation of the SNR. This is definitely lower than with two polarizations, but this is uncritical for this test. We labeled this solutions with ‘V.’
- V1
The simplified model (Sect. 7) for VGOS telescopes was used to create the schedules. The observations were scheduled regularly. Each activity lasted for 70 s. The first 30 s was reserved for the slewing, whereas the remaining 40 s was used for the observation.
- V2
The model described in Appendix B modeling the slewing duration was used. However, the observation time was restricted to 40 s, too.
8.2 Results
We solved the MILP for five Intensive sessions with three different setups. In most cases, the target gap of 0.1% was not reached (see the column denoted with ‘gap’ in Table 2) and the solution was stopped after 24 h of computation. Thus, about 15 days of computation were necessary to create the results. This is also the reason for the rather small sample of investigated sessions.
We start with comparing the solution of M1 with sked. In Table 2, column gap, it can be seen that the solution type M1 reached an optimal state (gap = 0.0) in two cases and that in the remaining three cases it is very close to the optimum. The sky coverage score or the objective function is always better for the solution of M1 compared with sked (Table 3). In three out of five cases, the standard deviation of the estimated UT1-UTC parameter is better, too. However, the improvement in quadrature (IIQ) is rather small, expect for session 18APR03XU (Table 4).
For the sessions 18MAY02XU and 18JUN01XU, the standard deviation of UT1-UTC is better for the schedules created with sked. However, the difference to the latter is marginal. This indicates that a good sky coverage score—as defined for solution M1—not necessarily leads to a solution with the smallest variance of UT1-UTC. In Fig. 10, the schedules created with sked and M1 are illustrated exemplarily for session 18APR03XU. The MILP approach schedules sources in the east and west that are not scheduled by sked, so that the observations cover a larger area of the sky plot. Moreover, sked observes one source three times. These observations are very close and thus do not improve the spatial coverage. The schedule of M1 observes the same source at most twice.
Due to the missing constraints on the maximal number of observations and the resulting more complex MILP, the gap of M2 is larger compared with M1. On average, the gap is 6% (Table 2). Only for the sessions 18MAR01XU and 18MAY02XU, additional observations were scheduled using M2. The gap of solution M3 is even larger (on average 12%). Nevertheless, for each session, additional observations were found. M3 found more observations than M2 because of the different objective function. In M3, each cell can be occupied twice: once in the first half of the session and another time in the second half of the session. Considering two observations within the same cell of which one is located in the first half of the session and the other in the second half, the second observation increases the score for setup M3 but not for M2. Thus, in setup M2 the MILP had no reason to schedule this second observation (unless other constraints force it, like a minimally required number of observations). Hence, specifying the temporal and spatial resolution of the sky coverage score high enough is essential to this approach (see M2 vs. M3). Excluding session 18MAY02XU, the average improvement in quadrature of UT1-UTC is \(5.8~\upmu \text {s}\) for solution M3. A possible reason why the variance of UT1-UTC cannot be improved for session 18MAY02XU is that no correlations were used for the stochastic model.

Sky plots of session 18APR03XU. Light gray transits are visible only from the station the sky plot corresponds to. The blue transits are visible from both stations. The dark part of the blue transits has enough SNR, whereas the light part does not. Each red point corresponds to an observation and it shows the position of the source at the beginning of the observation
To evaluate the simplified model, we compared the solution V1 (simplified model) with solution V2 (full model but with fixed observation duration). There is a significant difference in the required runtime necessary to find the optimal solution or rather a solution very close to it. The optimal schedule for all five Intensive sessions was found in less than a minute using the simplified model (solution V1). The solution of each schedule corresponding to the setup V2 was stopped after 24 h. The schedules created with setup V1 always have 51 observations (Table 5). When using the full model about 26 additional observations are found. Thus, the standard deviation of UT1-UTC is also better in the V2 scenario (more than one micro second). However, the simplified model can be further improved. Considering the observable part of the sky (Fig. 1), there is no need for a full rotation around the azimuth in the case of the baseline Wettzell–Kokee Park. In fact, the angle between the most westerly part of the visible sky and the most easterly part of the visible sky is smaller than 180 degrees. Thus, the constant slewing time could be reduced to 20 s without jeopardizing the validity of the schedules. Moreover, in a postprocessing step, the time not required for the slewing could be added to the observation time, if possible. These improvements would increase the number of observations and their SNR.
You can find further applications and comparisons of the simplified model in Corbin and Haas (2019).
9 Conclusions
Mixed-integer linear programming had been applied to optimize production and routing for quite some time. In this publication, we have shown that it can also be applied to VLBI scheduling with its many constraints. For validation, the new scheduling strategy using combinatorial optimization has been integrated into the VLBI software ivg::ASCoT. The set of all possible schedules satisfying the parameters of a valid VLBI schedule with respect to visibility, slew times, SNR, etc. is described with an MILP using inequality constraints.
The MILP maximizes the local sky coverage above each station with respect to a newly developed score. It partitions the sky into cells of equal size and similar shape multiple times and enlarges the number of cells each time. An occupied cell adds a gain to the sky coverage score depending on its size. The advantage of this method is that the distribution on the entire sky but also the local distribution of the observations has an impact on the score.
In order to evaluate the new approach, schedules already created with the software sked were also computed with the new approach using the same setup. Because of the long runtime, only five Intensive sessions (see Sect. 8) could be investigated in more detail. For all sessions, more observations were scheduled as compared with sked. In one case, six additional observations were found. The standard deviation of UT1-UTC could be reduced in four cases (on average \({6}~\upmu \text {s}\) improvement in quadrature). Only for one session, no improvement was achieved. Moreover, four Intensive sessions created with a prototype of the presented MILP have been observed, successfully. This indicates that the proposed MILP creates valid schedules.
The runtime of the MILP depends on several parameters, for example the number of sources, stations and atomic intervals, as well as on the duration of the session. To find the optimal solution of an Intensive session or a solution very close to the optimum, several hours of computations were necessary. However, the same problem can be described by a variety of different MILP formulations, with different runtimes. We have focused on modeling the VLBI observation process accurately and on avoiding strong simplifications and discretizations. Due to the long running times of our method, however, an interesting question for future research is whether there are justifiable simplifications that lead to an acceleration. For example, there could be more effective formulations for the cable wrap and the slewing of the telescopes. In fact, this part of the model requires a lot of constraints and variables and is the main reason for the long runtime.
In the future, scheduling needs to be done for modern VGOS telescopes which can reach any point on the sky within 30 s. For the time being, simplification of the scheduling process can be achieved by setting the slewing duration as a fixed parameter of 30 s for networks involving only fast-moving VGOS telescopes as is done in the current VGOS test sessions. With this restriction, the runtime is reduced drastically. In a postprocessing step, the time not required for the slewing could be added to the observation time, such that the idle time is decreased, to further improve the results. However, this should only be an interim stage as long as the solvers and the computational power are the limiting factors. As soon as the VGOS development group decides to quit the 30-second scheme, the simplifications need to be abandoned again and more sophisticated heuristics need to be applied.
For this, the solution of the MILP can be accelerated by computing a schedule with a fast sequential approach as a starting value for the MILP. Furthermore, instead of solving one large MILP, the session could be subdivided into parts, and for each subsession, a smaller MILP could be solved.
Finally, it can be stated that with this application we have demonstrated that MILP can be applied in geodesy as well. The MILP can be used in the future for the development of faster heuristics optimizing the sky coverage score. It is especially useful for evaluating those heuristics.
Data Availability
VLBI schedules are saved in .skd files or .vex files. The schedules of all observed VLBI experiments can be found at ftp://cddis.gsfc.nasa.gov/vlbi/ivsdata/aux/ or ftp://ivs.bkg.bund.de/pub/vlbi/ivsdata/aux/. For sked and the required catalogs, contact J. Gipson (john.m.gipson@nasa.gov), and contact A. Corbin for ivg::ASCoT.
Notes
For NP-hard problems the existence of an efficient and exact algorithm is extremely unlikely Garey and Johnson (1979).
The partial derivatives with respect to the clock offset and the ZWD for an observation in zenith are both one. The lower the elevation, the larger the derivative of the ZWD, which is the value of the mapping function. Thus, observations at low elevations allow station clocks and the ZWD to be well de-correlated.
The session codes are: q18258, q18259, q18286 and q18287.
Here, we used 40 s for the observation duration because the previous test cases M1–M3 showed that we get reasonable solution within a runtime of one day. This does not hamper the conclusions of this test.
According to Gipson (2016) further corrections have to be applied to the sensitivity of the telescope–receiver pair that is elevation-dependent and the flux density that depends on the constellation of the baseline to the source. Thus, the SNR is not constant over time and the reference epoch for the SNR computations is the beginning of the atomic interval.
References
Altamimi Z, Rebischung P, Métivier L, Collilieux X (2016) ITRF2014: a new release of the international terrestrial reference frame modeling nonlinear station motions. J Geophys Res Solid Earth 121(8):6109–6131
Artz T, Halsig S, Iddink A, Nothnagel A (2016) ivg::ASCoT: the development of a new VLBI software package. In: Behrend D, Baver KD, Armstrong KL (eds) IVS 2016 general meeting proceedings, “New Horizons with VGOS”, Johannesburg, South Africa, 13–19 Mar 2016. NASA/CP-2016-219016
Ball M, Barnhart C, Nemhauser G, Odoni A (2007) Chapter 1 air transportation: Irregular operations and control. In: Barnhart C, Laporte G (eds) Transportation, Handbooks in operations research and management science, vol 14. Elsevier, Amsterdam, pp 1–67
Barnhart C, Laporte G (2007) Preface. In: Barnhart C, Laporte G (eds) Transportation, Handbooks in operations research and management science, vol 14. Elsevier, Amsterdam, pp v–vii
Beaulieu H, Ferland JA, Gendron B, Michelon P (2000) A mathematical programming approach for scheduling physicians in the emergency room. Health Care Manag Sci 3(3):193–200
Beckers B, Beckers P (2012) A general rule for disk and hemisphere partition into equal-area cells. Comput Geometry 45(7):275–283
Bixby R, Rothberg E (2007) Progress in computational mixed integer programming—a look back from the other side of the tipping point. Ann Oper Res 149(1):37–41
Buchner J (2011) Dynamic scheduling and planning parallel observations on large radio telescope arrays with the square kilometre array in mind. Master’s thesis, Auckland University of Technology
Błażewicz J, Domschke W, Pesch E (1996) The job shop scheduling problem: conventional and new solution techniques. Eur J Oper Res 93(1):1–33
Caprara A, Kroon L, Monaci M, Peeters M, Toth P (2007) Chapter 3 passenger railway optimization. In: Barnhart C, Laporte G (eds) Transportation. Handbooks in Operations Research and Management Science, vol 14. Elsevier, Amsterdam, pp 129–187
Christiansen M, Fagerholt K, Nygreen B, Ronen D (2007) Chapter 4 maritime transportation. In: Barnhart C, Laporte G (eds) Transportation. Handbooks in Operations Research and Management Science, vol 14. Elsevier, Amsterdam, pp 189–284
Corbin A, Haas R (2019) Scheduling of twin telescopes and the impact on troposphere and UT1 estimation. In: Haas R, Garcia-Espada S, Lopez Fernandez JA (eds) Proceedings of the 24th European VLBI group for geodesy and astrometry working meeting. Centro Nacional de Información Geográfica (CNIG), pp 194–198
CPLEX II (2015) 12.6 user’s manual
Dantzig GB (1963) Linear programming and extensions. Princeton University Press, Princeton
Davis JL, Herring TA, Shapiro II, Rogers AEE, Elgered G (1985) Geodesy by radio interferometry: effects of atmospheric modeling errors on estimates of baseline length. Radio Sci 20(6):1593–1607
Durán G, Guajardo M, Miranda J, Sauré D, Souyris S, Weintraub A, Wolf R (2007) Scheduling the chilean soccer league by integer programming. INFORMS J Appl Anal 37(6):539–552
Fahrmeir L, Kneib T, Lang S, Marx B (2013) Regression: models, methods and applications. Springer, Berlin
Fey AL, Gordon D, Jacobs CS, Ma C, Gaume R, Arias E, Bianco G, Boboltz D, Böckmann S, Bolotin S et al (2015) The second realization of the international celestial reference frame by very long baseline interferometry. Astronom J 150(2):1–16
Fügenschuh A, Homfeld H, Huck A, Martin A (2006) Locomotive and Wagon scheduling in freight transport. In: Jacob R, Müller-Hannemann M (eds) 6th workshop on algorithmic methods and models for optimization of railways (ATMOS’06). OpenAccess series in informatics (OASIcs), vol 5. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, Dagstuhl
Garey MR, Johnson DS (1979) Computers and intractability: a guide to the theory of NP-completeness. W. H. Freeman & Co, New York
Gipson J (2016) Sked-VLBI scheduling software. Technical report, NASA Goddard Space Flight Center
Giuliano ME, Johnston MD (2008) Multi-objective evolutionary algorithms for scheduling the James Webb Space Telescope. In Proceedings of 18th international conference on automated planning and scheduling (ICAPS 2008), pp 107–115
Gurobi Optimization L (2019) Gurobi optimizer reference manual. Version 8.0 2018 Gurobi Optimization, LLC. https://www.gurobi.com/wp-content/plugins/hd_documentations/documentation/8.0/refman.pdf
Halsig S, Corbin A, Iddink A, Jaron F, Schubert T, Nothnagel A (2017) Current development progress in ivg::ASCoT. A new VLBI analysis software. In: Haas R, Elgered G (eds) Proceedings of the 23rd meeting of the European VLBI group for geodesy and astrometry working meeting, Gothenburg, Sweden, May 2017, pp 167–171
Johnston M, Adorf H-M (1992) Scheduling with neural networks—the case of the Hubble Space Telescope. Comput Oper Res 19(3):209–240
Koch K-R (2013) Parameter estimation and hypothesis testing in linear models. Springer, Berlin
Lambeck K (1980) The earth’s variable rotation: Geophysical causes and consequences. Cambridge University Press
Lampoudi S, Saunders E (2013) Telescope network scheduling: rationale and formalisms. In: Proceedings 2nd international conference on operations research and enterprise systems (ICORES 2013), pp 313–317
Lampoudi S, Saunders E, Eastman J (2015) An integer linear programming solution to the telescope network scheduling problem. In: Proceedings 4th international conference on operations research and enterprise systems (ICORES 2015), pp 331–337
Leek J, Artz T, Nothnagel A (2015) Optimized scheduling of vlbi ut1 intensive sessions for twin telescopes employing impact factor analysis. J Geodesy 89(9):911–924
MacMillan DS (1995) Atmospheric gradients from very long baseline interferometry observations. Geophys Res Lett 22(9):1041–1044
Marinelli F, Nocella S, Rossi F, Smriglio S (2011) A lagrangian heuristic for satellite range scheduling with resource constraints. Comput Oper Res 38(11):1572–1583
Moser I, van Straten W (2018) Dispatch approaches for scheduling radio telescope observations. Exp Astron 46(2):285–307
Nemhauser GL, Trick MA (1998) Scheduling a major college basketball conference. Oper Res 46(1):1–8
Niell AE (1996) Global mapping functions for the atmosphere delay at radio wavelengths. J Geophys Res 101(B02):3227–3246
Nilsson T, Böhm J, Wijaya DD, Tresch A, Nafisi V, Schuh H (2013) Path delays in the neutral atmosphere. In: Böhm J, Schuh H (eds) Atmospheric effects in space geodesy, Springer atmospheric sciences. Springer, Berlin, pp 73–136
Nothnagel A (2018) Very long baseline interferometry. In: Freeden W, Rummel R (eds) Handbuch der Geodäsie, Springer reference Naturwissenschaften. Springer, Berlin, pp 1–58
Nothnagel A, Artz T, Behrend D, Malkin Z (2017) International VLBI service for geodesy and astrometry. J Geodesy 91(7):711–721
Nothnagel A, Schnell D (2008) The impact of errors in polar motion and nutation on ut1 determinations from vlbi intensive observations. J Geodesy 82(12):863–869
Papadimitriou CH, Steiglitz K (1998) Combinatorial optimization: algorithms and complexity. Dover Publications, Mineola
Robert V (2007) Linear programming: foundations and extensions, vol 3. Springer, New York
Sovers OJ, Fanselow JL, Jacobs CS (1998) Astrometry and geodesy with radio interferometry: experiments, models, results. Rev Modern Phys 70(4):1393–1454
Steufmehl HJ (1994) Optimierung von Beobachtungsplänen in der Langbasisinterferometrie (VLBI). Deutsche Geodätische Kommission Bayer. Akad. Wiss, Reihe C, p 406
Sun J, Böhm J, Nilsson T, Krásná H, Böhm S, Schuh H (2014) New VLBI2010 scheduling strategies and implications on the terrestrial reference frames. J Geodesy 88(5):449–461
Wang J, Demeulemeester E, Qiu D (2016) A pure proactive scheduling algorithm for multiple earth observation satellites under uncertainties of clouds. Comput Oper Res 74:1–13
Williams HP (2013) Model building in mathematical programming, vol 5. Wiley, Hoboken
Acknowledgements
Open Access funding provided by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
J-H. Haunert and A. Nothnagel developed the idea of applying combinatorial optimization to VLBI scheduling; R. Haas simplified the approach for VGOS telescopes; A. Corbin and B. Niedermann developed, implemented and tested the integer linear program; the manuscript includes contributions from all authors.
Corresponding author
Appendices
Technical details
1.1 Implications
The presented MILP formulation particularly requires implications of the form
where \( condition \) either evaluates to zero or one expressing the truth values true and false, respectively. Such constraints are expressed in mixed-integer programming formulations as follows
where \( \varvec{\mathrm {M}}\, \) is a constant chosen appropriately large. If \( condition \) evaluates to 1, we obtain \( expression1 - expression2 \le 0\), which is equivalent to requiring \( expression1 \le expression2 \). Otherwise, if \( condition \) evaluates to 0, the constraint is trivially satisfied, which implies that \( expression1 \le expression2 \) is switched off as constraint. Further, implications of the form
can be transformed into two implications:
For multiple necessary conditions \(C_1,\dots ,C_k\), the implication
is transformed into
Moreover, for the binary variables \(x_1,\dots ,x_k\) an implication of the form
is transformed into
Finally, the implication
is transformed into
Model extensions for deployment in practice
In this section, the basic model (Sect. 6) is extended to model further constraints that are necessary to deploy the computed schedule in practice. We model the duration of the observation such that a specified SNR is reached. Furthermore, we introduce constraints to ensure that a source is not observed multiple times within a specified duration and to control the number of observations. Moreover, the time necessary to slew the telescopes is modeled more precisely and the movement restriction caused by the cable wrap (Fig. 7) is considered.
In order to realize those extensions, we slightly simplify the model by constructing the atomic intervals only based on \(T_{dt}\) omitting the times \(T_s\) (\(s\in S\)). The advantage is twofold. In the first place, the number of atomic intervals is significantly decreased. Secondly, the atomic intervals have unit length. However, with this assumption the transit of a source can be located in more than one cell during an atomic interval. To solve this ambiguity, we only count the cell that contains the beginning of the atomic interval. Hence, this assumption theoretically might have a negative impact on the achieved sky coverage, but considering Earth’s rotational speed of approximately \(\frac{1}{4} \frac{^{\circ }}{{\min }}\) and the length of the atomic intervals of 20–60 s the introduced error is negligible in practice.
1.1 Duration of observation
In the basic model (Sect. 6), the duration of observations is fixed. However, the duration of observation should be chosen such that a specified SNR is reached. We therefore replace Constraint C6 by the following constraints to model the duration of observations more accurately. For each baseline \(b \in B\), each observation \(o \in O_b\) and each source q in Q, the minimal time \( \mathrm {t_{\min }} (o,q)\) that is required to reach a specified SNR is pre-computed.Footnote 6 Let a and \(a'\) be the activities of o and
If the duration is smaller than a maximally permitted duration—which is introduced to avert too long observations of sources—the following constraints are added:
Otherwise, the source cannot be observed due to the low SNR and the following constraints are introduced instead:
Moreover, the following constraints ensure that both participating stations have the same observation duration:
1.2 Time between successive observations of the same source
A source should not be observed too often repetitively, because frequently observing the same source ties up resources, while it does not lead to a better sky coverage. We therefore introduce a hard constraint that requires that a source can only be observed once by the same telescope within a fixed period \( \mathrm {t_{\min }} \) of time.
To that end, we introduce the integer constant \(a. \mathsf {iSwitch} \in {\mathbb {N}}\) for every activity. It defines the index of the atomic interval that contains the switch time of the activity. This is a constant and not a variable because the switch time of an activity is contained in a pre-defined atomic interval. Moreover, for an activity a of a station \(s\in S\), let
be the set containing all preceding activities of a. Accordingly, let
be the set of all succeeding activities. Moreover, for two activities a and \(a'\) of the same station let \( A_{a,a'} = Succ _{a} \cap Pre _{a'} \) be the activities that lie between both activities (assuming that a precedes \(a'\)).
For each activity \(a \in A_s \), each preceding activity \(a' \in Pre _{a}\) and each source \(q \in Q\), we add the following constraint:
1.3 Number of observations
For our experiments (see Sect. 8), we introduce the possibility of enforcing a certain number of observations by introducing the following constraints,
where \( \mathrm {n_{\min }} \) and \( \mathrm {n_{max}} \) are the minimal and maximal number of observations, respectively. We observe that the first constraint might lead to an empty solution space, if \(n_{\min }\) is not chosen large enough. Still, both constraints are a helpful tool to evaluate our approach and to assess how UT1-UTC is affected by different geometric configurations without changing the number of observations.
1.4 Duration of slewing and cable wrap
In this section, we model the duration of the slewing phase more precisely and further incorporate constraints modeling a valid cable wrap. To that end, we introduce for each activity a the following variables.
- 1.
To keep track of the position of the cable end attached to the movable part of the telescope, the continuous variables \(a. \mathsf {StartWrap} \), \(a. \mathsf {SwitchWrap} \) and \(a. \mathsf {StopWrap} \) are introduced which correspond to the azimuthal position of the cable at \(a. \mathsf {startTime} \), \(a. \mathsf {switchTime} \) and \(a. \mathsf {stopTime} \), respectively. They are restricted to be within the limits of the cable wrap at each station.
- 2.
The integer variable \(a. \mathsf {iStart} \in {\mathbb {N}}\), which defines the index of the atomic interval that contains the start time of the activity.
- 3.
The integer variable \(a. \mathsf {iStop} \in {\mathbb {N}}\), which defines the index of the atomic interval that contains the stop time of the activity.
- 4.
The continuous variable \(a.\Delta \)ts, which corresponds to the minimum time required to slew the telescope between two observations.
- 5.
The binary decision variable \(a. \mathsf {dir} \in \{0,1\}\). We interpret the variable such that \(a. \mathsf {dir} =1\) if the telescope moves clockwise and counterclockwise otherwise.
- 6.
The continuous variable \(\Delta \varepsilon \in [0,90]\), which corresponds to the slew in elevation during the slewing step.
- 7.
For each atomic interval following the atomic interval \(a. \mathsf {iSwitch} \) and the atomic interval itself, a binary variable \(a. \mathsf {stop} (i) \in \{0,1\}\) is introduced. If the stop time of the activity is located in this interval, it is one; otherwise, it is zero. Only one of those variables of an activity can be one.
Index variables. We first introduce constraints that ensure that the index variables \(a. \mathsf {iStart} \) and \(a. \mathsf {iStop} \) are set correctly for each activity a (see Fig. 6). To that end, we introduce for each station \(s \in S\) and for each activity \(a\in A_s\) the following constraints:
Constraint C23 and Constraint C24 ensure that the variable \(a. \mathsf {iStart} \) is set to the index of the atomic interval that contains the start time of the activity. Analogously, by Constraint C25 and Constraint C26 the variable \(a. \mathsf {iStop} \) is set to the index of the atomic interval that contains the stop time of the activity. Constraint C27 ensures that at most one atomic interval is selected as interval that contains the stop time of the considered activity. Furthermore, for each station s, each activity \(a\in A_s\) and each atomic interval \(i \ge a. \mathsf {iSwitch} \) we introduce the following constraints ensuring that \(a. \mathsf {stop} (i)\) is one if the stop time of the activity a is located in the ith interval:
Start position of telescopes. We now introduce constraints that ensure that the variables are initialized correctly. To be consistent with sked, we assume that the telescopes are already tracking the first scheduled source at the specified start time of the session. For each station \(s \in S\) and for each activity \(a \in A_s\), the following constraints are introduced that set the slew angles of the first selected activity to zero.
For each station \(s \in S\), for each activity \(a \in A_s\) and for each source \( q \in Q\), we introduce the constraint
where \(C_{a,q}\) is equivalent to
and \(Az^0(q)\) corresponds to the azimuth of source q at the start of the first selected atomic interval (start of the session).
Continuous cable wrap. Next, we define constraints that ensure that the cable wrap (see Fig. 7) is recorded correctly. More precisely, for each station \(s \in S\), each activity \(a\in A_s\) and each succeeding activity \(a' \in Succ _{a}\) the following constraints are introduced to ensure that the cable position is correctly propagated from one selected activity to the next selected activity.
To that end, we introduce the expression
which we abbreviate with \( isNext (a,a')\) because it is only one if the activity \(a'\) is the next selected activity after the selected activity a.
Movements of telescope during tracking. In particular at high elevation angles, it may happen that the telescope has to track the source across several degrees of azimuth. In cases where this happens near the cable wrap limits, we have to model how to move the telescope during the observation phase such that the cable wrap remains valid. For each station \(s \in S\), each activity \(a\in A_s\), each source \(q \in Q\) and each atomic interval \(i \ge a. \mathsf {iSwitch} \), the change in azimuth during the tracking step \(a. \mathrm {\Delta Az_M} (q)\) is approximated by subtracting the azimuth of the observed source at the start of the atomic interval \( \mathsf {iSwitch} \) and the azimuth at the end of the atomic interval \( \mathsf {iStop} \). The following constraint is added:
The tracking in elevation during the observation period does not affect the cable wrap and thus does not have to be considered.
Long arc slewing. Similarly, we have to model how to do the slewing of the telescope such that the cable wrap always remains valid. However, this time we also consider the slewing in elevation because it has an impact on the time necessary for slewing the telescope. For each station \(s \in S\), each activity \(a\in A_s\), each succeeding activity \(a' \in Succ _{a}\), each source \(q \text { and } q' \in Q\), the change in azimuth required to rotate the telescope from source q to \(q'\) clockwise \(a. \mathrm {\Delta AzCW} (a')\) and counterclockwise \(a. \mathrm {\Delta AzCCW} (a')\) is approximated (see Fig. 7). This is done by subtracting the azimuth of the observed source at the start of the atomic interval \(a. \mathsf {iSwitch} \) and the azimuth of the subsequent observed source at the end of the atomic interval \(a'. \mathsf {iSwitch} \).
Moreover, the change in elevation \(a. \mathrm {\Delta El} (a')\) between the switch times of the activities a and \(a'\) is approximated by subtracting the elevation of the observed source at the start of the atomic interval \(a. \mathsf {iSwitch} \) and the elevation at the end of the atomic interval \(a'. \mathsf {iSwitch} \).
Time for slewing. The slew duration is approximated with the slew rate of the station in azimuth \( \mathrm {v_{Az}} (s) \) and elevation \( \mathrm {v_{El}} (s) \). For each station \(s\in S\) and each activity \(a \in A_s\), we introduce the following constraints.
Constraint C36 enforces that the duration of the slewing step is larger than the time required to slew the telescope in azimuth. Accordingly, Constraint C37 enforces that the duration of the slewing step is larger than the time required to slew the telescope in elevation. The variable \( a. {\Delta \varepsilon } \) includes not only the change during the slewing but also the one during the preceding tracking step. Thus, the term \( \left| \frac{a. {\Delta \varepsilon } }{ \mathrm {v_{El}} (s)} \right| \) is larger than necessary. However, this effect is small because the largest contribution is caused by the slewing.
Condition C5 is replaced by the following constraint to model the slewing duration accurately. For each station s and for each activity \(a\in A_s\), we require
Here, \( \mathrm {constTime} \) is a fixed time including the actions that are necessary before each observation.
1.5 Speeding up the solution
The following constraints are not required for valid schedules, but they speed up the process of finding a solution of the MILP formulation. For each station \(s \in S\), for each activity \(a \in A_s\) and for each preceding activity \(a'\in Pre _{a}\), we introduce the following constraints:
And for each succeeding activity \(a'\in Succ _{a}\), we introduce the constraints:
Constraint C39 sets all activities between the switch index and the end index to ‘not selected.’ Constraint C40 sets all activities between the start index and the switch index to ‘not selected.’ Constraint C41 enforces that the maximal duration between two succeeding observations is smaller than the specified value \(\Delta \mathrm {t_{max}} \). With this constraint, Constraints C7, C32, C34, C35, C40 and C39 do not have to be introduced for all succeeding or preceding activities but only for those having an effect on the solution.
In the case of a session with only one baseline, the inequality Constraints C15 and C16 can be replaced by equality constraints:
This is reducing the number of possible schedules. Moreover, in this case Constraint C19 is not necessary. By adding constraints ensuring that within the first intervals at least one observation is selected, the constraints for the start position of telescope, which are only relevant for the first observation, can be reduced, too.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Corbin, A., Niedermann, B., Nothnagel, A. et al. Combinatorial optimization applied to VLBI scheduling. J Geod 94, 19 (2020). https://doi.org/10.1007/s00190-020-01348-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00190-020-01348-w