
Abstract
While branch and bound based algorithms are a standard approach to solve single-objective (mixed-)integer optimization problems, multi-objective branch and bound methods are only rarely applied compared to the predominant objective space methods. In this paper we propose modifications to increase the performance of multi-objective branch and bound algorithms by utilizing scalarization-based information. We use the hypervolume indicator as a measure for the gap between lower and upper bound set to implement a multi-objective best-first strategy. By adaptively solving scalarizations in the root node to integer optimality we improve both, upper and lower bound set. The obtained lower bound can then be integrated into the lower bounds of all active nodes, while the determined solution is added to the upper bound set. Numerical experiments show that the number of investigated nodes can be significantly reduced by up to 83% and the total computation time can be reduced by up to 80%.
Similar content being viewed by others


1 Introduction
Many optimization problems occurring in real-word applications include a conflict of interests and goals, or secondary objectives, in a word, they are multi-objective. Thus, there is (in general) not one solution that optimizes all objectives at once. Following the a posteriori paradigm of decision making, we aim at determining the set of so-called efficient solutions or the images, the so-called non-dominated points, which cannot be improved in one objective without deterioration in at least one other objective. Thus, efficient solutions are reasonable choices for decision makers.
As we are considering specifically bi-objective integer linear programs and their solution with multi-objective branch and bound methods, the following literature survey will also focus on this and closely related topics. A comprehensive introduction to multi-objective optimization in general is given, e.g., in Steuer (1986), Ehrgott (2005).
Solution approaches for multi-objective optimization problems are often categorized in: objective space and decision space methods. Objective space methods scalarize the underlying problem, i. e., it is replaced by a series of single-objective problems to determine successively the set of efficient solutions. In the case of multi-objective integer programming, these scalarized problems can be solved with commercial integer programming solvers like CPLEX or Gurobi. The utilization of these optimized, single-criteria solvers are a major advantage and one of the reasons why those methods are predominant in multi-objective optimization.
There are numerous objective space methods and a popular one is the \({\varepsilon }\)-constraint method that was introduced for two objectives by Haimes et al. (1971). In every iteration the first objective is optimized with an updated constraint to ensure an improvement regarding the second objective. In Laumanns et al. (2006) an extension to three and more objectives is presented. Many approaches based on the \({\varepsilon }\)-constraint method have been published in the last decades, for example Boland et al. (2017) and Kirlik and Sayın (2014) combine the method with reduction of dimension in the tri- respectively multi-dimensional case.
The weighted sum scalarization is an objective space method based on the optimization of a weighted sum of the objective functions using non-negative weights. Note that not all efficient solutions can be determined as optimal solutions of the weighted sum scalarization using suitable weights (see, e. g. Aneja and Nair 1979). Efficient solutions which can be obtained by using weighted sum scalarization are denoted as supported efficicent and their corresponding non-dominated points are located on the boundary of the convex hull of feasible image points. Extensions of the weighted sum method to the multi-objective case are proposed in Przybylski et al. (2010a), Özpeynirci and Köksalan (2010), Bökler and Mutzel (2015), and Przybylski et al. (2019).
Ulungu and Teghem (1995) introduced the so-called two-phase method for bi-objective problems. In the first phase the extreme supported non-dominated points are generated with an algorithm similar to the initial weighted sum approach. In the second phase the remaining non-dominated points are generated by searching in triangles defined by two consecutive extreme supported non-dominated points. In Przybylski et al. (2008) and Tuyttens et al. (2000) problem specific algorithms are suggested for the second phase, while in Przybylski et al. (2010b) a two-phase method for problems with more than two objectives is proposed.
The augmented weighted Tchebycheff method, first presented in Steuer and Choo (1983), minimizes the augmented weighted Tchebycheff distance between a predefined reference point and the set of feasible image points. Dächert et al. (2012) suggested an adaptive choice of the augmentation term for the bi-objective case.
In Boland et al. (2015a), Boland et al. (2015b) (for the bi-objective case), Dächert and Klamroth (2014), and Klamroth et al. (2015) (for the tri- respectively multi-objective case) search region splitting methods are proposed. In this class of objective space methods, the search region (based on the already determined non-dominated points) is splitted into so-called search zones on which scalarizations are solved indpendently.
Besides their advantages, objective space methods share a shortcoming: In each iteration a scalarized integer program is solved from scratch. Even though in some objective space methods starting solutions can be transfered from previous iterations, a large number of very similar problems has to be solved. In order to avoid this effort, decision space methods, mainly the branch and bound method, have been increasingly investigated in the recent years.
Klein and Hannan (1982) developed one of the first branch and bound algorithms for multi-objective integeger programs with a typical one tree structure. In Kiziltan and Yucaoğlu (1983) a general branch and bound framework for multi-objective integer programs with binary variables is presented. Ulungu and Teghem (1997) and Visée et al. (1998) proposed problem specific branch and bound approaches for bi-objective Knapsack problems, where the latter approach is integrated in a two-phase method.
Mavrotas and Diakoulaki (1998) extend the branch and bound approach to multi-objective mixed integer programs. Parts of the algorithm are refined in Mavrotas and Diakoulaki (2005). In Vincent et al. (2013) this algorithm is improved and it is shown that the original algorithm is not correct because the final dominance test is incomplete. In Belotti et al. (2012) a branch and bound method is presented that can handle bi-objective mixed integer programs with continious variables in both objective functions.
The branch and bound method proposed in Sourd and Spanjaard (2008) uses a set of points as lower bound instead of just using a single point. Furthermore hyperplanes are used to fathom nodes by dominance. In Stidsen et al. (2014) this idea is continued. They use hyperplanes as a lower bound set that are generated by solving weighted sum scalarizations. Additionally they present the so-called Pareto branching and the slicing technique. With Pareto branching it is possible to divide the objective space to possibly ignore parts of it in specific nodes. Slicing partitions the objective space in equally large parts and a respective slice can be fathomed if it is dominated by an already found integer point. In Stidsen and Andersen (2018) this algorithm is improved and an approach to parallelize the algorithm is presented. Based on this, the idea Pareto branching is further investigated in Parragh and Tricoire (2019) and Gadegaard et al. (2019) for the bi-objective case and Forget et al. (2022) for the tri-objective case. A self-contained survey of multi-objective branch and bound approaches is given in Przybylski and Gandibleux (2017).
In this paper we present a bi-objective branch and bound algorithm that is augmented by scalarization-based information. We make use of optimized single-objective solvers for scalar integer programs and integrate the resulting information into the bi-objective branch and bound by improving lower and upper bounds. Furthermore, we propose a new adaptive node selection strategy, which relies on objective space information. In our numerical analysis we show the effectiveness of these improvements by comparing them with a generic multi-objective branch and bound algorithm, which we use as our baseline algorithm.
The remainder of the article is organized as follows: In Sect. 2, we introduce notations and definitions for multi-objective optimization. In Sect. 3, we present a general multi-objective branch and bound framework and its key components. Furthermore, we describe a specific (however standard) multi-objective branch and bound algorithm, which will be used as baseline implementation in our numerical tests. In Sect. 4, we present augmentations of the multi-objective branch and bound, that utilize objective space information to improve the node selection as well as the computation of upper and lower bounds. We provide numerical results in Sect. 5 and in Sect. 6, we outline conclusions and outlooks for further research.
2 Preliminaries
We introduce a general multi-objective integer linear program which can be written in the form:

Thereby, \(z(x){:=}(z_1(x),\ldots , z_p(x))^\top = C\cdot x \in \mathbb {R}^p\) (with \(p \ge 2\)) denotes the objective function vector, with \(C \in \mathbb {R}^{p\times n}\) the matrix of objective coefficients. The set of feasible solutions \(X{:=}\{x \in \mathbb {Z}^n: A \le b, x\ge 0 \}\) is a subset of the decision space \(\mathbb {R}^n\), while its image \(Y{:=}\{C\, x:x\in X\}\) is a subset of the objective space \(\mathbb {R}^p\).
We use the Pareto concept of optimality which relies on the componentwise order. Let \(y^1,y^2 \in \mathbb {R}^p\), then we define the corresponding dominance relations as follows:
-
\(y^1 \leqq y^2\), i.e., \(y^1\) weakly dominates \(y^2\) if \(y^1_k \le y^2_k\) for \(k=1,\ldots ,p\),
-
\(y^1 < y^2\), i.e., \(y^1\) strictly dominates \(y^2\) if \(y^1_k < y^2_k\) for \(k=1,\ldots ,p\),
-
\(y^1 \le y^2\), i.e., \(y^1\) dominates \(y^2\) if \(y^1 \leqq y^2\) and \(y^1 \ne y^2\).
A feasible solution \(x\in X\) is called efficient if there is no other solution \(\hat{x}\in X\) dominating it, i.e., \(z(\hat{x}) \le z(x)\). A feasible solution \(x\in X\) is called weakly efficient if there is no \(\hat{x}\in X\) such that \(z(\hat{x}) < z(x)\). The set of efficient solutions is denoted by \(X_E\). By \(Y_N= \{ z(x) \in Y:x\in X_E \}\) we denote the set of the non-dominated points in the objective space. Moreover, for any set \(Q\subseteq \mathbb {R}^p\) we denote by \(Q_N\) the set of its non-dominated points (i.e., \(q\in Q_N\iff \not \exists q'\in Q:q'\le q\)). For a comprehensive introduction to multi-objective optimization see, e. g., Ehrgott (2005).
In this article we consider a minimal complete set as solution of a multi-objective optimization problem. A minimal complete set denotes the set of all non-dominated points \(Y_N\) and one efficient solution for each non-dominated point. See Serafini (1987) for a comparison of solution concepts in multi-objective optimization.
A standard solution approach in multi-objective optimization is the weighted sum scalarization given in (\( WS _\lambda \)).

Obviously, every optimal solution of the weighted sum scalarization for \(\lambda \in \mathbb {R}^p_>{:=}\{\lambda \in \mathbb {R}^p:\lambda >0 \}\) is efficient for (MOILP). However, in general not all efficient solutions are optimal solutions of a corresponding weighted sum problem. An efficient solution \(x'\in X_E\) is called supported if there is a weighting vector \(\lambda ' \in \mathbb {R}^p_>\) such that \(x'\) is optimal for (\( WS _\lambda \)) for \(\lambda =\lambda '\), otherwise \(x'\) is unsupported. Note that the non-dominated points corresponding to supported efficient solutions are located on the boundary of the convex hull of Y, while the unsupported non-dominated points are located in its (relative) interior.
As already mentioned in the introduction the computation of upper and lower bounds on the non-dominated set is a crucial component of any multi-objective branch and bound algorithm. The tightest componentwise upper and lower bounds of \(Y_N\) are the ideal point \(y^I\) and the Nadir point \(y^N\) given by:
Obviously, \(y^I \leqq y \leqq y^N\) holds for every \(y\in Y_N\), i.e., \(Y_N\) is contained in the hyperbox spanned by the corner points \(y^I\) and \(y^N\). However, these single point bounds are in general very weak except for the degenerate case of \(y^I = y^N\). This motivates to consider bound sets instead of bounds consisting of a single point. We will rely on the definition of bound sets proposed in Ehrgott and Gandibleux (2007). Let \(\mathbb {R}^p_\geqq {:=}\{y \in \mathbb {R}^p:y\geqq 0\}\), then
-
A lower bound set \(\mathcal {L}\subset \mathbb {R}^p\) for \(Y_N\) is a
-
\(\mathbb {R}^p_\geqq \)-closed (i.e., the set \(\mathcal {L}+\mathbb {R}^p_\geqq \) is closed),
-
\(\mathbb {R}^p_\geqq \)-bounded (i.e., there exists a \(y\in \mathbb {R}^p\) such that \(\mathcal {L}\subset y+\mathbb {R}^p_\geqq \))
-
stable set (i.e., \(\mathcal {L}\subset (\mathcal {L}+\mathbb {R}^p_\geqq )_N\)),
such that \(Y_N \subset (\mathcal {L}+\mathbb {R}^p_\geqq )\).
-
-
An upper bound set \(\mathcal {U}\subset \mathbb {R}^p\) for \(Y_N\) is a
-
\(\mathbb {R}^p_\geqq \)-closed,
-
\(\mathbb {R}^p_\geqq \)-bounded,
-
stable sets,
such that \(Y_N \subset {{\,\textrm{cl}\,}}\bigl ((\mathcal {U}+\mathbb {R}^p_\geqq )^\complement \bigr )\).
-
The upper bound and lower bound that we will define for our branch and bound framework in Sect. 3 will suit these definitions. We say a lower bound \(\mathcal {L}\) is weakly dominated by an upper bound \(\mathcal {U}\) if for all \(l \in \mathcal {L}\) there exists an \(u\in \mathcal {U}\) such that \(u \leqq l\).
In the following we restrict ourselves to bi-objective binary linear optimization problems, i. e., problems with two linear objective functions and variables \(x \in \{ 0,1 \}^n\):

3 A generic multi-objective branch and bound framework
In this section we present a generic multi-objective branch and bound framework, which we specify and augment by using scalarization based information in the then following sections.
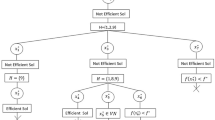
Branch and bound methods follow a “divide and conquer” paradigm. A problem that is too hard to be solved directly, is divided into smaller and thus easier subproblems. Thereby, subproblems are associated with nodes in a tree data structure according to their descent, i.e., node \(i\) is a descendant node of node \(j\) iff the feasible set of the subprobem associated with node \(i\) is a subset of the feasible set of the subproblem associated with node \(j\). The corresponding subproblems of the child nodes are created by subdividing the feasible set of the corresponding (sub)problem of the parent node. Starting with the root node, to which the original optimization problem is associated, the algorithm selects in each iteration one active node and updates its lower bound and upper bound. Then the active node can be fathomed if the corresponding subproblem is either solved or irrelevant for the determination of a minimal complete set. If we cannot prune we subdivide the corresponding problem into new subproblems and create corresponding child nodes (branching). For a more detailed introduction and survey of multi-objective branch and bound algorithms see Przybylski and Gandibleux (2017). A recent survey of single-objective branch and bound frameworks is given e.g. in Morrison et al. (2016). In the following we specify the lower bound, upper bound, branching rule and node selection we use in our framework.
Lower bound: Lower bound sets are often determined by solving relaxations of the respective subproblem. Like in the single-objective case, the most frequently used relaxations are linear and convex relaxations. In order to solve the linear relaxation we are using in our framework, we apply Benson’s outer approximation algorithm (Benson 1998; Ehrgott et al. 2012). The algorithm is initiated with a lower bound, which is improved in every iteration by generating cuts. Due to the outer approximation structure the algorithm can be aborted at any time returning a valid lower bound. Alternatively, linear (or convex) relaxations can be obtained using a dichotomic scheme (see, for example, Aneja and Nair 1979; Özpeynirci and Köksalan 2010; Przybylski et al. 2010a). In the following we denote a lower bound set \(\mathcal {L}\) as convex lower bound set or convex lower bound if \(\mathcal {L}+ \mathbb {R}^2_\ge \) is a convex set. Note that the set \(\mathcal {L}\) is thereby not necessarily convex.
Upper bound: The upper bound set, in the following denoted by \(\mathcal {U}\), is stored in the form of a so-called incumbent list. Throughout the run of the algorithm, it contains all integer feasible solutions and their corresponding outcome vectors that are not dominated by another feasible solution found so far. In every iteration the extreme supported solutions of the computed lower bound sets are checked for integer feasibility. An integer feasible solution \(\bar{x}\in X\) is then appended to the incumbent list, if there is no \(x\in \mathcal {U}\) dominating \(\bar{x}\), i. e., \(C(x)\le C(\bar{x})\). If a new solution \(\bar{x}\) is added to the incumbent list \(\mathcal {U}\) all solutions \(x\in \mathcal {U}\) which are dominated by \(\bar{x}\) (\(C(\bar{x})\le C(x)\)) are removed from it, that is
Note that an update of the incumbent list requires a subsequent update of the list of local upper bounds. A detailed description of local upper bounds, their computation and update in an arbitrary number of criteria is given in Klamroth et al. (2015). In this framework we start with an empty upper bound set. However, it is also possible to initialize the incumbent list by heuristic methods, or by solving scalarizations like, e.g., in the two-phase method (Ulungu and Teghem 1995; Visée et al. 1998).
Node selection: In every iteration of the algorithm an unexplored node is selected from the tree of subproblems. This node is called active node. The order in which the nodes of the tree are considered has a significant impact on the number of created nodes that have to be explored and thus on the computation time.
Two types of strategies need to be distinguished: static strategies and dynamic strategies. The two most common examples of static strategies are the depth-first strategy and the breadth-first strategy. Most multi-objective branch and bound algorithms in literature follow a depth-first strategy. Thus, we use this strategy for our baseline implementation as well.
In contrast to the single-objective case, dynamic node selection strategies are rarely applied in the multi-objective case. Dynamic node selection strategies are, for example, applied in Belotti et al. (2012), Stidsen et al. (2014), Jesus et al. (2021).
Fathoming: In order to avoid the total enumeration of all feasible solutions, nodes are fathomed if the respective subproblem is either solved to optimality or does not contain solutions which are necessary to determine a minimal complete set. In particular, there are three different situations in which a node can be fathomed:
-
i)
Fathoming by infeasibility: If the LP-relaxation of a subproblem is infeasible then the corresponding subproblem is infeasible as well, since the feasible set of the subproblem is a subset of the feasible set of its relaxation.
-
ii)
Fathoming by optimality: Similar to the single-objective case we can fathom a node by optimality if the lower bound \(\mathcal {L}\) is equal to the upper bound \(\mathcal {U}\). This implies the subproblem is solved to optimality and the associated node must not be subdiveded further. However, this can happen in the multi-objective case only if the lower and upper bound consist of the same single point, namely the ideal point.
-
iii)
Fathoming by dominance: A node can be fathomed by dominance if all feasible solutions of this subproblem are dominated by points in the incumbent list. In order to check dominance for all feasible outcome vectors of a subproblem we compare the lower bound \(\mathcal {L}\) of the corresponding node to the current upper bound \(\mathcal {U}\). If for all \(l \in \mathcal {L}\) there is a point in the incumbent list \(u\in \mathcal {U}\) with \(u \leqq l\) then all feasible points in the subtree are dominated by the current incumbent list. In other words, if there is no local upper bound defined by \(\mathcal {U}\) above the computed lower bound the node can be fathomed by dominance.
Branching: As mentioned in the beginning of this section, one of the key aspects of branch and bound is iterative subdivision into smaller subproblems. Thereby subproblems are associated with nodes in a tree, such that the subproblem associated to a child node is obtained by one branching step. Since we consider binary optimization problems (BO01LP), we can divide a (sub)problem into two new subproblems by fixing a specific variable to 0 and respectively to 1 in the other subproblem. This results in a binary branch and bound tree.
The branching rule determines which variable is selected as branching variable in each iteration. Thereby, one distinguishes between static and dynamic strategies. Static strategies determine an order of the variables in advance. In each iteration of the algorithm the next variable in this list is used as branching variable. With dynamic strategies the branching variable is selected by considering information obtained from previous iterations, i.e., from the solution of (linear) relaxations of (sub)problems.
The basic idea of static strategies for single-objective problems is to sort the variables, beginning with the most promising according to the objective function values (see, e. g., Kellerer et al. 2004). However, this cannot be easily extended to the multi-objective case due to conflicting objective functions. Nevertheless there are some approaches to extend static strategies to the multi-objective case (see for example Ulungu and Teghem 1997; Bazgan et al. 2009).
In contrast to most of the published papers which apply static strategies we use a dynamic strategy as proposed in Belotti et al. (2012). By solving the linear relaxation of a (sub)problem we obtain the lower bound set \(\mathcal {L}\). For all extreme points of \(\mathcal {L}\) we check how often a variable is fractional in the corresponding solutions. As branching variable we choose the one which is most often fractional.
4 Using objective space information in multi-objective branch and bound
In this section, we propose modifications which improve the computational efficiency of bi-objective branch and bound algorithms in two critical aspects. One of the weaknesses of multi-objective branch and bound as compared to its single-objective counterpart is the bounding procedure. While any feasible solution \(\bar{x}\in X\) dominates w.r.t. one (linear) objective a half-space in decision space (i.e., \(\{x\in \mathbb {R}^n:c^\top x \ge c^\top \bar{x}\}\)), the set of feasible solutions which are dominated by a solution \(\bar{x}\) in \(p\ge 2\) objective functions (\(C\in \mathbb {R}^{p\times n}\)) forms a cone \(\{x\in \mathbb {R}^n:C\, x \geqq C \,\bar{x}\}\). The cone of dominated solutions is smaller the more the objective functions are in conflict, leading also to a larger number of efficient solutions. This implies that a significant part of the branch and bound tree has to be enumerated and only a small number of branches can be pruned by dominance. Despite of this general problem in multi-objective optimization, this asks for good bounding procedures to avoid the unnecessary evaluation of dominated branches. This however, requires good solutions in the incumbent list as well as tight lower bounds.
In order to achieve this, we suggest a new branching strategy and the hybridization of branch and bound with objective space methods. We determine scalarized subproblems adapted to the state of the branch and bound and solve these to integer optimality.
4.1 Branching strategy
The branching strategy comprises two subsequent decisions: the choice of the active node and its branching into subproblems, i. e. the decision on which variable the subproblem is branched. This second step is denoted as branching rule. We discuss these two steps together since the order in which the nodes are considered has a significant impact on the branched variable. Instead of the static depth- or breadth-first we use a dynamic node selection strategy, while we rely on the most fractional rule as branching rule.
The basic idea of our strategy is quite simple and a natural extension of choosing the largest gap in the single-objective case (see, for example, Dechter and Pearl 1985). For every created node we compute the approximate hypervolume gap between lower and upper bound. We use the definition of hypervolume proposed in Zitzler and Thiele (1999). In every iteration we choose the node with the largest hypervolume gap as active node (cf. Jesus et al. (2021)). Note that when a node is created during the branching process, the approximated hypervolume gap of the parent node is assigned to it. We distinguish two variants of the hypervolume gap: the total hypervolume gap and the local hypervolume gap. While the total hypervolume gap measures the volume of the search region, i. e. the volume between lower and upper bound set, the local hypervolume gap approach considers only the volume of the largest search zone, i. e. the gap between a local upper bound and the lower bound set. For a more detailed definition of search regions and search zones we refer to Klamroth et al. (2015).

Example of computation of the two different approximated hypervolume gap approaches
Figure 1 illustrates the two different approaches. Here, \(z^1,\ldots , z^4 \in K \subset \mathcal {U}\) are points of the incumbent list and \(lu^1,\ldots , lu^3\) are their corresponding local upper bounds, where K is a subset of the incumbent list containing just the points above the lower bound of node \(\bar{n}\). The green line represents the lower bound. Figure 1a shows how to measure the total hypervolume gap of a node \(\bar{n}\), in the following denoted by \(thg(\bar{n})\). For this approach we consider the approximated search region of the corresponding node. Since there is a natural order in the bi-objective case, it is possible to consider the approximated search zone of the first local upper bound, i.e. the local upper bound with the smallest \(z_1\)-value. Therefore we define the two spanning points, which, together with the corresponding local upper bound, define a triangle. The spanning points of a local upper bound lu are defined by \(sp^i (lu) {:=}\{ l \in \mathcal {L}:l_{3-i} = lu_{3-i} \}, i = 1,2\). So, the approximate hypervolume gap of lu is given by
For the remaining local upper bounds we compute the hypervolume of slices as shown in the illustration. The hypervolume of the slice of \(lu^i,i=1,\dots , \vert K \vert -1\) is defined as
So, the total (approximated) hypervolume gap, which is assigned to node \(\bar{n}\), is given by
The Fig. 1b–d show the computation of the local hypervolume gap. The local hypervolume gap of a node \(\bar{n}\) is considered as the largest approximated hypervolume gap of a local upper bound corresponding to points in K. Therefore, the the local hypervolume gap, which is assigned to node \(\bar{n}\), is defined by
In the given example, B is the largest approximated hypervolume and therefore is assigned to node \(\bar{n}\).
Note that in our presented algorithms in Sect. 4.2 the local upper bound is initialized with the point \((\infty ,\infty )^\top \). Therefore, it is possible to apply the new branching strategies immediately at the beginning of the algorithm. Obviously, this approximation may neglect significantly large parts of the search regions and search zones. However, the idea of the approximated hypervolume gap eases computation and saves time. The efficiency of these new dynamic branching strategies is shown in Sect. 5.
4.2 Augmenting branch and bound with IP scalarizations
In this subsection, we introduce a method to incorporate scalarizations into branch and bound. We build a hybrid branch and bound algorithm combining the partial enumeration of decision space with objective space information by solving scalarizations to integer optimality.
An integer optimal solution \(\bar{x}\) of a scalarization can be used to update upper and lower bound. Obviously, the corresponding image point \(z(\bar{x})\) can be added to the incumbent list. Moreover, a scalarizing function and its optimal solution \(\bar{x}\) define a level set, which can be included in the lower bound set for all descendant nodes. In order to utilize these improved lower bounds in all nodes we solve the IP scalarizations in the root node.
4.2.1 Using weighted sum scalarization
During the run of the branch and bound algorithm, a strategy triggers the IP solution of weighted sum scalarizations in the root node. Thus, we solve problem (\( WS _\lambda \)) for for adaptively chosen values of \(\lambda \in \mathbb {R}^2_>\). Although we solve the IP scalarization in the root node the parameter \(\lambda \) is gained from the currently active node. Thereby, \(\lambda \) is determined by the largest approximated local hypervolume gap in the active node. This gap is spanned by two points in the incumbent list together with their local upper bound. Note that these points spanning the largest gap are already determined if the local hypervolume gap branching strategy is applied. The corresponding value of \(\lambda \) is determined by computing the normal to the hyperplane that is defined by those two points. Once \(\lambda \) is obtained, we can solve problem (\( WS _\lambda \)) with a single-objective integer linear programming solver. Let \(\bar{x}^\lambda \) be the optimal solution of the weighted sum scalarization with weighting vector \(\lambda \), then \(z(\bar{x}^\lambda )\) is a supported non-dominated point of (BO01LP). Thus, we can add this point to the incumbent list (if it was not found in previous iterations) and filter the resulting list for non-dominance. Moreover, the solution of integer scalarizations can also be used to tighten the lower bound set, since the level set \(\{z\in \mathbb {R}^2:\lambda ^\top z= WS _\lambda (\bar{x}^\lambda )\}\) provides the valid inequality \(\lambda ^\top z(x) \ge WS _\lambda (\bar{x}^\lambda ) \) for all \(x\in X\).

Example of updating the lower and upper bound with the usage of the weighted sum scalarization
Figure 2 illustrates the update of the lower and upper bound set. In Fig. 2a, \(z^1,\dots ,z^4\) indicate points that are currently in the incumbent list \(\mathcal {U}\) and \(lu^1,\dots ,lu^3\) are the corresponding local upper bounds. The point \(z(\bar{x}^\lambda )\) is obtained by solving a weighted sum scalarization (\( WS _\lambda \)) to integer optimality. Since the new point is not contained in the incumbent list so far, we can update the upper bound as it is shown in Fig. 2b. The new incumbent list then reads as \(\mathcal {U}{:=}\{z(\bar{x}^\lambda )\}\cup \{z\in \mathcal {U}:z(\bar{x}^\lambda ) \nleqq z\}\). Moreover, the lower bound set \(\mathcal {L}\) can be updated by integrating the blue hyperplane into the lower bound set, i. e. \(\mathcal {L}{:=}\{z\in \mathcal {L}+\mathbb {R}^2_\geqq :\lambda ^\top z \ge WS (\bar{x}^\lambda ) \}_N\) as it is shown in Fig. 2c, d. In this situation, both—the lower and upper bound—are updated, which is not the case in general.
The example illustrates the benefits of hybridizing multi-objective branch and bound with IP scalarizations. Due to weak bounding, nodes may not be fathomed by dominance even if they do not contain additional non-dominated points. The tighter upper bound increases the probability of fathoming a node by dominance in later iterations of the algorithm. Also, the lower bound might be improved. Since we are solving an IP scalarization in the root node, the obtained optimal level set is a valid inequality for all subproblems. We combine our new branching strategy and the augmentation with IP scalarizations to our first hybrid branch and bound approach.
Hybrid Branch and Bound Algorithm using Weighted Sum Scalarization
-
Lower bound: linear relaxation
-
Upper bound: incumbent list
-
Node selection: node with the largest total/local hypervolume gap
-
Branching rule: most fractional
-
Adaptively solve weighted sum scalarizations in the root node to integer optimality to improve lower and upper bounds by objective space information
Instead of using a static depth-first strategy (as in the general branch and bound framework in Sect. 3) we apply the dynamic strategy based on the hypervolume gap (c.f. Sect. 4.1). Even though the extreme points of the lower bound sets might be updated by the weighted sum scalarization, the branching variable is selected based on the original lower bounds. This is due to the fact that the preimages of such intersection points of IP scalarizations and the lower bound set are in general not available. Note that the weighted sum IP scalarizations are included adaptively into the branch and bound. The description of their algorithmic control, however, is postponed to Sect. 4.3.
In order to conclude the description of the proposed hybrid branch and bound algorithm using weighted sum scalarizations, we want to briefly discuss its advantages and shortcomings. Firstly, it is easy to determine the scalarization parameter \(\lambda \) and to integrate the hyperplane into the lower bound set. Its advantage, however, is that the lower bound remains convex. Therefore, the check for fathoming by dominance remains intuitive. Unfortunately, the weighted sum scalarization can only find supported efficient solutions and the lower bound cannot be improved beyond the convex hull of \(Y_N\). This motivates us to consider the augmented weighted Tchebycheff scalarization, a scalarization approach which can determine also unsupported efficient solutions.
4.2.2 Using augmented weighted Tchebycheff scalarization
We start by defining the weighted Tchebycheff norm: Let \(w_i > 0,\; i=1,\ldots ,p\) be positive weights with \(\sum _{i=1}^p w_i = 1\). Then the weighted Tchebycheff norm of a vector \(z\in \mathbb {R}^p\) is defined by
So, the weighted Tchebycheff scalarization of a multi-objective optimization problem (MOILP) with respect to a given reference point \(s\in \mathbb {R}^p\) can be written as:
If the reference point is chosen such that \(s<z(x)\) for all \(x\in X\), every efficient solution can be determined as optimal solution of the weighted Tchebycheff scalarization (2) by variation of \(w\in \mathbb {R}^p_+\) (see, e.g., Miettinen 1998). Nevertheless, optimal solutions of the weighted Tchebycheff scalarization correspond in general only to weakly efficient solutions of the multi-objective problem (Steuer and Choo 1983; Miettinen 1998). This shortcoming is compensated by an additive augmentation term in the augmented weighted Tchebycheff norm
where \(\Vert z\Vert _1 = \vert z_1\vert +\cdots +\vert z_p\vert \) denotes the \(L_1\)-norm, \(w_i \ge 0\), \(i=1,\ldots , p\), \(\sum _{i=1}^p w_i = 1\) and \(\tau >0\). Steuer and Choo (1983) proposed the augmented weighted Tchebycheff scalarization given in (\(AWT_\tau ^w\)).

Thereby, the augmentation term makes the augmented weighted Tchebycheff norm a strongly monotone norm and thus the objective function of (\(AWT_\tau ^w\)) a strongly increasing achievement scalarizing function (Miettinen 1998). Consequently, every optimal solution of (\(AWT_\tau ^w\)) is efficient for (MOILP).
Note that an appropriate choice of the parameter \(\tau \) is difficult in general. On the one hand, too small values of \(\tau \) may lead to numerical difficulties. On the other hand, non-supported efficient solutions might be suboptimal for (\(AWT_\tau ^w\)) if the value of \(\tau \) is too large. However, for bi-objective integer programming (Dächert et al. 2012) propose an adaptive method to determine an optimal value of \(\tau \). We use the proposed parameters \(w_1,w_2\) and \(\tau \) for our method.
As a reference point s we use the local ideal point of two adjacent non-dominated points. Since the augmented weighted Tchebycheff scalarization can only determine non-dominated points (and the corresponding efficient solutions) which are (strictly) dominated by the reference point, we obtain a non-dominated point in this box.

Example of updating the lower and upper bound with the usage of the augmented weighted Tchebycheff scalarization
The goal to improve the lower bound set beyond the convex hull of non-dominated points is the motivation to solve augmented weighted Tchebycheff scalarizations to integer optimality. Figure 3 shows an example how such an update of the bounds could look like. Here, \(z^1\) and \(z^2\) are two known non-dominated points (obtained with the weighted sum IP scalarization). Point \(z^3\) is a non-supported non-dominated point that has not been found yet in Fig. 3a. By using the local ideal point of \(z^1\) and \(z^2\) as the reference point s, Fig. 3b illustrates how the non-dominated point \(z^3\) is found by applying the augmented weighted Tchebycheff scalarization. In Fig. 3c, d the resulting improvements of the lower and upper bound are shown. Obviously the lower bound is improved beyond the convex hull of \(Y_N\). We now define our second hybrid branch and bound approach:
Hybrid Branch and Bound Algorithm using Augmented Weighted Tchebycheff Scalarization
-
Lower bound: linear relaxation
-
Upper bound: incumbent list
-
Node selection: node with the biggest total/local hypervolume gap
-
Branching rule: most fractional
-
Adaptively solve weighted sum and augmented weighted Tchebycheff scalarizations in the root node to integer optimality to improve lower and upper bounds by objective space information
In addition to the weighted sum scalarization, we use the augmented weighted Tchebycheff scalarization. Since two adjacent non-dominated points are required as input of the augmented weighted Tchebycheff scalarization, we cannot rely on points in the incumbent list, which are only non-dominated so far. In fact, we apply augmented weighted Tchebycheff IP scalarizations only to boxes spanned by points obtained as optimal solutions of the weighted sum scalarization. Thus, we do not rely on parameters from the currently active node, but solve the augmented weighted Tchebycheff scalarization in the largest area defined by two adjacent known non-dominated points.
When using augmented weighted Tchebycheff IP scalarizations, the lower bound can become tighter than the convex hull of the set of non-dominated points, which reduces the area where new non-dominated points can be found. Additionally, we can find non-supported non-dominated points in early stages of the algorithm. This improves the upper bound in the beginning resulting in a higher chance of fathoming a node by dominance. However, this also implies that the lower bound gets non-convex in general, which makes the fathoming tests significantly harder, and the lower bound improves only locally.
4.3 Algorithmic control of IP scalarizations
In the previous subsections we did not specify when to solve IP scalarizations, which implies a significant computational cost itself. However, this might be the most crucial part within the presented methods. Obviously, we aim at gaining as much information as possible by solving IP scalarizations. More objective space information will lead to tighter bounds that reduce the number of created nodes, due to a higher probability of fathoming by dominance and smaller search zones. Moreover, a reduced number of created nodes will reduce the total computation time. At the same time, solving overly many IP scalarizations will have a negative impact on the computation time. Furthermore, at a certain point the lower and upper bound will not improve anymore when solving additional IP scalarizations.
So, there exists a trade-off between the reduction of the number of created subproblems and the decrease of the computation time. The difficulty is to find an appropriate condition to trigger an IP scalarization. Obviously, solving IP scalarizations more frequently in the beginning of the branch and bound algorithm is very promising. The earlier the lower and upper bounds are improved the more nodes might be fathomed. Moreover, solving the IP scalarization when the active node has weak bounds will lead to stronger improvements than in later stages of the algorithm. This is complemented by our adaptive branching strategy, which tends to select subproblems with weak lower bounds first.
The hybrid branch and bound algorithm using augmented weighted Tchebycheff scalarization entails also another problem. The augmented weighted Tchebycheff scalarization improves the lower bound just locally. If we use this scalarization at the beginning of the algorithm instead of the weighted sum scalarization, this could lead to an increase of created nodes. Once again, the intuitive idea is to start with the weighted sum IP scalarization more frequently in the beginning of the algorithm. This ensures that the lower bound improves globally at early stages of the branch and bound. The augmented weighted Tchebycheff scalarization should be used in later stages of the algorithm to find non-supported non-dominated points and to improve the lower bound locally. The efficiency of this idea and other approaches will be shown in the next section where we present numerical test results.
5 Numerical results
All algorithms were implemented in Julia 1.7.1 and the linear relaxations were solved with Bensolve 2.1 (Löhne and Weißing 2017). The numerical tests were executed on a single core of a 3.20 GHz Intel® Core™ i7-8700 CPU processor in a computer with 32 GB RAM, running under openSUSE linux Leap 15.3.
We present numerical results of our new approaches and compare them to the general branch and bound framework presented in Sect. 3 which we use as baseline implementation. We consider three different types of problems: multidimensional knapsack problems, assignment problems and discrete facility location problems. The implementation of the proposed multiobjective branch and bound method and the considered benchmark instances are publicly available (Bauß and Stiglmayr 2023). Multiple combinations of parameter settings are used to solve these test problems. Thereby, we compare the average number of explored nodes, the average number of solved IPs and the average computation time for 20 instances per problem size. The different evaluated approaches are
-
the generic bi-objective Branch and Bouch (BB),
-
bi-objective branch and bound using the local (BS1) respectively global (BS2) hypervolume gap as node selection criterion,
-
hybrid branch and bound including weighted sum IP scalarizations (WS), and
-
different combinations of the hybrid branch and bound algorithm using weighted sum IP scalarization (M1.\(\alpha \).\(\beta \)) and hybrid branch and bound algorithm using weighted sum and augmented weighted Tchebycheff IP scalarization (M2.\(\alpha \).\(\beta \).\(\gamma \)).
The parameter \(\alpha \in \{1,2,3\}\) controls how often IP scalarizations are applied. Since the number of IP scalarizations is chosen depending on the problem class, the meaning of the different values for \(\alpha \) is described in detail in the corresponding subsections. In general, however, the larger the parameter \(\alpha \) is chosen, the fewer IP scalarizations are solved. With \(\beta \) we distinguish between the local (\(\beta =1\)) and the global (\(\beta =2\)) hypervolume gap strategy. In the hybrid branch and bound algorithm using augmented weighted Tchebycheff scalarization we also distinguish between integrating the objective space information of the augmented weighted Tchebycheff into the lower bound (\(\gamma =1\)) or not (\(\gamma =2\)).
Note that the parameter values have been chosen based on preliminary results obtained from a different sets of instances, where they shown to provide good results. Thus, the parameter values are chosen depending on the problem class but are not optimized w.r.t. the specific test instances. Hence, we avoid an instance depending fitting of the parameters to the data set.
5.1 Bi-objective multidimensional knapsack problems
We consider bi-objective, multidimensional knapsack problems with one, two and three linear restrictions (i. e. \(m=1,2,3\)). For every problem size we randomly generate 20 instances of the form
with \(c^k_i \in [50,100]\), \(w_i \in [ 5,15]\), \(b = 5\, n, v_{ij}\in [ 5,15]\) and \(d_j=\left\lfloor \frac{r\,n}{2}\right\rfloor \) with \(r\in [5,15]\). Depending on the parameter \(\alpha \) we specify when and how often IP scalarizations are solved. In M1.1.\(\beta \) and WS we apply the weighted sum scalarization every 10-th iterations. In M1.2.\(\beta \) we apply it every 10-th iteration but only within the first \(n^2\) iterations. In M1.3.\(\beta \) we apply the weighted sum scalarization every 10-th iteration within the first \(n^2/3\) iterations, every n-th iteration within the next \(n^2/3\) iterations and every 2n-th iteration within the third \(n^2/3\) iterations. In M2.1.\(\beta \).\(\gamma \) we apply the weighted sum scalarization every 10-th iteration and every 50-th iteration the augmented weighted Tchebycheff scalarization is used instead. In M2.2.\(\beta \).\(\gamma \) we operate like in M1.2.\(\beta \) but after the first \(n^2\) iterations we apply the augmented weighted Tchebycheff scalarization every 50-th iteration. In M2.3.\(\beta \).\(\gamma \) we operate like in M1.3.\(\beta \) but after the first \(n^2\) iterations we apply the augmented weighted Tchebycheff scalarization every 50-th iteration. If a scalarization cannot be applied or the same IP scalarization has already been solved before, no IP scalarization is solved in that iteration.
First of all, we notice that our branching strategies have a huge impact on the number of explored nodes and the computation time in knapsack problems. We observe that in general the local hypervolume gap strategy works better than the global hypervolume gap strategy. With the local strategy we can reduce the number of explored nodes by up to \(76\%\) (Table 1c, b) and the computation time by up to \(73\%\) (Table 1c). Although the local strategy works better the global hypervolume gap strategy has also a significant impact. The number of explored nodes can be reduced by up to \(58\%\) (Table 2c) and the computation time by up to \(52\%\) (Table 2c). The number of nodes and the computation time is reduced in all our approaches and we can notice that combinations with the local hypervolume strategy work better.
By limiting the number of solved weighted sum IPs (i. e. in M1.2.\(\beta \), M1.3.\(\beta \), M2.2.\(\beta \).\(\gamma \) and M2.3.\(\beta \).\(\gamma \)) we notice two consequences. The number of nodes increases while the number of solved IPs decreases. Although the number of nodes (and thus the number of considered subproblems) is increasing, the total computation time decreases. This implies that the reduced computation time to solve IP scalarizations compensates the increase of nodes, which results in a trade-off between the number of explored nodes and the computation time. Another interesting aspect can be observed in M2.\(\alpha \).\(\beta \).1 and M2.\(\alpha \).\(\beta \).2. The computation time can be reduced if we do not integrate the augmented weighted Tchebycheff objective level set into the lower bound. This can be explained by the fact that the lower bound improvements of augmented weighted Tchebycheff are only local and do not compensate the computation time needed to integrate the information. The intuitive assumption that the number of explored nodes will then rise significantly is false. So, both our branching strategies work better, if we do not consider the local updates of the lower bound.
We can reach a reduction of the explored nodes by up to \(83\%\) (Table 2b) and a reduction of the computation time by up to \(80\%\) (Table 2b) in the best case. The strategies M2.1.1.1 and M2.1.1.2 seem to work best for knapsack problems. In most cases these two strategies have the largest impact on the number of explored nodes. Nevertheless, M2.1.1.2 achieves for all instance sizes the best computation times, since computation time is saved by not integrating the augmented weighted Tchebycheff objective space information into the lower bound. Note that with rising numbers of variables and constraints the hybridization techniques have larger impact on the performance of the branch and bound algorithm.
5.2 Bi-objective assignment problems
We consider bi-objective assignment problems having \(n=\ell ^2\) variables,

where the cost coefficients \(c_{ij}^k \in \left[ 50,100 \right] \). The algorithmic strategy for the solution of IP scalarizations depending on the value of the parameter \(\alpha \) is chosen similarly to the previous case of knapsack problems. However, we adapt the boundaries due to the different number of nodes to explore in assignment problems. In M1.1.\(\beta \) weighted sum scalarizations are solved every 10-th iteration to integer optimality. In M1.2.\(\beta \) we apply the weighted sum every 10-th iteration within the first \(n\cdot \ell \) iterations. In M1.3.\(\beta \) we apply the weighted sum every 10-th iteration within the first \(n\cdot \ell /3\) iterations, every \(\ell \)-th iteration in the next \(n\cdot \ell /3\) iterations and every n-th iteration in the third \(n\cdot \ell /3\) iterations. For M.2.\(\alpha \).\(\beta \).\(\gamma \) we use the same algorithmic strategy as in hybrid branch and bound for knapsack problems. If a scalarization cannot be applied or an IP with identical objective function has been solved prior, no IP is solved in that iteration.
Due to the total unimodularity of the assignment problem, the weighted sum scalarizations do in general not improve the lower bound sets of subproblems. However, in situations where the weighted sum IP scalarization generates a supported efficient solution, whose corresponding non-dominated point is not an extreme point of the lower bound set, the local upper bounds move closer to the lower bound set. This reduces the gap between upper and lower bound and may lead to a decrease of the explored subproblems. Note that this update of the upper bound set may also have the contrary effect (the number of considered subproblems increases), since it can change the order in which the subproblems are considered. Although in general the weighted sum IP scalarizations are necessary to determine non-dominated points based on which the augmented weighted Tchebycheff scalarization can be applied, they are redundant for assignment problems due to the total unimodularity of their constraint matrix. Thus, all extreme supported non-dominated points (and their corresponding solutions) are obtained as extreme points of the lower bound set by the linear relaxation of the original problem which is solved in the root node of the branch and bound tree. However, we do not adjust our branch and bound algorithm for totally unimodular problem classes to maintain comparable numerical results and general applicability.
Our branching strategies have a significant impact on the number of explored nodes and the computation time. Again, the local hypervolume gap performs better than the global hypervolume gap strategy. With the local strategy we can reduce the number of explored nodes by up to \(39\%\) (Table 3c) and the computation time by up to \(33\%\) (Table 3c). Using the global hypervolume gap strategy we can reduce the number of explored nodes by up to \(12\%\) (Table 3b) and the computation time by up to \(12\%\) (Table 3b). We reach a reduction of the explored nodes by up to \(46\%\) (Table 3d) and a reduction of the computation time by up to \(42\%\) (Table 3d), in the best case. Again, the strategies M2.1.1.1 and M2.1.1.2 seem to work the best for assignment problems in terms of explored nodes. Nevertheless, M2.1.1.2 leads to a better computation time which can be explained by the same argument as before. Furthermore, strategy BS1 works very well and is able to compete with the previously mentioned strategies with respect to number of nodes and computation time without solving a single IP scalarization.
5.3 Bi-objective discrete facility location problems
We consider discrete facility location problems of the form

where \(\ell \) is the number of customers and q the number of facilities. We randomly generate coordinates of \(\ell \) customers and q facilities in a square with length 200. The costs of the first objective function correspond to the \(l_1\)-distances between the customers and facilities, while the costs of the second objective function are randomly generated (i. e. \(c_{ij}^2\in [1,200]\)) and \(f_j^k\in [200,400]\). The number of variables is \(n=(\ell +1)\,q\). We restrict the numerical tests to problems where the number of facilities is \(20\%\) of the number of customers. Again, we need to specify when and how often integer scalarizations are applied: We use the same methods as before but adapt the boundaries due to the different number of nodes to explore in discrete facility location problems. In M1.1.\(\beta \) we apply the weighted sum IP scalarization every 10-th iteration. In M1.2.\(\beta \) we apply the weighted sum every 10-th iteration within the first \(n^2/4\) iterations. In M1.3.\(\beta \) we apply the weighted sum scalarization every 10-th iteration in the first \(n^2/4\) iterations, every n/2-th iteration in the next \(n^2/4\) iterations and every n-th iteration in the third \(n^2/4\) iterations. In M.2.\(\alpha \).\(\beta \).\(\gamma \) we operate analogous to the methods used for knapsack and assignment problems. If a scalarization cannot be applied or an IP with identical objective function has been solved prior, no IP is solved in that iteration.
Again, both new branching strategies have an impact on the number of explored nodes and the computation time. The local strategy, once more, leads to better results, namely reduction of the explored nodes by up to \(52\%\) (Table 4d) and reduction of the computation time by up to \(45\%\) (Table 4d). With the global hypervolume gap strategy we can reach a reduction of the explored nodes by up to \(24\%\) (Table 4d) and a reduction of the computation time by up to \(21\%\) (Table 4d). In the best case we can reach a reduction of the explored nodes by up to \(57\%\) (Table 4d) and of the computation time by up to \(50\%\) (Table 4d). Once again, M2.1.1.2 seems to be the best choice with respect to the number of explored nodes and with a rising number of variables it is also the best choice regarding the computation time. With a smaller number of variables, BS1 leads to good results with respect to both aspects without solving a single IP.

Visualization of branch and bound node reduction and runtime reduction for varying test instance sizes on a selection of approaches
5.4 Summary
In all of the three tested problem classes (knapsack, assignment, discrete facility location) a significant reduction of the number of explored nodes and the computation time can be realized with all presented combinations of the hybrid branch and bound approach. With increasing problem size (number of variables) the impact of the presented augmentations increases. Furthermore, the approaches perform better on problems where the gap between \(Y_N\) and the solution of the linear relaxation is larger compared to totally unimodular problems. The reduction in terms of the number of branch and bound nodes and runtime we achieve with the proposed methods as compared to plain branch and bound is visualized in Fig. 4 for varying instance sizes.
The local hypervolume gap strategy for the node selection outperforms the global hypervolume gap strategy in our numerical tests. A reason for this is that in the global hypervolume gap strategy many small search zones can add up to a large gap although the lower bound might be quite close to the non-dominated points. The local hypervolume gap strategy chooses the node with the largest search zone, which has the biggest potential to reduce this gap. Moreover, the local hypervolume gap strategy aims at an uniform distribution of points in the incumbent list. In our numerical test, M2.1.1.2 turn out to be the best choice in most cases with respect to the number of explored nodes and computation time. In this version, we use the local hypervolume gap strategy for the choice of the active node, every 10-th iteration the weighted sum IP scalarization is applied and every 50-th iteration we apply the augmented weighted Tchebycheff scalarization instead. Futhermore, the objective space information gained by the augmented weighted Tchebycheff scalarization is not used to update the lower bound set, since its local improvements do not compensate the increased computation time. Although we need to solve more IPs than in most other approaches, the computation time is the lowest compared to the others. So, using the augmented weighted Tchebycheff scalarization in the beginning of the branch and bound works best. Due to the likelihood of finding non-supported non-dominated points in the early stages of the algorithm, the upper bound can be further improved. This results to a higher probability of fathoming a node by dominance. Nevertheless, with version BS1 we also achive a remarkable reduction in terms of the number of explored nodes and computation time by using the local hypervolume gap strategy for node selection.
6 Conclusion and outlook
In this paper, we propose two approaches to incorporate objective space information in bi-objective branch and bound. By using the local or global (approximated) hypervolume gap as a node selection criterion, we adapt the run of the branch and bound algorithm to the problem instance. Additionally, we adaptively solve scalarizations to integer optimality to improve the lower and the upper bound set by the obtained objective space information. Our numerical results show the effectiveness of both approaches and in particular of their combination. The dynamic branching rule based on the local (approximated) hypervolume gap has large impact on the number of explored subproblems, is compuationally efficient and can be easily integrated in other multi-objective branch and bound algorithms.
While we tested in this paper the individual contributions of our augmentations on a generic bi-objective branch and bound, we will continue to extend our ideas to multiple dimensions and integrate them into a competetive multi-objective branch and bound framework. Particularly in higher dimensions, it may be promising to combine our approaches with objective space branching.
Data availability
The implementation in Julia and the used test datasets are available in Git repository https://git.uni-wuppertal.de/bauss/augmented-bi-objective-branch-and-bound.
References
Aneja YP, Nair KPK (1979) Bicriteria transportation problem. Manag Sci 25(1):73–78. https://doi.org/10.1287/mnsc.25.1.73
Bauß J, Stiglmayr M (2023) Augmented Bi-objective Branch and Bound. Git repository. https://git.uni-wuppertal.de/bauss/augmented-bi-objective-branch-and-bound
Bazgan C, Hugot H, Vanderpooten D (2009) Solving efficiently the 0–1 multi-objective knapsack problem. Comput Oper Res 36(1):260–279. https://doi.org/10.1016/j.cor.2007.09.009
Belotti P, Soylu B, Wiecek MM (2012) A branch-and-bound algorithm for biobjective mixed-integer programs. Technical report. https://optimization-online.org/?p=12266
Benson HP (1998) An outer approximation algorithm for generating all efficient extreme points in the outcome set of a multiple objective linear programming problem. J Glob Optim 13(1):1–24. https://doi.org/10.1023/A:1008215702611
Bökler F, Mutzel P (2015) Output-sensitive algorithms for enumerating the extreme nondominated points of multiobjective combinatorial optimization problems. In: Algorithms—ESA 2015. Springer, Berlin, pp 288–299. https://doi.org/10.1007/978-3-662-48350-3_25
Boland N, Charkhgard H, Savelsbergh M (2015a) A criterion space search algorithm for biobjective integer programming: the balanced box method. INFORMS J Comput 27(4):735–754. https://doi.org/10.1287/ijoc.2015.0657
Boland N, Charkhgard H, Savelsbergh M (2015b) A criterion space search algorithm for biobjective mixed integer programming: the triangle splitting method. INFORMS J Comput 27(4):597–618. https://doi.org/10.1287/ijoc.2015.0646
Boland N, Charkhgard H, Savelsbergh M (2017) The quadrant shrinking method: a simple and efficient algorithm for solving tri-objective integer programs. Eur J Oper Res 260(3):873–885. https://doi.org/10.1016/j.ejor.2016.03.035
Dächert K, Klamroth K (2014) A linear bound on the number of scalarizations needed to solve discrete tricriteria optimization problems. J Glob Optim 61(4):643–676. https://doi.org/10.1007/s10898-014-0205-z
Dächert K, Gorski J, Klamroth K (2012) An augmented weighted Tchebycheff method with adaptively chosen parameters for discrete bicriteria optimization problems. Comput Oper Res 39(12):2929–2943. https://doi.org/10.1016/j.cor.2012.02.021
Dechter R, Pearl J (1985) Generalized best-first search strategies and the optimality of \({{\rm A}} ^*\). J ACM 32(3):505–536. https://doi.org/10.1145/3828.3830
Ehrgott M (2005) Multicriteria Optimization. Springer, Berlin. https://doi.org/10.1007/3-540-27659-9
Ehrgott M, Gandibleux X (2007) Bound sets for biobjective combinatorial optimization problems. Comput Oper Res 34(9):2674–2694. https://doi.org/10.1016/j.cor.2005.10.003
Ehrgott M, Löhne A, Shao L (2012) A dual variant of Benson’s “outer approximation algorithm’’ for multiple objective linear programming. J Glob Optim 52:757–778
Forget N, Gadegaard SL, Klamroth K, Nielsen LR, Przybylski A (2022) Branch-and-bound and objective branching with three or more objectives. Comput Oper Res 148:106012. https://doi.org/10.1016/j.cor.2022.106012
Gadegaard SL, Nielsen LR, Ehrgott M (2019) Bi-objective branch-and-cut algorithms based on LP relaxation and bound sets. INFORMS J Comput 31(4):790–804. https://doi.org/10.1287/ijoc.2018.0846
Haimes Y, Lasdon L, Wismer D (1971) On a bicriterion formation of the problems of integrated system identification and system optimization. IEEE Trans Syst Man Cybernet. https://doi.org/10.1109/TSMC.1971.4308298
Jesus AD, Paquete L, Derbel B, Liefooghe A (2021) On the design and anytime performance of indicator-based branch and bound for multi-objective combinatorial optimization. In: Proceedings of the genetic and evolutionary computation conference. ACM, Lille. https://doi.org/10.1145/3449639.3459360
Kellerer H, Pferschy U, Pisinger D (2004) Knapsack problems. Springer, Berlin. https://doi.org/10.1007/978-3-540-24777-7
Kirlik G, Sayın S (2014) A new algorithm for generating all nondominated solutions of multiobjective discrete optimization problems. Eur J Oper Res 232(3):479–488. https://doi.org/10.1016/j.ejor.2013.08.001
Kiziltan G, Yucaoğlu E (1983) An algorithm for multiobjective zero-one linear programming. Manag Sci 29(12):1444–1453. https://doi.org/10.1287/mnsc.29.12.1444
Klamroth K, Lacour R, Vanderpooten D (2015) On the representation of the search region in multi-objective optimization. Eur J Oper Res 245(3):767–778. https://doi.org/10.1016/j.ejor.2015.03.031
Klein D, Hannan E (1982) An algorithm for the multiple objective integer linear programming problem. Eur J Oper Res 9(4):378–385. https://doi.org/10.1016/0377-2217(82)90182-5
Laumanns M, Thiele L, Zitzler E (2006) An efficient, adaptive parameter variation scheme for metaheuristics based on the epsilon-constraint method. Eur J Oper Res 169(3):932–942. https://doi.org/10.1016/j.ejor.2004.08.029
Löhne A, Weißing B (2017) The vector linear program solver bensolve—notes on theoretical background. Eur J Oper Res 260(3):807–813. https://doi.org/10.1016/j.ejor.2016.02.039
Mavrotas G, Diakoulaki D (1998) A branch and bound algorithm for mixed zero-one multiple objective linear programming. Eur J Oper Res 107(3):530–541. https://doi.org/10.1016/s0377-2217(97)00077-5
Mavrotas G, Diakoulaki D (2005) Multi-criteria branch and bound: a vector maximization algorithm for mixed 0–1 multiple objective linear programming. Appl Math Comput 171(1):53–71. https://doi.org/10.1016/j.amc.2005.01.038
Miettinen K (1998) Nonlinear multiobjective optimization. Springer, New York. https://doi.org/10.1007/978-1-4615-5563-6
Morrison DR, Jacobson SH, Sauppe JJ, Sewell EC (2016) Branch-and-bound algorithms: a survey of recent advances in searching, branching, and pruning. Discret Optim 19:79–102. https://doi.org/10.1016/j.disopt.2016.01.005
Özpeynirci Ö, Köksalan M (2010) An exact algorithm for finding extreme supported nondominated points of multiobjective mixed integer programs. Manag Sci 56(12):2302–2315. https://doi.org/10.1287/mnsc.1100.1248
Parragh SN, Tricoire F (2019) Branch-and-bound for bi-objective integer programming. INFORMS J Comput 31(4):805–822. https://doi.org/10.1287/ijoc.2018.0856
Przybylski A, Gandibleux X (2017) Multi-objective branch and bound. Eur J Oper Res 260(3):856–872. https://doi.org/10.1016/j.ejor.2017.01.032
Przybylski A, Gandibleux X, Ehrgott M (2008) Two phase algorithms for the bi-objective assignment problem. Eur J Oper Res 185(2):509–533. https://doi.org/10.1016/j.ejor.2006.12.054
Przybylski A, Gandibleux X, Ehrgott M (2010a) A recursive algorithm for finding all nondominated extreme points in the outcome set of a multiobjective integer programme. INFORMS J Comput 22(3):371–386. https://doi.org/10.1287/ijoc.1090.0342
Przybylski A, Gandibleux X, Ehrgott M (2010b) A two phase method for multi-objective integer programming and its application to the assignment problem with three objectives. Discrete Optim 7(3):149–165. https://doi.org/10.1016/j.disopt.2010.03.005
Przybylski A, Klamroth K, Lacour R (2019) A simple and efficient dichotomic search algorithm for multi-objective mixed integer linear programs. arXiv. https://doi.org/10.48550/ARXIV.1911.08937
Serafini P (1987) Some considerations about computational complexity for multi objective combinatorial problems. In: Recent advances and historical development of vector optimization. Springer, Berlin, pp 222–232. https://doi.org/10.1007/978-3-642-46618-2_15
Sourd F, Spanjaard O (2008) A multiobjective branch-and-bound framework: application to the biobjective spanning tree problem. INFORMS J Comput 20(3):472–484. https://doi.org/10.1287/ijoc.1070.0260
Steuer RE (1986) Multiple criteria optimization: theory, computation and application. Wiley, New York. https://doi.org/10.1002/oca.4660100109
Steuer RE, Choo E-U (1983) An interactive weighted Tchebycheff procedure for multiple objective programming. Math Program 26(3):326–344. https://doi.org/10.1007/BF02591870
Stidsen T, Andersen KA (2018) A hybrid approach for biobjective optimization. Discret Optim 28:89–114. https://doi.org/10.1016/j.disopt.2018.02.001
Stidsen T, Andersen KA, Dammann B (2014) A branch and bound algorithm for a class of biobjective mixed integer programs. Manag Sci 60(4):1009–1032. https://doi.org/10.1287/mnsc.2013.1802
Tuyttens D, Teghem J, Fortemps P, Nieuwenhuyze KV (2000) Performance of the MOSA method for the bicriteria assignment problem. J Heurist 6(3):295–310. https://doi.org/10.1023/a:1009670112978
Ulungu EL, Teghem J (1995) The two phases method: an efficient procedure to solve bi-objective combinatorial optimization problems. Found Comput Decis Sci 20:149–156
Ulungu EL, Teghem J (1997) Solving multi-objective knapsack problem by a branch-and-bound procedure. In: Multicriteria analysis. Springer, Berlin, pp 269–278. https://doi.org/10.1007/978-3-642-60667-0_26
Vincent T, Seipp F, Ruzika S, Przybylski A, Gandibleux X (2013) Multiple objective branch and bound for mixed 0–1 linear programming: corrections and improvements for the biobjective case. Comput Oper Res 40(1):498–509. https://doi.org/10.1016/j.cor.2012.08.003
Visée M, Teghem J, Pirlot M, Ulungu EL (1998) Two-phases method and branch and bound procedures to solve the bi-objective knapsack problem. J Glob Optim 12(2):139–155. https://doi.org/10.1023/A:1008258310679
Zitzler E, Thiele L (1999) Multiobjective evolutionary algorithms: a comparative case study and the strength pareto approach. IEEE Trans Evol Comput 3(4):257–271. https://doi.org/10.1109/4235.797969
Funding
Open Access funding enabled and organized by Projekt DEAL. The authors thankfully acknowledge financial support by Deutsche Forschungsgemeinschaft, Project Number KL 1076/11-1.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bauß, J., Stiglmayr, M. Augmenting bi-objective branch and bound by scalarization-based information. Math Meth Oper Res (2024). https://doi.org/10.1007/s00186-024-00854-3
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00186-024-00854-3