
Abstract
The problem of optimal estimation of location and scale parameters of absolutely continuous distributions, by means of two-dimensional confidence regions based on L-statistics, is considered. The case, when the sample size is random and tends to infinity, is studied. The paper can be considered as a supplement to Zaigraev and Alama-Bućko (Metrika 81:283–305, 2018) in case of samples of random size.
Similar content being viewed by others


1 Introduction
The problem of optimal confidence interval/region estimation is one of the classical problems of Mathematical Statistics. Although, it has mainly been investigated for a single unknown parameter, the multivariate case has also quite a rich history, starting with confidence regions of rectangular shape (see, e.g., S̆idák 1967) and ending with those of arbitrary shape (see, e.g., Czarnowska and Nagaev 2001; Alama-Bućko et al. 2006; Zaigraev and Alama-Bućko 2013, 2017, 2018). But in all the cases only samples of non-random size have been taken into account.
Here, the samples of random size are studied and the case of two unknown parameters is considered, where the first parameter \(\vartheta _1\in \mathbb {R}\) is location and the second parameter \(\vartheta _2>0\) is scale. Therefore, two-dimensional confidence regions as estimators of \(\vartheta =(\vartheta _1, \vartheta _2)\) are considered. A solution to the problem of construction of the optimal confidence region for large samples was obtained, e.g., in Zaigraev and Alama-Bućko (2013, 2018). Thus, this note can be considered as a supplement to Zaigraev and Alama-Bućko (2018) in case of samples of random size.
Traditionally, the size of the available sample is assumed to be deterministic, but in practice the size of the data available for statistical analysis can be often treated as random. Indeed, quite often the number of observations available is unknown until the end of the recording process and also can be treated as an (random) observation. This is the case, for example, in insurance statistics, where in different accounting periods the numbers of insurance claims are different. Or in medical statistics, where the number of patients with a particular disease varies from month to month due, e.g., to seasonal factors or from year to year due, e.g., to some epidemic. In these cases, the number of observations available, as well as the observations themselves, are previously unknown and should be treated as random.
In this note, we discuss the problem described above for samples of random size and compare the quality of estimators constructed from samples of random and non-random size.
We start with notation, assumptions and a review of the construction of the optimal confidence region given in Zaigraev and Alama-Bućko (2018) for samples of non-random size (Sect. 2), while our main result is given in Sect. 3. In that section we essentially use the results from Korolev (2000) and Bening and Korolev (2005).
2 Notation and recollections
Let \(\textbf{x}=(x_1,x_2,\ldots ,x_n)\) be a sample from a distribution \(\mathbb {P}_{\vartheta },\) that is \(\{x_i\}^n_{i=1}\) are assumed to be independent real-valued random variables having the distribution \(\mathbb {P}_{\vartheta }.\) Let \(F=F_{(0,1)}\) be the continuous distribution function corresponding to \(\mathbb {P}_{(0,1)}\) and let
be the quantile function. The distribution \(\mathbb {P}_{(0,1)}\) is assumed to be absolutely continuous with the density function f. Let \(x_{m_1:n}, x_{m_2:n},\ldots ,x_{m_k:n}\) be the order statistics corresponding to the sample \(\textbf{x},\ 1\leqslant m_1<m_2<\ldots <m_k\leqslant n,\) and let \(0<p_1<p_2<\ldots<p_k<1\) be such numbers that \(m_i/n-p_i=o(n^{-1/2}),\) as \(n\rightarrow \infty ,\) and \(f(F^{-1}(p_i))>0,\ i=1,\ldots ,k.\) In what follows we confine ourselves with the case of central order statistics (the treatment of the more general case for samples of deterministic size is detailed in Zaigraev and Alama-Bućko (2018)).
We propose to base the construction of optimal confidence region for \(\vartheta \) on L-statistics \(t_1(\cdot )\) and \(t_2(\cdot )\) being the asymptotically best linear unbiased estimators of \(\vartheta _1\) and \(\vartheta _2,\) respectively. As it is well-known (see, e.g., Masoom Ali and Umbach (1998) or Zaigraev and Alama-Bućko (2018)), these estimators look as follows:
where
\(\textbf{1}_k=(1,\ldots ,1)\in \mathbb {R}^k,\ \textbf{u}=(F^{-1}(p_1),\ldots ,F^{-1}(p_k)),\ V=(V_{ij})^k_{i,j=1}\) with
Note that the well-known result on the form of the asymptotic distribution of selected central order statistics, established by Mosteller (see Mosteller (1946) or David and Nagaraja (2003), Subsection 10.3), is used here.
Let \(\alpha \in (0,1)\) be a given small number, while \(\textbf{y}=(y_1,y_2,\ldots ,y_n)\) be a sample from the distribution \(\mathbb {P}_{(0,1)}.\) Denote \(T_n(\textbf{y})=(-t_1(\textbf{y})/t_2(\textbf{y}),1/t_2(\textbf{y})-~\!1).\) Taking a set \(A_n\in \mathcal {B}^2\) such that \(\mathbb {P}_{(0,1)}\left( \sqrt{n}T_n(\textbf{y})\in A_n\right) =1-\alpha ,\) one can obtain
(here \(\mathcal {B}^2\) denotes the \(\sigma \)-algebra of Borel subsets of \(\mathbb {R}^2\)).
Thus, the set
is a confidence region of level \(1-\alpha \) for \(\vartheta ;\) its quality can be characterized by the risk function defined as
where \(\lambda _2\) is the Lebesgue measure on \(\mathcal {B}^2.\) Under the assumption that the density function \(g_n\) of \(T_n(\textbf{y})\) is continuous and such that
the confidence region \(B_{A^*_n}\) with
is optimal among all the confidence regions of the form (1), that is it has the smallest value of (2) (see Einmahl and Mason (1992)), where \(z_{\alpha }\) is defined by the equation
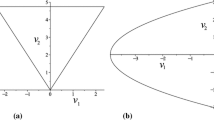
and \(\bar{g}_n(\textbf{v})=(1/n)g_n(\textbf{v}/\sqrt{n})\) is the density function of \(\sqrt{n}T_n(\textbf{y}).\) Moreover, Zaigraev and Alama-Bućko (2017; 2018), have established that \(\sqrt{n}T_n(\textbf{y})\) has asymptotically, as \(n\rightarrow \infty ,\) 2-dimensional normal distribution \(\mathcal{N}_2(0,W)\) and the set \(A^*_n,\) as \(n\rightarrow \infty ,\) tends to the ellipse \(A_0=\{\textbf{v}\in \mathbb {R}^2\!: \textbf{v}W^{-1}\textbf{v}^T\leqslant 2\ln {\alpha ^{-1}}\},\) where
Therefore,
Since \(\lim _{n\rightarrow \infty }\mathbb {E}_{\vartheta }t_2^2(\textbf{x})=\theta _2^2\lim _{n\rightarrow \infty }\mathbb {E}_{(0,1)}t_2^2(\textbf{y})=\theta _2^2,\) the order of the risk function \(\mathbb {R}(\vartheta ,B_{A^*_n})\) for positive and finite limit value of \(\det W\) is 1/n, as \(n\rightarrow ~\!\infty .\)
3 Main result
From now on the notation \({\mathop {\Longrightarrow }\limits ^{D}}\) means the convergence of random variables or random vectors in distribution. Let \((N_n)_{n\geqslant 1}\) be a sequence of integer-valued non-negative random variables such that \(N_n\) and \(x_1, x_2,\ldots , x_n\) are independent for any n. We assume that
(A) \(\ N_n\rightarrow \infty \) in probability, \(N_n/n{\mathop {\Longrightarrow }\limits ^{D}}Y,\) as \(n\rightarrow \infty ,\) and \(\mathbb {E}N_n=n\ \forall n\in {\mathbb N},\) where Y is a non-degenerate random variable having an absolutely continuous distribution with a distribution function G and a density function g.
The next example contains a sequence \((N_n)_{n\geqslant 1}\), for which condition (A) is fulfilled.
Example
Assume that a random variable X has a negative binomial distribution with parameters \(r>0\) and \(p\in (0,1)\) (denote as \(\mathcal{N}\mathcal{B}(r,p)\) distribution), i.e.
with \(\mathbb {E}X=r(1-p)/p.\) If r is non-integer, then \({r+k-1\atopwithdelims ()k}\) is interpreted as
Note that \(\mathcal{N}\mathcal{B}(1,p)\) is the geometric distribution (denoted further as Geo(p)).
Bening and Korolev (2005) show that if the random variable \(N_n\) has \(\mathcal{N}\mathcal{B}(m/2, m/(m+2n))\) distribution given \(m>0, n\in {\mathbb N},\) then \(N_n/n{\mathop {\Longrightarrow }\limits ^{D}}U_{m/2},\) as \(n\rightarrow \infty ,\) where \(U_{m/2}\) is a random variable having the gamma distribution G(m/2, m/2) (it is the scaled \(\chi ^2_m\) distribution) with the density
In particular, if the random variable \(N_n\) has \({ Geo}(1/(n+1))\) distribution, \(n\in {\mathbb N},\) then \(N_n/n{\mathop {\Longrightarrow }\limits ^{D}}U_1\) (\(U_1\) has the standard exponential distribution), as \(n\rightarrow \infty .\)
The next result is due to Korolev (2000) and describes the asymptotic distribution of selected central order statistics in case of samples of random size. It can be considered as a generalization of Mosteller’s result.
Theorem 1
Assume that assumptions made in Sect. 2 and assumption (A) hold. As \(n\rightarrow \infty ,\)
where \(Z_{k,V}\) stands for the random vector having the k-variate normal distribution \(\mathcal{N}_k(0,V).\) The distribution function and the density of the limit distribution can be written as
respectively, where \(\Phi _{k,V}\) and \(\phi _{k,V}\) denotes the distribution function and the density corresponding to \(\mathcal{N}_k(0,V),\) respectively.
It is worth noting that the limit distribution, established in Theorem 1, belongs to the class of elliptical distributions.
The adaptation of Theorem 1 to the random variables \((N_n)_{n\geqslant 1},\) having negative binomial distributions, gives the following result.
Corollary
If the random variable \(N_n\) has \(\mathcal{N}\mathcal{B}(m/2, m/(m+2n))\) distribution, \(n\in {\mathbb N},\) then under the conditions of Theorem 1, as \(n\rightarrow \infty ,\)
where \(T_k(m,V)\) is a random vector having k-dimensional Student distribution with the density
If the random variable \(N_n\) has \({ Geo}(1/(n+1))\) distribution, \(n\in {\mathbb N},\) then the above limit distribution is \(T_k(2,V).\)
In what follows, let \(\mathcal{G}(s), s>0,\) be the Laplace transform of the function g, while \(\mathcal{G}^{-1}\) be the inverse function to \(\mathcal{G},\) that is
The inverse function exists since the derivative
is always negative.
The next result determines the asymptotic of the optimal confidence region in case of samples of random size.
Theorem 2
Under the conditions of Theorem 1,
-
1.
\(\sqrt{n}T_{N_n}(\textbf{y})\ {\mathop {\Longrightarrow }\limits ^{D}} Z_{2,W}/\sqrt{Y},\) as \(n\rightarrow \infty ,\) and the density of the limit distribution has the form
$$\begin{aligned} h(\textbf{v})=\int ^{\infty }_0u\varphi _{2,W}(\sqrt{u}\textbf{v})g(u)du,\quad \textbf{v}\in \mathbb {R}^2. \end{aligned}$$(5)In particular, if the random variable \(N_n\) has \(\mathcal{N}\mathcal{B}(m/2,m/(m+2n))\) distribution, \(n\in {\mathbb N},\) then the random vector \(Z_{2,W}/\sqrt{Y}\) has \(T_2(m,W)\) distribution; if the random variable \(N_n\) has \({ Geo}(1/(n+1))\) distribution, \(n\in {\mathbb N},\) then the random vector \(Z_{2,W}/\sqrt{Y}\) has \(T_2(2,W)\) distribution.
-
2.
The set \(A^*_n,\) as \(n\rightarrow \infty ,\) tends to the ellipse \(A'_0=\{\textbf{v}\in \mathbb {R}^2: \textbf{v}W^{-1}\textbf{v}^T\leqslant 2\mathcal{G}^{-1}(\alpha )\},\) and
$$\begin{aligned} \lim _{n\rightarrow \infty } \lambda _2(A^*_n)=\lambda _2(A'_0)=2\pi \sqrt{\det W}\mathcal{G}^{-1}(\alpha ). \end{aligned}$$
Proof
The proof of the first part is based on Theorem 1 and the limit distribution of \(\sqrt{n}T_{N_n}(\textbf{y}),\) that established similarly as the limit distribution of the corresponding statistic for the samples of non-random size (see Corollary 1 of Zaigraev and Alama-Bućko (2018)). As to the proof of the second part, note that the function h, defined by (5), can be written as
The set \(A^*_n,\) as \(n\rightarrow \infty ,\) approximates the set \(A'_0=\{\textbf{v}\in \mathbb {R}^2: \ \ h(\textbf{v})\geqslant z'_{\alpha }\},\) where \(z'_{\alpha }\) is defined by the equality
Since
the function \(-\mathcal{G}'\) is monotonically decreasing, that is why
for some \(a>0\) and, moreover, \(\lambda _2(A'_0)=2a\pi \sqrt{\textrm{det} W}.\)
Changing the variables in (6): \(v_1=r\cos \beta , v_2=r\sin \beta , r\geqslant 0,\beta \in [0,2\pi ),\) we obtain
where \(\sigma ^2(\beta )=[\cos \beta \ \sin \beta ]W^{-1}[\cos \beta \ \sin \beta ]^T.\) Since
we obtain
From (7) it follows that taking \(z'_{\alpha }=0\) we get \(a=+\infty ,\) and the same reasoning as above leads us to the formula
Substituting (9) in (8), we have
and \(\lambda _2(A'_0)=2\pi \sqrt{\det W}\mathcal{G}^{-1}(\alpha ).\) \(\square \)
Remark 1
The value \(\lambda _2(A'_0)=2\pi \sqrt{\det W}\mathcal{G}^{-1}(\alpha )\) from Theorem 2 is larger than \(\lambda _2(A_0)=2\pi \sqrt{\det W}\ln \alpha ^{-1}\) from Sect. 2. Indeed, since \(\mathbb {E}Y=1,\) from Jensen’s inequality it follows that \(\mathbb {E}\alpha ^Y>\alpha ^{\mathbb {E}Y}=\alpha ,\) i.e.
Example
(continuation) If the random variable \(N_n\) has \(\mathcal{N}\mathcal{B}(m/2, m/(m+2n))\) distribution, \(n\in {\mathbb N},\) then the function h has the form (see (4) for \(k=2\)):
In this case the function g is defined by (3) and
while
Therefore, \(A'_0=\{\textbf{v}\in \mathbb {R}^2: \textbf{v}W^{-1}{} \textbf{v}^T\leqslant m\left( \alpha ^{-2/m}-1\right) \},\) and
Evidently, \(\lambda _2(A'_0)>\lambda _2(A_0)\quad \Longleftrightarrow \)
The last inequality is a consequence of the known inequality: \(x-1>\ln {x}\) \(\forall x>1.\) Moreover, note that \(m(\alpha ^{-2/m}-1)\rightarrow 2\ln {\alpha }^{-1}\), as \(m\rightarrow \infty .\)
Remark 2
If the distribution of Y is degenerate and \(N_n/n\rightarrow 1\) in probability, as \(n\rightarrow \infty ,\) then the results for samples of random size do not differ from those, obtained when the sample size is non-random (Sect. 2).
References
Alama-Bućko M, Nagaev AV, Zaigraev A (2006) Asymptotic analysis of minimum volume confidence regions for location-scale families. Appl Math (Warszawa) 33:1–20
Bening VE, Korolev VYu (2005) On an application of the Student distribution in the theory of probability and mathematical statistics. Theory Probab Appl 49:377–391
Czarnowska A, Nagaev AV (2001) Confidence regions of minimal area for the scale-location parameter and their applications. Appl Math (Warszawa) 28:125–142
David HA, Nagaraja HN (2003) Order statistics. Wiley, New York, p 458
Einmahl JHJ, Mason DM (1992) Generalized quantile processes. Ann Stat 20:1062–1078
Korolev VYu (2000) Asymptotic properties of sample quantiles constructed from samples with random sizes. Theory Probab Appl 44:394–399
Masoom Ali M, Umbach D (1998) Optimal linear inference using selected order statistics in location-scale models. In: Handbook of statistics, vol 17, North-Holland, Amsterdam, pp 183–213
Mosteller F (1946) On some useful inefficient statistics. Ann Math Stat 17:377–408
S̆idák Z (1967) Rectangular confidence regions for the means of multivariate normal distributions. J Am Stat Assoc 62(318):626–633
Zaigraev A, Alama-Bućko M (2013) On optimal choice of order statistics in large samples for the construction of confidence regions for the location and scale. Metrika 76:577–593
Zaigraev A, Alama-Bućko M (2017) Asymptotics of the optimal confidence region for shift and scale, based on two order statistics. In: Statistical methods of estimation and testing hypotheses, in Russian, Perm University, Perm, pp 49-65 (2006); translated in: J Math Sci 220(6):763-776
Zaigraev A, Alama-Bućko M (2018) Optimal choice of order statistics under confidence region estimation in case of large samples. Metrika 81:283–305
Acknowledgements
The author is grateful to the referee for useful corrections improving the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zaigraev, A. A note on asymptotics of the risk function under confidence region estimation in case of large samples of random size. Metrika 87, 201–209 (2024). https://doi.org/10.1007/s00184-023-00910-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00184-023-00910-8