
Abstract
In the process of rotating machinery fault diagnosis (RMFD), the lack of feature conditions leads to the problem of low accuracy of traditional rule-based reasoning methods FD. This paper proposed a knowledge graph (KG)-driven device FD method and applied it to RMFD. First, we proposed a multi-level KG construction method to get multi-source data based on each level and analyzed the levels that affected the system state. A single-level KG was constructed through data features, and a multilevel KG with a stereostructure was built using a multi-source data fusion model as data support for FD. Second, we proposed an approach based on multilevel KG and Bayes theory to detect the system state and located the source of faults by combining the KG reasoning based on relational paths, then used the relationships between the structures of rotating mechanical equipment for fault cause reasoning and used the KG as a knowledge base for a reason using machine learning. Finally, the proposed method was validated using a steelworks motor as an example and compared with other ways, such as rule-based FD. The results show that under the condition of missing input features, the accuracy of the proposed method reaches 91.1%, which is significantly higher than other methods and effectively solves the problem of low diagnostic accuracy.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the iron and steel process industry, every year, because of a variety of equipment failures caused by production line shutdowns and low production efficiency caused by substantial economic losses, so to find a more accurate identification of equipment FD program for the production operation of the safety and stability and cost reduction plays an important role.
Traditional methods for equipment FD usually rely on expert experience and rule bases [1,2,3]. Ding et al. [4] proposed a class of FD methods for triangular nonlinear uncertain systems by calculating the residuals between the model output values and the actual measured values. The diagnostic method requires an in-depth understanding of the mechanism model of the equipment failure process. When the analytical model deviates from the actual situation, it will cause a sizeable diagnostic deviation [5,6,7], which poorly applies to rotating mechanical equipment with complex mechanisms models and variable working conditions, by introducing the support vector machine to monitor the equipment data for multi-faceted data analysis, processing, extracting the fault characteristics of the equipment, and diagnosing the faults [8, 9]. The diagnostic method does not rely on precise mechanism models and combines the powerful computational capability of computers with FD, which is universal for equipment FD. Yang et al. [10] used a convolutional neural network to extract transferable features from raw vibration data and develop a regularization term for multi-layer domain adaptation and pseudo-label learning that reduces distributional differences and inter-class distances of the learned transferable features, providing higher diagnostic accuracy. However, the method has very high requirements for the accuracy of extracted fault features, and the interpretability of the diagnostic results is limited because of the lack of fault knowledge and process knowledge support [11]. Knowledge-based FD methods can solve this problem, which have good interpretability, do not need to construct complex mathematical mechanism models, and also can update the fault knowledge.
In recent years, KGs have attracted much attention, and various approaches have emerged [12], by constructing a graph-based data organization structure [13] that describes the various concepts, entities, and relationships between entities of a device; provides better organization, management, and understanding of large amounts of information [14]; supports efficient data retrieval; and handles complex and varied associative representations [15] to form a KG for the troubleshooting of RM equipment. Fault knowledge is organized and stored as ternary groups to achieve semantic representation of faults, which is conducive to the mining of diagnostic knowledge [16,17,18], solves the problem of the accuracy of personnel diagnosis and decision-making, improves the intelligence of equipment FD, and reduces the occurrence of issues such as unplanned shutdowns of steel production line equipment. Li et al. [19] proposed an alarm KG based on graph neural networks to guide fault localization using network alarm knowledge. Factual knowledge stored in a knowledge base or KG is used as FD and integrated to improve the intelligent application of the device [20, 21]. Although the above FD methods do not require the establishment of complex mechanism models for RM, and the results are highly interpretable, the method still lacks the knowledge of RM FD and its coupled knowledge linkage for further mining and utilization, and the accuracy of the diagnostic inputs is highly required.
Steel manufacturing scenarios are characterized by various equipment types, highly complex relationships between equipment and failures, incomplete historical data recorded by maintenance personnel, and many sudden and rare failure phenomena that go unrecorded. Therefore, if there is a lot of equipment or fault-related missing data, diagnosis results will also appear more significant bias. To solve the above problems, Li et al. [22] used the limited auxiliary knowledge provided by the graph neural network in the test phase to calculate the embedding vector of the new entity and solve the problem of a missing feature. Tanon et al. [23] used a completeness-aware scoring function for relational association rules and proposed that the rule-ranking approach had significantly higher accuracy in detecting missing entities. Xiong et al. [24] proposed a method with knowledge-based reasoning that uses reinforcement learning with pre-trained embeddings to predict whether a relationship exists between a head entity and a given tail entity. To improve reasoning scalability, the analysis in [25] further validated that distributing rule-based reasoning to the edge reduces reasoning latency and network bandwidth usage [26, 27] combined symbolic reasoning methods or Bayes modeling, deep representation learning techniques in KG to handle complex reasoning with relational paths and symbolic logic, and capture uncertainty with probabilistic reasoning to improve the accuracy and reliability of FD. However, the method has rarely been applied in KG construction methods for complex industrial processes. Based on the above, the contributions of this article are summarized as follows.
-
(1)
We propose a FD scheme based on a multilevel KG and Bayes theory. To better express the intricate relationship between the influencing factors, this paper adopts the KG to construct more comprehensive information, and the KG is used as a knowledge base to detect the system state and locate the source of faults by reasoning using machine learning. The constructed KG is used as data support for subsequent FD.
-
(2)
We propose a multi-level KG construction method to enable the constructed KG to provide robust data support for FD. It analyzes the layers that affect the state of the system, acquires multi-source data according to each level, construct a single-level KG based on the data characteristics, and then use the multi-source data fusion model to fuse each level’s data to form a multi-level KG with comprehensive content coverage and structural stereo.
2 KG and intelligent manufacturing
In intelligent manufacturing, KGs can be utilized for various purposes, including data integration, knowledge representation and reasoning, and smart manufacturing visualization. The capacity of KGs to generate KGs offers data support and analytical support for manufacturing processes. KGs are able to semantically model and link production data from various sources. KGs can be used in intelligent manufacturing for knowledge representation and reasoning to optimize production. They can also be used for advanced manufacturing visualization to help users better comprehend and analyze production data.
2.1 KG fundamental concepts and techniques
KG is a method for visualizing things, qualities, relationships, and the connections between them so that computers may more readily comprehend and utilize the data. It is a semi-structured, semantic representation of data that can be used in several domains, including data mining, information retrieval, and natural language processing. Techniques such as entity identification, relationship extraction [17, 28], knowledge representation [29,30,31], and reasoning [21, 32, 33] are some methods used in KGs. Recognizing entities in the text is known as entity recognition while extracting relationships between entities from the text that is known as relationship extraction. Knowledge representation is the representation of entities, attributes, and relationships in a machine-readable format. For example, it represented knowledge using the Resource Description Framework (RDF) format, reasoning is inferring new knowledge based on knowledge that already exists (Figs. 1, 2, and 3).

A KG diagram

The process of constructing a KG

The process of constructing a KG
2.2 Ontology-based knowledge representation methods
An ontology-based knowledge representation is a semantic structure that represents the associations between entities, concepts, and relationships. A shared conceptual model known as an ontology represents domain information, such as entities, characteristics, relationships, and constraints. The first-order logical formula can represent the knowledge in the ontology.
For any concept c, if an instance i satisfies the definition of concept c, then i must belong to the set of instances I.
Alternatively, the knowledge in the ontology can be represented using description logic. Description logic is a formal language that is used to describe semantic constraints between concepts and relations [34].
where C1 and C2 are two concepts, respectively. r is a relationship between these two concepts; x is a variable. If a relation r exists such that instance x fulfills the definitions of concepts C1 and C2, then x must also satisfy concepts C1 and C2.
2.3 KG-based reasoning methods
2.3.1 KG reasoning method based on relational paths
The KG inference method based on relational paths is based on exploring the relational ways between entities and concepts, getting expansion nodes for multidimensional expansion, and inferring the association between the two through new entities and concepts [24]. A relational path is a list of relationships, which are used to connect entities and concepts in a KG. For instance, A->B->C indicates that entity A and entity C are connected by entity B.
The KG can be seen as a directed graph G = (V, E), where V is the set of the graph’s nodes, and E is the set of its edges, with each edge indicating the connection between two nodes. Define the path P(v1, v2) between two nodes, v1 and v2, as a series of directed edges leading from a set of nodes v1 to v2, where the path’s length is equal to the number of its boundaries.
The set of paths R is the set of all possible relational paths, where each path r ∈ R is a sequence of relational types. For instance, (r1, r2, r3) is a relational path of length three where the nodes are connected by edges of type r1, r2 and r3. Define the score S(P(v1, v2), r) of path P(v1, v2) as the sum of the scores of all edges on the path. With the help of statistical and machine learning techniques, edge scores can be learned and predicted. Examples include scores based on the edges’ frequency, similarity, importance, or other properties.
Path score computation can create KG reasoning based on relational paths [35]. The relational path score from node v1 to node v2 can be calculated using all paths r in the path set R, given a beginning node v1 and a target node v2.
where S(P(v1, v2), r) stands for path P(v1, v2, r) score, and the max operator implies choosing the path with the highest score out of all available paths. Ultimately, the links or properties between nodes using the path score were determined. Examples include forecasting the value of a node attribute, the existence of a relationship between two nodes, or the kind of an unidentified node.
2.3.2 Bayes-based reasoning methods
In Bayes’ reasoning, getting or extracting state probabilities to satisfy conditions usually involves two steps: (1) constructing a Bayes network using already known data and prior knowledge and (2) update the probability distribution based on observed evidence by using Bayes’ rule.
First, build a Bayesian network, in the example of equipment failure prediction, we need to collect data about equipment states and failures and build a Bayesian network model. A Bayes network is a graph model comprising nodes and directed edges, where nodes represent random variables (e.g., equipment status, time, environmental conditions) and directed edges represent dependencies between these variables. Then, the prior probability is determined, which in Bayesian networks refers to the probability distribution in the absence of any observational evidence. These prior probabilities can be determined based on historical data, expert knowledge, or domain experience. For example, the a priori probability that a device works properly may be high because the device is usually in a normal state.
Then, observational evidence is collected. In practice, we collect observational evidence, such as sensor data of the current device state or other relevant information. This observational evidence will be used to update the a priori probability to get the posterior probabilities, i.e., the probability distributions after a particular condition is observed.
The probability distribution is then updated using Bayes’ rule, which has the general form of Bayes’ rule once observational evidence has been collected:
where P(A| B) is the posterior probability of event A observation evidence B; P(B| A) is the likelihood probability of event A given observational evidence B; P(A) is the a priori probability, i.e., the probability in the absence of observational evidence; P(B) is the marginal probability of evidence B. By computing Bayes’ rule, we can update the prior probabilities and get the posterior probabilities. This gives the state probabilities that satisfy the observational evidence.
Finally, prediction or diagnosis is performed, and with the updated posterior probabilities, we can perform fault prediction or diagnosis. For example, based on the state and time of the device and based on new observational evidence, we can predict the probability of the device failing at a future time. In practical applications, the Bayes inference may require several iterations, especially when there is evidence from multiple observations. Each time new evidence is available to us, the probability distribution is updated to get a more accurate prediction or diagnosis.
3 FD method of RM based on KG
A KG is a graphical model for representing knowledge that represents entities, attributes, and relationships as nodes and edges and links them semantically. KGs are used to RMFD. The feature vectors of mechanical problems can be compared and reasoned with the entities, attributes, and relationships in the KG to quickly identify the root causes of faults and provide appropriate repair solutions. KG-based FD techniques are more accurate and efficient than conventional ones [36].
This study covers KG building in its KG-based malfunction diagnostics of RM [16]: (1) KG construction; (2) data acquisition and process; (3) feature match and inference; (4) FD and repair.
3.1 KG construction
The relevant knowledge ontology must be represented as graph entities and relationships to carry out KG-based defect diagnosis of RM. The entity includes RM (indicating the concept of RM), faults (indicating possible faults of RM, such as bearing faults, gear faults, motor faults), and sensors (indicating sensors used to monitor the operating status of RM, such as vibration sensors, temperature sensors, pressure sensors) [24].
Relationship includes the occurrence of a fault (indicating that a certain fault has occurred in the RM), monitored (indicating that the sensor has monitored a particular operating state of the RM), and causes (indicating that a specific fault may cause other faults to occur).
3.2 Data acquisition and process
In order to build a KG of RM, data needs to be gained from the operation of RM and transformed into a KG. Data preprocessing is the processing of feature data, such as normalization and standardization, to facilitate subsequent standardized models [37]. According to the specific data requirements and production process deployment of sensors, to get the vibration signal, temperature signal, current signal, and other information of RM, data processing, including data clean, data label, data quality test, and other steps, is necessary to facilitate the subsequent construction and analysis of the KG.
-
(1)
Data clean
Data clean is to complete the processing, such as the filter, de-noise, and error correction on the samples to ensure the quality and usability of the data [38]. Since the data source is a variety of sensor devices and the format and quality of the data vary, it is necessary to apply data cleaning techniques in a targeted manner to deal with the vast amount of RM operation data. First, define the error type, then identify the error instances, correct the errors, implement data clean, document the error instances and error types, and finally change the data collection program to reduce the occurrence of errors. The clean data process is:
-
(2)
Data label
The data collection and clean after the data need specific data annotation methods to get high-quality, applicable labeled data of algorithms and models. In data labeling, it is necessary to adopt appropriate labeling methods according to the application scenarios of RM, different data formats, and different labels. In RMFD, there are more data formats involved. There are various sensors in the automatic acquisition of the signal data, so it is necessary to consider multiple data types of data labeling methods.
-
(3)
Data quality testing
Labeled data needs to be evaluated according to specific quality annotations to improve the quality of data label continuously. In KG construction and intelligent service development, because of the continuous updating of operational data, it is necessary to continuously adjust and optimize the data collection and annotation methods in real time to improve the effectiveness of various subsequent models and algorithms.
The annotation quality assessment algorithm used in this paper is the majority voting (MV) algorithm. MV is a commonly used algorithm for labeling quality assessment. The basic idea is to assume that there are m labeled tasks t1, t2…tm, each task t1 corresponds to a binary classification. To improve the quality of annotation and the reliability of annotation, the object xi to be labeled is assigned to N labelers (total M employees, N<M). The labeling result of each annotator is \({y}_i^j\in \left\{0,1\right\}\), and then, the final label of xi is inferred from \({y}_i^1,{y}_i^2\dots {y}_i^N\), the formula is:
By obtaining large-scale labeled data that meets the data requirements for subsequent training of various models and algorithms, it realizes the construction and development of a RMFD-KG and provides solid and reliable data support for KG management and intelligent services.
3.3 Feature match and inference
The core of the overall diagnosis system is feature matching and reasoning for RM defect diagnosis based on KGs. This part comprises subsequent two phases specifically:
3.3.1 Feature matching
Feature matching is the process of matching the entities and relationships in the KG with the feature data to find the entities and relationships related to RM faults. Graph matching algorithms can carry out this procedure, and the most common algorithm is based on sub-graph isomorphism [39].
Feature extraction [40, 41] converts sensor data from rotating machinery into feature vectors, e.g., frequency domain and time domain features of vibration signals. By comparing the extracted feature vectors with the entities in the KG to determine the entities linked to RM failures, entity matching seeks to maximize the correlation. To identify the corresponding mechanical component and defect-type entities, RM feature vectors can be matched to the RM entities in the KG. Relationship matching is matching feature vectors with relationships in the KG to find relationships related to RM faults. In order to determine the relationships between mechanical components and the fault types corresponding to them, RM feature vectors can be matched with the vibration feature relationships in the KG.
f = (f1, f2, ⋯fn) represents the feature vector, and n represents the features’ dimension. G(V, E) represents the KG, whereas V represents the collection of items and concepts. E stands for the collection of relationships between concepts and entities. vi can be used to represent an entity. The relationship can be represented as ei, j, where i, j is the entity number.
where vi, k is the k eigenvalue of entity vi. Entities and relationships connected to RM failures can be found based on the findings of the similarity calculation.
3.3.2 Reasoning
Faulty reasoning in RM is based on monitoring and analyzing parameters such as vibration, sound, and temperature, and inferring the type and location of faults based on specific discrimination rules [42, 43]. The inference matching method is a model-based FD method that models the operating state of RM as a set of mathematical equations and solves and analyzes these equations based on actual monitoring data to determine the cause of mechanical failure.
The key to the reasoning matching approach is constructing a mathematical model of the rotating machine that contains details relating to its structure, dynamics, and operational parameters. The equipment’s equation of state is produced based on this data to characterize the properties of the machinery, such as responsiveness and vibration under various fault states. For a piece of machinery that has failed, the actual state of the machinery is matched to a known failure model to determine the type and location of the failure.
For FD, reasoning matching techniques often employ probabilistic and statistical methods. Assuming that there are potential fault states (N) for the equipment, each failure is represented by a letter s1, s2, ⋯sN, and each failure state has a probability of P(s1), P(s2), ⋯P(sN), the sum of the fault probabilities is expressed as:
Suppose that M-measured parameters, x1, x2, ⋯xM, characterize the machine’s state, with xk representing the parameter’s value (k). Suppose that the state of the machinery can be represented by an M-dimensional vector as:
where xi, k is the parameter’s value (k) in state si. According to the equation of the state of the machinery, the probability distribution function, designated as fi, k(xk), for each parameter in each failure state, where k = 1, 2, ⋯, M, i = 1, 2, ⋯, N.
L monitored parameters are y1, y2, ⋯, yL, where yj stands for the j parameter’s value. According to the monitoring data, the actual value of each parameter is expressed as:
where ϵj is the measurement error corresponding to the actual value. If the errors satisfy a Gaussian distribution and have a mean value of 0, it can be called Gaussian white noise and are assumed to be independent.
The posterior probability of each reasoned cause of fault is calculated by Bayes’ theorem, which is:
According to Bayes’ theorem, given the actual measured value as:
The posterior probability that the equipment is in fault state Si can be calculated as:
Hence, by bringing \(P\left({S}_i|\hat{\textbf{Y}}\right)\) into the monitoring parameter model, it is possible to construct \(p\left(\hat{y}j|{\textbf{X}}_{\textbf{i}},{S}_i\right)\), which stands for the probability distribution function of the j monitoring parameter under the fault condition Si, where \(p\left(\hat{y}j|{\textbf{X}}_{\textbf{i}},{S}_i\right)\) is the probability distribution function of the j monitoring parameter in the fault state Si. It is calculated by bringing fi, k(xk) into the monitoring parameter model. Finally, by comparing the size of the posterior probability \(P\left({S}_i|\hat{\textbf{Y}}\right)\), the nature and location of the mechanical breakdown can be identified. The fault type of the machinery is represented by the fault state Si with the highest a posteriori probability. The fault location of the machinery can be identified by examining the abnormal values of each parameter in the state vector Xi.
The reasoning above process must account for the impact of measurement errors, which might affect monitoring data and thus cause mistakes in the deduction of the mechanical state. Hence, when calculating \(p\left({\hat{y}}_j|{\textbf{X}}_{\textbf{i}},{S}_i\right)\), it is necessary to consider the impact of measurement inaccuracy. Preprocessing the monitoring data with a Kalman filter is a frequently used strategy.
In addition, when the device has missing data, i.e., certain critical information is unavailable. The NP-complete problem is solved using probabilistic graphical models Bayes networks to model the relationship between devices and faults, which can handle missing data and infer unknown information through probabilistic inference. In addition, for some complex mechanical systems, it may be necessary to use more sophisticated FD algorithms, such as deep learning-based FD methods. In this case, deep neural networks can learn the complex relationship between mechanical states and faults while monitoring data is used to train the network model for eventual FD.
3.4 FD and repair
3.4.1 Fault prediction
The prediction of equipment FD using KG techniques is an effective method. In contrast, Bayes’ methods can be used to predict faults in advance considering the time factor. Bayesian methods are statistical learning methods that can be used to update probability estimates as new information is continuously acquired. In equipment failure prediction, we can use Bayes methods to model failure prediction to consider the effect of time on the prediction results. The following is a primary step:
First, collect data related to equipment failures, including equipment operating status, maintenance records, and sensor data. This data is then collated into a KG, where nodes represent device states or parameters and edges represent correlations between them. We create a Bayes network model using the collected data and KG. A Bayes network is a graphical model representing dependencies between random variables. Here, device state and time are random variables with possible probabilistic dependencies. In Bayes networks, time is usually introduced as a critical random variable. We can categorize time into different time windows, such as hourly, daily, or monthly, to capture changes in device status. Updating probability estimates, we can continuously update the probability estimates in a Bayes network over time. Whenever there is new data or an observed change in the state of a device, we can use Bayes’ rule to update the associated probability distribution. In this way, we can more accurately predict equipment failure probability. Failure Prediction:
Failure prediction is possible using probability estimation in Bayes networks. By calculating the conditional probability of a device failure in a time window, we can drive the probability that a device may fail in the future. It is important to note that Bayes’ methods can consider the time factor and incorporate other relevant factors, such as environmental conditions and equipment utilization, to improve prediction accuracy. In addition, Bayes methods can be used for FD, i.e., updating the probability estimates based on the observed state information in the event of a device failure further to determine the cause and location of the failure.
3.4.2 Fault classification
The relevant knowledge and rules in the KG are utilized to identify the types of defects and causes of faults in equipment by evaluating the operation data and fault data of RM. Repair suggestions are made as per the findings of the diagnosis and the KG’s repair techniques. It may consist of repair techniques, tools, supplies, etc. In addition, the KG’s pertinent rules and knowledge are continuously updated as per the actual circumstances surrounding machinery operation and maintenance records, allowing the KG to be adjusted to the exact operating circumstances of machinery. The classification of fault types in this paper is based on the fault’s nature, cause, or effect to categorize faults that occur in equipment or systems. This helps to understand better the modes and mechanisms by which faults occur and guides preventing, diagnosing, and repairing imperfections. Specific fault classifications include:
-
Mechanical failure: refers to a malfunction caused by the failure or damage of a mechanical component, such as worn, broken, or loose parts
-
Electrical failure: involves the failure of electrical components or circuits, such as shorted or open wires and motor failures
-
Electronic failure: involves the failure of an electronic component or electronic system, e.g., integrated circuit failure and electronic equipment failure
-
Environmental faults: failures related to external environmental factors, such as excessive temperature, humidity, and dust accumulation
-
Fatigue failure: a material fatigue failure because of prolonged use or repetitive loading
-
Power failure: failures involving the power transmission system, such as engine failure and transmission failure
4 Instance verification
In this paper, we use a steel mill motor as an example to build a motor defect diagnosis KG based on the method mentioned above, then confirm the viability of the way, and test the diagnostic performance.
4.1 Motor FD-KG construction
4.1.1 Motor FD knowledge ontology
-
(1)
Establishment of ontology concept
The device structure class V1 is used to describe a collection of concepts for the structure of a motor. It is possible to determine the hierarchical structure of each subsystem, component, and part of the motor based on its structural makeup in accordance with the top-down principle. Some of the equipment structure concept ontology is shown in Table 1.
The set of concepts for each measurement point used to track the motor’s operational state is called the measurement point class V2. The measurement points can be categorized as temperature measurement points, vibration measurement points, current measurement points, etc., based on the various monitoring status value categories. The measurement point class concept ontology is shown in Table 2.
Class V3 of fault phenomena is a collection of concepts about the different traits a motor displays when a fault occurs. These signs and features include changes in physical quantities, sounds, vibrations, etc. They can determine the type and location of a motor failure. The notion of fault phenomena class can be further subdivided into many categories, including high vibration, high temperature, and high current, based on the various features of the signs. The fault phenomena class concept ontology is shown in Table 3.
The fault cause class V4 is used to describe a collection of concepts that may lead to the cause of a motor failure. The repair advice class V5 is a collection of concepts that describe the advice given for the causes of failure. Examples of concept ontology for the cause of failure class and the maintenance recommendation class are shown in Table 4.
-
(2)
Establishment of ontology relations
According to the representation of RMFD knowledge ontology, the relationships between the concepts of each ontology of the motor are represented, as shown in Fig. 4.

Equipment ontology model
4.1.2 Representation of motor FD knowledge
Based on the established motor FD knowledge ontology, motor FD knowledge is obtained and expressed as a triad, and the labels of the entities are defined. Then, a triplet relationship table to identify the relationship is created.
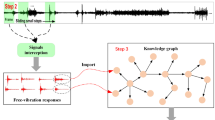
Neo4j, a graphical database, is used to store the data of the triad knowledge and finish developing the motor KG-FD once the entity and relational tables of the triad of motor FD knowledge have been established. The KG for motor problem diagnostics includes multiple entities, their relationships, and relevant quantitative statistical information. In other words, it is a diagram that incorporates entity type and relationship type information that can help in motor troubleshooting. The motor KG after the construction is completed, with a partial relationship and node visualization diagram, as shown in Fig. 5.

Electric motor KG
4.2 Testing of KG-based diagnostic methods
In order to test the diagnostic performance of the KG-based diagnostic method for RM, this paper is based on the historical fault case data of a steel mill motor, considering the huge amount of operation data, a part of data with and without faults was selected from 10,000 times of data according to a certain ratio for testing. Twenty-four fault cases with complete signs were obtained, and the test cases were designed based on a steel mill motor’s historical fault case data. The test case design steps are as follows:
aaa
-
(1)
Get the correspondence between the faults and the signs from the historical cases, and each fault has n signs;
-
(2)
There are numerous different features for each sort of motor failure. By missing varying numbers of features, test cases can be generated. For example, for a fault with 5 different signs, test cases can be generated as follows:
-
①
Missing 1 feature:
Each feature is removed from the fault feature and generates a brand-new fault feature as a test case. If there are 5 features, 5 test cases are generated, each of which removes 1 of the features;
-
②
Missing 2 features:
Two features in each group are removed from the fault characteristics, and a new fault characteristic is generated as a test case. If there are 5 features, C(5,2)=10 test cases are generated, each of which removes 2 different features from each test case;
-
③
Missing n-1 features:
Remove all features except the last one and generate a new fault feature as a test case. All the remaining features are combined to generate a new fault feature as a test case. If there are 5 features, and 1 of the features and 2 of the features have been removed, C(5,3)=10 test cases are generated. For each test instance, 3 of these various features are selected.
This enables the production of several test cases encompassing various combinations of fault features to test the precision and robustness of the motor FD system.
This study uses a motor winding short circuit fault to illustrate the test case design. When the features of the condition, namely an increase in motor temperature, abnormal current, motor vibration, and abnormal sound, appear, a fault may be present. The relationship between various features is a “with” connection, meaning that the motor winding short circuit defect can only be determined when all the features above occur at the same time. Information on test samples is used to verify diagnostic methods, as shown in Table 5.
In general, several diagnostic outcomes could occur during a FD task, some of which could be accurate or inaccurate. To evaluate the performance of a FD system, the metric of diagnostic accuracy can be used. The diagnostic accuracy is calculated as follows.
where N is the total number of samples. CP is the number of correctly diagnosed samples, and diagaccur is the accuracy rate.
The test samples are put through diagnostic verification, which involves fully incorporating the sign phenomena into the test sample. The number of accurate diagnoses was 24, and the number of correct diagnoses in the test cases with missing signs was 120. The diagnostic results are shown in Table 6.
The FD accuracy is only 80% when the input signs are completed. This is because, in the constructed KG, there is a one-to-many mapping relationship between the fault phenomenon and the cause of the fault. There is also a situation where the complete fault phenomenon required for diagnosis is satisfied by inputting one fault phenomenon.
In this instance, the method suggested in this research produces many outcomes for FD. If numerous diagnostic results cannot be further sorted according to the information given, it may result in inaccurate diagnostic results, lowering the diagnostic accuracy.
As a result, a one-to-many mapping relationship must be considered when creating a FD system because various conditions and distinct causes may generate the same defect phenomenon. Hence, when performing fault-cause identification, it is vital to consider the potential causes of failure and deliver multiple diagnostic results under a thorough and integrated analysis.
This requires domain expertise, troubleshooting algorithms, and practical application experience. To quickly repair and maintain the equipment and increase its dependability and operational efficiency, test data and failure phenomena are studied to identify the root cause of the failure and the diagnostic findings. Probabilistic models or machine learning techniques might be considered to address these issues and improve the precision and dependability of FD.
4.3 Comparison with traditional diagnosis methods
The rule-based FD approach and the KG-FD method were compared. Furthermore, the diagnostic performance of a KG-based FD method for RM was tested in the case of missing feature phenomena. The validity and applicability of KG-FD methods in the absence of featureatic phenomena can be evaluated, and the references for further FD research can be provided by contrasting and analyzing the benefits and drawbacks of these two approaches. After that, based on the combined motor FD information, the motor FD rules were extracted. It is performed to diagnose the aforementioned 120 test cases exhibiting missing fault phenomena. The diagnostic results are presented in Table 7 (method 1 is the KG-FD approach and method 2 is the rule-based FD method).
The results obtained in Table 7 indicate that the diagnostic accuracy of method 1 using the KG was 91.1%, which was higher than the diagnostic accuracy of method 2. In the absence of features phenomena, the diagnosis based on KG is superior to the standard rule-based FD reasoning method. This can be successfully applied to solve the problem of making a correct diagnosis without features phenomena.
5 Conclusions and outlook
In this paper, we propose a FD method based on KG-driven devices, which derives the causes of faults based on the relationship between the known data information and the structure of the device when the fault data is missing, and the causes of the faults are eliminated or confirmed. Firstly, the RMFD knowledge map is constructed to model and describe the failure modes and characteristics of RM, organize the knowledge of various failure phenomena, causes, and characteristic parameters of RM into ternary groups, and establish the relationship between them. Then, the relationship information between the structures in the KG is utilized to determine the fault type and location of the machinery through Bayes inference by probabilistic and statistical methods when there is a lack of fault data, which further improves the accuracy of FD. To prove the method’s superiority, we validate the model using a steel mill motor as an example, and the experimental data show that the proposed method has high reliability and validity in real scenarios. In addition, it significantly improved accuracy compared to rule-based FD methods. In our future work, we will focus on developing an efficient reasoning algorithm on KG-based FD methods for driving devices to provide more efficient information and extend it to other complex industrial scenarios.
Data availability
The authors do not have permission to share data.
References
Yang L, Wang Y, Lan Y, Chen L et al (2017) A data envelopment analysis (DEA)-based method for rule reduction in extended belief-rule-based systems. Knowl-Based Syst 123:174–187. https://doi.org/10.1016/j.knosys.2017.02.021
Gegov AE, Arabikhan F, Sanders DA (2015) Rule base simplification in fuzzy systems by aggregation of inconsistent rules. J Intell Fuzzy Syst 28:1331–1343. https://doi.org/10.3233/IFS-141418
Chen M, Zhou Z, Zhang B et al (2021) A novel combination belief rule base model for mechanical equipment fault diagnosis. Chin J Aeronaut 35(05):158–178. https://doi.org/10.1016/j.cja.2021.08.037
Ding Q, Peng X, Zhong X et al (2017) Fault diagnosis of nonlinear uncertain systems with triangular form. J Control Sci Eng 6354208:1–9. https://doi.org/10.1155/2017/6354208
Liu X, Gao X, Han J (2016) Observer-based fault detection for high-order nonlinear multi-agent systems. J Frankl Inst 353:72–94. https://doi.org/10.1016/j.jfranklin.2015.09.022
Guo R, Guo K, Gan Q et al (2016) Fault diagnosis for actuators in a class of nonlinear systems based on an adaptive fault detection observer. Math Probl Eng 7:1–12. https://doi.org/10.1155/2016/2618534
Yin S, Zhu X (2015) Intelligent particle filter and its application to fault detection of nonlinear system. IEEE Trans Ind Electron 62:3852–3861. https://doi.org/10.1109/TIE.2015.2399396
Ji J, Qu J, Chai Y et al (2018) An algorithm for sensor fault diagnosis with EEMD-SVM. Trans Inst Meas Control 40:1746–1756. https://doi.org/10.1177/0142331217690579
Rapur JS, Tiwari R (2018) Automation of multi-fault diagnosing of centrifugal pumps using multi-class support vector machine with vibration and motor current signals in frequency domain. J Braz Soc Mech Sci Eng 40:1–21. https://doi.org/10.1007/S40430-018-1202-9
Bin Y, Yaguo L, Feng J et al (2019) An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech Syst Signal Process 122:692–706. https://doi.org/10.1016/J.YMSSP.2018.12.051
Li C, Hu S, Gao S et al (2016) Real-time grayscale-thermal tracking via Laplacian sparse representation. International Conference on Multimedia Modeling pp 54-65, https://doi.org/10.1007/978-3-319-27674-8_6.
Chen X, Jia S, Xiang Y (2020) A review: knowledge reasoning over knowledge graph. Expert Syst Appl 141(Mara):112948.1–112948.21. https://doi.org/10.1016/j.eswa.2019.112948
Trisedya BD, Qi J, Zhang R (2019) Entity alignment between knowledge graphs using attribute embeddings. In: AAAI Conference on Artificial Intelligence, pp 297–304. https://doi.org/10.1609/AAAI.V33I01.3301297
Zheng Z, Liu Y, Zhang Y et al (2020) TCMKG: a deep learning based traditional Chinese medicine knowledge graph platform. In: 2020 IEEE International Conference on Knowledge Graph (ICKG), pp 560–564. https://doi.org/10.1109/ICBK50248.2020.00084
Wang H, Du H, Qi G et al (2022) Construction of a linked data set of COVID-19 knowledge graphs: development and applications. JMIR Med Inform 10(5):37215. https://doi.org/10.2196/37215
Han H, Wang J, Wang X et al (2022) Construction and evolution of fault diagnosis knowledge graph in industrial process. IEEE Trans Instrum Meas 71:1–12. https://doi.org/10.1109/TIM.2022.3200429
Li Z, Chen H, Qi R et al (2021) DocR-BERT: document-level R-BERT for chemical-induced disease relation extraction via Gaussian probability distribution. IEEE J Biomed Health Inform 26:1341–1352. https://doi.org/10.1109/JBHI.2021.3116769
Tan J, Qiu Q, Guo W et al (2021) Research on the construction of a knowledge graph and knowledge reasoning model in the field of urban traffic. Sustainability 13:3191. https://doi.org/10.3390/SU13063191
Li Z, Zhao Y, Li Y et al (2021) Fault Localization based on knowledge graph in software-defined optical networks. J Lightwave Technol 39:4236–4246. https://doi.org/10.1109/JLT.2021.3071868
Chi Y, Wang ZJ, Leung VC (2022) Distributed knowledge inference framework for intelligent fault diagnosis in IIoT systems. IEEE Trans Netw Sci Eng 9:3152–3165. https://doi.org/10.1109/TNSE.2021.3128171
Cambria E, Ji S, Pan S et al (2021) Knowledge graph representation and reasoning. Neurocomputing 461:494–496. https://doi.org/10.1016/j.neucom.2021.05.101
Li Y, Tarlow D, Brockschmidt M et al (2015) Gated graph sequence neural networks. Comp Sci 68:6303–6318 Corpus ID: 8393918
Tanon TP, Stepanova D, Razniewski S et al (2017) Completeness-aware rule learning from knowledge graphs. In: International Workshop on the Semantic Web, pp 507–525. https://doi.org/10.1007/978-3-319-68288-4_30
Xiong W, Hoang T, Wang WY (2017) DeepPath: a reinforcement learning method for knowledge graph reasoning. In: Conference on Empirical Methods in Natural Language Processing, pp 564–573. https://doi.org/10.18653/v1/D17-1060
Su X, Li P, Riekki J et al (2018) Distribution of semantic reasoning on the edge of internet of things. In: 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom), pp 1–9. https://doi.org/10.1109/PERCOM.2018.8444596
Tran HN, Cambria E, Hussain A (2016) Towards GPU-based common-sense reasoning: using fast subgraph matching. Cogn Comput 8:1074–1086. https://doi.org/10.1007/s12559-016-9418-4
Cambria E, Li Y, Xing F, Poria S et al (2020) SenticNet 6: ensemble application of symbolic and subsymbolic AI for sentiment analysis. In: Proceedings of the 29th ACM International Conference on Information & Knowledge Management, pp 105–114. https://doi.org/10.1145/3340531.3412003
Zhang M, Qian T, Liu B (2022) Exploit feature and relation hierarchy for relation extraction. IEEE ACM Trans Audio Speech Lang Process 30:917–930. https://doi.org/10.1109/taslp.2022.3153256
Zhao F, Xu T, Jin L, Jin H (2021) Convolutional network embedding of text-enhanced representation for knowledge graph completion. IEEE Internet Things J 8:16758–16769. https://doi.org/10.1109/jiot.2020.3039750
Zhang Z, Liu J, Evans RD et al (2021) A design communication framework based on structured knowledge representation. IEEE Trans Eng Manag 68:1650–1662. https://doi.org/10.1109/TEM.2020.3002648
Mou X, Mao L, Liu H et al (2022) Spherical linguistic petri nets for knowledge representation and reasoning under large group environment. IEEE Trans Artif Intell 3:402–413. https://doi.org/10.1109/tai.2022.3140282
Tian L, Zhou X, Wu Y et al (2022) Knowledge graph and knowledge reasoning: a systematic review. J Electron Sci Technol 20(2):159–186. https://doi.org/10.1016/j.jnlest.2022.100159
Gao J, Liu X, Chen Y et al (2021) MHGCN: multiview highway graph convolutional network for cross-lingual entity alignment. Tsinghua Sci Technol 27(4):719–728. https://doi.org/10.26599/tst.2021.9010056
Wang Y, Cungen C (2020) Research on event classification based on event attributes. J Chin J Inf 34(10):39–50
Yang Z, Wang Y, Gan J, Li H, Lei N (2021) Design and research of intelligent question-answering (Q&A) system based on high school course knowledge graph. Mob Netw Appl 26:1884–1890. https://doi.org/10.1007/s11036-020-01726-w
Wang Q, Wang S, Wei B et al (2021) Weighted K-NN classification method of bearings fault diagnosis with multi-dimensional sensitive features. IEEE Access 9:45428–45440. https://doi.org/10.1109/ACCESS.2021.3066489
Alexandropoulos SN, Kotsiantis SB, Vrahatis MN (2019) Data preprocessing in predictive data mining. Knowl Eng Rev 34:1–33. https://doi.org/10.1017/S026988891800036X
Mahdavi M, Neutatz F, Visengeriyeva L et al (2019) Towards automated data cleaning workflows. Lernen, Wissen, Daten, Analysen 2454:10–19 Corpus ID: 202760055
Tan H, Xie S, Ma W et al (2022) Correlation feature distribution matching for fault diagnosis of machines. Reliab Eng Syst Saf 231:108981. https://doi.org/10.1016/j.ress.2022.108981
Zebari RR, Abdulazeez AM, Zeebaree DQ et al (2020) A comprehensive review of dimensionality reduction techniques for feature selection and feature extraction. J Appl Sci Technol Trends 1(2):56–70. https://doi.org/10.38094/jastt1224
Ma S, Han Q, Chu F (2023) Sparse representation learning for fault feature extraction and diagnosis of rotating machinery. Expert Syst Appl. https://doi.org/10.1016/j.eswa.2023.120858
Bian J, Mao Z, Liu Y et al (2021) Construction and reasoning method of fault knowledge graph with application of engineering machinery. In: 2021 China Automation Congress (CAC), pp 2577–2581. https://doi.org/10.1109/cac53003.2021.9727906
Liu R, Fu R, Xu K et al (2023) A review of knowledge graph-based reasoning technology in the operation of power systems. Appl Sci 13(7):4357. https://doi.org/10.3390/app13074357
Acknowledgements
The authors acknowledge the support of the National Key Research and Development Program project (2019YFB1705000).
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions This work was supported by the National Key Research and Development Program project (2019YFB1705000).
Author information
Authors and Affiliations
Contributions
CC: conceptualization, methodology, data collection and analysis, investigation, writing—original draft preparation, reviewing and editing; ZJ: conceptualization, supervision, methodology, data collection and analysis, writing-reviewing and editing; HW: supervision, methodology, data collection and analysis, writing—reviewing and editing; JW: conceptualization, supervision, methodology, data analysis, investigation, writing—reviewing and editing; JL: conceptualization, supervision, methodology, data analysis, investigation, writing—reviewing, and editing; LS: conceptualization, supervision, methodology, data analysis, and investigation.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cai, C., Jiang, Z., Wu, H. et al. Research on knowledge graph-driven equipment fault diagnosis method for intelligent manufacturing. Int J Adv Manuf Technol 130, 4649–4662 (2024). https://doi.org/10.1007/s00170-024-12998-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-024-12998-x