
Abstract
Cloud manufacturing represents a valuable tool to enable wide sharing of manufacturing services and solutions by connecting suppliers and customers in large-scale manufacturing networks through a cloud platform. In this context, with increasing manufacturing network size at global scale, the elevated number of manufacturing solutions offered via cloud platform to connected customers can increase the complexity of decision-making, resulting in poor user experience from a customer perspective. To tackle this issue, in this paper, an intelligent decision-making support tool based on a manufacturing service recommendation system (RS) is designed and developed to provide for tailored manufacturing solution recommendation to customers in a cloud manufacturing system. A machine learning procedure based on neural networks for data regression is employed to process historical data on user manufacturing solution preferences and to carry out the automatic extraction of key features from incoming user instances and compatible manufacturing solutions generated by the cloud platform. In this way, the machine learning procedure is able to perform a customer segmentation and build a recommendation list characterized by a ranking of manufacturing solutions which is tailored to the specific customer profile. With the aim to validate the proposed intelligent decision-making support system, a case study is simulated within the framework of a cloud manufacturing platform delivering dynamic sharing of sheet metal cutting manufacturing solutions. The system capability is discussed in terms of machine learning performance as well as industrial applicability and user selection likelihood.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In modern industrial framework, the broad sharing of manufacturing services and solutions within large-scale manufacturing networks is strongly supported by cloud manufacturing (CMfg). The latter allows to connect suppliers and customers via a cloud platform by integrating Industry 4.0 key enabling technologies such as cloud computing and Internet of things (IoT) [1,2,3].
Most CMfg platforms are designed to dynamically manage and combine the manufacturing service offers and demands in the network with the aim to deliver on-demand manufacturing solutions according to a service-oriented model [1, 3, 4]. On the one hand, manufacturing enterprises are enabled to put together their resources and competences as manufacturing services for sharing them on the CMfg platform [5]. On the other hand, the cloud assembles the large number of distributed manufacturing resources available in the manufacturing network to offer manufacturing solutions to customers according to a pay-as-you-go model [6].
CMfg platforms can be managed according to either a centralized or decentralized approach [6, 7]. In the centralized approach, the CMfg platform employs the customer manufacturing service requirements and specifications in order to make up customized manufacturing solutions and eventually selects the best manufacturing solution on behalf of the customers. On the other hand, in the decentralized approach, the CMfg platform retains the role of assembling the manufacturing solutions, but the customers select their preferred manufacturing solution (on the basis of their own preferences and multiple decision-making criteria) among those assembled by the CMfg platform [6]. In the latter case, with the rapid growth of the number of services which are published and shared on cloud platforms, the complexity of decision-making may become a relevant issue [5]. As a matter of fact, with increasing manufacturing network size at global scale, the elevated number of manufacturing solutions offered by the cloud platform (related to the numerous available services and resources in the network) can result in information overload and poor user experience from a customer perspective [8].
To this aim, the employment of a manufacturing service recommendation system (RS) could play an essential role in helping the user identify the best manufacturing solutions to fulfil the required task, thus improving the efficiency of the cloud manufacturing platform [5, 6, 9].
Recommendation systems (or recommender systems) are a subclass of information filtering systems consisting of software tools and techniques aimed at predicting the rating or preference a user would give to an item so as to provide suggestions that are most likely of interest to the specific user [Wikipedia] [10].
RS has been successfully applied to support decision-making in various domains, including commercial applications (as product or service recommenders), entertainment (as playlist generators for video and music services like Netflix, YouTube, and Spotify), or content recommenders for social media platforms (such as Facebook and Twitter), tourism, e-learning, news [11].
In the field of Cloud Manufacturing, recommendation systems can play a crucial role by supporting the customer in the identification of the best services to fulfil the required manufacturing task [6, 8].
Accordingly, this research work proposes a customized recommendation system to develop an intelligent decision-making support tool able to provide for tailored manufacturing solution recommendation to customers in a cloud manufacturing system. The proposed RS employs a machine learning procedure based on neural networks for data regression which, on the one hand, processes track record on former customer selections of manufacturing solutions and, on the other hand, carries out the automatic extraction of key features from incoming manufacturing solution requests submitted by the customers and the available manufacturing solutions generated by the cloud platform. Following this approach, the machine learning procedure is able to perform a customer segmentation and build a recommendation list characterized by a ranking of manufacturing solutions which is tailored to the specific customer profile. With the aim to validate the proposed intelligent decision-making support system, a case study is simulated within the framework of a cloud manufacturing platform delivering dynamic sharing of sheet metal cutting manufacturing solutions [1]. The reported simulated case study takes into account 950 suppliers and 60 customers in order to evaluate the approach in a large-scale manufacturing network. Ground truth criteria were set based on the user instances as a regression learner was initially trained with 15 customers. The system capability is discussed in terms of machine learning performance and industrial applicability as well as user selection likelihood.
2 State of the art
The use of innovative ICT key enabling technologies has triggered a paradigm shift in industries which has been identified as the fourth industrial revolution, known as Industry 4.0, in particular in the manufacturing sector [12]. Industry 4.0 aims at improving manufacturing systems automation, efficiency, and performance and allowing dynamic value-creation networks through the combination of new emerging technologies, including cloud computing, Internet of things (IoT), Cyber-Physical Systems (CPS), Service Oriented Architecture (SOA), and Industrial Information Integration [12,13,14]. In Industry 4.0, smart devices are able of integrating devices, systems, and organizations to allow for real-time data exchange and sharing, and using anything, anywhere, anytime communication with the aim to sense, capture, and transmit data [12]. The virtual space and the physical world are integrated through embedded systems, IoT, and CPS [14,15,16].
In the scientific literature, Industry 4.0 has been investigated from diverse perspectives. For example, Kim [17] conducted a comprehensive review on emerging IT trends relevant to Industry 4.0, such as IoT, big data, and cloud computing, and introduced the enabling technologies of CPS and their applications in industries [17]. Lu [16] reviewed the current research on Industry 4.0 key enabling technologies, major applications in industries, and identified research trends and challenges. Da Xu et al. [12] reviewed the recent research on Industry 4.0 from the industrial perspective, introducing current industrial applications and analyzing the research challenges and future trends associated with Industry 4.0. Li [18] compared Industry 4.0 and Made-in-China 2025 to investigate the relationship between technological entrepreneurship and socio-economic changes in emerging economies. Haleem and Javaid [19] identified different components of Industry 4.0 and explained the critical ones with particular reference to additive manufacturing (AM) applications in Industry 4.0. Yli-Ojanperä et al. [20] surveyed the literature on Industry 4.0 architectures in a factory context and assessed awareness and compatibility with reference architecture models developed by industry-driven initiatives [20]. Reinhardt et al. [21] investigated the state of industry preparedness for the adoption of Industry 4.0 worldwide so as to provide a base of information to both industry and academia that can be used to deduce the future industrial strategy and direction. Chen [22] illustrated the challenges and future developments of CPS, showing the questions that still need to be solved to trigger and to ease the integration of the physical and cyber worlds. One relevant issue is the lack of multidisciplinary experts able to engineer Industry 4.0 applications that are often very complex [23]. Da Xu [24] discussed the potential contribution of systems science to Industry 4.0, pointing out that systems science is needed to deal with the great systems complexity in Industry 4.0 and the surrounding industrial ecosystem.
Within Industry 4.0, cloud manufacturing (CMfg) is emerging as a valuable tool offering the possibility to realize a large-scale connection in smart manufacturing networks. Cloud manufacturing allows to deliver on-demand manufacturing services to several industrial users throughout the Internet based on advanced Industry 4.0 key enabling technologies such as cloud computing, Internet of things, and Cyber-Physical Systems [2,3,4, 25, 26]. By involving distributed enterprises with the role of suppliers and customers, CMfg offers the opportunity to set up large-scale smart manufacturing networks where the remote manufacturing facilities can be managed as cloud manufacturing services registered into a cloud service platform [9, 27,28,29].
With the rapid increase of the number of services made available on the CMfg platforms, the complexity of decision-making is rapidly becoming a challenge for customers, calling for an effective manufacturing service recommendation algorithm [5, 9].
Recommendation systems (RSs) have been recently developed as tools to identify the best subset of items among all the alternatives which are appropriate to the requests and the preferences of users [11]. The need for providing recommendations by filtering a whole range of available alternatives emerged as a consequence of the enormous growth and variety of information available on the Web as well as the development of e-commerce and new e-business services. The huge variety of items (products and services) offered on the web frequently overwhelm users, who find it difficult to arrive at the most appropriate choices and often experience poor decision-making [10, 30].
“Item” is the generic term utilized to indicate what the system recommends to users, e.g. what product to buy, what music to listen to, or what online news to read. Based on the user’s preferences and constraints, RSs aim at predicting the most suitable products or services in order to provide customized recommendations as ranked lists of items. To this scope, recommendation systems collect information from users concerning their preferences which are either explicitly expressed or are extrapolated by interpreting the actions of the user [10, 31]. Upon a user’s request, RSs generate recommendations based on knowledge and data about users, available items, and preceding transactions collected and stored in personalized databases.
In the literature, several categories of recommender systems have been proposed, which can be classified based on the application domain, the employed knowledge, and the implemented recommendation algorithm, which defines how the utility of a recommendation is predicted [10]. The classification proposed by Burke [32] distinguishes between six different classes of recommendation approaches: Content-Based (the system learns to recommend items that are similar to the ones that the user liked in the past), Collaborative Filtering (recommendations to the active user are made based on items that other users with similar tastes liked in the past), Demographic (items are recommended based on the demographic profile of the user), Knowledge-Based (items are recommended based on specific domain knowledge about how specific item features meet users’ needs and preferences), Community-Based (items are recommended based on the preferences of the user’s friends by acquiring information about the social relations of the users and the preferences of the user’s friends), and Hybrid Recommender Systems (based on the combination of the above-mentioned techniques).
Collaborative filtering is one of the most popular RS prediction approaches and has been widely implemented for providing accurate recommendations to active users [10, 11]. The task of collaborative filtering is to predict the preferences (typically expressed as numerical ratings) of an active user for unseen items given preferences of other users.
With the development of cloud computing applications, new service recommendation algorithms based on different approaches have been developed. For instance, Fuzzy approaches for cloud service recommendation were proposed in the literature. An innovative collaborative filtering–based recommendation system for cloud services using Fuzzy Formal Concept Analysis (Fuzzy FCA) was presented in Mezni and Abdeljaoued [33], while a Fuzzy Ontology structure for cloud service recommendation built upon semantic technologies was proposed in Balaji et al. [34].
Regression-based approaches were also investigated. Mild and Natter compared collaborative filtering approaches to regression models, determining that for a large number of data, regression with model selection can provide significantly better recommendations than traditional collaborative filtering [35]. In this framework, Li et al. [36] presented a recommendation system based on weighted linear regression models. Vucetic and Obradovic [37] developed a novel regression-based approach for collaborative filtering to efficiently address the problem of data sparsity and prediction latency that characterize other collaborative filtering approaches.
More recently, machine learning techniques for service recommendation have been increasingly studied. Wang et al. presented a new regression model based on support vector machine (SVM) classification and an improved particle swarm optimization (PSO) for the development of an electronic movie personalized recommendation system [38]. In its implementation, a SVM classification model was first established to obtain a preliminary movie recommendation list based on which a SVM regression model is applied to predict movies’ ratings.
Among the several available machine learning techniques, deep learning is claiming growing attention. The literature provides diverse applications of deep neural networks for recommendation systems. Covington et al. developed a DNN architecture for recommending YouTube videos, splitting the problem into two distinct sub-problems: candidate generation and ranking [39]. Cheng et al. [40] proposed a Wide & Deep learning approach, made of jointly trained wide linear models and DNNs to combine the benefits of memorization and generalization for recommender systems. Tkachenko [41] adopted a model-free Q-learning to train a DNN to map a client position in the state space to rewards associated with possible marketing actions.
With specific reference to the manufacturing field, few applications of RSs in different cloud manufacturing frameworks have been reported in the very recent literature.
In Liu and Chen [11], a novel clustering-based and trust-aware RS for reliable cloud manufacturing service recommendation was developed with the main purpose to automatically predict the personalized Quality of Service (QoS) value of CMFg services and enable the users to rapidly retrieve the most appropriate cloud services without being overwhelmed by irrelevant services.
In Hao et al. [5], a new manufacturing service recommendation algorithm based on Time-aware Targeted Reconstructing Service Descriptions (T-TRSD), taking into account the evolving characteristics of the cloud manufacturing services, was developed with the aim to accurately identify the functional requirements of developers, quickly select proper manufacturing services, and create service compositions.
In Alinani et al. [6], a recommendation system based on collaborative filtering for cloud manufacturing was proposed to identify the best services for the required manufacturing tasks as well as allow the customer to make informed decisions on the basis of the earlier track record of services. The proposed RS splits the manufacturing task into many sub-tasks and identifies the best match services based on item-based similarity and similarities between other users based on collaborative filtering.
In Simeone et al. [8], a deep neural network (DNN) paradigm was adopted to allow for the automatic learning of optimal solution recommendation list based both on customers’ past experiences and new choices.
Following this approach, this research work proposes the development of a machine learning–based manufacturing service recommendation system to provide for tailored manufacturing solution recommendation to customers in a cloud manufacturing system. As a further development of the preliminary research work on cloud manufacturing reported in Simeone et al. [9] and Simeone et al. [1], an original machine learning–based regression approach employing three-layer feed-forward neural networks (NN) is adopted to develop the recommendation system. The latter is then integrated within the intelligent decision-making support module of a cloud manufacturing platform designed to deliver smart sharing of manufacturing services in large-scale manufacturing networks. To perform the solution recommendation, the RS performs a customer segmentation based on previous history of customer preferences, taking into account multiple criteria related to time, cost, and resource efficiency. In this way, this work addresses the research gap related to the lack of a suitable recommendation system specifically developed for customers of a cloud manufacturing platform for which the multi-criteria decision-making process is particularly complex.
The newly developed recommendation system centred on a NN-based regression model has been proposed to overcome the limitations of a pure collaborative filtering approach, which is the most common approach in recommendation systems, when dealing with manufacturing services. As a matter of fact, in this case, the recommended item is the tailored manufacturing service solution provided by a supplier. Such item includes customer, supplier, and solution features, where each customer is characterized by unique features, resulting in each solution being unique. As a result, the CF algorithm cannot be directly applied in an effective way to the proposed recommendation system as it is unlikely that similar users or items based on users’ preferences are found in this context. Hence, a NN-based regression model was designed and trained through scoring each manufacturing solution. At the same time, inspired by the mechanism of CF, the similarity concept was used to build key indicators to characterize the manufacturing solutions based on the assumption that the customers’ preferences would change according to the production requirements. From such considerations, the use of similar solutions as the indicator to update the recommendation system has been adopted for more accurate and widely applicable recommendations.
Moreover, to tackle the issue of large-scale networks, the intelligent decision-making support system based on the newly developed RS is implemented within a cloud manufacturing platform connecting numerous customers and suppliers.
3 Framework
The manufacturing service recommendation system proposed in this paper is developed as a new tool for the intelligent decision-making support module of the cloud manufacturing platform presented in Simeone et al. [1]. Such cloud manufacturing platform aims at enabling the dynamic and smart sharing of sheet metal cutting services in a manufacturing network with increased resource efficiency. Smart manufacturing solutions are delivered on demand through the platform, by dynamically managing and optimally matching the several sheet metal cutting offers and demands in the network and assembling the requests into convenient manufacturing service solutions through data storage and intelligent computation algorithms.
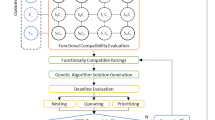
Figure 1 shows the structure of the cloud manufacturing platform which includes three main modules, i.e. a database module, an intelligent assessment and optimization module, and a decision-making module. The latter represents a support tool for both the supplier, to suggest the best production strategy, and the customer, to propose the best manufacturing solutions. With reference to this second objective, the integration of the newly developed RS within the decision-making module allows to provide for tailored manufacturing solution recommendation to customers in the CMfg platform. As a matter of fact, the RS is able to build a recommendation list characterized by a ranking of manufacturing solutions which is tailored to the specific customer profile.

Cloud manufacturing platform scheme
3.1 Cloud manufacturing platform operation
The cloud manufacturing platform developed in Simeone et al. [1] allows customers and suppliers to register their manufacturing service offers and requests with specific reference to sheet metal cutting processes.
On the one hand, any customer calling for a manufacturing service can enter a customer instance, Ci, including the following data:
where IDci is the automatically assigned instance number, Qci the batch quantity (part units to be produced), tci the part thickness (mm), mci the material, Tci the cutting technology, DLci the customer deadline, CADci the CAD file, and Lci the customer location.
On the other hand, as the key objective of the CMfg platform is to improve time, cost, and resource efficiency by promoting nesting of different sheet metal cutting instances (e.g. from customers and suppliers), any supplier can enter a supplier instance, Si, expressed as follows:
where IDsj is the automatically assigned instance number, Qsj the batch quantity (units), Msj the machine tool, with details on the machine model, technology, tolerance, power consumption, cutting parameters, kerf width, availability, and scrap rate [8], Asj the metal sheet size, CADsj the CAD file of supplier jobs to be completed by the deadline DLsj, and Lsj the supplier location.
To select compatible instances, the cloud manufacturing platform, shown in Fig. 1, performs a functional compatibility assessment by verifying that materials, thicknesses, and technologies offered by the supplier match those required by the customer and that the tolerances indicated by the customer are not tighter than those allowed by the supplier machine tool.
Afterwards, the set of compatible instances is processed by an optimization engine to generate suitable combinations of customer and supplier instances based on parts geometries so as to maximize the surface utilization rate (SUR), i.e. the ratio of utilized area over the whole sheet metal area. In this respect, considering the sheet metal cutting process nature, the problem is configurable as 2D nesting [5, 19, 25, 40].
A decision-making module supports the supplier in the selection of the best production strategy, specifically according to three drivers:
-
Surface utilization rate (%)
-
Processing time (hours)
-
Deadline compatibility
Concerning the customer, the decision-making support module assists the user in the evaluation and assessment of the best manufacturing solutions ranked according to the simultaneous comparison of six drivers [1], such as:
-
Surface utilization rate (%)
-
Energy cost (CNY)
-
Distance cost (CNY)
-
Processing time (hours)
-
Number of suppliers
-
Supplier(s) rating
In this paper, as a further development of the cloud platform, the enhancement of the customer decision-making support module via the implementation of a RS providing for tailored manufacturing solution recommendation to customers is proposed based on the framework reported in Fig. 2.

Recommendation system framework
In this framework, customer and supplier instances are collected as they are submitted to the cloud manufacturing platform.
Subsequently, the instances are processed in order to extract and compute a number of features related to the customer and supplier data and requirements. Afterward, the customer, supplier, material, and solution features are grouped to form an input feature vector. The optimization engine is then responsible to generate solutions which are characterized by a set of solution features.
At this point, the platform performs a customer segmentation based on the customer features in order to classify the customer profile in a predefined category. Based on this segmentation, the manufacturing solutions generated by the cloud platform are ranked according to the computation of a score.
Based on the customer segmentation results, the solution features are utilized to build the ground truth aimed at constructing the target vector to be utilized for regression purposes.
The input feature vector and the target vector are then used to train a machine learning–based regression system. The trained model obtained in this way is then tested on a new unlabelled input feature vector related to a new batch of customers, suppliers, materials, and solution features.
The estimated results are therefore compared to the real customer selection, determined with simulated ground truth built based on customer segmentation criteria. In case the estimated solution ranking does not match with the ground truth-based scores, the recommendation system will perform a retraining and updating process to improve the ranking estimation.
3.2 Features and dataset
The proposed recommendation system automatically extracts and computes a number of features from the customers and suppliers instances. Such features are used as input for the machine learning–based regression model according to the following procedure.
With reference to the customer instance, the feature set comprises:
-
The batch quantity, Qci (units), automatically retrieved from the instance data
-
The available time, ATci (hours), computed as difference between the deadline and the instance submission date, both available in the instance data
-
The perimeter, pci (mm), and the area, Aci (mm2), of the part, extracted from the customer CAD file
An example of customer instance input data is reported in Fig. 3, representing the customer GUI including customer instance, computed features, and CAD file visualization. The customer features set is reported in vectorial form in Eq. 3.

Customer instance input data
Likewise, the supplier instance features set (SFj) is specified in Eq. 4 and it includes:
-
The batch quantity, Qsj (units), automatically retrieved from the instance data
-
The cutting speed vsj (m/min) retrieved from the machine tool model specifications in the supplier instance submission
-
The machine power consumption Psj (kW) retrieved from the machine tool model specifications in the supplier instance submission
-
The perimeter psj (mm) and the area Asj (mm2) of the part, extracted from the CAD file uploaded by the supplier
-
The supplier rating score Rsj (%)
An example of supplier instance input data is reported in Fig. 4, representing the supplier GUI including supplier instance, computed features, and CAD file visualization. The supplier features set is reported in vectorial form in Eq. 4.

Supplier instance input data
The optimization module generates a number of K manufacturing solutions, for each of which a set of Solution features (SolFk) is automatically computed as shown in Eq. 5:
where SURk is the surface utilization rate, PTk the processing time (hours), Ek the energy consumption cost (CNY), and Dk the distance cost (CNY).
Additionally, features about the material can be included as represented in Eq. 6:
where MCk is the material unitary cost (CNY/Kg); tk is the sheet metal thickness (mm).
By merging the features sets of customer, supplier, solution, and material, an input feature vector, IFVk, made of 16 features is obtained, as reported in Eq. 7. Such feature dataset will be used as input for machine learning regression.
3.3 Model training
The proposed recommendation system is constructed using a machine learning–based regression approach. In this respect, a target dataset is required and obtained from past solution selection history by the customers.
The relationship between the customer requirements and the most suitable solutions is investigated via machine learning. The intelligent regression is aimed at understanding and learning the solution selected by customers based on the data embedded in the customer instances, the supplier characteristics, and the solution characteristics.
A number of intelligent algorithms can be used for this purpose, such as neural network (NN), support vector regression [42], Gaussian process regression (GPR), regression trees (RT) [43], and ensemble learning (EL) systems [44].
In this research work, a three-layer feed-forward neural network (NN) is employed for regression purposes [45].
The regression learner is trained using the customer, supplier, solution, and material features as input, and the solution scores as target.
In this paper, the target vector is obtained by performing a customer segmentation according to the definition of ground truth criteria based on customers likely preferences, for which the system will assign to each solution a score (SSk) ranging from 10 to 0, where 10 is assigned to the solution assumed to be most likely selected (k∗).
Due to the diverse numerical ranges of the various features, the IFV is pre-processed through a data scaling, normalization, or standardization procedure [46] prior to the training phase.
3.4 Ranking assessment, updating, and retraining
The ranking obtained via machine learning regression is then assessed by performing a comparison with the ground truth data, with reference to the solution characterized by the highest score.
In case the customer selection (k∗) does not coincide with the estimated best solution (\( \hat{k} \)), the solution index characterized by the estimated highest score does not correspond to the solution index with the highest score computed via ground truth. Hence, the solution ranking has to be subjected to an updating procedure, which is carried out in the following way:
-
Compute the pairwise Manhattan distance [47] between the selected solution and all the other solutions, normalized between 0 and 10, through Eq. 8:
where SSk∗ represents the score of the solution which was actually selected by the customer (k∗).
-
Assign a score equal to 10 to the selected solution
-
Subsequently, an updated solution ranking is established by re-computing the solution scores \( {SS}_k^u \) according to Eq. 9:
3.5 System performance evaluation
The performance of the proposed recommendation system is evaluated by considering diverse aspects related to the regression goodness and effectiveness.
The regression training and testing performances are carried out by considering an error indicator, namely the Root Mean Square Error (RMSE) to assess the machine learning regression capabilities, where a low RMSE value (ideally equal to zero) indicates an excellent regression.
The retraining effect quantification is carried out by comparing the RMSE improvement in correspondence of the regression learner retraining. As the updated scores yield to a lower regression RMSE value, the retraining procedure can be considered effective.
The effectiveness of the recommendation system is evaluated by quantifying the number of solutions which are more likely to be selected by the users.
In this respect, the ground truth solution list can be divided into three subsets, namely Top 3, Top 10, and Others according to their position in the ranking based on their scores. In practice, the Top 3 subset is a list of the three highest ranking items, the Top 10 subset is a list including from the fourth to the tenth highest ranking items, while the Others subset is a list including all the remaining ranked items. Subsequently, the evaluation is carried out by examining which of the three subsets the best predicted solution falls within. Clearly, more predicted solutions within the Top 3 subset indicate a better estimation performance.
In order to quantify the improvement of the updated solution ranking compared to the initial estimation, i.e. how the updating procedure brought the estimation results closer to the ground truth, the following steps are applied:
-
Identify the customer instances which need to be updated, i.e. those for which the predicted result does not match the customer actual choice.
-
For each customer instance to be updated, select the Top 10 solutions according to the ground truth.
-
For the Top 10 solutions, compute the indicators as per Eq. 10:
where ∆P indicates the mean difference between the Top 10 ground truth solution scores (\( {SS}_k^{GT} \)) and the Top 10 predicted scores (\( {SS}_k^{est} \)), and ∆U indicates the mean difference between the Top 10 ground truth solution scores and the Top 10 updated scores (\( {SS}_k^u \)). For a generic customer instance, a lower value of ∆U compared to ∆P shows how the solution ranking update brings the score closer to the ground truth values.
-
Repeat these steps for every customer or batch of customers.
4 Case study
To exemplify the methodology proposed in this paper, a case study was simulated taking into account 60 customers. Each customer has the possibility to choose from 950 compatible manufacturing solutions resulting from as many suppliers.
The dataset including 60 customers and 950 suppliers was considered large enough to prove the concepts developed in this framework, taking into account that the proposed platform deals with manufacturing services and, compared to e-commerce platforms, it is characterized by longer cycle times and a lower number of services.
A number of simplifying assumptions were taken into account for this case study, as reported below:
-
One single material was considered (aluminium), so material features were neglected.
-
All the parts thicknesses were set constant to 6 mm while the density was 2702 kg/m3.
-
The number of suppliers required for each solution is always one.
Tables 1 and 2 report examples of customer and supplier data (instances and features) used in the simulated case study.
With reference to customer #1, Table 3 reports an example of the solution features computed by the cloud platform.
In this work, the electricity cost was retrieved from the State Grid Corporation of China website (http://www.sgcc.com.cn) and the transportation costs were estimated from http://www.chinawutong.com. The machine specifications were retrieved from https://www.trumpf.com.
The surface utilization rate (SUR) was computed using the software Solid Edge 2D Nesting 2020 by Siemens (https://solidedge.siemens.com).
Processing time, energy cost, part weight, and distance costs were computed for each solution according to Eq. 11.
4.1 Customers segmentation and ground truth definition
With reference to the case study datasets reported in Tables 1, 2, and 3, customer segmentation criteria were simulated to define their preference history in order to build the ground truth. The segmentation procedure was performed by assigning weights to the solution features on the basis of a number of different conditions (listed in Table 4) characterizing the customer instance. For each condition, the following solution features weights were defined: user rating weight, WR, surface utilization rate weight, WSUR, processing time weight, WPT, energy cost weight, WE, and distance cost weight, WD.
The customer segmentation has been simulated to cover a number of likely scenarios through specific conditions:
-
Condition 1: Customers with particular geometrical requirements, represented here as a geometrical complexity ratio (area-to-perimeter ratio) higher than 0.025 (arbitrary threshold based on common geometrical features), will likely prefer to select solutions characterized by with a supplier rating score. To simulate this condition, a weight of 0.6 was assigned to the supplier rating, while the weight of each remaining feature was set to 0.1.
-
Condition 2: Customers requesting a large batch size (here assumed to consist of more than 6000 units) will likely prefer solutions with higher SUR and less energy and distance cost to reduce the total cost. To simulate such condition, SUR, energy cost, and distance cost were respectively assigned weights of 0.4, 0.2, and 0.2, while the weight of each remaining feature was set to 0.1.
-
Condition 3: Customers with tight time requirements, represented here as those with an available time not longer than 144 h, will likely prefer solutions with shorter processing time, closer location, and better logistics services. To simulate such condition, supplier rating, processing time, and distance cost were respectively assigned weights of 0.2, 0.3, and 0.3, while the weight of each remaining feature was set to 0.1.
Additional scenarios have been considered for the ground truth simulation by combining the above-mentioned conditions. Customers who have more stringent requirements are represented by intersecting two basic customer segmentation conditions. For those, reassigning the weighted value by averaging the weighted value of each solution feature in the two basic conditions. Customers who have no apparent requirements are modelled by an equal distribution of eights that each solution feature is assigned a 0.2 weighted value.
For each manufacturing solution, the values of the five solution features, user rating, R, surface utilization rate, SUR, processing time, PT, energy cost, E, and distance cost, D, were normalized from 0 to 10 according to the following rules: the bigger the better for the User Rating and SUR, the smaller the better for processing time, energy cost, and distance cost.
Based on the features weights and the normalized features values, each solution was assigned a ground truth score, SSij, according to Eq. 12.
The scores range from 0 to 10, with 10 representing the best solution, i.e. the solution which is assumed to be most likely selected by the customer, and 0 representing the worst solution, i.e. the least preferred solution by the customer.
4.2 Machine learning–based regression
Machine learning–based regression was employed in the recommendation system to predict the most suitable manufacturing solutions for given customer instances.
A three-layer feed-forward neural network (NN) with sigmoid hidden neurons and linear output neurons was used for regression purposes and trained with the scaled conjugate gradient backpropagation algorithm (trainscg) [45].
The input layer contains 14 neurons corresponding to the following: the customer features, i.e. Qci, Aci, pci, and ATci, the supplier features, i.e. Qsj, Asj, psj, vsj, Psj, and Rsj, and the solution features, i.e. the SURk, PTk, Ek, and Dk.
The output layer contains 1 neuron which represents the manufacturing solution score according to the NN prediction.
The learning dataset was randomly divided into training (70%), validation (15%), and testing (15%) subsets. The number of hidden neurons was set to 14. The neural network architecture is reported in Fig. 5.

Neural network configuration
The system was initialized by training the NN with 15 customers and 950 suppliers for a total of 14,250 training samples and it was tested on a new batch of 15 customers.
Then, the predicted results were compared to the ground truth and the updating procedure was applied to the new 15 customers. Subsequently, the NN was re-trained using 15 + 15 = 30 customers and 30 × 950 = 28500 training samples and tested on a new batch of 15 customers.
This procedure was repeated until the total number of 60 customers was reached. The various datasets utilized in the NN runs are reported in Table 5.
5 Results and discussion
The assessment of the recommendation system proposed in this paper and exemplified in the case study can be carried out according to three principal performance measures, namely the training performance, the test performance, and the updating effect on the ranking. The results are presented in the remainder of this section along with a discussion on the system capabilities.
5.1 Training performance
The NN assessment was evaluated using the root mean square error (RMSE) as performance indicator. The chart in Fig. 6 shows very small RMSE values for all the training runs. The slightly increasing trend can be explained by the fact that, at every retraining, new customers with new ground truth criteria were added.

NN training performance
5.2 Test performance and retraining effect
Figure 7 reports the NN regression test performances for runs #1 to #3 comparing the RMSE obtained with retraining (blue squares) and without retraining (red dots).

Retraining effect on NN test performance
The chart highlights how the retraining improves the system test performances in terms of RMSE as the blue squares are increasingly lower than the red dots as a new retraining is carried out.
To assess the effectiveness of the decision-making system, a lookup chart is reported in Fig. 8, comparing the number of solutions falling within the Top 3, Top 10, and Other subsets for the three different runs as per Section 3.5.

Lookup chart
The stacked bar chart shows how the retraining process improves the performance of the system also in terms of solution ranking. The upward trend of the blue bars remarks how the system is increasingly able to estimate solutions which will be considered Top 3 by the customer, while the red bars, i.e. Top 10 solutions, have a slightly decreasing trend and the Others solutions (yellow bars), i.e. those which will be less likely to be chosen by the customers, tend to zero in both Run #2 and Run #3.
The results of the above-mentioned procedure are illustrated in Fig. 9.

Ranking update effect in Run #1 (a), Run #2 (b), and Run #3 (c)
By comparing the three charts, it is possible to see how the ∆P and ∆U indicators have to be computed for a higher number of instances in correspondence of Run #1 (Fig. 9a), indicating that specifically 10 instances had to be updated and in most cases there is a sensible difference between ∆P and ∆U.
As the system retrains, in correspondence of Run #2, it is possible to observe that the update indicators were computed for 9 instances, showing a little improvement, also in terms of accuracy as the difference between ∆P and ∆U results less evident in most cases (Fig. 9b).
The last run, i.e. Run #3, shows how the retraining yielded to a more appreciable improvement. In particular, Fig. 9c displays only 5 instances to be updated and a very small, if not negligible, difference between ∆P and ∆U.
The results show how customer features, supplier features, and solution features can be effectively used to predict the customer behaviour in selecting an appropriate solution and how the neural network–based regression is capable to capture the customer “ground truth” in order to make up a valuable recommendation system.
Moreover, periodical retraining of the NN demonstrated to sensibly improve the system performance in terms of RMSE and, more concretely, by lowering the number of customer solutions to be updated and enhancing the estimation of the “best solutions,” i.e. the solutions which are most likely to be selected by the customer.
5.3 Simulation vs industrial implementation
The reported case study was developed via simulation of ground truth criteria for customer segmentation, while the industrial implementation of the proposed recommendation system requires a number of preliminary steps for the system initialization.
In a real industrial context, in fact, ground truth data have to be retrieved from the customer solution selection history. In this respect, a way to initialize the system can be represented by assigning a ranking based on the input feature vectors, specifically:
-
Assign the selected solution a score equal to 10, i.e. \( {SS}_{k^{\ast }}=10 \)
-
Compute the distance between the selected solution and all the other solutions based on the input feature vector (IFVk) elements, as per Eq. 13
where f represents the number of the IFVk features, i.e. 16. Such distance should be then normalized in the range [0,10].
-
Rank the solution scores according to the distance, as per Eq. 14
Alternatively, clustering algorithms [48] can be utilized to perform a customer segmentation to learn customer preferences and compute the weights to be used for regression learning.
As regards the possibility to introduce new users, when a new supplier joins the platform, the system requests to provide a variety of certifications (machinery, quality standard compliance, sustainability, energy, etc.). Upon the validation of such certificates, the supplier will be assigned an initial rating. Regular checks and inspections could be considered for the implementation phase to update the supplier rating.
Finally, it is worth mentioning some considerations on the industrial implementation from a platform perspective. The connection among users is here defined as the matching of supplier and customer instances yielding to a number of manufacturing services solutions. Such mechanism is characterized by fairly loose time constraints as the output of the system consists in a recommendation list, which, by its very nature, has to be reviewed and analyzed by the customer. The Graphic User Interface and the database have no particular requirements in terms of programming complexity, for which the implementation phase can rely on a widely used database management system technology such as SQL. A computational issue for the implementation can be represented by the large number of users (yet resulting in a reduced number of compatible instances); however, all the required features, i.e. customer, supplier, and solution, are retrieved from the database, computed from the CAD file calculated in the optimization module. Such operations are characterized by a low complexity and therefore do not require particularly powerful computer systems. A value added of the proposed platform is represented by the simple mechanism of the Neural Network, for which training and retraining operations do not represent a computational burden as they can be operated offline and in any case they require a relatively short computation time with a suitably powerful computer.
6 Conclusions
In this paper, an intelligent decision-making support tool based on a manufacturing service Recommendation System (RS) was designed and developed with the aim to provide for tailored manufacturing solution recommendation to customers of a cloud manufacturing platform. The recommendation system was based on a machine learning–based regression approach employing a three-layer feed-forward neural network (NN). The NN was applied to perform a customer segmentation by processing historical data on former manufacturing solution selections and to build a recommendation list characterized by a ranking of manufacturing solutions personalized for the specific customer profile. In order to validate the newly developed intelligent decision-making support system, a case study was simulated within the framework of a cloud manufacturing platform delivering sheet metal cutting manufacturing solutions. The machine learning performance as well as industrial applicability of the method was discussed. The case study results showed how the machine learning approach was able to employ customer features, supplier features, and solution features to effectively predict the customer behaviour in terms of manufacturing solutions selection in order to make up a valuable recommendation system. Moreover, periodical retraining of the NN demonstrated to sensibly improve the system performance, increasing the number of manufacturing solutions identified by the recommendation system which were actually within the Top 3 selections of customers based on the ground truth.
Data availability
The datasets generated and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Simeone A, Deng B, Caggiano A (2020) Resource efficiency enhancement in sheet metal cutting industrial networks through cloud manufacturing. Int J Adv Manuf Technol 107:1345–1365. https://doi.org/10.1007/s00170-020-05083-6
Xu X (2012) From cloud computing to cloud manufacturing. Robot Comput Integr Manuf 28(1):75–86. https://doi.org/10.1016/j.rcim.2011.07.002
Zhang L, Luo Y, Tao F, Li BH, Ren L, Zhang X, Guo H, Cheng Y, Hu A, Liu Y (2014) Cloud manufacturing: a new manufacturing paradigm. Enterp Inf Syst 8(2):167–187. https://doi.org/10.1080/17517575.2012.683812
Tao F, Zhang L, Venkatesh VC, Luo Y, Cheng Y (2011) Cloud manufacturing: a computing and service- oriented manufacturing model. Proc Inst Mech Eng B J Eng Manuf 225(10):1969–1976. https://doi.org/10.1177/0954405411405575
Hao Y, Fan Y, Zhang J (2019) Service recommendation based on description reconstruction in cloud manufacturing. Int J Comput Integr Manuf 32(3):294–306. https://doi.org/10.1080/0951192X.2019.1571242
Alinani K, Liu D, Zhou D, Wang G (2019) Recommender system for decentralized cloud manufacturing. In: Wang G, Bhuiyan M, De Capitani di Vimercati S, Ren Y (eds) Dependability in sensor, cloud, and big data systems and applications. DependSys 2019. Communications in Computer and Information Science, vol 1123. Springer, Singapore. https://doi.org/10.1007/978-981-15-1304-6_14
Wu D, Greer MJ, Rosen DW, Schaefer D (2013) Cloud manufacturing: strategic vision and state-of-the-art. J Manuf Syst 32(4):564–579. https://doi.org/10.1016/j.jmsy.2013.04.008
Simeone A, Caggiano A, Deng B, Boun L (2019b) A deep learning based-decision support tool for solution recommendation in cloud manufacturing platforms. Procedia CIRP 86:68–73. https://doi.org/10.1016/j.procir.2020.01.019
Simeone A, Caggiano A, Boun L, Deng B (2019a) Intelligent cloud manufacturing platform for efficient resource sharing in smart manufacturing networks. Procedia CIRP 79(July):233–238. https://doi.org/10.1016/j.procir.2019.02.056
Ricci F, Rokach L, Shapira B (2015) Recommender systems handbook. 2nd edn. Springer US, p XVII. https://doi.org/10.1007/978-1-4899-7637-6
Liu J, Chen Y (2019) A personalized clustering-based and reliable trust-aware QoS prediction approach for cloud service recommendation in cloud manufacturing. Knowl-Based Syst 174:43–56. https://doi.org/10.1016/j.knosys.2019.02.032
Da Xu L, Xu EL, Li L (2018) Industry 4.0: state of the art and future trends. Int J Prod Res 56(8):2941–2962. https://doi.org/10.1080/00207543.2018.1444806
Da Xu L (2020a) Industry 4.0—frontiers of fourth industrial revolution. Syst Res Behav Sci 37(4):531–534. https://doi.org/10.1002/sres.2719
Zhang C, Chen Y (2020) A review of research relevant to the emerging industry trends: Industry 4.0, iot, blockchain, and business analytics. J Ind Inf Integr Manag 5(1):165–180. https://doi.org/10.1142/S2424862219500192
Aceto G, Persico V, Pescapé A (2020) Industry 4.0 and health: internet of things, big data, and cloud computing for healthcare 4.0. J Ind Inf Integr 18(October 2019):100129. https://doi.org/10.1016/j.jii.2020.100129
Lu Y (2017) Cyber physical system (CPS)-based industry 4.0: a survey. J Ind Inf Integr Manag 02(03):1750014. https://doi.org/10.1142/s2424862217500142
Kim JH (2017) A review of cyber-physical system research relevant to the emerging IT trends: industry 4.0, IoT, big data, and cloud computing. J Ind Inf Integr Manag 02(03):1750011. https://doi.org/10.1142/s2424862217500117
Li L (2018) China’s manufacturing locus in 2025: with a comparison of “Made-in-China 2025” and “Industry 4.0.”. Technol Forecast Soc Chang 135(August 2017):66–74. https://doi.org/10.1016/j.techfore.2017.05.028
Haleem A, Javaid M (2019) Additive manufacturing applications in industry 4.0: a review. J Ind Inf Integr Manag 04(04):1930001. https://doi.org/10.1142/s2424862219300011
Yli-Ojanperä M, Sierla S, Papakonstantinou N, Vyatkin V (2019) Adapting an agile manufacturing concept to the reference architecture model industry 4.0: a survey and case study. J Ind Inf Integr 15(October 2018):147–160. https://doi.org/10.1016/j.jii.2018.12.002
Reinhardt IC, Oliveira DJC, Ring DDT (2020) Current perspectives on the development of industry 4.0 in the pharmaceutical sector. J Ind Inf Integr 18(January):100131. https://doi.org/10.1016/j.jii.2020.100131
Chen H (2017) Theoretical foundations for cyber-physical systems: a literature review. J Ind Inf Integr Manag 02(03):1750013. https://doi.org/10.1142/s2424862217500130
Peruzzini M, Stjepandić J (2018) Editorial to the special issue “Transdisciplinary analytics in supply chain management.”. J Manag Anal 5(2):75–80. https://doi.org/10.1080/23270012.2018.1443405
Da Xu L (2020b) The contribution of systems science to Industry 4.0. Syst Res Behav Sci 37(4):618–631. https://doi.org/10.1002/sres.2705
Jiang L, Da Xu L, Cai H, Jiang Z, Bu F, Xu B (2014) An IoT-oriented data storage framework in cloud computing platform. IEEE Trans Ind Inf 10(2):1443–1451. https://doi.org/10.1109/TII.2014.2306384
Liu Y, Wang L, Wang XV, Xu X, Zhang L (2018) Scheduling in cloud manufacturing : state-of-the- art and research challenges. Int J Prod Res 7543:1–26. https://doi.org/10.1080/00207543.2018.1449978
Cao Y, Wang S, Kang L, Gao Y (2016) A TQCS-based service selection and scheduling strategy in cloud manufacturing. (174):235–251. https://doi.org/10.1007/s00170-015-7350-5
Cheng Y, Bi L, Tao F, Ji P (2018) Hypernetwork-based manufacturing service scheduling for distributed and collaborative manufacturing operations towards smart manufacturing. J Intell Manuf 31:1707–1720. https://doi.org/10.1007/s10845-018-1417-8
Tao F, Cheng J, Cheng Y, Gu S, Zheng T, Yang H (2017) SDMSim: a manufacturing service supply–demand matching simulator under cloud environment. Robot Comput Integr Manuf 45:34–46. https://doi.org/10.1016/j.rcim.2016.07.001
Lu L, Xu L, Xu B, Li G, Cai H (2018) Fog computing approach for music cognition system based on machine learning algorithm. IEEE Trans Comput Soc Syst 5(4):1142–1151. https://doi.org/10.1109/TCSS.2018.2871694
Chi-Hsien K, Nagasawa S (2019) Applying machine learning to market analysis: knowing your luxury consumer. J Manag Anal 6(4):404–419. https://doi.org/10.1080/23270012.2019.1692254
Burke R (2007) Hybrid web recommender systems. In: The adaptive web. Springer Berlin, Heidelberg, pp 377–408
Mezni H, Abdeljaoued T (2018) A cloud services recommendation system based on Fuzzy Formal Concept Analysis. Data Knowl Eng 116:100–123. https://doi.org/10.1016/j.datak.2018.05.008
Balaji BS, Karthikeyan NK, Raj Kumar RS (2018) Fuzzy service conceptual ontology system for cloud service recommendation. Comput Electr Eng 69:435–446. https://doi.org/10.1016/j.compeleceng.2016.09.013
Mild A, Natter M (2002) Collaborative filtering or regression models for Internet recommendation systems? J Target Meas Anal Mark 10:304–313. https://doi.org/10.1057/palgrave.jt.5740055
Li C, Wang Z, Cao S, He L (2018) WLRRS: a new recommendation system based on weighted linear regression models. Comput Electr Eng 66:40–47. https://doi.org/10.1016/j.compeleceng.2018.02.005
Vucetic S, Obradovic Z (2005) Collaborative filtering using a regression-based approach. Knowl Inf Syst 7:1–22. https://doi.org/10.1007/s10115-003-0123-8
Wang X, Luo F, Qian Y, Ranzi G (2016) A personalized electronic movie recommendation system based on support vector machine and improved particle swarm optimization. PLoS One 11(11):e0165868. https://doi.org/10.1371/journal.pone.0165868
Covington P, Adams J, Sargin E (2016) Deep neural networks for YouTube recommendations. https://doi.org/10.1145/2959100.2959190
Cheng H-T, Ispir M, Anil R, Haque Z, Hong L, Jain V et al (2016) Wide & deep learning for recommender systems. In: Proceedings of the 1st Workshop on Deep Learning for Recommender Systems - DLRS 2016. ACM Press, New York, pp 7–10. https://doi.org/10.1145/2988450.2988454
Tkachenko Y (2015) Autonomous CRM control via CLV approximation with deep reinforcement learning in discrete and continuous action space. ArXiv Preprint ArXiv 1504:01840
Zhang F, O’Donnell LJ (2020) Support vector regression. In: Machine learning. Elsevier, pp 123–140. https://doi.org/10.1016/B978-0-12-815739-8.00007-9
Loh W (2011) Classification and regression trees. WIREs Data Min Knowl Discovery 1(1):14–23. https://doi.org/10.1002/widm.8
Mendes-Moreira J, Soares C, Jorge AM, De Sousa JF (2012) Ensemble approaches for regression: a survey. ACM Comput Surv 45:1–40. https://doi.org/10.1145/2379776.2379786
Møller MF (1993) A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw 6(4):525–533. https://doi.org/10.1016/S0893-6080(05)80056-5
Nawi NM, Atomi WH, Rehman MZ (2013) The effect of data pre-processing on optimized training of artificial neural networks. Procedia Technol 11:32–39. https://doi.org/10.1016/j.protcy.2013.12.159
Craw S (2017) Manhattan distance. In: Encyclopedia of machine learning and data mining. https://doi.org/10.1007/978-1-4899-7687-1_511
Ruppert D (2004) The elements of statistical Learning: Data Mining, Inference, and Prediction. J Am Stat Assoc. https://doi.org/10.1198/jasa.2004.s339
Funding
Open access funding provided by Università degli Studi di Napoli Federico II within the CRUI-CARE Agreement. The research results presented in this paper are based on the activities carried out in the framework of the project CLOUD MODE “CLOUD Manufacturing for On-Demand manufacturing sErvices” (000011--ALTRI_DR_3450_2016_RICERCA_ ATENEO-CAGGIANO) funded by the University of Naples Federico II within the “Programma per il finanziamento della ricerca di Ateneo” (2016–2019) and the Research Start-up Fund Subsidized Project of Shantou University, China (No. NFT17004).
Author information
Authors and Affiliations
Contributions
Conceptualization: Alessandro Simeone and Alessandra Caggiano; data curation: Alessandro Simeone and Yunfeng Zeng; formal analysis: Alessandro Simeone and Alessandra Caggiano; funding acquisition: Alessandro Simeone and Alessandra Caggiano; investigation: Alessandro Simeone, Alessandra Caggiano, and Yunfeng Zeng; methodology: Alessandro Simeone; project administration: Alessandro Simeone and Alessandra Caggiano; resources: Alessandro Simeone and Alessandra Caggiano; software: Yunfeng Zeng; Supervision: Alessandro Simeone and Alessandra Caggiano; validation: Alessandro Simeone and Alessandra Caggiano; visualization: Alessandro Simeone and Yunfeng Zeng; writing - original draft preparation: Alessandro Simeone; writing - review and editing: Alessandra Caggiano and Alessandro Simeone.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent to publish
Not applicable.
Code availability
The custom software code generated during the current study is not publicly available due to confidentiality policy.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Simeone, A., Zeng, Y. & Caggiano, A. Intelligent decision-making support system for manufacturing solution recommendation in a cloud framework. Int J Adv Manuf Technol 112, 1035–1050 (2021). https://doi.org/10.1007/s00170-020-06389-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-020-06389-1