
Abstract
The optimal design of nanoparticles with respect to their optical properties is one of the main foci within nanoparticle technology. In this contribution, we suggest a new design optimization method in the framework of which the discrete dipole approximation (DDA) is used to approximate the solution of Maxwell’s equation in time-harmonic form. In the core of the optimization method, each dipole is repeatedly assigned a material property from a given material catalog until a local minimum for the chosen design objective is obtained. The design updates are computed using a separable model of the optimization objective, which can be solved to global optimality, giving rise to a sequential global optimization (SGP) algorithm. We suggest different types of separable models, among them exact separable models as well as tight approximations of the latter which are numerically tractable. The application of the DDA method in the framework of structural design methods widens the spectrum of numerically tractable layout problems in optical applications as, compared to finite element based approaches, significantly more complex design spaces can be investigated.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In this paper, a material optimization method for the optimal layout of nanoparticles and nanoparticle assemblies with respect to a desired optical property is developed. Nanoparticles, as well as colloidal supraparticles, which are specially arranged assemblies of nanoparticles, give rise to interesting optical properties and have thus become more and more attractive in a wide variety of research fields (Khan et al. 2019). Especially, the investigation of structural colors and their application in industry has become increasingly interesting over the last decade, see, e.g., Zhao et al. (2012); Kawamura et al. (2016); Xiao et al. (2017); England et al. (2017); Goerlitzer et al. (2018); Wang et al. (2020).
In order to predict optical properties of nanoparticles using computers, the underlying electromagnetic scattering problem has to be solved (see Fig. 1 for a visualization). Therefore, simulation methods are used, which provide approximate solutions to the Maxwell’s equations in time-harmonic form. In the simplest case, i.e., radial symmetric particles, the electromagnetic behavior can be obtained from Mie-theory (Mie 1908; Bohren and Huffman 1998). The optical scattering properties of assemblies of multiple particles can be approximated by the so-called T-matrix method (Waterman 1965, 1971; Mackowski 1994). In both these approaches, vector spherical wave functions are used to describe the electromagnetic fields. While these methods are rather efficient and allow to predict properties for relatively large particle assemblies, they are applicable only as long as the shape and composition of the individual particles in the assembly is sufficiently simple. It is also interesting to note that—to the best of our knowledge—these methods have not been used in the context of mathematical optimization so far.

Electromagnetic scattering problem where the object \(\Omega\) is illuminated by an incident light. Both, direction/polarization of incident light and orientation of the object are characterized by a reference coordinate system. For a detailed description of the particular problem, see Sect. 1.1 in Mishchenko et al. (2006)
In contrast to the Mie- and T-Matrix-based methods and their relatives, the finite element method (FEM) allows to predict electromagnetic fields for rather arbitrarily composed objects. However, in the context of topology optimization, typically, a high resolution of the design domain is required resulting in large number of unknowns in the FEM problem. To give an example, if a 3-dimensional object is represented via its piecewise constant material properties on a regular grid, using \(10^5\) cells, the boundaries of the object still appear rather coarse, while the solution of the corresponding FE system, using standard edge elements, is already very demanding with respect to both, computation time and memory consumption. The latter is particularly true, as in the FEM surrounding material has to be added and the absorbing boundary conditions have to be handled, e.g., by adding a perfectly matching layer (PML). Thus, a way larger domain than the object of interest itself has to be discretized. Of course, for a fixed design, adaptive concepts can be used to improve the situation; however, this is very involved, if the layout changes drastically in the course of the optimization. As a remedy, inspired by Monk (2003), in Semmler and Stingl (2021), a hybrid finite element approach based on both, finite element approximations and superposition of vector spherical wave functions, was developed. It allows for individual particles of rather arbitrary shape and composition; however, within the hybrid approach, the electromagnetic properties of the individual particles are pre-calculated in an offline phase. Based on these offline calculations, optimization tasks can be carried out, in which positions and orientations of the predefined particles (described themselves by a large number of elements) can be varied. In contrast to this, in this article, we are more interested in varying the composition of the particles themselves utilizing a genuine topology optimization approach. Rather than using the FEM method, we suggest to numerically approximate the solution of Maxwell’s equations by the discrete dipole approximation (DDA) (DeVoe 1964; Purcell and Pennypacker 1973; Draine and Flatau 1994). The advantage of this choice is twofold: first, highly efficient and parallel implementations of the DDA method, see, e.g., DDScat (Draine and Flatau 1994), OpenDDA (Donald et al. 2009), and ADDA (Yurkin and Hoekstra 2011), allow simulating the electromagnetic behavior of 3D particles using fine design discretizations even on high-end desktop computers. And second, the structure of the complex equation systems obtained from DDA can be exploited by the sequential global programming (SGP) method recently suggested in Semmler et al. (2018). As a consequence, the range of numerically tractable topology optimization problems relying on approximate solutions of the 3D time-harmonic Maxwell’s equations can be significantly extended.
While we use SGP in combination with DDA in this paper, design approaches in literature typically combine the FEM with the so-called SIMP (solid isotropic material with penalization) method, which originally was developed for the optimization of elastic structures (Bendsoe and Sigmund 2004), and in Sigmund and Jensen (2003) applied for the first time for complex state systems. The SIMP method is based on interpolation between two admissible materials and an appropriate penalization scheme which renders undesired intermediate material properties unattractive. In the context of electromagnetics, the use of this method was first reported in Diaz and Sigmund (2010). Generalizations of the SIMP idea to more than two admissible materials can be found in the literature under the name discrete material optimization (DMO), see, e.g., Stegmann and Lund (2005); Hvejsel and Lund (2011). The trick is here to essentially allow for all convex combinations of the given, finitely many, discrete materials and employ again a scheme which penalizes intermediate material choices. The resulting continuous optimization problems are then solved by established constrained optimization solvers in a “black box” manner. Probably, the most prominent among the utilized solvers in the design optimization community is the method of moving asymptotes (MMA), see, e.g., Svanberg (1987); Bruyneel et al. (2002). In both, MMA and the SGP method, our working horse in this paper, the original optimization problem is approximated by a sequence of simpler problems, in which nonlinear functions are approximated by separable models which are first-order correct. However, there is an important difference: while MMA relies on the convexity as well as smoothness of the resulting model problems, both these assumptions do not have to hold in SGP. This has two advantages. First, in general, in SGP, we can work with much better separable approximations. Indeed, in this article, we propose the so-called exact separable models along with tight tractable approximations. We will demonstrate in the numerical section of this article that this can help to escape from certain local minima with a poor value for the cost function. Moreover, as already indicated above, the ability to compute these models is closely related to the choice of the DDA approach. Second, design problems with more than two materials can be treated in a much more straightforward manner, i.e., without using higher dimensional interpolation models as used in DMO.
We finally would like to note that applications of material optimization methods in the context of electromagnetics range from optimal design problems to improve different optical properties of nanoparticles and particulate systems (Pendry et al. 2006; Andkjær and Sigmund 2011; Semmler and Stingl 2021), via the design optimization of nano-antennas and waveguides (Hassan et al. 2015; Semmler et al. 2015; Hassan et al. 2020), to inverse problems, where the material distribution is reconstructed from the information obtained from the scattered electromagnetic field (Colton and Kress 2013). The computational approaches for all the above examples are based on finite element approximations of the solution of the time-harmonic Maxwell’s or Helmholtz equations. In literature, there are only a few works dealing with dipole-based optimization in the framework of electromagnetics. In Zecca et al. (2019), e.g., a DDA-based non-self-adjoint variational formulation of electromagnetism combined with a gradient-descent method to compute a design update is used to optimize different electromagnetic devices. Furthermore, for the efficient inverse design of fluctuating thermal sources, based on a reformulation of a standard DDA approach, called thermal DDA (T-DDA) (Edalatpour and Francoeur 2014), an evolutionary lattice design approach was proposed in Salary and Mosallaei (2019). Manuscripts dealing with pixel-based design optimization in the context of electromagnetics using finite difference time domain (FDTD) approaches can be found, e.g., in Kecebas and Sendur (2021) and Yang et al. (2021). However, most of the examples studied in the mentioned papers are two-dimensional, and therefore, the computational complexity is significantly lower compared to the three-dimensional examples considered in this manuscript. In particular, even in the very few three-dimensional examples, the number of design degrees of freedom is orders of magnitude lower than in our paper. An, at the first glance, rather similar concept to the one we will discuss throughout this paper is developed in Boutami and Fan (2019a), Boutami and Fan (2019b) and further applied in Boutami et al. (2020) for the optimization of photonic devices. Similar as in our approach, design updates are carried out in a dipole-by-dipole fashion. However, the state variable as well as the value of the cost function are directly updated after each variation of a dipole. The advantage of this is that such state updates can be done in an efficient manner. On the other hand, the dipole-based approach corresponds to a kind of a coordinate-wise descent method, which typically leads to a high number of iterations. The resulting algorithm therefore seems to be restricted to problems with a moderate design resolution. In contrast, in our approach, we use the idea of separability to generate a model of the objective, which is almost exact as long as only individual dipoles are modified, but at the same time is a local first-order model, on the basis of which the complete design domain can be updated at once. A main advantage of this is, that the separable model can be combined with gradient-based optimization techniques, which typically results in a low number of required (outer) iterations. Additionally, in contrast to the coordinate-wise descent method, the minimization of the separable model can be parallelized in a straightforward way. Therefore—in combination with DDA—we can consider more complex examples with a way finer resolution of the design and computational domain. To be concrete, in the papers mentioned above, the design degrees of freedom are in the range of up to a few tens of thousands, while we consider examples where the design domain is discretized into much more than \(10^6\) elements. Taking the comparably small size of the particles and particle systems considered in our paper into account, the DDA approach provides a very accurate solution to the considered state problems. As a consequence, as long as systems are studied, for which the magnitude of the refractive index is sufficiently small, see, e.g., Table 1 in Yurkin and Hoekstra (2007), the accuracy of the state solution provided by the DDA method compares to that of high-quality finite element approaches, but at the same time, we can allow for a much finer design resolution.
Our manuscript is structured as follows: In Sect. 2 a framework for multi-material optimization is presented. The multi-material optimization is described as a discrete assignment problem with a finite number of available materials. Then, a relaxation of this problem is introduced, in which the set of admissible materials is expanded to a graph, the nodes of which correspond to the originally available materials. Moreover, two penalization terms are defined. The first is used to penalize undesired materials arising from the relaxation, while the second penalizes irregularity in the design distribution. In Sect. 3, the notion of separable exact and separable first-order approximations is introduced. Furthermore, the so-called sequential global programming (SGP) is explained for a generic class of optimization problems defined on graphs. A special emphasis is given to the solution of the sub-problems, which require the minimization of a separable function over the graph structured set of admissible materials. Section 4 briefly describes the discrete dipole approximation (DDA) approach. In particular, the concept of polarizabilities is introduced and the DDA system, a complex system of linear equations, is derived. It is further shown how the system matrix depends on materials available for optimization. Section 5 deals with separable approximations of optical property functions and constitutes the heart of this article. Based on the Sherman–Morrison–Woodbury matrix identity, separable exact models are stated for a wide class of objective functions, which depend linearly on the solution of the state problem. Then, using an approximation for the inverse of the system matrix, separable first-order approximations can be obtained, which are close to the exact ones. These general results are then used to derive separable models of important optical property functions. At the end of this section, a numerical comparison of the separable models with the real objective function and more traditional gradient models is presented. To show the applicability and capability of the DDA-SGP approach, different test cases are discussed in Sect. 6. We start with an academic proof of concept example, continue to a multi-material optimization problem, in which the material catalog comprises more than two admissible materials and—by an appropriately chosen objective function—the complete visible spectrum is discussed. We end with the optimization of a full particulate system, more precisely a photonic crystal. We further use the last example, to test the performance of the DDA-SGP algorithm when combining sets of dipoles into one design degree of freedom. The combination of design variables plays an important role, when synthesizability is taken into account.
2 Multi-material optimization
The main question within multi-material optimization is “where to put which material for optimal performance?”. To model this, a given design space is subdivided into finitely many design elements. Then, to each of these design elements, a material from a catalog of admissible materials can be assigned. If the material catalog consists of only finitely many materials, the resulting problem is a discrete assignment problem. In practice, the number of design elements is typically very high, which renders this assignment problem too complex to be solved by modern combinatorial optimization solvers to global optimality. Rather than this, a relaxation of the discrete material catalog is used, allowing also for convex combinations of the given materials. Based on this, gradient-based optimization methods can be used to find non-trivial locally optimal solutions. The intermediate materials artificially added by this procedure are typically undesired. Therefore, these materials are penalized to encourage convergence toward a design consisting of material assignments from the original catalog only. This idea is shared by the so-called discrete material optimization (DMO) methods, see, e.g., Stegmann and Lund (2005); Hvejsel and Lund (2011), and the recently developed concept of sequential global programming, see Semmler et al. (2018) and Sect. 3.
2.1 Discrete assignment problem
We first want to introduce the so-called discrete assignment problem. For this, we divide a given design space \(\Omega\), describing the geometrical object to be optimized, into a finite number of design cells \((i = 1,\dots ,N)\). Every cell is associated with one of the M materials from a material catalog \({\mathcal {U}}= \{u_1,\dots ,u_M\}\) (see Fig. 2).

On the left side, the catalog of admissible materials \({\mathcal {U}}= \{u_1,\dots ,u_M\}\) is visualized. The right side shows the design space \(\Omega\) discretized into a finite number of design cells. In the framework of the DDA approach, a material is characterized by its complex refractive index and the design cells are given by dipoles
Note that every used material is described by a material property. For instance, in the framework of the discrete dipole approximation, materials can be characterized by their complex refractive indices, see Sect. 4.
Now, let \({\mathbf {u}}\) and \({\mathcal {U}}_{ad}^D\) denote the design vector and discrete admissible set, respectively, such that
Then, the discrete assignment problem reads as
where J is a real-valued objective function, which can be evaluated for each admissible design. For particular choices of J in the context of optical properties of nanoparticles, we refer to Sects. 5.1 and 5.2.
2.2 Relaxation
To be able to use gradient-based optimization techniques, we relax problem (1). For this, we introduce a graph \({\mathcal {G}}=(V,E)\) with vertices \(v\in V\), corresponding to materials \(u \in {\mathcal {U}}\) and edges \(\{e_1,\dots ,e_{N_E}\} \subset V \times V\) connecting the latter. Here, \(N_E\) denotes the total number of edges in the graph \({\mathcal {G}}\). We assume that every vertex \(v \in V\) is at least part of one edge. For an exemplary visualization, we refer to Fig. 3.

Examples of graphs for two different sets of admissible materials. In this case, the graphs are complete, which means that each material is connected with every other material by an edge
Next, we introduce a parameterization of \({\mathcal {G}}\). For this, it is convenient to use the abbreviation \(I_E {:}{=}\{1,\dots ,N_E\}\).
Definition 1
(Parameterization of \({\mathcal {G}}\)) We call the mapping \(U : I_E \times [0,1] \rightarrow {\mathbb {C}}\) the parameterization of \({\mathcal {G}}\) if and only if (iff) the following hold:
-
1.
U is twice continuously differentiable with respect to the second variable.
-
2.
U is an endpoint interpolation, i.e.,
$$\begin{aligned} U(\ell ,0) = u_{e_\ell ^1}, \quad U(\ell ,1) = u_{e_\ell ^2} \quad \forall \ell \in I_E, \end{aligned}$$where \(e_\ell = (v_\ell ^1, v_\ell ^2)\) is the \(\ell\)-th edge in \({\mathcal {G}}\) and \(u_{e_\ell ^1}\), \(u_{e_\ell ^2}\) are the materials associated with the vertices \(v_\ell ^1, v_\ell ^2\), respectively.
-
3.
For all \(\ell ,i \in I_E\) and \(\rho \in (0,1)\), \(q \in [0,1]\) with \((\ell ,\rho ) \ne (i,q)\), we have
$$\begin{aligned} U(\ell ,\rho ) \ne U(i,q). \end{aligned}$$
Condition 3 of the above parameterization implies that the edges of \({\mathcal {G}}\) do not intersect each other. In particular, a node of the graph cannot correspond to an interior point of an edge.
We can now use this parameterization to define the continuous version of the admissible set as
Note that our design variable is now parameterized by \(\ell\) and \(\rho\), where \(\ell\) denotes the edge index and \(\rho\) is a continuous variable, sometimes referred to as pseudo-density or grayness. Both these names have their origin in topology optimization with only two materials, where ‘white’ stands for void or a very soft material, while ‘black’ represents a strong material. Then, any intermediate choice is termed a ‘gray’ material and can be interpreted as a material with adjusted density. Although there is no such interpretation in optics, we continue to use the term grayness also here.
Remark 2
In this paper, we simply use linear combinations of the properties of the admissible materials, i.e., parameterizations of the following type:
Here, \(u_{e_\ell ^1}, u_{e_\ell ^2}\) describe the complex refractive indices of materials \(e_\ell ^1, e_\ell ^2\), respectively. For such a parameterization, intermediate choices of \(\rho \in (0,1)\) can be interpreted as alloys or composites. Therefore, the above parameterization is indeed also physically motivated.
In order to avoid undesired materials (e.g., materials in \({\mathcal {U}}_{ad}\setminus {\mathcal {U}}_{ad}^D\)), we penalize them in the optimization with a so-called grayness penalization function \(J_{gray}: {\mathcal {U}}_{ad}\rightarrow {\mathbb {R}}\) given by
with \({{\tilde{J}}}_{gray} : \{ U(\ell ,\rho ) \ \vert \ (\ell ,\rho ) \in I_E \times [0,1]\} \rightarrow {\mathbb {R}}\) defined for all \(\ell \in I_E\) by
Due to condition 3 of Definition 1, the above mapping is well defined.
Moreover, to get rid of possible artifacts in the final material distribution, we introduce the following irregularity penalization function \(J_{reg}: {\mathcal {U}}_{ad}\rightarrow {\mathbb {R}}\) given by
This term penalizes designs \({\mathbf {u}}\) which are not close to a smoothed design \({\mathbf {F}}{\mathbf {u}}\). The smoothed design is computed using the filter matrix \({\mathbf {F}}\) given by
with \(\phi _i\) chosen such that \(\sum _{j=1}^N {\mathbf {F}}_{ij} = 1\), filter radius \(R > 0\), \({\mathbf {r}}_i\) being the position of design element i, and \(\Vert {{\mathbf {r}}_i - {\mathbf {r}}_j} \Vert\) describing the Euclidean distance between design element i and j. Such filter matrices are frequently used in topology optimization, see, e.g., Bourdin (2001).
Together with the grayness function \(J_{gray}\), we have the penalty term
with non-negative scalar weights \(\gamma _1\) and \(\gamma _2\).
3 Sequential global programming
Let us consider the optimization problem
where the objective J is again a real-valued function and \({\mathcal {U}}_{ad}\) is a graph structured set of admissible materials formally introduced in the previous section.
We start with some definitions, which will be used throughout this paper.
Definition 3
(Separable function on \({\mathbb {C}}^N\)) A function \(g : {\mathbb {C}}^N \rightarrow {\mathbb {R}}\) is called separable on \({\mathbb {C}}^N\), iff there exist \({\bar{g}}_i : {\mathbb {C}}\rightarrow {\mathbb {R}}\) for all \(i = 1,\ldots ,N\) such that
Definition 4
(Separable exact model) Let \(N\in {\mathbb {N}}\) and \(f\in C({\mathbb {C}}^N;{\mathbb {R}})\) be given. A separable function \(g\in C({\mathbb {C}}^N;{\mathbb {R}})\) is called a separable exact model of f at \(({\tilde{\mathbf {u}}} \in {{\mathbb {C}}^{N}})\), iff
-
\(g({\tilde{{\mathbf {u}}}} + \delta_u e_i) = f({\tilde{{\mathbf {u}}}} + \delta_u e_i),\) \({\quad \forall \delta_u}\in {\mathbb {C}},\ \forall i=1,\ldots,N,\)
-
where \(e_i\) denotes the i-th unit vector in \(({\mathbb{R}}^N)\).
In general, we can compute a separable exact model of a given objective function J by
where \({\tilde{{\mathbf {u}}}}\) is an arbitrary point. The functions \({\tilde{S}}_i\) describe the material change in design element i and are given by
where \(e_i\) is the i-th unit vector. Note that we can always define a separable exact model of an objective function in this way. However, every evaluation of S requires N evaluations of J, and hence, there is no sense in using S to approximate J in practice. Fortunately, for a broad class of objective functions, reformulations of J can be found, which are much cheaper to evaluate. We demonstrate this in Sects. 5.1 and 5.2 for objective functions corresponding to optical properties like the extinction cross section and the angular-dependent scattering magnitude. We further will derive close approximations of these separable exact models. We call these separable first-order approximations.
Definition 5
(Separable first-order approximation) Let \(N\in {\mathbb {N}}\) and \(f\in C^1({\mathbb {C}}^N;{\mathbb {R}})\) be given. The function \(g\in C^1({\mathbb {C}}^N;{\mathbb {R}})\) is a separable first-order approximation of f in \({\mathbf {u}}\in {\mathbb {C}}^N\), iff
-
1.
g is separable,
-
2.
\(g({\mathbf {u}}) = f({\mathbf {u}})\),
-
3.
\(\nabla g({\mathbf {u}}) = \nabla f({\mathbf {u}})\).
Note that every separable exact model is always a separable first-order approximation. Compared to a standard separable first-order model, like a gradient model, the separable exact model is still globally correct as long as only one degree of freedom is approximated.
The principal idea of the sequential global programming (SGP) approach is to replace the original optimization problem by a sequence of sub-problems, in which the objective function J is approximated by a separable first-order model. Every sub-problem is thus characterized by a separable objective, which is minimized over the unchanged admissible set \({\mathcal {U}}_{ad}\). Exploiting this specific structure, all sub-problems are solved to global optimality. It is noted that for this neither convexity of S nor for \({\mathcal {U}}_{ad}\) is required.
An outline of the SGP algorithm is provided by Algorithm 1. We start with an admissible initial guess \({\mathbf {u}}^0\) and choose some algorithmic parameters: an initial proximal point parameter \(\tau \ge 0\), a related update parameter \(\theta > 1\), a constant \(\mu \ge 0\), which is used to decide about the termination of the inner loop and an outer stopping tolerance \(\epsilon \ge 0\). Then, the algorithm begins with the evaluation of the objective function J at \({\mathbf {u}}^0\). In the inner loop, the sub-problem is solved to global optimality. The objective of the sub-problem consists of the separable approximation S at the current iterate \({\mathbf {u}}^n\) plus a proximal point term \(\tau \Vert {{\mathbf {u}}^n-{\mathbf {u}}} \Vert _p^p\), which is used to enforce global convergence. The global minimizer of the sub-problem is denoted by \({\mathbf {u}}^*\). Now, the objective function J is evaluated at \({\mathbf {u}}^*\) while the regularization parameter \(\tau\) is incremented by \(\theta\). Once the descent is good enough, the inner loop is stopped, \({\mathbf {u}}^*\) becomes the new iterate and the algorithm continues with the outer loop. The overall algorithm terminates if the distance of old and new outer iterate is sufficiently small.
Note that the inner loop realizes a globalization strategy: as long as the solution of the sub-problem does not provide sufficient descent for the objective of the original problem, the parameter \(\tau\) is increased. As a consequence, the solution \({\mathbf {u}}^*\) is pushed closer toward the previous iterate \({\mathbf {u}}^n\).

For the solution of the sub-problem (cf. inner loop of Algorithm 1), we heavily exploit the separable structure of the model objective \(S({\mathbf {u}}^n;{\mathbf {u}}) +\tau \Vert {{\mathbf {u}}^n-{\mathbf {u}}} \Vert _p^p\) as well as the graph structure of \({\mathcal {U}}_{ad}\): For each design element (\(i = 1, \dots , N\)), we loop over all edges \(e \in E\) of the admissible set. On each edge e, the optimal design \({\mathbf {w}}_e^*\) is computed by solving a univariate optimization problem over the interval [0, 1]. We then evaluate and store the corresponding cost function value \({\mathbf {j}}^*_e\). Once we have looped over all edges, we find the edge \(e^*\) with the smallest function value, i.e., \({\mathbf {j}}^*_{e^*} \le {\mathbf {j}}^*_e\) for all \(e \in E\). The corresponding design \({\mathbf {w}}_{e^*}^*\) is then the optimal choice for the i-th design element. Thus, we set \({\mathbf {u}}^*_i = {\mathbf {w}}_{e^*}^*\). Once the loop over the design elements is completed, we have found the global minimizer \({\mathbf {u}}^*=({\mathbf {u}}_1^*,\ldots ,{\mathbf {u}}_N^*)^\top\) for our model problem.
In (Semmler et al. 2018, Lemma 4.9), it is proven that the inner loop of the above algorithm terminates after a finite number of iterations. Furthermore, for a local convergence result in a more general setting, we refer to Theorem 4.10 in Semmler et al. (2018). In Theorem 4.12 in the same paper, it is also shown that the final material distribution derived from Algorithm 1 is a first-order optimal solution to the objective function J.
Remark 6
-
1.
In general, the separable function S is non-convex. Despite this, the sub-problem in the inner loop of Algorithm 1 is solved to global optimality.
-
2.
The sequential global programming is perfectly parallelizable due to its separability, which means that the minimization can be done for each design element independently.
4 Discrete dipole approximation
The discrete dipole approximation (DDA) approach, originally introduced by Purcell and Pennypacker (1973), approximates the solution of time-harmonic Maxwell’s equations, see, e.g., Lakhtakia (1992); Draine and Flatau (1994); Kahnert (2003). The idea of DDA is to discretize the physical problem into N dipoles (\(i = 1,\dots ,N\)) with polarizabilities \(\alpha _i \in {\mathbb {C}}\) and positions \({\mathbf {r}}_i\). The state variables in DDA are the polarizations \({\mathbf {P}}_i = \alpha _i {\mathbf {E}}_i\) for all i, which depend on \({\mathbf {E}}_i \in {\mathbb {C}}^3\), the electric field at position \({\mathbf {r}}_i\). The latter can be written as the sum of the incident electric field \({\mathbf {E}}_{I,i}\) and further terms, encoding interactions with the other \(N-1\) dipoles. Spelling this out for all \(i = 1,\dots ,N\) we obtain the complex valued system of equations
in which \({\mathbf {E}}_I\) is a predefined incident beam, see, e.g., (Yurkin and Hoekstra 2011, Sec. 4.6), and \({\mathbf {A}}\in {\mathbb {C}}^{3N \times 3N}\) is the interaction matrix. The interaction matrix is made up of \(3\times 3\) blocks which are defined as follows:
Here \(\mathrm {i}\) denotes the imaginary unit, \(k = \frac{2\pi }{\lambda c}\) with wavelength \(\lambda\) and speed of light in vacuum c, \({\mathbf {r}}_{ij} = {\mathbf {r}}_i - {\mathbf {r}}_j\), and \(r_{ij} = \Vert {{\mathbf {r}}_{ij}} \Vert\) (cf. (Draine and Flatau 1994, Eq. 6)).
The choice for the polarizability \(\alpha _i\) is non-trivial, and there are several options with radiative corrections available. Nevertheless, most of them are based on the Clausius—Mossotti polarizability, see, e.g., (Draine and Flatau 1994, Eq. 1), which is given for the complex refractive index \(u\in {\mathbb {C}}\setminus \{\pm \mathrm {i}\sqrt{2}\}\) by
where d is the inter dipole spacing. We note that the off-diagonal part of the system matrix \({\mathbf {A}}\) does not depend on the refractive index of the material.
Based on the solution \({\mathbf {P}}\) of the system \({\mathbf {A}}{\mathbf {P}}= {\mathbf {E}}_I,\) we can compute different scattering quantities, like the extinction cross section, or the total electric field which is the sum of the incident electric field and the scattered field, see (Purcell and Pennypacker 1973, Eq. 3).
In the material optimization setting, we pursue in this article, the system matrix \({\mathbf {A}}\) depends on the choice of the material in each design element, i.e., each dipole. We recall that the material property in dipole i is described by the complex refractive index \({\mathbf {u}}_i\). Therefore, using Eq. (10), we can write \({\mathbf {A}}\) for a given design \({\mathbf {u}}\in {\mathbb {C}}^N\) as
where \({\mathbf {A}}^0\) is identical to \({\mathbf {A}}\) in all off-diagonal entries but has zeros on its diagonal, and \({\mathbf {B}}_i {:}{=}[e_{3i-2}, e_{3i-1}, e_{3i}] \in {\mathbb {R}}^{3N\times 3}\) for all \(i = 1,\dots ,N\) with \(e_j\) denoting the j-th unit vector in \({\mathbb {R}}^{3N}\).
In the remainder of this article, we omit the superscript “CM”, since we will always use the Clausius–Mossotti formula (10) to characterize the polarizability.
5 Separable approximations
In this section, we consider an objective function of the form
where \(\Re\) maps a complex number to its real part. Here, \({\mathbf {P}}({\mathbf {u}})\) denotes the unique solution of the following DDA system with material assignment \({\mathbf {u}}\):
For the precise definition of \({\mathbf {A}}({\mathbf {u}})\), we refer to Sect. 4. It is readily seen that the cost function J is linear in the state variable \({\mathbf {P}}\), but a nonlinear function of the design variable \({\mathbf {u}}\). In the following, we present, on the basis of the Sherman–Morrison–Woodbury formula, a separable exact model of the function J in Eq. (12). Therefore, we introduce the following notation. Let \(z_1,z_2 \in {\mathbb {C}}\), then
As outlined in Sect. 3, using an arbitrary \({\tilde{{\mathbf {u}}}} \in {\mathbb {C}}^N,\) a separable exact model of J can be written down in a brute force manner as
The following theorem provides a numerically more accessible form of this model.
Theorem 7
(Separable exact model for (13)) Let \({\mathbf {L}}\in {\mathbb {C}}^{3N}\) be given, and define \(S:({\mathbb {C}}^N)^2 \rightarrow {\mathbb {R}}\) for all \(({\tilde{{\mathbf {u}}}},{\mathbf {u}}) \in ({\mathbb {C}}^N)^2\) as follows,
where
and \(\beta ({\tilde{{\mathbf {u}}}}_i,{\mathbf {u}}_i)\) is given by Eq. (14). Then, the function \({\mathbf {u}}\mapsto S({\tilde{{\mathbf {u}}}};{\mathbf {u}})\) is a separable exact model according to Definition 4 of \(J: {\mathbb {C}}^N \rightarrow {\mathbb {R}}\),
where \({\mathbf {P}}({\mathbf {u}})\) is the unique solution of the state Eq. (13), and \({\mathbf {Q}}({\mathbf {u}})\) is the unique solution of the adjoint equation,
Proof
We just have to show that the model \(S({\tilde{{\mathbf {u}}}};{\mathbf {u}})\) satisfies the generic Eq. (15). We first compute \(J({\tilde{{\mathbf {u}}}} + ({\mathbf {u}}_i - {\tilde{{\mathbf {u}}}}_i)e_i)\) for the specific form of J given in Eq. (12). From the state Eq. (13), we get
and hence
Therefore, we have
Together with
representation (11) implies
and thus
The Sherman–Morrison–Woodbury formula yields then
From this we get, using Eq. (16) and the adjoint Eq. (17):
Finally, summing from \(i=1,\ldots ,N\) and adding the term \(J({\tilde{{\mathbf {u}}}})(1-N)\) on both sides, we conclude
\(\square\)
As the explicit computation of the inverse of the DDA matrix is typically prohibitive, we further show that we still obtain a separable first-order approximation, if we replace the matrix \({\mathbf {A}}({\tilde{{\mathbf {u}}}})^{-1}\) in the expression for \({\mathbf {C}}_i({\tilde{{\mathbf {u}}}},{\mathbf {u}}_i),\ i=1,\ldots ,N\) from Eq. (16) by an arbitrary \(3N \times 3N\)-matrix.
Theorem 8
(Separable first-order approximation of (13)) Let \({\mathbf {L}}\in {\mathbb {C}}^{3N}\) be given, and define \(S_{\mathbf {F}}:({\mathbb {C}}^N)^2 \rightarrow {\mathbb {R}}\) for all \(({\tilde{{\mathbf {u}}}},{\mathbf {u}}) \in ({\mathbb {C}}^N)^2\) as follows
where
with \({\mathbf {F}}\in {\mathbb {C}}^{3N\times 3N}\) arbitrary, and \(\beta ({\tilde{{\mathbf {u}}}}_i,{\mathbf {u}}_i)\) defined by Eq. (14). Then, the function \({\mathbf {u}}\mapsto S_{\mathbf {F}}({\tilde{{\mathbf {u}}}};{\mathbf {u}})\) is a separable first-order approximation according to Definition 5 of \(J: {\mathbb {C}}^N \rightarrow {\mathbb {R}}\),
in the point of approximation \({\tilde{{\mathbf {u}}}}\), where \({\mathbf {P}}({\mathbf {u}})\) and \({\mathbf {Q}}({\mathbf {u}})\) are the unique solutions of (13) and (17), respectively.
Proof
Due to \(\beta ({\tilde{{\mathbf {u}}}}_i,{\tilde{{\mathbf {u}}}}_i)=0\), the sum in the expression for \(S_{\mathbf {F}}({\tilde{{\mathbf {u}}}};{\tilde{{\mathbf {u}}}})\) vanishes, and we immediately have \(S_{\mathbf {F}}({\tilde{{\mathbf {u}}}};{\tilde{{\mathbf {u}}}})=J({\tilde{{\mathbf {u}}}})\). Next we look at the first derivative. We first provide a derivative formula for \({\mathbf {P}}\). For this, we apply the implicit function theorem \({\mathbf {P}}({\tilde{{\mathbf {u}}}})\) to the function \(f({\tilde{{\mathbf {u}}}},{\mathbf {y}}) := {\mathbf {A}}({\tilde{{\mathbf {u}}}}) {\mathbf {y}}- {\mathbf {E}}_I\). We observe that \(f({\tilde{{\mathbf {u}}}},{\mathbf {y}})=0\) if and only if \({\mathbf {y}}={\mathbf {P}}({\tilde{{\mathbf {u}}}})\) and further
and thus
Together with \({\mathbf {A}}({\tilde{{\mathbf {u}}}})^{-1} {\mathbf {L}}= {\mathbf {Q}},\) we get
For the derivative of \(S_{\mathbf {F}}({\tilde{{\mathbf {u}}}};{\mathbf {u}}),\) we have
and thus
Now, taking the structure of \({\mathbf {B}}_i\) into account, both derivative formulae coincide. Finally, the approximation is separable by construction. \(\square\)
The strength of a separable exact model is that—as long as we vary only one variable—it is fully correct, even if we are far away from \({\tilde{{\mathbf {u}}}}\). This is in clear contrast to a typical first-order model. In order to maintain this property at least in an approximate manner, instead of choosing an arbitrary matrix \({\mathbf {F}}\) in Eq. (18), we opt for an approximation of \({\mathbf {A}}({\tilde{{\mathbf {u}}}})^{-1}\), which is computationally accessible.
In detail, we suggest using the inverse of the diagonal of the original system matrix as an approximation of the inverse system matrix, i.e.,
An interpretation of this in terms of a Neumann series is presented in Appendix B. We further note that the approximation in Eq. (19) corresponds to a Jacobi preconditioner, as it is used in DDA together with an iterative solver to compute an approximate solution of the linear system (7), see (Yurkin and Hoekstra 2011, Sec. 7.1).
Now, using
and Eq. (19), we observe
Further
and therefore, we have
Based on this argument, we will use the following instantiation of the class of separable models introduced in Theorem 8. In Sect. 5.4, a comparison of this model and more simplified once is shown.
Corollary 9
Let \({\mathbf {L}}\in {\mathbb {C}}^{3N}\) be given, and define \(S_{\mathbf {N}}:({\mathbb {C}}^N)^2 \rightarrow {\mathbb {R}}\) for all \(({\tilde{{\mathbf {u}}}},{\mathbf {u}}) \in ({\mathbb {C}}^N)^2\) as follows
Then, the function \({\mathbf {u}}\mapsto S_{\mathbf {N}}({\tilde{{\mathbf {u}}}};{\mathbf {u}})\) is a separable first-order approximation according to Definition 5 of \(J: {\mathbb {C}}^N \rightarrow {\mathbb {R}}\),
in the point of approximation \({\tilde{{\mathbf {u}}}}\), where \({\mathbf {P}}({\mathbf {u}})\) and \({\mathbf {Q}}({\mathbf {u}})\) are the unique solutions of (13) and (17), respectively.
Remark 10
(Generalization to nonlinear functions)
-
1.
For the objective function \(J({\mathbf {u}}) {:}{=}g({\mathbf {P}}({\mathbf {u}}))\), where \(g : {\mathbb {C}}^{3N} \rightarrow {\mathbb {R}}\) is a nonlinear function, we can in general no longer compute a separable exact model. However, we can approximate it by a linearization in g, e.g., at \({\tilde{{\mathbf {u}}}}\in {\mathbb {C}}^{N}\):
$$\begin{aligned} J({\mathbf {u}})&= g({\mathbf {P}}({\mathbf {u}})) \\&\approx g({\mathbf {P}}({\tilde{{\mathbf {u}}}})) + \nabla g({\mathbf {P}}({\tilde{{\mathbf {u}}}}))\, ({\mathbf {P}}({\mathbf {u}}) - {\mathbf {P}}({\tilde{{\mathbf {u}}}})) \\&= g({\mathbf {P}}({\tilde{{\mathbf {u}}}})) - \nabla g({\mathbf {P}}({\tilde{{\mathbf {u}}}}))\, {\mathbf {P}}({\tilde{{\mathbf {u}}}}) + \nabla g({\mathbf {P}}({\tilde{{\mathbf {u}}}}))\, {\mathbf {P}}({\mathbf {u}}). \end{aligned}$$For the last term, we can now derive again a separable exact and first-order model like before.
-
2.
For the objective function \(J({\mathbf {u}}) {:}{=}g({\mathbf {L}}^\top {\mathbf {P}}({\mathbf {u}}))\), where \(g : {\mathbb {C}}\rightarrow {\mathbb {R}}\) is a polynomial and \({\mathbf {L}}\in {\mathbb {C}}^{3N}\), we can also compute a separable exact model as well as a separable first-order approximation of the above objective function in the same way and with the same properties described before. Rather than proving this in general, we refer to Sect. 5.2 where this is shown for the angular-dependent scattering magnitude which indeed can be written as a quadratic polynomial.
In the following, we want to determine separable first-order approximations for some optical properties, including the extinction and angular-dependent scattering magnitude.
5.1 Extinction cross section
The sum of absorption and scattering of light is related to the extinction cross section which is—using the terminology of Sect. 4—defined by (Draine and Flatau 1994, Eq. 8)
where \({\mathbf {P}}({\mathbf {u}})\) is the unique solution of the state Eq. (13), and \(\Im\) maps a complex number to its imaginary part. It is thus readily seen that the extinction cross section is of the form of the objective function given in Eq. (12). Therefore, using Corollary 9, a reasonable separable first-order approximation is given as
where \({\mathbf {Q}}({\mathbf {u}})\) is the unique solution of the adjoint equation
5.2 Angular-dependent scattering magnitude
Assume in the following that the incident electric field is a plane wave given by
where \({\mathbf {p}}\) is the polarization and \({\mathbf {d}}\) the direction of the incident field, respectively. Furthermore, we assume that the polarization is perpendicular to the direction of the incident wave, i.e., \({\mathbf {p}}\perp {\mathbf {d}}\).
We are now interested in the proportion of energy that is scattered in an arbitrary scattering direction, defined by a unit vector \({\mathbf {a}}\). For that we start with the scattering amplitude, see (Yurkin and Hoekstra 2011, Eq. 27), defined as
where \({\mathbf {P}}({\mathbf {u}})\) is the unique solution of the state Eq. (13). The desired angular-dependent scattering magnitude \(C_{sca}\) in direction \({\mathbf {a}}\) is then given by
We now define \({\tilde{{\mathbf {E}}}}({\mathbf {a}}) \in {\mathbb {C}}^{3N\times 3}\) as
where \(({\tilde{{\mathbf {E}}}}({\mathbf {a}}))_j\) is the j-th \(3 \times 3\) block in the complex matrix \({\tilde{{\mathbf {E}}}}({\mathbf {a}})\) and, assume, without loss of generality, that the incident electric wave has unity amplitude, i.e., \(\left|{\mathbf {E}}_I \right| = 1\). Then, we can write the angular-dependent scattering magnitude as
Note that if we consider the scattering in exactly the back direction of the incident field (\({\mathbf {a}}= -{\mathbf {d}}\)), this is equivalent to the so-called backscattering magnitude \(B_{sca}\) (cf. (Virkki et al. 2013, Eq. 8)), i.e., it holds
Remark 11
(Backscattering magnitude) In the special case where the incident wave propagates along the \(x_3\)-axis, i.e., \({\mathbf {d}}= (0,0,1)^\top\), and we consider the scattering direction \({\mathbf {a}}=-{\mathbf {d}}\), \({\tilde{{\mathbf {E}}}}\) can be written as \({\tilde{{\mathbf {E}}}} = {\mathbf {E}}_I^{x_1} + {\mathbf {E}}_I^{x_2}\), where \({\mathbf {E}}_I^{x_1}\), \({\mathbf {E}}_I^{x_2}\) are the incident electric fields with \(x_1\)-, \(x_2\)-polarization, respectively. In Sect. 6.3, we consider this situation, where we want to optimize the backscattering magnitude for a photonic crystal.
Theorem 12
(Separable exact model for scattering magnitude (25)) Let \({\mathbf {a}}\) be the desired scattering direction. Further, let \({\mathbf {P}}({\mathbf {u}})\) be the unique solution of the state Eq. (13), and \({\mathbf {Q}}({\mathbf {u}})\) denote the adjoint variable solving the adjoint equation
Moreover, let the function \(S_{sca}:({\mathbb {C}}^N)^2 \rightarrow {\mathbb {R}}\) be defined for all \(({\tilde{{\mathbf {u}}}},{\mathbf {u}}) \in ({\mathbb {C}}^N)^2\) as follows,
where
and
with \(\beta ({\tilde{{\mathbf {u}}}}_i,{\mathbf {u}}_i)\) given by Eq. (14). Then, the function \({\mathbf {u}}\mapsto S_{sca}({\tilde{{\mathbf {u}}}};{\mathbf {u}})\) is—according to Definition 4—a separable exact model of the angular-dependent scattering magnitude from Eq. (24).
Proof
For a proof, see Appendix c. \(\square\)
Again, we obtain a separable first-order model, if we replace the inverse DDA matrix \({\mathbf {A}}({\tilde{{\mathbf {u}}}})^{-1}\) in Eq. (27) by an arbitrary approximation \({\mathbf {F}}\).
Theorem 13
(Separable first-order model for scattering magnitude (25)) Let \({\mathbf {a}}\) be the desired scattering direction. Further, let \({\mathbf {P}}({\mathbf {u}})\) and \({\mathbf {Q}}({\mathbf {u}})\) be the unique solutions of (13) and (26), respectively. Moreover, let \(S_{{\mathbf {F}},{sca}}:({\mathbb {C}}^N)^2 \rightarrow {\mathbb {R}}\) be defined for all \(({\tilde{{\mathbf {u}}}},{\mathbf {u}}) \in ({\mathbb {C}}^N)^2\) as follows
with
and
where \({\mathbf {F}}\in {\mathbb {C}}^{3N\times 3N}\) arbitrary, and \(\beta ({\tilde{{\mathbf {u}}}}_i,{\mathbf {u}}_i)\) defined by Eq. (14). Then, the function \({\mathbf {u}}\mapsto S_{{\mathbf {F}},{sca}}({\tilde{{\mathbf {u}}}};{\mathbf {u}})\) is—according to Definition 5—a separable first-order approximation of the angular-dependent scattering magnitude (24) in the point of approximation \({\tilde{{\mathbf {u}}}}\).
Proof
The proof can be found in Appendix D and is analogous to the proof of Theorem 8. \(\square\)
We again approximate the inverse of the system matrix \({\mathbf {A}}({\tilde{{\mathbf {u}}}})^{-1}\) in the above matrix function \({\mathbf {C}}_i({\tilde{{\mathbf {u}}}},{\mathbf {u}}_i)\) from Eq. (27) using the first element of the Neumann series, which yields,
Therefore, we have
where \({\mathbf {P}}({\mathbf {u}})\) and \({\mathbf {Q}}({\mathbf {u}})\) are the unique solutions of (13) and (26), respectively. With this expression for \(\gamma _i\), we now have a separable first-order approximation \(S_{{\mathbf {N}},sca}\) according to Definition 5 of the angular-dependent scattering magnitude \(C_{sca}\) given by Eq. (24).
Remark 14
In most applications, not the scattering magnitude in a specific direction is of interest, but the scattering energy in a predefined segment of an observation sphere, which we call the monitor \({\mathcal {O}}\) (see Fig. 4). The corresponding cost function integrates the angular-dependent cross section over this monitor. The resulting expression can be well approximated by Romberg’s quadrature rule as follows:
Here, n is the number of integration points \({\mathbf {a}}^j\) on the monitor \({\mathcal {O}}\), and \(\omega _j\) are quadrature weights for all \(j=1,\ldots ,n\). Obviously, the right hand side is a linear combination of the angular-dependent scattering magnitudes for the directions determined by the integration points \({\mathbf {a}}^j\). Consequently, all of the above results determined in this section carry over to this function. In particular, separable exact and first-order models are obtained by computing a weighted sum of separable models computed as described in Theorems 12 and 13.

Visualization of the scattering problem where all the energy scattered in direction of a monitor \({\mathcal {O}}\), here, a spherical cap, is of interest (cf. Remark 14)
5.3 Separable model for penalization function
In this section, we want to briefly describe how we can derive separable models for the grayness and irregularity penalization function from Equs. (2) and (3), respectively.
Note that the grayness function \(J_{gray}\) is separable by definition.
To derive a separable model for the irregularity penalization function \(J_{reg}\), we can again use Eq. (15). First, we have
with \({{\textbf {M}}}{:}{=}({\textbf{F}}-\mathbbm {1}_N)^\top ({\textbf{F}}-\mathbbm {1}_N)\). The material change in design element i for an arbitrary \({\tilde{{\mathbf {u}}}} \in {\mathbb {C}}^N\) is then given by
Therefore, we can conclude that our separable model for the irregularity penalization function \(J_{reg}\) is given by
Obviously, the above separable model \(S_{reg}\) is a univariate quadratic function.
5.4 Accuracy of separable models
In the following, we want to emphasize the accuracy of the proposed separable first-order models with the Jacobi-type approximation of the inverse of the DDA system matrix \({\mathbf {A}}\) as introduced in Eq. (22) and Theorem 13 with expression (29) for \(\gamma _i\). For this, we compare for an exemplary setting the proposed separable model with the true objective function as well as the linear first-order model, i.e., a gradient model, which is obviously also separable.
For the comparison of the models, we focus on an individual spherical particle with \(0.1 \mu m\) diameter and a wavelength of \(0.6 \mu m\). The particle is discretized into approximately \(7 \cdot 10^4\) active dipoles. The admissible set of materials is given by \(u_1 = 1.59\) and \(u_2 = 1.59 + 0.6\mathrm {i}\), which are connected by an edge like it is discussed in Sect. 2.2. Note, that these materials will also be used in Example 6.3. The initial material distribution is given first by a homogeneous design, where each dipole of the sphere consists of the first material. We want to discuss the models derived for the extinction cross section, see Sect. 5.1, as well as for the backscattering magnitude, cf. Sect. 5.2.
For comparison of the models, in the following, the material of one single design element, i.e., the polarizability of a single dipole, is changed. This means the material property for this dipole is gradually changed from \(u_1\) (material 1) for \(\rho = 0\) to \(u_2\) (material 2) for \(\rho = 1\) by the interpolation parameter \(\rho \in [0,1]\). Then, for each \(\rho\) on the edge connecting the materials, the DDA system is solved in order to get the real objective function \(\sigma _{ext}\) (Eq. (21)) and \(B_{sca}\) (Eq. (25)), see solid blue curves in the top plots in Figs. 5 and 6, respectively. We further point out that the blue curves in the top graphs coincide exactly with the answer provided by the separable exact models suggested previously in this section. Then, to compute the separable first-order approximations \(S_{{\mathbf {N}},ext}\) and \(S_{{\mathbf {N}},sca}\), we compute the DDA solution only in the point of approximation (\(\rho = 0\) for the left plots, \(\rho =1\) for the plots on the right) and approximate the function values at all \(\rho \in [0,1]\), cf. solid red curves in the top plots in Figs. 5 and 6, respectively. Note that for the respective right plots, we start with material 2 (\(\rho =1\)) in the changing dipole. Since the separable model for the extinction cross section is almost exact in the considered setting, the blue curve is hidden by the red curve. Additionally, the solid yellow curve corresponds to a primitive gradient model. We can see that our separable model approximates the behavior of the physical objective function quite well, while the gradient model is—in the case of the backscattering—not approximating the true objective function very well.
This gets even worse when penalization of intermediate material comes into play. There are two possible ways of simple separable first-order models. The naive first one is to build a linear model for the objective function including the grayness penalization (dashed-dotted yellow curves) and the more sophisticated is to have a gradient model for the physical part of the objective function and add to this the grayness penalization function (dashed yellow curves) which is separable by construction, see Eq. (2).

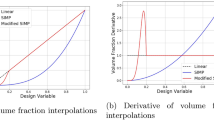
We visualize the accuracy of the derived separable approximations for an exemplary setting described in Sect. 5.4. The plots correspond to the extinction cross section (see Eq. (21)), and describe the setting where we start with \(\rho =0\) in the left column and \(\rho = 1\) in the right column for the changing dipole. For the top plots, we have Solid lines: models without grayness penalization; dashed lines: models with grayness penalization; dashed-dotted lines: linear model for objective function including grayness penalization function. The bottom plots show the model error of our separable model, the linear model, and the linear model for the objective function including grayness penalization. It is seen that in all cases, the chosen separable model provides a very tight approximation of the objective function over the full design interval. This is in sharp contrast to typical first-order approximations, which provide tight approximations close to the expansion point only

We visualize the accuracy of the derived separable approximations for an exemplary setting described in Sect. 5.4. The plots correspond to the backscattering magnitude (see Eq. (25)). Function values for the different models are shown in the top row, while error plots are presented in the bottom row. For a detailed description of the meaning of the colors and the line style used in each plot, we refer to the caption of Fig. 5
Furthermore, the plots in the bottom row of Figs. 5 and 6 show the absolute error of the considered models compared to the true objective function. We can see that in all cases, the model error in our separable first-order approximation (see red curves in the bottom row of the plots) is several orders of magnitude lower compared to the error in the linear models (see yellow curves in the bottom row of the plots). Obviously, the error in the linear model for the objective function including grayness penalization is the worst, see yellow dashed-dotted lines. Note that the errors of the models with grayness penalization (the dashed blue and dashed red curves in the upper row plots) are the same as the errors of the models without penalization; therefore these are not displayed again.
6 Examples
To illustrate the presented framework, we discuss in this section three different examples. The first example is an academic proof of concept example, where our material catalog consists of two artificial materials. We also show the optimization of this example on a high-performance computing (HPC) environment and point out the corresponding benefits. Last but not least, we will test our SGP method against the MMA method (Svanberg 1987).
The purpose of the second example is twofold: On the one hand, we want to discuss a multi-material optimization problem with more than two admissible materials. On the other hand, we demonstrate that we can consider a full spectrum of wavelengths, rather than an individual one.
In our last example, we consider the minimization of the backscattering magnitude for a photonic crystal. Here, we first optimize each dipole of one particle in the system separately. In a further step, we show how we can combine some sets of dipoles/design elements in our model. Using this, we are able to assign only one material property to each individual particle and to enforce that during optimization the material properties of each particle remain completely homogeneous. Then, the third step is to investigate the effect of grayness penalization to avoid undesired materials.
Note that in the following, every used material is characterized by its complex refractive index u. Unless otherwise stated, we set \(\gamma _1 = 0\) and \(\gamma _2 = 0\) in the penalty term (5), which means that there is no grayness or irregularity penalization.
The presented SGP approach was implemented in MATLAB ver. R2020a as well as in a C++ library for highly parallel computations. For the solution of the DDA system, we used the open-source project ADDA (Yurkin and Hoekstra 2011) for the MATLAB implementation, and OpenDDA (Donald et al. 2009) for our C++ code.
6.1 Academic example
The objective in this optimization example is to reduce the extinction cross section as defined in Eq. (21) of a ball with \(0.35\mu m\) diameter at a wavelength of \(\lambda = 0.4\mu m\). The particle is illuminated by an unpolarized plane wave which propagates in \(x_3\)-direction. The background medium surrounding the object is chosen to be vacuum (\(u_b = 1.0\)). The material catalog consists of two artificial materials:
At first, the object is uniformly discretized with a dipole spacing \(d=3.5nm\), which results in a total number of around \(5.4 \cdot 10^5\) active dipoles—this is at the same time the number of optimization variables we have to handle in our optimization model. We start with a particle where each dipole consists of the second material. So, the initial material distribution is given by \({\mathbf {u}}^0_i = u_2\) for all \(i=1,\ldots ,N\).
For this setting, the initial extinction cross section is computed to be \(\sigma _{ext}({\mathbf {u}}^0) = 0.4480 \mu m^2\). Since the initial material distribution is homogeneous (only material 2) and the particle is a sphere, we can also use Mie-theory to compute optical properties, from which we obtain \(\sigma _{ext}({\mathbf {u}}^0) = 0.4415 \mu m^2\). Increasing the resolution up to a corresponding dipole distance of \(d=0.875 nm\), the DDA method provides an objective function value of \(\sigma _{ext}({\mathbf {u}}^0) = 0.4431 \mu m^2\). This is in nice correspondence with the Mie prediction.
To minimize the extinction, we ran our DDA-SGP approach for different resolutions and initial designs \({\mathbf {u}}^0\). The corresponding convergence graphs, showing the history of the objective function values, are displayed in Fig. 7. We note that one SGP iteration means that we have to solve one times the state and the adjoint equation. Therefore, in one major iteration, we have to solve the DDA system twice (cf. Algorithm 1).

Convergence history of the objective function for the academic example (see Sect. 6.1) for different resolutions and initial material distributions
Table 1 shows the final extinction cross section for different resolutions. Comparing the function values for the different solutions, we can observe that our method is not sensitive with regard to the chosen resolution as long as it is sufficiently fine. Additionally, the result appears to be, for this problem, independent of the initial material distribution. This means that the SGP algorithm finds stable local optima.
The optimized material distribution for the problem with \(d=3.5 nm\) is shown in Figure 8, where the material distribution for the first and second material is visualized separately.

Final material distribution for the academic example (Sect. 6.1) with a dipole distance of 3.5nm; left: material 1; right: material 2
Additionally, we want to investigate, if the visibility of the optimized particle (computed here via the extinction cross section) is reduced for the entire spectrum of visible light. For this, we use the final material distribution \({\mathbf {u}}^*\) from Fig. 8 (\(d=3.5nm\)) and compute, using the DDA method, the corresponding extinction cross section for a large number of wavelengths in the interval \([0.4\mu m, 0.8\mu m]\). Figure 9 shows the initial spectrum for the material distributions where each dipole consists of material \(u_1\) or \(u_2\), respectively, as well as for the optimized material distribution \({\mathbf {u}}^*\). We can see that the design derived from the optimization of only one wavelength (\(\lambda = 0.4\mu m\)) behaves also quite good for the whole wavelengths range: the extinction is significantly reduced for all wavelengths in the visible spectrum. This observation is not too surprising, as the material parameters were chosen to be wavelength independent. Finally, we would like to note that still a better result could be obtained, if we would optimize for all wavelengths in the desired interval simultaneously.

Extinction spectra for the material distributions where each dipole consists of material \(u_1\) or \(u_2\), respectively, as well as for the optimized design \({\mathbf {u}}^*\) for the academic optimization example (see Sect. 6.1)
Note that the above optimization was done on a single desktop computer, with 8 Intel Xeon E3-1245V6 processors, each with 4 cores, and a total of 32GB of RAM. On this computer, we cannot benefit that much from the separability/parallelizability of our model and algorithm. Nevertheless, we could go down to a dipole spacing, i.e., the distance between two adjacent dipoles, of 3.5nm.
As pointed out already in Sect. 3, the SGP approach is based on the concept of separability. As a consequence, the optimization can be carried out independently for each dipole. As also the DDA solver, we were using itself is designed for the use on parallel architectures, we decided to develop a version of our software that can be used in a high-performance environment. To demonstrate its efficiency, we have run the same problem as before with a much higher resolution on the Emmy Cluster from the Regional Computing Center at the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) in Germany. Doing so, we were able to discretize the design domain with a dipole spacing of 0.875nm, which is already in the range of a few atomic distances (\(\approx 0.1 nm\)). This resulted in a total number of around \(3.3 \cdot 10^7\) active dipoles (see Fig. 10 for the final material distribution), which is about 64 times more than we were able to use on the desktop PC.

Final material distribution for the academic example (Sect. 6.1) with a dipole distance of 0.875nm; left: material 1; right: material 2
Furthermore, in Table 2, wall-clock times as well as times for the optimization used on the personal computer and the HPC environment are given. Since both, the DDA code and the code for the sub-problem solution in the optimization can be fully parallelized on the HPC environment, the calculations are way faster than on our single desktop computer. Obviously, the most time is needed for solving the state and adjoint problem, which means for solving the DDA systems. The time for optimization on both machines is only a minor part of the total time. This can be partly explained by the computational complexity formulae for both these steps, which are \({\mathcal {O}}(N_T \log (N_T))\) for DDA (and also the adjoint), assuming a constant number of iterations for the iterative solver, see, e.g., Yurkin et al. (2006) and Yurkin (2016), and \({\mathcal {O}}(N)\) for the solution of the optimization sub-problem, where N is the number of design dipoles and \(N_T\) is the total number of dipoles including the “inactive” ones.
With the DDA-SGP approach implemented in a HPC environment we can further, for example, increase the number of incident directions, or compute a lot of more wavelengths in a spectrum in parallel, i.e., we can also refine the resolution in the wavelength range. Furthermore, the usage of the high-performance computing library can also be interesting for large particle assemblies, as studied in Sect. 6.3.
Remark 15
We also performed experiments where we used the irregularity penalization introduced in Eq. (3) to get rid of the ring in the final design from Fig. 8 computed with \(d=3.5nm\). Therefore, we have chosen \(\gamma _2 = 5.0\cdot 10^{-6}\) in Eq. (5) with filter radius \(R=0.014\) in Eq. (4). As a result, we obtained essentially the same material distributions as before, but the ring was “smoothed out.” Comparing the corresponding value of the objective function, which amounted to \(\sigma _{ext}({\mathbf {u}}^*_{reg})=0.1801 \mu m^2\) with the one without irregularity penalization (see Table 1), we could observe a relatively small difference. We concluded from this that the ring structure in the above designs is of minor importance.
We finally want to use our academic optimization example to compare the presented SGP approach with the well-known MMA algorithm. For that, we take the example described in detail in the beginning of Sect. 6.1 with a dipole distance of \(d = 7nm\). We perform two different experiments. First, no grayness penalization is used throughout the optimization process (i.e., \(\gamma _1 = 0\)). The convergence history of the objective function for both solvers is visualized in Fig. 11 (solid lines). We see, that MMA converges much slower than our SGP approach. When we stopped MMA after 200 iterations, the computed function value was still far away from the value found by SGP. The gap between MMA and SGP gets even larger, when we consider grayness penalization, i.e., the grayness penalization function (2) is now added to the objective function with a weight of \(\gamma _1 = 10^{-5}\) (cf. Eq. (5)). Comparing the convergence history of the cost function (see dashed lines in Fig. 11), we see that, while SGP finds still a good local optimum close to the one without penalization, the function value for the design computed by MMA is now much worse. In order to understand this situation a bit better, we had a closer look at the iteration history in both cases. For SGP, we found that in all but two iterations a fully ‘black-and-white’ solution was generated, i.e., no intermediate material properties were used. Beyond that, checking the projected gradient, we found that each of these points is Karush-Kuhn-Tucker (KKT) points. That means, SGP has visited in total 9 KKT points until it stopped, thereby permanently improving the value of objective functions. Quite contrary to this, MMA approached a KKT point (also ‘black-and-white’) with a rather poor function value after a little bit more than 10 iterations and was not able to escape from this anymore. The reason why SGP can cope much better with the situation is the way better approximation, which is used in the sub-problems: while in MMA, even a (locally) concave function is approximated by a convex model, in SGP the concave character is maintained. Thus, thanks to the global solution strategy applied for the solution of the sub-problem, SGP has the chance to escape from poor local minima.

Comparison of the SGP and the MMA method. Shown is the convergence history of the objective function for the academic example (see Sect. 6.1) with \(d=7nm\). Solid lines: optimization without grayness penalization; dashed lines: optimization with grayness penalization (\(\gamma _1 = 10^{-5}\))
6.2 Multi-material example
The purpose of this example is to demonstrate the ability of our approach to treat a multi-material optimization problem with a material catalog consisting of more than two admissible materials. Moreover, we discuss in more detail the optimization for a whole range of wavelengths.
Again, we focus on the optimization of the extinction cross section given by Eq. (21), but in this case for a wavelength spectrum ranging from \(0.4 \mu m\) to \(0.7 \mu m\). We want to minimize on the left part of the extinction spectrum and maximize on the right. Therefore, our objective function is the numerical approximation of the weighted mean value in the visible range of light given by
with
and
We consider a sphere with \(0.3 \mu m\) diameter which is illuminated by a \(x_1\)-polarized incident plane wave propagating in positive \(x_3\)-direction. As medium for the background, we choose ethanol with \(u_b \approx 1.36\). The three admissible materials are given by silica, titanium dioxide, and goethite, with wavelength-dependent complex refractive indices \(u_1\), \(u_2\), and \(u_3\), respectively. For the corresponding complex refractive indices, we refer to Malitson (1965) for silica, and DeVore (1951) for titanium dioxide. For goethite, see Appendix A.
The graph structured set of admissible materials is visualized in Fig. 12. Note, that we consider a complete graph, which means that each node is connected by an edge with every other node.

Graph structured admissible set of materials for the multi-material optimization example, see Sect. 6.2
In this case, we choose a dipole spacing of \(d = 1.5nm\), such that we have about \(4.2 \cdot 10^6\) active dipoles. We start with a material distribution where all dipoles consist of a homogeneous mixture of \(50\%\) silica and \(50\%\) titanium dioxide, which would mean that we are for all design elements on edge \(e_1\) with intermediate value \(\rho =\frac{1}{2}\) (cf. Fig. 12). With this, the initial material distribution in each design element i is given by
and the corresponding initial objective function value is \(J({\mathbf {u}}^0) = 1.2050\mu m^3\). Furthermore, homogeneous designs for the catalog materials lead to the following function values: \(J(u_1 {\mathbf {e}}) = 0.0245\mu m^3\), \(J(u_2 {\mathbf {e}}) = -0.6721\mu m^3\), and \(J(u_3 {\mathbf {e}}) = 0.29147\mu m^3\). Here, \({\mathbf {e}}\) is a vector of size N with all entries equal to 1. Fig. 13 shows the initial spectra for different initial material distributions.

Initial spectra for different initial material distributions \({\mathbf {u}}^0\) for the multi-material optimization problem, see Subsection 6.2
The DDA-SGP approach yields the following results. If we choose \(\gamma _1 = \gamma _2 = 0\) in Eq. (5) (no penalization), then we obtain the final material distribution shown in Fig. 14. We denote this by \({\mathbf {u}}^*\). We can observe that there are some undesired geometric artifacts at the boundary of the materials. In order to improve on this, we activated the irregularity penalization term (3) in the cost function.

Final material distribution \({\mathbf {u}}^*\) for the multi-material optimization example (Sect. 6.2) with a dipole distance of 1.5nm without penalization; red: silica; blue: titanium dioxide; green: goethite
In detail, we choose the parameters \(\gamma _2 = 10^{-6}\) in Eq. (5) and \(R=0.006\) in the filter matrix (4). The corresponding optimized design is given in Fig. 15 and denoted by \({\mathbf {u}}^*_{reg}\). We note that to compute \({\mathbf {u}}^*_{reg}\), we again started the optimization with the initial homogeneous material distribution given in Eq. (31).

Final material distribution \({\mathbf {u}}^*_{reg}\) for the multi-material optimization example (Sect. 6.2) with a dipole distance of 1.5nm and irregularity penalization (\(\gamma _2 = 10^{-6},\ R=0.006\)); red: silica; blue: titanium dioxide; green: goethite
In Fig. 16, the initial and optimized spectra are shown. The corresponding convergence histories of the cost function are given in Fig. 17. The final objective function values are given by \(J({\mathbf {u}}^*) = -0.8308 \mu m^3\) and \(J({\mathbf {u}}^*_{reg}) = -0.8254 \mu m^3\). We can see that the penalization of irregularity does not significantly affect the spectrum as well as the corresponding function value, but the design looks much better since most of the artifacts are smoothed out.

Initial and optimized spectra for the multi-material optimization problem, see Sect. 6.2

6.3 Optimization of a photonic crystal
In this example, we want to investigate how our model works for particle assemblies. We consider a photonic crystal, that is an ensemble of several nanoparticles, with the following properties. We have a system with 7 layers of closed packed spherical particles, each with a diameter of \(0.05 \mu m\), that are arranged in a hexagonal pattern. In each layer, we consider around 10 by 10 particles which are uniformly discretized with the dipole distance \(d = 2 nm\). This results in a total number of active dipoles of about \(5.1 \cdot 10^{6}\) dipoles, which are about \(8.2 \cdot 10^{3}\) dipoles per particle. The object to be optimized is shown in Fig. 18.

Photonic crystal (cf. Sect. 6.3) with 7 layers of closed packed particles. Each particle has a diameter of \(0.05 \mu m\)
We want to minimize the backscattering magnitude given by Eq. (25) for a wavelength of \(\lambda = 0.6 \mu m\). Note that we consider now the scattering in exactly the negative direction of the incident field. The particulate system is illuminated by an unpolarized plane wave propagating in positive \(x_3\)-direction. The particle ensemble is embedded in vacuum, and the material catalog consists of two admissible materials. The first one is polystyrene with \(u_1 = 1.59\) which is non-absorbing. The second material has absorbing properties similar to a carbon black-polystyrene composite with \(u_2 = 1.59 + 0.6\mathrm {i}\). The values of the backscattering magnitude for the two admissible materials are given by \(B_{sca}(u_1 {\mathbf {e}}) = 0.1667\) and \(B_{sca}(u_2{\mathbf {e}}) = 0.0969\), where \({\mathbf {e}}\) again is a vector of size N with all entries equal to 1. Therefore, we start the optimization with a material distribution where each dipole of the system consists of pure polystyrene, i.e., \({\mathbf {u}}^0 = u_1 {\mathbf {e}}\).
In a first experiment, all dipoles in the system are treated as individual design variables. As every individual particle is made up from many dipoles, one and the same particle can be assigned different material properties in different positions. The solution we obtain from this study serves as a reference solution. Due to the ultimate design freedom in this setting, it is expected that this reference solution provides—in terms of the function value—a lower bound for more realistic designs. The final material distribution \({\mathbf {u}}^*_{ref}\) is displayed in Fig. 19, where the red color corresponds to the first material, the blue color to the second one, and the colors in between correspond to mixed material properties.

Final material distribution \({\mathbf {u}}^*_{ref}\) for the optimization of the photonic crystal (see Sect. 6.3, setting 1), where each dipole was considered as an individual design variable; red: material 1; blue: material 2
In a second setting, we add the restriction that each of the individual particles in our system remains homogeneous throughout the optimization. This implies that all dipoles belonging to one and the same particle in the photonic crystal have to be assigned the same material data from our graph-like admissible set of materials. In order to realize this in practice, we collapse all design variables belonging to the same particle into one. While the design freedom is significantly reduced in this way, the total number of active dipoles stay the same as before.
Figure 20 shows the corresponding optimized material distribution denoted by \({\mathbf {u}}^*_{hom}\). Comparing this result with the reference solution, the following interpretation may be provided: every mixed or “gray” particle may be interpreted as a macroscopic mean over material properties of assigned to its dipoles in the reference solution. Comparing also the corresponding values of the objective function for the above cases (see Fig. 23; red and blue curve), it is observed that despite the much more restrictive approach essentially the same value for the backscattering is obtained. An explanation for this could be that the topological structure within the individual particles is of minor significance. Rather than this, only the ratio of the amount of material 1 and material 2 is important. For the optimized design of our reference solution \({\mathbf {u}}^*_{ref},\) we have \(B_{sca}({\mathbf {u}}^*_{ref}) = 2.8022 \cdot 10^{-4}\), where for the final design \({\mathbf {u}}^*_{hom}\) from setting 2, we have \(B_{sca}({\mathbf {u}}^*_{hom}) = 3.1899 \cdot 10^{-4}\). It is further worth to note that the composite materials obtained in the second approach appear way more accessible to synthesis compared to the first setting.
We finally note that, when collapsing several dipoles into one design variable, we partly give up the separability of the SGP model. Despite this, the comparison with the reference optimization shows that we still find a good local minimum.

Final material distribution \({\mathbf {u}}^*_{hom}\) for the optimization of the photonic crystal (see Sect. 6.3, setting 2), where only one design variable was assigned to each individual particle; red: material 1; blue: material 2
In a third setting, we finally want to get rid of all intermediate material properties, which are not corresponding to a node in the admissible material catalog. In order to realize this, we add the grayness penalization function (2) to the cost function by choosing a suitable parameter \(\gamma _1 > 0\) in Eq. (5). In this example, we took \(\gamma _1 = 10^{-4}\). The resulting material distribution \({\mathbf {u}}^*_{gray}\) is now indeed free of any intermediate material properties (see Fig. 21). The corresponding backscattering value is given by \(B_{sca}({\mathbf {u}}^*_{gray}) = 8.5430 \cdot 10^{-4}\). Compared with the result of setting 2, the objective function value gets worse. Approximately, 2.7 times more light energy is scattered back. Moreover, in Fig. 22, the optimized designs are shown sliced in the \(x_2-x_3\) plane. We can see how the final material distribution obtained from the three different settings is structured in the interior of the particle assembly.

Final material distribution \({\mathbf {u}}^*_{gray}\) for the optimization of the photonic crystal (see Sect. 6.3, setting 3), where only one design variable was assigned to each individual particle and intermediate material choices were penalized; red: material 1; blue: material 2

Slice of the final material distribution in the \(x_2-x_3\) plane obtained from the three different settings to optimize the photonic crystal (see Sect. 6.3). The top material distribution corresponds to the first setting, where all dipoles in the system are treated as individual design elements. The design in the middle corresponds to the optimization with only one design variable per individual particle, and the bottom one to the optimization of individual particles with penalization of intermediate material choices
The convergence history of the objective function for the three cases discussed above is shown in Fig. 23. We can see the effect of grayness penalization. The algorithm converges faster (in only 7 iterations) than without penalization, because it pushes the design parameters relatively quickly toward 0 or 1. This is why—despite the good characteristics of the almost exact separable approximation—the penalty parameter should be chosen with care. If it is chosen too large, it is more likely that the algorithm gets trapped in undesirable local optima.

Remark 16
To overcome the problems in choosing the grayness parameter, we could apply a so-called continuation scheme for the grayness parameter \(\gamma _1\), see, e.g., (Sigmund and Petersson 1998, Sect. 4). This means, we would update \(\gamma _1\) in every iteration depending on the current value of the grayness penalization function. Another possibility would be to use more building blocks, i.e., more admissible materials. For example, one could allow a finite number of composites made of the two materials with predefined material fractions. The resulting problem could still be treated by the DDA-SGP method.
7 Concluding remarks
The combination of discrete dipole approximation and multi-material optimization is a promising field of research. We have demonstrated that the high spatial resolution possible with DDA and the usage of tight approximations of separable exact models within SGP-type algorithms allows to efficiently predict optimized layouts for nanoparticles and particle assemblies. It was shown that—in contrast to the established solver MMA—SGP is able to escape from certain local minima with a poor value of the objective. Moreover, the SGP method allows to work with continuous as well as discrete material catalogs. In DDA, the continuous material parameterizations can be interpreted in terms of alloys.
The presented concept was implemented in a fully parallel manner in C++, and applied to different 3D problems. The parallelization is especially useful when considering many wavelengths, incident directions, and polarizations.
In the future, we would like to apply the presented DDA-SGP method to more realistic design setups and to put more emphasis on synthesizability. Realistic design setups come along with distributed orientations of particles as well as continuous ranges of wavelengths and scattering directions, see, e.g., (Semmler et al. 2015, Sect. 2.1). To handle this in an exact manner and to avoid spurious local minima, which may be introduced by an a priori discretization, we aim to combine the ideas of SGP and the continuous stochastic gradient scheme (CSG) introduced in Pflug et al. (2020).
References
Anderson DZ (1984) Alignment of resonant optical cavities. Appl Opt 23(17):2944–2949
Andkjær J, Sigmund O (2011) Topology optimized low-contrast all-dielectric optical cloak. Appl Phys Lett 98:21112
Bendsoe M, Sigmund O (2004) Topol Optim: Theory, Methods, Appl. Engineering online library, Springer, Berlin, Heidelberg
Bohren CF, Huffman DR (1998) Absorption Scatt Light Small Part. Wiley, New York
Bourdin B (2001) Filters in topology optimization. Int J Num Methods Eng 50:2143–2158
Boutami S, Fan S (2019) Efficient pixel-by-pixel optimization of photonic devices utilizing the Dyson’s equation in a Green’s function formalism: Part I. Implementation with the method of discrete dipole approximation. J Opt Soc Am B 36(9):2378–2386
Boutami S, Fan S (2019) Efficient pixel-by-pixel optimization of photonic devices utilizing the Dyson’s equation in a Green’s function formalism: Part II. Implementation using standard electromagnetic solvers. J Opt Soc Am B 36(9):2387–2394
Boutami S, Hassan K, Dupré C, Baud L, Fan S (2020) Experimental demonstration of silicon photonic devices optimized by a flexible and deterministic pixel-by-pixel technique. Appl Phys Lett 117(7):071104
Bruyneel M, Duysinx P, Fleury C (2002) A family of MMA approximations for structural optimization. Struct Multidisc Optim 24:263–276
Colton D, Kress R (2013) Inverse Acoustic and Electromagnetic Scattering Theory. Springer, New York
DeVoe H (1964) Optical properties of molecular aggregates. I. Classical model of electronic absorption and refraction. J Chem Phys 41(2):393–400
DeVore JR (1951) Refractive indices of rutile and sphalerite. J Opt Soc Am 41(6):416–419
Diaz A, Sigmund O (2010) A topology optimization method for design of negative permeability metamaterials. Struct Multidisc Optim 41(2):163–177
Donald J, Golden A, Jennings S (2009) Opendda: a novel high-performance computational framework for the discrete dipole approximation. Int J High Performance Comput Appl 23:1
Draine BT, Flatau PJ (1994) Discrete-dipole approximation for scattering calculations. J Optical Soc Am A 11(4):1491
Edalatpour S, Francoeur M (2014) The thermal discrete dipole approximation (T-DDA) for near-field radiative heat transfer simulations in three-dimensional arbitrary geometries. J Quantitative Spect Radiative Transfer 133:364–373
England GT, Russell C, Shirman E, Kay T, Vogel N, Aizenberg J (2017) The optical janus effect: Asymmetric structural color reflection materials. Adv Mater 29:1606876
Gladstone JH, Dale TP (1863) XIV. Researches on the refraction, dispersion, and sensitiveness of liquids. Philosophical Transac Royal Soc London 153:317–343
Goerlitzer ESA, Klupp Taylor RN, Vogel N (2018) Bioinspired photonic pigments from colloidal self-assembly. Adv Mater 30(28):1706654
Hassan E, Noreland D, Augustine R, Wadbro E, Berggren M (2015) Topology optimization of planar antennas for wideband near-field coupling. IEEE Transac Antennas and Propagation 63(9):4208–4213
Hassan E, Scheiner B, Michler F, Berggren M, Wadbro E, Röhrl F, Zorn S, Weigel R, Lurz F (2020) Multilayer Topology Optimization of Wideband SIW-to-Waveguide Transitions. IEEE Transactions on Microwave Theory and Techniques 68(4):1326–1339
Hvejsel CF, Lund E (2011) Material interpolation schemes for unified topology and multi-material optimization. Struct Multidisc Optim 43(6):811–825
Kahnert F (2003) Numerical methods in electromagnetic scattering theory. J Quantitative Spectro Radiative Transfer 79–80:775–824
Kawamura A, Kohri M, Morimoto G, Nannichi Y, Taniguchi T, Kishikawa K (2016) Full-color biomimetic photonic materials with iridescent and non-iridescent structural colors. Sci Rep 6:33984
Kecebas MA, Sendur K (2021) Broadband high-temperature thermal emitter/absorber designed by the adjoint method. J Opt Soc Am B 38(10):3189–3198
Khan I, Saeed K, Khan I (2019) Nanoparticles: Properties, applications and toxicities. Arabian J Chem 12(7):908–931
Lakhtakia A (1992) Strong and weak forms of the method of moments and the coupled dipole method for scattering of time-harmonic electromagnetic fields. Int J Modern Phys C - IJMPC 3:583–603
Mackowski DW (1994) Calculation of total cross sections of multiple-sphere clusters. J Optical Soc America A 11(11):2851
Maeda H, Maeda Y (2011) Spectroscopic Ellipsometry Study on Refractive Index Spectra of Colloidal \(\beta\)-FeOOH Nanorods with Their Self-Assembled Thin Films. Langmuir 27(6):2895–2903
Malitson IH (1965) Interspecimen comparison of the refractive index of fused Silica\(\ast\),\(\dagger\). J Opt Soc Am 55(10):1205–1209
Mie G (1908) Beiträge zur Optik trüber Medien, speziell kolloidaler Metallösungen. Annalen der Physik 330(3):377–445
Mishchenko MI, Travis LD, Lacis AA (2006) Multiple Scattering of Light by Particles: Radiative Transfer and Coherent Backscattering. Cambridge University Press, Cambridge
Monk P (2003) Finite Element Methods for Maxwell’s Equations. Oxford University Press, London
Pendry JB, Schurig D, Smith DR (2006) Controlling electromagnetic fields. Science 312(5781):1780–1782
Pflug L, Bernhardt N, Grieshammer M, Stingl M (2020) CSG: A new stochastic gradient method for the efficient solution of structural optimization problems with infinitely many states. Struct Multidisc Optim 61(6):2595–2611
Purcell EM, Pennypacker CR (1973) Scattering and absorption of light by nonspherical dielectric grains. Astrophysical J 186:705–714
Salary MM, Mosallaei H (2019) Inverse design of radiative thermal meta-sources via discrete dipole approximation model. J Appl Phys 125(16):163107
Semmler J, Stingl M (2021) On the efficient optimization of optical properties of particulate monolayers by a hybrid finite element approach. Struct Multidisc Optim 63:1219–1242
Semmler J, Pflug L, Stingl M, Leugering G (2015) Shape optimization in electromagnetic applications. New Trends in Shape Optimization 166:251–269
Semmler J, Pflug L, Stingl M (2018) Material optimization in transverse electromagnetic scattering applications. SIAM J Sci Comput 40(1):B85–B109
Sigmund O, Jensen JS (2003) Systematic Design of Phononic Band-Gap Materials and Structures by Topology Optimization. Philosophical Transactions: Mathematical, Physical and Engineering Sciences 361:1001–1019
Sigmund O, Petersson J (1998) Numerical instabilities in topology optimization: a survey on procedures dealing with checkerboards, mesh-dependencies and local minima. Struct Optim 16(1):68–75
Stegmann J, Lund E (2005) Discrete material optimization of general composite shell structures. Int J Numeric Methods Eng 62(14):2009–2027
Svanberg K (1987) The method of moving asymptotes–a new method for structural optimization. Int J Numerical Methods Eng 24(2):359–373
Virkki A, Muinonen K (2013) Penttilä A (2013) Circular polarization of spherical-particle aggregates at backscattering. J Quantitative Spectroscopy Radiative Transfer 126:150–159
Wang J, Sultan U, Goerlitzer ESA, Mbah CF, Engel M, Vogel N (2020) Structural color of colloidal clusters as a tool to investigate structure and dynamics. Advanced Functional Mater 30(26):1907730
Waterman PC (1965) Matrix formulation of electromagnetic scattering. Proceedings of the IEEE 53(8):805–812
Waterman PC (1971) Symmetry, Unitarity, and Geometry in Electromagnetic Scattering. Physical Review D 3(4):825–839
Xiao M, Hu Z, Wang Z, Li Y, Tormo AD, Thomas NL, Wang B, Gianneschi NC, Shawkey MD, Dhinojwala A (2017) Bioinspired bright noniridescent photonic melanin supraballs. Science Adv 3(9):e1701151
Yang S, Jia H, Zhang L, Dai J, Fu X, Zhou T, Zhang G, Yang L (2021) Gradient-probability-driven discrete search algorithm for on-chip photonics inverse design. Opt Express 29(18):28751–28766
Yurkin MA (2016) Capabilities of the discrete dipole approximation for large particle systems. In: 2016 URSI International Symposium on Electromagnetic Theory (EMTS), pp 386–389
Yurkin MA, Hoekstra AG (2007) The discrete dipole approximation: An overview and recent developments. J Quantitative Spectroscopy and Radiative Transfer 106:558–589
Yurkin MA, Hoekstra AG (2011) The discrete-dipole-approximation code ADDA: Capabilities and known limitations. J Quantitative Spectro Radiative Transfer 112(13):2234–2247
Yurkin MA, Maltsev VP, Hoekstra AG (2006) Convergence of the discrete dipole approximation. II. An extrapolation technique to increase the accuracy. J Opt Soc Am A 23(10):2592–2601
Zecca R, Marks DL, Smith DR (2019) Variational design method for dipole-based volumetric artificial media. Opt Express 27(5):6512–6527
Zhao Y, Xie Z, Gu H, Zhu C, Gu Z (2012) Bio-inspired variable structural color materials. Chem Soc Rev 41(8):3297–3317
Acknowledgements
This work has been funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)—Project-ID 416229255 – SFB 1411.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Replication of results
All parameters and data required for the application of the DDA-SGP method are documented in the numerical section of this article. Moreover, the C++ source code of the presented approach is available through GitLab (https://gitlab.com/MOGLI_BM/sgp-dda).
Additional information
Responsible Editor: Ole Sigmund
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Complex refractive index of goethite
In order to obtain a refractive index for goethite, we use a modified version of the refractive index of isomorph \(\beta\)-FeOOH (akaganeite) determined by Maeda and Maeda (2011). For this, the akaganeite refractive index is density corrected by applying the Gladstone-Dale (Gladstone and Dale 1863) and Anderson (Anderson 1984) method. The resulting complex refractive index is given in Table 3.
Appendix B: Neumann series
We discuss briefly how the inverse of the DDA system matrix \({\mathbf {A}}\), defined by Eqs. (8) - (9), can be approximated by means of the Neumann series. Let us denote the block diagonal of \({\mathbf {A}}\) by \({\mathbf {A}}^D\) given by
and the off-diagonal part by \({\mathbf {A}}^O\) defined by
Then, we can write \({\mathbf {A}}= {\mathbf {A}}^D + {\mathbf {A}}^O\), and therefore
Note that the right hand side of the above equation is now in the form \((\mathbbm {1} - T)^{-1}\) with
We get from the Neumann series, that
Using, for instance, only the first two elements, we have
and therefore
which yields
Since, due to the specific structure of the DDA matrix, the diagonal entries of the second matrix on the right hand side are zero and the separable model, see Theorem 7, only depends on the diagonal entries of the inverse system matrix \({\mathbf {A}}^{-1}\), we can approximate the diagonal of \({\mathbf {A}}^{-1}\) by \(({\mathbf {A}}^D)^{-1}\). As documented in Sect. 5.4, this choice already results in a rather tight approximation of the corresponding separable exact models for the particular objective functions we investigate in this article. In general, better approximations may be achieved by taking additional terms of Eq. (32) into account.
Appendix C: Proof of Theorem 12
In the following, we want to derive a separable exact model of the angular-dependent scattering magnitude (cf. Theorem 12). Following the same computations as in the beginning of Sect. 5, it holds
with \({\mathbf {B}}_i {:}{=}[e_{3i-2}, e_{3i-1}, e_{3i}]\) and \(\beta ({\tilde{{\mathbf {u}}}}_i,{\mathbf {u}}_i) = \alpha ({\tilde{{\mathbf {u}}}}_i)^{-1} - \alpha ({\mathbf {u}}_i)^{-1}\). Then, using the Sherman–Morrison–Woodbury formula, we have
Using the state equation \({\mathbf {A}}({\mathbf {u}}){\mathbf {P}}({\mathbf {u}})={\mathbf {E}}_I\) and the expression
it follows
With the definition of \({\tilde{{\mathbf {E}}}}\) from Eq. (23) and the assumption that the incident electric wave has unity amplitude, we obtain
Letting now \({\mathbf {Q}}({\mathbf {u}})\) be the adjoint variable, solving the adjoint problem \({\mathbf {A}}({\mathbf {u}}){\mathbf {Q}}= {\tilde{{\mathbf {E}}}}({\mathbf {a}})\), the above equation simplifies to
Using the identity
for \(a,b \in {\mathbb {C}}\), we can conclude that
with
The separable exact model for the angular-dependent scattering magnitude is therefore given by
Note that the above model is separable and exact by definition.
Appendix D: Proof of Theorem 13
By construction, the approximation \(S_{{\mathbf {F}},sca}({\tilde{{\mathbf {u}}}};{\mathbf {u}})\) from Theorem 13 is separable. We also have that
since \(\beta ({\tilde{{\mathbf {u}}}}_i,{\tilde{{\mathbf {u}}}}_i)\) and thus also \({\tilde{\gamma }}_i({\tilde{{\mathbf {u}}}},{\tilde{{\mathbf {u}}}}_i)\) vanish for all \(i=1,\ldots ,N.\)
For the first-order property, we have to compute the gradient of \(S_{{\mathbf {F}},sca}({\tilde{{\mathbf {u}}}};{\mathbf {u}})\) with respect to \({\mathbf {u}}\). The derivative of \({\tilde{\gamma }}_i({\tilde{{\mathbf {u}}}},{\mathbf {u}}_i)\) with respect to \({\mathbf {u}}_i\) is given by
Therefore, we obtain
Now, using \({\tilde{\gamma }}_i({\tilde{{\mathbf {u}}}},{\tilde{{\mathbf {u}}}}_i) = 0\), and
we immediately get
Finally, analogously as in the proof of Theorem 8, we use the implicit function theorem to show that the derivative of the angular-dependent scattering magnitude \(C_{sca}({\mathbf {a}},{\tilde{{\mathbf {u}}}})\) coincides with Eq. (33).
Therefore, the model given in Theorem 13 is a separable first-order approximation of the angular-dependent scattering magnitude (25) in the point of approximation \({\tilde{{\mathbf {u}}}}\).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nees, N., Pflug, L., Mann, B. et al. Multi-material design optimization of optical properties of particulate products by discrete dipole approximation and sequential global programming. Struct Multidisc Optim 66, 5 (2023). https://doi.org/10.1007/s00158-022-03376-w
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00158-022-03376-w