
Abstract
It is generally accepted that H. Friedman’s gap condition is closely related to iterated collapsing functions from ordinal analysis. But what precisely is the connection? We offer the following answer: In a previous paper we have shown that the gap condition arises from an iterative construction on transformations of partial orders. Here we show that the parallel construction for linear orders yields familiar collapsing functions. The iteration step in the linear case is an instance of a general construction that we call ‘Bachmann–Howard derivative’. In the present paper, we focus on the unary case, i.e., on the gap condition for sequences rather than trees and, correspondingly, on addition-free ordinal notation systems. This is partly for convenience, but it also allows us to clarify a phenomenon that is specific to the unary setting: As shown by van der Meeren, Rathjen and Weiermann, the gap condition on sequences admits two linearizations with rather different properties. We will see that these correspond to different recursive constructions of sequences.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
There is clearly a parallel between Higman’s lemma [1] and Kruskal’s theorem [2] on embeddings of sequences and trees, respectively. Not least, this parallel is manifest in the fact that both results have an elegant proof by Nash-Williams’s minimal bad sequence method [3]. If one wants to make the parallel more precise, it is natural to start with the observation that both sequences and trees are recursive data types. Such a data type can be constructed as the initial fixed point of a suitable transformation. For example, the initial fixed point of \(Z\mapsto 1+X\times Z\) is the set \(\textsf {Seq}(X)\) of sequences with entries in X, while the initial fixed point of \(X\mapsto \textsf {Seq}(X)\) is the set of ordered finite trees. In [4] we have studied certain general transformations of partial orders that we call normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilators (alluding to Girard’s [5] dilators on linear orders). If W is a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator, then its initial fixed point \({\mathcal {T}}{\mathcal {W}}\) carries a canonical partial order. In the aforementioned examples, this order coincides with the usual embedding relation from Higman’s lemma and Kruskal’s theorem. Thus both these results are instances of a general fact, which we call the uniform Kruskal theorem: If the normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W preserves well partial orders (wpos), then the so-called Kruskal fixed point \(\mathcal TW\) is a wpo itself. Together with Rathjen and Weiermann, the present author has shown that the uniform Kruskal theorem is equivalent to \(\Pi ^1_1\)-comprehension [4] (in the setting of reverse mathematics [6]). This is particularly interesting because it means that the uniform Kruskal theorem exhausts the full strength of the minimal bad sequence method (which has been analyzed by Marcone [7]), in contrast to Kruskal’s original theorem. We note that constructions similar to \(W\mapsto {\mathcal {T}} W\) had previously been studied by Hasegawa [8, 9] and Weiermann [10].
Harvey Friedman has introduced a gap condition on embeddings of trees, which leads to a much stronger version of Kruskal’s theorem (see the presentation by Simpson [11]). Schütte and Simpson [12] have studied the corresponding condition for embeddings of sequences. As observed by Hasegawa [8, 9], Weiermann [10] and van der Meeren [13], the gap condition is related to iterations of constructions such as \(W\mapsto {\mathcal {T}} W\). One way to make this precise has been worked out by the present author [14]: Given a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W and a partial order X, one can construct a relativized Kruskal fixed point \({\mathcal {T}}{\mathcal {W}}(X)\) that comes with a bijection
Here addition denotes disjoint union, i. e., we have functions \(\iota _X:X\rightarrow {\mathcal {T}}{\mathcal {W}}(X)\) and \(\kappa _X:W(\mathcal TW(X))\rightarrow {\mathcal {T}}{\mathcal {W}}(X)\) such that \({\mathcal {T}}{\mathcal {W}} (X)\) is the disjoint union of their images. The order on \({\mathcal {T}} W(X)\) is determined by certain inequalities between the values of \(\iota _X\) and \(\kappa _X\) (see [14]). The transformation \(X\mapsto {\mathcal {T}} W(X)\) can again be equipped with the structure of a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator, which we call the Kruskal derivative of W. From now on, the notation \({\mathcal {T}} W\) will be reserved for this \({{\textsf{P}}}{{\textsf{O}}}\)-dilator. The single fixed point from [4] should thus be denoted by \({\mathcal {T}} W(0)\), where 0 stands for the empty order. The principle of \(\Pi ^1_1\)-comprehension is still equivalent to the statement that \({\mathcal {T}} W\) preserves wpos if W does. Now that \({\mathcal {T}} W\) is a transformation rather than a single order, we can iterate the construction: Let \({\mathbb {T}}_0\) be the identity on partial orders, considered as a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator. Given \(\mathbb T_n\), define \({\mathbb {T}}_{n+1}^-\) as the Kruskal derivative of \(\textsf {Seq}\circ {\mathbb {T}}_n\). Then put \(\mathbb T_{n+1}:={\mathbb {T}}_n\circ {\mathbb {T}}_{n+1}^-\). In [14] it is shown that \({\mathbb {T}}_n(0)\) is isomorphic to the set of trees with labels in \(\{0,\dots ,n-1\}\), ordered according to Friedman’s strong gap condition. The analogous (but much simpler) result for a certain collection of sequences is discussed below.
The equivalence between \(\Pi ^1_1\)-comprehension and the uniform Kruskal theorem has been derived from a previous result on the level of linear orders. Each dilator D (i. e., each suitable transformation of well orders) gives rise to a linear order \(\vartheta D\), which we call the Bachmann–Howard fixed point of D (since it relativizes the Bachmann–Howard ordinal or, more precisely, the notation system from [15]). By an earlier result of the author [16,17,18,19], \(\Pi ^1_1\)-comprehension is equivalent to the statement that \(\vartheta D\) is a well order for any dilator D. In the present paper, we will relativize the construction of \(\vartheta D\) to a linear order X. This results in a Bachmann–Howard fixed point \(\vartheta D(X)\) over X, which comes with a bijection
analogous to (1.1). The appropiate inequalities between different values of \(\iota _X\) and \(\vartheta _X\) will, once again, be a crucial part of the definition. As above, the notation \(\vartheta D\) is now reserved for the transformation \(X\mapsto \vartheta D(X)\), while the single fixed point from [19] should be denoted by \(\vartheta D(0)\). We will see that the transformation \(\vartheta D\) can again be equipped with the structure of a dilator. This dilator \(\vartheta D\) will be called the Bachmann–Howard derivative of D.
Let us discuss the relation between Kruskal and Bachmann–Howard derivatives. By a linearization of a partial order P by a linear order X we shall mean an order-reflecting surjection \(f:X\rightarrow P\). Here, order-reflecting means that \(f(x)\le _P f(y)\) implies \(x\le _X y\), which also ensures that f is injective. Note that this coincides with the usual notion of linearization if we identify X with its image under f. A linearization of a \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W by a dilator D is a natural family of linearizations \(D(X)\rightarrow W(X)\), one for each linear order X. We will show that any linearization of W by D can be transformed into a linearization of the Kruskal derivative \({\mathcal {T}} W\) by the Bachmann–Howard derivative \(\vartheta D\).
We now consider an application of our general constructions. In [20], van der Meeren, Rathjen and Weiermann study a certain collection of sequences with gap condition, as well as its linearization by iterated collapsing functions. We will give the following systematic reconstruction of these objects:
-
(1)
Let \(\textsf {S}^0_0\) and \(\textsf {T}^0_0\) be the identity on partial and linear orders, respectively (considered as a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator and a dilator in the sense of Girard).
-
(2)
Define \(\textsf {S}^0_{n+1}\) as the Kruskal derivative of \(\textsf {S}^0_n\), and \(\textsf {T}^0_{n+1}\) as the Bachmann–Howard derivative of \(\textsf {T}^0_n\).
-
(3)
Write 1 for the order with a single element. Then \(\textsf {S}^0_n(1)\) coincides with the set of sequences \(\overline{{\mathbb {S}}}_n[0]\) from [20, Definition 12], ordered by Friedman’s strong gap condition. Furthermore, \(\textsf {T}^0_n(1)\) coincides with the system \(T_n[0]\) of collapsing functions from [20, Definitions 24 to 27].
Now the fact that \(T_n[0]\cong \textsf {T}^0_n(1)\) is a linearization of \(\overline{{\mathbb {S}}}_n[0]\cong \textsf {S}^0_n(1)\) is immediate by the general result from the previous paragraph, which thus replaces the explicit verification in [20, Lemmas 10 and 11]. More importantly, our reconstruction clarifies two conceptual points. First, it confirms that gap condition and collapsing functions are closely related, maybe even more closely than expected: they arise by entirely parallel constructions on partial and linear orders, respectively. Secondly, the collapsing functions studied in [20] (and the variant with addition in [21]) are supposed to generalize Rathjen’s notation system for the Bachmann–Howard ordinal (see [4]). But do they provide “the right" generalization? Our reconstruction shows that, in a certain precise sense, the answer is positive.
Let us emphasize that previous work of Hasegawa, Weiermann and van der Meeren is fundamental for the present paper. The concrete results that we derive on linearizations of the gap condition for sequences—in particular Corollaries 5.11, 5.20 and 5.21—were first shown by Rathjen, Weiermann and van der Meeren [20]. Beyond these concrete results, our approach is heavily informed by the many insights from the PhD thesis of van der Meeren [13] and his papers with Rathjen and Weiermann [22, 23] on the gap condition for trees. The achievement of the present paper is that it develops these insights in terms of dilators, which provide a framework that is both rigorous and very general.
In order to indicate that our constructions cover a larger range of applications, we sketch two possible modifications. In the first of these we put \(\textsf {T}_0=\textsf {T}^0_0\) and \(\textsf {T}_{n+1}=\textsf {T}_n\circ \textsf {T}_{n+1}^-\), where \(\textsf {T}_{n+1}^-\) is defined as the Bachmann–Howard derivative of \(\textsf {T}_n\) (note the similarity with the clause \(\mathbb T_{n+1}={\mathbb {T}}_n\circ {\mathbb {T}}_{n+1}^-\) from the discussion of [14] above). It seems that \(\textsf {T}_n(1)\) is a linearization of the order \({\mathbb {S}}_n\) from [20], which is more liberal than the order \(\overline{{\mathbb {S}}}_n[0]\). For the second modification, consider a dilator S that linearizes the \({{\textsf{P}}}{{\textsf{O}}}\)-dilator \(\textsf {Seq}\) from above (e. g. take \(S=\omega _2\) as below). Let \(D_0\) be the identity on linear orders, define \(D_{n+1}^-\) as the Bachmann–Howard derivative of \(S\circ D_n\), and set \(D_{n+1}:=D_n\circ D_{n+1}^-\). Since the construction is entirely parallel to the one from [14] (discussed above), this should yield a linearization of Friedman’s gap condition on trees. We expect that the linear orders \(D_n(0)\) are closely related to the iterated collapsing functions with addition that are studied in [21]. Details of both modifications remain to be checked. We have sketched them to indicate the potential breadth of our approach.
As observed by van der Meeren, Rathjen and Weiermann [20], the linearization of \(\textsf {S}^0_n(1)\cong \overline{{\mathbb {S}}}_n[0]\) by \(\textsf {T}^0_n(1)\cong T_n[0]\) does not have maximal order type. It is expected that this phenomenon is specific to the case of sequences, i. e., that collapsing functions do exhaust the maximal order type for trees. Our approach provides some justification for this expectation, or at least a systematic explanation. To present the latter, we consider sequences on a more concrete level: The elements of \(\textsf {S}^0_n(X)\) can be represented in the form \(\langle i_1,\dots ,i_k,x\rangle \) with \(i_1=0\) and \(x\in X\) (and with some further conditions, see Definition 5.1 below). In view of (1.1), the fact that \(\textsf {S}^0_{n+1}\) is the Kruskal derivative of \(\textsf {S}^0_n\) is witnessed, amongst others, by injections
We will see that these functions are given by
Note that \(j_1\) is the second entry on the right that is equal to zero, which guarantees that \(\kappa ^n_X\) is injective. To generalize the construction from sequences to trees, think of the last entry of an element \(\langle i_1,\dots ,i_k,x\rangle \in \textsf {S}^0_n(X)\) as a leaf labelled by x. Indeed, the orders \({\mathbb {T}}_n(X)\) from above (studied in [14]) consist of trees with labels from \(\{0,\dots ,n-1\}\cup X\), where labels from X are allowed at leaves only. We can now point out a crucial difference between sequences and trees: A sequence different from \(\langle \rangle \) (the empty sequence) has a single leaf with known location (the last entry). This means that it suffices to record the leaf label and the rest of the sequence or, more formally, that we have a bijection
In the case of trees, there are many possible locations for leaf labels, and a similar bijection does not appear to be available. It turns out that we get an alternative construction of the gap condition on sequences (but not on trees). To describe this construction, we recall that the set \(\textsf {Seq}(Z)\) of finite sequences in Z is the initial Kruskal fixed point of the transformation \(X\mapsto 1+Z\times X\), i. e., that we have
Here \(Z\times X\) is the usual product of partial orders, where \((z,x)\le _{Z\times X}(z',x')\) is equivalent to the conjunction of \(z\le _Z z'\) and \(x\le _X x'\). The order \(1+Z\times X\) contains a further element but no other strict inequalities. We will see that there is an isomorphism
of partial orders, for each \(n\in {\mathbb {N}}\). Together with (1) to (3) from above, this yields a second construction of sequences with gap condition in terms of Kruskal derivatives (or fixed points). While the two constructions coincide for partial orders, it turns out that they differ in the linear case. Given a linear order Z, we define \(\omega _2(Z)\) as the initial Bachmann–Howard fixed point of the transformation \(X\mapsto 1+Z\times X\), i. e., we set
Note that, in the linear case, the single element of 1 lies below all elements of \(Z\times X\), while \((z,x)\le _{Z\times X}(z',x')\) holds if we have \(z<_Z z'\) or (\(z=z'\) and \(x\le _X x'\)). More concretely, one can represent \(\omega _2(Z)\) by the set of finite sequences in Z, as one checks with the help of Theorem 2.9 below. With \({z_0}^\frown \langle z_1,\ldots ,z_k\rangle :=\langle z_0,\ldots ,z_k\rangle \), the order on \(\omega _2(Z)\) is characterized by the following clauses (as before Theorem 2.2 in [24]):
-
(i)
we always have \(\langle \rangle <z^\frown \sigma \) and \(\sigma <z^\frown \sigma \),
-
(ii)
given \((z,\sigma )<(z',\sigma ')\) in \(Z\times \omega _2(Z)\) and \(\sigma <z'^\frown \sigma '\), we get \(z^\frown \sigma <z'^\frown \sigma '\).
To turn \(\omega _2\) into a dilator (see Definition 2.1 below), it suffices to set
For an ordinal \(\alpha \) and a number \(n\in {\mathbb {N}}\), the ordinal \(\omega _n^\alpha \) is explained by the recursive clauses \(\omega _0^\alpha =\alpha \) and \(\omega _{n+1}^\alpha =\omega ^{\omega _n^\alpha }\) (towers of exponentials in the sense of ordinal arithmetic). The resulting ordinal \(\omega _2^\alpha \) is isomorphic to the order \(\omega _2(1+\alpha )\) from (1.3), as shown in [24]. We now define linear orders \(\textsf {OT}^0_n\) by the recursive clauses
As we will see, \(\textsf {OT}^0_n\) coincides with the order \(OT_n[0]\) from [20, Section 5] (up to a typo in the cited reference, see Sect. 5 below). Important results of the cited paper can now be deduced from general facts about Bachmann–Howard fixed points: First, the parallel between (1.2) and (1.4) ensures that \(OT_n[0]\) linearizes \(\textsf {S}^0_n(1)\cong \overline{{\mathbb {S}}}_n[0]\). Secondly, iterated applications of the result from [24] show that \(OT_n[0]\) has order type \(\omega _{2n-1}:=\omega _{2n-1}^1=\omega _{2n}^0\), for any \(n>0\). In [20] this fact was established by explicit computations that involve the addition-free Veblen functions, which may seem somewhat ad hoc. Let us recall that \(\omega _{2n-1}\) is the maximal order type of the partial order \(\textsf {S}^0_n(1)\cong \overline{{\mathbb {S}}}_n[0]\), as shown in [20] (based on results from [12]).
To summarize, the present paper introduces the general notion of Bachmann–Howard derivative. The latter allows us to give two systematic reconstructions of the gap condition on finite sequences. While the two constructions yield the same result in the case of partial orders, the versions for linear orders lead to two different systems of collapsing functions, both of which have been studied in [20]. The first construction does not realize the maximal order type (in the case of sequences) but seems to be of greater general interest, since it is readily extended from sequences to trees (cf. [14]). The second construction exploits a property that is specific to sequences, and it realizes the maximal order type.
2 Theory, part 1: Bachmann–Howard derivatives
In this section we define the notion of Bachmann–Howard derivative, by making the informal explanation from the introduction precise. We then give a proof of existence and uniqueness, including a criterion that is useful for applications.
To recall the definition of dilators, we need some terminology: Write \([X]^{<\omega }\) for the set of finite subsets of a set X. Each \(f:X\rightarrow Y\) induces a function
This yields an endofunctor \([\cdot ]^{<\omega }\) on the category of sets. Given \(a\in [X]^{<\omega }\), we will write  for the inclusion map, provided that X is clear from the context. Let \({{\textsf{L}}}{{\textsf{O}}}\) be the category of linear orders and order embeddings. We will omit the forgetful functor from orders to sets (and thus apply \([\cdot ]^{<\omega }\) to orders). Conversely, a subset of an order will often be considered as a suborder. Finally, let us agree that \({\text {rng}}(f)\) denotes the range (in the sense of image) of f.
for the inclusion map, provided that X is clear from the context. Let \({{\textsf{L}}}{{\textsf{O}}}\) be the category of linear orders and order embeddings. We will omit the forgetful functor from orders to sets (and thus apply \([\cdot ]^{<\omega }\) to orders). Conversely, a subset of an order will often be considered as a suborder. Finally, let us agree that \({\text {rng}}(f)\) denotes the range (in the sense of image) of f.
Definition 2.1
An \({{\textsf{L}}}{{\textsf{O}}}\)-dilator consists of a functor \(D:{{\textsf{L}}}{{\textsf{O}}}\rightarrow {{\textsf{L}}}{{\textsf{O}}}\) and a natural transformation \({\text {supp}}:D\Rightarrow [\cdot ]^{<\omega }\) such that the so-called support condition
holds for any \({{\textsf{L}}}{{\textsf{O}}}\)-morphism \(f:X\rightarrow Y\) and any \(\sigma \in D(Y)\). If, in addition, D(X) is well founded for any well order X, then \((D,{\text {supp}}^D)\) is called a \({{\textsf{W}}}{{\textsf{O}}}\)-dilator.
Note that the converse of the implication in the definition is automatic since \({\text {supp}}\) is natural. There is at most one natural transformation \({\text {supp}}:D\Rightarrow [\cdot ]^{<\omega }\) that satisfies the support condition, since \({\text {supp}}_X(\sigma )\) is determined as the minimal \(a\subseteq X\) with \(\sigma \in {\text {rng}}(D(\iota _a))\). Furthermore, such a natural transformation exists if, any only if, D preserves pullbacks and direct limits, as verified in [16, Remark 2.2.2]. This means that our definition of \({{\textsf{W}}}{{\textsf{O}}}\)-dilators coincides with Girard’s definition of dilators [5]. We have added the prefix \({{\textsf{W}}}{{\textsf{O}}}\) for clarity, since we will later consider variants of dilators on partial orders.
As supports are uniquely determined, we often write D instead of \((D,{\text {supp}})\). Sometimes (but not always) we then write \({\text {supp}}^D\) to refer to \({\text {supp}}\). Let us write
if the equality holds and we have \({\text {supp}}_a(\sigma _0)=a\). This notation allows us to formulate a version of Girard’s normal form theorem:
Lemma 2.2
Consider an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D and a linear order X. Each \(\sigma \in D(X)\) has a unique normal form \(\sigma ={}_{{\text {NF}}}D(\iota _a)(\sigma _0)\). The latter satisfies \(a={\text {supp}}_X(\sigma )\).
Proof
For \(\sigma =D(\iota _a)(\sigma _0)\) we have \({\text {supp}}_X(\sigma )={\text {supp}}_a(\sigma _0)\) by naturality. Now the existence of a normal form with \(a={\text {supp}}_X(\sigma )\) follows from the support condition. Uniqueness holds as \(\sigma \) determines a and as the embedding \(D(\iota _a)\) is injective. \(\square \)
As observed by Girard, the normal form theorem entails that dilators are determined (up to natural isomorphism) by their restrictions to the category of finite linear orders. Since this category is essentially small, these restrictions can be represented by sets (rather than proper classes). A formalization in second order arithmetic is available for the countable case (see e. g. [19] for details). In the present paper we do not work in a specific base theory.
To define the Bachmann–Howard derivative \(\vartheta D\) of an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D we must, in particular, specify a transformation \(X\mapsto \vartheta D(X)\) of linear orders. The following definition constructs the required orders from syntactic material. A more abstract characterization, which can be easier to handle in applications, will be given later. We point out that the orders \(\vartheta D(X)\) are relativized versions of the Bachmann–Howard fixed points that we have constructed in [19].
Definition 2.3
Let us consider an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D. For each linear order X, we define a set \(\vartheta D(X)\) of terms and a binary relation \(<_{\vartheta D(X)}\) on that set by simultaneous recursion. The set \(\vartheta D(X)\) is generated by the following clauses:
-
(i)
For each element \(x\in X\) we have a term \({\overline{x}}\in \vartheta D(X)\).
-
(ii)
Given a finite set \(a\subseteq \vartheta D(X)\) that is linearly ordered by \(<_{\vartheta D(X)}\), we add a term \(\vartheta \langle a,\sigma \rangle \) for each element \(\sigma \in D(a)\) with \({\text {supp}}^D_a(\sigma )=a\).
For \(s,t\in \vartheta D(X)\) we stipulate that \(s<_{\vartheta D(X)}t\) holds if, and only if, one of the following clauses applies:
-
(i’)
We have \(s={\overline{x}}\) and \(t={\overline{y}}\) with \(x<_X y\).
-
(ii’)
The term s is of the form \({\overline{x}}\) while t is of the form \(\vartheta \langle b,\tau \rangle \).
-
(iii’)
We have \(s=\vartheta \langle a,\sigma \rangle \) and \(t=\vartheta \langle b,\tau \rangle \), the restriction of \(<_{\vartheta D(X)}\) to \(a\cup b\) is a linear order, and one of the following holds:
-
We have \(D(\iota _a)(\sigma )<_{D(a\cup b)}D(\iota _b)(\tau )\) for the inclusions
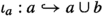 and
and 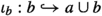 . Furthermore, we have \(s'<_{\vartheta D(X)}t\) for all \(s'\in a\).
. Furthermore, we have \(s'<_{\vartheta D(X)}t\) for all \(s'\in a\). -
We have \(s\le _{\vartheta D(X)}t'\) for some \(t'\in b\) (i. e., we have \(s<_{\vartheta D(X)}t'\) or s and \(t'\) are the same term).
-
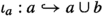 and
and 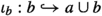 . Furthermore, we have
. Furthermore, we have To justify the recursion in detail, one can argue as follows: In a first step, ignore the reference to \(<_{\vartheta D(X)}\) in order to generate a larger set \(\vartheta _0D(X)\supseteq \vartheta D(X)\). More precisely, declare that \(\vartheta _0D(X)\) contains \(\vartheta \langle a,\sigma \rangle \) whenever \(a\subseteq \vartheta _0D(X)\) is finite and \(\sigma \in D(a)\) holds with respect to some linear order on a. Then define a length function \(l:\vartheta _0D(X)\rightarrow {\mathbb {N}}\) by recursion over terms, stipulating
Finally, decide \(r\in \vartheta D(X)\) and \(s<_{\vartheta D(X)}t\) by simultaneous recursion on l(r) and \(l(s)+l(t)\), respectively. For example, we can decide \(r\in \vartheta D(X)\) for \(r=\vartheta \langle a,\sigma \rangle \) as follows: Recursively decide \(a\subseteq \vartheta D(X)\) and compute the restriction of \(<_{\vartheta D(X)}\) to a. If the latter is a linear order, then check \(\sigma \in D(a)\) and \({\text {supp}}^D_a(\sigma )=a\) with respect to it. At various places in Definition 2.3, we have required that certain restrictions of \(<_{\vartheta D(X)}\) are linear. The purpose was to ensure that \(D:{{\textsf{L}}}{{\textsf{O}}}\rightarrow {{\textsf{L}}}{{\textsf{O}}}\) is only applied to (morphisms of) linear orders. Ex post, linearity is automatic by the following proposition, which is proved as in the non-relativized case (see [19, Proposition 4.1]).
Proposition 2.4
The relation \(<_{\vartheta D(X)}\) is a linear order on \(\vartheta D(X)\).
The syntactic construction of \(\vartheta D(X)\) can be hard to apply, even in simple cases. For this reason, we now develop a more abstract characterization.
Definition 2.5
Consider an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D and a linear order X. A Bachmann–Howard fixed point of D over X consists of a linear order Z and functions \(\iota :X\rightarrow Z\) and \(\vartheta :D(Z)\rightarrow Z\) with the following properties:
-
(i)
The function \(\iota :X\rightarrow Z\) is an order embedding.
-
(ii)
We have \(\iota (x)<_Z\vartheta (\sigma )\) for all \(x\in X\) and \(\sigma \in D(Z)\).
-
(iii)
If we have \(\sigma <_{D(Z)}\tau \) as well as \(z<_Z\vartheta (\tau )\) for all \(z\in {\text {supp}}^D_Z(\sigma )\), then we have \(\vartheta (\sigma )<_Z\vartheta (\tau )\). Furthermore, \(z<_Z\vartheta (\sigma )\) holds for any \(z\in {\text {supp}}^D_Z(\sigma )\).
Let us extend the syntactic orders \(\vartheta D(X)\) into Bachmann–Howard fixed points:
Definition 2.6
To define \(\iota _X:X\rightarrow \vartheta D(X)\) and \(\vartheta _X:D(\vartheta D(X))\rightarrow \vartheta D(X)\), we stipulate \(\iota _X(x)={\overline{x}}\) and \(\vartheta _X(\sigma )=\vartheta \langle a,\sigma _0\rangle \) for \(\sigma ={}_{{\text {NF}}}D(\iota _a)(\sigma _0)\).
As expected, we obtain the following:
Proposition 2.7
The tuple \((\vartheta D(X),\iota _X,\vartheta _X)\) explained by Definitions 2.3 and 2.6 is a Bachmann–Howard fixed point of D over X.
Proof
It is immediate that conditions (i) and (ii) from Definition 2.5 are satisfied. Concerning condition (iii), we point out that \(s<_{\vartheta D(X)}\vartheta _X(\sigma )\) is immediate for a term of the form \(s={\overline{x}}\), by clause (ii’) of Definition 2.3. The remaining conditions are verified as in the non-relativized case, for which we refer to [19, Theorem 4.1]. \(\square \)
In the non-relativized case, [19, Theorem 4.2] shows that \(\vartheta D(0)\) can be embedded into any Bachmann–Howard fixed point of D over the empty set. Here we establish a stronger categorical property, which will be useful below (see [14, Section 3] for parallel constructions in the context of partial orders).
Definition 2.8
A Bachmann–Howard fixed point \((Z,\iota ,\vartheta )\) of D over X is called initial if any Bachmann–Howard fixed point \((Z',\iota ',\vartheta ')\) of D over X admits a unique order embedding \(f:Z\rightarrow Z'\) such that

is a commutative diagram.
By the usual categorical argument, initial Bachmann–Howard fixed points are unique up to isomorphism. The following yields existence and a useful criterion.
Theorem 2.9
Consider an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D and a linear order X. For any Bachmann–Howard fixed point \((Z,\iota ,\vartheta )\) of D over X, the following are equivalent:
-
(i)
We have \(Z={\text {rng}}(\iota )\cup {\text {rng}}(\vartheta )\), and there is a function \(h:Z\rightarrow {\mathbb {N}}\) such that \(z\in {\text {supp}}^D_Z(\sigma )\) entails \(h(z)<h(\vartheta (\sigma ))\), for any \(\sigma \in D(Z)\).
-
(ii)
The Bachmann–Howard fixed point \((Z,\iota ,\vartheta )\) is initial.
Furthermore, the Bachmann–Howard fixed point from Proposition 2.7 is initial.
Proof
We first assume (i) and derive (ii). Aiming at the latter, we consider an arbitrary Bachmann–Howard fixed point \((Z',\iota ',\vartheta ')\) of D over X. The diagram from Definition 2.8 commutes if, and only if, we have
The idea is to read these equations as a recursive definition of f, which is possible in view of the following observations: First, \(\iota \) and \(\vartheta \) are injective by clauses (i) and (iii) of Definition 2.5 (see also [16, Lemma 2.1.7]). Secondly, the union \(Z={\text {rng}}(\iota )\cup {\text {rng}}(\vartheta )\) is necessarily disjoint, by clause (ii) of the same definition. Finally, the composition \(f\circ \iota _a\) does only depend on values of f on arguments \(z\in a={\text {supp}}^D_Z(\sigma )\), for which a recursive call is justified due to \(h(z)<h(\vartheta (\sigma ))\). In view of these observations, there can be at most one embedding \(f:Z\rightarrow Z'\) with the required properties. To show that there is one, we first define a length function \(l:Z\rightarrow {\mathbb {N}}\) by the recursive clauses \(l(\iota (x))=0\) and \(l(\vartheta (\sigma ))=1+\sum _{z\in {\text {supp}}^D_Z(\sigma )}2\cdot l(z)\), which are justified as above. By simultaneous induction on l(z) and \(l(z_0)+l(z_1)\) one can now check that \(f(z)\in Z'\) is defined and that \(z_0<_Zz_1\) entails \(f(z_0)<_{Z'}f(z_1)\). The motivation for the simultaneous verification is that \(f\circ \iota _a\) needs to be an embedding for \(D(f\circ \iota _a)\) to be defined. The only interesting case in the induction concerns an inequality
Crucially, we must have \(z<_Z\vartheta (\tau )\) for all elements \(z\in {\text {supp}}^D_X(\sigma )\), since \(\vartheta (\tau )\le _Z z\) would entail \(\vartheta (\tau )<_Z\vartheta (\sigma )\), by clause (iii) of Definition 2.5. If \(\sigma <_{D(Z)}\tau \) fails, we get \(\vartheta (\sigma )\le _Z z'\) for some \(z'\in {\text {supp}}^D_Z(\tau )\), for the same reason. Writing \(\sigma ={}_{{\text {NF}}}D(\iota _a)(\sigma _0)\) and \(\tau ={}_{{\text {NF}}}D(\iota _b)(\tau _0)\), we can use the induction hypothesis to show that one of the following must hold (write \(f\circ \iota _a=f\!\restriction \!(a\cup b)\circ \iota _a'\) with  ):
):
-
We have \(D(f\circ \iota _a)(\sigma _0)<_{D(Z')} D(f\circ \iota _b)(\tau _0)\) and \(z<_{Z'}f(\vartheta (\tau ))=\vartheta '(D(f\circ \iota _b)(\tau _0))\) for all \(z\in [f]^{<\omega }({\text {supp}}^D_Z(\sigma ))={\text {supp}}^D_{Z'}(D(f\circ \iota _a)(\sigma _0))\).
-
We have \(\vartheta '(D(f\circ \iota _a)(\sigma _0))\le _{Z'}z'\) for some \(z'\in {\text {supp}}^D_{Z'}(D(f\circ \iota _b)(\tau _0))\).
In either case, clause (iii) of Definition 2.5 yields
Next, we use the criterion provided by (i) to show that the Bachmann–Howard fixed point \((\vartheta D(X),\iota _X,\vartheta _X)\) from Proposition 2.7 is initial. To see that we have
it suffices to observe that the same condition \({\text {supp}}^D_a(\sigma )=a\) appears in clause (ii) of Definition 2.3 and in the definition of normal forms (as given in the paragraph before Lemma 2.2). Let us now define \(h:\vartheta D(X)\rightarrow {\mathbb {N}}\) by recursion over terms, setting \(h(\overline{x})=0\) and \(h(\vartheta \langle a,\sigma _0\rangle )=1+\max \{h(s)\,|\,s\in a\}\). To see that this function has the required property, it suffices to recall that \(\sigma ={}_{{\text {NF}}}D(\iota _a)(\sigma _0)\in D(\vartheta D(X))\) entails \({\text {supp}}^D_{\vartheta D(X)}(\sigma )=a\), by Lemma 2.2. Finally, it is now easy to conclude that (ii) implies (i), because any initial Bachmann–Howard fixed point must be isomorphic to \((\vartheta D(X),\iota _X,\vartheta _X)\) (see the proof of [14, Theorem 3.5] for details). \(\square \)
Now that we have established existence and uniqueness up to isomorphism, we will sometimes speak of ‘the’ initial Bachmann–Howard fixed point of D over X and denote ‘it’ by \(\vartheta D(X)\) (i. e., this notation is no longer reserved for the specific term systems from Definition 2.3). In [14] we have introduced a notion of Kruskal derivative for dilators of partial orders. We now define the corresponding notion in the context of linear orders.
Definition 2.10
A Bachmann–Howard derivative of an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D consists of an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator \(\vartheta D\) and natural families of functions
such that \((\vartheta D(X),\iota _X,\vartheta _X)\) is an initial Bachmann–Howard fixed point of D over X, for each linear order X.
To avoid misunderstanding, we point out that the functions \(\vartheta _X\) need not be order embeddings. Hence we do not have a natural transformation \(\vartheta :D\circ \vartheta D\Rightarrow \vartheta D\) between endofunctors of linear orders (but the naturality condition is the same).
Proposition 2.11
Assume that, for each linear order X, we are given an initial Bachmann–Howard fixed point \((\vartheta D(X),\iota _X,\vartheta _X)\) of D over X. There is a unique way to extend this data into a Bachmann–Howard derivative of D.
Proof
We first show that the given map \(X\mapsto \vartheta D(X)\) can be uniquely extended into a functor. Given an embedding \(f:X\rightarrow Y\) of linear orders, it is straightforward to check that \((\vartheta D(Y),\iota _Y\circ f,\vartheta _Y)\) is a Bachmann–Howard fixed point of D over X. Since \((\vartheta D(X),\iota _X,\vartheta _X)\) is initial, there is a unique embedding \(\vartheta D(f):\vartheta D(X)\rightarrow \vartheta D(Y)\) such that the following is a commutative diagram:

The very same diagram (with the triangle written as a square) must commute if the functions \(\iota _X\) and \(\vartheta _X\) are to be natural in X. Hence there is a unique extension into a functor \(\vartheta D:{{\textsf{L}}}{{\textsf{O}}}\rightarrow {{\textsf{L}}}{{\textsf{O}}}\) with the required properties. It remains to consider the extension into an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator. First observe that the required functions
are necessarily unique, as naturality and the implication from Definition 2.1 require
where
 are the inclusions. For existence we use the characterization from part (i) of Theorem 2.9. It allows us to define supports by the recursive clauses
are the inclusions. For existence we use the characterization from part (i) of Theorem 2.9. It allows us to define supports by the recursive clauses
Naturality and the implication from Definition 2.1 are checked by induction. For details we refer to the analogous argument for partial orders (see [14, Theorem 4.2]). \(\square \)
Together with the last sentence of Theorem 2.9, we get existence:
Corollary 2.12
Any \({{\textsf{L}}}{{\textsf{O}}}\)-dilator has a Bachmann–Howard derivative.
By an isomorphism between \({{\textsf{L}}}{{\textsf{O}}}\)-dilators \((D,{\text {supp}}^D)\) and \((E,{\text {supp}}^E)\) we simply mean a natural isomorphism \(\eta :D\Rightarrow E\) of functors. This is justified because the supports are automatically respected, i. e. we have \({\text {supp}}^E\circ \eta ={\text {supp}}^D\). For an isomorphism this is particularly easy to see (cf. the paragraph before [14, Theorem 4.4]). It is also true but more subtle when \(\eta \) is merely a natural transformation (see [5]). We can now formulate the appropriate uniqueness result:
Proposition 2.13
If \((\vartheta ^0D,\iota ^0,\vartheta ^0)\) and \((\vartheta ^1D,\iota ^1,\vartheta ^1)\) are two Bachmann–Howard derivatives of the same \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D, then there is a unique natural isomorphism \(\eta :\vartheta ^0D\Rightarrow \vartheta ^1D\) such that the diagram

commutes for every linear order X.
Proof
Existence and uniqueness of isomorphisms \(\eta _X:\vartheta ^0D(X)\rightarrow \vartheta ^1D(X)\) as in the diagram are due to the assumption that \((\vartheta ^0D(X),\iota ^0_X,\vartheta ^0_X)\) and \((\vartheta ^1D(X),\iota ^1_X,\vartheta ^1_X)\) are initial Bachmann–Howard fixed points of D over X. The non-trivial claim of the proposition is that these isomorphisms are natural in X. This is shown as in the corresponding result for partial orders, for which we refer to [14, Theorem 4.4]. \(\square \)
In the next section we will want to take iterated Bachmann–Howard derivatives. To see that the result is still unique, one should check that the derivatives of isomorphic \({{\textsf{L}}}{{\textsf{O}}}\)-dilators are isomorphic. This follows from the previous result and the following observation, which is shown as in the partial case (see [14, Proposition 4.6]).
Lemma 2.14
If \((\vartheta E,\iota ,\vartheta )\) is a Bachmann–Howard derivative of E and \(\eta :D\Rightarrow E\) is a natural isomorphism, then \((\vartheta E,\iota ,\vartheta \bullet \eta )\) is a Bachmann–Howard derivative of D, where \(\vartheta \bullet \eta :D\circ \vartheta E\Rightarrow \vartheta E\) is given by \((\vartheta \bullet \eta )_X=\vartheta _X\circ \eta _{\vartheta E(X)}\).
Having established existence and uniqueness, we will speak of ‘the’ Bachmann–Howard derivative of D and denote ‘it’ by \(\vartheta D\). To complete the basic theory of Bachmann–Howard derivatives, we should show that \(\vartheta D\) is a \({{\textsf{W}}}{{\textsf{O}}}\)-dilator (i. e., preserves well foundedness) when the same holds for D. Since a particularly short proof of this fact exploits the connection with partial orders, we defer this result until Corollary 4.3 below.
3 Application, part 1: unary collapsing functions
In the introduction we have described a recursive construction of \({{\textsf{L}}}{{\textsf{O}}}\)-dilators \(\textsf {T}^0_n\). Starting with the identity functor \(\textsf {T}^0_0:{{\textsf{L}}}{{\textsf{O}}}\rightarrow {{\textsf{L}}}{{\textsf{O}}}\) (which is an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator with support functions \({\text {supp}}_X:\textsf {T}^0_0(X)=X\rightarrow [X]^{<\omega }\) given by \({\text {supp}}_X(x)=\{x\}\)), we have defined \(\textsf {T}^0_{n+1}\) as the Bachmann–Howard derivative of \(\textsf {T}^0_n\). This construction is explained and justified by the results of Sect. 2. Also in the introduction, we have claimed that \(\textsf {T}^0_n(1)\) coincides with the order \(T_n[0]\) from [20] (where 1 is the order with a single element). This claim will be proved in the present section.
Due to the uniqueness results from Sect. 2 we can argue ‘the other way around’. This means that we will not, at first, consider \(\textsf {T}^0_n\) as given by a recursive construction. Instead, we will give an ad hoc definition of \(\textsf {T}^0_n\), which extends the definition of the term systems \(T_n[0]\cong \textsf {T}_n(1)\) from [20]. In a second step, we will define transformations \(\iota ^n:{\text {Id}}\Rightarrow \textsf {T}^0_{n+1}\) and \(\vartheta ^n:\textsf {T}^0_n\circ \textsf {T}^0_{n+1}\Rightarrow \textsf {T}^0_{n+1}\) that turn \(\textsf {T}^0_{n+1}\) into a Bachmann–Howard derivative of \(\textsf {T}^0_n\). By Proposition 2.13 and Lemma 2.14, this will entail that our ad hoc definition and the recursive construction yield the same result after all (up to natural isomorphism).
Definition 3.1
Given a linear order X, we generate a set \(\textsf {T}(X)\) of terms and a function \(S:\textsf {T}(X)\rightarrow {\mathbb {N}}\cup \{-1\}\) by simultaneous recursion:
-
(i)
For each \(x\in X\), include a term \({\overline{x}}\in \textsf {T}(X)\) with \(S({\overline{x}})=-1\).
-
(ii)
Given \(s\in \textsf {T}(X)\) and \(i\ge \max \{S(s)-1,0\}\), add \(\vartheta _is\in \textsf {T}(X)\) with \(S(\vartheta _is)=i\).
For each \(i\in {\mathbb {N}}\cup \{-1\}\), let \(k_i:\textsf {T}(X)\rightarrow \textsf {T}(X)\) be given by the recursive clauses
To define a binary relation \(<_{\textsf {T}(X)}\) on \(\textsf {T}(X)\), we declare that \(s<_{\textsf {T}(X)}t\) holds if, and only if, one of the following clauses applies:
-
(i’)
We have \(s={\overline{x}}\) and \(t={\overline{y}}\) with \(x<_X y\).
-
(ii’)
The term s is of the form \({\overline{x}}\) while t is of the form \(\vartheta _jt'\).
-
(iii’)
We have \(s=\vartheta _is'\) and \(t=\vartheta _jt'\), and one of the following holds:
-
We have \(i<j\).
-
We have \(i=j\), \(s'<_{\textsf {T}(X)}t'\) and \(k_i(s')<_{\textsf {T}(X)}t\).
-
We have \(i=j\) and \(s\le _{\textsf {T}(X)} k_j(t')\).
-
Concerning the last clause, we clarify that \(s\le _{\textsf {T}(X)}t\) abbreviates the disjunction of \(s<_{\textsf {T}(X)}t\) and the statement that s and t are the same term.
To justify the definition of \(<_{\textsf {T}(X)}\) one can employ the function \(h:\textsf {T}(X)\rightarrow {\mathbb {N}}\) given by \(h({\overline{x}})=0\) and \(h(\vartheta _is)=h(s)+1\). An easy induction shows \(h(k_i(s))\le h(s)\). It follows that \(s<_{\textsf {T}(X)}t\) can be decided by recursion on \(h(s)+h(t)\).
Lemma 3.2
The relation \(<_{\textsf {T}(X)}\) on \(\textsf {T}(X)\) is a linear order.
Proof
For a term \(s=\vartheta _is'\in \textsf {T}(X)\), the s-secure subterms of s are defined as follows: The term \(s'\) is s-secure. And if \(\vartheta _jt\) with \(j\ge i\) is s-secure, then so is t. More intuitively, t is s-secure if we have \(s'=\vartheta _{j_1}\ldots \vartheta _{j_n}t\) with \(j_1,\dots ,j_n\ge i\). If t is s-secure for \(s=\vartheta _is'\), then the following holds: First, \(k_i(t)\) is s-secure. Secondly, we either have \(k_i(t)=k_i(s')\), or t is \(k_i(s')\)-secure with \(k_i(s')=\vartheta _is''\) for the same i. We will establish the following two statements simultaneously by induction on s. To see that the restriction to s-secure subterms is necessary, consider the counterexample that would arise from \(s=\vartheta _1\vartheta _0\vartheta _1\vartheta _10\) and \(t=\vartheta _1\vartheta _10=k_1(t)\).
-
(1)
If t is s-secure with \(s=\vartheta _is'\), then we cannot have \(s\le _{\textsf {T}(X)}k_i(t)\).
-
(2)
We do not have \(s<_{\textsf {T}(X)}s\).
In the induction step for (1), we use side induction on t. We may write \(k_i(t)=\vartheta _it'\), because the conclusion is trivial when \(k_i(t)\) has a different form. Let us exclude all reasons for which \(s\le _{\textsf {T}(X)}k_i(t)\) could hold: First, note that \(h(k_i(t))\le h(t)<h(s)\) excludes equality. Secondly, given that t is s-secure, the same holds for \(t'\). Thus the side induction hypothesis excludes \(s\le _{\textsf {T}(X)}k_i(t')\). Finally, the only remaining reason would involve \(k_i(s')<_{\textsf {T}(X)}k_i(t)\). The latter entails that \(k_i(s')\) and \(k_i(t)\) are different, by part (2) of the simultaneous induction hypothesis. It follows that t is \(k_i(s')\)-secure, so that the main induction hypothesis excludes \(k_i(s')<_{\textsf {T}(X)}k_i(t)\). Concerning the induction step for (2), we note that only terms of the form \(s=\vartheta _is'\) are interesting. Since the induction hypothesis excludes \(s'<_{\textsf {T}(X)}s'\), the inequality \(s<_{\textsf {T}(X)}s\) would require \(s\le _{\textsf {T}(X)} k_i(s')\). This, however, is excluded by part (1). Trichotomy and transitivity are readily established by induction on the combined term complexity (e. g., on \(h(s)+h(t)\) for trichotomy between s and t). \(\square \)
Together with trichotomy, statement (1) from the previous proof yields:
Corollary 3.3
We have \(k_i(s)<_{\textsf {T}(X)}\vartheta _is\) whenever \(\vartheta _is\in \textsf {T}(X)\).
We will be particularly interested in the following suborders of \(\textsf {T}(X)\).
Definition 3.4
For \(n\in {\mathbb {N}}\) and a linear order X, define \(\textsf {T}_n(X)\subseteq \textsf {T}(X)\) as the suborder of terms that contain indices below n only. Equivalently, \(\textsf {T}_n(X)\) is generated just as \(\textsf {T}(X)\), but with the additional restriction \(i<n\) in clause (ii) of Definition 3.1. Furthermore, we define \(\textsf {T}^0_n(X)=\{s\in \textsf {T}_n(X)\,|\,S(s)\le 0\}\) as the suborder of terms that have the form \({\overline{x}}\) or outer index 0. We will also write \(<_{\textsf {T}(X)}\) (or just <) for the restriction of this order to \(\textsf {T}_n(X)\) and \(\textsf {T}^0_n(X)\).
As mentioned before, we have the following connection:
Corollary 3.5
The orders \(T_n\) and \(T_n[0]\) from [20, Section 2.3.3] coincide with our orders \(\textsf {T}_n(1)\) and \(\textsf {T}^0_n(1)\), respectively (where 1 is the order with a single element).
Proof
If we write \(1=\{0\}\) and identify \({\overline{0}}\in \textsf {T}_n(1)\) with \(0\in T_n\), the definitions coincide except at one point: Definition 27 of [20] declares that \(s>t\) and \(\vartheta _is\le k_i(t)\) imply \(\vartheta _is<\vartheta _i t\). In the corresponding clause (iii’) of our Definition 3.1, we have omitted the condition \(s>t\), because it turns out to be superfluous: According to [20, Lemma 9] (cf. also Corollary 3.3 above) we have \(k_i(t)<\vartheta _it\). Hence it follows from transitivity that \(\vartheta _is\le k_i(t)\) alone entails \(\vartheta _is<\vartheta _i t\). \(\square \)
We want to show that \(\textsf {T}^{0}_{n+1}\) is a Bachmann–Howard derivative of \(\textsf {T}^0_n\). Officially, this claim does only make sense once we have specified a dilator \(\textsf {T}^0_n\) that extends the transformation \(X\mapsto \textsf {T}^0_n(X)\) of linear orders. We defer this extension until later, because we want to start with the most interesting part of the construction:
Definition 3.6
For each number \(n\in {\mathbb {N}}\) and any linear order X, we define a function \(\sigma ^n_X:\textsf {T}_n\circ \textsf {T}^0_{n+1}(X)\rightarrow \textsf {T}_{n+1}(X)\) by the recursive clauses
Now we define \(\vartheta ^n_X:\textsf {T}^0_n\circ \textsf {T}^0_{n+1}(X)\rightarrow \textsf {T}^0_{n+1}(X)\) by setting \(\vartheta ^n_X(s)=\vartheta _0\sigma ^n_X(s)\). Finally, let \(\iota ^n_X:X\rightarrow \textsf {T}^0_{n+1}(X)\) be given by \(\iota ^n_X(x)={\overline{x}}\).
Note that elements \(r={\overline{x}}\in \textsf {T}^0_{n+1}(X)\) give rise to elements \({\overline{r}}=\overline{{\overline{x}}}\in \textsf {T}_n\circ \textsf {T}^0_{n+1}(X)\). We have
For \(i\ge 0\), it follows that the condition \(i\ge S(s)-1\) from Definition 3.1 is equivalent to \(i+1\ge S(\sigma ^n_X(s))-1\). This justifies the second clause in the definition of \(\sigma ^n_X\). To justify the definition of \(\vartheta ^n_X\), it suffices to note that \(s\in \textsf {T}^0_n\circ \textsf {T}^0_{n+1}(X)\) entails \(S(s)\le 0\) and hence \(0\ge S(\sigma ^n_X(s))-1\). To formulate the next result, we need one new piece of notation: For \(s\in \textsf {T}(X)\), the value \(k_{-1}(s)\in \textsf {T}(X)\) is always of the form \({\overline{x}}\) with \(x\in X\). We define \(\underline{k}:\textsf {T}(X)\rightarrow X\) by setting
In particular, \(s\in \textsf {T}^0_n\circ \textsf {T}^0_{n+1}(X)\) yields \(\underline{k}(s)\in \textsf {T}^0_{n+1}(X)\). We will see that the following proposition ensures the crucial clause (iii) of Definition 2.5.
Proposition 3.7
The function \(\sigma ^n_X:\textsf {T}_n\circ \textsf {T}^0_{n+1}(X)\rightarrow \textsf {T}_{n+1}(X)\) is an order isomorphism, for each \(n\in {\mathbb {N}}\) and any linear order X. Furthermore, the following holds for all \(s,t\in \textsf {T}^0_n\circ \textsf {T}^0_{n+1}(X)\):
-
If we have \(s<t\) and \(\underline{k}(s)<\vartheta ^n_X(t)\), then we have \(\vartheta ^n_X(s)<\vartheta ^n_X(t)\).
-
We have \(\underline{k}(s)<\vartheta ^n_X(s)\).
Proof
An easy induction over an arbitrary term \(r\in \textsf {T}_{n+1}(X)\) shows that it lies in the range of \(\sigma ^n_X\). As preparation for the rest of the proof, one inductively shows
for \(i\in {\mathbb {N}}\cup \{-1\}\). In the crucial case of a term \(s={\overline{r}}\), this follows from \(k_i(s)=s\) and \(\sigma ^n_X(s)=r=k_{i+1}(r)\), where the latter relies on \(S(r)\le i+1\) due to \(r\in \textsf {T}^0_{n+1}(X)\). Now an easy induction on \(h(s)+h(t)\) shows that \(s<t\) implies \(\sigma ^n_X(s)<\sigma ^n_X(t)\). This implication does automatically upgrade to an equivalence, as we are concerned with linear orders. In particular \(\sigma ^n_X\) is injective, and indeed an order isomorphism. Concerning the claims about \(\vartheta ^n_X\), we first note that \(\underline{k}(s)<\vartheta ^n_X(t)\) entails
Since we already know that \(s<t\) entails \(\sigma ^n_X(s)<\sigma ^n_X(t)\), we get
under the given assumptions. Arguing as before, we see that the remaining claim amounts to \(k_0(\sigma ^n_X(s))<\vartheta _0\sigma ^n_X(s)\), which holds by Corollary 3.3. \(\square \)
As promised, we now extend \(\textsf {T}^0_n\) (and in the process also \(\textsf {T}_n\)) into an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator.
Definition 3.8
For each embedding \(f:X\rightarrow Y\) of linear orders, we define a function \(\textsf {T}(f):\textsf {T}(X)\rightarrow \textsf {T}(Y)\) by the recursive clauses
Furthermore, we define functions \({\text {supp}}^\textsf {T}_X:\textsf {T}(X)\rightarrow [X]^{<\omega }\) by setting
We will also write \({\text {supp}}^T_X\) for the restrictions of this function to \(\textsf {T}_n(X)\) and to \(\textsf {T}^0_n(X)\). By \(\textsf {T}_n(f):\textsf {T}_n(X)\rightarrow \textsf {T}_n(Y)\) and \(\textsf {T}^0_n(f):\textsf {T}^0_n(X)\rightarrow \textsf {T}^0_n(Y)\) we denote the restrictions of \(\textsf {T}(f)\) with (co-)domains as given.
It is immediate that we have \(S(\textsf {T}(f)(s))=S(s)\), which confirms that the functions \(\textsf {T}(f)\), \(\textsf {T}_n(f)\) and \(\textsf {T}^0_n(f)\) are well-defined with the indicated codomains. We have given recursive definitions because they easily generalize from sequences to more complicated data types (cf. the treatment of trees in [14]). In the present case, it may simplify matters if we observe
Let us now verify the following:
Proposition 3.9
The previous definition extends \(\textsf {T}_n\) and \(\textsf {T}^0_n\) into \({{\textsf{L}}}{{\textsf{O}}}\)-dilators.
Proof
A straightforward induction over \(s\in \textsf {T}(X)\) shows \(k_i(\textsf {T}(f)(s))=\textsf {T}(f)(k_i(s))\). Given an order embedding \(f:X\rightarrow Y\), one can now check
by induction over \(h(s)+h(t)\) (for \(h:\textsf {T}(X)\rightarrow {\mathbb {N}}\) as given after Definition 3.1). Two more easy inductions show that \(\textsf {T}\) respects identity morphisms and compositions. It follows that \(\textsf {T}_n\) and \(\textsf {T}^0_n\) are endofunctors of linear orders. By the definition of \(\underline{k}\) and the first line of this proof, we have \(\underline{k}(T(f)(s))=f(\underline{k}(s))\). This yields
so that \({\text {supp}}^\textsf {T}\) is natural. To conclude that \(\textsf {T}_n\) is a dilator, we show
by induction over \(r\in \textsf {T}_n(Y)\), still for \(f:X\rightarrow Y\). In the base case of a term \(r={\overline{y}}\) we observe \({\text {supp}}^\textsf {T}_Y(r)=\{\underline{k}({\overline{y}})\}=\{y\}\). By the antecedent of our implication we may write \(y=f(x)\), which yields \(r=\textsf {T}_n(f)({\overline{x}})\) as desired. In the step for \(r=\vartheta _ir'\) we note that \(k_{-1}(r)=k_{-1}(r')\) entails \({\text {supp}}^\textsf {T}_Y(r)={\text {supp}}^\textsf {T}_Y(r')\). Given the antecedent of our implication, we can thus invoke the induction hypothesis to get \(r'=\textsf {T}_n(f)(r_0')\) for some \(r_0'\in \textsf {T}_n(X)\). In view of \(S(r_0')=S(\textsf {T}(f)(r_0'))=S(r')\) we may form the term \(\vartheta _ir_0'\in \textsf {T}_n(X)\) to get \(r=\textsf {T}_n(f)(\vartheta _ir_0')\in {\text {rng}}(\textsf {T}_n(f))\). In order to deduce the analogous implication for \(\textsf {T}^0_n\), we need only observe that \(\textsf {T}_n(f)(r_0)=r\in \textsf {T}^0_n(Y)\) entails \(S(r_0)=S(r)\le 0\) and hence \(r_0\in \textsf {T}^0_n(X)\subseteq \textsf {T}_n(X)\). \(\square \)
The following theorem is the main result of this section. We write \(\iota ^n\) and \(\vartheta ^n\) for the families of functions \(\iota ^n_X:X\rightarrow \textsf {T}^0_{n+1}(X)\) and \(\vartheta ^n_X:\textsf {T}^0_n\circ \textsf {T}^0_{n+1}(X)\rightarrow \textsf {T}^0_{n+1}(X)\), which are indexed by the linear order X (cf. Definition 3.6).
Theorem 3.10
The Bachmann–Howard derivative of \(\textsf {T}^0_n\) is given by \((\textsf {T}^0_{n+1},\iota ^n,\vartheta ^n)\), for each number \(n\in \mathbb N\).
Proof
A straightforward induction over terms shows that the functions \(\sigma ^n_X\) from Definition 3.6 are natural in X. One can conclude that the same holds for \(\iota ^n_X\) and \(\vartheta ^n_X\). In view of Definition 2.10, it remains to show that \((\textsf {T}^0_{n+1}(X),\iota ^n_X,\vartheta ^n_X)\) is an initial Bachmann–Howard fixed point of \(\textsf {T}^0_n\) over X, whenever X is a linear order. Clauses (i) and (ii) of Definition 2.5 are immediate by our constructions. Clause (iii) holds by Proposition 3.7 and the definition of \({\text {supp}}^\textsf {T}\). To complete the proof, we verify the criteria from part (i) of Theorem 2.9. The first criterion demands
To see that this holds, consider a term \(\vartheta _0s\in \textsf {T}^0_{n+1}(X)\). We note that \(s\in \textsf {T}_{n+1}(X)\) must satisfy \(S(s)\le 1\), due to Definition 3.1. From Proposition 3.7 we know that \(\sigma ^n_X\) is surjective, which yields \(s=\sigma ^n_X(s')\) for some \(s'\in \textsf {T}_n\circ \textsf {T}^0_{n+1}(X)\). By the paragraph after Definition 3.6 we get \(S(s')=-1\) or \(S(s')=S(s)-1\le 0\), which means that we even have \(s'\in \textsf {T}^0_n\circ \textsf {T}^0_{n+1}(X)\). We now see
as required. The second criterion requires a function \(h:\textsf {T}^0_{n+1}(X)\rightarrow {\mathbb {N}}\) with
We show that this holds for (the restriction of) the function \(h:\textsf {T}(X)\rightarrow {\mathbb {N}}\) from the paragraph after Definition 3.1. By our definition of supports, the only possibility is \(r=\underline{k}(s)\). By induction over \(s\in \textsf {T}_n\circ \textsf {T}^0_{n+1}(X)\) one can verify \(h(\underline{k}(s))\le h(\sigma ^n_X(s))\). In view of \(h(\vartheta ^n_X(s))=h(\vartheta _0\sigma ^n_X(s))=h(\sigma ^n_X(s))+1\) this yields the claim. \(\square \)
The \({{\textsf{L}}}{{\textsf{O}}}\)-dilator \(\textsf {T}^0_n\) has been defined in two different ways: First, we have constructed \(\textsf {T}^0_n\) in terms of iterated Bachmann–Howard derivatives, according to steps (1) and (2) from the introduction. Secondly, we have given an ad hoc construction of \(\textsf {T}^0_n\) in Definitions 3.1, 3.4 and 3.8. The results of the two constructions coincide by Theorem 3.10, as explained in the first two paragraphs of this section. Let us point out that there is, nevertheless, an interesting difference: For the ad hoc definition of \(\textsf {T}^0_n\), we needed to define \(\textsf {T}_n\) as an auxiliary construct (which also appears in many inductive verifications). In contrast, the recursive construction via Bachmann–Howard derivatives yields \(\textsf {T}^0_n\) directly.
4 Theory, part 2: connecting with Kruskal derivatives
In Sect. 2 we have introduced the Bachmann–Howard derivative \(\vartheta D\) of an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D. A parallel construction on the level of partial orders was previously studied in [14]: For each suitable dilator W on partial orders, it yields the so-called Kruskal derivative \({\mathcal {T}} W\). In the present section we establish fundamental connections between Bachmann–Howard and Kruskal derivatives, i. e., between the linear and the partial case.
Important notions from [14] will be recalled informally, but the reader may need to consult the cited reference for precise definitions. A function \(f:X\rightarrow Y\) between partial orders is a quasi embedding if it is order reflecting, i. e., if \(f(x)\le _Y f(x')\) implies \(x\le _X x'\). We consider the category \({{\textsf{P}}}{{\textsf{O}}}\) of partial orders with the quasi embeddings as morphisms. A \({{\textsf{P}}}{{\textsf{O}}}\)-dilator is a functor \(W:{{\textsf{P}}}{{\textsf{O}}}\rightarrow {{\textsf{P}}}{{\textsf{O}}}\) that satisfies certain conditions, in particular a support condition as in Definition 2.1 above (see [14, Definition 2.1] for details). We call W a \(\textsf{WPO}\)-dilator if, in addition, W(X) is a well partial order whenever the same holds for X. By \(W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}:{{\textsf{L}}}{{\textsf{O}}}\rightarrow {{\textsf{P}}}{{\textsf{O}}}\) we denote the restriction of a \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W to the category of linear orders. Also, we sometimes consider an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D as a functor \(D:{{\textsf{L}}}{{\textsf{O}}}\rightarrow {{\textsf{P}}}{{\textsf{O}}}\), i. e., we implicitly compose it with the inclusion  . We can then consider \(\nu \) as in the following:
. We can then consider \(\nu \) as in the following:
Definition 4.1
By a quasi embedding of an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D into a \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W we mean a natural transformation \(\nu :D\Rightarrow W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\).
Note that \(\nu \) consists of a quasi embedding \(\nu _X:D(X)\rightarrow W(X)\) for each linear order X. If a \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W satisfies a certain normality condition, then it has an essentially unique Kruskal derivative \({\mathcal {T}} W\) (see Definition 2.3 and Section 4 of [14]). The latter comes with natural families of functions
indexed by the partial order X. From Sect. 2 above we recall that the Bachmann–Howard derivative \(\vartheta D\) of an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D comes with functions
where X does now range over linear orders. Together with Theorem 4.8 below, the following result provides the connection between Kruskal and Bachmann–Howard derivatives. The theorem extends [4, Theorem 4.5], in which \(\nu ^+_X\) is only constructed for the empty order \(X=0\). Even though the main idea remains the same, we provide full details, as the setting and notation in [4] are somewhat different.
Theorem 4.2
Let \(\nu :D\Rightarrow W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) be a quasi embedding of an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D into a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W. There is a unique quasi embedding \(\nu ^+:\vartheta D\Rightarrow {\mathcal {T}} W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) such that the diagram

commutes for each linear order X.
Proof
By Lemma 2.2, each \(\sigma \in D\circ \vartheta D(X)\) has a normal form \(\sigma ={}_{{\text {NF}}}D(\iota _a)(\sigma _0)\) with \(a\subseteq \vartheta D(X)\) and \(\sigma _0\in D(a)\). Note that \(\nu _{\vartheta D(X)}\circ D(\iota _a)=W(\iota _a)\circ \nu _a\) holds since \(\nu \) is natural. Hence the diagram in the theorem commutes if, and only if, we have
The idea is to read these equations as recursive clauses, which is justified as follows: According to Definition 2.10, the tuple \((\vartheta D(X),\iota ^D_X,\vartheta ^D_X)\) is an initial Bachmann–Howard fixed point of D over X. By (the proof of) Theorem 2.9, it follows that the functions \(\iota ^D_X\) and \(\vartheta ^D_X\) are injective, and that \(\vartheta D(X)\) is the disjoint union of their ranges. Furthermore, the same theorem yields a function \(h:\vartheta D(X)\rightarrow {\mathbb {N}}\) such that
holds for any element \(\sigma \in D\circ \vartheta D(X)\). Here \({\text {supp}}^D\) is the support that comes with the \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D (see Definition 2.1 and the discussion that follows it). Now recall that \(\sigma ={}_{{\text {NF}}}D(\iota _a)(\sigma _0)\) entails \({\text {supp}}^D_{\vartheta D(X)}(\sigma )=a\), by Lemma 2.2. This means that the clauses above define \(\nu ^+_X(s)\) by recursion over h(s). More precisely, a straightforward induction on h(s) shows that the value \(\nu ^+_X(s)\) is uniquely determined, i. e., that there is at most one quasi embedding \(\nu ^+_X\) such that the diagram in the theorem commutes. The proof of existence is somewhat more subtle, since we must simultaneously show that \(\nu ^+_X\) is a quasi embedding, in order to ensure that \(W(\nu ^+_X\circ \iota _a)\) is defined. Let us define \(l:\vartheta D(X)\rightarrow {\mathbb {N}}\) by stipulating \(l(\iota ^D_X(x))=0\) and
which is itself a recursion based on h. By simultaneous induction on the values l(r) and \(l(s)+l(t)\) one can now show that \(\nu ^+_X(r)\in {\mathcal {T}}W(X)\) is defined and that we have
To establish this implication, we distinguish cases according to the forms of s and t. First assume \(s=\iota ^D_X(x)\) and \(t=\iota ^D_X(y)\). Then the antecedent of our implication amounts to \(\iota ^W_X(x)\le _{{\mathcal {T}}W(X)}\iota ^W_X(y)\). According to [14, Definition 3.1] we get \(x\le _X y\). Now \(s\le _{\vartheta D(X)}t\) follows by clause (i) of Definition 2.5 above. By the same definition, we always have \(s\le _{\vartheta D(X)}t\) for terms of the form \(s=\iota ^D_X(x)\) and \(t=\vartheta ^D_X(\tau )\). For terms \(s=\vartheta ^D_X(\sigma )\) and \(t=\iota ^D_X(y)\), say with \(\sigma ={}_{{\text {NF}}}D(\iota _a)(\sigma _0)\), we have
again by [14, Definition 3.1]. It remains to compare terms \(s=\vartheta ^D_X(\sigma )\) and \(t=\vartheta ^D_X(\tau )\). We write \(\sigma ={}_{{\text {NF}}}D(\iota _a)(\sigma _0)\) and \(\tau ={}_{{\text {NF}}}D(\iota _b)(\tau _0)\) and assume
According to [14, Definition 3.1], this inequality can hold for two different reasons. In the first case we have \(\nu ^+_X(s)\le _{{\mathcal {T}}W(X)}t'\) for some element
By [4, Lemmas 4.2 and 4.4] any quasi embedding of an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator into a \({{\textsf{P}}}{{\textsf{O}}}\)-dilator respects supports. This means that we have \({\text {supp}}^W_b(\nu _b(\tau _0))={\text {supp}}^D_b(\tau _0)=b\), where the last equality comes from the normal form condition (see the paragraph before Definition 2.2). We can thus write \(t'=\nu ^+_X(t_0')\) for some \(t_0'\in b\). The latter entails that we have \(l(t_0')<l(t)\), so that we get \(s\le _{\vartheta D(X)}t_0'\) by induction hypothesis. By Lemma 2.2 we have \(b={\text {supp}}^D_{\vartheta D(X)}(\tau )\), so that clause (iii) of Definition 2.5 allows us to conclude \(t_0'<_{\vartheta D(X)}\vartheta ^D_X(\tau )=t\). Now transitivity yields \(s\le _{\vartheta D(X)}t\), as desired (in fact the inequality is strict in this case). In the remaining case, the above inequality \(\nu ^+_X(s)\le _{{\mathcal {T}}W(X)}\nu ^+_X(t)\) holds because we have
Let us factor \(\iota _a=\iota _{a\cup b}\circ \iota _a'\) and \(\iota _b=\iota _{a\cup b}\circ \iota _b'\) with  . The induction hypothesis ensures that \(\nu ^+_X\circ \iota _{a\cup b}\) is a quasi embedding, which allows us to form the quasi embedding \(W(\nu ^+_X\circ \iota _{a\cup b})\). The previous inequality thus entails
. The induction hypothesis ensures that \(\nu ^+_X\circ \iota _{a\cup b}\) is a quasi embedding, which allows us to form the quasi embedding \(W(\nu ^+_X\circ \iota _{a\cup b})\). The previous inequality thus entails
Due to the naturality of \(\nu \), we get \(\nu _{a\cup b}\circ D(\iota _a')(\sigma _0)\le _{W(a\cup b)}\nu _{a\cup b}\circ D(\iota _b')(\tau _0)\). Since \(\nu _{a\cup b}\) reflects the order while \(D(\iota _{a\cup b})\) preserves it, this entails
In order to conclude \(s=\vartheta ^D_X(\sigma )\le _{\vartheta D(X)}\vartheta ^D_X(\tau )=t\) by clause (iii) of Definition 2.5, it remains to show that we have
Analogous to the above, we get
as well as \(b={\text {supp}}^W_{a\cup b}\left( W(\iota _b')\circ \nu _b(\tau _0)\right) \). Due to inequality (4.1) and the assumption that W is normal (cf. [14, Definition 2.3]), it follows that any \(r\in a\) admits an \(r'\in b\) with \(r\le _{\vartheta D(X)}r'\) (note that the inequality holds in \(\vartheta D(X)\) because \(a\cup b\) is a suborder of the latter). Once again, clause (iii) of Definition 2.5 yields \(r'<_{\vartheta D(X)}\vartheta ^D_X(\tau )\). Now transitivity allows us to conclude \(r<_{\vartheta D(X)}\vartheta ^D_X(\tau )\), as needed. This completes the simultaneous proof that \(\nu ^+_X\) is well defined and a quasi embedding. It remains to show naturality. Given a quasi embedding \(f:X\rightarrow Y\), we prove
by induction over h(s), for \(h:\vartheta D(X)\rightarrow {\mathbb {N}}\) as above. The crucial case concerns a term \(s=\vartheta ^D_X(\sigma )\), say with \(\sigma ={}_{{\text {NF}}}D(\iota _a)(\sigma _0)\). Using the naturality of \(\vartheta ^D\), we get
In order to apply \(\nu ^+_Y\) to the expression on the right side, we need to determine the normal form of \(D(\vartheta D(f)\circ \iota _a)(\sigma _0)\). Consider the restriction \(\vartheta D(f)\!\restriction \!a:a\rightarrow b\) with codomain \(b:=[\vartheta D(f)]^{<\omega }(a)\). In view of \(\vartheta D(f)\circ \iota _a=\iota _b\circ (\vartheta D(f)\!\restriction \!a)\) we get
This expression is in normal form, since the naturality of supports yields
where \({\text {supp}}^D_a(\sigma _0)=a\) comes from the normal form condition for \(\sigma ={}_{{\text {NF}}}D(\iota _a)(\sigma _0)\). By the recursive definition of \(\nu ^+_Y\), we now obtain
The naturality of \(\nu \) yields \(\nu _b(\sigma _1)=W(\vartheta D(f)\!\restriction \!a)\circ \nu _a(\sigma _0)\) and hence
Since \(r\in a\) entails \(h(r)<h(s)\), we have \(\nu ^+_Y\circ \vartheta D(f)\circ \iota _a={\mathcal {T}}W(f)\circ \nu ^+_X\circ \iota _a\) by induction hypothesis. Putting things together, we can finally conclude
as needed for the inductive proof that \(\nu ^+\) is natural. \(\square \)
We now deduce the result that was promised at the end of Sect. 2. Our proof is somewhat indirect but nevertheless instructive, as it connects several fundamental facts. Even though we do not formalize the present paper in a specific meta theory, we point out that the following argument uses \(\Pi ^1_1\)-comprehension, in the form of the minimal bad sequence lemma. This is unavoidable by the results of [17, 19].
Corollary 4.3
If D is a \({{\textsf{W}}}{{\textsf{O}}}\)-dilator (i. e., preserves well foundedness), then so is its Bachmann–Howard derivative \(\vartheta D\).
Proof
That \(\vartheta D\) is an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator is guaranteed by Definition 2.10 (but see also Proposition 2.11). It remains to show that \(\vartheta D(X)\) is a well order when the same holds for X. According to [4, Section 5] there is a quasi embedding \(\nu :D\Rightarrow W_D\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) into a normal \(\textsf{WPO}\)-dilator \(W_D\). By the previous theorem we get a quasi embedding
for each linear order X. Assume that X is a well order and hence a well partial order. Then \({\mathcal {T}}W_D(X)\) is also a well partial order, by [14, Proposition 2.7] (which is proved by the minimal bad sequence method of Nash-Williams [3]). Given an infinite sequence \(s_0,s_1,\dots \) in \(\vartheta D(X)\), we get a sequence \(\nu ^+_X(s_0),\nu ^+_X(s_1),\dots \) in \({\mathcal {T}}W_D(X)\). Since the latter is a well partial order, there are \(i<j\) such that we have \(\nu ^+_X(s_i)\le _{{\mathcal {T}}W_D(X)}\nu ^+_X(s_j)\). We can infer \(s_i\le _{\vartheta D(X)}s_j\), as \(\nu ^+_X\) is a quasi embedding and hence order reflecting. This shows that \(\vartheta D(X)\) is a well order. \(\square \)
As an immediate consequence of our general approach, we re-obtain the following known result about the orders \(T_n[0]\) from [20, Section 2.3.3].
Corollary 4.4
The order \(T_n[0]\) is well founded for each \(n\in {\mathbb {N}}\).
Proof
In the previous section we have studied \({{\textsf{L}}}{{\textsf{O}}}\)-dilators \(\textsf {T}^0_n\) with \(T_n[0]\cong \textsf {T}^0_n(1)\). It suffices to show that these are \({{\textsf{W}}}{{\textsf{O}}}\)-dilators. We argue by induction on n. In the base we need only observe \(\textsf {T}^0_n(X)\cong X\). The step is covered by the previous corollary, as \(\textsf {T}^0_{n+1}\) is the Bachmann–Howard derivative of \(\textsf {T}^0_n\), by Theorem 3.10. \(\square \)
Let \(f:X\rightarrow Y\) be a quasi embedding between partial orders. If X is linear and f is surjective, then we call f a linearization (of Y by X). This coincides with the usual notion if we identify X with its image under f. Linearizations are particularly important, as they are related to maximal order types and independence results (see e. g. [11, 25,26,27]). We introduce the corresponding functorial notion:
Definition 4.5
Consider an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D and a \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W. A quasi embedding \(\nu :D\Rightarrow W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) is called a linearization (of W by D) if \(\nu _X:D(X)\rightarrow W(X)\) is surjective for each linear order X.
Our next goal is to identify a condition which ensures that the quasi embedding \(\nu ^+:\vartheta D\Rightarrow {\mathcal {T}} W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) from Theorem 4.2 is a linearization. As the following example shows, the assumption that \(\nu :D\Rightarrow W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) is a linearization does not suffice.
Example 4.6
We define a transformation \(X\mapsto W(X)\) of partial orders by
If \(f:X\rightarrow Y\) is a quasi embedding, then \(x'\not \le _Xx\) implies \(f(x')\not \le _Yf(x)\). We thus get a function \(W(f):W(X)\rightarrow W(Y)\) by setting \(W(f)(x,x')=(f(x),f(x'))\). Let us also define functions \({\text {supp}}^W_X:W(X)\rightarrow [X]^{<\omega }\) by putting \({\text {supp}}^W_X(x,x')=\{x,x'\}\). It is straightforward to verify that this data constitutes a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator. Here it is crucial that the support condition
is only required when \(f:X\rightarrow Y\) is an embedding, rather than just a quasi embedding (see [14, Definition 2.1]). In the present case, the support condition does in fact imply that f is order preserving. For each linear order X, we put
Given that X is linear, the underlying sets of D(X) and W(X) are equal. We may thus declare that \(D(f):D(X)\rightarrow D(Y)\) and \({\text {supp}}^D_X:D(X)\rightarrow [X]^{<\omega }\) coincide with W(f) and \({\text {supp}}^W_X\), respectively, for any embedding \(f:X\rightarrow Y\) of linear orders. It is easy to see that this yields an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator. The identity maps \(\nu _X:D(X)\rightarrow W(X)\) constitute a linearization \(\nu :D\Rightarrow W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\). Theorem 4.2 gives rise to a quasi embedding \(\nu ^+:\vartheta D\Rightarrow {\mathcal {T}}W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\), which we shall now describe concretely. For each partial order X, we consider a collection \({\mathcal {B}}(X)\) of structured binary trees with leaf labels from X, which is recursively generated as follows:
-
For each \(x\in X\) we have an element \({\overline{x}}\in {\mathcal {B}}(X)\) (a single node with label x).
-
Given \(s,s'\in {\mathcal {B}}(X)\) we add an element \(\circ (s,s')\in {\mathcal {B}}(X)\) (the tree in which the root has immediate subtrees s and \(s'\)).
To extend \({\mathcal {B}}\) into a functor (currently on sets but later on orders), we stipulate
We also define support functions \({\text {supp}}^{{\mathcal {B}}}_X:\mathcal B(X)\rightarrow [X]^{<\omega }\) by setting
To describe the Kruskal derivative \({\mathcal {T}}W\) of W, we first define a partial order \(\le ^W_{{\mathcal {B}}(X)}\) on \({\mathcal {B}}(X)\). The latter coincides with the usual embeddability relation for labelled trees, which can be given by the following recursive clauses:
-
(i)
If we have \(x\le _X y\), then we have \({\overline{x}}\le ^W_{{\mathcal {B}}(X)}{\overline{y}}\).
-
(ii)
We have \(s\le ^W_{{\mathcal {B}}(X)}\circ (s,s')\) and \(s'\le ^W_{{\mathcal {B}}(X)}\circ (s,s')\).
-
(iii)
If we have \(s\le ^W_{{\mathcal {B}}(X)}t\) and \(s'\le ^W_{{\mathcal {B}}(X)}t'\), then we have \(\circ (s,s')\le ^W_{{\mathcal {B}}(X)}\circ (t,t')\).
One can check that this turns \({\mathcal {B}}\) into a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator. Indeed, \({\mathcal {B}}\) is the Kruskal derivative of \(X\mapsto X^2\), where the order on \(X^2\) extends the one on W(X) in the obvious way. In view of \(W(X)\subsetneq X^2\), we now define \({\mathcal {T}}W(X)\subseteq {\mathcal {B}}(X)\) as the smallest suborder that contains all elements \({\overline{x}}\) and contains \(\circ (s,s')\) for any \(s,s'\in {\mathcal {T}}W(X)\) with \(s'\not \le ^W_{{\mathcal {B}}(X)} s\). We can turn \({\mathcal {T}}W\) into a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator by restricting the constructions from above. Let us define
by setting \(\iota ^W_X(x)={\overline{x}}\) and \(\kappa ^W_X(s,s')=\circ (s,s')\). As one readily verifies, these functions witness that \({\mathcal {T}}W\) is the Kruskal derivative of W (so that the notation \({\mathcal {T}}W\) is indeed justified). To describe the Bachmann–Howard derivative \(\vartheta D\) of D, we first refine \(\le ^W_{{\mathcal {B}}(X)}\) into a linear order \(\le _{\mathcal B(X)}^D\) on \({\mathcal {B}}(X)\). The latter is characterized by the following clauses together with (i-iii) above (with \(\le ^D_{{\mathcal {B}}(X)}\) at the place of \(\le ^W_{{\mathcal {B}}(X)}\)):
-
(iv)
We have \({\overline{x}}<_{{\mathcal {B}}(X)}^D\circ (t,t')\) for any terms of the given forms.
-
(v)
If we have \(s<_{{\mathcal {B}}(X)}^Dt\) and \(s'<_{{\mathcal {B}}(X)}^D\circ (t,t')\), we have \(\circ (s,s')<^D_{{\mathcal {B}}(X)}\circ (t,t')\).
Analogous to the above, let \(\vartheta D(X)\subseteq {\mathcal {B}}(X)\) be the smallest (linear) suborder that contains all elements \({\overline{x}}\) and contains \(\circ (s,s')\) for any \(s,s'\in \vartheta D(X)\) with \(s<^D_{{\mathcal {B}}(X)} s'\). To turn \(\vartheta D\) into an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator, it suffices to restrict the functions \({\mathcal {B}}(f)\) and \({\text {supp}}^{{\mathcal {B}}}_X\) from above. We define
as the restrictions of \(\iota ^W_X\) and \(\kappa ^W_X\), i. e. by \(\iota ^D_X(x)={\overline{x}}\) and \(\vartheta ^D_X(s,s')=\circ (s,s')\). These functions witness that \(\vartheta D\) is the Bachmann–Howard derivative of D. Since \(\le ^D_{{\mathcal {B}}(X)}\) refines \(\le ^W_{{\mathcal {B}}(X)}\), we have \(\vartheta D(X)\subseteq {\mathcal {T}}W(X)\). One can verify that the inclusion maps

satisfy the conditions from Theorem 4.2, which characterize \(\nu ^+\) uniquely. We now consider \(X=\{0,1,2\}\) with the usual linear order. The element \(\circ (\circ ({\overline{0}},\overline{1}),{\overline{2}})\in {\mathcal {B}}(X)\) is contained in \({\mathcal {T}}W(X)\) but not in \(\vartheta D(X)\), so that \(\nu ^+_X\) is not surjective. This means that \(\nu ^+:\vartheta D\Rightarrow {\mathcal {T}}W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) is no linearization, even though \(\nu :D\Rightarrow W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) is one.
The previous example suggests the following notion:
Definition 4.7
A \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W is called flat if the support condition
holds for any quasi embedding \(f:X\rightarrow Y\) between partial orders (recall that [14, Definition 2.1] does only require this condition for embeddings).
As expected, we get the following (cf. Theorem 4.2):
Theorem 4.8
Consider a linearization \(\nu :D\Rightarrow W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) of a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W by an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator D. If W is flat, then \(\nu ^+:\vartheta D\Rightarrow {\mathcal {T}}W\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) is again a linearization.
Proof
Given a linear order X, we need to show that \(\nu ^+_X:\vartheta D(X)\rightarrow {\mathcal {T}}W(X)\) is surjective. According to [14, Definition 4.1], the order \(\mathcal {T} W(X)\) comes with functions \(\iota ^W_X:X\rightarrow {\mathcal {T}}W(X)\) and \(\kappa ^W_X:W\circ {\mathcal {T}}W(X)\rightarrow {\mathcal {T}}W(X)\) that turn it into an initial Kruskal fixed point. By [14, Theorem 3.5] we get a function \(h:{\mathcal {T}}W(X)\rightarrow {\mathbb {N}}\) with
For \(s\in {\mathcal {T}}W(X)\) we shall now show \(s\in {\text {rng}}(\nu ^+_X)\) by induction on h(s). Also by [14, Theorem 3.5], it suffices to consider the following two cases: First, let us look at an element \(s=\iota ^W_X(x)\). Here we obtain \(s=\nu ^+_X(\iota ^D_X(x))\in {\text {rng}}(\nu ^+_X)\) by the diagram in Theorem 4.2. Secondly, consider \(s=\kappa ^W_X(\sigma )\). The induction hypothesis yields
Let us recall that \(\nu ^+_X\) is a quasi embedding but no embedding (unless \({\mathcal {T}}W(X)\) is linear). Hence the support condition from [14, Definition 2.1] does not apply. But since W is flat we get \(\sigma \in {\text {rng}}(W(\nu ^+_X))\) anyway. We also know that \(\nu _{\vartheta D(X)}\) is surjective, by the assumption that \(\nu \) is a linearization. Thus we may write
Due to the diagram in Theorem 4.2, we then obtain
as needed to complete the inductive proof. \(\square \)
In the following section we will construct sequences with gap condition via iterated Kruskal derivatives. The following result will ensure that all \({{\textsf{P}}}{{\textsf{O}}}\)-dilators in this construction are flat.
Proposition 4.9
We consider a normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilator W. If W is flat, then so is its Kruskal derivative \({\mathcal {T}}W\).
Proof
Given a quasi embedding \(f:X\rightarrow Y\), we need to prove the support condition
for arbitrary \(s\in {\mathcal {T}}W(Y)\). Similarly to the previous proof, this can be achieved by induction on h(s), where \(h:{\mathcal {T}}W(Y)\rightarrow \mathbb N\) with
is provided by [14, Theorem 3.5]. An element \(s=\iota ^W_Y(y)\) has support \(\{y\}\), by the proof of [14, Theorem 4.2]. Given that the premise of the support condition holds, we thus get \(y=f(x)\) for some \(x\in X\). The diagram in [14, Definition 4.1] yields
as required. It remains to consider an element \(s=\kappa ^W_Y(\sigma )\). Here we have
again by the proof of [14, Theorem 4.2]. Assuming the premise of the support condition for s, we can thus invoke the induction hypothesis to get
Using the assumption that W is flat, we obtain
Now the diagram in [14, Definition 4.1] yields
as needed for the inductive proof that \({\mathcal {T}}W\) is flat. \(\square \)
5 Application, part 2: linearizing the gap condition for sequences
As shown in Sect. 3, one can reconstruct certain collapsing functions by taking iterated Bachmann–Howard derivatives (of dilators on linear orders). In the present section we show that sequences with Friedman’s gap condition arise from a completely parallel construction in terms of Kruskal derivatives (of dilators on partial orders). This confirms that there is an extremely tight connection between collapsing functions and the gap condition. Also in this section, we give a second iterative construction that yields the same gap condition but different collapsing functions. This explains a phenomenon from [20], as discussed in the introduction of the present paper.
Definition 5.1
For each partial order X, let \(\textsf {S}(X)\) and \(S:\textsf {S}(X)\rightarrow \mathbb N\cup \{-1\}\) be generated by clauses (i) and (ii) from Definition 3.1 (with \(\textsf {S}\) at the place of \(\textsf {T}\), so that \(\textsf {S}(X)=\textsf {T}(X)\) when X is linear). Also, let \(k_i:\textsf {S}(X)\rightarrow \textsf {S}(X)\) for \(i\in {\mathbb {N}}\cup \{-1\}\) be given as in the cited definition. To define a binary relation \(\le _{\textsf {S}(X)}\) on \(\textsf {S}(X)\), we declare that \(s\le _{\textsf {S}(X)}t\) holds if, and only if, one of the following clauses is satisfied:
-
(i’)
We have \(s={\overline{x}}\) and \(t={\overline{y}}\) with \(x\le _X y\).
-
(ii’)
We have \(t=\vartheta _jt'\) with \(s\le _{\textsf {S}(X)}k_j(t')\) (where s can be of the form \({\overline{x}}\) or \(\vartheta _is'\)).
-
(iii’)
We have \(s=\vartheta _is'\) and \(t=\vartheta _it'\) (for the same i) with \(s'\le _{\textsf {S}(X)}t'\).
Furthermore, let \(\textsf {S}_n(X)\subseteq \textsf {S}(X)\) consist of the terms with indices \(i<n\) only, and put \(\textsf {S}^0_n(X)=\{s\in \textsf {S}_n(X)\,|\,S(s)\le 0\}\) (cf. Definition 3.4). We will always consider these subsets with (the restrictions of) the relation \(\le _{\textsf {S}(X)}\) (sometimes written as \(\le \)).
Let \(h:\textsf {S}(X)\rightarrow {\mathbb {N}}\) be given as in the paragraph after Definition 3.1. Once again we have \(h(k_i(s))\le h(s)\), so that \(s\le _{\textsf {S}(X)}t\) can be decided by recursion on \(h(s)+h(t)\). Let us begin with a preparatory result:
Lemma 5.2
If we have \(s\le _{\textsf {S}(X)}t\), then we get \(k_i(s)\le _{\textsf {S}(X)}k_i(t)\) for any \(i\in {\mathbb {N}}\).
Proof
We argue by induction on \(h(s)+h(t)\). First, assume that \(s\le \vartheta _jt'=t\) holds because of \(s\le k_j(t')\). We then get \(k_i(s)\le k_i(k_j(t'))\) by induction hypothesis. For \(j\le i\) we have \(k_i(k_j(t'))=k_j(t')\), so that we obtain \(k_i(s)\le k_j(t')\) and then
For \(j>i\) we get \(k_i(k_j(t'))=k_i(t')\) and thus \(k_i(s)\le k_i(t')=k_i(t)\). Secondly, assume that \(s=\vartheta _js'\le \vartheta _jt'=t\) holds because of \(s'\le t'\). For \(i<j\) we have \(k_i(s)=k_i(s')\) and \(k_i(t)=k_i(t')\), so that it suffices to invoke the induction hypothesis. For \(i\ge j\) we have \(k_i(s)=s\) and \(k_i(t)=t\), which means that the claim is trivial. \(\square \)
The following is known for \(X=1=\{0\}\) (see e. g. [20]), but the author has not found a reference for the (straightforward) generalization.
Lemma 5.3
The relation \(\le _{\textsf {S}(X)}\) on \(\textsf {S}(X)\) is a partial order.
Proof
Reflexivity is immediate by induction over terms. To establish antisymmetry one first shows that \(s\le t\) entails \(h(s)\le h(t)\), by induction over \(h(s)+h(t)\). The point is that \(t\le s\) becomes impossible if \(s\le t=\vartheta _jt'\) holds by clause (ii’) above, since we then have
Antisymmetry between s and t is now straightforward by induction on \(h(s)+h(t)\). To show that \(r\le s\) and \(s\le t\) imply \(r\le t\), one uses induction on \(h(r)+h(s)+h(t)\). In the most interesting case we have \(r\le s=\vartheta _is'\) because of \(r\le k_i(s')\), while \(s\le t=\vartheta _i t'\) is due to \(s'\le t'\). The previous lemma ensures \(k_i(s')\le k_i(t')\). Using the induction hypothesis, we get \(r\le k_i(t')\) and then \(r\le \vartheta _it'=t\). \(\square \)
For \(X=1=\{0\}\) we get \({\overline{0}}\le _{\textsf {S}(1)}s\) by a straightforward induction over \(s\in \textsf {S}(X)\). This means that our order \((\textsf {S}_n(1),\le _{\textsf {S}(1)})\) coincides with the order \((T_n,\trianglelefteq )\) defined in [20, Section 2.3.3]. According to [20, Lemma 10], we thus have the following (see the cited reference for a precise definition of the gap condition):
Corollary 5.4
If we identify \(\vartheta _{i_1}\ldots \vartheta _{i_n}0\in \textsf {S}_n(1)\) with the sequence \(\langle i_1,\dots ,i_n\rangle \), then \(\le _{\textsf {S}(1)}\) coincides with the strong gap embeddability relation due to H. Friedman.
Analogous to Sect. 3, we will show that \(\textsf {S}^0_{n+1}\) is the Kruskal derivative of \(\textsf {S}^0_n\). Let us first turn \(\textsf {S}_n\) and \(\textsf {S}^0_n\) into \({{\textsf{P}}}{{\textsf{O}}}\)-dilators.
Definition 5.5
For each quasi embedding \(f:X\rightarrow Y\) between partial orders, let \(\textsf {S}(f):\textsf {S}(X)\rightarrow \textsf {S}(Y)\) be defined by the clauses from Definition 3.8 (with \(\textsf {S}\) at the place of \(\textsf {T}\)). Let \(\underline{k}:\textsf {S}(X)\rightarrow X\) be given as in the paragraph before Proposition 3.7. For a partial order X, we now define \({\text {supp}}^\textsf {S}_X:\textsf {S}(X)\rightarrow [X]^{<\omega }\) by \({\text {supp}}^\textsf {S}_X(s)=\{\underline{k}(s)\}\). We will also write \({\text {supp}}^\textsf {S}_X\) for the restrictions of this function to \(\textsf {S}_n(X)\) and to \(\textsf {S}^0_n(X)\). Furthermore, we write \(\textsf {S}_n(f):\textsf {S}_n(X)\rightarrow \textsf {S}_n(Y)\) and \(\textsf {S}^0_n(f):\textsf {S}^0_n(X)\rightarrow \textsf {S}^0_n(Y)\) for the restrictions of \(\textsf {S}(f)\) with the indicated (co-)domains.
As expected, we have the following:
Proposition 5.6
Definition 5.5 extends \(\textsf {S}_n\) and \(\textsf {S}^0_n\) into normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilators.
Proof
Most verifications are completely parallel to the proof of Proposition 3.9, but two additional observations are needed: First, the map \(f\mapsto \textsf {S}(f)\) on morphisms preserves not only embeddings but also quasi embeddings, as required by clause (i) of [14, Definition 2.1]. Secondly, normality amounts to the implication
which holds by Lemma 5.2 (since we have \(\underline{k}(r)=x\) for \(k_{-1}(r)={\overline{x}}\)). \(\square \)
Let us now describe the extension into a Kruskal derivative:
Definition 5.7
For each number \(n\in {\mathbb {N}}\) and any partial order X, let
be given by the clauses from Definition 3.6. Now define functions
by setting \(\kappa ^n_X(s)=\vartheta _0\sigma ^n_X(s)\) and \(\iota ^n_X(x)={\overline{x}}\).
Arguing as in the proof of Proposition 3.7, one can show the following:
Proposition 5.8
The function \(\sigma ^n_X:\textsf {S}_n\circ \textsf {S}^0_{n+1}(X)\rightarrow \textsf {S}_{n+1}(X)\) is an order isomorphism, for each number \(n\in {\mathbb {N}}\) and any partial order X.
Proof
To show that \(\sigma ^n_X\) is surjective and order preserving, one argues as in the proof of Proposition 3.7. It remains to show that \(\sigma ^n_X\) reflects the order, i. e., that
holds for \(s,t\in \textsf {S}_n\circ \textsf {S}^0_{n+1}(X)\). We argue by induction on \(h(s)+h(t)\) and discuss the two most interesting cases: First consider terms of the form \(s={\overline{r}}\) and \(t=\vartheta _jt'\). In view of \(r\in \textsf {T}^0_{n+1}(X)\) we have \(r={\overline{x}}\) or \(\vartheta _0r'\), which means that
can only be due to \(\sigma ^n_X(s)\le k_{j+1}(\sigma ^n_X(t'))=\sigma ^n_X(k_j(t'))\), where the equality comes from the proof of Proposition 3.7. By induction hypothesis we get \(s\le k_j(t')\) and then \(s\le \vartheta _jt'=t\), as desired. Let us also consider \(s=\vartheta _is'\) and \(t={\overline{r}}\). For terms of these forms, the inequality \(s\le t\) is always false. To show that \(\sigma ^n_X(s)\le \sigma ^n_X(t)\) is false as well, we observe
where \(S(r)\le 0\) is due to \(r\in \textsf {T}^0_n(X)\). On the other hand, a straightforward induction on \(h(s_0)+h(t_0)\) shows that \(s_0\le t_0\) implies \(S(s_0)\le S(s_1)\). \(\square \)
In the following, \(\iota ^n\) and \(\kappa ^n\) denote the families of functions \(\iota ^n_X:X\rightarrow \textsf {S}^0_{n+1}(X)\) and \(\kappa ^n_X:\textsf {S}^0_n\circ \textsf {S}^0_{n+1}(X)\rightarrow \textsf {S}^0_{n+1}(X)\), respectively, indexed by the partial order X. We recall from [14, Section 4] that Kruskal derivatives are essentially unique. Hence the following means that the recursive construction from the introduction is uniquely realized by the normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilators \(\textsf {S}^0_n\) that we have defined in the present section.
Theorem 5.9
The Kruskal derivative of \(\textsf {S}^0_n\) is given by \((\textsf {S}^0_{n+1},\iota ^n,\kappa ^n)\).
Proof
Part (i) of [14, Definition 4.1] requires that \((\textsf {S}^0_{n+1}(X),\iota ^n_X,\kappa ^n_X)\) is an initial Kruskal fixed point of \(\textsf {S}^0_n\) over X, for each partial order X. The most interesting conditions from the definition of Kruskal fixed point (see [14, Definition 3.1]) demand
for \(x\in X\) and \(s,t\in \textsf {S}^0_n\circ \textsf {S}^0_{n+1}(X)\). In view of \(\kappa ^n_X(t)=\vartheta _0\sigma ^n_X(t)\), the left side of the first equivalence is indeed equivalent to
as in the proof of Proposition 3.7. Similarly, the left side of the second equivalence is equivalent to the disjunction of \(\sigma ^n_X(s)\le \sigma ^n_X(t)\) and \(\kappa ^n_X(s)\le \underline{k}(t)\). This is equivalent to the right side, as \(\sigma ^n_X\) is an order embedding. To show that our fixed point is initial we use the criterion from [14, Theorem 3.5], which demands that we have \(\textsf {S}^0_{n+1}(X)={\text {rng}}(\iota ^n_X)\cup {\text {rng}}(\kappa ^n_X)\) and \(h(\underline{k}(s))<h(\kappa ^n_X(s))\) for some \(h:\textsf {S}^0_{n+1}(X)\rightarrow {\mathbb {N}}\). These requirements can be verified as in the proof of Theorem 3.10. It remains to show that part (ii) of [14, Definition 4.1] is satisfied, i. e., that the functions \(\iota ^n_X\) and \(\kappa ^n_X\) are natural in X. This is readily reduced to the naturality of \(\sigma ^n_X\), which can be established by induction over terms, as in the proof of Theorem 3.10. \(\square \)
We can now use our general approach to re-derive two results that were previously shown by explicit computations. In view of Corollaries 3.5 and 5.4, we focus on the case of \(X=1\). The following is a special case of H. Friedman’s result on tree embeddings with the gap condition (see [11]). For the case of sequences, the result was analyzed by Schütte and Simpson [12] (see also [20, Section 2.2]).
Corollary 5.10
The order \(\textsf {S}^0_n(1)\) (sequences with gap condition, cf. Corollary 5.4) is a well partial order for each \(n\in {\mathbb {N}}\).
Proof
We argue by induction on n to show that \(X\mapsto \textsf {S}^0_n(X)\) preserves well partial orders. The base case is immediate in view of \(\textsf {S}^0_n(X)\cong X\). The induction step is covered by [14, Corollary 4.5], given that \(\textsf {S}^0_{n+1}\) is the Kruskal derivative of \(\textsf {S}^0_n\). \(\square \)
As in the previous section, a surjective quasi embedding \(f:X\rightarrow Y\) between a linear order X and a partial order Y is called a linearization. The following result was first established by a concrete verification in [20, Lemma 11], which provides additional information: it shows that one can take \(\nu ^n_1\) to be the identity on the underlying set \(\textsf {T}^0_n(1)=\textsf {S}^0_n(1)\). This information could also be tracked through our general constructions, but we will not do so: the forte of our approach is precisely that fewer concrete computations are necessary.
Corollary 5.11
For each \(n\in {\mathbb {N}}\) we have a linearization \(\nu ^n_1:\textsf {T}^0_n(1)\rightarrow \textsf {S}^0_n(1)\) of the partial order \(\textsf {S}^0_n(1)\) (sequences with gap condition) by the linear order \(\textsf {T}^0_n(1)\) (collapsing functions, cf. Sect. 3).
Proof
As preparation, we use induction on n to show that \(\textsf {S}^0_n\) is flat in the sense of Definition 4.7. The induction step is covered by Proposition 4.9. For the base case we recall \(\textsf {S}^0_0(Y)=\{{\overline{y}}\,|\,y\in Y\}\). Given \(f:X\rightarrow Y\) with
we write \(y=f(x)\) to get \(\overline{y}=\overline{f(x)}=\textsf {S}^0_0(f)({\overline{x}})\in {\text {rng}}(\textsf {S}^0_0(f))\). The point is that this works for any quasi embedding f, not just for embeddings. By recursion on n, we now construct linearizations \(\nu ^n:\textsf {T}^0_n\Rightarrow \textsf {S}^0_n\!\restriction \!{{\textsf{L}}}{{\textsf{O}}}\) in the sense of Definition 4.5. For \(n=0\) we can define \(\nu ^0_X\) as the identity map on \(\textsf {T}^0_0(X)=\{{\overline{x}}\,|\,x\in X\}=\textsf {S}^0_0(X)\). In the step we define \(\nu ^{n+1}\) as the quasi embedding \((\nu ^n)^+\) from Theorem 4.2. This is justified because \(\textsf {T}^0_{n+1}\) and \(\textsf {S}^0_{n+1}\) are the Bachmann–Howard and Kruskal derivative of \(\textsf {T}^0_n\) and \(\textsf {S}^0_n\), respectively, by Theorems 3.10 and 5.9. From Theorem 4.8 we learn that \(\nu ^{n+1}\) is a linearization, given that the same holds for \(\nu ^n\) and that \(\textsf {S}^0_n\) is flat. \(\square \)
The linearization of \(\textsf {S}^0_n(1)\) by \(\textsf {T}^0_n(1)\) does not realize the maximal order type, as shown in [20] (see also the introduction of the present paper). We will now present a different construction of \(\textsf {S}^0_n(1)\) in terms of iterated Kruskal fixed points. Interestingly, the parallel construction in terms of Bachmann–Howard fixed points yields the order \(OT_n[0]\) from [20, Section 5], which differs from \(\textsf {T}^0_n(1)\) and does realize the maximal order type of \(\textsf {S}^0_n(1)\). The idea is to consider the following transformations \(W_n\), which are readily shown to be normal \({{\textsf{P}}}{{\textsf{O}}}\)-dilators.
Definition 5.12
For each \(n\in {\mathbb {N}}\) and any partial order X we put
To define a partial order on \(W_n(X)\), we declare that 0 is incomparable to all other elements, and that we have
Given a quasi embedding \(f:X\rightarrow Y\), we define \(W_n(f):W_n(X)\rightarrow W_n(Y)\) by \(W_n(f)(0)=0\) and \(W_n(f)(s,x)=(s,f(x))\). Also, let \({\text {supp}}_X:W_n(X)\rightarrow [X]^{<\omega }\) be given by \({\text {supp}}_X(0)=\emptyset \) and \({\text {supp}}_X(s,x)=\{x\}\).
We will show that \(\textsf {S}^0_{n+1}(1)\) is the initial Kruskal fixed point of \(W_n\) over \(0=\emptyset \). This gives rise to a recursive construction, since \(W_n\) does only depend on \(\textsf {S}^0_n(1)\), and since initial objects are unique up to isomorphism.
Definition 5.13
To construct a function \(\pi _n:\textsf {S}_n(1)\times \textsf {S}^0_{n+1}(1)\rightarrow \textsf {S}_{n+1}(1)\), we define \(\pi _n(s,t)\) by recursion over the term s, setting
We then define \(\kappa _n:W_n(\textsf {S}^0_{n+1}(1))\rightarrow \textsf {S}^0_{n+1}(1)\) by \(\kappa _n(0)={\overline{0}}\) and \(\kappa _n(s,t)=\vartheta _0\pi _n(s,t)\). Let us also agree to write \(\iota _n:0\rightarrow \textsf {S}^0_{n+1}(1)\) for the empty function.
To see that the definition of \(\pi _n\) is justified, one should observe that we have
This also shows that \(s\in \textsf {S}^0_n(1)\) entails \(S(\pi _n(s,t))\le 1\), as needed to justify the definition of \(\kappa _n\). As promised, we have the following:
Theorem 5.14
The tuple \((\textsf {S}^0_{n+1}(1),\iota _n,\kappa _n)\) is the initial Kruskal fixed point of \(W_n\) over 0, for each number \(n\in {\mathbb {N}}\).
Proof
Let us abbreviate \(Z=\textsf {S}^0_{n+1}(1)\). To show that we have a Kruskal fixed point, we need to prove that the equivalence
is satisfied for all \(\sigma ,\tau \in W_n(Z)\) (cf. [14, Definition 3.1]). For \(\sigma =0\), both sides of the equivalence hold, since we have \({\overline{0}}\le _Z t\) for any \(t\in Z\) (see the paragraph before Corollary 5.4). For \(\sigma \ne 0\) and \(\tau =0\), both sides of the equivalence fail. Now consider \(\sigma =(s,t)\) and \(\tau =(s',t')\). Then our equivalence amounts to
Given that \(t'\in \textsf {S}^0_{n+1}(1)\) entails \(k_{i+1}(t')=t'\), an auxiliary induction over \(s'\) yields
For \(i=-1\) we get \(k_{-1}(s')={\overline{0}}\) and hence \(k_0(\pi _n(s',t'))=\pi _n({\overline{0}},t')=t'\). In view of Definition 5.1, this entails that the last equivalence reduces to
The latter can be shown by induction over \(h(s)+h(s')\), where we admit \(s,s'\) from the bigger set \(\textsf {S}_n(1)\supset \textsf {S}^0_n(1)\) to make the induction go through. For \(s={\overline{0}}=s'\), both sides of our equivalence amount to \(t\le _Z t'\). Now consider \(s={\overline{0}}\) and \(s'=\vartheta _jr'\). In view of \(S(\pi _n(s,t))=S(t)\le 0<j+1\) and \(\pi _n(s',t')=\vartheta _{j+1}\pi _n(r',t')\), the left side of the desired equivalence is equivalent to
Inductively, this is equivalent to the conjunction of \(s\le _{\textsf {S}(1)}k_j(r')\) and \(t\le _Z t'\). We can conclude since both \(s\le _{\textsf {S}(1)}s'\) and \(s\le _{\textsf {S}(1)}k_j(r')\) are automatic for \(s={\overline{0}}\). If we have \(s=\vartheta _ir\) and \(s'={\overline{0}}\), then both sides of the desired equivalence fail. To see this, note that we have
and \(S(s)=i>-1=S(s')\). At the same time, a straightforward induction shows that \(s_0\le _{\textsf {S}(1)}s_1\) entails \(S(s_0)\le S(s_1)\). Finally, consider \(s=\vartheta _ir\) and \(s'=\vartheta _jr'\). The left side of the desired equivalence can hold for two reasons: First, assume that we have \(\pi _n(s,t)\le _{\textsf {S}(1)}k_{j+1}(\pi _n(r',t'))\). As before, we get \(s\le _{\textsf {S}(1)}k_j(r')\) and \(t\le _Z t'\). The former entails \(s\le _{\textsf {S}(1)}s'\), as needed for the right side. Now assume that the left side holds because we have \(i=j\) and \(\pi _n(r,t)\le _{\textsf {S}(1)}\pi _n(r',t')\). Inductively we get \(r\le _{\textsf {S}(1)}r'\) and \(t\le _Z t'\), and the former entails \(s\le _{\textsf {S}(1)}s'\). By reading the given argument backwards, one obtains the implication from right to left. To show that our Kruskal fixed point is initial, we apply the criterion from [14, Theorem 3.5]. As preparation, one shows that any \(r\in \textsf {S}_{n+1}(1)\) lies in the range of \(\pi _n\), using induction over r. To conclude that \(\kappa _n\) is surjective, it suffices to observe that \(\vartheta _0r\in \textsf {S}^0_{n+1}(1)\) requires \(S(r)\le 1\), so that \(r=\pi _n(s,t)\) forces \(S(s)\le 0\) and hence
Finally, we need to verify that
holds for all \(\sigma \in W_n(Z)=W_n(\textsf {S}^0_{n+1}(1))\). For \(\sigma =0\) we have \({\text {supp}}_Z(\sigma )=\emptyset \), so that the condition is void. For \(\sigma =(s,t)\) we have \({\text {supp}}_Z(\sigma )=\{t\}\), which means that the claim amounts to \(h(t)<h(\kappa _n(s,t))\). This reduces to \(h(t)\le h(\pi _n(s,t))\), which is readily established by induction over s. \(\square \)
We have just seen a reconstruction of \(\textsf {S}^0_n(1)\) via iterated Kruskal fixed points. In the following, we show that the parallel construction for Bachmann–Howard fixed points yields the orders \(OT_n[0]\) from [20, Section 5]. Let us first recall the latter.
Definition 5.15
For each \(n\in {\mathbb {N}}\) we construct a set \(\textsf {OT}_n\) of terms. Simultaneously, each term \(s\in \textsf {OT}_n\) is associated with a number \(S(s)\in \{-1,\dots ,n-1\}\) and finite subsets \(K_i(s)\subseteq \textsf {OT}_n\) for \(i\ge -1\), according to the following clauses:
-
(i)
We have a term \({\overline{0}}\in \textsf {OT}_n\) with \(S({\overline{0}})=-1\) and \(K_i({\overline{0}})=\emptyset \).
-
(ii)
Given \(s,t\in \textsf {OT}_n\) and \(i<n\) with \(i\ge \max \{S(s)-1,S(t),0\}\) and \(K_i(s)=\emptyset \), we add a term \(\theta _ist\in \textsf {OT}_n\) with \(S(\theta _ist)=i\) and
$$\begin{aligned} K_j(\theta _ist)={\left\{ \begin{array}{ll} \{\theta _ist\} &{} \hbox { if}\ i\le j,\\ K_j(s)\cup K_j(t) &{} \text {otherwise}. \end{array}\right. } \end{aligned}$$
To define a binary relation \(<_{\textsf {OT}}\) on \(\textsf {OT}_n\), we declare that \(r<_{\textsf {OT}}r'\) holds if, and only if, one of the following clauses applies:
-
(i’)
We have \(r={\overline{0}}\) and \(r'\ne {\overline{0}}\).
-
(ii’)
We have \(r=\theta _ist\) and \(r'=\theta _js't'\) with \(i<j\).
-
(iii’)
We have \(r=\theta _ist\) and \(r'=\theta _is't'\), and one of the following holds:
-
We have \(s<_{\textsf {OT}}s'\) and \(t<_{\textsf {OT}}r'=\theta _is't'\).
-
We have \(s=s'\) and \(t<_{\textsf {OT}}t'\).
-
We have \(\theta _ist=r\le _{\textsf {OT}}t'\) (i. e. \(r<_{\textsf {OT}}t'\) or \(r=t'\) as terms).
-
Finally, we set \(\textsf {OT}^0_n=\{s\in \textsf {OT}_n\,|\,S(s)\le 0\}\). We will also write \(<_{\textsf {OT}}\) for the restriction of the given relation to this set.
The reader may have noticed that our definition of \(<_{\textsf {OT}}\) looks somewhat different from the one in [20, Definition 37]. This has the following context: First, the cited reference also defines \(<_{\textsf {OT}}\) on a larger set that contains terms \(\theta _ist\) with \(K_i(s)\ne \emptyset \). This leads to additional conditions that are void in our case. Secondly, we have declared that \(\theta _ist\le _{\textsf {OT}}t'\) entails \(\theta _ist<_{\textsf {OT}}\theta _is't'\). In [20], this implication has \(s'<_{\textsf {OT}}s\) as an additional assumption. At the same time, [20, Lemma 23] shows that \(t'<\theta _is't'\) does always hold. As it is transitive, the order from [20] will thus satisfy our stronger implication, so that the two definitions coincide. On a different note, [20, Definition 40] declares that we have
It is easy to see that this yields \(OT_n[0]=\{{\overline{0}}\}\), which contradicts [20, Corollary 6]. Presumably, this is a typo that should be corrected into
Strictly speaking, this is only explained when we have \(n>1\), so that \(\theta _1{\overline{0}}{\overline{0}}\) is available. For the corrected definition one can show \(OT_n[0]=\textsf {OT}^0_n\) by a straightforward induction over terms. The following was left implicit in [20]:
Lemma 5.16
The relation \(<_{\textsf {OT}}\) is a linear order on \(\textsf {OT}_n\), for each \(n\in {\mathbb {N}}\).
Proof
Define \(h:\textsf {OT}_n\rightarrow {\mathbb {N}}\) recursively by \(h({\overline{0}})=0\) and \(h(\theta _ist)=h(s)+h(t)+1\). A straightforward induction over \(h(r)+h(s)+h(t)\) shows that the conjunction of \(r<_{\textsf {OT}}s\) and \(s<_{\textsf {OT}}t\) implies \(r<_{\textsf {OT}}t\). We can now establish \(r\not <_{\textsf {OT}}r\) by induction over h(r). This is readily reduced to \(r=\theta _ist\not \le _{\textsf {OT}}t\). In view of \(\theta _ist\in \textsf {OT}_n\) we must have \(S(t)\le i\), which leaves a term of the form \(t=\theta _is't'\) as the only interesting case (with the same i as in \(r=\theta _ist\)). We trivially have \(\theta _is't'\le _{\textsf {OT}}t\), which provides the inequality \(t=\theta _is't'<_{\textsf {OT}}\theta _ist=r\). Now if \(r\le _{\textsf {OT}}t\) was true, then transitivity would yield \(t<_{\textsf {OT}}t\), which contradicts the induction hypothesis. Finally, trichotomy between s and t follows by a straightforward induction over \(h(s)+h(t)\). \(\square \)
Parallel to the above, our aim is to show that \(\textsf {OT}^0_{n+1}\) is the initial Bachmann–Howard fixed point of the following \({{\textsf{L}}}{{\textsf{O}}}\)-dilators \(D_n\) over the empty order 0.
Definition 5.17
For each \(n\in {\mathbb {N}}\) and any linear order X we put
To define a linear order on \(D_n(X)\), we declare that 0 is the smallest element, and that we have
For any embedding \(f:X\rightarrow Y\), we define a function \(D_n(f):D_n(X)\rightarrow D_n(Y)\) by \(D_n(f)(0)=0\) and \(D_n(f)(s,x)=(s,f(x))\). Also, let \({\text {supp}}_X:D_n(X)\rightarrow [X]^{<\omega }\) be given by \({\text {supp}}_X(0)=\emptyset \) and \({\text {supp}}_X(s,x)=\{x\}\).
Let us construct the functions that Definition 2.5 requires:
Definition 5.18
Let the map \(\textsf {OT}_n\ni s\mapsto s^+\in \textsf {OT}_{n+1}\) be given by the recursive clauses \({\overline{0}}^+={\overline{0}}\) and \((\theta _ist)^+=\theta _{i+1}s^+t^+\). Now define \(\vartheta _n:D_n(\textsf {OT}^0_{n+1})\rightarrow \textsf {OT}^0_{n+1}\) by
Let us also agree to write \(\iota _n:0\rightarrow \textsf {OT}^0_{n+1}\) for the empty function.
To justify the definition of \(s^+\in \textsf {OT}_{n+1}\), one should simultaneously check
In particular we get \(K_0(s^+)=\emptyset \), as an easy induction over s yields \(K_{-1}(s)=\emptyset \). For \(s\in \textsf {OT}^0_n\) we also obtain \(S(s^+)\le 1\), so that we indeed have \(\vartheta _n(s,t)=\theta _0s^+t\in \textsf {OT}^0_{n+1}\) for \((s,t)\in D_n(\textsf {OT}^0_{n+1})\). We can now establish the promised result:
Theorem 5.19
The tuple \((\textsf {OT}^0_{n+1},\iota _n,\vartheta _n)\) is an initial Bachmann–Howard fixed point of \(D_n\) over 0, for each number \(n\in {\mathbb {N}}\).
Proof
As preparation one checks that \(s<_{\textsf {OT}}t\) implies \(s^+<_{\textsf {OT}}t^+\), by a straightforward induction over \(h(s)+h(t)\) (cf. [20, Lemma 24]). Abbreviating \(Z=\textsf {OT}^0_{n+1}\), we now verify the two conditions from clause (iii) of Definition 2.5. First, we need to show that \(z\in {\text {supp}}_Z(\sigma )\) implies \(z<_Z\vartheta _n(\sigma )\), for any \(\sigma \in D_n(Z)\). In the case of \(\sigma =0\) we have \({\text {supp}}_Z(\sigma )=\emptyset \), which means that the condition is void. For \(\sigma =(s,t)\) we have \({\text {supp}}_Z(s,t)=\{t\}\), so that the claim amounts to
In the proof of Lemma 5.16 we have shown \(\theta _0s^+t\not \le _{\textsf {OT}}t\), which suffices due to trichotomy (in view of \(S(t)\le 0\) it is easy to give a direct argument as well). The second condition from clause (iii) of Definition 2.5 does essentially amount to
Assuming that the left side holds, we have \(s_0^+=s_1^+\) and \(t_0<_{\textsf {OT}}t_1\), or \(s_0^+<_{\textsf {OT}}s_1^+\) and \(t_0<_Z\theta _0s_1^+t_1\), using the fact that we have shown as preparation. In either case, the right side follows by clause (iii’) of Definition 5.15. To show that our fixed point is initial, we use the criterion from Theorem 2.9. Let us first observe
for \(h:\textsf {OT}^0_{n+1}\rightarrow {\mathbb {N}}\) as in the proof of Lemma 5.16. It remains to show that the function \(\vartheta _n:D_n(\textsf {OT}^0_{n+1})\rightarrow \textsf {OT}^0_{n+1}\) is surjective. An easy induction shows that any element \(s\in \textsf {OT}_{n+1}\) with \(K_0(s)=\emptyset \) can be written as \(s=s_0^+\) for some \(s_0\in \textsf {OT}_n\). For \(S(s)\le 1\) we get \(s_0\in \textsf {OT}^0_n\), and it is straightforward to conclude. \(\square \)
Finally, we use our general approach to re-derive two known results. The following was first shown as a consequence of [20, Lemma 25].
Corollary 5.20
For each \(n\in {\mathbb {N}}\) we have a linearization \(f_n:\textsf {OT}^0_n\rightarrow \textsf {S}^0_n(1)\) of the partial order \(\textsf {S}^0_n(1)\) (sequences with gap condition) by the linear order \(\textsf {OT}^0_n\) (binary collapsing functions, cf. [20, Section 5]).
Proof
We construct \(f_n\) by recursion over \(n\in {\mathbb {N}}\). In the base case, let \(f_0\) be the identity on \(\textsf {OT}^0_0=\{\overline{0}\}=\textsf {S}^0_0(1)\). Given \(f_n\), we get a linearization \(\nu :D_n\Rightarrow W_n\) by setting \(\nu _X(0)=0\) and \(\nu _X(s,x)=(f_n(s),x)\). It is easy to see that \(W_n\) is flat (cf. Definition 4.7). Theorems 4.2 and 4.8 yield a linearization \(\nu ^+:\vartheta D_n\Rightarrow {\mathcal {T}}W_n\). From Theorems 5.14 and 5.19 we know that \({\mathcal {T}}W_n(0)\) and \(\vartheta D_n(0)\) coincide with \(\textsf {S}^0_{n+1}(1)\) and \(\textsf {OT}^0_{n+1}\), respectively (up to isomorphism). Hence setting
completes the recursive construction. \(\square \)
The following result was first shown in [20, Corollaries 6 and 7]. The proof in the cited paper goes via an addition-free variant of the Veblen functions. In the author’s opinion, our general approach leads to a more transparent argument:
Corollary 5.21
For each \(n\ge 1\), the linear order \(\textsf {OT}^0_n\) has order type \(\omega _{2n-1}\), which means that it realizes the maximal order type of the partial order \(\textsf {S}^0_n(1)\).
Proof
Recall that we have \(\omega ^\alpha _0=\alpha \) and \(\omega ^\alpha _{n+1}=\omega ^{\omega ^\alpha _n}\). We will show
by induction over \(n\in {\mathbb {N}}\). This entails the first claim of the corollary, as \(n\ge 1\) yields
In the base case of our induction, it suffices to recall \(\textsf {OT}^0_0=\{{\overline{0}}\}\) and \(\omega ^0_0=0\). The induction step relies on [24, Theorem 2.2]. To state the latter, consider an arbitrary ordinal \(\alpha \). Analogous to Definition 5.17, we get an \({{\textsf{L}}}{{\textsf{O}}}\)-dilator \(D^\alpha \) with
According to the cited theorem, we have \(\vartheta D^\alpha (0)\cong \omega _2^\alpha \). From Theorem 5.19 we know \(\textsf {OT}^0_{n+1}\cong \vartheta D_n(0)\) with \(D_n(X)=1+\textsf {OT}^0_n\times X\). Now the induction hypothesis provides a natural isomorphism \(D_n\cong D^\alpha \) for \(\alpha =\omega ^0_{2n}\). In view of Lemma 2.14 (and the uniqueness of initial fixed points), we obtain
as needed to complete the induction step. Finally, let us give references for the fact that \(\textsf {S}^0_n(1)\) has maximal order type \(\omega _{2n-1}\), for \(n\ge 1\). In the paragraph after Lemma 5.3 we have observed that our order \(\textsf {S}^0_n(1)\) coincides with the order \((T_n[0],\trianglelefteq )\) from [20, Section 2.2.3]. The cited reference shows that this order is isomorphic to a certain collection \(\overline{{\mathbb {S}}}_n[0]\) of sequences with the strong gap condition. According to [20, Lemma 3 and Corollary 2] (based on work by Schütte and Simpson [12]), that collection has maximal order type \(\omega _{2n-1}\), for \(n\ge 1\). \(\square \)
References
Higman, G.: Ordering by divisibility in abstract algebras. Proc. Lond. Math. Soc. 3(2), 326–336 (1952)
Kruskal, J.: Well-quasi-ordering, the tree theorem, and Vazsonyi’s conjecture. Trans. Am. Math. Soc. 95(2), 210–225 (1960)
Nash-Williams, C.S.J.A.: On well-quasi-ordering finite trees. Proc. Camb. Philos. Soc. 59, 833–835 (1963)
Freund, A., Rathjen, M., Weiermann, A.: Minimal bad sequences are necessary for a uniform Kruskal theorem. Adv. Math. 400, article no. 108265, 44 pages (2022)
Girard, J.-Y.: \({\Pi ^1_2}\)-logic, part 1: dilators. Ann. Pure Appl. Logic 21, 75–219 (1981)
Simpson, S.G.: Subsystems of second order arithmetic. In: Perspectives in Logic. Cambridge University Press (2009)
Marcone, A.: On the logical strength of Nash–Williams’ theorem on transfinite sequences. In: Hodges, W., Hyland, M., Steinhorn, C., Truss, J. (eds.) Logic: From Foundations to Applications (Oxford). Oxford University Press, pp. 327–351 (1996)
Hasegawa, R.: Well-ordering of algebras and Kruskal’s theorem. In: Jones, N.D., Hagiya, M., Sato, M. (eds.) Logic, Language and Computation, Lecture Notes in Computer Science, vol. 792 (1994)
Hasegawa, R.: An analysis of divisibility orderings and recursive path orderings. In: Shyamasundar, R.K., Ueda, K. (eds.) Advances in Computing Science—ASIAN’97, Lecture Notes in Computer Science, vol. 1345 (1997)
Weiermann, A.: A computation of the maximal order type of the term ordering on finite multisets. In: Ambos-Spies, K., Löwe, B., Merkle, W. (eds.) Mathematical Theory and Computational Practice. CiE 2009, Lecture Notes in Computer Science, vol. 5635 (2009)
Simpson, S.G.: Nonprovability of certain combinatorial properties of finite trees. In: Harrington, L.A., Morley, M.D., Sčědrov, A., Simpson, S.G. (eds.) Harvey Friedman’s Research on the Foundations of Mathematics, Studies in Logic and the Foundations of Mathematics, vol. 117, pp. 87–117. North-Holland (1985)
Schütte, K., Simpson, S.G.: Ein in der reinen Zahlentheorie unbeweisbarer Satz über endliche Folgen von natürlichen Zahlen. Archiv für Mathematische Logik und Grundlagenforschung 25, 75–89 (1985)
van der Meeren, J.: Connecting the two worlds: well-partial-orders and ordinal notation systems, PhD thesis, Ghent University (2015)
Freund, A.: From Kruskal’s theorem to Friedman’s gap condition. Math. Struct. Comput. Sci. 8(30), 952–975 (2020)
Rathjen, M., Weiermann, A.: Proof-theoretic investigations on Kruskal’s theorem. Ann. Pure Appl. Logic 60, 49–88 (1993)
Freund, A.: Type-Two Well-Ordering Principles, Admissible Sets, and \({\Pi }^1_1\)-Comprehension, PhD thesis, University of Leeds. http://etheses.whiterose.ac.uk/20929/ (2018)
Freund, A.: \({\Pi }^1_1\)-comprehension as a well-ordering principle. Adv. Math. 355, article no. 106767, 65 pages (2019)
Freund, A.: A categorical construction of Bachmann–Howard fixed points. Bull. Lond. Math. Soc. 51(5), 801–814 (2019)
Freund, A.: Computable aspects of the Bachmann–Howard principle. J. Math. Logic 20(2), article no. 2050006, 26 pages (2020)
van der Meeren, J., Rathjen, M., Weiermann, A.: Ordinal notation systems corresponding to Friedman’s linearized well-partial-orders with gap-condition. Arch. Math. Logic 56, 607–638 (2017)
Weiermann, A., Wilken, G.: Ordinal arithmetic with simultaneously defined theta-functions. Math. Logic Q. 57(2), 116–132 (2011)
van der Meeren, J., Rathjen, M., Weiermann, A.: Well-partial-orderings and the big Veblen number. Arch. Math. Logic 54(1–2), 193–230 (2015)
van der Meeren, J., Rathjen, M., Weiermann, A.: An order-theoretic characterization of the Howard–Bachmann–hierarchy. Arch. Math. Logic 56(1–2), 79–118 (2017)
Freund, A.: Predicative collapsing principles. J. Symb. Logic 85(1), 511–530 (2020)
de Jongh, D., Parikh, R.: Well-partial orderings and hierarchies. Indagationes Mathematicae 80(3), 195–207 (1977)
Aschenbrenner, M., Pong, W.Y.: Orderings of monomial ideals. Fundamenta Mathematicae 181, 27–74 (2004)
Knight, J.F.: Lange, K.: Lengths of developments in \(K((G))\). Selecta Mathematica 25, article no. 14, 36 pages (2019)
Funding
Open Access funding enabled and organized by Projekt DEAL. The work of Anton Freund has been funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - Project number 460597863.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Freund, A. Bachmann–Howard derivatives. Arch. Math. Logic 62, 581–618 (2023). https://doi.org/10.1007/s00153-022-00851-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00153-022-00851-5
Keywords
- Ordinal collapsing functions
- Friedman’s gap condition
- Bachmann–Howard ordinal
- Dilators
- Well partial orders