
Abstract
We study the integration problem on Hilbert spaces of (multivariate) periodic functions.The standard technique to prove lower bounds for the error of quadrature rules uses bump functions and the pigeon hole principle. Recently, several new lower bounds have been obtained using a different technique which exploits the Hilbert space structure and a variant of the Schur product theorem. The purpose of this paper is to (a) survey the new proof technique, (b) show that it is indeed superior to the bump-function technique, and (c) sharpen and extend the results from the previous papers.
Similar content being viewed by others
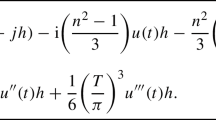

Avoid common mistakes on your manuscript.
1 Introduction
1.1 Overview
We study the integration problem on reproducing kernel Hilbert spaces of multivariate periodic functions. That is, we consider Hilbert spaces H of complex-valued and continuous functions on \([0,1]^d\) which admit a complete orthogonal system of trigonometric monomials. This scale of functions contains the classical Sobolev Hilbert spaces of isotropic, mixed or anisotropic smoothness (see, e.g., [7, 32]) as well as the weighted Korobov spaces which are common in tractability studies (see, e.g., [8] and the references therein).
We are interested in the error \(e_n(H)\), which is the smallest possible difference (in the operator norm) between the integration functional and a quadrature rule using up to n function values. This corresponds to the worst case setting of information-based complexity, see, e.g., [29, 30, 34]. It is standard to prove lower bounds for \(e_n(H)\) using the bump-function technique: If we construct 2n bump functions in H with disjoint support, then n of the supports do not contain a quadrature point and therefore, for the fooling function given by the sum of the corresponding bumps divided by its norm, the quadrature rule outputs zero and the error of the quadrature rule is bounded below by the integral of the fooling function. This simple technique goes back at least to [2] and leads to optimal lower bounds for many classical spaces from the above family. Interestingly, however, it is not sufficient to prove optimal lower bounds in the extreme cases when the functions in the Hilbert space are either very smooth (analytic) or barely continuous. In these cases, optimal lower bounds were recently obtained using a different technique which exploits the Hilbert space structure and a variant of the Schur product theorem, see [12, 13, 38]. In this paper, we want to (a) survey the new proof technique, (b) show that it is indeed superior to the bump-function technique, and (c) sharpen and extend the results from the previous papers. The structure of this paper is as follows:
-
The precise setting is introduced in Sect. 1.2. An overview of results is given in Sect. 1.3.
-
In Sect. 2, we first show that the bump function technique fails in certain ranges of smoothness. We then describe the new technique, which we will refer to as the Schur technique. We do this for a more general family of reproducing kernel Hilbert spaces than the above, see Theorem 2.
-
In Sect. 3, we present some general lower bounds on the error \(e_n(H)\) for the spaces of periodic functions. As a corollary, we also obtain a new result on the largest possible gap between the error of sampling algorithms and general algorithms for \(L_2\)-approximation on reproducing kernel Hilbert spaces with finite trace, see Sect. 3.3. We improve a lower bound from [13], further narrowing the gap to the best known upper bounds from [5, 19, 25].
-
In Sect. 4, we derive new lower bounds for function spaces which combine the fractional isotropic smoothness \(s=d/2\) with an additional logarithmic term. Since this ensures that function values are well-defined and that the functions in the space are continuous, while isotropic smoothness \(s=d/2\) without any logarithmic perturbation is not enough, we refer to this setting as spaces of small smoothness. We consider also function spaces of mixed smoothness, where the borderline is given by \(s=1/2\) independently on the dimension d. Spaces combining fractional and logarithmic smoothness have been studied, e.g., in [6, 11, 17, 24].
-
In Sect. 5, we obtain lower bounds for the case of large smoothness, namely, for analytic periodic functions. We present a result on the curse of dimensionality, which is in sharp contrast to a recent result from [10], and an asymptotic lower bound that complements recent error bounds for classes of analytic functions on \(\mathbb {R}^d\) from [16, 23].
1.2 Preliminaries
Let H be a reproducing kernel Hilbert space (RKHS) on a non-empty set D. That is, H shall be a Hilbert space of functions \(f:D\rightarrow \mathbb {C}\) such that point evaluation
is continuous for each \(x\in D\). This means that for every \(x\in D\), there is a function \(K(x,\cdot )\in H\) such that \(\delta _x = \langle \cdot , K(x,\cdot ) \rangle _H\). The function
is called the reproducing kernel of H. We refer to [1] and [4] for basics on RKHSs. We are interested in the computation of a continuous functional on H, that is, an operator of the form
with some \(h\in H\). The main interest lies within integration functionals of the form
with a probability measure \(\mu \) on D. Clearly, if the functional \(\textrm{INT}_\mu \) is continuous, then it can be written in the form (1). In this case, the corresponding representer h satisfies
We want to compute \(S_h(f)\) using a quadrature rule
with nodes \(x_k\in D\) and weights \(a_k \in \mathbb {C}\). The worst-case error of the quadrature rule is defined by
We are interested in the error of the best possible quadrature rule, which we denote by
In this paper, we will mainly consider Hilbert spaces of multivariate periodic functions, defined as follows. Here, \(e_k = \exp (2\pi i \langle k, \cdot \rangle )\) denotes the trigonometric monomial with frequency \(k\in \mathbb {Z}^d\). The Fourier coefficients of an integrable function \(f:[0,1]^d \rightarrow \mathbb {C}\) are defined by
Definition 1
Let \(\lambda \in \ell _1(\mathbb {Z}^d)\) be a non-negative sequence. Then \(H_\lambda \) denotes the set of all continuous functions \(f\in C([0,1]^d)\) with \(\hat{f}(k)=0\) for all \(k\in \mathbb {Z}^d\) with \(\lambda _k=0\) and
The condition (3) implies that the Fourier series of \(f\in H_\lambda \) converges point-wise (and even uniformly) for all \(x\in \mathbb {R}^d\),
and that f is continuous as a 1-periodic function on \(\mathbb {R}^d\). Moreover,
and thus, the space \(H_\lambda \) is a reproducing kernel Hilbert space. The trigonometric monomials \((e_k)_{k\in \mathbb {Z}^d}\) are a complete orthogonal system in \(H_\lambda \) and the reproducing kernel of \(H_\lambda \) is given by
We note that the space \(H_\lambda \) can be defined analogously for bounded sequences \(\lambda \not \in \ell _1(\mathbb {Z}^d)\) as the space of all \(f\in L_2([0,1]^d)\) satisfying (3). In this case, however, function evaluation is not well defined and \(H_\lambda \) it is not a reproducing kernel Hilbert space. The most common choices (see, e.g., [32] or [22]) of the sequence \(\lambda \) include
-
1.
\(\lambda _k = (1+|k|^{2})^{-s}\) for \(s\ge 0\) and \(k\in \mathbb {Z}^d\). In that case, \(H_\lambda \) is the Sobolev space of periodic functions with isotropic smoothness. If s is a positive integer, then an equivalent norm on \(H_\lambda \) is given by
$$\begin{aligned} \Vert f\Vert ^2_{H_{\lambda }}\,\asymp \, \sum _{\Vert \alpha \Vert _1\le s}\Vert D^{\alpha }f\Vert _2^2. \end{aligned}$$ -
2.
\(\lambda _k = \prod _{j=1}^d (1 + |k_j|^{2})^{-s}\) for \(k\in \mathbb {Z}^d\) and \(s>0\). In this way, we obtain the spaces of periodic functions with dominating mixed smoothness. If \(s\in \mathbb {N}\) is a positive integer, then also these spaces allow for an equivalent norm given in terms of derivatives, namely
$$\begin{aligned} \Vert f\Vert ^2_{H_{\lambda }} \,\asymp \, \sum _{\Vert \alpha \Vert _\infty \le s}\Vert D^{\alpha }f\Vert _2^2. \end{aligned}$$
On the space \(H_\lambda \), we consider the integration problem with respect to the Lebesgue measure \(\lambda ^d\) on \([0,1]^d\), that is, we take \(\mu = \lambda ^d\). In this case, the representer of the functional \(\textrm{INT}_\mu \) is given by the constant function \(h \equiv \lambda _0\). For this standard integration problem on the unit cube, we leave out the \(S_h\) in the notation of the error, writing \(e_n(H_\lambda )\) instead of \(e_n(H_\lambda ,S_h)\), \(e(Q_n,H)\) instead of \(e(Q_n,H,S_h)\) and we simply write \(\textrm{INT}\) instead of \(\textrm{INT}_\mu \). The initial error in this case is given by
In analogy to the numbers \(e_n(H_\lambda )\), we also define the sampling numbers
and the approximation numbers
which reflect the error of the best possible (linear) algorithm for \(L_2\)-approximation using at most n function values or n arbitrary linear measurements, respectively.
Further notation For sequences \((a_n)\) and \((b_n)\), we write \(a_n \lesssim b_n\) if there is a constant \(c>0\) such that \(a_n \le c\, b_n\) for all but finitely many n. We write \(a_n \gtrsim b_n\) if \(b_n \lesssim a_n\) and \(a_n \asymp b_n\) if both relations are satisfied. If H is a Hilbert space, \(H'\) denotes the space of all continuous linear functionals on H.
1.3 Results
As mentioned earlier, the main purpose of the paper is to survey a new proof technique for lower bounds on the error \(e_n(H_\lambda )\). Here, we gather some of the new results obtained in this paper using the new technique.
The first category of results concerns the asymptotic behavior of the errors \(e_n(H_\lambda )\) and \(g_n(H_\lambda )\) in the case of small smoothness, i.e., in the case that \(\lambda \) decays barely fast enough to ensure that \(H_\lambda \) is a reproducing kernel Hilbert space. For function spaces \(H_\lambda \) with fractional isotropic smoothness d/2 and logarithmic smoothness \(\beta >1/2\), i.e., if \(\lambda \) is given by (19), we obtain
see Corollary 4. Of special interest is the logarithmic gap between the sampling and the approximation numbers, which has been shown in [13] for the univariate case, and is now extended to the multivariate case. The lower bound on the integration error follows from a result for more general sequences \(\lambda \), see Theorem 4, and cannot be proven by the standard technique of bump functions, see Sect. 2.1. We also prove the same relation (5) for the (multivariate) spaces of fractional mixed smoothness 1/2 and logarithmic smoothness \(\beta >1/2\), where \(\lambda \) is given by (22), see Sect. 4.2.
Second, we obtain new results on the numbers \(e_n^*(\sigma )\) and \(g_n^*(\sigma )\), which reflect the worst possible behavior of the nth minimal integration error and sampling number, respectively, on reproducing kernel Hilbert spaces for any given sequence \((\sigma _n)_{n\in \mathbb {N}}\) of singular values, see Sect. 3.3 for a precise definition. We obtain that, up to universal constants, both these numbers are equivalent to
see Corollary 3. The new thing here is again the lower bound, the upper bound is known from [5].
Thirdly, we also derive a result on the curse of dimensionality. We obtain that the curse is present for numerical integration and \(L_2\)-approximation on classes of the form
for any weight function \(g:\mathbb {N}_0 \rightarrow (0,\infty )\) and \(p=2\), see Theorem 7. This is in sharp contrast to recent tractability results for analogous classes with \(p=1\), see [10] for numerical integration and [18] for \(L_2\) approximation.
2 Proof Techniques for Lower Bounds
In this section, we discuss techniques to prove lower bounds for the integration error \(e_n(H_\lambda )\). We show the limits of the bump-function technique, which is probably the most common technique, and describe a new method used in this paper. We note that there are other proof techniques which we do not discuss here like the technique of decomposable kernels from [28] and a method from [31]. We only compare our new approach with the most standard technique.
2.1 Limits of the Bump-Function Technique
The most well-known technique to prove lower bounds for the integration problem is the use of bump functions. It is based on the observation (cf. [29, Chapter 4]) that a lower bound for \(e(Q_n,H)\) for a fixed quadrature rule \(Q_n\) with nodes \(x_1,\hdots ,x_n\) is equivalent to the construction of a function f, which vanishes at the sampling points, i.e., with \(f(x_1)=\hdots =f(x_n)=0\), and which has simultaneously large integral \(\textrm{INT}(f)\) and small norm \(\Vert f\Vert _H.\) This leads to \(Q_n(f)=0\) and the lower bound
A function like this is called a fooling function. One way how to construct such a fooling function to a given \(Q_n\) is to start with a bump function, i.e., with a smooth periodic function \(\varphi \in C([0,1])\) with \(\mathrm{supp\,}\varphi \subset [0,1/(2n)]\) and consider its translates \(\varphi (x-j/(2n))\) for \(j=0,\dots ,2n-1\) (and similarly for the multivariate case). By the pigeonhole principle, there are at least n of these dilates, which vanish at all the sampling points \(x_1,\dots ,x_n\). Adding them, we then obtain the fooling function f.
The use of this (rather intuitive) technique can be traced back at least to [2]. It is probably the most widely used method to prove lower bounds for numerical integration and other approximation problems, where one is limited to the use of function values, cf. [26, 27, 34]. The main reason for its wide use is surely that it often leads to optimal results. Note however that for example in [37] it was necessary to combine the bump-function technique with the Khintchine inequality to obtain optimal lower bounds in certain limiting cases.
The aim of this section is to show that the technique of bump functions can only provide sub-optimal results for the integration problem on \(H_\lambda \) in the cases that
-
The sequence \(\lambda \) decays very slowly. This means that \(H_\lambda \) contains functions with low smoothness, which are just about continuous.
-
The sequence \(\lambda \) decays very fast. This means that the functions in \(H_\lambda \) are very smooth or even analytic.
In the second case, it is rather obvious that the bump function technique does not work. If \(\lambda \) decays fast enough (for example if \(|\lambda _k|\le c_1\exp (-c_2 |k|)\) for some \(c_1,c_2>0\) and all \(k\in \mathbb {Z}\), c.f. [3, §25]), all functions in \(H_\lambda \) are analytic and since there is no analytic function with compact support (except the zero function), any fooling function obtained by the bump-function technique will not be contained in the space \(H_\lambda \).
We now show the sub-optimality of the bump-function technique in the case of small smoothness. To ease the presentation, we consider only the case \(d=1\), but we note that similar results can be obtained in the multivariate case. We consider sequences of the form
which are just about summable. It was shown in [13, Theorem 4] and it also follows from Corollary 4 below that
This lower bound is sharp, see [13, Proposition 1] and [5]. Here, we are going to prove the following.
Theorem 1
Let \(\lambda \in \ell _1(\mathbb {Z})\) be given by (6). There exists an absolute constant \(C>0\) such that for every even \(n\ge 2\) and every \(\varphi \in C([0,1])\) with \(\textrm{supp}\,\varphi \subset [0,1/(2n)]\) there exists \(\{z_1,\dots ,z_n\}\subset \{j/(2n):j=0,\dots ,2n-1\}\) such that the function
satisfies
Theorem 1 shows that no matter how we choose the bump function \(\varphi \in C([0,1])\) with support in [0, 1/(2n)], it is possible to choose the set of sampling points \(X=\{x_1,\dots ,x_n\}\subset [0,1]\) in such a way that leaving from the sum
the terms which do not vanish on X does not provide a fooling function sufficient to show (7). In other words, the classical bump function technique cannot yield the sharp lower bound on \(e_n(H_\lambda )\) in (5).
Before we come to the proof of Theorem 1, we need a characterization of the norm of f in the space \(H_\lambda \) in terms of first order differences, which are defined for every \(0<h<1\) simply by
Here, we interpret f as a periodic function defined on all \(\mathbb {R}\), which makes \(\Delta _h f(x)\) indeed well-defined for all \(x\in [0,1]\). Furthermore, \(\Vert \Delta _hf\Vert _2\) denotes the norm of \(x\mapsto \Delta _hf(x)\) in \(L_2([0,1])\). The following proposition is in principle a special case of [6, Theorem 10.9], where a characterization by first and higher order differences is given for Besov spaces of generalized smoothness on \(\mathbb {R}^d\). We provide a short and direct proof for reader’s convenience.
Proposition 1
Let \(\lambda \in \ell _1(\mathbb {Z})\) be given by (6). Then \(f\in C([0,1])\) belongs to \(H_\lambda \) if, and only if,
is finite. Furthermore, \(\Vert f\Vert _{H_\lambda }^2\) is equivalent to (10) with the constants independent of \(f\in C([0,1])\).
Proof
Let \(f\in C([0,1])\). Then
for all \(k\in \mathbb {Z}\) and, by orthonormality of \((e_k)_{k\in \mathbb {Z}}\) in \(L_2([0,1])\),
To simplify the notation, we denote
and obtain
For \(j\in \mathbb {Z}\) we put
and we will show that \(\gamma _j \asymp 1/\lambda _j\) for all \(j\in \mathbb {Z}\) with universal constants of equivalence which do not depend on j. In view of (3), this will finish the proof.
The estimate of \(\gamma _j\) for \(j=0\) can be always achieved by changing the constants of equivalence. Let \(j\not =0.\) Then
The estimate of \(\gamma _j\) from above is then obtained by
which finishes the proof. \(\square \)
Proof of Theorem 1
Fix \(\varphi \in C([0,1])\) with \(\textrm{supp}\,\varphi \subset [0,1/(2n)]\) and an even integer \(n\ge 2\). We set
i.e.,
We define \(\varphi ^{(n)}\) again by (8) and obtain by Hölder’s inequality
To estimate \(\Vert \varphi ^{(n)}\Vert _{H_\lambda }\) from below, observe that if \(x\in \left[ \frac{4j+1}{2n},\frac{4j+2}{2n}\right] \) and \(1/(2n)\le h\le 2/(2n)\), then \(x+h\in \left[ \frac{4j+2}{2n},\frac{4j+4}{2n}\right] \) and \(\varphi ^{(n)}(x+h)=0\). Therefore,
and, using Proposition 1,
Together with (11), this finishes the proof. \(\square \)
Remark 1
We point out also another reason, why Theorem 1 is rather counter-intuitive. Motivated by an explicit formula for the optimal fooling function for equi-distributed sampling points we consider (for fixed \(n\in \mathbb {N}\)) the bump function
and \(\varphi _n(t)=0\) if \(t\not \in [0, 1/(2n)]\). Then indeed \(\varphi _n\in C([0,1])\) and
Note, that \(\Phi _n(t)\) indeed vanishes in the points \(t=j/(2n), j=0,\dots ,2n.\)
Finally, an easy calculation reveals that
with constants of equivalence independent of n. Theorem 1 therefore shows, that removing some of the bumps from the sum in (12) can actually increase the norm of such a function. Indeed, if \(\varphi ^{(n)}\) is the function constructed in Theorem 1 using the \(\varphi _n\) from (12), then the integrals of \(\Phi _n\) and \(\varphi ^{(n)}\) are comparable and (13) together with (9) shows that \(\Vert \varphi ^{(n)}\Vert _{H_\lambda }/\Vert \Phi _n\Vert _{H_\lambda }\) grows (at least) as \(\sqrt{\log (n)}\) if n tends to infinity.
2.2 The Schur Technique
So how can we prove lower bounds for the integration problem in the cases where the bump-function technique does not work? The recent results for small smoothness and for analytic functions have been obtained using a certain modification of the classical Schur product theorem on the entry-wise product of positive semi-definite matrices. We will describe this technique now in the general setting of Sect. 1.2. That is, we are given a RKHS H with kernel K on a domain D and a functional \(S_h\) represented by \(h\in H\).
The first ingredient of this technique is a characterization of lower bounds on numerical integration via the positive definiteness of certain matrices involving the kernel K and the representer h of the integral from [13].
Proposition 2
Let H be a RKHS on a domain D with the kernel \(K:D\times D\rightarrow \mathbb {C}\) and let \(h\in H\). Then, for every \(\alpha >0\),
if, and only if, the matrix
is positive semi-definite for all \(\{x_1,\dots , x_n\} \subset D.\)
Proof
Let \(Q_n\) be given by (2). Then we denote \(a=(a_1,\dots ,a_n)^*\), \({\textbf{h}}=(h(x_1),\dots ,h(x_n))^*\) and \({\textbf{K}}=(K(x_j,x_k))_{j,k=1}^n\) and obtain
Let us assume now that \({\textbf{K}}-\alpha {\textbf{h}}{\textbf{h}}^*\) is positive-semidefinite. If \(a^*{\textbf{K}}a=0\), then also \(a^*{\textbf{h}}{\textbf{h}}^*a=|a^*{\textbf{h}}|^2=0\) and (15) implies that \(e(Q_n,H,S_h)^2\ge \Vert h\Vert _H^2.\) If \(a^*{\textbf{K}}a\) is positive, then we continue (15) by
We use that \(a^*{\textbf{K}}a-\alpha a^*{\textbf{h}}{\textbf{h}}^*a=a^*{\textbf{K}}a-\alpha |a^*{\textbf{h}}|^2\ge 0\) and take the infimum over all quadrature formulas \(Q_n\) and obtain that \(e_n(H,S_h)^2=\inf _{Q_n}e(Q_n,H,S_h)^2\ge \Vert h\Vert _H^2-\alpha ^{-1}.\)
On the other hand, assume that (14) holds. Then \(e(Q_n,H,S_h)^2\ge \Vert h\Vert _H^2-\alpha ^{-1}\) for every quadrature formula \(Q_n\) with arbitrary nodes \(\{x_1,\dots ,x_n\}\subset D\) and arbitrary weights \(a_1,\dots ,a_n\in \mathbb {C}\). If \(a^*{\textbf{K}}a=0\), then it follows from (15) that \(2\mathrm{Re\,}(a^*{\textbf{h}})\le \alpha ^{-1}\) holds for a and all its complex multiples. Hence, \(a^*{\textbf{h}}=0\) and \(a^*{\textbf{K}}a-\alpha a^*{\textbf{h}}{\textbf{h}}^*a=0.\) If \(a^*{\textbf{K}}a\) is positive, then we can assume (possibly after rescaling a with a non-zero \(t\in \mathbb {C}\)) that \(a^*{\textbf{h}}=a^*{\textbf{K}}a\), in which case (16) becomes an identity. Hence, \(a^*{\textbf{K}}a\ge \alpha |a^*{\textbf{h}}|^2\) and the result follows. \(\square \)
The second ingredient is a lower bound on the entry-wise square of a positive semi-definite matrix related to the Schur product theorem, which was proven in [38]. If \(M=(M_{i,j})_{i,j=1}^n\in \mathbb {C}^{n\times n}\), then we denote by \(\overline{M}=({\overline{M}}_{i,j})_{i,j=1}^n\) the matrix with complex conjugated entries and by \(M\circ \overline{M}\) the matrix with entries \(|M_{i,j}|^2\). Furthermore, \(\mathrm{diag\,}M\) is the column vector of the diagonal entries of M.
Proposition 3
Let \(M\in \mathbb {C}^n\times \mathbb {C}^n\) be a self-adjoint positive semi-definite matrix. Then
is also positive semi-definite.
Propositions 2 and 3 can be easily combined to obtain lower bounds for numerical integration. We state it under the assumption that the kernel \(K:D\times D\rightarrow \mathbb {C}\) can be written as a sum of squares of reproducing kernels with constant diagonal. To be more specific, we assume that K can be written as
where \(M_i:D\times D\rightarrow \mathbb {C}\) are positive semi-definite functions on D, which are constant on the diagonal, i.e., \(M_{{i}}(x,x)=c_i\ge 0\) for all \(x\in D\). Then \(K(x,x)=\kappa {:=}\sum _{i=1}^m c_i^2\) for every \(x\in D\) and also K is constant on the diagonal.
Theorem 2
Let H be a RKHS on a domain D with the kernel \(K:D\times D\rightarrow \mathbb {C}\), which can be written as a sum of squares of reproducing kernels with constant diagonal, and let \(1\in H\). Consider the integration problem \(S=S_h\) with the constant representer \(h=1\). Then
where \(\kappa \) is the value of K on the diagonal.
Proof
Let K be written as in (17) and let \(M_i(x,x)=c_i\). Further, let \(x_1,\hdots ,x_n \in D\). Then \((M_i(x_j,x_k))_{j,k=1}^n\) is positive semi-definite and by Proposition 3, so is the matrix
Therefore, also the sum of these matrices over all \(i\le m\), i.e., the matrix
is positive semi-definite. By Proposition 2, together with \(h=1\), this implies the error bound. \(\square \)
In particular, one needs at least \(\frac{1}{2} \Vert 1 \Vert _H^2 \cdot K(x,x)\) quadrature points in order to reduce the initial error by a factor of two. This insight is often already enough to prove the curse of dimensionality, see [12] and Sect. 5. Surprisingly, Theorem 2 can also be used to prove new results on the order of convergence of the integration error. This path is described in the next section.
OpenProblem 1
The Conjecture 2 of [15] suggests that, if \(f:\mathbb {R}^d\rightarrow \mathbb {R}\) is non-negative and has a non-negative Fourier transform, then the matrix
is positive semi-definite for every \(n\in \mathbb {N}\) and every choice of \(\{x_1,\dots ,x_n\}\subset \mathbb {R}^d.\) Let us note that Proposition 3 together with the classical Bochner theorem (cf. [38, Theorem 5]) gives an affirmative answer to this conjecture if \(f=g^2\), where \(g:\mathbb {R}^d\rightarrow \mathbb {R}\) has a non-negative Fourier transform. But in its full generality, the Conjecture 2 of [15] seems to be still open.
3 Some General Lower Bounds for Periodic Functions
We now transfer Theorem 2 to the setting of periodic function spaces \(H_\lambda \) on \(D=[0,1]^d\). We start with a result for sequences \(\lambda \in \ell _1(\mathbb {Z}^d)\) which are given as a sum of convolution squares in Sect. 3.1. We extend this result to the more general class of sequences which can be written as a non-increasing function of a norm in Sect. 3.2. As this covers all non-increasing sequences in the univariate case, we obtain as a corollary a new and sharp result on the largest possible error \(e_n(H)\) for any fixed sequence of approximation numbers in Sect. 3.3.
3.1 Sums of Squares
Recall, that the reproducing kernel \(K_\lambda \) of \(H_\lambda \) for a non-negative and summable sequence \(\lambda =(\lambda _k)_{k\in \mathbb {Z}^d}\) is given by (4). The square of its absolute value is then given by
Therefore, we define the convolution of two non-negative sequences \(\lambda , \theta \in \ell _1(\mathbb {Z}^d)\) by
A straightforward calculation shows that \(\lambda *\theta \in \ell _1(\mathbb {Z}^d)\) and that \(\Vert \lambda *\theta \Vert _1 = \Vert \lambda \Vert _1 \cdot \Vert \theta \Vert _1\). This notation allows us to reformulate (18) as \(|K_\lambda |^2=K_{\lambda *\lambda }\). We say that \(\lambda \) is a sum of convolution squares if there are \(\lambda ^{(i)} \in \ell _1(\mathbb {Z}^d)\), \(i\le m\), such that \(\lambda = \sum _{i\le m} \lambda ^{(i)} *\lambda ^{(i)}\). Theorem 2 then takes the following form.
Corollary 1
If \(\lambda \in \ell _1(\mathbb {Z}^d)\) is a sum of convolution squares, then
Proof
Since both sides of the inequality are homogeneous in \(\lambda \), we may assume that \(\lambda _0 =1\). In this case, the representer of the integral on \(H_\lambda \) is given by \(h=1\), where \(\Vert h \Vert _{H_\lambda }^2 = 1\). By (18), we obtain
Therefore, we may apply Theorem 2 and simply have to note that \(K_\lambda (x,x)=\Vert \lambda \Vert _1\). \(\square \)
This is a generalization of [13, Theorem 1] which covers the case \(d=1\) and \(m=1\).
3.2 Norm-Decreasing Sequences
Our next step is to save Corollary 1 for more general sequences \(\lambda \), which are not given as a sum of convolution squares. Namely, we consider sequences of the form \(\lambda _k = g( \Vert k \Vert )\), where \(\Vert \cdot \Vert \) is a norm on \(\mathbb {R}^d\) and \(g:[0,\infty ) \rightarrow [0,\infty )\) is monotonically decreasing. We call such sequences \(\Vert \cdot \Vert \)-decreasing. Clearly, \(\lambda \) is \(\Vert \cdot \Vert \)-decreasing if and only if it satisfies \(\lambda _k \le \lambda _\ell \) for all \(k,\ell \in \mathbb {Z}^d\) with \(\Vert k \Vert \ge \Vert \ell \Vert \).
Theorem 3
Let \(\lambda \in \ell _1(\mathbb {Z}^d)\) be \(\Vert \cdot \Vert \)-decreasing. Then
Proof
Again, since both sides of the stated inequality are homogeneous with respect to \(\lambda \), we may assume that \(\sum _{k\in \mathbb {Z}^d} \lambda _{2k}=1\). We set \(\mu _\ell = 2^{-1/2} \lambda _{2\ell }\). By the triangle inequality, one of the two relations \(2\Vert k\Vert \ge \Vert \ell \Vert \) or \(2\Vert k+\ell \Vert \ge \Vert \ell \Vert \) must hold for each pair \(k,\ell \in \mathbb {Z}^d\), and therefore \(\lambda _{2k} \le \lambda _\ell \) or else \(\lambda _{2k+2\ell } \le \lambda _\ell \). Thus we have for all \(\ell \in \mathbb {Z}^d\) that
Moreover, \((\mu *\mu )_0 \le \lambda _0/2\). We put \(\nu = \mu *\mu + t \delta _0\) and choose \(t\ge \lambda _0/2\) such that \(\nu _0 = \lambda _0\). Then \(\nu \) is a sum of convolution squares. It follows from Corollary 1 and \(\nu \le \lambda \) that
with
\(\square \)
Theorem 3 is well-suited to prove the curse of dimensionality, see Sect. 5. However, we can also tune it to be used for results on the asymptotic behavior of the nth minimal error.
Theorem 4
Let \(\lambda \in \ell _1(\mathbb {Z}^d)\) be \(\Vert \cdot \Vert \)-decreasing. For \(n\in \mathbb {N}\), we let \(r_n\) be the norm of the \((4n-1)\)th element in a \(\Vert \cdot \Vert \)-increasing rearrangement of \((2\mathbb {Z})^d\), i.e.,
Then
Note that \(r_n \asymp n^{1/d}\) for all norms \(\Vert \cdot \Vert =\Vert \cdot \Vert _p\) with \(1\le p \le \infty \).
Proof
Choose \(m\in \mathbb {Z}^d\) with \(\Vert m \Vert = r_n\). We define \(\tau \in \ell _1(\mathbb {Z}^d)\) by setting \(\tau _k=\lambda _k\) for \(\Vert k \Vert >r_n\) and \(\tau _k=\lambda _m\) for \(0<\Vert k \Vert \le r_n\) as well as
Then \(\tau \) is \(\Vert \cdot \Vert \)-decreasing and bounded above by \(\lambda \). Moreover,
and thus Theorem 3 gives \(e_n(H_{\lambda })^2 \ge e_n(H_{\tau })^2\ge \tau _0/2\), which leads to the stated lower bound. \(\square \)
In the univariate case, the previous result looks as follows.
Corollary 2
Let \(\lambda \in \ell _1(\mathbb {Z})\) be non-negative, symmetric and monotonically decreasing on \(\mathbb {N}_0\). Then
Proof
We apply Theorem 4 for \(d=1\) and \(\Vert \cdot \Vert =\vert \cdot \vert \). Therefore, \(r_n=4n-2\) and because of monotonicity and symmetry, we get
\(\square \)
This improves upon our previous result [13, Theorem 4], where we obtained a similar lower bound but only under an additional regularity assumption on the sequence \(\lambda \).
3.3 Detour: The Power of Function Values for \(L_2\) Approximation
Recently, there has been an increased interest in the comparison of standard information given by function values and general linear information for the problem of \(L_2\) approximation. We refer to [5, 19, 20, 25, 33] for recent upper bounds and to [12, 13] for lower bounds. Let us denote by \(\Omega \) the set of all pairs \((H,\mu )\) consisting of a separable RKHS H on an arbitrary set D and a measure \(\mu \) on D such that H is embedded into \(L_2(D,\mu )\). For \((H,\mu )\in \Omega \), we define the sampling numbers
and the approximation numbers
One is interested in the largest possible gap between the two concepts, that is, given a sequence \(\sigma _0\ge \sigma _1\ge \hdots \) and an integer \(n \ge 0\), one considers
It is known from [14] that \(g_n^*(\sigma )=\sigma _0\), whenever \(\sigma \not \in \ell _2\). On the other hand, it was proven in [5] that there is a universal constant \(c\in \mathbb {N}\) such that, whenever \(\sigma \in \ell _2\),
We obtain a matching lower bound as a consequence of Corollary 2. For the spaces \(H_\lambda \), the sequence of the squared approximation numbers equals the non-increasing rearrangement of the sequence \(\lambda \). Here, we use that approximation on \(H_\lambda \) is harder than integration, namely, \(e_n(H_\lambda )\le g_n(H_\lambda )\). Indeed, if \(S_n=\sum _{i=1}^n g_i \delta _{x_i}\) is a sampling operator, then we consider the quadrature formula \(Q_n(f)=\int _0^1 S_n(f)(x) \,\textrm{d}x\) and obtain
We apply Corollary 2 for the Hilbert spaces \(H_\lambda \) with \(\lambda _k=\sigma _{|2k|}^2\) and obtain
This improves upon the currently best known lower bound from [13, Theorem 2] in the sense that our lower bound holds for all and not just infinitely many \(n\in \mathbb {N}_0\). Moreover, due to \(e_n(H) \le g_n(H)\) and the fact that our lower bounds are proven for the integration problem, an analogous result holds with \(g_n^*(\sigma )\) replaced by
where \(\Omega _0\) is the set of pairs \((H,\mu ) \in \Omega \) such that \(\mu \) is a probability measure. Thus, we have the following corollary.
Corollary 3
There are universal constants \(0<c<1<C\) such that, for any sequence \(\sigma _0 \ge \sigma _1 \ge \hdots \) and any integer \(n\ge 0\), we have
In this sense, the worst possible behavior of the sampling numbers (or the minimal integration error) for a given sequence of approximation numbers \(\sigma \) is always described by the sequence \(\sigma ^*\). If \(\sigma \) is regularly decreasing in the sense that \(\sigma _n \asymp \sigma _{2n}\), we obtain that
Let us consider the case of polynomial decay, that is, \(\sigma _n \asymp n^{-\alpha } \log ^{-\beta } n\). This sequence is square-summable if and only if \(\alpha >1/2\) or \(\alpha =1/2\) and \(\beta >1/2\). In the case \(\alpha >1/2\) it follows that \(g_n^*(\sigma ) \asymp \sigma _n^* \asymp \sigma _n\). For the reproducing kernel Hilbert spaces \(H_\lambda \) of multivariate periodic functions the sequence of approximation numbers is always square-summable. Thus there can only be a gap between the concepts of sampling and approximation numbers in the case \(\alpha =1/2\). This corresponds to function spaces of small smoothness which are discussed in the next section.
4 Lower Bounds for Small Smoothness
In this section, we consider various function spaces of small smoothness. Spaces of that type appeared already in [24] to characterize path regularity of the Wiener process. We refer also to [17] to recent results on this subject and to [6] for an extensive treatment of function spaces with logarithmic smoothness. These spaces are of particular interest to us, since
-
This is the only case where an asymptotic gap between the approximation numbers and the sampling numbers is possible, see Sect. 3.3.
-
The standard technique of bump functions does not yield optimal lower bounds, see Sect. 2.1.
In [13], we obtained lower bounds for the univariate Sobolev spaces which merge fractional smoothness 1/2 and logarithmic smoothness. We want to extend these results to the multivariate case. In the multivariate regime, there are different smoothness scales that generalize the univariate smoothness scale. We consider spaces of isotropic smoothness and spaces of mixed smoothness.
4.1 Isotropic Smoothness
In the case of isotropic smoothness, we consider sequences of the form
where \(\vert \cdot \vert \) denotes the Euclidean norm on \(\mathbb {Z}^d\). This sequence is \(\vert \cdot \vert \)-decreasing and we may therefore apply Theorem 4 to obtain the following result. Recall that the approximation numbers and sampling numbers are defined in Sect. 3.3.
Corollary 4
Let \(\lambda \) be given by (19). Then
and
Proof
Recall that \(a_n(H_\lambda )^2\) is the \((n+1)\)st largest entry of \(\lambda \). We have
for \(\varepsilon \rightarrow 0^+\) and this easily implies the asymptotic behavior of \(a_n(H_\lambda )\). Recalling that \(e_n(H_\lambda ) \le g_n(H_\lambda )\), the upper bounds on \(e_n(H_\lambda )\) and \(g_n(H_\lambda )\) follow from [5, Theorem 1] and
The lower bounds follow from Theorem 4 and (20) as the condition \(|2k|>r_n\) excludes only \(\mathcal O(n)\) approximation numbers from the sum in the lower bound of Theorem 4. \(\square \)
We remark that, without much additional work, the norm characterization from Proposition 1 can be generalized to \(H_\lambda \) with \(\lambda \) given by (19). In this case we need differences of higher order, which are defined for \(h,x\in \mathbb {R}^d\) inductively by
Using this notation, the multivariate counterpart of Proposition 1 then reads as follows.
Proposition 4
Let \(\lambda \in \ell _1(\mathbb {Z}^d)\) be given by (19) and let \(M>d/2\) be an integer. Then \(f\in C([0,1]^d)\) belongs to \(H_\lambda \) if, and only if,
is finite. Furthermore, \(\Vert f\Vert _{H_\lambda }^2\) is equivalent to (21) with the constants independent of \(f\in C([0,1]^d)\).
The proof resembles very much the proof of Proposition 1 and we leave out the rather technical details, cf. also [6, Theorem 10.9], where one can find a more general characterization for function spaces defined on whole \(\mathbb {R}^d\). Note that in contrast to the univariate case (10), where h was from the unit interval (0, 1), we now consider in (21) all directions h from the unit ball of \(\mathbb {R}^d.\) Similar to the univariate case, using Proposition 4 instead of Proposition 1, one can show that the bump function technique would not suffice to prove the lower bound on \(e_n(H_\lambda )\) in Corollary 4.
OpenProblem 2
A logarithmic gap between upper and lower bounds of the worst-case error for numerical integration was recently observed also in [11] for Sobolev spaces of functions on the unit sphere \({\mathbb S}^d\subset {\mathbb R}^{d+1}.\) As conjectured already in [11], we also believe that the existing lower bound can be improved. Unfortunately, our results can not be directly applied in this setting, because the norm of a function in these function spaces is defined in terms of its decomposition into the orthonormal basis of spherical harmonics instead of the trigonometric system. Still, it might be possible to transfer our results to the sphere by
-
showing that our lower bounds from Corollary 4 already hold for the subspace \(H_\lambda ^\circ \) of functions with compact support in \((0,1)^d\) and
-
establishing an equivalent characterization of the spaces of generalized smoothness on the sphere using a decomposition of unity and lifting of the spaces \(H_\lambda ^\circ \) in analogy to [35, Section 27],
or alternatively, by working with Theorem 2 directly and a closer examination of (sums of) squares of kernels of Sobolev spaces on the sphere. For the first approach, Proposition 4 might help. For the second approach, the paper [9] might be useful.
4.2 Mixed Smoothness
We consider spaces of small mixed smoothness. The space is defined as the d-fold tensor product of the univariate space of mixed smoothness from Sect. 2.1. This results in the space \(H_\lambda \) with
Here, \(\lambda \) is not norm-decreasing and therefore we cannot use Theorem 4. However, it will turn out that already the lower bound from the univariate space is sharp in this case. The approximation numbers for \(d>1\) have the same asymptotic behavior as in the case \(d=1\).
Theorem 5
Let \(\lambda \) be given by (22). Then
This is in sharp contrast to the spaces of mixed smoothness \(s>1/2\), where the approximation numbers for \(d>1\) have a lower speed of convergence than for \(d=1\), see for example [7, Theorem 4.45]. The proof of Theorem 5 is based on the following combinatorial lemma, which is in contrast to [22, Lemma 3.2]. For \(r\ge 1\) and \(d\in \mathbb {N}\), we denote
and \(N(r,d) = \# M(r,d)\).
Lemma 1
For fixed \(d\in \mathbb {N}\),
Proof
We prove the statement by induction. Clearly, the statement is true for \(d=1\). Let \(d>1\) and let the statement be true for \(N(r,d-1)\). Then
In the case \(|n|\le \sqrt{r}\), we have
and thus
In the case \(|n|\ge \sqrt{r}\), \(n\in M(r,1)\), we have \(\log ^{2\beta }(e+|n|)\asymp \log ^{2\beta }(e+r)\) and thus,
\(\square \)
Proof of Theorem 5
The sequence of approximation numbers \(a_{n,d}{:=}a_n(H_\lambda ,L_2)\) is the decreasing rearrangement of the sequence \((\sqrt{\lambda _k})_{k\in \mathbb {Z}^d}\). With \(\lambda _0 =1\), we get \(a_{n,d} \ge \sqrt{\lambda _{(n,0,...,0)}}\) and the lower bound is obvious. The upper bound is obtained from Lemma 1. Given \(n\ge 3\), we choose \(r=r(n) \asymp n\log ^{2\beta }n\) such that \(N(r,d) \le n\). Since
we have \(a_{n,d} < r(n)^{-1/2}\) and the statement is proven. \(\square \)
OpenProblem 3
It would be interesting to determine the so-called asymptotic constants
in the case of mixed smoothness 1/2 with logarithmic perturbation. Opposed to Theorem 5, the asymptotic constants might reveal a dependence of the asymptotic decay upon the dimension d. The asymptotic constants for mixed smoothness \(s>1/2\) have been determined in [22]. In contrast to larger smoothness, the asymptotic constants for mixed smoothness 1/2 with logarithmic perturbation cannot decay as a function of d.
Now, we immediately obtain the behavior of the sampling numbers and the integration error on the spaces of mixed smoothness 1/2 with logarithmic perturbation.
Theorem 6
Let \(\lambda \) be given by (22). Then
Proof
The upper bound follows from Theorem 5 and [5, Corollary 2]. The proof of the lower bound is essentially transferred from the one-dimensional case. For that sake, we denote by \(\overline{\lambda }=(\overline{\lambda }_k)_{k\in \mathbb {Z}}\) the sequence introduced in (6). Note that \(\overline{\lambda }_k=\lambda _{ke_1}\), where \(e_1=(1,0,\dots ,0)\) is the first canonical unit vector. To prove now the lower bound for \(\textrm{INT}\), let \(Q_n\) be a quadrature formula on \(H_{\lambda }\) with nodes \(x_1,\dots , x_n\in [0,1]^d\). For \(x\in [0,1]^d\) and \(k\le d\), let \(x^{(k)} \in [0,1]\) denote the kth coordinate of x. With \(Q_n^{(1)}\) we denote the quadrature rule with nodes \(x_1^{(1)},\dots , x_n^{(1)}\in [0,1]\) and the same weights as in \(Q_n\). By Corollary 4 or [13, Theorem 4] there is a function \(f^{(1)}:[0,1] \rightarrow \mathbb {C}\) in the unit ball of \(H_{\overline{\lambda }}\) such that
The function
is contained in the unit ball of \(H_{\lambda }\) and satisfies \(Q_n(f)=Q_n^{(1)}(f^{(1)})\) and \(\int _{[0,1]^d} f(x)\,dx=\int _0^1 f^{(1)}(x)\,dx\). Thus,
\(\square \)
OpenProblem 4
As [5, Corollary 2] is only an existence result, the upper bound on the integration error in Theorem 6 is not constructive and does not tell us how to choose the quadrature points optimally. The results from [19, 36] show that \(\mathcal O(n\log n)\) i.i.d. uniformly distributed quadrature points are suitable with high probability to achieve an error of order \(e_n(H_\lambda )\). In the case of isotropic smoothness \(s>d/2\), it is known that \(\mathcal O(n)\) such points suffice, see [21], and the question arises whether the same holds true for other spaces from the family \(H_\lambda \), \(\lambda \in \ell _1(\mathbb {Z}^d)\).
5 Lower Bounds for Large Smoothness
We discussed in Sect. 4 that the bump-function technique does not provide optimal lower bounds for numerical integration of functions from \(H_{\lambda }\) as introduced in Definition 1 if the sequence \(\lambda =(\lambda _k)_{k\in \mathbb {Z}^d}\) is large, i.e., if it is barely square-summable. Quite naturally, the technique fails also in the other extremal regime - namely when the sequence \(\lambda \) decays very rapidly. Then the space \(H_\lambda \) consists only of analytic functions and, therefore, contains no bump functions with compact support at all.
Function spaces of analytic functions have a long history. Nevertheless, it is an active research question whether or not their use can help to avoid the curse of dimension for numerical integration and approximation. Based on the technique of [31], the more recent papers [23] and [16] present lower bounds for numerical integration of such classes of functions which avoid any use of bump functions. Here, we prove the curse of dimension for a class of analytic functions that is in connection with a recent result of [10]. In the paper [10], it was shown that the integration problem on
is polynomially tractable already for very slowly increasing functions \(g:\mathbb {N}_0\rightarrow (0,\infty )\), namely, for \(g(k)=\max (1,\log (k))\). We contrast this very nice result by showing that the integration problem suffers from the curse of dimension for essentially any non-trivial function g if we replace \(|\hat{f}(k)|\) by \(|\hat{f}(k)|^2\) in the definition of \(F_d^1.\)
Theorem 7
Let \(d\ge 2\) and let \(g:\mathbb {N}_0\rightarrow [0,\infty ]\) be any non-decreasing function with \(g(2)\le \tau <\infty \). If \(4n-1\le 3^d\), then the worst-case error for the numerical integration on the class
satisfies \(e_n(F_d^2)^2\ge 1/(2\tau )\). Hence, numerical integration suffers from the curse of dimension on the classes \(F_d^2.\)
Proof
We identify the class \(F_d^2\) with \(H_\lambda \), where \(\lambda _k=1/g(\Vert k\Vert _\infty )\). Then we simply apply Theorem 3 and obtain
\(\square \)
We also add an asymptotic lower bound for analytic functions. We only write down the univariate case for simplicity. Recall that all the functions in \(H_\lambda \) are analytic if the sequence \(\lambda \) decays geometrically and that a lower bound on \(e_n(H_\lambda )\) in this case cannot possibly be proven with the bump function technique. We therefore write down the lower bound obtained with the Schur technique. We note, however, that a similar lower bound might be proven in this case with the technique from [31].
Corollary 5
Let \(\lambda _k \ge c\, \omega ^{-|k|}\) for some \(c>0\), \(\omega >1\) and all \(k\in \mathbb {Z}\). Then
Proof
This follows immediately from Corollary 2. \(\square \)
References
Aronszajn, N.: Theory of reproducing kernels. Trans. Amer. Math. Soc. 68, 337–404 (1950)
Bakhvalov, N. S.: On the approximate calculation of multiple integrals, J. Complexity 31(4), 502–516, 2015; translation of N. S. Bakhvalov, Vestnik MGU, Ser. Math. Mech. Astron. Phys. Chem. 4, 3–18, in Russian (1959)
Bary, N.K.: A Treatise on Trigonometric Series, vol. I. A Pergamon Press Book, The Macmillan Company, New York (1964)
Berlinet, A., Thomas-Agnan, C.: Reproducing Kernel Hilbert spaces in Probability and Statistics. Kluwer Academic Publishers, Boston (2004)
Dolbeault, M., Krieg, D., Ullrich, M.: A sharp upper bound for sampling numbers in \(L_2\). Appl. Comput. Harmon. Anal. 63, 113–134 (2023)
Domínguez, O., Tikhonov, S.: Function spaces of logarithmic smoothness: embeddings and characterizations. Mem. Amer. Math. Soc. (2023). https://doi.org/10.1090/memo/1393
Dũng, D., Temlyakov, V., Ullrich, T.: Hyperbolic Cross Approximation, Advanced Courses in Mathematics. CRM Barcelona. Birkhäuser/Springer, Cham (2018)
Ebert, A., Pillichshammer, F.: Tractability of approximation in the weighted Korobov space in the worst case setting - a complete picture. J. Complex. 67, 101571 (2021)
Gasper, G.: Linearization of the product of Jacobi polynomials I. Canadian J. Math. 22, 171–175 (1970)
Goda, T.: Polynomial tractability for integration in an unweighted function space with absolutely convergent Fourier series, to appear in Proc. Amer. Math. Soc
Grabner, P.J., Stepanyuk, T.A.: Upper and lower estimates for numerical integration errors on spheres of arbitrary dimension. J. Complex. 53, 113–132 (2019)
Hinrichs, A., Krieg, D., Novak, E., Vybíral, J.: Lower bounds for the error of quadrature formulas for Hilbert spaces. J. Complex. 65, 101544 (2021)
Hinrichs, A., Krieg, D., Novak, E., Vybiral, J.: Lower bounds for integration and recovery in L2. J. Complex. 72, 101662 (2022)
Hinrichs, A., Novak, E., Vybíral, J.: Linear information versus function evaluations for \(L_2\)-approximation. J. Approx. Theory 153(1), 97–107 (2008)
Hinrichs, A., Vybíral, J.: On positive positive-definite functions and Bochner’s theorem. J. Complex. 27, 264–272 (2011)
Irrgeher, C., Kritzer, P., Leobacher, G., Pillichshammer, F.: Integration in Hermite spaces of analytic functions. J. Complex. 31(3), 380–404 (2015)
Kempka, H., Schneider, C., Vybíral, J.: L Path regularity of Brownian motion and Brownian sheet, to appear in Constr. Approx
Krieg, D.: Tractability of sampling recovery on unweighted function classes, arXiv:2304.14169, (2023)
Krieg, D., Ullrich, M.: Function values are enough for \(L_2\)-approximation. Found. Comput. Math. 21, 1141–1151 (2021)
Krieg, D., Ullrich, M.: Function values are enough for \(L_2\)-approximation, part II. J. Complex. 66, 101569 (2021)
Krieg, D., Sonnleitner, M.: Random points are optimal for the approximation of Sobolev functions, to appear in IMA J. Numer. Anal
Kühn, T., Sickel, W., Ullrich, T.: Approximation of mixed order Sobolev functions on the d-torus: asymptotics, preasymptotics, and d-dependence. Constr. Approx. 42(3), 353–398 (2015)
Kuo, F.Y., Sloan, I.H., Woźniakowski, H.: Multivariate integration for analytic functions with Gaussian kernels. Math. Comp. 86(304), 829–853 (2017)
Lévy, P.: Théorie de l’des Variables Aléatoires, Monographies des Probabilités; calcul des probabilités et ses applications, publiées sous la direction de E. Borel, no. 1. Paris: Gauthier-Villars, (1937)
Nagel, N., Schäfer, M., Ullrich, T.: A new upper bound for sampling numbers. Found. Comput. Math. 22(2), 445–468 (2022)
Novak, E.: Deterministic and stochastic error bounds in numerical analysis. Lecture notes in mathematics. Springer, Berlin (1998)
Novak, E., Triebel, H.: Function spaces in Lipschitz domains and optimal rates of convergence for sampling. Constr. Approx. 23, 325–350 (2006)
Novak, E., Woźniakowski, H.: Intractability results for integration and discrepancy. J. Complex. 17(2), 388–441 (2001)
Novak, E., Woźniakowski, H.: Tractability of Multivariate Problems, Volume I: Linear Information, European Mathematical Society, Zürich, (2008)
Novak, E., Woźniakowski, H.: Tractability of multivariate problems, volume II: Standard Information for Functionals. Eur. Math. Soc. Zürich. 3, 2 (2010)
Sloan, I.H., Woźniakowski, H.: An intractability result for multiple integration. Math. Comp. 66, 1119–1124 (1997)
Temlyakov, V.N.: Approximation of Periodic Functions. Nova Science Publishers Inc, Commack, NY, Computational Mathematics and Analysis Series (1993)
Temlyakov, V.N.: On optimal recovery in \(L_2\). J. Complex. 65, 101545 (2020)
Traub, J.F., Wasilkowski, G.W., Woźniakowski, H.: Information-based complexity. Academic Press, New York (1988)
Triebel, H.: Theory of Function Spaces II. Birkhäuser, Basel (1992)
Ullrich, M.: On the worst-case error of least squares algorithms for \(L_2\)-approximation with high probability. J. Complex. 60, 101484 (2020)
Vybíral, J.: Dilation operators and sampling numbers. J. Funct. Spaces Appl. 6, 17–46 (2008)
Vybíral, J.: A variant of Schur’s product theorem and its applications. Adv. Math. 368, 107140 (2020)
Funding
Open access funding provided by Johannes Kepler University Linz.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Communicated by Gabriela Steidl.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The research of David Krieg is supported by the Austrian Science Fund (FWF) Project M 3212-N. The research of Jan Vybíral was supported by the grant P202/23/04720 S of the Czech Science Foundation and by the European Regional Development Fund-Project “Center for Advanced Applied Science” (No. CZ.02.1.01/0.0/0.0/16_019/0000778).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Krieg, D., Vybíral, J. New Lower Bounds for the Integration of Periodic Functions. J Fourier Anal Appl 29, 41 (2023). https://doi.org/10.1007/s00041-023-10021-7
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00041-023-10021-7