
Abstract
In this article, we establish a new approach for removing natural growth trends from tree-ring samples, also called detrending. We demonstrate this approach using Ocotea porosa (Nees & Mart) Barroso trees. Nondestructive samples were collected in General Carneiro city, located in the Brazilian southern region (Paraná state). To remove natural tree growth trends, principal components analysis (PCA) was applied on the tree-ring series as a new detrending method. From this, we obtained the tree-ring indices by reconstructing the tree-ring series without the first principal component (PC), which we expect to represent the natural growth trend. The performance of this PCA method was then compared to other detrending methods commonly used in dendrochronology, such as the cubic spline method, negative exponential or linear regression curve, and the regional curve standardization method. A comparison of these methods showed that the PCA detrending method can be used as an alternative to traditional methods since (1) it preserves the low-frequency variance in the 566-year chronology and (2) represents an automatic way to remove the natural growth trends of all individual measurement series at the same time. Moreover, when implemented using the alternating least squares (ALS) method, the PCA can deal with tree-ring series of different lengths.

Source: Modified from CNCFlora (2012)

Source: Laboratório de Registros Naturais (LRN)-UNIVAP

Source: Laboratório de Registros Naturais (LRN)-UNIVAP

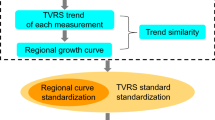
Source: Laboratório de Registros Naturais (LRN)-UNIVAP









Similar content being viewed by others

Availability of data
Data can be obtained from the authors upon request.
Change history
13 July 2021
A Correction to this paper has been published: https://doi.org/10.1007/s00024-021-02807-x
References
Amoroso, M. M., Daniels, L. D., & Larson, B. C. (2012). Temporal patterns of radial growth in declining Austrocedrus chilensis forests in Northern Patagonia: The use of tree-rings as an indicator of forest decline. Forest Ecology and Management, 265, 62–70.
Autin, J., Gennaretti, F., Arseneault, D., & Bégin, Y. (2015). Biases in RCS tree ring chronologies due to sampling heights of trees. Dendrochronologia, 36, 13–22.
Berrêdo, V. D. (2015). Vulnerabilidade de biomassa às mudanças climáticas: O caso da mata atlântica no estado do paraná. Ph.D. thesis, UFRJ/COOPE. Programa de Planejamento Energético, Rio de Janeiro.
Biondi, F., & Qeadan, F. (2008). A theory-driven approach to tree-ring standardization: Defining the biological trend from expected basal area increment. Tree-Ring Research, 64(2), 81–96. https://doi.org/10.3959/2008-6.1.
Brienen, R. J. W., & Zuidema, P. A. (2005). Relating tree growth to rainfall in Bolivian rain forests: A test for six species using tree ring analysis. Ecophysiology, 146(1), 1.
Briffa, K., Bartholin, T., Eckstein, D., Jones, P. D., Karlén, W., Schweingruber, F. H., & Zetterberg, P. (1990). A 1,400-year tree-ring record of summer temperatures in Fennoscandia. Nature, 346, 434–439.
Briffa, K. R., Jones, P. D., Schweingruber, F. H., Karlén, W., & Shiyatov, S. G. (1996). Tree-ring variables as proxy-climate indicators: Problems with low-frequency signals. In P. D. Jones, R. S. Bradley, & J. Jouzel (Eds.), Climatic variations and forcing mechanisms of the last 2000 years (pp. 9–41). Berlin: Springer.
Briffa, K. R., & Melvin, T. M. (2011). A closer look at regional curve standardization of tree-ring records: Justification of the need, a warning of some pitfalls, and suggested improvements in its application (pp. 113–145). Dordrecht: Springer.
Carvalho, P. E. R. (1994). Espécies florestais Brasileiras: Recomendações silviculturais, potencialidades e uso da madeira. Colombo: EMBRAPA.
Carvalho, P. E. R. (2003). Espécies arbóreas Brasileiras: Embrapa informação tecnológica (Vol. 1). Colombo: Embrapa Florestas.
CNCFlora. (2012). Ocotea porosa in lista vermelha da flora brasileira versão 2012.2 centro nacional de conservação da flora. http://cncflora.jbrj.gov.br/portal/pt-br/profile/Ocotea porosa
Cook, E., Briffa, K., Shiyatov, S., & Mazepa, V. (1990). Tree-ring standardization and growth-trend estimation. Methods of dendrochronology: Applications in the environmental sciences.
Cook, E. R. (1985). A time series analysis approach to tree ring standardization. Master’s thesis, University of Arizona.
Cook, E. R., & Peters, K. (1997). Calculating unbiased tree-ring indices for the study of climatic and environmental change. The Holocene, 7(3), 361–370.
Cosmo, N. L., Gogosz, A. M., Nogueira, A. C., Bona, C., & Kuniyoshi, Y. S. (2009). Morfologia do fruto, da semente e morfo-anatomia da da plântula de Vitex megapotamica (Spreng.) Moldenke (Lamiaceae). Acta Botanica Brasilica, 23(52), 389–397.
Dray, S., & Josse, J., (2015). Principal component analysis with missing values: A comparative survey of methods. Plant Ecology, 216(5), 657–667. https://hal.archives-ouvertes.fr/hal-01260054
Enright, N. J. (1984). Principal components analysis of tree-ring/climate relationships in white spruce (Picea glauca) from Schefferville, Canada. Journal of Biogeography, 11(4), 353–361.
Fekedulegn, D., Colbert, J., Hicks, R., & Schuckers, M. (2002). Coping with multicollinearity: An example on application of principal components regression in dendroecology. Pap: USDA Forest Service Northeast. Res. Station. Res.
Flower, A., & Smith, D. (2011). A dendroclimatic reconstruction of June–July mean temperature in the northern Canadian rocky mountains. Dendrochronologia, 29, 55–63.
Fritts, H. C. (1976). Tree rings and climate. Tucson: The University of Arizona Press.
General Carneiro, P. (2020). Dados gerais. [Online; Accessed 20-Outubro-2019]. http://www.generalcarneiro.pr.gov.br/municipio/dados-gerais/
Helama, S., Lindholm, M., Timonen, M., & Eronen, M. (2004). Detection of climate signal in dendrochronological data analysis: A comparison of tree-ring standardization methods. Theoretical and Applied Climatology, 79, 239–54.
Helama, S., Lindholm, M., Timonen, M., Meriläinen, J., & Eronen, M. (2002). The supra-long Scots pine tree-ring record for Finnish Lapland: Part 2, interannual to centennial variability in summer temperatures for 7500 years. The Holocene, 12(6), 681–687.
Helama, S., Melvin, T. M., & Briffa, K. R. (2017). Regional curve standardization: State of the art. The Holocene, 27(1), 172–177.
Huntington, E. (1914). The climatic factor as illustrated in Arid America. No. 192. Carnegie Institution of Washington, Washington.
Klein, R. M. (1963). Importância prática da fitossociologia para a silvicultura brasileira. Anais do I Simpósio de reflorestamento da região da araucária (pp. 1–61). Brasil: Curitiba.
Lindholm, M., Eronen, M., Timonen, M., & Merilainen, J. (1999). A ring-width chronology of Scots pine from northern Lapland covering the last two millennia. Annales Botanici Fennici, 36, 119–126.
Lorensi, C., & Prestes, A. (2016). Dendroclimatological reconstruction of spring-summer precipitation for Fazenda Rio Grande, PR, with samples of Araucaria angustifolia (Bertol.) Kuntze. Revista Árvore, 40, 347–354.
Maes, S. L., Vannoppen, A., Altman, J., Van den Bulcke, J., Decocq, G., De Mil, T., et al. (2017). Evaluating the robustness of three ring-width measurement methods for growth release reconstruction. Dendrochronologia, 46, 67–76.
Marchesan, R., Mattos, P. P., Bortoli, C., & Rosot, N. C. (2006). Caracterização física, química e anatômica da madeira de Ocotea porosa (Nees & C. Mart.) Barroso. Tech. Rep. 161, Colombo, PR, comunicado Técnico.
Melvin, T. M., & Briffa, K. R. (2014a). Crust: Software for the implementation of regional chronology standardisation: Part 1. signal-free rcs. Dendrochronologia.
Melvin, T. M., & Briffa, K. R. (2014b). CRUST: Software for the implementation of regional chronology standardisation: Part 1. Signal-free RCS. Dendrochronologia, 32(1), 7–20.
Miller, D. L., Mora, C. I., Grissino-Mayer, H. D., Mock, C. J., Uhle, M. E., & Sharp, Z. (2006). Tree-ring isotope records of tropical cyclone activity. Proceedings of the National Academy of Sciences, 103(39), 14294–14297.
Piermattei, A., Crivellaro, A., Carrer, M., & Urbinati, C. (2014). The “blue ring’’: Anatomy and formation hypothesis of a new tree-ring anomaly in conifers. Trees, 29(2), 613–620.
Prestes, A. (2009). Relação sol-terra estudada através de anéis de crescimento de coníferas do holoceno recente e triássico. Ph.D. thesis, Instituto Nacional de Pesquisas Espaciais, São José dos Campos.
Regazzi, A. J. (2000). Análise Multivariada, notas de aula INF 766. Departamento de Informática da Universidade Federal de Viçosa.
Reitz, R., Klein, R. M., & Reis, A. (1978). Projeto madeiras de Santa Catarina. Itajaí: Herbário Barbosa Rodrigues.
Shi, F., Yang, B., Linderholm, H. W., Seftigen, K., Yang, F., Yin, Q., et al. (2020). Ensemble standardization constraints on the influence of the tree growth trends in dendroclimatology. Climate Dynamics, 54(7–8), 3387–3404.
Speer, J. H. (1971). Fundamentals of Tree-Ring Research. Library of Congress Cataloging-in-Publication Data.
Stepka, T. F. (2013). Modelagem do crescimento e dendrocronologia em árvores nativas de Araucaria angustifolia, Cedrela fissilis e Ocotea porosa no sul do brasil. Ph.D. thesis, Universidade Federal do Paraná, Paraná.
Stuiver, M., & Quay, P. D. (1980). Changes in atmospheric carbon-14 attributed to a variable sun. Science, 207(4426), 11–19.
Tomazello Filho, M., Lisi, C. S., Hansen, N., & Cury, G. (2004). Anatomical features of increment zones in different tree species in the state of São Paulo, Brazil. Scientia Forestalis, 66, 46–55.
Zhang, X., & Chen, Z. (2017). A new method to remove the tree growth trend based on ensemble empirical mode decomposition. Trees, 31, 405–413.
Zhou, Y., Wilkinson, D., Schreiber, R., & Pan, R. (2008). Large-scale parallel collaborative filtering for the Netflix prize (pp. 337–348).
Acknowledgements
We appreciate FAPESP support by the projects FAPESP–2009/02907-8 and CNPq (305249/2018-5) and CAPES and FVE (Fundação Vale Paraibana de Ensino) for the scholarships provided to Daniela Oliveira da Silva.
Funding
This research was supported by FAPESP–(2009/02907-8) and CNPq (305249/2018-5).
Author information
Authors and Affiliations
Contributions
DOS contributed significantly to preparing the introduction, dataset and methodology, and conclusions. VK developed the idea of this manuscript. AP was responsible for the acquisition of the dataset and its preconditioning. HGM contributed to the methodology description. TA collaborated in the revision of the text and description of the results. IRS contributed to the data analysis.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Principal Components Analysis
Appendix A: Principal Components Analysis
Let \(X \in {\mathbb {R}}^{n \times m}\) be the data matrix whose m columns represent the variables \(x_1, x_2, \ldots , x_m\), zero-centered by hypothesis, and the n rows represent the observations of each of them, as described by

where \(\mathrm {X}_i \in {\mathbb {R}}^{m}\) is a row vector that corresponds to the ith observation, with \(1 \le i \le n\). The idea in the standard derivation of PCA is to find a direction determined by a unit vector \(q \in {\mathbb {R}}^{m}\) such that the variance of projections \(y_{i}\) associated to observations \(\mathrm {X}_{i}\) is maximum, as illustrated in Fig. 14.

Representation of some observations, restricted to variables \(x_{1}, x_{2}\) and \(x_{3}\), and the direction q that maximize the variance of the projections \(y_{i}\)
The projection of \(\mathrm {X}_i\) onto the unit vector q is given by \(y_{i} = \mathrm {X}_iq\), so that the variance of all projections is defined by
where \(C_{X} \in {\mathbb {R}}^{m \times m}\) is the covariance matrix associated to the original set of variables and can be rewritten in a more convenient way as follows:
The covariance matrix \(C_{X}\) has some properties that form the basis to the understanding of PCA, and, in order to visualize them, it is necessary to expand \(C_{X}\) in Eq. (3) considering that the observations are of the form \(\mathrm {X}_{i} = \begin{bmatrix} x_{i1}&x_{i2}&\cdots&x_{im}\end{bmatrix}\), resulting in
Equation (4) shows that \(C_{X}\) is a symmetric matrix due to the symmetry of covariance, and therefore, it has a orthonormal set of m eigenvectors, and it is orthogonally diagonalizable, so that there is an orthogonal matrix \(Q \in {\mathbb {R}}^{m\times m}\) such that
where \(D_{X} = \text {diag}(\lambda _{1}, \lambda _{2}, \ldots , \lambda _{m})\) is a diagonal matrix with the eigenvalues of \(C_{X}\) ordered in such a way that \(\lambda _{1} \ge \lambda _{2} \ge \cdots \ge \lambda _{m}\) and \(Q = \begin{bmatrix}q_{1}&q_{2}&\ldots&q_{m}\end{bmatrix}\), whose column \(q_{i} \in {\mathbb {R}}^{m}\) is the respective eigenvector of \(\lambda _{i}\). Besides that, \(C_{X}\) is a positive semidefinite matrix such that if \(y \in {\mathbb {R}}^{m}\) is a nonzero vector, then
where equality can only be obtained when \(\mathrm {X}_{i} = 0\) since \(y \ne 0\). As a consequence, the eigenvalues of \(C_{X}\) are nonnegative, which is consistent because they represent the variance of each principal component, as will be seen later. Finally, note that the diagonal elements of the matrix correspond to the variances of each variable \(x_{1}, x_{2}, \ldots , x_{m}\), whereas the off-diagonal elements correspond to all possibilities of covariance between these variables.
In order to maximize the variance in Eq. (2), it is necessary to solve an optimization problem involving the quadratic form with one constraint, as stated in
The standard way to approach such a problem is by the Lagrange multiplier method that allows one to combine an objective function with a sequence of constraints, producing the Lagrange function, which in this case, is given by
By differentiating (7) and equating the result to zero, considering that \(\frac{\partial q^Tq}{\partial q} = 2q^T\) and \(\frac{\partial q^TC_{X}q}{\partial q} = 2q^TC_{X}\), one gets
Equation (8) is a major result since it indicates that the direction q that maximizes the variance V is given by the eigenvectors of the covariance matrix \(C_{X}\), and as a consequence, the numerical value of V is given by the respective eigenvalue \(\lambda\), as indicated by
Nevertheless, since the matrix \(C_{X}\) has a set of m orthonormal eigenvectors, which one maximizes V? This question can be answered by observing Eq. (9), where one can conclude that the eigenvector with the largest eigenvalue is the one that maximizes it. Since the eigenvalues are ordered, one can make the following statements:
-
(a)
\(q_{1}\) is the direction of largest variance \(\lambda _{1}\) of the original data set;
-
(b)
\(q_{2}\) is the direction of the second-largest variance \(\lambda _{2}\) and so on.
An important point that deserves attention is the perpendicular distances \(d_{i}\) of observations \(\mathrm {X}_{i}\) relative to line \(\ell\), as illustrated in Fig. 14. Mathematically, \(d_{i}\) is given by
The goal is to verify that the variance D of these distances is minimized when the variance of the projections V is maximized. To do this, it is necessary to square Eq. (10), allowing us to express \(d_{i}^2\) in matrix form as follows:
From Eq. (11) one can obtain a closed expression for variance D, as in
Note that Eq. (12) indicates that when V is maximum, D is minimum due to the minus sign, since the other term is constant. This explains why the eigenvectors seem to fit the cloud of observations when they overlap in the same plot.
With the largest variance directions determined by the eigenvalues of \(C_{X}\), all that remains is to project the observations \(\mathrm {X}_{i}\) in the eigenspace of \(C_{X}\). Since the projection \(\mathrm {X}_{i}\) in the direction of \(q_{j}\) is given by \(y_{ij} = \mathrm {X}_{i}q_{j}\), by doing this for all eigenvectors indexed by \(1\le j \le m\), there is a new representation of \(\mathrm {X}_{i}\) given by the row vector \(Y_{i} = \begin{bmatrix}\mathrm {X}_{i}q_{1}&\mathrm {X}_{i}q_{2}&\dots&\mathrm {X}_{i}q_{m} \end{bmatrix}\). Thus, for all observations indexed by \(1 \le i \le n\), one can get a new representation for the original data set, denoted by the matrix \(Y \in {\mathbb {R}}^{n\times m}\), as given by

where the new variables \(y_{1}, y_{2}, \ldots , y_{m}\) are named principal components. It should be noted that the entry \(y_{ij} = \mathrm {X}_{i}q_{j}\) corresponds to the score of the ith observation in the jth principal component, whereas the eigenvector \(q_{j}\) is the so-called coefficient vector of this component. This nomenclature comes from the fact that the entry \(y_{ij}\) is written as a linear combination whose coefficients are the entries of \(q_{j}\), as follows:
In general, the new representation of the original data set as given by the Eq. (13) is not made considering all the columns of matrix Q. The idea is to reduce the dimension of the original data set disregarding the columns that represent the principal components with the smallest variances, resulting in a new set of variables that represents the original ones with a certain degree of accuracy. For example, suppose that only the first \(k<< m\) principal components are used to represent a data set in an m-dimensional space. The accuracy of this representation is defined in terms of how much the total variance remains in the k-dimensional space and is given as a percentage as follows:
where it is quite common to get high values with only two principal components. Note that with Eq. (13), it becomes possible to obtain the original data matrix X by multiplying both sides on the right by \(Q^T\), as indicated by
One of the main results of PCA can be noticed when calculating the covariance matrix \(C_{Y}\) associated to the principal components, as given by
Substituting Eq. (5) into Eq. (17), it turns out that \(C_{Y}\) is a diagonal matrix,
whereby matrix equality follows that \(\text {var}(y_{j}) = \lambda _{j}\), that is, the eigenvalues of \(C_{X}\) are the variances of the principal components. Moreover, note that there is no covariance between them, indicating that they are unrelated.
1.1 A.1 Alternating Least Squares
The alternating least squares (ALS) is a matrix factorization algorithm that plays an important role in the context of collaborative filtering (CF) in recommendation systems. Specifically, CF is a technique used to make predictions about the interests of a user based on their preferences over a set of available items (Zhou et al., 2008), which can be movies and/or songs in streaming platforms, for example. In this sense, to illustrate the ALS, suppose that a video streaming platform has \(n_{u}\) users and \(n_{m}\) movies available which can be rated. In that scenario, it is convenient to define a user-movie matrix \(R \in {\mathbb {R}}^{n_{u}\times n_{m}}\) whose entry \(r_{ij}\) represents the rating score of movie j by user i. Unfortunately, the matrix R has a lot of missing entries since a user only rates a subset of the available movies. The purpose of a recommendation system is to estimate these missing entries based on the previous ratings of the users.
The idea is to perform a low-rank approximation of the user-movie matrix R by introducing a user feature matrix \(U \in {\mathbb {R}}^{n_{f}\times n_{u}}\) and a movie feature matrix \(M \in {\mathbb {R}}^{n_{f}\times n_{m}}\) in such a way that \(r_{ij} \approx u_{i}^Tm_{j} \forall i \in \{1,\ldots ,n_{u}\}, \forall j \in \{1,\ldots ,n_{m}\}\) or \(R \approx U^TM\), where \(u_{i} \in {\mathbb {R}}^{n_{f}}\) and \(m_{j} \in {\mathbb {R}}^{n_{f}}\) are the user and movie feature vectors, respectively (Zhou et al., 2008). The \(n_{f}\) is the dimension of the feature space. In this sense, the matrices U and M are determined by minimizing the least squares error of the known ratings, i.e.,
where I denotes the index set of known ratings, \(n_{u_{i}}\) the number of ratings of user i, and \(n_{m_{j}}\) the number of ratings of movie j. The term involving \(\lambda\) in Eq. (19) is a regularization term to prevent overfitting in ALS (Zhou et al., 2008). It is noteworthy that the objective function in Eq. (19) is non-convex due to the term \(u_{i}^{T} m_{j}\), but if one of the matrices is fixed, U for example, then it becomes a convex function of M and vice versa. In this way, the approach used to solve this minimization problem is to fix U and optimize M, then fix M and optimize U until convergence is established by some stopping criterion. Actually, this fact explains the word alternating in the ALS name. Specifically, to do the optimization, it suffices to perform a matrix differentiation in Eq. (19) considering that one of the matrices is held constant and equates the result to zero. In this sense, suppose that M is given, then the columns of matrix U will be
where E is the \(n_{f}\times n_{f}\) identity matrix, \(M_{I_{i}} = [m_{j}]_{j \in I_{i}}\), and \(R(i, I_{i})\) is the ith row vector of R considering only the columns with indexes in \(I_{i}\) (Zhou et al., 2008). Similarly, by carrying out the same procedure, but considering that U is given, it results
where \(U_{I_{j}} = [u_{i}]_{i\in I_{j}}\), and \(R(I_{j}, j)\) is a column vector of R considering only the rows with indexes in \(I_{j}\), which represents the set of users who rated movie j.
By using Eqs. (20) and (21) in the ALS algorithm, one can find the matrix \(\tilde{R} = U^TM\) that fits the known entries of matrix R and fills the missing ones.
Rights and permissions
About this article

Cite this article
da Silva, D.O., Klausner, V., Prestes, A. et al. Principal Components Analysis: An Alternative Way for Removing Natural Growth Trends. Pure Appl. Geophys. 178, 3131–3149 (2021). https://doi.org/10.1007/s00024-021-02776-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00024-021-02776-1