
Abstract
In this article, we define a generalization of the domino shuffling algorithm for tilings of the Aztec diamond to the interacting k-tilings recently introduced by S. Corteel, A. Gitlin, and the first author. We describe the algorithm both in terms of dynamics on a system of colored particles and as operations on the dominos themselves.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
Domino tilings of the Aztec diamond were first introduced by Elkies, Kuperberg, Larsen, and Propp [12] in their study of alternating-sign matrices. See Fig. 1 for an example of a domino tiling of rank 3. In their work, the authors introduced domino shuffling, an algorithm by which one can generate a tiling of the Aztec diamond of rank \((N+1)\) from a tiling of the Aztec diamond of rank N. Using this they were able to derive a recursive formula for the number of tilings. Solving this recursion, they found the beautiful result:
Theorem 1.1
The number of tilings of the Aztec diamond of rank N is given by
The shuffling algorithm has since proved very useful in the study of these tilings. An immediate benefit is that shuffling allows for efficient exact sampling with arbitrary weights [23]. Furthermore, it has also been used as a tool for asymptotic analysis, in the following way: One central result in the study of tilings of the Aztec diamond is the arctic circle theorem [16]. It states that for large N, a uniformly random tiling exhibits a brickwork pattern in four regions (called frozen regions or polar regions), one adjacent to each corner of the Aztec diamond, whose union is approximately the region outside of the largest circle (called the arctic circle) that can be inscribed in the Aztec diamond. The strategy used in the original proof of this fact was a careful analysis of the shuffling algorithm [16].
There are many ways to view domino shuffling. Originally it was described using sequences of moves that one must perform with the dominos on the tilings themselves, see [15, 23]. Furthermore, when viewed as a deterministic discrete time dynamical system on the weights, domino shuffling is an example of a cluster integrable system [14]. This is a consequence of the fact that the shuffling algorithm consists of a collection of structure preserving local moves called spider moves. Alternatively, one can see it as an example of dynamics on a certain space of particle configurations, as first observed by Nordenstam [21]. With a restricted class of weights, these particle dynamics can be re-derived using the algebraic structure of the Schur process [2, 3, 5, 6].
In this article, we describe a generalization of the shuffling algorithm. Recently, in [8] the authors described a model of k interacting tilings of the Aztec diamond. The authors computed the partition function of the model by relating it the LLT polynomials of Lascoux, Leclerc, and Thibon [19]. We generalize the shuffling algorithm to these interacting k-tilings.
More precisely, a k-tiling of the Aztec diamond is a collection of k domino tilings of the Aztec diamond. We consider the tilings to be indexed by colors, which are ordered. Thinking of the different tilings as being overlaid one on top of the other, we define an interaction between two of the tilings as an instance of a local configuration of the form

where above blue is the smaller color in our ordering and red the larger. We assign a weight to the k-tilings given by \(t^{{\# interactions}} \).
We equip k-tilings with the probability measure under which the probability of a k-tiling is proportional to its weight. Even restricting to just \(k=2\), this distribution on 2-tilings is an integrable one parameter deformation of the double dimer model, which is obtained by setting the interaction strength \(t = 1\). In the large N limit, the model appears to exhibit many of the same phenomena as the dimer model, including arctic curves and limit shapes. On the other hand, the properties of these limit shapes and arctic curves appear to be very different from those observed in the dimer model. See Appendix B for a brief discussion and several simulations.
In addition to questions about limit shapes and arctic curves, there are many other natural questions one can ask about the coupling between the 2 (or k) interacting tilings in the scaling limit. For example, near the arctic curve we expect to observe a one parameter deformation of k independent Airy processes, in which each color’s edge fluctuations are coupled in a nontrivial way. It would also be interesting to study the global height fluctuations, and in particular how the fluctuations of different colors are coupled together. We expect that the efficient sampling algorithm provided by our main theorem below could be an important tool for the investigation of these questions.
The following is a special case of the main result.
Theorem 1.2
The following algorithm generates a random k-tiling of the rank-N Aztec diamond with probability proportional to its weight.
Algorithm: Start with a rank-0 Aztec diamond. To get from a rank-\((T-1)\) to rank-T k-tiling,
-
1.
Slide and destroy as in the normal domino shuffle, independently for each color.
-
2.
Fill in empty \(2\times 2\) squares according to the rule:
-
1.
For the smallest color put two horizontal dominoes with probability
$$\begin{aligned} \frac{t^{\#_1(1)}}{1+t^{\#_1(1)}} \end{aligned}$$where

Do all of these first.
-
2.
Now do all the larger colors from smallest to largest. For color \(l>1\), put two horizontal dominoes with probability
$$\begin{aligned} \frac{t^{\#_1(l)+\#_2(l)}}{1+t^{\#_1(l)+\#_2(l)}} \end{aligned}$$where
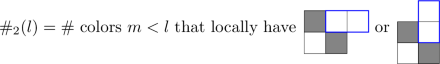
and \(\#_1(l)\) is as in part (a).
This gives a k-tiling of the Aztec diamond whose rank has increased by one.
-
1.

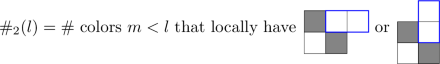
Repeat steps (1) and (2) until you get a rank-N Aztec diamond.
The main tools we use are the Cauchy and branching identities for the LLT polynomials, as these allow us to apply a general construction of Borodin and Ferrari [2]. In fact, a standard bijection allows one to view a k-tiling as a tuple of interlaced particle arrays. The aforementioned construction (after some calculation) prescribes explicit transition probabilities for these particles, such that if the initial particle positions correspond to a random rank-N tiling, then the update generates a random k-tiling of rank-(\(N+1\)). Using the bijection to interpret the dynamics as local moves on dominos, we obtain the shuffling algorithm in Theorem 4.1 in the text, which gives Theorem 1.2 by setting the weights to be uniform. This Markov chain on colored particle arrays generalizes the Markov chain on a single particle array described in [3, Section 2], which corresponds to the usual shuffling algorithm.
In addition to the proof of Theorem 1.2 using LLT polynomials, in Appendix A we give an alternative proof which employs a local resampling procedure which generalizes the resampling coming from the spider move. The resampling relies on a set of relationships between local partition functions, which are listed in Lemma A.1. Contrary to the one color case, these relations are not sufficient to produce a shuffling algorithm for k-tilings with arbitrary weights. However, they can still be used to construct a shuffling algorithm for certain choices of weights, including uniform weights, which is the setting of Theorem 1.2.
The paper is organized as follows:
-
1.
In Sect. 2, we give a brief review of background material. We begin by reviewing the Aztec diamond and stating some fundamental results. We focus on highlighting the relationship with interlacing partitions, interlacing arrays of particles, and Schur polynomials which will be useful in later sections. We then define the k-tilings. We state some fundamental results from [8]. We also state the necessary properties of the LLT polynomials that will be used in the subsequent sections. Of particular importance to what follows is the bijection between tilings and particle configurations.
-
2.
In Sect. 3, we present the Markov chain on colored interlacing particle configurations which preserves a class of probability measures on colored particle arrays called ‘LLT processes’. First, we review the one color case, which is the Schur case, and then we describe the generalization to multiple colors, which is powered by LLT polynomials.
-
3.
In Sect. 4, we interpret the particle dynamics described in the previous section as an operation on dominos. We review the shuffling algorithm for a single tiling of the Aztec diamond before describing the corresponding result for the k-tiling. The main result is an algorithm for generating random k-tilings with probability proportional to their weight.
-
4.
In Sect. 5, we summarize our results and give some possible avenues of future research.
-
5.
In Appendix A, we give an alternate description of our shuffling algorithm in terms of a generalization of the ‘spider move’ on the underlying double dimer model.
-
6.
Finally, in Appendix B, we present some simulations of the k-tilings generated using our shuffling algorithm. As noted above, the coupled tilings appear to exhibit limit shapes and arctic curves. We give a discussion of the apparent features.
2 Background
2.1 Tilings of Aztec Diamond
2.1.1 The Aztec Diamond
Let \(A_{N}\) be the union of faces of \({\mathbb {Z}}^2\) which are entirely contained in the region \(|x| +|y| \le N+1\). A tiling of the Aztec diamond of rank N is a covering of the region \(A_{N}\) with \(2 \times 1\) or \(1 \times 2\) dominos so that each square of the region is covered exactly once by a domino. Given N, we give a checkerboard coloring of the faces of \({\mathbb {Z}}^2\) so that the left square in the top row of \(A_N\) is colored black. Thus, any domino placed in a tiling can be one of four types, depending on its orientation and on the color of its left-most (for horizontal tiles) or bottom-most (for vertical tiles) square. See Fig. 1 for an example.

The four possible dominos and an example of a tiling of the Aztec diamond of rank 3
Label the faces by \((i, j) \in ({\mathbb {Z}}+\frac{1}{2})^2\), and label the diagonals from 0 to 2N by declaring that the face (i, j) is on diagonal \(j-i + N\). See Fig. 2.

An example of our conventions for labeling the faces and diagonals. The Aztec diamond is aligned so that its center is at \((0,0)\in {\mathbb {Z}}^2\). The diagonal labels are shown on the South-West boundary. The highlighted face has label \((i,j)=(2.5,-0.5)\). Note that “white diagonals” are odd and “black diagonals” are even
We assign a (position dependent) weight to each domino in a tiling. Let \(C_N = (c_1, \dots , c_N), B_N = (b_1, \dots , b_N)\) be two tuples of real numbers. The domino weights we are interested in are given by:
-
Suppose a horizontal domino D is occupying the two squares (faces) which have coordinates \((i, j), (i+1, j)\) with (i, j) on diagonal \(2 m-1\). Then the weight of this domino is \(c_m\).
-
Suppose a horizontal domino D in a tiling is occupying the two squares \((i, j), (i+1, j)\) with (i, j) on diagonal 2m. Then the weight of D is \(b_{N-m+1}\).
-
The weights of vertical dominos are 1.
The weight of a whole tiling T is given by the product of the weights of each domino,
Define the rank-N Aztec diamond partition function with these weights as
The probability of a random rank-N tiling is given by
Theorem 2.1
([6]). The partition function of the Aztec diamond of rank N with the above weights is given by
One of the ways this theorem can be proved is via the machinery of Schur polynomials, the basics of which we briefly review in the next subsection.
2.1.2 Schur Polynomials and Interlacing Partitions
A partition \(\lambda = (\lambda _1,\lambda _2, \lambda _3, \ldots )\) is a non-negative sequence of integers such that \(\lambda _1 \ge \lambda _2 \ge \lambda _3 \ge \ldots \). We associate to \(\lambda \) its Young diagram \(D(\lambda ) \subseteq {\mathbb {Z}}\times {\mathbb {Z}}\), given as
We draw our diagrams in French notation, in the first quadrant such that the cell (i, j) is placed in the i-th row from the bottom and j-th column from the left, as shown in the below example:

We refer to the elements in \(D(\lambda )\) as cells. The cell labeled above has coordinates (1,3). The content of a cell \(u = (i,j)\) in the i-th row and j-th column of the Young diagram is \(c(u) = i-j\). The marked cell above has content \(c((1,3))=-2\). The size of a partition is the number of cells in its Young diagram and is denoted by \(|\lambda |\). The above partition has size \(|\lambda | =4+2+1=7\). See Fig. 3 for another example.
Given two partitions, \(\lambda \) and \(\mu \), we say that \(\mu \) is contained in \(\lambda \) and write \(\mu \subset \lambda \) if the Young diagram of \(\mu \) is a subset of the Young diagram of \(\lambda \). Given that \(\mu \subset \lambda \) we can define the skew diagram \(\lambda /\mu \) as the Young diagram of \(\lambda \) with the cells from the Young diagram of \(\mu \) removed.
To a partition we can associate an infinite sequence of particles and holes by assigning a particle to every vertical edge on the boundary of its Young diagram, and a hole to every horizontal edge. This is known as the Maya diagram of the partition. See Fig. 3. Note that the Maya diagram has a unique content line such that the number of particles to the right of this line is equal to the number of holes to the left. We call this the zero-content line and view it as the center of our Maya diagram. If we place the Maya diagram on \({\mathbb {Z}}+ \frac{1}{2}\) centered at zero then the position \(x_i\) of the i-th particle (counting from right to left) is given by
For every partition \(\lambda \) we can associate a second partition \(\lambda '\) known as the conjugate of \(\lambda \). The conjugate \(\lambda '\) is defined as the partition whose Young diagram is given by reflecting the Young diagram of \(\lambda \) across its zero-content line. For example, \(\lambda =(4,3,2,2,1)\), the partition in Fig. 3, has conjugate \(\lambda '= (5,4,2,1)\).
Given two partitions \(\lambda \) and \(\mu \) say that \(\lambda \) and \(\mu \) interlace if
and write \(\lambda \succeq \mu \). Say that \(\lambda \) and \(\mu \) co-interlace if their conjugate partitions interlace and write \(\lambda \succeq ' \mu \). Note that \(\mu \preceq \lambda \) implies that \(\mu \subset \lambda \).

The Young diagram of the partition \(\lambda =(4,3,2,2,1)\) along with its Maya diagram: \(\ldots \bullet \bullet \hspace{5.0pt}\circ \bullet \circ \bullet \bullet \circ \bullet \circ \bullet \hspace{5.0pt}\circ \circ \ldots \). The red line indicates the zero-content line of the Young diagram. We have \(|\lambda | = 12\) (color figure online)
Recall that given two partitions \(\mu \subset \lambda \) and variables \(X_n = (x_1,\dots , x_n)\) the skew-Schur polynomial is defined as
Here the sum is over all semi-standard Young tableaux of shape \(\lambda /\mu \), where a semi-standard Young tableaux is a filling of the cells of the diagram by the integers \(1,\ldots ,n\) such that they are weakly increasing along the rows and strictly increasing up the columns, and
where \(\sigma _i\) is the number of times i appears in the filling \(\sigma \). The polynomials \(s_{\lambda /\mu }(X_n)\) are symmetric in the variables \((x_1,\dots , x_n)\).
Here we state some basic identities satisfied by Schur polynomials that will be useful for us (see [20] for more details). For any sets of variables \(X = (x_1, \dots , x_l), Y = (y_1, \dots , y_p)\), we have
Proposition 2.2
([20]). Branching rule:
Dual Skew-Cauchy Identity:
2.1.3 The Aztec Diamond and Schur Processes
There is a bijection between tilings of the Aztec diamond of rank N and sequences of interlacing partitions
Given a tiling of the Aztec diamond of rank N assign particles and holes to the dominos according to the rules

Along each diagonal slice of the Aztec diamond view the resulting sequence of particles and holes as the Maya diagram of some partition by extending it infinitely to the South-West with particles and infinitely to the North-East by holes. Let us index the slices starting from 0, such that \(\mu ^{(i)}\) is the partition along slice \(2i-2\) and \(\lambda ^{(i)}\) is the partition along slice \(2i-1\). Note that \(\mu ^{(1)}=\mu ^{(N+1)}=\emptyset \) is forced. Figure 4 gives an example of our notation and this bijection. One can check [6, 17] that the requirement that these partitions come from a valid tiling is exactly the interlacing condition given in Eq. (4).

Left and center: assigning partitions to slices of the Aztec diamond. The red line indicates the zero-content line for the partitions. Right: the tiling corresponding to all partitions being empty for the Aztec diamond of rank 3
Given the bijection from tilings to sequences of interlacing partitions
described above, one can write the weight of the tiling in terms of Schur polynomials. The weight of a tiling is given by
where here we used the notation \((\lambda /\mu )' {:}{=}\lambda '/\mu ' \).
Remark 2.3
A probability measure on sequences of partitions of the form
with \(u_1,\dots , u_N, v_1,\dots , v_N \in {\mathbb {R}}_{>0}\) is a particular case of a Schur Process. Schur processes are well-studied. Using them one can derive exact determinantal formulas for correlation functions and study various statistics of random tilings asymptotically as \(N \rightarrow \infty \), see [4] for a survey and see also [22].
In particular, we have
Proposition 2.4
([6]). The partition function of the Aztec diamond of rank N is given by
where the sum is over all tuples of partitions \(\lambda ^{(1)}, \mu ^{(2)}, \lambda ^{(2)}, \dots , \mu ^{(N)}, \lambda ^{(N)}\) satisfying the interlacing condition Eq. (4).
By repeated applications of the identities in Proposition 2.2, the above simplifies to the product in Theorem 2.1.
It will often be more convenient to consider only the particle positions. From this point of view, the tiling becomes an array of interlacing particles. Let \(x^{(n)} = \{x_1^{(n)}> x^{(n)}_2> \cdots > x^{(n)}_n \}\) be the position of particles corresponding to \(\lambda ^{(n)}\), and \(y^{(n)} = \{y_1^{(n)}> y^{(n)}_2> \cdots > y^{(n)}_{n-1} \}\) those corresponding to \(\mu ^{(n)}\). A set of particle positions corresponds to a tiling if and only if they satisfy the interlacing conditions
and the bounds
for each \(n = 1, \dots , N\). See Fig. 5 for several examples.
2.2 Coupled Tilings and LLT Polynomials
2.2.1 k-Tilings of the Aztec Diamond
In this section we define the interacting k-tilings of the Aztec Diamond. See [8] for a more detailed discussion.
Consider an Aztec diamond of rank N. A k-tiling \(\varvec{T} = (T^{(1)},\ldots ,T^{(k)})\) is a k-tuple of tilings of the Aztec diamond. We will often draw the different tilings in different colors (see Fig. 5) and refer to tiling \(T^{(a)}\) as being color a. We order the colors so that color a is smaller than color b if \(a<b\).
If \(C_N = (c_1, \dots , c_N), B_N = (b_1, \dots , b_N)\), each of the tilings \(T^{(a)}\) has its own weight \(\text {wt}(T^{(a)})\) by giving the horizontal dominos weights \(c_m, b_{N-m+1}\) on diagonals \(2\,m -1 \) and \(2\,m\), respectively, as described in Sect. 2.1.1. Now we define an interaction between pairs of tilings. Consider two tilings \(T^{(a)}\) and \(T^{(b)}\) with \(a<b\). Let blue be the smaller color and red the larger color. We define an interaction between the two tilings to be any instance of the local configuration

when the two tilings are superimposed on top of one another.
Remark 2.5
A k-tiling with these interactions is called the “white-pink” model in [8].
Now we can define the weights we use for k-tilings.
Definition 2.6
The weight of a k-tiling is
As usual we will study the probability measure on k-tilings where the probability of each k-tiling is proportional to its weight:
The partition function \(Z^{(k)}_{AD}(C_N,B_N;t)\) (the sum of weights over all states, as defined in (1)) can be written in a simple product form.
Theorem 2.7
([8]). The partition function \(Z^{(k)}_{AD}(C_N,B_N;t)\) of the k-tilings of the Aztec diamond of rank N is given by
Note that when \(t=1\) the tilings are independent and we have
that is, the partition function is a product of k copies of the partition function for a single tiling of the Aztec diamond, as one would expect. More surprisingly, when \(t=0\) we have
that is, the partition function of the k-tiling is equal to the partition function of a single tiling. See [8] for a bijective proof of this fact.

An example of a 3-tiling of the rank-3 Aztec diamond along with the corresponding particles. This k-tiling corresponds to the sequence of interlacing tuples of partitions: \(((0),(0),(0))\preceq ((2),(3),(1)) \succeq ' ((2),(2),(0))\preceq ((2,1),(2,0),(1,0)) \succeq ' ((1,0),(1,0),(0,0)) \preceq ((1,1,0),(1,0,0),(0,0,0)) \succeq ' ((0,0,0),(0,0,0),(0,0,0))\)
2.2.2 LLT Polynomials
While Schur polynomials were valuable in studying the single tilings of the Aztec diamond, for the k-tilings it is the LLT polynomials that are useful.
LLT polynomials are certain symmetric polynomials introduced by Lascoux, Leclerc, and Thibon [19] as the generating functions of semi-standard ribbon tableaux counting a spin statistic. Recently, a version of these polynomials called coinversion LLT polynomials were constructed as the partition function of a class of integrable lattice models [1, 9, 10, 13]. In [8], the authors used the lattice model formulation of the coinversion LLT polynomials to compute the partition function of the interacting k-tilings of the Aztec diamond that are the focus of this paper.
Here we collect the relevant definitions and properties of the coinversion LLT polynomials.
Let \(\varvec{\lambda }/\varvec{\mu } = (\lambda ^{(1)}/\mu ^{(1)},\ldots ,\lambda ^{(k)}/\mu ^{(k)})\) be a k-tuple of skew-partitions. Define \(\text {SSYT}(\varvec{\lambda }/\varvec{\mu }) = \text {SSYT}(\lambda ^{(1)}/\mu ^{(1)})\times \ldots \times \text {SSYT}(\lambda ^{(k)}/\mu ^{(k)})\) to be k-tuples of semi-standard Young tableaux. Given a k-tuple of semi-standard fillings \(\varvec{\sigma }\in \text {SSYT}(\varvec{\lambda }/\varvec{\mu })\), \(\varvec{\sigma } = (\sigma ^{1},\ldots ,\sigma ^{k})\), we draw them so that Young diagrams are aligned along content lines. See Example 2.8.
Example 2.8
Let \(\varvec{\lambda }/\varvec{\mu } = ((3,1), (2,2,2)/(1,1,1), (1), (2,1)/(2))\). Below is one possible semi-standard filling of \(\varvec{\lambda }/\varvec{\mu }\). The top row labels the contents of each diagonal line.

The green cells are an example of a coinversion triple with \(x=4\), \(y=4\), and \(z=\infty \). The yellow cells are an example of an strict coinversion triple with \(x=0\), \(y=2\), and \(z=7\).
Define a triple to be entries in the content aligned Young diagrams of the form

where
-
1.
y is an entry of \(\sigma ^{(a)}\) and x, z are entries in \(\sigma ^{(b)}\), with \(1\le a < b \le k\).
-
2.
y and z lie along the same content line.
We say that is a coinversion triple if
and a strict coinversion triple if
While y must be in the Young diagram of \(\lambda ^{(a)}/\mu ^{(a)}\), we let \(x=0\) and \(z=\infty \) if they are not in the Young diagram of \(\lambda ^{(b)}/\mu ^{(b)}\).
Define the coinversion LLT polynomial by
where the sum is over k-tuples of semi-standard Young tableaux with shapes given by \(\varvec{\lambda }/\varvec{\mu }\) and \(\text {coinv}(\varvec{\sigma })\) is the number of coinversion triples in the filling.
We will also need a ‘dual’ version of the polynomials. Define \(\mathcal {{\tilde{L}}}\) by
where the sum is over k-tuples of tableaux that are weakly increasing up columns and strictly increasing across rows, and \(\text {stcoinv}(\varvec{\sigma })\) counts the number of strict coinversion triples in the filling. Example 2.8 gives an example of both a coinversion and strict coinversion triple.
Example 2.9
Let \(\varvec{\lambda } = ((3),(2))\). The coinversion LLT polynomial in two variables \(x_1,x_2\) is given by
Note that when \(t=1\) we have
where
Remark 2.10
Note that here our notation differs slightly from that of [8]. Our \(\mathcal {{\tilde{L}}}\) are the same as their \({\mathcal {L}}^P\). Also, our \({\tilde{d}}(\varvec{\lambda }, \varvec{\mu })\) in the Cauchy identity, Prop. 2.12, is the same as their \(d^P(\varvec{\lambda }, \varvec{\mu })\). It can be written
The polynomials \({\mathcal {L}}\) and \(\mathcal {{\tilde{L}}}\) satisfy the following properties:
-
1.
They are symmetric in the \(x_i\).
-
2.
When \(k=1\) we have
$$\begin{aligned} \begin{aligned} {\mathcal {L}}_{\varvec{\lambda }/\varvec{\mu }}(X_n;t) =&s_{\lambda ^{(1)}/\mu ^{(1)}}(X_n) \\ \mathcal {{\tilde{L}}}_{\varvec{\lambda }/\varvec{\mu }}(X_n;t) =&s_{(\lambda ^{(1)}/\mu ^{(1)})'}(X_n). \end{aligned} \end{aligned}$$ -
3.
When \(t=1\) we have
$$\begin{aligned} \begin{aligned} {\mathcal {L}}_{\varvec{\lambda }/\varvec{\mu }}(X_n;1) =&\prod _{i=1}^k s_{\lambda ^{(i)}/\mu ^{(i)}}(X_n) \\ \mathcal {{\tilde{L}}}_{\varvec{\lambda }/\varvec{\mu }}(X_n;1) =&\prod _{i=1}^k s_{(\lambda ^{(i)}/\mu ^{(i)})'}(X_n). \end{aligned} \end{aligned}$$
In addition, we have the following propositions.
Proposition 2.11
(Branching rule, [13]). The \({\mathcal {L}}\) and \(\mathcal {{\tilde{L}}}\) satisfy the branching rules
Proposition 2.12
(Cauchy identity, [13]). The \({\mathcal {L}}\) and \(\mathcal {{\tilde{L}}}\) satisfy the Cauchy identity
where \({\tilde{d}}(\varvec{\lambda },\varvec{\nu })\) has an explicit formula given in Eq. (10).
If \(\varvec{\nu }=\varvec{\mu }=\varvec{0}\), then this simplifies to
See [13] for proofs of these properties via integrable vertex models.
Remark 2.13
Note that when \(k=1\) this reduces to the dual Cauchy identity for Schur polynomials.
We will also need the following definitions: The size of a k-tuple of partitions is denoted \(|\varvec{\lambda }|\) and is given by the sum of the sizes of each partition in the tuple. We say that two k-tuples of partitions \(\varvec{\lambda }\) and \(\varvec{\mu }\) (co-)interlace if for each \(i=1,\ldots , k\) we have that \(\lambda ^{(i)}\) and \(\mu ^{(i)}\) (co-)interlace. We write \(\varvec{\lambda } \succeq \varvec{\mu }\) or \(\varvec{\lambda } \succeq ' \varvec{\mu }\), for interlacing and co-interlacing, respectively.
To each k-tiling we associate partitions \(\varvec{\lambda }^{(i)} = (\varvec{\lambda }^{(i, 1)}, \dots , \varvec{\lambda }^{(i, k)})\), \(\varvec{\mu }^{(i)} = (\varvec{\mu }^{(i, 1)}, \dots , \varvec{\mu }^{(i, k)})\), \(i= 1, \dots , N\), where \(\varvec{\lambda }^{(i, a)}\) denotes the Maya diagram along slice \(2 i-1\) for color a, and \(\varvec{\mu }^{(i,a)}\) the Maya diagram along slice \(2 i - 2\). In order for a sequence of partitions to correspond to a valid tiling they must satisfy
See Fig. 5 for an example.
Proposition 2.14
([8]). In terms of the corresponding Maya diagrams
the weight of a k-tiling of the Aztec diamond of rank N can be written as
Note that when we have only a single variable, the LLT polynomials can be written
In particular, they are monomials. It will be useful in the proof of Prop. 3.9 to know precisely how each partition contributes to the powers of t in each of these monomials.
Lemma 2.15
Fix two colors \(b>a\) and consider the i-th row of color a in \(\varvec{\lambda }\).
-
1.
For the coinversion LLT polynomial \({\mathcal {L}}_{\varvec{\lambda }/\varvec{\mu }}(x;t)\), there is an interaction between this row and row j of color b whenever
$$\begin{aligned} \min (\varvec{\lambda }_j^{(b)}-j,\varvec{\lambda }_i^{(a)}-i) - \max (\varvec{\mu }_j^{(b)}-j,\varvec{\mu }_i^{(a)}-i) \ge 0 \end{aligned}$$in which case it contributes
$$\begin{aligned} \begin{aligned}&\min (\varvec{\lambda }_j^{(b)}-j,\varvec{\lambda }_i^{(a)}-i) - \max (\varvec{\mu }_j^{(b)}-j,\varvec{\mu }_i^{(a)}-i) \\&\qquad \qquad + {\textbf{1}}\{\varvec{\lambda }_j^{(b)}-j< \varvec{\lambda }_i^{(a)}-i \} \end{aligned} \end{aligned}$$(15)to the total power of t in \({\mathcal {L}}_{\varvec{\lambda }/\varvec{\mu }}(x;t)\).
-
2.
For the dual LLT polynomial \(t^{{\tilde{d}}(\varvec{\lambda },\varvec{\mu })} \mathcal {{\tilde{L}}}_{\varvec{\lambda }/\varvec{\mu }}(y;t)\), there is an interaction between this row and row j of color b whenever
$$\begin{aligned} \varvec{\lambda }_j^{(b)}-j = \varvec{\mu }_j^{(b)}-j+1 = \varvec{\mu }_i^{(a)}-i = \varvec{\lambda }_i^{(a)}-i \end{aligned}$$(16)in which case it contributes a single power of t to the total power of t in \(t^{{\tilde{d}}(\varvec{\lambda },\varvec{\mu })} \mathcal {{\tilde{L}}}_{\varvec{\lambda }/\varvec{\mu }}(y;t)\).
Proof
This follows from the discussion in Section 4.4 of [8]. \(\square \)
As with the single tiling of the Aztec diamond, we can associate to each k-tiling a particle configuration. In this case, we have particles of k colors, one for each tiling. For each color, the particles must satisfy the required interlacing conditions (5) and (6). Again, see Fig. 5 for an example.
3 Markov Chains on Colored Interlacing Arrays
In this section we define a Markov chain on colored interlacing particle arrays which will be equivalent to the shuffling algorithm under the identification between particle arrays and k-tilings described in Sect. 2. The essential ingredients are the Cauchy identities and branching rule for LLT polynomials. Using these, we apply a construction whose original form was introduced in [11], and which was further developed in the case of random tilings in [2, 3]. We first elaborate on the (well-known) construction in the one color Schur case, and then describe the corresponding generalization to the LLT case.
3.1 Markov Chains on Schur Processes
Recall that under the bijection to interlacing partitions, the probability measure on domino tilings becomes
As mentioned in Remark 2.3, this is an example of a Schur process. Now we introduce transition kernels which are building blocks for Markov chains that map Schur processes to other Schur processes. For generalizations of this construction and more details, see [3, 4] and references therein.
Suppose that \(b, c_1,c_2,\dots \) are positive real numbers, and denote the tuple \(c_{[1,k]} = (c_1,\dots , c_k)\). Define transition probabilities by
where
which can be computed by the Cauchy identity.
We have, by the dual skew-Cauchy identity (3) and the branching rule (2), respectively,
Note that \(p^{\uparrow }_{\lambda \rightarrow \mu }\) is nonzero only if \(\lambda \subset \mu \) and we view this as the partition growing from \(\lambda \) to \(\mu \). Similarly, \(p^{\downarrow }_{\lambda \rightarrow \mu }\) is nonzero only if \(\mu \subset \lambda \) and we view this as the partition shrinking.
A key property of the transition kernels \(p^{\uparrow }, p^{\downarrow }\) is their commutation:
This property also follows from the skew-Cauchy and branching identities.
Using these, we will define transition probabilities out of which our Markov chain will be built. Now, let \(c_1,\dots , c_N, b_1,\dots , b_N\) be positive real numbers. Define \(c_{[i, j]} {:}{=}(c_i,\dots , c_j)\). Given partitions \(\lambda \) and \(\nu \), define the transition probabilities to a new partition \({\tilde{\lambda }}\) by
With this we can describe a Markov chain acting on the set of sequences of partitions
Definition 3.1
(Schur parallel update [3]). Given a sequence of partitions interlaced as above, the transition probabilities for updates \(\mu ^{(k)} \rightarrow {\tilde{\mu }}^{(k)}\) and \(\lambda ^{(k)} \rightarrow {\tilde{\lambda }}^{(k)}\) are defined as follows:
-
1.
For each \(k =2, \dots , N+1\), set \({\tilde{\mu }}^{(k)} = \lambda ^{(k-1)}\).
-
2.
For each \(k =1, \dots , N+1\), update \(\lambda ^{(k)} \rightarrow {\tilde{\lambda }}^{(k)}\) with transition probabilities
$$\begin{aligned} \tilde{P}_k({\tilde{\lambda }}^{(k)} | \lambda ^{(k)},{\tilde{\mu }}^{(k)})\;. \end{aligned}$$
Now we note that we may write the Schur process corresponding to a rank-N domino tiling of the Aztec diamond as
This form is useful in the following proposition.
Proposition 3.2
([3]). Suppose \(\lambda ^{(1)},\mu ^{(2)}, \lambda ^{(2)}, \ldots ,\mu ^{(N)},\lambda ^{(N)}\) are sampled from the Schur process
and suppose \(\mu ^{(N+1)} = \lambda ^{(N+1)} = \emptyset \) deterministically.
Then after the Schur parallel update, the updated partitions
are distributed according to the Schur process
Remark 3.3
This proposition is a special case of well-known facts (again see e.g., [3, 4]), but we include a proof for clarity of exposition, and in particular because this proof generalizes immediately to the multi-colored case.
Proof
Using Eq. (18), we must show
Indeed, first note that since \({\tilde{\mu }}^{(i)}=\lambda ^{(i-1)}\) deterministically, we are not summing over the \(\lambda ^{(i)}\). In particular, the numerators of the transition probability \(\prod _{n=1}^{N+1} \tilde{P}_n({\tilde{\lambda }}^{(n)} | \lambda ^{(n)},{\tilde{\mu }}^{(n)})\) are
and thus can be pulled out of the sum. Moreover, this product is exactly the Schur process we desire. We are left to show that the denominator of the transition probabilities cancels with what remains in the numerator.
Consider the sum over \(\mu ^{(2)}\). The relevant term is
Using the commutation relation (17) we have
This is precisely the denominator of \(\tilde{P}_2\) and we see that the terms cancel.
More generally, for \(k = 2, \dots , N+1\), one can see that the sum over \(\mu ^{(k)}\) cancels with the denominator of \(\tilde{P}_k\) through the commutation relation
\(\square \)
Computing the transition probabilities in terms of particle positions
respectively, one observes that we can define the Schur parallel update in terms of the particles as follows:
-
1.
For each \(n =2, \dots , N+1\), set \(\tilde{y}^{(n)} = x^{(n-1)}\).
-
2.
For each \(n =1, \dots , N+1\), update \(x^{(n)} \rightarrow \tilde{x}^{(n)}\) according to the rules:
-
If either \(\tilde{x}_i^{(n)} = x_i^{(n)}\) or \(\tilde{x}_i^{(n)} = x_i^{(n)}+1\) is forced in order to preserve interlacing with \(\tilde{y}^{(n)}\), then transition accordingly with probability 1.
-
Otherwise,
$$\begin{aligned} \tilde{x}^{(n)}_i = {\left\{ \begin{array}{ll} x^{(n)}_i + 1 &{} \text { with probability } \frac{c_k b_{N-k+2}}{1 + c_k b_{N-k+2}} \\ x^{(n)}_i &{} \text { otherwise } \end{array}\right. }. \end{aligned}$$
These transitions are independent for \(1 \le i \le n \le N+1\).
-
Remark 3.4
That the Markov chain has this form follows from the discussion of the Aztec diamond shuffling algorithm in [3]. It will also follow from our generalization to multiple colors in the next section.
Now we have the following proposition, which follows directly from Proposition 3.2.
Proposition 3.5
Let \(x^{(1)}, y^{(2)}, \dots , x^{(N-1)}, y^{(N)}, x^{(N)}, x^{(N+1)}, y^{(N+1)}\) be a random array of interlaced particles such that \(x^{(1)}, y^{(2)}, \dots , x^{(N-1)}, y^{(N)}, x^{(N)}\) are sampled according to the Schur process
and
deterministically. Then after the Schur parallel update, the particles \(\tilde{x}^{(n)}\), \(\tilde{y}^{(n)}\), \(n= 1,\dots , N+1\), are distributed according to
3.2 Markov Chains on LLT Processes
Now we generalize the Markov chain above to a Markov chain on k-tuples of interlacing partitions. While the definition in terms of interlacing partitions will follow directly from machinery of LLT polynomials, the interpretation as particle dynamics will require careful computation.
Let \(c_1,\dots , c_N, b_1,\dots , b_N \in {\mathbb {R}}_{> 0}\). Define the LLT process to be a probability measure on arrays of tuples of partitions given by
Recall that this probability measure describes random k-tilings (Proposition 2.14).
The transition kernels from which we will build the Markov chain are, for \(c = (c_1,\dots , c_l)\) and \(b, c' \in {\mathbb {R}}\),
These transition kernels satisfy a similar commutation relation to Equation (17):
Proposition 3.6
In the exact same way as in the Schur case, we can write the LLT process as
We define the following update step that we will use for transitioning from rank N to rank \((N + 1)\).
Definition 3.7
(LLT parallel update). Suppose we are given a k-tuple of sequences of interlaced partitions
The transition probabilities for updates \(\varvec{\mu }^{(k)} \rightarrow \tilde{\varvec{\mu }}^{(k)}\) and \(\varvec{\lambda }^{(k)} \rightarrow \tilde{\varvec{\lambda }}^{(k)}\) are defined as follows:
-
1.
For each \(n =2, \dots , N+1\), set \(\tilde{\varvec{\mu }}^{(n)} = \varvec{\lambda }^{(n-1)}\).
-
2.
For each \(n =1, \dots , N+1\), update \(\varvec{\lambda }^{(n)} \rightarrow \tilde{\varvec{\lambda }}^{(n)}\) with transition probabilities
$$\begin{aligned} \tilde{P}_n(\tilde{\varvec{\lambda }} | \varvec{\lambda },\tilde{\varvec{\mu }}) {:}{=}\frac{ p^{\uparrow }_{\varvec{\lambda }\rightarrow \tilde{\varvec{\lambda }}}(c_{[1,n]} |b_{N-n+2}) p^{\downarrow }_{\tilde{\varvec{\lambda }} \rightarrow \tilde{\varvec{\mu }}}(c_{[1,n-1]}|c_{n})}{ \sum _{\kappa } p^{\uparrow }_{\varvec{\lambda }\rightarrow \varvec{\kappa }}(c_{[1,n]}|b_{N-n+2}) p^{\downarrow }_{\varvec{\kappa } \rightarrow \tilde{\varvec{\mu }}}(c_{[1,n-1]}|c_{n})}\;. \end{aligned}$$
As in the Schur case we have
Proposition 3.8
Suppose \(\varvec{\lambda }^{(1)},\varvec{\mu }^{(2)}, \varvec{\lambda }^{(2)}, \ldots ,\varvec{\mu }^{(N)},\varvec{\lambda }^{(N)}\) are sampled from the LLT process
and suppose \(\varvec{\mu }^{(N+1)} = \varvec{\lambda }^{(N+1)} = {\textbf{0}}\) deterministically.
Then after the LLT parallel update the new partitions
are distributed according to the LLT process
Proof
By writing the LLT process as in Equation (21) and using the commutation relations (20), we may exactly reuse the calculation from the proof of Proposition 3.2, replacing each \(\lambda ^{(i)}, \mu ^{(i)}, {\tilde{\lambda }}^{(i)}, {\tilde{\mu }}^{(i)}\) there with \(\varvec{\lambda }^{(i)}, \varvec{\mu }^{(i)}, \tilde{\varvec{\lambda }}^{(i)}, \tilde{\varvec{\mu }}^{(i)}\) here. \(\square \)
Through our bijection between interlacing tuples of partitions and multi-colored interlacing particle arrays we can view the Markov chain on LLT processes as dynamics on our particles. In the following proposition we compute the transition probabilities in this chain in terms of the corresponding interlacing particle arrays. See Fig. 6 for an example of the particle jump probabilities along one row and see Fig. 7 for an example of the full particle update.
Proposition 3.9
Let
be a random sequence of tuples of partitions sampled from the LLT process (19), and choose \( \varvec{\lambda }^{(N+1)} = \varvec{\mu }^{(N+1)} = \varvec{0} \) deterministically. These correspond to particles at positions
Let
be the sequence of tuples of partitions after the update, corresponding to particle positions
Then the dynamics on the multi-colored interlacing particle arrays defined below is equivalent to the LLT parallel update defined in Definition 3.7.
For each \(n = 1, \dots , N+1\), update the particles as follows:
-
1.
If \(n \ge 2\), set \(\tilde{{\textbf{y}}}^{(n)} = \varvec{x}^{(n-1)}\) deterministically.
-
2.
Given \( \varvec{x}^{(n)}\) and \(\tilde{{\textbf{y}}}^{(n)}\), \(\tilde{\varvec{x}}^{(n)}\) can be sampled according to the following rules:.
For each \(l = 1,\dots , k\)
-
If \(\varvec{x}^{(n, l)}_i = \tilde{{\textbf{y}}}^{(n, l)}_i-1\) then
$$\begin{aligned} \tilde{\varvec{x}}^{(n, l)}_i = \varvec{x}^{(n, l)}_i+1 \end{aligned}$$with probability 1.
-
If \(\varvec{x}^{(n, l)}_i = \tilde{{\textbf{y}}}^{(n, l)}_{i-1}-1\) then
$$\begin{aligned} \tilde{\varvec{x}}^{(n, l)}_i = \varvec{x}^{(n, l)}_i \end{aligned}$$with probability 1.
-
Otherwise,
$$\begin{aligned} \tilde{\varvec{x}}^{(n, l)}_i = {\left\{ \begin{array}{ll} \varvec{x}^{(n, l)}_i + 1 &{} \text { with probability } \frac{c_n b_{N-n+2}t^{\#_i(n,l)}}{1 + c_n b_{N-n+2}t^{\#_i(n,l)}} \\ \varvec{x}^{(n, l)}_i &{} \text { otherwise } \end{array}\right. } \end{aligned}$$
where
 (22)
(22)These transitions are independent for each \(1 \le i \le n \le N+1\), \(1 \le l \le k\). In (22), we allow \(j = 1,\dots , n\), and we use the convention that \(\varvec{\tilde{y}}_n^{(n, m)} = -n + 1/2\).
-

Proof
First let us recall that for the Markov chain on LLT processes, at level n the transition probabilities are proportional to the product of the transition kernels
To simplify notation, in what follows we let \(c = c_n, b = b_{N-n+2}\), and \(\tilde{\varvec{\lambda }} =\varvec{{\tilde{\lambda }}}^{(n)}, \varvec{\lambda } = \varvec{\lambda }^{(n)},\tilde{\varvec{\mu }} = \tilde{\varvec{\mu }}^{(n)}\). We see that the probability of a particular \(\tilde{\varvec{\lambda }} \) under \(\tilde{P}_n(\tilde{\varvec{\lambda }} | \varvec{\lambda },\tilde{\varvec{\mu }}) \) is proportional to
where we have only kept factors depending on \(\tilde{\varvec{\lambda }}\).
It is not hard to see from the definition of LLT polynomials that the quantity \(\tilde{{\mathcal {L}}}_{\tilde{\varvec{\lambda }}/\varvec{\lambda }}(b;t)\) will be 0 unless \(\varvec{{\tilde{\lambda }}}\) corresponds to a configuration where all particles jump by at most 1. Furthermore, if \(\varvec{\lambda }, \varvec{{\tilde{\mu }}}\) correspond to a particle configuration where there are particles forced to jump or stay, then \({\mathcal {L}}_{\tilde{\varvec{\lambda }}/\tilde{\varvec{\mu }}}(c;t)\) will be 0 unless \(\tilde{\varvec{\lambda }}\) corresponds to a configuration where all of these particles do in fact jump or stay. Therefore, the possible k-tuples \(\varvec{{\tilde{\lambda }}}\) correspond exactly to the possible outcomes of particle jumps in the proposition.
Thus, to prove the proposition, it suffices to show that for these k-tuples \(\varvec{{\tilde{\lambda }}}\), the ratios of their transition probabilities are equal to the ratios of the particle transition probabilities described in the proposition. It is enough to compare the ratio for pairs of \(\tilde{\varvec{x}}\) which differ by a single non-forced particle jump, as any ratio of the particle transition probabilities can be written as a product of such simple ratios. For concreteness, suppose the jump was made by particle i of color l.
Two particle configurations differing by a single particle jump are equivalent to two tuples of partitions differing by the corresponding single cell in one of their Young diagrams. Define \(\varvec{\delta }(l, i) = (\varvec{\delta }(l, i)^{(1)}, \dots , \varvec{\delta }(l, i)^{(k)})\), where
From the above discussion, we see that we must show that
where \(\#_i(n,l)\) is defined in (22), and \(\tilde{ \varvec{\lambda }}^{(l)}_i = \varvec{\lambda }^{(l)}_i\).
To show that the powers of c and b are correct in the equality (23), recall Eq. (14): for LLT polynomials with a single variable we have
Since the Young diagram of \((\tilde{\varvec{\lambda }} + \varvec{\delta }(l, i))/\varvec{\lambda }\) has exactly one more cell than that of \(\tilde{\varvec{\lambda }} /\varvec{\lambda }\), the numerator will have exactly one extra factor of b, and similarly one extra factor of c.
We are left to show the powers of t match on both sides of (23). The powers of t on the LHS of (23) come from two sources: interactions between color l and colors \(m>l\), and interactions between color l and colors \(m<l\). We show in detail that the contributions when the color m is larger give exactly the first term in (22). A similar analysis can be done to show that the contributions when the color m is smaller give the second term in (22).
Looking at the first term of (22), note the particle position inequalities
can be written in terms of the parts of the partitions as
We will show that in the LHS of (23) we get an extra power of t in the numerator that is not present in the denominator exactly when there exists an m and j where the above inequality holds.
To do so we do an exhaustive check over all possible relative positions of the corresponding particles and in each case use Lemma 2.15 to determine the powers of t on the LHS of (23). This casework is listed below:
-
1.
If \(\tilde{\varvec{\lambda }}_j^{(m)}-j > \tilde{\varvec{\lambda }}_i^{(l)}-i\) and \(\tilde{\varvec{\mu }}_j^{(m)}-j \ge \tilde{\varvec{\mu }}_i^{(l)}-i\) there are three subcases for the contribution from Eq. (15):
-
1.
If \(\tilde{\varvec{\lambda }}_i^{(l)}-i \ge \tilde{\varvec{\mu }}_j^{(m)}-j\) then there is a power of \(t^{\tilde{\varvec{\lambda }}_i^{(l)}-i +1 - \tilde{\varvec{\mu }}_j^{(m)}+j}\) in the numerator and \(t^{\tilde{\varvec{\lambda }}_i^{(l)}-i - \tilde{\varvec{\mu }}_j^{(m)}+j}\) in the denominator.
-
2.
If \(\tilde{\varvec{\lambda }}_i^{(l)}-i +1 = \tilde{\varvec{\mu }}_j^{(m)}-j\) then there is a power of \(t^0\) in the numerator and no contribution to the denominator.
-
3.
If \(\tilde{\varvec{\lambda }}_i^{(l)}-i + 1 < \tilde{\varvec{\mu }}_j^{(m)}-j\) there is no contribution to either the numerator or the denominator.
For the contribution of Eq. (16), note there is no contribution to the denominator since \(\tilde{\varvec{\lambda }}_j^{(m)}-j \ne \tilde{\varvec{\lambda }}_i^{(l)}-i\). In the numerator there is no contribution since \(\varvec{\lambda }_i^{(l)}-i \ne \tilde{\varvec{\lambda }}_i^{(l)}-i + 1\). Overall, we get a net power of t in the ratio in case (a) and none in the other cases.
-
1.
-
4.
If \(\tilde{\varvec{\lambda }}_j^{(m)}-j > \tilde{\varvec{\lambda }}_i^{(l)}-i\) and \(\tilde{\varvec{\mu }}_j^{(m)}-j < \tilde{\varvec{\mu }}_i^{(l)}-i\), note that we must have \(\tilde{\varvec{\lambda }}_i^{(l)}-i \ge \tilde{\varvec{\mu }}_i^{(l)}-i\). Then from Eq. (15) we get a \(t^{\tilde{\varvec{\lambda }}_i^{(l)} - i - \tilde{\varvec{\mu }}_i^{(l)}+i}\) in the denominator and a \(t^{\tilde{\varvec{\lambda }}_i^{(l)}+1 - i - \tilde{\varvec{\mu }}_i^{(l)}+i}\) in the numerator. Equation (16) does not contribute to either for the same reason as in case 1. Overall, we have a net power of t in the ratio.
-
5.
If \(\tilde{\varvec{\lambda }}_j^{(m)}-j < \tilde{\varvec{\lambda }}_i^{(l)}-i\) and \(\tilde{\varvec{\mu }}_j^{(m)}-j \ge \tilde{\varvec{\mu }}_i^{(l)}-i\) then from Eq. (15) we get a \(t^{\tilde{\varvec{\lambda }}_j^{(m)} - j - \tilde{\varvec{\mu }}_j^{(m)}+j + 1}\) in both the numerator and the denominator. Equation (16) does not contribute to either, again, for the same reason as in case 1. Overall, there is no net power of t in the ratio.
-
6.
If \(\tilde{\varvec{\lambda }}_j^{(m)}-j < \tilde{\varvec{\lambda }}_i^{(l)}-i\) and \(\tilde{\varvec{\mu }}_j^{(m)}-j < \tilde{\varvec{\mu }}_i^{(l)}-i\) then for the contribution from Eq. (15) we have two subcases:
-
1.
If \(\tilde{\varvec{\lambda }}_j^{(m)}-j\ge \tilde{\varvec{\mu }}_i^{(l)}-i\) then we get a \(t^{\tilde{\varvec{\lambda }}_j^{(m)} - j - \tilde{\varvec{\mu }}_i^{(l)}+i +1}\) in both the numerator and the denominator.
-
2.
Otherwise, there is no contribution to either.
Equation (16) still does not contribute to either for the same reasons as above. Overall there is no net power of t in the ratio.
-
1.
-
3.
If \(\tilde{\varvec{\lambda }}_j^{(m)}-j = \tilde{\varvec{\lambda }}_i^{(l)}-i\) and \(\tilde{\varvec{\mu }}_j^{(m)}-j \ge \tilde{\varvec{\mu }}_i^{(l)}-i\) then from Eq. (15) we get a \(t^{\tilde{\varvec{\lambda }}_j^{(m)} - j - \tilde{\varvec{\mu }}_j^{(m)}+j }\) in the denominator and a \(t^{\tilde{\varvec{\lambda }}_j^{(m)} - j - \tilde{\varvec{\mu }}_j^{(m)}+j +1}\) in the numerator. Here the extra power of t in the numerator comes from the indicator \({\textbf{1}}\{\tilde{\varvec{\lambda }}_j^{(m)}-j < \tilde{\varvec{\lambda }}_i^{(l)}-i+1\}\) in (15). Note that (16) does not contribute to the numerator as \(\tilde{\varvec{\lambda }}_j^{(m)}-j \ne \tilde{\varvec{\lambda }}_i^{(l)}-i+1\). The contribution from Eq. (16) to the denominator can be split into two subcases:
-
1.
If \(\tilde{\varvec{\lambda }}_j^{(m)} - j = \varvec{\lambda }_j^{(m)}-j+1\), it contributes a single power of t to the denominator.
-
2.
Otherwise, it contributes nothing to the denominator.
Overall, there is no net power of t in the ratio if \(\tilde{\varvec{\lambda }}_j^{(m)} - j = \varvec{\lambda }_j^{(m)}-j+1\), and a net power of t otherwise.
-
1.
-
3.
If \(\tilde{\varvec{\lambda }}_j^{(m)}-j = \tilde{\varvec{\lambda }}_i^{(l)}-i\) and \(\tilde{\varvec{\mu }}_j^{(m)}-j < \tilde{\varvec{\mu }}_i^{(l)}-i\), note that we must have \(\tilde{\varvec{\lambda }}_j^{(m)}-j \ge \tilde{\varvec{\mu }}_i^{(l)}-i\). Then for the contribution from Eq. (15) we get a \(t^{\tilde{\varvec{\lambda }}_j^{(m)} - j - \tilde{\varvec{\mu }}_i^{(l)}+i }=1\) in the denominator and a \(t^{\tilde{\varvec{\lambda }}_j^{(m)} - j - \tilde{\varvec{\mu }}_i^{(l)}+i +1}=t\) in the numerator. Equation (16) does not contribute to the numerator for the same reason as in case 5. The contribution to the denominator from Eq. (16) can be split into two subcases:
-
1.
If \(\tilde{\varvec{\lambda }}_j^{(m)} - j = \varvec{\lambda }_j^{(m)}-j+1\), it contributes a single power of t to the denominator.
-
2.
Otherwise, it contributes nothing to the denominator.
Overall, there is no net power of t in the ratio if \(\tilde{\varvec{\lambda }}_j^{(m)} - j = \varvec{\lambda }_j^{(m)}-j+1\), and a net power of t otherwise.
-
1.
One can check the ratio of the powers of t is given by
exactly as we desired. Summing over all \(m>l\) and all j gives the first term in Eq. (22).
\(\square \)

Shown is a possible configuration of particles of the Maya diagrams on diagonals 2, 3 and 4, after step one of the update. We use the convention blue \( = 1<\) red \(= 2<\) green \( = 3\). The solid red arrow denotes a forced jump for the red particle to preserve the interlacing of the red particles. Supposing we have \(c_i = b_i \equiv 1\), the dashed red arrow denotes a jump which will happen with probability \(\frac{t^2}{1 + t^2}\), because \(\varvec{\tilde{y}}_2^{(2, 1)} \le \varvec{x}_2^{(2, 2)}+1 \le \varvec{x}_2^{(2, 1)}\) and \(\varvec{\tilde{y}}_2^{(2, 3)} \le \varvec{x}_2^{(2, 2)} \le \varvec{x}_2^{(2, 3)}\). Similarly, the dashed green arrow denotes a jump which has probability \(\frac{t}{1 + t}\) (color figure online)
As a simple example of the particle dynamics, one may set all parameters \(b_i\),\(c_i\) equal to 1 and consider \(\varvec{x}^{(1)}\), that is, the bottom level of particles. Along this row we have exactly one particle of each color, and the marginal evolution of these particles is itself a Markov chain. At each step each particle independently either stays in place or jumps by 1 to the right. The probability for the particle of color l, at position \(\varvec{x}_1^{(1, l)}\), to jump is
where
In other words, if at time T particles are ordered \(0,1,\dots , n-1\) from right to left, breaking ties by putting larger colors first, the jump probability of particle i is \(\frac{t^i}{1 + t^i}\). When \(t<1\), we see that if a particle falls behind the other it becomes discouraged and moves more slowly, while for \(t>1\) it becomes determined to catch up and moves more quickly.

Here we illustrate one possibility for the random update of the particle configuration of the \(k = 3\)-tiling of size \(N = 3\) shown in Fig. 5. First, shown is the initial configuration, augmented with an extra empty tuple of Maya diagrams. Second, the particles are shown after both step 1 and the forced jumps of step 2. Finally, one possible outcome of step 2 is shown
4 Shuffling
In this section we show how the particle dynamics defined in Sect. 3 can be described as an algorithm which acts directly on the tilings by sliding, destroying, and creating dominos. In the one color case, this is known as the domino shuffling algorithm [12, 23].
4.1 Interpretation in Terms of Dominos: Schur Case
Domino shuffling is a sampling algorithm to generate a random rank-N domino tiling. Via the bijection between tilings and interlacing particle arrays, the particle dynamics defined in Sect. 3.1 coincides with the shuffling algorithm. Here we will review the shuffling algorithm, and refer the reader to Propp [23] for more details.
Recall that we assign weights \(c_i\) to the horizontal dominos on the diagonal slice \(2 i - 1\), and \(b_{N-i+1}\) to the horizontal dominos on slice 2i, respectively, for \(i = 1,\dots , N\). Take two additional numbers \(c_{N+1}, b_{N+1}\). We now describe a way to randomly sample a tiling of rank \(N+1\) given one of rank N, such that if the original one is sampled with weights \((c_1, \dots , c_N), (b_N, \dots , b_1)\), the one obtained from the algorithm will be sampled with weights \((c_1, \dots , c_{N+1}), (b_{N+1}, \dots , b_1)\).
Given the checkerboard coloring of the squares of rank-N Aztec diamond, recall that there are four types of dominos which can appear in a tiling. They are shown in Fig. 1. Label these four types of dominos as S (South), W (West), N (North), E (East), respectively. Given a tiling T of rank N, following three steps will lead to a tiling \(T'\) of rank \(N+1\):
-
1.
(Sliding) S dominos slide one unit South, W dominos slide one unit West, N dominos slide one unit North, and E dominos slide one unit East
-
2.
(Destruction) If two dominos cross each other’s path as they slide, both are destroyed and deleted from the tiling.
-
3.
(Creation) What remains will be a partial tiling of rank \(N+1\). The un-tiled portion will be a disjoint union of \(2 \times 2\) blocks (in a unique way). Fill in each \(2 \times 2\) block independently with either a vertical pair or a horizontal pair of dominos, with probabilities
$$\begin{aligned} \text { vertical: }&\;\; \frac{1}{1 + c_i b_{N-i+2} }\\ \text { horizontal: }&\;\; \frac{c_i b_{N-i+2}}{1 + c_i b_{N-i+2}} \end{aligned}$$where here \(2 i - 1\) is the diagonal of the lower left square in the block, with respect to the indexing of diagonals on the rank-\((N+1)\) Aztec diamond.
The correspondence of the shuffling algorithm to the particle process is well-known [3]. The following facts, from which the equivalence of shuffling and the particle transition probabilities can be deduced, will be useful for us in the next section:
-
Slides west correspond to a particle being forced to stay.
-
Slides north correspond to a particle being forced to jump.
-
Creations correspond to a particle which can either stay or jump.
For an example, see the red tiling and red particles in Fig. 7.
4.2 Interpretation in Terms of Dominos: LLT Case
We now state the analogous shuffling algorithm corresponding to the LLT particle process.
Theorem 4.1
The following algorithm generates a random k-tiling of the rank-N Aztec diamond with probability proportional to its weight.
Algorithm: Start with a rank-0 Aztec diamond. To get from a rank-\((T-1)\) to rank-T k-tiling,
-
1.
Slide and destroy as in the normal domino shuffle, independently for each color.
-
2.
Fill in empty \(2\times 2\) squares according to the rule:
-
1.
For the smallest color put a horizontal pair of dominoes with probability
$$\begin{aligned} \frac{c_i b_{N-i+2} t^{\#_1(1)}}{1+c_i b_{N-i+2} t^{\#_1(1)}} \end{aligned}$$where

where here 2i is the diagonal of the lower left square in the block, otherwise put a vertical pair. Do all of these first.
-
2.
Now do all the larger colors from smallest to largest. For color \(l>1\), put a horizontal pair of dominoes with probability
$$\begin{aligned} \frac{c_i b_{N-i+2} t^{\#_1(l)+\#_2(l)}}{1+c_i b_{N-i+2} t^{\#_1(l)+\#_2(l)}} \end{aligned}$$where

and \(\#_1(l)\) is as in part (a), otherwise put a vertical pair.
This gives a k-tiling of the Aztec diamond whose rank has increased by one.
-
1.


Repeat steps (1) and (2) until you get a rank-N Aztec diamond.
Proof
It suffices to show that the update step corresponds to the update of tuples of interlacing arrays of particles described in Proposition 3.9. For each color, the transition probabilities only differ from those of the usual domino shuffling algorithm through the creation probabilities. As in the one color domino shuffling, creations correspond to particles which can jump or stay, with creation of a horizontal pair corresponding to a particle jumping by 1 and creation of a vertical pair corresponding to staying. It is enough to show that the power of t in the creation step described above corresponds to the power of t in the jump probability of the particle process.
Consider a color l, and a larger color m, which we represent by blue and red, respectively. Suppose that we are doing a creation for color l and in that \(2 \times 2\) box the red configuration looks like one of the three configurations given in the definition of \(\#_1\) in the theorem statement. Given these domino configurations, we can give the possibilities for the corresponding red and blue particle configurations. These are shown in Fig. 8. Note that in each case the particle configuration contributes a power of t to the blue particle’s jump probability in (22). On the other hand, it is also clear from Fig. 8 that these are all of the possible cases in which red particles contribute a power of t to the blue particle’s jump probability in (22).

Three cases in which the dominos of a larger color m (in red) contribute a factor of t to the creation probabilities of a smaller color l (in blue). In each case we also show the relative positions of the blue particle, which is jumping, with the nearby red particles whose positions lead to the contribution of the power of t. We use the same notation as in Proposition 3.9; in particular, \(\varvec{x}^{(n, l)}_{i}\) and \(\varvec{x}^{(n, m)}_{j}\) denote the blue and red particles in the \(x^{(n)}\) diagonal before the update. By the update rules for \(\varvec{y}\) particles (c.f. Proposition 3.9), these agree with the particle positions \(\varvec{\tilde{y}}^{(n+1,l)}_{i}\) and \( \varvec{\tilde{y}}^{(n+1,m)}_{j}\) in the \(y^{(n+1)}\) diagonal after the update, which are shown in the figure. Note that the figures are still valid if \(j = n\); in this case the bottom-most red particle would be off of the Aztec diamond. The dashed blue circle indicates where the blue particle would be if it does not jump, the solid blue circle indicates where the particle would be if it jumped (color figure online)
Now consider a color l, and a smaller color m, which we represent by red and blue, respectively (so again blue is the smaller color, but now red is the color whose transition probability we are discussing). Suppose that we are doing a creation for the red dominos in a \(2 \times 2\) box, and that the blue dominos there look like one of the two configurations in the definition of \(\#_2\) in the theorem statement. Then the possibilities for the corresponding red and blue particle configurations are shown in Fig. 9. Again we see that one of these cases occurs if and only if the red particle’s transition probability obtains a power of t from blue in (22).

Four cases in which the smaller color m (in blue) contributes a factor of t to the creation probability of a larger color l (in red). Similarly to Fig. 8, we use \(\varvec{x}_i^{(n,l)}, \varvec{x}_j^{(n,m)}\) to denote particle positions of the \(x^{(n)}\) diagonal at the previous time step, which agree with the particle positions \(\varvec{\tilde{y}}^{(n+1)}\) of the \(y^{(n+1)}\) diagonal at the next time step. The dashed red circle indicates where the red particle would be if it does not jump, the solid red circle indicates where the particle would be if it jumped (color figure online)
As a result, the powers of t that we pick up from \(\#_1(l) + \#_2(l)\) are exactly the powers of t described in Proposition 3.9.
\(\square \)
5 Conclusion
In this article we generalize the domino shuffling algorithm for tilings of the Aztec diamond to shuffling algorithm for interacting k-tilings studied in [8]. We present this algorithm in a variety of ways:
-
1.
As a Markov chain on LLT processes, which generalize the well-studied Schur processes.
-
2.
As a sequence of local moves on the dominos themselves.
-
3.
And through a generalization of the ‘spider move’ on the underlying dimer models (see Appendix A).
It is intriguing that despite the increased complexity of the k-tilings compared to standard tilings of the Aztec diamond, the shuffling algorithm remains very familiar. In terms of moves on the dominos, the increase in complexity is confined only to how new pairs of dominos are created. This has interesting combinatorial consequences. In fact, it can be used to give a alternate proof that the partition function of the k-tilings of rank N is given by \(Z^{(k)}_{AD} = \left( 2(1+t)\right) ^{\left( {\begin{array}{c}N+1\\ 2\end{array}}\right) }\).
Using this shuffling algorithm allows fast sampling of the k-tilings. In simulations one finds that these k-tilings appear to show very interesting asymptotic features, including the presence of arctic curves and limit shapes. See Appendix B. One might hope that, just as for the standard tilings of the Aztec diamond, the shuffling algorithm may in the future be useful in the study of this asymptotic behavior.
References
Aggarwal, A., Borodin, A., Wheeler, M.: Colored fermionic vertex models and symmetric functions. arXiv:2101.01605 (2021)
Borodin, A., Ferrari, P.L.: Anisotropic growth of random surfaces in 2+1 dimensions. Commun. Math. Phys. 325, 603–684 (2014). arXiv:0804.3035 [math-ph]
Borodin, A., Ferrari, P.L.: Random tilings and Markov chains for interlacing particles. Markov Process. Relat. Fields 24(3), 419–451 (2018)
Borodin, A., Gorin, V.: Lectures on integrable probability. In: Probability and Statistical Physics in St. Petersburg, volume 91 of Proceedings of Symposia in Pure Mathematics, pp. 155–214. AMS (2016). arXiv:1212.3351 [math.PR]
Boutillier, C., Bouttier, J., Chapuy, G., Corteel, S., Ramassamy, S.: Dimers on rail yard graphs. Ann. Inst. Henri Poincaré D 4(4), 479–539 (2017)
Bouttier, J., Chapuy, G., Corteel, S.: From Aztec diamonds to pyramids: steep tilings. Trans. Am. Math. Soc. 369(8), 5921–5959 (2017)
Chhita, S., Toninelli, F.L.: A (2 + 1)-dimensional anisotropic KPZ growth model with a smooth phase. Commun. Math. Phys. 367(2), 483–516 (2019)
Corteel, S., Gitlin, A., Keating, D.: Colored vertex models and \(k\)-tilings of the aztec diamond. arXiv:2202.06020 [math.CO] (2022)
Corteel, S., Gitlin, A., Keating, D., Meza, J.: A vertex model for LLT polynomials. Int. Math. Res. Not. rnab165 (2021)
Curran, M.J., Frechette, C., Yost-Wolff, C., Zhang, S.W., Zhang, V.: A lattice model for super LLT polynomials. arXiv:2110.07597 (2021)
Diaconis, P., Fill, J.: Strong stationary times via a new form of duality. Ann. Probab. 18, 1483–1522 (1990)
Elkies, N., Kuperberg, G., Larsen, M., Propp, J.: Alternating-sign matrices and domino tilings. I. J. Algebraic Combin. 1(2), 111–132 (1992)
Gitlin, A., Keating, D.: A vertex model for supersymmetric LLT polynomials. arXiv:2110.10273 (2021)
Goncharov, A.B., Kenyon, R.: Dimers and cluster integrable systems. Ann. Sci. Éc. Norm. Supér. (4) 46(5), 747–813 (2013)
Janvresse, E., de la Rue, T., Velenik, Y.: A note on domino shuffling. Electron. J. Comb. 13(1):Research Paper R30, 20 (2006)
Jockusch, W., Propp, J., Shor, P.: Random domino tilings and the arctic circle theorem. arXiv:hep-th/9801068 (1998)
Johansson, K.: Non-intersecting paths, random tilings and random matrices. Probab. Theory Relat. Fields 123(2), 249–260 (2002)
Kenyon, R.: An introduction to the dimer model. In: School and Conference on Probability Theory, ICTP Lect. Notes, XVII, pp. 267–304. Abdus Salam Int. Cent. Theoret. Phys, Trieste (2004)
Lascoux, A., Leclerc, B., Thibon, J.-Y.: Ribbon tableaux, Hall–Littlewood functions, quantum affine algebras, and unipotent varieties. J. Math. Phys. 38(2), 1041–1068 (1997)
Macdonald, I.G.: Symmetric Functions and Hall Polynomials. Oxford University Press, Oxford (1998)
Nordenstam, E.: On the shuffling algorithm for domino tilings. Electron. J. Probab. 15(3), 75–95 (2010). arXiv:0802.2592 [math.PR]
Okounkov, A., Reshetikhin, N.: Correlation function of Schur process with application to local geometry of a random 3-dimensional Young diagram. J. AMS 16(3), 581–603 (2003). arXiv:math/0107056 [math.CO]
Propp, J.: Generalized domino-shuffling. Theor. Comput. Sci. 303(2–3), 267–301 (2003)
Acknowledgements
The authors would like to thank Alexei Borodin, Sylvie Corteel, and Ananth Sridhar for many useful discussions.
Funding
’Open Access funding provided by the MIT Libraries’
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Vadim Gorin.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Generalized Spider Move

Starting with an Aztec diamond of rank 2 the above local moves construct an Aztec diamond of rank 3. The first transformation is a boundary decoration, the second consists of a collection of spider moves, and the final transformation is the contraction of degree two vertices. The randomization of these local moves leads to the Markov chain on dimer configurations known as the shuffling algorithm

Starting with a double dimer configuration on the Aztec diamond of rank 1, the shuffling algorithm produces one on an Aztec diamond of rank 2. The weight of the configuration before the shuffling can be computed as the product over cells of cell weights in the top right picture, using the local interactions listed in (24). This gives a weight of t. The weight of the configuration after the shuffling can be computed as the product of the local interactions listed in (25) over the cells in the bottom left picture; this also gives a total weight of t. One can check that for both the \(N = 1\) and \(N =2\) domino tiling corresponding to the top left and bottom right configurations, the weight is indeed t, c.f. the domino interactions in Sect. 2.2
Here we will sketch an alternate proof of the correctness of the shuffling algorithm, Theorem 1.2, using a generalization of the ‘spider move’ on the underlying dimer model. See [14, 23] for details on the shuffling algorithm and the spider move in the one color case. Throughout this section we will assume the reader is familiar with the bijection between domino tilings and dimer covers, see [18]. For simplicity we will only consider the case where we have two colors, blue and red, with blue smaller than red.
We call a cell a face of the Aztec diamond which has a white vertex in the top left, as shown below

In what follows, when we show a small patch of a graph, dashed lines mean the patch is a portion of a larger graph. The labels indicate the weight assigned to a dimer that occupies the corresponding edge. When it is clear from the context, we sometimes also use the term ‘cell’ to refer to both the patch of graph and the dimers occupying edges of that face in a dimer configuration. As we are considering double dimer configurations, we will color the dimers red and blue to distinguish the two configurations.
Define interactions to be local configurations of the form

A dimer occupying the dashed edge adjacent to a vertex v denotes that a dimer occupies one of the other edges adjacent v that are not part of the cell.
Note that if we consider the underlying dimer configuration of a 2-tiling of the Aztec diamond, the product over all cells of \(t^{{\# interactions}}\) agrees with the product of the domino interactions defined in Sect. 2.2. See Fig. 11, top, for an example.
Now consider applying the spider move to the cell above. This results in a new patch of graph with different edge weights

where unlabelled edges have weight 1. After doing this local transformation to each cell in the Aztec diamond and then contracting all valence two vertices, one gets an Aztec diamond of one larger rank. We depict this process in Fig. 10. We will also refer to these patches as cells.
After the spider moves, in the double dimer configuration we now count interactions of the form

since the product over cells of these interactions will agree with the domino interactions we get after the contraction of degree two vertices. For an example compare the interactions in the configurations in the bottom row of Fig. 11.
Note that for the usual dimer model, if
then for each choice of boundary condition for the patch, there is an equality of partition functions on the cell before and after the spider move, up to an overall factor of \(\Delta = ac+bd\). To set some notation we list these equations below. Note that if x is a cell with a configuration of dimers, w(x) denotes the product of weights of occupied edges, and the weights are implicitly updated as described above after the spider move.

We label the boundary condition by the type of move that it corresponds in the shuffling when going from the domain on the LHS to the domain on the RHS. In the equations that follow, we will label a boundary condition for a cell by an arrow to indicate left/right/up/down, a ‘c’ for creation, or a ‘d’ for destruction.
For the double dimer model the situation is more complicated. A boundary condition \((\alpha \beta )\) for a cell consists of a boundary condition \(\alpha \) for the blue configuration and a boundary condition \(\beta \) for the red one. Define C as the set of boundary conditions \((\alpha \beta )\) for a cell such that
-
\(\alpha = c\) and \(\beta \in \{c, \leftarrow , \downarrow \} \) or
-
\(\alpha \in \{c, \leftarrow , \downarrow \}\) and \(\beta = c \)
and define D as the set of boundary conditions \((\alpha \beta )\) such that
-
\(\alpha = d\) and \(\beta \in \{d, \leftarrow , \downarrow \} \) or
-
\(\alpha \in \{d, \leftarrow , \downarrow \}\) and \(\beta = d \).
We have the following relation between partition functions before and after the spider move.
Lemma A.1
Let the weights after the spider move be
For any pair of boundary conditions \(\alpha , \beta \in \{c,d,\rightarrow ,\leftarrow ,\uparrow ,\downarrow \}\) for each color, denote by \(Z_{\alpha \beta }\) the partition function of the domain with these boundary conditions before the spider move, and \(Z'_{\alpha \beta }\) that of the domain after the spider move. Then
where \(\Delta = ac+bd \) and \(\Gamma = \frac{ac+bd}{act+bd}\).
Proof
As there are only 36 choices of boundary condition, one can check (by hand or via computer) that the required 36 equations are satisfied. \(\square \)
As an example, \(Z_{d\downarrow }\) means the partition function for the domain where the smaller color has the “Destruction” boundary condition while the larger color has the “Down” boundary condition. For boundary conditions of type \((d,\downarrow )\) one can check

which is consistent as \(c' = \frac{a}{ac+bd}\).
The following combinatorial lemma, whose proof we omit, will be useful.
Lemma A.2
For any double dimer configuration on the Aztec diamond of rank N, along each SW-NE diagonal of cells the difference between the number of cells with local boundary condition of type \((\alpha \beta ) \in C\) and those of type \((\alpha \beta ) \in D\) is equal to 1.
Suppose that in a double dimer configuration, we have a cell x with boundary condition \((\alpha \beta )\). We define the transition probability \({\mathbb {P}}(x \rightarrow x')\) from x to a double dimer configuration \(x'\) in the cell after performing the spider move as
where \(Z_{\alpha \beta }'\) denotes the partition function in this cell after the spider move with the boundary conditions \((\alpha \beta )\), as in Lemma A.1.
Now we define the shuffling algorithm of Theorem 1.2 in terms of local moves; we will apply the spider move to each cell of the Aztec diamond and re-sample the double dimer configuration in each cell. In more detail, suppose that \(T^{(N+1)}\) is a double dimer configuration of the rank-\((N+1)\) Aztec diamond. Note that \(T^{(N+1)}\) corresponds uniquely to a double dimer configuration on the graph obtained from the rank-N Aztec diamond by decorating the boundary and performing spider moves at each cell (see Fig. 10, bottom left). We denote by \(x^{(N+1)} \) the local configuration in each cell of this graph. For a double dimer cover \(T^{(N)}\) of the rank-N Aztec diamond, we define
where \(x^{(N)}\) is the configuration in cell x in \(T^{(N)}\) and \(x^{(N+1)}\) is as described above. If all weights are constant, which is the uniform case, the transition probabilities defined above coincide with those of Theorem 1.2.
Alternate proof of Thm. 1.2 for the case of two colors
Consider a random 2-tiling \(T^{(N)}\) of the Aztec diamond of rank N. The tiling is made up of gluing together dimer configurations in each cell. The weight of a 2-tiling is given by product over cells of the weight in each cell. Let \(Z^{(N)}\) be the partition function for these 2-tilings.
By applying the spider move to each cell and then contracting all valence two vertices we get a 2-tiling of the rank-\((N+1)\) Aztec diamond (see Fig. 10). The probability to obtain a specific 2-tiling \(T^{(N+1)}\), whose configuration in cell x before the contraction step is denoted \(x^{(N+1)}\), is given by
In the final line \(\Gamma (x)\) denotes the value of \(\Gamma \) for the weights a, b, c, d of the cell x, and we have implicitly updated the weights in the last line. In the last equality we use the relations from Lemma A.1.
If \(\Gamma \) is constant, that is, \(\Gamma (x) = r\) for all cells x, then using Lemma A.2 we see that
that is, the probability we get a 2-tiling \(T^{(N+1)}\) via our shuffling algorithm is proportional to the weight of that 2-tiling, \(w(T^{(N+1)}) = \prod _{\hbox { cells}\ x} w(x^{(N+1)})\).
Note that if we choose uniform weights, so that in each cell \(a=b=c=d\), then they remain uniform after each step of the shuffling. Furthermore, for this choice of weights, \(\Gamma = \frac{2}{1+t}\). It follows that the shuffling algorithm works in this case. \(\square \)
Remark A3
While for the standard (1-tiling) domino shuffling algorithm the above argument allows for arbitrary edge weights, in the 2-tiling case there are extra restrictions on the weights. Note that for the shuffling to work, it is sufficient for the \(\Gamma (x)\) to be constant along each diagonal at each step of the algorithm. That is, after using the shuffling to go from rank N to rank \(N+1\), the updated \(\Gamma (x)\)’s, defined using the updated weights, should still remain constant as the cell x ranges along a SW-NE diagonal. This imposes much stricter constraints on the edge weights; for example, we believe that this shuffling algorithm is not applicable in the setting of “doubly periodic” weights, as is considered in the single color case in [7].
Simulations
In this section, we present several simulations of the coupled tilings made using the shuffling algorithm.

A 3-tiling of rank \(N=256\) generated by the shuffling algorithm with \(t=1\) and \(c_i=b_i=1\) for all \(i=1,\ldots ,N\)

A 2-tiling of rank \(N=256\) generated by the shuffling algorithm with \(t=0.2\) and \(c_i=b_i=1\) for all \(i=1,\ldots ,N\)

A 2-tiling of rank \(N=256\) generated by the shuffling algorithm with \(t=0.2\) and \(c_i=b_i=2\) for all \(i=1,\ldots ,N\)

A 2-tiling of rank \(N=256\) generated by the shuffling algorithm with \(t=0.2\) and \(c_i=b_i=0.5\) for all \(i=1,\ldots ,N\)

A 2-tiling of rank \(N=256\) generated by the shuffling algorithm with \(t=5\) and \(c_i=b_i=2\) for all \(i=1,\ldots ,N\)

A 2-tiling of rank \(N=256\) generated by the shuffling algorithm with \(t=0\) and \(c_i=b_i=5\) for all \(i=1,\ldots ,N\)

A 2-tiling of rank \(N=256\) generated by the shuffling algorithm with \(t=10000\) and \(c_i=b_i=1\) for all \(i=1,\ldots ,N\)

A 3-tiling of rank \(N=256\) generated by the shuffling algorithm with \(t=0.2\) and \(c_i=b_i=2\) for all \(i=1,\ldots ,N\)
Notice that the tilings appear to exhibit a limit shape phenomenon, with regions of frozen dominos separated from a disorder region by an arctic curve. When \(t<1\) the arctic curves appear to have a cusp along the SE boundary, for example see Figs. 13, 14, 15, 19. When \(t>1\) the cusp appears along the NW boundary instead, see Figs. 16 and 18. Note when \(t=0\), southern region of frozen horizontal dominos vanishes and the frozen region in the cusp becomes large, see Fig. 17. When \(t\rightarrow \infty \) the western region of frozen vertical dominos vanishes and is replaced by the frozen region from the cusp, see Fig. 18. In simulations with three colors there seems to be two cusps appearing, Fig. 19. The arctic curves for \(t=0,\infty \) can in fact be computed, similarly to what was done in Theorem 5.4 of [8].
Surprisingly, the large scale features, such as arctic curves, always seem to look the same for each color, despite the fact that the coupling is not symmetric between the colors. Of course for \(t=1\), Fig. 12, this symmetry follows from the fact that the tilings are independent. For \(t=0,\infty \), Figs. 17 and 18, arguments similar to those in Theorem 5.4 and Lemma 6.1 of [8] show that asymptotically the arctic curves are in fact the same. It should be possible to strengthen the cited theorem to show that the limiting height functions are also the same. However, for the intermediate values of t it is unclear why there should exist such a symmetry.
Comparing Figs. 15 and 16 we see that there appears to be a symmetry with respect to taking \(t,b,c\mapsto \frac{1}{t},\frac{1}{b},\frac{1}{c}\). This follows from a similar argument to Lemma 6.1 of [8].
A more detailed numerical analysis of the limit shapes and their fluctuations using the shuffling algorithm to generate random samples would be an interesting follow-up to the current work.
Remark B1
In [8] they define two different versions of the coupled tilings which they call the “purple-gray’ model and the “white-pink” model. They then prove results about the purple-gray model. In this article, we study the white-pink model, so the results do not immediately apply. However, one can show, by very similar arguments, that analogous results to Theorem 5.4 and Lemma 6.1 of [8] hold in the white-pink model as well.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Keating, D., Nicoletti, M. Shuffling Algorithm for Coupled Tilings of the Aztec Diamond. Ann. Henri Poincaré (2024). https://doi.org/10.1007/s00023-023-01407-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00023-023-01407-w