
Abstract
Multidisciplinary design optimization (MDO) is concerned with solving design problems involving coupled numerical models of complex engineering systems. While various MDO software frameworks exist, none of them take full advantage of state-of-the-art algorithms to solve coupled models efficiently. Furthermore, there is a need to facilitate the computation of the derivatives of these coupled models for use with gradient-based optimization algorithms to enable design with respect to large numbers of variables. In this paper, we present the theory and architecture of OpenMDAO, an open-source MDO framework that uses Newton-type algorithms to solve coupled systems and exploits problem structure through new hierarchical strategies to achieve high computational efficiency. OpenMDAO also provides a framework for computing coupled derivatives efficiently and in a way that exploits problem sparsity. We demonstrate the framework’s efficiency by benchmarking scalable test problems. We also summarize a number of OpenMDAO applications previously reported in the literature, which include trajectory optimization, wing design, and structural topology optimization, demonstrating that the framework is effective in both coupling existing models and developing new multidisciplinary models from the ground up. Given the potential of the OpenMDAO framework, we expect the number of users and developers to continue growing, enabling even more diverse applications in engineering analysis and design.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Numerical simulations of engineering systems have been widely developed and used in industry and academia. Simulations are often used within an engineering design cycle to inform design choices. Design optimization—the use of numerical optimization techniques with engineering simulation—has emerged as a way of incorporating simulation into the design cycle.
Multidisciplinary design optimization (MDO) arose from the need to simulate and design complex engineering systems involving multiple disciplines. MDO serves this need in two ways. First, it performs the coupled simulation of the engineering system, taking into account all the interdisciplinary interactions. Second, it performs the simultaneous optimization of all design variables, taking into account the coupling and the interdisciplinary design trade-offs. MDO is sometimes referred to as MDAO (multidisciplinary analysis and optimization) to emphasize that the coupled analysis is useful on its own. MDO was first conceived to solve aircraft design problems, where disciplines such as aerodynamics, structures, and controls are tightly coupled and require design trade-offs (Haftka 1977). Since then, numerical simulations have advanced in all disciplines, and the power of computer hardware has increased dramatically. These developments make it possible to advance the state-of-the-art in MDO, but other more specific developments are needed.
There are two important factors when evaluating MDO strategies: implementation effort and the computational efficiency. The implementation effort is arguably the most important because if the work required to implement a multidisciplinary model is too large, the model will simply never be built. One of the main MDO implementation challenges is that each analysis code consists of a specialized solver that is typically not designed to be coupled to other codes or to be used for numerical optimization. Additionally, these solvers are often coded in different programming languages and use different interfaces. These difficulties motivated much of the early development of MDO frameworks, which provided simpler and more efficient ways to link discipline analyses together.
While these MDO frameworks introduce important innovations in software design, modular model construction, and user interface design, they treat each discipline analysis as an explicit function evaluation; that is, they assume that each discipline is an explicit mapping between inputs and outputs. This limits the efficiency of the nonlinear solution algorithms that could be used to find a solution to the coupled multidisciplinary system. Furthermore, these MDO frameworks also present the combined multidisciplinary model as an explicit function to the optimizer, which limits the efficiency when computing derivatives for gradient-based optimization of higher-dimensional design spaces. Therefore, while these first framework developments addressed the most pressing issue by significantly lowering the implementation effort for multidisciplinary analysis, they did not provide a means for applying the most efficient MDO techniques.
The computational efficiency of an MDO implementation is governed by the efficiency of the coupled (multidisciplinary) analysis and the efficiency of the optimization. The coupled analysis method that is easiest to implement is a fixed-point iteration (also known as nonlinear block Gauss–Seidel iteration), but for strongly coupled models, Newton-type methods are potentially more efficient (Haftka et al. 1992; Heil et al. 2008; Keyes et al. 2013; Chauhan et al. 2018). When it comes to numerical optimization, gradient-based optimization algorithms scale much better with the number of design variables than gradient-free methods. The computational efficiency of both Newton-type analysis methods and gradient-based optimization is, in large part, dependent on the cost and accuracy with which the necessary derivatives are computed.
One can always compute derivatives using finite differences, but analytic derivative methods are much more efficient and accurate. Despite the extensive research into analytic derivatives and their demonstrated benefits, they have not been widely supported in MDO frameworks because their implementation is complex and requires deeper access to the analysis code than can be achieved through an approach that treats all analyses as explicit functions. Therefore, users of MDO frameworks that follow this approach are typically restricted to gradient-free optimization methods, or gradient-based optimization with derivatives computed via finite differences.
The difficulty of implementing MDO techniques with analytic derivatives creates a significant barrier to their adoption by the wider engineering community. The OpenMDAO framework aims to lower this barrier and enable the widespread use of analytic derivatives in MDO applications.
Like other frameworks, OpenMDAO provides a modular environment to more easily integrate discipline analyses into a larger multidisciplinary model. However, OpenMDAO V2 improves upon other MDO frameworks by integrating discipline analyses as implicit functions, which enables it to compute derivatives for the resulting coupled model via the unified derivatives equation (Martins and Hwang 2013). The computed derivatives are coupled in that they take into account the full interaction between the disciplines in the system. Furthermore, OpenMDAO is designed to work efficiently in both serial and parallel computing environments. Thus, OpenMDAO provides a means for users to leverage the most efficient techniques, regardless of problem size and computing architecture, without having to incur the significant implementation difficulty typically associated with gradient-based MDO.
This paper presents the design and algorithmic features of OpenMDAO V2 and is structured to cater to different types of readers. For readers wishing to just get a quick overview of what OpenMDAO is and what it does, reading this introduction, the overview of applications (Section 7, especially Fig. 13), and the conclusions (Section 8) will suffice. Potential OpenMDAO users should also read Section 3, which explains the basic usage and features through a simple example. The remainder of the paper provides a background on MDO frameworks and the history of OpenMDAO development (Section 2), the theory behind OpenMDAO (Section 4), and the details of the major new contributions in OpenMDAO V2 in terms of multidisciplinary solvers (Section 5) and coupled derivative computation (Section 6).
2 Background
The need for frameworks that facilitate the implementation of MDO problems and their solution was identified soon after MDO emerged as a field. Various requirements have been identified over the years. Early on, Salas and Townsend (1998) detailed a large number of requirements that they categorized under software design, problem formulation, problem execution, and data access. Later, Padula and Gillian (2006) more succinctly cited modularity, data handling, parallel processing, and user interface as the most important requirements. While frameworks that fulfill these requirements to various degrees have emerged, the issue of computational efficiency and scalability has not been sufficiently highlighted or addressed.
The development of commercial MDO frameworks dates back to the late 1990s with iSIGHT (Golovidov et al. 1998), which is now owned by Dassault Systèmes and renamed Isight/SEE. Various other commercial frameworks have been developed, such as Phoenix Integration’s ModelCenter/CenterLink, Esteco’s modeFRONTIER, TechnoSoft’s AML suite, Noesis Solutions’ Optimus, SORCER (Kolonay and Sobolewski 2011), and Vanderplaats’ VisualDOC (Balabanov et al. 2002). These frameworks have focused on making it easy for users to couple multiple disciplines and to use the optimization algorithms through graphical user interfaces (GUIs). They have also been providing wrappers to popular commercial engineering tools. While this focus has made it convenient for users to implement and solve MDO problems, the numerical methods used to converge the multidisciplinary analysis (MDA) and the optimization problem are usually not state-of-the-art. For example, these frameworks often use fixed-point iteration to converge the MDA. When derivatives are needed for a gradient-based optimizer, finite-difference approximations are used rather than more accurate analytic derivatives.
When solving MDO problems, we have to consider how to organize the discipline analysis models, the problem formulation, and the optimization algorithm in order to obtain the optimum design with the lowest computational cost possible. The combination of the problem formulation and organizational strategy is called the MDO architecture. MDO architectures can be either monolithic (where a single optimization problem is solved) or distributed (where the problem is partitioned into multiple optimization subproblems). Martins and Lambe (2013) describe this classification in more detail and present all known MDO architectures.
To facilitate the exploration of the various MDO architectures, Tedford and Martins (2006) developed pyMDO. This was the first object-oriented framework that focused on automating the implementation of different MDO architectures (Martins et al. 2009). In pyMDO, the user defined the general MDO problem once, and the framework would reformulate the problem in any architecture with no further user effort. Tedford and Martins (2010) used this framework to compare the performance of various MDO architectures, concluding that monolithic architectures vastly outperform the distributed ones. Marriage and Martins (2008) integrated a semi-analytic method for computing derivatives based on a combination of finite-differencing and analytic methods, showing that the semi-analytic method outperformed the traditional black-box finite-difference approach.
The origins of OpenMDAO began in 2008, when Moore et al. (2008) identified the need for a new MDO framework to address aircraft design challenges at NASA. Two years later, Gray et al. (2010) implemented the first version of OpenMDAO (V0.1). An early aircraft design application using OpenMDAO to implement gradient-free efficient global optimization was presented by Heath and Gray (2012). Gray et al. (2013) later presented benchmarking results for various MDO architectures using gradient-based optimization with analytic derivatives in OpenMDAO.
As the pyMDO and OpenMDAO frameworks progressed, it became apparent that the computation of derivatives for MDO presented a previously unforeseen implementation barrier.
The methods available for computing derivatives are finite-differencing, complex-step, algorithmic differentiation, and analytic methods. The finite-difference method is popular because it is easy to implement and can always be used, even without any access to source code, but it is subject to large inaccuracies. The complex-step method (Squire and Trapp 1998; Martins et al. 2003) is not subject to these inaccuracies, but it requires access to the source code to implement. Both finite-difference and complex-step methods become prohibitively costly as the number of design variables increases because they require rerunning the simulation for each additional design variable.
Algorithmic differentiation (AD) uses a software tool to parse the code of an analysis tool to produce new code that computes derivatives of that analysis (Griewank 2000; Naumann 2011). Although AD can be efficient, even for large numbers of design variables, it does not handle iterative simulations efficiently in general.
Analytic methods are the most desirable because they are both accurate and efficient even for iterative simulations (Martins and Hwang 2013). However, they require significant implementation effort.
Analytic methods can be implemented in two different forms: the direct method and the adjoint method. The choice between these two methods depends on how the number of functions that we want to differentiate compares to the number of design variables. In practice, the adjoint method tends to be the more commonly used method.
Early development of the adjoint derivative computation was undertaken by the optimal control community in the 1960s and 1970s (Bryson and Ho 1975), and the structural optimization community adapted those developments throughout the 1970s and 1980s (Arora and Haug 1979). This was followed by the development of adjoint methods for computational fluid dynamics (Jameson 1988), and aerodynamic shape optimization became a prime example of an application where the adjoint method has been particularly successful (Peter and Dwight 2010; Carrier et al. 2014; Chen et al. 2016).
When computing the derivatives of coupled systems, the same methods that are used for single disciplines apply. Sobieszczanski-Sobieski (1990) presented the first derivation of the direct method for coupled systems, and Martins et al. (2005) derived the coupled adjoint method. One of the first applications of the coupled adjoint method was in high-fidelity aerostructural optimization (Martins et al. 2004). The results from the work on coupled derivatives highlighted the promise of dramatic computational cost reductions, but also showed that existing frameworks were not able to handle these methods. Their implementation required linear solvers and support for distributed memory parallelism that no framework had at the time.
In an effort to unify the theory for the various methods for computing derivatives, Martins and Hwang (2013) derived the unified derivatives equation. This new generalization showed that all the methods for computing derivatives can be derived from a common equation. It also showed that when there are both implicitly and explicitly defined disciplines, the adjoint method and chain rule can be combined in a hybrid approach. Hwang et al. (2014) then realized that this theoretical insight provided a sound and convenient mathematical basis for a new software design paradigm and set of numerical solver algorithms for MDO frameworks. Using a prototype implementation built around the unified derivatives equation (Martins and Hwang 2016), they solved a large-scale satellite optimization problem with 25,000 design variables and over 2 million state variables (Hwang et al. 2014). Later, Gray et al. (2014) developed OpenMDAO V1, a complete rewrite of the OpenMDAO framework based on the prototype work of Hwang et al. with the added ability to exploit sparsity in a coupled multidisciplinary model to further reduce computational cost.
Collectively, the work cited above represented a significant advancement of the state-of-the-art for MDO frameworks. The unified derivatives equation, combined with the new algorithms and framework design, enabled the solution of significantly larger and more complex MDO problems than had been previously attempted. In addition, OpenMDAO had now integrated three different methods for computing total derivatives into a single framework: finite-difference, analytic, and semi-analytic. However, this work was all done using serial discipline analyses and run on a serial computing environment. The serial computing environment presented a significant limitation, because it precluded the integration of high-fidelity analyses into the coupled models.
To overcome the serial computing limitation, Hwang and Martins (2018) parallelized the data structures and solver algorithms from their prototype framework, which led to the modular analysis and unified derivatives (MAUD) architecture. Hwang and Martins (2015) used the new MAUD prototype to solve a coupled aircraft allocation-mission-design optimization problem. OpenMDAO V1 was then modified to incorporate the ideas from the MAUD architecture. Gray et al. (2018a) presented an aeropropulsive design optimization problem constructed in OpenMDAO V1 that combined a high-fidelity aerodynamics model with a low-fidelity propulsion model, executed in parallel. One of the central features of the MAUD architecture, enabling the usage of parallel computing and high-fidelity analyses, was the use of hierarchical, matrix-free linear solver design. While advantageous for large parallel models, this feature was inefficient for smaller serial models. The need to support both serial and parallel computing architectures led to the development of OpenMDAO V2, a second rewrite of the framework, which is presented in this paper.
Recently, the value of analytic derivatives has also motivated the development of another MDO framework, GEMS, which is designed to implement bi-level distributed MDO architectures that might be more useful in some industrial settings (Gallard et al. 2017). This stands in contrast to OpenMDAO, which is focused mostly on the monolithic MDO architectures for best possible computational efficiency.
3 Overview of OpenMDAO V2
In this section, we introduce OpenMDAO V2, present its overall approach, and discuss its most important feature—efficient derivative computation. To help with the explanations, we introduce a simple model and optimization problem that we use throughout Sections 3 and 4.
3.1 Basic description
OpenMDAO is an open-source software framework for multidisciplinary design, analysis, and optimization (MDAO), also known as MDO. It is primarily designed for gradient-based optimization; its most useful and unique features relate to the efficient and accurate computation of the model derivatives. We chose the Python programming language to develop OpenMDAO because it makes scripting convenient, it provides many options for interfacing to compiled languages (e.g., SWIG and Cython for C and C++, and F2PY for Fortran), and it is an open-source language. OpenMDAO facilitates the solution of MDO problems using distributed-memory parallelism and high-performance computing (HPC) resources by leveraging MPI and the PETSc library (Balay et al. 2018).
3.2 A simple example
This example consists of a model with one scalar input, x, two “disciplines” that define state variables (y1, y2), and one scalar output, f. The equations for the disciplines are
where Discipline 1 computes y1 explicitly and Discipline 2 computes y2 implicitly. The equation for the model output f is
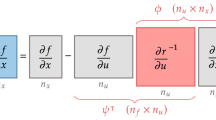
Figure 1 visualizes the variable dependencies in this model using a design structure matrix. We show components that compute variables on the diagonal and dependencies on the off-diagonals. From Fig. 1, we can easily see the feedback loop between the two disciplines, as well as the overall sequential structure with the model input, the coupled disciplines, and the model output. We will refer back to this model and optimization problem periodically throughout Sections 3 and 4.

Extended design structure matrix (XDSM) (Lambe and Martins 2012) for the simple model. Components that compute variables are on the diagonal, and dependencies are shown on the off-diagonals, where an entry above the diagonal indicates a forward dependence and vice versa. Blue indicates an independent variable, green indicates an explicit function, and red indicates an implicit function
To minimize f with respect to x using gradient-based optimization, we need the total derivative df/dx. In Section 3.4, we use this example to demonstrate how OpenMDAO computes the derivative.
3.3 Approach and nomenclature
OpenMDAO uses an object-oriented programming paradigm and an object composition design pattern. Specific functionalities via narrowly focused classes are combined to achieve the desired functionality during execution. In this section, we introduce the four most fundamental types of classes in OpenMDAO: Component, Group, Driver, and Problem. Note that for the Component class, the end user actually works with one of its two derived classes, ExplicitComponent or ImplicitComponent, which we describe later in this section.
MDO has traditionally considered multiple “disciplines” as the units that need to be coupled through coupling variables. In OpenMDAO, we consider more general components, which can represent a whole discipline analysis or can perform a smaller subset of calculations representing only a portion of a whole discipline model. Components share a common interface that allows them to be integrated to form a larger model. This modular approach allows OpenMDAO to automate tasks that are performed repeatedly when building multidisciplinary models. Instances of the Component class provide the lowest-level functionality representing basic calculations. Each component instance maps input values to output values via some calculation. A component could be a simple explicit function, such as y = sin(x); it could involve a long sequence of code; or it could call an external code that is potentially written in another language. In multidisciplinary models, each component can encapsulate just a part of one discipline, a whole discipline, or even multiple disciplines. In our simple example, visualized in Fig. 1, there are four components: Discipline 1 and the model output are components that compute explicit functions, Discipline 2 is a component that computes an implicit function, and the model input is a special type of component with only outputs and no inputs.
Another fundamental class in OpenMDAO is Group, which contains components, other groups, or a mix of both. The containment relationships between groups and components form a hierarchy tree, where a top-level group contains other groups, which contain other groups, and so on, until we reach the bottom of the tree, which is composed only of components. Group instances serve three purposes: (1) they help to package sets of components together, e.g., the components for a given discipline; (2) they help create better-organized namespaces (since all components and variables are named based on their ancestors in the tree); and (3) they facilitate the use of hierarchical nonlinear and linear solvers. In our simple example, the obvious choice is to create a group containing Discipline 1 and Discipline 2, because these two form a coupled pair that needs to be converged for any given value of the model input. The hierarchy of groups and components collectively form the model.
Children of the Driver base class define algorithms that iteratively call the model. For example, a subclass of Driver might implement an optimization algorithm or execute design of experiments (DOE). In the case of an optimization algorithm, the design variables are a subset of the model inputs, and the objective and constraint functions are a subset of the model outputs.
Instances of the Problem class perform as a top-level container, holding all other objects. A problem instance contains both the groups and components that constitute the model hierarchy and also contains a single driver instance. In addition to serving as a container, a Problem also provides the user interface for model setup and execution.
Figure 2 illustrates the relationships between instances of the Component, Group, and Driver classes and introduces the nomenclature for derivatives. The Driver repeatedly calls model (i.e., the top-level instance of Group, which in turn contains groups that contain other groups that contain the component instances). The derivatives of the model outputs with respect to the model inputs are considered to be total derivatives, while the derivatives of the component outputs with respect to the component inputs are considered to be partial derivatives. This is not the only way to define the difference between partial and total derivatives, but this is a definition that suits the present context and is consistent with previous work on the computation of coupled derivatives (Martins et al. 2005). In the next section, we provide a brief explanation of how OpenMDAO computes derivatives.

Relationship between Driver, Group, and Component classes. An instance of Problem contains a Driver instance, and the Group instance named “model.” The model instance holds a hierarchy of Group and Component instances. The derivatives of a model are total derivatives, and the derivatives of a component are partial derivatives
3.4 Derivative computation
As previously mentioned, one of the major advantages of OpenMDAO is that it has the ability to compute total derivatives for complex multidisciplinary models very efficiently via a number of different techniques. Total derivatives are derivatives of model outputs with respect to model inputs. In the example problem from Section 3.2, the total derivative needed to minimize the objective function is just the scalar df/dx. Here, we provide a high-level overview of the process for total derivative computation because the way it is done in OpenMDAO is unique among computational modeling frameworks. The mathematical and algorithmic details of total derivative computation are described in Section 4.
Total derivatives are difficult and expensive to compute directly, especially in the context of a framework that must deal with user-defined models of various types. As mentioned in the introduction, there are various options for computing derivatives: finite-differencing, complex-step, algorithmic differentiation, and analytic methods. The finite-difference method can always be used because it just requires rerunning the model with a perturbation applied to the input. However, the accuracy of the result depends heavily on the magnitude of the perturbation, and the errors can be large. The complex-step method yields accurate results, but it requires modifications to the model source code to work with complex numbers. The computational cost of these methods scales with the number of input variables, since the model needs to be rerun for a perturbation in each input. OpenMDAO provides an option to use either of these methods, but their use is only recommended when the ease of implementation justifies the increase in computational cost and loss of accuracy.
As described in the introduction, analytic methods have the advantage that they are both efficient and accurate. OpenMDAO facilitates the derivative computation for coupled systems using analytic methods, including the direct and adjoint variants. To use analytic derivative methods in OpenMDAO, the model must be built such that any internal implicit calculations are exposed to the framework. This means that the model must be cast as an implicit function of design variables and implicit variables with associated residuals that must be converged. For explicit calculations, OpenMDAO performs the implicit transformation automatically, as discussed in Section 4.3. When integrating external analysis tools with built-in solvers, this means exposing the residuals and the corresponding state variable vector. Then, the total derivatives are computed in a two-step process: (1) compute the partial derivatives of each component and (2) solve a linear system of equations that computes the total derivatives. The linear system in step 2 can be solved in a forward (direct) or a reverse (adjoint) form. As mentioned in the introduction, the cost of the forward method scales linearly with the number of inputs, while the reverse method scales linearly with the number of outputs. Therefore, the choice of which form to use depends on the ratio of the number of outputs to the number of inputs. The details of the linear systems are derived and discussed in Section 4. For the purposes of this section, it is sufficient to understand that the total derivatives are computed by solving these linear systems, and that the terms in these linear systems are partial derivatives that need to be provided.
In the context of OpenMDAO, partial derivatives are defined as the derivatives of the outputs of each component with respect to the component inputs. For an ExplicitComponent, which is used when outputs can be computed as an analytic function of the inputs, the partial derivatives are the derivatives of these outputs with respect to the component inputs. For an ImplicitComponent, which is used when a component provides OpenMDAO with residual equations that need to be solved, the partial derivatives are derivatives of these residuals with respect to the component input and output variables. Partial derivatives can be computed much more simply and with lower computational cost than total derivatives. OpenMDAO supports three techniques for computing partial derivatives: full-analytic, semi-analytic, and mixed-analytic.
When using the full-analytic technique, OpenMDAO expects each and every component in the model to provide partial derivatives. These partial derivatives can be computed either by hand differentiation or via algorithmic differentiation. For the example model in Section 3.2, the partial derivatives can easily be hand-derived. Discipline 1 is an ExplicitComponent defined as \(y_{1} = {y_{2}^{2}}\) (one input and one output), so we only need the single partial derivative:
Discipline 2 is an ImplicitComponent, so it is defined as a residual that needs to be driven to zero, R = exp(−y1y2) − xy2 = 0. In this case, we need the partial derivatives of this residual function with respect to all the variables:
Finally, we also need the partial derivatives of the objective function component:
When using the semi-analytic technique, OpenMDAO automatically computes the partial derivatives for each component using either the finite-difference or complex-step methods. This is different from applying these methods to the whole model because it is done component by component, and therefore it does not require the re-convergence of the coupled system. For instances of an ImplicitComponent, only partial derivatives of the residual functions are needed (e.g., (5), (6), and (7) in the example). Since residual evaluations do not involve any nonlinear solver iterations, approximating their partial derivatives is much less expensive and more accurate. The technique is called “semi-analytic” because while the partial derivatives are computed numerically, the total derivatives are still computed analytically by solving a linear system.
In the mixed-technique, some components provide analytic partial derivatives, while others approximate the partials with finite-difference or complex-step methods. The mixed-technique offers great flexibility and is a good option for building models that combine less costly analyses without analytic derivatives and computationally expensive analyses that do provide them. If the complex-step method is used for some of the partial derivatives, the net result is effectively identical to the fully-analytic method. If finite differences are used to compute some of the partial derivatives, then some accuracy is lost, but overall the net result is still better than either the semi-analytic approach or finite differencing the coupled model to compute the total derivatives.
3.5 Implementation of the simple example
We now illustrate the use of the OpenMDAO basic classes by showing the code implementation of the simple model we presented in Section 3.2.
The run script is listed in Fig. 3. In Block 1, we import several classes from the OpenMDAO API, as well as the components for Discipline 1 and Discipline 2, which we show later in this section. In Block 2, we instantiate the four components shown in Fig. 1, as well as a group that combines the two disciplines, called states_group. In this group, we connect the output of Discipline 1 to the input of Discipline 2 and vice versa. Since there is coupling within this group, we also assign a Newton solver to be used when running the model and a direct (LU) solver to be used for the linear solutions required for the Newton iterations and the total derivative computation. For the model output, we define a component “inline,” using a convenience class provided by the OpenMDAO standard library. In Block 3, we create the top-level group, which we appropriately name as model, and we add the relevant subsystems to it and make the necessary connections between inputs and outputs.

Run script for the simple example. This script depends on a disciplines file that defines the components for disciplines 1 and 2 (see Fig. 4)
In Block 4, we specify the model inputs and model outputs, which in this case correspond to the design variable and objective function, respectively, since we are setting up the model to solve an optimization problem. In Block 5, we create the problem, assign the model and driver, and run setup to signal to OpenMDAO that the problem construction is complete so it can perform the necessary initialization. In Block 6, we illustrate how to set a model input, run the model, and read the value of a model output, and in Block 7, we run the optimization algorithm and print the results.
In Fig. 4, we define the actual computations and partial derivatives for the components for the two disciplines. Both classes inherit from OpenMDAO base classes and implement methods in the component API, but they are different because Discipline 1 is explicit while Discipline 2 is implicit. For both, setup is where the component declares its inputs and outputs, as well as information about the partial derivatives (e.g., sparsity structure and whether to use finite differences to compute them). In Discipline 1, compute maps inputs to outputs, and compute_partials is responsible for providing partial derivatives of the outputs with respect to inputs. In Discipline 2, apply_nonlinear maps inputs and outputs to residuals, and linearize computes the partial derivatives of the residuals with respect to inputs and outputs. More details regarding the API can be found in the documentation on the OpenMDAO website.Footnote 1

Definition of the components for Discipline 1 and Discipline 2 for the simple example, including the computation of the partial derivatives
The component that computes the objective function is built using the inline ExecComp. ExecComp is a helper class in the OpenMDAO standard library that provides a convenient shortcut for implementing an ExplicitComponent for simple and inexpensive calculations. This provides the user a quick mechanism for adding basic calculations like summing values or subtracting quantities. However, ExecComp uses the complex-step method to compute the derivatives, so it should not be used for expensive calculations or where there is a large input array.
Figure 5 shows a visualization of the model generated automatically by OpenMDAO. The hierarchy structure of the groups and components is shown on the left, and the dependency graph is shown on the right. This diagram is useful for understanding how data is exchanged between components in the model. Any connections above the diagonal indicate feed-forward data relationships, and connections below the diagonal show feedback relationships that require a nonlinear solver.

Visualization of the simple model generated automatically by OpenMDAO. In the hierarchy tree on the left, the darker blue blocks are groups, the lighter blue blocks are components, pink blocks are component inputs, and gray blocks are component outputs
4 Theory
As previously mentioned, one of the main goals in OpenMDAO is to efficiently compute the total derivatives of the model outputs (f) with respect to model inputs (x), and we stated that we could do this using partial derivatives computed with analytic methods. For models consisting purely of explicit functions, the basic chain rule can be used to achieve this goal. However, when implicit functions are present in the model (i.e., any functions that require iterative nonlinear solvers), the chain rule is not sufficient. In this section, we start by deriving these methods and then explain how they are implemented in OpenMDAO.
4.1 Analytic methods: direct and adjoint
Given a function F(x,y), where x is a vector n inputs, and y is a vector of m variables that depends implicitly on x, then
where we distinguish the quantity f from the function F that computes it using lowercase and uppercase, respectively. Using this notation, total derivatives account for the implicit relation between variables, while the partial derivatives are just explicit derivatives of a function (Hwang and Martins 2018). The only derivative in the right-hand side of (9) that is not partial is dy/dx, which captures the change in the converged values for y with respect to x. Noting the implicit dependence by R(x,y) = 0, we can differentiate it with respect to x to obtain
Re-arranging this equation, we get the linear system
Now dy/dx can be computed by solving this linear system, which is constructed using only partial derivatives. This linear system needs to be solved n times, once for each component of x, with the column of ∂R/∂x that corresponds to the element of x as the right-hand side. Then, dy/dx can be used in (9) to compute the total derivatives. This approach is known as the direct method.
There is another way to compute the total derivatives based on these equations. If we substitute the linear system (11) into the total derivative (9), we obtain
By grouping the terms [∂R/∂y]− 1 and ∂F/∂y, we get an m-vector, ψ, which is the adjoint vector. Instead of solving for dy/dx with (11) (the direct method), we can instead solve a linear system with [∂F/∂y]T as the right-hand side to compute ψ:
This linear system needs to be solved once for each function of interest f. If f is a vector variable, then the right-hand side for each solution is the corresponding row of ∂F/∂y. The transpose of the adjoint vector, ψT, can then be used to compute the total derivative,
This is the adjoint method, and the derivation above shows why the computational cost of this method is proportional to the number of outputs and independent of the number of inputs. Therefore, if the number of inputs exceeds the number of outputs, the adjoint method is advantageous, while if the opposite is true, then the direct method has the advantage. The main idea of these analytic methods is to compute total derivatives (which account for the solution of the models) using only partial derivatives (which do not require the solution of the models).
As mentioned in Section 2, these analytic methods have been extended to MDO applications (Sobieszczanski-Sobieski 1990; Martins et al. 2005; Martins and Hwang 2013). All of these methods have been used in MDO applications, but as was discussed in Section 2, the implementations tend to be highly application specific and not easily integrated into an MDO framework.
To overcome the challenge of application-specific derivative computations, Hwang and Martins (2018) developed the MAUD architecture, which provides the mathematical and algorithmic framework to combine the chain rule, direct, and adjoint methods into a single implementation that works even when using models that utilize distributed-memory parallelism, such as computational fluid dynamics (CFD) and finite element analysis (FEA) codes.
4.2 Nonlinear problem formulation
OpenMDAO V1 and V2 were designed based on the algorithms and data structures of MAUD, but V2 includes several additions to the theory and algorithms to enable more efficient execution for serial models. In this section, we summarize the key MAUD concepts and present the new additions in OpenMDAO V2 that make the framework more efficient for serial models. The core idea of MAUD is to formulate any model (including multidisciplinary models) as a single nonlinear system of equations. This means that we concatenate all variables—model inputs and outputs, and both explicit and implicit component variables—into a single vector of unknowns, u. Thus, in all problems, we can represent the model as R(u) = 0, where R is a residual function defined in such a way that this system is equivalent to the original model.
For the simple example from Section 3.2, our vector of unknowns would be u = (x,y1,y2,f), and the correct residual function is
Although the variable x is not an “unknown” (it has a value that is set explicitly), we reformulate it into an implicit form by treating it as an unknown and adding a residual that forces it to the expected value of x∗. Using this approach, any computational model can be written as a nonlinear system of equations such that the solution of the system yields the same outputs and intermediate values as running the original computational model.
Users do not actually need to reformulate their problems in this fully implicit form because OpenMDAO handles the translation automatically via the ExplicitComponent class, as shown in the code snippet in Fig. 4. However, the framework does rely on the fully implicit formulation for its internal representation.
The key benefit of representing the whole model as a single monolithic nonlinear system is that we can use the unified derivatives equation (Martins and Hwang 2013; Hwang and Martins 2018), which generalizes all analytic derivative methods. The unified derivatives equation can be written as
where u is a vector containing inputs, implicitly defined variables, and outputs, and R represents the corresponding residual functions. The matrix du/dr contains a block with the total derivatives that we ultimately want (i.e., the derivatives of the model outputs with respect to the inputs, df/dx). Again, we use lowercase and uppercase to distinguish between quantities and functions, as well as the convention for total and partial derivatives introduced earlier. For the simple example in Section 3.2, the total derivative matrix is
where the middle term shows the expanded total derivative matrix and the right-most term simplifies these derivatives. The middle term is obtained by inserting u = [x,y1,y2,f]T and \(r = [r_{x}, r_{y_{1}}, r_{y_{2}}, r_{f}]^{T}\). The simplification in the right-most term is possible because from (15), we know that for example,
In this example, the left equality of the unified derivatives (16) corresponds to the forward form, which is equivalent to the direct method, while the right equality corresponds to the reverse form, which is equivalent to the adjoint method. Solving the forward form solves for one column of the total derivative matrix at a time, while the reverse mode solves for one row at a time. Thus, the forward mode requires a linear solution for each input, while the the reverse mode requires a linear solution for each output.
Although the full matrix du/dr is shown in (17), we do not actually need to solve for the whole matrix; the optimizer only needs the derivatives of the model outputs with respect to model inputs. The needed derivatives are computed by solving for the appropriate columns (forward mode) or rows (reverse mode) one at a time using OpenMDAO’s linear solver functionality.
4.3 API for group and component classes
To recast the entire model as a single nonlinear system, the Component and Group classes both define the following five API methods:
-
apply_nonlinear(p,u,r): Compute the residuals (r) given the inputs (p) and outputs (u) of the component or group.
-
solve_nonlinear(p,u): Compute the converged values for the outputs given the inputs.
-
linearize(p,u): Perform any one-time linearization operations, e.g., computing partial derivatives of the residuals or approximating them via finite differences.
-
apply_linear(du,dr): Compute a Jacobian-vector product, and place the result in the storage vector. For the forward mode, this product is
$$ \mathrm{d}r = \left[ \frac{\partial R}{\partial u} \right] \mathrm{d}u , $$(18)and for the reverse mode, it is
$$ \mathrm{d}u = \left[ \frac{\partial R}{\partial u} \right]^{T} \mathrm{d}r . $$(19) -
solve_linear(du,dr): Multiply the inverse of the Jacobian with the provided right-hand side vector (or solve a linear system to compute the product without explicitly computing the inverse), and place the result in the storage vector. For the forward mode,
$$ \mathrm{d}u = \left[ \frac{\partial R}{\partial u} \right]^{-1} \mathrm{d}r , $$(20)while for the reverse mode,
$$ \mathrm{d}r = \left( \left[ \frac{\partial R}{\partial u} \right]^{T}\right)^{-1} \mathrm{d}u . $$(21)
Up to this point, we have commonly referred to the unknown vector (u) and the residual vector (r), but the API methods above introduce several new vectors that have not been previously discussed. The input vector (p) contains values for any variables that are constant relative to a given location in the model hierarchy. For any given component, the set of inputs is clear. For a group, the inputs are composed of the set of any variables that do not have an associated output owned by one of the children of that group. For example, referring back to Fig. 5, the states_group has the variable x in its input vector, and the output_group has the variables y1 and y2 in its input vector. At the top level of that model, the input vector is empty, and all variables are contained within the unknown vector. There are also the du and dr vectors, which are used to contain the source and product for matrix-vector-product methods. For a detailed description of the relationship between the p and u vectors, and how the API methods as well as the du and dr vectors enable efficient solution of the unified derivatives equations, see the original MAUD paper (Hwang and Martins 2018).
Both Group and Component classes must implement these five methods, but default implementations are provided in many cases. All five methods are implemented in the Group class in OpenMDAO’s standard library, which is used to construct the model hierarchy. For subclasses of ExplicitComponent, such as Discipline1 in Fig. 4, the user does not directly implement any of the five basic API methods. Instead, the user implements the compute and compute_partials methods that the ExplicitComponent base class uses to implement the necessary lower level methods, as shown in Algorithm 1. The negative sign in line 8 of Algorithm 1 indicates that the partial derivatives for the implicit transformation are the negative of the partial derivatives for the original explicit function. As shown in (15), the implicit transformation for the explicit output f is given by
which explains the negative sign.

For subclasses of ImplicitComponent, such as Discipline2 in Fig. 4, only apply_nonlinear is strictly required, and solve_nonlinear is optional. (The base class implements a method that does not perform any operations.) For many models, such as the example in Fig. 3, it is sufficient to rely on one of the nonlinear solvers in OpenMDAO’s standard library to converge the implicit portions of a model. Alternatively, a component that wraps a complex discipline analysis can use solve_nonlinear to call the specialized nonlinear solver built into that analysis code.
In the following section, we discuss the practical matter of using the API methods to accomplish the nonlinear and linear solutions required to execute OpenMDAO models. In both the nonlinear and linear cases, there are two strategies employed, depending on the details of the underlying model being worked with: monolithic and hierarchical. While in our discussion we recommend using each strategy for certain types of models, in actual models, the choice does not need to be purely one or the other. Different strategies can be employed at different levels of the model hierarchy to match the particular needs of any specific model.
In addition, the usage of one strategy for the nonlinear solution does not prescribe that same strategy for the linear solution. In fact, it is often the case that a model using the hierarchical nonlinear strategy would also use the monolithic linear strategy. The converse is also true: Models that use the monolithic nonlinear strategy will often use the hierarchical linear strategy. This asymmetry of nonlinear and linear solution strategies is one of the central features in OpenMDAO that enables the framework to work efficiently with a range or models that have vastly different structures and computational needs.
5 Monolithic and hierarchical solution strategies
OpenMDAO uses a hierarchical arrangement of groups and components to organize models, define execution order, and control data passing. This hierarchical structure can also be used to define nonlinear and linear solver hierarchies for models. While in some cases it is better to match the solver hierarchy closely to that of the model structure, in most cases, better performance is achieved when the solver structure is more monolithic than the associated model. The framework provides options for both nonlinear and linear solvers and allows the user to mix them at the various levels of the model hierarchy to customize the solver strategy for any given model.
The hierarchical model structure and solver structure used in OpenMDAO were first proposed as part of the MAUD architecture (Hwang and Martins 2018). In addition, MAUD also included several algorithms that implement monolithic and hierarchical solvers in the model hierarchy that OpenMDAO also adopted: monolithic Newton’s method, along with hierarchical versions of nonlinear block Gauss–Seidel, nonlinear block Jacobi, linear block Gauss–Seidel, and linear block Jacobi. In addition to these solvers, OpenMDAO V2 implements a new hierarchical nonlinear solver that improves performance for very tightly coupled models (e.g., hierarchical Newton’s method). It also includes a monolithic linear solver strategy that enables much greater efficiency for serial models.
This section describes the new contributions in Open-MDAO, along with a summary of the relevant strategies and solver algorithms adopted from the MAUD architecture.
5.1 Nonlinear solution strategy
Although the user may still implement any explicit analyses in the traditional form using ExplicitComponent, OpenMDAO internally transforms all models into the implicit form defined by MAUD, i.e., R(u) = 0. For the simple example problem from Section 3.2, this transformation is given by (15). While the transformation is what makes it possible to leverage the unified derivatives equation to compute total derivatives, it also yields a much larger implicit system that now represents the complete multidisciplinary model including all intermediate variables. The larger system is more challenging to converge and may not be solvable in monolithic form. OpenMDAO provides a hierarchical nonlinear strategy that allows individual subsystems in the model to be solved first, which makes the overall problem more tractable. The hierarchical nonlinear strategy represents a trade-off between solution robustness and solution efficiency because it is typically more robust and more expensive.
5.1.1 Monolithic nonlinear strategy
In some cases, treating the entire model as a single monolithic block provides a simple and efficient solution strategy. This is accomplished with a pure Newton’s method that iteratively applies updates to the full u vector until the residual vector is sufficiently close to zero, via
In practice, pure Newton’s method is usually used together with a globalization technique, such as a line search, to improve robustness for a range of initial guesses. OpenMDAO’s Newton solver uses these methods in its actual implementation. For simplicity, we omit the globalization techniques from the following descriptions. Since these techniques do not change the fundamentals of Newton’s method, we can do this without loss of generality.
Algorithm 2 shows the pseudocode for a pure Newton’s method implemented using the OpenMDAO API. All variables are treated as implicit and updated in line 4, which uses solve_linear to implement (23). Note that solve_nonlinear is never called anywhere in Algorithm 2; only apply_nonlinear is called to compute the residual vector, r. This means that no variables—not even outputs of an ExplicitComponent—have their values directly set by their respective components. When the pure Newton’s method works, as is the case for the states_group in the example model shown in Fig. 5, it is a highly efficient algorithm for solving a nonlinear system. The challenge with pure Newton’s method is that even with added globalization techniques, it still may not converge for especially complex models with large numbers of states. Pure Newton’s method is particularly challenging to apply to large multidisciplinary models built from components that wrap disciplinary analyses with their own highly customized nonlinear solver algorithms. This is because some specialized disciplinary solvers include customized globalization schemes (e.g., pseudo time continuation) and linear solver preconditioners that a pure Newton’s method applied at the top level of the model cannot directly take advantage of.

5.1.2 Hierarchical nonlinear strategy
For some models, the monolithic nonlinear strategy may be numerically unstable and fail to converge on a solution. In those cases, the hierarchical strategy may provide more robust solver behavior. Consider that each level of the model hierarchy, from the top-level model group all the way down to the individual components, contains a subset of the unknowns vector, uchild, and the corresponding residual equations, Rchild(uchild) = 0. For any level of the hierarchy, a given subsystem (which can be a component or group of components) is a self-contained nonlinear system, where any variables from external components or groups are inputs that are held constant for that subsystem’s solve_nonlinear. Therefore, we can apply a nonlinear solver to any subsystem in the hierarchy to converge that specific subset of the nonlinear model. The hierarchical nonlinear strategy takes advantage of this subsystem property to enable more robust top-level solvers.
OpenMDAO implements a number of nonlinear solution algorithms that employ a hierarchical strategy. The most basic two algorithms are the nonlinear block Gauss–Seidel and nonlinear block Jacobi algorithms used by Hwang and Martins (2018). Both of these algorithms use simple iterative strategies that repetitively call solve_nonlinear for all the child subsystems in sequence, until the residuals are sufficiently converged.
OpenMDAO V2 introduces a new hierarchical Newton’s method solver that extends the use of this strategy to multidisciplinary models composed of a set of more tightly coupled subsystems. Compared to the pure Newton’s method of Algorithm 2, the hierarchical Newton algorithm adds an additional step that recursively calls solve_nonlinear on all child subsystems of the parent system, as shown in Algorithm 3.

We refer to Algorithm 3 as the hierarchical Newton’s method, because although each child subsystem solves for its own unknowns (uchild), the parent groups are responsible for those same unknowns as well. Since each level of the hierarchy sees the set of residuals from all of its children, the size of the Newton system (the number of state variables it is converging) increases as one moves higher up the hierarchy, making it increasingly challenging to converge. The recursive solution of subsystems acts as a form of nonlinear preconditioning or globalization to help stabilize the solver, but fundamentally, the top-level Newton solver is dealing with the complete set of all residual equations from the entire model.
There is another, arguably more common, formulation for applying Newton’s method to nested models where the solver at any level of the model hierarchy sees only the subset of the implicit variables that it alone is responsible for. In this formulation, the Newton system at any level is much smaller because it does not inherit the states and residuals from any child systems. Instead, it treats any child calculations as if they were purely explicit. We refer to this formulation as the “reduced-space Newton’s method.” In Appendix 2, we prove that the application of the hierarchical Newton’s method yields the exact same solution path as that of a reduced-space Newton’s method. The proof demonstrates that exact recursive solutions for uchild (i.e., Rchild(uchild) = 0) (lines 1, 2, 8, and 9 in Algorithm 3) reduce the search space for the parent solver to only the subset of the u vector that is owned exclusively by the current system and not by any of the solvers from its children.
While perfect sub-convergence is necessary to satisfy the conditions of the proof, in practice, it is not necessary to fully converge the child subsystems for every top-level hierarchical Newton iteration. Once the nonlinear system has reached a sufficient level of convergence, the recursion can be turned off, reverting the solver to the more efficient monolithic strategy.
A hybrid strategy that switches between monolithic and hierarchical strategies was investigated by Chauhan et al. (2018) in a study where they found that the best performing nonlinear solver algorithm changes with the strength of the multidisciplinary coupling. Their results underscore the need for OpenMDAO to support both hierarchical and monolithic nonlinear solver architectures, because they show that different problems require different treatments. The mixture of the two often yields the best compromise between stability and performance.
In addition to the hierarchical Newton’s method solver, OpenMDAO also provides a gradient-free hierarchical Broyden solver that may offer faster convergence than the nonlinear Gauss–Seidel or nonlinear Jacobi solvers. In Appendix 3, we also prove that the Broyden solver exhibits the same equivalence between the hierarchical and reduced-space formulations.
5.2 Linear solution strategy
As discussed above, some nonlinear solvers require their own linear solvers to compute updates for each iteration. OpenMDAO also uses a linear solver to compute total derivatives via (16). The inclusion of linear solvers in the framework, and the manner in which they can be combined, is one of the unique features of OpenMDAO.
There are two API methods that are useful for implementing linear solvers: apply_linear and solve_linear. In an analogous fashion to the nonlinear solvers, the linear solvers can employ either a monolithic or hierarchical strategy. In this context, a monolithic strategy is one that works with the entire partial derivatives Jacobian (∂R/∂u) as a single block in-memory. A hierarchical linear strategy is one that leverages a matrix-free approach.
5.2.1 Hierarchical linear strategy
The hierarchical linear solver strategy is an approach that relies on the use of the apply_linear and solve_linear methods in the OpenMDAO API. As such, it is a matrix-free strategy. This strategy was originally proposed by Hwang and Martins (2018), and we refer the reader to that work for a more detailed presentation of these concepts, including an extensive treatment of how parallel data passing is integrated into this linear strategy. OpenMDAO implements the hierarchical linear solver strategy proposed by MAUD to support integration with computationally expensive analyses, i.e., parallel distributed memory analyses such as CFD and FEA. Models that benefit from this strategy tend to have fewer than ten components that are computationally expensive, with at least one component having on the order of a hundred thousand unknowns. The linear block Gauss–Seidel and linear block Jacobi solvers are the two solvers in the OpenMDAO standard library that use the hierarchical strategy. Algorithms 4 and 5 detail the forward (direct) formulation of the two hierarchical linear solvers. There are also separate reverse (adjoint) formulations for these solvers, which are explained in more detail by Hwang and Martins (2018). For integration with PDE solvers, the forward and reverse forms of these algorithms allow OpenMDAO to leverage existing, highly specialized linear solvers used by discipline analyses as part of a recursive preconditioner for a top-level OpenMDAO Krylov subspace solver in a coupled multidisciplinary model (Hwang and Martins 2018).


5.2.2 Monolithic linear strategy
Although the hierarchical linear solver strategy is an efficient approach for models composed of computationally expensive analyses, it can introduce significant overhead for models composed of hundreds or thousands of computationally simple components. The hierarchical linear solver strategy relies on the use of the apply_linear and solve_linear methods, which only provide linear operators that must be recursively called on the entire model hierarchy. While recursion is generally expensive in and of itself, the cost is exacerbated because OpenMDAO is written in Python, an interpreted language where loops are especially costly. For many models, it is feasible to assemble the entire partial derivative Jacobian matrix in memory, which then allows the use of a direct factorization to solve the linear system more efficiently. As long as the cost of computing the factorization is reasonable, this approach is by far the simplest and most efficient way to implement the solve_linear method. This represents a significant extension from the previously developed hierarchical formulation (Hwang and Martins 2018), and as we will show in Section 5.3, this approach is crucial for good computational performance on models with many components.
The matrix assembly can be done using either a dense matrix or a sparse matrix. In the sparse case, OpenMDAO relies on the components to declare the nonzero partial derivatives, as shown in Fig. 4. Broadly speaking, at the model level, the partial derivative Jacobian is almost always very sparse, even for simple models. Figure 5, which includes a visualization of [∂R/∂u]T, shows that even a small model has a very sparse partial derivative Jacobian. In the vast majority of cases, the factorization is more efficient when using a sparse matrix assembly.
The monolithic linear solver strategy is primarily designed to be used with a direct linear solver. A direct factorization is often the fastest, and certainly the simplest type of linear solver to apply. However, this strategy can also be used with a Krylov subspace solver, assuming we either do not need to use a preconditioner or want to use a preconditioner that is also compatible with the monolithic strategy (e.g., incomplete LU factorization). Krylov subspace solvers are unique because they can be used with both the hierarchical and monolithic linear solver strategies, depending on what type of preconditioner is applied.
Monolithic and hierarchical linear solver strategies can be used in conjunction with each other as part of a larger model. At any level of the model hierarchy, a monolithic strategy can be used, which causes all components below that level to store their partial derivatives in the assembled Jacobian matrix. Above that level, however, a hierarchical linear solver strategy can still be used. This mixed linear solver strategy is crucial for achieving good computational efficiency for larger models. Aeropropulsive design optimization is a good example where this is necessary. Gray et al. (2018a) coupled a RANS CFD analysis to a 1-D propulsion model using OpenMDAO with a hierarchical linear solver strategy to combine the matrix-free Krylov subspace from the CFD with the monolithic direct solver used for the propulsion analysis.
5.3 Performance study for mixed linear solver strategy
The specific combination of hierarchical and monolithic linear solvers that will give the best performance is very model-specific, which is why OpenMDAO’s flexibility to allow different combinations is valuable.
This sensitivity of computational performance to solver strategy can be easily demonstrated using an example model built using the OpenAeroStruct (Jasa et al. 2018b) library. OpenAeroStruct is a modular, lower-fidelity, coupled aerostructural modeling tool which is built on top of OpenMDAO V2. Consider a notional model that computes the average drag coefficient for a set of aerostructural wing models at different angles of attack, as shown in Fig. 6. The derivatives of average drag with respect to the shape design variables can be computed via a single reverse model linear solution. This reverse mode solution was tested with two separate solver strategies: (1) pure monolithic with a direct solver at the top of the model hierarchy and (2) mixed hierarchical/monolithic with a linear block Gauss–Seidel solver at the top and direct solver angle of attack case.

Model hierarchy, data connectivity, and linear solver strategy for an OpenAeroStruct model with four flight conditions
Figure 7 compares the computational costs of these two linear solver strategies and examines how the computational cost scales with increasing number of components. For this problem, the scaling is achieved by increasing the number of angle of attack conditions included in the average. As the number of angle of attack cases increases, the number of components and number of variables goes up as well, since each case requires its own aerostructural analysis group. The data in Fig. 7 shows that both linear solver strategies scale nearly linearly with an increasing number of variables, which indicates very good scaling for the direct solver. This solver relies on the sparse LU factorization in SciPy (Oliphant 2007). However, the difference between the purely monolithic and the mixed hierarchical/monolithic linear solver strategies is 1.5 to 2 orders of magnitude in total computation time. This difference in computational cost is roughly independent of problem size, which demonstrates that the mixed strategy is fundamentally more efficient than the pure monolithic one.

Scaling of computational cost for a single linear solution versus number of components in the model. Two solver strategies are compared: pure monolithic (orange) and mixed (blue). The average slope of the two data sets indicates nearly linear scaling for both, but there is a two-order-of-magnitude difference in actual cost
6 Efficient methods for computing total derivatives of sparse models
As discussed in Section 4, when using the unified derivative equation to analytically compute the total derivative Jacobian, one linear solution is required for each model input in forward mode; alternatively, in reverse mode, one linear solution is required for each model output. However, when the model exhibits certain types of sparsity patterns, it is possible to compute the complete total derivative Jacobian matrix using fewer linear solutions than the number of model inputs or model outputs. Furthermore, when properly exploited, these sparsity structures can also change the preferred solution mode (forward or reverse) from what would normally be expected. In this section, we present two specific types of sparsity structure and discuss how OpenMDAO exploits them to reduce the computational cost of computing derivatives for models where they are present. The first sparsity pattern arises from separable model variables and allows for the multiple linear solutions to be computed simultaneously using a single right-hand-side vector; thus, it requires only one linear solution. The second sparsity pattern arises from models where one component output provides the input to many downstream components that do not depend on each other. This enables multiple linear solutions to be computed in parallel via multiple parallel linear solutions on multiple right-hand sides.
6.1 Combining multiple linear solutions using graph coloring
Typically, a single linear solution corresponds to a single model input (forward/direct mode) or a single model output (reverse/adjoint mode). When a portion of the total derivative Jacobian has a block-diagonal structure, a coloring technique can be applied to combine linear solutions for multiple model inputs or multiple model outputs into a single linear solution. This reduces the cost for computing the total derivative Jacobian. Consider a notional problem with seven model inputs (a,b,c0,c1,c2,c3,c4) and six model outputs (g0,g1,g2,g3,g4,f) with the total derivative Jacobian structure illustrated in Fig. 8. Since there are more model inputs than outputs, the reverse mode would normally be faster.

Total derivative Jacobian structure for a notional model where the model outputs are all separable with respect to the ci inputs. a The full Jacobian structure with coloring to indicate the potential for simultaneous solutions. b The collapsed Jacobian structure that takes advantage of the coloring
However, as we can infer from Fig. 8, the five ci inputs affect the six outputs (g0, ..., g4,f) independently. Therefore, these inputs can share a single color, and the linear system only requires a single forward solution. Combining multiple linear solutions is accomplished by combining multiple columns of the identity matrix from (16) into a single right-hand side, as shown in Fig. 9. Normally, a combined right-hand side would yield sums of total derivatives, but if we know that certain terms are guaranteed to be zero (e.g., dg0/dc1 = 0, dg1/dc2 = 0), we can safely combine the right-hand side vectors.

Combining multiple linear solutions
In this case, using forward mode would require two separate linear solutions for a and b, and then a single additional combined linear solution for the set (c0,…,c4), as illustrated in Figs. 8a and 9b. Since this case is colored in forward mode, the subscripts (i,j,k) in Fig. 9b are associated with the denominator of the total derivatives, indicating that each solution yields derivatives of all the outputs with respect to a single input. In Fig. 9a, [du/dri|j|k] indicates the need to use three separate linear solutions. In Fig. 9b, [du/dri+j+k] indicates that the three right-hand sides can be added as
to form a single linear system that can compute all three sets of total derivatives.
Using coloring, the complete total derivative Jacobian can be constructed using only three linear solutions in a colored forward mode. The original uncolored solution method would require six linear solutions in reverse mode. Therefore, the colored forward mode is faster than using the uncolored reverse mode.
There is a well-known class of optimal control problems that is specifically formulated to create total derivative Jacobians that can be efficiently colored. Betts and Huffman (1991) describe their “sparse finite-differencing” method, where multiple model inputs are perturbed simultaneously to approximate total derivatives with respect to more than one input at the same time. Sparse finite-differencing is applicable only to forward separable problems, but OpenMDAO can leverage coloring in both forward and reverse directions because analytic derivatives are computed with linear solutions rather than a numerical approximations of the nonlinear analysis. The ability to leverage both forward and reverse modes for coloring gives the analytic derivatives approach greater flexibility than the traditional sparse finite-differencing and makes it applicable to a wider range of problems.
Although the notional example used in this section provides a very obvious coloring pattern, in general coloring a total derivative Jacobian is extremely challenging. OpenMDAO uses an algorithm developed by Coleman and Verma (1998) to perform coloring, and it uses a novel approach to computing the total derivative sparsity. More details are included in Appendix 1.
6.1.1 Computational savings from combined linear solutions
The combined linear solution feature is leveraged by the Dymos optimal control library, which is built using OpenMDAO. To date, Dymos has been used to solve a range of optimal control problems (Falck et al. 2019), including canonical problems such as Bryson’s minimum time to climb problem (Bryson 1999), as well as the classic brachistochrone problem posed by Bernoulli (1696). It has also been used to solve more complex optimal trajectory problems for electric aircraft (Falck et al. 2017; Schnulo et al. 2018).
To demonstrate the computational improvement, we present results showing how the cost of solving for the total derivatives Jacobian scales with and without the combined linear solutions feature for Bryson’s minimum time to climb problem implemented in the Dymos example problem library. Figure 10 shows the variation of the total derivatives computation time as a function of the number of time steps used in the model. The greater the number of time steps, the greater the number of constraints in the optimization problem for which we need total derivatives. We can see that the combined linear solution offers significant reductions in the total derivative computation time, and more importantly, shows superior computational scaling.

Comparison of total derivatives computation time computed with (blue) and without (orange) the combined linear solution feature
6.2 Sparsity from quasi-decoupled parallel models
Combining multiple linear solutions offers significant computational savings with no requirement for additional memory allocation; thus, it is a highly efficient technique for reducing the computational cost of solving for total derivatives, even when running in serial. However, it is not possible to use that approach for all models. In particular, a common model structure that relies on parallel execution for computational efficiency, which we refer to as “quasi-decoupled,” prevents the use of combined linear solutions and demands a different approach to exploit its sparsity. In this section, we present a method for performing efficient linear solutions for derivatives of quasi-decoupled systems that enables the efficient use of parallel computing resources for reverse mode linear solutions.
A quasi-decoupled model is one with an inexpensive serial calculation bottleneck at the beginning, followed by a more computationally costly set of parallel calculations for independent model outputs. The data passing in this model is such that one set of outputs gets passed to multiple downstream components that can run in parallel. A typical example of this structure can be found in multipoint models, where the same analysis is run at several different points, e.g., multiple CFD analyses that are run for the same geometry, but at different flow conditions (Reuther et al. 1999; Kenway and Martins 2016; Gallard et al. 2013). In these cases, the geometric calculations that translate the model inputs to the computational grid are the serial bottleneck, and the multiple CFD analyses are the decoupled parallel computations, which can be solved in an embarrassingly parallel fashion. This model can be run efficiently in the forward direction for nonlinear solutions—making it practically forward decoupled—but the linear reverse mode solutions to compute total derivatives can no longer be run in parallel.
One possible solution to address this challenge is to employ a constraint aggregation approach (Kreisselmeier and Steinhauser 1979; Lambe et al. 2017). This approach allows the adjoint method to work efficiently because it collapses many constraint values into a single scalar, hence recovering the adjoint method efficiency. Though this may work in some cases, constraint aggregation is not well-suited to problems where the majority of the constraints being aggregated are active at the optimal solution, as is the case for equality constraints. In these situations, the conservative nature of the aggregations function is problematic because it prevents the optimizer from tightly satisfying all the equalities. Kennedy and Hicken (2015) developed improved aggregation methods that offer a less conservative and more numerically stable formulation, but despite the improvements, aggregation is still not appropriate for all applications. In these cases, an alternate approach is needed to maintain efficient parallel reverse mode (adjoint) linear solutions.
When aggregation cannot be used, OpenMDAO uses a solution technique that retains the parallel efficiency at the cost of a slight increase in required memory. First, the memory allocated for the serial bottleneck calculations in the right-hand side and solution vectors is duplicated across all processors. Only the variables associated with the bottleneck calculation are duplicated, and the variables in the computationally expensive parallel calculations remain the same. This duplication is acceptable because the bottleneck calculation requires an insignificant amount of memory compared to the parallel calculations. The duplication of the memory effectively decouples the portions of the model that require more memory and computational effort, so OpenMDAO can then perform multiple linear solutions in parallel across multiple processors. This approach for parallel reverse derivative solutions was first proposed by Hwang and Martins (2015) and has been adapted into the OpenMDAO framework. It is described below for completeness and to provide context for the performance results presented.
Figure 11 compares the reverse mode linear solution between a basic reverse mode solution and a parallel reverse mode solution. Note that the left-hand side matrices in Fig. 11 are upper triangular because the reverse mode solutions use [∂R/∂u]T. In this notional model, the first component on the diagonal is the inexpensive serial bottleneck that all following calculations depend on. Then, there are two parallel expensive computational groups represented by components (2,3,4) and (5,6,7), each of which computes a model output. We assume that group 1 is allocated in processor 1, and group 2 is allocated in processor 2.

Parallel derivative computation for a reverse mode solution (Hwang and Martins 2015). Group 1 contains components 2, 3, and 4, and group 2 contains components 5, 6, and 7. We assume groups 1 and 2 are allocated on different processors. Without the ability to solve multiple right-hand sides simultaneously, processor 2 would be idling in a, and processor 1 would be idling in b. In c, each processor can solve for the derivatives of its own group simultaneously
Using the basic reverse mode requires two sequential linear solutions. During the first solution, illustrated in Fig. 11a, processor 1 solves for the derivative of the output of group 1, while processor 2 idles. Similarly, during the second solution, illustrated in Fig. 11b, processor 2 solves for the derivatives of the outputs of group 2, while processor 1 idles.
Using the parallel reverse mode, both processors independently loop over the two right-hand sides to compute two linear solutions, as shown in Fig. 11c. For processor 1, the first right-hand side computes derivatives of the group 1 model output, while the second performs no operations. For processor 2, the first right-hand side does not require any operations, and the second computes derivatives of the group 2 model output. Therefore, the parallel reverse mode of Fig. 11c takes advantage of embarrassingly parallel execution. Note that in Fig. 11c, there are grayed out portions of the vectors, indicating that memory is not allocated for those variables on that particular processor.
6.2.1 Computational savings from parallel reverse mode
We now demonstrate the performance of parallel reverse mode derivatives computation using the combined allocation-mission-design (AMD) problem developed by Hwang and Martins (2015). In this problem, an airline with four existing aircraft and one new aircraft design allocates these aircraft for 128 individual routes to maximize operational profit. This model was executed on a parallel cluster with 140 cores, ensuring that the mission constraints are handled in parallel. A number of the constraints exhibit the quasi-decoupled structure because there are separate sets related to each of the 128 missions which can all be computed in parallel, but they all depend on a single upstream calculation that creates the reverse mode bottleneck.
In Fig. 12, we show the total derivatives computation time with and without parallel reverse mode for a range of different model sizes. The models were scaled up by refining the time discretization of the mission integration, which also created more physical constraints for each mission. The calculation is significantly faster with parallel reverse mode, but more importantly, the parallel reverse mode makes the cost to compute total derivatives nearly independent of the size of the problem.

Comparison of total derivatives computation time calculated with and without parallel reverse mode
7 Applications
The usefulness and efficiency of OpenMDAO has already been demonstrated in a variety of applications. All of these applications have been the subject of previous publications and will not be detailed here. Instead, we present an overview of these applications to illustrate the wide range of model fidelities, problem structures, and disciplines that can be handled by OpenMDAO. For each application, we highlight the computational performance and OpenMDAO features that were used. The applications are listed in Fig. 13, where we show the extended design structure matrix (XDSM) (Lambe and Martins 2012) for each problem and list the design variables, objective functions, and constraints.

Summary of applications of OpenMDAO to engineering design optimization problems
One of the first practical engineering problems, and the first example of an optimal control problem, solved with OpenMDAO V2 was a satellite MDO problem that maximized the data downloaded by varying satellite design parameters (related to solar panels, antenna, and radiators) as well as time dependent variables (power distribution, trajectory, and solar panel controls) (Gray et al. 2014). This problem was originally implemented using a bare-bones implementation of MAUD (Hwang et al. 2014). The modeled disciplines consisted of orbit dynamics, attitude dynamics, cell illumination, temperature, solar power, energy storage, and communication. The optimization involved over 25,000 design variables and 2.2 million state variables and required 100 CPU-h to converge to the optimum result in a serial computation (Hwang et al. 2014). The satellite model is broken down into around 100 different components, which greatly simplified the task of deriving the analytic partial derivatives by hand. This problem exhibits the quasi-decoupled structure discussed in Section 6.2, and in OpenMDAO V2, the model was able to run in around 6 h of wall time, running in on 6 CPUs using parallel derivative computation.
The first integration of a specialized high-fidelity solver in OpenMDAO was done to perform the design optimization of an aircraft considering allocation, trajectory optimization, and aerodynamic performance with the objective of maximizing airline profit (Hwang et al. 2019). The aerodynamics were modeled using the ADflow CFD solver (Lyu et al. 2013), which has an adjoint implementation to efficiently compute derivatives of the aerodynamic force coefficients with respect to hundreds of wing shape variables. In this work, the ADflow solver was integrated into the overall model in an explicit form, which greatly simplified the integration and reduced the number of variables that OpenMDAO needed to track. The optimization problem consisted of over 6000 design variables and 23,000 constraints, and it was solved in about 10 h using 128 processors. This work relied heavily on OpenMDAO’s support for parallel computing to efficiently evaluate multiple aerodynamic points simultaneously. Related work on this problem by Roy et al. (2018a) expanded the problem to a mixed integer optimization that considered the airline allocation portion of the problem in a more correct discrete form, which demonstrated the flexibility of the framework to expand beyond purely gradient-based optimization.
The OpenMDAO interface to ADflow, first developed in the work mentioned above, was later reworked into an implicit form that exposed the full state vector of the flow solution to the framework. The new wrapper was then used in a series of propulsion-airframe integration optimization studies that were the first to demonstrate the framework’s ability to compute high-fidelity coupled derivatives. A CFD model of a tightly integrated fuselage and propulsor was coupled to a one-dimensional engine cycle model to build an aeropropulsive model, which enabled the detailed study of boundary layer ingestion (BLI) effects (Gray et al. 2018a) and the simultaneous design of aerodynamic shape and propulsor sizing for BLI configurations (Gray and Martins 2018; Gray et al. 2018b). The thermodynamic cycle analysis tool was developed using OpenMDAO as a standalone propulsion modeling library based on a chemical-equilibrium analysis technique (Gray et al. 2017). This new modeling library was the first engine cycle analysis capability that included analytic derivative computation (Hearn et al. 2016). The development of the cycle analysis tool in OpenMDAO was ultimately what motivated the addition of the new monolithic linear solver strategy to the framework, and coupling that model to the high-fidelity aerodynamic solver required the implementation of a mixed hierarchical-monolithic linear solver strategy in the coupled model.
Jasa et al. (2018b) developed OpenAeroStruct, a low-order wing aerostructural library whose development was motivated by the absence of a tool for fast wing design optimization. OpenAeroStruct implements a vortex lattice model for the aerodynamic analysis and a beam finite-element model for structural analysis. These analyses are coupled, enabling the aerostructural analysis of lifting surfaces. Each of the models was implemented in OpenMDAO from the ground up, making use of the hierarchical representation and solvers for the best possible coupled solution efficiency, as demonstrated in Fig. 7. As a result, OpenAeroStruct efficiently computes aerostructural derivatives through the coupled-adjoint method, enabling fast aerostructural analysis (solutions in seconds) and optimizations (converged results in minutes). OpenAeroStruct has already been used in a number of applications (Friedman et al. 2017; Chaudhuri et al. 2017; Palar and Shimoyama 2017; Cook et al. 2017a, b; Bons et al. 2019; Lam et al. 2018; Tracey and Wolpert 2018; Cook 2018; Baptista and Poloczek 2018; Peherstorfer et al. 2018; Chauhan and Martins 2018). Significant computational efficiency was achieved for OpenAeroStruct by using the sparse-assembled Jacobian matrix feature with a monolithic linear solver strategy, thanks to the highly sparse nature of many of the underlying calculations.
Chung et al. (2018) developed a framework for setting up structural topology optimization problems and formulations. Using this platform, they implemented three popular topology optimization approaches. Even though structural topology optimization involves only one discipline, they found that the framework benefited from the modularity and the more automated derivative computation. The increased modularity made it easier to restructure and extend the code, allowing the authors to quickly change the order of operations in the process to demonstrate the importance of correct sequencing. This structural topology optimization framework is expected to facilitate future developments in multiscale and multidisciplinary topology optimization. This work, in addition to OpenAeroStruct, provides an excellent example of using OpenMDAO as a low-level software layer to develop new disciplinary analysis solvers.
Hwang and Ning (2018) developed and integrated low-fidelity propeller, aerodynamic, structural, and mission analysis models using OpenMDAO for NASA’s X-57 Maxwell research aircraft, which features distributed electric propulsion. They solved MDO problems with up to 101 design variables and 74 constraints that converged in a few hundred model evaluations. Numerical experiments showed the scaling of the optimization time with the number of mission points was, at worst, linear. The inclusion of a fully transient mission analysis model of the aircraft performance was shown to offer significantly different results from a basic multipoint optimization formulation. The need to include the transient analysis is an example of why analytic derivatives are needed for these types of problems: They offer the required computational efficiency and accuracy that could not be achieved using monolithic finite differencing.
Other work that used OpenMDAO V2 includes a framework for the solution of ordinary differential equations (Hwang and Munster 2018), a conceptual design model for aircraft electric propulsion (Brelje and Martins 2018), and a mission planning tool for the X-57 aircraft (Schnulo et al. 2018).
Application-focused work has included the design of a next-generation airliner considering operations and economics (Roy et al. 2018b), design and trajectory optimization of a morphing wing aircraft (Jasa et al. 2018a), and trajectory optimization of an aircraft with a fuel thermal management system (Jasa et al. 2018c). OpenMDAO is also being used extensively by the wind energy community for wind turbine design (Ning and Petch 2016; Barrett and Ning 2018; Zahle et al. 2016, 2018; McWilliam et al. 2018; Graf et al. 2018; Dykes et al. 2018) and wind farm layouts (Thomas et al. 2017; Stanley and Ning 2018).
8 Conclusions
The OpenMDAO framework was developed to facilitate the multidisciplinary analysis and design optimization of complex engineering systems. While other frameworks exist for the same purpose, OpenMDAO has evolved in the last few years to incorporate state-of-the-art algorithms that enable it to address optimization problems of unprecedented scale and complexity.
Two main areas of development made this possible: algorithms for the solution of coupled systems and methods for the computation of derivatives. The development of efficient derivative computation was motivated by the fact that gradient-based optimization is our only hope for solving large-scale problems that involve computationally expensive models; thus, efficient gradient computations that are scalable are required. Because most models and coupled systems exhibit some degree of sparsity in their problem structure, OpenMDAO takes advantage of the sparsity for both storage and computation.
To achieve the efficient solution of coupled systems, OpenMDAO implements known state-of-the-art monolithic methods and has developed a flexible hierarchical approach that enables users to group models according to the problem structure so that computations can be nested, parallelized, or both.
To compute total coupled derivatives efficiently in a scalable way, OpenMDAO uses analytic methods in two modes: forward and reverse. The forward mode is equivalent to the coupled direct method, and its cost scales linearly with the number of design variables. The reverse mode is equivalent to the coupled-adjoint method, and its cost scales linearly with the number of functions of interest—but it is independent of the number of design variables. This last characteristic is particularly desirable because many problems have a number of design variables that is larger than the number of functions of interest (objective and constraints). Furthermore, in cases with large numbers of constraints, these can often be aggregated.
Problem sparsity was also exploited in the coupled derivative computation by a new approach we developed that uses graph coloring. We also discussed a few other techniques to increase the efficiency of derivative computations using the hierarchical problem representation.
The algorithms in OpenMDAO work best if the residuals of the systems involved are available, but when they are not available, it is possible to formulate the models solely in terms of their inputs and outputs.
The efficiency and scalability of OpenMDAO were demonstrated in several examples. We also presented an overview of various previously published applications of OpenMDAO to engineering design problems, including satellite, wing, and aircraft design. Some of these problems involved tens of thousands of design variables and similar number of constraints. Other problems involved costly high-fidelity models, such as CFD and finite element structural analysis with millions of degrees of freedom. While the solution of the problems in these applications would have been possible with single purpose implementations, OpenMDAO made it possible to use state-of-the-art methods with a much lower development effort.
Based on the experience of these applications, we conclude that while OpenMDAO can handle traditional disciplinary analysis models effectively, it is most efficient when these models are developed from the ground up using OpenMDAO with a fine-grained modularity to take full advantage of the problem sparsity, lower implementation effort, and built-in derivative computation.
9 Replication of results
Most of the codes required to replicate the results in this paper are available under open-source licenses and are maintained in version control repositories. The OpenMDAO framework is available from GitHub (http://github.com/OpenMDAO). The OpenMDAO website (http://openmdao.org) provides installation instructions and a number of examples. The code for the simple example of Section 3 is listed in Figs. 3 and 4 and can be run once OpenMDAO is installed as is. The scripts used to produce the scaling plots in Figs. 7 and 10 are available as supplemental material in this paper. In addition to requiring OpenMDAO to be installed, these scripts require OpenAeroStruct (http://github.com/mdolab/OpenAeroStruct) and Dymos (http://github.com/OpenMDAO/dymos). The scaling plots for the AMD problem (Fig. 12) involve a complex framework that includes code that is not open source, and therefore, we are not able to provide scripts for these results. Finally, although no results are shown in the applications mentioned in Section 7, the code for two of these applications—OpenAeroStruct (http://github.com/mdolab/OpenAeroStruct) and the satellite MDO (http://github.com/OpenMDAO/CADRE)—is also available.
References
Arora J, Haug EJ (1979) Methods of design sensitivity analysis in structural optimization. AIAA J 17(9):970–974. https://doi.org/10.2514/3.61260
Balabanov V, Charpentier C, Ghosh DK, Quinn G, Vanderplaats G, Venter G (2002) Visualdoc: a software system for general purpose integration and design optimization. In: 9th AIAA/ISSMO symposium on multidisciplinary analysis and optimization. Atlanta
Balay S, Abhyankar S, Adams M, Brown J, Buschelman K, Dalcin L, Dener A, Eijkhout V, Gropp W, Karpeyev D, Kaushik D, Knepley M, May D, McInnes LC, Mills R, Munson T, Rupp K, Sanan P, Smith B, Zampini S, Zhang H (2018) PETSc users manual. Tech. Rep. ANL-95/11 - Revision 3.10, Argonne National Laboratory
Baptista R, Poloczek M (2018) Bayesian optimization of combinatorial structures. In: Dy J, Krause A (eds) Proceedings of the 35th international conference on machine learning, PMLR, Stockholmsmässan, Stockholm Sweden, Proceedings of Machine Learning Research, vol 80. pp 462–471. http://proceedings.mlr.press/v80/baptista18a.html
Barrett R, Ning A (2018) Integrated free-form method for aerostructural optimization of wind turbine blades. Wind Energy 21(8):663–675. https://doi.org/10.1002/we.2186
Bernoulli J (1696) A new problem to whose solution mathematicians are invited. Acta Eruditorum 18:269
Betts JT, Huffman WP (1991) Trajectory optimization on a parallel processor. J Guid Control Dyn 14(2):431–439. https://doi.org/10.2514/3.20656
Bons N, He X, Mader CA, Martins JRRA (2019) Multimodality in aerodynamic wing design optimization. AIAA Journal https://doi.org/10.2514/1.J057294, (In press)
Brelje BJ, Martins JRRA (2018) Development of a conceptual design model for aircraft electric propulsion with efficient gradients. In: Proceedings of the AIAA/IEEE electric aircraft technologies symposium. Cincinnati. https://doi.org/10.2514/6.2018-4979
Bryson AE (1999) Dynamic optimization. Addison Wesley Longman, Menlo Park
Bryson AE, Ho YC (1975) Applied optimal control: optimization, estimation, and control. Wiley, Hoboken
Carrier G, Destarac D, Dumont A, Méheut M, Din ISE, Peter J, Khelil SB, Brezillon J, Pestana M (2014) Gradient-based aerodynamic optimization with the elsA software. In: 52nd aerospace sciences meeting. https://doi.org/10.2514/6.2014-0568
Chaudhuri A, Lam R, Willcox K (2017) Multifidelity uncertainty propagation via adaptive surrogates in coupled multidisciplinary systems. AIAA J, 235–249. https://doi.org/10.2514/1.J055678
Chauhan SS, Martins JRRA (2018) Low-fidelity aerostructural optimization of aircraft wings with a simplified wingbox model using OpenAeroStruct. In: Proceedings of the 6th international conference on engineering optimization, EngOpt 2018. Springer, Lisbon, pp 418–431. https://doi.org/10.1007/978-3-319-97773-7_38
Chauhan SS, Hwang JT, Martins JRRA (2018) An automated selection algorithm for nonlinear solvers in MDO. Struct Multidiscip Optim 58(2):349–377. https://doi.org/10.1007/s00158-018-2004-5
Chen S, Lyu Z, Kenway GKW, Martins JRRA (2016) Aerodynamic shape optimization of the Common Research Model wing-body-tail configuration. J Aircr 53(1):276–293. https://doi.org/10.2514/1.C033328
Chung H, Hwang JT, Gray JS, Kim HA (2018) Implementation of topology optimization using OpenMDAO. In: 2018 AIAA/ASCE/AHS/ASC structures, structural dynamics, and materials conference. AIAA AIAA, Kissimmee. https://doi.org/10.2514/6.2018-0653
Coleman TF, Verma A (1998) The efficient computation of sparse Jacobian matrices using automatic differentiation. SIAM J Sci Comput 19(4):1210–1233
Cook LW (2018) Effective formulations of optimization under uncertainty for aerospace design. PhD thesis, University of Cambridge. https://doi.org/10.17863/CAM.23427
Cook LW, Jarrett JP, Willcox KE (2017a) Extending horsetail matching for optimization under probabilistic, interval, and mixed uncertainties. AIAA J 56(2):849–861. https://doi.org/10.2514/1.J056371
Cook LW, Jarrett JP, Willcox KE (2017b) Horsetail matching for optimization under probabilistic, interval and mixed uncertainties. In: 19th AIAA non-deterministic approaches conference, p 0590 . https://doi.org/10.2514/6.2017-0590
Dykes K, Damiani R, Roberts O, Lantz E (2018) Analysis Of ideal towers for tall wind applications. In: 2018 wind energy symposium. AIAA. https://doi.org/10.2514/6.2018-0999
Falck RD, Chin JC, Schnulo SL, Burt JM, Gray JS (2017) Trajectory optimization of electric aircraft subject to subsystem thermal constraints. In: 18th AIAA/ISSMO multidisciplinary analysis and optimization conference. Denver
Falck RD, Gray JS, Naylor B (2019) Optimal control within the context of multidisciplinary design, analysis, and optimization. In: AIAA SciTech forum, AIAA. https://doi.org/10.2514/6.2019-0976
Friedman S, Ghoreishi SF, Allaire DL (2017) Quantifying the impact of different model discrepancy formulations in coupled multidisciplinary systems. In: 19th AIAA non-deterministic approaches conference, p 1950. https://doi.org/10.2514/6.2017-1950
Gallard F, Meaux M, Montagnac M, Mohammadi B (2013) Aerodynamic aircraft design for mission performance by multipoint optimization. In: 21st AIAA computational fluid dynamics conference. American Institute of Aeronautics and Astronautics. https://doi.org/10.2514/6.2013-2582
Gallard F, Lafage R, Vanaret C, Pauwels B, Guénot D, Barjhoux PJ, Gachelin V, Gazaix A (2017) GEMS: a Python library for automation of multidisciplinary design optimization process generation. In: 18th AIAA/ISSMO multidisciplinary analysis and optimization conference
Gebremedhin AH, Manne F, Pothen A (2005) What color is your Jacobian? Graph coloring for computing derivatives. SIAM Rev 47(4):629–705
Golovidov O, Kodiyalam S, Marineau P, Wang L, Rohl P (1998) Flexible implementation of approximation concepts in an MDO framework. In: 7th AIAA/USAF/NASA/ISSMO symposium on multidisciplinary analysis and optimization. American Institute of Aeronautics and Astronautics. https://doi.org/10.2514/6.1998-4959
Graf P, Dykes K, Damiani R, Jonkman J, Veers P (2018) Adaptive stratified importance sampling: hybridization of extrapolation and importance sampling Monte Carlo methods for estimation of wind turbine extreme loads. Wind Energy Science (Online) 3(2). https://doi.org/10.5194/wes-3-475-2018
Gray J, Moore KT, Naylor BA (2010) OpenMDAO: an open source framework for multidisciplinary analysis and optimization. In: Proceedings of the 13th AIAA/ISSMO multidisciplinary analysis optimization conference, Fort Worth, TX, AIAA, 2010- 9101
Gray J, Moore KT, Hearn TA, Naylor BA (2013) Standard platform for benchmarking multidisciplinary design analysis and optimization architectures. AIAA J 51(10):2380–2394. https://doi.org/10.2514/1.J052160
Gray J, Hearn T, Moore K, Hwang JT, Martins JRRA, Ning A (2014) Automatic evaluation of multidisciplinary derivatives using a graph-based problem formulation in OpenMDAO. In: Proceedings of the 15th AIAA/ISSMO multidisciplinary analysis and optimization conference, Atlanta. https://doi.org/10.2514/6.2014-2042
Gray J, Mader CA, Kenway GKW, Martins JRRA (2018a) Modeling boundary layer ingestion using a coupled aeropropulsive analysis. J Aircr 55(3):1191–1199. https://doi.org/10.2514/1.C034601
Gray JS, Martins JRRA (2018) Coupled aeropropulsive design optimization of a boundary layer ingestion propulsor. The Aeronautical Journal. https://doi.org/10.1017/aer.2018.120, (In press)
Gray JS, Chin J, Hearn T, Hendricks E, Lavelle T, Martins JRRA (2017) Chemical equilibrium analysis with adjoint derivatives for propulsion cycle analysis. J Propuls Power 33(5):1041–1052. https://doi.org/10.2514/1.B36215
Gray JS, Kenway GKW, Mader CA, Martins JRRA (2018b) Aeropropulsive design optimization of a turboelectric boundary layer ingestion propulsion. In: AIAA aviation technology, integration and operations conference. Atlanta. https://doi.org/10.2514/6.2018-3976
Griewank A (2000) Evaluating derivatives. SIAM, Philadelphia
Haftka RT (1977) Optimization of flexible wing structures subject to strength and induced drag constraints. AIAA J 15(8):1101–1106. https://doi.org/10.2514/3.7400
Haftka RT, Sobieszczanski-Sobieski J, Padula SL (1992) On options for interdisciplinary analysis and design optimization. Struct Optim 4:65–74. https://doi.org/10.1007/BF01759919
He P, Mader CA, Martins JRRA, Maki KJ (2018) An aerodynamic design optimization framework using a discrete adjoint approach with OpenFOAM. Comput Fluids 168:285–303. https://doi.org/10.1016/j.compfluid.2018.04.012
Hearn DT, Hendricks E, Chin J, Gray JS, Moore DKT (2016) Optimization of turbine engine cycle analysis with analytic derivatives. In: 17th AIAA/ISSMO multidisciplinary analysis and optimization conference, part of AIAA Aviation 2016 (Washington, DC). https://doi.org/10.2514/6.2016-4297
Heath C, Gray J (2012) OpenMDAO: framework for flexible multidisciplinary design, analysis and optimization methods. In: Proceedings of the 53rd AIAA structures, structural dynamics and materials conference, Honolulu, HI, AIAA-2012-1673
Heil M, Hazel AL, Boyle J (2008) Solvers for large-displacement fluid–structure interaction problems: segregated versus monolithic approaches. Comput Mech 43(1):91–101. https://doi.org/10.1007/s00466-008-0270-6
Hwang JT, Martins JRRA (2015) Parallel allocation-mission optimization of a 128-route network. In: Proceedings of the 16th AIAA/ISSMO multidisciplinary analysis and optimization conference. Dallas. https://doi.org/10.2514/6.2015-2321
Hwang JT, Martins JRRA (2018) A computational architecture for coupling heterogeneous numerical models and computing coupled derivatives. ACM Trans Math Softw 44(4):37. https://doi.org/10.1145/3182393
Hwang JT, Munster DW (2018) Solution of ordinary differential equations in gradient-based multidisciplinary design optimization. In: 2018 AIAA/ASCE/AHS/ASC structures, structural dynamics, and materials conference. Kissimmee, FL. https://doi.org/10.2514/6.2018-1646
Hwang JT, Ning A (2018) Large-scale multidisciplinary optimization of an electric aircraft for on-demand mobility. In: 2018 AIAA/ASCE/AHS/ASC structures, structural dynamics, and materials conference. AIAA AIAA, Kissimmee. https://doi.org/10.2514/6.2018-1384
Hwang JT, Lee DY, Cutler JW, Martins JRRA (2014) Large-scale multidisciplinary optimization of a small satellite’s design and operation. J Spacecr Rocket 51(5):1648–1663. https://doi.org/10.2514/1.A32751
Hwang JT, Jasa J, Martins JRRA (2019) High-fidelity design-allocation optimization of a commercial aircraft maximizing airline profit. Journal of Aircraft. https://doi.org/10.2514/1.C035082, (In press)
Jameson A (1988) Aerodynamic design via control theory. J Sci Comput 3(3):233–260
Jasa JP, Hwang JT, Martins JRRA (2018a) Design and trajectory optimization of a morphing wing aircraft. In: 2018 AIAA/ ASCE/AHS/ASC structures, structural dynamics, and materials conference. AIAA SciTech Forum, Orlando. https://doi.org/10.2514/6.2018-1382
Jasa JP, Hwang JT, Martins JRRA (2018b) Open-source coupled aerostructural optimization using Python. Struct Multidiscip Optim 57:1815–1827. https://doi.org/10.1007/s00158-018-1912-8
Jasa JP, Mader CA, Martins JRRA (2018c) Trajectory optimization of supersonic air vehicle with thermal fuel management system. In: AIAA/ISSMO multidisciplinary analysis and optimization conference. Atlanta. https://doi.org/10.2514/6.2018-3884
Jones M, Plassmann P (1993) A parallel graph coloring heuristic. SIAM J Sci Comput 14(3):654–669. https://doi.org/10.1137/0914041
Karp RM, Wigderson A (1985) A fast parallel algorithm for the maximal independent set problem. J Assoc Comput Mach 32(4):762–773
Kenway GKW, Martins JRRA (2016) Multipoint aerodynamic shape optimization investigations of the Common Research Model wing. AIAA J 54(1):113–128. https://doi.org/10.2514/1.J054154
Kennedy GJ, Hicken JE (2015) Improved constraint-aggregation methods. Comput Methods Appl Mech Eng 289:332–354. https://doi.org/10.1016/j.cma.2015.02.017
Keyes DE, McInnes LC, Woodward C, Gropp W, Myra E, Pernice M, Bell J, Brown J, Clo A, Connors J, Constantinescu E, Estep D, Evans K, Farhat C, Hakim A, Hammond G, Hansen G, Hill J, Isaac T, Jiao X, Jordan K, Kaushik D, Kaxiras E, Koniges A, Lee K, Lott A, Lu Q, Magerlein J, Maxwell R, McCourt M, Mehl M, Pawlowski R, Randles AP, Reynolds D, Riviere B, Rude U, Scheibe T, Shadid J, Sheehan B, Shephard M, Siegel A, Smith B, Tang X, Wilson C, Wohlmuth B (2013) Multiphysics simulations: challenges and opportunities. Int J High Perform Comput Appl 27(1):4–83. https://doi.org/10.1177/1094342012468181
Kolonay RM, Sobolewski M (2011) Service oriented computing environment (SORCER) for large scale, distributed, dynamic fidelity aeroelastic analysis. In: Optimization, international forum on aeroelasticity and structural dynamics, IFASD 2011, 26-30
Kreisselmeier G, Steinhauser R (1979) Systematic control design by optimizing a vector performance index. In: International federation of active controls symposium on computer-aided design of control systems. Zurich. https://doi.org/10.1016/S1474-6670(17)65584-8
Lam R, Poloczek M, Frazier P, Willcox KE (2018) Advances in Bayesian optimization with applications in aerospace engineering. In: 2018 AIAA non-deterministic approaches conference, p 1656. https://doi.org/10.2514/6.2018-1656
Lambe AB, Martins JRRA (2012) Extensions to the design structure matrix for the description of multidisciplinary design, analysis, and optimization processes. Struct Multidiscip Optim 46:273–284. https://doi.org/10.1007/s00158-012-0763-y
Lambe AB, Martins JRRA, Kennedy GJ (2017) An evaluation of constraint aggregation strategies for wing box mass minimization. Struct Multidiscip Optim 55(1):257–277. https://doi.org/10.1007/s00158-016-1495-1
Lyu Z, Kenway GK, Paige C, Martins JRRA (2013) Automatic differentiation adjoint of the Reynolds-averaged Navier–Stokes equations with a turbulence model. In: 21st AIAA computational fluid dynamics conference. San Diego. https://doi.org/10.2514/6.2013-2581
Mader CA, Martins JRRA, Alonso JJ, van der Weide E (2008) ADJoint: an approach for the rapid development of discrete adjoint solvers. AIAA J 46(4):863–873. https://doi.org/10.2514/1.29123
Marriage CJ, Martins JRRA (2008) Reconfigurable semi-analytic sensitivity methods and MDO architectures within the πMDO framework. In: Proceedings of the 12th AIAA/ISSMO multidisciplinary analysis and optimizaton conference Victoria. British Columbia. https://doi.org/10.2514/6.2008-5956
Martins JRRA, Hwang JT (2013) Review and unification of methods for computing derivatives of multidisciplinary computational models. AIAA J 51(11):2582–2599. https://doi.org/10.2514/1.J052184
Martins JRRA, Hwang JT (2016) Multidisciplinary design optimization of aircraft configurations—part 1: a modular coupled adjoint approach. Lecture series, Von Karman Institute for Fluid Dynamics, Rode Saint Genèse, Belgium, ISSN0377-8312
Martins JRRA, Lambe AB (2013) Multidisciplinary design optimization: a survey of architectures. AIAA J 51(9):2049–2075. https://doi.org/10.2514/1.J051895
Martins JRRA, Sturdza P, Alonso JJ (2003) The complex-step derivative approximation. ACM Trans Math Softw 29(3):245–262. https://doi.org/10.1145/838250.838251
Martins JRRA, Alonso JJ, Reuther JJ (2004) High-fidelity aerostructural design optimization of a supersonic business jet. J Aircr 41(3):523–530. https://doi.org/10.2514/1.11478
Martins JRRA, Alonso JJ, Reuther JJ (2005) A coupled-adjoint sensitivity analysis method for high-fidelity aero-structural design. Optim Eng 6(1):33–62. https://doi.org/10.1023/B:OPTE.0000048536.47956.62
Martins JRRA, Marriage C, Tedford NP (2009) pyMDO: an object-oriented framework for multidisciplinary design optimization. ACM Trans Math Softw 36(4):20:1–20:25. https://doi.org/10.1145/1555386.1555389
McWilliam MK, Zahle F, Dicholkar A, Verelst D, Kim T (2018) Optimal aero-elastic design of a rotor with bend-twist coupling. J Phys Conf Ser 1037(4):042009. http://stacks.iop.org/1742-6596/1037/i=4/a=042009
Moore K, Naylor B, Gray J (2008) The development of an open-source framework for multidisciplinary analysis and optimization. In: Proceedings of the 10th AIAA/ISSMO multidisciplinary analysis and optimization conference. Victoria, BC, Canada, AIAA 2008-6069
Naumann U (2011) The art of differentiating computer programs—an introduction to algorithmic differentiation. SIAM
Nielsen EJ, Kleb WL (2006) Efficient construction of discrete adjoint operators on unstructured grids using complex variables. AIAA J 44(4):827–836. https://doi.org/10.2514/1.15830
Ning A, Petch D (2016) Integrated design of downwind land-based wind turbines using analytic gradients. Wing Energy 19(12):2137–2152. https://doi.org/10.1002/we.1972
Oliphant TE (2007) Python for scientific computing. Comput Sci Eng 9(3):10. https://doi.org/10.1109/MCSE.2007.58
Padula SL, Gillian RE (2006) Multidisciplinary environments: a history of engineering framework development. In: Proceedings of the 11th AIAA/ISSMO multidisciplinary analysis and optimization conference, AIAA 2006-7083. https://doi.org/10.2514/6.2006-7083
Palar PS, Shimoyama K (2017) Polynomial-chaos-kriging-assisted efficient global optimization. In: 2017 IEEE symposium series on computational intelligence (SSCI). IEEE, pp 1–8. https://doi.org/10.1109/SSCI.2017.8280831
Peherstorfer B, Beran PS, Willcox KE (2018) Multifidelity Monte Carlo estimation for large-scale uncertainty propagation. In: 2018 AIAA non-deterministic approaches conference, p 1660. https://doi.org/10.2514/6.2018-1660
Peter JEV, Dwight RP (2010) Numerical sensitivity analysis for aerodynamic optimization: a survey of approaches. Comput Fluids 39(3):373–391. https://doi.org/10.1016/j.compfluid.2009.09.013
Reuther JJ, Jameson A, Alonso JJ, Rimlinger MJ, Saunders D (1999) Constrained multipoint aerodynamic shape optimization using an adjoint formulation and parallel computers, part 1. J Aircr 36(1):51–60. https://doi.org/10.2514/2.2413
Roy S, Crossley WA, Moore KT, Gray JS, Martins JRRA (2018a) Next generation aircraft design considering airline operations and economics. In: 2018 AIAA/ASCE/AHS/ASC structures, structural dynamics, and materials conference. Kissimmee, FL. https://doi.org/10.2514/6.2018-1647
Roy S, Crossley WA, Moore KT, Gray JS, Martins JRRA (2018b) Next generation aircraft design considering airline operations and economics. In: AIAA/ASCE/AHS/ASC structures, structural dynamics and materials conference. Kissimmee. https://doi.org/10.2514/6.2018-1647
Salas AO, Townsend JC (1998) Framework requirements for MDO application development. In: 7th AIAA/USAF/NASA/ISSMO symposium on multidisciplinary analysis and optimization, pp 98–4740
Schnulo SL, Jeff Chin RDF, Gray JS, Papathakis KV, Clarke SC, Reid N, Borer NK (2018) Development of a multi-segment mission planning tool for SCEPTOR X-57. In: 2018 multidisciplinary analysis and optimization conference AIAA. Atlanta. https://doi.org/10.2514/6.2018-3738
Sobieszczanski-Sobieski J (1990) Sensitivity of complex, internally coupled systems. AIAA J 28(1):153–160. https://doi.org/10.2514/3.10366
Squire W, Trapp G (1998) Using complex variables to estimate derivatives of real functions. SIAM Rev 40(1):110–112
Stanley APJ, Ning A (2018) Coupled wind turbine design and layout optimization with non-homogeneous wind turbines. Wind Energy Science. https://doi.org/10.5194/wes-2018-54
Tedford NP, Martins JRRA (2006) On the common structure of MDO problems: a comparison of architectures. In: Proceedings of the 11th AIAA/ISSMO multidisciplinary analysis and optimization conference. Portsmouth, VA, AIAA 2006-7080
Tedford NP, Martins JRRA (2010) Benchmarking multidisciplinary design optimization algorithms. Optim Eng 11(1):159–183. https://doi.org/10.1007/s11081-009-9082-6
Thomas J, Gebraad P, Ning A (2017) Improving the FLORIS wind plant model for compatibility with gradient-based optimization. Wind Eng 41(5):313–329. https://doi.org/10.1177/0309524X17722000
Tracey BD, Wolpert D (2018) Upgrading from Gaussian processes to student’s-T processes. In: 2018 AIAA non-deterministic approaches conference, p 1659. https://doi.org/10.2514/6.2018-1659
Welsh DJA, Powell MB (1967) An upper bound for the chromatic number of a graph and its application to timetabling problems. Comput J 10(1):85–86. https://doi.org/10.1093/comjnl/10.1.85
Zahle F, Tibaldi C, Pavese C, McWilliam MK, Blasques JPAA, Hansen MH (2016) Design of an aeroelastically tailored 10 MW wind turbine rotor. J Phys Conf Ser 753(6):062008. http://stacks.iop.org/1742-6596/753/i=6/a=062008
Zahle F, Sørensen NN, McWilliam MK, Barlas A (2018) Computational fluid dynamics-based surrogate optimization of a wind turbine blade tip extension for maximising energy production. In: Journal of Physics: Conference Series, The Science of Making Torque from Wind, vol 1037. Milano. https://doi.org/10.1088/1742-6596/1037/4/042013
Acknowledgements
The authors would like to thank the NASA ARMD Transformational Tools and Technologies project for their support of the OpenMDAO development effort. Joaquim Martins was partially supported by the National Science Foundation (award number 1435188). We would like to acknowledge the invaluable advice from Gaetan Kenway and Charles Mader on efficient implementation of OpenMDAO for high-fidelity work. Also invaluable was the extensive feedback provided by Eric Hendricks, Rob Falck, and Andrew Ning. Finally, we would also like to thank Nicolas Bons, Benjamin Brelje, Anil Yildirim, and Shamsheer Chauhan for their review of this manuscript and their helpful suggestions.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest.
Additional information
Responsible Editor: Jose Herskovits
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Coloring of total derivative Jacobians
1.1 1.1 Determining total derivative coloring
In the simple problem illustrated in Fig. 8, the forward coloring of the model inputs is obvious. However, for a large problem with an unordered total Jacobian matrix, it is not easy to identify coloring. There are a wide variety of serial coloring algorithms (Welsh and Powell 1967; Karp and Wigderson 1985; Jones and Plassmann 1993; Coleman and Verma 1998; Gebremedhin et al. 2005), originally developed for coloring partial derivative Jacobians. There are also a set of parallel coloring algorithms that have been developed for parallel distributed-memory applications, such as CFD (Jones and Plassmann 1993; Nielsen and Kleb 2006; Mader et al. 2008; Lyu et al. 2013; He et al. 2018). What we propose here is that these coloring algorithms are now also applicable for coloring total derivative Jacobian calculations based on the unified derivatives (16).
To apply a coloring algorithm, we need to know the total derivative Jacobian sparsity pattern a priori, but this information is not easily available. However, the sparsity pattern of the partial derivative Jacobian matrix, ∂R/∂u, is known to OpenMDAO a priori from the combination of user-declared partial derivatives and the connections made during model construction. Therefore, we developed a method in OpenMDAO that computes the total derivative sparsity given the partial derivative Jacobian sparsity.
To determine the total Jacobian sparsity pattern for a given state, OpenMDAO computes a randomized partial derivative matrix using linear solutions of (16) with randomized values for ∂R/∂u. Intuitively, one can understand how using randomized partial derivatives would yield a relatively robust estimate of the total derivative sparsity pattern, but we provide a more detailed logical argument for why this approach is appropriate here. A single randomized total derivative Jacobian is likely to give the correct sparsity pattern, but we can reduce the likelihood of errors in the sparsity by summing the absolute value of multiple randomly generated total derivative Jacobians.
Once we have the total derivative sparsity pattern, OpenMDAO applies a coloring algorithm based on the work of Coleman and Verma (1998) to identify the reduced set of linear solutions needed to compute the total derivative Jacobian. As we demonstrate in Section 5.3, coloring can offer significant performance improvements for problems that have sparse total derivative Jacobians.
1.2 1.2 Justification for coloring with randomized total derivative Jacobians
In theory, it would be possible to color the total derivative Jacobian based on the actual Jacobian computed around the initial condition of the model. There is a risk, however, that the initial condition of the model will happen to be at a point where some of the total derivatives in the model are incidentally zero, although they will take nonzero values elsewhere in the design space. The incidental zero would potentially result in an incorrect coloring, and so it is to be avoided if possible. Instead of using the actual Jacobian values, we generate a randomized total derivative Jacobian that is statistically highly unlikely to create any incidental zero values.
From (16), we know that the total derivative Jacobian matrix, du/dr, is equal to the inverse of the partial derivative Jacobian matrix, ∂R/∂u. Our task reduces to the general mathematical problem of determining the sparsity structure of a matrix inverse given the sparsity structure of the matrix itself, assuming that the matrix is large. First, we note that we do not need the sparsity structure of all of du/dr; we only need the rows and columns corresponding to df/dx, which is almost always a much smaller matrix because du/dr contains all the intermediate model variables as well as the model inputs and model outputs. From Cramer’s rule, we know that
which is to say that the (i,j)th entry of the inverse of the Jacobian is the quotient of the (i,j)th entry of the adjugate of the Jacobian and the determinant of the Jacobian. The Jacobian is invertible for well-posed models, so the determinant is always nonzero. Thus, only the numerator in (25) determines if a particular term is nonzero. If the matrix is n × n, where n is large, each term in the adjugate and, thus, the inverse is the sum of a large number of terms that are products of n − 1 partial derivatives.
If we produce a partial derivative Jacobian matrix with random values for all nonzero terms, it would be highly improbable that this sum of a large number of terms would be incidentally zero. Therefore, we assume that each entry of the inverse of the random partial derivative Jacobian that is zero is actually a zero in the sparsity structure of the true total derivative Jacobian.
Appendix 2: Equivalence between hierarchical and reduced-space Newton’s methods
OpenMDAO introduces a new hierarchical Newton’s method formulation for the sake of improved numerical flexibility; however, this proof shows that the new full-space method can be made mathematically identical to the more traditional reduced-space Newton’s method if one always fully converges the internal nonlinear system associated with Ry. Consider the residual of an arbitrary implicit function, Rx(x) = rx, at some non-converged value of x. If rx is actually a function of the nonlinear system Ry(x,y) = 0, converged for a specific value of x:
then we call Rx the reduced-space residual function, with the full space composed of the vectors x and y of lengths n and m, respectively.
Our ultimate goal is to solve for x such that Rx(x) = 0, using Newton’s method. The traditional Newton’s method iteration consists in computing Δx by solving a linear system of size n:
Expanding ∂Rx/∂x to account for the intermediate calculation of y gives
By differentiating (27) with respect to x, we find that
Combining (29) and (31) gives a formula for the Newton update of the reduced-space function as
Now, instead of the reduced-space form of (26), consider a full-space form that deals with both x and y simultaneously as one vector:
This full-space form is the mathematical representation used by OpenMDAO for any system—or subsystem, as demonstrated in (15). The Newton update for the flattened system must be solved for via a linear system of size (n + m):
If we apply the hierarchical Newton algorithm to the full-space formulation, then we can assume that any time (34) is solved, y has first been found such that that ry = 0. Expanding ∂Ru/∂u and setting ry = 0 in (34) yields
Solving (35) for Δy and back substituting yields
Now note that (32) and (36) are identical, and therefore applying the hierarchical Newton algorithm to the full-space model (size n + m) gives the exact same Δx as the reduced-space Newton algorithm applied to the smaller, reduced-space model (size n). Since the updates to Δx are the same, then assuming complete convergence of all child subsystems, the path that the hierarchical Newton’s method takes on the size (n + m) formulation will be identical to the path the reduced-space Newton’s method takes on the smaller size n formulation.
Appendix 3: Equivalence between recursive and hierarchical Broyden’s methods
Broyden’s second method computes an approximate update of the inverse Jacobian via
Then, the Newton update is applied using the approximate inverse Jacobian via
1.1 3.1 Reduced-space Broyden
Consider the same composite model structure given in (26) and (27). From (32), we know that
To simplify the algebra, we now define a new variable, β, as
Now we can substitute this into (37) to calculate the Broyden update to the inverse Jacobian as
Finally, if we substitute this into (38), we get the update to the state value:
1.2 3.2 Full-space Broyden
To apply Broyden’s method to the full-space formulation, we start from (35) for the Newton update of the full-space system, but now instead of an exact inverse Jacobian, we use the approximate inverse Jacobian, \(J_{n}^{-1}\), i.e.,
The full-space Broyden’s method gives
We use the closed form solution for the block inverse of a 2 × 2 matrix to obtain
We can simplify this by substituting (40) into (45), which yields
To further simplify, we define one more new variable, γ:
and then,
Now, returning to (44), we can compute each of the terms:
Since the residual ry is zero,
Putting it all together, we get
Performing the outer product and reducing yields
Now we substitute this into (23) to get the update to the state value:
Finally, we can solve for the Broyden updated Δx to obtain:
This matches the result from recursive Broyden in (42). We also end up with an update to y, but since we have assumed that a sub-solver will always drive Ry to zero, this update to y does not affect the path taken by the top-level full-space solver.
Rights and permissions
OpenAccess This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Gray, J.S., Hwang, J.T., Martins, J.R.R.A. et al. OpenMDAO: an open-source framework for multidisciplinary design, analysis, and optimization. Struct Multidisc Optim 59, 1075–1104 (2019). https://doi.org/10.1007/s00158-019-02211-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-019-02211-z