
Abstract
In this paper a new generalization of the hyper-Poisson distribution is proposed using the Mittag-Leffler function. The hyper-Poisson, displaced Poisson, Poisson and geometric distributions among others are seen as particular cases. This Mittag-Leffler function distribution (MLFD) belongs to the generalized hypergeometric and generalized power series families and also arises as weighted Poisson distributions. MLFD is a flexible distribution with varying shapes and has a unique mode at zero or it is unimodal with one/two non-zero modes. It can be under-, equi- or over- dispersed. Various distributional properties like recurrence relation for probability mass function, cumulative distribution function, generating functions, formulas for different type of moments, their recurrence relations, index of dispersion and its classification, log-concavity, reliability properties like survival, increasing failure rate, unimodality, and stochastic ordering with respect to hyper-Poisson distribution are discussed. A particular case of the distribution is shown to arise as the steady state probability of a queuing system under state dependent service rate. The distribution has been found to fare well when compared with the hyper-Poisson and COM-Poisson type negative binomial distributions in its suitability in empirical modeling of differently dispersed count data. It is therefore expected that the proposed MLFD with its interesting features and flexibility will be a useful addition as a model for count data.
Similar content being viewed by others

Introduction
The Poisson distribution is a popular model for count data. However its use is restricted by the equality of its mean and variance (equi-dispersion). Many models with the ability to represent under-, equi- and over- dispersion have been proposed in the research literature to overcome this restriction. Notable among these distributions are the hyper-Poisson (HP) of Bardwell and Crow (1964), generalized Poisson of Consul (1989), double-Poisson of Efron (1986), Poisson polynomial of Cameron and Johansson (1997), weighted Poisson of Castillo and Pérez-Casany (2005) and COM-Poisson of Conway and Maxwell (1962) (see also Shmueli et al., 2005).
Of these models the HP distribution was first proposed by Bardwell and Crow (1964) and Crow and Bardwell (1965). The probability mass function (pmf) of the HP with parameters (λ, β) distribution is given by
where \( \varphi \left(1,\beta; \lambda \right)={\displaystyle \sum_{j=0}^{\infty}\frac{(1)_j}{{\left(\beta \right)}_j}\frac{\lambda^j}{j!}}, \) is the confluent hypergeometric function and (β) j = β(β + 1) ⋯ (β + j − 1).
The pmf has a simple recurrence relation, that is,
The probability generating function (pgf) is given by
Staff (1964) studied a displaced Poisson distribution which is the HP distribution with the parameter β restricted to be a positive integer. The case when β is negative was investigated later by Staff (1967). The HP distribution attracted the attention of many researchers of late. Kemp (2002) dealt with a q-analogue of the distribution and Ahmad (2007) proposed a Conway-Maxwell-HP distribution. Roohi and Ahmad (2003a, 2003b) investigated moments of the HP distribution. Kumar and Nair (2011, 2012, 2013, 2015) studied various extensions and alternatives of the HP distribution. Sáez-Castillo and Conde-Sánchez (2013) studied a HP regression model for over-dispersed and under-dispersed count data. Best (2001) and Antic et al. (2006) considered the HP distribution in word length and text length research. Khazraee et al. (2015) investigated the application of the HP generalized linear model for analyzing motor vehicle crashes.
Since the HP distribution is an important model for applications and is able to handle under- and over- dispersion, where there are relatively fewer models with this feature, it is of interest to add further flexibility to the HP distribution especially for empirical modeling. Another advantage of such a generalization is that it will result in representing a larger family of distributions and avoids piecemeal analysis. In this paper we propose a new generalization of the HP distribution by replacing Γ(k + β) in (1) with Γ(α k + β), α > 0 and the normalization constant becomes E α, β (λ) which is the generalized Mittag-Leffler function defined by
Consequently the proposed distribution is called the Mittag-Leffler function distribution (MLFD). In general adding an extra parameter increases the complexity. However, for the MLFD, the extra parameter α adds flexibility but retains computational tractability since computation of E α, β (λ) does not pose a problem due to many software packages (example MATLAB) which offered routines for its quick computation. When α = β = 1, the MLFD is the Poisson distribution which is equi-dispersed. However for α, β ≠ 1, the MLFD still can be equi-dispersed and this characteristic allows more flexibility in modeling of equi-dispersion by a non-Poisson multi-parameter model compared to the single parameter Poisson model. The MLFD is shown to be log-concave and this confers a number of attractive properties for modeling and inference; see Walther (2009) for a good review of statistical modeling and inference with log-concave distributions. The proposed MLFD should not be confused with a class of discrete Mittag-Leffler distributions proposed by Pillai and Jayakumar (1995). It is pertinent to give a brief review of some developments in statistical models involving the Mittag-Leffler function.
The Mittag-Leffler function (with β = 1 in (2) and is denoted by E α (z)) was first introduced by Swedish mathematician Gosta Mittag-Leffler (1903; 1905) and it arises as the solution of a fractional differential equation. This function and its many extended versions were studied by many mathematicians over the years. Haubold et al. (2011) have given a good survey on the Mittag-Leffler function. Recently, this function has also been explored for applications in statistics. Pillai (1990) showed that 1 − E α (−z α), 0 < α ≤ 1 are valid cumulative distribution functions (cdf) and named it as Mittag-Leffler distribution with cdf and pdf respectively given by
Since for α = 1 this distribution reduces to the exponential distribution with mean 1, it can be treated as a generalization of the exponential distribution. Pillai (1990) studied different properties of this distribution. Jose and Pillai (1986), Jayakumar and Pillai (1993), Lin (1998), Jayakumar (2003), Jose et al. (2010) studied different aspects of this distribution.
Pillai and Jayakumar (1995) proposed a class of discrete Mittag-Leffler (DML) distributions having pgf P(z) = E(z X) = 1/[1 + c(1 − z)α]. The DML distribution arises as a mixture of the Poisson distribution with parameter θλ, where θ is a constant and λ follows the Mittag-Leffler distribution in (3). They have studied different properties of the DML distribution, gave a probabilistic derivation and an application in a first order autoregressive discrete process. The DML is also a particular case of the discrete Linnik distribution (Devroye, 1990).
Jose and Abraham (2011) introduced another discrete distribution based on the Mittag-Leffler function which arises when the exponential waiting time distribution in the usual Poisson process is replaced by the Mittag-Leffler distribution. The pmf of this distribution is
In this article we have taken a completely different route to propose a discrete distribution based on the Mittag-Leffler function. The proposed distribution, which under certain conditions also arises from a queuing theory setup, is simple and extremely flexible in its shape and modality and it can model under-, equi- and over- dispersed count data. Section 2 defines the MLFD and basic structural properties are given. MLFD as a distribution in a queuing system is given in Section 3. Reliability and stochastic ordering properties are discussed in Section 4. Section 5 deals with parameter estimation and examples of applications of MLFD. The conclusion is given in Section 6.
Mittag-Leffler Function Distribution: Definition and Properties
In this section we define the proposed MLFD and investigate its main distributional, reliability and ordering properties.
Definition 1. A discrete random variable X is said to follow the MLFD with parameters (λ, α, β) if its pmf is defined by
where \( {E}_{\alpha, \beta}\left(\lambda \right)={\displaystyle \sum_{j=0}^{\infty }{\lambda}^j/\varGamma \left(\alpha j+\beta \right)} \) is the generalized Mittag-Leffler function. The distribution henceforth will be denoted by MLFD (λ, α, β).
Remark 1: The MLFD pmf (5) may be obtained by replacing k ! in the Poisson pmf e − λ λ k/k ! with Γ(αk + β), and the normalization constant e − λ is now 1/E α, β (λ).
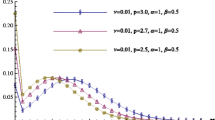
It may be noted that the proportion of zeros given by P(X = 0) = 1/{Γ(β) E α, β (λ)}, increases with increase in β (see Fig. 1(b)) when (λ, α) are fixed; increases with decrease in λ (see Fig. 1(c) and (d)) for fixed (α, β); and increases (decreases) with α > (<) 1 (see Fig. 1(e) and (f)) for fixed (λ, β). Whereas when β → 0+ the proportion of zeros decreases (see Fig. 1(b)) with the pmf proportional to λ k/Γ(αk) , k = 0, 1, 2, ⋯.

Plots of MLFD (λ, α, β) pmf for some values of the parameters
Recurrence relation between probabilities
The MLFD (λ, α, β) pmf in (5) has a simple recurrence relation given by
with P(X = 0) = 1/{Γ(β) E α, β (λ)}.
When α is a positive integer, (6) can be expressed as (αk + β) α P(X = k + 1) = λP(X = k).
The distribution exhibits long tailedness for 0 < α < 1 as the ratio of successive probabilities varies slowly (this corresponds to over-dispersion) as k tends to infinity while for α ≥ 1 this ratio tends to zero faster implying presence of a Poisson-type tail.
The recurrence relation in (6) facilitates easy computation of the probabilities. The computation of the normalizing constant E α, β (λ) is only required for P(X = 0).
Note that the recurrence relation (or the difference equation) in (6) reduces to that of HP (λ, β) distribution for α = 1 and displaced Poisson distribution when α = 1 and β is an integer (further discussed in Section 2.5.1).
Computation of the generalized Mittag-Leffler function Eαβ(λ)
For statistical inference and applications it is necessary to compute the generalized Mittag-Leffler function E α, β (λ), which is the normalizing constant, where
Numerical computation of the generalized Mittag-Leffler function is well-researched. Seybold and Hilfer (2008) gave a numerical algorithm for calculating the generalized Mittag-Leffler function for arbitrary complex argument z and real parameters α and β based on a Taylor series, exponentially improved asymptotics and integral representation. If |λ| ≤ 1, a simple way to compute E α, β (λ) is to calculate the terms a j = λ j/Γ(αj + β) in the infinite series E α, β (λ) by employing the recurrence relation a j + 1/a j = λ/(αj + β) with a 0 = 1/Γ(β) (see Lee et al., 2001). This avoids the computation of the gamma function Γ(x). The summation is terminated when a j is very small. The error estimate is given by Theorem 4.1 of Seybold and Hilfer (2008) which determines the number of terms N such that
For other values of λ, asymptotic series and integral representation (see equations (2.3), (2.4) and (2.7) of Seybold and Hilfer, 2008) are employed. Error estimates are also given for these cases. The computation of the Mittag-Leffler function is given by many software packages like Matlab (MLF (alpha, Z, P)) and Mathematica (MittagLefflerE [a, b, z]). (See also Gorenflo et al., 2002.) See also Garrappa (2015) for a recent contribution towards numerical evaluation of Mittag-Leffler function.
Shapes of pmf
The pmf of MLFD (λ, α, β) is plotted for a number of combinations of parameters to study the different shapes of the distribution.
From the plots of the pmf it is seen that the distribution can be unimodal with nonzero mode (see Fig. 1(a)) or it can have nonzero modes at two points (see Fig. 1(h)) or non-increasing with the mode at 0 (see Fig. 1(g)). See Section 4.3 item (i) for further discussion on the modes.
Cumulative distribution function and generating functions
The cumulative distribution function (cdf) of X ~ MLFD (λ, α, β) is seen to be
by using the known relation \( {\lambda}^r{E}_{\alpha, \beta + r\;\alpha}\left(\lambda \right)={E}_{\alpha, \beta}\left(\lambda \right)-{\displaystyle \sum_{j=0}^{r-1}{\lambda}^j/\varGamma \left(\alpha j+\beta \right)} \) (Haubold et al., 2011).
The pgf is given in terms of E α,β (λ) as
The moment generating function (mgf) and the factorial moment generating function (fmgf) are obtained from the pgf as
Related distributions and connections with other families of distributions
Particular cases of MLFD (λ, α, β)
The MLFD (λ, α, β) includes a number of well-known distributions as particular cases:
-
(i)
When α = β = 1, MLFD (λ, α, β) reduces to the Poisson distribution with parameter λ.
-
(ii)
When α = 0, β (≥0) MLFD (λ, α, β) becomes the geometric distribution with parameter λ provided 0 < λ < 1. Since for α → 0+, \( \underset{\alpha \to {0}^{+}}{ \lim }{E}_{\alpha, \beta}\left(\lambda \right)\to {\displaystyle \sum_{j=0}^{\infty}\frac{\lambda^j}{\varGamma \left(\beta \right)}}=\frac{1}{\left(1-\lambda \right)\varGamma \left(\beta \right)},0<\lambda <1 \) (Hanneken et al., 2009).
-
(iii)
When α = 1, β (≥0) MLFD (λ, α, β) reduces to the HP (λ, β) distribution (Bardwell and Crow, 1964; Johnson et al., 2005, p. 200).
Proof: \( P\left( X= k\right)=\frac{\lambda^k}{\varGamma \left( k+\beta \right){E}_{1,\beta}\left(\lambda \right)}, k=0,1,2,\cdots; \lambda >0 \) where \( {E}_{1,\beta}\left(\lambda \right)={\displaystyle \sum_{j=0}^{\infty }{\lambda}^j/\varGamma \left( j+\beta \right)=}{\displaystyle \sum_{j=0}^{\infty }{\lambda}^j/\left\{{\left(\beta \right)}_j\varGamma \left(\beta \right)\right\}} \) \( =\frac{1}{\varGamma \left(\beta \right)}{\displaystyle \sum_{j=0}^{\infty}\frac{(1)_j}{{\left(\beta \right)}_j}\frac{\lambda^j}{j!}}=\frac{\varphi \left(1,\beta; \lambda \right)}{\varGamma \left(\beta \right)} \).
Hence P(X = k) reduces to the pmf of HP (λ, β) distribution given in Eq. (1).
An alternative form of the pmf of the HP (λ, β) distribution when β > 1 can be seen as
since \( {E}_{1,\beta}\left(\lambda \right)=\frac{\lambda^{1-\beta}\;{e}^{\lambda}\;\gamma \left(\beta -1,\lambda \right)}{\varGamma \left(\beta -1\right)} \) (see Simon, 2013), where \( \gamma \left( u,\lambda \right)={\displaystyle \underset{0}{\overset{\lambda}{\int }}{e}^{- y}\;{y}^{u-1}\; dy} \) is the incomplete gamma function.
-
(iv)
When α = 1 and β (=t + 1) is a positive integer, MLFD (λ, α, β) reduces to the displaced Poisson distribution (see Staff, 1964; Johnson et al., 2005, p. 200) with parameter λ and t.
In addition, the following new distributions involving hyperbolic and error functions are also seen as particular cases.
-
(v)
When α = 2 and β = 2, MLFD (λ, α, β) reduces to a new discrete distribution with parameter λ and pmf
$$ P\left( X= k\right)=\frac{\lambda^{k+\left(1/2\right)}}{\varGamma \left(2\left( k+1\right)\right)}\frac{\kern0.24em 1}{ \sinh \left(\sqrt{\lambda}\right)}=\frac{{\left(\sqrt{\lambda}\right)}^{2 k+1}}{\left(2 k+1\right)!}\frac{\kern0.24em 1}{ \sinh \left(\sqrt{\lambda}\right)}, k=0,1,2,\cdots; \lambda >0, $$
since \( {E}_{2,2}\left(\lambda \right)= \sinh \left(\sqrt{\lambda}\right)/\sqrt{\lambda} \) (Haubold et al., 2011).
-
(vi)
When α = 2 and β = 1, MLFD (λ, α, β) reduces to a new distribution with parameter λ and pmf
$$ P\left( X= k\right)=\frac{\lambda^k}{\varGamma \left(2 k+1\right)}\frac{\kern0.24em 1}{ \cosh \left(\sqrt{\lambda}\right)}=\frac{{\left(\sqrt{\lambda}\right)}^{2 k}}{\left(2 k\right)!}\frac{\kern0.24em 1}{ \cosh \left(\sqrt{\lambda}\right)}, k=0,1,2,\cdots; \lambda >0 $$
since \( {E}_{2,1}\left(\lambda \right)= \cosh \left(\sqrt{\lambda}\right) \) (Haubold et al., 2011).
-
(vii)
When α = 1/2 and β = 1, MLFD (λ, α, β) reduces to a new distribution with parameter λ and pmf
$$ P\left( X= k\right)=\frac{ \exp \left(-{\lambda}^2\right)\kern0.24em {\lambda}^k}{\left( k/2\right)!\kern0.36em erfc\;\left(-\lambda \right)}, k=0,1,2,\cdots; \lambda >0 $$since \( {E}_{1/2,1}\left(\sqrt{\lambda}\right)= \exp \left(\lambda \right)\; erfc\;\left(-\sqrt{\lambda}\right) \) (Haubold et al., 2011) where erfc (λ) is the
complementary error function defined as \( erfc\;\left(\lambda \right)=1- e r f\left(\lambda \right)=1-\frac{2}{\sqrt{\pi}}{\displaystyle \underset{0}{\overset{\lambda}{\int }} \exp \left(-{t}^2\right)\; dt} \).
Also \( erfc\;\left(\lambda \right)=2\;\left[\frac{1}{\sqrt{2\pi}}{\displaystyle \underset{-\infty }{\overset{-\sqrt{2}\lambda}{\int }} \exp \left(-{t}^2/2\right)\; dt}\right]=2\varPhi \left(-\sqrt{2}\lambda \right) \), Φ(.) being the cdf of the standard normal distribution.
-
(viii)
MLFD (λ, α, β) degenerates with mass only at zero for either α → ∞ or β → ∞ or both and also when λ → 0+.
Remark 2. For 0 ≤ α ≤ 1, the MLFD (λ, α, β) can be viewed as a continuous bridge between the geometric (α = 0) and HP (α = 1) distributions in the range of the parameter α; in particular, the MLFD (λ, α, 1) can be viewed as a continuous bridge between the geometric (α = 0) and Poisson (α = 1) distributions in the range of the parameter α, a property also shared by the COM-Poisson distribution.
MLFD as weighted Poisson distribution
The MLFD (λ, α, β) is seen as a weighted Poisson distribution as follows: If X ~ Poisson (λ) having pmf
then for integer α and β it can be shown that weighted distribution with weight function 1/(k + 1)(α − 1)k + β − 1 gives the pmf of MLFD (λ, α, β). Since the weight function 1/(k + 1)(α − 1)k + β − 1 is monotonically decreasing in k for α, β > 1, MLFD (λ, α, β) is stochastically smaller than the Poisson distribution when α, β > 1. (See Patil et al. 1986; Ross, 1983; Castillo and Pérez-Casany, 2005)
MLFD as member of some families of discrete distributions
-
i.
MLFD (λ, α, β) is a member of the generalized hypergeometric family (Kemp 1968a, b). This can be checked by comparing the recurrence relation in Eq. (6) with that of the generalized hypergeometric distributions (see equation (2.63) in page 91 of Johnson et al., 2005).
-
ii.
MLFD (λ, α, β) is a member of the generalized power series distribution (Patil 1962, 1964) when λ is the primary parameter.
-
iii.
For fixed values of the parameters α and β, the MLFD (λ, α, β) is also a member of the exponential family of distributions.
Moments and related results
Denoting \( E\left({X}^r\right)={\mu}_r^{/} \), E(X [r]) = μ [r] and E[{X − E(X)}r] = μ r , x [r] = x (x − 1) ⋯ (x − r + 1) and using the relation \( E\left({X}_{\left[ r\right]}\right)={\mu}_r^{/}=\frac{d^r}{d{ s}^r}{\left. P(s)\right|}_{s=1} \), where P(s) is the pgf of MLFD (λ, α, β) mentioned in Section 2.4, and along with a result for the derivative of E α, β (λ) with respect to λ given by
we can derive the following formulas:
\( {\mu}_1^{/}=\lambda \frac{d}{ d\lambda} \log \left[{E}_{\alpha, \beta}\left(\lambda \right)\right]=\frac{E_{\alpha, \beta -1}\left(\lambda \right)}{\;\alpha\;{E}_{\alpha, \beta}\left(\lambda \right)}-\frac{1-\beta}{\alpha} \), provided α > 0 and β > 1.
\( {\mu}_2=\frac{1}{\alpha^2}\left\{\frac{E_{\alpha, \beta -2}\left(\lambda \right)}{\;{E}_{\alpha, \beta}\left(\lambda \right)}-{\left(\frac{E_{\alpha, \beta -1}\left(\lambda \right)}{\;{E}_{\alpha, \beta}\left(\lambda \right)}\right)}^2+\frac{E_{\alpha, \beta -1}\left(\lambda \right)}{\;{E}_{\alpha, \beta}\left(\lambda \right)}\right\} \), provided α > 0 and β > 2.
The variance can also be expressed as
The above results can alternatively be derived easily by first deriving E(αX + β)[r], r = 1, 2 and then simplifying.
In all the above expressions there is restriction on the values of β. This situation may be overcome by using the following relation repeatedly till the conditions are satisfied:
(see Erdelyi 1955; Hanneken et al., 2009).
The gamma function for negative argument can be computed using the formula (Fisher and Kilicman, 2012)
where \( \rho (n)={\displaystyle \sum_{i=1}^n\frac{1}{i}} \) and γ = − Γ /(1) is the Euler’s constant.
Recurrence relations of moments
The following recurrence relations hold:
-
(i)
$$ {\mu}_{r+1}^{/}=\lambda\;\frac{d}{ d\lambda}\;{\mu}_r^{/}+{\mu}_r^{/}\kern0.24em {\mu}_1^{/} $$
-
(ii)
$$ {\mu}_{r+1}=\lambda\;\frac{d}{ d\lambda}\;{\mu}_r+ r{\mu}_{r-1}\;{\mu}_2 $$
-
(iii)
$$ {\mu}_{{}^{\left[ r+1\right]}}=\lambda\;\frac{d}{ d\lambda}\;{\mu}_{{}^{\left[ r\right]}}+\left({\mu}_1^{/}- r\;\right){\mu}_{{}^{\left[ r\right]}} $$
-
(iv)
$$ E{\left(\alpha \left( X-1\right)+\beta \right)}_{\alpha}=\lambda +{\left(\beta -\alpha \right)}_{\alpha} P\left( X=0\right) $$
The relations (i) to (iii) can be proved by using the general relations for GPSD or by direct manipulation while (iv) follows from the difference equation in (6).
Since μ 2 > 0 and λ ≠ 0, \( {\mu}_2=\lambda\;\frac{d}{ d\lambda}\;{\mu}_1^{/}>0 \) implies \( \frac{d}{ d\lambda}\;{\mu}_1^{/}>0 \). Hence \( {\mu}_1^{/} \) is a monotonically increasing function of λ.
Alternative formulae for moments
An alternative formula for moments is given by
\( E\left[{\left( X+1\right)}_r\right]= r!{E}_{\alpha, \beta}^{r+1}\left(\lambda \right)/{E}_{\alpha, \beta}\left(\lambda \right) \),
where \( {E}_{\alpha, \beta}^{\rho}\left(\lambda \right)={\displaystyle \sum_{k=0}^{\infty}\frac{{\left(\rho \right)}_k}{k!}\frac{\lambda^k}{\varGamma \left(\alpha k+\beta \right)}} \) is the generalized Mittag-Leffler function (Prabhakar, 1971).
Proof: \( E\left[{\left( X+1\right)}_r\right]={\displaystyle \sum_{k=0}^{\infty}\frac{{\left( k+1\right)}_r{\lambda}^k}{\varGamma \left(\alpha k+\beta \right){E}_{\alpha, \beta}\left(\lambda \right)}} \) \( =\frac{r!}{E_{\alpha, \beta}\left(\lambda \right)}\;{\displaystyle \sum_{k=0}^{\infty}\frac{{\left( r+1\right)}_k}{k!}\frac{\lambda^k}{\varGamma \left(\alpha k+\beta \right)}} \)
since k ! (k + 1) r = r ! (r + 1) k .
Approximation of the mean and variance for large values of λ
Using the result that for large values of λ, E α,β (λ) → {λ (1 − β)/α exp(λ 1/α)}/α (see Gerhold, 2012) we can derive approximations for the mean and variance of MLFD (λ, α, β) as (1 − β + λ 1/α)/α and λ 1/α/α 2 respectively. The expression for the mean follows from either \( {\mu}_1^{/}=\frac{E_{\alpha, \beta -1}\left(\lambda \right)}{\;\alpha\;{E}_{\alpha, \beta}\left(\lambda \right)}+\frac{1-\beta}{\alpha} \) or directly from \( {\mu}_1^{/}=\lambda \frac{d}{ d\lambda} \log \left[{E}_{\alpha, \beta}\left(\lambda \right)\right] \). Then variance can be obtained by using the relation \( {\mu}_2=\lambda\;\frac{d}{ d\lambda}\;{\mu}_1^{/} \).
In particular for MLFD (λ, α, 1) the approximate mean and variance will be λ 1/α/α and λ 1/α/α 2. These approximations are good when α ∈ (0, 2] (see Simon, 2013) and may be useful in a regression formulation where the covariates are linked through the mean and variance.
Index of dispersion
The index of dispersion (ID) is given by ID = Variance/Mean. Contour plots of ID for different choices of parameters (α, β) keeping λ = 0.25 and λ = 5 fixed are presented in Fig. 2(a) and (b) respectively to depict the contours of ID. Labels on a given line indicate the value of ID on that line. In these figures, the ID of the region on the left (right) of a given line is more (less) than the ID value on that given line.

ID of MLFD (λ, α, β) for some values of the parameters
From Fig. 2 (a) and (b), it is obvious that the MLFD (λ, α, β) is very flexible with respect to the ID and is able to accommodate under-, equi- and over- dispersion in count data. Interestingly, this family includes a non-Poisson distribution with equi-dispersion when λ is kept fixed. Some such pairs of values for (α, β) can be easily taken from line of equi-dispersion in the contour plots in Fig. 2(a) when λ = 0.25 and from Fig. 2(b) when λ = 5.
Using results of the Section 2.6.3 for large values of λ it can be stated that the ID of MLFD (λ, α, β) is approximately given by λ 1/α/α((1 − β) + λ 1/α) which reduces to 1/α for MLFD. (λ, α, 1). Thus for large λ MLFD (λ, α, 1) expected to be over (under)- dispersed depending on α < (>)1, while MLFD (λ, α, β) will be under-dispersed in the region α > 1, β < 1.
MLFD (z, α, 1) as a distribution in a queuing system
MLFD (z, α, 1), like the COM-Poisson distribution, can be derived as the probability of the system being in the k-th state for a queuing system with state dependent service rate.
Consider a queuing system with Poisson inter arrival times with parameter λ, first-come- first-served policy, and exponential service times that depend on the system state (n-th state means n number of units in the system). The mean service time in the n-th state is μ n = μ (n α)[α], n ≥ 1 and μ n = μ for α = 0, where, 1/μ is the normal mean service time for a unit when that unit is the only one in the system and α is the pressure coefficient, a constant reflecting the degree to which the service rate of the system is affected by the system. For the sake of completeness, the proof that the probability is the pmf of MLFD (z, α, 1) where z = λ/μ is given as follows:
Following Conway and Maxwell (1962, p. 134–35), the system of differential difference equations are
and
From (7) we get P 0(t + Δ) − P 0(t) = − λ ΔP 0(t) + μ α ! ΔP 1(t) since μ 1 = μ(α) α = μα !. This implies, \( \underset{\varDelta \to 0}{ \lim}\frac{P_0\left( t+\varDelta \right)-{P}_0(t)}{\varDelta}=-\lambda\;{P}_0(t)+\mu\;\alpha !{P}_1(t) \)
or \( {P}_0^{/}(t)=-\lambda\;{P}_0(t)+\mu\;\alpha !{P}_1(t) \).
Assuming a steady state (i.e. \( {P}_n^{/}(t)=0 \) for all n), we get P 1(t) = zP 0(t)/α ! where λ/μ = z. Similarly, from (8), we get
\( \underset{\varDelta \to 0}{ \lim}\frac{P_n\left( t+\varDelta \right)-{P}_n(t)}{\varDelta}=-\left(\lambda +{\left( n\alpha \right)}_{\left[\alpha \right]}\mu\;\right){P}_n(t)+\lambda \kern0.24em {P}_{n-1}(t)+{\left(\left( n+1\right)\alpha \right)}_{\left[\alpha \right]}\mu\;{P}_{n+1}(t) \).
It follows that
because \( {P}_n^{/}(t)=0 \) for all n and λ/μ = z.
This implies that (z + (nα)[α] )P n (t) = z P n − 1(t) + ((n + 1)α)[α] P n + 1(t) since μ ≠ 0.
Putting n = 1 we get
(z + α !)P 1(t) = zP 0(t) + (2α)[α] P 2(t),
P 2(t) = {z 2/(2α) ! }P 0(t). Since α ! (2α)[α] = (2α) !
Similarly, for n = 2 we get
P 2(t) = {z 3/(3α) ! }P 0(t),
since (3α ! )(3α)[α] = (3α) !
In general, P n (t) = {z n/(nα) ! }P 0(t),
where \( {P}_0(t)=1/{\displaystyle \sum_{n=0}^{\infty}\left\{{z}^n/\left( n\alpha \right)!\right\}} \). This is the pmf of MLFD (z, α, 1).
In the case when α is not an integer one can use α ! = Γ(α + 1).
Reliability, stochastic ordering and log concavity
Discrete life time models have lately been a favorite subject of many studies since in many situations the life of a system may be observed as counts, and even when the life is measured in a continuous scale the actual observations may be recorded in a way making a discrete model more appropriate. It is therefore important to study the reliability properties of the proposed discrete distribution. Stochastic ordering is a closely related important area that has found applications in many diverse areas such as economics, reliability, survival analysis, insurance, finance, actuarial and management sciences (see Shaked and Shanthikumar, 2007). In this section we study the reliability properties and stochastic ordering of the MLFD (λ, α, β) distribution.
Survival and failure rate function
The survival and failure rate function for MLFD (λ, α, β) are respectively given by
This distribution has non decreasing failure rate function which we have shown later in section 4.3. The failure rate function r(t) is plotted in Fig. 3 for some choices of parameters to see how it behaves with changing parameter values. The values of r(t) tend to increase with α or β but decrease with increase in λ when other two parameters are kept fixed.

Failure rate of MLFD (λ, α, β) for some values of the parameters
Stochastic ordering with HP
The following result stochastically compares the MLFD (λ, α, β) with the HP (λ, β) by using the likelihood ratio order.
Definitions: Let X and Y be two discrete random variables with pmfs f(x) and g(x). Then X is said to be smaller than Y in the likelihood ratio order denoted by X ≤ lr Y if g(x)/f(x) increases in x over the union of the supports of X and Y; X is smaller than Y in the hazard rate order X ≤ hr Y if r X (t) ≥ r Y (t) for all t; X is smaller than Y in the mean residual life order X ≤ MRL Y if μ X (t) ≤ μ Y (t) for all t, where r X (.) and μ X (.) are respectively the hazard rate and mean residual life (MRL) functions of X.
Theorem 1. For α > 1, X ~ MLFD (λ, α, β) is smaller than Y ~ HP (λ, β) distribution in the likelihood ratio order i.e. X ≤ lr Y, while for 0 < α < 1, HP (λ, β) is greater than MLFD (λ, α, β) distribution in the likelihood ratio order i.e. Y ≤ lr X.
Proof: If X ~ MLFD (λ, α, β) and Y ~ HP (λ, β) then
For α > 1 this ratio is clearly increasing in n (see Shaked and Shanthikumar, 2007 and Gupta et al., 2014). Hence X ≤ lr Y is proved. While for 0 < α < 1, the ratio is decreasing in n which proves that Y ≤ lr X.
Corollary 1. For α > 1, X ~ MLFD (λ, α, β) is smaller than Y ~ HP (λ, β) distribution in the MRL life order that is X ≤ MRL Y.
Proof. The result follows since X ≤ lr Y ⇒ X ≤ hr Y ⇒ X ≤ MRL Y. (see Gupta et al., 2014).
Log-concavity
The log-concavity of any probability distribution has important implications on its reliability function, failure rate function, tail probabilities and moments. The MLFD (λ, α, β) has a log-concave pmf since for this distribution (Gupta et al., 1997)
\( \varDelta\;\eta (t)=\frac{P\left( t+1\right)}{P(t)}-\frac{P\left( t+2\right)}{P\left( t+1\right)}=\lambda \frac{\varGamma \left(\alpha\; t+\beta \right)\varGamma \left(\alpha\; t+2\;\alpha +\beta \right)-{\left\{\varGamma \left(\alpha\; t+\alpha +\beta \right)\right\}}^2}{\varGamma \left(\alpha\; t+\alpha +\beta \right)\varGamma \left(\alpha\; t+2\;\alpha +\beta \right)} \) > 0.
The following results are direct consequence of log-concavity (Mark, 1996):
-
i.
MLFD (λ, α, β) is a strongly unimodal distribution due to the log-concavity of its pmf (see Steutel 1985).
-
➢ MLFD (λ, α, β) has a unique mode at X = k if
-
$$ \varGamma \left(\alpha k+\beta \right)/\varGamma \left(\alpha k-\alpha +\beta \right)<\lambda <\varGamma \left(\alpha k+\alpha +\beta \right)/\varGamma \left(\alpha k+\beta \right) $$
-
Proof: This follows easily from the probability recurrence relation given in (5).
-
➢ MLFD (λ, α, β) has a non increasing pmf with a unique mode at X = 0 if λ < Γ(α + β)/Γ(β) (See the pmf plots in Fig. 1(g) for some choices of (λ, α, β) satisfying the condition.)
-
➢ MLFD (λ, α, β) has two modes at X = k and X = k + 1 if
-
$$ \lambda =\varGamma \left(\alpha k+\alpha +\beta \right)/\varGamma \left(\alpha k+\beta \right) $$
-
(See the pmf plot in Fig. 1(h) for some (λ, α, β) satisfying the condition.)
-
-
ii.
MLFD (λ, α, β) has non decreasing failure rate function.
-
iii.
MLFD (λ, α, β) has at most an exponential tail.
-
iv.
MLFD (λ, α, β) remains log-concave if truncated.
-
v.
\( \frac{P\left( X= i+ k\right)}{P\left( X= i\right)}\ge \frac{P\left( X= j+ k\right)}{P\left( X= j\right)}\;\mathrm{f}\mathrm{o}\mathrm{r}\kern0.24em i< j \).
Data Fitting
Parameter estimation
Suppose that we have a sample of size n from MLFD (λ, α, β) reported as grouped frequencies in k classes, like (X, f) = {(x 1, f 1), (x 2, f 2,), . . . , (x k , f k )}, where f i is the frequency of i-th observed value x i and n = ∑f i is the sample size. Then the log-likelihood function is given by
\( \log L\left(\left.{x}_1,{x}_2,\cdots, {x}_k\right|\;\lambda, \alpha, \beta \right)=\left({\displaystyle \sum_{i=1}^k{f}_i\;{x}_i}\right) \log \lambda -{\displaystyle \sum_{i=1}^k{f}_i \log \varGamma \left(\alpha\;{x}_i+\beta \right)}- n \log {E}_{\alpha, \beta}\left(\lambda \right) \).
Numerical optimization method is used to obtain the maximum likelihood estimates (MLE) of the parameters required for the data fitting and the likelihood ratio test.
Numerical examples
Here we have considered two frequency data sets. The first data set in Table 1 is about trips made by Dutch households owning at least one car during a particular survey week in 1989 (van Ophem, 2000). This data is slightly over-dispersed with Mean = 3.038, Variance = 3.410 and index of dispersion (ID) = 1.123. The second data set in Table 2 is the frequency distribution of the α - particles emitted by a radioactive substance in 2608 periods, each of 7.5 sec (Rutherford and Geiger, 1910). This data is slightly under-dispersed with Mean = 3.872, Variance = 3.695 and index of ID = 0.9543
The MLFD (λ, α, β) model is a generalization/extension of the HP (λ, β) and MLFD (λ, α, 1). Therefore the MLFD (λ, α, β) model has been fitted and compared with the HP (λ, β), MLFD (λ, α, 1) to ascertain the benefits accrued through the proposed generalization. In addition, we have also considered a recently introduced three-parameter distribution namely the COM-Poisson type negative binomial [COMNB (λ, α, β)] distribution having pmf P(X = k) = (λ) k α k/{(k !)β S β,λ (α)}, k = 0, 1, 2, ⋯ where S β,λ (α) is the normalizing constant (Chakraborty and Ong, 2016) for comparative data fitting. The performances of various distributions are compared using the AIC (Akaike Information Criterion) defined as AIC = −2 log L + 2 k, where k is the number of parameter(s) and log L is the maximum of log-likelihood for a given data set (Burnham and Anderson, 2004). We also provide chi-square goodness of fit statistics with p-values. In Tables 1 and 2 the degrees of freedoms for χ 2 are given alongside its value and the standard errors for parameter estimates are given within parentheses.
From Table 1 it can be seen that the MLFD (λ, α, β) gives the best fit since it has the lowest χ 2 value and is also the first choice in model selection with lowest AIC value. Moreover MLFD (λ, α, β) is the only distribution with good fit at 1% since its p-value is more than 0.01 while for the rest the p-values are less than 0.01.
From Table 2 considering the χ 2 values together with p-values it can be seen that all the distributions except the COMNB (λ, α, β) give adequate fits. But among them the MLFD (λ, α, β) gives the best fit since it has the lowest value of χ 2 with the highest p-value. It is also the selected model because it has the lowest AIC value.
Conclusion
A new generalization of the HP distribution which is a continuous bridge between the geometric and HP is derived using the generalized Mittag-Leffler function. Some known and new distributions are seen as particular cases of this distribution. This new generalization belongs to the generalized power series, generalized hypergeometric families and also arises as weighted Poisson distributions. Like the HP, COM-Poisson and generalized Poisson distributions, this distribution is also able to cater for under-, equi- and over- dispersion. Although the new generalization of the HP distribution has an extra parameter, it is computationally not more complicated than the HP since it retains the two-term probability recurrence formula and the normalizing constant, in terms of the generalized Mittag-Leffler function, is readily computed. It has many interesting probabilistic and reliability properties and is found to be a better empirical model than the HP distribution.
References
Ahmad, M.: A short note on Conway-Maxwell-hyper Poisson distribution. Pak J Stat 23, 135–137 (2007)
Antic, G., Stadlober, E., Grzybek, P., Kelih, E.: Word length and frequency distributions in different text genres. In: Spiliopoulou, M., Kruse, R., Nürnberger, A., Borgelt, C., Gaul, W. (eds.) From Data and Information Analysis to Knowledge Engineering, pp. 310–317. Springer, Heidelberg (2006)
Bardwell, G.E., Crow, E.L.: A two parameter family of hyper-Poisson distributions. J Am Stat Assoc 59, 133–141 (1964)
Best, K.: Kommentierte Bibliographie zum Göttinger Projekt. In: Best, K.-H. (ed.) Häufigkeitsverteilungen in Texten, pp. 248–310. Pest & Gutschmidt, Göttingen (2001)
Burnham, K.P., Anderson, D.R.: Multimodel Inference, Understanding AIC and BIC in model selection. Sociological Methods and Research 33, 261–304 (2004)
Cameron, A.C., Johansson, P.: Count Data Regression Using series expansions: with applications. J Appl Econ 12(3), 203–223 (1997)
Castillo, J.D., Pérez-Casany, M.: Over-dispersed and under-dispersed Poisson generalizations. Journal of Statistical Planning and Inference 134, 486–500 (2005)
Chakraborty, S., Ong, S.H.: A COM-Poisson-type generalization of the negative binomial distribution. Communications in Statistics -Theory and Methods 45(14), 4117–4135 (2016)
Consul, P.C.: Generalized Poisson distributions: properties and applications. Marcel Dekker Inc, New York/Basel (1989)
Conway, R.W., Maxwell, W.L.: A queuing model with state dependent service rates. J Ind Eng 12, 132–136 (1962)
Crow, E.L., Bardwell, G.E.: Estimation of the parameters of the hyper-Poisson distributions. In: Patil, G.P. (ed.) Classical and Contagious Discrete Distributions, pp. 127–140. Pergamon, Oxford (1965)
Devroye, L.: A note on Linnik’s distribution. Statistics and Probability Letters 9, 305–306 (1990)
Efron, B.: Double Exponential-Families and their use in Generalized Linear-Regression. J Am Stat Assoc 81(395), 709–721 (1986)
Erdelyi, A.: Higher transcendental functions, vol. 3. McGraw-Hill, New York (1955)
Fisher, B., Kilicman, A.: Some results on the gamma function for negative integers. Appl Math Inf Sci 6(2), 173–176 (2012)
Garrappa, R.: Numerical evaluation of two and three parameter Mittag-Leffler functions. Siam J Numer Anal 53(3), 1350–1369 (2015)
Gerhold, S.: Asymptotics for a variant of the Mittag-Leffler function. Integral Transforms and Special functions 23(6), 397–403 (2012)
Gorenflo, R., Joulia, L., Luchko, Y.: Computation of the Mittag-Leffler function Eα, β(z) and its derivatives. Fractional Calculus & Applied Analysis 5(4), 491–518 (2002)
Gupta, P.L., Gupta, R.C., Tripathi, R.C.: On the monotonic properties of discrete failure Rates. Journal of Statistical Planning and Inference 65, 255–268 (1997)
Gupta, R.C., Sim, S.Z., Ong, S.H.: Analysis of discrete data by Conway-Maxwell Poisson distribution. AStA Advances in Data Analysis 98, 327–343 (2014)
Hanneken, J.W., Achar, B.N.N., Puzio, R., Vaught, D.M.: Properties of the Mittag–Leffler function for negative alpha. Phys Scr. T136, 014037, 1–5 (2009). doi:10.1088/0031-8949/2009/T136/014037
Haubold, H.J., Mathai, A.M., Saxena, R.K.: Mittag-Leffler functions and their applications. J Applied Math, Article ID 298628, p. 51 (2011). doi:10.1155/2011/298628
Jayakumar, K.: On Mittag-Leffler process. Math Comput Model 37, 1427–1434 (2003)
Jayakumar, K., Pillai, R.N.: The first order autoregressive Mittag-Leffler process. J Appl Probab 30, 462–466 (1993)
Johnson, N.L., Kemp, A.W., Kotz, S.: Univariate Discrete Distributions. Wiley, New York (2005)
Jose, K.K., Abraham, B.: A count data model based on Mittag-Leffler inter arrival times. Statistica 71(4), 501–514 (2011)
Jose, K.K., Pillai, R.N.: In: Yagen Thomas, P. (ed.) Generalized autoregressive time series models in Mittag-Leffler variables. Recent Advances in Statistics, pp. 96–103. (1986)
Jose, K.K., Uma, P., Seethalekshmi, V., Haubold, H.J.: Generalized Mittag-Leffler processes for applications in astrophysics and time series modelling. In: Haubold, H.J., Mathai, A.M. (eds.) Proceedings of the third UN/ESA/NASA workshop on the International Heliophysical Year 2007 and Basic sciences, Astrophysics and Space Science Proceedings, pp. 79–92. (2010). doi:10.1007/978-3-642-03325-4_9
Kemp, A.W.: Studies in Univariate discrete distribution theory based on the generalized hypergeometric function and associated differential equations. PhD Thesis. The Queen’s University of Belfast, Belfast (1968a)
Kemp, A.W.: A wide class of discrete distributions and the associated differential equations. Sankhya, Series A 30, 401–410 (1968b)
Kemp, C.D.: q-analogues of the hyper-Poisson distribution. Journal of Statistical Planning and Inference 101, 179–183 (2002)
Khazraee, S.H., Sáez-Castillo, A.J., Geedipally, S.R.: Lord D: Application of the hyper-Poisson generalized linear model for analyzing motor vehicle crashes. Risk Anal 35(5), 919–930 (2015)
Kumar, C.S., Nair, B.U.: A modified version of hyper-Poisson distribution and its applications. J Stat Appl 6, 23–34 (2011)
Kumar, C.S., Nair, B.U.: An alternative hyper-Poisson distribution. Statistica 3, 357–369 (2012)
Kumar, C.S., Nair, B.U.: Modified alternative hyper -Poisson distribution. In: Kumar, C.S., Chacko, M., Sathar, E.I.A. (eds.) Collection of recent statistical methods and applications, Department of Statistics, pp. 97–109. University of Kerala publication, Trivandrum (2013)
Kumar, C.S., Nair, B.U.: On a class of hyper-Poisson and alternative hyper-Poisson distributions. OPSEARCH (Operational Research Society of India) 52(1), 86–100 (2015). doi:10.1007/s12597-013-0169-7
Lee, P.A., Ong, S.H., Srivastava, H.M.: Some integrals of the products of Laguerre polynomials. Internat J Comput Math 78, 303–321 (2001)
Lin, G.D.: On Mittag-Leffler distribution. Journal of Statistical Planning and Inference 74, 1–9 (1998)
Mark, Y.A.: Log-concave probability distributions: Theory and statistical testing. Working paper, Published by Center for Labour Market and Social Research, University of Aarhus and the Aarhus School of Business, WorkingPaper 96–01, (1996)
Mittag-Leffler, G.: Sur la nouvelle fonction Eα(x). Comptes Rendus Acad Sci Paris 137, 554–558 (1903)
Mittag-Leffler, G.: Sur la représentation analytique d’une branche uniforme d’une fonction monogene. Acta Math 29, 101–181 (1905)
Patil, G.P.: Estimation by two moments method for generalized power series distribution and certain applications. Sankhya, B 24(3&4), 201–214 (1962)
Patil, G.P.: In: Rao, C.R. (ed.) Estimation for the generalized power series distribution with two parameters and its application to binomial distribution. Contributions to Statistics, pp. 335–344. Calcutta: Statistical Publishing Society; Oxford, Pergamon (1964)
Patil, G.P., Rao, C.R., Ratnaparkhi, M.V.: On discrete weighted distributions and their use in model for observed data. Communications in Statistics-Theory and Methods 15(3), 907–918 (1986)
Pillai, R.N.: On Mittag-Leffler functions and related distributions. Ann Inst Statist Math 42, 157–161 (1990)
Pillai, R.N., Jayakumar, K.: Discrete Mittag-Leffler distributions. Statistics & Probability Letters 23, 271–274 (1995)
Prabhakar, T.R.: A singular integral equation with a generalized Mittag-Leffler function in the Kernel. Yokohama Math J 19, 7–15 (1971)
Roohi, A., Ahmad, M.: Estimation of the parameter of hyper-Poisson distribution using negative moments. Pak J Stat 19, 99–105 (2003a)
Roohi, A., Ahmad, M.: Inverse ascending factorial moments of the hyper-Poisson probability distribution. Pak J Stat 19, 273–280 (2003b)
Ross, S.M.: Stochastic Processes. Wiley, New York (1983)
Rutherford, E., Geiger, H.: The probability variations in the distribution of α- particles. Philos Mag 20, 698–704 (1910)
Sáez-Castillo, A.J., Conde-Sánchez, A.: A hyper-Poisson regression model for over-dispersed and under-dispersed count data. Computational Statistics and Data Analysis 61, 148–157 (2013)
Seybold, H., Hilfer, R.: Numerical algorithm for calculating the generalized Mittag -Leffler function. SIAM J Numer Anal 47(1), 69–88 (2008)
Shaked, M., Shanthikumar, J.G.: Stochastic Orders. Springer Verlag (2007)
Shmueli, G., Minka, T.P., Kadane, J.B., Borle, S., Boatwright, S.: A useful distribution for fitting discrete data-revival of the Conway-Maxwell Poisson distribution. Appl Stat 54, 127–142 (2005)
Simon, T.: Mittag - Leffler functions and complete monotonicity. arXiv: 1312. 4513v [math.CA] (2013)
Staff, P.J.: The displaced Poisson distribution. Australian Journal of Statistics 6, 12–20 (1964)
Staff, P.J.: The displaced Poisson distribution. Region B. Journal of American Statistical Association 62(318), 643–654 (1967)
Steutel, F.W.: In: Kotz, S., Johnson, N.L., Read, C.B. (eds.) Log-concave and log-convex distributions. Volume 5, Encyclopedia of Statistical Sciences. (1985)
van Ophem, H.: Modeling selectivity in count-data models. J Bus Econ Stat 18, 503–511 (2000)
Walther, G.: Inference and modeling with log-concave distributions. Stat Sci 24(3), 319–327 (2009)
Acknowledgements
The first author wishes to acknowledge the hospitality of Institute of Mathematical Sciences, University of Malaya during his visit to the institute in the summer of 2014. S.H. Ong wishes to acknowledge support in parts from Ministry of Education FRGS grant FP045-2015A and University of Malaya’s UMRGS grant RP009A-13AFR. The authors also wish to acknowledge the significant comments and suggestions of the Associate Editor and reviewers in earlier versions of the paper which have helped to improve the presentation tremendously.
Authors’ contributions
Both authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Chakraborty, S., Ong, S.H. Mittag - Leffler function distribution - a new generalization of hyper-Poisson distribution. J Stat Distrib App 4, 8 (2017). https://doi.org/10.1186/s40488-017-0060-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40488-017-0060-9
Keywords
- Index of dispersion
- Reliability
- Log-concavity
- Unimodality
- Stochastic ordering
- Generalized power series
- Hypergeometric family
- Empirical modeling